




Highlights
What is already known?
-
• Shrinkage estimation may be used to effectively and robustly borrow information between related data sources.
-
• Shrinkage estimation may alternatively be motivated via a meta-analytic-predictive (MAP) approach.
What is new?
-
• A MAP approach remains sensible down to the extreme case of only a single study.
-
• The MAP prior’s usual features are retained, in addition, there are connections to power prior and bias allowance approaches.
Potential impact for RSM readers
-
• MAP priors are useful for constructing empirically motivated priors based on external/historical data.
-
• MAP priors may serve as an additional motivation for related approaches (bias allowance models and power priors).
-
• Practical application is straightforward using existing software packages.
1 Introduction
The potential of clinical research is commonly limited by data sparsity issues; such problems particularly arise in the context of rare diseases, where the number of potential study subjects is small, or in pediatric indications, where ethical considerations may limit the recruitment of patients. The large variety of rare diseases still means that a sizeable proportion of the population is affected by rare diseases, posing a considerable economic burden. Even in more common indications, data sparsity problems may arise, for example, when the focus is on smaller sub-populations, or when novel treatments or standards of care emerge. In any of these cases, the careful consideration of all potentially relevant evidence available is essential.Reference Gagne, Thompson, O’Keefe and Kesselheim 1 – Reference Gamalo-Siebers, Savic and Basu 3 When evidence from a single experiment, such as a clinical trial, is not sufficiently conclusive on its own, it may sometimes help to view the data in the context of related instances (similar experiments) in order to yield more confident conclusions. This idea is explicitly implemented in shrinkage estimation, where a hierarchical model is set up accounting for estimation uncertainly at the study level as well as for variability (and similarity) between studiesReference Morris and Lysy 4 , Reference Gelman and Hill 5 ; models of this kind are commonly also used in the context of meta-analysis.Reference Fleiss 6 , Reference Röver 7 The borrowing-of-information taking place between the study of primary interest and the external data may be viewed in terms of the overarching joint model as a meta-analytic-combined (MAC) approach, or, equivalently, by formulating the meta-analytic predictive (MAP) prior that explicates the information contributed by the external data to the shrinkage estimate.Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander 8 A particular special case is given when a single (“target”) study is supported by a single (“source”) study; such situations are not uncommon, and shrinkage estimation here has proven useful.Reference Röver and Friede 9 – Reference Lesaffre, Qi, Banbeta and van Rosmalen 11 Application of a hierarchical model makes it behave dynamically in the sense that more or less information is borrowed, depending on the apparent similarity of target and source data.Reference Röver and Friede 9 When considering this case in terms of the implied MAP prior, the “meta-analysis” involved here is based on a single study, which may appear somewhat counterintuitive at first. It is this perceived contradiction that we aim to address here; while a meta-analysis is commonly thought of as involving larger amounts of data, we will see that a hierarchical model may essentially be fit also to a single data point, and sensible predictions may be derived. Such a smallest-possible meta-analysis does not pose a conceptual problem, and there is no reason to abandon the general concept even if the amount of historical data drops below a couple of studies. It only implies that, due to the particular sparsity of data, prior specification within the model receives special importance, a problem which, however, is common in meta-analysis of few studies in general,Reference Röver, Bender and Dias 12 and which analogously applies for alternative (and closely related) borrowing methods, such as power priors or bias allowance models.Reference Lesaffre, Qi, Banbeta and van Rosmalen 11 , Reference Welton, Sutton, Cooper, Abrams and Ades 13 Since others appear to have struggled with or shied away from the idea of a single-study meta-analysis where in fact it may have been a viable option,Reference Iglesias, Muller and Zaugg 14 , Reference Harari, Soltanifar, Verhoek and Heeg 15 it seems worthwhile to investigate this special case a bit closer. Closer inspection of this particular case then also highlights how the properties of this MAP prior materialize, as well as its close connection to bias allowance and power prior approaches.
The remainder of this article is structured as follows: in Section 2, the normal–normal hierarchical model (NNHM) is introduced, the meta-analysis model which then is the basis for shrinkage estimation between a pair of studies, and for the MAP prior based on a single study. The ideas will be illustrated in two practical examples in Section 3. Section 3.1 discusses an application in paediatric Alport syndrome that was originally formulated in terms of a shrinkage estimation problem. Section 3.2 introduces a trial design application in cardiology, where information from a similar past study is designated for consideration in the eventual analysis via an informative MAP prior. Section 4 then closes with a brief discussion.
2 Shrinkage estimation using two studies
2.1 The normal–normal hierarchical model
The most common model for random-effects meta-analysis is given by the NNHM. It implements sampling error as well as between-study heterogeneity using normal distributions. The data are given in terms of k estimates
$y_i$
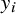 and associated standard errors
$s_i$
and associated standard errors
$s_i$
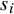 (
$i=1,\ldots ,k$
(
$i=1,\ldots ,k$
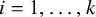 ). Each individual study aims to quantify a parameter
$\theta _i$
). Each individual study aims to quantify a parameter
$\theta _i$
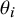 , so that
, so that

The underlying parameters
$\theta _i$
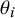 are not necessarily identical for all studies, instead some amount of (between-study) heterogeneity is allowed for, expressed as
are not necessarily identical for all studies, instead some amount of (between-study) heterogeneity is allowed for, expressed as

Often the overall mean
$\mu $
 is the aim of the analysis, while sometimes the study-specific parameters
$\theta _i$
is the aim of the analysis, while sometimes the study-specific parameters
$\theta _i$
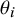 are also of interest.Reference Röver and Friede
9
,
Reference Wandel, Neuenschwander, Röver and Friede
16
The heterogeneity, while important, usually remains a nuisance parameter. In the context of “shrinkage estimation” of the
$\theta _i$
are also of interest.Reference Röver and Friede
9
,
Reference Wandel, Neuenschwander, Röver and Friede
16
The heterogeneity, while important, usually remains a nuisance parameter. In the context of “shrinkage estimation” of the
$\theta _i$
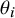 , an interesting aspect is that the problem may be motivated in two ways; classically, one may think of shrinkage estimation as a joint analysis of all (k) estimates, which also returns estimates of any
$\theta _i$
, an interesting aspect is that the problem may be motivated in two ways; classically, one may think of shrinkage estimation as a joint analysis of all (k) estimates, which also returns estimates of any
$\theta _i$
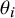 parameter along the way; this is also denoted as the meta-analytic-combined (MAC) approach. The problem, however, may also be factored into the evidence stemming from the ith study alone, as well as the information provided by the remaining (
$k-1$
parameter along the way; this is also denoted as the meta-analytic-combined (MAC) approach. The problem, however, may also be factored into the evidence stemming from the ith study alone, as well as the information provided by the remaining (
$k-1$
 ) estimates. Shrinkage estimation then may be interpreted as the analysis of the ith study, based on a prior distribution that results as the predictive distribution derived from a meta-analysis of the other (
$k-1$
) estimates. Shrinkage estimation then may be interpreted as the analysis of the ith study, based on a prior distribution that results as the predictive distribution derived from a meta-analysis of the other (
$k-1$
 ) studies; this prior is denoted as the meta-analytic-predictive (MAP) prior. Both MAC and MAP approaches are equivalent and yield identical shrinkage estimates.Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander
8
) studies; this prior is denoted as the meta-analytic-predictive (MAP) prior. Both MAC and MAP approaches are equivalent and yield identical shrinkage estimates.Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander
8
In the following, we will focus on the special case of only two studies (
$k=2$
 ). For the shrinkage estimate (
$\theta _2$
). For the shrinkage estimate (
$\theta _2$
 ), this implies a MAP prior that is based on a single study (i.e., the data provided through
$y_1$
), this implies a MAP prior that is based on a single study (i.e., the data provided through
$y_1$
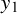 and
$s_1$
and
$s_1$
 ). While this may appear odd at first, the idea readily applies also in this special case, as will be demonstrated in the following. Analysis may generally be performed based on informative or uninformative priors for
$\mu $
). While this may appear odd at first, the idea readily applies also in this special case, as will be demonstrated in the following. Analysis may generally be performed based on informative or uninformative priors for
$\mu $
 , while a proper, informative prior is required for
$\tau $
, while a proper, informative prior is required for
$\tau $
 .Reference Röver
7
,
Reference Röver, Bender and Dias
12
The case of only
$k=2$
.Reference Röver
7
,
Reference Röver, Bender and Dias
12
The case of only
$k=2$
 studies is also closely connected to the related concepts of power prior
Reference Röver and Friede
9
or bias allowance models.Reference Welton, Sutton, Cooper, Abrams and Ades
13
,
Reference Pocock
17
studies is also closely connected to the related concepts of power prior
Reference Röver and Friede
9
or bias allowance models.Reference Welton, Sutton, Cooper, Abrams and Ades
13
,
Reference Pocock
17
2.2 Uniform prior for the overall mean effect (
$\mu $
 )
)

Priors for the overall mean parameter (
$\mu $
 ) in the NNHM may be specified as informative or as uninformative. For (more or less informative) priors, normal distributions are an obvious choice, also since these lead to analytically simple inference. Quite commonly, effect priors however are chosen as uninformative and (improper) uniform, not least due to certain analogies to frequentist meta-analysis procedures.Reference Röver
7
In case of an (improper, non-informative) uniform prior for
$\mu $
) in the NNHM may be specified as informative or as uninformative. For (more or less informative) priors, normal distributions are an obvious choice, also since these lead to analytically simple inference. Quite commonly, effect priors however are chosen as uninformative and (improper) uniform, not least due to certain analogies to frequentist meta-analysis procedures.Reference Röver
7
In case of an (improper, non-informative) uniform prior for
$\mu $
 , certain expressions turn out particularly simple, which is also why we will focus on this particular, yet insightful, common and practically relevant case in the following. As the (improper) uniform prior constitutes the limiting case of an increasingly uninformative effect prior, the following considerations may also be viewed as relating to the limiting behavior for increasingly uninformative priors (e.g., for normal priors when their variance approaches infinity). The uniform effect prior leads to a normal conditional posterior for the overall mean effect
$\mu $
, certain expressions turn out particularly simple, which is also why we will focus on this particular, yet insightful, common and practically relevant case in the following. As the (improper) uniform prior constitutes the limiting case of an increasingly uninformative effect prior, the following considerations may also be viewed as relating to the limiting behavior for increasingly uninformative priors (e.g., for normal priors when their variance approaches infinity). The uniform effect prior leads to a normal conditional posterior for the overall mean effect
$\mu $
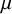 , with moments given by
, with moments given by

and a marginal heterogeneity likelihood that is constant (independent of
$\tau $
 ), so that the heterogeneity’s posterior equals its prior.Reference Röver
7
This seems reasonable, since (as long as the overall mean effect prior is uniform) a single observation
$y_1$
), so that the heterogeneity’s posterior equals its prior.Reference Röver
7
This seems reasonable, since (as long as the overall mean effect prior is uniform) a single observation
$y_1$
 does not provide information on the heterogeneity
$\tau $
does not provide information on the heterogeneity
$\tau $
 .
.
2.3 The MAP prior for the effect in a new study
The MAP prior results as the posterior predictive distribution for a “new,” second study’s (study-specific) effect
$\theta _2$
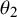 given the data from the first study (
$y_1$
given the data from the first study (
$y_1$
 ,
$s_1$
,
$s_1$
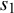 ). In the NNHM framework, the conditional predictive distribution again is normal with mean
). In the NNHM framework, the conditional predictive distribution again is normal with mean

and variance

(see also (2.2) and (2.3), and the more detailed derivation in Appendix A.1). These expressions make sense in the present context: We know
$\theta _1$
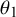 with accuracy given by the standard error
$s_1$
with accuracy given by the standard error
$s_1$
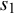 , and we know that the difference between
$\theta _1$
, and we know that the difference between
$\theta _1$
 and
$\theta _2$
and
$\theta _2$
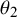 is normally distributed with variance
$2\tau ^2$
is normally distributed with variance
$2\tau ^2$
 , so that the (conditional) variance expression results as a corresponding sum.Reference Röver and Friede
9
As pointed out above, information on heterogeneity (
$\tau $
, so that the (conditional) variance expression results as a corresponding sum.Reference Röver and Friede
9
As pointed out above, information on heterogeneity (
$\tau $
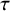 ) so far is based on the prior only; the heterogeneity in this context generally requires a proper, informative prior (since
$k<3$
) so far is based on the prior only; the heterogeneity in this context generally requires a proper, informative prior (since
$k<3$
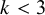 ).Reference Röver
7
,
Reference Röver, Bender and Dias
12
).Reference Röver
7
,
Reference Röver, Bender and Dias
12
The eventual (marginal) predictive distribution (marginalized over the distribution of
$\tau $
 ) hence results as a normal scale mixture
Reference Lee, McLachlan, Balakrishnan, Colton, Everitt, Piegorsch, Ruggeri and Teugels
18
,
Reference Lindsay
19
with fixed mean (2.4) and with variance as given in (2.5), where
$\tau $
) hence results as a normal scale mixture
Reference Lee, McLachlan, Balakrishnan, Colton, Everitt, Piegorsch, Ruggeri and Teugels
18
,
Reference Lindsay
19
with fixed mean (2.4) and with variance as given in (2.5), where
$\tau $
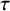 is distributed according to the specified prior. In particular, one may think of the MAP prior as the first study’s point estimate
$p(\theta _1|y_1,s_1)$
is distributed according to the specified prior. In particular, one may think of the MAP prior as the first study’s point estimate
$p(\theta _1|y_1,s_1)$
 convolved with the prior predictive distribution
$p(\theta _2|\theta _1,\tau )$
convolved with the prior predictive distribution
$p(\theta _2|\theta _1,\tau )$
 and then marginalized over
$\tau $
and then marginalized over
$\tau $
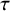 . The MAP prior is symmetric around
$y_1$
. The MAP prior is symmetric around
$y_1$
 , and its (marginal) variance results from (2.5) as
, and its (marginal) variance results from (2.5) as

where the expectation
${\mathrm {E}}[\tau ^2]$
 depends on the assigned heterogeneity prior. For a range of common prior specifications, this expectation may be derived analytically; Table A1 in Appendix A.4 lists some popular cases. From this expression, one can see that the relative magnitudes of
$s_1^2$
depends on the assigned heterogeneity prior. For a range of common prior specifications, this expectation may be derived analytically; Table A1 in Appendix A.4 lists some popular cases. From this expression, one can see that the relative magnitudes of
$s_1^2$
 and
${\mathrm {E}}[\tau ^2]$
and
${\mathrm {E}}[\tau ^2]$
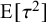 determine whether the resulting MAP prior’s variance is dominated by estimation uncertainty (regarding
$\theta _1$
determine whether the resulting MAP prior’s variance is dominated by estimation uncertainty (regarding
$\theta _1$
 ) or anticipated heterogeneity (
$\tau $
) or anticipated heterogeneity (
$\tau $
 ). These two variance components may in fact also be considered to reflect so-called “type A” and “type B” uncertainties relating to measurement uncertainty and background knowledge, respectively, which together sum up to form the combined standard uncertainty
$u_c$
). These two variance components may in fact also be considered to reflect so-called “type A” and “type B” uncertainties relating to measurement uncertainty and background knowledge, respectively, which together sum up to form the combined standard uncertainty
$u_c$
 (the square root of (2.6)).Reference Kirkup
20
,
Reference van der Bles, van der Linden and Freeman
21
(the square root of (2.6)).Reference Kirkup
20
,
Reference van der Bles, van der Linden and Freeman
21
Since the MAP prior results as a normal scale mixture, it is generally heavier-tailed than a normal distribution, which has implications for the resulting operating characteristics. A heavy-tailed (MAP-) prior means that in combination with a (“shorter-tailed”) normal likelihood, the likelihood will dominate in case of a prior-data conflict.Reference O’Hagan and Pericchi 22 Such robustness properties have in fact been noted and demonstrated in the meta-analysis context, as these lead to a dynamic borrowing behavior.Reference Röver and Friede 9 The MAP priors’ tail behavior will also be illustrated for some examples below (Figures 4 and 5).
Another way to quantify the precision of a prior distribution is by relating it to a number of observations that would in a certain sense convey an equivalent amount of information. In the following, we will use two approaches to this effect. Firstly, a prior may be assessed in terms of a corresponding absolute effective sample size (ESS) (here: number of patients), this will be done by quoting ESSs based on the expected local-information-ratio (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
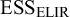 ). This measure is based on the prior density’s curvature and it ensures predictive consistency, that is, on expectation, the posterior’s ESS will be the sum of the prior’s
${\mathrm {ESS}_{\mathrm {ELIR}}}$
). This measure is based on the prior density’s curvature and it ensures predictive consistency, that is, on expectation, the posterior’s ESS will be the sum of the prior’s
${\mathrm {ESS}_{\mathrm {ELIR}}}$
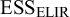 plus the actual sample size.Reference Neuenschwander, Weber, Schmidli and O’Hagan
23
Secondly, the added information from including the prior in a specific analysis may be expressed in terms of the (relative) gain in ESS.Reference Röver and Friede
9
This is based on comparing the relative width of a confidence interval with and without considering the informative prior, and then determining by what factor the sample size would have needed to be increased to yield the same precision gain (see also Appendix A.2).
plus the actual sample size.Reference Neuenschwander, Weber, Schmidli and O’Hagan
23
Secondly, the added information from including the prior in a specific analysis may be expressed in terms of the (relative) gain in ESS.Reference Röver and Friede
9
This is based on comparing the relative width of a confidence interval with and without considering the informative prior, and then determining by what factor the sample size would have needed to be increased to yield the same precision gain (see also Appendix A.2).
2.4 The bias allowance model connection
In the 2-study case, there is a one-to-one correspondence between the NNHM and a simple bias allowance model
Reference Welton, Sutton, Cooper, Abrams and Ades
13
; instead of the NNHM assumption (2.2) in combination with a uniform prior for the overall mean effect
$\mu $
 and heterogeneity prior
$p_\star (\tau )$
and heterogeneity prior
$p_\star (\tau )$
 as in Section 2.1, one may specify
as in Section 2.1, one may specify


with prior
$p(\beta )=\frac {1}{\sqrt {2}}\,p_{\star }\bigl (\frac {\beta }{\sqrt {2}}\bigr )$
 for the standard deviation
$\beta $
for the standard deviation
$\beta $
 .Reference Röver and Friede
9
This “reference model” is different in that one estimate (the reference, or “target”
$y_2$
.Reference Röver and Friede
9
This “reference model” is different in that one estimate (the reference, or “target”
$y_2$
 ) directly relates to
$\alpha $
) directly relates to
$\alpha $
 , while the other one (the “source”
$y_1$
, while the other one (the “source”
$y_1$
 ) is associated with an additional offset to account for potential bias. The shrinkage estimates of
$\theta _i$
) is associated with an additional offset to account for potential bias. The shrinkage estimates of
$\theta _i$
 , however, can be shown to be identical in both models as long as a uniform prior for the overall mean effect (
$\mu $
, however, can be shown to be identical in both models as long as a uniform prior for the overall mean effect (
$\mu $
 ) is used.Reference Röver and Friede
9
The reference model may be considered a variation of Pocock’s bias model or, more generally, a bias allowance model.Reference Welton, Sutton, Cooper, Abrams and Ades
13
,
Reference Pocock
17
,
Reference Neuenschwander, Schmidli, Lesaffre, Baio and Boulanger
24
The
$\beta $
) is used.Reference Röver and Friede
9
The reference model may be considered a variation of Pocock’s bias model or, more generally, a bias allowance model.Reference Welton, Sutton, Cooper, Abrams and Ades
13
,
Reference Pocock
17
,
Reference Neuenschwander, Schmidli, Lesaffre, Baio and Boulanger
24
The
$\beta $
 parameter, which only differs from
$\tau $
parameter, which only differs from
$\tau $
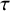 by a scaling factor of
$\sqrt {2}$
by a scaling factor of
$\sqrt {2}$
 , may also help motivating a heterogeneity prior, as it directly relates to the expected difference between
$\theta _2$
, may also help motivating a heterogeneity prior, as it directly relates to the expected difference between
$\theta _2$
 and
$\theta _1$
and
$\theta _1$
 , without reference to a common overall mean
$\mu $
, without reference to a common overall mean
$\mu $
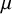 .
.
2.5 The power prior connection
There is also a connection to a so-called power prior, which has been proposed as an approach for deliberate down-weighting of prior information. It is intended for a prior distribution that itself results as a posterior, and the power prior results from applying an exponent
$a_0$
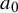 (with
$0 \leq a_0 \leq 1$
(with
$0 \leq a_0 \leq 1$
 ) to its likelihood contribution.Reference Neuenschwander, Schmidli, Lesaffre, Baio and Boulanger
24
,
Reference Ibrahim and Chen
25
When conditioning on a fixed
$\tau $
) to its likelihood contribution.Reference Neuenschwander, Schmidli, Lesaffre, Baio and Boulanger
24
,
Reference Ibrahim and Chen
25
When conditioning on a fixed
$\tau $
 value, the (conditional) MAP prior is normal with moments given in (2.4) and (2.5); in particular, note that
$\tau ^2$
value, the (conditional) MAP prior is normal with moments given in (2.4) and (2.5); in particular, note that
$\tau ^2$
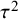 acts additively on the “plain” variance (
$s_1^2$
acts additively on the “plain” variance (
$s_1^2$
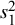 ). In this context, a power prior with fixed exponent
$a_0$
). In this context, a power prior with fixed exponent
$a_0$
 on the other hand would correspond to a
${\mathrm {Normal}}\Bigl (y_1,\,\frac {s_1^2}{a_0}\Bigr )$
on the other hand would correspond to a
${\mathrm {Normal}}\Bigl (y_1,\,\frac {s_1^2}{a_0}\Bigr )$
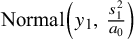 distribution, where the (inverse) exponent acts multiplicatively on the variance. Both MAP and power prior then are identical if
$a_0=\bigl (2\frac {\tau ^2}{s_1^2}+1\bigr )^{-1}$
distribution, where the (inverse) exponent acts multiplicatively on the variance. Both MAP and power prior then are identical if
$a_0=\bigl (2\frac {\tau ^2}{s_1^2}+1\bigr )^{-1}$
 .Reference Röver and Friede
9
,
Reference Chen and Ibrahim
26
,
Reference Pawel, Aust, Held and Wagenmakers
27
It is interesting to note that the relationship between
$a_0$
.Reference Röver and Friede
9
,
Reference Chen and Ibrahim
26
,
Reference Pawel, Aust, Held and Wagenmakers
27
It is interesting to note that the relationship between
$a_0$
 and
$\tau $
and
$\tau $
 here depends on the ratio
$\frac {\tau }{s_1}$
here depends on the ratio
$\frac {\tau }{s_1}$
 ; Pawel et al. (2024)Reference Pawel, Aust, Held and Wagenmakers
27
point out that the exponent
$a_0$
; Pawel et al. (2024)Reference Pawel, Aust, Held and Wagenmakers
27
point out that the exponent
$a_0$
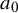 directly relates to the “relative” heterogeneity as expressed though the popular
$I^2$
directly relates to the “relative” heterogeneity as expressed though the popular
$I^2$
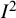 statistic,Reference Higgins and Thompson
28
which in this case simply equals
$I^2=\frac {\tau ^2}{\tau ^2+s_1^2}$
statistic,Reference Higgins and Thompson
28
which in this case simply equals
$I^2=\frac {\tau ^2}{\tau ^2+s_1^2}$
 . The exponent may then directly be expressed as a function of the corresponding
$I^2$
. The exponent may then directly be expressed as a function of the corresponding
$I^2$
 as
$a_0=\frac {1-I^2}{1+I^2}$
as
$a_0=\frac {1-I^2}{1+I^2}$
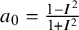 . While a prior probability distribution for
$\tau $
. While a prior probability distribution for
$\tau $
 is readily motivated with reference to the effect scale of
$y_i$
is readily motivated with reference to the effect scale of
$y_i$
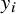 and
$\theta _i$
and
$\theta _i$
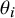 ,Reference Röver, Bender and Dias
12
specification of a fixed
$\alpha _0$
,Reference Röver, Bender and Dias
12
specification of a fixed
$\alpha _0$
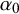 value remains tricky, and a prior distribution may be even harder to motivate, as it would implicitly relate to the
$I^2$
value remains tricky, and a prior distribution may be even harder to motivate, as it would implicitly relate to the
$I^2$
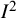 scale. On the other hand, through the above functional correspondence, any prior for the heterogeneity
$\tau $
scale. On the other hand, through the above functional correspondence, any prior for the heterogeneity
$\tau $
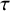 immediately implies a corresponding distribution for the exponent
$a_0$
immediately implies a corresponding distribution for the exponent
$a_0$
 ; an example is illustrated in Appendix A.5.
; an example is illustrated in Appendix A.5.
3 Two practical applications
3.1 Pediatric Alport example
3.1.1 Application
Gross et al. (2020)Reference Gross, Tönshoff and Weber 29 performed a randomized controlled trial (RCT) in Alport syndrome to investigate the effects of ramipril, an angiotensin-converting enzyme inhibitor (ACEi). Recruitment of participants to the RCT was hampered by the rare and pediatric nature of the disease, and so the analysis of the RCT had been planned with the inclusion of observational data from an open-label arm and a natural disease cohort.Reference Gross, Friede and Hilgers 30 Time to disease progression was a co-primary endpoint, and from the observational data, a hazard ratio (HR) of 0.53 [0.22, 1.29] was estimated based on 70 patients. Only 20 patients entered into the RCT, and an HR of 0.51 [0.12, 2.20] was estimated. The data are also summarized in Table 1.
Alport example data from Gross et al. (2020).Reference Gross, Tönshoff and Weber 29

Table 1 Long description
The table consists of six columns and two data rows.
Column headers from left to right are: i, Estimate, n sub i, Hazard ratio H R, and a grouped header log-H R which contains two sub-columns y sub i and s sub i.
Row 1:
- i: 1
- Estimate: Observational
- n sub i: 70
- Hazard ratio H R: 0.53 with a confidence interval of 0.22, 1.29
- log-H R y sub i: -0.635
- log-H R s sub i: 0.451
Row 2:
- i: 2
- Estimate: R C T
- n sub i: 20
- Hazard ratio H R: 0.51 with a confidence interval of 0.12, 2.20
- log-H R y sub i: -0.673
- log-H R s sub i: 0.742
The analysis was then performed by jointly considering both log-HR estimates in an NNHM, anticipating a reasonable amount of heterogeneity between them (expressed through a
$\text {half-Normal}(0.5)$
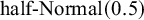 prior for
$\tau $
prior for
$\tau $
 ), and deriving a shrinkage estimate for the RCT effect (
$\theta _2$
), and deriving a shrinkage estimate for the RCT effect (
$\theta _2$
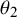 ). The resulting estimate then was substantially more precise than if the RCT data were considered in isolation; the HR was estimated at 0.52 [0.19, 1.39].Reference Gross, Tönshoff and Weber
29
). The resulting estimate then was substantially more precise than if the RCT data were considered in isolation; the HR was estimated at 0.52 [0.19, 1.39].Reference Gross, Tönshoff and Weber
29
To make the flow of information transparent, we may now derive the corresponding MAP prior reflecting the information contributed by the observational data. Figure 1 illustrates MAP-prior, likelihood, and posterior (shrinkage estimate) for the Alport example. The MAP prior here has a mean of
$y_i=-0.63$
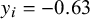 and a variance of
$s_1^2 + 2\,{\mathrm {E}}[\tau ^2] = 0.45^2 + 2\times 0.5^2 = 0.84^2$
and a variance of
$s_1^2 + 2\,{\mathrm {E}}[\tau ^2] = 0.45^2 + 2\times 0.5^2 = 0.84^2$
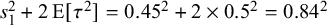 . While the observational sample size was 70 patients, the MAP prior’s effective sample size (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
. While the observational sample size was 70 patients, the MAP prior’s effective sample size (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
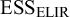 ) is at only 26 patients (i.e., 37% of originally 70 actual patients).Reference Neuenschwander, Weber, Schmidli and O’Hagan
23
The eventual shrinkage interval is only 67% as wide as the original, implying a substantial “effective gain in sample size”Reference Röver and Friede
9
; such a precision increase would otherwise have required more than doubling the sample size (by the addition of 24 extra patients). So in this case, the absolute (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
) is at only 26 patients (i.e., 37% of originally 70 actual patients).Reference Neuenschwander, Weber, Schmidli and O’Hagan
23
The eventual shrinkage interval is only 67% as wide as the original, implying a substantial “effective gain in sample size”Reference Röver and Friede
9
; such a precision increase would otherwise have required more than doubling the sample size (by the addition of 24 extra patients). So in this case, the absolute (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
 ) estimate matches well the observed precision gain.
) estimate matches well the observed precision gain.
Illustration of MAP-prior, likelihood, and (shrinkage-) posterior for the Alport example discussed in Section 3.1.Reference Gross, Tönshoff and Weber 29 The horizontal lines at the bottom indicate point estimates and corresponding 95% intervals.

Figure 1 Long description
The x-axis is labeled log minus H R and ranges from minus 3 to 2. A vertical dashed line marks the zero point. Three bell-shaped curves are centered near minus 0.7.
* The blue curve, representing likelihood R C T, is the widest and shortest.
* The orange curve, representing M A P prior observational, has a medium height and width.
* The green curve, representing shrinkage R C T, is the tallest and narrowest, indicating the highest precision.
Below the x-axis, three horizontal lines with central diamond markers represent point estimates and 95 percent intervals.
* The top orange line is the longest, spanning from approximately minus 2.4 to 1.1.
* The middle blue line spans from approximately minus 2.1 to 0.8.
* The bottom green line is the shortest, spanning from approximately minus 1.6 to 0.3.
All three diamond markers are vertically aligned at approximately minus 0.7.
3.1.2 Variations of the MAP prior
The heterogeneity (
$\tau $
 ) prior was specified as a
${\text {half-Normal}}(0.5)$
) prior was specified as a
${\text {half-Normal}}(0.5)$
 distribution, which is a reasonably conservative choice for endpoints such as HRs, as it covers “reasonable” and up to “fairly high” levels of heterogeneity (
$\tau \leq 1$
distribution, which is a reasonably conservative choice for endpoints such as HRs, as it covers “reasonable” and up to “fairly high” levels of heterogeneity (
$\tau \leq 1$
 ) and leaves a small prior probability for “fairly extreme” amounts (
$\tau>1$
) and leaves a small prior probability for “fairly extreme” amounts (
$\tau>1$
 ).Reference Röver, Bender and Dias
12
,
Reference Friede, Röver, Wandel and Neuenschwander
31
Since conclusions heavily depend on the heterogeneity prior settings, it may however be interesting to investigate the effects of a range of reasonable alternative specifications; in particular, we will consider different prior scales and different distribution families. Among the various assumptions implemented in the analysis, a “too optimistic” heterogeneity prior (favoring small heterogenity) might yield results inappropriately close to a common-effect analysis, while overly “pessimistic” or “conservative” assumptions may on the other hand eventually lead to very little borrowing of information.
).Reference Röver, Bender and Dias
12
,
Reference Friede, Röver, Wandel and Neuenschwander
31
Since conclusions heavily depend on the heterogeneity prior settings, it may however be interesting to investigate the effects of a range of reasonable alternative specifications; in particular, we will consider different prior scales and different distribution families. Among the various assumptions implemented in the analysis, a “too optimistic” heterogeneity prior (favoring small heterogenity) might yield results inappropriately close to a common-effect analysis, while overly “pessimistic” or “conservative” assumptions may on the other hand eventually lead to very little borrowing of information.
Assuming that
$s_1=0.451$
 (as in the present example, see Table 1), we can illustrate the resulting MAP prior when varying the heterogeneity prior scale. Figure 2 shows the likelihood of the observational estimate along with the corresponding MAP priors for half-normal heterogeneity priors with scales 0.25, 0.50, and 1.00. Increasing the heterogeneity prior scale yields a MAP prior that becomes increasingly wider than the plain likelihood alone. In the present case, the effect scale was a logarithmic HR, and on the logarithmic scale, the original MAP prior (based on a
${\text {half-Normal}}(0.5)$
(as in the present example, see Table 1), we can illustrate the resulting MAP prior when varying the heterogeneity prior scale. Figure 2 shows the likelihood of the observational estimate along with the corresponding MAP priors for half-normal heterogeneity priors with scales 0.25, 0.50, and 1.00. Increasing the heterogeneity prior scale yields a MAP prior that becomes increasingly wider than the plain likelihood alone. In the present case, the effect scale was a logarithmic HR, and on the logarithmic scale, the original MAP prior (based on a
${\text {half-Normal}}(0.5)$
 heterogeneity prior) covers a range of
$y_1 \pm 1.72$
heterogeneity prior) covers a range of
$y_1 \pm 1.72$
 with 95% probability. On the exponentiated scale (see also the top axis in Figure 2), a difference of 1.72 in log-HR would correspond to a 5.6-fold larger HR. If one switched to a
${\text {half-Normal}}(0.25)$
with 95% probability. On the exponentiated scale (see also the top axis in Figure 2), a difference of 1.72 in log-HR would correspond to a 5.6-fold larger HR. If one switched to a
${\text {half-Normal}}(0.25)$
 or
${\text {half-Normal}}(1.0)$
or
${\text {half-Normal}}(1.0)$
 prior instead, the range would change to
$y_1\pm 1.13$
prior instead, the range would change to
$y_1\pm 1.13$
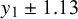 or
$y_1\pm 3.18$
or
$y_1\pm 3.18$
 instead, corresponding to multiplicative factors of 3.1 or 24.0, respectively.
instead, corresponding to multiplicative factors of 3.1 or 24.0, respectively.
Illustration of the resulting MAP-prior for varying heterogeneity prior scales. The dashed line indicates the likelihood of the observational data alone for comparison.

Figure 2 Long description
The graph features two x-axes and one y-axis. The bottom x-axis is labeled prediction theta sub 2 log scale with ticks at y sub 1, y sub 1 plus 1, y sub 1 plus 2, y sub 1 plus 3, and y sub 1 plus 4. The top x-axis is labeled prediction theta sub 2 exponentiated with ticks at e super y sub 1, 2 e super y sub 1, 5 e super y sub 1, 10 e super y sub 1, 20 e super y sub 1, and 50 e super y sub 1. The y-axis is labeled density ranging from 0.0 to 0.8.
Four curves are plotted, all peaking at the vertical line corresponding to y sub 1:
* Observational: A dashed grey line with the highest peak at approximately 0.9 density, showing the narrowest distribution and sharpest decline.
* H N 0.25: A solid light blue line peaking at approximately 0.75 density. It is wider than the observational curve.
* H N 0.50: A solid orange line peaking at approximately 0.6 density.
* H N 1.00: A solid purple line with the lowest peak at approximately 0.45 density, showing the flattest and widest distribution.
As the heterogeneity prior scale increases from 0.25 to 1.00, the curves become lower and broader, with thicker tails extending further to the right toward y sub 1 plus 4.
Half-normal distributions are a common and obvious choice as heterogeneity priors, possible reasons may be familiarity and availability, as well as a “flat” shape near the origin and a rather short tail.Reference Röver, Bender and Dias 12 Variations of the distribution family commonly do not alter conclusions dramatically as long as they cover a similar range, as manifested, for example, in a common prior median.
Illustration of MAP-prior’s dependence on the heterogeneity prior distribution family. The different heterogeneity priors shown here all share the same prior median.

Figure 3 Long description
The graph features two x-axes and one y-axis. The bottom x-axis is labeled prediction theta sub 2 log scale with tick marks at y sub 1, y sub 1 plus 1, y sub 1 plus 2, y sub 1 plus 3, and y sub 1 plus 4. The top x-axis is labeled prediction theta sub 2 exponentiated with tick marks at e super y sub 1, 2e super y sub 1, 5e super y sub 1, 10e super y sub 1, 20e super y sub 1, and 50e super y sub 1. The y-axis is labeled density and ranges from 0.0 to 0.8.
A legend in the top right identifies eight curves.
- half-Normal 0.50 in brown.
- half-t 4, 0.46 in orange.
- half-Cauchy 0.34 in yellow.
- half-logistic 0.31 in pink.
- exponential 0.49 in green.
- Lomax 6, 2.75 in dark blue.
- Lomax 1, 0.34 in light blue.
- non-R C T represented by a black dashed line.
Data trends. All curves originate near a density of 0.3 to 0.4 at the left edge. The non-R C T dashed line forms a sharp peak at x equals y sub 1 with a density of approximately 0.9. The other seven prior distribution curves form a lower, broader cluster of peaks also centered around y sub 1, with maximum densities between 0.55 and 0.6. As the x-axis increases toward y sub 1 plus 4, all curves show an asymptotic decay toward zero density, with the Lomax and Cauchy distributions exhibiting slightly thicker tails than the dashed non-R C T line.
The MAP-priors’ cumulative distribution functions corresponding to the densities shown in Figure 3.

Figure 4 Long description
The line graph features two horizontal axes and one vertical axis. The primary x axis at the bottom is labeled prediction theta sub 2 log scale with tick marks at y sub 1, y sub 1 plus 1, y sub 1 plus 2, y sub 1 plus 3, and y sub 1 plus 4. The secondary x axis at the top is labeled prediction theta sub 2 exponentiated with tick marks at e super y sub 1, 2 e super y sub 1, 5 e super y sub 1, 10 e super y sub 1, 20 e super y sub 1, and 50 e super y sub 1. The y axis is labeled cumulative distribution function ranging from 0.5 to 1.0.
Multiple asymptotic curves rise from the bottom left toward the top right. A dashed black line representing non R C T rises most steeply, reaching a value of 1.0 near y sub 1 plus 1. A cluster of colored lines follows a similar but less steep trajectory, including half-Normal 0.50 in brown, half-t 4, 0.46 in orange, half-Cauchy 0.34 in yellow, half-logistic 0.31 in purple, exponential 0.49 in green, and Lomax 6, 2.75 in dark blue. A light blue line representing Lomax 1, 0.34 shows the shallowest curve, remaining below the others as it approaches 1.0.
A legend in the bottom right corner identifies the eight categories with corresponding colored squares. A vertical gray line intersects the x axis at y sub 1, and a horizontal dotted gray line intersects the y axis at 0.5.
The MAP-priors’ densities on a logarithmic scale (see also Figure 3). Note that the likelihood for the observational data alone follows a parabola shape here, while the corresponding MAP priors are clearly much heavier-tailed.

Figure 5 Long description
The graph uses a logarithmic scale for both axes. The horizontal x-axis represents prediction theta sub 2. The bottom labels show log scale values: y sub 1, y sub 1 plus 1, y sub 1 plus 2, y sub 1 plus 3, and y sub 1 plus 4. The top labels show exponentiated values: e super y sub 1, 2 e super y sub 1, 5 e super y sub 1, 10 e super y sub 1, 20 e super y sub 1, and 50 e super y sub 1. The vertical y-axis represents density with values from 0.005 to 0.500.
A dashed black line representing non-R C T data forms a steep parabola, peaking near y sub 1 and dropping sharply toward the x-axis before y sub 1 plus 2.
Seven solid colored curves represent different M A P priors. All peak near y sub 1 at a density of approximately 0.500 but exhibit much heavier tails than the dashed line, extending across the full width of the graph. From top to bottom at the far right of the x-axis, the curves are ordered as follows:
* Lomax 1, 0.34 in light blue
* Lomax 6, 2.75 in dark blue
* half-Cauchy 0.34 in yellow
* half-t 4, 0.46 in gold
* exponential 0.49 in green
* half-logistic 0.31 in purple
* half-Normal 0.50 in orange
A vertical gray line marks the peak position at y sub 1.
MAP priors corresponding to alternative specifications to a
${\text {half-Normal}}(0.5)$
 for the heterogeneity are illustrated in Figure 3. A range of distribution families is used, with their scale parameters specified such that all correspond to a common prior median for
$\tau $
for the heterogeneity are illustrated in Figure 3. A range of distribution families is used, with their scale parameters specified such that all correspond to a common prior median for
$\tau $
 (of
$0.34$
(of
$0.34$
 ). These different heterogeneity prior families are also shown in Appendix A.3. The resulting MAP prior densities themselves are hard to distinguish. Differences are more noticeable when focusing on the tail behavior, for example, considering cumulative distribution functions (as shown in Figure 4) or logarithmic densities (shown in Figure 5). One can see that heavier-tailed heterogeneity priors also yield correspondingly heavier-tailed MAP-priors. The heterogeneity and the corresponding MAP priors’ properties are also summarized and compared in Table 2 in terms of prior quantiles and effective sample sizes (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
). These different heterogeneity prior families are also shown in Appendix A.3. The resulting MAP prior densities themselves are hard to distinguish. Differences are more noticeable when focusing on the tail behavior, for example, considering cumulative distribution functions (as shown in Figure 4) or logarithmic densities (shown in Figure 5). One can see that heavier-tailed heterogeneity priors also yield correspondingly heavier-tailed MAP-priors. The heterogeneity and the corresponding MAP priors’ properties are also summarized and compared in Table 2 in terms of prior quantiles and effective sample sizes (
${\mathrm {ESS}_{\mathrm {ELIR}}}$
 ).
).
Summaries of MAP priors resulting from several settings for the heterogeneity (
$\tau $
 ) prior. The half-normal(0.5) prior is contrasted with half-normal priors of differing scale, as well as with priors of differing distributional families, but with matching prior medians. Note that in the context of the present example, the MAP prior’s domain corresponds to logarithmic hazard ratios (log-HRs). Quantiles are centered at
$y_1$
) prior. The half-normal(0.5) prior is contrasted with half-normal priors of differing scale, as well as with priors of differing distributional families, but with matching prior medians. Note that in the context of the present example, the MAP prior’s domain corresponds to logarithmic hazard ratios (log-HRs). Quantiles are centered at
$y_1$


Table 2 Long description
The table is organized into eight columns. The first three columns define the tau Prior: Family, Scale, and Median. The subsequent columns provide the resulting M A P prior summaries: E S S sub E L I R, Standard Deviation, and three Quantiles (theta sub 2 minus y sub 1) at 95.0%, 97.5%, and 99.5%.
* Row 1: Half-normal, Scale 0.50, Median 0.34, E S S 26.6, SD 0.84, Quantiles 1.32, 1.72, 2.72.
* Row 2: Half-normal, Scale 0.25, Median 0.17, E S S 45.7, SD 0.57, Quantiles 0.93, 1.13, 1.62.
* Row 3: Half-normal, Scale 1.00, Median 0.67, E S S 12.8, SD 1.48, Quantiles 2.35, 3.18, 5.19.
* Row 4: Half-t with nu equals 4, Scale 0.46, Median 0.34, E S S 25.3, SD 1.02, Quantiles 1.45, 1.98, 3.58.
* Row 5: Half-Cauchy, Scale 0.34, Median 0.34, E S S 23.4, SD blank, Quantiles 2.45, 4.85, 24.02.
* Row 6: Half-logistic, Scale 0.31, Median 0.34, E S S 25.8, SD 0.91, Quantiles 1.39, 1.85, 3.09.
* Row 7: Exponential, Scale 0.49, Median 0.34, E S S 24.5, SD 1.07, Quantiles 1.56, 2.19, 3.96.
* Row 8: Lomax with alpha equals 6, Scale 2.75, Median 0.34, E S S 24.0, SD 1.31, Quantiles 1.70, 2.50, 5.05.
* Row 9: Lomax with alpha equals 1, Scale 0.34, Median 0.34, E S S 23.1, SD blank, Quantiles 3.29, 7.05, 37.17.
It is sometimes also instructive to observe the effects of variations of the prior on the resulting estimates; for example, varying the heterogeneity prior scale allows for a sensitivity (or tipping point) analysis. Such an analysis is shown in Appendix A.6; the amount of borrowing is reflected in the shrinkage interval’s width, but in the present example, inference would not change qualitatively, and a log-HR of zero always remains included.
3.2 Heart failure example
The Spirit-HF trial has been designed in order to test the efficacy of spironolactone in patients with heart failure (HF).Reference Pieske
32
Spironolactone is expected to reduce cardiovascular mortality as well as hospitalizations due to HF, and had previously been investigated in the Topcat trial.Reference Pitt, Pfeiffer and Assmann
33
Both studies refer to the composite of (recurrent) HF hospitalization and cardiovascular death as the primary endpoint to evaluate treatment efficacy. Despite a sizeable sample size of 3,445 patients and a mean follow-up duration of more than three years, the Topcat trial failed to demonstrate statistical significance; the estimated HR was at 0.89 (0.77, 1.04) (
$p=0.14$
 ).Reference Pitt, Pfeiffer and Assmann
33
).Reference Pitt, Pfeiffer and Assmann
33
The analysis of the new Spirit-HF trial meanwhile is being planned, and may take into consideration the evidence already generated in the Topcat trial. One idea may be to derive a shrinkage estimate, anticipating some between-study heterogeneity, and dynamically borrowing information from the earlier study based on the corresponding MAP prior.Reference Röver and Friede
9
,
Reference Röver and Friede
10
For the between-study heterogeneity
$\tau $
 , use of a
${\text {half-Normal}}(0.25)$
, use of a
${\text {half-Normal}}(0.25)$
 prior may be appropriate. The heterogeneity prior may be motivated referring to anticipated levels of heterogeneity based on general considerationsReference Röver, Bender and Dias
12
or using empirical evidence, in particular in view of the similar study designs and the effect measure being a log-HR.Reference Lilienthal, Sturtz and Schürmann
34
prior may be appropriate. The heterogeneity prior may be motivated referring to anticipated levels of heterogeneity based on general considerationsReference Röver, Bender and Dias
12
or using empirical evidence, in particular in view of the similar study designs and the effect measure being a log-HR.Reference Lilienthal, Sturtz and Schürmann
34
In the present case, analysis is based on the logarithmic HR; the HR estimated in the Topcat trial corresponds to a log-HR of
$-0.117$
 with a standard error of
$0.077$
with a standard error of
$0.077$
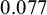 . The corresponding Topcat likelihood along with the resulting MAP prior is illustrated in Figure 6. The variance (squared standard error) of the Topcat study’s estimate was
$s_1^2=0.077^2$
. The corresponding Topcat likelihood along with the resulting MAP prior is illustrated in Figure 6. The variance (squared standard error) of the Topcat study’s estimate was
$s_1^2=0.077^2$
 while for the assumed heterogeneity prior the expected heterogeneity variance is
${\mathrm {E}}[\tau ^2]=0.25^2$
while for the assumed heterogeneity prior the expected heterogeneity variance is
${\mathrm {E}}[\tau ^2]=0.25^2$
 (see also Table A1), so that the resulting MAP prior’s variance (2.6) is
$s_1^2 + 2\,{\mathrm {E}}[\tau ^2] = 0.362^2$
(see also Table A1), so that the resulting MAP prior’s variance (2.6) is
$s_1^2 + 2\,{\mathrm {E}}[\tau ^2] = 0.362^2$
 , and the majority of the variance is due to epistemic uncertainty relating to the anticipated similarity of the Topcat and Spirit-HF parameters. The 95% prediction interval for the MAP prior is centered at the Topcat log-HR estimate and ranges from
$-0.899$
, and the majority of the variance is due to epistemic uncertainty relating to the anticipated similarity of the Topcat and Spirit-HF parameters. The 95% prediction interval for the MAP prior is centered at the Topcat log-HR estimate and ranges from
$-0.899$
 to
$+0.665$
to
$+0.665$
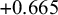 , corresponding to HRs in the range [
$0.407$
, corresponding to HRs in the range [
$0.407$
 ,
$1.945$
,
$1.945$
 ]. According to the MAP prior, the probability of a beneficial treatment effect (a log-HR below zero) is 71%. The MAP prior has an
${\mathrm {ESS}_{\mathrm {ELIR}}}$
]. According to the MAP prior, the probability of a beneficial treatment effect (a log-HR below zero) is 71%. The MAP prior has an
${\mathrm {ESS}_{\mathrm {ELIR}}}$
 of 399, that is, only 12% of the 3,445 actual Topcat patients, and 31% of the estimated enrolment of 1,300 Spirit-HF patients.Reference Pieske
32
This means that the prior derived from the Topcat data will not enter the eventual analysis as an additional 3,445 patients (as would be the case if both study populations were pooled naïvely), but instead we expect an accuracy corresponding to a total of some
$1,300+399$
of 399, that is, only 12% of the 3,445 actual Topcat patients, and 31% of the estimated enrolment of 1,300 Spirit-HF patients.Reference Pieske
32
This means that the prior derived from the Topcat data will not enter the eventual analysis as an additional 3,445 patients (as would be the case if both study populations were pooled naïvely), but instead we expect an accuracy corresponding to a total of some
$1,300+399$
 patients. The Spirit-HF study’s contribution to its own shrinkage estimate may also be assessedReference Röver and Friede
10
; assuming that both studies show the same dependence of standard error and sample size, the Spirit-HF study will account for a minimum of
$61\%$
patients. The Spirit-HF study’s contribution to its own shrinkage estimate may also be assessedReference Röver and Friede
10
; assuming that both studies show the same dependence of standard error and sample size, the Spirit-HF study will account for a minimum of
$61\%$
 in weight to the eventual effect estimate.
in weight to the eventual effect estimate.
Illustration of likelihood and corresponding MAP-prior for the heart failure example, using a
${\text {half-Normal}}(0.25)$
 prior for
$\tau $
prior for
$\tau $
 . The horizontal line at the bottom indicates the 95% prediction interval.
. The horizontal line at the bottom indicates the 95% prediction interval.

Figure 6 Long description
The graph features two X axes. The top axis represents hazard ratio H R with tick marks at 0.5, 1, and 2. The bottom axis represents log open parenthesis H R close parenthesis with values from negative 1.0 to 1.0. A vertical gray line marks the null value at H R equals 1 and log H R equals 0.0.
Two curves are plotted:
* T O P C A T likelihood is represented by a dashed black line forming a narrow, tall bell curve centered slightly to the left of the null line, approximately at log H R negative 0.1.
* M A P prior is represented by a solid red line forming a much wider, shorter bell curve. The area under this red curve is shaded gray. Its peak aligns vertically with the dashed curve's peak.
A legend in the top right corner identifies these two lines. At the bottom of the plot area, a horizontal red line with a diamond marker at its center indicates a 95 percent prediction interval, extending from approximately negative 0.9 to 0.7 on the log H R scale.
4 Discussion
Despite the seemingly odd notion of a meta-analysis of a single study, the use of MAP priors remains completely consistent down to the extreme case of only one data point. The “usual” toolbox remains available, including common prior specifications,Reference Röver, Bender and Dias
12
computation of ESSs,Reference Neuenschwander, Weber, Schmidli and O’Hagan
23
robustification,Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander
8
as well as common meta-analysis software (e.g., the bayesmeta or RBesT R packages)Reference Röver
7
,
Reference Weber, Li, Seaman, Kakizume and Schmidli
35
for practical implementation. In addition, for
$k=1$
 , there are connections to bias allowance and power prior models (see Section 2) that may help motivating a MAP approach (or vice versa). MAP priors based on a few estimates are generally rather heavy-tailed, which will ensure robust operating characteristics.Reference Röver and Friede
9
,
Reference Röver and Friede
10
,
Reference O’Hagan and Pericchi
22
For a few data points in general, and in particular for only a single data point, the prior specification for the heterogeneity parameter
$\tau $
, there are connections to bias allowance and power prior models (see Section 2) that may help motivating a MAP approach (or vice versa). MAP priors based on a few estimates are generally rather heavy-tailed, which will ensure robust operating characteristics.Reference Röver and Friede
9
,
Reference Röver and Friede
10
,
Reference O’Hagan and Pericchi
22
For a few data points in general, and in particular for only a single data point, the prior specification for the heterogeneity parameter
$\tau $
 gains in importance and needs to be particularly well-founded and convincing.Reference Röver, Bender and Dias
12
gains in importance and needs to be particularly well-founded and convincing.Reference Röver, Bender and Dias
12
While only the normal model (NNHM) was discussed here, the idea also extends to other model families; for example, derivation of a MAP prior would also work for a binomial-normal model (as implemented in the RBesT package).Reference Weber, Li, Seaman, Kakizume and Schmidli 35 Another related approach (with some similarity to the power prior) is given by the commensurate prior,Reference Hobbs, Carlin, Mandrekar and SD. 36 which, however, does not constitute a special case of the MAP prior. Empirical MAP priors may then be utilized in different ways, either to simply motivate a reasonable sample size (or other design aspects), or to implement explicit borrowing of historical information.Reference Schmidli, Neuenschwander and Friede 37 , Reference Muehlemann, Zhou, Mukherjee, Hossain, Roychoudhury and Russek-Cohen 38
When MAP priors are used to also inform the analysis, it is important to approach the evaluation of operating characteristics from a sensible angle; the naive application of classically “frequentist” measures to judge a Bayesian procedure, in particular when informative priors are involved, will often not provide a meaningful assessment of its actual features.Reference Gneiting, Balabdaoui and Raftery 39 – Reference Best, Ajimi, Neuenschwander, Saint-Hilary and Wandel 41
A common concern in the context of the use of historical data is that an informative prior might unduly dominate the eventual analysis; for example, in the HF example application, one might be worried that the much larger Topcat trial would swamp the data from the smaller Spirit-HF study. However, for the shrinkage estimate of interest here, the second study’s contribution is bounded by a minimum of
$61\%$
 within the suggested setup. This proportion would increase for a more conservative heterogeneity prior specificationReference Röver, Bender and Dias
12
or when implementing robustification,Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander
8
however, such modeling decisions should probably rather be based on considerations of prior information than on deduced operating characteristics.
within the suggested setup. This proportion would increase for a more conservative heterogeneity prior specificationReference Röver, Bender and Dias
12
or when implementing robustification,Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander
8
however, such modeling decisions should probably rather be based on considerations of prior information than on deduced operating characteristics.
Besides considerations of the value of “borrowed” information for a given parameter estimate, MAP priors based on historical data may also be interesting for the design of subsequent trials, with or without the eventual use of shrinkage estimation in the final analysis. Historical information may then help determining sensible ranges for nuisance parametersReference Schmidli, Neuenschwander and Friede 37 or sample sizes,Reference Lindley 42 , Reference Brutti, De Santis and Gubbiotti 43 for interim decisions,Reference Schmidli, Gsteiger, Roychoudhury, O’Hagan, Spiegelhalter and Neuenschwander 8 , Reference Neuenschwander, Roychoudhuri and Schmidli 44 or it may be used in a more comprehensive fashion to ensure a positive joint outcome.Reference Neuenschwander, Roychoudhuri and Schmidli 44 , Reference Pawel, Consonni and Held 45
Van Zwet et al. (2024) argue that the analysis of a single study should also account for heterogeneity of the treatment effect across studies. Therefore, they propose to consider analyses of individual studies also within an overarching NNHM framework similar to our approach presented here; using informative, empirically motivated priors for both
$\mu $
 and
$\tau $
and
$\tau $
 , inference may then be focused on the overall mean effect (
$\mu $
, inference may then be focused on the overall mean effect (
$\mu $
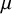 ) rather than the study-specific
$\theta _1$
) rather than the study-specific
$\theta _1$
 even in the analysis of only a single study.Reference Gelman
46
,
Reference van Zwet, Wiecek and Gelman
47
even in the analysis of only a single study.Reference Gelman
46
,
Reference van Zwet, Wiecek and Gelman
47
Author contributions
Conceptualization: C.R. and T.F.; Methodology: C.R.; Writing original draft: C.R. Both authors approved the final submitted draft.
Competing interest statement
The authors declare that no competing interests exist.
Data availability statement
The data supporting the findings of this study are openly available at Zenodo under the URL https://doi.org/10.5281/zenodo.18633334.
Funding statement
Support from the German Centre for Cardiovascular Research (Deutsches Zentrum für Herz-Kreislauf-Forschung e.V., DZHK) is gratefully acknowledged (Grant No. 81Z0300108).
A Appendix
A.1 Posterior predictive distribution
When an informative
${\mathrm {Normal}}({\mu _{\mathrm {p}}}, {\sigma _{\mathrm {p}}}^2)$
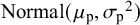 prior is assumed for the overall mean
$\mu $
prior is assumed for the overall mean
$\mu $
 , the posterior predictive distribution for a “new” study-specific mean
$\theta _{k+1}$
, the posterior predictive distribution for a “new” study-specific mean
$\theta _{k+1}$
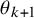 (conditional on a given heterogeneity value) is again normal with moments
(conditional on a given heterogeneity value) is again normal with moments


implying for the specific case of
$k=1$
 that
that


(see Röver (2020)Reference Röver
7
). One can already see that in the limiting case of an increasingly vague effect prior (
${\sigma _{\mathrm {p}}}\rightarrow \infty )$
 , the prior’s influence vanishes, and the (conditional) variance increases.
, the prior’s influence vanishes, and the (conditional) variance increases.
Specification of an improper uniform prior for the overall mean effect
$\mu $
 also leads to a proper posterior; the posterior predictive moments then are of the slightly simpler form
also leads to a proper posterior; the posterior predictive moments then are of the slightly simpler form


(see Röver (2020)Reference Röver
7
). In the case of a single study (
$k=1$
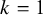 ), these expressions then simplify to
), these expressions then simplify to

Illustration of the several heterogeneity priors compared in Section 3.1.2 in terms of their probability density functions. All priors are scaled such that they have a common median of 0.34 (the median of a half-normal(0.5) prior; dashed line).

Figure A1 Long description
A line graph with the x-axis labeled heterogeneity tau ranging from 0.0 to 2.0 and the y-axis labeled prior density ranging from 0.0 to 3.0. A vertical dashed line is positioned at x equals 0.34, which is the common median for all distributions.
Seven curves are plotted, each starting at x equals 0.0 with varying initial densities and decaying as tau increases.
* Lomax 1, 0.34 in light blue has the highest peak at 3.0 and the sharpest initial decline, crossing below all other curves by x equals 0.5.
* Lomax 6, 2.75 in dark blue starts near 2.2.
* Exponential 0.49 in green starts near 2.0.
* Half-Cauchy 0.34 in yellow starts near 1.9.
* Half-t 4, 0.46 in gold starts near 1.65.
* Half-logistic 0.31 in pink starts near 1.6.
* Half-Normal 0.50 in brown starts at the lowest point near 1.58.
All curves intersect or converge as they approach the x-axis at higher values of tau, with the Lomax and Cauchy distributions exhibiting heavier tails than the half-normal and exponential curves.
A.2 Gain in effective sample size
The relative gain in information from a prior may be quantified using the gain in ESS, which is based on the relative width of 95% intervals with and without consideration of the (informative) prior. First, consider the relative width q, the ratio of interval widths (or standard errors) (
$q=\frac {\text { width using informative prior}}{\text { width using vague prior}}$
 ). Assuming that standard errors are proportional to the inverse of the square root of the sample size, the gain in ESS then is given by
$q^{-2}-1$
). Assuming that standard errors are proportional to the inverse of the square root of the sample size, the gain in ESS then is given by
$q^{-2}-1$
 . For example, if the informative prior yields an interval that is only half as wide (
$q=0.5$
. For example, if the informative prior yields an interval that is only half as wide (
$q=0.5$
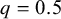 ), this would otherwise have required a quadrupled sample size, or a
$q^{-2}-1=300\%$
), this would otherwise have required a quadrupled sample size, or a
$q^{-2}-1=300\%$
 increase. If the interval is 90% as wide (
$q=0.9$
increase. If the interval is 90% as wide (
$q=0.9$
 ), this corresponds to an approximate
$q^{-2}-1=23\%$
), this corresponds to an approximate
$q^{-2}-1=23\%$
 increase.Reference Röver and Friede
9
increase.Reference Röver and Friede
9
A.3 Heterogeneity priors
Figures A1 and A2 show several prior densities and cumulative distribution functions (CDFs) discussed in Section 3.1.2 that are all scaled to a common median (of 0.34, the median of an HN(0.5) distribution).
Illustration of the several heterogeneity priors compared in Section 3.1.2 in terms of their cumulative distribution functions (CDFs). All priors are scaled such that they have a common median of 0.34 (dashed line).

Figure A2 Long description
A line graph with a logarithmic X axis labeled heterogeneity tau ranging from 0.01 to 5.00 and a Y axis labeled prior C D F ranging from 0.0 to 1.0. A vertical dashed line is positioned at the X axis value of 0.34. All seven curves intersect exactly at this dashed line at a Y axis value of 0.5.
From left to right, the curves follow these trends:
* The half-Normal 0.50 curve in orange is the steepest, reaching the upper asymptote of 1.0 first.
* The half-t 4, 0.46 curve in gold and half-Cauchy 0.34 curve in yellow follow closely behind.
* The half-logistic 0.31 curve in purple and exponential 0.49 curve in green show moderate slopes.
* The Lomax 6, 2.75 curve in dark blue and Lomax 1, 0.34 curve in light blue are the shallowest, with the light blue curve having the longest tail and approaching 1.0 most slowly.
A legend in the top left corner identifies each color-coded distribution.
Expected values of
$\tau ^2$
 based on various common (prior) distributions for
$\tau $
based on various common (prior) distributions for
$\tau $
 , depending on their scale parameter s. An asterisk (
$\ast $
, depending on their scale parameter s. An asterisk (
$\ast $
 ) indicates that there is no simple analytical expression. The half-Cauchy prior would be an additional option, but does not have a finite expectation (it is in fact also a special case of the half-Student-t prior, with
$\nu =1$
) indicates that there is no simple analytical expression. The half-Cauchy prior would be an additional option, but does not have a finite expectation (it is in fact also a special case of the half-Student-t prior, with
$\nu =1$
 degree of freedom)
degree of freedom)

Table A1 Long description
The table is organized into seven columns. The first column lists the Distribution, followed by four columns under the heading Standard deviation tau (Median, 95% Quantile, Expectation, and a condition column), and two columns under the heading Variance tau-squared (Expectation and a condition column).
* Row 1: tau follows a half-Normal distribution with scale s. Median is approximately 0.674s. 95% Quantile is approximately 1.96s. Expectation of tau is the square root of 2 all over pi times s, approximately 0.798s. Expectation of tau-squared is s-squared.
* Row 2: tau follows a half-Student-t distribution with nu degrees of freedom and scale s. Median and 95% Quantile are marked with an asterisk. Expectation of tau is 2 times the square root of nu all over pi, times Gamma of open parenthesis nu plus 1 close parenthesis all over 2, all over Gamma of open parenthesis nu all over 2 close parenthesis times open parenthesis nu minus 1 close parenthesis, multiplied by s, for nu greater than 1. Expectation of tau-squared is nu all over open parenthesis nu minus 2 close parenthesis times s-squared, for nu greater than 2.
* Row 3: tau follows a half-logistic distribution with scale s. Median is log 3 times s, approximately 1.10s. 95% Quantile is approximately 3.66s. Expectation of tau is log 4 times s, approximately 1.39s. Expectation of tau-squared is pi-squared all over 3 times s-squared, approximately 3.29s-squared.
* Row 4: tau follows an Exponential distribution with scale s. Median is log 2 times s, approximately 0.693s. 95% Quantile is approximately 3.00s. Expectation of tau is s. Expectation of tau-squared is 2s-squared.
* Row 5: tau follows a Lomax distribution with parameters alpha and s. Median is open parenthesis 2 to the power of 1 all over alpha, minus 1 close parenthesis times s. 95% Quantile is open parenthesis 20 to the power of 1 all over alpha, minus 1 close parenthesis times s. Expectation of tau is 1 all over open parenthesis alpha minus 1 close parenthesis times s, for alpha greater than 1. Expectation of tau-squared is 2 times Gamma of open parenthesis alpha minus 2 close parenthesis all over Gamma of alpha, times s-squared, for alpha greater than 2.
* Row 6: tau follows a Uniform distribution from 0 to s. Median is s all over 2. 95% Quantile is 0.95s. Expectation of tau is s all over 2. Expectation of tau-squared is 1 all over 3 times s-squared.
A.4 Variance of the MAP prior
The prior predictive distribution
$p(\theta _2|y_1,s_1)$
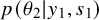 is a normal scale mixture with (constant) mean
$y_1$
is a normal scale mixture with (constant) mean
$y_1$
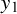 and (conditional) variance
$s_1^2+2\tau ^2$
and (conditional) variance
$s_1^2+2\tau ^2$
 , where
$\tau $
, where
$\tau $
 is distributed according to the specified heterogeneity prior. The mixture distribution’s marginal variance results as
${\mathrm {Var}}(\theta _2|y_1,s_1) = s_1^2 + 2\,{\mathrm {E}}[\tau ^2]$
is distributed according to the specified heterogeneity prior. The mixture distribution’s marginal variance results as
${\mathrm {Var}}(\theta _2|y_1,s_1) = s_1^2 + 2\,{\mathrm {E}}[\tau ^2]$
 and depends on the (prior) expectation of the squared heterogeneity
${\mathrm {E}}[\tau ^2]$
and depends on the (prior) expectation of the squared heterogeneity
${\mathrm {E}}[\tau ^2]$
 (see (2.6)). Table A1 summarizes expectations for
$\tau ^2$
(see (2.6)). Table A1 summarizes expectations for
$\tau ^2$
 for a range of common heterogeneity priors. Note also the related Table B1 in the appendix of Röver et al. (2021)Reference Röver, Bender and Dias
12
giving some additional details for the prior distributions shown here.
for a range of common heterogeneity priors. Note also the related Table B1 in the appendix of Röver et al. (2021)Reference Röver, Bender and Dias
12
giving some additional details for the prior distributions shown here.
A.5 Power prior exponent’s distribution
For any fixed heterogeneity value
$\tau $
 , the (conditional) MAP prior is equivalent to a power prior with exponent
$a_0=\bigl (2\frac {\tau ^2}{s_1^2}+1\bigr )^{-1}$
, the (conditional) MAP prior is equivalent to a power prior with exponent
$a_0=\bigl (2\frac {\tau ^2}{s_1^2}+1\bigr )^{-1}$
 (see also Section 2.5).Reference Röver and Friede
9
Through this functional relationship, any prior density
$p_\star (\tau )$
(see also Section 2.5).Reference Röver and Friede
9
Through this functional relationship, any prior density
$p_\star (\tau )$
 for the heterogeneity implies a corresponding prior for the exponent
$a_0$
for the heterogeneity implies a corresponding prior for the exponent
$a_0$
 with probability density function
with probability density function

Figure A3 illustrates such densities for an example value of
$s_1=0.451$
 (as in the Alport example from Section 3.1). The prior densities for
$a_0$
(as in the Alport example from Section 3.1). The prior densities for
$a_0$
 are shown for half-normal priors with scales 0.25, 0.50, and 1.00 (corresponding to the cases also illustrated in Figure 2).
are shown for half-normal priors with scales 0.25, 0.50, and 1.00 (corresponding to the cases also illustrated in Figure 2).
A value of
$a_0\!=\!1$
 for the exponent corresponds to full borrowing, while smaller values imply increasing degrees of discounting of prior information. While the
${\text {half-Normal}}(0.25)$
for the exponent corresponds to full borrowing, while smaller values imply increasing degrees of discounting of prior information. While the
${\text {half-Normal}}(0.25)$
 prior places a substantial share of prior probability near
$a_0\!=\!1$
prior places a substantial share of prior probability near
$a_0\!=\!1$
 , larger prior scale parameters correspond to less a-priori expected borrowing, eventually resulting in bimodal priors for
$a_0$
, larger prior scale parameters correspond to less a-priori expected borrowing, eventually resulting in bimodal priors for
$a_0$
 .
.
Illustration of prior distributions for the power prior exponent
$a_0$
 corresponding to certain prior distributions assumed for the heterogeneity
$\tau $
corresponding to certain prior distributions assumed for the heterogeneity
$\tau $
 (and
$s_1=0.451$
(and
$s_1=0.451$
 ).
).

Figure A3 Long description
The x-axis is labeled exponent a sub 0 and ranges from 0.0 to 1.0. The y-axis is labeled prior density and ranges from 0 to 6. A legend in the top left identifies three curves based on heterogeneity tau priors.
* H N 1.00 represented by a purple line starts at 0 and rises sharply to a peak density of approximately 4.8 at a sub 0 equals 0.05 then decays toward a density of 1 before a sharp spike at a sub 0 equals 1.0.
* H N 0.50 represented by a brown line starts at 0 and rises to a broader peak of approximately 1.5 at a sub 0 equals 0.15 then stays relatively flat before a sharp spike at a sub 0 equals 1.0.
* H N 0.25 represented by a light blue line remains near 0 until a sub 0 equals 0.2 then shows a steady asymptotic increase reaching its highest density of over 6 as a sub 0 approaches 1.0.
All three curves terminate at a sub 0 equals 1.0 with vertical spikes of varying heights.
Note that (as elaborated in Section 2.5) the mapping between
$\tau $
 and
$a_0$
and
$a_0$
 always depends on the “source” study’s standard error (
$s_1$
always depends on the “source” study’s standard error (
$s_1$
 ). A prior for
$\tau $
). A prior for
$\tau $
 may be motivated independent of
$s_1$
may be motivated independent of
$s_1$
 , while specification of a value (or distribution) for
$a_0$
, while specification of a value (or distribution) for
$a_0$
 may have odd consequences when varying the source study’s size or precision (
$s_1$
may have odd consequences when varying the source study’s size or precision (
$s_1$
 ).
).
Illustration of the effect of varying the (half-normal) heterogeneity prior’s scale on the resulting RCT shrinkage estimate from Section 3.1.

Figure A4 Long description
The graph features three axes. The horizontal X-axis represents the heterogeneity tau prior scale with values 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, and 10. The primary vertical Y-axis on the left represents the R C T shrinkage estimate theta sub 2 log H R ranging from negative 2.0 to 0.5. The secondary vertical Y-axis on the right represents the hazard ratio H R with a logarithmic scale ranging from 0.2 to 2. A horizontal dotted line is positioned at 0.0 on the left axis and 1 on the right axis. A vertical dotted line is positioned at the 0.5 mark on the X-axis. The data is plotted as nine green diamond points, each with a vertical error bar. The diamond points remain nearly constant at a log H R of approximately negative 0.65, which corresponds to a hazard ratio of 0.5. As the heterogeneity tau prior scale increases from left to right, the vertical error bars expand symmetrically. At the 0.02 scale, the error bar spans from approximately negative 1.4 to 0.1. By the 10 scale, the error bar has widened significantly, spanning from approximately negative 2.0 to 0.6.
A.6 Sensitivity analysis (Alport example)
In the Alport example application from Section 3.1, varying the half-Normal heterogeneity prior’s scale parameter affects the precision of the corresponding MAP prior, and with that, the eventual amount of borrowing from the observational data. Figure A4 shows how the resulting shrinkage estimate for the RCT is affected. A smaller prior scale leads to more borrowing and hence a shorter shrinkage interval eventually approaching the common-effect estimate. A larger prior scale leads to less borrowing, with the shrinkage interval eventually approaching the interval based on the RCT data alone. Since a log-HR of zero always remains included, in this example, there is no “tipping point” for the heterogeneity’s prior scale parameter.
A.7 Example R code
A.7.1 Alport example

Long description
The script begins with a data frame named Gross Et Al 2020 containing observational and R C T data with columns for patients, events, h r, lower, and upper bounds.
Key calculations include:
* loghr: log of Gross Et Al 2020 dollar sign h r.
* se: log of upper minus log of lower all over 2 times qnorm 0.975.
The script loads the metafor library to convert effect measures into an escalc object with measure G E N.
A joint meta-analysis is performed using the bayesmeta library with a half-normal prior for tau with a scale of 0.50. This is followed by a forestplot command with x-axis label log-H R.
The script then calculates shrinkage estimates using exp open bracket b m dollar sign theta close bracket and performs a separate meta-analysis on observational data only using the M A P approach.
Finally, it defines a color vector colvec for plotting, assigning red3 to map and blue to likeli.
A.7.2 Heart failure example

Long description
The code block begins by defining a color vector colvec with three named values: map equals blue3, like equals red3, and shrink equals green3.
Next, a sequence x is defined from negative 4 to 2.5 with a length of 200.
The plot function is called with x-axis limits of negative 3.5 to 2.0 and y-axis limits of 0.0 to 0.85. The main title is Alport example Gross et al. 2020 and the x-axis label is log-H R.
Three line layers are added to the plot:
1. M A P prior predictive density using map dposterior with theta equals x and predict equals T R U E, colored with colvec index 1.
2. R C T likelihood using dnorm with mean and standard deviation derived from es y i and es v i, colored with colvec index 2.
3. Posterior shrinkage estimate using b m dposterior for the individual R C T, colored with colvec index 3.
Finally, a horizontal line is added at h equals 0, a vertical dashed line is added at c 0 0, and a legend is placed in the topleft position containing labels for M A P prior observational, likelihood R C T, and shrinkage R C T using the defined color vector.
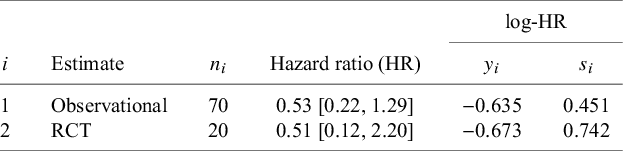
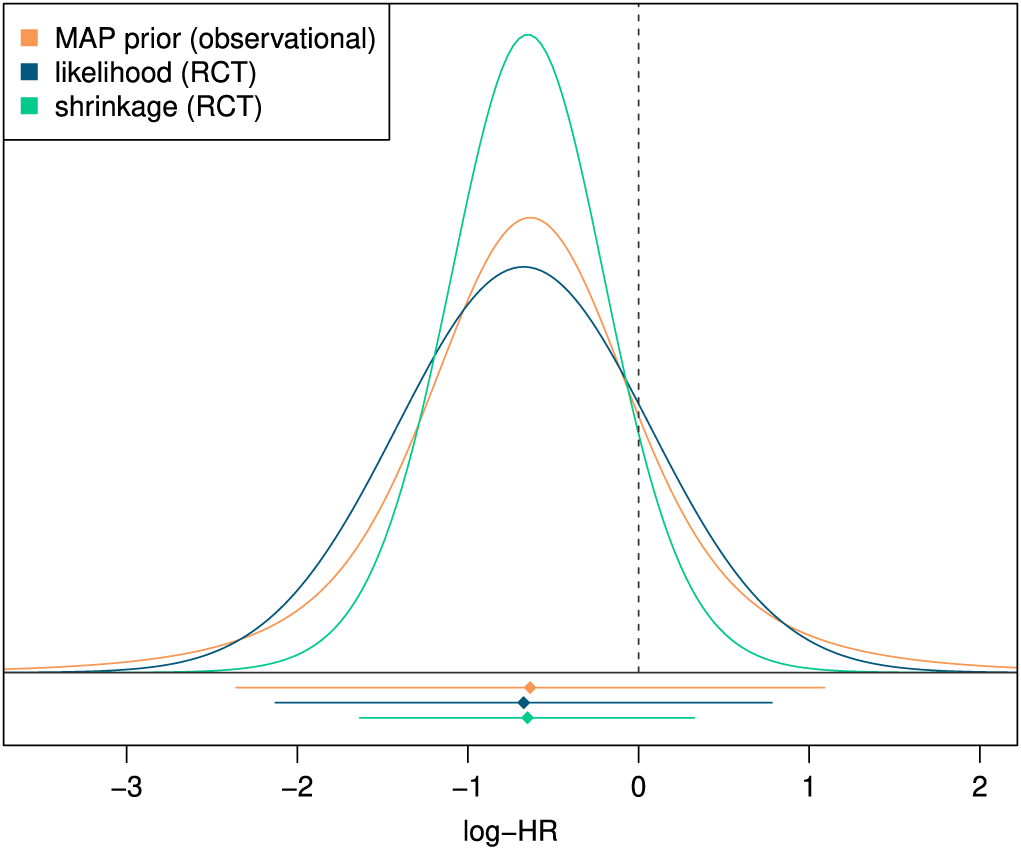
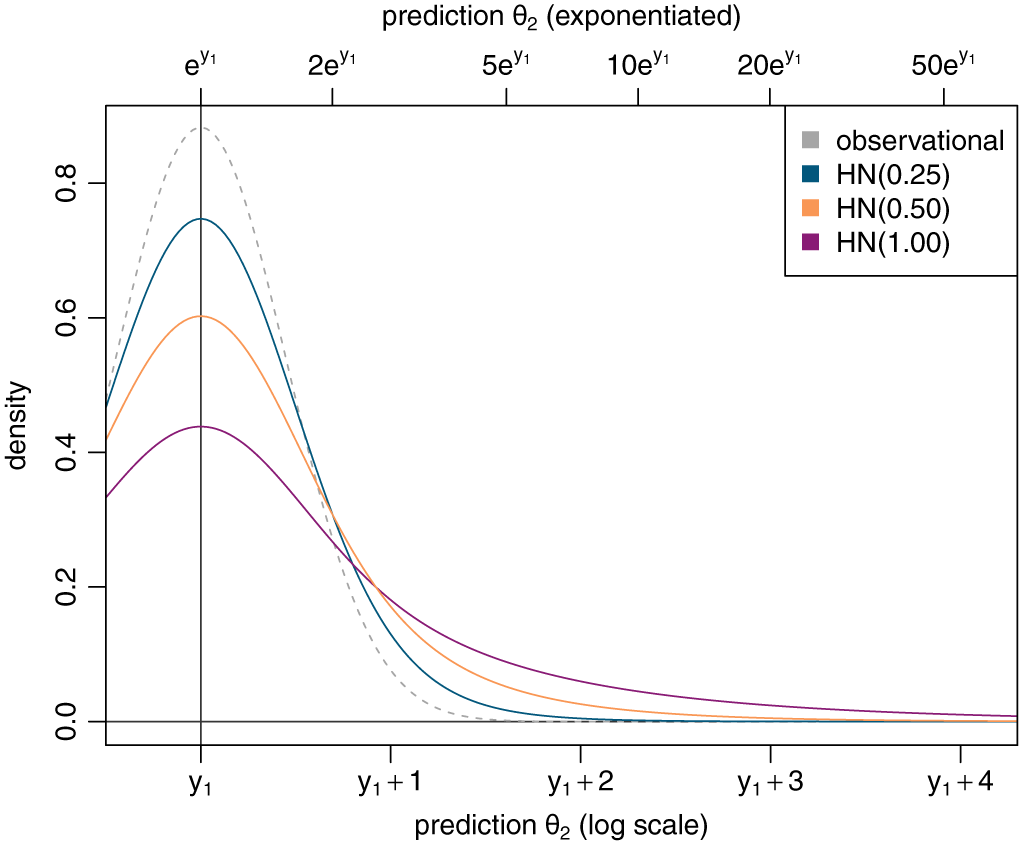
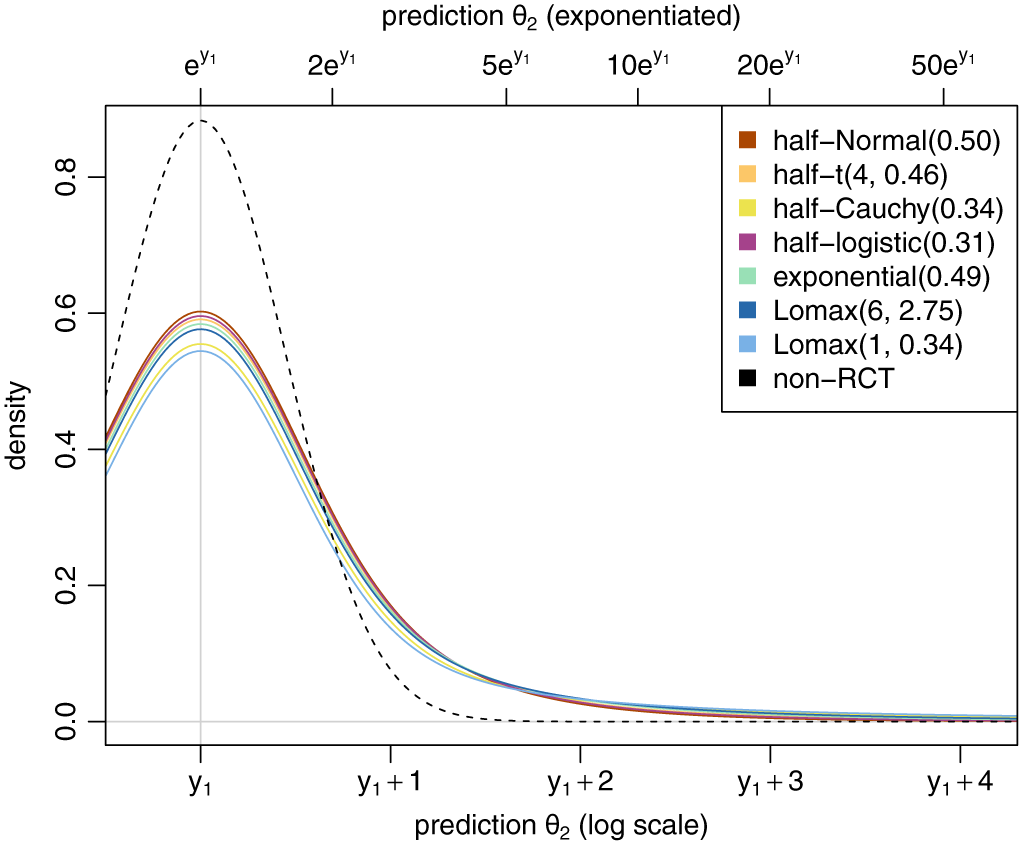
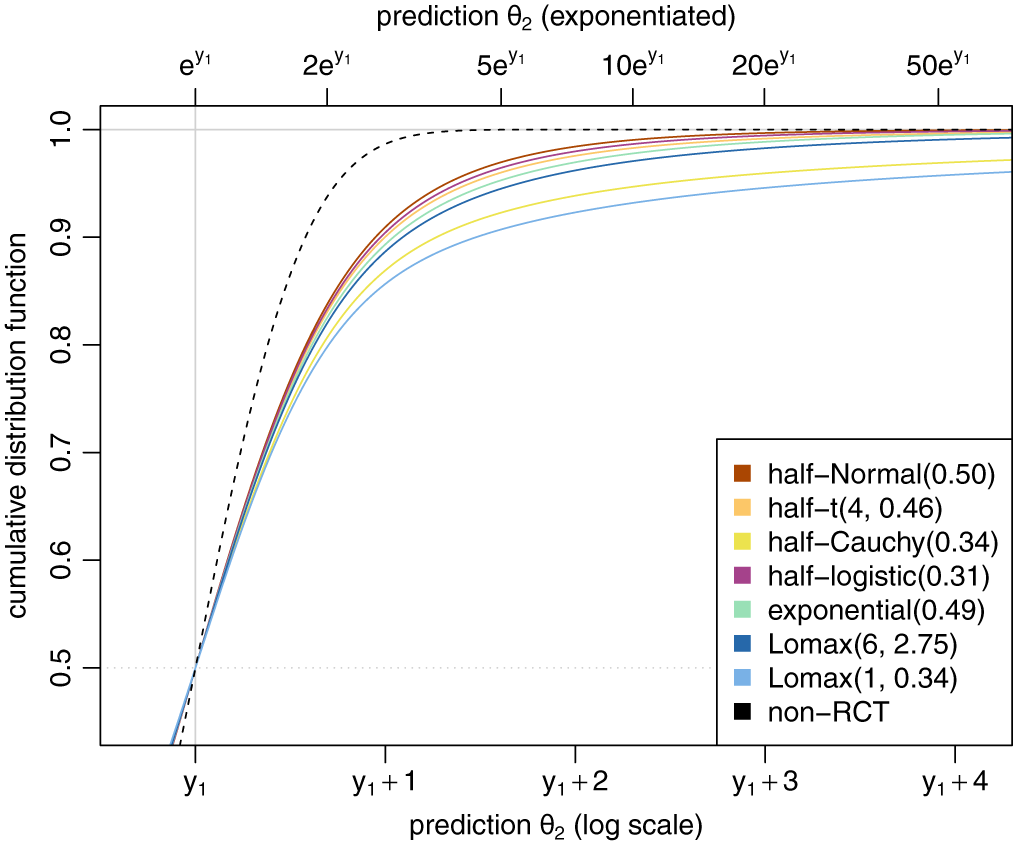
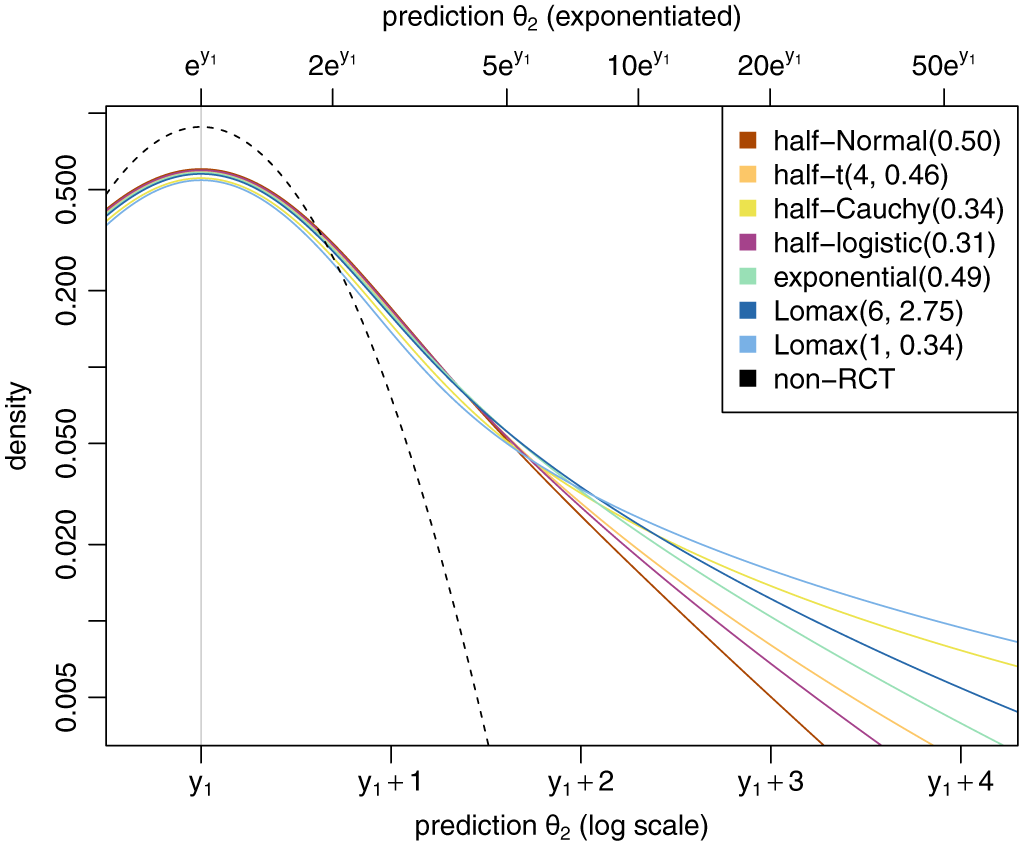
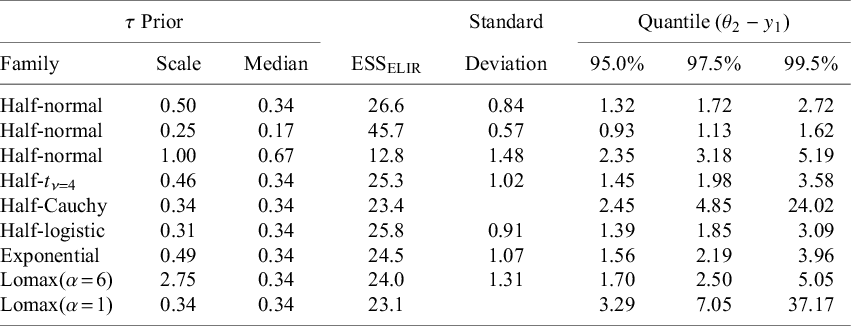


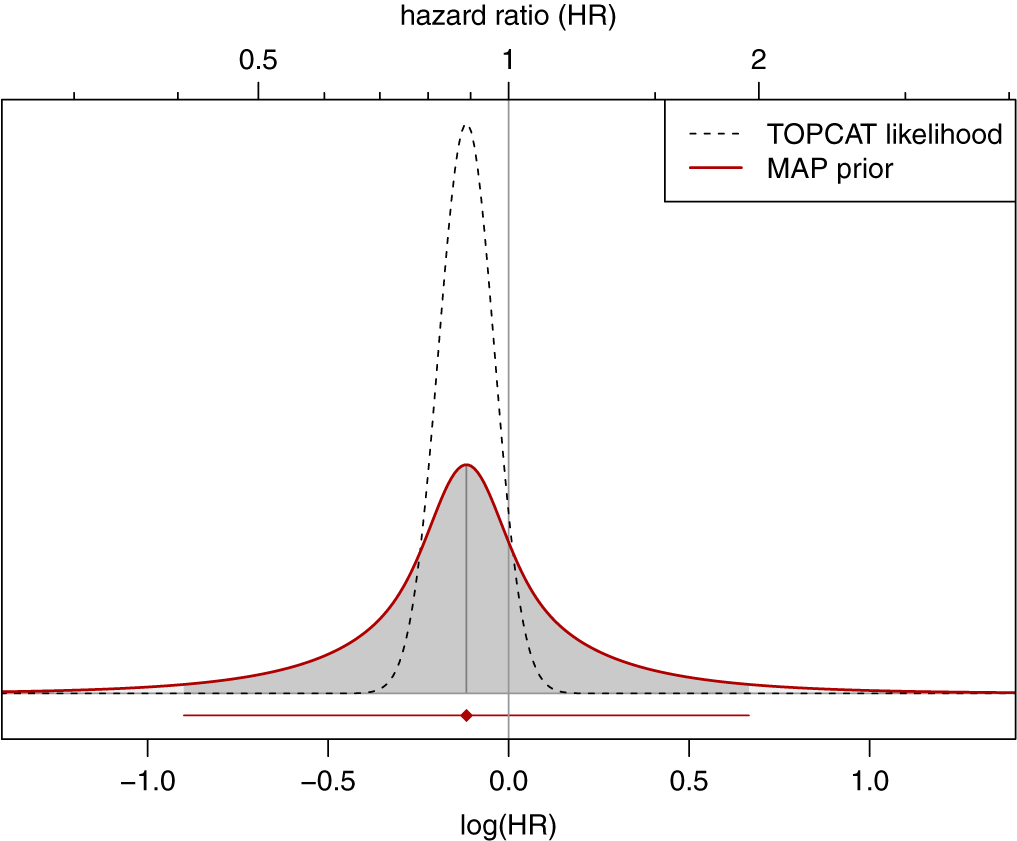


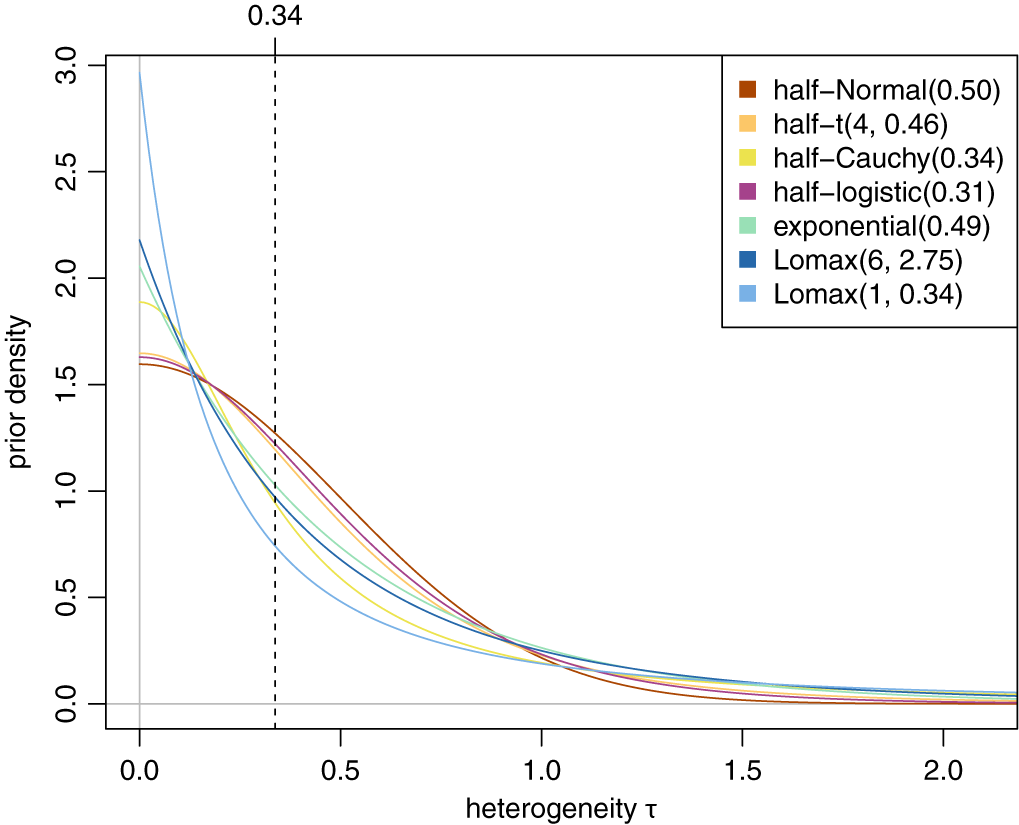
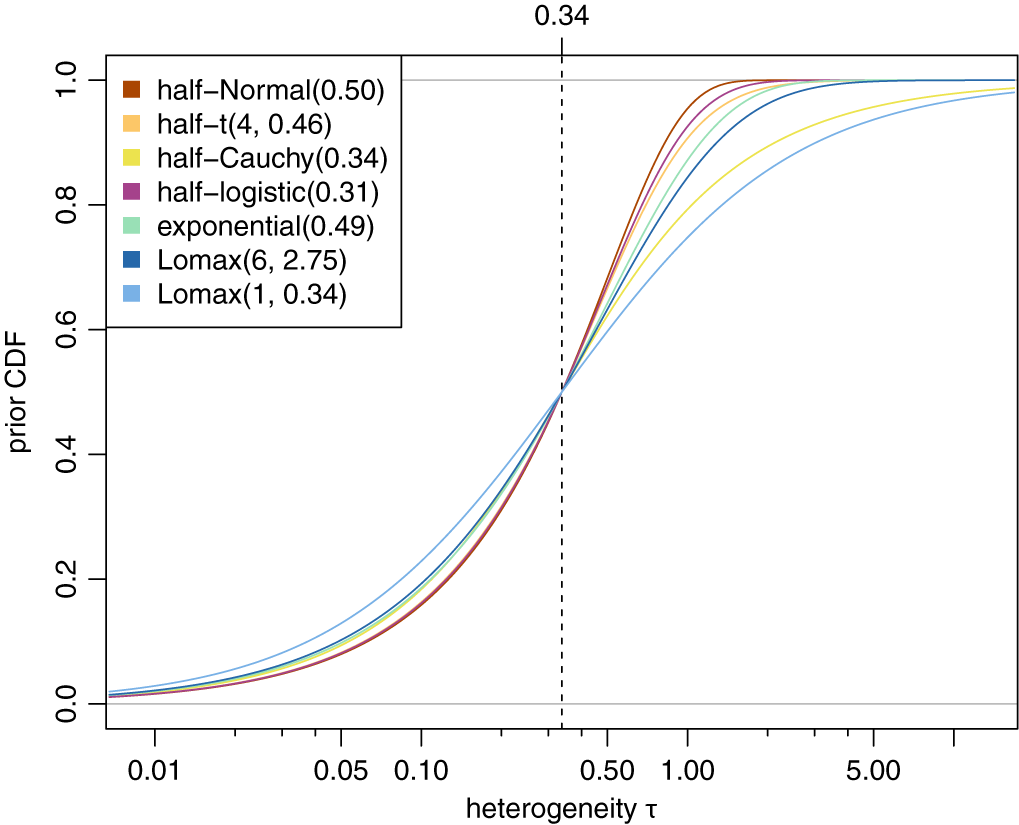
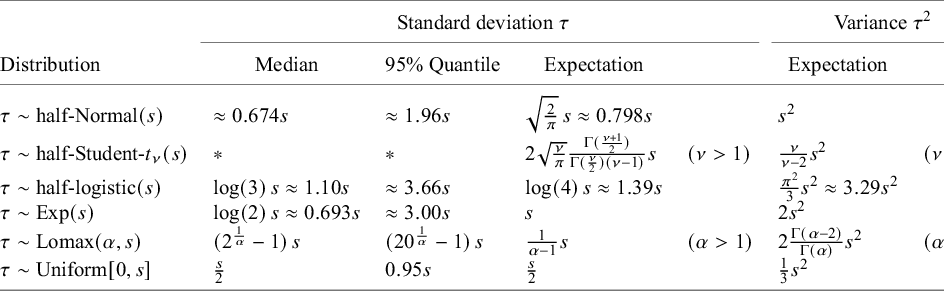




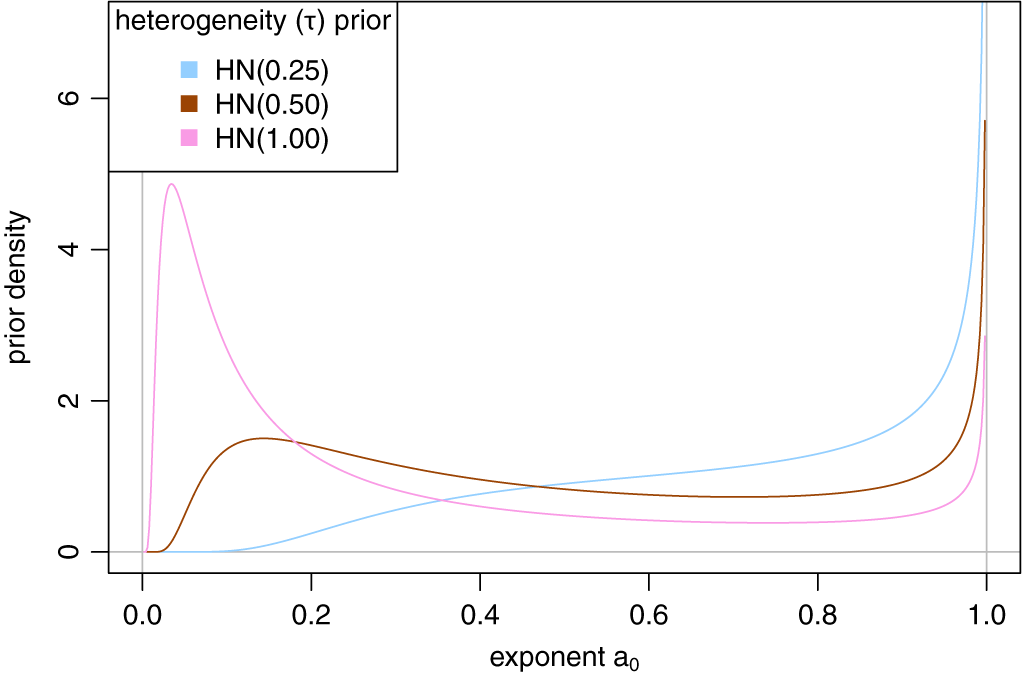



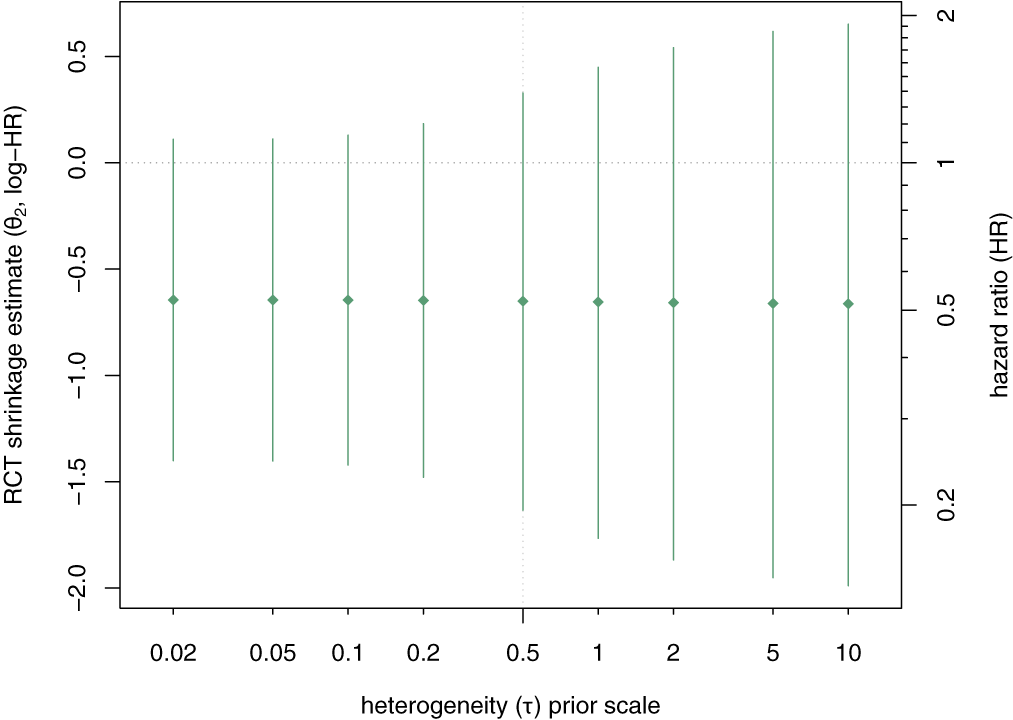

 Open access
Open access