
Contents
Introduction
Introduction to the Special Issue on Logic Programming and the Web
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 247-248
-
- Article
- Export citation
Regular Papers
N3Logic: A logical framework for the World Wide Web
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 249-269
-
- Article
- Export citation
Building Rules on Top of Ontologies for the Semantic Web with Inductive Logic Programming
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 271-300
-
- Article
- Export citation
-
Building rules on top of ontologies is the ultimate goal of the logical layer of the Semantic Web. To this aim, an ad-hoc markup language for this layer is currently under discussion. It is intended to follow the tradition of hybrid knowledge representation and reasoning systems, such as
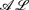 -log that integrates the description logic
-log that integrates the description logic 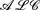 and the function-free Horn clausal language Datalog. In this paper, we consider the problem of automating the acquisition of these rules for the Semantic Web. We propose a general framework for rule induction that adopts the methodological apparatus of Inductive Logic Programming and relies on the expressive and deductive power of -log. The framework is valid whatever the scope of induction (description versus prediction) is. Yet, for illustrative purposes, we also discuss an instantiation of the framework which aims at description and turns out to be useful in Ontology Refinement.
and the function-free Horn clausal language Datalog. In this paper, we consider the problem of automating the acquisition of these rules for the Semantic Web. We propose a general framework for rule induction that adopts the methodological apparatus of Inductive Logic Programming and relies on the expressive and deductive power of -log. The framework is valid whatever the scope of induction (description versus prediction) is. Yet, for illustrative purposes, we also discuss an instantiation of the framework which aims at description and turns out to be useful in Ontology Refinement.
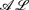 -log that integrates the description logic
-log that integrates the description logic 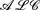 and the function-free Horn clausal language
and the function-free Horn clausal language Translating OWL and semantic web rules into prolog: Moving toward description logic programs
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 301-322
-
- Article
- Export citation
Querying XML documents in logic programming*
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 323-361
-
- Article
- Export citation
SWI-Prolog and the web
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 363-392
-
- Article
- Export citation
Query evaluation and optimization in the semantic web
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 393-409
-
- Article
- Export citation
Guarded hybrid knowledge bases12
-
- Published online by Cambridge University Press:
- 01 May 2008, pp. 411-429
-
- Article
- Export citation
-
Recently, there has been a lot of interest in the integration of Description Logics (DL) and rules on the Semantic Web. We define guarded hybrid knowledge bases (or g-hybrid knowledge bases) as knowledge bases that consist of a Description Logic knowledge base and a guarded logic program, similar to the
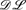 + log knowledge bases from Rosati (In Proceedings of the 10th International Conference on Principles of Knowledge Representation and Reasoning, AAAI Press, Menlo Park, CA, 2006, pp. 68–78.). g-Hybrid knowledge bases enable an integration of Description Logics and Logic Programming where, unlike in other approaches, variables in the rules of a guarded program do not need to appear in positive non-DL atoms of the body, i.e., DL atoms can act as guards as well. Decidability of satisfiability checking of g-hybrid knowledge bases is shown for the particular DL
+ log knowledge bases from Rosati (In Proceedings of the 10th International Conference on Principles of Knowledge Representation and Reasoning, AAAI Press, Menlo Park, CA, 2006, pp. 68–78.). g-Hybrid knowledge bases enable an integration of Description Logics and Logic Programming where, unlike in other approaches, variables in the rules of a guarded program do not need to appear in positive non-DL atoms of the body, i.e., DL atoms can act as guards as well. Decidability of satisfiability checking of g-hybrid knowledge bases is shown for the particular DL 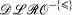 , which is close to OWL DL, by a reduction to guarded programs under the open answer set semantics. Moreover, we show 2-Exptime-completeness for satisfiability checking of such g-hybrid knowledge bases. Finally, we discuss advantages and disadvantages of our approach compared with + log knowledge bases.
, which is close to OWL DL, by a reduction to guarded programs under the open answer set semantics. Moreover, we show 2-Exptime-completeness for satisfiability checking of such g-hybrid knowledge bases. Finally, we discuss advantages and disadvantages of our approach compared with + log knowledge bases.
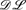 + log knowledge bases from Rosati (In Proceedings of the 10th International Conference on Principles of Knowledge Representation and Reasoning, AAAI Press, Menlo Park, CA, 2006, pp. 68–78.). g-Hybrid knowledge bases enable an integration of Description Logics and Logic Programming where, unlike in other approaches, variables in the rules of a guarded program do not need to appear in positive non-DL atoms of the body, i.e., DL atoms can act as guards as well. Decidability of satisfiability checking of g-hybrid knowledge bases is shown for the particular DL
+ log knowledge bases from Rosati (In Proceedings of the 10th International Conference on Principles of Knowledge Representation and Reasoning, AAAI Press, Menlo Park, CA, 2006, pp. 68–78.). g-Hybrid knowledge bases enable an integration of Description Logics and Logic Programming where, unlike in other approaches, variables in the rules of a guarded program do not need to appear in positive non-DL atoms of the body, i.e., DL atoms can act as guards as well. Decidability of satisfiability checking of g-hybrid knowledge bases is shown for the particular DL 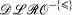 , which is close to OWL DL, by a reduction to guarded programs under the open answer set semantics. Moreover, we show 2-
, which is close to OWL DL, by a reduction to guarded programs under the open answer set semantics. Moreover, we show 2-