


Introduction
Lung cancer often presents in later stages, when curative treatment is less likely. Low-dose computed tomography (LDCT) screening for lung cancer has been shown to be effective at reducing mortality in people at high risk (Reference Duer, Yang and Robinson1). The extent to which LDCT screening for lung cancer is cost-effective has therefore received much attention.
In 2017, we systematically reviewed the published literature for cost-effectiveness studies of LDCT screening for lung cancer in high-risk populations (Reference Snowsill, Yang and Griffin2). Since then, we have twice updated the review, running database searches in 2020 (Reference Peters, Snowsill, Griffin, Robinson and Hyde3) and 2024 (now available in a report to funders, see Web Report at https://fundingawards.nihr.ac.uk/award/14/151/07). In total, we have identified 57 economic evaluations, set in 20 different countries. The earliest of those evaluations were published in 2001 and set in the United States (Reference Marshall, Simpson, Earle and Chu4;Reference Marshall, Simpson, Earle and Chu5), with more recent ones set in Asia (Reference Kim, Cho, Kim, Choi, Kim and Jo6;Reference Sheu, Wang, Hsu, Chung, Hsu and Shi7), particularly China (Reference Zhang, Chen and Li8;Reference Zhao, Gu and Yang9). As the evidence and discussion on the implementation of LDCT screening for lung cancer in high-risk populations has evolved, it is not surprising to observe so many evaluations in different territories. Many of these published economic evaluations may be used to support national decision making on LDCT screening for lung cancer, with a number of articles being explicit about this aim (e.g., in Hungary (Reference Nagy, Szilberhorn and Gyorbiro10), the Netherlands (Reference Al Khayat, Eijsink, Postma, van de Garde and van Hulst11;Reference ten Berge, Willems and Pan12), Korea (Reference Kim, Cho, Kim, Choi, Kim and Jo6), Taiwan (Reference Sheu, Wang, Hsu, Chung, Hsu and Shi7), and Austria (Reference ten Berge, Ramaker and Piazza13)). According to the Lung Cancer Policy Network (14), nine countries have national LDCT screening program for lung cancer.
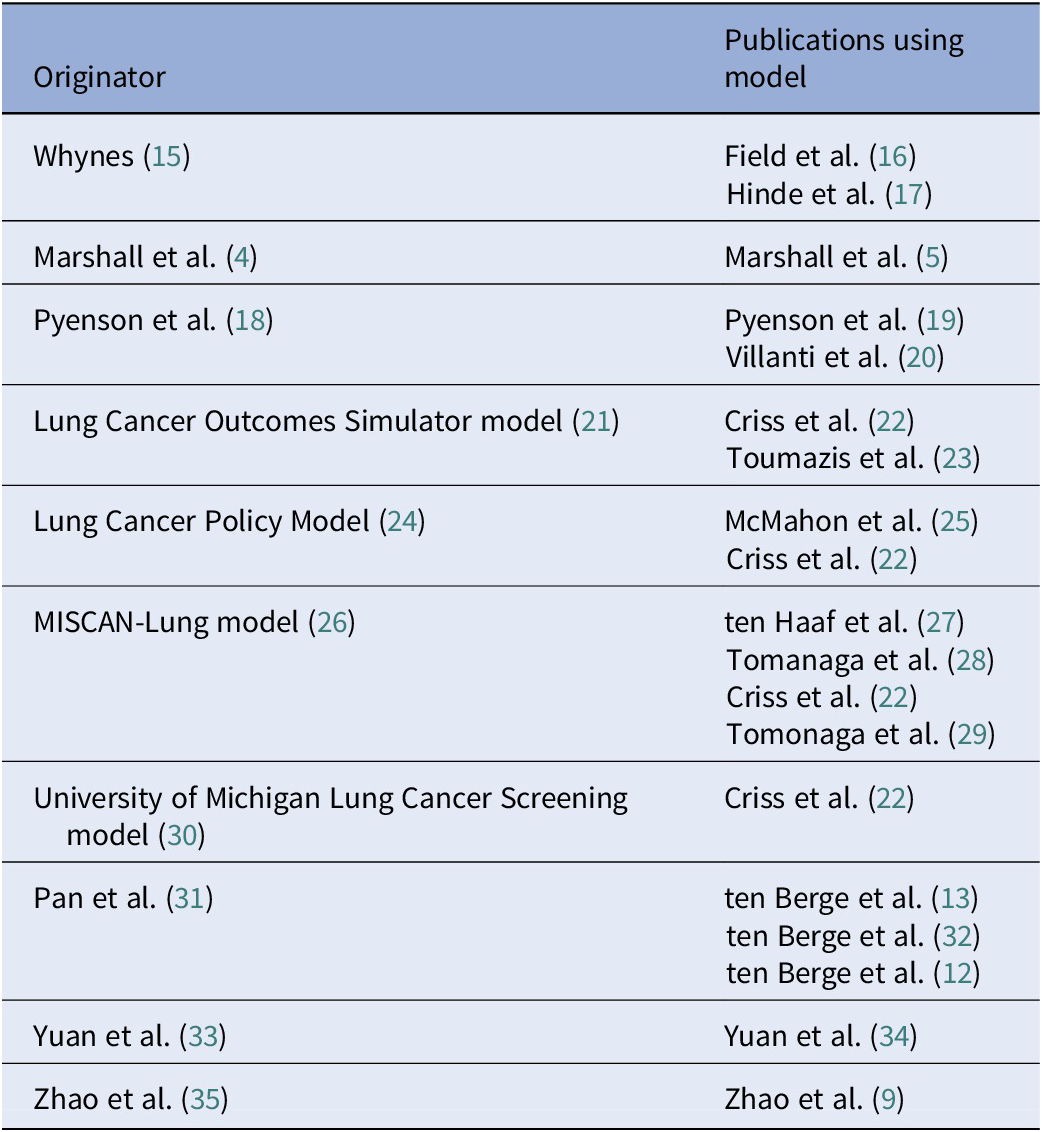
In our 2020 update, we highlighted variation across the 35 published model-based economic evaluations, noting 13 studies that had either used an existing model in their evaluations or taken very similar approaches (e.g., Whynes (Reference Whynes15), Field et al. (Reference Field, Duffy and Baldwin16), and Hinde et al. (Reference Hinde, Crilly and Balata17) for the UK setting), see Table 1. When we updated the review in 2024 with an additional 22 economic evaluations, we were surprised to find that only one of these newer evaluations (Reference Tomonaga, de Nijs, Bucher, de Koning and Ten Haaf29) had used a model published before 2021 (26). However, three of the newer models had been used in more than one economic evaluation, see Table 1.
Economic evaluations where existing models were used

Overall, we estimated that across the 57 total number of economic evaluations, there were 38 de novo models. These models, as far as we could determine, had not previously been used to evaluate the cost-effectiveness of lung cancer screening. Given that there had been over 20 years of published research evaluating the cost-effectiveness of LDCT screening for lung cancer, this was unexpectedly high. A similar observation has been made in the evaluation of screening for colorectal cancer: Adair et al. (Reference Adair, Lamrock, O’Mahony, Lawler and McFerran36) identified 52 de novo models in a systematic review of 78 model-based economic evaluations.
Avoiding research waste
At the outset, developing a de novo model, rather than adapting an existing model, may appear to have a number of advantages: It can be developed to answer the specific question of interest for the relevant policy maker, and there are no issues in trying to decide which, of a number of existing models, would be the most appropriate one to use. Furthermore, no model is provably correct, and standard peer review of a model does not necessarily validate it. If important aspects of the decision problem have not been captured in models that are repeatedly used, this is likely to lead to biased cost-effectiveness estimates, resulting in potentially misleading conclusions on which policy decisions are made. Initially, it may appear that a simple model is sufficient and can be developed quickly and cheaply (assuming there is some in-house expertise); for example, there are no costs for access to an existing model and no time spent trying to understand someone else’s model (which may have been developed in unfamiliar software).
However, we argue that models to evaluate cancer screening programs are necessarily complex. A model that has been developed quickly and cheaply is unlikely to have addressed the many important aspects of cancer screening. We require cancer screening models to appropriately consider features such as overdiagnosis, lead-time bias, length bias, and incidental findings, as well as being able to consider variation in how screening is delivered (e.g. targeting, stratification, and timing). Only models containing natural history components can achieve this. The development and validation of these models is a significant undertaking, often requiring years of sustained investment, as demonstrated by the Cancer Intervention and Surveillance Modeling Network (CISNET; https://cisnet.cancer.gov/).
CISNET brings together researchers funded by the National Cancer Institute in the United States who are using modeling to evaluate interventions for the prevention, screening, and treatment of different cancers. CISNET takes a comparative approach to modeling, aiming to use multiple models to address the same research question (Reference Criss, Cao and Bastani22;Reference Ten Haaf, Bastani and Cao37). This approach has the potential to be more informative than relying on a single model: When models provide similar results, this offers reassurance, but when results are not similar, this can help to identify important differences in the structure or implementation of the models.
In our review, very few publications commented on the availability of the models [one as open access (Reference Snowsill, Yang and Griffin2), one as being proprietary (Reference Behar Harpaz, Weber and Wade38), and two having code available upon (reasonable) request (Reference Al Khayat, Eijsink, Postma, van de Garde and van Hulst11;Reference Kumar, Cohen and van Klaveren39)]. Some earlier papers do report in detail many of their equations, for example, Whynes (Reference Whynes15) and Black et al. (Reference Black, Gareen and Soneji40), while Goffin et al. (Reference Goffin, Flanagan and Miller41;Reference Goffin, Flanagan and Miller42) provide a website for the OncoSim model, but the link is no longer live.
Although there are often practical barriers to using an existing model, a minimum expectation in the development of a new model would be an evaluation of the strengths and limitations of existing models. Developing new models that rectify the limitations of previous models would present advancement in modeling methods and reduce the huge potential for research waste. Not only is there waste if researchers are “re-inventing the wheel” but also if the lessons from implementing more, necessarily, complex models are not taken into account. In our last update in 2024, there appeared to be limited evolution of the previously published and reviewed models. This is concerning given that we deemed many of the more recent de novo lung cancer screening models to be less sophisticated than older models. For instance, the proportion of de novo models that are Markov models has increased: 87 percent of the de novo models published since 2021 were Markov models, compared to 30 percent published before 2021. We found that Markov models are less likely to allow for the impact of overdiagnosis and lead time bias and in more recent publications we noted greater uncertainty as to whether all important costs and outcomes are identified. More generally, simpler models (n = 42) only evaluated one frequency of screening, while the more complex models evaluated a range of policy questions on frequency and duration of screening. Not considering multiple frequencies and durations of screening strategies could lead to inadequate policy decisions being made (Reference Fabbro, Hahn, Novaes, O’Gralaigh and O’Mahony43).
To sum up: Poor reporting and inaccessible models force policy makers to commission new models; however, with limited timescales, such models may not be fit for purpose, potentially leading to significant waste of public money if suboptimal policy decisions are subsequently made.
The way forward
Future reports of model-based economic evaluations in cancer screening should meet the highest standards of transparency, and their underlying decision models should ideally be made open source or open access. Authors of already-published research should also consider placing models into the public domain.
Improving the completeness of reporting of models would allow better appraisal of the different models. In our review of evaluations for lung cancer screening, there were some studies where it was unclear whether they had used an existing model or developed a new model. For many studies, not all of the model information we sought could be extracted from the articles. The CHEERS statement was published in 2013 (updated in 2022) to help improve the quality of reporting of economic evaluations (Reference Husereau, Drummond and Augustovski44;Reference Husereau, Drummond and Petrou45). Of the 45 evaluations in our review that were published from 2014 onwards, only six (13 percent) declared using the CHEERS statement to report their evaluation (Reference Snowsill, Yang and Griffin2;Reference Zhang, Chen and Li8;Reference Zhao, Gu and Yang9;Reference Tomonaga, de Nijs, Bucher, de Koning and Ten Haaf29;Reference Du, Sidorenkov and Heuvelmans46;Reference Gómez-Carballo, Fernández-Soberón and Rejas-Gutiérrez47). However, by virtue of intending to be applicable to all methodologies for economic evaluation and not just decision modeling, the CHEERS statement does not require enough detail to make models reproducible. In the CHEERS 2022 explanation and elaboration (Reference Husereau, Drummond and Augustovski48), it is recommended that authors of reports of modeling studies may wish to follow separate reporting guidelines (Reference Brennan, Chick and Davies49–Reference Dahabreh, Trikalinos, Balk and Wong51). As many journals have the capacity for publishing supplementary materials or appendices, we believe these opportunities should be more widely used to provide more detailed descriptions of models, the assumptions made, and the data used. However, it is very rare that any attempt at reporting is more transparent than simply making the model open source.
Making models available to other researchers, preferably being open source would help to improve future modeling studies. The current move toward making research data open and available is reflected in requirements from certain funders (e.g., United Kingdom Research and Innovation). Many publishers and journals have introduced open data statements (e.g., Springer Nature, BMJ Journals, IJTAHC, Value in Health) but may also want to consider whether a model that is not open source, with little detail on methods, is of publication standard. Clearly some models cannot be made open as they contain commercially sensitive data; however this is unlikely the case for many applications, including lung cancer screening. Open source models allow adaptation and updates for specific questions and settings, building on the previous work. Having more models available for use by researchers would also provide opportunity for more comparison between model results, as well as foster collaboration. Initiatives such as CISNET are helpful in providing such a resource, and other funders, and policy makers, may see the benefit of such an approach. Beyond CISNET, there are other collaborations highlighting the importance of a comparative approach to modeling. This includes the Mount Hood Diabetes Challenge Network, which has been comparing the methods and results of different diabetes models since 2009 (https://www.mthooddiabeteschallenge.com/). At the last Mount Hood conference, in June 2025, seven different models took part in the challenges. A different approach is gaining recognition by national decision makers, including the National Institute for Health and Care Excellence in the UK (52) and the National Medicine’s Policy in Australia (53): the use of disease-specific reference models (Reference Haji Ali Afzali and Karnon54). As these organizations may be tasked with evaluating numerous interventions (e.g., treatments, procedures, diagnostics, and devices) within the same disease, the use of a single model has the potential to improve efficiency in decision making, reduce methodological inconsistencies, and improve transparency. There are of course challenges with this approach, such as ensuring the capture of all important aspects of the disease and multiple decision problems as well as providing the time and resources to develop and update such models.
For LDCT screening for lung cancer, policy makers in Asia (particularly in China) are now deluged by published economic evaluations of dubious quality, and there is no doubt pressure (due to high rates of smoking and lung cancer mortality) to make extremely consequential policy decisions on the basis of this evidence. Researchers worldwide who hold intellectual property rights over sophisticated economic models for lung cancer screening should consider the potential value to society from making those models more accessible.
Data availability statement
All data are publicly available from the individual studies.
Acknowledgements
This study was carried out within the Faculty of Health and Life Sciences at the University of Exeter, which receives funding from the National Institute for Health and Care Research (NIHR) Exeter HealthTech Research Centre (HRC), the NIHR Exeter Biomedical Research Centre (BRC), and the NIHR Applied Research Collaboration (South West Peninsula).
Author contribution
J.L.P., T.S., S.R., E.G., and C.H. all conceived and designed the study. J.P., T.S., and S.R. performed the systematic reviews, including database searching, screening, data extraction, and critical appraisal. J.P., T.S., E.G., and C.H. analyzed and interpreted the findings. J.P. drafted the manuscript, and all authors provided critical revisions of the paper. C.H. obtained the initial funding. All authors read and approved the final version.
Funding statement
The 2020 update was supported by the United Kingdom National Institute for Health Research Health Technology Assessment Programme (14/151/07). The authors received no financial support for the 2024 update, or for the writing of this manuscript.
Competing interests
T.S. reports membership of the NIHR Health Technology Assessment (General) Committee since 2024. E.G. reports consulting fees received for professional services relating to the Daiichi-Sankyo UK product quizartinib (Vanflyta) for patients with acute myeloid leukemia. J.P., S.R., and C.H. report no conflicts of interest.

 Open access
Open access