

1 Introduction
The multiple-choice (MC) item format has been implemented in educational assessments that are used across diverse content domains. MC items comprise two components: the stem prepares examinees for the test questions in providing the context and a motivating narrative; and the collection of response options contains the correct answer, called the “key,” and several incorrect alternatives, the “distractors.” Different from the dichotomous response format, MC items using the polytomous response format allegedly permit for collecting richer diagnostic information, while examinees need to spend less time on recording their answers. MC items are also less vulnerable to subjective scoring (cf. Burton et al., Reference Burton, Sudweeks, Merrill and Wood1991). In summary, the economy of MC items is likely one of the reasons for their persistent popularity not just in educational testing.
The MC item format has been adapted to accommodate also the cognitive diagnosis (CD) framework in educational measurement. Within CD, ability—or competence—in a curricular knowledge domain is perceived as a composite of cognitive skills called “attributes.” CD-based tests consist of items that require for a correct response mastery of different attributes. From the item responses, examinees’ ability can be inferred and evaluated in terms of attributes mastered and those needing study.
The polytomous items response format has also received considerable attention in the field of knowledge space theory (KST; for general presentations of KST, cf. Doignon and Falmagne (Reference Doignon, Falmagne, Batchelder, Colonius and Dzhafarov2017) and Falmagne and Doignon (Reference Falmagne and Doignon2011); for the specific connection between KST and CD, cf., e.g., Heller et al., Reference Heller, Stefanutti, Anselmi and Robusto2015, Reference Heller, Stefanutti, Anselmi and Robusto2016). Lucid discussions elaborating the sophisticated theoretical foundations of polytomous KST models and their connection with items using the polytomous response format in CD can be found, for example, in Stefanutti et al. (Reference Stefanutti, de Chiusole, Gondan and Maurer2020) and Stefanutti et al. (Reference Stefanutti, Spoto, Anselmi and de Chiusole2023).
Early approaches to analyzing MC items within the CD framework lacked sophistication such that the MC responses were simply dichotomized in scoring the key as 1 and the distractors as 0 (e.g., Lee et al., Reference Lee, Park and Taylan2011; Templin & Henson, Reference Templin and Henson2006). The dichotomized responses were then analyzed using one of the CD models—diagnostic classification model (DCM) hereafter—for binary responses. De la Torre’s (Reference de la Torre2009) Multiple-Choice Deterministic Inputs, Noisy “And” Gate (MC-DINA) model was the first DCM for analyzing MC items in considering the distractors explicitly as potential sources of diagnostic information. Recall that in case of the DINA model, a binary item can only discriminate between examinees, who have mastered all required attributes and those who fail one or more of these attributes. Extending the model to accommodate the MC item format is expected to increase the classification accuracy, as examinees can then be assigned to more than two groups. The implementation of the MC item format in de la Torre’s (Reference de la Torre2009) MC-DINA model, however, requires imposing the hierarchical structural constraint such that the attribute profiles of the distractors are contained within that of the key and within one another. This property is typically referred to as “nestedness.” Obviously, this nestedness requirement puts an extra burden on the test developer, as the options for item building are more constrained. In fact, later adaptations of the MC item format to CD—including the current implementation of de la Torre’s (Reference de la Torre2009) MC-DINA in the R package GDINA (Ma & de la Torre, Reference Ma and de la Torre2020)—have abandoned the nestedness requirement (e.g., DiBello et al., Reference DiBello, Henson and Stout2015; Ozaki, Reference Ozaki2015; Wang et al., Reference Wang, Chiu and Köhn2023).
The relaxation of the nestedness-condition, however, comes at a price. First, distractors may become redundant; that is, they do not contribute to any further diagnostic differentiation between examinees. The inclusion of redundant distractors in a test wastes valuable item space and may increase unsystematic error variance. Redundancy among distractors, however, may be difficult to detect. Second, undesirable diagnostic ambiguity can arise from distractors that are equally likely to be chosen by an examinee, but have distinct attribute profiles pointing at different diagnostic classifications. Recall that in the case of the “original” MC-DINA model (de la Torre, Reference de la Torre2009) the restriction that all distractors must be nested within each other avoids these issues. Comprehensive explanations and illustrations of these complex concepts are provided in Section 3.
Ozaki (Reference Ozaki2015) appears to be the first who observed this specific form of diagnostic ambiguity arising from relaxing the nestedness condition. As a remedy, he proposed “structured MC-DINA models” (MC-S-DINA) for pinpointing (and resolving) diagnostic ambiguity through augmenting the model with parameters that explicitly target potentially ill-separated effects of differential attribute mastery. The parameters of the MC-S-DINA models were estimated with MCMC.
In this article, a very different approach is presented to deal with diagnostic ambiguity and diagnostic redundancy as they might arise from removing the nestedness condition. Two criteria, plausible and proper, are developed that conceptualize these two phenomena as resulting from the inadequate specification of the distractors of an MC item. An item is said to be plausible if its distractors are not redundant. A redundant distractor is one that does not improve the classification of examinees beyond the response options already available for a given item. An item is called proper if its distractors allow for the unambiguous identification of an examinee’s ideal response. Two theorems are presented that serve as the theoretical foundation of the concepts of “plausible” and “proper” items.
The next section briefly reviews essential CD concepts and their adaptation to accommodate MC items like the MC-DINA model and the nonparametric classification method for MC items (MC-NPC). Section 3 presents the theory of “plausible” and “proper” items. Results of simulation studies conducted for the empirical evaluation of these two concepts are reported in Section 4, followed by two practical applications described in Section 5. The discussion section concludes with a summary of the main findings and some thoughts about potential limitations and future research avenues.
2 Review of key technical concepts
2.1 Cognitive diagnosis
DCMs for CD, a formative assessment framework in educational measurement, describe ability in a given knowledge domain as a composite of K cognitive skills—henceforth: “attributes”—that a student has mastered or not (DiBello et al., Reference DiBello, Roussos, Stout, Rao and Sinharay2007; Haberman & von Davier, Reference Haberman, von Davier, Rao and Sinharay2007; Leighton & Gierl, Reference Leighton and Gierl2007; Nichols et al., Reference Nichols, Chipman and Brennan1995; Rupp et al., Reference Rupp, Templin and Henson2010; Sessoms & Henson, Reference Sessoms and Henson2018; Tatsuoka, Reference Tatsuoka2009; von Daver & Lee, Reference von Daver and Lee2019). Attribute mastery is recorded as a K-dimensional binary vector
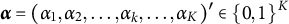 $\boldsymbol {\alpha } = (\alpha _1, \alpha _2, \ldots , \alpha _k, \ldots , \alpha _K)^{\prime } \in \{0,1\}^K$
. Distinct attribute profiles
$\boldsymbol {\alpha } = (\alpha _1, \alpha _2, \ldots , \alpha _k, \ldots , \alpha _K)^{\prime } \in \{0,1\}^K$
. Distinct attribute profiles
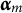 $\boldsymbol {\alpha }_m$
identify different classes of proficiency
$\boldsymbol {\alpha }_m$
identify different classes of proficiency
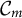 $\mathcal {C}_m$
,
$\mathcal {C}_m$
,
 $m = 1,2, \ldots , M=2^K$
(provided the attributes are not hierarchically organized). (The terms profile and vector are used interchangeably here.) The primary task of CD is to assign students to one of these M classes based on their performance in a test that targets proficiency in the knowledge domain in question. Said differently, examinees’ individual attribute vectors
$m = 1,2, \ldots , M=2^K$
(provided the attributes are not hierarchically organized). (The terms profile and vector are used interchangeably here.) The primary task of CD is to assign students to one of these M classes based on their performance in a test that targets proficiency in the knowledge domain in question. Said differently, examinees’ individual attribute vectors
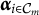 $\boldsymbol {\alpha }_{i \in \mathcal {C}_m}$
must be estimated (
$\boldsymbol {\alpha }_{i \in \mathcal {C}_m}$
must be estimated (
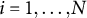 $i = 1, \ldots , N$
is the examinee index; for brevity,
$i = 1, \ldots , N$
is the examinee index; for brevity,
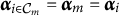 $\boldsymbol {\alpha }_{i \in \mathcal {C}_m} = \boldsymbol {\alpha }_m = \boldsymbol {\alpha }_i$
is often used, depending on the context).
$\boldsymbol {\alpha }_{i \in \mathcal {C}_m} = \boldsymbol {\alpha }_m = \boldsymbol {\alpha }_i$
is often used, depending on the context).
CD items require mastery of domain-specific attributes for a correct response. Similar to examinees, CD items are characterized by K-dimensional attribute profiles
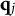 $\mathbf {q}_j$
, with entries
$\mathbf {q}_j$
, with entries
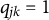 $q_{jk} = 1$
if a correct answer requires mastery of the
$q_{jk} = 1$
if a correct answer requires mastery of the
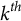 $k^{th}$
attribute
$k^{th}$
attribute
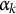 $\alpha _k$
, and 0 otherwise (
$\alpha _k$
, and 0 otherwise (
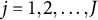 $j = 1,2, \ldots , J$
is the item index). (Notice that the zero vector is not admissible; thus, there are at most
$j = 1,2, \ldots , J$
is the item index). (Notice that the zero vector is not admissible; thus, there are at most
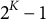 $2^K-1$
legitimate item–attribute profiles.)
$2^K-1$
legitimate item–attribute profiles.)
The collection of the item–attribute profiles of a CD assessment forms its Q-matrix
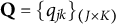 $\mathbf {Q} = \{q_{jk}\}_{(J \times K)}$
(Tatsuoka, Reference Tatsuoka1985) that establishes the associations between items and attributes. The Q-matrix of a test must be known and it must be complete. A Q-matrix is said to be complete if its specific composition can guarantee the identifiability of all realizable proficiency classes among examinees (Chiu et al., Reference Chiu, Douglas and Li2009; Köhn & Chiu, Reference Köhn and Chiu2016, Reference Köhn and Chiu2017, Reference Köhn and Chiu2019, Reference Köhn and Chiu2021). Q-completeness is the key requirement for the identifiability of DCMs (cf. Gu & Xu, Reference Gu and Xu2021).
$\mathbf {Q} = \{q_{jk}\}_{(J \times K)}$
(Tatsuoka, Reference Tatsuoka1985) that establishes the associations between items and attributes. The Q-matrix of a test must be known and it must be complete. A Q-matrix is said to be complete if its specific composition can guarantee the identifiability of all realizable proficiency classes among examinees (Chiu et al., Reference Chiu, Douglas and Li2009; Köhn & Chiu, Reference Köhn and Chiu2016, Reference Köhn and Chiu2017, Reference Köhn and Chiu2019, Reference Köhn and Chiu2021). Q-completeness is the key requirement for the identifiability of DCMs (cf. Gu & Xu, Reference Gu and Xu2021).
2.2 The MC-DINA model
The intuitive appeal of the simple conceptual elegance of the Deterministic Inputs, Noisy “AND” Gate (DINA) model (Haertel, Reference Haertel1989; Junker & Sijtsma, Reference Junker and Sijtsma2001; Macready & Dayton, Reference Macready and Dayton1977) is presumably the reason why the DINA model is arguably one of the most popular DCMs. The DINA is a conjunctive model, as the probability of a correct response is maximal only if an examinee has mastered all attributes required for a given item. Thus, each DINA item generates a bi-partition of the
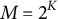 $M=2^K$
proficiency classes of the latent attribute space into groups of examinees who have mastered the attributes required for said item as opposed to those who have not. The item response function (IRF) of the DINA model is
$M=2^K$
proficiency classes of the latent attribute space into groups of examinees who have mastered the attributes required for said item as opposed to those who have not. The item response function (IRF) of the DINA model is
 $$\begin{align*}P(Y_{ij}=1 \mid \boldsymbol{\alpha}_i) = (1-s_j)^{\eta_{ij}} g_j^{(1-\eta_{ij})}, \end{align*}$$
$$\begin{align*}P(Y_{ij}=1 \mid \boldsymbol{\alpha}_i) = (1-s_j)^{\eta_{ij}} g_j^{(1-\eta_{ij})}, \end{align*}$$
where
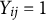 $Y_{ij}=1$
denotes the correct response to item j (otherwise,
$Y_{ij}=1$
denotes the correct response to item j (otherwise,
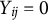 $Y_{ij}=0$
);
$Y_{ij}=0$
);
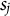 $s_j$
and
$s_j$
and
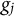 $g_j$
are slipping and guessing parameters, respectively, subject to
$g_j$
are slipping and guessing parameters, respectively, subject to
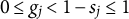 $ 0 \leq g_j < 1-s_j \leq 1$
; the ideal response (or conjunction parameter)
$ 0 \leq g_j < 1-s_j \leq 1$
; the ideal response (or conjunction parameter)
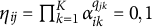 $\eta _{ij} = \prod _{k=1}^K \alpha _{ik}^{q_{jk}} = 0,1$
indicates whether examinee i has mastered all attributes required by item j.
$\eta _{ij} = \prod _{k=1}^K \alpha _{ik}^{q_{jk}} = 0,1$
indicates whether examinee i has mastered all attributes required by item j.
The MC-DINA model was proposed by de la Torre (Reference de la Torre2009) as an extension of the DINA model to accommodate MC items. Recall that each DINA item results in a bi-partition of the latent attribute space. In contrast, an MC item partitions the latent attribute space into a number of proficiency classes that is proportional to those of coded response options, thereby purportedly increasing the accuracy of examinee classification. (A response option is said to be “coded” or “cognitively based” if it is linked to an item attribute vector
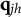 $\mathbf {q}_{jh}$
specifying the attribute requirements for an examinee who endorses this option; terminology and notation follow de la Torre (Reference de la Torre2009)). In case of the MC-DINA model, the polytomous response to item j is denoted as the random variable
$\mathbf {q}_{jh}$
specifying the attribute requirements for an examinee who endorses this option; terminology and notation follow de la Torre (Reference de la Torre2009)). In case of the MC-DINA model, the polytomous response to item j is denoted as the random variable
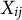 $X_{ij}$
, with the response options indexed by
$X_{ij}$
, with the response options indexed by
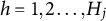 $h = 1, 2 \ldots , H_j$
. Let
$h = 1, 2 \ldots , H_j$
. Let
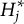 $H^{\ast }_j$
denote the number of coded options. Since not all options are coded,
$H^{\ast }_j$
denote the number of coded options. Since not all options are coded,
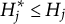 $H^{\ast }_j \leq H_j$
. “Non-coded” response options like “none of these” or “all of the above” are not associated with a specific attribute vector. Hence, as a convention, their item attribute vectors are written as a K-dimensional null vector,
$H^{\ast }_j \leq H_j$
. “Non-coded” response options like “none of these” or “all of the above” are not associated with a specific attribute vector. Hence, as a convention, their item attribute vectors are written as a K-dimensional null vector,
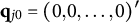 $\mathbf {q}_{j0} = (0,0, \ldots , 0)^{\prime }$
. The key always has the largest number of attributes; the attribute vectors of the coded response options must be nested within the q-vector of the key. Their attribute vectors must also be hierarchically nested within each other such that they form an ordinal scale with the key at the top. Notice that the IRF of the MC-DINA model is not provided in de la Torre’s (Reference de la Torre2009) original publication.
$\mathbf {q}_{j0} = (0,0, \ldots , 0)^{\prime }$
. The key always has the largest number of attributes; the attribute vectors of the coded response options must be nested within the q-vector of the key. Their attribute vectors must also be hierarchically nested within each other such that they form an ordinal scale with the key at the top. Notice that the IRF of the MC-DINA model is not provided in de la Torre’s (Reference de la Torre2009) original publication.
2.3 Removing the nestedness condition
As mentioned earlier, the nestedness requirement places an extra burden on test developers, as it constrains the options for item construction. To overcome this limitation, later adaptations of the MC item format for CD have abandoned the nestedness requirement—including the current implementation of de la Torre’s (Reference de la Torre2009) MC-DINA in the R package GDINA (Ma & de la Torre, Reference Ma and de la Torre2020). Other examples include Ozaki (Reference Ozaki2015), DiBello et al. (Reference DiBello, Henson and Stout2015), and Wang et al. (Reference Wang, Chiu and Köhn2023).
The latter, in introducing their nonparametric classification method for MC items (MC-NPC), were likely the first to provide a full formal treatment of MC items in cognitive diagnostic assessments without nestedness constraints on the attribute vectors of stems and distractors. MC-NPC is an adaptation of the nonparametric classification (NPC) method (Chiu & Douglas, Reference Chiu and Douglas2013) for the MC item format under the DINA model. The term “nonparametric” here means that NPC methods do not rely on parametric estimation of examinees’ proficiency class membership. Instead, they use a distance-based algorithm on the observed item responses: an examinee’s response vector is compared with each of the ideal response vectors of the M realizable proficiency classes, and classification is based on the closest match.
When the q-vectors of the coded response options are no longer required to be nested within each other and the q-vector of the key, the linear ordering of the options is lost. This changes the scale of the item response options from ordinal to nominal—a significant conceptual departure from de la Torre’s (Reference de la Torre2009) original MC-DINA and one that necessitates several adjustments in notation:
-
1. The original MC-DINA response option index,
 $h = 1, 2, \ldots , H_j$
, is replaced by the index
$l = 0, 1, 2, \ldots , H^{\ast }_j $
.
$h = 1, 2, \ldots , H_j$
, is replaced by the index
$l = 0, 1, 2, \ldots , H^{\ast }_j $
. -
2. The notation for the q-vector
$\mathbf {q}_{jh}$
is changed to one involving the index l:
$\mathbf {q}^{(l)}_j$
. -
3. All non-coded response options are indexed as
$l=0$
, having q-vectors
$\mathbf {q}^{(0)}_j$
. -
4. The key is now indexed as
$l = H^{\ast }_j$
; thus,
$\mathbf {q}^{(H^{\ast }_j)}_j$
. -
5. The indices
$l = 1, 2, \ldots , H^{\ast }_j - 1$
are assigned to the remaining coded response options. -
6. Let
$\mathbf {q}$
and
$\mathbf {q}^{\prime }$
denote the q-vectors of distinct coded response options. If
$\parallel \mathbf {q}_j \parallel _1 \hspace {.5em}> \hspace {.5em} \parallel \mathbf {q}^{\prime }_j \parallel _1$
, then
$l> l^{\prime }$
so that the notation becomes
$\mathbf {q}^{(l)}_j$
and
$\mathbf {q}^{(l^{\prime })}_j$
(and vice versa;
$\parallel \cdot \parallel _1$
denotes the
$L_1$
norm). If
$\mathbf {q}$
and
$\mathbf {q}^{\prime }$
are of the same length, then the response options are indexed based on their evaluation in lexicographic order—that is,
$l> l^{\prime }$
if the position of the first non-zero entry in
$\mathbf {q}$
precedes that in
$\mathbf {q}^{\prime }$
, and vice versa. Ties—both q-vectors share the position of the first non-zero entry—are ignored and the evaluation is based on the first position with distinct entries; such a position can always be identified because all coded response option q-vectors must be distinct. Formally, define the set
$\mathcal {L}(\mathbf {q}, \mathbf {q}^{\prime }) = \{ k \mid q_k> q^{\prime }_k, k = 1,2, \ldots , K \}$
. Notice that
$\mathcal {L}(\mathbf {q}, \mathbf {q}^{\prime }) \neq \mathcal {L}(\mathbf {q}^{\prime }, \mathbf {q})$
due to the evaluation of
$q_k$
and
$q^{\prime }_k$
in lexicographic order. If (1)
$$ \begin{align} \big( \parallel \mathbf{q}^{(l)}_j \parallel_1 \hspace{.5em} = \hspace{.5em} \parallel \mathbf{q}^{(l^{\prime})}_j \parallel_1 \big) \wedge \Big( \min \mathcal{L} \big( \mathbf{q}^{(l)}_j, \mathbf{q}^{(l^{\prime})}_j \big) < \min \mathcal{L} \big( \mathbf{q}^{(l^{\prime})}_j, \mathbf{q}^{(l)}_j \big) \Big), \end{align} $$
then
$l> l^{\prime }$
.
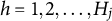
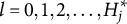
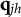
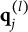
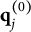
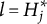
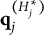
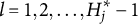
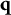
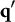

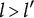
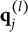
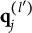
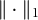
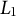
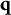
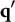
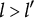
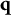
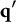
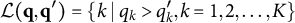
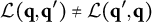
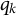
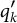

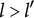
After the indices l of the item response options have been determined, the ideal response
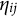 $\eta _{ij}$
of examinee i to item j can be computed
$\eta _{ij}$
of examinee i to item j can be computed
 $$ \begin{align} \eta_{ij} = \max_{l = 0,1,2, \ldots,H^{\ast}_j} \left\{ l\prod_{k=1}^K I[\alpha_{ik} \geq q_{jk}^{(l)}] \right\}, \end{align} $$
$$ \begin{align} \eta_{ij} = \max_{l = 0,1,2, \ldots,H^{\ast}_j} \left\{ l\prod_{k=1}^K I[\alpha_{ik} \geq q_{jk}^{(l)}] \right\}, \end{align} $$
where
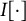 $I[\cdot ]$
denotes the indicator function. Then, in using Equation (2), the IRF of the MC-DINA model, with the nestedness condition removed, can be expressed as
$I[\cdot ]$
denotes the indicator function. Then, in using Equation (2), the IRF of the MC-DINA model, with the nestedness condition removed, can be expressed as
 $$ \begin{align} P(X_{ij}=l \mid \boldsymbol{\alpha}_i) = \begin{cases} \frac{1}{H_j} + \frac{H_j - H_j^{\ast} - 1}{H_j} \hspace{.3em} I[l = 0] \hspace{8em} \text{if } \eta_{ij} = 0\\[4pt]\Big( 1 - \sum\limits_{m \neq l} \varepsilon_{jml} \Big)^{I[\eta_{ij} = l, l> 0]} \prod_{l^{\prime} \neq l} \varepsilon_{jll^{\prime}}^{I[\eta_{ij} = l^{\prime}]} \hspace{2.7em} \text{if } \eta_{ij} > 0, \end{cases} \end{align} $$
$$ \begin{align} P(X_{ij}=l \mid \boldsymbol{\alpha}_i) = \begin{cases} \frac{1}{H_j} + \frac{H_j - H_j^{\ast} - 1}{H_j} \hspace{.3em} I[l = 0] \hspace{8em} \text{if } \eta_{ij} = 0\\[4pt]\Big( 1 - \sum\limits_{m \neq l} \varepsilon_{jml} \Big)^{I[\eta_{ij} = l, l> 0]} \prod_{l^{\prime} \neq l} \varepsilon_{jll^{\prime}}^{I[\eta_{ij} = l^{\prime}]} \hspace{2.7em} \text{if } \eta_{ij} > 0, \end{cases} \end{align} $$
where
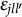 $\varepsilon _{jll^{\prime }}$
is the probability that the observed response level l disagrees with the ideal response level
$\varepsilon _{jll^{\prime }}$
is the probability that the observed response level l disagrees with the ideal response level
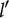 $l^{\prime }$
. (Because the manifest and ideal item responses, X and
$l^{\prime }$
. (Because the manifest and ideal item responses, X and
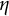 $\eta $
, now have more than two levels, addressing potential discrepancies between X and
$\eta $
, now have more than two levels, addressing potential discrepancies between X and
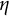 $\eta $
as “slips” and “guesses” appears inadequate, given the complexity of the MC setting involving multiple item parameters. The more general term “perturbation” should be preferred whenever observed and ideal responses disagree.) Typically, slipping and guessing are constrained to be less than 0.5 (otherwise, an individual mastering none of the attributes would have a probability greater than 0.5 to provide the correct answer). Of course, if there are more than two perturbation terms, then the desirable property is that
$\eta $
as “slips” and “guesses” appears inadequate, given the complexity of the MC setting involving multiple item parameters. The more general term “perturbation” should be preferred whenever observed and ideal responses disagree.) Typically, slipping and guessing are constrained to be less than 0.5 (otherwise, an individual mastering none of the attributes would have a probability greater than 0.5 to provide the correct answer). Of course, if there are more than two perturbation terms, then the desirable property is that
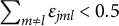 $\displaystyle { \sum\nolimits _{m \neq l} \varepsilon _{jml} < 0.5 }$
. An examinee with
$\displaystyle { \sum\nolimits _{m \neq l} \varepsilon _{jml} < 0.5 }$
. An examinee with
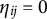 $\eta _{ij} = 0$
is not “attracted” (de la Torre, Reference de la Torre2009) to any of the coded response options. Instead, said examinee is assumed to pick one of the response options at random. If
$\eta _{ij} = 0$
is not “attracted” (de la Torre, Reference de la Torre2009) to any of the coded response options. Instead, said examinee is assumed to pick one of the response options at random. If
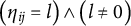 $\big ( \eta _{ij} = l \big ) \wedge \big ( l \neq 0 \big )$
, then examinee i is supposed to choose the coded response option
$\big ( \eta _{ij} = l \big ) \wedge \big ( l \neq 0 \big )$
, then examinee i is supposed to choose the coded response option
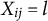 $X_{ij} = l$
with high probability; still, alternative response options may be chosen with non-zero probability. A comprehensive example illustrating the rationale underlying Equations (2) and (3) can be found on pp. 196–198 of Wang et al. (Reference Wang, Chiu and Köhn2023).
$X_{ij} = l$
with high probability; still, alternative response options may be chosen with non-zero probability. A comprehensive example illustrating the rationale underlying Equations (2) and (3) can be found on pp. 196–198 of Wang et al. (Reference Wang, Chiu and Köhn2023).
Please notice that, henceforth, the term “MC-DINA model” refers to the CDM defined in Equations (2) and (3) presented earlier. If de la Torre’s (Reference de la Torre2009) MC-DINA model is meant, then explicit reference is made to “de la Torre’s MC-DINA model.”
3 The theory of plausible and proper multiple-choice items
Recall that the nestedness condition imposed on the key and coded response options can create significant difficulties in test construction, simply because the number of such nested coded response options is limited. As a less restrictive alternative, two concepts—plausible and proper—are proposed.
3.1 Plausible multiple-choice items
An item is said to be plausible if its distractors are not redundant. A redundant distractor is one that does not improve the classification of examinees beyond the information provided by the existing response options for a given item.
Here is an illustration of this concept, using an item from a test on introductory statistics:
-
“Consider the dataset: 4, 6, 8, 10, 12. What is the sample variance of these data?”
Answering this item correctly requires mastery of two skills:
-
$\alpha _1$
: “Calculate squared deviations from the mean.”
-
$\alpha _2$
: “Calculate sample variance by dividing sum of squared deviations by
$n-1$
.”
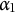
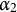

Notice that the entire test is designed to measure three attributes; the third one is
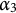 $\alpha _3$
: “Understand the relationship between variance and standard deviation (variance = SD
$\alpha _3$
: “Understand the relationship between variance and standard deviation (variance = SD
 $^2$
).” The response options for this MC item consisting of the key and three distractors are reported in Table 1. Recall that for MC items, once the nestedness condition is removed, the response categories are assigned levels based on the rationale described in the previous section and summarized in Equation (1). The assigned levels of the four response options are shown in the column “Level.”
$^2$
).” The response options for this MC item consisting of the key and three distractors are reported in Table 1. Recall that for MC items, once the nestedness condition is removed, the response categories are assigned levels based on the rationale described in the previous section and summarized in Equation (1). The assigned levels of the four response options are shown in the column “Level.”
Example: An MC item from an introductory statistics test

There are
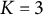 $K=3$
attributes; hence, there are
$K=3$
attributes; hence, there are
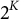 $2^K$
possible attribute profiles (i.e., proficiency classes). The associated ideal responses are computed using Equation (2). The complete set of
$2^K$
possible attribute profiles (i.e., proficiency classes). The associated ideal responses are computed using Equation (2). The complete set of
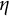 $\eta $
-scores for all proficiency classes is reported in Table 2 below. Notice that among the ideal responses there is a gap:
$\eta $
-scores for all proficiency classes is reported in Table 2 below. Notice that among the ideal responses there is a gap:
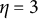 $\eta = 3$
is not identified based on the information provided by the key and the coded distractors. More to the point, the distractor with level
$\eta = 3$
is not identified based on the information provided by the key and the coded distractors. More to the point, the distractor with level
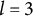 $l=3$
is ineffective, or redundant, because it does not contribute any information to identify its corresponding ideal response. This feature makes the item implausible. The formal definition of a “plausible” distractor is as follows.
$l=3$
is ineffective, or redundant, because it does not contribute any information to identify its corresponding ideal response. This feature makes the item implausible. The formal definition of a “plausible” distractor is as follows.
Ideal responses to the introductory statistics MC item

Definition 1. Suppose item j conforms to the MC-DINA model. Further, suppose that it has
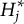 $H^\ast _j$
coded options. Let
$H^\ast _j$
coded options. Let
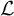 $\mathcal {L}$
be the latent space of all realizable attribute profiles. Item j is said to be plausible if
$\mathcal {L}$
be the latent space of all realizable attribute profiles. Item j is said to be plausible if
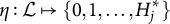 $\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective.
$\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective.
According to the definition, an item is plausible if its distractors allow examinees to be classified into
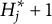 $H^\ast _j + 1$
groups. Recall that the example MC item from the statistics test was implausible because the response options allowed classification into only
$H^\ast _j + 1$
groups. Recall that the example MC item from the statistics test was implausible because the response options allowed classification into only
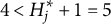 $4 < H^\ast _j + 1 = 5$
proficiency classes. However, this item can be “repaired” to become plausible by modifying the distractors such that Distractor 1 is deleted, which results in ideal responses identical to those in Table 2 except that
$4 < H^\ast _j + 1 = 5$
proficiency classes. However, this item can be “repaired” to become plausible by modifying the distractors such that Distractor 1 is deleted, which results in ideal responses identical to those in Table 2 except that
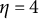 $\eta = 4$
is replaced by
$\eta = 4$
is replaced by
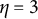 $\eta = 3$
because now
$\eta = 3$
because now
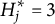 $H^{\ast }_j = 3$
. Of course, other modifications are possible that do not involve deleting distractors, but would instead require modifying the q-vectors of the distractos, which would essentially change the content of the item.
$H^{\ast }_j = 3$
. Of course, other modifications are possible that do not involve deleting distractors, but would instead require modifying the q-vectors of the distractos, which would essentially change the content of the item.
For succinctness and technical precision, some additional notation is introduced to formulate Theorem 1. The relation of “nestedness” is denoted by “
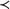 $\prec $
.” Specifically, for vectors
$\prec $
.” Specifically, for vectors
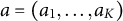 $ {a}=(a_1, \ldots , a_K)$
and
$ {a}=(a_1, \ldots , a_K)$
and
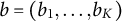 $ {b}=(b_1, \ldots , b_K)$
, write
$ {b}=(b_1, \ldots , b_K)$
, write
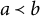 $ {a} \prec {b}$
if and only if
$ {a} \prec {b}$
if and only if
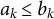 $a_k \leq b_k$
for all k, with
$a_k \leq b_k$
for all k, with
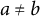 $ {a} \neq {b}$
. Similarly,
$ {a} \neq {b}$
. Similarly,
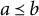 $ {a} \preceq {b}$
if and only if
$ {a} \preceq {b}$
if and only if
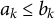 $a_k \leq b_k$
for all k. Without loss of generality, suppose all the coded options have been rearranged according to the rule described in Section 2.3. For item j, let
$a_k \leq b_k$
for all k. Without loss of generality, suppose all the coded options have been rearranged according to the rule described in Section 2.3. For item j, let
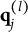 $\mathbf {q}_j^{(l)}$
denote the q-vector of the lth coded option. Using this notation, Theorem 1 establishes a criterion for identifying plausible MC items.
$\mathbf {q}_j^{(l)}$
denote the q-vector of the lth coded option. Using this notation, Theorem 1 establishes a criterion for identifying plausible MC items.
Theorem 1. Suppose item j conforms to the MC-DINA model. Then, item j is plausible if and only if
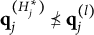 $\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
$\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
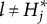 $l\neq H_j^\ast $
.
$l\neq H_j^\ast $
.
Verbally stated, Item j is plausible if and only if the q-vector of its key is not nested within any of the q-vectors of its distractors. The proof of Theorem 1 is presented in Appendix A.
Corollary 1. Suppose item j conforms to the MC-DINA model. If item j is plausible, then no coded distractor has q-vector
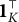 $\mathbf {1}^\top _K$
.
$\mathbf {1}^\top _K$
.
The corollary is an immediate consequence of the theorem and has significant practical value. If a coded distractor were to have q-vector
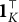 $\mathbf {1}^\top _K$
, then
$\mathbf {1}^\top _K$
, then
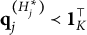 $\mathbf {q}_j^{(H_j^\ast )} \prec \mathbf {1}^\top _K$
must be true, implying that item j is not plausible. Thus, no such coded distractor can exist.
$\mathbf {q}_j^{(H_j^\ast )} \prec \mathbf {1}^\top _K$
must be true, implying that item j is not plausible. Thus, no such coded distractor can exist.
Theorem 1 and Corollary 1 allow for a more detailed analysis of the example MC item from the introductory statistics test. In particular, since the q-vector of Distractor 1 is
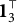 $\mathbf {1}^\top _3$
, the item is immediately identified as implausible by Corollary 1.
$\mathbf {1}^\top _3$
, the item is immediately identified as implausible by Corollary 1.
3.2 Proper multiple-choice items
An item is called proper if it allows for the unambiguous identification of an examinee’s ideal response. Notice that in case of de la Torre’s MC-DINA model, the restriction that all distractors must be nested within each other prevents such ambiguity.
Consider an example adapted from a binary item used by Tatsuoka (Reference Tatsuoka1984) as part of the test with which she collected her famous fraction-subtraction data:
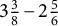 $3 \frac {3}{8} - 2 \frac {5}{6}$
. Köhn, Chiu, Oluwalana, Kim, and Wang (Reference Köhn, Chiu, Oluwalana, Kim and Wang2024) showed that Tatsuoka’s (Reference Tatsuoka1984) test involves four skills:
$3 \frac {3}{8} - 2 \frac {5}{6}$
. Köhn, Chiu, Oluwalana, Kim, and Wang (Reference Köhn, Chiu, Oluwalana, Kim and Wang2024) showed that Tatsuoka’s (Reference Tatsuoka1984) test involves four skills:
-
$\alpha _1$
: “Find a common denominator.”
-
$\alpha _2$
: “Borrow from the integer.”
-
$\alpha _3$
: “Apply subtraction to integer and fraction parts separately.”
-
$\alpha _4$
: “Convert a fraction to a whole number.”
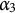
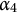
For the purpose of demonstrating the concept of a proper item, this binary item has been reformulated as an MC item, where the key requires mastery of the first three attributes,
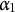 $\alpha _1$
,
$\alpha _1$
,
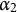 $\alpha _2$
, and
$\alpha _2$
, and
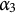 $\alpha _3$
. Here are the q-vectors of the MC version of
$\alpha _3$
. Here are the q-vectors of the MC version of
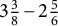 $3 \frac {3}{8} - 2 \frac {5}{6}$
:
$3 \frac {3}{8} - 2 \frac {5}{6}$
:

From the four attributes, 16 examinee proficiency classes can be identified ranging in attribute profiles from (0000), (1000), (0100),
 $\ldots $
to (1111). The item key separates proficiency classes (1110) and (1111) from all other classes. Recall that, according to de la Torre’s (Reference de la Torre2009) theory, individuals in proficiency class
$\ldots $
to (1111). The item key separates proficiency classes (1110) and (1111) from all other classes. Recall that, according to de la Torre’s (Reference de la Torre2009) theory, individuals in proficiency class
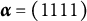 $\boldsymbol {\alpha } = (1111)$
should choose only the key and none of the two distractors although both require
$\boldsymbol {\alpha } = (1111)$
should choose only the key and none of the two distractors although both require
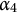 $\alpha _4$
, which individuals in (1111) have mastered. Examinees who master
$\alpha _4$
, which individuals in (1111) have mastered. Examinees who master
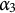 $\alpha _3$
and
$\alpha _3$
and
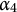 $\alpha _4$
but not all four attributes—that is, proficiency classes
$\alpha _4$
but not all four attributes—that is, proficiency classes
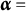 $\boldsymbol {\alpha } = $
(0011), (1011), and (0111)—should choose Distractor 1 due to the following reasoning:
$\boldsymbol {\alpha } = $
(0011), (1011), and (0111)—should choose Distractor 1 due to the following reasoning:
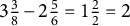 $3 \frac {3}{8} - 2 \frac {5}{6} = 1 \frac {2}{2} = 2$
. Concretely, Distractor 1 distinguishes
$3 \frac {3}{8} - 2 \frac {5}{6} = 1 \frac {2}{2} = 2$
. Concretely, Distractor 1 distinguishes
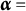 $\boldsymbol {\alpha } = $
(0011), (1011), and (0111) from all remaining proficiency classes. By contrast, examinees who master
$\boldsymbol {\alpha } = $
(0011), (1011), and (0111) from all remaining proficiency classes. By contrast, examinees who master
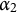 $\alpha _2$
and
$\alpha _2$
and
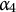 $\alpha _4$
but not all four attributes are likely to select Distractor 2, reasoning that
$\alpha _4$
but not all four attributes are likely to select Distractor 2, reasoning that
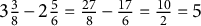 $3 \frac {3}{8} - 2 \frac {5}{6} = \frac {27}{8} - \frac {17}{6} = \frac {10}{2} = 5$
. More specifically, Distractor 2 distinguishes
$3 \frac {3}{8} - 2 \frac {5}{6} = \frac {27}{8} - \frac {17}{6} = \frac {10}{2} = 5$
. More specifically, Distractor 2 distinguishes
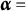 $\boldsymbol {\alpha } = $
(0101), (1101), and (0111) from all remaining proficiency classes.
$\boldsymbol {\alpha } = $
(0101), (1101), and (0111) from all remaining proficiency classes.
Diagnostic ambiguity arises because individuals in proficiency class
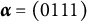 $\boldsymbol {\alpha } = (0111)$
may choose either Distractor 1 or Distractor 2. In other words, the current set of response options does not allow members of proficiency class (0111) to be identified unambiguously.
$\boldsymbol {\alpha } = (0111)$
may choose either Distractor 1 or Distractor 2. In other words, the current set of response options does not allow members of proficiency class (0111) to be identified unambiguously.
The concept of proper items serves to regulate and prevent such ambiguity. It is defined as follows.
Definition 2. Suppose item j conforms to the MC-DINA model. Item j is said to be proper if for every
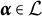 $\boldsymbol {\alpha } \in \mathcal {L}$
and
$\boldsymbol {\alpha } \in \mathcal {L}$
and
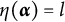 $\eta (\boldsymbol {\alpha }) = l$
,
$\eta (\boldsymbol {\alpha }) = l$
,
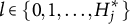 $l \in \{0, 1, \ldots , H^\ast _j\}$
, it is true that either
$l \in \{0, 1, \ldots , H^\ast _j\}$
, it is true that either
-
a)
$l = H^\ast _j$
or
-
b)
$l < H^\ast _j$
, subject to the constraint that if there exists an
$l' < l$
such that
$\mathbf {q}^{(l^\prime )}\prec \boldsymbol {\alpha }$
, then
$\mathbf {q}^{(l^\prime )} \prec \mathbf {q}^{(l)}$
for all
$l'$
must hold.
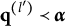
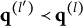
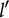
Now, let
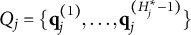 $Q_j=\{\mathbf {q}_j^{(1)}, \dots , \mathbf {q}_j^{(H_j^\ast -1)}\}$
be a set that includes the q-vectors of all the coded distractors. The next theorem presents a rule for the immediate detection of improper items without having to evaluate
$Q_j=\{\mathbf {q}_j^{(1)}, \dots , \mathbf {q}_j^{(H_j^\ast -1)}\}$
be a set that includes the q-vectors of all the coded distractors. The next theorem presents a rule for the immediate detection of improper items without having to evaluate
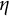 $\eta $
for all
$\eta $
for all
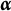 $\boldsymbol {\alpha }$
following the steps as implied by Definition 2.
$\boldsymbol {\alpha }$
following the steps as implied by Definition 2.
Theorem 2. Suppose item j conforms to the MC-DINA model. Item j is proper if and only if for each pair of its coded distractors with q-vectors
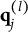 $\mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l)}$
and
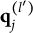 $\mathbf {q}_j^{(l')}$
in
$\mathbf {q}_j^{(l')}$
in
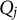 $Q_j$
, it is true that
$Q_j$
, it is true that
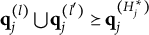 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
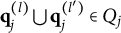 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
Verbally stated, Item j is proper if and only if the q-vector of the key is equal to or nested within the union of the q-vectors of two distractors, or the union of the q-vectors of two distractors is itself a distractor. The proof of Theorem 2 is presented in Appendix A.
Theorem 2 also points at a possibility how to repair the improper MC item from Tatsuoka’s (Reference Tatsuoka1984) fraction-subtraction test. Concretely, the item becomes proper if a third distractor is added, whose q-vector is the union of Distractors 1 and 2,
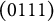 $(0111)$
, thereby resolving the diagnostic ambiguity:
$(0111)$
, thereby resolving the diagnostic ambiguity:

Indeed, Distractor 3 “does the trick,” as it isolates proficiency class
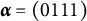 $\boldsymbol {\alpha } = (0111)$
. Members of this class may reason that
$\boldsymbol {\alpha } = (0111)$
. Members of this class may reason that
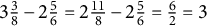 $3 \frac {3}{8} - 2 \frac {5}{6} = 2 \frac {11}{8} - 2 \frac {5}{6} = \frac {6}{2} = 3$
.
$3 \frac {3}{8} - 2 \frac {5}{6} = 2 \frac {11}{8} - 2 \frac {5}{6} = \frac {6}{2} = 3$
.
As a concluding remark, notice that a proper item may or may not be plausible. Said differently, plausible and proper do not condition each other. Consider these two simple examples:

Both of the items are proper; however, Item 1 is not plausible, but Item 2 is.
4 Simulation studies
Two simulation studies were conducted to investigate the impact of implausible and improper MC items on the classification of examinees. Synthetic responses were generated for MC assessments that were “contaminated” with an increasing number of implausible or improper items. As noted earlier, examinee classification is only affected by these two item types when the nestedness constraint on the key and the distractors is removed. This condition applies to the MC-DINA model and the MC-NPC method, which were therefore used side-by-side for classifying examinees. Because MC-DINA and MC-NPC are known to differ in performance depending on sample size—with MC-NPC typically outperforming the parametric estimation of MC-DINA when samples are small—both methods were evaluated across a broad range of sample sizes:
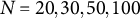 $N = 20, 30, 50, 100$
, and 300. This design allowed for a fair assessment of the relative performance of the two methods under varying conditions of data availability.
$N = 20, 30, 50, 100$
, and 300. This design allowed for a fair assessment of the relative performance of the two methods under varying conditions of data availability.
4.1 Study I: The effect of limitedly plausible MC items on the classification of examinees
4.1.1 Design
The two major experimental factors to be manipulated were sample size and “contamination” level—that is, the number of items in the test that were of limited plausibility (NU). The five levels of sample size,
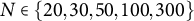 $N \in \{20, 30, 50, 100, 300\}$
, were completely crossed with the “contamination” levels of
$N \in \{20, 30, 50, 100, 300\}$
, were completely crossed with the “contamination” levels of
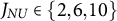 $J_{NU} \in \{2,6,10\}$
resulting in 15 experimental cells. Across all cells, the number of items was fixed at
$J_{NU} \in \{2,6,10\}$
resulting in 15 experimental cells. Across all cells, the number of items was fixed at
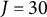 $J=30$
, that of attributes at
$J=30$
, that of attributes at
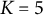 $K=5$
, and the number of response options for all items at
$K=5$
, and the number of response options for all items at
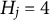 $H_j = 4$
or 5.
$H_j = 4$
or 5.
Random Q-matrices containing only plausible items—denoted as
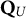 $\mathbf {Q}_U$
—were generated using the random multi-step procedure developed by Wang et al. (Reference Wang, Chiu and Köhn2023):
$\mathbf {Q}_U$
—were generated using the random multi-step procedure developed by Wang et al. (Reference Wang, Chiu and Köhn2023):
-
Step 1: The q-vectors of the keys were randomly generated such that they formed a Q-matrix which conformed to the completeness condition for the DINA model (cf. Chiu et al., Reference Chiu, Douglas and Li2009).
-
Step 2: For each key, the number of coded distractors was determined randomly in choosing from the set
$\{0, 1, \ldots , H_j^\ast -1\}$
. -
Step 3: For each coded distractor, the q-vector was selected from among the
$2^K - 1$
admissible item attribute patterns subject to the constraint that they were proper and plausible (i.e., allowed for the non-ambiguous identification of an examinee’s ideal response, and were non-redundant regarding examinee classification, respectively). -
Step 4: For each item, the key and the coded distractors were randomly assigned to
$H_j^\ast $
positions among the total of
$H_j$
positions (recall that non-coded distractors do not have q-vector entries in the Q-matrix).
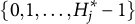
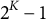
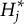
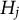
For each experimental cell, 10
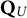 $\mathbf {Q}_U$
were generated and duplicated. Each of the 10 Q-matrices in the duplicated set was altered such that
$\mathbf {Q}_U$
were generated and duplicated. Each of the 10 Q-matrices in the duplicated set was altered such that
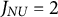 $J_{NU} = 2$
, 6, or 10 of the plausible items were turned into NU ones resulting in 10 Q-matrices
$J_{NU} = 2$
, 6, or 10 of the plausible items were turned into NU ones resulting in 10 Q-matrices
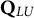 $\mathbf {Q}_{LU}$
. As an illustration, a pair of contaminated and uncontaminated Q-matrices containing only
$\mathbf {Q}_{LU}$
. As an illustration, a pair of contaminated and uncontaminated Q-matrices containing only
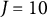 $J=10$
MC items (due to space restrictions) is shown in Table 3. Assume contamination level
$J=10$
MC items (due to space restrictions) is shown in Table 3. Assume contamination level
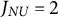 $J_{NU} = 2$
. The q-vector of the distractor in Item 3 was changed from (01001) to (11100), and that of the first distractor in Item 10 was changed from (00011) to (10111). These changes turned
$J_{NU} = 2$
. The q-vector of the distractor in Item 3 was changed from (01001) to (11100), and that of the first distractor in Item 10 was changed from (00011) to (10111). These changes turned
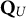 $\mathbf {Q}_U$
in the left panel to
$\mathbf {Q}_U$
in the left panel to
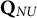 $\mathbf {Q}_{NU}$
in the right panel, with the number of coded options remaining unchanged. (Notice that, in following the convention, among the q-vectors with the same item identification number, the first one is the key.)
$\mathbf {Q}_{NU}$
in the right panel, with the number of coded options remaining unchanged. (Notice that, in following the convention, among the q-vectors with the same item identification number, the first one is the key.)
Example: A Q-matrix containing plausible items (left panel) and its altered correspondent containing two implausible items (underlain in yellow)

At each of the three contamination levels, the 10 uncontaminated Q-matrices
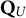 $\mathbf {Q}_{U}$
were contrasted with 10 contaminated Q-matrices
$\mathbf {Q}_{U}$
were contrasted with 10 contaminated Q-matrices
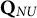 $\mathbf {Q}_{NU}$
. The motivation for this elaborate procedure for devising random Q-matrices was to control for potential bias in the composition of the Q-matrix that can mask the effect of the experimental factors.
$\mathbf {Q}_{NU}$
. The motivation for this elaborate procedure for devising random Q-matrices was to control for potential bias in the composition of the Q-matrix that can mask the effect of the experimental factors.
Recall the three contamination levels,
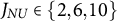 $J_{NU} \in \{2,6,10\}$
, were completely crossed with the five levels of sample size,
$J_{NU} \in \{2,6,10\}$
, were completely crossed with the five levels of sample size,
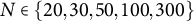 $N \in \{20, 30, 50, 100, 300\}$
, resulting in 15 experimental cells. For each cell, 20 random Q-matrices (10
$N \in \{20, 30, 50, 100, 300\}$
, resulting in 15 experimental cells. For each cell, 20 random Q-matrices (10
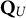 $\mathbf {Q}_{U}$
and 10
$\mathbf {Q}_{U}$
and 10
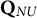 $\mathbf {Q}_{NU}$
) were generated; each random Q-matrix was used to generate 20 replicated datasets, resulting in a total of
$\mathbf {Q}_{NU}$
) were generated; each random Q-matrix was used to generate 20 replicated datasets, resulting in a total of
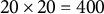 $20 \times 20 = 400$
datasets per experimental cell.
$20 \times 20 = 400$
datasets per experimental cell.
A few further technical explanations might be helpful. First, to control for confounding of the impact of NU-items on classification rates with that of improper items, all items were proper. Second, to rule out the possibility that differences in classification rates might be caused by different numbers of coded options, the latter was fixed for the two types of Q-matrices. Third, examinee attribute profiles were generated based on the multivariate normal threshold model (Chiu, et al., Reference Chiu, Douglas and Li2009), with variances equal to 1 and covariances sampled from Unif(0.3, 0.5). Fourth, following the design in Wang et al. (Reference Wang, Chiu and Köhn2023), the probability that an examinee in group
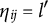 $\eta _{ij}=l^{\prime }$
was attracted by response level
$\eta _{ij}=l^{\prime }$
was attracted by response level
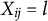 $X_{ij} = l$
of item j,
$X_{ij} = l$
of item j,
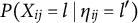 ${P(X_{ij} = l \mid \eta _{ij}=l^{\prime })}$
, was controlled by first generating a parameter
${P(X_{ij} = l \mid \eta _{ij}=l^{\prime })}$
, was controlled by first generating a parameter
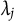 $\lambda _j$
from
$\lambda _j$
from
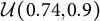 $\mathcal {U}(0.74, 0.9)$
for each item j. The probability
$\mathcal {U}(0.74, 0.9)$
for each item j. The probability
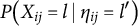 $P\big ( X_{ij} = l \mid \eta _{ij}=l^{\prime } \big )$
was then determined as
$P\big ( X_{ij} = l \mid \eta _{ij}=l^{\prime } \big )$
was then determined as
 $$\begin{align*}P\big( X_{ij} = l \mid \eta_{ij} = l^{\prime} \big) = \begin{cases} \frac{1}{H_j} + \frac{H_j - H_j^{\ast} - 1}{H_j} \hspace{.3em} I(l = 0) & \text{if } l^{\prime} = 0\\ \lambda_j & \text{if } l^{\prime}> 0 \text{ and } l = l^{\prime} \\ \frac{1 - \lambda_j}{H_j - 1} & \text{if } l^{\prime} > 0 \text{ and } l \neq l^{\prime}. \end{cases} \end{align*}$$
$$\begin{align*}P\big( X_{ij} = l \mid \eta_{ij} = l^{\prime} \big) = \begin{cases} \frac{1}{H_j} + \frac{H_j - H_j^{\ast} - 1}{H_j} \hspace{.3em} I(l = 0) & \text{if } l^{\prime} = 0\\ \lambda_j & \text{if } l^{\prime}> 0 \text{ and } l = l^{\prime} \\ \frac{1 - \lambda_j}{H_j - 1} & \text{if } l^{\prime} > 0 \text{ and } l \neq l^{\prime}. \end{cases} \end{align*}$$
4.1.2 Criteria of performance assessment
The accuracy of MC-NPC and MC-DINA in classifying examinees was quantified by the mean pattern-wise agreement rate (PAR) defined as
 $$\begin{align*}\text{PAR} = \frac{\sum_{r = 1}^R \sum_{i =1}^N I(\widehat{\boldsymbol{\alpha}}_{ir} = \boldsymbol{\alpha}_{ir})}{NR}, \end{align*}$$
$$\begin{align*}\text{PAR} = \frac{\sum_{r = 1}^R \sum_{i =1}^N I(\widehat{\boldsymbol{\alpha}}_{ir} = \boldsymbol{\alpha}_{ir})}{NR}, \end{align*}$$
where
 $i = 1, \ldots , N$
and
$i = 1, \ldots , N$
and
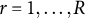 $r = 1, \ldots , R$
denote the examinee and replication index, respectively. For each condition, PAR quantifies the proportion of agreement between examinees’ true attribute profiles,
$r = 1, \ldots , R$
denote the examinee and replication index, respectively. For each condition, PAR quantifies the proportion of agreement between examinees’ true attribute profiles,
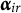 $\boldsymbol {\alpha }_{ir}$
, and their estimates,
$\boldsymbol {\alpha }_{ir}$
, and their estimates,
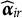 $\widehat {\boldsymbol {\alpha }}_{ir}$
.
$\widehat {\boldsymbol {\alpha }}_{ir}$
.
4.1.3 Results
Tables 4 and 5 report the PAR values for MC-NPC and MC-DINA, when
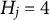 $H_j=4$
and
$H_j=4$
and
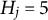 $H_j=5$
, respectively. The findings for both tables are very similar; hence, they are summarized together. First, notice that for the MC-NPC method, the PAR values in the first column
$H_j=5$
, respectively. The findings for both tables are very similar; hence, they are summarized together. First, notice that for the MC-NPC method, the PAR values in the first column
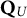 $\mathbf {Q}_U$
(i.e., Q-matrices containing plausible items only) are almost identical across the three cells, given a particular sample-size layer—a nice empirical demonstration of the high reliability of the MC-NPC classification. Second, notice that this stability, not too surprising, cannot be observed for the PAR values in the second column
$\mathbf {Q}_U$
(i.e., Q-matrices containing plausible items only) are almost identical across the three cells, given a particular sample-size layer—a nice empirical demonstration of the high reliability of the MC-NPC classification. Second, notice that this stability, not too surprising, cannot be observed for the PAR values in the second column
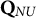 $\mathbf {Q}_{NU}$
(i.e., Q-matrices contaminated with different numbers of limitedly plausible items): the more limitedly plausible items a Q-matrix contains, the more the PAR values deteriorate. Third, the columns under the header “
$\mathbf {Q}_{NU}$
(i.e., Q-matrices contaminated with different numbers of limitedly plausible items): the more limitedly plausible items a Q-matrix contains, the more the PAR values deteriorate. Third, the columns under the header “
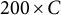 $200 \times C$
Replications” require an explanation. In a substantial number of the 200 replicated datasets, the MC-DINA algorithm encountered convergence issues such that the estimation process was disrupted and no classification result could be obtained; the proportions of these datasets are reported in parentheses (cf. columns “(C)”). In an attempt to accommodate these difficulties of MC-DINA, which are likely owed to the small sample size, the PAR values for MC-NPC were re-calculated only for these replications where MC-DINA converged. As was observed earlier, the PAR values in the
$200 \times C$
Replications” require an explanation. In a substantial number of the 200 replicated datasets, the MC-DINA algorithm encountered convergence issues such that the estimation process was disrupted and no classification result could be obtained; the proportions of these datasets are reported in parentheses (cf. columns “(C)”). In an attempt to accommodate these difficulties of MC-DINA, which are likely owed to the small sample size, the PAR values for MC-NPC were re-calculated only for these replications where MC-DINA converged. As was observed earlier, the PAR values in the
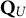 $\mathbf {Q}_U$
columns are stable within a sample size bracket for MC-NPC and MC-DINA. Both methods are sensitive to an increase in the number of limitedly plausible items, as it is accompanied by a decline in the PAR values. In general, the MC-NPC method clearly outperforms the MC-DINA algorithm.
$\mathbf {Q}_U$
columns are stable within a sample size bracket for MC-NPC and MC-DINA. Both methods are sensitive to an increase in the number of limitedly plausible items, as it is accompanied by a decline in the PAR values. In general, the MC-NPC method clearly outperforms the MC-DINA algorithm.
The effect of implausible items on the average PAR values obtained from MC-NPC and MC-DINA when
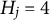 $H_j=4$
$H_j=4$

Note: “U” indicates the results for Q-matrices containing only plausible distractors. “NU” indicates the results for Q-matrices containing 2, 6, or 10 implausible distractors. “C” refers to the proportion of replications where the MC-DINA algorithm converged.
The effect of implausible items on the average PAR values obtained from MC-NPC and MC-DINA when
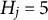 $H_j=5$
$H_j=5$

Note: “U” indicates the results for Q-matrices containing only plausible distractors. “NU” indicates the results for Q-matrices containing 2, 6, or 10 implausible distractors. “C” refers to the proportion of replications where the MC-DINA algorithm converged.
4.2 Study II: The effect of improper MC items on the classification of examinees
The purpose of this second simulation study was to examine to what extent the inclusion of improper items in an MC assessment affects the accuracy of the classification of examinees. However, the inclusion of improper items only affects the assignment of examinees to a few selected proficiency classes; which classes in particular depends on the specification of the q-vectors of the distractors of an improper item. Hence, the misclassification of examinees due to these improper items may be masked and hard to detect; especially, if the number of proficiency classes is large and the classification for the remaining classes is accurate. Therefore, in the second simulation study, only those proficiency classes were included that were potentially affected, given the composition of the q-vectors of the distractors of the improper items.
4.2.1 Design
Similar to Study I, the different sample sizes,
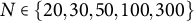 $N \in \{20,30,50,100,300\}$
, defined layers of the experimental design, within which four levels of contamination with 1, 2, 5, and 10 improper items were nested. Like in Study I, two types of Q-matrices were created for each contamination level,
$N \in \{20,30,50,100,300\}$
, defined layers of the experimental design, within which four levels of contamination with 1, 2, 5, and 10 improper items were nested. Like in Study I, two types of Q-matrices were created for each contamination level,
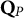 $\mathbf {Q}_{P}$
composed entirely of proper items (serving as a benchmark), and
$\mathbf {Q}_{P}$
composed entirely of proper items (serving as a benchmark), and
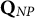 $\mathbf {Q}_{NP}$
, obtained from
$\mathbf {Q}_{NP}$
, obtained from
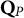 $\mathbf {Q}_{P}$
in replacing proper items by the aforementioned number of improper ones. To illustrate, the left panel of Table 6 displays five proper items that were changed into five improper ones displayed in the right panel. Notice that the five items in the right panel of Table 6 are proper for all proficiency classes except for the one having attribute profile
$\mathbf {Q}_{P}$
in replacing proper items by the aforementioned number of improper ones. To illustrate, the left panel of Table 6 displays five proper items that were changed into five improper ones displayed in the right panel. Notice that the five items in the right panel of Table 6 are proper for all proficiency classes except for the one having attribute profile
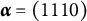 $\boldsymbol {\alpha } = (1110)$
.
$\boldsymbol {\alpha } = (1110)$
.
The proper Q-matrix
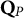 $\mathbf {Q}_{P}$
(left panel) and the corresponding improper Q-matrix
$\mathbf {Q}_{P}$
(left panel) and the corresponding improper Q-matrix
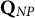 $\mathbf {Q}_{NP}$
(right panel);
$\mathbf {Q}_{NP}$
(right panel);
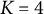 $K=4$
,
$K=4$
,
 $J=5$
$J=5$

Note: Notice that all items in
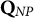 $\mathbf {Q}_{NP}$
are proper for all proficiency classes except for the one having attribute profile
$\mathbf {Q}_{NP}$
are proper for all proficiency classes except for the one having attribute profile
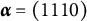 $\boldsymbol {\alpha } = (1110)$
.
$\boldsymbol {\alpha } = (1110)$
.
Imposing this specific feature across all experimental conditions (defined by the layers of sample size and the levels of item contamination nested within) required much stricter experimental control than in Study I. Thus, the 10-item version of
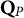 $\mathbf {Q}_{P}$
used throughout Study II was obtained in stacking the five-item Q-matrix shown in the left panel of Table 6 twice. Depending on which contamination level was required, 1, 2, 5, or 10 items in
$\mathbf {Q}_{P}$
used throughout Study II was obtained in stacking the five-item Q-matrix shown in the left panel of Table 6 twice. Depending on which contamination level was required, 1, 2, 5, or 10 items in
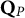 $\mathbf {Q}_{P}$
were changed resulting in the counterpart
$\mathbf {Q}_{P}$
were changed resulting in the counterpart
 $\mathbf {Q}_{NP}$
containing improper items.
$\mathbf {Q}_{NP}$
containing improper items.
Only examinees with attribute profile (1110) were included in the datasets and their responses were generated from the MC-DINA model following the same procedure used in Study I.
At each contamination level (nested within the sample size layers), a single proper Q-matrix
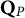 $\mathbf {Q}_{P}$
and a single improper Q-matrix
$\mathbf {Q}_{P}$
and a single improper Q-matrix
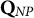 $\mathbf {Q}_{NP}$
were used to generate 100 replicated datasets resulting in a total of
$\mathbf {Q}_{NP}$
were used to generate 100 replicated datasets resulting in a total of
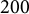 $200$
datasets per contamination level. Examinees were classified with MC-DINA and MC-NPC; the mean PAR value was computed to quantify the loss in classification.
$200$
datasets per contamination level. Examinees were classified with MC-DINA and MC-NPC; the mean PAR value was computed to quantify the loss in classification.
4.2.2 Results
The results of Study II are reported in Table 7. The columns under the header “
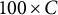 $100 \times C$
Replications” require an explanation. In a substantial number of the 100 replicated datasets, the MC-DINA algorithm encountered convergence issues such that the estimation process was disrupted and no classification result could be obtained. The proportions of these datasets are reported in parentheses (cf. columns “(C)”). In an attempt to accommodate these difficulties of MC-DINA, the PAR values for MC-NPC were re-calculated only for these replications where MC-DINA converged (cf. column “MC-DINA” under the headline “
$100 \times C$
Replications” require an explanation. In a substantial number of the 100 replicated datasets, the MC-DINA algorithm encountered convergence issues such that the estimation process was disrupted and no classification result could be obtained. The proportions of these datasets are reported in parentheses (cf. columns “(C)”). In an attempt to accommodate these difficulties of MC-DINA, the PAR values for MC-NPC were re-calculated only for these replications where MC-DINA converged (cf. column “MC-DINA” under the headline “
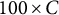 $100 \times C$
” replications).
$100 \times C$
” replications).
Impact of improper items on the mean PAR values from MC-NPC and MC-DINA

Note: “P” indicates the results when all distractors are proper. “NP” indicates the results when some distractors are improper. “C” identifies the proportion of replications with successful convergence.
Regardless of the sample size, the loss in examinee classification accuracy in response to an increase in the number of improper items is dramatic for MC-NPC as well as for MC-DINA. Similar to the observation made in Study I, the PAR values in case of Q-matrices not contaminated with improper items (cf. columns labeled “
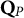 $\mathbf {Q}_P$
”) remained rather stable within a specific sample size bracket for MC-NPC as well as MC-DINA. However, the overall classification accuracy for MC-DINA is significantly lower than that of MC-NPC regardless of the particular sample size.
$\mathbf {Q}_P$
”) remained rather stable within a specific sample size bracket for MC-NPC as well as MC-DINA. However, the overall classification accuracy for MC-DINA is significantly lower than that of MC-NPC regardless of the particular sample size.
5 Practical applications
5.1 Application I: The R function distractor.check()
In this article, the theoretical foundation of the concepts of proper and plausible MC items has been derived for data conforming to the MC-DINA model. Similarly important is the development of tailored software capable of detecting limitedly plausible and improper items automatically instead of having to inspect all MC items of a test manually one by one—a tedious and error-prone procedure. In fact, as part of this study on plausible and proper MC items, the R function distractor.check() was developed for exactly that purpose. The only input required for the distractor.check() function is the Q-matrix of the test in question. Three examples are presented to demonstrate the usage of the distractor.check() function.
The first one is taken from the article by Ozaki (Reference Ozaki2015), who developed “structured MC-DINA models” (MC-S-DINA) for remedying diagnostic ambiguity arising from improper items. Ozaki (Reference Ozaki2015) purposefully created a Q-matrix where Items 21–30 were improper, as shown in Appendix B. The distractor.check() function was used to verify that this Q-matrix, indeed, was contaminated by 10 improper items; distractor.check() produced the following output:

Comment: Notice that Item 23 is not listed as improper; this is not attributable to a failure of the distractor.check() function but to the fact that the two distractors of Item 23 have identical q-vectors—an anomaly that is generally inadmissible (cf. de la Torre, Reference de la Torre2009; Wang et al., Reference Wang, Chiu and Köhn2023). The general assumption throughout this article is that the distractors of any MC item are distinct. Hence, the distractor.check() function does not include specific checks for q-vector identity.
The second example is a Q-matrix taken from the GDINA R package. Notice that the layout of the Q-matrix required to indicate explicitly which response options are the keys.

The third example is taken from a study by Wang et al. (Reference Wang, Chiu and Köhn2023), which appears to be the only published Q-matrix for MC items having coded distractors with non-nested attributes developed for “real”—non-simulated—assessment data.

The remaining Q-matrices found in the literature were all plausible and proper because all distractors were nested within the key: de la Torre (Reference de la Torre2009); Yamaguchi (Reference Yamaguchi2020); Ozaki (Reference Ozaki2015), Study I; and the simulated Q-matrices in the G-DINA package. The sole exception was the Q-matrix in Ozaki’s (Reference Ozaki2015) Study II, where, as was mentioned earlier, all items were plausible but items 21–30 were improper.
5.2 Application II: The effect of improper items on examinee classification
For this practical application to real-world data, the dataset analyzed in Wang et al. (Reference Wang, Chiu and Köhn2023) was revisited. The data consist of responses collected from 115 examinees (after excluding cases with missing data). The test comprised 30 items designed to measure five attributes that are reported in Table 8.
Attributes measured in the dataset used in Application II

The objective was to demonstrate the effect of improper items on examinee classification. To this end, a quasi-experimental, post hoc side-by-side analysis was conducted. First, the 30 items were screened to identify those that could be converted into improper items. Their q-vectors in the original Q-matrix were then modified accordingly. However, only Item 22 was found suitable for such modification. In its original, proper form, Item 22 had the following layout:
“Mei divides a plastic rope into 3 equal parts. Each part is
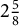 $2\frac {5}{8}$
meters long. What was the original total length of the plastic rope in meters?”
$2\frac {5}{8}$
meters long. What was the original total length of the plastic rope in meters?”
The four response options with their originally coded q-vectors are:
 $$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{3}{8} & & \text{non-coded} \\ \text{(B)} & 3 \frac{7}{8} & & \mathbf{q}_{_{(B)}} = (01000) \\ \text{(C)} & 5 \frac{5}{8} & & \text{non-coded} \\ \text{(D)} & 7 \frac{7}{8} & & \mathbf{q}_{_{(D)}} = (01011). \end{array} \end{align*}$$
$$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{3}{8} & & \text{non-coded} \\ \text{(B)} & 3 \frac{7}{8} & & \mathbf{q}_{_{(B)}} = (01000) \\ \text{(C)} & 5 \frac{5}{8} & & \text{non-coded} \\ \text{(D)} & 7 \frac{7}{8} & & \mathbf{q}_{_{(D)}} = (01011). \end{array} \end{align*}$$
Option (D) was the key, while Option (B) was the only coded distractor. Re-examining Item 22 suggested that Option (C) could reasonably be turned into a coded distractor having q-vector
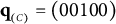 $\mathbf {q}_{_{(C)}} = (00100)$
. The rationale supporting this idea was that students who chose Option (C)—calculating
$\mathbf {q}_{_{(C)}} = (00100)$
. The rationale supporting this idea was that students who chose Option (C)—calculating
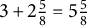 $3 + 2\frac {5}{8} = 5\frac {5}{8}$
—had mastered only attribute
$3 + 2\frac {5}{8} = 5\frac {5}{8}$
—had mastered only attribute
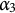 $\alpha _3$
, but not the other skills required to solve Item 22 correctly. This interpretation was further supported by Item 10, which contained a distractor with the same response structure as Option (C) but was coded. Item 10 is shown below:
$\alpha _3$
, but not the other skills required to solve Item 22 correctly. This interpretation was further supported by Item 10, which contained a distractor with the same response structure as Option (C) but was coded. Item 10 is shown below:
“
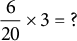 $\dfrac {6}{20}\times 3 = \ ?$
”
$\dfrac {6}{20}\times 3 = \ ?$
”
The response options were
 $$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{18}{20} & & \mathbf{q}_{_{(A)}} = (00010) \\ \text{(B)} & \frac{18}{60} & & \text{non-coded} \\ \text{(C)} & 3 \frac{6}{20} & & \mathbf{q}_{_{(C)}} = (00100) \\ \text{(D)} & \frac{12}{20} & & \text{non-coded.} \end{array} \end{align*}$$
$$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{18}{20} & & \mathbf{q}_{_{(A)}} = (00010) \\ \text{(B)} & \frac{18}{60} & & \text{non-coded} \\ \text{(C)} & 3 \frac{6}{20} & & \mathbf{q}_{_{(C)}} = (00100) \\ \text{(D)} & \frac{12}{20} & & \text{non-coded.} \end{array} \end{align*}$$
Option (A) was the key. Notice that Option (C) has the same structure as Option (C) of Item 22:
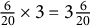 $\frac {6}{20}\times 3 = 3 \frac {6}{20}$
. However, whereas Option (C) of Item 22 was non-coded, Option (C) of Item 10 was coded as
$\frac {6}{20}\times 3 = 3 \frac {6}{20}$
. However, whereas Option (C) of Item 22 was non-coded, Option (C) of Item 10 was coded as
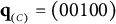 $\mathbf {q}_{_{(C)}} = (00100)$
. In both cases, though, one can argue that examinees who selected Option (C) demonstrated mastery of attribute
$\mathbf {q}_{_{(C)}} = (00100)$
. In both cases, though, one can argue that examinees who selected Option (C) demonstrated mastery of attribute
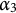 $\alpha _3$
—the ability to add fractions—while failing to multiply them, a rationale consistent with that applied to Option (C) of Item 22.
$\alpha _3$
—the ability to add fractions—while failing to multiply them, a rationale consistent with that applied to Option (C) of Item 22.
Consequently, the response options for Item 22 were modified so that the q-vectors for the key and the two distractors, Options (B) and (C), became
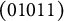 $(01011)$
,
$(01011)$
,
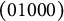 $(01000)$
, and
$(01000)$
, and
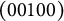 $(00100)$
, respectively, while Option (A) remained uncoded:
$(00100)$
, respectively, while Option (A) remained uncoded:
 $$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{3}{8} & & \text{non-coded} \\ \text{(B)} & 3 \frac{7}{8} & & \mathbf{q}_{_{(B)}} = (01000) \\ \text{(C)} & 5 \frac{5}{8} & & \mathbf{q}_{_{(C)}} = (00100) \\ \text{(D)} & 7 \frac{7}{8} & & \mathbf{q}_{_{(D)}} = (01011). \end{array} \end{align*}$$
$$\begin{align*}\begin{array}{lcccr} \text{(A)} & \frac{3}{8} & & \text{non-coded} \\ \text{(B)} & 3 \frac{7}{8} & & \mathbf{q}_{_{(B)}} = (01000) \\ \text{(C)} & 5 \frac{5}{8} & & \mathbf{q}_{_{(C)}} = (00100) \\ \text{(D)} & 7 \frac{7}{8} & & \mathbf{q}_{_{(D)}} = (01011). \end{array} \end{align*}$$
According to Theorem 2, turning Option (C) into a coded distractor makes Item 22 improper because the union of the q-vectors of Options (B) and (C) is not included among the response options. Such a modification can be justified by a general feature of the MC-DINA model: proper and plausible items with
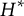 $H^\ast $
coded options classify examinees into
$H^\ast $
coded options classify examinees into
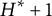 $H^\ast + 1$
classes. Increasing the number of coded distractors broadens the spectrum of proficiency classes, leading to finer-grained classification. However, if an item is improper, it is likely to introduce ambiguity thereby decrease classification accuracy. Thus, the goal of this application was to test whether coding Option (C) of Item 22 as
$H^\ast + 1$
classes. Increasing the number of coded distractors broadens the spectrum of proficiency classes, leading to finer-grained classification. However, if an item is improper, it is likely to introduce ambiguity thereby decrease classification accuracy. Thus, the goal of this application was to test whether coding Option (C) of Item 22 as
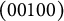 $(00100)$
—which renders Item 22 improper—indeed results in a loss of classification accuracy.
$(00100)$
—which renders Item 22 improper—indeed results in a loss of classification accuracy.
However, with real data, assessing classification accuracy is complicated by the fact that true examinee attribute profiles are unknown. Consequently, the straightforward PAR scores used in the simulations are not applicable. To address this dilemma, for each examinee, a K-dimensional attribute subscore vector (Oh & Chiu, Reference Oh and Chiu2025; Wang et al., Reference Wang, Chiu and Köhn2023) was calculated from their observed responses. Attribute subscores represent the proportion of items requiring a given attribute that the examinee answered correctly. These subscores were then used to assess the consistency of the estimated examinee attribute profiles: high subscores should correspond to 1 entries in
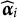 $\widehat {\boldsymbol {\alpha }}_i$
and low subscores to 0. Any discrepancy—a 1 where there should be a 0, or vice versa—indicates inconsistency between observed performance and estimated proficiency.
$\widehat {\boldsymbol {\alpha }}_i$
and low subscores to 0. Any discrepancy—a 1 where there should be a 0, or vice versa—indicates inconsistency between observed performance and estimated proficiency.
To isolate the impact of modifying Item 22, a shorter test of 12 items was constructed from the original 30. The subset included Items 1, 4, 9, 10, 11, 16, 18, 19, 20, 22, 23, and 28, selected according to the following criteria: (a) the Q-matrix remains complete, (b) when multiple items shared identical q-vectors, only one was retained, (c) 33% of the items included coded distractors (a proportion similar to the 30% in the original test), and (d) Item 22 was included. This dataset was analyzed using the MC-DINA model implemented in the MCmodel() function in the GDINA package, with both, the proper and the modified-improper Q-matrices. The focus was on examinees whose classification was expected to be directly affected by the improper Item 22—specifically, those who mastered attributes
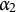 $\alpha _2$
and
$\alpha _2$
and
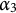 $\alpha _3$
and were assigned to proficiency classes
$\alpha _3$
and were assigned to proficiency classes
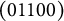 $(01100)$
,
$(01100)$
,
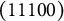 $(11100)$
,
$(11100)$
,
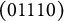 $(01110)$
,
$(01110)$
,
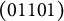 $(01101)$
,
$(01101)$
,
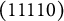 $(11110)$
, or
$(11110)$
, or
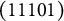 $(11101)$
. Examinees with attribute vectors
$(11101)$
. Examinees with attribute vectors
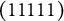 $(11111)$
and
$(11111)$
and
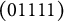 $(01111)$
were disregarded, as they were expected to choose the key according to the MC-DINA theory.
$(01111)$
were disregarded, as they were expected to choose the key according to the MC-DINA theory.
Table 9 displays the estimated attribute profiles of the focused examinees under the two Q-matrices, alongside the subscores. Highlighted rows indicate examinees whose classification changed due to the introduction of the improper distractor.
Estimated attribute profiles under the proper and improper Q-matrices and subscores; highlighted rows indicate classification changes

As shown in Table 9, four examinees’ classifications shifted from
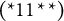 $(*11**)$
to
$(*11**)$
to
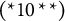 $(*10**)$
. However, three of these examinees answered all items requiring attribute
$(*10**)$
. However, three of these examinees answered all items requiring attribute
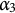 $\alpha _3$
correctly based on their subscores, but they were classified as non-masters of
$\alpha _3$
correctly based on their subscores, but they were classified as non-masters of
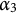 $\alpha _3$
under the improper Q-matrix. This demonstrates how improper item can reduce the validity of classification results.
$\alpha _3$
under the improper Q-matrix. This demonstrates how improper item can reduce the validity of classification results.
6 Discussion and conclusion
The concepts of plausible and proper MC items explore uncharted territory in CD research. Diagnostic redundancy and ambiguity were not an issue in CD assessments with MC items as long as the q-vectors of the coded distractors were constrained to be nested within the key and within each other, forming an “upside-down staircase” with the key at its top. The ordinal response scale implicitly defined by this nestedness constraint—and implemented in de la Torre’s (Reference de la Torre2009) MC-DINA model, the first CDM for MC items—ensured tight control over the diagnostic plausibility of the coded distractors of MC items. At the same time, however, the nestedness constraint imposes a serious burden on the construction of coded response options and poses challenges to assembling CD tests with MC items; especially, when large item pools are required, as in computer-adaptive testing, where item banks typically consist of hundreds or thousands of items. Relaxing the nestedness constraint therefore has clear practical benefits, but these do not come without cost: diagnostic redundancy and ambiguity in examinee classification emerge as new challenges to item and test construction.
Ozaki (Reference Ozaki2015) was apparently the first to discuss diagnostic ambiguity as a possible consequence of using MC items without the nestedness constraint. He proposed addressing this issue by modifying the parameterization of de la Torre’s MC-DINA model, thereby creating the “structured MC-DINA” (MC-S-DINA) models, which seek to remedy diagnostic ambiguity by explicit modeling it through the addition of extra parameters to de la Torre’s MC-DINA model.
The research presented in this article has a broader scope, addressing not only diagnostic ambiguity but also the presumably more prevalent issue of diagnostic redundancy. The concepts of proper and plausible MC items introduced in this article provide a theoretical framework for the technical description and analysis of both diagnostic redundancy and ambiguity. The theorems and proofs establish a solid technical foundation for the concepts of proper and plausible items, as well as strategies for remediating diagnostic redundancy and ambiguity in practice. The proposition advanced here is to redefine the set of coded distractors by modifying their q-vectors. Section Application II provides evidence from real-world data illustrating how undetected improper items can jeopardize examinee classification. In conclusion, three closely related questions remain to be addressed.
First, Simulation Study II might give the impression that diagnostic ambiguity arising from improper MC items is only a marginal problem that (i) only affects examinees in just a few proficiency classes and (ii) is typically offset by the remaining MC items in a test that are plausible and proper. The validity of this assessment certainly awaits further studies and more data. At this early stage, however, one claim can be made with certainty: diagnostic ambiguity due to improper items poses a bigger problem whenever the number of items is small, leaving too few items to compensate for improperness. Such a situation might occur in computerized adaptive testing for CD, where the selection of the next item depends on just one or two prior responses. If these happen to be improper, then the examinee is at risk of misclassification and being sent down an incorrect path. More generally, the impact of implausible and improper MC items on diagnostic accuracy in computerized adaptive testing for CD appears to be a promising avenue for future research.
Second, are diagnostic ambiguity and redundancy arising from improper and implausible MC items related to “misconceptions”—that is, the misinterpretation of the task posed by an item? DiBello et al. (Reference DiBello, Henson and Stout2015) and Stefanutti et al. (Reference Stefanutti, de Chiusole, Gondan and Maurer2020, Reference Stefanutti, Spoto, Anselmi and de Chiusole2023) discuss in detail the structure and function of examinee misconceptions from a CD and KST point of view, respectively. They develop sophisticated strategies for modeling this intriguing phenomenon to tap into its diagnostic potential. However, diagnostic ambiguity and redundancy originate from a different source than misconceptions. The former clearly are the product of poorly constructed item–attribute vectors that do not permit for the desirable diagnostic accuracy or fail to add any additional diagnostic insights. Misconceptions, on the other hand, are persistent mistakes made by an examinee due to the erroneous interpretation of the task posed by the item. In CD, misconceptions can be detected by constructing specific q-vectors that intentionally include, for example, attribute(s) irrelevant to the task at hand, but that an examinee believes are required to solve that item. In short, diagnostic ambiguity and redundancy stem from faulty test construction, whereas misconceptions arise on the examinee’s side and can be “lured out” by crafting clever but incorrect response options. Still, since most approaches to modeling misconceptions employ an MC item setting, the question is as to what extent the proposed theorems on proper and plausible MC items might also be applicable to the study of misconceptions.
Third, many researchers in CD and KST have investigated conditions for model identifiability (e.g., Chen et al., Reference Chen, Liu, Xu and Ying2015; Gu & Xu, Reference Gu and Xu2019, Reference Gu and Xu2021; Spoto & Stefanutti, Reference Spoto and Stefanutti2020, Reference Spoto and Stefanutti2023; Xu & Shang, Reference Xu and Shang2018; Xu & Zhang, Reference Xu and Zhang2016). But what can be said about the MC-DINA model and its identifiability? Do diagnostic ambiguity and redundancy in MC items undermine model identifiability? Can theoretical concepts like proper and plausible help establish identifiability of models for MC items in CD?—The short answer to these complex questions is “not yet.” Different from identifiability of the DINA model—a well-researched topic (cf. Gu & Xu, Reference Gu and Xu2021; Spoto & Stefanutti, Reference Spoto and Stefanutti2020, Reference Spoto and Stefanutti2023)—too little is known about the prerequisites for identifiability of the MC-DINA model, with or without the nestedness condition in place. For binary CDMs, the key requirement for identifiability is completeness of the Q-matrix (cf. Chiu et al., Reference Chiu, Douglas and Li2009; Gu & Xu, Reference Gu and Xu2021; Köhn & Chiu, Reference Köhn and Chiu2017). At present, conditions of Q-completeness for CDMs for MC items are unknown, in not to mention other side-conditions of identifiability as they have been established for binary CDMs. A reasonable conjecture, however, is that, in addition to the completeness of the Q-matrix, the conditions described by the concepts of proper and plausible MC items may also be necessary for establishing the identifiability of the MC-DINA model, since completeness of the Q-matrix seemingly requires the assumption of plausible and proper items. Models for MC items in CD thus open a rich field for future research. Complex topics like model identifiability should be a high priority, especially the question of whether concepts like proper and plausible can be integrated into the broader framework of model identifiability and Q-completeness, which is directly related to the assignment of examinees to their true proficiency profiles.
Funding statement
This research received no specific grant funding form any funding agency, commercial, or not-for-profit sectors.
Competing interests
The authors have no competing interests relevant to the content of this article to claim.
Appendix A
Proof of Theorem 1
Theorem 1. Suppose item j conforms to the MC-DINA model. Item j is plausible if and only if
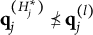 $\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
$\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
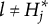 $l\neq H_j^\ast $
.
$l\neq H_j^\ast $
.
Proof Proof. (
$\Rightarrow $
)

Suppose item j is plausible. Then, according to Definition 1, the mapping
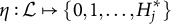 $\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective. Assume that there exists an
$\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective. Assume that there exists an
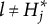 $l \neq H_j^\ast $
such that
$l \neq H_j^\ast $
such that
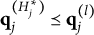 $\mathbf {q}_j^{(H_j^\ast )} \preceq \mathbf {q}_j^{(l)}$
. For those
$\mathbf {q}_j^{(H_j^\ast )} \preceq \mathbf {q}_j^{(l)}$
. For those
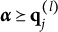 $\boldsymbol {\alpha } \succeq \mathbf {q}_j^{(l)}$
, it is true that
$\boldsymbol {\alpha } \succeq \mathbf {q}_j^{(l)}$
, it is true that
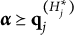 $\boldsymbol {\alpha } \succeq \mathbf {q}_j^{(H_j^\ast )}$
due to
$\boldsymbol {\alpha } \succeq \mathbf {q}_j^{(H_j^\ast )}$
due to
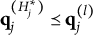 $\mathbf {q}_j^{(H_j^\ast )} \preceq \mathbf {q}_j^{(l)}$
. Hence,
$\mathbf {q}_j^{(H_j^\ast )} \preceq \mathbf {q}_j^{(l)}$
. Hence,
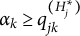 $\alpha _k \geq q_{jk}^{(H_j^\ast )}$
for all k. As a result, for these
$\alpha _k \geq q_{jk}^{(H_j^\ast )}$
for all k. As a result, for these
 $\boldsymbol {\alpha }$
, their ideal responses
$\boldsymbol {\alpha }$
, their ideal responses
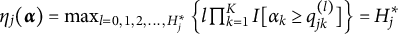 $\eta _j(\boldsymbol {\alpha }) = \max _{l = 0,1,2, \ldots ,H^{\ast }_j} \Big \{ l\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(l)}] \Big \} = H_j^\ast $
.
$\eta _j(\boldsymbol {\alpha }) = \max _{l = 0,1,2, \ldots ,H^{\ast }_j} \Big \{ l\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(l)}] \Big \} = H_j^\ast $
.
For the remaining
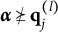 $\boldsymbol {\alpha } \nsucceq \mathbf {q}_j^{(l)}$
, there exists at least one k such that
$\boldsymbol {\alpha } \nsucceq \mathbf {q}_j^{(l)}$
, there exists at least one k such that
 $\alpha _k = 0$
and
$\alpha _k = 0$
and
 $q_{jk}^{(l)} = 1$
. Therefore,
$q_{jk}^{(l)} = 1$
. Therefore,
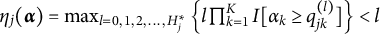 $\eta _j(\boldsymbol {\alpha }) = \max _{l = 0,1,2, \ldots ,H^{\ast }_j} \Big \{ l\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(l)}] \Big \} < l$
. In conclusion, there does not exist an
$\eta _j(\boldsymbol {\alpha }) = \max _{l = 0,1,2, \ldots ,H^{\ast }_j} \Big \{ l\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(l)}] \Big \} < l$
. In conclusion, there does not exist an
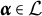 $\boldsymbol {\alpha } \in \mathcal {L}$
such that
$\boldsymbol {\alpha } \in \mathcal {L}$
such that
 $\eta (\boldsymbol {\alpha }) = l$
, implying that the function
$\eta (\boldsymbol {\alpha }) = l$
, implying that the function
 $\eta $
is not surjective, which contradicts the assumption that item j is plausible. Hence, if item j is plausible,
$\eta $
is not surjective, which contradicts the assumption that item j is plausible. Hence, if item j is plausible,
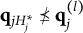 $\mathbf {q}_{jH_j^\ast }\npreceq \mathbf {q}_j^{(l)}$
for all
$\mathbf {q}_{jH_j^\ast }\npreceq \mathbf {q}_j^{(l)}$
for all
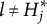 $l\neq H_j^\ast $
.
$l\neq H_j^\ast $
.
(
 $\Leftarrow $
) Suppose
$\Leftarrow $
) Suppose
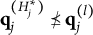 $\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
$\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
for all
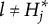 $l\neq H_j^\ast $
. To show that item j is plausible, the following cases are considered:
$l\neq H_j^\ast $
. To show that item j is plausible, the following cases are considered:
Case 1:
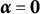 $\boldsymbol {\alpha } = \mathbf {0}$
. In this case,
$\boldsymbol {\alpha } = \mathbf {0}$
. In this case,
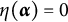 $\eta (\boldsymbol {\alpha }) = 0$
.
$\eta (\boldsymbol {\alpha }) = 0$
.
Case 2:
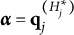 $\boldsymbol {\alpha } = \mathbf {q}_j^{(H_j^\ast )}$
. In this case,
$\boldsymbol {\alpha } = \mathbf {q}_j^{(H_j^\ast )}$
. In this case,
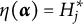 $\eta (\boldsymbol {\alpha }) = H_j^\ast $
.
$\eta (\boldsymbol {\alpha }) = H_j^\ast $
.
Case 3:
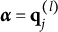 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)}$
, where
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)}$
, where
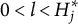 $0 < l < H_j^\ast $
. Because
$0 < l < H_j^\ast $
. Because
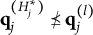 $\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
, or equivalently,
$\mathbf {q}_j^{(H_j^\ast )}\npreceq \mathbf {q}_j^{(l)}$
, or equivalently,
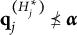 $\mathbf {q}_j^{(H_j^\ast )}\npreceq \boldsymbol {\alpha }$
, there exists a k such that
$\mathbf {q}_j^{(H_j^\ast )}\npreceq \boldsymbol {\alpha }$
, there exists a k such that
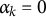 $\alpha _k = 0$
but
$\alpha _k = 0$
but
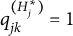 $q_{jk}^{(H_j^\ast )} = 1$
. Hence, for
$q_{jk}^{(H_j^\ast )} = 1$
. Hence, for
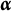 $\boldsymbol {\alpha }$
,
$\boldsymbol {\alpha }$
,
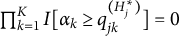 $\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(H_j^\ast )}] = 0$
, which implies that
$\prod _{k=1}^K I[\alpha _k \geq q_{jk}^{(H_j^\ast )}] = 0$
, which implies that
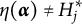 $\eta (\boldsymbol {\alpha }) \neq H_j^\ast $
. Now, because
$\eta (\boldsymbol {\alpha }) \neq H_j^\ast $
. Now, because
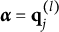 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)}$
, l is the highest level that
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)}$
, l is the highest level that
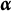 $\boldsymbol {\alpha }$
can endorse. Hence,
$\boldsymbol {\alpha }$
can endorse. Hence,
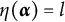 $\eta (\boldsymbol {\alpha }) = l$
, which means there exists at least one
$\eta (\boldsymbol {\alpha }) = l$
, which means there exists at least one
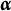 $\boldsymbol {\alpha }$
such that
$\boldsymbol {\alpha }$
such that
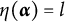 $\eta (\boldsymbol {\alpha }) = l$
.
$\eta (\boldsymbol {\alpha }) = l$
.
Case 4: The remaining
 $\boldsymbol {\alpha }$
. Each of them will be mapped to an element in
$\boldsymbol {\alpha }$
. Each of them will be mapped to an element in
 $\{0, 1, \ldots , H^\ast _j\}$
.
$\{0, 1, \ldots , H^\ast _j\}$
.
According to the above cases, it is true that
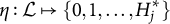 $\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective, implying that item j is plausible.
$\eta : \mathcal {L} \mapsto \{0, 1, \ldots , H_j^\ast \}$
is surjective, implying that item j is plausible.
Proof of Theorem 2
Theorem 2. Suppose item j conforms to the MC-DINA model. Item j is proper if and only if for each pair of its coded distractors with q-vectors
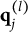 $\mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l)}$
and
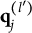 $\mathbf {q}_j^{(l')}$
in
$\mathbf {q}_j^{(l')}$
in
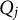 $Q_j$
, it is true that
$Q_j$
, it is true that
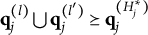 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
Proof. (
$\Rightarrow $
)

Suppose the item is proper. Assume that there exist
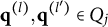 $\mathbf {q}^{(l)}, \mathbf {q}^{(l^\prime )} \in Q_j$
, where
$\mathbf {q}^{(l)}, \mathbf {q}^{(l^\prime )} \in Q_j$
, where
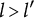 $l> l'$
, such that
$l> l'$
, such that
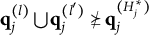 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
and
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
and
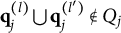 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
. Because
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
. Because
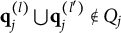 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
, it implies that
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
, it implies that
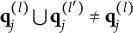 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l)}$
and
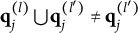 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l')}$
as both
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l')}$
as both
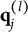 $\mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l)}$
and
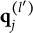 $\mathbf {q}_j^{(l')}$
are in
$\mathbf {q}_j^{(l')}$
are in
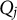 $Q_j$
. Hence,
$Q_j$
. Hence,
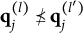 $\mathbf {q}_j^{(l)} \npreceq \mathbf {q}_j^{(l')}$
and
$\mathbf {q}_j^{(l)} \npreceq \mathbf {q}_j^{(l')}$
and
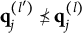 $\mathbf {q}_j^{(l')} \npreceq \mathbf {q}_j^{(l)}$
.
$\mathbf {q}_j^{(l')} \npreceq \mathbf {q}_j^{(l)}$
.
Now consider
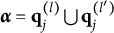 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. Suppose
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. Suppose
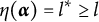 $\eta (\boldsymbol {\alpha }) = l^\ast \geq l$
. Because
$\eta (\boldsymbol {\alpha }) = l^\ast \geq l$
. Because
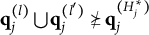 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
, or equivalently,
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
, or equivalently,
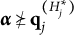 $\boldsymbol {\alpha } \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
, it can be concluded that examinees with attribute profile
$\boldsymbol {\alpha } \nsucceq \mathbf {q}_j^{(H^\ast _j)}$
, it can be concluded that examinees with attribute profile
 $\boldsymbol {\alpha }$
will not choose the key and thus
$\boldsymbol {\alpha }$
will not choose the key and thus
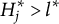 $H^\ast _j> l^\ast $
, which means
$H^\ast _j> l^\ast $
, which means
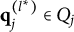 $\mathbf {q}_j^{(l^\ast )}\in Q_j$
and
$\mathbf {q}_j^{(l^\ast )}\in Q_j$
and
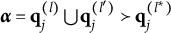 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succ \mathbf {q}_j^{(l^\ast )}$
. Note that
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succ \mathbf {q}_j^{(l^\ast )}$
. Note that
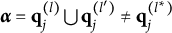 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l^\ast )}$
because
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l^\ast )}$
because
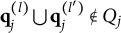 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
but
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \notin Q_j$
but
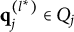 $\mathbf {q}_j^{(l^\ast )} \in Q_j$
. Because
$\mathbf {q}_j^{(l^\ast )} \in Q_j$
. Because
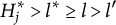 $H^\ast _j> l^\ast \geq l > l'$
, there are several cases that require further discussions:
$H^\ast _j> l^\ast \geq l > l'$
, there are several cases that require further discussions:
Case 1:
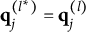 $\mathbf {q}_j^{(l^\ast )} = \mathbf {q}_j^{(l)}$
. The item will not be proper because
$\mathbf {q}_j^{(l^\ast )} = \mathbf {q}_j^{(l)}$
. The item will not be proper because
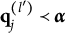 $\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
, but
$\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
, but
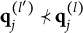 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
or equivalently,
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
or equivalently,
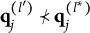 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
.
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
.
Case 2:
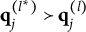 $\mathbf {q}_j^{(l^\ast )} \succ \mathbf {q}_j^{(l)}$
. Assume that
$\mathbf {q}_j^{(l^\ast )} \succ \mathbf {q}_j^{(l)}$
. Assume that
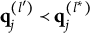 $\mathbf {q}_j^{(l')} \prec \mathbf {q}_j^{(l^\ast )}$
. Consequently,
$\mathbf {q}_j^{(l')} \prec \mathbf {q}_j^{(l^\ast )}$
. Consequently,
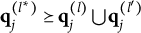 $\mathbf {q}_j^{(l^\ast )} \succeq \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
, which contradicts the fact that
$\mathbf {q}_j^{(l^\ast )} \succeq \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
, which contradicts the fact that
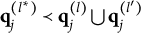 $\mathbf {q}_j^{(l^\ast )} \prec \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. Hence, in this case, it must be true that
$\mathbf {q}_j^{(l^\ast )} \prec \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. Hence, in this case, it must be true that
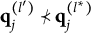 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
. Because
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
. Because
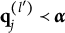 $\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
but
$\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
but
 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
, the item is not proper.
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
, the item is not proper.
Case 3:
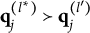 $\mathbf {q}_j^{(l^\ast )}\succ \mathbf {q}_j^{(l')}$
. For the same rationale as that in Case 2, it is also true that
$\mathbf {q}_j^{(l^\ast )}\succ \mathbf {q}_j^{(l')}$
. For the same rationale as that in Case 2, it is also true that
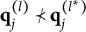 $\mathbf {q}_j^{(l)} \nprec \mathbf {q}_j^{(l^\ast )}$
, which, again, implies that the item is not proper.
$\mathbf {q}_j^{(l)} \nprec \mathbf {q}_j^{(l^\ast )}$
, which, again, implies that the item is not proper.
Case 4:
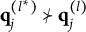 $\mathbf {q}_j^{(l^\ast )}\nsucc \mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l^\ast )}\nsucc \mathbf {q}_j^{(l)}$
and
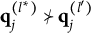 $\mathbf {q}_j^{(l^\ast )} \nsucc \mathbf {q}_j^{(l')}$
. Because
$\mathbf {q}_j^{(l^\ast )} \nsucc \mathbf {q}_j^{(l')}$
. Because
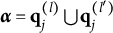 $\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
, it is true that
$\boldsymbol {\alpha } = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
, it is true that
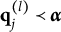 $\mathbf {q}_j^{(l)} \prec \boldsymbol {\alpha }$
and
$\mathbf {q}_j^{(l)} \prec \boldsymbol {\alpha }$
and
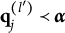 $\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
. However,
$\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
. However,
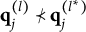 $\mathbf {q}_j^{(l)} \nprec \mathbf {q}_j^{(l^\ast )}$
and
$\mathbf {q}_j^{(l)} \nprec \mathbf {q}_j^{(l^\ast )}$
and
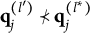 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
implying that the item is not proper. Based on the above cases, the item is not proper, which contradicts to the assumption. Hence, it must be true that
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l^\ast )}$
implying that the item is not proper. Based on the above cases, the item is not proper, which contradicts to the assumption. Hence, it must be true that
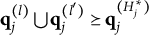 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
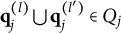 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
.
(
 $\Leftarrow $
) Suppose that for every pair of distractors
$\Leftarrow $
) Suppose that for every pair of distractors
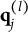 $\mathbf {q}_j^{(l)}$
and
$\mathbf {q}_j^{(l)}$
and
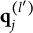 $\mathbf {q}_j^{(l')}$
in
$\mathbf {q}_j^{(l')}$
in
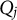 $Q_j$
, it is true that
$Q_j$
, it is true that
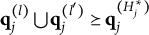 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \succeq \mathbf {q}_j^{(H^\ast _j)}$
or
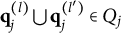 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
. Assume that the item is not proper. Then, there exists some
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
. Assume that the item is not proper. Then, there exists some
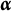 $\boldsymbol {\alpha }$
, where
$\boldsymbol {\alpha }$
, where
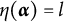 $\eta (\boldsymbol {\alpha }) = l$
, such that
$\eta (\boldsymbol {\alpha }) = l$
, such that
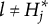 $l \neq H^\ast _j$
and there exists a
$l \neq H^\ast _j$
and there exists a
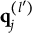 $\mathbf {q}_j^{(l')}$
such that
$\mathbf {q}_j^{(l')}$
such that
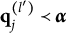 $\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
but
$\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
but
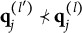 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
. Because
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
. Because
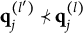 $\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
, it can be concluded that
$\mathbf {q}_j^{(l')} \nprec \mathbf {q}_j^{(l)}$
, it can be concluded that
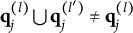 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l)}$
. Because
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \neq \mathbf {q}_j^{(l)}$
. Because
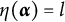 $\eta (\boldsymbol {\alpha }) = l$
, it is true that
$\eta (\boldsymbol {\alpha }) = l$
, it is true that
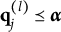 $\mathbf {q}_j^{(l)}\preceq \boldsymbol {\alpha }$
. Because
$\mathbf {q}_j^{(l)}\preceq \boldsymbol {\alpha }$
. Because
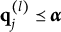 $\mathbf {q}_j^{(l)}\preceq \boldsymbol {\alpha }$
and
$\mathbf {q}_j^{(l)}\preceq \boldsymbol {\alpha }$
and
 $\mathbf {q}_j^{(l')}\prec \boldsymbol {\alpha }$
, it is true that
$\mathbf {q}_j^{(l')}\prec \boldsymbol {\alpha }$
, it is true that
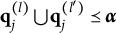 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \preceq \boldsymbol {\alpha }$
. In addition, because
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \preceq \boldsymbol {\alpha }$
. In addition, because
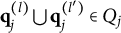 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
, and
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \in Q_j$
, and
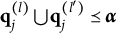 $\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \preceq \boldsymbol {\alpha }$
,
$\mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')} \preceq \boldsymbol {\alpha }$
,
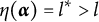 $\eta (\boldsymbol {\alpha }) = l^\ast> l$
, where
$\eta (\boldsymbol {\alpha }) = l^\ast> l$
, where
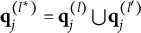 $\mathbf {q}_j^{(l^\ast )} = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. This is a contradiction because
$\mathbf {q}_j^{(l^\ast )} = \mathbf {q}_j^{(l)} \bigcup \mathbf {q}_j^{(l')}$
. This is a contradiction because
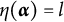 $\eta (\boldsymbol {\alpha }) = l$
. Hence,
$\eta (\boldsymbol {\alpha }) = l$
. Hence,
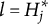 $l = H^\ast _j$
or if there exists a
$l = H^\ast _j$
or if there exists a
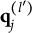 $\mathbf {q}_j^{(l')}$
such that
$\mathbf {q}_j^{(l')}$
such that
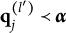 $\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
, then
$\mathbf {q}_j^{(l')} \prec \boldsymbol {\alpha }$
, then
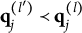 $\mathbf {q}_j^{(l')} \prec \mathbf {q}_j^{(l)}$
, which implies that the item is proper.
$\mathbf {q}_j^{(l')} \prec \mathbf {q}_j^{(l)}$
, which implies that the item is proper.


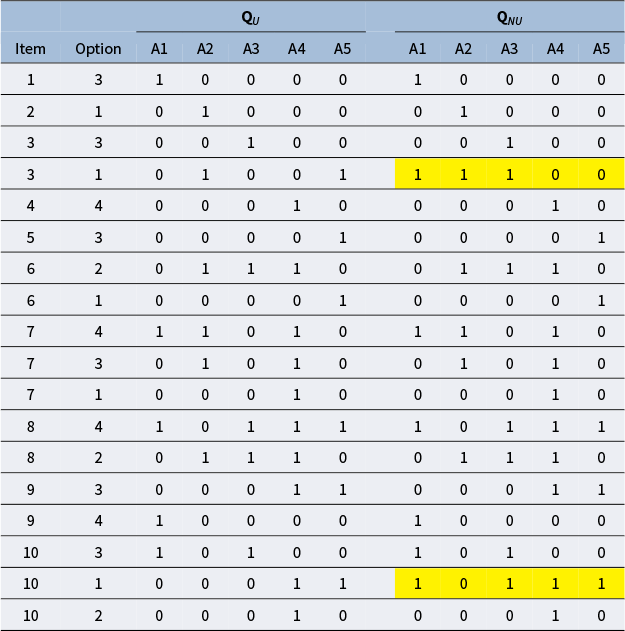
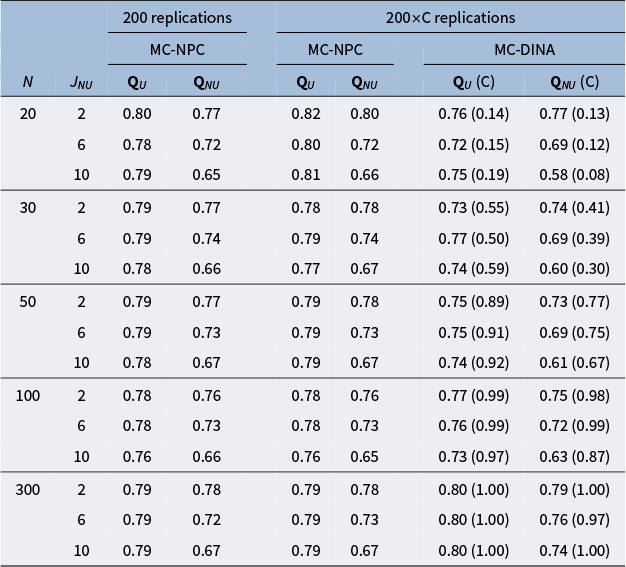

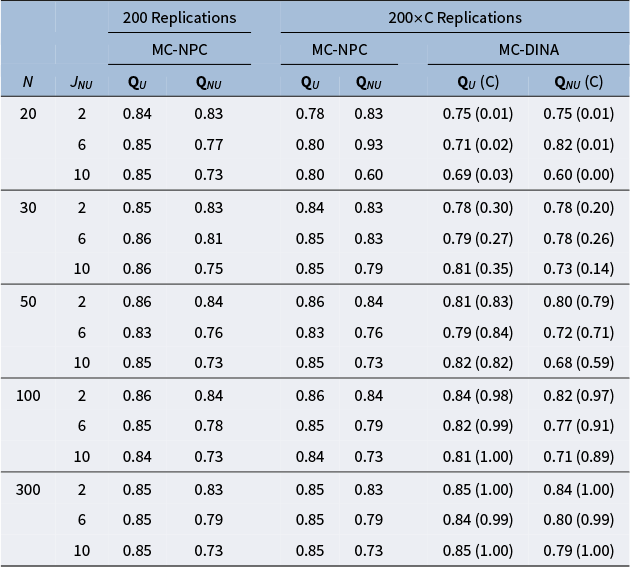

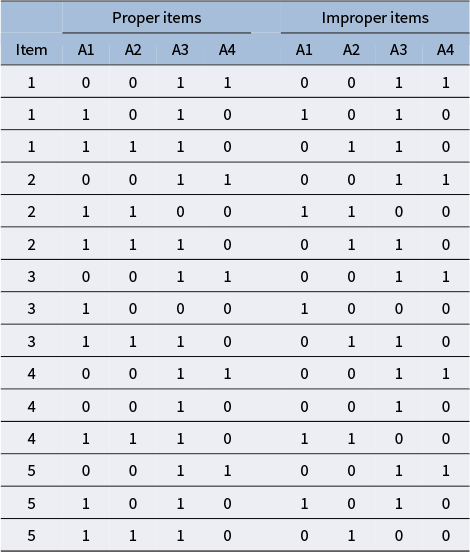




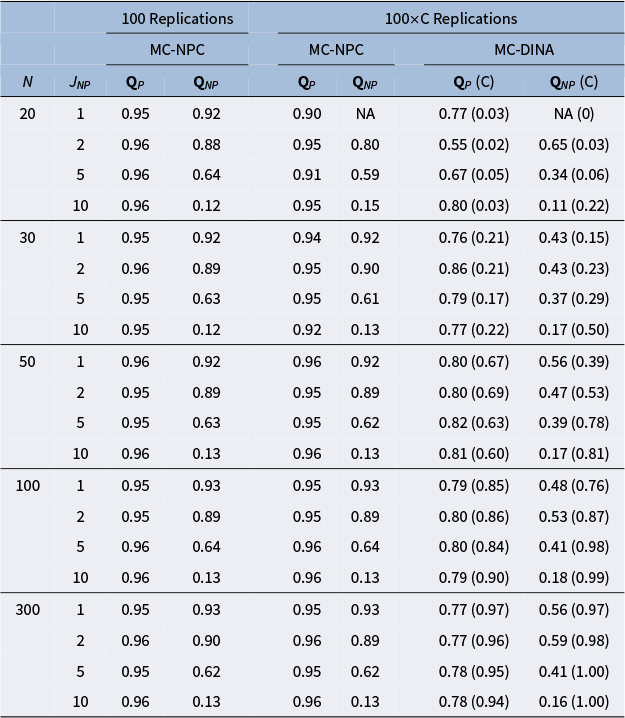

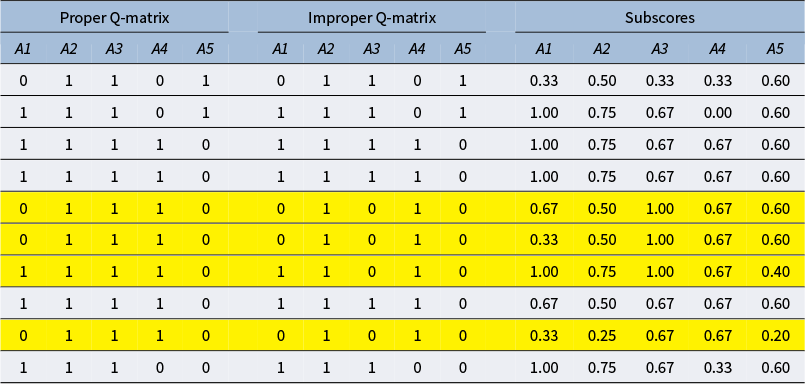

 Open access
Open access