


1 Introduction
Social scientists are often interested in studying the effects of policies, events and interventions. For this purpose, causal inference methods, such as difference-in-differences (DID), have gained widespread use in the analysis of time-series cross-sectional data, or long panel data (Arkhangelsky and Imbens Reference Arkhangelsky and Imbens2024; Liu, Wang, and Xu Reference Liu, Wang and Xu2024; Xu Reference Xu, Box-Steffensmeier, Christenson and Sinclair-Chapman2024). However, DID-type estimates commonly assume parallel trends between treatment and control units in the absence of treatment, which proves difficult to evaluate and is often implausible (see, e.g., Chiu et al. Reference Chiu, Lan, Liu and Xu2025; Hassell and Holbein Reference Hassell and Holbein2024; Roth Reference Roth2022). Following the premise that a convex weighted combination of control units can better replicate the counterfactual trajectory of the treated (Abadie, Diamond, and Hainmueller Reference Abadie, Diamond and Hainmueller2015), synthetic control methods (SCMs)Footnote 1 have gained recognition as a path-breaking innovation for causal inference with time-series cross-sectional data (Xu Reference Xu, Box-Steffensmeier, Christenson and Sinclair-Chapman2024).
While SCMs have been widely applied to univariate outcomes (e.g., Becher, Gonz´alez, and Stegmueller Reference Becher, González and Stegmueller2023; Hilbig and Riaz Reference Hilbig and Riaz2024; Pinotti Reference Pinotti2015), political scientists often encounter multivariate, compositional data in the form of proportions. As Katz and King (Reference Katz and King1999) noted decades ago: “Compositional data are also common in political science and economics (as in multiparty voting data, the allocation of ministerial portfolios among political parties, trade flows or international conflict directed from each nation to several others, or proportions of budget expenditures in each of several categories).” In compositional data, each proportion is bound between 0 and 1, and all proportions sum to 1. Because components are constrained and interdependent, compositional data warrant approaches that account for these properties (Jackson Reference Jackson2002; Lipsmeyer et al. Reference Lipsmeyer, Philips, Rutherford and Whitten2019; Martin and Vanberg Reference Martin and Vanberg2026; Philips, Rutherford, and Whitten Reference Philips, Rutherford and Whitten2016; Tomz, Tucker, and Wittenberg Reference Tomz, Tucker and Wittenberg2002). As we show further on, this also applies to synthetic controls.
When the theoretical interest centers on changes across multiple proportions of the same whole, separate applications of SCMs to different proportions violate what we term the constant control comparison. Each synthetic control application generates its own set of weights, resulting in different control groups for each proportion. This can lead to treatment effect estimates that violate an essential sum constraint. In compositional data, the sum of changes should generally equal zero because an increase in one proportion necessarily implies a decrease in another.
A practical way to align SCMs with the constant control comparison for compositional data is to model outcomes jointly, applying a common set of weights across proportions. We integrate common weights, previously studied for synthetic controls (Sun, Ben-Michael, and Feller Reference Sun, Ben-Michael and Feller2025; Tian, Lee, and Panchenko Reference Tian, Lee and Panchenko2023), into the synthetic DID (SDID) framework, which generalizes over DID and a range of SCMs (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021). We formally demonstrate that this approach adheres to the compositional data constraints, thereby offering a more accurate interpretation of estimated treatment effects for proportional outcomes. A freely available R package propsdid (Stoetzer and Bogatyrev Reference Stoetzer and Bogatyrev2026) implements the estimation.
Our simulation study reveals that for compositional outcomes, SCMs with common weights are more accurate compared to DID (especially when the parallel trends assumption fails) and avoid the inconsistencies that arise from applying SCMs separately to each proportion. We illustrate this approach with two empirical applications with proportional outcomes. Across both the Spanish “Just Transition” case (Bolet, Green, and González-Eguino Reference Bolet, Green and González-Eguino2024) and the Polish anti-LGBTQ resolutions case (Haas et al. Reference Haas, Bogatyrev, Abou-Chadi, Klüver and Stoetzerforthcoming), we show that SCMs without common weights generate logically inconsistent estimates whose sum deviates substantially from zero. In contrast, using common weights yields balanced and interpretable results across the outcome space, thereby refining the conclusions of the original analysis.Footnote 2
Our contribution bridges the research on compositional data (Aitchison Reference Aitchison1982; Jackson Reference Jackson2002; Katz and King Reference Katz and King1999; Lipsmeyer et al. Reference Lipsmeyer, Philips, Rutherford and Whitten2019; Martin and Vanberg Reference Martin and Vanberg2026; Philips et al. Reference Philips, Rutherford and Whitten2016; Tomz et al. Reference Tomz, Tucker and Wittenberg2002) with the younger and burgeoning field of causal inference in panel data settings (recently reviewed by Arkhangelsky and Imbens Reference Arkhangelsky and Imbens2024, Roth et al. Reference Roth, Sant’Anna, Bilinski and Poe2023 and Xu Reference Xu, Box-Steffensmeier, Christenson and Sinclair-Chapman2024). We define the concept of constant control comparison and establish that it yields coherent estimates across compositional outcomes. As we show, this condition is generally not satisfied by the common practice of applying SCMs separately to each outcome. We theoretically and practically demonstrate that common weights (Sun et al. Reference Sun, Ben-Michael and Feller2025; Tian et al. Reference Tian, Lee and Panchenko2023) address this shortcoming, both for the original SCM (Abadie, Diamond, and Hainmueller Reference Abadie, Diamond and Hainmueller2010; Abadie et al. Reference Abadie, Diamond and Hainmueller2015) and its advanced successors with unit-shifts and time weights (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021). The common weights approach is particularly relevant when researchers analyze compositional panel data with multiple pre-treatment periods, including settings where parallel trends are doubtful or only a few treated units are available.
2 Compositional outcomes and synthetic control methods
2.1 Conventional approaches
Political scientists frequently analyze compositional outcomes, such as vote shares, budget allocations, ministerial portfolios or trade flows (Katz and King Reference Katz and King1999). A defining feature of such data is that the individual proportions are bounded between zero and one and must sum to unity. This, in turn, constrains causal effects: when one proportion increases, another necessarily decreases. Any method that estimates effects on these outcomes separately risks producing results that are inconsistent or difficult to interpret. Thus, compositional outcome variables present distinct challenges for causal inference (Arnold et al. Reference Arnold, Berrie, Tennant and Gilthorpe2020).Footnote 3
For causal inference with time-series cross-sectional data, a natural starting point is DID. Although DID was originally developed for single outcomes, its application to compositional data is straightforward. For example, Cremaschi, Bariletto, and De Vries (Reference Cremaschi, Bariletto and Vries2025) estimate ATTs of plant disease on party vote shares in the Italian region of Apulia, using uninfected Apulian municipalities as a DID control group across different parties. The choice of the control group can be data-driven: Selb and Munzert (Reference Selb and Munzert2018) use either all German counties not exposed to Hitler’s speeches or only their subsample matched by covariates to estimate the speech on the vote shares of Nazis and Communists. Regardless of how the control group is chosen, DID allows researchers to keep the control group constant across proportions, thereby avoiding logical inconsistencies.
In contrast to DID, where the control group is pre-selected by the researcher, SCMs construct a synthetic “untreated” version of the treated group by reweighting control units to match the pre-exposure trends of the treated. This feature makes SCMs particularly useful when treatment and control units follow different trajectories before exposure, indicating a likely violation of the (post-exposure) parallel trends assumption required by the DID methods. Although the original SCM (Abadie et al. Reference Abadie, Diamond and Hainmueller2010, Reference Abadie, Diamond and Hainmueller2015) was designed for small-sample single-unit case studies and did not allow for intercept shifts between the treated and control trajectories, more recent methodological advancements (e.g., Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021; Ben-Michael et al. Reference Ben-Michael, Feller and Rothstein2021; Doudchenko and Imbens Reference Doudchenko and Imbens2016; Ferman and Pinto Reference Ferman and Pinto2021) have addressed these limitations and shown improved performance, both in small-sample and large panel data settings. However, these approaches did not take compositional outcomes into account. A key complication in applying SCMs to interrelated outcomes is that control unit weights are estimated separately for each outcome. Even when starting with the same untreated (donor) unit pool, fitting different outcome trajectories can yield different synthetic controls across outcomes. This can in turn produce effect estimates that are logically incompatible across outcomes, which becomes obvious with compositional data.
Outside compositional data setups, some previous research has explored ways to maintain consistency across outcomes in synthetic control estimates. One solution previously adopted by researchers is to calculate the weights for just one outcome and use them in all outcome models. Indeed, after calculating synthetic control weights based on the regional GDP and its predictors, Pinotti (Reference Pinotti2015) uses the same weights to estimate the effects of organized crime on the GDP and the homicide rate.Footnote 4 However, deriving synthetic control weights from only one outcome variable risks over-fitting its pre-treatment trends (Abadie Reference Abadie2021) and neglects the core purpose of SCMs for other outcomes. For SCMs in particular, Sun et al. (Reference Sun, Ben-Michael and Feller2025) suggest optimizing the pre-treatment fit for concatenated standardized outcomes (see also Tian et al. Reference Tian, Lee and Panchenko2023) or the average of standardized outcomes. Furthermore, extensions of the classical SCM have been proposed to balance the entire distribution of a treated unit’s outcome (Gunsilius Reference Gunsilius2023). While currently focused on univariate outcomes, this framework could in principle be extended to K-dimensional vectors by modeling them as multivariate distributions and constructing weights through appropriate distributional matching.
Building upon this literature, our article provides a statistical foundation for using SCMs with compositional data. In the following example, we illustrate the issues that arise when researchers apply SCMs to proportions.
2.2 Pitfalls of separate estimation: An illustration
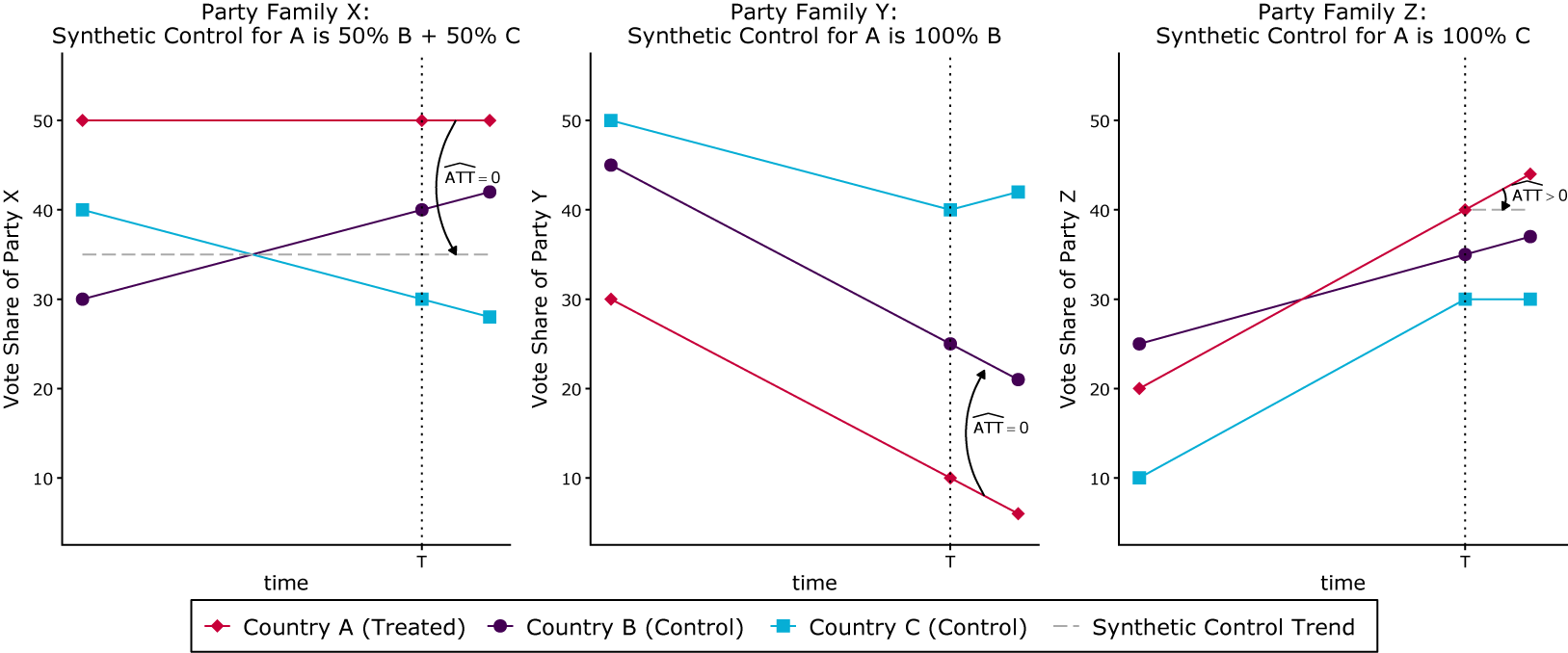
Before discussing estimators in abstract terms, we present a deliberately simplified hypothetical example to illustrate why separate estimation of compositional outcomes can yield logically incompatible treatment effects and thus motivates the search for a joint approach. Consider three countries A, B and C, where country A is affected by a treatment at time T, while countries B and C were not treated and constitute the donor pool for creating synthetic controls for outcomes of interest. Suppose that we are interested in the treatment effects on party vote shares in country A, and all the voters in each country choose among three party families: X (e.g., left), Y (e.g., center-right) and Z (e.g., far right). Thus, the synthetic controls for the vote shares of each party in country A are obtained by weighting the vote shares of the same party family in countries B and C.
In the approach to synthetic controls currently prevalent in political science, one would apply the method to each outcome variable separately (e.g., Cremaschi et al. Reference Cremaschi, Rettl, Cappelluti and Vries2024), often focusing on one party of interest (e.g., Becher et al. Reference Becher, González and Stegmueller2023; Hilbig and Riaz Reference Hilbig and Riaz2024). Following a synthetic approach with intercept shifts, in our example, a researcher interested in the treatment effects would create a synthetic control for each party X, Y and Z separately, trying to approximate that party’s pre-treatment trend in A by congenial party trends in B and C. For example, if A’s pre-treatment trend is a bisector between the trends in B and C, then the optimal synthetic control for A comprises B and C half-and-half (Figure 1, left). However, this does not mean that synthetic controls for the vote shares of Y and Z assign the same weights to countries B and C. For the vote share of party family Y, the synthetic control for country A is constructed entirely from country B, while for party family Z, it is constructed entirely from country C (Figure 1, center and right). As a result, the estimated treatment effect in country A is zero for parties X and Y, but positive for Z. This discrepancy arises even though the true vote shares across X, Y and Z necessarily sum to one (100%) in every country and period.
Illustrative example of inconsistencies in synthetic control weights across proportional outcomes (party vote shares).

Thus, using SCMs on each party X, Y and Z separately can lead to effect estimates that do not sum to zero because each estimate is essentially obtained using a different control. In practice, different comparisons across outcomes can yield conflicting findings for elements of the same whole. This incompatibility may not be apparent when analyzing a single party, but it becomes observable when effects are estimated across multiple parties (or when abstention is regarded as a part in the composition), as recommended by the literature on compositional outcomes and electoral effects (Cohen, Krause, and Abou-Chadi Reference Cohen, Krause and Abou-Chadi2024; Katz and King Reference Katz and King1999; Lipsmeyer et al. Reference Lipsmeyer, Philips, Rutherford and Whitten2019; Philips, Rutherford, and Whitten Reference Philips, Rutherford and Whitten2015, Reference Philips, Rutherford and Whitten2016).
In what follows, we formally discuss how a joint synthetic control estimation for multiple outcomes addresses this pitfall (Sections 3 and 4) and evaluate its performance in simulation (Section 5) and empirical implications (Section 6).
3 Constant control comparison
To analyze causal effects on compositional data, we formally introduce the constant control comparison, a sufficient condition that ensures treatment effect estimates satisfy the sum constraint. We focus on a balanced panel with N units at T time points. For each unit
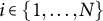 $i \in \{1, \ldots , N\}$
, treatment status is indicated by
$i \in \{1, \ldots , N\}$
, treatment status is indicated by
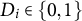 $D_i \in \{0,1\}$
. We observe
$D_i \in \{0,1\}$
. We observe
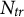 $N_{tr}$
treated (
$N_{tr}$
treated (
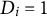 $D_i = 1$
) and
$D_i = 1$
) and
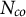 $N_{co}$
untreated control units (
$N_{co}$
untreated control units (
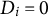 $D_i = 0$
). For notational simplicity, we arrange the unit indices i so that all treated units follow all untreated units
$D_i = 0$
). For notational simplicity, we arrange the unit indices i so that all treated units follow all untreated units
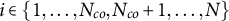 $i\in \{1,\ldots , N_{co},N_{co}+1, \ldots ,N\}$
. In this section, we consider the case where exposure to treatment occurs in the last period
$i\in \{1,\ldots , N_{co},N_{co}+1, \ldots ,N\}$
. In this section, we consider the case where exposure to treatment occurs in the last period
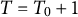 $T = T_{0} + 1$
, but the notation and results generalize to multiple post-treatment periods.
$T = T_{0} + 1$
, but the notation and results generalize to multiple post-treatment periods.
The compositional outcomes of interest
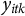 $y_{itk}$
form a vector
$y_{itk}$
form a vector
 $(y_{it1},\ldots ,y_{itK})$
of length K for each unit
$(y_{it1},\ldots ,y_{itK})$
of length K for each unit
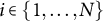 $i \in \{1,\ldots ,N\}$
and time point
$i \in \{1,\ldots ,N\}$
and time point
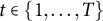 $t \in \{1,\ldots ,T\}$
. For the post-treatment period, we introduce potential outcomes under the control condition
$t \in \{1,\ldots ,T\}$
. For the post-treatment period, we introduce potential outcomes under the control condition
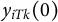 $y_{iTk}(0)$
and under the treatment condition
$y_{iTk}(0)$
and under the treatment condition
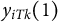 $y_{iTk}(1)$
. We focus on estimating the average treatment effects on the treated (ATT) for each compositional outcome:
$y_{iTk}(1)$
. We focus on estimating the average treatment effects on the treated (ATT) for each compositional outcome:
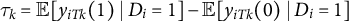 $\tau _k = \mathbb {E}[y_{iTk}(1) \mid D_{i} = 1] - \mathbb {E}[y_{iTk}(0) \mid D_{i} = 1]$
. Since the outcomes for the treated units under treatment are observable,
$\tau _k = \mathbb {E}[y_{iTk}(1) \mid D_{i} = 1] - \mathbb {E}[y_{iTk}(0) \mid D_{i} = 1]$
. Since the outcomes for the treated units under treatment are observable,
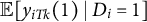 $\mathbb {E}[y_{iTk}(1) \mid D_{i} = 1]$
can be estimated from the data in a consistent and unbiased way as
$\mathbb {E}[y_{iTk}(1) \mid D_{i} = 1]$
can be estimated from the data in a consistent and unbiased way as
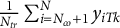 $ \frac {1}{N_{tr}} \sum _{i=N_{co} +1}^N y_{iTk}$
. However, the counterfactual
$ \frac {1}{N_{tr}} \sum _{i=N_{co} +1}^N y_{iTk}$
. However, the counterfactual
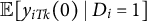 $\mathbb {E}[y_{iTk}(0)\mid D_i=1]$
must be estimated from control outcomes. To do this, SCMs calculate a set of non-negative weights
$\mathbb {E}[y_{iTk}(0)\mid D_i=1]$
must be estimated from control outcomes. To do this, SCMs calculate a set of non-negative weights
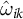 $\hat {\omega }_{ik}$
that align the control outcomes with the pre-exposure trajectory of the treated units. This weighting principle underlies the classic SCM (Abadie et al. Reference Abadie, Diamond and Hainmueller2010, Reference Abadie, Diamond and Hainmueller2015), where weights are chosen so that
$\hat {\omega }_{ik}$
that align the control outcomes with the pre-exposure trajectory of the treated units. This weighting principle underlies the classic SCM (Abadie et al. Reference Abadie, Diamond and Hainmueller2010, Reference Abadie, Diamond and Hainmueller2015), where weights are chosen so that
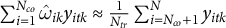 $\sum _{i=1}^{N_{co}} \hat {\omega }_{ik} y_{itk} \approx \frac {1}{N_{tr}} \sum _{i=N_{co}+1}^{N} y_{itk}$
for all
$\sum _{i=1}^{N_{co}} \hat {\omega }_{ik} y_{itk} \approx \frac {1}{N_{tr}} \sum _{i=N_{co}+1}^{N} y_{itk}$
for all
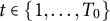 $~ t \in \{1, \ldots , T_0\}$
and for all
$~ t \in \{1, \ldots , T_0\}$
and for all
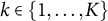 $k \in \{1, \ldots , K\}$
. Its extensions with intercept shifts (Ferman and Pinto Reference Ferman and Pinto2021) and the SDID method (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021) further include additive unit-level shifts and time weights
$k \in \{1, \ldots , K\}$
. Its extensions with intercept shifts (Ferman and Pinto Reference Ferman and Pinto2021) and the SDID method (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021) further include additive unit-level shifts and time weights
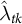 $\hat {\lambda }_{tk}$
, as formally described in Section 1 of the Supplementary Material.
$\hat {\lambda }_{tk}$
, as formally described in Section 1 of the Supplementary Material.
By definition of compositional data, all K proportions
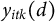 $y_{itk}(d)$
are bound between 0 and 1 and sum to 1 for all observations i, time points t and the two treatment states
$y_{itk}(d)$
are bound between 0 and 1 and sum to 1 for all observations i, time points t and the two treatment states
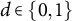 $d \in \{0,1\}$
. Thus, under the compositional constraint, the sum of average treatment effects on the separate proportions should be zero.
$d \in \{0,1\}$
. Thus, under the compositional constraint, the sum of average treatment effects on the separate proportions should be zero.
Lemma 1 Constraint on ATTs for proportions
For compositional data where
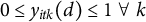 $0 \leq y_{itk}(d) \leq 1~\forall ~k$
and
$0 \leq y_{itk}(d) \leq 1~\forall ~k$
and
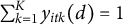 $\sum _{k=1}^K y_{itk}(d) = 1$
, it holds that
$\sum _{k=1}^K y_{itk}(d) = 1$
, it holds that
 $$ \begin{align} \sum_{k=1}^K {\tau}_k = \sum_{k=1}^K \mathbb{E}[y_{iTk}(1) - y_{iTk}(0) \mid D_{i} = 1] = 0, \end{align} $$
$$ \begin{align} \sum_{k=1}^K {\tau}_k = \sum_{k=1}^K \mathbb{E}[y_{iTk}(1) - y_{iTk}(0) \mid D_{i} = 1] = 0, \end{align} $$
where
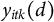 $y_{itk}(d)$
is the potential outcome under treatment status
$y_{itk}(d)$
is the potential outcome under treatment status
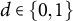 $d \in \{0,1\}$
.
$d \in \{0,1\}$
.
It holds by linearity of expectation: the sum of the treatment effects equals the expected difference between the total proportion under treatment and under control, and since both totals are constrained to equal one, the expectation is zero (see also Section 2 of the Supplementary Material). Lemma 1 implies that if one proportion increases under treatment exposure, another has to decrease, leading to a sum constraint over the treatment effects of zero. Violations of the constraint on the ATTs lead to contradictory interpretations of the effects on different proportions and can make it difficult to interpret the results.
To see whether synthetic control estimators satisfy Lemma 1, we integrate compositional outcomes with the SDID framework (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021). SDID generalizes over both DID and a range of SCMs, both with and without additive unit-level shifts and/or time weights. Section 1 of the Supplementary Material formally describes the method following Arkhangelsky et al. (Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021). The SDID estimator for proportion k can be written as a weighted double difference.
Definition 1 SDID estimator
 $$ \begin{align} \begin{aligned} \widehat{\tau}_k^{\mathrm{sdid}} &= \underbrace{ \left( \frac{1}{N_{\mathrm{tr}}} \sum_{i=N_{\mathrm{co}}+1}^{N} y_{iTk} - \sum_{j=1}^{N_{\mathrm{co}}} \omega_{jk} \, y_{jTk} \right) }_{\text{post-treatment: treated vs. weighted control}} \\ &\quad - \underbrace{ \left( \frac{1}{N_{\mathrm{tr}}} \sum_{i=N_{\mathrm{co}}+1}^{N} \sum_{t=1}^{T_0} \lambda_{tk} \, y_{itk} - \sum_{j=1}^{N_{\mathrm{co}}} \omega_{jk} \sum_{t=1}^{T_0} \lambda_{tk} \, y_{jtk} \right) }_{\text{time-weighted pre-treatment: treated vs. weighted control}} \; , \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \widehat{\tau}_k^{\mathrm{sdid}} &= \underbrace{ \left( \frac{1}{N_{\mathrm{tr}}} \sum_{i=N_{\mathrm{co}}+1}^{N} y_{iTk} - \sum_{j=1}^{N_{\mathrm{co}}} \omega_{jk} \, y_{jTk} \right) }_{\text{post-treatment: treated vs. weighted control}} \\ &\quad - \underbrace{ \left( \frac{1}{N_{\mathrm{tr}}} \sum_{i=N_{\mathrm{co}}+1}^{N} \sum_{t=1}^{T_0} \lambda_{tk} \, y_{itk} - \sum_{j=1}^{N_{\mathrm{co}}} \omega_{jk} \sum_{t=1}^{T_0} \lambda_{tk} \, y_{jtk} \right) }_{\text{time-weighted pre-treatment: treated vs. weighted control}} \; , \end{aligned} \end{align} $$
where
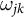 $\omega _{jk}$
are of non-negative unit weights that sum to one:
$\omega _{jk}$
are of non-negative unit weights that sum to one:
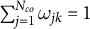 $\sum _{j=1}^{N_{co}} \omega _{jk} = 1$
and
$\sum _{j=1}^{N_{co}} \omega _{jk} = 1$
and
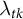 $\lambda _{tk}$
are non-negative time weights that sum to one:
$\lambda _{tk}$
are non-negative time weights that sum to one:
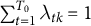 $\sum _{t=1}^{T_0} \lambda _{tk} = 1$
for all k.
$\sum _{t=1}^{T_0} \lambda _{tk} = 1$
for all k.
In case of compositional data, cross-outcome weight invariance is crucial to whether the ATT sum constraint holds. For standard DID, all weights are the same across outcomes by construction:
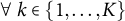 $\forall ~k \in \{1,\ldots , K\}$
, unit weights
$\forall ~k \in \{1,\ldots , K\}$
, unit weights
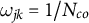 $\omega _{jk} = 1/N_{co}$
and time weights
$\omega _{jk} = 1/N_{co}$
and time weights
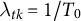 $\lambda _{tk} = 1/T_0$
. However, SCMs choose unit weights to fit the pre-treatment outcomes, as formally discussed in Section 1 of the Supplementary Material. Separate applications of SCMs to proportions can yield weights that can differ across outcomes for the same unit: there exist
$\lambda _{tk} = 1/T_0$
. However, SCMs choose unit weights to fit the pre-treatment outcomes, as formally discussed in Section 1 of the Supplementary Material. Separate applications of SCMs to proportions can yield weights that can differ across outcomes for the same unit: there exist
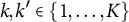 $ k, k' \in \{1, \ldots , K\}$
with
$ k, k' \in \{1, \ldots , K\}$
with
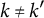 $k \neq k'$
such that
$k \neq k'$
such that
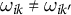 $\omega _{ik} \neq \omega _{ik'}$
.
$\omega _{ik} \neq \omega _{ik'}$
.
In contrast, we define the constant control comparison for compositional data in the following way.
Definition 2 Constant control comparison imposes the same unit weights
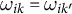 $\omega _{ik} = \omega _{ik'}$
and time weights
$\omega _{ik} = \omega _{ik'}$
and time weights
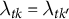 $\lambda _{tk} = \lambda _{tk'}$
for all proportional outcomes
$\lambda _{tk} = \lambda _{tk'}$
for all proportional outcomes
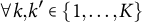 $\forall k, k' \in \{1,\ldots ,K\}$
with
$\forall k, k' \in \{1,\ldots ,K\}$
with
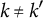 $k \neq k'$
in the estimation of the counterfactual expectation
$k \neq k'$
in the estimation of the counterfactual expectation
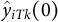 $\hat {y}_{iTk}(0)$
using the SDID estimator (see Definition 1).
$\hat {y}_{iTk}(0)$
using the SDID estimator (see Definition 1).
The constant control comparison enables the use of the same weights for all proportional outcomes of a unit. We denote them by
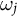 $\omega _j$
and
$\omega _j$
and
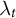 $\lambda _{t}$
in the SDID estimator, rather than outcome-specific
$\lambda _{t}$
in the SDID estimator, rather than outcome-specific
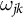 $\omega _{jk}$
and
$\omega _{jk}$
and
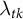 $\lambda _{tk}$
. These common weights across outcomes are a sufficient (though not necessary) condition that the constraint on ATTs for proportional outcomes is met.
$\lambda _{tk}$
. These common weights across outcomes are a sufficient (though not necessary) condition that the constraint on ATTs for proportional outcomes is met.
Theorem 1 Sufficiency of constant control comparison
Under constant control comparison (see Definition 2), the SDID estimates of the ATT (see Definition 1) satisfy the constraint on the ATTs for proportions (see Lemma 1), that is, sum to zero:
 $$ \begin{align} \begin{aligned} \sum_{k=1}^K \hat{\tau}_k &= { \big[ \underbrace{\frac{1}{N_{\mathrm{tr}}}\sum_{i=N_{\mathrm{co}}+1}^{N} \sum_{k=1}^K y_{iTk}}_{=1}\ -\ \underbrace{\sum_{j=1}^{N_{\mathrm{co}}} \omega_j \sum_{k=1}^K y_{jTk}}_{=\sum_j \omega_j \cdot 1=1}\big]\ }\\ &\quad { -\ \big[ \underbrace{\frac{1}{N_{\mathrm{tr}}}\sum_{i=N_{\mathrm{co}}+1}^{N}\sum_{t=1}^{T_0}\lambda_t \sum_{k=1}^K y_{itk}}_{=\sum_t \lambda_t \cdot 1=1}\ -\ \underbrace{\sum_{j=1}^{N_{\mathrm{co}}} \omega_j \sum_{t=1}^{T_0}\lambda_t \sum_{k=1}^K y_{jtk}}_{=\sum_j \omega_j \sum_t \lambda_t \cdot 1=1}\big]} = 0. \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \sum_{k=1}^K \hat{\tau}_k &= { \big[ \underbrace{\frac{1}{N_{\mathrm{tr}}}\sum_{i=N_{\mathrm{co}}+1}^{N} \sum_{k=1}^K y_{iTk}}_{=1}\ -\ \underbrace{\sum_{j=1}^{N_{\mathrm{co}}} \omega_j \sum_{k=1}^K y_{jTk}}_{=\sum_j \omega_j \cdot 1=1}\big]\ }\\ &\quad { -\ \big[ \underbrace{\frac{1}{N_{\mathrm{tr}}}\sum_{i=N_{\mathrm{co}}+1}^{N}\sum_{t=1}^{T_0}\lambda_t \sum_{k=1}^K y_{itk}}_{=\sum_t \lambda_t \cdot 1=1}\ -\ \underbrace{\sum_{j=1}^{N_{\mathrm{co}}} \omega_j \sum_{t=1}^{T_0}\lambda_t \sum_{k=1}^K y_{jtk}}_{=\sum_j \omega_j \sum_t \lambda_t \cdot 1=1}\big]} = 0. \end{aligned} \end{align} $$
If the constant control comparison is violated, the sum-to-zero constraint on the ATTs for proportions does not necessarily hold (see Section 2 of the Supplementary Material for an illustrative counterexample with weights that differ across outcomes). The same logic extends to the demeaned weighting estimator of Doudchenko and Imbens (Reference Doudchenko and Imbens2016), ass shown in Section 3 of the Supplementary Material. In the context of SCMs, re-estimating weights separately for each outcome can therefore violate the constraint. To satisfy the constraint on the ATTs for compositional data, we propose using common weights for all proportions to ensure a constant control comparison.Footnote 5
4 Implementing common weights in synthetic difference-in-differences
Based on the insights from Section 3, we formulate an SDID approach that follows the constant control comparison. In contrast to the original method (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021), we reconfigure the minimization problem to obtain the same set of unit and time weights across outcomes. While common weights have been previously introduced for synthetic controls, with one treated unit (Sun et al. Reference Sun, Ben-Michael and Feller2025; Tian et al. Reference Tian, Lee and Panchenko2023), we adopt them for SDID.
Our approach to SCMs for compositional data imposes the same set of unit weights for all proportional outcomes
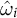 $\hat {\omega }_{i}$
and does the same for time weights
$\hat {\omega }_{i}$
and does the same for time weights
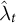 $\hat {\lambda }_{t}$
in the case of synthetic DID. The control unit weights
$\hat {\lambda }_{t}$
in the case of synthetic DID. The control unit weights
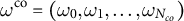 ${\omega }^{\mathrm {co}} = ({\omega }_0,{\omega }_1,\ldots ,{\omega }_{N_{co}})$
are obtained by minimizing the squared deviations of the weighted control outcomes from the average treated outcomes across all proportions:
${\omega }^{\mathrm {co}} = ({\omega }_0,{\omega }_1,\ldots ,{\omega }_{N_{co}})$
are obtained by minimizing the squared deviations of the weighted control outcomes from the average treated outcomes across all proportions:
 $$ \begin{align} \hat{\omega}^{\mathrm{co}} & = \underset{{\omega}^{\mathrm{co}} \in \Omega}{\mathop{\mathrm{arg\,min}}} ~ \ell_{unit}({\omega}^{\mathrm{co}}) , ~ \text{where} \\ \nonumber & \ell_{unit}({\omega}^{\mathrm{co}}) = \sum_{k=1}^{K} \Bigg ( \sum_{t=1}^{T_0} \left( {\omega}_{0} + \sum_{i=1}^{N_{co}} {\omega}_{i} y_{itk} - \frac{1}{N_{tr}} \sum_{i=N_{co}+1}^{N} y_{itk} \right)^2 \Bigg ) + \xi^2 T_0 \sum_{i=1}^{N_{co}} \omega_{i}^2, \\ \nonumber & \Omega = \Bigg \{{\omega}^{\mathrm{co}} : \omega_{0} \in \mathbb{R}, ~\omega_{i} \in \mathbb{R}_{+} ~\forall ~ i \in \{1, \ldots, N_{co}\}, ~\sum_{i=1}^{N_{co}} \omega_i = 1 \Bigg \}. \end{align} $$
$$ \begin{align} \hat{\omega}^{\mathrm{co}} & = \underset{{\omega}^{\mathrm{co}} \in \Omega}{\mathop{\mathrm{arg\,min}}} ~ \ell_{unit}({\omega}^{\mathrm{co}}) , ~ \text{where} \\ \nonumber & \ell_{unit}({\omega}^{\mathrm{co}}) = \sum_{k=1}^{K} \Bigg ( \sum_{t=1}^{T_0} \left( {\omega}_{0} + \sum_{i=1}^{N_{co}} {\omega}_{i} y_{itk} - \frac{1}{N_{tr}} \sum_{i=N_{co}+1}^{N} y_{itk} \right)^2 \Bigg ) + \xi^2 T_0 \sum_{i=1}^{N_{co}} \omega_{i}^2, \\ \nonumber & \Omega = \Bigg \{{\omega}^{\mathrm{co}} : \omega_{0} \in \mathbb{R}, ~\omega_{i} \in \mathbb{R}_{+} ~\forall ~ i \in \{1, \ldots, N_{co}\}, ~\sum_{i=1}^{N_{co}} \omega_i = 1 \Bigg \}. \end{align} $$
The same set of weights is chosen to optimize the pre-treatment fit jointly over all
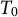 $T_0$
pre-treatment periods and K outcomes. The objective function in problem (4) further includes a regularization parameter
$T_0$
pre-treatment periods and K outcomes. The objective function in problem (4) further includes a regularization parameter
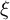 $\xi $
, which penalizes extreme weights using a squared
$\xi $
, which penalizes extreme weights using a squared
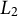 $L_2$
norm of the weight vector.Footnote
6
Controlling the dispersion this way facilitates the uniqueness and stability of the solution, leading to more robust estimations (see also Doudchenko and Imbens Reference Doudchenko and Imbens2016). Combining the control-unit weights
$L_2$
norm of the weight vector.Footnote
6
Controlling the dispersion this way facilitates the uniqueness and stability of the solution, leading to more robust estimations (see also Doudchenko and Imbens Reference Doudchenko and Imbens2016). Combining the control-unit weights
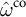 $\hat {\omega }^{\mathrm {co}}$
with uniform weights
$\hat {\omega }^{\mathrm {co}}$
with uniform weights
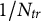 ${1}/{N_{tr}}$
for treated units yields the full-sample unit weights:
${1}/{N_{tr}}$
for treated units yields the full-sample unit weights:
 $$ \begin{align} \hat{\omega}_i = \begin{cases} \hat{\omega}^{\mathrm{co}}_i, & i=1,\ldots,N_{co},\\ \frac{1}{N_{tr}}, & i=N_{co}+1,\ldots,N. \end{cases} \end{align} $$
$$ \begin{align} \hat{\omega}_i = \begin{cases} \hat{\omega}^{\mathrm{co}}_i, & i=1,\ldots,N_{co},\\ \frac{1}{N_{tr}}, & i=N_{co}+1,\ldots,N. \end{cases} \end{align} $$
As in the case of unit weights, we compute pre-treatment time weights
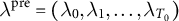 $\lambda ^{\mathrm {pre}}=(\lambda _0,\lambda _1,\ldots ,\lambda _{T_0})$
jointly for all K outcomes by solving:
$\lambda ^{\mathrm {pre}}=(\lambda _0,\lambda _1,\ldots ,\lambda _{T_0})$
jointly for all K outcomes by solving:

 $$ \begin{align} \hat{\lambda}^{\mathrm{pre}} & = \underset{\lambda^{\mathrm{pre}} \in \Lambda}{\mathop{\mathrm{arg\,min}}} ~ \ell_{time}({\lambda}^{\mathrm{pre}}) , ~ \text{where} \\ \nonumber & \ell_{time}({\lambda}^{\mathrm{pre}}) = \sum_{k=1}^K \Bigg ( \sum_{i=1}^{N_{co}} \left( {\lambda}_{0} + \sum_{t=1}^{T_0} {\lambda}_{t} y_{itk} - \frac{1}{T-T_0} \sum_{t=T_0+1}^{T} y_{itk} \right)^2 \Bigg ), \\ \nonumber & \Lambda = \Bigg \{ \lambda^{\mathrm{pre}} :\ \lambda_{0}\in\mathbb{R},\ \lambda_{t}\in\mathbb{R}_{+}\ \forall\, t\in\{1,\ldots,T_0\},\ \sum_{t=1}^{T_0} \lambda_t = 1 \Bigg \}. \end{align} $$
$$ \begin{align} \hat{\lambda}^{\mathrm{pre}} & = \underset{\lambda^{\mathrm{pre}} \in \Lambda}{\mathop{\mathrm{arg\,min}}} ~ \ell_{time}({\lambda}^{\mathrm{pre}}) , ~ \text{where} \\ \nonumber & \ell_{time}({\lambda}^{\mathrm{pre}}) = \sum_{k=1}^K \Bigg ( \sum_{i=1}^{N_{co}} \left( {\lambda}_{0} + \sum_{t=1}^{T_0} {\lambda}_{t} y_{itk} - \frac{1}{T-T_0} \sum_{t=T_0+1}^{T} y_{itk} \right)^2 \Bigg ), \\ \nonumber & \Lambda = \Bigg \{ \lambda^{\mathrm{pre}} :\ \lambda_{0}\in\mathbb{R},\ \lambda_{t}\in\mathbb{R}_{+}\ \forall\, t\in\{1,\ldots,T_0\},\ \sum_{t=1}^{T_0} \lambda_t = 1 \Bigg \}. \end{align} $$
Together, the pre-treatment weights and the uniform post-treatment weights form the full period time weights:
 $$ \begin{align} \hat\lambda_t = \begin{cases} \hat{\lambda}^{\mathrm{pre}}_t, & t=1,\ldots,T_0,\\ \frac{1}{T-T_0}, & t=T_0+1,\ldots,T. \end{cases} \end{align} $$
$$ \begin{align} \hat\lambda_t = \begin{cases} \hat{\lambda}^{\mathrm{pre}}_t, & t=1,\ldots,T_0,\\ \frac{1}{T-T_0}, & t=T_0+1,\ldots,T. \end{cases} \end{align} $$
Using both
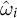 $\hat {\omega }_i$
from Equation (5) and
$\hat {\omega }_i$
from Equation (5) and
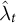 $\hat \lambda _t$
from Equation (7), we now obtain the SDID estimates for each outcome k from the following two-way fixed effects regression:
$\hat \lambda _t$
from Equation (7), we now obtain the SDID estimates for each outcome k from the following two-way fixed effects regression:
 $$ \begin{align} (\hat{\tau}_k^{sdid},\hat{\mu}_{k}, \hat{\alpha}_{ik},\hat{\beta}_{tk}) = \underset{\tau,\mu, \alpha,\beta}{\mathrm{arg\,min}} \Bigg \{ \sum_{i=1}^N \sum_{t=1}^T \left( y_{itk} - \mu_k - \alpha_{ik} - \beta_{tk} - D_{it} \tau \right)^2 \hat{\omega}_i \hat{\lambda}_t \Bigg \}, \end{align} $$
$$ \begin{align} (\hat{\tau}_k^{sdid},\hat{\mu}_{k}, \hat{\alpha}_{ik},\hat{\beta}_{tk}) = \underset{\tau,\mu, \alpha,\beta}{\mathrm{arg\,min}} \Bigg \{ \sum_{i=1}^N \sum_{t=1}^T \left( y_{itk} - \mu_k - \alpha_{ik} - \beta_{tk} - D_{it} \tau \right)^2 \hat{\omega}_i \hat{\lambda}_t \Bigg \}, \end{align} $$
where
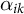 $\alpha _{ik}$
are unit fixed effects and
$\alpha _{ik}$
are unit fixed effects and
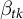 $\beta _{tk}$
are time fixed effects for each outcome.
$\beta _{tk}$
are time fixed effects for each outcome.
Algorithm 1 summarizes the overall procedure for the SDID estimator with common weights. We first calculate the regularization parameter and then compute the unit weights followed by the time weights. Afterward, we obtain the treatment effect estimates using the weighted two-way regression for each proportion.
Alternatively, a similar procedure can be used to estimate classic SCM models, usually applied in contexts with one treatment unit (Abadie et al. Reference Abadie, Diamond and Hainmueller2010, Reference Abadie, Diamond and Hainmueller2015). For this algorithm, described in Section 4 of the Supplementary Material, we skip the time weight estimation, excluding the time weights from the regression model. We further exclude the constant in the calculation of the unit weights, which does not allow for an intercept shift in pre-treatment trends. For compositional proportional outcomes, we implement common weights for both the synthetic DID and the classic synthetic control in our R-package propsdid (Stoetzer and Bogatyrev Reference Stoetzer and Bogatyrev2026), which extends the synthdid package (Hirshberg Reference Hirshberg2022) to multivariate outcomes with constant control comparisons.
To estimate the uncertainty around our treatment effect estimates from SDID with common weights, we rely on the same approaches to variance estimation as in Arkhangelsky et al. (Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021): clustered bootstrap (Efron Reference Efron1979), jackknife methods (Miller Reference Miller1974) and placebo inference (Abadie et al. Reference Abadie, Diamond and Hainmueller2010). The latter is particularly valuable when there are very few treated units and involves applying placebo treatments to control units to estimate the level of noise, similar to the approach of Conley and Taber (Reference Conley and Taber2011). Each of these methods strikes a balance between computational complexity and robustness, depending on the structure of the dataset. For large panels, bootstrap is often favored for its reliability, whereas the jackknife and placebo methods provide useful alternatives when computational efficiency or small-sample concerns are more pressing. In our application, we rely on the jackknife method.
5 Simulation study
In this section, we evaluate the statistical performance of the synthetic control estimator with common weights for compositional outcomes. Estimation error in the classic SCM generally arises from two sources: approximation error, reflecting the donor pool’s inability to reproduce the treated unit’s counterfactual path, and estimation error, resulting from overfitting idiosyncratic noise in pre-treatment outcomes (Abadie et al. Reference Abadie, Diamond and Hainmueller2010). While regularization can mitigate overfitting, approximation bias can persist even as the number of pre-treatment periods increases (Ferman and Pinto Reference Ferman and Pinto2021).
Recent work suggests that aggregating information across multiple related outcomes can stabilize weight estimation. By fitting a common set of weights in the classic SCM under a shared latent factor structure, researchers can effectively average out idiosyncratic variation, yielding tighter finite-sample bias bounds than separate weights (Sun et al. Reference Sun, Ben-Michael and Feller2025; Tian et al. Reference Tian, Lee and Panchenko2023). Intuitively, this improves the signal-to-noise ratio in the pre-treatment matching objective.
These insights are relevant here, yet they do not directly map onto SDID with compositional outcomes. While Arkhangelsky et al. (Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021) establish consistency and asymptotic normality for univariate SDID, the estimator already incorporates unit and time weights that reduce variance. It is therefore an open question whether the gains from common weights scale in SDID as they do in classic synthetic control settings. Moreover, the simplex constraint implies a non-linear outcome space, which makes it analytically challenging to derive formal bias bounds using standard linear factor models.
We therefore rely on a comprehensive simulation study, calibrated to panel data structures commonly used in political science, to assess finite-sample performance, focusing on whether common weights preserve statistical efficiency while ensuring coherent interpretation of compositional treatment effects.
To define the data-generating process (DGP) for our simulation study, we use a dynamic latent-state model. The panel data consist of N units observed over T time periods, with outcomes given by K proportions that sum to one in each unit–time cell. A subset of
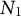 $N_1$
units is exposed to treatment from period
$N_1$
units is exposed to treatment from period
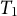 $T_1$
onward.Footnote
7
For each unit i and proportion k, outcomes are driven by two latent components: a level and a trend. The level captures persistent, unit-specific differences in baseline support for a given proportion, while the trend captures unit-specific trajectories over time. Both components are unit- and proportion-specific. At the start of the panel (
$T_1$
onward.Footnote
7
For each unit i and proportion k, outcomes are driven by two latent components: a level and a trend. The level captures persistent, unit-specific differences in baseline support for a given proportion, while the trend captures unit-specific trajectories over time. Both components are unit- and proportion-specific. At the start of the panel (
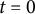 $t=0$
), we draw initial latent states from normal distributions:
$t=0$
), we draw initial latent states from normal distributions:
 $$ \begin{align} \gamma_{i,k,0} \sim \mathcal{N}(\mu_{\gamma_{k,0}}, \sigma_{\gamma_{k,0}}), \quad \upsilon_{i,k,0} \sim \mathcal{N}(\mu_{\upsilon_{k,0}}, \sigma_{\upsilon_{k,0}}), \end{align} $$
$$ \begin{align} \gamma_{i,k,0} \sim \mathcal{N}(\mu_{\gamma_{k,0}}, \sigma_{\gamma_{k,0}}), \quad \upsilon_{i,k,0} \sim \mathcal{N}(\mu_{\upsilon_{k,0}}, \sigma_{\upsilon_{k,0}}), \end{align} $$
where
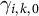 $\gamma _{i,k,0}$
denotes the levels and
$\gamma _{i,k,0}$
denotes the levels and
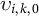 $\upsilon _{i,k,0}$
denotes the trends. The hyperparameters (
$\upsilon _{i,k,0}$
denotes the trends. The hyperparameters (
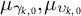 $\mu _{\gamma _{k,0}},\mu _{\upsilon _{k,0}}$
) control cross-unit heterogeneity at baseline. The trends are particularly useful for simulating violations of parallel trends assumption, since treated and control units may differ in their pre-treatment trajectories even if levels are similar. We therefore let treatment assignment depend on latent characteristics of one proportion j, by defining a weighted scalar index
$\mu _{\gamma _{k,0}},\mu _{\upsilon _{k,0}}$
) control cross-unit heterogeneity at baseline. The trends are particularly useful for simulating violations of parallel trends assumption, since treated and control units may differ in their pre-treatment trajectories even if levels are similar. We therefore let treatment assignment depend on latent characteristics of one proportion j, by defining a weighted scalar index
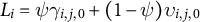 $L_i = \psi \gamma _{i,j,0} + (1 - \psi )\upsilon _{i,j,0}$
which allows treatment selection to depend either on baseline levels (
$L_i = \psi \gamma _{i,j,0} + (1 - \psi )\upsilon _{i,j,0}$
which allows treatment selection to depend either on baseline levels (
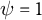 $\psi = 1$
) or trends (
$\psi = 1$
) or trends (
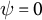 $\psi = 0$
). Units with higher values of
$\psi = 0$
). Units with higher values of
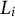 $L_i$
are more likely to be treated, with assignment probabilities given by a logistic function:
$L_i$
are more likely to be treated, with assignment probabilities given by a logistic function:
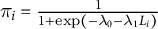 $\pi _i = \frac {1}{1 + \exp (-\lambda _0 - \lambda _1 L_i)}$
, where
$\pi _i = \frac {1}{1 + \exp (-\lambda _0 - \lambda _1 L_i)}$
, where
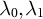 $\lambda _0,\lambda _1$
are hyperparameter that sets the strength of treatment selection based on latent factors. Treatment is then assigned such that exactly
$\lambda _0,\lambda _1$
are hyperparameter that sets the strength of treatment selection based on latent factors. Treatment is then assigned such that exactly
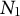 $N_1$
units are treated.Footnote
8
$N_1$
units are treated.Footnote
8
Latent levels evolve over time according to autoregressive processes:
 $$\begin{align*}\gamma_{i,k,t+1} = \rho_{\gamma_k}\gamma_{i,k,t} + \upsilon_{i,k,t} + \epsilon_{\gamma_{i,k,t}}, \quad \upsilon_{i,k,t+1} = \rho_{\upsilon_k}\upsilon_{i,k,t} + \epsilon_{\upsilon_{i,k,t}}, \end{align*}$$
$$\begin{align*}\gamma_{i,k,t+1} = \rho_{\gamma_k}\gamma_{i,k,t} + \upsilon_{i,k,t} + \epsilon_{\gamma_{i,k,t}}, \quad \upsilon_{i,k,t+1} = \rho_{\upsilon_k}\upsilon_{i,k,t} + \epsilon_{\upsilon_{i,k,t}}, \end{align*}$$
with normally distributed shocks. These dynamics generate persistent unit-level heterogeneity and smoothly evolving trends.Footnote 9 For each unit, time and proportion, we construct a latent outcome
 $$\begin{align*}\widetilde{Y}_{i,k,t} = \gamma_{i,k,t} + \tilde{\tau}_k W_{i,t} + \delta_{k,t} + \epsilon_{i,k,t}, \end{align*}$$
$$\begin{align*}\widetilde{Y}_{i,k,t} = \gamma_{i,k,t} + \tilde{\tau}_k W_{i,t} + \delta_{k,t} + \epsilon_{i,k,t}, \end{align*}$$
where
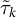 $\tilde {\tau }_k$
denotes the latent treatment shift,
$\tilde {\tau }_k$
denotes the latent treatment shift,
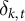 $\delta _{k,t}$
denotes common time shocks that are drawn from a normal distribution
$\delta _{k,t}$
denotes common time shocks that are drawn from a normal distribution
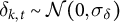 $ \delta _{k,t} \sim \mathcal {N}(0, \sigma _{\delta }) $
and
$ \delta _{k,t} \sim \mathcal {N}(0, \sigma _{\delta }) $
and
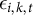 $\epsilon _{i,k,t}$
denotes idiosyncratic noise. Observed outcomes are obtained via a multinomial link:
$\epsilon _{i,k,t}$
denotes idiosyncratic noise. Observed outcomes are obtained via a multinomial link:
 $$\begin{align*}Y_{i,k,t} = \frac{\exp(\widetilde{Y}_{i,k,t})}{\sum_{k=1}^K \exp(\widetilde{Y}_{i,k,t})}, \end{align*}$$
$$\begin{align*}Y_{i,k,t} = \frac{\exp(\widetilde{Y}_{i,k,t})}{\sum_{k=1}^K \exp(\widetilde{Y}_{i,k,t})}, \end{align*}$$
which ensures that proportions are non-negative and sum to one. This DGP allows us to flexibly vary sample size, time horizon, treatment selection and the presence of level-differences or trends, while preserving the compositional structure of the outcomes.
Our simulation DGP differs from the static low-rank factor model commonly used to justify synthetic control and SDID estimators. Standard theoretical results assume that outcomes follow a factor structure of the form
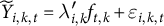 $\widetilde {Y}_{i,k,t} = \lambda _{i,k}' f_{t,k} + \varepsilon _{i,k,t}$
, where
$\widetilde {Y}_{i,k,t} = \lambda _{i,k}' f_{t,k} + \varepsilon _{i,k,t}$
, where
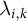 $\lambda _{i,k}$
denotes unit- and outcome-specific factor loadings,
$\lambda _{i,k}$
denotes unit- and outcome-specific factor loadings,
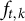 $f_{t,k}$
denotes outcome- and time-specific factors and
$f_{t,k}$
denotes outcome- and time-specific factors and
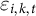 $\varepsilon _{i,k,t}$
is an idiosyncratic error term (see, e.g., Ferman, Pinto, and Possebom Reference Ferman, Pinto and Possebom2020; Xu Reference Xu2017). In this formulation, the loadings are fixed over time and no explicit temporal structure is imposed on the factors, which are treated as unrestricted time-specific parameters. In contrast, we allow the latent factors to evolve autoregressively over time.
$\varepsilon _{i,k,t}$
is an idiosyncratic error term (see, e.g., Ferman, Pinto, and Possebom Reference Ferman, Pinto and Possebom2020; Xu Reference Xu2017). In this formulation, the loadings are fixed over time and no explicit temporal structure is imposed on the factors, which are treated as unrestricted time-specific parameters. In contrast, we allow the latent factors to evolve autoregressively over time.
An autoregressive factor process can be written in companion form as a first-order linear state-space system by stacking lagged factors into an augmented state vector (see, e.g., Hamilton Reference Hamilton1994, 372–374). Consequently, dynamic factor models have an equivalent static representation in higher dimension. Our DGP therefore remains within the class of linear low-rank factor models underlying synthetic control estimators, while introducing structured temporal dependence that is not typically emphasized in the theoretical literature.Footnote 10 We adopt this dynamic specification because many proportional political outcomes, such as vote shares, exhibit substantial persistence and evolve gradually over time. The autoregressive structure thus reflects the empirical properties of these outcomes more closely than a static factor model.
We analyze scenarios with four proportions and a latent treatment effect on the first proportion (for an example, see Section 5 of the Supplementary Material).Footnote 11 The simulation scenarios contain 5 and 10 time points, where the treatment occurs either in the final period or in the last two periods. We consider 50, 200 and 1,000 units, with treatment proportions of 10% and 50%, and one and two treatment periods. The different scenarios reflect common data settings in applied work and vary the number of available pre-treatment control units, which is relevant for mitigating approximation error in the construction of counterfactual outcome trajectories. Treatment assignment is implemented in two ways: based either on levels or on trends. This allows us to evaluate performance under different selection mechanisms, including cases with clear violations of the parallel trends assumption, where synthetic methods are expected to perform particularly well compared to standard DID.Footnote 12 We draw 1,000 independent samples for each of 48 combinations and estimate DID using two-way fixed effects, an SC and an SDID model separately for each outcome, as well as SC and SDID with common weights across proportional outcomes. We compare the estimates based on standard deviation, root-mean-square error (RMSE) and absolute-valued bias. We also calculate the absolute deviation of the sum of the treatment effect estimates on the separate proportions, which under the constant control comparisons should be zero.Footnote 13
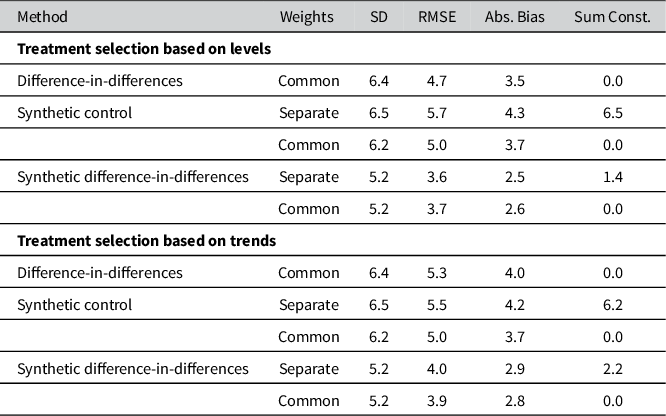
Table 1 reports results aggregated across all parameter settings, distinguishing between treatment selection based on levels and trends, with performance metrics averaged over all proportions. The table first highlights the importance of respecting the sum constraint when estimating treatment effects on proportional outcomes. Standard SCMs violate this constraint substantially, with average deviations of nearly 7 percentage points under both treatment selection designs. SDID also exhibits non-negligible violations of the sum constraint, though to a lesser extent, with deviations of around 2 percentage points. In contrast, the methods with common weights strictly satisfy the sum constraint by construction, yielding zero violations in all scenarios. This ensures that the interpretation of estimated effects across all proportions remains coherent.
Monte Carlo evaluation for different estimation methods and weights

Note: For treatment selection on local levels and local trends, we report the standard deviation (SD), root-mean-square error (RMSE) and absolute bias (Abs. Bias), averaged across outcomes, along with the sum constraint (Sum Const.). All values are scaled by 100. Results are based on 96,000 samples, with Monte Carlo standard errors below 0.05 for all metrics.
Turning to overall performance, measured by RMSE and absolute bias, the synthetic control estimators with common weights perform at least as well as their unconstrained counterparts. Under treatment selection based on levels, SDID with common weights achieves the lowest RMSE, matching SDID with separate weights while additionally eliminating violations of the sum constraint. A similar pattern emerges when treatment selection is based on trends, where SDID with common weights again slightly improves upon SDID with separate weights in terms of RMSE and absolute bias and exhibits marginally lower bias, although the differences between the two estimators are small in both regimes. For the classic synthetic control, the common weights approach clearly outperforms the unconstrained estimator, consistently reducing RMSE and indicating structural advantages in reducing both overall error and systematic bias, in line with the findings of Sun et al. (Reference Sun, Ben-Michael and Feller2025).
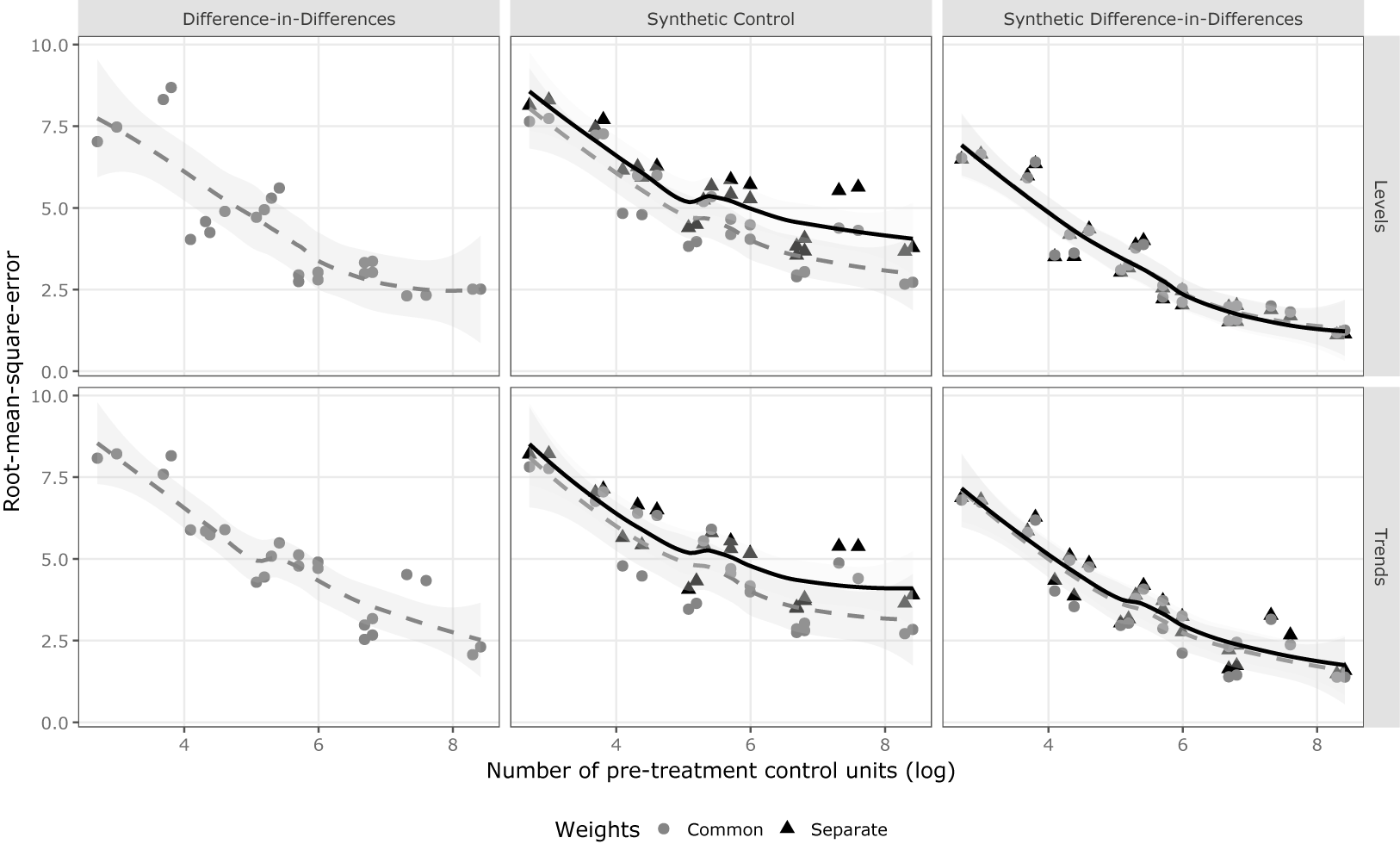
We observe this pattern in more detail when we evaluate how the RMSE develops over an increasing number of observations. The relevant aspect for the reduction in estimation error in SCMs is the number of available pre-treatment control units. Figure 2 shows that increasing the number of pre-treatment control units reduces the RMSE for all estimation approaches. It further highlights that SCMs are preferable in terms of the RMSE for both selection on trends and levels, with SDID having the best performance. When comparing common and separate weights strategies, we again observe that for SC, the common weights approach reveals some advantages, while for SDID, the two approaches have comparable RMSE values. Only in the case of treatment selection based on trends do we see slightly better rates of decreasing RMSE for common weights approaches.
Root-mean-squared-error (RMSE) of different estimation methods and weights. Monte Carlo simulations vary the number of pre-treatment control units (natural-log scale on the x-axis) and the treatment assignment based on levels (top row) or trends (bottom row).

Overall, the simulations confirm the central role the constant control comparison plays in ensuring the sum constraint for treatment effects on proportional outcomes. The results from the simulation study highlight that imposing separate weights across outcomes does not yield superior performance relative to the common weights estimators. This shows that enforcing the sum constraint does not come at the cost of efficiency, but ensures that the effect estimates add up.
6 Empirical applications
6.1 Climate policy and party outcomes
We apply our synthetic control framework to reevaluate the findings of Bolet et al. (Reference Bolet, Green and González-Eguino2024). While the original study focuses on a single party’s vote share, we analyze the full set of party vote shares as a compositional outcome. This illustrates how separate synthetic controls can generate incoherent treatment effects, and common weights resolves this problem.
Bolet et al. (Reference Bolet, Green and González-Eguino2024) study the electoral effects of a compensatory “Just Transition Agreement” in Spanish coal-mining areas using municipal election data from 2008 to 2019. Across a range of DID specifications comparing mining and non-mining municipalities in three Spanish provinces, they report a positive effect of about 1.8 percentage points on PSOE’s vote share in 2019, which they interpret as an electoral reward for the incumbent party. However, the underlying theoretical argument implies a reallocation of votes from opposition parties toward the government, raising the question of how the policy affects the full vector of vote-share proportions.
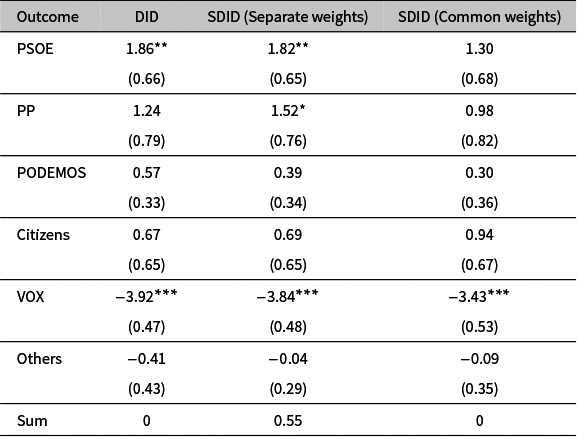
We first replicate their analysis for all major parties using a DID specification, which includes indicators for treatment status, the post-treatment period and their interaction.Footnote 14 The DID estimates in Table 2 confirm the main finding that support for the PSOE increases by around 1.86 percentage points. At the same time, we estimate a substantial decline in support for the far right VOX of roughly 3.9 percentage points. The mainstream opposition party PP also gains about 1.2 percentage points, although this effect is not statistically significant, and the remaining parties register smaller and statistically insignificant changes. As discussed above for DID, the estimated effects across all parties sum to zero, reflecting the compositional nature of vote shares.
Estimates of the effects of the Just Transition Agreement on party vote shares (p.p.) in the 2019 Spanish elections using difference-in-differences (DID) and synthetic difference-in-differences (SDID) with separate and common weights

Note: Entries are point estimates; subrows report jackknife standard errors. *
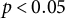 $p < 0.05$
, **
$p < 0.05$
, **
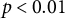 $p < 0.01$
, and ***
$p < 0.01$
, and ***
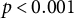 $p < 0.001$
. N = 2,455.
$p < 0.001$
. N = 2,455.
We next apply SDID with separate weights. In the application, treated and control municipalities exhibit visibly non-parallel pre-treatment voting trends (see Figure 2 in Bolet et al. Reference Bolet, Green and González-Eguino2024), making SDID well suited for constructing more accurate counterfactual vote-share trajectories for each party. The SDID estimates in Table 2 are similar in magnitude to the DID results, but both PSOE and PP now exhibit statistically significant positive effects. This points to a joint mainstream gain from voter deradicalization rather than a benefit confined to the governing party. However, the estimates here no longer satisfy the compositional constraint. Summing the effects yields a net increase of
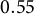 $0.55$
percentage points across parties, contradicting the fact that vote shares must sum to one. This inconsistency arises because separate SDID estimates each party using outcome-specific synthetic controls, thereby comparing different counterfactuals across components of the same composition.
$0.55$
percentage points across parties, contradicting the fact that vote shares must sum to one. This inconsistency arises because separate SDID estimates each party using outcome-specific synthetic controls, thereby comparing different counterfactuals across components of the same composition.
Finally, we apply the SDID estimator with common weights, which enforces a constant control comparison across all parties. The resulting estimates in Table 2 satisfy the sum-to-zero constraint by construction. These estimates are generally smaller than in the previous approaches, but still indicate a decline of about 3.43 percentage points for VOX. The effects on PSOE and PP remain positive, but are not statistically significant at conventional levels. This suggests that the Just Transition Agreement did not primarily benefit the governing party, but rather decreased electoral gains of the far right. This pattern is obscured when outcomes are analyzed separately, but becomes transparent once the full composition is modeled jointly with common weights.
Overall, this application demonstrates the benefits of SCMs with common weights for panel data studies with proportional outcomes. The synthetic controls with common weights maximize the fit of pre-treatment trends between control and treated units, while keeping the effects balanced with each other. Analyzing the complete set of vote shares substantively suggests that the Just Transition Agreement did not just benefit the governing party; rather, it deradicalized voters, reducing support for the far right. While our evidence complements and challenges the initial conclusions drawn by Bolet et al. (Reference Bolet, Green and González-Eguino2024), this application primarily serves to highlight how accounting for the compositional nature of vote shares allows for logically consistent and interpretable estimates across multiple proportions.
6.2 Anti-LGBTQ policies and turnout-adjusted vote shares
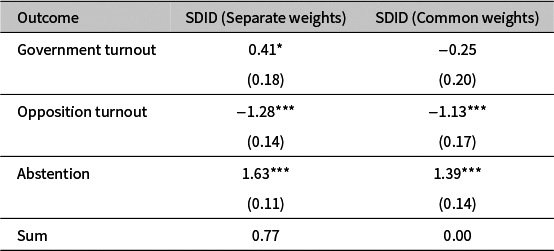
As a second application, we revisit the Polish case analyzed by Haas et al. (Reference Haas, Bogatyrev, Abou-Chadi, Klüver and Stoetzerforthcoming), who estimate the electoral effects of municipal anti-LGBTQ resolutions prior to the 2019 parliamentary elections. In their main analysis, Haas et al. (Reference Haas, Bogatyrev, Abou-Chadi, Klüver and Stoetzerforthcoming) apply SDID separately to the following voting outcomes: government turnout (votes for the ruling party divided by eligible voters), opposition turnout (votes for other parties divided by eligible voters) and overall turnout. Recasting the latter outcome as abstention, defined as the share of eligible voters who did not vote for any party, we focus on three proportions of the same whole, of the electorate. While this differs from Section 6.1, which focused on shares of valid votes, both settings are compositional.
Table 3 contrasts the original SDID with separate weights and our SDID with common weights on the full municipal panel (
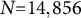 $N{=}14{,}856$
). Three differences are central. First, while the voter demobilization found by Haas et al. (Reference Haas, Bogatyrev, Abou-Chadi, Klüver and Stoetzerforthcoming) is also evident in our results, the effect becomes smaller in magnitude under common weights:
$N{=}14{,}856$
). Three differences are central. First, while the voter demobilization found by Haas et al. (Reference Haas, Bogatyrev, Abou-Chadi, Klüver and Stoetzerforthcoming) is also evident in our results, the effect becomes smaller in magnitude under common weights:
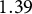 $1.39$
percentage points versus
$1.39$
percentage points versus
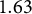 $1.63$
percentage points with separate weights. Second, due to common weights, the government turnout estimate changes sign and loses its statistical significance. Third, and most consequential for interpretation, the separate-weights SDID yields effects that do not respect the composition, whereas the common-weights SDID sums to
$1.63$
percentage points with separate weights. Second, due to common weights, the government turnout estimate changes sign and loses its statistical significance. Third, and most consequential for interpretation, the separate-weights SDID yields effects that do not respect the composition, whereas the common-weights SDID sums to
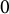 $0$
by construction. This discrepancy is large relative to the component estimates under separate weights and can distort substantive inferences across categories. In contrast, common weights deliver a coherent account of proportional outcomes: abstention increases to about the same extent as turnout for the opposition decreases, while there is little to no change on the ruling party side.
$0$
by construction. This discrepancy is large relative to the component estimates under separate weights and can distort substantive inferences across categories. In contrast, common weights deliver a coherent account of proportional outcomes: abstention increases to about the same extent as turnout for the opposition decreases, while there is little to no change on the ruling party side.
Estimates of the effects of anti-LGBTQ resolutions on turnout-adjusted outcomes (in p.p.) in the 2019 Polish parliamentary election using synthetic difference-in-differences (SDID) with separate vs. common weights

Note: Entries are point estimates; subrows report jackknife standard errors. *
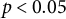 $p < 0.05$
, **
$p < 0.05$
, **
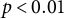 $p < 0.01$
, and ***
$p < 0.01$
, and ***
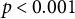 $p < 0.001$
. N = 14,856.
$p < 0.001$
. N = 14,856.
This second application demonstrates the practical value of using common weights to ensure coherent estimates when outcomes are proportions. It complements our first application by demonstrating the same coherence benefits in analyses where turnout is explicitly part of the outcome vector.
7 Discussion
While DID and SCMs applied separately to each outcome can be problematic in compositional settings, our joint cross-outcome estimation provides a practical approach that yields coherent results. Even for univariate outcomes, the parallel trends assumption required for DID is often implausible (Chiu et al. Reference Chiu, Lan, Liu and Xu2025; Hassell and Holbein Reference Hassell and Holbein2024), making it even less likely to hold simultaneously for each component of a compositional outcome. Although SCMs offer a promising alternative, applying them separately to each component violates the constant control comparison, as we demonstrate. By using common weights across outcomes, we restore this coherence while maintaining statistical performance comparable to separate estimation in our simulations.
Our study builds on a long methodological tradition to take compositional data seriously (Aitchison Reference Aitchison1982; Arnold et al. Reference Arnold, Berrie, Tennant and Gilthorpe2020; Cohen and Hanretty Reference Cohen and Hanretty2024; Jackson Reference Jackson2002; Katz and King Reference Katz and King1999; Lipsmeyer et al. Reference Lipsmeyer, Philips, Rutherford and Whitten2019; Martin and Vanberg Reference Martin and Vanberg2026; Philips et al. Reference Philips, Rutherford and Whitten2016; Tomz et al. Reference Tomz, Tucker and Wittenberg2002). We formally embed compositional outcomes into causal inference with time-series cross-sectional data, central to many recent methodological advances (Arkhangelsky and Imbens Reference Arkhangelsky and Imbens2024; Blackwell and Glynn Reference Blackwell and Glynn2018; Imai and Kim Reference Imai and Kim2019; Imai, Kim, and Wang Reference Imai, Kim and Wang2023; Liu et al. Reference Liu, Wang and Xu2024; Roth et al. Reference Roth, Sant’Anna, Bilinski and Poe2023; Xu Reference Xu, Box-Steffensmeier, Christenson and Sinclair-Chapman2024). Whenever proportions are studied, common weights can serve as a building block for the whole range of SCMs—from the standard original (Abadie et al. Reference Abadie, Diamond and Hainmueller2010, Reference Abadie, Diamond and Hainmueller2015) to demeaned (Doudchenko and Imbens Reference Doudchenko and Imbens2016; Ferman and Pinto Reference Ferman and Pinto2021), penalized (Abadie and L’Hour Reference Abadie and L’Hour2021), augmented (Ben-Michael et al. Reference Ben-Michael, Feller and Rothstein2021) and dynamic (Cao and Chadefaux Reference Cao and Chadefaux2025) synthetic controls as well as synthetic DID (Arkhangelsky et al. Reference Arkhangelsky, Athey, Hirshberg, Imbens and Wager2021) and triply robust panel estimators (Athey et al. Reference Athey, Imbens, Qu and Vivianoforthcoming). Our SDID implementation also applies to general multi-outcome settings, providing a unified control comparison and reducing discretion in outcome by outcome modeling, which enforces the sum constraint in case of compositional data.
Our approach is most appropriate when interest lies in the joint evolution of all proportional outcomes. As our empirical applications illustrate, many outcomes in political science are inherently compositional, and analyzing a single component in isolation risks losing information and oversimplifying the substantive picture (Katz and King Reference Katz and King1999; Philips et al. Reference Philips, Rutherford and Whitten2015, Reference Philips, Rutherford and Whitten2016). However, when substantive interest centers on a single component and confounding factors are highly component-specific, separate weighting strategies may be preferable. While our simulations show that SDID with common weights performs competitively under the DGPs considered here, a formal characterization of the conditions under which common or separate weights are preferred across a broader range of proportional settings remains an open question. Because the simplex constraint induces a nonlinear outcome geometry, deriving analytic bias bounds within standard linear factor-model frameworks is nontrivial, representing an important direction for future research.
When using common weights, researchers should still respect the data requirements and assumptions of the underlying SCM. While exact pre-treatment fit for all K outcomes may not always be achievable, it remains for researchers to assess the adequacy of fit in each application. Yet compared to separate outcome modeling, common weights may reduce the need for extensive pre-treatment data for each outcome (Abadie Reference Abadie2021). Relying on the deterministic linear relationship among the proportions and the constant control comparison, synthetic controls can be constructed even for outcomes with limited pre-exposure data, such as a vote share for a newly formed political party. For instance, while new parties may have not participated or received no votes in past elections, our approach allows for the calculation of synthetic control weights based on the voting results of other parties. This capability is akin to using strong predictors of post-intervention values to mitigate the challenges posed by the lack of pre-exposure periods. Future research should investigate these potential benefits more systematically.
The implications of our research extend beyond SCMs. The constant control comparison principle we outlined can be relevant for other causal inference techniques that rely on lagged outcome adjustment or impute counterfactual outcomes, such as matching (Imai et al. Reference Imai, Kim and Wang2023; Kellogg et al. Reference Kellogg, Mogstad, Pouliot and Torgovitsky2021), trajectory balancing (Hazlett and Xu Reference Hazlett and Xu2018) or imputation-based methods (Athey et al. Reference Athey, Bayati, Doudchenko, Imbens and Khosravi2021; Borusyak, Jaravel, and Spiess Reference Borusyak, Jaravel and Spiess2024; Liu et al. Reference Liu, Wang and Xu2024; Xu Reference Xu2017). For instance, when researchers use matching to study the effect of a treatment on voting, applying separate matching weights for each party’s vote share can lead to estimates that violate the sum constraint, rendering the results difficult to interpret. We highlight the importance of adapting causal inference approaches for producing meaningful results with compositional data.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/pan.2026.10046.
Data availability statement
Replication data and code for this article have been published in the Political Analysis Harvard Dataverse at https://doi.org/10.7910/DVN/MPUEIC (Bogatyrev and Stoetzer Reference Bogatyrev and Stoetzer2026).
Acknowledgements
The authors thank Nicola Bariletto, Denis Cohen, Thad Dunning, Paul Kellstedt, Tom Pepinsky, Anton Strezhnev, the participants of the European Political Science Association (EPSA) 2024 conference, the Society for Political Methodology (Polmeth) 2024 annual meeting, seminar audience at Bocconi University as well as anonymous reviewers for their helpful comments for earlier versions of the article. The usual disclaimer applies.
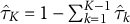
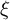
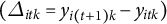


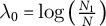
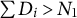
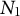
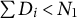
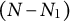
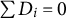
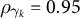
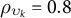
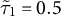
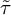
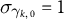
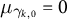
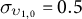
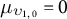
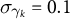
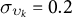
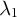



 Open access
Open access