


Impact statement
The weight-sharing network enables efficient and robust reconstruction of three-dimensional turbulent flows from sparse measurements, without requiring ground truth data during training. This capability expands the potential for practical 3D flow reconstruction in experimental settings and advances the design of data-driven models for fluid mechanics systems.
1. Introduction
In many practical applications concerning turbulent flows, the data is often sparse. Various strategies have been developed to reconstruct flow fields from sparse measurements. Modal decomposition-based methods, such as gappy proper orthogonal decomposition (POD), have been used to estimate the flow in areas without measurements but may not work well when these areas are large (Everson and Sirovich, Reference Everson and Sirovich1995; Venturi and Karniadakis, Reference Venturi and Karniadakis2004; Gunes et al., Reference Gunes, Sirisup and Karniadakis2006; Nekkanti and Schmidt, Reference Nekkanti and Schmidt2023). Sequential methods, such as the ensemble Kalman filter (Evensen, Reference Evensen2009), can reconstruct flows from sensor measurements, but their accuracy depends on the quality of the incorporated reduced-order model (Colburn et al., Reference Colburn, Cessna and Bewley2011; Mons et al., Reference Mons, Chassaing, Gomez and Sagaut2016; Suzuki and Hasegawa, Reference Suzuki and Hasegawa2017; Nóvoa et al., Reference Nóvoa, Racca and Magri2024). Adjoint-based variational methods can be used to accurately reconstruct flows from sensor measurements. Although variational methods constrain physical constraints, they may become unstable over a long reconstruction window in chaotic flows (Wang et al., Reference Wang, Hu and Blonigan2014; Mons et al., Reference Mons, Chassaing, Gomez and Sagaut2016; Franceschini et al., Reference Franceschini, Sipp and Marquet2020; Huhn and Magri, Reference Huhn and Magri2020; Zaki and Wang, Reference Zaki and Wang2021). Ensemble-variational methods have been used to reconstruct 3D unsteady channel flows from instantaneous sparse measurements and statistical observations (Mons et al., Reference Mons, Du and Zaki2021; Wang and Zaki, Reference Wang and Zaki2021; Zaki and Wang, Reference Zaki and Wang2021), and to reconstruct mean flows from particle image velocimetry measurements (He et al., Reference He, Li and Liu2025). These methods, however, require a large number of 3D simulations, which makes them computationally expensive.
Neural networks have also been increasingly applied to reconstruct velocity and pressure fields. From sparse measurements, network architectures such as autoencoders (Erichson et al., Reference Erichson, Mathelin, Yao, Brunton, Mahoney and Kutz2020; Dubois et al., Reference Dubois, Gomez, Planckaert and Perret2022; Kelshaw and Magri, Reference Kelshaw and Magri2024), generative adversarial networks (Buzzicotti et al., Reference Buzzicotti, Bonaccorso, Di Leoni and Biferale2021; Kim et al., Reference Kim, Kim, Won and Lee2021; Yu et al., Reference Yu, Yousif, Zhang, Hoyas, Vinuesa and Lim2022; Yousif et al., Reference Yousif, Yu, Hoyas, Vinuesa and Lim2023), and transformers (Santos et al., Reference Santos, Fox, Mohan, O’Malley, Viswanathan and Lubbers2023) have been used to reconstruct two-dimensional (2D) flows including bluff body wakes, isotropic turbulence, and rotating turbulence. From 2D low-resolution data, convolutional neural networks (CNNs) are commonly used to recover high-resolution 2D flow fields (Fukami et al., Reference Fukami, Fukagata and Taira2019; Güemes et al., Reference Güemes, Sanmiguel Vila and Discetti2022; Kelshaw and Magri, Reference Kelshaw and Magri2024; Matsuo et al., Reference Matsuo, Fukami, Nakamura, Morimoto and Fukagata2024). Reconstructing three-dimensional (3D) turbulent flows poses a greater challenge because of the high dimensionality of the problem. Chatzimanolakis et al. (Reference Chatzimanolakis, Weber and Koumoutsakos2024) controlled 3D flows with a learning algorithm pre-trained on 2D flows. Physics-informed neural networks (PINNs) (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019) have been used to reconstruct 3D flows in different sensor setups, such as turbulent channel flow from tracked particles (Clark Di Leoni et al., Reference Clark Di Leoni, Agarwal, Zaki, Meneveau and Katz2023), and wakes from sparse, point measurements (Zhang and Zhao, Reference Zhang and Zhao2021; Rui et al., Reference Rui, Chen, Ni, Yuan and Zeng2023). Convolutional neural networks (CNNs) (Özbay and Laizet, Reference Özbay and Laizet2023; Xuan and Shen, Reference Xuan and Shen2023) and generative models (Dubois et al., Reference Dubois, Gomez, Planckaert and Perret2022; Yu et al., Reference Yu, Yousif, Zhang, Hoyas, Vinuesa and Lim2022; Yousif et al., Reference Yousif, Yu, Hoyas, Vinuesa and Lim2023) have been employed to infer missing information from limited measurements in 3D domains. Instantaneous velocities within wall-bounded flows have been reconstructed from wall quantities only using CNNs and generative adversarial networks (Guastoni et al., Reference Guastoni, Güemes, Ianiro, Discetti, Schlatter, Azizpour and Vinuesa2021; Cuéllar et al., Reference Cuéllar, Güemes, Ianiro, Flores, Vinuesa and Discetti2024). However, these methods require the full flow field to be known during training, which limits their applicability when the full flow field is not available.
When ground truth data is unavailable, physics-informed neural networks have been used to infer the flow field at unknown locations from known point measurements, but the training of PINNs requires knowing the time coordinates (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019; Zhang and Zhao, Reference Zhang and Zhao2021). Without initial conditions and with data organised on regular grids, computer vision approaches have been used to reconstruct 3D flows. CNNs have been used to reconstruct flows such as 2D steady biological flows (Gao et al., Reference Gao, Sun and Wang2021) and 2D turbulent Kolmogorov flows (Kelshaw and Magri, Reference Kelshaw and Magri2024; Mo and Magri, Reference Mo and Magri2025; Page, Reference Page2025). In particular, Page (Reference Page2025) and Buzzicotti et al. (Reference Buzzicotti, Bonaccorso, Di Leoni and Biferale2021) tested their methods in 2D flows. (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019; Buzzicotti et al., Reference Buzzicotti, Bonaccorso, Di Leoni and Biferale2021; Mo and Magri, Reference Mo and Magri2025) reconstructed flows without the full flow field in the training, using sensor setups that may be difficult to implement in experiments. When the data comes from experiments, the types of data and the locations of measurement points are limited by the experimental techniques. Non-intrusive methods, such as particle tracking, are often preferred over intrusive methods, as they do not disturb the flow.
Currently, there are no non-intrusive methods to measure static pressure directly (Tavoularis and Nedić, Reference Tavoularis and Nedić2024), which appears in the incompressible Navier–Stokes equations. Instead, pressure is often obtained at walls via pressure taps (McKeon and Engler, Reference McKeon, Engler, Tropea, Yarin and Foss2007; Cal et al., Reference Cal, Lebrón, Castillo, Kang and Meneveau2010; Brackston, Reference Brackston2017), or solved for from well-resolved velocity fields using the incompressible Navier–Stokes equations (Pröbsting et al., Reference Pröbsting, Scarano, Bernardini and Pirozzoli2013; van Oudheusden, Reference van Oudheusden2013; Tavoularis and Nedić, Reference Tavoularis and Nedić2024). Among non-intrusive methods for measuring velocities, particle image velocimetry (PIV) is a robust method when spatially resolved velocity is required. PIV provides in-flow velocity measurements on a regular grid and is capable of measuring time-resolved velocities up to three dimensions in a plane (Tavoularis and Nedić, Reference Tavoularis and Nedić2024). Volumetric velocity can be obtained by measuring multiple planes in the same experiment. For example, by scanning the measurement planes across the domain (Zhu et al., Reference Zhu, Jiang, Lefauve, Kerswell and Linden2024), measuring simultaneously multiple planes arranged either in parallel (Ganapathisubramani et al., Reference Ganapathisubramani, Longmire, Marusic and Pothos2005; Pfadler et al., Reference Pfadler, Dinkelacker, Beyrau and Leipertz2009; Cal et al., Reference Cal, Lebrón, Castillo, Kang and Meneveau2010) or perpendicular to each other (Morton and Yarusevych, Reference Morton and Yarusevych2016; Chandramouli et al., Reference Chandramouli, Memin, Heitz and Fiabane2019), or using tomographic PIV (Pröbsting et al., Reference Pröbsting, Scarano, Bernardini and Pirozzoli2013). The regular grid and spatial resolution of PIV measurements make them a good starting point for 3D flow reconstruction.
Using POD, Druault and Chaillou (Reference Druault and Chaillou2007) reconstructed the mean in-cylinder flow from multiple PIV planes; Hamdi et al. (Reference Hamdi, Assoum, Abed-Meraïm and Sakout2018) reconstructed an impinging jet from multiple parallel planes; and Chandramouli et al. (Reference Chandramouli, Memin, Heitz and Fiabane2019) reconstructed a 3D turbulent flow from two planes perpendicular to each other, using both experimental and synthetic data. A 3D stratified flow has also been reconstructed from multiple experimental PIV planes using PINN (Zhu et al., Reference Zhu, Jiang, Lefauve, Kerswell and Linden2024). Synthetic data on a regular grid have also been used to develop methods for reconstructing 3D flows. Pérez et al. (Reference Pérez, Le Clainche and Vega2020) reconstructed a cylinder wake from multiple parallel planes of velocities. CNN-based methods have been used to reconstruct 3D free surface flow from surface measurements (Xuan and Shen, Reference Xuan and Shen2023), and other turbulent flows from a cross-plane setup (two planes perpendicular to each other) (Yousif et al., Reference Yousif, Yu, Hoyas, Vinuesa and Lim2023). Özbay and Laizet (Reference Özbay and Laizet2023) reconstructed the 3D wake of a cylinder from both a cross-plane and multiple parallel planes taken from simulations.
Many physical systems such as flows have symmetries and obey conservation laws, which have been exploited in multiple works on flow reconstruction. One of these symmetries is homogeneity, i.e., the flow is statistically invariant under translation (Pope, Reference Pope2000). When reconstructing 3D flows from multiple planes, Chandramouli et al. (Reference Chandramouli, Memin, Heitz and Fiabane2019) used the homogeneous assumption to design their reconstruction method so that the method does not require the full 3D flow field. Neural networks can also be designed to enforce certain properties on their output, such as conservation of energy (Greydanus et al., Reference Greydanus, Dzamba and Yosinski2019), conservation of mass (Mohan et al., Reference Mohan, Lubbers, Chertkov and Livescu2023; Page, Reference Page2025), and periodicity (Ozan and Magri, Reference Ozan and Magri2023).
The overarching goal of this paper is to develop a neural network to reconstruct three-dimensional turbulent flows from sparse and noisy data, inspired by experimental configurations, without using the full flow field in the training. The method is tested on the flow reconstruction of 3D turbulent flows from a small number of planes of velocity measurements and a plane of pressure measurements at the boundary of the flow. We design a CNN-based weight-sharing network to both reduce the number of parameters needed for the reconstruction of the 3D flow and to exploit the homogeneous directions in the flow. The paper is structured as follows. We describe the sensor setup and the network in Section 2. We present the reconstructed flow from non-noisy measurements in Section 3, including three special sensor configurations that are closer to experimental conditions. We then present the reconstructed flow from noisy measurements in Section 4. We draw our conclusion in Section 5.
2. Methodology
In this section, we first describe the dataset to be reconstructed and how the measurements are taken (Section 2.1). Then, we introduce the network designed for 3D reconstruction (Section 2.3).
2.1. Dataset and measurements
The 3D turbulent Kolmogorov flow dataset is generated with a pseudo-spectral solver KolSol (Kelshaw, Reference Kelshaw2023) by solving the incompressible Navier-Stokes equations
 $$ \left\{\begin{array}{l}\nabla \cdot \boldsymbol{u}={\mathcal{R}}_d\left(\boldsymbol{u}\right)\\ {}\frac{\partial \boldsymbol{u}}{\partial t}+\boldsymbol{u}\cdot \nabla \boldsymbol{u}+\nabla p-\frac{1}{\mathit{\operatorname{Re}}}\varDelta \boldsymbol{u}-\boldsymbol{g}={\mathcal{R}}_m\left(\boldsymbol{u},p\right),\end{array}\right. $$
$$ \left\{\begin{array}{l}\nabla \cdot \boldsymbol{u}={\mathcal{R}}_d\left(\boldsymbol{u}\right)\\ {}\frac{\partial \boldsymbol{u}}{\partial t}+\boldsymbol{u}\cdot \nabla \boldsymbol{u}+\nabla p-\frac{1}{\mathit{\operatorname{Re}}}\varDelta \boldsymbol{u}-\boldsymbol{g}={\mathcal{R}}_m\left(\boldsymbol{u},p\right),\end{array}\right. $$
where
 $ \boldsymbol{u}\left(\boldsymbol{x},t\right)\in {\mathrm{\mathbb{R}}}^{N_u} $
and
$ \boldsymbol{u}\left(\boldsymbol{x},t\right)\in {\mathrm{\mathbb{R}}}^{N_u} $
and
 $ p\left(\boldsymbol{x},t\right)\in \mathrm{\mathbb{R}} $
are the velocity and pressure at location
$ p\left(\boldsymbol{x},t\right)\in \mathrm{\mathbb{R}} $
are the velocity and pressure at location
 $ \boldsymbol{x} $
and time
$ \boldsymbol{x} $
and time
 $ t $
,
$ t $
,
 $ {N}_u $
is the number of velocity components, and
$ {N}_u $
is the number of velocity components, and
 $ \mathcal{R}(\cdot ) $
is a residual of the equation, which is zero when the equation is exactly solved. With this non-dimensionalization, the Reynolds number
$ \mathcal{R}(\cdot ) $
is a residual of the equation, which is zero when the equation is exactly solved. With this non-dimensionalization, the Reynolds number
 $ \mathit{\operatorname{Re}} $
is the inverse of the kinematic viscosity. The flow is subjected to sinusoidal forcing
$ \mathit{\operatorname{Re}} $
is the inverse of the kinematic viscosity. The flow is subjected to sinusoidal forcing
 $ \boldsymbol{g}={\boldsymbol{e}}_1\sin \left(k{\boldsymbol{x}}_2\right) $
, where
$ \boldsymbol{g}={\boldsymbol{e}}_1\sin \left(k{\boldsymbol{x}}_2\right) $
, where
 $ \boldsymbol{e}={\left[\mathrm{1,0,0}\right]}^T $
and the forcing wavenumber is
$ \boldsymbol{e}={\left[\mathrm{1,0,0}\right]}^T $
and the forcing wavenumber is
 $ k=4 $
. The dataset,
$ k=4 $
. The dataset,
 $ \boldsymbol{D} $
, consists of four time series of 3D Kolmogorov flows, initialised with different initial conditions. Each time series is generated with
$ \boldsymbol{D} $
, consists of four time series of 3D Kolmogorov flows, initialised with different initial conditions. Each time series is generated with
 $ \mathit{\operatorname{Re}}=34 $
, with 32 wavenumbers and the time step
$ \mathit{\operatorname{Re}}=34 $
, with 32 wavenumbers and the time step
 $ \Delta {t}^{\ast }=0.005 $
. A snapshot is saved every 20 time steps and interpolated onto a grid of
$ \Delta {t}^{\ast }=0.005 $
. A snapshot is saved every 20 time steps and interpolated onto a grid of
 $ 64\times 64\times 64 $
points in the physical space, resulting in a time step of
$ 64\times 64\times 64 $
points in the physical space, resulting in a time step of
 $ \Delta t=0.1 $
. Each time series contains 500 snapshots, which is longer than the decorrelation time of the Kolmogorov flow. The combined dataset
$ \Delta t=0.1 $
. Each time series contains 500 snapshots, which is longer than the decorrelation time of the Kolmogorov flow. The combined dataset
 $ \boldsymbol{D} $
contains
$ \boldsymbol{D} $
contains
 $ 2000 $
snapshots. The dataset is validated by comparing its time-averaged properties with those found in the literature. The mean
$ 2000 $
snapshots. The dataset is validated by comparing its time-averaged properties with those found in the literature. The mean
 $ {u}_1 $
averaged across three directions is shown in Figure 1c, where the average
$ {u}_1 $
averaged across three directions is shown in Figure 1c, where the average
 $ {u}_1 $
in the forced direction
$ {u}_1 $
in the forced direction
 $ {x}_2 $
has a sinusoidal profile matching the frequency of the forcing term, and the averaged velocity is
$ {x}_2 $
has a sinusoidal profile matching the frequency of the forcing term, and the averaged velocity is
 $ 0 $
in other directions. Given a long enough dataset, the mean of a 3D turbulent Kolmogorov flow is expected to have the same velocity profile as its laminar form, independent of the Reynolds number (Borue and Orszag, Reference Borue and Orszag1996), which is shown in the 3D plots of velocities and pressure in Figure 1a. The turbulent kinetic energy spectrum shows the exponential decay of energy, which matches the results obtained by Shebalin and Woodruff (Reference Shebalin and Woodruff1997). Figure 1 shows that the combined dataset has converged and has the expected mean velocity profile and energy spectrum.
$ 0 $
in other directions. Given a long enough dataset, the mean of a 3D turbulent Kolmogorov flow is expected to have the same velocity profile as its laminar form, independent of the Reynolds number (Borue and Orszag, Reference Borue and Orszag1996), which is shown in the 3D plots of velocities and pressure in Figure 1a. The turbulent kinetic energy spectrum shows the exponential decay of energy, which matches the results obtained by Shebalin and Woodruff (Reference Shebalin and Woodruff1997). Figure 1 shows that the combined dataset has converged and has the expected mean velocity profile and energy spectrum.
The mean properties of the 3D Kolmogorov flow dataset. (a) Mean velocities and pressure. (b) Turbulent kinetic energy spectrum. (c) Mean
 $ {u}_1 $
averaged over each of the spatial directions, compared with the forcing term.
$ {u}_1 $
averaged over each of the spatial directions, compared with the forcing term.

All three velocity components are measured at all grid points
 $ {\boldsymbol{x}}_s $
on three planes: an
$ {\boldsymbol{x}}_s $
on three planes: an
 $ {x}_2-{x}_3 $
plane at
$ {x}_2-{x}_3 $
plane at
 $ {x}_1=\pi $
, and two
$ {x}_1=\pi $
, and two
 $ {x}_1-{x}_2 $
planes at
$ {x}_1-{x}_2 $
planes at
 $ {x}_3=0.5\pi $
and
$ {x}_3=0.5\pi $
and
 $ 1.5\pi $
. Pressure is measured at all grid points
$ 1.5\pi $
. Pressure is measured at all grid points
 $ {\boldsymbol{x}}_{in} $
on the
$ {\boldsymbol{x}}_{in} $
on the
 $ {x}_1-{x}_3 $
plane at
$ {x}_1-{x}_3 $
plane at
 $ {x}_2=0 $
. Velocities and pressure are measured at different planes to reflect that these quantities are typically measured with different instruments in experiments. The planes are shown in Figure 2. The collection of all measurements
$ {x}_2=0 $
. Velocities and pressure are measured at different planes to reflect that these quantities are typically measured with different instruments in experiments. The planes are shown in Figure 2. The collection of all measurements
 $ \xi \left(\boldsymbol{D}\right)=\left\{\boldsymbol{U}\left({\boldsymbol{x}}_s\right),\boldsymbol{P}\left({\boldsymbol{x}}_{in}\right)\right\} $
contains both the velocity measured at
$ \xi \left(\boldsymbol{D}\right)=\left\{\boldsymbol{U}\left({\boldsymbol{x}}_s\right),\boldsymbol{P}\left({\boldsymbol{x}}_{in}\right)\right\} $
contains both the velocity measured at
 $ {\boldsymbol{x}}_s $
and the pressure measured at
$ {\boldsymbol{x}}_s $
and the pressure measured at
 $ {\boldsymbol{x}}_{in} $
. The pressure measurements
$ {\boldsymbol{x}}_{in} $
. The pressure measurements
 $ \boldsymbol{P}\left({\boldsymbol{x}}_{in}\right) $
are used as inputs to the network. The measurements account for approximately 3.8% of the total number of variables in a snapshot. The number of
$ \boldsymbol{P}\left({\boldsymbol{x}}_{in}\right) $
are used as inputs to the network. The measurements account for approximately 3.8% of the total number of variables in a snapshot. The number of
 $ {x}_1-{x}_2 $
planes is determined by testing and reducing the number of planes until the relative errors from both networks exceed 50%; the details can be found in Appendix A. The sensor configuration described here is used for all test cases in this paper except for the cases presented in Section 3.1.
$ {x}_1-{x}_2 $
planes is determined by testing and reducing the number of planes until the relative errors from both networks exceed 50%; the details can be found in Appendix A. The sensor configuration described here is used for all test cases in this paper except for the cases presented in Section 3.1.
Pressure is measured at the plane
 $ {x}_2=0 $
. Three planes of velocities are taken at
$ {x}_2=0 $
. Three planes of velocities are taken at
 $ {x}_1=\pi $
,
$ {x}_1=\pi $
,
 $ {x}_3=0.5\pi $
, and
$ {x}_3=0.5\pi $
, and
 $ 1.5\pi $
. The pressure is used as input to the network, and all measurements are used as collocation points.
$ 1.5\pi $
. The pressure is used as input to the network, and all measurements are used as collocation points.

2.2. The physics-constrained dual-branch convolutional neural network
In previous work, we designed a physics-constrained dual-branch convolutional neural network (PC-DualConvNet) to reconstruct 2D flows from sparse measurements in Mo and Magri (Reference Mo and Magri2025). In this paper, we modify the PC-DualConvNet to reconstruct 3D flows (Figure 3), which we will now refer to as the PC-DualConvNet. Periodic padding is used in convolutions to reflect the periodic boundary conditions of the flow under investigation. We will refer to the 2D version of the PC-DualConvNet used in Mo and Magri (Reference Mo and Magri2025), which constitutes part of the weight-sharing network (Section 2.3), as the 2D PC-DualConvNet.
Schematic of the PC-DualConvNet with 3D convolutions.

2.3. The weight-sharing network
Part of the difficulty in reconstructing 3D flows is the large demand on computational resources. CNNs need fewer parameters than other types of commonly used networks, such as fully-connected networks or transformers, but a large amount of resources is still required for three-dimensional convolutions. The Kolmogorov flow is statistically homogeneous in all but the forced direction (Borue and Orszag, Reference Borue and Orszag1996). When homogeneous directions are present, the statistical dimension of the flow is reduced (Pope, Reference Pope2000). For example, if one direction is homogeneous in a 3D flow, then the flow is statistically 2D. We develop a weight-sharing network to both reduce the number of parameters and to fully utilise the homogeneity in the flow. Part of the network parameters are shared across the
 $ {x}_3 $
direction, hence the name weight-sharing network. The shared part is based on the 2D PC-DualConvNet (Mo and Magri, Reference Mo and Magri2025), which is the 2D version of the PC-DualConvNet presented in Section 2.2.
$ {x}_3 $
direction, hence the name weight-sharing network. The shared part is based on the 2D PC-DualConvNet (Mo and Magri, Reference Mo and Magri2025), which is the 2D version of the PC-DualConvNet presented in Section 2.2.
The network, shown in Figure 4, can be broken down into three parts:
-
• Input processing: Pressure input
 $ {\boldsymbol{P}}_{in} $
at any instance in time, which is a 2D matrix, is passed through a 2D convolutional layer and a fully-connected layer, resulting in a 2D matrix.
$ {\boldsymbol{P}}_{in} $
at any instance in time, which is a 2D matrix, is passed through a 2D convolutional layer and a fully-connected layer, resulting in a 2D matrix. -
• The 2D inner network: The 2D matrix from the previous step is split along an axis, which will become
$ {x}_3 $
in the output, into vectors. Each vector is passed through the same 2D PC-DualConvNet (orange block) and becomes an intermediate result on a
$ {x}_1-{x}_2 $
plane, to enforce that homogeneous directions are statistically invariant. These intermediate planes are then stacked along the
$ {x}_3 $
direction. -
• The 3D CNN: The stacked output from the previous step is passed through multiple layers of 3D convolutions and resizing via linear interpolation to produce the final output with the correct dimensions.




Schematics of the weight-sharing network. The input pressure
 $ {\boldsymbol{P}}_{in} $
(first white block) is a 2D matrix of pressure measurements at
$ {\boldsymbol{P}}_{in} $
(first white block) is a 2D matrix of pressure measurements at
 $ {x}_2=0 $
. It is passed through a 2D convolution layer and a fully-connected layer to produce another 2D matrix, which is then split into vectors along an axis, which will later become
$ {x}_2=0 $
. It is passed through a 2D convolution layer and a fully-connected layer to produce another 2D matrix, which is then split into vectors along an axis, which will later become
 $ {x}_3 $
direction in the final output. Each vector is then passed through the same PC-DualConvNet (orange block) to produce an intermediate 2D result representing a
$ {x}_3 $
direction in the final output. Each vector is then passed through the same PC-DualConvNet (orange block) to produce an intermediate 2D result representing a
 $ {x}_1-{x}_2 $
plane. These intermediate results are stacked along
$ {x}_1-{x}_2 $
plane. These intermediate results are stacked along
 $ {x}_3 $
direction to form a 3D intermediate result, which is then passed through multiple 3D convolutions and reshaping layers to produce the final reconstructed flow
$ {x}_3 $
direction to form a 3D intermediate result, which is then passed through multiple 3D convolutions and reshaping layers to produce the final reconstructed flow
 $ \hat{\boldsymbol{D}} $
.
$ \hat{\boldsymbol{D}} $
.

If we had an infinite number of snapshots of a single
 $ {x}_1-{x}_2 $
plane, then every possible realisation of the flow on a plane would be represented in the training data. However, when only a finite number of snapshots is available, only parts, and not all, of the weights are shared across the
$ {x}_1-{x}_2 $
plane, then every possible realisation of the flow on a plane would be represented in the training data. However, when only a finite number of snapshots is available, only parts, and not all, of the weights are shared across the
 $ {x}_3 $
direction to avoid too much restriction on the network. Sharing parts of the weights informs the network that the flow is statistically similar along the
$ {x}_3 $
direction to avoid too much restriction on the network. Sharing parts of the weights informs the network that the flow is statistically similar along the
 $ {x}_3 $
direction, which is an efficient use of available data.
$ {x}_3 $
direction, which is an efficient use of available data.
2.4. Mean-enforced loss and snapshot-enforced loss
Neural networks are trained to minimise the value of a loss function
 $ \mathrm{\mathcal{L}} $
, which measures the error between the reference data
$ \mathrm{\mathcal{L}} $
, which measures the error between the reference data
 $ \boldsymbol{D} $
and the reconstructed flow
$ \boldsymbol{D} $
and the reconstructed flow
 $ \hat{\boldsymbol{D}} $
. The loss function contains information on both the measurements and the physics of the flow. We define the sensor loss
$ \hat{\boldsymbol{D}} $
. The loss function contains information on both the measurements and the physics of the flow. We define the sensor loss
 $ {\mathrm{\mathcal{L}}}_o $
to be
$ {\mathrm{\mathcal{L}}}_o $
to be
 $$ {\mathrm{\mathcal{L}}}_o\left(\hat{\boldsymbol{D}},\boldsymbol{D}\right)=\parallel \xi \left(\hat{\boldsymbol{D}}\right)-\xi \left(\boldsymbol{D}\right){\parallel}_2^2, $$
$$ {\mathrm{\mathcal{L}}}_o\left(\hat{\boldsymbol{D}},\boldsymbol{D}\right)=\parallel \xi \left(\hat{\boldsymbol{D}}\right)-\xi \left(\boldsymbol{D}\right){\parallel}_2^2, $$
which is the
 $ {\mathrm{\ell}}_2 $
norm of the difference between the measurements and the reconstructed flow at the measurement planes. We also define the physics losses
$ {\mathrm{\ell}}_2 $
norm of the difference between the measurements and the reconstructed flow at the measurement planes. We also define the physics losses
 $$ {\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{D}\right)=\parallel {\mathcal{R}}_d\left(\boldsymbol{U}\right){\parallel}_2^2, $$
$$ {\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{D}\right)=\parallel {\mathcal{R}}_d\left(\boldsymbol{U}\right){\parallel}_2^2, $$
 $$ {\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{D}\right)=\parallel {\mathcal{R}}_m\left(\boldsymbol{U},\boldsymbol{P}\right){\parallel}_2^2, $$
$$ {\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{D}\right)=\parallel {\mathcal{R}}_m\left(\boldsymbol{U},\boldsymbol{P}\right){\parallel}_2^2, $$
where
 $ {\mathrm{\mathcal{L}}}_{mom} $
and
$ {\mathrm{\mathcal{L}}}_{mom} $
and
 $ {\mathrm{\mathcal{L}}}_{div} $
are the
$ {\mathrm{\mathcal{L}}}_{div} $
are the
 $ {\mathrm{\ell}}_2 $
norm of the residuals the momentum and continuity equations in (2.1), respectively. In the network, the derivatives are computed per batch with a fourth-order central difference scheme at the interior points, and a second-order forward/backward difference scheme at the boundaries.
$ {\mathrm{\ell}}_2 $
norm of the residuals the momentum and continuity equations in (2.1), respectively. In the network, the derivatives are computed per batch with a fourth-order central difference scheme at the interior points, and a second-order forward/backward difference scheme at the boundaries.
When the measurements are accurate and precise, the snapshot-enforced loss
 $ {\mathrm{\mathcal{L}}}^s $
(Gao et al., Reference Gao, Sun and Wang2021; Mo and Magri, Reference Mo and Magri2025) minimises only the physics-related losses, while the sensor loss is enforced to be
$ {\mathrm{\mathcal{L}}}^s $
(Gao et al., Reference Gao, Sun and Wang2021; Mo and Magri, Reference Mo and Magri2025) minimises only the physics-related losses, while the sensor loss is enforced to be
 $ 0 $
. The harder constraint on the sensor measurements means that the network cannot output trivial solutions. We define the snapshot-enforced loss as
$ 0 $
. The harder constraint on the sensor measurements means that the network cannot output trivial solutions. We define the snapshot-enforced loss as
 $$ {\mathrm{\mathcal{L}}}^s={\lambda}_{div}{\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{\Phi} \right)+{\lambda}_{mom}{\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{\Phi} \right), $$
$$ {\mathrm{\mathcal{L}}}^s={\lambda}_{div}{\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{\Phi} \right)+{\lambda}_{mom}{\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{\Phi} \right), $$
where
 $ {\boldsymbol{\Phi}}^T=\left[{\boldsymbol{\Phi}}_u^T,{\boldsymbol{\Phi}}_p^T\right] $
is defined as
$ {\boldsymbol{\Phi}}^T=\left[{\boldsymbol{\Phi}}_u^T,{\boldsymbol{\Phi}}_p^T\right] $
is defined as
 $$ {\boldsymbol{\Phi}}_{\boldsymbol{u}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{ll}\boldsymbol{U}\left(\boldsymbol{x}\right)& \mathrm{where}\;\boldsymbol{x}\in {\boldsymbol{x}}_s,\\ {}\hat{\boldsymbol{U}}\left(\boldsymbol{x}\right)& \mathrm{otherwise}.\end{array}\right.{\boldsymbol{\Phi}}_{\boldsymbol{p}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{ll}\boldsymbol{P}\left(\boldsymbol{x}\right)& \mathrm{where}\;\boldsymbol{x}\in {\boldsymbol{x}}_{in},\\ {}\hat{\boldsymbol{P}}\left(\boldsymbol{x}\right)& \mathrm{otherwise}.\end{array}\right. $$
$$ {\boldsymbol{\Phi}}_{\boldsymbol{u}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{ll}\boldsymbol{U}\left(\boldsymbol{x}\right)& \mathrm{where}\;\boldsymbol{x}\in {\boldsymbol{x}}_s,\\ {}\hat{\boldsymbol{U}}\left(\boldsymbol{x}\right)& \mathrm{otherwise}.\end{array}\right.{\boldsymbol{\Phi}}_{\boldsymbol{p}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{ll}\boldsymbol{P}\left(\boldsymbol{x}\right)& \mathrm{where}\;\boldsymbol{x}\in {\boldsymbol{x}}_{in},\\ {}\hat{\boldsymbol{P}}\left(\boldsymbol{x}\right)& \mathrm{otherwise}.\end{array}\right. $$
Practically, we enforce the measurements by replacing the network output with measurements if measurements are available for the grid points. When the measurements are noisy, we use the mean-enforced loss
 $ {\mathrm{\mathcal{L}}}^m $
(Mo and Magri, Reference Mo and Magri2025), which are designed to reconstruct flows from measurements with white noise. The mean-enforced loss enforces the mean of the measurements while placing a constraint on the instantaneous measurements. The mean-enforced loss is defined as
$ {\mathrm{\mathcal{L}}}^m $
(Mo and Magri, Reference Mo and Magri2025), which are designed to reconstruct flows from measurements with white noise. The mean-enforced loss enforces the mean of the measurements while placing a constraint on the instantaneous measurements. The mean-enforced loss is defined as
 $$ {\mathrm{\mathcal{L}}}^m={\lambda}_o{\mathrm{\mathcal{L}}}_o\left(\hat{\boldsymbol{D}},\boldsymbol{D}\right)+{\lambda}_{div}{\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{\Phi} \right)+{\lambda}_{mom}{\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{\Phi} \right), $$
$$ {\mathrm{\mathcal{L}}}^m={\lambda}_o{\mathrm{\mathcal{L}}}_o\left(\hat{\boldsymbol{D}},\boldsymbol{D}\right)+{\lambda}_{div}{\mathrm{\mathcal{L}}}_{div}\left(\boldsymbol{\Phi} \right)+{\lambda}_{mom}{\mathrm{\mathcal{L}}}_{mom}\left(\boldsymbol{\Phi} \right), $$
where
 $ {\boldsymbol{\Phi}}^T=\left[{\boldsymbol{\Phi}}_u^T,{\boldsymbol{\Phi}}_p^T\right] $
is
$ {\boldsymbol{\Phi}}^T=\left[{\boldsymbol{\Phi}}_u^T,{\boldsymbol{\Phi}}_p^T\right] $
is
 $$ {\boldsymbol{\Phi}}_{\boldsymbol{u}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{l}\overline{\boldsymbol{U}}\left(\boldsymbol{x}\right)+{\hat{\boldsymbol{U}}}^{\prime}\left(\boldsymbol{x}\right)\hskip0.4em \mathrm{where}\hskip0.4em \boldsymbol{x}\in {\boldsymbol{x}}_s,\\ {}\hat{\boldsymbol{U}}\hskip0.4em \mathrm{otherwise}.\end{array}\right.\hskip2.12em {\boldsymbol{\Phi}}_{\boldsymbol{p}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{l}\overline{\boldsymbol{P}}\left(\boldsymbol{x}\right)+{\hat{\boldsymbol{P}}}^{\prime}\left(\boldsymbol{x}\right)\hskip0.4em \mathrm{where}\hskip0.4em \boldsymbol{x}\in {\boldsymbol{x}}_{in},\\ {}\hat{\boldsymbol{P}}\hskip0.4em \mathrm{otherwise}.\end{array}\right. $$
$$ {\boldsymbol{\Phi}}_{\boldsymbol{u}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{l}\overline{\boldsymbol{U}}\left(\boldsymbol{x}\right)+{\hat{\boldsymbol{U}}}^{\prime}\left(\boldsymbol{x}\right)\hskip0.4em \mathrm{where}\hskip0.4em \boldsymbol{x}\in {\boldsymbol{x}}_s,\\ {}\hat{\boldsymbol{U}}\hskip0.4em \mathrm{otherwise}.\end{array}\right.\hskip2.12em {\boldsymbol{\Phi}}_{\boldsymbol{p}}\left(\boldsymbol{x}\right)=\left\{\begin{array}{l}\overline{\boldsymbol{P}}\left(\boldsymbol{x}\right)+{\hat{\boldsymbol{P}}}^{\prime}\left(\boldsymbol{x}\right)\hskip0.4em \mathrm{where}\hskip0.4em \boldsymbol{x}\in {\boldsymbol{x}}_{in},\\ {}\hat{\boldsymbol{P}}\hskip0.4em \mathrm{otherwise}.\end{array}\right. $$
The symbols
 $ \overline{\ast} $
and
$ \overline{\ast} $
and
 $ {\ast}^{\prime } $
denote the time-averaged and fluctuating quantities, respectively. For a more detailed explanation of the snapshot-enforced and the mean-enforced losses, the reader is referred to (Mo and Magri, Reference Mo and Magri2025).
$ {\ast}^{\prime } $
denote the time-averaged and fluctuating quantities, respectively. For a more detailed explanation of the snapshot-enforced and the mean-enforced losses, the reader is referred to (Mo and Magri, Reference Mo and Magri2025).
3. Flow reconstruction from planes
We show the results on the flow reconstruction of 3D turbulent flows from measurement planes and the snapshot-enforced loss. We compare the results obtained using PC-DualConvNet and the weight-sharing network. The network parameters for this section are listed in Appendix A.
The results show good agreement with the reference data for both networks statistically. There is little difference between the two networks when comparing the mean flow (Figure 5) or the energy spectrum (Figure 6). The networks correctly infer the correct energy spectrum up to approximately wavenumber 10, which contains the majority of the energy in the flow.
Time average of the volumes. From left to right, the columns are: the reference data, the flow reconstructed from the weight-sharing network, and the flow reconstruction from the PC-DualConvNet.

The turbulent kinetic energy of the reference flow, the flow reconstructed using the weight-sharing network, and the flow reconstructed using the PC-DualConvNet.

The instantaneous 3D flow structures are shown in Figure 7. The vorticity at each grid point
 $ \boldsymbol{\omega} $
is computed by taking the curl of the velocity, i.e.,
$ \boldsymbol{\omega} $
is computed by taking the curl of the velocity, i.e.,
 $ \boldsymbol{\omega} =\nabla \times \boldsymbol{u} $
. Between the measurement planes (
$ \boldsymbol{\omega} =\nabla \times \boldsymbol{u} $
. Between the measurement planes (
 $ {x}_3=0.5\pi $
and
$ {x}_3=0.5\pi $
and
 $ 1.5\pi $
), the PC-DualConvNet can reconstruct the vorticity accurately, and the weight-sharing network generally correctly identifies the locations of the vortex cores (see, for example, the
$ 1.5\pi $
), the PC-DualConvNet can reconstruct the vorticity accurately, and the weight-sharing network generally correctly identifies the locations of the vortex cores (see, for example, the
 $ {x}_3=2\pi $
plane).
$ {x}_3=2\pi $
plane).
An instantaneous snapshot of the vorticity magnitude
 $ \parallel \omega \parallel $
, showing only grid points where the vorticity magnitude is over one standard deviation larger than the mean. From left to right, the columns are: the reference data, the flow reconstructed from the weight-sharing network, and the flow reconstruction from the PC-DualConvNet.
$ \parallel \omega \parallel $
, showing only grid points where the vorticity magnitude is over one standard deviation larger than the mean. From left to right, the columns are: the reference data, the flow reconstructed from the weight-sharing network, and the flow reconstruction from the PC-DualConvNet.

A summary of the results is shown in Table 1. The relative error of a reconstructed flow
 $ \epsilon $
is defined as
$ \epsilon $
is defined as
 $$ \epsilon =\sqrt{\frac{\parallel \hat{\boldsymbol{D}}-\boldsymbol{D}{\parallel}_2^2}{\parallel \boldsymbol{D}{\parallel}_2^2}}\hskip0.48em \left(\%\right). $$
$$ \epsilon =\sqrt{\frac{\parallel \hat{\boldsymbol{D}}-\boldsymbol{D}{\parallel}_2^2}{\parallel \boldsymbol{D}{\parallel}_2^2}}\hskip0.48em \left(\%\right). $$
The relative error
 $ \unicode{x025B} $
, the physics loss (
$ \unicode{x025B} $
, the physics loss (
 $ {\mathrm{\mathcal{L}}}_p $
=
$ {\mathrm{\mathcal{L}}}_p $
=
 $ {\mathrm{\mathcal{L}}}_{mom} $
+
$ {\mathrm{\mathcal{L}}}_{mom} $
+
 $ {\mathrm{\mathcal{L}}}_{div} $
), and the sensor loss
$ {\mathrm{\mathcal{L}}}_{div} $
), and the sensor loss
 $ {\mathrm{\mathcal{L}}}_o $
(mean
$ {\mathrm{\mathcal{L}}}_o $
(mean
 $ \pm $
standard deviation) of the reconstruction results from planes of measurements, averaged over five tests with different random initialisations of network weights
$ \pm $
standard deviation) of the reconstruction results from planes of measurements, averaged over five tests with different random initialisations of network weights

The physics loss
 $ {\mathrm{\mathcal{L}}}_p $
is the unweighted sum of all physics-related losses,
$ {\mathrm{\mathcal{L}}}_p $
is the unweighted sum of all physics-related losses,
 $ {\mathrm{\mathcal{L}}}_{mom} $
and
$ {\mathrm{\mathcal{L}}}_{mom} $
and
 $ {\mathrm{\mathcal{L}}}_{div} $
. The reference flow has a non-zero physics loss due to the different methods used for computing gradients in the network and in the solver. Whilst the network uses a mix of second- and fourth-order finite difference schemes to compute gradients, the pseudospectral solver (Kelshaw, Reference Kelshaw2023) uses the explicit forward-Euler scheme for temporal gradients, and the Fourier Transform to obtain accurate spatial gradients. The weight-sharing network achieves lower values in both the relative error and the physics loss, and with a smaller standard deviation, compared to the PC-DualConvNet. The sensor loss of the weight-sharing network is over twice as large as that of the PC-DualConvNet, despite the weight-sharing network achieving a lower relative error and physics loss. By comparing the sensor losses, which are evaluated only locally in the training set, and relative errors, which are evaluated globally, for both the PC-DualConvNet and the weight-sharing network, we find the PC-DualConvNet has a lower sensor loss, while the weight-sharing network has a lower relative error. By partially sharing weights across the
$ {\mathrm{\mathcal{L}}}_{div} $
. The reference flow has a non-zero physics loss due to the different methods used for computing gradients in the network and in the solver. Whilst the network uses a mix of second- and fourth-order finite difference schemes to compute gradients, the pseudospectral solver (Kelshaw, Reference Kelshaw2023) uses the explicit forward-Euler scheme for temporal gradients, and the Fourier Transform to obtain accurate spatial gradients. The weight-sharing network achieves lower values in both the relative error and the physics loss, and with a smaller standard deviation, compared to the PC-DualConvNet. The sensor loss of the weight-sharing network is over twice as large as that of the PC-DualConvNet, despite the weight-sharing network achieving a lower relative error and physics loss. By comparing the sensor losses, which are evaluated only locally in the training set, and relative errors, which are evaluated globally, for both the PC-DualConvNet and the weight-sharing network, we find the PC-DualConvNet has a lower sensor loss, while the weight-sharing network has a lower relative error. By partially sharing weights across the
 $ {x}_3 $
direction, the weight-sharing network learns that all
$ {x}_3 $
direction, the weight-sharing network learns that all
 $ {x}_1-{x}_2 $
planes are statistically similar, thereby reducing overfitting to the measurement planes, and improving generalization. Overfitting is a prominent issue when the data is noisy, which will be discussed in Section 4.1.
$ {x}_1-{x}_2 $
planes are statistically similar, thereby reducing overfitting to the measurement planes, and improving generalization. Overfitting is a prominent issue when the data is noisy, which will be discussed in Section 4.1.
The differences between the networks are more visible when comparing individual planes within the 3D domain. Figure 8 shows two instantaneous
 $ {x}_1-{x}_2 $
planes taken from the reference and reconstructed flow, the top row at
$ {x}_1-{x}_2 $
planes taken from the reference and reconstructed flow, the top row at
 $ {x}_3=0.56\pi $
, which is close to the measured plane at
$ {x}_3=0.56\pi $
, which is close to the measured plane at
 $ {x}_3=0.5\pi $
, and the bottom row at
$ {x}_3=0.5\pi $
, and the bottom row at
 $ {x}_3=\pi $
, which is further away from any measured plane. Both planes shown in Figure 8 are unseen by the network during training. At both
$ {x}_3=\pi $
, which is further away from any measured plane. Both planes shown in Figure 8 are unseen by the network during training. At both
 $ {x}_3 $
, the reconstructed velocity
$ {x}_3 $
, the reconstructed velocity
 $ {u}_1 $
(Figure 8 left) from the weight-sharing network has retained the flow structures expected of an instantaneous snapshot. However, PC-DualConvNet, which needs more parameters than the weight-sharing network, has larger errors at
$ {u}_1 $
(Figure 8 left) from the weight-sharing network has retained the flow structures expected of an instantaneous snapshot. However, PC-DualConvNet, which needs more parameters than the weight-sharing network, has larger errors at
 $ {x}_3=\pi $
, and tends to converge toward the mean flow. The weight-sharing network infers the pressure field more accurately than the PC-DualConvNet, despite no pressure data has been used in training (Figure 8 right).
$ {x}_3=\pi $
, and tends to converge toward the mean flow. The weight-sharing network infers the pressure field more accurately than the PC-DualConvNet, despite no pressure data has been used in training (Figure 8 right).
Two
 $ {x}_1-{x}_2 $
planes taken from the reconstructed flow at
$ {x}_1-{x}_2 $
planes taken from the reconstructed flow at
 $ {x}_3=0.56\pi $
and
$ {x}_3=0.56\pi $
and
 $ \pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
$ \pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
 $ {x}_3=0.5\pi $
and
$ {x}_3=0.5\pi $
and
 $ 1.5\pi $
. Moving further away from the measured plane, the reconstruction from the weight-sharing network is closer to the reference solution, whereas the PC-DualConvNet tends to converge toward the mean flow. An example of this difference can be seen in the bottom row, which shows a plane taken at
$ 1.5\pi $
. Moving further away from the measured plane, the reconstruction from the weight-sharing network is closer to the reference solution, whereas the PC-DualConvNet tends to converge toward the mean flow. An example of this difference can be seen in the bottom row, which shows a plane taken at
 $ {x}_3=\pi $
.
$ {x}_3=\pi $
.

3.1. Reconstruction from special sensor arrangements
Reconstruction from different sensor arrangements that are commonly found in experiments is analysed. These sensor arrangements include a single cross-plane (Section 3.1.1), measurements without out-of-plane velocities (Section 3.1.2), a cuboid placed inside the domain with no sensors (Section 3.1.3).
3.1.1. Single cross-plane
In this section, we test the reconstruction from a single cross-plane. Figure 9a shows the location of the velocity measurements. The pressure inputs are taken from the same grid points as in Section 2.1. Appendix A provides more details on the tests to determine the minimum number of planes needed for accurate reconstruction. When only a single cross-plane is used, the reconstruction relative errors for PC-DualConvNet and the weight-sharing network are 78% and 62%, respectively. Both networks achieve a similar reconstructed turbulent kinetic energy (Figure 9b), which are not significantly different from reconstructing from two
 $ {x}_1-{x}_2 $
planes in Section 3. By comparing slices in the reconstructed domain (Figure 9c), we can see that the reconstructed flow field by the PC-DualConvNet has lost resemblance to the reference data at
$ {x}_1-{x}_2 $
planes in Section 3. By comparing slices in the reconstructed domain (Figure 9c), we can see that the reconstructed flow field by the PC-DualConvNet has lost resemblance to the reference data at
 $ {x}_3=1.72\pi $
. The difference between the networks is more pronounced in the pressure field, where the PC-DualConvNet fails to reconstruct the low pressure region in the centre of the slices, while the weight-sharing network successfully reconstructs those regions.
$ {x}_3=1.72\pi $
. The difference between the networks is more pronounced in the pressure field, where the PC-DualConvNet fails to reconstruct the low pressure region in the centre of the slices, while the weight-sharing network successfully reconstructs those regions.
Reconstructed flow from a single cross-plane. (a) The locations of the velocity measurement planes, consisting of one
 $ {x}_1-{x}_2 $
measurement plane and a one
$ {x}_1-{x}_2 $
measurement plane and a one
 $ {x}_2-{x}_3 $
measurement plane, at the centre of the domain. (b) The turbulent kinetic energy of the reconstructed flow fields. (c) Two slices of the reconstructed flow at
$ {x}_2-{x}_3 $
measurement plane, at the centre of the domain. (b) The turbulent kinetic energy of the reconstructed flow fields. (c) Two slices of the reconstructed flow at
 $ {x}_3=1.09\pi $
and
$ {x}_3=1.09\pi $
and
 $ 1.72\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
$ 1.72\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
 $ {x}_3=\pi $
.
$ {x}_3=\pi $
.

3.1.2. No out-of-plane measurements
The most common form of PIV is the planar PIV, which measures only two velocity components (no out-of-plane velocity) on a 2D plane (Tavoularis and Nedić, Reference Tavoularis and Nedić2024). In this section, we test the proposed weight-sharing network to reconstruct the Kolmogorov flow from three planes located at the same coordinates as in Section 2.1, but with no out-of-plane velocity components on each plane. In other words, the two
 $ {x}_1-{x}_2 $
planes has no velocity measurements in the
$ {x}_1-{x}_2 $
planes has no velocity measurements in the
 $ {x}_3 $
direction, and the
$ {x}_3 $
direction, and the
 $ {x}_2-{x}_3 $
plane has no measurements in the
$ {x}_2-{x}_3 $
plane has no measurements in the
 $ {x}_1 $
direction, as shown in Figure 10. The relative error of the reconstructed flow is 56% higher than the error obtained by reconstructing from three-component measurements, as shown in Section 3, but it is lower than the error obtained by reconstructing from a single set of cross-plane (Section 3.1.1). Figure 11 shows that there is no significant difference in the turbulent kinetic energy of the flow reconstructed from two-component measurement planes to three-component measurement planes.
$ {x}_1 $
direction, as shown in Figure 10. The relative error of the reconstructed flow is 56% higher than the error obtained by reconstructing from three-component measurements, as shown in Section 3, but it is lower than the error obtained by reconstructing from a single set of cross-plane (Section 3.1.1). Figure 11 shows that there is no significant difference in the turbulent kinetic energy of the flow reconstructed from two-component measurement planes to three-component measurement planes.
Planar measurements with no out-of-plane velocity components. The velocity and pressure measurements are used as collocation points and the pressure measurements are used as the inputs to the network.

The turbulent kinetic energy of the reference flow, the flow reconstructed from two-component measurement planes, and three-component measurement planes.

Figure 12 compares the instantaneous results of the reconstructed flow from two-component planes to the reference at two unseen planes. For both slices shown in Figure 12 the reconstructed flow has correctly captured the structures in the reference flow. The results demonstrates the network’s potential to reconstruct from planar PIV.
Two instantaneous slices of the reconstructed flow at
 $ {x}_3=\pi $
and
$ {x}_3=\pi $
and
 $ 0.56\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
$ 0.56\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
 $ {x}_3=0.5\pi $
and
$ {x}_3=0.5\pi $
and
 $ 1.5\pi $
.
$ 1.5\pi $
.

3.1.3. Spatial gaps within the domain
In some experimental situations, measurements are not available on all grid points even in the measurement planes. For example, measurements may be unavailable or unreliable around an immersed bluff body (Morimoto et al., Reference Morimoto, Fukami and Fukagata2021). In this section, we reconstruct the flow from the same measurement planes as in Section 2.1, but with a cuboid in the domain from which all sensors are removed, as shown in Figure 13. The cube has length
 $ 0.47\pi $
with one vertex at
$ 0.47\pi $
with one vertex at
 $ \left(\mathrm{0.78,0.15,1.06}\right)\pi $
; all sides are aligned with the
$ \left(\mathrm{0.78,0.15,1.06}\right)\pi $
; all sides are aligned with the
 $ \mathbf{x} $
axes. For each velocity measurement plane, 5.5% grid points are made unavailable in training. The results are shown in Figure 14. The top row shows an unseen slice and the bottom row is a measurement plane used in training. The grey box shows the cube in which no measurements are available. On both unseen planes, the reconstructed flow has captured all the structures shown in the reference flow, even within the region with no sensors. Figure 15 shows the area where the vorticity magnitude is large than one standard deviation of the mean, showing only the area hidden by the cube. The reconstructed instantaneous vorticity magnitude within the missing area shows the same structures as the reference flow. The mean relative error, averaged over several tests, for the case with missing area is 49.3%, which is similar to the mean relative error of Section 3. The results show that the region with no sensors (5.5% of grid points per measurement plane) has no detrimental effect on the quality of the reconstruction, both in terms of instantaneous reconstructed snapshots and the overall reconstruction error.
$ \mathbf{x} $
axes. For each velocity measurement plane, 5.5% grid points are made unavailable in training. The results are shown in Figure 14. The top row shows an unseen slice and the bottom row is a measurement plane used in training. The grey box shows the cube in which no measurements are available. On both unseen planes, the reconstructed flow has captured all the structures shown in the reference flow, even within the region with no sensors. Figure 15 shows the area where the vorticity magnitude is large than one standard deviation of the mean, showing only the area hidden by the cube. The reconstructed instantaneous vorticity magnitude within the missing area shows the same structures as the reference flow. The mean relative error, averaged over several tests, for the case with missing area is 49.3%, which is similar to the mean relative error of Section 3. The results show that the region with no sensors (5.5% of grid points per measurement plane) has no detrimental effect on the quality of the reconstruction, both in terms of instantaneous reconstructed snapshots and the overall reconstruction error.
All measurements within the cube are removed.

Two instantaneous slices of the reconstructed flow at
 $ {x}_3=\pi $
and
$ {x}_3=\pi $
and
 $ 0.56\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
$ 0.56\pi $
, which are unseen by the network during training. The measurements used in training are taken on planes at
 $ {x}_3=0.5\pi $
and
$ {x}_3=0.5\pi $
and
 $ 1.5\pi $
. The grey box represent areas in which there are no measurements.
$ 1.5\pi $
. The grey box represent areas in which there are no measurements.

Areas of the reference (left) and reconstructed (right) flows within the region with sensors. The colourmap shows the areas where the magnitude of the vorticity
 $ \parallel \omega \parallel $
is larger than one standard deviation.
$ \parallel \omega \parallel $
is larger than one standard deviation.

4. Flow reconstruction from noisy measurements
In this section, we reconstruct the flow using the same sensor setup as described in Section 2.1, but with added white noise. The noise
 $ e $
at a single instance in time and any grid point is drawn from a Gaussian distribution
$ e $
at a single instance in time and any grid point is drawn from a Gaussian distribution
 $ e\sim \mathcal{N}\left(0,{\sigma}_e\right) $
, where
$ e\sim \mathcal{N}\left(0,{\sigma}_e\right) $
, where
 $ {\sigma}_e $
is the standard deviation of the noise. The signal-to-noise ratio (SNR) is defined as SNR
$ {\sigma}_e $
is the standard deviation of the noise. The signal-to-noise ratio (SNR) is defined as SNR
 $ =10\log \left({\sigma}^2/{\sigma}_e^2\right) $
, where
$ =10\log \left({\sigma}^2/{\sigma}_e^2\right) $
, where
 $ \sigma $
is the standard deviation of a component (such as a velocity or pressure) of the measurements. In this section, we reconstruct the flow from measurements with an SNR=15, using the mean-enforced loss. We show the process of selecting the hyperparameters in Section 4.1, and the reconstructed flow in Section 4.2.
$ \sigma $
is the standard deviation of a component (such as a velocity or pressure) of the measurements. In this section, we reconstruct the flow from measurements with an SNR=15, using the mean-enforced loss. We show the process of selecting the hyperparameters in Section 4.1, and the reconstructed flow in Section 4.2.
4.1. Selecting the hyperparameters
Before we can use the network to reconstruct the flow, we select a set of hyperparameters for the network that we expect will lead to an accurate reconstruction of the entire 3D flow. We use only the noisy data in the hyperparameter selection. During the selection process, we perform multiple tests with the training dataset composed of the measurements taken from the planes shown in Section 2.1 with added white noise at SNR=15. The same noisy training dataset will also be used later in Section 4.2. Given that we are interested in a spatial reconstruction from sparse measurements, the validation dataset should provide information about a network’s ability to generalise to unseen regions of the flow. Thus, our validation dataset is the set of measurements from
 $ {x}_1-{x}_2 $
plane at
$ {x}_1-{x}_2 $
plane at
 $ {x}_3=\pi $
, which is unseen by the network during training. The validation sensor loss is then
$ {x}_3=\pi $
, which is unseen by the network during training. The validation sensor loss is then
 $ \parallel \hat{\boldsymbol{U}}\left({x}_3=\pi \right),{\boldsymbol{U}}_n\left({x}_3=\pi \right){\parallel}_2^2 $
, where
$ \parallel \hat{\boldsymbol{U}}\left({x}_3=\pi \right),{\boldsymbol{U}}_n\left({x}_3=\pi \right){\parallel}_2^2 $
, where
 $ \hat{\boldsymbol{U}} $
is the reconstructed velocity field and
$ \hat{\boldsymbol{U}} $
is the reconstructed velocity field and
 $ {\boldsymbol{U}}_n $
is the noisy reference velocity field. The training sensor loss is
$ {\boldsymbol{U}}_n $
is the noisy reference velocity field. The training sensor loss is
 $ \parallel \xi \left(\hat{\boldsymbol{D}}\right),\xi \left({\boldsymbol{D}}_n\right){\parallel}_2^2 $
. Since the training sensor loss is computed with pressure measurements, but the validation sensor loss is not, the two losses are not expected to be similar in magnitude. Instead, we are interested in their correlation.
$ \parallel \xi \left(\hat{\boldsymbol{D}}\right),\xi \left({\boldsymbol{D}}_n\right){\parallel}_2^2 $
. Since the training sensor loss is computed with pressure measurements, but the validation sensor loss is not, the two losses are not expected to be similar in magnitude. Instead, we are interested in their correlation.
Figure 16 shows the quantities of interest for tests performed with different sets of hyperparameters. The bottom panel of Figure 16b shows that the validation sensor loss follows the training sensor loss, showing a linear relationship. In contrast, no monotonic relationship between the validation and training sensor loss for the PC-DualConvNet is observed (Figure 16a bottom panel). By comparing how the validation sensor loss changes with the training sensor loss for the two different network structures, we can see that the weight-sharing network generalizes to unseen regions of the flow, which is the purpose of its design. The linear relationship also means that we can assess the generalization error of the weight-sharing network by assessing the reconstructed flow on known grid points. This is not possible with the PC-DualConvNet, as a lower training loss does not correspond to a lower validation loss.
Quantities of interest for tests performed with different sets of hyperparameters for (a) the 3D PC-DualConvNet and (b) the weight-sharing network. Each data point represents a test with a distinct set of hyperparameters. Top panel: the validation sensor loss plotted against the physics loss for tests with different sets of hyperparameters, coloured by the relative error (not used in the selection process). The red star marks the set of hyperparameters selected. Validation sensor loss is computed at the plane at
 $ {x}_3=\pi $
, which is not seen by the networks during training. Bottom panel: validation sensor loss against the training sensor loss.
$ {x}_3=\pi $
, which is not seen by the networks during training. Bottom panel: validation sensor loss against the training sensor loss.

The top panels of Figure 16a,b show how the validation sensor loss changes with the physics loss for PC-DualConvNet and the weight-sharing network, respectively. The data points are coloured by the relative error. However, we will not use the relative error during the hyperparameter selection process because the computation of the relative loss requires the full flow field, to which we assume we do not have access.
To select the hyperparameters, we consider two losses: the validation sensor loss and the physics loss. If the measurements are not noisy, we wish the training process to minimise both losses. However, in the case of noisy measurements, the lowest validation loss may not correspond to the most accurate reconstruction because the loss is computed with the noisy data
 $ {\boldsymbol{D}}_n $
. Without using information from the ground truth, or the SNR, we also cannot estimate the lower bound for the sensor loss. Therefore, we also cannot set a threshold for the validation sensor loss. On the other hand, we cannot choose the set of hyperparameters which leads to the lowest physics loss because a low physics loss only shows that the reconstructed flow is a solution to the Navier-Stokes equation, but does not show whether this solution corresponds to the measurements. Instead, we look for a compromise by identifying a point where a decrease in the physics loss leads to an increase in the validation sensor loss, and choose the set of hyperparameters at the turning point. The selected sets of hyperparameters for both networks are marked by a star in Figure 16, and the values of the selected hyperparameters are listed in Appendix C.
$ {\boldsymbol{D}}_n $
. Without using information from the ground truth, or the SNR, we also cannot estimate the lower bound for the sensor loss. Therefore, we also cannot set a threshold for the validation sensor loss. On the other hand, we cannot choose the set of hyperparameters which leads to the lowest physics loss because a low physics loss only shows that the reconstructed flow is a solution to the Navier-Stokes equation, but does not show whether this solution corresponds to the measurements. Instead, we look for a compromise by identifying a point where a decrease in the physics loss leads to an increase in the validation sensor loss, and choose the set of hyperparameters at the turning point. The selected sets of hyperparameters for both networks are marked by a star in Figure 16, and the values of the selected hyperparameters are listed in Appendix C.
4.2. Results from noisy measurements
Using the hyperparameters selected in Section 4.1, we reconstruct the 3D turbulent flow from measurement planes shown in Section 2.1 with added white noise at SNR=15. A summary of the results is shown in Table 2, where the means and standard deviations are computed over five tests, each with different random initialisation of white noise and network weights. Similar to the results from non-noisy measurements in Section 3, the weight-sharing network has a lower relative error with a smaller standard deviation, showing that the network becomes less sensitive to the realisation of random noise and weight initialisation by sharing weights.
The relative error and the physics loss (mean
 $ \pm $
standard deviation) of the reconstruction results from planes of noisy measurements, averaged over five tests with different random noise and different initialisations of network weights.
$ \pm $
standard deviation) of the reconstruction results from planes of noisy measurements, averaged over five tests with different random noise and different initialisations of network weights.

Similar to our observation in Section 3, the two networks perform similarly when comparing the time-averaged flow, shown in Figure 17. The reconstructed
 $ {u}_3 $
by the weight-sharing network shows a numerical artefact in the
$ {u}_3 $
by the weight-sharing network shows a numerical artefact in the
 $ {x}_3 $
direction, which is the result of the weight sharing. However, given that the weight-sharing network achieved a similar level of physics loss compared to the PC-DualConvNet, the effect of this artefact is minimal. This artifact highlights the contrasting performances of the weight-sharing network and the PC-DualConvNet when applied to challenging training cases. The weight-sharing network tends to infer the flow field along the
$ {x}_3 $
direction, which is the result of the weight sharing. However, given that the weight-sharing network achieved a similar level of physics loss compared to the PC-DualConvNet, the effect of this artefact is minimal. This artifact highlights the contrasting performances of the weight-sharing network and the PC-DualConvNet when applied to challenging training cases. The weight-sharing network tends to infer the flow field along the
 $ {x}_3 $
dimension, whereas the PC-DualConvNet tends to fill the unknown regions with the time-averaged flow, as previously observed in Section 3.
$ {x}_3 $
dimension, whereas the PC-DualConvNet tends to fill the unknown regions with the time-averaged flow, as previously observed in Section 3.
The mean flow. From left to right are: reference 3D data, reconstructed with the weight-sharing network, and reconstructed with the PC-DualConvNet. The top and bottom rows are the velocities and pressure fields, respectively.

This difference in behaviours can also be seen in the instantaneous flow structures shown in Figure 18. The high vorticity regions in the flow reconstructed with the weight-sharing network forms tubes that are straighter compared to the reference flow, a result of the unseen
 $ {x}_1-{x}_2 $
planes being similar due sharing weights over the
$ {x}_1-{x}_2 $
planes being similar due sharing weights over the
 $ {x}_3 $
direction. On the other hand, the flow reconstructed with the PC-DualConvNet contains small isolated pockets of high vorticity regions that are not seen in the reference flow, a result of the network fitting closely to the noise in the measurements.
$ {x}_3 $
direction. On the other hand, the flow reconstructed with the PC-DualConvNet contains small isolated pockets of high vorticity regions that are not seen in the reference flow, a result of the network fitting closely to the noise in the measurements.
An instantaneous snapshot of the vorticity magnitude
 $ \parallel \omega \parallel $
, showing only the grid points where the vorticity magnitude is over one standard deviation larger than the mean vorticity magnitude of the reference flow. From left to right, the columns are: the reference data, the flow reconstructed from noisy measurements using the weight-sharing network, and reconstructed using the PC-DualConvNet.
$ \parallel \omega \parallel $
, showing only the grid points where the vorticity magnitude is over one standard deviation larger than the mean vorticity magnitude of the reference flow. From left to right, the columns are: the reference data, the flow reconstructed from noisy measurements using the weight-sharing network, and reconstructed using the PC-DualConvNet.

More details of the reconstructed flow are shown using two slices taken within the domain in Figure 19. At
 $ {x}_3=0.5\pi $
, which is part of the training data, the reconstructed instantaneous
$ {x}_3=0.5\pi $
, which is part of the training data, the reconstructed instantaneous
 $ {u}_1 $
for both networks is less noisy compared to the noisy measurements in the training set, and matches well with the reference data. At the same
$ {u}_1 $
for both networks is less noisy compared to the noisy measurements in the training set, and matches well with the reference data. At the same
 $ {x}_3 $
, the reconstructed pressure has a reduced range (the difference between the largest and smallest values is smaller) in the middle of the domain. Near
$ {x}_3 $
, the reconstructed pressure has a reduced range (the difference between the largest and smallest values is smaller) in the middle of the domain. Near
 $ {x}_2= $
0 and 2
$ {x}_2= $
0 and 2
 $ \pi $
the pressure reconstruction is more accurate because pressure data is available at
$ \pi $
the pressure reconstruction is more accurate because pressure data is available at
 $ {x}_2=0 $
and periodic boundary conditions are imposed via periodic padding in convolution. Comparing the slices at
$ {x}_2=0 $
and periodic boundary conditions are imposed via periodic padding in convolution. Comparing the slices at
 $ {x}_3=0.94\pi $
, which is unseen in training, we find that the weight-sharing network better captures the main changes in the flow. Especially in the reconstructed pressure, where the weight-sharing network captured a rotation in the alignment of the two low-pressure areas in the middle of the domain, but not the PC-DualConvNet. These results show that both networks are capable of reconstructing the flow from noisy measurements, producing reasonable instantaneous flow fields and accurate reconstructed mean flow fields. The weight-sharing network has proven to be more suitable when the available data is limited to a few planes, as it can generalise to areas of the domain that are away from the measured planes, with fewer parameters.
$ {x}_3=0.94\pi $
, which is unseen in training, we find that the weight-sharing network better captures the main changes in the flow. Especially in the reconstructed pressure, where the weight-sharing network captured a rotation in the alignment of the two low-pressure areas in the middle of the domain, but not the PC-DualConvNet. These results show that both networks are capable of reconstructing the flow from noisy measurements, producing reasonable instantaneous flow fields and accurate reconstructed mean flow fields. The weight-sharing network has proven to be more suitable when the available data is limited to a few planes, as it can generalise to areas of the domain that are away from the measured planes, with fewer parameters.
Velocity
 $ {u}_1 $
and pressure
$ {u}_1 $
and pressure
 $ p $
snapshots at different
$ p $
snapshots at different
 $ {x}_3 $
. Columns show the reference flow, the flow with added white noise, the flow reconstructed by the weight-sharing network and the flow reconstructed by the PC-DualConvNet (left to right). The top row for each variable shows a plane at
$ {x}_3 $
. Columns show the reference flow, the flow with added white noise, the flow reconstructed by the weight-sharing network and the flow reconstructed by the PC-DualConvNet (left to right). The top row for each variable shows a plane at
 $ {x}_3=0.5\pi $
, which is part of the training dataset. The bottom row for each variable shows a plane at
$ {x}_3=0.5\pi $
, which is part of the training dataset. The bottom row for each variable shows a plane at
 $ {x}_3=0.94\pi $
, which is unseen by the network during training, and also not a validation plane used for selecting the hyperparameters in Section 4.1.
$ {x}_3=0.94\pi $
, which is unseen by the network during training, and also not a validation plane used for selecting the hyperparameters in Section 4.1.

5. Conclusion
In this paper, we reconstruct 3D turbulent flows with homogeneity from sparse measurements using a weight-sharing network to infer the full flow field, without relying on ground truth data during training. The measurements comprise three planes of in-flow velocity and one additional plane of boundary pressure. The weight-sharing network applies identical network parameters along the homogeneous direction, enabling more efficient data utilization and reducing computational memory requirements. We compare the PC-DualConvNet, adapted from Mo and Magri (Reference Mo and Magri2025), with the weight-sharing network. First, we reconstruct a 3D Kolmogorov flow from noise-free measurements using the snapshot-enforced loss. Both networks accurately reconstruct time-averaged 3D flow fields and recover the correct energy spectrum up to wavenumber 10, containing most of the flow energy. The weight-sharing network and the PC-DualConvNet achieve relative errors of approximately 49% and 55%, respectively. Analysis of reconstructed snapshots shows that the weight-sharing network can infer flow structures in regions distant from the measurement planes. We also investigate sensor configurations to mimic experimental conditions with a single set of cross planes, measurement planes without out-of-plane velocity components, and a configuration in which a region of the flow does not contain sensors. Second, we reconstruct the flow from measurements with added white noise at a signal-to-noise ratio of 15, using the mean-enforced loss. For the weight-sharing network, we show that the validation sensor loss, which is computed on a plane unseen during training, decreases with the training sensor loss. However, for the PC-DualConvNet, the validation sensor loss does not follow the training sensor loss. Therefore, we conclude that the weight-sharing network generalizes better to unseen regions of the flow, and that the training sensor loss reliably estimates the generalization error for this network. By using the training sensor loss as an estimator, more data can be allocated for training instead of validation, which is beneficial when data is limited. The relative errors for flow reconstruction from noisy measurements are approximately 10% higher than those from noise-free data, but qualitative analysis shows that noise does not significantly impact reconstructed flow structures. In summary, both PC-DualConvNet and the weight-sharing network can reconstruct 3D turbulent Kolmogorov flows from planar measurements, a configuration similar to experimental setups. The weight-sharing network demonstrates good generalization to unseen regions of the flow, minimizes trainable parameters, and offers increased robustness, and less unpredictable behaviours, to hyperparameter selection. In this work, multiple sensor configurations and measurement scenarios with additive Gaussian noise were evaluated. For real-world applications and to enable deployment on experimental data, further studies incorporating different coloured noise types and varying Reynolds numbers should be conducted. The network and the loss functions do not require the location of the velocity sensors to be hard coded. To fully exploit the flexibility of the network, data from mixed sources using different sensor configurations, such as a mix of experimental and simulated data, may be combined into a single training set. Based on previous results (Mo and Magri, Reference Mo and Magri2025), the proposed methods are anticipated to be applicable to high-Reynolds-number flows with some hyperparameter tuning.
Data availability statement
The codes to perform all the tests in this paper can be found at https://github.com/MagriLab/FlowReconstructionFromExperiment. All data is available upon request.
Author contribution
Conceptualization-Equal: Y.M., L.M.; Funding Acquisition-Lead: L.M.; Project Administration-Lead: L.M.; Resources-Lead: L.M.; Software-Lead: Y.M.; Supervision-Lead: L.M.; Validation-Lead: Y.M.; Visualization-Lead: Y.M.; Writing – Original Draft-Lead: Y.M., L.M.; Writing – Review & Editing-Equal: Y.M., L.M.
Funding statement
We acknowledge funding from the Engineering and Physical Sciences Research Council, UK and financial support from the ERC Starting Grant PhyCo 949388. L.M. is also grateful for the support from the grant EU-PNRR Young-Researcher TWIN ERC-PI_0000005.
Competing interests
The authors declare no conflict of interest.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Appendices
A. Hyperparameters and the minimum number of planes
In this section, we test the minimum number of
 $ {x}_1-{x}_2 $
measurement planes needed to reconstruct the 3D Kolmogorov flows using both the PC-DualConvNet and the weight-sharing network. We reduce the number of
$ {x}_1-{x}_2 $
measurement planes needed to reconstruct the 3D Kolmogorov flows using both the PC-DualConvNet and the weight-sharing network. We reduce the number of
 $ {x}_1-{x}_2 $
measurement planes, while keeping the single
$ {x}_1-{x}_2 $
measurement planes, while keeping the single
 $ {x}_2-{x}_3 $
plane unchanged, until the relative errors of the reconstructed flows from both networks exceed 50%. We start by selecting a set of hyperparameters to reduce the unweighted sum of the physics and sensor loss (
$ {x}_2-{x}_3 $
plane unchanged, until the relative errors of the reconstructed flows from both networks exceed 50%. We start by selecting a set of hyperparameters to reduce the unweighted sum of the physics and sensor loss (
 $ {\mathrm{\mathcal{L}}}_p+{\mathrm{\mathcal{L}}}_o $
) using test cases with eight
$ {\mathrm{\mathcal{L}}}_p+{\mathrm{\mathcal{L}}}_o $
) using test cases with eight
 $ {x}_1-{x}_2 $
measurement planes, evenly spaced in the
$ {x}_1-{x}_2 $
measurement planes, evenly spaced in the
 $ {x}_3 $
direction. Figure A1 shows the training curves of the tests conducted during the hyperparameter selection process; each test uses a different set of hyperparameters. The tests with the selected hyperparameters are highlighted in red. Figure A1 (left panel) shows the tests using PC-DualConvNet. Among the unselected tests (black), the differences in hyperparameters result in different final loss values, but the training curves follow a similar downward trend. However, the test with the selected hyperparameters (red) clearly shows a faster decrease of the loss than the other tests (black). This difference in the training curve highlights the importance of hyperparameters in the training of the PC-DualConvNet. The selected hyperparameters are detailed in Tables A1 and A2. The learning rate schedules are taken from (Mo and Magri, Reference Mo and Magri2025). Using the selected set of hyperparameters, we reduce the number of measurement planes and plot the resulting mean squared error (MSE) and physics loss of the reconstructed flow fields in Figure A2. By MSE, we refer to the
$ {x}_3 $
direction. Figure A1 shows the training curves of the tests conducted during the hyperparameter selection process; each test uses a different set of hyperparameters. The tests with the selected hyperparameters are highlighted in red. Figure A1 (left panel) shows the tests using PC-DualConvNet. Among the unselected tests (black), the differences in hyperparameters result in different final loss values, but the training curves follow a similar downward trend. However, the test with the selected hyperparameters (red) clearly shows a faster decrease of the loss than the other tests (black). This difference in the training curve highlights the importance of hyperparameters in the training of the PC-DualConvNet. The selected hyperparameters are detailed in Tables A1 and A2. The learning rate schedules are taken from (Mo and Magri, Reference Mo and Magri2025). Using the selected set of hyperparameters, we reduce the number of measurement planes and plot the resulting mean squared error (MSE) and physics loss of the reconstructed flow fields in Figure A2. By MSE, we refer to the
 $ {\mathrm{\ell}}_2 $
norm of the difference between the reference and reconstructed flow at all grid points,
$ {\mathrm{\ell}}_2 $
norm of the difference between the reference and reconstructed flow at all grid points,
 $ \parallel \boldsymbol{D}-\hat{\boldsymbol{D}}{\parallel}_2^2 $
. Both the MSE and the physics loss show that the weight-sharing network achieves lower values for both metrics when there are two or fewer
$ \parallel \boldsymbol{D}-\hat{\boldsymbol{D}}{\parallel}_2^2 $
. Both the MSE and the physics loss show that the weight-sharing network achieves lower values for both metrics when there are two or fewer
 $ {x}_1-{x}_2 $
measurement planes. The relative errors from both networks when there is only one
$ {x}_1-{x}_2 $
measurement planes. The relative errors from both networks when there is only one
 $ {x}_1-{x}_2 $
plane are much larger than 50%, and the reconstructed flow fields lose resemblance to the reference data. Therefore, we report the results of reconstructing the 3D Kolmogorov flows from two
$ {x}_1-{x}_2 $
plane are much larger than 50%, and the reconstructed flow fields lose resemblance to the reference data. Therefore, we report the results of reconstructing the 3D Kolmogorov flows from two
 $ {x}_1-{x}_2 $
planes in the main text (Section 3).
$ {x}_1-{x}_2 $
planes in the main text (Section 3).
The unweighted sum of the physics and sensor loss of the tests in the hyperparameter selection. Left: PC-DualConvNet. Right: weight-sharing network.

The hyperparameters of the PC-DualConvNet used to reconstruct the 3D Kolmogorov flows in Section 3

The hyperparameters of the weight-sharing network used to reconstruct the 3D Kolmogorov flows in Section 3

(Left) the mean squared error and (right) the physics loss of the reconstructed from fields from different number of
 $ {x}_1-{x}_2 $
measurement planes.
$ {x}_1-{x}_2 $
measurement planes.

B. Model training time
This section discusses the training time of the networks used in Section 3. Table B1 shows the number of parameters and the average update and inference time of the PC-DualConvNet and the weight-sharing network. The PC-DualConvNet has approximately 500 times more parameters than the weight-sharing network, and approximately double the inference time, meaning that the weight-sharing network uses less memory and is faster during inference. However, the average update times of the two networks are within 10% of each other, which means that both networks take a similar amount of time to train despite the large difference in the number of parameters. Upon closer inspection, we found the bottleneck of the update time to be the computation of the physics loss. Table B2 shows that the average time to compute the physics loss for a 50-snapshot batch is 84.4 ms, which is over 40% of the update times for both networks, and over double the time taken to compute the mean squared error (MSE) of the full flow field. The time to compute the sensor loss is negligible in comparison. When scaling up the datasets for future work, we must take into account the time to compute the physics loss and investigate ways to speed up this computation.
Number of trainable parameters; the average time to compute one update (including a forward pass, computing the loss, and applying the update); and the average inference time (forward pass only). Timed using a 50-snapshot batch on an NVIDIA RTX8000 GPU. Functions are compiled with jax.jit

The average time to compute loss using a 50-snapshot batch on an NVIDIA RTX8000 GPU. Functions are compiled with jax.jit

C. Model and training parameters for noisy data
Tables C1 and C2 show the hyperparameters used to reconstruct the 3D Kolmogorov flows from noisy measurements in Section 4 using the PC-DualConvNet and the weight-sharing network, respectively.
The hyperparameters of the PC-DualConvNet used to reconstruct the 3D Kolmogorov flows in Section 4

The hyperparameters of the weight-sharing network used to reconstruct the 3D Kolmogorov flows in Section 4

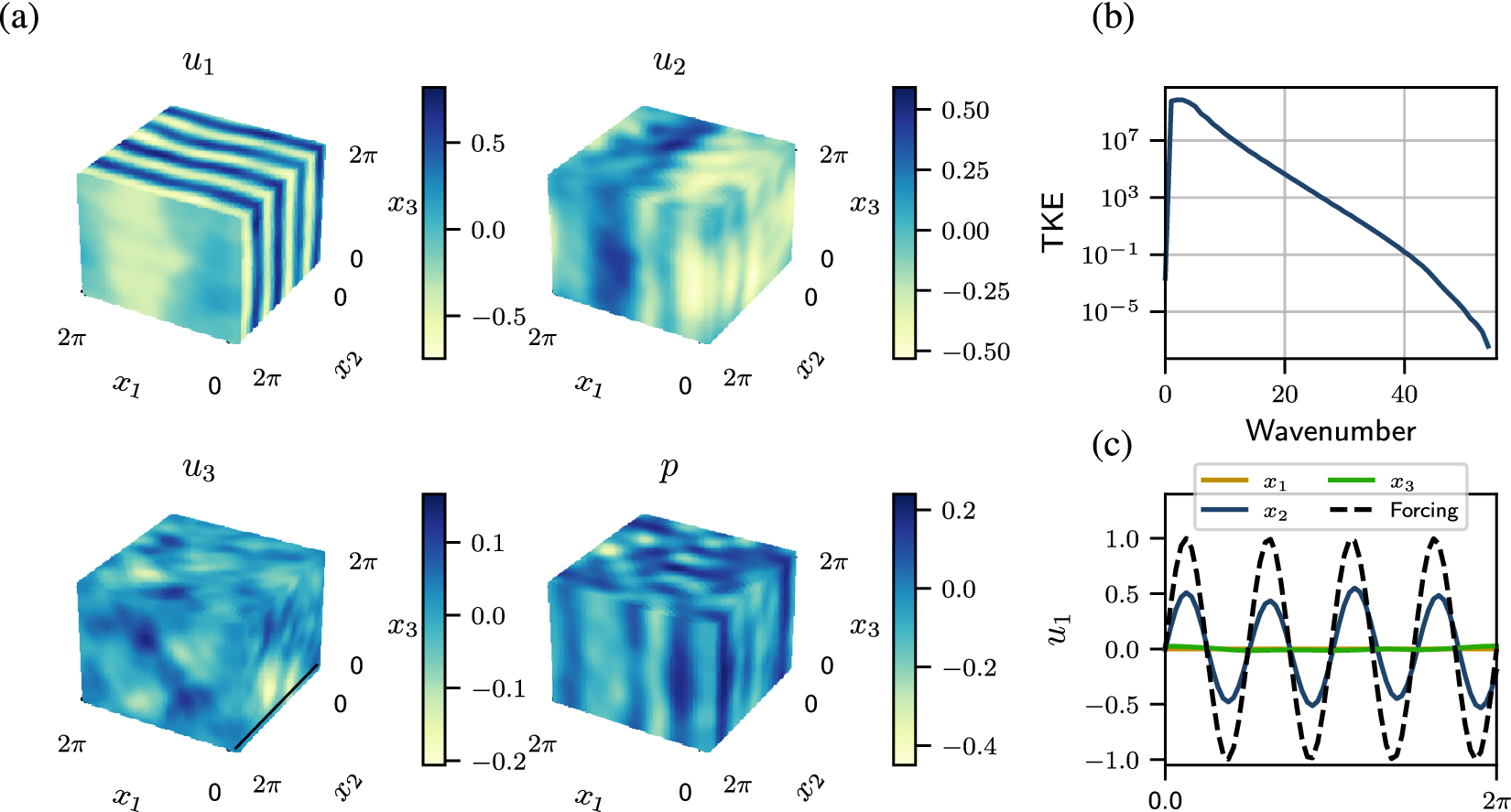





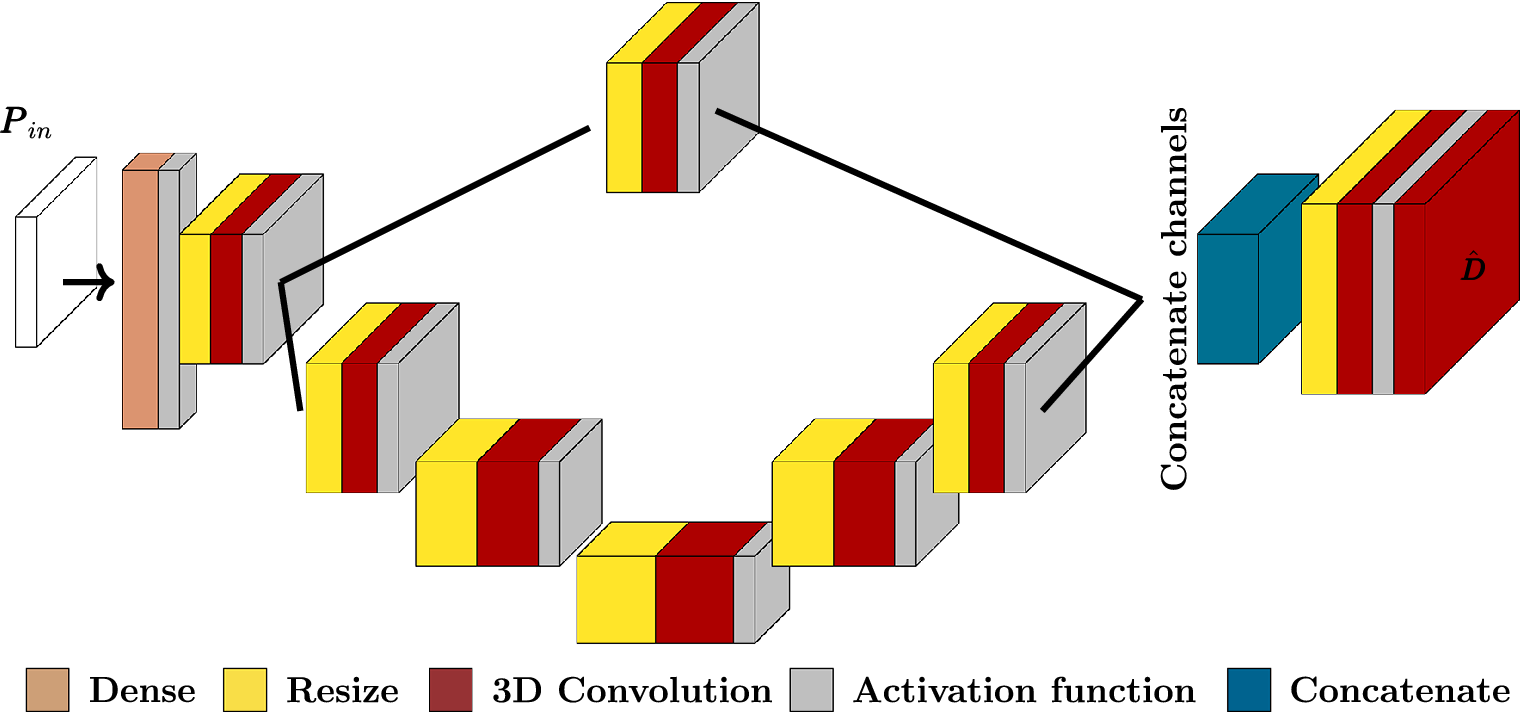
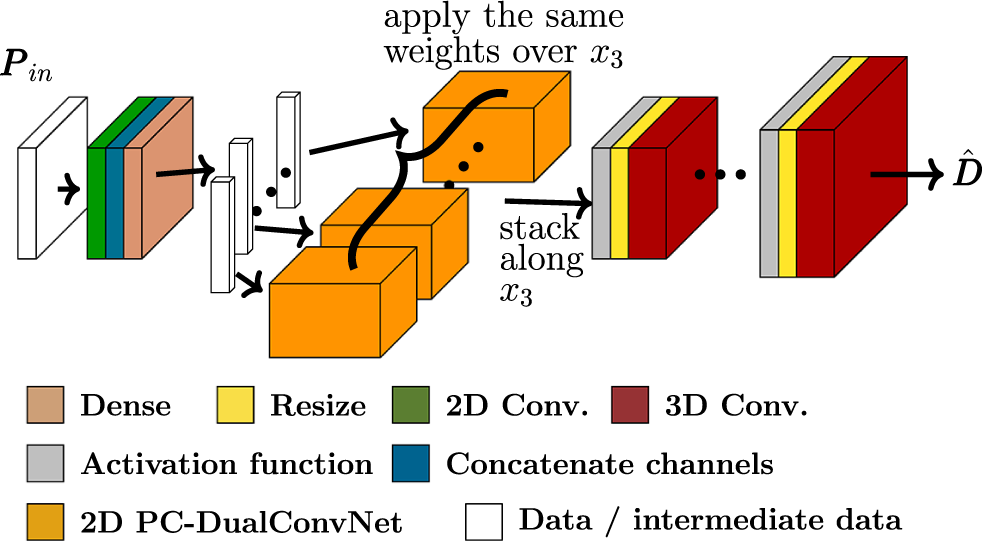






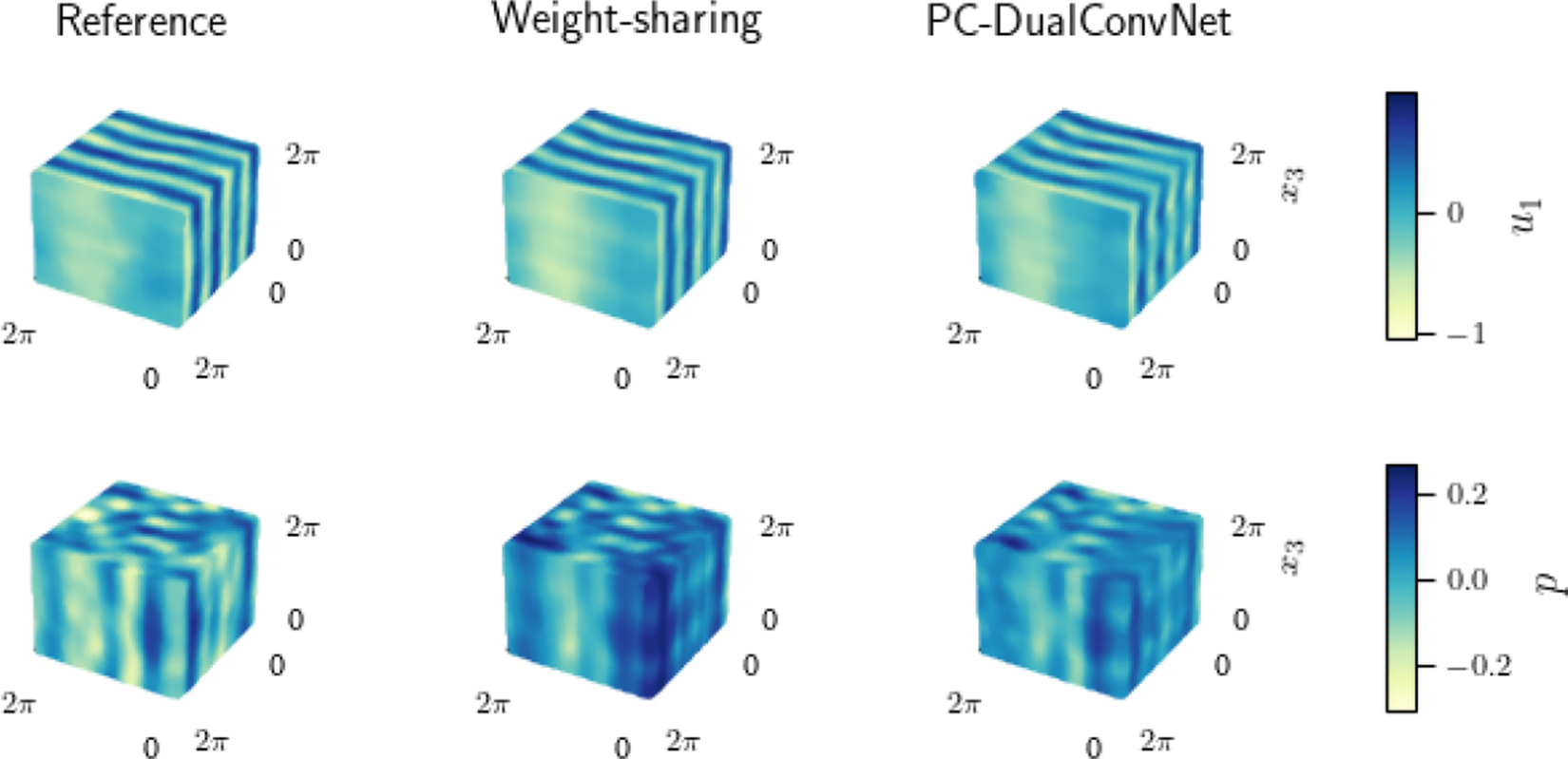
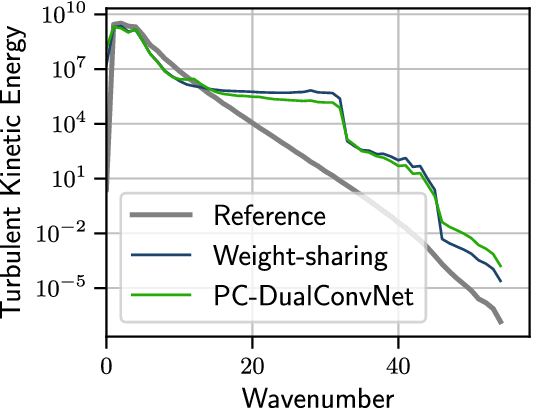
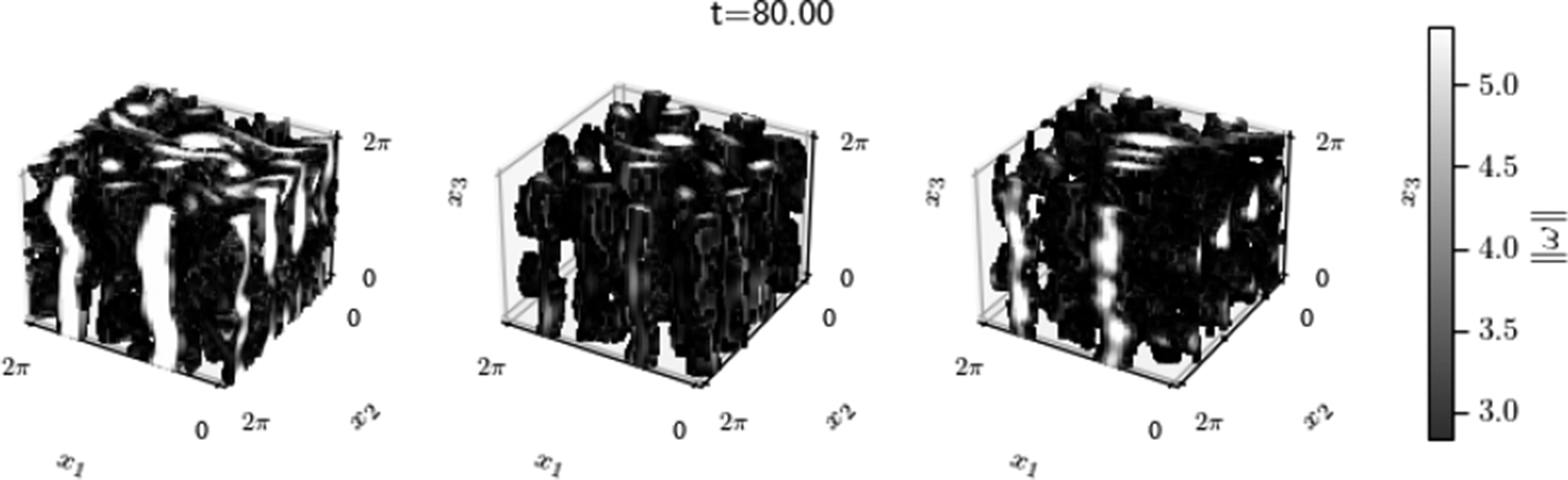








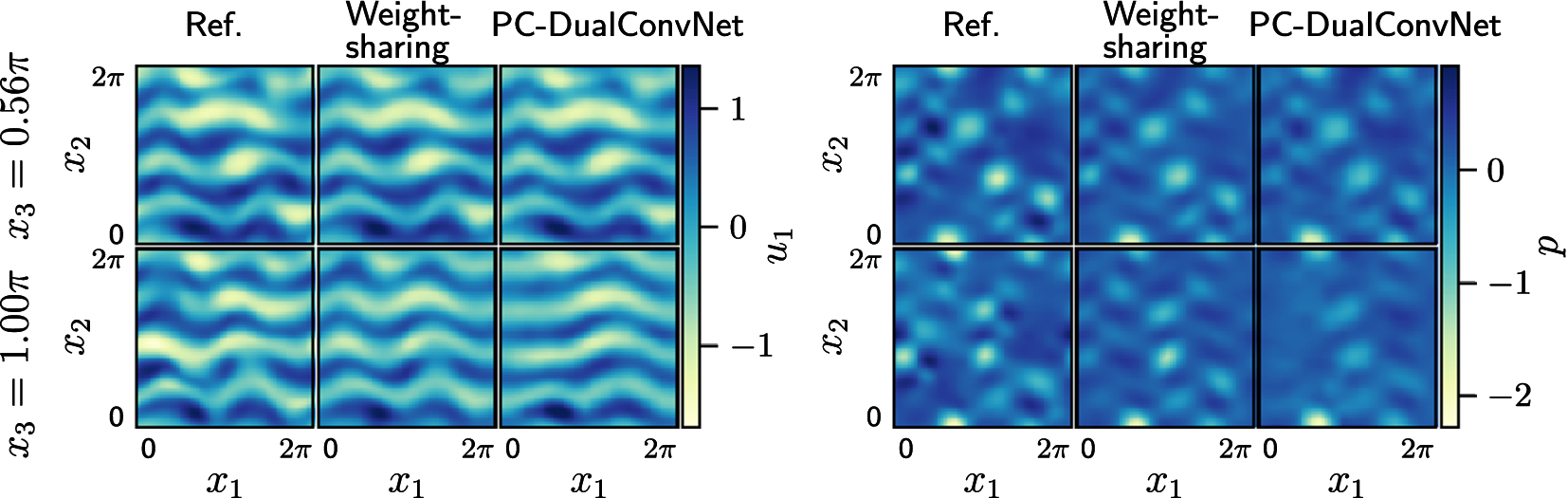






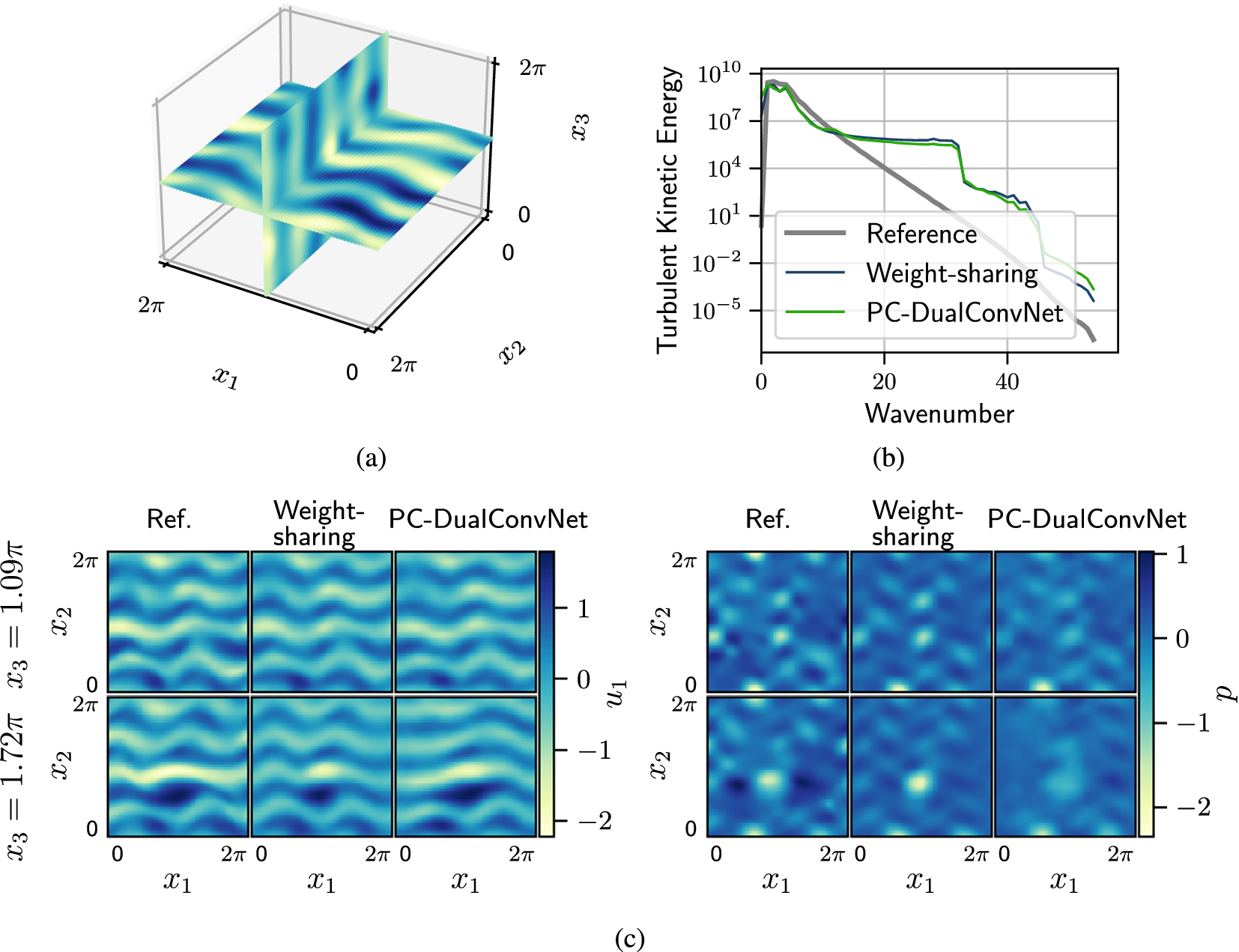





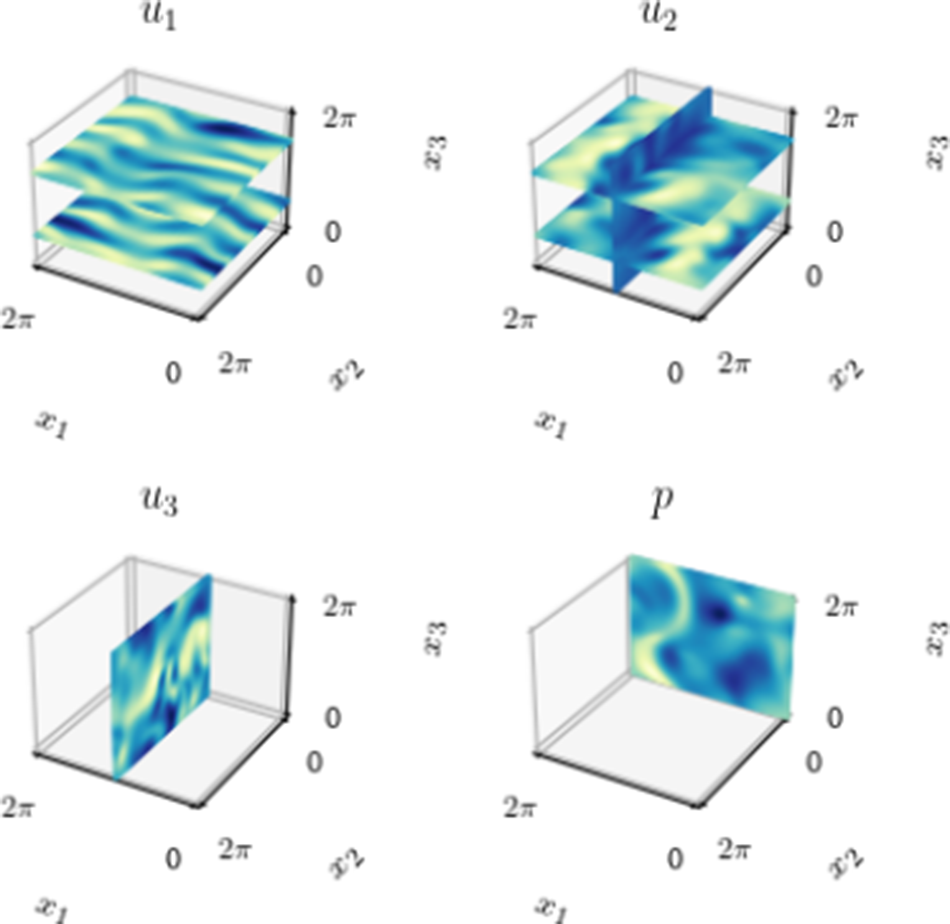
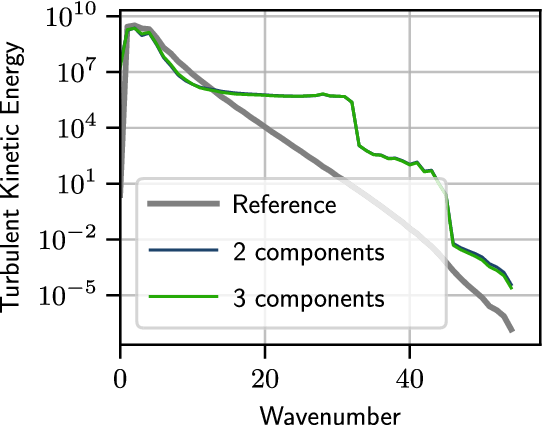
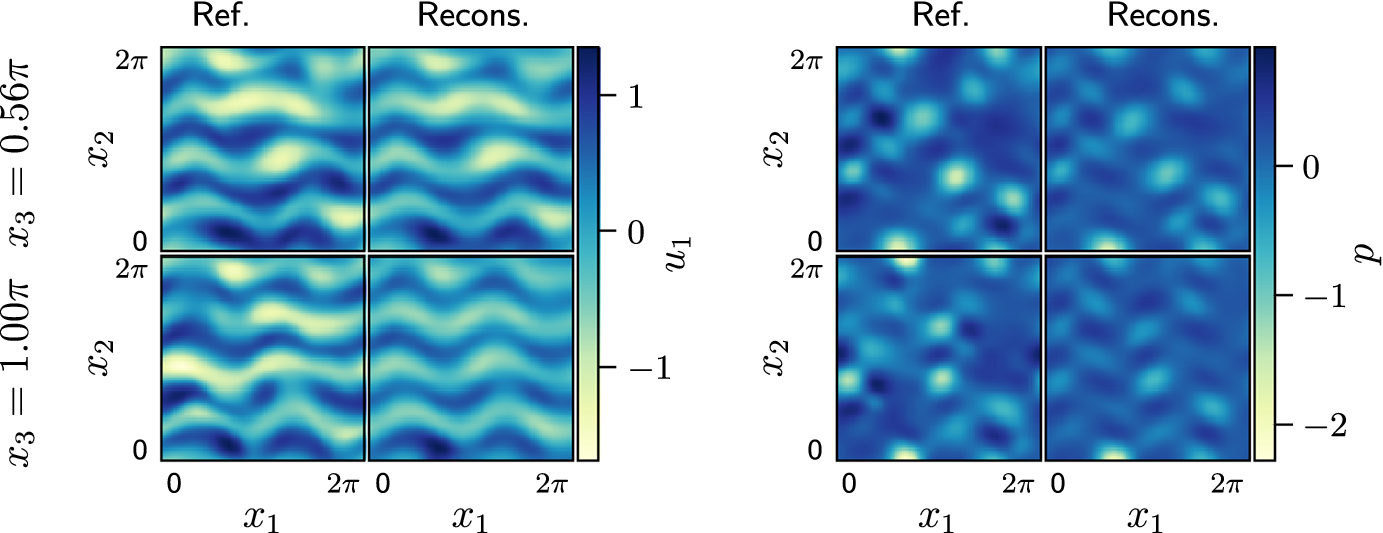




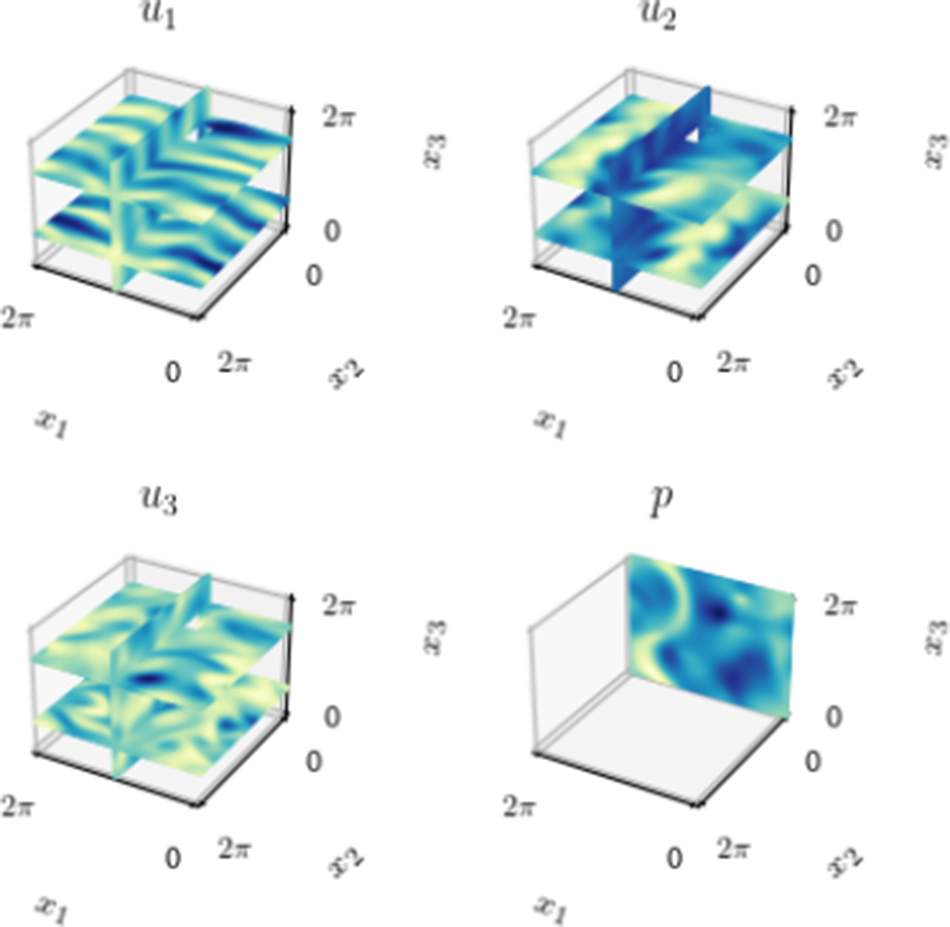
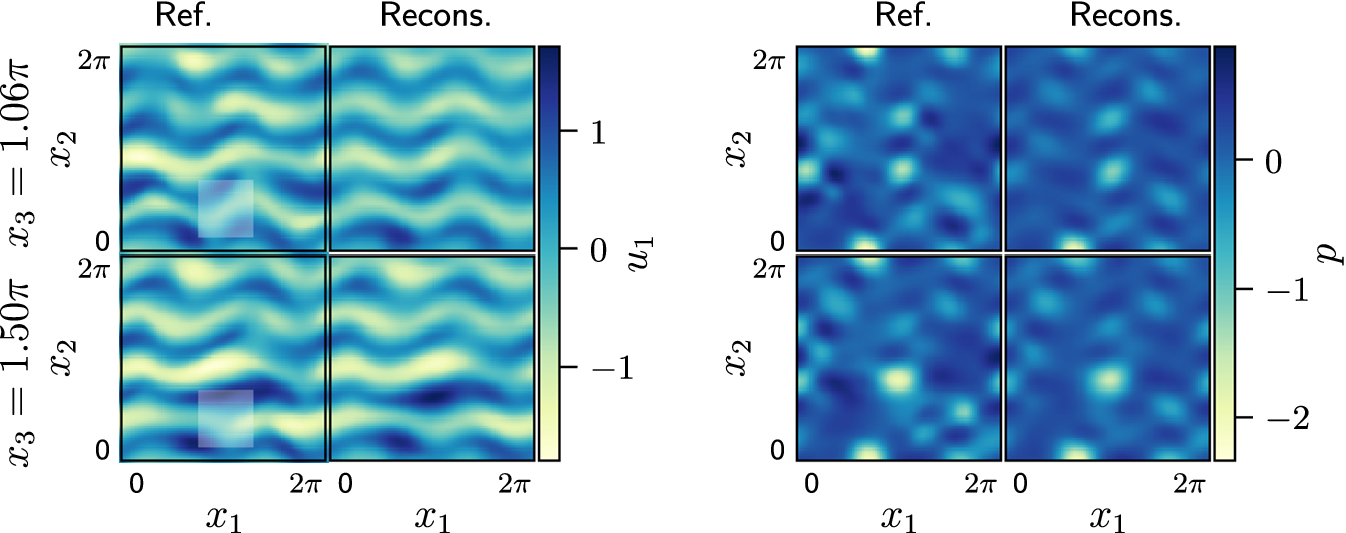




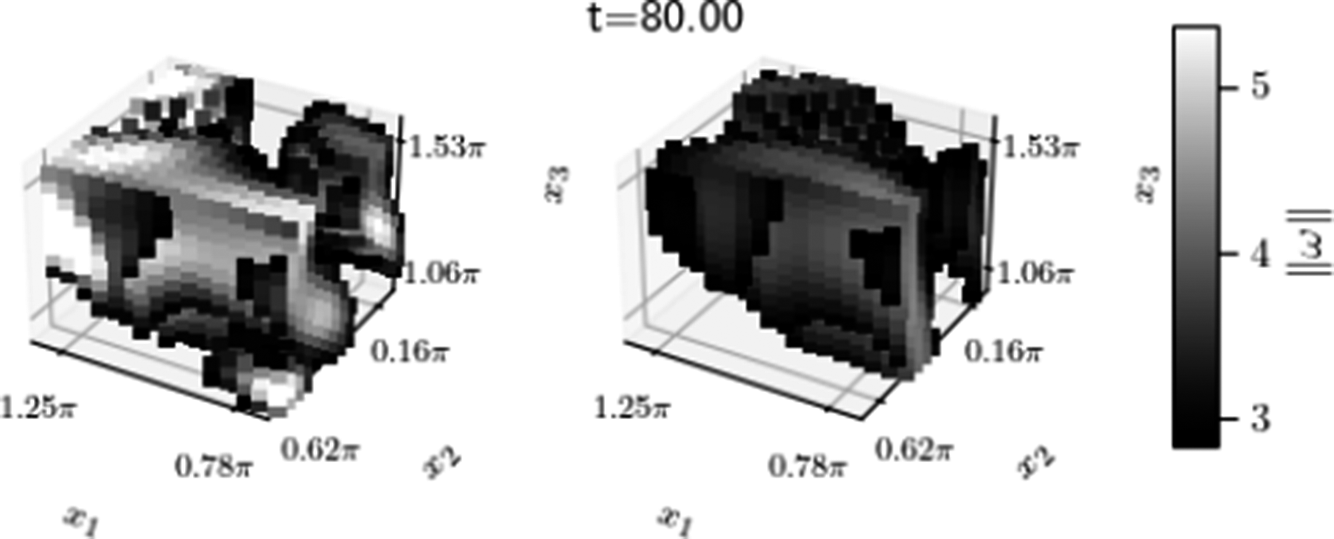

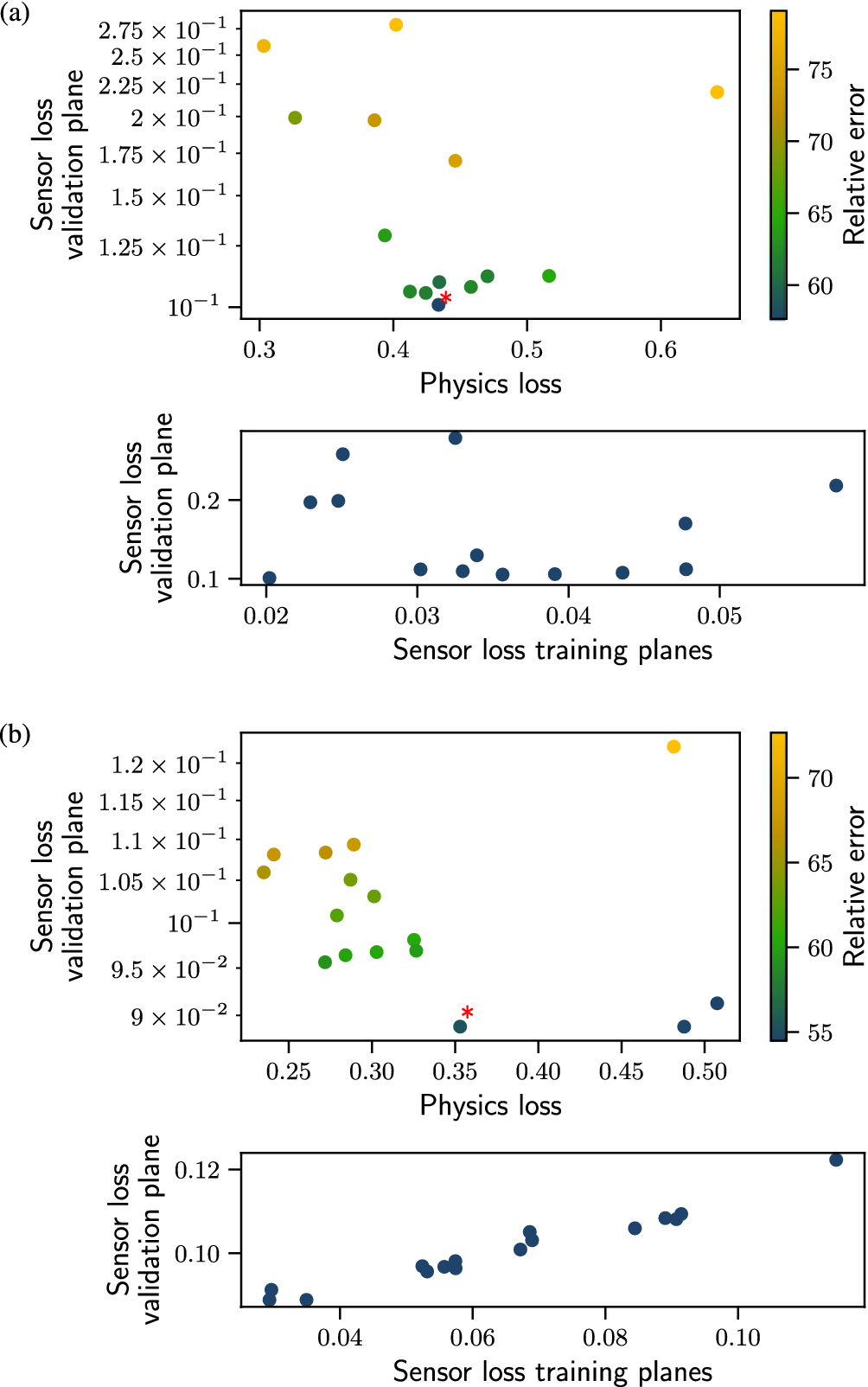



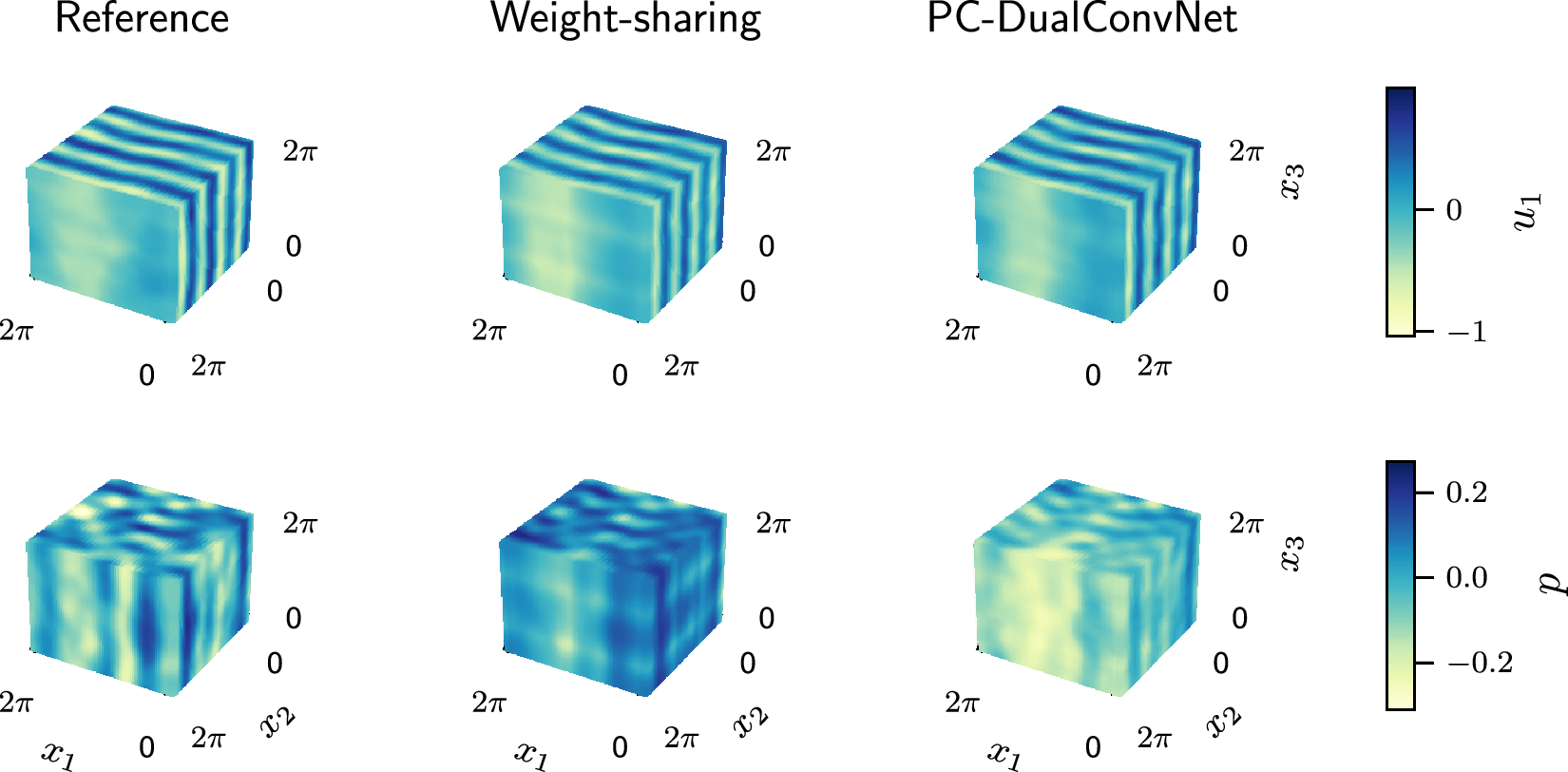
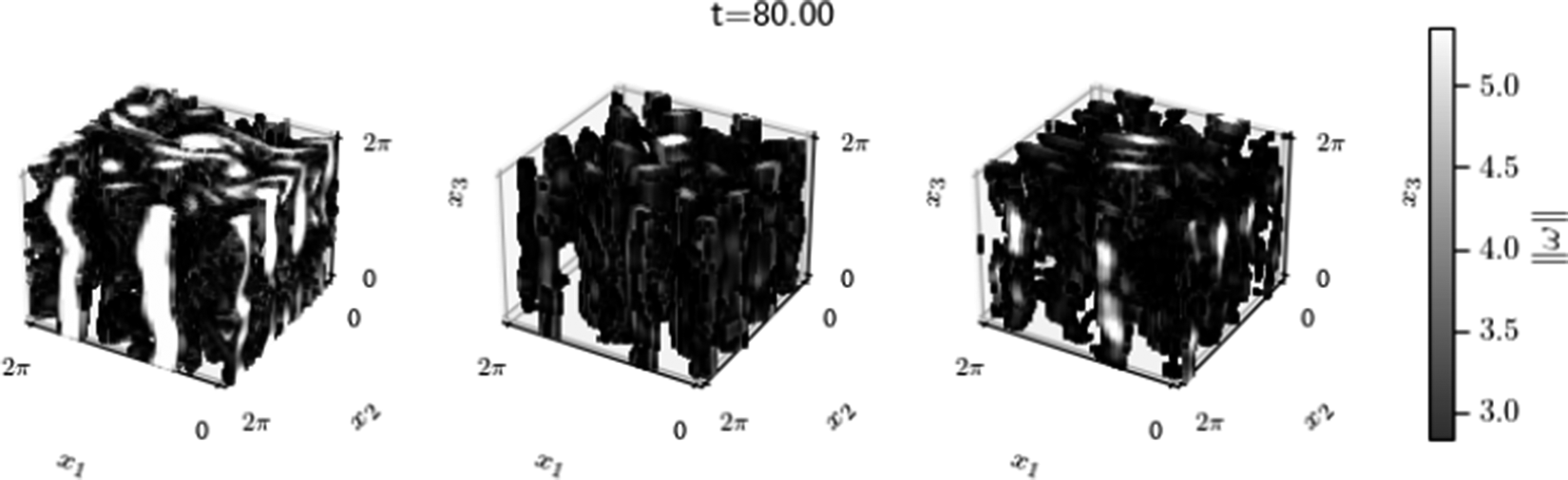

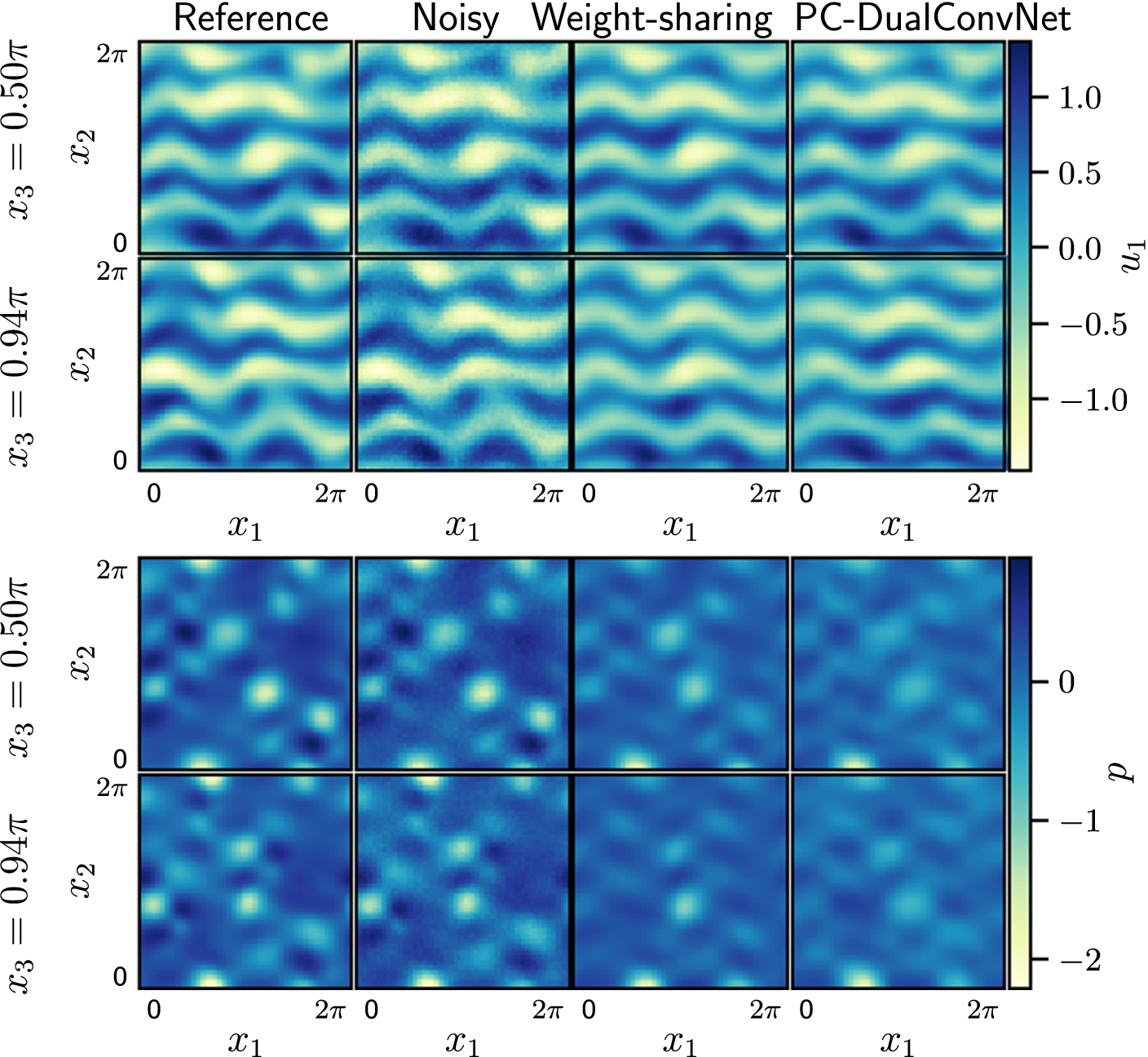





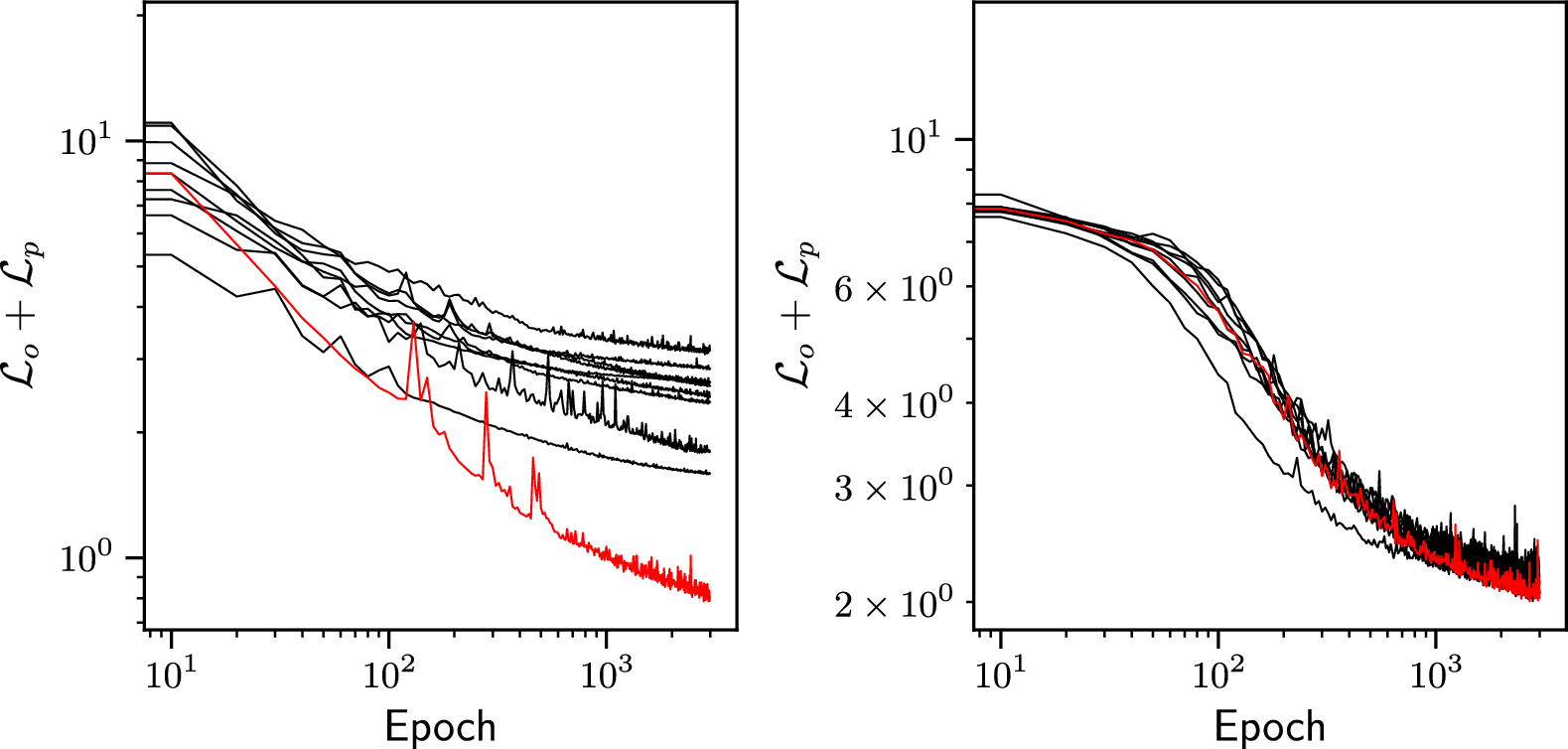


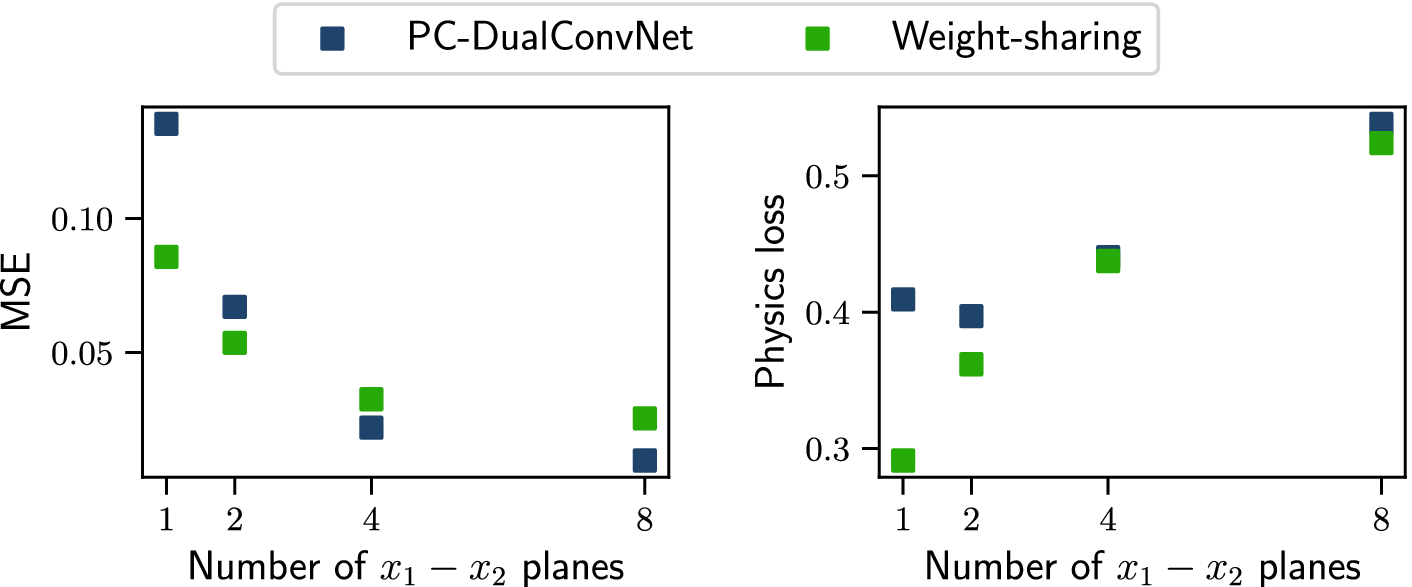






 Open access
Open access
Comments
No Comments have been published for this article.