



Social media summary
How does knowledge accumulate across generations, and what shapes how individuals learn and from whom they learn? Using a mathematical model, we show that stochasticity in learning generates variation in knowledge, strengthening cultural selection, increasing cumulative knowledge, and shaping the evolution of learning strategies and transmission pathways.
1. Introduction
Individuals use knowledge to perform behaviours that enhance survival and reproduction. This knowledge can be acquired either through personal experience (individual learning), such as trial-and-error learning (e.g., Dugatkin Reference Dugatkin2008, Ghirlanda and Lind Reference Ghirlanda and Lind2017), or from other individuals (social learning), for example, through imitation (e.g., Zentall Reference Zentall2006, Dugatkin Reference Dugatkin2008, Bates and Byrne Reference Bates and Byrne2010). Social learning can occur through a wide variety of pathways (Cavalli-Sforza and Feldman, Reference Cavalli-Sforza and Feldman1981, Boyd and Richerson, Reference Boyd and Richerson1985, Laland, Reference Laland2004, van Schaik, Reference Schaik2016, Kendal et al., Reference Kendal, Boogert, Rendell, Laland, Webster and Jones2018, Camacho-Alpízar and Guillette, Reference Camacho-Alpízar and Guillette2023), including, for instance, vertical transmission (from parent to offspring) and oblique transmission (from unrelated older individuals). The way individuals allocate resources to different learning behaviours across their lifetime affects the population dynamics of knowledge and can support its gradual accumulation and refinement across generations. This process, known as cumulative knowledge or cumulative culture, is widely regarded as a key factor in the ecological success of humans (Henrich, Reference Henrich2015, van Schaik, Reference Schaik2016), and growing evidence suggests that it may also contribute to adaptive behaviours in non-human animals (Hunt and Gray, Reference Hunt and Gray2003, Sasaki and Biro, Reference Sasaki and Biro2017, Jesmer et al., Reference Jesmer, Merkle, Goheen, Aikens, Beck, Courtemanch, Hurley, McWhirter, Miyasaki, Monteith and Kauffman2018, Gunasekaram et al., Reference Gunasekaram, Battiston, Sadekar, Padilla-Iglesias, van Noordwijk, Furrer, Manica, Bertranpetit, Whiten, van Schaik, Vinicius and Migliano2024).
Learners’ individual and social learning strategies influence changes in knowledge within a population by shaping cultural deviation and cultural selection, the two key mechanisms underlying population change in any cultural trait and understood here as a socially transmissible trait (see Henrich and Boyd, Reference Henrich and Boyd2002, El Mouden et al., Reference Mouden, André, Morin and Nettle2014, Aguilar and Akçay, Reference Aguilar and Akçay2018, Nettle, Reference Nettle2020, Mesoudi, Reference Mesoudi2021). First, cultural deviation occurs when the learning process, on average, leads to differences between the knowledge of learners and that of their exemplars. This mechanism can either promote knowledge accumulation, for example, when learners produce new or refine existing knowledge by individual learning after social learning (e.g., Enquist et al., Reference Enquist, Ghirlanda, Jarrick and Wachtmeister2008, Aoki et al., Reference Aoki, Wakano and Lehmann2012a, Nakahashi, Reference Nakahashi2013, Kempe et al., Reference Kempe, Lycett and Mesoudi2014, Wakano and Miura, Reference Wakano and Miura2014, André and Baumard, Reference André and Baumard2020, Denton et al., Reference Denton, Ram and Feldman2023), or constrain it, as when learners tend to acquire a lower level of knowledge than their exemplars (e.g., Henrich and Boyd, Reference Henrich and Boyd2002, Henrich, Reference Henrich2004). Second, cultural selection arises when some individuals serve as exemplars more frequently, amplifying the transmission of their specific knowledge or cultural trait and generating variation in the transmission success of different knowledge or cultural variants (Cavalli-Sforza and Feldman, Reference Cavalli-Sforza and Feldman1981, Boyd and Richerson, Reference Boyd and Richerson1985, Micheletti, Reference Micheletti2020). Cultural selection may arise from either (i) non-random exemplar choice or (ii) differences in survival and reproduction among individuals with different knowledge or cultural traits (though some authors use the term cultural selection specifically for mechanism (i); Cavalli-Sforza and Feldman, Reference Cavalli-Sforza and Feldman1981, Mesoudi, Reference Mesoudi2011). Cultural selection is generally expected to support cumulative knowledge, as it tends to favour cultural variants that are more well-adapted to environmental conditions, for example, when individuals with more adaptive cultural variants tend to be chosen as learning exemplars (e.g., Henrich, Reference Henrich2004, Powell et al., Reference Powell, Shennan and Thomas2009, Kobayashi and Aoki, Reference Kobayashi and Aoki2012), or when such variants enhance survival and fecundity, allowing them to spread by increasing opportunities for oblique (e.g., Nakahashi, Reference Nakahashi2010) and vertical transmission (e.g., Tureček et al., Reference Tureček, Slavík, Kozák and Havlíček2019), respectively. Mathematical models have shown that the strength of cultural selection, and thus its potential to drive cumulative knowledge, increases with population variance in cultural traits (Cavalli-Sforza and Feldman, Reference Cavalli-Sforza and Feldman1981, Boyd and Richerson, Reference Boyd and Richerson1985).
In turn, knowledge dynamics shape what individuals can acquire through social learning, thereby influencing selection pressures on the allocation of resources across different types of learning behaviour. This feedback between knowledge accumulation and learning strategies gives rise to complex coevolutionary dynamics, also shaped by trade-offs between learning and other functions essential for survival and reproduction (for empirical evidence on such trade-offs, see Mery and Kawecki, Reference Mery and Kawecki2004, Burger et al., Reference Burger, Kolss, Pont and Kawecki2008, Snell-Rood et al., Reference Snell-Rood, Davidowitz and Papaj2011, Jaumann et al., Reference Jaumann, Scudelari and Naug2013, Kotrschal et al., Reference Kotrschal, Rogell, Bundsen, Svensson, Zajitschek, Brännström, Immler, Maklakov and Kolm2013, Christiansen et al., Reference Christiansen, Szin and Schausberger2016, Evans et al., Reference Evans, Smith and Raine2017, Padamsey and Rochefort, Reference Padamsey and Rochefort2023). A large body of theoretical work has examined these dynamics and how ecological factors influence the allocation of resources to different forms of learning and the emergence of cumulative knowledge (Nakahashi, Reference Nakahashi2010, Reference Nakahashi2013, Aoki et al., Reference Aoki, Wakano and Lehmann2012b, Lehmann et al., Reference Lehmann, Wakano and Aoki2013, Wakano and Miura, Reference Wakano and Miura2014, Kobayashi et al., Reference Kobayashi, Wakano and Ohtsuki2015, Reference Kobayashi, Ohtsuki and Wakano2016, Mullon and Lehmann, Reference Mullon and Lehmann2017, Ohtsuki et al., Reference Ohtsuki, Wakano and Kobayashi2017, Maisonneuve et al., Reference Maisonneuve, Lehmann and Mullon2025). Nevertheless, the effect of cultural selection is generally neglected in these models (with few exceptions such as Kobayashi et al., Reference Kobayashi, Ohtsuki and Wakano2016), often because these models assume a deterministic knowledge acquisition process at the individual level, which removes variation that can be selected upon.
However, cultural selection is likely to influence the coevolution of cumulative knowledge and learning strategies, as learning is inherently stochastic; for example, the success of trial-and-error learning often depends on chance discoveries of adaptive cultural variants, leading to individual variation in knowledge. While not their primary focus, Kobayashi et al. (Reference Kobayashi, Ohtsuki and Wakano2016) showed that stochasticity in individual learning promotes investment in social learning by amplifying the effect of cultural selection (caused by knowledge-based choice of social exemplars), thereby increasing overall population knowledge and increasing what can be acquired socially. However, in contrast to the assumptions of Kobayashi et al. (Reference Kobayashi, Ohtsuki and Wakano2016), individuals in natural populations may not always be able to reliably assess the knowledge of others and to use it to guide their social learning decisions (Argyle and McHenry, Reference Argyle and McHenry1971, Lutz and Keil, Reference Lutz and Keil2002, Wood et al., Reference Wood, Kendal and Flynn2012, Jiménez and Mesoudi, Reference Jiménez and Mesoudi2019, Hirel et al., Reference Hirel, Meunier, Mundry, Rakoczy, Fischer and Keupp2025). This underscores the need to investigate how stochasticity in learning affects the coevolution of cumulative knowledge and learning strategies without knowledge-based choice of social exemplars.
Furthermore, there is a lack of predictions about how stochasticity in learning affects the evolution of the choice among transmission pathways (e.g., vertical vs. oblique), or the trade-offs between learning and other functions essential for survival and reproduction. Stochasticity in learning could affect these features because it increases uncertainty about the knowledge held by potential exemplars. Previous models have shown that, under such uncertainty, selection favours learning knowledge that affects fecundity from parents rather than from other adults (McElreath and Strimling, Reference McElreath and Strimling2008). This suggests that stochasticity in learning may play an important role in shaping the allocation between vertical and oblique transmission.
In this study, we examine how stochasticity in learning influences knowledge accumulation by developing an evolutionary model in which learning is described as a stochastic process. The model tracks the evolution of the overall resource allocation to learning and fecundity, as well as the allocation of time across different types of learning (vertical, oblique, and individual learning). This allows us to examine how stochasticity influences the evolution of learning strategies, specifically, the pathways individuals use to acquire information through social learning and the trade-off between investment in learning and reproduction. By allowing knowledge to accumulate over generations, our framework also captures the coevolutionary feedback between learning strategies and knowledge accumulation.
2. Model
2.1. Life-cycle
We consider a large, asexual population where individuals acquire information that enhances fecundity and survival. This includes information such as the location of food sources, the edibility of different foods, or instructions on how to build and use a tool. Each individual possesses a quantity of adaptive information, referred to as knowledge, which is treated as a quantitative variable in our analysis. In each generation, the population goes through the following life-cycle events (see Fig. 1a). (1) Adults produce offspring according to a Poisson process with a mean depending on their knowledge. (2) Offspring acquire knowledge socially from adults and through individual learning through a stochastic learning process. (3) Parents die. Offspring go through a density-dependent survival stage, where their knowledge affects survival. Those surviving become the adults of the next generation, and the cycle starts again. As a result of reproduction and survival, the number of individuals is not fixed and may vary across generations.
Model overview. (a) Illustration of the life cycle. (b) Illustration of the learning process. A focal individual can obtain knowledge (e.g., the skill set to crack nuts open, denoted by 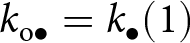 $k_{\mathrm{o}\bullet}=k_{\bullet}(1)$ and represented here as a round set) by learning from three sources: (i) vertically from its parent (with knowledge
$k_{\mathrm{o}\bullet}=k_{\bullet}(1)$ and represented here as a round set) by learning from three sources: (i) vertically from its parent (with knowledge 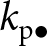 $k_{\mathrm{p}\bullet}$; blue arrow); (ii) obliquely from a randomly selected adult (with knowledge
$k_{\mathrm{p}\bullet}$; blue arrow); (ii) obliquely from a randomly selected adult (with knowledge 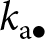 $k_{\mathrm{a}\bullet}$, the knowledge of the parent
$k_{\mathrm{a}\bullet}$, the knowledge of the parent 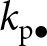 $k_{\mathrm{p}\bullet}$ and the oblique exemplar
$k_{\mathrm{p}\bullet}$ and the oblique exemplar 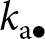 $k_{\mathrm{a}\bullet}$ can also overlap and thus be redundant; green arrow); and (iii) individually, when it produces its own knowledge (in pink). See the main text in Section 2.2.2 for more details. (c) A realisation of knowledge accumulation with a lifetime: individual knowledge
$k_{\mathrm{a}\bullet}$ can also overlap and thus be redundant; green arrow); and (iii) individually, when it produces its own knowledge (in pink). See the main text in Section 2.2.2 for more details. (c) A realisation of knowledge accumulation with a lifetime: individual knowledge 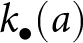 $k_{\bullet}(a)$ of a focal offspring against its age
$k_{\bullet}(a)$ of a focal offspring against its age 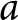 $a$ (realisation of the stochastic process defined by eq. (2) with traits
$a$ (realisation of the stochastic process defined by eq. (2) with traits 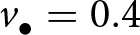 $v_{\bullet} = 0.4$,
$v_{\bullet} = 0.4$, 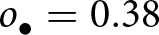 $o_{\bullet} = 0.38$ and
$o_{\bullet} = 0.38$ and  $\lambda_{\bullet}=0.82$ for the offspring; and parameters
$\lambda_{\bullet}=0.82$ for the offspring; and parameters  $\beta_{\mathrm{v}}=3$,
$\beta_{\mathrm{v}}=3$,  $\beta_{\mathrm{o}} = 2.4$,
$\beta_{\mathrm{o}} = 2.4$,  $\alpha = 2$,
$\alpha = 2$,  $\epsilon=0.25$,
$\epsilon=0.25$,  $\rho=0.05$,
$\rho=0.05$,  $\sigma_\mathrm{v}=\sigma_\mathrm{o}=0.1$,
$\sigma_\mathrm{v}=\sigma_\mathrm{o}=0.1$,  $\sigma_\mathrm{i}=0.3$,
$\sigma_\mathrm{i}=0.3$,  $k_{\mathrm{p}\bullet} = k_{\mathrm{a}\bullet} = 2.45$). The dashed line shows knowledge accumulation in the absence of stochasticity in learning, that is, when
$k_{\mathrm{p}\bullet} = k_{\mathrm{a}\bullet} = 2.45$). The dashed line shows knowledge accumulation in the absence of stochasticity in learning, that is, when  $\sigma_\mathrm{v}=\sigma_\mathrm{o}=\sigma_\mathrm{i}=0$. (d) Knowledge accumulation within a lineage: mean’s adult knowledge
$\sigma_\mathrm{v}=\sigma_\mathrm{o}=\sigma_\mathrm{i}=0$. (d) Knowledge accumulation within a lineage: mean’s adult knowledge  ${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}$ within an
${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}$ within an  ${\boldsymbol{x}_\bullet}$-lineage at each generation
${\boldsymbol{x}_\bullet}$-lineage at each generation 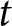 $t$ (obtained from an individual-based simulation using the same parameters as in panel c, with trait mutation turned off and starting with a population of one ancestral individual with no knowledge, we set
$t$ (obtained from an individual-based simulation using the same parameters as in panel c, with trait mutation turned off and starting with a population of one ancestral individual with no knowledge, we set  $k_{\mathrm{p}\bullet} = k_{\mathrm{a}\bullet} = 0$ for the ancestral individual, with
$k_{\mathrm{p}\bullet} = k_{\mathrm{a}\bullet} = 0$ for the ancestral individual, with  $\gamma = 0.1$,
$\gamma = 0.1$,  $f_\mathrm{0}=5$,
$f_\mathrm{0}=5$,  $s_\mathrm{0}=1$,
$s_\mathrm{0}=1$,  $\eta_\mathrm{f}=25$,
$\eta_\mathrm{f}=25$, 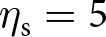 $\eta_\mathrm{s}=5$,
$\eta_\mathrm{s}=5$, 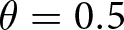 $\theta=0.5$); see Appendix D for more detail on individual-based simulations). The shaded area corresponds to cumulative knowledge (where individuals, on average, possess more knowledge than they could acquire through individual learning alone, i.e., where
$\theta=0.5$); see Appendix D for more detail on individual-based simulations). The shaded area corresponds to cumulative knowledge (where individuals, on average, possess more knowledge than they could acquire through individual learning alone, i.e., where 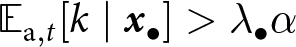 ${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} \gt \lambda_{\bullet} \alpha$). The dashed line shows the expected knowledge of a random adult of an
${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} \gt \lambda_{\bullet} \alpha$). The dashed line shows the expected knowledge of a random adult of an  ${\boldsymbol{x}_\bullet}$-lineage at equilibrium
${\boldsymbol{x}_\bullet}$-lineage at equilibrium 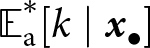 ${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ predicted by our analysis (see Section 2.3).
${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ predicted by our analysis (see Section 2.3).

During stage (2) of the life cycle, offspring perform sequentially three different types of learning: first, they learn from their parent (vertical learning), then from a randomly selected adult (oblique learning), and finally by themselves (individual learning; see Fig. 1b). All individuals learn during a fixed time, which we normalise to 1. Accordingly, the time allocated to vertical, oblique, and individual learning must sum to one. Two evolving traits shape how individuals allocate their time across the three different types of learning: the amount of time 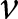 $v$ spent learning vertically (Table 1 for a list of symbols); the amount of time
$v$ spent learning vertically (Table 1 for a list of symbols); the amount of time  $o$ spent learning obliquely; so that
$o$ spent learning obliquely; so that 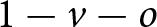 $1 - v - o$ is spent learning individually.
$1 - v - o$ is spent learning individually.
Key symbols and their definitions

Moreover, we assume that an evolving trait  $\lambda{\in[0,1]}$ controls the overall trade-off between allocating resources to learning and fecundity. Higher values of
$\lambda{\in[0,1]}$ controls the overall trade-off between allocating resources to learning and fecundity. Higher values of  $\lambda$ enhance the efficiency of all learning types but at the cost of reduced fecundity. For instance,
$\lambda$ enhance the efficiency of all learning types but at the cost of reduced fecundity. For instance,  $\lambda$ may reflect developmental costs or the metabolic expenditure associated with learning ability.
$\lambda$ may reflect developmental costs or the metabolic expenditure associated with learning ability.
Next, we describe in detail how traits affect the three life cycle stages (Section 2.2) and then outline the approach used to analyse the cultural and the evolutionary dynamics (Section 2.3).
2.2. Traits effects and knowledge throughout the life-cycle
2.2.1. Adult reproduction
We start by considering a focal adult from an arbitrary generation, characterised by traits  ${{\boldsymbol{x}_\bullet}=}(v_{\bullet}, o_{\bullet}, \lambda_{\bullet})$ and amount of knowledge
${{\boldsymbol{x}_\bullet}=}(v_{\bullet}, o_{\bullet}, \lambda_{\bullet})$ and amount of knowledge  $k_{\mathrm{p}\bullet} \in \mathbb{R}$. This knowledge is the realised outcome of a stochastic learning process experienced during the individual’s offspring stage (detailed in the next section). The expected number of offspring of the focal adult, referred to as fecundity, is given by
$k_{\mathrm{p}\bullet} \in \mathbb{R}$. This knowledge is the realised outcome of a stochastic learning process experienced during the individual’s offspring stage (detailed in the next section). The expected number of offspring of the focal adult, referred to as fecundity, is given by
 \begin{equation}
f({\boldsymbol{x}_\bullet}, k_{\mathrm{p}\bullet}) = \left(1-\lambda_{\bullet}\right)^\theta \, \left(f_\mathrm{0} + \eta_\mathrm{f} \, k_{\mathrm{p}\bullet} \right),
\end{equation}
\begin{equation}
f({\boldsymbol{x}_\bullet}, k_{\mathrm{p}\bullet}) = \left(1-\lambda_{\bullet}\right)^\theta \, \left(f_\mathrm{0} + \eta_\mathrm{f} \, k_{\mathrm{p}\bullet} \right),
\end{equation} where 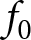 $f_\mathrm{0}$ is the baseline fecundity without investment into learning, and
$f_\mathrm{0}$ is the baseline fecundity without investment into learning, and  $\eta_\mathrm{f}$ is a conversion factor translating knowledge into fecundity. For example, in a context where knowledge enhances offspring care,
$\eta_\mathrm{f}$ is a conversion factor translating knowledge into fecundity. For example, in a context where knowledge enhances offspring care,  $\eta_\mathrm{f}$ would be high. An individual’s fecundity is reduced by its investment
$\eta_\mathrm{f}$ would be high. An individual’s fecundity is reduced by its investment  $\lambda_{\bullet}$ in learning, reflecting costs associated with acquiring learning abilities, as well as the metabolic expenses involved in the learning process itself. The parameter
$\lambda_{\bullet}$ in learning, reflecting costs associated with acquiring learning abilities, as well as the metabolic expenses involved in the learning process itself. The parameter  $\theta { \gt 0}$ controls the strength and shape of this fecundity penalty: higher values of
$\theta { \gt 0}$ controls the strength and shape of this fecundity penalty: higher values of  $\theta$ amplify the fecundity cost of learning, while lower values make this cost more gradual. This implementation of the learning–fecundity trade-off differs from earlier models, in which the trade-off between learning and reproduction is typically expressed through the allocation of time among learning and other functions (Lehmann et al., Reference Lehmann, Feldman and Kaeuffer2010, Reference Lehmann, Wakano and Aoki2013, Wakano and Miura, Reference Wakano and Miura2014, Mullon and Lehmann, Reference Mullon and Lehmann2017).
$\theta$ amplify the fecundity cost of learning, while lower values make this cost more gradual. This implementation of the learning–fecundity trade-off differs from earlier models, in which the trade-off between learning and reproduction is typically expressed through the allocation of time among learning and other functions (Lehmann et al., Reference Lehmann, Feldman and Kaeuffer2010, Reference Lehmann, Wakano and Aoki2013, Wakano and Miura, Reference Wakano and Miura2014, Mullon and Lehmann, Reference Mullon and Lehmann2017).
2.2.2. Offspring learning
Next, we consider an offspring of the focal adult. This focal offspring inherits the parent’s traits  $(v_{\bullet}, o_{\bullet}, \lambda_{\bullet})$, barring mutation. Let us denote by
$(v_{\bullet}, o_{\bullet}, \lambda_{\bullet})$, barring mutation. Let us denote by  $k_{\bullet}(a) \in \mathbb{R}$ the knowledge this offspring bears at age
$k_{\bullet}(a) \in \mathbb{R}$ the knowledge this offspring bears at age  $a \in [0,1]$ (where
$a \in [0,1]$ (where  $a=0$ is birth). Building on the models of Kobayashi et al. (Reference Kobayashi, Ohtsuki and Wakano2016) and Maisonneuve et al. (Reference Maisonneuve, Lehmann and Mullon2025) (where differences with our model are outlined in Appendix A.1), we model learning as a continuous-time stochastic process, in which individuals acquire knowledge at a deterministic rate on average, but this accumulation is subject to random fluctuations. Specifically, the knowledge
$a=0$ is birth). Building on the models of Kobayashi et al. (Reference Kobayashi, Ohtsuki and Wakano2016) and Maisonneuve et al. (Reference Maisonneuve, Lehmann and Mullon2025) (where differences with our model are outlined in Appendix A.1), we model learning as a continuous-time stochastic process, in which individuals acquire knowledge at a deterministic rate on average, but this accumulation is subject to random fluctuations. Specifically, the knowledge  $k_{\bullet}(a)$ of the focal offspring at each age
$k_{\bullet}(a)$ of the focal offspring at each age  $a \in [0,1] $ is a realisation of the following stochastic differential equation
$a \in [0,1] $ is a realisation of the following stochastic differential equation
 \begin{equation}
\frac{\mathrm{d} k_{\bullet}(a)}{\mathrm{d} a} = \begin{cases}
\lambda_{\bullet} \, \big(\beta_{\mathrm{v}} + \sigma_\mathrm{v} \, \eta(a)\big) \, \left[(1-\epsilon) \, k_{\mathrm{p}\bullet}-k_{\bullet}(a)\right] & \text{for } a \in [0, v_{\bullet}) \\
\lambda_{\bullet} \, \big(\beta_{\mathrm{o}} + \sigma_\mathrm{o} \, \eta(a)\big) \, \left[(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho \, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)\right] & \text{for } a \in [v_{\bullet}, v_{\bullet}+o_{\bullet}) \\
\lambda_{\bullet} \, \big(\alpha + \sigma_\mathrm{i} \, \eta(a)\big) & \text{for } a \in [v_{\bullet} + o_{\bullet}, 1],
\end{cases}
\end{equation}
\begin{equation}
\frac{\mathrm{d} k_{\bullet}(a)}{\mathrm{d} a} = \begin{cases}
\lambda_{\bullet} \, \big(\beta_{\mathrm{v}} + \sigma_\mathrm{v} \, \eta(a)\big) \, \left[(1-\epsilon) \, k_{\mathrm{p}\bullet}-k_{\bullet}(a)\right] & \text{for } a \in [0, v_{\bullet}) \\
\lambda_{\bullet} \, \big(\beta_{\mathrm{o}} + \sigma_\mathrm{o} \, \eta(a)\big) \, \left[(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho \, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)\right] & \text{for } a \in [v_{\bullet}, v_{\bullet}+o_{\bullet}) \\
\lambda_{\bullet} \, \big(\alpha + \sigma_\mathrm{i} \, \eta(a)\big) & \text{for } a \in [v_{\bullet} + o_{\bullet}, 1],
\end{cases}
\end{equation}where the initial condition is  $k_{\bullet}(0) = 0$. The term
$k_{\bullet}(0) = 0$. The term  $\eta(a)$ is the standard white noise term from stochastic calculus that introduces rapid and highly irregular fluctuations in the learning process at each age
$\eta(a)$ is the standard white noise term from stochastic calculus that introduces rapid and highly irregular fluctuations in the learning process at each age  $a$, with zero mean and no temporal correlation (Gardiner, Reference Gardiner1985, chapter 4.1). Each realisation of the random white noise term
$a$, with zero mean and no temporal correlation (Gardiner, Reference Gardiner1985, chapter 4.1). Each realisation of the random white noise term  $\eta(a)$ over
$\eta(a)$ over  $a \in [0,1]$ determines a corresponding realisation of knowledge acquisition
$a \in [0,1]$ determines a corresponding realisation of knowledge acquisition  $k_{\bullet}(a)$ over
$k_{\bullet}(a)$ over  $a \in [0,1]$ (e.g., Fig. 1c).
$a \in [0,1]$ (e.g., Fig. 1c).
Equation (2) says that the focal offspring first learns from its parent. Vertical learning occurs over a duration of length  $v_{\bullet}$, during which the focal offspring acquires knowledge instantaneously at a rate proportional to a stochastic vertical transmission rate,
$v_{\bullet}$, during which the focal offspring acquires knowledge instantaneously at a rate proportional to a stochastic vertical transmission rate, 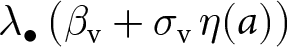 $\lambda_{\bullet}\,\big(\beta_{\mathrm{v}} + \sigma_\mathrm{v} \,\eta(a)\big)$, which increases with the net investment in learning
$\lambda_{\bullet}\,\big(\beta_{\mathrm{v}} + \sigma_\mathrm{v} \,\eta(a)\big)$, which increases with the net investment in learning  $\lambda_{\bullet}$. The term
$\lambda_{\bullet}$. The term  $\sigma_\mathrm{v} \,\eta(a)$ describes the impact of stochastic events during vertical learning at age
$\sigma_\mathrm{v} \,\eta(a)$ describes the impact of stochastic events during vertical learning at age  $a$, where the parameter
$a$, where the parameter  $\sigma_\mathrm{v}$ controls the magnitude of the impact of learning stochasticity. When
$\sigma_\mathrm{v}$ controls the magnitude of the impact of learning stochasticity. When  $\sigma_\mathrm{v} = 0$, learning occurs with no stochastic fluctuations. The knowledge acquisition rate is assumed to be proportional to the difference
$\sigma_\mathrm{v} = 0$, learning occurs with no stochastic fluctuations. The knowledge acquisition rate is assumed to be proportional to the difference  $(1-\epsilon) \, k_{\mathrm{p}\bullet} - k_{\bullet}(a)$, between the knowledge currently available
$(1-\epsilon) \, k_{\mathrm{p}\bullet} - k_{\bullet}(a)$, between the knowledge currently available  $(1-\epsilon) \, k_{\mathrm{p}\bullet}$ from the parent and the focal offspring’s knowledge
$(1-\epsilon) \, k_{\mathrm{p}\bullet}$ from the parent and the focal offspring’s knowledge  $k_{\bullet}(a)$, where
$k_{\bullet}(a)$, where  $\epsilon\in[0,1]$ is the proportion of knowledge that becomes obsolete between two generations. Indeed, as the amount of available knowledge decreases, the focal offspring is less likely, on average, to encounter new information during interactions with its parent, thereby slowing the learning process.
$\epsilon\in[0,1]$ is the proportion of knowledge that becomes obsolete between two generations. Indeed, as the amount of available knowledge decreases, the focal offspring is less likely, on average, to encounter new information during interactions with its parent, thereby slowing the learning process.
Secondly, the focal offspring learns from a random adult, whose knowledge is denoted by  $k_{\mathrm{a}\bullet}$, for a duration of length
$k_{\mathrm{a}\bullet}$, for a duration of length  $o_{\bullet}$. Similar to the parent’s knowledge,
$o_{\bullet}$. Similar to the parent’s knowledge,  $k_{\mathrm{a}\bullet}$ results from a realisation of the stochastic learning process undergone by the oblique exemplar in the previous generation (see details below). During oblique learning, the instantaneous knowledge acquisition rate is proportional to the product of a stochastic oblique transmission rate,
$k_{\mathrm{a}\bullet}$ results from a realisation of the stochastic learning process undergone by the oblique exemplar in the previous generation (see details below). During oblique learning, the instantaneous knowledge acquisition rate is proportional to the product of a stochastic oblique transmission rate,  $\lambda_{\bullet}\,\big(\beta_{\mathrm{o}} + \sigma_\mathrm{o} \,\eta(a)\big)$, and of the amount of knowledge held by the oblique exemplar that the focal offspring has yet acquired, which is assumed to be given by
$\lambda_{\bullet}\,\big(\beta_{\mathrm{o}} + \sigma_\mathrm{o} \,\eta(a)\big)$, and of the amount of knowledge held by the oblique exemplar that the focal offspring has yet acquired, which is assumed to be given by  $(1 - \epsilon) \,k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)$. This expression accounts for both the overlap between the parent’s and the exemplar’s knowledge, and the knowledge the offspring has already acquired obliquely. This expression assumes that, on average, the knowledge held by two adults in the population overlaps by a proportion
$(1 - \epsilon) \,k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)$. This expression accounts for both the overlap between the parent’s and the exemplar’s knowledge, and the knowledge the offspring has already acquired obliquely. This expression assumes that, on average, the knowledge held by two adults in the population overlaps by a proportion  $\rho\in[0,1]$. Consequently, the knowledge of the parent and of the oblique exemplar also overlaps by the same proportion
$\rho\in[0,1]$. Consequently, the knowledge of the parent and of the oblique exemplar also overlaps by the same proportion  $\rho$. At the end of the vertical learning phase (i.e., at age
$\rho$. At the end of the vertical learning phase (i.e., at age  $v_{\bullet}$), the focal offspring has acquired from its parent a quantity of knowledge
$v_{\bullet}$), the focal offspring has acquired from its parent a quantity of knowledge 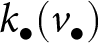 $k_{\bullet}(v_{\bullet})$, of which a quantity
$k_{\bullet}(v_{\bullet})$, of which a quantity  $\rho \, k_{\bullet}(v_{\bullet})$ is also known by the oblique exemplar. The total amount of knowledge that the focal offspring can potentially acquire from the oblique exemplar is therefore
$\rho \, k_{\bullet}(v_{\bullet})$ is also known by the oblique exemplar. The total amount of knowledge that the focal offspring can potentially acquire from the oblique exemplar is therefore 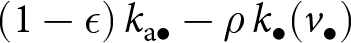 $(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet})$. At age
$(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet})$. At age 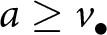 $a\geq v_{\bullet}$, the focal offspring has already acquired from the oblique exemplar a quantity of knowledge
$a\geq v_{\bullet}$, the focal offspring has already acquired from the oblique exemplar a quantity of knowledge  $k_{\bullet}(a) - k_{\bullet}(v_{\bullet})$, which is precisely the amount gained beyond what was acquired from the parent. Hence, the remaining knowledge available from the oblique exemplar at age
$k_{\bullet}(a) - k_{\bullet}(v_{\bullet})$, which is precisely the amount gained beyond what was acquired from the parent. Hence, the remaining knowledge available from the oblique exemplar at age  $a\geq v_{\bullet}$ is
$a\geq v_{\bullet}$ is 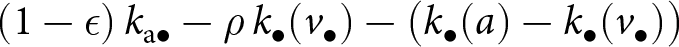 $(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)$. Note that the average overlap in knowledge between two adults,
$(1 - \epsilon) \, k_{\mathrm{a}\bullet} - \rho\, k_{\bullet}(v_{\bullet}) - \big(k_{\bullet}(a) - k_{\bullet}(v_{\bullet})\big)$. Note that the average overlap in knowledge between two adults,  $\rho$, may reflect environmental features. For instance, environmental heterogeneity can lead individuals to produce different knowledge that addresses different ecological challenges, thereby reducing overlap.
$\rho$, may reflect environmental features. For instance, environmental heterogeneity can lead individuals to produce different knowledge that addresses different ecological challenges, thereby reducing overlap.
Thirdly, the focal offspring learns individually at an instantaneous stochastic rate proportional to  $\lambda_{\bullet}\,\big(\alpha + \sigma_\mathrm{i} \,\eta(a)\big)$ for the remaining
$\lambda_{\bullet}\,\big(\alpha + \sigma_\mathrm{i} \,\eta(a)\big)$ for the remaining  $1-v_{\bullet}-o_{\bullet}$ time. The parameter
$1-v_{\bullet}-o_{\bullet}$ time. The parameter  $\sigma_\mathrm{i}$ captures the amplitude of stochastic variation in individual learning, reflecting, for example, fluctuations in attention or intrinsic randomness in the mechanistic processes underlying learning, such as trial-and-error. During each learning phase, the rate of knowledge acquisition is proportional to the offspring’s net investment in learning
$\sigma_\mathrm{i}$ captures the amplitude of stochastic variation in individual learning, reflecting, for example, fluctuations in attention or intrinsic randomness in the mechanistic processes underlying learning, such as trial-and-error. During each learning phase, the rate of knowledge acquisition is proportional to the offspring’s net investment in learning  $\lambda_{\bullet}$. As a result, when there is no such investment (i.e.,
$\lambda_{\bullet}$. As a result, when there is no such investment (i.e.,  $\lambda_{\bullet}=0$), the focal offspring does not acquire any knowledge at any age (i.e.,
$\lambda_{\bullet}=0$), the focal offspring does not acquire any knowledge at any age (i.e.,  $\forall a \in [0,1],\, k_{\bullet}(a)=0$). Due to stochasticity, the learning rate may occasionally become negative during each learning phase, implying that the offspring may lose knowledge. This could reflect situations where miscommunication or exploration leads to confusion, or replacement of previously held information by incorrect alternatives.
$\forall a \in [0,1],\, k_{\bullet}(a)=0$). Due to stochasticity, the learning rate may occasionally become negative during each learning phase, implying that the offspring may lose knowledge. This could reflect situations where miscommunication or exploration leads to confusion, or replacement of previously held information by incorrect alternatives.
Note that both the knowledge of the parent  $k_{\mathrm{p}\bullet}$ and that of the oblique exemplar
$k_{\mathrm{p}\bullet}$ and that of the oblique exemplar  $k_{\mathrm{a}\bullet}$ of the focal offspring result from realisations of the stochastic learning process experienced by those individuals in the previous generation. Specifically, their knowledge is obtained as an instantiation of
$k_{\mathrm{a}\bullet}$ of the focal offspring result from realisations of the stochastic learning process experienced by those individuals in the previous generation. Specifically, their knowledge is obtained as an instantiation of  $k_{\bullet}(1)$, where
$k_{\bullet}(1)$, where 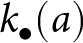 $k_{\bullet}(a)$ denotes a realisation at age
$k_{\bullet}(a)$ denotes a realisation at age 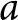 $a$ of the stochastic differential equation defined in eq. (2), with the values of
$a$ of the stochastic differential equation defined in eq. (2), with the values of  $k_{\mathrm{p}\bullet}$ and
$k_{\mathrm{p}\bullet}$ and  $k_{\mathrm{a}\bullet}$ on the right-hand side corresponding to the knowledge values of the parent’s own parent and oblique exemplar, and, in the case of the focal’s oblique exemplar, to those of its own learning exemplars. Since both reproduction and survival are affected by knowledge, the realised parental knowledge
$k_{\mathrm{a}\bullet}$ on the right-hand side corresponding to the knowledge values of the parent’s own parent and oblique exemplar, and, in the case of the focal’s oblique exemplar, to those of its own learning exemplars. Since both reproduction and survival are affected by knowledge, the realised parental knowledge  $k_{\mathrm{p}\bullet}$ and oblique exemplar knowledge
$k_{\mathrm{p}\bullet}$ and oblique exemplar knowledge  $k_{\mathrm{a}\bullet}$ among the offspring are not solely determined by the stochastic learning process defined in eq. (2), but also by reproduction and survival, and thus by offspring survival, which we next specify.
$k_{\mathrm{a}\bullet}$ among the offspring are not solely determined by the stochastic learning process defined in eq. (2), but also by reproduction and survival, and thus by offspring survival, which we next specify.
2.2.3. Offspring survival
After completing their learning, the offspring enter a density-dependent survival stage. Let  $k_{\mathrm{o}\bullet} = k_{\bullet}(1)$ denote the knowledge acquired by the focal offspring at the end of the learning phase, where
$k_{\mathrm{o}\bullet} = k_{\bullet}(1)$ denote the knowledge acquired by the focal offspring at the end of the learning phase, where  $k_{\bullet}(1)$ is the outcome of eq. (2). The probability of survival of the focal offspring is given by
$k_{\bullet}(1)$ is the outcome of eq. (2). The probability of survival of the focal offspring is given by
 \begin{equation}
s(k_{\mathrm{o}\bullet}, n_\mathrm{o}) = \frac{\tilde{s}(k_{\mathrm{o}\bullet})}{1 + \gamma \, n_\mathrm{o}},
\end{equation}
\begin{equation}
s(k_{\mathrm{o}\bullet}, n_\mathrm{o}) = \frac{\tilde{s}(k_{\mathrm{o}\bullet})}{1 + \gamma \, n_\mathrm{o}},
\end{equation}where  $n_\mathrm{o}$ is the total number of offspring produced by all adults and
$n_\mathrm{o}$ is the total number of offspring produced by all adults and  $\gamma \gt 0$ is a parameter controlling the strength of density dependence. The numerator
$\gamma \gt 0$ is a parameter controlling the strength of density dependence. The numerator  $\tilde{s}(k_{\mathrm{o}\bullet})$, which modulates survival probability, is given by
$\tilde{s}(k_{\mathrm{o}\bullet})$, which modulates survival probability, is given by
 \begin{equation}
\tilde{s}(k_{\mathrm{o}\bullet}) = s_\mathrm{0} + \eta_\mathrm{s} \, k_{\mathrm{o}\bullet},
\end{equation}
\begin{equation}
\tilde{s}(k_{\mathrm{o}\bullet}) = s_\mathrm{0} + \eta_\mathrm{s} \, k_{\mathrm{o}\bullet},
\end{equation}where  $s_\mathrm{0}$ is the baseline survival, and
$s_\mathrm{0}$ is the baseline survival, and  $\eta_\mathrm{s}$ is the conversion factor that translates knowledge into survival. For example, in a context where knowledge enables predator recognition,
$\eta_\mathrm{s}$ is the conversion factor that translates knowledge into survival. For example, in a context where knowledge enables predator recognition,  $\eta_\mathrm{s}$ would be high. Parameter values are chosen in our analyses such that
$\eta_\mathrm{s}$ would be high. Parameter values are chosen in our analyses such that  $s(k_{\mathrm{o}\bullet},n_\mathrm{o})$ remains between 0 and 1 for all individuals.
$s(k_{\mathrm{o}\bullet},n_\mathrm{o})$ remains between 0 and 1 for all individuals.
2.3. Analyses
Here, we detail the hypotheses and the method we employ to investigate the joint cultural and evolutionary dynamics. Assuming a small mutation rate and a large population size, evolutionary change proceeds more slowly than cultural dynamics. This timescale separation allows us to analyse cultural dynamics while treating population trait values as constant and consider the knowledge dynamics within lineages of individuals bearing the same trait values (Mullon and Lehmann, Reference Mullon and Lehmann2017).
2.3.1. Cultural dynamics
We first aim to describe the equilibrium probability density of knowledge for a member of an  ${\boldsymbol{x}_\bullet}$-lineage, which is shaped both by the stochastic learning process defined in eq. (2), which enables both the production and intergenerational accumulation of knowledge, and by the effects of knowledge on fecundity and survival given in eqs. (1) and (3), since individuals who survive and reproduce are more likely to transmit their knowledge. In general, the learning process is too complicated to obtain an explicit expression for the probability density of knowledge. To make the analysis tractable, we assume that the outcomes of social learning are deterministic, in contrast to individual learning, where we assume that producing knowledge is inherently stochastic (i.e.,
${\boldsymbol{x}_\bullet}$-lineage, which is shaped both by the stochastic learning process defined in eq. (2), which enables both the production and intergenerational accumulation of knowledge, and by the effects of knowledge on fecundity and survival given in eqs. (1) and (3), since individuals who survive and reproduce are more likely to transmit their knowledge. In general, the learning process is too complicated to obtain an explicit expression for the probability density of knowledge. To make the analysis tractable, we assume that the outcomes of social learning are deterministic, in contrast to individual learning, where we assume that producing knowledge is inherently stochastic (i.e.,  $\sigma_\mathrm{v}=\sigma_\mathrm{o}=0$,
$\sigma_\mathrm{v}=\sigma_\mathrm{o}=0$, 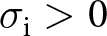 $\sigma_\mathrm{i} \gt 0$). This assumption is relaxed in individual-based simulations, which allow stochasticity in social learning and recover the same qualitative effects of stochasticity in learning on knowledge accumulation and traits evolution (Fig. S.10). Under this assumption, we can solve the stochastic differential equation (2) (see Appendix A.2). Using this solution, along with the effects of knowledge on fecundity and survival given in eqs. (1) and (3), we derive a recursion for the expected knowledge and its variance for a member of an
$\sigma_\mathrm{i} \gt 0$). This assumption is relaxed in individual-based simulations, which allow stochasticity in social learning and recover the same qualitative effects of stochasticity in learning on knowledge accumulation and traits evolution (Fig. S.10). Under this assumption, we can solve the stochastic differential equation (2) (see Appendix A.2). Using this solution, along with the effects of knowledge on fecundity and survival given in eqs. (1) and (3), we derive a recursion for the expected knowledge and its variance for a member of an  ${\boldsymbol{x}_\bullet}$-lineage (see Appendices A.3.1 and A.3.2). However, this recursion ultimately depends on the entire hierarchy of moments of the probability density of knowledge. To address this issue and be able to track the expected knowledge and its variance across generations, we employ a Gaussian closure approximation (see Appendix A.3.3). Note that the stationary distributions obtained from individual-based simulations suggest that a Gaussian approximation provides a good fit for the probability density of knowledge (see Fig. S.1). With this, we can then fully characterise the cultural equilibrium in terms of the expected knowledge and its variance (see Appendix A.4).
${\boldsymbol{x}_\bullet}$-lineage (see Appendices A.3.1 and A.3.2). However, this recursion ultimately depends on the entire hierarchy of moments of the probability density of knowledge. To address this issue and be able to track the expected knowledge and its variance across generations, we employ a Gaussian closure approximation (see Appendix A.3.3). Note that the stationary distributions obtained from individual-based simulations suggest that a Gaussian approximation provides a good fit for the probability density of knowledge (see Fig. S.1). With this, we can then fully characterise the cultural equilibrium in terms of the expected knowledge and its variance (see Appendix A.4).
2.3.2. Evolutionary dynamics
Under the assumptions of small mutation rate, small variance in knowledge, and a large population, the expected evolutionary dynamics can be inferred from the expected lineage fitness in a focal  ${\boldsymbol{x}_\bullet}$-lineage, i.e., the expected fitness of a random individual in that lineage (Mullon and Lehmann, Reference Mullon and Lehmann2017). We show in Appendix B.1 that the expected lineage fitness of an
${\boldsymbol{x}_\bullet}$-lineage, i.e., the expected fitness of a random individual in that lineage (Mullon and Lehmann, Reference Mullon and Lehmann2017). We show in Appendix B.1 that the expected lineage fitness of an  ${\boldsymbol{x}_\bullet}$-lineage in a population with mean traits
${\boldsymbol{x}_\bullet}$-lineage in a population with mean traits 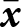 $\bar{\boldsymbol{x}}$ can be expressed as
$\bar{\boldsymbol{x}}$ can be expressed as
 \begin{equation}
W({\boldsymbol{x}_\bullet}, \bar{\boldsymbol{x}}) = \frac{f\big({\boldsymbol{x}_\bullet}, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\big) \, \tilde{s}\big( {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}{f\big(\bar{\boldsymbol{x}}, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}\big) \, \tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)},
\end{equation}
\begin{equation}
W({\boldsymbol{x}_\bullet}, \bar{\boldsymbol{x}}) = \frac{f\big({\boldsymbol{x}_\bullet}, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\big) \, \tilde{s}\big( {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}{f\big(\bar{\boldsymbol{x}}, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}\big) \, \tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)},
\end{equation}where  ${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ and
${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ and  ${\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$ are the expected knowledge after learning is complete and at cultural equilibrium for a random adult and a random offspring of an
${\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$ are the expected knowledge after learning is complete and at cultural equilibrium for a random adult and a random offspring of an  ${\boldsymbol{x}_\bullet}$-lineage. As we assume small variance in knowledge,
${\boldsymbol{x}_\bullet}$-lineage. As we assume small variance in knowledge, 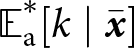 ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and  ${\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}$ coincide with the population mean adult and offspring knowledge.
${\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}$ coincide with the population mean adult and offspring knowledge.
The expected evolutionary dynamics can then be inferred from the selection gradient, defined as
 \begin{equation}
{\boldsymbol{S}}(\bar{\boldsymbol{x}}) =
\left.\nabla{W({\boldsymbol{x}_\bullet}, \bar{\boldsymbol{x}})}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}},
\end{equation}
\begin{equation}
{\boldsymbol{S}}(\bar{\boldsymbol{x}}) =
\left.\nabla{W({\boldsymbol{x}_\bullet}, \bar{\boldsymbol{x}})}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}},
\end{equation}where the operator  $\nabla$ acts such that, for any function of traits
$\nabla$ acts such that, for any function of traits  $u$, we have
$u$, we have
 \begin{equation}
\nabla u({\boldsymbol{x}_\bullet}) = \begin{pmatrix}
\frac{\partial u({\boldsymbol{x}_\bullet})}{\partial v_{\bullet}} \\ \frac{\partial u({\boldsymbol{x}_\bullet})}{\partial o_{\bullet}} \\ \frac{\partial u({\boldsymbol{x}_\bullet})}{\partial \lambda_{\bullet}}
\end{pmatrix}.
\end{equation}
\begin{equation}
\nabla u({\boldsymbol{x}_\bullet}) = \begin{pmatrix}
\frac{\partial u({\boldsymbol{x}_\bullet})}{\partial v_{\bullet}} \\ \frac{\partial u({\boldsymbol{x}_\bullet})}{\partial o_{\bullet}} \\ \frac{\partial u({\boldsymbol{x}_\bullet})}{\partial \lambda_{\bullet}}
\end{pmatrix}.
\end{equation} Each entry of the selection gradient indicates whether natural selection favours an increase or a decrease in the corresponding trait. According to invasion analysis (Leimar, Reference Leimar2009), the mean trait values  $\bar{\boldsymbol{x}}$ will eventually converge to a convergence stable trait vector denoted by
$\bar{\boldsymbol{x}}$ will eventually converge to a convergence stable trait vector denoted by  $\bar{\boldsymbol{x}}^*$, which either satisfies
$\bar{\boldsymbol{x}}^*$, which either satisfies  ${\boldsymbol{S}}(\bar{\boldsymbol{x}}^*) = 0$ or lies on the boundary of the phenotypic space. We use the expression of the selection gradient to highlight the distinct selective pressures acting on each learning trait and to numerically estimate the trait values
${\boldsymbol{S}}(\bar{\boldsymbol{x}}^*) = 0$ or lies on the boundary of the phenotypic space. We use the expression of the selection gradient to highlight the distinct selective pressures acting on each learning trait and to numerically estimate the trait values  $\bar{\boldsymbol{x}}^*$ favoured by selection starting from a population initially lacking any form of learning, that is, with ancestral traits
$\bar{\boldsymbol{x}}^*$ favoured by selection starting from a population initially lacking any form of learning, that is, with ancestral traits  $\bar{v} = \bar{o} = \bar{\lambda} = 0$ (see details in Appendix B.3). We thus focus only on the convergence stable trait vector reached from these ancestral trait values, as this corresponds to the biologically relevant scenario in which learning must first evolve before cultural dynamics operate. At
$\bar{v} = \bar{o} = \bar{\lambda} = 0$ (see details in Appendix B.3). We thus focus only on the convergence stable trait vector reached from these ancestral trait values, as this corresponds to the biologically relevant scenario in which learning must first evolve before cultural dynamics operate. At  $\bar{\boldsymbol{x}}^*$, we systematically verify if selection is stabilising (see details in Appendix B.3), ensuring the maintenance of a unimodal trait distribution. In all analyses, selection was found to be stabilising.
$\bar{\boldsymbol{x}}^*$, we systematically verify if selection is stabilising (see details in Appendix B.3), ensuring the maintenance of a unimodal trait distribution. In all analyses, selection was found to be stabilising.
To assess the robustness of our forthcoming analytical findings, we perform individual-based simulations that relax the previously stated assumptions (see details of individual-based simulations in Appendix D). In particular, we allow for small population sizes, allow 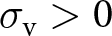 $\sigma_\mathrm{v} \gt 0$ and
$\sigma_\mathrm{v} \gt 0$ and  $\sigma_\mathrm{o} \gt 0$, and no longer assume that the probability density of knowledge is normal.
$\sigma_\mathrm{o} \gt 0$, and no longer assume that the probability density of knowledge is normal.
3. Results
3.1. Cultural dynamics
3.1.1. Cultural selection enhances cumulative knowledge
To reveal the effects of cultural selection on cumulative expected knowledge, we analyse the dynamics of knowledge in a given lineage. To this end, we first determine the realised knowledge  $k_{\mathrm{o}\bullet}$ acquired by a focal offspring in an
$k_{\mathrm{o}\bullet}$ acquired by a focal offspring in an  ${\boldsymbol{x}_\bullet}$-lineage, whose parent has knowledge
${\boldsymbol{x}_\bullet}$-lineage, whose parent has knowledge  $k_{\mathrm{p}\bullet}$ and who chooses an oblique exemplar with knowledge
$k_{\mathrm{p}\bullet}$ and who chooses an oblique exemplar with knowledge  $k_{\mathrm{a}\bullet}$. We show in Appendix A.2 that
$k_{\mathrm{a}\bullet}$. We show in Appendix A.2 that
 \begin{equation}
k_{\mathrm{o}\bullet} = \overbrace{\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \, (1-\epsilon) \,k_{\mathrm{p}\bullet}}^{\substack{\text{vertical learning}}}+\overbrace{\omega_\mathrm{o}({\boldsymbol{x}_\bullet}) \, \left[(1-\epsilon) \, k_{\mathrm{a}\bullet} - \rho \, \omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \, (1-\epsilon) \, k_{\mathrm{p}\bullet} \right]
}^{\substack{\text{oblique learning}}}+\overbrace{
\lambda_{\bullet} \, \alpha \, (1 - v_{\bullet} - o_{\bullet}) + \chi_\mathrm{k}}^{\substack{\text{individual learning}}},
\end{equation}
\begin{equation}
k_{\mathrm{o}\bullet} = \overbrace{\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \, (1-\epsilon) \,k_{\mathrm{p}\bullet}}^{\substack{\text{vertical learning}}}+\overbrace{\omega_\mathrm{o}({\boldsymbol{x}_\bullet}) \, \left[(1-\epsilon) \, k_{\mathrm{a}\bullet} - \rho \, \omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \, (1-\epsilon) \, k_{\mathrm{p}\bullet} \right]
}^{\substack{\text{oblique learning}}}+\overbrace{
\lambda_{\bullet} \, \alpha \, (1 - v_{\bullet} - o_{\bullet}) + \chi_\mathrm{k}}^{\substack{\text{individual learning}}},
\end{equation}where  $\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) = 1-\mathrm{e}^{-\lambda_{\bullet} \, \beta_{\mathrm{v}} \, v_{\bullet}}$ and
$\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) = 1-\mathrm{e}^{-\lambda_{\bullet} \, \beta_{\mathrm{v}} \, v_{\bullet}}$ and  $\omega_\mathrm{o}({\boldsymbol{x}_\bullet}) = 1-\mathrm{e}^{-\lambda_{\bullet} \, \beta_{\mathrm{o}} \, o_{\bullet}}$ are the proportion of available knowledge at the start of the vertical and oblique learning phases, respectively, that the focal offspring acquires. Each term in eq. (8) corresponds to the amount of knowledge acquired through each type of learning. The knowledge gained through vertical learning reduces the knowledge available through oblique learning, since parental knowledge overlaps with that of the oblique exemplar with proportion
$\omega_\mathrm{o}({\boldsymbol{x}_\bullet}) = 1-\mathrm{e}^{-\lambda_{\bullet} \, \beta_{\mathrm{o}} \, o_{\bullet}}$ are the proportion of available knowledge at the start of the vertical and oblique learning phases, respectively, that the focal offspring acquires. Each term in eq. (8) corresponds to the amount of knowledge acquired through each type of learning. The knowledge gained through vertical learning reduces the knowledge available through oblique learning, since parental knowledge overlaps with that of the oblique exemplar with proportion  $\rho$. As the offspring already acquired an amount
$\rho$. As the offspring already acquired an amount  $\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \,(1-\epsilon) \,k_{\mathrm{p}\bullet}$ of knowledge from its parent, the amount of non-redundant knowledge available at the start of oblique learning is
$\omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \,(1-\epsilon) \,k_{\mathrm{p}\bullet}$ of knowledge from its parent, the amount of non-redundant knowledge available at the start of oblique learning is  $(1-\epsilon)\, k_{\mathrm{a}\bullet} - \rho \,\omega_\mathrm{v}({\boldsymbol{x}_\bullet})\, (1-\epsilon) \,k_{\mathrm{p}\bullet}$. Finally, the knowledge acquired through individual learning
$(1-\epsilon)\, k_{\mathrm{a}\bullet} - \rho \,\omega_\mathrm{v}({\boldsymbol{x}_\bullet})\, (1-\epsilon) \,k_{\mathrm{p}\bullet}$. Finally, the knowledge acquired through individual learning  $\lambda_{\bullet}\, \alpha\, (1 - v_{\bullet} - o_{\bullet}) + \chi_\mathrm{k}$ depends on a realisation of a Gaussian random variable
$\lambda_{\bullet}\, \alpha\, (1 - v_{\bullet} - o_{\bullet}) + \chi_\mathrm{k}$ depends on a realisation of a Gaussian random variable  $\chi_\mathrm{k}$. This random variable has mean zero and variance
$\chi_\mathrm{k}$. This random variable has mean zero and variance  $\lambda_{\bullet}^2 \, \sigma_\mathrm{i}^2 \, (1-v_{\bullet}-o_{\bullet})$, which is proportional to the time allocated to individual learning
$\lambda_{\bullet}^2 \, \sigma_\mathrm{i}^2 \, (1-v_{\bullet}-o_{\bullet})$, which is proportional to the time allocated to individual learning  $1-v_{\bullet}-o_{\bullet}$.
$1-v_{\bullet}-o_{\bullet}$.
Having characterised the realised knowledge acquired by a focal offspring, we can now characterise the lineage-level dynamics at which cultural selection acts. Specifically, by taking the expectation in eq. (8), we show in Appendix A.3.1 that the expected knowledge  ${\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}$ of an offspring born to an adult of generation
${\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}$ of an offspring born to an adult of generation  $t$ of an
$t$ of an  ${\boldsymbol{x}_\bullet}$-lineage, when the expected value and variance of knowledge among adults are
${\boldsymbol{x}_\bullet}$-lineage, when the expected value and variance of knowledge among adults are  $\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]$ and
$\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]$ and  $\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]$, is given by
$\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]$, is given by
 \begin{equation}
{\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]} = p_\mathrm{il}({\boldsymbol{x}_\bullet}) + h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}_{\mathrm{a},t}[k \mid \bar{\boldsymbol{x}}]} + h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \left({\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} + \frac{{\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}}\right),
\end{equation}
\begin{equation}
{\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]} = p_\mathrm{il}({\boldsymbol{x}_\bullet}) + h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}_{\mathrm{a},t}[k \mid \bar{\boldsymbol{x}}]} + h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \left({\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} + \frac{{\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}}\right),
\end{equation}where  $p_\mathrm{il}({\boldsymbol{x}_\bullet}) = \lambda_{\bullet} \, \alpha \, (1 - v_{\bullet} - o_{\bullet})$, is the expected amount of knowledge produced through individual learning by the focal offspring, and
$p_\mathrm{il}({\boldsymbol{x}_\bullet}) = \lambda_{\bullet} \, \alpha \, (1 - v_{\bullet} - o_{\bullet})$, is the expected amount of knowledge produced through individual learning by the focal offspring, and  $h_\mathrm{ol}({\boldsymbol{x}_\bullet}) = (1-\epsilon) \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet})$ and
$h_\mathrm{ol}({\boldsymbol{x}_\bullet}) = (1-\epsilon) \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet})$ and  $h_\mathrm{vl}({\boldsymbol{x}_\bullet}) = (1-\epsilon) \, \omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \,\left( 1 - \rho \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet}) \right)$ are the oblique and vertical cultural heritabilities, respectively. The expressions for
$h_\mathrm{vl}({\boldsymbol{x}_\bullet}) = (1-\epsilon) \, \omega_\mathrm{v}({\boldsymbol{x}_\bullet}) \,\left( 1 - \rho \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet}) \right)$ are the oblique and vertical cultural heritabilities, respectively. The expressions for  $h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ and
$h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ and  $h_\mathrm{ol}({\boldsymbol{x}_\bullet})$ are obtained by identifying, in eq. (8), the coefficients multiplying parental knowledge
$h_\mathrm{ol}({\boldsymbol{x}_\bullet})$ are obtained by identifying, in eq. (8), the coefficients multiplying parental knowledge  $k_{\mathrm{p}\bullet}$ and oblique exemplar knowledge
$k_{\mathrm{p}\bullet}$ and oblique exemplar knowledge  $k_{\mathrm{a}\bullet}$ in the realised focal offspring knowledge
$k_{\mathrm{a}\bullet}$ in the realised focal offspring knowledge  $k_{\mathrm{o}\bullet}$. The term
$k_{\mathrm{o}\bullet}$. The term  $-\rho \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet})$ in
$-\rho \, \omega_\mathrm{o}({\boldsymbol{x}_\bullet})$ in  $h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ captures that, when parental and oblique knowledge overlap, knowledge acquired from the parent reduces the amount of knowledge that remains available through oblique learning. This interference effect reduces vertical, but not oblique, cultural heritability, because it scales with the amount of parental knowledge (see eq. (8)). Intuitively, this term corrects the vertical heritability
$h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ captures that, when parental and oblique knowledge overlap, knowledge acquired from the parent reduces the amount of knowledge that remains available through oblique learning. This interference effect reduces vertical, but not oblique, cultural heritability, because it scales with the amount of parental knowledge (see eq. (8)). Intuitively, this term corrects the vertical heritability 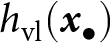 $h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ by accounting that a part of the knowledge acquired from the parent substitutes for knowledge that would otherwise have been acquired from oblique exemplars. The oblique and vertical cultural heritabilities, both lying between 0 and 1, can then be interpreted as the proportion of knowledge from the oblique and vertical exemplar that is effectively transmitted to a learner with traits
$h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ by accounting that a part of the knowledge acquired from the parent substitutes for knowledge that would otherwise have been acquired from oblique exemplars. The oblique and vertical cultural heritabilities, both lying between 0 and 1, can then be interpreted as the proportion of knowledge from the oblique and vertical exemplar that is effectively transmitted to a learner with traits 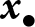 ${\boldsymbol{x}_\bullet}$.
${\boldsymbol{x}_\bullet}$.
The last two terms on the right-hand side of eq. (9) are the expected knowledge acquired from an oblique exemplar and from the parent. These terms depend on the corresponding cultural heritabilities, multiplied by the expected knowledge  ${\mathbb{E}_{\mathrm{a},t}[k \mid \bar{\boldsymbol{x}}]}$ of an oblique exemplar and that
${\mathbb{E}_{\mathrm{a},t}[k \mid \bar{\boldsymbol{x}}]}$ of an oblique exemplar and that  ${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} +{{\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]}\, \eta_\mathrm{f}}/{\big(f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}\big)}$ of a vertical exemplar. The expected knowledge of a vertical exemplar exceeds that of an average adult in the lineage, since individuals with greater knowledge produce more offspring and are overrepresented among vertical exemplars.
${\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]} +{{\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]}\, \eta_\mathrm{f}}/{\big(f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}\big)}$ of a vertical exemplar. The expected knowledge of a vertical exemplar exceeds that of an average adult in the lineage, since individuals with greater knowledge produce more offspring and are overrepresented among vertical exemplars.
The term  $h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{f}/\big(f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}\big)$ in (9) can be thought of as the response of expected knowledge to cultural selection (in analogy with the response to selection due to genetic inheritance; Lynch and Walsh, Reference Lynch and Walsh1998), due to differences in fecundity. Because individuals with greater knowledge tend to have higher fecundity, they are more likely to transmit their knowledge vertically, which biases transmission towards higher knowledge individuals and increases the expected knowledge within the lineage. The response to cultural selection is particularly pronounced when parents transmit a substantial portion of their knowledge to their offspring (i.e.,
$h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{f}/\big(f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}\big)$ in (9) can be thought of as the response of expected knowledge to cultural selection (in analogy with the response to selection due to genetic inheritance; Lynch and Walsh, Reference Lynch and Walsh1998), due to differences in fecundity. Because individuals with greater knowledge tend to have higher fecundity, they are more likely to transmit their knowledge vertically, which biases transmission towards higher knowledge individuals and increases the expected knowledge within the lineage. The response to cultural selection is particularly pronounced when parents transmit a substantial portion of their knowledge to their offspring (i.e.,  $h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ is great), there is significant knowledge difference between adults (i.e.,
$h_\mathrm{vl}({\boldsymbol{x}_\bullet})$ is great), there is significant knowledge difference between adults (i.e.,  ${\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]}$ is great), and knowledge strongly increases fecundity (i.e.,
${\operatorname{Var}_{\mathrm{a},t}[k\mid{\boldsymbol{x}_\bullet}]}$ is great), and knowledge strongly increases fecundity (i.e.,  $\eta_\mathrm{f}$ is great). The strength of the response to cultural selection diminishes as relative differences in fecundity with the lineage become less pronounced with increasing values of
$\eta_\mathrm{f}$ is great). The strength of the response to cultural selection diminishes as relative differences in fecundity with the lineage become less pronounced with increasing values of 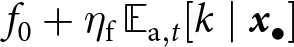 $f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}$.
$f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}_{\mathrm{a},t}[k \mid {\boldsymbol{x}_\bullet}]}$.
Following learning, the expected knowledge within a lineage is further shaped by survival to adulthood. After completing their learning, offspring go through the survival stage to reach adulthood in generation  $t+1$. We show in Appendix A.3.1 that the expected knowledge
$t+1$. We show in Appendix A.3.1 that the expected knowledge  $\bar{k}_{\mathrm{a},t+1}({\boldsymbol{x}_\bullet})$ of an adult of generation
$\bar{k}_{\mathrm{a},t+1}({\boldsymbol{x}_\bullet})$ of an adult of generation  $t+1$ in the
$t+1$ in the  ${\boldsymbol{x}_\bullet}$-lineage is
${\boldsymbol{x}_\bullet}$-lineage is
 \begin{equation}
{\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]} = {\mathbb{E}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} + \frac{{\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)},
\end{equation}
\begin{equation}
{\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]} = {\mathbb{E}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} + \frac{{\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)},
\end{equation}where  ${\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]}$ is the variance in the knowledge held by a randomly chosen offspring born to an adult of generation
${\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]}$ is the variance in the knowledge held by a randomly chosen offspring born to an adult of generation  $t$ in the
$t$ in the  ${\boldsymbol{x}_\bullet}$-lineage. The expected knowledge among adults is higher than that among offspring (i.e.,
${\boldsymbol{x}_\bullet}$-lineage. The expected knowledge among adults is higher than that among offspring (i.e.,  ${\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]} \gt {\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}$) since offspring with above-average knowledge are more likely to survive to adulthood. This effect is captured by the selection differential
${\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]} \gt {\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}$) since offspring with above-average knowledge are more likely to survive to adulthood. This effect is captured by the selection differential  ${{\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}}/{\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)}$, which is the difference between expected knowledge of surviving and all offspring within the lineage. This selection differential is particularly pronounced when there is a significant knowledge difference between offspring (i.e.,
${{\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}}/{\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)}$, which is the difference between expected knowledge of surviving and all offspring within the lineage. This selection differential is particularly pronounced when there is a significant knowledge difference between offspring (i.e.,  ${\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]}$ is great) and knowledge strongly increases survival (i.e.,
${\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]}$ is great) and knowledge strongly increases survival (i.e.,  $\eta_\mathrm{s}$ is great). The selection differential diminishes as relative differences in survival within the lineage become less pronounced with increasing values of
$\eta_\mathrm{s}$ is great). The selection differential diminishes as relative differences in survival within the lineage become less pronounced with increasing values of  $\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)$. The response of an individual’s expected knowledge to cultural selection due to variation in survival depends on how knowledge is transmitted to the new offspring cohort. It equals
$\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big)$. The response of an individual’s expected knowledge to cultural selection due to variation in survival depends on how knowledge is transmitted to the new offspring cohort. It equals  $h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, \operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}] \,\eta_\mathrm{s}/\tilde{s}\big(\mathbb{E} _{\mathrm{o},t}[k |\bar{\boldsymbol{x}}]\big) +h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}/\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big) $ (obtained by substituting the expression of
$h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, \operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}] \,\eta_\mathrm{s}/\tilde{s}\big(\mathbb{E} _{\mathrm{o},t}[k |\bar{\boldsymbol{x}}]\big) +h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}_{\mathrm{o},t}[k \mid {\boldsymbol{x}_\bullet}]} \,\eta_\mathrm{s}/\tilde{s}\big({\mathbb{E}_{\mathrm{o},t}[k\mid{\boldsymbol{x}_\bullet}]}\big) $ (obtained by substituting the expression of  $\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]$ from eq. (10) and
$\mathbb{E}_{\mathrm{a},t+1}[k \mid {\boldsymbol{x}_\bullet}]$ from eq. (10) and  $\mathbb{E}_{\mathrm{a},t+1}[k \mid \bar{\boldsymbol{x}}]$ from eq. (10) with
$\mathbb{E}_{\mathrm{a},t+1}[k \mid \bar{\boldsymbol{x}}]$ from eq. (10) with  ${\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}$ into eq. (9) with
${\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}$ into eq. (9) with  $t=t+1$ and identifying the terms corresponding to cultural selection).
$t=t+1$ and identifying the terms corresponding to cultural selection).
Taken together, eqs. (9) and (10) allow us to characterise the expected knowledge at equilibrium. We focus on the expected knowledge in adults only, as this is sufficient to uncover the mechanisms shaping expected knowledge. We show in Appendix A.4.1 that the equilibrium expected adult knowledge in the  ${\boldsymbol{x}_\bullet}$-lineage satisfies
${\boldsymbol{x}_\bullet}$-lineage satisfies
 \begin{equation}
{\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} = \frac{\overbrace{p_\mathrm{il}({\boldsymbol{x}_\bullet}) + h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}^{\substack{\text{knowledge acquired through individual}\\ \text{learning and from an oblique exemplar}}} + \overbrace{\frac{h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} + \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}}^{\substack{\text{cultural selection}}}}{\underbrace{1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})}_{\substack{\text{knowledge accumulation}\\\text{within the lineage due}\\\text{to vertical transmission}}}},
\end{equation}
\begin{equation}
{\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} = \frac{\overbrace{p_\mathrm{il}({\boldsymbol{x}_\bullet}) + h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}^{\substack{\text{knowledge acquired through individual}\\ \text{learning and from an oblique exemplar}}} + \overbrace{\frac{h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} + \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}}^{\substack{\text{cultural selection}}}}{\underbrace{1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})}_{\substack{\text{knowledge accumulation}\\\text{within the lineage due}\\\text{to vertical transmission}}}},
\end{equation}where the superscript  $^*$ indicates that the quantities are evaluated at equilibrium (see also Fig. 1d). The first two terms in the numerator of eq. (11) are the expected amount of knowledge acquired through individual and from an oblique exemplar. The remaining terms in the numerator are the increase in expected knowledge driven by cultural selection resulting from differences in fecundity and survival within the lineage due to variation in knowledge. The denominator of eq. (11) captures the inter-generational accumulation of knowledge within the lineage due to vertical transmission. This can be seen by expressing
$^*$ indicates that the quantities are evaluated at equilibrium (see also Fig. 1d). The first two terms in the numerator of eq. (11) are the expected amount of knowledge acquired through individual and from an oblique exemplar. The remaining terms in the numerator are the increase in expected knowledge driven by cultural selection resulting from differences in fecundity and survival within the lineage due to variation in knowledge. The denominator of eq. (11) captures the inter-generational accumulation of knowledge within the lineage due to vertical transmission. This can be seen by expressing  $1/\big(1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})\big)$ as
$1/\big(1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})\big)$ as  $1 + \sum_{t=1}^\infty h_\mathrm{vl}({\boldsymbol{x}_\bullet})^t$, where
$1 + \sum_{t=1}^\infty h_\mathrm{vl}({\boldsymbol{x}_\bullet})^t$, where  $h_\mathrm{vl}({\boldsymbol{x}_\bullet})^t$ is the proportion of knowledge acquired by an ancestor
$h_\mathrm{vl}({\boldsymbol{x}_\bullet})^t$ is the proportion of knowledge acquired by an ancestor  $t$ generations ago that is effectively transmitted to the focal individual. Since
$t$ generations ago that is effectively transmitted to the focal individual. Since 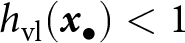 $h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \lt 1$, the cumulative contribution of ancestors remains bounded.
$h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \lt 1$, the cumulative contribution of ancestors remains bounded.
We find that offspring exhibit a slightly lower expected knowledge than adults (i.e.,  ${\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \lt {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2) because offspring with above-average knowledge are more likely to survive and become adults. In contrast, offspring and adults have the same expected knowledge (i.e.,
${\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \lt {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2) because offspring with above-average knowledge are more likely to survive and become adults. In contrast, offspring and adults have the same expected knowledge (i.e.,  ${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}={\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2) when knowledge does not affect survival to adulthood (i.e.,
${\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}={\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2) when knowledge does not affect survival to adulthood (i.e.,  $\eta_\mathrm{s}=0$).
$\eta_\mathrm{s}=0$).
3.1.2. Learning stochasticity enhances knowledge by increasing knowledge variance
Our results reveal that cultural selection promotes knowledge accumulation. Because the strength of cultural selection increases with knowledge variance (see eq. (11)), we next investigate the mechanisms shaping this variance. We focus on variance in adults knowledge only, as this is sufficient to identify the mechanisms shaping variance in knowledge. In Appendix A.4.2, we show that the equilibrium variance in the knowledge held by an adult from the  ${\boldsymbol{x}_\bullet}$-lineage satisfies
${\boldsymbol{x}_\bullet}$-lineage satisfies
 \begin{equation}
\begin{aligned}
&{\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} = \\ &\frac{\overbrace{\lambda_{\bullet}^2 \, \sigma_\mathrm{i}^2 \, (1 - v_{\bullet} - o_{\bullet})}^{\substack{\text{variance produced by}\\\text{stochasticity in learning}}} + \overbrace{h_\mathrm{ol}({\boldsymbol{x}_\bullet})^2 \,{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}^{\substack{\text{variance transmitted }\\\text{from oblique exemplars}}} \overbrace{- \left( \frac{h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} \right)^2 - \left( \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}\right)^2}^{\substack{\text{cultural selection reducing knowledge variance}}}}{\underbrace{1-h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2}_{\substack{\text{variance accumulation}\\ \text{within the lineage due}\\ \text{to vertical transmission}}}}.
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
&{\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} = \\ &\frac{\overbrace{\lambda_{\bullet}^2 \, \sigma_\mathrm{i}^2 \, (1 - v_{\bullet} - o_{\bullet})}^{\substack{\text{variance produced by}\\\text{stochasticity in learning}}} + \overbrace{h_\mathrm{ol}({\boldsymbol{x}_\bullet})^2 \,{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}^{\substack{\text{variance transmitted }\\\text{from oblique exemplars}}} \overbrace{- \left( \frac{h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, {\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} \right)^2 - \left( \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}\right)^2}^{\substack{\text{cultural selection reducing knowledge variance}}}}{\underbrace{1-h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2}_{\substack{\text{variance accumulation}\\ \text{within the lineage due}\\ \text{to vertical transmission}}}}.
\end{aligned}
\end{equation} The first term in the numerator of eq. (12) is the knowledge variance produced by stochasticity in individual learning. This term increases with the level of learning stochasticity  $\sigma_\mathrm{i}$, investment in learning
$\sigma_\mathrm{i}$, investment in learning  $\lambda_{\bullet}$, and the time allocated to individual learning
$\lambda_{\bullet}$, and the time allocated to individual learning  $1-v_{\bullet}-o_{\bullet}$. If learning were deterministic (i.e.,
$1-v_{\bullet}-o_{\bullet}$. If learning were deterministic (i.e.,  $\sigma_\mathrm{i}=0$), no knowledge variance would be produced, and the only solution to eq. (12) would be
$\sigma_\mathrm{i}=0$), no knowledge variance would be produced, and the only solution to eq. (12) would be  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}=0$ (see proof in Appendix A.4.3). The second term in the numerator accounts for variance transmitted from oblique exemplars. The remaining terms in the numerator are the effect of cultural selection, which reduces knowledge variance. Because survival to adulthood reduces knowledge variance, the equilibrium variance in the knowledge held by an adult
${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}=0$ (see proof in Appendix A.4.3). The second term in the numerator accounts for variance transmitted from oblique exemplars. The remaining terms in the numerator are the effect of cultural selection, which reduces knowledge variance. Because survival to adulthood reduces knowledge variance, the equilibrium variance in the knowledge held by an adult  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ is generally slightly lower than that of an offspring
${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}$ is generally slightly lower than that of an offspring  ${\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$ (see Fig. S.2). When knowledge does not affect survival (i.e.,
${\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$ (see Fig. S.2). When knowledge does not affect survival (i.e.,  $\eta_\mathrm{s}=0$), the two variances are equal (i.e.,
$\eta_\mathrm{s}=0$), the two variances are equal (i.e.,  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}={\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2). Finally, the denominator of eq. (12) describes the accumulation of knowledge variance within the
${\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}={\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}$; see Fig. S.2). Finally, the denominator of eq. (12) describes the accumulation of knowledge variance within the  ${\boldsymbol{x}_\bullet}$-lineage through vertical transmission. This can be seen by expressing
${\boldsymbol{x}_\bullet}$-lineage through vertical transmission. This can be seen by expressing  $1/\big(1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)$ as
$1/\big(1 - h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)$ as  $1 + \sum_{t=1}^\infty \big(h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)^t$, where
$1 + \sum_{t=1}^\infty \big(h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)^t$, where 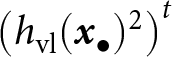 $\big(h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)^t$ is the proportion of knowledge variance from lineage members
$\big(h_\mathrm{vl}({\boldsymbol{x}_\bullet})^2\big)^t$ is the proportion of knowledge variance from lineage members  $t$ generations ago that is effectively transmitted to current lineage members.
$t$ generations ago that is effectively transmitted to current lineage members.
Altogether eqs. (11) and (12) reveal that, by generating knowledge variance, stochastic individual learning amplifies cultural selection and enhances cumulative knowledge. By numerically estimating  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and
${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (see Appendix A.4.4 for details on the procedure) for different values of
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (see Appendix A.4.4 for details on the procedure) for different values of  $\sigma_\mathrm{i}$, we confirm that increased stochasticity in individual learning
$\sigma_\mathrm{i}$, we confirm that increased stochasticity in individual learning  $\sigma_\mathrm{i}$ increases population knowledge variance
$\sigma_\mathrm{i}$ increases population knowledge variance  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$, which in turn lead to an increase in mean knowledge
${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$, which in turn lead to an increase in mean knowledge  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (Fig. 2a).
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (Fig. 2a).
The accumulation of knowledge. (a) Population mean knowledge  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (solid line) and population knowledge variance
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (solid line) and population knowledge variance  ${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (dashed line) at cultural equilibrium according to intensity of stochastic effects in individual learning
${\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (dashed line) at cultural equilibrium according to intensity of stochastic effects in individual learning  $\sigma_\mathrm{i}$ (left axis gives the scale of cumulative knowledge, and right axis gives the scale of knowledge variance). (b) Population mean knowledge
$\sigma_\mathrm{i}$ (left axis gives the scale of cumulative knowledge, and right axis gives the scale of knowledge variance). (b) Population mean knowledge  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ according to intensity of stochastic effects in individual learning
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ according to intensity of stochastic effects in individual learning  $\sigma_\mathrm{i}$ for different individual learning rates per fraction of investment allocated to learning
$\sigma_\mathrm{i}$ for different individual learning rates per fraction of investment allocated to learning  $\alpha$. Default parameters are:
$\alpha$. Default parameters are: 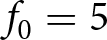 $f_\mathrm{0}=5$,
$f_\mathrm{0}=5$,  $s_\mathrm{0}=1$,
$s_\mathrm{0}=1$,  $\beta_{\mathrm{v}}=1.4$,
$\beta_{\mathrm{v}}=1.4$,  $\beta_{\mathrm{o}}=1.3$,
$\beta_{\mathrm{o}}=1.3$,  $\alpha = 0.1$,
$\alpha = 0.1$,  $\epsilon = 0.05$,
$\epsilon = 0.05$, 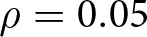 $\rho=0.05$,
$\rho=0.05$,  $\sigma_\mathrm{i} = 0.1$,
$\sigma_\mathrm{i} = 0.1$,  $\eta_\mathrm{f}=25$,
$\eta_\mathrm{f}=25$, 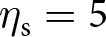 $\eta_\mathrm{s}=5$,
$\eta_\mathrm{s}=5$,  $\bar{v}=0.3$,
$\bar{v}=0.3$,  $\bar{o}=0.2$,
$\bar{o}=0.2$,  $\bar{\lambda}=0.9$.
$\bar{\lambda}=0.9$.

Remarkably, stochasticity in individual learning  $\sigma_\mathrm{i}$ can foster knowledge accumulation even in populations with low average knowledge-production ability (e.g.,
$\sigma_\mathrm{i}$ can foster knowledge accumulation even in populations with low average knowledge-production ability (e.g.,  $\alpha=0.001$; see Fig. 2b). When stochasticity is particularly high, cultural selection becomes the dominant force driving knowledge acquisition. As a result, populations with different average knowledge-production abilities tend to carry similar levels of mean knowledge, whereas, in the absence of stochasticity, they exhibit marked differences in mean knowledge (see Fig. 2b). Additionally, because knowledge improves both fecundity and survival, greater stochasticity in individual learning
$\alpha=0.001$; see Fig. 2b). When stochasticity is particularly high, cultural selection becomes the dominant force driving knowledge acquisition. As a result, populations with different average knowledge-production abilities tend to carry similar levels of mean knowledge, whereas, in the absence of stochasticity, they exhibit marked differences in mean knowledge (see Fig. 2b). Additionally, because knowledge improves both fecundity and survival, greater stochasticity in individual learning 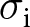 $\sigma_\mathrm{i}$ is associated with larger population size (see Fig. S.3). The effect of cultural selection in enhancing the mean knowledge
$\sigma_\mathrm{i}$ is associated with larger population size (see Fig. S.3). The effect of cultural selection in enhancing the mean knowledge 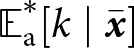 ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ is stronger when knowledge strongly increases fecundity and survival (i.e., when
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ is stronger when knowledge strongly increases fecundity and survival (i.e., when  $\eta_\mathrm{f}$ and
$\eta_\mathrm{f}$ and  $\eta_\mathrm{s}$ are higher; see Fig. S.4), and when vertical and oblique cultural heritability are higher (Fig. S.5).
$\eta_\mathrm{s}$ are higher; see Fig. S.4), and when vertical and oblique cultural heritability are higher (Fig. S.5).
3.2. Evolutionary dynamics
3.2.1. Trade-off between fecundity and learning
With knowledge distribution at equilibrium characterised, we now use the selection gradient to investigate the effect of selection on the evolution of the learning traits. By substituting eq. (5) into eq. (6), we obtain the direction of selection on the traits
 \begin{equation}
{\boldsymbol{S}}(\bar{\boldsymbol{x}}) = \overbrace{\frac{\left.\nabla (1-\lambda_{\bullet})^\theta\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{(1-\bar{\lambda})^\theta}}^{\substack{\text{learning traits effects on fecundity}}}
+\overbrace{\frac{\eta_\mathrm{f} \, \left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}+\frac{\eta_\mathrm{s}\,\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)}}^{\substack{\text{learning traits effects lineage members' expected knowledge}}},
\end{equation}
\begin{equation}
{\boldsymbol{S}}(\bar{\boldsymbol{x}}) = \overbrace{\frac{\left.\nabla (1-\lambda_{\bullet})^\theta\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{(1-\bar{\lambda})^\theta}}^{\substack{\text{learning traits effects on fecundity}}}
+\overbrace{\frac{\eta_\mathrm{f} \, \left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}+\frac{\eta_\mathrm{s}\,\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)}}^{\substack{\text{learning traits effects lineage members' expected knowledge}}},
\end{equation}where the gradient operator  $\nabla$ is defined in eq. (7).
$\nabla$ is defined in eq. (7).
The first term in eq. (13) describes selection arising from the fecundity costs associated with investment in learning. The remaining terms describe the effect of selection resulting from the impact of learning traits on the expected knowledge of members of a lineage. The strength of these selection pressures diminishes with increasing values of  $f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and
$f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ and  $\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)$, as relative differences in fecundity and survival among lineages become less pronounced.
$\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid \bar{\boldsymbol{x}}]}\big)$, as relative differences in fecundity and survival among lineages become less pronounced.
Overall, eq. (13) indicates that the evolution of learning traits results from a trade-off between the fecundity costs incurred and the knowledge gained. We focus on evaluating the trait values  $\bar{\boldsymbol{x}}^* = (\bar{v}^*, \bar{o}^*, \bar{\lambda}^*)$ favoured by selection in the long-term starting from a population initially expressing
$\bar{\boldsymbol{x}}^* = (\bar{v}^*, \bar{o}^*, \bar{\lambda}^*)$ favoured by selection in the long-term starting from a population initially expressing  $\bar{\boldsymbol{x}} = (0, 0, 0)$ (see Appendix B.3 for details on the procedure). Numerical estimates of the average learning traits at
$\bar{\boldsymbol{x}} = (0, 0, 0)$ (see Appendix B.3 for details on the procedure). Numerical estimates of the average learning traits at  $\bar{\boldsymbol{x}}^*$ reveal that the fecundity costs can prevent the emergence of learning, particularly when individual learning is inefficient at producing knowledge (i.e., low
$\bar{\boldsymbol{x}}^*$ reveal that the fecundity costs can prevent the emergence of learning, particularly when individual learning is inefficient at producing knowledge (i.e., low  $\alpha$; see Fig. S.6a). As
$\alpha$; see Fig. S.6a). As 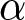 $\alpha$ increases, learning can emerge abruptly rather than gradually, because the emergence of learning allows knowledge to accumulate across generations, promoting further social learning and further learning investment in turn.
$\alpha$ increases, learning can emerge abruptly rather than gradually, because the emergence of learning allows knowledge to accumulate across generations, promoting further social learning and further learning investment in turn.
Fecundity costs also shape the evolution of the learning traits: when the fecundity costs associated with learning investment are higher (i.e.,  $\theta$ is higher), individuals invest less in learning (i.e.,
$\theta$ is higher), individuals invest less in learning (i.e.,  $\bar{\lambda}^*$ is lower; Fig. S.6b). This rapidly limits the evolution of both types of social learning (i.e.,
$\bar{\lambda}^*$ is lower; Fig. S.6b). This rapidly limits the evolution of both types of social learning (i.e.,  $\bar{v}^*=\bar{o}^*=0$; Fig. S.6b). Indeed, when the fecundity cost exponent
$\bar{v}^*=\bar{o}^*=0$; Fig. S.6b). Indeed, when the fecundity cost exponent  $\theta$ is higher, individuals allocate more resources to reproduction and less to learning at
$\theta$ is higher, individuals allocate more resources to reproduction and less to learning at  $\bar{\boldsymbol{x}}^*$ (i.e.,
$\bar{\boldsymbol{x}}^*$ (i.e.,  $\bar{\lambda}^*$ is lower; Fig. S.6b), which restricts knowledge production and consequently reduces the benefits of social learning. In the following numerical analyses, we set
$\bar{\lambda}^*$ is lower; Fig. S.6b), which restricts knowledge production and consequently reduces the benefits of social learning. In the following numerical analyses, we set  $\theta=0.1$, a value that permits the evolution of social learning.
$\theta=0.1$, a value that permits the evolution of social learning.
3.2.2. Trade-off between different types of learning
To better understand the effect of selection on the learning traits, we decompose their effect on the expected knowledge of adults in the  ${\boldsymbol{x}_\bullet}$-lineage. We show in Appendix B.2 that
${\boldsymbol{x}_\bullet}$-lineage. We show in Appendix B.2 that  $\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ satisfies
$\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ satisfies
 \begin{equation}
\begin{aligned}
&\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}} = \frac{1}{1 - h_\mathrm{vl}(\bar{\boldsymbol{x}})} \times\\
&\Bigg[
\overbrace{\nabla p_\mathrm{il}({\boldsymbol{x}_\bullet}) + \nabla h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} +
\nabla h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, \left({\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} + \frac{{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} \,\eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}\right)
}^{\substack{\text{learning traits effects on learning}}}
\\ & + \underbrace{h_\mathrm{vl}(\bar{\boldsymbol{x}}) \, \nabla \frac{{\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} + \nabla \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}}_{\substack{\text{learning traits effects on cultural selection}}} \Bigg]\Bigg|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}.
\end{aligned}
\end{equation}
\begin{equation}
\begin{aligned}
&\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}} = \frac{1}{1 - h_\mathrm{vl}(\bar{\boldsymbol{x}})} \times\\
&\Bigg[
\overbrace{\nabla p_\mathrm{il}({\boldsymbol{x}_\bullet}) + \nabla h_\mathrm{ol}({\boldsymbol{x}_\bullet}) \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} +
\nabla h_\mathrm{vl}({\boldsymbol{x}_\bullet}) \, \left({\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} + \frac{{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} \,\eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \,{\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}}\right)
}^{\substack{\text{learning traits effects on learning}}}
\\ & + \underbrace{h_\mathrm{vl}(\bar{\boldsymbol{x}}) \, \nabla \frac{{\operatorname{Var}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{f}}{f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}} + \nabla \frac{{\operatorname{Var}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]} \, \eta_\mathrm{s}}{\tilde{s}\big({\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\big)}}_{\substack{\text{learning traits effects on cultural selection}}} \Bigg]\Bigg|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}.
\end{aligned}
\end{equation} (Appendix B.2). The terms on the second line describe the impact of learning traits on knowledge acquisition. This marginal effect depends on how traits 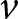 $v$,
$v$,  $o$, and
$o$, and  $\lambda$ influence the knowledge produced individually, as well as that acquired from oblique and vertical exemplars. The marginal knowledge gained through individual learning is
$\lambda$ influence the knowledge produced individually, as well as that acquired from oblique and vertical exemplars. The marginal knowledge gained through individual learning is  $\left.\nabla p_\mathrm{il}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$. The marginal knowledge gained from oblique and vertical exemplars depends on the effect of the learning traits on the oblique
$\left.\nabla p_\mathrm{il}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$. The marginal knowledge gained from oblique and vertical exemplars depends on the effect of the learning traits on the oblique  $\left.\nabla h_\mathrm{ol}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ and vertical
$\left.\nabla h_\mathrm{ol}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ and vertical  $\left.\nabla h_\mathrm{vl}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ cultural heritability, multiplied by the expected knowledge of a parent and an oblique exemplar. Since the traits
$\left.\nabla h_\mathrm{vl}({\boldsymbol{x}_\bullet})\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ cultural heritability, multiplied by the expected knowledge of a parent and an oblique exemplar. Since the traits  $v$ and
$v$ and  $o$ enhance the time allocated to vertical and oblique learning, but reduce the time available for individual knowledge production, their evolution is shaped by trade-offs between different types of learning. The terms on the third line describe the impact of learning traits on cultural selection acting on the expected adult knowledge in the lineage. Learning traits can impact cultural selection by impacting the variance in potential knowledge, as well as the expected fecundity and survival within the lineage.
$o$ enhance the time allocated to vertical and oblique learning, but reduce the time available for individual knowledge production, their evolution is shaped by trade-offs between different types of learning. The terms on the third line describe the impact of learning traits on cultural selection acting on the expected adult knowledge in the lineage. Learning traits can impact cultural selection by impacting the variance in potential knowledge, as well as the expected fecundity and survival within the lineage.
The selection pressure scales as  ${1}/{\big(1 - h_\mathrm{vl}(\bar{\boldsymbol{x}})\big)}$, which captures the inter-generational accumulation of the effects of learning traits on knowledge acquisition and on cultural selection, due to vertical transmission. This can be seen by expressing this factor as
${1}/{\big(1 - h_\mathrm{vl}(\bar{\boldsymbol{x}})\big)}$, which captures the inter-generational accumulation of the effects of learning traits on knowledge acquisition and on cultural selection, due to vertical transmission. This can be seen by expressing this factor as  $1 + \sum_{t=1}^\infty h_\mathrm{vl}(\bar{\boldsymbol{x}})^t$, where
$1 + \sum_{t=1}^\infty h_\mathrm{vl}(\bar{\boldsymbol{x}})^t$, where  $h_\mathrm{vl}(\bar{\boldsymbol{x}})^t$ is the population mean proportion of knowledge initially acquired by an ancestor that is transmitted to a direct descendant
$h_\mathrm{vl}(\bar{\boldsymbol{x}})^t$ is the population mean proportion of knowledge initially acquired by an ancestor that is transmitted to a direct descendant 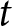 $t$ generations later. This formulation highlights that a change in knowledge in one generation, driven by a change in learning traits, influences the knowledge of all future descendants within the lineage. By capturing the cumulative effects of these interactions, which occur among relatives, the evolutionary dynamics thus incorporate multi-generational kin selection effects.
$t$ generations later. This formulation highlights that a change in knowledge in one generation, driven by a change in learning traits, influences the knowledge of all future descendants within the lineage. By capturing the cumulative effects of these interactions, which occur among relatives, the evolutionary dynamics thus incorporate multi-generational kin selection effects.
To understand selection on the learning traits, we also need to examine  $\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ (see eq. (13)). The term
$\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ (see eq. (13)). The term  $\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ is equal to
$\left.\nabla {\mathbb{E}^*_{\mathrm{o}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ is equal to 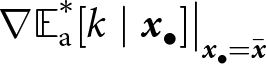 $\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ minus the effect of learning traits on cultural selection due to differences in survival (see eq. (B.25)). This difference arises because offspring have not yet undergone survival themselves.
$\left.\nabla {\mathbb{E}^*_{\mathrm{a}}[k \mid {\boldsymbol{x}_\bullet}]}\right|_{{\boldsymbol{x}_\bullet}=\bar{\boldsymbol{x}}}$ minus the effect of learning traits on cultural selection due to differences in survival (see eq. (B.25)). This difference arises because offspring have not yet undergone survival themselves.
Altogether eqs. (13) and (14) reveal that the evolution of learning traits is influenced by the trade-off between knowledge acquisition from different learning types. Numerically estimating the mean trait values  $\bar{\boldsymbol{x}}^*$ favoured by selection reveals that individuals allocate significant time to both vertical and oblique learning (i.e., high
$\bar{\boldsymbol{x}}^*$ favoured by selection reveals that individuals allocate significant time to both vertical and oblique learning (i.e., high  $\bar{v}^*$ and
$\bar{v}^*$ and 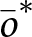 $\bar{o}^*$; see Fig. S.6c) when knowledge remains relevant over time (i.e., low
$\bar{o}^*$; see Fig. S.6c) when knowledge remains relevant over time (i.e., low  $\epsilon$; e.g., in a stable environment). Under these conditions, individuals can acquire substantial knowledge socially. Since social learning becomes more efficient in stable environments, individuals tend to invest significant resources into learning (i.e., high
$\epsilon$; e.g., in a stable environment). Under these conditions, individuals can acquire substantial knowledge socially. Since social learning becomes more efficient in stable environments, individuals tend to invest significant resources into learning (i.e., high  $\bar{\lambda}^*$; see Fig. S.6c). The trade-off between vertical and oblique learning depends on the overlap in knowledge between two adults
$\bar{\lambda}^*$; see Fig. S.6c). The trade-off between vertical and oblique learning depends on the overlap in knowledge between two adults  $\rho$. When there is a high knowledge overlap between adults (i.e., high
$\rho$. When there is a high knowledge overlap between adults (i.e., high  $\rho$), individuals tend to skip the oblique learning phase at
$\rho$), individuals tend to skip the oblique learning phase at  $\bar{\boldsymbol{x}}^*$ (i.e.,
$\bar{\boldsymbol{x}}^*$ (i.e.,  $\bar{o}^*=0$; see Fig. S.6d), since we assume individuals learn more easily from parent (i.e.,
$\bar{o}^*=0$; see Fig. S.6d), since we assume individuals learn more easily from parent (i.e.,  $\beta_{\mathrm{v}} \gt \beta_{\mathrm{o}}$). Conversely, when there is a low knowledge overlap between adults (i.e., low
$\beta_{\mathrm{v}} \gt \beta_{\mathrm{o}}$). Conversely, when there is a low knowledge overlap between adults (i.e., low 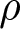 $\rho$), at
$\rho$), at 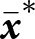 $\bar{\boldsymbol{x}}^*$ individuals allocate time to oblique learning (i.e.,
$\bar{\boldsymbol{x}}^*$ individuals allocate time to oblique learning (i.e.,  $\bar{o}^* \gt 0$), enabling them to acquire knowledge not available from their parents (see Fig. S.6d). This outcome is consistent with the results of Maisonneuve et al. (Reference Maisonneuve, Lehmann and Mullon2025) (see Appendix B.4 for details). Although it strongly influences the learning schedule, the overlap in knowledge between two adults
$\bar{o}^* \gt 0$), enabling them to acquire knowledge not available from their parents (see Fig. S.6d). This outcome is consistent with the results of Maisonneuve et al. (Reference Maisonneuve, Lehmann and Mullon2025) (see Appendix B.4 for details). Although it strongly influences the learning schedule, the overlap in knowledge between two adults  $\rho$ has little effect on resource allocation between learning and fecundity at the reached evolutionary equilibrium (i.e., little effect on
$\rho$ has little effect on resource allocation between learning and fecundity at the reached evolutionary equilibrium (i.e., little effect on  $\bar{\lambda}^*$; see Fig. S.6d).
$\bar{\lambda}^*$; see Fig. S.6d).
3.2.3. Learning stochasticity promotes social learning
We now investigate the impact of stochasticity in individual learning, quantified by the parameter  $\sigma_\mathrm{i}$, on the evolution of learning traits. We show that as
$\sigma_\mathrm{i}$, on the evolution of learning traits. We show that as  $\sigma_\mathrm{i}$ increases, individuals tend to engage more in both vertical and oblique learning at
$\sigma_\mathrm{i}$ increases, individuals tend to engage more in both vertical and oblique learning at  $\bar{\boldsymbol{x}}^*$ (i.e.,
$\bar{\boldsymbol{x}}^*$ (i.e.,  $\bar{v}^*$ and
$\bar{v}^*$ and  $\bar{o}^*$ increase; see Fig. 3a). This is because high
$\bar{o}^*$ increase; see Fig. 3a). This is because high 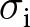 $\sigma_\mathrm{i}$ allows the population to accumulate substantial knowledge (see Fig. 3g), resulting in cultural exemplars possessing greater knowledge. Under high
$\sigma_\mathrm{i}$ allows the population to accumulate substantial knowledge (see Fig. 3g), resulting in cultural exemplars possessing greater knowledge. Under high  $\sigma_\mathrm{i}$, the increased efficiency of social learning then drives individuals to invest more resources in learning at
$\sigma_\mathrm{i}$, the increased efficiency of social learning then drives individuals to invest more resources in learning at  $\bar{\boldsymbol{x}}^*$ (i.e., high
$\bar{\boldsymbol{x}}^*$ (i.e., high  $\bar{\lambda}^*$; see Fig. 3d). This effect is especially pronounced in populations with low knowledge-production ability: stochasticity in learning can drive the evolution of great investment in learning (e.g.,
$\bar{\lambda}^*$; see Fig. 3d). This effect is especially pronounced in populations with low knowledge-production ability: stochasticity in learning can drive the evolution of great investment in learning (e.g.,  $\bar{\lambda}^*\approx0.95$ when
$\bar{\lambda}^*\approx0.95$ when  $\alpha=0.025$ and
$\alpha=0.025$ and  $\sigma_\mathrm{i}=0.25$; see Fig. S.7), whereas in its absence, investment in learning would be low (e.g.,
$\sigma_\mathrm{i}=0.25$; see Fig. S.7), whereas in its absence, investment in learning would be low (e.g.,  $\bar{\lambda}^*\approx0.2$ when
$\bar{\lambda}^*\approx0.2$ when  $\alpha=0.025$ and
$\alpha=0.025$ and  $\sigma_\mathrm{i}=0$; see Fig. S.7). However, in populations with very low knowledge-production ability, individuals evolve to allocate all resources to fecundity and none to learning, so greater stochasticity in learning has no effect (e.g.,
$\sigma_\mathrm{i}=0$; see Fig. S.7). However, in populations with very low knowledge-production ability, individuals evolve to allocate all resources to fecundity and none to learning, so greater stochasticity in learning has no effect (e.g.,  $\alpha=0.001$; see Fig. S.7). The impact of
$\alpha=0.001$; see Fig. S.7). The impact of  $\sigma_\mathrm{i}$ on learning traits at
$\sigma_\mathrm{i}$ on learning traits at  $\bar{\boldsymbol{x}}^*$ also weakens when the obsolescence rate is high, as rapid knowledge decay across generations limits knowledge accumulation (e.g.,
$\bar{\boldsymbol{x}}^*$ also weakens when the obsolescence rate is high, as rapid knowledge decay across generations limits knowledge accumulation (e.g.,  $\epsilon=0.25$; Fig. S.6e). Although higher
$\epsilon=0.25$; Fig. S.6e). Although higher  $\sigma_\mathrm{i}$ leads to investing more in learning at the expense of fecundity (i.e., higher
$\sigma_\mathrm{i}$ leads to investing more in learning at the expense of fecundity (i.e., higher  $\bar{\lambda}^*$), the resulting enhancement in population mean knowledge still leads to larger population sizes at
$\bar{\lambda}^*$), the resulting enhancement in population mean knowledge still leads to larger population sizes at  $\bar{\boldsymbol{x}}^*$ (see Fig. 3g).
$\bar{\boldsymbol{x}}^*$ (see Fig. 3g).
Evolution of learning traits. (a–c) Learning schedule (y-axis) at  $\bar{\boldsymbol{x}}^*$ against the intensity of stochastic effects in individual learning
$\bar{\boldsymbol{x}}^*$ against the intensity of stochastic effects in individual learning  $\sigma_\mathrm{i}$ (x-axis) for different values of the conversion factor that translates knowledge into fecundity
$\sigma_\mathrm{i}$ (x-axis) for different values of the conversion factor that translates knowledge into fecundity  $\eta_\mathrm{f}$ and survival benefits
$\eta_\mathrm{f}$ and survival benefits  $\eta_\mathrm{s}$. Blue, green, and pink areas represent time spent performing vertical, oblique, and individual learning, respectively. (d–f) Investment in learning
$\eta_\mathrm{s}$. Blue, green, and pink areas represent time spent performing vertical, oblique, and individual learning, respectively. (d–f) Investment in learning  $\bar{\lambda}^*$ at
$\bar{\lambda}^*$ at  $\bar{\boldsymbol{x}}^*$ corresponding to panels a–c. (g–j) Population mean knowledge
$\bar{\boldsymbol{x}}^*$ corresponding to panels a–c. (g–j) Population mean knowledge  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}^*]}$ (blue) and adult population size
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}^*]}$ (blue) and adult population size 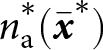 $n_\mathrm{a}^*(\bar{\boldsymbol{x}}^*)$ (black) at
$n_\mathrm{a}^*(\bar{\boldsymbol{x}}^*)$ (black) at  $\bar{\boldsymbol{x}}^*$ corresponding to panels a–c (left axis gives scale of knowledge, and right axis gives scale of population size, with
$\bar{\boldsymbol{x}}^*$ corresponding to panels a–c (left axis gives scale of knowledge, and right axis gives scale of population size, with  $\gamma=10^{-4}$). Default parameters are the same as in Fig. 2 with
$\gamma=10^{-4}$). Default parameters are the same as in Fig. 2 with  $\theta=0.1$.
$\theta=0.1$.

Individual-based simulations, which notably relax the assumption of a Gaussian probability density of knowledge, confirm that greater stochasticity in individual learning promotes both increased time allocated to social learning and greater investment in learning at  $\bar{\boldsymbol{x}}^*$ and leads to higher population mean knowledge and population size (see Fig. S.9). In addition, simulations that relax the assumption of non-stochastic social learning (i.e., allowing
$\bar{\boldsymbol{x}}^*$ and leads to higher population mean knowledge and population size (see Fig. S.9). In addition, simulations that relax the assumption of non-stochastic social learning (i.e., allowing  $\sigma_\mathrm{v} \gt 0$ or
$\sigma_\mathrm{v} \gt 0$ or  $\sigma_\mathrm{o} \gt 0$) reveal similar patterns under increased stochasticity in vertical and oblique learning (see Fig. S.10).
$\sigma_\mathrm{o} \gt 0$) reveal similar patterns under increased stochasticity in vertical and oblique learning (see Fig. S.10).
However, when adults knowledge significantly overlaps, an increase in  $\sigma_\mathrm{i}$ results in a greater allocation of time to vertical learning and a reduced allocation to oblique learning at
$\sigma_\mathrm{i}$ results in a greater allocation of time to vertical learning and a reduced allocation to oblique learning at 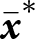 $\bar{\boldsymbol{x}}^*$ (e.g., increase in
$\bar{\boldsymbol{x}}^*$ (e.g., increase in  $\bar{v}^*$ and decrease in
$\bar{v}^*$ and decrease in  $\bar{o}^*$ when
$\bar{o}^*$ when  $\rho=0.4$; see Fig. S.6f). In this regime, both parents and other adults provide access to similar knowledge units, so selection favours the most effective social learning mode for acquiring this shared knowledge. Under higher stochasticity in individual learning, the average knowledge of parents
$\rho=0.4$; see Fig. S.6f). In this regime, both parents and other adults provide access to similar knowledge units, so selection favours the most effective social learning mode for acquiring this shared knowledge. Under higher stochasticity in individual learning, the average knowledge of parents  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} + {{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} \,\eta_\mathrm{f}}/{\big(f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}\big)}$ increases more than that of oblique exemplars
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} + {{\operatorname{Var}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]} \,\eta_\mathrm{f}}/{\big(f_\mathrm{0} + \eta_\mathrm{f} \, {\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}\big)}$ increases more than that of oblique exemplars  ${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (see Fig. S.8) since parents tend to have higher fertility and, consequently, above-average knowledge. As a result, when learning is more stochastic, offspring acquire more of the shared knowledge from their parents.
${\mathbb{E}^*_{\mathrm{a}}[k \mid \bar{\boldsymbol{x}}]}$ (see Fig. S.8) since parents tend to have higher fertility and, consequently, above-average knowledge. As a result, when learning is more stochastic, offspring acquire more of the shared knowledge from their parents.
3.2.4. Selection promotes learning from selected individuals
We now turn to the question of whom individuals should learn from when knowledge varies across the population. Specifically, we investigate which social learning exemplars are favoured by natural selection when knowledge improves survival and/or fecundity.
When knowledge enhances fecundity but does not affect survival (i.e., when 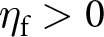 $\eta_\mathrm{f} \gt 0$ and
$\eta_\mathrm{f} \gt 0$ and  $\eta_\mathrm{s}=0$), increased stochasticity in individual learning (i.e., increased
$\eta_\mathrm{s}=0$), increased stochasticity in individual learning (i.e., increased  $\sigma_\mathrm{i}$) leads to allocating more time to vertical learning rather than oblique learning at
$\sigma_\mathrm{i}$) leads to allocating more time to vertical learning rather than oblique learning at  $\bar{\boldsymbol{x}}^*$ (i.e., a rise in
$\bar{\boldsymbol{x}}^*$ (i.e., a rise in  $\bar{v}^*$ but not in
$\bar{v}^*$ but not in  $\bar{o}^*$; see Fig. 3b). In that case, stochasticity in individual learning leads to uncertainty in the knowledge held by potential social learning exemplars. Being a parent then acts as a cue for high fecundity and, therefore, greater knowledge. By contrast, when knowledge increases survival but does not affect fecundity (i.e., when
$\bar{o}^*$; see Fig. 3b). In that case, stochasticity in individual learning leads to uncertainty in the knowledge held by potential social learning exemplars. Being a parent then acts as a cue for high fecundity and, therefore, greater knowledge. By contrast, when knowledge increases survival but does not affect fecundity (i.e., when 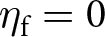 $\eta_\mathrm{f}=0$ and
$\eta_\mathrm{f}=0$ and  $\eta_\mathrm{s} \gt 0$), increased stochasticity in individual learning (i.e., increased
$\eta_\mathrm{s} \gt 0$), increased stochasticity in individual learning (i.e., increased  $\sigma_\mathrm{i}$) leads to allocating more time to both vertical and oblique learning at
$\sigma_\mathrm{i}$) leads to allocating more time to both vertical and oblique learning at  $\bar{\boldsymbol{x}}^*$ (i.e., a rise in
$\bar{\boldsymbol{x}}^*$ (i.e., a rise in  $\bar{v}^*$ and
$\bar{v}^*$ and  $\bar{o}^*$; see Fig 3c). It follows that because adults who are available as social learning exemplars, whether during vertical or oblique learning, have survived until adulthood, their survival is a cue for sizable knowledge. In summary, when stochasticity in learning renders the knowledge of social learning exemplars unpredictable, natural selection favours learning from individuals who exhibit cues for possessing sizable knowledge (e.g., being a parent or having survived to adulthood).
$\bar{o}^*$; see Fig 3c). It follows that because adults who are available as social learning exemplars, whether during vertical or oblique learning, have survived until adulthood, their survival is a cue for sizable knowledge. In summary, when stochasticity in learning renders the knowledge of social learning exemplars unpredictable, natural selection favours learning from individuals who exhibit cues for possessing sizable knowledge (e.g., being a parent or having survived to adulthood).
3.2.5. Selection promotes stochasticity in learning
The results so far show that stochasticity in individual learning, quantified by  $\sigma_\mathrm{i}$, markedly affects both the cultural and evolutionary dynamics, and in perhaps counterintuitive ways. Yet, these results may not have traction if
$\sigma_\mathrm{i}$, markedly affects both the cultural and evolutionary dynamics, and in perhaps counterintuitive ways. Yet, these results may not have traction if  $\sigma_\mathrm{i}$ itself is selected away. Here, we show that learning stochasticity can in fact be favoured by selection. We relax the assumption of fixed
$\sigma_\mathrm{i}$ itself is selected away. Here, we show that learning stochasticity can in fact be favoured by selection. We relax the assumption of fixed  $\sigma_\mathrm{i}$ by introducing an additional evolving trait
$\sigma_\mathrm{i}$ by introducing an additional evolving trait  ${\zeta} \in [0, +\infty)$ that increases stochasticity (i.e.,
${\zeta} \in [0, +\infty)$ that increases stochasticity (i.e.,  $\forall {\zeta} \in[0,+\infty), \, \sigma_\mathrm{i}'({\zeta}) \gt 0$). For instance,
$\forall {\zeta} \in[0,+\infty), \, \sigma_\mathrm{i}'({\zeta}) \gt 0$). For instance,  $\zeta$ may be a behavioural tendency towards exploration during learning. We assume that learning is inherently stochastic, such that even in the absence of any trait promoting stochasticity (i.e., when
$\zeta$ may be a behavioural tendency towards exploration during learning. We assume that learning is inherently stochastic, such that even in the absence of any trait promoting stochasticity (i.e., when  ${\zeta} = 0$), a small baseline level of stochasticity remains (i.e.,
${\zeta} = 0$), a small baseline level of stochasticity remains (i.e., 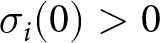 $\sigma_i(0) \gt 0$, but small). In Appendix C, we show that selection always favours the emergence of the trait
$\sigma_i(0) \gt 0$, but small). In Appendix C, we show that selection always favours the emergence of the trait  ${\zeta}$. This is because in a lineage with traits
${\zeta}$. This is because in a lineage with traits  ${\boldsymbol{x}_\bullet}=(v_{\bullet}, o_{\bullet}, \lambda_{\bullet}, {\zeta}_{\bullet})$,
${\boldsymbol{x}_\bullet}=(v_{\bullet}, o_{\bullet}, \lambda_{\bullet}, {\zeta}_{\bullet})$,  ${\zeta}_{\bullet}$ increases knowledge variance (see eq. (C.13)), thereby strengthening cultural selection and leading to higher expected knowledge (see eqs. (C.6) and (C.7)). This effect is further amplified under strong vertical transmission, as increases in expected knowledge driven by cultural selection accumulate across generations within the lineage (see eqs. (C.6) and (C.7)). These results thus confirm the potent role of
${\zeta}_{\bullet}$ increases knowledge variance (see eq. (C.13)), thereby strengthening cultural selection and leading to higher expected knowledge (see eqs. (C.6) and (C.7)). This effect is further amplified under strong vertical transmission, as increases in expected knowledge driven by cultural selection accumulate across generations within the lineage (see eqs. (C.6) and (C.7)). These results thus confirm the potent role of  $\sigma_\mathrm{i}$ on both the cultural and evolutionary dynamics.
$\sigma_\mathrm{i}$ on both the cultural and evolutionary dynamics.
4. Discussion
We here first derived the dynamics of individual knowledge in a population using a stochastic model of learning that links generations through vertical and oblique transmission. We showed that as long as the learning process generates variability in knowledge, and knowledge is transmitted across generations, cultural selection, driven by differences in transmission linked to individual knowledge levels, will inevitably impact the dynamics of knowledge. By estimating the population mean of individual knowledge at equilibrium, our model shows that such cultural selection enhances cumulative knowledge. Those who, by chance, acquire greater knowledge are more likely to survive to adulthood, allowing them to interact with potential learners from the next generation, and to produce more offspring, thereby increasing opportunities for vertical transmission. As a result, individuals with higher knowledge are more likely to pass it on, thereby promoting knowledge accumulation across generations. Our results show that stochasticity in learning amplifies the action of natural selection by promoting variation in knowledge levels.
Our findings are consistent with previous theoretical work in which cultural selection arises because learners preferentially choose more knowledgeable exemplars (e.g., Henrich, Reference Henrich2004, Powell et al., Reference Powell, Shennan and Thomas2009, Kobayashi and Aoki, Reference Kobayashi and Aoki2012). In addition, our results highlight that cultural selection can operate even when learners cannot directly assess exemplar knowledge, as long as individuals with greater knowledge are still more likely to transmit, an effect also shown by Cavalli-Sforza and Feldman (Reference Cavalli-Sforza and Feldman1981). Thus, cultural selection is likely to contribute to the improvement of any form of adaptive knowledge that enhances fecundity or survival, even when it is difficult to identify which individuals possess greater knowledge. This may be particularly relevant for knowledge whose benefits are not directly observable because they may be delayed, probabilistic, or rely on hidden causal mechanisms, such as knowledge related to food processing, medicine, rituals, ecological knowledge, or institutional knowledge.
Stochasticity in learning has been extensively studied in reinforcement learning through the effects of random exploration of novel ‘actions’ (which can be thought of as cultural variants in our framework) on learning (Kaelbling et al., Reference Kaelbling, Littman and Moore1996, Ladosz et al., Reference Ladosz, Weng, Kim and Hyondong2022, Hao et al., Reference Hao, Yang, Tang, Bai, Liu, Meng, Liu and Wang2024). By increasing the chance of discovering high-reward actions, random exploration enhances the efficiency of selecting and retaining such actions, thereby improving reinforcement learning. While this role of stochasticity is well established, our results demonstrate that it can also enhance the efficiency of social learning, provided knowledge-biased transmission. In stationary environments, the advantages of random exploration in reinforcement learning generally decline as learners approach the optimal action (e.g., Tokic, Reference Tokic, Dillmann, Beyerer, Hanebeck and Schultz2010, Zhang et al., Reference Zhang, Hongkang, Wang, Liu, Chen, Songtao, Liu, Murugesan and Chaudhury2023). In contrast, in our model, greater stochasticity remains consistently advantageous because knowledge is unbounded and becomes obsolete due to environmental change. If we were instead to consider a cultural trait with an optimum (e.g., an ideal tool design or behaviour suited to a specific ecological challenge), then, much like in reinforcement learning, stochasticity would likely promote early cultural improvement by enabling the discovery of more adaptive variants, but slow convergence as the population’s traits approach their optimal value. For example, combining individual learning through trial-and-error with social transmission, trait variability across trials can speed convergence when the cultural trait is simple, but increases the distance from the optimum at equilibrium (Lehmann and Wakano, Reference Lehmann and Wakano2013).
Our results also show that, by enhancing cumulative knowledge, the cultural selection introduced by stochasticity in learning favours the evolution of extended social learning phases, as individuals can acquire substantial knowledge from exemplars. In addition, since social learning can provide a large amount of knowledge under these conditions, stochasticity in learning also promotes the evolution of more efficient learning, despite associated fecundity costs. This enables individuals to acquire a greater amount of knowledge during the social learning phase. Our findings may contribute to understanding how the mode of knowledge acquisition differs across knowledge types that vary in the extent of stochasticity in their production. For example, the production of opaque knowledge, such as adaptive taboos (Henrich and Henrich, Reference Henrich and Henrich2010), adaptive supernatural beliefs (Lightner and Hagen, Reference Lightner and Hagen2022), or food preparation methods that trigger complex chemical reactions (Beck, Reference Beck1992), may be particularly stochastic, as their adaptive value is not readily apparent and it is difficult to intentionally produce knowledge that reliably enhances survival and fecundity. Due to this opacity, such knowledge likely became adaptive through a gradual accumulation of random improvements over time. As a result, individuals can acquire far more of this type of knowledge through social learning than they could by independently discovering it. Our results, therefore, predict that opaque knowledge would be primarily acquired socially. This could be the case for knowledge related to food preparation among the Aka Pygmies. Indeed, interviewed individuals reported that they had acquired all of their knowledge related to the preparation of koko, magnoc, and palm wine through social learning (Hewlett and Cavalli-Sforza, Reference Hewlett and Cavalli-Sforza1986). By contrast, other forms of knowledge, such as basic hunting techniques, navigating terrain, or learning to avoid predators, may rely on more transparent causal relationships. As a result, their acquisition may involve less stochasticity and is more likely to occur through individual learning. Nevertheless, stochasticity in knowledge production is likely to explain only part of the variation in modes of knowledge acquisition across knowledge types. Other factors, including the costs of producing knowledge, the need for motor skill practice, the ease of assessing success, and obsolescence, may also play important roles.
Our results reveal that whether knowledge affects fecundity or survival shapes the evolution of learning traits. For instance, when knowledge enhances only fecundity, natural selection favours individuals who mainly learn from their parents rather than from unrelated adults, consistent with the findings of McElreath and Strimling (Reference McElreath and Strimling2008). This is because, when stochasticity introduces variability in knowledge levels, parents tend to have above-average reproductive success and are therefore more likely to possess above-average knowledge. In contrast, randomly chosen adults tend to have average reproductive success and are not particularly likely to possess higher levels of knowledge. Therefore, individuals can acquire more knowledge by learning from their parents than from random adults. One interpretation is that parenthood serves as a cue for possessing knowledge that enhances fecundity, whereas simply being an adult provides no such indication. These findings suggest that knowledge enhancing fecundity should be preferentially acquired from parents. This pattern is supported by empirical evidence from the Aka Pygmies: interviewed individuals reported acquiring, on average, 85.6% of their knowledge about infant care from their parents, compared to 80.7% for knowledge across all domains (Hewlett and Cavalli-Sforza, Reference Hewlett and Cavalli-Sforza1986).
Our results rely on several assumptions that merit further discussion. In particular, we assume that knowledge affects survival and fecundity linearly. This assumption does not affect our conclusions regarding the impact of stochasticity in learning on cumulative knowledge and the evolution of learning traits. However, nonlinear fitness effects could alter knowledge dynamics and the evolutionary trajectories of learning traits, thereby quantitatively affecting our results. For instance, if knowledge yields increasing returns on survival and fecundity, individuals who possess above-average knowledge would gain greater advantages as knowledge accumulates in the population. This would amplify knowledge accumulation, since variation in knowledge would more strongly translate into differences in survival to adulthood and fecundity, thereby increasing cultural selection. As potential exemplars would carry a higher level of knowledge, selection would favour greater reliance on social learning. By contrast, if knowledge yields diminishing returns, we would expect the opposite outcome: knowledge accumulation would slow, and the evolutionary pressure for social learning would weaken.
We also make specific assumptions about the learning process. We assume that learning occurs sequentially through vertical, oblique, and individual phases. Although this is a simplification, it aligns with a general developmental pattern: social learning is more common early in life, while individual learning becomes more prevalent with age (Reader and Laland, Reference Reader and Laland2001, Biesmeijer and Seeley, Reference Biesmeijer and Seeley2005, Noble et al., Reference Noble, Byrne and Whiting2014, Carr et al., Reference Carr, Kendal and Flynn2015). In humans, the sources of social learning also tend to shift, from primarily vertical transmission during childhood, to greater reliance on oblique transmission in later life stages (Hewlett et al., Reference Hewlett, Fouts, Boyette and Hewlett2011, Demps et al., Reference Demps, Zorondo-Rodríguez, García and Reyes-García2012, Garfield et al., Reference Garfield, Garfield and Hewlett2016). In addition, we assume that individuals produce knowledge at a constant average rate, a simplification that allows us to focus on intergenerational knowledge accumulation without explicitly modelling the mechanistic processes underlying individual learning (but see Lehmann and Wakano, Reference Lehmann and Wakano2013, for a model with temporal cultural dynamics with mechanistic individual learning). Finally, we assume that the overlap in knowledge between two adults  $\rho$ is constant. Allowing
$\rho$ is constant. Allowing  $\rho$ to emerge endogenously from the learning process could affect our results. Increased stochasticity in learning would reduce overlap in knowledge among adults, making oblique exemplars more likely to possess knowledge not held by parents and thereby promoting greater reliance on oblique learning.
$\rho$ to emerge endogenously from the learning process could affect our results. Increased stochasticity in learning would reduce overlap in knowledge among adults, making oblique exemplars more likely to possess knowledge not held by parents and thereby promoting greater reliance on oblique learning.
Our study highlights the central role of stochasticity in learning in favouring cumulative knowledge and driving the evolution of learning behaviours. Such stochasticity may be widespread, not only because some level is inevitable, but also because our results show that selection favours increased stochasticity, as it increases the expected knowledge of lineage members when vertical transmission is non-negligible. However, fully understanding the evolution of traits underlying stochasticity in learning requires considering potential trade-offs; for example, a greater tendency to explore may be energetically costly or increase risk exposure. Another trade-off arises because exploratory behaviour may slow the rate of knowledge production, as random exploration is more likely to generate non-functional outcomes than functional ones. Incorporating this effect would require explicitly modelling the mechanistic processes underlying individual learning. These insights point to promising directions for future research on the evolutionary dynamics of traits impacting knowledge acquisition and their role in shaping cumulative cultural knowledge.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/ehs.2026.10044.
Acknowledgements
LM would like to thank Arthur Weyna and Cédric Perret for the useful discussions.
Author contributions
LM and LL conceived and designed the study. LM developed the codes and performed the analyses. LM wrote the manuscript with contributions from LL.
Financial support
This research received no specific grant from any funding agency, commercial or not-for-profit sectors.
Conflicts of interest
The authors declare no conflicts of interest.
Research transparency and reproducibility interest
All the codes used in this study are accessible at github.com/Ludovic-Maisonneuve/stochasticity_evolution_learning.
Data availability
n/a
AI declaration
LM has used AI tools to identify grammatical and spelling errors and to enhance the overall fluency of the text.


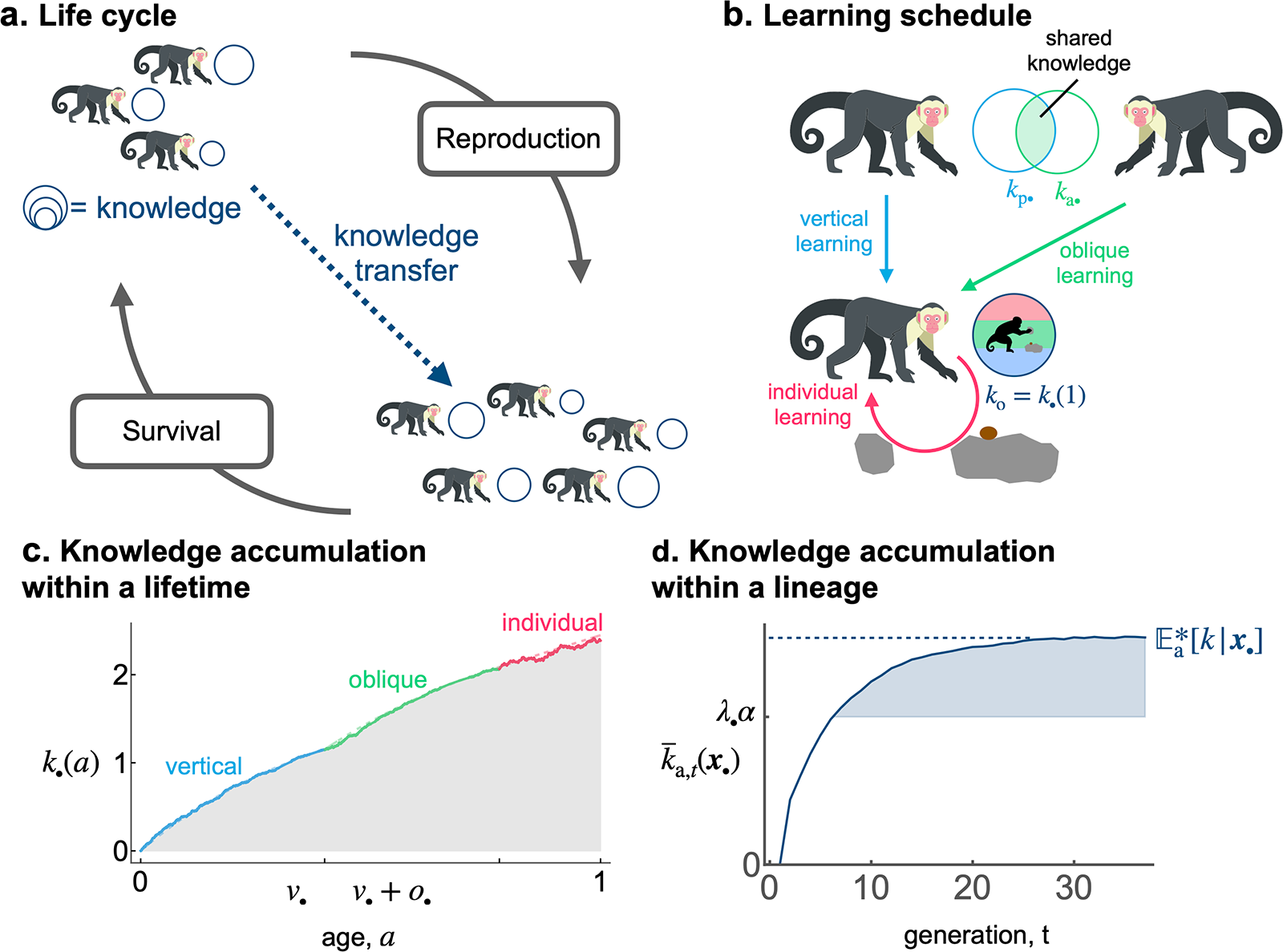




















































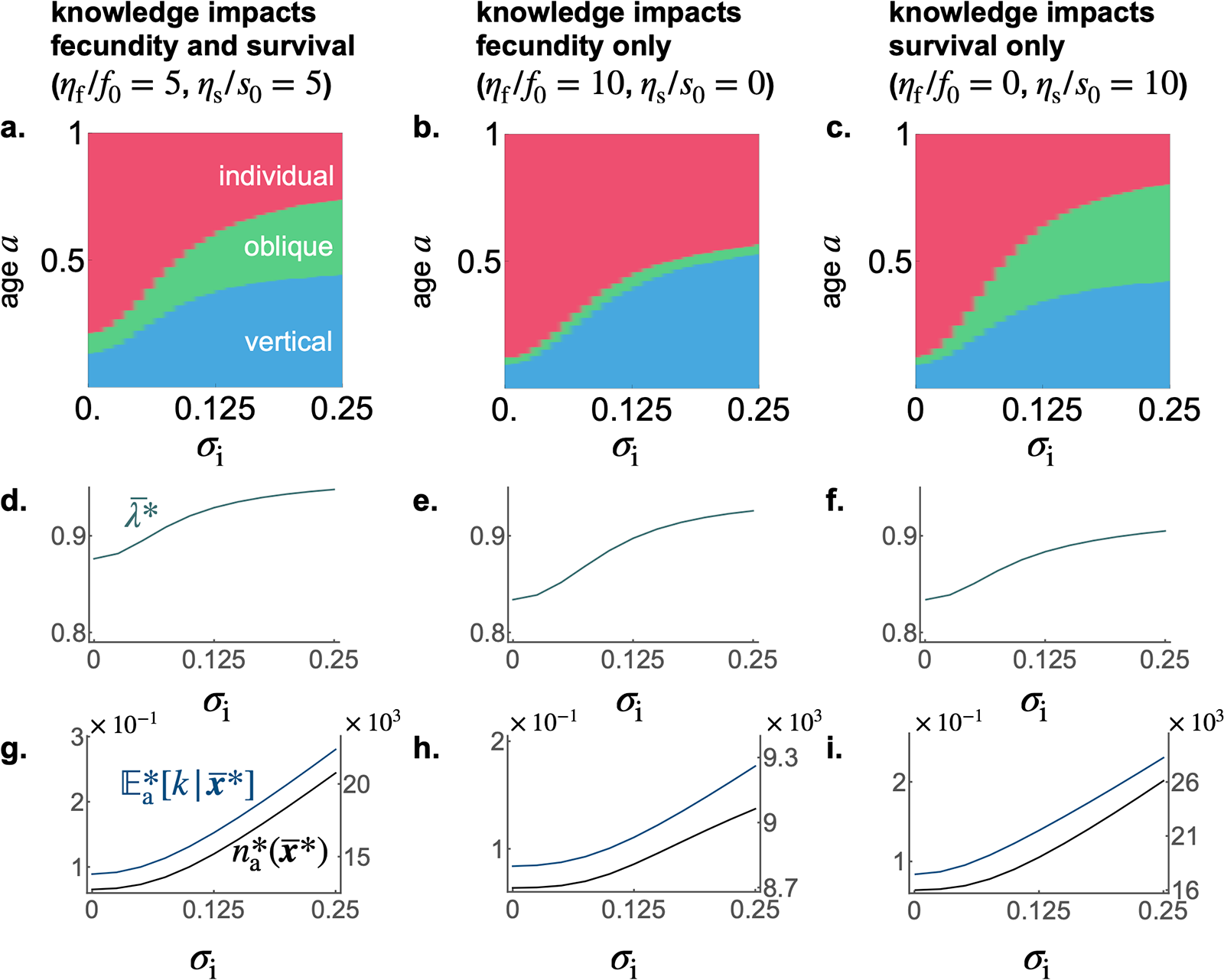














 Open access
Open access