


Introduction
Early language development is the basis for further language acquisition (Hohm et al., Reference Hohm, Jennen-Steinmetz, Schmidt and Laucht2007). Additionally, it is related to emotional and social development (Griffiths et al., Reference Griffiths, Goh, Norbury and the2020; Rose et al., Reference Rose, Ebert and Weinert2016) as well as later academic achievement (Bleses et al., Reference Bleses, Makransky, Dale, Højen and Ari2016). In early lexical development, great variability exists at the beginning of word production and the speed of vocabulary growth (Bates et al., Reference Bates, Dale, Thal, Fletcher and MacWhinney1995; Szagun & Steinbrink, Reference Szagun and Steinbrink2004). To improve clinical decisions on how and when to support children with low language abilities professionally, we need to understand basic language acquisition further. This study contributes to knowledge about vocabulary growth trajectories in early childhood. The focus of this paper is on the statistical description of lexical growth curves for different subgroups (classes) in a community sample of children ranging from 18 months to three years of age.
Early vocabulary growth patterns
There are considerable individual differences with regard to the active vocabulary in early child development. Typically, children speak their first words around their first birthday. Bloom et al. (Reference Bloom, Tinker and Margulis1993) calculated an average age of 1;1 with an interindividual range of 0;10 to 1;5 for the first spoken word (N=14).
At the beginning of word production, vocabulary increases take place very slowly. Typically, vocabulary acquisition subsequently accelerates within the second half of the second year of life. Vocabulary then grows from first words to a command of hundreds of words within this time period (Mayor & Plunkett, Reference Mayor and Plunkett2010; Reznick & Goldfield, Reference Reznick and Goldfield1992). The acceleration of word production is favoured, inter alia, by the fact that first sentences are produced in form of word combinations and that articulation improves constantly in this phase. In addition to a basic vocabulary, the prerequisite for faster vocabulary growth is an understanding of object permanence, a symbolic awareness, and the ability to segment and categorise (Ptok et al., Reference Ptok, Kühn and Miller2014).
For some children, the acceleration in lexical growth happens in the form of a spurt. Traditionally, a vocabulary spurt can be defined as a sudden increase in vocabulary size. According to Bloom et al. (Reference Bloom, Tinker and Margulis1993), the average age for a child to experience the beginning of a vocabulary spurt was an age of 1;6, with a minimum age of 1;3 and a maximum age of 2;2. However, there are different definitions of a vocabulary spurt. In a statistical reanalysis of speech data, Ganger and Brent (Reference Ganger and Brent2004) questioned the vocabulary spurt as a typical pattern of growth and could verify it only for a fifth of all children (N=38). Their definition of having a spurt was better model fit (likelihood ratios) of word learning rate for a logistic function in comparison to a quadratic function. While a quadratic function shows an increase in growth with a constant rate of change, a logistic function distinguishes a transition between two different growth rates with a mathematical inflection point. Otherwise, a quadratic function resembles a logistic function in form. Additionally, Mayor and Plunkett (Reference Mayor and Plunkett2010) argued that the vocabulary spurt is not a sudden leap in vocabulary growth but that a phase of slow linear acquisition is followed by a phase of increased speed of vocabulary acquisition.
Other growth patterns, such as gradual continuous increases or staircase-shaped patterns with many short accelerations, have also been identified in empirical studies. For example, Goldfield and Reznick (Reference Goldfield and Reznick1990) evaluated mothers’ diary entries and found a significant acceleration in vocabulary acquisition for 13 children, while noted gradual linear growth for five children between the ages of 1;2 and 1;10. Robinson and Mervis (Reference Robinson and Mervis1998) showed accelerated vocabulary growth at the age of 1;7 and a second acceleration at 2;0 years of age in a single case study. Specific growth patterns, such as many short accelerations or a transition between two distinguished growth rates, can only be shown for individuals since children reach such a point at their own pace. In the studies mentioned above, sample sizes are limited, since observing individual lexical growth is time-consuming. Additionally, most of the children were aged younger than two years old. Possibly, some children might have had a late acceleration in vocabulary growth in their third year of life.
In German, Kauschke and Hofmeister (Reference Kauschke and Hofmeister2002) collected spontaneous speech data longitudinally from 32 children at four measuring time points (ages 1;1, 1;3, 1;9, and 3;0) and observed an exponential vocabulary growth between 1;1 and 1;9 followed by a flattened acceleration, therefore describing a quadratic growth trend for all four measuring times. In the standardisation study of the German adaptation of the MacArthur-Bates Communicative Development Inventories named “FRAKIS” (Szagun et al., Reference Szagun, Stumper and Schramm2009, Reference Szagun, Stumper and Schramm2014, Reference Szagun, Stumper and Schramm2023), an acceleration of growth was evident from age 1;9. The variability was particularly strong between ages 1;9 and 2;3. Here, data were collected cross-sectional (N=1,240; n≥80 for every age group per month between 1;6 to 2;6). The description of growth curve patterns in different studies is dependent on the examined age range as well as the methods used to analyse the data.
Trajectories of language development for subgroups
There are longitudinal studies focussing on language development trajectories for distinct subgroups. However, there is still a lack of research in this field, which can be attributed to many factors including different aims of the studies, different samplings (e.g., specifically children with low language abilities, different age ranges), different numbers of assessment points, different language aspects, as well as different methods of analysis. Subgroup names (characterisation) and size are distinct in every study.
As the focus is not on growth curve patterns, some studies are conducted with a focus limited to only two assessment points. For example, Law et al. (Reference Law, Rush, Anandan, Cox and Wood2012) aimed to analyse factors that predict language change of children in the UK between the ages of three and five years. Expressive vocabulary data were analysed using linear regression. The authors describe four patterns of change in children’s vocabulary (N=13,016): “typical” (92.7%), “consistently low” (1.5%), “increasingly vulnerable” (1.4%), and “resilient” (4.4%). They conclude that early language deficits partly remain constant, but this indicator does not allow for an individual prognosis. Zambrana et al. (Reference Zambrana, Pons, Eadie and Ystrom2014) conducted another study with two assessment points. This study examined whether an integrative model of important risk factors predicts trajectories of “persistent”, “recovering”, or “late-onset” language delay using multinomial logistic regression analysis. Language abilities of Norwegian children (N=10,587) from age three to five were assessed using maternal reports of the Ages and Stages Questionnaire. Across time, participants had “persistent” (3.0%), “transient” (5.0%), and “late-onset” (6.5%) language delay. The other children (85.5%) showed language skills within the normal range at both time points analysed in the study. Furthermore, Armstrong et al. (Reference Armstrong, Scott, Whitehouse, Copland, Mcmahon and Arnott2017) conducted a study based on two assessment points. They investigated risk factors of language difficulties in Australian children (N=783) from two to ten years old using logistic regression analysis. They identified three subgroups of “late talkers”. Children had “consistently low” (5.6%), “improved” (5.9%), and “deteriorated” (23.2%) language abilities.
It is important to note that it is not possible to display a growth curve with data collection limited to only two assessment points. Existing longitudinal studies with at least three measurement times have generally been concerned with children from different age ranges (children older than those in the current study). For example, Snowling et al. (Reference Snowling, Duff, Nash and Hulme2016) focused on language trajectories of children with language impairment or being at risk of having language impairment. The authors of the study analysed children’s receptive and productive grammar and vocabulary at three assessment points (ages 3;6, 5;6, and 8;0) and postulated three developmental trajectories of language impairment. Children (N=220) were characterised as having either “resolving” (5.5%), “persisting” (9.6%), or “emerging” (19.1%) language impairment, whereas 65.9% of the sample population demonstrated “typical” language development. Klem et al. (Reference Klem, Hagtvet, Hulme and Gustafsson2016) used a second-order growth mixture model and identified four latent classes of language development in Norwegian children (N=600) aged four to six years old with different growth trajectories of language ability: “low-performing” (10.3%), “high-performing” (55.2%), and two distinct subgroups of “intermediate-performing” children (19.0% and 15.5%). Data were collected at three time points (4;0, 5;0, and 6;0 years of age). The growth rates were parallel for the four distinct classes. This suggests that language abilities have a stable course during the analysed age range and are not as variable as in earlier language acquisition. McKean et al. (Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017) used longitudinal trajectory latent class modelling to evaluate language data of Australian children (N=1,279) assessed at four time points (4;0, 5;0, 7;0, and 11;0 years of age) with the clinical evaluation of language fundamentals. They identified three distinct trajectories. Subgroups were described as having “stable” (94%), “low-decreasing” (4%), and “low-improving” (2%) language acquisition.
There is an overlap of children’s age to the current examined age range, when there is known to be great variability in language acquisition, in the following longitudinal studies. Although not focussing on language growth curves, Kühn et al. (Reference Kühn, Sachse and von Suchodoletz2016) investigated language development in a sample of German-speaking “late talkers” in comparison to a matched sample of “non-late talkers” and a third group of “borderline cases” (children with low language in either the parent report form or the standardised test as opposed to confirming results in both). Children (N=106) were examined at four measuring times at the age of 2;1, 3;1, 4;7, and 5;10 via standardised German language tests on the following: productive vocabulary, grammar, and language comprehension. Analysis of variance showed one-third of early “late talkers” still had language delay at the last assessment time. Interestingly, differences between “non-late talkers” and “borderline cases” were not significant at later measurements, and discrepancies with respect to language ability of all the children who were surveyed were reduced as the children aged. As the focus of the study was on “late talkers” and groups were fixed at the first assessment point, the need for naturally observed language trajectories in children persists.
Valla et al. (Reference Valla, Birkeland, Hofoss and Slinning2017) used latent class analysis to identify common pathways within different developmental areas in Norwegian infants (N=1,555) from four to 24 months using six measuring times (4, 6, 9, 12, 16, and 24 months of age). Two latent classes of communication skills measured by the Ages and Stages Questionnaire were conducted, one subgroup of infants with “typical” language acquisition (94%) and one subgroup of infants with “declining” communication skills (8%). The analysis did not allow for the division of more classes, leaving information about subgroups limited.
Ukoumunne et al. (Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012) identified five different language development profiles in a community sample of Australian children (N=1,113) using latent class analysis. Children were assessed at five measuring times between eight months and four years of age (aged 0;8, 1;0, 2;0, 3;0, and 4;0). Varied language components were measured at different times using the Communication and Symbolic Behaviour Scales (CSBS) at the first two measurements, the MacArthur-Bates Communicative Development Inventories at the third and fourth measurements and the Clinical Evaluation of Language Fundamentals at the fifth measuring time. The sample was trichotomised at each assessment point fixing language scores to be “typical” (85%), “precocious” (8%), or “impaired” (7%), which excludes the natural division of classes. The results present classification into subgroups of “typical” (75.2%), “precocious – late” (10.1%), “impaired – early” (6.2%), “impaired – late” (4.8%), and “precocious – early” (3.8%) language trajectories. One-third of the children surveyed had an unstable course of development. It is also worth noting that the study displayed heterogeneity within the classes. The results of the studies listed above emphasise the heterogeneity that exists in child language trajectories.
Effects of demographic factors on language trajectories
In addition to early linguistic competencies, demographic variables such as socioeconomic status, gender, birth order, multilingualism, and others play a significant role in language development (e.g., Fenson et al., Reference Fenson, Dale, Reznick, Bates, Thal and Pethick1994; Hoff, Reference Hoff2003; Junker & Stockman, Reference Junker and Stockman2002; Reilly et al., Reference Reilly, Bavin, Bretherton, Conway, Eadie, Cini, Prior, Ukoumunne and Wake2009; Szagun et al., Reference Szagun, Stumper and Schramm2009, Reference Szagun, Stumper and Schramm2014). Hammer et al. (Reference Hammer, Morgan, Farkas, Hillemeier, Bitetti and Maczuga2017) found that being a boy, having a lower socioeconomic background, and having siblings significantly increase the risk of being a “late talker” at 2;0 years of age. Zambrana et al. (Reference Zambrana, Pons, Eadie and Ystrom2014) reported that male children, in general, are at an increased risk for having a language delay trajectory. The risk for boys having a “persistent” language delay trajectory was significantly higher than for “late-onset” language delay but not for “transient” language delay. In preschool-aged children, there is a correlation between being male and having a language delay. It should, however, also be noted that this correlation differs for distinct language trajectories. McKean et al. (Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017) showed a positive correlation between a “low-improving” language trajectory, having a nonnative-speaking background and social disadvantage. A mothers’ level of education was also a predictor for belonging to the subgroups of “increasingly vulnerable” and “resilient” vocabulary in the study of Law et al. (Reference Law, Rush, Anandan, Cox and Wood2012). Snowling et al. (Reference Snowling, Duff, Nash and Hulme2016) reported on social disadvantage being a predictor for having a trajectory of “persisting” language delay. Armstrong et al. (Reference Armstrong, Scott, Whitehouse, Copland, Mcmahon and Arnott2017) found that children with “deteriorated” language skills were more likely to be male, to have fathers who had not completed their secondary education, and to have low family income as opposed to “typically” developing children. The correlations of language trajectories and different demographic factors differ between distinct subgroups. To enlarge basic knowledge about different effects of demographic factors on distinct growth curve patterns across normal variability helps to understand the meaning of the factors regarding low language trajectories.
Current study
The aim of the current study was to analyse vocabulary growth longitudinally in L1 German-speaking children aged 18 months to three years old. The focus of this study was the statistical description of distinct lexical growth trajectories, showing the variability in early language acquisition as opposed to clinical classification. Importantly, the observed data should decide on subgroup classification without any a priori artificially fixed classifications. We assumed a quadratic growth curve for vocabulary due to the acceleration in vocabulary growth that usually occurs within the second year of life. We hypothesised different trajectories of lexical growth for specific subgroups with below or above-average lexical abilities. Furthermore, we were interested in the distribution of the characteristic values of socioeconomic status, gender, birth order, and multilingualism between different subgroups (latent classes) of lexical growth. In the case of multilingualism, only children who speak German as their dominant first language were considered in the analysis. We predicted a positive correlation between higher socioeconomic status, being a girl, being a firstborn, and being raised in a monolingual environment with above-average vocabulary trajectories, as well as lower socioeconomic status, being a boy, having older siblings and being raised in a multilingual environment with below-average vocabulary trajectories.
Method
Participants
Participants consisted of a community sample recruited from the register of the city of Hanover, Germany. The children selected represented an age group of all the children who turned 18 months of age within the following two months. Five hundred families were contacted via mail. They received an incentive of five Euros for every completed questionnaire, which they either returned by mail or filled out online. Two hundred and nineteen families (43.8%) decided to participate in the study. As four of the participating families had twins, we had a positive response from the parents of 223 children. Twenty-five children were excluded for the following reasons: twenty children did not speak German as their dominant language (In the case of multilingualism, parents were asked, if German was the language mostly used in the home.). Three returned questionnaires could not be assigned to the existing address list due to insufficient information. One child had a different age and did not exist in the original address list. Another child was too old and the questionnaire was returned too late (more than two months later). Another two questionnaires were returned too late at the first assessment time, but these families kept participating at the following assessment times. After the return and dropout numbers were excluded, the sample size consisted of 198 children. As some parent reports were not returned or returned too late at single assessment times, there are data of 161 children participating at all four measurement times. Children were aged 1;6, 2;0, 2;6, and 3;0 (+/− 2 months) at the times of measurement. Slightly more than half of the children were male (53.50%; n=106), and more than half were first in the birth order or an only child (59.10%; n=117). One-fifth of all participants were raised multilingual with German being their dominant language (20.70%; n=41). Ethical approval was granted by the University Research Ethics Committee of the University of Hanover and all parents signed a consent form.
Procedure
The study uses a longitudinal design to model early child vocabulary growth over time. Data were collected at four measurement times, each six months apart, using the normed German parent’s questionnaire on early child language development called FRAKIS-K (Szagun et al., Reference Szagun, Stumper and Schramm2009, Reference Szagun, Stumper and Schramm2014, Reference Szagun, Stumper and Schramm2023). FRAKIS-K is the short version of FRAKIS, which is the German adaptation of the MacArthur-Bates communicative development inventory for toddlers (German CDI). The FRAKIS-K consists of a vocabulary list of 102 words as well as three grammatical questions concerning usage of plural, usage of articles, and the ability to combine words. Parents rate their child’s productive language when filling out the report form. FRAKIS(-K) was normed on a sample of over one thousand German-speaking children from the ages of 1;6 to 2;6 (norm data available for every month). FRAKIS-K has shown very good reliability and validity (Szagun et al., Reference Szagun, Stumper and Schramm2014). It was validated using the long FRAKIS word list (600 words), which in turn was validated on spontaneous speech samples. The split-half reliability (Spearman-Brown) was .99 (FRAKIS) and .95 (FRAKIS-K). The internal consistency (Cronbach’s alpha) was very high at .97 to .99 (FRAKIS) and .99 (FRAKIS-K) and the retest reliability was .87 to .95 (FRAKIS) and .94 (FRAKIS-K) after partialisation of age. According to Pearson (bivariate correlation), the correlation with spontaneous speech was .93 and for the partial correlation .83. The authors have explained the high interscale correlations with the strong correlation between the acquisition of vocabulary and grammar. Although the long version FRAKIS was additionally used in our study for data collection at assessment times two, three, and four, only the vocabulary list of the short version FRAKIS-K was used in the analysis of this article. The correlation between the long and short word list in our sample was between r = .989 and r = .994 (p < .001) at the second, third, and fourth assessment. At the first measurement time, only the short word list was used. In addition to FRAKIS-K, parents completed a demographic questionnaire at the first assessment point. It included questions about their child’s age, gender, multilingualism, multiple birth, premature birth, medical problems, day care attendance, birth order, and socioeconomic status (SES). Concerning multilingualism, parents were asked which languages were used in the family. However, only German language proficiency was assessed. SES data were related to the number and age of people living in the household, and their respective educational qualifications, occupations, and financial resources.
Statistical analysis
SES was calculated based on the method used in the KIGGS study, which has been a long-term study on the health and well-being of children and adolescents in Germany by the Robert Koch Institute (German federal government agency and research institute responsible for disease control and prevention) (Lampert et al., Reference Lampert, Müters, Stolzenberg, Kroll and Group2014). In the KiGGS study, each household was assigned a numerical value for each of the three status dimensions education, occupation, and financial resources, which were then calculated to determine the overall SES index of the household. As less than half of participants in our study gave information about their financial resources, our SES index only reflected information regarding the education and occupation of the caregivers. Using more than one information to capture SES gives a more comprehensive view on the life situation. To reflect the status dimension education, numerical values between 1.0 and 7.0 were assigned for the household’s “highest” education. For the status dimension occupation, numerical values between 1.0 and 6.4 were assigned for the household’s “highest” occupation. Two independent coder rated occupations using job descriptions plus information on working conditions and earning potential from the German Federal Employment Agency (Bundesagentur für Arbeit, 2011a, 2011b, 2015). Interrater reliability was 78.13%. All discrepancies were discussed until mutual agreements were reached. Possible values for the SES were between 2.0 and 13.4.
A growth mixture model (GMM) was set up to obtain vocabulary trajectories for naturally grouped classes. Statistical analysis of the GMM was conducted using M-Plus software (Muthén & Muthén, 1998–Reference Muthén and Muthén2017), version 8.7. GMM captures interindividual differences in intraindividual change over time. GMM allows for differences in growth parameters (trajectories) across unobserved subpopulations, which results in separate growth models for each subpopulation (latent class). Additionally, GMM accounts for within-class variation (Muthén, Reference Muthén and Kaplan2004). GMM uses information on vocabulary abilities from all assessment times in order to estimate classes. To decide on the number of classes, different fit and information criteria were taken into account as well as interpretability concerning group sizes and complexity of the model. Estimates of loglikelihood H0 value (Log Lik.; Lo et al., Reference Lo, Mendell and Rubin2001), Akaike information criteria (AIC; Akaike, Reference Akaike1974), Bayesian information criteria (BIC; Schwarz, Reference Schwarz1978), and sample size adjusted BIC (ssaBIC; Sclove, Reference Sclove1987) were used. Lower estimates of all these indices suggest a better model fit. Furthermore, the classification quality of each model was compared by the entropy value. An entropy value close to one suggests an overall good model fit (Geiser, Reference Geiser2013).
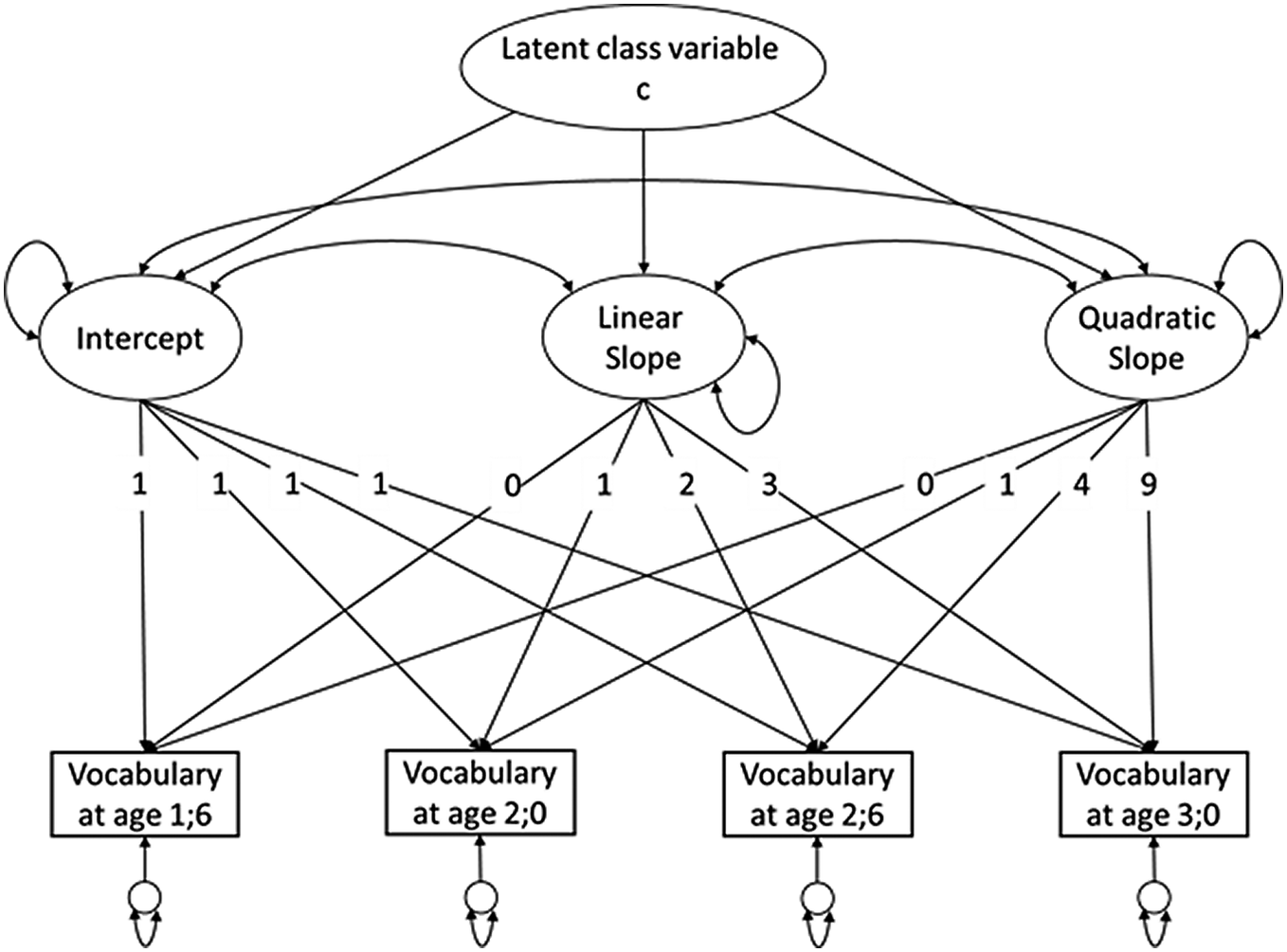
Figure 1 displays the model used to analyse vocabulary growth over time in our sample. The latent class variable c is a categorical variable which represents the unobserved subpopulation membership for each child. It is a trajectory class variable and has a direct impact on the intercept (expected mean value of Y when all X=0) and slope (growth rate) factors. In turn, the latent growth factors (intercept and slope) have a direct effect on the measured variable “vocabulary”. The squares represent the vocabulary as the observed manifest variables ascertained via the FRAKIS-K at the four measurement times. The model assumes quadratic growth and equal time intervals between the time points. The quadratic slope allows for a curvilinear growth rate. GMM also assumes that all measurements are influenced by random measurement errors. These are represented by the measurement error variables (shown as empty circles), which also have a direct effect on the observed variables. Variances and covariances are symbolised with arrows in both directions. Model parameters were neither fixed nor further constrained, but rather left free, leaving the variance and covariance parameters to be estimated by the observed data. Before analysing the GMM to estimate trajectories for subgroups, a linear latent growth curve model and a quadratic latent growth curve model were calculated in M-Plus (model without the categorical variable c, meaning one class for the whole sample), displaying a preference for quadratic growth in the sample (model fit for the linear growth curve model: χ2[df] = 169.996 [5], p = .000; CFI = .476; RMSEA = .408; SRMR = .204; model fit for the quadratic growth curve model: χ2[df] = 3.530 [1], p = .060; CFI = .992; RMSEA = .113; SRMR = .021).
The GMM used to analyse vocabulary trajectories for subgroups.

Finally, characteristic values of subgroups concerning gender, birth order, multilingualism, and SES were analysed with regard to frequency distribution and their statistical significance with ANOVA using SPSS (IBM Corp., 2021).
Results
Descriptive statistics
Table 1 shows the statistical distribution of age and vocabulary score of FRAKIS-K at each assessment point.
Distribution of age (months) and vocabulary at each assessment point (N=198)

SES index informed by education and occupation presented a high socioeconomic background on average (M = 10.31, SD = 2.26, Min = 3.8, Max = 13.4). Nevertheless, data collected from children from all socioeconomic backgrounds are reflected in our study.
Results of the GMM for subgroups
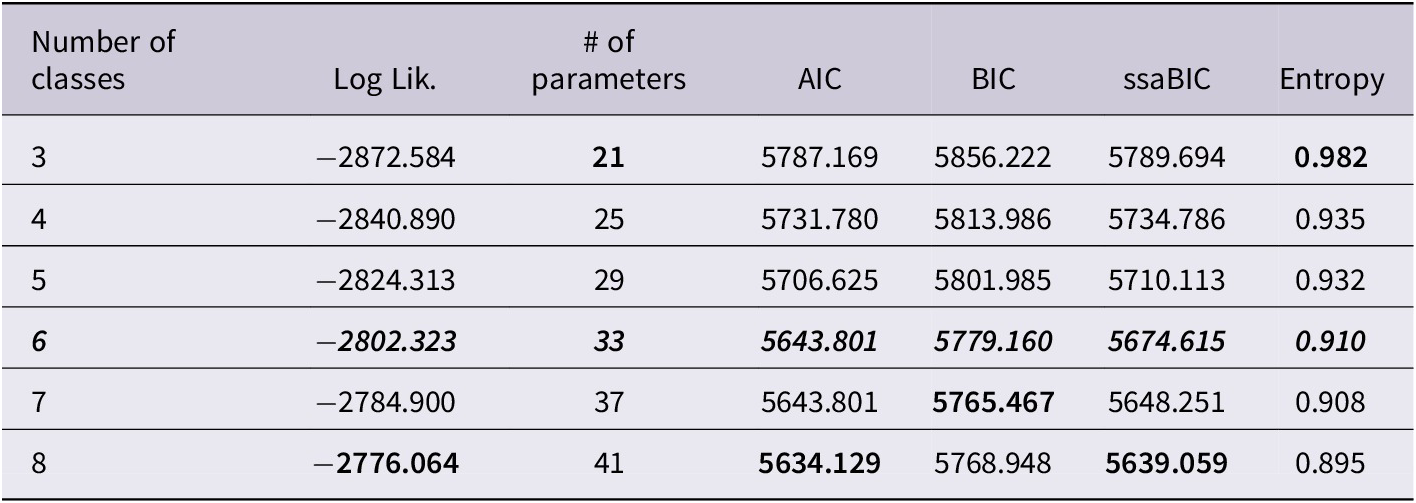
A GMM (Figure 1) with no fixed parameters was set up to analyse vocabulary growth for subgroups. Table 2 shows fit and information criteria of the GMM with three to eight classes.
Fit and information criteria of the GMM with 3 to 8 classes

Note. Log Lik. = Loglikelihood H0 value; AIC = Akaike; BIC = Bayesian; ssaBIC = sample size adjusted BIC;
The model consisting of fewer classes has the highest value of entropy, which means less randomness and more certainty for individuals ending up in a certain class. On the other hand, the more classes that were added, the lower the AIC (lowest for eight classes) and BIC (lowest for seven classes) numbers sank, which also indicates a better fit. However, with more classes, there was a very low number of data in some classes, which led to doubts about the existence of such classes. Since GMM is an exploratory technique, a priori theory is the best judge (Muthén, Reference Muthén2003). The models with three to five classes each differentiated between one main subgroup (“typical”), two to three subgroups with high vocabulary, and none to one group with low vocabulary, whereas the model with six classes differentiates between three subgroups of low vocabulary. There is strong clinical interest in growing our knowledge base on the topic of slow vocabulary growth. As indicated above, different growth trajectories of children with low language abilities have been described in other studies. The model with six classes indicates relatively good model fit indices. This information is tempered by the fact that it had two classes with little data. One class of children with vocabulary scores far above average contained only four children. However, this was indeed a real class, which also existed in exactly the same way for a lower number of classes (three, four, and five classes). Another class of children with vocabulary scores far below average contained only three children. This class existed for six and more (seven and eight) classes in the same way and should be interpreted with caution. We considered it to be equivalent to the class of children with vocabulary scores far above average on the other end of developmental profiles (that is to say, both are statistical outliers).
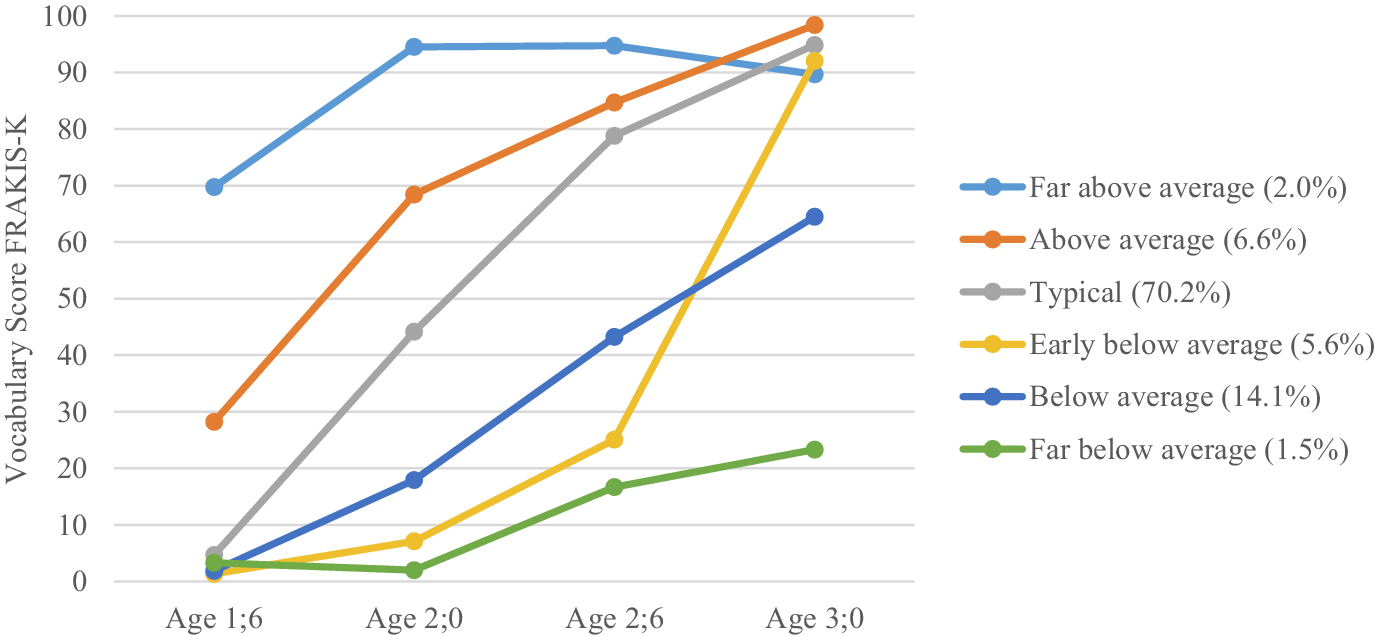
Figure 2 displays the mean vocabulary growth for six subgroups (latent classes). One hundred and thirty-nine children were considered having a “typical” vocabulary development. We considered this class to be “typical” because it contains most of the sample (70.2%) and because the vocabulary score of this subgroup ranks in the middle, comparatively (between the 21st and 91st percentile). Thirteen children had vocabulary scores “above average”, and four children had vocabulary scores that can be ranked “far above average” throughout the measured age span. The class of vocabulary scores which are considered “below average” contains 28 children, the class of vocabulary scores considered “far below average” includes three children. Eleven children had vocabulary scores below average at the ages of 1;6 to 2;6 but caught up with their typically developing peers by the age of 3;0 (“early below average”). The observed and estimated mean vocabulary scores for each class at every assessment point are listed in table 3.
Observed mean vocabulary of the six classes.

Vocabulary score of FRAKIS-K and demographic characteristics of the latent classes

Demographic characteristics of the latent classes
In addition to vocabulary abilities, Table 3 summarises demographic characteristics of the participants, namely gender, birth order, multilingualism, and SES for each latent class. The highest percentage of male participants was found in the “early-below-average” subgroup. The highest percentage of firstborns/only children are to be found within the “above-average” and “far-above-average” subgroups. However, group differences for gender and birth order were not significant. The percentage of children being raised with more than one language increased within the subgroups from “(far)-above-average” to “typical”, “early-below-average” and “(far)-below-average” vocabulary development. Nevertheless, differentiation of multilingualism between classes was not significant (p = .056) as well. SES was higher for the same subgroup order from children with “far-above-average” vocabulary having the highest SES to children with “far-below-average” vocabulary having the lowest SES. Group differences for SES were highly significant (p < .001).
Discussion
The aim of this study was to identify distinct vocabulary growth trajectories in a community sample of L1 German-speaking children from 18 months to three years of age and characterise the identified subgroups regarding SES, gender, birth order and multilingualism, when German was the dominant language. The statistical description of vocabulary growth trajectories for subgroups enlarges our understanding of vocabulary growth in early childhood.
Comparisons of language growth trajectories in subgroups
Six distinct latent classes of vocabulary trajectories were identified in the GMM. Two percent of children fell into the subgroup of having vocabulary abilities “far above average”, 6.6% “above average”, 70.2% “typical”, 14.1% “below average”, 5.6% “early below average” but caught up with their peers over time, and 1.5% “far below average”. Comparison of group size to other research is regarded with caution since samples, measurements, and analyses differ. In some other studies the focus is specifically placed on children with low language abilities from the beginning. Moreover, different age ranges were examined (e.g., children from three or four years of age in Law et al., Reference Law, Rush, Anandan, Cox and Wood2012; McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Zambrana et al., Reference Zambrana, Pons, Eadie and Ystrom2014; and children until the age of two years in Valla et al., Reference Valla, Birkeland, Hofoss and Slinning2017). Although Ukoumunne et al. (Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012) did examine children of a community sample within the same age range as in the current study at multiple measurement times (children aged 0;8 to 4;0 years of age at five measurement times), they trichotomised their sample at each assessment point fixing language scores to be “typical” (85%), “precocious” (8%), or “impaired” (7%). In contrast, GMM analysis in our study allows the observed data to decide group size, which allows for a natural classification of group membership.
The subgroup of children with “typical” vocabulary growth applies to the majority of the sample. The mean vocabulary score is a little higher for this subgroup than the vocabulary mean for the whole sample size since there are more children within the three “below-average” subgroups than the two “above-average” subgroups. While the middle 80 percent of all observed developmental proficiency is often characterised as within the norm in clinical classification practice, GMM allows for a more natural division between classes. In this case, children’s active vocabulary performance between the 21st and 91st percentile seems to be classifiable as “typical”. Whereas group size in our sample is comparable to the “typical” class in Ukoumunne and colleagues (Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012), the percentage of children with a typical developmental growth is larger in other longitudinal studies on early language trajectories, e.g., more than 90 percent of children in McKean et al. (Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017) and Valla et al. (Reference Valla, Birkeland, Hofoss and Slinning2017). One of the reasons is that McKean et al. (Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017) and Valla et al. (Reference Valla, Birkeland, Hofoss and Slinning2017) decided to include fewer classes (3 and 2) in their latent class analyses. In our study, a quadratic growth pattern allowed for an acceleration of lexical growth from age 1;6 to 2;6 with a subsequent flattened growth curve. Kauschke and Hofmeister (Reference Kauschke and Hofmeister2002) also found a quadratic but not linear growth curve of vocabulary in German children one to three years old in spontaneous speech data. They describe a strong increase in vocabulary growth up to age 1;9, and a subsequently flattened acceleration up to age 3;0. In our data, the growth curve flattens after age 2;6. This concurs with the vocabulary spurt and other accelerated growth patterns that usually occur in the second year of life – with big variability (e.g. Bates et al., Reference Bates, Dale, Thal, Fletcher and MacWhinney1995; Bloom et al., Reference Bloom, Tinker and Margulis1993; Mayor & Plunkett, Reference Mayor and Plunkett2010). Here, the vocabulary spurt is meant as an increase in vocabulary growth, as described by Mayor and Plunkett (Reference Mayor and Plunkett2010). An erratic increase measured via an inflection point can only be identified when examining trajectories for individuals, as recorded in Ganger and Brent (Reference Ganger and Brent2004) for some children.
Vocabulary scores of children with “above-average” vocabulary abilities are significantly higher than those of children within the “typical” group throughout all assessment points. Group differences of vocabulary size between the two groups are less pronounced at age 2;6 and 3;0. The variability in lexical acquisition seems to decrease with age. The two “precocious” subgroups described by Ukoumunne et al. (Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012) show a comparable approximation to the “typical” trajectory at this age. Also, group sizes are comparable, whereas Klem et al. (Reference Klem, Hagtvet, Hulme and Gustafsson2016) classified a “high-performing” subgroup in a GMM that contained more than half of the sample size. At the latter, trajectories were parallel to the two subgroups of “intermediate-performing” children, meaning language growth was stable at the measured age. However, children were older than in our study. Most studies do not identify a subgroup of children with exceptionally high language performance. Either the studies focus specifically on children with low language (e.g., Kühn et al., Reference Kühn, Sachse and von Suchodoletz2016; Snowling et al., Reference Snowling, Duff, Nash and Hulme2016) or they identify fewer classes (e.g., McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Valla et al., Reference Valla, Birkeland, Hofoss and Slinning2017).
The subgroup of children with “below-average” vocabulary abilities has the second largest class size. The lexical trajectory for children in this class is significantly below the trajectory of the “typical” subgroup throughout the measured age span. The difference is small at age 1;6, when active vocabulary score is close to zero for the “typical” and all “below-average” subgroups but gets more pronounced as children age. Klem et al. (Reference Klem, Hagtvet, Hulme and Gustafsson2016) described a similar class of “low-performing” children which is slightly smaller than the analogous group in our study. Klem et al. (Reference Klem, Hagtvet, Hulme and Gustafsson2016) also used GMM, but analysed a different age group (four to six-year olds). Other studies describe a smaller group size for “consistently low” language (e.g., 1.5% in Law et al., Reference Law, Rush, Anandan, Cox and Wood2012) or “persistent” language delay (e.g., 3% in Zambrana et al., Reference Zambrana, Pons, Eadie and Ystrom2014) or do not describe this growth pattern (e.g., Ukoumunne et al., Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012). Reasons are different methods and different group classification of children performing below average. Further examination would be useful to conclude if children in the “below-average” subgroup are in need of clinical assistance.
Whereas a meaningful acceleration within the growth curve is not visible for children in the “below-average” group, an acceleration in vocabulary growth is evident for children in the “early below average” group from the age of 2;6, beginning one year later than for “typically” developing children would otherwise be the case. The lexical trajectory of these children is remarkably low from the beginning but approaches the “typical” trajectory at 3;0 years of age. Although named differently, subgroups of children with “early-below-average” language profiles have been described in many studies (Armstrong et al., Reference Armstrong, Scott, Whitehouse, Copland, Mcmahon and Arnott2017; Kühn et al., Reference Kühn, Sachse and von Suchodoletz2016; Law et al., Reference Law, Rush, Anandan, Cox and Wood2012; McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Ukoumunne et al., Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012; Zambrana et al., Reference Zambrana, Pons, Eadie and Ystrom2014). A similarity we see between our data and the findings of Ukoumunne et al. (Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012) is an approximation of the “impaired-early” (early-below-average) language growth curve to the “typical” and “precocious-early(/late)” (above average) children at age 3;0.
Although some studies identified a class of children who developed below-average language skills over time despite having average language abilities in the beginning of the study (McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Ukoumunne et al., Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012; Valla et al., Reference Valla, Birkeland, Hofoss and Slinning2017), our research did not confirm this finding. The different age ranges examined may be one explanation for the discrepancy in results between the studies.
Finally, the two classes of children with “far-above” and “far-below-average” vocabulary abilities contain statistical outliers at both ends of developmental pathways. Highly advanced children reach the same vocabulary score as their typically developing peers one year earlier, at age 2;0 instead of 3;0. Further differences cannot be shown due to ceiling effects. “Far-below-average” children are still more than a year behind their typically developing peers at age 3;0. Due to the small number of children classified in these classes, characterisation cannot be generalised.
Contributions of demographic characteristics
Unexpectedly, group differences regarding gender, birth order, and multilingualism (German being the dominant language) were not significant, unlike shown in other studies (Armstrong et al., Reference Armstrong, Scott, Whitehouse, Copland, Mcmahon and Arnott2017; Hoff, Reference Hoff2003; McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Reilly et al., Reference Reilly, Bavin, Bretherton, Conway, Eadie, Cini, Prior, Ukoumunne and Wake2009; Zambrana et al., Reference Zambrana, Pons, Eadie and Ystrom2014). However, there were more girls and more firstborns in the “above-average” subgroup, as well as more boys and younger siblings in the “early-below-average” subgroup. The mean of gender and birth order in the “typical” class is comparable to the mean of the whole sample. However, gender and birth order might not be as important for vocabulary trajectories as other demographic aspects. Regarding multilingualism, a lower percentage of children growing up with more than one language is to be found in the subgroups with “above-average” vocabulary scores and a higher percentage of these children can be found in classes with “below-average” vocabulary scores. It is important to acknowledge, that only the German vocabulary of children raised in a multilingual home environment was assessed, not the vocabulary abilities in other spoken languages, and therefore, not the true vocabulary proficiency. For this reason, children who did not speak German as their dominant home language were excluded from the study, which led to a low number of multilingual children in the sample. Both, exclusion of children who did not speak German as their dominant home language, as well as a low number of children being raised in a multilingual home, might have been reasons that group differences regarding multilingualism were not significant in our sample. However, there was a tendency for significance regarding multilingual children with different lexical trajectories in our study. As significance of multilingualism on language acquisition and later academic achievement has been displayed in other studies (Hoff, Reference Hoff2013), further research should analyse this aspect in other samples.
Our findings concur with the existing research regarding the SES of the distinct subgroups. Group differences for SES are highly significant. The highest SES is found in the “(far)-above-average” class, followed by the “typical” one, then “early below average”, and “(far) below average” which concurs with other findings (Armstrong et al., Reference Armstrong, Scott, Whitehouse, Copland, Mcmahon and Arnott2017; Law et al., Reference Law, Rush, Anandan, Cox and Wood2012; McKean et al., Reference McKean, Wraith, Eadie, Cook, Mensah and Reilly2017; Snowling et al., Reference Snowling, Duff, Nash and Hulme2016). As emphasised by others (e.g., Hoff, Reference Hoff2013), SES is a very important aspect of language acquisition and should be considered when discussing targeted language support for infants. In our study, SES distinguishes between all subgroups of the whole range of vocabulary proficiency trajectories.
Limitations
This study has some limitations. First, intervals between measurements were six months apart. More frequent assessments would have allowed for more precise determinations about the type and timing of the growth patterns. Second, there were missings due to drop out. Not all participants provided data at all four assessment points. However, classification is possible using GMM estimation. Third, there are possible ceiling effects. Since the parent report form FRAKIS-K is designed and normed for children between the age of 1;6 and 2;6, it is no surprise that most children reach the high end of the vocabulary score at age 3;0. However, with exception of statistical outliers with far-above-average vocabulary abilities, lexical growth can still be shown for all classes until the age of 3;0. Group differences for vocabulary at the last assessment point are highly significant, although the score is similar for four subgroups. Lower variability at a higher age has also been shown by others (e.g., Ukoumunne et al., Reference Ukoumunne, Wake, Carlin, Bavin, Lum, Skeat, Williams, Conway, Cini and Reilly2012). Also, Kauschke and Hofmeister (Reference Kauschke and Hofmeister2002) showed a flattening of the growth curve through spontaneous speech data of German-speaking children at this age. Furthermore, parent report forms in form of vocabulary checklists do not capture children’s entire productive vocabulary, although parents validly rate their children’s abilities (Fenson et al., Reference Fenson, Dale, Reznick, Bates, Thal and Pethick1994). Moreover, two of the identified classes contain very few participants. Choosing a model with fewer classes (three, four, or five classes) would also have contained the “far-above-average” class of four participants, but then it would not have differentiated between children with low vocabulary abilities. Finally, SES is rather high in the sample (as in other similar studies). Although participants were recruited from a full age group of the city register of Hanover, participation was voluntary. While families with a high SES participated in higher percentages, families with a low SES score were also represented in the study.
Conclusion
In this study, latent growth curves for vocabulary development of subgroups (latent classes) were examined for the ages ranging from 18 months to three years old. Six distinct trajectories of vocabulary growth in German-speaking children were identified and characterised using a GMM. Children’s lexical growth trajectories were classified as “far above average” (2.0%), “above average” (6.6%), “typical” (70.2%), “below average” (14.1%), “early below average” but caught up with their peers by age 3;0 (5.6%), and “far below average” (1.5%). SES differed highly significant between subgroups. This is a major contribution to the description of vocabulary growth curve patterns for subgroups from the whole developmental range (community sample) at this age span. However, it would be beneficial if the study was replicated in a bigger sample that would be more representative. Participants were from one city in Germany and had a high socioeconomic background on average. Furthermore, bigger group size in the GMM analysis would give more certainty to the results. Regarding the impact of early language acquisition on further development of language, emotional and social behaviour as well as academic achievement, there is a special interest of identifying children with below-average language development in order to support them in their development. Between ages 2;0 and 2;6 more than one-fifth of all children who participated in our study had low productive vocabulary abilities. Most of these children still had vocabulary abilities significantly below average at age 3;0. Results of this study support the idea of targeted support for children with low productive vocabulary in combination with having a low SES in the family (Hoff, Reference Hoff2013). Finally yet importantly, using GMM to model vocabulary growth in order to show trajectories for distinct latent classes offers a methodological framework for future studies. GMM allows for estimation of natural division between subgroups while taking all the observed data into account. Compared to fixed classification of groups, GMM allows for more distinction and possibly more accurate predictions about which children may need more support and attention.
Acknowledgements
This research was supported financially by the “Wege in die Forschung II” grant from the University of Hanover. We thank all the families who participated in this study and the students who assisted collecting and preparing the data.
Competing interest
We have no known competing interests to disclose.



 Open access
Open access