


Introduction
Task demand in reading, or the varying need to read texts in different contexts, impacts reading strategies and reading comprehension (Hautala et al., Reference Hautala, Salmerón, Tolvanen, Loberg and Leppänen2022; Meng et al., Reference Meng, Lan, Yan, Marsh and Liversedge2020; Schotter et al., Reference Schotter, Bicknell, Howard, Levy and Rayner2014). This is why task demand has been widely discussed by reading researchers and educators, who hope to unlock the potential of appropriately imposed task demand in helping learners improve their reading. Although some empirical studies have investigated how readers read texts under different reading demands in monomodal contexts, previous research focuses on non-interactive media; few studies investigate how people read in more dynamic interactive multimedia like video games with real-time and fine-grained measurements. Yet the research gap is surprising, as video gameplay is one of the most popular hobbies, with 2.6 billion gamers worldwide (Video gaming worldwide—Statistics & Facts, 2024). More importantly, the rise of gaming has unleashed the pedagogical potential for using text in interactive multimedia. For example, identifying task-based reading patterns in video games can be useful for educational monitoring and intervention in language learning (Lan et al., Reference Lan, Liao and Kruger2025).
Against this background, the current study aims to investigate how players read subtitles in video games under two levels of reading demand (low vs. high). The literature review begins by outlining the theoretical foundation of reading in digital media contexts. This is followed by a review of empirical studies discussing how task demand modulates reading in monomodal psychological experiments and multimedia, which lays a foundation for the current study.
Theoretical foundations of subtitle reading in video games
Subtitles in video games constitute one form of in-game text. In-game text often explains the gameplay rules and storylines, which directly impact players’ actions, game progression, and gaming experience (Mangiron, Reference Mangiron2016). Specifically, O’Hagan and Mangiron (Reference O’Hagan and Mangiron2013) defined in-game text as “all the text present in the user interface (UI) (such as menus, help messages, tutorials and system messages), narrative and descriptive passages, and all dialogs that are not voiced-over and only appear in written form, such as conversations held with non-playable characters (NPCs), who are driven by the game system and cannot be controlled by the player” (p 122). In-game text can be either connected or unconnected to the fictional world described by the game. The in-game text shaping the gaming world (“diegetic”) includes narrative text and unvoiced dialog scripts (“subtitles”), while the in-game text less relevant to the gameplay storylines (“non-diegetic”) includes text on the user interface, system messages, and tutorials related to game control.
Unlike other in-game text, subtitles in video games are often accompanied by soundtracks, as they are transcripts of conversations between the player and non-player characters, or narrations in cutscenes. Subtitles can present content that is not directly related to background visuals, such as background stories. Moreover, subtitles typically change as the game progresses and are rarely repeated or have supplementary visuals. They only reappear if the player is “killed” and must return to a previous checkpoint in the game. Although subtitles are pervasively present in various forms and flexible in digital media, previous research focused on how people process subtitles cognitively in non-interactive media (i.e., media that are consumed passively, such as videos) (Bisson et al., Reference Bisson, Van Heuven, Conklin and Tunney2014; De Linde & Kay, Reference De Linde and Kay1999; Perego et al., Reference Perego, Del Missier, Porta and Mosconi2010; Szarkowska et al., Reference Szarkowska, Ragni, Szkriba, Orrego-Carmona and Black2025). Relatively little is known about how they process texts in interactive multimedia, particularly video games.
Subtitle reading is assumed to utilize the same cognitive mechanisms involved in reading in general. Linguistic knowledge, orthographic knowledge, and general knowledge are the three primary sources interactively engaged in reading, which are further constrained by cognitive mechanisms such as perceptual memory, long-term memory, and limited processing resources, according to reading theories and models on word-to-text integration (Perfetti & Stafura, Reference Perfetti and Stafura2014; Reichle, Reference Reichle2021; Reichle et al., Reference Reichle, Pollatsek and Rayner2006). However, in video games, reading subtitles is not the primary task but rather a supplementary one, supporting the integration of text and images to build mental models. Thus, besides sharing similar cognitive mechanisms for traditional reading, theories of multimedia information processing offer additional insights into how individuals engage with text in multimodal contexts.
The first insight is that different sensory inputs, such as visual and auditory information, are processed in parallel channels that operate independently yet coordinate systematically. Relevant theories, such as the Dual-Coding Theory (DCT) (Paivio, Reference Paivio1990), the multicomponent model of working memory (Baddeley & Hitch, Reference Baddeley and Hitch1974; Baddeley et al., Reference Baddeley, Hitch and Allen2021), and the Cognitive Theory of Multimedia Learning (CTML) (Mayer, Reference Mayer and Ross2002, Reference Mayer2005), propose that visual and auditory information are processed in separate capacity-limited channels but work together systematically with the engagement of sensory memory, working memory, and long-term memory. A second insight is that text-image processing in multimedia is not uniform but involves distinct stages and mechanisms, as illustrated by theoretical frameworks ranging from ITPC, SPECT, VNG, and the MIL frameworks, each emphasizing different aspects of multimodal comprehension. For example, the Integrated Model of Text and Picture Comprehension (ITPC) (Schnotz, Reference Schnotz2005) describes the text-image integration process as involving three successive stages: surface, propositional, and mental model representations. On the other hand, more recent frameworks like the Scene Perception and Event Comprehension Theory (SPECT) (Loschky et al., Reference Loschky, Larson, Smith and Magliano2020) and Visual Narrative Grammar (VNG) (Cohn, Reference Cohn2014, Reference Cohn2020) focus on multimodal comprehension in sequential image contexts such as comics, films, and storyboards. SPECT emphasizes semantic processing, showing how perceptual and memory-driven mechanisms jointly construct event models in working memory while sustaining them in long-term memory. VNG, by contrast, stresses syntactic organization, proposing that image sequences follow a narrative grammar that structures meaning at the discourse level. SPECT and VNG together explain how semantic and structural mechanisms jointly underpin sequential image comprehension. Additionally, more closely related to reading in multimedia, the Multimodal Integrated-Language (MIL) framework (Liao et al., Reference Liao, Yu, Reichle and Kruger2021) provides a specific account of how cognitive systems for attention, memory, language processing, and oculomotor control are coordinated to support the reading of subtitles with auditory and visual inputs in videos. It assumes the text-image processing stages involve sequential allocation of attention to language-related representations but allows for concurrent processing of verbal and non-verbal inputs.
Interactive multimedia, such as video games, adds another complex layer on top of text-image processing: the interactions between players and the computer interface. The interactions between players and video games are assumed to impact text processing behavior. In non-interactive multimedia such as subtitled films, subtitles primarily support information conveyed by the soundtrack and on-screen visuals. The cognitive processes involve mutual modulation between subtitle processing and the simultaneous processing of visuals, sounds, and their interrelated mechanics (Kruger et al., Reference Kruger, Wisniewska and Liao2022; Liao et al., Reference Liao, Yu, Reichle and Kruger2021). In contrast, in video games, players not only process and integrate texts with other sensory inputs but also respond dynamically to the game environment, making decisions and updating their actions in real-time. For example, in some adventure video games such as Detroit: Become Human, the menu-based, subtitled dialogs between the characters often determine how the game progresses. The interactions among the basic elements of language, actions, and their interpretable relations construct the meaning during gameplay and immerse players into the gaming world (Ryan, Reference Ryan2009). It is the rich multimodal representations for immersive meaning-making and the immediate feedback on players’ performance that make video games good materials for literacy development and language learning, as well as cognitive skill training in education and therapy (Gee, Reference Gee2003, Reference Gee2004; Green, Reference Green and Bowman2018; Nash & Brady, Reference Nash and Brady2022).
Besides the multimodal contexts and interaction between the computer interface and players, the embedded task demands in video games also distinguish video games from other media. It has been widely acknowledged that task demand in reading impacts reading strategies and reading comprehension (Hautala et al., Reference Hautala, Salmerón, Tolvanen, Loberg and Leppänen2022; Meng et al., Reference Meng, Lan, Yan, Marsh and Liversedge2020; Schotter et al., Reference Schotter, Bicknell, Howard, Levy and Rayner2014). One theory that addresses task demand in reading more generally is the Reading as Problem Solving (RESOLV) model (Britt et al., Reference Britt, Durik and Rouet2022; Rouet et al., Reference Rouet, Britt and Durik2017). The RESOLV model is based on the observation that digital reading facilitates problem-solving and decision-making for different goals within certain physical and social contexts. The two major mental models affecting digital reading are (1) contexts and (2) the tasks derived from the contexts. Specifically, contexts include physical and social environments and readers’ traits (e.g., motivation, interest, and ability), which are relatively stable. While reading tasks are continuously updated and adapted to readers’ embedded contexts. According to the RESOLV framework, contexts and interpreted task sets shape reading demand, which in turn determines readers’ reading strategies and outcomes. This has been confirmed by recent empirical studies on online reading, showing that readers vary in their strategies (e.g., navigation methods) on digital media depending on the demand imposed by contextual factors and embedded tasks (Hahnel et al., Reference Hahnel, Ramalingam, Kroehne and Goldhammer2023; Ma et al., Reference Ma, Cain and Ushakova2024; Norberg et al., Reference Norberg, Han, Cho and Fraundorf2025; Wang et al., Reference Wang, Mousavi, Lu and Gao2023).
In addition, some recent theories and frameworks focus more specifically on reading in the context of video games. For example, Cutting and Deterding (Reference Cutting and Deterding2022) proposed the Task-Attention Theory of Game Learning, which specifically targets attentional control and learning in video games. Based on this theory, attention to different gaming elements moderates learning, which in turn promotes the subsequent attention allocation to task-relevant information. Factors impacting the players’ attentional mechanism include (1) factors that direct attention, such as mechanics, goals, uncertainty, and rewards in game design; (2) factors that demand attention, such as perceptual load, cognitive load, and time and performance pressure; and (3) other attention-demanding factors in non-interactive media. These attentional-related factors are potential modulators of text processing in interactive media. On the other hand, the Gamer Response and Decision (GRAD) Framework (Gillern, Reference Gillern2016; von Gillern, Reference von Gillern2016) seeks to explain how individuals navigate and process various multimodal symbols to make decisions and learn within video games. These multimodal symbols can be broadly categorized into written language, oral language, visual representations, audio sources, and tactile experiences. Under this categorization, subtitles in video games are primarily written language. Specifically, the multimodal symbols constitute the player’s experience (e.g., dialogs in the cut scenes) and assign affordances to the in-game elements (e.g., whether a block is movable or not), which impact how players translate their understanding into dynamic and nested goals (von Gillern, Reference von Gillern2016). The nested goals define the actions of the players. For example, the overarching goal of completing the game branches into sub-tasks, such as defeating enemies, which are further divided into smaller, actionable tasks, like how to eliminate an enemy (von Gillern, Reference von Gillern2016). Throughout the gaming experience, meta-cognition modulates the process of self-regulating, planning, evaluating, and monitoring actions (von Gillern & Stufft, Reference von Gillern and Stufft2023).
Together, these multimodal theories or frameworks primarily explain how verbal, visual, and auditory information are represented and integrated in multimedia comprehension. They focus on the structural assumptions of multimodal information processing, including dual-channel representation, limited working memory capacity, and sequential or concurrent allocation of attentional resources. Besides, task demand and nested goals in video games also guide players to actively control and adapt their reading and action strategies in real time.
Empirical findings on task demand in non-interactive reading
How task demand influences reading behavior and comprehension was first extensively investigated in highly controlled experiments using monomodal screens. These studies demonstrated that task demand affects both word-level and sentence-level processing. Specifically, task effects emerged very early in the eye movement record and were pervasive, influencing temporal and spatial aspects of eye movements (Kaakinen & Hyönä, Reference Kaakinen and Hyönä2010). For example, Kaakinen and Hyönä (Reference Kaakinen and Hyönä2010) investigated how proofreading (i.e., checking words for spelling errors) and reading for comprehension instructions influence eye movements during sentence reading. At the sentence level, participants made more fixations, shorter saccades, and had longer mean fixation durations during proofreading than during reading for comprehension. At the word level, the initial landing position on words shifted leftward, saccade lengths were shorter, first fixation and gaze durations were longer, and the probability of refixation was higher in the proofreading condition. More importantly, interactions between task demand and word length or word frequency were observed in gaze duration, indicating that proofreading produced stronger word length and word frequency effects than reading for comprehension. Notably, the longer and/or infrequent words are fixated on longer than shorter and/or frequent words (Inhoff & Rayner, Reference Inhoff and Rayner1986; Rayner & Duffy, Reference Rayner and Duffy1986; Rayner et al., Reference Rayner, Slattery, Drieghe and Liversedge2011), the observation of which has been serving as a benchmark for lexical processing in reading. In another monomodal sentence reading study, White et al. (Reference White, Warrington, McGowan and Paterson2015) found participants exhibited shorter reading times, fewer fixations, and shorter fixation durations when scanning for a topic than when reading for comprehension. At the word level, word frequency effects were observed under both levels of reading demand in the first-pass measures. However, later measures revealed interactive effects of task and word frequency, with larger word frequency effects on total reading times and regressions to the critical word during reading for comprehension. These word-level findings suggest that while early lexical processing mechanisms were similar across the two tasks, differences in reading demand influenced post-lexical processing and likely required distinct reading strategies.
The influence of reading demand on eye-movement patterns has also been observed in studies comparing different types of reading, such as regular reading, thorough reading, skimming, and spell checking of single pages of text (Strukelj & Niehorster, Reference Strukelj and Niehorster2018), as well as in other task-oriented reading conducted in monomodal contexts (León et al., Reference León, Moreno, Escudero, Olmos, Ruiz and Lorch2019; Lyu et al., Reference Lyu, McCrudden and Bohn-Gettler2024; Mills et al., Reference Mills, Hollingworth, Van der Stigchel, Hoffman and Dodd2011; Vidal-Abarca et al., Reference Vidal-Abarca, Salmerón and Mañá2011; Weiss et al., Reference Weiss, Kretzschmar, Schlesewsky, Bornkessel-Schlesewsky and Staub2018; Zhang et al., Reference Zhang, Hyönä, Cui, Zhu and Li2019). For digital reading, such as web-based information, texts are more likely to be presented non-linearly, which creates different reading purposes and thus different cognitive demands for text comprehension (Hahnel et al., Reference Hahnel, Goldhammer, Kröhne and Naumann2017). In digital reading, the reading demand placed on readers is driven by the specific contexts and the tasks derived from the contexts (Britt et al., Reference Britt, Durik and Rouet2022; Rouet et al., Reference Rouet, Britt and Durik2017). Thus, reading demand can vary considerably from one context to another.
Studies indicating how reading demand affects reading in multimodal contexts have only recently emerged. Compared with studies of reading demand in monomodal contexts, it is more challenging in multimedia contexts to provide participants with specific task instructions without compromising the ecological validity of the experiment. A more appropriate approach is to manipulate the multimodal information that is presented within the multimedia environment instead. Findings suggest that reading demand modulates both word-level and sentence-level processing in multimedia environments.
For example, Liao et al. (Reference Liao, Yu, Reichle and Kruger2021) investigated how the presence or absence of concurrent video content and variations in presentation speed influence subtitle reading. In their study, the presence of video was assumed to reduce reading demand, whereas the absence of concurrent video increased the demand placed on subtitle processing. The authors found that, at the subtitle level, fixations were shorter and more frequent in the presence of video across different subtitle speeds, whereas mean saccade lengths remained comparable. At the word level, the magnitudes of the word length and frequency effects were modulated by both the presence of concurrent video and subtitle speed. For example, the Length × Frequency interaction in gaze duration (an indicator of word recognition) was significant only when the video was absent. In the absence of video, the word frequency effect increased with longer word length, and the word length effect became stronger for infrequent words. However, when the video was present, frequency and length effects were still observed, but did not interact. Regarding total reading times on words (reflecting post-lexical processing), the frequency effect was evident under both video conditions but was more pronounced when the video was present. These findings suggest that while eye movements are influenced by word processing difficulty, they are also modulated by the global constraints imposed by the multimedia context.
Subtitle speed is another factor influencing reading demand in videos, as it determines the amount of text that can be processed during its on-screen display. Previous studies have examined how subtitle speed affects processing at both the subtitle and word levels. In addition to sentence-level and word-level measures, another common metric is the proportion of reading time (i.e., the percentage of time viewers spend reading subtitles relative to the subtitle’s total display duration) (Szarkowska et al., Reference Szarkowska, Ragni, Szkriba, Orrego-Carmona and Black2025). Findings from these studies indicate that readers spend more time proportionally reading subtitles at faster presentation rates. For example, in a study investigating how subtitle speed affects subtitle reading among L1 and L2 viewers (with an average subtitle speed of 16.25 characters per second (CPS), ranging from 4 to 27.65 CPS), Szarkowska et al. (Reference Szarkowska, Ragni, Szkriba, Orrego-Carmona and Black2025) found that as subtitle speed increased, both L1 and L2 viewers showed shorter gaze durations and total reading times on subtitle words, while word skipping rate increased. Similarly, Kruger et al. (Reference Kruger, Wisniewska and Liao2022) examined how subtitle speed modulates reading behavior at the word level. The authors found that as subtitle speed increased from 12 CPS to 28 CPS, viewers skipped more words, completed fewer subtitles, and reread fewer words following both horizontal and vertical eye movements.
In sum, varying reading demands have been shown to influence both lexical and post-lexical processing in non-interactive environments. In monomodal contexts, experimental manipulations of reading demand typically focus on task instructions. While in multimedia, reading demand is often manipulated through changes in the multimodal presentation of subtitles, such as the accompanying video or the presentation speed, to preserve the ecology of the media.
Current study
As indicated in the previous sections, few studies investigated how the reading demand in interactive multimedia, such as video games, impacts sentence-level and word-level processing. Against this background, the current exploratory study aims to examine how players process subtitles in video games under two different levels of reading demands (high vs. low). To this end, we used a popular commercial video game as the experimental platform to maximize the ecological validity. Specifically, this between-subjects study recruited 104 participants (98 were included in the final analysis). Participants were randomly assigned to one of two groups based on soundtrack language: English (L1) or Polish (FL, a foreign language unknown to participants). All in-game text was in English. Each participant played the same chapter of Detroit: Become Human in a natural gameplay setting. The key experimental manipulation was the language of the soundtrack accompanying the subtitles, which was intended to modulate reliance on in-game text without disrupting immersion. A silent condition was not included, as it was considered unnatural to the current game setting.
Materials
Chapter 1 in Detroit: Become Human is chosen as a case study. Detroit: Become Human is a widely applauded video game that has been successful in sales in recent years (Wikipedia, 2026). Detroit: Become Human is set in a future where androids work in every aspect of human lives. Similar to other long games, Chapter 1 in Detroit: Become Human is a tutorial chapter. In the tutorial chapter, players are introduced to the background story and main game commands (Wildfeuer & Stamenković, Reference Wildfeuer and Stamenković2022). In Chapter 1, The Hostage, Connor (an android played by the participants) is sent as a negotiator to a hostage situation where he faces a disgruntled deviant android who killed his owner and took his owner’s child hostage. Connor’s success depends on quickly finding information about the incident and calming the deviant down. The exchanges between characters are menu-based communication presented with subtitles, which are the dominant textual elements (see Figure 1). The negotiation between the avatar and the kidnapper further affects the player’s subsequent actions and leads to different endings.
Example of subtitles (screenshot from Detroit: Become Human).

Participants
To determine the appropriate sample size for this study, a power analysis was conducted using G * Power 3.1.9.7 (Faul et al., Reference Faul, Erdfelder, Lang and Buchner2007). A paired t-test (dependent means) was selected as the statistical test, with an alpha level (α) of 0.05, a power (1−β) of 0.95, and an effect size (Cohen’s dz) of 0.5, which represents a medium effect size. The analysis was set to a two-tailed test, ensuring that differences in either direction would be detected. The G * Power results indicate that to achieve these parameters, a total sample size of 54 participants (degrees of freedom = 53) would be required to detect a meaningful effect with statistical significance (p < 0.05). Finally, 104 participants were recruited to account for potential attrition and ensure adequate statistical power. The data of 6 participants were excluded due to either technical issues or recent experiences with the game, resulting in a final sample of 98 participants for whom the eye-movement data were analyzed.
The 98 participants were native English speakers (46 female, 52 male) aged between 17 and 32 (M = 19.27, SD = 2.42). All participants confirmed that they did not understand Polish. In the post-experiment questionnaire, participants reported a range of gaming habits. The gamer category was adopted from Dale and Shawn Green (Reference Dale and Shawn Green2017). Among the participants, 28 were multi-genre gamers, who played a variety of game types for more than 5 hours per week, 24 were pure-genre gamers, who played a single game genre for 5 hours per week and any other genres for no more than 3 hours, and 34 were casual gamers, playing between 1.5 and 5 hours per week. The final 12 participants were non-gamers, with fewer than 1.5 hours of gameplay per week. The average gameplay experience was 9.98 years (SD = 3.44). The majority of participants (79.38%) had over 8 years of gaming experience. At the outset of analysis, both scatter plot visualizations and model fitting showed that neither gamer type nor gaming experiences (including gaming years and gaming frequency) explained differences in eye-movement measures among players. Thus, these factors were not included in the analysis. Moreover, the gamer category was not included in the analysis because (1) the categories were self-reported, (2) they may overlap with computer literacy, and (3) gameplay skills are not developed through standardized training as in formal education. The survey results show that our participants varied widely in their gameplay skills and experiences, suggesting that they are representative of general gamers in the population.
The participants were all from Macquarie University and participated in this study in exchange for research course credits or $25 gift vouchers. Participants identified themselves as non-dyslexic with normal or corrected-to-normal vision. None of the participants had played the game before. This study was approved by the ethics committee of the authors’ home university (ethics approval number: 52024645755523).
Apparatus
The game was played in sound-isolated booths equipped with over-ear headphones, a monitor, a standard keyboard, and a mouse. An EyeLink Duo Portable eye-tracker with a sampling rate of 1000 Hz was used to record participants’ eye movement during game playing. SR Research WebLink software was used to present the stimuli. The experimental materials were displayed using HP computers with Intel i7 processors, 16GB of RAM, RTX3070 GPUs, and on 27-inch monitors.
Procedure
Participants were tested individually. After entering the laboratory, participants reconfirmed whether they met the pre-screening conditions and provided written and verbal consent. Participants were seated 75 cm away from the screen and were asked to keep their overt eye movements within the focal range of the eye tracker. A 9-point calibration and eye-tracking validation process was then performed. Only eye-tracking calibrations that resulted in an average error value of less than 0.50 degrees and a maximum error value of less than 1.00 degrees were accepted to maximize tracking accuracy. Recalibration was performed until this criterion was met.
Participants were randomly assigned to the L1 soundtrack group or the FL soundtrack group. The participants were then introduced to the background of the story, and they were told the key to completing Connor’s mission was to collect as many details as possible. They were asked to finish the game in 30 minutes; otherwise, the game would end. This time limit was determined based on pilot studies and the average length of a walkthrough gameplay on YouTube, which is around 15 to 20 minutes. After completing the game, participants filled out the questionnaire on their gaming habits. The entire experiment took approximately 50–60 minutes (including equipment set-up).
Measures
The area of interest (AOI) for subtitles was defined with fixed upper and lower boundaries, with a few exceptions for two-line subtitles. Specifically, the vertical boundaries were set at [1150, 1380], while the horizontal boundaries extended 50 pixels beyond the leftmost and rightmost words. These boundary settings accounted for systematic errors and saccadic mislanding, based on visualized eye-movement data in Data Viewer (SR Research). At the word level, AOIs were divided according to the subtitle-level boundaries (using the same upper and lower limits), while the horizontal space between words was distributed evenly. See Figure 2 for subtitle-level AOI.
Subtitle-level and word-level AOIs (screenshot from Data Viewer, SR research).

It is important to note that eye-movement measures in the present videogame context may not map onto cognitive processes in the same way as in natural reading. Unlike static text, game subtitles are dynamic, transient, and embedded within a visually demanding, interactive environment. As a result, eye-movement behavior may be driven not only by linguistic processing but also by factors such as time pressure, shifting visual attention, competition with game imagery, and players’ manual actions. Consequently, all eye-movement indices reported here are likely to reflect a combination of linguistic processing and task-driven attentional demand. Therefore, the present findings should be interpreted with the understanding that they arise from a complex interplay of language processing and the situational constraints of gameplay.
Subtitle-level eye-movement measures
The global measures aim to detect the patterns and differences in subtitle reading at two levels of reading demand during gameplay. For the fixation-related measures, fixation counts are the total number of fixations on each subtitle. Dwell time percentage is the proportion of the total fixation time on each subtitle relative to its total presentation time. Mean fixation duration is the average duration of fixations in each subtitle. They all reflect how much attention is allocated to subtitles at two levels of reading demand. These fixation-related eye-movement measures also reflect the reading speed of the readers, which is a compound measure of reading expertise (Nárai et al., Reference Nárai, Amora, Vidnyánszky and Weiss2021). In sum, fixation-related eye movements reflect reading efficiency and sometimes reading capacity in most contexts.
For the saccade-related measures, subtitle skipping rate is the proportion of subtitles that were not fixated, relative to the total number of subtitles presented to each participant. Progressive saccade length is the average amplitude of forward saccades in each subtitle. Regression rates are the proportion of the saccades that move backward (against the reading direction) relative to the total number of saccades in each subtitle. And regression length is the average amplitude of backward saccades in each subtitle. These saccadic eye-movement measures were considered as the saccadic programming directly impacting the success with which information is extracted from the attended regions. In sum, saccade-related eye movements generally indicate oculomotor control in reading.
Word-level eye-movement measures
The local measures aim to measure more fine-grained word-reading patterns on subtitles in two levels of reading demand. First is the word skipping rate, which is defined as the proportion of words that are not fixated once during the gameplay session. Readers may skip words when the orthographic properties of an upcoming word are short or familiar to the readers (Inhoff et al., Reference Inhoff, Gregg and Radach2018; Rayner & Raney, Reference Rayner and Raney1996; Rayner, Reichle, et al., Reference Rayner, Liversedge and White2006). Specifically, word skipping rates are related to the early stage of lexical processing (Reichle, Reference Reichle2021) and efficiency of parafoveal processing guided by covert attention in reading (Reingold et al., Reference Reingold, Sheridan, Meadmore, Drieghe and Liversedge2016; Slattery & Yates, Reference Slattery and Yates2018). However, word skipping may also occur if full or partial subtitles are not processed. Second are the two eye-movement measures closely related to the word frequency effect: gaze duration (the sum of all fixations on a word before the eyes move away for the first time) and total fixation time (the sum of all fixations on a word, including regressions and rereading) (Rayner, Liversedge, et al., Reference Rayner, Liversedge and White2006).
The word frequency effect describes the phenomenon where words that are lower in frequency typically receive longer fixations (either first-pass or total time) than high-frequency words (Rayner & Duffy, Reference Rayner and Duffy1986). The word frequency effect was found to explain around 30–40% of the variance in word recognition tasks (Brysbaert et al., Reference Brysbaert, Mandera and Keuleers2018) and is considered one of the most robust markers of language performance across reading contexts (Rayner & Raney, Reference Rayner and Raney1996; Schilling et al., Reference Schilling, Rayner and Chumbley1998; Szarkowska et al., Reference Szarkowska, Ragni, Orrego-Carmona, Black, Szkriba, Kruger, Krejtz and Silva2024; White et al., Reference White, Warrington, McGowan and Paterson2015; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018). The word frequency has a direct effect on lexical access and oculomotor control, affecting first-pass reading measures for word recognition, such as gaze duration (Hyönä et al., Reference Hyönä, Pollatsek, Koski and Olkoniemi2020; Rayner, Reference Rayner1998; Schilling et al., Reference Schilling, Rayner and Chumbley1998; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018; Zhang et al., Reference Zhang, Miller, Cleveland and Cortina2018). While eye-movement measures like total fixation time reflect more delayed processing (Hyönä et al., Reference Hyönä, Pollatsek, Koski and Olkoniemi2020). Total fixation time is influenced not only by lexical factors but also by later, post-lexical processes related to integrating the word meaning into a broader linguistic structure (Hyönä et al., Reference Hyönä, Pollatsek, Koski and Olkoniemi2020; Rayner, Reference Rayner2009). In sum, the word frequency effect is a strong indicator of reading efficiency (Mor & Prior, Reference Mor and Prior2022).
As this study was conducted in Australia, the Australian wordlist from the Corpus of Global Web-Based English (GloWbE), which consists of 1.9 billion words/1.8 million texts (https://www.corpusdata.org/corpora.asp), was selected to calculate word frequency.
Analyses
Before model fitting, exploratory data analysis was conducted by using histograms to inspect variable distributions and to identify potential transformations needed to improve model fit. Based on the distribution of the outcome variables, generalized or linear mixed-effects models (G/LMMs) (Baayen et al., Reference Baayen, Davidson and Bates2008; Faraway, Reference Faraway2016; Nakagawa & Schielzeth, Reference Nakagawa and Schielzeth2013) were used. The specific features of the subtitles were not considered, but both subtitles and participants were included as random effects. The models were built using the “lme4” (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) and “lmerTest” (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017) packages in R (version 4.2.0), using restricted maximum likelihood estimation (REML) for LMMs and maximum likelihood (ML) for GLMMs to handle uneven datasets, ensure unbiased estimates of variance components, and thus improve the accuracy of fixed effects.
The reference level for the conditions was set as “English soundtrack” (L1) in contrast to the “Polish soundtrack” (FL) conditions. For subtitle-level analyses, the soundtrack conditions were treated as fixed effects, with random effects for participants and subtitles. For word-level analyses, the soundtrack conditions, word frequency, and their interactions were treated as fixed effects, with participants and words as random effects. Word frequencies were incorporated into the models as scaled and centered continuous variables, based on the Zipf scale or log10 (frequency per billion words). In the current set of eye-movement models, VIFs were not reported, as the predictors were specified such that problematic collinearity is not expected (e.g., through model structure and variable specification). To correct positive skew, the dependent measure was computed as log-transformed based on the distribution of the histograms. Backward elimination was chosen as the model selection strategy, where we began with the largest model and eliminated variables one by one until the model converged and all remaining variables were important to the model. If there were multiple model candidates, the model with a lower AIC was selected.
Results
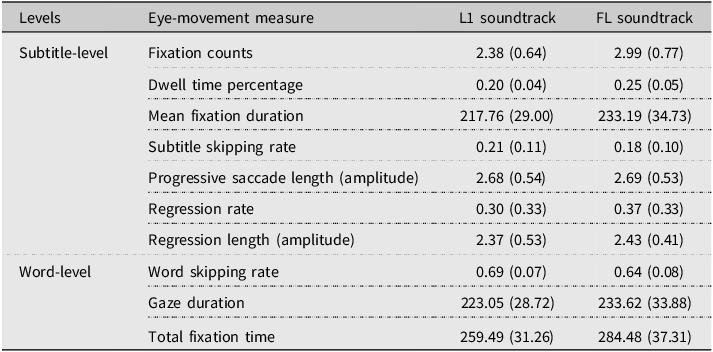
On average, each participant encountered 97.85 subtitles (SD = 7.62), which made up around 624.00 words (SD = 50.14) during the gameplay. A total of 56 participants in the L1 soundtrack group and 42 in the FL soundtrack group were included in the final data analysis. Fixation durations shorter than 60 ms or longer than 800 ms were removed from analyses to ensure the gazes were meaningful in reading (Eskenazi, Reference Eskenazi2024; Eskenazi & Folk, Reference Eskenazi and Folk2017; Negi & Mitra, Reference Negi and Mitra2020). Descriptive statistics of subtitle-level and word-level eye-movement measures between the two reading demands are shown in Table 1. The model fitting and the results of the analysis for each eye-movement measure are presented in Table 2.
The mean (and standard deviation) of global eye-movement measures (L1 vs. FL)

Summary of G/LMM models and major impact factors

Subtitle-level eye-movement measures
Fixation-related measures. The G/LMMs analyses revealed that, players in the FL group (vs. players in L1 group) had significantly more fixations (estimate = 0.191, 95% CI [0.107, 0.274], p < 0.001), longer dwell time percentage (estimate = 0.215, 95% CI [0.130, 0.300], p < 0.001), and longer mean fixation durations (estimate = 0.061, 95% CI [0.008, 0.114], p = 0.024) on each subtitle.
Saccadic measures. The G/LMMs analyses revealed that, players in the FL group (vs. players in L1 group) did not differ significantly in progressive saccade length (estimate = –0.001, 95% CI [–0.076, 0.074], p = 0.978), regression length (estimate = 0.024, 95% CI [–0.054, 0.101], p = 0.553), but did show significantly higher regression rates (estimate = 0.274, 95% CI [0.102, 0.446], p = 0.002). Although not significant, players in the FL group also showed marginally lower skipping rates than those in the L1 group (odds ratio = 0.730, 95% CI [0.52, 1.01], p = 0.057).
In sum, at the subtitle level, players in the FL group had more and longer fixations, as well as higher regression rates, but saccade length was not affected by condition. These eye-movement patterns suggest that the players in the higher reading demand condition experienced more processing effort in extracting information from the subtitles (reflecting reading depth), but may not in locating relevant information (oculomotor control in reading) or limitations in reading capacity.
Word-level eye-movement measures
As mentioned, the word frequency effect was also considered in the G/LMMs analyses. The models revealed that players in the FL group skipped significantly fewer words than those in the L1 group (estimate = −0.30, 95% CI [−0.47, −0.12], p < 0.001). A significant main effect of word frequency was also observed, with higher-frequency words (vs. lower-frequency words) more likely to be skipped (estimate = 0.46, 95% CI [0.35, 0.57], p < 0.001). Importantly, the interaction between word frequency and the soundtrack conditions was significant (estimate = −0.06, 95% CI [−0.10, −0.03], p < 0.001), indicating that players in the FL group had a weaker word frequency effect: increases in word frequency resulted in smaller increases in skipping probability of players in the FL group compared to those in the L1 group.
For gaze duration, the LMM model revealed a significant main effect of word frequency, such that gaze duration decreased as word frequency increased (estimate = −0.03, 95% CI [−0.04, −0.01], p < 0.001). But there were no significant effects of soundtrack (estimate = 0.03, 95% CI [−0.02, 0.09], p = 0.158) nor soundtrack x word frequency interaction (estimate = 0.00, 95% CI [−0.01, 0.01], p = 0.945), suggesting that the influence of soundtrack on gaze duration did not differ between the two groups.
For total fixation time, the LMM model revealed a significant main effect of word frequency, with total fixation time per word decreasing as word frequency increased (estimate = –0.051, 95% CI [–0.069, –0.033], p < 0.001). A significant main effect of soundtrack was also found, with players in the FL group showing longer total fixation times than those in the L1 group (estimate = 0.079, 95% CI [0.027, 0.130], p = 0.003). No interaction between word frequency and soundtrack was observed (estimate = –0.009, 95% CI [–0.024, 0.006], p = 0.221).
In sum, the reading demand manipulated by the soundtrack showed limited influence on lexical processing. An interaction between soundtrack and word frequency was observed in word skipping, where the players in the FL condition exhibited a weaker word-frequency effect in the early stage of lexical processing, probably as a result of parafoveal processing guided by covert attention. However, no effects of the soundtrack were found on gaze duration, the primary indicator of lexical processing effort, or lexical access. By contrast, a higher reading demand more clearly affected post-lexical processing. A significant main effect of soundtrack was found on total fixation time, with the players in the FL condition having longer total fixation durations than players in the L1 condition, although the effect of word frequency did not differ between groups. This pattern indicates that reading demand imposed by the FL soundtrack increased post-lexical integrative processing effort, even though they did not alter the sensitivity to word frequency at this stage.
Discussion
Digital media has been changing the functions and formats of texts while shaping our digital literacy over the past decades. Although much is known about reading in traditional media, little is understood about how people process texts in interactive multimedia such as video games. By manipulating the intelligibility of video game soundtracks to create high versus low reading demand, the current study examined how task demand impacts subtitle reading in video games while preserving the ecological validity of gameplay. The current study analyzed the subtitle-level and word-level processing of 98 players (56 in the L1 group and 42 in the FL group) who are native English speakers.
The results showed that, at the subtitle level, no group differences were found for subtitle skipping rate and saccade lengths. However, the players in the FL group (vs. the L1 group) had significantly more fixations, higher regression rates, higher dwell time percentages, and longer mean fixation durations, indicating greater processing effort in extracting textual information from subtitles. The subtitle-level results suggested that a high reading demand during gameplay in the current study primarily affected temporal aspects of processing, which are closely tied to reading speed (i.e., reading efficiency). In contrast, they appear to have less impact on spatial landing measures (i.e., saccade lengths), which are more related to oculomotor control in reading. The results imply that the differences observed between the two groups are driven more by contextual factors than by inherent reading capacity. In other words, under high reading demand, players did not markedly alter eye-movement paths but compensated for comprehension requirements by extending the fixation duration and re-reading. This aligns with prior findings that longer fixations are typically interpreted as signs of more effortful integration in task-based reading (Kaakinen & Hyönä, Reference Kaakinen and Hyönä2010; Rayner, Reference Rayner1998; Yeari et al., Reference Yeari, van den Broek and Oudega2015).
At the word level, the players in the FL soundtrack group showed a lower word-skipping rate than those in the L1 group. The word frequency effect was found, whose magnitude indicates the efficiency of lexical access (Mor & Prior, Reference Mor and Prior2022). Importantly, the interaction between word frequency and soundtrack condition indicated that the FL group exhibited a smaller magnitude of word-frequency effect than the L1 group in skipping behavior. Although a significant main effect of soundtrack was observed for skipping, no effects of soundtrack were observed for gaze duration. Specifically, as word skipping rates are related to parafoveal processing guided by covert attention in reading (Reingold et al., Reference Reingold, Sheridan, Meadmore, Drieghe and Liversedge2016; Slattery & Yates, Reference Slattery and Yates2018), the interaction between word frequency and the FL soundtrack may reflect reduced efficiency in parafoveal processing under higher reading demand. However, this effect did not extend to gaze duration, which showed no influence of soundtrack condition or its interaction with word frequency, indicating that the core effort of lexical access remained stable at two levels of reading demand. In contrast to monomodal reading contexts, where low-frequency words are typically more sensitive to experimental manipulations (as reflected in gaze duration) (Kaakinen & Hyönä, Reference Kaakinen and Hyönä2010), the present gameplay environment did not produce differential effects on gaze duration for high- versus low-frequency words at two levels of reading demand.
In later post-lexical processing, indexed by total fixation time, no interaction between word frequency and reading demand was found. Instead, only the main effects of the word frequency and the soundtrack were observed, with the FL group spending a longer time fixating on words than the L1 group overall. This pattern suggests that reading demand imposed by the soundtrack increased post-lexical processing effort, but relatively stable lexical processing effort remained in both reading demand conditions, echoing the results found by White et al. (Reference White, Warrington, McGowan and Paterson2015) in monomodal reading. It could be that the soundtrack functioned as a domain-general auditory distractor, drawing attentional resources away from efficient reading. At later stages of post-lexical processing, this influence manifested not as a modulation of word-frequency sensitivity but as a general increase in processing effort, as reflected in the significant main effect of soundtrack condition on total fixation time, but no interaction with word frequency.
These findings in the current study also echo the above-mentioned theories, frameworks, and models explaining how reading demand and multimodal resources drive players’ attentional control in reading in non-interactive and interactive multimedia. During gameplay in the current study, readers need to process text and integrate information from other modalities (e.g., visual, auditory, manual). Under higher reading demand in the FL condition, fixation-based measures indicated greater processing effort during word and subtitle reading. In contrast, when reading demand was lower (i.e., the L1 group), players had higher word-skipping rates, suggesting more efficient allocation of attention, although this pattern did not extend to subtitle skipping. The differences imposed by the two levels of reading demand were primarily reflected in temporal eye-movement measures rather than spatial ones, indicating that higher reading demand increased processing effort but did not alter saccadic patterns or the spatial distribution of attention.
Furthermore, the findings of this study have broader implications for digital reading across different media. For example, based on the RESOLV theory, reading strategies are not a fixed behavior but vary with reading environment, reader proficiency, and task demand in digital literacy today (Britt et al., Reference Britt, Durik and Rouet2022; Rouet et al., Reference Rouet, Britt and Durik2017). This observation is further supported by comparing the findings of the present study with those reported in the existing literature. Word skipping rates are typically influenced by linguistic factors, such as word length and frequency, as well as contextual factors, including word predictability (Rayner et al., Reference Rayner, Slattery, Drieghe and Liversedge2011; Slattery & Yates, Reference Slattery and Yates2018). The overall word skipping rates in the current study ranged between 64–69% in the two soundtrack conditions, which is way higher than the 30% word skipping rates in the literature (Rayner, Reference Rayner2009; Rayner et al., Reference Rayner, Schotter, Masson, Potter and Treiman2016; Slattery & Yates, Reference Slattery and Yates2018). Specifically, the skipping rate is about 10% for long and unpredictable words, compared to around 36% for short and predictable ones in sentence reading (Rayner et al., Reference Rayner, Slattery, Drieghe and Liversedge2011). While reading subtitles in videos, the word skipping rates were around 30–50% at different subtitle speeds (Kruger et al., Reference Kruger, Wisniewska and Liao2022; Szarkowska et al., Reference Szarkowska, Ragni, Szkriba, Orrego-Carmona and Black2025) and readers’ language proficiency (i.e., L1 vs. L2) (Kruger et al., Reference Kruger, Wisniewska and Liao2022; Szarkowska et al., Reference Szarkowska, Ragni, Szkriba, Orrego-Carmona and Black2025). On the other hand, the regression rates in the current study ranged between 30–37%, which is also higher than the 5–20% regression rates reported in previous studies (Inhoff et al., Reference Inhoff, Kim and Radach2019; Rayner, Reference Rayner1998, Reference Rayner2009).
The discrepancy in word-skipping and regression rates observed in video games in the current study, compared with sentence reading in monomodal and non-interactive contexts, may have deeper underlying causes related to daily media use. The cognitively demanding multimedia, such as video games, may encourage users to rely more on gist extraction and more accessible contextual cues, allowing them to integrate textual gist schemata with information from other modalities (e.g., images). Living with digital media, people may get used to using parafoveal and peripheral vision to monitor subtitle reading while coping with other multimodal resources (Lan et al., Reference Lan, Liao and Kruger2025). For example, such monitoring ability enables players to predict and skip high-frequency or highly predictable words more adeptly. Instead of word-by-word processing, players in video games may thus adopt a non-linear and keyword extraction reading strategy (Lan et al., Reference Lan, Liao and Kruger2025). Such non-linear reading patterns were also observed in other digital reading contexts (Hahnel et al., Reference Hahnel, Goldhammer, Kröhne and Naumann2017). It is also possible that, under time constraints and the cognitive demands of coordinating multimodal information, players lacked sufficient visual resources to finish reading an entire line of subtitles. This may also account for the high word skipping rates in gameplay contexts. However, it should be noted that some basic reading patterns remain consistent, such as the word frequency effect, where high-frequency words are skipped more often than low-frequency words (Inhoff & Rayner, Reference Inhoff and Rayner1986). Thus, the present study provides an extension to established findings, supporting the view of reading as an adaptive system and offering new insights for digital reading patterns.
Moreover, including participants and subtitles as random factors at the subtitle and word level greatly improved all models’ explanatory power (see Table 2 for the marginal R-squared and conditional R-squared in the full models), again emphasizing the role of individual differences and contextual factors in reading across media. This variability is supported by questionnaire data and varied widely in the types of games they typically played (e.g., action, strategy, role-play, adventure, and hybrid), as mentioned in the “Participants” section. The considerable individual differences in eye-movement measures observed in this study reflect previous findings that the rise of digital media has introduced profound individual variability in digital literacy skills (Lo, Reference Lo, Tong, Ma and Tso2020; Ma et al., Reference Ma, Cain and Ushakova2024).
Finally, the insignificant difference in some eye-movement measures could also be explained by the multimodality of video games. This multimodality may help players understand the gaming contexts holistically, assisting in the construction of event models based on a combination of visual and auditory cues, and agency in the game context, which reduces the need for processing the subtitles in depth. It could also be that this interactive context may trigger the activation of long-term memory schemas rather than procedural memory, which may streamline some aspects of reading and reduce the need for deliberate attentional allocation (Sweller, Reference Sweller1988), potentially contributing to the absence of additional significant effects in saccadic measures at the subtitle level. However, this interpretation should be approached cautiously, as the role of multimodal support (external) and metacognitive strategies (internal) of the players in subtitle reading is still unclear during gameplay.
Limitations
The present exploratory study has four limitations that should be noted.
First is the potential “side effect” of the FL soundtrack condition, as the foreign soundtrack could introduce auditory distraction, although the experimental design in our study differs dramatically from those used in research on auditory distraction. In the present study, L1 and FL soundtrack conditions create different subtitle reading demands, preserving the natural gaming environment at maximum. Yet such a design on the soundtrack has its limitations. It is disputed whether the FL soundtrack condition would potentially introduce additional auditory distraction compared to the silent condition, according to studies on auditory distractions. Compared to silent reading conditions, unintelligible background speech yields longer reading time, more fixations, and more regressions (Yan et al., Reference Yan, Meng, Liu, He and Paterson2018). However, it was shown that unintelligible speech did not cause differences in reading speed, fixation counts, regression counts, average fixation duration, and saccade length compared to the silent reading condition (Meng et al., Reference Meng, Lan, Yan, Marsh and Liversedge2020). Moreover, the findings are mixed on whether such foreign-language backgrounds impair reading comprehension (Vasilev et al., Reference Vasilev, Kirkby and Angele2018; Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019). More recent studies suggested that only semantic interference has a detrimental effect (Meng et al., Reference Meng, Lan, Yan, Marsh and Liversedge2020; Vasilev et al., Reference Vasilev, Liversedge, Rowan, Kirkby and Angele2019; Yan et al., Reference Yan, Meng, Liu, He and Paterson2018). Although these studies use foreign languages as asynchronous auditory distractions and differ dramatically from the current study in many ways, the potential impact of introducing an FL soundtrack should still be acknowledged.
Second, we selected only one widely acclaimed video game as a case study. Given the wide variety of video game genres on the market, the differences between gamers may vary across different gaming contexts. For example, in more action-oriented games that require quicker reflexes and control, non-gamers and players unfamiliar with the genre may struggle more with mastering game controls, leaving them with fewer cognitive resources to devote to in-game text. Third, as participants were recruited on campus, most of them are young adults. The findings of the current study may not be applied to other age groups.
Finally, we did not test how players comprehended the game; its effect on comprehension (i.e., mental construction) is unclear. We also did not have uniform criteria to test players’ performance. This is because the current game has multiple endings in each chapter, and each player has a customized experience. It is difficult to compare the gameplay experience and comprehension across participants. Future studies could investigate the construction of mental models in video games by more qualitative measures, such as semi-structured interviews.
Conclusion
The present findings support the claim that contexts and the tasks derived from the contexts modulate reading behavior across media (Rouet et al., Reference Rouet, Britt and Durik2017). Specifically, the tasks embedded in the contexts modulate the general attention allocation in subtitle-level and word-level processing. Compared to more traditional reading experiment paradigms, reading in video games displays more non-linear patterns and is strongly shaped by individual differences and contextual factors (e.g., subtitles and soundtrack). The present research fills the gap in reading studies within highly interactive multimedia. It provides exploratory empirical evidence for multimedia learning. The identified task-based reading patterns in video games can be useful for educational monitoring and intervention for language learning. For example, when educators emphasize contextual comprehension, adding a redundant soundtrack can help reduce students’ cognitive load by easing the burden of visual information. Conversely, in situations where the goal is for students to focus on learning the orthographic forms of words, omitting the accompanying soundtrack may be more effective, allowing learners to process the written forms at a deeper level. Finally, video games are an integral part of our hobbies today; yet their pedagogical potential remains underexplored and calls for more empirical investigation.
Replication package
All data, supplementary materials, and analysis code for this study are available at the first author’s Open Science Framework repository: https://osf.io/ugxsz/.
Acknowledgments
The authors thank Associate Professor Sijia Chen and the anonymous reviewers for their insightful comments.
Competing interests
The authors declare no conflicts of interest.
Ethical standards
This study was approved by Macquarie University Human Research Ethics Committee (ethics approval number: 52024645755523).




 Open access
Open access