


1. Introduction
Keyword extraction from texts is important for information retrieval and NLP tasks (document searching within a larger database, document indexing, feature extraction, and automatic summarization) (Schütze et al. Reference Schütze, Manning and Raghavan2008; Firoozeh et al. Reference Firoozeh, Nazarenko, Alizon and Daille2020; Alami et al. Reference Alami Merrouni, Frikh and Ouhbi2020). As an analytical tool, keywords reflect the meaning of a text and help to extract its topics. Hence, keywords and their extraction schemes are also employed in discourse analysis (Bondi and Scott Reference Bondi and Scott2010). Our focus will be on this analytical aspect of keywords.
Keyword extraction is challenging, as the state-of-the-art results demonstrate (Kaur and Gupta Reference Kaur and Gupta2010; Hasan and Ng Reference Hasan and Ng2014; Siddiqi and Sharan Reference Siddiqi and Sharan2015). A possible explanation is the lack of a sufficiently comprehensive definition of the keyword concept. Keywords are generally non-polysemic nouns (i.e., nouns that do not have many sufficiently different meanings) related to text topics (Bondi and Scott Reference Bondi and Scott2010).
Computer science approaches to keyword extraction fall into three main groups; see section 2. First, there are supervised methods, which usually require a large training set to learn which keywords should be found and where to find them (Turney Reference Turney2003; Gollapalli, Li, and Yang Reference Gollapalli, Li and Yang2017;Song and Hu Reference Song, Song and Hu2003; Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018). The second group involves unsupervised methods that demand a corpus of texts for contrastive learning (Sparck Jones Reference Sparck1972; Robertson Reference Robertson2004; Ando and Zhang Reference Ando and Zhang2005; Scott and Tribble Reference Scott and Tribble2006). The third group involves methods that apply to a single text, that is, a text that does not belong to any corpus. Methods from this group rely on statistical (Luhn, Reference Luhn1958; Matsuo and Ishizuka Reference Matsuo and Ishizuka2004; Rose et al. Reference Rose, Engel, Cramer and Cowley2010; Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018), or graph-theoretical features of a word in a text (Mihalcea and Tarau Reference Mihalcea and Tarau2004; Wan and Xiao Reference Wan and Xiao2008; Bougouin, Boudin, and Daille Reference Bougouin, Boudin and Daille2013; Florescu and Caragea Reference Florescu and Caragea2017); see section 2. The oldest method from this group is LUHN which selects sufficiently frequent content words of a text (Luhn, Reference Luhn1958). One of the latest state-of-the-art methods from the third group is YAKE (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018, Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020).
Here, we focus on keyword extraction from literary works without supervision and corpus. One purpose of this task is to extract topical groups of keywords. We concentrate on well-known literary works because the confirmation of their keywords and topics should be available to practically anyone with a general education. (Sometimes, manual keyword extraction and validation require specialist expertise.) Another reason to work with literary works is that regular keyword extraction schemes can be applied to discourse analysis (Bondi and Scott Reference Bondi and Scott2010).
Our keyword extraction method belongs to the third group and is based on the specific spatial distribution of keywords in the text; see section 3. Systematic studies of the spatial distribution of words were initiated by Zipf (Reference Zipf1945) and continued by Yngve (Reference Yngve1956) and Herdan (Reference Herdan1966); see section 2. Ortuño et al. (Reference Ortuño, Carpena, Bernaola-Galván, Munoz and Somoza2002) and Herrera and Pury (Reference Herrera and Pury2008) suggested to employ the spatial distribution for detecting the keywords; see section 2. This suggestion was taken up by Carretero-Campos et al. (Reference Carretero-Campos, Bernaola-Galván, Coronado and Carpena2013), Mehri and Darooneh (Reference Mehri and Darooneh2011), Mehri et al. (Reference Mehri, Jamaati and Mehri2015), and Zhou and Slater (Reference Zhou and Slater2003).
However, several questions were open with these proposals. What are the best indicators for keywords based on spatial distribution-based methods? How do they compare to existing unsupervised single-text methods? Which keyword-extracting tasks can they help with?
We research these questions and to a large extent answer them. We use the spatial distribution of words for keyword detection, and our unsupervised and corpus-independent method is based on comparing the second (and sixth) moments of this distribution before and after a random permutation of words. By doing so, we capture two types of keywords: global and local. Global keywords are spread through the text and their spatial distribution becomes more homogeneous after a random permutation of words. By contrast, local keywords are found in particular parts of a text and clustered together. After a random permutation, their distribution becomes more homogeneous, and this can be employed for keyword detection. Analyzing several classical texts, we saw that this structural difference between the keywords indeed closely relates to the content of the text; for example, global and local keywords refer to (resp.) the main and secondary characters of the text. Thus, global keywords give the general idea of the text, whereas local keywords focus our attention on parts of the text. We note that the importance of global and local keywords was already understood in linguistics (Scott and Tribble Reference Scott and Tribble2006), but no systematic method was proposed there for their detection. Related ideas on different types of keywords appeared in Carpena et al. (Reference Carpena, Bernaola-Galván, Carretero-Campos and Coronado2016).
Our method provides significantly better precision and recall of keyword extraction than several known methods, including LUHN (Luhn, Reference Luhn1958) and YAKE (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018 Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020), KeyBERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), KEA (Witten et al. Reference Witten, Paynter, Frank, Gutwin and Nevill-Manning1999), and WINGNUS (Nguyen and Luong Reference Nguyen and Luong2010) (the first three methods are unsupervised and the latter two are supervised). We noted that despite its relative sophistication, for single-word keywords (i.e., not keyphrases) extracted from literary works, YAKE provides results that always approximately coincide with those of LUHN, though it outperforms graph-based methods (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020) (we confirmed this point for texts studied here). Hence, we do not show comparison results with the latter group of methods. We also implemented for our texts another statistics-based method, RAKE (Rose et al. Reference Rose, Engel, Cramer and Cowley2010), to confirm that YAKE outperforms it.
The advantage of our method is found via human annotators who determine if the extracted words are keywords based on their previous knowledge of classic literature texts in our database. There is moderate to substantial agreement between annotators. Additionally, we gave two indirect, but human-independent indications of the advantage of our method over the above methods. First, words extracted by our method have a longer length (in letters) than English content words on average. Therefore, we can infer indirectly that our method extracts text-specific words because it is known that the length of content words correlates with their average informativeness (Piantadosi, Tily, and Gibson Reference Piantadosi, Tily and Gibson2012). Second, our method extracts more nouns. This is a proxy for keyword extraction since keywords are mostly nouns (Firoozeh et al. Reference Firoozeh, Nazarenko, Alizon and Daille2020).
In contrast to existing methods, our method is able to find topics from the text, that is, annotators were able to identify topical groups from a set of keywords extracted via our method. For the studied texts, serious topic extraction proved to be impossible with all alternative methods considered, including keyword extraction methods, as well as via several NLP topic modeling methods; see section 5.6. Our method is also nearly language-independent, as verified using translations in three languages: English, Russian, and French. It is only for long texts that our keyword extraction method is more efficient. For short texts our method does apply, but its efficiency of keyword extraction is similar to those of LUHN and YAKE. Still, its power in extracting the textual topics remains even for short texts.
To find out the limitations of our method, and to gain an understanding of what a keyword means conceptually, we aimed to relate keywords to the higher-order structures of texts, that is, the fact that literary texts are generally divided into chapters. This was accomplished by developing a method of keyword extraction that is based on chapter division. Even though this method is less efficient than our main method, it is easier to use in practice (for texts that already have many chapters), and it has the potential for further development; see section 6.
The rest of the paper is organized as follows. The next section reviews related work. In section 3, we discuss the main method analyzed in this work. Section 4 shows how the method applies to a classic and well-known text: Anna Karenina by L. Tolstoy. Section 5 evaluates our results in various ways. The inter-annotator agreement is also discussed in this section. Section 6 is devoted to the keyword extraction method that employs the fact that a long text is divided over sufficiently many chapters. The final section summarizes the discussion. Here, we emphasize that we considered only single-word keywords, and the extension of our method to extraction of keyphrases is an open problem.
2. Related work
In discussing various keyword extraction methods, one must remember that they are not universally applicable: each task (e.g., information retrieval, information extraction, document classification, and content analysis) requires its own methods. Keyword extraction methods are roughly divided into three groups: supervised, unsupervised but employing a text corpus, and unsupervised methods that apply to a single text. While in the context of the content analysis, we naturally focus on the last group and we shall also briefly review the two other groups.
Supervised methods are discussed in Gollapalli et al. (Reference Gollapalli, Li and Yang2017), Turney (Reference Turney2003), Song and Hu (Reference Song, Song and Hu2003), and Martinc et al., (Reference Martinc, Škrlj and Pollak2022). For general reviews on such methods, see Kaur and Gupta (Reference Kaur and Gupta2010), Siddiqi and Sharan (Reference Siddiqi and Sharan2015), Firoozeh et al. (Reference Firoozeh, Nazarenko, Alizon and Daille2020), and Alami Merrouni et al. (Reference Alami Merrouni, Frikh and Ouhbi2020). The supervision (training) stage normally demands a large training set with
 $\gt 10^4$
documents. Hence, such methods are prone to over-fitting and do not seem to be applicable for keyword extraction from a single literary work, though such applications are not excluded in principle and should be studied in the future. Some supervised approaches for keyword extraction employ linguistic-based handcrafted rules (Hulth Reference Hulth2003; Mihalcea and Tarau Reference Mihalcea and Tarau2004; Firoozeh et al. Reference Firoozeh, Nazarenko, Alizon and Daille2020), which however lack language independence.
$\gt 10^4$
documents. Hence, such methods are prone to over-fitting and do not seem to be applicable for keyword extraction from a single literary work, though such applications are not excluded in principle and should be studied in the future. Some supervised approaches for keyword extraction employ linguistic-based handcrafted rules (Hulth Reference Hulth2003; Mihalcea and Tarau Reference Mihalcea and Tarau2004; Firoozeh et al. Reference Firoozeh, Nazarenko, Alizon and Daille2020), which however lack language independence.
Unsupervised approaches include methods from statistics, information theory, and graph-based ranking (Siddiqi and Sharan Reference Siddiqi and Sharan2015; Firoozeh et al. Reference Firoozeh, Nazarenko, Alizon and Daille2020; Alami Merrouni et al. Reference Alami Merrouni, Frikh and Ouhbi2020). The most recent review of unsupervised approaches is Nadim, Akopian, and Matamoros (Reference Nadim, Akopian and Matamoros2023). The best-known and widely used statistical approach is perhaps TF-IDF scoring function (Schütze et al. Reference Schütze, Manning and Raghavan2008; Sparck Jones Reference Sparck1972; Robertson Reference Robertson2004; Ando and Zhang Reference Ando and Zhang2005). Ideas that are similar to TF-IDF were independently researched in corpus linguistics (Scott and Tribble Reference Scott and Tribble2006; Bondi and Scott Reference Bondi and Scott2010). The method assumes that relevant words appear frequently in the given text and rarely in other texts in the corpus. Thus, the TF-IDF function relies on the existence of the corpus, that is, it does not apply to a single text.
Other unsupervised methods do apply to a single text. The first such method was proposed by Luhn (Reference Luhn1958). It takes frequent content words as keyword candidates, excludes both high-probable content words and low-probable content words, and selects the rest as keyword candidates (Luhn, Reference Luhn1958). RAKE (Rose et al. Reference Rose, Engel, Cramer and Cowley2010) and YAKE (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018 Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020) are two other methods that employ statistical information and apply it to a single document (without a corpus). In particular, YAKE emerged as the current state-of-the-art keyword extraction algorithm.
In graph-based methods (Mihalcea and Tarau Reference Mihalcea and Tarau2004; Wan and Xiao Reference Wan and Xiao2008; Florescu and Caragea Reference Florescu and Caragea2017; Reference Škrlj, Repar and PollakŠkrlj et al. 2019), a text is represented as a graph where nodes are words and relations between words are expressed by edges. Normally, better-connected nodes (e.g., as determined by PageRank algorithm) relate to keywords, though other network features such as betweenness and closeness were also studied in the context of keyword extraction (Brin and Page, Reference Brin and Page1998; Boudin Reference Boudin2013). These methods mainly differ by the principles used to generate edges between words (Bougouin et al. Reference Bougouin, Boudin and Daille2013). Graph-based methods need only text information and hence are corpus-independent compared to TF-IDF. They can be semantically driven and agnostic of languages (Duari and Bhatnagar Reference Duari and Bhatnagar2019).
KeyBERT is another unsupervised method of keyword extraction (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018). It inherits the pretrained BERT model (Bidirectional Encoder Representations from Transformers) developed by Google that understands the context of words in a sentence by considering the words that come before and after it. BERT is large language model that was trained on a large text corpus (including the entire English Wikipedia and the BookCorpus dataset) to learn language representations. Three recent keyword extraction methods that employ language models are Schopf et al. (Reference Schopf, Klimek and Matthes2022), Tsvetkov and Kipnis (Reference Tsvetkov and Kipnis2023), and Liang et al. (Reference Liang, Wu, Li and Li2021).
Zipf and Fowler initiated systematic studies of the spatial distribution (or gap distribution) of words in texts (Zipf, Reference Zipf1945). Yngve (Reference Yngve1956) and Herdan (Reference Herdan1966) noted that the gap distribution of words is far from random and that this fact can be employed in quantitative linguistics. A pertinent open question is how to characterize this randomness (Brainerd, Reference Brainerd1976; Zörnig, Reference Zörnig1984 Reference Zörnig2010; Carpena et al. Reference Carpena, Bernaola-Galván, Carretero-Campos and Coronado2016). Ortuño et al. (Reference Ortuño, Carpena, Bernaola-Galván, Munoz and Somoza2002) specifically applied the spatial distribution of words for detecting keywords in a single text, that is, without training and without a corpus. In (Ortuño et al. Reference Ortuño, Carpena, Bernaola-Galván, Munoz and Somoza2002), the variance of the spatial distribution is used for finding clustered words that are related to keywords. Later works (Herrera and Pury Reference Herrera and Pury2008; Mehri and Darooneh Reference Mehri and Darooneh2011; Carretero-Campos et al. Reference Carretero-Campos, Bernaola-Galván, Coronado and Carpena2013; Mehri et al. Reference Mehri, Jamaati and Mehri2015) suggest several modifications that appear to improve the results. Herrera and Pury (Reference Herrera and Pury2008) proposed to combine Shannon’s information measure with the spatial distribution and studied the keyword distribution of The Origin of Species by Charles Darwin. Information-theoretic measures were also tried in Carretero-Campos et al. (Reference Carretero-Campos, Bernaola-Galván, Coronado and Carpena2013), Mehri and Darooneh (Reference Mehri and Darooneh2011), and Mehri et al. (Reference Mehri, Jamaati and Mehri2015). An alternative metric for keyword extraction was proposed by Zhou and Slater (Reference Zhou and Slater2003). However, this variety of methods employing spatial distribution was not applied to a sufficiently large database. Also, no systematic comparison was attempted with the existing methods of keyword extraction from a single text. It was also unclear to which specific keyword-extracting tasks these methods apply. These issues are researched below.
3. Method
Below we discuss our method for keyword extraction (sections 3.2, 3.3) and describe implementation details; see sections 3.4 and 3.5. Section 3.1 introduces ideas on the example of spatial frequency, which shows interesting behavior but does not result in productive keyword indicators.
3.1 Distribution of words: spatial frequency
Our texts were lemmatized and freed from functional words (stop words); see section 3.4 for details. Let
 $w_{[1]},\ldots, w_{[\ell ]}$
denote all occurrences of a word
$w_{[1]},\ldots, w_{[\ell ]}$
denote all occurrences of a word
 $w$
along the text. Let
$w$
along the text. Let
 $\zeta _{i}$
denotes the number of words (different from
$\zeta _{i}$
denotes the number of words (different from
 $w$
) between
$w$
) between
 $w_{[i]}$
and
$w_{[i]}$
and
 $w_{[i+1]}$
; that is,
$w_{[i+1]}$
; that is,
 $\zeta _{\,i}+1\geq 1$
is the number of space symbols between
$\zeta _{\,i}+1\geq 1$
is the number of space symbols between
 $w_{[i]}$
and
$w_{[i]}$
and
 $w_{[i+1]}$
. Define the first empirical moment for the distribution of
$w_{[i+1]}$
. Define the first empirical moment for the distribution of
 $\zeta _{\,i}+1$
(Yngve, Reference Yngve1956; Deng et al. Reference Deng, Xie, Deng and Allahverdyan2021):
$\zeta _{\,i}+1$
(Yngve, Reference Yngve1956; Deng et al. Reference Deng, Xie, Deng and Allahverdyan2021):
 \begin{align} C_1[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1). \end{align}
\begin{align} C_1[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1). \end{align}
Eq. (1) is not defined for
 $\ell =1$
, that is, for words that occur only once; hence, such words are to be excluded from consideration, that is, they will not emerge as keywords.
$\ell =1$
, that is, for words that occur only once; hence, such words are to be excluded from consideration, that is, they will not emerge as keywords.
Note that
 $C_1[w]$
is the average period of the word
$C_1[w]$
is the average period of the word
 $w$
. Hence, the spatial frequency
$w$
. Hence, the spatial frequency
 $\tau (w)$
can be defined via (Ortuño et al. Reference Ortuño, Carpena, Bernaola-Galván, Munoz and Somoza2002; Yngve, Reference Yngve1956; Carpena et al. Reference Carpena, Bernaola-Galván, Hackenberg, Coronado and Oliver2009; Montemurro and Zanette Reference Montemurro and Zanette2010):
$\tau (w)$
can be defined via (Ortuño et al. Reference Ortuño, Carpena, Bernaola-Galván, Munoz and Somoza2002; Yngve, Reference Yngve1956; Carpena et al. Reference Carpena, Bernaola-Galván, Hackenberg, Coronado and Oliver2009; Montemurro and Zanette Reference Montemurro and Zanette2010):
 \begin{align} \tau [w]\equiv 1/C_1[w]. \end{align}
\begin{align} \tau [w]\equiv 1/C_1[w]. \end{align}
The smallest value
 $\frac{1}{N-1}$
of
$\frac{1}{N-1}$
of
 $\tau [w]$
is attained for
$\tau [w]$
is attained for
 $\ell =2$
, where
$\ell =2$
, where
 $w$
occurs as the first and last word of the text. The largest value
$w$
occurs as the first and last word of the text. The largest value
 $\tau [w]=1$
is reached when all instances of
$\tau [w]=1$
is reached when all instances of
 $w$
occur next to each other (strong clusterization of
$w$
occur next to each other (strong clusterization of
 $w$
).
$w$
).
We compare
 $\tau [w]$
with the ordinary frequency
$\tau [w]$
with the ordinary frequency
 $f[w]$
of word
$f[w]$
of word
 $w$
:
$w$
:
 \begin{align} f[w]=N_w/N, \end{align}
\begin{align} f[w]=N_w/N, \end{align}
where
 $N_w$
is the number of times
$N_w$
is the number of times
 $w$
appeared in the text (
$w$
appeared in the text (
 $N_w=\ell$
), while
$N_w=\ell$
), while
 $N$
is the full number of words in the text. Now,
$N$
is the full number of words in the text. Now,
 $f[w]$
is obviously invariant under any permutation of words in the text.
$f[w]$
is obviously invariant under any permutation of words in the text.
Note that
 $(\ell -1)(C_1[w]-1)$
equals to the number of words that differ from
$(\ell -1)(C_1[w]-1)$
equals to the number of words that differ from
 $w$
and occur between
$w$
and occur between
 $w_{[1]}$
and
$w_{[1]}$
and
 $w_{[\ell ]}$
. Hence,
$w_{[\ell ]}$
. Hence,
 $\tau [w]$
will stay intact at least under any permutation of words in that part of the text which is located between
$\tau [w]$
will stay intact at least under any permutation of words in that part of the text which is located between
 $w_{[1]}$
and
$w_{[1]}$
and
 $w_{[\ell ]}$
. This class of permutation is sufficiently big for frequent words (in the sense of (3)), where
$w_{[\ell ]}$
. This class of permutation is sufficiently big for frequent words (in the sense of (3)), where
 $w_{[1]}$
[
$w_{[1]}$
[
 $w_{[\ell ]}$
] occurs close to the beginning [end] of the text. Consequently, we expect that a random permutation of all words in the text will leave
$w_{[\ell ]}$
] occurs close to the beginning [end] of the text. Consequently, we expect that a random permutation of all words in the text will leave
 $\tau [w]$
nearly intact for frequent words:
$\tau [w]$
nearly intact for frequent words:
 $\tau [w]\approx \tau _{\textrm{perm}}[w]$
. Indeed, we observed such a relation empirically. We also observed that there are many infrequent words for which
$\tau [w]\approx \tau _{\textrm{perm}}[w]$
. Indeed, we observed such a relation empirically. We also observed that there are many infrequent words for which
 $\tau [w]\gg \tau _{\textrm{perm}}[w]$
, that is, such words are well clustered (before permutation).
$\tau [w]\gg \tau _{\textrm{perm}}[w]$
, that is, such words are well clustered (before permutation).
These relations can be made quantitative by noting for frequent words the following implication of the above invariance. Aiming to calculate
 $\tau _{\textrm{perm}}[w]$
for a given frequent word
$\tau _{\textrm{perm}}[w]$
for a given frequent word
 $w$
, we can employ the Bernoulli process of random text generation, assuming that
$w$
, we can employ the Bernoulli process of random text generation, assuming that
 $w$
is generated independently from others, with probability of
$w$
is generated independently from others, with probability of
 $w$
(not
$w$
(not
 $w$
) equal to
$w$
) equal to
 $f[w]$
(
$f[w]$
(
 $1-f[w]$
); see (3). For spatial interval
$1-f[w]$
); see (3). For spatial interval
 $s$
between the occurrences of
$s$
between the occurrences of
 $w$
, the Bernoulli process produces the geometric distribution
$w$
, the Bernoulli process produces the geometric distribution
 ${p}(s)=(1-f[w])^sf[w]$
, where for sufficiently long texts we can assume that
${p}(s)=(1-f[w])^sf[w]$
, where for sufficiently long texts we can assume that
 $s$
changes from
$s$
changes from
 $0$
to
$0$
to
 $\infty$
, and
$\infty$
, and
 $\sum _{s=0}^\infty p(s)=1$
. We emphasize that this model is not precise for a random permutation in texts, but it turns out to be sufficient for estimating
$\sum _{s=0}^\infty p(s)=1$
. We emphasize that this model is not precise for a random permutation in texts, but it turns out to be sufficient for estimating
 $\tau _{\textrm{perm}}[w]$
. The mean of this distribution is
$\tau _{\textrm{perm}}[w]$
. The mean of this distribution is
 \begin{align} f[w]{\sum }_{s=0}^{\infty }s(1-f[w])^s={(1-f[w])}/{f[w]}. \end{align}
\begin{align} f[w]{\sum }_{s=0}^{\infty }s(1-f[w])^s={(1-f[w])}/{f[w]}. \end{align}
The inverse of (4) estimates
 $\tau _{\textrm{perm}}[w]$
for frequent words
$\tau _{\textrm{perm}}[w]$
for frequent words
 $\tau _{\textrm{perm}}[w]\simeq f[w]/(1-f[w])$
. On the other hand, we have
$\tau _{\textrm{perm}}[w]\simeq f[w]/(1-f[w])$
. On the other hand, we have
 $\tau [w]\simeq f[w]/(1-f[w])$
for frequent words; see Figures 1 and 2. Two of the most famous world literature texts are described in these figures. Figure 1 refers to Anna Karenina by L. Tolstoy (the total number of words
$\tau [w]\simeq f[w]/(1-f[w])$
for frequent words; see Figures 1 and 2. Two of the most famous world literature texts are described in these figures. Figure 1 refers to Anna Karenina by L. Tolstoy (the total number of words
 $N\approx 3.5\times 10^5$
), and Figure 2 refers to Animal Farm by G. Orwell (
$N\approx 3.5\times 10^5$
), and Figure 2 refers to Animal Farm by G. Orwell (
 $N\approx 3\times 10^4$
). The length difference between the two texts is reflected in the difference between
$N\approx 3\times 10^4$
). The length difference between the two texts is reflected in the difference between
 $\tau [w]$
and
$\tau [w]$
and
 $f[w]/(1-f[w])$
. Figure 1 shows that relation:
$f[w]/(1-f[w])$
. Figure 1 shows that relation:
 \begin{align} f[w]/(1-f[w])\lesssim \tau [w], \end{align}
\begin{align} f[w]/(1-f[w])\lesssim \tau [w], \end{align}
holds for the majority of words with approximate equality for frequent words. In Figure 2, relation (5) holds for frequent words but is violated for some not-frequent words. For both figures, we see that
 $\tau [w]$
can be significantly larger than
$\tau [w]$
can be significantly larger than
 $f[w]/(1-f[w])$
for certain non-frequent words, indicating that the distribution of such words is clustered. We checked that there are not many keywords among such words, that is, the magnitude of
$f[w]/(1-f[w])$
for certain non-frequent words, indicating that the distribution of such words is clustered. We checked that there are not many keywords among such words, that is, the magnitude of
 $\tau [w](1-f[w])/f[w]$
is not a productive indicator for the keywords. More refined quantities are needed to this end.
$\tau [w](1-f[w])/f[w]$
is not a productive indicator for the keywords. More refined quantities are needed to this end.
For Anna Karenina by L. Tolstoy (Tolstoy Reference Tolstoy2013), we show space frequency
 $\tau [w]=1/C_1[w]$
and
$\tau [w]=1/C_1[w]$
and
 $1/C_2[w]$
versus word rank for all distinct words
$1/C_2[w]$
versus word rank for all distinct words
 $w$
of the text; cf. Eqs. (1, 6). We also show two additional quantities:
$w$
of the text; cf. Eqs. (1, 6). We also show two additional quantities:
 $1/C_2[w]=1/C_{2\,\textrm{perm}}(w)$
after a random permutation of words in the text, and
$1/C_2[w]=1/C_{2\,\textrm{perm}}(w)$
after a random permutation of words in the text, and
 $f[w]/(1-f[w])$
, where
$f[w]/(1-f[w])$
, where
 $f[w]$
is the frequency of
$f[w]$
is the frequency of
 $w$
; see Eqs. (5, 3). Ranking of distinct words is done via
$w$
; see Eqs. (5, 3). Ranking of distinct words is done via
 $f[w]$
, that is, the most frequent word got rank 1, etc. It is seen that
$f[w]$
, that is, the most frequent word got rank 1, etc. It is seen that
 $C_{2\,\textrm{perm}}[w]\lt C_{2}[w]$
holds for frequent words. Both
$C_{2\,\textrm{perm}}[w]\lt C_{2}[w]$
holds for frequent words. Both
 $C_{2\,\textrm{perm}}[w]\lt C_{2}[w]$
and
$C_{2\,\textrm{perm}}[w]\lt C_{2}[w]$
and
 $C_{2\,\textrm{perm}}[w]\gt C_{2}[w]$
hold for less frequent words. Not shown in the figure: a random permutation of the words in the text leaves
$C_{2\,\textrm{perm}}[w]\gt C_{2}[w]$
hold for less frequent words. Not shown in the figure: a random permutation of the words in the text leaves
 $\tau [w]$
unaltered for frequent words, while
$\tau [w]$
unaltered for frequent words, while
 $\tau [w]$
generically increases for less frequent words (clusterization); cf. Eq. (5).
$\tau [w]$
generically increases for less frequent words (clusterization); cf. Eq. (5).

For Animal Farm (AF) by G. Orwell, we show the same quantities as for Anna Karenina (AK) in Figure 1 (also the same notations). AK is 11.6 times longer than AF; see Table 1. Some differences between these texts are as follows. Inequality
 $C_{2\,\textrm{perm}}(w)\lt C_2(w)$
holds for a lesser number of frequent words in AF compared with AK. Domain
$C_{2\,\textrm{perm}}(w)\lt C_2(w)$
holds for a lesser number of frequent words in AF compared with AK. Domain
 $C_{2\,\textrm{perm}}(w)\lt C_2(w)$
and
$C_{2\,\textrm{perm}}(w)\lt C_2(w)$
and
 $C_{2\,\textrm{perm}}(w)\gt C_2(w)$
are well separated in AK, and not so well separated in AF. For AF, relation (5) can be violated for some infrequent words.
$C_{2\,\textrm{perm}}(w)\gt C_2(w)$
are well separated in AK, and not so well separated in AF. For AF, relation (5) can be violated for some infrequent words.

3.2 The keyword extraction method: the second moment of the spatial distribution
Given Eq. (1), let us define the second moment of the spatial distribution for word
 $w$
$w$
 \begin{equation} C_2[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1)^2. \end{equation}
\begin{equation} C_2[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1)^2. \end{equation}
 $C_2[w]$
is not invariant to those word permutations that left invariant
$C_2[w]$
is not invariant to those word permutations that left invariant
 $C_1[w]$
; cf. the discussion before (5). Figures 1 and 2 show that for sufficiently frequent words
$C_1[w]$
; cf. the discussion before (5). Figures 1 and 2 show that for sufficiently frequent words
 $w$
,
$w$
,
 $C_2[w]$
decreases after a random permutation. Indeed, frequent words are distributed in the text inhomogeneously. A random permutation makes this distribution more homogeneous and hence makes
$C_2[w]$
decreases after a random permutation. Indeed, frequent words are distributed in the text inhomogeneously. A random permutation makes this distribution more homogeneous and hence makes
 $C_{2\, \textrm{perm}}[w]\lt C_2[w]$
for frequent words. For this conclusion, we need the second (or higher-order) moment in (6). Appendix B presents a numerical illustration of this effect and also illustrates that
$C_{2\, \textrm{perm}}[w]\lt C_2[w]$
for frequent words. For this conclusion, we need the second (or higher-order) moment in (6). Appendix B presents a numerical illustration of this effect and also illustrates that
 $C_{1}$
does not catch it.
$C_{1}$
does not catch it.
Analyzed long texts: Anna Karenina, War and Peace, part I, and War and Peace, part II by L. Tolstoy; Master and Margarita by M. Bulgakov; Twelve Chairs by I. Ilf and E. Petrov; The Glass Bead Game by H. Hesse; Crime and Punishment by F. Dostoevsky. Shorter texts: The Heart of Dog by M. Bulgakov; Animal Farm by G. Orwell. Alchemist by P. Coelho. Next to each text, we indicate the number of words in it, stop words included.
For long texts we extracted for each text the same number of
 $\approx 300$
potential keywords via each method: our method (implemented via Eqs. (8, 9, 10)), LUHN and YAKE. The numbers below are percentages, that is,
$\approx 300$
potential keywords via each method: our method (implemented via Eqs. (8, 9, 10)), LUHN and YAKE. The numbers below are percentages, that is,
 $15.6= 15.6\%$
. For each text, the first percentage shows the values of precision (Prec.), that is, the fraction of keywords which were identified as keywords by human annotators. The second percentage shows recall (Rec.): the fraction of keywords that the methods were able to extract compared to ground-truth keywords; see (25). The third percentage shows the F1 score; see (26).
$15.6= 15.6\%$
. For each text, the first percentage shows the values of precision (Prec.), that is, the fraction of keywords which were identified as keywords by human annotators. The second percentage shows recall (Rec.): the fraction of keywords that the methods were able to extract compared to ground-truth keywords; see (25). The third percentage shows the F1 score; see (26).
For short texts, we extracted via each method
 $\sim 100$
words. Our method was implemented via Eq. (13); only the precision is shown. For longer texts, our method provides sizable advantages compared with LUHN and YAKE. For shorter texts the three methods are comparable (the values for recall are not shown)
$\sim 100$
words. Our method was implemented via Eq. (13); only the precision is shown. For longer texts, our method provides sizable advantages compared with LUHN and YAKE. For shorter texts the three methods are comparable (the values for recall are not shown)

The situation changes for less frequent words: now it is possible that for some words non-frequent words we get
 $C_{2\, \textrm{perm}}[w]\gt C_2[w]$
; see Appendix B for examples. Those words are clustered in the original text, while after a random permutation, their distribution is more homogeneous; see Figures 1 and 2. For a long text Anna Karenina, the words where
$C_{2\, \textrm{perm}}[w]\gt C_2[w]$
; see Appendix B for examples. Those words are clustered in the original text, while after a random permutation, their distribution is more homogeneous; see Figures 1 and 2. For a long text Anna Karenina, the words where
 $C_{2\, \textrm{perm}}[w]$
is noticeably larger than
$C_{2\, \textrm{perm}}[w]$
is noticeably larger than
 $C_2[w]$
appear at rank
$C_2[w]$
appear at rank
 $\approx 300$
(the rank is decided by frequency (3)); see Figure 1. There is no such a sharp threshold value for a shorter text Animal Farm, as Figure 2 shows. Using Eq. (6), we define
$\approx 300$
(the rank is decided by frequency (3)); see Figure 1. There is no such a sharp threshold value for a shorter text Animal Farm, as Figure 2 shows. Using Eq. (6), we define
 \begin{equation} {A[w]}=\frac{C_{2\,\textrm{perm}}[w]}{C_2[w]}, \end{equation}
\begin{equation} {A[w]}=\frac{C_{2\,\textrm{perm}}[w]}{C_2[w]}, \end{equation}
where
 $C_{2\,\textrm{perm}}[w]$
is calculated via Eq. (6) but after a random permutation of all words of the text.
$C_{2\,\textrm{perm}}[w]$
is calculated via Eq. (6) but after a random permutation of all words of the text.
When checking the values of
 $A[w]$
for all distinct words of several texts, our annotators concluded that sufficiently small and sufficiently large values of
$A[w]$
for all distinct words of several texts, our annotators concluded that sufficiently small and sufficiently large values of
 $A[w]$
in Eq. (7):
$A[w]$
in Eq. (7):
 \begin{align} A[w]\leq \frac{1}{5},\end{align}
\begin{align} A[w]\leq \frac{1}{5},\end{align}
 \begin{align}A[w]\geq 5, \end{align}
\begin{align}A[w]\geq 5, \end{align}
can be employed for deducing certain keywords of the text. Eq. (8) extracts global keywords of the text, that is, keywords that go through the whole text. Eq. (9) refers to local keywords, that is, those that appear in specific places of the text. In Figure 1, they are seen as local maxima of
 $1/C_2[w]$
. Local keywords are naturally located in the domain of infrequent words.
$1/C_2[w]$
. Local keywords are naturally located in the domain of infrequent words.
Taking in Eq. (8) a smaller threshold values
 \begin{align} \frac{1}{5}\leq A[w]\leq \frac{1}{3}, \end{align}
\begin{align} \frac{1}{5}\leq A[w]\leq \frac{1}{3}, \end{align}
leads to selecting a group of lower-frequency global keywords. Below we shall refer to Eq. (8) and Eq. (10) as (resp.) strong and weak cases.
Relations of Eq. (8) and Eq. (9) with (resp.) global and local keywords make intuitive sense. As we checked in detail, spaces between global keywords assume a broad range of values. This distribution becomes more uniform after the random permutation; hence, the the second moment decreases; cf. Eq. (8). Local keywords refer to infrequent words, are localized in a limited range of text and are clustered. Hence, a random permutation increases the second moment; cf. Eq. (9).
Let us comment on the choice of parameters in Eqs. (8, 10). This choice was taken as empirically adequate for Anna Karenina, that is, it led to extracting sufficiently many local and global keywords. (Other choices led to fewer global and/or local keywords.) After that, it was applied for all long texts [see Table 1] and led to adequate results.
As our method relies on random permutations, our results are formally dependent on the realization of these permutations. (Random permutations of words were generated via Python’s numpy library; see Appendix A.) Such a dependence is weak: we noted that only a few keywords change from one realization to another. However, we cannot avoid random permutations; see section 7 for further discussion.
3.3 Modification of the method for shorter texts
Criteria (8, 9) based on
 $A(w)$
from Eq. (7) are not sufficiently powerful for discriminating between the keywords and ordinary words in sufficiently short texts; for example, in Animal Farm depicted on Figure 2. We found two modifications of the method that apply to short texts. The first option is to look at local maxima and minima of
$A(w)$
from Eq. (7) are not sufficiently powerful for discriminating between the keywords and ordinary words in sufficiently short texts; for example, in Animal Farm depicted on Figure 2. We found two modifications of the method that apply to short texts. The first option is to look at local maxima and minima of
 $A(w)$
. The second, better option is to modify the order of the moment in Eq. (6). Instead of the second moment in Eq. (6), we employed the sixth moment
$A(w)$
. The second, better option is to modify the order of the moment in Eq. (6). Instead of the second moment in Eq. (6), we employed the sixth moment
 \begin{align} C_6[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1)^6. \end{align}
\begin{align} C_6[w]=\frac{1}{\ell -1}{\sum }_{i=1}^{\ell -1} \,(\zeta _{\,i}+1)^6. \end{align}
This modification leads to an indicator (13), which is more susceptible to inhomogeneity and clustering. Now
 $A_6[w]$
is defined analogously to Eq. (7), but via Eq. (11),
$A_6[w]$
is defined analogously to Eq. (7), but via Eq. (11),
 \begin{align} A_6[w]=\frac{C_{6\,\textrm{perm}}[w]}{C_6[w]}, \end{align}
\begin{align} A_6[w]=\frac{C_{6\,\textrm{perm}}[w]}{C_6[w]}, \end{align}
and for extracting keywords we can apply [cf. Eqs. (8, 9)]:
 \begin{align} A_6[w]\leq \frac{1}{3}, \,\,\, A_6[w]\geq 3. \end{align}
\begin{align} A_6[w]\leq \frac{1}{3}, \,\,\, A_6[w]\geq 3. \end{align}
The utility of Eqs. (12, 13) was determined for the short text Animal Farm and then applied for all other short texts; see Table 1.
3.4 Lemmatization of texts
English texts were preprocessed using WordNetLemmatizer imported from nltk.stem; see Appendix A. This library looks for lemmas of words from the WordNet database. The lemmatization uses corpus for excluding stop words (functional words) and WordNet corpus to produce lemmas. WordNetLemmatizer identifies the intended part of speech and meaning of a word in a sentence, as well as within the larger context surrounding that sentence, such as neighboring sentences or even an entire text. We applied this lemmatization algorithm on nouns, adjectives, verbs, and adverbs to get maximal clean up of the text. Any stemming procedure will be inappropriate for our purposes of extracting keywords, since stemming may mix different parts of speech.
For inflected languages (e.g., Russian), the lemmatization rules are more complex. For French and Russian texts, we used (resp.) lemmatizers LEFFF and pymystem3; see Appendix A.
3.5 Implementation of LUHN and YAKE
Here, we briefly discuss how we implemented Luhn’s method (LUHN) for keyword extraction (Luhn, Reference Luhn1958). The method starts with ranking the distinct words of the text according to their frequency (more frequent words got a larger rank):
 $\{f_r\}_{r=1}^n$
, where
$\{f_r\}_{r=1}^n$
, where
 $f_r$
is the word frequency and
$f_r$
is the word frequency and
 $r$
is its rank. Next, one cuts off the high-frequency and low-frequency words and selects the remaining words
$r$
is its rank. Next, one cuts off the high-frequency and low-frequency words and selects the remaining words
 $\{f_r\}_{r=r_{\textrm{min}}}^{r_{\textrm{max}}}$
as candidates for keywords. Hence, the method amounts to selecting the above cutoffs
$\{f_r\}_{r=r_{\textrm{min}}}^{r_{\textrm{max}}}$
as candidates for keywords. Hence, the method amounts to selecting the above cutoffs
 $r_{\textrm{min}}$
and
$r_{\textrm{min}}$
and
 $r_{\textrm{max}}$
: the high-frequency words are to be omitted because there are many stop words there that normally are not considered as keywords. Low-frequency words are to be omitted since they are not relevant to the semantics of the text. Once we already skipped functional words from our texts, we did not apply the high-frequency cutoff, that is, we take
$r_{\textrm{max}}$
: the high-frequency words are to be omitted because there are many stop words there that normally are not considered as keywords. Low-frequency words are to be omitted since they are not relevant to the semantics of the text. Once we already skipped functional words from our texts, we did not apply the high-frequency cutoff, that is, we take
 $r_{\textrm{min}}=1$
. For the low-frequency threshold, we employed a hypothesis that the essence of Luhn’s method is related to Zipf’s law, that is, to the law that fits the rank-frequency curve of distinct words of a text to a power law (Zipf, Reference Zipf1945); Allahverdyan, Deng, and Wang Reference Allahverdyan, Deng and Wang2013). It is known that the power-law fitting works approximately till the rank
$r_{\textrm{min}}=1$
. For the low-frequency threshold, we employed a hypothesis that the essence of Luhn’s method is related to Zipf’s law, that is, to the law that fits the rank-frequency curve of distinct words of a text to a power law (Zipf, Reference Zipf1945); Allahverdyan, Deng, and Wang Reference Allahverdyan, Deng and Wang2013). It is known that the power-law fitting works approximately till the rank
 $r_{10}$
so that for
$r_{10}$
so that for
 $r\geq r_{10}$
the number of words having the same frequency
$r\geq r_{10}$
the number of words having the same frequency
 $f_r$
is
$f_r$
is
 $10$
or larger (Allahverdyan et al. Reference Allahverdyan, Deng and Wang2013). For
$10$
or larger (Allahverdyan et al. Reference Allahverdyan, Deng and Wang2013). For
 $r\gt r_{10}$
, the rank-frequency curve starts to show steps that cannot be fitted to a single power-law curve, that is, the proper Zipf’s law becomes ill defined for
$r\gt r_{10}$
, the rank-frequency curve starts to show steps that cannot be fitted to a single power-law curve, that is, the proper Zipf’s law becomes ill defined for
 $r\gt r_{10}$
(Allahverdyan et al. Reference Allahverdyan, Deng and Wang2013). Hence, we selected the rank
$r\gt r_{10}$
(Allahverdyan et al. Reference Allahverdyan, Deng and Wang2013). Hence, we selected the rank
 $r_{\textrm{max}}=r_{10}$
. This choice shows reasonable results in practice.
$r_{\textrm{max}}=r_{10}$
. This choice shows reasonable results in practice.
Both LUHN and our method are based on a unique idea with a straightforward implementation. In contrast, YAKE incorporates various tools and ideas along with numerous empirical formulas (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018 Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020) (the same, but with a lesser degree holds for RAKE (Rose et al. Reference Rose, Engel, Cramer and Cowley2010)). In particular, YAKE includes textual context of candidate keywords, sentence structure, sliding windows for keyword selection, statistics of n-grams, nontrivial (and multi-parametric) scoring process, etc. We worked with the version of YAKE that was implemented via a Python package; see Appendix A. We employed YAKE both with and without preprocessing of texts. In the second case, YAKE was better at extracting capitalized proper nouns (such words are frequently keywords). Otherwise, its performance did not change much. This advantage of YAKE is due to a specific tool implemented in it: YAKE looks for capitalized words which do not appear in the beginning of a sentence. Such a tool is easy to implement in any keyword searching method, but we avoided doing that, since we are interested in checking ideas behind Eqs. (6–13). Therefore, we mostly discuss YAKE’s outcomes after preprocessing.
4. Keywords extracted from Anna Karenina
The above keyword extraction method was applied to several texts of classic literature; see Table 1. (Our data for texts from Table 1 is freely available at https://github.com/LidaAleksanyan/keywords_extraction_data/tree/master, while our codes are available at https://github.com/LidaAleksanyan/spatial_keyword_extraction.) Among them, we choose one of the most known works of classic literature, Anna Karenina by L. Tolstoy, and analyze in detail the implications of our method in extracting and interpreting its keywords. The evaluation of extracted keywords was done by annotators with expert knowledge of classic Russian literature and specifically works by Tolstoy. The agreement between annotators is moderate to substantial; see Table 2.
The values of Cohen’s kappa (14) for the agreement in keyword extraction tasks between two annotators for three different texts; see section 5.2. The keyword extraction employed the method discussed in Table 1 and section 3.2. Results for global and local keywords are shown separately. It is seen that the agreement is better for global keywords. A possible explanation is that the annotators do not focus on text details

4.1 Comparison with known methods of keyword extraction and language independence
Using Anna Karenina (Tolstoy Reference Tolstoy2013), we compared our approach discussed in section 3.2 with two well-known methods that also apply to a single text (i.e., do not require corpus): LUHN and YAKE; see section 3.5.
Two hundred eighty-two words were extracted via each method, and the keywords were identified. Tables 1 and 3 show that for three languages (English, Russian, and French) our method is better in terms of both precision and recall; see Appendix C for a reminder of these concepts. The relatively poor performance of YAKE and LUHN can be explained by their focus on relatively short content words that are not likely to be keywords. We quantified this by calculating the mean number of letters in each set of 282 words. For our method, LUHN and YAKE the mean is (resp.) 6.95, 5.43, and 5.5; cf. the fact that the average number of letters in English content word is 6.47 (for stop word it is 3.13) (Miller, Newman, and Friedman, Reference Miller, Newman and Friedman1958).
Comparison of three different keyword extraction methods for English, Russian, and French versions of Anna Karenina. Percentages for keywords indicate the precision [cf. Table 1], while ‘nouns’ means the percentage of nouns in candidate words that were not identified as keywords. For all cases, our method fares better than LUHN and YAKE

The three methods have scores for words. In LUHN and our method, the score coincides with the word frequency. For YAKE, the scores are described by Campos et al. (Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018 Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020). However, for LUHN and YAKE, the score did not correlate with the feature of being keyword. For our method it certainly did, that is, by selecting only high-score words we can significantly enlarge the percentage of keywords compared to what is seen in Table 1. These two facts (low density of keywords plus no correlation with their score) make it impossible to extract topical groups of keywords via LUHN and YAKE; cf. the discussion after Eq. (9).
Another comparison criterion between the three methods is the amount of nouns in words that were not identified as keywords. Indeed, once keywords are predominantly nouns, a method that extracts more nouns (e.g., more nouns in candidate words that were not identified as keywords) has an advantage. In this respect, our method fares better than both LUHN and YAKE; see Table 3.
Table 3 also addresses the language independence of the three methods that were studied in three versions (English, Russian, and French) of Anna Karenina. Our method performs comparably for English and Russian, which are morphologically quite distinct languages. For French the performance is worse, but overall still comparable with English and Russian. Altogether, our method applies to different languages. This confirms an intuitive expectation that spatial structure features embedded into Eqs. (6–13) are largely language-independent.
4.2 Topical groups extracted via extracted keywords
Anna Karenina features more than a dozen major characters and many lesser characters. Annotators separated keywords into nine topical groups:
 $^{(1)}$
proper names of major characters;
$^{(1)}$
proper names of major characters;
 $^{(2)}$
proper names of secondary characters;
$^{(2)}$
proper names of secondary characters;
 $^{(3)}$
animal names;
$^{(3)}$
animal names;
 $^{(4)}$
trains and railway;
$^{(4)}$
trains and railway;
 $^{(5)}$
hunting;
$^{(5)}$
hunting;
 $^{(6)}$
rural life and agriculture;
$^{(6)}$
rural life and agriculture;
 $^{(7)}$
local governance (zemstvo);
$^{(7)}$
local governance (zemstvo);
 $^{(8)}$
nobility life and habits; and
$^{(8)}$
nobility life and habits; and
 $^{(9)}$
religion; see Table 4.
$^{(9)}$
religion; see Table 4.
Words of Anna Karenina extracted via our method. For global keywords strong and weak cases mean (resp.) that the words
 $w$
were chosen according to
$w$
were chosen according to
 $A(w)\leq \frac{1}{5}$
and
$A(w)\leq \frac{1}{5}$
and
 $\frac{1}{5}\leq A(w)\leq \frac{1}{3}$
; cf. Eqs. (8, 10). Local keywords were chosen according to
$\frac{1}{5}\leq A(w)\leq \frac{1}{3}$
; cf. Eqs. (8, 10). Local keywords were chosen according to
 $A(w)\geq{5}$
; see Eq. (9). For each column, the words were arranged according to their frequency Eq. (3). Keyword classes are denoted by upper indices; see details in the text. The last group
$A(w)\geq{5}$
; see Eq. (9). For each column, the words were arranged according to their frequency Eq. (3). Keyword classes are denoted by upper indices; see details in the text. The last group
 $^{(10)}$
denotes words that were identified as keywords but did not belong to any of the above groups. Words without the upper index were not identified as keywords
$^{(10)}$
denotes words that were identified as keywords but did not belong to any of the above groups. Words without the upper index were not identified as keywords

The names of these characters are keywords because they inform us about the character’s gender (’anna’ vs. ’vronsky’), age (’alexandrovitch’ vs. ’seryozha’) and the social strata; for example, ’tit’ versus ’levin’. Proper nouns provide additional information due to name symbolism employed by Tolstoy; for example, ’anna’=’grace’ ’alexey’=’reflector’ ’levin’=’leo’ is the alter ego of Tolstoy (Gustafson Reference Gustafson2014).
All the main character names came out from our method as strong global keywords holding condition
 $A[w]\leq \frac{1}{5}$
in Eq. (8): ’levin’, ’anna’, ’vronsky’, ’kitty’, ’alexey’, ’stepan’, ’dolly’, ’sergey’; see Table 4 for details. Many pertinent lesser characters came out as local keywords, as determined via Eq. (9); for example, ’vassenka’, ’golenishtchev’, ’varvara’; see Table 4. Important characters that are not the main actors came out as weak global keywords, for example, ’seryozha’, ’yashvin’, and ’sviazhsky’.
$A[w]\leq \frac{1}{5}$
in Eq. (8): ’levin’, ’anna’, ’vronsky’, ’kitty’, ’alexey’, ’stepan’, ’dolly’, ’sergey’; see Table 4 for details. Many pertinent lesser characters came out as local keywords, as determined via Eq. (9); for example, ’vassenka’, ’golenishtchev’, ’varvara’; see Table 4. Important characters that are not the main actors came out as weak global keywords, for example, ’seryozha’, ’yashvin’, and ’sviazhsky’.
The novel is also known for its animal characters that play an important role in Tolstoy’s symbolism (Gustafson Reference Gustafson2014). Our method extracted as local keywords the four main animal characters: ’froufrou’, ’gladiator’ ’laska’, and ’krak’. Trains are a motif throughout the novel (they symbolize the modernization of Russia), with several major plot points taking place either on passenger trains or at stations in Russia (Tolstoy Reference Tolstoy2013; Gustafson Reference Gustafson2014). Our method extracted among the global keywords ’carriage’, ’platform’, and ’rail’. Hunting scenes are important in the novel depicting the life of Russian nobility. Accordingly, our method extracted keywords related to that activity: ’snipe’, ’gun’, and ’shoot’. Two major social topics considered in the novel are local democratic governance (Zemstvo) and the agricultural life of by then mostly rural Russia. For the first, we extracted keywords: ’district’, ’bailiff’, ’election’ etc. And for the second: ’mow’, ’lord’, ’acre’, etc. A large set of keywords are provided by Russian nobility’s living and manners, including their titles, professions, and habits; see Table 4. Religion and Christian faith is an important subject of the novel. In this context, we noted keyword ’Lord’, ’priest’, and ’deacon’; see Table 4. Finally, a few words stayed out of these topical groups but was identified as keywords: ’lesson’, ’crime’, ’cheat’, ’salary’, ’irrational’, ’law’, ’skate’, and ’tribe’.
5. Evaluation
5.1 Precision and recall
Results obtained for Anna Karenina are confirmed for several other texts; cf. Table 1. We extracted for each text the same number of
 $\approx 300$
potential keywords via three methods: our method (implemented via Eqs. (8, 9, 10)), LUHN and YAKE. The precise number of extracted words depends on the text.
$\approx 300$
potential keywords via three methods: our method (implemented via Eqs. (8, 9, 10)), LUHN and YAKE. The precise number of extracted words depends on the text.
As seen from Table 1, for long texts (with the length roughly comparable with Anna Karenina), our method outperforms both LUHN and YAKE in terms of the precision, that is, the relative number of extracted keywords which is defined as the number of keywords extracted via the given method (for each text) divided over the total number of words proposed by the method as potential keywords. The advantage of our method is also seen in terms of recall, which is the number of keywords extracted via the given method (for each text) divided over the full number of keywords announced by an annotator for the text. (The definitions of precision and recall are reminded in Appendix C; in particular, the above results were found via Eqs. (25).) Importantly, for YAKE and LUHN the values of recall are lower than
 $0.5$
, while for our method they are sizably larger than
$0.5$
, while for our method they are sizably larger than
 $0.5$
meaning that our method extracted the majority of potential keywords; see Table 1.
$0.5$
meaning that our method extracted the majority of potential keywords; see Table 1.
In this context, we distinguish between long and short texts; cf. Table 1. For short texts, our method needs modifications that are described above. After these modifications, our method implemented via Eq. (13) produces for short texts nearly the same results as LUHN and YAKE; see Table 1. For short texts, we extracted via each method the same number of
 $\sim 100$
words. However, our method still has an important advantage, since it allows us to extract topical groups of short texts nearly in the same way as for long texts; see Table 5 where we analyze topical groups of The Heart of Dog by M. Bulgakov. We emphasize that this feature is absent for LUHN and YAKE.
$\sim 100$
words. However, our method still has an important advantage, since it allows us to extract topical groups of short texts nearly in the same way as for long texts; see Table 5 where we analyze topical groups of The Heart of Dog by M. Bulgakov. We emphasize that this feature is absent for LUHN and YAKE.
Here we discuss topical groups extracted from a short text. Heart of Dog by M. Bulgakov is a known satirical novella that shows the post-revolutionary Moscow (first half of the 1920s) under social changes, the emergence of new elites of Stalin’s era, and science-driven eugenic ideas of the intelligentsia. Eventually, the novella is about the life of a homeless dog Sharik (a standard name for an unpedigreed dog in Russia) picked up for medical and social experiments. The majority of keywords below were not even extracted via LUHN and/or YAKE

5.2 Inter-anontator agreement
The performance of any keyword extraction method is evaluated by annotators. First, annotators should be provided with guidelines on the extraction process; for example, characters are keywords and pay more attention to nouns and less to verbs and adjectives, etc. Second, two (or more) annotators are independently given the set of keywords extracted by our algorithm from the same set of texts, and they mark words that they consider as keywords. So each annotator will get at the end a list of keywords versus non-keyword. Annotators are influenced by various subjective factors: background, prior knowledge, taste, etc. However, the situation will not be subjective if different annotators produce similar results. To quantify the agreement between annotators, we employed Cohen’s kappa
 $\kappa$
; see Table 2. This statistical measure assesses inter-annotator agreement when working on categorical data in linguistics, psychology, and information retrieval; see (Cook Reference Cook2005) for review. It accounts for chance agreement and provides a more robust evaluation of agreement than the simple percentage. Cohen’s
$\kappa$
; see Table 2. This statistical measure assesses inter-annotator agreement when working on categorical data in linguistics, psychology, and information retrieval; see (Cook Reference Cook2005) for review. It accounts for chance agreement and provides a more robust evaluation of agreement than the simple percentage. Cohen’s
 $\kappa$
reads
$\kappa$
reads
 \begin{align} \kappa =\frac{p_o-p_e}{1-p_e}, -1\geq \kappa \geq 1,\end{align}
\begin{align} \kappa =\frac{p_o-p_e}{1-p_e}, -1\geq \kappa \geq 1,\end{align}
 \begin{align} p_o=p(A=\textrm{k},B=\textrm{k})+p(A=\textrm{nk},B=\textrm{nk}),\end{align}
\begin{align} p_o=p(A=\textrm{k},B=\textrm{k})+p(A=\textrm{nk},B=\textrm{nk}),\end{align}
 \begin{align} p_e=p(A=\textrm{k})p(B=\textrm{k})+p(A=\textrm{nk})p(B=\textrm{nk}), \end{align}
\begin{align} p_e=p(A=\textrm{k})p(B=\textrm{k})+p(A=\textrm{nk})p(B=\textrm{nk}), \end{align}
where
 $p(A=\textrm{k},B=\textrm{k})$
is the joint probability for annotators
$p(A=\textrm{k},B=\textrm{k})$
is the joint probability for annotators
 $A$
and
$A$
and
 $B$
to identify keyword,
$B$
to identify keyword,
 $p(A=\textrm{nk},B=\textrm{nk})$
is the same for non-keywords (denoted by
$p(A=\textrm{nk},B=\textrm{nk})$
is the same for non-keywords (denoted by
 $\textrm{nk}$
),
$\textrm{nk}$
),
 $p(A=\textrm{k})$
is the marginal probability, etc. Hence,
$p(A=\textrm{k})$
is the marginal probability, etc. Hence,
 $p_o$
is the agreement probability, while
$p_o$
is the agreement probability, while
 $p_e$
is the probability to agree by chance. Now
$p_e$
is the probability to agree by chance. Now
 $\kappa \to p_o$
for
$\kappa \to p_o$
for
 $p_e\to 0$
, while for
$p_e\to 0$
, while for
 $p_e\lesssim 1$
even a relatively small, but positive difference
$p_e\lesssim 1$
even a relatively small, but positive difference
 $p_o-p_e$
is sufficient for
$p_o-p_e$
is sufficient for
 $\kappa \to 1$
.
$\kappa \to 1$
.
Numerical interpretation of
 $\kappa$
is as follows (Cook Reference Cook2005). No agreement:
$\kappa$
is as follows (Cook Reference Cook2005). No agreement:
 $\kappa \lt 0$
. Slight agreement:
$\kappa \lt 0$
. Slight agreement:
 $0.2\gt \kappa \gt 0$
. Fair agreement:
$0.2\gt \kappa \gt 0$
. Fair agreement:
 $0.4\gt \kappa \gt 0.2$
. Moderate agreement:
$0.4\gt \kappa \gt 0.2$
. Moderate agreement:
 $0.6\gt \kappa \gt 0.4$
. Substantial agreement:
$0.6\gt \kappa \gt 0.4$
. Substantial agreement:
 $0.8\gt \kappa \gt 0.6$
. Following these steps we got an agreement, which is between moderate and substantial both for short and long texts; see Table 2. The agreement is better for global keywords, as expected.
$0.8\gt \kappa \gt 0.6$
. Following these steps we got an agreement, which is between moderate and substantial both for short and long texts; see Table 2. The agreement is better for global keywords, as expected.
5.3 Comparison with RAKE
The method we developed was compared with two unsupervised keyword extraction methods that are among the best, LUHN and YAKE. As an additional comparison, let us take a look at RAKE (Rapid Automatic Keyword Extraction), another unsupervised method (Rose et al. Reference Rose, Engel, Cramer and Cowley2010). Its standard implementation in https://pypi.org/project/python-rake/ requires that punctuation signs and stop words are conserved in the text. It returns keyphrases that we partitioned into separate words. Here are the first (i.e., the highest score) 50 words extracted by RAKE for Anna Karenina (English version): finesses, ces, toutes, par-dessus, passer, influence, mot, nihilist, le, moral, disons, plaisir, h FC;bsch, recht, auch, ich, brisé, est, en, moule, le, monde, du, merveilles, sept, les, jusqu, tomber, va, poulet, ce, blague, une, est, ça, tout, devoir, votre, oubliez, vous, et, ausrechnen, sich, lässt, das, terre-á-terre, excessivement, mais, amour, le, filez, vous. These words are mostly French and German (not English), and they are certainly far from being keywords.
5.4 Comparison with KeyBERT
In section 2, we mentioned KeyBERT, an unsupervised method that uses BERT to convert the input text and potential keywords into high-dimensional vectors (embeddings) Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2018). These embeddings capture the semantic meaning of the words and phrases. BERT is a transformer deep neural network with at least 110 million parameters, which looks for the context of words by considering the entire sentence in a bidirectional way. KeyBERT generates a list of candidate keywords and keyphrases from the input text. For each candidate keyword/keyphrase, KeyBERT calculates the similarity between the embedding of the candidate and the embedding of the entire input text. High similarity means a higher score for a potential keyword.
We applied KeyBERT to Anna Karenina. To apply it efficiently, we extracted two-word keyphrases (which could then be split into different keywords if necessary). Below we present the 100 highest-score results of these applications together with their scores. Only nine single keywords were actually extracted over 200 words: anna, karenina, marriage, annushka, madame, peasant, karenins, and sviazhsky; that is, the performance is much lower than for our method. The fact of two-word keyphrases provides additional information, but this information is of a specific type: it associates anna with words such as husband, wife, marriage, household, love, married, sincerely, woman, madame, fashionable, courteously, unpardonable, emotionalism, lady, etc. This provides some information about what anna does or is involved in. We recall from our extensive discussion in section 4 that Anna Karenina is certainly not solely about Anna Karenina but presents an epochal representation of Russian life at the end of nineteenth century.
Hence, when evaluated over long texts, KeyBERT performed worse than our method in terms of precision, recall, and topic extraction. We exemplified these facts on Anna Karenina, but they hold for several other long texts we checked.
(’anna husband’, 0.4899); (’anna karenina’, 0.489); (’anna wife’, 0.4878); (’wife anna’, 0.4833); (’household anna’, 0.4813); (’karenina anna’, 0.4755); (’husband anna’, 0.4676); (’karenina marriage’, 0.4615); (’love anna’, 0.4607); (’anna involuntarily’, 0.4606); (’superfluous anna’, 0.4595); (’karenina husband’, 0.4585); (’anna sincerely’, 0.4533); (’married anna’, 0.4499); (’care anna’, 0.4464); (’anna married’, 0.4455); (’anna annushka’, 0.4446); (’anna commonplace’, 0.4443); (’anna unnaturalness’, 0.4424); (’arrange anna’, 0.4422); (’anna strangely’, 0.4417); (’anna love’, 0.4415); (’anna irritates’, 0.4413); (’anna peasant’, 0.4406); (’anna courteously’, 0.4406); (’woman anna’, 0.4404); (’anna unpardonably’, 0.4403); (’anna distress’, 0.4401); (’dear anna’, 0.4399); (’anna wonderfully’, 0.4395); (’anna unmistakably’, 0.4387); (’anna fashionable’, 0.4382); (’madame karenina’, 0.438); (’anna dear’, 0.4379); (’anna lovely’, 0.4375); (’anna emotionalism’, 0.437); (’anna woman’, 0.4367); (’annushka anna’, 0.4363); (’distinctly anna’, 0.4359); (’intensely anna’, 0.4353); (’living anna’, 0.4348); (’anna fascinate’, 0.4344); (’perceive anna’, 0.4344); (’recognize anna’, 0.4343); (’anna rarely’, 0.4343); (’maid anna’, 0.4342); (’remarkable anna’, 0.434); (’dress anna’, 0.4326); (’irritate anna’, 0.4323); (’karenina leo’, 0.4302); (’person anna’, 0.43); (’anna lady’, 0.429); (’anna sister’, 0.4281); (’repeat anna’, 0.4276); (’anna occupation’, 0.4276); (’anna meant’, 0.4274); (’unusual anna’, 0.4271); (’expression anna’, 0.4268); (’anna karenin’, 0.4264); (’karenins household’, 0.426); (’turn anna’, 0.4258); (’anna write’, 0.4255); (’peasant anna’, 0.4253); (’sincerely anna’, 0.4253); (’unbecoming anna’, 0.425); (’anna madame’, 0.4245); (’occupation anna’, 0.4242); (’discern anna’, 0.4242); (’anna kindly’, 0.4239); (’anna care’, 0.4229); (’anna mentally’, 0.4227); (’anna constantly’, 0.4223); (’altogether anna’, 0.4222); (’word anna’, 0.4209); (’couple anna’, 0.4209); (’special anna’, 0.4208); (’anna interpose’, 0.4204); (’anna query’, 0.4203); (’anna dreamily’, 0.4202); (’uttered anna’, 0.4202); (’delight anna’, 0.4199); (’indicate anna’, 0.4196); (’description anna’, 0.4195); (’anna anna’, 0.4194); (’anna sviazhsky’, 0.4187); (’complain anna’, 0.4184); (’exceptional anna’, 0.4182); (’anna irritable’, 0.4175); (’anna properly’, 0.4174); (’meet anna’, 0.417); (’anna indifferently’, 0.4167); (’anna manner’, 0.4165); (’anna resolutely’, 0.4164); (’anna memorable’, 0.4163); (’anna wholly’, 0.4161); (’anna sisterinlaw’, 0.4158); (’anna special’, 0.4158); (’articulate anna’, 0.4153); (’explain anna’, 0.4152); (’anna recognize’, 0.4151)
5.5 Comparison with supervised methods
We compare our results with two supervised methods: KEA (Witten et al. Reference Witten, Paynter, Frank, Gutwin and Nevill-Manning1999) and WINGNUS (Nguyen and Luong Reference Nguyen and Luong2010). These two methods were selected because they are relatively new, their software is free, and their structure is well documented in literature. The implementation of both cases were taken from pke python library: https://github.com/boudinfl/pke/tree/master?tab=readme-ov-file. Both methods were trained on the semeval2010 dataset available from https://aclanthology.org/S10-1004/. This dataset amounts to 284 abstracts from scientific articles included in this dataset, which were annotated by both authors and independent annotators.
The performance of KEA and WINGNUS was checked on long texts from Table 1. Their performance is generally lower than for our method. Here are two examples framed in terms of precision. For Anna Karenina KEA and WINGNUS led to 12.3% and 10%, respectively. For Master and Margarita, these numbers are 15.3% and 8.3%, respectively; cf. Table 1.
5.6 Comparison with topic modeling methods
Above we described how human annotators can deduce topical groups of Anna Karenina using keywords extracted by our method. The same task—known as topic modeling—is achieved algorithmically (i.e., without human intervention) by several known NLP methods (Pedregosa et al. Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel, Blondel, Prettenhofer, Weiss, Dubourg, Vanderplas, Passos, Cournapeau, Brucher, Perrot and Duchesnay2011). We focused on three known topic modeling methods (all of them were applied without supervising), and below we compare their efficiency with our results. Before proceeding, let us note that topic modeling is generally applied to an entire corpus of texts, not just a single one. However, there are reasons to believe it can also be applied to a sufficiently long text.
Non-Negative Matrix Factorization (NNMF) is an unsupervised method of topic modeling that applies to a single text; see Appendix A. Its implementation for Anna Karenina produced the following 10 potential topics (their number is a hyperparameter of the model).
T-1: levin, vronsky, anna, kitty, alexey, alexandrovitch, arkadyevitch, stepan, room, wife.
T-2: walked, beauty, maid, gentleman, people, frou, complete, carriage, completely, coming
T-3: living, sviazhsky, meaning, mare, kitty, book, natural, listening, friends, suppose
T-4: read, work, ivanovitch, coat, drove, agriculture, lack, hearing, matters, living
T-5: serpuhovskoy, received, young, desire, pass, asleep, set, action, clerk, stay
T-6: doctor, stahl, coming, today, passion, porter, silence, movement, object, levin
T-7: tanya, remember, game, deal, live, mamma, walking, bare, easy, hurriedly
T-8: noticed, possibility, christian, dmitrievitch, feelings, fall, forget, success, stopped, suffer
T-9: early, covered, recognized, angrily, connection, expression, figure, breathing, nice, friend
T-10: scythe, nobility, elections, minutes, promised, extreme, afraid, decided, ordered, lifting
Only one of them (T-1) was reliable and approximately coincided with the first topical group (proper names of major characters) discussed above; see Table 4. This is not surprising, since this topical group contains the most frequent content words of the text. Other topics extracted by NNMF turn out to be meaningless, that is, they do not correspond to any topical group of the text.
We applied two alternative topic modeling methods: Truncated SVD and LDA (Latent Dirichlet Allocation); see Appendix A. Truncated SVD applied to a single text. LDA was attempted both for a single text directly and after training on a group of
 $\approx 100$
long texts. Both methods produced similar results: several topics were discovered, but all those topics were closely related to each other. Eventually, this situation amounts to only one sensible topic: the proper names of major characters. Let us illustrate this situation on the main topic discovered by LDA for Anna Karenina: levin, vronsky, anna, arkadyevitch, alexey, kitty, hand, stepan, long, alexandrovitch. In variations of this topic, hand can be changed to wife, or brother, etc. Likewise, LDA extracted (effectively) a single topic for other long texts, for example, Master and Margarita. This topic is based on the following words: margarita, ivan, hand, procurator, began, asked, woland, pilate, master, koroviev. Again, besides began and asked, these are the proper names of the main characters.
$\approx 100$
long texts. Both methods produced similar results: several topics were discovered, but all those topics were closely related to each other. Eventually, this situation amounts to only one sensible topic: the proper names of major characters. Let us illustrate this situation on the main topic discovered by LDA for Anna Karenina: levin, vronsky, anna, arkadyevitch, alexey, kitty, hand, stepan, long, alexandrovitch. In variations of this topic, hand can be changed to wife, or brother, etc. Likewise, LDA extracted (effectively) a single topic for other long texts, for example, Master and Margarita. This topic is based on the following words: margarita, ivan, hand, procurator, began, asked, woland, pilate, master, koroviev. Again, besides began and asked, these are the proper names of the main characters.
In sum, NNMF, LDA, and truncated LDA produced consistent results for the studied long texts: they extracted a single topic based on the proper names of the main characters. This cannot be considered as a productive result.
5.7 Comparison with the standard database
We created all of the above databases in order to evaluate the method we employed. The standard databases should also be used in such cases. Hence, we analyzed a database of 100 theses [see https://github.com/LIAAD/KeywordExtractor-Datasets?tab=readme-ov-file#theses]. The average length of texts from this database is roughly comparable with the length of short texts from Table 1. Each of these texts was annotated manually and got 10 keywords. We also implemented LUHN, YAKE, and our method, each extracting 10 keywords from every database text. The evaluation of each method was based on the standard F1 score, which is the harmonic mean of the precision and recall; see (23) in Appendix C. The evaluation results are as follows. For eight database texts, all three methods produced zero F1 score. For the remaining 92 texts, LUHN wins (i.e., its F1 score is largest among three) in 73 cases, YAKE wins in 68 cases, and our method is the winner in 62 cases from 92, that is, the performance of all three methods is comparable. (The concrete values of the F1 score can be looked up from https://github.com/LidaAleksanyan/keywords_extraction_data/tree/master) This is an expected conclusion for two independent reasons. First, the average length of the texts from the database is comparable with that of short texts from Table 1, where we also see roughly equal performance of all three methods. Second, the extracted number of keywords is small (i.e., 10). Even for longer texts, we would not see a well-defined advantage of our method for such a small number of extracted keywords. Unfortunately, standard databases do not have sufficiently many extracted keywords per text, even when the text is complex and structured.
6. Keyword extraction and distribution of words over chapters
Long texts are frequently divided into sufficiently many chapters. It is an interesting question whether this fact can be employed as an independent criterion for extracting keywords. To search for such criteria, let us introduce the following basic quantities. Given a word
 $w$
and chapters
$w$
and chapters
 $c=1,..,N_{\textrm{chap}}$
, we define
$c=1,..,N_{\textrm{chap}}$
, we define
 $m_w(c)\geq 0$
as the number of times
$m_w(c)\geq 0$
as the number of times
 $w$
appeared in chapter
$w$
appeared in chapter
 $c$
. Likewise, let
$c$
. Likewise, let
 $V_w(s)$
be the number of chapters, where
$V_w(s)$
be the number of chapters, where
 $w$
appeared
$w$
appeared
 $s\geq 0$
times; that is,
$s\geq 0$
times; that is,
 $\sum _{s\geq s_0}V_w(s)$
is the number of chapters, where
$\sum _{s\geq s_0}V_w(s)$
is the number of chapters, where
 $w$
appears at least
$w$
appears at least
 $s_0$
times. We have
$s_0$
times. We have
 \begin{align} {\sum }_{c=1}^{N_{\textrm{chap}}}m_w(c)=N_w,\end{align}
\begin{align} {\sum }_{c=1}^{N_{\textrm{chap}}}m_w(c)=N_w,\end{align}
 \begin{align} {\sum }_{s\geq 0}sV_w(s)=N_w, \end{align}
\begin{align} {\sum }_{s\geq 0}sV_w(s)=N_w, \end{align}
where
 $N_w$
is the number of times
$N_w$
is the number of times
 $w$
appears in the text; cf. Eq. (3). Hence, when taking a random occurrence of word
$w$
appears in the text; cf. Eq. (3). Hence, when taking a random occurrence of word
 $w$
, we shall see
$w$
, we shall see
 $w$
appearing in chapter
$w$
appearing in chapter
 $c$
with probability
$c$
with probability
 $m_w(c)/N_w$
. Likewise,
$m_w(c)/N_w$
. Likewise,
 $sV_w(s)/N_w$
is the probability
$sV_w(s)/N_w$
is the probability
 $w$
will appear in a chapter, where
$w$
will appear in a chapter, where
 $w$
is encountered
$w$
is encountered
 $s$
times.
$s$
times.
It appears that quantities deduced from
 $m_w(c)/N_w$
do not lead to useful predictions concerning keywords. In particular, this concerns the entropy
$m_w(c)/N_w$
do not lead to useful predictions concerning keywords. In particular, this concerns the entropy
 $-\sum _{c=1}^{N_{\textrm{chap}}}\frac{m_w(c)}{N_w}\ln \frac{m_w(c)}{N_w}$
and correlation function
$-\sum _{c=1}^{N_{\textrm{chap}}}\frac{m_w(c)}{N_w}\ln \frac{m_w(c)}{N_w}$
and correlation function
 $\sum _{c_1,c_2=1}^{N_{\textrm{chap}}} |c_1-c_2|m_w(c_1)m_w(c_2)$
together with some of its generalizations. In contrast, the following mean [cf. Eq. (6) with Eq. (19)]:
$\sum _{c_1,c_2=1}^{N_{\textrm{chap}}} |c_1-c_2|m_w(c_1)m_w(c_2)$
together with some of its generalizations. In contrast, the following mean [cf. Eq. (6) with Eq. (19)]:
 \begin{align} {\sum }_{s\geq 0}\frac{s^2V_w(s)}{N_w}, \end{align}
\begin{align} {\sum }_{s\geq 0}\frac{s^2V_w(s)}{N_w}, \end{align}
related to
 $sV_w(s)/N_w$
predicts sufficiently many global keywords; see Table 6. Similar results are found upon using the entropy
$sV_w(s)/N_w$
predicts sufficiently many global keywords; see Table 6. Similar results are found upon using the entropy
 $-{\sum }_{s\geq 0}\frac{sV_w(s)}{N_w}\ln \frac{sV_w(s)}{N_w}$
instead of Eq. (19). This formula is calculated for each word and then words with the largest value of Eq. (19) are selected. For Anna Karenina, at least the first 35–36 words selected in this way are keywords. Minor exclusions are seen in Table 6, which also shows that this method is much better than YAKE both in quantity and quality of keyword extraction. The advantage of this chapter-based method is that it does not depend on random permutations. Hence, it will be easier in practical implementations. The drawbacks are seen above: it depends on the existence of sufficiently many chapters (hence, it certainly does not apply to texts with a few or no chapters), and it addresses only some of the keywords.
$-{\sum }_{s\geq 0}\frac{sV_w(s)}{N_w}\ln \frac{sV_w(s)}{N_w}$
instead of Eq. (19). This formula is calculated for each word and then words with the largest value of Eq. (19) are selected. For Anna Karenina, at least the first 35–36 words selected in this way are keywords. Minor exclusions are seen in Table 6, which also shows that this method is much better than YAKE both in quantity and quality of keyword extraction. The advantage of this chapter-based method is that it does not depend on random permutations. Hence, it will be easier in practical implementations. The drawbacks are seen above: it depends on the existence of sufficiently many chapters (hence, it certainly does not apply to texts with a few or no chapters), and it addresses only some of the keywords.
First column: 36 words from Anna Karenina that have the highest score of YAKE (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018, Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020). Keywords are indicated by the number of their group; see Table 4. Among 36 words, there are 25 non-keywords. Keywords refer mostly to group
 $^{(1)}$
. Second column: 36 words of Anna Karenina extracted via looking at the distribution of words over chapters, that is, at the largest value of Eq. (19). Only 2 words out of 36 are not keywords. Several keyword groups are represented
$^{(1)}$
. Second column: 36 words of Anna Karenina extracted via looking at the distribution of words over chapters, that is, at the largest value of Eq. (19). Only 2 words out of 36 are not keywords. Several keyword groups are represented

7. Discussion and conclusion
We proposed a method for extracting keywords from a single text. The method employs a spatial structure in word distribution. Our unsupervised method extends previous proposals, applies to a single text (i.e., it does not need databases), and demonstrates two pertinent applications: extracting the main topics of the text and separating between local and global keywords. For long texts, our analysis confirms that such a separation is semantically meaningful; see (Scott and Tribble Reference Scott and Tribble2006; Carpena et al. Reference Carpena, Bernaola-Galván, Carretero-Campos and Coronado2016) for related ideas about various types of keywords. The method was illustrated in several classic literature texts; see Table 1. In researching the performance of our method, we relied on expert evaluation of keywords (that show from moderate to substantial inter-annotator agreement). As expected, the agreement is better for global keywords. An important aspect of our method is that allows to extract topics of text by looking at keywords. In particular, we focused on the analysis of topics of Anna Karenina and Heart of Dog.
Both in terms of precision and recall, our method outperforms several existing methods for keyword extraction. These methods include LUHN (Luhn, Reference Luhn1958), YAKE (Campos et al. Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2018 Reference Campos, Mangaravite, Pasquali, Jorge, Nunes and Jatowt2020) (which outperforms graph-based methods), RAKE (Rose et al. Reference Rose, Engel, Cramer and Cowley2010), KEA (Witten et al. Reference Witten, Paynter, Frank, Gutwin and Nevill-Manning1999), WINGNUS (Nguyen and Luong Reference Nguyen and Luong2010), and KeyBERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018). We mostly compare with YAKE and LUHN, because these are our closest competitors. For sufficiently long texts, the advantage of our method compared to LUHN and YAKE is both quantitative (since it extracts
 $2-3$
times more words than LUHN and YAKE), and qualitative, because LUHN and YAKE do not extract the topics, do not distinguish between local and global keywords, and do not have efficient ranking of keywords. For shorter text, only one advantage persists: our method helps to extract topical groups; see Table 1 and Table 5. We show that our method generally extracts more nouns and longer content words than YAKE and LUHN. There are correlations between these features and the features of being a keyword; Piantadosi et al. (Reference Piantadosi, Tily and Gibson2012) and Firoozeh et al. (Reference Firoozeh, Nazarenko, Alizon and Daille2020) provide additional arguments along these lines. Our method is also language-independent, as we checked with several translations of the same text. It shares this advantage with LUHN and YAKE.
$2-3$
times more words than LUHN and YAKE), and qualitative, because LUHN and YAKE do not extract the topics, do not distinguish between local and global keywords, and do not have efficient ranking of keywords. For shorter text, only one advantage persists: our method helps to extract topical groups; see Table 1 and Table 5. We show that our method generally extracts more nouns and longer content words than YAKE and LUHN. There are correlations between these features and the features of being a keyword; Piantadosi et al. (Reference Piantadosi, Tily and Gibson2012) and Firoozeh et al. (Reference Firoozeh, Nazarenko, Alizon and Daille2020) provide additional arguments along these lines. Our method is also language-independent, as we checked with several translations of the same text. It shares this advantage with LUHN and YAKE.
We demonstrated that our method of identifying topical groups of texts (where human annotators employ keywords extracted by our method) produced significantly better results than algorithmic methods of topic modeling such as Non-Negative Matrix Factorization, Truncated SVD, and LDA (Latent Dirichlet Allocation); see Appendix A.
We also worked out a method for keyword extraction that uses the fact that a text has sufficiently many chapters. This method is easy to implement and works better than LUHN and YAKE, but it is inferior to the previous one. However, we believe this method does have the potential for further development, for example, for clarifying the conceptual meaning of keywords and relating it with higher-order textual structures.
Our method is targeted to extract local and global keywords. Their spatial distribution moments have different behavior with respect to random permutations; see Eqs. (8–10). For short texts, the difference between local and global keywords is blurred; see Figure 2. Put differently, local and global keywords are not so different from each other. Hence, our method is not efficient (or more precisely nearly as efficient as YAKE and LUHN) in extracting keywords from short texts; see Table 1 . We are currently searching for modifications of our method that can outperform those two methods also for shorter texts. We believe that this should be feasible because our method was able to extract topical groups of a short text; see Table 5.
Future work will include adding n-gram analysis functionality to extract not only single words but also phrases of two or more words from a text. In particular, these keyphrases are important for reflecting the aspects that were not studied in this work, that is, relations of keywords to the style of the text. Brin and Page (Reference Brin and Page1998); Papagiannopoulou and Tsoumakas (Reference Papagiannopoulou and Tsoumakas2020); Katz (Reference Katz1996) provide useful information on how to find keyphrases from keyword extractions. Another useful idea for extracting keyphrases is to study co-occurrences between candidate keywords; see, for example, Matsuo and Ishizuka (Reference Matsuo and Ishizuka2004) for this technique. A more remote but important application will be to employ keywords for facilitating text compression methods (Allahverdyan and Khachatryan Reference Allahverdyan and Khachatryan2023).
The present work leaves open the issue of finding an adequate model for random text so that the implementation of a random permutation (on which our method relies) is not needed; see section 3.2. We were not able to employ theoretical models of a random text proposed by Yngve (Reference Yngve1956), Herdan (Reference Herdan1966), Herrera and Pury (Reference Herrera and Pury2008), and Mehri and Darooneh (Reference Mehri and Darooneh2011) because these models frequently imply asymptotic limits that are not reached for keywords. Further ideas about modeling the random gap distribution in non-asymptotic situations were proposed by Zörnig (Reference Zörnig1984, Reference Zörnig2010), Carpena et al. (Reference Carpena, Bernaola-Galván, Carretero-Campos and Coronado2016), and Allahverdyan et al. (Reference Allahverdyan, Deng and Wang2013). We plan to address them in the future. Ideally, once the proper random model for the gap distribution is understood, random permutations will not be needed.
Acknowledgments
This work was supported by SCS of Armenia, grant No. 21AG-1C038. It is a pleasure to thank Narek Martirosyan for participating in initial stages of this work. We acknowledge discussions with A. Khachatryan, K. Avetisyan, and Ts. Ghukasyan. We thank S. Tamazyan for helping us with French texts.
Appendix A. Software employed
– Our data for texts from Table 1 is freely available at https://github.com/LidaAleksanyan/keywords_extraction_data/tree/master. Our codes are available at https://github.com/LidaAleksanyan/spatial_keyword_extraction.
– Natural Language Toolkit (NLTK) is available at https://github.com/nltk/nltk.
– We used the following Python package with YAKE algorithm implementation: https://pypi.org/project/yake/.
– We used the following Python package for KeyBERT: https://pypi.org/project/keybert/
– For French and Russian texts we used (resp.) French LEFFF Lemmatizer https://github.com/ClaudeCoulombe/FrenchLefffLemmatizer, and A Python wrapper of the Yandex Mystem 3.1 morphological analyzer pymystem3 https://github.com/nlpub/pymystem3.
– Non-Negative Matrix Factorization (NNMF) was employed via https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.NMF.html.
– LDA (Latent Dirichlet Allocation) was employed via https://radimrehurek.com/gensim/models/ldamodel.html.
– Truncated SVD was employed via https://scikit-learn.org/stable/modules/generated/sklearn. decomposition.TruncatedSVD.html.
– The software for random permutations was taken from numpy.random.permutation: https://numpy.org/doc/stable/reference/random/generated/numpy.random.permutation.html.
– The implementations of KEA and WINGNUS were taken from https://github.com/boudinfl/pke/tree/master?tab=readme-ov-file.
– The semeval2010 dataset is available from https://aclanthology.org/S10-1004/.
Appendix B. Numerical illustrations of Eq. (6)
Here, we illustrate on simple numerical examples how
 $C_2[w]$
defined via Eq. (6) can both increase or decrease after the distribution of words is made more homogeneous. We also illustrate that
$C_2[w]$
defined via Eq. (6) can both increase or decrease after the distribution of words is made more homogeneous. We also illustrate that
 $C_1[w]$
[cf. Eq. (1)] does not distinguish between homogeneous and inhomogeneous distributions. Take in Eq. (6) the following parameters:
$C_1[w]$
[cf. Eq. (1)] does not distinguish between homogeneous and inhomogeneous distributions. Take in Eq. (6) the following parameters:
 $N=10$
and
$N=10$
and
 $\ell =4$
. Consider the following three distributions of words and the respective values of
$\ell =4$
. Consider the following three distributions of words and the respective values of
 $C_2[w]$
(
$C_2[w]$
(
 $\bar w$
means any word different from
$\bar w$
means any word different from
 $w$
):
$w$
):
 \begin{align} w\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\, w\, w\, w,\qquad C_2[w]=17, \qquad C_1[w]=3,\end{align}
\begin{align} w\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\, w\, w\, w,\qquad C_2[w]=17, \qquad C_1[w]=3,\end{align}
 \begin{align} \bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,{w}\, w\, w\, w,\qquad C_2[w]=1,\qquad \,C_1[w]=1,\end{align}
\begin{align} \bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,\bar{w}\,{w}\, w\, w\, w,\qquad C_2[w]=1,\qquad \,C_1[w]=1,\end{align}
 \begin{align} w\,\bar{w}\,\bar{w}\,{w}\,\bar{w}\,\bar{w}\,{w}\, \bar{w}\, \bar{w}\, w,\qquad C_2[w]=9, \qquad \,C_1[w]=3. \end{align}
\begin{align} w\,\bar{w}\,\bar{w}\,{w}\,\bar{w}\,\bar{w}\,{w}\, \bar{w}\, \bar{w}\, w,\qquad C_2[w]=9, \qquad \,C_1[w]=3. \end{align}
Eq. (20) shows an inhomogeneous distribution of
 $w$
, where
$w$
, where
 $w$
appears both at the beginning of the text and its end. It has a large value of
$w$
appears both at the beginning of the text and its end. It has a large value of
 $C_2$
. Eq. (21) is a strongly clustered distribution of
$C_2$
. Eq. (21) is a strongly clustered distribution of
 $w$
with the minimal value of
$w$
with the minimal value of
 $C_2$
. Eq. (22) shows the homogeneous distribution of
$C_2$
. Eq. (22) shows the homogeneous distribution of
 $w$
, its value of
$w$
, its value of
 $C_2$
is intermediate between the above two. It is seen that
$C_2$
is intermediate between the above two. It is seen that
 $C_1$
does not distinguish between (20) and (22).
$C_1$
does not distinguish between (20) and (22).
Appendix C. Precision versus recall
For short texts, where the number of extracted and compared keywords is around 10–20, one employs the following standard definitions of precision and recall. For a given a text
 $T$
, an annotator
$T$
, an annotator
 $A$
extracts set of keywords
$A$
extracts set of keywords
 $w(T,A)$
. Next, an automated method
$w(T,A)$
. Next, an automated method
 $M$
extracts a set
$M$
extracts a set
 $w(T,M)$
of candidate keywords. Let
$w(T,M)$
of candidate keywords. Let
 $N[w]$
be the number of elements in set
$N[w]$
be the number of elements in set
 $w$
. Now define precision (
$w$
. Now define precision (
 $\textrm{Pre}$
) and recall (
$\textrm{Pre}$
) and recall (
 $\textrm{Rec}$
) for the present case as:
$\textrm{Rec}$
) for the present case as:
 \begin{align} \textrm{Pre}(T,M,A)=\frac{N[w(T,A)\cap w(T,M)]}{N[w(T,M)]}, \qquad \textrm{Rec}(T,M,A)=\frac{N[w(T,A)\cap w(T,M)]}{N[w(T,A)]}. \end{align}
\begin{align} \textrm{Pre}(T,M,A)=\frac{N[w(T,A)\cap w(T,M)]}{N[w(T,M)]}, \qquad \textrm{Rec}(T,M,A)=\frac{N[w(T,A)\cap w(T,M)]}{N[w(T,A)]}. \end{align}
Note that these definitions come from more general concepts, where the precision is defined as (relevant retrieved instances)/(all retrieved instances), while the recall is (relevant retrieved instances)/(all relevant instances). In application of these more general concepts to (23), it is assumed that all words extracted by human annotator are by definition keywords.
However, definitions in (23) need to be modified for longer texts, where the automated methods offer many (up to 100–200) keywords, possibly joined in topical groups. We do not expect that human annotators (even those knowing the text beforehand) can extract apriori such a large amount of keywords more or less precisely. Hence, for long texts the experiments with annotators were carried out differently. Annotator
 $A$
studied all words extracted for a given text
$A$
studied all words extracted for a given text
 $T$
by all the involved
$T$
by all the involved
 $S$
methods
$S$
methods
 $\{M_k\}_{k=1}^S$
, and only after that completed his/her final list of words
$\{M_k\}_{k=1}^S$
, and only after that completed his/her final list of words
 $\bar w(T,A)$
. This set is larger (or equal) than the union of all keywords:
$\bar w(T,A)$
. This set is larger (or equal) than the union of all keywords:
 \begin{align} \cup _{k=1}^S \bar w(T,M_k,A)\subset \bar w(T,A), \end{align}
\begin{align} \cup _{k=1}^S \bar w(T,M_k,A)\subset \bar w(T,A), \end{align}
where
 $\bar w(T,M_k,A)$
is the set of keywords identified by
$\bar w(T,M_k,A)$
is the set of keywords identified by
 $A$
in a list of potential keywords extracted from
$A$
in a list of potential keywords extracted from
 $T$
using method
$T$
using method
 $M_k$
, and where
$M_k$
, and where
 $\bar w(T,A)$
can contain keywords that are not in
$\bar w(T,A)$
can contain keywords that are not in
 $\cup _{k=1}^S w(T,M_k,A)$
, though it can happen that
$\cup _{k=1}^S w(T,M_k,A)$
, though it can happen that
 $w(T,A)=\cup _{k=1}^S \bar w(T,M_k,A)$
.
$w(T,A)=\cup _{k=1}^S \bar w(T,M_k,A)$
.
Now the analogs of (23) are defined (for a given annotator
 $A$
, and a given precision method
$A$
, and a given precision method
 $M$
) as:
$M$
) as:
 \begin{align} \overline{\textrm{Pre}}(T,M,A)=\frac{N[\bar w(T,M,A) ]}{N[w(T,M)]}, \qquad \overline{\textrm{Rec}}(T,M,A)=\frac{N[\bar w(T,M,A)]}{N[\bar w(T,A)]}. \end{align}
\begin{align} \overline{\textrm{Pre}}(T,M,A)=\frac{N[\bar w(T,M,A) ]}{N[w(T,M)]}, \qquad \overline{\textrm{Rec}}(T,M,A)=\frac{N[\bar w(T,M,A)]}{N[\bar w(T,A)]}. \end{align}
Finally, remind that once recall and precision change between 0 and 1, a balanced way to account for both is to calculate their harmonic mean, which is standardly known as F1 score:
 \begin{align} F1=2\,\frac{\overline{\textrm{Pre}}(T,M,A)\overline{\textrm{Rec}}(T,M,A)}{\overline{\textrm{Pre}}(T,M,A)+\overline{\textrm{ Rec}}(T,M,A)}. \end{align}
\begin{align} F1=2\,\frac{\overline{\textrm{Pre}}(T,M,A)\overline{\textrm{Rec}}(T,M,A)}{\overline{\textrm{Pre}}(T,M,A)+\overline{\textrm{ Rec}}(T,M,A)}. \end{align}


















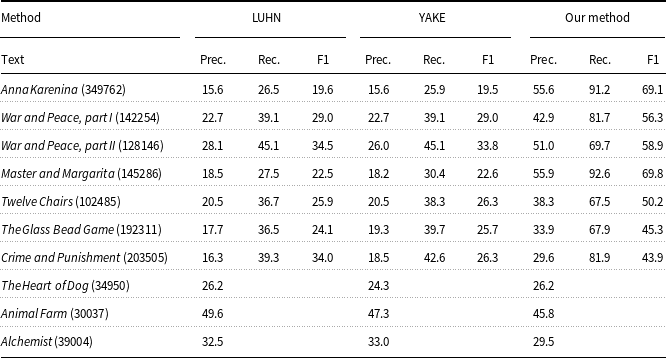



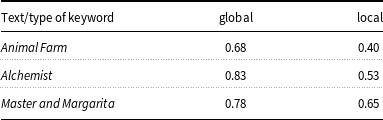

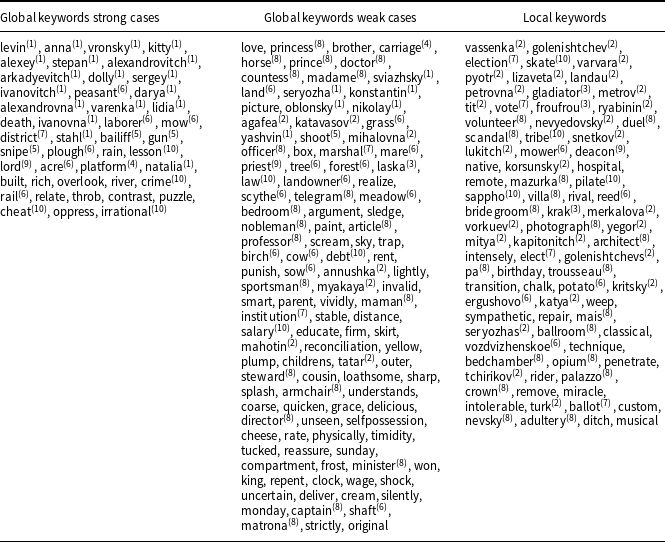





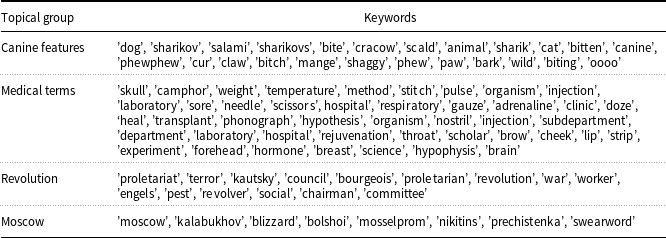



 Open access
Open access