


1 Introduction
Item response theory (IRT) models (van der Linden, Reference van der Linden2016) are commonly used when analyzing large-scale assessments and achievement tests. In IRT, the scale used for the latent variable
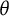 $\theta $
is inherently arbitrary. This means that it lacks a natural origin or unit (Lord, Reference Lord1975). For reasons of statistical identifiability, interpretability, and computational convenience within estimation algorithms, it is common practice to assume
$\theta $
is inherently arbitrary. This means that it lacks a natural origin or unit (Lord, Reference Lord1975). For reasons of statistical identifiability, interpretability, and computational convenience within estimation algorithms, it is common practice to assume
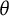 $\theta $
is continuous and follows a specific distribution, typically the standard normal distribution (
$\theta $
is continuous and follows a specific distribution, typically the standard normal distribution (
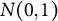 $N(0,1)$
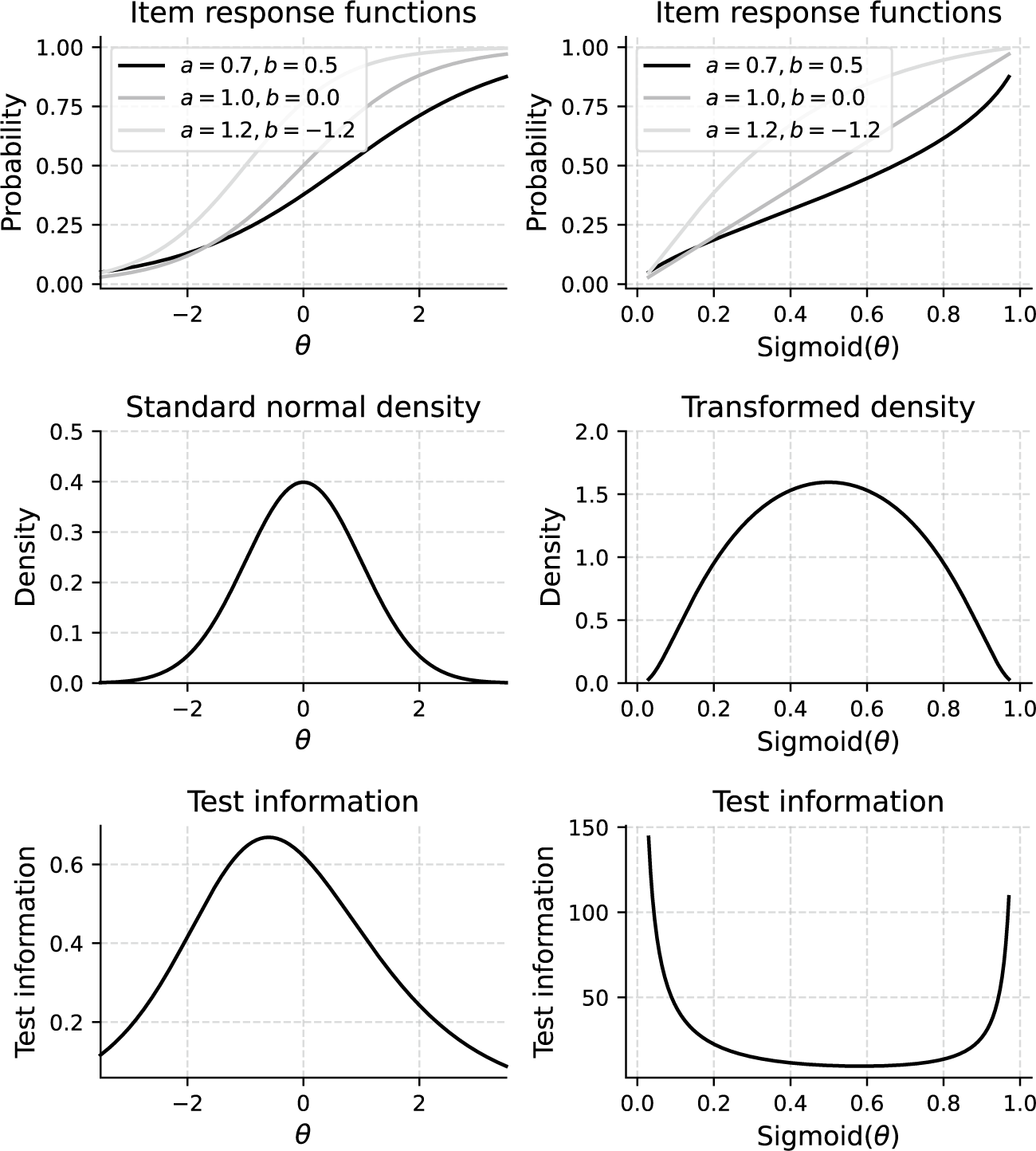
). For example, estimation methods, such as marginal maximum likelihood (MML; Bock & Aitkin, Reference Bock and Aitkin1981) and Bayesian approaches (Levy & Mislevy, Reference Levy and Mislevy2017), are designed around such distributional assumptions. Because the scale is arbitrary, any monotonic transformation (one that preserves the rank order of individuals) can be applied without changing the model’s fundamental properties. Figure 1 demonstrates this principle by applying the sigmoid transformation to the original
$N(0,1)$
). For example, estimation methods, such as marginal maximum likelihood (MML; Bock & Aitkin, Reference Bock and Aitkin1981) and Bayesian approaches (Levy & Mislevy, Reference Levy and Mislevy2017), are designed around such distributional assumptions. Because the scale is arbitrary, any monotonic transformation (one that preserves the rank order of individuals) can be applied without changing the model’s fundamental properties. Figure 1 demonstrates this principle by applying the sigmoid transformation to the original
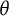 $\theta $
scale of a three-item test using the two-parameter logistic (2PL) model. Although the shape of the
$\theta $
scale of a three-item test using the two-parameter logistic (2PL) model. Although the shape of the
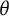 $\theta $
distribution changes, the relative ordering of test-takers and the original response probabilities are preserved, resulting in an equally valid representation of the IRT model. However, the slopes of the item response functions (IRFs) and, as a direct consequence, also the test and item information curves (Hambleton & Swaminathan, Reference Hambleton and Swaminathan1985, Chapter 6) change profoundly. As a result, distances on the latent trait scale only have meaning in relation to other people in the population from which the sample of test takers used to fit the model was drawn. These issues have been known for a long time and have been discussed previously by Lord (Reference Lord1975).
$\theta $
distribution changes, the relative ordering of test-takers and the original response probabilities are preserved, resulting in an equally valid representation of the IRT model. However, the slopes of the item response functions (IRFs) and, as a direct consequence, also the test and item information curves (Hambleton & Swaminathan, Reference Hambleton and Swaminathan1985, Chapter 6) change profoundly. As a result, distances on the latent trait scale only have meaning in relation to other people in the population from which the sample of test takers used to fit the model was drawn. These issues have been known for a long time and have been discussed previously by Lord (Reference Lord1975).
Item response functions,
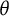 $\theta $
distributions, and test information curves before and after sigmoid transformation of
$\theta $
distributions, and test information curves before and after sigmoid transformation of
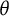 $\theta $
scale.
$\theta $
scale.
Note: In the upper plots, a and b refer to the slope and difficulty parameters of the 2PL model as later described in Equation (1).

The overall aim of this article is to introduce a scale transformation, which we refer to as the bit scale transformation to circumvent these issues. Instead of arbitrarily deciding on a distribution and tying the latent trait scale to the test taker population, bit scales are metric scales tied to the test items. To define bit scales, we will use ideas from information theory (Cover & Thomas, Reference Cover and Thomas2006; Shannon, Reference Shannon1948). The utility of bit scales will be illustrated through two empirical examples and a simulation study.
Another alternative to the
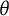 $\theta $
scores includes D-scores (Dimitrov, Reference Dimitrov2024), which are scores computed from the test takers’ response vector, and are weighted by the expected difficulties of the items. The expected difficulty of an item is obtained analytically from its IRT parameters. Additionally, the use of surprisal arc length has been proposed (Ramsay et al., Reference Ramsay, Li and Wiberg2020, Reference Ramsay, Li, Wallmark and Wiberg2024). A limitation, however, with using arc length is that it is not defined when the probability of a correct response is zero. This situation can occur when we use an IRT model, which gives small or zero probabilities, which is the case for many commonly used IRT models. Examples include the 2PL model (Birnbaum, Reference Birnbaum, Lord and Novick1968) and the generalized partial credit (GPC) model (Muraki, Reference Muraki1992) introduced in the next section. The proposed approach avoids this problem and can thus be seen as a refinement of the use of arc length.
$\theta $
scores includes D-scores (Dimitrov, Reference Dimitrov2024), which are scores computed from the test takers’ response vector, and are weighted by the expected difficulties of the items. The expected difficulty of an item is obtained analytically from its IRT parameters. Additionally, the use of surprisal arc length has been proposed (Ramsay et al., Reference Ramsay, Li and Wiberg2020, Reference Ramsay, Li, Wallmark and Wiberg2024). A limitation, however, with using arc length is that it is not defined when the probability of a correct response is zero. This situation can occur when we use an IRT model, which gives small or zero probabilities, which is the case for many commonly used IRT models. Examples include the 2PL model (Birnbaum, Reference Birnbaum, Lord and Novick1968) and the generalized partial credit (GPC) model (Muraki, Reference Muraki1992) introduced in the next section. The proposed approach avoids this problem and can thus be seen as a refinement of the use of arc length.
The rest of this article is structured as follows. In the next section, IRT is briefly summarized, including the two models we will use. Section 3 provides a brief introduction to information theory, and surprisal and entropy are described. The fourth section introduces bit scores and bit scales, followed by the fifth section, which contains two empirical illustrations with real test data and a software note. This is followed by a simulation study where bias, standard error (SE), and root mean squared error (RMSE) are examined for both binary and polytomously scored items. The article ends with a discussion with some concluding remarks that includes suggestions on how bit scales can be used in practice.
2 Item response theory
IRT provides a framework for modeling the relationship between an individual’s latent trait (e.g., ability and attitude) and their responses to items on a test or questionnaire (van der Linden, Reference van der Linden2016). Unlike classical test theory, which primarily focuses on total test scores, IRT examines responses at the item level. A central concept in IRT is the IRF, which mathematically describes the probability of a specific response to an item given the level of the latent trait.
We consider a test comprising J items, indexed by
 $j=1, \dots , J$
. The response of an individual to item j is denoted by
$j=1, \dots , J$
. The response of an individual to item j is denoted by
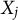 $X_j$
and is considered a random variable. We denote the possible item responses for item j as
$X_j$
and is considered a random variable. We denote the possible item responses for item j as
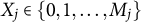 $X_j \in \{0, 1, \dots , M_j\}$
and the probability to respond with
$X_j \in \{0, 1, \dots , M_j\}$
and the probability to respond with
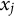 $x_j$
at a given ability level
$x_j$
at a given ability level
 $\theta $
(the IRF) as
$\theta $
(the IRF) as
 $P(X_j=x_j \mid \theta )$
. Several specific IRT models exist, differing in the functional form of the IRF and the item parameters used. Below, we define the models relevant to this article.
$P(X_j=x_j \mid \theta )$
. Several specific IRT models exist, differing in the functional form of the IRF and the item parameters used. Below, we define the models relevant to this article.
For items scored as correct/incorrect, the most common models belong to the logistic family. The 2PL model (Birnbaum, Reference Birnbaum, Lord and Novick1968) defines the probability of a correct response (
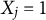 $X_j=1$
) to item j given
$X_j=1$
) to item j given
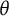 $\theta $
as
$\theta $
as
 $$ \begin{align} P(X_j=1 \mid \theta) = \frac{e^{a_j(\theta - b_j)}}{1 + e^{a_j(\theta - b_j)}}, \end{align} $$
$$ \begin{align} P(X_j=1 \mid \theta) = \frac{e^{a_j(\theta - b_j)}}{1 + e^{a_j(\theta - b_j)}}, \end{align} $$
where
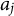 $a_j$
is the discrimination parameter, indicating how well the item differentiates between individuals with different trait levels (higher
$a_j$
is the discrimination parameter, indicating how well the item differentiates between individuals with different trait levels (higher
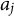 $a_j$
means steeper slope of the IRF), and
$a_j$
means steeper slope of the IRF), and
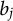 $b_j$
is the difficulty parameter, representing the trait level required for a 50% chance of a correct response. The probability of an incorrect response is
$b_j$
is the difficulty parameter, representing the trait level required for a 50% chance of a correct response. The probability of an incorrect response is
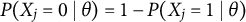 $P(X_j=0 \mid \theta ) = 1 - P(X_j=1 \mid \theta )$
.
$P(X_j=0 \mid \theta ) = 1 - P(X_j=1 \mid \theta )$
.
For items with more than two ordered response categories, the GPC (Muraki, Reference Muraki1992) Model models the probability of responding with
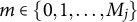 $m \in \{0, 1, \dots , M_j\}$
on item j as
$m \in \{0, 1, \dots , M_j\}$
on item j as
 $$ \begin{align} P(X_j=m \mid \theta) = \begin{cases} \dfrac{1} {1+\sum_{g=1}^{M_j}\left[\exp \sum_{t=1}^g a_{j} (\theta - b_{jt})\right]}, & \text{if } m = 0\\ \dfrac{\exp \sum_{t=1}^{m}a_{j}(\theta - b_{jt})} {1+\sum_{g=1}^{M_j}\left[\exp\sum_{t=1}^g a_{j} (\theta-b_{jt})\right]}, & \text{otherwise,} \end{cases} \end{align} $$
$$ \begin{align} P(X_j=m \mid \theta) = \begin{cases} \dfrac{1} {1+\sum_{g=1}^{M_j}\left[\exp \sum_{t=1}^g a_{j} (\theta - b_{jt})\right]}, & \text{if } m = 0\\ \dfrac{\exp \sum_{t=1}^{m}a_{j}(\theta - b_{jt})} {1+\sum_{g=1}^{M_j}\left[\exp\sum_{t=1}^g a_{j} (\theta-b_{jt})\right]}, & \text{otherwise,} \end{cases} \end{align} $$
where
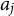 $a_j$
is the item discrimination parameter, and
$a_j$
is the item discrimination parameter, and
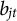 $b_{jt}$
are threshold parameters, defining the points on the
$b_{jt}$
are threshold parameters, defining the points on the
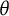 $\theta $
scale at which the probability of responding with a score of t surpasses that of responding with
$\theta $
scale at which the probability of responding with a score of t surpasses that of responding with
 $t-1$
.
$t-1$
.
The IRT models considered in this study, as well as most unidimensional IRT models, rely on the following fundamental assumptions (e.g., Hambleton & Swaminathan, Reference Hambleton and Swaminathan1985, Chapter 2):
-
• Unidimensionality: The model assumes that only a single latent trait
 $\theta $
underlies the individuals’ responses to the set of items.
$\theta $
underlies the individuals’ responses to the set of items. -
• Local independence: Given an individual’s latent trait level
$\theta $
, their responses to different items are statistically independent. That is,
$P(X_1=x_1, \dots , X_J=x_J \mid \theta ) = \prod _{j=1}^J P(X_j=x_j \mid \theta )$
. -
• Monotonicity: As the latent variable
$\theta $
increases, the probability of a higher score on an item also increases.
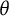
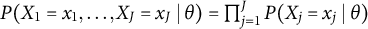
3 Information theory
Information theory, originally proposed by Shannon (Reference Shannon1948) and later discussed in Cover and Thomas (Reference Cover and Thomas2006) and Stone (Reference Stone2022), is the mathematical representation of the transmission of messages through a communication system. In a test setting, each possible item response can be seen as a message and the communication system is the test as noted by Ramsay et al. (Reference Ramsay, Li, Wallmark and Wiberg2024)). In information theory, an important concept is self-information, or the term surprisal coined by Tribus (Reference Tribus1961). Surprisal is derived from the probability of a particular event occurring from a random variable. The transformation
 $$ \begin{align} S(P)=-\log_2(P)\, \end{align} $$
$$ \begin{align} S(P)=-\log_2(P)\, \end{align} $$
converts a probability P into surprisal, and thus
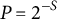 $P=2^{-S}$
converts a surprisal into probability. Thus, probability and surprisal can be viewed as two different ways to look at a response option. Due to the logarithmic transformation, surprisal ranges from 0 to ∞. For an event that is certain to occur, with a probability of 1, the surprisal is 0, there is no surprise, as we know that the event will occur. A rare event yields more information and thus a higher surprisal value, and if
$P=2^{-S}$
converts a surprisal into probability. Thus, probability and surprisal can be viewed as two different ways to look at a response option. Due to the logarithmic transformation, surprisal ranges from 0 to ∞. For an event that is certain to occur, with a probability of 1, the surprisal is 0, there is no surprise, as we know that the event will occur. A rare event yields more information and thus a higher surprisal value, and if
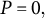 $P=0,$
the surprisal is
$P=0,$
the surprisal is
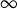 $\infty $
. As surprisal has metric properties, we can add, subtract, and multiply it with positive constants.
$\infty $
. As surprisal has metric properties, we can add, subtract, and multiply it with positive constants.
The surprisal transformation is not new, as it has been used in many areas in statistics, such as in the definitions of log-odds transform, negative log likelihood, deviance (Kullback, Reference Kullback1959), and in mathematical psychology, it is used in the theory of choice (Luce, Reference Luce1959). Surprisal satisfies the requirements of a ratio scale (Stevens, Reference Stevens1946): it possesses an absolute zero (corresponding to an event with probability 1), is nonnegative, and is additive for independent events (Shannon, Reference Shannon1948). Also, using surprisal instead of probability often simplifies computations, as the occurrence of multiple independent events results in multiplication when dealing with probabilities, but becomes addition after being transformed into surprisal.
Entropy quantifies the average level of uncertainty in a random variable’s possible outcomes. It is the expected surprisal. For an item j with possible response options
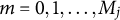 $m=0, 1, \ldots , M_j$
, and a test taker with latent trait θ we can define entropy as
$m=0, 1, \ldots , M_j$
, and a test taker with latent trait θ we can define entropy as
 $$ \begin{align} H_j(\theta)=-\sum_{m=0}^{M_j} P(X_j=m \mid \theta)\log_2 P(X_j=m \mid \theta)= \sum_{m=0}^{M_j} P(X_j=m \mid \theta) S(X_j=m \mid \theta). \end{align} $$
$$ \begin{align} H_j(\theta)=-\sum_{m=0}^{M_j} P(X_j=m \mid \theta)\log_2 P(X_j=m \mid \theta)= \sum_{m=0}^{M_j} P(X_j=m \mid \theta) S(X_j=m \mid \theta). \end{align} $$
When
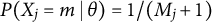 $P(X_j=m \mid \theta )=1/(M_j+1)$
for all possible response options m, the entropy is maximized. Entropy can be seen as a measure of the lack of structure and when every response option probability except one is zero, it reflects certainty (Ramsay et al., Reference Ramsay, Li, Wallmark and Wiberg2024).
$P(X_j=m \mid \theta )=1/(M_j+1)$
for all possible response options m, the entropy is maximized. Entropy can be seen as a measure of the lack of structure and when every response option probability except one is zero, it reflects certainty (Ramsay et al., Reference Ramsay, Li, Wallmark and Wiberg2024).
4 Bit scales
The surprisal transformation in (3) is measured in bits and quantifies uncertainty. Unlike probability, it has metric properties. The term “bits” originates from the field of digital computing and “Bit” is an abbreviation for “binary digit.” In the context of information theory, one bit represents the amount of uncertainty (or information gain) in each outcome of a random variable with two equally likely outcomes, like a fair coin flip. Just as the expectation of a random variable measured in meters inherits the same unit of measurement as the original random variable, entropy inherits the bit unit and quantifies the expected information gain across all outcomes.
The
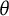 $\theta $
scale is fundamentally ordinal. However, it is evident in Equation (4) that as θ changes, H
j
(θ) also changes. We leverage this relationship to construct a new scale for the latent trait based on the cumulative change in entropy. Since entropy, as the expected surprisal, is measured in bits (a ratio-level unit), the cumulative measure of its change will also be on a ratio scale. We define the item bit score, located on the item bit scale, as the total distance traveled in H
j
(θ) after moving from the minimum θ, θ
(0), to the test taker’s estimated θ,
$\theta $
scale is fundamentally ordinal. However, it is evident in Equation (4) that as θ changes, H
j
(θ) also changes. We leverage this relationship to construct a new scale for the latent trait based on the cumulative change in entropy. Since entropy, as the expected surprisal, is measured in bits (a ratio-level unit), the cumulative measure of its change will also be on a ratio scale. We define the item bit score, located on the item bit scale, as the total distance traveled in H
j
(θ) after moving from the minimum θ, θ
(0), to the test taker’s estimated θ,
 $\hat{\theta} $
$\hat{\theta} $
 $$ \begin{align} \begin{aligned} B_j(\hat{\theta})= \int_{\theta^{(0)}}^{\hat{\theta}} \left|\frac{dH_j(\theta)}{d\theta}\right| d\theta. \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} B_j(\hat{\theta})= \int_{\theta^{(0)}}^{\hat{\theta}} \left|\frac{dH_j(\theta)}{d\theta}\right| d\theta. \end{aligned} \end{align} $$
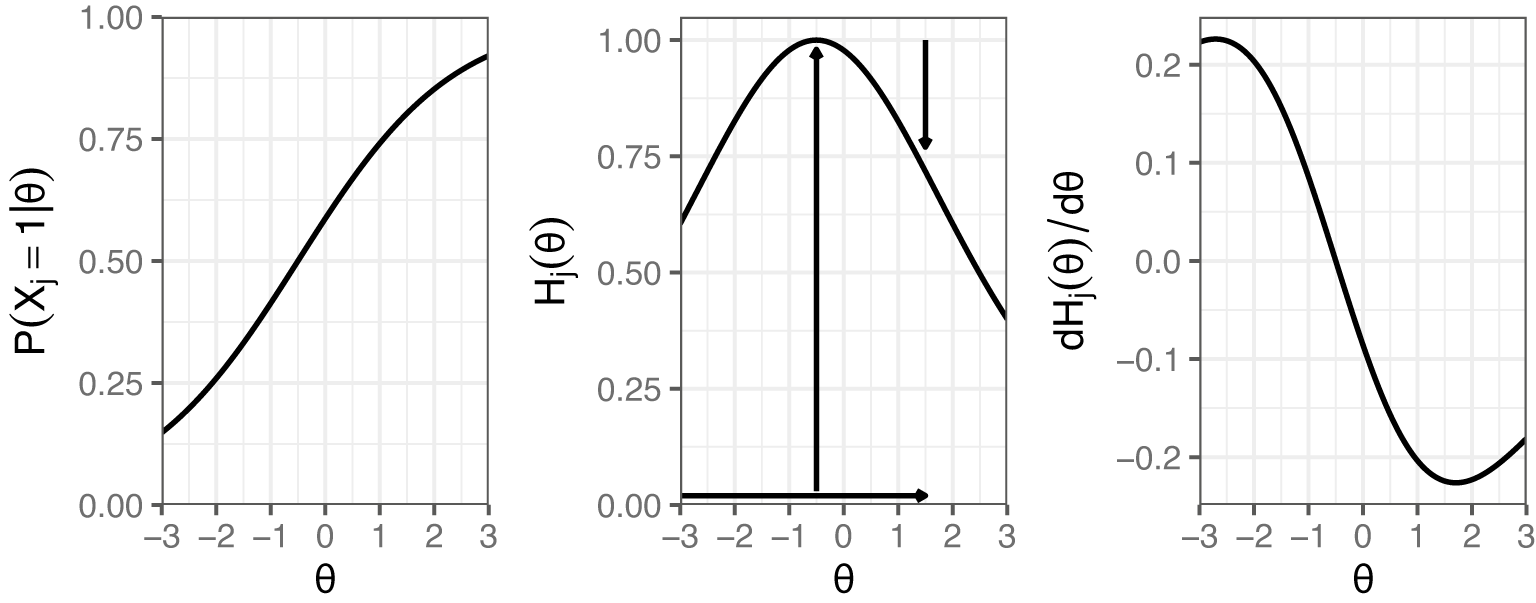
The procedure for calculating these bit scores is depicted in the middle plot of Figure 2. Using an example of a test taker with an estimated
 $\theta $
of
$\theta $
of
 $1.5$
on the first item from Figure 1, we can trace the entropy changes starting from the minimum
$1.5$
on the first item from Figure 1, we can trace the entropy changes starting from the minimum
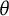 $\theta $
. As indicated by the vertical arrows, the entropy initially increases by 1 bit (from when
$\theta $
. As indicated by the vertical arrows, the entropy initially increases by 1 bit (from when
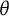 $\theta $
approaches
$\theta $
approaches
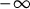 $-\infty $
) and subsequently decreases by 0.28 bits. The final bit score is obtained by adding the absolute magnitudes of these changes, resulting in 1+0.28=1.28 bits. The entropy curve measures the amount of uncertainty in the item response at each level of
$-\infty $
) and subsequently decreases by 0.28 bits. The final bit score is obtained by adding the absolute magnitudes of these changes, resulting in 1+0.28=1.28 bits. The entropy curve measures the amount of uncertainty in the item response at each level of
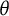 $\theta $
(Stone, Reference Stone2022), and this uncertainty of course changes as
$\theta $
(Stone, Reference Stone2022), and this uncertainty of course changes as
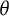 $\theta $
changes. The entropy bit score thus measures the change in item response uncertainty as a test taker progresses across the latent trait continuum. A possible interpretation would be that, on average, a test taker with
$\theta $
changes. The entropy bit score thus measures the change in item response uncertainty as a test taker progresses across the latent trait continuum. A possible interpretation would be that, on average, a test taker with
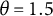 $\theta =1.5$
has obtained 1.28 out of the total 2 bits of latent trait information contained within the item.
$\theta =1.5$
has obtained 1.28 out of the total 2 bits of latent trait information contained within the item.
Example IRF to the left with its corresponding entropy curve in the middle, and the derivative of the entropy curve to the right. The vertical arrows in the entropy plot show the distances added up to compute the item bit score for a test taker with an estimated
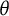 $\theta $
of 1.5.
$\theta $
of 1.5.

As IRT models typically assume local independence, we can use that assumption to add the item bit scores together to get a bit score for the whole test based on the item bit scores as a function of θ as follows:
 $$ \begin{align} B(\hat{\theta})=\sum_{j=1}^J B_j(\hat{\theta}). \end{align} $$
$$ \begin{align} B(\hat{\theta})=\sum_{j=1}^J B_j(\hat{\theta}). \end{align} $$
Both item bit scores and test bit scores are monotonic one-to-one functions of
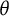 $\theta $
, and like any other such transformation, they can be used as a valid replacement for
$\theta $
, and like any other such transformation, they can be used as a valid replacement for
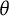 $\theta $
.
$\theta $
.
One might naturally question how the ordinal
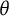 $\theta $
scale can be transformed into a ratio scale. The justification lies in a fundamental change of the variable being measured: the bit scale does not quantify the latent trait as a static coordinate, but rather quantifies the accumulated resolution of uncertainty provided by the test items regarding that trait. While the coordinate
$\theta $
scale can be transformed into a ratio scale. The justification lies in a fundamental change of the variable being measured: the bit scale does not quantify the latent trait as a static coordinate, but rather quantifies the accumulated resolution of uncertainty provided by the test items regarding that trait. While the coordinate
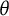 $\theta $
is arbitrary, the item response surprisals
$\theta $
is arbitrary, the item response surprisals
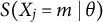 $S(X_j=m \mid \theta )$
and their corresponding entropy curves are absolute. Consequently, the bit scale satisfies the requirements of a ratio scale (Stevens, Reference Stevens1946):
$S(X_j=m \mid \theta )$
and their corresponding entropy curves are absolute. Consequently, the bit scale satisfies the requirements of a ratio scale (Stevens, Reference Stevens1946):
-
• Absolute origin: The scale is mathematically anchored at the lower boundary of the integration,
$\theta ^{(0)}$
. A bit score of 0 implies that, relative to this starting point, the test has not yet distinguished the test-taker from the minimum measurable state. There is an absolute absence of accumulated information change. -
• Standardized unit: Unlike the standardized units of
$\theta ,$
which depend on population variance, the “bit” is a fixed unit of information derived directly from probability. One bit of entropy corresponds to the uncertainty of a binary event with
$P=0.5$
. This unit is invariant across items, tests, and populations. -
• Equality of intervals and ratios: Because the score is defined as an integral (Equation (5)), it is inherently additive. A test taker with a score of 4 bits has traversed exactly twice the informational distance of a test taker with 2 bits.
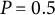
Thus, scores on the bit scale are naturally comparable between different populations as long as there are common items in the tests taken by each population. While
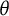 $\theta $
is typically tied to the test taker population and assumed to be standard normally distributed, bit scores are tied to the test items and invariant to the population taking the test. A test bit score of 0 means that the measured latent trait is at the minimum or below what can be measured with the items in the test, while a maximum score (all bits from all items) means that the test taker is at the maximum or above what the test can measure.
$\theta $
is typically tied to the test taker population and assumed to be standard normally distributed, bit scores are tied to the test items and invariant to the population taking the test. A test bit score of 0 means that the measured latent trait is at the minimum or below what can be measured with the items in the test, while a maximum score (all bits from all items) means that the test taker is at the maximum or above what the test can measure.
The maximum score corresponds to the total accumulated entropy change across all items. In the simplest case, for a binary item where the probability of a correct response goes from 0 to 1 (assuming a model with no guessing probability incorporated), the entropy increases from 0 to 1 bit (at
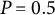 $P=0.5$
) and then decreases back to 0. The total bit score for such an item would be
$P=0.5$
) and then decreases back to 0. The total bit score for such an item would be
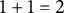 $1+1=2$
bits. Thus, for a test consisting of J binary items, the bit scale ranges from 0 to
$1+1=2$
bits. Thus, for a test consisting of J binary items, the bit scale ranges from 0 to
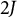 $2J$
. Extending the interpretation from the single item case, the total bit score represents the aggregate resolution of uncertainty across the entire test. For example, consider a hypothetical test consisting of 10 items similar to the one in Figure 2. Since each item has a total information capacity of 2 bits, the maximum possible score for the test is 20 bits. In this context, a test taker with a test bit score of 12.8 has obtained 12.8 out of the 20 bits of latent trait information contained within the test structure. This score reflects the cumulative informational distance the test taker has traversed along the measurement scale.
$2J$
. Extending the interpretation from the single item case, the total bit score represents the aggregate resolution of uncertainty across the entire test. For example, consider a hypothetical test consisting of 10 items similar to the one in Figure 2. Since each item has a total information capacity of 2 bits, the maximum possible score for the test is 20 bits. In this context, a test taker with a test bit score of 12.8 has obtained 12.8 out of the 20 bits of latent trait information contained within the test structure. This score reflects the cumulative informational distance the test taker has traversed along the measurement scale.
For more complex cases with polytomously scored items or when there is guessing incorporated in the chosen IRT model, the maximum bit score is harder to know in advance. In such cases, bit scores may appear a bit arbitrary, especially for those unfamiliar with the methodology. In such cases, the entire bit scale can be linearly rescaled to range from 0 to 100 or 0 to 1, which changes the score interpretation to percentages of test information (bits) attained at a given score. Next, we derive the SE and asymptotic distribution for ML-estimated bit scores.
4.1 Standard errors and asymptotics of bit scores
We denote the true
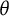 $\theta $
score of a test taker as
$\theta $
score of a test taker as
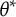 $\theta ^\ast$
and their ML estimate as
$\theta ^\ast$
and their ML estimate as
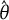 $\hat {\theta }$
and make the assumption that the estimated IRFs are the true ones. It is well established that the estimator
$\hat {\theta }$
and make the assumption that the estimated IRFs are the true ones. It is well established that the estimator
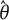 $\hat {\theta }$
is consistent for
$\hat {\theta }$
is consistent for
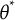 $\theta ^*$
and that, asymptotically,
$\theta ^*$
and that, asymptotically,
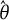 $\hat {\theta }$
follows a normal distribution with mean
$\hat {\theta }$
follows a normal distribution with mean
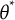 $\theta ^*$
and variance
$\theta ^*$
and variance
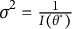 $\sigma ^2 = \frac {1}{I(\theta ^*)}$
(van der Vaart, Reference van der Vaart2000, Chapter 5.5). Here,
$\sigma ^2 = \frac {1}{I(\theta ^*)}$
(van der Vaart, Reference van der Vaart2000, Chapter 5.5). Here,
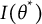 $I(\theta ^*)$
represents the Fisher information evaluated at
$I(\theta ^*)$
represents the Fisher information evaluated at
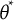 $\theta ^*$
, defined as
$\theta ^*$
, defined as
 $$ \begin{align*} I(\theta^*) = \mathrm{E}_{\mathbf{X}}\left[\left(\frac{\partial \ell(\theta^* | \mathbf{X})}{\partial \theta^*}\right)^{2}\right]=- \mathrm{E}_{\mathbf{X}}\left[\frac{\partial^{2} \ell(\theta^* | \mathbf{X})}{\partial \theta^{*2}}\right], \end{align*} $$
$$ \begin{align*} I(\theta^*) = \mathrm{E}_{\mathbf{X}}\left[\left(\frac{\partial \ell(\theta^* | \mathbf{X})}{\partial \theta^*}\right)^{2}\right]=- \mathrm{E}_{\mathbf{X}}\left[\frac{\partial^{2} \ell(\theta^* | \mathbf{X})}{\partial \theta^{*2}}\right], \end{align*} $$
where
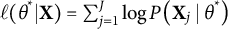 $\ell (\theta ^* | \mathbf {X})=\sum _{j=1}^J \log P\left (\mathbf {X}_j \mid \theta ^*\right )$
is the log-likelihood of
$\ell (\theta ^* | \mathbf {X})=\sum _{j=1}^J \log P\left (\mathbf {X}_j \mid \theta ^*\right )$
is the log-likelihood of
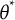 $\theta ^*$
given response vector
$\theta ^*$
given response vector
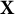 $\mathbf {X}$
, available from the model IRFs, and the expectation is taken over all possible values of
$\mathbf {X}$
, available from the model IRFs, and the expectation is taken over all possible values of
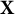 $\mathbf {X}$
. That is, we have
$\mathbf {X}$
. That is, we have
 $\hat {\theta } \xrightarrow {d} N(\theta ^*, \sigma ^2)$
. Thus, it follows from the delta method (van der Vaart, Reference van der Vaart2000, Chapter 3) that
$\hat {\theta } \xrightarrow {d} N(\theta ^*, \sigma ^2)$
. Thus, it follows from the delta method (van der Vaart, Reference van der Vaart2000, Chapter 3) that
 $$ \begin{align} B_j(\hat{\theta}) &\xrightarrow{d} N(B_j(\theta^*), \sigma^2B_j'(\theta^*)^2) \end{align} $$
$$ \begin{align} B_j(\hat{\theta}) &\xrightarrow{d} N(B_j(\theta^*), \sigma^2B_j'(\theta^*)^2) \end{align} $$
 $$ \begin{align} B(\hat{\theta}) &\xrightarrow{d} N(B(\theta^*), \sigma^2B'(\theta^*)^2)=N\left(B(\theta^*), \sigma^2\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2\right), \end{align} $$
$$ \begin{align} B(\hat{\theta}) &\xrightarrow{d} N(B(\theta^*), \sigma^2B'(\theta^*)^2)=N\left(B(\theta^*), \sigma^2\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2\right), \end{align} $$
where
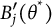 $B_j'(\theta ^*)$
is the derivative of
$B_j'(\theta ^*)$
is the derivative of
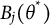 $B_j(\theta ^*)$
. By the Fundamental Theorem of Calculus,
$B_j(\theta ^*)$
. By the Fundamental Theorem of Calculus,
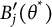 $B_j'(\theta ^*)$
is the integrand of
$B_j'(\theta ^*)$
is the integrand of
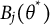 $B_j(\theta ^*)$
evaluated at the upper integration limit
$B_j(\theta ^*)$
evaluated at the upper integration limit
 $$ \begin{align*} B_j'(\theta^*) = \frac{d}{d\theta^*} \int_{\theta^{(0)}}^{\theta^*} \left|\frac{dH_j(\theta)}{d\theta}\right| d\theta = \left|\frac{dH_j(\theta^*)}{d\theta^*}\right|. \end{align*} $$
$$ \begin{align*} B_j'(\theta^*) = \frac{d}{d\theta^*} \int_{\theta^{(0)}}^{\theta^*} \left|\frac{dH_j(\theta)}{d\theta}\right| d\theta = \left|\frac{dH_j(\theta^*)}{d\theta^*}\right|. \end{align*} $$
From Equation (7), we see that for each item bit score, the SE of
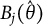 $B_j(\hat {\theta })$
is simply the SE of the ML estimate of
$B_j(\hat {\theta })$
is simply the SE of the ML estimate of
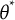 $\theta ^*$
multiplied by
$\theta ^*$
multiplied by
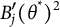 $B_j'(\theta ^*)^2$
, the magnitude of the slope of the item entropy curve at
$B_j'(\theta ^*)^2$
, the magnitude of the slope of the item entropy curve at
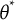 $\theta ^*$
.
$\theta ^*$
.
In IRT, item information and test information are commonly used to quantify the accuracy with which an item or test measures an individual’s ability level (Hambleton & Swaminathan, Reference Hambleton and Swaminathan1985, Chapter 6). Bit scale test and item information can also be retrieved by asymptotic theory. Under standard regularity conditions, these information metrics can be computed from the reciprocal of the variance of
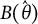 $B(\hat {\theta })$
$B(\hat {\theta })$
 $$ \begin{align} I_{B}(\theta^*) =& \frac{1}{\sigma^2\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2} = \frac{I(\theta^*)}{\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2}, \end{align} $$
$$ \begin{align} I_{B}(\theta^*) =& \frac{1}{\sigma^2\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2} = \frac{I(\theta^*)}{\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2}, \end{align} $$
 $$ \begin{align} I_{jB}(\theta^*) =& \frac{I_j(\theta^*)}{\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2}, \end{align} $$
$$ \begin{align} I_{jB}(\theta^*) =& \frac{I_j(\theta^*)}{\left[\sum_{j=1}^JB_j'(\theta^*)\right]^2}, \end{align} $$
for test and item information, respectively, where
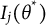 $I_j(\theta ^*)$
is the Fisher information about
$I_j(\theta ^*)$
is the Fisher information about
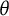 $\theta $
given by item j at
$\theta $
given by item j at
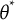 $\theta ^*$
. Note that all
$\theta ^*$
. Note that all
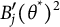 $B_j'(\theta ^*)^2$
are still used for bit scale item information, since the scale itself relies on all items.
$B_j'(\theta ^*)^2$
are still used for bit scale item information, since the scale itself relies on all items.
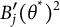 $B_j'(\theta ^*)^2$
is the information from the item response about the test bit score. This also means that the item information sums up to the test information just like with the traditional
$B_j'(\theta ^*)^2$
is the information from the item response about the test bit score. This also means that the item information sums up to the test information just like with the traditional
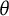 $\theta $
scale. That is, we have
$\theta $
scale. That is, we have
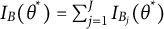 $I_{B}(\theta ^*)=\sum ^{J}_{j=1}I_{B_j}(\theta ^*)$
since
$I_{B}(\theta ^*)=\sum ^{J}_{j=1}I_{B_j}(\theta ^*)$
since
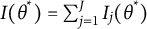 $I(\theta ^*)=\sum ^{J}_{j=1}I_j(\theta ^*)$
. Since the denominator in Equation (9) is simply a scaling factor derived from the bit scale transformation itself, it is independent of a specific test taker’s response pattern. Thus, the observed Fisher information can be written as
$I(\theta ^*)=\sum ^{J}_{j=1}I_j(\theta ^*)$
. Since the denominator in Equation (9) is simply a scaling factor derived from the bit scale transformation itself, it is independent of a specific test taker’s response pattern. Thus, the observed Fisher information can be written as
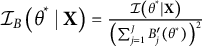 $\mathcal {I}_B\left (\theta ^* \mid \mathbf {X}\right )=\frac {\mathcal {I}\left (\theta ^*\mid \mathbf {X}\right )}{\left (\sum _{j=1}^J B_j^{\prime }\left (\theta ^*\right )\right )^2}$
, where
$\mathcal {I}_B\left (\theta ^* \mid \mathbf {X}\right )=\frac {\mathcal {I}\left (\theta ^*\mid \mathbf {X}\right )}{\left (\sum _{j=1}^J B_j^{\prime }\left (\theta ^*\right )\right )^2}$
, where
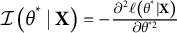 $\mathcal {I}\left (\theta ^*\mid \mathbf {X}\right )=-\frac {\partial ^2 \ell \left (\theta ^* \mid \mathbf {X}\right )}{\partial \theta ^{* 2}}$
is the observed Fisher information on the
$\mathcal {I}\left (\theta ^*\mid \mathbf {X}\right )=-\frac {\partial ^2 \ell \left (\theta ^* \mid \mathbf {X}\right )}{\partial \theta ^{* 2}}$
is the observed Fisher information on the
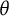 $\theta $
scale for a given response vector
$\theta $
scale for a given response vector
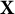 $\mathbf {X}$
.
$\mathbf {X}$
.
4.2 Relationship to other functions of
$\theta $
Fisher information is a function of
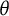 $\theta $
just like the bit score itself. However, it is not a monotonic transformation of
$\theta $
just like the bit score itself. However, it is not a monotonic transformation of
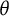 $\theta $
, and thus not a valid score scale for an IRT model. Fisher information is a local measure of precision often used to construct error bands, while the bit scale is a cumulative metric that defines the score scale itself.
$\theta $
, and thus not a valid score scale for an IRT model. Fisher information is a local measure of precision often used to construct error bands, while the bit scale is a cumulative metric that defines the score scale itself.
One should also consider the similarities between the bit score and expected sum score at a given
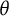 $\theta $
, defined as
$\theta $
, defined as
 $$ \begin{align*} \tau(\theta) = \sum_{j=1}^J E(X_j \mid \theta) = \sum_{j=1}^J \sum_{m=0}^{M_j} m P(X_j=m \mid \theta). \end{align*} $$
$$ \begin{align*} \tau(\theta) = \sum_{j=1}^J E(X_j \mid \theta) = \sum_{j=1}^J \sum_{m=0}^{M_j} m P(X_j=m \mid \theta). \end{align*} $$
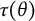 $\tau (\theta )$
is, just like the bit score, a valid
$\tau (\theta )$
is, just like the bit score, a valid
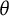 $\theta $
transformation tied to the test. However, the unit is different (bits vs. observed test score). The expected sum score accumulates the magnitude of the response probabilities at a given
$\theta $
transformation tied to the test. However, the unit is different (bits vs. observed test score). The expected sum score accumulates the magnitude of the response probabilities at a given
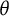 $\theta $
weighted by predefined item scores. In contrast, the bit score is invariant to the predefined item scores (the magnitude of m in the above equation) making it less sensitive to predetermined notions of which items are more or less important. Instead, the bit score accumulates the change in bits of uncertainty across the
$\theta $
weighted by predefined item scores. In contrast, the bit score is invariant to the predefined item scores (the magnitude of m in the above equation) making it less sensitive to predetermined notions of which items are more or less important. Instead, the bit score accumulates the change in bits of uncertainty across the
 $\theta $
scale. As a consequence, non-informative items without much slope in their curves or items that are easy to guess correctly can have a huge impact on the expected sum score. With the bit score, the impact of such items can be greatly reduced. As an extreme example, an item with a flat IRF (where the probability to respond correctly is constant) contributes a constant amount to the expected sum score (provided the probability is nonzero), but the same item contributes nothing to the bit score.
$\theta $
scale. As a consequence, non-informative items without much slope in their curves or items that are easy to guess correctly can have a huge impact on the expected sum score. With the bit score, the impact of such items can be greatly reduced. As an extreme example, an item with a flat IRF (where the probability to respond correctly is constant) contributes a constant amount to the expected sum score (provided the probability is nonzero), but the same item contributes nothing to the bit score.
5 Two empirical illustrations
In this section, we provide two real data examples to illustrate the usefulness of bit scales. In the first example, we use data from the Swedish national mathematics test for high school students to show how bit scales can be used for model comparison when fitting models to the same data but with fitting algorithms using different assumptions about the
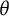 $\theta $
distribution. In the second example, we use data from the Swedish Scholastic Aptitude Test (SweSAT) to illustrate how bit scales can be used directly to link latent trait scores between IRT models fitted to different test forms with different populations when there are common (anchor) items available.
$\theta $
distribution. In the second example, we use data from the Swedish Scholastic Aptitude Test (SweSAT) to illustrate how bit scales can be used directly to link latent trait scores between IRT models fitted to different test forms with different populations when there are common (anchor) items available.
5.1 Bit scores when latent trait scale assumptions differ
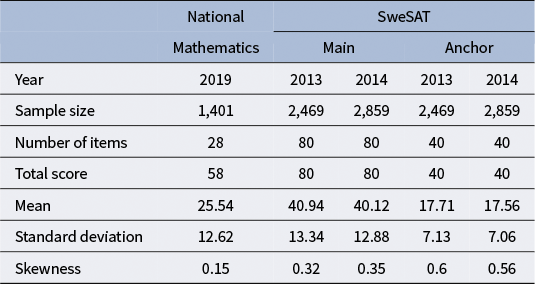
The national mathematics test used in this example is a key component of the Mathematics 3c course in Swedish high schools. Taking this course is mandatory for students on the natural science and technology tracks, although it is available as an optional course for others. Administered at the end of the term, the outcome of this test carries considerable weight in determining the student’s final grade for the course. It features several different types of items, each contributing a varying amount of points to the total score. Summary statistics from the utilized dataset can be found in the corresponding column in Table 1.
Summary statistics for each test form

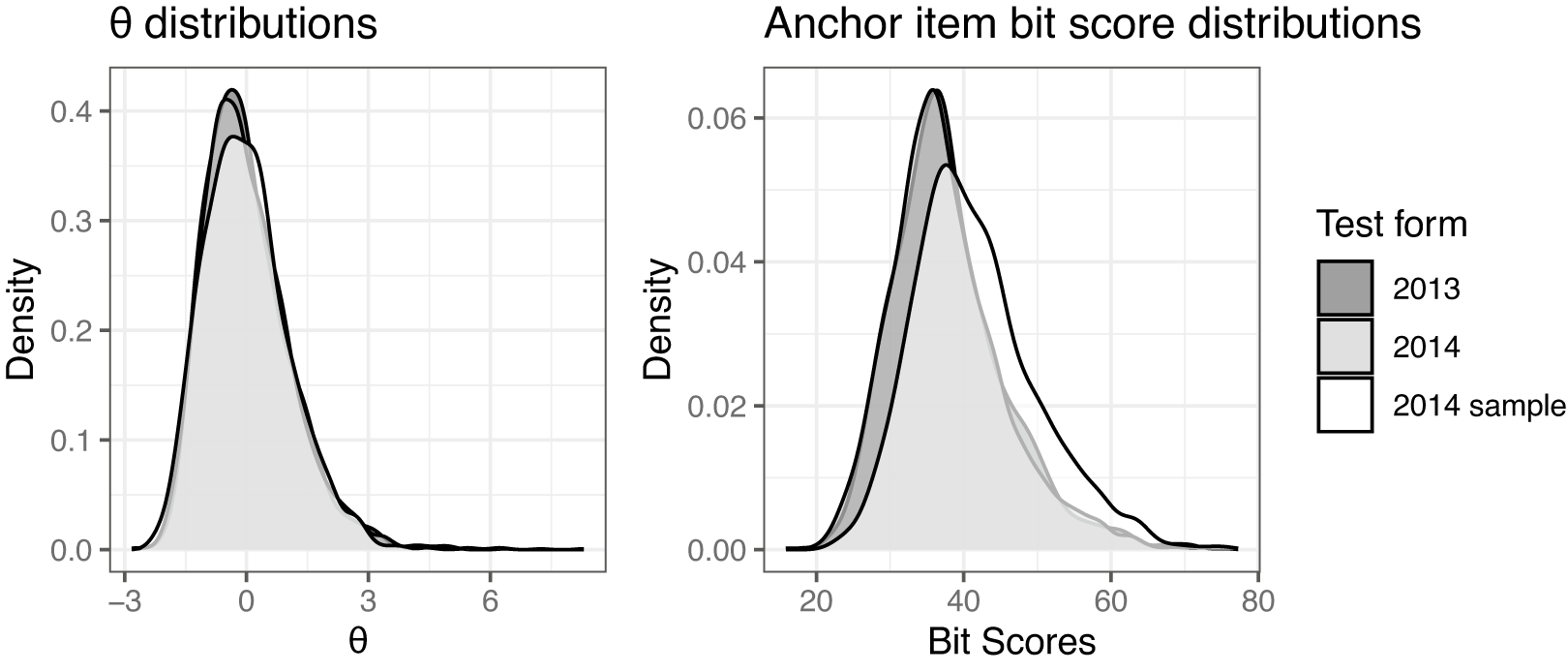
The GPC model (Equation (2)), chosen for its applicability to polytomously scored partial credit items, was fitted using two variants of MML implemented in the mirt package (Chalmers, Reference Chalmers2012). One under the assumption of a standard normal latent trait distribution, and the other using the empirical histogram estimation method (Bock & Aitkin, Reference Bock and Aitkin1981). The resulting score distributions from each model are shown in Figure 3 on both the bit and
 $\theta $
scales. The empirical histogram
$\theta $
scales. The empirical histogram
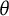 $\theta $
distribution has a larger variance (1.55) than its counterpart under the standard normal assumption (1.06). However, after transforming both scales to the bit scale, the distributions are more similar, and the score ranges are close to identical.
$\theta $
distribution has a larger variance (1.55) than its counterpart under the standard normal assumption (1.06). However, after transforming both scales to the bit scale, the distributions are more similar, and the score ranges are close to identical.
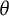 $\theta $
and bit score distributions for GPC models fitted with and without constraints on the
$\theta $
and bit score distributions for GPC models fitted with and without constraints on the
 $\theta $
scale.
$\theta $
scale.

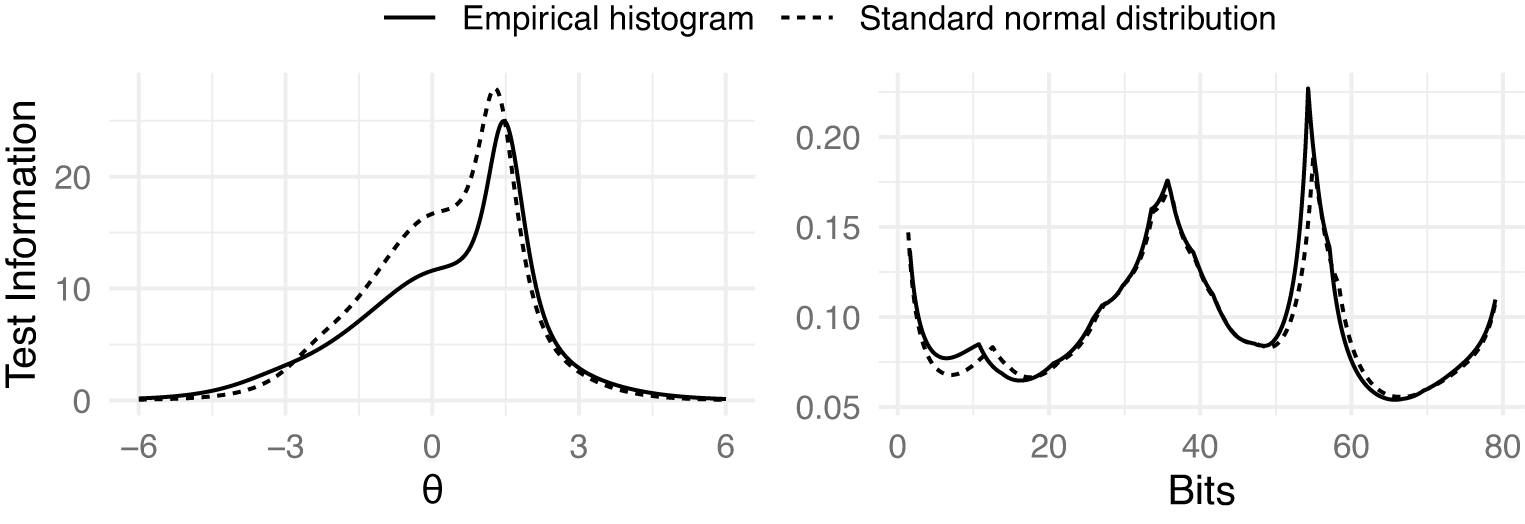
We also note in Figure 4 that the test information curves differ substantially depending on the chosen scale. On the
 $\theta $
scale, the information curve is unimodal. This is largely a consequence of the fitting algorithm and the assumption of a standard normal distribution, which tends to compress measurement precision into a single smooth peak. In this case, the information is highest for above average test takers.
$\theta $
scale, the information curve is unimodal. This is largely a consequence of the fitting algorithm and the assumption of a standard normal distribution, which tends to compress measurement precision into a single smooth peak. In this case, the information is highest for above average test takers.
Fisher information for GPC models fitted with and without constraints on the
 $\theta $
scale. Information is represented on both the
$\theta $
scale. Information is represented on both the
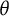 $\theta $
and the bit scales.
$\theta $
and the bit scales.

In contrast, the bit scale information curve exhibits multimodality. This shape is not an artifact but a reflection of the non-linear stretching of the scale defined by the specific items in the test. Because the bit scale expands in regions of high entropy change (high discrimination) and compresses elsewhere instead of being arbitrarily defined, it reveals a more granular structure of the test’s measurement precision. In this specific example, the peaks in the bit scale information curve (Figure 4) align with the peaks observed in the bit score distribution (Figure 3). Just like the
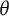 $\theta $
scale, the bit scale also suggests that the test is most informative for test takers above the population average. However, it also reveals distinct clusters of examinee scores and information that was hidden by the arbitrary standard normal assumption of the
$\theta $
scale, the bit scale also suggests that the test is most informative for test takers above the population average. However, it also reveals distinct clusters of examinee scores and information that was hidden by the arbitrary standard normal assumption of the
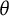 $\theta $
scale.
$\theta $
scale.
Therefore, while the
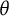 $\theta $
scale imposes a unimodal structure, the bit scale reveals that measurement precision for this specific test form is not uniform, but rather concentrated in specific zones defined by the item set. If items were added or removed, the bit scale—and consequently the shape of the information curve—would adapt to reflect the new measurement structure.
$\theta $
scale imposes a unimodal structure, the bit scale reveals that measurement precision for this specific test form is not uniform, but rather concentrated in specific zones defined by the item set. If items were added or removed, the bit scale—and consequently the shape of the information curve—would adapt to reflect the new measurement structure.
5.2 Equating IRT models with bit scales using anchor items
Bit scales can be used directly to compare latent trait scores between different IRT models when there are common (anchor) items available. We use data from two administrations of the SweSAT to illustrate this. The SweSAT is a binary-scored multiple-choice test with a quantitative and a verbal part that are equated separately. Each part contains 80 items and either a verbal or a quantitative anchor test with 40 items is given to a smaller number of test takers for the purpose of equating. Here, we are only considering the verbal part. Refer to Table 1 for summary statistics.
Since bit scores are tied to the test items, we can compute bit scores using only the items that are commonly available on both test administrations to provide a common bit scale between models even if test takers from different populations took each test form. For scoring, the
 $\theta $
scores should still be estimated as accurately as possible using all items in the test, but then the bit scores should be computed using only the anchor items for a given
$\theta $
scores should still be estimated as accurately as possible using all items in the test, but then the bit scores should be computed using only the anchor items for a given
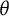 $\theta $
. We fitted three separate 2PL models using MML. The first two models utilized the complete datasets from the 2013 and 2014 test administrations, respectively. We observed that these populations exhibited similar ability distributions. Therefore, to provide a clearer demonstration of bit scale utility for contrasting ability groups, we constructed a third dataset. This involved sampling 1,000 test-takers from the 2014 administration, with selection probabilities weighted by the square of each test taker’s sum score relative to the total sum of squared scores, effectively creating a higher-ability sample. The third 2PL model was fitted to this specific sample.
$\theta $
. We fitted three separate 2PL models using MML. The first two models utilized the complete datasets from the 2013 and 2014 test administrations, respectively. We observed that these populations exhibited similar ability distributions. Therefore, to provide a clearer demonstration of bit scale utility for contrasting ability groups, we constructed a third dataset. This involved sampling 1,000 test-takers from the 2014 administration, with selection probabilities weighted by the square of each test taker’s sum score relative to the total sum of squared scores, effectively creating a higher-ability sample. The third 2PL model was fitted to this specific sample.
The score distributions on both the
 $\theta $
and bit scales (computed using only the anchor items) are shown in Figure 5 for all models. On the
$\theta $
and bit scales (computed using only the anchor items) are shown in Figure 5 for all models. On the
 $\theta $
scale, all three curves are, as expected, close to standard normally distributed by assumption and the chosen fitting algorithm, though there is not a perfect overlap. On the bit scale, we see that the full dataset distributions are overlapping, but the more able sample has a larger portion of high scorers than the other samples. Since the bit scores use the same items, they are on the same scale and directly comparable.
$\theta $
scale, all three curves are, as expected, close to standard normally distributed by assumption and the chosen fitting algorithm, though there is not a perfect overlap. On the bit scale, we see that the full dataset distributions are overlapping, but the more able sample has a larger portion of high scorers than the other samples. Since the bit scores use the same items, they are on the same scale and directly comparable.
Latent score distributions.

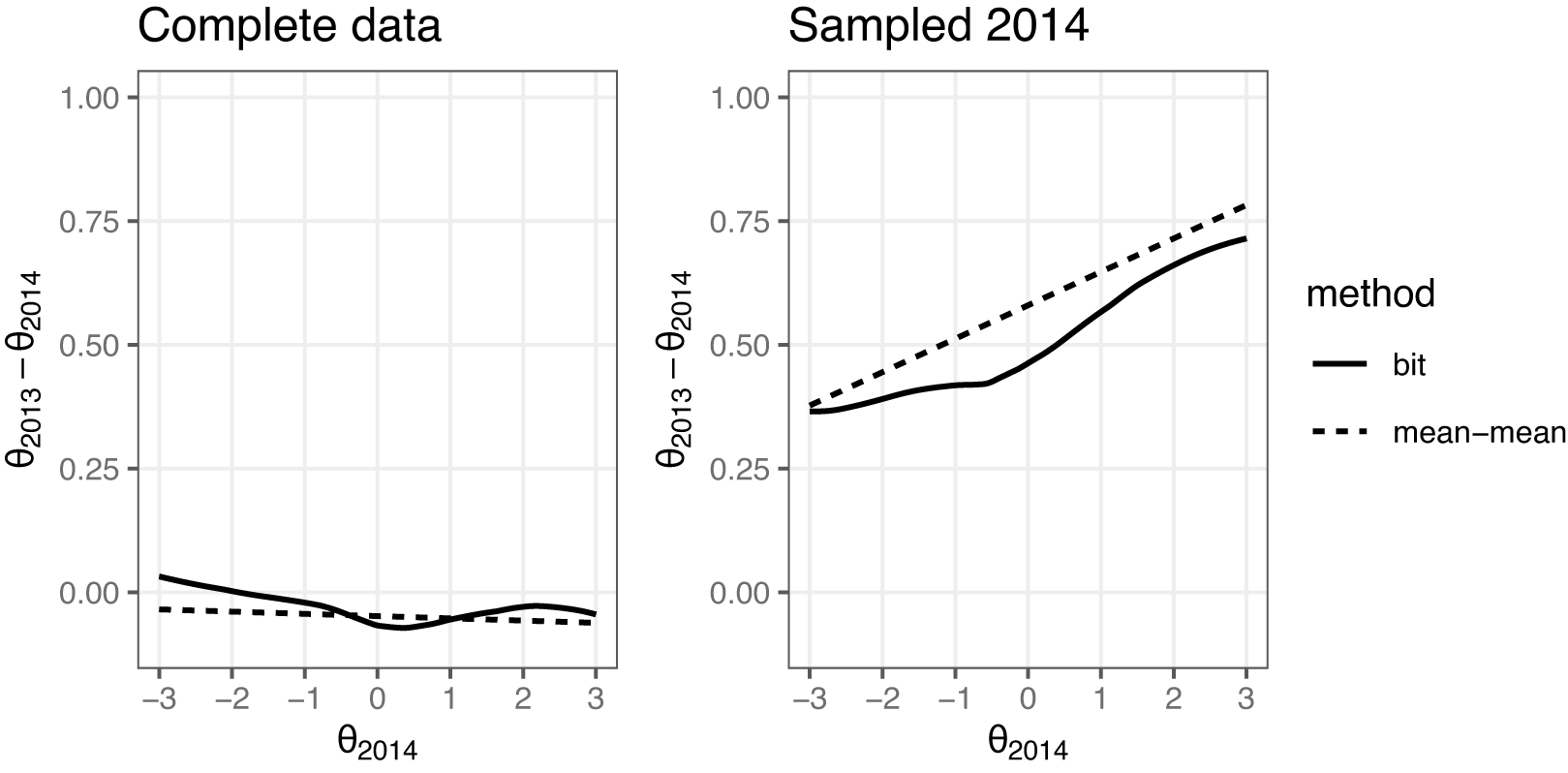
Figure 6 shows the transformation of a sequence of
 $\theta $
scores on the 2014 model scales. The anchor item bit scores were first computed using the 2014 dataset model. The scores were then converted to the 2013
$\theta $
scores on the 2014 model scales. The anchor item bit scores were first computed using the 2014 dataset model. The scores were then converted to the 2013
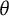 $\theta $
scale using the inverse of the bit score transformation with the 2013 dataset model. The resulting transformations are contrasted against the commonly used mean–mean linking (Kolen & Brennan, Reference Kolen and Brennan2014, Chapter 6.3) for comparison. In mean–mean linking, a constant, derived from the ratio between the average discrimination parameters of the common items on the two forms, adjusts one form’s item parameters to the other’s scale. This results in a linear scale transformation. Since the bit scale method allows for non-linear scale relationships, it should better capture the relationship between the scales when it is not strictly linear.
$\theta $
scale using the inverse of the bit score transformation with the 2013 dataset model. The resulting transformations are contrasted against the commonly used mean–mean linking (Kolen & Brennan, Reference Kolen and Brennan2014, Chapter 6.3) for comparison. In mean–mean linking, a constant, derived from the ratio between the average discrimination parameters of the common items on the two forms, adjusts one form’s item parameters to the other’s scale. This results in a linear scale transformation. Since the bit scale method allows for non-linear scale relationships, it should better capture the relationship between the scales when it is not strictly linear.
 $\theta $
score transformation utilizing anchor item computed bit scores contrasted against the mean–mean linking method.
$\theta $
score transformation utilizing anchor item computed bit scores contrasted against the mean–mean linking method.

When the complete dataset from 2014 was used, both methods suggest that the test taker groups are very similar in ability, and the transformation in Figure 6 is close to being one-to-one, as shown in the plot on the left. When the more able sample of 2014 was used to fit the 2014 model, both methods agree that the equivalent scores on the 2013 scales are somewhat higher, especially at the upper end of the
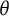 $\theta $
scale.
$\theta $
scale.
6 Simulation study
A simulation study was conducted to examine the asymptotic properties of bit scores and evaluate the bit score SEs derived in Section 4.1. Data were generated using the 2PL model. The item parameters were randomly sampled. Discrimination parameters were sampled from a lognormal distribution with mean
 $0$
and variance
$0$
and variance
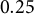 $0.25$
while difficulty parameters were sampled from a standard normal distribution. These distributions are commonly used in other simulation studies (Feinberg & Rubright, Reference Feinberg and Rubright2016). We examined test forms with 20, 40, 80, and 160 items. The simulation procedure is described in Algorithm 1. Note that the item parameters (and thus the IRFs) are assumed to be known and fixed throughout all iterations. This is similar to typical
$0.25$
while difficulty parameters were sampled from a standard normal distribution. These distributions are commonly used in other simulation studies (Feinberg & Rubright, Reference Feinberg and Rubright2016). We examined test forms with 20, 40, 80, and 160 items. The simulation procedure is described in Algorithm 1. Note that the item parameters (and thus the IRFs) are assumed to be known and fixed throughout all iterations. This is similar to typical
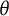 $\theta $
estimation methods, such as EAP, MAP, and ML for which the SEs are computed conditional on a given model. To analyze the behavior of the SE across the ability scale, we used a grid of evenly spaced true
$\theta $
estimation methods, such as EAP, MAP, and ML for which the SEs are computed conditional on a given model. To analyze the behavior of the SE across the ability scale, we used a grid of evenly spaced true
 $\theta $
values. This grid is not intended to represent a realistic population distribution; however, this is not necessary since the item parameters were fixed a priori and not estimated from simulated population data. The R package mirt (Chalmers, Reference Chalmers2012) was used to fit the models and estimate the
$\theta $
values. This grid is not intended to represent a realistic population distribution; however, this is not necessary since the item parameters were fixed a priori and not estimated from simulated population data. The R package mirt (Chalmers, Reference Chalmers2012) was used to fit the models and estimate the
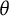 $\theta $
scores. The bitscale R package (Wallmark, Reference Wallmark2025a) was used to estimate the bit scores. The simulation code is available on Github at https://github.com/joakimwallmark/bit-scale-simulation.
$\theta $
scores. The bitscale R package (Wallmark, Reference Wallmark2025a) was used to estimate the bit scores. The simulation code is available on Github at https://github.com/joakimwallmark/bit-scale-simulation.

6.1 Evaluation measures
We used bias, SE, and RMSE as evaluation measures. Bias was calculated for ability and bit scores, respectively, as
 $$ \begin{align*}\operatorname{\mathrm{Bias}}(\theta_{true, i}) = \bar{\hat{\theta}}_{i} - \theta_{true, i}\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{Bias}}(\theta_{true, i}) = \bar{\hat{\theta}}_{i} - \theta_{true, i}\end{align*} $$
and
 $$ \begin{align*}\operatorname{\mathrm{Bias}}(B(\theta_{true, i})) = \bar{\hat{B}}_{i} - B(\theta_{true, i}),\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{Bias}}(B(\theta_{true, i})) = \bar{\hat{B}}_{i} - B(\theta_{true, i}),\end{align*} $$
where
 $\bar {\hat {\theta }}_{i} = \frac {1}{R} \sum _{r=1}^{R} \hat {\theta }_{r,i}$
and
$\bar {\hat {\theta }}_{i} = \frac {1}{R} \sum _{r=1}^{R} \hat {\theta }_{r,i}$
and
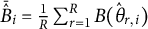 $\bar {\hat {B}}_{i} = \frac {1}{R} \sum _{r=1}^{R} B(\hat {\theta }_{r,i})$
are the mean estimates of the
$\bar {\hat {B}}_{i} = \frac {1}{R} \sum _{r=1}^{R} B(\hat {\theta }_{r,i})$
are the mean estimates of the
 $\theta $
and the bit score, respectively. The
$\theta $
and the bit score, respectively. The
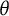 $\theta $
and bit score SE were obtained from
$\theta $
and bit score SE were obtained from
 $$ \begin{align*}\operatorname{\mathrm{SE}}(\theta_{true, i}) = \sqrt{\frac{1}{R-1} \sum_{r=1}^{R} (\hat{\theta}_{r,i} - \bar{\hat{\theta}}_{i})^2}\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{SE}}(\theta_{true, i}) = \sqrt{\frac{1}{R-1} \sum_{r=1}^{R} (\hat{\theta}_{r,i} - \bar{\hat{\theta}}_{i})^2}\end{align*} $$
and
 $$ \begin{align*}\operatorname{\mathrm{SE}}(B(\theta_{true, i})) = \sqrt{\frac{1}{R-1} \sum_{r=1}^{R} (B(\hat{\theta}_{r,i}) - \bar{\hat{B}}_{i})^2},\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{SE}}(B(\theta_{true, i})) = \sqrt{\frac{1}{R-1} \sum_{r=1}^{R} (B(\hat{\theta}_{r,i}) - \bar{\hat{B}}_{i})^2},\end{align*} $$
respectively. Finally, the
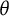 $\theta $
and bit score RMSE were computed using
$\theta $
and bit score RMSE were computed using
 $$ \begin{align*}\operatorname{\mathrm{RMSE}}(\theta_{true, i}) = \sqrt{\frac{1}{R} \sum_{r=1}^{R} (\hat{\theta}_{r,i} - \theta_{true, i})^2}\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{RMSE}}(\theta_{true, i}) = \sqrt{\frac{1}{R} \sum_{r=1}^{R} (\hat{\theta}_{r,i} - \theta_{true, i})^2}\end{align*} $$
and
 $$ \begin{align*}\operatorname{\mathrm{RMSE}}(B(\theta_{true, i})) = \sqrt{\frac{1}{R} \sum_{r=1}^{R} (B(\hat{\theta}_{r,i}) - B(\theta_{true, i}))^2}.\end{align*} $$
$$ \begin{align*}\operatorname{\mathrm{RMSE}}(B(\theta_{true, i})) = \sqrt{\frac{1}{R} \sum_{r=1}^{R} (B(\hat{\theta}_{r,i}) - B(\theta_{true, i}))^2}.\end{align*} $$
6.2 Simulation study results
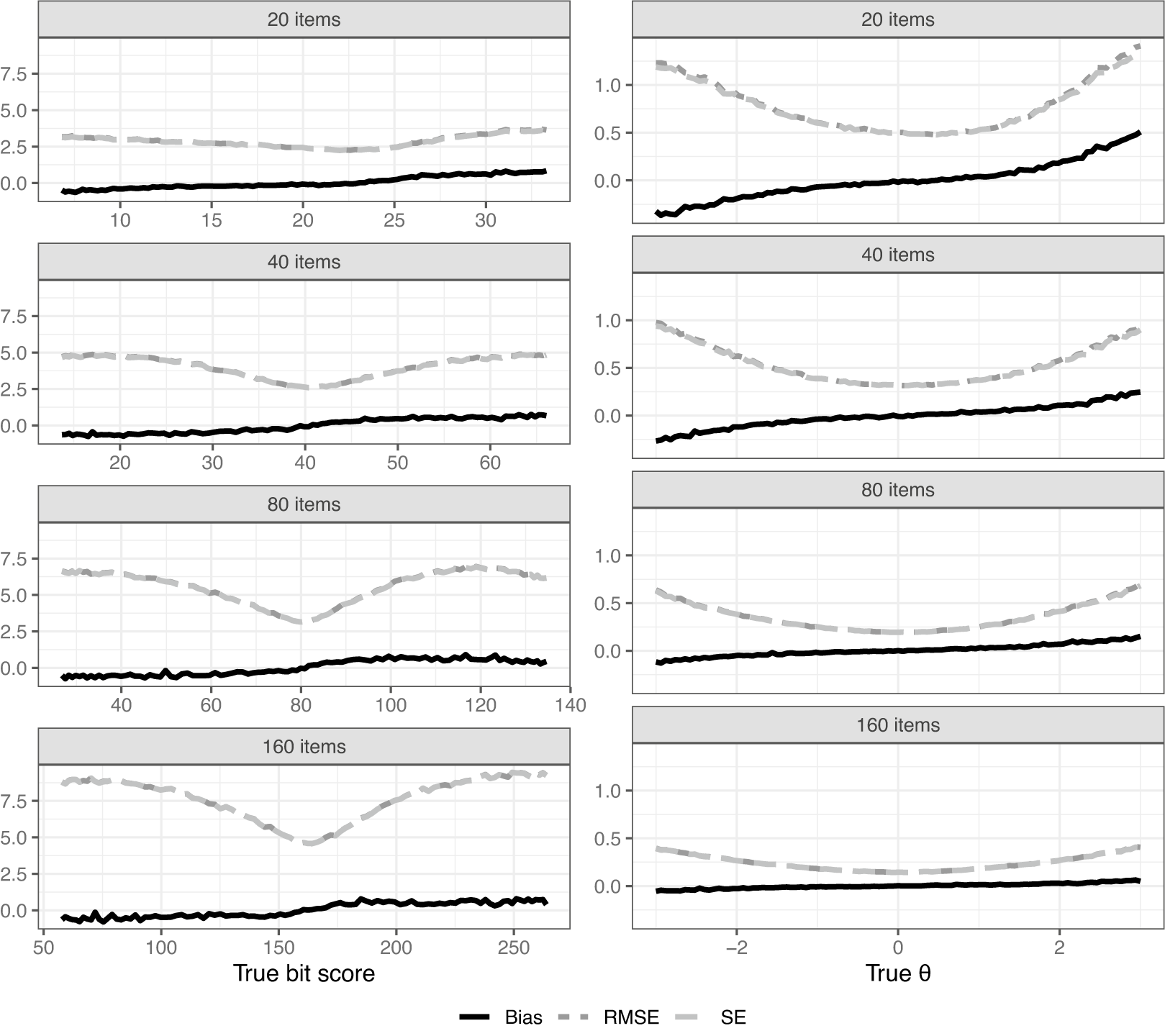
Figure 7 shows bias, SE, and RMSE over the entire score scale. Of course, magnitudes cannot be directly compared because we are on different scales between plots. It is well known that a total score of zero or a perfect score results in
 $\theta $
estimates of negative/positive infinity when using ML for score estimation. Because of this, estimated
$\theta $
estimates of negative/positive infinity when using ML for score estimation. Because of this, estimated
 $\theta $
scores of negative and positive infinity were arbitrarily set to
$\theta $
scores of negative and positive infinity were arbitrarily set to
 $-$
6 and 6, respectively, to be able to calculate the metrics for the
$-$
6 and 6, respectively, to be able to calculate the metrics for the
 $\theta $
estimator. This adjustment is not needed for the bit scores. Despite this adjustment, it is clear that there is some substantial bias in absolute terms when using the
$\theta $
estimator. This adjustment is not needed for the bit scores. Despite this adjustment, it is clear that there is some substantial bias in absolute terms when using the
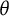 $\theta $
scale in scenarios with fewer items. Note, however, that the distances do not actually mean much because of the arbitrary nature of the
$\theta $
scale in scenarios with fewer items. Note, however, that the distances do not actually mean much because of the arbitrary nature of the
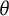 $\theta $
scale. A one unit increase in
$\theta $
scale. A one unit increase in
 $\theta $
simply means one standard deviation in the arbitrarily chosen population distribution, but it says nothing about how much a respondent has actually improved on the test. This makes the bit scale a more natural choice when evaluating latent trait estimator performance in IRT settings using distance metrics, such as bias, SE, and RMSE due to the metric properties of the bit scale. It also performs well in situations like this without adjustment, where
$\theta $
simply means one standard deviation in the arbitrarily chosen population distribution, but it says nothing about how much a respondent has actually improved on the test. This makes the bit scale a more natural choice when evaluating latent trait estimator performance in IRT settings using distance metrics, such as bias, SE, and RMSE due to the metric properties of the bit scale. It also performs well in situations like this without adjustment, where
 $\theta $
estimates can end up being infinitely small/large. The bias is also relatively small compared to the SEs in all settings. It should be noted that while the expected sum score is also a valid transformation of
$\theta $
estimates can end up being infinitely small/large. The bias is also relatively small compared to the SEs in all settings. It should be noted that while the expected sum score is also a valid transformation of
 $\theta $
that avoids infinite estimates, its bias, SE, and RMSE are not directly comparable to the bit scale due to the difference in units (score points vs. bits).
$\theta $
that avoids infinite estimates, its bias, SE, and RMSE are not directly comparable to the bit scale due to the difference in units (score points vs. bits).
Bias, RMSE, and SE across the bit and
 $\theta $
scales. Note that the SE and RMSE curves are close to overlapping due to the small bias in most settings.
$\theta $
scales. Note that the SE and RMSE curves are close to overlapping due to the small bias in most settings.

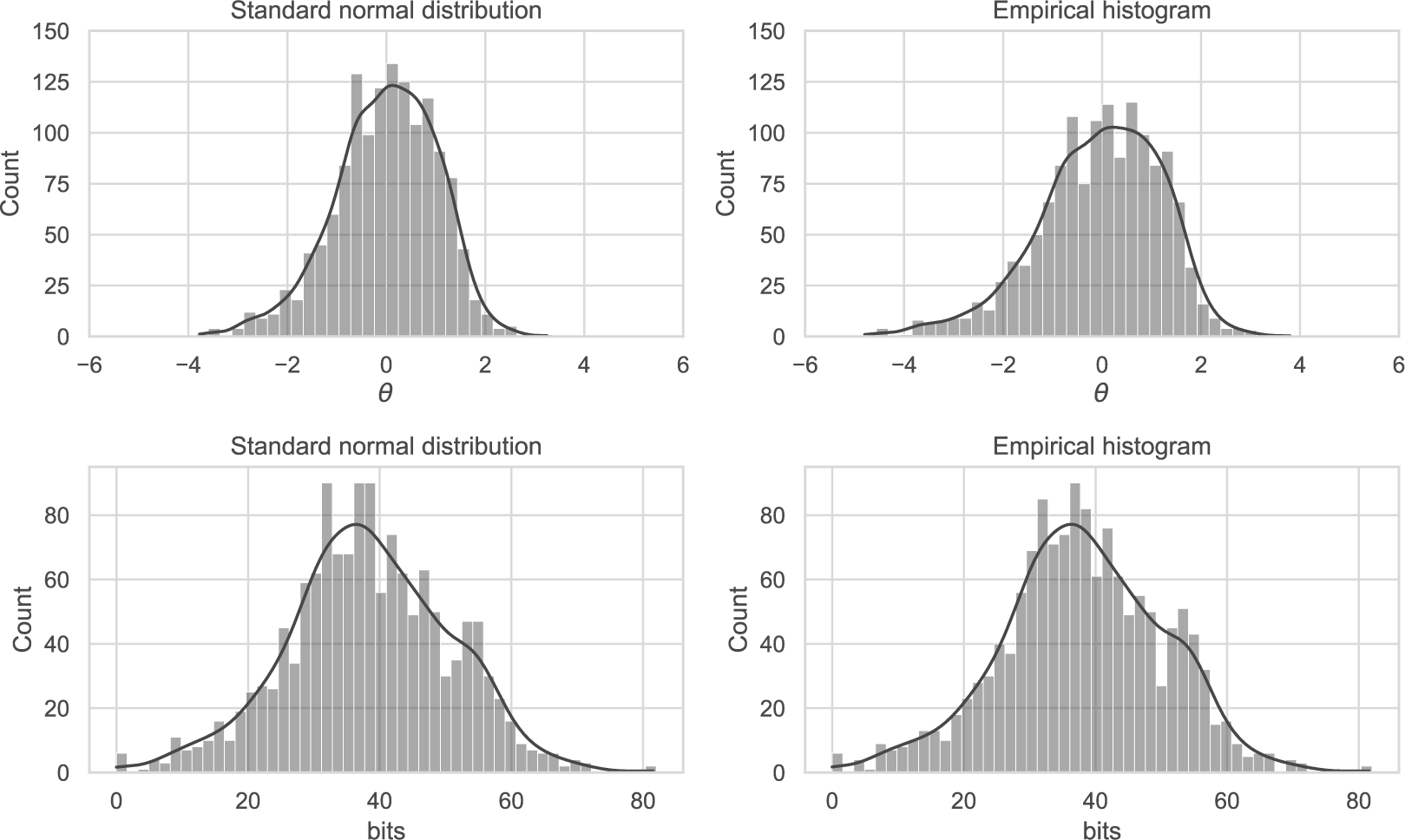
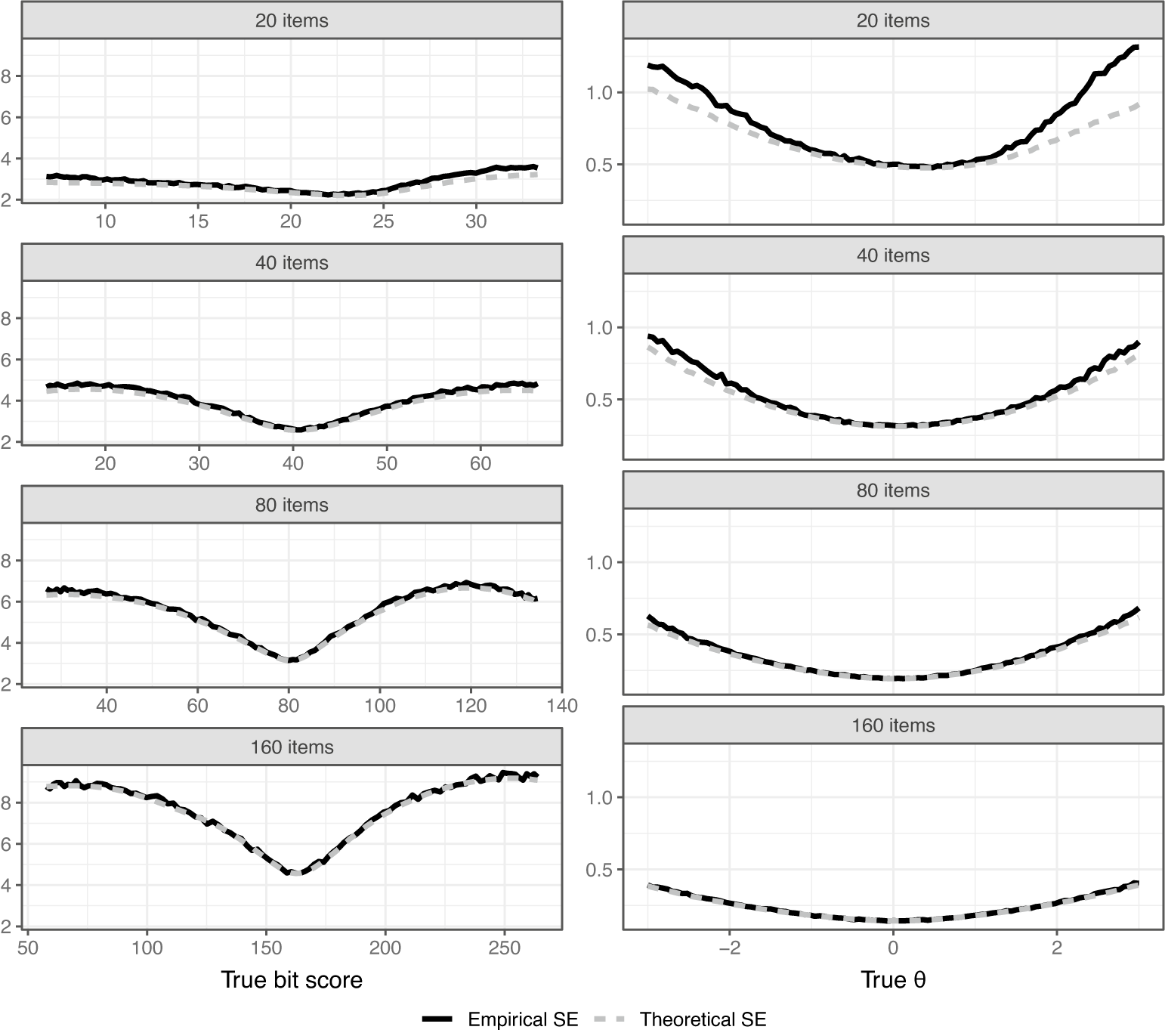
Figure 8 compares the empirical and theoretical SEs for the scales. Theoretical SEs for perfect/zero scores are undefined and were thus ignored in the simulations. We see that for both scale transformations, the theoretical SEs slightly underestimate the actual SEs with fewer items, but become more accurate as the number of items increases. This is expected from asymptotic theory and the derivations given in Section 4.1. The bit score SEs are larger when more items are used since each item increases the length of the entire scale. If one prefers a fixed length, the bit scale could be linearly rescaled to span, for example, from 0 to 100 as mentioned previously in Section 4. The interpretation would then be the percentage of bits of information within the test that a test taker has attained at a certain score.
Simulation evaluation of theoretical SEs for ML-estimated bit and
 $\theta $
scores.
$\theta $
scores.

7 Discussion
In this article, we introduced the bit scale, a novel metric transformation for latent trait scores derived from unidimensional IRT models. The primary motivation was to address the inherent arbitrariness of the traditional
 $\theta $
scale, whose interpretation is often tied to specific population assumptions (typically
$\theta $
scale, whose interpretation is often tied to specific population assumptions (typically
 $N(0,1)$
) and on which distances are ambiguous (Lord, Reference Lord1975). By leveraging fundamental concepts from information theory, specifically surprisal and entropy (Cover & Thomas, Reference Cover and Thomas2006; Shannon, Reference Shannon1948), the bit scale provides a score metric anchored to the properties of the test items rather than the distribution of test-takers.
$N(0,1)$
) and on which distances are ambiguous (Lord, Reference Lord1975). By leveraging fundamental concepts from information theory, specifically surprisal and entropy (Cover & Thomas, Reference Cover and Thomas2006; Shannon, Reference Shannon1948), the bit scale provides a score metric anchored to the properties of the test items rather than the distribution of test-takers.
The bit scale approach builds on related ideas using information-theoretic concepts by Ramsay et al. (Reference Ramsay, Li, Wallmark and Wiberg2024), but avoids calculation issues when surprisals approach infinity (response probabilities approach zero), which occur with many IRT models. Furthermore, adding a single item to a test results in a fixed and predictable increase in the length of the score scale. This is not the case with the Ramsay et al. (Reference Ramsay, Li, Wallmark and Wiberg2024) methodology where arc length is utilized for scoring. This additive nature of the bit scale should arguably also make bit scale score calculations more intuitive and easier to grasp. Furthermore, just like with arc length scores (Ramsay et al., Reference Ramsay, Li, Wallmark and Wiberg2024) methodology and the D-scoring approach by Dimitrov (Reference Dimitrov2024), the bit scale is bounded and positive, making it more intuitive for the general public for which concepts, such as negative scores and scores approaching infinity may be confusing and hard to grasp. As mentioned in Section 4, the bit scale can also be rescaled to range from 0 to 100 or 0 to 1 if one prefers, which changes the score interpretation to percentages of test information (bits) attained at a given score.
Our proposed bit score, defined in Equations (5) and (6), quantifies the cumulative change in expected item surprisal (entropy) along the latent trait continuum. This construction yields a scale with metric properties and an absolute zero, where units are measured in “bits.” A key advantage highlighted is that distances on the bit scale have a consistent meaning related to the uncertainty resolved by responding to the test items, regardless of the underlying
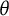 $\theta $
scale’s distribution. This was illustrated in the first empirical example (Section 5.1), where fitting a GPC model with and without a distributional assumption resulted in different
$\theta $
scale’s distribution. This was illustrated in the first empirical example (Section 5.1), where fitting a GPC model with and without a distributional assumption resulted in different
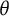 $\theta $
distributions but highly comparable bit score distributions (Figure 3). Furthermore, the Fisher information curves commonly utilized in IRT analysis lack consistency on differently scaled
$\theta $
distributions but highly comparable bit score distributions (Figure 3). Furthermore, the Fisher information curves commonly utilized in IRT analysis lack consistency on differently scaled
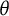 $\theta $
axes (Figures 1 and 4). The bit scale resolves this issue by providing a metric scale on which IRF slopes, and in turn also Fisher information, are more meaningful, arguably providing a more stable representation of measurement precision across the range of ability.
$\theta $
axes (Figures 1 and 4). The bit scale resolves this issue by providing a metric scale on which IRF slopes, and in turn also Fisher information, are more meaningful, arguably providing a more stable representation of measurement precision across the range of ability.
The second empirical illustration (Section 5.2) demonstrated the practical utility of bit scales for equating or linking latent trait scores from different test forms administered to potentially different populations, provided common anchor items exist. By computing bit scores based solely on the anchor items, we established a common, item-anchored metric enabling direct comparison of latent trait levels across the 2013 and 2014 SweSAT administrations, even when simulating a population shift (Figure 5). This offers a conceptually straightforward alternative or complement to traditional linking methods (e.g., mean–mean and characteristic curve methods (Kolen & Brennan, Reference Kolen and Brennan2014)), particularly as it naturally handles potential non-linear relationships between scales induced by model differences or population variations, as shown in Figure 6. Future research should, however, more thoroughly examine the efficiency of the bit scale linking method against other approaches.
The simulation study (Section 6) investigated the statistical properties of ML-estimated bit scores. The results indicated that bit score estimates exhibit low bias, especially with longer tests, and behave consistently with asymptotic theory (Figure 7). The derived SEs (Section 4.1), based on the delta method, provided a good approximation of the empirical SEs, particularly for longer tests (Figure 8), validating their use for quantifying uncertainty in bit scores. Notably, the bit scale transformation naturally handles cases with perfect or zero scores, where ML estimates of
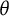 $\theta $
diverge to
$\theta $
diverge to
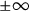 $\pm \infty $
, offering a practical advantage in score estimation and evaluation across the entire ability range. The availability of implementations in R (bitscale) and Python (IRTorch) facilitates the adoption and further exploration of bit scales by researchers and practitioners (Wallmark, Reference Wallmark2025a, Reference Wallmark2025b).
$\pm \infty $
, offering a practical advantage in score estimation and evaluation across the entire ability range. The availability of implementations in R (bitscale) and Python (IRTorch) facilitates the adoption and further exploration of bit scales by researchers and practitioners (Wallmark, Reference Wallmark2025a, Reference Wallmark2025b).
Despite the promising characteristics of the bit scale, some limitations and areas for future research warrant discussion. First, the derivation of SEs in Section 4.1 assumes the item parameters (and thus the IRFs) are known without error. While the bit scale is designed to be invariant to population assumptions, its stability is still contingent on the precision of the underlying item parameter estimates. This uncertainty is not propagated into the bit score SEs presented here. This problem is not unique to the bit scores, and most
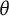 $\theta $
estimation methods also make the same assumption, such as EAP, MAP, and ML implemented in the mirt package (Chalmers, Reference Chalmers2012). Future work could explore methods that incorporate item parameter uncertainty into the variance estimation of bit scores (Yang et al., Reference Yang, Hansen and Cai2012). Furthermore, evaluating the metric stability of a fitted model, as proposed by Feuerstahler (Reference Feuerstahler2022), could provide a valuable diagnostic tool to assess the quality of the bit scale itself due to uncertainty of the item parameters.
$\theta $
estimation methods also make the same assumption, such as EAP, MAP, and ML implemented in the mirt package (Chalmers, Reference Chalmers2012). Future work could explore methods that incorporate item parameter uncertainty into the variance estimation of bit scores (Yang et al., Reference Yang, Hansen and Cai2012). Furthermore, evaluating the metric stability of a fitted model, as proposed by Feuerstahler (Reference Feuerstahler2022), could provide a valuable diagnostic tool to assess the quality of the bit scale itself due to uncertainty of the item parameters.
Second, the computation of bit scores involves numerical integration (Equation (5)), which, while straightforward for common IRT models using standard software, might become more complex for highly intricate models or require careful implementation choices regarding the integration grid (
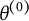 $\theta ^{(0)}$
and density). Third, while “bits” provide a theoretically grounded unit, practitioners and test-takers accustomed to norm-referenced scores (like z-scores or T-scores) may require guidance and illustrative examples to fully internalize the meaning and interpretation of bit scores. One should note that utilizing the bit scale for some analysis does not exclude the use of the
$\theta ^{(0)}$
and density). Third, while “bits” provide a theoretically grounded unit, practitioners and test-takers accustomed to norm-referenced scores (like z-scores or T-scores) may require guidance and illustrative examples to fully internalize the meaning and interpretation of bit scores. One should note that utilizing the bit scale for some analysis does not exclude the use of the
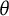 $\theta $
scale, and they can of course be used in conjunction.
$\theta $
scale, and they can of course be used in conjunction.
Further investigation into the relationship between bit scale information (Equation (10)) and traditional Fisher information under various scaling conditions would be valuable. Comparing the performance of bit scale-based linking with established equating methods across a wider range of data conditions (e.g., different anchor test lengths, population differences, and model misfit) would also be beneficial. Exploring the application of bit scales in contexts like computerized adaptive testing (CAT), where maintaining a consistent and meaningful scale across adaptive test administrations is crucial, could also prove fruitful.
It is worth pointing out that the bit scale does not affect model fit, and can thus be used in conjunction with most analytical methods that accompany IRT, such as differential item functioning and various item and person fit metrics (van der Linden, Reference van der Linden2018).
In conclusion, the bit scale offers a theoretically sound and practically useful transformation for IRT scores. By grounding the latent trait metric in the information provided by the test items, it overcomes key limitations associated with the arbitrary nature of the conventional
 $\theta $
scale. Its metric properties, invariance to population assumptions, and utility in model comparison and linking suggest that bit scales can be a valuable tool for enhancing the interpretation, comparability, and evaluation of measurement outcomes in educational and psychological assessment.
$\theta $
scale. Its metric properties, invariance to population assumptions, and utility in model comparison and linking suggest that bit scales can be a valuable tool for enhancing the interpretation, comparability, and evaluation of measurement outcomes in educational and psychological assessment.
Software availability
To facilitate the application of the bit scale and encourage further research, open-source implementations have been developed for both the R and Python programming environments. For R users, the method is implemented in the package bitscale (Wallmark, Reference Wallmark2025a). This package is designed to interface with fitted IRT models from the mirt package (Chalmers, Reference Chalmers2012). It provides functions to compute item and test bit scores, estimate standard errors, and produce bit scale-related visualizations. The source code, installation instructions, and usage examples are available at https://github.com/joakimwallmark/bitscale.
For Python users, the bit scale is natively supported in the IRTorch package (Wallmark, Reference Wallmark2025b). IRTorch is a standalone IRT package that leverages PyTorch for automatic differentiation and model estimation, making it suitable for modern machine learning workflows. The bit scale transformation is available as a rescaling method within the package’s API. Comprehensive documentation and tutorials can be found at https://irtorch.readthedocs.io/, and the source code is hosted at https://github.com/joakimwallmark/irtorch.
Acknowledgements and declarations
The research was funded by the Swedish Wallenberg MMW grant 2019.0129 and the Swedish Research Council 2022-02046. The authors thank the editor, associate editor, and the three anonymous reviewers for their constructive comments. During the preparation of this work, the authors used generative AI for English proof-reading of parts of the article. The authors reviewed and edited the generated content as needed and take full responsibility for the content of the publication.











 Open access
Open access