


1. Introduction
Value at risk (VaR) is a standard risk measure used to capture tail risks in quantitative financial risk management. Mathematically, VaR is defined as the left continuous version of the generalized inverse function
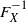 $F^{-1}_X$
of the distribution function
$F^{-1}_X$
of the distribution function
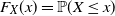 $F_X(x) = \mathbb {P}(X \leq x)$
of a random variable
$F_X(x) = \mathbb {P}(X \leq x)$
of a random variable
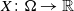 $X \colon \Omega \rightarrow \mathbb {R}$
, which represents an uncertain amount of financial loss, that is,
$X \colon \Omega \rightarrow \mathbb {R}$
, which represents an uncertain amount of financial loss, that is,
 \begin{align*}\mathrm {VaR}_\alpha (X) \;:\!=\; \inf \{x\in \mathbb {R}; \ F_X(x)\geq \alpha \} \equiv F^{-1}_X(\alpha ),\end{align*}
\begin{align*}\mathrm {VaR}_\alpha (X) \;:\!=\; \inf \{x\in \mathbb {R}; \ F_X(x)\geq \alpha \} \equiv F^{-1}_X(\alpha ),\end{align*}
where
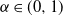 $\alpha \in (0, 1)$
represents the confidence level of a risk manager and
$\alpha \in (0, 1)$
represents the confidence level of a risk manager and
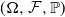 $(\Omega , \mathcal {F}, \mathbb {P})$
is a given probability space. VaR is widely used in financial practice because it is tractable and easy to understand. However, VaR lacks subadditivity, which is one of the important properties for a risk measure to appropriately reflect the effect of risk diversification. Here, a risk measure
$(\Omega , \mathcal {F}, \mathbb {P})$
is a given probability space. VaR is widely used in financial practice because it is tractable and easy to understand. However, VaR lacks subadditivity, which is one of the important properties for a risk measure to appropriately reflect the effect of risk diversification. Here, a risk measure
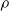 $\rho $
is called subadditive if and only if
$\rho $
is called subadditive if and only if
 \begin{align}\rho (X+Y) \leq \rho (X) + \rho (Y)\end{align}
\begin{align}\rho (X+Y) \leq \rho (X) + \rho (Y)\end{align}
for any random variables X, Y defined on
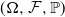 $(\Omega , \mathcal {F}, \mathbb {P})$
. Note that we can easily find an example where the subadditivity of VaR is violated. For instance, if we assume that
$(\Omega , \mathcal {F}, \mathbb {P})$
. Note that we can easily find an example where the subadditivity of VaR is violated. For instance, if we assume that
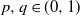 $p, q\in (0, 1)$
satisfy
$p, q\in (0, 1)$
satisfy
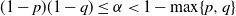 $(1-p)(1-q) \leq \alpha < 1 - \max \{p, q\}$
for a given
$(1-p)(1-q) \leq \alpha < 1 - \max \{p, q\}$
for a given
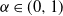 $\alpha \in (0, 1)$
, we see that
$\alpha \in (0, 1)$
, we see that
 \[\mathrm {VaR}_\alpha (X + Y) > \mathrm {VaR}_\alpha (X) + \mathrm {VaR}_\alpha (Y)\]
\[\mathrm {VaR}_\alpha (X + Y) > \mathrm {VaR}_\alpha (X) + \mathrm {VaR}_\alpha (Y)\]
for a random variable X (resp. Y) whose distribution is given by the Bernoulli distribution with parameter p (resp. q).
In this paper, we consider the subadditivity of VaRs from another perspective. Specifically, we investigate a pair of random variables (X, Y) satisfying the subadditivity (1) with
 $\rho = \mathrm {VaR}_\alpha $
for ‘any confidence level
$\rho = \mathrm {VaR}_\alpha $
for ‘any confidence level
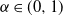 $\alpha \in (0, 1)$
’. More generally, we say that VaR is subadditive for a random vector
$\alpha \in (0, 1)$
’. More generally, we say that VaR is subadditive for a random vector
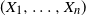 $(X_1, \ldots , X_n)$
if and only if the inequality
$(X_1, \ldots , X_n)$
if and only if the inequality
 \begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \leq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1)\end{align}
\begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \leq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1)\end{align}
holds. Then we show that such a random vector
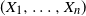 $(X_1, \ldots , X_n)$
is limited to the case where
$(X_1, \ldots , X_n)$
is limited to the case where
 $(X_1, \ldots , X_n)$
is comonotonic. This result also gives a new equivalent condition for the comonotonicity of random vectors.
$(X_1, \ldots , X_n)$
is comonotonic. This result also gives a new equivalent condition for the comonotonicity of random vectors.
2. Main results
To begin, we introduce the definition of the comonotonicity of random vectors.
Definition 1. Let
 $n\in \mathbb {N}$
.
$n\in \mathbb {N}$
.
-
(i) A set
 $A\subset \mathbb {R}^n$
is called comonotonic if and only if, for any
$(x_1, \ldots , x_n), (y_1, \ldots , y_n)\in A$
with
$x_i < y_i$
for some
$i = 1, \ldots , n$
, it follows that
$x_j \leq y_j$
for each
$j = 1, \ldots , n$
.
$A\subset \mathbb {R}^n$
is called comonotonic if and only if, for any
$(x_1, \ldots , x_n), (y_1, \ldots , y_n)\in A$
with
$x_i < y_i$
for some
$i = 1, \ldots , n$
, it follows that
$x_j \leq y_j$
for each
$j = 1, \ldots , n$
. -
(ii) A random vector
$(X_1, \ldots , X_n)$
is called comonotonic if and only if the support of the distribution of
$(X_1, \ldots , X_n)$
is a comonotonic set.
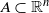
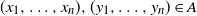
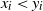
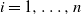

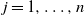
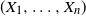
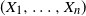
The following theorem is our main result.
Theorem 1. Assume that
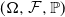 $(\Omega , \mathcal {F}, \mathbb {P})$
is atomless and let
$(\Omega , \mathcal {F}, \mathbb {P})$
is atomless and let
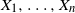 $X_1, \ldots , X_n$
be integrable random variables. Then the following statements are equivalent.
$X_1, \ldots , X_n$
be integrable random variables. Then the following statements are equivalent.
-
(i) For any
$\alpha \in (0, 1)$
, it holds that
$\mathrm {VaR}_\alpha \bigl(\sum ^n_{i=1}X_i\bigr) \leq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i)$
. -
(ii)
$(X_1, \ldots , X_n)$
is comonotonic.

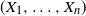
Remark 1.
(Equivalent conditions for comonotonicity.) The following properties are well known as equivalent conditions for the comonotonicity of a random vector
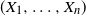 $(X_1, \ldots , X_n)$
(see [Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke5], [Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke6], [Reference McNeil, Frey and Embrechts9]).
$(X_1, \ldots , X_n)$
(see [Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke5], [Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke6], [Reference McNeil, Frey and Embrechts9]).
-
(E1) The dependency structure of
$(X_1, \ldots, X_n)$
is represented by the following copula:
\[M(u_1, \ldots , u_n) = \min \{u_1, \ldots , u_n\}, \quad u_1, \ldots , u_n\in [0, 1].\]
-
(E2) There exists a uniformly distributed random variable U such that
$(X_1, \ldots , X_n)$
and
$(F^{-1}_{X_1}(U), \ldots , F^{-1}_{X_n}(U))$
have the same distribution. -
(E3) There exist a random variable Z and non-decreasing functions
$f_1, \ldots , f_n$
such that
$(X_1, \ldots , X_n)$
and
$(f_1(Z), \ldots , f_n(Z))$
have the same distribution.
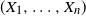

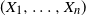
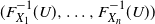
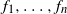
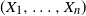
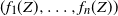
If
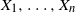 $X_1, \ldots , X_n$
are integrable, the comonotonicity of
$X_1, \ldots , X_n$
are integrable, the comonotonicity of
 $(X_1, \ldots , X_n)$
is equivalent to the following condition [Reference Cheung1, Reference Cheung2, Reference Mao and Hu10].
$(X_1, \ldots , X_n)$
is equivalent to the following condition [Reference Cheung1, Reference Cheung2, Reference Mao and Hu10].
-
(E4) Each random vector
$(\tilde {X}_1, \ldots , \tilde {X}_n)\in \mathcal {R}(F_{X_1}, \ldots , F_{X_n})$
satisfies where
\[\sum ^n_{i=1}\tilde {X}_i \leq _\mathrm {cx} \sum ^n_{i=1}X_i,\]
$\mathcal {R}(F_{X_1}, \ldots , F_{X_n})$
is the Fréchet class with marginal distributions
$F_{X_1}, \ldots , F_{X_n}$
; that is, and we write
\[\mathcal {R}(F_{X_1}, \ldots , F_{X_n}) = \{(\tilde {X}_1, \ldots , \tilde {X}_n); \ F_{\tilde {X}_i} = F_{X_i}, \ i = 1, \ldots , n\},\]
$X\leq _\mathrm {cx} Y$
for random variables X and Y if
$\mathbb {E}[X] = \mathbb {E}[Y]$
and
\[\mathbb {E}[\!\max \{X - c, 0\}] \leq \mathbb {E}[\!\max \{Y - c, 0\}], \quad c\in \mathbb {R}.\]


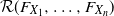
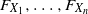

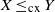
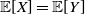

Furthermore, for the square-integrable case, the Pareto optimality for the convex order
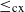 $\leq _\mathrm {cx}$
and the optimal coupling condition under the Wasserstein distance (when
$\leq _\mathrm {cx}$
and the optimal coupling condition under the Wasserstein distance (when
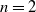 $n=2$
) have been separately studied as equivalent conditions for the comonotonicity. See [Reference Cuesta-Albertos, Rüschendorf and Tuero-Diaz3] and [Reference Denuit, Dhaene, Ghossoub and Robert4] for details.
$n=2$
) have been separately studied as equivalent conditions for the comonotonicity. See [Reference Cuesta-Albertos, Rüschendorf and Tuero-Diaz3] and [Reference Denuit, Dhaene, Ghossoub and Robert4] for details.
Our result implies that (2) is also equivalent to the comonotonicity of
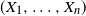 $(X_1, \ldots , X_n)$
. Moreover, we see that (2) implies
$(X_1, \ldots , X_n)$
. Moreover, we see that (2) implies
 \begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) = \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1){,}\end{align}
\begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) = \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1){,}\end{align}
due to Theorem 1 and the comonotonic subadditivity of VaRs, and hence (2) and (3) are equivalent.
Remark 2.
(Elliptic distributions.) Elliptic distributions are known to be consistent with the subadditivity of VaRs. That is, if
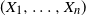 $(X_1, \ldots , X_n)$
is elliptically distributed, the subadditivity of VaRs,
$(X_1, \ldots , X_n)$
is elliptically distributed, the subadditivity of VaRs,
 \begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \leq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i){,}\end{align}
\begin{align}\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \leq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i){,}\end{align}
is guaranteed; thus we can use the VaR as if it is a coherent risk measure when
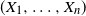 $(X_1, \ldots , X_n)$
follows an elliptic distribution, including normal distributions and t-distributions. However, we must keep in mind that (4) does not always hold for ‘all’
$(X_1, \ldots , X_n)$
follows an elliptic distribution, including normal distributions and t-distributions. However, we must keep in mind that (4) does not always hold for ‘all’
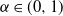 $\alpha \in (0, 1)$
.
$\alpha \in (0, 1)$
.
Indeed, Theorem 1 in [Reference Embrechts, McNeil and Straumann7] implies that if
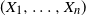 $(X_1, \ldots , X_n)$
is elliptically distributed and square-integrable, (4) holds for each
$(X_1, \ldots , X_n)$
is elliptically distributed and square-integrable, (4) holds for each
 $\alpha \in [1/2, 1)$
. Similarly to the proof of Theorem 1 in [Reference Embrechts, McNeil and Straumann7], if
$\alpha \in [1/2, 1)$
. Similarly to the proof of Theorem 1 in [Reference Embrechts, McNeil and Straumann7], if
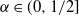 $\alpha \in (0, 1/2]$
, we can verify the opposite inequality; that is, we see the ‘superadditivity’ of the VaR:
$\alpha \in (0, 1/2]$
, we can verify the opposite inequality; that is, we see the ‘superadditivity’ of the VaR:
 \[\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \geq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1/2].\]
\[\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) \geq \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1/2].\]
Thus, if we further assume (2), we obtain
 \[\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) = \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1/2].\]
\[\mathrm {VaR}_\alpha \Biggl(\sum ^n_{i=1}X_i\Biggr) = \sum ^n_{i=1}\mathrm {VaR}_\alpha (X_i), \quad \alpha \in (0, 1/2].\]
This implies that
 \begin{align}\sigma _i\sigma _j(1 - \rho _{ij}) = 0, \quad i, j = 1, \ldots , n,\end{align}
\begin{align}\sigma _i\sigma _j(1 - \rho _{ij}) = 0, \quad i, j = 1, \ldots , n,\end{align}
where
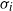 $\sigma _i$
is the standard deviation of
$\sigma _i$
is the standard deviation of
 $X_i$
and
$X_i$
and
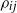 $\rho _{ij}$
is the correlation of
$\rho _{ij}$
is the correlation of
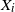 $X_i$
and
$X_i$
and
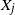 $X_j$
. In other words, for any
$X_j$
. In other words, for any
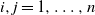 $i, j = 1, \ldots , n$
, it holds that ‘if both
$i, j = 1, \ldots , n$
, it holds that ‘if both
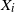 $X_i$
and
$X_i$
and
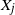 $X_j$
are non-deterministic,
$X_j$
are non-deterministic,
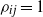 $\rho _{ij} = 1$
’. Then we can verify that
$\rho _{ij} = 1$
’. Then we can verify that
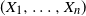 $(X_1, \ldots , X_n)$
is comonotonic. Indeed, if given
$(X_1, \ldots , X_n)$
is comonotonic. Indeed, if given
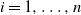 $i = 1, \ldots, n$
such that
$i = 1, \ldots, n$
such that
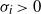 $\sigma _i > 0$
and letting
$\sigma _i > 0$
and letting
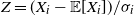 $Z = (X_i - \mathbb {E}[X_i])/\sigma _i$
and
$Z = (X_i - \mathbb {E}[X_i])/\sigma _i$
and
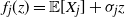 $f_j(z) = \mathbb {E}[X_j] + \sigma _jz$
for each
$f_j(z) = \mathbb {E}[X_j] + \sigma _jz$
for each
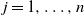 $j = 1, \ldots , n$
, we see that
$j = 1, \ldots , n$
, we see that
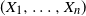 $(X_1, \ldots , X_n)$
has the same distribution as
$(X_1, \ldots , X_n)$
has the same distribution as
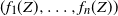 $(f_1(Z), \ldots , f_n(Z))$
.
$(f_1(Z), \ldots , f_n(Z))$
.
Proof of Theorem
1. It suffices to show that (i) implies (ii). Put
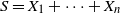 $S = X_1 + \cdots + X_n$
. Because
$S = X_1 + \cdots + X_n$
. Because
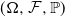 $(\Omega , \mathcal {F}, \mathbb {P})$
is atomless, Lemma A.32 in [Reference Föllmer and Schied8] implies that there is a uniformly distributed random variable U such that
$(\Omega , \mathcal {F}, \mathbb {P})$
is atomless, Lemma A.32 in [Reference Föllmer and Schied8] implies that there is a uniformly distributed random variable U such that
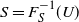 $S = F^{-1}_{S}(U)$
a.s. Now we define
$S = F^{-1}_{S}(U)$
a.s. Now we define
 \[\hat{X}_i = F^{-1}_{X_i}(U), \quad i = 1, \ldots , n.\]
\[\hat{X}_i = F^{-1}_{X_i}(U), \quad i = 1, \ldots , n.\]
Then Lemma A.23 in [Reference Föllmer and Schied8] implies that the distribution of
 $\hat {X}_i$
is the same as that of
$\hat {X}_i$
is the same as that of
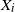 $X_i$
for each
$X_i$
for each
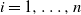 $i = 1, \ldots , n$
. Thus we get
$i = 1, \ldots , n$
. Thus we get
 \begin{align}\mathbb {E}[Z] = 0,\end{align}
\begin{align}\mathbb {E}[Z] = 0,\end{align}
where
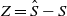 $Z = \hat{S} - S$
and
$Z = \hat{S} - S$
and
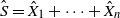 $\hat{S} = \hat {X}_1 + \cdots + \hat{X}_n$
.
$\hat{S} = \hat {X}_1 + \cdots + \hat{X}_n$
.
Meanwhile, from condition (i), we have that
 \[F^{-1}_{S}(\alpha ) \leq \sum ^n_{i=1}F^{-1}_{X_i}(\alpha ), \quad \alpha \in (0, 1).\]
\[F^{-1}_{S}(\alpha ) \leq \sum ^n_{i=1}F^{-1}_{X_i}(\alpha ), \quad \alpha \in (0, 1).\]
Substituting
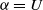 $\alpha = U$
, we get
$\alpha = U$
, we get
 \[S = F^{-1}_{S}(U) \leq \hat{S} \quad \mbox {a.s.},\]
\[S = F^{-1}_{S}(U) \leq \hat{S} \quad \mbox {a.s.},\]
so
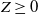 $Z\geq 0$
a.s. Combining this with (6), we see that Z must be equal to zero a.s.; that is,
$Z\geq 0$
a.s. Combining this with (6), we see that Z must be equal to zero a.s.; that is,
 \begin{align}\hat{S} = S \quad \mbox {a.s.}\end{align}
\begin{align}\hat{S} = S \quad \mbox {a.s.}\end{align}
Because
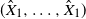 $(\hat {X}_1, \ldots, \hat {X}_1)$
is comonotonic, condition (E4) holds for
$(\hat {X}_1, \ldots, \hat {X}_1)$
is comonotonic, condition (E4) holds for
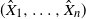 $(\hat {X}_1, \ldots , \hat {X}_n)$
and thus
$(\hat {X}_1, \ldots , \hat {X}_n)$
and thus
 \begin{align*}\sum ^n_{i=1}\tilde {X}_i \leq _\mathrm {cx} \hat {S}, \quad (\tilde {X}_1, \ldots , \tilde {X}_n)\in \mathcal {R}(F_{X_1}, \ldots , F_{X_n}).\end{align*}
\begin{align*}\sum ^n_{i=1}\tilde {X}_i \leq _\mathrm {cx} \hat {S}, \quad (\tilde {X}_1, \ldots , \tilde {X}_n)\in \mathcal {R}(F_{X_1}, \ldots , F_{X_n}).\end{align*}
Combining this with (7) and using (E4) again, we conclude that
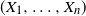 $(X_1, \ldots , X_n)$
is comonotonic.
$(X_1, \ldots , X_n)$
is comonotonic.
Funding information
The research reported in this work was partially supported by JSPS KAKENHI grant 20K03731. The support is gratefully acknowledged.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

 Open access
Open access