

1. Introduction
This paper will show how to use fine-tuning on a few benchmarks such as SQuAD and GLUE, as well as a task based on ImageNet. In our previous Emerging Trends article on inference (Church et al. Reference Church, Yuan, Guo, Wu, Yang and Chen2021), we posted code on GitHubFootnote 1 because code in blogs and hubs tends to be too demanding for the target audience (poets). This paper will discuss code on PaddleHubFootnote 2 and HuggingFaceHub,Footnote 3 since these examples are very well done, and the target audience for this paper is more advanced (and less inclusive).
Finally, we will end on a cautionary note. Based on the success of fine-tuning on a number of benchmarks, one might come away with the impression that fine-tuning is all we need. However, we believe the glass is half-full: while there is much that can be done with fine-tuning, there is always more to do. Fine-tuning has become popular recently, largely because it works so well on so many of our most popular benchmarks. But the success of fine-tuning can also be interpreted as a criticism of these benchmarks. Many of these benchmarks tend to focus too much on tasks that are ideal for fine-tuning, and not enough on opportunities for improvement.
1.1 Pre-training, fine-tuning, and inference
Much of the recent literature in deep nets involves three processes:
-
1. Pre-training base (foundation) models
• Language: BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), ERNIE (Sun et al. Reference Sun, Wang, Li, Feng, Tian, Wu and Wang2020; Sun et al. Reference Sun, Wang, Feng, Ding, Pang, Shang, Liu, Chen, Zhao and Lu2021)
• Speech: wav2vecFootnote 4 (Baevski et al. Reference Baevski, Zhou, Mohamed and Auli2020)
• Vision: ResNet (He et al. Reference He, Zhang, Ren and Sun2016), VIT (Wu et al. Reference Wu, Xu, Dai, Wan, Zhang, Yan, Tomizuka, Gonzalez, Keutzer and Vajda2020)
2. Fine-tuning (this paper)
3. Inference (Church et al. Reference Church, Yuan, Guo, Wu, Yang and Chen2021).
There will be relatively little discussion of inference in this paper since that topic was covered in our previous article, except to point out that inference is the least demanding of the three tasks, in terms of both programming skills and computational resources. Inference takes a fine-tuned model as input, as well as features, x, for a novel input, and outputs a predicted label, 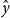 $\hat{y}$. The examples discussed in footnote Footnote 1 are short (10–100 lines of code) and easy to read. They cover a wide range of use cases in natural language processing (sentiment analysis, named entity recognition, question answering (QA/SQuAD), machine translation), as well as use cases in vision and speech. From a commercial perspective, inference is probably more profitable than training.
$\hat{y}$. The examples discussed in footnote Footnote 1 are short (10–100 lines of code) and easy to read. They cover a wide range of use cases in natural language processing (sentiment analysis, named entity recognition, question answering (QA/SQuAD), machine translation), as well as use cases in vision and speech. From a commercial perspective, inference is probably more profitable than training.
The literature, however, focuses on training, because training is more challenging than inference. The terminology is still in a state of flux. Base models are sometimes referred to as pre-trained models (PTMs) (Han et al. Reference Han, Zhang, Ding, Gu, Liu, Huo, Qiu, Zhang, Han, Huang, Jin, Lan, Liu, Liu, Lu, Qiu, Song, Tang, Wen, Yuan, Zhao and Zhu2021) or Foundation Models (Bommasani et al. Reference Bommasani, Hudson, Adeli, Altman, Arora, von Arx, Bernstein, Bohg, Bosselut, Brunskill, Brynjolfsson, Buch, Card, Castellon, Chatterji, Chen, Creel, Davis, Demszky, Donahue, Doumbouya, Durmus, Ermon, Etchemendy, Ethayarajh, Fei-Fei, Finn, Gale, Gillespie, Goel, Goodman, Grossman, Guha, Hashimoto, Henderson, Hewitt, Ho, Hong, Hsu, Huang, Icard, Jain, Jurafsky, Kalluri, Karamcheti, Keeling, Khani, Khattab, Kohd, Krass, Krishna, Kuditipudi, Kumar, Ladhak, Lee, Lee, Leskovec, Levent, Li, Li, Ma, Malik, Manning, Mirchandani, Mitchell, Munyikwa, Nair, Narayan, Narayanan, Newman, Nie, Niebles, Nilforoshan, Nyarko, Ogut, Orr, Papadimitriou, Park, Piech, Portelance, Potts, Raghunathan, Reich, Ren, Rong, Roohani, Ruiz, Ryan, RÉ, Sadigh, Sagawa, Santhanam, Shih, Srinivasan, Tamkin, Taori, Thomas, TramÈr, Wang, Wang, Wu, Wu, Wu, Xie, Yasunaga, You, Zaharia, Zhang, Zhang, Zhang, Zhang, Zheng, Zhou and Liang2021). These models are typically pre-trained on large quantities of data, often without annotations/labels, as shown in Tables 1–2.
Base models are large in two respects: model size and training data
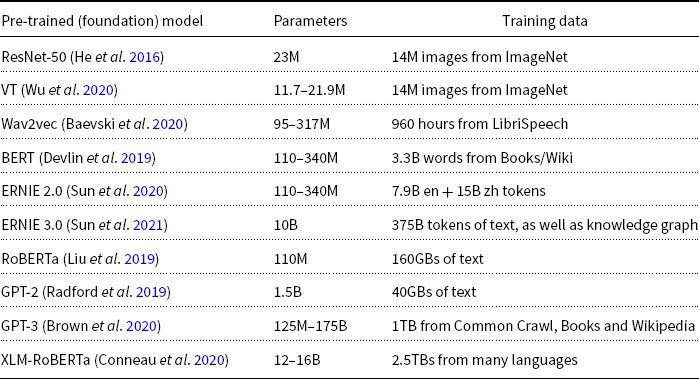
Some popular datasets for training base models

With the exception of GPT-3 and ERNIE 3.0, most PTMs in the literature can be downloaded from hubs such as PaddleHub,Footnote 5 HuggingFaceHub,Footnote 6 and FairseqFootnote 7 (Ott et al. Reference Ott, Edunov, Baevski, Fan, Gross, Ng, Grangier and Auli2019).
Historically, many of these hubs started with models for natural language processing, though they are beginning to expand into other fields such as speech (SpeechBrainFootnote 8 (Ravanelli et al. Reference Ravanelli, Parcollet, Plantinga, Rouhe, Cornell, Lugosch, Subakan, Dawalatabad, Heba and Zhong2021) and ESPnetFootnote 9 (Watanabe et al. Reference Watanabe, Hori, Karita, Hayashi, Nishitoba, Unno, Enrique Yalta Soplin, Heymann, Wiesner, Chen, Renduchintala and Ochiai2018; Hayashi et al. Reference Hayashi, Yamamoto, Inoue, Yoshimura, Watanabe, Toda, Takeda, Zhang and Tan2020; Inaguma et al. Reference Inaguma, Kiyono, Duh, Karita, Yalta, Hayashi and Watanabe2020; Li et al. Reference Li, Shi, Zhang, Subramanian, Chang, Kamo, Hira, Hayashi, Boeddeker, Chen and Watanabe2021)) and vision (VITFootnote 10 (Dosovitskiy et al. Reference Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit and Houlsby2021; Tolstikhin et al. Reference Tolstikhin, Houlsby, Kolesnikov, Beyer, Zhai, Unterthiner, Yung, Steiner, Keysers, Uszkoreit, Lucic and Dosovitskiy2021; Steiner et al. Reference Steiner, Kolesnikov, Zhai, Wightman, Uszkoreit and Beyer2021; Chen, Hsieh, and Gong Reference Chen, Hsieh and Gong2021)).
Base models tend to be very general and can be applied to a broad set of downstream applications, which is necessary to make the business case work, since pre-training is expensive.
The terms, pre-training and fine-tuning, became popular following (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), though these terms can be found in earlier work (Howard and Ruder Reference Howard and Ruder2018):Footnote 11
There are two steps in our framework: pre-training and fine-tuning. During pre-training, the model is trained on unlabeled data over different pre-training tasks. For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters. (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019)
Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019) follow this discussion of pre-training and fine-tuning by introducing a running example in their Figure 1, where a large BERT base model is pre-trained on a large corpus of unlabeled training data. Then, at fine-tuning time, the PTM is refined to produce three separate models for three separate downstream tasks: (a) a question answering task (SQuAD), (b) a named entity task, and (c) a task from the GLUE benchmark, MNLI, that involves textual entailment (Dagan, Glickman, and Magnini Reference Dagan, Glickman and Magnini2005). This paper will focus on the fine-tuning proposal in Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019) and will not discuss recently proposed alternatives such as Pattern-Exploiting Training (Schick and Schütze Reference Schick and Schütze2021).
The terms, fine-tuning, transfer learning, and classification/regression heads, are similar to one another, though there are some important differences. Fine-tuning is a relatively new term compared to transfer learning.Footnote 12 Venues such as NeurIPS (formerly NIPS) used to be more theoretical a decade ago. Older papers such as Pan and Yang (Reference Pan and Yang2009) used to provide more definitions; more recent treatments characterize newer terms such as fine-tuning by example without formal definitions.
In contrast to classification/regression heads, fine-tuning implies updates to many/most layers within the model. Classification and regression heads treat the last layer of the model as input features, X, and predict outputs, 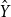 $\hat{Y}$, using classification (if gold labels, Y, are symbolic) or regression (if gold labels, Y, are continuous).
$\hat{Y}$, using classification (if gold labels, Y, are symbolic) or regression (if gold labels, Y, are continuous).
1.2 Labeled/unlabeled training data
Fine-tuning is exciting for a number of reasons. One of many reasons is the combination of labeled and unlabeled training data. There has been a long tradition in artificial intelligence (AI), dating back to semi-supervised learning (Zhu Reference Zhu2005) and co-training (Blum and Mitchell Reference Blum and Mitchell1998) and probably earlier discussions dating back to 1970s, in search of ways to combine small amounts of labeled training data with vast quantities of unlabeled training data. In many use cases, it is possible to find vast quantities of unlabeled data. Since labeled data tend to be much harder to come by, it is desirable to find ways to achieve high performance with as little labeled data as possible.
Labeled data tend to be expensive in a number of respects: money, time, grief, unreliable labels, and unfair labor practices. It has become standard practice to use Amazon Mechanical Turk to label data (Callison-Burch Reference Callison-Burch2009; Finin et al. Reference Finin, Murnane, Karandikar, Keller, Martineau and Dredze2010; Pavlick et al. Reference Pavlick, Post, Irvine, Kachaev and Callison-Burch2014; Nangia and Bowman Reference Nangia and Bowman2019), though there are many concerns with this practice, including questions about the so-called “gig economy” and invisible labor (Hara et al. Reference Hara, Adams, Milland, Savage, Callison-Burch and Bigham2018).Footnote 13, Footnote 14
In language applications, pre-training typically uses unlabeled data and fine-tuning uses labeled data. In vision and speech, both pre-training and fine-tuning are based on labeled data, though the labels for pre-training may be quite different from the labels for fine-tuning. In Section 2.1, for example, we will discuss a vision classification task where pre-training uses 1000 classes from ImageNet and fine-tuning uses 5 different classes (flowers). It is amazing that fine-tuning works as well as it does, even when fine-tuning is given a surprisingly small training set of flowers. It appears that fine-tuning is “unreasonably effective” in transferring knowledge from pre-trained base models (ResNet for ImageNet) to novel tasks (flower classification).
It is common to refer to training with labels as supervised learning and training without labels as unsupervised learning. Supervised methods are provided both input features, x, and output labels, y, at training time, whereas unsupervised methods are given x but not y. In both cases, the task is to learn a model that can be applied to novel inputs to predict labels, 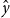 $\hat{y}$, at inference time. Evaluations compare the predicted labels,
$\hat{y}$, at inference time. Evaluations compare the predicted labels, 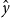 $\hat{y}$, to gold labels, y, in a held out test set.
$\hat{y}$, to gold labels, y, in a held out test set.
1.3 Balance, samples, and populations of interest
Fine-tuning offers a promising way to deal with various realities. Domain shift happens. It is very likely that a real user will ask a real product to do something that is very different from the training data. It is also likely that PTMs will need to be updated periodically, as the world changes.
Of course, it would be better to pre-train on more relevant data in the first place. In practice, the data for pre-training tend to be more catch-as-catch-can than a balanced corpus. Balance is taken more seriously in lexicography than machine learning:
It was also believed that quality (balance) mattered, but there were few, if any, empirical studies to justify such beliefs. It was extremely controversial when engineers such as Mercer questioned these deeply held beliefs in 1985Footnote 15 with: “there is no data like more data.” Most people working on corpus-based methods in lexicography were deeply committed to balance as a matter of faith, and were deeply troubled by Mercer’s heresy. (Church and Bian Reference Church and Bian2021)
In contrast to datasets such as those in Table 2, lexicographers prefer balanced corpora such as the Brown Corpus (Kučera and Francis 1967; Francis and Kučera 1979; Francis and Kučera 1982) and British National CorpusFootnote 16 (BNC) (Aston and Burnard Reference Aston and Burnard1998; Burnard Reference Burnard2002). The Brown Corpus was designed to be a sample of contemporary American English. The BNC is similar but for British English. The BNC is also larger and more recent, though neither the Brown Corpus nor BNC would be considered large or recent by modern standards. The Brown Corpus contains 1M words from the 1960s, and the BNC contains 100M words from the 1990s.
There is some evidence from psycholinguistics supporting both sides of the debate between balance and catch-as-catch-can; correlations of corpus statistics and psycholinguistic norms tend to improve with quality (balance) as well as quantity (corpus size) (Rapp Reference Rapp2014a; Rapp Reference Rapp2014b).
Fine-tuning could be viewed as a mechanism to correct for mismatches between training data and the population of interest. We tend to think of the test data as the population of interest, but actually, what really matters is the data that will be seen at inference time. Evaluations assume that the test set is representative of what real users will use the system for, but that may or may not be the case. In practice, the test set is often very similar to the training set, probably more similar than either are to what real users are likely to expect from a real product. This is especially likely to be the case if test sets and training sets are collected before the product is shipped, and the world changes after the product ships and before users have a chance to use the product.
It is important to match test and training data as much as possible to application scenarios. Consider medical applications and BioBERT (Lee et al. Reference Lee, Yoon, Kim, Kim, Kim, So and Kang2020). BioBERT is more effective than BERT on a number of medical benchmarks, probably because BioBERT was trained on dataFootnote 17 that are more appropriate for those use cases.
In short, it is often worth the effort to train on data that are as representative as possible to the population of interest, namely inputs that likely to be seen at inference time.
1.4 Amortizing large upfront pre-training costs over many apps
Factoring the training task into pre-training and fine-tuning makes it possible to amortize large upfront investments in pre-training over many use cases. The business case for factoring is attractive because fine-tuning is relatively inexpensive compared to pre-training.
PTMs are somewhat similar to general purpose CPU chips. In the early days of Intel, they had a number of customers that wanted special purpose chips. Rather than designing a different custom chip for each customer, Intel invested in general purpose technology that could be customized as needed for many different use cases. In retrospect, the wisdom of general purpose solutions seems self-evident, though it was far from obvious at the time (Faggin Reference Faggin2009).
1.5 Costs
This paper will focus on fine-tuning, which is more demanding than inference but less demanding than pre-training base models, in terms of both programming prerequisites and computational resources. As for computational resources, inference can be done without GPUs, fine-tuning requires at least one GPU, and pre-training is typically performed on a large cluster of GPUs. As for speed, inference takes seconds/minutes, fine-tuning takes hours, and pre-training takes days/weeks.
Costs tend to increase with both the size of the model and the size of the data. Current base models are large in both respects, as shown in Tables 1–2. Going forward, we can expect base models to become even larger in the future (Hestness et al. Reference Hestness, Narang, Ardalani, Diamos, Jun, Kianinejad, Patwary, Ali, Yang and Zhou2017; Kaplan et al. Reference Kaplan, McCandlish, Henighan, Brown, Chess, Child, Gray, Radford, Wu and Amodei2020).
Most base models in the literature were trained in well-funded industrial laboratories that have access to large GPU clusters, and large datasets. Training base models may be too expensive for universities and start-up companies as discussed in Section 1.3 of Bommasani et al. (Reference Bommasani, Hudson, Adeli, Altman, Arora, von Arx, Bernstein, Bohg, Bosselut, Brunskill, Brynjolfsson, Buch, Card, Castellon, Chatterji, Chen, Creel, Davis, Demszky, Donahue, Doumbouya, Durmus, Ermon, Etchemendy, Ethayarajh, Fei-Fei, Finn, Gale, Gillespie, Goel, Goodman, Grossman, Guha, Hashimoto, Henderson, Hewitt, Ho, Hong, Hsu, Huang, Icard, Jain, Jurafsky, Kalluri, Karamcheti, Keeling, Khani, Khattab, Kohd, Krass, Krishna, Kuditipudi, Kumar, Ladhak, Lee, Lee, Leskovec, Levent, Li, Li, Ma, Malik, Manning, Mirchandani, Mitchell, Munyikwa, Nair, Narayan, Narayanan, Newman, Nie, Niebles, Nilforoshan, Nyarko, Ogut, Orr, Papadimitriou, Park, Piech, Portelance, Potts, Raghunathan, Reich, Ren, Rong, Roohani, Ruiz, Ryan, RÉ, Sadigh, Sagawa, Santhanam, Shih, Srinivasan, Tamkin, Taori, Thomas, TramÈr, Wang, Wang, Wu, Wu, Wu, Xie, Yasunaga, You, Zaharia, Zhang, Zhang, Zhang, Zhang, Zheng, Zhou and Liang2021):Footnote 18
[R]esearch on building foundation [base] models themselves has occurred almost exclusively in industry — big tech companies such as Google, Facebook, Microsoft, or Huawei
The cost of training base models came up several times at a recent Stanford Workshop on Foundation Models;Footnote 19, Footnote 20 academics may not have the means to train base models, especially if costs continue to escalate.
In addition to concerns in academia, there are also concerns with costs in industry. Larger models are expensive to run in the cloud, and infeasible at the edge (in a phone). These concerns have motivated work on compression methods (Hinton, Vinyals, and Dean Reference Hinton, Vinyals and Dean2015; Howard et al. Reference Howard, Zhu, Chen, Kalenichenko, Wang, Weyand, Andreetto and Adam2017; Cheng et al. Reference Cheng, Wang, Zhou and Zhang2017; Gupta and Agrawal Reference Gupta and Agrawal2020; Su et al. Reference Su, Chen, Feng, Liu, Liu, Sun, Tian, Wu and Wang2021). These methods compress a large model down to a smaller one. In hubs, these smaller models are often labeled as tiny and/or mobile. It appears that the best way to train a tiny mobile model is to train a large model and then compress it. One might have thought that one could get to a better place directly, by training the tiny model in the obvious way, but experience suggests that indirect route via a larger model is more effective than the direct route.
Compression methods may also play an important role for energy policies and global warming. There has been some concern about energy consumption during training (Strubell, Ganesh, and McCallum Reference Strubell, Ganesh and McCallum2019), but actually, energy consumption during training is relatively small compared to energy consumption at inference time. If a billion users use your speech recognition model every day for a few years, then the one-time upfront investments to train the model are a round-off error compared to the recurring costs of running the model in production. Assuming that energy costs (and all other costs) scale with the size of the model, then the size of the model in production is far more important than the size of the model during training. Thus, we should not feel too guilty about training a large model, as long as we compress the model before we ship it to a billion users.
1.6 Further reading
It is hard to keep up with all the recent progress. Performance on benchmarks keeps going up and up and up. Many of the papers are very recent. In addition to the papers cited in this paper, an excellent overview of recent progress can be found here.Footnote 21 There are also many excellent blogs, tutorials, and surveys on fine-tuning and pre-trainingFootnote 22, Footnote 23, Footnote 24 (Ruder et al. Reference Ruder, Peters, Swayamdipta and Wolf2019; Han et al. Reference Han, Zhang, Ding, Gu, Liu, Huo, Qiu, Zhang, Han, Huang, Jin, Lan, Liu, Liu, Lu, Qiu, Song, Tang, Wen, Yuan, Zhao and Zhu2021).
2. Examples of fine-tuning
This section will discuss three examples of fine-tuning. Code is based on PaddleHub and HuggingFaceHub.
2.1 Flowers: An example of fine-tuning
As mentioned in Section 1.2, fine-tuning is “unreasonably effective” in transferring knowledge from pre-trained base models (ResNet for ImageNet) to novel tasks (flower classification). This subsection will discuss a simplified version the 102 Category Flower DatasetFootnote 25 (Nilsback and Zisserman Reference Nilsback and Zisserman2008). Performance on that task continues to improve.Footnote 26 Top performing systems (Kolesnikov et al. Reference Kolesnikov, Beyer, Zhai, Puigcerver, Yung, Gelly and Houlsby2020) are using fine-tuning, as well as more data and more ideas. The simplified version uses 5 classes as opposed to 102.
There are a number of tutorials that explain how to fine-tune a base model to classify flowers.Footnote 27 We have posted some code for this example on GitHub.Footnote 28 Our code is based on an example from PaddleHub.Footnote 29
These examples start with ResNetFootnote 30 (He et al. Reference He, Zhang, Ren and Sun2016) as a pre-trained base model. The base model was trained on 14M images and 1000 classes from ImageNet (Deng et al. Reference Deng, Dong, Socher, Li, Li and Fei-Fei2009). The fine-tuning task is to modify the base model to recognize 5 types of flowers instead of the 1000 ImageNet classes. The 5 flower classes are: rose, tulip, daisy, sunflower, and dandelion. Six examples of flowers and class labels are shown in Figure 1.
Some pictures of flowers with labels.

For fine-tuning, we are given a training set and a validation set. Both sets consist of pictures of flowers, x, labeled with the 5 classes, y. There are 2915 flowers in the training set, and 383 flowers in the validation set. The validation set is used to measure error. That is, after fine-tuning, the model is given a picture from the validation set, x, and asked to predict a label, 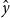 $\hat{y}$. These predictions,
$\hat{y}$. These predictions, 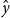 $\hat{y}$, are compared with gold labels, y, to produce a score.
$\hat{y}$, are compared with gold labels, y, to produce a score.
At inference/evaluation time, we are given a novel picture, x, and a set of possible class labels such as the 5 classes of flowers. The model predicts a label, 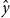 $\hat{y}$, one of the class labels. Before fine-tuning, the model is performing at chance since the ImageNet uses different classes. After fine-tuning, the model is considerably better than chance, though far from state of the art (SOTA).
$\hat{y}$, one of the class labels. Before fine-tuning, the model is performing at chance since the ImageNet uses different classes. After fine-tuning, the model is considerably better than chance, though far from state of the art (SOTA).
Fine-tuning is just one of many tools in the toolbox. If one wants to top the leaderboard, one needs an “unfair advantage,” something better than what the competition is likely to do. Since fine-tuning is now well established within the literature, one should assume that the competition is likely to do that. One is unlikely to do much better than the competition (or much worse than the competition) if one uses obvious methods (such as fine-tuning) in obvious ways.
2.2 SQuAD: Another example of fine-tuning
SQuAD 1.1 (Stanford Question Answering Dataset) (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) and SQuAD 2.0 (Rajpurkar, Jia, and Liang Reference Rajpurkar, Jia and Liang2018) are a popular benchmark for question answering (Q&A). Several solutions are posted on GitHub.Footnote 31 These are all very short (less than 40 lines) and easy to read. There are many blogsFootnote 32 and videos discussing inference with BERT-like models that have been fine-tuned for SQuAD. This video has 32k views on YouTube.Footnote 33 The large number of views makes it clear that many people want to know how to do this.
What is the SQuAD task? The inputs, x, are questions and short documents (containing no more than 512 subword tokens). Outputs, y, are answers. By construction, answers are spans, substrings of the input documents. For example:
• Input Document: The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title.
• Input Question: What does AFC stand for?
• Output Gold Answer: American Football Conference
The solutions above download a model that has already been fine-tuned for SQuAD. Suppose we want to fine-tune our own model. How can we do that? We have posted a short shell script on GitHubFootnote 34 based on an example from HuggingFaceHub.Footnote 35 HuggingFaceHub’s page reports F1 of 88.52 and exact_match accuracy of 81.22. We ran our shell script five times and obtained slightly worse results: F1 of 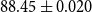 $88.45 \pm 0.020$, and exact_match of
$88.45 \pm 0.020$, and exact_match of 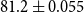 $81.2 \pm 0.055$. Standard deviations are small but non-zero, because results vary slightly from one run to another. If you run these scripts, your results are likely to be similar, though not exactly the same as what is reported here.
$81.2 \pm 0.055$. Standard deviations are small but non-zero, because results vary slightly from one run to another. If you run these scripts, your results are likely to be similar, though not exactly the same as what is reported here.
Our script is borrowed from the first (and simplest) solution on the HuggingFaceHub page in footnoteFootnote 35. That page provides a number of variations of this solution. The last solution on that page is considerably better in terms of F1 (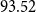 $93.52$). There are a number of factors that contribute to these improvements, including: (a) better pre-trained base models, (b) better hyperparameters, and (c) more GPUs.
$93.52$). There are a number of factors that contribute to these improvements, including: (a) better pre-trained base models, (b) better hyperparameters, and (c) more GPUs.
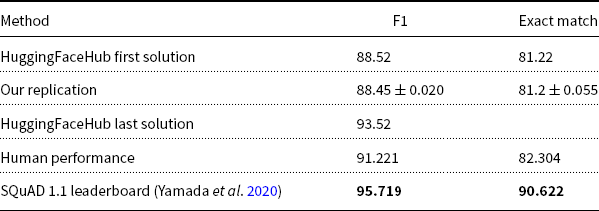
Table 3 shows the numbers reported above, as well as one more row for the SOTA solution (Yamada et al. Reference Yamada, Asai, Shindo, Takeda and Matsumoto2020) from two leaderboards: (a) SQuAD 1.1Footnote 36 and (b) papers with code.Footnote 37 Estimates for human performance from Rajpurkar et al. (Reference Rajpurkar, Zhang, Lopyrev and Liang2016) are posted on the SQuAD 1.1 leaderboard.
Some SQuAD 1.1 results
2.2.1 Alchemy, unrealistic expectations, and other concerns
The simple description of fine-tuning sounds simple, though there are many details that can make a big difference in practice for reasons that are not well understood. NeurIPS (formerly NIPS) used to be more rigorous and more theoretical, but these days, the practice is well ahead of the theory. Ali Rahimi and Ben Recht suggested that “machine learning has become alchemy” in a controversial test-of-time-award talk at NIPS-2017.Footnote 38
There have been many booms and busts in AI over the decades (Church Reference Church2011). Expectations tend to increase during booms, inevitably leading to the next bust. There can be benefits to hyping our successes, especially in the short-term, but in the long-term, it is risky (and counter-productive) to set unrealistic expectations.
While fine-tuning performance is impressive on the SQuAD benchmark, and may exceed human performance in certain evaluations, we should not fool ourselves into believing that we have accomplished more than we have:Footnote 39
Microsoft researchers have created technology that uses artificial intelligence to read a document and answer questions about it about as well as a human…. Ming Zhou, assistant managing director of Microsoft Research Asia, said the SQuAD dataset results are an important milestone, but… people are still much better than machines at comprehending … language… This milestone is just a start.Footnote 40
Based on successes such as SQuAD, the community may believe that modern methods based on BERT will out-perform older rule-based systems, at least for SQuAD-like questions. However, for special cases of SQuAD questions such as acronyms: AFC (American Football Conference), we found that a rule-based solution, Ab3P (Sohn et al. Reference Sohn, Comeau, Kim and Wilbur2008), is better than BERT (Liu et al. Reference Liu, Huang, Cai and Church2021). BERT-type models may not be the best way to capture constraints on spelling/sound such as acronyms, puns, alliteration, rhymes, and meter (e.g., iambic pentameter).
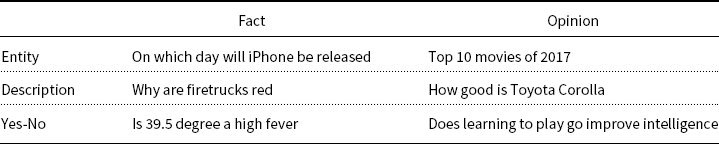
While fine-tuning works well on simple factoid questions in SQuAD, it is not clear what will be needed to deal with real questions in such search logs such as those in Table 4 from the DuReader benchmarkFootnote 41 (He et al. Reference He, Liu, Liu, Lyu, Zhao, Xiao, Liu, Wang, Wu, She, Liu, Wu and Wang2018).
English glosses of six types of questions from Chinese search logs
2.3 GLUE: Yet another example of fine-tuning
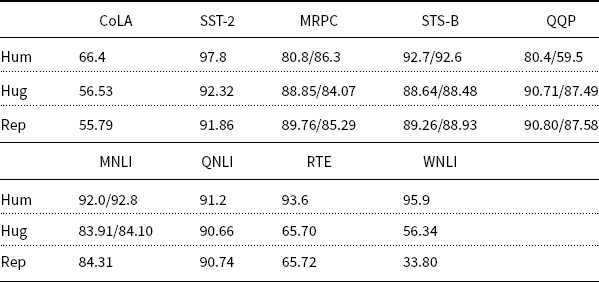
Our final example of fine-tuning is the GLUE benchmark (Wang et al. Reference Wang, Singh, Michael, Hill, Levy and Bowman2018). The benchmark consists of 9 tasks, as shown in Table 5. There are 9 training sets and 9 test sets for each of the 9 tasks. Fine-tuning combines a base model such as BERT and a training set to produce a model. In this way, we construct 9 models and evaluate them on the 9 test sets. The 9 tasks in the GLUE benchmark use different metrics, as documented in the HuggingFace tutorial for fine-tuning for GLUE.Footnote 42
GLUE Results for Human, HuggingFaceHub and Our replication
As for evaluation, many of the tasks score by accuracy, though some score by F1 and correlation. In all cases, larger numbers are better. Performance is reported on the leaderboard.Footnote 43 SuperGLUEFootnote 44 (Wang et al. Reference Wang, Pruksachatkun, Nangia, Singh, Michael, Hill, Levy, Bowman, Wallach, Larochelle, Beygelzimer, d’ Alché-Buc, Fox and Garnett2019) is an updated version of GLUE.Footnote 45
Leaderboards rank systems by average performance. It may not be appropriate to average metrics of performance based on incompatible scales: accuracy, F1, and correlation.
At a recent ACL-2021 workshop on Benchmarking,Footnote 46 John Mashey suggested replacing arithmetic means with geometric means, based on his experience with the SPEC benchmark, an important benchmark for measuring CPU performance over the last few decadesFootnote 47 (Mashey Reference Mashey2005).
Performance on GLUE leaderboards is currently close to human performance.Footnote 48 Estimates of human performance in Table 5 are based on Nangia and Bowman (Reference Nangia and Bowman2019).
The Hug scores in Table 5 are from the URL in footnote Footnote 42. Our replication uses a short shell scriptFootnote 49 that also makes use of the URL in footnote Footnote 42. According to the HuggingFace documentation, all of these fine-tuning tasks can be completed in a few hours on a single GPU. Our replications were run on a single GPU, and none of the tasks took more than a few hours.
The names of the tasks are not that useful for understanding what these tasks are measuring. We find the instructions to the human annotatorsFootnote 50 to be helpful for this purpose. The GLUE tasks tend to reflect the particular interests of the researchers that created the benchmark, and may not be as representative of the larger field of natural language processing.
2.3.1 Winograd schema
Of the 9 tasks, WNLI (Winograd Schema) is the most challenging. The most frequent label baseline is about 65% accurate on this task. Note that both Hug and Rep in Table 5 are well below this baseline. Following Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019), many authors exclude this task because this task is so hard, and also because this task may not be suitable for fine-tuning.
Winograd Schema was designed to be hard for machines but easy for people (Levesque, Davis, and Morgenstern Reference Levesque, Davis and Morgenstern2012). There was a Winograd Schema Challenge at IJCAI-16, where no system did better than chance (Davis, Morgenstern, and Ortiz Reference Davis, Morgenstern and Ortiz2017). The fine-tuning recipe described in this paper is no better than most-frequent-class guessing (65%). Until recently, most systems were no better than guessing, but now, the systems at the top of the leaderboard achieve about 90% on WNLI, closer to human performance of 96% (Nangia and Bowman Reference Nangia and Bowman2019). It is not clear how these systems reach that impressive level of performance, though there are a few recent papers that provide some clues (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019; Sakaguchi et al. Reference Sakaguchi, Le Bras, Bhagavatula and Choi2020).
3. GPT-3 teaser
Recently, there has been quite a bit of excitement surrounding GPT-3. GPT-3 is a large PTM, but unlike the other models in Table 1, GPT-3 is probably not suitable for fine-tuning. In addition, access to GPT-3 is limited to a relatively small set of people that have been granted permission to use the beta version of the API.
GPT-3 is amazingly fluent, but not credible enough for fact checking:
To the extent that a use case places importance on the truth of the outputs provided, it is not a good fit for GPT-3. (Dale Reference Dale2021)
Following a suggestion by Percy LiangFootnote 51 at a recent workshop at Stanford,Footnote 52 we gave GPT-3 the prompt: “In 1885, Stanford University was…” GPT-3 produced the following:
-
• In 1885, Stanford University was founded by Leland and Jane Stanford in memory of their only child, recently deceased.
-
• In 1887, the first successful gasoline powered automobile in the United States was manufactured in Cleveland, Ohio by Charles and Frank Duryea.
-
• In 1887, the American Federation of Labor was founded.
-
• In 1887, the Salvation Army was formally incorporated in London, England.
-
• In 1890, the American Red Cross was established by Clara Barton.
-
• In 1891, the Salvation Army in the United States was founded.
-
• In 1892, the Boston Red Sox baseball team was established.
-
• In 1893, the first Miss America Pageant was held in New York City.
-
• In 1895, the National Association for the Advancement of Colored People (NAACP) was founded.
-
• In 1895, the National Council of Women of the United States was founded.
-
• In 1897, the Boston Symphony Orchestra gave its first performance.
-
• In 1897, the first American open tennis tournament was held at the Newport Casino in Rhode Island.
-
• In 1897, the first practical typewriter was patented by Christopher Sholes.
-
• In 1897, the first winner of the Nobel Peace Prize was born.
-
• In 1899, the first automobile race was held at Narragansett Park in Cranston, Rhode Island.
-
• In 1900, the first automobile race was held at Narragansett Park in Cranston, Rhode Island.
-
• In 1900, the National Association for the Advancement of Colored People (NAACP) was founded.
The output feels like a farce. The first few statements are reasonably plausible, especially when the prompt matches a Wikipedia page. But the argument quickly degenerates into contradictions, tautologies, repetitions, etc. Many of the dates are wrong. A few are off by decades.
There are concerns about bias (Abid, Farooqi, and Zou Reference Abid, Farooqi and Zou2021). While there are plenty of awful pages on the web, we are even more concerned about GPT-3’s tendency to (mis)-quote authors out-of-context without attribution. Misquoting seems like a more dangerous violation of ethics than repeating what someone actually said. GPT-3 has a tendency to make up “facts,” and say them in a way that people might actually believe what it says.
There are quite a few blogsFootnote 53 that attempt to characterize what GPT-3 “understands” and what it does not “understand.” A number of evaluations are currently under review. One can probably show that GPT-3 can add two small numbers,Footnote 54 but when asked to add two big numbers, or to compute more complicated expressions, it just makes up answers.
Timelines such as the one above should be in chronological order, but GPT-3 does not appear to understand time, space, negation, etc. Given observations like these, it has been suggested that GPT-3 might be more appropriate for generating fiction (and poetry) than nonfiction. But GPT-3 does not appear to master rhyming or meter.
There was another case where we kept asking GPT-3 to generate more and more output because the argument always seemed to be just about to get to the point. But then we realized that we were reading into the argument more than there was. The argument was never going to get to the point, because there was no point (or even a point of view). The argument was not going anywhere. There was no structure to the argument. In fact, it is probably a mistake to refer to output from GPT-3 as an “argument.”
As suggested in Dale (Reference Dale2021), GPT-3 must be good for something. It is so amazingly fluent. One possible use case is to help language learners (and others) to write more fluent prose. With an appropriate user interface, it should be possible to provide authors with the opportunity to improve fluency without changing the content too much. In this way, it should be possible to address Pascale Fung’s concerns about “safety” in her comments at the workshop mentioned in footnote Footnote 52.
4. Conclusions
Performance on a number of leaderboards has improved dramatically because of advances in fine-tuning. This paper described three examples of fine-tuning: (a) flowers (Section 2.1), (b) SQuAD (Section 2.2), and (c) GLUE (Section 2.3). In all three cases, we provided a short shell script on GitHub.Footnote 55 These scripts point to tutorials on PaddleHub and HuggingFaceHub (see footnotes 2 and 3). Our replications have performance that is close to the performance reported in the tutorials.
There are many more use cases for fine-tuning. We have used fine-tuning in speech for classifying emotions and Alzheimer’s disease (Yuan et al. Reference Yuan, Cai, Zheng, Huang and Church2021b; Yuan et al. Reference Yuan, Cai, Bian, Ye and Church2021a). Fine-tuning is likely to become one of the more popular methods for an extremely wide range of use cases in many fields including computational linguistics, speech, and vision.
That said, while the performance of fine-tuning is impressive on many benchmarks and may exceed human performance in certain evaluations, we should not fool ourselves into believing that we have accomplished more than we have. There are good reasons for caution, though maybe not for the reasons suggested in Bender et al. (Reference Bender, Gebru, McMillan-Major and Shmitchell2021). The problem is not so much that the models are too big, or that they are just memorizing the training data, but we are concerned about “sucking the oxygen out of the room.” That is, while fine-tuning is addressing many important and practical problems that matter on many benchmarks, there are many other issues that are also important and need to be addressed such as time, space, negation, order, and structure. Fine-tuning is a very effective hammer because many tasks look like nails, but it is unlikely that fine-tuning is all we need, because not all tasks look like nails.







 Open access
Open access