


1 Introduction
Latent class models (LCMs; Goodman, Reference Goodman1974; Lazarsfeld, Reference Lazarsfeld and Henry1968) are popular tools for uncovering unobserved subgroups from multivariate categorical responses, with broad applications in social and behavioral sciences (Berzofsky et al., Reference Berzofsky, Biemer and Kalsbeek2014; Korpershoek et al., Reference Korpershoek, Kuyper and van der Werf2015; Wang & Hanges, Reference Wang and Hanges2011; Zeng et al., Reference Zeng, Gu and Xu2023). At the core of an LCM, we aim to identify K latent classes of N individuals based on their categorical responses to J items. In this article, we focus on the widely used LCMs with binary responses, which are prevailing in educational assessments (correct/wrong responses to test questions) and social science surveys (yes/no responses to survey items). Accurately and efficiently recovering latent classes in large N and large J settings remains a significant statistical and computational challenge.
Traditional approaches to LCM are typically based on maximum likelihood estimation. In the classical random-effect formulation, the latent class labels of subjects are treated as random variables, and the model is estimated by the marginal maximum likelihood (MML) approach, in which the latent labels are marginalized out. The expectation–maximization (EM) algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977) is often used for this purpose, but it becomes computationally expensive and lacks theoretical guarantees in the modern regime, where both N and J are large. In contrast, the joint maximum likelihood (JML) approach adopts a fixed-effect perspective, treating the latent class labels as unknown parameters to be estimated. However, due to the inherent non-convexity of the joint likelihood function, JML is still highly sensitive to initialization and prone to be trapped in local optima. Recently, Zeng et al. (Reference Zeng, Gu and Xu2023) showed that JML is consistent under the large N and large J regime. Nonetheless, they do not provide any algorithmic guarantee, and the convergence rate established therein is polynomial in J, whose optimality remains unclear.
In this article, we consider a different approach related to spectral clustering, which leverages the intrinsic approximate low-rank structure of the data matrix and is computationally efficient. In psychometrics and related fields, the common heuristic practice for spectral clustering is to first construct a similarity matrix among individuals or items, apply eigenvalue decomposition to it, and then perform K-means clustering of the eigenspace embeddings (Chen et al., Reference Chen, Li, Liu, Xu and Ying2017; Von Luxburg, Reference Von Luxburg2007). More recently, Chen and Li (Reference Chen and Li2019) directly perform the singular value decomposition (SVD) on a regularized version of the data matrix itself. Similar ideas have also been developed for nonlinear item factor analysis (Zhang et al., Reference Zhang, Chen and Li2020) and the grade-of-membership model (Chen & Gu, Reference Chen and Gu2024).
We next explain our idea of directly adapting the SVD to perform spectral clustering for binary-response LCMs. We collect the binary responses in an
 $N\times J$
matrix
$N\times J$
matrix
 $\mathbf {R}$
with binary entries, then under the typical LCM assumption, the
$\mathbf {R}$
with binary entries, then under the typical LCM assumption, the
 $\mathbf {R}$
can be written as
$\mathbf {R}$
can be written as
 $\mathbf {R}=\mathbb {E}[\mathbf {R}]+\mathbf {E}$
, where
$\mathbf {R}=\mathbb {E}[\mathbf {R}]+\mathbf {E}$
, where
 $\mathbb {E}[\mathbf {R}]$
is the low-rank “signal” matrix due to the existence of K latent classes, and
$\mathbb {E}[\mathbf {R}]$
is the low-rank “signal” matrix due to the existence of K latent classes, and
 $\mathbf {E}$
is a mean-zero “noise” matrix. Denote by
$\mathbf {E}$
is a mean-zero “noise” matrix. Denote by
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
the truncated rank-K SVD of
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
the truncated rank-K SVD of
 ${\mathbf {R}}$
, then
${\mathbf {R}}$
, then
 ${\mathbf {R}}\approx \widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
approximately captures the “signal” part. In particular, we first extract
${\mathbf {R}}\approx \widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
approximately captures the “signal” part. In particular, we first extract
 $\widehat {\mathbf {U}}$
, the leading K left singular vectors of the data matrix to perform dimensionality reduction. Then we apply K-means clustering algorithm on the N rows of
$\widehat {\mathbf {U}}$
, the leading K left singular vectors of the data matrix to perform dimensionality reduction. Then we apply K-means clustering algorithm on the N rows of
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
, the left singular vectors weighted by their corresponding singular values
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
, the left singular vectors weighted by their corresponding singular values
 $\widehat {\boldsymbol {\Sigma }}$
, to obtain the latent class label estimates. While variants of this simple yet efficient algorithm have attracted significant attention in network analysis (Zhang, Reference Zhang2024) and sub-Gaussian mixture models (Zhang & Zhou, Reference Zhang and Zhou2024), it has not been widely explored or studied in the context of LCMs. The only exception is the recent work by Lyu et al. (Reference Lyu, Chen and Gu2025), which extended spectral clustering to LCMs with individual-level degree heterogeneity and showed that spectral methods can lead to exact recovery of the latent class labels in certain regime. However, whether the spectral method gives an optimal way for estimating latent class labels in LCMs remains unknown. In this article, we resolve this question by proposing a novel two-stage method:
$\widehat {\boldsymbol {\Sigma }}$
, to obtain the latent class label estimates. While variants of this simple yet efficient algorithm have attracted significant attention in network analysis (Zhang, Reference Zhang2024) and sub-Gaussian mixture models (Zhang & Zhou, Reference Zhang and Zhou2024), it has not been widely explored or studied in the context of LCMs. The only exception is the recent work by Lyu et al. (Reference Lyu, Chen and Gu2025), which extended spectral clustering to LCMs with individual-level degree heterogeneity and showed that spectral methods can lead to exact recovery of the latent class labels in certain regime. However, whether the spectral method gives an optimal way for estimating latent class labels in LCMs remains unknown. In this article, we resolve this question by proposing a novel two-stage method:
-
1. First step: Obtain initial latent class labels of individuals via the SVD-based spectral clustering, which leverages the approximate low-rankness of the data matrix.
-
2. Second step: Refine the latent class labels through a single step of likelihood maximization, which “sharpens” the coarse initial labels using the likelihood information.
This hybrid approach simultaneously takes advantage of the scalability of spectral methods and leverages the Bernoulli likelihood information to achieve a vanishing exponential error rate for clustering. We provide rigorous theoretical guarantees for our method. In summary, our method is both computationally fast and statistically optimal in the regime with a large number of items. Therefore, this work provides a useful tool to aid psychometric researchers and practitioners to perform latent class analysis of modern high-dimensional data. We emphasize that our method has no requirement on the magnitude of J compared to N, and even allows J to be much larger than N.
The rest of this article is organized as follows. After reviewing the setup of LCMs for binary responses in Section 2, we discuss the performance of spectral clustering and propose our main algorithm in Section 3. In Section 4, we establish theoretical guarantees and statistical optimality of our algorithm. We evaluate our method’s performance in numerical experiments in Section 5. The proofs of the theoretical results are included in the Appendix.
Notation: We use bold capital letters, such as
 $\mathbf {A},\mathbf {B},\ldots $
to denote matrices and bold lowercase
$\mathbf {A},\mathbf {B},\ldots $
to denote matrices and bold lowercase
 ${\boldsymbol a},{\boldsymbol b},\ldots $
to denote vectors. For any positive integer m, denote
${\boldsymbol a},{\boldsymbol b},\ldots $
to denote vectors. For any positive integer m, denote
 $[m]:=\{1,\ldots ,m\}$
. For any matrix
$[m]:=\{1,\ldots ,m\}$
. For any matrix
 $\mathbf {A}\in \mathbb {R}^{N\times J}$
and any
$\mathbf {A}\in \mathbb {R}^{N\times J}$
and any
 $i\in [N]$
and
$i\in [N]$
and
 $j\in [J]$
, we use
$j\in [J]$
, we use
 $A_{i,j}$
to denote its entry on the i-th row and j-th column, and use
$A_{i,j}$
to denote its entry on the i-th row and j-th column, and use
 $\mathbf {A}_{i,:}$
(or
$\mathbf {A}_{i,:}$
(or
 $\mathbf {A}_{:,j}$
) to denote its i-th row (or j-th column) vector. Let
$\mathbf {A}_{:,j}$
) to denote its i-th row (or j-th column) vector. Let
 $\lambda _k\left (\mathbf {A}\right )$
denote the k-th largest singular value of
$\lambda _k\left (\mathbf {A}\right )$
denote the k-th largest singular value of
 $\mathbf {A}$
for
$\mathbf {A}$
for
 $k=1,\ldots ,\min \left \{N,J\right \}$
. Let
$k=1,\ldots ,\min \left \{N,J\right \}$
. Let
 $\left \|\cdot \right \|$
denote the spectral norm (operator norm) for matrices and
$\left \|\cdot \right \|$
denote the spectral norm (operator norm) for matrices and
 $\ell _2$
norm for vectors, and
$\ell _2$
norm for vectors, and
 $\left \| \cdot \right \|_{\mathrm {F}}$
denote the Frobenius norm for matrices. For two non-negative sequences
$\left \| \cdot \right \|_{\mathrm {F}}$
denote the Frobenius norm for matrices. For two non-negative sequences
 $\{a_N\}$
and
$\{a_N\}$
and
 $\{b_N\}$
, we write
$\{b_N\}$
, we write
 $a_N\lesssim b_N$
(or
$a_N\lesssim b_N$
(or
 $a_N\gtrsim b_N$
) if there exists some constant
$a_N\gtrsim b_N$
) if there exists some constant
 $C>0$
independent of N such that
$C>0$
independent of N such that
 $a_N\le Cb_N$
(or
$a_N\le Cb_N$
(or
 $b_N\le Ca_N$
);
$b_N\le Ca_N$
);
 $a_N\asymp b_N$
if
$a_N\asymp b_N$
if
 $a_N\lesssim b_N$
and
$a_N\lesssim b_N$
and
 $b_N\lesssim a_N$
hold simultaneously;
$b_N\lesssim a_N$
hold simultaneously;
 $a_N=o(b_N)$
if
$a_N=o(b_N)$
if
 $b_N>0$
and
$b_N>0$
and
 $a_N/b_N\rightarrow 0$
.
$a_N/b_N\rightarrow 0$
.
2 Latent class model with binary responses
We consider a dataset of N individuals (e.g., survey or assessment respondents and voters) and J items (e.g., questions in a survey or an assessment and policy items). The observed data are represented as a binary response matrix
 $\mathbf {R}\in \left \{0,1\right \}^{N\times J}$
, where
$\mathbf {R}\in \left \{0,1\right \}^{N\times J}$
, where
 $R_{i,j}=1$
indicates a positive response from individual i to item j, and
$R_{i,j}=1$
indicates a positive response from individual i to item j, and
 $R_{i,j}=0$
otherwise. Each individual i belongs to one of K latent classes, and we encode the class membership by a latent vector
$R_{i,j}=0$
otherwise. Each individual i belongs to one of K latent classes, and we encode the class membership by a latent vector
 ${\boldsymbol s}^\star =\left (s_1^\star ,\dots ,s_N^\star \right )$
, where
${\boldsymbol s}^\star =\left (s_1^\star ,\dots ,s_N^\star \right )$
, where
 $s_i^\star \in [K]$
. The interpretation of the latent classes is characterized by an item parameter matrix
$s_i^\star \in [K]$
. The interpretation of the latent classes is characterized by an item parameter matrix
 $\boldsymbol {\Theta }=(\theta _{j,k})\in [0,1]^{J\times K}$
, where
$\boldsymbol {\Theta }=(\theta _{j,k})\in [0,1]^{J\times K}$
, where
 $\theta _{j,k}$
denotes the probability that an individual in class k gives a positive response to item j:
$\theta _{j,k}$
denotes the probability that an individual in class k gives a positive response to item j:
 $$ \begin{align} \mathbb P(R_{i,j}=1\mid s_i^\star=k) = \theta_{j,k},\quad \forall i\in[N], j\in[J]. \end{align} $$
$$ \begin{align} \mathbb P(R_{i,j}=1\mid s_i^\star=k) = \theta_{j,k},\quad \forall i\in[N], j\in[J]. \end{align} $$
Under the LCM, a subject’s J responses are usually assumed to be conditionally independent given his or her latent class membership.
The traditional likelihood-based approach takes a random-effect perspective to LCMs and maximizes the marginal likelihood. This approach treats the latent class labels
 $\{s_i\}$
as random by assuming
$\{s_i\}$
as random by assuming
 $ p_k=\mathbb {P}\left (s_i=k\right )$
for each k and marginalizing
$ p_k=\mathbb {P}\left (s_i=k\right )$
for each k and marginalizing
 $s_i$
out:
$s_i$
out:
 $$ \begin{align} L\left(\boldsymbol{\Theta}\mid \mathbf{R}\right)= \sum_{i\in[N]} \log\left(\sum_{k\in[K]} p_k\prod_{j\in[J]} \Big( \theta_{j,k}^{R_{i,j}} \left(1-\theta_{j,k}\right)^{1-R_{i,j}}\Big)\right). \end{align} $$
$$ \begin{align} L\left(\boldsymbol{\Theta}\mid \mathbf{R}\right)= \sum_{i\in[N]} \log\left(\sum_{k\in[K]} p_k\prod_{j\in[J]} \Big( \theta_{j,k}^{R_{i,j}} \left(1-\theta_{j,k}\right)^{1-R_{i,j}}\Big)\right). \end{align} $$
A standard approach for maximizing the marginal likelihood is the EM algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977). However, EM is highly sensitive to initialization. Poor initial values often lead to convergence at local maxima, so practitioners resort to multiple random restarts at substantial computational cost. Moreover, when both J and K grow large, the computation for evaluating the objective in (2) becomes numerically unstable due to its log-sum-of-products structure.
Another strategy is to consider the fixed-effect LCM, where the JML naturally comes into play. In particular, the joint log-likelihood function of latent label vector
 ${\boldsymbol s}$
and item parameters
${\boldsymbol s}$
and item parameters
 ${\boldsymbol{\Theta}} $
can be written as
${\boldsymbol{\Theta}} $
can be written as
 $$ \begin{align} L\left({\boldsymbol s},{\boldsymbol{\Theta}}\mid \mathbf R\right) = \sum_{i\in[N]} \sum_{j\in[J]} \Big(R_{i,j} \log\left(\theta_{j,s_i}\right) + (1-R_{i,j}) \log\left(1-\theta_{j,s_i}\right)\Big). \end{align} $$
$$ \begin{align} L\left({\boldsymbol s},{\boldsymbol{\Theta}}\mid \mathbf R\right) = \sum_{i\in[N]} \sum_{j\in[J]} \Big(R_{i,j} \log\left(\theta_{j,s_i}\right) + (1-R_{i,j}) \log\left(1-\theta_{j,s_i}\right)\Big). \end{align} $$
The simple structure of (3) implies that the optimization of JML can be decoupled across
 $[N]$
and
$[N]$
and
 $[J]$
. While JML is known to be inconsistent in low-dimensional settings (Neyman & Scott, Reference Neyman and Scott1948), the recent study by Zeng et al. (Reference Zeng, Gu and Xu2023) has shown that JML can achieve consistent estimation of the latent labels in the high-dimensional regime. This property makes the JML approach appealing for large-scale modern datasets. It is worth noting that JML can be regarded as a version of classification EM (CEM; Celeux & Govaert, Reference Celeux and Govaert1992), but with the difference of omitting the class proportion parameters. See Section 3.3 for more details.
$[J]$
. While JML is known to be inconsistent in low-dimensional settings (Neyman & Scott, Reference Neyman and Scott1948), the recent study by Zeng et al. (Reference Zeng, Gu and Xu2023) has shown that JML can achieve consistent estimation of the latent labels in the high-dimensional regime. This property makes the JML approach appealing for large-scale modern datasets. It is worth noting that JML can be regarded as a version of classification EM (CEM; Celeux & Govaert, Reference Celeux and Govaert1992), but with the difference of omitting the class proportion parameters. See Section 3.3 for more details.
Throughout the article, we consider the fixed-effect LCM and our goal is to recover the true latent labels
 ${\boldsymbol s}^\star $
from large-scale and high-dimensional data with
${\boldsymbol s}^\star $
from large-scale and high-dimensional data with
 $N,J\to \infty $
. The performance of any clustering method is evaluated via the Hamming error up to label permutations:
$N,J\to \infty $
. The performance of any clustering method is evaluated via the Hamming error up to label permutations:
 $$ \begin{align} \ell\left( {\boldsymbol s}, {\boldsymbol s}^\star\right):=\min_{\pi\in{\mathfrak S}_K}\frac{1}{N}\sum_{i\in[N]}\mathbb{I}\left( s_i\ne \pi\left(s_i^\star\right)\right), \end{align} $$
$$ \begin{align} \ell\left( {\boldsymbol s}, {\boldsymbol s}^\star\right):=\min_{\pi\in{\mathfrak S}_K}\frac{1}{N}\sum_{i\in[N]}\mathbb{I}\left( s_i\ne \pi\left(s_i^\star\right)\right), \end{align} $$
where
 ${\mathfrak S}_K$
denotes the set of all permutation maps
${\mathfrak S}_K$
denotes the set of all permutation maps
 $\pi $
from
$\pi $
from
 $[K]\to [K]$
. This metric accounts for the inherent symmetry in clustering structure.
$[K]\to [K]$
. This metric accounts for the inherent symmetry in clustering structure.
3 Two-stage clustering algorithm
3.1 Spectral clustering for the latent class model
Our primary goal is to estimate the latent label vector
 ${\boldsymbol s}^\star $
. However, maximizing the joint likelihood (3) directly still suffers from computationally intractable for large N and J. We first consider spectral clustering, which is a computationally efficient method that leverages the approximate low-rank structure of the data matrix. Let
${\boldsymbol s}^\star $
. However, maximizing the joint likelihood (3) directly still suffers from computationally intractable for large N and J. We first consider spectral clustering, which is a computationally efficient method that leverages the approximate low-rank structure of the data matrix. Let
 $\mathbf {Z}=(Z_{i,j})\in \left \{0,1\right \}^{N\times K}$
be a latent class membership matrix with
$\mathbf {Z}=(Z_{i,j})\in \left \{0,1\right \}^{N\times K}$
be a latent class membership matrix with
 $Z_{i,k}=1$
if
$Z_{i,k}=1$
if
 $s^\star _i=k$
and
$s^\star _i=k$
and
 $Z_{i,l}=0$
otherwise. Under the fixed-effect LCM, we have
$Z_{i,l}=0$
otherwise. Under the fixed-effect LCM, we have
 $R_{i,j}\sim \text {Bern}\left (\sum _{k=1}^{K}Z_{i,k}\theta _{j,k}\right )$
and we can write
$R_{i,j}\sim \text {Bern}\left (\sum _{k=1}^{K}Z_{i,k}\theta _{j,k}\right )$
and we can write
 $R_{i,j}=\sum _{k=1}^{K}Z_{i,k}\theta _{j,k}+E_{i,j}$
, where
$R_{i,j}=\sum _{k=1}^{K}Z_{i,k}\theta _{j,k}+E_{i,j}$
, where
 $\sum _{k=1}^{K}Z_{i,k}\theta _{j,k} = \mathbb E[R_{i,j}]$
and
$\sum _{k=1}^{K}Z_{i,k}\theta _{j,k} = \mathbb E[R_{i,j}]$
and
 $E_{i,j}$
is mean-zero random noise. We have the following crucial decomposition of the data matrix
$E_{i,j}$
is mean-zero random noise. We have the following crucial decomposition of the data matrix
 $\mathbf {R}$
into two additive components using matrix notation:
$\mathbf {R}$
into two additive components using matrix notation:
 $$ \begin{align} \mathbf R = \underbrace{\mathbf{Z}}_{N\times K} \underbrace{{\boldsymbol{\Theta}}^\top}_{K\times J} + \underbrace{\mathbf{E}}_{\text{noise}}. \end{align} $$
$$ \begin{align} \mathbf R = \underbrace{\mathbf{Z}}_{N\times K} \underbrace{{\boldsymbol{\Theta}}^\top}_{K\times J} + \underbrace{\mathbf{E}}_{\text{noise}}. \end{align} $$
Here,
 $\mathbf {Z}\boldsymbol {\Theta }^\top = \mathbb E[\mathbf {R}]$
is the “signal” part containing the crucial latent class information (and thus is low-rank as
$\mathbf {Z}\boldsymbol {\Theta }^\top = \mathbb E[\mathbf {R}]$
is the “signal” part containing the crucial latent class information (and thus is low-rank as
 $K\ll \min \left \{N,J\right \}$
), and
$K\ll \min \left \{N,J\right \}$
), and
 $\mathbf {E}=(E_{i,j})\in \mathbb {R}^{N\times J}$
is a mean-zero “noise” matrix with
$\mathbf {E}=(E_{i,j})\in \mathbb {R}^{N\times J}$
is a mean-zero “noise” matrix with
 $\mathbb E[\mathbf {E}] = \mathbb E[\mathbf {R} - \mathbb E[\mathbf {R}]] = \mathbf {0}_{N\times J}$
.
$\mathbb E[\mathbf {E}] = \mathbb E[\mathbf {R} - \mathbb E[\mathbf {R}]] = \mathbf {0}_{N\times J}$
.
Given the above observation (5), we first briefly outline the rationale of spectral clustering under the oracle noiseless setting (i.e., when
 $\mathbf {E}=\mathbf {0}$
). Let
$\mathbf {E}=\mathbf {0}$
). Let
 $\mathbf {Z}\boldsymbol {\Theta }^\top = \mathbf {U}\boldsymbol {\Sigma }\mathbf {V}^\top $
be the rank-K SVD of
$\mathbf {Z}\boldsymbol {\Theta }^\top = \mathbf {U}\boldsymbol {\Sigma }\mathbf {V}^\top $
be the rank-K SVD of
 $\mathbf {Z}\boldsymbol {\Theta }^\top $
. Notably, the ith row vector in
$\mathbf {Z}\boldsymbol {\Theta }^\top $
. Notably, the ith row vector in
 $\mathbf {U}\boldsymbol {\Sigma }$
can be written as
$\mathbf {U}\boldsymbol {\Sigma }$
can be written as
 $$ \begin{align} {\boldsymbol e}_i^\top\mathbf{U}\boldsymbol{\Sigma}={\boldsymbol e}_i^\top\mathbf{Z}\boldsymbol{\Theta}^\top\mathbf{V}=\sum_{k=1}^KZ_{i,k}\boldsymbol{\Theta}_{:,k}^\top\mathbf{V}=\boldsymbol{\Theta}_{:,s_i}^\top\mathbf{V},\quad \forall i\in[N]. \end{align} $$
$$ \begin{align} {\boldsymbol e}_i^\top\mathbf{U}\boldsymbol{\Sigma}={\boldsymbol e}_i^\top\mathbf{Z}\boldsymbol{\Theta}^\top\mathbf{V}=\sum_{k=1}^KZ_{i,k}\boldsymbol{\Theta}_{:,k}^\top\mathbf{V}=\boldsymbol{\Theta}_{:,s_i}^\top\mathbf{V},\quad \forall i\in[N]. \end{align} $$
Thus, data points in the same latent class have identical row vectors in
 $\mathbf {U}\boldsymbol {\Sigma }$
, namely, one of the K distinct vectors
$\mathbf {U}\boldsymbol {\Sigma }$
, namely, one of the K distinct vectors
 $\left \{\boldsymbol {\Theta }_{:,k}^\top \mathbf {V}\right \}_{k=1}^K$
. Hence, the true latent class label information can be readily read off from rows of
$\left \{\boldsymbol {\Theta }_{:,k}^\top \mathbf {V}\right \}_{k=1}^K$
. Hence, the true latent class label information can be readily read off from rows of
 $\mathbf {U}\boldsymbol {\Sigma }$
. In the realistic noisy data setting, denote by
$\mathbf {U}\boldsymbol {\Sigma }$
. In the realistic noisy data setting, denote by
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
the top-K SVD of the data matrix
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
the top-K SVD of the data matrix
 $\mathbf {R}$
. Then intuitively,
$\mathbf {R}$
. Then intuitively,
 $\mathbf {U}\boldsymbol {\Sigma }$
would be well-approximated by
$\mathbf {U}\boldsymbol {\Sigma }$
would be well-approximated by
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
provided that
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
provided that
 $\mathbf {E}$
is relatively small in magnitude, and the row vectors of
$\mathbf {E}$
is relatively small in magnitude, and the row vectors of
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
are noisy point clouds distributed around the K points. Therefore, K-means clustering can deliver reasonable estimates of class labels. We illustrate this point using an numerical example in Figure 1, where the row vectors of
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
are noisy point clouds distributed around the K points. Therefore, K-means clustering can deliver reasonable estimates of class labels. We illustrate this point using an numerical example in Figure 1, where the row vectors of
 $\mathbf {U}\boldsymbol {\Sigma }$
(left) and
$\mathbf {U}\boldsymbol {\Sigma }$
(left) and
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
(right) are plotted as points in
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
(right) are plotted as points in
 $\mathbb R^2$
, respectively.
$\mathbb R^2$
, respectively.
An illustration for spectral clustering: row vectors of
 $\mathbf {U}\boldsymbol {\Sigma }$
(left) and
$\mathbf {U}\boldsymbol {\Sigma }$
(left) and
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
(right). Setting:
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
(right). Setting:
 $N=500$
,
$N=500$
,
 $J=250$
, and
$J=250$
, and
 $K=3$
.
$K=3$
.

Figure 1 Long description
The left panel displays three individual points spread across the plot, each at distinct positions along Dimension 1 and Dimension 2. The right panel shows three compact horizontal clusters of points, each cluster aligned at a different value along Dimension 2 but sharing similar values along Dimension 1. Both panels have axes labeled Dimension 1 on the x-axis and Dimension 2 on the y-axis, with ranges from negative twelve to negative six for Dimension 1 and negative six to six for Dimension 2.
The above high-level idea can be formalized as the spectral clustering algorithm (Algorithm 1), investigated in Zhang and Zhou (Reference Zhang and Zhou2024) for sub-Gaussian mixture models. Algorithm 1 first obtains the rank-K SVD of
 $\mathbf {R}$
denoted by
$\mathbf {R}$
denoted by
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
, and then performs K-means clustering on the rows of
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}\widehat {\mathbf {V}}^\top $
, and then performs K-means clustering on the rows of
 $\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
, the left singular vectors weighted by the singular values.
$\widehat {\mathbf {U}}\widehat {\boldsymbol {\Sigma }}$
, the left singular vectors weighted by the singular values.
Remark 1. An equivalent formulation of (3) aggregates the
 $2^{J}$
unique response patterns (weighted by their frequencies). We do not adopt this perspective because it becomes less suitable, both computationally and theoretically, for high-dimensional data with very large J. On the computational side, our approach does not rely on evaluating the likelihood through these unique response patterns. On the theoretical side, our spectral method is motivated by the approximate low-rank structure of the
$2^{J}$
unique response patterns (weighted by their frequencies). We do not adopt this perspective because it becomes less suitable, both computationally and theoretically, for high-dimensional data with very large J. On the computational side, our approach does not rely on evaluating the likelihood through these unique response patterns. On the theoretical side, our spectral method is motivated by the approximate low-rank structure of the
 $N\times J$
binary response matrix
$N\times J$
binary response matrix
 $\mathbf {R} \in \mathbb {R}^{N \times J}$
itself, which does not utilize the unique response patterns.
$\mathbf {R} \in \mathbb {R}^{N \times J}$
itself, which does not utilize the unique response patterns.

Algorithm 1: Long description
The heading states Algorithm 1: Spectral clustering (Spec). The data matrix R is in R to the N times J, with K latent classes. The result is estimated latent class labels s tilde in open bracket K close bracket to the N. Step 1: Perform rank-K S V D on R to obtain the summation from i equals 1 to K of lambda i times u hat i times v hat i transpose, where lambda 1 is greater than or equal to lambda 2 and so on, greater than or equal to lambda K, greater than or equal to zero. U hat equals open parenthesis u 1, dot dot dot, u K close parenthesis in R to the N times K, and V hat equals open parenthesis v 1, dot dot dot, v K close parenthesis in R to the J times K. Step 2: Perform K-means on the rows of U hat Sigma, or equivalently R V hat, i.e., open parenthesis s tilde, c tilde k for k in open bracket K close bracket close parenthesis equals arg min over s in open bracket K close bracket to the N, c tilde k for k in open bracket K close bracket in R to the K, of the summation over i in open bracket N close bracket of the norm squared of U hat i, Sigma minus c s i.
3.2 One-step likelihood refinement with spectral initialization
Despite computationally efficient, spectral clustering itself ignores the likelihood information in the LCM that might improve statistical accuracy. This motivates our proposed Algorithm 2 named spectral clustering with one-step likelihood refinement algorithm, or SOLA for short.
In particular, the first stage is to perform spectral clustering to obtain an initial class label estimate
 $\widetilde {\boldsymbol s}$
. This stage utilizes the inherent approximate low-rank structure of data but does not use the likelihood information. In the second stage, recall the joint likelihood function defined in (3) as
$\widetilde {\boldsymbol s}$
. This stage utilizes the inherent approximate low-rank structure of data but does not use the likelihood information. In the second stage, recall the joint likelihood function defined in (3) as
 $$ \begin{align*} L\left({\boldsymbol s},{\boldsymbol{\Theta}}\mid \mathbf R\right) = \sum_{i\in[N]} \sum_{j\in[J]} \Big(R_{i,j} \log\left(\theta_{j,s_i}\right) + (1-R_{i,j}) \log\left(1-\theta_{j,s_i}\right)\Big). \end{align*} $$
$$ \begin{align*} L\left({\boldsymbol s},{\boldsymbol{\Theta}}\mid \mathbf R\right) = \sum_{i\in[N]} \sum_{j\in[J]} \Big(R_{i,j} \log\left(\theta_{j,s_i}\right) + (1-R_{i,j}) \log\left(1-\theta_{j,s_i}\right)\Big). \end{align*} $$
We then perform the following two steps:
-
1. (Maximization) For fixed
 $\widetilde {\boldsymbol s}$
, find the
$\boldsymbol {\Theta }$
maximizing the objective
$ L\left (\widetilde {\boldsymbol s},{\boldsymbol{\Theta}} \mid \mathbf R\right )$
, which turns out to have a explicit solution as
$$ \begin{align*}\widehat\theta_{j,k}= \frac{\sum_{i\in[N]} R_{i,j} \mathbb{I}\left(\widetilde s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(\widetilde s_i=k\right)},\quad \forall j\in[J],~ k\in[K]. \end{align*} $$
$\widetilde {\boldsymbol s}$
, find the
$\boldsymbol {\Theta }$
maximizing the objective
$ L\left (\widetilde {\boldsymbol s},{\boldsymbol{\Theta}} \mid \mathbf R\right )$
, which turns out to have a explicit solution as
$$ \begin{align*}\widehat\theta_{j,k}= \frac{\sum_{i\in[N]} R_{i,j} \mathbb{I}\left(\widetilde s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(\widetilde s_i=k\right)},\quad \forall j\in[J],~ k\in[K]. \end{align*} $$
In other words, this is the sample average of the j-th column of
$\mathbf {R}$
based on estimated class labels
$\left \{i\in [N]:\widetilde s_i=k\right \}$
. -
2. (Assignment) Given
$\widehat {\boldsymbol {\Theta }}$
, the objective function
$ L({\boldsymbol s},\widehat {\boldsymbol {\Theta }}\mid {\mathbf R})$
can be decoupled into N terms, each corresponding to an individual data point, and it is equivalent to assign label
$k\in [K]$
to sample i which maximize the log-likelihood independently for each
$i\in [N]$
:
$$ \begin{align*} \widehat s_i = \operatorname*{\mbox{arg max}}_{k\in[K]} \sum_{j\in[J]} \Big[R_{i,j} \log\Big(\widehat\theta_{j,k}\Big) + (1-R_{i,j}) \log\Big(1-\widehat\theta_{j,k}\Big)\Big],\quad i\in[N]. \end{align*} $$











It is readily seen that these two steps increase the joint likelihood monotonically. However, convergence to true
 ${\boldsymbol s}^\star $
depends on the performance of the initial estimator
${\boldsymbol s}^\star $
depends on the performance of the initial estimator
 $\widetilde {\boldsymbol s}$
in the first stage, which we obtained using spectral clustering. The above details are summarized in Algorithm 2, and we provide its algorithmic guarantee in Section 4.
$\widetilde {\boldsymbol s}$
in the first stage, which we obtained using spectral clustering. The above details are summarized in Algorithm 2, and we provide its algorithmic guarantee in Section 4.

Algorithm 2: Long description
The algorithm is titled ‘Algorithm 2: SOLA.’ The data input is a matrix R in the set of real numbers to the N by J, with rank K. The result is estimated labels s-bar in the set of K to the N. Step 1 initializes label estimates as s-tilde equals Spec of R. Step 2, labeled Maximization, computes initial center estimates: theta-bar sub j,k equals the summation over i in N of R sub i,j times the indicator function that s-tilde sub i equals k, all over the summation over i in N of the indicator function that s-tilde sub i equals k, for j in J and k in K. This is equation (7). Step 3, labeled Assignment, performs one-step likelihood-based refinement: s-bar sub i equals the argument maximum over k in K of the sum over j in J of R sub i,j times the logarithm of theta-bar sub j,k plus the quantity one minus R sub i,j times the logarithm of one minus theta-bar sub j,k, for i in N. This is equation (8).
Interestingly, our two-stage procedure resonates with the spirit of the “initialize-and-refine” scheme that has been used in network analysis for stochastic block models (SBMs) (Chen et al., Reference Chen, Liu and Ma2022; Gao et al., Reference Gao, Ma, Zhang and Zhou2017; Lyu et al., Reference Lyu, Li and Xia2023), while the model considered here differs fundamentally in that LCMs handle high-dimensional response data without relying on pairwise interaction structures inherent to SBMs.
In practice, we observe that performing multiple likelihood-based refinement steps may lead to improved convergence and performance compared to the one-step refinement procedure. Thus, we also consider a multiple-step refinement variant of Algorithm 2, which we denote by SOLA+, in the later simulation studies. We set the number of “Maximization
 $+$
Assignment” refinement steps for SOLA+ to be
$+$
Assignment” refinement steps for SOLA+ to be
 $10$
in all our simulations. In principle, one could also adapt the algorithm by monitoring the change in the joint log-likelihood values and stopping the algorithm once the absolute difference between successive iterations falls below a small threshold (Di Mari et al., Reference Di Mari, Bakk, Oser and Kuha2023).
$10$
in all our simulations. In principle, one could also adapt the algorithm by monitoring the change in the joint log-likelihood values and stopping the algorithm once the absolute difference between successive iterations falls below a small threshold (Di Mari et al., Reference Di Mari, Bakk, Oser and Kuha2023).
3.3 Extension: Classification EM refinement
Our proposed framework can be readily extended to one-step CEM refinement, where CEM is another widely used approach to estimate LCMs (Celeux & Govaert, Reference Celeux and Govaert1992; Zeng et al., Reference Zeng, Gu and Xu2023). It can be regarded as a variant of the standard EM algorithm designed specifically for clustering. Unlike traditional EM, which calculates “soft” assignments by estimating the probability that each observation belongs to every latent class, CEM uses “hard” assignments: each observation is directly assigned to the class with the highest posterior probability. By explicitly modeling the mixture proportion parameters for the latent classes, CEM adjusts the likelihood to account for varying cluster sizes. Concretely, in our setting, one can adapt the one-step refinement in Algorithm 2 to a CEM step by including class proportions. Besides updating
 $\widehat {\theta }_{j,k}$
as in (7), we also estimate the proportion parameters
$\widehat {\theta }_{j,k}$
as in (7), we also estimate the proportion parameters
 $\widehat {{\boldsymbol p}} = (\widehat p_1,\ldots ,\widehat p_K)\in [0,1]^K$
by
$\widehat {{\boldsymbol p}} = (\widehat p_1,\ldots ,\widehat p_K)\in [0,1]^K$
by
 $$ \begin{align} \widehat{p}_k \;=\; \frac{1}{N} \sum_{i=1}^N \mathbb{I}\{\widetilde{s}_i = k\}, \quad k \,\in\, [K]. \end{align} $$
$$ \begin{align} \widehat{p}_k \;=\; \frac{1}{N} \sum_{i=1}^N \mathbb{I}\{\widetilde{s}_i = k\}, \quad k \,\in\, [K]. \end{align} $$
Then, for each individual i, we update their latent class label based on both the item parameters and the estimated class proportions:
 $$ \begin{align} \widehat s_i \;=\; \arg\max_{k \in [K]} \Biggl[\log \widehat p_k \;+\; \sum_{j=1}^J \Bigl(\,R_{i,j}\,\log\widehat{\theta}_{j,k} \;+\; (1 - R_{i,j})\,\log\bigl(1 - \widehat{\theta}_{j,k}\bigr)\Bigr) \Biggr]. \end{align} $$
$$ \begin{align} \widehat s_i \;=\; \arg\max_{k \in [K]} \Biggl[\log \widehat p_k \;+\; \sum_{j=1}^J \Bigl(\,R_{i,j}\,\log\widehat{\theta}_{j,k} \;+\; (1 - R_{i,j})\,\log\bigl(1 - \widehat{\theta}_{j,k}\bigr)\Bigr) \Biggr]. \end{align} $$
This one-step CEM update replaces the likelihood-refinement stage of our two-stage estimator: start with spectral clustering, then perform the CEM step above. We provide its theoretical guarantee in Section 4. In practice, one could easily generalize the above CEM procedure to a multiple-step refinement variant, which is analogous to SOLA+.
4 Theoretical guarantees
To deliver the theoretical results, we start by making the following mild model assumptions.
Assumption 1.
 $\theta _{j,k}\in [c_\theta ,C_{\theta }]$
for some universal constants
$\theta _{j,k}\in [c_\theta ,C_{\theta }]$
for some universal constants
 $0<c_\theta <C_\theta <1$
, and
$0<c_\theta <C_\theta <1$
, and
 $j\in [J]$
,
$j\in [J]$
,
 $k\in [K]$
.
$k\in [K]$
.
Assumption 2.
 $\min _{k\in [K]}\left |\left \{i\in [N]:s_i^\star =k\right \}\right |\ge \alpha N/K$
for some universal constant
$\min _{k\in [K]}\left |\left \{i\in [N]:s_i^\star =k\right \}\right |\ge \alpha N/K$
for some universal constant
 $\alpha \in (0,1]$
.
$\alpha \in (0,1]$
.
Assumption 1 is a standard assumption for considering a compact parameter space for
 $\boldsymbol {\Theta }$
. Assumption 2 is imposed for both practical consideration and technical reason. Without this, rare classes could be statistically indistinguishable and computationally unstable to estimate.
$\boldsymbol {\Theta }$
. Assumption 2 is imposed for both practical consideration and technical reason. Without this, rare classes could be statistically indistinguishable and computationally unstable to estimate.
4.1 Theoretical guarantee of spectral clustering
In this section, we introduce the theoretical guarantee of spectral clustering (Algorithm 1). To that end, we define some necessary notations. The difficulty of recovering
 $\mathbf {s}^\star $
depends on how distinct the latent classes are, which, in the context of spectral clustering, is characterized by the following quantity:
$\mathbf {s}^\star $
depends on how distinct the latent classes are, which, in the context of spectral clustering, is characterized by the following quantity:
 $$ \begin{align} \Delta:=\min_{k_1\ne k_2\in[K]}\left\|\boldsymbol{\Theta}_{:,k_1}-\boldsymbol{\Theta}_{:,k_2}\right\| = \min_{k_1\ne k_2\in[K]}\left[\sum_{j=1}^J (\theta_{j,k_1} - \theta_{j,k_2})^2\right]^{1/2}. \end{align} $$
$$ \begin{align} \Delta:=\min_{k_1\ne k_2\in[K]}\left\|\boldsymbol{\Theta}_{:,k_1}-\boldsymbol{\Theta}_{:,k_2}\right\| = \min_{k_1\ne k_2\in[K]}\left[\sum_{j=1}^J (\theta_{j,k_1} - \theta_{j,k_2})^2\right]^{1/2}. \end{align} $$
This quantity measures the minimal Euclidean distance between any two class-specific item parameter vectors. Intuitively, a larger
 $\Delta $
yields a larger gap between the columns of
$\Delta $
yields a larger gap between the columns of
 $\boldsymbol {\Theta }$
and a bigger distinction among the latent classes, and therefore produces clearer separation in the spectral embeddings (referring to (6)), making recovery of the true class labels easier. In addition, let
$\boldsymbol {\Theta }$
and a bigger distinction among the latent classes, and therefore produces clearer separation in the spectral embeddings (referring to (6)), making recovery of the true class labels easier. In addition, let
 $\lambda _1\ge \cdots \ge \lambda _K>0$
denote the singular values of
$\lambda _1\ge \cdots \ge \lambda _K>0$
denote the singular values of
 $\mathbb {E}[\mathbf {R}]=\mathbf {Z}\boldsymbol {\Theta }^\top $
in decreasing order. The following result characterizes the clustering error of Algorithm 1.
$\mathbb {E}[\mathbf {R}]=\mathbf {Z}\boldsymbol {\Theta }^\top $
in decreasing order. The following result characterizes the clustering error of Algorithm 1.
Proposition 1 (Adapted from Theorem 3.1 in Zhang & Zhou, Reference Zhang and Zhou2024).
Define
 $\sigma ^2_{\theta }:=\left (1-2\theta \right )/\left [2\log \left (\left (1-\theta \right )\theta ^{-1}\right )\right ]$
for
$\sigma ^2_{\theta }:=\left (1-2\theta \right )/\left [2\log \left (\left (1-\theta \right )\theta ^{-1}\right )\right ]$
for
 $\theta \in (0,1)\backslash \left \{1/2\right \}$
and
$\theta \in (0,1)\backslash \left \{1/2\right \}$
and
 $\sigma ^2_{\theta }:=1/4$
for
$\sigma ^2_{\theta }:=1/4$
for
 $\theta =1/2$
, and let
$\theta =1/2$
, and let
 $\bar \sigma :=\max _{j,k}\sigma _{\theta _{j,k}}$
. Assume
$\bar \sigma :=\max _{j,k}\sigma _{\theta _{j,k}}$
. Assume
 $\text {rank}\left (\boldsymbol {\Theta }\right )=K$
,
$\text {rank}\left (\boldsymbol {\Theta }\right )=K$
,
 $\alpha N/K^2 \ge 10$
and
$\alpha N/K^2 \ge 10$
and
 $$ \begin{align} \min\left\{\frac{\Delta}{\alpha^{-1/2}K\left(1+\sqrt{\frac{J}{N}}\right)\bar\sigma},\frac{\lambda_K}{\left(\sqrt{N}+\sqrt{J}\right)\bar\sigma}\right\}\rightarrow\infty. \end{align} $$
$$ \begin{align} \min\left\{\frac{\Delta}{\alpha^{-1/2}K\left(1+\sqrt{\frac{J}{N}}\right)\bar\sigma},\frac{\lambda_K}{\left(\sqrt{N}+\sqrt{J}\right)\bar\sigma}\right\}\rightarrow\infty. \end{align} $$
Then, for the spectral clustering estimator
 $\widetilde {\boldsymbol s}$
in Algorithm 1, we have
$\widetilde {\boldsymbol s}$
in Algorithm 1, we have
 $$ \begin{align} \mathbb{E} \ell\left(\widetilde {\boldsymbol s},{\boldsymbol s}^\star\right)\le \exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1-o(1)\right)\right)+\exp\left(-\frac{N}{2}\right), \end{align} $$
$$ \begin{align} \mathbb{E} \ell\left(\widetilde {\boldsymbol s},{\boldsymbol s}^\star\right)\le \exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1-o(1)\right)\right)+\exp\left(-\frac{N}{2}\right), \end{align} $$
where
 $\ell (\cdot ,\cdot )$
is defined in (4). Moreover, if further assume that
$\ell (\cdot ,\cdot )$
is defined in (4). Moreover, if further assume that
 $\Delta ^2\ge 8\left (1+c\right )\bar \sigma ^2\log N$
for any constant
$\Delta ^2\ge 8\left (1+c\right )\bar \sigma ^2\log N$
for any constant
 $c>0$
, then we have
$c>0$
, then we have
 $\ell \left (\widetilde {\boldsymbol s},{\boldsymbol s}^\star \right )=0$
with probability
$\ell \left (\widetilde {\boldsymbol s},{\boldsymbol s}^\star \right )=0$
with probability
 $1-\exp \left (-N/2\right )-\exp \left (-\Delta /\bar \sigma \right )$
.
$1-\exp \left (-N/2\right )-\exp \left (-\Delta /\bar \sigma \right )$
.
Proposition 1 delivers that the simple and computationally efficient spectral clustering can essentially lead to exponentially small error rate with respect to the latent class separation
 $\Delta $
. Notably, we can have exact recovery of all latent class labels (i.e.,
$\Delta $
. Notably, we can have exact recovery of all latent class labels (i.e.,
 $\ell \left (\widetilde {\boldsymbol s},{\boldsymbol s}^\star \right )$
with
$\ell \left (\widetilde {\boldsymbol s},{\boldsymbol s}^\star \right )$
with
 $\widetilde s_i=\pi (s_i)$
for all
$\widetilde s_i=\pi (s_i)$
for all
 $i=1,\ldots ,N$
) with high probability as long as
$i=1,\ldots ,N$
) with high probability as long as
 $\Delta ^2/\bar \sigma ^2\ge 8\left (1+c\right )\log N$
. In the LCM we study, we have
$\Delta ^2/\bar \sigma ^2\ge 8\left (1+c\right )\log N$
. In the LCM we study, we have
 $\bar \sigma \le 1/4$
by definition, and hence it suffices to have
$\bar \sigma \le 1/4$
by definition, and hence it suffices to have
 $\Delta ^2\ge 2(1+c)\log N$
to achieve exact recovery. This is not hard to achieve even for slowly growing number of items, because if we have constant separation of item parameters for each item with
$\Delta ^2\ge 2(1+c)\log N$
to achieve exact recovery. This is not hard to achieve even for slowly growing number of items, because if we have constant separation of item parameters for each item with
 $\delta = \min _{k_1\neq k_2\in [K],j\in [J]} |\theta _{j,k_1} - \theta _{j,k_2}|$
, then
$\delta = \min _{k_1\neq k_2\in [K],j\in [J]} |\theta _{j,k_1} - \theta _{j,k_2}|$
, then
 $\Delta ^2 = J\delta ^2$
. In this case, having
$\Delta ^2 = J\delta ^2$
. In this case, having
 $J> 2(1+c)\delta ^{-2} \log N$
for exact recovery corresponds to a moderately growing dimension. In sharp contrast, the JML estimator analyzed in Zeng et al. (Reference Zeng, Gu and Xu2023) only achieves a polynomial convergence rate of order
$J> 2(1+c)\delta ^{-2} \log N$
for exact recovery corresponds to a moderately growing dimension. In sharp contrast, the JML estimator analyzed in Zeng et al. (Reference Zeng, Gu and Xu2023) only achieves a polynomial convergence rate of order
 $O (J^{-1/2})$
. Moreover, they cannot achieve exact recovery according to the technical condition and conclusion therein. Therefore, the new spectral estimator
$O (J^{-1/2})$
. Moreover, they cannot achieve exact recovery according to the technical condition and conclusion therein. Therefore, the new spectral estimator
 $\widetilde {\boldsymbol s}$
represents a substantial improvement with exponential error decay in (13).
$\widetilde {\boldsymbol s}$
represents a substantial improvement with exponential error decay in (13).
We also note that the condition (12) on
 $\Delta $
and
$\Delta $
and
 $\lambda _K$
is mild and can be easily satisfied in the modern high-dimensional data setting. We next give a concrete example. Let us consider a common generative setting for item parameters
$\lambda _K$
is mild and can be easily satisfied in the modern high-dimensional data setting. We next give a concrete example. Let us consider a common generative setting for item parameters
 $\boldsymbol {\Theta }$
, where its entries are i.i.d. generated from the Beta distribution.
$\boldsymbol {\Theta }$
, where its entries are i.i.d. generated from the Beta distribution.
Proposition 2. Consider
 $\theta _{j,k} \stackrel {i.i.d.}{\sim } \text {Beta}(a,b)$
for all
$\theta _{j,k} \stackrel {i.i.d.}{\sim } \text {Beta}(a,b)$
for all
 $j \in [J]$
and
$j \in [J]$
and
 $k \in [K]$
with
$k \in [K]$
with
 $a,b>0$
. Define
$a,b>0$
. Define
 $$ \begin{align*}B:=\frac{a\left(a+b+a\left(a+b\right)^{-1}\right)}{\left(a+b\right)\left(a+b+1\right)},\end{align*} $$
$$ \begin{align*}B:=\frac{a\left(a+b+a\left(a+b\right)^{-1}\right)}{\left(a+b\right)\left(a+b+1\right)},\end{align*} $$
then, under Assumption 2, we have
 $\lambda _K\gtrsim \sqrt {\alpha B NJ}$
and
$\lambda _K\gtrsim \sqrt {\alpha B NJ}$
and
 $\Delta \gtrsim \sqrt {BJK}$
with probability at least
$\Delta \gtrsim \sqrt {BJK}$
with probability at least
 $1-K(e^{-c_1B^2J}+e^{-c_2 BJ})$
for some universal constants
$1-K(e^{-c_1B^2J}+e^{-c_2 BJ})$
for some universal constants
 $c_1,c_2\in (0,1)$
.
$c_1,c_2\in (0,1)$
.
Proposition 2 entails that the condition on
 $\Delta $
and
$\Delta $
and
 $\lambda _K$
for the success of spectral clustering in Proposition 1 can be easily satisfied when
$\lambda _K$
for the success of spectral clustering in Proposition 1 can be easily satisfied when
 $\boldsymbol {\Theta }$
consists of Beta distributed entries, a common assumption in Bayesian inference for the LCM. Specifically, combined with Assumption 1, a sufficient condition on B for spectral clustering to have the desirable error control (13) would be
$\boldsymbol {\Theta }$
consists of Beta distributed entries, a common assumption in Bayesian inference for the LCM. Specifically, combined with Assumption 1, a sufficient condition on B for spectral clustering to have the desirable error control (13) would be
 $B\gg K(\frac {1}{N}+\frac {1}{J})$
, which is easily satisfied if the Beta parameters a and b are of the constant order.
$B\gg K(\frac {1}{N}+\frac {1}{J})$
, which is easily satisfied if the Beta parameters a and b are of the constant order.
Despite the above nice theoretical guarantee for spectral clustering, the clustering error’s reliance on the Euclidean metric
 $\Delta $
in Proposition 1 is inherent from the general framework analyzed in Zhang and Zhou (Reference Zhang and Zhou2024), and it turns out to be not statistically optimal due to ignorance of the likelihood information. We will discuss and address this issue next.
$\Delta $
in Proposition 1 is inherent from the general framework analyzed in Zhang and Zhou (Reference Zhang and Zhou2024), and it turns out to be not statistically optimal due to ignorance of the likelihood information. We will discuss and address this issue next.
4.2 Fundamental statistical limit for LCMs
In this section, we provide the understanding of the information-theoretic limit (fundamental statistical limit) of clustering in LCMs. To compare different statistical procedures, we consider the minimax framework that had been widely considered in both statistical decision theory and information theory in the past decades (Le Cam, Reference Le Cam2012; Takezawa, Reference Takezawa2005). The minimax risk is defined as the infimum, over all possible estimators, of the maximum loss (here, the mis-clustering error) taken over the entire parameter space. In other words, it is the rate of the best estimator one can have among all statistical procedures in the worst-case scenario.
Formally, we establish the minimax lower bound for mis-clustering error under the fixed-effect LCM in the following result, whose proof is adapted from Lyu et al. (Reference Lyu, Chen and Gu2025) and can be found in Section B.1.
Theorem 1 (Minimax lower bound).
Consider the following parameter space for
 $\mathbb {E}[\mathbf {R}]$
:
$\mathbb {E}[\mathbf {R}]$
:
 $$ \begin{align*} &{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right):=\left\{\bar{\mathbf{R}}:\bar R_{i,j}=\theta_{j,s_i}, {\boldsymbol s}\in[K]^{N}, \theta_{j,k}\in[0,1] , \forall i\in[N], j\in[J], k\in[K]\right\}. \end{align*} $$
$$ \begin{align*} &{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right):=\left\{\bar{\mathbf{R}}:\bar R_{i,j}=\theta_{j,s_i}, {\boldsymbol s}\in[K]^{N}, \theta_{j,k}\in[0,1] , \forall i\in[N], j\in[J], k\in[K]\right\}. \end{align*} $$
Define
 $I^\star :=\min _{k_1\ne k_2\in [K]}\sum _{j\in [J]}I (\theta _{j,k_1},\theta _{j,k_2} )$
with
$I^\star :=\min _{k_1\ne k_2\in [K]}\sum _{j\in [J]}I (\theta _{j,k_1},\theta _{j,k_2} )$
with
 $$ \begin{align*} I(p,q):=-2\log\left(\sqrt{pq}+\sqrt{\left(1-p\right)\left(1-q\right)}\right), \quad \forall p,q\in(0,1), \end{align*} $$
$$ \begin{align*} I(p,q):=-2\log\left(\sqrt{pq}+\sqrt{\left(1-p\right)\left(1-q\right)}\right), \quad \forall p,q\in(0,1), \end{align*} $$
then we have
 $$ \begin{align} \inf_{\widehat{\boldsymbol s} }\sup_{{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right)}\mathbb{E}\ell\left(\widehat {\boldsymbol s},{\boldsymbol s}^\star\right)\ge \exp\left(-\frac{I^\star}{2}\left(1+o(1)\right)\right), \end{align} $$
$$ \begin{align} \inf_{\widehat{\boldsymbol s} }\sup_{{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right)}\mathbb{E}\ell\left(\widehat {\boldsymbol s},{\boldsymbol s}^\star\right)\ge \exp\left(-\frac{I^\star}{2}\left(1+o(1)\right)\right), \end{align} $$
where the infimum is taken over all possible estimators of the latent class labels.
Roughly speaking, Theorem 1 informs us that under the fixed-effect LCM, the error rate
 $\exp (-I^\star /2 )$
is the lowest possible clustering error rate that no estimator can uniformly surpass. Notably,
$\exp (-I^\star /2 )$
is the lowest possible clustering error rate that no estimator can uniformly surpass. Notably,
 $I(p,q)$
is exactly the Renyi divergence (Rényi, Reference Rényi1961) of order
$I(p,q)$
is exactly the Renyi divergence (Rényi, Reference Rényi1961) of order
 $1/2$
between two Bernoulli distributions, Bern
$1/2$
between two Bernoulli distributions, Bern
 $(p)$
and Bern
$(p)$
and Bern
 $(q)$
, and hence
$(q)$
, and hence
 $\sum _{j\in [J]}I(\theta _{j,k_1},\theta _{j,k_2})$
can be interpreted as the Renyi divergence between two Bernoulli random vectors with parameters
$\sum _{j\in [J]}I(\theta _{j,k_1},\theta _{j,k_2})$
can be interpreted as the Renyi divergence between two Bernoulli random vectors with parameters
 $\boldsymbol {\Theta }_{:,k_1}$
and
$\boldsymbol {\Theta }_{:,k_1}$
and
 $\boldsymbol {\Theta }_{:,k_2}$
, respectively.
$\boldsymbol {\Theta }_{:,k_2}$
, respectively.
 $I^\star $
can be regarded as the overall signal-to-noise ratio (SNR) which further takes account into all possible pairs of
$I^\star $
can be regarded as the overall signal-to-noise ratio (SNR) which further takes account into all possible pairs of
 $(k_1,k_2)\in [K]^2$
with
$(k_1,k_2)\in [K]^2$
with
 $k_1\ne k_2$
. Although the form of
$k_1\ne k_2$
. Although the form of
 $I^\star $
might seem complicated at its first glance, it actually exactly reflects the likelihood information in the LCMs. By definition of the minimax lower bound, we know that
$I^\star $
might seem complicated at its first glance, it actually exactly reflects the likelihood information in the LCMs. By definition of the minimax lower bound, we know that
 $\exp (-I^\star /2 )$
cannot be larger than the spectral clustering error rate
$\exp (-I^\star /2 )$
cannot be larger than the spectral clustering error rate
 $\exp (-\Delta ^2/(8\bar \sigma ^2) )$
obtained in Proposition 1. We will discuss this in more detail in Section 4.4.
$\exp (-\Delta ^2/(8\bar \sigma ^2) )$
obtained in Proposition 1. We will discuss this in more detail in Section 4.4.
In the following, we take a closer look at why the quantity
 $I^\star $
shows up as the fundamental statistical limit. We analyze an idealized scenario where the true item parameters
$I^\star $
shows up as the fundamental statistical limit. We analyze an idealized scenario where the true item parameters
 $\boldsymbol {\Theta }$
are known, which we term as the oracle setting. For simplicity, we consider
$\boldsymbol {\Theta }$
are known, which we term as the oracle setting. For simplicity, we consider
 $K=2$
latent classes and
$K=2$
latent classes and
 $I^\star =\sum _{j\in [J]}I(\theta _{j,1},\theta _{j,2})$
. In this regime, we can relate the clustering problem for the i-th sample to the following binary hypothesis testing problem:
$I^\star =\sum _{j\in [J]}I(\theta _{j,1},\theta _{j,2})$
. In this regime, we can relate the clustering problem for the i-th sample to the following binary hypothesis testing problem:
 $$ \begin{align*} H_0:s_i^\star=1,\quad \text{v.s.} \quad H_0:s_i^\star=2. \end{align*} $$
$$ \begin{align*} H_0:s_i^\star=1,\quad \text{v.s.} \quad H_0:s_i^\star=2. \end{align*} $$
By the Neyman–Pearson lemma, the test that gives the optimal Type-I plus Type-II error is the likelihood ratio test. Consequently, the oracle classifier assigns an observation to the class that maximizes the log-likelihood:
 $$ \begin{align} \bar s_i = \operatorname*{\mbox{arg max}}_{k\in[2]} \sum_{j\in[J]} \Big[R_{i,j} \log\theta_{j,k} + (1-R_{i,j}) \log\left(1-\theta_{j,k}\right)\Big]. \end{align} $$
$$ \begin{align} \bar s_i = \operatorname*{\mbox{arg max}}_{k\in[2]} \sum_{j\in[J]} \Big[R_{i,j} \log\theta_{j,k} + (1-R_{i,j}) \log\left(1-\theta_{j,k}\right)\Big]. \end{align} $$
Assuming without loss of generality that
 $s^\star _i=1$
, one can show that the mis-clustering probability satisfies
$s^\star _i=1$
, one can show that the mis-clustering probability satisfies
 $$ \begin{align*} &\mathbb{P}\left(\bar s_i\ne s^\star_i\right) =\mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,2}\left(1-\theta_{j,1}\right)}{\theta_{j,1}\left(1-\theta_{j,2}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,1}}{1-\theta_{j,2}}\right)\le \exp\left(-\frac{\sum_{j\in[J]}I(\theta_{j,1},\theta_{j,2})}{2}\right). \end{align*} $$
$$ \begin{align*} &\mathbb{P}\left(\bar s_i\ne s^\star_i\right) =\mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,2}\left(1-\theta_{j,1}\right)}{\theta_{j,1}\left(1-\theta_{j,2}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,1}}{1-\theta_{j,2}}\right)\le \exp\left(-\frac{\sum_{j\in[J]}I(\theta_{j,1},\theta_{j,2})}{2}\right). \end{align*} $$
In other words, the above error rate in the oracle setting directly informs the information-theoretic limit of any clustering procedure in the LCM with binary responses, as indicated by Theorem 1. Note that the oracle estimator (15) that achieves this optimal rate is constructed using the true
 $\boldsymbol {\Theta }$
and cannot be applied in practice. Later, we will construct a computationally feasible estimator (i.e., our SOLA estimator) that achieves this optimal rate without relying on prior knowledge of
$\boldsymbol {\Theta }$
and cannot be applied in practice. Later, we will construct a computationally feasible estimator (i.e., our SOLA estimator) that achieves this optimal rate without relying on prior knowledge of
 $\boldsymbol {\Theta }$
.
$\boldsymbol {\Theta }$
.
4.3 Theoretical guarantee of SOLA
In this section, we give the theoretical guarantee of SOLA. To facilitate the theoretical analysis, we consider a sample-splitting variant of SOLA (Algorithm 3), where the sample data points are randomly partitioned into two subsets
 ${\mathcal{S}}_1,{\mathcal{S}}_2$
of size
${\mathcal{S}}_1,{\mathcal{S}}_2$
of size
 $\lceil N/2\rceil $
and
$\lceil N/2\rceil $
and
 $N-\lceil N/2\rceil $
. The key idea is to estimate
$N-\lceil N/2\rceil $
. The key idea is to estimate
 $\boldsymbol {\Theta }$
using one subset of samples, and then update labels for the remaining ones. The procedure can be repeated by switching the roles of the two subsets, and we can obtain labels for all samples. Finally, an alignment step is needed due to the permutation ambiguity of clustering in the two subsets. We have the following result, whose proof is deferred to Section B.2.
$\boldsymbol {\Theta }$
using one subset of samples, and then update labels for the remaining ones. The procedure can be repeated by switching the roles of the two subsets, and we can obtain labels for all samples. Finally, an alignment step is needed due to the permutation ambiguity of clustering in the two subsets. We have the following result, whose proof is deferred to Section B.2.

Algorithm 3: Long description
The flowchart begins with the title Algorithm 3 SOLA with sample splitting. Step 1 defines the data matrix R as a binary matrix of size N by J, index sets S sub 1 and S sub 2, and number of clusters K. The result is the estimated labels s hat superscript E, a vector of length N with entries in K. Step 1 instructs to construct sub-matrices R sub S sub 1 and R sub S sub 2 from R using the index sets. Step 2 initializes label estimates as s hat superscript m equals Spec of R sub S sub m, for m equals 1 and 2. Step 3 defines initial center estimates as theta hat sub j k superscript m equals the sum over i in S sub m of R sub i j times the indicator that s hat sub i superscript m equals k, all over the sum over i in S sub m of the indicator that s hat sub i superscript m equals k, for all j in J, k in K, m equals 1, 2. Step 4 performs one-step likelihood-based refinement, updating s tilde sub i superscript l as the argument over k in K that maximizes the sum over j in J of R sub i j times log of theta hat sub j k superscript m plus one minus R sub i j times log of one minus theta hat sub j k superscript m, for i in S sub l, l not equal to m in 1, 2. Equation 16 is referenced here. Step 5 aligns labels by setting s tilde sub i equals s tilde sub i superscript 1 for i in S sub 1. For S sub 2, pi hat is defined as the permutation in S sub K that minimizes the Frobenius norm of theta hat superscript 1 minus theta hat superscript 2 times G sub pi, where S sub K is the set of all permutations of K and G sub pi is the column permutation matrix for pi. The final labels for S sub 2 are set as pi hat of s tilde sub i superscript 2.
Theorem 2. Suppose Assumptions 1 and 2 and the assumptions of Proposition 1 hold. In addition, assume that
 $N\gtrsim K\log N$
,
$N\gtrsim K\log N$
,
 $JK\lesssim \min \{\exp (-c\Delta ^2/\bar \sigma ^2 ),N^{\gamma _0}\}$
, for some universal constants
$JK\lesssim \min \{\exp (-c\Delta ^2/\bar \sigma ^2 ),N^{\gamma _0}\}$
, for some universal constants
 $0<c<1/8$
and
$0<c<1/8$
and
 $\gamma _0>0$
. If the SNR condition satisfies
$\gamma _0>0$
. If the SNR condition satisfies
 $$ \begin{align*} \frac{\Delta/\bar\sigma}{\sqrt{J}K^{3/4}\left(\log N\right)^{1/4}/N^{1/4}}\rightarrow\infty, \end{align*} $$
$$ \begin{align*} \frac{\Delta/\bar\sigma}{\sqrt{J}K^{3/4}\left(\log N\right)^{1/4}/N^{1/4}}\rightarrow\infty, \end{align*} $$
then, for
 $\widehat {\boldsymbol s}$
from Algorithm 3, we have
$\widehat {\boldsymbol s}$
from Algorithm 3, we have
 $$ \begin{align*} \mathbb{E}\ell \left(\widehat {\boldsymbol s}, {\boldsymbol s}^\star\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
$$ \begin{align*} \mathbb{E}\ell \left(\widehat {\boldsymbol s}, {\boldsymbol s}^\star\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
Combining Theorems 1 and 2, we can see that the estimator of Algorithm 3 achieves the fundamental statistical limit and is optimal for estimating the latent class labels. We have several remarks on Theorem 2. First, it is interesting to consider the regime when
 $J=o (\sqrt {\frac {N\log N}{K}} )$
, since otherwise the SNR condition would already implies exact recovery (perfect estimation of latent class labels with high probability) for spectral clustering, as shown by Theorem 2 and Proposition 1. Second, the sample splitting step is crucial in the current proof of Theorem 2 to decouple the dependence between
$J=o (\sqrt {\frac {N\log N}{K}} )$
, since otherwise the SNR condition would already implies exact recovery (perfect estimation of latent class labels with high probability) for spectral clustering, as shown by Theorem 2 and Proposition 1. Second, the sample splitting step is crucial in the current proof of Theorem 2 to decouple the dependence between
 $R_{i,j}$
and
$R_{i,j}$
and
 $\widehat {\boldsymbol {\Theta }}$
in (8). This step serves purely as a theoretical device to facilitate the theoretical analysis of clustering error rate, as commonly adopted in theoretical statistics (Abbe, Reference Abbe2018; Lei & Zhu, Reference Lei and Zhu2017; Rinaldo et al., Reference Rinaldo, Wasserman and G’Sell2019; Vu, Reference Vu2018). In practice, halving the sample only increases the estimation error of
$\widehat {\boldsymbol {\Theta }}$
in (8). This step serves purely as a theoretical device to facilitate the theoretical analysis of clustering error rate, as commonly adopted in theoretical statistics (Abbe, Reference Abbe2018; Lei & Zhu, Reference Lei and Zhu2017; Rinaldo et al., Reference Rinaldo, Wasserman and G’Sell2019; Vu, Reference Vu2018). In practice, halving the sample only increases the estimation error of
 $\widehat {\boldsymbol {\Theta }}$
by a constant factor, which is negligible in theory and immaterial in practice when the sample size N is large. Alternatively, it may be possible in the future to show that the same theoretical guarantee holds for the original version of SOLA, that is, Algorithm 2, by developing a leave-one-out analysis similar to that in Zhang and Zhou (Reference Zhang and Zhou2024). However, the analysis will be highly technical and much more involved than that in Zhang and Zhou (Reference Zhang and Zhou2024) and beyond the scope of our current focus. Last, although sample splitting simplifies theoretical analysis, it may not be necessary in practice; we use the original SOLA (Algorithm 2) for all numerical experiments and observe satisfactory empirical results.
$\widehat {\boldsymbol {\Theta }}$
by a constant factor, which is negligible in theory and immaterial in practice when the sample size N is large. Alternatively, it may be possible in the future to show that the same theoretical guarantee holds for the original version of SOLA, that is, Algorithm 2, by developing a leave-one-out analysis similar to that in Zhang and Zhou (Reference Zhang and Zhou2024). However, the analysis will be highly technical and much more involved than that in Zhang and Zhou (Reference Zhang and Zhou2024) and beyond the scope of our current focus. Last, although sample splitting simplifies theoretical analysis, it may not be necessary in practice; we use the original SOLA (Algorithm 2) for all numerical experiments and observe satisfactory empirical results.
Remark 2. Our work is related to the Tensor-EM method introduced by Zeng et al. (Reference Zeng, Gu and Xu2023), which also follows an initialization-and-refinement strategy. In the high level, both our methods require moment-based methods in the initialization. However, there are two important distinctions. Zeng et al. (Reference Zeng, Gu and Xu2023) employ a tensor decomposition that leverages higher-order moments and can be computationally intensive and unstable. In contrast, our spectral initialization exploits only the second moment of data (since SVD of the data matrix is equivalent to eigendecomposition of the Gram matrix), making it both simple and efficient. Second, the error rate established in Zeng et al. (Reference Zeng, Gu and Xu2023) is of polynomial order, that is,
 $O\bigl (J^{-1/2}\bigr )$
, whereas our SOLA achieves the statistically optimal exponential error rate with respect to
$O\bigl (J^{-1/2}\bigr )$
, whereas our SOLA achieves the statistically optimal exponential error rate with respect to
 $I^\star $
.
$I^\star $
.
As an extension of Theorem 2, we have a similar theoretical guarantee for the one-step CEM refinement proposed in Section 3.3, whose proof is given in Section B.4.
Corollary 1. Suppose the conditions in Corollary 2 hold. Consider the output of Algorithm 3 with (16) replaced by (9) and sample splitting version of (10), we have
 $$ \begin{align*} \mathbb{E}\ell \left(\widehat {\boldsymbol s}, {\boldsymbol s}^\star\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
$$ \begin{align*} \mathbb{E}\ell \left(\widehat {\boldsymbol s}, {\boldsymbol s}^\star\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
Theorem 1 indicates that one-step CEM refinement achieves the same exponential error rate
 $\exp (-I^*/2)$
as Algorithm 3. There might be a gap between these two methods when Assumption 2 does not hold, which is an interesting future direction to consider.
$\exp (-I^*/2)$
as Algorithm 3. There might be a gap between these two methods when Assumption 2 does not hold, which is an interesting future direction to consider.
4.4 Comparison of spectral clustering and SOLA
In this section, we compare the convergence rate of spectral clustering and SOLA under LCM. While spectral clustering is widely employed due to its computational efficiency and solid theoretical guarantees in general clustering settings, we demonstrate that SOLA attains minimax-optimal clustering error rates in LCMs that spectral clustering fails to achieve.
In view of Theorem 1, the minimax-optimal clustering error rate for LCM is of order
 $\exp (-I^\star /2 )$
. On the other hand, spectral clustering is shown to achieve the error rate scaling as
$\exp (-I^\star /2 )$
. On the other hand, spectral clustering is shown to achieve the error rate scaling as
 $\exp (-\Delta ^2/(8\bar \sigma ^2) )$
in Proposition 1. To understand the difference between these two quantities, we have the following result, whose proof can be found in Section B.5.
$\exp (-\Delta ^2/(8\bar \sigma ^2) )$
in Proposition 1. To understand the difference between these two quantities, we have the following result, whose proof can be found in Section B.5.
Proposition 3. Assume that (a)
 $\min _{k_1\ne k_2\in [K]}\left |\Omega _0(k_1,k_2)\right |\gtrsim J$
, where
$\min _{k_1\ne k_2\in [K]}\left |\Omega _0(k_1,k_2)\right |\gtrsim J$
, where
 $\Omega _0(k_1,k_2):= \{j\in [J]:\left |\theta _{j,k_1}-\theta _{j,k_2}\right |=o(1) \}$
and (b)
$\Omega _0(k_1,k_2):= \{j\in [J]:\left |\theta _{j,k_1}-\theta _{j,k_2}\right |=o(1) \}$
and (b)
 $\min _{k\in [K]}\left |\left \{j\in [J]:\left |\theta _{j,k}-1/2\right |>c_0\right \}\right |\gtrsim J$
for some universal constant
$\min _{k\in [K]}\left |\left \{j\in [J]:\left |\theta _{j,k}-1/2\right |>c_0\right \}\right |\gtrsim J$
for some universal constant
 $c_0>0$
. Then we have
$c_0>0$
. Then we have
 $$ \begin{align*} \exp\left(-\frac{I^\star}{2}\right) &\lesssim\exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1+c\right)\right), \end{align*} $$
$$ \begin{align*} \exp\left(-\frac{I^\star}{2}\right) &\lesssim\exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1+c\right)\right), \end{align*} $$
for some universal constant
 $c>0$
.
$c>0$
.
A few comments are in order regarding Proposition 3. First, under the conditions (a) and (b), the rate of spectral clustering becomes sub-optimal (in order) due to a loose constant in the exponent as the latent class separation
 $\Delta \rightarrow \infty $
. Second, it is important to note that the mis-clustering error
$\Delta \rightarrow \infty $
. Second, it is important to note that the mis-clustering error
 $\ell (\widehat {\boldsymbol s}, {\boldsymbol s}^*)$
takes values in the finite set
$\ell (\widehat {\boldsymbol s}, {\boldsymbol s}^*)$
takes values in the finite set
 $\left \{0,1/N,\ldots ,1\right \}$
according to the definition (4). Given this, it is only meaningful to compare error rates when the exponent
$\left \{0,1/N,\ldots ,1\right \}$
according to the definition (4). Given this, it is only meaningful to compare error rates when the exponent
 $\Delta ^2/\bar \sigma ^2$
(or
$\Delta ^2/\bar \sigma ^2$
(or
 $I^\star $
) does not exceed a constant factor of
$I^\star $
) does not exceed a constant factor of
 $\log N$
, since otherwise exact clustering of all subjects is achieved with high probability. To see this, we use Markov inequality to get
$\log N$
, since otherwise exact clustering of all subjects is achieved with high probability. To see this, we use Markov inequality to get
 $$ \begin{align*}\mathbb{P}(\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \neq 0) = \mathbb{P}(\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \ge 1/N) \leq N \mathbb{E}\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \leq N \exp\left(-C\log N\right) \to 0, \end{align*} $$
$$ \begin{align*}\mathbb{P}(\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \neq 0) = \mathbb{P}(\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \ge 1/N) \leq N \mathbb{E}\ell(\widehat{\boldsymbol s}, {\boldsymbol s}^*) \leq N \exp\left(-C\log N\right) \to 0, \end{align*} $$
for a constant
 $C>1$
. In view of this, the condition (a) helps us exclude the trivial case where
$C>1$
. In view of this, the condition (a) helps us exclude the trivial case where
 $I^\star \asymp \Delta ^2\asymp J$
, which would only allow
$I^\star \asymp \Delta ^2\asymp J$
, which would only allow
 $J\lesssim \log N$
. Third, the essential order difference occurs when most of
$J\lesssim \log N$
. Third, the essential order difference occurs when most of
 $\theta _{j,k}$
’s are bounded away from
$\theta _{j,k}$
’s are bounded away from
 $1/2$
. To see this, consider the scenario when
$1/2$
. To see this, consider the scenario when
 $K=2$
,
$K=2$
,
 $\theta _{j,1}=0.5$
, and
$\theta _{j,1}=0.5$
, and
 $\theta _{j,2}=0.5-\delta $
for some
$\theta _{j,2}=0.5-\delta $
for some
 $\delta =o(1)$
. Then we have
$\delta =o(1)$
. Then we have
 $\Delta =\frac {1}{2}J\delta ^2$
and
$\Delta =\frac {1}{2}J\delta ^2$
and
 $I^\star =-J\log \left (\sqrt {\frac {1}{2}\left (\frac {1}{2}-\delta \right )}+\sqrt {\frac {1}{2}\left (\frac {1}{2}+\delta \right )}\right )=\frac {1}{2}J\delta ^2\left (1+o(1)\right )$
. This implies that without condition (b), the exponents
$I^\star =-J\log \left (\sqrt {\frac {1}{2}\left (\frac {1}{2}-\delta \right )}+\sqrt {\frac {1}{2}\left (\frac {1}{2}+\delta \right )}\right )=\frac {1}{2}J\delta ^2\left (1+o(1)\right )$
. This implies that without condition (b), the exponents
 $\Delta $
and
$\Delta $
and
 $I^\star $
are of the same order, resulting in at most a constant-factor difference in clustering error for spectral clustering and SOLA. We also conduct numerical experiments in Section 5 to verify the necessity of (b).
$I^\star $
are of the same order, resulting in at most a constant-factor difference in clustering error for spectral clustering and SOLA. We also conduct numerical experiments in Section 5 to verify the necessity of (b).
4.5 Estimation of the number of latent classes K
In practice, the true number of latent classes K may be unknown. To see how we can estimate K from data, recall that
 $\mathbf {R}=\mathbf {Z}\boldsymbol {\Theta }^\top +\mathbf {E}$
. By Weyl’s inequality and classical random-matrix theory (Vershynin, Reference Vershynin2018), the singular values of
$\mathbf {R}=\mathbf {Z}\boldsymbol {\Theta }^\top +\mathbf {E}$
. By Weyl’s inequality and classical random-matrix theory (Vershynin, Reference Vershynin2018), the singular values of
 $\mathbf {R}$
satisfy
$\mathbf {R}$
satisfy
 $$ \begin{align*}\left|\lambda_i\left(\mathbf{R}\right)-\lambda_i\left(\mathbf{Z}\boldsymbol{\Theta}^\top\right)\right|\le \left\|\mathbf{E}\right\|=O_p\left(\sqrt{J}+\sqrt{N}\right),\quad i\in[N\wedge J].\end{align*} $$
$$ \begin{align*}\left|\lambda_i\left(\mathbf{R}\right)-\lambda_i\left(\mathbf{Z}\boldsymbol{\Theta}^\top\right)\right|\le \left\|\mathbf{E}\right\|=O_p\left(\sqrt{J}+\sqrt{N}\right),\quad i\in[N\wedge J].\end{align*} $$
Since
 $\mathbf {Z}\boldsymbol {\Theta }^\top $
has exactly K nonzero singular values
$\mathbf {Z}\boldsymbol {\Theta }^\top $
has exactly K nonzero singular values
 $\lambda _1\ge \cdots \ge \lambda _K>0$
, and Proposition 2 shows that
$\lambda _1\ge \cdots \ge \lambda _K>0$
, and Proposition 2 shows that
 $\lambda _K\gtrsim \sqrt {\alpha BNJ}$
under a common generative setting, the top K singular values of
$\lambda _K\gtrsim \sqrt {\alpha BNJ}$
under a common generative setting, the top K singular values of
 $\mathbf {R}$
lie well above the noise level. Accordingly, we estimate K by counting how many singular values of
$\mathbf {R}$
lie well above the noise level. Accordingly, we estimate K by counting how many singular values of
 $\mathbf {R}$
exceed a threshold slightly above the noise level:
$\mathbf {R}$
exceed a threshold slightly above the noise level:
 $$ \begin{align} \widehat K=\left|\left\{i\in[N\wedge J]:\lambda_i\left(\mathbf{R}\right)>2.01 \left(\sqrt{J}+\sqrt{N}\right)\right\}\right|. \end{align} $$
$$ \begin{align} \widehat K=\left|\left\{i\in[N\wedge J]:\lambda_i\left(\mathbf{R}\right)>2.01 \left(\sqrt{J}+\sqrt{N}\right)\right\}\right|. \end{align} $$
Here, the factor
 $2.01$
ensures we count only those singular values contributed by the low-rank signal. We have the following lemma certifying the consistency of
$2.01$
ensures we count only those singular values contributed by the low-rank signal. We have the following lemma certifying the consistency of
 $\widehat K$
, whose proof is deferred to Section B.6.
$\widehat K$
, whose proof is deferred to Section B.6.
Lemma 1. Instate the assumptions of Proposition 1. For
 $\widehat K$
defined in (17), we have
$\widehat K$
defined in (17), we have
 $$ \begin{align*}\mathbb{P}\left(\widehat K=K\right)=1-o(1),\qquad \text{as~}N,J\rightarrow\infty.\end{align*} $$
$$ \begin{align*}\mathbb{P}\left(\widehat K=K\right)=1-o(1),\qquad \text{as~}N,J\rightarrow\infty.\end{align*} $$
This thresholding rule provides a formal analog of the classical scree-plot method (Cattell, Reference Cattell1966; Zhang et al., Reference Zhang, Chen and Li2020), and its proof shares a similar spirit of Theorem 2 in Zhang et al. (Reference Zhang, Chen and Li2020) but with a sharper characterization of the constant factor in the noise magnitude.
5 Numerical experiments
5.1 Simulation studies
We compare our proposed methods SOLA (Algorithm 2) and
 $\text {SOLA}+$
(Algorithm 2 with multiple steps refinement), with spectral method (Zhang & Zhou, Reference Zhang and Zhou2024), EM (Linzer & Lewis, Reference Linzer and Lewis2011), and Tensor-CEM (Zeng et al., Reference Zeng, Gu and Xu2023). For the EM algorithm, we employ the popular polca package (Linzer & Lewis, Reference Linzer and Lewis2011) in R, and for Tensor-CEM, we use the original MATLAB code (Zeng et al., Reference Zeng, Gu and Xu2023) for tensor initialization combined with our R-based implementation of the CEM refinement. Our evaluation focuses on three aspects: (a) clustering accuracy, (b) stability, and (c) computational efficiency. Throughout the simulations, we generate the true latent label
$\text {SOLA}+$
(Algorithm 2 with multiple steps refinement), with spectral method (Zhang & Zhou, Reference Zhang and Zhou2024), EM (Linzer & Lewis, Reference Linzer and Lewis2011), and Tensor-CEM (Zeng et al., Reference Zeng, Gu and Xu2023). For the EM algorithm, we employ the popular polca package (Linzer & Lewis, Reference Linzer and Lewis2011) in R, and for Tensor-CEM, we use the original MATLAB code (Zeng et al., Reference Zeng, Gu and Xu2023) for tensor initialization combined with our R-based implementation of the CEM refinement. Our evaluation focuses on three aspects: (a) clustering accuracy, (b) stability, and (c) computational efficiency. Throughout the simulations, we generate the true latent label
 $\left \{s_i^\star \right \}_{i=1}^N$
independently uniformly from
$\left \{s_i^\star \right \}_{i=1}^N$
independently uniformly from
 $[K]$
and set
$[K]$
and set
 $K=3$
,
$K=3$
,
 $N=2J$
. The parameters
$N=2J$
. The parameters
 $\theta _{j,k}$
are independently sampled from Beta
$\theta _{j,k}$
are independently sampled from Beta
 $(\beta _1,\beta _2)$
. We generate
$(\beta _1,\beta _2)$
. We generate
 $200$
independent replicates and report the average mis-clustering error and computation time, excluding any replicates in which the algorithm fails (Tensor-CEM and EM). Notably, our algorithm is numerically stable without any failures in all simulations.
$200$
independent replicates and report the average mis-clustering error and computation time, excluding any replicates in which the algorithm fails (Tensor-CEM and EM). Notably, our algorithm is numerically stable without any failures in all simulations.
Remark 3 (EM implementations: polca vs. LatentGOLD).
Beyond polca, we also evaluated LatentGOLD (Vermunt & Magidson, Reference Vermunt and Magidson2005), which implements a robust EM routine with safeguards against numerical underflow. Table 1 reports a representative comparison across three regimes (
 $N=2J$
,
$N=2J$
,
 $N=J$
, and
$N=J$
, and
 $N=J/2$
), showing that LatentGOLD is substantially more stable and accurate than polca in these settings. Our overall message remains unchanged: EM-type methods can be competitive in the classical regime with relatively large N and smaller J, whereas SOLA/SOLA+ become increasingly advantageous as J grows and the problem enters the high-dimensional regime (with J comparable to or larger than N). While retaining polca for comparison purposes in our large-scale simulation studies, we emphasize that when analyzing data with a small-to-moderate J, it is recommended to use LatentGOLD for their better numerical stability and performance.
$N=J/2$
), showing that LatentGOLD is substantially more stable and accurate than polca in these settings. Our overall message remains unchanged: EM-type methods can be competitive in the classical regime with relatively large N and smaller J, whereas SOLA/SOLA+ become increasingly advantageous as J grows and the problem enters the high-dimensional regime (with J comparable to or larger than N). While retaining polca for comparison purposes in our large-scale simulation studies, we emphasize that when analyzing data with a small-to-moderate J, it is recommended to use LatentGOLD for their better numerical stability and performance.
Clustering error across different methods and settings under
 $100$
replicates
$100$
replicates

Table 1 Long description
The table has four columns for methods: S O L A, S O L A plus, E M by polca, and E M by LatentGold. Three rows represent different settings. First row, N equals 190, J equals 95, labeled N equals 2 J: S O L A 0.0815, S O L A plus 0.0772, E M by polca 0.3022, E M by LatentGold 0.0645. Second row, N equals 95, J equals 95, labeled N equals J: S O L A 0.1760, S O L A plus 0.1745, E M by polca 0.4642, E M by LatentGold 0.2609. Third row, N equals 75, J equals 150, labeled N equals J all over 2: S O L A 0.0411, S O L A plus 0.0411, E M by polca 0.5002, E M by LatentGold 0.2795. Clustering error is lowest for S O L A and S O L A plus in all settings, highest for E M by polca.
Simulation 1: Latent class estimation accuracy for dense
 \ $\boldsymbol {\Theta }$
close to
\ $\boldsymbol {\Theta }$
close to
 $1/2$
. In the first simulation, we set
$1/2$
. In the first simulation, we set
 $(\beta _1,\beta _2)=(5,5)$
. Under these parameters, the entries of
$(\beta _1,\beta _2)=(5,5)$
. Under these parameters, the entries of
 $\boldsymbol {\Theta }$
tend to be close to
$\boldsymbol {\Theta }$
tend to be close to
 $0.5$
. As shown in Figure 2, our proposed methods achieve lower mis-clustering errors compared to the alternative approaches. In this setting, the improvement of SOLA over the plain spectral clustering method is negligible, which is expected since
$0.5$
. As shown in Figure 2, our proposed methods achieve lower mis-clustering errors compared to the alternative approaches. In this setting, the improvement of SOLA over the plain spectral clustering method is negligible, which is expected since
 $\theta _{j,k}$
’s values near
$\theta _{j,k}$
’s values near
 $0.5$
reduce the additional gain from incorporating the likelihood information. This observation supports the necessity of having
$0.5$
reduce the additional gain from incorporating the likelihood information. This observation supports the necessity of having
 $\theta _{j,k}$
’s well separated from
$\theta _{j,k}$
’s well separated from
 $0.5$
(see Proposition A.1) to have likelihood-based refinement improve upon spectral clustering. It is also worth noting that Tensor-CEM performs poorly when both the number of items J and the sample size N are small, likely due to instability introduced by its tensor-based initialization step.
$0.5$
(see Proposition A.1) to have likelihood-based refinement improve upon spectral clustering. It is also worth noting that Tensor-CEM performs poorly when both the number of items J and the sample size N are small, likely due to instability introduced by its tensor-based initialization step.
Simulation 1: Mis-clustering proportions versus number of items J. Entries of
 \ $\boldsymbol {\Theta }$
are independently generated from
\ $\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta} (5,5)$
.
$\text {Beta} (5,5)$
.

Figure 2 Long description
The x-axis is labeled Number of items J (sample size N equals 2 J), ranging from 20 to 100. The y-axis is labeled Misclustering Proportion, ranging from 0.1 to 0.5. Five methods are plotted: E M (red circles, solid line), S O L A (olive triangles, dashed line), S O L A plus (green squares, dashed line), S V D (blue plus signs, dash-dot line), and Tensor dash C E M (pink squares, dotted line). All methods start near 0.5 misclustering proportion at low J values. As J increases, all lines show a downward trend. E M and Tensor dash C E M decrease more gradually, while S O L A, S O L A plus, and S V D drop sharply and converge near 0.1 at high J values. The legend is positioned above the plot, with each method’s symbol and color clearly indicated.
Simulation 2: Latent class estimation accuracy for sparse item parameters
 $ \ \boldsymbol {\Theta }$
. In the second simulation, we choose
$ \ \boldsymbol {\Theta }$
. In the second simulation, we choose
 $(\beta _1,\beta _2)=(1,8)$
, a sparse scenario, where the
$(\beta _1,\beta _2)=(1,8)$
, a sparse scenario, where the
 $\theta _{j,k}$
’s tend to be close to
$\theta _{j,k}$
’s tend to be close to
 $0$
. Figure 3 illustrates that our proposed methods exhibit superior clustering accuracy when N and J are small, while maintaining competitive performance as these dimensions increase. In this sparse setting, the traditional EM algorithm performs the worst because
$0$
. Figure 3 illustrates that our proposed methods exhibit superior clustering accuracy when N and J are small, while maintaining competitive performance as these dimensions increase. In this sparse setting, the traditional EM algorithm performs the worst because
 $\theta _{j,k}$
’s are near the boundary (close to
$\theta _{j,k}$
’s are near the boundary (close to
 $0$
), making it difficult for random initializations to converge to optimal solutions. Furthermore, the gap between spectral clustering and SOLA becomes more pronounced when the
$0$
), making it difficult for random initializations to converge to optimal solutions. Furthermore, the gap between spectral clustering and SOLA becomes more pronounced when the
 $\theta _{j,k}$
’s are bounded away from
$\theta _{j,k}$
’s are bounded away from
 $0.5$
.
$0.5$
.
Simulation 2: Mis-clustering proportions versus number of items J. Entries of
 \ $\boldsymbol {\Theta }$
are independently generated from
\ $\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta} (1,8)$
.
$\text {Beta} (1,8)$
.

Figure 3 Long description
The x-axis is labeled Number of items J with values from 30 to 90. The y-axis is labeled Misclustering Proportion, ranging from 0.1 to 0.5. Five methods are compared: E M (red circles, solid line), S O L A (olive triangles, dashed line), S O L A plus (green squares, dashed line), S V D (blue pluses, dashed line), and Tensor-C E M (magenta hollow squares, dotted line). All methods show a general decrease in misclustering proportion as J increases. E M starts near 0.5 and decreases to about 0.3, remaining consistently higher than the other methods. S O L A, S O L A plus, and S V D overlap closely, starting near 0.43 and dropping below 0.15 as J increases. Tensor-C E M starts at 0.5, decreases more sharply, and converges with the other non-E M methods for higher J. The legend is at the top, with method names and symbols.
Simulation 3: Stability analysis. We next assess the stability of the different methods under the sparse setting
 $(\beta _1,\beta _2)=(1,8)$
. In particular, we record a “failure” point if either (a) the estimated number of classes degenerates from the pre-specified K to a smaller value or (b) the algorithm produces an error during execution. As shown in Figure 4, our proposed methods are robust across a wide range of N and J without any failures in any simulation trial. In particular, the failure rate for Tensor-CEM exceeds 15% for small N and J, likely due to its sensitive initialization, while the EM algorithm becomes increasingly unstable as the dimensions grow. These results underscore the robustness of our SOLA approaches.
$(\beta _1,\beta _2)=(1,8)$
. In particular, we record a “failure” point if either (a) the estimated number of classes degenerates from the pre-specified K to a smaller value or (b) the algorithm produces an error during execution. As shown in Figure 4, our proposed methods are robust across a wide range of N and J without any failures in any simulation trial. In particular, the failure rate for Tensor-CEM exceeds 15% for small N and J, likely due to its sensitive initialization, while the EM algorithm becomes increasingly unstable as the dimensions grow. These results underscore the robustness of our SOLA approaches.
Simulation 3: Failure rate versus the number of items J. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta} (1,8)$
.
$\text {Beta} (1,8)$
.

Figure 4 Long description
The x-axis is labeled Number of items J (sample size N equals 2 J), ranging from 20 to 100. The y-axis is labeled Failure Rate, spanning 0.00 to 0.18. Five methods are plotted: E M (red circles), S O L A (green triangles), S O L A plus (green squares), S V D (blue plus signs), and Tensor-C E M (pink squares with dotted line). Tensor-C E M starts at the highest failure rate near 0.18 at J equals 20 and decreases sharply to below 0.02 by J equals 100. The other methods remain close to zero throughout, with minor fluctuations. The legend is positioned at the top, showing all method symbols and colors.
Simulation 4: Computational efficiency. Finally, we compare the computation time required by each method. In our experiments, the SVD step and our SOLA and
 $\text {SOLA}+$
algorithms are implemented in R. The total computation time for Tensor-CEM is the sum of the MATLAB initialization and the R refinement stages. As reported in Table 2 and illustrated in Figure 5, our proposed methods are significantly faster than both the EM and Tensor-CEM approaches, with computation time comparable to that of SVD.
$\text {SOLA}+$
algorithms are implemented in R. The total computation time for Tensor-CEM is the sum of the MATLAB initialization and the R refinement stages. As reported in Table 2 and illustrated in Figure 5, our proposed methods are significantly faster than both the EM and Tensor-CEM approaches, with computation time comparable to that of SVD.
Simulation 4: Running time (seconds) of different methods

Table 2 Long description
The table has two rows for J values 25 and 95, and five columns for methods S V D, S O L A, S O L A plus, E M, and Tensor dash C E M. For J equals 25, running times are: S V D 4.15 times 10 to the minus 4, S O L A 8.62 times 10 to the minus 4, S O L A plus 4.19 times 10 to the minus 3, E M 1.42 times 10 to the minus 2, Tensor dash C E M 5.12 times 10 to the minus 1. For J equals 95, running times are: S V D 2.33 times 10 to the minus 3, S O L A 4.66 times 10 to the minus 3, S O L A plus 2.51 times 10 to the minus 2, E M 1.80 times 10 to the minus 1, Tensor dash C E M 6.95 times 10 to the minus 1. Running times increase for all methods as J increases, with Tensor dash C E M consistently the slowest and S V D the fastest.
Simulation 4: Running time (seconds) of different methods.

Figure 5 Long description
The box plot displays running time in seconds on the y-axis and five methods on the x-axis, ordered left to right as E M, S O L A, S O L A plus, S V D, and Tensor dash C E M. E M shows a median near 0.2 with outliers up to 0.4. S O L A, S O L A plus, and S V D have medians at zero with minimal spread and a few small outliers. Tensor dash C E M has the highest median near 0.7, with a tight interquartile range and outliers above 0.75. Red dots indicate outliers for each method.
Simulation 5: Latent class estimation accuracy under different regimes. In the fifth simulation study, we also employ Spec-EM (EM algorithm initialized by spectral clustering), motivated by the fact that when the number of items is moderately large, spectral clustering provides an effective initialization for the classical EM algorithm for LCMs. In particular, we consider the following regimes: (i)
 $N=J$
(Figure 6), (ii)
$N=J$
(Figure 6), (ii)
 $N=J/2$
(Figure 7), (iii) fix
$N=J/2$
(Figure 7), (iii) fix
 $N=100$
and vary J (Figure 8), (iv) fix
$N=100$
and vary J (Figure 8), (iv) fix
 $J=100$
and vary N (Figure 9), (v) fix
$J=100$
and vary N (Figure 9), (v) fix
 $J=30$
and vary N (Figure 10), and (vi)
$J=30$
and vary N (Figure 10), and (vi)
 $N=J$
with
$N=J$
with
 $\left \{s_i^\star \right \}_{i=1}^N$
being independently generated from
$\left \{s_i^\star \right \}_{i=1}^N$
being independently generated from
 $[3]$
with probability
$[3]$
with probability
 $(p_1,p_2,p_3)=(1/6,1/3,1/2)$
(Figure 11). In all these settings, we set
$(p_1,p_2,p_3)=(1/6,1/3,1/2)$
(Figure 11). In all these settings, we set
 $(\beta _1,\beta _2)=(1,8)$
. In addition, we consider (vii)
$(\beta _1,\beta _2)=(1,8)$
. In addition, we consider (vii)
 $N=J$
under the fixed design of
$N=J$
under the fixed design of
 $\boldsymbol {\Theta }$
(Figure 12), where the fixed item parameter matrix
$\boldsymbol {\Theta }$
(Figure 12), where the fixed item parameter matrix
 $\boldsymbol \Theta $
is constructed by vertically concatenating copies of a
$\boldsymbol \Theta $
is constructed by vertically concatenating copies of a
 $5\times 3$
block matrix
$5\times 3$
block matrix
 $\boldsymbol \Theta _0$
as follows:
$\boldsymbol \Theta _0$
as follows:
 $$\begin{align*}\boldsymbol\Theta=\begin{bmatrix} \boldsymbol\Theta_0\\ \vdots\\ \boldsymbol\Theta_0 \end{bmatrix}\Bigg\}~b~\text{copies},\qquad \boldsymbol\Theta_0:=\begin{bmatrix} 0.3 & 0.7 & 0.7\\ 0.3 & 0.7 & 0.3\\ 0.7 & 0.3 & 0.7\\ 0.7 & 0.3 & 0.3\\ 0.7 & 0.7 & 0.3 \end{bmatrix}. \end{align*}$$
$$\begin{align*}\boldsymbol\Theta=\begin{bmatrix} \boldsymbol\Theta_0\\ \vdots\\ \boldsymbol\Theta_0 \end{bmatrix}\Bigg\}~b~\text{copies},\qquad \boldsymbol\Theta_0:=\begin{bmatrix} 0.3 & 0.7 & 0.7\\ 0.3 & 0.7 & 0.3\\ 0.7 & 0.3 & 0.7\\ 0.7 & 0.3 & 0.3\\ 0.7 & 0.7 & 0.3 \end{bmatrix}. \end{align*}$$
Here, the block matrix
 $\boldsymbol \Theta _0$
is vertically stacked b times to yield
$\boldsymbol \Theta _0$
is vertically stacked b times to yield
 $J=5b$
items with
$J=5b$
items with
 $K=3$
latent classes. It is clear that SOLA and SOLA+ perform significantly better in most scenarios except the most traditional large-N, small-J regime, where Spec-EM performs better. This underpins both the validity of SOLA and spectral clustering.
$K=3$
latent classes. It is clear that SOLA and SOLA+ perform significantly better in most scenarios except the most traditional large-N, small-J regime, where Spec-EM performs better. This underpins both the validity of SOLA and spectral clustering.
Simulation 5-1: Mis-clustering proportions versus number of items J under
 $N=J$
. Entries of
$N=J$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 6 Long description
The x axis shows Number of items J, ranging from 30 to 90, with sample size N equal to J. The y axis shows Misclustering Proportion from 0.2 to 0.5. Six methods are plotted: E M (red circles), S O L A (green squares), S O L A plus (brown triangles), S V D (blue squares), Spec dash E M (cyan plus signs), and Tensor dash C E M (magenta asterisks). E M starts near 0.45 and remains above 0.4 across all J. S O L A and S O L A plus drop sharply below 0.3 as J increases, reaching the lowest values near 0.2 at J equals 90. S V D, Spec dash E M, and Tensor dash C E M show intermediate performance, with Tensor dash C E M and S V D converging near 0.2 at high J. All methods except E M show decreasing misclustering proportion as J increases.
Simulation 5-2: Mis-clustering proportions versus number of items J under
 $N=0.5J$
. Entries of
$N=0.5J$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 7 Long description
The x axis shows Number of items J, ranging from 80 to 140, with sample size N equals 0.5 J. The y axis shows Misclustering Proportion from 0.1 to 0.5. Six methods are plotted: E M (red circles), S O L A (green squares), S V D (blue crosses), S O L A plus (brown triangles), Spec-E M (cyan plus signs), and Tensor-C E M (pink stars). E M and Spec-E M maintain high misclustering proportions near 0.5 across all J values. S O L A, S V D, S O L A plus, and Tensor-C E M start at about 0.3 and decrease steadily to below 0.1 as J increases. All methods are labeled in the legend at the top left.
Simulation 5-3: Mis-clustering proportions versus number of items J under
 $N=100$
. Entries of
$N=100$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 8 Long description
The x axis is labeled Number of items J, with sample size N equals 100, ranging from 100 to 250. The y axis is labeled Misclustering Proportion, ranging from 0.0 to 0.5. Six methods are plotted: E M (red circles), S O L A (green squares), S V D (blue crosses), S O L A plus (brown triangles), Spec-E M (cyan dashed line with plus signs), and Tensor-C E M (pink stars). E M maintains the highest misclustering proportion, around 0.45, across all J values. Spec-E M shows a moderate error rate, fluctuating near 0.33. S O L A, S V D, S O L A plus, and Tensor-C E M all start near 0.2 at J equals 100 and decrease steadily, converging below 0.05 by J equals 250. All methods except E M and Spec-E M show improved clustering accuracy as J increases.
Simulation 5-4: Mis-clustering proportions versus sample size N under
 $J=100$
. Entries of
$J=100$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 9 Long description
The x axis displays sample size N ranging from 100 to 250, with J fixed at 100. The y axis shows misclustering proportion from 0 to 0.5. Six methods are plotted: E M (red circles) starts at 0.45 and decreases steadily to 0.25 as N increases. Spec-E M (cyan plus) begins near 0.4 and drops sharply to below 0.1. Tensor-C E M (magenta asterisk) starts at 0.2 and decreases to about 0.08. S O L A (green square), S O L A plus (brown triangle), and S V D (blue crosshatch) all begin near 0.1 and decrease slightly, converging below 0.08. All methods show decreasing misclustering with increasing sample size, with E M consistently highest and S O L A, S O L A plus, S V D lowest.
Simulation 5-5: Mis-clustering proportions versus sample size N under
 $J=30$
. Entries of
$J=30$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 10 Long description
The x-axis is labeled Sample size N number of items J equals 30, ranging from 75 to 250 in increments of 25. The y-axis is labeled Misclustering Proportion, ranging from 0.35 to 0.50. Six methods are shown: E M red circles, S O L A green squares, S V D blue open squares, S O L A plus brown triangles, Spec-E M cyan plus signs, and Tensor-C E M magenta asterisks. All methods show a general decrease in misclustering proportion as N increases. Spec-E M consistently achieves the lowest misclustering proportions, dropping from about 0.42 at N equals 75 to below 0.35 at N equals 250. Tensor-C E M remains the highest, fluctuating around 0.48 to 0.50. E M starts near 0.47 and decreases to about 0.39. S O L A, S V D, and S O L A plus cluster between 0.40 and 0.37 at higher N. The legend appears at the top left, with method names and corresponding symbols and colors.
Simulation 5-6: Mis-clustering proportions versus number of items J under imbalanced latent classes with
 $N=J$
. Entries of
$N=J$
. Entries of
 $\boldsymbol {\Theta }$
are independently generated from
$\boldsymbol {\Theta }$
are independently generated from
 $\text {Beta}(1,8)$
.
$\text {Beta}(1,8)$
.

Figure 11 Long description
The x-axis shows Number of items J ranging from 30 to 90, with sample size N equal to J. The y-axis shows Misclustering Proportion from 0.2 to 0.5. Six methods are compared: E M (red circles), S O L A (green squares), S V D (blue crosses), S O L A plus (brown triangles), Spec-E M (cyan dashed line with pluses), and Tensor-C E M (magenta stars and dashed line). All methods start near 0.45 misclustering at J equals 30. As J increases, Tensor-C E M and Spec-E M show the steepest decline, reaching about 0.2 at J equals 90. E M remains highest, ending near 0.4. S O L A, S V D, and S O L A plus cluster together, declining to about 0.3 at J equals 90. The legend is at the top left.
Simulation 5-7: Mis-clustering proportions versus number of items J under
 $N=J$
. The
$N=J$
. The
 $\boldsymbol {\Theta }$
matrix is set to a fixed design matrix.
$\boldsymbol {\Theta }$
matrix is set to a fixed design matrix.

Figure 12 Long description
The x-axis is labeled Number of items J with sample size N equals J, ranging from 20 to 100. The y-axis is labeled Misclustering Proportion, ranging from 0 to 0.35. Six methods are shown: E M (red circles, solid line), S O L A (green squares, solid line), S V D (blue open squares, solid line), S O L A plus (brown triangles, solid line), Spec-E M (cyan plus, solid line), and Tensor-C E M (magenta stars, dashed line). E M starts at the highest misclustering proportion near 0.33 at J equals 20 and decreases steadily to about 0.07 at J equals 100, always above the other methods. The other five methods cluster closely together, starting near 0.23 at J equals 20 and decreasing rapidly to below 0.05 by J equals 100. Tensor-C E M starts slightly higher than the other non-E M methods but converges with them as J increases. All methods show a decreasing trend in misclustering proportion as J increases.
Simulation 6: Estimation of number of latent classes. Our theoretical guarantee for the selection criterion of K relies on random matrix theory under the asymptotic regime
 $N,J \to \infty $
. This means relatively large N and J are needed for the theoretical guarantee to hold, which is consistent with our focus on high-dimensional data. The constant “2” in the threshold reflects a worst-case bound and can indeed be conservative, especially when entries of
$N,J \to \infty $
. This means relatively large N and J are needed for the theoretical guarantee to hold, which is consistent with our focus on high-dimensional data. The constant “2” in the threshold reflects a worst-case bound and can indeed be conservative, especially when entries of
 $\boldsymbol {\Theta }$
are mostly concentrated away from
$\boldsymbol {\Theta }$
are mostly concentrated away from
 $1/2$
. To illustrate its effectiveness in practice, we have performed simulation studies with
$1/2$
. To illustrate its effectiveness in practice, we have performed simulation studies with
 $N=2J$
and
$N=2J$
and
 $K=3$
, under several generative mechanisms for
$K=3$
, under several generative mechanisms for
 $\boldsymbol {\Theta }$
(i.i.d. Beta
$\boldsymbol {\Theta }$
(i.i.d. Beta
 $(1,1)$
, Beta
$(1,1)$
, Beta
 $(1,4)$
, and Beta
$(1,4)$
, and Beta
 $(1,5)$
, which reflect different sparsity levels, and also the fixed design as described in Simulation 5). As shown in Table 3, the criterion successfully recovers K in high-dimensional regimes. Our real-data analysis in Section 5.2 also demonstrates that the method works well when the data are sufficiently large. For smaller N and J, we recommend that practitioners use classical information criteria, such as BIC, as a more reliable and interpretable tool for selecting K.
$(1,5)$
, which reflect different sparsity levels, and also the fixed design as described in Simulation 5). As shown in Table 3, the criterion successfully recovers K in high-dimensional regimes. Our real-data analysis in Section 5.2 also demonstrates that the method works well when the data are sufficiently large. For smaller N and J, we recommend that practitioners use classical information criteria, such as BIC, as a more reliable and interpretable tool for selecting K.
Proportion of successfully selecting
 $\widehat{K}$
to be the true K based on
$\widehat{K}$
to be the true K based on
 $200$
simulation replicates, under different generative mechanisms of the item parameters
$200$
simulation replicates, under different generative mechanisms of the item parameters
 $\boldsymbol \Theta =(\theta _{j,k})_{J\times K}$
$\boldsymbol \Theta =(\theta _{j,k})_{J\times K}$

Table 3 Long description
The table has four rows for item parameter mechanisms and six columns for J values: one thousand, one thousand two hundred, one thousand four hundred, one thousand six hundred, one thousand eight hundred, two thousand. The first row, Fixed design of item parameters, shows one hundred percent for all J values. The second row, theta sub j k i dot i dot d dot sim Beta one one, also shows one hundred percent for all J values. The third row, theta sub j k i dot i dot d dot sim Beta one four, shows zero percent for one thousand and one thousand two hundred, then one hundred percent for one thousand four hundred and higher. The fourth row, theta sub j k i dot i dot d dot sim Beta one five, shows zero percent for one thousand through one thousand six hundred, seventy percent for one thousand eight hundred, and one hundred percent for two thousand. The table demonstrates that the proportion of correct K selection increases with J for Beta one four and Beta one five, but remains perfect for Fixed and Beta one one designs.
5.2 Real data example
We further evaluate the performance of our methods on the United States 112th Senate Roll Call Votes data, which is publicly available at https://legacy.voteview.com/senate112.htm. The dataset contains voting records for
 $J=486$
roll calls by
$J=486$
roll calls by
 $102$
U.S. senators. Following the preprocessing procedure in Lyu et al. (Reference Lyu, Chen and Gu2025), we convert the response matrix to binary and remove senators who are neither Democrats nor Republicans, as well as those with more than
$102$
U.S. senators. Following the preprocessing procedure in Lyu et al. (Reference Lyu, Chen and Gu2025), we convert the response matrix to binary and remove senators who are neither Democrats nor Republicans, as well as those with more than
 $10\%$
missing votes. This results in a final sample of
$10\%$
missing votes. This results in a final sample of
 $N=94$
senators. For the remaining missing entries, we impute values by randomly assigning
$N=94$
senators. For the remaining missing entries, we impute values by randomly assigning
 $0$
or
$0$
or
 $1$
with probability equal to the positive response rate observed from each senator’s non-missing votes.
$1$
with probability equal to the positive response rate observed from each senator’s non-missing votes.
We compare the performance of the methods considered in our simulation studies. Table 4 summarizes the mis-clustering error and computation time (in seconds) for each method. Interestingly, the SVD approach yields an error comparable to those obtained with SOLA and SOLA+, suggesting that the refinement step may be unnecessary for this dataset. This observation can be partially explained by our remark following Theorem 2: when the number of items J is substantially larger than the number of individuals N, spectral clustering alone can perform very well. In contrast, the traditional EM method exhibits significantly higher mis-clustering error, and EM and Tensor-CEM suffer from high computational cost in this large-J regime.
Mis-clustering error and running time (seconds) of different methods on Senate Roll Call Votes data

Table 4 Long description
The table has five columns for methods S V D, S O L A, S O L A plus, E M, and Tensor-C E M. The first row under the header lists mis-clustering error values: S V D 0.0212, S O L A 0.0212, S O L A plus 0.0212, E M 0.117, Tensor-C E M 0.0212. The second row lists running times in seconds: S V D 0.00179, S O L A 0.0344, S O L A plus 0.0503, E M 3.125, Tensor-C E M 5.154. All methods except E M achieve the lowest error of 0.0212, while S V D is the fastest and Tensor-C E M is the slowest.
We also validate the performance of our method for estimating K on this real dataset. In particular, the threshold defined in (17) is
 $2.01\times (\sqrt {486}+\sqrt {94})\approx 63.8$
. The first three largest singular values of
$2.01\times (\sqrt {486}+\sqrt {94})\approx 63.8$
. The first three largest singular values of
 $\mathbf {R}$
are
$\mathbf {R}$
are
 $\{148.1,\,64.4,\,16.6\}$
, which leads to an estimated number of clusters
$\{148.1,\,64.4,\,16.6\}$
, which leads to an estimated number of clusters
 $\widehat K=2$
. Notably, this estimated value exactly matches the known number of clusters in the dataset (i.e.,
$\widehat K=2$
. Notably, this estimated value exactly matches the known number of clusters in the dataset (i.e.,
 $K=2$
).
$K=2$
).
6 Discussion
In this work, we have proposed SOLA, a simple yet powerful two-stage algorithm, under binary-response LCMs. Our method efficiently exploits the low-rank structure of the response matrix and further leverages the likelihood information. We have proved that SOLA attains the optimal mis-clustering rate and achieves the fundamental statistical limit. We have also empirically demonstrated its superior accuracy, stability, and speed compared to other methods.
Several interesting directions remain for future research. Many applications involve multivariate polytomous responses with more than two categories for each item. Extending SOLA to handle polytomous-response LCMs is an important future direction. It remains intriguing to investigate how to modify the algorithm accordingly and obtain similar theoretical guarantees. In addition, beyond estimation, practitioners often also want to conduct statistical inference on item parameters
 $\boldsymbol {\Theta }$
. It is worth exploring that whether we can build on SOLA to develop an estimator of item parameters
$\boldsymbol {\Theta }$
. It is worth exploring that whether we can build on SOLA to develop an estimator of item parameters
 $\boldsymbol {\Theta }$
together with confidence intervals.
$\boldsymbol {\Theta }$
together with confidence intervals.
Funding statement
This research is partially supported by the NSF Grant DMS-2210796.
Competing interests
The authors declare none.
A Appendix of the proofs
We present a general version of Proposition 3. To this end, we introduce some additional notation. For
 $\forall j\in [J]$
and
$\forall j\in [J]$
and
 $k_1\ne k_2\in [K]$
, define
$k_1\ne k_2\in [K]$
, define
 $\Delta _{j,k_1,k_2}^2:={\left (\theta _{j,k_1}-\theta _{j,k_2}\right )^2}/\left [8(\sigma ^2_{\theta _{j,k_1}}\vee \sigma ^2_{\theta _{j,k_2}})\right ]$
. We have the following result, whose proof can be found in Section B.5.
$\Delta _{j,k_1,k_2}^2:={\left (\theta _{j,k_1}-\theta _{j,k_2}\right )^2}/\left [8(\sigma ^2_{\theta _{j,k_1}}\vee \sigma ^2_{\theta _{j,k_2}})\right ]$
. We have the following result, whose proof can be found in Section B.5.
Proposition A.1. For any
 $k_1\ne k_2\in [K]$
, define
$k_1\ne k_2\in [K]$
, define
 $$ \begin{align*} \tau_{k_1,k_2}:=\frac{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \tau \left(\theta_{j,k_1}\right)}{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}}\left(1+\eta\right), \quad \tau(x)=\frac{1-2x}{2x(1-x)\log\left(\left(1-x\right)/x\right)}, \end{align*} $$
$$ \begin{align*} \tau_{k_1,k_2}:=\frac{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \tau \left(\theta_{j,k_1}\right)}{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}}\left(1+\eta\right), \quad \tau(x)=\frac{1-2x}{2x(1-x)\log\left(\left(1-x\right)/x\right)}, \end{align*} $$
for some
 $\eta =o(1)$
. Assume that (a)
$\eta =o(1)$
. Assume that (a)
 $\max _{k_1\ne k_2\in [K]}\left |\Omega ^c_0(k_1,k_2)\right |=O(1),$
where
$\max _{k_1\ne k_2\in [K]}\left |\Omega ^c_0(k_1,k_2)\right |=O(1),$
where
 $\Omega _0(k_1,k_2):=\left \{j\in [J]:\left |\theta _{j,k_1}-\theta _{j,k_2}\right |=o(1)\right \}$
, then we have
$\Omega _0(k_1,k_2):=\left \{j\in [J]:\left |\theta _{j,k_1}-\theta _{j,k_2}\right |=o(1)\right \}$
, then we have
 $$ \begin{align*} \exp\left(-\frac{I^\star}{2}\right) \lesssim\exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1+\underline{\tau}\right)\right), \end{align*} $$
$$ \begin{align*} \exp\left(-\frac{I^\star}{2}\right) \lesssim\exp\left(-\frac{\Delta^2}{8\bar\sigma^2}\left(1+\underline{\tau}\right)\right), \end{align*} $$
where
 $\underline {\tau }:=\min _{k_1\ne k_2\in [K]}\tau _{k_1,k_2}$
. Furthermore, if (b)
$\underline {\tau }:=\min _{k_1\ne k_2\in [K]}\tau _{k_1,k_2}$
. Furthermore, if (b)
 $\min _{k\in [K]}\left |\left \{j\in [J]:\left |\theta _{j,k}-1/2\right |>c_0\right \}\right |\gtrsim J$
for some universal constant
$\min _{k\in [K]}\left |\left \{j\in [J]:\left |\theta _{j,k}-1/2\right |>c_0\right \}\right |\gtrsim J$
for some universal constant
 $c_0>0$
, then we have
$c_0>0$
, then we have
 $\underline {\tau }>c_{\tau }$
for some universal constant
$\underline {\tau }>c_{\tau }$
for some universal constant
 $c_\tau>0$
.
$c_\tau>0$
.
B Proofs of main results
B.1 Proof of Theorem 1
The proof can be adapted from Theorem S.4 in Lyu et al. (Reference Lyu, Chen and Gu2025) by fixing the individual degree parameters therein to be all
 $1$
’s. We only sketch essential modifications here. Let
$1$
’s. We only sketch essential modifications here. Let
 $$ \begin{align*}{\mathcal{P}}_\Theta:=\left\{\widetilde{\boldsymbol{\Theta}}:\widetilde{\theta_{j,k}}\in[c_\theta,C_\theta],j\in[J],k\in[K], \max_{j\in[J]}\max_{k\ne k^\prime} \left|\widetilde\theta_{j,k}-\widetilde\theta_{j,k^\prime}\right|=o(1)\right\}.\end{align*} $$
$$ \begin{align*}{\mathcal{P}}_\Theta:=\left\{\widetilde{\boldsymbol{\Theta}}:\widetilde{\theta_{j,k}}\in[c_\theta,C_\theta],j\in[J],k\in[K], \max_{j\in[J]}\max_{k\ne k^\prime} \left|\widetilde\theta_{j,k}-\widetilde\theta_{j,k^\prime}\right|=o(1)\right\}.\end{align*} $$
Following the construction of
 ${\mathcal{V}}^*$
and the proof of Theorem S.4 in Lyu et al. (Reference Lyu, Chen and Gu2025), it suffices to consider the following space:
${\mathcal{V}}^*$
and the proof of Theorem S.4 in Lyu et al. (Reference Lyu, Chen and Gu2025), it suffices to consider the following space:
 $$ \begin{align*} \bar{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right):=\left\{\bar{\mathbf{R}}:\bar R_{i,j}=\theta_{j,s_i}, {\boldsymbol s}\in{\mathcal{V}}^*, \boldsymbol{\Theta}\in{\mathcal{P}}_\Theta\right\}. \end{align*} $$
$$ \begin{align*} \bar{\mathcal{P}}_K\left({\boldsymbol s},\boldsymbol{\Theta}\right):=\left\{\bar{\mathbf{R}}:\bar R_{i,j}=\theta_{j,s_i}, {\boldsymbol s}\in{\mathcal{V}}^*, \boldsymbol{\Theta}\in{\mathcal{P}}_\Theta\right\}. \end{align*} $$
Then we can follow the proof of Theorem S.4 in Lyu et al. (Reference Lyu, Chen and Gu2025). Notice that in the proof of Lemma S.2, the argument therein still holds by allowing
 $p_{1,j}\asymp p_{2,j}\asymp 1$
and
$p_{1,j}\asymp p_{2,j}\asymp 1$
and
 $\left |p_{1,j}-p_{2,j}\right |=o\left (p_{1,j}\right )$
. We can then get the desired result by directly applying the modified Lemma S.2 without further lower bounding it.
$\left |p_{1,j}-p_{2,j}\right |=o\left (p_{1,j}\right )$
. We can then get the desired result by directly applying the modified Lemma S.2 without further lower bounding it.
B.2 Proof of Theorem 2
Initialization: We start with investigating the performance of
 $ \ \widehat \theta ^{(m)}_{j,k}$
’s. To this end, for any
$ \ \widehat \theta ^{(m)}_{j,k}$
’s. To this end, for any
 $\rho =o(1)$
, we define the event
$\rho =o(1)$
, we define the event
 $$ \begin{align} {\mathcal{E}}_{\rho,m}:=\left\{\min_{\pi\in {\mathfrak G}_K}\max_{j\in[J],k\in[K]} \left|\widehat\theta^{(m)}_{j,k}-\theta_{j,\pi\left(k\right)}\right|\le \rho I^\star/J\right\}. \end{align} $$
$$ \begin{align} {\mathcal{E}}_{\rho,m}:=\left\{\min_{\pi\in {\mathfrak G}_K}\max_{j\in[J],k\in[K]} \left|\widehat\theta^{(m)}_{j,k}-\theta_{j,\pi\left(k\right)}\right|\le \rho I^\star/J\right\}. \end{align} $$
The following lemma indicates that (B.1) holds with high probability, whose proof is deferred to Section C.1.
Lemma B.1. There exists some absolute constant
 $c_0\in (0,1)$
such that
$c_0\in (0,1)$
such that
 $\mathbb {P}({\mathcal{E}}_{\rho ,m})\ge 1-\exp (-(1-c_0)\Delta ^2/(8\bar \sigma ^2) )$
for
$\mathbb {P}({\mathcal{E}}_{\rho ,m})\ge 1-\exp (-(1-c_0)\Delta ^2/(8\bar \sigma ^2) )$
for
 $m\in [2]$
with
$m\in [2]$
with
 $\rho =o(1/K)$
.
$\rho =o(1/K)$
.
One-step refinement: In the following, we will derive the clustering error for
 $i\in {\mathcal{S}}_1$
. Fix any
$i\in {\mathcal{S}}_1$
. Fix any
 $k\in [K]\backslash \left \{s_i^\star \right \}$
. Without loss of generality, we assume that
$k\in [K]\backslash \left \{s_i^\star \right \}$
. Without loss of generality, we assume that
 $\pi = \text {Id}$
(identity map with
$\pi = \text {Id}$
(identity map with
 $\pi (k)=k$
for all k) in (B.1) as otherwise we can replace
$\pi (k)=k$
for all k) in (B.1) as otherwise we can replace
 $\theta _{j,k}$
with
$\theta _{j,k}$
with
 $\theta _{j,\pi (k)}$
and
$\theta _{j,\pi (k)}$
and
 $\theta _{j,s_i^*}$
with
$\theta _{j,s_i^*}$
with
 $\theta _{j,\pi (s_i^*)}$
in the following derivation. By definition, we have
$\theta _{j,\pi (s_i^*)}$
in the following derivation. By definition, we have
 $$ \begin{align} \mathbb{I}\left(\widehat s_i=k\right)&\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}\right)\notag\\[4pt] &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}-\delta I^\star\right)\notag\\[4pt] &\quad +\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\left(\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta^{(2)}_{j,k}\right)}-\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\right)\right.\notag\\[4pt] &\ge \left.\sum_{j\in[J]}\left(\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}-\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}\right)+\delta I^\star\right), \end{align} $$
$$ \begin{align} \mathbb{I}\left(\widehat s_i=k\right)&\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}\right)\notag\\[4pt] &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}-\delta I^\star\right)\notag\\[4pt] &\quad +\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\left(\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta^{(2)}_{j,k}\right)}-\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\right)\right.\notag\\[4pt] &\ge \left.\sum_{j\in[J]}\left(\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}-\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}\right)+\delta I^\star\right), \end{align} $$
where
 $\delta =o(1)$
is some sequence to be determined later. We start with bounding the first term in (B.2). By the Chernoff bound, we obtain that
$\delta =o(1)$
is some sequence to be determined later. We start with bounding the first term in (B.2). By the Chernoff bound, we obtain that
 $$ \begin{align} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}-\delta I^\star\right)\notag\\[4pt] &\le \exp\left(-\sum_{j\in[J]}\log\sqrt{\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}}+\frac{\delta I^\star}{2}\right)\prod_{j=1}^J\left(\sqrt{\theta_{j,s^\star_i}\theta_{j,k}}\sqrt{\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}}+1-\theta_{j,s^\star_i}\right)\notag\\[4pt] &\le \exp\left(\frac{\delta I^\star}{2}\right)\exp\left(-\frac{I^\star}{2}\right)=\exp\left(-\frac{I^\star}{2}\left(1-\delta\right)\right). \end{align} $$
$$ \begin{align} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\ge \sum_{j\in[J]}\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}-\delta I^\star\right)\notag\\[4pt] &\le \exp\left(-\sum_{j\in[J]}\log\sqrt{\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}}+\frac{\delta I^\star}{2}\right)\prod_{j=1}^J\left(\sqrt{\theta_{j,s^\star_i}\theta_{j,k}}\sqrt{\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}}+1-\theta_{j,s^\star_i}\right)\notag\\[4pt] &\le \exp\left(\frac{\delta I^\star}{2}\right)\exp\left(-\frac{I^\star}{2}\right)=\exp\left(-\frac{I^\star}{2}\left(1-\delta\right)\right). \end{align} $$
Using this, we can bound the second term in (B.2) as
 $$ \begin{align} &\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\left(\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta^{(2)}_{j,k}\right)}-\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\right)\ge \sum_{j\in[J]}\left(\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}-\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}\right)+\delta I^\star\right)\notag\\[4pt] &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,s^\star_i}}{\widehat \theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\notag\\[4pt] &\quad +\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\theta_{j,k}}{1-\widehat\theta^{(2)}_{j,k}}>\frac{\delta}{4}I^\star\right). \end{align} $$
$$ \begin{align} &\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\left(\log\frac{\widehat\theta^{(2)}_{j,k}\left(1-\widehat\theta^{(2)}_{j,s^\star_i}\right)}{\widehat\theta^{(2)}_{j,s^\star_i}\left(1-\widehat\theta^{(2)}_{j,k}\right)}-\log\frac{\theta_{j,k}\left(1-\theta_{j,s^\star_i}\right)}{\theta_{j,s^\star_i}\left(1-\theta_{j,k}\right)}\right)\ge \sum_{j\in[J]}\left(\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\widehat\theta^{(2)}_{j,k}}-\log\frac{1-\theta_{j,s^\star_i}}{1-\theta_{j,k}}\right)+\delta I^\star\right)\notag\\[4pt] &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\theta_{j,s^\star_i}}{\widehat \theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\notag\\[4pt] &\quad +\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\theta_{j,k}}{1-\widehat\theta^{(2)}_{j,k}}>\frac{\delta}{4}I^\star\right). \end{align} $$
For the first term in (B.4), we proceed by noticing that
 $$ \begin{align} &\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)\notag\\ &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right). \end{align} $$
$$ \begin{align} &\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)\notag\\ &\le \mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right). \end{align} $$
Let
 $\delta =\rho ^{\epsilon }$
for
$\delta =\rho ^{\epsilon }$
for
 $\epsilon \in (0,1)$
and
$\epsilon \in (0,1)$
and
 $\lambda =c\rho ^{-\epsilon }$
for some constant
$\lambda =c\rho ^{-\epsilon }$
for some constant
 $c>0$
depending only on
$c>0$
depending only on
 $c_\theta $
and
$c_\theta $
and
 $C_\theta $
, then by Chernoff bound on the first term of (B.5), we obtain that
$C_\theta $
, then by Chernoff bound on the first term of (B.5), we obtain that
 $$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\overset{(a)}{\le} \mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\frac{\rho I^\star}{J}>\frac{c_\theta\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda R_{i,j}\frac{\rho I^\star}{J}\right) \overset{(b)}{\le} \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\prod_{j=1}^J\left(1+2\lambda\theta_{i,j}\frac{\rho I^\star}{J}\right)\\ &\le \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\exp\left(\rho \cdot 2C_\theta I^\star\right)\overset{(c)}{\le} \exp\left(- \frac{ I^\star}{2}\right), \end{align*} $$
$$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\overset{(a)}{\le} \mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\frac{\rho I^\star}{J}>\frac{c_\theta\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda R_{i,j}\frac{\rho I^\star}{J}\right) \overset{(b)}{\le} \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\prod_{j=1}^J\left(1+2\lambda\theta_{i,j}\frac{\rho I^\star}{J}\right)\\ &\le \exp\left(-\lambda\frac{c_\theta\delta}{8}I^\star\right)\exp\left(\rho \cdot 2C_\theta I^\star\right)\overset{(c)}{\le} \exp\left(- \frac{ I^\star}{2}\right), \end{align*} $$
where (a) holds due to (B.1) and
 $\log (1+x)\le x$
for
$\log (1+x)\le x$
for
 $x>-1$
, (b) holds due to
$x>-1$
, (b) holds due to
 $e^{x}-1\le 2x$
for
$e^{x}-1\le 2x$
for
 $0<x<1$
and the fact that
$0<x<1$
and the fact that
 ${\lambda \rho I^\star }/{J}\lesssim {\rho ^{1-\epsilon }\Delta ^2}/{J}=o(1)$
, and (c) holds due to the choice of
${\lambda \rho I^\star }/{J}\lesssim {\rho ^{1-\epsilon }\Delta ^2}/{J}=o(1)$
, and (c) holds due to the choice of
 $\lambda =c\rho ^{-\varepsilon }$
. For the second term of (B.5), by the independence between
$\lambda =c\rho ^{-\varepsilon }$
. For the second term of (B.5), by the independence between
 $\widehat \theta ^{(2)}_{j,k}$
and
$\widehat \theta ^{(2)}_{j,k}$
and
 $\left \{R_{i,j},j\in [J]\right \}$
, we get
$\left \{R_{i,j},j\in [J]\right \}$
, we get
 $$ \begin{align*} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[1+\theta_{j,k}\left(\mathbb{E} \exp\left(\lambda \log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)-1\right)\right]. \end{align*} $$
$$ \begin{align*} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[1+\theta_{j,k}\left(\mathbb{E} \exp\left(\lambda \log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)-1\right)\right]. \end{align*} $$
To bound the above term, notice that
 $$ \begin{align*} \mathbb{E} \left(\exp\left(\lambda \log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)-1\right)\le \left(\exp\left(\lambda \log \frac{1}{c_\theta}\right)-1\right)\mathbb{P}\left({\mathcal{E}}^c_{\rho,2}\right)\le \exp\left(\lambda \log \frac{1}{c_\theta}-\frac{\Delta^2}{16\bar\sigma^2}\right). \end{align*} $$
$$ \begin{align*} \mathbb{E} \left(\exp\left(\lambda \log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)-1\right)\le \left(\exp\left(\lambda \log \frac{1}{c_\theta}\right)-1\right)\mathbb{P}\left({\mathcal{E}}^c_{\rho,2}\right)\le \exp\left(\lambda \log \frac{1}{c_\theta}-\frac{\Delta^2}{16\bar\sigma^2}\right). \end{align*} $$
Since we can always choose
 $\rho \rightarrow 0$
sufficiently slow such that
$\rho \rightarrow 0$
sufficiently slow such that
 $$ \begin{align*} \lambda\log\frac{1}{c_\theta}\lesssim \frac{1}{\rho^{\varepsilon}}\lesssim\frac{\Delta^2}{\bar\sigma^2}\asymp I^\star, \end{align*} $$
$$ \begin{align*} \lambda\log\frac{1}{c_\theta}\lesssim \frac{1}{\rho^{\varepsilon}}\lesssim\frac{\Delta^2}{\bar\sigma^2}\asymp I^\star, \end{align*} $$
we can conclude that
 $$ \begin{align*} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[1+\theta_{j,k}\exp\left(-c{I^\star}\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\left(1+\frac{C_\theta}{\exp\left(c{I^\star}\right)}\right)^J\le\exp\left(-\frac{I^\star}{2}\right). \end{align*} $$
$$ \begin{align*} \mathbb{P}&\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[1+\theta_{j,k}\exp\left(-c{I^\star}\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\left(1+\frac{C_\theta}{\exp\left(c{I^\star}\right)}\right)^J\le\exp\left(-\frac{I^\star}{2}\right). \end{align*} $$
where the last inequality due to the fact that
 $ (1+C_\theta {\exp (-c{I^\star })} )^J=O(1)$
provided that
$ (1+C_\theta {\exp (-c{I^\star })} )^J=O(1)$
provided that
 $\exp (c{I^\star } )\ge J$
. We thereby arrive at
$\exp (c{I^\star } )\ge J$
. We thereby arrive at
 $$ \begin{align} \mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)\le 2\exp\left(-\frac{I^\star}{2}\right). \end{align} $$
$$ \begin{align} \mathbb{P}\left(\sum_{j\in[J]}R_{i,j}\log\frac{\widehat\theta^{(2)}_{j,k}}{\theta_{j,k}}>\frac{\delta}{4}I^\star\right)\le 2\exp\left(-\frac{I^\star}{2}\right). \end{align} $$
The second term in (B.4) can be bounded in the same fashion. For the third term in (B.4), we have
 $$ \begin{align*} &\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\notag\\ &\le\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right). \end{align*} $$
$$ \begin{align*} &\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\notag\\ &\le\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)+\mathbb{I}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right). \end{align*} $$
Similarly, we can bound the expectation of the first term in the above equation as
 $$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda \left(R_{i,j}-1\right)\frac{\rho I^*}{J}\right)\\ &\overset{(a)}{\le} \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\prod_{j=1}^J\left(1+\frac{C_{\theta}\rho I^*}{2J}\right)\\ &\le \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\exp\left(\rho \cdot \frac{C_\theta I^*}{2}\right)\le \exp\left(-\frac{I^\star}{2}\right), \end{align*} $$
$$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\prod_{j=1}^J\mathbb{E} \exp\left(\lambda \left(R_{i,j}-1\right)\frac{\rho I^*}{J}\right)\\ &\overset{(a)}{\le} \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\prod_{j=1}^J\left(1+\frac{C_{\theta}\rho I^*}{2J}\right)\\ &\le \exp\left(-\lambda\frac{\left(1-C_{\theta}\right)\delta}{8}I^\star\right)\exp\left(\rho \cdot \frac{C_\theta I^*}{2}\right)\le \exp\left(-\frac{I^\star}{2}\right), \end{align*} $$
where (a) holds due to
 $e^{-x}\le 1-x/2$
for
$e^{-x}\le 1-x/2$
for
 $x\in [0,1]$
. Similarly, we have that
$x\in [0,1]$
. Similarly, we have that
 $$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right)\mathbb{E} \exp\left(\lambda \log\frac{1-\widehat\theta^{(2)}_{j,s_i^*}}{1-\theta_{j,s_i^*}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right) \exp\left(\lambda \log\frac{1}{1-C_{\theta}}\right)\mathbb{P}\left({\mathcal{E}}^c_{\rho,2}\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right) \exp\left(-cI^*\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)C_{\theta}^J\left(1+\frac{1}{c_{\theta}\exp\left(cI^*\right)}\right)^J\le \exp\left(-\frac{I^\star}{2}\right), \end{align*} $$
$$ \begin{align*} &\mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)>\frac{\delta}{8}I^\star\right)\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right)\mathbb{E} \exp\left(\lambda \log\frac{1-\widehat\theta^{(2)}_{j,s_i^*}}{1-\theta_{j,s_i^*}}\mathbb{I}\left({\mathcal{E}}^c_{\rho,2}\right)\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right) \exp\left(\lambda \log\frac{1}{1-C_{\theta}}\right)\mathbb{P}\left({\mathcal{E}}^c_{\rho,2}\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)\prod_{j=1}^J\left[\theta_{j,s_i^*}+\left(1-\theta_{j,s_i^*}\right) \exp\left(-cI^*\right)\right]\\ &\le \exp\left(-\lambda\frac{\delta}{8}I^\star\right)C_{\theta}^J\left(1+\frac{1}{c_{\theta}\exp\left(cI^*\right)}\right)^J\le \exp\left(-\frac{I^\star}{2}\right), \end{align*} $$
provided that
 $\exp (c{I^\star })\ge J$
. We thus get that
$\exp (c{I^\star })\ge J$
. We thus get that
 $$ \begin{align} \mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\le 2\exp\left(-\frac{I^\star}{2}\right). \end{align} $$
$$ \begin{align} \mathbb{P}\left(\sum_{j\in[J]}\left(R_{i,j}-1\right)\log\frac{1-\widehat\theta^{(2)}_{j,s^\star_i}}{1-\theta_{j,s^\star_i}}>\frac{\delta}{4}I^\star\right)\le 2\exp\left(-\frac{I^\star}{2}\right). \end{align} $$
The last term in (B.4) can be bounded in the same fashion. By (B.2), (B.3), (B.4), (B.6), and (B.7), we thereby arrive at
 $$ \begin{align*} \mathbb{P}\left(\widehat s_i=k\right)\le \exp\left(-\frac{I^\star}{2}\left(1-\rho^\epsilon\right)\right)+8\exp\left(-\frac{I^\star}{2}\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
$$ \begin{align*} \mathbb{P}\left(\widehat s_i=k\right)\le \exp\left(-\frac{I^\star}{2}\left(1-\rho^\epsilon\right)\right)+8\exp\left(-\frac{I^\star}{2}\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
We thus conclude that
 $$ \begin{align*} \frac{1}{\left|{\mathcal{S}}_1\right|} \mathbb{E}\sum_{i\in{\mathcal{S}}_1}\mathbb{I}\left(\widehat s_i\ne s^\star_i\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
$$ \begin{align*} \frac{1}{\left|{\mathcal{S}}_1\right|} \mathbb{E}\sum_{i\in{\mathcal{S}}_1}\mathbb{I}\left(\widehat s_i\ne s^\star_i\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right). \end{align*} $$
The proof for the case
 $i\in {\mathcal{S}}_2$
can be conducted in the same fashion. We can conclude that
$i\in {\mathcal{S}}_2$
can be conducted in the same fashion. We can conclude that
 $$ \begin{align*} \frac{1}{\left|{\mathcal{S}}_2\right|} \mathbb{E}\sum_{i\in{\mathcal{S}}_2}\mathbb{I}\left(\widehat s_i\ne \pi_0\left(s^\star_i\right)\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right) \end{align*} $$
$$ \begin{align*} \frac{1}{\left|{\mathcal{S}}_2\right|} \mathbb{E}\sum_{i\in{\mathcal{S}}_2}\mathbb{I}\left(\widehat s_i\ne \pi_0\left(s^\star_i\right)\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right) \end{align*} $$
for some
 $\pi _0\in {\mathfrak G}_K$
.
$\pi _0\in {\mathfrak G}_K$
.
Label alignment: We then proceed with the proof for label alignment. Recall that without loss of generality, we have assumed that
 $ \ell (\widetilde {\boldsymbol s}^{(1)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_1})= \ell _0(\widetilde {\boldsymbol s}^{(1)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_1} )$
and
$ \ell (\widetilde {\boldsymbol s}^{(1)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_1})= \ell _0(\widetilde {\boldsymbol s}^{(1)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_1} )$
and
 $ \ell (\widetilde {\boldsymbol s}^{(2)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_2})= \ell _0(\widetilde {\boldsymbol s}^{(2)},\pi _0({\boldsymbol s}^{\star }_{{\mathcal{S}}_2}))$
for some
$ \ell (\widetilde {\boldsymbol s}^{(2)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_2})= \ell _0(\widetilde {\boldsymbol s}^{(2)},\pi _0({\boldsymbol s}^{\star }_{{\mathcal{S}}_2}))$
for some
 $\pi _0\in {\mathfrak G}_K$
. Notice that
$\pi _0\in {\mathfrak G}_K$
. Notice that
 $$ \begin{align*} \ell_0\left(\widehat {\boldsymbol s}_{{\mathcal{S}}_2},{\boldsymbol s}^{\star}_{{\mathcal{S}}_2}\right)=\ell_0\left(\widehat\pi(\widehat {\boldsymbol s}^{(2)}),{\boldsymbol s}^{\star}_{{\mathcal{S}}_2}\right)=\ell_0\left(\widehat {\boldsymbol s}^{(2)},\widehat\pi^{-1}({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right). \end{align*} $$
$$ \begin{align*} \ell_0\left(\widehat {\boldsymbol s}_{{\mathcal{S}}_2},{\boldsymbol s}^{\star}_{{\mathcal{S}}_2}\right)=\ell_0\left(\widehat\pi(\widehat {\boldsymbol s}^{(2)}),{\boldsymbol s}^{\star}_{{\mathcal{S}}_2}\right)=\ell_0\left(\widehat {\boldsymbol s}^{(2)},\widehat\pi^{-1}({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right). \end{align*} $$
It suffices to show that
 $\widehat \pi =\pi _0^{-1}$
, then we have
$\widehat \pi =\pi _0^{-1}$
, then we have
 $$ \begin{align*} \mathbb{E}\ell_0\left(\widehat {\boldsymbol s}^{(2)},\widehat\pi^{-1}({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right)=\mathbb{E}\ell_0\left(\widehat {\boldsymbol s}^{(2)},\pi_0({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right), \end{align*} $$
$$ \begin{align*} \mathbb{E}\ell_0\left(\widehat {\boldsymbol s}^{(2)},\widehat\pi^{-1}({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right)=\mathbb{E}\ell_0\left(\widehat {\boldsymbol s}^{(2)},\pi_0({\boldsymbol s}^{\star}_{{\mathcal{S}}_2})\right)\le \exp\left(-\frac{I^\star}{2}\left(1-o(1)\right)\right), \end{align*} $$
as desired. By definition, we have
 $$ \begin{align*} \left\| \widehat{\boldsymbol{\Theta}}^{(1)}-\widehat{\boldsymbol{\Theta}}^{(2)}\mathbf{G}_{\pi_0^{-1}} \right\|_{\mathrm{F}}^2&=\sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\widehat\theta_{j,\pi_0^{-1}(k)}^{(2)}\right|^2\\ &\le \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\theta_{j,k}\right|^2+ \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(2)}_{j,\pi_0^{-1}(k)}-\theta_{j,k}\right|^2\le 2\rho KI^\star. \end{align*} $$
$$ \begin{align*} \left\| \widehat{\boldsymbol{\Theta}}^{(1)}-\widehat{\boldsymbol{\Theta}}^{(2)}\mathbf{G}_{\pi_0^{-1}} \right\|_{\mathrm{F}}^2&=\sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\widehat\theta_{j,\pi_0^{-1}(k)}^{(2)}\right|^2\\ &\le \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\theta_{j,k}\right|^2+ \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(2)}_{j,\pi_0^{-1}(k)}-\theta_{j,k}\right|^2\le 2\rho KI^\star. \end{align*} $$
On the other hand, for any
 $\pi \in {\mathfrak G}_K$
and
$\pi \in {\mathfrak G}_K$
and
 $\pi \ne \pi _0^{-1}$
, we have
$\pi \ne \pi _0^{-1}$
, we have
 $$ \begin{align*} \left\| \widehat{\boldsymbol{\Theta}}^{(1)}-\widehat{\boldsymbol{\Theta}}^{(2)}\mathbf{G}_{\pi} \right\|_{\mathrm{F}}^2&=\sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\widehat\theta_{j,\pi(k)}^{(2)}\right|^2\\ & \ge \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right|^2-\rho KI^\star. \end{align*} $$
$$ \begin{align*} \left\| \widehat{\boldsymbol{\Theta}}^{(1)}-\widehat{\boldsymbol{\Theta}}^{(2)}\mathbf{G}_{\pi} \right\|_{\mathrm{F}}^2&=\sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta^{(1)}_{j,k}-\widehat\theta_{j,\pi(k)}^{(2)}\right|^2\\ & \ge \sum_{j\in[J]}\sum_{k\in[K]}\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right|^2-\rho KI^\star. \end{align*} $$
It suffices to show that
 $ \sum _{j\in [J]}\sum _{k\in [K]}\left |\widehat \theta _{j,\pi (k)}^{(2)}-\theta _{j,k}\right |^2>4\rho K I^\star $
. Observe that
$ \sum _{j\in [J]}\sum _{k\in [K]}\left |\widehat \theta _{j,\pi (k)}^{(2)}-\theta _{j,k}\right |^2>4\rho K I^\star $
. Observe that
 $$ \begin{align*} \left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right|&=\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}+\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\\ &\ge \left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|-\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}\right|. \end{align*} $$
$$ \begin{align*} \left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right|&=\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}+\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\\ &\ge \left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|-\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}\right|. \end{align*} $$
Notice that
 $\left |\widehat \theta _{j,\pi (k)}^{(2)}-\theta _{j,\pi \circ \pi _0(k)}\right |=\left |\widehat \theta _{j,k}^{(2)}-\theta _{j,\pi _0(k)}\right |\le \rho I^\star /J$
, we have
$\left |\widehat \theta _{j,\pi (k)}^{(2)}-\theta _{j,\pi \circ \pi _0(k)}\right |=\left |\widehat \theta _{j,k}^{(2)}-\theta _{j,\pi _0(k)}\right |\le \rho I^\star /J$
, we have
 $$ \begin{align*} &\sum_{j=1}^J\sum_{k=1}^K\left(\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right)^2\\ &\ge \sum_{j=1}^J\sum_{k=1}^K\left(\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right)^2-2\sum_{j=1}^J\sum_{k=1}^K\left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}\right|\\ &\ge \sum_{j=1}^J\sum_{k=1}^K\left(\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right)^2-\frac{2\rho I^\star}{J}\sum_{j=1}^J\sum_{k=1}^K\left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\\ &\ge \left(\sum_{k=1}^K\mathbb{I}\left(\pi\circ\pi_0(k)\ne k\right)\right) \left(\Delta^2-4C_\theta\rho I^\star\right)\ge \Delta^2, \end{align*} $$
$$ \begin{align*} &\sum_{j=1}^J\sum_{k=1}^K\left(\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,k}\right)^2\\ &\ge \sum_{j=1}^J\sum_{k=1}^K\left(\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right)^2-2\sum_{j=1}^J\sum_{k=1}^K\left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\left|\widehat\theta_{j,\pi(k)}^{(2)}-\theta_{j,\pi\circ \pi_0(k)}\right|\\ &\ge \sum_{j=1}^J\sum_{k=1}^K\left(\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right)^2-\frac{2\rho I^\star}{J}\sum_{j=1}^J\sum_{k=1}^K\left|\theta_{j,\pi\circ \pi_0(k)}-\theta_{j,k}\right|\\ &\ge \left(\sum_{k=1}^K\mathbb{I}\left(\pi\circ\pi_0(k)\ne k\right)\right) \left(\Delta^2-4C_\theta\rho I^\star\right)\ge \Delta^2, \end{align*} $$
where the last inequality holds due to the fact that
 $\pi \ne \pi _0^{-1}$
,
$\pi \ne \pi _0^{-1}$
,
 $\Delta ^2\asymp I^\star \rightarrow \infty ,$
and
$\Delta ^2\asymp I^\star \rightarrow \infty ,$
and
 $\rho =o(1)$
. The proof is thus completed by using
$\rho =o(1)$
. The proof is thus completed by using
 $\rho =o(1/K)$
.
$\rho =o(1/K)$
.
B.3 Proof of Proposition 2
Notice that
 $\lambda _K\ge \lambda _{K}\left (\mathbf {Z}\right )\lambda _{K}\left (\boldsymbol {\Theta }\right )$
. To get a lower bound for
$\lambda _K\ge \lambda _{K}\left (\mathbf {Z}\right )\lambda _{K}\left (\boldsymbol {\Theta }\right )$
. To get a lower bound for
 $\lambda _K$
, it suffices to obtain lower bounds for
$\lambda _K$
, it suffices to obtain lower bounds for
 $\lambda _{K}(\mathbf {Z})$
and
$\lambda _{K}(\mathbf {Z})$
and
 $\lambda _{K}(\boldsymbol {\Theta })$
. First note that
$\lambda _{K}(\boldsymbol {\Theta })$
. First note that
 $$ \begin{align*} \mathbf{Z}^\top\mathbf{Z}=\text{diag}\left(\left|\left\{i:s_i^\star=1\right\}\right|,\ldots,\left|\left\{i:s_i^\star=K\right\}\right|\right). \end{align*} $$
$$ \begin{align*} \mathbf{Z}^\top\mathbf{Z}=\text{diag}\left(\left|\left\{i:s_i^\star=1\right\}\right|,\ldots,\left|\left\{i:s_i^\star=K\right\}\right|\right). \end{align*} $$
We thus obtain
 $\lambda _{K}(\mathbf {Z})\ge \sqrt {\alpha N/K}$
. On the other hand, by Proposition 2 in Lyu et al. (Reference Lyu, Chen and Gu2025), we obtain that for any
$\lambda _{K}(\mathbf {Z})\ge \sqrt {\alpha N/K}$
. On the other hand, by Proposition 2 in Lyu et al. (Reference Lyu, Chen and Gu2025), we obtain that for any
 $\delta \in (0,1)$
,
$\delta \in (0,1)$
,
 $$ \begin{align*} \mathbb{P}\left(\lambda_K\left(\boldsymbol{\Theta}^\top\boldsymbol{\Theta}\right)\ge \left(1-\delta\right) BJK\right)\le K\left(e^{-\delta^2B^2J/16}+e^{-3\delta BJ/8}\right). \end{align*} $$
$$ \begin{align*} \mathbb{P}\left(\lambda_K\left(\boldsymbol{\Theta}^\top\boldsymbol{\Theta}\right)\ge \left(1-\delta\right) BJK\right)\le K\left(e^{-\delta^2B^2J/16}+e^{-3\delta BJ/8}\right). \end{align*} $$
Denote the above event as
 ${\mathcal{E}}_{\theta }$
, under which we arrive at
${\mathcal{E}}_{\theta }$
, under which we arrive at
 $\lambda _K(\boldsymbol {\Theta })\ge (1-\delta /2)\sqrt {BJK}$
.
$\lambda _K(\boldsymbol {\Theta })\ge (1-\delta /2)\sqrt {BJK}$
.
To obtain a lower bound for
 $\Delta $
, it suffices to use Lemma S.1 in Lyu et al. (Reference Lyu, Chen and Gu2025) to get
$\Delta $
, it suffices to use Lemma S.1 in Lyu et al. (Reference Lyu, Chen and Gu2025) to get
 $\Delta \ge \sqrt {2}\lambda _K(\boldsymbol {\Theta })$
. We get the desired result by setting
$\Delta \ge \sqrt {2}\lambda _K(\boldsymbol {\Theta })$
. We get the desired result by setting
 $\delta =1/2$
.
$\delta =1/2$
.
B.4 Proof of Corollary 1
The proof follows the same argument as that of Theorem 2. We only sketch the modifications here. Without loss of generality, we only consider sample data points in
 ${\mathcal{S}}_1$
. First note that by Proposition 3.1 in Zhang and Zhou (Reference Zhang and Zhou2024), we have
${\mathcal{S}}_1$
. First note that by Proposition 3.1 in Zhang and Zhou (Reference Zhang and Zhou2024), we have
 $\ell (\widetilde {\boldsymbol s}^{(2)},{\boldsymbol s}_{{\mathcal{S}}_2}^\star )=o(1)$
with probability at least
$\ell (\widetilde {\boldsymbol s}^{(2)},{\boldsymbol s}_{{\mathcal{S}}_2}^\star )=o(1)$
with probability at least
 $1-O(e^{-N\vee J})$
. Hence, we get that
$1-O(e^{-N\vee J})$
. Hence, we get that
 $$ \begin{align*} \log\left(\frac{\widehat p_k}{\widehat \pi_{s_i^\star}}\right)=\log\left(\frac{\widehat p_k}{ p_k}\right)+\log\left(\frac{ \pi_{s_i^\star}}{ \widehat \pi_{s_i^\star}}\right)+\log\left(\frac{ p_k}{\pi_{s_i^\star}}\right)\lesssim \log\left(\frac{1}{\alpha}\right)=o\left(I\right) \end{align*} $$
$$ \begin{align*} \log\left(\frac{\widehat p_k}{\widehat \pi_{s_i^\star}}\right)=\log\left(\frac{\widehat p_k}{ p_k}\right)+\log\left(\frac{ \pi_{s_i^\star}}{ \widehat \pi_{s_i^\star}}\right)+\log\left(\frac{ p_k}{\pi_{s_i^\star}}\right)\lesssim \log\left(\frac{1}{\alpha}\right)=o\left(I\right) \end{align*} $$
with probability at least
 $1-O(e^{-N\vee J} )$
, where we’ve used Assumption 2. This indicates that the impact of this additional term is ignorable, that is,
$1-O(e^{-N\vee J} )$
, where we’ve used Assumption 2. This indicates that the impact of this additional term is ignorable, that is,
 $$ \begin{align*} \mathbb{P}\left( \log\left(\frac{\widehat p_k}{\widehat \pi_{s_i^\star}}\right)>{c\delta}I^\star\right)\le O\left(e^{-N\vee J}\right) \end{align*} $$
$$ \begin{align*} \mathbb{P}\left( \log\left(\frac{\widehat p_k}{\widehat \pi_{s_i^\star}}\right)>{c\delta}I^\star\right)\le O\left(e^{-N\vee J}\right) \end{align*} $$
for some universal constant
 $c>0$
. The remaining proof follows from that of Theorem 2 line by line.
$c>0$
. The remaining proof follows from that of Theorem 2 line by line.
B.5 Proof of Proposition 4
Specifically, we fix
 $j\in \Omega _0(k_1,k_2)$
and
$j\in \Omega _0(k_1,k_2)$
and
 $k_1\ne k_2\in [K]$
in the following analysis. Note that
$k_1\ne k_2\in [K]$
in the following analysis. Note that
 $$ \begin{align*} &-2\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\\[4pt] &=-\log\left(1-\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2-2\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\right)\\[4pt] &\ge \left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2+2\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right). \end{align*} $$
$$ \begin{align*} &-2\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\\[4pt] &=-\log\left(1-\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2-2\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\right)\\[4pt] &\ge \left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2+2\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right). \end{align*} $$
When
 $\theta _{j,k_1}+\theta _{j,k_2}\le 1$
, we have
$\theta _{j,k_1}+\theta _{j,k_2}\le 1$
, we have
 $$ \begin{align*} 1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}&=\frac{\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\right)^2-\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}{1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}}\\[4pt] &=\frac{\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2}{1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\theta_{j,k_1}\theta_{j,k_2}+1-\theta_{j,k_1}-\theta_{j,k_2}}}\\[4pt] &=C_{\theta_{j,k_1},\theta_{j,k_2}}\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2. \end{align*} $$
$$ \begin{align*} 1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}&=\frac{\left(1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}\right)^2-\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}{1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}}\\[4pt] &=\frac{\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2}{1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\theta_{j,k_1}\theta_{j,k_2}+1-\theta_{j,k_1}-\theta_{j,k_2}}}\\[4pt] &=C_{\theta_{j,k_1},\theta_{j,k_2}}\left(\sqrt{\theta_{j,k_1}}-\sqrt{\theta_{j,k_2}}\right)^2. \end{align*} $$
When
 $\theta _{j,k_2}+\theta _{j,k_1}>1$
, we have that
$\theta _{j,k_2}+\theta _{j,k_1}>1$
, we have that
 $$ \begin{align*} 1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}&=\frac{\left(1-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)^2-\theta_{j,k_1}\theta_{j,k_2}}{1-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}+\sqrt{\theta_{j,k_1}\theta_{j,k_2}}}\\[4pt] &=\frac{\left(\sqrt{1-\theta_{j,k_1}}-\sqrt{1-\theta_{j,k_2}}\right)^2}{1+\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\theta_{j,k_1}\theta_{j,k_2}-\left(\theta_{j,k_1}+\theta_{j,k_2}-1\right)}}\\[4pt] &=C_{\theta_{j,k_1},\theta_{j,k_2}}\left(\sqrt{1-\theta_{j,k_1}}-\sqrt{1-\theta_{j,k_2}}\right)^2. \end{align*} $$
$$ \begin{align*} 1-\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}&=\frac{\left(1-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)^2-\theta_{j,k_1}\theta_{j,k_2}}{1-\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}+\sqrt{\theta_{j,k_1}\theta_{j,k_2}}}\\[4pt] &=\frac{\left(\sqrt{1-\theta_{j,k_1}}-\sqrt{1-\theta_{j,k_2}}\right)^2}{1+\sqrt{\theta_{j,k_1}\theta_{j,k_2}}-\sqrt{\theta_{j,k_1}\theta_{j,k_2}-\left(\theta_{j,k_1}+\theta_{j,k_2}-1\right)}}\\[4pt] &=C_{\theta_{j,k_1},\theta_{j,k_2}}\left(\sqrt{1-\theta_{j,k_1}}-\sqrt{1-\theta_{j,k_2}}\right)^2. \end{align*} $$
Here, for any
 $\theta _1,\theta _2\in [0,1],$
we define
$\theta _1,\theta _2\in [0,1],$
we define
 $$ \begin{align*} C_{\theta_1,\theta_2}:=\begin{cases} \left(1-\sqrt{\theta_{1}\theta_{2}}+\sqrt{\theta_{1}\theta_{2}+1-\theta_{1}-\theta_{2}}\right)^{-1}, & \theta_1+\theta_2\le 1\\[4pt] \left(1+\sqrt{\theta_{1}\theta_{2}}-\sqrt{\theta_{1}\theta_{2}-\left(\theta_{1}+\theta_{2}-1\right)}\right)^{-1}, & \theta_1+\theta_2> 1. \end{cases} \end{align*} $$
$$ \begin{align*} C_{\theta_1,\theta_2}:=\begin{cases} \left(1-\sqrt{\theta_{1}\theta_{2}}+\sqrt{\theta_{1}\theta_{2}+1-\theta_{1}-\theta_{2}}\right)^{-1}, & \theta_1+\theta_2\le 1\\[4pt] \left(1+\sqrt{\theta_{1}\theta_{2}}-\sqrt{\theta_{1}\theta_{2}-\left(\theta_{1}+\theta_{2}-1\right)}\right)^{-1}, & \theta_1+\theta_2> 1. \end{cases} \end{align*} $$
In addition, let
 $\bar C_{\theta _1,\theta _2}:=2C_{\theta _1,\theta _2}\sqrt {\theta _1\theta _2}$
. Hence, we conclude that
$\bar C_{\theta _1,\theta _2}:=2C_{\theta _1,\theta _2}\sqrt {\theta _1\theta _2}$
. Hence, we conclude that
 $$ \begin{align*} -2\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\ge\left(1+\bar C_{\theta_{j,k_1},\theta_{j,k_2}}\right)\textsf{D}_2\left(\theta_{j,k_1},\theta_{j,k_2}\right), \end{align*} $$
$$ \begin{align*} -2\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)\ge\left(1+\bar C_{\theta_{j,k_1},\theta_{j,k_2}}\right)\textsf{D}_2\left(\theta_{j,k_1},\theta_{j,k_2}\right), \end{align*} $$
where for any
 $\theta _1,\theta _2\in [0,1]$
, we define
$\theta _1,\theta _2\in [0,1]$
, we define
 $$ \begin{align*} \textsf{D}_2\left(\theta_1,\theta_2\right):=\begin{cases} \left(\sqrt{\theta_1}-\sqrt{\theta_2}\right)^2, & \theta_1+\theta_2\le 1\\[4pt] \left(\sqrt{1-\theta_1}-\sqrt{1-\theta_2}\right)^2, & \theta_1+\theta_2> 1. \end{cases} \end{align*} $$
$$ \begin{align*} \textsf{D}_2\left(\theta_1,\theta_2\right):=\begin{cases} \left(\sqrt{\theta_1}-\sqrt{\theta_2}\right)^2, & \theta_1+\theta_2\le 1\\[4pt] \left(\sqrt{1-\theta_1}-\sqrt{1-\theta_2}\right)^2, & \theta_1+\theta_2> 1. \end{cases} \end{align*} $$
By the definition of
 $\Omega _0(k_1,k_2)$
, we have either (i)
$\Omega _0(k_1,k_2)$
, we have either (i)
 $\theta _{j,k_1}\vee \theta _{j,k_2}< 1/2$
and
$\theta _{j,k_1}\vee \theta _{j,k_2}< 1/2$
and
 $\theta _{j,k_1}+\theta _{j,k_2}\le 1$
or (ii)
$\theta _{j,k_1}+\theta _{j,k_2}\le 1$
or (ii)
 $\theta _{j,k_1}\wedge \theta _{j,k_2}> 1/2$
and
$\theta _{j,k_1}\wedge \theta _{j,k_2}> 1/2$
and
 $\theta _{j,k_1}+\theta _{j,k_2}> 1$
.
$\theta _{j,k_1}+\theta _{j,k_2}> 1$
.
We start with case (i). Without loss of generality, we assume
 $\frac {1}{2}>\theta _{j,k_1}>\theta _{j,k_2}$
and denote
$\frac {1}{2}>\theta _{j,k_1}>\theta _{j,k_2}$
and denote
 $\theta :=\theta _2$
,
$\theta :=\theta _2$
,
 $\delta :=\theta _1-\theta _2=o(1)$
. By definition, we have
$\delta :=\theta _1-\theta _2=o(1)$
. By definition, we have
 $$ \begin{align*} -\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)&=\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{2}\left(\sqrt{\theta+\delta}-\sqrt{\theta}\right)^2\left(1+o(1)\right)\\ &=\delta^2\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{8\theta}\left(1+o(1)\right)\\ &=\frac{\delta^2}{8\theta\left(1-\theta\right)}\left(1+o(1)\right). \end{align*} $$
$$ \begin{align*} -\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)&=\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{2}\left(\sqrt{\theta+\delta}-\sqrt{\theta}\right)^2\left(1+o(1)\right)\\ &=\delta^2\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{8\theta}\left(1+o(1)\right)\\ &=\frac{\delta^2}{8\theta\left(1-\theta\right)}\left(1+o(1)\right). \end{align*} $$
On the other hand, we have
 $$ \begin{align*} \frac{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)}=\delta^2\frac{\log\left(\left(1-\theta\right)/\theta\right)}{4\left(1-2\theta\right)}. \end{align*} $$
$$ \begin{align*} \frac{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)}=\delta^2\frac{\log\left(\left(1-\theta\right)/\theta\right)}{4\left(1-2\theta\right)}. \end{align*} $$
This implies that
 $$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)\right)}=\frac{1-2\theta}{2\theta\left(1-\theta\right)\log\left(\left(1-\theta\right)/\theta\right)}(1+o(1)). \end{align*} $$
$$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)\right)}=\frac{1-2\theta}{2\theta\left(1-\theta\right)\log\left(\left(1-\theta\right)/\theta\right)}(1+o(1)). \end{align*} $$
Define the function
 $$ \begin{align*} \tau(x)=\frac{1-2x}{2x(1-x)\log\left(\left(1-x\right)/x\right)},\quad g(x)=\left(-2x^2+2x-1\right)\log\left(\frac{1}{x}-1\right)-2x+1 \end{align*} $$
$$ \begin{align*} \tau(x)=\frac{1-2x}{2x(1-x)\log\left(\left(1-x\right)/x\right)},\quad g(x)=\left(-2x^2+2x-1\right)\log\left(\frac{1}{x}-1\right)-2x+1 \end{align*} $$
for
 $0<x<{1}/{2}$
. Some algebra gives that
$0<x<{1}/{2}$
. Some algebra gives that
 $$ \begin{align*} \tau^{\prime}\left(x\right)=\frac{g(x)}{2x^2\left(1-x\right)^2\log^2\left(\frac{1}{x}-1\right)}. \end{align*} $$
$$ \begin{align*} \tau^{\prime}\left(x\right)=\frac{g(x)}{2x^2\left(1-x\right)^2\log^2\left(\frac{1}{x}-1\right)}. \end{align*} $$
Note that
 $$ \begin{align*} g^\prime(x)=\frac{\left(1-2x\right)^2}{x(1-x)}+2\left(1-2x\right)\log\left(\frac{1}{x}-1\right)>0, \end{align*} $$
$$ \begin{align*} g^\prime(x)=\frac{\left(1-2x\right)^2}{x(1-x)}+2\left(1-2x\right)\log\left(\frac{1}{x}-1\right)>0, \end{align*} $$
for
 $0<x<{1}/{2}$
, which implies that
$0<x<{1}/{2}$
, which implies that
 $g(x)< \lim _{x\rightarrow \frac {1}{2}} g(x)=0$
. Hence, we have
$g(x)< \lim _{x\rightarrow \frac {1}{2}} g(x)=0$
. Hence, we have
 $\tau ^\prime (x)< 0$
and
$\tau ^\prime (x)< 0$
and
 $\tau (x)> \lim _{x\rightarrow \frac {1}{2}} \tau (x)=1$
. Thus, we have
$\tau (x)> \lim _{x\rightarrow \frac {1}{2}} \tau (x)=1$
. Thus, we have
 $$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)\right)}=\tau(\theta)(1+o(1))>1, \end{align*} $$
$$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\left(\sigma^2_{\theta_{j,k_1}}\vee \sigma^2_{\theta_{j,k_1}}\right)\right)}=\tau(\theta)(1+o(1))>1, \end{align*} $$
where
 $\tau (\theta )$
is monotone decreasing as
$\tau (\theta )$
is monotone decreasing as
 $\theta $
increases to
$\theta $
increases to
 $1/2$
and
$1/2$
and
 $\tau (\theta )\rightarrow \infty $
as
$\tau (\theta )\rightarrow \infty $
as
 $\theta \rightarrow 0$
.
$\theta \rightarrow 0$
.
The analysis for case (ii) is essentially the same and hence omitted. Combining (i) and (ii), we can arrive at
 $$ \begin{align*} I_{k_1,k_2}=\sum_{j\in\Omega_0\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)+\sum_{j\in\Omega_0^c\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right) \end{align*} $$
$$ \begin{align*} I_{k_1,k_2}=\sum_{j\in\Omega_0\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)+\sum_{j\in\Omega_0^c\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right) \end{align*} $$
and
 $$ \begin{align*} \exp\left(-\frac{I_{k_1,k_2}}{2}\right)&=\exp\left(-\frac{1}{2}\sum_{j\in\Omega_0\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)\right)\exp\left(-\frac{1}{2}\sum_{j\in\Omega_0^c\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)\right)\\ &\gtrsim\exp\left(-\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \frac{I\left(\theta_{j,k_1},\theta_{j,k_2}\right)/2}{\Delta^2_{j,k_1,k_2}}\right)\\ &\gtrsim\exp\left(-\frac{\sum_{j\in[J]}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\bar\sigma^2}\left(1+\tau_{k_1,k_2}\right)\right), \end{align*} $$
$$ \begin{align*} \exp\left(-\frac{I_{k_1,k_2}}{2}\right)&=\exp\left(-\frac{1}{2}\sum_{j\in\Omega_0\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)\right)\exp\left(-\frac{1}{2}\sum_{j\in\Omega_0^c\left(k_1,k_2\right)}I\left(\theta_{j,k_1},\theta_{j,k_2}\right)\right)\\ &\gtrsim\exp\left(-\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \frac{I\left(\theta_{j,k_1},\theta_{j,k_2}\right)/2}{\Delta^2_{j,k_1,k_2}}\right)\\ &\gtrsim\exp\left(-\frac{\sum_{j\in[J]}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\bar\sigma^2}\left(1+\tau_{k_1,k_2}\right)\right), \end{align*} $$
where the inequality holds due to the assumption
 $\left |\Omega ^c_0\right |=O(1)$
, and
$\left |\Omega ^c_0\right |=O(1)$
, and
 $$ \begin{align*} \tau_{k_1,k_2}:=\frac{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \tau \left(\theta_{j,k_1}\right)}{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}}\left(1+o(1)\right). \end{align*} $$
$$ \begin{align*} \tau_{k_1,k_2}:=\frac{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}\cdot \tau \left(\theta_{j,k_1}\right)}{\sum_{j\in\Omega_0\left(k_1,k_2\right)}\Delta^2_{j,k_1,k_2}}\left(1+o(1)\right). \end{align*} $$
B.6 Proof of Lemma 1
In light of Corollary 3.12, Remark 3.13 in Bandeira and Van Handel (Reference Bandeira and Van Handel2016), and Theorem 6.10 in Boucheron et al. (Reference Boucheron, Lugosi and Massart2013), for
 $t\ge 0,$
we have
$t\ge 0,$
we have
 $$ \begin{align*} \mathbb{P}\left(\left\|\mathbf{E}\right\|\ge \frac{(1+\varepsilon)\sqrt{2}}{2}\left(\sqrt{N}+\sqrt{J}\right)+C_{\varepsilon}\sqrt{\log\left(N\wedge J\right)}+t\right)\le (N\wedge J)e^{-t^2/2}. \end{align*} $$
$$ \begin{align*} \mathbb{P}\left(\left\|\mathbf{E}\right\|\ge \frac{(1+\varepsilon)\sqrt{2}}{2}\left(\sqrt{N}+\sqrt{J}\right)+C_{\varepsilon}\sqrt{\log\left(N\wedge J\right)}+t\right)\le (N\wedge J)e^{-t^2/2}. \end{align*} $$
By choosing
 $t=2\sqrt {\log (N\wedge J )}$
and
$t=2\sqrt {\log (N\wedge J )}$
and
 $\varepsilon =\sqrt {2}-1$
, for
$\varepsilon =\sqrt {2}-1$
, for
 $N,J$
large enough, we obtain that
$N,J$
large enough, we obtain that
 $$ \begin{align*} \mathbb{P}\left(\left\|\mathbf{E}\right\|\ge 2\left(\sqrt{N}+\sqrt{J}\right)\right)\le (N\wedge J)^{-1}. \end{align*} $$
$$ \begin{align*} \mathbb{P}\left(\left\|\mathbf{E}\right\|\ge 2\left(\sqrt{N}+\sqrt{J}\right)\right)\le (N\wedge J)^{-1}. \end{align*} $$
This implies that
 $ \lambda _{K+1}\left (\mathbf {R}\right )\le \left \|\mathbf {E}\right \|\le 2\left (\sqrt {J}+\sqrt {N}\right )$
with probability
$ \lambda _{K+1}\left (\mathbf {R}\right )\le \left \|\mathbf {E}\right \|\le 2\left (\sqrt {J}+\sqrt {N}\right )$
with probability
 $1-o(1)$
. On the other hand, by assumption in Proposition 1 on
$1-o(1)$
. On the other hand, by assumption in Proposition 1 on
 $\sigma _{K}(\mathbb {E} \mathbf {R})$
, we obtain that
$\sigma _{K}(\mathbb {E} \mathbf {R})$
, we obtain that
 $$ \begin{align*} \lambda_{K}\left(\mathbf{R}\right)\ge \lambda_{K}\left(\mathbb{E} \mathbf{R}\right)-\left\|\mathbf{E}\right\|=\omega\left(\sqrt{N}+\sqrt{J}\right) \end{align*} $$
$$ \begin{align*} \lambda_{K}\left(\mathbf{R}\right)\ge \lambda_{K}\left(\mathbb{E} \mathbf{R}\right)-\left\|\mathbf{E}\right\|=\omega\left(\sqrt{N}+\sqrt{J}\right) \end{align*} $$
with probability
 $1-o(1)$
. This completes the proof of Lemma 1.
$1-o(1)$
. This completes the proof of Lemma 1.
B.7 Special case when there exists
$\theta _{j,k}$
close to
$1/2$


For
 $\theta <1/2$
, we have
$\theta <1/2$
, we have
 $$ \begin{align*} \sigma^2_\theta=\frac{1-2\theta}{2\log\left(\left(1-\theta\right)/\theta\right)}=\left(\frac{1}{2}-\theta\right)\frac{1}{\log\left(1+\frac{1}{\theta}-2\right)}\ge \frac{\theta}{2}. \end{align*} $$
$$ \begin{align*} \sigma^2_\theta=\frac{1-2\theta}{2\log\left(\left(1-\theta\right)/\theta\right)}=\left(\frac{1}{2}-\theta\right)\frac{1}{\log\left(1+\frac{1}{\theta}-2\right)}\ge \frac{\theta}{2}. \end{align*} $$
For
 $\theta>1/2$
, we have
$\theta>1/2$
, we have
 $$ \begin{align*} \sigma^2_\theta=\frac{2\theta-1}{2\log\left(\theta/\left(1-\theta\right)\right)}=\left(\theta-\frac{1}{2}\right)\frac{1}{\log\left(1+\frac{2\theta-1}{1-\theta}\right)}\ge \frac{1-\theta}{2}. \end{align*} $$
$$ \begin{align*} \sigma^2_\theta=\frac{2\theta-1}{2\log\left(\theta/\left(1-\theta\right)\right)}=\left(\theta-\frac{1}{2}\right)\frac{1}{\log\left(1+\frac{2\theta-1}{1-\theta}\right)}\ge \frac{1-\theta}{2}. \end{align*} $$
Denote
 $\bar \theta :=\operatorname *{\mbox {arg min}}_{\theta \in \left \{\theta _{j,k},j\in [J], k\in [K]\right \}}\left |\frac {1}{2}-\theta \right |$
and
$\bar \theta :=\operatorname *{\mbox {arg min}}_{\theta \in \left \{\theta _{j,k},j\in [J], k\in [K]\right \}}\left |\frac {1}{2}-\theta \right |$
and
 $\bar \delta :=\left |\frac {1}{2}-\bar \theta \right |$
, then we simply have
$\bar \delta :=\left |\frac {1}{2}-\bar \theta \right |$
, then we simply have
 $$ \begin{align*} \bar\sigma^2=\sigma^2_{\bar\theta}\ge \frac{\bar\theta\wedge\left(1-\bar\theta\right)}{2}=\frac{1}{4}\left(1-2\bar\delta\right). \end{align*} $$
$$ \begin{align*} \bar\sigma^2=\sigma^2_{\bar\theta}\ge \frac{\bar\theta\wedge\left(1-\bar\theta\right)}{2}=\frac{1}{4}\left(1-2\bar\delta\right). \end{align*} $$
We thereby have
 $$ \begin{align*} \frac{1}{8\bar\sigma^2}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2\le \frac{1}{2\left(1-2\bar\delta\right)}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2. \end{align*} $$
$$ \begin{align*} \frac{1}{8\bar\sigma^2}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2\le \frac{1}{2\left(1-2\bar\delta\right)}\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2. \end{align*} $$
We have
 $\bar \delta =o(1)$
by assumption, and without loss of generality assume
$\bar \delta =o(1)$
by assumption, and without loss of generality assume
 $\frac {1}{2}>\theta _{j,k_1}>\theta _{j,k_2}$
and denote
$\frac {1}{2}>\theta _{j,k_1}>\theta _{j,k_2}$
and denote
 $\theta :=\theta _2$
,
$\theta :=\theta _2$
,
 $\delta :=\theta _1-\theta _2=o(1)$
. Then we have
$\delta :=\theta _1-\theta _2=o(1)$
. Then we have
 $$ \begin{align*} \frac{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\bar\sigma^2}=\frac{\delta^2}{2}\left(1+o(1)\right). \end{align*} $$
$$ \begin{align*} \frac{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2}{8\bar\sigma^2}=\frac{\delta^2}{2}\left(1+o(1)\right). \end{align*} $$
On the other hand, we have
 $$ \begin{align*} -\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)&=\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{2}\left(\sqrt{\theta+\delta}-\sqrt{\theta}\right)^2\left(1+o(1)\right)\\ &=\delta^2\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{8\theta}\left(1+o(1)\right)\\ &=\frac{\delta^2}{8\theta\left(1-\theta\right)}\left(1+o(1)\right), \end{align*} $$
$$ \begin{align*} -\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)&=\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{2}\left(\sqrt{\theta+\delta}-\sqrt{\theta}\right)^2\left(1+o(1)\right)\\ &=\delta^2\frac{\left(1+\bar C_{\theta+\delta,\theta}\right)}{8\theta}\left(1+o(1)\right)\\ &=\frac{\delta^2}{8\theta\left(1-\theta\right)}\left(1+o(1)\right), \end{align*} $$
where we’ve used the fact that
 $\bar C_{\theta +\delta ,\theta }=\frac {\theta }{1-\theta }(1+o(1)).$
This implies that
$\bar C_{\theta +\delta ,\theta }=\frac {\theta }{1-\theta }(1+o(1)).$
This implies that
 $$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\bar\sigma^2\right)}=\frac{1}{4\theta\left(1-\theta\right)}(1+o(1))>1, \end{align*} $$
$$ \begin{align*} \frac{-\log\left(\sqrt{\theta_{j,k_1}\theta_{j,k_2}}+\sqrt{\left(1-\theta_{j,k_1}\right)\left(1-\theta_{j,k_2}\right)}\right)}{\left(\theta_{j,k_1}-\theta_{j,k_2}\right)^2/\left(8\bar\sigma^2\right)}=\frac{1}{4\theta\left(1-\theta\right)}(1+o(1))>1, \end{align*} $$
where the last inequality holds due to
 $\theta <1/2$
.
$\theta <1/2$
.
C Proofs of lemmas
C.1 Proof of Lemma B.1
To keep notation simple in the analysis, for any
 ${\boldsymbol s}\in [K]^N$
, we define
${\boldsymbol s}\in [K]^N$
, we define
 $$ \begin{align*} \theta_{j,k}\left({\boldsymbol s}\right):=\frac{\sum_{i\in[N]} R_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}, \quad j\in[J],k\in[K]. \end{align*} $$
$$ \begin{align*} \theta_{j,k}\left({\boldsymbol s}\right):=\frac{\sum_{i\in[N]} R_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}, \quad j\in[J],k\in[K]. \end{align*} $$
The following result is needed, whose proof is deferred to Section C.2.
Lemma C.1. Suppose Assumptions 1 and 2 hold. For any
 $\gamma _0>0$
, there exist some absolute constants
$\gamma _0>0$
, there exist some absolute constants
 $C_1,C_2>0$
depending only on
$C_1,C_2>0$
depending only on
 $\gamma _0$
such that with probability at least
$\gamma _0$
such that with probability at least
 $1-2JKN^{-\left (2\gamma _0+1\right )}$
,
$1-2JKN^{-\left (2\gamma _0+1\right )}$
,
 $$ \begin{align} \max_{s:\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)\le {\alpha }/\left(2K\right)}\max_{j\in[J],k\in[K]} \frac{\left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\left({\boldsymbol s}^\star\right)\right|}{\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)}\le \frac{C_1 K}{\alpha}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right), \end{align} $$
$$ \begin{align} \max_{s:\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)\le {\alpha }/\left(2K\right)}\max_{j\in[J],k\in[K]} \frac{\left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\left({\boldsymbol s}^\star\right)\right|}{\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)}\le \frac{C_1 K}{\alpha}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right), \end{align} $$
and
 $$ \begin{align} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|>C_2\bar\sigma\sqrt{\frac{K \log N}{\alpha N}}, \end{align} $$
$$ \begin{align} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|>C_2\bar\sigma\sqrt{\frac{K \log N}{\alpha N}}, \end{align} $$
where
 $\ell _0\left ({\boldsymbol s},{\boldsymbol s}^\prime \right ):=\frac {1}{N}\sum _{i\in [N]}\mathbb {I}\left (s_i\ne s_i^\prime \right )$
. As a result, for any (possibly random)
$\ell _0\left ({\boldsymbol s},{\boldsymbol s}^\prime \right ):=\frac {1}{N}\sum _{i\in [N]}\mathbb {I}\left (s_i\ne s_i^\prime \right )$
. As a result, for any (possibly random)
 ${\boldsymbol s}\in [K]^N$
such that
${\boldsymbol s}\in [K]^N$
such that
 $\ell _0({\boldsymbol s},{\boldsymbol s}^\star )\le {\alpha }/(2K)$
, we have
$\ell _0({\boldsymbol s},{\boldsymbol s}^\star )\le {\alpha }/(2K)$
, we have
 $$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\right|\le\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)\cdot {\frac{ C_1K}{\alpha}}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right)+C_2\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
$$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\right|\le\ell_0\left({\boldsymbol s},{\boldsymbol s}^\star\right)\cdot {\frac{ C_1K}{\alpha}}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right)+C_2\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
with probability at least
 $1-2JKN^{-(2\gamma _0+1)}$
.
$1-2JKN^{-(2\gamma _0+1)}$
.
By Proposition 1 and Markov’s inequality, we obtain that if
 $$ \begin{align*} \min\left\{\frac{\Delta/\bar\sigma}{K\left(1+\sqrt{\frac{J}{N}}\right)}, \frac{\lambda_K/\bar\sigma}{\left(\sqrt{N}+\sqrt{J}\right)}\right\}\rightarrow\infty, \end{align*} $$
$$ \begin{align*} \min\left\{\frac{\Delta/\bar\sigma}{K\left(1+\sqrt{\frac{J}{N}}\right)}, \frac{\lambda_K/\bar\sigma}{\left(\sqrt{N}+\sqrt{J}\right)}\right\}\rightarrow\infty, \end{align*} $$
then for
 $m\in [2]$
, with probability exceeding at least
$m\in [2]$
, with probability exceeding at least
 $1-\exp (-(1-c_0)\Delta ^2/(8\bar \sigma ^) )$
, we have
$1-\exp (-(1-c_0)\Delta ^2/(8\bar \sigma ^) )$
, we have
 $$ \begin{align*} \ell\left(\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star}_{{\mathcal{S}}_m}\right)\le \exp\left(-\left(1-c_0\right)\frac{\Delta^2}{8\bar\sigma^2}\right), \end{align*} $$
$$ \begin{align*} \ell\left(\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star}_{{\mathcal{S}}_m}\right)\le \exp\left(-\left(1-c_0\right)\frac{\Delta^2}{8\bar\sigma^2}\right), \end{align*} $$
where
 ${\boldsymbol s}^{\star }_{{\mathcal{S}}_m}$
is sub-vector of
${\boldsymbol s}^{\star }_{{\mathcal{S}}_m}$
is sub-vector of
 ${\boldsymbol s}^\star $
with the index set
${\boldsymbol s}^\star $
with the index set
 ${\mathcal{S}}_m$
, and we’ve used that
${\mathcal{S}}_m$
, and we’ve used that
 $\exp(-N/2 )<\exp (-(1-c_0 )\Delta ^2/(8\bar \sigma ^2 ) )$
. Without loss of generality, we assume
$\exp(-N/2 )<\exp (-(1-c_0 )\Delta ^2/(8\bar \sigma ^2 ) )$
. Without loss of generality, we assume
 $ \ell \left (\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_m}\right )= \ell _0\left (\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_m}\right )$
. Combined with Lemma C.1, we then have
$ \ell \left (\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_m}\right )= \ell _0\left (\widetilde {\boldsymbol s}^{(m)},{\boldsymbol s}^{\star }_{{\mathcal{S}}_m}\right )$
. Combined with Lemma C.1, we then have
 $$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\widehat\theta^{(m)}_{j,k}-\theta_{j,k}\right|\le C_1\exp\left(-\left(1-c_0\right)\frac{\Delta^2}{8\bar\sigma^2}\right)+C_2\bar\sigma\sqrt{\frac{K \log N}{ N}} \end{align*} $$
$$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\widehat\theta^{(m)}_{j,k}-\theta_{j,k}\right|\le C_1\exp\left(-\left(1-c_0\right)\frac{\Delta^2}{8\bar\sigma^2}\right)+C_2\bar\sigma\sqrt{\frac{K \log N}{ N}} \end{align*} $$
with probability at least
 $1-\exp \left (-\left (1-c_0\right )\Delta ^2/\left (8\bar \sigma ^2\right )\right )-\exp \left (-C\sqrt {N/K}\right )-N^{-\left (1+\gamma _0\right )}$
, provided that there exists some universal constant
$1-\exp \left (-\left (1-c_0\right )\Delta ^2/\left (8\bar \sigma ^2\right )\right )-\exp \left (-C\sqrt {N/K}\right )-N^{-\left (1+\gamma _0\right )}$
, provided that there exists some universal constant
 $\gamma _0>0$
such that
$\gamma _0>0$
such that
 $$ \begin{align*} JK \lesssim N^{\gamma_0},\quad N\gtrsim K\log N. \end{align*} $$
$$ \begin{align*} JK \lesssim N^{\gamma_0},\quad N\gtrsim K\log N. \end{align*} $$
The proof is completed by noticing that
 $I^\star \asymp \Delta ^2/\bar \sigma ^2$
,
$I^\star \asymp \Delta ^2/\bar \sigma ^2$
,
 $JK\le \exp \left (\left (1-c_1\right )\Delta ^2/\left (8\bar \sigma ^2\right )\right )$
for some
$JK\le \exp \left (\left (1-c_1\right )\Delta ^2/\left (8\bar \sigma ^2\right )\right )$
for some
 $c_1\in (c_0,1)$
,
$c_1\in (c_0,1)$
,
 $\bar \sigma \asymp 1,$
and
$\bar \sigma \asymp 1,$
and
 $$ \begin{align*} \frac{\Delta}{{J^{1/2}}K^{3/4}\left(\log N\right)^{1/4}/{N^{1/4}}}\rightarrow\infty. \end{align*} $$
$$ \begin{align*} \frac{\Delta}{{J^{1/2}}K^{3/4}\left(\log N\right)^{1/4}/{N^{1/4}}}\rightarrow\infty. \end{align*} $$
C.2 Proof of Lemma C.1
We introduce the following notations:
 $$ \begin{align*} \bar\theta_{j,k}\left({\boldsymbol s}\right):= \frac{\sum_{i\in[N]} \theta_{i,s_i^\star}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)},\quad {\mathfrak E}_{j,k}(s):=\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}. \end{align*} $$
$$ \begin{align*} \bar\theta_{j,k}\left({\boldsymbol s}\right):= \frac{\sum_{i\in[N]} \theta_{i,s_i^\star}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)},\quad {\mathfrak E}_{j,k}(s):=\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}. \end{align*} $$
By definition, we have
 $\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )=\theta _{j,k}$
and
$\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )=\theta _{j,k}$
and
 ${\mathfrak E}_{j,k}(s)=\theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}\right )$
, and hence
${\mathfrak E}_{j,k}(s)=\theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}\right )$
, and hence
 $$ \begin{align} & \left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\right|\notag\\ &= \left|\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}\right)+\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)+\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\left({\boldsymbol s}^\star\right)+\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|\notag\\ &\le \left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|+\left|\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)\right|+\left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|. \end{align} $$
$$ \begin{align} & \left|\theta_{j,k}\left({\boldsymbol s}\right)-\theta_{j,k}\right|\notag\\ &= \left|\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}\right)+\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)+\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\left({\boldsymbol s}^\star\right)+\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|\notag\\ &\le \left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|+\left|\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)\right|+\left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|. \end{align} $$
We first bound the term
 $ \left |{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left ({\boldsymbol s}^\star \right )\right |$
. Notice that
$ \left |{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left ({\boldsymbol s}^\star \right )\right |$
. Notice that
 $$ \begin{align} &\left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|\notag\\ &\le \left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}-\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|+\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}-\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\notag\\ &\le \frac{1}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\left(\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i=k, s^\star_i\ne k\right)\right|+\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i\ne k, s^\star_i= k\right)\right|\right)\notag\\ &+\left|\frac{\sum_{i\in[N]} \left[\mathbb{I}\left(s^\star_i=k\right)-\mathbb{I}\left(s_i=k\right)\right]}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|. \end{align} $$
$$ \begin{align} &\left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|\notag\\ &\le \left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}-\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|+\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}-\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\notag\\ &\le \frac{1}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\left(\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i=k, s^\star_i\ne k\right)\right|+\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i\ne k, s^\star_i= k\right)\right|\right)\notag\\ &+\left|\frac{\sum_{i\in[N]} \left[\mathbb{I}\left(s^\star_i=k\right)-\mathbb{I}\left(s_i=k\right)\right]}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|. \end{align} $$
Note that the following fact holds for any
 ${\boldsymbol s}\in [K]^N$
such that
${\boldsymbol s}\in [K]^N$
such that
 $\ell \left ({\boldsymbol s},{\boldsymbol s}^\star \right )\le \alpha /\left (2K\right )$
:
$\ell \left ({\boldsymbol s},{\boldsymbol s}^\star \right )\le \alpha /\left (2K\right )$
:
 $$ \begin{align*} \sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)\ge \sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)-\sum_{i\in[N]} \mathbb{I}\left(s^\star_i\ne s_i\right)\ge \frac{\alpha N}{K}-\frac{\alpha N}{2K}\ge \frac{\alpha N}{2K}. \end{align*} $$
$$ \begin{align*} \sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)\ge \sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)-\sum_{i\in[N]} \mathbb{I}\left(s^\star_i\ne s_i\right)\ge \frac{\alpha N}{K}-\frac{\alpha N}{2K}\ge \frac{\alpha N}{2K}. \end{align*} $$
Combined with the fact that
 $\left |E_{i,j}\right |\le 1$
, we thus obtain the following bound for the first term in (C.4):
$\left |E_{i,j}\right |\le 1$
, we thus obtain the following bound for the first term in (C.4):
 $$ \begin{align*} \frac{1}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\left(\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i=k, s^\star_i\ne k\right)\right|+\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i\ne k, s^\star_i= k\right)\right|\right)\le \frac{4K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
$$ \begin{align*} \frac{1}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\left(\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i=k, s^\star_i\ne k\right)\right|+\left|\sum_{i\in[N]}E_{i,j}\mathbb{I}\left(s_i\ne k, s^\star_i= k\right)\right|\right)\le \frac{4K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
Next, we bound the second term in (C.4). By General Hoeffding’s inequality, we obtain that
 $$ \begin{align*} \mathbb{P}\left(\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\ge t \right)\le 2\exp\left(-\frac{ct^2}{\bar\sigma^2N_k}\right). \end{align*} $$
$$ \begin{align*} \mathbb{P}\left(\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\ge t \right)\le 2\exp\left(-\frac{ct^2}{\bar\sigma^2N_k}\right). \end{align*} $$
By choosing
 $t=\bar \sigma \sqrt {CN_k \log N}$
for some sufficiently large
$t=\bar \sigma \sqrt {CN_k \log N}$
for some sufficiently large
 $C>0$
, we have that
$C>0$
, we have that
 $$ \begin{align*} \left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\le C\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
$$ \begin{align*} \left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right|\le C\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
with probability exceeding
 $1-N^{-2\gamma _0-1}$
for some large constant
$1-N^{-2\gamma _0-1}$
for some large constant
 $\gamma _0>0$
. In addition, we have
$\gamma _0>0$
. In addition, we have
 $$ \begin{align*} \left|\frac{\sum_{i\in[N]} \left[\mathbb{I}\left(s^\star_i=k\right)-\mathbb{I}\left(s_i=k\right)\right]}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|&\le \frac{2K}{\alpha N}\left(\left|\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k,s_i\ne k\right)\right|+\left|\sum_{i\in[N]} \mathbb{I}\left(s^\star_i\ne k,s_i= k\right)\right|\right)\\ &\lesssim \frac{K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
$$ \begin{align*} \left|\frac{\sum_{i\in[N]} \left[\mathbb{I}\left(s^\star_i=k\right)-\mathbb{I}\left(s_i=k\right)\right]}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|&\le \frac{2K}{\alpha N}\left(\left|\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k,s_i\ne k\right)\right|+\left|\sum_{i\in[N]} \mathbb{I}\left(s^\star_i\ne k,s_i= k\right)\right|\right)\\ &\lesssim \frac{K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
From (C.4) and a union bound over
 $j\in [J]$
and
$j\in [J]$
and
 $k\in [K]$
, we arrive at
$k\in [K]$
, we arrive at
 $$ \begin{align*} \max_{j\in[J],k\in[K]}\left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|\lesssim {\alpha^{-1}K\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right)}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right) \end{align*} $$
$$ \begin{align*} \max_{j\in[J],k\in[K]}\left|{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left({\boldsymbol s}^\star\right)\right|\lesssim {\alpha^{-1}K\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right)}\left(1+\bar\sigma\sqrt{\frac{K\log N}{\alpha N}}\right) \end{align*} $$
with probability at least
 $1-JKN^{-2\gamma _0-1}$
.
$1-JKN^{-2\gamma _0-1}$
.
Next, we bound the term
 $\left |\bar \theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )\right |$
. Notice that by definition
$\left |\bar \theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )\right |$
. Notice that by definition
 $\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )=\theta _{j,k}$
, hence
$\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )=\theta _{j,k}$
, hence
 $$ \begin{align*} \left|\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)\right| =\left|\frac{\sum_{i\in[N]}\sum_{k^\prime\in[K]} \left(\theta_{i,k}-\theta_{i,k^\prime}\right)\mathbb{I}\left(s_i=k,s_i^\star=k^\prime\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|\le \frac{2K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
$$ \begin{align*} \left|\bar\theta_{j,k}\left({\boldsymbol s}\right)-\bar\theta_{j,k}\left({\boldsymbol s}^\star\right)\right| =\left|\frac{\sum_{i\in[N]}\sum_{k^\prime\in[K]} \left(\theta_{i,k}-\theta_{i,k^\prime}\right)\mathbb{I}\left(s_i=k,s_i^\star=k^\prime\right)}{\sum_{i\in[N]} \mathbb{I}\left(s_i=k\right)}\right|\le \frac{2K}{\alpha }\ell\left({\boldsymbol s},{\boldsymbol s}^\star\right). \end{align*} $$
It suffices to bound
 $\left |\theta _{j,k}\left ({\boldsymbol s}^\star \right )-\theta _{j,k}\right |$
by
$\left |\theta _{j,k}\left ({\boldsymbol s}^\star \right )-\theta _{j,k}\right |$
by
 $$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|= \max_{j\in[J],k\in[K]}\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right| \le C\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
$$ \begin{align*} \max_{j\in[J],k\in[K]} \left|\theta_{j,k}\left({\boldsymbol s}^\star\right)-\theta_{j,k}\right|= \max_{j\in[J],k\in[K]}\left|\frac{\sum_{i\in[N]} E_{i,j}\mathbb{I}\left(s^\star_i=k\right)}{\sum_{i\in[N]} \mathbb{I}\left(s^\star_i=k\right)}\right| \le C\bar\sigma\sqrt{\frac{K \log N}{\alpha N}} \end{align*} $$
with probability exceeding
 $1-JKN^{-2\gamma _0-1}$
.
$1-JKN^{-2\gamma _0-1}$
.
Collecting (C.3) and the bounds for
 $ \left |{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left ({\boldsymbol s}^\star \right )\right |$
,
$ \left |{\mathfrak E}_{j,k}(s)-{\mathfrak E}_{j,k}\left ({\boldsymbol s}^\star \right )\right |$
,
 $\left |\bar \theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )\right |$
, and
$\left |\bar \theta _{j,k}\left ({\boldsymbol s}\right )-\bar \theta _{j,k}\left ({\boldsymbol s}^\star \right )\right |$
, and
 $\left |\theta _{j,k}\left ({\boldsymbol s}^\star \right )-\theta _{j,k}\right |$
, we can complete the proof.
$\left |\theta _{j,k}\left ({\boldsymbol s}^\star \right )-\theta _{j,k}\right |$
, we can complete the proof.
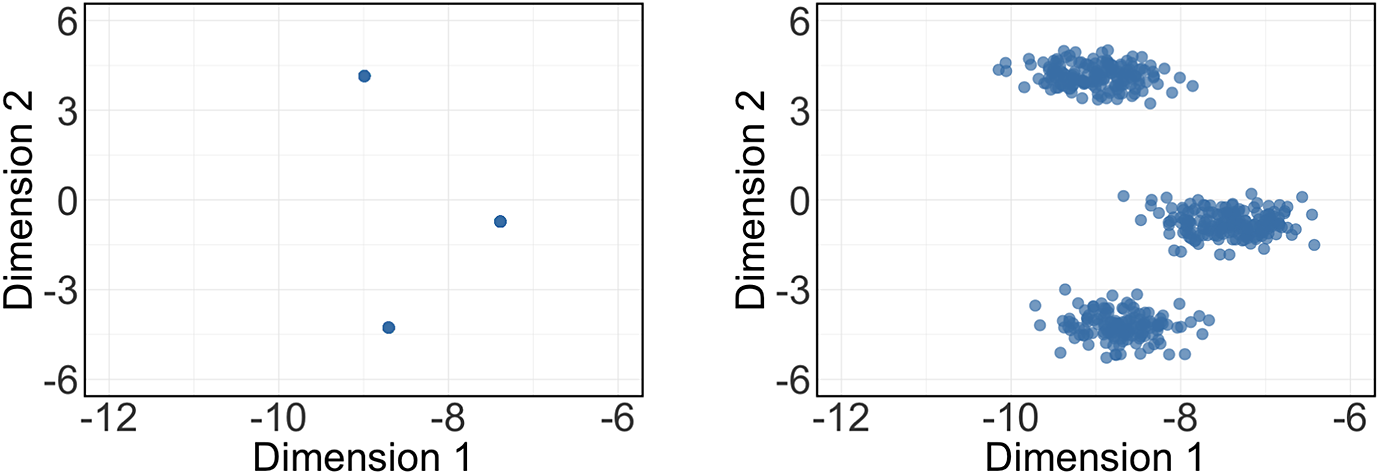








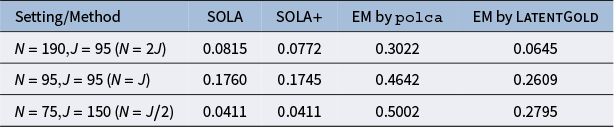

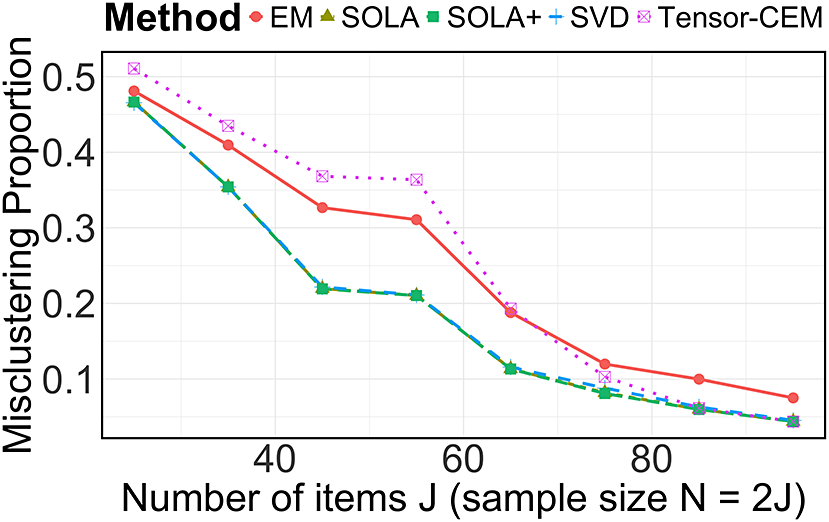


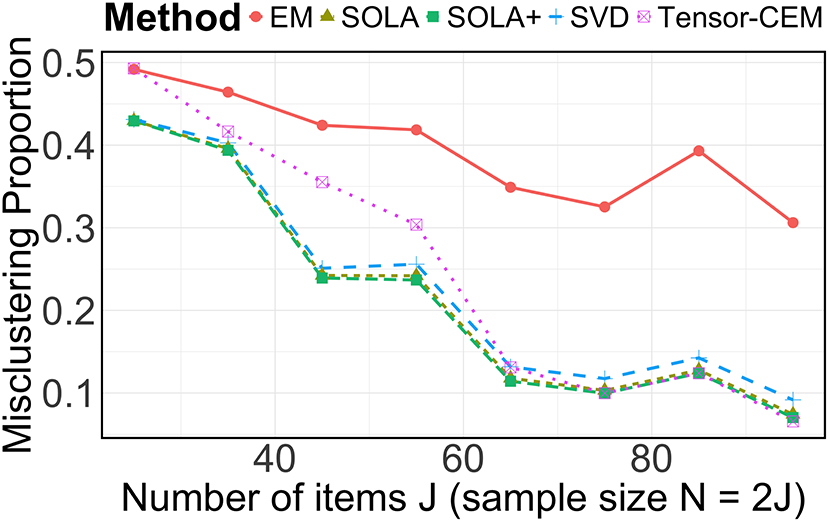


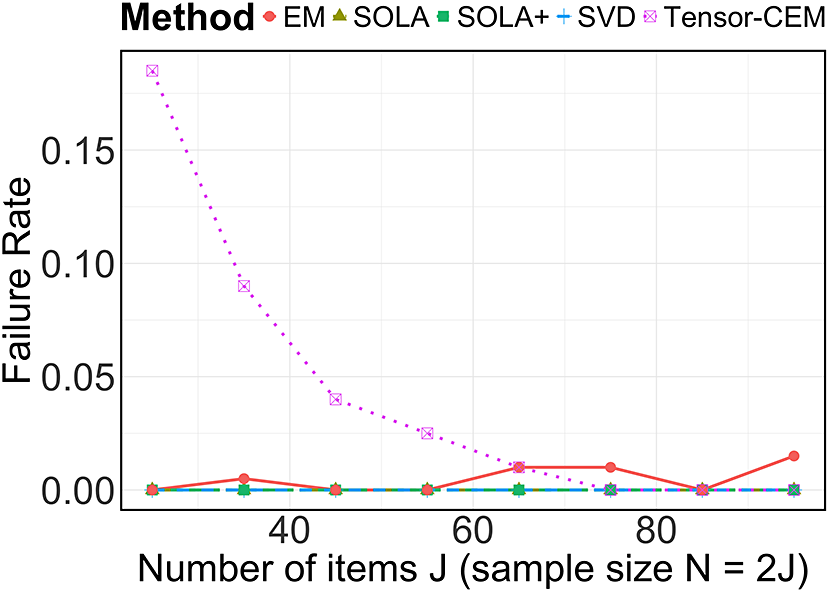



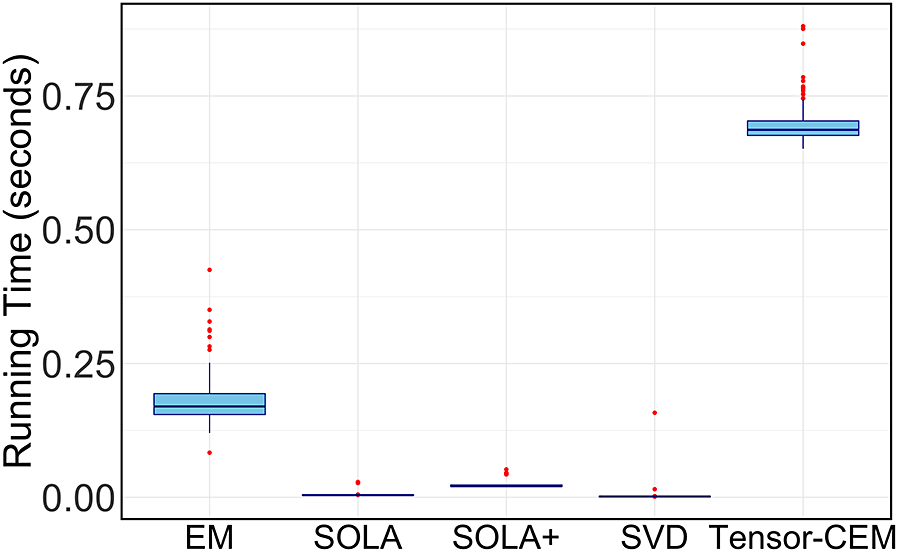
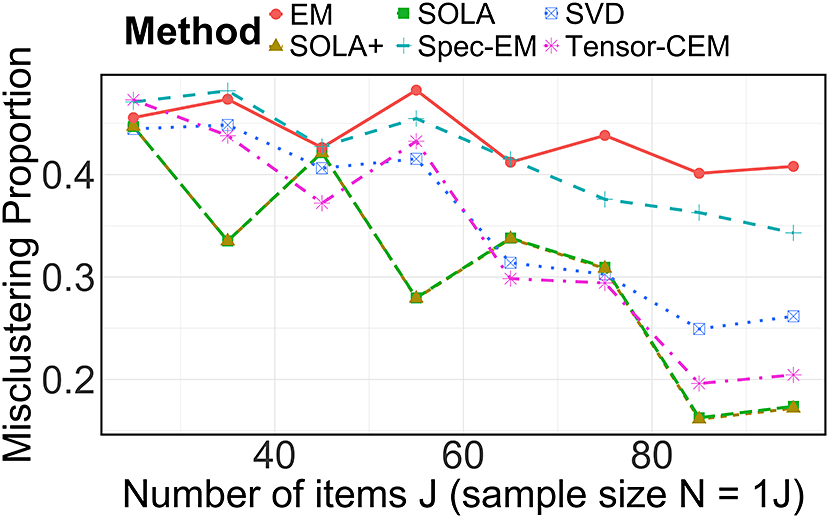



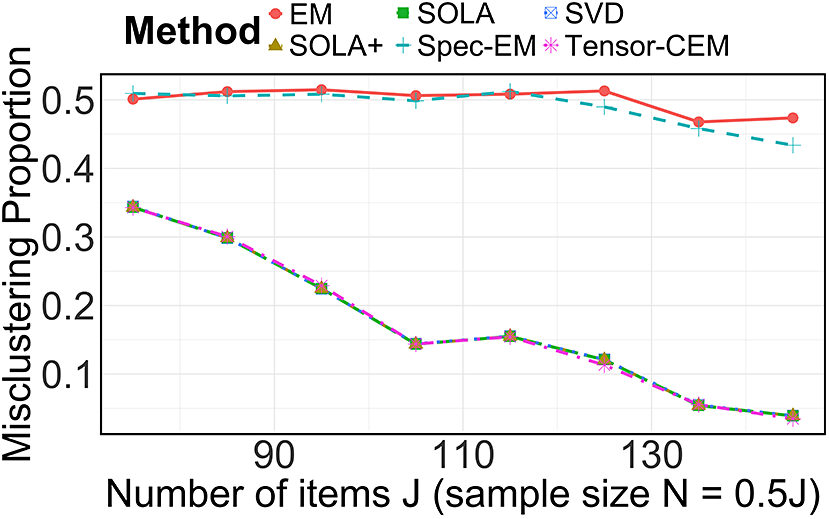



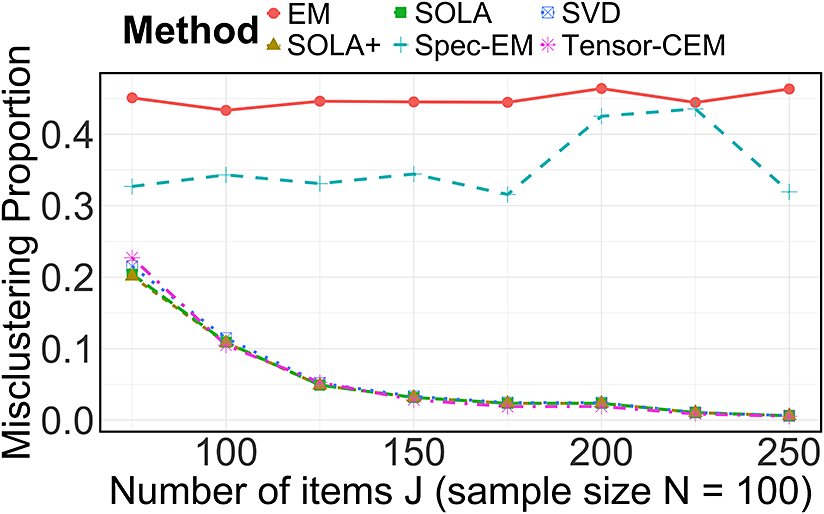



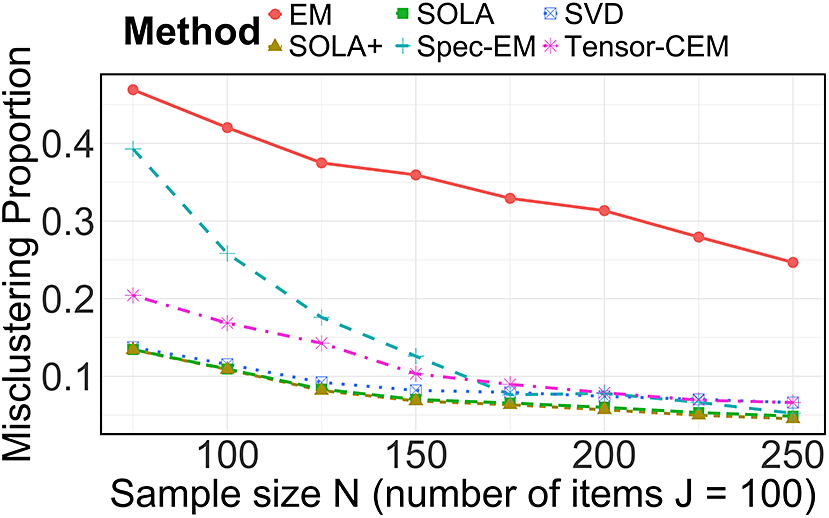











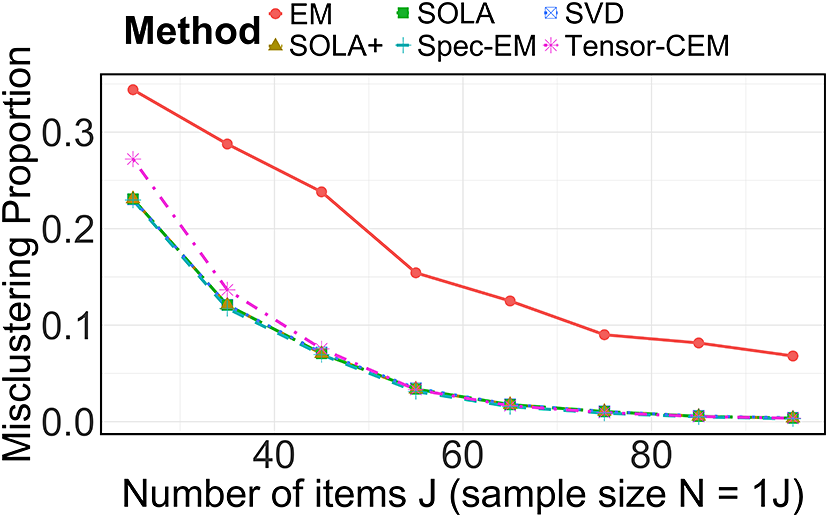


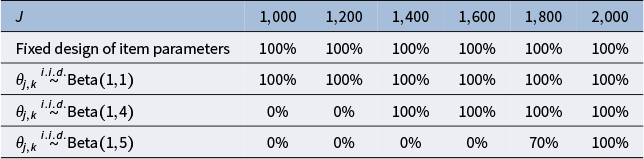



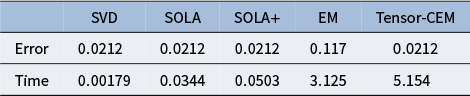

 Open access
Open access