



Highlights
What is already known?
Screening abstracts for systematic reviews is a labor-intensive process. Large language models, like generative pre-trained transformer (GPT), have been suggested as tools to help categorize abstracts into study types—such as randomized controlled trials (RCTs) or animal studies—before screening, potentially reducing the number of references to review and making the process more efficient. However, there has been no direct comparison of how well GPT performs this task compared to more established models like bidirectional encoder representations from transformer (BERT).
What is new?
We introduce a new dataset of abstracts, labeled by humans according to 14 different study types. Using this dataset, we evaluated how well different GPT and BERT models classify these study types. Our results show that BERT models are particularly effective at this task, making them a good choice for sorting abstracts before systematic review. In fact, BERT models consistently outperformed the newer GPT models in this specific task.
Potential impact for RSM readers
Using BERT models to pre-screen abstracts could reduce the workload of systematic reviews, especially for larger collections of references. And importantly, while GPT models have advanced features and are trained on massive datasets, they were consistently outperformed by the more traditional BERT models for this type of classification.
Abbreviations

1 Introduction
Systematic reviews are fundamental to evidence-based medicine and research.Reference Cumpston, Li and Page1, Reference Marianna, Doneva, Howells, Leenaars and Ineichen2 Yet conducting these reviews is highly time-consuming, especially the screening of abstracts identified during a comprehensive literature search.Reference Bannach-Brown, Hair, Bahor, Soliman, Macleod and Liao3, Reference Marshall, Johnson, Wang, Rajasekaran and Wallace4 Typically, this screening requires substantial resources with two independent human reviewers and potentially a third one for resolution. As a result, the manual screening of a large number of abstracts can take months,Reference Borah, Brown, Capers and Kaiser5 a challenge exacerbated by the ever-increasing volume of scientific publications.Reference Ineichen, Rosso and Macleod6 One approach to mitigate the screening burden is to use medical subject headings (MeSH), which provide a standardized vocabulary that refines searches and can reduce irrelevant results. However, their coverage can be incomplete or delayed, and exploiting the full potential of MeSH terminology is an area of active research.Reference Lowe and Barnett7, Reference Wang, Scells, Koopman and Zuccon8
With the development of natural language processing (NLP) technologies, particularly large language models (LLMs), there is potential to reduce the manual effort involved in abstract screening. A promising approach is to use such models to trim the number of citations before title and abstract screening, e.g., by classifying articles by study types, such as RCTs, animal studies, systematic reviews, or narrative reviews. Traditional machine learning methods, such as support vector machines and convolutional neural networks, have been successfully used to classify RCTs,Reference Marshall, Noel-Storr, Kuiper, Thomas and Wallace9, Reference Cohen, Smalheiser and McDonagh10 often outperforming built-in search filters in databases. These models have also been used to develop Multi-Tagger, a system of publication type and study design taggers supporting biomedical indexing and evidence-based medicine. Multi-Tagger covers 50 publication types, including reviews, editorials, and cohort studies.Reference Cohen, Schneider and Fu11 The release of the transformer architecture in 2017 created a new wave of research into Deep Learning, leading to the appearance of the first LLMs.Reference Vaswani, Shazeer and Parmar12 It was closely followed by the release of the BERT models, which have since been actively applied to the task of text classification in general and the classification of study types, e.g., in relation to animal-alternative methods.Reference Neves, Klippert and Knöspel13 More recently, generative models, such as generative pre-trained transformer (GPT) and LLaMA, have also been put to the task of text classification.Reference Sun, Li and Li14, Reference Kumar, Sharma and Bedi15 With this, LLMs have proven to reduce the screening burden of large abstract collections.Reference Van IJzendoorn, Habets, Vinkers and Otte16, Reference Abogunrin, Queiros, Bednarski, Sumner, Baehrens and Witzmann17
However, key gaps remain: First, current methods lack detailed classification levels for study types needed for specific systematic reviews.Reference Van IJzendoorn, Habets, Vinkers and Otte16 For example, no existing model can automatically classify key study types, such as in vitro studies, animal studies, or studies assessing therapeutic interventions important, for example, for animal or translational systematic reviews.Reference Van IJzendoorn, Habets, Vinkers and Otte16, Reference Van Luijk, Bakker, Rovers, Ritskes-Hoitinga, De Vries and Leenaars18, Reference Ineichen, Held, Salanti, Macleod and Wever19 Second, despite the growing popularity of generative models like GPT, there is a lack of empirical data on how these newer models perform in text classification against established transformer-based models, such as BERT. Third, a challenge in advancing these technologies is the need for high-quality, manually annotated data, which is essential for fine-tuning and evaluating models’ performance. Without available annotated datasets, the refinement and successful deployment of NLP models in specialized domains remain constrained.Reference Fries, Seelam and Altay20
To address these gaps, our study has three objectives: first, to develop a manually annotated dataset of abstracts for various study types found in PubMed; second, use this corpus to train different transformer-based models from the BERT family to automatically classify PubMed abstracts by study type; and third, to compare the performance of these NLP methods with the newer generative LLMs, concretely GPT-3.5 and GPT-4.
2 Materials and methods
2.1 Approach and study design
We focused our study on neuroscience, one of the largest biomedical research fields. The data used for classification includes titles, abstracts, keywords, and journal names of research studies found on PubMed. We did not conduct a sample size calculation but relied on a convenience sample of slightly over 2,500 abstracts for our human-annotated corpus of 14 study types. This manually annotated corpus was then used to: 1) assess the performance of GPT-based models in automatically classifying these study types and 2) fine-tune various BERT-based models to compare their performance against GPT in classifying these study types. Details are described in the following paragraphs.
2.2 Data
2.2.1 Data collection
To obtain the initial set of relevant PubMed-IDs (PMIDs), we searched PubMed using the following search string: “Central nervous system diseases [MeSH] OR Mental Disorders Psychiatric illness [MeSH]” (search date: November 27, 2023). Out of 2,788,345 PMIDs, we randomly sampled 2,000 PMIDs for which we fetched the meta-data (title, abstract, author keywords, MeSH terms, journal name, PubMed date of publication, and date of journal publication). Although author keywords and MeSH terms may appear similar, they serve different purposes: Authors typically choose a small set of keywords based on the focus of their article, while indexers systematically assign standardized MeSH terms to place the work within a broader framework.Reference Névéol, Doğan and Lu21
2.2.2 Data annotation
We developed detailed annotation guidelines for the different study types which were iteratively improved through three rounds of revision (see Section a of the Supplementary Material or https://osf.io/3yxqh/). The final guidelines are provided in Table S1 in the Supplementary Material. We use a classification system that categorizes study types according to their methodological design, study population, and intervention type. We defined “intervention” specifically in the context of therapeutic intervention, excluding diagnostic procedures or similar procedures. We pre-defined the following 15 study type classes, which are largely mutually exclusive and applied in the following hierarchy:
-
1. Study-protocol
-
2. Human-systematic-review
-
3. Non-systematic-review
-
4. Human-RCT-non-drug-intervention (RCT)
-
5. Human-RCT-drug-intervention
-
6. Human-RCT-non-intervention
-
7. Human-case-report
-
8. Human-non-RCT-non-drug-intervention
-
9. Human-non-RCT-drug-intervention
-
10. Animal-systematic-review
-
11. Animal-non-drug-intervention
-
12. Animal-drug-intervention
-
13. Animal-other
-
14. In-vitro-study
-
15. Remaining (a class for all remaining study types not belonging to any of the above mentioned classes).
Notably, we made a post-hoc decision to exclude the class Animal-systematic-review as we did not identify any such studies in our corpus (see Section 2.2.3). This left us with 14 classes. We will refer to this number of classes in the following.
Two raters (SdV and BVI) independently assigned these study type classes to the set of 2000 references based on title, abstract, and journal name. Conflicts were resolved by discussion. To assess inter-rater agreement, we calculated Cohen’s Kappa statistics. Four references were excluded in accordance with the annotation guidelines (not being in the realm of neuroscience and/or not in English). All annotations and the conflict resolution were performed in the web-based annotation tool Prodigy.Reference Montani and Honnibal22
Next, to create labels for the binary classification task, we mapped each of the classes either to “Animal” or “Other.” This allowed us to evaluate the models’ abilities in distinguishing between animal and non-animal studies.
2.2.3 Dataset enrichment
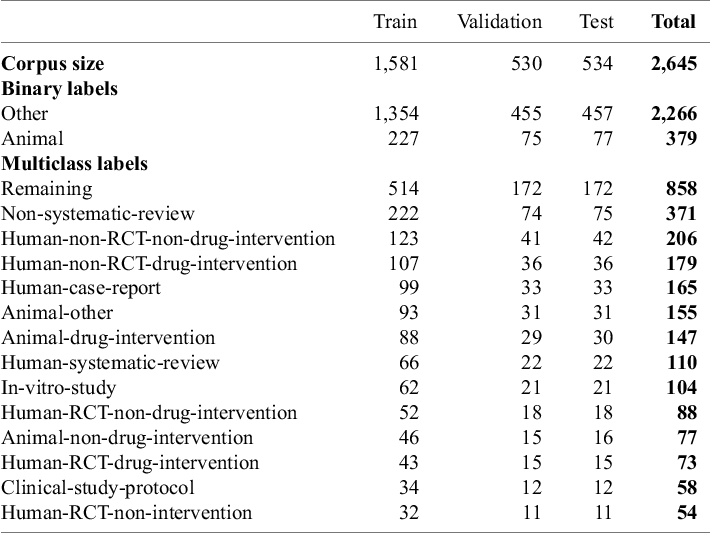
The manually annotated corpus showed a very uneven distribution of study types, with some classes having very few samples (e.g., Human-RCT-non-intervention) and the Remaining class containing three times as many samples as the second largest class. Fine-tuning BERT-based models on this unbalanced dataset poses a risk that the model will be biased towards over-predicting the larger classes and performing poorly on the underrepresented classes. See Figure 6a in the Supplementary Material and Section g of the Supplementary Material for the effect of enrichment on the performance of BERT-based models. At the same time, having very few examples of a class in our test set can lead to unreliable performance metrics, high variance in evaluation results, and poor representation of real-world performance. We thus made a post hoc decision to augment each of the minority classes with 50 additional abstracts (Table 1). These additional instances stemmed from previous systematic reviews conducted by our group.
Annotated corpus: The table presents key statistics of the dataset after the stratified splitting into train, validation, and test sets

Note: The numeric values represent the number of records in the respective category
2.2.4 Data splits for model training and evaluation
We split the full dataset of 2,645 references into three datasets for training, validation, and testing with a 0.6-0.2-0.2 ratio, resulting in sub-corpora of 1,851, 530, and 534 samples, respectively (Table 1). The train and validation split are only used for fine-tuning the BERT-based models, while the held-out test set is used for both BERT and GPT evaluation. A random sample from the validation dataset was used to select the most promising GPT prompts (see Section 2.3.2).
To ensure that all classes are present across all parts of the split, we employed a stratification strategy which ensured that all classes were present across all dataset splits. Each dataset record included the following fields: title, abstract, author keywords, and journal name. Note that we did not include MeSH terms, as empirical evaluations for a similar task have shown no positive impact on performance.Reference Neves, Klippert and Knöspel13
2.3 GPT-based models
2.3.1 Setup
We employed two generative LLMs developed by OpenAI: GPT-3.5-turbo and GPT-4-turbo-preview.Reference Brown, Mann, Ryder, Larochelle, Ranzato, Hadsell, Balcan and Lin23, 24 These models have been trained on publicly available data (e.g., Common Crawl, a public dataset of web page data [https://commoncrawl.org] and Wikipedia) and licensed third-party data.Reference Brown, Mann, Ryder, Larochelle, Ranzato, Hadsell, Balcan and Lin23, 24 GPT models generate text by predicting the next word in a sequence, based on the context of the previous words. GPT-4 is an advancement over GPT-3.5, featuring a larger model size, enhanced performance (including in the domain of medicine),Reference Sandmann, Riepenhausen, Plagwitz and Varghese25, Reference Kipp26 and more extensive training data.
We utilized the OpenAI chat-completion API to obtain responses from both models.27 Each abstract’s classification was run in an independent session, and since the API currently does not have a memory function, there is no transfer of information or bias from one abstract to another. The classification task was structured as a question-answering problem, where GPT was prompted to identify the most suitable study type from a predefined study type set based on the paper’s title, abstract, journal name and, when available, keywords. The analysis was conducted with the temperature parameter set at 0 to reduce the randomness of responses (compared to higher values producing more creative and random outputs).
Furthermore, to deal with variation in GPT responses, we configured the output format of the API call to a specific structured output type (“json_object”). Additionally, we used a fuzzy matching approach to account for minor differences between model outputs and expected labels.
2.3.2 Prompting strategy
We pre-defined three prompting strategies:
-
1. Zero-shotReference Nori, King, McKinney, Carignan and Horvitz28, Reference Brin, Sorin and Vaid29
The model is given the classification prompt without any additional context, examples, or specific instructions, relying solely on its pre-trained knowledge.
-
2. contextual clues (CC)30
The model is provided with our detailed annotation guidelines (see Section a of the Supplementary Material and Table S1 in the Supplementary Material for the full version and Section b of the Supplementary Material and Table S2 in the Supplementary Material for the shortened version). These guidelines outline the classification criteria and labeling conventions, enabling the model to use these information to create an output.
-
3. chain-of-thought (CoT)30, Reference Nori, Lee and Zhang31
The model is instructed to generate a chain of thought (step-by-step reasoning) before providing its final classification. This process encourages explicit reasoning and can improve accuracy by making the decision process more transparent.
For prompt engineering, i.e., designing the input instructions given to the model, we followed OpenAI’s Prompt Engineering Guidelines30 and other published recommendations.Reference Meskó32 Prompts are summarized in Table 2 and detailed in Section j of the Supplementary Material.
Overview of employed prompting strategies

Note: Detailed prompts are listed in Section j of the Supplementary Material.
The “original annotation guidelines” refer to the complete guidelines (see Section a of the Supplementary Material and Table S1 in the Supplementary Material).
For the annotation guidelines, see Sections a and b of the Supplementary Material and Tables S1 and S2 in the Supplementary Material.
Abbreviations: CC, contextual clues; CoT, chain-of-thought.
We tested both, 1) classification into one of 14 categories (multi-class) or 2) just two (“Animal” versus “Other,” binary) due to the following reasons: First, it allowed us to compare the performance of BERT-based and GPT-based models on a simpler binary classification task. Second, it allowed us to construct a hierarchical classification pipeline, i.e., a two-step approach where binary classification is followed by more detailed classification (i.e., a form of the Chain-of-Thought-prompting-strategy). We also briefly explored in-context learning (few-shot)Reference Nori, Lee and Zhang31 as a prompting strategy, i.e., giving the model a few examples in the prompt (Table S10 in the Supplementary Material). The selection of few-shot examples was based on,Reference Jimenez Gutierrez, McNeal and Washington33, Reference Liu, Shen, Zhang, Dolan, Carin and Chen34 as follows:
-
1. Random Few-Shots: In this approach, the classification examples (few-shots) were randomly selected from the training split.
-
2. K-Nearest Neighbor (K-NN): Here, the few-shot examples were chosen based on the closest neighbors to each test example from the training split.
2.3.3 Experiments
We first tested the prompting strategies on random samples of 50 abstracts from the validation dataset. To compare GPT with BERT performance, we re-ran all the prompts on the test set (enriched with keywords), see Table S8 in the Supplementary Material. In addition, we tested them on the test split without keywords (Table S9 in the Supplementary Material).
Due to relatively high API costs of GPT-4, we decided to only run the most promising prompts (based on their performance with GPT-3.5) and at least one prompt of each prompting strategy on GPT-4. In total, we tested eight selected prompts on GPT-4 (Table 3).
Performance metrics for GPT-3.5-turbo and GPT-4-turbo-preview (for selected prompting strategy) as well as for BERT models (multi-class classification)

Note: Text in bold indicates the best performance
Performance of GPT models is measured on the enriched dataset with keywords.
Abbreviations: CC, contextual clues; CoT, chain-of-thought; “P2_H,” “P2_HIERARCHY,” i.e., hierarchical prompt 2; “b_P3,” binary prompt 3, upon whose outputs this hierarchical labeling was based (see Tables S6 and S7 in the Supplementary Material).
2.4 BERT-based models
2.4.1 Setup
BERT differs from GPT primarily in its training objective. While GPT is trained to predict the next token in a sequence using only the left (previous) context in a unidirectional manner, BERT uses a bidirectional approach through masked language modeling (MLM).Reference Devlin, Chang, Lee and Toutanova35 In MLM, random tokens are masked during training, and BERT learns to predict them using both the left and right context. This bidirectional conditioning enables BERT to capture richer contextual representations.Reference Devlin, Chang, Lee and Toutanova35, Reference Artetxe, Du, Goyal, Zettlemoyer, Stoyanov, Goldberg, Kozareva and Zhang36
We fine-tuned seven BERT models (accessed via https://huggingface.co/):
-
• bert-base-uncased (BERT-base);Reference Devlin, Chang, Lee and Toutanova35
-
• scibert_scivocab_uncased (SciBERT);Reference Beltagy, Lo and Cohan37
-
• biobert-v1.1 (BioBERT);Reference Lee, Yoon and Kim38
-
• Bio_ClinicalBERT (ClinicalBERT);Reference Huang, Altosaar and Ranganath39
-
• BiomedNLP-BiomedBERT-base-uncased-abstract (BiomedBERT);Reference Chakraborty, Bisong, Bhatt, Wagner, Elliott, Mosconi, Scott, Bel and Zong40
-
• BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext (PubMedBERT);Reference Gu, Tinn and Cheng41
-
• BioLinkBERT-base (BioLinkBERT).Reference Yasunaga, Leskovec, Liang, Muresan, Nakov and Villavicencio42
Hyperparameter optimization is detailed in Table S4 in the Supplementary Material and Section e of the Supplementary Material. For more detailed information about the models, see Section d of the Supplementary Material. Model selection was guided by the considerations of accessibility, domain-specificity, performance, but also size, giving preference to smaller (base) versions of the models. We also took into account the BLURB leaderboard of models in the domain of biomedicine.Reference Gu, Tinn and Cheng41
The input text consisted of the journal name, title, abstract, and—if available—keywords, combined into a single string. We did not apply further text preprocessing. Instead, we used the built-in tokenizers (AutoTokenizers) provided with each model to convert the text into tokens. Inputs were padded or cut off to a maximum length of 256 tokens (approximately 200–250 words), based on prior hyperparameter tuning. Default model settings and hyperparameters were used unless specified otherwise in Table S4 in the Supplementary Material and Section e of the Supplementary Material.
We fine-tuned on the train split and validated on the val (validation) split. The fine-tuned models were then evaluated on the previously unseen held-out test split.
2.4.2 Experiments
For all experiments with BERT-based models, we used two classification types: binary and multi-class (see Section 2.3.2).
2.5 Comparative analysis with existing datasets
As a simple baseline for the binary classification task, we used the MeSH terms assigned to the studies. If they contained “animal,” the study was assigned this label, while the remaining studies were assigned the label “other.”
To validate our dataset, we compared it with two recently published abstract classification corpora, Multi-Tagger and GoldHamster.Reference Cohen, Schneider and Fu11, Reference Neves, Klippert and Knöspel13, Reference Menke, Kilicoglu and Smalheiser43 The GoldHamster dataset supports classification of PubMed abstracts into experimental models, including “in vivo,” “organs,” “primary cells,” “immortal cell lines,” “invertebrates,” “humans,” “in silico,” and “other.” Due to incomplete documentation, we re-implemented their model locally and fine-tuned it on the provided dataset before applying it to the 2,645 abstracts in our corpus. A direct performance comparison with GoldHamster was only feasible for binary classification, where we mapped the “in_vivo” label to “Animal” and all others to “Other.” The additional categories were analyzed to gain further insight into our annotations.
Multi-Tagger focuses on human-related studies, providing classification for 50 labels on publication types (e.g., review and case report) and clinically relevant study designs (e.g., case-control study and retrospective study). We retrieved the predicted probability scores for all PubMed articles (up to 2024) from the publicly available dataset at Multi-Tagger File Download, along with threshold values reported to yield the highest F1-scores. Although these labels were not directly comparable to our own, they offered additional context and aided our understanding of the scope and consistency of our annotations.
2.6 Performance evaluation
To evaluate classification performance in our text classification task, we treat each label in a one-versus-rest manner, thus transforming the problem into a set of binary classification tasks. This allows us to assess how well the model identifies each individual class against all others.
For each class, we compute precision, recall, and F1 score, defined as:
-
•
 $ \text {Precision} = \frac {\text {Number of correctly predicted instances of the class}}{\text {Total number of instances predicted as that class}}$
, also referred to as positive predictive value.
$ \text {Precision} = \frac {\text {Number of correctly predicted instances of the class}}{\text {Total number of instances predicted as that class}}$
, also referred to as positive predictive value. -
•
$ \text {Recall} = \frac {\text {Number of correctly predicted instances of the class}}{\text {Total number of actual instances of that class}} $
, also referred to as sensitivity. -
•
$\text {F1} = \frac {2 \cdot \text {Precision} \cdot \text {Recall}}{\text {Precision} + \text {Recall}}$
, i.e., the harmonic mean of precision and recall.

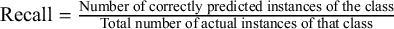

To assess the reliability of these metrics, we compute confidence intervals. Precision and recall intervals are calculated using binomial proportion methods,Reference Brown, Cai and DasGupta44 while F1 confidence intervals are estimated analytically following.Reference Takahashi, Yamamoto, Kuchiba and Koyama45
For aggregated (multi-class) performance, we report weighted precision, recall, and F1 scores. These are computed as class-wise scores weighted by the number of true instances in each class:
 $$\begin{align*}\text{Weighted Metric} = \sum_{i=1}^{C} w_i \cdot \text{Metric}_i, \quad \text{where } w_i = \frac{n_i}{\sum_{j=1}^{C} n_j} \end{align*}$$
$$\begin{align*}\text{Weighted Metric} = \sum_{i=1}^{C} w_i \cdot \text{Metric}_i, \quad \text{where } w_i = \frac{n_i}{\sum_{j=1}^{C} n_j} \end{align*}$$
with n i being the number of true instances in class i, and C the number of classes. This formulation accounts for class imbalance.
Confidence intervals for these aggregated metrics are computed using bootstrapping, where we resample the test set (with replacement) multiple times, compute the metrics for each sample, and derive empirical confidence intervals from the resulting distributions. All calculations are based on validated implementations from a publicly available Python library.Reference Gildenblat46 More mathematical detail is provided in Section c of the Supplementary Material.
3 Results
3.1 Corpus
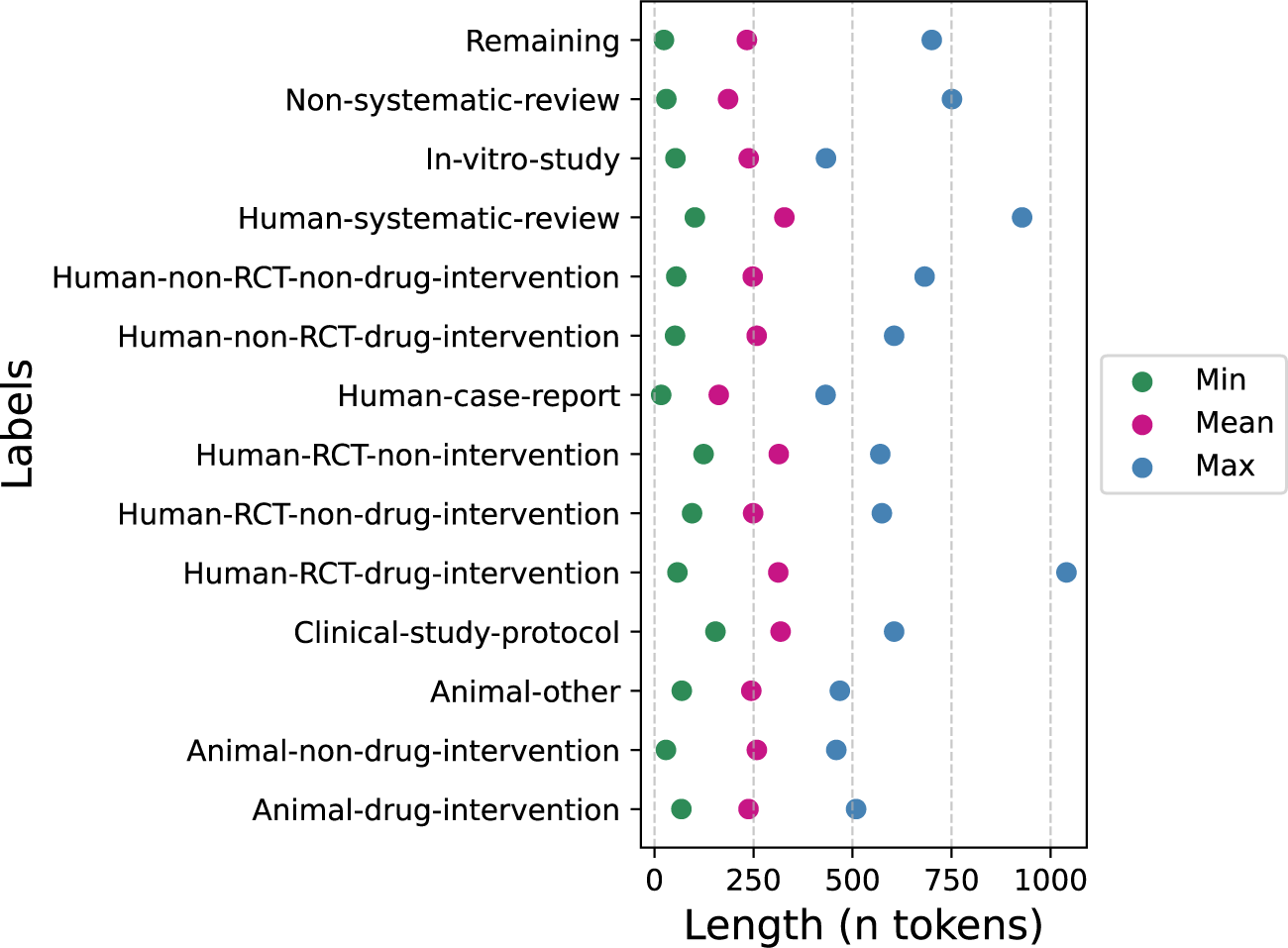
The final corpus contained 2,645 samples (1,996 from the original annotation and 649 added to increase underrepresented classes) (Table 1). We encountered no error messages from the PubMed API and successfully retrieved all available data. All records included a title and abstract, while 6 lacked a journal name and 18 were missing MeSH terms. The largest proportion of missing data was for author keywords, which were absent in around 60% of records across all labels, except for Human-Systematic-Review and Clinical-Study-Protocol, which had about 30% missing (Figure 5 in the Supplementary Material). The inter-annotator-agreement (IAA) for the human annotation according to Cohen’s Kappa was 0.55 (95%-CI: 0.49–0.61, moderate agreement) for the first round and 0.71 (0.63–0.79, substantial agreement) for the second round. The most represented class was the Remaining class with a total of 858 samples, followed by Non-systematic-review with 371 samples. The smallest class was Human-RCT-non-intervention with 54 samples. 379 samples were animal studies and 2,266 were non-animal studies. The mean abstract length was 237 words (min 17–max 1040) (Figure 1 and Table S3 in the Supplementary Material).
Abstract length per class, calculated on the whole dataset before splitting into train, validation, and test sets.

3.2 GPT models
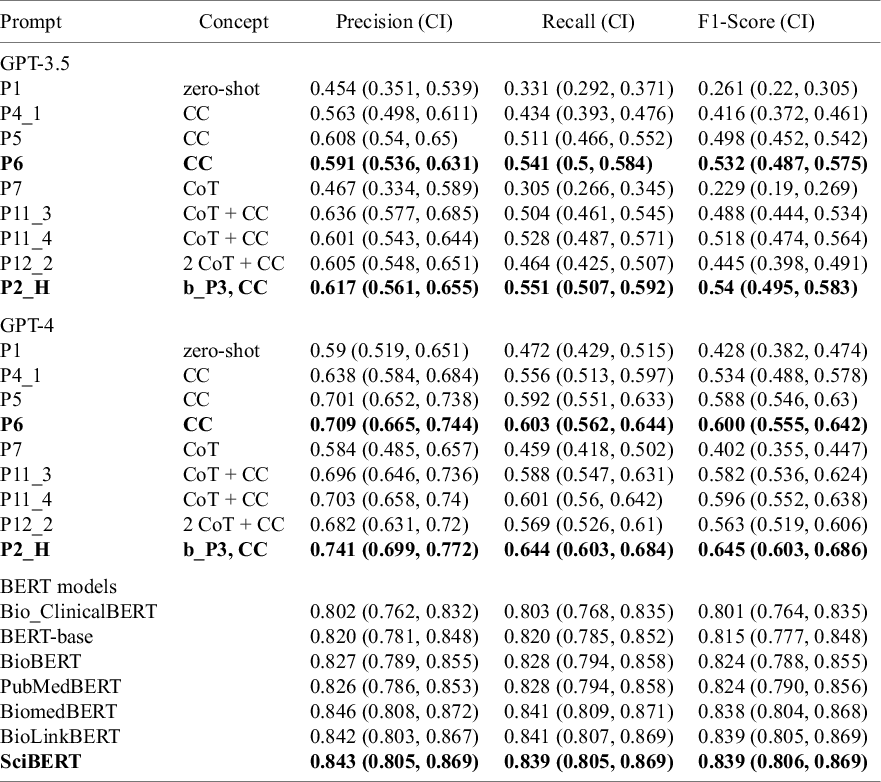
GPT models performed almost perfectly in the binary text classification task (i.e., “Animal” versus “Other”) with F1-scores up to 0.99 (Table S6 in the Supplementary Material). However, this performance dropped substantially for multi-class classification (considering all 14 study classes) with F1-scores between 0.261 and 0.645. GPT-4 consistently outperformed GPT-3.5 (maximum F1-scores 0.540 versus 0.645, respectively) (Table 3 and Figure 2) (only the most promising prompts were tested on GPT-4).
Per-class performance comparison between the best performing prompting strategy for GPT-3.5 and GPT-4 (P2_H_b3, CC), and SciBERT with 95%-confidence intervals.

For multi-class classification, the best performing prompting strategy was hierarchical prompting, i.e., to first classify into “Animal” studies versus “Other” (non-animal) studies, followed by further sub-classification into the 14 classes (with the highest performing prompt being “P2_H_b3” “P2_HIERARCHY” based upon binary prompt P3, Table S7 in the Supplementary Material). The second-best performing prompt was multi-class-prompt P6 (adding the complete annotation guidelines to the GPT-prompt). The lowest performing strategy was zero-shot prompting, i.e., prompting the model without any additional context. All performance metrics for GPT-3.5 are reported in Tables S7 and S8 in the Supplementary Material.
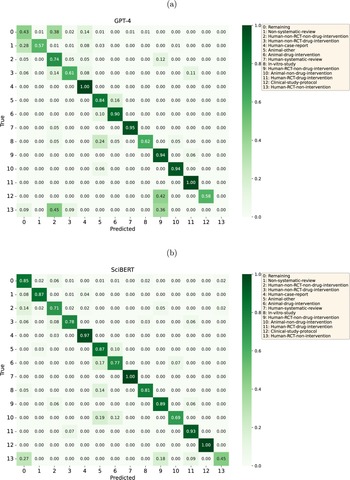
GPT-4’s most inaccurately predicted classes were Human-RCT-non-intervention (0% correctly identified, commonly confused with Human-non-RCT-non-drug-intervention and Human-RCT-non-drug-intervention), Non-systematic-review (57%, commonly confused with Remaining), and Study-protocol (58%, commonly confused with Human-RCT-non-drug-intervention). In addition, the class Remaining was commonly confused with Human-non-RCT-non-drug-intervention (Figure 3). We did not observe an association between class sizes and model performance.
Confusion matrices of the best-performing (a) prompting strategy for the GPT-based model (GPT-4, P2_H_b3, CC) and (b) the BERT-based models (SciBERT).

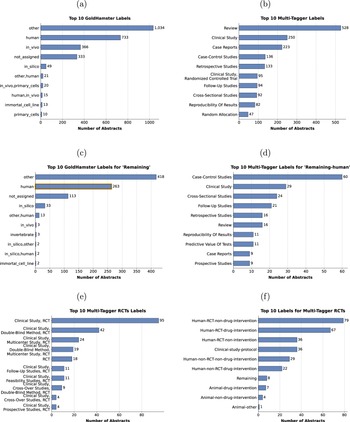
Overview of top ten predicted labels based on the GoldHamster or Multi-Tagger corpus for (a, b) the full dataset, (c) the abstracts annotated as Remaining in our corpus, and (d) the abstracts annotated as Remaining in our corpus and as human by GoldHamster, highlighted in orange in (c). Subfigure (e) shows the top ten labels from Multi-Tagger containing Randomized Control Trials, abbreviated as RCT, and (f) the corresponding assigned labels to this set of articles in our dataset.

3.3 BERT models
The fine-tuned BERT models also performed almost perfectly in the binary text classification task (i.e., “Animal” versus “Other”) with F1-scores up to 0.99 (Table S6 in the Supplementary Material). And, in contrast to GPT models, this performance remained high for multi-class classification (considering all 14 study classes) with F1-scores between 0.80 and 0.84 for different BERT models (Table 3), with SciBERT being the top-performing model.
SciBERT’s most inaccurately predicted classes were Human-RCT-non-intervention (45% correctly identified, commonly confused with Remaining and Human-RCT-non-drug-intervention) and Animal-non-drug-intervention (69%, commonly confused with the classes Animal-other or Animal-drug-intervention) (Figure 3). The size of the classes (ranging from 54 to 858) was not associated with model performance.
3.4 GPT versus BERT
Overall, SciBERT (the best performing BERT model) outperformed both GPT-3.5 and GPT-4 (Table 4 and Figure 2). Despite overlapping confidence intervals, there was a clear trend that SciBERT also outperformed GPT at class-level for most classes, except that GPT-4 outperformed SciBERT for Human-RCT-drug-intervention, Animal-non-drug-intervention, and Animal-drug-intervention (Figure 2 and Figure S2 in the Supplementary Material).
Top performing models and strategies among the GPT and BERT models, evaluated in the multi-class classification task

Abbreviations: “P2_H_b3” is hierarchical prompt P2, “P2_HIERARCHY,” whose prediction was based upon the predictions of binary prompt P3.
3.5 Comparison to related work
The MeSH-based approach performed well in capturing nearly all animal articles (high recall). However, it mislabeled more articles as Animal, which resulted in lower precision. As a result, its overall F1-score was lower than that of the ML-based models (Table S5 in the Supplementary Material).
The GoldHamster model most frequently predicted the labels Other, Human, and In vivo. The model returned no label for around 300 abstracts when the model was uncertain about the correct classification (Figure 4a). For the abstracts in our Remaining category, the GoldHamster model likewise assigned the general category Other most often, followed by Human and not assigned (Figure 4c). Notably, the category In silico was also present. In the binary classification task, the model trained on the GoldHamster corpus performed comparably to SciBERT trained on our dataset (Table S5 in the Supplementary Material). Although its precision for Animal was slightly lower, its recall was higher, likely because multiple labels for some studies led to both more false positives and a broader capture of relevant studies.
When keeping only the Multi-Tagger labels whose scores exceed the provided optimal threshold, there were more than 1000 studies without an assigned label (S1a). To mitigate this, we selected the label with the highest score, when the probability for none of the labels achieved the Multi-Tagger defined thresholds. The top predicted labels over the whole datasets were Review, Clinical Study, and Case Report (Figure 4b). Case-Control Studies, Cross-Sectional Studies, and Retrospective Studies were the most common classifications for the articles we labeled as Remaining (S1b).
We were also interested in the case where the model trained on the GoldHamster dataset predicted Human study type, while our accepted label was Remaining. The most frequent labels predicted by Multi-Tagger for those 263 studies were Case-Control Studies, Clinical Study, and Cross-Sectional Studies (Figure 4d). Furthermore, articles assigned an RCT label by Multi-Tagger were also mostly identified as such in our dataset (Figure 4e and f).
4 Discussion
4.1 Main findings
This study aimed to use GPT-based LLMs for classification of scientific study types and to compare these models with smaller fine-tuned BERT-based language models. We find that GPT models, including the newer GPT-4, show only mediocre performance in classifying scientific study types, such as RCTs or animal studies. The greatest performance boost, although still moderate, was observed using contextual clues by providing the actual annotation guidelines to GPT. BERT models consistently outperformed GPT models by a substantial margin, reaching F1-scores above 0.8 for most study classes.
4.2 Findings in the context of existing evidence
We present a new human-annotated corpus of scientific abstracts tailored to various types of systematic reviews. This corpus includes abstracts relevant for clinical systematic reviews that often involve RCTs, e.g., of therapeutic interventions.Reference Lasserson, Thomas and Higgins47 Additionally, it covers study types pertinent to preclinical systematic reviews,Reference Sena, Currie, McCann, Macleod and Howells48 such as animal and in-vitro studies, with sub-classifications specifically for research into therapeutic interventions. This provides much greater granularity than existing corpora,Reference Van IJzendoorn, Habets, Vinkers and Otte16 making it a resource for, e.g., systematic reviews of preclinical studies.Reference Ineichen, Held, Salanti, Macleod and Wever19
Transformer-based models like BERT, i.e., a type of deep learning model architecture originally developed for text processing, have been used in the screening of scientific articles by automatically classifying study types,Reference Abogunrin, Queiros, Bednarski, Sumner, Baehrens and Witzmann17 reaching high sensitivity and specificity for differentiating a smaller number of different study types.Reference Van IJzendoorn, Habets, Vinkers and Otte16 BERT-models are pre-trained on a vast corpus of text and subsequently fine-tuned to perform specific tasks like text classification.Reference Devlin, Chang, Lee and Toutanova35 Consequently, the BERT family of models has become foundational when fine-tuning models for specific applications like classification, and for a target domain like medicine.Reference Gu, Tinn and Cheng41 For instance, BioBERT, pre-trained on extensive biomedical corpora, excels in biomedical text mining tasks and can be adapted into even more specialized models.Reference Lee, Yoon and Kim38 Our findings show that SciBERT may perform best in terms of the F1-score, though the small differences and overlapping confidence intervals compared to other BERT models preclude firm conclusions. Interestingly, it has been shown that combining different BERT models in an ensemble could enhance the performance of automated text classification even further, achieving sensitivities for text classification as high as 96%.Reference Qin, Liu and Wang49
As expected, GPT-4 showed better performance in study type classification than its predecessor, GPT-3.5, although its overall performance remained moderate. Notably, even advanced prompting strategiesReference Meskó32, Reference Sivarajkumar, Kelley, Samolyk-Mazzanti, Visweswaran and Wang50 that incorporated Contextual Clues (providing annotation guidelines) and Chain-of-Thought (explicit step-by-step reasoning) provided only marginal improvements in performance. For multi-class classification, the more traditional BERT models consistently outperformed the GPT models across all performance metrics in our sample. This is particularly striking given the exceptional abilities of GPT models in natural language understanding and generation across various applications. For instance, GPT models have shown remarkable results in the USMLE—a comprehensive three-step exam that evaluates clinical competency for medical licensure in the United StatesReference Nori, King, McKinney, Carignan and Horvitz28, Reference Brin, Sorin and Vaid29, Reference Taloni, Borselli and Scarsi51—and have even surpassed human performance in text annotation tasks.Reference Gilardi, Alizadeh and Kubli52 This serves as a reminder that, being generative models, their impressive language generation abilities may not necessarily predict good performance on classification tasks, particularly multi-class and domain-specific tasks. Notably, GPT-models have been used with some success to automatically perform title and abstract screening for systematic reviews,Reference Tran, Gartlehner and Yaacoub53– Reference Khraisha, Put, Kappenberg, Warraitch and Hadfield56 though it has not yet reached the level of fully replacing even one human reviewer, let alone two.Reference Tran, Gartlehner and Yaacoub53 We also considered fine-tuning open-weight LLMs. However, GPT models already offer a strong baseline and fine-tuning is costly and time-consuming. With limited academic resources, we chose GPT for its competitive results out of the box.
We showed that using MeSH terms to differentiate between animal and other study types, resulted in more false positive animal-study classifications. This aligns with findings that some MeSH terms are not good discriminators for study types, due to their broader assignment.Reference Neves, Klippert and Knöspel13 We did not experiment with integrating MeSH terms into the text for fine-tuning/GPT prediction, as similar approaches were extensively evaluated in related work and showed no performance improvement.Reference Neves, Klippert and Knöspel13
A comparison with the labels predicted by the GoldHamster model showed high agreement in identifying animal studies. At the same time, the fine-grained annotations in our dataset and the GoldHamster corpus appear complementary. Notably, our work differentiates animal studies by intervention type (drug versus non-drug), whereas the GoldHamster corpus also covers non-animal study models, such as in-silico approaches. The GoldHamster model assigned a large proportion of studies to the non-specific Other class, suggesting additional relevant categories that are not captured by either dataset. Using the Multi-Tagger annotations revealed that these unlabeled studies mostly concern clinical studies in humans, including case-control or observational studies, which was not the focus in our dataset. For articles annotated as RCTs, Multi-Tagger can provide more detail for the study design, while our annotations help differentiate between RCTs of different intervention types. Applying the optimal Multi-Tagger thresholds would leave over 1,000 studies in our corpus unlabeled, given Multi-Tagger’s exclusive focus on human-relevant articles. Those observations suggest a promising future research direction to merge those related datasets to create a more comprehensive resource.
4.3 Limitations
Our study has a number of limitations: First, the natural distribution of study types in PubMed resulted in an imbalanced dataset, with, e.g., study protocols or non-interventional RCTs being underrepresented. The Remaining class, which includes all studies not fitting into other specified categories, was almost three times larger than the second largest class. Although we maintained this distribution to reflect real-world scenarios, we manually enriched each of the smaller classes with an additional 50 samples to partially mitigate the uneven class distribution and resolve the issue of severely underrepresented classes. Future research could assess how a more balanced class distribution could affect BERT model performance.
Second, although we employed various advanced prompting strategies, we did not explore role modeling with GPT that might enhance its effectiveness (e.g., “You are a systematic reviewer”). Future studies could also look into lightweight model adaptation methods like delta-tuning methods,Reference Ding, Qin and Yang57 such as BitFitReference Zaken, Ravfogel and Goldberg58 and adaptersReference Houlsby, Giurgiu and Jastrzebski59 to optimize performance.
Third, our use of GPT models was limited to GPT-3.5-turbo and GPT-4-turbo-preview, excluding other available API versions. Fourth, it was decided that model calibration (i.e., aligning the model’s confidence scores with actual accuracy) would exceed the technical scope of the study. We recognize, however, that the calibration between confidence and performanceReference Desai and Durrett60 would be essential for studies focusing on the creation of robust and optimized models.
Finally, limitations in the study scope and generalizability should be mentioned. While not a limitation of this study specifically, the applicability of automated study-type classification may be restricted to biomedical research. Fields, such as education or ecology, may lack clearly defined study types, limiting the usefulness of such approaches. Furthermore, our sampled articles were retrieved using a query focused on the neuroscience domain. While our aim was to develop study type definitions that are broadly useful for biomedical text mining, the resulting corpus is specific to neuroscience. However, we believe that the key features a classification model uses to identify study types are largely independent of the disease domain. Nonetheless, further experiments are required to assess the generalizability of our approach across other areas of biomedical research.
4.4 Strengths
Our study has two main strengths: First, we introduce a highly granular, dual-annotated abstract corpus designed for fine-tuning LLMs. This allows for more precise adaptations to specific tasks within text classification. Second, we conducted a comprehensive comparison of state-of-the-art GPT models, incorporating advanced prompting strategies, against a range of established BERT models. This approach enhances capabilities beyond those of PubMed indexing or MeSH terms.
4.5 Conclusions
Our study demonstrates that LLMs, particularly those based on BERT, can be used for classification of study types for systematic reviews. These models are especially effective for this task. Specifically, trimming a reference library prior to formal abstract screening with such an approach could dramatically reduce human workload during the abstract screening phase of systematic reviews. As the volume of scientific publications continues to grow, employing such tools will be critical in keeping abreast with scientific evidence.
Acknowledgements
We thank Yvain de Viragh and Naïm de Viragh for their help with conception and data analysis of our study.
Author contributions
Conception and design of study: S.E.D., S.d.V., B.V.I.; Acquisition of data: S.E.D., S.d.V.; Experimental setup and execution: S.E.D., S.d.V., H.H.; Analysis of data: S.E.D., S.d.V., H.H.; Interpretation of data: all authors; Drafting the initial manuscript: S.E.D., S.d.V., H.H., B.V.I. All authors critically revised the draft.
Competing interest statement
The authors declare that no competing interests exist.
Data availability statement
All data and code that support the findings of this study are available in our public GitHub repository (https://github.com/Ineichen-Group/StudyTypeTeller). For any questions regarding the data, metadata, or code analysis, contact the corresponding author, S.E.D.
Funding statement
This study was funded by the Swiss National Science Foundation (Grant No. 407940-206504, to B.V.I.) UZH Digital Entrepreneur Fellowship (to B.V.I.), and Universities Federation for Animal Welfare (to B.V.I.). The sponsors had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Ethics statement
This study only used publicly available data sets and not ethical approval was required.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/rsm.2025.10031.







 Open access
Open access