


1. Introduction
Artificial intelligence is a powerful domain leveraging the potential of computer science and mathematics to create intelligent systems that enhance various aspects of our modern life, including the economy, education, industry, and social fields. Machine translation (MT) systems have already been proposed on many online platforms. However, there is a notable deficiency in the translation of Arabic dialects, resulting in several limitations, such as hindering progress in the industry and impeding the integration of the Arab world.
Machine translation is a system developed to bridge the communication gap between people from different regions and linguistic backgrounds. It employs various approaches, including rule-based MT (Shiwen and Xiaojing Reference Shiwen and Xiaojing2014), example-based MT (Somers Reference Somers1999), statistical MT (Zens, Och, and Ney Reference Zens, Och and Ney2002; Lopez Reference Lopez2008), and NMT. NMT relies on neural networks to learn complex patterns and alignments between words in different languages. It has proven highly effective, outperforming previous approaches in a wide range of language pairs and domains (Luong et al Reference Luong, Pham and Manning2015; Almahairi et al. Reference Almahairi, Cho, Habash and Courville2016; Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey and Dean2016; Stahlberg Reference Stahlberg2020). The neural system uses two stacks in its internal architecture: an encoder and a decoder. These components work together to transform a sequence of words into new word sequences representing the translation output. Despite the vast amount of existing literature on NMT, the majority of studies primarily focus on Latin languages due to the availability of resources and data (Bahdanau, Cho, and Bengio Reference Bahdanau, Cho and Bengio2014; Sutskever, Vinyals, and Le Reference Sutskever, Vinyals and Le2014; Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017). Translating from Standard Arabic into Maghrebi (North African) dialects and vice versa presents a challenging but under-researched topic. The Maghrebi region covers a significant population, and addressing this research gap would greatly facilitate communication among its inhabitants. Moreover, advancing translation would play a crucial role in analysing texts written in Maghrebi dialects, particularly from social media platforms. Translating to and from Maghrebi dialects poses several challenges. Firstly, the Maghrebi dialects present significant distinctions in various linguistic aspects, including vocabulary, pronunciation, and syntactic structures (Younes et al. Reference Younes, Souissi, Achour and Ferchichi2020). For instance, the Moroccan dialect features unique lexical items (Skiredj et al. Reference Skiredj, Azhari, Berrada and Ezzini2024) that set it apart from Algerian dialects, which, in turn, differ in syntax and vocabulary from the Tunisian and Libyan dialects. These differences highlight the linguistic diversity within the region, posing significant challenges for translation between the dialects and Standard Arabic. Additionally, these dialects have evolved as distinct languages over time. They are particularly influenced by many languages, notably French, English, and Spanish. In addition, these dialects are generally spoken languages, with written documents being either rare or poorly structured. As a result, developing stable and consistent linguistic resources, such as dictionaries and corpora, becomes challenging. It is important to mention that until now, existing translation tools, such as those offered by Google, Microsoft, and DeepL, do not include these dialects. Very powerful commercial LLMs such as ChatGPT and Gemini are able to process these languages, yet achieving precise translation remains a challenge. Therefore, the contributions of this work are as follows:
-
• We propose BERT-TransDial,Footnote a a modified Transformer architecture designed to analyse the impact of integrating transfer learning from BERT-based embedding layers for multi-dialect translation.
-
• We evaluated the performance of BERT-TransDial by comparing it with the vanilla transformer using various tokenisation methods and with the pre-trained NLLB-200-distilled-350 M model. Additionally, we examine how preprocessing techniques influence the experimental results.
-
• We conducted an ablation study to analyse the effects of modifying architectural components and parameter freezing on model performance.
-
• A human evaluation was conducted to assess the qualitative results of BERT-TransDial and to compare it with Gemini and ChatGPT.
The rest of this paper is structured as follows: Section 2 provides an overview of related works. In Section 3, we state the problem. Section 4 is devoted to the proposed method, and Section 5 covers the experiments, including data, implementation details, and experimental methods. Sections 3 and 7 present the results and human evaluation study. Finally, in the last two sections, we discuss and conclude our work.
2. Related works
In this section, we present related work on NMT, organised into two subsections. The first one addresses the challenges of translating low-resource Arabic dialects, while the second explores the incorporation of language models into NMT architectures.
2.1 Low-resource language
Several studies aimed to enhance MT performance for low-resource languages, beginning with exploring preprocessing techniques on parallel corpora. Muischnek and Müürisep (Reference Muischnek and Müürisep2019) introduced a set of filtering methods designed to exclude problematic sentences during the training process. These techniques proved to be particularly effective for translating morphologically rich languages, such as Estonian and Latvian. Standard Arabic also possesses rich morphology. To address this, Almahairi et al. (Reference Almahairi, Cho, Habash and Courville2016) employed orthographic normalisation for Arabic, along with morphology-aware tokenisation (Tok + Norm + ATB). They presented a first neural approach for Arabic, resulting in a BLEU improvement of more than 4.98 over the baseline. In another study, Al-Ibrahim and Duwairi (Reference Al-Ibrahim and Duwairi2020) introduced an RNN encoder-decoder approach, conducting experiments on both word-level and sentence-level datasets. To translate from the Jordanian dialect to MSA, the results show an accuracy of 91% using the word-level experiment and 63% using the Seq2Seq dataset. In a study by Farhan et al. (Reference Farhan, Talafha, Abuammar, Jaikat, Al-Ayyoub, Tarakji and Toma2020), a comparison was conducted on two systems of D2SLT (Dialectal to Standard Language Translation) employing attentional sequence-to-sequence models (Luong et al. Reference Luong, Pham and Manning2015; Sutskever et al. Reference Sutskever, Vinyals and Le2014) and Google’s Neural Machine Translation (GNMT) (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey and Dean2016). Additionally, the authors introduced an unsupervised learning approach to translating from Jordanian to MSA. They trained each system on parallel corpora from Saudi-MSA or Egyptian-MSA and tested the models using the Jordanian-MSA parallel corpus. The highest result in the unsupervised setting is 32.14 BLEU metric and 48.25 in the supervised setting. By extending the focus to low-resource languages, Baniata et al. (Reference Baniata, Ampomah and Park2021) proposed a neural approach based on a transformer architecture (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017). They used the WordPiece tokeniser as a subword unit (Sennrich, Haddow, and Birch Reference Sennrich, Haddow and Birch2015) to decompose each word into subwords, thereby enhancing the representation of the attention matrix. This approach has been highly effective in translating Arabic dialects to MSA. Baniata et al. have also proposed a new Reverse Positional Encoding (Baniata, Kang, and Ampomah Reference Baniata, Kang and Ampomah2022) layer for the same context, aiming to capture the positions of right-to-left texts and enhance translation quality for Arabic dialects. Furthermore, Slim et al. (Reference Slim, Melouah, Faghihi and Sahib2022) conducted a comparative study between the sequence-to-sequence approaches using recurrent neural networks with and without attention mechanisms (Luong et al. Reference Luong, Pham and Manning2015). Given the limited size of the available parallel corpus, their contribution involved employing transductive transfer learning on the aforementioned architectures. This approach aimed to enhance translation quality by transferring the final model weights of the parent model to the child one. Thus, resulting in a remarkable increase in the BLEU score. In Slim and Melouah (Reference Slim and Melouah2024), they incrementally transfer knowledge from a large set of Arabic dialects – MSA (Grandparent Model) – to Maghrebi dialects – MSA (Parent Model) – and then to the specified low-resource dialects (Child Model), such as Algerian, Tunisian, and Moroccan, using the Transformer and attention-based sequence-to-sequence models. The results obtained using Transformer showed improvements over traditional transfer learning methods of 80%, 62%, and 58% for Algerian, Tunisian, and Moroccan dialects, respectively. While Kchaou et al. (Reference Kchaou, Boujelbane and Hadrich2023) focused on enhancing the translation of Tunisian Dialects-MSA by employing various data augmentation techniques, including the Back-Translation Augmentation Method (BTAM), Contextual Data Augmentation, and Semi-supervised Data Augmentation. Their approach demonstrated an improved BLEU score after augmenting the training data. The evaluation was conducted on a NMT system, specifically the transformers, which achieved the optimal BLEU score, reaching 60. Furthermore, Faheem et al. (Reference Faheem, Wassif, Bayomi and Abdou2024) investigated semi-supervised NMT for translating Egyptian dialects into MSA. They employed two distinct datasets: one parallel dataset containing sentences in both dialects and a monolingual dataset where the source is not connected to the target language during training. They conducted three translation systems: attention-based seq2seq, which learns embeddings using a shared vocabulary between the two languages; the unsupervised transformer model, which depends only on monolingual data; and the last system, which uses a parallel dataset for the supervised learning phase and then adjusts the monolingual data during the learning process. The results show that the semi-supervised learning approach outperformed both the supervised and unsupervised approaches, achieving a BLEU score of 29.5.
2.2 Transfer learning
The study by Clinchant et al. (Reference Clinchant, Jung and Nikoulina2019) investigated various approaches to integrate BERT, a large pre-trained model, into an NMT system for the English-German translation task. The study explored several approaches, which included substituting the traditional embeddings with BERT parameters, initialising the model with BERT, and subsequently freezing it before proceeding with fine-tuning. These adaptations resulted in a notable increase in the BLEU score when contrasted with the baseline performance. However, it is worth mentioning that this study did not provide a clear conclusion on which approach improves the robustness of target sentence translation.
By incorporating a pretrained language model (PLM) into a sequence-to-sequence model, the authors in Guo et al. (Reference Guo, Zhang, Xu, Chen and Chen2021) introduced a novel architecture that utilises adapter modules to fine-tune the BERT model. During this fine-tuning process, a latent variable ‘z’ was introduced to the model. This variable enables the automatic selection of the appropriate adapter, thus enhancing its capabilities. Including our previously discussed approaches, Guo and Le Nguyen (Reference Guo and Le Nguyen2020) conducted a study that leveraged BERT to capture contextual information for document-level translation in both the encoder and decoder of the Transformer NMT model. This involved considering the preceding and following sentences around the current input sentence
 $x_{t}$
to generate the target sentence
$x_{t}$
to generate the target sentence
 $y_{t}$
. This method has demonstrated its effectiveness on TED and News datasets. In addition, Kadaoui et al. (Reference Kadaoui, Magdy, Waheed, Khondaker, El-Shangiti, Nagoudi and Abdul-Mageed2023) presented a comparative study between LLMs (Bard, ChatGPT, GPT-4, NLLB, and other commercial systems) in performing MT tasks across ten diverse varieties of Arabic. The results of this study show that GPT-4 and ChatGPT generally achieve better results compared to the others in all experiments. Yang et al. (Reference Yang, Wang, Zhou, Zhao, Zhang, Yu and Li2020) proposed the framework
$y_{t}$
. This method has demonstrated its effectiveness on TED and News datasets. In addition, Kadaoui et al. (Reference Kadaoui, Magdy, Waheed, Khondaker, El-Shangiti, Nagoudi and Abdul-Mageed2023) presented a comparative study between LLMs (Bard, ChatGPT, GPT-4, NLLB, and other commercial systems) in performing MT tasks across ten diverse varieties of Arabic. The results of this study show that GPT-4 and ChatGPT generally achieve better results compared to the others in all experiments. Yang et al. (Reference Yang, Wang, Zhou, Zhao, Zhang, Yu and Li2020) proposed the framework
 $CT_{NMT}$
to address problems encountered when fine-tuning BERT and GPT2 language models to a transformer architecture for rich-resource languages. They introduced asymptotic distillation, dynamic switching, and rate-scheduled learning techniques to preserve previous pre-trained knowledge, prevent catastrophic forgetting of language model knowledge, and adjust the learning spaces according to a scheduled policy, respectively. The fusion of all these techniques gives the highest scores, with BLEU scores of 30.1 for En-De, 42.3 for En-Fr, and 38.9 for En-Zh corpora.
$CT_{NMT}$
to address problems encountered when fine-tuning BERT and GPT2 language models to a transformer architecture for rich-resource languages. They introduced asymptotic distillation, dynamic switching, and rate-scheduled learning techniques to preserve previous pre-trained knowledge, prevent catastrophic forgetting of language model knowledge, and adjust the learning spaces according to a scheduled policy, respectively. The fusion of all these techniques gives the highest scores, with BLEU scores of 30.1 for En-De, 42.3 for En-Fr, and 38.9 for En-Zh corpora.
3. Problem statement
NMT systems transform a sentence into its translated form in another language. The first deep learning models proposed to tackle this issue were introduced in 2013 and primarily relied on the RNN encoder-decoder architecture (Kalchbrenner et al. Reference Kalchbrenner and Blunsom2013; Cho et al. Reference Cho, Van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014), which converts the input sentence
 $X=\{x_{1},x_{2}, \ldots ,x_{n}\}$
into a more concise representation denoted as ‘c’, represented as a fixed-length vector. To generate the next word
$X=\{x_{1},x_{2}, \ldots ,x_{n}\}$
into a more concise representation denoted as ‘c’, represented as a fixed-length vector. To generate the next word
 $y_{i}$
using a decoder stack, the system considers the input sentence X and the previously generated words
$y_{i}$
using a decoder stack, the system considers the input sentence X and the previously generated words
 $\{y_{t-1}, y_{t-2},\ldots , y_{1}\}$
, along with the context vector ‘c’.
$\{y_{t-1}, y_{t-2},\ldots , y_{1}\}$
, along with the context vector ‘c’.
This architecture poses a potential issue when translating long sentences. As proposed by Bahdanau et al. (Reference Bahdanau, Cho and Bengio2014), an attention mechanism was introduced to address this concern. It is calculated as a function of each hidden state of the encoder and the previous hidden state of the decoder. While this architecture gives good translation results, it comes at the cost of increased computational power and time consumption due to the use of recurrent neural networks in its internal structure. In contrast, the Transformer, introduced by Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017), is an innovative architecture primarily built upon attention mechanisms, feed-forward layers, layer normalisation, and residual connections. It excels at parallel processing of sequential data, resulting in faster training times compared to other models. The NMT problem can be formulated as the following conditional distribution:
 \begin{equation} P(y_{t} | y_{1,\dots ,t-1};\;X;\;\Theta ) \end{equation}
\begin{equation} P(y_{t} | y_{1,\dots ,t-1};\;X;\;\Theta ) \end{equation}
Where X =
 $\{x_1,x_2,\dots , x_n\}$
represents the input sentence,
$\{x_1,x_2,\dots , x_n\}$
represents the input sentence,
 $\{y_1,y_2, \dots , y_{t-1}\}$
are previously generated words with
$\{y_1,y_2, \dots , y_{t-1}\}$
are previously generated words with
 $1\lt t\lt m$
, where
$1\lt t\lt m$
, where
 $m$
and
$m$
and
 $n$
indices are the lengths of
$n$
indices are the lengths of
 $Y$
and
$Y$
and
 $X$
, respectively.
$X$
, respectively.
 $\Theta$
represents the model parameters optimised during the training process by minimising the cross-entropy loss function.
$\Theta$
represents the model parameters optimised during the training process by minimising the cross-entropy loss function.
The BERT-TransDial architecture: integration of a fine-tuned BERT-based embedding layer into a Transformer model, replacing the default token embedding and positional encoding components.

4. Approach
In this section, we present the proposed method by describing how the BERT input and output representations are integrated before the original encoder and decoder stacks of the transformer architecture, as depicted in Figure 1.
4.1 BERT input and output representation
In our approach, we employed bidirectional encoder representations from transformers (BERT) (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), a pre-trained model in natural language processing. BERT leverages the encoder stacks of the Transformer architecture and is trained using two primary tasks: Next Sentence Prediction (NSP) and Masked Language Modelling (MLM). NSP helps BERT understand the relationships between sentences, while MLM trains the model to predict masked or missing words within a sentence. BERT’s training uses a massive corpus from the web, making it capable of capturing a wide range of linguistic patterns and semantic information. For our specific translation tasks, we leverage BERT’s capabilities to translate the Maghrebi dialects to/from MSA. Specifically, we enhance the encoder and decoder blocks by integrating a pre-trained embedding layer from the BERT language model. This layer, depicted in Figure 1 as the BERT input and output representation blocks, includes token embedding, segment embedding, and positional encoding. By integrating these components, we effectively substitute the original embedding and positional encoding methods of the Transformer architecture with BERT’s embedding features.
In practice, we use DarijaBERT’s (Gaanoun et al. Reference Gaanoun, Naira, Allak and Benelallam2023) embedding layer for the BERT input representation and ArabicBERT (Safaya, Abdullatif, and Yuret Reference Safaya, Abdullatif and Yuret2020) for the BERT output representation when translating from Maghrebi dialects to MSA. Conversely, when translating from MSA to Maghrebi dialects, we reverse this configuration, employing ArabicBERT for the input representation and DarijaBERT for the output representation.
DarijaBERT was primarily trained on Moroccan dialect text, with additional data from Algerian, Tunisian, and Libyan dialects (which were considered noise due to the difficulty of isolating dialects during the data collection process). It utilised a total of three million sentences for training, including data from tweets, YouTube comments, and story datasets, resulting in a model size of 691 MB. It employed the WordPiece technique on the dataset, generating an 80,000-token vocabulary, and was trained with 147 million parameters.
ArabicBERT was trained on an unshuffled version of the OSCAR Arabic classic dataset and incorporates Arabic data from Wikipedia, amounting to a total of 8.2 billion words. The model employs WordPiece tokenisation, resulting in a vocabulary size of 32,000 tokens.
5. Experiments
In this section, we describe the experimental setup, including the dataset, implementation details, and the methods used to compare the BERT-TransDial architecture against existing approaches.
5.1 Data
In this paper, we use the same dataset investigated by Baniata et al. (Reference Baniata, Ampomah and Park2021). This dataset, known as PMM-MAG, comprises PADIC (Meftouh et al. Reference Meftouh, Harrat, Jamoussi, Abbas and Smaili2015), MPCA (Bouamor et al. Reference Bouamor, Habash and Oflazer2014), and the MADAR corpus (Bouamor et al. Reference Bouamor, Habash, Salameh, Zaghouani, Rambow, Abdulrahim and Oflazer2018), including Moroccan, Algerian, Tunisian, and Libyan dialects. The corpora include some unprocessed data. To assess its impact on NMT, we applied a set of preprocessing techniques as referred to in (Muischnek et al. Reference Muischnek and Müürisep2019; Baniata et al. Reference Baniata, Ampomah and Park2021). These techniques involve removing diacritics, duplicate values with different translations in the source and target, non-Arabic words, special characters, numbers, multiple whitespaces, elongations, and normalising Arabic text (by removing repeated letters and normalising ![]() into
into ![]() sentence pairs).
sentence pairs).
5.2 Implementation details
The dataset used throughout our experiments, incorporating the specified corpora, comprises a total of 57,736 sentence pairs for MSA and Maghrebi dialects. The dataset was randomly divided into three parts: 20% for testing and 80% for training, with 20% of the training data reserved for validation. In all experiments, we used a fixed batch size of 128 and employed 8 parallel attention layers or heads with a
 $d_{model}$
dimension of 768. Both the encoder and decoder blocks consisted of 6 layers. The position-wise feed-forward network had a dimension of 1024, and we maintained a consistent maximum sequence length of 30 for all datasets (training, test, validation). Additionally, the Adam optimisation algorithm (Kingma and Ba Reference Kingma and Ba2014) is employed with an initial learning rate of
$d_{model}$
dimension of 768. Both the encoder and decoder blocks consisted of 6 layers. The position-wise feed-forward network had a dimension of 1024, and we maintained a consistent maximum sequence length of 30 for all datasets (training, test, validation). Additionally, the Adam optimisation algorithm (Kingma and Ba Reference Kingma and Ba2014) is employed with an initial learning rate of
 $10^{-6}$
, and the training process was conducted over 150 epochs using a machine accelerated by four NVIDIA A100-SXM4-80 GB GPUs (Kissami et al. Reference Kissami, Basmadjian, Chakir and Abid2025).
$10^{-6}$
, and the training process was conducted over 150 epochs using a machine accelerated by four NVIDIA A100-SXM4-80 GB GPUs (Kissami et al. Reference Kissami, Basmadjian, Chakir and Abid2025).
5.3 Experimental methods
Five experiments, including ours, were conducted to assess BERT-TransDial’s effectiveness in bidirectional translation between MSA and Maghrebi dialects. These experiments aim to address the research question: How does our modified transformer architecture with BERT affect model performance compared to existing methods?
Experiment 1: We employed the BPE algorithm (Shibata et al. Reference Shibata, Kida, Fukamachi, Takeda, Shinohara, Shinohara and Arikawa1999), a method designed to assign new characters to frequently repeated substrings. This tokenisation process was applied separately for the input and output languages of our dataset using the ‘tokenizers’ Python library.Footnote b This resulted in vocabulary sizes of 27,695 for the Maghrebi dialects and 26,404 for MSA. With the data tokenised using BPE, we then proceeded to train the transformer model.
Experiment 2: As a second experiment, we used the WordPiece tokeniser (Schuster et al. Reference Schuster and Nakajima2012; Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey and Dean2016) for both input and output data within the transformer system. This data-driven approach effectively manages rare words. Its efficiency lies in its capability to handle unknown words seamlessly, as it accurately segments entire words into meaningful units. We used BERT tokenisers to perform this task, which already employs the WordPiece segmentation technique, using specific models for each language: ArabicBERT for MSA and DarijaBERT for Maghrebi dialects.
Experiment 3: We trained the transformer architecture (referred to as the Baseline Transformer), this time employing the ‘batch_encode_plus’ method, an indexing technique from the pre-trained BERT model. With this method, we converted each sentence in our parallel dataset into a vector of indices, which were then fed into the embedding layer of both the encoder and decoder stacks of the original transformer architecture. Specifically, we used separate models, ArabicBERT and DarijaBERT, to handle MSA and Maghrebi dialects, respectively.
Experiment 4: We benchmarked our approach with the pre-trained open-source transformer model NLLB-200 (No Language Left Behind [Costa-jussà et al. Reference Costa-jussà, Cross, Çelebi, Elbayad, Heafield and Heffernan2022]) for translating Maghrebi dialects to and from MSA. To ensure a fair comparison with our experiments, we fine-tuned the ‘facebook/nllb-200-distilled-600M’ model with a reduced architecture, using only 3 encoder and decoder layers instead of the original 12. This modification reduced the model size to approximately 350 M parameters. We fine-tuned this adjusted model with specific hyperparameters of 100 epochs and a batch size of 16. Since the entire pretrained model was used without excluding any layers of its components, it required more memory and computational time compared to other experiments. These hyperparameters were chosen to optimise resource usage while leveraging its multilingual capabilities for our MT task.
Experiment 5: In BERT-TransDial, we modified the Transformer architecture to incorporate transfer learning from the pre-trained language model BERT. This adaptation includes substituting the token embedding and positional encoding layers with the embedding layer of BERT, as this pre-trained layer already includes them. We implemented this adaptive method using separate BERT models for the source and target languages, specifically DarijaBERT for Maghrebi dialects and ArabicBERT for MSA.
Throughout all these experiments, we assessed both preprocessed and raw data to evaluate their respective impacts on the NMT system.
6. Results
In this section, we analyse the results of our study in three parts. First, we present the quantitative results in the Experimental Results subsection, including the BLEU score (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), the BERTScore Precision, denoted as
 $\text{P}_{\text{BERT}}$
Footnote
c
(Zhang et al. Reference Zhang, Kishore, Wu, Weinberger and Artzi2019), ChrF (Popocić Reference Popović2015), and METEOR (Banerjee et al. Reference Banerjee and Lavie2005) to ensure a comprehensive evaluation of BERT-TransDial’s performance (Kocmi et al. Reference Kocmi, Federmann, Grundkiewicz, Junczys-Dowmunt, Matsushita and Menezes2021). Following this, the Ablation Study investigates specific changes within BERT-TransDial. Finally, the qualitative results explore the translation output using BERT-TransDial on the test set, offering qualitative insights into its effectiveness beyond quantitative metrics.
$\text{P}_{\text{BERT}}$
Footnote
c
(Zhang et al. Reference Zhang, Kishore, Wu, Weinberger and Artzi2019), ChrF (Popocić Reference Popović2015), and METEOR (Banerjee et al. Reference Banerjee and Lavie2005) to ensure a comprehensive evaluation of BERT-TransDial’s performance (Kocmi et al. Reference Kocmi, Federmann, Grundkiewicz, Junczys-Dowmunt, Matsushita and Menezes2021). Following this, the Ablation Study investigates specific changes within BERT-TransDial. Finally, the qualitative results explore the translation output using BERT-TransDial on the test set, offering qualitative insights into its effectiveness beyond quantitative metrics.
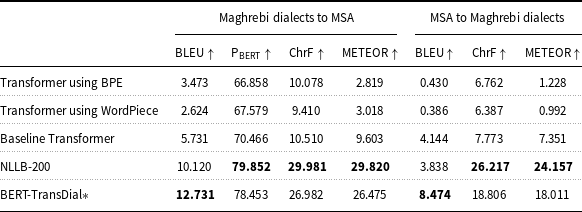
Quantitative results on the test set with preprocessed data using BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics for both translation directions
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics for both translation directions

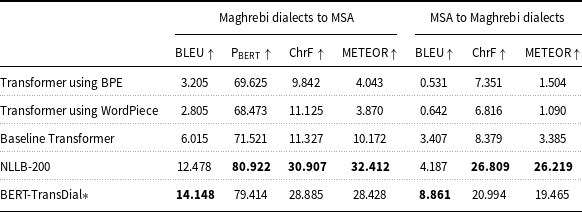
Quantitative results on the test set with raw data using BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics for both translation directions
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics for both translation directions

6.1 Experimental results
The translation results of our experiments on the Maghrebi dialects and MSA in both directions are presented in Tables 1 and 2.
-
– Table 1 summarises the results of translation obtained using the beam search decoding strategy with a beam width of 5 for both directions: Maghrebi dialects to MSA and MSA to Maghrebi dialects, using preprocessed data. The results indicate that the third experiment, ‘Baseline Transformer’, outperformed the first and second experiments (using BPE and WordPiece tokenisers) for Maghrebi dialects to MSA translation, achieving higher BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Furthermore, in the fifth experiment, ‘BERT-TransDial’, the model demonstrated superior performance across all metrics compared to the ‘Baseline Transformer’. For the reverse direction (MSA to Maghrebi dialects), similar results were observed: the ‘BERT-TransDial’ model achieved the best results overall, surpassing the ‘Baseline Transformer’, which in turn outperformed the ‘BPE and WordPiece’ models. The fourth experiment, involving fine-tuning the ‘NLLB-200’ model, demonstrated enhanced translation quality in both directions based on
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. However, the ‘BERT-TransDial’ model achieved the highest BLEU score in both translation directions, further highlighting its overall effectiveness.
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Furthermore, in the fifth experiment, ‘BERT-TransDial’, the model demonstrated superior performance across all metrics compared to the ‘Baseline Transformer’. For the reverse direction (MSA to Maghrebi dialects), similar results were observed: the ‘BERT-TransDial’ model achieved the best results overall, surpassing the ‘Baseline Transformer’, which in turn outperformed the ‘BPE and WordPiece’ models. The fourth experiment, involving fine-tuning the ‘NLLB-200’ model, demonstrated enhanced translation quality in both directions based on
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. However, the ‘BERT-TransDial’ model achieved the highest BLEU score in both translation directions, further highlighting its overall effectiveness. -
– Table 2 presents the results obtained using raw parallel data. Experiment 5, ‘BERT-TransDial’, emerged as the most effective approach, surpassing the baseline transformer for Maghrebi dialects to MSA and MSA to Maghrebi dialects, respectively. In contrast, Experiments 1 and 2, which used ‘BPE’ and ‘wordPiece’, displayed the poorest results, with lower BLEU, ChrF, and METEOR scores, indicating inferior translation quality compared to the other experiments. As reflected by the higher BLEU score, BERT-TransDial surpasses the fine-tuned ‘NLLB-200’ model in translating to and from MSA. However, when considering other metrics (
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR), the NLLB-200 model performs better in translation quality.



Curves (a) and (b) in Figure 2 represent the training and validation losses for the translation tasks from MSA to Maghrebi dialects and from Maghrebi dialects to MSA on raw data, respectively. Both curves display decreasing values over 150 epochs. The small difference between the training and validation losses indicates that the model has effectively learned meaningful patterns from the data, enabling strong generalisation to unseen examples for both tasks. During the inference phase, the model with the lowest validation loss is employed to generate translations. The quantitative results of these translations are presented in Tables 1 and 2.
Training and validation losses for MSA to Maghrebi dialects (a) and Maghrebi dialects to MSA (b) on raw data.

6.2 Ablation study
In this section, we investigate the impact of BERT’s embedding position and parameter freezing on BERT-TransDial’s performance. First, we analyse the integration of BERT’s embedding in the encoder or the decoder. Next, we compare the performance of BERT-TransDial with and without parameter freezing in translating Maghrebi dialects to/from MSA.
6.2.1 BERT’s embedding position
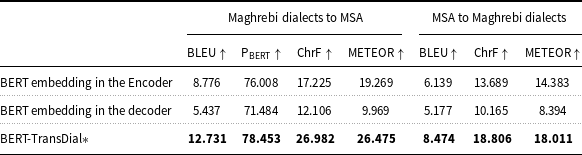
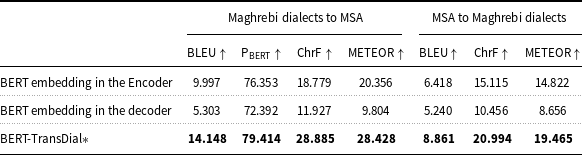
In this section, we present the results of an ablation study to assess the effectiveness of the BERT-TransDial architecture. This exploration involves preserving the original token embedding and positional encoding from the vanilla Transformer in the encoder while replacing them in the decoder with the embedding layer derived from the pre-trained BERT model (referred to as ‘BERT’s embedding in the decoder’). Additionally, we conducted a second experiment by replacing the Transformer’s embedding layer with the BERT embedding layer, but this time in the encoder (referred to as ‘BERT’s embedding in the encoder’). These experiments aim to discern the optimal integration point for BERT’s embedding within our architecture.
The incorporation of BERT’s embedding in the encoder stack in both Tables 3 and 4 resulted in improved performance compared to when employing it in the decoder. As shown in Table 3 (for preprocessed data), the results demonstrate consistently significant improvement in BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Moreover, BERT-TransDial achieves superior performance in translating Maghrebi dialects to and from MSA. Table 4 confirms these findings, showcasing the superiority of ‘BERT’s embedding in the encoder’ over the decoder across all the evaluation metrics. These results underscore the efficacy of integrating BERT embeddings during the encoding phase and provide insight into the performance of the BERT-TransDial across both raw and preprocessed data cases.
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Moreover, BERT-TransDial achieves superior performance in translating Maghrebi dialects to and from MSA. Table 4 confirms these findings, showcasing the superiority of ‘BERT’s embedding in the encoder’ over the decoder across all the evaluation metrics. These results underscore the efficacy of integrating BERT embeddings during the encoding phase and provide insight into the performance of the BERT-TransDial across both raw and preprocessed data cases.
Results of the ablation study (BERT’s Embedding Position) on the test set for preprocessed data

Results of the ablation study (BERT’s Embedding Position) on the test set for raw data

Results of the ablation study (with and without parameter freezing) on the test set for raw data

6.2.2 With and without parameter freezing
Table 5 compares the performance of BERT-TransDial with and without parameter freezing for translating Maghrebi dialects and MSA, using BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR as evaluation metrics. For the translation of Maghrebi dialects to/from MSA, the approach without parameter freezing significantly outperforms the one with freezing, achieving better BLEU,
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR as evaluation metrics. For the translation of Maghrebi dialects to/from MSA, the approach without parameter freezing significantly outperforms the one with freezing, achieving better BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Similarly, for translating from MSA to Maghrebi dialects, the approach without parameter freezing shows superior performance across all metrics. These results indicate that the proposed approach without parameter freezing provides significantly better translation quality and accuracy, evidenced by higher evaluation scores, suggesting that parameter freezing may hinder the model’s performance in this context.
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores. Similarly, for translating from MSA to Maghrebi dialects, the approach without parameter freezing shows superior performance across all metrics. These results indicate that the proposed approach without parameter freezing provides significantly better translation quality and accuracy, evidenced by higher evaluation scores, suggesting that parameter freezing may hinder the model’s performance in this context.
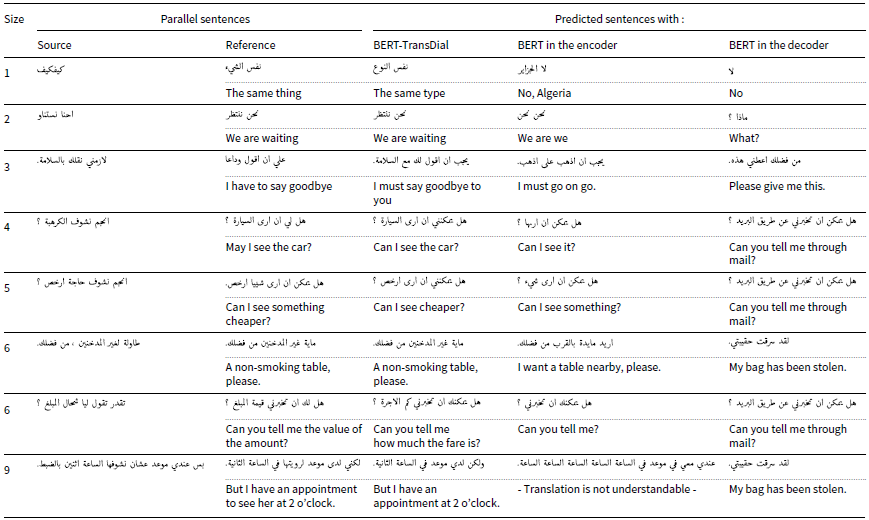
6.3 Qualitative results
Table 6 presents the qualitative results of the ‘BERT-TransDial’, ‘BERT in the Encoder’, and ‘BERT in the Decoder’ in translating from Maghrebi dialects into MSA. The ‘BERT-TransDial’ effectively preserves the intended meaning of sentences across varying lengths, showing particular strength in translating shorter sentences. For instance, in the first example, the source sentence ‘ is translated to
is translated to  ‘the same type’ in English. This aligns contextually with
‘the same type’ in English. This aligns contextually with  and is considered correct, whereas the other systems produced incorrect translations. Similarly, for the source sentence
and is considered correct, whereas the other systems produced incorrect translations. Similarly, for the source sentence  , BERT-TransDial translates it to
, BERT-TransDial translates it to  , ‘Can I see cheaper?’ in English. While this translation omits the word ‘something’, it remains contextually valid according to the reference ‘Can I see something cheaper?’ On the other hand, ‘BERT in the Encoder’ generates
, ‘Can I see cheaper?’ in English. While this translation omits the word ‘something’, it remains contextually valid according to the reference ‘Can I see something cheaper?’ On the other hand, ‘BERT in the Encoder’ generates  missing out the word
missing out the word  (‘cheaper’), which captures the core message. Meanwhile, BERT in the decoder produces a completely incorrect translation. Out of the eight sentences presented in Table 6, BERT-TransDial successfully translates the majority, demonstrating its ability to provide reasonable and contextually meaningful translations of Maghrebi dialects into MSA.
(‘cheaper’), which captures the core message. Meanwhile, BERT in the decoder produces a completely incorrect translation. Out of the eight sentences presented in Table 6, BERT-TransDial successfully translates the majority, demonstrating its ability to provide reasonable and contextually meaningful translations of Maghrebi dialects into MSA.
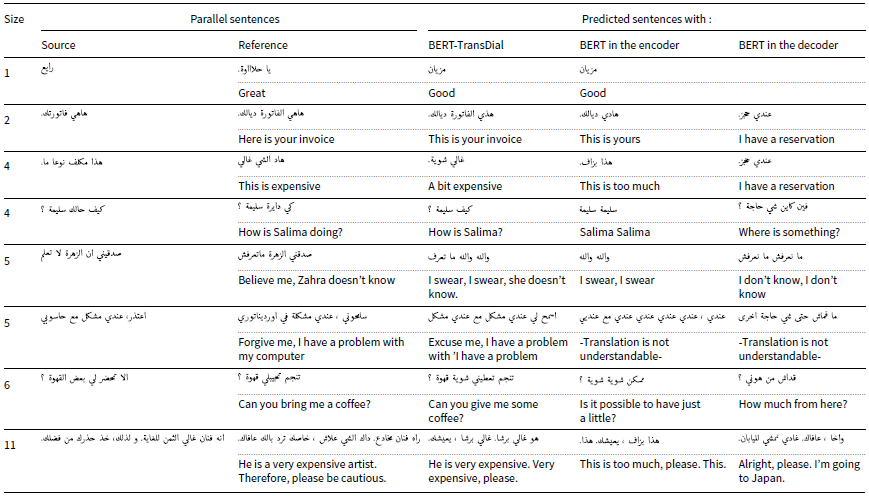
In the reverse direction, the BERT-TransDial system demonstrates acceptable translation quality, outperforming the ‘BERT in the Encoder’ and ‘BERT in the Decoder’ models. As shown in Table 7, BERT-TransDial generates translations that are reasonably correct, though some mistranslations occur. For instance, in row 4, the source sentence  is translated as
is translated as ![]() ‘How is Salima?’ While it omits the word ‘doing’, the translation remains contextually accurate. Similarly, in row 5, the input sentence
‘How is Salima?’ While it omits the word ‘doing’, the translation remains contextually accurate. Similarly, in row 5, the input sentence  is translated as
is translated as  missing the noun ‘Zahra’, which reduces the clarity of the output. Nevertheless, it still maintains meaningful aspects of the original sentence, whereas the outputs from the other systems are entirely incorrect. In conclusion, our approach provides reasonably accurate translations for both tasks, with significant improvements when translating into MSA (Table 6), effectively maintaining meaning and detail. This contrasts with the reverse translation task, where the output captures the broader idea but lacks specificity. Among the other systems, ‘BERT in the Encoder’ produces relatively better results compared to ‘BERT in the Decoder’ in both Tables 6 and 7.
missing the noun ‘Zahra’, which reduces the clarity of the output. Nevertheless, it still maintains meaningful aspects of the original sentence, whereas the outputs from the other systems are entirely incorrect. In conclusion, our approach provides reasonably accurate translations for both tasks, with significant improvements when translating into MSA (Table 6), effectively maintaining meaning and detail. This contrasts with the reverse translation task, where the output captures the broader idea but lacks specificity. Among the other systems, ‘BERT in the Encoder’ produces relatively better results compared to ‘BERT in the Decoder’ in both Tables 6 and 7.
Qualitative translation outputs from Maghrebi dialects to MSA generated by the proposed BERT-TransDial model, BERT in the encoder, and BERT in the decoder. The table includes source inputs, reference translations, and corresponding outputs for model comparison

Qualitative translation outputs from MSA to Maghrebi dialects generated by the proposed BERT-TransDial model, BERT in the encoder, and BERT in the decoder. The table includes source inputs, reference translations, and corresponding outputs for model comparison

To analyse systematic errors causing the low BLEU scores, a representative subset of the data was selected. We detected several systematic errors, namely semantic drift, which occurs when the model produces fluent but meaning-changed translations (e.g., 
 $\rightarrow$
$\rightarrow$
 ). Dialectal lexical errors, which misinterpret totally Maghrebi vocabulary
). Dialectal lexical errors, which misinterpret totally Maghrebi vocabulary 
 $\rightarrow$
$\rightarrow$
 . Structural divergence with partial adequacy, which captures cases where intent is preserved but syntactic realisation is non-standard
. Structural divergence with partial adequacy, which captures cases where intent is preserved but syntactic realisation is non-standard 
 $\rightarrow$
$\rightarrow$
 . Finally, idiomaticity, a major challenge in dialects, occurs when idiomatic expressions are rendered in grammatically correct but pragmatically wrong forms; for instance, the source sentence
. Finally, idiomaticity, a major challenge in dialects, occurs when idiomatic expressions are rendered in grammatically correct but pragmatically wrong forms; for instance, the source sentence  , which means ‘Mind your business’, was literally translated to
, which means ‘Mind your business’, was literally translated to  , which means ‘Enter in the market of your head’.
, which means ‘Enter in the market of your head’.
7. Human evaluation
In this section, (
 $i$
) we present human evaluation (Schuff et al. Reference Schuff, Vanderlyn, Adel and Vu2023) metrics employed to assess the quality of translations generated by the BERT-TransDial architecture, and (
$i$
) we present human evaluation (Schuff et al. Reference Schuff, Vanderlyn, Adel and Vu2023) metrics employed to assess the quality of translations generated by the BERT-TransDial architecture, and (
 $ii$
) compare the translations produced by BERT-TransDial with those of the LLMs Gemini and ChatGPT.
$ii$
) compare the translations produced by BERT-TransDial with those of the LLMs Gemini and ChatGPT.
7.1 Pilot rating experiment
In this experiment, we employed a human evaluation metric through a pilot rating experiment. Seven native speakers of Maghrebi dialects and Standard Arabic were selected for this purpose. The objective was to confirm how well the quantitative results align with human-generated translations. During the testing phase, we randomly chose 20 sentences for each case from the generated translations. Specifically, we selected 20 sentences for predicted Maghrebi dialects and 20 for predicted MSA translations using raw data. The same process was repeated for BERT-TransDial with preprocessed data. In total, 80 sentences were evaluated, and ratings were assigned on a Likert scale ranging from 1 to 7 (7 = ‘Flawless Translation’, 6 = ‘Very Good’, 5 = ‘Good’, 4 = ‘Acceptable’, 3 = ‘Poor’, 2 = ‘Very Poor’, 1 = ‘Incomprehensible’), as described by Marta et al. (Reference Costa-jussà, Zampieri and Pal2018).
Average results of pilot rating experiment for BERT-TransDial

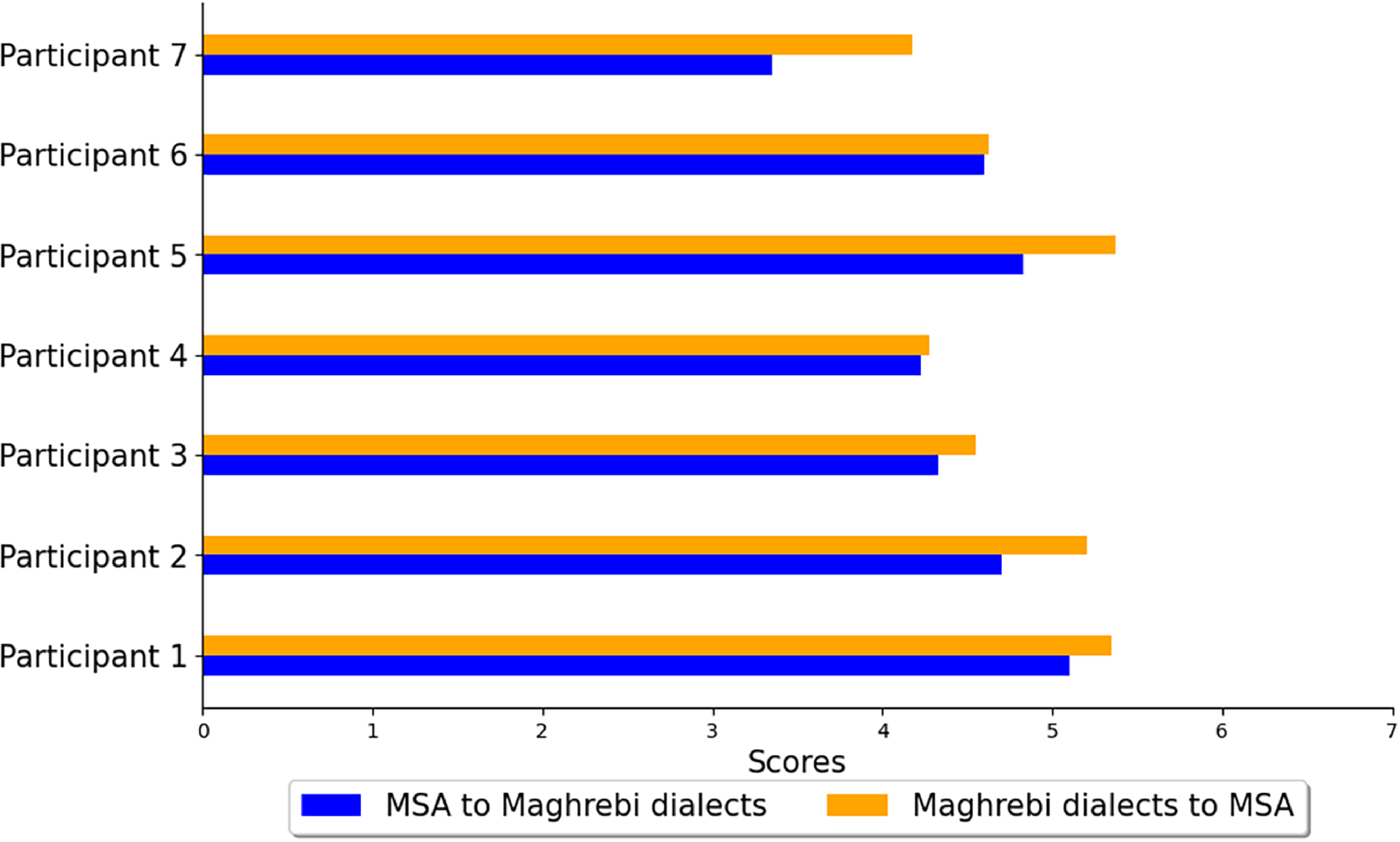
Table 8 presents the average results from the pilot rating experiment using BERT-TransDial. For the Maghrebi dialects to MSA direction, the average score with raw data is 4.82, slightly decreasing to 4.75 with preprocessed data, both considered in the moderate to good range on a 7-point scale. In the reverse direction (MSA to Maghrebi dialects), the scores are 4.26 for raw data and 4.62 for preprocessed data. Notably, 33.21% of sentences translated into Maghrebi dialects and 42.85% translated into MSA received ratings of 6 or higher, indicating that a significant portion of the translations were rated positively. Overall, these results suggest a favourable perception of the model’s performance, particularly in translating Maghrebi dialects to MSA. Figure 3 provides a visual representation of the ratings from each participant, offering insights into the consistency of the evaluations.
7.2 Ranking experiment
In the second human evaluation experiment, we compared the results of BERT-TransDial with those of LLMs. The seven participants were tasked with ranking the translation outputs generated by BERT-TransDial, ChatGPT (GPT-4o), and Gemini (1.5 Flash). Using zero-shot prompting, we employed the template prompt suggested by Kadaoui et al. (Reference Kadaoui, Magdy, Waheed, Khondaker, El-Shangiti, Nagoudi and Abdul-Mageed2023), where several LLMs were compared and found to provide better performance than other candidate prompts for MT tasks.Footnote d Subsequently, participants were instructed to vote for the correct translations without being informed about which system produced each translation. In this task, we used a total of eighty sentences: 40 segments were designated for translating into MSA, and 40 for translating into Maghrebi dialects.
Visualisation displaying the pilot rating experiment, where each bar plot displays a rating ranging from 1 to 7 for each participant, assessing the translation quality produced by BERT-TransDial for Maghrebi dialects and MSA translation generations.

Table 9 summarises the percentage results of the ranking experiment, with inter-annotation agreements between participants of 0.809 and 0.788 for translating into MSA and Maghrebi dialects, respectively, as measured by Average Pairwise Kendall’s Tau. The analysis indicates that ChatGPT consistently produces high-quality translations in both cases compared to Gemini and BERT-TransDial. Gemini ranked second, while BERT-TransDial was least preferred. Despite this, it is important to note that BERT-TransDial is not directly comparable to ChatGPT and Gemini in terms of trainable parameters and model size. Nevertheless, BERT-TransDial still gained a notable portion of the preferences, demonstrating its potential as an efficient alternative for translation tasks.
8. Discussion
BERT-TransDial outperforms other experiments in terms of translation quality. This improvement is attributed to the use of a pre-trained embedding layer, which represents input and output sentences using a specific BERT-based language model. In contrast, other experiments give lower BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores due to their dependence on indexing methods ‘Wordpiece and BPE’ for segmented Maghrebi dialects and MSA words. These methods require large-scale datasets to achieve high precision in output. Additionally, such models are trained with randomly initialised embedding layers, which limits their performance. Similar limitations are observed in the baseline model, which employs indexing methods from the tokenisers of ArabicBERT and DarijaBERT. The NLLB-200 shows comparable results to those of BERT-TransDial. Although NLLB-200 is a pre-trained model with approximately 350 M trainable parameters, the approach outperforms it in BLEU scores for both translation tasks. This indicates that BERT-TransDial generates translations with higher n-gram precision compared to NLLB-200, predicting each word in a lexically and syntactically coherent manner than NLLB-200, closely aligned with expected patterns in the unseen test data than NLLB-200. While this latter achieves slightly better results in other metrics (
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR scores due to their dependence on indexing methods ‘Wordpiece and BPE’ for segmented Maghrebi dialects and MSA words. These methods require large-scale datasets to achieve high precision in output. Additionally, such models are trained with randomly initialised embedding layers, which limits their performance. Similar limitations are observed in the baseline model, which employs indexing methods from the tokenisers of ArabicBERT and DarijaBERT. The NLLB-200 shows comparable results to those of BERT-TransDial. Although NLLB-200 is a pre-trained model with approximately 350 M trainable parameters, the approach outperforms it in BLEU scores for both translation tasks. This indicates that BERT-TransDial generates translations with higher n-gram precision compared to NLLB-200, predicting each word in a lexically and syntactically coherent manner than NLLB-200, closely aligned with expected patterns in the unseen test data than NLLB-200. While this latter achieves slightly better results in other metrics (
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR), these differences reflect its focus on semantic accuracy. Nevertheless, BERT-TransDial remains comparable to NLLB-200 across all metrics, demonstrating its effectiveness. Note that we used a reduced version of NLLB-200-distilled-600 M to match BERT-TransDial’s size, which may not fully reflect its original performance.
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR), these differences reflect its focus on semantic accuracy. Nevertheless, BERT-TransDial remains comparable to NLLB-200 across all metrics, demonstrating its effectiveness. Note that we used a reduced version of NLLB-200-distilled-600 M to match BERT-TransDial’s size, which may not fully reflect its original performance.
Human evaluation scores – Raking experiment

BERT-TransDial achieved results of 12.731 in BLEU, 78.453 in
 $\text{P}_{\text{BERT}}$
, 26.982 in ChrF, and 26.475 in METEOR for preprocessed data, and 14.148 in BLEU, 79.414 in
$\text{P}_{\text{BERT}}$
, 26.982 in ChrF, and 26.475 in METEOR for preprocessed data, and 14.148 in BLEU, 79.414 in
 $\text{P}_{\text{BERT}}$
, 28.885 in ChrF, and 28.428 in METEOR for raw data when translating MSA to Maghrebi dialects and Maghrebi dialects to MSA, respectively. Generating MSA is inherently more accurate than Maghrebi dialects, as the latter includes a wider variety of dialects, also affected by the lack of standardised rules and the rich morphology of Arabic dialects. Notably, both preprocessed and raw data produce approximately similar results with our approach, though performance is slightly better with raw data. We attribute this to the design of BERT models, which were pre-trained on diverse web and book raw corpora that contain a mix of structured and unstructured text. Preprocessing steps such as removing diacritics or punctuation can eliminate important linguistic features, making the text harder to interpret. This may lead to word ambiguities, reduced clarity in sentence structure, and affect the capacity of the model to capture overall context. In contrast, raw data preserves crucial features and contextual patterns, allowing it to better exploit the richness present in the input. Furthermore, in the ablation study, we observe that integrating the BERT’s embedding layer into the encoder achieves superior results compared to its use in the decoder. This is due to the fact that incorporating the BERT embedding weights into the encoder results in a better representation of the input sentence, which allows the decoder to clearly align the input sentence with the target language, making it easier to generate a relevant and accurate translation in the target language. Moreover, BERT-TransDial, which involves integrating BERT’s embeddings into both the encoder and the decoder within the vanilla transformer, outperforms using BERT embedding in only the encoder or the decoder, achieving higher BLEU, ChrF, and METEOR scores. Next, BERT-TransDial performs significantly better without parameter freezing across all metrics (BLEU,
$\text{P}_{\text{BERT}}$
, 28.885 in ChrF, and 28.428 in METEOR for raw data when translating MSA to Maghrebi dialects and Maghrebi dialects to MSA, respectively. Generating MSA is inherently more accurate than Maghrebi dialects, as the latter includes a wider variety of dialects, also affected by the lack of standardised rules and the rich morphology of Arabic dialects. Notably, both preprocessed and raw data produce approximately similar results with our approach, though performance is slightly better with raw data. We attribute this to the design of BERT models, which were pre-trained on diverse web and book raw corpora that contain a mix of structured and unstructured text. Preprocessing steps such as removing diacritics or punctuation can eliminate important linguistic features, making the text harder to interpret. This may lead to word ambiguities, reduced clarity in sentence structure, and affect the capacity of the model to capture overall context. In contrast, raw data preserves crucial features and contextual patterns, allowing it to better exploit the richness present in the input. Furthermore, in the ablation study, we observe that integrating the BERT’s embedding layer into the encoder achieves superior results compared to its use in the decoder. This is due to the fact that incorporating the BERT embedding weights into the encoder results in a better representation of the input sentence, which allows the decoder to clearly align the input sentence with the target language, making it easier to generate a relevant and accurate translation in the target language. Moreover, BERT-TransDial, which involves integrating BERT’s embeddings into both the encoder and the decoder within the vanilla transformer, outperforms using BERT embedding in only the encoder or the decoder, achieving higher BLEU, ChrF, and METEOR scores. Next, BERT-TransDial performs significantly better without parameter freezing across all metrics (BLEU,
 $\text{P}_{\text{BERT}}$
, METEOR, ChrF) for both translation directions (Table 6). This suggests that allowing the model’s parameters to update weights during training improves its ability to learn and adapt to an adequate representation for both language pairs, leading to more accurate and correct translations. Freezing parameters limits the model’s capacity to fully capture the BERT’s embedding knowledge, whereas not freezing them allows for more effective fine-tuning and optimisation.
$\text{P}_{\text{BERT}}$
, METEOR, ChrF) for both translation directions (Table 6). This suggests that allowing the model’s parameters to update weights during training improves its ability to learn and adapt to an adequate representation for both language pairs, leading to more accurate and correct translations. Freezing parameters limits the model’s capacity to fully capture the BERT’s embedding knowledge, whereas not freezing them allows for more effective fine-tuning and optimisation.
Additionally, the qualitative results presented in Tables 6 and 7 demonstrate the effectiveness of BERT-TransDial. The model successfully translated the majority of sentences in both directions. Nonetheless, we observed that certain translation errors could be attributed to linguistic features such as irregular morphology, semantic drift, dialect-specific vocabulary, lexical errors, and the absence of standardised written form – factors that complicate consistent translation across dialects. These challenges, previously discussed in Sections 1 and 6.3, reflect the linguistic variability found in Maghrebi dialects and help explain some of the difficulties the model encountered. Notably, human evaluation during pilot rating experiments provided positive feedback, with scores ranging from 4 to nearly 5, highlighting the consistency of the proposed method. However, our approach achieved the lowest percentages compared to Gemini and ChatGPT, primarily due to its limited performance on lengthy sentences. As reflected in Figure 4, the BLEU score peaks at sentence lengths of 5 to 10 tokens but declines significantly for longer in both directions. The ChrF score in Plot (a) shows a more gradual decline, remaining relatively stable for longer sentences, while in Plot (b), ChrF experiences a significant drop with increased sentence length. Similarly, METEOR fluctuates for shorter sentences but follows a consistent decrease as sentence length increases, reflecting the model’s sensitivity to translating complex and lengthy sentences. The Transformer architecture is generally effective at handling long sequences, thanks to its use of multi-head attention. However, in our case, the limitation likely stems from the training data: first, it does not include explicit dialect labels, which restricts the possibility of conducting a detailed cross-dialect performance analysis; second, it contains relatively few long sentences. Specifically, we verified that the average sentence length is 7.66 words for MSA and 5.99 words for Maghrebi dialects, indicating that longer sequences are relatively infrequent. In this context, analysing the impact of data augmentation techniques (Li et al. Reference Li, Liu, Huang, Zhu and Zhao2019; Lamar et al. Reference Lamar and Kaya2023; Diab et al. Reference Diab, Sadat and Semmar2024) and leveraging them to enrich the training set, particularly with longer and more diverse sentence structures, could help mitigate these limitations.
Quantitative metrics based on sentence length were analysed for (a) translation from Maghrebi dialects to MSA and (b) translation from MSA to Maghrebi dialects, using raw data.

9. Conclusion
In summary, in this work, we tackled the problem of translating low-resource languages, a challenging research topic in NMT. These languages deviate from standard grammatical rules, leading to a lack of accurate preprocessing methods that directly impact their vector representation. In this paper, we introduced an NMT approach for translation between standard Arabic and North African dialects. We employed a neural architecture that integrates transfer learning in a hybrid manner. It incorporates pre-trained embedding blocks from ArabicBERT and DarijaBERT within the encoder and the decoder of a vanilla transformer architecture. This study provides an empirical analysis of the performance of this hybrid design, aiming to better understand its contribution to translation quality. The approach was evaluated using BLEU,
 $\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics, as well as human evaluation through rating and ranking experiments. Our future work will focus on incorporating more Arabic dialects where per-dialect performances are analysed to gain a deeper understanding of these dialects, as well as improving the model’s ability to handle lengthy and complex inputs to improve its overall performance and applicability. This includes extending the dataset with longer examples and applying data augmentation techniques to increase the diversity and complexity of input sentences, while also exploring the integration of smaller LLMs as a future direction, where model size and computational cost remain important constraints.
$\text{P}_{\text{BERT}}$
, ChrF, and METEOR metrics, as well as human evaluation through rating and ranking experiments. Our future work will focus on incorporating more Arabic dialects where per-dialect performances are analysed to gain a deeper understanding of these dialects, as well as improving the model’s ability to handle lengthy and complex inputs to improve its overall performance and applicability. This includes extending the dataset with longer examples and applying data augmentation techniques to increase the diversity and complexity of input sentences, while also exploring the integration of smaller LLMs as a future direction, where model size and computational cost remain important constraints.
Acknowledgments
Experiments presented in this paper were carried out using the supercomputer Toubkal, supported by Mohammed VI Polytechnic University (https://www.um6p.ma), and the African Supercomputing Center (ASCC).
Competing interests
The author(s) declare none.











 Open access
Open access