

1. Introduction
In educational surveys, an item response theory (IRT) model is used to model the conditional distribution of a vector of item responses \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X} = \{X_1\text {, }X_2\text {, }\ldots \text {, }X_n\}$$\end{document} as a function of a latent random variable (ability) \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\Theta }$$\end{document}
as a function of a latent random variable (ability) \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\Theta }$$\end{document} , where the item response functions are monotonically increasing in ability. The IRT model characterizes the latent variable \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
, where the item response functions are monotonically increasing in ability. The IRT model characterizes the latent variable \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} , and the goal of educational surveys is to estimate the distribution of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
, and the goal of educational surveys is to estimate the distribution of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} which we denote by f. Together, the IRT model and the ability distribution induce the following statistical model:
which we denote by f. Together, the IRT model and the ability distribution induce the following statistical model:

where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document} is the true data distribution of which we obtain a sample. Throughout this paper, we assume that the IRT model is given, and focus on the unknown f. We consider the usual case where the item responses \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i$$\end{document}
is the true data distribution of which we obtain a sample. Throughout this paper, we assume that the IRT model is given, and focus on the unknown f. We consider the usual case where the item responses \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i$$\end{document} are discrete with a finite number of possible realizations but note that the results remain the same when the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i$$\end{document}
are discrete with a finite number of possible realizations but note that the results remain the same when the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i$$\end{document} are continuous and sums are replaced by integrals.
are continuous and sums are replaced by integrals.
There are four possible approaches to estimate f from the observed data. The first entails the use of a function T such that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T(\mathbf {X}) \sim \Theta $$\end{document} . If \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}$$\end{document}
. If \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}$$\end{document} is discrete, realizations of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T(\mathbf {X})$$\end{document}
is discrete, realizations of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T(\mathbf {X})$$\end{document} are discrete as well. The second approach requires a function T such that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T(\mathbf {X}) \overset{\mathcal {L}}{\longrightarrow }\Theta $$\end{document}
are discrete as well. The second approach requires a function T such that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T(\mathbf {X}) \overset{\mathcal {L}}{\longrightarrow }\Theta $$\end{document} , i.e., a random variable that, asymptotically, has the same distribution as \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
, i.e., a random variable that, asymptotically, has the same distribution as \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} . This can be any T that is a consistent estimator of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
. This can be any T that is a consistent estimator of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} such as the Maximum Likelihood (ML) or Weighted ML (WML) estimator (Warm, Reference Warm1989). The third approach is to use the data to generate a random variable \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*$$\end{document}
such as the Maximum Likelihood (ML) or Weighted ML (WML) estimator (Warm, Reference Warm1989). The third approach is to use the data to generate a random variable \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*$$\end{document} such that
such that ![]() and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*\sim \Theta $$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*\sim \Theta $$\end{document} . By definition, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
. By definition, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta ^*$$\end{document} are exchangeable and their joint density can be written as follows:
are exchangeable and their joint density can be written as follows:

where summation is over all possible realizations of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}$$\end{document} . The conditional distributions \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta \mid \mathbf {X})$$\end{document}
. The conditional distributions \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta \mid \mathbf {X})$$\end{document} are posterior distributions and it easily follows that the marginal distribution of draws from these posteriors equals the population distribution. Thus, if we sample from the correct posteriors, the population distribution can be recovered in a straightforward way. The problem, however, is that we do not know the correct posterior because we do not know f. In practice, we would therefore use a prior distributionFootnote 1g to generate random variables \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \mid \mathbf {X}$$\end{document}
are posterior distributions and it easily follows that the marginal distribution of draws from these posteriors equals the population distribution. Thus, if we sample from the correct posteriors, the population distribution can be recovered in a straightforward way. The problem, however, is that we do not know the correct posterior because we do not know f. In practice, we would therefore use a prior distributionFootnote 1g to generate random variables \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \mid \mathbf {X}$$\end{document} (i.e., sample from the posteriors \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta \mid \mathbf {X})$$\end{document}
(i.e., sample from the posteriors \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta \mid \mathbf {X})$$\end{document} ). The random variables \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \mid \mathbf {X}$$\end{document}
). The random variables \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \mid \mathbf {X}$$\end{document} are called plausible values (PVs) in the psychometric literature (Mislevy, Reference Mislevy1991; Mislevy, Beaton, Kaplan, & Sheehan, Reference Mislevy, Beaton, Kaplan and Sheehan1993). Using PVs to estimate f constitutes the fourth and final approach and the one this paper is about.
are called plausible values (PVs) in the psychometric literature (Mislevy, Reference Mislevy1991; Mislevy, Beaton, Kaplan, & Sheehan, Reference Mislevy, Beaton, Kaplan and Sheehan1993). Using PVs to estimate f constitutes the fourth and final approach and the one this paper is about.
In this paper, we prove that under mild regularity conditions, PVs are random variables of the form \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta }\mid \mathbf {X}$$\end{document} such that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \overset{\mathcal {L}}{\longrightarrow }\Theta $$\end{document}
such that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } \overset{\mathcal {L}}{\longrightarrow }\Theta $$\end{document} . That is, we will show that the marginal distribution of the PVs is a consistent estimator of f. More specifically, let
. That is, we will show that the marginal distribution of the PVs is a consistent estimator of f. More specifically, let

denote the marginal distribution of the PVs.
This distribution is intractable but easily sampled from; that is, nature provides realizations from \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document} , which we then use to sample PVsFootnote 2.
, which we then use to sample PVsFootnote 2.
It is well known that the empirical cumulative distribution function (ecdf) of the PVs is a consistent estimator of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} as the number of persons goes to infinity. Our main goal is to demonstrate that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
as the number of persons goes to infinity. Our main goal is to demonstrate that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} in turn converges in law to f (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } = \Theta _{\tilde{g}} \overset{\mathcal {L}}{\longrightarrow }\Theta _f$$\end{document}
in turn converges in law to f (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{\Theta } = \Theta _{\tilde{g}} \overset{\mathcal {L}}{\longrightarrow }\Theta _f$$\end{document} ) as the number of items goes to infinity. The following example gives a foretaste of what this paper is about.
) as the number of items goes to infinity. The following example gives a foretaste of what this paper is about.
Example 1
We generate responses of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = $$\end{document} 10,000 persons on a test consisting of n Rasch items with difficulty parameters sampled uniformly between \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$-1$$\end{document}
10,000 persons on a test consisting of n Rasch items with difficulty parameters sampled uniformly between \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$-1$$\end{document} and 1. The ability distribution f is a mixture with two normal components whose ecdf is shown in the left panel of Fig. 1. One component may, for instance, be the distribution for the boys and the other one is that for the girls.
and 1. The ability distribution f is a mixture with two normal components whose ecdf is shown in the left panel of Fig. 1. One component may, for instance, be the distribution for the boys and the other one is that for the girls.
The analyst is unaware of the difference between the boys and the girls and chooses g to be a standard normal distribution. We now generate a single PV for each of the N persons; once for a test with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 10$$\end{document} items and once for a test with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 40$$\end{document}
items and once for a test with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 40$$\end{document} items. The PV distributions are shown in the right panel of Fig. 1. Figure 1 shows that the distribution of the PVs is not the standard normal. In fact, with 40 items, it begins to resemble the true ability distribution even though the population model is clearly wrong.
items. The PV distributions are shown in the right panel of Fig. 1. Figure 1 shows that the distribution of the PVs is not the standard normal. In fact, with 40 items, it begins to resemble the true ability distribution even though the population model is clearly wrong.
Ecdfs of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N =$$\end{document} 10,000 draws from \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta )$$\end{document}
10,000 draws from \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta )$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N =$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N =$$\end{document} 10,000 draws from the standard normal prior distribution \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta )$$\end{document}
10,000 draws from the standard normal prior distribution \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta )$$\end{document} are shown in both panels (in gray in the right panel). Ecdfs of the marginal distributions of PVs are shown in the right panel.
are shown in both panels (in gray in the right panel). Ecdfs of the marginal distributions of PVs are shown in the right panel.

Instead of proving that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges in law to f, we will prove a stronger result. Namely, that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
converges in law to f, we will prove a stronger result. Namely, that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges to f in Expected Kullback-Leibler (EKL) divergence (Kullback & Leibler, Reference Kullback and Leibler1951) as the number of items n tends to infinity.
converges to f in Expected Kullback-Leibler (EKL) divergence (Kullback & Leibler, Reference Kullback and Leibler1951) as the number of items n tends to infinity.
Definition
The Expected (posterior) Kullback-Leibler (EKL) divergence between \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _f \mid \mathbf {X}$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _g\mid \mathbf {X}$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _g\mid \mathbf {X}$$\end{document} , w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document}
, w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document} is
is

where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f\text { ; }\Theta _g\mid \mathbf {X})$$\end{document} denotes the Kullback-Leibler (KL) divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document}
denotes the Kullback-Leibler (KL) divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\Theta \mid \mathbf {X})$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\Theta \mid \mathbf {X})$$\end{document} with respect to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document}
with respect to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document} , with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$0\ln (0)\equiv 0$$\end{document}
, with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$0\ln (0)\equiv 0$$\end{document} .
.
Throughout this paper, we assume that all divergences are finite, which is true if the support of g contains that of f (i.e., f is absolutely continuous w.r.t. g) almost everywhere (a.e.). Note that the KL and EKL divergences that we use in this paper are non-symmetric in their arguments, yet their values are always non-negative and zero if and only if the compared probability distributions are the same a.e. (see Theorem 9.6.1 in Cover & Thomas, Reference Cover and Thomas1991, p. 232).
We demonstrate in the next section that convergence in EKL divergence is indeed stronger than convergence in law. Then, we prove that EKL divergence is monotonically non-increasing in n and tends to zero as the number of items n tends to infinity: Informally, this means that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} will always get closer to f as n grows, as we saw in the example. Having thus established our main result, we discuss a number of implications for educational surveys and show that quite a lot can be learned from PVs. Throughout, PISA data will be used for illustration. The paper ends with a discussion.
will always get closer to f as n grows, as we saw in the example. Having thus established our main result, we discuss a number of implications for educational surveys and show that quite a lot can be learned from PVs. Throughout, PISA data will be used for illustration. The paper ends with a discussion.
2. Convergence in EKL divergence implies convergence in law
To demonstrate that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges in law to f, it is sufficient to prove that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
converges in law to f, it is sufficient to prove that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges to f in KL divergence as this implies convergence in law (DasGupta, Reference DasGupta2008, p. 21). The following theorem implies that convergence in EKL divergence is stronger than convergence in KL divergence.
converges to f in KL divergence as this implies convergence in law (DasGupta, Reference DasGupta2008, p. 21). The following theorem implies that convergence in EKL divergence is stronger than convergence in KL divergence.
Theorem 1
Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f, the KL divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{\tilde{g}}$$\end{document}
and assuming that the support of g contains the support of f, the KL divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{\tilde{g}}$$\end{document} w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{f}$$\end{document}
w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{f}$$\end{document} , i.e.,
, i.e.,

is always smaller than or equal to EKL divergence. That is,

Proof
We start with rewriting the logarithm of the ratio of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} over f
over f

using Jensen’s inequality. Thus, we obtain

Integrating both sides of this expression w.r.t. f gives the desired result:

It follows that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges in law to f if \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
converges in law to f if \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} converges to f in EKL. Proving convergence in EKL will be the burden of the ensuing sections.\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
converges to f in EKL. Proving convergence in EKL will be the burden of the ensuing sections.\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
3. Monotone Convergence of Plausible Values
Before we can state our first result in Theorem 2, we need two Lemma’s.
Lemma 1
Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f, the EKL divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _f \mid \mathbf {X}$$\end{document}
and assuming that the support of g contains the support of f, the EKL divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _f \mid \mathbf {X}$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _g \mid \mathbf {X}$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _g \mid \mathbf {X}$$\end{document} , w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document}
, w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\Theta \mid \mathbf {X})$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document} , equals prior divergence minus marginal divergence, that is,
, equals prior divergence minus marginal divergence, that is,

Proof
Using the definition of the posterior, and given the IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}\mid \theta )$$\end{document} , we rewrite the EKL divergence as follows:
, we rewrite the EKL divergence as follows:

where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_g)$$\end{document} is the distribution of the data under the prior g. Using properties of the logarithm, we obtain
is the distribution of the data under the prior g. Using properties of the logarithm, we obtain

If we sum over the possible values of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}$$\end{document} in the first term and integrate over \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document}
in the first term and integrate over \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} in the second term, respectively, we obtain
in the second term, respectively, we obtain

It follows that EKL divergence of the posterior distribution is equal to the difference between prior divergence \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f\text { ; }\Theta _g)$$\end{document} and marginal divergence \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\mathbf {X}_f\text { ; }\mathbf {X}_g)$$\end{document}
and marginal divergence \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\mathbf {X}_f\text { ; }\mathbf {X}_g)$$\end{document} (i.e., divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_g)$$\end{document}
(i.e., divergence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_g)$$\end{document} w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document}
w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X}_f)$$\end{document} ).\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
).\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
Lemma 1 implies that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbb {E}(\Delta (\Theta _f\text { ; }\Theta _g\mid \mathbf {X}_f))$$\end{document} equals zero if and only if prior divergence is equal to marginal divergence. Since the divergences are finite and non-negative, we find that
equals zero if and only if prior divergence is equal to marginal divergence. Since the divergences are finite and non-negative, we find that

We will now prove that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\mathbf {X}_f\text { ; }\mathbf {X}_g)$$\end{document} is a monotone non-decreasing sequence in the number of items n with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f\text { ; }\Theta _g)$$\end{document}
is a monotone non-decreasing sequence in the number of items n with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f\text { ; }\Theta _g)$$\end{document} as an upper bound. To this aim, we consider what happens to marginal divergence when an item is added ( i.e., n is increased to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n+1$$\end{document}
as an upper bound. To this aim, we consider what happens to marginal divergence when an item is added ( i.e., n is increased to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n+1$$\end{document} ). To fix the notation, let \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_1\text {, } X_2\text {, } ...$$\end{document}
). To fix the notation, let \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_1\text {, } X_2\text {, } ...$$\end{document} denote an infinite sequence of item responses, with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_n$$\end{document}
denote an infinite sequence of item responses, with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_n$$\end{document} the n-th element and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}_n$$\end{document}
the n-th element and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbf {X}_n$$\end{document} a vector consisting of the first n elements of this sequence.
a vector consisting of the first n elements of this sequence.
Lemma 2
Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f, the marginal divergence for \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n+1$$\end{document}
and assuming that the support of g contains the support of f, the marginal divergence for \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n+1$$\end{document} observations is larger than or equal to marginal divergence for n observations:
observations is larger than or equal to marginal divergence for n observations:

Proof
The marginal divergence for \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n+1$$\end{document} items is
items is

Conditioning on the first n observations and factoring the distribution, we obtain

This is equal to

a result closely related to the chain rule of KL divergence (Cover & Thomas, Reference Cover and Thomas1991, p. 23). Since \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbb {E}(\Delta (X_{f,n+1}\text { ; }X_{g,n+1}\mid \mathbf {X}_{f,n})) \ge 0$$\end{document} , we see that
, we see that

\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
Theorem 2
(Monotonicity Theorem) Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbb {E}(\Delta (\Theta _f{\text { ; }}\Theta _g\mid \mathbf {X}_{f,n}))$$\end{document}
and assuming that the support of g contains the support of f, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbb {E}(\Delta (\Theta _f{\text { ; }}\Theta _g\mid \mathbf {X}_{f,n}))$$\end{document} is monotone non-increasing in the number of items n.
is monotone non-increasing in the number of items n.
Proof
From Lemmas 1 and 2, we obtain

and Lemma 1 shows that the difference of the first and the last terms is equal to the EKL divergence for n items. Thus, we have

This implies a sequence of EKL divergences which adheres to the (in-)equality:

i.e., a monotone non-increasing sequence in n with lower bound 0. Since prior divergence is finite by assumption, it is an upper bound for this sequence. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
4. Large Sample Properties of Plausible Values
The Monotonicity Theorem shows that the sequence of EKL divergences converges in an embedding in which \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document} . This does not imply that the marginal distribution of PVs converges to f, since the sequence of EKL divergences may converge to a number that is strictly larger than zero. We have yet to show that the sequence of EKL divergences converges to zero. Since by Lemma 1 the EKL divergence is equal to the difference between prior and marginal divergence, we may equivalently show that the inequality
. This does not imply that the marginal distribution of PVs converges to f, since the sequence of EKL divergences may converge to a number that is strictly larger than zero. We have yet to show that the sequence of EKL divergences converges to zero. Since by Lemma 1 the EKL divergence is equal to the difference between prior and marginal divergence, we may equivalently show that the inequality

becomes an equality as \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document} .
.
Theorem 3
(Convergence Theorem) Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f,
and assuming that the support of g contains the support of f,

if the sequence of posteriors converges to a degenerate distribution.
Proof
We start with a direct proof of (2) (suppressing the dependence on n). Note first that,

using Jensen’s inequality in the last line. Taking expectations w.r.t. \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P_f(\mathbf {X})$$\end{document} gives the inequality in (2). Similarly, we obtain
gives the inequality in (2). Similarly, we obtain

such that

Since f is absolutely continuous w.r.t. g, we obtain that both \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{f(\theta ) }{g(\theta )}$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\ln \frac{f(\theta ) }{g(\theta )}$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\ln \frac{f(\theta ) }{g(\theta )}$$\end{document} are uniformly integrable. Convergence in probability of both posteriors (w.r.t. f and g as prior) is then sufficient to guarantee the equality in (3) (e.g., Venkatesh, Reference Venkatesh2013, pp. 480–481), since under these conditions we may change the order of limits and integration.\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
are uniformly integrable. Convergence in probability of both posteriors (w.r.t. f and g as prior) is then sufficient to guarantee the equality in (3) (e.g., Venkatesh, Reference Venkatesh2013, pp. 480–481), since under these conditions we may change the order of limits and integration.\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
The Convergence Theorem relies on posterior consistency. The regularity conditions that imply posterior consistency can be found in many places. For unidimensional monotone IRT models, the regularity conditions for strong consistency (i.e., almost sure convergence) can be found in Chang and Stout (Reference Chang and Stout1993, pp. 42–43). As a courtesy to the reader, we list their conditions in Appendix 1. Chang and Stout (Reference Chang and Stout1993, pp. 43–45) argued that in practice these conditions are “very general and appropriate hypotheses” (p. 51). Similar conditions can be found in Chang (Reference Chang1996) for polytomous IRT models.
Combining Theorem 1, the Monotonicity Theorem, and the Convergence Theorem, we arrive at our final result.
Theorem 4
(Monotone Convergence Theorem) Given an IRT model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\mathbf {X} \mid \theta )$$\end{document} and assuming that the support of g contains the support of f and the sequence of posteriors converges to a degenerate distribution, then \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f{\text { ; }}\Theta _{\tilde{g}}) \rightarrow 0$$\end{document}
and assuming that the support of g contains the support of f and the sequence of posteriors converges to a degenerate distribution, then \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Delta (\Theta _f{\text { ; }}\Theta _{\tilde{g}}) \rightarrow 0$$\end{document} , monotonically, and furthermore, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{\tilde{g}} \overset{\mathcal {L}}{\longrightarrow }\Theta _f$$\end{document}
, monotonically, and furthermore, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta _{\tilde{g}} \overset{\mathcal {L}}{\longrightarrow }\Theta _f$$\end{document} .
.
Proof
Under the stated assumptions, the Convergence Theorem implies that the EKL divergence converges to zero as n tends to infinity. Convergence is monotone by Theorem 2. From Theorem 1, we consequently obtain

Since convergence in KL divergence implies convergence in law (DasGupta, Reference DasGupta2008, p. 21), we have

\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}
In summary, the Monotone Convergence Theorem states that (under mild regularity conditions) the marginal distribution of PVs \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} is a consistent estimator of the true ability distribution f.
is a consistent estimator of the true ability distribution f.
5. Implications
In plain words, the Monotone Convergence Theorem implies that we can use PVs to learn about the true distribution of ability. In this section, we discuss some of the practical implications of this result using PISA data for illustration. We remind the reader that g is a prior distribution, f the true distribution, and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} the marginal distribution of the PVs.
the marginal distribution of the PVs.
5.1. What can we learn from Plausible Values?
What can we learn about the “correct” population model \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta )$$\end{document} when we are using PVs from the “wrong” posterior \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta \mid \mathbf {X}=\mathbf {x})$$\end{document}
when we are using PVs from the “wrong” posterior \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta \mid \mathbf {X}=\mathbf {x})$$\end{document} ? A common misconception is that the marginal distribution of PVs equals the population model (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} = g$$\end{document}
? A common misconception is that the marginal distribution of PVs equals the population model (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} = g$$\end{document} ) and nothing can be learned from PVs over that which is already known from the population model (prior distribution) (e.g., Kreiner & Christensen, Reference Kreiner and Christensen2014). This is true, if and only if, the population model is the true ability distribution (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g = f$$\end{document}
) and nothing can be learned from PVs over that which is already known from the population model (prior distribution) (e.g., Kreiner & Christensen, Reference Kreiner and Christensen2014). This is true, if and only if, the population model is the true ability distribution (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g = f$$\end{document} ). This is not likely and in practice we expect to see that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} \ne g$$\end{document}
). This is not likely and in practice we expect to see that \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} \ne g$$\end{document} .
.
Example 2
(PISA) To illustrate that the PV distribution may diverge from the prior in applications, we analyze data from the 2006 PISA cycle. More specifically, we used the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 26$$\end{document} items intended to assess reading ability in booklet 6 made by \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N =$$\end{document}
items intended to assess reading ability in booklet 6 made by \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N =$$\end{document} 1738 Canadian students (see Appendix 2 for details of this analysis). A single PV was generated for each student using the One Parameter Logistic Model (OPLM; Verhelst & Glas, Reference Verhelst, Glas, Fischer and Molenaar1995) as IRT model, and a standard normal distribution as prior. The ecdf of N draws from the prior distribution g (solid gray line) and the ecdf of the generated PVs using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=26$$\end{document}
1738 Canadian students (see Appendix 2 for details of this analysis). A single PV was generated for each student using the One Parameter Logistic Model (OPLM; Verhelst & Glas, Reference Verhelst, Glas, Fischer and Molenaar1995) as IRT model, and a standard normal distribution as prior. The ecdf of N draws from the prior distribution g (solid gray line) and the ecdf of the generated PVs using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=26$$\end{document} items are shown in Fig. 2 (solid black line). The marginal distribution of the PVs is clearly different from the specified prior distribution.
items are shown in Fig. 2 (solid black line). The marginal distribution of the PVs is clearly different from the specified prior distribution.
Ecdf of PVs (\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} ) and N draws from a standard normal prior distribution (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta )=\phi (\theta )$$\end{document}
) and N draws from a standard normal prior distribution (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\theta )=\phi (\theta )$$\end{document} ) in the PISA example.
) in the PISA example.

If the population model is misspecified (i.e., \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g \ne f$$\end{document} ), we can still learn a lot from looking at the PV distribution. The PV distribution provides a consistent estimate of the true ability distribution, which is at least as plausible as the population model which figures as a prior. Specifically, it follows from the Monotonicity Theorem that, if \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g \ne f$$\end{document}
), we can still learn a lot from looking at the PV distribution. The PV distribution provides a consistent estimate of the true ability distribution, which is at least as plausible as the population model which figures as a prior. Specifically, it follows from the Monotonicity Theorem that, if \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g \ne f$$\end{document} , and hence \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} \ne g$$\end{document}
, and hence \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g} \ne g$$\end{document} , the marginal distribution of PVs \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
, the marginal distribution of PVs \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} is closer to f than g is; as we saw in Example 1. Moreover, we can use PVs to evaluate the fit of the population model by testing the hypothesis \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0 : \tilde{g} = g$$\end{document}
is closer to f than g is; as we saw in Example 1. Moreover, we can use PVs to evaluate the fit of the population model by testing the hypothesis \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0 : \tilde{g} = g$$\end{document} against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1 : \tilde{g} \ne g$$\end{document}
against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1 : \tilde{g} \ne g$$\end{document} . If \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document}
. If \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document} is rejected, there is no reason to be interested in g: \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
is rejected, there is no reason to be interested in g: \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} is our best guess of what the true distribution of ability would look like.
is our best guess of what the true distribution of ability would look like.
Example 3
(PISA continued) We use the PISA example to illustrate that we can test the hypothesis \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0: \tilde{g} = g$$\end{document} against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1: \tilde{g} \ne g$$\end{document}
against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1: \tilde{g} \ne g$$\end{document} using real data with a relatively small number of observations, and that the power of this test is increasing with n. To this aim, we randomly assigned each student two items out of the 26 items that were available. Figure 2 shows the ecdf of the PVs using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 2$$\end{document}
using real data with a relatively small number of observations, and that the power of this test is increasing with n. To this aim, we randomly assigned each student two items out of the 26 items that were available. Figure 2 shows the ecdf of the PVs using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 2$$\end{document} items (dashed line). It is clear that even with two items, the marginal distribution of PVs differs from the specified prior distribution and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document}
items (dashed line). It is clear that even with two items, the marginal distribution of PVs differs from the specified prior distribution and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document} does not hold (this test is performed in the next example, see Table 1). Figure 2 also shows that the PV distributions diverge from the prior distribution as n increases, thereby increasing the probability to reject \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document}
does not hold (this test is performed in the next example, see Table 1). Figure 2 also shows that the PV distributions diverge from the prior distribution as n increases, thereby increasing the probability to reject \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0$$\end{document} if it is wrong.
if it is wrong.
Average values of KS test statistic using PISA data to compare \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} with the prior distributions used to generate \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document}
with the prior distributions used to generate \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} .
.

Values over 0.046 are significant at an \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\alpha }$$\end{document} level of 0.05.
level of 0.05.
5.2. Choose a flexible population model
The population model is formally a prior and, under the conditions of the Monotone Convergence Theorem, becomes irrelevant as the number of items becomes large. Essentially, this is an instance of the common finding that the data overrule the prior when the number of observations increases. In practice, however, there is a natural limit to the number of items that can be administered which raises the question how we can favor convergence without increasing the number of items.
The answer comes from Lemma 1 which suggests that convergence of the PV distribution to the true distribution of ability is faster if prior divergence is reduced. Thus, for a given n, we would like prior divergence to be as small as possible (i.e., we would like g to resemble f). When little or nothing is known about f, we may achieve this using a flexible prior; that is, one that easily adapts to different shapes. Otherwise, we may look at the PV distribution found in previous editions of the study to improve the prior. Convergence is also improved if we adopt an empirical Bayesian approach and estimate the parameters of the prior so that it adapts itself to the data as much as possible (see, for instance; White, Reference White1982). Using, for instance, a normal prior in Example 1 would help to discover the bimodality of the true ability distribution with less items.
Example 4
(PISA Continued) We use the previously established OPLM model with three prior distributions ordered in terms of flexibility:
-
1. A standard normal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(0\text {, }1)$$\end{document}
 .
. -
2. A normal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(\mu \text {, }\sigma ^2)$$\end{document}
with mean \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu $$\end{document} and variance \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}. -
3. A PCA regression prior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(\widehat{\varvec{\Lambda }}\varvec{\beta }\text {, }\sigma ^2)$$\end{document}
, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\Lambda }}$$\end{document} constitutes the principal component scores estimated on student covariates assessed in the PISA student questionnaire. We use the first 50 principal components explaining roughly \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$60~\%$$\end{document} of the variance in the student questionnaire.







The parameters of the prior distribution are estimated using the Gibbs sampler (Geman & Geman, Reference Geman and Geman1984) with non-informative hyper-priors (Gelman, Carlin, Stern, & Rubin, Reference Gelman, Carlin, Stern and Rubin2004).
For each prior distribution, we test the hypothesis \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_0 : \tilde{g} = g$$\end{document} against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1 : \tilde{g} \ne g$$\end{document}
against \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$H_1 : \tilde{g} \ne g$$\end{document} using the two-sample Kolmogorov-Smirnov (KS) test. For the second and third prior, we ran an additional 1000 iterations of the Gibbs sampler. In each iteration, we generated one PV for each person, generate a sample of size N from the prior, and compute the KS test statistic. Thus, we obtained 1000 replications for the test statistic, which were then averaged. The results are shown in Table 1 and confirm that prior divergence decreases as more flexible prior distributions are used.
using the two-sample Kolmogorov-Smirnov (KS) test. For the second and third prior, we ran an additional 1000 iterations of the Gibbs sampler. In each iteration, we generated one PV for each person, generate a sample of size N from the prior, and compute the KS test statistic. Thus, we obtained 1000 replications for the test statistic, which were then averaged. The results are shown in Table 1 and confirm that prior divergence decreases as more flexible prior distributions are used.
Our main concern is whether or not the PV distribution converges to the true ability distribution. Since we do not know the true ability distribution, we compare our results with the best guess that we have, i.e., the distribution of PVs obtained by using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 26$$\end{document} items and the PCA regression prior. We repeated the procedure to obtain Table 1, but instead of comparing the generated PVs with draws from the prior, we compared the generated PVs with the PVs generated using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 26$$\end{document}
items and the PCA regression prior. We repeated the procedure to obtain Table 1, but instead of comparing the generated PVs with draws from the prior, we compared the generated PVs with the PVs generated using \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 26$$\end{document} items and the PCA regression prior. The results in Table 2 show that the PV distributions converge to a single (true) distribution as n increases and/or the prior becomes more flexible.
items and the PCA regression prior. The results in Table 2 show that the PV distributions converge to a single (true) distribution as n increases and/or the prior becomes more flexible.
Average values of KS test statistic using PISA data to compare \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tilde{g}$$\end{document} using different prior distributions with the best guess.
using different prior distributions with the best guess.

It is important to note that there is a limit to the amount of parameters that we can estimate, and thus the amount of flexibility that we can achieve in practice. This can be seen in Example 4. For \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document} , Table 2 seems to suggest that the normal prior works better than the more flexible PCA regression prior. This counter intuitive result only holds for \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document}
, Table 2 seems to suggest that the normal prior works better than the more flexible PCA regression prior. This counter intuitive result only holds for \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document} and is due to the poor estimation of hyper-parameters that results when both N and n are small. The normal prior has just two parameters, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu $$\end{document}
and is due to the poor estimation of hyper-parameters that results when both N and n are small. The normal prior has just two parameters, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu $$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} , whereas the PCA regression prior has 52 parameters, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta } = \{\beta _0\text {, }\beta _1\text {, }...\text {, }\beta _{50}\}$$\end{document}
, whereas the PCA regression prior has 52 parameters, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta } = \{\beta _0\text {, }\beta _1\text {, }...\text {, }\beta _{50}\}$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} . Since the standard errors accumulate for the generated PV distributions, we expect to observe larger variations in the generated PV distributions using the PCA regression prior. These larger variations are reflected in the value of the KS test statistic.
. Since the standard errors accumulate for the generated PV distributions, we expect to observe larger variations in the generated PV distributions using the PCA regression prior. These larger variations are reflected in the value of the KS test statistic.
5.3. What if we miss a covariate?
A remarkable feature of Example 1 is that the PV distribution reveals the difference between boys and girls even though sex was not included as a covariate in the population model. This is consistent with our results. Given the conditions of the Monotone Convergence Theorem, the distribution of plausible values

is a consistent estimator of the population distribution \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta \mid z_1\text {, }z_2)$$\end{document} , for sets of covariates \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_1$$\end{document}
, for sets of covariates \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_1$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_2$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_2$$\end{document} ; even when \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_2$$\end{document}
; even when \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_2$$\end{document} is the empty set (i.e., if we miss all covariates). It also means that a secondary analyst who happens to observe the student’s sex will, when n is sufficiently large, recover the difference between boy and girls even if the PVs have been generated with a population model that contains no covariates at all.
is the empty set (i.e., if we miss all covariates). It also means that a secondary analyst who happens to observe the student’s sex will, when n is sufficiently large, recover the difference between boy and girls even if the PVs have been generated with a population model that contains no covariates at all.
Plausible value distributions of boys and girls with and without gender as a covariate in the PISA example.

Example 5
(PISA Continued) We look at the distribution of boys and girls in Canada who took booklet 6 using PISA’s final student weights. To generate the PVs we consider two prior distributions; the flexible \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathcal {N}(\mu \text {, }\sigma ^2)$$\end{document} prior distribution without covariates, and the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathcal {N}(\widehat{\varvec{\Lambda }}\varvec{\beta }\text {, }\sigma ^2)$$\end{document}
prior distribution without covariates, and the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathcal {N}(\widehat{\varvec{\Lambda }}\varvec{\beta }\text {, }\sigma ^2)$$\end{document} prior distribution which included gender as a predictor (i.e., it was a covariate in the PCA).
prior distribution which included gender as a predictor (i.e., it was a covariate in the PCA).
Figure 3 shows the PV distributions of boys and girls weighted by the PISA student weights. It is clear that the weighted distributions of PVs under the two prior distributions are indistinguishable, apart from sampling error. We also see that the girls perform better than the boys. The weighted average ability for the boys was estimated at 0.180 and that of girls at 0.242. The weighted standard deviation of ability for the boys was estimated at 0.304 and that of the girls at 0.282. Note that the differences in variances between boys and girls would not have been found in a latent regression model unless it had been explicitly modeled.
What it means for n to be “sufficiently large” depends on the effect of the covariate on the distribution of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} ; that is, for large effects relatively many items are needed, and for small effects relatively few items are needed. It also depends on the population model. Institutions that release PVs typically include a large set of covariates in the population model on the argument that any covariate that a secondary analyst might be interested in must be included, directly or by proxy, to avoid bias in secondary analysis of the PVs. Schofield, Junker, Taylor, and Black (Reference Schofield, Junker, Taylor and Black2015) make this claim precise and, in accordance with our results, argue that bias should vanish when \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document}
; that is, for large effects relatively many items are needed, and for small effects relatively few items are needed. It also depends on the population model. Institutions that release PVs typically include a large set of covariates in the population model on the argument that any covariate that a secondary analyst might be interested in must be included, directly or by proxy, to avoid bias in secondary analysis of the PVs. Schofield, Junker, Taylor, and Black (Reference Schofield, Junker, Taylor and Black2015) make this claim precise and, in accordance with our results, argue that bias should vanish when \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document} . We agree to the current practice to include as many covariates as possible because it reduces prior divergence but note that a flexible prior with or without covariates can be used to the same effect. A simple extension of Example 1 would illustrate, for instance, that, if a binary predictor is excluded from the population model, the correct coefficient will be recovered even for small n when the prior distribution is a mixture of two normal distributions.
. We agree to the current practice to include as many covariates as possible because it reduces prior divergence but note that a flexible prior with or without covariates can be used to the same effect. A simple extension of Example 1 would illustrate, for instance, that, if a binary predictor is excluded from the population model, the correct coefficient will be recovered even for small n when the prior distribution is a mixture of two normal distributions.
If the population model is a regression model in which a covariate is missing, this may not only lead to bias in the PV distributions but may also lead to bias in parameter estimates for effects that are part of the modelFootnote 3, or one might not observe that the missing covariate makes the unknown f skewed. This means that we run the risk of performing an incorrect inference about the unknown f if we look at the population model. It follows from our results that the marginal distribution of the PVs will always be a better estimate of f than the population model is in this situation, even if we do not recover the correct regression coefficient of the missing covariate.
6. Discussion
In this paper, we have proved that, under mild regularity conditions, the empirical distribution of the PVs is a consistent estimator of the distribution of ability in the population, and that convergence is monotone in an embedding in which the number of items tends to infinity. In plain words, this implies that we can use PVs to learn about the true distribution of ability in the population. We have used this result to clear up some of the misconceptions about PVs, and also to show how they can be used in the analyses of educational surveys. Thus far, PVs have been used in educational surveys mostly to simplify secondary analyses. Our result suggests that the distribution of PVs could play the leading role, using the population model merely as a vehicle to produce PVs.
The population model is properly seen as a prior and the consistency of the PV distribution as an estimator of the true distribution is essentially the common result that the data overrule the prior when the number of observations increases. We have demonstrated that convergence of the PV distribution to the true distribution of ability can be improved if we estimate the parameters \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\lambda }$$\end{document} of the prior distribution, but it does not imply that it makes sense to interpret the estimates \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document}
of the prior distribution, but it does not imply that it makes sense to interpret the estimates \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document} when the prior distribution is misspecified. Technically, as the number of persons in the sample, N, tends to infinity, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document}
when the prior distribution is misspecified. Technically, as the number of persons in the sample, N, tends to infinity, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document} are the parameter values that minimize prior divergence under the prior w.r.t. the true ability distribution (White, Reference White1982). However, when the prior distribution is misspecified and prior divergence is not zero, the result of White (Reference White1982) does not tell us how wrong our conclusions are when inference is based on \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document}
are the parameter values that minimize prior divergence under the prior w.r.t. the true ability distribution (White, Reference White1982). However, when the prior distribution is misspecified and prior divergence is not zero, the result of White (Reference White1982) does not tell us how wrong our conclusions are when inference is based on \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\widehat{\varvec{\lambda }}$$\end{document} .
.
In closing, we mention a limitation of our results. Our results imply that if the sequence of posteriors converges to a degenerate distribution as n tends to infinity, then the marginal distribution of PVs converges to the unknown f. For models where the “if" part is resolved, our results (i.e., Theorems 3, 4) apply.
Appendix 1: The regularity conditions in Chang and Stout (1993)
In order to prove their Theorem 2, Chang and Stout (Reference Chang and Stout1993) require five regularity conditions. Before we give these conditions, we need to fix some notation. Let \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i$$\end{document} denote the response of a person to an item i, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i = 1$$\end{document}
denote the response of a person to an item i, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i = 1$$\end{document} denotes a correct response and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i=0$$\end{document}
denotes a correct response and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$X_i=0$$\end{document} an incorrect response, where
an incorrect response, where

where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P_i(\theta )$$\end{document} denotes the probability of a correct response for a person with ability \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document}
denotes the probability of a correct response for a person with ability \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document} , and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document}
, and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document} is unknown and has the domain \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(-\infty \text {, }\infty )$$\end{document}
is unknown and has the domain \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(-\infty \text {, }\infty )$$\end{document} or some subinterval thereof. Chang and Stout (Reference Chang and Stout1993, p. 38) made two assumptions about the unidimensional IRT model:
or some subinterval thereof. Chang and Stout (Reference Chang and Stout1993, p. 38) made two assumptions about the unidimensional IRT model:
-
1. Local independence:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(X_1 = x_1\text {, }\ldots \text {, }X_n = x_n\mid \theta ) = \prod _{i=1}^n P_i(\theta )^{x_i}(1-P_i(\theta ))^{1-x_i}. \end{aligned}$$\end{document}
-
2. Monotonicity: each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_i(\theta )$$\end{document}
is strictly increasing in \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document}.



Note that these conditions are standard assumptions in parametric unidimensional IRT models, and are satisfied for the commonly used One-, Two- and Three-parameter logistic and normal ogive models.
Fix any \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta _0 \in \Theta $$\end{document} (the latent space), then the five regularity conditions are as follows (Chang & Stout, Reference Chang and Stout1993, pp. 42–43):
(the latent space), then the five regularity conditions are as follows (Chang & Stout, Reference Chang and Stout1993, pp. 42–43):
-
(A1) Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \in \Theta $$\end{document}
, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Theta $$\end{document} is \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(-\infty \text {, }\infty )$$\end{document} or a bounded or unbounded interval of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(-\infty \text {, }\infty )$$\end{document}. Let the prior density \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta )$$\end{document} be continuous and positive at \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta _0$$\end{document}, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta _0$$\end{document} is assumed to be the true value of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document}. -
(A2) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_i(\theta )$$\end{document}
is twice continously differentiable and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P_i^{\prime }(\theta )$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P_i^{\prime \prime }(\theta )$$\end{document} are bounded in absolute value uniformly with respect to both \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta $$\end{document} and i in some closed interval \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N_0$$\end{document} of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta _0 \in \Theta $$\end{document}. -
(A3) For every fixed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \ne \theta _0$$\end{document}
, assume for some given \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c(\theta ) > 0$$\end{document},
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \overline{\lim _{n\rightarrow \infty }} \text { }\frac{1}{n} \sum _{i=1}^n \mathbb {E}_{\theta _0}\left( \frac{P_i(\theta )^{X_i}(1-P_i(\theta )^{1-X_i}}{P_i(\theta _0)^{X_i}(1-P_i(\theta _0)^{1-X_i}}\right) \le -c(\theta ), \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sup _i\left| \lambda _i(\theta )\right| = \sup _i\left| \log \left( \frac{P_i(\theta )}{1-P_i(\theta )}\right) \right| < \infty . \end{aligned}$$\end{document}(For a sequence of real numbers \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{a_n\}$$\end{document}
, if \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lim _{n\rightarrow \infty } a_n$$\end{document} does not exist, then \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\{a_n\}$$\end{document} must have more than one limit point. In this case, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\overline{\lim _{n\rightarrow \infty }} \text { }a_n$$\end{document} denotes the largest such or upper limit point. Also, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathbb {E}_{\theta _0}(W)$$\end{document} denotes the expectation of W with \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta = \theta _0$$\end{document} assumed.) -
(A4) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{I^{\prime }_i(\theta )\}$$\end{document}
and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\{\lambda _i^{\prime }(\theta )\}$$\end{document} and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\{\lambda _i^{\prime \prime }(\theta )\}$$\end{document} are bounded in absolute value uniformly in i and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta \in N_0$$\end{document}, where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N_0$$\end{document} is specified in (A2) above. -
(A5)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \liminf _{n \rightarrow \infty } \frac{1}{n} I^{(n)}(\theta _0) > c(\theta _0) > 0. \end{aligned}$$\end{document}That is, asymptotically, the average information at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _0$$\end{document}
is bounded away from 0.































Note that we have used \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(\theta )$$\end{document} to denote the prior density and i to index the items, whereas Chang and Stout (Reference Chang and Stout1993) used \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Pi (\theta )$$\end{document}
to denote the prior density and i to index the items, whereas Chang and Stout (Reference Chang and Stout1993) used \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Pi (\theta )$$\end{document} and j, respectively, in their manuscript.
and j, respectively, in their manuscript.
Appendix 2: Details about the PISA analyses
We used item response data from Booklet 6 in the 2006 PISA cycle. Specifically, we used the responses from \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 1768$$\end{document} Canadian students to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 28$$\end{document}
Canadian students to \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 28$$\end{document} items intended to assess reading ability. The data of 30 students were omitted due to missing responses, and we fitted a One Parameter Logistic Model (OPLM; Verhelst & Glas, Reference Verhelst, Glas, Fischer and Molenaar1995) on data from the remaining \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 1738$$\end{document}
items intended to assess reading ability. The data of 30 students were omitted due to missing responses, and we fitted a One Parameter Logistic Model (OPLM; Verhelst & Glas, Reference Verhelst, Glas, Fischer and Molenaar1995) on data from the remaining \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 1738$$\end{document} students.
students.
The item difficulties were estimated using conditional maximum likelihood and the item discriminations were estimated using marginal maximum likelihood using the OPLM package (Verhelst, Glas, & Verstralen, Reference Verhelst, Glas and Verstralen1995). We used cross-validation for estimation of the (discrete) item discriminations; First, the discriminations were estimated based on data from a random selection of 1200 students. At this stage, we deleted two items that did not fit the scale (items 6 and 8). The remaining \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n = 26$$\end{document} items scaled reasonably well in this sample, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}= 133.067$$\end{document}
items scaled reasonably well in this sample, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}= 133.067$$\end{document} , \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$df =90$$\end{document}
, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$df =90$$\end{document} , \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p = 0.0022$$\end{document}
, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p = 0.0022$$\end{document} (for a description of the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}$$\end{document}
(for a description of the \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}$$\end{document} statistic see Verhelst et al., Reference Verhelst, Glas and Verstralen1995). Second, the parameters were validated on data from the remaining 538 students, and scaled well, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}= 118.686, df =90, p=0.0231$$\end{document}
statistic see Verhelst et al., Reference Verhelst, Glas and Verstralen1995). Second, the parameters were validated on data from the remaining 538 students, and scaled well, \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$R_{1C}= 118.686, df =90, p=0.0231$$\end{document} .
.
The estimated item parameters are shown in Table 3, where a indicates item discrimination and b item difficulty (category thresholds for polytomous items). For polytomous items, score categories are indicated within parentheses after the item number.
Parameters of the estimated IRT model for the PISA example.




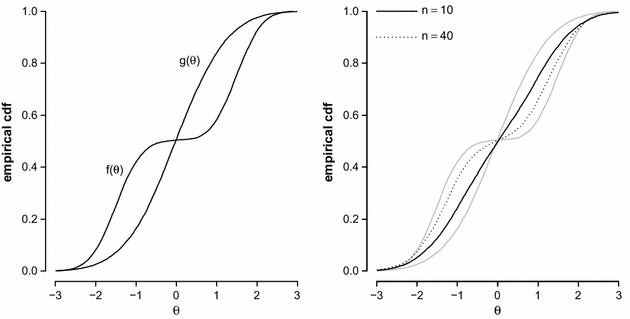




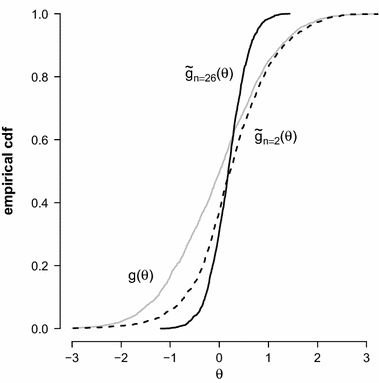


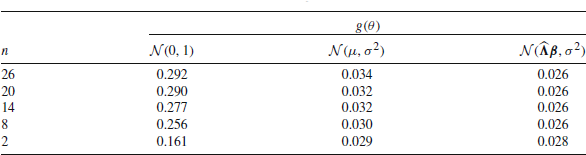


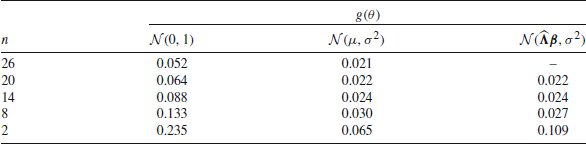

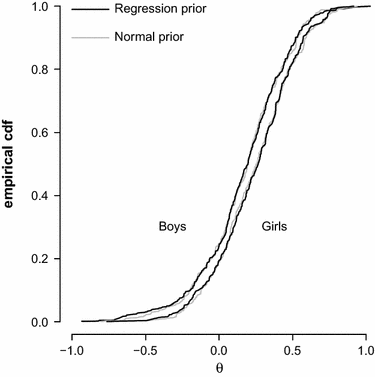

 Open access
Open access