


1. IntroductionFootnote 1
This article examines the role of prosody in the interpretation of two distinct question structures that can convey the non-canonical meaning of surprise: qu’est-ce que (e.g., qu’est-ce que tu racontes?, What is it you tell, ‘What are you talking about?’) and c’est quoi ce NP (e.g., c’est quoi ce truc?, It is what this thing, ‘What is this thing’?) in French. It reports on a perception experiment seeking to determine whether prosodic cues enable listeners to differentiate between the canonical, i.e., information-seeking, construal and the non-canonical, i.e., surprise-disapproval construal of string identical qu’est-ce que questions and c’est quoi ce NP questions. It aims to contribute to a better understanding of the role of prosody in the profiling of questioning speech acts. It is argued that a surprise construal and an information-seeking construal can be distinguished based on prosodic cues. More specifically, a longer duration (in time) of the sentence and a longer duration of the question word are associated with surprise questions. However, this result is reported to be more reliable in the case of c’est quoi ce NP, which turns out to be a more conventionalized surprisal construction than qu’est-ce que questions. First, the theoretical background regarding non-canonical questions is presented in Section 2. Section 3 is devoted to the experimental design of the perception study. Section 4 presents the results of the experiment. Section 5 provides a discussion of those results.
2. Background
In the classical philosophical approach to speech acts (Searle, Reference Searle1969), questions are categorized as directives that have the illocutionary force of requesting information from the addressee. A canonical question is an information-seeking question (ISQ) asked by an ignorant speaker who expects the addressee to be knowledgeable. The illocutionary force of a canonical question matches the interrogative clause type.Footnote 2 More recently, Farkas (Reference Farkas2022, p. 297) refined this definition by associating canonical questions with the following default contextual assumptions made by the discourse participants: speaker ignorance, addressee competence, addressee compliance and issue resolution goal. In a canonical information seeking act, the speaker does not know the answer and assumes the addressee knows the missing information. The issue that is raised is expected to be resolved in the immediate future: “the act of placing an issue on the Table steers the conversation towards a state in which the issue is resolved, as a result of the speech act” (Farkas, Reference Farkas2022, p. 325). A non-canonical question arises when these default assumptions are overridden by a special context or markers that induce special discourse effects. Non-canonical questions have a range of functions that deviate from the information-seeking one. They may introduce bias, a non-neutral epistemic state (either total ignorance or full knowledge in the case of rhetorical questions), or the speaker’s emotional state (see Trotzke (Reference Trotzke2023) for a comprehensive study of all types of non-canonical questions). They are traditionally viewed as indirect speech acts (Celle, Reference Celle2018) and their form and prosody are expected to differ from those of canonical questions. Non-canonical questions typically highlight an element in the information structure and convey the speaker’s attitude, which may be reflected in marked word order, marked wh-elements, special modal particles (Trotzke, Reference Trotzke2023) or other “indicators of indirectness” (Meibauer, Reference Meibauer2019). Recent studies suggest that far from solely relying on context and conversational implicature, the pairing between certain forms and their non-canonical meaning may result from a “natural convention” (Simons & Zollman, Reference Simons and Zollman2019) derived from pragmatic competence.
In French, speakers have a choice between a wide range of wh-interrogatives to ask a question. A what question may be formed either with the interrogative particle est-ce que adjoined to the interrogative que word (qu’est-ce que tu racontes?, What is it you tell, ‘What are you talking about?’) or using an in situ declarative question (Beyssade, Reference Beyssade2006, p. 181) followed by a right dislocation (c’est quoi ce projet?, It is what this project, ‘What is this project about?’). A third option would be an interrogative marked by subject clitic-verb inversion (Que racontes-tu?, What tell you, ‘What are you talking about?’, possibly followed by a right dislocation (Qu’est-ce ce projet?, What is this project, ‘What is this project about?’), but this is uncommon in spoken language. Several studies (Blanche-Benveniste (Reference Blanche-Benveniste1997), Boucher (Reference Boucher, Breul and Göbbel2010b), Coveney (Reference Coveney2012), Druetta (Reference Druetta, Béguelin, Coveney and Guryev2018) among others) have pointed out that the subject clitic-verb inversion structure has been gradually replaced by the qu’est-ce que question and the in situ question, which both exhibit the preferred word order in French, i.e., SV(O). We further argue that these questions may both be used either canonically to ask for information or non-canonically to indicate the speaker’s surprise and disapproval, meaning ‘What the heck are you talking about?’ and ‘What the hell is this project about?’.
Turning to the syntax-prosody interface, one might suggest that certain prosodic patterns coupled with certain sentence structures contribute to the conventionalization of non-canonical questions, rather than the expression of secondary meaning through indirect speech acts. Surprise questions (SQs)Footnote 3 are a case in point. They emerge as a question type in its own right not only syntactically but also prosodically in languages where the same syntax may be used in canonical and non-canonical questions.Footnote 4 In Estonian, for instance, prosody allows differentiating between string-identical interrogative sentences that may either express surprise or seek information (Asu et al., Reference Asu, Sahkai and Lippus2023). SQs are characterized by enhanced prosody that conveys both surprise, i.e., emotional expressivity (Celle & Pélissier, Reference Celle and Pélissier2022) and non-canonicity, i.e., the non-information-seeking function. Asu et al. (Reference Asu, Sahkai and Lippus2023) argue that emotional expressivity is emphatically realized by a longer duration and a wider pitch range, while non-canonicity is reflected through lower mean, initial and final pitch and creaky voice. They also point out that prosody signals a characteristic information structure by marking counterexpectation with a focal accent.
In French as well, prosody allows differentiating between string-identical SQs and ISQs. As shown in Celle and Pélissier (Reference Celle and Pélissier2022)’s production experiment, qu’est-ce que questions and c’est quoi ce NP (it is what this NP, that is, an in situ question with a right dislocation) exhibit different prosodic features when elicited to express surprise or to request information. While ISQs are characterized by a rising final contour, this is not the case for SQs, which do not seek information but request an explanation for a surprising phenomenon that is put in focus by the wh-word. In SQs, the speaker’s epistemic and affective state is caused by some state of affairs that contradicts their expectations. As in Estonian, lengthening and a slower speech rate have been identified as crucial for marking expressivity and non-canonicity.
This article investigates how prosody helps the hearer to recognize the speaker’s intentions. It reports on a perception experiment based on string-identical questions with c’est quoi ce NP and with qu’est-ce que that participants had to judge. In other words, participants had to rely on prosodic cues such as length and type of contours to identify either the non-emotional information-seeking intent or the underlying expression of surprise. In the latter case, this inferential process amounts to decoding expressed vocal cues, as happens in the process of emotion communication (Scherer et al., Reference Scherer, Clark-Polner and Mortillaro2011). In the literature, accuracy scores in the decoding of emotions are reported to be higher in nonlinguistic emblematic expressions (such as yuck! expressing disgust) or vocal bursts than in speech-embedded emotion expressions, except in the case of surprise (Hawk et al., Reference Hawk, Van Kleef, Fischer and Van Der Schalk2009). Indeed, previous studies on surprise have shown that effortful prosodic features such as expanded pitch range and pitch level trigger an interpretation of surprise in cue words (Lai, Reference Lai2009). However, Lai (Reference Lai2009) also argues that speech-embedded prosody is not sufficient to interpret these cue words as expressing surprise without context. Furthermore, right and really, as isolated cue words, do not pattern alike, which she puts down to the inherent interrogative semantics of really, as opposed to right. This indicates that the prosodic surprise features strengthen the questioning meaning when it is already semantically encoded. Interestingly, her findings suggest a semantic correlation between the surprise and information seeking ratings. In and of themselves, the prosodic correlates of surprise are not sufficient to lead to the perception of questioning. With an underlying questioning semantics, however, questioning is strengthened by surprise prosodic features.
Based on these findings, we hypothesize that prosodic cues are a valid indicator to decode SQs and ISQs, all the more so as the sense of questioning is present in all of our stimuli. Although not information-seeking, SQs are biased questions (Celle & Pélissier, Reference Celle and Pélissier2022) that do request an explanation for what is deemed contrary to the speaker’s expectations.Footnote 5
3. Methods
Participants
Forty-seven participants took part in the experiment at the end of 2021, all with French as a native language, with ages ranging from 19 to 61 (mean: 23.77, median: 21, SD: 7.76). All were residents in Ile-de-France, i.e., in the Paris region. All had normal or corrected to normal vision and audition. Forty-four participants described themselves as bilinguals, i.e., speaking English above a B2 level. Fifteen of the participants grew up with other languages, with a range of various European and non-Indo-European languages.
Materials
Stimuli design: The 24 pairs of sentences from a previous production experiment (Celle & Pélissier, Reference Celle and Pélissier2022) were used, i.e., 12 pairs of string-identical SQs and ISQs with qu’est-ce que and 12 pairs with c’est quoi ce NP. As the goal of this experiment was to see whether listeners could rely on prosodic cues produced by speakers to differentiate between the canonical and non-canonical interpretation of the sentence, we used the recordings obtained from the production experiment instead of having the stimuli recorded by a trained speaker. This guarantees that our results are not the product of the trained speaker making an overt difference between the two conditions during the recording phase, but reflect perception of what speakers produce (more) naturally.Footnote 6 The production experiment yielded recordings from 19 French speakers who each recorded three times half the material (each sentence was only recorded in its ISQ or SQ version). For the perception experiment, we chose to have two repetitions of each item in each condition (i.e., 2 repetitions of each of the 12 pairs with C’est quoi and 12 pairs with Qu’est-ce que), yielding a total of 96 stimuli to select. The full list of stimuli is available in the Appendix.
The selection procedure for the specific items to be used as stimuli went as follows. First, all male speakers were removed from the pool to guarantee more harmony in the stimuli.Footnote 7 Second, the first author of this article pre-selected recordings from the production experiment that i) corresponded to the expected meaning of the item and ii) were clear and of the best quality possible, with a limit of five recordings per item. After this first selection phase, some speakers from the original experiment were left with just one recording (participants 10 and 15) due to a poorer quality of their recordings. We additionally removed one speaker who did not have an adequate recording of one of the items, which left us with 12 speakers. One recording per condition was then selected by the second author of this article for each item based on the pre-selection made by the first author, according to the following constraints: (1) each speaker must contribute two recordings, one per condition (ISQ/SQ), (2) those two recordings cannot be from the same item. For example, if a recording from speaker 13 was selected for the ISQ interpretation of item 1 of the C’est quoi set, then this speaker could not contribute the recording of the SQ interpretation of that same item. As we chose two recordings per item condition, this means that in the final set of stimuli, we have a total of eight sentences per speaker, two for an ISQ and two for an SQ for each marker, all from different item pairs.
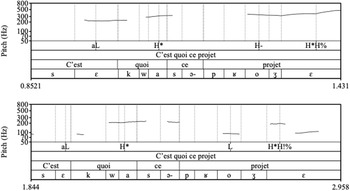
Acoustic analysis: We then proceeded to an acoustic analysis of duration and pitch of these 96 items. We used the Polytonia (Mertens, Reference Mertens2021) script for Praat (Boersma & Weenink, Reference Boersma and Weenink2016) to perform an acoustico-perceptual annotation of tones. The resulting tonal analyses were then translated into ToBI annotation, following the principles of French prosodic grammar (Delais-Roussarie et al., Reference Delais-Roussarie, Post, Avanzi, Buthke, Di Cristo, Feldhausen, Jun, Martin, Meisenburg, Rialland, Sichel-Bazin, Yoo, Frota and Prieto2015): generally, one tone is assigned per content word, unless perceptual grouping with the following material is evident. In c’est quoi constructions, quoi forms a content word and carries a pitch accent, and the following NP also bears a pitch accent, followed by a final boundary tone. In our qu’est-ce que constructions, the correspondence between grammatical forms and prosodic features is more complex since the sentences can be longer. Finally, we corrected detection and annotation errors by carefully listening to and systematically inspecting the F0 contour, especially in cases where laughter or devoicing caused pitch-tracking failures. Examples of F0 contours can be seen in Figures 1 and 2 below.
Example 1: F0 contours for ISQ reading (above) and SQ reading (below) of the sentence “C’est quoi ce projet?” ‘What is this project?’.

Example 2: F0 contours and segmentation for ISQ reading (above) and SQ reading (below) of the sentence “Qu’est-ce que tu racontes?” ‘What are you saying?’.

The analysis showed that duration is a significant prosodic cue that allows differentiating surprise questions from information seeking questions, SQs being longer that ISQs for both constructions (497 vs 350 ms; β = 0.15, SE = 0.29, t(30) = 5.11, p < .0001 for c’est quoi constructions and 390 vs 295 ms; β = 0.10, SE = 0.25, t(26) = 3.79, p < .001 for qu’est-ce que constructions). While some variability is observed, rising contours appear in ISQs while the contours associated with SQs are falling (L*L%), especially on the final word.Footnote 8 In particular, there were more low-high contours on c’est quoi for ISQs than SQs (χ 2(4) = 12.01, p = .017;Footnote 9 standardized residuals (SR) = |3.25|,Footnote 10 23 vs. 12 occurrences) and more high (HH*) and falling (HL*) contours for SQs (respective standardized residuals: |2.10| with 6 vs. 1 occurrences and |2.13| with 4 vs 0 occurrences). Contours on the final noun were significantly different, with more rising contours for ISQs (χ2 = 27.42, p < .0001, SR = |3.47|) and more falling contours for SQs (SR = |3.40|). For qu’est-ce que, the analysis of the contours on the question word showed a significant effect of condition (χ2 = 10.03, p = .025) with more falling contours (HL) for surprise than for information (SR = |2.06|). The difference between conditions was also significant on the final contour (χ2 = 25.19, p < .0001), with more rising contours for ISQs (SR = |3.43|, 11vs. 1 occurrence) and falling contours for SQs (SR = |3.42|, 16 vs. 4 occurrences).
List preparation: These 96 items were then used to constitute four different lists in the following manner. Each list contained both conditions of each pair for both markers (i.e., participants heard all the conditions), but each item was presented three times (twice in the same condition, once in a different condition) to prevent the development of response strategies by the participants, in three different voices. This means that only 72 of the 96 stimuli were presented in a given list. Which condition was repeated was counterbalanced across lists as well as specific recordings (i.e., if list A contained item ‘c’est quoi Item 1’ in its ISQ version twice and its SQ version once, then list B contained ‘c’est quoi Item 1’ in its SQ version twice and once in its ISQ version). The remaining two lists served to counterbalance which of the two recordings was used for the condition presented only once. Six filler items from the original experiment, whose interpretation was constrained by syntax (i.e., more canonical questions and exclamatives), were also included (e.g., “Quelle maison il a achetée?” ‘What house did he buy?’ or “Quelle femme il a épousée!”, ‘What a woman he married!’). Each filler was presented in both conditions to the participants, yielding 12 additional stimuli per list, each recorded by a different speaker. The fillers were the same across all lists. Each of the four lists thus contained a total of 84 stimuli.
Procedure
The experiment was run online with PCIbex (Zehr & Schwartz, Reference Zehr and Schwartz2018), an interface that provides tools to run online experiments. Participants were instructed (in French) to listen to a sentence once and then decide on the intention of the speaker between an information request and expressing surprise (binary choice). Instructions in French are available in the Appendix. Participants answered by using a key on the keyboard or the mouse. No response time was collected.Footnote 11 The experiment started with four practice sentences with a different marker from the experimental sentences (Quel) and which were either questions or exclamatives, based on their prosody (e.g., Quel manteau tu as choisi, ‘What coat did you choose?/What a coat you chose!’). Participants then responded to the 84 items of the list presented in a randomised order to guarantee the absence of response strategies. Distribution of participants across lists was done automatically by PCIbex. The whole experiment took between 20 and 30 minutes to complete. No compensation was offered to participants.
Statistical analyses
All analyses were carried out using R v. 4.2.1 (R Core Team, 2020) and package lme4 v. 1.1.31 (Bates et al., Reference Bates, Maechler, Bolker, Walker, Christensen, Singmann, Dai, Grothendieck and Green2015).
The dependent variable was accuracy, i.e., whether participants chose the expected meaning of the item (information-seeking question or surprise), coded as a binary variable (0: unexpected answer, 1: expected answer). The accuracy data was analysed with a generalized linear mixed effect model (glmer() function), with a binomial family and a logit link. For each dependent variable of interest, a model was first constructed with the following contrast-coded factors and their interactions as fixed effects: condition (ISQ: −0.5 vs. SQ: 0.5) and question word (Q-word) (c’est quoi: −0.5 vs qu’est-ce que: 0.5). The random effects structure always included an intercept by participant, an intercept by item, and an intercept by speaker (of the stimulus) to account for variability in production. A random slope for condition by participant was added when relevant unless it led to singularity issues. To solve convergence issues, the Bobyqa optimizer was used and the maximal number of iterations was increased to 20,000 (Powell, Reference Powell2009). We used an alpha level of .05 for determining significance. The significance of main effects and interactions was assessed by model comparisons with the anova() function. Estimates are reported from a summary of the model. 95% confidence intervals were calculated using the Wald method with the confint.merMod() function of lme4. The R2 Marginal and R2 Conditional, which summarize respectively the explanatory power of the fixed-effects structure and the combined explanatory power of the fixed and random effects structure, were calculated using the r.squaredGLMM() function of the MuMIn package version 1.47.1 (Barton, Reference Barton2020). For binomial models, the theoretical R2 are reported. Follow-up tests were carried out with estimated marginal means and trends with the emmeans() function of the package emmeans (Lenth, Reference Lenth2017) and interaction plots were plotted with the interactions package (Long, Reference Long2019). P values were adjusted with the Benjamini-Hochberg procedure (Benjamini & Hochberg, Reference Benjamini and Hochberg1995) to correct for multiple comparisons. Model fit was evaluated with the DHARMa package (Hartig, Reference Hartig2024). A detailed report of the analyses including model fit and residual tests is available here: https://osf.io/qawms/overview?view_only=09b5d28da9ca47b6b74c76a7c4b6b2aa.
4. Results
General performance
Participants performed above chance on critical stimuli (M = 75.71%, SD = 7.00%), as confirmed by a one-sided t-test (t(46) = 25.14, p adj < .0001, 95% CI = [73.99, Inf]), demonstrating a reliable ability to distinguish between SQs and ISQs without any contextual help (Cohen’s d = 3.67, i.e., an effect considered “large”). There was a significant effect of condition (ISQ vs. SQ) on the accuracy in the perception task (β = −1.01, 95% CI [−1.64; −0.37], z = −3.12, p adj = 0.003, R2 Marginal = 0.053, R2 Conditional = 0.42), as participants were more accurate on ISQs (M = 81.97%, SD = 10.76) than on SQs (M = 69.44%, SD = 10.55).
Link with production
To see whether the results of the production experiment reported in Celle and Pélissier (Reference Celle and Pélissier2022) related to performance in perception, we looked at whether the duration of the question word, the contour of the question word and the contour on the final word influenced accuracy in recognition. We examined the duration of the full sentences, and then the duration of each question word separately. For the following models, the effect of condition is not investigated as it is already significant in the full model presented above. Only the results relating to the duration in production and contours are reported in detail.
Full sentences
The interaction between duration of the full sentence and question word was significant (β = −0.96, 95% CI [−1.72; −0.19], z = −2.47, p adj = .015, R2 Marginal = 0.08, R2 Conditional = 0.42): the effect of duration was only significant with the c’est quoi marker (β = 0.64, 95% CI [0.21; 1.07], z = 2.94, p adj = .004), not with qu’est-ce que (p = .75). As can be seen in Figure 3, a longer total duration of the sentence was associated with more accurate categorizations of the sentence, but only with c’est quoi. This shows that for the c’est quoi sentences, the longer the full sentence was, the more likely participants were to classify it correctly, regardless of whether it was an ISQ or an SQ.
Predicted accuracy in discrimination between SQs and ISQs as a function of full sentence duration for each question word. Note that this graph reflects the results predicted by the generalized linear model and not the raw data. The x axis shows the duration of the full sentence in the auditory stimuli used in the experiment, and the y axis shows the accuracy predicted by the model based on the results of the perception experiment, taking into account fixed and random effects. The confidence interval is shown as a filled area around the slope.

C’est quoi
We next aimed to investigate the role of prosodic parameters (duration and contour of the question word, contour of the Final noun) on Accuracy depending on condition (ISQ vs SQ). We ran separate analyses for duration of the question word, question word contour and final noun contour.Footnote 12
The analyses of the duration of c’est quoi revealed a significant interaction between condition and duration of the question word (β = 1.62, 95% CI [0.84; 2.39], z = 4.08, p adj < .001, R2 Marginal = 0.16, R2 Conditional = 0.41). The interaction plot (see Figure 4) shows that when the duration of the question word was longer, participants performed better on ISQs and worse on SQs. This suggests that participants tended to classify utterances with a longer question word as SQs, confirming that a longer duration of the question word is associated with an SQ interpretation. Model comparisons also revealed a main effect of duration of c’est quoi (χ2 (1) = 37.38, p adj < .001) and condition (χ2 (1) = 49.38, p adj < .001).
Predicted accuracy in identification of ISQs and SQs as a function of the duration of C’est quoi. Note that this graph reflects the results predicted by the generalized linear model and not the raw data. The x axis shows the duration of the question word while the y axis shows the Accuracy in perception predicted by the model based on the results of the experiments. The confidence interval is represented by a filled area around the slope. This shows that accuracy for SQs increases with the duration of the marker, while performance for ISQs decreases.

The next analysis tested the effect of the contour of c’est quoi. As the only contour that occurred on several items in both ISQs and SQs was a low start followed by a high pitch accent (aL H*; 23 ISQ items, 12 SQs), two analyses were run: one limited to the aL H* contour, and one limited to the SQs to investigate the more variable contours occurring in that condition. As the acoustic analyses on the stimuli showed that the aL H* contour was reliably associated with ISQs (see above Materials – acoustic analysis of stimuli), we expected an effect of condition showing that participants performed better in the ISQ than SQ condition with this contour. Analyses confirmed this hypothesis (β = −1.72, 95% CI [−2.25; −1.18], z = −6.24, p adj < .001, R2 Marginal = 0.13, R2 Conditional = 0.36) – participants performed better with ISQs (88.20%) than SQs (73.91%) with this contour. The second analysis on SQsFootnote 13 did not reveal a significant effect of contour – participants were not more accurate in classifying SQs when the contour was one of those significantly associated with that category (i.e., H H* or H L*) compared to the contour associated with ISQ (i.e., aL H*).
A final analysis tested the effect of the final noun contour. Two contours were found to differ significantly between ISQs and SQs: a rising contour (H*H%) was associated with ISQs and a falling contour (L*L%) was associated with SQs. The effect of the contour was tested separately for each condition as there was a large imbalance in the number of stimuli with each contour between ISQs and SQs.Footnote 14 For ISQs, the effect of contour was significant (β = −1.02, 95% CI [−1.68; −0.36], z = −3.02, p adj = .005, R2 Marginal = 0.05, R2 Conditional = 0.29Footnote 15 ): participants were more accurate to classify utterances as ISQs when they followed the rising contour (92.98 %) than any other one (83.30 %). For SQs, the effect of contour was also significant (β = 1.09, 95% CI [0.59; 1.59], z = 4.29, p adj < .001, R2 Marginal = 0.29, R2 Conditional = 0.64). However, those results were unexpected, as participants were more accurate in classifying SQs when they followed another contour (so one not significantly associated with SQs in our dataset, 81.70%) than the contour associated with SQs (falling, 59.0%).Footnote 16 This suggests that, despite the fact that a falling contour was found to be significantly associated with SQs, it was not interpreted as a reliable cue by the listeners.
To summarize, participants were more accurate classifying SQs when the question word was longer, and more accurate classifying ISQs when the utterance followed a rising contour on the question word and on the final noun. This suggests that listeners used both contour and duration cues to distinguish between ISQs and SQs with c’est quoi.
Qu’est-ce que
We followed the same procedure as with c’est quoi. The first model included as fixed effects the condition (ISQ vs. SQ), the duration of the question word, and their interaction. This model revealed a significant interaction between condition and duration (β = 1.20, 95% CI [0.86; 1.53], z = 7.03, p adj < .001, R2 Marginal = 0.11, R2 Conditional = 0.31). Figure 5 shows that, indeed, accuracy dropped when the duration of qu’est-ce que increased. This means that ISQs with a longer question word tended to be falsely interpreted as SQs. In our production experiment, a lengthening of qu’est-ce was associated with SQs, so this suggests that duration may be a strong cue to SQ interpretation.
Accuracy in identification of ISQs and SQs as a function of the duration of “qu’est-ce que”. Note that this graph reflects the results predicted by the generalized linear model and not the raw data. The x axis shows the duration of the question word while the y axis shows the Accuracy in perception predicted by the model based on the results of the experiment. The confidence interval is represented by a filled area around the slope. This shows that accuracy for ISQs decreases with the duration of the marker, while performance for SQs slightly increases.

The second analysis investigated the role of the question word contour, focusing on three contours: low followed by early rise (aL Hi), high start (Hi), and falling (HL) (the latter one found to be significantly associated with SQs, see above Materials – acoustic analysis of stimuli).Footnote 17 Model comparisons revealed a significant interaction between condition and contour (χ2 (2) = 12.69, p adj = .003; R2 Marginal = 0.15, R2 Conditional = 0.32). Post-hoc analyses with emmeans() showed that, for SQs, accuracy was better when the question word followed a high start (Hi) contour compared to a low-high (aL Hi) contrast (Est. = −1.08, SE = 0.29, z = −3.80, p adj = .001), but participants were not more accurate with the falling contrast, despite its association with SQs in production. Additionally, for the aL Hi contrast, participants performed better with ISQs (86.18%) than SQs (55.34%), suggesting that this cue is possibly interpreted as a marker of information-seeking question, even though it was not reliably associated with this condition in the production of our stimuli (4 ISQs had this contour but 8 SQs).
The third analyses focused on the effect of the contour of the final word on accuracy.Footnote 18 The model for ISQs did not reveal an effect of the final contour (χ2 (1) = 0.44, p adj = .50), nor did the model for SQs (χ2 (1) = 0.55, p adj = .50). This suggests that the final contour in the qu’est-ce que sentences was not used as a cue to disambiguate between ISQ and SQ interpretations.
To summarize, participants were more accurate classifying SQs when the question word was longer. ISQs were more accurately categorized when the question word followed a rising contour. This suggests that listeners used both contour and duration cues to distinguish between ISQs and SQs with qu’est-ce que, like with c’est quoi.
5. Discussion
Overall, the participants performed above chance on critical stimuli, which suggests that prosody is a valid cue to distinguish between ISQs and SQs. However, participants were more accurate with ISQs. This gives credence to the idea that canonical questions can be self-containedly interpreted as such, while the surprise construal needs to be supported by an additional adequate context (see Lai (Reference Lai2009)). Interestingly, participants seem to rely on different cues to identify each interpretation: a rising contour on the question word (and, for c’est quoi ce NP, on the final noun) is associated with an ISQ interpretation, while a lengthening of the question word signals a surprise interpretation. Duration thus seems to be a prosodic cue that is reliably associated with surprise. Lengthening of the interrogative word correlates with a better performance on SQs but a worse performance on ISQs, as some ISQs were falsely construed as SQs. In the absence of context, lengthening is thus interpreted as a surprise cue by default, thus altering the threshold at which a question is perceived as surprising. This finding corroborates Jakobson (Reference Jakobson and Sebeok1960)’s claim that “emphatic prolongation” is a correlate of “emotive speech”. It also concurs with more recent studies on the effects of lengthening on wh-words (Trotzke & Turco, Reference Trotzke and Turco2015).
Note, however, that the two structures investigated do not fare evenly in this respect. Lengthening plays a significant role in decoding c’est quoi ce NP as an SQ both at the level of the question word and the full sentence. One might wonder why an in situ question with a right dislocation is more reliably interpreted as an SQ than a qu’est-ce que question. Our contention is that the surprise reading relies on a combination of syntactic, information-structural and prosodic features that are more easily perceived in the c’est quoi ce NP construction. As argued by Lefeuvre (Reference Lefeuvre, Dostie and Hadermann2015, p. 49), while left dislocations generally appear before statements, right dislocations tend to appear after interrogative sentences for information-structural reasons. An in situ question followed by a right dislocation puts the question word into focus. The post-focal entity appears in the right periphery of the clause “simply specifying what is to be elucidated.”Footnote 19 By making the focus salient, this construction enables the hearer to reliably interpret the question as either an ISQ or an SQ depending on the duration of the question word.
In the in situ question, quoi is a strong interrogative pronoun that occurs in a metrically-strong position, the primary accent on quoi marking the right boundary of the interrogative phrase. This demarcation separates the interrogative phrase from the dislocated constituent at three levels: i) at the syntactic level, the right dislocated constituent is separated from the clause structure; ii) at the information-structural level, focus and ground are also distinguished (see below). The lengthening of quoi corresponds to a metrical accent assigned to the last syllable of the interrogative phrase;Footnote 20 iii) at the illocutionary level, the interpretation of the clause as a question comes first, the identification of the subject the question is about being delayed.
The choice of an in situ question has an impact on the nature of the focus. The focus is a narrow focus, presenting only a constituent of the utterance as new information. Through the equative structure, the subject clitic pronoun c’ is cataphorically identified with the dislocated constituent. The latter consists of an NP in which the demonstrative designates an entity that is accessible to the speech participants. In other words, the referent belongs to the ground. It corresponds to background information. As pointed out by Stéfani & Horlacher (Reference Stéfani and Horlacher2017), the right dislocation is typically used to designate a referent that is immediately perceived. Clearly, the focus is not on the existence of that entity, but on its identification.

The partition between narrow focus and ground enables the hearer to better perceive what is in focus. In the information-seeking construal (a), an answer is expected to identify the designated referent. In the surprise reading (b), the longer duration of the interrogative word allows the hearer to infer that the presence of the designated referent in the situational context is counterexpectational. Lengthening is motivated by a clash between the speaker’s expectations (“That thing is not expected to be here”) and contextual evidence (“That thing is here”). There may be something odd about the referent or its location, which is reflected in the enhanced prosody of the focus. By using an evaluative right dislocation, the speaker has engaged in an “assessment activity” (Stéfani & Horlacher, Reference Stéfani and Horlacher2017) and the question calls for an explanation.
The insertion of the interrogative particle est-ce que in fronted position in the interrogative phrase qu’est-ce que is an alternative construction to ask a what-question. Systematic perusal of various corpora of spoken and literary French by Lefeuvre (Reference Lefeuvre, Dostie and Hadermann2015) reveals that the in situ construction (c’est quoi + right dislocation) is preferred over qu’est-ce que c’est to ask about the identity of a predicative element. Across corpora, the c’est quoi construction appears to be ten times more frequent than the qu’est-ce que construction. Lefeuvre found the earliest attestations of the c’est quoi construction to date to the 1920s and concludes that the in situ construction has established itself as the most common way of asking a question about a predicative element.
The c’est quoi question thus emerges as a new construction that is gradually replacing qu’est-ce que. Lefeuvre’s corpus-based results are in line with Boucher’s (Reference Boucher, Breul and Göbbel2010b, Reference Boucher2010a) claims that phrase-final stress placement in French results in the weakening of the initial position in interrogatives. At the information-structural level, focus marking similarly requires both prosodic phrasing and syntactic restructuring, as it cannot be marked with pitch accents. As argued by Féry (Reference Féry, Féry and Sternefeld2001, p. 2), “in French, due to the absence of lexical stress, the phonological counterpart of focus is different from that of many other European languages.”
Although the weak interrogative word (que) is reinforced by est-ce que in qu’est-ce que, fronted qu’est-ce que does not allow making the focus structure salient in the same way as c’est quoi does. Firstly, with qu’est-ce que the focus domain may be either broad (2), presenting the whole utterance as new information, or narrow (3):


As stated by Féry (Reference Féry, Féry and Sternefeld2001, p. 26), “the tonal phrasing is more clearly marked under narrow than under wide focus”, which might contribute to a better performance in the perception of the difference between SQs and ISQs in (3) than in (2).
Secondly, the clause structure of qu’est-ce que questions does not partition focus and ground. The interrogative word scopes over the ground: in qu’est-ce que tu racontes, it is presupposed that “you are talking about something”, while the fronted question word puts the nature of the object constituent in focus.
Therefore, the focus structure is not as prominent as in the case of c’est quoi ce NP, which separates the focus from the ground. This might explain why hearers are less accurate in distinguishing the qu’est-ce que pairs. While the long duration of the interrogative word (quoi) is a reliable cue to identify the focus as counterexpectational when prosodic phrasing coincides with the clausal boundaries, it is not sufficient if the focus domain is wider or not clearly separated from the ground.Footnote 22
Nonetheless, listeners do consider the duration of the first syllable of qu’est-ce que to be meaningful. In the case of information-seeking qu’est-ce que questions, the shorter realization of the first syllable was significantly recognized. Longer qu’est-ce was falsely associated with SQs. This indicates that hearers are aware that duration is an important prosodic cue to distinguish between ISQs and SQs, even if it is not sufficient.
One might put forward another reason for the better performance of the participants in c’est quoi questions with longer full sentences and a longer interrogative word. Lengthening is an unambiguous prosodic cue in the case of c’est quoi ce NP, whereas it may signal various types of non-canonicity in the case of qu’est-ce que. It is therefore more reliable in the former than in the latter.
Longer qu’est-ce is not restricted to the surprise meaning. It may also indicate a rhetorical question.Footnote 23 Rhetorical questions are typically associated with fronted interrogatives and are also prosodically marked by lengthening in French (Beyssade & Delais-Roussarie, Reference Beyssade and Delais-Roussarie2022) as in other languages such as Estonian (Asu et al., Reference Asu, Sahkai and Lippus2023), English (Dehé & Braun, Reference Dehé and Braun2019) or German (Braun et al., Reference Braun, Dehé, Neitsch, Wochner and Zahner2019).
By contrast, c’est quoi ce NP with a long realization of the question word can only be interpreted as an SQ. The rhetorical reading is ruled out with in situ questions (Quillard, Reference Quillard2001). While in situ interrogatives are compatible with echo questions, which are also marked through lengthening (Glasbergen-Plas et al., Reference Glasbergen-Plas, Gryllia and Doetjes2020), the right dislocation blocks the echo reading by drawing attention to some new referent. The anaphoric reading is excluded as soon as the resumptive pronoun c’ is pronounced, as it cataphorically refers to a referent in the ground.Footnote 24
This paves the way for an unambiguous surprise reading of the c’est quoi ce NP construction when the question word is pronounced with a long realization. This construal obtains regardless of context, which suggests that it does not depend on pragmatic inferencing. Therefore, we argue that this non-canonical surprise question should be regarded as a conventionalized form-prosody-function pairing. In the literature, a difference is generally made between two types of indirect speech acts. Building on Green (Reference Green, Cole and Morgan1975)’s distinction between hints and whimperative constructions in the directive use of interrogatives, Beyssade and Marandin (Reference Beyssade and Marandin2006) state that speech act assignment in indirect speech acts is based either on inferences or on “grammatical (lexical or constructional) means”. More recently, this distinction has been taken up to tease apart indirect speech acts from conventionalized non-canonical questions. Trotzke and Reimer (Reference Trotzke and Reimer2023) argue that surprise-disapproval questions in German (e.g. Was regnet das denn jetzt?, ‘Why is it raining now (of all times!)?’) involve different comprehension processes than indirect requests, such as Kannst du mir das Salz reichen? ‘Can you pass me the salt?’. In non-canonical questions, as opposed to indirect requests, the illocutionary force is encoded by the linguistic form. This leads to a more accurate interpretation, but at a higher processing cost. Furthermore, Trotzke and Reimer (Reference Trotzke and Reimer2023) point out that non-canonical speech acts are processed slower than their canonical counterparts. These differences in processing might explain why there is some variation between non-canonical qu’est-ce que and c’est quoi ce NP in our results. While the combination of lengthening of the interrogative word with the right dislocation in the c’est quoi ce NP construction can help the hearer to accurately identify the illocutionary force of the surprise question, this comprehension process is harder with qu’est-ce que because it may either contradict the sentence structure in the non-argumental use, or compete with other types of non-canonicity, such as rhetoricity.
One might also argue, as suggested by an anonymous reviewer, that the significantly higher frequency of c’est quoi than qu’est-ce que across spoken corpora (Lefeuvre, Reference Lefeuvre, Dostie and Hadermann2015) facilitates the listeners’ ability to better identify the pragmatic variants of c’est quoi through their prosody. Being more exposed to c’est quoi than to qu’est-ce que in actual communication settings, speakers become more proficient in prosodically distinguishing between the canonical and the non-canonical uses of c’est quoi. This difference can then result in higher entrenchment than in the case of qu’est-ce que. In a real world situation, speakers will also rely on context and on other lexical cues to select the right interpretation of a question. By narrowing down the focus on ambiguous string-identical questions, our perception study has shown that prosodic cues, and lengthening in particular, play a key role in the interpretation of a new form-function pairing.
6. Conclusion
The aim of our experiment was to determine if listeners can reliably use prosodic cues to distinguish between string-identical information-seeking questions and surprise questions. Results show that this is indeed the case, with listeners using cues such as the duration of the question word, its contour, and, in the case of c’est quoi ce NP, the contour of the final noun. Lengthening, which was previously found to be a consistent cue for surprise meanings in production (Celle & Pélissier, Reference Celle and Pélissier2022) was also associated with surprise by the listeners, which even led to falsely interpreted cases. However, the participants performed better with the c’est quoi ce NP construction than with the qu’est-ce que question in the surprise condition. This suggests that lengthening combined with narrow focus and syntactic restructuring is a reliable cue. Under such circumstances, the surprise meaning of questions is unambiguous and the construction provides a conventionalized form-prosody-function pairing. Our results thus indicate that the prosodic cue of lengthening is particularly strong combined with a cluster of semantic, syntactic and information-structural properties. While corroborating Jakobson’s (Reference Jakobson and Sebeok1960) claim that “emphatic prolongation” is a correlate of “emotive speech”, our findings also suggest that the perception of expressivity relies on lengthening in specific constructions. This non-tonal cue thus contributes to establishing a ‘new connection’ (Diewald et al., Reference Diewald, Dekalo, Czicza, Hilpert, Cappelle and Depraetere2021, pp. 89–90) between a form and expressive meaning.
Competing interests
none
Funding
none
APPENDIX – List of stimuli



3. Instructions in French
Instructions before the experiment
Lors de cette expérience, vous devrez écouter des phrases et dire quelle était l’intention de la personne qui parle parmi deux possibilités (exprime-t-elle un étonnement ou demande-t-elle une information ?). Appuyez sur la touche “E” du clavier pour l’étonnement et sur la touche “I” pour l’information.
Question displayed during the experiment
“La personne exprime-t-elle son étonnement ou demande-t-elle une information ?”





 Open access
Open access