


1. Introduction
The work in this paper is motivated by a question in the theory of integer random matrices but is of independent interest to the study of random walks on groups.
A random walk on a group
 $G$
is a Markov chain on
$G$
is a Markov chain on
 $G$
whose state after the
$G$
whose state after the
 $n$
th step is a product
$n$
th step is a product
 $X_1X_2\dots X_n$
for independent random elements
$X_1X_2\dots X_n$
for independent random elements
 $X_i \in G$
. Random walks on finite groups are well-studied in the time-homogeneous, ergodic regime, where the
$X_i \in G$
. Random walks on finite groups are well-studied in the time-homogeneous, ergodic regime, where the
 $X_i$
are all drawn from a fixed distribution supported on a generating set of
$X_i$
are all drawn from a fixed distribution supported on a generating set of
 $G$
. Such random walks are known to converge to the uniform distribution
$G$
. Such random walks are known to converge to the uniform distribution
 $\pi$
on
$\pi$
on
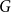 $G$
exponentially quickly. Namely, if we denote by
$G$
exponentially quickly. Namely, if we denote by
 $\nu _n$
the distribution of
$\nu _n$
the distribution of
 $X_1X_2\dots X_n$
, then
$X_1X_2\dots X_n$
, then
 \begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sigma ^n, \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sigma ^n, \end{equation*}
where
 $\sigma$
is the second-largest singular value of the Markov operator of the random walk and
$\sigma$
is the second-largest singular value of the Markov operator of the random walk and
 $||\nu _n - \pi ||_{L^2} \;:\!=\; \sqrt {\sum _{g \in G}(\nu _n(g) - |G|^{-1})^2}$
denotes the
$||\nu _n - \pi ||_{L^2} \;:\!=\; \sqrt {\sum _{g \in G}(\nu _n(g) - |G|^{-1})^2}$
denotes the
 $L^2$
distance between the measures
$L^2$
distance between the measures
 $\nu _n$
and
$\nu _n$
and
 $\pi$
viewed as functions
$\pi$
viewed as functions
 $G \to \mathbb{R}$
. See [Reference Saloff-Coste, Sznitman, Varadhan and Kesten10] for an excellent review of these kinds of walks.
$G \to \mathbb{R}$
. See [Reference Saloff-Coste, Sznitman, Varadhan and Kesten10] for an excellent review of these kinds of walks.
The above inequality comes from looking at norms of convolution operators on the space of signed measures on
 $G$
. If
$G$
. If
 $X$
and
$X$
and
 $Y$
are random elements of
$Y$
are random elements of
 $G$
distributed according to
$G$
distributed according to
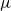 $\mu$
and
$\mu$
and
 $\nu$
respectively, then
$\nu$
respectively, then
 $XY$
is distributed according to the convolution
$XY$
is distributed according to the convolution
 \begin{equation*} (\mu * \nu ) (g) = \sum _{h \in G} \mu (h)\nu (h^{-1}g). \end{equation*}
\begin{equation*} (\mu * \nu ) (g) = \sum _{h \in G} \mu (h)\nu (h^{-1}g). \end{equation*}
In particular, if the
 $X_i$
are distributed according to
$X_i$
are distributed according to
 $\mu$
, then
$\mu$
, then
 $\nu _n$
is the
$\nu _n$
is the
 $n$
-fold convolution
$n$
-fold convolution
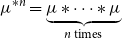 $\mu ^{*n} = \underbrace {\mu * \dots * \mu }_{n\text{ times}}$
. Since
$\mu ^{*n} = \underbrace {\mu * \dots * \mu }_{n\text{ times}}$
. Since
 $\pi * \mu = \pi$
, the difference
$\pi * \mu = \pi$
, the difference
 $\nu _n - \pi$
can then be expressed as
$\nu _n - \pi$
can then be expressed as
 $(\mu - \pi ) * \mu ^{*{n-1}}$
. The
$(\mu - \pi ) * \mu ^{*{n-1}}$
. The
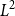 $L^2$
norm of this function can be bounded in terms of the operator norm of the convolution operator
$L^2$
norm of this function can be bounded in terms of the operator norm of the convolution operator
 $*\mu$
restricted to a suitable subspace, which is related to its second-largest singular value
$*\mu$
restricted to a suitable subspace, which is related to its second-largest singular value
 $\sigma$
.
$\sigma$
.
Some of the assumptions can be relaxed; for instance, Saloff-Coste and Zúñiga [Reference Saloff-Coste and Zúñiga11] studied convergence of time-inhomogeneous Markov chains, including random walks on finite groups, in the case where each step of the random walk is irreducible (in particular, supported on a generating set of
 $G$
). In that case, if we denote by
$G$
). In that case, if we denote by
 $\sigma _i$
the second-largest singular value of the
$\sigma _i$
the second-largest singular value of the
 $i$
th step,
$i$
th step,
 \begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \prod _{i=1}^n\sigma _i. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \prod _{i=1}^n\sigma _i. \end{equation*}
The condition that each step of the random walk is supported on a generating set is crucial because if the subgroup generated by the supports of the steps is a proper subgroup of
 $G$
, the random walk will surely stay in that subgroup. In that case, the second-largest singular value of the corresponding step is 1. Nevertheless, one may expect that if the supports of all steps taken together generate
$G$
, the random walk will surely stay in that subgroup. In that case, the second-largest singular value of the corresponding step is 1. Nevertheless, one may expect that if the supports of all steps taken together generate
 $G$
, the random walk might still equilibrate to the uniform distribution on
$G$
, the random walk might still equilibrate to the uniform distribution on
 $G$
.
$G$
.
A consequence of our first main result is the following theorem, which relaxes this “generating” assumption by extending part of [Reference Saloff-Coste and Zúñiga11, Theorem 3.5] to some time-inhomogeneous random walks where the probability measures driving each step need not be irreducible:
Theorem 1.1.
Let
 $G$
be a finite group, and let
$G$
be a finite group, and let
 $\mu _1, \mu _2, \dots , \mu _n$
be probability measures on
$\mu _1, \mu _2, \dots , \mu _n$
be probability measures on
 $G$
. For each subgroup
$G$
. For each subgroup
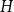 $H$
of
$H$
of
 $G$
, let
$G$
, let
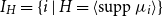 $I_H = \{i \mid H = \langle \operatorname {supp} \mu _i\rangle \}$
. Let
$I_H = \{i \mid H = \langle \operatorname {supp} \mu _i\rangle \}$
. Let
 $\mathcal{S}$
be a finite set of normal subgroups of
$\mathcal{S}$
be a finite set of normal subgroups of
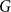 $G$
such that
$G$
such that
 $G = \left \langle \bigcup _{H \in \mathcal{S}} H\right \rangle$
. Write
$G = \left \langle \bigcup _{H \in \mathcal{S}} H\right \rangle$
. Write
 $\nu _n = \mu _1 * \dots * \mu _n$
. Also, for each
$\nu _n = \mu _1 * \dots * \mu _n$
. Also, for each
 $i$
, let
$i$
, let
 $\sigma _i$
be the second-largest singular value of
$\sigma _i$
be the second-largest singular value of
 $*\mu _i$
as an operator on
$*\mu _i$
as an operator on
 $L^2(\langle \operatorname {supp} \mu _i \rangle )$
. Let
$L^2(\langle \operatorname {supp} \mu _i \rangle )$
. Let
 $\pi$
be the uniform distribution on
$\pi$
be the uniform distribution on
 $G$
.
$G$
.
If
 $I_H$
is nonempty for each
$I_H$
is nonempty for each
 $H \in \mathcal{S}$
, we have
$H \in \mathcal{S}$
, we have
 \begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sum _{H \in \mathcal{S}} \left (\prod _{i \in I_H} \sigma _i\right )\!. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sum _{H \in \mathcal{S}} \left (\prod _{i \in I_H} \sigma _i\right )\!. \end{equation*}
We prove a more general version of this result in Theorem 2.1.
In particular, if a time-inhomogeneous random walk on a finite group has steps supported on enough subgroups, then it converges to the uniform distribution on the group with an exponential rate controlled by subgroups that appear infrequently or mix very slowly. Adding more probability measures to the convolution
 $\nu _n$
may not improve the convergence rate, but it never makes the bound worse because convolution with a probability measure is non-expansive in the
$\nu _n$
may not improve the convergence rate, but it never makes the bound worse because convolution with a probability measure is non-expansive in the
 $L^2$
norm. A nice consequence of this is that
$L^2$
norm. A nice consequence of this is that
 $\mathcal{S}$
need not be an exhaustive list of every normal subgroup for which
$\mathcal{S}$
need not be an exhaustive list of every normal subgroup for which
 $I_H$
is nonempty.
$I_H$
is nonempty.
The main difference between this result and [Reference Saloff-Coste and Zúñiga11, Theorem 3.5] is that [Reference Saloff-Coste and Zúñiga11] relaxes the time-homogeneity assumption for random walks but not the assumption that each step is supported on a generating set for the group. The new condition that the supports of the steps jointly generate
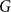 $G$
is substantially weaker than the assumption that the support of each step generates
$G$
is substantially weaker than the assumption that the support of each step generates
 $G$
.
$G$
.
The conditions of Theorem 1.1 can be weakened so that not all the subgroups
 $H_i$
need to be normal (see Theorem 2.1), but see Example 2.3 for why some hypothesis on the subgroups is necessary. In this paper, we apply Theorem 1.1 in the case where the ambient group
$H_i$
need to be normal (see Theorem 2.1), but see Example 2.3 for why some hypothesis on the subgroups is necessary. In this paper, we apply Theorem 1.1 in the case where the ambient group
 $G$
is abelian, so that the normality condition on the subgroups
$G$
is abelian, so that the normality condition on the subgroups
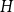 $H$
becomes vacuous. However, we emphasise that the theorem applies also to nonabelian groups and may have some interesting implications to random walks on nonabelian groups with many normal subgroups (e.g., the quaternion group
$H$
becomes vacuous. However, we emphasise that the theorem applies also to nonabelian groups and may have some interesting implications to random walks on nonabelian groups with many normal subgroups (e.g., the quaternion group
 $Q_8$
).
$Q_8$
).
Our main interest in developing this theorem is an application to limiting distributions of cokernels of random matrices. Wood [Reference Wood14, Theorem 2.9] and Nguyen and Wood [Reference Nguyen and Wood9, Theorem 1.1] showed that cokernels of integer-valued random matrices approach a universal limiting distribution in the following sense. Let
 $(M_n)_{n=1}^\infty$
be a sequence with each
$(M_n)_{n=1}^\infty$
be a sequence with each
 $M_n$
a random
$M_n$
a random
 $n\times (n + u)$
integer matrix with independent entries (
$n\times (n + u)$
integer matrix with independent entries (
 $u \geq 0$
). Wood showed that, under very weak conditions on the distributions of the entries of the
$u \geq 0$
). Wood showed that, under very weak conditions on the distributions of the entries of the
 $M_n$
, the distribution of the isomorphism class of the random group
$M_n$
, the distribution of the isomorphism class of the random group
 $\operatorname {coker}(M_n) \;:\!=\; \mathbb{Z}^n/M_n(\mathbb{Z}^{n+u})$
converges weakly (i.e., at any finite collection of primes) as
$\operatorname {coker}(M_n) \;:\!=\; \mathbb{Z}^n/M_n(\mathbb{Z}^{n+u})$
converges weakly (i.e., at any finite collection of primes) as
 $n \to \infty$
to the distribution
$n \to \infty$
to the distribution
 $\lambda _u$
on isomorphism classes of profinite abelian groups defined as follows: if
$\lambda _u$
on isomorphism classes of profinite abelian groups defined as follows: if
 $A \sim \lambda _u$
and
$A \sim \lambda _u$
and
 $B$
is a finite abelian
$B$
is a finite abelian
 $p$
-group, then
$p$
-group, then
 \begin{equation*} \mathbb{P}[A_p \cong B] = \frac {1}{|B|^u|\operatorname {Aut}(B)|}\prod _{k= u + 1}^\infty (1 - p^{-k}) \end{equation*}
\begin{equation*} \mathbb{P}[A_p \cong B] = \frac {1}{|B|^u|\operatorname {Aut}(B)|}\prod _{k= u + 1}^\infty (1 - p^{-k}) \end{equation*}
independently for all primes
 $p$
, where
$p$
, where
 $A_p$
is the
$A_p$
is the
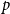 $p$
-part of
$p$
-part of
 $A$
. If further
$A$
. If further
 $u \geq 1$
, then
$u \geq 1$
, then
 $\lambda _u$
is supported on isomorphism classes of finite abelian groups, and for finite abelian
$\lambda _u$
is supported on isomorphism classes of finite abelian groups, and for finite abelian
 $B$
we have
$B$
we have
 \begin{equation*} \lambda _u(B) = \frac {1}{|B|^u |\operatorname {Aut}(B)|}\prod _{k= u + 1}^\infty \zeta (k)^{-1}, \end{equation*}
\begin{equation*} \lambda _u(B) = \frac {1}{|B|^u |\operatorname {Aut}(B)|}\prod _{k= u + 1}^\infty \zeta (k)^{-1}, \end{equation*}
where
 $\zeta$
denotes the Riemann zeta function. Nguyen and Wood weakened the conditions on the entries and showed strong (pointwise) convergence to
$\zeta$
denotes the Riemann zeta function. Nguyen and Wood weakened the conditions on the entries and showed strong (pointwise) convergence to
 $\lambda _u$
. The phenomenon that the limiting distribution of
$\lambda _u$
. The phenomenon that the limiting distribution of
 $\mathbb{Z}^n/M_n(\mathbb{Z}^{n+u})$
is rather insensitive to the distributions of the entries of
$\mathbb{Z}^n/M_n(\mathbb{Z}^{n+u})$
is rather insensitive to the distributions of the entries of
 $M_n$
is an example of universality. The distributions
$M_n$
is an example of universality. The distributions
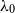 $\lambda _0$
and
$\lambda _0$
and
 $\lambda _1$
are known as the Cohen-Lenstra distributions, and are conjectured to describe the distributions of class groups of imaginary and real quadratic number fields, respectively.
$\lambda _1$
are known as the Cohen-Lenstra distributions, and are conjectured to describe the distributions of class groups of imaginary and real quadratic number fields, respectively.
In her 2022 ICM talk, Wood [Reference Wood15, Open Problem 3.10] asks if the universality class of
 $\lambda _u$
can be extended to cokernels of matrices with some dependent entries. There are a few specific results in this direction. Most recently, Nguyen and Wood [Reference Nguyen and Wood9, Theorem 1.1] show that the distribution
$\lambda _u$
can be extended to cokernels of matrices with some dependent entries. There are a few specific results in this direction. Most recently, Nguyen and Wood [Reference Nguyen and Wood9, Theorem 1.1] show that the distribution
 $\lambda _1$
is universal for Laplacians of Erdős-Rényi random directed graphs. Mészáros [Reference Mészáros5] shows that
$\lambda _1$
is universal for Laplacians of Erdős-Rényi random directed graphs. Mészáros [Reference Mészáros5] shows that
 $\lambda _0$
is universal for Laplacians of random regular directed graphs. Friedman and Washington [Reference Friedman, Washington, de Koninck and Levesque2] show that the cokernels of the random matrices
$\lambda _0$
is universal for Laplacians of random regular directed graphs. Friedman and Washington [Reference Friedman, Washington, de Koninck and Levesque2] show that the cokernels of the random matrices
 $I - M$
, where
$I - M$
, where
 $M$
is drawn at random from the multiplicative Haar measure on
$M$
is drawn at random from the multiplicative Haar measure on
 $\operatorname {GL}_{2g}(\mathbb{Z}_p)$
, approach the
$\operatorname {GL}_{2g}(\mathbb{Z}_p)$
, approach the
 $p$
-part of
$p$
-part of
 $\lambda _0$
as
$\lambda _0$
as
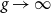 $g \to \infty$
. However, when there is too much dependence in the entries of the random matrices, one gets different (but often related) limiting distributions, for example in the case of symmetric matrices [Reference Wood13], Laplacians of random regular undirected graphs [Reference Mészáros5], products of independent random integral matrices [Reference Nguyen and Van Peski8], and quadratic polynomials in Haar-random matrices [Reference Cheong and Kaplan1].
$g \to \infty$
. However, when there is too much dependence in the entries of the random matrices, one gets different (but often related) limiting distributions, for example in the case of symmetric matrices [Reference Wood13], Laplacians of random regular undirected graphs [Reference Mészáros5], products of independent random integral matrices [Reference Nguyen and Van Peski8], and quadratic polynomials in Haar-random matrices [Reference Cheong and Kaplan1].
There are more recent examples where the amount of dependence can be controlled quantitatively. For instance, Mészáros [Reference Mészáros6] shows that cokernels of Haar-random band matrices over
 $\mathbb{Z}_p$
converge to the
$\mathbb{Z}_p$
converge to the
 $p$
-part of
$p$
-part of
 $\lambda _0$
if and only if the width of the band grows fast enough. Kang et al. [Reference Kang, Lee and Yu3] show that certain random matrices over
$\lambda _0$
if and only if the width of the band grows fast enough. Kang et al. [Reference Kang, Lee and Yu3] show that certain random matrices over
 $\mathbb{Z}_p$
with some entries fixed to zero have cokernels converging to the
$\mathbb{Z}_p$
with some entries fixed to zero have cokernels converging to the
 $p$
-part of
$p$
-part of
 $\lambda _0$
, but fixing too many entries to zero prevents convergence to
$\lambda _0$
, but fixing too many entries to zero prevents convergence to
 $\lambda _0$
.
$\lambda _0$
.
It is natural to ask just how much (and what kind of) dependence is allowed between the entries of sequences of random matrices before their cokernels leave the universality class of
 $\lambda _u$
.
$\lambda _u$
.
The main application of Theorem 2.1 in this paper is a Theorem 1.2 below, which extends the result of [Reference Wood14] to matrices with a rather general form of dependence in their rows and columns. We introduce a regularity condition on matrices,
 $(w, h, \varepsilon )$
-balanced, in Definitions 3.2 and 3.8. Generally, it means that the matrix can be written as a block matrix where the blocks have height at most
$(w, h, \varepsilon )$
-balanced, in Definitions 3.2 and 3.8. Generally, it means that the matrix can be written as a block matrix where the blocks have height at most
 $h$
, width at most
$h$
, width at most
 $w$
, are all independent, and each satisfy some regularity condition depending on
$w$
, are all independent, and each satisfy some regularity condition depending on
 $\varepsilon$
. The key detail is that the blocks of the matrix may have dependent entries, as long as there is no dependence between blocks. (The
$\varepsilon$
. The key detail is that the blocks of the matrix may have dependent entries, as long as there is no dependence between blocks. (The
 $(w, h, \varepsilon )$
-balanced condition is invariant under permutation of rows and columns, so one can also think of a
$(w, h, \varepsilon )$
-balanced condition is invariant under permutation of rows and columns, so one can also think of a
 $(w, h, \varepsilon )$
-balanced matrix as a block matrix which is at most
$(w, h, \varepsilon )$
-balanced matrix as a block matrix which is at most
 $h$
blocks tall, at most
$h$
blocks tall, at most
 $w$
blocks wide, and such that the entries of each block are independent of each other, while some dependence between different blocks is allowed.) With this condition, we have:
$w$
blocks wide, and such that the entries of each block are independent of each other, while some dependence between different blocks is allowed.) With this condition, we have:
Theorem 1.2.
Let
 $u \geq 0$
be an integer. Let
$u \geq 0$
be an integer. Let
 $(w_n)_n, (h_n)_n$
,
$(w_n)_n, (h_n)_n$
,
 $(\varepsilon _n)_n$
be sequences of real numbers such that
$(\varepsilon _n)_n$
be sequences of real numbers such that
 $w_n = O(n^{\alpha _1})$
,
$w_n = O(n^{\alpha _1})$
,
 $h_n = O(n^{\alpha _2})$
and
$h_n = O(n^{\alpha _2})$
and
 $\varepsilon _n = \Omega ( n^{-\beta })$
for some
$\varepsilon _n = \Omega ( n^{-\beta })$
for some
 $0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
$0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
 \begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
\begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
For each integer
 $n \geq 0$
, let
$n \geq 0$
, let
 $M_n$
be an
$M_n$
be an
 $(w_n, h_n, \varepsilon _n)$
-balanced
$(w_n, h_n, \varepsilon _n)$
-balanced
 $n \times (n + u)$
random matrix with entries in
$n \times (n + u)$
random matrix with entries in
 $\mathbb{Z}$
. Then the distribution of
$\mathbb{Z}$
. Then the distribution of
 $\operatorname {coker}(M_n)$
converges weakly to
$\operatorname {coker}(M_n)$
converges weakly to
 $\lambda _u$
as
$\lambda _u$
as
 $n \to \infty$
. In other words, if
$n \to \infty$
. In other words, if
 $Y \sim \lambda _u$
, then for every positive integer
$Y \sim \lambda _u$
, then for every positive integer
 $a$
and every abelian group
$a$
and every abelian group
 $H$
with exponent dividing
$H$
with exponent dividing
 $a$
we have
$a$
we have
 \begin{equation*} \lim _{n\to \infty } \mathbb{P}[\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H]. \end{equation*}
\begin{equation*} \lim _{n\to \infty } \mathbb{P}[\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H]. \end{equation*}
Here
 $w_n = O(n^{\alpha _1})$
means that there is a constant
$w_n = O(n^{\alpha _1})$
means that there is a constant
 $A$
independent of
$A$
independent of
 $n$
such that
$n$
such that
 $w_n \leq An^{\alpha _1}$
, and
$w_n \leq An^{\alpha _1}$
, and
 $\varepsilon _n = \Omega (n^{-\beta })$
means that there is a constant
$\varepsilon _n = \Omega (n^{-\beta })$
means that there is a constant
 $B$
independent of
$B$
independent of
 $n$
such that
$n$
such that
 $\varepsilon _n \geq Bn^{-\beta }$
.
$\varepsilon _n \geq Bn^{-\beta }$
.
The key idea of the proof of Theorem 1.2 uses the moment method developed in [Reference Wood13] and [Reference Wood14]. Understanding the cokernel of a random integer matrix reduces to finding the probability that each random column maps to zero under an arbitrary surjective group homomorphism
 $f\colon \mathbb{Z}^n \to G$
for an arbitrary abelian group
$f\colon \mathbb{Z}^n \to G$
for an arbitrary abelian group
 $G$
. To handle dependent columns, we treat several columns at a time and look at the induced surjection
$G$
. To handle dependent columns, we treat several columns at a time and look at the induced surjection
 $(\mathbb{Z}^n)^m \to G^m$
. We view the image of a random element of
$(\mathbb{Z}^n)^m \to G^m$
. We view the image of a random element of
 $(\mathbb{Z}^n)^m$
as a random walk in
$(\mathbb{Z}^n)^m$
as a random walk in
 $G^m$
and apply Theorem 2.1 to approximate the distribution of this image. Since the surjection
$G^m$
and apply Theorem 2.1 to approximate the distribution of this image. Since the surjection
 $f$
is arbitrary, we have very little control over the distribution of the steps of this walk. In particular, they are almost never supported on all of
$f$
is arbitrary, we have very little control over the distribution of the steps of this walk. In particular, they are almost never supported on all of
 $G^m$
, which is why we need Theorem 2.1 to handle random walk steps supported on proper subgroups. The
$G^m$
, which is why we need Theorem 2.1 to handle random walk steps supported on proper subgroups. The
 $(w, h, \varepsilon )$
-balanced condition allows us to bound the singular values of the associated convolution operators and get quantitative bounds on the error in terms of
$(w, h, \varepsilon )$
-balanced condition allows us to bound the singular values of the associated convolution operators and get quantitative bounds on the error in terms of
 $w$
,
$w$
,
 $h$
, and
$h$
, and
 $\varepsilon$
.
$\varepsilon$
.
This random walk model works for most surjections
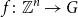 $f\colon \mathbb{Z}^n \to G$
. However, there is a certain (controlled, by Lemma 3.16) number of exceptionally pathological surjections
$f\colon \mathbb{Z}^n \to G$
. However, there is a certain (controlled, by Lemma 3.16) number of exceptionally pathological surjections
 $\mathbb{Z}^n \to G$
. For these surjections, we use the
$\mathbb{Z}^n \to G$
. For these surjections, we use the
 $\varepsilon$
-balanced condition to give a bound on how much each can affect the computation of the moments. This bound gets better the more independent blocks of columns we can find in the random matrix in question (in other words, the narrower each block is). As a result, there is an additional constraint on
$\varepsilon$
-balanced condition to give a bound on how much each can affect the computation of the moments. This bound gets better the more independent blocks of columns we can find in the random matrix in question (in other words, the narrower each block is). As a result, there is an additional constraint on
 $w_n$
that forces us to restrict it more, explaining the asymmetry between
$w_n$
that forces us to restrict it more, explaining the asymmetry between
 $\alpha _1$
and
$\alpha _1$
and
 $\alpha _2$
in the conditions.
$\alpha _2$
in the conditions.
The actual constraint that one should expect is that there is a tradeoff between regularity and block size for each individual block. As a given block gets wider, one needs to impose a stronger
 $\varepsilon$
-balancedness condition on it. On the other hand, smaller blocks may be allowed to be less regular without compromising the universality. A statement of this form follows directly from our proof, but we present the results with a uniform bound on block sizes and balancedness for simplicity.
$\varepsilon$
-balancedness condition on it. On the other hand, smaller blocks may be allowed to be less regular without compromising the universality. A statement of this form follows directly from our proof, but we present the results with a uniform bound on block sizes and balancedness for simplicity.
There is a considerable body of literature pertaining to random matrices with complex entries, with analogous universality results about distributions of eigenvalues. If
 $\{M_n\}$
is a sequence of
$\{M_n\}$
is a sequence of
 $n\times n$
random complex matrices whose entries are independent, with appropriately normalised mean and variance, the empirical distribution of the eigenvalues of
$n\times n$
random complex matrices whose entries are independent, with appropriately normalised mean and variance, the empirical distribution of the eigenvalues of
 $M_n$
converges to the circular law, which is the uniform distribution on the unit disc in
$M_n$
converges to the circular law, which is the uniform distribution on the unit disc in
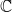 $\mathbb{C}$
[Reference Tao, Van and Krishnapur12]. The universality of the circular law for spectra of a wide class of random complex block matrices was proved by Nguyen and O’Rourke in [Reference Nguyen and O’Rourke7]. However, we note that [Reference Nguyen and O’Rourke7] shows universality for block matrices with i.i.d. blocks of constant size, whereas our blocks are allowed to grow in size with the matrices.
$\mathbb{C}$
[Reference Tao, Van and Krishnapur12]. The universality of the circular law for spectra of a wide class of random complex block matrices was proved by Nguyen and O’Rourke in [Reference Nguyen and O’Rourke7]. However, we note that [Reference Nguyen and O’Rourke7] shows universality for block matrices with i.i.d. blocks of constant size, whereas our blocks are allowed to grow in size with the matrices.
1.1 Notation and terminology
For a finite set
 $S$
, we use
$S$
, we use
 $L^2(S)$
to denote the space of signed measures (equivalently, real-valued functions) on
$L^2(S)$
to denote the space of signed measures (equivalently, real-valued functions) on
 $S$
, equipped with the norm
$S$
, equipped with the norm
 $||f||_{L^2(S)}^2 = \sum _{s\in S} |f(s)|^2$
. When the set
$||f||_{L^2(S)}^2 = \sum _{s\in S} |f(s)|^2$
. When the set
 $S$
is implicit, we write
$S$
is implicit, we write
 $||f||_{L^2}$
for
$||f||_{L^2}$
for
 $||f||_{L^2(S)}$
. Any set map
$||f||_{L^2(S)}$
. Any set map
 $f\colon S \to T$
defines a pushforward map
$f\colon S \to T$
defines a pushforward map
 $f_*\colon L^2(S) \to L^2(T)$
by
$f_*\colon L^2(S) \to L^2(T)$
by
 $f_*\mu (t) = \mu (f^{-1}(t))$
. We say a signed measure
$f_*\mu (t) = \mu (f^{-1}(t))$
. We say a signed measure
 $\nu$
is uniform on
$\nu$
is uniform on
 $T \subset S$
if
$T \subset S$
if
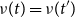 $\nu (t) = \nu (t')$
for
$\nu (t) = \nu (t')$
for
 $t, t' \in T$
. For a point
$t, t' \in T$
. For a point
 $f \in \mathbb{R}^n$
with the Euclidean metric and a linear subspace
$f \in \mathbb{R}^n$
with the Euclidean metric and a linear subspace
 $W \subset \mathbb{R}^n$
, we write
$W \subset \mathbb{R}^n$
, we write
 $d_{L^2}(f, W)$
for the distance between
$d_{L^2}(f, W)$
for the distance between
 $f$
and its orthogonal projection onto
$f$
and its orthogonal projection onto
 $W$
. Note that this is equal to
$W$
. Note that this is equal to
 $\inf _{g \in W} |f - g|$
. If
$\inf _{g \in W} |f - g|$
. If
 $G$
is a finite group, any signed measure
$G$
is a finite group, any signed measure
 $\mu$
defines a linear convolution operator (or, if
$\mu$
defines a linear convolution operator (or, if
 $\mu$
is a probability measure, Markov operator)
$\mu$
is a probability measure, Markov operator)
 $*\mu$
on
$*\mu$
on
 $L^2(G)$
given by
$L^2(G)$
given by
 $\nu \mapsto \nu * \mu$
. When we discuss the second-largest singular value of an operator, we are counting with multiplicity; for example, if the singular values of
$\nu \mapsto \nu * \mu$
. When we discuss the second-largest singular value of an operator, we are counting with multiplicity; for example, if the singular values of
 $M$
are
$M$
are
 $1, 1, 0$
, then its second-largest singular value is
$1, 1, 0$
, then its second-largest singular value is
 $1$
.
$1$
.
For two finite or profinite groups
 $G, G'$
, we write
$G, G'$
, we write
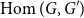 $\operatorname {Hom}(G, G')$
for the set of (continuous) group homomorphisms from
$\operatorname {Hom}(G, G')$
for the set of (continuous) group homomorphisms from
 $G$
to
$G$
to
 $G'$
and
$G'$
and
 $\operatorname {Sur}(G, G')$
for the set of (continuous) surjective group homomorphisms from
$\operatorname {Sur}(G, G')$
for the set of (continuous) surjective group homomorphisms from
 $G$
to
$G$
to
 $G'$
. For a subset
$G'$
. For a subset
 $S \subseteq G$
, we denote by
$S \subseteq G$
, we denote by
 $\langle S \rangle$
the (closed) subgroup of
$\langle S \rangle$
the (closed) subgroup of
 $G$
generated by
$G$
generated by
 $S$
. We refer to the identity element of a group as
$S$
. We refer to the identity element of a group as
 $e$
.
$e$
.
A probability measure or distribution is a measure with total mass 1 (not signed). The uniform distribution on
 $G$
is usually denoted
$G$
is usually denoted
 $\pi$
and is the measure on
$\pi$
and is the measure on
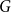 $G$
with
$G$
with
 $\pi (g) = 1/|G|$
for
$\pi (g) = 1/|G|$
for
 $g \in G$
. We use
$g \in G$
. We use
 $\mathbb{P}[\cdot ]$
for probability and
$\mathbb{P}[\cdot ]$
for probability and
 $\mathbb{E}[\cdot ]$
for expectation. We denote by
$\mathbb{E}[\cdot ]$
for expectation. We denote by
 $\operatorname {supp} \mu$
the support of a measure
$\operatorname {supp} \mu$
the support of a measure
 $\mu$
. If a random variable
$\mu$
. If a random variable
 $X$
has law
$X$
has law
 $\mu$
, we write
$\mu$
, we write
 $X \sim \mu$
.
$X \sim \mu$
.
For a positive integer
 $n$
, we write
$n$
, we write
 $[n]$
for the set
$[n]$
for the set
 $\{1, \dots , n\}$
.
$\{1, \dots , n\}$
.
If
 $a_n$
and
$a_n$
and
 $b_n$
are sequences of positive real numbers, we write
$b_n$
are sequences of positive real numbers, we write
 $a_n = O(b_n)$
if there is a constant
$a_n = O(b_n)$
if there is a constant
 $0 \lt K \lt \infty$
such that
$0 \lt K \lt \infty$
such that
 $a_n \leq Kb_n$
for all
$a_n \leq Kb_n$
for all
 $n$
, and we write
$n$
, and we write
 $a_n = \Omega (b_n)$
if there is a constant
$a_n = \Omega (b_n)$
if there is a constant
 $0 \lt K \lt \infty$
such that
$0 \lt K \lt \infty$
such that
 $a_n \geq Kb_n$
for all
$a_n \geq Kb_n$
for all
 $n$
, i.e., if
$n$
, i.e., if
 $b_n = O(a_n)$
. We write
$b_n = O(a_n)$
. We write
 $a_n = o(b_n)$
if, for each constant
$a_n = o(b_n)$
if, for each constant
 $K \lt \infty$
, there is a natural number
$K \lt \infty$
, there is a natural number
 $n_0$
such that
$n_0$
such that
 $a_n \leq Kb_n$
when
$a_n \leq Kb_n$
when
 $n \geq n_0$
.
$n \geq n_0$
.
2. Random walks
This section is devoted to proving the following stronger version of Theorem 1.1 from the introduction:
Theorem 2.1.
Let
 $G$
be a finite group and suppose we have a sequence of surjective homomorphisms
$G$
be a finite group and suppose we have a sequence of surjective homomorphisms
For
 $0 \leq j \leq k$
, define
$0 \leq j \leq k$
, define
 $\tilde {Q}_j\colon G \twoheadrightarrow G_j$
by
$\tilde {Q}_j\colon G \twoheadrightarrow G_j$
by
 $\tilde {Q}_j = Q_j\circ Q_{j-1}\circ \dots \circ Q_1$
(so
$\tilde {Q}_j = Q_j\circ Q_{j-1}\circ \dots \circ Q_1$
(so
 $\tilde {Q}_0 = \operatorname {id}_G$
), and for
$\tilde {Q}_0 = \operatorname {id}_G$
), and for
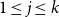 $1 \leq j \leq k$
define
$1 \leq j \leq k$
define
 $H_j \trianglelefteq G_{j-1}$
by
$H_j \trianglelefteq G_{j-1}$
by
 $H_j = \ker Q_j$
.
$H_j = \ker Q_j$
.
Let
 $\mu _1, \dots , \mu _n$
be probability measures on
$\mu _1, \dots , \mu _n$
be probability measures on
 $G$
. Let
$G$
. Let
 $\nu _n = \mu _1*\dots * \mu _n$
. For each
$\nu _n = \mu _1*\dots * \mu _n$
. For each
 $j = 1, \dots , k$
, let
$j = 1, \dots , k$
, let
 $I_j = \{i \mid \langle \operatorname {supp} (\tilde {Q}_{j-1})_* \mu _i \rangle = H_j \}$
. Let
$I_j = \{i \mid \langle \operatorname {supp} (\tilde {Q}_{j-1})_* \mu _i \rangle = H_j \}$
. Let
 $\pi$
be the uniform distribution on
$\pi$
be the uniform distribution on
 $G$
.
$G$
.
For
 $i \in I_j$
, let
$i \in I_j$
, let
 $\sigma _i$
be the second-largest singular value of the
$\sigma _i$
be the second-largest singular value of the
 $(\tilde {Q}_{j-1})_* \mu _i$
-random walk on
$(\tilde {Q}_{j-1})_* \mu _i$
-random walk on
 $H_j$
. If each
$H_j$
. If each
 $I_j$
is nonempty, we have
$I_j$
is nonempty, we have
 \begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G_{j-1}| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right ) = \sum _{j=1}^k \frac {\prod _{i=j}^{k} |H_i| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G_{j-1}| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right ) = \sum _{j=1}^k \frac {\prod _{i=j}^{k} |H_i| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{equation*}
In the case where
 $k = 1$
and
$k = 1$
and
 $H_1 = G$
, we recover the first part of [Reference Saloff-Coste and Zúñiga11, Theorem 3.5]. We postpone the proof that Theorem 2.1 implies Theorem 1.1 until the end of this section.
$H_1 = G$
, we recover the first part of [Reference Saloff-Coste and Zúñiga11, Theorem 3.5]. We postpone the proof that Theorem 2.1 implies Theorem 1.1 until the end of this section.
The condition involving the sequence of surjective homomorphisms is an artefact of the inductive proof of the theorem. We are motivated by the special case where the support of each
 $\mu _i$
generates a normal subgroup of
$\mu _i$
generates a normal subgroup of
 $G$
. However, the proof proceeds by showing that the pushforward of
$G$
. However, the proof proceeds by showing that the pushforward of
 $\nu _n$
is close to uniform in
$\nu _n$
is close to uniform in
 $G_k$
, then in
$G_k$
, then in
 $G_{k-1}$
. We use the steps
$G_{k-1}$
. We use the steps
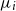 $\mu _i$
with
$\mu _i$
with
 $i \in I_j$
only when analysing the pushforward of
$i \in I_j$
only when analysing the pushforward of
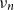 $\nu _n$
to
$\nu _n$
to
 $G_j$
, so we do not always need to make assumptions about the subgroup of
$G_j$
, so we do not always need to make assumptions about the subgroup of
 $G$
generated by the support of each measure
$G$
generated by the support of each measure
 $\mu _i$
. We state Theorem 2.1 in full generality because this stronger form is more easily applicable to nonabelian (for example, nilpotent) groups.
$\mu _i$
. We state Theorem 2.1 in full generality because this stronger form is more easily applicable to nonabelian (for example, nilpotent) groups.
The following example gives a case that is covered by Theorem 2.1 but not by the weaker Theorem 1.1:
Example 2.2. Consider the dihedral group
 $G = D_{2n} = \langle r, s \mid r^n = s^2 = (rs)^2 = e\rangle$
with
$G = D_{2n} = \langle r, s \mid r^n = s^2 = (rs)^2 = e\rangle$
with
 $n \gt 2$
. The subgroup
$n \gt 2$
. The subgroup
 $H_1 = \langle r\rangle$
is normal, but the subgroup
$H_1 = \langle r\rangle$
is normal, but the subgroup
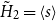 $\tilde {H}_2 = \langle s\rangle$
is not normal. We have
$\tilde {H}_2 = \langle s\rangle$
is not normal. We have
 $G_1 = D_{2n}/\langle r\rangle = \mathbb{Z}/2\mathbb{Z}$
generated by the image of
$G_1 = D_{2n}/\langle r\rangle = \mathbb{Z}/2\mathbb{Z}$
generated by the image of
 $s$
, so the image of
$s$
, so the image of
 $\langle s\rangle$
in the quotient is normal. Let
$\langle s\rangle$
in the quotient is normal. Let
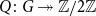 $Q\colon G \twoheadrightarrow \mathbb{Z}/2\mathbb{Z}$
be the quotient map. Let
$Q\colon G \twoheadrightarrow \mathbb{Z}/2\mathbb{Z}$
be the quotient map. Let
 $\mu$
be a measure on
$\mu$
be a measure on
 $\langle r\rangle$
with second-largest singular value
$\langle r\rangle$
with second-largest singular value
 $\sigma$
. Consider the following random walk on
$\sigma$
. Consider the following random walk on
 $D_{2n}$
:
$D_{2n}$
:
-
• For
 $i$
odd,
$\mu _i = \mu$
.
$i$
odd,
$\mu _i = \mu$
. -
• For
$i$
even,
$\mu _i(s) = p$
and
$\mu _i(e) = 1 - p$
.





In other words, to take
 $2k$
steps of this random walk, we take a sequence of
$2k$
steps of this random walk, we take a sequence of
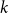 $k$
random rotations, then flip
$k$
random rotations, then flip
 $k$
weighted coins to decide whether to insert a reflection between each pair of random rotations.
$k$
weighted coins to decide whether to insert a reflection between each pair of random rotations.
Say
 $i$
is even; we compute the singular value
$i$
is even; we compute the singular value
 $\sigma _i$
. In matrix form the operator
$\sigma _i$
. In matrix form the operator
 $*(Q_*\mu _i)$
on
$*(Q_*\mu _i)$
on
 $L^2(\mathbb{Z}/2\mathbb{Z}) \cong \mathbb{R}^2$
is given by
$L^2(\mathbb{Z}/2\mathbb{Z}) \cong \mathbb{R}^2$
is given by
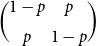 $\bigg(\begin{matrix} 1 - p & p \\ p & 1 - p \end{matrix}\bigg)$
. It is symmetric, so the singular values are just the absolute values of the eigenvalues. The vector
$\bigg(\begin{matrix} 1 - p & p \\ p & 1 - p \end{matrix}\bigg)$
. It is symmetric, so the singular values are just the absolute values of the eigenvalues. The vector
 $\bigg(\begin{matrix} 1 \\ -1 \end{matrix}\bigg)$
is a
$\bigg(\begin{matrix} 1 \\ -1 \end{matrix}\bigg)$
is a
 $(1 - 2p)$
-eigenvector. Thus, the singular values of
$(1 - 2p)$
-eigenvector. Thus, the singular values of
 $*\mu _i$
are 1 and
$*\mu _i$
are 1 and
 $|1 - 2p|$
, so
$|1 - 2p|$
, so
 $\sigma _i = |1 - 2p|$
. Theorem 2.1 says that
$\sigma _i = |1 - 2p|$
. Theorem 2.1 says that
 \begin{equation*} ||\mu _1 * \dots * \mu _{2k} - \pi ||_{L^2}^2 \leq \sigma ^k + |1 - 2p|^k. \end{equation*}
\begin{equation*} ||\mu _1 * \dots * \mu _{2k} - \pi ||_{L^2}^2 \leq \sigma ^k + |1 - 2p|^k. \end{equation*}
In particular, if
 $p = 1/2$
, the random walk mixes on
$p = 1/2$
, the random walk mixes on
 $D_{2n}$
half as fast as the
$D_{2n}$
half as fast as the
 $\mu$
-random walk mixes on
$\mu$
-random walk mixes on
 $\langle r\rangle \cong \mathbb{Z}/n\mathbb{Z}$
.
$\langle r\rangle \cong \mathbb{Z}/n\mathbb{Z}$
.
Although Theorem 2.1 makes weaker assumptions on the subgroups than Theorem 1.1, it is not possible to fully remove the normality assumption, as the following example shows:
Example 2.3. Consider the alternating group
 $A_5$
. Recall that
$A_5$
. Recall that
 $A_5$
is generated by the 3-cycles
$A_5$
is generated by the 3-cycles
 $(1\; 2\; 3), (1\; 2\; 4), (1\; 2\; 5)$
.
$(1\; 2\; 3), (1\; 2\; 4), (1\; 2\; 5)$
.
Consider the following three-step time-inhomogeneous “random walk” on
 $A_5$
:
$A_5$
:
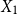 $X_1$
is uniformly distributed on
$X_1$
is uniformly distributed on
 $\langle (1\; 2\; 3)\rangle$
,
$\langle (1\; 2\; 3)\rangle$
,
 $X_2$
is uniformly distributed on
$X_2$
is uniformly distributed on
 $\langle (1\; 2\; 4)\rangle$
, and
$\langle (1\; 2\; 4)\rangle$
, and
 $X_3$
is uniformly distributed on
$X_3$
is uniformly distributed on
 $\langle (1\;2\;5)\rangle$
. We wish to understand the random element
$\langle (1\;2\;5)\rangle$
. We wish to understand the random element
 $X_1X_2X_3 \in A_5$
.
$X_1X_2X_3 \in A_5$
.
The step distributions
 $\mu _1, \mu _2, \mu _3$
on the respective cyclic groups all have second-largest singular value zero. So, if the conclusion of Theorem 2.1 held in this situation, one might expect that
$\mu _1, \mu _2, \mu _3$
on the respective cyclic groups all have second-largest singular value zero. So, if the conclusion of Theorem 2.1 held in this situation, one might expect that
 $X_1X_2X_3$
is uniformly distributed on
$X_1X_2X_3$
is uniformly distributed on
 $A_5$
. However, this is not the case. For instance, if
$A_5$
. However, this is not the case. For instance, if
 $X_1X_2X_3$
were uniform on
$X_1X_2X_3$
were uniform on
 $A_5$
, then
$A_5$
, then
 $X_1X_2X_3$
would map
$X_1X_2X_3$
would map
 $3$
to
$3$
to
 $4$
with probability
$4$
with probability
 $1/5$
. But in fact,
$1/5$
. But in fact,
 $X_1X_2X_3$
maps
$X_1X_2X_3$
maps
 $3$
to
$3$
to
 $4$
with probability zero (because
$4$
with probability zero (because
 $X_2X_3$
fixes
$X_2X_3$
fixes
 $3$
with probability 1, while
$3$
with probability 1, while
 $X_1$
can only map
$X_1$
can only map
 $3$
to
$3$
to
 $1$
,
$1$
,
 $2$
, or
$2$
, or
 $3$
with positive probability).
$3$
with positive probability).
The essential obstruction to mixing in this case is evidently related to noncommutativity. The image of
 $3$
under
$3$
under
 $X_1X_2X_3$
is restricted because the only one of
$X_1X_2X_3$
is restricted because the only one of
 $X_1$
,
$X_1$
,
 $X_2$
, and
$X_2$
, and
 $X_3$
that can move
$X_3$
that can move
 $3$
happens at the end of the sequence. What is really happening here is that even though the distribution of
$3$
happens at the end of the sequence. What is really happening here is that even though the distribution of
 $X_1$
is uniform on each coset of
$X_1$
is uniform on each coset of
 $\langle (1\; 2\; 3)\rangle$
, multiplication by
$\langle (1\; 2\; 3)\rangle$
, multiplication by
 $X_2$
destroys this property. We need some normality assumption on the subgroups involved so that taking additional random walk steps does not erase progress we have already made toward the uniform distribution.
$X_2$
destroys this property. We need some normality assumption on the subgroups involved so that taking additional random walk steps does not erase progress we have already made toward the uniform distribution.
The proof of Theorem 2.1 mainly consists of linear algebra. When a group
 $G$
is finite, we can view measures on
$G$
is finite, we can view measures on
 $G$
as finite tuples of numbers, i.e., as vectors in
$G$
as finite tuples of numbers, i.e., as vectors in
 $\mathbb{R}^G$
. We start by defining some notation describing this picture.
$\mathbb{R}^G$
. We start by defining some notation describing this picture.
Consider the space
 $\mathcal{M} = L^2(G)$
of
$\mathcal{M} = L^2(G)$
of
 $\mathbb{R}$
-valued functions on a finite group
$\mathbb{R}$
-valued functions on a finite group
 $G$
. Since
$G$
. Since
 $G$
is finite,
$G$
is finite,
 $\mathcal{M} \cong \mathbb{R}^G$
(with the Euclidean norm). Let
$\mathcal{M} \cong \mathbb{R}^G$
(with the Euclidean norm). Let
 $\mathcal{M}_0 = \{\nu \in \mathcal{M} \mid \nu (G) = 0\}$
. Let
$\mathcal{M}_0 = \{\nu \in \mathcal{M} \mid \nu (G) = 0\}$
. Let
 $\mathcal{P} \subseteq \mathcal{M}$
be the set of signed measures
$\mathcal{P} \subseteq \mathcal{M}$
be the set of signed measures
 $\nu$
on
$\nu$
on
 $G$
with
$G$
with
 $\nu (G) = 1$
. Note that
$\nu (G) = 1$
. Note that
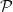 $\mathcal{P}$
and
$\mathcal{P}$
and
 $\mathcal{M}$
are parallel affine hyperplanes in
$\mathcal{M}$
are parallel affine hyperplanes in
 $\mathbb{R}^G$
. Probability measures on
$\mathbb{R}^G$
. Probability measures on
 $G$
are points in the simplex formed by the part of
$G$
are points in the simplex formed by the part of
 $\mathcal{P}$
in the positive orthant. The orthogonal complement to
$\mathcal{P}$
in the positive orthant. The orthogonal complement to
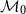 $\mathcal{M}_0$
is the line spanned by the uniform probability measure
$\mathcal{M}_0$
is the line spanned by the uniform probability measure
 $\pi$
on
$\pi$
on
 $G$
, and
$G$
, and
 $\operatorname {span}\{\pi \}$
intersects
$\operatorname {span}\{\pi \}$
intersects
 $\mathcal{P}$
at
$\mathcal{P}$
at
 $\pi$
and nowhere else.
$\pi$
and nowhere else.
Any measure
 $\mu _i$
on
$\mu _i$
on
 $G$
acts by on
$G$
acts by on
 $\mathcal{M}$
by convolution on the right. If
$\mathcal{M}$
by convolution on the right. If
 $\mu _i$
is a probability measure, the convolution operator
$\mu _i$
is a probability measure, the convolution operator
 $M_i\colon \nu \mapsto \nu *\mu _i$
also sends
$M_i\colon \nu \mapsto \nu *\mu _i$
also sends
 $\mathcal{P}$
into itself. The following lemma tells us that, in this case,
$\mathcal{P}$
into itself. The following lemma tells us that, in this case,
 $M_i$
contracts the distance between points of
$M_i$
contracts the distance between points of
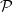 $\mathcal{P}$
and
$\mathcal{P}$
and
 $\pi$
.
$\pi$
.
Lemma 2.4.
Let
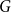 $G$
be any finite group and
$G$
be any finite group and
 $\mu$
a probability measure on
$\mu$
a probability measure on
 $G$
. Let
$G$
. Let
 $M$
be the convolution operator
$M$
be the convolution operator
 $\nu \mapsto \nu * \mu$
and let
$\nu \mapsto \nu * \mu$
and let
 $\sigma$
be the second-largest singular value of
$\sigma$
be the second-largest singular value of
 $M$
on
$M$
on
 $L^2(G)$
.
$L^2(G)$
.
-
(1) If
$\nu$
is a signed measure on
$G$
, then
\begin{equation*} ||M\nu ||_{L^2} \leq ||\nu ||_{L^2}. \end{equation*}
-
(2) If
$\nu , \nu '$
are signed measures on
$G$
with
$\nu (G) = \nu '(G)$
, then
\begin{equation*} ||M\nu - M\nu '||_{L^2} \leq \sigma ||\nu - \nu '||_{L^2}. \end{equation*}







Proof. Part (1) is a case of Young’s convolution inequality for unimodular groups. To prove part (2), we will show that
 $\sigma$
is the
$\sigma$
is the
 $L^2$
operator norm of
$L^2$
operator norm of
 $M$
on the subspace of
$M$
on the subspace of
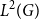 $L^2(G)$
consisting of signed measures with total mass 0.
$L^2(G)$
consisting of signed measures with total mass 0.
Let
 $M^*$
be the adjoint operator to
$M^*$
be the adjoint operator to
 $M$
. Observe that
$M$
. Observe that
 $M^*$
is also a convolution operator, given by
$M^*$
is also a convolution operator, given by
 $\nu \mapsto \nu * \check {\mu }$
, where
$\nu \mapsto \nu * \check {\mu }$
, where
 $\check {\mu }(g) = \mu (g^{-1})$
for
$\check {\mu }(g) = \mu (g^{-1})$
for
 $g \in G$
. Thus,
$g \in G$
. Thus,
 $M^*M$
is the convolution operator given by
$M^*M$
is the convolution operator given by
 $\nu \mapsto \nu * \mu * \check {\mu }$
. In particular,
$\nu \mapsto \nu * \mu * \check {\mu }$
. In particular,
 $M$
and
$M$
and
 $M^*M$
are each given by convolution with a probability measure, so they have a shared 1-eigenvector: the uniform measure
$M^*M$
are each given by convolution with a probability measure, so they have a shared 1-eigenvector: the uniform measure
 $\pi$
on
$\pi$
on
 $G$
. The largest singular value of a real matrix coincides with its
$G$
. The largest singular value of a real matrix coincides with its
 $L^2$
operator norm. By part (1), the operator norm of
$L^2$
operator norm. By part (1), the operator norm of
 $M$
is at most 1, so the largest eigenvalue of
$M$
is at most 1, so the largest eigenvalue of
 $M^*M$
is exactly 1. Let
$M^*M$
is exactly 1. Let
 $L^2(G)_0 = \operatorname {span}\{\pi \}^\perp$
. Since
$L^2(G)_0 = \operatorname {span}\{\pi \}^\perp$
. Since
 $\pi$
is an eigenvector of
$\pi$
is an eigenvector of
 $M$
, the operator
$M$
, the operator
 $M$
restricts to an operator on
$M$
restricts to an operator on
 $L^2(G)_0$
, and since
$L^2(G)_0$
, and since
 $(M|_{L^2(G)_0})^*(M|_{L^2(G)_0}) = (M^*M)|_{L^2(G)_0}$
, the singular values of
$(M|_{L^2(G)_0})^*(M|_{L^2(G)_0}) = (M^*M)|_{L^2(G)_0}$
, the singular values of
 $M|_{L^2(G)_0}$
are the singular values of
$M|_{L^2(G)_0}$
are the singular values of
 $M$
with a copy of 1 (the largest singular value of
$M$
with a copy of 1 (the largest singular value of
 $M$
) excluded. Thus, the operator norm and largest singular value of
$M$
) excluded. Thus, the operator norm and largest singular value of
 $M|_{L^2(G)_0}$
is the second-largest singular value of
$M|_{L^2(G)_0}$
is the second-largest singular value of
 $M$
, which is
$M$
, which is
 $\sigma$
. If
$\sigma$
. If
 $\nu (G) = \nu '(G)$
, then
$\nu (G) = \nu '(G)$
, then
 $\nu - \nu ' \in L^2(H)_0$
, so
$\nu - \nu ' \in L^2(H)_0$
, so
 \begin{equation*} ||M(\nu - \nu ')||_{L^2} \leq \sigma ||\nu - \nu '||_{L^2}. \end{equation*}
\begin{equation*} ||M(\nu - \nu ')||_{L^2} \leq \sigma ||\nu - \nu '||_{L^2}. \end{equation*}
Remark 2.5. When the support of
 $\mu$
does not generate
$\mu$
does not generate
 $G$
, the conclusion of Lemma 2.4(2) still holds. However, we have
$G$
, the conclusion of Lemma 2.4(2) still holds. However, we have
 $\sigma = 1$
, so Lemma 2.4(2) gives no useful information. For this reason, in Theorem 2.1, we write
$\sigma = 1$
, so Lemma 2.4(2) gives no useful information. For this reason, in Theorem 2.1, we write
 $I_j = \{i \mid \langle \operatorname {supp}(\tilde {Q}_{j-1})_*\mu _i \rangle = H_j\}$
rather than
$I_j = \{i \mid \langle \operatorname {supp}(\tilde {Q}_{j-1})_*\mu _i \rangle = H_j\}$
rather than
 $I_j = \{i \mid \operatorname {supp}(\tilde {Q}_{j-1})_*\mu _i \subseteq H_j\}$
.
$I_j = \{i \mid \operatorname {supp}(\tilde {Q}_{j-1})_*\mu _i \subseteq H_j\}$
.
The second part of Lemma 2.4 implies that if the support of
 $\mu _i$
generates
$\mu _i$
generates
 $G$
and
$G$
and
 $\nu$
is a probability measure, then
$\nu$
is a probability measure, then
 $||M_i\nu - \pi ||_{L^2} \leq \sigma _i||\nu - \pi ||_{L^2}$
, so applying
$||M_i\nu - \pi ||_{L^2} \leq \sigma _i||\nu - \pi ||_{L^2}$
, so applying
 $M_i$
to a probability measure
$M_i$
to a probability measure
 $n$
times contracts the distance to
$n$
times contracts the distance to
 $\pi$
by a factor of
$\pi$
by a factor of
 $\sigma _i^n$
. More generally, if the support of each
$\sigma _i^n$
. More generally, if the support of each
 $\mu$
generates
$\mu$
generates
 $G$
, then applying any combination of
$G$
, then applying any combination of
 $M_i$
in any order contracts the distance to
$M_i$
in any order contracts the distance to
 $\pi$
by the appropriate product of
$\pi$
by the appropriate product of
 $\sigma _i$
factors. However, when the support of
$\sigma _i$
factors. However, when the support of
 $\mu _i$
is contained in a proper subgroup of
$\mu _i$
is contained in a proper subgroup of
 $G$
, the second-largest singular value of
$G$
, the second-largest singular value of
 $M_i$
as an operator on
$M_i$
as an operator on
 $\mathcal{M}$
is always 1. In this case, Lemma 2.4(2) applied to
$\mathcal{M}$
is always 1. In this case, Lemma 2.4(2) applied to
 $G$
gives no useful information.
$G$
gives no useful information.
The key idea in the proof of Theorem 2.1 is that even though we cannot say outright that applying the operator
 $M_i$
moves a probability measure closer to uniform, we will show in Lemma 2.8 that
$M_i$
moves a probability measure closer to uniform, we will show in Lemma 2.8 that
 $M_i$
moves a probability measure closer to some (explicit) subspace of
$M_i$
moves a probability measure closer to some (explicit) subspace of
 $\mathcal{M}$
containing
$\mathcal{M}$
containing
 $\pi$
. This subspace depends on the subgroup generated by the support of
$\pi$
. This subspace depends on the subgroup generated by the support of
 $\mu _i$
. If we choose enough subspaces that their intersection is just
$\mu _i$
. If we choose enough subspaces that their intersection is just
 $\{\pi \}$
, then we will be able to show that successive application of different
$\{\pi \}$
, then we will be able to show that successive application of different
 $M_i$
’s moves a probability measure closer to that intersection, that is, to the uniform probability measure. The condition that our chosen subspaces intersect in
$M_i$
’s moves a probability measure closer to that intersection, that is, to the uniform probability measure. The condition that our chosen subspaces intersect in
 $\{\pi \}$
is exactly the condition
$\{\pi \}$
is exactly the condition
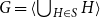 $G = \langle \bigcup _{H \in S} H\rangle$
in Theorem 1.1, or the condition that
$G = \langle \bigcup _{H \in S} H\rangle$
in Theorem 1.1, or the condition that
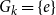 $G_k = \{e\}$
in Theorem 2.1.
$G_k = \{e\}$
in Theorem 2.1.
For each subgroup
 $H \leq G$
, let
$H \leq G$
, let
 $\mathcal{M}_H \subseteq \mathcal{M}$
be the space of functions on
$\mathcal{M}_H \subseteq \mathcal{M}$
be the space of functions on
 $\mathcal{M}$
which are uniform on each left coset of
$\mathcal{M}$
which are uniform on each left coset of
 $H$
(i.e., for
$H$
(i.e., for
 $\nu \in \mathcal{M}_H$
and
$\nu \in \mathcal{M}_H$
and
 $g_1, g_2 \in G$
with
$g_1, g_2 \in G$
with
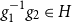 $g_1^{-1}g_2 \in H$
,
$g_1^{-1}g_2 \in H$
,
 $\nu (g_1) = \nu (g_2)$
). As
$\nu (g_1) = \nu (g_2)$
). As
 $H$
ranges over enough subgroups of
$H$
ranges over enough subgroups of
 $G$
, these subspaces
$G$
, these subspaces
 $\mathcal{M}_H$
are precisely the subspaces we want the
$\mathcal{M}_H$
are precisely the subspaces we want the
 $M_i$
’s to move a measure closer to.
$M_i$
’s to move a measure closer to.
We now give two easy lemmas which will help us work with each subspace
 $\mathcal{M}_H$
concretely.
$\mathcal{M}_H$
concretely.
Lemma 2.6.
Let
 $G$
be a finite group and
$G$
be a finite group and
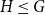 $H \leq G$
be a subgroup. Let
$H \leq G$
be a subgroup. Let
 $\nu \in \mathcal{M}$
. Let
$\nu \in \mathcal{M}$
. Let
 $\tilde {\nu } \in \mathcal{M}_H$
be the signed measure on
$\tilde {\nu } \in \mathcal{M}_H$
be the signed measure on
 $G$
given by
$G$
given by
 $\tilde {\nu }(gh) = \frac {\nu (gH)}{|H|}$
for
$\tilde {\nu }(gh) = \frac {\nu (gH)}{|H|}$
for
 $h \in H$
. Then
$h \in H$
. Then
 $\tilde {\nu }$
is the orthogonal projection of
$\tilde {\nu }$
is the orthogonal projection of
 $\nu$
onto the subspace
$\nu$
onto the subspace
 $\mathcal{M}_H$
of
$\mathcal{M}_H$
of
 $\mathcal{M}$
. In particular,
$\mathcal{M}$
. In particular,
 $d_{L^2}(\nu , \mathcal{M}_H) = ||\nu - \tilde {\nu }||_{L^2}$
.
$d_{L^2}(\nu , \mathcal{M}_H) = ||\nu - \tilde {\nu }||_{L^2}$
.
Proof. We have decompositions
 \begin{equation*} \mathcal{M}_H = \bigoplus _{gH \in G/H} \operatorname {span}\{\pi _{gH}\} \subset \bigoplus _{gH \in G/H} L^2(gH) = \mathcal{M}, \end{equation*}
\begin{equation*} \mathcal{M}_H = \bigoplus _{gH \in G/H} \operatorname {span}\{\pi _{gH}\} \subset \bigoplus _{gH \in G/H} L^2(gH) = \mathcal{M}, \end{equation*}
where
 $\pi _{gH} \in L^2(gH)$
is given by
$\pi _{gH} \in L^2(gH)$
is given by
 $\pi (gh) = 1/\sqrt {|H|}$
for all
$\pi (gh) = 1/\sqrt {|H|}$
for all
 $h \in H$
. The projection operator
$h \in H$
. The projection operator
 $\mathcal{M} \to \mathcal{M}_H$
decomposes as a direct sum of projection operators, one for each coset of
$\mathcal{M} \to \mathcal{M}_H$
decomposes as a direct sum of projection operators, one for each coset of
 $H$
. In
$H$
. In
 $L^2(gH)$
, projection onto
$L^2(gH)$
, projection onto
 $\operatorname {span}\{\pi _{gH}\}$
is given by inner product with
$\operatorname {span}\{\pi _{gH}\}$
is given by inner product with
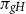 $\pi _{gH}$
, and we have
$\pi _{gH}$
, and we have
 $\left \langle \nu |_{gH},\pi _{gH}\right \rangle \pi _{gH} = \tilde {\nu }|_{gH}$
, which means the projection of
$\left \langle \nu |_{gH},\pi _{gH}\right \rangle \pi _{gH} = \tilde {\nu }|_{gH}$
, which means the projection of
 $\nu$
onto
$\nu$
onto
 $\mathcal{M}_H$
is
$\mathcal{M}_H$
is
 $\tilde {\nu }$
.
$\tilde {\nu }$
.
Lemma 2.7.
Let
 $G$
be a finite group and
$G$
be a finite group and
 $H$
a normal subgroup of
$H$
a normal subgroup of
 $G$
. Let
$G$
. Let
 $\mu \in L^2(G)$
. Then
$\mu \in L^2(G)$
. Then
 $*\mu \colon L^2(G) \to L^2(G)$
preserves
$*\mu \colon L^2(G) \to L^2(G)$
preserves
 $\mathcal{M}_H$
, i.e.,
$\mathcal{M}_H$
, i.e.,
 $\mathcal{M}_H * \mu \subseteq \mathcal{M}_H$
.
$\mathcal{M}_H * \mu \subseteq \mathcal{M}_H$
.
Proof. Suppose
 $\nu \in \mathcal{M}_H$
, so
$\nu \in \mathcal{M}_H$
, so
 $\nu$
is uniform on each left coset of
$\nu$
is uniform on each left coset of
 $H$
. Since
$H$
. Since
 $H$
is normal, its left and right cosets coincide, so
$H$
is normal, its left and right cosets coincide, so
 $\nu$
is uniform on each right coset of
$\nu$
is uniform on each right coset of
 $H$
. Say
$H$
. Say
 $X \sim \nu$
and
$X \sim \nu$
and
 $Y \sim \mu$
are independent, so
$Y \sim \mu$
are independent, so
 $\nu * \mu$
is the distribution of
$\nu * \mu$
is the distribution of
 $XY$
. We have
$XY$
. We have
 $\mathbb{P}[X = hg] = \mathbb{P}[X = h'g]$
for all
$\mathbb{P}[X = hg] = \mathbb{P}[X = h'g]$
for all
 $h, h' \in H$
and
$h, h' \in H$
and
 $g \in G$
. For
$g \in G$
. For
 $y \in G$
, we therefore have
$y \in G$
, we therefore have
 \begin{equation*} \mathbb{P}[XY = hg \mid Y = y] = \mathbb{P}[X = hgy^{-1}] = \mathbb{P}[X = h'gy^{-1}] = \mathbb{P}[XY = h'g \mid Y = y] \end{equation*}
\begin{equation*} \mathbb{P}[XY = hg \mid Y = y] = \mathbb{P}[X = hgy^{-1}] = \mathbb{P}[X = h'gy^{-1}] = \mathbb{P}[XY = h'g \mid Y = y] \end{equation*}
for all
 $h, h' \in H$
and
$h, h' \in H$
and
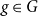 $g \in G$
. Summing over
$g \in G$
. Summing over
 $y$
shows
$y$
shows
 $(\nu * \mu )(hg) = (\nu * \mu )(h'g)$
for all
$(\nu * \mu )(hg) = (\nu * \mu )(h'g)$
for all
 $h, h' \in H$
and
$h, h' \in H$
and
 $g \in G$
. So,
$g \in G$
. So,
 $\nu * \mu$
is uniform on right cosets (hence also left cosets) of
$\nu * \mu$
is uniform on right cosets (hence also left cosets) of
 $H$
and
$H$
and
 $\nu * \mu \in \mathcal{M}_H$
.
$\nu * \mu \in \mathcal{M}_H$
.
The previous two lemmas will be used together to show that convolution with a probability measure brings another probability measure closer to each subspace
 $\mathcal{M}_H \subseteq \mathcal{M}$
(corresponding to a normal subgroup
$\mathcal{M}_H \subseteq \mathcal{M}$
(corresponding to a normal subgroup
 $H \trianglelefteq G$
). Lemma 2.6 allows us to relate the distance between a measure
$H \trianglelefteq G$
). Lemma 2.6 allows us to relate the distance between a measure
 $\nu$
and the subspace
$\nu$
and the subspace
 $\mathcal{M}_H$
to the distance between
$\mathcal{M}_H$
to the distance between
 $\nu$
and another measure
$\nu$
and another measure
 $\widetilde {\nu }$
; we will then use Lemma 2.4 to show that this distance is contracted by convolving with a probability measure
$\widetilde {\nu }$
; we will then use Lemma 2.4 to show that this distance is contracted by convolving with a probability measure
 $\mu$
. Then Lemma 2.7 is used to show that the resulting contracted distance bounds the difference between the new convolved probability measure
$\mu$
. Then Lemma 2.7 is used to show that the resulting contracted distance bounds the difference between the new convolved probability measure
 $\nu * \mu$
and the same subspace
$\nu * \mu$
and the same subspace
 $\mathcal{M}_H$
. As a consequence, we obtain a bound on the distance between a convolution of many probability measures and the subspace
$\mathcal{M}_H$
. As a consequence, we obtain a bound on the distance between a convolution of many probability measures and the subspace
 $\mathcal{M}_H$
:
$\mathcal{M}_H$
:
Lemma 2.8.
Let
 $G$
be a finite group and
$G$
be a finite group and
 $H$
a normal subgroup of
$H$
a normal subgroup of
 $G$
. Let
$G$
. Let
 $\mu _1, \dots , \mu _n$
be probability measures on
$\mu _1, \dots , \mu _n$
be probability measures on
 $G$
and
$G$
and
 $\nu _n = \mu _1 * \dots * \mu _n$
. Let
$\nu _n = \mu _1 * \dots * \mu _n$
. Let
 $I_H = \{1 \leq i \leq n \mid \langle \operatorname {supp} \mu _i\rangle = H\}$
. For each
$I_H = \{1 \leq i \leq n \mid \langle \operatorname {supp} \mu _i\rangle = H\}$
. For each
 $i \in I_H$
, let
$i \in I_H$
, let
 $\sigma _i$
be the second-largest singular value of
$\sigma _i$
be the second-largest singular value of
 $*\mu _i$
on
$*\mu _i$
on
 $H$
. Let
$H$
. Let
 $\mathcal{M}_H \subseteq L^2(G)$
be the set of signed measures on
$\mathcal{M}_H \subseteq L^2(G)$
be the set of signed measures on
 $G$
that are uniform on left cosets of
$G$
that are uniform on left cosets of
 $H$
. Then
$H$
. Then
 \begin{equation*} d_{L^2}(\nu _n, \mathcal{M}_H)^2 \leq \frac {|G| - 1}{|G|}\prod _{i \in I_H} \sigma _i^2. \end{equation*}
\begin{equation*} d_{L^2}(\nu _n, \mathcal{M}_H)^2 \leq \frac {|G| - 1}{|G|}\prod _{i \in I_H} \sigma _i^2. \end{equation*}
Proof. We say
 $\nu _0 = \delta _e$
is the Dirac measure on the identity of
$\nu _0 = \delta _e$
is the Dirac measure on the identity of
 $G$
, so that
$G$
, so that
 $\nu _{m+1} = \nu _m * \mu _{m+1}$
for all
$\nu _{m+1} = \nu _m * \mu _{m+1}$
for all
 $0 \leq m \lt n$
.
$0 \leq m \lt n$
.
We will show the following statement by induction on
 $n$
:
$n$
:
 \begin{equation} d_{L^2}(\nu _n, \mathcal{M}_H)^2 \leq \frac {|G| - 1}{|G|}\prod _{\substack {i \in I_H \\ i \leq n}} \sigma _i^2. \end{equation}
\begin{equation} d_{L^2}(\nu _n, \mathcal{M}_H)^2 \leq \frac {|G| - 1}{|G|}\prod _{\substack {i \in I_H \\ i \leq n}} \sigma _i^2. \end{equation}
First, we have
 $d_{L^2}(\delta _e, \mathcal{M}_H)^2 \leq ||\delta _e - \pi ||_{L^2}^2 = 1 - \frac {1}{|G|}$
. This proves
$d_{L^2}(\delta _e, \mathcal{M}_H)^2 \leq ||\delta _e - \pi ||_{L^2}^2 = 1 - \frac {1}{|G|}$
. This proves
 $P(0)$
.
$P(0)$
.
Now suppose
 $P(n)$
holds. Let
$P(n)$
holds. Let
 $\tilde {\nu }_n$
be the orthogonal projection of
$\tilde {\nu }_n$
be the orthogonal projection of
 $\nu _n$
onto
$\nu _n$
onto
 $\mathcal{M}_H$
, described explicitly in Lemma 2.6. Then note that
$\mathcal{M}_H$
, described explicitly in Lemma 2.6. Then note that
 $||\nu _n - \tilde {\nu }_n||_{L^2} = d_{L^2}(\nu _n, \mathcal{M}_H)$
.
$||\nu _n - \tilde {\nu }_n||_{L^2} = d_{L^2}(\nu _n, \mathcal{M}_H)$
.
There are two cases, depending on whether
 $n + 1 \in I_H$
:
$n + 1 \in I_H$
:
Suppose
 $\langle \operatorname {supp} \mu _{n+1} \rangle \neq H$
, so
$\langle \operatorname {supp} \mu _{n+1} \rangle \neq H$
, so
 $n + 1 \notin I_H$
. By Lemma 2.4(1),
$n + 1 \notin I_H$
. By Lemma 2.4(1),
 $||\nu _{n+1} - \tilde {\nu }_n*\mu _{n+1}||_{L^2} \leq ||\nu _n - \tilde {\nu }_n||_{L^2}$
.
$||\nu _{n+1} - \tilde {\nu }_n*\mu _{n+1}||_{L^2} \leq ||\nu _n - \tilde {\nu }_n||_{L^2}$
.
By Lemma 2.7, we have
 $\tilde {\nu }_n * \mu _{n+1} \in \mathcal{M}_H$
, and
$\tilde {\nu }_n * \mu _{n+1} \in \mathcal{M}_H$
, and
 \begin{equation*} d_{L^2}(\nu _{n+1}, \mathcal{M}_H) \leq ||\nu _{n+1} - \tilde {\nu }_n*\mu _{n+1}||_{L^2} \leq ||\nu _n - \tilde {\nu }_n||_{L^2} = d_{L^2}(\nu _n, \mathcal{M}_H). \end{equation*}
\begin{equation*} d_{L^2}(\nu _{n+1}, \mathcal{M}_H) \leq ||\nu _{n+1} - \tilde {\nu }_n*\mu _{n+1}||_{L^2} \leq ||\nu _n - \tilde {\nu }_n||_{L^2} = d_{L^2}(\nu _n, \mathcal{M}_H). \end{equation*}
Now suppose
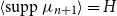 $\langle \operatorname {supp} \mu _{n+1} \rangle = H$
, so
$\langle \operatorname {supp} \mu _{n+1} \rangle = H$
, so
 $n + 1 \in I_H$
.
$n + 1 \in I_H$
.
For
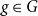 $g \in G$
, define
$g \in G$
, define
 $g_*\colon L^2(G) \to L^2(G)$
by
$g_*\colon L^2(G) \to L^2(G)$
by
 $g_*\nu (h) = \nu (g^{-1}h)$
. Note that
$g_*\nu (h) = \nu (g^{-1}h)$
. Note that
 $g_*$
is an automorphism of normed spaces, and for signed measures
$g_*$
is an automorphism of normed spaces, and for signed measures
 $\nu$
and
$\nu$
and
 $\mu$
, we have
$\mu$
, we have
 $g_*(\nu * \mu ) = g_*\nu * \mu$
. For each left coset
$g_*(\nu * \mu ) = g_*\nu * \mu$
. For each left coset
 $gH$
of
$gH$
of
 $H$
we have
$H$
we have
 \begin{align*} ||(\nu _n * \mu _{n+1})|_{gH} - (\tilde {\nu }_n * \mu _{n+1})|_{gH}||_{L^2(gH)} &= ||(g^{-1}_*(\nu _n * \mu _{n+1}))|_{H} - (g^{-1}_*(\tilde {\nu }_n * \mu _{n+1}))|_{H}||_{L^2(H)} \\ &= ||(g^{-1}_*\nu _n * \mu _{n+1})|_{H} - (g^{-1}_*\tilde {\nu }_n * \mu _{n+1})|_{H}||_{L^2(H)} \end{align*}
\begin{align*} ||(\nu _n * \mu _{n+1})|_{gH} - (\tilde {\nu }_n * \mu _{n+1})|_{gH}||_{L^2(gH)} &= ||(g^{-1}_*(\nu _n * \mu _{n+1}))|_{H} - (g^{-1}_*(\tilde {\nu }_n * \mu _{n+1}))|_{H}||_{L^2(H)} \\ &= ||(g^{-1}_*\nu _n * \mu _{n+1})|_{H} - (g^{-1}_*\tilde {\nu }_n * \mu _{n+1})|_{H}||_{L^2(H)} \end{align*}
Since
 $\mu _{n+1}$
is supported on a subset of
$\mu _{n+1}$
is supported on a subset of
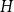 $H$
, for any
$H$
, for any
 $\nu \in L^2(G)$
we have
$\nu \in L^2(G)$
we have
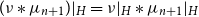 $(\nu * \mu _{n+1})|_{H} = \nu |_{H} * \mu _{n+1}|_H$
. Thus,
$(\nu * \mu _{n+1})|_{H} = \nu |_{H} * \mu _{n+1}|_H$
. Thus,
 \begin{equation*} ||(\nu _n * \mu _{n+1})|_{gH} - (\tilde {\nu }_n * \mu _{n+1})|_{gH}||_{L^2(gH)} = ||g^{-1}_*\nu _n|_{H} * \mu _{n+1}|_{H} - g^{-1}_*\tilde {\nu }_n|_{H} * \mu _{n+1}|_{H_j}||_{L^2(H)}. \end{equation*}
\begin{equation*} ||(\nu _n * \mu _{n+1})|_{gH} - (\tilde {\nu }_n * \mu _{n+1})|_{gH}||_{L^2(gH)} = ||g^{-1}_*\nu _n|_{H} * \mu _{n+1}|_{H} - g^{-1}_*\tilde {\nu }_n|_{H} * \mu _{n+1}|_{H_j}||_{L^2(H)}. \end{equation*}
By Lemma 2.6,
 $\tilde {\nu }_n|_{gH}$
is uniform on
$\tilde {\nu }_n|_{gH}$
is uniform on
 $gH$
with total mass
$gH$
with total mass
 $\nu _n(gH)$
, so
$\nu _n(gH)$
, so
 $g^{-1}_*\tilde {\nu }_n|_{H}$
is uniform on
$g^{-1}_*\tilde {\nu }_n|_{H}$
is uniform on
 $H$
with total mass
$H$
with total mass
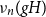 $\nu _n(gH)$
. Thus,
$\nu _n(gH)$
. Thus,
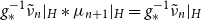 $g^{-1}_*\tilde {\nu }_n|_{H} * \mu _{n+1}|_{H} = g^{-1}_*\tilde {\nu }_n|_{H}$
.
$g^{-1}_*\tilde {\nu }_n|_{H} * \mu _{n+1}|_{H} = g^{-1}_*\tilde {\nu }_n|_{H}$
.
Applying Lemma 2.4(2) on
 $H$
, we get
$H$
, we get
 \begin{align*} ||g^{-1}_*\nu _n|_{H} * \mu _{n+1}|_{H} - g^{-1}_*\tilde {\nu }_n|_{H}||_{L^2(H)} &\leq \sigma _{n+1}||g^{-1}_*\nu _n|_{H} - g^{-1}_*\tilde {\nu }_n|_{H}||_{L^2(H)} \\ &= \sigma _{n+1}||(\nu _n - \tilde {\nu }_n)|_{gH}||_{L^2(gH)}. \end{align*}
\begin{align*} ||g^{-1}_*\nu _n|_{H} * \mu _{n+1}|_{H} - g^{-1}_*\tilde {\nu }_n|_{H}||_{L^2(H)} &\leq \sigma _{n+1}||g^{-1}_*\nu _n|_{H} - g^{-1}_*\tilde {\nu }_n|_{H}||_{L^2(H)} \\ &= \sigma _{n+1}||(\nu _n - \tilde {\nu }_n)|_{gH}||_{L^2(gH)}. \end{align*}
Adding up over cosets of
 $H$
gives
$H$
gives
 \begin{equation*} ||\nu _{n+1} - \tilde {\nu }_n||_{L^2(G)} \leq \sigma _{n+1}||\nu _n - \tilde {\nu }_n||_{L^2(G)}. \end{equation*}
\begin{equation*} ||\nu _{n+1} - \tilde {\nu }_n||_{L^2(G)} \leq \sigma _{n+1}||\nu _n - \tilde {\nu }_n||_{L^2(G)}. \end{equation*}
Hence,
 \begin{equation*} d_{L^2}(\nu _{n+1}, \mathcal{M}_{H}) \leq ||\nu _{n+1} - \tilde {\nu }_n||_{L^2(G)} \leq \sigma _{n+1}||\nu _n - \tilde {\nu }_n||_{L^2(G)} = \sigma _{n+1}d_{L^2}(\nu _n, \mathcal{M}_{H}). \end{equation*}
\begin{equation*} d_{L^2}(\nu _{n+1}, \mathcal{M}_{H}) \leq ||\nu _{n+1} - \tilde {\nu }_n||_{L^2(G)} \leq \sigma _{n+1}||\nu _n - \tilde {\nu }_n||_{L^2(G)} = \sigma _{n+1}d_{L^2}(\nu _n, \mathcal{M}_{H}). \end{equation*}
By induction, we get
 \begin{equation*} d_{L^2}(\nu _n, \mathcal{M}_{H})^2 \leq \frac {|G| - 1}{|G|}\prod _{\substack {i \in I_{H} \\ i \leq n}} \sigma _i^2. \end{equation*}
\begin{equation*} d_{L^2}(\nu _n, \mathcal{M}_{H})^2 \leq \frac {|G| - 1}{|G|}\prod _{\substack {i \in I_{H} \\ i \leq n}} \sigma _i^2. \end{equation*}
Note that if
 $H$
is a subgroup of
$H$
is a subgroup of
 $G$
and
$G$
and
 $P\colon G \twoheadrightarrow G/H$
is the projection onto the left coset space, then one can identify
$P\colon G \twoheadrightarrow G/H$
is the projection onto the left coset space, then one can identify
 $L^2(G/H)$
with
$L^2(G/H)$
with
 $\mathcal{M}_H$
as follows:
$\mathcal{M}_H$
as follows:
Lemma 2.9.
Let
 $G$
be a finite group and
$G$
be a finite group and
 $H$
a subgroup. Let
$H$
a subgroup. Let
 $\mathcal{M}_H \subset L^2(G)$
be the space of measures uniform on left cosets of
$\mathcal{M}_H \subset L^2(G)$
be the space of measures uniform on left cosets of
 $H$
. Let
$H$
. Let
 $P\colon G \twoheadrightarrow G/H$
send each element to the corresponding left coset of
$P\colon G \twoheadrightarrow G/H$
send each element to the corresponding left coset of
 $H$
. Then the map
$H$
. Then the map
 $\phi \colon L^2(G) \to L^2(G/H)$
sending
$\phi \colon L^2(G) \to L^2(G/H)$
sending
 $\mu$
to
$\mu$
to
 $|H|^{-1/2} P_*\nu$
restricts to an isometry of normed spaces
$|H|^{-1/2} P_*\nu$
restricts to an isometry of normed spaces
 $\phi |_{\mathcal{M}_H}\colon \mathcal{M}_H \cong L^2(G/H)$
. Moreover,
$\phi |_{\mathcal{M}_H}\colon \mathcal{M}_H \cong L^2(G/H)$
. Moreover,
 $(\phi |_{\mathcal{M}_H})^{-1}\circ \phi$
is the orthogonal projection map
$(\phi |_{\mathcal{M}_H})^{-1}\circ \phi$
is the orthogonal projection map
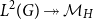 $L^2(G) \twoheadrightarrow \mathcal{M}_H$
.
$L^2(G) \twoheadrightarrow \mathcal{M}_H$
.
Proof. The map
 $\phi |_{\mathcal{M}_H}$
is norm-preserving because if
$\phi |_{\mathcal{M}_H}$
is norm-preserving because if
 $\nu$
is uniform on left cosets of
$\nu$
is uniform on left cosets of
 $H$
, then
$H$
, then
 $\nu (gH) = |H|\nu (g)$
for
$\nu (gH) = |H|\nu (g)$
for
 $g \in G$
. Indeed, we have
$g \in G$
. Indeed, we have
 \begin{align*} |||H|^{-1/2} P_*\nu ||_{L^2(G/H)} &= \frac {1}{|H|}\sum _{gH \in G/H} |\nu (gH)|^2 = \frac {1}{|H|^2} \sum _{g \in G} |\nu (gH)|^2 = \frac {1}{|H|^2}\sum _{g \in G} |H|^2 |\nu (g)|^2\nonumber \\ &= ||\nu ||_{L^2(G)}. \end{align*}
\begin{align*} |||H|^{-1/2} P_*\nu ||_{L^2(G/H)} &= \frac {1}{|H|}\sum _{gH \in G/H} |\nu (gH)|^2 = \frac {1}{|H|^2} \sum _{g \in G} |\nu (gH)|^2 = \frac {1}{|H|^2}\sum _{g \in G} |H|^2 |\nu (g)|^2\nonumber \\ &= ||\nu ||_{L^2(G)}. \end{align*}
The inverse map
 $(\phi |_{\mathcal{M}_H})^{-1}$
is given by
$(\phi |_{\mathcal{M}_H})^{-1}$
is given by
 $(\phi |_{\mathcal{M}_H})^{-1}(\mu )(g) = \mu (gH)/|H|$
. The fact that
$(\phi |_{\mathcal{M}_H})^{-1}(\mu )(g) = \mu (gH)/|H|$
. The fact that
 $(\phi |_{\mathcal{M}_H})^{-1}\circ \phi$
is the orthogonal projection map
$(\phi |_{\mathcal{M}_H})^{-1}\circ \phi$
is the orthogonal projection map
 $L^2(G) \to \mathcal{M}_H$
follows from Lemma 2.6.
$L^2(G) \to \mathcal{M}_H$
follows from Lemma 2.6.
Identifying
 $L^2(G/H)$
with
$L^2(G/H)$
with
 $\mathcal{M}_H$
will allow us to prove Theorem 2.1 by induction. Using Lemma 2.8, we can say that a random walk approaches the subspace
$\mathcal{M}_H$
will allow us to prove Theorem 2.1 by induction. Using Lemma 2.8, we can say that a random walk approaches the subspace
 $\mathcal{M}_H$
. Then, we can consider its projection onto
$\mathcal{M}_H$
. Then, we can consider its projection onto
 $\mathcal{M}_H$
as a random walk on
$\mathcal{M}_H$
as a random walk on
 $G/H$
. This allows us to ignore all random walk steps supported in
$G/H$
. This allows us to ignore all random walk steps supported in
 $H$
. The key ingredient that allows us to combine Lemma 2.8 with the inductive hypothesis is the following lemma:
$H$
. The key ingredient that allows us to combine Lemma 2.8 with the inductive hypothesis is the following lemma:
Lemma 2.10.
Let
 $G$
be a finite group and
$G$
be a finite group and
 $H \leq G$
. Let
$H \leq G$
. Let
 $\pi$
be the uniform distribution on
$\pi$
be the uniform distribution on
 $G$
and let
$G$
and let
 $\mu$
be any signed measure on
$\mu$
be any signed measure on
 $G$
. Let
$G$
. Let
 $P\colon G \twoheadrightarrow G/H$
be the set map sending each element of
$P\colon G \twoheadrightarrow G/H$
be the set map sending each element of
 $G$
to the corresponding left coset of
$G$
to the corresponding left coset of
 $H$
. Let
$H$
. Let
 $\mathcal{M}_H \subseteq L^2(G)$
be the set of signed measures uniform on left cosets of
$\mathcal{M}_H \subseteq L^2(G)$
be the set of signed measures uniform on left cosets of
 $H$
. Then
$H$
. Then
 \begin{equation*} ||\mu - \pi ||_{L^2(G)}^2 = \frac {1}{|H|}||P_* \mu - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \end{equation*}
\begin{equation*} ||\mu - \pi ||_{L^2(G)}^2 = \frac {1}{|H|}||P_* \mu - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \end{equation*}
Proof. Let
 $\tilde {\mu }$
be the orthogonal projection of
$\tilde {\mu }$
be the orthogonal projection of
 $\mu$
onto
$\mu$
onto
 $\mathcal{M}_H$
. By Lemma 2.6, we have
$\mathcal{M}_H$
. By Lemma 2.6, we have
 $P_*\mu = P_*\tilde {\mu }$
. Then
$P_*\mu = P_*\tilde {\mu }$
. Then
 \begin{align*} ||\mu - \pi ||_{L^2(G)}^2 &= ||\tilde {\mu } - \pi ||_{L^2(G)}^2 + ||\mu - \tilde {\mu }||_{L^2(G)}^2 \\ &= \frac {1}{|H|}||P_* \tilde {\mu } - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \\ &= \frac {1}{|H|}||P_* \mu - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \end{align*}
\begin{align*} ||\mu - \pi ||_{L^2(G)}^2 &= ||\tilde {\mu } - \pi ||_{L^2(G)}^2 + ||\mu - \tilde {\mu }||_{L^2(G)}^2 \\ &= \frac {1}{|H|}||P_* \tilde {\mu } - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \\ &= \frac {1}{|H|}||P_* \mu - P_* \pi ||_{L^2(G/H)}^2 + d_{L^2}(\mu , \mathcal{M}_H)^2 \end{align*}
The final lemma before the proof of Theorem 2.1 is a pair of facts about pushforwards to quotients:
Lemma 2.11.
Let
 $G$
be a finite group and
$G$
be a finite group and
 $H$
a normal subgroup. Let
$H$
a normal subgroup. Let
 $P\colon G \twoheadrightarrow G/H$
be the projection. Then:
$P\colon G \twoheadrightarrow G/H$
be the projection. Then:
-
(1) If
$\mu , \nu \in L^2(G)$
, we have
$P_*(\mu * \nu ) = P_*\mu * P_*\nu$
. -
(2) Suppose
$\mu \in L^2(G)$
and the second-largest singular value of
$*\mu$
on
$\langle \operatorname {supp} \mu \rangle$
is
$\sigma$
. Then the second-largest singular value of
$*(P_*\mu )$
on
$P(\langle \operatorname {supp} \mu \rangle )$
is at most
$\sigma$
.









Proof.
-
(1) We have
Since left cosets of
\begin{align*} P_*(\mu * \nu )(gH) &= \sum _{h \in H} (\mu * \nu )(gh) = \sum _{h \in H}\sum _{k \in G} \mu (k)\nu (k^{-1}gh)\nonumber \\ &= \sum _{kH \in G/H}\sum _{h \in H} \mu (kh)\nu (h^{-1}k^{-1}gH) \end{align*}
$H$
are right cosets too,
$h^{-1}k^{-1}gH = k^{-1}gH$
, so
\begin{equation*} P_*(\mu * \nu )(gH) = \sum _{kH \in G/H}\sum _{h \in H} \mu (kh)\nu (k^{-1}gH) = \sum _{kH \in G/H} \mu (kH)\nu (k^{-1}gH) = P_*\mu * P_*\nu . \end{equation*}
-
(2) By restricting to the projection
$\langle \operatorname {supp} \mu \rangle \twoheadrightarrow P(\langle \operatorname {supp} \mu \rangle )$
we may as well assume
$\langle \operatorname {supp} \mu \rangle = G$
.Recall (from the proof of Lemma 2.4(2)) that the second-largest singular value of
$*\mu$
is the operator norm of
$*\mu$
acting on the subspace
$L^2(G)_0$
of measures with total mass 0. Suppose
$\sigma '$
is the second-largest singular value of
$*(P_*\mu )$
. ThenLet
\begin{equation*} \sigma ' = \sup _{\substack {\nu \in L^2(G/H) \\ \nu (G/H) = 0}} \frac {||\nu * P_*\mu ||_{L^2(G/H)}}{||\nu ||_{L^2(G/H)}} \end{equation*}
$\mathcal{M}_H \subseteq L^2(G)$
be the space of signed measures uniform on cosets of
$H$
. By Lemma 2.9 and part (1) of this lemma, we haveThen by Lemma 2.9 again, we have
\begin{equation*} \sup _{\substack {\nu \in L^2(G/H) \\ \nu (G/H) = 0}} \frac {||\nu * P_*\mu ||_{L^2(G/H)}}{||\nu ||_{L^2(G/H)}} = \sup _{\substack {\tilde {\nu } \in \mathcal{M}_H \\ \tilde {\nu }(G) = 0}} \frac {||P_*\tilde {\nu } * P_*\mu ||_{L^2(G/H)}}{||\tilde {\nu }||_{L^2(G/H)}} = \sup _{\substack {\tilde {\nu } \in \mathcal{M}_H \\ \tilde {\nu }(G) = 0}} \frac {||P_*(\tilde {\nu } * \mu )||_{L^2(G/H)}}{||P_*\tilde {\nu }||_{L^2(G/H)}} \end{equation*}
\begin{equation*} \sigma ' = \sup _{\substack {\tilde {\nu } \in \mathcal{M}_H \\ \tilde {\nu }(G) = 0}} \frac {||P_*(\tilde {\nu } * \mu )||_{L^2(G/H)}}{||P_*\tilde {\nu }||_{L^2(G/H)}} = \sup _{\substack {\tilde {\nu } \in \mathcal{M}_H \\ \tilde {\nu }(G) = 0}} \frac {||\tilde {\nu } * \mu ||_{L^2(G)}}{||\tilde {\nu }||_{L^2(G)}} \leq \sup _{\substack {\tilde {\nu } \in L^2(G) \\ \tilde {\nu }(G) = 0}} \frac {||\tilde {\nu } * \mu ||_{L^2(G)}}{||\tilde {\nu }||_{L^2(G)}} = \sigma \end{equation*}












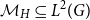



Proof of Theorem
2.1. We will prove the following statement by induction on
 $r$
:
$r$
:
 \begin{align} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 \leq \sum _{j = r + 1}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{align}
\begin{align} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 \leq \sum _{j = r + 1}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{align}
When
 $r = k$
, the right hand side of
$r = k$
, the right hand side of
 $P(r)$
is 0. Since both
$P(r)$
is 0. Since both
 $(\tilde {Q}_r)_* \nu _n$
and
$(\tilde {Q}_r)_* \nu _n$
and
 $(\tilde {Q}_r)_* \pi$
are the unique probability measure on
$(\tilde {Q}_r)_* \pi$
are the unique probability measure on
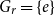 $G_r = \{e\}$
, the left hand side is also 0, so
$G_r = \{e\}$
, the left hand side is also 0, so
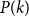 $P(k)$
holds.
$P(k)$
holds.
Now suppose
 $P(r + 1)$
holds. We will show
$P(r + 1)$
holds. We will show
 $P(r)$
holds.
$P(r)$
holds.
Since
 $(\tilde {Q}_r)_* \pi$
is the uniform distribution on
$(\tilde {Q}_r)_* \pi$
is the uniform distribution on
 $G_r$
, Lemma 2.10 applied to
$G_r$
, Lemma 2.10 applied to
 $G_r$
and
$G_r$
and
 $H_{r+1}$
says
$H_{r+1}$
says
 \begin{align*} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 &= \frac {1}{|H_{r+1}|}||(\tilde {Q}_{r+1})_* \nu _n - (\tilde {Q}_{r+1})_* \pi ||_{L^2(G_{r+1})}^2 + d_{L^2}((\tilde {Q}_r)_* \nu _n, \mathcal{M}_{H_{r+1}})^2 \end{align*}
\begin{align*} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 &= \frac {1}{|H_{r+1}|}||(\tilde {Q}_{r+1})_* \nu _n - (\tilde {Q}_{r+1})_* \pi ||_{L^2(G_{r+1})}^2 + d_{L^2}((\tilde {Q}_r)_* \nu _n, \mathcal{M}_{H_{r+1}})^2 \end{align*}
where
 $\mathcal{M}_{H_{r+1}}$
is the subspace of
$\mathcal{M}_{H_{r+1}}$
is the subspace of
 $L^2(G_r)$
consisting of measures uniform on cosets of
$L^2(G_r)$
consisting of measures uniform on cosets of
 $H_{r+1}$
. By the inductive hypothesis,
$H_{r+1}$
. By the inductive hypothesis,
 \begin{align*} \frac {1}{|H_{r+1}|}||(\tilde {Q}_{r+1})_* \nu _n - (\tilde {Q}_{r+1})_* \pi ||_{L^2(G_{r+1})}^2 &\leq \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_{r+1}||H_{r+1}|}\left (\prod _{i \in I_j} \sigma _i^2\right ) \\ &= \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{align*}
\begin{align*} \frac {1}{|H_{r+1}|}||(\tilde {Q}_{r+1})_* \nu _n - (\tilde {Q}_{r+1})_* \pi ||_{L^2(G_{r+1})}^2 &\leq \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_{r+1}||H_{r+1}|}\left (\prod _{i \in I_j} \sigma _i^2\right ) \\ &= \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{align*}
By Lemma 2.11(1), we have
 $(\tilde {Q}_r)_* \nu _n = (\tilde {Q}_r)_* \mu _1 * \dots * (\tilde {Q}_r)_* \mu _n$
, so by Lemma 2.8 applied to
$(\tilde {Q}_r)_* \nu _n = (\tilde {Q}_r)_* \mu _1 * \dots * (\tilde {Q}_r)_* \mu _n$
, so by Lemma 2.8 applied to
 $G_r$
,
$G_r$
,
 $H_{r+1}$
, and the measures
$H_{r+1}$
, and the measures
 $(\tilde {Q}_r)_* \mu _i$
, we get
$(\tilde {Q}_r)_* \mu _i$
, we get
 \begin{equation*} d_{L^2}((\tilde {Q}_r)_* \nu _n, \mathcal{M}_{H_{r+1}})^2 \leq \frac {|G_r| - 1}{|G_r|} \prod _{i \in I_{r + 1}} \sigma _i^2. \end{equation*}
\begin{equation*} d_{L^2}((\tilde {Q}_r)_* \nu _n, \mathcal{M}_{H_{r+1}})^2 \leq \frac {|G_r| - 1}{|G_r|} \prod _{i \in I_{r + 1}} \sigma _i^2. \end{equation*}
Hence,
 \begin{align*} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 & \leq \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right ) + \frac {|G_r| - 1}{|G_r|}\prod _{i \in I_{r+1}} \sigma _i^2 \\ &= \sum _{j = r + 1}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right ), \end{align*}
\begin{align*} ||(\tilde {Q}_r)_* \nu _n - (\tilde {Q}_r)_* \pi ||_{L^2(G_r)}^2 & \leq \sum _{j = r + 2}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right ) + \frac {|G_r| - 1}{|G_r|}\prod _{i \in I_{r+1}} \sigma _i^2 \\ &= \sum _{j = r + 1}^k \frac {|G_{j-1}| - 1}{|G_r|}\left (\prod _{i \in I_j} \sigma _i^2\right ), \end{align*}
completing the induction. When
 $r = 0$
, we get
$r = 0$
, we get
 \begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G_{j-1}| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G_{j-1}| - 1}{|G|}\left (\prod _{i \in I_j} \sigma _i^2\right )\!. \end{equation*}
Now we show how Theorem 2.1 implies Theorem 1.1 by giving a corollary slightly stronger than Theorem 1.1.
Corollary 2.12.
Let
 $G$
be a finite group, and let
$G$
be a finite group, and let
 $\mu _1, \mu _2, \dots , \mu _n$
be probability measures on
$\mu _1, \mu _2, \dots , \mu _n$
be probability measures on
 $G$
. For each subgroup
$G$
. For each subgroup
 $H$
of
$H$
of
 $G$
, let
$G$
, let
 $I_H = \{i \mid H = \langle \operatorname {supp} \mu _i\rangle \}$
. Let
$I_H = \{i \mid H = \langle \operatorname {supp} \mu _i\rangle \}$
. Let
 $H_1, \dots , H_k$
be a finite set of subgroups of
$H_1, \dots , H_k$
be a finite set of subgroups of
 $G$
such that
$G$
such that
 $G = \left \langle \bigcup _{j = 1}^k H_j\right \rangle$
and the image of
$G = \left \langle \bigcup _{j = 1}^k H_j\right \rangle$
and the image of
 $H_j$
in
$H_j$
in
 $G/H_1\cdots H_{j-1}$
is a normal subgroup for all
$G/H_1\cdots H_{j-1}$
is a normal subgroup for all
 $1 \leq j \leq k$
. Write
$1 \leq j \leq k$
. Write
 $\nu _n = \mu _1 * \dots * \mu _n$
. Also, for each
$\nu _n = \mu _1 * \dots * \mu _n$
. Also, for each
 $i$
, let
$i$
, let
 $\sigma _i$
be the second-largest singular value of
$\sigma _i$
be the second-largest singular value of
 $*\mu _i$
as an operator on
$*\mu _i$
as an operator on
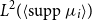 $L^2(\langle \operatorname {supp} \mu _i \rangle )$
. Let
$L^2(\langle \operatorname {supp} \mu _i \rangle )$
. Let
 $\pi$
be the uniform distribution on
$\pi$
be the uniform distribution on
 $G$
.
$G$
.
If
 $I_{H_j}$
is nonempty for each
$I_{H_j}$
is nonempty for each
 $1 \leq j \leq k$
, we have
$1 \leq j \leq k$
, we have
 \begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sum _{j = 1}^k \left (\prod _{i \in I_{H_j}} \sigma _i\right )\!. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2} \leq \sum _{j = 1}^k \left (\prod _{i \in I_{H_j}} \sigma _i\right )\!. \end{equation*}
Proof. We have
 $\bigcup _{j = 1}^k H_j \subseteq H_1 \cdots H_k$
, so
$\bigcup _{j = 1}^k H_j \subseteq H_1 \cdots H_k$
, so
 $H_1\cdots H_k = G$
. Let
$H_1\cdots H_k = G$
. Let
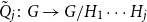 $\tilde {Q}_j\colon G \to G/H_1\cdots H_j$
be the projection. For
$\tilde {Q}_j\colon G \to G/H_1\cdots H_j$
be the projection. For
 $i \in I_{H_j}$
, let
$i \in I_{H_j}$
, let
 $\sigma _i'$
be the second-largest singular value of
$\sigma _i'$
be the second-largest singular value of
 $*(\tilde {Q}_{j-1})_*\mu _i$
on
$*(\tilde {Q}_{j-1})_*\mu _i$
on
 $\tilde {Q}_{j-1}(\langle \operatorname {supp} \mu _i\rangle ) = \tilde {Q}_{j-1}(H_j)$
. By Lemma 2.11(2), we have
$\tilde {Q}_{j-1}(\langle \operatorname {supp} \mu _i\rangle ) = \tilde {Q}_{j-1}(H_j)$
. By Lemma 2.11(2), we have
 $\sigma _i' \leq \sigma _i$
. Then applying Theorem 2.1 to the sequence
$\sigma _i' \leq \sigma _i$
. Then applying Theorem 2.1 to the sequence
 \begin{equation*} G \longrightarrow G/H_1 \longrightarrow G/H_1H_2 \longrightarrow \cdots \longrightarrow G/H_1\cdots H_k = \{e\} \end{equation*}
\begin{equation*} G \longrightarrow G/H_1 \longrightarrow G/H_1H_2 \longrightarrow \cdots \longrightarrow G/H_1\cdots H_k = \{e\} \end{equation*}
we get that
 \begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G/H_1\cdots H_{j-1}| - 1}{|G|} \left (\prod _{i \in I_{H_j}} (\sigma _i')^2 \right ) \leq \sum _{j=1}^k \left (\prod _{i \in I_{H_j}} \sigma _i^2 \right )\!. \end{equation*}
\begin{equation*} ||\nu _n - \pi ||_{L^2}^2 \leq \sum _{j=1}^k \frac {|G/H_1\cdots H_{j-1}| - 1}{|G|} \left (\prod _{i \in I_{H_j}} (\sigma _i')^2 \right ) \leq \sum _{j=1}^k \left (\prod _{i \in I_{H_j}} \sigma _i^2 \right )\!. \end{equation*}
Then the corollary follows by subadditivity of square root.
We obtain Theorem 1.1 from Corollary 2.12 because the image of a normal subgroup under a surjection is normal.
3. Universality for random groups
The goal of this section is to prove Theorem 1.2.
To prove Theorem 1.2, we will use the moment method of Wood (see [Reference Wood13, Reference Wood14]) as follows. Let
 $X_1, X_2, \dots$
be a sequence of random finitely generated abelian groups and
$X_1, X_2, \dots$
be a sequence of random finitely generated abelian groups and
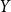 $Y$
be a random finitely generated abelian group. Let
$Y$
be a random finitely generated abelian group. Let
 $a \gt 0$
be an integer and
$a \gt 0$
be an integer and
 $A$
the set of isomorphism classes of abelian groups with exponent dividing
$A$
the set of isomorphism classes of abelian groups with exponent dividing
 $a$
. If for every
$a$
. If for every
 $G \in A$
we have
$G \in A$
we have
 \begin{equation} \lim _{n\to \infty } \mathbb{E}[\#\operatorname {Sur}(X_n, G)] = \mathbb{E}[\#\operatorname {Sur}(Y, G)] \leq |\wedge ^2 G| \end{equation}
\begin{equation} \lim _{n\to \infty } \mathbb{E}[\#\operatorname {Sur}(X_n, G)] = \mathbb{E}[\#\operatorname {Sur}(Y, G)] \leq |\wedge ^2 G| \end{equation}
then for every
 $H \in A$
we have
$H \in A$
we have
 \begin{equation} \lim _{n\to \infty } \mathbb{P}[X_n \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] \end{equation}
\begin{equation} \lim _{n\to \infty } \mathbb{P}[X_n \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] \end{equation}
[Reference Wood14, Theorem 3.1]. The quantity
 $\mathbb{E}[\#\operatorname {Sur}(X_n, G)]$
is called the
$\mathbb{E}[\#\operatorname {Sur}(X_n, G)]$
is called the
 $G$
-moment of
$G$
-moment of
 $X_n$
.
$X_n$
.
Remark 3.1. We can put a topology on the set of (isomorphism classes of) finitely generated abelian groups given by a basis of open sets of the form
 \begin{equation*} U_{a, H} = \{X \text{ finitely generated abelian} \mid X \otimes \mathbb{Z}/a\mathbb{Z} \cong H\}\end{equation*}
\begin{equation*} U_{a, H} = \{X \text{ finitely generated abelian} \mid X \otimes \mathbb{Z}/a\mathbb{Z} \cong H\}\end{equation*}
indexed by positive integers
 $a$
and abelian groups
$a$
and abelian groups
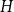 $H$
of exponent dividing
$H$
of exponent dividing
 $a$
. The assertion that
$a$
. The assertion that
 $(**)$
holds for all choices of
$(**)$
holds for all choices of
 $a$
and
$a$
and
 $H$
is equivalent to the assertion that the distribution of
$H$
is equivalent to the assertion that the distribution of
 $X_n$
converges weakly to the distribution of
$X_n$
converges weakly to the distribution of
 $Y$
in this topology. In particular, if
$Y$
in this topology. In particular, if
 $(*)$
holds for all abelian groups
$(*)$
holds for all abelian groups
 $G$
, then the distribution of
$G$
, then the distribution of
 $X_n$
converges weakly to the distribution of
$X_n$
converges weakly to the distribution of
 $Y$
. See [Reference Liu and Wood4] for more details on this topology in a slightly different setting.
$Y$
. See [Reference Liu and Wood4] for more details on this topology in a slightly different setting.
We explain this in more detail in the proof of Theorem 1.2 in Section 3.5 at the end of this paper.
If
 $Y \sim \lambda _u$
, then [Reference Wood14, Lemma 3.2] gives
$Y \sim \lambda _u$
, then [Reference Wood14, Lemma 3.2] gives
 \begin{equation*} \mathbb{E}[\#\operatorname {Sur}(Y, G)] = |G|^{-u}. \end{equation*}
\begin{equation*} \mathbb{E}[\#\operatorname {Sur}(Y, G)] = |G|^{-u}. \end{equation*}
Following this strategy, we obtain Theorem 1.2 as a corollary of Theorem 3.19, which states that if
 $X_n$
are the cokernels of
$X_n$
are the cokernels of
 $n\times (n+u)$
random matrices satisfying appropriate conditions, then
$n\times (n+u)$
random matrices satisfying appropriate conditions, then
 $\lim _n\mathbb{E}[\#\operatorname {Sur}(X_n, G)] = |G|^{-u}$
.
$\lim _n\mathbb{E}[\#\operatorname {Sur}(X_n, G)] = |G|^{-u}$
.
When
 $X_n$
is the cokernel of a random
$X_n$
is the cokernel of a random
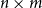 $n\times m$
matrix
$n\times m$
matrix
 $M$
, the problem of counting surjections from
$M$
, the problem of counting surjections from
 $X_n$
into
$X_n$
into
 $G$
can be attacked with combinatorics. Say
$G$
can be attacked with combinatorics. Say
 $X_n = \mathbb{Z}^n/\Lambda$
, where
$X_n = \mathbb{Z}^n/\Lambda$
, where
 $\Lambda$
is a random subgroup of
$\Lambda$
is a random subgroup of
 $\mathbb{Z}^n$
(e.g., the column space of a random integer matrix). Then surjections
$\mathbb{Z}^n$
(e.g., the column space of a random integer matrix). Then surjections
 $X_n \to G$
correspond one-to-one with surjections
$X_n \to G$
correspond one-to-one with surjections
 $\mathbb{Z}^n \to G$
which vanish on
$\mathbb{Z}^n \to G$
which vanish on
 $\Lambda$
. It follows from linearity of expectation that
$\Lambda$
. It follows from linearity of expectation that
 \begin{equation*} \mathbb{E}[\#\operatorname {Sur}(\mathbb{Z}^n/\Lambda , G)] = \sum _{f \in \operatorname {Sur}(\mathbb{Z}^n, G)} \mathbb{P}[f(\Lambda ) = 0]. \end{equation*}
\begin{equation*} \mathbb{E}[\#\operatorname {Sur}(\mathbb{Z}^n/\Lambda , G)] = \sum _{f \in \operatorname {Sur}(\mathbb{Z}^n, G)} \mathbb{P}[f(\Lambda ) = 0]. \end{equation*}
In the case of cokernels of random matrices,
 $\Lambda$
is the subgroup generated by the columns of the random matrix, viewed as random elements of
$\Lambda$
is the subgroup generated by the columns of the random matrix, viewed as random elements of
 $\mathbb{Z}^n$
. But we can also view
$\mathbb{Z}^n$
. But we can also view
 $M$
as a random element of
$M$
as a random element of
 $(\mathbb{Z}^n)^m$
. Given a map
$(\mathbb{Z}^n)^m$
. Given a map
 $f\colon \mathbb{Z}^n \to G$
, we get by abuse of notation a map
$f\colon \mathbb{Z}^n \to G$
, we get by abuse of notation a map
 $f\colon (\mathbb{Z}^n)^m \to G^m$
applying
$f\colon (\mathbb{Z}^n)^m \to G^m$
applying
 $f$
to each component. Then we have that
$f$
to each component. Then we have that
 $f(\Lambda ) = 0$
if and only if
$f(\Lambda ) = 0$
if and only if
 $f(M) = 0$
. Thus, we want to bound the probabilities
$f(M) = 0$
. Thus, we want to bound the probabilities
 $f(M) = 0$
. Past work on random matrices with independent entries (e.g., [Reference Nguyen and Wood9]) has observed that if
$f(M) = 0$
. Past work on random matrices with independent entries (e.g., [Reference Nguyen and Wood9]) has observed that if
 $Z$
is a random tuple in
$Z$
is a random tuple in
 $\mathbb{Z}^n$
with independent, sufficiently regular components, then for most
$\mathbb{Z}^n$
with independent, sufficiently regular components, then for most
 $f \in \operatorname {Sur}(\mathbb{Z}^n, G)$
, the element
$f \in \operatorname {Sur}(\mathbb{Z}^n, G)$
, the element
 $f(Z) \in G$
is close to uniformly distributed. Applying this to each column independently allows us to compute
$f(Z) \in G$
is close to uniformly distributed. Applying this to each column independently allows us to compute
 $\mathbb{P}[f(M) = 0]$
. In this work, we apply the same principle to consider several columns of a random matrix at a time.
$\mathbb{P}[f(M) = 0]$
. In this work, we apply the same principle to consider several columns of a random matrix at a time.
3.1 Balanced elements
The following definition captures the idea that a random element in a group is not too concentrated in a particular coset.
Definition 3.2.
Let
 $G$
be a group. A
$G$
be a group. A
 $G$
-valued random variable
$G$
-valued random variable
 $X$
is
$X$
is
 $\varepsilon$
-balanced if for any proper subgroup
$\varepsilon$
-balanced if for any proper subgroup
 $H \lt G$
and element
$H \lt G$
and element
 $g \in G$
, we have
$g \in G$
, we have
 $\mathbb{P}[X \in gH] \leq 1 - \varepsilon$
.
$\mathbb{P}[X \in gH] \leq 1 - \varepsilon$
.
This definition agrees with the definition in [Reference Wood14] when
 $G$
is a finite cyclic group. Here is an example of an
$G$
is a finite cyclic group. Here is an example of an
 $\varepsilon$
-balanced random variable that does not take values in a cyclic group.
$\varepsilon$
-balanced random variable that does not take values in a cyclic group.
Example 3.3. Let
 $G$
be a finitely generated group with finite generating set
$G$
be a finitely generated group with finite generating set
 $S$
containing the identity, and let
$S$
containing the identity, and let
 $X$
be a random variable supported on
$X$
be a random variable supported on
 $S$
with
$S$
with
 $\min _{g \in S} \mathbb{P}[X = g] = \varepsilon$
. Then
$\min _{g \in S} \mathbb{P}[X = g] = \varepsilon$
. Then
 $X$
is
$X$
is
 $\varepsilon$
-balanced.
$\varepsilon$
-balanced.
Indeed, suppose
 $H$
is a subgroup of
$H$
is a subgroup of
 $G$
and
$G$
and
 $g \in G$
such that
$g \in G$
such that
 $\mathbb{P}[X \in gH] \gt 1 - \varepsilon$
. Then
$\mathbb{P}[X \in gH] \gt 1 - \varepsilon$
. Then
 $\mathbb{P}[X \in gH] = 1$
, so
$\mathbb{P}[X \in gH] = 1$
, so
 $S \subset gH$
. Since
$S \subset gH$
. Since
 $S$
contains the identity element of
$S$
contains the identity element of
 $G$
, we must have
$G$
, we must have
 $gH = H$
, and since
$gH = H$
, and since
 $S \subset gH = H$
, we must have
$S \subset gH = H$
, we must have
 $H = G$
.
$H = G$
.
In this paper, we consider
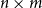 $n \times m$
integer matrices as elements of the abelian group
$n \times m$
integer matrices as elements of the abelian group
 $(\mathbb{Z}^n)^m$
. For each subset
$(\mathbb{Z}^n)^m$
. For each subset
 $S$
of
$S$
of
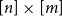 $[n] \times [m]$
, we have a quotient map
$[n] \times [m]$
, we have a quotient map
 $\pi _S$
from
$\pi _S$
from
 $(\mathbb{Z}^n)^m$
onto
$(\mathbb{Z}^n)^m$
onto
 $\mathbb{Z}^S$
given by taking the entries of a matrix indexed by pairs in
$\mathbb{Z}^S$
given by taking the entries of a matrix indexed by pairs in
 $S$
. We say that a subset of the entries of a random matrix
$S$
. We say that a subset of the entries of a random matrix
 $M$
with indices
$M$
with indices
 $S$
is jointly
$S$
is jointly
 $\varepsilon$
-balanced if
$\varepsilon$
-balanced if
 $\pi _S(M)$
is
$\pi _S(M)$
is
 $\varepsilon$
-balanced in
$\varepsilon$
-balanced in
 $\mathbb{Z}^S$
.
$\mathbb{Z}^S$
.
The new definition of
 $\varepsilon$
-balanced has some desirable properties that help construct new examples of
$\varepsilon$
-balanced has some desirable properties that help construct new examples of
 $\varepsilon$
-balanced random variables.
$\varepsilon$
-balanced random variables.
Lemma 3.4.
-
(1) If
$\pi \colon G \twoheadrightarrow Q$
is a surjective homomorphism of groups and
$X$
is
$\varepsilon$
-balanced in
$G$
, then
$\pi (X)$
is
$\varepsilon$
-balanced in
$Q$
. -
(2) Let
$G, G'$
be groups,
$X$
be
$\varepsilon$
-balanced in
$G$
, and
$Y$
be
$\varepsilon$
-balanced in
$G'$
. If
$X$
and
$Y$
are independent, then
$(X, Y)$
is
$\varepsilon$
-balanced in
$G\times G'$
.






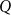











Proof.
-
(1) Let
$qK \subsetneq Q$
be a coset of a proper subgroup of
$Q$
. Let
$\tilde {q} \in \pi ^{-1}(q)$
, so
$\pi ^{-1}(qK) = \tilde {q}\pi ^{-1}(K)$
is a coset of a proper subgroup of
$G$
. Since
$X$
is
$\varepsilon$
-balanced,as desired.
\begin{equation*} \mathbb{P}[\pi (X) \in qK] \leq \mathbb{P}[X \in \tilde {q}\pi ^{-1}(K)] \leq 1 - \varepsilon , \end{equation*}
-
(2) Let
$kH$
be a coset of a proper subgroup of
$G \times G'$
. Note thatRecall that the intersection of two cosets in a group is either empty or a coset of their intersection. In particular,
\begin{equation*} \mathbb{P}[(X, Y) \in kH] = \mathbb{P}[(X, e) \in (e, Y^{-1})kH] = \mathbb{P}[(X, e) \in (e, Y^{-1})kH \cap (G \times \{e\})]. \end{equation*}
$(e, Y^{-1})kH \cap (G \times \{e\})$
is either empty or a coset of a subgroup of
$G \times \{e\}$
.
There are two cases, depending on whether
$(e, Y^{-1})kH \cap (G \times \{e\})$
is always a proper subset of
$G \times \{e\}$
:-
i. If
$(e, y^{-1})kH \cap (G \times \{e\}) \subsetneq G \times \{e\}$
for all
$y \in G'$
:Condition on
$Y = y$
for some fixed
$y \in G'$
. Since
$X$
and
$Y$
are independent, and
$X$
is
$\varepsilon$
-balanced,
\begin{equation*} \mathbb{P}[(X, e) \in (e, Y^{-1})kH \cap (G \times \{e\}) \mid Y = y] = \mathbb{P}[(X, e) \in (e, y^{-1})kH \cap (G \times \{e\})] \leq 1- \varepsilon . \end{equation*}
-
ii. If
$G \times \{e\} \subseteq (e, y^{-1})kH$
for some
$y \in Y$
, then
$(e, e) \in (e, y^{-1})kH$
, so in particular
$(e, y^{-1})kH$
is a subgroup of
$G \times G'$
and we must have
$(e, y^{-1})kH = H$
. We claim that
$H = G \times H'$
for some proper subgroup
$H'$
of
$G'$
.Indeed, let
$\pi \colon G\times G' \to G'$
be the projection and let
$H' = \pi (H)$
. On one hand, clearly
$H \subseteq G \times \pi (H)$
. On the other, if
$(g, h') \in G \times H'$
, then
$h' = \pi (g', h)$
for some
$(g', h) \in H$
. Then
$(g, h') = (g(g')^{-1}, e)(g', h)$
. Since
$(g(g')^{-1}, e) \in G \times \{e\} \subseteq H$
, we have
$(g, h') \in H$
. Hence
$H = G \times H'$
. Note that
$H' \lneq G'$
, or else
$H = G \times G'$
is not a proper subgroup.Then
\begin{equation*} \mathbb{P}[(X, Y) \in kH] = \mathbb{P}[Y \in H'] \leq 1 - \varepsilon . \end{equation*}
Hence, in both cases we have
$\mathbb{P}[(X, Y) \in kH] \leq 1 - \varepsilon$
and since this holds for every proper coset
$kH$
, we have that
$(X, Y)$
is balanced. -


























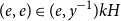


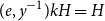

















Note that Lemma 3.4 gives us a nice way to build up
 $\varepsilon$
-balanced matrices. If the entries of a random matrix can be partitioned into independent subsets and each of these subsets of the entries is jointly
$\varepsilon$
-balanced matrices. If the entries of a random matrix can be partitioned into independent subsets and each of these subsets of the entries is jointly
 $\varepsilon$
-balanced, then the whole matrix is
$\varepsilon$
-balanced, then the whole matrix is
 $\varepsilon$
-balanced. For example, any matrix with independent,
$\varepsilon$
-balanced. For example, any matrix with independent,
 $\varepsilon$
-balanced entries (as in [Reference Wood14]) is
$\varepsilon$
-balanced entries (as in [Reference Wood14]) is
 $\varepsilon$
-balanced as a matrix.
$\varepsilon$
-balanced as a matrix.
When a random variable is
 $\varepsilon$
-balanced, we can get an upper bound on the associated singular value.
$\varepsilon$
-balanced, we can get an upper bound on the associated singular value.
Lemma 3.5.
Suppose
 $G$
is a finite group and
$G$
is a finite group and
 $X$
is
$X$
is
 $\varepsilon$
-balanced in
$\varepsilon$
-balanced in
 $G$
with distribution
$G$
with distribution
 $\mu$
. Let
$\mu$
. Let
 $\sigma$
be the second-largest singular value of the operator
$\sigma$
be the second-largest singular value of the operator
 $* \mu$
on
$* \mu$
on
 $L^2(G)$
. Then
$L^2(G)$
. Then
 \begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{2|G|^3}\right )\!. \end{equation*}
\begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{2|G|^3}\right )\!. \end{equation*}
Proof. Note that
 $\sigma$
is the square root of the second-largest eigenvalue of the operator
$\sigma$
is the square root of the second-largest eigenvalue of the operator
 $*\nu \;:\!=\; * \mu * \check {\mu }\colon L^2(G) \to L^2(G)$
, where
$*\nu \;:\!=\; * \mu * \check {\mu }\colon L^2(G) \to L^2(G)$
, where
 $*\check {\mu }$
is the adjoint to the operator
$*\check {\mu }$
is the adjoint to the operator
 $*\mu$
, given by
$*\mu$
, given by
 $\check {\mu }(g) = \mu (g^{-1})$
. The operator
$\check {\mu }(g) = \mu (g^{-1})$
. The operator
 $*\nu$
is the transition operator for a random walk on
$*\nu$
is the transition operator for a random walk on
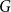 $G$
, where each step is a difference of two independent copies of
$G$
, where each step is a difference of two independent copies of
 $X$
.
$X$
.
In particular, note that
 $\nu = \check {\nu }$
. For any generating set
$\nu = \check {\nu }$
. For any generating set
 $\Sigma$
of
$\Sigma$
of
 $G$
, [Reference Saloff-Coste, Sznitman, Varadhan and Kesten10, Theorem 6.2] applied to
$G$
, [Reference Saloff-Coste, Sznitman, Varadhan and Kesten10, Theorem 6.2] applied to
 $\Sigma \cup \Sigma ^{-1}$
shows that the second-largest eigenvalue
$\Sigma \cup \Sigma ^{-1}$
shows that the second-largest eigenvalue
 $\sigma ^2$
of
$\sigma ^2$
of
 $*\nu$
is bounded above by
$*\nu$
is bounded above by
 \begin{equation*} \sigma ^2 \leq 1 - \frac {m}{D^2}, \end{equation*}
\begin{equation*} \sigma ^2 \leq 1 - \frac {m}{D^2}, \end{equation*}
where
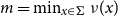 $m = \min _{x\in \Sigma }\nu (x)$
and
$m = \min _{x\in \Sigma }\nu (x)$
and
 $D$
is the diameter of the Cayley graph of
$D$
is the diameter of the Cayley graph of
 $(G, \Sigma )$
. In particular,
$(G, \Sigma )$
. In particular,
 $D \leq |G|$
.
$D \leq |G|$
.
The goal is to choose an appropriate
 $\Sigma$
to bound
$\Sigma$
to bound
 $m$
from below. Note that if
$m$
from below. Note that if
 $X_1$
and
$X_1$
and
 $X_2$
are
$X_2$
are
 $\varepsilon$
-balanced and independent, then so is
$\varepsilon$
-balanced and independent, then so is
 $X_1X_2^{-1}$
(via conditioning on
$X_1X_2^{-1}$
(via conditioning on
 $X_2$
). In particular,
$X_2$
). In particular,
 $\nu$
is
$\nu$
is
 $\varepsilon$
-balanced.
$\varepsilon$
-balanced.
We proceed iteratively. Having chosen
 $x_1, \dots , x_{n-1}$
(including the empty set
$x_1, \dots , x_{n-1}$
(including the empty set
 $n = 1$
), if
$n = 1$
), if
 $\langle x_1, \dots , x_{n-1} \rangle = G$
then we are done. Otherwise, since
$\langle x_1, \dots , x_{n-1} \rangle = G$
then we are done. Otherwise, since
 $\nu$
is
$\nu$
is
 $\varepsilon$
-balanced,
$\varepsilon$
-balanced,
 $\nu (\langle x_1, \dots , x_{n-1} \rangle ) \leq 1 - \varepsilon$
. Choose
$\nu (\langle x_1, \dots , x_{n-1} \rangle ) \leq 1 - \varepsilon$
. Choose
 \begin{equation*} x_n = \operatorname {argmax}_{x\in G\setminus \langle x_1, \dots , x_{n-1} \rangle } \nu (x). \end{equation*}
\begin{equation*} x_n = \operatorname {argmax}_{x\in G\setminus \langle x_1, \dots , x_{n-1} \rangle } \nu (x). \end{equation*}
Since
 $\nu (\langle x_1, \dots , x_{n-1} \rangle ) \leq 1 - \varepsilon$
, we have
$\nu (\langle x_1, \dots , x_{n-1} \rangle ) \leq 1 - \varepsilon$
, we have
 $\nu (G\setminus \langle x_1, \dots , x_{n-1} \rangle ) \geq \varepsilon$
, so
$\nu (G\setminus \langle x_1, \dots , x_{n-1} \rangle ) \geq \varepsilon$
, so
 $\nu (x_n) \geq \frac {\varepsilon }{|G\setminus \langle x_1, \dots , x_{n-1} \rangle |} \geq \frac {\varepsilon }{|G|}$
.
$\nu (x_n) \geq \frac {\varepsilon }{|G\setminus \langle x_1, \dots , x_{n-1} \rangle |} \geq \frac {\varepsilon }{|G|}$
.
Hence we have
 $m \geq \frac {\varepsilon }{|G|}$
, so
$m \geq \frac {\varepsilon }{|G|}$
, so
 \begin{equation*} \sigma \leq \sqrt {1 - \frac {\varepsilon }{|G|^3}} \leq 1 - \frac {\varepsilon }{2|G|^3} \leq \exp \left (-\frac {\varepsilon }{2|G|^3}\right ), \end{equation*}
\begin{equation*} \sigma \leq \sqrt {1 - \frac {\varepsilon }{|G|^3}} \leq 1 - \frac {\varepsilon }{2|G|^3} \leq \exp \left (-\frac {\varepsilon }{2|G|^3}\right ), \end{equation*}
as desired.
With some more work, we can get a better bound on the singular values when
 $G$
is abelian using an argument based on [Reference Wood13, Lemmas 2.1, 2.2]:
$G$
is abelian using an argument based on [Reference Wood13, Lemmas 2.1, 2.2]:
Lemma 3.6.
Suppose
 $G$
is a finite abelian group of exponent dividing
$G$
is a finite abelian group of exponent dividing
 $a$
and
$a$
and
 $X$
is
$X$
is
 $\varepsilon$
-balanced in
$\varepsilon$
-balanced in
 $G$
with distribution
$G$
with distribution
 $\mu$
. Let
$\mu$
. Let
 $\sigma$
be the second-largest singular value of the operator
$\sigma$
be the second-largest singular value of the operator
 $*\mu$
on
$*\mu$
on
 $L^2(G)$
. Then
$L^2(G)$
. Then
 \begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{a^2}\right )\!. \end{equation*}
\begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{a^2}\right )\!. \end{equation*}
Proof. As in the proof of Lemma 3.5, we consider the operator
 $*\nu \;:\!=\; *\mu *\check {\mu }$
. The second-largest eigenvalue
$*\nu \;:\!=\; *\mu *\check {\mu }$
. The second-largest eigenvalue
 $\sigma ^2$
of
$\sigma ^2$
of
 $*\nu$
is equal to the spectral radius of the restriction
$*\nu$
is equal to the spectral radius of the restriction
 $(*\nu )|_{L^2(G)_0}$
, where
$(*\nu )|_{L^2(G)_0}$
, where
 $L^2(G)_0$
is the space of signed measures on
$L^2(G)_0$
is the space of signed measures on
 $G$
of total mass
$G$
of total mass
 $0$
, as in Section 2.
$0$
, as in Section 2.
The spectral radius of
 $(*\nu )|_{L^2(G)_0}$
is bounded above by the operator norm
$(*\nu )|_{L^2(G)_0}$
is bounded above by the operator norm
 $||(*\nu |_{L^2(G)_0})^n||^{1/n}$
for any natural number
$||(*\nu |_{L^2(G)_0})^n||^{1/n}$
for any natural number
 $n$
, i.e.,
$n$
, i.e.,
 \begin{equation*} \sigma ^2 \leq ||(*\nu |_{L^2(G)_0})^n||^{1/n}. \end{equation*}
\begin{equation*} \sigma ^2 \leq ||(*\nu |_{L^2(G)_0})^n||^{1/n}. \end{equation*}
We will compute this upper bound.
Let
 $\lambda \in L^2(G)_0$
with
$\lambda \in L^2(G)_0$
with
 $||\lambda ||_{L^2(G)_0} = 1$
, and let
$||\lambda ||_{L^2(G)_0} = 1$
, and let
 $Y \sim \lambda + \pi$
be a
$Y \sim \lambda + \pi$
be a
 $G$
-valued random variable, where
$G$
-valued random variable, where
 $\pi$
is the uniform distribution on
$\pi$
is the uniform distribution on
 $G$
. Let
$G$
. Let
 $X_1, \dots , X_n, \check {X}_1, \dots , \check {X}_n$
be independent, identically distributed
$X_1, \dots , X_n, \check {X}_1, \dots , \check {X}_n$
be independent, identically distributed
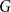 $G$
-valued random variables drawn from
$G$
-valued random variables drawn from
 $\mu$
. Then
$\mu$
. Then
 $Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i$
is distributed according to
$Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i$
is distributed according to
 $\lambda *(\nu )^{*n} + \pi$
, so we have
$\lambda *(\nu )^{*n} + \pi$
, so we have
 \begin{equation*} ||\lambda *(\nu )^{*n}||_{L^2(G)_0}^2 = \sum _{g \in G} \left |\mathbb{P}\left [Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i = g\right ] - \frac {1}{|G|}\right |^2. \end{equation*}
\begin{equation*} ||\lambda *(\nu )^{*n}||_{L^2(G)_0}^2 = \sum _{g \in G} \left |\mathbb{P}\left [Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i = g\right ] - \frac {1}{|G|}\right |^2. \end{equation*}
Let
 $G^* = \operatorname {Hom}(G, S^1)$
be the Pontryagin dual of
$G^* = \operatorname {Hom}(G, S^1)$
be the Pontryagin dual of
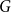 $G$
.
$G$
.
By the discrete Fourier transform, we have
 \begin{align*} \left |\mathbb{P}\left [Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i = g\right ] - \frac {1}{|G|}\right | &= \left |\frac {1}{|G|}\sum _{\chi \in G^* \setminus \{0\}}\mathbb{E}\left [\chi \left (Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i - g\right )\right ]\right | \\ &\leq \frac {1}{|G|}\sum _{\chi \in G^* \setminus \{0\}}\left |\mathbb{E}\left [\chi (Y - g)\right ]\right |\prod _{i=1}^n \left |\mathbb{E}\left [\chi (X_i)\right ]\mathbb{E}\left [-\chi (\check {X}_i)\right ] \right | \end{align*}
\begin{align*} \left |\mathbb{P}\left [Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i = g\right ] - \frac {1}{|G|}\right | &= \left |\frac {1}{|G|}\sum _{\chi \in G^* \setminus \{0\}}\mathbb{E}\left [\chi \left (Y + \sum _{i=1}^nX_i - \sum _{i=1}^n \check {X}_i - g\right )\right ]\right | \\ &\leq \frac {1}{|G|}\sum _{\chi \in G^* \setminus \{0\}}\left |\mathbb{E}\left [\chi (Y - g)\right ]\right |\prod _{i=1}^n \left |\mathbb{E}\left [\chi (X_i)\right ]\mathbb{E}\left [-\chi (\check {X}_i)\right ] \right | \end{align*}
We examine the terms
 $\mathbb{E}\left [\chi (X_i)\right ]$
and
$\mathbb{E}\left [\chi (X_i)\right ]$
and
 $\mathbb{E}\left [-\chi (\check {X}_i)\right ]$
for
$\mathbb{E}\left [-\chi (\check {X}_i)\right ]$
for
 $\chi$
a character of
$\chi$
a character of
 $G$
. By Lemma 3.4(a), the random variable
$G$
. By Lemma 3.4(a), the random variable
 $\chi (X_i)$
is
$\chi (X_i)$
is
 $\varepsilon$
-balanced in the (necessarily cyclic) subgroup
$\varepsilon$
-balanced in the (necessarily cyclic) subgroup
 $\chi (G) \subset S^1$
. By [Reference Wood13, Lemma 2.2], since
$\chi (G) \subset S^1$
. By [Reference Wood13, Lemma 2.2], since
 $\chi (X_i)$
is a
$\chi (X_i)$
is a
 $\varepsilon$
-balanced random element of a nontrivial subgroup of the
$\varepsilon$
-balanced random element of a nontrivial subgroup of the
 $a$
th roots of unity, we have
$a$
th roots of unity, we have
 $|\mathbb{E}[\chi (X_i)]| \leq \exp \left (-\frac {\varepsilon }{a^2}\right )$
. We have the same bound for
$|\mathbb{E}[\chi (X_i)]| \leq \exp \left (-\frac {\varepsilon }{a^2}\right )$
. We have the same bound for
 $|\mathbb{E}\left [-\chi (\check {X}_i)\right ]|$
.
$|\mathbb{E}\left [-\chi (\check {X}_i)\right ]|$
.
So,
 \begin{align*} ||\lambda *(\nu )^{*n}||_{L^2(G)_0}^2 &\leq \sum _{g \in G}\left (\frac {1}{|G|}\sum _{\chi \in G^*\setminus \{0\}}\left |\mathbb{E}\left [\chi (Y - g)\right ]\right |\prod _{i=1}^n \left |\mathbb{E}\left [\chi (X_i)\right ]\mathbb{E}\left [-\chi (\check {X}_i)\right ] \right | \right )^2 \\ &\leq |G|\exp \left (-\frac {4n\varepsilon }{a^2}\right ) \end{align*}
\begin{align*} ||\lambda *(\nu )^{*n}||_{L^2(G)_0}^2 &\leq \sum _{g \in G}\left (\frac {1}{|G|}\sum _{\chi \in G^*\setminus \{0\}}\left |\mathbb{E}\left [\chi (Y - g)\right ]\right |\prod _{i=1}^n \left |\mathbb{E}\left [\chi (X_i)\right ]\mathbb{E}\left [-\chi (\check {X}_i)\right ] \right | \right )^2 \\ &\leq |G|\exp \left (-\frac {4n\varepsilon }{a^2}\right ) \end{align*}
which means
 \begin{equation*} ||(*\nu |_{L^2(G)_0})^n||^{1/n} \leq |G|^{1/2n}\exp \left (-\frac {2\varepsilon }{a^2}\right ) \end{equation*}
\begin{equation*} ||(*\nu |_{L^2(G)_0})^n||^{1/n} \leq |G|^{1/2n}\exp \left (-\frac {2\varepsilon }{a^2}\right ) \end{equation*}
and, taking the limit as
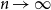 $n\to \infty$
, we obtain
$n\to \infty$
, we obtain
 \begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{a^2}\right ) \end{equation*}
\begin{equation*} \sigma \leq \exp \left (-\frac {\varepsilon }{a^2}\right ) \end{equation*}
as we wanted.
Now we will use the
 $\varepsilon$
-balanced condition to give a related balancedness condition for matrices that contains information about how balanced and independent the entries are.
$\varepsilon$
-balanced condition to give a related balancedness condition for matrices that contains information about how balanced and independent the entries are.
Definition 3.7.
Let
 $S$
be a finite set. A partition of
$S$
be a finite set. A partition of
 $S$
is a collection
$S$
is a collection
 $\mathcal{P} = \{P_1, \dots , P_k\} \subseteq 2^S$
, such that
$\mathcal{P} = \{P_1, \dots , P_k\} \subseteq 2^S$
, such that
 $S = P_1 \sqcup P_2 \sqcup \dots \sqcup P_k$
and each
$S = P_1 \sqcup P_2 \sqcup \dots \sqcup P_k$
and each
 $P_i$
is nonempty. We say
$P_i$
is nonempty. We say
 $|\mathcal{P}| = \max _i \#P_i$
and
$|\mathcal{P}| = \max _i \#P_i$
and
 $\#\mathcal{P} = k$
. If
$\#\mathcal{P} = k$
. If
 $\sigma \subseteq 2^{S}$
, write
$\sigma \subseteq 2^{S}$
, write
 $\cup \sigma$
for
$\cup \sigma$
for
 $\bigcup _{S\in \sigma } S$
.
$\bigcup _{S\in \sigma } S$
.
Note that
 $\#\mathcal{P}\cdot |\mathcal{P}| \geq \#S$
.
$\#\mathcal{P}\cdot |\mathcal{P}| \geq \#S$
.
The next definition specifies the kinds of restrictions we will give for the matrices in our universality class. The idea is that we can split up the columns of the matrix and then the rows, so that the resulting sections of the matrix are
 $\varepsilon$
-balanced.
$\varepsilon$
-balanced.
If
 $M$
is an
$M$
is an
 $n\times m$
matrix,
$n\times m$
matrix,
 $S = \{s_1 \lt \dots \lt s_k\} \subset [n]$
, and
$S = \{s_1 \lt \dots \lt s_k\} \subset [n]$
, and
 $T = \{t_1 \lt \dots \lt t_\ell \} \subset [m]$
, then
$T = \{t_1 \lt \dots \lt t_\ell \} \subset [m]$
, then
 $M_{S, T}$
is the
$M_{S, T}$
is the
 $k\times \ell$
matrix
$k\times \ell$
matrix
 $(M_{s_i, t_j})_{1 \leq i \leq k, 1 \leq j \leq \ell }$
.
$(M_{s_i, t_j})_{1 \leq i \leq k, 1 \leq j \leq \ell }$
.
Definition 3.8.
An
 $n\times m$
random matrix
$n\times m$
random matrix
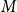 $M$
with entries in a ring
$M$
with entries in a ring
 $R$
is
$R$
is
 $(w, h, \varepsilon )$
-balanced if there is a partition
$(w, h, \varepsilon )$
-balanced if there is a partition
 $\mathcal{Q} = \{Q_1, \dots , Q_r\}$
of
$\mathcal{Q} = \{Q_1, \dots , Q_r\}$
of
 $[m]$
and a partition
$[m]$
and a partition
 $\mathcal{P} = \{P_1, \dots , P_\ell \}$
of
$\mathcal{P} = \{P_1, \dots , P_\ell \}$
of
 $[n]$
with
$[n]$
with
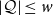 $|\mathcal{Q}| \leq w$
,
$|\mathcal{Q}| \leq w$
,
 $|\mathcal{P}| \leq h$
, and such that each random matrix
$|\mathcal{P}| \leq h$
, and such that each random matrix
 $M_{P_i, Q_j}$
is
$M_{P_i, Q_j}$
is
 $\varepsilon$
-balanced in the additive abelian group
$\varepsilon$
-balanced in the additive abelian group
 $(R^{\#P_i})^{\#Q_j}$
and the random matrices
$(R^{\#P_i})^{\#Q_j}$
and the random matrices
 $M_{P_i, Q_j}$
are independent.
$M_{P_i, Q_j}$
are independent.
If
 $|\mathcal{P}| = |\mathcal{Q}| = 1$
then we recover the definition of
$|\mathcal{P}| = |\mathcal{Q}| = 1$
then we recover the definition of
 $\varepsilon$
-balanced from [Reference Wood14] and other related work.
$\varepsilon$
-balanced from [Reference Wood14] and other related work.
Now we are ready to state the main theorem of this section:
Theorem 3.9.
Let
 $u \geq 0$
be an integer. Let
$u \geq 0$
be an integer. Let
 $(w_n)_n, (h_n)_n$
,
$(w_n)_n, (h_n)_n$
,
 $(\varepsilon _n)_n$
be sequences of real numbers such that
$(\varepsilon _n)_n$
be sequences of real numbers such that
 $w_n = O(n^{\alpha _1})$
,
$w_n = O(n^{\alpha _1})$
,
 $h_n = O(n^{\alpha _2})$
and
$h_n = O(n^{\alpha _2})$
and
 $\varepsilon _n = \Omega ( n^{-\beta })$
for some
$\varepsilon _n = \Omega ( n^{-\beta })$
for some
 $0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
$0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
 \begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
\begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
For each integer
 $n \geq 0$
, let
$n \geq 0$
, let
 $M_n$
be an
$M_n$
be an
 $(w_n, h_n, \varepsilon _n)$
-balanced
$(w_n, h_n, \varepsilon _n)$
-balanced
 $n \times (n + u)$
random matrix with entries in
$n \times (n + u)$
random matrix with entries in
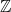 $\mathbb{Z}$
. Let
$\mathbb{Z}$
. Let
 $Y \sim \lambda _u$
. Then for all positive integers
$Y \sim \lambda _u$
. Then for all positive integers
 $a$
and abelian groups
$a$
and abelian groups
 $H$
of exponent dividing
$H$
of exponent dividing
 $a$
we have
$a$
we have
 \begin{equation*} \lim _{n\to \infty } \mathbb{P}[\!\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H}). \end{equation*}
\begin{equation*} \lim _{n\to \infty } \mathbb{P}[\!\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H}). \end{equation*}
Together with Remark 3.1, this gives Theorem 1.2. A more detailed proof is given in Section 3.5.
As discussed at the beginning of this section, we will prove this by computing the limiting moments of
 $\operatorname {coker}(M_n)$
, which involves estimating
$\operatorname {coker}(M_n)$
, which involves estimating
 $\mathbb{P}[f(M_n) = 0]$
for maps
$\mathbb{P}[f(M_n) = 0]$
for maps
 $\mathbb{Z}^n \to G$
.
$\mathbb{Z}^n \to G$
.
Remark 3.10. The same proof will work as written when the entries of
 $M_n$
come from any ring
$M_n$
come from any ring
 $R$
with at most one quotient to
$R$
with at most one quotient to
 $\mathbb{Z}/a\mathbb{Z}$
for any positive integer
$\mathbb{Z}/a\mathbb{Z}$
for any positive integer
 $a$
. Some examples of interest are the
$a$
. Some examples of interest are the
 $p$
-adic integers
$p$
-adic integers
 $\mathbb{Z}_p$
or a product
$\mathbb{Z}_p$
or a product
 $\prod _i \mathbb{Z}_{p_i}$
for some collection of distinct primes
$\prod _i \mathbb{Z}_{p_i}$
for some collection of distinct primes
 $p_i$
. We will find that when
$p_i$
. We will find that when
 $R$
has exactly one quotient to
$R$
has exactly one quotient to
 $\mathbb{Z}/a\mathbb{Z}$
, then for any finite abelian group
$\mathbb{Z}/a\mathbb{Z}$
, then for any finite abelian group
 $G$
of exponent dividing
$G$
of exponent dividing
 $a$
, the limiting
$a$
, the limiting
 $G$
-moment of
$G$
-moment of
 $\operatorname {coker}(M_n)$
is
$\operatorname {coker}(M_n)$
is
 $|G|^{-u}$
. Then we get the conclusion of Theorem 3.9 for those
$|G|^{-u}$
. Then we get the conclusion of Theorem 3.9 for those
 $a$
for which
$a$
for which
 $R$
has a quotient to
$R$
has a quotient to
 $\mathbb{Z}/a\mathbb{Z}$
.
$\mathbb{Z}/a\mathbb{Z}$
.
3.2 Bounds for most maps
It turns out that
 $(w, h, \varepsilon )$
-balanced is a strong enough condition that we can get bounds on
$(w, h, \varepsilon )$
-balanced is a strong enough condition that we can get bounds on
 $\mathbb{P}[f(M) = 0]$
for the vast majority of maps
$\mathbb{P}[f(M) = 0]$
for the vast majority of maps
 $f$
.
$f$
.
Definition 3.11.
If
 $V$
is an abelian group with generating set
$V$
is an abelian group with generating set
 $S$
and
$S$
and
 $T \subseteq S$
, we write
$T \subseteq S$
, we write
 $V_{\setminus T}$
for the subgroup
$V_{\setminus T}$
for the subgroup
 $\langle S \setminus T \rangle$
of
$\langle S \setminus T \rangle$
of
 $V$
. When
$V$
. When
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
or
$V = (\mathbb{Z}/a\mathbb{Z})^n$
or
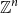 $\mathbb{Z}^n$
we implicitly take
$\mathbb{Z}^n$
we implicitly take
 $S$
to be the “standard basis”.
$S$
to be the “standard basis”.
Let
 $\mathcal{P} = \{P_1, \dots , P_\ell \}$
be a partition of
$\mathcal{P} = \{P_1, \dots , P_\ell \}$
be a partition of
 $S$
and
$S$
and
 $G$
be a finite abelian group. A function
$G$
be a finite abelian group. A function
 $f\colon V \to G$
is a
$f\colon V \to G$
is a
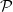 $\mathcal{P}$
-code of distance
$\mathcal{P}$
-code of distance
 $w$
if for any
$w$
if for any
 $\sigma \subset \mathcal{P}$
with
$\sigma \subset \mathcal{P}$
with
 $|\cup \sigma | \lt w$
, we have
$|\cup \sigma | \lt w$
, we have
 $f(V_{\setminus \cup \sigma }) = G$
.
$f(V_{\setminus \cup \sigma }) = G$
.
To approximate
 $\mathbb{P}[f(M) = 0]$
for codes
$\mathbb{P}[f(M) = 0]$
for codes
 $f$
, we will split the matrices
$f$
, we will split the matrices
 $M$
into independent sets of columns. Each such set of
$M$
into independent sets of columns. Each such set of
 $r$
random columns gets mapped to something close to uniform in
$r$
random columns gets mapped to something close to uniform in
 $G^r$
. The following lemma is analogous to [Reference Wood14, Lemma 2.1].
$G^r$
. The following lemma is analogous to [Reference Wood14, Lemma 2.1].
Lemma 3.12.
Let
 $n, r \geq 1$
be integers. Let
$n, r \geq 1$
be integers. Let
 $G$
be a finite abelian group and let
$G$
be a finite abelian group and let
 $a$
be a multiple of the exponent of
$a$
be a multiple of the exponent of
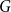 $G$
. Let
$G$
. Let
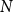 $N$
be the number of subgroups of
$N$
be the number of subgroups of
 $G$
. Let
$G$
. Let
 $\varepsilon \gt 0$
be a real number. Let
$\varepsilon \gt 0$
be a real number. Let
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
$V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
 $\mathcal{P} = \{P_i\}$
be a partition of
$\mathcal{P} = \{P_i\}$
be a partition of
 $[n]$
and let
$[n]$
and let
 $\ell = |\mathcal{P}|$
. Let
$\ell = |\mathcal{P}|$
. Let
 $f \in \operatorname {Hom}(V, G)$
be a
$f \in \operatorname {Hom}(V, G)$
be a
 $\mathcal{P}$
-code of distance
$\mathcal{P}$
-code of distance
 $w \lt n$
.
$w \lt n$
.
Let
 $M$
be an
$M$
be an
 $n\times r$
random matrix in
$n\times r$
random matrix in
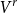 $V^r$
such that the matrices
$V^r$
such that the matrices
 $M_{P_i, [r]}$
are independent and
$M_{P_i, [r]}$
are independent and
 $\varepsilon$
-balanced as random elements of
$\varepsilon$
-balanced as random elements of
 $((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
.
$((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
.
Let
 $g_1, \dots , g_r \in G$
. Then
$g_1, \dots , g_r \in G$
. Then
 \begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_r)] - |G|^{-r}| \leq N\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ) \end{equation*}
\begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_r)] - |G|^{-r}| \leq N\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ) \end{equation*}
Proof. Let
 $e_1, \dots , e_n$
be the standard generating set for
$e_1, \dots , e_n$
be the standard generating set for
 $V$
. For
$V$
. For
 $i = 1, \dots , \#\mathcal{P}$
, let
$i = 1, \dots , \#\mathcal{P}$
, let
 $V_i = \langle e_j \mid j \in P_i\rangle \cong \mathbb{Z}^{\#P_i}$
.
$V_i = \langle e_j \mid j \in P_i\rangle \cong \mathbb{Z}^{\#P_i}$
.
The idea is to treat
 $f(M)$
as a random walk in
$f(M)$
as a random walk in
 $G^r$
. We have
$G^r$
. We have
 \begin{equation*} f(M) = \sum _{i=1}^{\#\mathcal{P}}f(M_{P_i, [r]}), \end{equation*}
\begin{equation*} f(M) = \sum _{i=1}^{\#\mathcal{P}}f(M_{P_i, [r]}), \end{equation*}
where
 $M_{P_i, [r]}$
is interpreted as an
$M_{P_i, [r]}$
is interpreted as an
 $\varepsilon$
-balanced random element of
$\varepsilon$
-balanced random element of
 $V_i^r \cong ((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
, a subgroup of
$V_i^r \cong ((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
, a subgroup of
 $((\mathbb{Z}/a\mathbb{Z})^n)^r$
.
$((\mathbb{Z}/a\mathbb{Z})^n)^r$
.
Let
 $S = \{H \leq G^r \mid H = f(V_i^r) \text{ for at least }w/\ell N\text{ values of }i\}$
. Note that
$S = \{H \leq G^r \mid H = f(V_i^r) \text{ for at least }w/\ell N\text{ values of }i\}$
. Note that
 $f(V_i^r) = f(V_i)^r$
, so as
$f(V_i^r) = f(V_i)^r$
, so as
 $i$
ranges over
$i$
ranges over
 $1, \dots , \#\mathcal{P}$
there are at most
$1, \dots , \#\mathcal{P}$
there are at most
 $N$
possible values for
$N$
possible values for
 $f(V_i^r)$
, each an
$f(V_i^r)$
, each an
 $r$
th power of a subgroup of
$r$
th power of a subgroup of
 $G$
. Let
$G$
. Let
 $I = \{i \mid f(V_i^r) \notin S\}$
. Then
$I = \{i \mid f(V_i^r) \notin S\}$
. Then
 $\#I \leq w/\ell$
, and so
$\#I \leq w/\ell$
, and so
 $|\bigcup _{i \in I} P_i| \leq w$
. Since
$|\bigcup _{i \in I} P_i| \leq w$
. Since
 $f$
is a
$f$
is a
 $\mathcal{P}$
-code of distance
$\mathcal{P}$
-code of distance
 $w$
, it remains surjective if we discard all of these indices, which means the images of the
$w$
, it remains surjective if we discard all of these indices, which means the images of the
 $V_i^r$
s with
$V_i^r$
s with
 $f(V_i^r) \in S$
generate
$f(V_i^r) \in S$
generate
 $G^r$
. In other words, we have
$G^r$
. In other words, we have
 $\langle \bigcup _{H \in S} H\rangle = G^r$
. The subgroups in
$\langle \bigcup _{H \in S} H\rangle = G^r$
. The subgroups in
 $S$
will be the ones we use in the random walk, applying Theorem 1.1.
$S$
will be the ones we use in the random walk, applying Theorem 1.1.
By the definition of
 $S$
, for each
$S$
, for each
 $H$
in
$H$
in
 $S$
we have
$S$
we have
 $\#I_H \geq w/\ell N$
. By Lemma 3.4, the steps
$\#I_H \geq w/\ell N$
. By Lemma 3.4, the steps
 $f(M_{P_i, [r]})$
are
$f(M_{P_i, [r]})$
are
 $\varepsilon$
-balanced, which means that by Lemma 3.6 the second-largest singular value
$\varepsilon$
-balanced, which means that by Lemma 3.6 the second-largest singular value
 $\sigma _i$
of the
$\sigma _i$
of the
 $i$
th step
$i$
th step
 $f(M_{P_i, [r]})$
is bounded above:
$f(M_{P_i, [r]})$
is bounded above:
 $\sigma _i \leq \exp \left (-\frac {\varepsilon }{a^2}\right )$
(using the fact that each
$\sigma _i \leq \exp \left (-\frac {\varepsilon }{a^2}\right )$
(using the fact that each
 $f(M_{P_i, [r]})$
is supported on a subgroup of
$f(M_{P_i, [r]})$
is supported on a subgroup of
 $G^r$
, which still has exponent dividing
$G^r$
, which still has exponent dividing
 $a$
).
$a$
).
Hence by Theorem 1.1 we have
 \begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_r)] - |G|^{-r}| \leq \sum _{H\in S}\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ) \leq N\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ), \end{equation*}
\begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_r)] - |G|^{-r}| \leq \sum _{H\in S}\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ) \leq N\exp \left (-\frac {\varepsilon w}{\ell Na^2}\right ), \end{equation*}
as desired.
To combine these estimates we will use a result in the flavour of [Reference Wood14, Lemma 2.3]:
Lemma 3.13.
Let
 $x_1, \dots , x_m \geq -1$
be real numbers such that
$x_1, \dots , x_m \geq -1$
be real numbers such that
 $\sum _{i=1}^m \max \{0, x_i\} \leq \log 2$
. Then
$\sum _{i=1}^m \max \{0, x_i\} \leq \log 2$
. Then
 \begin{equation*} \left |\prod _{i=1}^m (1 + x_i) - 1\right | \leq 2\sum _{i=1}^m |x_i| \end{equation*}
\begin{equation*} \left |\prod _{i=1}^m (1 + x_i) - 1\right | \leq 2\sum _{i=1}^m |x_i| \end{equation*}
and
 \begin{equation*} \sum _{i=1}^m \min \{0, x_i\} \leq \prod _{i=1}^m (1 + x_i) - 1 \leq 2\sum _{i=1}^m \max \{0, x_i\}. \end{equation*}
\begin{equation*} \sum _{i=1}^m \min \{0, x_i\} \leq \prod _{i=1}^m (1 + x_i) - 1 \leq 2\sum _{i=1}^m \max \{0, x_i\}. \end{equation*}
Proof. The first statement follows from the second statement because
 $\max \{0, x_i\} \leq |x_i|$
and
$\max \{0, x_i\} \leq |x_i|$
and
 $\min \{0, x_i\} \geq -|x_i|$
. So, we will show the second statement.
$\min \{0, x_i\} \geq -|x_i|$
. So, we will show the second statement.
First, assume
 $x_i \leq 0$
for all
$x_i \leq 0$
for all
 $i$
. In that case,
$i$
. In that case,
 \begin{equation*} \prod _{i=1}^m (1 + x_i) \geq 1 + \sum _{i=1}^m x_i. \end{equation*}
\begin{equation*} \prod _{i=1}^m (1 + x_i) \geq 1 + \sum _{i=1}^m x_i. \end{equation*}
Next, assume
 $x_i \geq 0$
for all
$x_i \geq 0$
for all
 $i$
. Using the fact that
$i$
. Using the fact that
 $1 + x_i \leq e^{x_i}$
, we get
$1 + x_i \leq e^{x_i}$
, we get
 \begin{equation*} \prod _{i=1}^m (1 + x_i) \leq e^{\sum _{i=1}^m x_i}. \end{equation*}
\begin{equation*} \prod _{i=1}^m (1 + x_i) \leq e^{\sum _{i=1}^m x_i}. \end{equation*}
We have
 $e^x - 1 = 2x$
at
$e^x - 1 = 2x$
at
 $x = 0$
and
$x = 0$
and
 $\frac {d}{dx}(e^x - 1) \leq \frac {d}{dx}(2x)$
for
$\frac {d}{dx}(e^x - 1) \leq \frac {d}{dx}(2x)$
for
 $x \leq \log 2$
, so
$x \leq \log 2$
, so
 $e^x - 1 \leq 2x$
for
$e^x - 1 \leq 2x$
for
 $0 \leq x \leq \log 2$
. Hence, if
$0 \leq x \leq \log 2$
. Hence, if
 $\sum _{i=1}^m x_i \leq \log 2$
, then
$\sum _{i=1}^m x_i \leq \log 2$
, then
 $\exp \left (\sum _{i=1}^m x_i\right ) - 1 \leq 2\sum _{i=1}^m x_i$
.
$\exp \left (\sum _{i=1}^m x_i\right ) - 1 \leq 2\sum _{i=1}^m x_i$
.
Now consider the general case. By replacing each negative
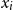 $x_i$
with zero, we can only increase the product
$x_i$
with zero, we can only increase the product
 $\prod _{i=1}^m (1 + x_i)$
. On the other hand, by replacing each positive
$\prod _{i=1}^m (1 + x_i)$
. On the other hand, by replacing each positive
 $x_i$
with zero, we can only decrease it. Hence, for general
$x_i$
with zero, we can only decrease it. Hence, for general
 $x_i$
, we get
$x_i$
, we get
 \begin{align*} \sum _{i=1}^m \min \{0, x_i\} &\leq \prod _{i=1}^m (1 + \min \{0, x_i\}) - 1 \leq \prod _{i=1}^m (1 + x_i) - 1 \leq \prod _{i=1}^m (1 + \max \{0, x_i\}) - 1\nonumber \\ &\leq 2\sum _{i=1}^m \max \{0, x_i\}. \end{align*}
\begin{align*} \sum _{i=1}^m \min \{0, x_i\} &\leq \prod _{i=1}^m (1 + \min \{0, x_i\}) - 1 \leq \prod _{i=1}^m (1 + x_i) - 1 \leq \prod _{i=1}^m (1 + \max \{0, x_i\}) - 1\nonumber \\ &\leq 2\sum _{i=1}^m \max \{0, x_i\}. \end{align*}
Applying this lemma with
 $x_i$
being the error in Lemma 3.12 multiplied by
$x_i$
being the error in Lemma 3.12 multiplied by
 $|G|^r$
yields an estimate on the probability that the whole matrix maps to zero:
$|G|^r$
yields an estimate on the probability that the whole matrix maps to zero:
Lemma 3.14.
Let
 $u \geq 0$
be an integer. Let
$u \geq 0$
be an integer. Let
 $G$
be a finite abelian group and let
$G$
be a finite abelian group and let
 $a$
be a multiple of the exponent of
$a$
be a multiple of the exponent of
 $G$
. Let
$G$
. Let
 $(w_n)_n, (h_n)_n, (\delta _n)_n, (\varepsilon _n)_n$
be sequences of real numbers such that
$(w_n)_n, (h_n)_n, (\delta _n)_n, (\varepsilon _n)_n$
be sequences of real numbers such that
 $h_n\log$
$h_n\log$
 $n = o\left (n\varepsilon _n\delta _n\right )$
and
$n = o\left (n\varepsilon _n\delta _n\right )$
and
 $w_nh_n = o\left (n\varepsilon _n\delta _n\right )$
.
$w_nh_n = o\left (n\varepsilon _n\delta _n\right )$
.
For a natural number
 $n$
, let
$n$
, let
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
$V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
 $M$
be an
$M$
be an
 $(w_n, h_n, \varepsilon _n)$
-balanced
$(w_n, h_n, \varepsilon _n)$
-balanced
 $n\times (n + u)$
random matrix with entries in
$n\times (n + u)$
random matrix with entries in
 $\mathbb{Z}/a\mathbb{Z}$
. Let
$\mathbb{Z}/a\mathbb{Z}$
. Let
 $\mathcal{P}$
be the row partition associated to
$\mathcal{P}$
be the row partition associated to
 $M$
and let
$M$
and let
 $f \in \operatorname {Hom}(V, G)$
be a
$f \in \operatorname {Hom}(V, G)$
be a
 $\mathcal{P}$
-code of distance
$\mathcal{P}$
-code of distance
 $n\delta _n$
.
$n\delta _n$
.
Then for all
 $g_1, \dots , g_{n+u} \in G$
, we have
$g_1, \dots , g_{n+u} \in G$
, we have
 \begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] - |G|^{-n-u}| = o\left (\frac {1}{|G|^{n+u}}\right )\!. \end{equation*}
\begin{equation*} |\mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] - |G|^{-n-u}| = o\left (\frac {1}{|G|^{n+u}}\right )\!. \end{equation*}
Proof. Let
 $\mathcal{P}$
and
$\mathcal{P}$
and
 $\mathcal{Q}$
be the row and column partitions for
$\mathcal{Q}$
be the row and column partitions for
 $M$
as in the definition of
$M$
as in the definition of
 $(w_n, h_n, \varepsilon _n)$
-balanced. Let
$(w_n, h_n, \varepsilon _n)$
-balanced. Let
 $M_i = M_{[n], Q_i}$
for each
$M_i = M_{[n], Q_i}$
for each
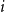 $i$
. Let
$i$
. Let
 $g_{Q_i} = (g_j \mid j \in Q_i)$
. By independence,
$g_{Q_i} = (g_j \mid j \in Q_i)$
. By independence,
 \begin{equation*} \mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] = \prod _i \mathbb{P}[f(M_i) = g_{Q_i}]. \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] = \prod _i \mathbb{P}[f(M_i) = g_{Q_i}]. \end{equation*}
For each
 $i$
, let
$i$
, let
 $x_i = |G|^{\#Q_i}\mathbb{P}[f(M_i) = g_{Q_i}] - 1$
. By Lemma 3.12, we have
$x_i = |G|^{\#Q_i}\mathbb{P}[f(M_i) = g_{Q_i}] - 1$
. By Lemma 3.12, we have
 \begin{align*} |x_i| &\leq N|G|^{\#Q_i}\exp \left (-\frac {n\varepsilon _n \delta _n}{Nh_na^2}\right ) \\ &\leq N|G|^{w_n}\exp \left (-\frac {n\varepsilon _n \delta _n}{Nh_na^2}\right )\!. \end{align*}
\begin{align*} |x_i| &\leq N|G|^{\#Q_i}\exp \left (-\frac {n\varepsilon _n \delta _n}{Nh_na^2}\right ) \\ &\leq N|G|^{w_n}\exp \left (-\frac {n\varepsilon _n \delta _n}{Nh_na^2}\right )\!. \end{align*}
Hence we have
 \begin{equation*} \log |x_i| \leq \log N + w_n\log |G| - \frac {n\varepsilon _n \delta _n}{N h_na^2}. \end{equation*}
\begin{equation*} \log |x_i| \leq \log N + w_n\log |G| - \frac {n\varepsilon _n \delta _n}{N h_na^2}. \end{equation*}
Since
 $h_n\log n = o(n\varepsilon _n\delta _n)$
, we have
$h_n\log n = o(n\varepsilon _n\delta _n)$
, we have
 $\lim _{n\to \infty } \frac {n\varepsilon _n\delta _n}{2Nh_na^2} - \log n = \infty$
. In particular,
$\lim _{n\to \infty } \frac {n\varepsilon _n\delta _n}{2Nh_na^2} - \log n = \infty$
. In particular,
 $\log |x_i| \to -\infty$
as
$\log |x_i| \to -\infty$
as
 $n\to \infty$
.
$n\to \infty$
.
By Lemma 3.13, we therefore have that for such
 $n$
,
$n$
,
 \begin{align*} ||G|^{n+u}\mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] - 1| &= \left |\prod _{i=1}^m|G|^{\#Q_i}\mathbb{P}[f(M_i) = g_{Q_i}]| - 1\right | \\ &= \left |\prod _{i=1}^m (1 + x_i) - 1\right | \\ &\leq 2\sum _{i=1}^m |x_i| \\ &\leq 2Nn\exp \left (-\frac {n\varepsilon _n\delta _n}{2Nh_na^2}\right )\!. \end{align*}
\begin{align*} ||G|^{n+u}\mathbb{P}[f(M) = (g_1, \dots , g_{n+u})] - 1| &= \left |\prod _{i=1}^m|G|^{\#Q_i}\mathbb{P}[f(M_i) = g_{Q_i}]| - 1\right | \\ &= \left |\prod _{i=1}^m (1 + x_i) - 1\right | \\ &\leq 2\sum _{i=1}^m |x_i| \\ &\leq 2Nn\exp \left (-\frac {n\varepsilon _n\delta _n}{2Nh_na^2}\right )\!. \end{align*}
Since
 $\lim _{n\to \infty } \frac {n\varepsilon _n\delta _n}{2Nh_na^2} - \log n = \infty$
, the right hand side converges to
$\lim _{n\to \infty } \frac {n\varepsilon _n\delta _n}{2Nh_na^2} - \log n = \infty$
, the right hand side converges to
 $0$
as
$0$
as
 $n\to \infty$
.
$n\to \infty$
.
3.3 Bounds for the rest of the maps
This gives results for the case when
 $f$
is a code, but we still need to account for non-codes. To do this, we will show that non-codes make up a negligible proportion of all maps
$f$
is a code, but we still need to account for non-codes. To do this, we will show that non-codes make up a negligible proportion of all maps
 $V \to G$
and thus contribute only a small error term to the sum
$V \to G$
and thus contribute only a small error term to the sum
 $\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M), G)]$
. However it turns out that splitting maps into codes and non-codes is not enough to get this bound. Instead, as in [Reference Nguyen and Wood9, Reference Wood14], and similar work, we will categorise non-codes by how far they are from being codes.
$\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M), G)]$
. However it turns out that splitting maps into codes and non-codes is not enough to get this bound. Instead, as in [Reference Nguyen and Wood9, Reference Wood14], and similar work, we will categorise non-codes by how far they are from being codes.
If
 $D$
is an integer with prime factorisation
$D$
is an integer with prime factorisation
 $\prod _i p_i^{e_i}$
, we write
$\prod _i p_i^{e_i}$
, we write
 $\ell (D) = \sum _i e_i$
.
$\ell (D) = \sum _i e_i$
.
Definition 3.15.
If
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
and
$V = (\mathbb{Z}/a\mathbb{Z})^n$
and
 $\mathcal{P}$
is a partition of the “standard basis” of
$\mathcal{P}$
is a partition of the “standard basis” of
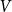 $V$
, the
$V$
, the
 $(\mathcal{P},\delta )$
-depth of
$(\mathcal{P},\delta )$
-depth of
 $f \in \operatorname {Hom}(V, G)$
is the maximal positive
$f \in \operatorname {Hom}(V, G)$
is the maximal positive
 $D$
such that there is a
$D$
such that there is a
 $\sigma \subset \mathcal{P}$
with
$\sigma \subset \mathcal{P}$
with
 $|\cup \sigma | \lt \ell (D)\delta n$
such that
$|\cup \sigma | \lt \ell (D)\delta n$
such that
 $D = [G \;:\; f(V_{\setminus \cup \sigma })]$
, or 1 if there is no such
$D = [G \;:\; f(V_{\setminus \cup \sigma })]$
, or 1 if there is no such
 $D$
.
$D$
.
We can count the number of
 $f$
that have given
$f$
that have given
 $(\mathcal{P}, \delta )$
-depth:
$(\mathcal{P}, \delta )$
-depth:
Lemma 3.16.
If
 $D \gt 1$
, then the number of
$D \gt 1$
, then the number of
 $f \in \operatorname {Hom}(V, G)$
of
$f \in \operatorname {Hom}(V, G)$
of
 $(\mathcal{P}, \delta )$
-depth
$(\mathcal{P}, \delta )$
-depth
 $D$
is at most
$D$
is at most
 \begin{equation*} K\binom {n}{\lceil \ell (D)\delta n\rceil - 1}2^{\ell (D)\delta n}|G|^nD^{-n + \ell (D)\delta n}, \end{equation*}
\begin{equation*} K\binom {n}{\lceil \ell (D)\delta n\rceil - 1}2^{\ell (D)\delta n}|G|^nD^{-n + \ell (D)\delta n}, \end{equation*}
where
 $K$
is the number of subgroups of
$K$
is the number of subgroups of
 $G$
of index
$G$
of index
 $D$
.
$D$
.
Proof. For each
 $f$
of
$f$
of
 $(\mathcal{P},\delta )$
-depth
$(\mathcal{P},\delta )$
-depth
 $D$
, there is a
$D$
, there is a
 $\sigma \subset \mathcal{P}$
as described in Definition 3.15. There must be some set
$\sigma \subset \mathcal{P}$
as described in Definition 3.15. There must be some set
 $S \subset [n]$
with
$S \subset [n]$
with
 $\#S = \lceil \ell (D)\delta n\rceil - 1$
and
$\#S = \lceil \ell (D)\delta n\rceil - 1$
and
 $\cup \sigma \subseteq S$
. There are
$\cup \sigma \subseteq S$
. There are
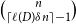 $\binom {n}{\lceil \ell (D)\delta n\rceil - 1}$
choices of
$\binom {n}{\lceil \ell (D)\delta n\rceil - 1}$
choices of
 $S$
, and for each choice of
$S$
, and for each choice of
 $S$
, there are certainly at most
$S$
, there are certainly at most
 $2^{\#S} = 2^{\lceil \ell (D)\delta n\rceil - 1} \leq 2^{\ell (D)\delta n}$
choices of
$2^{\#S} = 2^{\lceil \ell (D)\delta n\rceil - 1} \leq 2^{\ell (D)\delta n}$
choices of
 $\cup \sigma$
. Since
$\cup \sigma$
. Since
 $\mathcal{P}$
is a partition,
$\mathcal{P}$
is a partition,
 $\cup \sigma$
uniquely determines
$\cup \sigma$
uniquely determines
 $\sigma$
, so there are at most
$\sigma$
, so there are at most
 $2^{\ell (D)\delta n}$
choices of
$2^{\ell (D)\delta n}$
choices of
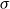 $\sigma$
for each choice of
$\sigma$
for each choice of
 $S$
.
$S$
.
Now we count how many
 $f$
of
$f$
of
 $(\mathcal{P},\delta )$
-depth
$(\mathcal{P},\delta )$
-depth
 $D$
have each choice of
$D$
have each choice of
 $\sigma$
, so fix
$\sigma$
, so fix
 $\sigma$
. There are
$\sigma$
. There are
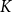 $K$
subgroups of
$K$
subgroups of
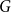 $G$
of index
$G$
of index
 $D$
, so there are
$D$
, so there are
 $K$
options for
$K$
options for
 $f(V_{\setminus \cup \sigma })$
.
$f(V_{\setminus \cup \sigma })$
.
Fix a subgroup
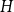 $H$
of
$H$
of
 $G$
with index
$G$
with index
 $D$
. We now count the number of
$D$
. We now count the number of
 $f$
with
$f$
with
 $f(V_{\setminus \cup \sigma }) \subseteq H$
. There are at most
$f(V_{\setminus \cup \sigma }) \subseteq H$
. There are at most
 $|H|^{n - |\cup \sigma |}$
maps from
$|H|^{n - |\cup \sigma |}$
maps from
 $V_{\setminus \cup \sigma }$
to
$V_{\setminus \cup \sigma }$
to
 $H$
, and for each such map, there are at most
$H$
, and for each such map, there are at most
 $|G|^{|\cup \sigma |}$
homomorphisms from
$|G|^{|\cup \sigma |}$
homomorphisms from
 $V$
to
$V$
to
 $G$
which restrict appropriately. Hence, there are at most
$G$
which restrict appropriately. Hence, there are at most
 \begin{equation*} |H|^{n - |\cup \sigma |}|G|^{|\cup \sigma |} = |G|^{n - |\cup \sigma |}D^{-n + |\cup \sigma |}|G|^{|\cup \sigma |} = |G|^nD^{-n + |\cup \sigma |} \leq |G|^nD^{-n + \ell (D)\delta n} \end{equation*}
\begin{equation*} |H|^{n - |\cup \sigma |}|G|^{|\cup \sigma |} = |G|^{n - |\cup \sigma |}D^{-n + |\cup \sigma |}|G|^{|\cup \sigma |} = |G|^nD^{-n + |\cup \sigma |} \leq |G|^nD^{-n + \ell (D)\delta n} \end{equation*}
maps
 $f$
with
$f$
with
 $f(V_{\setminus \cup \sigma }) = H$
. Combined with the counts of choices of
$f(V_{\setminus \cup \sigma }) = H$
. Combined with the counts of choices of
 $\sigma$
and subgroups of
$\sigma$
and subgroups of
 $G$
of index
$G$
of index
 $D$
, we get the lemma.
$D$
, we get the lemma.
For non-codes, we do not get precise estimates on
 $\mathbb{P}[f(M) = 0]$
, but we can get upper bounds.
$\mathbb{P}[f(M) = 0]$
, but we can get upper bounds.
Lemma 3.17.
Let
 $r \geq 1$
be an integer. Let
$r \geq 1$
be an integer. Let
 $G$
be a finite abelian group and let
$G$
be a finite abelian group and let
 $a$
be a multiple of the exponent of
$a$
be a multiple of the exponent of
 $G$
. Let
$G$
. Let
 $N$
be the number of subgroups of
$N$
be the number of subgroups of
 $G$
. Let
$G$
. Let
 $\varepsilon \gt 0$
and
$\varepsilon \gt 0$
and
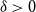 $\delta \gt 0$
be real numbers. Let
$\delta \gt 0$
be real numbers. Let
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
$V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
 $\mathcal{P} = \{P_1, \dots , P_m\}$
be a partition of
$\mathcal{P} = \{P_1, \dots , P_m\}$
be a partition of
 $[n]$
and let
$[n]$
and let
 $\ell = |\mathcal{P}|$
. Let
$\ell = |\mathcal{P}|$
. Let
 $f \in \operatorname {Hom}(V, G)$
have
$f \in \operatorname {Hom}(V, G)$
have
 $(\mathcal{P}, \delta )$
-depth
$(\mathcal{P}, \delta )$
-depth
 $D \gt 1$
with
$D \gt 1$
with
 $[G \;:\; f(V)] \lt D$
.
$[G \;:\; f(V)] \lt D$
.
Let
 $M$
be an
$M$
be an
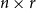 $n\times r$
random matrix in
$n\times r$
random matrix in
 $V^r$
such that the matrices
$V^r$
such that the matrices
 $M_{P_i, [r]}$
are independent and
$M_{P_i, [r]}$
are independent and
 $\varepsilon$
-balanced as random elements of
$\varepsilon$
-balanced as random elements of
 $((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
.
$((\mathbb{Z}/a\mathbb{Z})^{\#P_i})^r$
.
Then
 \begin{equation*} \mathbb{P}[f(M) = 0] \leq (1 - \varepsilon )\left (D^r|G|^{-r} + N\exp \left (-\frac {\varepsilon \delta n}{2N\ell a^2}\right )\right )\!. \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = 0] \leq (1 - \varepsilon )\left (D^r|G|^{-r} + N\exp \left (-\frac {\varepsilon \delta n}{2N\ell a^2}\right )\right )\!. \end{equation*}
Proof. Since
 $f$
has
$f$
has
 $(\mathcal{P},\delta )$
-depth
$(\mathcal{P},\delta )$
-depth
 $D$
, there is a
$D$
, there is a
 $\sigma \subset \mathcal{P}$
with
$\sigma \subset \mathcal{P}$
with
 $|\cup \sigma | \lt \ell (D)\delta n$
such that
$|\cup \sigma | \lt \ell (D)\delta n$
such that
 $D = [G \;:\; f(V_{\setminus \cup \sigma })]$
. Let
$D = [G \;:\; f(V_{\setminus \cup \sigma })]$
. Let
 $f(V_{\setminus \cup \sigma }) =\colon H$
. Since
$f(V_{\setminus \cup \sigma }) =\colon H$
. Since
 $[G \;:\; f(V)] \lt D$
, we cannot have that
$[G \;:\; f(V)] \lt D$
, we cannot have that
 $\sigma$
is empty.
$\sigma$
is empty.
Write
 $f(M) = \sum _{j\notin \sigma }f(M_{P_j, [r]}) + \sum _{j\in \sigma }f(M_{P_j, [r]})$
. So,
$f(M) = \sum _{j\notin \sigma }f(M_{P_j, [r]}) + \sum _{j\in \sigma }f(M_{P_j, [r]})$
. So,
 \begin{equation*} \mathbb{P}[f(M) = 0] = \mathbb{P}[f(M) \in H]\mathbb{P}\left [\sum _{j\notin \sigma }f(M_{P_j, [r]}) = -\sum _{j\in \sigma }f(M_{P_j, [r]}) \ \middle |\ f(M) \in H\right ]. \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = 0] = \mathbb{P}[f(M) \in H]\mathbb{P}\left [\sum _{j\notin \sigma }f(M_{P_j, [r]}) = -\sum _{j\in \sigma }f(M_{P_j, [r]}) \ \middle |\ f(M) \in H\right ]. \end{equation*}
We bound the two probabilities on the right side separately. Note that since
 $\sum _{j\in \sigma }f(M_{P_j, [r]}) \in H$
, we have
$\sum _{j\in \sigma }f(M_{P_j, [r]}) \in H$
, we have
 $f(M) \in H$
exactly when
$f(M) \in H$
exactly when
 $\sum _{j\notin \sigma }f(M_{P_j, [r]}) \in H$
. Since
$\sum _{j\notin \sigma }f(M_{P_j, [r]}) \in H$
. Since
 $[G \;:\; f(V)] \lt [G \;:\; H]$
, there must be some
$[G \;:\; f(V)] \lt [G \;:\; H]$
, there must be some
 $i \in \sigma$
such that
$i \in \sigma$
such that
 $f(M_{P_i, [r]})$
reduces to a nonzero element of
$f(M_{P_i, [r]})$
reduces to a nonzero element of
 $G/H$
. Conditioning on all other
$G/H$
. Conditioning on all other
 $M_{P_k, [r]}$
for
$M_{P_k, [r]}$
for
 $k \neq i$
, by the
$k \neq i$
, by the
 $\varepsilon$
-balanced assumption we have that
$\varepsilon$
-balanced assumption we have that
 \begin{equation*} \mathbb{P}\left [f(M) \in H\right ] = \mathbb{P}\left [f(M_{P_i, [r]}) \equiv -\sum _{j \in \sigma \setminus \{i\}}f(M_{P_j, [r]}) \pmod {H}\right ] \leq 1 - \varepsilon . \end{equation*}
\begin{equation*} \mathbb{P}\left [f(M) \in H\right ] = \mathbb{P}\left [f(M_{P_i, [r]}) \equiv -\sum _{j \in \sigma \setminus \{i\}}f(M_{P_j, [r]}) \pmod {H}\right ] \leq 1 - \varepsilon . \end{equation*}
For the second probability, let
 $\mathcal{P}'$
be the partition of
$\mathcal{P}'$
be the partition of
 $[n]\setminus \cup \sigma$
induced by
$[n]\setminus \cup \sigma$
induced by
 $\mathcal{P}$
. Notice that
$\mathcal{P}$
. Notice that
 $f|_{V_{\setminus \cup \sigma }}$
is a
$f|_{V_{\setminus \cup \sigma }}$
is a
 $\mathcal{P}'$
-code of distance
$\mathcal{P}'$
-code of distance
 $\delta n$
. Indeed, suppose there is some
$\delta n$
. Indeed, suppose there is some
 $\tau \subset \mathcal{P}'$
with
$\tau \subset \mathcal{P}'$
with
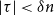 $|\tau | \lt \delta n$
inducing some
$|\tau | \lt \delta n$
inducing some
 $\tau ' \subset \mathcal{P}$
with
$\tau ' \subset \mathcal{P}$
with
 $f(V_{\setminus \cup (\sigma \cup \tau )}) \neq H$
. Then the image of
$f(V_{\setminus \cup (\sigma \cup \tau )}) \neq H$
. Then the image of
 $f|_{V_{\setminus \cup (\sigma \cup \tau )}}$
would have index strictly greater than
$f|_{V_{\setminus \cup (\sigma \cup \tau )}}$
would have index strictly greater than
 $D$
, contradicting maximality of
$D$
, contradicting maximality of
 $D$
.
$D$
.
Now we can apply Lemma 3.12 to the submatrix
 $M_{[n]\setminus \cup \sigma , [r]}$
and the code
$M_{[n]\setminus \cup \sigma , [r]}$
and the code
 $f$
mapping it into
$f$
mapping it into
 $H^r$
. If
$H^r$
. If
 $N'$
is the number of subgroups of
$N'$
is the number of subgroups of
 $H$
and
$H$
and
 $\ell ' = |\mathcal{P}'|$
, then conditioning on
$\ell ' = |\mathcal{P}'|$
, then conditioning on
 $M_{P_j, [r]}$
for
$M_{P_j, [r]}$
for
 $j \in \sigma$
gives
$j \in \sigma$
gives
 \begin{align*} \mathbb{P}\left [\sum _{j\notin \sigma }f(M_{P_j, [r]}) = -\sum _{j\in \sigma }f(M_{P_j, [r]}) \ \middle |\ f(M) \in H\right ] &\leq |H|^{-r} + N'\exp \left (-\frac {\varepsilon \delta n}{2N'\ell 'a^2}\right ) \\ &\leq D^r|G|^{-r} + N\exp \left (-\frac {\varepsilon \delta n}{2N\ell a^2}\right ), \end{align*}
\begin{align*} \mathbb{P}\left [\sum _{j\notin \sigma }f(M_{P_j, [r]}) = -\sum _{j\in \sigma }f(M_{P_j, [r]}) \ \middle |\ f(M) \in H\right ] &\leq |H|^{-r} + N'\exp \left (-\frac {\varepsilon \delta n}{2N'\ell 'a^2}\right ) \\ &\leq D^r|G|^{-r} + N\exp \left (-\frac {\varepsilon \delta n}{2N\ell a^2}\right ), \end{align*}
and the lemma follows.
Finally, we use Lemma 3.13 again to get a bound for the full
 $n\times (n+u)$
matrix:
$n\times (n+u)$
matrix:
Lemma 3.18.
Let
 $u \geq 0$
be an integer. Let
$u \geq 0$
be an integer. Let
 $G$
be a finite abelian group and let
$G$
be a finite abelian group and let
 $a$
be a multiple of the exponent of
$a$
be a multiple of the exponent of
 $G$
. Let
$G$
. Let
 $(w_n)_n, (h_n)_n, (\delta _n)_n, (\varepsilon _n)_n$
be sequences of real numbers such that
$(w_n)_n, (h_n)_n, (\delta _n)_n, (\varepsilon _n)_n$
be sequences of real numbers such that
 $h_n\log$
$h_n\log$
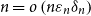 $n = o\left (n\varepsilon _n\delta _n\right )$
and
$n = o\left (n\varepsilon _n\delta _n\right )$
and
 $w_nh_n = o\left (n\varepsilon _n\delta _n\right )$
.
$w_nh_n = o\left (n\varepsilon _n\delta _n\right )$
.
For a natural number
 $n$
, let
$n$
, let
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
$V = (\mathbb{Z}/a\mathbb{Z})^n$
. Let
 $M$
be an
$M$
be an
 $(w_n, h_n, \varepsilon _n)$
-balanced
$(w_n, h_n, \varepsilon _n)$
-balanced
 $n\times (n + u)$
random matrix with entries in
$n\times (n + u)$
random matrix with entries in
 $\mathbb{Z}/a\mathbb{Z}$
. Let
$\mathbb{Z}/a\mathbb{Z}$
. Let
 $\mathcal{P}$
be the row partition associated to
$\mathcal{P}$
be the row partition associated to
 $M$
and let
$M$
and let
 $f \in \operatorname {Hom}(V, G)$
have
$f \in \operatorname {Hom}(V, G)$
have
 $(\mathcal{P}, \delta _n)$
-depth
$(\mathcal{P}, \delta _n)$
-depth
 $D \gt 1$
, with
$D \gt 1$
, with
 $[G \;:\; f(V)] \lt D$
.
$[G \;:\; f(V)] \lt D$
.
Then there is a constant
 $K \gt 0$
depending only on
$K \gt 0$
depending only on
 $u$
,
$u$
,
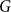 $G$
,
$G$
,
 $\alpha$
,
$\alpha$
,
 $\beta$
, and the sequences
$\beta$
, and the sequences
 $h_n$
,
$h_n$
,
 $w_n$
such that for all
$w_n$
such that for all
 $n$
,
$n$
,
 \begin{equation*} \mathbb{P}[f(M) = 0] \leq K\exp \left (-\varepsilon _n\frac {n}{w_n}\right )D^n|G|^{-n}. \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = 0] \leq K\exp \left (-\varepsilon _n\frac {n}{w_n}\right )D^n|G|^{-n}. \end{equation*}
Proof. Let
 $\mathcal{Q}$
be the column partition for
$\mathcal{Q}$
be the column partition for
 $M$
as in the definition of
$M$
as in the definition of
 $(w_n, h_n, \varepsilon _n)$
-balanced. Let
$(w_n, h_n, \varepsilon _n)$
-balanced. Let
 $M_i = M_{[n], Q_i}$
for each
$M_i = M_{[n], Q_i}$
for each
 $i$
. By independence,
$i$
. By independence,
 \begin{equation*} \mathbb{P}[f(M) = 0] = \prod _i \mathbb{P}[f(M_i) = 0]. \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = 0] = \prod _i \mathbb{P}[f(M_i) = 0]. \end{equation*}
For each
 $i$
, let
$i$
, let
 $x_i = \frac {|G|^{\#Q_i}D^{-\#Q_i}}{1 - \varepsilon _n}\mathbb{P}[f(M_i) = 0] - 1$
. By Lemma 3.17, we have
$x_i = \frac {|G|^{\#Q_i}D^{-\#Q_i}}{1 - \varepsilon _n}\mathbb{P}[f(M_i) = 0] - 1$
. By Lemma 3.17, we have
 \begin{align*} \max \{0, x_i\} &\leq N|G|^{\#Q_i}D^{-\#Q_i}\exp \left (-\frac {n\varepsilon _n \delta _n}{2Nh_n a^2}\right ) \\ &\leq N|G|^{w_n}D^{-w_n}\exp \left (-\frac {n\varepsilon _n \delta _n}{2Nh_n a^2}\right )\!. \end{align*}
\begin{align*} \max \{0, x_i\} &\leq N|G|^{\#Q_i}D^{-\#Q_i}\exp \left (-\frac {n\varepsilon _n \delta _n}{2Nh_n a^2}\right ) \\ &\leq N|G|^{w_n}D^{-w_n}\exp \left (-\frac {n\varepsilon _n \delta _n}{2Nh_n a^2}\right )\!. \end{align*}
By the same argument as in the proof of Lemma 3.14, we find that
 \begin{align*} \frac {(D^{-1}|G|)^{n+u}}{(1 - \varepsilon _n)^{\#\mathcal{Q}}}\mathbb{P}[f(M) = 0] - 1 = o(1) \end{align*}
\begin{align*} \frac {(D^{-1}|G|)^{n+u}}{(1 - \varepsilon _n)^{\#\mathcal{Q}}}\mathbb{P}[f(M) = 0] - 1 = o(1) \end{align*}
and
 \begin{equation*} \mathbb{P}[f(M) = 0] = (1 + o(1))(1 - \varepsilon _n)^{\#\mathcal{Q}}(D^{-1}|G|)^{-n-u} \leq (1 + o(1))\exp (-\varepsilon _n\#\mathcal{Q})(D^{-1}|G|)^{-n-u} \end{equation*}
\begin{equation*} \mathbb{P}[f(M) = 0] = (1 + o(1))(1 - \varepsilon _n)^{\#\mathcal{Q}}(D^{-1}|G|)^{-n-u} \leq (1 + o(1))\exp (-\varepsilon _n\#\mathcal{Q})(D^{-1}|G|)^{-n-u} \end{equation*}
The conclusion follows from
 $\#\mathcal{Q} \geq \frac {n}{w_n}$
.
$\#\mathcal{Q} \geq \frac {n}{w_n}$
.
3.4 Computing the moments
Finally, we can combine all these results to compute the limiting moments for cokernels of
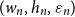 $(w_n, h_n, \varepsilon _n)$
-balanced random matrices. The most delicate part of this proof is the part where we handle the non-codes. This will involve a careful choice of the sequence
$(w_n, h_n, \varepsilon _n)$
-balanced random matrices. The most delicate part of this proof is the part where we handle the non-codes. This will involve a careful choice of the sequence
 $\delta _n$
.
$\delta _n$
.
Theorem 3.19.
Let
 $u \geq 0$
be an integer. Let
$u \geq 0$
be an integer. Let
 $G$
be a finite abelian group and let
$G$
be a finite abelian group and let
 $a$
be a multiple of the exponent of
$a$
be a multiple of the exponent of
 $G$
(including zero). Let
$G$
(including zero). Let
 $(w_n)_n, (h_n)_n$
,
$(w_n)_n, (h_n)_n$
,
 $(\varepsilon _n)_n$
be sequences of real numbers such that
$(\varepsilon _n)_n$
be sequences of real numbers such that
 $w_n = O(n^{\alpha _1})$
,
$w_n = O(n^{\alpha _1})$
,
 $h_n = O(n^{\alpha _2})$
and
$h_n = O(n^{\alpha _2})$
and
 $\varepsilon _n = \Omega (n^{-\beta })$
for some real numbers
$\varepsilon _n = \Omega (n^{-\beta })$
for some real numbers
 $0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
$0 \leq \alpha _1, \alpha _2, \beta \lt 1$
satisfying
 \begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
\begin{equation*}2\alpha _1 + \alpha _2 \lt 1 - 2\beta . \end{equation*}
For each natural number
 $n$
, let
$n$
, let
 $M_n$
be an
$M_n$
be an
 $(w_n, h_n, \varepsilon _n)$
-balanced
$(w_n, h_n, \varepsilon _n)$
-balanced
 $n \times (n + u)$
random matrix with entries in
$n \times (n + u)$
random matrix with entries in
 $\mathbb{Z}/a\mathbb{Z}$
. Then
$\mathbb{Z}/a\mathbb{Z}$
. Then
 \begin{equation*} \lim _{n\to \infty }\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] = |G|^{-u}. \end{equation*}
\begin{equation*} \lim _{n\to \infty }\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] = |G|^{-u}. \end{equation*}
When
 $a = 0$
, we mean that
$a = 0$
, we mean that
 $M_n$
is a matrix over
$M_n$
is a matrix over
 $\mathbb{Z}$
. The conditions on
$\mathbb{Z}$
. The conditions on
 $w_n, h_n, \varepsilon _n$
can be weakened somewhat with more careful accounting.
$w_n, h_n, \varepsilon _n$
can be weakened somewhat with more careful accounting.
Proof. Let
 $V = (\mathbb{Z}/a\mathbb{Z})^n$
. Following the discussion at the beginning of this section, we have
$V = (\mathbb{Z}/a\mathbb{Z})^n$
. Following the discussion at the beginning of this section, we have
 \begin{equation*} \mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] = \sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0]. \end{equation*}
\begin{equation*} \mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] = \sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0]. \end{equation*}
Thus,
 \begin{align*} \left |\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] - \frac {1}{|G|^u}\right | &=\left |\sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^u}\right | \\ &= \left |\sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0] - \sum _{f \in \operatorname {Hom}(V, G)}\frac {1}{|G|^{n + u}}\right | \\ &\leq \sum _{f \in \operatorname {Sur}(V, G)}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right |. \end{align*}
\begin{align*} \left |\mathbb{E}[\#\operatorname {Sur}(\operatorname {coker}(M_n), G)] - \frac {1}{|G|^u}\right | &=\left |\sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^u}\right | \\ &= \left |\sum _{f \in \operatorname {Sur}(V, G)}\mathbb{P}[f(M_n) = 0] - \sum _{f \in \operatorname {Hom}(V, G)}\frac {1}{|G|^{n + u}}\right | \\ &\leq \sum _{f \in \operatorname {Sur}(V, G)}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right |. \end{align*}
We will break this sum into a term coming from codes and a few terms coming from non-codes. Then we will bound each of the terms individually using Lemmas 3.14 and 3.18.
Since
 $2\alpha _1 + \alpha _2 \lt 1 - 2\beta$
, we have
$2\alpha _1 + \alpha _2 \lt 1 - 2\beta$
, we have
 $\alpha _1 + \beta \lt 1 - \beta - \alpha _1 - \alpha _2$
. Choose
$\alpha _1 + \beta \lt 1 - \beta - \alpha _1 - \alpha _2$
. Choose
 $\gamma \gt 0$
such that
$\gamma \gt 0$
such that
 \begin{equation*} \alpha _1 + \beta \lt \gamma \lt 1 - \beta - \alpha _1 - \alpha _2 \end{equation*}
\begin{equation*} \alpha _1 + \beta \lt \gamma \lt 1 - \beta - \alpha _1 - \alpha _2 \end{equation*}
and let
 $\delta _n = n^{-\gamma }$
. We have
$\delta _n = n^{-\gamma }$
. We have
 $w_nh_n = O(n^{\alpha _1 + \alpha _2}) = o(n^{1 - \beta - \gamma }) = o(n\varepsilon _n\delta _n)$
and
$w_nh_n = O(n^{\alpha _1 + \alpha _2}) = o(n^{1 - \beta - \gamma }) = o(n\varepsilon _n\delta _n)$
and
 $h_n\log n = O(n^{\alpha _1 + \alpha _2}) = o(n\varepsilon _n\delta _n)$
as well, so
$h_n\log n = O(n^{\alpha _1 + \alpha _2}) = o(n\varepsilon _n\delta _n)$
as well, so
 $\delta _n$
satisfies the conditions for Lemmas 3.14 and 3.18.
$\delta _n$
satisfies the conditions for Lemmas 3.14 and 3.18.
Let
 $\mathcal{P}, \mathcal{Q}$
be the row and column partitions witnessing the
$\mathcal{P}, \mathcal{Q}$
be the row and column partitions witnessing the
 $(w_n, h_n, \varepsilon _n)$
-balancedness of
$(w_n, h_n, \varepsilon _n)$
-balancedness of
 $M_n$
. We have
$M_n$
. We have
 \begin{align} \nonumber &\sum _{f \in \operatorname {Sur}(V, G)}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \\ &\qquad \qquad \leq \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ code of distance }n\delta _n}}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \end{align}
\begin{align} \nonumber &\sum _{f \in \operatorname {Sur}(V, G)}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \\ &\qquad \qquad \leq \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ code of distance }n\delta _n}}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \end{align}
 \begin{align} &\qquad \qquad \qquad + \sum _{\substack {D \gt 1 \\ D \mid |G|}}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] \end{align}
\begin{align} &\qquad \qquad \qquad + \sum _{\substack {D \gt 1 \\ D \mid |G|}}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] \end{align}
 \begin{align} &\qquad \qquad \qquad + \sum _{\substack {D \gt 1 \\ D \mid |G|}}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}} \frac {1}{|G|^{n+u}} \end{align}
\begin{align} &\qquad \qquad \qquad + \sum _{\substack {D \gt 1 \\ D \mid |G|}}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}} \frac {1}{|G|^{n+u}} \end{align}
 \begin{align} &\qquad \qquad \qquad + \sum _{f \in \operatorname {Hom}(V, G) \setminus \operatorname {Sur}(V, G)} \frac {1}{|G|^{n+u}} \end{align}
\begin{align} &\qquad \qquad \qquad + \sum _{f \in \operatorname {Hom}(V, G) \setminus \operatorname {Sur}(V, G)} \frac {1}{|G|^{n+u}} \end{align}
For notational convenience, we will use
 $K$
to denote a constant that is allowed to change in each line as long as it remains a constant depending only on
$K$
to denote a constant that is allowed to change in each line as long as it remains a constant depending only on
 $a, u, \alpha _1, \alpha _2, \beta , (h_n)_n, (w_n)_n, G$
.
$a, u, \alpha _1, \alpha _2, \beta , (h_n)_n, (w_n)_n, G$
.
Wood showed in the proof of [Reference Wood14, Theorem 2.9] that (4) is bounded above by
 $Ke^{-n\log 2} = o(1)$
. By Lemma 3.14, we can bound (1):
$Ke^{-n\log 2} = o(1)$
. By Lemma 3.14, we can bound (1):
 \begin{align*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ code of distance }n\delta _n}}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \leq |G|^no\left (\frac {1}{|G|^{n+u}}\right ) = o(1). \end{align*}
\begin{align*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ code of distance }n\delta _n}}\left |\mathbb{P}[f(M_n) = 0] - \frac {1}{|G|^{n + u}}\right | \leq |G|^no\left (\frac {1}{|G|^{n+u}}\right ) = o(1). \end{align*}
To bound (2) and (3) we use Lemma 3.16: for each
 $D \gt 1$
, there are at most
$D \gt 1$
, there are at most
 \begin{equation*} K\binom {n}{\lceil \ell (D)n\delta _n\rceil - 1}2^{\ell (D)n\delta _n}|G|^nD^{-n + \ell (D)n\delta _n} \end{equation*}
\begin{equation*} K\binom {n}{\lceil \ell (D)n\delta _n\rceil - 1}2^{\ell (D)n\delta _n}|G|^nD^{-n + \ell (D)n\delta _n} \end{equation*}
maps of
 $(\mathcal{P}, \delta _n)$
-depth
$(\mathcal{P}, \delta _n)$
-depth
 $D$
. We will start by using this bound from Lemma 3.16 to get a slightly weaker bound whose limit behaviour is easier to understand. A standard inequality says that
$D$
. We will start by using this bound from Lemma 3.16 to get a slightly weaker bound whose limit behaviour is easier to understand. A standard inequality says that
 $\binom {n}{k} \leq \left (\frac {ne}{k}\right )^k$
, so for
$\binom {n}{k} \leq \left (\frac {ne}{k}\right )^k$
, so for
 $\lceil \ell (D)n\delta _n\rceil \geq 2$
(which is the case for
$\lceil \ell (D)n\delta _n\rceil \geq 2$
(which is the case for
 $n$
large enough, independent of
$n$
large enough, independent of
 $D$
)
$D$
)
 \begin{align*} \binom {n}{\lceil \ell (D)n\delta _n\rceil - 1} &\leq \left (\frac {ne}{\lceil \ell (D)n\delta _n\rceil - 1}\right )^{\lceil \ell (D)n\delta _n\rceil - 1} \\ &\leq \left (\frac {2ne}{\ell (D)n\delta _n}\right )^{\ell (D)n\delta _n} \\ &= \left (\frac {2e}{\ell (D)\delta _n}\right )^{\ell (D)n\delta _n} \\ &= \exp \left (\ell (D)n\delta _n\left (1 + \log 2 - \log \ell (D) - \log \delta _n\right )\right )\!. \end{align*}
\begin{align*} \binom {n}{\lceil \ell (D)n\delta _n\rceil - 1} &\leq \left (\frac {ne}{\lceil \ell (D)n\delta _n\rceil - 1}\right )^{\lceil \ell (D)n\delta _n\rceil - 1} \\ &\leq \left (\frac {2ne}{\ell (D)n\delta _n}\right )^{\ell (D)n\delta _n} \\ &= \left (\frac {2e}{\ell (D)\delta _n}\right )^{\ell (D)n\delta _n} \\ &= \exp \left (\ell (D)n\delta _n\left (1 + \log 2 - \log \ell (D) - \log \delta _n\right )\right )\!. \end{align*}
Hence, the number of maps of
 $(\mathcal{P}, \delta _n)$
-depth
$(\mathcal{P}, \delta _n)$
-depth
 $D$
is at most
$D$
is at most
 \begin{align*} &K|G|^nD^{-n}\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right )\right )\\ &= K|G|^n\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right ) - n\log D\right ) \\ &\leq K|G|^n\exp \left (\ell (|G|)n\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) - n\log 2\right ) \qquad \mathrm{(*)} \end{align*}
\begin{align*} &K|G|^nD^{-n}\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right )\right )\\ &= K|G|^n\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right ) - n\log D\right ) \\ &\leq K|G|^n\exp \left (\ell (|G|)n\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) - n\log 2\right ) \qquad \mathrm{(*)} \end{align*}
Since
 $\lim _{\delta \to 0} \delta \log \delta = 0$
and
$\lim _{\delta \to 0} \delta \log \delta = 0$
and
 $\delta _n \to 0$
as
$\delta _n \to 0$
as
 $n\to \infty$
, for large enough
$n\to \infty$
, for large enough
 $n$
(depending on
$n$
(depending on
 $|G|$
and the rate of decay of the sequence
$|G|$
and the rate of decay of the sequence
 $\delta _n$
) we have
$\delta _n$
) we have
 $\ell (|G|)\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) \leq \frac {1}{2}\log 2$
, which means that for large enough
$\ell (|G|)\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) \leq \frac {1}{2}\log 2$
, which means that for large enough
 $n$
,
$n$
,
 \begin{align*} \sum _{D \mid |G|}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}} \frac {1}{|G|^{n+u}} &\leq \sum _{D \mid |G|} K|G|^{-u}\exp \left (\ell (|G|)n\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) - n\log 2\right ) \\ &\leq \sum _{D \mid |G|} K\exp \left (-\frac {\log 2}{2}n\right ) \\ &\leq K\exp \left (-\frac {\log 2}{2}n\right ) = o(1), \end{align*}
\begin{align*} \sum _{D \mid |G|}\sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}} \frac {1}{|G|^{n+u}} &\leq \sum _{D \mid |G|} K|G|^{-u}\exp \left (\ell (|G|)n\delta _n\left (\log \frac {4e|G|}{\ell (|G|)} - \log \delta _n\right ) - n\log 2\right ) \\ &\leq \sum _{D \mid |G|} K\exp \left (-\frac {\log 2}{2}n\right ) \\ &\leq K\exp \left (-\frac {\log 2}{2}n\right ) = o(1), \end{align*}
bounding (3) as desired.
Finally, we need to bound (2). From Lemma 3.18, we have that if
 $f$
has
$f$
has
 $(\mathcal{P}, \delta _n)$
-depth
$(\mathcal{P}, \delta _n)$
-depth
 $D$
,
$D$
,
 \begin{equation*} \mathbb{P}[f(M_n) = 0] \leq K\exp \left (-\varepsilon _n\frac {n}{w_n}\right )D^n|G|^{-n}, \end{equation*}
\begin{equation*} \mathbb{P}[f(M_n) = 0] \leq K\exp \left (-\varepsilon _n\frac {n}{w_n}\right )D^n|G|^{-n}, \end{equation*}
which, combined with (*), gives
 \begin{align*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] &\leq K\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right ) -\frac {n\varepsilon _n}{w_n}\right )\!. \end{align*}
\begin{align*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] &\leq K\exp \left (\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right ) -\frac {n\varepsilon _n}{w_n}\right )\!. \end{align*}
The term
 $\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right )$
is bounded above by a constant multiple of
$\ell (D)n\delta _n\left (\log \frac {4eD}{\ell (D)} - \log \delta _n\right )$
is bounded above by a constant multiple of
 $n^{1 - \gamma }\log n$
for large enough
$n^{1 - \gamma }\log n$
for large enough
 $n$
, whereas
$n$
, whereas
 $\frac {n\varepsilon _n}{w_n}$
is bounded below by a constant multiple of
$\frac {n\varepsilon _n}{w_n}$
is bounded below by a constant multiple of
 $n^{1 - \beta - \alpha _1}$
. Since
$n^{1 - \beta - \alpha _1}$
. Since
 $\gamma \gt \alpha _1 + \beta$
, we have
$\gamma \gt \alpha _1 + \beta$
, we have
 $n^{1 - \gamma }\log n = o(n^{1 - \beta - \alpha _1})$
, so that the term in the exponent goes to
$n^{1 - \gamma }\log n = o(n^{1 - \beta - \alpha _1})$
, so that the term in the exponent goes to
 $-\infty$
as
$-\infty$
as
 $n\to \infty$
. Thus,
$n\to \infty$
. Thus,
 \begin{equation*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] = o(1), \end{equation*}
\begin{equation*} \sum _{\substack {f \in \operatorname {Sur}(V, G) \\ f \text{ of }(\mathcal{P}, \delta _n)\text{-depth }D}}\mathbb{P}[f(M_n) = 0] = o(1), \end{equation*}
giving us a bound on (2). Since each of (1), (2), (3), and (4) is
 $o(1)$
, we obtain the claim of the theorem.
$o(1)$
, we obtain the claim of the theorem.
As explained at the beginning of this section, the results of [Reference Wood14, Theorem 3.1, Lemma 3.2] imply that Theorem 3.9 follows from Theorem 3.19.
3.5 Weak convergence and proof of Theorem 1.2
We now give a proof of Theorem 1.2 from Theorem 3.9, expanding on Remark 3.1. This idea is due to Liu and Wood in [Reference Liu and Wood4], although their topological space consists of profinite groups.
Let
 $\mathcal{A}$
be the set of isomorphism classes of finitely generated abelian groups.
$\mathcal{A}$
be the set of isomorphism classes of finitely generated abelian groups.
Recall that for a positive integer
 $a$
and finite abelian group
$a$
and finite abelian group
 $H$
with exponent dividing
$H$
with exponent dividing
 $a$
we defined
$a$
we defined
 \begin{equation*} U_{a, H} = \{X \text{ finitely generated abelian}\mid X \otimes \mathbb{Z}/a\mathbb{Z} \cong H\} \subset \mathcal{A}. \end{equation*}
\begin{equation*} U_{a, H} = \{X \text{ finitely generated abelian}\mid X \otimes \mathbb{Z}/a\mathbb{Z} \cong H\} \subset \mathcal{A}. \end{equation*}
If
 $Y \sim \lambda _u$
, then
$Y \sim \lambda _u$
, then
 $\mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H})$
.
$\mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H})$
.
The sets
 $U_{a, H}$
cover
$U_{a, H}$
cover
 $\mathcal{A}$
. Moreover, suppose
$\mathcal{A}$
. Moreover, suppose
 $U_{a, H} \cap U_{a', H'}$
is nonempty. Then it consists of groups
$U_{a, H} \cap U_{a', H'}$
is nonempty. Then it consists of groups
 $G$
with
$G$
with
 $G \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
and
$G \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
and
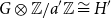 $G \otimes \mathbb{Z}/a'\mathbb{Z} \cong H'$
. Note that both of these quotients are determined by
$G \otimes \mathbb{Z}/a'\mathbb{Z} \cong H'$
. Note that both of these quotients are determined by
 $G \otimes \mathbb{Z}/aa'\mathbb{Z}$
(in fact, considering
$G \otimes \mathbb{Z}/aa'\mathbb{Z}$
(in fact, considering
 $\operatorname {lcm}(a, a')$
is enough). So,
$\operatorname {lcm}(a, a')$
is enough). So,
 $U_{a, H} \cap U_{a', H'}$
is covered by the disjoint sets
$U_{a, H} \cap U_{a', H'}$
is covered by the disjoint sets
 $U_{aa', H''}$
as
$U_{aa', H''}$
as
 $H''$
ranges over all finite abelian groups of exponent dividing
$H''$
ranges over all finite abelian groups of exponent dividing
 $aa'$
with
$aa'$
with
 $H'' \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
and
$H'' \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
and
 $H'' \otimes \mathbb{Z}/a'\mathbb{Z} \cong H'$
. Thus, the sets
$H'' \otimes \mathbb{Z}/a'\mathbb{Z} \cong H'$
. Thus, the sets
 $U_{a, H}$
form a basis for a topology on
$U_{a, H}$
form a basis for a topology on
 $\mathcal{A}$
. From now on, we will view
$\mathcal{A}$
. From now on, we will view
 $\mathcal{A}$
as a second-countable topological space with this topology.
$\mathcal{A}$
as a second-countable topological space with this topology.
We can give a smaller basis for the same topology by considering only
 $a = k!$
for positive integers
$a = k!$
for positive integers
 $k$
. If
$k$
. If
 $H$
is a finite abelian group with exponent dividing
$H$
is a finite abelian group with exponent dividing
 $k!$
, let
$k!$
, let
 $U_{(k), H} \;:\!=\; U_{k!, H}$
. We observe that if
$U_{(k), H} \;:\!=\; U_{k!, H}$
. We observe that if
 $a \mid a'$
, then we can write
$a \mid a'$
, then we can write
 $U_{a, H}$
as a finite disjoint union of
$U_{a, H}$
as a finite disjoint union of
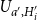 $U_{a', H'_i}$
, where
$U_{a', H'_i}$
, where
 $H_i$
ranges over all finite abelian groups of exponent dividing
$H_i$
ranges over all finite abelian groups of exponent dividing
 $a'$
such that
$a'$
such that
 $H'_i \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
. Thus, the sets
$H'_i \otimes \mathbb{Z}/a\mathbb{Z} \cong H$
. Thus, the sets
 $U_{(k), H}$
also form a basis for the topology on
$U_{(k), H}$
also form a basis for the topology on
 $\mathcal{A}$
.
$\mathcal{A}$
.
The sets
 $U_{(k), H}$
enjoy the property that if
$U_{(k), H}$
enjoy the property that if
 $k \leq k'$
, then either
$k \leq k'$
, then either
 $U_{(k'), H'} \subseteq U_{(k), H}$
or
$U_{(k'), H'} \subseteq U_{(k), H}$
or
 $U_{(k'), H'} \cap U_{(k), H} = \varnothing$
. In particular, every open set in
$U_{(k'), H'} \cap U_{(k), H} = \varnothing$
. In particular, every open set in
 $\mathcal{A}$
is a countable disjoint union of the basic opens
$\mathcal{A}$
is a countable disjoint union of the basic opens
 $U_{(k), H}$
. To see this, suppose
$U_{(k), H}$
. To see this, suppose
 $U$
is an open set in
$U$
is an open set in
 $\mathcal{A}$
. Then consider the collection of basic opens
$\mathcal{A}$
. Then consider the collection of basic opens
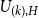 $U_{(k), H}$
in
$U_{(k), H}$
in
 $U$
and the subcollection of these which are maximal with respect to inclusion. We observe that ascending chains of basic opens in
$U$
and the subcollection of these which are maximal with respect to inclusion. We observe that ascending chains of basic opens in
 $\mathcal{A}$
stabilise, so every basic open
$\mathcal{A}$
stabilise, so every basic open
 $U_{(k), H}$
in
$U_{(k), H}$
in
 $U$
is contained in a maximal such basic open, and therefore
$U$
is contained in a maximal such basic open, and therefore
 $U$
is the union of its maximal basic opens. Two different such maximal basic opens are necessarily disjoint by the above discussion, so we are done.
$U$
is the union of its maximal basic opens. Two different such maximal basic opens are necessarily disjoint by the above discussion, so we are done.
Proof of Theorem 1.2. In Theorem 3.9, we showed that in the setting of Theorem 1.2, we have the convergence statement
 \begin{equation*} \lim _{n\to \infty } \mathbb{P}[\!\operatorname{coker}(M_n) \in U_{a, H}] = \lim _{n\to \infty } \mathbb{P}[\!\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H}) \end{equation*}
\begin{equation*} \lim _{n\to \infty } \mathbb{P}[\!\operatorname{coker}(M_n) \in U_{a, H}] = \lim _{n\to \infty } \mathbb{P}[\!\operatorname {coker}(M_n) \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \mathbb{P}[Y \otimes \mathbb{Z}/a\mathbb{Z} \cong H] = \lambda _u(U_{a, H}) \end{equation*}
for any positive integer
 $a$
and finite abelian group
$a$
and finite abelian group
 $H$
of exponent dividing
$H$
of exponent dividing
 $a$
. We now explain why this implies weak convergence in the topology we have just defined on
$a$
. We now explain why this implies weak convergence in the topology we have just defined on
 $\mathcal{A}$
.
$\mathcal{A}$
.
Let
 $U$
be an open set in
$U$
be an open set in
 $\mathcal{A}$
. Write
$\mathcal{A}$
. Write
 $U$
as a countable disjoint union of basic opens
$U$
as a countable disjoint union of basic opens
 $U_i = U_{(k_i), H_i}$
:
$U_i = U_{(k_i), H_i}$
:
 \begin{equation*} U = \bigsqcup _{i=1}^\infty U_i. \end{equation*}
\begin{equation*} U = \bigsqcup _{i=1}^\infty U_i. \end{equation*}
Then by countable additivity and Fatou’s lemma, we have
 \begin{align*} \lambda _u(U) &= \sum _{i=1}^\infty \lambda _u(U_i) \\ &= \sum _{i=1}^\infty \lim _{n\to \infty } \mathbb{P}[\operatorname {coker}(M_n) \in U_i] \\ &\leq \liminf _{n\to \infty }\sum _{i=1}^\infty \mathbb{P}[\operatorname {coker}(M_n) \in U_i] \\ &= \liminf _{n\to \infty }\mathbb{P}[\operatorname {coker}(M_n) \in U]. \end{align*}
\begin{align*} \lambda _u(U) &= \sum _{i=1}^\infty \lambda _u(U_i) \\ &= \sum _{i=1}^\infty \lim _{n\to \infty } \mathbb{P}[\operatorname {coker}(M_n) \in U_i] \\ &\leq \liminf _{n\to \infty }\sum _{i=1}^\infty \mathbb{P}[\operatorname {coker}(M_n) \in U_i] \\ &= \liminf _{n\to \infty }\mathbb{P}[\operatorname {coker}(M_n) \in U]. \end{align*}
By the Portmanteau theorem, this assertion for every open
 $U$
is equivalent to weak convergence of the distribution of
$U$
is equivalent to weak convergence of the distribution of
 $\operatorname {coker}(M_n)$
to
$\operatorname {coker}(M_n)$
to
 $\lambda _u$
.
$\lambda _u$
.
On the other hand, weak convergence of the distribution of
 $\operatorname {coker}(M_n)$
to
$\operatorname {coker}(M_n)$
to
 $\lambda _u$
would imply the convergence statement of Theorem 3.9 because each
$\lambda _u$
would imply the convergence statement of Theorem 3.9 because each
 $U_{a, H}$
is both open and closed in
$U_{a, H}$
is both open and closed in
 $\mathcal{A}$
.
$\mathcal{A}$
.
Acknowledgements
The author was supported by the NSF Graduate Research Fellowship Program, the Caltech Summer Undergraduate Research Fellowship program, and the Samuel P. and Frances Krown SURF Fellowship. The author thanks Melanie Wood and Omer Tamuz for mentorship and Alexander Gorokhovsky, Seth Berman, Sandra O’Neill, and Hoi Nguyen for insightful conversations. The author also thanks Gilyoung Cheong, Yifeng Huang, Hoi Nguyen, Roger Van Peski, Will Sawin, and Melanie Wood for helpful comments on an earlier draft of this manuscript. We especially thank the anonymous referees for comments that inspired a significant improvement to the condition in Theorem 3.9.
