


Introduction
Human sentence processing involves the weighted integration of different linguistic cues (e.g., word order, noun phrase animacy, and semantic plausibility) to arrive at a coherent interpretation of meaning. The Competition Model (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987; Li & MacWhinney, Reference Li, MacWhinney and Chapelle2012; MacWhinney, Reference MacWhinney and MacWhinney1987) provides a framework for understanding and predicting how cues will influence language processing and comprehension. Crucially, languages rely on different cues to mark sentence information, such as semantic roles. Moreover, cues differ in their strength and reliability, in that some cues are more reliable than others for determining the meaning of sentences. Competition between cues occurs when cues point to diverging interpretations, such as when English passive sentences subvert canonical SVO word order.
According to the Competition Model, learning an additional language is partially a process of learning how to attend to different processing cues in the target language. Learners will initially map their first language (L1) cues to second language (L2) input, which can result in processing errors when two languages use different cues to mark the same information (e.g., determining the agent in a sentence). Gaining proficiency in an L2 is thus a function of learning the different cues important to the L2, especially if they differ from L1 cues (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987; McManus, Reference McManus2021).
Evidence from both L1 and L2 processing research has provided empirical evidence attesting to the predictions of the Competition Model across a variety of languages (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987; Harrington, Reference Harrington1987; Kilborn, Reference Kilborn1989; Liu et al., Reference Liu, Bates and Li1992; Mcdonald, Reference Mcdonald1987; Su, Reference Su2001; Walter et al., Reference Walter, Fischer and Cai2024; Zhao et al., Reference Zhao, Vanek and MacWhinney2025). Following this extensive research on cue competition in single-sentence processing, there has been some interest in how these mechanisms operate within broader discourse contexts (Pan & Felser, Reference Pan and Felser2011; Su, Reference Su2004). Such research is important because psycholinguistic models of discourse processing suggest that readers and listeners construct mental situation models that are continuously updated with new information (Just & Carpenter, Reference Just and Carpenter1980; O’Brien & Cook, Reference O’Brien and Cook2016; van den Broek & Helder, Reference van den Broek and Helder2017), and meaning that prior information is considered while reading new sentences.
However, little research to date has investigated the potential for discourse information to act as a cue and/or mitigate potential syntactic cue competition (c.f., Su, Reference Su2004). In the current study, we consider both questions, asking whether semantic information in discourse can override a syntactic cue that disagrees with the semantic information. We further examine whether L1–L2 cue similarity interacts with competition between discourse and syntactic cues during L2 sentence processing. To do so, we investigate how English monolinguals and two groups of English L2 speakers (Taiwanese Mandarin L1 and Japanese L1) attend to conflicts between a syntactic cue (agentive by-phrases) and semantic plausibility cues when processing English passive sentences. We address the following two key questions: (1) how L1 and L2 English speakers resolve competition between discourse-level semantic cues and sentence-internal syntactic cues, and (2) whether cross-linguistic differences in cue reliability lead to different sentence representations in L2 speakers from different L1 backgrounds.
L2 Sentence processing and cue competition
According to the Competition Model, language users attend to different language-specific cues to extract semantic information, such as thematic roles, from sentences (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987; Li & MacWhinney, Reference Li, MacWhinney and Chapelle2012; MacWhinney, Reference MacWhinney and MacWhinney1987; Zhao et al., Reference Zhao, Vanek and MacWhinney2025). These cues include syntactic features (word order, structural position) and morphological markers (case marking, agreement), which vary systematically across languages in their strength and reliability. For example, in English, word order is a strong cue for determining agents in canonical SVO sentences (e.g., the woman wrote the book), but is less reliable in noncanonical sentences, such as passives. In these cases, the by-phrase in passive sentences (e.g., The book was written by the woman) serves as a strong cue for agent identification.
There are many theoretical models and explanations of L1–L2 influence, such as the feature reassembly model, the Bilingual Interactive Activation Plus (BIA+), the Revised Hierarchical Model, and so on (Lardiere, Reference Lardiere2009; Tokowicz, Reference Tokowicz2014). Here, we choose to focus on the Competition Model, because a core prediction of the Competition Model is the influence of cue strength and L1 transfer effects on L2 sentence processing strategies. In this model, L2 learners initially map their L1 cue strategies onto L2 input, which can result in processing difficulties when languages use different cues to mark semantic information (Li & MacWhinney, Reference Li, MacWhinney and Chapelle2012; Liu et al., Reference Liu, Bates and Li1992; Tokowicz et al., Reference Tokowicz, Warren and Tolentino2024). A large number of empirical studies have applied the Competition Model to the study of L2 sentence processing, exploring how L2 learners adjust their use of linguistic cues based on exposure and L1–L2 similarities. In this research, L2 learners initially apply L1 cues to L2 sentence processing, but this effect attenuates as L2 proficiency increases (Zhao et al., Reference Zhao, Vanek and MacWhinney2025). These effects have been compared across many different language pairs, such as Dutch and English (Mcdonald, Reference Mcdonald1987), and English and German (Kilborn, Reference Kilborn1989). These studies showed that when processing English sentences, English speakers relied more heavily on word order, whereas Dutch and German speakers relied more strongly on morphology, suggesting the influence of L1 cues on L2 (English) sentence processing. Similar results have been attained when testing Japanese learners of English (Harrington, Reference Harrington1987), Mandarin Chinese speakers of English (Liu et al., Reference Liu, Bates and Li1992; Su, Reference Su2001; Zhao & Fan, Reference Zhao and Fan2021), English, Dutch, Italian, Polish, and Swedish learners of Chinese (Liang et al., Reference Liang, Chondrogianni and Chen2022), and learners of artificial languages (Walter et al., Reference Walter, Fischer and Cai2024).
Discourse-level cue competition and L2 sentence processing
While previous research on this theme has focused primarily on sentence-level cue competition, real-world language processing occurs within rich discourse contexts that provide additional pragmatic cues to sentence meaning and inferences (O’Brien et al., Reference O’Brien, Cook and Lorch2015). Discourse context can either support or conflict with sentence-level cues, creating different types of competition scenarios (van den Broek & Helder, Reference van den Broek and Helder2017). When discourse context supports syntactic analysis (plausible scenarios), cue competition may be minimal. However, when discourse context conflicts with syntactic structure (implausible scenarios), speakers must resolve competition between syntactic and semantic cues. Following predictions of the Competition Model, speakers will weigh these cues based on their learned reliability, with L1 and L2 speakers showing different weighting patterns based on their linguistic background and level of target language proficiency.
However, few studies have tested cue competition in discourse settings (cf. Su, Reference Su2004). In their study, Su (Reference Su2004) tested competition among word order, animacy, and discourse context among L1 Chinese and L1 English speakers (i.e., no L2 learners were involved). Short contexts were provided before target sentences, which varied in their word order (e.g., noun verb noun; verb noun noun) and animacy of noun phrases (e.g., animate-animate; animate-inanimate). The contexts biased either the first or second noun to be the doer of the sentence, and participants were asked to listen to the sentence and then indicate the agent. The results showed that discourse information decreased reliance on word order cues, but more so for the Chinese speakers when compared to the English speakers. In other words, discourse-level information mitigated cue competition for L1 speakers, but this effect was stronger in one language (Chinese).
An open question is whether L1–L2 cue transfer effects will emerge when studying L2 processing and comprehension of larger discourse contexts, when compared to the traditional single-sentence methods many Competition Model studies use. The rationale behind this question is that L2 speakers are thought to rely more strongly on discourse-level information when compared to L1 speakers (Cunnings, Reference Cunnings2017; Hopp, Reference Hopp, Godfroid and Hopp2022b). Models such as the Shallow Structure Hypothesis (SSH) posit that L2 speakers must rely more strongly on semantic and pragmatic information because their L2 syntactic parses are more shallow when compared to L1 speakers (Clahsen & Felser, Reference Clahsen and Felser2006, Reference Clahsen and Felser2018). Alternative accounts argue that L2 speakers differ not in the quality of the syntactic representation, but instead, in the memory-based retrieval strategies, where L2 speakers give more weight to discourse-level cues when considering the meaning of sentences after initial parsing (Cunnings, Reference Cunnings2017).
Regardless of these different explanations, empirical studies attest to a stronger influence of discourse-level cues among L2 speakers when compared to L1 speakers (Crible et al., Reference Crible, Wetzel and Zufferey2021; Felser & Drummer, Reference Felser and Drummer2022; Hopp, Reference Hopp2022a; Pan & Felser, Reference Pan and Felser2011). For example, when processing prepositional phrases that could modify either a VP or an NP positioned within the same sentence, Chinese learners of English were better able to determine the modifier when the discourse context supported the VP or NP referent. In contrast, native English speakers showed no such sensitivity to the discourse context (Pan & Felser, Reference Pan and Felser2011). In a different study, French and Dutch learners of English showed comparability to a native English speaker baseline when processing correct and incorrect uses of English discourse connectives if and when (Zufferey et al., Reference Zufferey, Mak, Degand and Sanders2015). However, in the same study, negative transfer effects emerged when learners judged a subset of the same target sentences in isolation. Both groups of learners had lower accuracy when judging English connectives involving cue competition with their L1 equivalent structures (if for French and when for Dutch). The implication was that supporting information from prior discourse was able to mitigate L1–L2 cue competition for these target structures.
As such, the scope of cue competition shifts when considering whether sentences are processed in isolation or within larger discourse contexts. Following the logic from models such as the SSH, there is a general weighting of semantic over syntactic information for L2 speakers when compared to L1. It follows then that for L2 speakers, discourse information (or, semantic cues) may also partially override localized sentence L1–L2 cue competition in L2 sentence processing. This possibility, however, also recognizes the influence of L2 proficiency. As proficiency in the target language increases, learners begin to rely less on mapping of L1 cues and instead learn how L2 cues operate (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987). Yet, L2 processing studies show that even highly proficient L2 learners will rely more heavily on semantic versus syntactic information during L2 sentence processing (e.g., Deniz, Reference Deniz2022). In other words, discourse information, such as semantic plausibility, may serve as a stronger cue for L2 speakers when compared to L1 speakers, even at relatively high levels of L2 proficiency.
Passive formation in English, Japanese, and Taiwanese Mandarin
The current study examines how discourse information interacts with L1–L2 cue similarity. To do so, we compare responses to agentive wh-questions for English passive by-phrases embedded in short story contexts. We collected data from English monolinguals, L1 Mandarin learners of English in Taiwan, and L1 Japanese learners of English. Our study has two primary goals: (1) assess and compare cue weighting strategies among the monolingual and L2 English groups when syntactic and semantic cues conflict in our implausible vignettes, and (2) examine these strategies in light of cross-linguistic differences in cue reliability and L2 proficiency between the Japanese and Mandarin Chinese speakers.
The English passive and cue competition
English passives are considered marked constructions for several reasons. First, unlike their active counterparts, passives display an unusual mapping of grammatical relation and thematic role against the Thematic Hierarchy (Fillmore et al., Reference Fillmore, Bach and Harms1968; Larson, Reference Larson1988), allowing the theme to override the agent and constitute the subject. Second, through the demotion of the agent and the promotion of the theme to subject status, passive constructions usually display a different word order than canonical active transitives. Third, the passive construction in English and many other Indo-European languages has been shown to have low frequency in discourse and is acquired later than the active. All these factors make the passive an ideal testing ground for cue competition during English sentence processing.
In English, passivization (1) features a fronted theme that occupies the subject position and a demoted agent realized as an optional oblique introduced by the preposition by. This preposition constitutes a strong syntactic cue signaling agentive interpretation in passive constructions (Wanner, Reference Wanner2009; Xiao et al., Reference Xiao, McEnery and Qian2006).
However, this preposition is not linked uniquely to the agent semantic role, and can also introduce locative phrases, as in (2):
This bifunctionality creates syntactic ambiguity in English passives, because a by-phrase may introduce either an agent or a locative/bystander complement. Although the ambiguity may be reduced by animacy, where both phrases co-occur in the same sentence as two adjuncts, in which case the agent by-phrase must precede the adjunct by-phrase, as in (3), the ambiguity is salient when the locative phrase is an animate NP with no occurring agent by-phrase, as in (4).
Cross-linguistic cue reliability: Japanese
Like English, Japanese employs several valency-decreasing operations, including the ase and niyotte passives (Iwasaki, Reference Iwasaki and Hasegawa2018; Washio, Reference Washio1987). As with English passives, these constructions feature a fronted theme in the subject/nominative position and an optional agent-denoting postposition phrase (PP). In Japanese, this PP is introduced by the marker ni, as in (5a). Similar to the English preposition by, the marker ni may also introduce locative PPs, as in (5b). It is also possible for a passive sentence to contain two ni-marked adjuncts, one expressing the agent and the other the locative, as in (5c).

The parallel between English by and Japanese ni means that both languages present speakers with the same cue reliability challenge: the agent-marking morpheme can also signal locative information in certain conditions. If Japanese learners of English transfer their L1 cue weighting strategies to English, the resulting English by should be a similarly less reliable marker of agentive semantic roles, potentially leading to similar competition resolution patterns as native English speakers when syntactic and semantic cues conflict.Footnote 1
Cross-linguistic cue reliability: Mandarin Chinese
Mandarin Chinese presents a different cue reliability pattern that should lead to direct transfer effects in L2 English processing. Like Japanese and English, Mandarin possesses a detransitivizing construction commonly analyzed as a passive (Chu, Reference Chu1973; Hashimoto, Reference Hashimoto1988; Pan & Hu, Reference Pan, Hu and Aronoff2021). Similar to the English passive, this construction is characterized by fronting of the theme and demotion of the agent to an optional preposition phrase introduced by the marker bei (6).

Similar to the English preposition by, the Mandarin passive marker bei serves as a reliable cue for indicating the agent role (Li et al., Reference Li, Bates and MacWhinney1993). However, this marker differs crucially from English by in its cue reliability: bei is not compatible with locative NPs. This is because, as in (7a), locative obliques in Mandarin are introduced by a distinct preposition: zai, as seen in (7b):

This cross-linguistic difference in cue reliability has important implications for our current study. Mandarin speakers know the passive marker bei is a highly reliable cue for agentive interpretation with no locative ambiguity. When processing English passives, this L1 experience should lead Mandarin speakers to weigh the syntactic cue (by-phrase = agent) more heavily than Japanese speakers, who have learned that the equivalent marker (ni) is less reliable due to its locative ambiguity. The result should be a stronger agentive bias for English by for Mandarin Chinese when compared to Japanese speakers.
Hypotheses
Based on our review of the theoretical predictions made by the SSH and Competition Model, as well as the typological differences among English, Japanese, and Mandarin Chinese, at least two hypotheses are possible. We formalize these as Hypotheses 1 and 2.
Hypothesis 1. Semantic cues will be stronger for L2 speakers, and syntactic cues will be stronger for L1 speakers.
Hypothesis 2. English L1 speakers and Japanese L2 speakers of English have a weaker agentive bias for by when compared to Mandarin L2 speakers of English.
In addition to investigating these two competing hypotheses, we consider whether reliance on semantic versus syntactic cues becomes more target-like with higher L2 proficiency.
Materials
Our study design used short text vignettes containing three sentences each. Using vignettes allowed us to embed different target sentences within the same discourse contexts. In one condition, semantic information in the discourse and syntactic cues in the target sentence both implicated the same event participant as the agent of an action. In another condition, the semantic and syntactic cues were in contrast, pointing towards two different NPs.
Vignette design
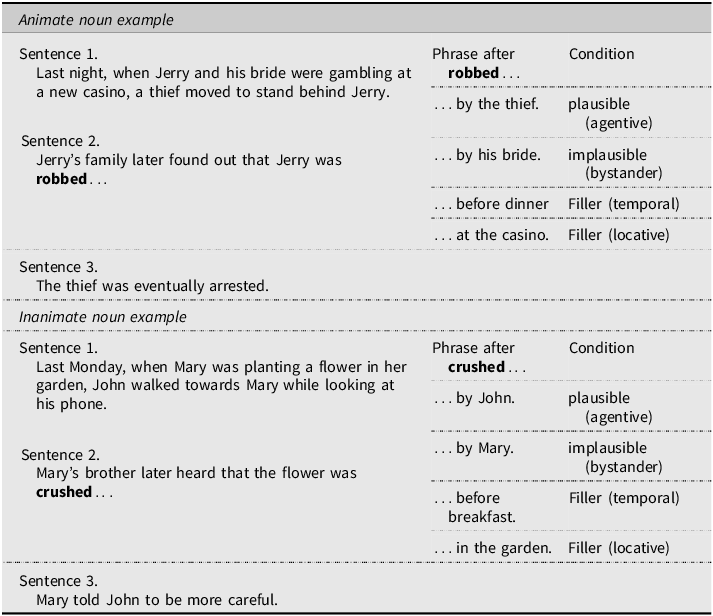
In order to create competition between discourse-level information and the agentive by-phrase, we created 20 three-sentence stories using transitive verbs biased towards a completed action. The stories were divided so that 12 included animate human objects and eight included inanimate objects as themes (this was done primarily to introduce variation in the nouns and verbs used across the stories). Each story had four versions, two target versions (by-phrase with plausible or implausible agents) and two filler versions (a temporal or locative prepositional phrase). Animate stories featured three participants: a named theme (Jerry), an unnamed bystander (his wife), and an unnamed agent (a thief). Inanimate stories included a named bystander (Mary) interacting with an object theme (a flower) and a named agent (John). All stories followed the same structure: the first sentence established a past timeframe using past progressive, the second sentence reported someone learning about the event, and the final sentence reinforced the agent’s role. We controlled for word frequency, balanced gender in names, standardized sentence lengths, and avoided repetition of names, verbs, and locations across stories. Examples are shown in Table 1.
Examples of story stimuli and their different conditions, with key verbs bolded

The two conditions critical to our study were stories in which an agentive interpretation of the by-phrase agreed or conflicted with the semantic information of the vignette. In each vignette, a specific event participant was described in a way that primed expectations for that event participant to be the agent of the main action. For example, a thief is described as moving behind some unsuspecting newlyweds, or John is described as walking past a garden whilst distracted by his mobile phone. In each case, these actions position those event participants to be the agents of the subsequent action (the thief commits the robbery; John crushes a flower). If the by-phrase included those event participants (e.g., the flower was crushed by John), an agentive reading of the by-phrase was congruent with these expectations (plausible text condition). If the by-phrase included a different event participant (e.g., Jerry was robbed by his bride), an agentive reading would conflict with these expectations (implausible text condition). Crucially, the target sentence in the implausible scenario remains true and accurate under a locative reading (e.g., near his bride, near Mary), but is false if interpreted as agentive. For the animate vignettes, these expectations were further enhanced via semantic links between the nouns and verbs used in the by-phrases (e.g., thief has stronger semantic links to robbery when compared to bride). The filler conditions were included to prevent participants from identifying the focus of the study (i.e., the by-phrase) and encourage them to pay attention to all aspects of each vignette.
Norming study
We conducted a norming study to verify whether the implausible vignettes triggered a noticeable conflict between semantic and syntactic information. This was achieved by gathering ratings of plausibility for vignettes in the four different conditions. We chose plausibility ratings because we wanted to test whether the events described in each vignette seemed believable, with the expectation that the bystander NP versions should be less plausible than the agentive versions.
Norming method and procedure
Stimuli included the 20 vignettes as described in Section “Vignette design”, split into four lists of twenty stories each, with text condition counterbalanced across the lists. We designed a plausibility rating task using jsPsych (de Leeuw, Reference de Leeuw2015) and recruited 40 monolingual speakers of English living in the United States from the research crowdsourcing website Prolific Academic (Age: min = 18, max = 57, M = 33.5, SD = 10.6; 52.5% female, 45% male, 2.5% prefer not to answer). Participants were evenly and randomly assigned to one of the four counterbalanced lists of 20 stories. Each trial presented full text from a randomly selected story vignette, along with a 5-point rating scale (1 = not at all plausible, 5 = highly plausible) with the following instructions:
Plausibility is a measure of how likely you think something can occur. For example, being full after eating a meal is more plausible than being hungry after eating a meal. However, one could still feel hungry after eating a meal. It is just less plausible when compared to being full. Your task is to rate each story you read on a scale of plausibility. The scale ranges from 1 (not at all plausible) to 5 (highly plausible). When making your ratings, please consider all aspects of the story. Also, take your time – please do not rush your answers.
Statistical analysis
We fit a Bayesian multilevel mixed effects regression model with plausibility ratings as the dependent variable and a two-way interaction between story condition (plausible, implausible, temporal filler, locative filler) and theme type (animate vs. inanimate) as the predictor variable. To fit our model, we used the brms package (Bürkner, Reference Bürkner2017) in R (R Core Team, 2025) with a generic weakly informative prior normal distribution (a mean of 0 and a standard deviation of 1). The predictor variables were contrast-coded using the contr.equalprior function from bayestestR (Makowski et al., Reference Makowski, Ben-Shachar and Lüdecke2019), assigning each level of the variable to equalized marginal prior distributions. We included subjects and items as random intercepts, with a random slope of story condition fit on both subjects and items. After fitting the model, we obtained pairwise comparisons of posterior distributions using the emmeans package (Lenth, Reference Lenth2024).
We subjected these pairwise comparisons to a region of practical equivalence (ROPE) test using the bayestestR package. These analyses measure which proportion of a credible interval from the posterior distribution falls within a user-defined ROPE, centered around zero (i.e., representing both the absence of an effect as well as the practical absence of an effect). Essentially, if a high percentage of a credible interval from a posterior distribution related to any one effect falls within a ROPE, it can be thought to reflect the absence of a meaningful effect. Much like frequentist approaches, which use a 0.05 threshold for p-values, decisions about what counts as a significant effect based on the percentage of a distribution that falls within a ROPE are arbitrary. In this data, we opted to describe our effects in relation to one another and avoid designating any effect using binary classifications of significant or not significant. We use a 95% credible interval in all our analyses. For the plausibility ratings, we used the built-in functionality of the bayestestR package to define the ROPE.
Results
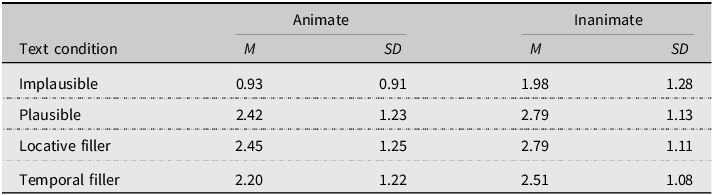
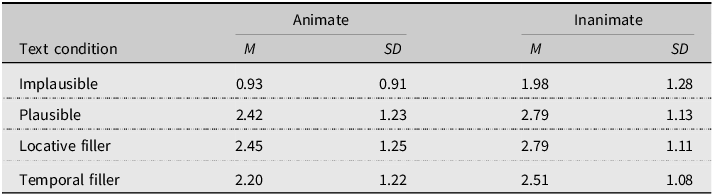
Means and standard deviations of plausibility ratings for the four different story versions are displayed in Table 2, with two noteworthy observations. First, the plausibility ratings are lower for the implausible text condition when compared to the other three conditions. Second, the plausibility ratings are lower for stories with animate themes (compared to inanimate) for all four text conditions. For animate stories, pairwise comparisons confirmed that ratings were reliably lower for the implausible versions when compared to the other three text conditions (all ROPE = 0%). For inanimate stories, reliable differences were found between implausible and the plausible or locative stories (ROPE = 0%); however, the comparison to temporal fillers had a ROPE overlap of 9.41%, indicating their difference was less credible. Additionally, the difference between ratings for the animate and inanimate versions of the implausible stories was also reliable (ROPE = 0%), whereas these differences were not reliable for the other three conditions. As such, these data provide evidence that the implausible stories were perceived to be less plausible than the plausible condition, but also suggest that differences in the animacy of the theme of the by-phrase moderated this effect, with animate themes resulting in lower perceptions of plausibility when compared to inanimate themes. For the sake of space, we provide the full statistical contrasts as an Appendix in the online Supplemental Materials.
Descriptive statistics of plausibility ratings
Experimental study
The norming study confirmed that the stories in the implausible condition were seen as reliably less plausible than the plausible versions. We then conducted a reading comprehension experiment with participants from the three language backgrounds relevant to our research hypotheses.
Method
Text comprehension questions
Three comprehension questions with two possible answers were created for each story. The questions asked about the agent of the main verb (who verb-ed THEME?), the time of the main verb event (when was THEME verb-ed?), or the location of the main verb event (where was THEME verb-ed?). The agent question answer options included the two NPs in the vignette (bystander and semantically-biased agent), and the locative and temporal questions were included as fillers (so that participants would not learn to rely solely on the NP in the by-phrase when reading). The location question answer options included the location mentioned in the story or a different location that was not mentioned in any of the other stories. The temporal question answer options included the time mentioned at the start of the sentence or an incorrect time for all conditions aside from the temporal fillers. For those stories, the temporal question included options related to the time mentioned in the temporal preposition + NP after the verb. These possibilities are summarized in Table 3.
Example comprehension questions

Reading task
We used the same 20 vignettes described in Section “Materials”. The stimuli were separated into similar counterbalanced lists and presented using a non-cumulative self-paced reading (SPR) design. In this paradigm, a reader sees the first word on their screen, with underlines representing placeholder spots for the rest of the words in a text. The reader then pushes a key to advance to the next word, which subsequently masks the previous word, and thus only one word is presented at any one time. We used non-cumulative SPR because we wanted to prevent participants from being able to refer back to previous text during the task, forcing a heavy reliance on memory representations of the event participants in the text. We collected reading times during this task, but do not report them here, as our theoretical question concerned the memory representations formed during reading rather than the online processing difficulty reflected in reading times. Our dependent measure was therefore accuracy on the comprehension questions that followed each vignette.
LexTALE English proficiency
We incorporated a version of the LexTALE test of English proficiency (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012) into our jsPsych survey. The LexTALE test includes 40 real English words and 20 English nonwords. Participants see the words one at a time and indicate if they think the word is real or not by clicking on buttons labeled as yes or no. Only accuracy and not reaction time is used to calculate the scores. As such, LexTALE scores are primarily a measure of vocabulary knowledge, but validation studies have found associations between LexTALE scores and general measures of English proficiency for advanced users of English (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012). The primary benefit of LexTALE is that it is relatively quick (around five minutes), which means a consistent measure of English proficiency can be collected from participants at the time of the experiment.
Participants
Three groups of participants were recruited: English monolinguals living in the United States, Mandarin Chinese learners of English living in Taiwan, and Japanese learners of English living in Japan. An initial wave of 147 monolingual English speakers was recruited from the online research crowdsourcing platform Prolific Academic. To be eligible, participants needed to reside in the United States and indicate they were monolingual speakers of English (they also did not participate in the norming study). An additional 104 Mandarin Chinese L1 learners of English and 89 Japanese L1 learners of English were recruited from university student populations in Taiwan and Japan through the aid of colleagues who work at these universities. We also encouraged any of the participants in Taiwan or Japan who completed the study to pass the recruitment details of our study on to their classmates.
Some of the L2 participants were removed from the final data analysis due to low accuracy on the practice and/or filler items (see section Results). As such, the final composition of the participant groups was 147 Monolingual English speakers (Mage = 26.02, SDage = 8.79, 77.5% female, 21.1% male, 1.3% prefer not to answer), 73 Japanese (Mage = 22.05, SDage = 7.25, 52.1% female, 43.8% male, 4.1% prefer not to answer), and 98 Taiwanese Mandarin (Mage = 22.28, SDage = 4.24, 75.5% female, 21.4% male, 3.1% prefer not to answer). In terms of the proficiency scores, the LexTALE were Japanese M = 64.34, SD = 9.28, Min = 51.25, Max = 93.75; Taiwanese M = 61.43, SD = 11.89, Min = 40.00, Max = 96.25. Age of English Exposure was Japanese M = 9.26, SD = 3.47, Min = 0, Max = 13; Taiwanese M = 7.40, SD = 2.77, Min = 1, Max = 14.
Procedure
The experiment was conducted using a web browser. Instructions were provided in English and Mandarin Chinese or Japanese for L2 participants. Participants completed a demographic survey including age, sex, and language status. English L2 participants also reported their age of English acquisition, daily English usage percentage, and completed the LexTALE proficiency test. Participants were then introduced to the reading task, instructed to use the spacebar to advance through stories, and told they would answer three questions after each story. They completed a practice session with three similar texts that lacked the key prepositional constructs before proceeding to the main task.
During the reading task, participants read 20 stories in a random order from counterbalanced lists. Texts appeared in 20-point Trebuchet MS black font on a gray background. The first sentence (20 words) was presented as one line, with the second and third sentences below. A fixation cross over the first word was replaced by the actual word when participants pressed the spacebar, revealing placeholder lines for the remaining words. Participants read at their own pace, advancing words with the spacebar. The three comprehension questions appeared individually after each text, with two answer options as adjacent buttons. Question order and answer placement were randomly assigned per participant.
Statistical analysis
We again employed Bayesian multilevel mixed effects regression models to test our predictions. For these data, our outcome variable was the binary response to the who comprehension question asked after each story. The binary response was coded so that a score of 1 was assigned when participants chose the NP in the by-phrase, with other answers being scored as 0. We created logistic models following a Bernoulli distribution and logit link using the brms package (Bürkner, Reference Bürkner2017) in R (R Core Team, 2025). Estimated marginal means and trends were calculated using emmeans (Lenth, Reference Lenth2024), and we used the same ROPE method from the bayestestR package (Makowski et al., Reference Makowski, Ben-Shachar and Lüdecke2019) to determine the significance of the effects in the models. All models were trained on 10,000 iterations. Because these models were logistic regressions, we present the posterior distributions in terms of probability.
Model 1: Agent selection model
The first model included data from all three language groups, with a three-way interaction among language group (English, Japanese, Mandarin), story condition (plausible vs. implausible; we did not analyse data from the filler story conditions), and animacy (animate vs. Inanimate; included to control for any differences in how animate vs. inanimate NPs were interpreted). All variables were contrast-coded to include equal marginal prior distributions for all levels of each factor. Random intercepts with a random slope of the interaction between story condition and animacy were fit for subjects, with a random slope of vignette condition fit for items. We again fit a generic weakly informative prior using a normal distribution with a mean of 0 and standard deviation of 1. Random effects were kept at the default priors (Student t-distribution with mean of 0 and standard deviation of 2.5).
Model 2: L2 English proficiency model
For the L2 participants, we fit a model that included our two measures of L2 English proficiency (LexTALE and Age of English Exposure) and responses for the implausible stories only. The model included three-way interactions among language group (Japanese or Mandarin), vignette animacy (animate or inanimate), and either LexTALE English proficiency scores or Age of English Exposure values (z-scored with a mean of 0 and standard deviation of 1). Random intercepts were fit for subjects and items, with a random slope of animacy fit for subjects. We used the same contrasts and prior specifications as the previous model.
Predictions
H1. Our first hypothesis incorporates predictions of the SSH (i.e., that semantic information is more salient for L2 speakers) into the cue framework of the Competition Model. Because semantic information is thought to be a more reliable cue for L2 speakers, the Japanese and Mandarin L1 participants should have a lower frequency of choosing the by-phrase NP as the agent in the implausible vignette condition when compared to the L1 English speakers. However, this difference will be moderated by L2 English proficiency, with higher proficiency reducing the reliance on semantic cues and thus increasing the probability of choosing the by-phrase NP as the agent in the implausible vignette condition.
H2. Following the Competition Model, this hypothesis predicts that the strength of syntactic cues within the by-phrase will interact with corresponding L1 structures. Because English by and Japanese ni are multifunctional (allowing for agentive or locative interpretations), a testable prediction is that there will be a weaker agentive bias for English by (for Japanese, this is reinforced through similar L1–L2 cues). In contrast, Mandarin speakers have distinct L1 cues with specialized cue strengths: bei for agentive functions and zai for locative functions. When mapping onto English by, only the agentive cue strength from bei transfers, and thus, there will be a stronger agentive bias for these speakers. This means that the Mandarin speakers should choose the by-phrase NP as the agent at a higher rate when compared to the Japanese and English speakers for the implausible vignettes. However, this effect should be weaker for Mandarin participants with higher L2 English proficiency, as they should rely less on direct mapping of L1 to L2 cues.
Results
We first prepared the data for analysis by identifying any participants with extremely low accuracy scores on comprehension questions. We removed any participant with lower than 70% accuracy on the practice questions and/or the comprehension questions for the plausible and filler story conditions. In total, 16 participants from the Japanese group and six participants from the Taiwanese group were removed for low accuracy.
Descriptive statistics
Figure 1 presents the proportion of answers indicating whether the by-phrase NP was chosen as the agent, divided into vignettes with animate or inanimate themes in the by-phrase. All participants chose the by-phrase NP as the agent in plausible vignettes at a higher percentage when compared to implausible vignettes, and this difference was larger when comparing between animate versions of the vignettes. This interaction was largely driven by a difference within the plausible vignettes, where participants almost always chose the by-phrase NP as the agent for animate vignettes. In contrast, the percentages were relatively similar between animate and inanimate versions within the implausible condition.
Proportion of answers choosing the by-phrase NP as agent when answering the who-questions (raw data).

Model 1: Agent selection
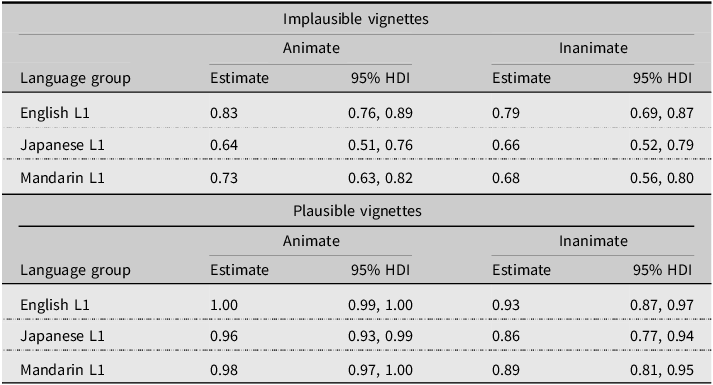
The relative differences among the percentages seen in Figure 1 were replicated by the multilevel model, which predicted a high probability for choosing the by-phrase NP as the agent in the animate (>96%) and inanimate (>89%) plausible vignettes for all three language groups (see Table 4). Within-group comparisons confirmed these differences were credible, in that the probability of choosing the by-phrase NP was lower for implausible vignettes, regardless of animacy (All ROPE = 0%; full contrasts provided in Supplemental Material).
Model predicted probability of choosing by-phrase NP as agent
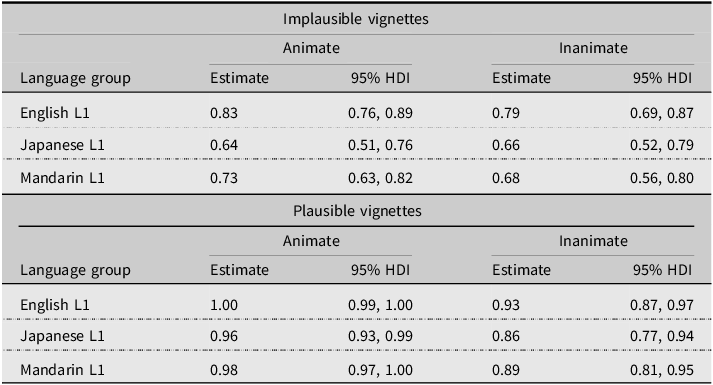
HDI = highest density interval. Estimate is median of posterior distribution. Positive estimates reflect higher probability of choosing the by-phrase NP.
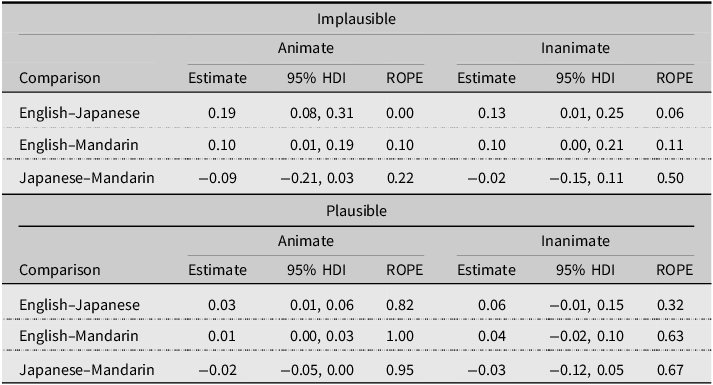
Between-group comparisons, shown in Table 5, revealed comparable by-phrase NP selection among the groups in plausible vignettes across both animacy versions (all ROPE ≥ 32%), indicating baseline similarity in response patterns. For the implausible vignettes, language-specific differences emerged with varying degrees of certainty. For animate themed versions, English monolinguals showed higher by-phrase NP selection than the Japanese L1 group (Estimate = 0.19, 95% HDI [0.08, 0.31], ROPE = 0%), with the credible interval clearly excluding the ROPE. The difference between English monolinguals and Mandarin L1 showed a similar direction but with greater ROPE overlaps (Estimate = 0.10, 95% HDI [0.01, 0.19], ROPE = 10%). For inanimate themed versions, the English monolingual to Japanese L1 comparison again showed higher by-phrase NP selection for English monolinguals, though with slightly more uncertainty (Estimate = 0.13, 95% HDI [0.01, 0.25], ROPE = 6%), and the English monolingual to Mandarin L1 comparison showed a comparable pattern (Estimate = 0.10, 95% HDI [0.00, 0.21], ROPE = 11%). Japanese L1 and Mandarin L1 speakers did not differ meaningfully from each other in either animacy condition (ROPE ≥ 22%). In order to better understand these overlaps, we plot the posterior distributions and the ROPE in Figure 2 for these contrasts.
Pairwise comparisons among language groups for by-phrase NP selection

ROPE range [−0.045, 0.045], HDI = highest density interval. Estimate is median of posterior distribution. Positive estimates reflect higher probability of choosing the by-phrase NP.
Posterior distributions of between-group contrasts comparing agent selection for implausible and plausible vignettes across animate and inanimate themes. For plausible vignettes, heavy overlap with the ROPE indicates comparability among the groups. For implausible vignettes, English speakers differed from both L2 groups, with the strongest effects between English and Japanese speakers for animate themes, while Japanese and Mandarin speakers remained comparable.

There are three main conclusions to draw from Model 1. First, both L1 and L2 participants were less likely to choose the by-phrase NP as the agent for implausible versus plausible vignettes. Yet, the likelihood of choosing the by-phrase NP was still higher than the other NP, even within the implausible stories. This finding suggests discourse-level information was being used by participants when answering the who question after the implausible stories, but only sometimes. Second, this tendency was stronger for the L2 participants, suggesting they drew more heavily from discourse than syntactic information when accessing their memory representations of the vignettes. Third, agent selection behavior in the implausible stories was more similar than different between the JP and TW participants, with a predicted difference of 2 to 9% (see Table 5). These results provide support for Hypothesis 1, with the strongest evidence found for animate implausible vignettes: L2 English speakers relied more heavily on semantic cues, whereas L1 English speakers had stronger reliance on syntactic cues. In contrast, Hypothesis 2 was not supported: Japanese and Mandarin L2 speakers showed similar patterns, and Japanese L1 speakers diverged more strongly from English monolinguals when compared to Mandarin L1 speakers, contrary to predictions of L1–L2 cue similarity.
Model 2: English proficiency
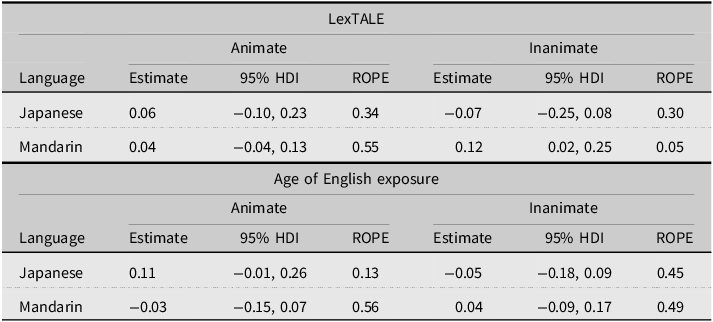
Model 2 examined agent selection within implausible stories for the Japanese L1 and Mandarin L1 participants in the context of two measures of English proficiency (LexTALE and Age of English Exposure). Results indicated that for Mandarin L1 speakers, higher LexTALE scores were associated with a higher probability of choosing the by-phrase NP in inanimate versions of the implausible vignettes (specifically, a one standard deviation increase in LexTALE was associated with a 12% probability increase; ROPE = 5%). All other effects were small and overlapped strongly with the ROPE, indicating no other credible effects. These contrasts are shown in Table 6 and plotted in Figure 3.
Effects of L2 English proficiency on probability of choosing by-phrase NP

ROPE range [−0.045, 0.045], HDI = highest density interval. Estimate is median of posterior distribution. Positive estimates reflect higher probability of choosing the by-phrase NP.
Posterior distributions of effects of L2 English proficiency measures on probability of choosing by-phrase NP as agent for the implausible vignettes. There was only one credible effect: higher LexTALE scores for Mandarin speakers were associated with higher probability of choosing the by-phrase NP for inanimate versions.

Discussion
To investigate how L1 and L2 English speakers interpret thematic roles when semantic and syntactic cues align or conflict, we collected data from monolingual English speakers, Taiwanese Mandarin speakers, and Japanese speakers of English. We measured comprehension of target sentences containing by-phrases embedded in short vignettes. The NP included in the by-phrase was either congruent (plausible condition) or not congruent (implausible condition) with the semantic information in the opening and closing sentences of the vignette. Participants read the vignettes one word at a time, answering three wh-questions after each vignette (who, when, and where).
We examined how participants reconciled discourse-level semantic cues with syntactic structure in implausible story contexts. We compared two possible hypotheses based on the Competition Model and its integration with the SSH. These hypotheses led to contrasting predictions: (H1) held that L2 speakers will attend more strongly to semantic cues when compared to L1 speakers, whereas the other (H2) held that L2 speakers would be influenced by L1–L2 cue similarity when making their decisions. Overall, our results provide stronger support for H1 when compared to H2.
L1 and L2 comprehension of implausible vignettes
When reading plausible and implausible stories about past events, our L1 and L2 participants reliably interpreted the NP encoded by the by-phrase to be the agent of the event. This effect is unremarkable for the plausible vignettes, because the semantic and syntactic cues both supported interpreting the by-phrase NP as the agent. Yet, more often than not, participants made similar agent selection choices for implausible vignettes—choosing the by-phrase NP as the agent—even when such an interpretation conflicted with semantic information that came before and after reading the target sentence. This finding attests to a strong agentive cue of the English by-phrase when associated with an animate NP for both the L1 and L2 participants.
However, the weighting of this cue differed among our participant groups—and in the direction we had predicted—with L1 English speakers being more strongly influenced by the syntactic cue when faced with competition between syntax and semantics. In fact, while the probability difference between plausible and implausible stories for these participants was ∼12 to 17%, this reflected a probability decrease from 100% to 83% (animate) or 93% to 79% (inanimate; see Table 4). In other words, L1 English speakers would choose the by-phrase NP as the agent at least ∼80% of the time, even when information in the surrounding discourse conflicted with such a choice. The difference between plausible and implausible vignettes does suggest that discourse information can influence cue weighting for English speakers, but only to a relatively weak degree, mirroring previous research showing similar weak effects of prior discourse information on cue strength (Su, Reference Su2004).
In contrast to the L1 English speakers, results from Model 1 indicated the L2 participants made those same decisions when reading implausible stories about 68–73% (Mandarin) or 64–66% (Japanese) of the time (Table 4). This finding reflects the attested tendency for L2 speakers to rely more heavily on semantic and discourse-level information during L2 sentence processing (Clahsen & Felser, Reference Clahsen and Felser2018; Hopp, Reference Hopp, Godfroid and Hopp2022b). Recall that the SPR task we used was non-cumulative, meaning that words did not remain on the screen after participants read them. Such a task induces a greater reliance on memory representations, and it is under these conditions that L2 speakers are especially prone to rely more heavily on semantic versus syntactic information when recalling information (Cunnings, Reference Cunnings2017). This does not mean that the L2 participants were unable to process the syntactic information, but rather that the syntactic cue was less influential during the mental construction of the stories for L2 participants.
Effects of L1–L2 cue mapping
Our second hypothesis predicted that differences between the Mandarin and Japanese participants’ L1 structures would influence their agent selection behavior. If the unifunctional agentive nature of Mandarin bei is mapped to English by through cue transfer, as predicted by the Competition Model (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987), English by would become a valid and reliable cue for marking agentive roles in passive sentences for Mandarin speakers. When comparing the Mandarin speakers to the Japanese speakers, the descriptive results suggest that the Mandarin participants did indeed interpret the by-phrase NP as the agent at a rate higher than the Japanese participants. Statistically, however, these differences were not robust, as there was a great deal of overlap between the posterior distributions of their differences (Figure 2). What this means is that the L2 speaker groups were more similar than different, and that predictions related to cue transfer were not supported.
The lack of any strong evidence for cue transfer effects in the current data may be attributed to our use of larger discourse contexts when compared to prior research focusing on the processing of single sentences. In such contexts, differences between L1 and L2 cues provide robust evidence of cue weighting strategies, L1 to L2 influence, and L2 to L1 influence (Bates & MacWhinney, Reference Bates, MacWhinney and MacWhinney1987; Liu et al., Reference Liu, Bates and Li1992; Su, Reference Su2004). Any heuristics based on syntactic cues may therefore give way to semantic strategies when such information is available. For example, sentence stimuli used in prior studies, such as FOX EAT CAT and BOOK EAT FOX, are designed to amplify syntactic violations (Liu et al., Reference Liu, Bates and Li1992), making cue transfer more apparent and measurable. So it may be the case that our predictions related to cue transfer are less realistic when the L2 is working with larger and more cohesive discourse contexts, such as our story vignettes. This finding does not call into question the overall predictions of the Competition Model. Instead, we believe they support the main point—that in these contexts the L2 speakers relied on what was (to them) the most reliable cue to understanding meaning: the discourse semantics. That this also follows the predictions of the SSH showcases complementary rather than completely opposed predictions for our data.
However, it may also be the case that differences in L2 proficiency between the L2 groups may have affected the agent selection behavior and influence of L1 cues. Our second statistical model addressed this question and found a credible effect for the Mandarin speakers. Increases in LexTALE scores were associated with a higher chance of choosing the by-phrase NP as the agent, but only for the inanimate versions of the implausible vignettes. This means that higher proficiency Mandarin speakers were more similar to the L1 English speakers. That such a finding held only for the Mandarin group may, in turn, provide evidence of cue transfer, in that increased L2 proficiency strengthened the similarity between agentive bei and by (and moreover may have reduced the need to rely on semantic cues). In contrast, while the Japanese speakers may have been better equipped to incorporate the multifunctional nature of English by based on L1 cue similarity, the vignettes we used all made a locative interpretation very difficult, as the by-phrase NP was always an animate noun (not to be confused with the animacy contrast of the themes). Therefore, our stimuli may have enhanced the reliability and validity of agentive cues, which may have come more easily to the Mandarin speakers because of a perceived clear L1 to L2 mapping. However, this interpretation remains speculative and requires future research with contexts allowing locative interpretations in order to verify. And, in our study, a locative interpretation may not have been considered at all, meaning that the transfer related to any ambiguity of by was never made possible (this point is discussed further in the limitations).
Moreover, the fact that this proficiency effect only occurred for vignettes with inanimate themes is puzzling, as we did not initially expect the animacy of the theme would affect agent selection (to be clear, all possible agents were animate). Yet our plausibility norming study indicated animate-themed vignettes were taken as less plausible than the inanimate-themed vignettes (Table 2). This means people were more accepting of the events in our stories happening to inanimate objects versus people, and may, in turn, suggest a further interaction with the variety of verbs and event participants used in our stimuli. We accounted for some of this inherent variance among stimuli by using random intercepts and slopes in our multilevel models, yet the animacy effect suggests that when events involve human themes, additional constraints on typical event structures may create conditions under which proficiency differences became more apparent.
Limitations
This study is not without its limitations. Firstly, our use of a non-cumulative SPR design means that participants could not review prior information in the vignettes. This was intentional, but future work should incorporate such processing data into its analyses. For instance, future investigation with eye-tracking methods in a design that allows participants to review prior information in the vignettes while reading would provide further information about whether readers are returning to semantic cues in the stories when encountering conflicting syntactic cues.
We are also aware that wide-scale use of the LexTALE test has recently come under scrutiny as a general measure of L2 proficiency (Puig-Mayenco et al., Reference Puig-Mayenco, Chaouch-Orozco, Liu and Martín-Villena2023). The main problem is that LexTALE is primarily designed to measure the proficiency of learners who are already at relatively advanced levels of L2 proficiency. Although our participants were all university students who had undertaken English language training throughout their schooling, our study would have further benefited from additional measures of L2 proficiency as a means to triangulate this effect. Moreover, LexTALE is largely a measure of vocabulary knowledge, which may not have been important for processing the vignettes in our study.
A final yet crucial limitation is the nature of ambiguity in our stimuli. Our desire to test a given cue (in this case, English by) was motivated by the possibility of agentive or locative interpretations. In practice, however, our use of agentive NPs in the by-phrase made the locative interpretation more difficult to obtain. While locative interpretation would allow for a pathway to reconcile any discrepancies between syntax and semantics, it is also the case that interpreting human bystanders as a location in a by-phrase is admittedly less common (though structurally allowed in syntax), particularly when compared to other prepositions such as near or behind. As such, although a locative interpretation can be made, this is only possible if the reader is willing to put in the requisite effort to construct such an interpretation. In our current design, we are unable to confidently determine whether participants made such an interpretation, which may further explain the lack of L1–L2 transfer effects.
Conclusion
We examined how L1 and L2 English speakers negotiate a competition between semantic and syntactic cues during discourse processing. Our study showed that the agentive bias of the English by-phrase is strong and robust, persisting in both L1 and L2 interpretations even in light of conflicts with discourse-level semantic information. Although we predicted that relative similarity between L1–L2 cues would influence L2 processing behavior, results from our Bayesian regression models indicate more similarity than difference among the L2 groups. This may be partially a function of recruiting relatively high-proficiency L2 speakers, as well as general similarity (rather than conflict) between L1–L2 cues. An important contribution of this work is our consideration of how global discourse-level cues interact with localized syntactic cues, and we encourage future research to continue investigating cue competition and other similar effects within discourse contexts.
Supplementary material
The supplementary material for this article can be found at https://osf.io/kbwun/
Replication package
Full data, code, and appendices are provided on the Open Science Framework: https://osf.io/kbwun/.
Author contributions
Skalicky: Conceptualization, data curation, formal analysis, funding acquisition, investigation, methodology, software, validation, visualization, writing—original draft.
Chen: Conceptualization, funding acquisition, investigation, methodology, writing—reviewing and editing.
Competing interests
The author(s) has/have no competing interests to declare.
Ethical standard
This research was approved by the Victoria University of Wellington Human Ethics Committee #29346. Informed consent was obtained from all participants reported in this study.





 Open access
Open access