


Introduction
The evaluation of new diagnostic tests requires the assessment of the diagnostic test accuracy, usually in terms of sensitivity and specificity. It consists in confronting the index test results with the presence/absence of the target condition. The reference standard is the best method available for attesting the target condition [Reference Bossuyt1]. However, in many cases it is not a Gold Standard, it does not have sensitivity and specificity of 100%. This imperfection of the reference standard translates into the misclassification of patients with regard to the target condition and entails biased estimates of the prevalence and accuracy of new diagnostic tests [Reference Valenstein2–Reference Miller7]. Different solutions have been proposed and reviewed to evaluate diagnostic test accuracy in the presence of an imperfect Gold standard as the correction of accuracy parameters according to external data or the use of multiple reference standards (expert panel, composite reference standard) [Reference Rutjes4, Reference Reitsma5]. An alternative is to rely on a purely statistical approach, the latent class framework, sometimes referred to as latent class models (LCM), latent class analyses (LCA) or mixture models [Reference Hui and Walter8–Reference Hadgu, Dendukuri and Hilden16]. This method defines the true target condition status as two latent classes and estimates of the sensitivities and specificities of the diagnostic tests, possibly including the imperfect Gold standard, according to these latent classes. LCMs have sparked a growing interest in Biostatistics with contributions evaluating their robustness to the misspecification of the assumption of independence between diagnostic tests conditionally on the true condition status [Reference Torrance-Rynard and Walter17–Reference Menten, Boelaert and Lesaffre21], recommending methods to assess this assumption [Reference Qu, Tan and Kutner10, Reference van Smeden14, Reference Reiser and Lin22–Reference van Kollenburg, Mulder and Vermunt24] and proposing extensions to take into account such misspecification [Reference Qu, Tan and Kutner10, Reference Goetghebeur12, Reference Dendukuri, Hadgu and Wang25, Reference Xu and Craig26].
In the recent years, clinical applications of this approach have been reported in the medical and veterinary literature. However, the models and the underlying assumptions or application conditions were rarely evaluated whereas such violations can lead to biased reported estimates of diagnostic accuracy [Reference van Smeden14].
Diarrhoeal diseases are responsible for 550 million people falling ill yearly, including 220 million children under the age of 5 years and campylobacter bacteria is the most frequent cause of bacterial gastroenteritis worldwide. Campylobacter infections are generally mild but can be fatal among very young children, elderly and immunosuppressed individuals [27]. Its diagnosis relies on stool cultures that have a moderate sensitivity because of the fragility and special culture requirement of campylobacter bacteria (microaerobic environment): a too long contact with a not controlled atmosphere may inhibit the growth of the bacteria. By contrast, specificity is expected to be very high as it may almost only be altered by bacterial contamination. As campylobacter growth is also slow and usually takes more than 48 h, other diagnostic tests (immunoenzymatic, molecular and immunochromatographic methods) have been developed and are available. They are easy to apply and interpret and their results are obtained much more quickly than those of culture (from 30 minutes to 2 h). However, their diagnostic accuracy cannot be correctly assessed using conventional comparisons due to the imperfect reference standard of culture [Reference Bessède28–Reference Regula30]. For example, true cases missed by culture but detected by the new test would be incorrectly classified as false positives. By accounting for the imperfection of culture, LCMs, by contrast, have the potential to correctly estimate the diagnostic accuracy of these new tests. In addition, LCMs can take into account a conditional dependence between tests, which arises for example when different tests make the same error. In campylobacter diagnosis, it might be the case when considering various immunological tests, especially if based on the same campylobacter antigens.
In this work, we aimed at carefully applying the LCM methodology to evaluate diagnostic test accuracy through a real case study, the evaluation of new rapid diagnostic tests of campylobacter. Based on current recommendations [Reference van Smeden14] and statistical developments, we specifically explored the means to assess goodness of fit of LCMs, mostly regarding the sparseness of the data and the violation of the conditional independence assumption and to implement extended LCMs involving random effects.
Methods
Study population
Our analysis relies on data from two studies that included every stool specimen obtained from a patient with a gastrointestinal illness at Bordeaux University Hospital (Bordeaux, France) from June to October 2009 and at Lyon University Hospital (Lyon, France) from February to September 2012 [Reference Bessède28, Reference Freydiere31]. Stools were sent to the laboratory at room temperature without transport medium. The fresh, unpreserved stools were tested for culture within 4 h after arriving at the laboratory. The remaining part of the stool samples was then frozen at −80 °C. The other tests were performed together, once a week, after the samples were thawed. For the Lyon study, culture and immunochromatographic tests were performed in Lyon, ELISAs and polymerase chain reaction (PCR) were performed in Bordeaux.
Diagnostic tests
Every stool specimen was tested by five different diagnostic tests for campylobacter briefly described below. For more details, please refer to Bessède et al. [Reference Bessède28]:
− Culture. A stool suspension was prepared, plated on a Karmali agar (Oxoid, Basingstoke, Hampshire, UK) and the plates were incubated for a maximum of 3 days in a microaerobic atmosphere. Colonies resembling campylobacter colonies were tested with a MALDI-TOF mass spectrometer.
− Rapid immunochromatographic tests. ImmunoCardSTAT!Campy (Meridian Bioscience, Inc., Cincinnati, OH, USA) was used according to the manufacturer's instructions. It is an immunochromatographic test which detects specific campylobacter antigens on a band. The result was read and validated if the control line band was clearly visible.
− ELISAs. Two different tests were used: RIDASCREEN® Campylobacter (R-Biopharm AG) and Premier® Campy (Meridian Bioscience, Inc.), both according to the manufacturer's instructions.
− Real-time PCR. The real-time PCR and hybridisation reactions were performed according to the method published by Ménard et al., using a LightCycler thermocycler (Roche Diagnostics, Meylan, France) [Reference Ménard32].
Statistical analysis
We considered different specifications of LCM to estimate diagnostic accuracy parameters (sensitivity, specificity, negative and positive predictive values) of each test and the prevalence of campylobacter infection in the study population.
Standard LCM
The LCM assumes that the true target condition status, campylobacter infection in our case, is not observed. It is statistically defined by a binary latent variable with two modalities corresponding to the absence and the presence of the disease (called disease-free latent class and disease latent class, respectively). The disease prevalence is thus given by the probability P to belong to the disease latent class. Sensitivity Sek and specificity Spk of each test k (k = 1,…,K) correspond to the conditional probabilities of each test result given the latent classes.
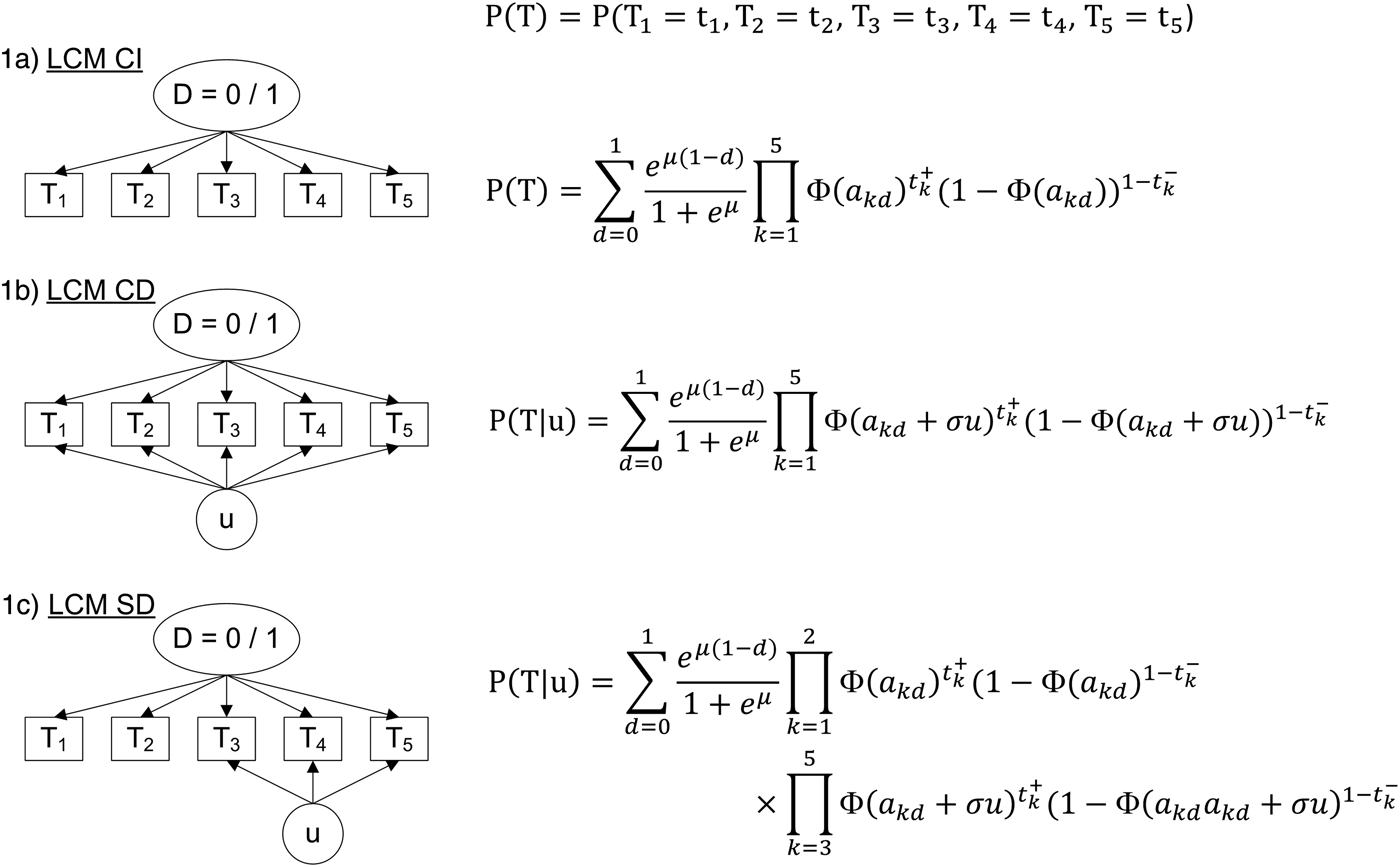
The standard LCM (LCM CI, Fig. 1a) relies on the central assumption, called ‘conditional independence assumption’, that test results are independent given the latent classes. Based on this assumption, the probability of observing a response profile for the K tests denoted T 1 to T K can be expressed as the sum of two terms, one per class:
 $$\eqalign{& P(T_1 = t_1,\;T_2 = t_2, \cdots ,\;T_K = t_K) = \cr & p\;\; \times \;\;\prod\limits_{k = 1}^K {\left[ {Se_k^{t_k^ + } \times \left( {1 - Se_k^{t_k^ - } } \right)} \right]} \quad ({\rm disease\;latent\;class}) \cr & + \;(1 - p) \times \prod\limits_{k = 1}^K {\left[ {Sp_k^{t_k^ - } \times \left( {1 - Sp_k^{t_k^ + } } \right)} \right]} \quad ({\rm disease} - {\rm free\;latent\;class})} $$
$$\eqalign{& P(T_1 = t_1,\;T_2 = t_2, \cdots ,\;T_K = t_K) = \cr & p\;\; \times \;\;\prod\limits_{k = 1}^K {\left[ {Se_k^{t_k^ + } \times \left( {1 - Se_k^{t_k^ - } } \right)} \right]} \quad ({\rm disease\;latent\;class}) \cr & + \;(1 - p) \times \prod\limits_{k = 1}^K {\left[ {Sp_k^{t_k^ - } \times \left( {1 - Sp_k^{t_k^ + } } \right)} \right]} \quad ({\rm disease} - {\rm free\;latent\;class})} $$ with t k the result of test T k noted 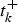 $t_k^ + $ if positive and
$t_k^ + $ if positive and 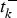 $t_k^ - $ if negative.
$t_k^ - $ if negative.
Diagram (left panel) and corresponding profile probability (right panel) for three latent class models assuming different dependence structures, CampyLCA study, France, 2016. LCM CI, latent class model under conditional independence; LCM CD, latent class model with a residual dependence common to all tests; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests. Ovals and rectangles indicate latent quantities and observed quantities, respectively: D = 0/1: unobserved presence/absence of campylobacter infection; T 1: Culture Karmali; T 2: Real-time PCR; T 3: Ridascreen®; T 4: Premier®Campy®; T 5: ImmunoCardStat!®Campy; u: random residual dependence which follows a standard Gaussian distribution. In the equations, t k+ and t k− indicate a positive and negative result for test T k, respectively; Φ is the standard cumulative Gaussian distribution function; parameters to estimate are (akd)k = 1,…,K, d = 0, 1 for the probit transformations of sensitivities and specificities, μ for the logit transformation of the prevalence and σ for the intensity of the individual random deviation.
In estimation procedures, Sek and Spk probabilities (for k = 1, …, K) are usually modelled using a probit link while the prevalence p is usually modelled using a logit link [Reference Qu, Tan and Kutner10, Reference Goetghebeur12].
Extended LCMs
The conditional independence assumption is rarely verified in practice so we investigated two main alternatives which consider residual dependences between tests through individual random effects [Reference Qu, Tan and Kutner10, Reference Goetghebeur12]:
− A LCM with a common residual dependence between the tests (LCM CD, Fig. 1b). In this model, an individual random intercept, added to the probit model for the sensitivities and specificities of the tests, captures the residual correlation between tests.
− A LCM with a specific residual dependence within the three immunoenzymatic tests (Premier®Campy, Ridascreen®, ImmunoCard Stat!®Campy) (LCM SD, Fig. 1c). In this model, an individual random intercept is added to the probit models only for a subset of tests suspected to be conditionally dependent.
Estimation of standard and extended LCMs
Parameters of LCMs were estimated in the maximum likelihood framework. Identifiability of LCMs requires that the number of parameters does not exceed 2K–1 (2K being the number of possible dichotomous tests combinations). So, at least three tests in LCM CI and four tests in LCM CD and SD are necessary to estimate all the parameters (2K sensitivity/specificity parameters, plus one for prevalence plus one for the intensity associated with the random intercept in LCM CD and LCM SD). We implemented the models using RandomLCA package [Reference Beath33] and NLMIXED procedure (SAS Institute, Inc., SAS software version 9.3, Cary, North Carolina). Because convergence towards local maxima is frequently encountered in mixture models [Reference Biernacki, Celeux and Govaert34], we considered 100 sets of random initial values, either completely at random (with R) or chosen within clinically plausible ranges (with SAS) to ensure convergence towards the global maximum. The introduction of a random effect in the likelihood for LCM CD and LCM SD induced an integral that had to be numerically solved [Reference Chen and Hung35]. It was done with adaptive Gaussian quadratures implemented in both programs. After convergence, two-sided 95% confidence interval (95% CI) of each parameter was obtained by a Monte Carlo approximation.
A posteriori evaluation of LCM
As recommended by some authors [Reference Qu, Tan and Kutner10, Reference Goetghebeur12, Reference van Smeden14, Reference Formann23, Reference van Kollenburg, Mulder and Vermunt24], we used a series of post-fit criteria and posterior analyses to thoroughly assess the models:
(1) Models were compared in terms of Akaike Information Criterion.
(2) Absence of residual dependence between the tests was verified using goodness-of-fit statistics which compare model predictions with observations (Pearson, Likelihood Ratio and Power Divergence statistics). Both the asymptotic Chi-square distribution and empirical distributions were considered for the statistic under the null hypothesis. Indeed, in the context of sparse data (many profiles with low frequencies), results with the asymptotic distribution may not apply and only those obtained with empirical distributions are recommended [Reference Goetghebeur12, Reference Reiser and Lin22–Reference van Kollenburg, Mulder and Vermunt24, Reference Van Smeden36]. The empirical distribution was obtained by generating a large number of samples (n = 500) from the null assumption and computing the corresponding statistic; the P-value was deduced from the quantile which corresponded to the statistic in the observed sample.
(3) Pairwise residual correlations and bivariate residual statistics were calculated to detect potential residual dependences between pairs of diagnostic tests that were not correctly taken into account [Reference Qu, Tan and Kutner10, Reference Goetghebeur12, Reference van Kollenburg, Mulder and Vermunt24, Reference Sepúlveda, Vicente-Villardón and Galindo37].
(4) Leave-one-test-out analyses were performed by removing one by one each immunoenzymatic test in order to assess their influence on the diagnostic accuracy of the other medical tests [Reference van Smeden14].
In supplementary simulations, we assessed the type-I error rates obtained with the asymptotic distributions of statistics from point 2 in the specific case of our application data to better appreciate the performances of usual statistics in our sparseness context. The type I error rate quantifies the percentage of times when the test concludes that observations and predictions significantly differ while they actually do not. We also evaluated the power of the same statistics relying on the empirical distributions to detect a violation to the conditional independence assumption. The power quantifies the percentage of times when the test concludes that observations and predictions significantly differ and they actually do.
Statistical tests were all performed at the significance level of 5%.
Results
From the 32 profiles of test responses possible with five dichotomous diagnostic tests (25), 17 were observed and only 10 included at least three patients (Table 1) among the 623 patient samples. This underlines the sparseness of our data. The most frequent profiles were ‘all tests negative’ (83.8%) and ‘all tests positive’ (6.6%). According to the classical reference standard, bacteriological culture, the prevalence of campylobacter infection was 9.0% (95% CI 8.8–9.3).
Test results profiles: observed and predicted (by the Latent Class Models) number of patients for each combination of test results, CampyLCA Study, France, 2016
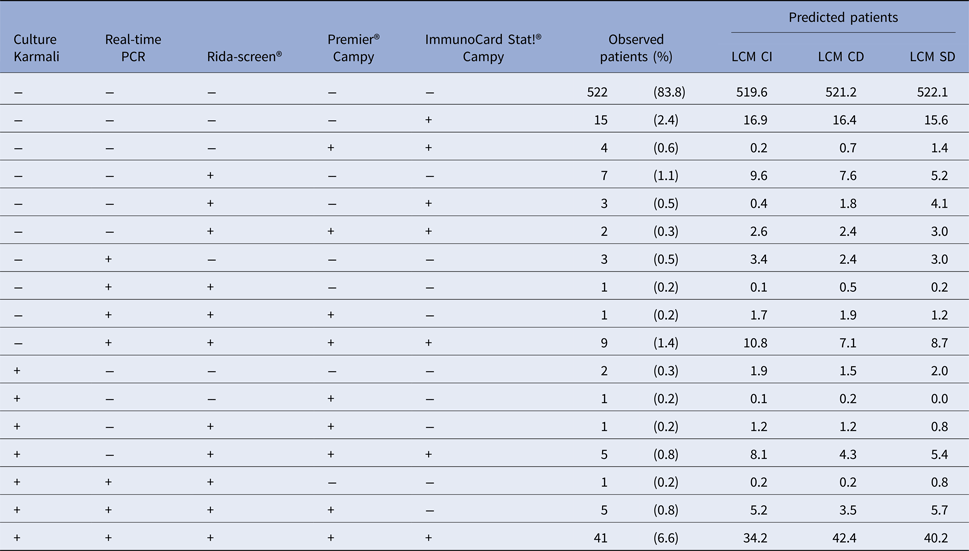
LCM CD, latent class model with a residual dependence common to all tests; LCM CI, latent class model under conditional independence; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
Predicted profiles frequencies estimated with the three LCMs were globally close to observed frequencies (Table 1) but the two models considering a residual dependence (LCM CD and LCM SD) were closer at least for the most frequent profiles. For instance, the ‘all negative tests’ profile was predicted at 519.6, 521.2 and 522.1 with LCM CI, CD and SD., respectively, for 522 patients observed; similarly, the ‘all tests positive’ profile was predicted at 34.2, 42.4 and 40.2 with LCM CI, CD and SD, respectively, for 41 patients observed. Note that among the 15 non-observed profiles, two profiles with LCM CI and CD model and one profile for LCM SD had predicted frequencies above one (data not shown).
Comparison of LCM CI, CD and SD models in terms of goodness of fit is summarised in Table 2. We only interpret in the following the statistics based on empirical distributions due to the sparseness of our data; results based on the asymptotic distributions are given only to illustrate their lack of reliability in the presence of sparseness. LCM CI under conditional independence hypothesis presented the worst Akaike information criterion and this specification was highly rejected by all statistics. The LCM CD provided an improved Akaike information criterion (by 17.6 points) but all the test statistics still rejected the adequacy of the model. LCM SD provided the best Akaike information criterion (improved by 29.6 points compared with LCM CI and 12.0 compared with LCM CD) and none of the goodness-of-fit tests rejected the specification of LCM SD even if P-values were just above the significance threshold. We explored other dependency structures but the latter, based on biological knowledge, remained the most satisfying one.
Akaike information criterion and goodness-of-fit statistics for each model, CampyLCA Study, France, 2016
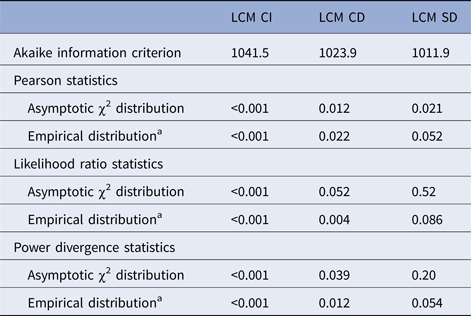
LCM CD, latent class model with a residual dependence common to all tests; LCM CI, latent class model under conditional independence; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
a The P-value when using the empirical distribution was calculated as one minus the percentile of the statistic in 500 samples generated under the null assumption.
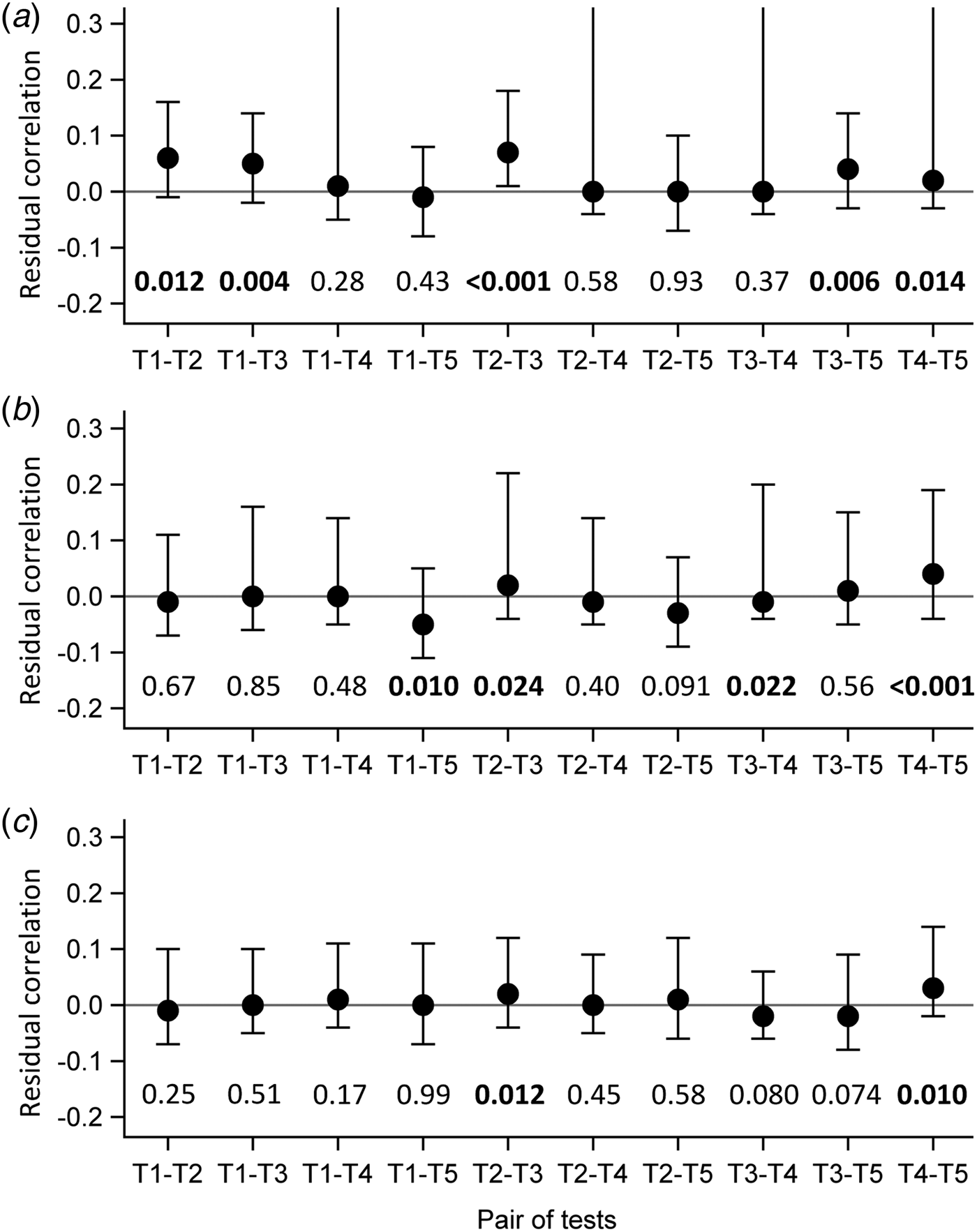
Evaluation of the local independence hypothesis is shown in Figure 2. While residual correlations were not highlighted for LCM CD or SD based on their 95% confidence interval, bivariate statistics rejected the local independence hypothesis at the 5% level for four pairs of tests in LCM CD and still for two pairs of tests for LCM SD.
Evaluation of local independence hypothesis by residual correlations and their 95% confidence interval, as well as by P-values of bivariate statistics, CampyLCA study, France, 2016. (a) Residual correlations for latent class model under conditional independence; (b) Residual correlations for latent class model with a residual dependence common to all tests; (c) Residual correlations for latent class model with a residual dependence specific to the three immunoenzymatic tests. T 1: Culture Karmali; T 2: Real-time PCR; T 3: Ridascreen®; T 4: Premier®Campy; T 5: ImmunoCard Stat!®Campy. Residual correlations presented with dots (point estimates) and bars (95% confidence intervals). P-values of bivariate statistics are provided above each pair of tests described on the horizontal axis.
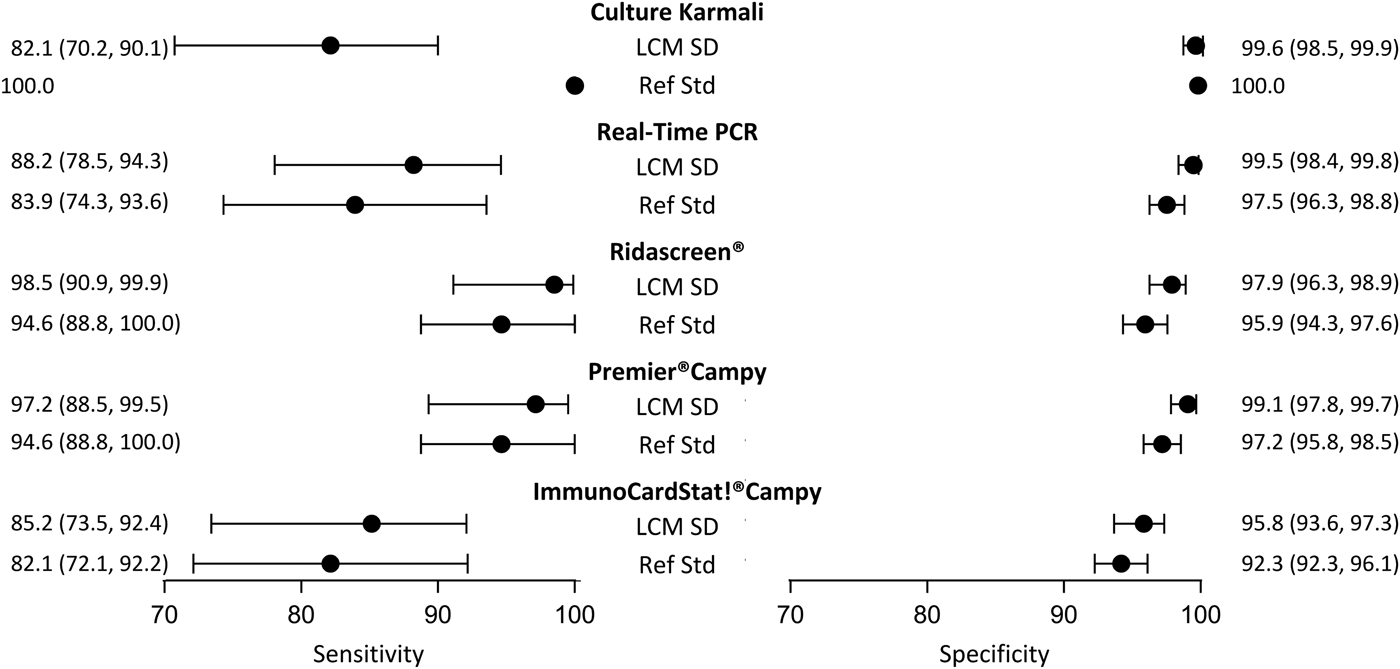
Although it did not satisfy all the criteria, the LCM SD model presented the best evaluations. According to this model (Table 3), the prevalence of campylobacter infection was estimated at 10.5% (95% CI 8.4–13.3). The standard error of the random effect specific to the three immunoenzymatic tests was statistically different from zero (estimated at 1.6, (95% CI 0.9−2.4)). The diagnostic accuracy of the different medical tests according to LCM SD are displayed and compared with those obtained when using the culture as the reference standard in Figure 3. As expected, culture presented a moderate sensitivity (82.1%, (95% CI 70.2–90.1)). Using culture as the reference standard resulted in a systematic underestimation of other tests sensitivities and specificities. According to LCM SD model Ridascreen® and Premier®Campy tests showed the best compromise between sensitivity and specificity, both above 97%. Estimations and 95% CI of accuracy parameters of all medical tests according to all the LCMs are given in Table 3.
Diagnostic accuracy estimates (point estimate and 95% confidence interval) of campylobacter infection tests according to the LCM SD model and to culture as the reference standard, CampyLCA study, France, 2016. LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests; Ref Std: culture Karmali.
Diagnostic accuracy of medical tests according to LCM models, CampyLCA Study, France, 2016

95% CI, two-sided 95% confidence interval.
LCM CD, latent class model with a residual dependence common to all tests; LCM CI, latent class model under conditional independence; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
NE, not estimated because of estimate on the boundary.
p, prevalence of campylobacter infection.
σ, random effect.
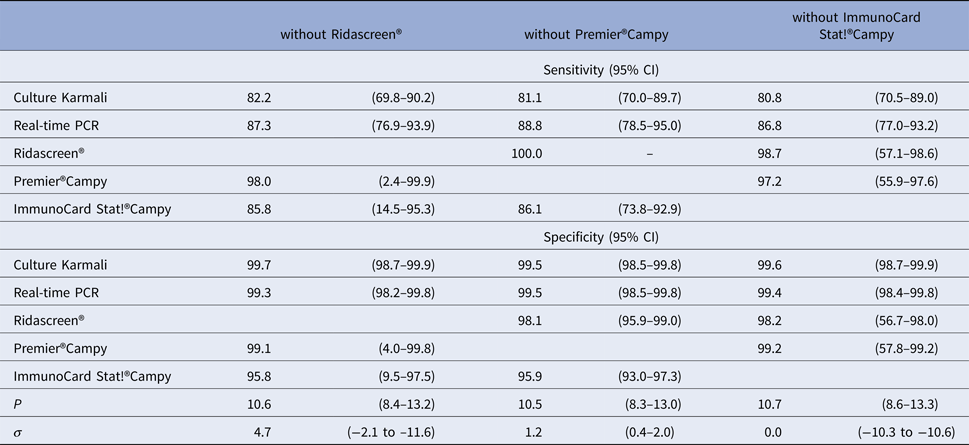
We note that leave-one-test-out analyses did not show relevant differences in the prevalence and diagnostic accuracy when removing each immunoenzymatic medical tests one by one (Table 4).
Diagnostic accuracy of medical tests according to leave-one-test-out analyses for LCM SD model, CampyLCA study, France, 2016
LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
95% CI, two-sided 95% confidence interval.
p, prevalence of campylobacter infection.
σ, random effect.
Discussion
Using a reference standard whose diagnostic accuracy is known to be far from perfection necessarily leads to biased estimations of new detection tests if the imperfection is not properly taken into account. Based on a dataset of 623 patient samples, the diagnostic accuracy of five tests of campylobacter infection was estimated by using LCMs to palliate the imperfection of the bacteriological culture. The model with a specific dependence within the three immunoenzymatic tests showed the best performances in terms of fit and compliance with LCM assumptions. The prevalence of infection was estimated about 10%. LCM results confirmed the moderate sensitivity and almost perfect specificity of the culture. Ridascreen® and Premier®Campy showed very high sensitivities (98.5% and 97.2%, respectively) and very high specificities (97.9% and 99.1%, respectively) confirming their potential usefulness for diagnosing campylobacter infection in clinical practice.
As expected with the moderate sensitivity of culture, the prevalence of infection was higher when estimated by LCM, even if the difference remained tenuous. The incorrect use of culture as a reference standard also led to the underestimation of sensitivity and specificity of all the index tests. Indeed, when using a reference standard with moderate sensitivity and perfect specificity, as a culture, the patients falsely considered as disease-free contribute to wrongly classify positive results of index tests as ‘false positives’ and negative results as ‘true negatives’. For index tests with high sensitivity, this leads to a systematic underestimation of their sensitivity and specificity (as found in our application) and, to a greater extent, of their positive predictive value. In our campylobacter case, the use of bacteriological culture as a reference standard underestimated the positive predictive value of index tests from 12% to 18%.
Classically, LCMs rely on the assumption of conditional independence between tests. This hypothesis is implausible in many clinical situations but rarely evaluated in the literature while its violation may induce biased estimations of diagnostic accuracy [Reference van Smeden14]. It is, therefore, crucial to assess different structures of residual correlation and rely on the technical and biological mechanisms of index tests for the choice of the structures [Reference Collins and Albert38]. We proposed, for instance, a specific dependence between the three immunoenzymatic tests because of their common characteristics to detect campylobacter antigens. Assessing LCM models and their assumptions is not straightforward. We used different goodness-of-fit statistics and local residual dependence checking (pairwise graphs and testing) methods that were proposed in the literature. We showed that conclusions could vary according to the method, confirming the need to perform different checks in order to obtain a body of evidence on the adequacy of the model and ensure the credibility of the results. Indeed, all the tests rejected the adequacy of conditional independence and common dependence LCMs but while the global tests did not reject the adequacy of the specific dependence LCM, some bivariate statistics still rejected the local independence assumption at the level of 5%. One may question the power of global tests compared with the bivariate statistics. Yet, with our sample size, global tests using empirical distributions showed high capabilities to detect violation of conditional independence assumption with statistical power ranging from 87% to 95% according to a supplementary simulation study (Table 5).
Statistical power of goodness-of-fit statistics (in %) using empirical distribution to detect violation of the conditional independence hypothesis when applying LCM CI model, CampyLCA study, France, 2016

LCM CI, latent class model under conditional independence; LCM CD, latent class model with a residual dependence common to all tests; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
Statistical power is defined as the percentage of times the test concludes that observations and predictions significantly differ (at a 5% significance level) when they actually do.
In our case example, three of the five diagnostic tests were immunoenzymatic tests (two ELISAs and one immunochromatographic test). We took into account the induced correlation with the specific random effect and this specification of LCM provided the best solution. However, the bigger weight of immunoenzymatic tests could have still influenced the diagnostic accuracy results estimated with LCM SD. To assess to which extent the results were influenced, we re-estimated the model by excluding one immunoenzymatic test at a time in a ‘leave-one-test out’ procedure. We found out that the point estimates were not much different although wider confidence intervals were obtained. In our case study, patients were recruited in two hospitals which could have induced a residual dependence within the hospital. We evaluated a potential impact of the study hospital on our results by adding a study hospital variable in the final LCM. The introduction of the study hospital did not significantly modify the estimation of prevalence of campylobacter (β = 0.29, p = 0.30) or diagnosis performances of the five tests (β = 0.34, p = 0.11).
Sparse data are almost inherent in diagnostic test evaluation due to the improvement of index tests and the limited sample sizes. Profiles with perfectly concordant responses (‘all positive’ and ‘all negative’) bring together almost all of the information (e.g. 90.4% in our application) while most of the discordant responses comprise no or a few observations only. As a result, asymptotic distributions of goodness-of-fit tests do not apply and empirical distributions under the null hypothesis have to be derived [Reference Formann23, Reference van Kollenburg, Mulder and Vermunt24, Reference Van Smeden36]. With the level of sparseness of our data, we confirmed the impaired type-I error rates of the statistics using asymptotic distributions with either too conservative (type I error rates down to 0.002) or anticonservative (type I error rates up to 0.116) tests (Table 6) while by definition, the type-I error remained correct when using the empirical distribution. In our application, this translated into discordant results between asymptotic and empirical distributions, especially for the model with specific dependence. We also observed that P-values resulting from different statistics were more consistent when using empirical distributions. The use of quantitative test results may solve the sparseness problem and may allow more precise specification by including covariates or multiple random effects for example. However, this would also require some reflection about how to summarise quantitative tests results and provide useful criteria for the clinical decision.
Type-I error rates of goodness-of-fit statistics (in %) using asymptotic distribution for each model, CampyLCA study, France, 2016

LCM CI, latent class model under conditional independence; LCM CD, latent class model with a residual dependence common to all tests; LCM SD, latent class model with a residual dependence specific to the three immunoenzymatic tests.
Type I error rate is defined as the percentage of times the test concludes that observations and predictions significantly differ (at a 5% significance level) while they actually do not. The nominal value of type I error rate is 5%.
Beyond their use for diagnostic accuracy assessment, LCMs remain complex models that require specific attention. The likelihood of LCM is often multimodal so that algorithms may converge to local maxima. To ensure convergence to the global maximum of Likelihood, required for correct inference, multiple sets of initial values can be used (we considered 100 sets in our application). In addition, the inclusion of random effects to account for the possible residual dependency induces a numerical integration in the likelihood which highly complicates the estimation process and may also pose convergence problems, in particular in SAS Proc NLMIXED in our experience. For instance, in the LCM with a common dependence estimated with this procedure, a simulation study highlighted biased estimations with unacceptable parameter coverage rates while the procedure under R provided correct inference with no bias and acceptable coverage rates (results not shown).
Because the target condition does not rely on a clinical definition, LCMs can be considered as a black box and make clinicians feel uncomfortable about what the results represent [Reference Reitsma5, Reference Pepe and Janes20]. Moreover, the statistical classification may not fully coincide with pre-existing knowledge of the target condition or it may even refer to a related, but different condition [Reference Walter6, Reference Collins and Albert38]. This approach becomes meaningful when all index tests included in the model rely on an established clinical and biological background and the condition definition is not ambiguous. That explains why LCMs are very popular in the infectious field where the condition is clearly defined (i.e., presence or absence of the bacteria) and where tests directly identify the presence of the microorganism or of its antigens or DNA [Reference Collins and Albert38]. Note that other approaches dealing with the imperfection of the reference standard (discrepant analysis, composite reference standard) have been highly criticised in the literature for not satisfying basic requirements of the diagnostic accuracy assessment [Reference Reitsma5, Reference Schiller39, Reference Hadgu, Dendukuri and Wang40].
A critical limit of LCM approach lies in the number of available index tests needed to implement the models: three tests for the basic model and more for extended ones. Some authors recommended the use of at least 10 tests to ensure the distinction between different correlation structures [Reference Albert and Dodd19]. In our context, with five tests, we did find differences between the LCMs structures hereby reported. Note that other LCMs structures, which performed worse than the specific dependence model, are not reported.
From a practical point of view, our feeling is that a major current drawback of LCM techniques for diagnostic accuracy assessment lies in the gap between recommendations that advise a search for specific correlation structure, posterior evaluation, goodness-of-fit statistics and graphs and programs available in standard software [Reference van Smeden14, Reference Collins and Huynh15, Reference Albert and Dodd19, Reference Reiser and Lin22–Reference van Kollenburg, Mulder and Vermunt24, Reference Van Smeden36–Reference Collins and Albert38]. Model specifications are relatively limited, the correct convergence of models is not systematically ensured and a posteriori evaluation usually requires programming skills, which reduces the applicability of LCMs in the clinical epidemiology community.
In conclusion, the imperfection of the reference standard precludes the valid estimation of diagnostic accuracy parameters of new tests using standard methods and no good solution has been proposed so far. LCMs constitute a promising way to overcome it, on the condition that they are correctly specified and assessed [Reference van Smeden14]. However, this technique still requires substantial developments in usual software in particular to become a veritable solution for statisticians or epidemiologists involved in clinical epidemiology research.
Acknowledgements
The authors thank Olivier Dauwalder and Anne-Marie Freydière for providing the data from the Lyon study.
Conflicts of interest:
None.










 Open access
Open access