


Introduction
A central task in language acquisition is learning how to mark ‘who did what to whom’ in basic canonical sentences. The way that this marking is instantiated, and hence the task facing learners, varies considerably from language to language. For example, languages such as English rely heavily on word order to convey meaning (e.g., compare The boy kicked the girl and The girl kicked the boy). In many languages, however, this type of meaning is conveyed primarily by inflectional morphology. For example, Lithuanian – the focus of the present study – indicates the SUBJECT and OBJECT noun using, respectively, NOMINATIVE and ACCUSATIVE case-marking morphemes (and hence, in principle, allows for a great deal of flexibility with regard to word order; e.g., [The]girl + ACC kicked [The]boy + NOM). The same is true for three-argument constructions (e.g., The man carried [the boy to the chair / the chair to the boy]; The man put [the boy on the table / the table on the boy]) which, in Lithuanian, involve the use of ACCUSATIVE and GENITIVE case, respectively.
Morphological systems in such highly inflected languages can be extremely complex. For example, in Lithuanian, one of the most highly inflected Indo-European languages, the noun case-marking system requires mastery of over 100 different inflectional morphemes marking number (singular or plural), case (nominative, genitive, dative, accusative, instrumental, locative, or vocative), and declension (8 subclasses). Nevertheless, some older accounts of acquisition, from different theoretical perspectives, argued that, despite this complexity, children's morphological acquisition is rapid and virtually error free (e.g., Harris & Wexler, Reference Harris, Wexler and Clashen1996; Hoekstra & Hyams, Reference Hoekstra and Hyams1998; Maratsos, Reference Maratsos, Damon, Kuhn and Siegler1998; Thordardottir & Weismer, Reference Thordardottir and Weismer1998; Wexler, Reference Wexler1998). More recently, a consensus has been emerging that the acquisition of such complex systems necessarily requires a great deal of learning. Indeed, under even radically nativist accounts (e.g., Hoekstra & Hyams, Reference Hoekstra and Hyams1998; Wexler, Reference Wexler1998), the individual case-marking morphemes themselves must be learned from the input on a language-by-language basis.
A consensus has been emerging too that, perhaps unsurprisingly given the complexity of the system, children do make errors of commission (as opposed to omission). After all, for languages such as Lithuanian that do not have ‘bare’ noun (or verb) forms, if the child has not yet learned the relevant word form or morpheme, her only option – other than saying nothing at all – is to instead use one that she has learned, which frequently constitutes an error. (Frequently, but not always: given the high degree of syncretism in many systems, a ‘wrong’ form may often turn out to be right.)
Constructivist accounts of these errors (e.g., Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015; Dąbrowska, Reference Dąbrowska2004, Reference Dąbrowska2006, Reference Dąbrowska2008; Dąbrowska & Szczerbinski, Reference Dąbrowska and Szczerbinski2006; Dąbrowska & Tomasello, Reference Dąbrowska and Tomasello2008; Gathercole, Sebástian, & Soto, Reference Gathercole, Sebastián and Soto1999; Krajewski, Lieven, & Theakston, Reference Krajewski, Lieven and Theakston2012; Krajewski, Theakston, Lieven, & Tomasello, Reference Krajewski, Theakston, Lieven and Tomasello2011; Matthews & Theakston, Reference Matthews and Theakston2006; Räsänen, Ambridge, & Pine, Reference Räsänen, Ambridge and Pine2014; Rubino & Pine, Reference Rubino and Pine1998) generally focus on the competition between individual ready-inflected forms stored in the system, and phonological analogy across them.
Generativist accounts tend to place more emphasis on the notion of default forms that emerge when the target form is unavailable, whether this is – for example – nominative singular in Russian noun case marking (e.g., Pesetsky, Reference Pesetsky2013; Wexler, Schütze, & Rice, Reference Wexler, Schütze and Rice1998) or the -ed morpheme in the English past tense system (see Pinker & Ullman, Reference Pinker and Ullman2002, for a review). That said, many generativist accounts do allow – in at least some circumstances – for frequency-sensitive storage and retrieval of inflected forms, and even phonological analogy across them (e.g., Albright & Hayes, 2003; Alegre & Gordon, Reference Alegre and Gordon1999; Clahsen, Reference Clahsen1999; Hartshorne & Ullman, Reference Hartshorne and Ullman2006; Pinker, Reference Pinker1984; Prasada & Pinker, Reference Prasada and Pinker1993).
A third class of account that is highly relevant to the present work combines aspects of both constructivist and generativist approaches. The pre-/protomorphological approach (e.g., Bittner, Dressler, & Kilani-Schoch, Reference Bittner, Dressler and Kilani-Schoch2003; Kenstowicz & Kisseberth, Reference Kenstowicz and Kisseberth2014; Stephany & Voeikova, Reference Stephany and Voeikova2009) shares with generativist approaches “the assumption of the development of symbolic rules” (Stephany & Voeikova, Reference Stephany and Voeikova2009, p. 5). However, as a non-nativist approach, the pre-/protomorphological approach shows greater overlap with constructivist usage-based approaches (e.g., Bybee, Reference Bybee2001). Both assume that children start out with rote-learned, (usually) base forms such as nominative singular (the premorphological stage) before (in the protomorphological stage) acquiring two or three distinct forms of the same lemma (miniparadigms). These stored forms allow children to “construct morphological patterns by analogy” (Stephany & Voeikova, Reference Stephany and Voeikova2009, p. 4), in a similar way to that assumed under (for example) Bybee's (Reference Bybee2001) usage-based approach.
Thus, despite some differences regarding both the initial state and the adult endpoint, constructivist/usage-based, generativist, and pre-/protomorphological accounts all agree that children must learn morphological paradigms by abstracting across the input. The aim of the present study, then, is to begin to move beyond the generativist–constructivist theoretical divide, and to investigate in detail exactly how children abstract across the input that they hear to acquire a productive system of inflectional morphology. Our focus is on three factors (each outlined in more detail below). The first is word-form frequency. Many studies have shown that children make fewer errors when attempting to produce target forms that are frequent in the input (e.g., Orsolini, Fanari, & Bowles, Reference Orsolini, Fanari and Bowles1998; Ragnarsdóttir, Simonsen, & Plunkett, Reference Ragnarsdóttir, Simonsen and Plunkett1999; Theakston, Lieven, Pine, & Rowland, Reference Theakston, Lieven, Pine and Rowland2004; see Ambridge, Kidd, Rowland, & Theakston, Reference Ambridge, Kidd, Rowland and Theakston2015, for a review). The second is phonological neighbourhood density, or type frequency. Inflectional patterns that apply to phonologically defined classes with many members (i.e., with high type frequency) tend to show higher rates of correct production, and lower rates of error, than inflectional patterns that apply to more sparsely populated classes (e.g., Barðdal, Reference Barðdal2008; Baus, Costa, & Carreiras, Reference Baus, Costa and Carreiras2008; Bowerman & Choi, Reference Bowerman, Choi, Bowerman and Levinson2001; Bybee Reference Bybee1995, Reference Bybee2001; Dąbrowska & Szczerbinski, Reference Dąbrowska and Szczerbinski2006; Forrester & Plunkett, Reference Forrester and Plunkett1994; Hare, Elman, & Daughterty, Reference Hare, Elman and Daughtery1995; Kirjavainen, Nikolaev, & Kidd, Reference Kirjavainen, Nikolaev and Kidd2012; Köpcke, Reference Köpcke1998; Marchman, Reference Marchman1997; Marchman, Wulfeck, & Weismer, Reference Marchman, Wulfeck and Weismer1999; Nicoladis, Palmer, & Marentette, Reference Nicoladis, Palmer and Marentette2007; Plunkett & Nakisa, Reference Plunkett and Nakisa1997; Rispens & De Bree, Reference Rispens and De Bree2014, Reference Rispens and de Bree2015; Ševa et al., Reference Ševa, Kempe, Brooks, Mironova, Pershukova and Fedorova2007; Stephany & Voeikova, Reference Stephany and Voeikova2009; Storkel, Armbruster, & Hogan, Reference Storkel, Armbruster and Hogan2006; Suttle & Goldberg, Reference Suttle and Goldberg2011). The third is competition or defaulting. When attempting to produce a low-frequency inflected form, children often incorrectly produce a higher-frequency form of the relevant noun (see Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015, and Räsänen et al., Reference Räsänen, Ambridge and Pine2014, Reference Räsänen, Ambridge and Pine2015, for Spanish, English, and Finnish, respectively). Although each of these effects enjoys considerable empirical support, the present study is the first to investigate all three across an (almost) complete paradigm.
In order to quantify the importance of these factors, it is necessary to investigate parts of the system that show a relatively high error rate: If children show close to 100% correct inflection, there is no by-item variation for these predictors to explain. This necessarily means using an elicited-production paradigm. In naturalistic corpora, low-frequency forms – exactly those for which children might be expected to make errors – are rarely attempted. For example, Babyonyshev's (Reference Babyonyshev and Phillips1993) naturalistic study of the Russian noun system (similar in many respects to the Lithuanian system under investigation here) recorded 861 instances of nouns, 73% of which were in nominative case. Locative (prepositional) and instrumental case appeared three times and never, respectively. Similarly, in a naturalistic study of a single Lithuanian child, Voeikova and Savickienė (Reference Voeikova and Savickienė2001) reported that 72% of nouns appeared in nominative case only. Indeed, all of the corpus studies summarised in Stephany and Voeikova (Reference Stephany and Voeikova2009) – with learners of Turkish, Finnish, Yucatec Maya, Estonian, Croatian, Russian, Greek, Austrian German, Italian, Spanish, French, and Palestinian Arabic – observed pre- and protomorphological stages in which children used each noun in only one or a handful of its possible inflectional forms respectively.
Most relevant to the present work is Savickienė’s (Reference Savickienė2003) corpus study of Lithuanian noun morphology. This study found that, after an initial period characterised by a preponderance of nominative singular forms, genitive, accusative, and vocative singular forms emerged (at around 1;8), together with nominative plural forms. Other forms emerged later, or were still to appear by the end of the study. In terms of declension classes, the earliest to emerge were the masculine –as and –ys classes (1.1 and 1.3 according to Savickienė’s classification system) and the feminine –a and –ė classes (2.1 and 2.3). While these data are extremely useful for building up a picture of development, they do not provide definitive evidence regarding productivity. With corpus data, it is not possible to determine whether – on the one hand – apparent early rote-use reflects sampling (i.e., perhaps the child uses less frequent forms of each noun that were not captured in the recording) or – on the other hand – apparent later productivity reflects rote-learning of several forms of each noun (e.g., Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015; Rubino & Pine, Reference Rubino and Pine1998). To fully assess productivity, we need experimental elicited production studies; in particular those using novel nouns whose forms cannot have been rote learned (e.g., the present Study 2).
A number of previous elicited production studies of complex morphological systems have been conducted, including several focusing on Polish noun inflection; another system that is similar to Lithuanian in many relevant respects (e.g., Dąbrowska, Reference Dąbrowska2004, Reference Dąbrowska2006, Reference Dąbrowska2008; Dąbrowska & Szczerbinski, Reference Dąbrowska and Szczerbinski2006; Dąbrowska & Tomasello, Reference Dąbrowska and Tomasello2008; Krajewski et al., Reference Krajewski, Theakston, Lieven and Tomasello2011, Reference Krajewski, Lieven and Theakston2012). Although these studies provided some support for input-based accounts, none attempted to test the whole inflectional paradigm and therefore risk missing pockets of the system that are predicted to show particularly high error rates. Neither did these studies include both familiar and novel nouns, which – as we will see – is crucial for establishing when and how children generalise their knowledge of individual word forms to inflect noun stems that we can be certain they have not encountered before. Although Lithuanian noun morphology development has been researched in detail using naturalistic data (e.g., Savickienė, Reference Savickienė2003), relatively few experimental studies have been carried out; those that have focused on the role of diminutives in gender agreement (Savickienė, Kempe, & Brooks, Reference Savickienė, Kempe and Brooks2009), of working memory on word and non-word repetition (Krivickaitė & Dabašinskienė, Reference Krivickaitė and Dabašinskienė2013), and the distribution of nouns and other parts of speech (e.g., Dabašinskienė, Reference Dabašinskienė2012; Dabašinskienė & Kamandulytė, Reference Dabašinskienė and Kamandulytė2009; Savickienė, Reference Savickienė2001), rather than morphological acquisition per se.
The present study therefore investigates the acquisition of a complex system of inflectional morphology – noun case marking in Lithuanian – using both familiar and novel nouns, and studying the whole inflectional paradigm, including all declension, number, and case combinations (with the exception of vocative case in the familiar noun study). Before outlining the input-based predictions to be tested, we first present a brief overview of the system.
Lithuanian noun morphology
Lithuanian is a morphologically rich Baltic language and has a complex system of noun inflection. The system comprises two numbers (singular and plural), two genders (masculine and feminine), and seven cases (nominative, genitive, dative, accusative, instrumental, locative, and vocative). Semantically speaking, each case plays multiple roles, but the main uses are summarised in Table 1. Each noun belongs to a declension class, which determines the pattern of endings across the cases (see Table 2).
Table 1 Main uses of Lithuanian cases

Table 2 System of Lithuanian noun declension

Note. Endings for the singular locative case for declensions 1.2–5.1 formally include the phonemes shown in parentheses, but the contracted colloquial forms are widely used, and were therefore also accepted as correct forms in the present study.
Although several different classification systems have been proposed (based on similarities at the level of stem-endings and stress pattern, e.g., Kazlauskienė, Kamandulytė, & Savickienė, Reference Kazlauskienė, Kamandulytė and Savickienė2004; Savickienė, Reference Savickienė2003), the standard system includes five declensions, with the first declension divided into three sub-declensions (1.1, 1.2, 1.3), and the second declension into two (2.1, 2.2). Each (sub-)declension contains nouns of a particular gender; the system does not have different masculine and feminine endings within a particular sub-declension. Descriptively speaking, the declension class of a particular noun is determined by the ending of the nominative singular form.
Although complex in terms of the number of different endings, the system is highly regular. With very few exceptions, all that varies between different case- and number-marked forms of nouns within the same declension is the inflectional morpheme following the stem (e.g., –as, –o, –ui, –ą, –u, –e, -e/–ai, for singular nouns in declension 1.1). The stem itself does not change, with the exception of a handful of stems ending in –t or –d, which change to –č and –dž, respectively, in some number+case combinations. Some nouns also require the addition of a softener, –i, between the stem and the inflection (all of which begin with a vowel). Of the 140 cells in the complete paradigm, 51 are filled by endings that are unique, and 89 by endings that are repeated once or more elsewhere in the paradigm (though almost always marking the same case). Excluded from the present study (and Table 2) are declensions 3.2 and 5.2. However, there are very few nouns in these sub-declensions (37 in total, according to Kazlauskienė et al., Reference Kazlauskienė, Kamandulytė and Savickienė2004), and they are inflected in almost exactly the same way as those in declensions 3.1 and 5.1, respectively.
The present study
The aim of the present study is to test a generalised input-based account of the acquisition of inflectional noun morphology. This account is most obviously consistent with a constructivist approach to language acquisition (including the pre-/protomorphological approach) but, as discussed above, is consistent with any account that assumes an important role for frequency-based competition between, and phonological analogy across, stored ready-inflected word forms (including a number of generativist accounts). Specifically, our aim is to test the prediction that errors will be predicted by the three following properties of the input (shown in bold), reflecting three mechanisms assumed by an input-based account (shown in bold italics).
1. Input frequency of the target (direct retrieval). An important mechanism under input-based accounts is direct retrieval of the relevant word form (i.e., a stored noun form bearing the correct case + number marking) from memory. The assumption is that storage is probabilistic: the greater the frequency with which the relevant form has been witnessed, the greater the likelihood that it is available for retrieval.
2. Phonological neighbourhood density (analogy). A second mechanism is generation of a target form by analogy with stored forms that (a) are phonologically similar to the target (i.e., are from the same declension subclass), and (b) bear appropriate morphological marking. For example, assume that the child can access the nominative singular citation form voras ‘spider’ (which is always the case in the present study, since the experimenter supplies this form) and needs to produce the genitive singular form. If she has the stored forms vaikas ‘child-NOM + SNG’, and vaiko ‘child-GEN + SNG’, she can generate the target form by phonological analogy (i.e., –as NOM + SNG → –o GEN + SNG). Since this process is probabilistic, the greater the number of forms available for analogy (i.e., the greater the phonological neighbourhood density), the greater the analogical support for the generalization. For the purposes of this study, we define phonological neighbourhood density simply as the number of nouns in each declension class. Although other approaches are possible (e.g., calculating phonological clusters using computational modelling; e.g., Albright & Hayes, Reference Albright and Hayes2003), this simpler measure perfectly suits our present purposes, since declension classes by definition reflect phonological similarity, particularly with regard to the way that they inflect for different cases. In other literature (e.g., the corpus studies summarised in Stephany & Voeikova, Reference Stephany and Voeikova2009), this measure is referred to as the type frequency of the declension class. Thus the prediction that children will show better performance for nouns with higher phonological neighbourhood density (PND) / declension class size corresponds exactly to the prediction of the pre-/protomorphological approach that children will show better performance with declension classes that have higher type frequency.
Strictly speaking, what is relevant here is not the size of each declension class in the adult grammar (the measure we use, taking counts from a reference grammar), but in each individual child's lexicon. However, because this is – of course – impossible to measure, we use counts from the adult grammar as a proxy. If no effect of PND is observed, then we cannot rule out the fact that this measure is not a sufficient proxy for children's knowledge. However, if an effect of PND is observed (in the predicted direction), this demonstrates that a definition of PND in terms of the adult grammar – while of course not perfect – in practice constitutes a sufficiently good proxy to explain at least some aspects of children's performance.
Note that, because both procedures are probabilistic, (1) direct retrieval and (2) generation by phonological analogy are not mutually exclusive in any one instance: a retrieved form might have insufficient strength to yield an output without the additive effect of phonological analogy, or vice versa.
3. Availability of competing forms (competition or defaulting). If the output strength of the target form (as generated by 1 and 2) is weak, it may be outcompeted by a different form of the relevant noun. Often, this form maintains the case and number of the target but uses an incorrect declension class (e.g., Gvozdev's, Reference Gvozdev1949, study of Russian); a phenomenon later described as inflectional imperialism (Slobin, Reference Slobin1968). However, input-based accounts do not necessarily predict that all errors will be of this type; and neither do we anticipate that this will be the case. For example, errors of incorrect person/number marking (rather than declension class) have been recorded in other European languages (see Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015, and Räsänen et al., Reference Räsänen, Ambridge and Pine2014, Reference Räsänen, Ambridge and Pine2015, for evidence of this effect in Spanish, English, and Finnish, respectively). This analysis is necessarily more exploratory than for the two mechanisms discussed above, since the precise prediction depends on the particular theory under investigation. When determining which ‘default’ form the child will produce in lieu of the target, constructivist accounts emphasise the role of word-form frequency, while many generativist accounts incorporate the notion of a morphosyntactic default (in this case, presumably nominative singular). These two possibilities are difficult to disentangle, given that the form assumed to be the default is usually also the most frequent (and, furthermore, often the form with the lowest degree of phonological complexity). However, not all errors are predicted to reflect either frequency-based or morphosyntactic defaulting. Because learners are not aiming blindly, but have at least some idea of the relevant case+number semantics, such errors will often constitute what Leonard, Caselli, and Devescovi (Reference Leonard, Caselli and Devescovi2002, p. 287) call “near misses … forms that differ from the target by a single feature”. In this particular study, such misses would constitute errors of case, or number, or declension class.
In summary, the aim of the present study, which elicited both familiar and novel nouns across the entire declension-, case-, and number-marking Lithuanian noun paradigm, was to investigate a generalised input-based account of the acquisition of inflectional morphology. This account predicts that the rate of correct production versus errors will be predicted positively by (1) input frequency of the target form (reflecting direct retrieval), and (2) number of phonological neighbours (reflecting analogy), and that (3) the majority of errors will reflect substitution by a more frequent form that, under some accounts, constitutes a morphosyntactic default. Study 1, which uses familiar nouns, tests all three predictions. Study 2, which uses novel nouns, is designed to constitute a particularly stringent test of the claim that when direct retrieval of a form is not possible (as is always the case for novel nouns), children rely on phonological analogy with stored forms. This claim is particularly central to input-based approaches, as this type of phonological analogy constitutes an explanation of how children move beyond rote-learning, and eventually achieve adult-like productivity.
Study 1: Familiar Nouns
Method
Participants
Eighteen participants, six boys and twelve girls aged 4;0–5;5 (M = 4;10), were recruited from and tested in nurseries in Kaunas, Lithuania. Written consent was obtained from the parents and the nursery head teacher. All children were normally developing, monolingual speakers of Lithuanian.
Design and materials
Noun stimuli
Nouns selected were two syllables long in the nominative and the majority of other cases, except for several target forms in the locative case and/or 5.1 declension, which require additional suffixes. As explained in the ‘Introduction’, words with stems ending in –d or –t, and therefore requiring stem changes, as well as words with the softener -i- were excluded (e.g., med-is → medž-ių ‘tree SNG:NOM → trees PLR:GEN’). Only inanimate objects were used, in order to avoid any semantic gender associations (for some animals, occupations, etc., in addition to the ‘default’ noun form, a masculine/feminine form is used when referring to a particular individual of that gender). Nouns were chosen to be easy to illustrate in still pictures and to span a large frequency range, while all still being familiar to young children. We selected two nouns from each declension; one each towards the lower and upper ends of the frequency range. This distinction was not used as a variable, but rather as means to ensure variability within stimulus nouns.
Cases and declensions
All cases and declensions were tested, except for nominative case (used for the experimenter's prompt form) and declensions 3.2 (masc.) and 5.2 (fem.), as these are extremely rare and the relevant nouns did not fulfil the selection criteria. Additionally, the vocative case was excluded, as it is used when addressing someone, predominantly a living person/animal, and hence was unsuitable for use with the inanimate objects in this study.
Visual stimuli
192 stimulus pictures were created. Thirty-two depicted the stimulus object in a neutral context (to be described by the experimenter using nominative case), in either singular or plural form. The remainder depicted a girl interacting with the same objects in a way designed to elicit the use of different cases: genitive, dative, accusative, instrumental, or locative. For each case, we chose a context (see Table 3) that would be (a) a clear and unambiguous cue to the relevant case form, (b) familiar to young children, (c) relatively easy to illustrate in still pictures, and (d) applicable across the entire range of object nouns. Ideally, we would have used two or more different semantic contexts per case, but this was not possible given these four constraints (and would also have entailed scaling up the already intensive testing schedule by a factor of two or more). A selection of pictures can be seen in Figure 1.

Fig. 1. Sample of pictures and accompanying descriptions used in the familiar noun study.
Table 3 Stimulus sentences by case

Procedure
Children were tested in their nursery over five days, with two sessions taking place each day. Testing took place in a quiet corner of the play-group room. The experimenter showed the child a picture of an object and stated its name using the nominative case (Tai yra … ‘This is …’). Then, the experimenter showed the child another picture of the same object, but with a girl interacting with it in a certain way. The experimenter began a sentence describing the picture, but always omitted the last word: the name of the object in question. The child was then expected to finish the sentence using the appropriate case-marked form of the relevant noun. The full list of stimulus sentences is shown in Table 3. It is important to emphasise that each sentence frame is not only a clear and unambiguous cue for the relevant case form, but also features a scenario with which young children are undoubtedly familiar (e.g., The girl is waving at … [DAT], playing with … [INST], picking up … [ACC]). Thus any errors observed cannot be explained away by arguing that children were unable to infer the intended case of the target form. Similarly, both the intended number (singular/plural) and declension class of the target form are readily observable from the picture+sentence prompt and the experimenter-supplied nominative form, respectively.
Children's responses were noted by hand and also audio-recorded for checking later, and each was rewarded with a sticker. If children did not respond, they were gently encouraged to do so. However, if the child remained reluctant after this second prompt, the experimenter moved onto the next stimulus picture (note that such trials were not scored as incorrect, but instead discarded as missing data).
Because the total number of trials (160) was too great for young children, each child completed 40 trials, selected using a pseudo-randomisation procedure. This procedure ensured that each item appeared an equal number of times across children (or as close as possible, given missing data), and that each child completed 20 singular trials and 20 plural trials.
Frequency counts
In order to test the predictions outlined above, we obtained the following frequency counts:
• Input frequency of the target word-form (tokens). An online database of 140 million written and spoken words (Current Lithuanian Language Corpus, <http://tekstynas.vdu.lt/>) was used to find counts of lexical forms used in the familiar noun study (see Table A1). In the case of homophones (e.g., šaka ‘branch’ can be either 2.1 SNG NOM or 2.1 SNG INST), 200 entries at random were checked in context and the proportions applied to the total word count.
• Phonological neighbourhood density (types). Type frequency counts for each declension, which correspond to phonological class size / neighbourhood density, were taken from Kazlauskienė et al. (Reference Kazlauskienė, Kamandulytė and Savickienė2004), who analysed 26,188 noun entries in a popular dictionary (Current Lithuanian Language Dictionary, 4th ed., 2000). These counts are shown in Table 4.
Table 4 Type frequency (phonological neighbourhood density) of each of eight declensions (corresponding to phonological classes), based on 26,188 nouns (types)


Results
Of a total of 720 responses, 402 (55.83%) were coded as correct, 243 (33.75%) as incorrect (i.e., the target noun, but with an incorrect number and/or declension and/or case-marked inflection), and 75 (10.42%) as missing or unscorable responses which could not be counted towards any particular defaulting form (e.g., non-target noun, diminutive form). Note that, although the rate of unscorable responses might be considered relatively high, by excluding such responses (rather than treating them as errors), we are conservatively minimising the chances of observing the predicted effects of word-form frequency and phonological neighbourhood density (unless one is prepared to argue that children are more likely to produce unscorable responses for high-frequency targets from large neighbourhoods; i.e., the easiest rather than the most difficult forms).
Once the unscorable responses were removed, the percentage of correct responses increased to 62.33% (38.66% errors).Footnote 1 While this error rate is considerably higher than that observed in naturalistic studies of this and similar systems (e.g., Babyonyshev, Reference Babyonyshev and Phillips1993; Voeikova & Savickienė, Reference Voeikova and Savickienė2001), the difference is not surprising, given that (as discussed in the ‘Introduction’), in typical naturalistic corpora, over 70% of nouns appear only in the most frequent, citation form (nominative singular), with some lower-frequency cases – exactly those that would be expected to show higher error rates – virtually unattested. In any case, the input-based account that we are investigating does not make any predictions regarding the absolute error rate, but rather the way that the error rate will vary on the basis of word-form frequency and phonological neighbourhood density. Thus, from a methodological point of view, a relatively high error rate is beneficial, as it increases the amount of by-item variance for these predictors to explain.
The response data broken down by number, declension, and case, after removing unscorable responses, are summarised in Table 5. The important point to note for our purposes is simply that rates of correct production versus error vary considerably across the paradigm, from 100% (for singular forms for relatively common declensions) to 0% (for plural forms from the rare fifth declension). In terms of case, it is unsurprising to note that the instrumental and locative cases – virtually unattested in the Russian child data of Babyonyshev (Reference Babyonyshev and Phillips1993) – show some of the lowest rates of performance.
Table 5 Mean (and standard deviation) proportion of correct responses by number, declension, and case

Investigating input-based predictors
According to the account under investigation, the rate of correct production versus errors will be predicted positively by (1) input frequency of the target form (reflecting direct retrieval), and (2) number of phonological neighbours (reflecting analogy). To test these predictions, we conducted an incremental (forward) hierarchical mixed-effects regression (lme4 package; Bates, Méchler, Bolker, Walker, Reference Bates, Mäechler, Bolker and Walker2015) in R (R Core Team, 2014), with the predictors in the corresponding order: (0) age, (1) target word form frequency, (2) phonological neighbourhood density (number of nouns in the relevant declension), and (3) target word form frequency × phonological neighbourhood density (interactions with age were not included, as the models would not converge).
In accordance with recent recommendations (e.g., Barr, Levy, Scheepers, & Tilly, Reference Barr, Levy, Scheepers and Tilly2013), we used maximal models, with random intercepts for subject and item (noun lemma), and by-subject random slopes for target word-form frequency (correlated with the intercept for the familiar noun study, non-correlated for the novel noun study). The addition of any further random slopes (whether correlated with the intercept or not) caused convergence failure. Also in accordance with the recommendations of Barr et al., we obtained p-values for each individual main effect and interaction term (see Table 6) using the model-comparison procedure (via the ANOVA function of the lme4 package). This involves calculating the difference in log-likelihood values between a model with and without the predictor being added on that step (shown in the column labelled χ 2), and obtaining the associated p-value from the chi-square distribution (column labelled p (χ2)). The Mean (β), Standard Error (SE) and Z statistics shown for each term are from the full model. Also shown (purely for completeness) are p-values derived from the Z (normal) distribution (shown in the column labelled p (Z)). However, note that, in line with the recommendations of Barr et al., we determine statistical significance (at p < .05) not on the basis of these p-values, which are unreliable in many cases, but on the basis of those obtained from the model-comparison procedure.
Table 6 The influence of age, lexical frequency, and phonological neighbourhood on correct response rates for familiar nouns (Study 1)
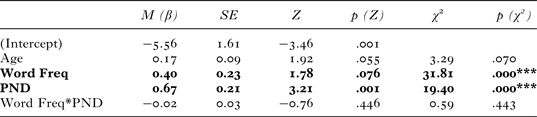
Note. *** = p < .001.
The analysis (see Table 6) revealed significant main effects of word form frequency (p < .001) and phonological neighbourhood density (p < .001), but no significant interaction between the two. The positive beta values for the main effects show that, as predicted, the greater the relevant frequency predictor, the greater the likelihood of a correct response vs. errors.
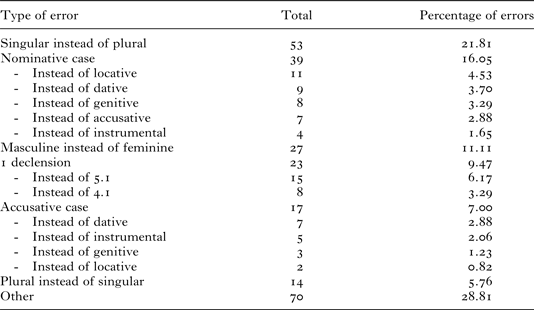
Error-types analysis
Table 7 summarises the different types of errors made by children, not including unscorable responses (i.e., including only errors in which children produced the target noun with incorrect number, case, or declension marking). It is clear that the pattern of errors is not compatible with an explanation based solely on the systematic substitution of target forms by either (a) the single most frequent form of that noun or (b) a single morphosyntactic default form (as might be predicted by an oversimplistic version of a constructivist and generativist account, respectively). That is, although the form that children produce is almost always more frequent / morphosyntactically basic than the target (e.g., singular rather than plural; nominative/accusative rather than other cases), it is by no means always the single most frequent / morphosyntactically basic form. Rather, the majority of errors reflect near misses that involve children substituting singular for plural (maintaining case, even when this is not nominative/accusative), masculine for feminine (again maintaining even low-frequency cases, and plural number), or nominative/accusative for one of the less frequent cases (maintaining declension class, even for low-frequency classes, and plural number). Furthermore, over a quarter of all scorable errors were ‘other’ errors that did not straightforwardly reflect either defaulting or near misses.
Table 7 Types of errors for familiar nouns (Study 1)
Discussion
Study 1 investigated Lithuanian children's acquisition of noun morphology, focusing on familiar nouns. As predicted by an input-based account, effects of word-form frequency and phonological neighbourhood density were observed. An analysis of the errors produced revealed that, although children showed some tendency to frequency-based or morphosyntactic defaulting, a large proportion of errors could not straightforwardly be explained by either of these mechanisms. These errors presumably reflect some interaction of frequency-based, semantic, linguistic, and phonological factors that is not easily explained by any current verbal account; one that would likely be elucidated by future computational modelling work.
Perhaps surprisingly, no main effect of age was observed (and presumably the lack of age-related variability is behind the convergence failure of the models that included age as an interaction). One possibility is that, although the children in this study would generally be considered to be relatively old in terms of morphological acquisition, even the oldest are not yet nearing adult-like levels of abstract knowledge. Note that the relatively high error rates in this study cannot be explained away as a simple task effect whereby children are not aware of the case that is required in each picture context. As Table 5 shows, three of the five cases (dative, genitive, and instrumental) showed 100% correct performance for at least one combination of declension+number, with accusative and locative not far behind on 89% and 86%, respectively. Neither is it plausible to argue that children of this age do not understand the singular/plural distinction, particularly given that – again – some individual cells showed almost 90% correct performance for plurals.
Perhaps the most likely possibility, then, is that even the older children tested in Study 1 have not yet reached adult-like levels of productivity, and are still relying rather heavily on direct retrieval of ‘ready-inflected’ case-marked noun forms. In order to investigate this possibility, we conducted a second study using novel nouns. This eliminates the possibility of direct lexical retrieval from memory, and so allows for a more accurate estimate of the level of children's abstract knowledge, as well as more direct evidence regarding the role of phonological analogy.
Study 2: Novel Nouns
Method
Participants
Twenty-three children in total, nine boys and fifteen girls aged 4;1–5;5 (M = 4;9), were recruited from and tested in nurseries in Kaunas, Lithuania. Written consent was obtained from the parents and the nursery head teacher. All children were normally developing, monolingual speakers of Lithuanian.
Materials and procedure
This study included 112 (16 nominative) pictures in similar format to Study 1. The only differences were that the inanimate objects with which the girl was interacting were replaced with novel creatures (one per declension), which also allowed the vocative case to be included. Furthermore, this change allows us to investigate whether the findings of Study 1 also generalise to animate nouns. A sample of pictures and sentences used in the study can be seen in Figure 2, while the full list of novel nouns in the singular nominative form can be found in Table A2, and the full list of stimulus sentences can be found in Table 3.

Fig. 2. Sample of pictures and accompanying descriptions in the novel noun study.
Because the total number of trials (96) was too great for young children, each child completed 24 trials, selected using a pseudo-randomisation procedure which ensured that each item appeared an equal number of times across children (or as close as possible, given missing data), and that each child completed 12 singular trials and 12 plural trials. The same phonological neighbourhood density counts were used as for Study 1 (though, since all nouns were novel, the word-form frequency predictor was not used).
Results
Of a total of 552 responses, 188 (34.06%) were coded as correct, 211 (38.29%) as incorrect (i.e., the target noun, but with an incorrect number and/or declension and/or case-marked inflection), and 153 (27.72%) as unscorable (e.g., non-target noun, diminutive form) or missing. Once the unscorable responses were removed, the percentage of correct responses increased to 47.11% (52.89% errors).Footnote 2 With regard to this high error rate, it has been acknowledged since the original study of Berko (Reference Berko1958) that novel-noun (‘wug’) tests impose considerable task demands on young children. Thus we would certainly not wish to claim that Lithuanian four- to five-year-olds have acquired less than half of the case-marking system. At the same time, it is not clear what would constitute a ‘true’ error rate for a novel-noun study, since the error rate cannot, of course, be meaningfully compared against rates obtained from naturalistic data. Thus we again avoid drawing conclusions on the basis of this overall error rate, and focus instead on the prediction of unevenness across the paradigm, in a way that corresponds to the input, in this case with regard to phonological neighbourhood density.
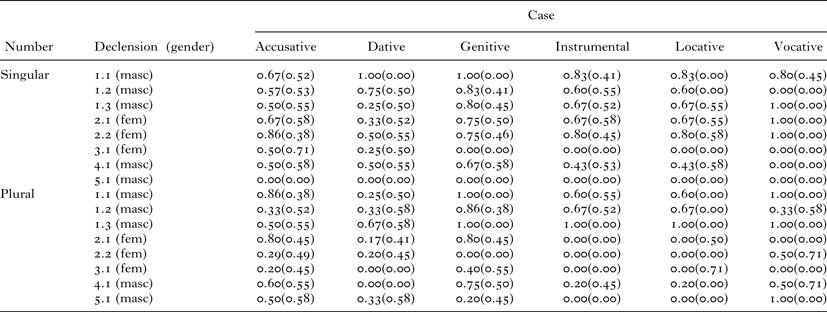
The response data broken down by number, declension, and case are summarised in Table 8. Again, the important point to note for our purposes is simply that rates of correct production versus error vary considerably across the paradigm, from 100% to 0%. Again, the relatively infrequent locative and instrumental cases show very high error rates with, in many cells, no child providing the correct inflection. Thus, although we again acknowledge the difficulties associated with this type of task, these data – when compared against the much lower error rates observed for many of these cells in Study 1 – are consistent with the possibility that even four- to five-year-olds’ knowledge of some low-frequency case-marking morphemes remains tied to individual nouns.
Table 8 Correct responses by number, declension, and case (novel nouns)
Investigating input-based predictors
The aim of this analysis was to investigate the prediction of an input-based account that, when producing novel nouns, children will rely on phonological analogy to stored exemplars and hence show an effect of phonological neighbourhood density (for obvious reasons, the prediction of direct lexical retrieval cannot be tested with novel nouns). Novel nouns allow for a particularly stringent investigation of the role of phonological analogy: Since all forms are novel, phonological analogy to stored forms is presumably the only mechanism that children can possibly use to produce the intended target form.
A mixed-effects regression model, conducted in the same way as for Study 1, revealed main effects of age (p = .012) and phonological neighbourhood density (p = .005), but no significant interaction (see Table 9). The positive beta values for the significant predictors indicate higher correct response rates for (a) older children, and (b) novel nouns from larger phonological neighbourhoods.
Table 9 The influence of age and phonological neighbourhood density on correct response rates for novel nouns (Study 2)

Note. * = p < .05; ** = p < .01.
Discussion
The results from the novel noun study (Study 2) show largely the same pattern as the results of the familiar noun study (Study 1), although, as expected, the overall correct response rate was lower. As for Study 1, phonological neighbourhood density was a positive predictor of the rate of correct forms vs. errors. This constitutes a particularly clear role for phonological analogy since, given that all forms were novel, this is the only plausible mechanism by which children could have successfully produced the target form (unlike in Study 1 where, in principle, an apparent effect of phonological neighbourhood density could have arisen from an unintended correlation between this measure and, for example, noun semantics or some form of token frequency). One difference was that, unlike for familiar nouns (Study 1), a significant main effect of age was observed, with older children producing more correct forms. This is not unexpected, as all theories of language suggest that children improve with age. A possible reason why age was a significant predictor in this study, but not Study 1, is that tasks involving novel stimuli place a greater load on short-term memory / processing capacity, which increases with age (e.g., Gathercole, Pickering, Ambridge, & Waring, Reference Gathercole, Pickering, Ambridge and Waring2004). While it may seem a trivial task for adults, holding in working memory (in the ‘phonological loop’) the complete phonological form of a novel noun while simultaneously computing an inflected form by phonological analogy with stored forms is by no means a trivial task for young children. This process can break down in a number of ways, including forgetting the novel noun entirely (which would increase the rate of unscorable responses, though not the error rate), and – because the stem is decaying rapidly – terminating the search process early before optimal forms for analogy have been found.
General Discussion
The aim of this elicitation study was to investigate children's acquisition of the system of Lithuanian noun infection, in order to test the predictions of a generalised-input based account. Two major findings emerged. First, consistent with this prediction, children's rates of correct production were positively correlated with the input frequency of the target noun form (for familiar nouns), and with the phonological neighbourhood density of the noun (for both familiar and novel nouns). These findings echo those of a number of previous studies of other paradigms that have investigated word-form frequency and phonological neighbourhood density (see ‘Introduction’). Second, unlike the previous studies of Aguado-Orea and Pine (Reference Aguado-Orea and Pine2015), Dąbrowska and Tomasello (Reference Dąbrowska and Tomasello2008), Räsänen, Ambridge, and Pine (Reference Räsänen, Ambridge and Pine2014, Reference Räsänen, Ambridge and Pine2015), and Rubino and Pine (Reference Rubino and Pine1998), the pattern of errors was not compatible with the systematic substitution of target forms by either (a) the most frequent form of that noun or (b) a single morphosyntactic default form, as might be predicted by naive versions of a constructivist and generativist account, respectively. Rather, the majority of errors reflected near misses that involve substitution of singular for plural, masculine for feminine, or nominative/accusative for one of the less frequent case (e.g., Leonard et al., Reference Leonard, Caselli and Devescovi2002).
The finding of effects of input frequency and phonological neighbourhood density are consistent with a growing consensus in the literature that, whether or not children are born with some highly abstract knowledge of the system, morphological paradigms themselves are acquired by means of frequency-sensitive storage and retrieval of inflected forms, and phonological analogy across them (e.g., Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015; Albright & Hayes, Reference Albright and Hayes2003; Alegre & Gordon, Reference Alegre and Gordon1999; Clahsen, Reference Clahsen1999; Dąbrowska, Reference Dąbrowska2004, Reference Dąbrowska2006, Reference Dąbrowska2008; Dąbrowska & Szczerbinski, Reference Dąbrowska and Szczerbinski2006; Dąbrowska & Tomasello, Reference Dąbrowska and Tomasello2008; Gathercole et al., Reference Gathercole, Sebastián and Soto1999; Hartshorne & Ullman, Reference Hartshorne and Ullman2006; Krajewski et al., Reference Krajewski, Theakston, Lieven and Tomasello2011, Reference Krajewski, Lieven and Theakston2012; Matthews & Theakston, Reference Matthews and Theakston2006; Pinker, Reference Pinker1984; Prasada & Pinker, Reference Prasada and Pinker1993; Räsänen et al., Reference Räsänen, Ambridge and Pine2014; Rubino & Pine, Reference Rubino and Pine1998; Stephany & Voeikova, Reference Stephany and Voeikova2009). Also consistent with this view is the finding that, although we acknowledge that elicited production tasks can be difficult for children, even the relatively old children tested in the present study did not yet appear to have adult-like command of the system.
The patterning of children's errors, however, is not well explained by current accounts, whether generativist, constructivist, or somewhere in between (e.g., the pre-/protomorphological approach; Bittner et al., Reference Bittner, Dressler and Kilani-Schoch2003; Kenstowicz & Kisseberth, Reference Kenstowicz and Kisseberth2014; Stephany & Voeikova, Reference Stephany and Voeikova2009). Many generativist accounts (including some that also incorporate roles for storage and analogy) argue that children's errors reflect defaulting to an unmarked form that steps in whenever the target form is unavailable (e.g., Hoekstra & Hyams, Reference Hoekstra and Hyams1998; Marcus et al., Reference Marcus, Pinker, Ullman, Hollander, Rosen, Xu and Clahsen1992; Prasada & Pinker, Reference Prasada and Pinker1993; Wexler, Reference Wexler1998; Wexler et al., Reference Wexler, Schütze and Rice1998). Constructivist accounts (particularly Aguado-Orea & Pine, Reference Aguado-Orea and Pine2015; Räsänen et al., Reference Räsänen, Ambridge and Pine2014, Reference Räsänen, Ambridge and Pine2015; Rubino & Pine, Reference Rubino and Pine1998) argue that children's errors reflect defaulting to the particular inflectional form of the target word that has the highest frequency in the input (normally, the same form that is posited as the morphosyntactic default under generativist accounts). Although, in the present study, children did produce a good number of defaulting errors of this type, such errors were outnumbered by near misses that involve substitution of singular for plural, masculine for feminine, or nominative/accusative for one of the less frequent cases.
Generativist accounts could potentially explain such errors by positing that each particular feature (e.g., number, gender, case) has a particular default setting, and that children default at the level of these individual features, rather than whole word forms. Constructivist accounts could potentially explain such errors by positing that different forms compete on the basis not only of their strength in memory (a function of input frequency) or phonological support (a function of neighbourhood density), but also their semantics or function (e.g., genitive singular and genitive plural are used in similar semantic contexts such as possession, differing only in number). Although this type of competition would seem implicit in most constructivist accounts (and in particular the competition model of MacWhinney, Reference MacWhinney2004, and MacWhinney & Bates, Reference MacWhinney and Bates1989), probably the only way to derive concrete empirical predictions from such accounts, given their multifactorial nature, is to implement them as computational models. As discussed in more detail below, computational models would also be useful for investigating whether adding to constructivist accounts formal symbolic rules – as under the pre/protomorphological approach – would yield improved coverage of the data, and, in particular, of patterns of error. This, then, is a promising direction for future research.
One potential objection to the findings and conclusions set out above is that some of the children's errors might have resulted from their failure to understand which particular target context was being elicited on a given sentence-completion trial. However, as we saw in the ‘Introduction’, the intended case (as well as number and declension class) is readily and unambiguously observable from the citation form, picture, and/or sentence prompt supplied by the experimenter. Recall also that, for Study 1 and 2, respectively, three and four of the five cases showed 100% correct performance for at least one combination of declension+number, with the others on 86% or better. Similarly, it is not plausible to argue that children did not appreciate the highly salient and simple cue for plurality (i.e., one versus two objects in the picture), given the existence of individual cells for which children showed 100% correct performance on plurals.
Another objection is that, with only 18 (Study 1) and 23 children (Study 2) participating, and each completing only a quarter of the full experiment, our study was underpowered. Although it was able to detect main effects of both phonological neighbourhood density (type frequency) and word-form frequency (token frequency), it is important to acknowledge that it is indeed underpowered for the detection of interactions. Therefore, the present study should certainly not be taken as evidence against any prediction of an interaction between these factors. For example, there is some evidence to suggest that effects of phonological neighbourhood density are larger when target word-form frequency is low, hence necessitating the need for analogy (e.g., Räsänen, Ambridge, & Pine, Reference Räsänen, Ambridge and Pine2015). Future studies should attempt to rectify this problem, for example by focusing on a subset of the entire inflectional paradigm (we are happy to share our stimuli with any researchers who wish to do so). The error analysis reported here would also benefit from replication with a larger sample size, in terms of both participants and items, since patterns and types of error can be highly child- and item-specific.
Thus far, we have presented our findings as support for a generalised input-based account, largely abstracting across differences between generativist, constructivist, and pre-/protomorphological approaches. We now therefore turn to the question of whether our findings can be used to discriminate between these approaches. This question is not a straightforward one to answer, since accounts are rarely sufficiently detailed to generate precise quantitative predictions that can be tested against the data (though see the English study of Albright & Hayes, Reference Albright and Hayes2003, for one exception). Considering first generativist accounts, although such accounts are not generally associated with explicit predictions of word-form frequency and phonological neighbourhood density, they are not necessarily incompatible in principle with such effects. After all, as we saw in the ‘Introduction’, most generativist accounts allow for at least some rote storage of word forms, yielding effects of token frequency, and some also allow for phonological analogy across stored forms, yielding effects of phonological neighbourhood density (e.g., Albright & Hayes, Reference Albright and Hayes2003; Alegre & Gordon, Reference Alegre and Gordon1999; Clahsen, Reference Clahsen1999; Hartshorne & Ullman, Reference Hartshorne and Ullman2006). The challenge for generativist accounts – given that rote storage and phonological analogy could in principle be sufficient for acquisition – is to motivate the need for (a) innate knowledge of inflection in some form and (b) formal symbolic rules; two assumptions shared by most if not all generativist accounts.
Constructivist accounts, while explicitly predicting effects of word-form frequency and phonological neighbourhood density, are still a long way from offering a complete explanation of the acquisition process. As discussed above, these accounts do not yet offer a satisfactory explanation of the particular types of errors observed in the present study; nor do they offer a detailed explanation of how effects of token and type frequency interact either with one another, or with semantic or functional factors. Turning finally to the pre-/protomorphological approach, as a non-nativist approach, it largely shares the strengths and weaknesses of constructivist accounts. One important difference, however, is that while constructivist accounts posit only storage, analogy, and competition, the pre-/protomorphological approach additionally assumes “the development of symbolic rules” (Stephany & Voeikova, Reference Stephany and Voeikova2009, p. 5). Determining whether symbolic rules would allow for improved coverage of the present dataset is beyond the scope of this paper, as it would require the development of computational models with and without such rules (as, for example, in the English study of Albright & Hayes, Reference Albright and Hayes2003).
To conclude, future research, ideally involving computational modelling, will be required to iron out details regarding the precise nature of the system, and whether it shows any quantitative changes as a function of development. Given the error rates observed in the present study, answering the second part of this question will presumably necessitate testing older children. In the meantime, the present study suggests that children abstract morphological systems gradually, in a way that is highly sensitive to properties of the input.
Appendix
Table A1 Word-form frequencies
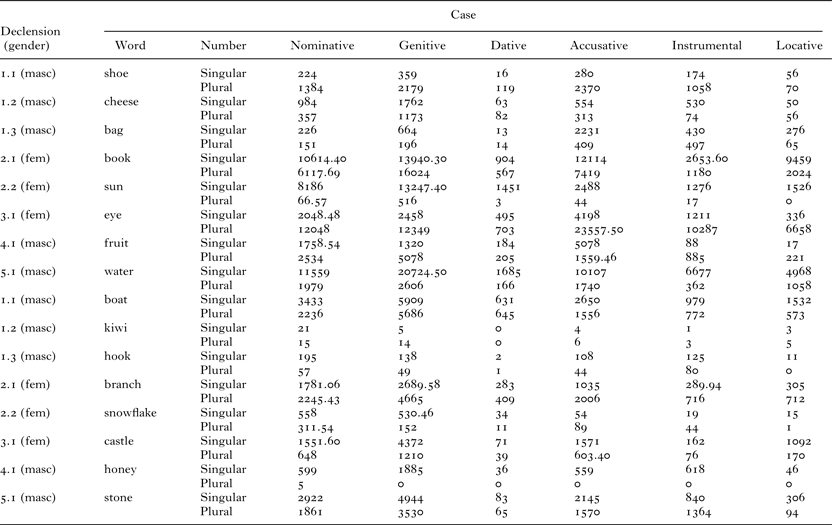
Table A2 Novel nouns in the singular nominative form















 Open access
Open access