


1. Introduction
Vedic is the earliest attested stage of Sanskrit and the language of the Vedas (and ancillae), a large corpus of mostly metrical liturgical texts. Vedic meters, like all Sanskrit meters, are quantitative, meaning that each meter permits only certain patterns of heavy and light syllables, among other restrictions, such as the placement of the caesura (obligatory word break). This article treats the prevailing meters of the Rigveda (Jamison & Brereton Reference Jamison and Brereton2014), the oldest and largest of the four Vedas (late 2nd millennium BCE; approximately 39,833 metrical lines and 171,086 words).
In terms of prosodic typology, Vedic is what is commonly known as a pitch accent language, but given that its accent was arguably purely tonal (see below), it could also be called a restricted tone system (cf. Voorhoeve Reference Voorhoeve1973, Hyman Reference Hyman, Goldsmith, Riggle and Alan2011b). Although I will continue to use the term accent, its phonetic realization should be understood to be tone, not stress. This article uses meter to explore the prosodic properties of Vedic, reinforcing that the accent was probably not associated with phonetic stress.
Each Vedic word has exactly one accent, with certain well-known exceptions:Footnote 1 vocatives, main-clause finite verbs, and certain clitics are unaccented (except when line- or sentence-initial). Less commonly, words have two accents (viz. infinitives in -tavái and some compounds, mostly coordinative). Accent is not restricted to a window like it is in, say, Ancient Greek. It can (and frequently does) occur on any syllable of the word, regardless of length.
Vedic accent is lexically distinctive and largely unpredictable in roots. Numerous minimal pairs are found, such as those in (a–c) of Table 1 (Poucha Reference Poucha1943:131–5 gives eighty-eight such pairs; Sandell Reference Sandell2023a:305).Footnote 2 Accent also interacts richly with morphology. For example, in (d–e), accent alone distinguishes case/number forms (Yates Reference Yates2020). In verbs, the position of accent often varies within the paradigm. For instance, for imperatives of hu ‘sacrifice’, accent is initial in (f), medial in (g), and final in (h) (Whitney Reference Whitney1889:245). Accent also distinguishes derivational forms, as in (i–j). In the latter, it determines whether the compound is endocentric or exocentric.
Examples of lexically and grammatically distinctive accent.

Accent thus bears an enormous functional load in the Vedic lexicon and grammar. Syllable weight, by contrast, plays a relatively minor role in these domains: accent placement is largely independent of weight,Footnote 3 and weight does not often influence morphology.Footnote 4 Strikingly, in poetic metrics, the situation is reversed: accent plays no role (as this article will confirm), while weight is thoroughly regulated. To be sure, accent is critical to the tradition—proper recitation depends on it. However, from a generative perspective, accent does not interact systematically with metrical positions. This is the consensus (e.g. Arnold Reference Arnold1905:6, 106, West Reference West1987:2). Macdonell (Reference Macdonell1910:77) states that ‘accent exercises no influence on the rhythm of versification’. Lubotsky (Reference Lubotsky, Semeka and Pankratov1995) observes that handbooks’ statements to the effect that ‘accents have no impact on the metre’ are ‘certainly correct’ (though he argues for other poetic roles; see Section 4.1). In this respect, Vedic resembles Ancient Greek, whose pitch accent is likewise largely if not entirely irrelevant for meter (West:ibid., Maas Reference Maas1962:§8, Raven Reference Raven1962:§13, Allen Reference Allen1973:262, Golston & Riad Reference Golston and Riad2000:109f, Henriksson Reference Henriksson2022:9; but cf. Abritta Reference Abritta2015, Reference Abritta2018, Reference Abritta2019 on possible poetic functions).
The lack of a decisive role for accent in Vedic meter is made plain by the relatively flat rate of accentedness across metrical positions. Figure 1 displays the percentage of accented syllables (solid lines) in each position of three meters (see Section 2 on the meters), alongside the percentage of heavy syllables (dashed lines) for comparison. A syllable is heavy iff it contains a long vowel, diphthong, or coda. Weight shows clear alternation, especially in cadences (shaded), where it is nearly categorical. The cadence refers to the final part of the line, which is the most strictly regulated (see Section 2). Accent, by contrast, displays no obvious alternation. While accent does decline across the line, this reflects various independent factors: first, words are on average longer later in the line, owing to functional material at the left periphery (cf. Hale Reference Hale and Watkins1987) and end-weight preferences (cf. Ryan Reference Ryan2019a). Second, as mentioned, certain word classes carry accent only when clause- or line-initial. Third, unaccented words are more likely to be enclitic than proclitic. Finally, the basic word order is verb-final, and main-clause finite verbs are unaccented.
Percentage of syllables that are accented (solid line) or heavy (dashed line) in three Vedic meters. Cadences are shaded.

While Figure 1 confirms that accent lacks the categorical regulation of weight—which has always been obvious—it does not rule out preferential accent-meter interactions. The observed rates are not entirely flat, and even to the extent that they are, it is possible that the expected rates would look rather different, when controlling for other factors. This article conducts statistical tests controlling for word shape (syllable-weight template) and category, which independently influence accent distribution in lines. The results consistently show no metrical sensitivity to accent, corroborating the conventional wisdom. That said, one significant effect does emerge: accent is disfavored line-finally in all meters (even after taking into account the already low rates predicted by word shape/category distributions). However, the same effect appears in Vedic prose, suggesting that this tonal NonFinality (Section 5) is not determined by meter.
Beyond meter, I examine four other potential roles of accent in Vedic poetics: first, accentual responsion between lines (cf. Lubotsky Reference Lubotsky, Semeka and Pankratov1995); second, tendencies to avoid accentual clash or lapse across words; third, accentual formulas (overrepresented sequences); and finally, stricter weight-mapping in accented as opposed to unaccented syllables. All tests yield negative results. Accent appears to be inert not only in Vedic metrics, but in Vedic poetics more generally. While it is impossible to prove a negative—future research may yet uncover some role for accent—this article refutes several straightforward hypotheses.
Aside from the article’s methodological contributions, these findings bear on poetic typology, Indo-European linguistics, and prosodic typology. Implications for poetic typology are elaborated next, in Section 1.1, followed by historical-linguistic and typological implications concerning ‘pitch accent’ in Section 1.2. The corpus study begins in Section 2. The discussion is largely front-loaded in order to clarify the rationales for undertaking this kind of study and to highlight the ways in which the negative results are still informative.
1.1. Implications for poetic typology
1.1.1 Prosodic hybridity in quantitative meters
While it is possible for a meter to regulate a single prosodic property (stress, weight, or tone), the development of poetic typology has revealed that meters are frequently hybrid, regulating multiple properties. A meter is hybrid (per Ryan Reference Ryan2017) if the metrical grammar crucially invokes more than one prosodic feature. A meter does not qualify as hybrid merely if multiple prosodic features co-occur. To give an example of each situation, the Latin dactylic hexameter is hybrid because it regulates both weight and (separately) stress: the distribution of stress in the cadence is more regular than constraints on weight alone would predict (Sturtevant Reference Sturtevant1923, Allen Reference Allen1973:337, Ryan Reference Ryan2017:585–91). By contrast, Classical Chinese regulated verse is not hybrid, to my knowledge. Even if it is true that the two tonal categories (even vs. oblique) are also distinguished by duration (Jakobson Reference Jakobson, Pomorska and Rudy1960/1987:74, Yip Reference Yip, Aronoff and Oehrle1984), the metrical grammar need not refer to both tone and weight. The one piggybacks on the other.
Cross-linguistically, quantitative meters are frequently hybrid, also invoking stress, if present (on tone, see below). The case of Latin has already been mentioned. Other hybrid, stress-sensitive quantitative meters can be found across Indo-European, including Czech, Hindi, Old Norse, and Serbian (Batinic Reference Batinic1975, Fairbanks Reference Fairbanks, Dimock, Kachru and Krishnamurti1992, Ryan Reference Ryan2017, Kiparsky Reference Kiparsky2020:30). Stress-weight hybrid meters can also be found outside of Indo-European, as in Finnish, Hungarian, and Tamil (ibid.). In some of the aforementioned cases (e.g. Latin, Old Norse), the meter regulates weight and stress independently, using separate constraints; in others (e.g. Kalevala Finnish, Tamil), the meter regulates weight and stress jointly, such that weight is regulated only (or most strictly) in stressed syllables. Either way, an adequate metrical grammar must refer to both properties; they do not simply covary.
That said, quantitative meters in languages with stress are apparently not always sensitive to stress (e.g. perhaps Classical Arabic; Maling Reference Maling1973:13–15). Thus, while meters may be prosodically hybrid, they are not generally prosodically maximal (regulating all available prosodic features). Hence the questions: Which (combinations of) prosodic properties do meters regulate, and in which types of languages? Case studies like the present one are critical to fleshing out this typology, as hybridity can be gradient, requiring statistical methods to (dis)confirm.
In all the hybrid quantitative meters just mentioned, the second property is stress. In languages with tone or tone accent, but not phonetic stress—e.g. Vedic, Ancient Greek,Footnote 5 Hausa, Japanese, Somali—quantitative meters appear less likely to be hybrid, though further study is needed. By hypothesis, a quantitative meter may never impose constraints on tone (unless it co-occurs with phonetic stress). This article supports this hypothesis for Vedic, though the other cases require more scrutiny. If the hypothesis holds up, the greater role of stress in quantitative meter compared to tone is an explanandum. Some considerations are as follows. First, stress is more likely than high tone to have duration as a phonetic correlate. Further, stress is more likely to exhibit metrical properties in natural language (Hyman Reference Hyman2009, Reference Hyman2011a). One cannot simply say that tone is metrically irrelevant in general, as tone often interacts with stress or weight in natural language (de Lacy Reference de Lacy2002, Hyman Reference Hyman2009, Gordon Reference Gordon and van de Weijer2023), and tonal meters are attested (Kiparsky Reference Kiparsky2020:32). Even within Indo-European, the Serbian epic meter has been shown to regulate tone, in addition to stress and weight (Milenković & Ryan Reference Milenković and Ryan2025). Importantly for present considerations, however, tone regulation in that meter is claimed to be conditioned by stress.Footnote 6
1.1.2. Meter-language homologies
The inertness of accent in Vedic meter is also informative with respect to questions of meter-language homology, that is, the extent to which the structures of meters can be predicted from properties of their languages (e.g. Hanson & Kiparsky Reference Hanson and Kiparsky1996:294f, Kiparsky Reference Kiparsky2020:30f). It is a truism that a meter can only regulate prosodic features that are present in the language. But when multiple prosodic features are available, which ones do meters select, and how are they operationalized as constraints? The Vedic case refutes some conceivable hypotheses. For one, we see that the properties targeted by meters are not selected according to their importance (functional load, active constraints, accessibility, frequency, etc.) in the grammar or lexicon. As discussed, accent plays a greater role in Vedic as a language than does weight. Second, one cannot say that the meter targets properties that play a significant role in the lexical (as opposed to postlexical) phonology, as Vedic accent once again meets this criterion, while weight is comparatively marginal. Furthermore, Vedic accent is not in general opaque or otherwise difficult to identify, whereas the grammar’s testimony about syllable weight (e.g. whether codas are moraic) is more obscure.Footnote 7
At any rate, while syllable weight per se is marginal in Vedic grammar, it is not wholly irrelevant (fn. 4), and perhaps more importantly, vowel length is contrastive, which, while not weight, might bootstrap quantitative meter. The correlation between contrastive vowel length and quantitative meter has long been noted. While (nearly?) all quantitative meters exist in languages with contrastive length, the converse does not hold: languages with contrastive length may opt for stress-based meters (e.g. Middle English). But languages with contrastive vowel length and tone (or ‘tone accent’) evidently favor quantitative meters.
Finally, it should be mentioned that metrics does not exist in a phonological vacuum; cultural transmission plays a part, especially if meters are borrowed (Gunkel Reference Gunkel, Gunkel, Katz, Vine and Weiss2016). Vedic meters arguably inherit a quantitative tradition from Proto-Indo-European (e.g. Kiparsky Reference Kiparsky, Gunkel and Hackstein2018). Even so, the typological questions remain unaffected, as Proto-Indo-European also had the accent.
In conclusion, both tone (accent) and time (contrastive length) are lexically distinctive in Vedic, but the meter regulates only one of these dimensions, namely, time. This case confirms that prosodic importance (in various senses) in natural language does not entail a place in poetics.
1.2. The nature and realization of Vedic accent
1.2.1. Phonetic realization (preamble)
The Vedic accent is generally described as being a pitch/tone accent. The Sanskrit tradition, for its part, treats it in exclusively tonal terms, with no allusions to emphasis (Whitney Reference Whitney1889:28). The accent may be regarded as a high tone. In extant recitational traditions, it is part of a rising trajectory that might not peak (depending on the text/school) until the following syllable. Nevertheless, at the time of composition, the peak almost certainly fell on the accented syllable (see Section 3.5). The tone-bearing unit (TBU) is the syllable, not the mora.
While the accent was undoubtedly correlated with pitch, there is some debate as to whether it was also associated with stress. This article maintains that at least phonetic stress, in the sense of phonetic correlates of prominence besides tone, is not supported. I return to the stress question at the end of this section, after first summarizing the typological characteristics of the accent.
1.2.2. Privativity
The system is almost entirely privative, meaning that lexically, there is a single, fixed tone pattern associated with the accent (as in, say, Tokyo Japanese), not multiple contrasting patterns (as in, say, Serbian). In other words, words are distinguished by the location or presence vs. absence of accent, not by the type of accent. I say ‘almost entirely’ because aside from the regular high-tone accent (udātta), there exists a second type of accent called the ‘independent svarita’. The latter, however, is rare in the Rigveda (0.1% of accents in the restored text), and is merely a time-compressed version of the former, arising from devocalization (Beguš Reference Beguš, Jamison, Melchert and Vine2016:3f). Therefore, in this article, I conflate udātta with independent svarita as accent.Footnote 8
1.2.3. Culminativity
For the most part, accent is culminative, meaning that at most one may appear per prosodic word (PWd). The apparent exceptions (many coordinative compounds, occasional determinative compounds, and infinitives in -tavái) can be analyzed as being single morphosyntactic words comprising multiple PWds. Kiparsky (Reference Kiparsky2010) argues that coordinative compounds comprise separate PWds in the lexical phonology (explaining their double accentuation), but are fused into single PWds in the postlexical phonology, while still retaining both accents (explaining other respects in which they behave as single PWds). Thus, one might say that accent is lexically culminative, but not necessarily surface-culminative.
1.2.4. Obligatoriness
To a first approximation, every non-clitic word is lexically accented and must surface with an accent. However, a PWd is surface-unaccented if it is a vocative nounFootnote 9 or main-clause finite verb (unless in either case it is line- or sentence-initial). Between these cases and clitics, twenty percent of orthographic words are unaccented in the Rigveda. Thus, obligatoriness largely holds, but with certain systematic exceptions.
1.2.5. Metricality
As mentioned, there is no ‘window’ for accent; it is free to appear on any syllable, no matter how long the word. Although accent distribution in words exhibits statistical tendencies (e.g. in long words, it is more likely to be early than late; Sandell Reference Sandell2023a:426–28), there are no conspicuous spikes, prohibitions, or patterns as might suggest an underlying metrical system. In disyllables, for instance, accent is roughly equally likely to be initial or final. (This remains true if one takes only light-light or heavy-heavy disyllables, such that weight is irrelevant; see Sandell Reference Sandell2023a:429) Moreover, possible tendencies notwithstanding (fn. 3), accent placement is not determined by weight, as minimal pairs make clear (Table 1). Nor is there any secondary accent, iterativity, rhythmicity, avoidance of clash or lapse (including across words; Section 4.2), or bimoraic prosodic minimality. A PWd may be
 $ {\mathrm{C}}_0\overset{\smile }{\mathrm{V}} $
.
$ {\mathrm{C}}_0\overset{\smile }{\mathrm{V}} $
.
1.2.6. Segmental interactions
Cross-linguistically, stress often conditions segmental effects, such as licensing contrasts, preventing reductions, or triggering fortitions (Hyman Reference Hyman2009:217, Reference Hyman2011a:202, Franich Reference Franich2021:370f). I am not aware of any synchronic interactions between accent and phonotactics in Vedic (see also Sandell Reference Sandell2023a:340f).Footnote 10
1.2.7. The stress question
I assume, with Jun (Reference Jun and Jun2005:439), Hyman (Reference Hyman2009:219, 231, Reference Hyman2011a:200–202), van der Hulst (Reference van der Hulst, van Oostendorp, Ewen, Hume and Rice2011:21, 2012:1516), and others, that a language can have stress, tone, or both (or possibly neither). I take the term ‘accent’ to be neutral with respect to realization (Abercrombie Reference Abercrombie1991, Gussenhoven Reference Gussenhoven2004:42, van der Hulst Reference van der Hulst, van Oostendorp, Ewen, Hume and Rice2011:21, etc.). There is no question that Vedic accent was cued (at least) by pitch. A priori, this situation could reflect accent being (i) purely tonal (autosegmental High), (ii) an intonational pitch accent associated with a stressed syllable, or (iii) stress cued (in part) by pitch (cf. Sandell Reference Sandell2023a:294–96).
Given the evidence already presented, along with the results of the present study, I take the first position to have the most support. Accent is generally inert with respect to the several diagnostics of metricality just enumerated, including segmental effects. As for culminativity and obligatoriness, these properties are typical of stress, but not incompatible with tone (Hyman Reference Hyman2006, Reference Hyman2009), on top of which, both have exceptions in Vedic: culminativity does not apply to the postlexical PWd (Kiparsky Reference Kiparsky2010), and obligatoriness is violated by certain classes of words. At any rate, even if the Vedic accent were strictly culminative, languages with tone accent but not stress can have that property (e.g. Tokyo Japanese, Somali, Western Basque dialects, Kinga, and Nubi; Hualde et al. Reference Hualde, Elordieta, Gaminde, Smiljanić, Gussenhoven and Warner2002:578f, Hyman Reference Hyman2006:238, Reference Hyman2009:215, 219). Somali further offers a striking parallel to Vedic: ‘finite verbs in main clauses are toneless’, but verbs are otherwise toned (Hyman Reference Hyman2006:238).
As for Vedic accent being an intonational pitch accent (associating with stressed syllables), I will cite a few considerations contra, albeit overlooking much nuance (cf. Sandell Reference Sandell2023a:295–99). First, the accent type is invariant.Footnote 11 Second, accent is insensitive to information structure (e.g. focus, givenness). Third, there are no boundary tones or other effects related to illocutionary force. Fourth, though unaccented clitics exist, most function words are accented, and remain so when stacked within phrases under broad focus, regardless of their position in the phrase.
On balance, then, there is little evidence that, beyond the attested high tone, Vedic accent was associated with phonetic stress, that is, additional correlates of prominence such as duration, intensity, spectral tilt, hyperarticulation, or phonatory effects (cf. Hyman Reference Hyman2011a:217, van der Hulst Reference van der Hulst2012:1508, 1513). Since the original phonetics cannot be observed, this inference is based in part on typological considerations like the foregoing. Nevertheless, another consideration is morphophonology, which is beyond the scope of this overview. Some recent grammatical analyses of Vedic accent (Yates Reference Yates2020, Sandell Reference Sandell2023a:296–335) refer to the accent as ‘stress’, but presumably because they employ feet, not out of a commitment to any particular phonetic realization. The preceding considerations invite skepticism as to whether the system is foot-based (such that stress is involved even in an abstract sense), but the present article does not engage with the rich morphophonology of the language that the other authors tackle.
Meter furnishes another, indirect means of probing whether the Vedic tone accent was accompanied by stress. In languages with stress—especially when stress is active in the lexical phonology (Kiparsky Reference Kiparsky2020:30)—the vast majority of quantitative meters are sensitive to it, whereas quantitative meters in languages with tone or tone accent (but not stress) are perhaps never sensitive to it (Section 1.1). Thus, while not clinching, the inertness of Vedic accent in every tested aspect of meter and poetics favors a realization as tone, not stress-plus-tone.
In conclusion, this article supports Vedic as a language with (largely) culminative tone accent without stress, in which respect it resembles languages such as Tokyo Japanese, Western Basque, and Somali. (To be sure, these languages vary in other respects, including the extent to which obligatoriness is enforced.) Vedic is less likely to be a language in which tone (whether lexical or intonational) associates with stress, as in Serbian (Inkelas & Zec Reference Inkelas and Zec1988), Franconian (Köhnlein Reference Köhnlein2016, Köhnlein et al. Reference Köhnlein, Cameron and Coppola2025), or Swedish (Riad Reference Riad2012, Morén-Duolljá Reference Morén-Duolljá2013). Another reason to test for fine-grained sensitivity to accent is that if the meter were sensitive to it, suggesting stress, one could turn around and use the meter to reassess the stress pattern of the language. For example, do vocatives, received as toneless, bear stress nevertheless? Such questions turn out to be moot, since the meter is insensitive to accent.
2. The corpus and its coding
2.1. Meters
For present purposes, the meters of the Rigveda are classified according to the number of syllables per line (in the restored text), being eight, eleven, or twelve.Footnote 12 Other line lengths, which are very infrequent, are set aside. Moreover, only the regular versions of these three line types are considered, each of which has a particular line structure. Less frequent line types are excluded, despite having the requisite number of syllables.Footnote 13 Further, the Vālakhilya section (0.8% of the corpus) is excluded, being an interpolation. Finally, repeated lines are excluded after their first instances (reducing the corpus by another 6.7%). After these exclusions, 33,229 lines remain (11,234 eight-syllable, 15,620 eleven-syllable, and 6,375 twelve-syllable), comprising the regular dimeter and trimeter corpus employed here.Footnote 14 Dimeter refers to the eight-syllable line, which is divided evenly into opening and cadence, albeit with no caesura. Trimeter refers to the eleven- and twelve-syllable lines, which feature a break between the opening and cadence and a caesura after the fourth or fifth position (both positions are available in both meters; Arnold Reference Arnold1905). For transparency, I refer to the three line types as meters 8, 11, and 12.
2.2. Strong and weak positions
Some tests below invoke positional strength, operationalized as follows. As is evident from Figure 1, in all three meters, weight-mapping is the most regular in the cadence. Regularity manifests both in strictness—each position being nearly categorically heavy or light—and also in the rhythmic, binary alternation between lights and heavies. Based on these criteria, the cadence comprises the final four positions of meters 8 and 11 and the final five of meter 12 (Lubotsky Reference Lubotsky, Semeka and Pankratov1995:515). Adopting terminology from generative metrics (e.g. Halle & Keyser Reference Halle and Keyser1971, Kiparsky Reference Kiparsky1977, Prince Reference Prince, Kiparsky and Youmans1989, Hanson & Kiparsky Reference Hanson and Kiparsky1996, Hayes et al. Reference Hayes, Wilson and Shisko2012), I refer to cadential positions that are normally filled by heavies as Strong (S) and those that are normally filled by lights as Weak (W). The remaining, pre-cadential positions are coded as Other (O). The three meters then have the forms in 1.

Two caveats are due about this treatment of strong vs. weak positions. First, in all meters, line-final position is conventionally understood to be indifferent to weight. As Figure 1 reveals, it is heavy roughly eighty percent of the time across meters. This applies even to meter 11, where I just referred to final position as weak. In generative metrics, positional strength is abstract—one might refer to an iambic or trochaic cadence—and final indifference is a license. More importantly, cross-linguistically, final indifference applies only to weight, not to stress or tone (Ryan Reference Ryan2019b:139). Thus, if accent were regulated by Vedic meter, a priori, one would not expect line-final position to be exempt. A second caveat is that the restriction of strong/weak to the cadence is not meant to suggest that there are no weight tendencies or strong/weak positions elsewhere in the line. But such tendencies are weaker (see Figure 1) and more complex: for example, in meters 11 and 12, caesura is usually immediately followed by a pair of lights, but the location of caesura is not fixed. Another reason to focus on the cadence is that if accent were metrically relevant, one might expect its effects to be clearest there, given that the cadence is metrically the strictest part of the line not just in Vedic, but cross-linguistically (ibid., deCastro-Arrazola Reference deCastro-Arrazola2018).
An anonymous reviewer raises the valid concern that even though weight is more strongly regulated in the cadence, hypothetically, that might not be true for accent, if accent is regulated. I therefore rerun every test with an alternative scheme in which S and W positions are coded throughout the line, as described in Section 3.6. For cohesion, I postpone presenting those tests until Section 3.6 rather than interleaving them throughout the article, but they yield qualitatively the same (negative) results as the original tests as coded in example 1.
2.3. Part of speech
At various points, I control for part of speech, based on annotations by Hellwig et al. (Reference Hellwig, Hettrich, Modi and Pinkal2018) (see also Hellwig et al. Reference Hellwig, Scarlata, Ackermann and Widmer2020). These top-level labels include noun, adjective, verb, adverb, verbal noun, and (in fewer than one percent of cases) other. Different parts of speech are distributed differently in the line (e.g. later in the line, verbs become more frequent relative to nouns) and also have different inherent accentual tendencies (e.g. verbs are more likely to be finally accented than nouns). Additionally, based on the same source, I distinguish between vocative and non-vocative nouns, as vocatives have special accentual behavior: their accent (if any) can only be word-initial. Vocatives are usually unaccented, but when line- or clause-initial (or when chained with other vocatives that are such), they receive a default initial accent. This is the only morphosyntactic category for which the location of accent in the word is determined by position in the line. Vocatives are therefore often excluded below.
2.4. Word shape
Some tests control for each word’s metrifiable shape, which affects where the word can appear in the line (Devine & Stephens Reference Devine and Stephens1994:74–79, Gunkel Reference Gunkel2010, Ryan Reference Ryan2011:419). To a first approximation, a word’s shape can be regarded as its syllable-weight template (e.g. light-heavy-light). However, more detail is needed for the peripheral syllables, whose weights are context-sensitive. Here, word shape encodes (i) whether all non-final syllables are heavy or light, (ii) whether the word begins with a vowel or consonant, and (iii) the weight class of the ultima (four levels). Vowel-initiality matters because a word-initial vowel may coalesce with a preceding vowel, in which case the resulting syllable is heavy.Footnote 15 For the ultima, I define four weight classes based on the rime, namely, VVC, V, V:, and VC/e/o. VVC (where VV is any long vowel or diphthong) is always heavy. V is usually light, but may glide or coalesce with a following vowel, potentially forming a heavy. V: is any long monophthong (not counting e and o, which, while long, function as diphthongs); before a consonant, a V: ultima is heavy; before a vowel, it coalesces, glides, or stands in hiatus (in which case it usually shortens). Finally, VC/e/o (where V is short) is heavy before a consonant and light before a vowel. In this manner, every word is coded for its metrifiable shape, which constrains its distribution in meter (e.g. agním ‘Agni’ is V-heavy-VC/e/o, mahā́n ‘great’ is C-light-VVC, and sukr˳tyáyā ‘by good deeds’ is C-light-heavy-light-V:).
2.5. Word type
Finally, word shape and part of speech can be combined into a single index termed word type. For example, agním ‘Agni’ is type V-heavy-VC/e/o-noun. These combinations are able to capture any idiosyncratic effects of word shape in different categories, both in terms of the distribution of words within the line and in terms of accentual tendencies within words.
3. Tests for the interaction of accent with meter
The tests in this section probe whether accent interacts systematically with meter. Specifically, they gauge whether accent is over- or underrepresented in strong vs. weak positions (both compared to each other and compared to other positions, outside of the cadence). If meter regulated accent, one might expect accent to be preferred in strong positions and/or avoided in weak positions. The present tests—treating disyllables (Section 3.1), monosyllables (Section 3.2), and longer words (Section 3.3), respectively—support no such interactions. Additionally, because it is possible that meter interacts with accent in other ways, this section also undertakes exploratory analysis via the visualization of accent distribution in the meters under controlled conditions.
3.1. Disyllable distribution
A disyllable may be initially or finally accented, or unaccented. The present test considers only accented disyllables, so as not to bias the results by the distribution of word-level accentedness (i.e. whether the word contains an accent or not), which, as discussed, declines across the line for reasons independent of meter. Furthermore, I exclude vocatives for the reasons discussed (Section 2). If accent were regulated by meter, one might expect to see the ratio of initially- to finally-accented disyllables vary systematically across positions. In particular, if accent behaved directionally like weight, one might expect it to be preferred in strong positions and/or avoided in weak positions.Footnote 16 That is, one might expect the ratio of σ́σ to σσ́ to be higher spanning strong-weak as opposed to weak-strong positions (cf. Hayes et al. Reference Hayes, Wilson and Shisko2012:701 on stress in English).
Figure 2 shows the percentage of accented disyllables that are initially accented in each position of the three meters. Position here refers to the locus of the word’s initial syllable. Strong and weak positions (as defined in Section 2) are shaded and striped, respectively. Error bars are 95% confidence intervals using Wilson (Reference Wilson1927) scores. While the plots for meters 8 and 12 might suggest a weak tendency for accent-meter alignment within the cadence, the cadential rates are generally in the range of the rates elsewhere in the line. Moreover, meter 11, the most frequent meter, shows no such pattern. An additional caveat is that the plots do not control for weight. For instance, in general, heavy-light words are more likely to be initially accented than light-heavy words (52% vs. 43%, including indeterminate ultimas in both groups). This alone might inflate the incidence of accent in strong positions relative to weak positions. Therefore, it is important to control for weight.
Percentage of disyllables starting in each position that are initially as opposed to finally accented. Solid-shaded positions are strong, striped positions weak.

Mixed-effects logistic regression is used to assess the overall effect of positional strength on accent while controlling for weight (word shape) and part of speech. The model predicts whether each accented disyllable
 $ \left(n=42,540\right) $
is initially accented. The lone fixed-effect predictor is position type (strong, weak, or other). As random effects, I employ the specific metrical position (e.g. ‘11-5’), each with its own intercept (i.e. bias for accent, modulo other factors). I also include random intercepts for word type, which combines word shape with part of speech (Section 2). Finally, the model includes random slopes for position type conditioned on word type, which corrects for any idiosyncratic tendencies of particular word types to be initially accented in particular position types. The regression formula is given in 2.Footnote
17
$ \left(n=42,540\right) $
is initially accented. The lone fixed-effect predictor is position type (strong, weak, or other). As random effects, I employ the specific metrical position (e.g. ‘11-5’), each with its own intercept (i.e. bias for accent, modulo other factors). I also include random intercepts for word type, which combines word shape with part of speech (Section 2). Finally, the model includes random slopes for position type conditioned on word type, which corrects for any idiosyncratic tendencies of particular word types to be initially accented in particular position types. The regression formula is given in 2.Footnote
17
The results (fit by glmmTMB; Brooks et al. Reference Brooks, Kristensen, van Benthem, Magnusson, Berg, Nielsen, Skaug, Mächler and Bolker2017) are provided in Table 2. The
 $ p $
-values are not significant (i.e. all are
$ p $
-values are not significant (i.e. all are
 $ p>0.05 $
), but the model does not directly test strong vs. weak; rather, it compares strong and weak separately to the baseline (pre-cadence positions). To check all three possible contrasts, a post hoc Tukey’s test is conducted using emmeans (Lenth Reference Lenth2024). This test confirms that strong and weak positions are neither distinct from the baseline nor from each other (lowest
$ p>0.05 $
), but the model does not directly test strong vs. weak; rather, it compares strong and weak separately to the baseline (pre-cadence positions). To check all three possible contrasts, a post hoc Tukey’s test is conducted using emmeans (Lenth Reference Lenth2024). This test confirms that strong and weak positions are neither distinct from the baseline nor from each other (lowest
 $ p=0.67 $
).
$ p=0.67 $
).
Regression table for fixed effects in the disyllable model.

In conclusion, with weight being controlled, there is no significant tendency for the accents of disyllables to be aligned with strong positions or avoided in weak ones.
3.2. Monosyllable distribution
A second, independent test is conducted, now on monosyllables. Since the location of accent cannot vary in a monosyllable, the present test differs from the previous one in not being confined to accented words. Rather, the distribution of accented monosyllables is compared to that of unaccented monosyllables, in either case excluding vocatives. (The remaining unaccented monosyllables comprise clitics and occasionally verbs.) The overall rates are shown in Figure 3. Because a line-initial word must be accented, the rate is 100% for that position. The general uptrend in accentedness from the second position to the middle of the line plausibly reflects the distribution of clitics, which frequently follow the line-initial word (Hale Reference Hale and Watkins1987). Moreover, the spikes at positions five and six of meters 11 and 12 reflect the avoidance of an enclitic immediately following caesura.
Percentage of monosyllables in each position that are accented.

At any rate, the interest here is the cadence, and whether accent correlates with strong vs. weak positions. The figure suggests no such correlation for meters 8 and 12, though some cycling is observed in meter 11. Nevertheless, the figure does not control for weight or part of speech. Under a weight- and category-controlled regression, as in Section 3.1 (except now excluding line-initial position, which is categorically accented here), no pairing of position types (strong, weak, or pre-cadential) is significant (lowest Tukey’s test
 $ p=0.83 $
;
$ p=0.83 $
;
 $ n=\mathrm{18,045} $
).
$ n=\mathrm{18,045} $
).
That said, Figure 3 reveals another way in which accent might interact with meter: across meters, the accent rate drops in line-final position, regardless of whether that position is strong or weak. Indeed, when a fixed effect for line finality is added to the previous model, it is significant
 $ \left(p=0.002\right) $
, while position type remains non-significant (lowest
$ \left(p=0.002\right) $
, while position type remains non-significant (lowest
 $ p=0.36 $
). The effect of line-finality will be confirmed in Section 3.4.
$ p=0.36 $
). The effect of line-finality will be confirmed in Section 3.4.
3.3. Other word shapes: an omnibus model
Monosyllables (Section 3.2) and disyllables (Section 3.1) together account for thirty-eight percent of the syllables in the corpus. The majority of syllables—and hence potential data—are furnished by longer words, to which this section turns. While the previous tests had dichotomous outcomes (initial vs. final accent for disyllables; accented vs. not for monosyllables), for longer words, more outcomes are possible, making a dichotomous test inappropriate. For example, in a trisyllable, accent (if any) could be initial, medial, or final.
One approach to handling longer words would be to switch from a by-word model (as in previous tests) to a by-syllable model, in which the outcome is the accentuation of each syllable in the corpus, restoring dichotomy. Alas, such an approach should not be used to judge significance, as it violates an assumption of logistic regression (Sonderegger Reference Sonderegger2023): within each word, the accentuation of each syllable is not an independent datum, since words typically have at most a single accent.
I therefore employ a word-based Monte Carlo method, using random permutations to obtain
 $ p $
-values.Footnote
18 Let a (single-accented) word of any length be denoted strong-aligned if its accent coincides with a strong position, and likewise for other position types, as illustrated for some possible trisyllable alignments to meter 8 in Table 3.
$ p $
-values.Footnote
18 Let a (single-accented) word of any length be denoted strong-aligned if its accent coincides with a strong position, and likewise for other position types, as illustrated for some possible trisyllable alignments to meter 8 in Table 3.
Some possible alignments of a trisyllable’s accent with meter 8.

For a given word shape, one can compute its corpus-wide strong-alignment rate, which is 21.2% for single-accented, non-vocative trisyllables in the regular meter corpus. The question is whether this observed rate is higher or lower than expected by chance. A chance baseline is computed by randomly permuting (shuffling) the accent patterns of trisyllables while leaving their loci intact. Under one such permutation, 20.9% of trisyllables are strong-aligned. The near-identity of the real and false (randomized) rates suggests that the poets were not sensitive to accent when localizing trisyllables. However, the method just outlined is incomplete, since the false rate varies on each computation; any single estimate might be an outlier. This is where the Monte Carlo method comes in. The false rate is recomputed a large number of times (here, 1,000). The
 $ p $
-value is then the proportion of trials in which the false rate exceeds the real rate, which is 0.026 in this case. While this
$ p $
-value is then the proportion of trials in which the false rate exceeds the real rate, which is 0.026 in this case. While this
 $ p $
-value is ostensibly significant, this simple illustration did not control for weight or part of speech. Moreover, the effect size is tiny (real 21.2% vs. mean false rate of 21.0%).
$ p $
-value is ostensibly significant, this simple illustration did not control for weight or part of speech. Moreover, the effect size is tiny (real 21.2% vs. mean false rate of 21.0%).
The permutation method generalizes to any number of word shapes of any specificity, provided that accent patterns are exchanged only between shapemates. To illustrate, Table 4 shows three arbitrary word types (specified as in Section 2) with their real and false (one trial) strong-alignment rates. For each trial, the weighted sum of real rates (here, 26.6%) is compared to that of false rates (here, 26.2%). The Monte Carlo
 $ p $
-value is the proportion of trials in which the overall false rate exceeds the overall real rate (here,
$ p $
-value is the proportion of trials in which the overall false rate exceeds the overall real rate (here,
 $ p=0.61 $
). Once again, this example is only an illustration of the method, not a full result.
$ p=0.61 $
). Once again, this example is only an illustration of the method, not a full result.
A sample of word types and their real vs. false alignments on one trial.

Full results for all single-accent, non-vocative words of three or more syllables in the regular meter corpus
 $ \left(n=\mathrm{49,692}\right) $
are given in Table 5. Five hypothetical position types are tested. The first row pits strong positions (as defined above) against all other positions, finding that the real rate of accent alignment is virtually identical to the expected (mean false) rate. Weak positions are likewise non-significant.Footnote
19
$ \left(n=\mathrm{49,692}\right) $
are given in Table 5. Five hypothetical position types are tested. The first row pits strong positions (as defined above) against all other positions, finding that the real rate of accent alignment is virtually identical to the expected (mean false) rate. Weak positions are likewise non-significant.Footnote
19
Final Monte Carlo results for various position types.

Line-finality, however, is significant in Table 5, in that over all 1,000 trials, the real rate is less than the expected rate
 $ \left(p<0.001\right) $
.Footnote
20 Because strong and weak positions overlap with line-final position, they were retested in the final two rows of Table 5 by counting only non-final strong/weak positions. With this adjustment, weak remains non-significant, but strong becomes significant, albeit with a small effect size (19.9% vs. 19.4%).
$ \left(p<0.001\right) $
.Footnote
20 Because strong and weak positions overlap with line-final position, they were retested in the final two rows of Table 5 by counting only non-final strong/weak positions. With this adjustment, weak remains non-significant, but strong becomes significant, albeit with a small effect size (19.9% vs. 19.4%).
The same method can be used to gauge not only position types, but specific metrical positions, which is useful for seeing whether the effects just discussed are consistent across positions of each type, serving as cross-validation. In Figure 4, each dot is the odds ratio of observed to expected alignment (where the expected rate is the mean of 1,000 permutations), and 95% confidence intervals are the [2.5, 97.5] percentiles of trials. I note the following. First, the overall range of odds ratios is small (most being between 0.9 and 1.1, where one represents no difference). Second, most of the error bars overlap with one (and even more would with any penalty for multiple tests). Third, and most importantly, other than final position, position types (strong or weak) do not behave consistently as classes. In particular, 43% of strong positions are above the baseline (60% if line-final strong positions are excluded). Similarly, 50% of weak positions are above the baseline (60% if the line-final weak position is excluded).
Monte Carlo observed vs. expected rates for each position as odds ratios.

To conclude, this section, treating polysyllables, finds a significant and reliable effect for line-final position such that across meters, final accent is avoided relative to the shape- and category-controlled baseline. As for strong positions, although this section finds that they tend significantly to align with accent in the aggregate, the tendency is small (half a percent) and inconsistent across individual strong positions. I therefore take the present results to agree with those of Sections 3.1–3.2, which likewise find no reliable effect of strong or weak positions, but support a line-final effect.
3.4. The avoidance of line-final accent
As just discussed, across meters, line-final position significantly disfavors accent, even when controlling for the expected rates of specific contexts using random effects. This section follows up on two items. First, it reinforces that the effect is largely consistent across word types, and therefore unlikely to be an epiphenomenon of specific words or grammatical types (which happen to be oxytone) being underrepresented line-finally for independent reasons. Second, I test whether Vedic prose also exhibits the preferential avoidance of line-final accent, in which case it would not be a specifically poetic phenomenon.
In the metrical corpus, for single-accented, non-vocative words of at least two syllables, Figure 5 shows the ten most frequent word types (as defined in Section 2). Each type is accompanied by its rate of word-final accent in two contexts, namely, non-line-final (left, lighter bar) and line-final (right, darker bar). For the first eight types, the line-final rate is lower, while the final two rows are essentially ties. The model in 3 confirms the generalization for all word types (including those not shown in Figure 5). Word-final accent significantly reduces the likelihood of a word’s appearing line-finally (odds ratio 0.78,
 $ p<0.0001 $
,
$ p<0.0001 $
,
 $ n=\mathrm{92,232} $
). The random intercepts for word type (e.g. C-heavy-VC/e/o-noun) as well as for specific word identity (e.g. agním) reinforce that this effect is not being driven by particular items.Footnote
21
$ n=\mathrm{92,232} $
). The random intercepts for word type (e.g. C-heavy-VC/e/o-noun) as well as for specific word identity (e.g. agním) reinforce that this effect is not being driven by particular items.Footnote
21
Ten most frequent word types, each with its rate of word-final accent when non-line-final (light) vs. line-final (dark). In almost every case, the line-final rate is lower.

I turn now to Vedic prose in order to test whether line-final accent is also disfavored in non-metrical contexts. As an accented Vedic prose corpus, I employ the prose sections of the Taittirīya Saṃhitā (also known as the Black Yajurveda) and Taittirīya Brāhmaṇa.Footnote 22 To (largely) filter out metered material, I exclude all lines of eight, eleven, or twelve syllables. After further removing duplicate lines, 20,850 lines remain. The analysis here considers only accented words of at least two syllables, and further excludes line-initial words.Footnote 23
As Figure 6 reveals, tonal N
on
F
inality (see Section 5) is once again in strong effect. Because weight is unregulated in prose, word shape is replaced by word size in syllables. For all word sizes, word-final accent is significantly less likely line-finally than line-medially. Logistic regression (same formula as in example 3, except using word size in lieu of word type) confirms that the effect is general, and not being driven by specific words or word sizes (odds ratio 0.49,
 $ p<0.0001 $
,
$ p<0.0001 $
,
 $ n=\mathrm{64,404} $
). I conclude that while tonal Non
Finality is robust in the Rigveda, it is not a metrical phenomenon, but more general the language.
$ n=\mathrm{64,404} $
). I conclude that while tonal Non
Finality is robust in the Rigveda, it is not a metrical phenomenon, but more general the language.
Word sizes (2–6 syllables) in Vedic prose, each with its rate of word-final accent when non-line-final (light) vs. line-final (dark). In every case, the line-final rate is lower.

A reader asks whether NonF inality also holds of word-level phonology, and it does, but only as a tendency in longer words. For disyllables, accent is roughly equally likely to be initial or final, but for increasingly long words, final accent is increasingly underrepresented (Sandell Reference Sandell2023a:425–28). For example, 14% of quadrisyllables (by type) have final accent (ibid.). To be sure, this word-level NonFinality does not directly explain the line-level NonFinality found in this section. The regression models include random effects for word type and identity, which means that regardless of how infrequent final accent is in words, it is even less frequent line-finally. For example, for a quadrisyllabic noun with a particular weight pattern, the model predicts a baseline rate of line-finality via the random intercepts. If one adds the information that the quadrisyllable is finally accented, that rate is adjusted downwards by the fixed effect.
Thus, the following type of explanation would not be compatible with this section’s results: line-final accent is underrepresented because longer words tend to be line-final, and they are unlikely to be finally accented. The random effects undermine such an explanation. Likewise, one cannot say that the effect is driven by unaccented words being more likely line-finally, since the model only uses accented words as data. A successful explanation would need to apply generally across word types (shapes and parts of speech). For example, perhaps there is a low boundary tone L% which is felt to be in tension with H]
 $ {}_{\iota } $
. I do not claim that this is the actual explanation, just that it is the type of explanation that is needed.
$ {}_{\iota } $
. I do not claim that this is the actual explanation, just that it is the type of explanation that is needed.
The reader also raises the point that Vedic poetry and prose are both high-register genres, in which sentences are carefully crafted, and might therefore be more responsive to euphony than ordinary language. It is true: I have shown that line- or sentence-level NonFinality is not confined to meter, but the effect might not hold for all registers.
3.5. The post-accentual fall (svarita) is also not a target of alignment
Throughout the article, I test meter’s alignment with the phonological locus of high-tone accent, termed udātta ‘raised’ and indicated in romanization by the acute. In phonetic realization, the udātta is rising, with the peak achieved either late in the syllable or on the following syllable, depending on the text/tradition (Macdonell Reference Macdonell1910:77, Beguš Reference Beguš, Jamison, Melchert and Vine2016:4). The post-udātta syllable (if not itself udātta or immediately pre-udātta) is realized with a sharp drop known as the svarita (ibid.), which Pāṇini 1.2.31 defines as samāhāra ‘compound’, in the sense of high + low. One could imagine that this fall is perceptually salient.
I will test whether svarita is better aligned with the meter than udātta presently, but find it a priori unlikely, for two reasons. First, svarita is merely an ‘allotone’, dependent on the phonological accent (udātta).Footnote 24 It is common for accented words to lack the svarita altogether due to their context; svarita, unlike udātta, is a post-lexical, phrasal phenomenon.Footnote 25 Second, svarita was almost certainly not the pitch peak at composition. Some recitational traditions still reach the peak on the udātta, including the padapāṭha version of the Rigveda recorded in Kerala in 1961 (Witzel Reference Witzel, Oettinger, Schaffner and Steer2020). Sandell (Reference Sandell2023a:294) concludes that ‘[g]eographically separate regions thus preserved the original Vedic intonational system without peak delay’.
Nevertheless, to be thorough, I test whether the svarita is better aligned to the meter than the udātta. Here, a word-shape-specific test is inappropriate, given svarita’s phrasal nature. I therefore consider overall alignment with strong vs. weak positions in the regular meter corpus, excluding line-final position. For udātta, the strong-to-weak ratio is 1.17 (15,571 to 13,289). For svarita, it is 0.94 (11,967 to 12,725). Svarita is not better aligned than the udātta.
3.6. An alternative, more inclusive coding scheme for positional strength
While weight is regulated more strictly in the cadence than elsewhere in the line, if accent were regulated, the same generalization might not hold for accent. Therefore, my original coding scheme for positional strength (Section 2), which recognizes strong and weak positions only within cadences (pre-cadence positions being ‘other’), might be overconservative. In this section, I rerun the tests above (disyllable, monosyllable, and omnibus), but now coding strength throughout (most of) the line, as in 4. The overall verdict remains negative: there is no discernible correlation between accent and positional strength.

For all three meters, the opening (i.e. first four positions) is, if anything, abstractly iambic (WSWS), as suggested by the distribution of weight in Figure 1. (I have confirmed that when word shape is controlled, the weight biases remain.) Meters 11 and 12 further exhibit a ‘break’ of three positions (5–7) between the opening and cadence, which I leave coded as ‘other’. While weight in Figure 1 might suggest that all three positions are weak, because there is no regular rhythmic alternation, and because caesura interrupts this span (in one of two possible positions), analyzing strength in this part of the line is less straightforward.
Under this new scheme, the disyllable test (Section 3.1) is non-significant (
 $ \beta =-0.019,p=0.88 $
for strong vs. weak), as is the monosyllable test (Section 3.2) (
$ \beta =-0.019,p=0.88 $
for strong vs. weak), as is the monosyllable test (Section 3.2) (
 $ \beta =0.245,p=0.57 $
). While monosyllable accentedness appears to alternate in openings in Figure 3, a general effect of position type is not supported (given also the random effects for word type). An effect might be supported if openings were analyzed separately from the rest of the line, but aside from concerns about fishing, such a test would not be probative: recall that the monosyllable test (unlike the other tests) considers only whether words are accented; as such, it largely reduces to a test of the distribution of clitichood. Clitics are richly constrained at the left periphery (e.g. Wackernagel’s law). Further, the trend in Figure 3 contradicts the posited iambic pattern. Finally, it would be surprising, perhaps universal-breaking, for the meter to regulate a prosodic feature in the opening but not the cadence.
$ \beta =0.245,p=0.57 $
). While monosyllable accentedness appears to alternate in openings in Figure 3, a general effect of position type is not supported (given also the random effects for word type). An effect might be supported if openings were analyzed separately from the rest of the line, but aside from concerns about fishing, such a test would not be probative: recall that the monosyllable test (unlike the other tests) considers only whether words are accented; as such, it largely reduces to a test of the distribution of clitichood. Clitics are richly constrained at the left periphery (e.g. Wackernagel’s law). Further, the trend in Figure 3 contradicts the posited iambic pattern. Finally, it would be surprising, perhaps universal-breaking, for the meter to regulate a prosodic feature in the opening but not the cadence.
The omnibus Monte Carlo tests for longer words (Section 3.3) are borderline here. For strong positions (coded as in example 4, but excluding line-final position as in Section 3.3), the alignment of the real corpus is 35.7%, vs. a mean of 35.4% over 1,000 permutations
 $ \left(p=0.018\right) $
. For (non-final) weak positions, the real rate is 34.0% vs. a mean of 33.7% for permutations
$ \left(p=0.018\right) $
. For (non-final) weak positions, the real rate is 34.0% vs. a mean of 33.7% for permutations
 $ \left(p=0.993\right) $
. In both cases, the difference is miniscule (0.3%). Moreover, for weak positions, the directionality is the opposite of the prediction: accent occurs in weak positions more often in the real corpus than it does in the permutations.
$ \left(p=0.993\right) $
. In both cases, the difference is miniscule (0.3%). Moreover, for weak positions, the directionality is the opposite of the prediction: accent occurs in weak positions more often in the real corpus than it does in the permutations.
4. Tests of other possible poetic phenomena
4.1. Accentual responsion
Thus far, I have focused on ways in which accent might interact with Vedic meter. Beyond meter, other poetic uses of accent are conceivable. This section considers whether accentual contours tend to agree (in whole or in part) between adjacent lines, a (possible) phenomenon that I refer to as accentual responsion.Footnote 26 (‘Accentual rhyme’ would be another way of putting it.) Lubotsky (Reference Lubotsky, Semeka and Pankratov1995) proposes that the Rigveda exhibits various kinds of accentual correspondence between lines, exemplifying them but not testing them statistically.
I begin by extracting all couplets from the regular meter corpus (Section 2), where a couplet is operationalized as adjacent a and b lines, or c and d lines, provided that their length (and hence meter) is the same (see Gunkel & Ryan Reference Gunkel, Ryan, Gunkel and Hackstein2018 on the Rigvedic couplet). The resulting corpus comprises 13,400 couplets, eighty-one percent of the original corpus.Footnote
27 Among these couplets, 0.98% agree (i.e. have repeated accent patterns). As a baseline of expectation, the couplets can be shuffled, such that each couplet-initial (a or c) line is paired with a randomly chosen line of the same length from another verse. As in Section 3.3, the shuffle can be iterated many times to increase the reliability of the estimate and obtain a
 $ p $
-value – the Monte Carlo method. In this case, for 1,000 trials, the mean false rate is 0.72%
$ p $
-value – the Monte Carlo method. In this case, for 1,000 trials, the mean false rate is 0.72%
 $ \left(p=0.001\right) $
.
$ \left(p=0.001\right) $
.
While this
 $ p $
-value is ostensibly significant, it is flawed. The method fails to control for other kinds of parallelism that incidentally inflate accentual responsion. For example, consider 5.38.5 (lines c–d) in example 5 (translation Jamison & Brereton Reference Jamison and Brereton2014), one of the rare couplets with full agreement in accent. Whenever one or more words are repeated in the same position across lines—for any reason—it increases the likelihood that the lines as wholes will match in accent.Footnote
28 Additionally, the couplet in 5 illustrates a less trivial point: even absent literal repetition, structural parallelism can induce accentual agreement. Here, both lines begin with a vocative noun. Because a line-initial vocative must be initially accented (Section 2), this grammatical parallelism entails accentual parallelism. The same would hold if the vocatives were line-final (both unaccented), or if both lines ended with principal-clause finite verbs (both unaccented), and so forth. Thus, even purely syntactic parallelism (which abounds; Gonda Reference Gonda1959, Klein Reference Klein2001, Reference Klein2002) stacks the deck in favor of accentual agreement relative to the randomized baseline.
$ p $
-value is ostensibly significant, it is flawed. The method fails to control for other kinds of parallelism that incidentally inflate accentual responsion. For example, consider 5.38.5 (lines c–d) in example 5 (translation Jamison & Brereton Reference Jamison and Brereton2014), one of the rare couplets with full agreement in accent. Whenever one or more words are repeated in the same position across lines—for any reason—it increases the likelihood that the lines as wholes will match in accent.Footnote
28 Additionally, the couplet in 5 illustrates a less trivial point: even absent literal repetition, structural parallelism can induce accentual agreement. Here, both lines begin with a vocative noun. Because a line-initial vocative must be initially accented (Section 2), this grammatical parallelism entails accentual parallelism. The same would hold if the vocatives were line-final (both unaccented), or if both lines ended with principal-clause finite verbs (both unaccented), and so forth. Thus, even purely syntactic parallelism (which abounds; Gonda Reference Gonda1959, Klein Reference Klein2001, Reference Klein2002) stacks the deck in favor of accentual agreement relative to the randomized baseline.
It would be impossible to control for every conceivable kind of parallelism, but spurious parallelism can be reduced by excluding any couplet in which (i) any word is repeated between lines or (ii) the two lines have the same number of words. For consistency, I apply these criteria to both real and scrambled couplets. If the poets strive for accentual responsion per se, it should obtain independently of other kinds of parallelism. The criteria just stated only partially break parallelism; much of it will remain in the real couplets (e.g. syntactic parallelism between lines with different numbers of words, the same lexeme being repeated but with different endings, etc.). At any rate, even this partial reduction in parallelism is enough to eliminate the effect: among real couplets, the rate of responsion is now 0.58%; among scrambled couplets, 0.65%
 $ \left(p=0.87\right) $
.
$ \left(p=0.87\right) $
.
So far, I have tested only for exact correspondence between lines. It is also conceivable that the poets favored partial correspondence (between parts of lines and/or skipping positions). To test this looser hypothesis, I adopt various strictness thresholds based on the Levenshtein edit distance between the two accent patterns (i.e. the number of substitutions needed to bring the patterns into alignment). Results for distances up to two are given in Table 6. (For greater distances, the baseline exceeds 50%.) Although one of the distances is marginally significant, the effect size is miniscule (0.36% higher than chance). Given further that it is sandwiched between non-significant results,Footnote 29 on top of which uncaptured parallelism surely remains in the real couplets, I take the overall verdict to be negative.
Monte Carlo results for accentual responsion.

A simpler but more limited test focuses on specific word shapes in specific positions. For example, consider all couplets in which both lines begin with a disyllable
 $ \left(n=\mathrm{3,503}\right) $
. From these, I exclude any couplet in which the two disyllables are the same word, leaving 2,751 couplets. The question is whether the accent pattern of word A (from the first line) is predictive of that of word B (from the second). Based on the contingencies in Table 7, it is not (Fisher’s exact test odds ratio 0.91,
$ \left(n=\mathrm{3,503}\right) $
. From these, I exclude any couplet in which the two disyllables are the same word, leaving 2,751 couplets. The question is whether the accent pattern of word A (from the first line) is predictive of that of word B (from the second). Based on the contingencies in Table 7, it is not (Fisher’s exact test odds ratio 0.91,
 $ p=0.21 $
). In the table, ‘10’ refers to initial accent, ‘01’ to final accent. The conclusion is the same for line-final disyllables, not shown (odds ratio 0.87,
$ p=0.21 $
). In the table, ‘10’ refers to initial accent, ‘01’ to final accent. The conclusion is the same for line-final disyllables, not shown (odds ratio 0.87,
 $ p=0.31 $
).
$ p=0.31 $
).
Accent patterns of successive line-initial disyllables.

Other kinds of accentual correspondence are logically possible. One could imagine, for instance, that responsion obtains between couplets rather than lines, in which case a would correspond with c, and b with d. I reran the test in Table 6 with this treatment (using a/c and b/d as couplets) and got similar results: while the
 $ p $
-values are borderline, the caveats to Table 6 apply.Footnote
30 In conclusion, this section has tested some simple possible scenarios for accentual responsion, finding no support for the phenomenon in the Rigveda.
$ p $
-values are borderline, the caveats to Table 6 apply.Footnote
30 In conclusion, this section has tested some simple possible scenarios for accentual responsion, finding no support for the phenomenon in the Rigveda.
4.2. Accentual clash and lapse
Some languages avoid adjacent prominent syllables, a configuration known as clash (e.g.Tilsen Reference Tilsen, Fuchs, Weirich, Pape and Perrier2012:122f). In a tonal context, the Obligatory Contour Principle (OCP) penalizes adjacent identical tones (e.g. Hyman Reference Hyman, Goldsmith, Riggle and Alan2011b:494ff). Additionally, some languages avoid adjacent unstressed syllables, a configuration known as stress lapse (e.g. Gordon Reference Gordon2004). (Lapse is less likely to apply to tone, but I test it anyway.) Together, constraints against clash and lapse favor alternation in prominence. That is, if both *Clash and *Lapse are undominated, stress occurs on every other syllable. Because Vedic tonal accent is culminative (at most one per word, barring unusual cases), clash and lapse are moot within words. Nevertheless, it remains possible that they might emerge as preferences across words (reminiscent of the rhythm rule of English; e.g. Tilsen Reference Tilsen, Fuchs, Weirich, Pape and Perrier2012). Specifically, if clash/OCP were active, it might manifest in the underrepresentation of bigrams of the form σ*σ́ σ́* (i.e. adjacent accents across a word boundary). Likewise, if lapse were active, one might observe a dispreference for boundaries flanked by unaccented syllables.
Table 8 is set up like Table 7, except that now words A and B are adjacent words within the line. There is no contingency between the accent patterns of the two words (Fisher’s exact test odds ratio 1.01,
 $ p=0.76 $
). Trisyllables (of type 100 vs. 001) were also tested, with no effect (odds ratio 0.87,
$ p=0.76 $
). Trisyllables (of type 100 vs. 001) were also tested, with no effect (odds ratio 0.87,
 $ p=0.13 $
). In conclusion, I find no evidence for the OCP or accentual lapse in word arrangements in the Rigveda.
$ p=0.13 $
). In conclusion, I find no evidence for the OCP or accentual lapse in word arrangements in the Rigveda.
Accent patterns of successive disyllables.

4.3. Accentual formulas
Like clash and lapse, the question of accentual formulas concerns syntagmatic tendencies in accent arrangement, except now more generally: When arranging words, are there particular sequences of accent that the poets favor above chance? This section finds no such tendencies.
As an initial test, let a line’s accentual cadence be the accent pattern of its final five syllables.Footnote
31 In the regular meter corpus, all
 $ {2}^5=32 $
possible combinations are attested except 11111 (all-accented). The frequency of each such pattern in the real corpus (even when zero) is compared to that of ‘scrambled’ corpora. Each scrambled corpus
$ {2}^5=32 $
possible combinations are attested except 11111 (all-accented). The frequency of each such pattern in the real corpus (even when zero) is compared to that of ‘scrambled’ corpora. Each scrambled corpus
 $ \left(n=10\right) $
randomly permutes the word accent patterns of the real corpus while keeping the loci of word types (Section 2) fixed, such that the weight, boundary, and part of speech patterns are held constant. For each accentual cadence, an observed vs. expected (O/E) value is computed and significance-tested (exact binomial test, Bonferroni-adjusted for thirty-two tests). For example, pattern 10110 occurs 229 times in the real corpus and 2,211 times in the ten scrambles, making for an O/E of 1.04 (adjusted
$ \left(n=10\right) $
randomly permutes the word accent patterns of the real corpus while keeping the loci of word types (Section 2) fixed, such that the weight, boundary, and part of speech patterns are held constant. For each accentual cadence, an observed vs. expected (O/E) value is computed and significance-tested (exact binomial test, Bonferroni-adjusted for thirty-two tests). For example, pattern 10110 occurs 229 times in the real corpus and 2,211 times in the ten scrambles, making for an O/E of 1.04 (adjusted
 $ p=1 $
). Of all thiery-two accentual cadences, only one has a positive, significant O/E, namely, 00110 (odds ratio 1.14,
$ p=1 $
). Of all thiery-two accentual cadences, only one has a positive, significant O/E, namely, 00110 (odds ratio 1.14,
 $ p=0.02 $
). However, the effect size is small, the
$ p=0.02 $
). However, the effect size is small, the
 $ p $
-value is marginal, and the greater likelihood might simply reflect the avoidance of line-final accent that was already established (Section 3.4), which inflates the O/Es of all 0-final accentual cadences.
$ p $
-value is marginal, and the greater likelihood might simply reflect the avoidance of line-final accent that was already established (Section 3.4), which inflates the O/Es of all 0-final accentual cadences.
Since an accentual formula might hypothetically occur elsewhere in the line, I use the same method to test five-position sequences starting from line-initial position. Of thirty-two patterns (all of which are attested in the real corpus), none has an O/E of significantly greater than one. In conclusion, I find no evidence of accentual formulas in the Rigveda.
4.4. Accent-modulated weight mapping
This section tests for one final possible role of accent in Vedic meter, which is that weight is regulated more strictly in accented syllables. Typologically, this phenomenon has been observed for stress and weight. Ryan (Reference Ryan2017) refers to it as stress-modulated weight mapping. The meter of the Finnish Kalevala, for instance, is a quantitative trochaic tetrameter, such that odd positions are heavy and even positions light, especially later in the line. However, this mapping rule is stringently enforced only for stressed syllables; unstressed syllables are largely free to be heavy or light in any position (ibid., Kiparsky Reference Kiparsky and Gribble1968). One could imagine a similar tendency in Vedic, such that exceptions to the quantitative template might be less frequent under accent. From the regular meter corpus, I take only non-line-final, cadential strong and weak positions (Section 2). In these positions, the overall rate of exceptionality (i.e. light in strong or heavy in weak) is 3.3%. Considering only accented syllables in these positions, the rate is 4.2%; for unaccented syllables, it is 2.9%.Footnote 32 In sum, no regular effect of accentual modulation is supported.
5. Conclusion
Having tested several possible ways in which Vedic pitch accent could conceivably play a role in its meter, the overall verdict is negative. Independent tests of monosyllables, disyllables, and longer words—all controlling for word shape and part of speech—failed to find any significant, consistent interaction of accent with strong or weak positions, or any other systematic effects in meter. Moreover, beyond meter, four other potential poetic phenomena involving accent were tested, all unsupported. In particular, no evidence was found for accentual responsion between lines or couplets, accentual clash/OCP or lapse, accentual formulas, or greater strictness under accent.
One positive finding did emerge: Accent is actively avoided line-finally, both in strong- and weak-final meters. However, the effect is found also in prose, and is thus not specific to meter. The relevant constraint is tonal N on F inality, as attested elsewhere. In Nkore, for instance, a high tone is proscribed at the end an intonation phrase (Odden Reference Odden2005:319); similar cases are Haya (Hyman Reference Hyman2009:223) and Silozi (Bickmore Reference Bickmore2024:219). In example 6, Nkore omugúzi is underlyingly high-final, as (d) reveals, but the tone retracts phrase-finally in (c). In Vedic, the repair differs: instead of tone flop, the avoidance would seem to arise from tendencies involving word order and/or lexical selection. Further study is needed.

The metrical inertness of Vedic accent supports (along with other evidence) its realization as purely tonal, as opposed to tone co-occurring with stress (Sections 1.1–1.2). Additionally, given that accent is critical for lexical and grammatical distinctions, its absence from the meter/poetics reinforces that languages do not simply import prosodic features into their poetics according to importance in the grammar or lexicon (functional load, grammatical activity, accessibility, transparency, frequency, etc.). Syllable weight, by contrast, which is regulated by the meter, plays a comparatively marginal role in Vedic grammar. That said, vowel length, though not weight per se, is contrastive (as well as manipulated morphologically by gradation), which likely helps to make quantitative meter available.
Put simply, Vedic meter is concerned only with timing, and tone is not timing. In this respect, its metrics resembles that of Ancient Greek, or Hausa (Hayes & Schuh Reference Hayes and Schuh2019), though tone’s role in those systems has not been scrutinized as thoroughly (and the latter is influenced by the metrics of Arabic, which lacks tone). While cross-linguistically, some meters regulate tone extensively (e.g. Vietnamese; Kiparsky Reference Kiparsky2020:32) or as part of a suite of features (e.g. Serbian; Jakobson Reference Jakobson1952, Batinic Reference Batinic1975, Zec Reference Zec, Hanson and Inkelas2009, Milenković & Ryan Reference Milenković and Ryan2025), Vedic represents the opposite pole, being purely quantitative in its metrics, despite being a kind of tone language.
Although these results bear out the conventional wisdom (that Vedic accent is unregulated by its meters) and are therefore unsurprising, that wisdom is underinformed, being based on the absence of categorical constraints on accent. Possible significant tendencies or interactions have gone largely unstudied. This article’s contribution lies not only in its findings, but in its methodology, controlling for word shapes and categories through mixed-effects models (Sections 3.1–3.2) and the Monte Carlo method (Sections 3.3 and 4.1). This study also addresses a possible ‘file drawer’ problem. In over a century of scholarship, I am probably not the first to test for accentual preferences in Vedic meter, yet no such analysis has been published.Footnote 33 Scholars might have conducted preliminary tests and, encountering weak effects or methodological complications, abandoned the inquiry or failed to publish negative results. This article establishes that the question has been systematically investigated, though further possible interactions remain to be tested, both in Vedic and in other quantitative traditions.
Acknowledgments
I am grateful to Dieter Gunkel and Ryan Sandell for comments on an earlier draft of this article, and to Laura McPherson and two anonymous referees for their helpful feedback. Any remaining errors are my own.
Data availability statement
The data underlying this article are drawn from the Rigveda, a classical text freely available in multiple public editions and digital repositories.
Conflict of interest statement
The author declares no conflict of interest.
Funding disclosure statement
This research received no external funding.
Ethics statement
This research required no ethical approval.












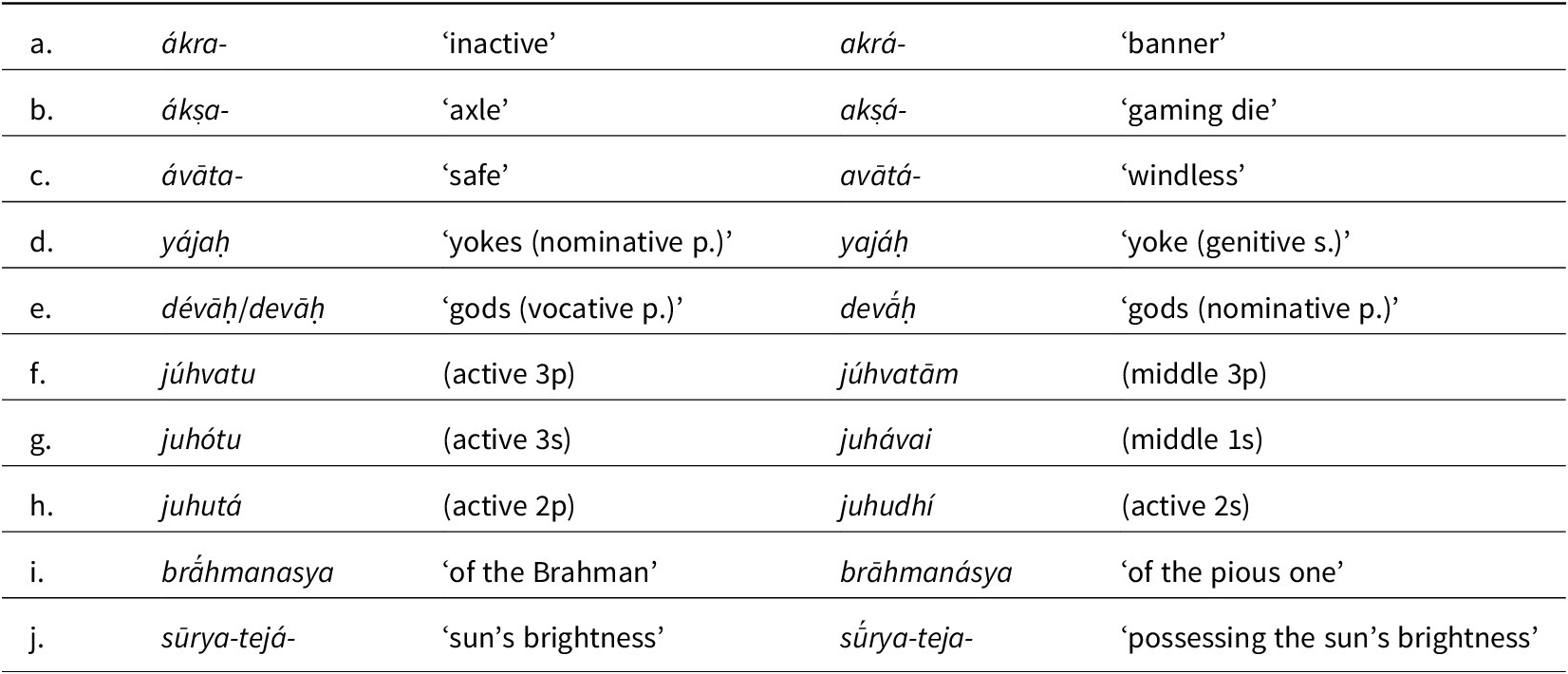
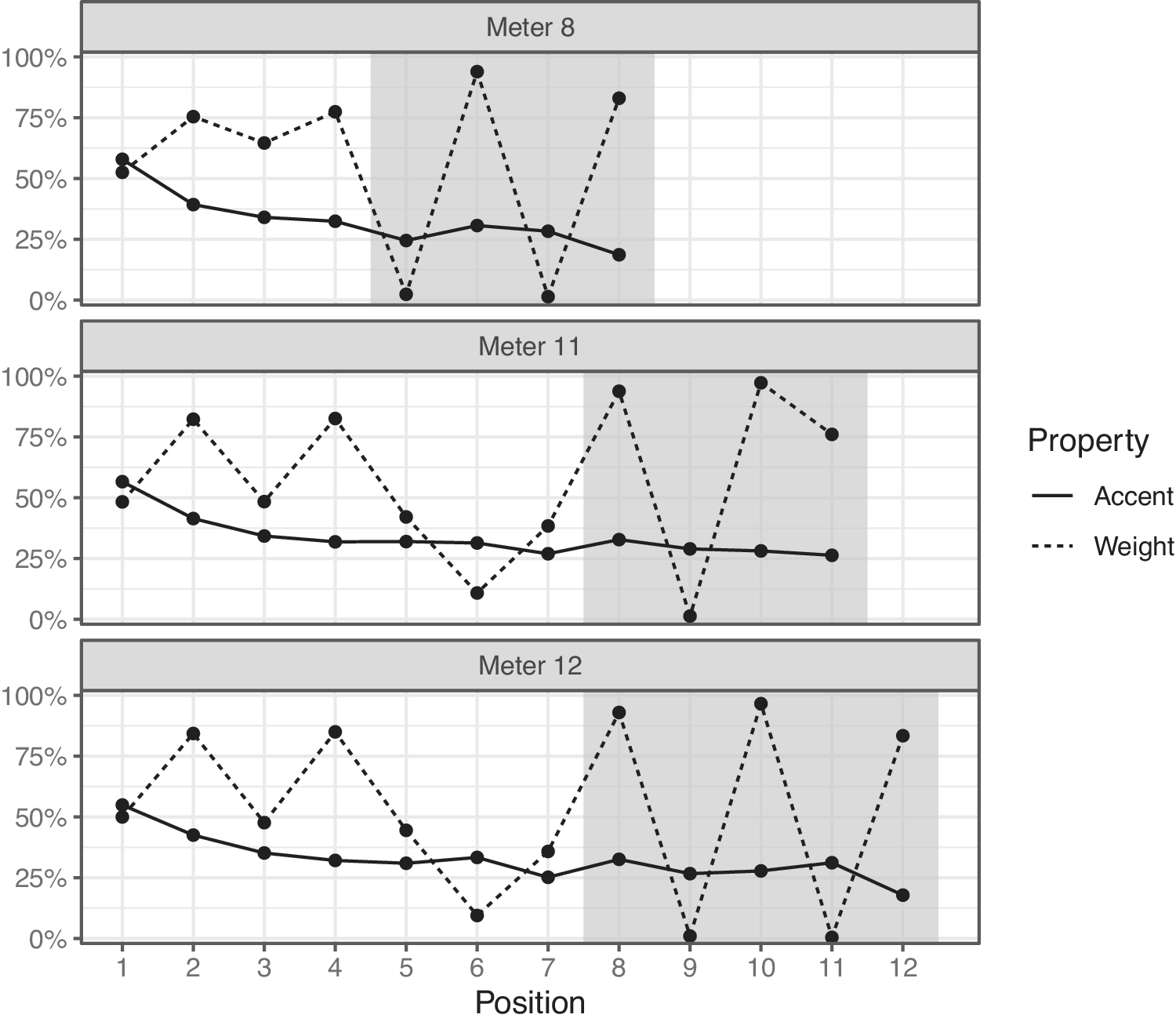
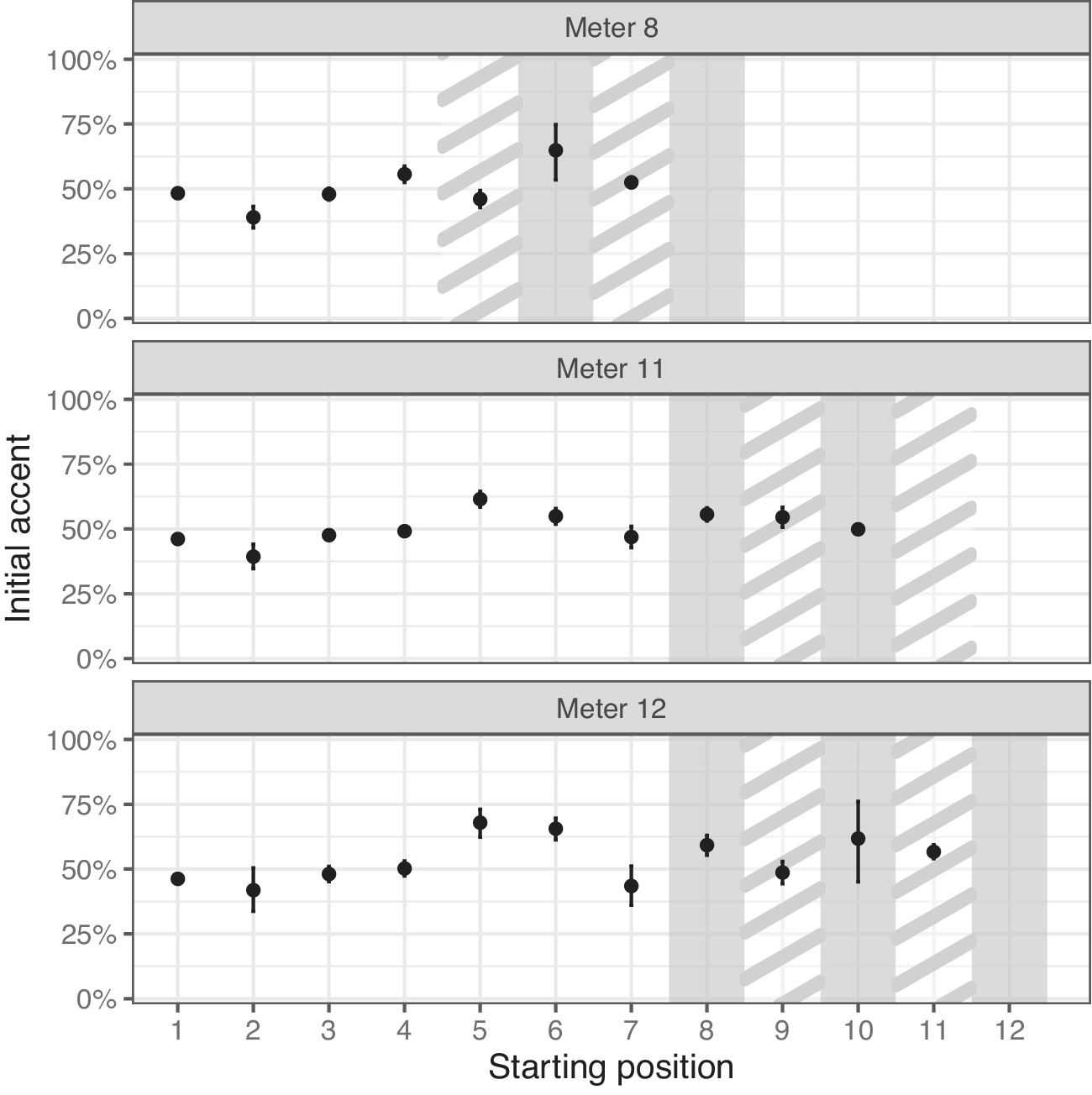

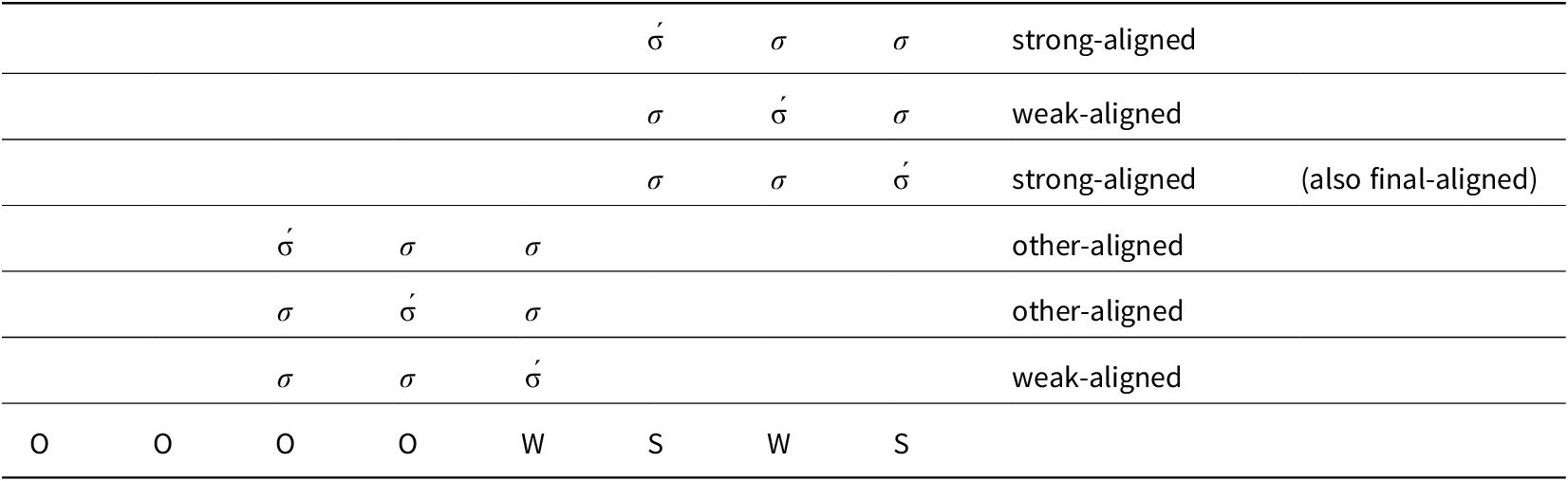

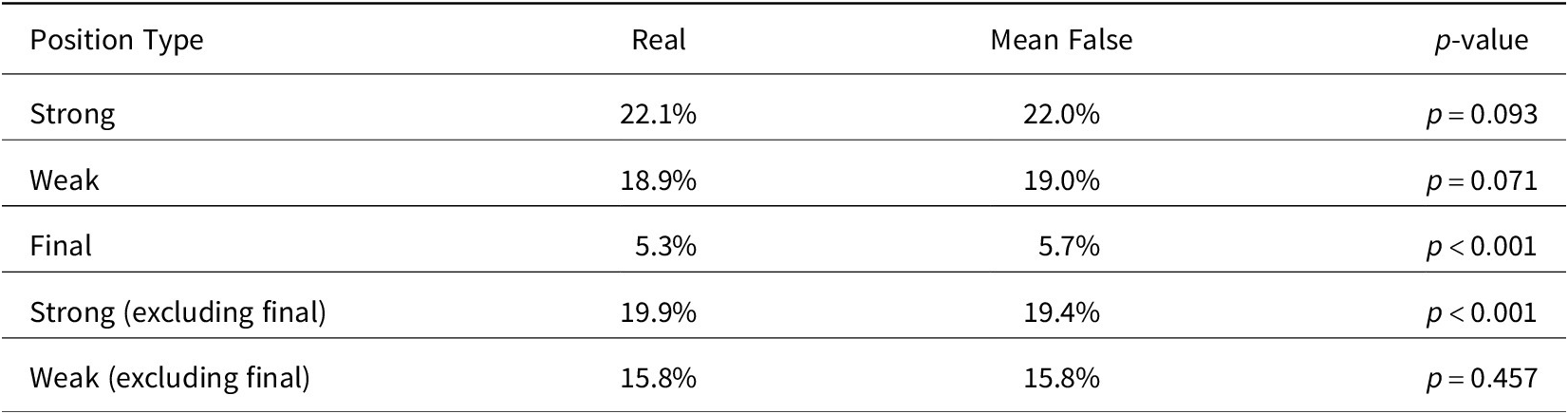
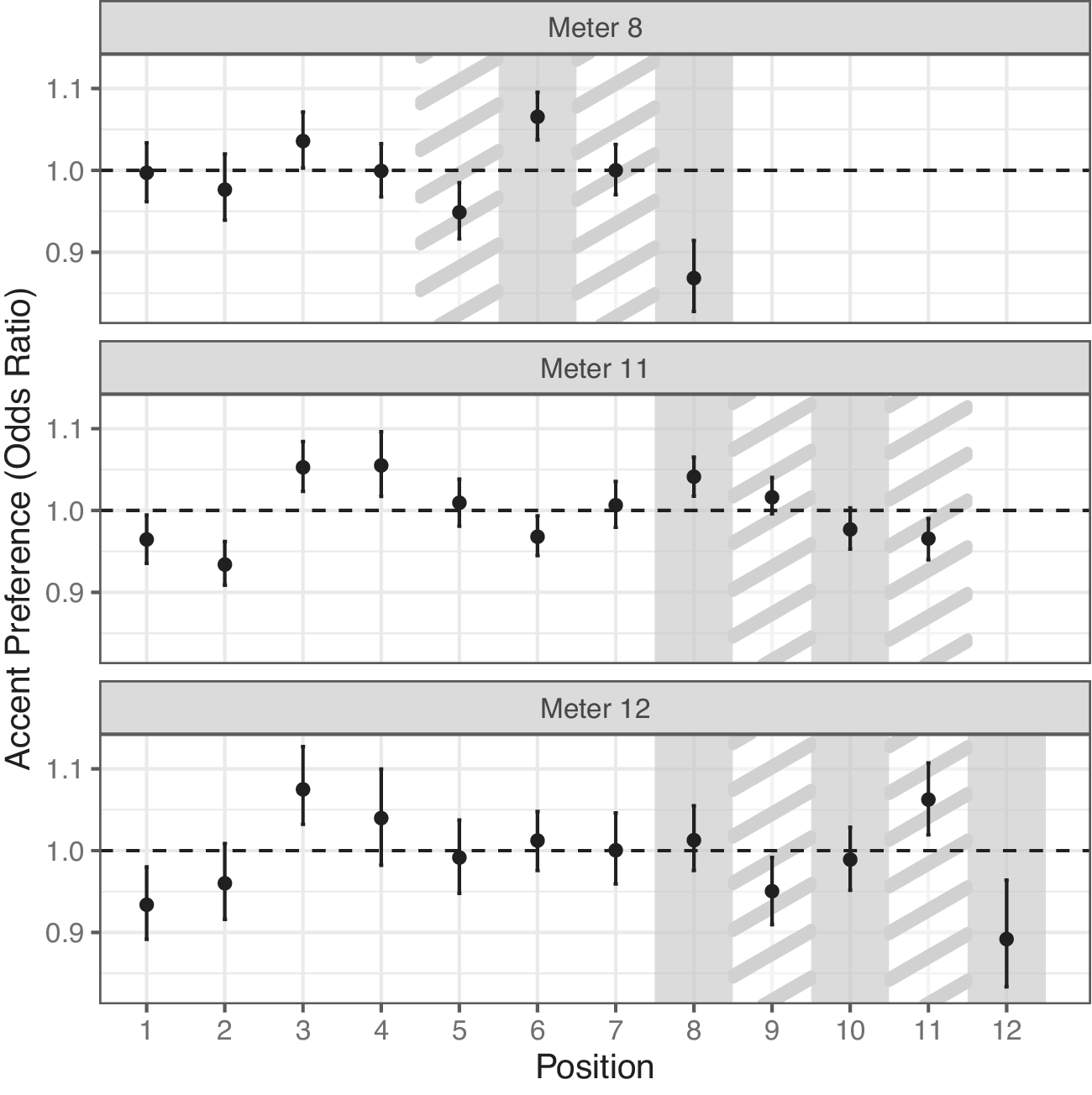
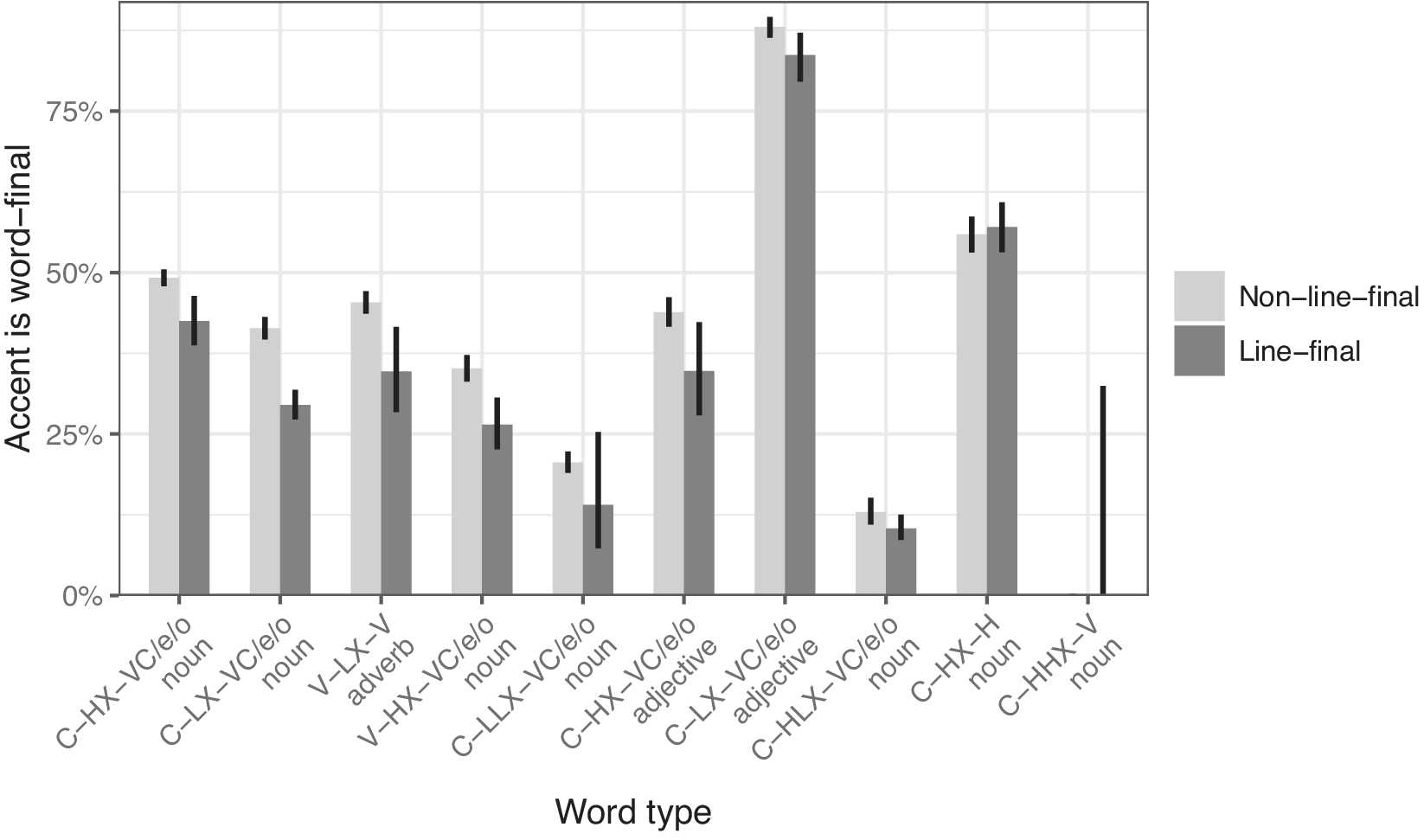
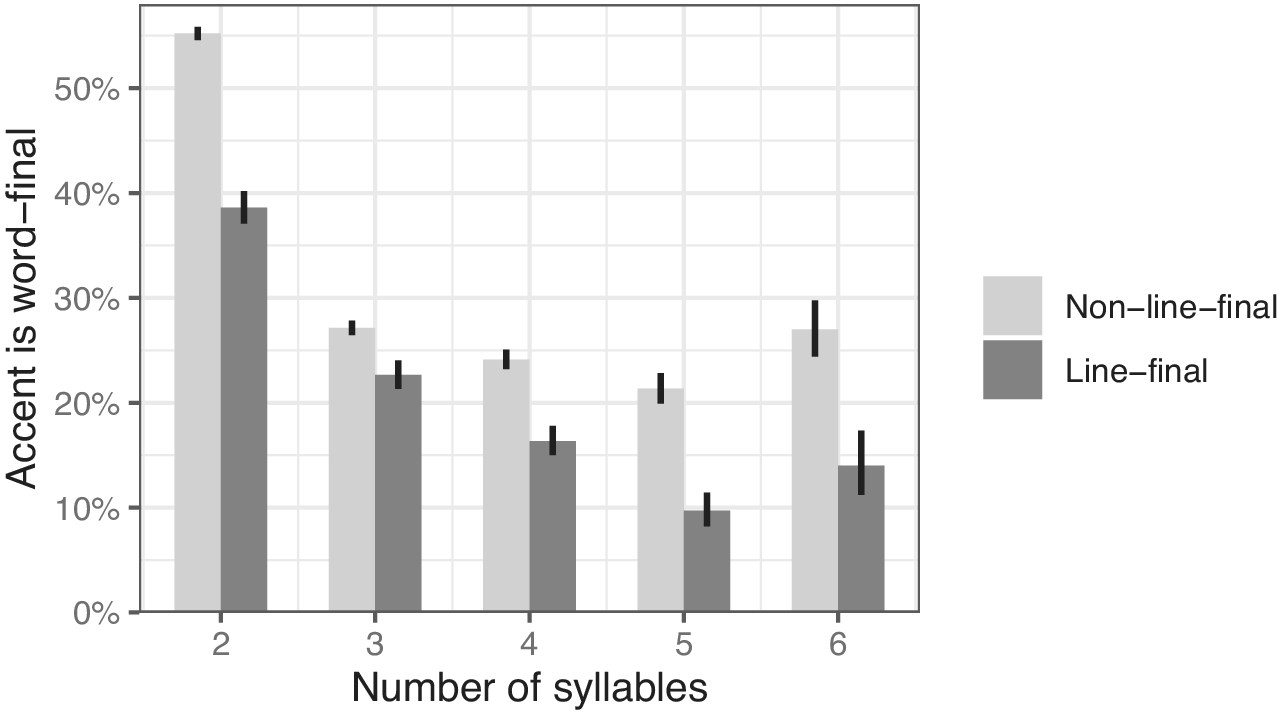




 Open access
Open access