


1 Introduction
Much research in the social and political sciences involves estimating the positions of actors, such as politicians or political parties, in latent ideological and policy spaces, such as the left-right or liberal-to-conservative continuum. Widely used approaches involve the automatic processing of text documents produced by these actors, such as party manifestos (Laver, Benoit, and Garry Reference Laver, Benoit and Garry2003; Slapin and Proksch Reference Slapin and Proksch2008) or legislative speeches (Lauderdale and Herzog Reference Lauderdale and Herzog2016). Other approaches involve human coding by experts (Budge Reference Budge2001) or crowd workers (Benoit et al. Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016). Yet other approaches rely on other inputs, such as roll call votes (Poole and Rosenthal Reference Poole and Rosenthal1985), Twitter connections (Barberá Reference Barberá2015), or campaign donations (Bonica Reference Bonica2014).
We propose a new approach to position text documents in ideological and policy spaces using instruction-tuned large language models (LLMs) and evaluate its performance. These models are LLMs optimized for dialog use cases and are typically interacted with via chatbots such as ChatGPT. We build on the direct query method introduced by Le Mens et al. (Reference Le Mens, Kovács, Hannan and Pros2023a) who measured the typicality of text documents in concepts by asking GPT-4 for typicality scores. We directly ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to obtain position estimates of longer texts or political actors.
We focus on four scaling tasks using texts of different types, contexts, and lengths. First, we position individual tweets published by US Representatives and Senators by directly asking LLMs where these stand on the left-right ideological spectrum. Second, we position senators of the 117th US Congress on the same dimension by averaging the position estimates of a sample of the tweets they published during the Congress session. Third, we position party manifestos on the economic and social policy dimensions. We ask the LLMs for the positions of each sentence on these dimensions and average the LLM responses to obtain position estimates of the party manifestos. Fourth, we apply this approach to position speeches by EU legislators, in 10 different languages, about a policy proposal on the ‘anti-subsidy’ to ‘pro-subsidy’ scale. This allows us to explore the potential of this approach for comparative research with multilingual data.
Several articles have shown that LLMs can produce text annotations (classifications in discrete categories such as relevant/irrelevant or a topic among a limited set of candidate topics) that are in good agreement with those produced by human coders (e.g., Gilardi, Alizadeh, and Kubli Reference Gilardi, Alizadeh and Kubli2023; Törnberg Reference Törnberg2025; Ziems et al. Reference Ziems, Held, Shaikh, Chen, Zhang and Yang2023). However, little work has used LLMs to produce position estimates of political texts in ideological and policy spaces, which is the essence of text scaling, a core task in political science (see Benoit et al. (Reference Benoit2020) for a discussion of the difference between the two tasks). We know of only two recent studies that rely on the text generation capabilities of LLMs to estimate policy and ideological positions. Our approach differs from both. The first study used GPT-3 as a probabilistic text classifier to obtain the posterior probability that a sentence in a party manifesto is “Conservative” or “Liberal” and defined the position of the manifesto as the average (across sentences) of the difference between these probabilities (Ornstein, Blasingame, and Truscott Reference Ornstein, Blasingame and Truscott2024). Our approach directly asks the LLM for the position of text on the focal dimension, and we find that it performs better.Footnote 1 The second study asked GPT 3.5 and Llama 2 to compare pairs of politicians on a particular dimension and used these pairwise comparisons to construct estimates of politician position on unidimensional scales (e.g., gun control support) (Wu et al. Reference Wu, Nagler, Tucker and Messing2023). We ask LLMs to position political texts produced by political actors instead of asking them to position political actors based on their names. Our approach is thus applicable even to political actors about whom the LLM has little information.
2 Methods and data
2.1 Obtaining position estimates with LLMs
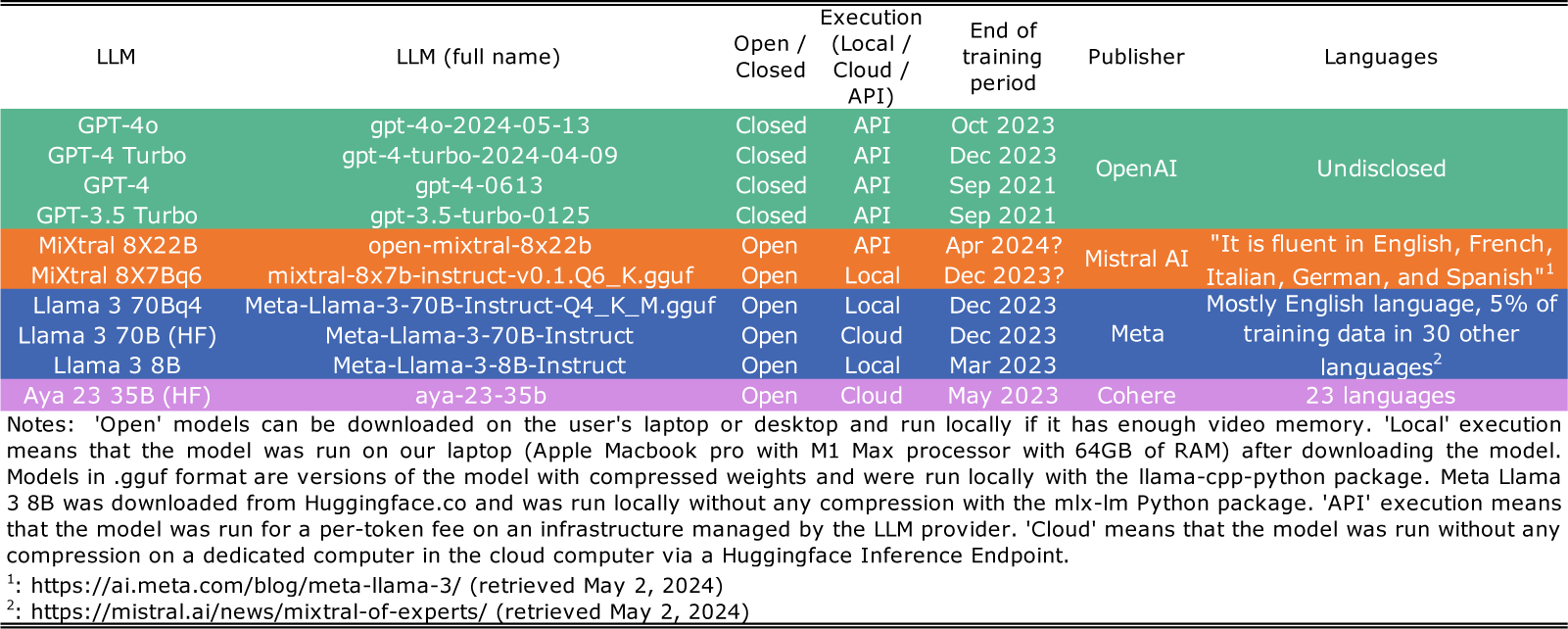
Table 1 lists the LLMs we used for text scaling, including their open or closed status. These consist of a set of the most recent and largest LLMs available at the end of May 2024.Footnote 2
LLMs used for the comparative analyses.
To obtain a position estimate of a text with an LLM, we submitted a prompt that contained a “user message” instructing it to return such an estimate. For example, to locate a tweet on the left-to-right-wing scale, we used:
You will be provided with the text of a tweet published by a member of the US Congress. Where does this text stand on the ‘left’ to ‘right’ wing scale? Provide your response as a score between 0 and 100 where 0 means ‘Extremely left’ and 100 means ‘Extremely right’. If the text does not have political content, set the score to “NA”. You will only respond with a JSON object with the key Score. Do not provide explanations.
 $\ll $
Text of the tweet
$\ll $
Text of the tweet
 $\gg $
$\gg $
In all cases, we set the temperature parameter to 0, to ensure that the LLM would generate its response by selecting the most likely next token, and thus make the LLM responses as deterministic as possible (to ensure replicability). We also set the maximum number of tokens in the response to 20. This parameter does not affect the nature of the message returned by LLMs; it cuts the response down to 20 tokens if the LLM intended to generate a longer response. This ensures speed (token generation tends to be relatively slow) and limits costs (pay-per-use APIs charge per token submitted in the prompt and per token returned in the response). Finally, whenever this option was available, we set the response format to be a JSON object.
To obtain the position of a party manifesto or a policy speech, we proceeded in a similar way with each sentence of the text documents. We then took the average of the positions of the sentences for which the LLM returned a numeric score, mimicking the approach used by Benoit et al. (Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016) with human coders.
The supplementary material and the replication package available on Code OceanFootnote 3 provide the exact prompts and further details.
2.2 Data
2.2.1 Tweets Published by US Congress Members After the Training Cut-off of GPT-4
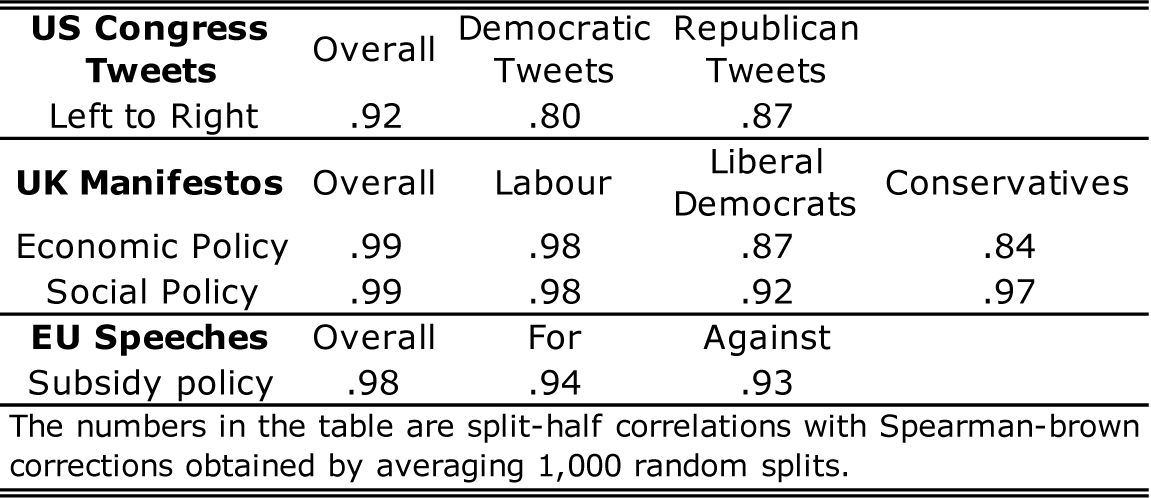
These data allow us to assess the performance of a modern LLM on prediction data we are certain were not part of the LLM pre-training data. We used the 900 tweets originally analyzed in Le Mens et al. (Reference Le Mens, Kovács, Hannan and Pros2023a). In November 2023, we recruited 597 Prolific participants to each rate 30 tweets by answering the following question: “Where does this text stand on the “left” to “right” wing scale? If the text does not have political content, select “Not Applicable”.” Participants were not given any instructions as to what we meant by “left” or “right.” The crowdsourced position estimate of a tweet is the average of these ratings. All tweets, except one, received at least one position rating (different from “NA”), leading to a test data set of 899 tweets and their crowdsourced position estimates. This measure is highly reliable overall and within-party (Table 2).
Reliability of the measures based on human ratings used as benchmark for assessing the performance of position estimates produced with LLMs.
2.2.2 Senators of the 117th Congress
We obtained the list of senators from VoteView.com, their Twitter usernames, and downloaded the tweets they published during the Congress session through the Twitter API. We used random samples of 100 tweets published by each senator during the 117th Congress session (January 3, 2021 to January 3, 2023). We excluded two senators who published fewer than 100 tweets during the Congress sessions. We use as a benchmark the first dimension Nokken–Poole period-specific DW-NOMINATE score, a well-established position estimate based on senators’ roll-call votes.
2.2.3 British Party Manifestos
We obtained the texts, expert coding estimates, and crowd coding estimates from the replication package of Benoit et al. (Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016). We positioned the 18 British party manifestos on an economic policy dimension (from left- to right-wing) and on a social policy dimension (from conservative to liberal). We used as a benchmark the Expert Coding estimates that were constructed by Benoit et al. based on the sentence position estimates provided by a crowd of experts (political scientists). This measure is overall highly reliable and has varying levels of within-party reliability (table 2).
2.2.4 Multilingual Setting: EU Policy Speeches in 10 Languages
We also positioned the 36 speeches of a European Parliament debate on a policy proposal concerning state subsidies originally analyzed in Benoit et al. on the pro- to anti-subsidy dimension. These were delivered in 10 different languages by speakers who then voted for or against the proposal. Benoit et al. (Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016) obtained 6 crowdsourced position estimates for each speech from crowdworkers coding the official translations in English, German, Greek, Italian, Polish, and Spanish. We took the simple average of the six crowd-coding estimates as a benchmark. This setting is challenging not only because of its multilingual nature but also because the speeches vary in style (e.g. technical, case-focused, rhetorical) and require knowledge of the debate context to be understood.
3 Results
3.1 Tweets Published by Members of the US Congress After the Training Cut-off of GPT-4
The LLMs returned “NA” for a subset of tweets, indicating that they judged that these tweets did not have enough political content to return a position estimate (see Supplementary Material for further discussion). The correlations between the position estimates produced by the best LLMs and crowdsourcing are very high, as shown in Figure 1. Position estimates reflect differences between-party and within-party.
Positioning tweets published by members of the US Congress on the left-right ideological spectrum (
 $N=899$
).
$N=899$
).
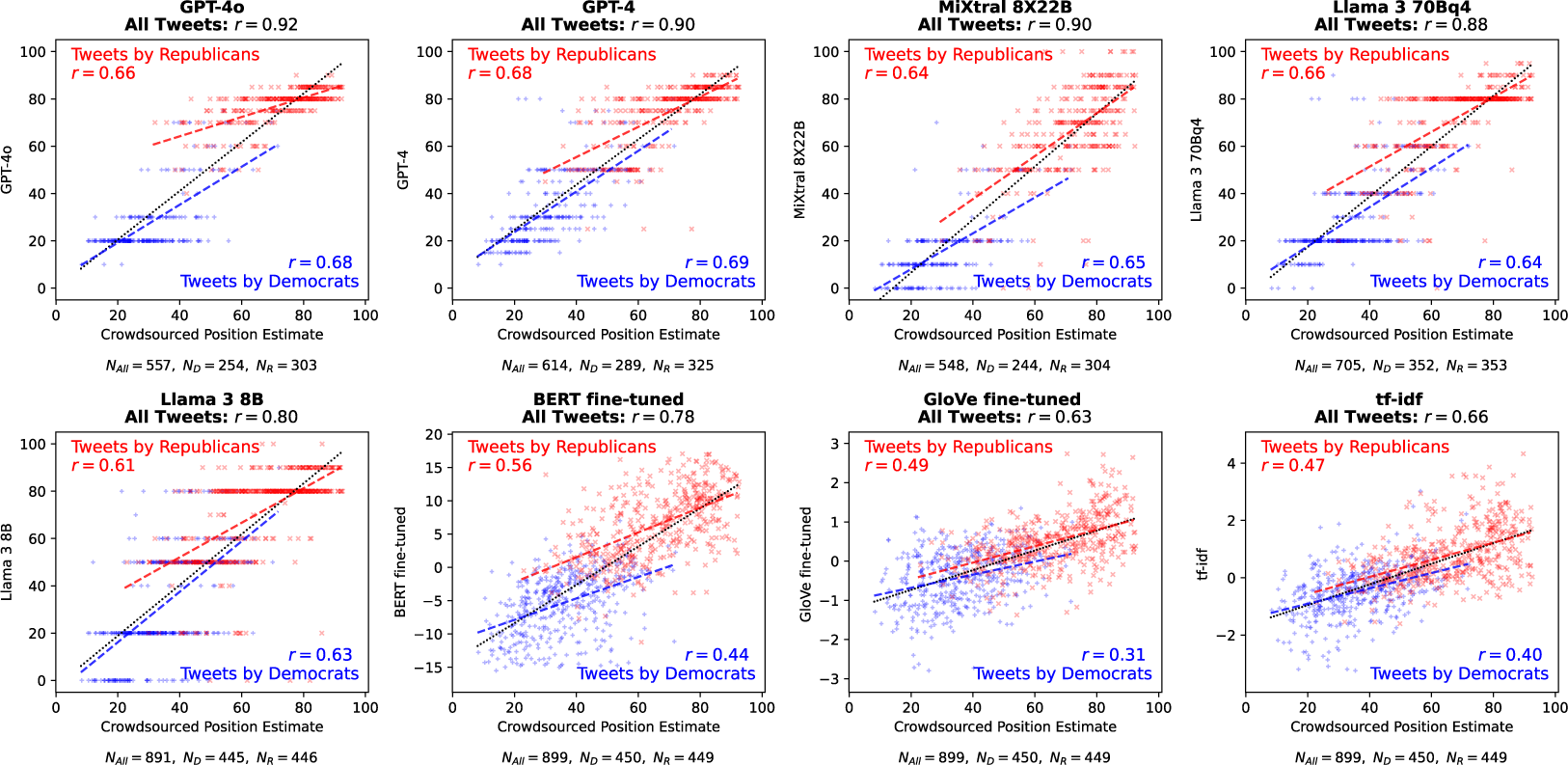
To compare these results with those obtained through approaches that do not require the submission of prompts to an LLM, we computed the typicality of each tweet in the Republican and the Democratic parties using probabilistic text classifiers and defined the position of a tweet as the difference between these two typicalities. The training data consist of approximately 1 million tweets published by members of the US Congress during the 116th and 117th Congress sessions.
We used text classifiers based on fine-tuned BERT (the highest performing approach in Le Mens et al. (Reference Le Mens, Kovács, Hannan and Pros2023b)), fine-tuned GloVe word embeddings and a naive Bayes classifier based on word frequencies (TF-IDF).Footnote 4 None of these approaches matches the best-performing LLMs, especially when it comes to capturing within-party differences.
3.2 Senators of the 117th US Congress
This setting differs from the previous one in that the benchmark positions are not based on human coding but on the voting behavior of the senators.
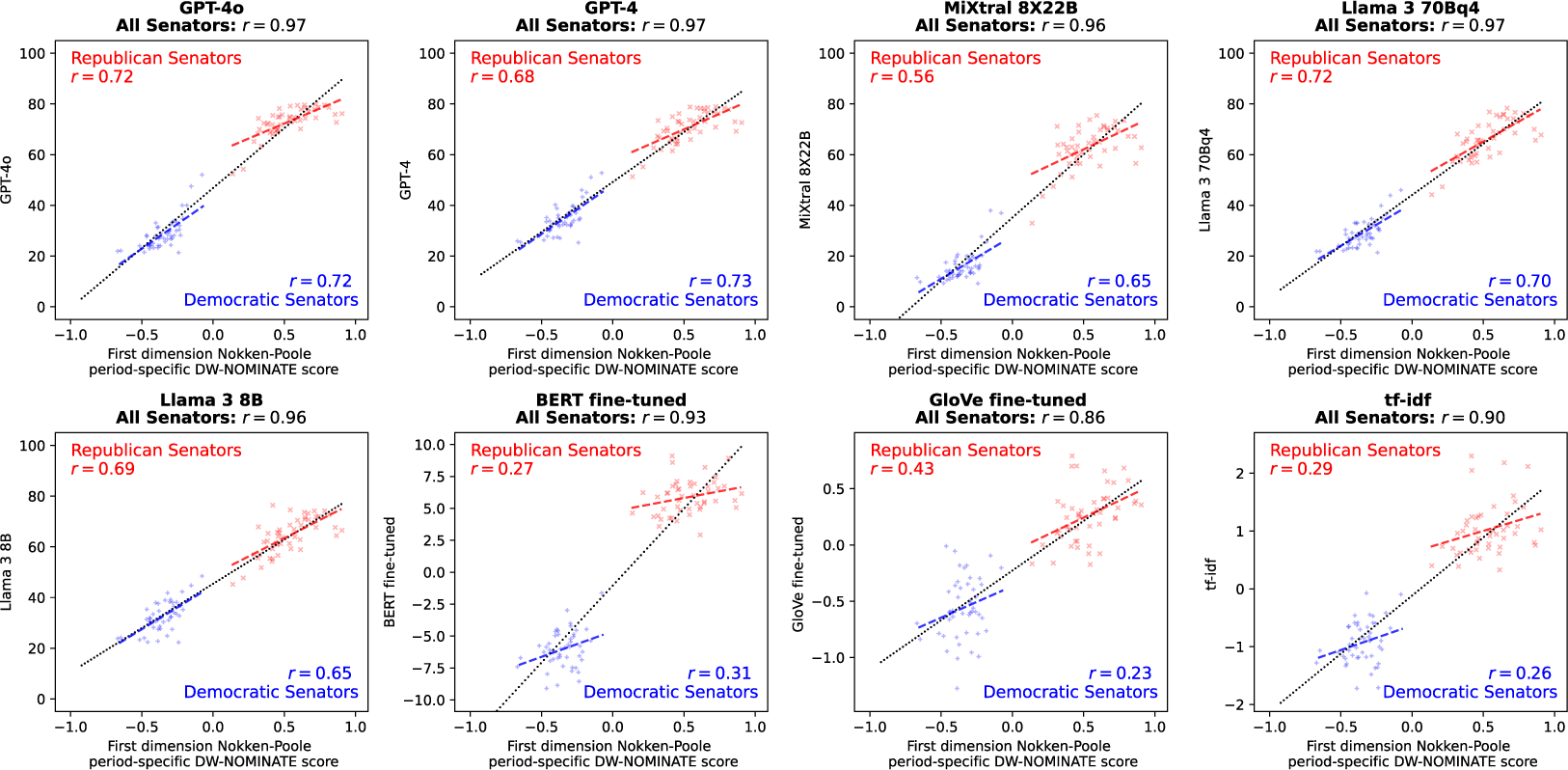
The position estimate of a senator is the average position of their tweets on the left-right ideological spectrum. Figure 2 shows that the resulting position estimates are highly correlated with those based on the roll call votes of the senators during that Congress session (Nokken and Poole Reference Nokken and Poole2004), overall and within the party. These correlations are also higher than those produced by supervised classifiers used to obtain typicality measures of tweets in the two parties. The position estimates produced with LLMs are also highly correlated with those based on campaign funding (2020 CF scores, Bonica (Reference Bonica2014)), although less so within-party (Figure A8).
Positioning Senators of the 117th Congress on the left-right ideological spectrum based on a random sample of 100 of their tweets (
 $N=98$
). Each dot represents a senator (‘+’: Democrats, ‘x’: Republicans).
$N=98$
). Each dot represents a senator (‘+’: Democrats, ‘x’: Republicans).
3.3 British Party Manifestos
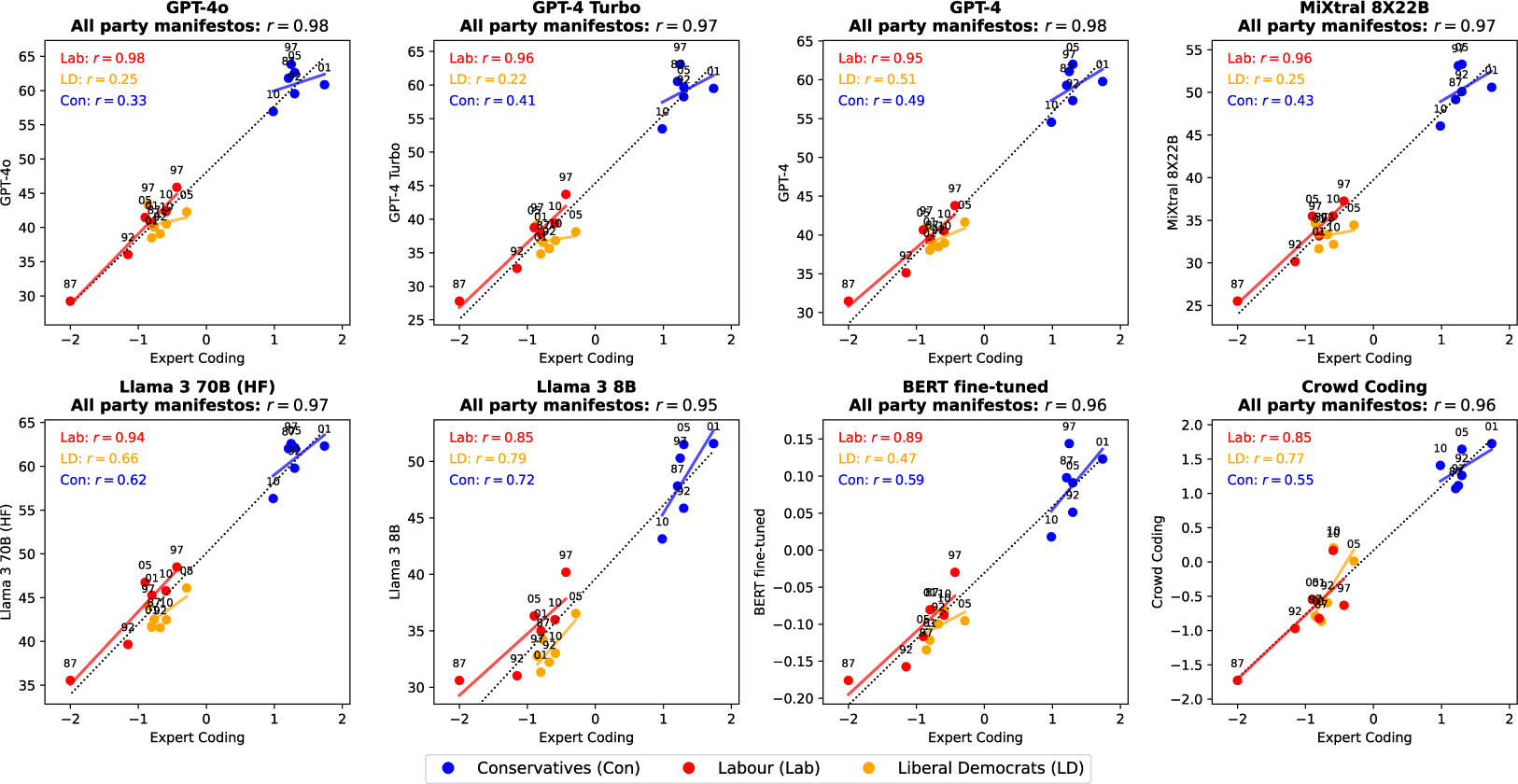
The position estimates obtained with the highest performing LLMs are very highly correlated with the Expert Coding estimates, at a level comparable to the position estimates produced with crowd workers (Figures 3 and 4). This is the case not only overall, but also within political parties. These results were obtained without providing any description of the policy dimension to the LLMs. Similar results hold when including such descriptions (Figures A10 and A11).
Positioning British party manifestos on the Economic policy dimension (left to right wing scale). The numbers next to the dots indicate the years of the manifestos.
Positioning British party manifestos on the Social policy dimension (liberal to conservative scale). The numbers next to the dots indicate the years of the manifestos.
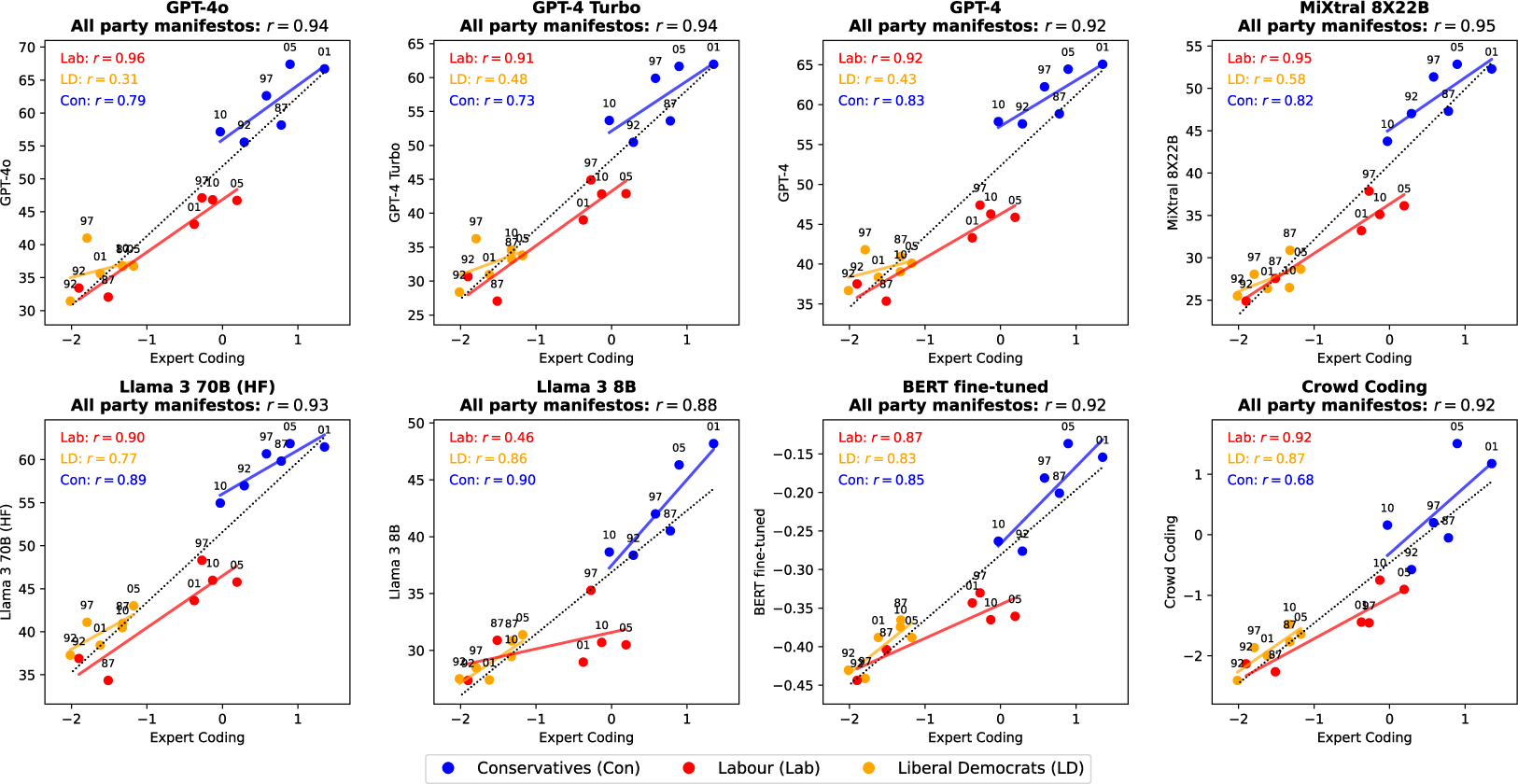
We also trained a BERT-based supervised probabilistic text classifier (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) using the crowdworkers’ ratings collected by Benoit et al. (Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016), and used it to obtain position estimates of the manifestos’ sentences and, in turn, of the manifestos. This approach did not yield better results than those obtained with the best LLMs, although the latter were (most likely) not specifically trained to position these party manifestos.
3.4 Multilingual Setting: EU Policy Speeches in 10 Languages
We obtained position estimates of the speeches on the “anti-subsidy” to “pro-subsidy” dimension by submitting each sentence to the LLMs in its original language with instructions (in English) including background information on the context of the debate.
For the highest performing LLMs (GPT-4o and, to a lesser extent, GPT-4 Turbo, MiXtral 8X22B, Llama 3 70B, Aya 23 35B), the correlation between the benchmark and the position estimates obtained is high overall, and also when we separate the speeches by speakers who voted for and against the policy (Figure 5).
Positioning EU legislative speeches in 10 languages on the “anti-subsidy” to “pro-subsidy” dimension.
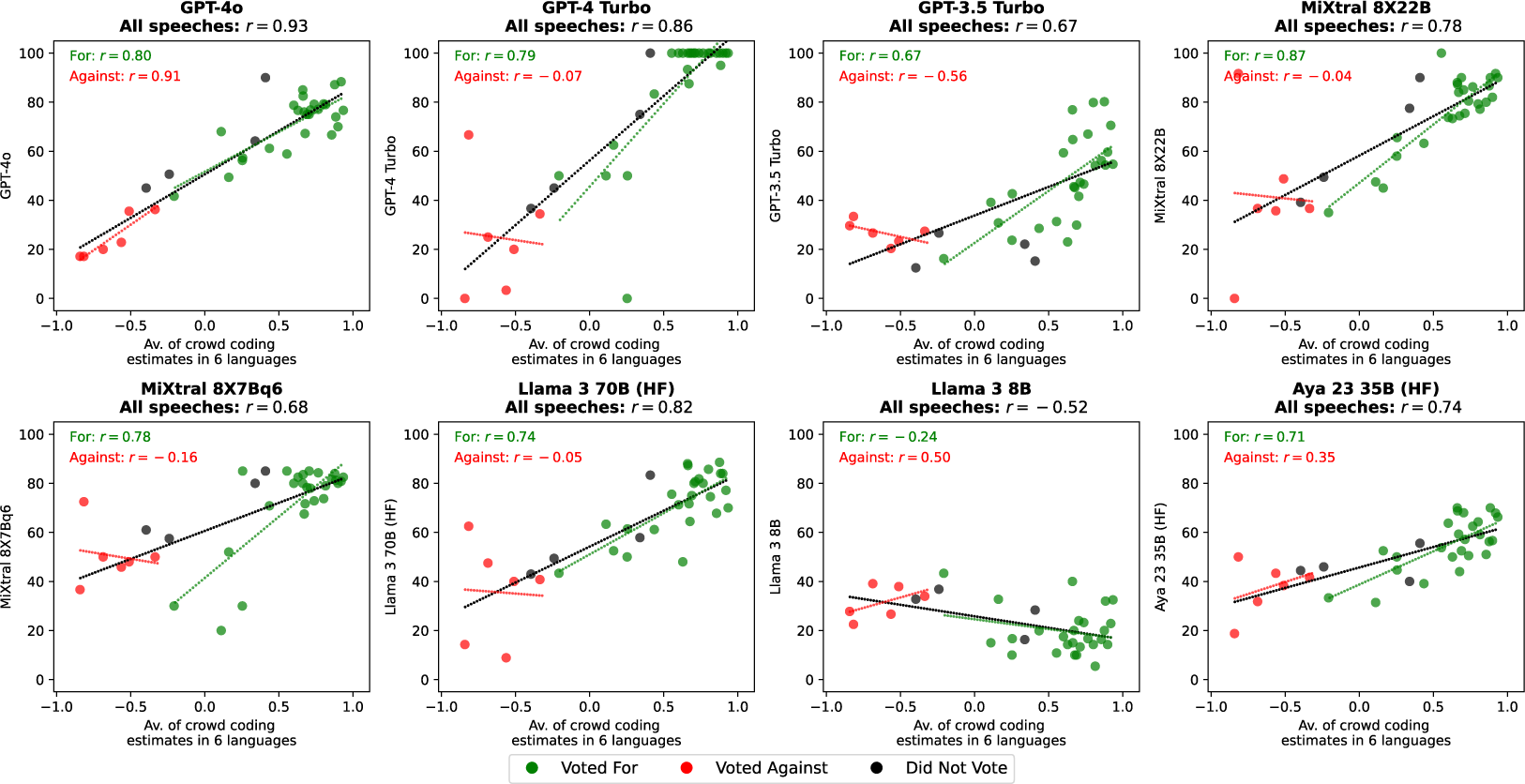
Results obtained with the translations of the speeches in the 6 languages used to obtain the crowd coding estimates show that the best models perform well across languages (Supplementary Material).
4 Discussion
These results demonstrate that “asking” modern instruction-tuned LLMs for the position of short texts in ideological spaces can produce valid position estimates. These can be used, in turn, to position political actors such as politicians, as we illustrated with US senators. We showed that asking LLMs for the positions of sentences in ideological and policy spaces and averaging the responses produces valid positions of party manifestos and policy speeches. The position estimates of the party manifestos produced with the best LLMs are as accurate as the crowdsourced position estimates. And with individual tweets, ancillary analyses show that the position estimates returned by the best LLMs are as accurate as the average of the ratings of about 4 or more independent human coders (Supplementary Material).
This approach has the potential to expand the scope of text analysis due to its high accuracy, speed, ease of implementation, and reproducibility (for open LLMs). Moreover, querying instruction-tuned LLMs is much less costly than human coding even with the most expensive pay-per-use API (GPT-4): $1.5 versus £1,626 for the 900 tweets analyzed in Section 3.1.
Which LLM should researchers choose? Five main considerations come into play: accuracy with respect to a relevant benchmark, cost, speed, data protection, and reproducibility. If testing reveals no significant accuracy difference between open and closed LLMs, we recommend that researchers use open LLMs such as MiXtral (8X22B) and Llama 3 for text scaling tasks, at least in English. Their architecture and weights are freely available for download, which guarantees the reproducibility of research results and a high level of data protection (if executed locally or on a secure cloud machine).
For multilingual settings, it seems that GPT-4o (a proprietary model) has a marked advantage compared to the best open models at the time of writing, but some LLM designers are releasing open LLMs especially designed to perform well in multiple languages (e.g., the Aya series by Cohere). Some LLMs perform better in some languages than in others (Supplementary Material) and systematic accuracy differences across languages can bias the results of downstream econometric analyses. Developing approaches to deal with this differential measurement error would help realize the potential of LLMs in comparative research.
Another decision is whether to position long text documents in a single prompt or to split them into shorter parts, such as sentences. At this stage, we do not have a clear recommendation on this issue. Positioning party manifestos in a single prompt leads to lower performance than the sentence-by-sentence and averaging approach (Supplementary Material). In contrast, positioning senators by submitting their tweets in a single prompt did not cause significant performance degradation (Supplementary Material). Assessing where and when the single-prompt approach leads to performance degradation is an interesting avenue for future research.
When interpreting the results of the LLM-based approach for positioning political actors such as politicians or parties, it is important to remember that position estimates are based on the text documents submitted to the LLMs. Therefore, the validity of the resulting estimates is limited by the information contained in these texts. In the case of party positions, our approach resembles the approach of the Comparative Manifesto Project but differs from approaches that rely on surveys of experts about their perception of party positions, such as the Chapel Hill Expert Survey. This also implies that the results obtained with LLMs might differ from those obtained from expert surveys in the same way that those obtained by human coding can differ from those obtained with expert surveys because the inputs used to produce the position estimates differ.
The high correlations between position estimates produced with LLMs and human coders reported in this research note could tempt readers to use this approach in other domains while skipping the validation stage. But we advise them against doing so. LLMs are well-known for generating biased and unreliable results in some empirical settings. Until other researchers have shown that asking (and averaging) a particular LLM provides accurate scaling results in a variety of empirical settings and focal latent dimensions, we cannot be sure about the breadth of settings in which LLMs perform well for scaling tasks and, a fortiori, other measurement or coding tasks. Until more is known about the range of domains in which LLMs perform well at scaling and other measurement tasks, case-by-case empirical validation remains essential.
Acknowledgments
We thank the reviewers, Hauke Licht, Christopher Wratil, Xavier Fernandez-Marin, Fabrizio Gilardi, Kenneth Benoit, and participants in the AI-PSR workshop at the University of Barcelona for valuable comments and discussion.
Data Availability Statement
Replication code for this article has been published in Code Ocean, a computational reproducibility platform that enables users to run the code, and can be viewed interactively at https://doi.org/10.24433/CO.0323087.v1. A preservation copy of the same code and data can also be accessed via Dataverse at https://doi.org/10.7910/DVN/YFM0BW (Le Mens and Gallego Reference Le Mens and Gallego2024).
Funding
This research was funded by ERC Consolidator Grant 772268 from the European Commission to G.L.M, ICREA Academia grants to A.G and G.L.M, grants PID2021-123111OB-I00 (A.G.) and PID2022-137908NB-I00 (G.L.M.) funded by MICIN/AEI/10.13039/501100011033 and by “ERDF/UE A way of making Europe”, and the Severo Ochoa Programme for Centres of Excellence in R&D (Barcelona School of Economics CEX2019-000915-S) funded by MCIN/AEI/10.13039/501100011033.
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2024.29.














 Open access
Open access