


1. Introduction
Machine translation (MT) is routinely evaluated using various segment-level similarity metrics against one or more reference translations. At the same time, reference translations acquired in the standard way are often criticized for their flaws of various types. For several high-resourced language pairs, MT quality reaches levels comparable to the quality of the reference translation (Hassan et al. Reference Hassan, Aue, Chen, Chowdhary, Clark, Federmann, Huang, Junczys-Dowmunt, Lewis, Li, Liu, Liu, Luo, Menezes, Qin, Seide, Tan, Tian, Wu, Wu, Xia, Zhang, Zhang and Zhou2018; Freitag et al. Reference Freitag, Rei, Mathur, Lo, Stewart, Avramidis, Kocmi, Foster, Lavie and Martins2022) and sometimes MT even significantly surpasses humans in a particular evaluation setting (Popel et al. Reference Popel, Tomkova, Tomek, Kaiser, Uszkoreit, Bojar and Žabokrtskỳ2020). Given this, one could conclude that state-of-the-art MT has reached the point where reference-based evaluation is no longer reliable and we have to resort to other methods (such as targeted expert evaluation of particular outputs), even if they are costly, subjective, and possibly impossible to automate.
The narrow goal of the presented work is to allow for an “extension of the expiry date” for reference-based evaluation methods. In a broader perspective, we want to formulate a methodology for creating reference translations which avoid the often-observed deficiencies of “standard” or “professional” reference translations, be it multiple interfering phenomena, inappropriate expressions, ignorance of topic-focus articulation (information structure), or other abundant shortcomings in the translation, indicating their authors’ insensitivity to the topic itself, but above all to the source and target language. To this end, we introduce so-called optimal reference translations (ORT), which are intended to represent optimal (ideal or excellent) human translations (should they be the subject of a translation quality evaluation).Footnote a We focus on document-level translation and evaluation, which is in line with current trends in MT research (Maruf, Saleh, and Haffari Reference Maruf, Saleh and Haffari2019; Ma, Zhang, and Zhou Reference Ma, Zhang and Zhou2020; Gete et al. Reference Gete, Etchegoyhen, Ponce, Labaka, Aranberri, Corral, Saralegi, Ellakuria and Martín-Valdivia2022; Castilho Reference Castilho2022) and also this special issue of NLE. We hope that ORT will represent a new approach to the evaluation of excellent MT outputs by becoming a gold standard in the true sense of the word. Our work is concerned with the following questions:
-
How to navigate future MT research for languages for which the quality level of MT is already very good?
-
Is it worth creating an expensive optimal reference translation to compare with MT?
-
If various groups of annotators evaluate optimal reference and standard translations, will they all recognize the difference in quality?
Subsequently, our contributions are as follows:
-
definition of optimal reference translation and an in-depth analysis of evaluations and the relationship between evaluation and translation editing;
-
reflection on what it means to be a high-quality translation for different types of annotators;
-
publication of the Optimal Reference Translations of English
 $\rightarrow$
Czech dataset with a subset evaluated in aforementioned manner.
$\rightarrow$
Czech dataset with a subset evaluated in aforementioned manner.

After discussing related work in this context (Section 2), we focus on defining ORT and describe its creation process (Section 3). Next, we describe our evaluation campaign of ORT, the data, annotation interface, and annotation instructions (Section 3.2). We then turn to a statistical perspective of our data and measure the predictability of human ratings (e.g. Overall rating from Spelling, Style, Meaning, etc.) using automated metrics (Section 4). We pay special attention to predicting document-level rating from segment level. In the penultimate Section 5, we provide a detailed qualitative analysis of human annotations and discuss this work in the greater perspective of human evaluation of translations (Section 6). Analysis code and collected data are publicly available.Footnote b
2. Related work
Evaluating translations (machine or human) is without doubt an extremely demanding discipline. Researchers have recently contributed several possible ways to approach the evaluation of translation quality in high-resource settings. We focus on the latest findings in this area, which—like our contribution—look for a possible new direction where future translation quality evaluation can proceed. The presented study is primarily concerned with the evaluation of human translations (“standard” vs. our optimal references) but the same evaluation methodology is applicable to machine translation.
Recently, Freitag et al. (Reference Freitag, Rei, Mathur, Lo, Stewart, Avramidis, Kocmi, Foster, Lavie and Martins2022) discussed metrics that were evaluated on how well they correlate with human ratings at the system and segment level. They recommended using neural-based metrics instead of overlap metrics like BLEU which correlate poorly with human ratings, and demonstrated their superiority across four different domains. Another relevant finding was that expert-based evaluation (MQM, Multidimensional Quality Metrics, Lommel et al. Reference Lommel, Uszkoreit and Burchardt2014)) is more reliable than DA (Direct Assessment, Graham et al. (Reference Graham, Baldwin, Moffat and Zobel2013)), as already confirmed by Freitag et al. (Reference Freitag, Foster, Grangier, Ratnakar, Tan and Macherey2021). The MQM method relies on a fine-grained error analysis and is used for quality assurance in the translation industry. Popović (Reference Popović2020) proposed a novel method for manual evaluation of MT outputs based on marking issues in the translated text but not assigning any scores, nor classifying errors. The advantage of this method is that it can be used in various settings (any genre/domain and language pair, any generated text).
Other unresolved issues in the field of translation evaluation include the question of whether it is better to evaluate in a source- or reference-based fashion. As evidenced by, for example, Kocmi et al. (Reference Kocmi, Bawden, Bojar, Dvorkovich, Federmann, Fishel, Gowda, Graham, Grundkiewicz and Haddow2022), reference-based human judgements are biased by unstable quality of references. For some language pairs and directions, however, it is still the main method of assessment. Licht et al. (Reference Licht, Gao, Lam, Guzman, Diab and Koehn2022) proposed a new scoring metric which is focused primarily on meaning and emphasises adequacy rather than fluency, for several reasons (e.g. meaning preservation is a pressing challenge for low-resource language pairs and assessing fluency is much more subjective).
Methods for automatic human translation quality estimation exist (Specia and Shah Reference Specia and Shah2014; Yuan Reference Yuan2018), though the field focuses primarily on machine translation quality estimation. Furthermore, the definition of translation quality remains elusive and is plagued by subjectivity and low assessment agreement (House Reference House2001; Kunilovskaya et al. Reference Kunilovskaya2015; Guerberof Reference Guerberof2017).
3. Optimal reference translations
Our optimal reference translation (ORT) represents the ideal translation solution under the given conditions. Its creation is accompanied by the following phases and factors:
-
diversity at the beginning (multiple translations are available from different translators, that is, in principle there are at least two independently-created translations available),
-
discussion among experienced translation theoreticians/ linguists in search for the best possible solutions, leading to consensus,
-
editing the newly created translations, reaching a point where none of the translation creators comes up with a better solution.
Another important condition is the documentation of all stages of the translation creation (archiving the initial solutions, notes on shortcomings, suggestions for other potential solutions, notes on translation strategies and procedures, record of the discussion among the authors, reasons why a solution was rejected, record of the amount of time spent on each text, etc.). The final characteristic of the creation of an optimal reference translation is the considerable amount of time spent by the creators on the analysis, discussion, and creation of new translations. In our definition of ORT, optimality therefore refers to:
-
a carefully thought-out and documented translation process, and
-
the quality of the resulting translation.
It however does not include the time aspect, in the sense of minimizing the time spent on the translation process. This choice is likely one more key distinction from “professional” translation. Incontestably, more than one version of ORT may be produced. The resulting ORT may vary depending on the individuality of its creators. Of course, the creators take into account the purpose and intended audience of ORT, just like in standard translations, but different collectives of ORT creators may perceive the intended purpose and audience differently or consider finer details of these aspects. Moreover, factors such as idiolect, age, experience, etc. can also play a large role, but unlike standard translations, there must always be a consensus among the creators of ORT.
3.1 Translation creation
The underlying dataset without the evaluation has already been described in Czech (Kloudová et al. Reference Kloudová, Mraček, Bojar and Popel2023). The 130 original English texts (news articles available from the Internet, covering topics ranging from politics and economics to sports and social events) were translated from English into Czech by three human translators for the Conference on Machine Translation 2020 (WMT20). The three translators were hired by WMT organizers from a translation agency. The resulting three independent parallel Czech translations (P1, P2, P3) serve as basic reference translations, from which a final “optimal reference translation” could be synthesized. It was anticipated that our creators of ORT (two translators-cum-theoreticians—professionals who deal with translation from both a practical and a theoretical point of view)Footnote c would always choose the best translation solutions from the existing three versions, or create new solutions if necessary. However, the available translations from the first-stage translators were often of insufficient quality. Therefore, in the creation of our optimal reference translations, more emphasis was placed on the input of the creators of the final version rather than on the synthesis of existing translations.
The process of creating our ORT can be described as follows: our tandem of translators-cum-theoreticians worked as a translator and revisor pair. One of them produced a first version, which the other carefully compared with the original and critiqued if necessary. Notes on the first version of the translations were given in the form of comments on individual segments of the text. The author of the first version of the translations subsequently accepted or, with justification (and subsequent discussion), did not accept the suggestions in the comments. The crucial point in the discussion was always that the final solution should be fully in line with the beliefs of both translation authors. It is worth mentioning that the discussion between the two creators had, to a large extent, the written form of exchanging notes. ORT thus do not demand live, synchronous, attention of the creators.
The result of this process was two versions of ORT (many more versions could have evolved, though, our priority was not diversity, but above all quality—so we decided to create two versions in parallel, N1 and N2). The first version (denoted N1) is closer to the original both in terms of meaning and linguistic (especially syntactic) structure. The second version (N2) is probably more readable, idiomatic and fluent, being even closer to the Czech news style, both syntactically, for example, by emphasizing the ordering of syntactic elements typical of news reporting, and lexically, for example, by a more varied choice of synonyms. The presented work is centred around the evaluation of the various human translations. Because N2 has not been created for all segments of the translation (not all the original segments allowed an appropriate linguistic variation, that is, N1 was identical to N2), we decided not to use it. Thus, four translations were included in the evaluation—one optimal reference translation (N1) in addition to the three existing human translations.
In Figure 1, we show the sources and example translations (P1, P2, P3), together with one of the two versions of our optimal translation, N1. During the evaluation, each translation can be further edited by annotators in which case we identify the resulting segment as, for example, “P1 EDIT by annotator A4.” We will encounter examples in Section 5.
Example translations of the same source into Czech. Literal transcriptions of the translations are shown in italics. N1: translatologist collaboration (optimal translation), P1: professional translation agency (post-edited MT), P2, P3: professional translation agency.

3.2 Annotation campaign
3.2.1 Annotators
We hired 11 native Czech annotators for the evaluation of translations in three groups: (1) four professional translators,Footnote d (2) four non-experts, (3) three students of MA Study Programme Translation and/or Interpreting: Czech and English at the Institute for Translation Studies.Footnote e Their proficiency and end-campaign questionnaire responses are presented in Section 4.1.
3.2.2 Data
Out of the original data (Section 3.1), we randomly selected, with manual verification, 8 consecutive segments in 20 documents which were to be annotated. We refer to these 8 segments as documents because they contain most of the documents’ main points. Each segment corresponds approximately to one sentence, though they are longer (31 source tokens on average) than what we would find typical for the news domain. The data contain document-level phenomena (e.g. discourse), so segments cannot be translated and evaluated independently.
First 5 rows of a screen for a single document with source and 4 translations in parallel. Screens were accessed by annotators in an online spreadsheet programme. Note: Scalable graphics—zoom in.
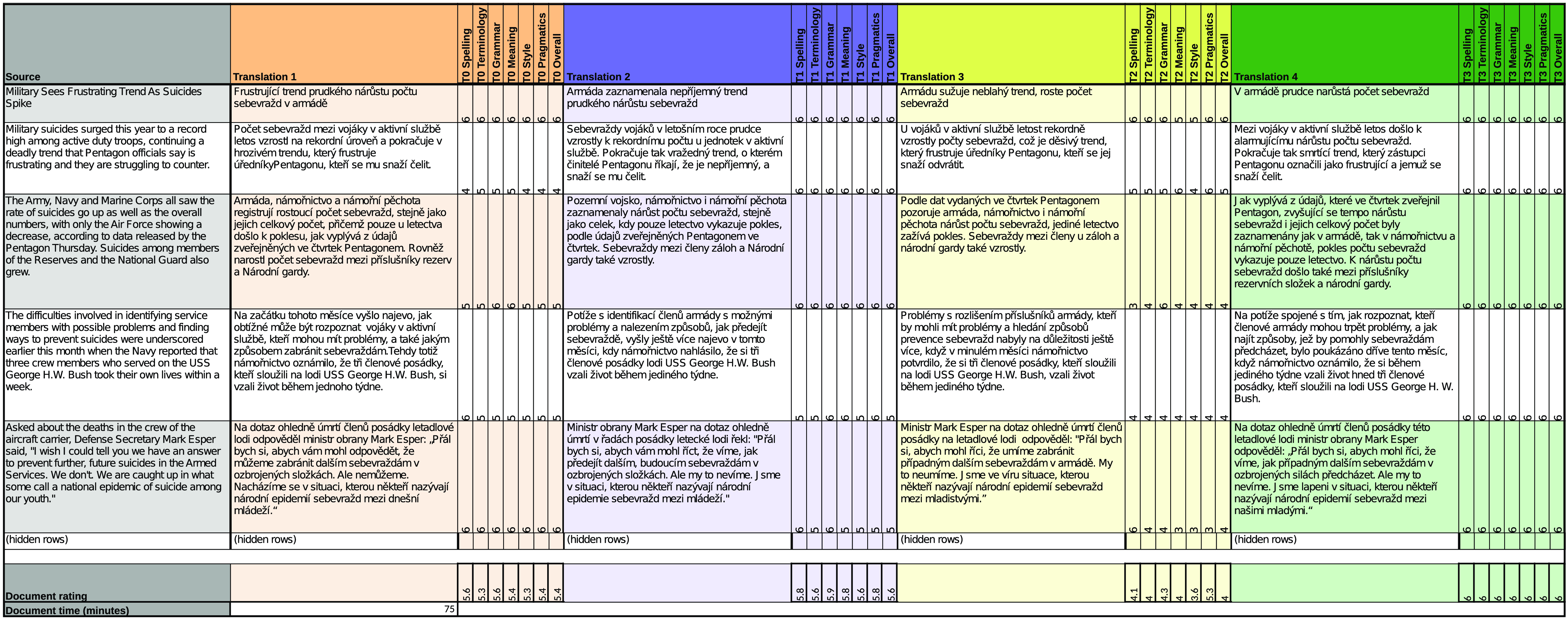
3.2.3 Annotation interface
We provided the annotators with online spreadsheets which showed the source text and all four translation hypotheses. This way each translation could be compared against the others while having the context available (e.g. to check for consistency). Each hypothesis column was distinguished by a colour, as shown in Figure 2, and based on annotator feedback (Section 4.1), we believe that it was manageable to perform annotations despite the amount of information shown. We showed the rest of segments in the source language for context but did not provide any translation hypotheses for the annotators to consult or rate. Each of the 20 documents was shown in a separate tab/sheet. The annotators worked on the evaluation in a span of 3 months in an uncontrolled environment.
3.2.4 Annotation instructions
The task for annotators was three-fold, see Section 8 for the full annotation guidelines.
-
Grade each segment translation on a decimal scale from 0 (least) to 6 (most) in categories Spelling, Terminology, Grammar, Meaning, Style, Pragmatics and Overall (e.g.
$4.0 \,{\rm or}\, 5.8$
). This scale was chosen to balance the number of attraction points for annotators (integers) and to contain a middle point (3). -
Grade each document as a whole on the same scale and categories.
-
If a segment would not receive the highest grade, there would be something wrong in the translation. Therefore, the annotators should edit the hypothesis translation into a state to which they would give it the maximal scores.

4. Quantitative analysis
4.1 Annotator questionnaire
After the annotation campaign, the annotators filled a brief survey with questions about their perception of the task and their strategy.
We did not constrain the annotators in what order they should perform the annotations. As a result, they employed various approaches, most popular being segment-category-translation.Footnote f While we attempted to not introduce a bias, almost all annotators filled in categories one by one as they were organized in the user interface.Footnote g This could have an effect on the rating. For example, by establishing and drawing attention to the specific 6 features, the final Overall rating may be influenced primarily by them and it would not have been if the ordering was reversed. Pragmatics and Overall were reported as the hardest to evaluate, while Spelling was the easiest, especially because errors in spelling can be seen even without deeper translatological analysis and there were not many of them in the translations. The annotators self-reported utilizing the preceding and following context around half the time to check for document-level consistency. While they proceeded mostly linearly, about 20% (self-reported estimate) of previously completed segments were later changed. We intentionally shuffled the ordering of translations (columns in each sheet) so that the annotators would not build a bias towards the translation source in, for example, the second column. However, the annotators reported that despite this, they were sometimes able to recognize a specific translation source based on various artefacts, such as systematically not translating or localizing foreign names.
4.2 Collected annotations
We do not do any preprocessing or filtering of the collected data. This is justified by our all annotators working on the same set of documents and by the fact that we have established connections with each of the annotators and deem them trustworthy. Any bias of an annotator’s rating would therefore be present in all documents which would not hinder even absolute comparisons. Nevertheless, we examine annotator variation later in this section. In total for 20 documents, we collected:
-
7k segment-level annotations (1.8k annotations of 4 translation hypotheses). Each hypothesis is edited unless it received a very high score (in 4k cases). This amounts to 49k ratings across all categories.
-
880 document-level annotations (220 annotations of 4 translation hypotheses.) This amounts to 6.2k ratings across all categories.
4.3 Quality of initial translations
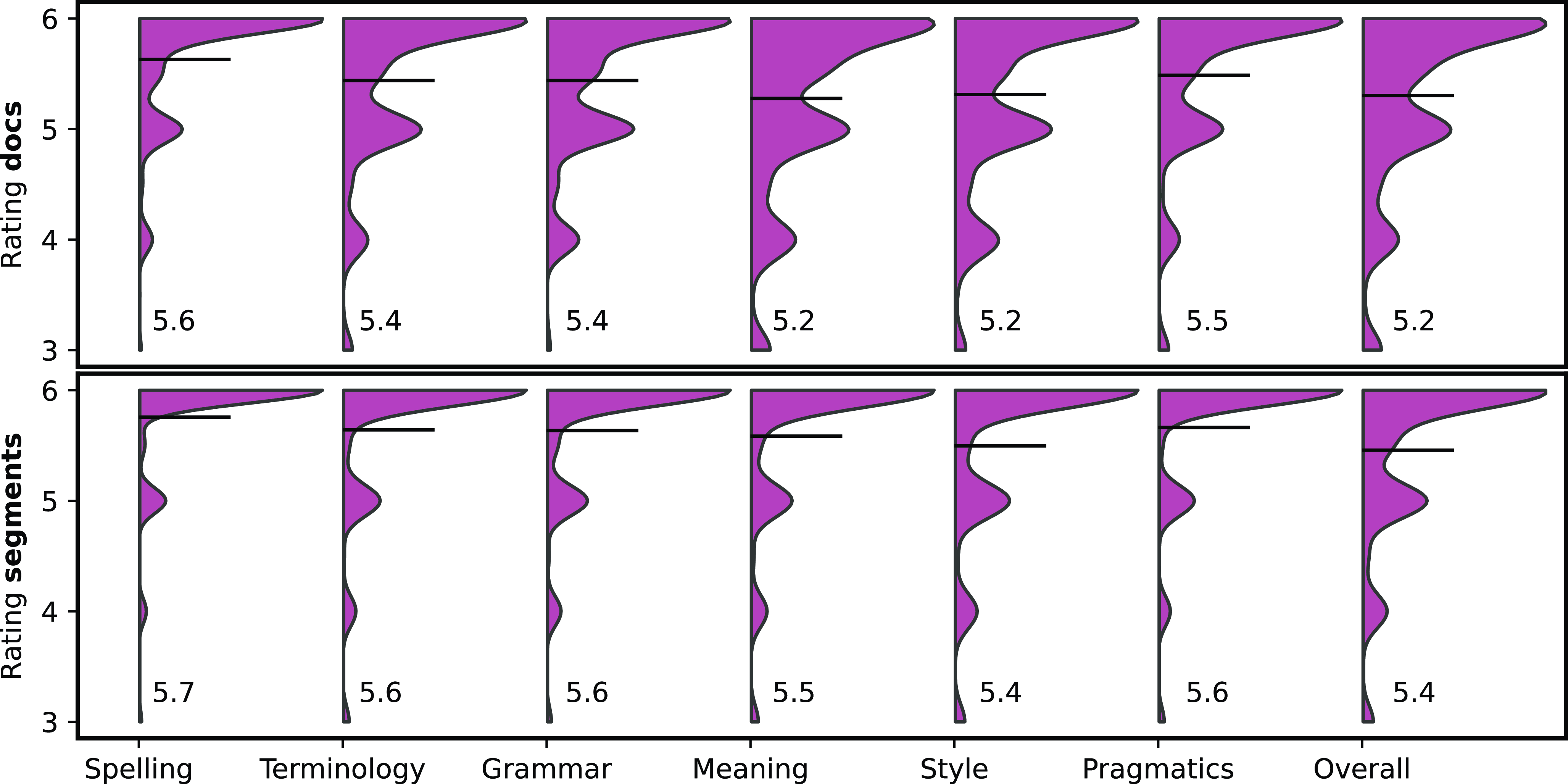
Recall the grading scale from 0 (least) to 6 (most). The translation sources (P1, P2, and P3) were of varying quality, as shown in Figure 3. Overwhelmingly, N1 was evaluated the highest followed by P1, P2 and P3, in this order. Furthermore, there is a strong connection between the ratings on segment and document level and also across evaluation categories.
The density distribution of features in Figure 4 shows the natural tendency of annotators to use integer scores. It also shows that all features are heavily skewed towards high scores and that on average documents receive lower scores than their segments.
Averages of ratings for different translation sources on document (top-left) and segment (bottom-right) level across features.

Distribution densities of ratings of each collected variable (thin tail cropped
 $\geq$
3 for higher resolution of high-density values). Numbers and horizontal lines show feature means.
$\geq$
3 for higher resolution of high-density values). Numbers and horizontal lines show feature means.
4.4 Inter-annotator agreement
To measure inter-annotator agreement, we aggregate pairwise annotator Pearson correlations on the segment level.Footnote
h
At first, this agreement is quite low (
 $\rho$
= 0.33). It can however be explained upon closer inspection of agreement across translations. While inter-annotator correlations for the worst translation P3 were
$\rho$
= 0.33). It can however be explained upon closer inspection of agreement across translations. While inter-annotator correlations for the worst translation P3 were
 $\rho$
= 0.50, the best translation had
$\rho$
= 0.50, the best translation had
 $\rho$
= 0.13. We hypothesize that with less variance and therefore signal for rating, the inter-annotator agreement drops. This is even more visible from the pairwise annotator correlations for the Grammar category, in which N1 has made almost no errors (
$\rho$
= 0.13. We hypothesize that with less variance and therefore signal for rating, the inter-annotator agreement drops. This is even more visible from the pairwise annotator correlations for the Grammar category, in which N1 has made almost no errors (
 $\rho$
= 0.03). In 28% of cases, the ordering of Overall scores for segments was the same between pairs of annotators and in 66% of cases they differed by only one transposition. In other words, the difference in the score ordering was 2 positions or more only in 8% of cases. Further individual effects of annotators are discussed in Section 4.6.
$\rho$
= 0.03). In 28% of cases, the ordering of Overall scores for segments was the same between pairs of annotators and in 66% of cases they differed by only one transposition. In other words, the difference in the score ordering was 2 positions or more only in 8% of cases. Further individual effects of annotators are discussed in Section 4.6.
4.5 Modelling overall quality from components
In this section, we attempt to model the Overall category based on individual categories, degree of translation editing, and individual annotators.
4.5.1 Other categories individually
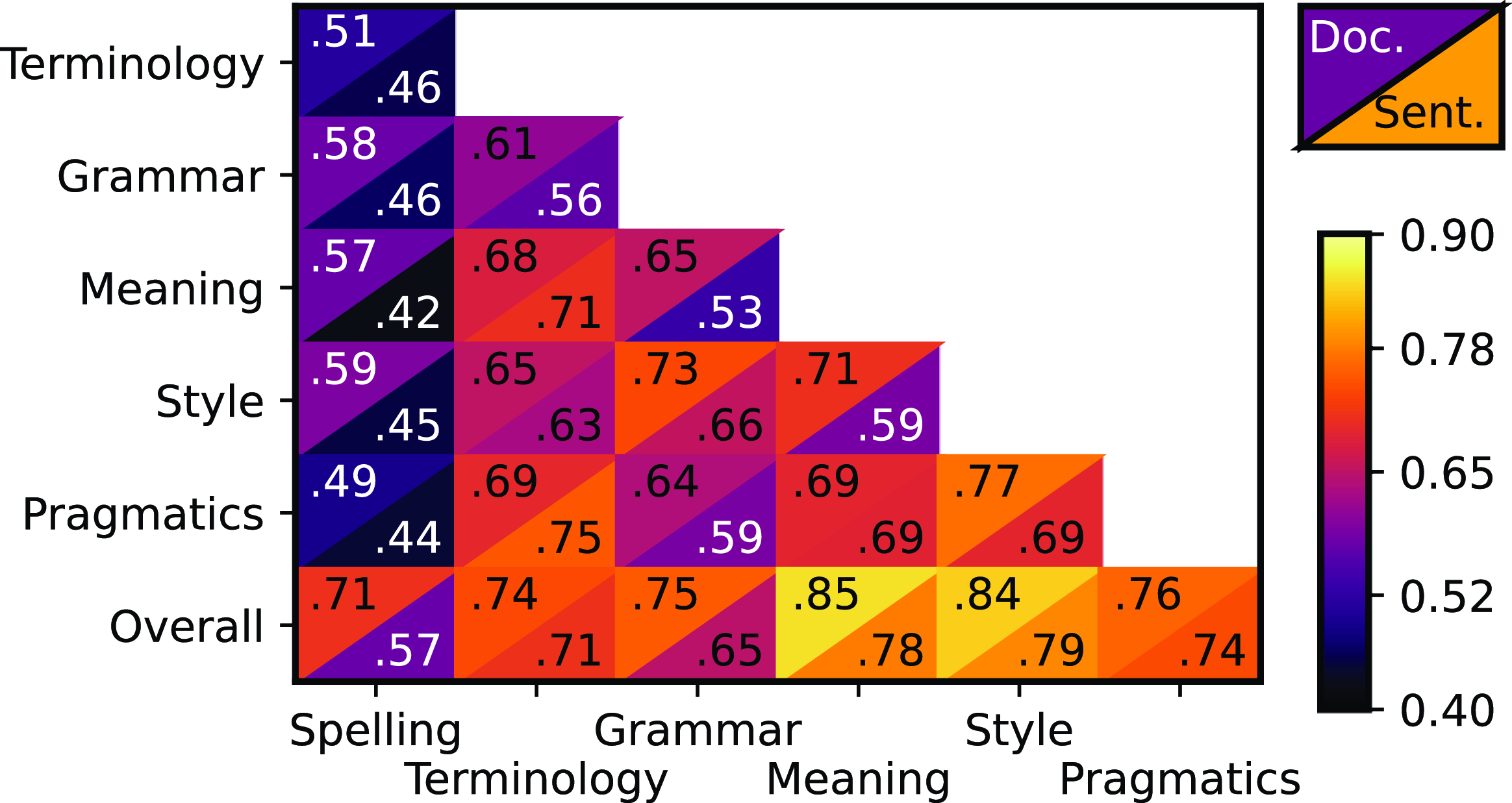
We first consider the predictability of individual categories and measure it using Pearson’s correlation (0 = no relationship, 1 = perfect linear relationship). For both the document and segment level, we observe similar correlations, see Figure 5. Notably, spelling is much less predictive of other categories than the rest. A possible explanation is that this was the least common mistake and the values are therefore concentrated around the highest possible score (Figure 4). Overall correlates the most with Meaning and Style. This can be explained similarly because those features had the largest variances.
Pearson’s correlations between individual features on document (top-left) and segment (bottom-right) level.
4.5.2 Linear regression on other categories
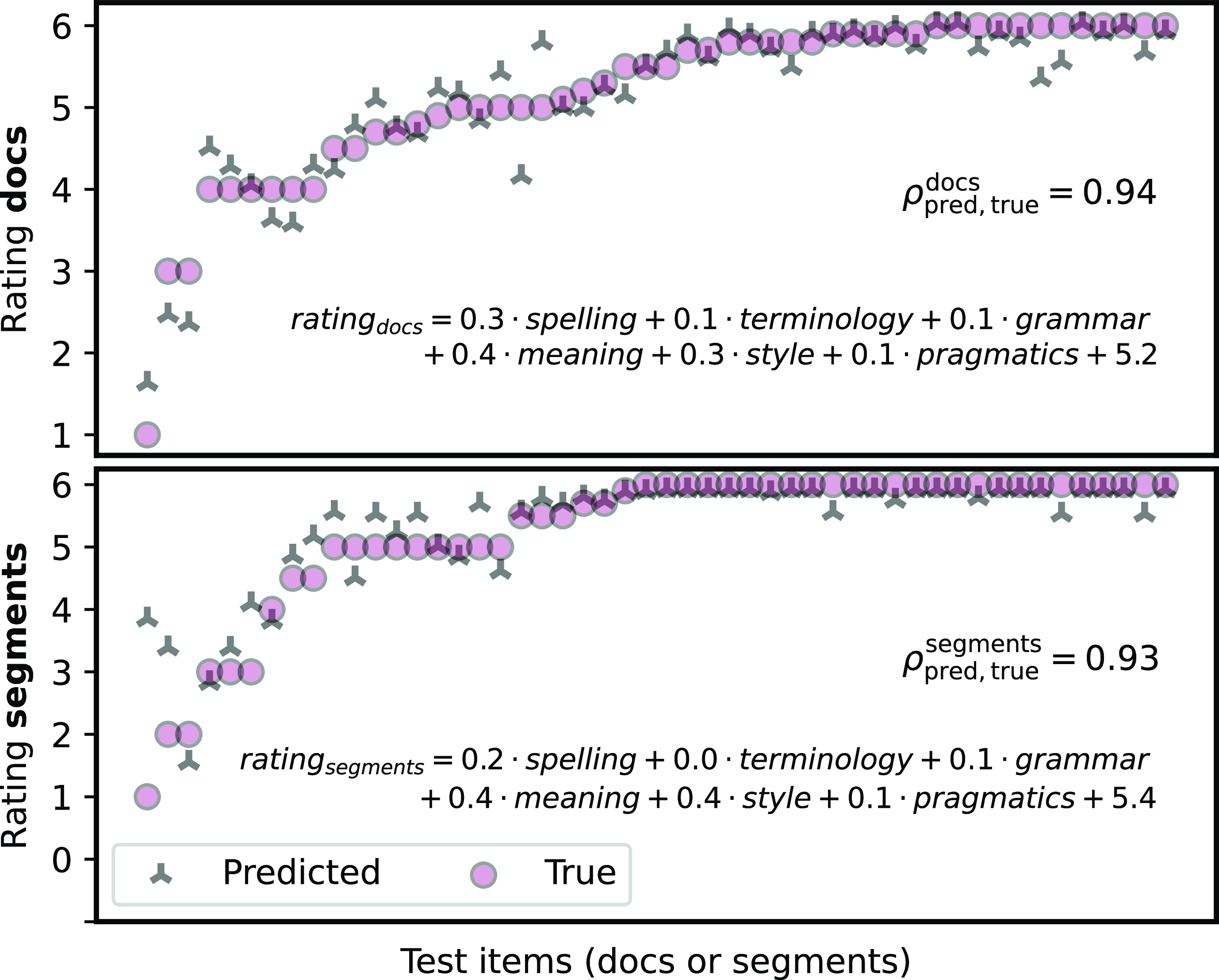
We treat the prediction of Overall from other categories as a regression task with 6 numerical input features (Spelling, Terminology, etc) and one numerical output feature (Overall). We subtract the mean to preserve only the variance to be able to interpret the learned coefficients of a linear regression model. We split document- and segment-level ratings into train/test as 778/100 and 6925/100, respectively. Figure 6 shows the results of fitting two linear regression models together with the coefficients of individual variables. Because the distributions of features are similar, as documented in Figure 4, we can interpret the magnitude of the coefficient as the importance in determining the Overall score. For both the document and segment level, Spelling and Meaning have the highest impact while Terminology and Style have the least impact.Footnote i The linear regression model is further negatively affected by the non-linearity of the human bias towards round numbers, which the model is not able to take into consideration. The fitted coefficients are confirmed by annotator responses in the questionnaire in which Meaning, Style, and Pragmatics were most important to them when evaluating Overall.
Predictions of linear regression models (on document and segment level) for all test set items sorted by true Overall score. Formulas show fitted coefficients and Pearson’s correlations with the true scores. Only a random subset of points shown for visibility.
Segment-level Pearson’s correlations between the collected scores and automated metrics between the original and edited versions of a segment. Colour is based on absolute value of the correlation (note TER).Footnote j

4.5.3 Automated metrics
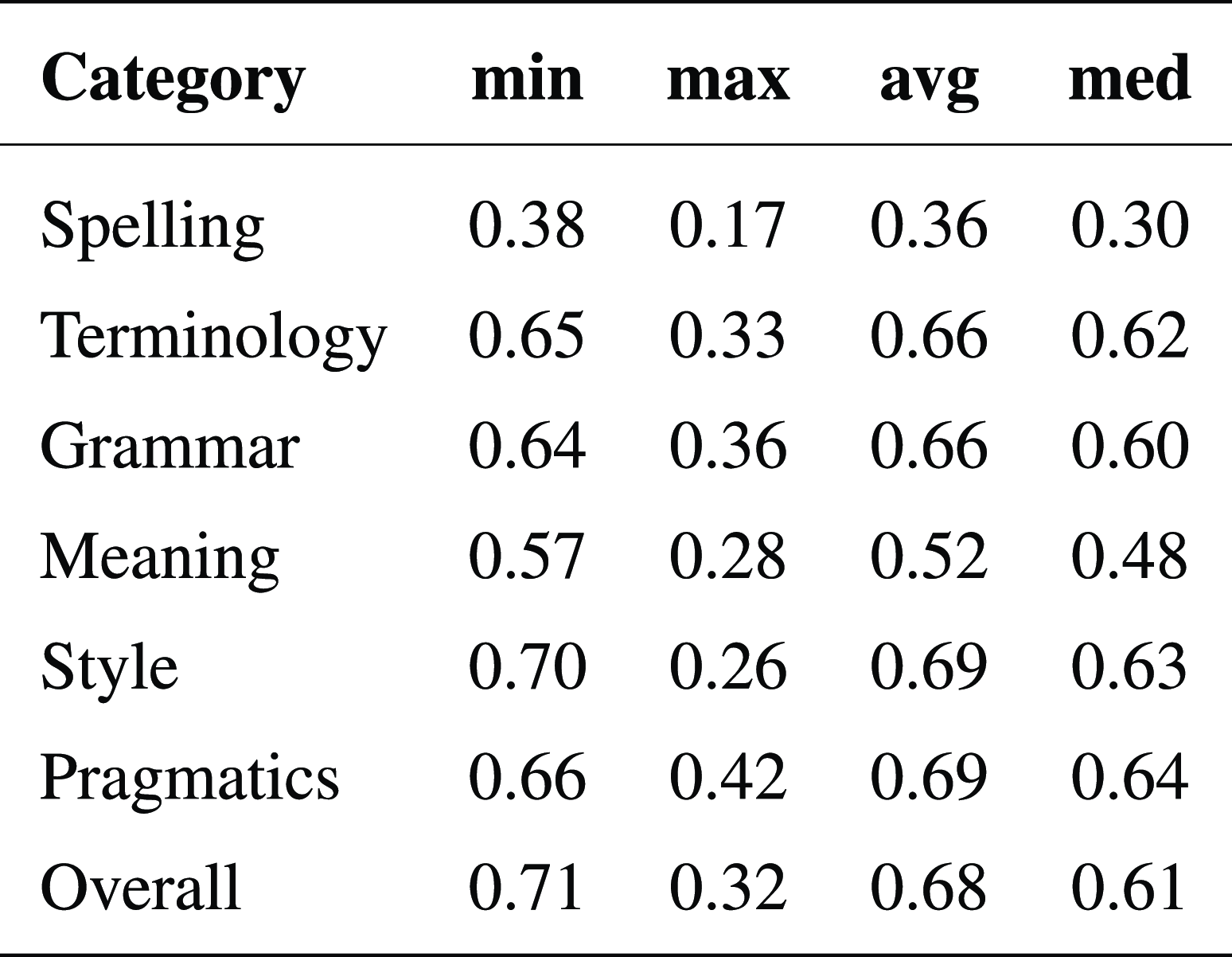
As mentioned in Section 3.2, annotators were tasked to post-edit texts to a state which they would be content with. As a result, the annotators post-edited 62% of all the segments on average. We compute several automatic metric scores between the original and edited versions of segments and compare them to the collected scores, such as Overall. This allows us to answer the question: Does the post-edited distance (as measured by automated metrics) correspond to the annotator score (negatively)? The results in Figure 7 show that there is very little difference between individual metrics. Most score categories are equally predictive with the exception of Overall (most) and Spelling (least). The explanation for this phenomena for Spelling is again (Section 4.4) much lower variance. Overall, the more the annotators changed the original text in their post-editing, the lower score they assigned to the hypothesis. Including the metrics in the prediction of Overall in Section 4.5.2 does not provide any additional improvement on top of other categories (final segment-level
 $\rho$
is still
$\rho$
is still
 $0.93$
).
$0.93$
).
4.6 Annotator differences
Distribution densities of ratings of Overall for individual annotators.
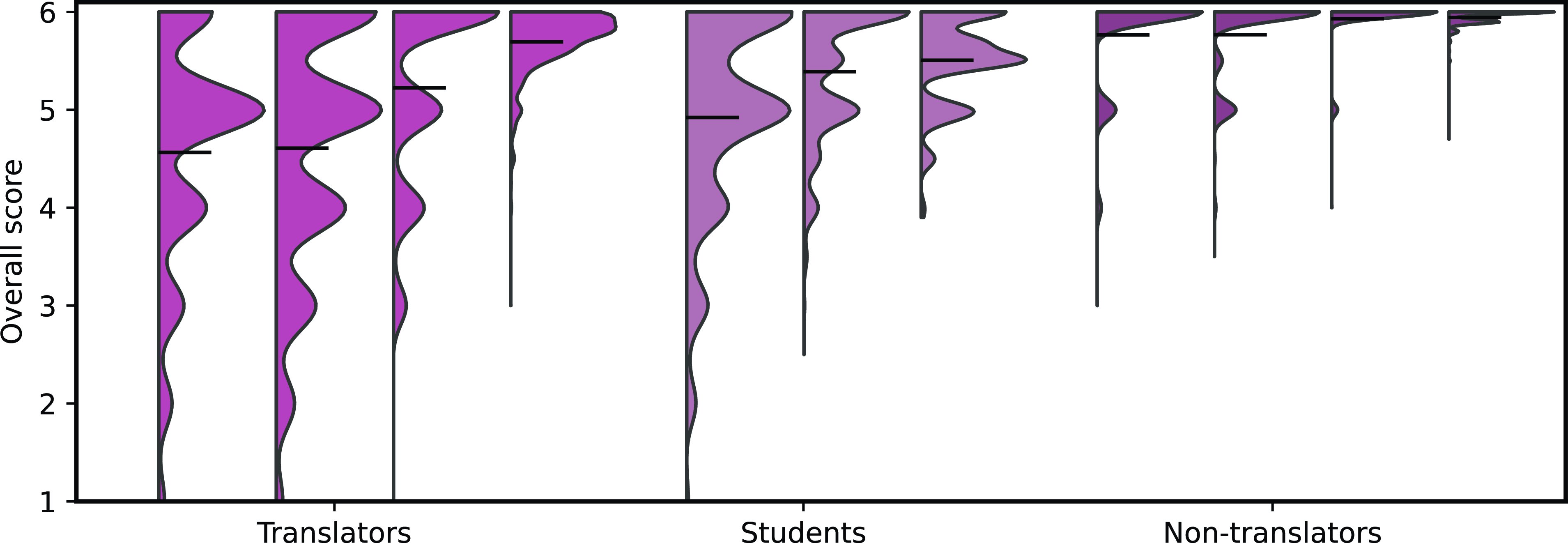
Recall that we considered three types of annotators: professional translators, students of translation and non-translators. Despite the same annotation guidelines, their approach to the task was vastly different. For example, Figure 8 shows the distribution of segment-level ratings of Overall. Professional translators produced much more varying and spread-out distribution, especially compared to non-translators, who rated most segments very high. The group differences should be taken into account when modelling the annotation process statistically. When predicting segment-level Overall from other categories, as in Section 4.5.2, the individual annotator Pearson correlation ranges from as high as
 $0.98$
to as low as
$0.98$
to as low as
 $0.59$
. Similar to results of Karpinska et al. (Reference Karpinska, Akoury and Iyyer2021), we find that expert annotators are important and have less noise. The average correlations with Overall for the translator, student and non-translator groups are
$0.59$
. Similar to results of Karpinska et al. (Reference Karpinska, Akoury and Iyyer2021), we find that expert annotators are important and have less noise. The average correlations with Overall for the translator, student and non-translator groups are
 $0.93$
,
$0.93$
,
 $0.91$
and
$0.91$
and
 $0.80$
, respectively. The expertise feature alone yields
$0.80$
, respectively. The expertise feature alone yields
 $0.36$
correlation with Overall and users alone
$0.36$
correlation with Overall and users alone
 $0.45$
. This is expected as the groups and users have different means of the variable. This information can be used in combination with other predictive features to push the segment-level correlation from
$0.45$
. This is expected as the groups and users have different means of the variable. This information can be used in combination with other predictive features to push the segment-level correlation from
 $0.93$
(Figure 6) to
$0.93$
(Figure 6) to
 $0.95$
. Greater improvement is achieved when combined with the editing distance, such as pushing BLEU from
$0.95$
. Greater improvement is achieved when combined with the editing distance, such as pushing BLEU from
 $0.66$
(Figure 7) to
$0.66$
(Figure 7) to
 $0.76$
when individual annotators are considered as an input feature (one-hot encoded).
$0.76$
when individual annotators are considered as an input feature (one-hot encoded).
4.7 modelling document-level scores
Our annotation instructions explicitly reminded annotators to always consider the context. In other words, already our segment-level scores reflect the coherence and cohesion of the whole text, that is, how the text is organized and structured in the previous and/or subsequent segments. This is a rather important difference from automatic segment-level evaluation which discards any context. Annotators reported that in deciding document-level scores, they focused on the segments which were previously rated the lowest: that means, an individual poorly rated segment greatly influences the rating of the whole. We consider this observation essential for various future translation evaluations. We confirm this with results in Figure 9 where the min aggregation of segment-level ratings is a good prediction (comparable to or slightly better than avg) of the document-level rating. Based on segment-level ratings, we are able to predict document-level Overall quality with
 $\rho = 0.71$
.
$\rho = 0.71$
.
It is worth noting that a similarly high correlation (
 $\rho = 0.70$
) is achieved when predicting the document-level Style from the corresponding segment-level ratings. This category was supposed to reflect also the coherence and cohesion of the document. Annotators saw the entire original text but only evaluated certain translated segments. However, they were assumed to have read the entire source text and to use the information for their evaluation. This was reflected in the Style category.
$\rho = 0.70$
) is achieved when predicting the document-level Style from the corresponding segment-level ratings. This category was supposed to reflect also the coherence and cohesion of the document. Annotators saw the entire original text but only evaluated certain translated segments. However, they were assumed to have read the entire source text and to use the information for their evaluation. This was reflected in the Style category.
Example 1. SOURCE: The All England Club, which hosts the Wimbledon tournament, handed the fine to Williams after she reportedly caused damage during a practice round on the outside courts on June 30, according to The Associated Press and CNN.
ORIG: Klub All England Club, který hostí turnament, udělil dle zpravodajů The Associated Press a CNN Williams pokutu poté, co 30. června údajně způsobila škodu během cvičného kola venku na kurtech.
EDITED: Klub All England Club, který pořádá wimbledonský turnaj, udělil dle zpravodajů The Associated Press a CNN Williamsové pokutu poté, co 30. června údajně způsobila škodu během cvičného kola na venkovních kurtech.
In Example 1, the original translator (ORIG) did not consider the context of the whole document, translated only word for word and committed numerous interferences. It is completely unusual in the context of Wimbledon to use the phrase “hostí turnament” (hosts the tournament, both words being examples of lexical interference from English). In the context of tennis, the phrase “venku na kurtech” (out on the courts) is also unusual. In Czech, feminine names are typically marked using Czech morphology (e.g. Serena Williams
 $\rightarrow$
Serena Williamsová), which is the form predominantly found in the press. In this sentence, the name Williams follows the names The Associated Press and CNN, which is very confusing for the Czech reader. The feminine form thus makes the whole text easier to interpret and understand. The evaluator has correctly intervened in the text by using collocations such as “pořádá wimbledonský turnaj” (hosts the Wimbledon tournament) and writes about “venkovní kurty” (the outside courts) and uses the feminine form “Williamsová.” All these changes are highlighted in bold in Example 1 and demonstrate the evaluator’s (translation student) sense of textual continuity and their knowledge of the overall global context, which should have been the task of the original translator.
$\rightarrow$
Serena Williamsová), which is the form predominantly found in the press. In this sentence, the name Williams follows the names The Associated Press and CNN, which is very confusing for the Czech reader. The feminine form thus makes the whole text easier to interpret and understand. The evaluator has correctly intervened in the text by using collocations such as “pořádá wimbledonský turnaj” (hosts the Wimbledon tournament) and writes about “venkovní kurty” (the outside courts) and uses the feminine form “Williamsová.” All these changes are highlighted in bold in Example 1 and demonstrate the evaluator’s (translation student) sense of textual continuity and their knowledge of the overall global context, which should have been the task of the original translator.
Pearson’s correlations of predictions from segment-level aggregations to document-level scores. For example, for the Overall category with min aggregation:
 $\rho (\{d^{\text{Overall}}\,:\, d \in \mathcal{D}\}, \{\min \{s^{\text{Overall}}\,:\, s \in d\}\,:\, d \in \mathcal{D}\})$
.
$\rho (\{d^{\text{Overall}}\,:\, d \in \mathcal{D}\}, \{\min \{s^{\text{Overall}}\,:\, s \in d\}\,:\, d \in \mathcal{D}\})$
.
5. Qualitative analysis
If we take a closer look at the evaluation of all four translations by individual annotators, several types of qualitative comparisons can be made. We focus on the following two perspectives: characteristics of the segments (1) for which N1 scores worse than P{1,2,3} and (2) for which there are the biggest differences in ratings. Even though we include example translations in Czech, we provide explanations in English which are self-contained and hence do not require any knowledge of Czech.
5.1 N1 scores worse than P{1,2,3}
N1 was evaluated with the highest scores in comparison to P1, P2, and P3, across all assessed features (see Figure 3). However, there is a small number of segments in N1 which were evaluated worse than those in P{1,2,3}. For a better overview, the frequencies at which the translations P{1,2,3} were evaluated better than N1 in the Overall category are P1: 6.16%, P2: 4.96%, P3: 3.99%. We selected these segments (for each category, not only for Overall) and analysed them. In most cases, our analysis revealed that the evaluation and the related editing of the translation was conditioned by the erroneous judgement of the annotators, who did not check the correct wording/meaning/usage in Czech and were tempted by the source text and/or the wrong parallel translations P{1,2,3}. In other words, the optimal reference translation N1 stood the test and our analysis confirmed its quality, rather than the evaluators’ judgement.
Furthermore, we also encounter a reduced (imperfect) rating of some segments in N1, although no errors are apparent and no changes in the edited version have occurred in comparison to the original version. This finding is valid for all evaluated categories without exception. We list here a number of such segments with reduced (imperfect) rating for each category: Spelling: 1.0%, Terminology: 1.8%, Grammar: 2.0%, Meaning: 1.7%, Style: 2.8%, Pragmatics: 1.5%, Overall: 0.5%, any category: 5.4%. We perform a detailed qualitative analysis across all the seven rating categories.
5.1.1 Spelling
In the spelling category, the following segment in Example 2 demonstrates an ignorance on the part of the annotator (non-translator) and failure to reflect the correct spelling and declension of the name Narendra Modi in Czech (correctly in nominative singular: Naréndra Módí) and of the Czech equivalent to the verb harass (correctly: perzekvovat, although it often appears incorrectly as perzekuovat in the language usage). The proposed edits are wrong.
Example 2.
SOURCE: Sources said the action was in line with Prime Minister Narendra Modi’s address to the nation [
 $\ldots$
] when he had said some black sheep in the tax administration may have misused their powers and harassed taxpayers [
$\ldots$
] when he had said some black sheep in the tax administration may have misused their powers and harassed taxpayers [
 $\ldots$
]
$\ldots$
]
N1 ORIG (rating: 4.0): Podle zdrojů akce souvisí s projevem premiéra Naréndry Módího k národu [
 $\ldots$
] v němž prohlásil, že jisté černé ovce v systému daňové správy podle všeho zneužívaly své pravomoci a perzekvovaly daňové poplatníky [
$\ldots$
] v němž prohlásil, že jisté černé ovce v systému daňové správy podle všeho zneužívaly své pravomoci a perzekvovaly daňové poplatníky [
 $\ldots$
]
$\ldots$
]
N1 EDIT: Podle zdrojů akce souvisí s projevem premiéra Nara[!]ndra Modi k národu [
 $\ldots$
] v němž prohlásil, že jisté černé ovce v systému daňové správy podle všeho zneužívaly své pravomoci a perzekuovaly daňové poplatníky [
$\ldots$
] v němž prohlásil, že jisté černé ovce v systému daňové správy podle všeho zneužívaly své pravomoci a perzekuovaly daňové poplatníky [
 $\ldots$
]
$\ldots$
]
There are more segments with incorrect or unnecessary spelling edits. Unfortunately, some annotators not only erroneously “correct” what is actually right but also miscategorize the changes. We find erroneously corrected morphology in this category, etc. For example, for the source The man pleaded guilty to seven charges involving [
 $\ldots$
] the correct structure Muž se přiznal k sedmi trestným činum (dative case) týkajícím se (dative case) [
$\ldots$
] the correct structure Muž se přiznal k sedmi trestným činum (dative case) týkajícím se (dative case) [
 $\ldots$
] has been edited to Muž se přiznal k sedmi trestným činum (dative case) týkajících se (genitive case, grammatical incongruency) [
$\ldots$
] has been edited to Muž se přiznal k sedmi trestným činum (dative case) týkajících se (genitive case, grammatical incongruency) [
 $\ldots$
].
$\ldots$
].
It is quite surprising the extent to which annotators do not verify and follow up information, leaving errors in translations that are contained in the original. This is particularly evident in the spelling category. An example is a typo in the original: (Pete) Townsend (correctly Townshend; however, spelled correctly in the previous segment of the source text). P1 has Townsend, P2 Townshed [!], P3 Townsend. N1 uses the corrected form Townshend, but this form has been edited in the evaluation with the result Townsend.
Example 3. SOURCE: Sony, Disney Back To Work On Third Spider-Man Film
N1 ORIG (rating 3.0): Sony a Disney opět
 $_{\text{(again)}}$
spolupracují na třetím filmu o Spider-Manovi
$_{\text{(again)}}$
spolupracují na třetím filmu o Spider-Manovi
N1 EDIT: Sony a Disney
 $\emptyset$
spolupracují na třetím filmu o Spider-Manovi
$\emptyset$
spolupracují na třetím filmu o Spider-Manovi
5.1.2 Terminology
In the terminology category, we also detected unnecessary or erroneous corrections. For example, the correction of the segment in Example 3 does not fall under terminology (and demonstrates, inter alia, the annotator’s failure to verify the information; this time the annotator was actually a professional translator). The proposed edit is not correct/necessary.
5.1.3 Grammar
In the grammar category, the above-mentioned segment (Sony, Disney Back To Work On Third Spider-Man Film) plays an interesting role, rated also 3.0 in this category, without any other changes. The proposed change (mentioned above) does not reflect grammar or spelling. As it turned out, this segment achieved the same rating from this annotator in other categories, too, namely meaning, style, and overall quality. It affects the meaning only, though, being an erroneous change.
We agree with some changes in syntax, for example, in Example 4 (rating 5.0 for this segment by a student annotator).
Example 4. SOURCE: Homes were flooded and people waded through streets with water up to their knees in scenes normally seen only at the height of the monsoon.
N1 ORIG: Domy byly zaplavené a na ulicích se lidé brodili po kolena vodou, což bývá běžně k vidění jen v době, kdy monzunové období vrcholí.
N1 EDIT: Byly zaplaveny některé domy a na ulicích se lidé brodili po kolena ve vodě, což bývá běžně k vidění jen v době, kdy vrcholí monzunové období.
5.1.4 Meaning
In the meaning category, we observe several inconsistencies in evaluating translated segments for N1 vs P{1,2,3}. For example, reduced rating for N1 (4.0, by a non-translator) occurs in the following segment in Example 5, though, there are no changes in the edited version. Both the translations P1 and P2 score 6.0, even though there are several erroneous meaning units. The initial therapy is počáteční léčba in Czech, not vstupní, and the verb require does not mean here that the patient himself required the therapy but that his/her medical condition required it. The expression chief medical officer refers to the Czech equivalent hlavní/vedoucí/vrchní lékař, not ředitel resortu zdravotnictví (= Director of the Ministry of Health).
Example 5. SOURCE: All but one patient had gone through initial therapy. That patient did require the recollection of stem cells, chief medical officer James Stein said.
N1 ORIG (rating 4.0): Všichni pacienti až na jednoho absolvovali počáteční léčbu. U dotyčného pacienta bylo zapotřebí provést nový odběr kmenových buněk, uvedl hlavní lékař James Stein.
P1 ORIG (rating 6.0): Kromě jednoho prošli všichni pacienti počáteční terapií. Dotyčný pacient požadoval nový odběr kmenových buněk, uvedl hlavní lékař James Stein.
P2 ORIG (rating 6.0): Všichni kromě jednoho pacienta prošli vstupní léčbou. Tento pacient vyžadoval znovuodebrání kmenových buněk, uvedl ředitel resortu zdravotnictví James Stein.
N1 EDIT = N1 ORIG P1 EDIT = P1 ORIG
P2 EDIT = P2 ORIG
5.1.5 Style
In the style category, we agree with some edits made for N1, for example in the following segment in Example 6 rated 4.0. However, the rating of P1 is 6.0, although there have been very similar modifications to the style in the edited version of P1 as those in N1, and furthermore, the annotator (translator) uses the translation strategy proposed in N1 ORIG for his P1 EDIT version.
Example 6. SOURCE: Using data and artificial intelligence to try and boost revenues is part of HSBC’s broader push to squeeze more out of its large physical network and client data, a key priority for interim Chief Executive Noel Quinn.
N1 ORIG: Využití dat a umělé inteligence ke zvýšení příjmů je součástí širší strategie HSBC, která tak chce vytěžit více ze své rozsáhlé fyzické sítě a klientských dat, což je klíčovou prioritou prozatímního generálního ředitele Noela Quinna.
N1 EDIT: Využití dat a umělé inteligence ke zvýšení příjmů je součástí širší strategie HSBC, která tak chce ze své rozsáhlé fyzické sítě a klientských dat vytěžit víc. Jde o jednu z hlavních priorit prozatímního generálního ředitele Noela Quinna.
P1 ORIG: Využití dat a umělé inteligence ke zvýšení výnosů je součástí širšího tlaku na HSBC, aby vytěžila více ze své rozsáhlé fyzické sítě klientů a klientských dat, což je klíčovou prioritou dočasného generálního ředitele banky Noela Quinna.
P1 EDIT: Využití dat a umělé inteligence ke zvýšení výnosů je součástí širší strategie HSBC, která chce ze své rozsáhlé fyzické sítě klientů a z klientských dat vytěžit víc. Jde o hlavní prioritu dočasného generálního ředitele banky Noela Quinna.
5.1.6 Pragmatics
The evaluation in the category of pragmatics is also inconclusive and the analysis of N1 segments rated worse than P{1,2,3} segments does not provide any convincing data. For example, one of the annotators (non-translator) evaluates Example 7 N1 5.0, whereas P3 is evaluated 6.0. However, the only change we find in the edited version of N1 is the elimination of the adjective nadšenou, although nadšená chvála is a typical collocation in Czech, in contrast to the rather unusual formulation (and too literal translation) zářná chvála used in P3, which remained unchanged. Furthermore, New York Magazine is usually used in the Czech media in its original, not translated form. Nevertheless, P3 uses New Yorský magazín (the adjective does not even exist in Czech). Other inappropriate or non-existent word units used in P3 include: díky (= thanks to) used in a negative context, Gettysburgského projevu (correctly: Gettysburského, without g), pro svuj historický význam (correctly: pro jeho historický význam). The word order is not based on the principle of the Czech functional sentence perspective and is non-idiomatic and non-standard. We could give many more similar examples.
Example 7. SOURCE: Thunberg’s grim pronouncements have earned her savage criticism and glowing praise. New York Magazine called her “the Joan of Arc of climate change,” while The Guardian ranked her speech alongside President Lincoln’s Gettysburg Address for its historical significance.
N1 ORIG (rating 5.0): Hrozivé výroky vynesly Thunbergové ostrou kritiku i nadšenou chválu. New York Magazine ji nazval, ,Johankou z Arku klimatických změn“, zatímco The Guardian zařadil její projev pro jeho historický význam vedle projevu prezidenta Lincolna v Gettysburgu.
N1 EDIT: Hrozivé výroky vynesly Thunbergové ostrou kritiku i
 $\emptyset$
chválu. New York Magazine ji nazval, ,Johankou z Arku klimatických změn“, zatímco The Guardian zařadil její projev pro jeho historický význam vedle projevu prezidenta Lincolna v Gettysburgu.
$\emptyset$
chválu. New York Magazine ji nazval, ,Johankou z Arku klimatických změn“, zatímco The Guardian zařadil její projev pro jeho historický význam vedle projevu prezidenta Lincolna v Gettysburgu.
P3 ORIG (rating 6.0): Thunbergová si díky svým hrozivým výrokum vysloužila divokou vlnu kritiky a zářnou chválu. New Yorský magazín ji nazval,, Johankou z Arku klimatické změny, “zatímco The Guardian zařadil její projev vedle Gettysburgského projevu prezidenta Lincolna pro svůj historický význam.
P3 EDIT = P3 ORIG
5.1.7 Overall
The overall category shows similar inconsistencies as described in previous aspects. The annotators often neglect formal, meaning, and other errors, as shown above. Example 8 shows that different types of errors in P2 and P3 have been ignored. The annotator (non-translator) correctly substitutes the word kredit for úvěr in P3, but does not recognize the wrong structure pokud jde o dobré jméno in P2: the Czech word kredit (a sum of money (credit) or other value as a loan for a specified period of time for a specified consideration (e.g. interest)) can also have a colloquial meaning trust, respectability which is not the case here. The collocation public accommodations includes all services, that is not only accommodation but also catering, cultural activities (public spaces and commercial services that are available to the general public, such as restaurants, theatres, and hotels). The Czech word služby (= services) is correct, not ubytování (= accommodation). The trickiest collocation of this segment is jury service which is not soudnictví (= judiciary) in a general sense but, more specifically, účast v soudní porotě (= participation in jury trials). Leaving aside all the overlooked errors, the annotator evaluates P2 and P3 better than N1, although in N1 and P2 he/she made one change, in P3 two changes of a comparable nature.
Example 8. SOURCE: The Equality Act would extend nondiscrimination protections to LGBTQ individuals in credit, education, employment, housing, federal financial assistance, jury service and public accommodations.
N1 ORIG (rating 4.0): Zákon o rovnosti by měl rozšířit ochranu proti diskriminaci také na příslušníky sexuálních a genderových menšin, a to v oblasti úvěrů, vzdělávání, zaměstnání, bydlení, federální finanční pomoci, účasti v soudní porotě a služeb.
N1 EDIT: Zákon o rovnosti by měl rozšířit ochranu proti diskriminaci také na příslušníky sexuálních a genderových menšin, a to v oblasti úvěrů, vzdělávání, zaměstnání, bydlení, federální finanční pomoci, soudnictví a služeb.
P2 ORIG (rating 5.0): Zákon o rovnosti by měl rozšířit ochranu proti diskriminaci na LGBTQ jedince, pokud jde o dobré jméno, vzdělání, zaměstnání, bydlení, federální finanční pomoc, činnost porotců a veřejné ubytování.
P2 EDIT: Zákon o rovnosti by měl rozšířit ochranu proti diskriminaci na LGBTQ jedince, pokud jde o dobré jméno, vzdělání, zaměstnání, bydlení, federální finanční pomoc, soudnictví a veřejné ubytování.
P3 ORIG (rating 5.0): Zákon o rovnosti by zajišt’oval ochranu proti diskriminaci LGBTQ osobám v oblastech kreditu, vzdělání, zaměstnání, bydlení, federální finanční asistence, výkonu poradce a veřejného ubytování.
P3 EDIT: Zákon o rovnosti by zajišt’oval ochranu proti diskriminaci LGBTQ osobám v oblastech úvěrů, vzdělání, zaměstnání, bydlení, federální finanční asistence, výkonu soudnictví a veřejného ubytování.
Scores of subset of categories for a selected segment from the translation P3 by annotator A1 (translator) and annotators A{2,3,4} (non-translators).

5.2 Individual differences in ratings
This perspective detects and analyses segments with the biggest differences in ratings among annotators. In all categories in Figure 10, we find differences of at least 4.0 (Terminology and Grammar), 5.0 (Meaning, Style, Pragmatics, and Overall), or 6.0 (Spelling).
In this part, we would like to highlight selected segments with the biggest differences across relevant categories and focus on finding out the reasons for the observed discrepancies. The following segment in Example 9 shows a very low rating and multiple changes in the edited version by annotator A1, whereas annotators A2, A3, and A4 evaluate it with (almost) best scores and overlook even obvious (to the authors and translatologists) mistakes. In the example, we use subscripts for expressions of interests.
Example 9. SOURCE: The Central Board of Indirect Taxes and Customs (CBIC)–the agency that oversees GST and import tax collections–compulsorily retired 15 senior officers under Fundamental Rule 56 (J) on corruption and other charges, official sources said.
P3 ORIG:
Ústřední komise nepřímých daní a cel (UKNDC
2,4
)
—
agentura
3
, která dohlíží na daně ze zboží a služeb a vybrání vývozních dávek
 $_2$
—odvolala 15 vedoucích úředníků na základě
Základního Pravidla
1
56
(J)
1,3
o korupci a jiných obviněních, uvedly oficiální zdroje.
$_2$
—odvolala 15 vedoucích úředníků na základě
Základního Pravidla
1
56
(J)
1,3
o korupci a jiných obviněních, uvedly oficiální zdroje.
P3 EDIT by annotator A1 (translator): Ústřední rada pro nepřímé daně a cla (CBIC 2,4 ) — instituce 3 , která dohlíží na výběr daně ze zboží a služeb adovozních daní 2 —odvolala patnáct vysoce postavených úředníků na základě paragrafu 1 56 písm. j) 1,3 , o korupci a jiných obviněních, uvedly oficiální zdroje.
P3 EDIT by annotator A2 (non-translator): Ústřední komise nepřímých daní a cel (CBIC 2,4 ) — agentura 3 , která dohlíží na GST a daně z importu 2 —odvolala 15 vedoucích úředníků na základě paragrafu 1 56 (J) 1,3 o korupci a jiných obviněních, uvedly oficiální zdroje.
P3 EDIT by annotator A3 (non-translator): Ústřední komise nepřímých daní a cel (UKNDC 2,4 ) — agentura 3 , která dohlíží na daně ze zboží a služeb a vybrání vývozních dávek 2 —odvolala 15 vedoucích úředníků na základě Základního Pravidla 1 56 (J) 1,3 o korupci a jiných obviněních, uvedly oficiální zdroje.
P3 EDIT by annotator A4 (non-translator): Ústřední komise nepřímých daní a cel (CBIC 2,4 ) — agentura 3 , která dohlíží na daně ze zboží a služeb a vybrání vývozních dávek 2 —odvolala 15 vedoucích úředníků na základě Základního Pravidla 1 56 (j) 1,3 o korupci a jiných obviněních, uvedly oficiální zdroje.
Annotator A1 rightly notices errors in spelling (lower and upper case letters
 $_1$
), terminology (name of the institution and other terms
$_1$
), terminology (name of the institution and other terms
 $_2$
), meaning (unclear and contradictory statements
$_2$
), meaning (unclear and contradictory statements
 $_3$
), pragmatics (dealing with foreign realia and abbreviations
$_3$
), pragmatics (dealing with foreign realia and abbreviations
 $_4$
). These individual assessments are also reflected in the category Overall. On the other hand, the annotators A2, A3, A4 do not (mostly) notice the errors mentioned above or just change the wording of the abbreviation or replace the translation with the original abbreviation (A2) while maintaining the best rating. From our point of view, the correct annotator is A1 with their relevant, thoughtful and sensitive interventions in the text.
$_4$
). These individual assessments are also reflected in the category Overall. On the other hand, the annotators A2, A3, A4 do not (mostly) notice the errors mentioned above or just change the wording of the abbreviation or replace the translation with the original abbreviation (A2) while maintaining the best rating. From our point of view, the correct annotator is A1 with their relevant, thoughtful and sensitive interventions in the text.
There are many segments with similarly unbalanced ratings in our evaluation. As the analysis shows, the biggest problem is that some annotators fail to recognize most of the errors. Problematic is also lowering the rating even though no changes were made in the edited version. It is unclear whether the annotators simply did not pay enough attention to their task and whether they would have reached the same conclusions even after a more careful consideration of the whole task. Our qualitative analysis of selected segments confirms the findings presented in Figure 3: translators are the most rigorous and careful (average rating 5.00), students are slightly less attentive (5.3), and non-translators notice errors the least (5.8).
5.3 Document-level phenomena
In this section, we present examples that show the extent to which authors of translations P1, P2, P3, and N1, and especially, our evaluators have considered the context of the whole document. We examined the evaluated documents, including the source text and all four translations, looking for evidence of apparent respect or disregard for the document-level context.
Documents in which certain terms occur that should be consistent throughout the text and/or should correspond in a meaningful way to the thematic and pragmatic area, appear to be appropriate material to demonstrate this (spans marked with 1).Footnote k These observations are in line with MT evaluation methods focused on terminology (Zouhar, Vojtěchová, and Bojar Reference Zouhar, Vojtěchová and Bojar2020; Semenov and Bojar Reference Semenov and Bojar2022; Agarwal et al. Reference Agarwal, Agrawal, Anastasopoulos, Bentivogli, Bojar, Borg, Carpuat, Cattoni, Cettolo, Chen, Chen, Choukri, Chronopoulou, Currey, Declerck, Dong, Duh, Estève, Federico, Gahbiche, Haddow, Hsu, Mon Htut, Inaguma, Javorský, Judge, Kano, Ko, Kumar, Li, Ma, Mathur, Matusov, McNamee, P. McCrae, Murray, Nadejde, Nakamura, Negri, Nguyen, Niehues, Niu, Kr. Ojha, E. Ortega, Pal, Pino, van der Plas, Polák, Rippeth, Salesky, Shi, Sperber, Stüker, Sudoh, Tang, Thompson, Tran, Turchi, Waibel, Wang, Watanabe and Zevallos2023). Another phenomenon to be observed might be a particular way of spelling words, which generally have two or more accepted spellings and the convention is just to achieve a consistent spelling throughout the document (spans marked with 2).
Finally, for the topic-focus articulation, also called functional sentence perspective (spans marked with 3), it is crucial to respect the context of the whole document (Daneš Reference Daneš1974; Sgall, Hajicová, and Panevová Reference Sgall, Hajicová and Panevová1986; Hajičová et al. Reference Hajičová, Partee and Sgall2013). It is concerned with the distribution of information as determined by all meaningful elements, including context. In Example 12, evaluated by a non-translator, we selectively document the distribution of the degrees of communicative dynamism over sentence elements in Czech, which determines the orientation or perspective of the sentence (Firbas Reference Firbas1992).Footnote l
Our first example in this section, Example 10, illustrates the disregard for proper terminology. Translations P1,2 and N1 were not edited. The evaluator was a non-translator.
Example 10. SOURCE: All but one patient had gone through initial therapy. That patient did require the recollection of stem cells, chief medical officer James Stein said.
P1 ORIG: Kromě jednoho prošli všichni pacienti počáteční terapií. Dotyčný pacient požadoval
 $_{1 {(insisted\ on)}}$
nový odběr kmenových buněk, uvedl hlavní lékař
$_{1 {(insisted\ on)}}$
nový odběr kmenových buněk, uvedl hlavní lékař
 $_{1 {(chief\ medical\ officer)}}$
James Stein.
$_{1 {(chief\ medical\ officer)}}$
James Stein.
P2 ORIG: Všichni kromě jednoho pacienta prošli vstupní léčbou. Tento pacient vyžadoval
 $_{1 {(demanded)}}$
znovuodebrání kmenových buněk, uvedl ředitel resortu zdravotnictví
$_{1 {(demanded)}}$
znovuodebrání kmenových buněk, uvedl ředitel resortu zdravotnictví
 $_{1 {(Director\ of\ the\ Ministry\ of\ Health)}}$
James Stein.
$_{1 {(Director\ of\ the\ Ministry\ of\ Health)}}$
James Stein.
P3 ORIG: Každý, až na jedno pacienta, prošel počáteční terapií. Tento pacient potřeboval
 $_{1 {(needed)}}$
odebrání kmenových buněk, uvedl vrchní zdravotní dustojník
$_{1 {(needed)}}$
odebrání kmenových buněk, uvedl vrchní zdravotní dustojník
 $_{1 {(chief\ medical\ officer\ in\ command)}}$
James Stein.
$_{1 {(chief\ medical\ officer\ in\ command)}}$
James Stein.
P3 EDIT (non-translator): Každý, až na jedno pacienta, prošel počáteční terapií. Tento pacient vyžadoval
 $_{1 {(demanded)}}$
odebrání kmenových buněk, uvedl hlavní lékař
$_{1 {(demanded)}}$
odebrání kmenových buněk, uvedl hlavní lékař
 $_{1, {(chief\ medical\ officer)}}$
James Stein.
$_{1, {(chief\ medical\ officer)}}$
James Stein.
N1 ORIG: Všichni pacienti až na jednoho absolvovali počáteční léčbu. U dotyčného pacienta bylo zapotřebí
 $_{1 {(it\ was\ necessary)}}$
provést nový odběr kmenových buněk, uvedl hlavní lékař
$_{1 {(it\ was\ necessary)}}$
provést nový odběr kmenových buněk, uvedl hlavní lékař
 $_{1 {(chief\ medical\ officer)}}$
James Stein.
$_{1 {(chief\ medical\ officer)}}$
James Stein.
In the next example, evaluated by the same non-translator, P1, P2, and N1 are consistent in terminology and spelling in this document.
Example 11. (individual evaluation segments are separated with
 $|||$
)
$|||$
)
SOURCE: Three University of Dundee students have been named regional winners as top graduates in Europe.
 $|||$
The University of Dundee students were named as top graduates in their respective fields in Europe in the 2019 Global Undergraduate Awards, whilst five other students from the same university were praised by the judges.
$|||$
The University of Dundee students were named as top graduates in their respective fields in Europe in the 2019 Global Undergraduate Awards, whilst five other students from the same university were praised by the judges.
 $|||$
Professor Blair Grubb, Vice-Principal (Education) at the University, said: “To get to this stage, our students and graduates faced competition from peers attending some of the world’s top universities.”
$|||$
Professor Blair Grubb, Vice-Principal (Education) at the University, said: “To get to this stage, our students and graduates faced competition from peers attending some of the world’s top universities.”
 $|||$
“I would like to offer my warmest congratulations to Scott, Chester and Lola on this fantastic achievement, alongside the other Dundee representatives who were highly commended.”
$|||$
“I would like to offer my warmest congratulations to Scott, Chester and Lola on this fantastic achievement, alongside the other Dundee representatives who were highly commended.”
P3 ORIG: Tři studenti Univerzity v Dundee
 $_{1,2}$
byli jmenováni regionálními vítězi jakožto jedni z nejlepších absolventů v Evropě.
$_{1,2}$
byli jmenováni regionálními vítězi jakožto jedni z nejlepších absolventů v Evropě.
 $|||$
Studenti Dundeeské University
$|||$
Studenti Dundeeské University
 $_{1,2}$
byly jmenováni v soutěži Globální vysokoškolské ceny 2019 jakožto jedni z nejlepších absolventů ve svých příslušných oborech, zatímco porotci ocenili dalších pět studentů ze stejné university
$_{1,2}$
byly jmenováni v soutěži Globální vysokoškolské ceny 2019 jakožto jedni z nejlepších absolventů ve svých příslušných oborech, zatímco porotci ocenili dalších pět studentů ze stejné university
 $_{2}$
.
$_{2}$
.
 $|||$
Profesor a zástupce ředitele pro vzdělávání
$|||$
Profesor a zástupce ředitele pro vzdělávání
 $_{1}$
Blair Brubb university uvedl:, ,Aby se naši studenti a absolventi dostali do této fáze, museli čelit vrstevníkům z několika nejlepších universit
$_{1}$
Blair Brubb university uvedl:, ,Aby se naši studenti a absolventi dostali do této fáze, museli čelit vrstevníkům z několika nejlepších universit
 $_{2}$
světa. “
$_{2}$
světa. “
 $|||$
,,Chtěl bych srdečně poblahopřát Scottovi, Chesterovi A Lole za jejich fantastické úspěchy a zároveň velmi pochválit i ostatní reprezentanty Dundee
$|||$
,,Chtěl bych srdečně poblahopřát Scottovi, Chesterovi A Lole za jejich fantastické úspěchy a zároveň velmi pochválit i ostatní reprezentanty Dundee
 $_{1}$
.“
$_{1}$
.“
P3 EDIT (non-translator):
 $\ldots$
$\ldots$
 $|||$
$|||$
 $\ldots$
$\ldots$
 $|||$
Profesor a zástupce ředitele pro vzdělávání
$|||$
Profesor a zástupce ředitele pro vzdělávání
 $_{1}$
Blair Brubb
$_{1}$
Blair Brubb
 $\emptyset$
uvedl:, ,Aby se naši studenti a absolventi dostali do této fáze, museli čelit vrstevníkům z několika nejlepších universit
$\emptyset$
uvedl:, ,Aby se naši studenti a absolventi dostali do této fáze, museli čelit vrstevníkům z několika nejlepších universit
 $_{2}$
světa.“
$_{2}$
světa.“
 $|||$
$|||$
 $\ldots$
$\ldots$
Our third example in this section, Example 12, is represented by the article China Says It Didn’t Fight Any War Nor Invaded Foreign Land which discusses armed conflicts between China and other countries.
In Czech, it is common to put the adverbials of time at the beginning or in the middle of a sentence (depending on the meaning and function of other sentence elements). When appearing at the end of a sentence, they become the focus of the statement, so the communicative dynamism and sentence continuity may get broken (in 1979/ v roce/ roku 2017, in 1979/ v roce 1979, spans 3a). Based on the information in the previous text (Example 12), the diplomatic resolution (diplomatically resolved, vyřešen diplomaticky/ diplomatickou cestou) stands in contrast to the armed conflicts, so it represents the focus of the statement and should appear at the end of the sentence (after the verb) (spans 3b). Finally, the states Vietnam, Malaysia, the Philippines, Brunei, and Taiwan should be placed at the end of the Czech sentence (this becomes evident after reading and understanding the entire document where we are introduced to information about which countries China has had conflicts with) (spans 3c). The word claims (vznášejí nároky, mají protinároky, mají opačné nároky, si činí nárok) belongs to the topic of the statement.
Example 12. Previous article content:
China on Friday said it has not provoked a “single war or conflict” or “invaded a single square” of foreign land, skirting any reference to the 1962 war with India. “China has always been dedicated to resolving territorial and maritime delimitation disputes through negotiation and consultation,” stated an official white paper released, four days ahead of the country set to celebrate its 70th anniversary of the leadership of the ruling Communist Party of China (CPC) on October 1. “China safeguards world peace through real actions. Over the past 70 years, China has not provoked a single war or conflict, nor invaded a single square of foreign land,” the paper titled “China and the World in the New Era” said. The white paper, while highlighting the CPS’s “peaceful rise” made no reference of the bloody 1962 war with India and the vast tracts of land, especially in the Aksai Chin area, occupied by China. The Sino-India border dispute involving 3,488-km-long Line of Actual Control (LAC) remained unresolved. China also claims Arunachal Pradesh as part of South Tibet, which India contests. So far, the two countries held 21 rounds of Special Representatives talks to resolve the border dispute.
SOURCE: Besides the 1962 war, India and China had a major military standoff at Doklam in 2017 when the People’s Liberation Army (PLA) tried to lay a road close to India”s narrow Chicken Neck corridor connecting with the North-Eastern states in an area also claimed by Bhutan.
 $|||$
It was finally diplomatically resolved after which both sides pulled back their troops.
$|||$
It was finally diplomatically resolved after which both sides pulled back their troops.
 $|||$
China also had a major military conflict with Vietnam in 1979. China claims sovereignty over all of South China Sea. Vietnam, Malaysia, the Philippines, Brunei and Taiwan have counterclaims.
$|||$
China also had a major military conflict with Vietnam in 1979. China claims sovereignty over all of South China Sea. Vietnam, Malaysia, the Philippines, Brunei and Taiwan have counterclaims.
P1 ORIG: Kromě války v roce 1962 měly Indie a Čína velký konflifkt v Doklamu roku 2017
 $_{3a}$
, kdy se čínská lidová osvobozenská armáda (ČLOA) snažila postavit silnici blízko indického úzkého Kuřecího krku spojující severo-východní
$_{3a}$
, kdy se čínská lidová osvobozenská armáda (ČLOA) snažila postavit silnici blízko indického úzkého Kuřecího krku spojující severo-východní
 $_1$
země
$_1$
země
 $_1$
na území, na které si dělá nárok i Bhutan.
$_1$
na území, na které si dělá nárok i Bhutan.
 $|||$
Vše bylo zcela diplomaticky vyřešeno
$|||$
Vše bylo zcela diplomaticky vyřešeno
 $_{3b}$
poté, co obě strany stáhly svá vojska.
$_{3b}$
poté, co obě strany stáhly svá vojska.
 $|||$
Čína měla také veliký vojenský konflikt s Vietnamem
$|||$
Čína měla také veliký vojenský konflikt s Vietnamem
 $_{3c}$
v roce 1979
$_{3c}$
v roce 1979
 $_{3a}$
. Čína vyhlásila svrchovanost nad všemi moři od jihu Číny. Vietnam, Malajsie, Filipíny, Brunei a Tchaj-wan
$_{3a}$
. Čína vyhlásila svrchovanost nad všemi moři od jihu Číny. Vietnam, Malajsie, Filipíny, Brunei a Tchaj-wan
 $_{3c}$
mají protinároky.
$_{3c}$
mají protinároky.
P2 ORIG: Kromě války v roce 1962 hrozilo mezi Indií a Čínou vypuknutí většího vojenského konfliktu u Doklamské náhorní plošiny v roce 2017
 $_{3a}$
, když se Čínská lidová osvobozenecká armáda (PLA) pokusila vybudovat železnici poblíž úzkého indického koridoru Kuřecí krk, který spojuje západní a východní
$_{3a}$
, když se Čínská lidová osvobozenecká armáda (PLA) pokusila vybudovat železnici poblíž úzkého indického koridoru Kuřecí krk, který spojuje západní a východní
 $_1$
část Indie
$_1$
část Indie
 $_1$
v oblasti nárokované také Bhútánem.
$_1$
v oblasti nárokované také Bhútánem.
 $|||$
Nakonec bylo vše vyřešeno diplomatickou cestou
$|||$
Nakonec bylo vše vyřešeno diplomatickou cestou
 $_{3b}$
a obě strany stáhly své vojenské jednotky.
$_{3b}$
a obě strany stáhly své vojenské jednotky.
 $|||$
V roce 1979
$|||$
V roce 1979
 $_{3a}$
došlo také k velkému vojenskému konfliktu mezi Čínou a Vietnamem
$_{3a}$
došlo také k velkému vojenskému konfliktu mezi Čínou a Vietnamem
 $_{3c}$
. Čína si nárokuje svrchovanost nad celým Jihočínským mořem. Avšak Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
$_{3c}$
. Čína si nárokuje svrchovanost nad celým Jihočínským mořem. Avšak Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
 $_{3c}$
také vznášejí územní nároky na tuto oblast.
$_{3c}$
také vznášejí územní nároky na tuto oblast.
P3 ORIG: Kromě války v roce 1962 byla mezi Indií a Čínou velká vojenská patová situace v Doklamu v roce 2017
 $_{3a}$
, kdy se Lidová osvobozenecká armáda pokusila položit silnici v blízkosti úzkého indického koridoru Kuřecí krk, který Indii spojuje se severovýchodními
$_{3a}$
, kdy se Lidová osvobozenecká armáda pokusila položit silnici v blízkosti úzkého indického koridoru Kuřecí krk, který Indii spojuje se severovýchodními
 $_1$
státy
$_1$
státy
 $_1$
v oblasti, kterou si také nárokuje Bhútán.
$_1$
v oblasti, kterou si také nárokuje Bhútán.
 $|||$
Konflikt byl nakonec diplomaticky vyřešen
$|||$
Konflikt byl nakonec diplomaticky vyřešen
 $_{3b}$
a obě strany poté stáhly svá vojska.
$_{3b}$
a obě strany poté stáhly svá vojska.
 $|||$
Čína měla také větší vojenský konflikt s Vietnamem
$|||$
Čína měla také větší vojenský konflikt s Vietnamem
 $_{3c}$
v roce 1979
$_{3c}$
v roce 1979
 $_{3a}$
. Čína si nárokuje suverenitu nad celým Jihočínským mořem. Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
$_{3a}$
. Čína si nárokuje suverenitu nad celým Jihočínským mořem. Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
 $_{3c}$
mají opačné nároky.
$_{3c}$
mají opačné nároky.
N1 ORIG: Kromě války v roce 1962 hrozilo mezi Indií a Čínou vypuknutí většího ozbrojeného konfliktu v roce 2017
 $_{3a}$
u Doklamské náhorní plošiny, když se Čínská lidová osvobozenecká armáda (ČLOA) pokusila postavit železnici poblíž úzkého indického koridoru Kuřecí krk, který spojuje severní a východní
$_{3a}$
u Doklamské náhorní plošiny, když se Čínská lidová osvobozenecká armáda (ČLOA) pokusila postavit železnici poblíž úzkého indického koridoru Kuřecí krk, který spojuje severní a východní
 $_1$
část Indie
$_1$
část Indie
 $_1$
v oblasti nárokované také Bhútánem.
$_1$
v oblasti nárokované také Bhútánem.
 $|||$
Konflikt byl nakonec vyřešen diplomatickou cestou
$|||$
Konflikt byl nakonec vyřešen diplomatickou cestou
 $_{3b}$
, načež obě strany svá vojska stáhly.
$_{3b}$
, načež obě strany svá vojska stáhly.
 $|||$
V roce 1979
$|||$
V roce 1979
 $_{3a}$
došlo k většímu vojenskému konfliktu také mezi Čínou a Vietnamem
$_{3a}$
došlo k většímu vojenskému konfliktu také mezi Čínou a Vietnamem
 $_{3c}$
. Čína si nárokuje svrchovanost nad celým Jihočínským mořem, ovšem na tuto oblast si činí nárok také Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
$_{3c}$
. Čína si nárokuje svrchovanost nad celým Jihočínským mořem, ovšem na tuto oblast si činí nárok také Vietnam, Malajsie, Filipíny, Brunej a Tchaj-wan
 $_{3c}$
.
$_{3c}$
.
6. Discussion
Evaluating optimal reference translation(s) is in many ways a more difficult task than evaluating a “standard” (human or machine) translation. It is already a common practice in the translation industry to have multiple workers included in a translation of a single document (e.g. initial translator and quality assurance translator). Based on our analysis of the optimal reference translation evaluation, it turns out that it is very crucial who evaluates such translations: Do the annotators have professional translation experience, or are they students of translation, or laymen in the field? It appears that laypeople are less able to notice even critical mistakes in translations. As a result for quality assurance, hiring only annotators with lots of translating experience seems to be a requirement.
However, important to determine is who the translation is for. If it is for a wide audience who do not scrutinize the translation quality, it may not be worth the extra cost to hire highly skilled translation evaluators. In turn, for the evaluation of machine translation systems that have reached this very high level of quality, highly skilled evaluators are needed.
We do note, however, that perfect translations or annotations likely do not exist, only their approximations. The cost of uncovering more translation errors is likely hyperlinear—that is, two rounds of annotations do not uncover twice as many mistakes. Each use-case should therefore make explicit what the target quality level is and adjust the annotation protocol accordingly.
7. Conclusion
We defined the concept of optimal reference translation (ORT), geared towards regaining informative results in reference-based machine translation evaluation. We then performed a careful manual evaluation and post-editing of ORT in comparison with three standard professional translation. The evaluation confirms that ORT deserve their name and can be regarded as a truly golden reference. In fact, the few times when ORT did not score best were examples of errors in this follow-up annotation, not examples of ORT deficiencies. Additionally, we documented that manual evaluation at these high levels of quality cannot be delegated to inexperienced annotators. Only people with substantial translation experience are sensitive to the subtle differences and can provide qualified judgements.
7.1 Time range
To process one document in all four translations takes on average 25–75 minutes. Please indicate the time spent on the annotation of each document (in minutes) in the appropriate box in each sheet. If you are systematically outside this range, send us an email. Please note that annotating the first document usually takes much more time than annotating subsequent documents.
7.2 Future work
While we focused on evaluating human translations, the identical setup could be used for evaluating MT models, which we plan to address in future work. This is not part of the present work which is focused on showing that the reference translations usually used are of insufficient quality and need to be reconsidered. Our next step will be to assess which of the multitude of automatic metrics of MT quality are sensitive to the subtleties captured in our ORT and can thus be used to reliably evaluate MT outputs of high quality. This will again require careful expert manual evaluation.
8. Annotation guidelines
The following is the main part of instructions which were distributed to the annotators.
Introduction
The goal of this study is to annotate the translation quality in seven categories. There are 20 documents in the shared Google sheet, marked as Edit1, Edit2 etc. (Orig1,
 $\ldots$
are described later in the text). The first column contains the source text in English, followed by four Czech translations. However, only eight segments should be evaluated in each document. If you don’t see a translation for some segments, it is not meant to be evaluated. You will evaluate the translations both at the segment level and at the level of whole documents (or at the level of the eight continuous segments). You will also indicate a better translation if you are not satisfied with the current version. Please read the source text first. The following is a possible evaluation procedure, but it is up to you how you proceed. The next steps are (for individual translations): 1. reading the translation, 2. evaluating the segments, 3. evaluating the whole document, 4. editing the segments so that you are satisfied with the translations, 5. reading the entire newly created text and possibly making minor changes. Please keep in mind that although you are also evaluating the segments separately, they are always part of a larger text, so you should pay special attention to how they relate to each other, that is also to the coherence and cohesion of the whole text. This should also be reflected in the assessment (category “style” below).
$\ldots$
are described later in the text). The first column contains the source text in English, followed by four Czech translations. However, only eight segments should be evaluated in each document. If you don’t see a translation for some segments, it is not meant to be evaluated. You will evaluate the translations both at the segment level and at the level of whole documents (or at the level of the eight continuous segments). You will also indicate a better translation if you are not satisfied with the current version. Please read the source text first. The following is a possible evaluation procedure, but it is up to you how you proceed. The next steps are (for individual translations): 1. reading the translation, 2. evaluating the segments, 3. evaluating the whole document, 4. editing the segments so that you are satisfied with the translations, 5. reading the entire newly created text and possibly making minor changes. Please keep in mind that although you are also evaluating the segments separately, they are always part of a larger text, so you should pay special attention to how they relate to each other, that is also to the coherence and cohesion of the whole text. This should also be reflected in the assessment (category “style” below).
Evaluation of segments
Rate each of the four translations in the following seven categories on a scale from 0 (worst) to 6 (best):
-
spelling, punctuation, typography, typos,
-
terminology (correctness, consistency, normativity),
-
grammar: morphology (word forms) and syntax (sentence structure, functional sentence perspective),
-
meaning accuracy (mistranslation, addition, omission, untranslated text segment etc.),
-
style (appropriateness, consistency, idiomaticity, cross-sentence coherence and cohesion),
-
pragmatics (culture-specific reference, locale conventions, appropriateness for the Czech reader),
-
overall quality (evaluation of the translation in all the above-mentioned categories).
Important notes
You can rate from 0 (the worst rating) to 6 (the best rating); in addition to whole numbers (0, 1, 2, 3, 4, 5, 6), decimal numbers with one decimal place (e.g. 0.1 or 4.5) are allowed. It is not necessarily the goal to use the full range of ratings for individual translations, that is if you do not see an error in a given category (even if the translation of the rated segment is very easy and does not pose a challenge for the translator), you will rate the highest possible score (6). We leave it to the discretion of each evaluator to decide how serious they consider a particular error to be and how many points to deduct for it. If an error affects more than one category (typically, e.g., both categories 3 and 4), this should result in a reduced rating in all relevant categories.
Evaluation of documents
Rate the entire translation at the document level in the seven categories (the same as above for segment evaluation) on a scale from 0 to 6 (the same conditions as above for segment evaluation). The rating of the whole document is on the last line of each sheet.
Editing of translated segments
If a segment translation does not receive the highest rating (6) in overall quality, please edit the translation with minimal editing (changes, corrections) to the state that you would give the highest rating (6). To clarify, if translations 1, 2, 3, and 4 get an overall quality rating of 6, 5, 3, 6, respectively (for particular segments), you must edit translations 2 and 3 independently. The resulting translations should be based on the original translations, that is most of the time they will be different from each other even after your edits. You can use dictionaries or search the internet, but please do not use any machine translation systems. If possible, try not to copy text segments from previous translations, even if you like them. Since you probably weren’t satisfied with some of the translations and didn’t give them the highest possible rating, you have edited some segments. For comparison, you can look at the original translation (OrigT), which is in another sheet. For example, for document 3, the sheet is called Orig3 and is listed just after Edit3. Edit only the EditT sheet.















 Open access
Open access