

1 Introduction
We are compelled to understand and intervene in the dynamics of various complex systems in which different elements, such as human individuals, interact with each other. Such complex systems are often modeled by multiagent or network-based models that explicitly dictate how each individual behaves and influences other individuals. Stochastic processes are popular models for the dynamics of multiagent systems when it is realistic to assume random elements in how agents behave or in dynamical processes taking place in the system. For example, random walks have been successfully applied to describe locomotion and foraging of animals (Reference Codling, Plank and BenhamouCodling, Plank, & Benhamou, 2008; Reference Okubo and LevinOkubo & Levin, 2001), dynamics of neuronal firing (Reference Gabbiani and CoxGabbiani & Cox, 2010; Reference TuckwellTuckwell, 1988), and financial market dynamics (Reference Campbell, Lo and MacKinlayCampbell, Lo, & MacKinlay, 1997; Reference Mantegna and StanleyMantegna & Stanley, 2000) to name a few (see Reference Masuda, Porter and LambiotteMasuda, Porter, and Lambiotte [2017] for a review). Branching processes are another major type of stochastic processes that have been applied to describe, for example, information spread (Reference Eugster, Guerraoui, Kermarrec and MassouliéEugster et al., 2004; Reference Gleeson, Onaga and FennellGleeson et al., 2021), spread of infectious diseases (Reference BrittonBritton, 2010; Reference Farrington, Kanaan and GayFarrington, Kanaan, & Gay, 2003), cell proliferation (Reference JagersJagers, 1975), and the abundance of species in a community (Reference McGill, Etienne and GrayMcGill et al., 2007) as well as other ecological dynamics (Reference Black and McKaneBlack & McKane, 2012).
Stochastic processes in which the state of the system changes via discrete events that occur at given points in time are a major class of models for dynamics of complex systems (Reference Andersson and BrittonAndersson & Britton, 2000; Reference Barrat, Barthélemy and VespignaniBarrat, Barthélemy, & Vespignani, 2008; Reference Daley and GaniDaley & Gani, 1999; Reference de Arruda, Rodrigues and Morenode Arruda, Rodrigues, & Moreno, 2018; Reference Kiss, Miller and SimonKiss, Miller, & Simon, 2017a; Reference LiggettLiggett, 2010; Reference Shelton and CiardoShelton & Ciardo, 2014; Reference Singer and SpilermanSinger & Spilerman, 1976; Reference Van MieghemVan Mieghem, 2014). For example, in typical models for infectious disease spread, each infection event occurs at a given time
 such that an individual transitions instantaneously from a healthy to an infectious state. Such processes are called Markov jump processes when they satisfy certain independence conditions (Reference HansonHanson, 2007), which we will briefly discuss in Section 2.5. A jump is equivalent to a discrete event. In Markov jump processes, jumps occur according to Poisson processes. In this volume, we focus on how to simulate Markov jump processes. Specifically, we will introduce a set of exact and computationally efficient simulation algorithms collectively known as Gillespie algorithms. In the last technical section of this volume (i.e., Section 5), we will also consider more general, non-Markov, jump processes, in which the events are generated in more complicated manners than by Poisson processes. In the following text, we refer collectively to Markov jump processes and non-Markov jump processes as jump processes.
such that an individual transitions instantaneously from a healthy to an infectious state. Such processes are called Markov jump processes when they satisfy certain independence conditions (Reference HansonHanson, 2007), which we will briefly discuss in Section 2.5. A jump is equivalent to a discrete event. In Markov jump processes, jumps occur according to Poisson processes. In this volume, we focus on how to simulate Markov jump processes. Specifically, we will introduce a set of exact and computationally efficient simulation algorithms collectively known as Gillespie algorithms. In the last technical section of this volume (i.e., Section 5), we will also consider more general, non-Markov, jump processes, in which the events are generated in more complicated manners than by Poisson processes. In the following text, we refer collectively to Markov jump processes and non-Markov jump processes as jump processes.
The Gillespie algorithms were originally proposed in their general forms by Daniel Gillespie in 1976 for simulating systems of chemical reactions (Reference GillespieGillespie, 1976), whereas several specialized variants had been proposed earlier; see Section 3.1 for a brief history review. Gillespie proposed two different variants of the simulation algorithm, the direct method, also known as Gillespie’s stochastic simulation algorithm (SSA), or often simply the Gillespie algorithm, and the first reaction method. Both the direct and first reaction methods have found widespread use and in fields far beyond chemical physics. Furthermore, researchers have developed many extensions and improvements of the original Gillespie algorithms to widen the types of processes that we can simulate with them and to improve their computational efficiency.
The Gillespie algorithms are practical algorithms to simulate coupled Poisson processes exactly (i.e., without approximation error). Here “coupled” means that an event that occurs somewhere in the system potentially influences the likelihood of future events’ occurrences in different parts of the same system. For example, when an individual in a population,
 , gets infected by a contagious disease, the likelihood that a different healthy individual in the same population,
, gets infected by a contagious disease, the likelihood that a different healthy individual in the same population,
 , will get infected in the near future may increase. If interactions were absent, it would suffice to separately consider single Poisson processes, and simulating the system would be straightforward.
, will get infected in the near future may increase. If interactions were absent, it would suffice to separately consider single Poisson processes, and simulating the system would be straightforward.
We believe that the Gillespie algorithms are important tools for students and researchers that study dynamic social systems, where social dynamics are broadly construed and include both human and animal interactions, ecological systems, and even technological systems. While there already exists a large body of references on the Gillespie algorithms and their variants, most are concise, mathematically challenging for beginners, and focused on chemical reaction systems.
Given these considerations, the primary aim of this volume is to provide a detailed tutorial on the Gillespie algorithms, with specific focus on simulating dynamic social systems. We will realize the tutorial in the first part of the Element (Sections 2 and 3). In this part, we assume basic knowledge of calculus and probability. Although we do introduce stochastic processes and explain the Gillespie algorithms and related concepts with much reference to networks, we do not assume prior knowledge of stochastic processes or of networks. To understand the coding section, readers will need basic knowledge of programming. The second part of this Element (Sections 4 and 5) is devoted to a survey of recent advancements of Gillespie algorithms for simulating social dynamics. These advancements are concerned with accelerating simulations and/or increasing the realism of the models to be simulated.
2 Preliminaries
We review in this section mathematical concepts needed to understand the Gillespie algorithms. In Sections 2.1 to 2.3, we introduce the types of models we will be concerned with, namely jump processes, and in particular a simple type of jump process termed Poisson processes. In Sections 2.4 to 2.6, we derive the main mathematical properties of Poisson processes. The concepts and results presented in Sections 2.1 to 2.6 are necessary for understanding Section 3, where we derive the Gillespie algorithms. In Sections 2.7 and 2.8, we review two simple methods for solving the models that predate the Gillespie algorithms and discuss some of their shortcomings. These two final subsections motivate the need for exact simulation algorithms such as the Gillespie algorithms.
2.1 Jump Processes
Before getting into the nitty-gritty of the Gillespie algorithms, we first explore which types of systems they can be used to simulate. First of all, with the Gillespie algorithms, we are interested in simulating a dynamic system. This can be, for example, epidemic dynamics in a population in which the number of infectious individuals varies over time, or the evolution of the number of crimes in a city, which also varies over time in general. Second, the Gillespie algorithms rely on a predefined and parametrized mathematical model for the system to simulate. Therefore, we must have the set of rules for how the system or the individuals in it change their states. Third, Gillespie algorithms simulate stochastic processes, not deterministic systems. In other words, every time one runs the same model starting from the same initial conditions, the results will generally differ. In contrast, in a deterministic dynamical system, if we specify the model and the initial conditions, the behavior of the model will always be the same. Fourth and last, the Gillespie algorithms simulate processes in which changes in the system are primarily driven by discrete events taking place in continuous time. For example, when a chemical reaction obeying the chemical equation A
 B
B
 C
C
 D happens, one unit each of A and of B are consumed, and one unit each of C and of D are produced. This event is discrete in that we can count the event and say when the event happened, but it can happen at any point in time (i.e., time is not discretized but continuous).
D happens, one unit each of A and of B are consumed, and one unit each of C and of D are produced. This event is discrete in that we can count the event and say when the event happened, but it can happen at any point in time (i.e., time is not discretized but continuous).
We refer to the class of mathematical models that satisfy these conditions and may be simulated by a Gillespie algorithm as jump processes. In the remainder of this section, we explore these processes more extensively through motivating examples. Then, we introduce some fundamental mathematical definitions and results that the Gillespie algorithms rely on.
2.2 Representing a Population as a Network
Networks are an extensively used abstraction for representing a structured population, and Gillespie algorithms lend themselves naturally to simulate stochastic dynamical processes taking place in networks. In a network representation, each individual in the population corresponds to a node in the network, and edges are drawn between pairs of individuals that directly interact. What constitutes an interaction generally depends on the context. In particular, for the simulation of dynamic processes in the population, the interaction depends on the nature of the process we wish to simulate. For simulating the spread of an infectious disease, for example, a typical type of relevant interaction is physical proximity between individuals.
Formally, we define a network as a graph
 , where
, where
 is the set of nodes,
is the set of nodes,
 is the set of edges, and each edge
is the set of edges, and each edge
 defines a pair of nodes
defines a pair of nodes
 that are directly connected. The pairs
that are directly connected. The pairs
 may be ordered, in which case edges are directed (by convention from
may be ordered, in which case edges are directed (by convention from
 to
to
 ), or unordered, in which case edges are undirected (i.e.,
), or unordered, in which case edges are undirected (i.e.,
 connects to
connects to
 if and only if
if and only if
 connects to
connects to
 ). We may also add weights to the edges to represent different strengths of interactions, or we may even consider graphs that evolve in time (so-called temporal networks) to account for the dynamics of interactions in a population.
). We may also add weights to the edges to represent different strengths of interactions, or we may even consider graphs that evolve in time (so-called temporal networks) to account for the dynamics of interactions in a population.
We will primarily consider simple (i.e., static, undirected, and unweighted) networks in our examples. However, the Gillespie algorithms apply to simulated jump processes in all kinds of populations and networks. (For temporal networks, we need to extend the classic Gillespie algorithms to cope with the time-varying network structure; see Section 5.4.)
2.3 Example: Stochastic SIR Model in Continuous Time
We introduce jump processes and explore their mathematical properties by way of a running example. We show how we can use them to model epidemic dynamics using the stochastic susceptible-infectious-recovered (SIR) model.Footnote 1 For more examples (namely, SIR epidemic dynamics in metapopulation networks, the voter model, and the Lotka–Volterra model for predator–prey dynamics), see Section 3.4.
We examine a stochastic version of the SIR model in continuous time defined as follows. We consider a constant population of
 individuals (nodes). At any time, each individual is in one of three states: susceptible (denoted by
individuals (nodes). At any time, each individual is in one of three states: susceptible (denoted by
 ; meaning healthy), infectious (denoted by
; meaning healthy), infectious (denoted by
 ), or recovered (denoted by
), or recovered (denoted by
 ). The rules governing how individuals change their states are shown schematically in Fig. 1. An infectious individual that is in contact with a susceptible individual infects the susceptible individual in a stochastic manner with a constant infection rate
). The rules governing how individuals change their states are shown schematically in Fig. 1. An infectious individual that is in contact with a susceptible individual infects the susceptible individual in a stochastic manner with a constant infection rate
 . Independently of the infection events, an infectious individual may recover at any point in time, with a constant recovery rate
. Independently of the infection events, an infectious individual may recover at any point in time, with a constant recovery rate
 . If an infection event occurs, the susceptible individual that has been infected changes its state to I. If an infectious individual recovers, it transits from the I state to the R state. Nobody leaves or joins the population over the course of the dynamics. After reaching the R state, an individual cannot be reinfected or infect others again. Therefore, R individuals do not influence the increase or decrease in the number of S or I individuals. Because R individuals are as if they no longer exist in the system, the R state is mathematically equivalent to having died of the infection; once dead, an individual will not be reinfected or infect others.
. If an infection event occurs, the susceptible individual that has been infected changes its state to I. If an infectious individual recovers, it transits from the I state to the R state. Nobody leaves or joins the population over the course of the dynamics. After reaching the R state, an individual cannot be reinfected or infect others again. Therefore, R individuals do not influence the increase or decrease in the number of S or I individuals. Because R individuals are as if they no longer exist in the system, the R state is mathematically equivalent to having died of the infection; once dead, an individual will not be reinfected or infect others.
Rules of state changes in the SIR model. An infectious individual infects a susceptible neighbor at a rate
 . Each infectious individual recovers at a rate
. Each infectious individual recovers at a rate
 .
.
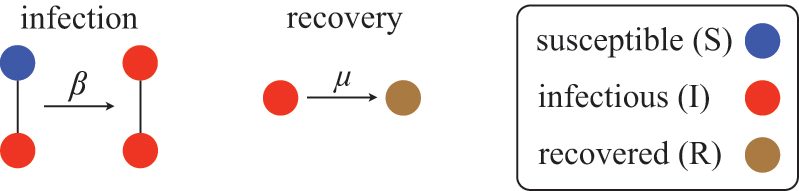
We typically start the stochastic SIR dynamics with a single infectious individual, which we refer to as the source or seed, and
 susceptible individuals (and thus no recovered individuals). Then, various infection and recovery events may occur. The dynamics stop when no infectious individuals are left. In this final situation, the population is composed entirely of susceptible and/or recovered individuals. Since both infection and recovery involve an infectious individual, and there are no infectious individuals left, the dynamics are stuck. The final number of recovered nodes, denoted by
susceptible individuals (and thus no recovered individuals). Then, various infection and recovery events may occur. The dynamics stop when no infectious individuals are left. In this final situation, the population is composed entirely of susceptible and/or recovered individuals. Since both infection and recovery involve an infectious individual, and there are no infectious individuals left, the dynamics are stuck. The final number of recovered nodes, denoted by
 , is called the epidemic size, also known as the final epidemic size or simply the final size.Footnote 2 The epidemic size tends to increase as the infection rate
, is called the epidemic size, also known as the final epidemic size or simply the final size.Footnote 2 The epidemic size tends to increase as the infection rate
 increases or as the recovery rate
increases or as the recovery rate
 decreases. Many other measures to quantify the behavior of the SIR model exist (Reference Pastor-Satorras, Castellano, Van Mieghem and VespignaniPastor-Satorras et al., 2015). For example, we may be interested in the time until the dynamics terminate or in the speed at which the number of infectious individuals grows in the initial stage of the dynamics.
decreases. Many other measures to quantify the behavior of the SIR model exist (Reference Pastor-Satorras, Castellano, Van Mieghem and VespignaniPastor-Satorras et al., 2015). For example, we may be interested in the time until the dynamics terminate or in the speed at which the number of infectious individuals grows in the initial stage of the dynamics.
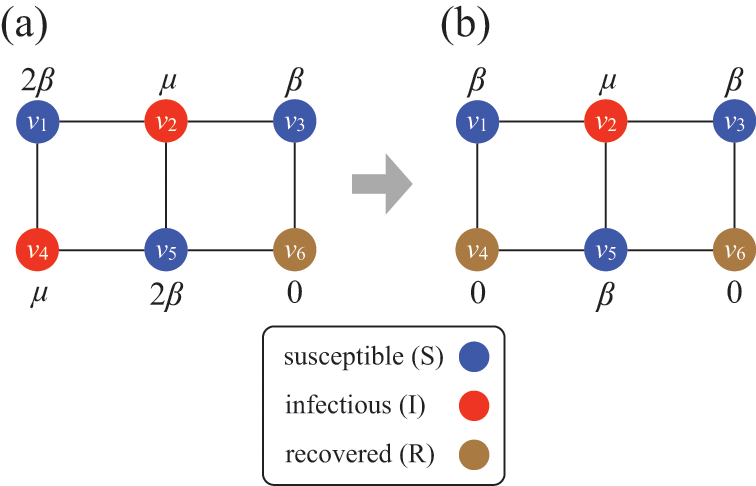
Consider Fig. 2(a), where individuals are connected as a network. We generally assume that infection may only occur between pairs of individuals that are directly connected by an edge (called adjacent nodes). For example, the node
 can infect
can infect
 and
and
 but not
but not
 . The network version of the SIR model is fully described by the infection rate
. The network version of the SIR model is fully described by the infection rate
 , the recovery rate
, the recovery rate
 , the network structure, that is, which node pairs are connected by an edge, and the choice of source node to initialize the dynamics.
, the network structure, that is, which node pairs are connected by an edge, and the choice of source node to initialize the dynamics.
Stochastic SIR process on a square-grid network with six nodes. (a) Status of the network at an arbitrary time
 . (b) Status of the network after
. (b) Status of the network after
 has recovered. The values attached to the nodes indicate the rates of the events that the nodes may experience next.
has recovered. The values attached to the nodes indicate the rates of the events that the nodes may experience next.
Mathematically, we describe the system by a set of coupled, constant-rate jump processes; constant-rate jump processes are known as Poisson processes (Box 1). Each possible event that may happen is associated to a Poisson process, that is, the recovery of each infectious individual is described by a Poisson process, and so is each pair of infectious and susceptible individuals where the former may infect the latter. The Poisson processes are coupled because an event generated by one process may alter the other processes by changing their rates, generating new Poisson processes, or making existing ones disappear. For example, after a node gets infected, it may in turn infect any of its susceptible neighbors, which we represent mathematically by adding new Poisson processes. This coupling implies that the set of coupled Poisson processes generally constitutes a process that is more complicated than a single Poisson process.
In the following subsections we develop the main mathematical properties of Poisson processes and of sets of Poisson processes. We will rely on these properties in Section 3 to construct the Gillespie algorithms that can simulate systems of coupled Poisson processes exactly. Note that the restriction to Poisson (i.e., constant-rate) processes is essential for the classic Gillespie algorithms to work; see Section 5 for recent extensions to the simulation of non-Poissonian processes.
A Poisson process is a jump process that generates events with a constant rate,
 .
.
Waiting-Time Distribution
The waiting times
 between consecutive events generated by a Poisson process are exponentially distributed. In other words,
between consecutive events generated by a Poisson process are exponentially distributed. In other words,
 obeys the probability density
obeys the probability density
 (2.1)
(2.1)
Memoryless Property
The waiting time left until a Poisson process generates an event given that a time
 has already elapsed since the last event is independent of
has already elapsed since the last event is independent of
 . This property is called the memoryless property of Poisson processes and is shown as follows:
. This property is called the memoryless property of Poisson processes and is shown as follows:
 (2.2)
(2.2)
where
 represents the conditional probability density that the next event occurs a time
represents the conditional probability density that the next event occurs a time
 after the last event given that time
after the last event given that time
 has already elapsed;
has already elapsed;
 is called the survival probability and is the probability that no event takes place for a time
is called the survival probability and is the probability that no event takes place for a time
 . The first equality in Eq. (2.2) follows from the definition of the conditional probability. The second equality follows from Eq. (2.1).
. The first equality in Eq. (2.2) follows from the definition of the conditional probability. The second equality follows from Eq. (2.1).
Superposition Theorem
Consider a set of Poisson processes indexed by
 . The superposition of the processes is a jump process that generates an event whenever any of the individual processes does. It is another Poisson process whose rate is given by
. The superposition of the processes is a jump process that generates an event whenever any of the individual processes does. It is another Poisson process whose rate is given by
 (2.3)
(2.3)
where
 is the rate of the
is the rate of the
 th Poisson process.
th Poisson process.
Probability of a Given Process Generating an Event in a Superposition of Poisson Processes
Consider any given event generated by a superposition of Poisson processes. The probability
 that the
that the
 th individual Poisson process has generated this event is proportional to the rate of the
th individual Poisson process has generated this event is proportional to the rate of the
 th process. In other words,
th process. In other words,
 (2.4)
(2.4)
2.4 Waiting-Time Distribution for a Poisson Process
We derive in this subsection the waiting-time distribution for a Poisson process, which characterizes how long one has to wait for the process to generate an event. It is often easiest to start from a discrete-time description when exploring properties of a continuous-time stochastic process. Therefore, we will follow this approach here. We use the recovery of a single node in the SIR model as an example in our development.
Let us partition time into short intervals of length
 . As
. As
 goes to zero, this becomes an exact description of the continuous-time process. An infectious individual recovers with probability
goes to zero, this becomes an exact description of the continuous-time process. An infectious individual recovers with probability
 after each interval given that it has not recovered before.Footnote 3
after each interval given that it has not recovered before.Footnote 3
Formally, we define the SIR process in the limit
 . Then, you might worry that the recovery event is unlikely to ever take place because the probability with which it happens during each time-step, that is,
. Then, you might worry that the recovery event is unlikely to ever take place because the probability with which it happens during each time-step, that is,
 , goes toward 0 when the step size
, goes toward 0 when the step size
 does so. However, this is not the case; because the number of time-steps in any given finite interval grows inversely proportional to
does so. However, this is not the case; because the number of time-steps in any given finite interval grows inversely proportional to
 , the probability to recover in finite time stays finite. For example, if we use a different step size
, the probability to recover in finite time stays finite. For example, if we use a different step size
 , which is ten times smaller than the original
, which is ten times smaller than the original
 , then the probability of recovery within the short duration of time
, then the probability of recovery within the short duration of time
 is indeed 10 times smaller than
is indeed 10 times smaller than
 (i.e.,
(i.e.,
 ). However, there are
). However, there are
 windows of size
windows of size
 in one time window of size
in one time window of size
 . So, we now have 10 chances for recovery to happen instead of only one chance. The probability for recovery to occur in any of these 10 time windows is equal to one minus the probability that it does not occur. The probability that the individual does not recover in time
. So, we now have 10 chances for recovery to happen instead of only one chance. The probability for recovery to occur in any of these 10 time windows is equal to one minus the probability that it does not occur. The probability that the individual does not recover in time
 is equal to
is equal to
 . Therefore, the probability that the individual recovers in any of the
. Therefore, the probability that the individual recovers in any of the
 windows is
windows is
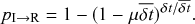 (2.5)
(2.5)
Equation (2.5) does not vanish as we make
 small. In fact, the Taylor expansion of Eq. (2.5) in terms of
small. In fact, the Taylor expansion of Eq. (2.5) in terms of
 yields
yields
 , where
, where
 represents “approximately equal to”. Therefore, to leading order, the recovery probabilities are the same between the case of a single time window of size
represents “approximately equal to”. Therefore, to leading order, the recovery probabilities are the same between the case of a single time window of size
 and the case of
and the case of
 time windows of size
time windows of size
 .
.
In the limit
 , the recovery event may happen at any continuous point in time. We denote by
, the recovery event may happen at any continuous point in time. We denote by
 the waiting time from the present time until the time of the recovery event. We want to determine the probability density function (probability density or pdf for short) of
the waiting time from the present time until the time of the recovery event. We want to determine the probability density function (probability density or pdf for short) of
 , which we denote by
, which we denote by
 . By definition,
. By definition,
 is equal to the probability that the recovery event happens in the interval
is equal to the probability that the recovery event happens in the interval
 for an infinitesimal
for an infinitesimal
 (i.e., for
(i.e., for
 ). To calculate
). To calculate
 , we note that the probability that the event occurs after
, we note that the probability that the event occurs after
 time windows, denoted by
time windows, denoted by
 , is equal to the probability that it did not occur during the first
, is equal to the probability that it did not occur during the first
 time windows and then occurs in the
time windows and then occurs in the
 th window. This probability is equal to
th window. This probability is equal to
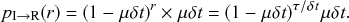 (2.6)
(2.6)
The first factor on the right-hand side of Eq. (2.6) is the probability that the event has not happened before the
 th window; it is simply equal to the probability that the event has not happened during a single window, raised to the power of
th window; it is simply equal to the probability that the event has not happened during a single window, raised to the power of
 . The second factor is the probability that the event happens in the
. The second factor is the probability that the event happens in the
 th window. By applying the identity
th window. By applying the identity
 , known from calculus (see Appendix), with
, known from calculus (see Appendix), with
 to Eq. (2.6), we obtain the pdf of the waiting time as follows:
to Eq. (2.6), we obtain the pdf of the waiting time as follows:
 (2.7)
(2.7)
Equation (2.7) shows the intricate connection between the Poisson process and the exponential distribution: the waiting time of a Poisson process with rate
 (here, specifically the recovery rate) follows an exponential distribution with rate
(here, specifically the recovery rate) follows an exponential distribution with rate
 (Box 1). This fact implies that the mean time we have to wait for the recovery event to happen is
(Box 1). This fact implies that the mean time we have to wait for the recovery event to happen is
 . The exponential waiting-time distribution actually completely characterizes the Poisson process. In other words, the Poisson process is the only jump process that generates events separated by waiting times that follow a fixed exponential distribution.
. The exponential waiting-time distribution actually completely characterizes the Poisson process. In other words, the Poisson process is the only jump process that generates events separated by waiting times that follow a fixed exponential distribution.
If we consider the infection process between a pair of S and I nodes in complete isolation from the other infection and recovery processes in the population, then exactly the same argument (Eq. (2.7)) holds true. In other words, the time until infection takes place between the two nodes is exponentially distributed with rate
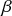 , that is,
, that is,
 (2.8)
(2.8)
However, in practice the infection process is more complicated than the recovery process because it is coupled to other processes. Specifically, if another process generates an event before the infection process does, then Eq. (2.8) may no longer hold true for the infection process in question. For example, consider a node
 that is currently susceptible and an adjacent node
that is currently susceptible and an adjacent node
 that is infectious, as in Fig. 2. For this pair of nodes, two events are possible:
that is infectious, as in Fig. 2. For this pair of nodes, two events are possible:
 may infect
may infect
 , or
, or
 may recover. As long as neither of the events has yet taken place, either of the two corresponding Poisson processes may generate an event at any point in time, following Eqs. (2.8) and (2.7), respectively. However, if
may recover. As long as neither of the events has yet taken place, either of the two corresponding Poisson processes may generate an event at any point in time, following Eqs. (2.8) and (2.7), respectively. However, if
 recovers before it infects
recovers before it infects
 , then the infection event is no longer possible, and so Eq. (2.8) no longer holds. We explore in the following two subsections how to mathematically deal with this coupling.
, then the infection event is no longer possible, and so Eq. (2.8) no longer holds. We explore in the following two subsections how to mathematically deal with this coupling.
2.5 Independence and Interdependence of Jump Processes
Most models based on jump processes and most simulation methods, including the Gillespie algorithms, implicitly assume that different concurrent jump processes are independent of each other in the sense that the internal state of one process does not influence another. This notion of independence may be a source of confusion because a given process may depend on the events generated earlier by other processes, that is, the processes may be coupled, as we saw is the case for the infection processes in the SIR model. In this section, we sort out the notions of independence and coupling and what they mean for the types of jump processes we want to simulate. We will also explore another type of independence of Poisson processes, which is their independence of the past, called the memoryless property.
We can state the independence assumption as the condition that different processes are only allowed to influence each other by changing the state of the system. In other words, at any point in time each process generates an event at a rate that is independent of all other processes given the current state of the system, that is, the processes are conditionally independent. For example, the rate at which
 infects
infects
 in Fig. 2(a) depends on
in Fig. 2(a) depends on
 being infectious and
being infectious and
 being susceptible (corresponding to the system’s current state). However, it does not depend on any internal state of
being susceptible (corresponding to the system’s current state). However, it does not depend on any internal state of
 ’s recovery process such as the time left until
’s recovery process such as the time left until
 recovers. Given the states of all nodes, the two processes are independent. Poisson processes are always conditionally independent in this sense. The conditional independence property follows directly from the fact that Poisson processes have constant rates by definition and thus are not influenced by other processes. The conditional independence is essential for the Gillespie algorithms to work. Even the recent extensions of the Gillespie algorithms to simulate non-Poissonian processes, which we review in Section 5, rely on an assumption of conditional independence between the jump processes.
recovers. Given the states of all nodes, the two processes are independent. Poisson processes are always conditionally independent in this sense. The conditional independence property follows directly from the fact that Poisson processes have constant rates by definition and thus are not influenced by other processes. The conditional independence is essential for the Gillespie algorithms to work. Even the recent extensions of the Gillespie algorithms to simulate non-Poissonian processes, which we review in Section 5, rely on an assumption of conditional independence between the jump processes.
We underline that the assumption of conditional independence does not imply that the different jump processes are not coupled with each other. Such uncoupled processes would indeed be boring. If the jump processes constituting a given system were all uncoupled, then they would not be able to generate any collective dynamics. On the technical side, there would in this case be no reason to consider the set of processes as one system. It would suffice to analyze each process separately. We would in particular have no need for the specialized machinery of the Gillespie algorithms since we could simply simulate each process by sampling waiting times from the corresponding exponential distribution (Box 1, Eq. (2.1)).
In fact, the conditional independence assumption allows different processes to be coupled, as long as they only do so by changing the physical state of the system. This is a natural constraint in many systems. For example, in chemical reaction systems, the processes (that is, chemical reactions) are coupled through discrete reaction events that use molecules of some chemical species to generate others. Similarly, in the SIR model different processes influence each other by changing the state of the nodes, that is, from S to I in an infection event or from I to R in a recovery event. In the example shown in Fig. 2, when node
 recovers, it decreases the probability that its neighboring susceptible node
recovers, it decreases the probability that its neighboring susceptible node
 gets infected within a certain time horizon compared with the scenario where
gets infected within a certain time horizon compared with the scenario where
 remains infectious. As this example suggests, the probability that a susceptible node gets infected depends on the past states of its neighbors. Therefore, over the course of the entire simulation, the dynamics of a node’s state (e.g.,
remains infectious. As this example suggests, the probability that a susceptible node gets infected depends on the past states of its neighbors. Therefore, over the course of the entire simulation, the dynamics of a node’s state (e.g.,
 ) are dependent on those of its neighbors (e.g.,
) are dependent on those of its neighbors (e.g.,
 and
and
 ).
).
Because of the coupling between jump processes, which is present in most systems of interest, we cannot simply simulate the system by separately generating the waiting times for each process according to Eq. (2.1). Any event that occurs will alter the processes to which it is coupled, thus rendering the waiting times we drew for the affected processes invalid. What the Gillespie algorithms do instead is to successively generate the waiting time until the next event, update the state of the system, and reiterate.
Besides being conditionally independent of each other, Poisson processes also display a temporal independence property, the so-called memoryless property (Box 1). In Poisson processes, the probability of the time to the next event,
 , is independent of how long we have already waited since the last event. In this sense, we do not need to worry about what has happened in the past. The only things that matter are the present status of the population (such as
, is independent of how long we have already waited since the last event. In this sense, we do not need to worry about what has happened in the past. The only things that matter are the present status of the population (such as
 is susceptible and
is susceptible and
 is infectious right now) and the model parameters (such as
is infectious right now) and the model parameters (such as
 and
and
 ). The memoryless property can be seen as a direct consequence of the exponential distribution of waiting times of Poisson processes (Box 1, Eq.(2.2)).
). The memoryless property can be seen as a direct consequence of the exponential distribution of waiting times of Poisson processes (Box 1, Eq.(2.2)).
2.6 Superposition of Poisson Processes
In this section, we explain a remarkable property of Poisson processes called the superposition theorem. The direct method exploits this theorem. Other methods, such as the rejection sampling algorithm (see Section 2.8) and the first reaction method, can also benefit from the superposition theorem to accelerate the simulations without impacting their accuracy.
Consider a susceptible individual
 in the SIR model that is in contact with
in the SIR model that is in contact with
 infectious individuals. Any of the
infectious individuals. Any of the
 infectious individuals may infect
infectious individuals may infect
 . Consider the case shown in Fig. 3(a), where
. Consider the case shown in Fig. 3(a), where
 . If we focus on a single edge connecting
. If we focus on a single edge connecting
 to one of its neighbors and ignore the other neighbors, the probability that
to one of its neighbors and ignore the other neighbors, the probability that
 is infected via this edge exactly in time
is infected via this edge exactly in time
 from now, where
from now, where
 is small, is given by
is small, is given by
 (see Eq. (2.8)). Each of
(see Eq. (2.8)). Each of
 ’s
’s
 neighbors may infect
neighbors may infect
 in the same manner and independently. The neighbor that does infect
in the same manner and independently. The neighbor that does infect
 is the one for which the corresponding waiting time is the shortest, provided that it does not recover before it infects
is the one for which the corresponding waiting time is the shortest, provided that it does not recover before it infects
 . From this we can intuitively see that the larger
. From this we can intuitively see that the larger
 is, the shorter the waiting time before
is, the shorter the waiting time before
 gets infected tends to be. To simulate the dynamics of this small system, we need to know, not when each of its neighbors would infect
gets infected tends to be. To simulate the dynamics of this small system, we need to know, not when each of its neighbors would infect
 , but rather the time until any of its neighbors infects
, but rather the time until any of its neighbors infects
 .
.
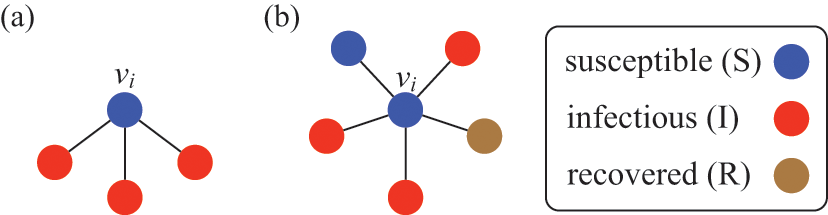
A susceptible node and other nodes surrounding it. (a) A susceptible node
 surrounded by three infectious nodes. (b) A susceptible node
surrounded by three infectious nodes. (b) A susceptible node
 surrounded by five nodes in different states.
surrounded by five nodes in different states.
To calculate the waiting-time distribution for the infection of
 by any of its neighbors, we again resort to the discrete-time view of the infection processes. Because the infection processes are independent, the probability that
by any of its neighbors, we again resort to the discrete-time view of the infection processes. Because the infection processes are independent, the probability that
 is not infected by any of its
is not infected by any of its
 infectious neighbors in a time window of duration
infectious neighbors in a time window of duration
 is given by
is given by
 (2.9)
(2.9)
Therefore, the probability that
 is infected after a time
is infected after a time
 (i.e.,
(i.e.,
 gets infected exactly in the
gets infected exactly in the
 th time window of length
th time window of length
 and not before) is given by
and not before) is given by
 (2.10)
(2.10)
Here, the factor
 is the survival probability that an infection does not happen for a time
is the survival probability that an infection does not happen for a time
 . The factor
. The factor
 is the probability that any of
is the probability that any of
 ’s infectious neighbors infects
’s infectious neighbors infects
 in the next time window,
in the next time window,
 .
.
Using the exponential identity
 with
with
 as we did in Section 2.4, we obtain in the continuous-time limit that
as we did in Section 2.4, we obtain in the continuous-time limit that
 (2.11)
(2.11)
where the first equality is obtained by noting that
 and rearranging the terms. In the same limit of
and rearranging the terms. In the same limit of
 , we obtain from Taylor expansion that
, we obtain from Taylor expansion that
 (2.12)
(2.12)
By combining Eqs. (2.10), (2.11), and (2.12), we obtain
 . Therefore, the probability density with which
. Therefore, the probability density with which
 gets infected at time
gets infected at time
 is given by
is given by
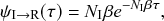 (2.13)
(2.13)
that is, the exponential distribution with rate parameter
 . By comparing Eqs. (2.8) and (2.13), we see that the effect of having
. By comparing Eqs. (2.8) and (2.13), we see that the effect of having
 infectious neighbors (see Fig. 3(a) for the case of
infectious neighbors (see Fig. 3(a) for the case of
 ) is the same as that of having just one infectious neighbor with an infection rate of
) is the same as that of having just one infectious neighbor with an infection rate of
 .
.
This is a convenient property of Poisson processes, known as the superposition theorem (see Box 1, Eq. (2.3) for the general theorem). To calculate how likely it is that a susceptible node
 will be infected in time
will be infected in time
 , one does not need to examine when the infection would happen or whether the infection happens for each of the infectious individuals contacting
, one does not need to examine when the infection would happen or whether the infection happens for each of the infectious individuals contacting
 . We are allowed to agglomerate all those effects into one infectious supernode as if the supernode infects
. We are allowed to agglomerate all those effects into one infectious supernode as if the supernode infects
 with rate
with rate
 . We refer to such a superposed Poisson process that induces a particular state transition in the system (in the present case, the transition from the S to the I state for
. We refer to such a superposed Poisson process that induces a particular state transition in the system (in the present case, the transition from the S to the I state for
 ) as a reaction channel, following the nomenclature in chemical reaction systems.
) as a reaction channel, following the nomenclature in chemical reaction systems.
This interpretation remains valid even if
 is adjacent to other irrelevant individuals. In the network shown in Fig. 3(b), the susceptible node
is adjacent to other irrelevant individuals. In the network shown in Fig. 3(b), the susceptible node
 has degree (i.e., number of other nodes that are connected to
has degree (i.e., number of other nodes that are connected to
 by an edge)
by an edge)
 . Three neighbors of
. Three neighbors of
 are infectious, one is susceptible, and one is recovered. In this case,
are infectious, one is susceptible, and one is recovered. In this case,
 will be infected at a rate of
will be infected at a rate of
 , the same as in the case of
, the same as in the case of
 in the network shown in Fig. 3(a).
in the network shown in Fig. 3(a).
In both cases, we are replacing three instances of the probability density of the time to the next infection event, each given by
 , by a single probability density
, by a single probability density
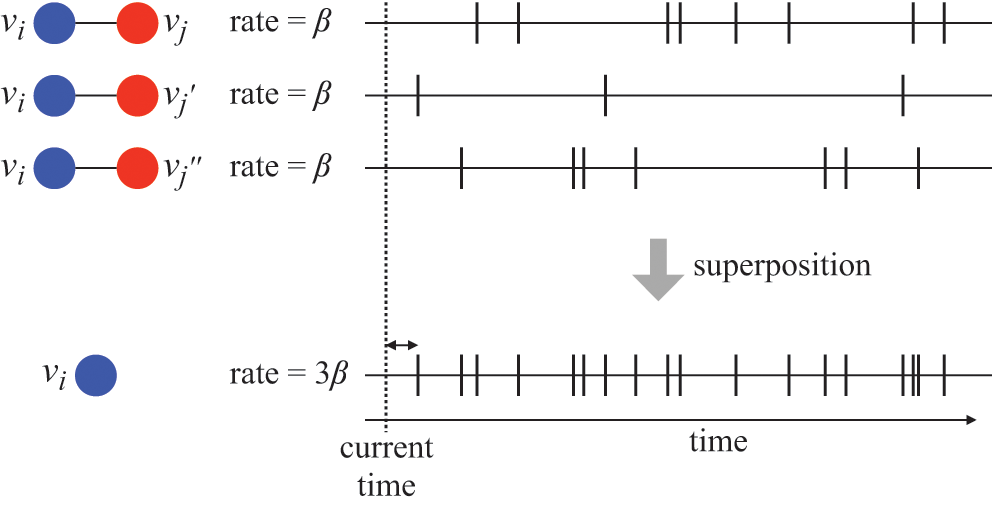
 . Representing the three infectious nodes by one infectious supernode, that is, one reaction channel, with three times the infection rate is equivalent to superposing the three Poisson processes into one. Figure 4 illustrates this superposition, showing the putative event times generated by each Poisson process as well as those generated by their superposition. The superposition theorem dictates that the superposition is a Poisson process with a rate of
. Representing the three infectious nodes by one infectious supernode, that is, one reaction channel, with three times the infection rate is equivalent to superposing the three Poisson processes into one. Figure 4 illustrates this superposition, showing the putative event times generated by each Poisson process as well as those generated by their superposition. The superposition theorem dictates that the superposition is a Poisson process with a rate of
 . This in particular means that we can draw the waiting time
. This in particular means that we can draw the waiting time
 until the first of the events generated by all the three Poisson processes happens (shown by the double-headed arrow in Fig. 4) directly from the exponential distribution
until the first of the events generated by all the three Poisson processes happens (shown by the double-headed arrow in Fig. 4) directly from the exponential distribution
 . Note that Poisson processes are defined as generating events indefinitely, and for illustrative purposes we show multiple events in Figure 4. However, in the SIR model only the first event in the superposed process will take place in practice. For example, once the event changes the state of
. Note that Poisson processes are defined as generating events indefinitely, and for illustrative purposes we show multiple events in Figure 4. However, in the SIR model only the first event in the superposed process will take place in practice. For example, once the event changes the state of
 from S to I, the node cannot be infected anymore, and therefore none of the three infection processes can generate any more events.
from S to I, the node cannot be infected anymore, and therefore none of the three infection processes can generate any more events.
Superposition of three Poisson processes. The event sequence in the bottom is the superposition of the three event sequences corresponding to each of the three edges connecting
 to its neighbors
to its neighbors
 ,
,
 , and
, and
 . The superposed event sequence generates an event whenever one of the three individual processes does. Note that edges (
. The superposed event sequence generates an event whenever one of the three individual processes does. Note that edges (
 ,
,
 ), (
), (
 ,
,
 ), and (
), and (
 ,
,
 ) generally carry different numbers of events in a given time window despite the rate of the processes (i.e., the infection rate,
) generally carry different numbers of events in a given time window despite the rate of the processes (i.e., the infection rate,
 ) being the same. This is due to the stochastic nature of Poisson processes.
) being the same. This is due to the stochastic nature of Poisson processes.
Let us consider again the snapshot of the SIR dynamics shown in Fig. 3(a), but this time we consider all the possible infection and recovery events. We can represent all the possible events that may occur by four reaction channels (i.e., Poisson processes). One channel represents the infection of the node
 by any of its neighbors, which happens at a rate
by any of its neighbors, which happens at a rate
 . We refer to this reaction channel as the first reaction channel. The three other channels each represent the recovery process of one of the infectious nodes. We refer to these three reaction channels as the second to the fourth reaction channels. We can use the same approach as above to obtain the probability density for the waiting time until the first event generated by any of the channels. However, to completely describe the dynamics, it is not sufficient to know when the next event happens. We also need to know which channel generates the event. Precisely speaking, we need to know the probability
. We refer to this reaction channel as the first reaction channel. The three other channels each represent the recovery process of one of the infectious nodes. We refer to these three reaction channels as the second to the fourth reaction channels. We can use the same approach as above to obtain the probability density for the waiting time until the first event generated by any of the channels. However, to completely describe the dynamics, it is not sufficient to know when the next event happens. We also need to know which channel generates the event. Precisely speaking, we need to know the probability
 that it is the
that it is the
 th reaction channel that generates the event. Using the definition of conditional probability, we obtain
th reaction channel that generates the event. Using the definition of conditional probability, we obtain
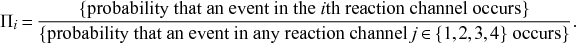 (2.14)
(2.14)
In a discrete-time description, the numerator in Eq. (2.14) is simply
 , where
, where
 and
and
 are the rates of the reaction channels. The denominator is equal to
are the rates of the reaction channels. The denominator is equal to
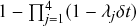 , which in the limit of small
, which in the limit of small
 can be Taylor expanded to
can be Taylor expanded to
 . Thus, the probability that the
. Thus, the probability that the
 th reaction channel has generated an event that has taken place is
th reaction channel has generated an event that has taken place is
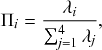 (2.15)
(2.15)
that is,
 is simply proportional to the rate
is simply proportional to the rate
 .
.
The same result holds true for general superpositions of Poisson processes (see Box 1).
2.7 Ignoring Stochasticity: Differential Equation Approach
We have introduced the types of models we are interested in and have explored their basic mathematical properties. We now turn our attention to the problem of how we can solve such models in practice. We consider again the SIR model. One simple strategy to solve it is to forget about the true stochastic nature of infection and recovery and approximate the processes as being deterministic. In this approach, we only track the dynamics of the mean numbers of susceptible, infectious, and recovered individuals. Such deterministic dynamics are described by a system of ordinary differential equations (ODEs). The ODE version of the SIR model has a longer history than the stochastic one, dating back to the seminal work by William Ogilvy Kermack and Anderson Gray McKendrick in the 1920s (Reference Kermack and McKendrickKermack & McKendrick, 1927). For the basic SIR model described previously, the corresponding ODEs are given by
 (2.16)
(2.16)
 (2.17)
(2.17)
 (2.18)
(2.18)
where
 ,
,
 , and
, and
 are the fractions of S, I, and R individuals, respectively. The
are the fractions of S, I, and R individuals, respectively. The
 terms in Eqs. (2.16) and (2.17) represent infection events, through which the number of S individuals decreases and the number of I individuals increases by the same amount. The
terms in Eqs. (2.16) and (2.17) represent infection events, through which the number of S individuals decreases and the number of I individuals increases by the same amount. The
 terms in Eqs. (2.17) and (2.18) represent recovery events.
terms in Eqs. (2.17) and (2.18) represent recovery events.
One can solve Eqs. (2.16), (2.17), and (2.18) either analytically, to some extent, or numerically using an ODE solver implemented in various programming languages. Suppose that we have coded up Eqs. (2.16), (2.17), and (2.18) into an ODE solver to simulate the infection dynamics (such as time courses of
 ) for various values of
) for various values of
 and
and
 . Does the result give us complete understanding of the original stochastic SIR model? The answer is negative (Reference Mollison, Isham and GrenfellMollison, Isham, & Grenfell, 1994), at least for the following reasons.
. Does the result give us complete understanding of the original stochastic SIR model? The answer is negative (Reference Mollison, Isham and GrenfellMollison, Isham, & Grenfell, 1994), at least for the following reasons.
First, the ODE is not a good approximation when
 is small. In Eqs. (2.16), (2.17), and (2.18), the variables are the fraction of individuals in each state. For example,
is small. In Eqs. (2.16), (2.17), and (2.18), the variables are the fraction of individuals in each state. For example,
 . The ODE description assumes that
. The ODE description assumes that
 can take any real value between 0 and 1 and that
can take any real value between 0 and 1 and that
 changes continuously as time goes by. However, in reality
changes continuously as time goes by. However, in reality
 is quantized, so it can take only the values
is quantized, so it can take only the values
 ,
,
 ,
,
 ,
,

 , and
, and
 , and it changes in steps of
, and it changes in steps of
 (e.g., it changes from
(e.g., it changes from
 to
to
 discontinuously). This discrete nature does not typically cause serious problems when
discontinuously). This discrete nature does not typically cause serious problems when
 is large, in which case
is large, in which case
 is close to being continuous. By contrast, the ODE model is not accurate when
is close to being continuous. By contrast, the ODE model is not accurate when
 is small due to the quantization effect. (Note that the ODE approach is problematic in some cases even when
is small due to the quantization effect. (Note that the ODE approach is problematic in some cases even when
 is large, i.e. near critical points, as we discuss in what follows.)
is large, i.e. near critical points, as we discuss in what follows.)
Second, even if
 is large, the actual dynamic changes in
is large, the actual dynamic changes in
 , for example, are not close to what the ODEs describe when the number of infectious individuals is small. For example, if
, for example, are not close to what the ODEs describe when the number of infectious individuals is small. For example, if
 , there are two infectious individuals. If one of them recovers,
, there are two infectious individuals. If one of them recovers,
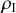 changes to
changes to
 , and this is a 50 percent decrease in
, and this is a 50 percent decrease in
 . The ODE assumes that
. The ODE assumes that
 changes continuously and is not ready to describe such a change. As another example, suppose that we initially set
changes continuously and is not ready to describe such a change. As another example, suppose that we initially set
 ,
,
 , and
, and
 . In other words, there is a single infectious seed, and all the other individuals are initially susceptible. In fact, the theory of the ODE version of the SIR model shows that
. In other words, there is a single infectious seed, and all the other individuals are initially susceptible. In fact, the theory of the ODE version of the SIR model shows that
 increases deterministically, at least initially, if
increases deterministically, at least initially, if
 , corresponding to the situation in which an outbreak of infection happens. However, in the stochastic SIR model, the only initially infectious individual may recover before it infects anybody even if
, corresponding to the situation in which an outbreak of infection happens. However, in the stochastic SIR model, the only initially infectious individual may recover before it infects anybody even if
 . When this situation occurs, the dynamics terminate once the initially infectious individual has recovered, and no outbreak is observed. Although the probability with which this situation occurs decreases as
. When this situation occurs, the dynamics terminate once the initially infectious individual has recovered, and no outbreak is observed. Although the probability with which this situation occurs decreases as
 increases, it is still not negligibly small for many large
increases, it is still not negligibly small for many large
 values. This is inconsistent with the prediction of the ODE model. It should be noted that another common way to initialize the system is to start with a small fraction of infectious individuals, regardless of
values. This is inconsistent with the prediction of the ODE model. It should be noted that another common way to initialize the system is to start with a small fraction of infectious individuals, regardless of
 . In this case, if we start the stochastic SIR dynamics in a large, well-mixed population and, for example, with 10 percent initially infectious individuals, the ODE version is sufficiently accurate at describing the stochastic SIR dynamics.
. In this case, if we start the stochastic SIR dynamics in a large, well-mixed population and, for example, with 10 percent initially infectious individuals, the ODE version is sufficiently accurate at describing the stochastic SIR dynamics.
Third, ODEs are not accurate at describing the counterpart stochastic dynamics when the system is close to a so-called critical point. For example, in the SIR model, given the value of the infection rate (i.e.,
 ), there is a value of the infection rate called the epidemic threshold, which we denote by
), there is a value of the infection rate called the epidemic threshold, which we denote by
 . For
. For
 , only a small number of the individuals will be infected (i.e., the final epidemic size is of
, only a small number of the individuals will be infected (i.e., the final epidemic size is of
 ). For
). For
 , the final epidemic size is large (i.e.,
, the final epidemic size is large (i.e.,
 ) with a positive probability. In analogy with statistical physics,
) with a positive probability. In analogy with statistical physics,
 is termed a critical point of the SIR model. Near criticality the fluctuations of
is termed a critical point of the SIR model. Near criticality the fluctuations of
 ,
,
 , and
, and
 are not negligible compared to their mean values, even for large
are not negligible compared to their mean values, even for large
 , and the ODE generally fails.
, and the ODE generally fails.
Fourth, ODEs are not accurate when dynamics are mainly driven by stochasticity rather than by the deterministic terms on the right-hand sides of the ODEs. This situation may happen even far from criticality or in a model that does not show critical dynamics. The voter model (see Section 4.10.3 for details) is such a case. In its simplest version, the voter model describes the tug-of-war between two equally strong opinions in a population of individuals. Because the two opinions are equally strong, the ODE version of the voter model predicts that the fraction of individuals supporting opinion A (and that of individuals supporting opinion B) does not vary over time, that is, one obtains
 , where
, where
 and
and
 are the fractions of individuals supporting opinions A and B, respectively. However, in fact, the opinion of the individuals flips here and there in the population due to stochasticity, and it either increases or decreases over time.
are the fractions of individuals supporting opinions A and B, respectively. However, in fact, the opinion of the individuals flips here and there in the population due to stochasticity, and it either increases or decreases over time.
To summarize, when stochasticity manifests itself, the approximation of the original stochastic dynamics by an ODE model is not accurate.
2.8 Rejection Sampling Algorithm
The most intuitive method to simulate the stochastic SIR model, while accounting for the stochastic nature of the model, is probably to discretize time and simulate the dynamics by testing whether each possible event takes place in each step. This is called the rejection sampling algorithm. Let us consider the stochastic SIR model on a small network composed of
 nodes, as shown in Fig. 2, to explain the procedure.
nodes, as shown in Fig. 2, to explain the procedure.
Assume that the state of the network (i.e., the states of the individual nodes) is as shown in Fig. 2(a) at time
 ; three nodes are susceptible, two nodes are infectious, and the other node is recovered. In the next time-step, which accounts for a time length of
; three nodes are susceptible, two nodes are infectious, and the other node is recovered. In the next time-step, which accounts for a time length of
 and corresponds to the time interval
and corresponds to the time interval
 , an infection event may happen in five ways:
, an infection event may happen in five ways:
 infects
infects
 ,
,
 infects
infects
 ,
,
 infects
infects
 ,
,
 infects
infects
 , and
, and
 infects
infects
 . Recovery events may happen for
. Recovery events may happen for
 and
and
 . Therefore, there are seven possible events in total, some of which may simultaneously happen in the next time-step.
. Therefore, there are seven possible events in total, some of which may simultaneously happen in the next time-step.
With the rejection sampling method, we sequentially (called asynchronous updating) or simultaneously (called synchronous updating) check whether or not each of these events happens in each time-step of length
 . Note that it is not possible to go to the limit of
. Note that it is not possible to go to the limit of
 in rejection sampling. In our example,
in rejection sampling. In our example,
 infects
infects
 with probability
with probability
 in a time-step. With probability
in a time-step. With probability
 , nothing occurs along this edge. In practice, to determine whether the event takes place or not, we draw a random number
, nothing occurs along this edge. In practice, to determine whether the event takes place or not, we draw a random number
 uniformly from
uniformly from
 . If
. If
 , the algorithm rejects the proposed infection event (thus the name rejection sampling). If
, the algorithm rejects the proposed infection event (thus the name rejection sampling). If
 , we let the infection occur. Then, under asynchronous updating, we change the state of
, we let the infection occur. Then, under asynchronous updating, we change the state of
 from S to I and update the set of possible events accordingly right away, and then proceed to check the occurrence of each of the remaining possible events in turn. Under synchronous updating, we first check whether each of the possible state changes takes place and note down the changes that take place. We then implement all the noted changes simultaneously. Regardless of whether we use asynchronous or synchronous updating, the infection event occurs with probability
from S to I and update the set of possible events accordingly right away, and then proceed to check the occurrence of each of the remaining possible events in turn. Under synchronous updating, we first check whether each of the possible state changes takes place and note down the changes that take place. We then implement all the noted changes simultaneously. Regardless of whether we use asynchronous or synchronous updating, the infection event occurs with probability
 .
.
If
 recovers, which occurs with probability
recovers, which occurs with probability
 , and none of the other six possible events occurs in the same time-step, the status of the network at time
, and none of the other six possible events occurs in the same time-step, the status of the network at time
 is as shown in Fig. 2(b). Then, in the next time-step,
is as shown in Fig. 2(b). Then, in the next time-step,
 may get infected,
may get infected,
 may recover,
may recover,
 may get infected, and
may get infected, and
 may get infected, which occurs with probabilities
may get infected, which occurs with probabilities
 ,
,
 ,
,
 , and
, and
 , respectively. In this manner, we carry forward the simulation by discrete steps until no infectious nodes are left.
, respectively. In this manner, we carry forward the simulation by discrete steps until no infectious nodes are left.
There are several caveats to this approach. First, the asynchronous and the synchronous updating schemes of the same stochastic dynamics model may lead to systematically different results (Reference Cornforth, Green and NewthCornforth, Green, & Newth, 2005; Reference Greil and DrosselGreil & Drossel, 2005; Reference Huberman and GlanceHuberman & Glance, 1993).
Second, one should set
 such that both
such that both
 and
and
 always hold true. In fact, the discrete-time interpretation of the original model is justified only when
always hold true. In fact, the discrete-time interpretation of the original model is justified only when
 is small enough to yield
is small enough to yield
 and
and
 .
.
Third, in the case of asynchronous updating, the order of checking the events is arbitrary, but it affects the outcome, particularly if
 is not tiny. For example, we can sequentially check whether each of the five infection events occurs and then whether each of the two recovery events occurs, completing one time-step, One can alternatively check the recovery events first and then the infection events. If we do so and
is not tiny. For example, we can sequentially check whether each of the five infection events occurs and then whether each of the two recovery events occurs, completing one time-step, One can alternatively check the recovery events first and then the infection events. If we do so and
 recovers in the time-step, then it is no longer possible that
recovers in the time-step, then it is no longer possible that
 infects
infects
 or
or
 in the same time-step because
in the same time-step because
 has recovered. If the infection events were checked before the recovery events, it is possible that
has recovered. If the infection events were checked before the recovery events, it is possible that
 infects
infects
 or
or
 before
before
 recovers in the same time-step.
recovers in the same time-step.
Fourth, some of the seven types of event cannot occur simultaneously in a single time-step regardless of whether the updating is asynchronous or synchronous, and regardless of the order in which we check the events in the asynchronous updating. For example, if
 has infected
has infected
 , then
, then
 cannot infect
cannot infect
 in the same time-step (or anytime later) and vice versa. In fact, from the susceptible node
in the same time-step (or anytime later) and vice versa. In fact, from the susceptible node
 ’s point of view, it does not matter which infectious neighbor, either
’s point of view, it does not matter which infectious neighbor, either
 or
or
 , infects
, infects
 . What is primarily important is whether
. What is primarily important is whether
 gets infected or not in the given time-step, whereas one wants to know who infected whom in some tasks such as contact tracing.
gets infected or not in the given time-step, whereas one wants to know who infected whom in some tasks such as contact tracing.
A useful method to mitigate the effect of overlapping events of this type is to take a node-centric view. The superposition theorem implies that
 will get infected according to a Poisson process with rate
will get infected according to a Poisson process with rate
 because it has two infectious neighbors (Section 2.6). By exploiting this observation, let us redefine the list of possible events at time
because it has two infectious neighbors (Section 2.6). By exploiting this observation, let us redefine the list of possible events at time
 . The node
. The node
 will get infected with probability
will get infected with probability
 (and will not get infected with probability
(and will not get infected with probability
 ). Nodes
). Nodes
 and
and
 will get infected with probabilities
will get infected with probabilities
 and
and
 , respectively. As before,
, respectively. As before,
 and
and
 recover with probability
recover with probability
 each. In this manner, we have reduced the number of possible events from seven to five. We are usually interested in simulating such stochastic processes in much larger networks or populations, where nodes tend to have a degree larger than in the network shown in Fig. 2. For example, if a node
each. In this manner, we have reduced the number of possible events from seven to five. We are usually interested in simulating such stochastic processes in much larger networks or populations, where nodes tend to have a degree larger than in the network shown in Fig. 2. For example, if a node
 has 50 infectious neighbors, implementing the rejection sampling using the probability that
has 50 infectious neighbors, implementing the rejection sampling using the probability that
 gets infected,
gets infected,
 , rather than checking if
, rather than checking if
 gets infected with probability
gets infected with probability
 along each edge that
along each edge that
 has with an infectious neighbor, will confer a fiftyfold speedup of the algorithm.
has with an infectious neighbor, will confer a fiftyfold speedup of the algorithm.
Rejection sampling is a widely used method, particularly in research communities where continuous-time stochastic process thinking does not prevail. In a related vein, many people are confused by being told that the infection and recovery rates
 and
and
 can exceed 1. They are accustomed to think in discrete time such that they are not trained to distinguish between the rate and probability. They are different; simply put, the rate is for continuous time, and the probability is for discrete time. Here we advocate that we should not use the discrete-time versions in general, despite their simplicity and their appeal to our intuition, for the following reasons (see Reference Gómez, Gómez-Gardeñes, Moreno and ArenasGómez, Gómez-Gardeñes, Moreno, and Arenas [2011] and Reference Fennell, Melnik and GleesonFennell, Melnik, and Gleeson [2016] for similar arguments).
can exceed 1. They are accustomed to think in discrete time such that they are not trained to distinguish between the rate and probability. They are different; simply put, the rate is for continuous time, and the probability is for discrete time. Here we advocate that we should not use the discrete-time versions in general, despite their simplicity and their appeal to our intuition, for the following reasons (see Reference Gómez, Gómez-Gardeñes, Moreno and ArenasGómez, Gómez-Gardeñes, Moreno, and Arenas [2011] and Reference Fennell, Melnik and GleesonFennell, Melnik, and Gleeson [2016] for similar arguments).
First, the use of a small
 , which is necessary to assure an accurate approximation of the actual continuous-time stochastic process, implies a large computation time. If the duration of time that one run of simulation needs is
, which is necessary to assure an accurate approximation of the actual continuous-time stochastic process, implies a large computation time. If the duration of time that one run of simulation needs is
 , one needs
, one needs
 discrete time-steps, which is large when
discrete time-steps, which is large when
 is small. How small should
is small. How small should
 be? It is difficult to say. If you run simulations with a choice of a small
be? It is difficult to say. If you run simulations with a choice of a small
 and calculate statistics of your interest or draw a figure for your report or paper, a good practice is to try the same thing after halving
and calculate statistics of your interest or draw a figure for your report or paper, a good practice is to try the same thing after halving
 . If the results do not noticeably change, then your original choice of
. If the results do not noticeably change, then your original choice of
 is probably small enough for your purpose. Otherwise, you need to make
is probably small enough for your purpose. Otherwise, you need to make
 smaller. It takes time to carry out such a check just to determine an appropriate
smaller. It takes time to carry out such a check just to determine an appropriate
 value. Many people skip it. The Gillespie algorithms do not rely on a discrete-time approximation and are also typically faster than rejection sampling with a reasonably small
value. Many people skip it. The Gillespie algorithms do not rely on a discrete-time approximation and are also typically faster than rejection sampling with a reasonably small
 value.
value.
Second, no matter how small
 is, the results of rejection sampling are only approximate. This is because it is exact only in the limit
is, the results of rejection sampling are only approximate. This is because it is exact only in the limit
 . By contrast, the Gillespie algorithms are always exact.
. By contrast, the Gillespie algorithms are always exact.
Proponents of the rejection sampling method may say that they want to define the model (such as the SIR model) in discrete time and run it rather than to consider the continuous-time version of the model and worry about the choice of
 or the accuracy of the rejection sampling. We recommend against this as well. In the SIR model in discrete time, any infectious individual
or the accuracy of the rejection sampling. We recommend against this as well. In the SIR model in discrete time, any infectious individual
 infects a neighboring susceptible individual
infects a neighboring susceptible individual
 with probability
with probability
 , and each infectious individual recovers with probability
, and each infectious individual recovers with probability
 . Then, there are at least two problems related to this. First, the order of the events affects dynamics in the case of asynchronous updating. Second, and more importantly, we do not know how to change the time resolution of the simulation when we need to. For example, if one simulation step currently corresponds to one hour, one may want to now simulate the same model with some more temporal detail such that one step corresponds to ten minutes. Because the physical time is now one sixth of the original one, should we multiply
. Then, there are at least two problems related to this. First, the order of the events affects dynamics in the case of asynchronous updating. Second, and more importantly, we do not know how to change the time resolution of the simulation when we need to. For example, if one simulation step currently corresponds to one hour, one may want to now simulate the same model with some more temporal detail such that one step corresponds to ten minutes. Because the physical time is now one sixth of the original one, should we multiply
 and
and
 by
by
 and do the same simulations? The answer is no. If the original time-step corresponds to
and do the same simulations? The answer is no. If the original time-step corresponds to
 , which is often implicit, then the probability that an infectious individual recovers in the continuous-time stochastic SIR model within time
, which is often implicit, then the probability that an infectious individual recovers in the continuous-time stochastic SIR model within time
 is
is
 , which we equate with
, which we equate with
 . Then, if we scale the time
. Then, if we scale the time
 times (e.g.,
times (e.g.,
 ), the probability that the recovery occurs in a new single time-step is
), the probability that the recovery occurs in a new single time-step is
 , which is not equal to
, which is not equal to
 . For example, with
. For example, with
 and
and
 , one obtains
, one obtains
 , whereas
, whereas
 .
.
3 Classic Gillespie Algorithms
The Gillespie algorithms overcome the two major drawbacks of the rejection sampling algorithm that we discussed near the end of Section 2.8; namely, its computational inefficiency and its reliance on a discrete-time approximation of the dynamics. The Gillespie algorithms are typically faster than rejection sampling, and they are stochastically exact (i.e., they generate exact realizations of the simulated jump processes). In this section, we present the two basic Gillespie algorithms for simulating coupled Poisson processes, largely in their original forms proposed by Daniel Gillespie: the first reaction method and the direct method. The two methods are mathematically equivalent (Reference GillespieGillespie, 1976). Nevertheless, the two algorithms have pros and cons in terms of ease of implementation and computational efficiency. Because these two factors depend on the model to be simulated, which algorithm one should select depends on the model as well as personal preference.
We first provide a brief history of the Gillespie algorithms (Section 3.1). We then introduce the first reaction method (Section 3.2) because it is conceptually the simpler of the two, followed by the direct method (Section 3.3), which builds on elements of the first reaction method but makes use of the superposition theorem (Box 1) to directly draw the waiting time between events. We end this section with example implementations in Python of the stochastic SIR dynamics.
3.1 Brief History
As the name suggests, the Gillespie algorithms are ascribed to American physicist Daniel Thomas Gillespie (Reference GillespieGillespie, 1976, Reference Gillespie1977). He originally proposed them in 1976 for simulating stochastic chemical reaction systems, and they have seen many applications as well as further algorithmic developments in this field. Nevertheless, the algorithms only rely on general properties of Poisson processes and not on any particular properties of chemical reactions. Therefore, the applicability of the Gillespie algorithms is much wider than to chemical reaction systems. In fact, they have been extensively used in simulations of multiagent systems both in unstructured populations and on networks. The only assumptions are that the system undergoes changes via sequences of discrete events (e.g., somebody infects somebody, somebody changes its internal state from a low-activity state to a high-activity state) and with a rate that stays constant in between events. Nevertheless, the latter assumption has been relaxed in recent extensions of the algorithms; we review these in Section 5.
There were precursors to the Gillespie algorithms. The American mathematician Joseph Leo Doob developed in his 1942 and 1945 papers the mathematical foundations of continuous-time Markov chains that underlie the Gillespie algorithms (Reference DoobDoob, 1942, Reference Doob1945). In the second of the two papers, he effectively proposed the direct method, although the focus of the paper was mathematical theory and he did not propose a computational implementation Reference DoobDoob (1945: pp. 465–466). Due to this, the algorithm is sometimes called the Doob–Gillespie algorithm. David George Kendall, who is famous for Kendall’s notation in queuing theory,Footnote 4 implemented an equivalent of the direct method to simulate a stochastic birth-death process on a computer as early as in 1950 (Reference KendallKendall, 1950). In 1953, Maurice Stevenson Bartlett, a British statistician, simulated the SIR model in a well-mixed population (i.e., every pair of individuals is directly connected to each other) using the direct method (Reference BartlettBartlett, 1953).
Independently of Gillespie, Alfred B. Bortz and colleagues also proposed the same algorithm as the direct method to simulate stochastic dynamics of Ising spin systems in statistical physics in 1975 (Reference Bortz, Kalos and LebowitzBortz, Kalos, & Lebowitz, 1975). Therefore, the direct method is also called the Bortz–Kalos–Lebowitz algorithm (or the n-fold way following the naming in their paper, and also rejection-free kinetic Monte Carlo and the residence-time algorithm). An even earlier paper published in 1966 in the same field proposed almost the same algorithm, with the only difference being that the waiting time between events was assumed to take a deterministic value rather than being stochastic as in the Gillespie algorithms (Reference Young and ElcockYoung & Elcock, 1966).
3.2 First reaction method
To introduce the first reaction method, we consider our earlier example of the SIR model on a six-node network (see Fig. 2(a)). Here two types of events may happen next: either a susceptible node becomes infected (S
 I), or an infectious node recovers (I
I), or an infectious node recovers (I
 R). The rates at which each node experiences a state transition are shown in Fig. 5(a), which replicates Fig. 2(a). For example,
R). The rates at which each node experiences a state transition are shown in Fig. 5(a), which replicates Fig. 2(a). For example,
 is twice as likely to be infected next as
is twice as likely to be infected next as
 is because
is because
 has two infectious neighbors whereas
has two infectious neighbors whereas
 has one infectious neighbor. Each event obeys a separate Poisson process. Therefore, let us first generate hypothetical event sequences according to each Poisson process with their respective rates (see Fig. 5(b)). In fact, we need to use at most only the first event in each sequence (shown in magenta in Fig. 5(b)). For example, in the event sequence for
has one infectious neighbor. Each event obeys a separate Poisson process. Therefore, let us first generate hypothetical event sequences according to each Poisson process with their respective rates (see Fig. 5(b)). In fact, we need to use at most only the first event in each sequence (shown in magenta in Fig. 5(b)). For example, in the event sequence for
 , the first event may be used, in which case
, the first event may be used, in which case
 will be infected. Once
will be infected. Once
 is infected, the subsequent events on the same event sequence will be discarded because
is infected, the subsequent events on the same event sequence will be discarded because
 will never be infected again. If
will never be infected again. If
 is infected, it will undergo another type of event, which is recovery. However, we cannot reuse the second or any subsequent events in the same sequence as the recovery event because the recovery occurs with rate
is infected, it will undergo another type of event, which is recovery. However, we cannot reuse the second or any subsequent events in the same sequence as the recovery event because the recovery occurs with rate
 , which is different from the rate
, which is different from the rate
 with which we have generated the event sequence for
with which we have generated the event sequence for
 . A lesson we learn from this example is that we should not prepare many possible event times beforehand because most of them would be discarded.
. A lesson we learn from this example is that we should not prepare many possible event times beforehand because most of them would be discarded.
Determination of the time to the next event in the SIR model using the Gillespie algorithms. (a) The current state of the system. The rate with which each node changes its state is shown next to the node. (b) The putative events generated by the Poisson process corresponding to each node, with the first event of each process shown in magenta. There is no event on the timeline of
 . This is because
. This is because
 is in the recovered state and no longer undergoes any state change; therefore the event rate of the Poisson process associated with
is in the recovered state and no longer undergoes any state change; therefore the event rate of the Poisson process associated with
 is equal to 0. The first reaction method generates a putative waiting time until the first event for each process and selects the smallest one. The direct method directly generates the waiting time until the first event in the superposed process (bottom of panel (b)).
is equal to 0. The first reaction method generates a putative waiting time until the first event for each process and selects the smallest one. The direct method directly generates the waiting time until the first event in the superposed process (bottom of panel (b)).

Given this reasoning, Gillespie proposed the first reaction method in one of his two original papers on the Gillespie algorithms (Reference GillespieGillespie, 1976). The idea of the first reaction method is to generate only the first putative event time (shown in magenta in Fig. 5(b)) for each node. These putative times correspond to when each node would experience a next event if nothing else happens in the rest of the system. We do not generate an event time for
 because this node is recovered, so it will never undergo any event. We then figure out which event occurs first. (In the example in Fig. 5(a), it is node
because this node is recovered, so it will never undergo any event. We then figure out which event occurs first. (In the example in Fig. 5(a), it is node
 that will change its state, and the state change is from I to R.)
that will change its state, and the state change is from I to R.)
To generate a putative waiting time for each node
 ,
,
 ,
,
 in practice, we use a general technique called inverse sampling, which proceeds as follows. For example, the time to the first event for
in practice, we use a general technique called inverse sampling, which proceeds as follows. For example, the time to the first event for
 obeys the exponential distribution
obeys the exponential distribution
 . The probability that the time to the next event is larger than
. The probability that the time to the next event is larger than
 , called the survival probability (also called the survival function and the complementary cumulative distribution function), is given by
, called the survival probability (also called the survival function and the complementary cumulative distribution function), is given by
 (3.1)
(3.1)
By definition,
 is a probability, so
is a probability, so
 . We have excluded
. We have excluded
 because it happens only in the limit
because it happens only in the limit
 . This exclusion does not cause any problem in the following development.
. This exclusion does not cause any problem in the following development.
Then, we draw a number
 from an unbiased random number generator that generates random numbers uniformly in the interval
from an unbiased random number generator that generates random numbers uniformly in the interval
 . The generated number
. The generated number
 is called a uniform
is called a uniform
 random variate. Any practical programming language has a function to generate uniform (pseudo) random variates. We do, however, advise against using a programming language’s standard pseudo-random number generator, which is typically of poor quality. You should instead use one from a scientific programming library or code it yourself. We will discuss some good practices for pseudorandom number generation in Section 4.9. Given
random variate. Any practical programming language has a function to generate uniform (pseudo) random variates. We do, however, advise against using a programming language’s standard pseudo-random number generator, which is typically of poor quality. You should instead use one from a scientific programming library or code it yourself. We will discuss some good practices for pseudorandom number generation in Section 4.9. Given
 , we then generate
, we then generate
 from the implicit equation
from the implicit equation
 (3.2)
(3.2)
For example, if we draw
 , we can find the unique
, we can find the unique
 value that satisfies Eq. (3.2). This method for generating random variates obeying a given distribution is called inverse (transform) sampling (Reference von Neumannvon Neumann, 1951). One can use this method for a general probability density function,
value that satisfies Eq. (3.2). This method for generating random variates obeying a given distribution is called inverse (transform) sampling (Reference von Neumannvon Neumann, 1951). One can use this method for a general probability density function,
 , as long as one can calculate its survival function,
, as long as one can calculate its survival function,
 , like in Eq. (3.1). In the present case, by combining Eqs. (3.1) and (3.2), we obtain
, like in Eq. (3.1). In the present case, by combining Eqs. (3.1) and (3.2), we obtain
 (3.3)
(3.3)
which leads to
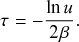 (3.4)
(3.4)
Note that

 because
because
 . Equation (3.4) is reasonable in the sense that a large event rate
. Equation (3.4) is reasonable in the sense that a large event rate
 will yield a small waiting time
will yield a small waiting time
 on average.
on average.
In the same manner, one can generate the putative times to the next event for
 ,
,
 ,
,
 , denoted by
, denoted by
 ,
,
 ,
,
 , using five uniform random variates. If the realized
, using five uniform random variates. If the realized
 ,
,
 ,
,
 values are as shown in Fig. 5(b), we conclude that node
values are as shown in Fig. 5(b), we conclude that node
 recovers next. Then, we change the state of
recovers next. Then, we change the state of
 from I to R and advance the clock by time
from I to R and advance the clock by time
 . Once
. Once
 recovers, the configuration of the six nodes will be the one given in Fig. 2(b). We then repeat the same procedure to find the next event given the updated set of processes corresponding to the nodes’ states after the event (i.e., we now have three infection processes with rate
recovers, the configuration of the six nodes will be the one given in Fig. 2(b). We then repeat the same procedure to find the next event given the updated set of processes corresponding to the nodes’ states after the event (i.e., we now have three infection processes with rate
 and one recovery process with rate
and one recovery process with rate
 ), and so on.
), and so on.
Note that in our example, the event rate changed for
 ,
,
 , and
, and
 , while it remained unchanged for
, while it remained unchanged for
 and
and
 . Therefore, we do not need to generate entirely new putative waiting times for
. Therefore, we do not need to generate entirely new putative waiting times for
 and
and
 . We just have to update
. We just have to update
 and
and
 as
as
 and
and
 , respectively, to account for the time
, respectively, to account for the time
 that has elapsed.
that has elapsed.
In this manner, we can reuse
 and
and
 (by subtracting
(by subtracting
 ) and avoid having to generate new pseudorandom numbers for redrawing
) and avoid having to generate new pseudorandom numbers for redrawing
 and
and
 . The effect of this frugality becomes important for larger systems where an event generally affects only a small fraction of the processes. The so-called next reaction method (Reference Gibson and BruckGibson & Bruck, 2000) exploits this idea to improve the computational efficiency of the first reaction method. Although the classic first reaction method did not make use of this trick, we include it here because it is simple to implement.
. The effect of this frugality becomes important for larger systems where an event generally affects only a small fraction of the processes. The so-called next reaction method (Reference Gibson and BruckGibson & Bruck, 2000) exploits this idea to improve the computational efficiency of the first reaction method. Although the classic first reaction method did not make use of this trick, we include it here because it is simple to implement.
Let us go back to our example. For
 , we no longer need to generate the time to the next event because
, we no longer need to generate the time to the next event because
 is now in the R state. For
is now in the R state. For
 and
and
 , we need to discard
, we need to discard
 and
and
 because they were generated under the assumption that the event rate was
because they were generated under the assumption that the event rate was
 . Now, we need to redraw the time to the next event for the two nodes according to the new distribution
. Now, we need to redraw the time to the next event for the two nodes according to the new distribution
 . For example, we reset
. For example, we reset
 , where
, where
 is a new uniform
is a new uniform
 random variate. Although the time
random variate. Although the time
 has passed to transit from the status of the network shown in Fig. 2(a) to that shown in Fig. 2(b), we do not need to take into account the elapsed time (i.e.,
has passed to transit from the status of the network shown in Fig. 2(a) to that shown in Fig. 2(b), we do not need to take into account the elapsed time (i.e.,
 ) when generating the new
) when generating the new
 and
and
 values. This is due to the memoryless property of Poisson processes (see Box 1), that is, what happened in the past, such as how much time has passed to realize the state transition of
values. This is due to the memoryless property of Poisson processes (see Box 1), that is, what happened in the past, such as how much time has passed to realize the state transition of
 , is irrelevant.
, is irrelevant.
The first reaction method in its general form is given in Box 2.
0. Initialization:
(a) Define the initial state of system, and set
 .
.(b) Calculate the rate
for each reaction channel
.(c) Draw
random variates
from a uniform distribution on
.(d) Generate a putative waiting time
for each reaction channel.
1. Select the reaction channel
with the smallest
, and set
.2. Perform the event on reaction channel
.3. Advance the time according to
.4. Update
and all other
that are affected by the event produced.5. Update putative waiting times:
(a) Draw new waiting times for reaction channel
and for the other reaction channels
whose
has changed, according to
with
being newly drawn from a uniform distribution on
.(b) Update the waiting times for all reaction channels
that have not been affected by the last event according to
.
6. Return to Step 1.






















3.3 Direct Method
The direct method exploits the superposition theorem to directly generate the waiting times between successive events in the full system of coupled Poisson processes. For expository purposes, we hypothetically generate an event sequence on each node with the respective rate, although only at most the first event in each sequence will be used. We then superpose the nodal event sequences into one Poisson process (see Fig. 5(b)). Owing to the superposition theorem (Box 1, Eq. (2.3)), the superposed event sequence is itself a Poisson process with a rate
 that is equal to the sum of the individual rates, that is,
that is equal to the sum of the individual rates, that is,
 .
.
Therefore, we can generate the time to the next event in the entire population using the inverse sampling method, which we introduced in Section 3.2, according to
 , where
, where
 is a uniform random variate in the interval
is a uniform random variate in the interval
 . We now know the time to the next event but not which node (or more generally, which one individual Poisson process) is responsible for the next event. This is because the superposition lacks information about the individual constituent event sequences.
. We now know the time to the next event but not which node (or more generally, which one individual Poisson process) is responsible for the next event. This is because the superposition lacks information about the individual constituent event sequences.
We thus need to determine which node produces the event. The mathematical properties of Poisson processes guarantee that the probability that a given node produces the event is proportional to its event rate (see Box 1, Eq. (2.4)). For example, in Fig. 6, where the event rates of the two nodes
 and
and
 are
are
 and
and
 , respectively, each event in the superposed event sequence comes from
, respectively, each event in the superposed event sequence comes from
 and
and
 with probability
with probability
 and
and
 , respectively. Therefore, the probability that the first event is generated by
, respectively. Therefore, the probability that the first event is generated by
 is
is
 . The probability it is generated by
. The probability it is generated by
 is
is
 . This is natural because the sequence for
. This is natural because the sequence for
 has on average twice as many events as that for
has on average twice as many events as that for
 . In our example (see Fig. 5), the
. In our example (see Fig. 5), the
 (with
(with
 ) that produces the next event is drawn with probability
) that produces the next event is drawn with probability
 , where
, where
 ,
,
 , and
, and
 . We will explain computational methods for doing this later.
. We will explain computational methods for doing this later.
Superposition of Poisson processes and how to determine which component Poisson processes contribute to an event in the superposed event sequence. We consider
 Poisson processes, one with rate
Poisson processes, one with rate
 and the other with
and the other with
 . The superposed Poisson process has rate
. The superposed Poisson process has rate
 . The next event in the superposed event sequence (shown in the dotted circle) belongs to process 1 with probability
. The next event in the superposed event sequence (shown in the dotted circle) belongs to process 1 with probability
 and process 2 with probability
and process 2 with probability
 .
.

Assume that
 generates the next event and transitions from state I to state R. Then, the new event rate for each node is as shown in Fig. 2(b). We advance the clock by
generates the next event and transitions from state I to state R. Then, the new event rate for each node is as shown in Fig. 2(b). We advance the clock by
 and go to the next step. Again, to determine the time to the following event, regardless of which node produces the event, we only need to consider the sum of the event rates of the six nodes, which is now given by
and go to the next step. Again, to determine the time to the following event, regardless of which node produces the event, we only need to consider the sum of the event rates of the six nodes, which is now given by
 . Then, the time to the next event, which we again denote by
. Then, the time to the next event, which we again denote by
 , is given by
, is given by
 , where
, where
 is a new uniform random variate. We draw another random number to determine which of the four eligible nodes,
is a new uniform random variate. We draw another random number to determine which of the four eligible nodes,
 ,
,
 ,
,
 , or
, or
 , produces the event and changes its state. (Note that
, produces the event and changes its state. (Note that
 and
and
 are recovered, so they cannot undergo a further state change.) The four remaining nodes are each selected with probability
are recovered, so they cannot undergo a further state change.) The four remaining nodes are each selected with probability
 and
and
 .
.
In this manner, we draw
 , determine which node produces the event, implement the state change, advance the clock by
, determine which node produces the event, implement the state change, advance the clock by
 , and repeat. This is Gillespie’s direct method.
, and repeat. This is Gillespie’s direct method.
Let us take a look at another example, which is the SIR model in a population composed of
 individuals, in which everybody is directly connected to anybody else (called a well-mixed population; equivalent to a complete graph; see Fig. 7 for an example). In contrast to the general network case, each individual in a well-mixed population is indistinguishable from the others. In the well-mixed population, it is not the case that, for example, an individual has two neighbors while another has three neighbors (such as in Fig. 2); they all have
individuals, in which everybody is directly connected to anybody else (called a well-mixed population; equivalent to a complete graph; see Fig. 7 for an example). In contrast to the general network case, each individual in a well-mixed population is indistinguishable from the others. In the well-mixed population, it is not the case that, for example, an individual has two neighbors while another has three neighbors (such as in Fig. 2); they all have
 neighbors. Recall that recovered individuals do not change their state again. Therefore, it suffices to consider
neighbors. Recall that recovered individuals do not change their state again. Therefore, it suffices to consider
 event sequences and their superposition to determine the time to the next event and which individual will produce the next event.
event sequences and their superposition to determine the time to the next event and which individual will produce the next event.
Complete graph with
 nodes.
nodes.
However, in the well-mixed population, we can make the procedure more efficient. Because everybody is alike, we do not need to keep track of the state of each individual.
In the case of a network, we generally need to distinguish between different susceptible individuals. For example, in Fig. 2(a), the susceptible nodes
 and
and
 are different because they have different sets of neighbors. Furthermore,
are different because they have different sets of neighbors. Furthermore,
 has degree 2, while
has degree 2, while
 has degree 3. Therefore, if
has degree 3. Therefore, if
 gets infected and changes its state, it is not equivalent to
gets infected and changes its state, it is not equivalent to
 getting infected. So, we must keep track of the state of each individual in a general network. By contrast, in the well-mixed population, such a distinction is irrelevant. Everybody is adjacent to all the other
getting infected. So, we must keep track of the state of each individual in a general network. By contrast, in the well-mixed population, such a distinction is irrelevant. Everybody is adjacent to all the other
 nodes, and the number of infectious neighbors is the same for any susceptible individual, that is, it is equal to
nodes, and the number of infectious neighbors is the same for any susceptible individual, that is, it is equal to
 . It does not matter which particular node gets infected in the next event. The only thing that matters for the SIR model in the well-mixed population is the number of susceptible, infectious, and recovered individuals, which is
. It does not matter which particular node gets infected in the next event. The only thing that matters for the SIR model in the well-mixed population is the number of susceptible, infectious, and recovered individuals, which is
 ,
,
 , and
, and
 , respectively.
, respectively.
It thus suffices to monitor these numbers. If an infection event happens, then
 decreases by one, and
decreases by one, and
 increases by one. If an infectious individual recovers, then
increases by one. If an infectious individual recovers, then
 decreases by one, and
decreases by one, and
 increases by one. Because the number of individuals is preserved over time, it holds true that
increases by one. Because the number of individuals is preserved over time, it holds true that
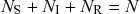 (3.5)
(3.5)
at any time. Because anybody is connected to everybody else, any susceptible individual has
 infectious neighbors, so it gets infected at rate
infectious neighbors, so it gets infected at rate
 . Because recovery occurs independently of a node’s neighbors, every infectious individual recovers at the same rate
. Because recovery occurs independently of a node’s neighbors, every infectious individual recovers at the same rate
 .
.
Based on this reasoning, we can aggregate the event sequences of the
 susceptible individuals into one even before considering which method we should use to simulate the SIR dynamics. (Therefore, this logic also works for the first reaction method and for rejection sampling.) Each event sequence corresponding to a single susceptible individual has the associated event rate
susceptible individuals into one even before considering which method we should use to simulate the SIR dynamics. (Therefore, this logic also works for the first reaction method and for rejection sampling.) Each event sequence corresponding to a single susceptible individual has the associated event rate
 . The superposed event sequence is a realization of a single Poisson process with rate
. The superposed event sequence is a realization of a single Poisson process with rate
 . If an event from this Poisson process occurs, one arbitrary susceptible individual gets infected. Likewise, we do not need to differentiate between the
. If an event from this Poisson process occurs, one arbitrary susceptible individual gets infected. Likewise, we do not need to differentiate between the
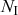 infectious individuals. So, we superpose the
infectious individuals. So, we superpose the
 event sequences, each of which has the associated event rate
event sequences, each of which has the associated event rate
 , into an event sequence, which is a realization of a Poisson process with rate
, into an event sequence, which is a realization of a Poisson process with rate
 . If an event from this Poisson process occurs, then an arbitrary infectious individual recovers.
. If an event from this Poisson process occurs, then an arbitrary infectious individual recovers.
In summary, in a well-mixed population we only need to consider two coupled Poisson processes, one corresponding to contracting infection at a rate
 , and the other corresponding to recovery at a rate
, and the other corresponding to recovery at a rate
 . In a single step of the direct method, we first determine the waiting time to the next event,
. In a single step of the direct method, we first determine the waiting time to the next event,
 . We set
. We set
 , where
, where
 is a uniformly random
is a uniformly random
 variate. Next, we determine which type of event happens, either the infection of a susceptible node (with probability
variate. Next, we determine which type of event happens, either the infection of a susceptible node (with probability
 ) or the recovery of an infectious node (with probability
) or the recovery of an infectious node (with probability
 ). We obtain
). We obtain
 (3.6)
(3.6)
If an infection event occurs, we decrease
 by 1 and increase
by 1 and increase
 by 1. If a recovery event occurs, we decrease
by 1. If a recovery event occurs, we decrease
 by 1 and increase
by 1 and increase
 by 1. In either case, we advance the clock by
by 1. In either case, we advance the clock by
 and go to the next step. We repeat the loop until
and go to the next step. We repeat the loop until
 hits 0.
hits 0.
In general applications of the direct method, we consider a set of
 independent Poisson processes with rates
independent Poisson processes with rates
 (
(
 ). The superposition of the
). The superposition of the
 Poisson processes is a single Poisson process with rate
Poisson processes is a single Poisson process with rate
 by the superposition theorem. Therefore, the time to the next event in the entire population,
by the superposition theorem. Therefore, the time to the next event in the entire population,
 , follows the exponential distribution given by
, follows the exponential distribution given by
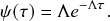 (3.8)
(3.8)
After time
 , the
, the
 th process produces the next event with probability
th process produces the next event with probability
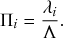 (3.9)
(3.9)
By drawing a random number obeying the categorical distribution over the
 possibilities given by
possibilities given by
 , we can then determine which Poisson process
, we can then determine which Poisson process
 generates one event. Gillespie’s original implementation does this by iterating over the list of
generates one event. Gillespie’s original implementation does this by iterating over the list of
 values (see Fig. 8).
values (see Fig. 8).
Linear search method for computing which Poisson process produces the next event for the entire population. We consider
 possible events, with respective rates
possible events, with respective rates
 ,
,
 ,
,
 , and
, and
 . Suppose that we draw a uniform random variate ranging between 0 and
. Suppose that we draw a uniform random variate ranging between 0 and
 whose value is
whose value is
 . We first check whether
. We first check whether
 falls inside the first interval; in practice, we check if
falls inside the first interval; in practice, we check if
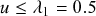 . Because this is not the case, we then check iteratively if it lies in each following interval. Because
. Because this is not the case, we then check iteratively if it lies in each following interval. Because
 , we find that
, we find that
 falls in the third interval from the left (dotted arrow). The iteration over
falls in the third interval from the left (dotted arrow). The iteration over
 as described in Step 2 in Box 3 thus stops in the third interval, and the method will select
as described in Step 2 in Box 3 thus stops in the third interval, and the method will select
 .
.

We summarize the steps of the direct method in Box 3. Similarly to the first reaction method, the direct method is easy to implement, but it is not very fast in its original form (see Fig. 8) when
 is large. For this reason more efficient algorithms have been proposed. We review them in Section 4.
is large. For this reason more efficient algorithms have been proposed. We review them in Section 4.
Although we have assumed in our example that a reaction channel (i.e., a Poisson process in the present case) is attached to each node/individual, this does not always have to be the case. As we have seen, in the case of the well-mixed population, we only need to track two reaction channels, that is, the number of susceptible individuals
 and the number of infectious individuals
and the number of infectious individuals
 . In a more complicated setting where the network structure changes in addition to the nodes’ states, some reaction channels are assigned to nodes, and other reaction channels may be assigned to the state of the edges, which may switch between on (i.e., edge available) and off (edge unavailable, or only weakly available) (Reference Clementi, Macci, Monti, Pasquale and SilvestriClementi et al., 2008; Reference Fonseca dos Reis, Li and MasudaFonseca dos Reis, Li, & Masuda, 2020; Reference Kiss, Berthouze, Taylor and SimonKiss et al., 2012; Reference Ogura and PreciadoOgura & Preciado, 2016; Reference Volz and MeyersVolz & Meyers, 2007; Reference Zhang, Moore and NewmanZhang, Moore, & Newman, 2017). In all of the preceding cases, the key assumptions are that all types of reaction channels that trigger events are Poisson processes and that their event rate may only change in response to events generated by Poisson processes occurring anywhere in the population/network.
. In a more complicated setting where the network structure changes in addition to the nodes’ states, some reaction channels are assigned to nodes, and other reaction channels may be assigned to the state of the edges, which may switch between on (i.e., edge available) and off (edge unavailable, or only weakly available) (Reference Clementi, Macci, Monti, Pasquale and SilvestriClementi et al., 2008; Reference Fonseca dos Reis, Li and MasudaFonseca dos Reis, Li, & Masuda, 2020; Reference Kiss, Berthouze, Taylor and SimonKiss et al., 2012; Reference Ogura and PreciadoOgura & Preciado, 2016; Reference Volz and MeyersVolz & Meyers, 2007; Reference Zhang, Moore and NewmanZhang, Moore, & Newman, 2017). In all of the preceding cases, the key assumptions are that all types of reaction channels that trigger events are Poisson processes and that their event rate may only change in response to events generated by Poisson processes occurring anywhere in the population/network.
0. Initialization:
(a) Define the initial state of the system, and set
.(b) Calculate the rate
for each reaction channel
.
1. Draw a random variate
from a uniform distribution on
, and generate the waiting time by
, where
is the total rate.2. Draw
from a uniform distribution on
. Select the event
to occur by iterating over
until we find the
for which
.3. Perform the event on reaction channel
.4. Advance the time according to
.5. Update
as well as all other
that are affected by the produced event.6. Return to Step 1.

















3.4 Codes
Here we present Python codes for the two classic Gillespie algorithms for simulating the SIR model. Then, we compare their output and runtimes to each other and to the rejection sampling algorithm presented in Section 2.8. We first show codes for the SIR model in a well-mixed population (Section 3.4.1). We then present implementations for the SIR model on a network (Section 3.4.2), which requires additional bookkeeping to track the dependencies between nodes and the varying number of reaction channels.
All our example codes rely on the NumPy library in Python for vectorized computation and for generating pseudorandom numbers. The following code imports the NumPy library and initializes the pseudorandom number generator (see Section 4.9 for a discussion of how to generate random numbers on a computer).

1 import numpy as np
2 from numpy.random import Generator, PCG64
3
4 seed = 42 # Set seed for PRNG state
5 rg = Generator(PCG64(seed)) # Initialize random number generator
The following codes as well as those for the rejection sampling algorithm and those for producing figures are found in Jupyter notebooks at github.com/naokimas/gillespie-tutorial.
3.4.1 SIR Model in Well-Mixed Populations
The major part of the code for simulating the SIR model is identical for the first reaction and direct methods and is simply related to updating and saving the system’s state. We thus show only the code needed for generating the waiting time and the next event in each iteration.
The following code snippet implements the first reaction method for the SIR model in a well-mixed population:

1 def draw_next_event_first_reaction(lambda_inf, lambda_rec):
2 ”’Input: total infection and recovery rates, lambda_inf=S*I*beta_k and lambda_rec=I*mu, respectively.
3 Output: selected reaction channel, i_selected, and waiting time until the event, tau.”’
4
5 # Draw a uniform random variate from (0,1] for each waiting time:
6 u = 1. - rg.random(2)
7
8 # Draw waiting times:
9 waiting_times = - np.log(u) / np.array([lambda_inf, lambda_rec])
10
11 # Select reaction with minimal tau:
12 tau = np.min(waiting_times)
13 i_selected = np.argmin(waiting_times)
14
15 return(i_selected, tau)
The following snippet implements the direct method:

1 def draw_next_event_direct(a_inf, a_rec):
2 ”’Input: total infection and recovery rates, lambda_inf=S*I*beta_k and lambda_rec=I*mu, respectively.
3 Output: selected reaction channel, i_selected, and the waiting time until the event, tau.”’
4
5 # Calculate cumulative rate:
6 Lambda = lambda_inf + lambda_rec
7
8 # Draw two uniform random variates from (0,1]:
9 u1, u2 = 1. - rg.random(2)
10
11 # Draw waiting time:
12 tau = - np.log(u1) / Lambda
13
14 # Select reaction and update state:
15 if u2 * Lambda
<
lambda_inf: # S-
>
I reaction
16 i_selected = 0
17 else: # I-
>
R reaction
18 i_selected = 1
19
20 return(i_selected, tau)
Finally, the following code snippet, which is common to the two methods, implements the state update after the next event has been selected and recalculates the values of the infection and recovery rates:

1 # Update state:
2 if i_selected == 0: # S-
>
I reaction
3 S -= 1; I += 1
4 else: # I-
>
R reaction
5 I -= 1; R += 1
6
7 # Update infection and recovery rates:
8 lambda_inf = S * I * beta_k # Infection rate
9 lambda_rec = I * mu # Recovery rate
We compare simulation results for the SIR model in a well-mixed population with
 individuals among the rejection sampling, Gillespie’s first reaction method, and Gillespie’s direct method in Fig. 9. The time-step used for rejection sampling shown in Fig. 9(a) is
individuals among the rejection sampling, Gillespie’s first reaction method, and Gillespie’s direct method in Fig. 9. The time-step used for rejection sampling shown in Fig. 9(a) is
 With this time-step, rejection sampling leads to an undershoot of the peak number of infectious individuals; compare Fig. 9(a) to Figs. 9(b) and 9(c). We also note that the average curves, shown by the solid lines, fail to capture the large variation and bimodal nature of the stochastic SIR dynamics in all the panels. Finally, we note that the average runtimes of the three different algorithms to generate one simulation are of the order of 300 ms for the rejection sampling algorithm and of the order of 10 ms for both the Gillespie algorithms.
With this time-step, rejection sampling leads to an undershoot of the peak number of infectious individuals; compare Fig. 9(a) to Figs. 9(b) and 9(c). We also note that the average curves, shown by the solid lines, fail to capture the large variation and bimodal nature of the stochastic SIR dynamics in all the panels. Finally, we note that the average runtimes of the three different algorithms to generate one simulation are of the order of 300 ms for the rejection sampling algorithm and of the order of 10 ms for both the Gillespie algorithms.
Evolution of the number of infectious individuals
 over time of the SIR model in a well-mixed population simulated using (a) the rejection sampling method, (b) the first reaction method, and (c) the direct method. The population is composed of
over time of the SIR model in a well-mixed population simulated using (a) the rejection sampling method, (b) the first reaction method, and (c) the direct method. The population is composed of
 individuals. The infection rate is
individuals. The infection rate is
 . The recovery rate is
. The recovery rate is
 . We carried out 1 000 simulations with each method. Each panel shows the number of infectious individuals over time. The overlapping thin red lines show the result for each of the 1 000 simulations. The thick black lines show the average over the 1 000 simulations. Note that a substantial portion of the simulations do not lead to any secondary infections; the red lines drop rapidly to zero, appearing as straight red lines at
. We carried out 1 000 simulations with each method. Each panel shows the number of infectious individuals over time. The overlapping thin red lines show the result for each of the 1 000 simulations. The thick black lines show the average over the 1 000 simulations. Note that a substantial portion of the simulations do not lead to any secondary infections; the red lines drop rapidly to zero, appearing as straight red lines at
 . Otherwise,
. Otherwise,
 increases first and then decays towards zero. The average behavior does not capture this bimodal nature of the stochastic dynamics.
increases first and then decays towards zero. The average behavior does not capture this bimodal nature of the stochastic dynamics.

3.4.2 SIR Model on a Network
To simulate the SIR model on a network, we rely on the NetworkX library in addition to NumPy to store and update information about nodes in the network as well as their event rates. We import NetworkX as follows:

1 import networkx as nx
The following code implements the generation of a single event of the SIR model on a network G using the first reaction method. Here, G stores the connections between nodes as well as each node’s state (S, I, or R), event rate, and putative waiting time.

1 def draw_next_event_first_reaction(G):
2 ”’Input: the network G.
3 Output: selected reaction channel, i_selected, and the waiting time until the event, tau.”’
4
5 # Get waiting times for active reaction channels from G:
6 node_indices = list(nx.get_node_attributes(G, ’tau’))
7 waiting_times = list(nx.get_node_attributes(G, ’tau’).values())
8
9 # Select reaction with minimal waiting time:
10 tau = np.min(waiting_times)
11
12 i_selected = np.where(waiting_times == tau)[0][0]
13
14 return(i_selected, tau)
The following code implements the generation of a single event of the SIR model on a network G using the direct method. Here, G stores the connections between nodes as well as each node’s state (S, I, or R) and its event rate.
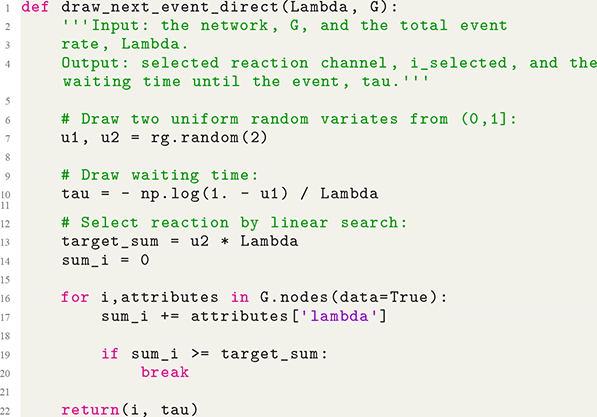
1 def draw_next_event_direct(Lambda, G):
2 ”’Input: the network, G, and the total event
3 rate, Lambda.
4 Output: selected reaction channel, i_selected, and the waiting time until the event, tau.”’
5
6 # Draw two uniform random variates from (0,1]:
7 u1, u2 = rg.random(2)
8
9 # Draw waiting time:
10 tau = - np.log(1. - u1) / Lambda
11
12 # Select reaction by linear search:
13 target_sum = u2 * Lambda
14 sum_i = 0
15
16 for i,attributes in G.nodes(data=True):
17 sum_i += attributes[’lambda’]
18
19 if sum_i
>
= target_sum:
20 break
21
22 return(i, tau)
Lines 13–20 implement the selection of the reaction channel that generates the next event using the simple algorithm illustrated in Fig. 8.
4 Computational Complexity and Efficient Implementations
In this section we investigate the computational efficiency of the Gillespie algorithms. We also review improvements that have been developed to make the algorithms more efficient when simulating systems with a large number of reaction channels.
A typical way to quantify the efficiency of stochastic algorithms, and the one we shall be concerned with here, is their expected time complexity. In the context of event-based simulations, it measures how an algorithm’s average runtime depends on the number of reaction channels,
 . While it is generally impossible to exactly calculate the expected runtime of an algorithm for all different use cases, we are often able to show how the algorithm’s average runtime scales with
. While it is generally impossible to exactly calculate the expected runtime of an algorithm for all different use cases, we are often able to show how the algorithm’s average runtime scales with
 for large
for large
 . We indicate the complexity of an algorithm using big-O notation,Footnote 5 where
. We indicate the complexity of an algorithm using big-O notation,Footnote 5 where
 means that the algorithm’s expected runtime is proportional to
means that the algorithm’s expected runtime is proportional to
 for large
for large
 . For example, an algorithm with expected runtime
. For example, an algorithm with expected runtime
 and another with expected runtime
and another with expected runtime
 both have linear time complexity, that is,
both have linear time complexity, that is,
 for
for
 .
.
As we shall see in Section 4.1, the classic implementations of the Gillespie algorithms presented in Section 3 have
 time complexity for each simulation step of the algorithms. While a linear time complexity may not seem computationally expensive, it is typical that the number of events taking place per time unit also scales linearly with the size of the system, namely
time complexity for each simulation step of the algorithms. While a linear time complexity may not seem computationally expensive, it is typical that the number of events taking place per time unit also scales linearly with the size of the system, namely
 in most of our examples. Thus, the number of computations per simulated unit of time then scales as
in most of our examples. Thus, the number of computations per simulated unit of time then scales as
 . This means that the overall time complexity of running a single simulation using the classic Gillespie algorithms is
. This means that the overall time complexity of running a single simulation using the classic Gillespie algorithms is
 , where
, where
 is the typical duration of a single simulation. An
is the typical duration of a single simulation. An
 computation time may be prohibitively expensive for large
computation time may be prohibitively expensive for large
 and
and
 . Because
. Because
 scales linearly with
scales linearly with
 at least, which occurs for sparse networks (i.e., networks with relatively few edges), we have at least
at least, which occurs for sparse networks (i.e., networks with relatively few edges), we have at least
 time complexity in this scenario.
time complexity in this scenario.
To make the Gillespie algorithms more efficient for large systems, researchers have come up with many algorithmic improvements to lower the computational complexity of both the bookkeeping and simulation steps of the algorithms. While these improved algorithms are more complex than the simple Gillespie algorithms presented in Section 3, many of these techniques are worth the effort to learn because they usually shorten the computation time immensely without sacrificing the exactness of the simulations. With these techniques, we may be able to simulate a large system that we could not simulate otherwise. However, we should note that, for systems with a small number of reaction channels, these methods will not confer a significant speedup and may even be slightly slower because they introduce some additional overhead. In this section we review several general methods that we believe to be the most important ones to be aware of for researchers looking to simulate social systems, although many more exist (see Reference Marchetti, Priami and ThanhMarchetti, Priami, and Thanh [2017] for a recent review).
We detail in Section 4.1 the computational complexity of each step of the original first reaction and direct methods. We next discuss in Section 4.2 a simple way to improve the computational efficiency of the direct method by grouping similar processes together to reduce the number of reaction channels. We then review algorithmic improvements that decrease the expected complexity of both the direct (Section 4.3) and first reaction (Section 4.4) methods to
 time. More recent methods further decrease the expected runtime of the direct method, which we review in Sections 4.5, 4.6, and 4.7. Other methods have been developed that sacrifice the exactness of the Gillespie algorithms to some extent for additional speed gains. Such methods are not the main focus of this Element, but we briefly review one such method, the tau-leaping method, in Section 4.8. We provide a short note on how to generate pseudorandom numbers needed for stochastic numerical simulations in Section 4.9. We end this section with example codes and simulation results (Section 4.10).
time. More recent methods further decrease the expected runtime of the direct method, which we review in Sections 4.5, 4.6, and 4.7. Other methods have been developed that sacrifice the exactness of the Gillespie algorithms to some extent for additional speed gains. Such methods are not the main focus of this Element, but we briefly review one such method, the tau-leaping method, in Section 4.8. We provide a short note on how to generate pseudorandom numbers needed for stochastic numerical simulations in Section 4.9. We end this section with example codes and simulation results (Section 4.10).
4.1 Average Complexity of the Classic Gillespie Algorithms
In this subsection we will analyze the runtime complexity of each step in Gillespie’s two algorithms. Knowing which parts of the algorithms are the most computationally expensive will also tell us which parts of the algorithms we should focus on to make them more efficient.
We first analyze the complexity of the steps of the first reaction method in the order they appear in Box 2:
Step 1: To find the smallest putative waiting time, we go through the entire list
. Because there are
elements in the list, this step requires
time.Steps 2–4: Updating the system’s state and event rates following an event requires a number of operations that is proportional to the number of reaction channels that are affected by the event.Footnote 6 In the case of a network, the number is often proportional to the average node degree. Typically the average node degree is relatively small and does not grow much with the size of the system, which we conventionally identify with the number of nodes. Such a network is referred to as a sparse network. So, this step takes
time. (However, for dense or heterogeneous networks, the number of reaction channels affected by an event may scale with
, in which case this step may take
time – see Section 4.7.)Step 5: To update the putative waiting times, we only have to generate new random variates for the reaction channel that generated the event and for those that changed their event rate due to the event. However, all the other waiting times still need to be updated in Step 5(b) in Box 2. Therefore, this step also has
time complexity.







We observe that, although we have avoided some costly parts of the original implementation of the first reaction method, which we introduced in Section 3.2, the algorithm still has linear time complexity. Thus, for systems with large
 , the first reaction method may be slow.
, the first reaction method may be slow.
Let us similarly analyze the time complexity per iteration of the direct method step-by-step in the order they appear in Box 3.
Step 1: Generating the waiting time requires generating a random variate and transforming it. This is a constant-time operation,
, because the runtime does not depend on
.Step 2: To find the reaction channel
that generates the event, we have to iterate through half of the list of the event rates on average. This step thus takes
time.Steps 3–5: The steps for updating the system’s state and event rates are identical to Steps 2–4 for the first reaction method. Therefore, these steps typically have
time complexity.





Our implementation of the first reaction method has two steps of linear time complexity, whereas the direct method only has a single step of linear time complexity. Therefore, the direct method may be slightly faster than the first reaction method. However, the former’s overall scaling with
 is still linear. So, the direct method may be slow for large
is still linear. So, the direct method may be slow for large
 , just like the first reaction method.
, just like the first reaction method.
4.2 Grouping Reaction Channels
A simple way to reduce the effective number of reaction channels in the direct method, and thus accelerate the sampling of the next event, is available when the rates
 only take a small number of different values. The strategy is to group
only take a small number of different values. The strategy is to group
 ’s that have the same
’s that have the same
 value and then apply a rounding operation, which is fast for a computer, to determine a unique value of
value and then apply a rounding operation, which is fast for a computer, to determine a unique value of
 to be selected (Reference SchulzeSchulze, 2002).
to be selected (Reference SchulzeSchulze, 2002).
This method works as follows. Consider an idealized situation in the SIR dynamics on a network in which
 ,
,
 ,
,
 , and
, and
 . Let us further assume that, at the present moment in time, 40 out of the 60 susceptible individuals are adjacent to three infectious nodes, and the other 20 are adjacent to two infectious nodes (Fig. 10). We can safely ignore the
. Let us further assume that, at the present moment in time, 40 out of the 60 susceptible individuals are adjacent to three infectious nodes, and the other 20 are adjacent to two infectious nodes (Fig. 10). We can safely ignore the
 recovered individuals because they do not generate an event. For each susceptible individual with three and two infectious neighbors, the rate to get infected is
recovered individuals because they do not generate an event. For each susceptible individual with three and two infectious neighbors, the rate to get infected is
 and
and
 , respectively. For each infectious individual, the recovery rate is
, respectively. For each infectious individual, the recovery rate is
 . Therefore, the total (i.e., cumulative) event rate is equal to
. Therefore, the total (i.e., cumulative) event rate is equal to
 . If the population is well-mixed and one just wants to track the numbers of the susceptible, infectious, and recovered individuals, one needs to prepare only two reaction channels, one for infection (i.e.,
. If the population is well-mixed and one just wants to track the numbers of the susceptible, infectious, and recovered individuals, one needs to prepare only two reaction channels, one for infection (i.e.,
 decreases by 1, and
decreases by 1, and
 increases by 1) with rate
increases by 1) with rate
 , and the other for recovery (i.e.,
, and the other for recovery (i.e.,
 decreases by 1, and
decreases by 1, and
 increases by 1) with rate
increases by 1) with rate
 . However, the population that we are considering is not well-mixed because the number of infectious neighbors that a susceptible individual has at each moment in time depends explicitly on the states of its neighbors in the network. We thus need to keep track of each individual’s state individually to be able to simulate the dynamics.
. However, the population that we are considering is not well-mixed because the number of infectious neighbors that a susceptible individual has at each moment in time depends explicitly on the states of its neighbors in the network. We thus need to keep track of each individual’s state individually to be able to simulate the dynamics.
Diagram of the state of each node undergoing the SIR dynamics. Out of the
 nodes, 40 nodes are susceptible and have three infectious neighbors (and other susceptible or recovered neighbors), 20 nodes are susceptible and have two infectious neighbors, 30 nodes are infectious, and 10 nodes are recovered.
nodes, 40 nodes are susceptible and have three infectious neighbors (and other susceptible or recovered neighbors), 20 nodes are susceptible and have two infectious neighbors, 30 nodes are infectious, and 10 nodes are recovered.
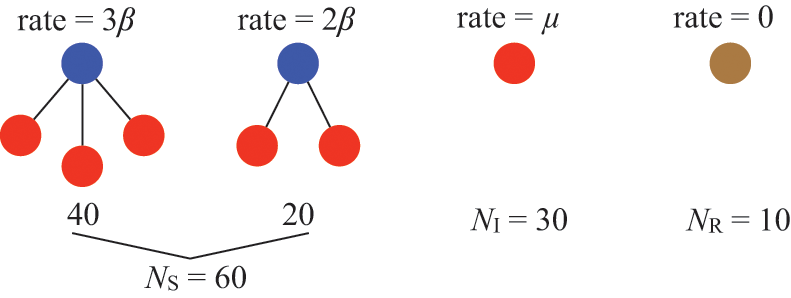
Each susceptible individual will generate the next event with probability
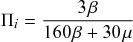 (4.1)
(4.1)
or
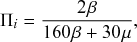 (4.2)
(4.2)
depending on whether it has three or two infectious neighbors, respectively, while each infectious individual will generate the event with probability
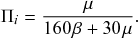 (4.3)
(4.3)
We group together the 40 susceptible individuals with three infectious neighbors, which altogether have a total rate of
 . Likewise, we group together the 20 susceptible individuals with two infectious neighbors, whose total rate is
. Likewise, we group together the 20 susceptible individuals with two infectious neighbors, whose total rate is
 . The group of infectious individuals finally has a total rate of
. The group of infectious individuals finally has a total rate of
 . Then, we determine which group is responsible for the next event. Because there are only three groups, this is computationally easy. In other words, we draw
. Then, we determine which group is responsible for the next event. Because there are only three groups, this is computationally easy. In other words, we draw
 from a uniform distribution on
from a uniform distribution on
 , and if
, and if
 , then it is group 1; if
, then it is group 1; if
 , then it is group 2; otherwise, it is group 3.
, then it is group 2; otherwise, it is group 3.
We can next easily determine which individual in the selected group experiences the event. If group 1 is selected, we need to select one from the 40 susceptible nodes. Because their event rate is the same (i.e.,
 ), they all have the same probability to be selected. Therefore, one can select the
), they all have the same probability to be selected. Therefore, one can select the
 th individual (with
th individual (with
 ) according to
) according to
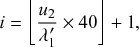 (4.4)
(4.4)
where
 denotes rounding down to the nearest integer. Note that, because group 1 was selected, we have conditioned on
denotes rounding down to the nearest integer. Note that, because group 1 was selected, we have conditioned on
 , and
, and
 is thus a uniform random variate on
is thus a uniform random variate on
 . Therefore,
. Therefore,
 is uniformly randomly distributed on
is uniformly randomly distributed on
 . By rounding down this number, we can sample each integer from 0 to 39 with equal probability, namely
. By rounding down this number, we can sample each integer from 0 to 39 with equal probability, namely
 . The term
. The term
 on the right-hand side of Eq. (4.4) lifts the sampled integer by one to guarantee that
on the right-hand side of Eq. (4.4) lifts the sampled integer by one to guarantee that
 is an integer between 1 and 40. Likewise, if group 2 has been selected, we set
is an integer between 1 and 40. Likewise, if group 2 has been selected, we set
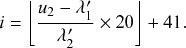 (4.5)
(4.5)
Because
 when group 2 is selected,
when group 2 is selected,
 is a uniform random variate on
is a uniform random variate on
 , and
, and
 is uniformly distributed on
is uniformly distributed on
 . Therefore,
. Therefore,
 yields an integer between 0 and 19 with equal probability (i.e.,
yields an integer between 0 and 19 with equal probability (i.e.,
 ), and Eq. (4.5) yields an integer between 41 and 60, each with probability
), and Eq. (4.5) yields an integer between 41 and 60, each with probability
 . Finally, if group 3 has been selected, we set
. Finally, if group 3 has been selected, we set
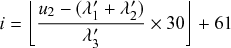 (4.6)
(4.6)
such that
 is an integer between 61 and 90, each with probability
is an integer between 61 and 90, each with probability
 .
.
Although we have considered an idealized scenario, the assumption that we can find groups of individuals sharing the event rate value is not unrealistic. In the homogeneous SIR model (i.e. where all individuals have the same susceptibility, infectiousness, and recovery rate), all the infectious individuals share the same event rate
 . Furthermore, we may be able to group the susceptible nodes according to their number of infectious neighbors and other factors. As events occur, the grouping will generally change and must thus be updated after the event. For example, if an infectious node recovers, then the group of infectious nodes, whose total event rate (for recovery) was
. Furthermore, we may be able to group the susceptible nodes according to their number of infectious neighbors and other factors. As events occur, the grouping will generally change and must thus be updated after the event. For example, if an infectious node recovers, then the group of infectious nodes, whose total event rate (for recovery) was
 , loses one member such that the total event rate is updated to
, loses one member such that the total event rate is updated to
 .
.
4.3 Logarithmic-Time Event Selection in the Direct Method Using a Binary Tree
We now move on to a general method for speeding up the direct method. To speed up the implementation, we use a binary tree data structure to store the
 values. This allows us to select the reaction channel
values. This allows us to select the reaction channel
 that will produce the next event (Step 2 in Box 3) in
that will produce the next event (Step 2 in Box 3) in
 operations instead of
operations instead of
 operations (Reference Gibson and BruckGibson & Bruck, 2000).Footnote 7 (See also Reference Blue, Beichl and SullivanBlue, Beichl, and Sullivan [1995] for earlier studies and Reference Wong and EastonWong and Easton [1980] for the general case of sampling from urns with a general categorical probability distribution
operations (Reference Gibson and BruckGibson & Bruck, 2000).Footnote 7 (See also Reference Blue, Beichl and SullivanBlue, Beichl, and Sullivan [1995] for earlier studies and Reference Wong and EastonWong and Easton [1980] for the general case of sampling from urns with a general categorical probability distribution
 .) Because the other steps of the direct method typically have constant time complexity, improving the time complexity of the event selection step will speed up the entire algorithm.
.) Because the other steps of the direct method typically have constant time complexity, improving the time complexity of the event selection step will speed up the entire algorithm.
The main idea is to store the
 values in the leaves of a binary tree and let each parent node store the sum of the values in its two child nodes (see Fig. 11(a)). By repeating this procedure for all the internal nodes of the tree, we reach the single root node on the top of the tree, to which the value
values in the leaves of a binary tree and let each parent node store the sum of the values in its two child nodes (see Fig. 11(a)). By repeating this procedure for all the internal nodes of the tree, we reach the single root node on the top of the tree, to which the value
 is assigned. For simplicity, we assume that
is assigned. For simplicity, we assume that
 is a power of 2 in Fig. 11(a) such that the tree is a perfect binary tree, that is, a binary tree where every level is completely filled. In fact,
is a power of 2 in Fig. 11(a) such that the tree is a perfect binary tree, that is, a binary tree where every level is completely filled. In fact,
 varies in the course of a single simulation in general, but if
varies in the course of a single simulation in general, but if
 is not a power of 2, we can simply pad leaves of the binary tree with zeros to get a perfect tree. For example, if
is not a power of 2, we can simply pad leaves of the binary tree with zeros to get a perfect tree. For example, if
 , we pad the two rightmost leaves in Fig. 11(a) with
, we pad the two rightmost leaves in Fig. 11(a) with
 . Then, these two reaction channels are never selected for event generation. If a next event changes the number of reaction channels from
. Then, these two reaction channels are never selected for event generation. If a next event changes the number of reaction channels from
 to
to
 , then we fill
, then we fill
 by a designated positive value as well as possibly have to renew the values of some of
by a designated positive value as well as possibly have to renew the values of some of
 ,
,
 ,
,
 .
.
Binary tree for drawing
 from a discrete distribution
from a discrete distribution
 . We assume
. We assume
 . (a) General case. (b) An example. The value in each nonleaf node of the tree is equal to the sum of its two child nodes’ values. There are
. (a) General case. (b) An example. The value in each nonleaf node of the tree is equal to the sum of its two child nodes’ values. There are
 hierarchical levels.
hierarchical levels.
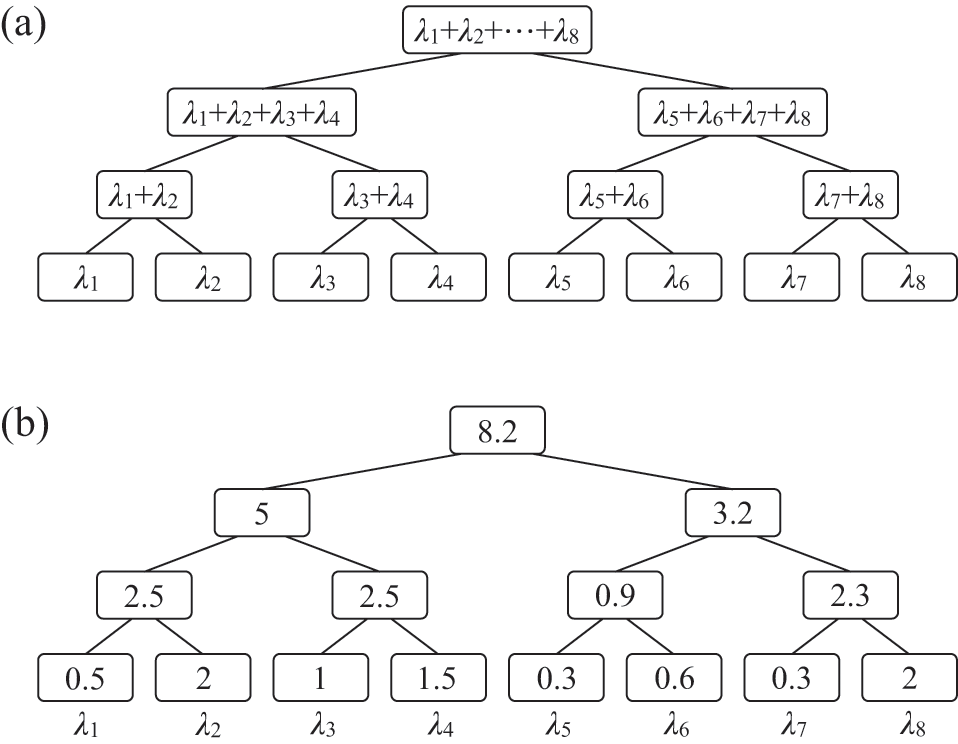
To determine which event occurs, we first draw a random variate
 from a uniform distribution on
from a uniform distribution on
 . We then start from the root node in the binary tree and look at the node’s left child. If
. We then start from the root node in the binary tree and look at the node’s left child. If
 is smaller than or equal to the value stored in the left child, we move to the left child and repeat the procedure. Otherwise, we subtract the value in the left child from
is smaller than or equal to the value stored in the left child, we move to the left child and repeat the procedure. Otherwise, we subtract the value in the left child from
 , move to the right child, and repeat. For example, if
, move to the right child, and repeat. For example, if
 and the binary tree is as given in Fig. 11(b), we move to the right child of the root node because
and the binary tree is as given in Fig. 11(b), we move to the right child of the root node because
 . Then, we update
. Then, we update
 by subtracting the value in the left child node:
by subtracting the value in the left child node:
 . Note that the new
. Note that the new
 value is a realization of a random variate uniformly distributed on
value is a realization of a random variate uniformly distributed on
 . Because the new
. Because the new
 , we next move to the left child of the node with value
, we next move to the left child of the node with value
 . We repeat this procedure until we reach a leaf. This leaf’s index is the selected value of
. We repeat this procedure until we reach a leaf. This leaf’s index is the selected value of
 . In the current example, we eventually reach the leaf node
. In the current example, we eventually reach the leaf node
 . There are
. There are
 levels in the binary tree if we do not count the root node of the tree. Therefore, determining a value of
levels in the binary tree if we do not count the root node of the tree. Therefore, determining a value of
 given
given
 requires
requires
 time.
time.
Once we have carried out the event associated with the selected
 value, we need to update the
value, we need to update the
 values that are affected by the event (typically including
values that are affected by the event (typically including
 ). In the binary tree we can complete the updating locally for each
). In the binary tree we can complete the updating locally for each
 , that is, by only changing the affected leaf and its parent nodes in the tree. For example, if
, that is, by only changing the affected leaf and its parent nodes in the tree. For example, if
 changes due to an event generated by the
changes due to an event generated by the
 th reaction channel, then, first of all, we replace
th reaction channel, then, first of all, we replace
 by the new value. Then, we need to replace the internal node of the binary tree just above
by the new value. Then, we need to replace the internal node of the binary tree just above
 by a new value owing to the change in the value of
by a new value owing to the change in the value of
 . For example, suppose that the new value of
. For example, suppose that the new value of
 is
is
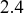 , which is
, which is
 larger than the previous
larger than the previous
 value (
value (
 as shown in Fig. 11(b)). Then, we need to increase the value of the parent of
as shown in Fig. 11(b)). Then, we need to increase the value of the parent of
 by
by
 so that we replace
so that we replace
 by
by
 . We repeat this procedure up through the hierarchical levels of the tree and update the values of the relevant internal nodes and finally that of the root node. Therefore, we need to update only
. We repeat this procedure up through the hierarchical levels of the tree and update the values of the relevant internal nodes and finally that of the root node. Therefore, we need to update only
 values per
values per
 value that changes. This is a small number compared to the total number of nodes in the binary tree, which is
value that changes. This is a small number compared to the total number of nodes in the binary tree, which is
 . Even if we need to update
. Even if we need to update
 for several
for several
 ’s, the total number of nodes in the binary tree to be updated is typically still small compared to
’s, the total number of nodes in the binary tree to be updated is typically still small compared to
 . (However, if we need to update a large fraction of the
. (However, if we need to update a large fraction of the
 , the number of updates may become comparable to or even surpass
, the number of updates may become comparable to or even surpass
 .) The steps for implementing the direct method with binary tree search and updating of the tree are shown in Box 4.
.) The steps for implementing the direct method with binary tree search and updating of the tree are shown in Box 4.
0. Initialization:
(a) Define the initial state of the system, and set
.(b) Calculate the rate
for each reaction channel
.(c) Initialize the binary tree:
i. Store each
in a leaf of a perfect binary tree with
leafs, where
denotes the smallest integer larger than or equal to
.ii. Fill the remaining leaf nodes with zeros.
iii. Move up through the remaining
levels of the tree, setting the value of each node equal to the sum of the values of its two child nodes.iv. The value in the root node is equal to the total rate
.
1. Draw a random variate
from a uniform distribution on
, and generate the waiting time by
.2. Binary tree search:
(a) Draw
from a uniform distribution on
.(b) Start from the root node.
(c) If
, where
is the value in the left child of the current node, then go to the left child. Otherwise, set
and go to the right child.(d) Repeat Step (c) until a leaf node is reached. The index
of the leaf node gives the reaction channel that produces the next event.
3. Perform the event on reaction channel
.4. Advance the time by setting
.5. Update
as well as all other
s that are affected by the produced event.6. Update the binary tree:
(a) For a reaction channel whose rate
changes, set
, where
and
are the new and old event rates, respectively.(b) Increase the value of the
th leaf and all its parents including the root node of the tree by
.(c) Repeat Steps (a) and (b) for all reaction channels
to be updated.
7. Return to Step 1.





























4.4 Next Reaction Method: Logarithmic-Time Version of the First Reaction Method
It is also possible to make the runtime of the first reaction method scale logarithmically with the number of reaction channels, that is, to make it have a
 time complexity. The improvements, collectively referred to as the next reaction method, were proposed in Reference Gibson and BruckGibson and Bruck (2000). Because both finding the smallest waiting time (Step 1 in Box 2) and updating the waiting times (Step 5 in Box 2) have
time complexity. The improvements, collectively referred to as the next reaction method, were proposed in Reference Gibson and BruckGibson and Bruck (2000). Because both finding the smallest waiting time (Step 1 in Box 2) and updating the waiting times (Step 5 in Box 2) have
 time complexity, we need to decrease the complexity of both steps to reduce the time complexity of the entire algorithm. The next reaction method implements three distinct improvements of the steps of the first reaction method. We describe each in turn.
time complexity, we need to decrease the complexity of both steps to reduce the time complexity of the entire algorithm. The next reaction method implements three distinct improvements of the steps of the first reaction method. We describe each in turn.
4.4.1 Switch to Absolute Time
One can make Step 5 of the first reaction method (see Box 2) more efficient simply by switching from storing the putative waiting times
 for each reaction channel
for each reaction channel
 to storing the putative absolute times of the next event, denoted by
to storing the putative absolute times of the next event, denoted by
 . Analogous to the original first reaction method, the event with the smallest time
. Analogous to the original first reaction method, the event with the smallest time
 is selected to happen next, and the current time is set to
is selected to happen next, and the current time is set to
 . Following the event, we only need to draw new waiting times for the reaction channel that generated the event,
. Following the event, we only need to draw new waiting times for the reaction channel that generated the event,
 , as well as for other reaction channels that are affected by the event. For these reaction channels, we reset the putative absolute time of the next event by adding the new waiting time drawn to the current time
, as well as for other reaction channels that are affected by the event. For these reaction channels, we reset the putative absolute time of the next event by adding the new waiting time drawn to the current time
 . Thus, for each reaction channel
. Thus, for each reaction channel
 that must be updated, we set
that must be updated, we set
 , where
, where
 is the new putative waiting time drawn. There is no need to update the putative absolute times of the next event for the other reaction channels because the absolute times of the next event for these reaction channels do not depend on the current time.
is the new putative waiting time drawn. There is no need to update the putative absolute times of the next event for the other reaction channels because the absolute times of the next event for these reaction channels do not depend on the current time.
In comparison, the putative waiting time until reaction channel
 will generate an event, namely
will generate an event, namely
 , does change for all the reaction channels following an event. This is because the waiting times are measured relative to the current time and thus change whenever the time advances. Therefore, the putative waiting times for all reaction channels need to be updated after each event in the original first reaction method. Because only a small number of reaction channels are affected by each event on average (except for systems that are densely connected or are in a critical phase), the use of the absolute time in place of the waiting time reduces the complexity of this step from
, does change for all the reaction channels following an event. This is because the waiting times are measured relative to the current time and thus change whenever the time advances. Therefore, the putative waiting times for all reaction channels need to be updated after each event in the original first reaction method. Because only a small number of reaction channels are affected by each event on average (except for systems that are densely connected or are in a critical phase), the use of the absolute time in place of the waiting time reduces the complexity of this step from
 to
to
 .
.
4.4.2 Reuse Putative Times to Generate Fewer Random Numbers
Gibson and Bruck also developed a procedure for generating new putative waiting times
 for the reaction channels that are different from
for the reaction channels that are different from
 and are affected by the event. Their idea is to reuse the old putative event time for each affected reaction channel. With this new procedure, one does not have to generate a new random variate to determine the new putative waiting time
and are affected by the event. Their idea is to reuse the old putative event time for each affected reaction channel. With this new procedure, one does not have to generate a new random variate to determine the new putative waiting time
 for each of these reaction channels. Let us denote by
for each of these reaction channels. Let us denote by
 the number of reaction channels affected by the event in the
the number of reaction channels affected by the event in the
 th reaction channel besides
th reaction channel besides
 itself. Then, this new procedure brings the number of random variates generated per reaction down from
itself. Then, this new procedure brings the number of random variates generated per reaction down from
 for the first reaction method to one for the next reaction method. While the introduction of this procedure does not change the computational complexity of the step, which remains
for the first reaction method to one for the next reaction method. While the introduction of this procedure does not change the computational complexity of the step, which remains
 , the reduction in the actual computation time may be considerable when pseudorandom number generation is much slower than arithmetic operations. However, this is generally less of a concern for newer pseudorandom number generators than it was earlier.
, the reduction in the actual computation time may be considerable when pseudorandom number generation is much slower than arithmetic operations. However, this is generally less of a concern for newer pseudorandom number generators than it was earlier.
The procedure takes advantage of the memoryless property of Poisson processes (see Box 1). Suppose that the rate for reaction channel
 has changed from
has changed from
 to
to
 owing to the event that has occurred in reaction channel
owing to the event that has occurred in reaction channel
 . The memoryless property means that if the reaction channel’s rate had remained unchanged, that is, if
. The memoryless property means that if the reaction channel’s rate had remained unchanged, that is, if
 , then the waiting time until the next event for reaction channel
, then the waiting time until the next event for reaction channel
 , that is,
, that is,
 , would follow the same exponential distribution as that of the original waiting time. Furthermore, any rescaling of an exponentially distributed random variable,
, would follow the same exponential distribution as that of the original waiting time. Furthermore, any rescaling of an exponentially distributed random variable,
 , is also an exponentially distributed variable, with a rescaled rate
, is also an exponentially distributed variable, with a rescaled rate
 . Thus, we define the new waiting time
. Thus, we define the new waiting time
 (4.7)
(4.7)
which is related to the old waiting time by the rescaling
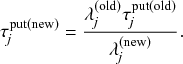 (4.8)
(4.8)
This
 follows the desired distribution of the new waiting time, that is,
follows the desired distribution of the new waiting time, that is,
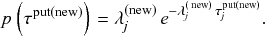 (4.9)
(4.9)
The combination of Eqs. (4.7), (4.8), and the definition
 implies that, for the reaction channels
implies that, for the reaction channels
 whose rates have changed, we can generate the new putative time of the next event according to
whose rates have changed, we can generate the new putative time of the next event according to
 (4.10)
(4.10)
4.4.3 Use an Indexed Priority Queue for Selecting the Next Event
Increasing the efficiency of Step 1 of the first reaction method, which finds the reaction channel with the smallest waiting time, is more involved than the first two improvements described in Sections 4.4.1 and 4.4.2. It relies on a data structure similar to the binary tree discussed in Section 4.3. Gibson and Bruck dubbed this structure an indexed priority queue, which is a binary heap, that is, a type of binary tree that is optimized for implementing a priority queue, coupled to an index array (see Fig. 12). The binary heap stores the putative times of the next event,
 , for all reaction channels, ordered from the smallest to the largest, and provides lookup of the smallest of them, namely
, for all reaction channels, ordered from the smallest to the largest, and provides lookup of the smallest of them, namely
 , in
, in
 time. The index array contains pointers to each reaction channel’s position in the binary heap to provide fast updating of the
time. The index array contains pointers to each reaction channel’s position in the binary heap to provide fast updating of the
 values, that is, in
values, that is, in
 time.
time.
Indexed priority queue for storing putative reaction times in the next reaction method. (a) Example of an indexed priority queue. The indexed priority queue consists of a binary heap (top) and an index array (bottom). The binary heap contains tuples
 , where
, where
 is the reaction channel number and
is the reaction channel number and
 the putative time when it would generate its next event. The nodes in the binary heap are ordered vertically by the value of
the putative time when it would generate its next event. The nodes in the binary heap are ordered vertically by the value of
 they store. The index array points to the node in the binary heap that corresponds to each reaction channel. (b) Configuration of the indexed priority queue after the value of
they store. The index array points to the node in the binary heap that corresponds to each reaction channel. (b) Configuration of the indexed priority queue after the value of
 has been updated to 2.9 and the values stored in the nodes have been rearranged to satisfy the vertical ordering of the
has been updated to 2.9 and the values stored in the nodes have been rearranged to satisfy the vertical ordering of the
 values. All entries of the binary heap and the index array that the updating has affected are marked in red.
values. All entries of the binary heap and the index array that the updating has affected are marked in red.
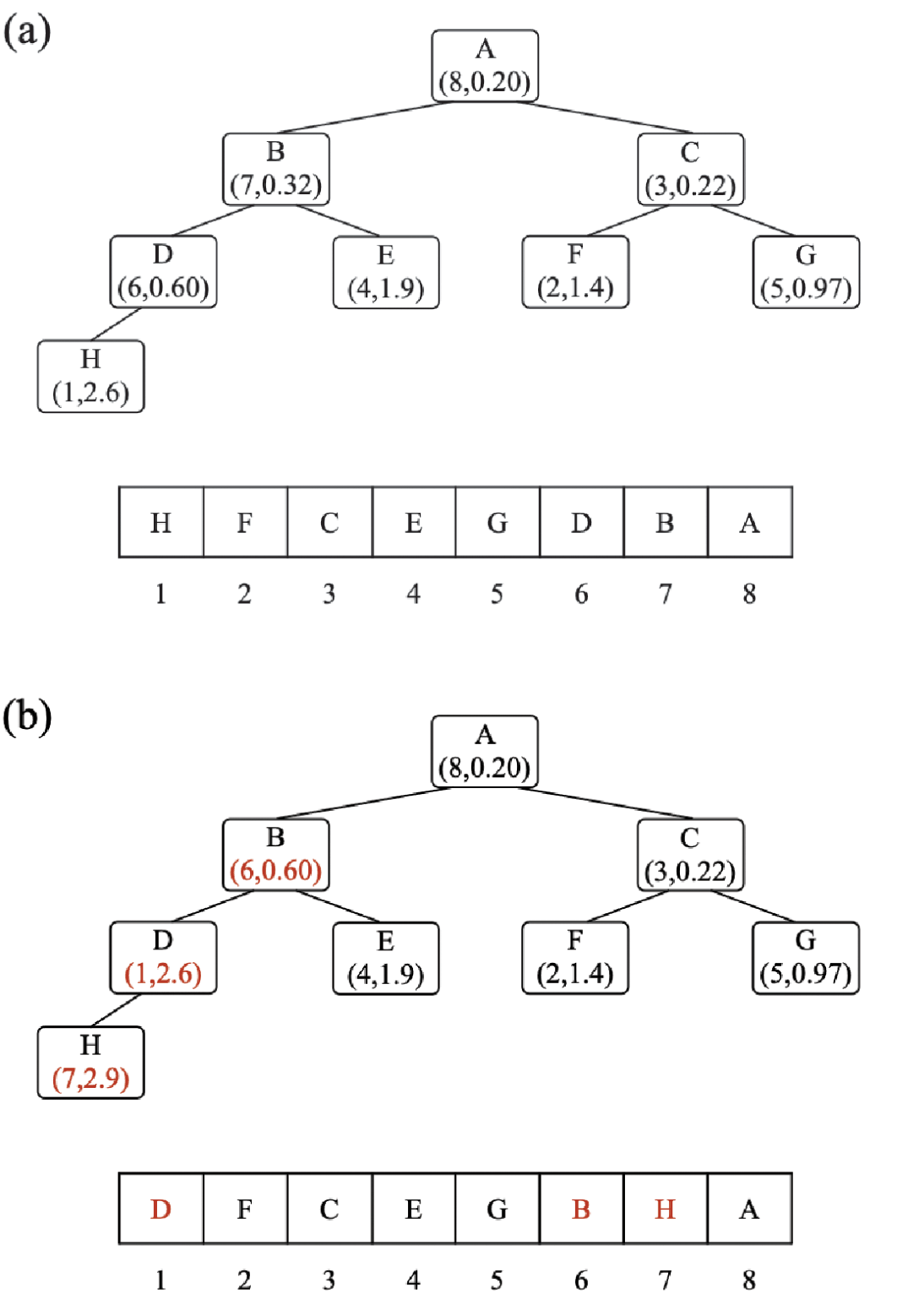
The binary heap is a complete binary tree that stores a pair
 in each node and is ordered such that each node has a
in each node and is ordered such that each node has a
 value that is smaller than that of both its children and larger than that of its parent, as shown in Fig. 12(a). Therefore, the heap stores the smallest
value that is smaller than that of both its children and larger than that of its parent, as shown in Fig. 12(a). Therefore, the heap stores the smallest
 value in the root node. This implies that finding the smallest putative event time requires only a single operation, that is, it has
value in the root node. This implies that finding the smallest putative event time requires only a single operation, that is, it has
 time complexity.
time complexity.
Because the nodes in the binary heap are not ordered by their reaction channel number
 , the index array (see Fig. 12) stores for each reaction channel
, the index array (see Fig. 12) stores for each reaction channel
 a pointer to the position of the node in the binary heap that corresponds to
a pointer to the position of the node in the binary heap that corresponds to
 . Specifically, the
. Specifically, the
 th entry of the index array points to the node in the binary heap that contains
th entry of the index array points to the node in the binary heap that contains
 . For example, in Fig. 12(a), the reaction channel 2 is located at node F in the tree. The index array removes the need to search through the binary heap to locate a given reaction channel and the corresponding event time. The index array thus enables us to find the nodes that need to be updated after an event in
. For example, in Fig. 12(a), the reaction channel 2 is located at node F in the tree. The index array removes the need to search through the binary heap to locate a given reaction channel and the corresponding event time. The index array thus enables us to find the nodes that need to be updated after an event in
 time.
time.
After updating the waiting time in a given node of the binary heap, we may need to update the ordering of the nodes in the binary heap to respect the order of putative event times across the hierarchical levels (i.e., descending order as one goes from any leaf node toward the root node). We perform this reordering by “bubbling” the values up and down: starting at the node whose value has changed, corresponding to reaction channel
 , say, we repeat either Step (1) or (2) in the following list, depending on the value of
, say, we repeat either Step (1) or (2) in the following list, depending on the value of
 , until one of the stopping conditions is satisfied.
, until one of the stopping conditions is satisfied.
(1) If the new
value is smaller than the
value stored in its parent node, swap
with the value in the parent node, and also swap the two nodes’ pointers in the index array. We repeat this procedure for the parent node.(2) Otherwise, that is, if the new
value is larger than or equal to the
value stored in its parent node, compare
to the
values in its two child nodes. If
is larger than the minimum of the two, swap
with the values in the child node that attains the minimum, and also swap the two nodes’ pointers in the index array. We repeat this procedure for the child node that attained the minimum of
before the swapping.∙ Stopping conditions: We repeat the procedure until the new
value is larger than its parent’s and smaller than both of its children’s. Alternatively, if the value
has bubbled up to the root node or down to a leaf, we also terminate the procedure.












This procedure allows us to update the binary heap in
 time for each reaction channel whose event rate has changed following an event. This is the most costly part of the algorithm. So, the next reaction method improves the overall runtime of the first reaction method from
time for each reaction channel whose event rate has changed following an event. This is the most costly part of the algorithm. So, the next reaction method improves the overall runtime of the first reaction method from
 to
to
 . Box 5 shows an implementation of the bubbling algorithm.
. Box 5 shows an implementation of the bubbling algorithm.
bubbling(node
 ):
):
If the
value in the node
is smaller than the
value in
’s parent node, parent(
), then
(a) swap
and parent(
), and update the index array correspondingly;(b) run bubbling(parent(
)).
Else if the
value in
is larger than the smaller
value of its two children, then
(a) swap
and the corresponding child node, min_child(
), and update the index array correspondingly;(b) run bubbling(min_child(
)).
Else, stop the bubbling algorithm.














To illustrate the bubbling procedure we turn to the example shown in Fig. 12(a). Suppose that the putative event time for reaction channel 7 changes from
 to
to
 following an event. We first update the value in node B of the binary heap. We then compare the value of
following an event. We first update the value in node B of the binary heap. We then compare the value of
 to the value in the parent node, node A, in Step (1). Because
to the value in the parent node, node A, in Step (1). Because
 is larger than the value stored in node A, we then compare
is larger than the value stored in node A, we then compare
 to the values stored in node B’s two child nodes in Step (2). Because
to the values stored in node B’s two child nodes in Step (2). Because
 is larger than the values in both the child nodes, we swap the values with the node containing the smallest of the two, which is node D, containing
is larger than the values in both the child nodes, we swap the values with the node containing the smallest of the two, which is node D, containing
 . We also update the index array by swapping the pointers of reaction channels 6 and 7. We then repeat the procedure for node D, which now contains
. We also update the index array by swapping the pointers of reaction channels 6 and 7. We then repeat the procedure for node D, which now contains
 . Because we just swapped the content of nodes B and D, we know that
. Because we just swapped the content of nodes B and D, we know that
 is larger than the value stored in node D’s parent node (i.e., node B). So, we compare
is larger than the value stored in node D’s parent node (i.e., node B). So, we compare
 to the value stored in the only child node of node D, namely, node H. We find that
to the value stored in the only child node of node D, namely, node H. We find that
 is larger than the value stored in node H (i.e.,
is larger than the value stored in node H (i.e.,
 ). Therefore, we swap the content of the two nodes, and we update the index array by swapping the pointers to channels 1 and 7. Because
). Therefore, we swap the content of the two nodes, and we update the index array by swapping the pointers to channels 1 and 7. Because
 is now stored in a leaf node, a stopping condition is satisfied, and we stop the procedure. Figure 12(b) shows the indexed priority queue after being updated.
is now stored in a leaf node, a stopping condition is satisfied, and we stop the procedure. Figure 12(b) shows the indexed priority queue after being updated.
One can also use the bubbling operation to initialize the indexed priority queue by successively adding nodes corresponding to each reaction channel. Because we initially need to add
 values of
values of
 (with
(with
 ), the initialization using bubbling takes
), the initialization using bubbling takes
 time. More efficient methods to initialize the priority queue exist (Reference Chen, Edelkamp, Elmasry and KatajainenChen et al., 2012). However, one runs the initialization only once during a simulation. Therefore, using an efficient initialization method would typically not much contribute to the algorithm’s runtime as a whole.
time. More efficient methods to initialize the priority queue exist (Reference Chen, Edelkamp, Elmasry and KatajainenChen et al., 2012). However, one runs the initialization only once during a simulation. Therefore, using an efficient initialization method would typically not much contribute to the algorithm’s runtime as a whole.
The binary search tree for the direct method and the binary heap for the next reaction method are both binary tree data structures and accelerate search. However, their aims are different. The binary tree for the direct method enables us to efficiently draw
 with probability
with probability
 , and the tree holds and updates all the
, and the tree holds and updates all the
 values (
values (
 ). The binary heap used in the next reaction method enables us to efficiently determine the
). The binary heap used in the next reaction method enables us to efficiently determine the
 that has the smallest
that has the smallest
 value, and the tree holds and updates all the
value, and the tree holds and updates all the
 values (
values (
 ). In both these structures, updating the values stored in the node (i.e.,
). In both these structures, updating the values stored in the node (i.e.,
 for the direct method or
for the direct method or
 for the next reaction method) following an event is less efficient than for the linear arrays used in their original implementation. Specifically, updating a value in the tree structures takes
for the next reaction method) following an event is less efficient than for the linear arrays used in their original implementation. Specifically, updating a value in the tree structures takes
 time as opposed to
time as opposed to
 time for the linear array. However, the improved direct and the next reaction methods still have an overall
time for the linear array. However, the improved direct and the next reaction methods still have an overall
 time complexity. In contrast, the original direct and first reaction methods have an overall
time complexity. In contrast, the original direct and first reaction methods have an overall
 time complexity due to the linear search, which costs
time complexity due to the linear search, which costs
 time. For large systems, the time saved by getting rid of the linear search is larger than the added overhead.
time. For large systems, the time saved by getting rid of the linear search is larger than the added overhead.
Finally, note that the binary heap has only
 nodes, which contrasts with the binary tree used for the direct method (Section 4.3), which has
nodes, which contrasts with the binary tree used for the direct method (Section 4.3), which has
 nodes in the ideal case of
nodes in the ideal case of
 being a power of 2. However, because the nodes in the binary heap are ordered according to their
being a power of 2. However, because the nodes in the binary heap are ordered according to their
 value and not their index, the binary heap also needs to store the reaction channel’s index
value and not their index, the binary heap also needs to store the reaction channel’s index
 in each node. In addition to the binary heap, the indexed priority queue also needs to store the index array, representing an additional
in each node. In addition to the binary heap, the indexed priority queue also needs to store the index array, representing an additional
 values. Thus, the indexed priority queue stores
values. Thus, the indexed priority queue stores
 values,
values,
 of which are floating-point numbers and
of which are floating-point numbers and
 are integers. In contrast, the binary tree stores
are integers. In contrast, the binary tree stores
 floating-point numbers. Therefore, the memory footprints of the indexed priority queue and the binary tree are similar.
floating-point numbers. Therefore, the memory footprints of the indexed priority queue and the binary tree are similar.
The steps for implementing the next reaction method are shown in Box 6.
0. Initialization:
(0) Define the initial state of the system, and set
.(b) Calculate the rate
for each reaction channel
.(c) Draw
random variates
from a uniform distribution on
.(d) Generate a putative event time
for each
.(e) Initialize the indexed priority queue: Sequentially for each reaction channel
, add a node containing the values
to the binary heap and its position to the index array, by performing the bubbling algorithm (see Box 5).
1. Select the reaction channel
corresponding to the root node in the heap (which has the smallest
).2. Perform the event on reaction channel
.3. Advance the time
.4. Update
and all other
that are affected by the event produced.5. Update the indexed priority queue:
(a) Draw a new putative waiting time for reaction channel
according to
, with
being drawn from uniform distribution on
, and set
.(b) Generate new
values for other reaction channels
whose
has changed, according to
.(c) For each reaction channel
whose
value has changed (including
), look up in the index array the node
that stores
in the binary heap; update
in the node
, and run the bubbling algorithm (see Box 5) to reorder the heap and update the index array.
6. Return to Step 1.
































4.5 Composition and Rejection Algorithm to Draw the Next Event in the Direct Method
Let us discuss a third method to draw an event
 with probability
with probability
 from a categorical distribution
from a categorical distribution
 in the direct method. The idea is to use the so-called composition and rejection (CR) algorithm (Reference SchulzeSchulze, 2008; Reference Slepoy, Thompson and PlimptonSlepoy, Thompson, & Plimpton, 2008). This is a general method to sample a random variate that obeys a given distribution (Reference von Neumannvon Neumann, 1951), which typically has a constant time complexity, namely,
in the direct method. The idea is to use the so-called composition and rejection (CR) algorithm (Reference SchulzeSchulze, 2008; Reference Slepoy, Thompson and PlimptonSlepoy, Thompson, & Plimpton, 2008). This is a general method to sample a random variate that obeys a given distribution (Reference von Neumannvon Neumann, 1951), which typically has a constant time complexity, namely,
 , and thus can be fast even for large systems.
, and thus can be fast even for large systems.
The idea is to first represent the categorical distribution
 as a bar graph. The bar graph corresponding to the distribution given by Fig. 8 is shown in Fig. 13. The total area of the bar graph is equal to 1. We consider a rectangle that bounds the entirety of the bar graph, shown by the dotted lines in Fig. 13. Then, we draw two random variates, denoted by
as a bar graph. The bar graph corresponding to the distribution given by Fig. 8 is shown in Fig. 13. The total area of the bar graph is equal to 1. We consider a rectangle that bounds the entirety of the bar graph, shown by the dotted lines in Fig. 13. Then, we draw two random variates, denoted by
 and
and
 , from the uniform distribution on
, from the uniform distribution on
 and consider the point (
and consider the point (
 ,
,
 ), where
), where
 . By construction, the point drawn is distributed uniformly (i.e., without bias) in the rectangle. If the point happens to be inside the area of the bar graph, it is in fact a uniformly random draw from the bar graph. Thus, the probability for the point to land inside the
. By construction, the point drawn is distributed uniformly (i.e., without bias) in the rectangle. If the point happens to be inside the area of the bar graph, it is in fact a uniformly random draw from the bar graph. Thus, the probability for the point to land inside the
 th bar is proportional to
th bar is proportional to
 in this case. The composition and rejection algorithm uses this property to draw the event that happens, without having to iterate over a list (or a binary tree) of
in this case. The composition and rejection algorithm uses this property to draw the event that happens, without having to iterate over a list (or a binary tree) of
 values, by simply judging which bar the point falls inside. In the example shown in Fig. 13, the point drawn, shown by the filled circle, belongs to
values, by simply judging which bar the point falls inside. In the example shown in Fig. 13, the point drawn, shown by the filled circle, belongs to
 , so we conclude that reaction channel 2 has produced the event. If the point does not fall inside any bar (e.g., the triangle in Fig. 13), we then reject this point and obtain another point by redrawing two new uniform random variates. In practice, we find a putative reaction channel to produce the event by
, so we conclude that reaction channel 2 has produced the event. If the point does not fall inside any bar (e.g., the triangle in Fig. 13), we then reject this point and obtain another point by redrawing two new uniform random variates. In practice, we find a putative reaction channel to produce the event by
 and adopt it if
and adopt it if
 ; we reject it otherwise. The steps of the CR algorithm for general cases are shown in Box 7. These steps replace Step 2 of the direct method in Box 3. We note that the meaning of the rejection here is the same as that for the rejection sampling algorithm (see Section 2.8) but that the two algorithms are otherwise different.
; we reject it otherwise. The steps of the CR algorithm for general cases are shown in Box 7. These steps replace Step 2 of the direct method in Box 3. We note that the meaning of the rejection here is the same as that for the rejection sampling algorithm (see Section 2.8) but that the two algorithms are otherwise different.
Bar graph for the composition and rejection algorithm. The height of each bar represents
 . Like in Fig. 8, we assume
. Like in Fig. 8, we assume
 ,
,
 ,
,
 ,
,
 , and
, and
 . The two points uniformly randomly sampled from the dotted rectangle are shown by a circle and triangle.
. The two points uniformly randomly sampled from the dotted rectangle are shown by a circle and triangle.

If the area of the bar graph, which is always equal to 1, is close to the area of the rectangle, the CR algorithm is efficient. This is because rejection then occurs with a small probability, and we only waste a small fraction of the random variates
 and
and
 , whose generation is typically the most costly part of the algorithm. In Fig. 13, the rectangle has area of
, whose generation is typically the most costly part of the algorithm. In Fig. 13, the rectangle has area of
 . Therefore, one rejects
. Therefore, one rejects
 of the generated random points on average. If the area of the box is much larger than one, which will generally happen when the event rates are heterogeneous and a few rates are much larger than the majority, then the CR algorithm is not efficient.
of the generated random points on average. If the area of the box is much larger than one, which will generally happen when the event rates are heterogeneous and a few rates are much larger than the majority, then the CR algorithm is not efficient.
In Reference SchulzeSchulze (2008) and Reference Slepoy, Thompson and PlimptonSlepoy et al. (2008), the authors went further to improve the CR algorithm to reduce the rejection probability. The idea is to organize the individual bars such that bars of similar heights are grouped together into a small number of groups and then to draw a rectangle to bound each group of bars. The probability for a group to generate the next event is proportional to the sum of the areas of the individual bars in the group. Because the number of groups is small, one can efficiently select the group that generates an event using a simple linear search. In many cases the number of groups does not depend on
 , and this step thus has constant time complexity,
, and this step thus has constant time complexity,
 . We then apply the original CR algorithm, given in Box 7, inside this group to select the individual reaction channel that generates the next event. This step is necessarily efficient since the reaction channels were grouped to have similar rates, so the area of the box corresponding to the group is not much larger than one. This implementation of the CR algorithm conserves its
. We then apply the original CR algorithm, given in Box 7, inside this group to select the individual reaction channel that generates the next event. This step is necessarily efficient since the reaction channels were grouped to have similar rates, so the area of the box corresponding to the group is not much larger than one. This implementation of the CR algorithm conserves its
 time complexity. It makes the rejection step more efficient at the cost of requiring an additional random variate and having to iterate through the list of groups to select the one that generates the event.
time complexity. It makes the rejection step more efficient at the cost of requiring an additional random variate and having to iterate through the list of groups to select the one that generates the event.
In both the original and improved CR algorithms, the time to determine
 does not depend on
does not depend on
 , so it has
, so it has
 time complexity in terms of
time complexity in terms of
 . In practice, the efficiency of the algorithm depends on the probability of rejection and on the complexity of regrouping the bars in the case of the improved CR algorithm.
. In practice, the efficiency of the algorithm depends on the probability of rejection and on the complexity of regrouping the bars in the case of the improved CR algorithm.
1. Generate two uniform random variates
.2. Set
.3. If
, we conclude that the
th reaction channel produces the event. Otherwise, return to Step 1.



4.6 Recycling Pseudorandom Numbers in the Direct Method
Each iteration of the direct method requires the generation of two uniform random variates,
 and
and
 ; one for generating the waiting time, and another for selecting the reaction channel that produces an event. Generating a pseudorandom number is generally more costly than simple arithmetic operations. However, as we mentioned in Section 4.4, recent pseudorandom number generators have substantially reduced the computational cost of generating random numbers. Nevertheless, there may be situations where it is preferable to generate as few random numbers as possible. Reference Yates and KlingbeilYates and Klingbeil (2013) proposes a method to recycle a single pseudorandom number to generate both
; one for generating the waiting time, and another for selecting the reaction channel that produces an event. Generating a pseudorandom number is generally more costly than simple arithmetic operations. However, as we mentioned in Section 4.4, recent pseudorandom number generators have substantially reduced the computational cost of generating random numbers. Nevertheless, there may be situations where it is preferable to generate as few random numbers as possible. Reference Yates and KlingbeilYates and Klingbeil (2013) proposes a method to recycle a single pseudorandom number to generate both
 and
and
 (see also Reference Masuda and RochaMasuda and Rocha [2018]). The method works as follows.
(see also Reference Masuda and RochaMasuda and Rocha [2018]). The method works as follows.
First, we generate a uniform random variate on
 denoted by
denoted by
 , where
, where
 . Second, we determine the reaction channel
. Second, we determine the reaction channel
 that produces the event, which satisfies
that produces the event, which satisfies
 (see Step 2 in Box 3). These steps are the same as those of the direct method. Now, we exploit the fact that
(see Step 2 in Box 3). These steps are the same as those of the direct method. Now, we exploit the fact that
 is uniformly distributed on
is uniformly distributed on
 given that the reaction channel
given that the reaction channel
 has been selected. This is because
has been selected. This is because
 is uniformly distributed between
is uniformly distributed between
 and
and
 (which is equal to
(which is equal to
 ). Therefore, we set
). Therefore, we set
 (4.11)
(4.11)
which is a uniform random variate on
 . Then, we generate the waiting time by
. Then, we generate the waiting time by
 (see Step 1 in Box 3).
(see Step 1 in Box 3).
There are two remarks. First, we need to determine
 and then determine
and then determine
 with this method. In contrast, one can first determine either
with this method. In contrast, one can first determine either
 or
or
 as one likes in the original direct method. Second, by generating two pseudorandom numbers from a one pseudorandom number, one is trading speed for accuracy. The variable
as one likes in the original direct method. Second, by generating two pseudorandom numbers from a one pseudorandom number, one is trading speed for accuracy. The variable
 has a smaller number of significant digits (i.e., less accuracy) compared to when one generates
has a smaller number of significant digits (i.e., less accuracy) compared to when one generates
 directly using a pseudorandom number generator as in the original direct method. However, this omission probably does not cause serious problems in typical cases as long as
directly using a pseudorandom number generator as in the original direct method. However, this omission probably does not cause serious problems in typical cases as long as
 is not extremely large because the
is not extremely large because the
 generated by the recycling direct method and the original direct method differ only slightly in the numerical value.
generated by the recycling direct method and the original direct method differ only slightly in the numerical value.
4.7 Network Considerations
In networks, where different nodes may have different degrees, and the number of infectious neighbors may be different even for same-degree nodes, it may be difficult to bookkeep, select, and update the
 values efficiently. So, we need careful consideration of these steps when simulating stochastic processes in networks (Reference Kiss, Miller and SimonKiss et al., 2017a; Reference St-Onge, Young, Hébert-Dufresne and DubéSt-Onge et al., 2019). A particular problem that arises in dense networks or for dynamic processes in heterogeneous networks that are close to a critical point is that the average number of reaction channels that are affected by each event can become extremely large. Concretely, it may be proportional to the number of reaction channels,
values efficiently. So, we need careful consideration of these steps when simulating stochastic processes in networks (Reference Kiss, Miller and SimonKiss et al., 2017a; Reference St-Onge, Young, Hébert-Dufresne and DubéSt-Onge et al., 2019). A particular problem that arises in dense networks or for dynamic processes in heterogeneous networks that are close to a critical point is that the average number of reaction channels that are affected by each event can become extremely large. Concretely, it may be proportional to the number of reaction channels,
 . In this case updating the event rates
. In this case updating the event rates
 (Step 4 in Boxes 2 and 6 and Step 5 in Boxes 3 and 4) no longer has an
(Step 4 in Boxes 2 and 6 and Step 5 in Boxes 3 and 4) no longer has an
 time complexity but
time complexity but
 . Because none of the methods just discussed improves this step, they then cannot improve the time complexity of the classic Gillespie algorithms in this situation.
. Because none of the methods just discussed improves this step, they then cannot improve the time complexity of the classic Gillespie algorithms in this situation.
Carefully designed event-based simulations, which are similar in spirit to the first reaction method, can significantly accelerate exact simulations of coupled jump processes, even for dense or heterogeneous networks and including the case of coupled non-Poissonian renewal processes (see also Section 5.5). An important assumption underlying this approach is that, once a node is infected, it will recover at a time that is drawn according to the distribution of recovery times regardless of what is going to happen elsewhere in the network. In this way, one can generate and store the recovery time of this node in a priority queue to be retrieved when the time comes. Codes for the SIR model and the susceptible-infectious-susceptible (SIS) model (i.e., individuals may get reinfected after a recovery) as well as for generating animation and snapshot figures are available at Reference Kiss, Miller and SimonKiss, Miller, and Simon (2017b). The corresponding pseudocode and explanation are available in Appendix A of Reference Kiss, Miller and SimonKiss, Miller, and Simon (2017a).
Another idea that can be used for speeding up simulations in this case is that of phantom processes, which is to assign a positive event rate to types of events that actually cannot occur. For example, an infectious node attempts to infect an already infectious or recovered node. If such an event is selected in a single step of the Gillespie algorithm, nothing actually occurs, and so the event is wasted. However, by designing such phantom processes carefully, one can simplify the updating of the list of all possible events upon the occurrence of events, leading to overall saving of computation time (Reference Cota and FerreiraCota & Ferreira, 2017).
St-Onge and colleagues have advanced related simulation methods in three main aspects (Reference St-Onge, Young, Hébert-Dufresne and DubéSt-Onge et al., 2019). First, they noted the fact that, in the case of the SIR and SIS models, any event, namely either the infection or the recovery event, involves an infectious individual. Therefore, we can reorganize the set of possible events such that they are grouped according to the individual infectious nodes. In other words, an infectious node either recovers with rate
 or infects one of its susceptible neighbors with rate
or infects one of its susceptible neighbors with rate
 . Therefore, the total event rate associated to an infectious node
. Therefore, the total event rate associated to an infectious node
 is equal to
is equal to
 , where
, where
 is the number of susceptible neighbors of
is the number of susceptible neighbors of
 . In this manner, one only has to monitor
. In this manner, one only has to monitor
 reaction channels during the process. Their second idea is to use the CR algorithm (Section 4.5). We have
reaction channels during the process. Their second idea is to use the CR algorithm (Section 4.5). We have
 (4.12)
(4.12)
for infectious nodes
 . Because infected nodes tend to be large-degree nodes (Reference Barrat, Barthélemy and VespignaniBarrat et al., 2008; Reference Pastor-Satorras, Castellano, Van Mieghem and VespignaniPastor-Satorras et al., 2015; Reference Pastor-Satorras and VespignaniPastor-Satorras & Vespignani, 2001), some
. Because infected nodes tend to be large-degree nodes (Reference Barrat, Barthélemy and VespignaniBarrat et al., 2008; Reference Pastor-Satorras, Castellano, Van Mieghem and VespignaniPastor-Satorras et al., 2015; Reference Pastor-Satorras and VespignaniPastor-Satorras & Vespignani, 2001), some
 ’s tend to be much larger than other
’s tend to be much larger than other
 ’s. To accelerate the sampling of the event
’s. To accelerate the sampling of the event
 that occurs in each step in this situation, they employed the improved CR algorithm of Reference Slepoy, Thompson and PlimptonSlepoy and colleagues (2008). Third, they employed phantom processes, corresponding to infections of already infectious nodes.
that occurs in each step in this situation, they employed the improved CR algorithm of Reference Slepoy, Thompson and PlimptonSlepoy and colleagues (2008). Third, they employed phantom processes, corresponding to infections of already infectious nodes.
Their algorithm has a time complexity of
 and is thus efficient in many cases. Their code, whose computational part is implemented in C++ for efficiency and whose interface is in Python, is available on Github (Reference St-OngeSt-Onge, 2019).
and is thus efficient in many cases. Their code, whose computational part is implemented in C++ for efficiency and whose interface is in Python, is available on Github (Reference St-OngeSt-Onge, 2019).
4.8 Tau-Leaping Method
There are various other algorithms that are related to the Gillespie algorithms and introduce some approximations to speed up the simulations. We briefly review just one such method here, the tau-leaping method, which Gillespie proposed in 2001. The method works by discretizing time into intervals of some chosen length,
 . In a given interval, the method draws a random variate to determine how many events have happened for each process
. In a given interval, the method draws a random variate to determine how many events have happened for each process
 , denoted by
, denoted by
 , and then updates the state of the system (Reference GillespieGillespie, 2001). For example, in a chemical reaction system,
, and then updates the state of the system (Reference GillespieGillespie, 2001). For example, in a chemical reaction system,
 is the increment in the number of molecules of the
is the increment in the number of molecules of the
 th species. Under the assumption that each
th species. Under the assumption that each
 stays constant between
stays constant between
 , where
, where
 is the current time,
is the current time,
 obeys a Poisson distribution with mean
obeys a Poisson distribution with mean
 . In other words, the number is equal to
. In other words, the number is equal to
 with probability
with probability
 . It is desirable to make
. It is desirable to make
 large enough to reduce the computation time as much as possible. On the other hand,
large enough to reduce the computation time as much as possible. On the other hand,
 should be small enough to guarantee that
should be small enough to guarantee that
 stays approximately constant in each time window of length
stays approximately constant in each time window of length
 in order to assure the accuracy of the simulation. In simulations of social dynamics, the tap-leaping methods are probably not relevant in most cases because a single event on the
in order to assure the accuracy of the simulation. In simulations of social dynamics, the tap-leaping methods are probably not relevant in most cases because a single event on the
 th reaction channel typically produces the state change of, for example, the
th reaction channel typically produces the state change of, for example, the
 th individual. Then, one needs to renew the
th individual. Then, one needs to renew the
 value. If this is the case, we cannot use the same
value. If this is the case, we cannot use the same
 to produce multiple events on the
to produce multiple events on the
 th reaction channel.
th reaction channel.
For other methods to accelerate the Gillespie algorithm or related algorithms, we refer to the review paper by Reference Goutsias and JenkinsonGoutsias and Jenkinson (2013).
4.9 Pseudorandom Number Generation
All stochastic simulation algorithms including the Gillespie algorithms rely on the generation of random numbers. We here give a brief and practical introduction to computer generation of random numbers for application to Monte Carlo simulations. We will not address the technical workings of random number generators here. An authoritative introduction to the subject is found in Chapter 7 of Reference Press, Teukolsky, Vetterling and FlanneryPress and colleagues (2007).
A pseudorandom number generator (PRNG) is a deterministic computer algorithm that generates a sequence of approximately random numbers. Such numbers are not truly random. So, we refer to them as pseudorandom (i.e., seemingly random) to distinguish them from numbers generated by a truly random physical process. However, the numbers need not be truly random in most applications. They just need to be random enough. In the context of Monte Carlo simulations, a working criterion for what constitutes a good PRNG is that simulation results based on it are indistinguishable from those obtained with a truly random source (Reference JonesJones, 2010).Footnote 8 Not all PRNGs satisfy this requirement. In fact, many standard PRNG algorithms still in use today have been shown to have serious flaws. To make this volume self-contained, we here explain some simple good practices to be followed and pitfalls to be avoided to ensure that the pseudorandom numbers that our simulations rely on are of sufficient quality. For a more detailed, yet not too technical, introduction to good and bad practices in pseudorandom number generation, we recommend Reference JonesJones (2010).
What constitutes a good PRNG depends on the application. For example, good PRNGs for Monte Carlo simulations are generally not random enough for cryptography applications. Conversely, while cryptographically secure PRNGs produce high-quality random sequences, they are generally much slower and are thus not optimal for Monte Carlo simulations. As this example suggests, the choice of PRNG involves a trade-off between the statistical quality of the generated sequence and the speed of generation. Nevertheless, many PRNGs now exist that are both fast and produce sequences that are sufficiently random for any Monte Carlo simulation. Ensuring that you use a good PRNG essentially boils down to checking two simple points: (1) do not use your programming language’s standard PRNG, and (2) properly seed the PRNG.
First, the most important rule to follow when choosing a PRNG is to never use your programming language’s standard PRNG! To ensure backwards compatibility, the standard random number generators in many programming languages are based on historical algorithms that do not produce good pseudorandom number sequences. (A nonexhaustive list of languages with bad PRNGs is found in Reference JonesJones [2010].) Extensive test suites such as TestU01 (Reference L’Ecuyer and SimardL’Ecuyer & Simard, 2007) and Dieharder (Reference Brown, Eddelbuettel and BauerBrown, Eddelbuettel, & Bauer, 2021) have been developed for testing the statistical quality of PRNGs.
Several fast and high-quality PRNGs are implemented in standard scientific computing libraries. So, using a good PRNG is as simple as importing it from one of these libraries.Footnote 9 For example, we obtained all simulations performed in Python that are shown in this tutorial using the 64-bit Permuted Congruential Generator (PCG64) (Reference O’NeillO’Neill, 2014), which is available in the standard NumPy library. For C++ code (see Section 4.10), we used the Mersenne Twister 19937 algorithm with improved initialization,Footnote 10 namely mt19937ar (Reference MatsumotoMatsumoto, 2021; Reference Matsumoto and NishimuraMatsumoto & Nishimura, 1998), which is available as part of the Boost and Libstdc++ libraries.
Second, we should properly seed the PRNG. PRNGs rely on an internal state, which they use to generate the next output in the random number sequence. The internal state is updated at each step of the algorithm. At the first use of the PRNG, one must initialize, or seed, the internal state. Proper initialization is crucial for the performance of a PRNG. In particular, earlier PRNGs suffered from high sensitivity to the seed value. For example, the original implementation of the Mersenne Twister algorithm is hard to seed due to its slow mixing time. This means that, if the bitstring corresponding to the initial state is not random enough (e.g., if it contains mostly zeros), up to the first one million generated numbers can be nonrandom. Recently proposed PRNGs generally do not show the same pathologies. So, as long as one uses a recently proposed, good PRNG, seeding the generator is not a problem except when one runs simulations in parallel. The initial seeding problems of the Mersenne Twister have been fixed in the mt19937ar version in 2002 (Reference MatsumotoMatsumoto, 2021). As another example, the PCG64 PRNG is easy to seed.
We need to be more careful on how to seed each instance of the PRNG when running simulations in parallel. An often used method to select the seed for a PRNG is to generate it automatically based on the system clock. However, this is a bad idea for launching many (e.g., thousands or more) simulations in parallel because many simulations will then tend to be initialized with the same or nearly the same seed. Any simulations launched with the same seed will produce exactly the same results, and those launched with close seeds may produce correlated results depending on the mixing properties of the PRNG. In both cases, this is wasteful. What is worse, if we are not aware that the simulation results are correlated, we will overestimate the precision of the obtained results. The safest way to seed the PRNG for parallel simulation is to use a jump-ahead operation that allows us to advance the internal state of the PRNG by an arbitrary amount of steps. With this method, one can initialize the PRNG of individual simulations with states that are sufficiently far from each other such that the pseudorandom number sequences generated by the different simulations are dissimilar. Methods for parallel seeding exist for both the Mersenne Twister (Reference Haramoto, Matsumoto, Nishimura, Panneton and L’EcuyerHaramoto et al., 2008) and PCG64 (Reference O’NeillO’Neill, 2014). If one wants to use a PRNG for which no efficient jump-ahead method exists, a better source of randomness than the system time should be used. On Unix machines, /dev/urandom is a choice. Note, however, that all PRNGs have a fixed cycle length, after which it will repeat itself deterministically. Therefore, one should use a PRNG with a sufficiently large cycle length (at least
 ) and a seed with a sufficient number of bits (at least
) and a seed with a sufficient number of bits (at least
 ) to avoid overlap between the pseudorandom number sequences generated by the PRNG.
) to avoid overlap between the pseudorandom number sequences generated by the PRNG.
4.10 Codes
Here we showcase some example simulations of event-based stochastic processes using the Gillespie algorithms. In practice, in scientific research in which the Gillespie algorithms are used, we often need to exactly run coupled jump processes on a large scale. For example, you may need to simulate a system composed of many agents, or you may have to repeat the same set of simulations for various parameter values to investigate the dependence of the results on the parameter values of your model. In such a situation, we often want to implement the Gillespie algorithms in a program language faster than Python. Therefore, we implemented the SIR model and three other dynamics in C/C++, which is typically much faster than in Python. We use the Mersenne Twister as the PRNG and only implement the direct method. Our C/C++ codes and the list of edges of the networks used in our demonstrations are available at Github (https://github.com/naokimas/gillespie-tutorial).
4.10.1 SIR Model
We provide codes for simulating the SIR model in well-mixed populations (sir-wellmixed.cc), for general networks using Gillespie’s original direct method (sir-net.cc), and for general networks using the binary search tree (see Section 4.3) to speed up the selection of the events (sir-net-binary-tree.cc). Time courses of the fractions of the susceptible, infectious, and recovered nodes from two runs of the SIR model with
 and
and
 on a regular random graph with
on a regular random graph with
 nodes are shown in Fig. 14. We started both runs from the same initial condition in which just one node, which was the same node in both runs, was infectious and the other
nodes are shown in Fig. 14. We started both runs from the same initial condition in which just one node, which was the same node in both runs, was infectious and the other
 nodes were susceptible. The figure illustrates the variability of the results due to stochasticity, which is lacking in the ODE version of the SIR model (Section 2.7).
nodes were susceptible. The figure illustrates the variability of the results due to stochasticity, which is lacking in the ODE version of the SIR model (Section 2.7).
Time courses of the fraction of the susceptible, infectious, and recovered nodes obtained from two runs of the SIR model. We set
 and
and
 . We used a regular random graph with
. We used a regular random graph with
 nodes and the nodes’ degree equal to five. In other words, each node has degree 5, and apart from that, we connect the nodes uniformly at random according to the configuration model (Reference Fosdick, Larremore, Nishimura and UganderFosdick et al., 2018). The network is the same for the two runs shown in (a) and (b). Each run started from the same initial condition in which a particular node was infectious and the other
nodes and the nodes’ degree equal to five. In other words, each node has degree 5, and apart from that, we connect the nodes uniformly at random according to the configuration model (Reference Fosdick, Larremore, Nishimura and UganderFosdick et al., 2018). The network is the same for the two runs shown in (a) and (b). Each run started from the same initial condition in which a particular node was infectious and the other
 nodes were susceptible.
nodes were susceptible.
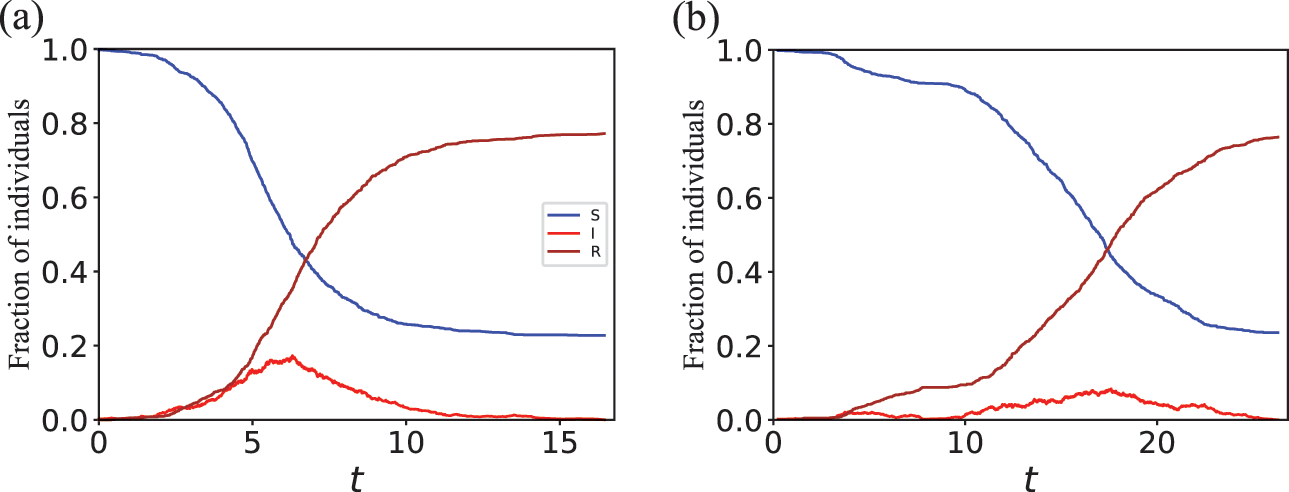
4.10.2 Metapopulation Model with SIR Epidemic Dynamics
Another example system that the Gillespie algorithms can be used for is the SIR model in a metapopulation network. Mobility may induce different contact patterns at different times. For example, we typically contact family members in the morning and evening, while we may contact workmates or schoolmates in the day time. The metapopulation model provides a succinct way to model network changes induced by mobility (Reference Anderson and MayAnderson & May, 1991; Reference Colizza, Barrat, Barthélemy and VespignaniColizza et al., 2006; Reference Colizza, Pastor-Satorras and VespignaniColizza, Pastor-Satorras, Vespignani, 2007; Reference Diekmann and HeesterbeekDiekmann & Heesterbeek, 2000; Reference HanskiHanski, 1998; Reference Hufnagel, Brockmann and GeiselHufnagel, Brockmann, & Geisel, 2004; ). We consider a network, where a node is a patch, also called a subpopulation, which is a container of individuals, modeling for example, a home, a workplace, a sports team meeting, or a pub. A network of patches is distinct from a network in which a node is an individual. In Fig. 15, there are
 patches connected as a network. Each individual is in either the S, I, or R state and is assumed to be situated in one patch; there are
patches connected as a network. Each individual is in either the S, I, or R state and is assumed to be situated in one patch; there are
 individuals in Fig. 15. An infectious individual infects each susceptible individual in the same patch with rate
individuals in Fig. 15. An infectious individual infects each susceptible individual in the same patch with rate
 . Crucially, an infectious individual does not infect susceptible individuals in other patches. An infectious individual recovers with rate
. Crucially, an infectious individual does not infect susceptible individuals in other patches. An infectious individual recovers with rate
 regardless of who are in the same patch.
regardless of who are in the same patch.
A metapopulation model network with
 patches and
patches and
 individuals. As in the previous similar figures, the blue, red, and brown circles represent susceptible, infectious, and recovered individuals, respectively.
individuals. As in the previous similar figures, the blue, red, and brown circles represent susceptible, infectious, and recovered individuals, respectively.

In addition, the individuals move from a patch to another. There are various mobility rules used in the metapopulation model (Reference Masuda and LambiotteMasuda & Lambiotte, 2020), but a simple one is the so-called continuous-time random walk. In its simplest variant, each individual moves with constant rate
 , which is often called the diffusion rate. In other words, each individual stays in the currently visited patch for a sojourn time
, which is often called the diffusion rate. In other words, each individual stays in the currently visited patch for a sojourn time
 , which follows the exponential distribution,
, which follows the exponential distribution,
 , before it moves to a neighboring patch. When the individual moves, it selects each neighboring patch with equal probability. For example, the infectious individual
, before it moves to a neighboring patch. When the individual moves, it selects each neighboring patch with equal probability. For example, the infectious individual
 in Fig. 15 moves to either of the neighboring patches with probability
in Fig. 15 moves to either of the neighboring patches with probability
 when it moves. The movements of different individuals are independent of each other, and the moving events occur independently of the infection or recovery events. Because we assumed that the time to the next move of each individual obeys an exponential distribution, we can use the Gillespie algorithms to simulate the SIR plus mobility dynamics as described by the standard metapopulation model.
when it moves. The movements of different individuals are independent of each other, and the moving events occur independently of the infection or recovery events. Because we assumed that the time to the next move of each individual obeys an exponential distribution, we can use the Gillespie algorithms to simulate the SIR plus mobility dynamics as described by the standard metapopulation model.
We provide a code (sir-metapop.cc) for simulating the SIR model in the metapopulation model to which one can feed an arbitrary network structure. Time courses of the numbers of S, I, and R individuals are qualitatively similar to those for the standard SIR model in well-mixed populations and networks.
4.10.3 Voter Model
Another typical example of collective dynamics is the voter model (Reference Barrat, Barthélemy and VespignaniBarrat et al., 2008; Reference Castellano, Fortunato and LoretoCastellano, Fortunato, & Loreto, 2009; Reference Holley and LiggettHolley & Liggett, 1975; Reference Krapivsky, Redner and Ben-NaimKrapivsky, Redner, & Ben-Naim, 2010; Reference LiggettLiggett, 1999). Suppose again that the individuals are nodes of a network. Each individual is a voter and takes either of the two states A and B, referred to as opinions (see Fig. 16). If two individuals adjacent on the network have the opposite opinions, the A individual, denoted by
 , tries to convince the B individual, denoted by
, tries to convince the B individual, denoted by
 , into supporting opinion A, in the same manner as an infectious individual infects a susceptible individual in the SIR model. This event occurs with rate
, into supporting opinion A, in the same manner as an infectious individual infects a susceptible individual in the SIR model. This event occurs with rate
 . At the same time,
. At the same time,
 tries to convince
tries to convince
 , who currently supports opinion A, into supporting opinion B, which occurs with rate
, who currently supports opinion A, into supporting opinion B, which occurs with rate
 . Clearly, the two opinions compete with each other. The time before
. Clearly, the two opinions compete with each other. The time before
 flips its opinion from B to A due to
flips its opinion from B to A due to
 obeys an exponential distribution given by
obeys an exponential distribution given by
 . Likewise, the time before
. Likewise, the time before
 flips its opinion from A to B due to
flips its opinion from A to B due to
 obeys an exponential distribution given by
obeys an exponential distribution given by
 . If
. If
 and nothing else occurs on the network for time
and nothing else occurs on the network for time
 from now,
from now,
 flips its opinion from B to A. This implies that
flips its opinion from B to A. This implies that
 loses the chance to convince
loses the chance to convince
 to take opinion B because
to take opinion B because
 itself now supports opinion A.
itself now supports opinion A.
Schematic of the voter model on a network.
Such a competition occurs on every edge of the network that connects two nodes with the opposite opinions. The dynamics stop when the unanimity of opinion A or that of opinion B has been reached. Then, there is no opinion conflict in the entire population. Note that opinion B does not emerge if everybody in the network has opinion A, and vice versa. For this and other reasons, the voter model is not a very realistic model of voting or collective opinion formation. However, the model has been extensively studied since its inception in the 1970s. The most usual setting is to assume
 (i.e., both opinions are equally influential) and ask questions such as the time until consensus (i.e., unanimity) and which opinion is likely to win depending on the initial conditions. When
(i.e., both opinions are equally influential) and ask questions such as the time until consensus (i.e., unanimity) and which opinion is likely to win depending on the initial conditions. When
 , the model is called the biased voter model, and an additional question to be asked is which opinion is likely to win depending on the imbalance between
, the model is called the biased voter model, and an additional question to be asked is which opinion is likely to win depending on the imbalance between
 and
and
 . Because there are only two types of events, associated with
. Because there are only two types of events, associated with
 and
and
 , and they occur with exponentially distributed waiting times, one can simulate the voter models, including biased ones, using the standard Gillespie algorithms.
, and they occur with exponentially distributed waiting times, one can simulate the voter models, including biased ones, using the standard Gillespie algorithms.
We provide codes for simulating the voter model in well-mixed populations (voter-wellmixed.cc), for general networks using Gillespie’s original direct method (voter-net.cc), and for general networks using a binary search tree (voter-net-binary-tree.cc). Time courses of the fraction of the nodes in opinion A from three runs of the unbiased voter model on a regular random graph with
 and
and
 nodes are shown in Fig. 17(a) and Fig. 17(b), respectively. All the runs for each network started from the same initial condition in which half the nodes are in opinion A and the other half in opinion B. The figure indicates that some runs terminate with the consensus of opinion A and the others with the consensus of opinion B. It takes much longer time before a consensus is reached with
nodes are shown in Fig. 17(a) and Fig. 17(b), respectively. All the runs for each network started from the same initial condition in which half the nodes are in opinion A and the other half in opinion B. The figure indicates that some runs terminate with the consensus of opinion A and the others with the consensus of opinion B. It takes much longer time before a consensus is reached with
 (Fig. 17(b)) than with
(Fig. 17(b)) than with
 (Fig. 17(a)), which is expected. Results for well-mixed populations (which one can produce with voter-wellmixed.cc) are similar to those shown in Fig. 17.
(Fig. 17(a)), which is expected. Results for well-mixed populations (which one can produce with voter-wellmixed.cc) are similar to those shown in Fig. 17.
Time courses of the fraction of the nodes with opinion A in the voter model in three different simulations. We use a regular random graph with nodes’ degree equal to five. We set (a)
 and (b)
and (b)
 . We set
. We set
 . Each run started from the initial condition in which half the nodes were in opinion A and the other half were in opinion B. The results for three runs are shown in different colors in each panel.
. Each run started from the initial condition in which half the nodes were in opinion A and the other half were in opinion B. The results for three runs are shown in different colors in each panel.

Lotka–Volterra Model
The Lotka–Volterra model describes dynamics of the numbers of prey and of predators under predator–prey interaction. It is common to formulate and analyze this dynamics as a system of ODEs, where the dependent variables represent the numbers of the prey and predators, and the independent variable is time. The ODE approach to the Lotka–Volterra model and its variants have been particularly useful in revealing mathematical underpinnings of oscillatory time courses of the numbers of prey and predators (Reference Hofbauer and SigmundHofbauer & Sigmund, 1988; Reference MurrayMurray, 2002). However, it is indispensable to consider stochastic versions of the Lotka–Volterra models (Reference Dobrinevski and FreyDobrinevski & Frey, 2012; Reference Gokhale, Papkou, Traulsen and SchulenburgGokhale et al., 2013; Reference Parker and KamenevParker & Kamenev, 2009) when the number of prey or of predators is small. (See Section 2.7 for a general discussion of the problems with ODE models.)
Consider a system composed of a single species of prey (which we call rabbits) and a single species of predator (which we call foxes). We denote the number of rabbits and that of foxes by
 and
and
 , respectively. The rules of how
, respectively. The rules of how
 and
and
 change stochastically are shown schematically in Fig. 18. A rabbit gives birth to another rabbit with rate
change stochastically are shown schematically in Fig. 18. A rabbit gives birth to another rabbit with rate
 . A fox dies with rate
. A fox dies with rate
 . A fox consumes a rabbit with rate
. A fox consumes a rabbit with rate
 , which by definition results in an increment of
, which by definition results in an increment of
 by one. This assumption is probably unrealistic because a fox would not give birth to its cub only by consuming one rabbit. (A fox probably has to eat many rabbits to be able to bear a cub.) The model furthermore ignores natural deaths of the rabbits. These omissions are for simplicity. Because the three types of events occur as Poisson processes with their respective rates and we also assume that different types of events occur independently of each other, one can simulate the stochastic Lotka–Volterra dynamics using the Gillespie algorithms.
by one. This assumption is probably unrealistic because a fox would not give birth to its cub only by consuming one rabbit. (A fox probably has to eat many rabbits to be able to bear a cub.) The model furthermore ignores natural deaths of the rabbits. These omissions are for simplicity. Because the three types of events occur as Poisson processes with their respective rates and we also assume that different types of events occur independently of each other, one can simulate the stochastic Lotka–Volterra dynamics using the Gillespie algorithms.
Rules of the stochastic Lotla–Volterra model with one prey species and one predator species.

The extension of the Lotka–Volterra system to the case of many species is straightforward. In this scenario, a species
 may act as prey toward some species and as predator toward some other species. A version of the Lotka–Volterra model for more than two species can be described by the birth rate of species
may act as prey toward some species and as predator toward some other species. A version of the Lotka–Volterra model for more than two species can be described by the birth rate of species
 , denoted by
, denoted by
 (with which one individual of species
(with which one individual of species
 bears another individual of the same species); the natural death rate of species
bears another individual of the same species); the natural death rate of species
 , denoted by
, denoted by
 ; and the rate of consumption of individuals of species
; and the rate of consumption of individuals of species
 by one individual of species
by one individual of species
 , denoted by
, denoted by
 (i.e., an individual of species
(i.e., an individual of species
 consumes an individual of species
consumes an individual of species
 with rate
with rate
 ).
).
We provide a code (lotka-volterra-wellmixed.cc) for simulating the stochastic single-prey single-predator Lotka–Volterra dynamics in a well-mixed population. Two sample time courses of the number of rabbits and that of foxes are shown in Fig. 19. In both runs, the initial condition was the same (i.e.,
 rabbits and
rabbits and
 foxes). We see oscillatory behavior of both species with time lags, which is well known to appear in the Lotka–Volterra model. In Fig. 19(a), the simulation terminated when the rabbits went extinct after two cycles of wax and wane. By contrast, in Fig. 19(b), the simulation terminated when the foxes went extinct after many cycles of wax and wane. The apparent randomness in the sequence of the height of the peaks in Fig. 19(b) is due to the stochasticity of the model.
foxes). We see oscillatory behavior of both species with time lags, which is well known to appear in the Lotka–Volterra model. In Fig. 19(a), the simulation terminated when the rabbits went extinct after two cycles of wax and wane. By contrast, in Fig. 19(b), the simulation terminated when the foxes went extinct after many cycles of wax and wane. The apparent randomness in the sequence of the height of the peaks in Fig. 19(b) is due to the stochasticity of the model.
Number of rabbits and foxes for two different runs of the stochastic Lotka–Volterra model in a well-mixed population. In both (a) and (b), we set
 ,
,
 ,
,
 , and there are initially
, and there are initially
 rabbits and
rabbits and
 foxes.
foxes.

The results shown in Fig. 19 are in stark contrast with those that the ODE version of the Lotka–Volterra model would produce in two aspects. First, the two time courses from the present stochastic simulations look very different from each other due to the stochasticity of the model. The ODE version will produce the same result every time if the simulation starts from the same initial conditions and one can safely ignore rounding errors. Second, the ODE version does not predict the extinction of one species;
 or
or
 can become tiny in the course of the dynamics, but it never hits zero in finite time. By contrast, the stochastic-process version always ends up in extinction of either species, although it may take long time before the extinction occurs. Once rabbits go extinct, the foxes will necessarily go extinct because there is no prey for the foxes to consume. With our code, a run terminates once rabbits go extinct in this case. On the contrary, if foxes go extinct first, then the number of rabbits will grow indefinitely because the predators are gone. In either case, there is no room for foxes to survive.
can become tiny in the course of the dynamics, but it never hits zero in finite time. By contrast, the stochastic-process version always ends up in extinction of either species, although it may take long time before the extinction occurs. Once rabbits go extinct, the foxes will necessarily go extinct because there is no prey for the foxes to consume. With our code, a run terminates once rabbits go extinct in this case. On the contrary, if foxes go extinct first, then the number of rabbits will grow indefinitely because the predators are gone. In either case, there is no room for foxes to survive.
5 Gillespie Algorithms for Temporal Networks and Non-Poissonian Jump Processes
Until now we have assumed that all events occur according to Poisson processes and that the interaction network, including the case of the well-mixed population, stays the same over the duration of the simulation. However, both of these assumptions are often violated in empirical social systems. In this section, we present algorithms that relax these assumptions and allow us to simulate processes with non-Poissonian dynamics and on networks whose structure evolves over time.
5.1 Temporal Networks
In general, interactions between individuals in a social system are not continually active, so the networks they define vary in time (Fig. 20). The statistics of both the dynamics of empirical temporal networks and the dynamic processes taking place on them are often strongly non-Poissonian, displaying both nonexponential waiting times and temporal correlations. Both the dynamics of empirical networks and of processes taking place on dynamic networks have been studied under the umbrella term of temporal networks (Reference HolmeHolme, 2015; Reference Holme and SaramäkiHolme & Saramäki, 2012, Reference Holme and Saramäki2013, Reference Holme and Saramäki2019; Reference Masuda and LambiotteMasuda & Lambiotte, 2020). In the following subsections, we present several recent extensions of the direct method to temporal network scenarios. Before that, let us clarify which situations we want to extend it to.
Schematic of a “switching” temporal network with
 nodes. The network switches from one static graph to another at discrete points in time.
nodes. The network switches from one static graph to another at discrete points in time.
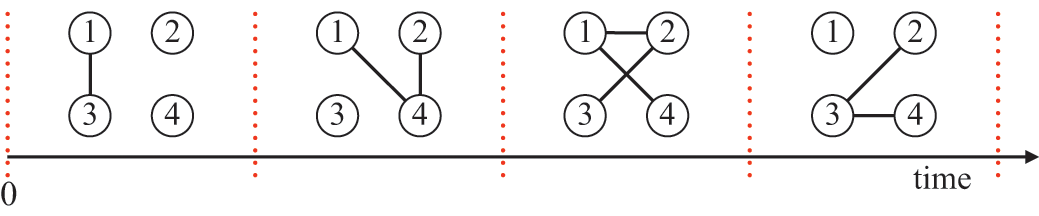
First, empirical sequences of discrete events tend to strongly deviate from Poisson processes. In a Poisson process, the distribution of interevent times is an exponential distribution. By contrast, events in empirical human activity data often do not exhibit exponential distributions. Figure 21 shows the distribution of interevent times
 between face-to-face encounters for an individual in a primary school. For reference, we also show an exponential distribution whose mean is the same as that of the empirical data. The empirical and exponential distributions do not resemble each other. In particular, the empirical distribution is much more skewed than the exponential distribution. It thus has a much larger chance of producing extreme values of
between face-to-face encounters for an individual in a primary school. For reference, we also show an exponential distribution whose mean is the same as that of the empirical data. The empirical and exponential distributions do not resemble each other. In particular, the empirical distribution is much more skewed than the exponential distribution. It thus has a much larger chance of producing extreme values of
 , both small and large. Typically, the right tail of the distribution (i.e., at large values of
, both small and large. Typically, the right tail of the distribution (i.e., at large values of
 ) is roughly approximated by a power-law distribution
) is roughly approximated by a power-law distribution
 , where
, where
 means proportional to, and
means proportional to, and
 is a constant, typically between 1 and 3. If one replaces the exponential
is a constant, typically between 1 and 3. If one replaces the exponential
 , which the Gillespie algorithm and the original stochastic multiagent models assume, by a power-law
, which the Gillespie algorithm and the original stochastic multiagent models assume, by a power-law
 , the results may considerably change. For example, for given
, the results may considerably change. For example, for given
 and
and
 values, epidemic spreading may be less likely to occur in the SIR model with interevent times
values, epidemic spreading may be less likely to occur in the SIR model with interevent times
 following a power-law distribution than with ones following an exponential distribution with the same mean (Reference Karsai, Kivelä and PanKarsai et al., 2011; Reference Kivelä, Pan and KaskiKivelä et al., 2012; Reference Masuda and HolmeMasuda & Holme, 2013; Reference Miritello, Moro and LaraMiritello, Moro, & Lara, 2011). Therefore, we are interested in simulating stochastic dynamics where the waiting times obey distributions that may differ from the exponential distribution. Such processes are called renewal processes. A Poisson process is the simplest example of a renewal process. It generates events at a constant rate irrespectively of the history of the events in the past and is thus called memoryless, which is also referred to as the process being Markovian. General renewal processes are not memoryless and are often referred to as being non-Markovian, especially in the physics literature. Note that, even in general renewal processes, each waiting time is independent of the past ones. However, the expected waiting time until the next event depends on the time elapsed since the last event.Footnote 11 In Sections 5.2 and 5.3, we will present two algorithms that simulate stochastic dynamics when
following a power-law distribution than with ones following an exponential distribution with the same mean (Reference Karsai, Kivelä and PanKarsai et al., 2011; Reference Kivelä, Pan and KaskiKivelä et al., 2012; Reference Masuda and HolmeMasuda & Holme, 2013; Reference Miritello, Moro and LaraMiritello, Moro, & Lara, 2011). Therefore, we are interested in simulating stochastic dynamics where the waiting times obey distributions that may differ from the exponential distribution. Such processes are called renewal processes. A Poisson process is the simplest example of a renewal process. It generates events at a constant rate irrespectively of the history of the events in the past and is thus called memoryless, which is also referred to as the process being Markovian. General renewal processes are not memoryless and are often referred to as being non-Markovian, especially in the physics literature. Note that, even in general renewal processes, each waiting time is independent of the past ones. However, the expected waiting time until the next event depends on the time elapsed since the last event.Footnote 11 In Sections 5.2 and 5.3, we will present two algorithms that simulate stochastic dynamics when
 can be nonexponential distributions.
can be nonexponential distributions.
Survival probability of interevent times between face-to-face encounters. Solid black line: empirical data; dashed blue line: exponential distribution having the same mean as that of the empirical data. The empirical data come from the “Primary School” data set from the SocioPatterns project (Reference Isella, Romano and BarratIsella et al., 2011). Events are face-to-face proximity relationships between an individual and other individuals in the school. We show the survival probability, that is,
 , instead of the distribution of interevent times,
, instead of the distribution of interevent times,
 , because
, because
 is more robust to noise in data. In other words, the vertical axis represents the fraction of the interevent times that are larger than the value specified on the horizontal axis. We selected the individual with the largest number of events and calculated all the interevent times for the selected individual. We omitted the largest interevent time, which is more than 10 times larger than the second largest one. The survival probability of the exponential distribution is given by
is more robust to noise in data. In other words, the vertical axis represents the fraction of the interevent times that are larger than the value specified on the horizontal axis. We selected the individual with the largest number of events and calculated all the interevent times for the selected individual. We omitted the largest interevent time, which is more than 10 times larger than the second largest one. The survival probability of the exponential distribution is given by
 .
.

Second, we may be interested in simulating a dynamic process on an empirically recorded temporal network (e.g., epidemic spread over a mobility network). We will here consider a representation of temporal networks in which the network changes discontinuously in discrete time points (Fig. 20), which we call switching networks. Such a representation is often practical since empirical temporal networks are generally recorded with finite time resolution and thus change only in discrete points in time. The Gillespie algorithms do not directly apply in this second case either. This is because, in switching networks, which events can occur and the rates at which they occur depend on time. In contrast, the classic Gillespie algorithms assume that the event rates stay constant in between events. We will present a temporal version of the direct method that can treat switching networks in Section 5.4.
Both non-Poissonian statistics of event times and temporally changing event rates can also occur in chemical reaction systems, for which the Gillespie algorithms were originally proposed. Several extensions have been developed in the chemical physics and computational biology literature to deal with these issues. Different from social systems, temporally changing event rates are often externally driven in such systems. For example, in cellular reaction systems the cell’s volume may change over time owing to cell growth. Such a volume change leads to changes in molecular concentrations and thus to temporally evolving reaction rates, similar to temporal networks. Extensions of the Gillespie algorithms have enabled, for example, simulating chemical reaction systems with time-varying volumes (Reference Carletti and FilisettiCarletti & Filisetti, 2012; Reference KierzekKierzek, 2002; Reference Lu, Volfson, Tsimring and HastyLu et al., 2004). There are also Gillespie algorithms for more generally fluctuating event rates (Reference AndersonAnderson, 2007). Another common phenomenon in chemical reaction systems is delays due to, for example, diffusion-limited reactions. Such delays lead to nonexponential waiting times, and several approaches have been developed to deal with this case (Reference AndersonAnderson, 2007; Reference Barrio, Burrage, Leier and TianBarrio et al., 2006; Reference Bratsun, Volfson, Tsimring and HastyBratsun et al., 2005; Reference CaiCai, 2007). While these issues are similar to those encountered in temporal networks, each has its particularities. Delays in chemical reaction systems lead to distributions of interevent times that are less skewed than the exponential distribution. In contrast, typical distributions of interevent times in social networks are more skewed than exponential distributions. Another difference is that external dynamics influencing chemical reaction systems are typically much slower than the reaction dynamics, while social network dynamics typically occur on the same scale or faster than the dynamics we want to simulate on networks. These facts pose specific challenges for the simulation algorithms. In fact, although some extensions of the Gillespie algorithms developed for chemical reaction systems may also be suitable for simulating multiagent systems and temporal networks, algorithms focusing specifically on the temporal network setting have emerged. We review them in this section.
5.2 Non-Markovian Gillespie Algorithm
The non-Markovian Gillespie algorithm is an extension of the direct method to the case in which interevent times are not distributed according to exponential distributions (Reference Boguñá, Lafuerza, Toral and SerranoBoguñá et al., 2014). It relaxes the assumption that the individual jump processes are Poisson processes and enables us to simulate general renewal processes.
We denote by
 the distribution of interevent times for the
the distribution of interevent times for the
 th reaction channel (where
th reaction channel (where
 ), which we assume is a renewal process. If
), which we assume is a renewal process. If
 is an exponential distribution, the
is an exponential distribution, the
 th renewal process is a Poisson process. If all
th renewal process is a Poisson process. If all
 s are exponential distributions, we can use the original Gillespie algorithms. When
s are exponential distributions, we can use the original Gillespie algorithms. When
 is not an exponential distribution, we need to know the time
is not an exponential distribution, we need to know the time
 since the last event for the process
since the last event for the process
 to be able to generate the time to the next event for that process.
to be able to generate the time to the next event for that process.
By definition, the interevent time
 between two successive events produced by the
between two successive events produced by the
 th process is given by
th process is given by
 . We want to know the next event time,
. We want to know the next event time,
 , where
, where
 is the time of the last event on the
is the time of the last event on the
 th reaction channel. The calculation of
th reaction channel. The calculation of
 is not straightforward to implement using the direct method because knowing the function
is not straightforward to implement using the direct method because knowing the function
 for each reaction channel is not enough on its own to simulate coupled renewal processes. In fact, we must be able to calculate not only the waiting time since the last event of the
for each reaction channel is not enough on its own to simulate coupled renewal processes. In fact, we must be able to calculate not only the waiting time since the last event of the
 th process, but since an arbitrary time
th process, but since an arbitrary time
 at which another process may have generated an event. Suppose that
at which another process may have generated an event. Suppose that
 has not produced an event for a time
has not produced an event for a time
 after its last event. (The current time is thus
after its last event. (The current time is thus
 .) We denote by
.) We denote by
 the waiting time until the next event starting from time
the waiting time until the next event starting from time
 . See Fig. 22 for a schematic definition of the different notions of times. The waiting time
. See Fig. 22 for a schematic definition of the different notions of times. The waiting time
 does not obey
does not obey
 . Instead,
. Instead,
 obeys the following conditional probability density with which the next event occurs at time
obeys the following conditional probability density with which the next event occurs at time
 given that no event has occurred between
given that no event has occurred between
 and
and
 :
:
Schematic definition of the different notions of times employed in this section and the relations between them.
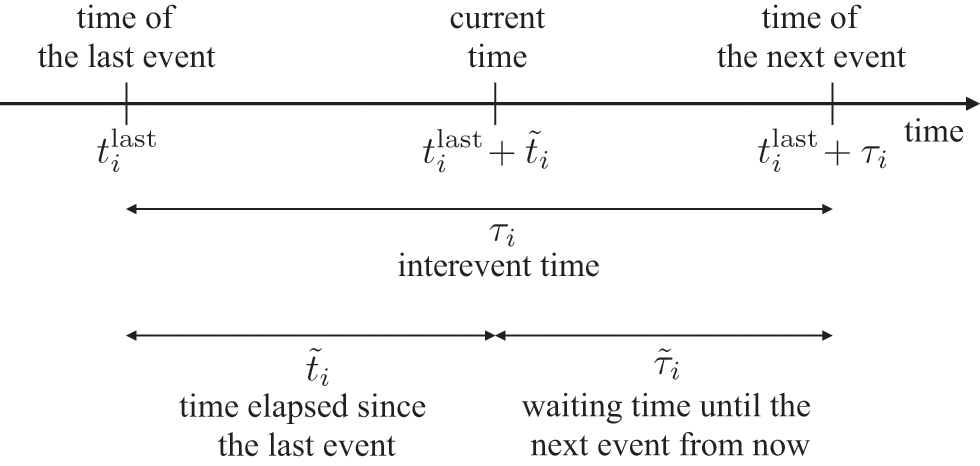
 (5.1)
(5.1)
Here
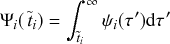 (5.2)
(5.2)
is the survival probability, that is, the probability that the interevent time is larger than
 . The preceding argument shows that the waiting time to the next event for each process explicitly depends on
. The preceding argument shows that the waiting time to the next event for each process explicitly depends on
 . Therefore, we need to record when the last event has happened (i.e,
. Therefore, we need to record when the last event has happened (i.e,
 , which is
, which is
 before the current time) to generate the waiting time.
before the current time) to generate the waiting time.
As an example, we consider a power-law distribution of interevent times given by
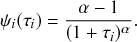 (5.3)
(5.3)
By substituting Eq. (5.3) into Eq. (5.1), we find the probability distribution for the waiting time
 until the
until the
 th renewal process generates its next event given that a time
th renewal process generates its next event given that a time
 has already elapsed since its last event:
has already elapsed since its last event:
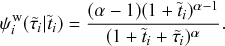 (5.4)
(5.4)
Due to the highly skewed shape of
 , the expected waiting time until the next event becomes longer if more time has already elapsed without an event; that is,
, the expected waiting time until the next event becomes longer if more time has already elapsed without an event; that is,
 tends to be longer than
tends to be longer than
 . One can show this counterintuitive result by comparing the mean values of
. One can show this counterintuitive result by comparing the mean values of
 and
and
 . The former is equal to
. The former is equal to
 . This is larger than the latter, which is given by
. This is larger than the latter, which is given by
 .
.
When
 is a Poisson process,
is a Poisson process,
 is an exponential distribution, and such a complication does not occur. The memoryless property of the exponential distribution yields
is an exponential distribution, and such a complication does not occur. The memoryless property of the exponential distribution yields
 , which we can verify by plugging the exponential distribution into Eq. (5.1):
, which we can verify by plugging the exponential distribution into Eq. (5.1):
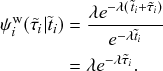 (5.5)
(5.5)
Therefore,
 does not depend on the time elapsed since the last event,
does not depend on the time elapsed since the last event,
 , and is the same as the original exponential distribution,
, and is the same as the original exponential distribution,
 . The original Gillespie algorithm fully exploits this property of Poisson processes.
. The original Gillespie algorithm fully exploits this property of Poisson processes.
To build a direct Gillespie method for simulating coupled renewal processes, we need to calculate two quantities: (i) the time until the next event in the entire population,
 , whichever process produces this event; (ii) the probability
, whichever process produces this event; (ii) the probability
 that the next event is produced by the
that the next event is produced by the
 th process. We denote by
th process. We denote by
 the probability density for the
the probability density for the
 th process, and not any other process, to generate the next event after a time
th process, and not any other process, to generate the next event after a time
 conditioned on the time elapsed since the last event of all processes in the population,
conditioned on the time elapsed since the last event of all processes in the population,
 . It should be noted that we need to condition on each
. It should be noted that we need to condition on each
 . This is because
. This is because
 depends not only on the
depends not only on the
 th renewal process generating an event after the waiting time
th renewal process generating an event after the waiting time
 but also on all the other processes not generating any event during this time. By putting all this together, we obtain
but also on all the other processes not generating any event during this time. By putting all this together, we obtain
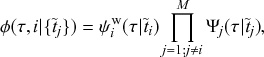 (5.6)
(5.6)
where
 is the conditional survival probability for the waiting time of the
is the conditional survival probability for the waiting time of the
 th process if it were running in isolation, given that its last event occurred a time
th process if it were running in isolation, given that its last event occurred a time
 ago.
ago.
Equation (5.6) is composed of two factors. The first factor is the probability density for the
 th process to generate the next event within a small time window around
th process to generate the next event within a small time window around
 (i.e., between
(i.e., between
 and
and
 from now, where
from now, where
 is infinitesimally small), corresponding to the probability density
is infinitesimally small), corresponding to the probability density
 . The other factor is the probability that none of the other
. The other factor is the probability that none of the other
 processes generates an event within this time window, corresponding to the product of the survival probabilities
processes generates an event within this time window, corresponding to the product of the survival probabilities
 over all
over all
 . Using Eq. (5.1), we obtain
. Using Eq. (5.1), we obtain
 as follows:
as follows:
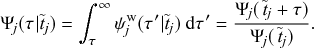 (5.7)
(5.7)
By substituting Eqs. (5.1) and (5.7) into Eq. (5.6), we obtain
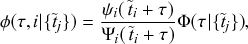 (5.8)
(5.8)
where
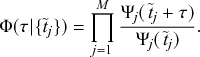 (5.9)
(5.9)
We interpret Eq. (5.8) as follows.
First,
 is the probability that the
is the probability that the
 th renewal process has not generated any event for a time
th renewal process has not generated any event for a time
 since its last event. The factor
since its last event. The factor
 is the probability that the same process has not generated any event for time
is the probability that the same process has not generated any event for time
 since its last event and it does not generate any event for another time
since its last event and it does not generate any event for another time
 . Therefore,
. Therefore,
 is the conditional probability that the
is the conditional probability that the
 th process does not generate any event during the next time
th process does not generate any event during the next time
 given that a time
given that a time
 has already elapsed since it generated its last event. Equation (5.9) gives the probability that none of the
has already elapsed since it generated its last event. Equation (5.9) gives the probability that none of the
 processes produces an event for time
processes produces an event for time
 . So, it is the survival probability for the entire population. In other words, it is the probability that the next event in the entire population occurs sometime after time
. So, it is the survival probability for the entire population. In other words, it is the probability that the next event in the entire population occurs sometime after time
 from now.
from now.
Second, the factor
 on the right-hand side of Eq. (5.8), is the probability density function that the
on the right-hand side of Eq. (5.8), is the probability density function that the
 th process generates an event at a time
th process generates an event at a time
 since its last event given that it has not generated any event before this time since the last event. Only this factor creates the dependence of
since its last event given that it has not generated any event before this time since the last event. Only this factor creates the dependence of
 on
on
 . Given this observation, we define
. Given this observation, we define
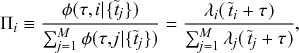 (5.10)
(5.10)
where
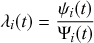 (5.11)
(5.11)
is the instantaneous rate of the
 th process.
th process.
In the original Gillespie algorithm, we equated the survival probability of the next event time for the entire population to
 , a random variate obeying a uniform density on
, a random variate obeying a uniform density on
 , to produce
, to produce
 using inverse sampling. Similarly, a non-Markovian Gillespie algorithm can use inverse sampling to produce
using inverse sampling. Similarly, a non-Markovian Gillespie algorithm can use inverse sampling to produce
 based on Eq. (5.9). However, once a uniform random variate
based on Eq. (5.9). However, once a uniform random variate
 is drawn, solving
is drawn, solving
 is time-consuming because one cannot explicitly solve
is time-consuming because one cannot explicitly solve
 for
for
 in general, and thus one must solve it by numerical integration to produce each single event. This restriction does not prevent the algorithm from working but makes it too slow to be of practical use in many cases.
in general, and thus one must solve it by numerical integration to produce each single event. This restriction does not prevent the algorithm from working but makes it too slow to be of practical use in many cases.
The non-Markovian Gillespie algorithm resolves this issue as follows. We first rewrite Eq. (5.9) as
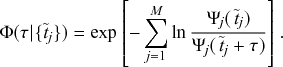 (5.12)
(5.12)
When
 is large, it is unlikely that no process generates an event during a long time interval. Therefore, the
is large, it is unlikely that no process generates an event during a long time interval. Therefore, the
 values realized as the solution of
values realized as the solution of
 will generally be small. This is equivalent to the situation in which
will generally be small. This is equivalent to the situation in which
 is tiny except for
is tiny except for
 . Based on this observation, we approximate Eq. (5.12) by a first-order cumulant expansion around
. Based on this observation, we approximate Eq. (5.12) by a first-order cumulant expansion around
 . This is done by the substitution of the following Taylor expansion of
. This is done by the substitution of the following Taylor expansion of
 :
:
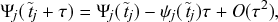 (5.13)
(5.13)
for
 , into Eq. (5.12). This substitution leads to the following simplified expression for
, into Eq. (5.12). This substitution leads to the following simplified expression for
 :
:
 (5.14)
(5.14)
where
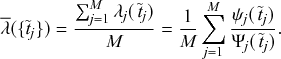 (5.15)
(5.15)
The variable
 is the average instantaneous event rate. By instantaneous, we mean that the event rate changes over time even if no event has happened, which contrasts with the situation of the Poisson processes. The variant of a Poisson process in which the event rate varies over time is called the nonhomogeneous Poisson process. However, the non-Markovian Gillespie algorithm assumes that the event rate
is the average instantaneous event rate. By instantaneous, we mean that the event rate changes over time even if no event has happened, which contrasts with the situation of the Poisson processes. The variant of a Poisson process in which the event rate varies over time is called the nonhomogeneous Poisson process. However, the non-Markovian Gillespie algorithm assumes that the event rate
 stays constant until the next event occurs somewhere in the coupled renewal processes. This is justified because the time to the next event,
stays constant until the next event occurs somewhere in the coupled renewal processes. This is justified because the time to the next event,
 , is small when
, is small when
 is large, and therefore the change in
is large, and therefore the change in
 should be negligible. See Reference Legault and MelbourneLegault and Melbourne (2019) for an application of the same idea to stochastic population dynamics in ecology when the environment is dynamically changing.
should be negligible. See Reference Legault and MelbourneLegault and Melbourne (2019) for an application of the same idea to stochastic population dynamics in ecology when the environment is dynamically changing.
Note that the Taylor expansion given by Eq. (5.13) assumes that all
 are analytical at
are analytical at
 . This is not always the case in practice, which may cause some terms to diverge in the Taylor expansion of
. This is not always the case in practice, which may cause some terms to diverge in the Taylor expansion of
 , where
, where
 is the process that has generated the last event. To deal with this, the authors proposed to simply remove the renewal process that has generated the last event from the summation in Eq. (5.15).
is the process that has generated the last event. To deal with this, the authors proposed to simply remove the renewal process that has generated the last event from the summation in Eq. (5.15).
We determine the time to the next event by solving
 for
for
 using the approximation given by Eq. (5.14). By doing this, we obtain
using the approximation given by Eq. (5.14). By doing this, we obtain
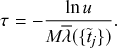 (5.16)
(5.16)
Now, the computation of
 is as fast as that for the original Gillespie algorithm except that the computation of
is as fast as that for the original Gillespie algorithm except that the computation of
 may be complicated to some extent. Because
may be complicated to some extent. Because
 should be small when
should be small when
 is large, one determines the process that generates this event by setting
is large, one determines the process that generates this event by setting
 in Eq. (5.10), that is,
in Eq. (5.10), that is,
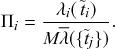 (5.17)
(5.17)
Equations (5.16) and (5.17) define the non-Markovian Gillespie algorithm (Reference Boguñá, Lafuerza, Toral and SerranoBoguñá et al., 2014). For Poisson processes, we have
 , and we recover the original direct method, which is given by Eqs. (3.8) and (3.9). Because the non-Markovian Gillespie algorithm assumes large
, and we recover the original direct method, which is given by Eqs. (3.8) and (3.9). Because the non-Markovian Gillespie algorithm assumes large
 , its accuracy is considered to be good for large
, its accuracy is considered to be good for large
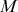 .
.
By putting together these results we can define an extension of the direct method of Gillespie to simulate coupled renewal processes. The algorithm is described in Box 8. For simplicity, we have assumed so-called ordinary renewal processes, in which all processes have had the last event at
 (Reference CoxCox, 1962; Reference Masuda and LambiotteMasuda & Lambiotte, 2020).
(Reference CoxCox, 1962; Reference Masuda and LambiotteMasuda & Lambiotte, 2020).
0. Initialization:
(a) Define the initial state of the system, and set
.(b) Initialize
for all
.(c) Calculate the rate
for all
.(d) Calculate
.
1. Draw a uniform random variate
from
, and generate the waiting time to the next event by
.2. Draw
from a uniform distribution on
. Select the event
to occur by iterating over
until we find the
for which
.3. Perform the event on reaction channel
.4. Advance the time according to
.(a) Update the list of times since the last event as
for all
, and set
.(b) If there are processes
whose distribution of interevent times has changed upon the event, update
for the affected
values, and reset
if necessary.(c) Update
for all
as well as
.
6. Return to Step 1.




























In the context of chemical reaction systems, Reference Carletti and FilisettiCarletti and Filisetti (2012) developed a second-order variant of the Gillespie algorithm for chemical reactions in a dynamically varying volume, which one can also use to simulate more general non-Markovian processes. The non-Markovian Gillespie algorithm we presented in this section can be seen as a first-order algorithm in terms of
 (see Eqs. (5.13) and (5.14)). The idea of the second-order variant is to use the Taylor expansion of
(see Eqs. (5.13) and (5.14)). The idea of the second-order variant is to use the Taylor expansion of
 up to the second order, namely
up to the second order, namely
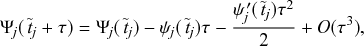 (5.18)
(5.18)
instead of Eq. (5.13). Then, one obtains
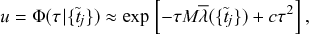 (5.19)
(5.19)
where
 is a constant. We refer to Reference Carletti and FilisettiCarletti and Filisetti (2012) for its precise form. Therefore, we set
is a constant. We refer to Reference Carletti and FilisettiCarletti and Filisetti (2012) for its precise form. Therefore, we set
 by solving the quadratic equation in terms of
by solving the quadratic equation in terms of
 :
:
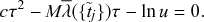 (5.20)
(5.20)
This second-order approximation should generally be a more accurate approximation than the first-order one. However, it comes at an increased computational cost for calculating
 . Furthermore, it still relies on an assumption of large
. Furthermore, it still relies on an assumption of large
 , which breaks down when
, which breaks down when
 is of the order of 1. For contagion processes, for example,
is of the order of 1. For contagion processes, for example,
 is typically of the order of 1 at the start or near the end of a simulation where it is often the case that only one or a few individuals are infectious.
is typically of the order of 1 at the start or near the end of a simulation where it is often the case that only one or a few individuals are infectious.
5.3 Laplace Gillespie Algorithm
In spite of the approximations made by the non-Markovian Gillespie algorithm to make it fast enough for practical applications, the algorithm still requires that we update the instantaneous event rates of all processes whenever an event occurs (Step 5(c) in Box 8). This makes its runtime linear in terms of the number of reaction channels
 . Note that we cannot lessen the time complexity by using any of the advanced methods discussed in Section 4. This is because these advanced methods only improve the efficiency of selecting the reaction channel in Step 2 in Box 8 and leave the overall time complexity of the entire algorithm to be linear. Note that using the binary search tree (Section 4.3) makes the algorithm less efficient because all nodes in the binary tree then need to be updated after each event, resulting in an algorithm with
. Note that we cannot lessen the time complexity by using any of the advanced methods discussed in Section 4. This is because these advanced methods only improve the efficiency of selecting the reaction channel in Step 2 in Box 8 and leave the overall time complexity of the entire algorithm to be linear. Note that using the binary search tree (Section 4.3) makes the algorithm less efficient because all nodes in the binary tree then need to be updated after each event, resulting in an algorithm with
 time complexity.
time complexity.
In this section, we explain an alternative generalization of the direct method to simulate non-Poissonian renewal processes. The algorithm, which we call the Laplace Gillespie algorithm, exploits mathematical properties of the Laplace transform (Reference Masuda and RochaMasuda & Rocha, 2018) to allow exact and fast simulation of non-Poissonian renewal processes with fat-tailed waiting-time distributions. It takes advantage of the fact that a fat-tailed distribution often can be expressed as a mixture of exponential distributions. In other words, an appropriately weighted average of
 over different values of
over different values of
 approximates a desired fat-tailed distribution well. This situation is schematically shown in Fig. 23. As nothing ever comes for free, the Laplace Gillespie algorithm does not work for simulating arbitrary renewal processes. It only works for renewal processes whose distribution of interevent times satisfies a condition known as complete monotocity, which we discuss in detail at the end of this section. Luckily, fat-tailed distributions of interevent times that are ubiquitous in human interaction dynamics are often well modeled by completely monotone functions, so that the Laplace Gillespie algorithm is broadly applicable to social systems.
approximates a desired fat-tailed distribution well. This situation is schematically shown in Fig. 23. As nothing ever comes for free, the Laplace Gillespie algorithm does not work for simulating arbitrary renewal processes. It only works for renewal processes whose distribution of interevent times satisfies a condition known as complete monotocity, which we discuss in detail at the end of this section. Luckily, fat-tailed distributions of interevent times that are ubiquitous in human interaction dynamics are often well modeled by completely monotone functions, so that the Laplace Gillespie algorithm is broadly applicable to social systems.
Schematic showing a mixture of exponential distributions and the mechanism of the Laplace Gillespie algorithm. One draws
 ,
,
 , and so forth from
, and so forth from
 . The probability density function
. The probability density function
 is called the mixing weight distribution, representing how probable each value of
is called the mixing weight distribution, representing how probable each value of
 is to be drawn. Once a
is to be drawn. Once a
 value is drawn, one generates the time to the next time,
value is drawn, one generates the time to the next time,
 , according to the exponential distribution
, according to the exponential distribution
 . As a result, one mixes exponential distributions with mixing weights
. As a result, one mixes exponential distributions with mixing weights
 to obtain the distribution of interevent times,
to obtain the distribution of interevent times,
 . Although each component distribution is an exponential distribution, the mixture may yield a fat-tailed distribution.
. Although each component distribution is an exponential distribution, the mixture may yield a fat-tailed distribution.

To explain the Laplace Gillespie algorithm, we first consider a single renewal process, which has an associated probability density function of interevent times
 . Our aim is to (repeatedly) produce interevent times,
. Our aim is to (repeatedly) produce interevent times,
 , that obey the probability density
, that obey the probability density
 . To this end, we first draw a rate of a Poisson process, denoted by
. To this end, we first draw a rate of a Poisson process, denoted by
 , from a fixed probability density
, from a fixed probability density
 . Second, we draw the next value of
. Second, we draw the next value of
 from the exponential distribution
from the exponential distribution
 as if we were running a Poisson process with rate
as if we were running a Poisson process with rate
 . Third, we advance the clock by
. Third, we advance the clock by
 and produce the event. Fourth, we repeat the procedure to determine the time to the next event. In other words, we redraw the rate, which we denote by
and produce the event. Fourth, we repeat the procedure to determine the time to the next event. In other words, we redraw the rate, which we denote by
 to avoid confusion, from the probability density
to avoid confusion, from the probability density
 and generate the time to the next event from the exponential distribution
and generate the time to the next event from the exponential distribution
 .
.
If the
 value drawn from
value drawn from
 happens to be large, then,
happens to be large, then,
 tends to be small, and vice versa. Because there is diversity in the value of
tends to be small, and vice versa. Because there is diversity in the value of
 , the eventual distribution of interevent times,
, the eventual distribution of interevent times,
 , is more dispersed than a single exponential distribution (Reference YannarosYannaros, 1994).
, is more dispersed than a single exponential distribution (Reference YannarosYannaros, 1994).
For a given
 , the process generated by this algorithm is a renewal process. By construction,
, the process generated by this algorithm is a renewal process. By construction,
 is the mixture of exponential distributions given by
is the mixture of exponential distributions given by
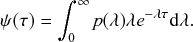 (5.21)
(5.21)
For example, if there are only two possible values of
 , namely
, namely
 and
and
 (
(
 ), one obtains
), one obtains
 (5.22)
(5.22)
where
 is the Dirac delta function. Equation (5.22) just says that
is the Dirac delta function. Equation (5.22) just says that
 occurs with probability
occurs with probability
 and
and
 occurs with probability
occurs with probability
 . Inserting Eq. (5.22) in Eq. (5.21) yields
. Inserting Eq. (5.22) in Eq. (5.21) yields
 (5.23)
(5.23)
namely a mixture of two exponential distributions. (See Reference Fonseca dos Reis, Li and MasudaFonseca dos Reis et al. [Reference Fonseca dos Reis, Li and Masuda2020]; Reference Jiang, Xie, Li, Zhou and SornetteJiang et al. [Reference Jiang, Xie, Li, Zhou and Sornette2016]; Reference Masuda and HolmeMasuda and Holme [2020]; and Reference Okada, Yamanishi and MasudaOkada, Yamanishi, and Masuda [2020] for analysis of interevent times with a mixture of two exponential distributions.)
As another example, let us consider the gamma distribution for the distribution of mixing weights, that is,
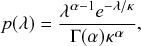 (5.24)
(5.24)
where
 and
and
 are the shape and scale parameters of the gamma distribution, respectively, and
are the shape and scale parameters of the gamma distribution, respectively, and
 (5.25)
(5.25)
is the gamma function. Inserting Eq. (5.24) in Eq. (5.21) yields
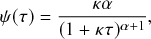 (5.26)
(5.26)
which is a power-law distribution (see the solid line in Fig. 24 for an example). Crucially, this example shows that one can create a power-law distribution, which is fat-tailed, by appropriately mixing exponential distributions, which are not fat-tailed.
Three power-law distributions: the distribution given by Eq. (5.26) with
 and
and
 , a Pareto distribution with
, a Pareto distribution with
 and
and
 , and a half-Cauchy distribution. Note that the three distributions follow the same asymptotic power law,
, and a half-Cauchy distribution. Note that the three distributions follow the same asymptotic power law,
 , as
, as
 .
.
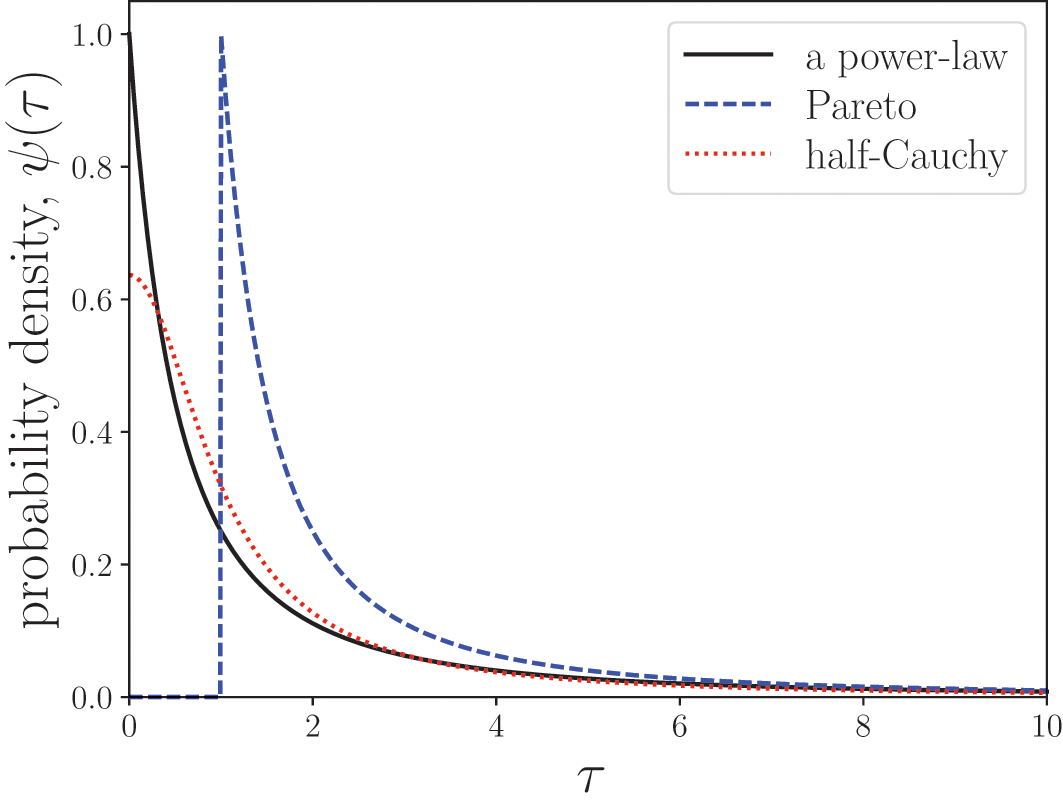
What we want to really simulate is an ensemble of
 simultaneously ongoing renewal processes that are governed by given distributions of interevent times,
simultaneously ongoing renewal processes that are governed by given distributions of interevent times,
 (
(
 ). We suppose that we can realize each
). We suppose that we can realize each
 as a mixture of exponential distributions by appropriately setting a distribution of mixing weights
as a mixture of exponential distributions by appropriately setting a distribution of mixing weights
 . In other words, we assume that we can find
. In other words, we assume that we can find
 satisfying
satisfying
 . The Laplace Gillespie algorithm for simulating such a system is described in Box 9.
. The Laplace Gillespie algorithm for simulating such a system is described in Box 9.
0. Initialization:
(a) Define the initial state of the system, and set
.(b) Initialize each of the
renewal processes by drawing the rate
of the
th Poisson process from
for all
.(c) Calculate the total event rate
.
(1) Draw a random variate
from a uniform distribution on (0, 1], and generate the waiting time to the next event by
.(2) Select the process that generates the next event with probability
.(3) Implement the event taking place on the
th renewal process.(4) Advance the clock according to
.(a) Update
if it has changed following the event.(b) Redraw a rate
according to
.(c) If there are other processes
whose distribution of interevent times has changed following the event on the
th process, update each affected
and redraw
from the new
. The event rates of the other processes remain unchanged.(d) Update the total event rate
.
6. Return to Step (1).





















In contrast to the non-Markovian Gillespie algorithm, the Laplace Gillespie algorithm is exact for arbitrary values of
 . Figure 25 shows an example in which the Laplace Gillespie algorithm is considerably more accurate than the non-Markovian Gillespie algorithm when
. Figure 25 shows an example in which the Laplace Gillespie algorithm is considerably more accurate than the non-Markovian Gillespie algorithm when
 (Fig. 25(a)), whereas both algorithms are sufficiently accurate when
(Fig. 25(a)), whereas both algorithms are sufficiently accurate when
 (Fig. 25(b)). In addition, the Laplace Gillespie algorithm tends to be faster than the non-Markovian Gillespie algorithm (Reference Masuda and RochaMasuda & Rocha, 2018) because it does not need to update all the
(Fig. 25(b)). In addition, the Laplace Gillespie algorithm tends to be faster than the non-Markovian Gillespie algorithm (Reference Masuda and RochaMasuda & Rocha, 2018) because it does not need to update all the
 values (with
values (with
 ) after each event. Used together with the binary tree structure (Section 4.3) or the composition and rejection method (Section 4.5), the Laplace Gillespie algorithm can thus simulate coupled renewal processes in
) after each event. Used together with the binary tree structure (Section 4.3) or the composition and rejection method (Section 4.5), the Laplace Gillespie algorithm can thus simulate coupled renewal processes in
 or
or
 time.
time.
Comparison between the non-Markovian Gillespie algorithm and the Laplace Gillespie algorithm. We use a power-law distribution of interevent times
 with
with
 . (a)
. (a)
 . (b)
. (b)
 . For each algorithm, the survival function of the interevent time distribution is plotted for just one of the
. For each algorithm, the survival function of the interevent time distribution is plotted for just one of the
 processes and compared against the ground truth, that is,
processes and compared against the ground truth, that is,
 .
.
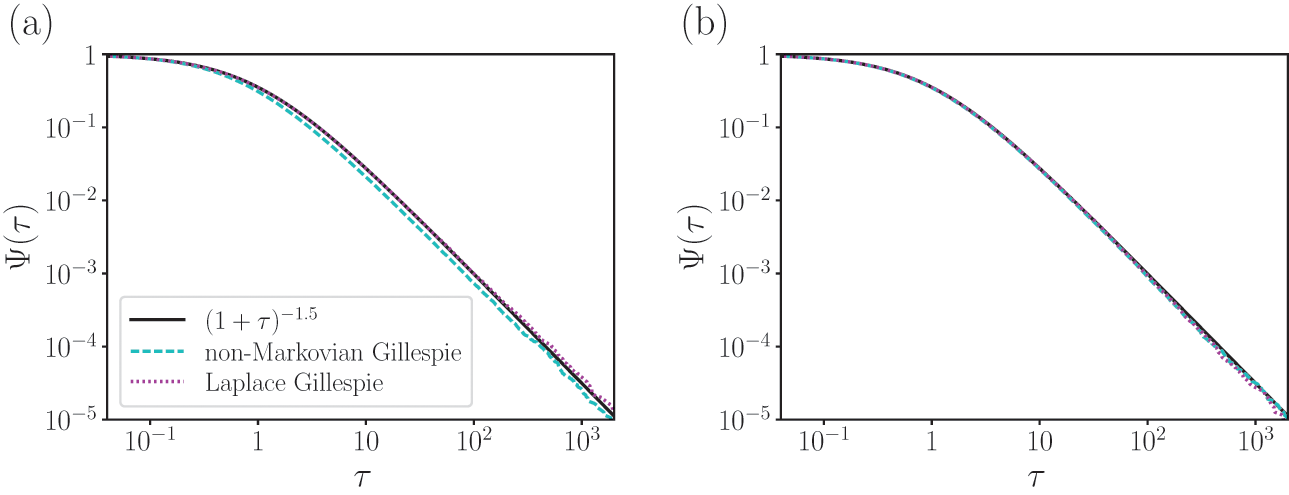
Not all functional forms for
 can be generated as a mixture of exponentials. In these cases we cannot use the Laplace Gillespie algorithm. By contrast, one can use the non-Markovian Gillespie algorithm for any
can be generated as a mixture of exponentials. In these cases we cannot use the Laplace Gillespie algorithm. By contrast, one can use the non-Markovian Gillespie algorithm for any
 in principle. To examine more formally to which cases the Laplace Gillespie algorithm is applicable, we integrate both sides of Eq. (5.21) to obtain
in principle. To examine more formally to which cases the Laplace Gillespie algorithm is applicable, we integrate both sides of Eq. (5.21) to obtain
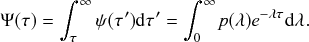 (5.27)
(5.27)
Equation (5.21) indicates that the survival probability of interevent times,
 , is the Laplace transform of
, is the Laplace transform of
 . Therefore, the Laplace Gillespie algorithm can simulate a renewal process if and only if
. Therefore, the Laplace Gillespie algorithm can simulate a renewal process if and only if
 is the Laplace transform of a probability density function on non-negative values.
is the Laplace transform of a probability density function on non-negative values.
It is mathematically known that a necessary and sufficient condition for the existence of
 is that
is that
 is completely monotone (Reference FellerFeller, 1971) and that
is completely monotone (Reference FellerFeller, 1971) and that
 . A function
. A function
 is said to be completely monotone if
is said to be completely monotone if
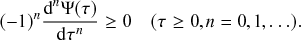 (5.28)
(5.28)
The condition
 is always satisfied since
is always satisfied since
 is a survival function. Equations (5.28) with
is a survival function. Equations (5.28) with
 and
and
 read
read
 and
and
 , respectively. These two inequalities are also always satisfied. Equation (5.28) offers nontrivial conditions when
, respectively. These two inequalities are also always satisfied. Equation (5.28) offers nontrivial conditions when
 . For example, the condition with
. For example, the condition with
 reads
reads
 (5.29)
(5.29)
that is,
 . Therefore,
. Therefore,
 must monotonically decrease with respect to
must monotonically decrease with respect to
 . This condition excludes the Pareto distribution, which is a popular form of power-law distribution,
. This condition excludes the Pareto distribution, which is a popular form of power-law distribution,
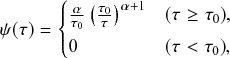 (5.30)
(5.30)
where
 and
and
 . We show the Pareto distribution with
. We show the Pareto distribution with
 and
and
 by the dashed line in Fig. 24. Note that
by the dashed line in Fig. 24. Note that
 discontinuously increases as
discontinuously increases as
 increases across
increases across
 ; note that the Pareto distribution is defined for
; note that the Pareto distribution is defined for
 (and
(and
 for
for
 ). Therefore, one cannot use the Laplace Gillespie algorithm when any
). Therefore, one cannot use the Laplace Gillespie algorithm when any
 is a Pareto distribution.
is a Pareto distribution.
To show another example of disqualified
 , consider Eq. (5.28) for
, consider Eq. (5.28) for
 , that is,
, that is,
 . The half-Cauchy distribution, which is another form of power-law distribution, defined by
. The half-Cauchy distribution, which is another form of power-law distribution, defined by
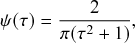 (5.31)
(5.31)
where
 , violates this condition. (See the red dotted line in Fig. 24 for a plot.) This is because
, violates this condition. (See the red dotted line in Fig. 24 for a plot.) This is because
 , whose sign depends on the value of
, whose sign depends on the value of
 . Specifically, the half-Cauchy distribution has an inflection point at
. Specifically, the half-Cauchy distribution has an inflection point at
 . Note that the half-Cauchy distribution satisfies the condition for
. Note that the half-Cauchy distribution satisfies the condition for
 (Eq. (5.29)) because
(Eq. (5.29)) because
 .
.
Complete monotonicity implies that the coefficient of variation (CV), defined by the standard deviation divided by the mean, of
 is larger than or equal to 1 (Reference YannarosYannaros, 1994). This is natural because an exponential distribution,
is larger than or equal to 1 (Reference YannarosYannaros, 1994). This is natural because an exponential distribution,
 , has a CV equal to one. Because we are mixing exponential distributions with different
, has a CV equal to one. Because we are mixing exponential distributions with different
 values, the CV for the mixture of exponential distributions must be at least 1. This necessary condition for complete monotonicity excludes some distributions having less dispersion (i.e., standard deviation) than exponential distributions.
values, the CV for the mixture of exponential distributions must be at least 1. This necessary condition for complete monotonicity excludes some distributions having less dispersion (i.e., standard deviation) than exponential distributions.
We stated various negative scenarios, but there are many distributions of interevent times,
 , for which the Laplace Gillespie algorithm works. The power-law distribution given by Eq. (5.26) is qualified because one can find the corresponding distribution of mixing weights, which is given by Eq. (5.24). In fact, using Eq. (5.26), we obtain
, for which the Laplace Gillespie algorithm works. The power-law distribution given by Eq. (5.26) is qualified because one can find the corresponding distribution of mixing weights, which is given by Eq. (5.24). In fact, using Eq. (5.26), we obtain
 (5.32)
(5.32)
It is easy to verify that this
 is a completely monotone function.
is a completely monotone function.
As a second example, assume that
 is a uniform density on
is a uniform density on
 (Reference HidalgoHidalgo, 2006). By Laplace transforming
(Reference HidalgoHidalgo, 2006). By Laplace transforming
 using Eq. (5.21), we obtain
using Eq. (5.21), we obtain
 (5.33)
(5.33)
which yields
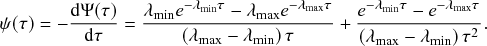 (5.34)
(5.34)
Assume that
 . If
. If
 , then
, then
 as
as
 , which is a power-law distribution with an exponential cutoff, often resembling empirical data. If
, which is a power-law distribution with an exponential cutoff, often resembling empirical data. If
 , then
, then
 as
as
 .
.
A third example is when the interevent time obeys a gamma distribution:
 (5.35)
(5.35)
For this
 , we can express
, we can express
 as the Laplace transform of
as the Laplace transform of
 if and only if
if and only if
 , and
, and
 is given by
is given by
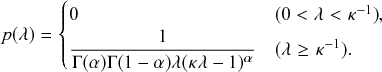 (5.36)
(5.36)
It is easy to verify that one obtains the exponential distribution by setting
 in Eq. (5.35). We refer to Reference Masuda and RochaMasuda and Rocha (2018) for more examples of renewal processes that the Laplace Gillespie algorithm can simulate.
in Eq. (5.35). We refer to Reference Masuda and RochaMasuda and Rocha (2018) for more examples of renewal processes that the Laplace Gillespie algorithm can simulate.
5.4 Temporal Gillespie Algorithm
The temporal Gillespie algorithm (Reference Vestergaard and GénoisVestergaard & Génois, 2015) is an adaptation of the direct method to simulate coupled jump processes taking place on switching temporal networks, namely networks whose structure changes discontinuously in discrete points in time (Fig. 20). For simplicity in the following presentation, and without loss of generality, we furthermore assume that both the network’s dynamics and the dynamical process start at time
 .
.
The starting point for developing a temporal Gillespie algorithm is a single isolated jump process
 , which has a time-varying event rate
, which has a time-varying event rate
 . Note that
. Note that
 may depend on both the “wall clock” time,
may depend on both the “wall clock” time,
 , and the time since the last event,
, and the time since the last event,
 . The explicit dependence on time
. The explicit dependence on time
 is not a property of the renewal processes considered in Sections 5.2 and 5.3, for which the event rate depends only on
is not a property of the renewal processes considered in Sections 5.2 and 5.3, for which the event rate depends only on
 . Conversely, if
. Conversely, if
 depends on
depends on
 but not on
but not on
 , the process is a nonhomogeneous Poisson process. In this Element we will only treat nonhomogeneous Poisson processes because they are simpler than the full problem in which the
, the process is a nonhomogeneous Poisson process. In this Element we will only treat nonhomogeneous Poisson processes because they are simpler than the full problem in which the
 depends on both
depends on both
 and
and
 . The derivation of the temporal Gillespie algorithm for the general case follows the same reasoning as for the algorithm for nonhomogeneous Poisson processes, but the mathematics is a bit more involved. We thus do not show the details here but refer interested readers to Reference Vestergaard and GénoisVestergaard and Génois (2015).
. The derivation of the temporal Gillespie algorithm for the general case follows the same reasoning as for the algorithm for nonhomogeneous Poisson processes, but the mathematics is a bit more involved. We thus do not show the details here but refer interested readers to Reference Vestergaard and GénoisVestergaard and Génois (2015).
Similar to how we calculated the waiting-time distribution for a Poisson process in Section 2.4, we first consider a discrete-time process and then take the continuous-time limit. More precisely, we want to know the probability that the
 th process does not generate an event in a given time window
th process does not generate an event in a given time window
 (i.e., its survival probability), which we denote by
(i.e., its survival probability), which we denote by
 . We approximate
. We approximate
 by subdividing the interval into
by subdividing the interval into
 small time-steps of size
small time-steps of size
 as follows:
as follows:
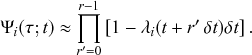 (5.37)
(5.37)
Taking the limit
 , we find the following exact expression for the survival probability using the exponential identity (Appendix):
, we find the following exact expression for the survival probability using the exponential identity (Appendix):
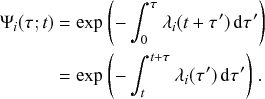 (5.38)
(5.38)
Equation (5.38) does not reduce to a simple exponential, except in the special case of a constant
 . It does not even reduce to an analytical expression in general. For example, in the SIR process on a predefined switching temporal network, the infection rate for a given susceptible node
. It does not even reduce to an analytical expression in general. For example, in the SIR process on a predefined switching temporal network, the infection rate for a given susceptible node
 changes whenever an edge appears or disappears between
changes whenever an edge appears or disappears between
 and an infectious node. Say, if a susceptible node
and an infectious node. Say, if a susceptible node
 has two infectious neighbors and now gets connected to another infectious neighbor, the rate with which
has two infectious neighbors and now gets connected to another infectious neighbor, the rate with which
 gets infected changes from
gets infected changes from
 to
to
 , where
, where
 is the infection rate per contact. This means that one cannot in general solve Eq. (5.38) analytically even for a simple constant-rate SIR process in a temporal network. Nevertheless, owing to the conditional independence property of the jump processes (see Section 2.5), we can still find a formal expression for the waiting time for the superposition of a set of
is the infection rate per contact. This means that one cannot in general solve Eq. (5.38) analytically even for a simple constant-rate SIR process in a temporal network. Nevertheless, owing to the conditional independence property of the jump processes (see Section 2.5), we can still find a formal expression for the waiting time for the superposition of a set of
 processes. The survival function for a set of
processes. The survival function for a set of
 processes is simply the product of the individual survival functions. Let
processes is simply the product of the individual survival functions. Let
 be the time of the last event amongst all
be the time of the last event amongst all
 processes. The survival function for the waiting time
processes. The survival function for the waiting time
 until the next event amongst all the processes is
until the next event amongst all the processes is
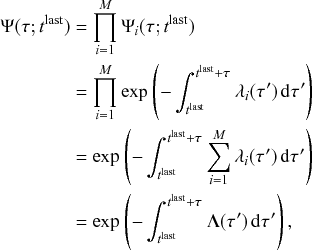 (5.39)
(5.39)
where we have defined the total instantaneous rate as
 (5.40)
(5.40)
Note that
 is simply
is simply
 times the average instantaneous rate, namely
times the average instantaneous rate, namely
 (see Section 5.2).
(see Section 5.2).
Due to the lack of an analytic expression for
 , we need to numerically integrate Eq. (5.39) to evaluate it. However, inverting Eq. (5.39) to directly draw the waiting time is computationally too expensive. To overcome this, the temporal Gillespie algorithm works instead with unitless, normalized waiting times. Given the waiting time,
, we need to numerically integrate Eq. (5.39) to evaluate it. However, inverting Eq. (5.39) to directly draw the waiting time is computationally too expensive. To overcome this, the temporal Gillespie algorithm works instead with unitless, normalized waiting times. Given the waiting time,
 , we define the normalized waiting time, denoted by
, we define the normalized waiting time, denoted by
 , as
, as
 (5.41)
(5.41)
The normalized waiting time follows an exponential distribution with an expected value of one. Therefore, it is easy to generate it using inverse sampling, that is, by
 , where
, where
 is a uniform random variate on
is a uniform random variate on
 . The (wall-clock) waiting time
. The (wall-clock) waiting time
 is found as the solution to Eq. (5.41) given the
is found as the solution to Eq. (5.41) given the
 value that we have generated.
value that we have generated.
In fact, all we have done for the moment is to exchange one implicit equation (Eq. (5.39)) for another (Eq. (5.41)). However, Eq. (5.41) is linear in
 , which makes it easier to solve and approximate numerically. This is, in particular, the case because we assumed that the temporal network changes only in discrete points in time, as schematically shown in Fig. 20. We let
, which makes it easier to solve and approximate numerically. This is, in particular, the case because we assumed that the temporal network changes only in discrete points in time, as schematically shown in Fig. 20. We let
 , and we denote by
, and we denote by
 the subsequent time points at which the temporal network changes. Then,
the subsequent time points at which the temporal network changes. Then,
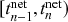 is the
is the
 th interval between network changes. Since the temporal network only changes in discrete steps,
th interval between network changes. Since the temporal network only changes in discrete steps,
 is piecewise constant. Therefore, one can solve Eq. (5.41) iteratively as follows. Suppose that we are given the time of the last event,
is piecewise constant. Therefore, one can solve Eq. (5.41) iteratively as follows. Suppose that we are given the time of the last event,
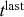 , and we want to find the time of the next event denoted by
, and we want to find the time of the next event denoted by
 . If there is no event yet, and we want to find the time of the first event, then we regard that
. If there is no event yet, and we want to find the time of the first event, then we regard that
 . We start from the time interval
. We start from the time interval
 between two successive switches of the network in which the last event took place, namely the interval that satisfies
between two successive switches of the network in which the last event took place, namely the interval that satisfies
 . We then sequentially check for each time interval
. We then sequentially check for each time interval
 ,
,
 ,
,
 ,
,
 , to determine in which interval
, to determine in which interval
 falls. In practice, we compare at each step the generated value of
falls. In practice, we compare at each step the generated value of
 to the value of the integral
to the value of the integral
 . The latter is efficiently calculated as the sum
. The latter is efficiently calculated as the sum
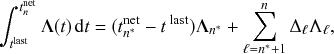 (5.42)
(5.42)
where
 is the length of the
is the length of the
 th interval between successive changes of the network, and
th interval between successive changes of the network, and
 is the value of
is the value of
 in this interval. If
in this interval. If
 , the sum in the second term on the right-hand side of Eq. (5.42) is the empty sum, that is, it has no summands and thus evaluates to zero, and the equation reduces to
, the sum in the second term on the right-hand side of Eq. (5.42) is the empty sum, that is, it has no summands and thus evaluates to zero, and the equation reduces to
 .
.
The smallest value of
 that satisfies
that satisfies
 determines the time interval in which the next event takes place. With that
determines the time interval in which the next event takes place. With that
 value, the precise time of the next event is given by
value, the precise time of the next event is given by
 (5.43)
(5.43)
Finally, we draw the Poisson process
 that produces the event at time
that produces the event at time
 with probability
with probability
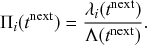 (5.44)
(5.44)
The steps of the temporal Gillespie algorithm are described in Box 10. It works by iterating over the list of times at which the network changes. Within each interval between the network’s switches, it compares the normalized waiting time,
 , to the total instantaneous rate integrated over the time interval,
, to the total instantaneous rate integrated over the time interval,
 (see Step 2). If
(see Step 2). If
 is larger than or equal to
is larger than or equal to
 , then nothing happens, and one subtracts
, then nothing happens, and one subtracts
 from
from
 and advances to the next interval,
and advances to the next interval,
 (see Step 2(a)). Alternatively, if
(see Step 2(a)). Alternatively, if
 is smaller than
is smaller than
 , then an event occurs within the
, then an event occurs within the
 th time window
th time window
 (see Step 2(b)). Then, the algorithm determines the timing of the event and selects the reaction channel to produce the event using any of the appropriate selection methods discussed earlier (see Sections 3.3, 4.3, and 4.5). It then updates the system, draws a new normalized waiting time, and repeats the procedure.
(see Step 2(b)). Then, the algorithm determines the timing of the event and selects the reaction channel to produce the event using any of the appropriate selection methods discussed earlier (see Sections 3.3, 4.3, and 4.5). It then updates the system, draws a new normalized waiting time, and repeats the procedure.
0. Initialization:
(a) Define the initial state of the system, and set
.(b) Set
and
.(c) Initialize the rates
for all
.(d) Calculate the total rate
.
1. Draw a normalized waiting time
, where
is a uniform random variate on
.2. Compare
to
:
(a) If
, then no reaction takes place in the
th time window.
i. Set
.ii. Advance to the next time window by setting
and
; update
.iii. Update all
affected by changes in the temporal network, and update
accordingly.iv. Return to Step 2.
(b) If
, then an event takes place at time
.
i. Select the reaction channel
that produces the event with probability
.ii. Update the time as
. Also update the remaining length of the present time window as
.iii. Update the rates
that are affected by the event, and update
accordingly.iv. Return to Step 1.



























Reference Vestergaard and GénoisVestergaard & Génois (2015) furthermore proposed to adapt the temporal Gillespie algorithm to simulate non-Markovian processes in temporal networks. To make the algorithm computationally efficient, they proposed two approximations to solve Eq. (5.41) by simply iterating over the times
 at which the network changes, as we did for nonhomogeneous Poisson processes. These approximations avoid having to use numerical integration to solve the implicit equation, which would make the algorithm slow for large systems.
at which the network changes, as we did for nonhomogeneous Poisson processes. These approximations avoid having to use numerical integration to solve the implicit equation, which would make the algorithm slow for large systems.
The first approximation is to regard the total instantaneous rate
 , which in the non-Markovian case can depend on the times since the last events for all
, which in the non-Markovian case can depend on the times since the last events for all
 processes, as constant during each interval
processes, as constant during each interval
 between the consecutive changes in the network. This approximation is accurate when the network changes much faster than the total rate
between the consecutive changes in the network. This approximation is accurate when the network changes much faster than the total rate
 does, namely when
does, namely when
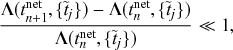 (5.45)
(5.45)
where
 is the change of
is the change of
 between two successive intervals. When simulating spreading processes in temporal networks, the network dynamics are often much faster than the spreading dynamics in practice. For example, the timescale of recordings of physical proximity networks is typically of the order of seconds to minutes while the infection and recovery of flu-like diseases occur in the order of hours to days (Reference Vestergaard and GénoisVestergaard & Génois, 2015). With this first approximation, one can directly apply Eq. (5.42) and use the same procedure as for the Poissonian case.
between two successive intervals. When simulating spreading processes in temporal networks, the network dynamics are often much faster than the spreading dynamics in practice. For example, the timescale of recordings of physical proximity networks is typically of the order of seconds to minutes while the infection and recovery of flu-like diseases occur in the order of hours to days (Reference Vestergaard and GénoisVestergaard & Génois, 2015). With this first approximation, one can directly apply Eq. (5.42) and use the same procedure as for the Poissonian case.
The second approximation is to use a first-order cumulant expansion, similar to the non-Markovian Gillespie algorithm (Section 5.2), in addition to the first approximation. It amounts to assuming that each
 is constant as long as no event takes place and no change of the network that directly affects the
is constant as long as no event takes place and no change of the network that directly affects the
 value takes place. One thus avoids having to update all the
value takes place. One thus avoids having to update all the
 values each time we go to the next time window (i.e., from
values each time we go to the next time window (i.e., from
 to
to
 ), and the algorithm runs much faster. To increase the accuracy of the algorithm when the number of reaction channels
), and the algorithm runs much faster. To increase the accuracy of the algorithm when the number of reaction channels
 is small and the cumulant expansion is not accurate (e.g., at the start or near the end of an SIR process where only a few nodes are typically infectious), they proposed a heuristic approach, in which one updates
is small and the cumulant expansion is not accurate (e.g., at the start or near the end of an SIR process where only a few nodes are typically infectious), they proposed a heuristic approach, in which one updates
 only if the time elapsed since the last update of
only if the time elapsed since the last update of
 exceeds a given threshold
exceeds a given threshold
 . They proposed to choose the value of
. They proposed to choose the value of
 as a given fraction of the expected waiting time of a single reaction channel. Therefore, when
as a given fraction of the expected waiting time of a single reaction channel. Therefore, when
 is large, the waiting time between events will almost never exceed
is large, the waiting time between events will almost never exceed
 , and the algorithm will be similar to the non-Markovian Gillespie algorithm. When
, and the algorithm will be similar to the non-Markovian Gillespie algorithm. When
 is small, the algorithm updates the
is small, the algorithm updates the
 more frequently, making it more accurate at an added computational cost.
more frequently, making it more accurate at an added computational cost.
With the above approximations, the application of the temporal Gillespie algorithm to general non-Markovian processes only slightly changes the implementation from that for the nonhomogeneous Poisson processes described in Box 10. We refer interested readers to Reference Vestergaard and GénoisVestergaard and Génois (2015) for details.
5.5 Event-Driven Simulation of the SIR Process
Holme proposed another efficient event-based algorithm, related to the first reaction method, when the time-stamped contact events are given as data (Reference HolmeHolme, 2021). Although the timing of the event is no longer stochastic, the overall dynamics are still stochastic. This is because, in the SIR model for example, infection upon each contact event occurs with a certain probability and recovery occurs as a Poisson process with rate
 . The efficiency of the Holme’s algorithm comes from multiple factors. Suppose that the
. The efficiency of the Holme’s algorithm comes from multiple factors. Suppose that the
 th node is infected and its neighboring node,
th node is infected and its neighboring node,
 , is susceptible. First, the algorithm tactically avoids searching all the contact events between
, is susceptible. First, the algorithm tactically avoids searching all the contact events between
 and
and
 when determining the event with which
when determining the event with which
 successfully infects
successfully infects
 . Second, it uses the binary heap to maintain a carefully limited set of times of the events with which infection may occur between pairs of nodes. The corresponding code for simulating the SIR model, implemented in C with a Python wrapper, is available on Github (Reference HolmeHolme, 2021).
. Second, it uses the binary heap to maintain a carefully limited set of times of the events with which infection may occur between pairs of nodes. The corresponding code for simulating the SIR model, implemented in C with a Python wrapper, is available on Github (Reference HolmeHolme, 2021).
6 Conclusions
The aim of this article has been twofold: to provide a tutorial of the standard Gillespie algorithms and to review recent Gillespie algorithms that improve upon their computational efficiency and extend their scope. While our emphasis and examples lean toward social multiagent dynamics in populations and networks, the applicability of the Gillespie algorithms and their variants is extensive. We believe that the present article is useful for students and researchers in various fields, such as epidemiology, ecology, control theory, artificial life, complexity sciences, and so on.
In fact, many models of adaptive networks, where the network change is induced by the change of the status of, for example, nodes, have been mostly described by ODEs and assume that the interaction strength between pairs of nodes varies in response to changes in individuals’ behavior (Reference Gross and BlasiusGross & Blasius, 2008; Reference Gross and SayamaGross & Sayama, 2009; Reference Wang, Andrews, Wu, Wang and BauchWang et al., 2015). If such changes occur in an event-driven manner, Gillespie algorithms are readily applicable. How to deploy and develop Gillespie algorithms and their variants to adaptive network scenarios is a practical concern.
We briefly discussed simulations on empirical time-stamped contact event data (Sections 5.4 and 5.5). In this setting, it is the given data that determines the times and edges (i.e., node pairs) of the events, which is contrary to the assumption of the Gillespie algorithms that jump-process models generate events. Despite the increasing demand of simulations on the given time-stamped contact event data, this is still an underexplored area of research. Reference Vestergaard and GénoisVestergaard and Génois (2015) and Reference HolmeHolme (2021) showed that ideas and techniques from the Gillespie algorithms are useful for such simulations although the developed algorithms are distinct from the historical Gillespie algorithms. This is another interesting area of future research.
Appendix Exponential Identity
In this appendix, we prove the identity
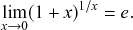 (A.1)
(A.1)
Because  is continuous in
is continuous in  , we obtain
, we obtain
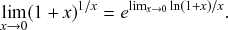 (A.2)
(A.2)Thus, we can prove Eq. (A.1) by showing that  . We do this using l’Hôpital’s rule as follows:
. We do this using l’Hôpital’s rule as follows:
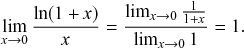 (A.3)
(A.3)Acknowledgments
We thank the SocioPatterns collaboration (see www.sociopatterns.org) for providing the experimental data set. N. M. thanks the following institutions for their financial support: the AFOSR European Office (under Grant No. FA9550-19-1-7024), the National Science Foundation (under Grant No. DMS-2052720), the Nakatani Foundation, the Sumitomo Foundation, and the Japan Science and Technology Agency (under Grant No. JPMJMS2021). C. L. V. was supported in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute).
Guido Caldarelli
Ca’ Foscari University of Venice
Guido Caldarelli is Full Professor of Theoretical Physics at Ca’ Foscari University of Venice. Guido Caldarelli received his Ph.D. from SISSA, after which he held postdoctoral positions in the Department of Physics and School of Biology, University of Manchester, and the Theory of Condensed Matter Group, University of Cambridge. He also spent some time at the University of Fribourg in Switzerland, at École Normale Supérieure in Paris, and at the University of Barcelona. His main scientific activity (interest?) is the study of networks, mostly analysis and modelling, with applications from financial networks to social systems as in the case of disinformation. He is the author of more than 200 journal publications on the subject, and three books, and is the current President of the Complex Systems Society (2018 to 2021).
About the Series
This cutting-edge series provides authoritative and detailed coverage of the underlying theory of complex networks, specifically their structure and dynamical properties. Each Element within the series will focus upon one of three primary topics: static networks, dynamical networks, and numerical/computing network resources.




































 Open access
Open access