


1. Introduction
Named Entity Recognition (NER) is a specialized subtask of Information Extraction that focuses on identifying and categorizing mentions of real-world entities in text (Jurafsky and Martin Reference Jurafsky and Martin2000; Li, Shang, and Chen Reference Li, Shang and Chen2021; Li et al. Reference Li, Chiu, Feng and Wang2022a). Common entity types such as Person, Location, and Organization are frequently encountered in abundant online sources such as news, websites, and social media, and thus form what are called generic domains. These domains have been extensively studied, and numerous datasets are readily available for research (Li et al. Reference Li, Sun, Meng, Liang, Wu and Li2020; Wang et al. Reference Wang, Jiang, Bách, Wang, Huang, Huang and Tu2021a). In contrast, entities in specialized application domains, also called low-resource domains (Dai and Adel Reference Dai and Adel2020; Liu, Chen, and Xu Reference Liu, Chen and Xu2022), like medical, legal, and financial sectors, are termed as long-tail entities (Cao et al. Reference Cao, Wang, Huang and Hu2020; Liu et al. Reference Liu, Li, Lu and Cheng2020). These domains are less commonly found in typical online text corpora. Additionally, the annotation of these specialized entities often demands technical expertise, making the generation of annotated datasets a challenging task (Hou et al. Reference Hou, Che, Lai, Zhou, Liu, Liu and Liu2020; Friedrich et al. Reference Friedrich, Adel, Tomazic, Hingerl, Benteau, Marusczyk and Lange2020). Given the critical role of annotated data in the development, training, and testing of NER models (Li Reference Li2022; Au, Lampos, and Cox Reference Au, Lampos and Cox2022), there is a growing interest in methodologies for building NER models in scenarios where annotated data are scarce or difficult to generate, as is the case with these low-resource domains (Mohammed, Khan, and Bashier Reference Mohammed, Khan and Bashier2016).
One such methodology is the application of data augmentation, which is a technique that improves the construction of effective NER models when annotated training data is limited or costly to obtain. This approach automatically generates new data samples by applying transformations to existing data (Wong et al. Reference Wong, Gatt, Stamatescu and McDonnell2016; Krizhevsky, Sutskever, and Hinton Reference Krizhevsky, Sutskever and Hinton2017; Shorten and Khoshgoftaar Reference Shorten and Khoshgoftaar2019). Originally popularized in the field of computer vision, data augmentation is gaining traction in Natural Language Processing (NLP) tasks, including NER (Xie et al. Reference Xie, Yang, Neubig, Smith and Carbonell2018; Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Li, Lu and Cheng2020, Reference Liu, Chen and Xu2022; Tikhomirov et al. Reference Tikhomirov, Loukachevitch, Sirotina and Dobrov2020). For example, a sentence like I have a cat named Serena could be transformed into You have a dog named Beethoven or I own a cat called Serena, thereby enriching the training set. These augmented sentences maintain the core structure of the original, while introducing variations that enhance the diversity of the training set.
Despite the growing interest, existing research has not sufficiently explored how the volume of augmented examples influences the performance of NER models. This is a crucial parameter that needs to be determined prior to model training. Additionally, many applications of NER require domain-specific entities; therefore, determining the best ways to create and augment the training data is important in the practical field of NLP. In this study, we examine the effectiveness of two specific data augmentation techniques, Mention Replacement (MR) and Contextual Word Replacement (CWR), across three datasets from various low-resource domains.
We experiment with different quantities of augmented sentences and diverse samples from these datasets, employing BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) and Bi-LSTM + CRF (Huang, Xu, and Yu Reference Huang, Xu and Yu2015), two widely used NER architectures (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022).
Consistent with prior research, our findings confirm that data augmentation is particularly beneficial for smaller datasets. However, for larger datasets, we observed that models trained with augmented data yielded equivalent or even inferior performance compared to those trained without augmentation. We examine the impact of varying amounts of augmented data on model performance as our key contribution. We demonstrate that there exists a saturation point beyond which additional augmentation may degrade model quality. This underscores the need for NER practitioners to carefully experiment with different volumes of augmented examples, as the optimal quantity cannot be predetermined.
Our experiments also reveal that CWR generally outperforms MR, and that BERT models benefit more from data augmentation than Bi-LSTM + CRF models, at least within the scope of our datasets.
The remainder of this paper is structured as follows: Section 2 provides an overview of NER models and text data augmentation techniques. Section 3 reviews prior works that have applied data augmentation to NER. Section 4 details the datasets, augmentation techniques, and experimental parameters. Finally, Section 5 presents and discusses our findings, and Section 6 concludes the paper.
2. Background
In this section, we present a review of NER techniques in the literature, as well as a summary of the best-known text augmentation methods, focusing mainly on the ones applied alongside those techniques.
2.1 NER techniques
In the realm of NER, various architectures have been proposed in the literature (Yadav and Bethard Reference Yadav and Bethard2018; Li et al. Reference Li, Sun, Han and Li2022b). Classical approaches include the Hidden Markov Model (HMM) (Baum and Petrie Reference Baum and Petrie1966), the Maximum-entropy Markov Model (MEMM) (McCallum, Freitag, and Pereira Reference McCallum, Freitag and Pereira2000), and the Conditional Random Fields (CRF) (Lafferty, McCallum, and Pereira Reference Lafferty, McCallum and Pereira2001). In addition to these, Deep Learning-based models, such as Long short-term Memory (LSTM) (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997) and Gated Recurrent Unit (GRU) (Cho et al. Reference Cho, van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014), have also emerged as effective architectures for NER tasks. While this diverse range of models offers a rich set of techniques for developing robust and accurate NER systems, two prominent architectures have shown exceptional performance within the context of NER, particularly in low-resource settings (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022).
The first, Bi-LSTM + CRF (Huang et al. Reference Huang, Xu and Yu2015), served as the standard for NER before the rise of Transformers. This architecture uses a bidirectional LSTM to process text in both directions, creating a rich representation of each word based on its full context. The critical component is the final CRF layer, which performs global label decoding. Instead of predicting each tag independently, the CRF considers the relationships between neighbor tags (e.g., ensuring an “I-ORG” tag always follows a “B-ORG”), which significantly reduces illegal tag sequences and improves overall consistency.
The second, BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), is an evolution of the Transformer architecture. Unlike previous models that process sequences linearly, BERT uses an attention mechanism to weigh the importance of every word in a sentence simultaneously. The model is first pre-trained on massive unlabeled corpora to learn general language patterns and is then fine-tuned on a specific NLP-task dataset. For the NER task, this process of fine-tuning leverages the model’s understanding derived from pre-training, but also tunes it to the specific dataset, allowing it to learn the unique context and the specific labels it needs to recognize (Dai and Adel Reference Dai and Adel2020).
Comparative studies often reveal that BERT models outperform Bi-LSTM + CRF models in NER tasks (Li et al. Reference Li, Sun, Han and Li2022b). However, it is important to consider the higher computational overhead associated with BERT, which typically involves the estimation of approximately 110 million parameters, compared to a typically lower parameter count for Bi-LSTM + CRF models. In our experiments, this count ranged from approximately 0.8 million to 2 million parameters, depending on the dataset.
2.2 Text augmentation methods
Data augmentation techniques for NER are generally categorized into two groups: substitution-based and language model-based (Zhang et al. Reference Zhang, Chen, Cui, Sheng, Liu and Xu2024). The former relies on exchanging tokens or entities with equivalents of the same type, drawing from the training corpus or external knowledge bases. In contrast, language model-based techniques utilize the predictive capabilities of discriminative or generative architectures. While discriminative models typically employ masked language modeling for token replacement, generative models exploit next-token prediction to synthesize entirely new sentences.
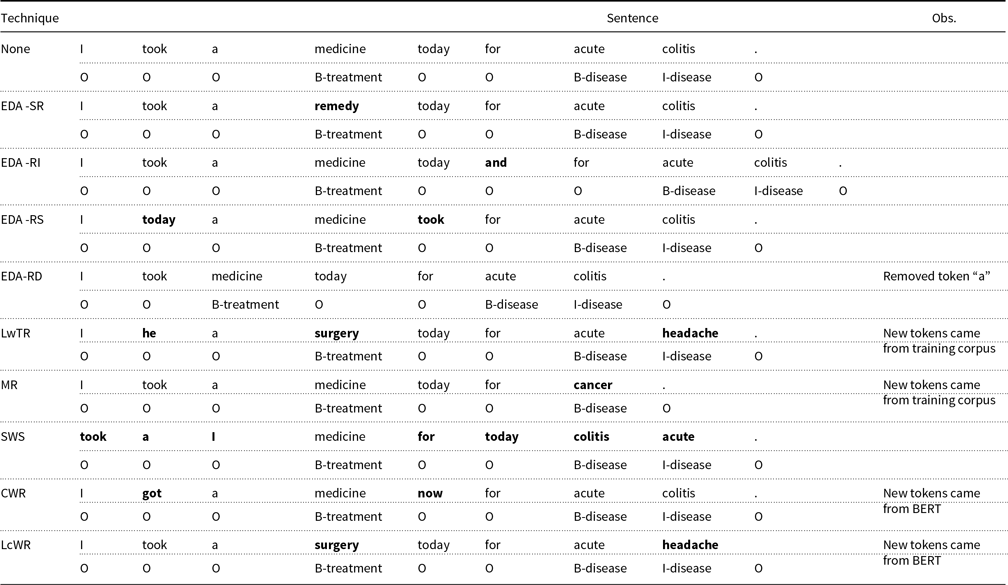
We summarize some of the best-known text augmentation techniques in the literature below, grouped into the two aforementioned categories. Table 1 shows examples of applying these techniques. We adopt the well-known IOB (Ramshaw and Marcus Reference Ramshaw and Marcus1995) tagging scheme. In this scheme, each target entity is tagged with its corresponding entity type, prefixed by “B-” (beginning). Tokens that do not belong to any relevant entity type are labeled as “O” (outside). For sequences of consecutive tokens that share the same entity type, the initial token is prefixed with “B-”, while subsequent tokens receive an “I-” (inside) prefix to denote a contiguous “chunk” of tokens.
Text augmentation techniques with examples

-
• Substitution-based methods
-
– Easy Data Augmentation (EDA) (Wei and Zou Reference Wei and Zou2019): EDA encompasses a suite of straightforward text manipulations, which include:
-
* Synonym Replacement (SR) — Replacing random words in a sentence with their corresponding synonyms from a thesaurus.
-
* Random Insertion (RI) — Inserting random synonyms of words at arbitrary positions in the sentence.
-
* Random Swap (RS) — Interchanging the positions of two randomly-selected words in the sentence.
-
* Random Deletion (RD) — Removing a randomly-chosen word from the sentence.
-
-
-
– Label-wise Token Replacement (LwTR) (Dai and Adel Reference Dai and Adel2020): This method involves replacing random words in a sentence with other words from the original training set that share the same label.
-
– Mention Replacement (MR) (Dai and Adel Reference Dai and Adel2020): An extension of LwTR, MR replaces randomly-selected mentions, that is, one or more contiguous tokens with a uniform label type, with other mentions from the original training set that have the same label type. The number of tokens in the replacement mention may differ from the original.
-
– Shuffle Within Segments (SWS) (Dai and Adel Reference Dai and Adel2020): In this approach, a sentence is segmented based on mentions (as defined in MR). Tokens within each segment are then randomly reordered.
-
• Language model-based methods
-
– Contextual Word Replacement (CWR) (Jiao et al. Reference Jiao, Yin, Shang, Jiang, Chen, Li, Wang and Liu2020): This method employs BERT models to replace words contextually within a sentence.
-
– Label-conditioned Word Replacement (LcWR) (Liu et al. Reference Liu, Chen and Xu2022): This technique utilizes a pre-trained BERT model that is fine-tuned to capture word-label dependencies for word replacement tasks.
-
In the field of NER, Bi-LSTM + CRF and BERT have been identified as particularly effective architectures for low-resource domains (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022). To both adhere to established research and examine the cost-effectiveness of data augmentation across different model types, we opted to utilize both architectures. For data augmentation, we focused on methods that are well regarded in the literature and have demonstrated improvements in the performance of the NER model (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Li, Lu and Cheng2020, Reference Liu, Chen and Xu2022; Jiao et al. Reference Jiao, Yin, Shang, Jiang, Chen, Li, Wang and Liu2020), while also being relatively simple to implement. Hence, we chose MR for augmenting tokens tagged with specific entity types, excluding those labeled “O,” and CWR for tokens specifically tagged as “O.” Detailed information on the implementation of these augmentation techniques is available in Section 4.
3. Related work
Next, we discuss previous work on data augmentation for NER models in this section. One particular issue with current data augmentation methods in the literature is that most of the work done on NLP tasks considers annotations at the sentence level rather than at the token level, as it should be the case with NER (Dai and Adel Reference Dai and Adel2020).
In a closely related study, Dai and Adel (Reference Dai and Adel2020) investigated the effectiveness of four text augmentation techniques, LwTR, SR, MR, and SWS, described in Section 2.2, on two specific low-resource domains: biomedical and materials science. These authors assessed the impact of text augmentation on NER models employing both Bi-LSTM + CRF and BERT architectures. Their findings indicate that none of the augmentation methods consistently outperforms the others, and that augmentation is more effective when applied to smaller (and random) subsets rather than to the entire dataset. Another relevant contribution comes from Liu et al. (Reference Liu, Chen and Xu2022), who introduced a novel text augmentation technique, LcWR, also described in Section 2.2, as well as an automatic sentence annotation approach using BERT, termed prompting with question answering. Additionally, they proposed a noise-reduction system to counteract the potential introduction of noisy data by the augmentation techniques. Their experiments, conducted on three datasets, including one in the low-resource domain of materials science, utilized both Bi-LSTM + CRF and BERT architectures. They found that their techniques not only improved the overall model quality but were particularly effective on smaller subsets of the datasets, while also generating more label-consistent augmented data.
Our work aligns with these studies in terms of the experimental protocol, as we too explore various text augmentation techniques across multiple low-resource domains, employing the same NER architectures. However, a key distinction lies in our exploration of different quantities of augmented instances, enabling us to evaluate the impact of these varying amounts on the quality of the NER models.
Another similar work conducted a comprehensive examination of text augmentation techniques on a dataset encompassing long-tail entities within academic papers (Liu et al. Reference Liu, Li, Lu and Cheng2020). The techniques used were Entity Replacement (ER), which is a variant of MR (Section 2.2) that replaces entities with alternative entities from sources other than the original training set, and Entity Mask (EM), which is similar to CWR (Section 2.2), but focuses exclusively on replacing entity tokens. The authors evaluated the impact of varying data augmentation scales: 20%, 50%, and 100% of the original dataset. This evaluation was performed using a model that seamlessly integrated BERT, Bi-LSTM, and CRF architectures. Their findings demonstrated an enhancement in model quality attributed to both ER and EM augmentation techniques. However, a noteworthy observation is the non-linear relationship between the volume of augmented examples and model improvement. This insight underscores the necessity for further exploration in this domain, as increasing the quantity of augmented data does not invariably bolster the model’s performance. Remarkably, this study stands as a pioneering contribution to the literature, being the sole research to rigorously assess the influence of diverse data augmentation magnitudes on NER models to our knowledge.
In another closely related work, Tikhomirov et al. (Reference Tikhomirov, Loukachevitch, Sirotina and Dobrov2020) introduce two innovative text augmentation techniques, termed “inner” and “outer” descriptor replacement. These techniques involve replacing non-specific entity mentions, termed as descriptors, with proper names to enhance specificity (e.g., replacing “medicine” with “Paracetamol”). The Inner variant applies this replacement to sentences in the original training set, whereas the Outer variant extends this to automatically annotate unlabeled sentences that contain descriptors and are outside the original dataset. These methods are applied to a dataset within the cybersecurity domain, a field characterized by its low-resource nature. However, the application is confined to a limited set of entity types, specifically virus and hacker. The authors carried out a comprehensive evaluation, assessing the impact of these augmentation techniques on models constructed using diverse architectures, including CRF, BERT, and two specially fine-tuned variations of BERT, denominated as RuBERT and RuCYBERT. These tailored models are explicitly designed to address the problem at hand. The empirical results indicate that while the introduced augmentation techniques enhance the model recall, a concomitant decline in precision is observed. Notably, substantial improvements are manifested in the CRF and BERT models. In contrast, the RuBERT and RuCYBERT models exhibit negligible enhancement, thereby alluding to the potential significance of fine-tuning prior to the application of data augmentation techniques. This observation propels further inquiry into the intricate interplay between fine-tuning and data augmentation, and their collective impact on model performance.
Finally, in Longpre et al. (Reference Longpre, Wang and DuBois2020), the authors assessed the efficacy of backtranslation alongside a suite of easy data augmentation (EDA) techniques, described in Section 2.2, across various NLP tasks, employing six diverse datasets and three distinct transformer architectures: BERT, RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019), and XLNet (Yang et al. Reference Yang, Dai, Yang, Carbonell, Salakhutdinov and Le2019). Despite not directly addressing NER, the research holds significance. Their findings reveal an inconsistent enhancement in quality by the examined text augmentation techniques on transformer models. This inconsistency underscores the critical role of the scale of pre-training in models constructed using transformers when contemplating the application of data augmentation. Furthermore, Longpre et al. (Reference Longpre, Wang and DuBois2020) propose a potential preference for task-related augmentation over task-agnostic methods, exemplified by the use of backtranslation for machine translation tasks.
In conclusion, there has been limited advancement in low-resource NER settings. This work aims to address this gap by conducting further experiments and presenting additional results. Utilizing established NER architectures and augmentation techniques, such as those outlined in Section 2.2, the experiments are designed in accordance with methods used in current research. In particular, there is a notable lack of research concerning the impact of the number of augmented sentences on NER models. Although one study has touched upon this issue (Liu et al. Reference Liu, Li, Lu and Cheng2020), it is of a smaller scale compared to the present work. The amount of augmentation is an important hyperparameter that must be set before training the model, as it can introduce noise and affect the quality of the dataset. By investigating the effect of different numbers of augmented sentences, as described in Section 4, this work aims to provide insights into how this parameter influences NER model quality.
4. Experimental setup
In this section, we present the details of the experiments we carried out on the effectiveness of data augmentation in different low-resource domain datasets.
4.1 Datasets
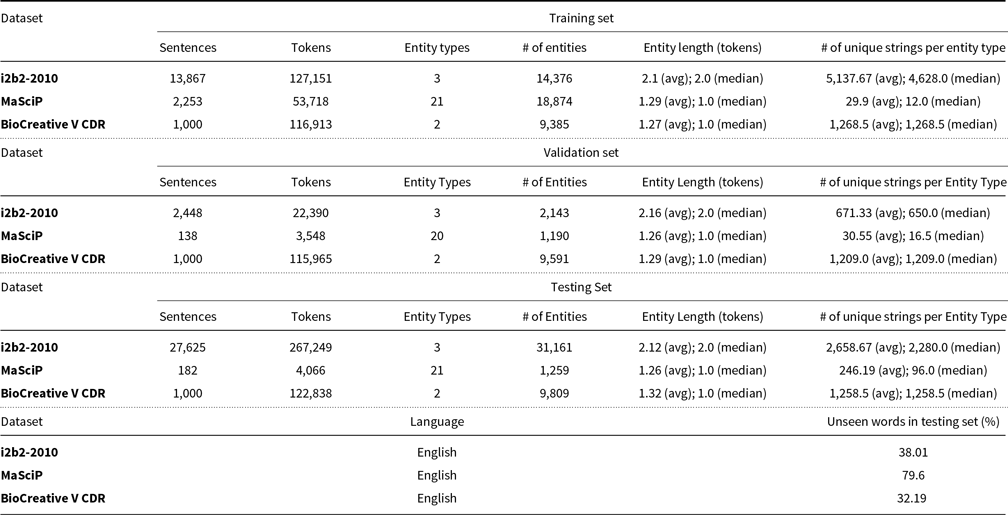
In our experiments, we used three different datasets, all of which are in the English language. Two are from the biomedical domain: BioCreative V CDR Task (Li et al. Reference Li, Sun, Johnson, Sciaky, Wei, Leaman, Davis, Mattingly, Wiegers and Lu2016), which contains ‘Chemical’ and ‘Disease’ entities, and i2b2-2010 (Uzuner et al. Reference Uzuner, South, Shen and DuVall2011), which includes ‘treatment’, ‘problem’, and ‘test’ types. The third dataset, MaSciP (Mysore et al. Reference Mysore, Jensen, Kim, Huang, Chang, Strubell, Flanigan, McCallum and Olivetti2019), is from the materials science domain, featuring a wide range of specialized entities related to synthesis protocols, including categories such as ‘Material’, ‘Operation’, ‘Apparatus-Descriptor’, ‘Condition-Type’, among others. Other articles on NER models (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022) previously used i2b2-2010 and MaSciP.
For all datasets, we used the train-dev-test split provided by the authors. For MaSciP, we the used NLTK default sentence tokenizer (PunktSentenceTokenizer Footnote a ). Table 2 summarizes the number of sentences, tokens, entities, and entity types in each dataset. We also present the average and median entity length in tokens in each dataset, as well as the average and median number of different unique strings per entity type. Finally, we also present the percentage of unique words in the testing set that were not seen in the training and validation sets.
Datasets used in the experiment

To assess the impact of data augmentation in various low-resource scenarios, we selected different sentence subsets from each training dataset: 50, 150, and 500 sentences, aligning with prior research (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022). Additionally, subsets amounting to 25%, 50%, and 75% of the original dataset size are chosen, provided these subsets exceed 500 sentences. The validation and testing datasets remain unaltered throughout the evaluation.
4.2 Data augmentation
We used two techniques in our experiments, MR and CWR, both described in Section 2. We applied two small changes to MR. First, we replaced the mentions in the sentences with new mentions only seen in the training subsets. This does not apply to the full dataset. This was done because we did not want the technique to use additional information from external sources, which would be the discarded part of the dataset for each subset. Second, we selected a random number of tokens of the new mention to produce more variability in the dataset. For augmented sentences with CWR, we applied the technique only to words whose tags are not of the target entity types of the dataset, that is, the annotated tag is “O”. In this way, we assume that BERT is not highly specialized in the low-resource language domains of the datasets, replacing only the words that require less technical expertise. By applying these two augmentation techniques separately and with the aforementioned changes, we can generate augmented sentences by applying data augmentation only to the tokens of target entity types (MR), and sentences where augmentation was applied only to tokens of tag “O” (CWR).
4.3 Setup
We selected two popular architectures used to build NER models, Bi-LSTM + CRF (Huang et al. Reference Huang, Xu and Yu2015) and BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). Following previous work (Dai and Adel Reference Dai and Adel2020), we used SciBERT (Beltagy, Lo, and Cohan Reference Beltagy, Lo and Cohan2019), a fine-tuned version of BERT for scientific texts, for datasets from the biomedical and materials science domains, and regular multilingual BERT for the other datasets. For each dataset and its subsets, we gradually increased the amount of augmented data in the training, ranging from 0% (original data without augmented data) to 500% (original data plus 5 times the amount of original data as augmented data). Finally, we used validation loss as a parameter to interrupt model training if it stopped decreasing for 5 epochs. This setup yields 532 groups of models, considering the combination of all datasets and subsets, architectures, and augmentation techniques and amounts. Each group consists of 10 models trained from scratch, which we evaluated in the testing data, in order to check model variance. We calculated the average F1-score of the models of each group, which we present in Section 5.
While datasets like MaSciP present a significantly higher classification difficulty due to the increased complexity of inter-class disambiguation, it is important to note that we present only the average F1-score for each group (calculated by taking the micro-average F1-score for each model and computing the mean). Although a per-class analysis would provide deeper insights, presenting this breakdown for every entity type would result in an overwhelming volume of data that would overshadow the primary trends of this research, given the scale of our experimental setup. Therefore, we report only the aggregated F1-score to maintain a standardized comparison across all architectures and datasets, consistent with established benchmarks in the field (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Li, Lu and Cheng2020).
All codes used in the experiments are publicly available to encourage the carrying out of more experiments.Footnote b
5. Results and discussion
We now present the results of experiments performed with the datasets described in Section 4 to study the effects of different amounts of data augmentation on the quality of NER models.
5.1 General results
In Figures 1 and 2, we plot a distinct graph for each dataset and architecture pair, using, respectively, MR and CWR as the augmentation technique. For each of these pairs, we plot the average F1-score of each 10-model group as a function of the amount of data augmentation used. Each curve in the graphs corresponds to a subset of the full dataset, both in terms of percentage (25%, 50%, 75%, and 100%) and in terms of the absolute number of sentences (50, 150, and 500). As detailed in Section 4, depending on the size of the dataset, not all percentages and absolute numbers of sentences were considered.
Effects of different amounts of augmented examples (MR) on average F1-score by model and dataset.

Effects of different amounts of augmented examples (CWR) on average F1-score by model and dataset.

Looking at Figures 1 and 2, we notice that the BERT models outperform the Bi-LSTM + CRF models for almost all datasets. This is consistent with previous results in the literature that compare BERT and Bi-LSTM + CRF models (Dai and Adel Reference Dai and Adel2020; Liu et al. Reference Liu, Chen and Xu2022).
We observe a modest increase in model quality for lower-sized subsets before the model starts to reduce the F1-score value, when analyzing models augmented with MR. However, for the full dataset and other larger subsets, the average F1-score has not increased, maintaining or losing quality. The only exceptions to this are MaSciP (BERT), in which every subset benefits from data augmentation. This reduction in F1-score may be a consequence of the introduction of invalid augmented data, which had their original ground-truth labels altered by the augmentation technique. An example of this noise introduction is the following: consider the sentence “Pt had HIDA scan which was negative for obstruction, and CT was unremarkable”, where “obstruction” is a B-PROBLEM entity. Searching for other entities of the same class, we may find “increased shortness of breath”. As MR selects a random number of tokens, a new augmented sentence could be “Pt had HIDA scan which was negative for of breath, and CT was unremarkable.”, which is a syntactically incorrect sentence. These kinds of sentences can be introduced in the dataset. This suggests that data augmentation should be used with caution, as the injection of high noise into the training dataset may cause models to overfit these invalid instances. This trade-off between diversity and validity has been reported in previous research (Dai and Adel Reference Dai and Adel2020; Xie et al. Reference Xie, Dai, Hovy, Luong and Le2020). These inconsistencies could also be due to other factors, such as the characteristics of the datasets or the parameters of the augmentation techniques. We believe that identifying these factors is an important area for future research.
Models augmented with CWR show similar results. However, we notice that more models benefit from data augmentation. This is an indicator that this technique produces more useful data variability than MR in the studied datasets, which makes sense, as BERT can suggest several different tokens. We also have more possible target replacements (“O” tokens) than when applying MR, which targets non-“O” tokens. On the other hand, we observe a more inconsistent pattern of improvement in F1-score across different subset sizes. This is also a consequence of the higher variability introduced by BERT, but on the negative side, where there is more noise introduced than actual valid augmented examples in the datasets.
5.2 Detailed results
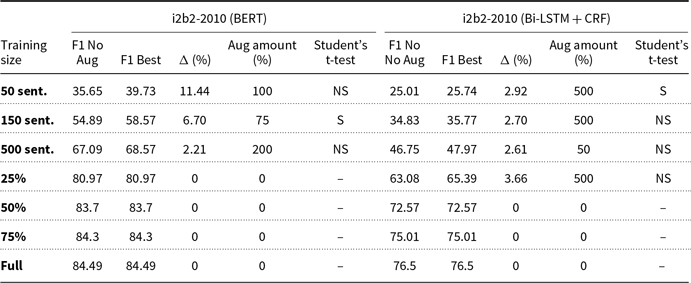
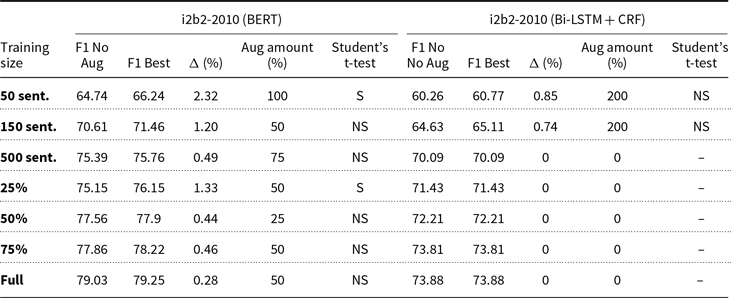
Tables 3–8 present a different perspective of the above results. We show the average F1-score for each subset and each model without data augmentation, and indicate which amount of augmentation yields the best models on average. This summarization yields 76 averages. We also determine whether the augmentation technique produces statistically significant differences between the model without augmentation and the best augmented model, determined by paired Student’s t-tests with a significance level of 0.05. This is only if the best amount of augmentation is greater than 0%. In these tables, we indicate the training size and, for each model, we present the F1-score of the model with no augmentation (column “F1 No Aug”), the F1-score of the best model (column “F1 Best”), the absolute difference in F1-score between these two (column “
 $\Delta$
”), and which augmentation amount yields the best model (column “Aug Amount”). Column “Student’s T-test” indicates the result of a Student’s t-test, if “
$\Delta$
”), and which augmentation amount yields the best model (column “Aug Amount”). Column “Student’s T-test” indicates the result of a Student’s t-test, if “
 $\Delta$
” is nonzero, where “S” indicates that the difference is statistically significant, and “NS” means that it is not.
$\Delta$
” is nonzero, where “S” indicates that the difference is statistically significant, and “NS” means that it is not.
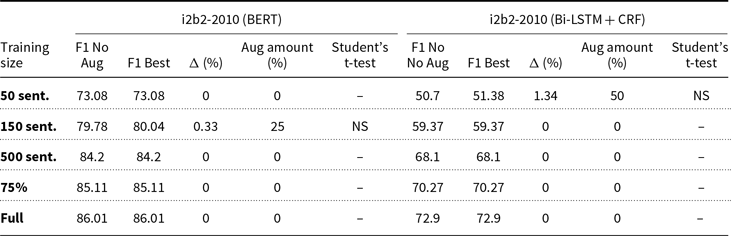
0% and best augmentation (MR) average F1-scores and applied paired Student’s t-tests for i2b2 dataset

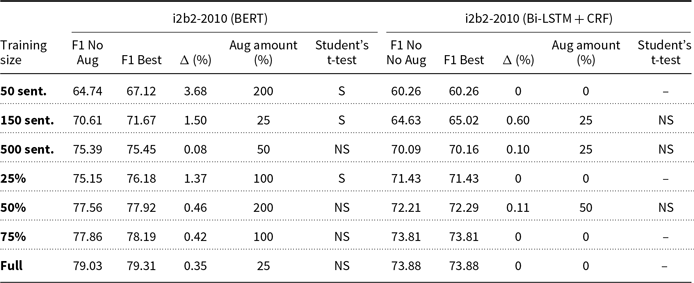
0% and best augmentation (MR) average F1-scores and applied paired Student’s t-tests for MaSciP dataset

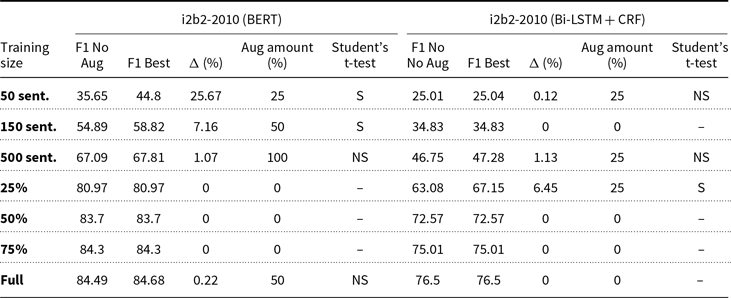
0% and best augmentation (MR) average F1-scores and applied paired Student’s t-tests for BioCreative dataset

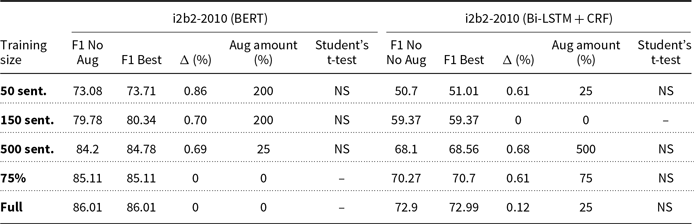
0% and best augmentation (CWR) average F1-scores and applied paired Student’s t-tests for i2b2 dataset

0% and best augmentation (CWR) average F1-scores and applied paired Student’s t-tests for MaSciP dataset

0% and best augmentation (CWR) average F1-scores and applied paired Student’s t-tests for BioCreative dataset

The pattern observed in the results of Section 5.1 can also be observed in these tables, where we see some smaller subsets benefiting from data augmentation, while larger subsets never improve. While we refer to ‘smaller’ datasets throughout this paper, it’s important to note that the term is relative and depends on the specific context and domain. For instance, in our experiments, we found that data augmentation was particularly beneficial for subsets of the datasets with fewer than 500 sentences, such as the 50-sentence subsets of the BioCreative dataset. However, this threshold may vary for other datasets or domains, and further research is needed to determine the optimal size for applying data augmentation techniques. Another observation is that there is no optimal predetermined amount of data augmentation, probably due to the random introduction of noise by the augmentation techniques. Because of this, we can conclude that NER practitioners should test different amounts of augmented examples in their models.
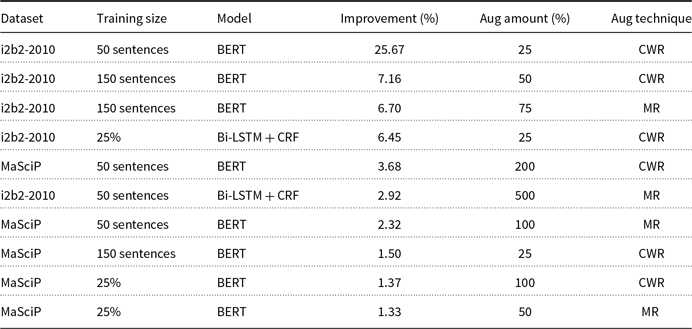
Table 9 summarizes the content of the previous tables, presenting all models that achieved statistically significant improvements by data augmentation. We sorted these models by improvement, in descending order. We note that 10 of the 76 best models, or 13,16%, were found to present statistically significant improvements in the average F1-score. The conclusions above are also evident here, that is, first, smaller subsets improve with data augmentation, unlike larger subsets, and second, in spite of these promising results, there is not an augmentation amount that yields the best results.
Summary of models improved by augmentation

We also observe that, for the datasets studied in this experiment, CWR yields more improved models than MR, that is, 6 versus 4. This can be an indication that CWR should be prioritized when selecting data augmentation techniques for NER models. We can also see that two of the three datasets benefit from data augmentation, where i2b2-2010 and MaSciP have 5 improved models each. Although i2b2-2010 and BioCreative are similar datasets in terms of domain and number of entities, models of the first dataset are improved by data augmentation, unlike models of the second dataset, which never improved. This contrasting effect can be explained by intrinsic differences in text style and annotation characteristics between the two sources. The i2b2-2010 dataset is based on relatively homogeneous clinical narratives where relations are often expressed locally and follow recurrent linguistic patterns; in this setting, data augmentation strategies are more likely to preserve relational semantics while increasing useful variability for training. In contrast, BioCreative relies on scientific abstracts in which chemical–protein relations depend on denser, highly specialized context and are often distributed across multiple sentences, in addition to involving normalization to controlled vocabularies. Under these more complex conditions, simple synthetic perturbations are more prone to introducing semantic noise or disrupting critical dependencies, which explains why augmentation fails to yield improvements and may even harm performance in the scientific domain.
Finally, BERT models are improved more than Bi-LSTM + CRF models, that is, 8 versus 2. This can be an indication that data augmentation suits BERT-based NER models better than Bi-LSTM + CRF-based ones.
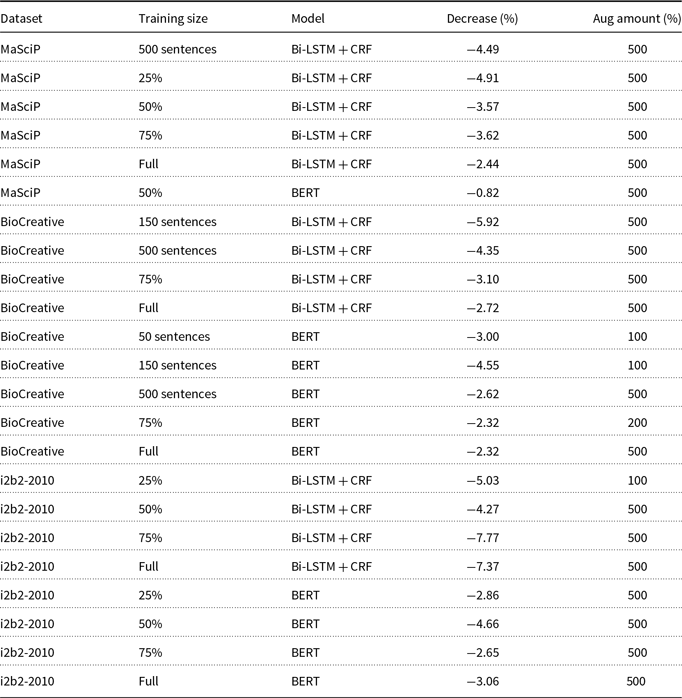
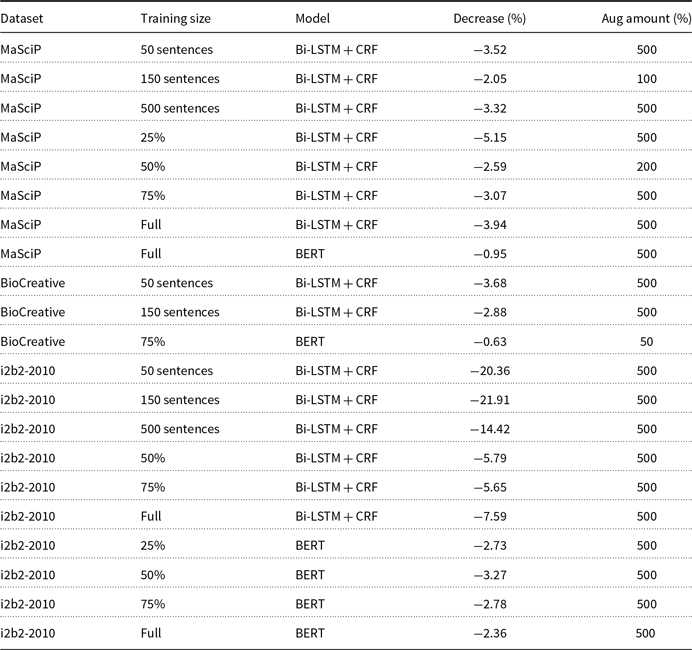
In order to assess whether models are truly worsened by large amounts of data augmentation, we developed Tables 10 and 11, which followed a similar process as Table 9: first, we selected the models with the most significant decrease in average F1-score and the models without data augmentation for each of the 76 aforementioned groups. Second, we performed paired Student’s t-tests with a significance level of 0.05 to determine if the difference in average F1-score between the worst model and the model without data augmentation is statistically significant, provided that the worst model is not the model without data augmentation (i.e., when every amount of data augmentation improved that group of models). We identified 44 models that exhibit statistically significant decreases in performance, with 23 identified by MR and 21 by CWR. We observed that the vast majority of these models were affected by the largest amount of data augmentation in our experiments (500%), indicating that the introduction of large amounts of data augmentation may introduce noise into the dataset rather than merely reflecting statistical variance.
Summary of models worsened by augmentation (MR)

Summary of models worsened by augmentation (CWR)

The results obtained in these experiments show that there is an unfilled potential for the improvement of low-resource NER models, where all models of the studied datasets have below 90% F1-score. Compared to other datasets of high-resource domains studied in the literature, where the quality of the model is higher (Yadav and Bethard Reference Yadav and Bethard2018; Li et al. Reference Li, Sun, Meng, Liang, Wu and Li2020; Zhong and Chen Reference Zhong and Chen2021; Wang et al. Reference Wang, Jiang, Bách, Wang, Huang, Huang and Tu2021a; Zhong and Chen Reference Zhong and Chen2021), there is still a margin for improvement of low-resource NER models.
5.3 Practical recommendations for data augmentation in low-resource NER
Based on the empirical evidence presented in Sections 5.1 and 5.2, we summarize below practical recommendations for applying data augmentation in low-resource NER settings.
First, data augmentation should be considered primarily in genuinely low-resource regimes. In our experiments, statistically significant improvements were observed almost exclusively for small training subsets (typically fewer than 500 sentences). For larger subsets, augmentation rarely improved performance and often degraded it.
Second, moderate amounts of augmentation should be preferred over aggressive augmentation. The largest augmentation rate evaluated (500%) was responsible for the majority of statistically significant performance degradations, indicating that excessive augmentation tends to introduce noise rather than useful variability.
Third, CWR is generally a safer default than MR. Across datasets and models, CWR produced more statistically significant improvements and fewer severe degradations, suggesting that contextual augmentation of non-entity tokens better preserves sentence validity.
Finally, BERT-based NER models benefit more consistently from data augmentation than Bi-LSTM + CRF models. Most improvements were observed for BERT, whereas Bi-LSTM + CRF models were more frequently harmed, particularly under large augmentation rates.
Overall, while no single augmentation configuration can be recommended universally, these results delineate clear boundaries within which data augmentation is more likely to be beneficial and less likely to be harmful.
6. Conclusion and future work
In this paper, we investigate the effectiveness of two representative data augmentation techniques, MR (Dai and Adel Reference Dai and Adel2020) and CWR (Jiao et al. Reference Jiao, Yin, Shang, Jiang, Chen, Li, Wang and Liu2020), when used for NER tasks on low-resource domain datasets, which contain long-tail entities. In our study, we use two popular neural architectures for NER, Bi-LSTM + CRF and BERT, to generate several different NER models with distinct configurations. For training, these configurations used subsets of varying sizes of the original datasets.
Specifically, we generated 532 groups of 10 models, from which we measure the average F1-score and pick the best one for each subset. This yields 76 averages, 10 of which are considered statistically significant improvements after using text augmentation. As these improved models were those trained using smaller subsets, our study further supports the notion that data augmentation for NER models is more effective for smaller training sets than for larger ones. We also verify that there is no predetermined optimal number of augmented instances that will certainly improve the model. Not only that, but also augmentation also reduces model quality in several other cases. Thus, NER practitioners should test different amounts, especially if the augmentation technique is prone to introducing spurious instances in the training data. We also show that, for the datasets studied in this paper, CWR yields models that are better than MR, and that data augmentation suits BERT NER models better than Bi-LSTM + CRF.
Our work on augmentation for NER in low-resource domains indicates that this landscape can still be improved in both the case of top-notch but high-demanding architectures, such as BERT, or in the case of competitive but less-demanding architectures, such as Bi-LSTM + CRF. While our study provides valuable insights into the effectiveness of data augmentation techniques for NER on low-resource domains, it also highlights several limitations that warrant further investigation.
Firstly, our findings show that data augmentation can introduce noise into the training data, which can potentially degrade the quality of the NER models. This is particularly evident in our experiments with larger subsets of the datasets, where data augmentation often resulted in lower average F1-scores compared to models trained without augmented data. This suggests that while data augmentation can help to increase the quantity of training data, it may also compromise its quality, leading to overfitting or poor generalization to unseen data.
To mitigate this issue, future research could explore more sophisticated or controlled augmentation techniques that minimize the introduction of noise. For example, one could consider techniques that take into account the semantic consistency between the original and augmented sentences, or that adjust the degree of augmentation based on the complexity or diversity of the dataset.
Secondly, our study assumes that all entities are equally important and should be augmented at the same rate. However, in many real-world applications, some entities may be more critical or rare than others, and therefore might benefit more from augmentation. Future work could investigate differential augmentation strategies that prioritize certain entity types based on their importance or rarity.
Lastly, our study focuses on two specific NER architectures (Bi-LSTM + CRF and BERT) and two text augmentation techniques (MR and CWR). While these methods are widely used and have shown promising results in many NLP tasks, they may not be optimal or applicable for all types of NER problems or domains. Future research should consider exploring other architectures and techniques (e.g., knowledge graphs to suggest new entities), as well as hybrid or ensemble methods that combine the strengths of multiple approaches. Also, as future work, we intend to explore the use of generative models, particularly large language models (LLMs), due to recent experiments adopting them in NER. We aim to implement LLMs not only as advanced NER models but also as innovative data augmentation techniques. By leveraging the generative capabilities of these models, we anticipate enhancing the robustness and accuracy of our NER systems while simultaneously enriching our datasets. This dual approach could lead to improved performance in diverse NER tasks and better adaptability to various domains.
Data availability statement
All datasets and subsets used in this project and all notebooks generated during the experiments are available in the following repository: https://github.com/arttorres0/augmented-ner-model.
Funding statement
This research is partially supported by Jusbrasil under the UFAM/Jusbrasil Doctoral Fellowship granted to Arthur Torres; by Diffbot Inc.; by CNPq under INCTs IAIA (406417/2022-9) and TILD-IAR (408490/2024-1), Project Rule2 DB (UNIVERSAL Proc. 400936/2025-9), and individual grants to Altigran da Silva (301925/2025-9 and Edleno Moura (310573/2023-8); by the Coordination for the Improvement of Higher Education Personnel-Brazil (CAPES) financial code 001; and by FAPEAM under the POSGRAD 2025 Program and the NeuralBond Project (UNIVERSAL 2023 Proc. 01.02.016301.04300/2023-04).
Competing interests
The authors have no conflicts of interest to declare that are relevant to the content of this article.



 Open access
Open access