

1 Introduction
Measurement bias in the form of differential item functioning (DIF) has received considerable attention in the literature of educational measurement. An item is known to exhibit DIF if the probability of success given ability differs from group to group. Models for DIF detection—also known as measurement invariance testing—have been developed in which an item–group interaction effect represents uniform DIF for an item. The logistic mixed-effects model have been defined for this purpose (Hartig et al., Reference Hartig, Köhler and Naumann2020; Van den Noortgate & De Boeck, Reference Van den Noortgate and De Boeck2005). Another popular model for DIF analysis is the multiple indicators, multiple causes (MIMIC) confirmatory factor model. In the MIMIC model, the measurement component contains an item-specific group effect, which represents the uniform DIF effect (Chen et al., Reference Chen, Li, Ouyang and Xu2023; Muthèn, Reference Muthèn1985). In the multiple-group item response theory (MG-IRT) model group-specific IRT functions can be estimated, which can be compared to the common (invariant) item response functions across groups (Bock & Zimowski, Reference Bock, Zimowski, Linden and Hambleton1997; Köhler et al., Reference Köhler, Hartig, Khorramdel and Pokropek2024).
Methods based on item–group interaction effects (uniform DIF) have the disadvantage that the interactions need to be estimated and assessed for significance. This places restrictions on the required sample size for each group to estimate the interaction effect with sufficient precision. For more than two groups, the assessment of DIF becomes a multiple hypothesis testing problem and requires pairwise-group comparisons. Furthermore, for non-uniform DIF, the estimation and assessment of the interaction between the level of ability and group membership for an item have proven to be challenging. There are only a few studies reporting about performances of methods for non-uniform DIF detection (Narayanon & Swaminathan, Reference Narayanon and Swaminathan1996).
A concurrent (non-)uniform DIF analysis of all test items is computationally very challenging due to the large number of interaction effects and the required large sample sizes. Recently, regularized DIF methods have been developed using a lasso-type procedure for model selection and parameter estimation (e.g., Belzak & Bauer, Reference Belzak and Bauer2020; Schauberger & Mair, Reference Schauberger and Mair2020), which allows the explicit parameterization of all possible DIF effects for all items with the restriction that no more than 50% of the items show DIF. The regularized DIF (lasso) method supports the identification of DIF only through estimation, where non-zero estimated effects are considered DIF. However, the procedure does not provide constructs like P-values and confidence intervals of the lasso (DIF) estimates, making it impossible to assess the significance of the estimated DIF effects. Belzak and Bauer (Reference Belzak and Bauer2020) recommended re-fitting the final model to compute P-values and confidence intervals of the DIF parameters given selected anchor items obtained through regularization. However, they also reported that this leads to naive intervals and P-values—ignoring the impact of the data-dependent model selection on statistical inference—and intervals are too short and will show under coverage. The uncertainty regarding the selection of the DIF items needs to be integrated into the statistical inference to guarantee its validity. However, performing inference after data-driven model selection is a very complex task but inherently connected to lasso-type procedures (Zhang et al., Reference Zhang, Khalili and Asgharian2022).
Valid and consistent methods based on model comparisons require a baseline model, which requires known anchor items. Constrained (nested) versions of the baseline model can be tested to detect (non-uniform) invariant items (Chalmers, Reference Chalmers2012). To test a set of items for DIF, a sequential test procedure is required, for which it is not exactly clear in what order to test the items. When interest is in DIF in discriminations and difficulties, the number of restricted models to examine can increase quickly, since constrained versions of the baseline model are needed for both parameters. Furthermore, sequentially or iteratively testing for DIF leads to a multiple hypothesis testing problem, which requires a correction to control the family-wise error rate.
1.1 The disadvantages of random item parameters
To enable a simultaneous DIF analysis of all items, and to avoid a model-selection procedure, Bayesian IRT models for DIF have been developed (e.g., De Jong et al., Reference De Jong, Steenkamp and Fox2007; Verhagen & Fox, Reference Verhagen and Fox2013). They are constructed from a random item parameter model, also known as a random item effects model, in which random item parameters describe differences in item parameters across groups. The model defines a common measurement scale across groups by assuming group-specific (random) item parameters, which are assumed to be normally distributed around invariant item parameters. The random item parameter variance is used to assess the degree of measurement variance. When the variance is (approximately) zero, it represents no DIF (measurement invariance), and if greater than zero, it represents DIF (measurement variance).
The random item parameter approach has several disadvantages. The method is not suitable for non-sampled groups for which the normality assumption of the random item parameters does not apply, or a few sampled groups for which the random item parameter variance cannot be accurately estimated. Another disadvantage is that DIF is represented by a random item parameter variance of zero, which is a boundary value on the parameter space. This complicates the specification of an objective prior for the variance parameter but also complicates assessing data evidence in favor of DIF under the random item parameter model. Furthermore, the random item parameter model, similar to DIF interaction models, places restrictions on the required group sizes to estimate random item effects with sufficient precision. This is particularly a problem for examining DIF in discrimination parameters, which relies on accurate group-specific discrimination estimates.
1.2 From random item parameters to a structured covariance matrix
To avoid the disadvantages of the random item parameter model, Fox et al. (Reference Fox, Mulder and Sinharay2017) and Fox et al. (Reference Fox, Koops, Feskens and Beinhauer2020) proposed a Bayesian covariance structure model for DIF testing (BCSM-MI). In their modeling approach, dependence among item responses caused by DIF is not modeled by random item parameters but through a structured covariance matrix. When assuming DIF, the IRT’s local independence assumption does not hold, which means that the item response data are not independently distributed given person and invariant item parameters. The item response data are assumed to be correlated within each group, caused by an item–group interaction. The correlation is zero when measurement invariance holds, and it is greater than zero when measurement invariance is violated.
The BCSM-MI has the advantage that it does not include any group-specific item parameters, and subsequently does not make any assumptions about the distribution of the group-specific item parameters. This makes the BCSM-MI suitable for assessing DIF for two or more groups and for randomly and non-randomly selected groups. Furthermore, a correlation of zero (representing no DIF) is not a boundary value on the parameter space. This makes it possible to define a noninformative prior about the DIF assumption and to assess data evidence in favor of DIF under the BCSM-MI. Furthermore, the assumption of uniform DIF (item–group interaction) is represented by a single covariance parameter, but also non-uniform DIF (item-specific person–group interaction) is represented by a single covariance parameter. Without requiring any item–group interaction effects, the assessment of DIF in discriminations and difficulties can be executed with more similar levels of confidence.
In this study, the BCSM-MI for uniform DIF is generalized to assess non-uniform DIF for unbalanced groups. DIF is manifested through differences in difficulty or discrimination or both across groups. Although Fox et al. (Reference Fox, Koops, Feskens and Beinhauer2020) introduced a structured covariance matrix representing the assumption of uniform and non-uniform DIF for a balanced design, their developed Markov chain Monte Carlo (MCMC) algorithm and simulation results were restricted to uniform DIF. Their MCMC algorithm is extended to include the estimation of (item-specific) covariance parameters—a dependence structure implied by item-specific person–group interactions—while also accounting for unequal group sizes. The conditional distribution of each covariance parameter is identified as a product of shifted-inverse gamma distributions (Fox et al., Reference Fox, Mulder and Sinharay2017), which is shown through eigenvector decompositions. Lower bound restrictions for the covariance parameters, ensuring a positive-definite covariance matrix, are integrated in the shifted-inverse gamma priors. This facilitates efficient posterior sampling of covariance parameters as part of the MCMC algorithm.
Next, the BCSM-MI is introduced, in which a structured covariance matrix represents the assumption of uniform and non-uniform DIF. Subsequently, a short comparison is given with some conventional DIF tests, and shortcomings in relation to the proposed Bayesian DIF tests are discussed. In Section 4, the proposed inference method is described, including the derivation of the posterior distribution of the covariance parameters. In Section 5, a Bayes factor (BF) test is proposed for assessing hypotheses concerning non-uniform DIF. In Section 6, the performance of the BCSM-MI for the assessment of non-uniform DIF is shown through simulation studies. An illustration of the method is given using a PISA study and results are compared to an MG-IRT analysis. Finally, in Section 8, a discussion is given of possible extensions of the method and of the used covariance priors.
2 The BCSM-MI method
The BCSM-MI is introduced by considering the random item parameter model for binary item responses (Fox, Reference Fox2010, Verhagen & Fox, Reference Verhagen and Fox2013). The random item parameters, denoted as
$a_{kj}$
 and
$b_{kj}$
and
$b_{kj}$
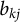 , are assumed to be normally distributed with mean
$a_k$
, are assumed to be normally distributed with mean
$a_k$
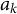 and
$b_k$
and
$b_k$
 and variance
$\sigma _{a_k}$
and variance
$\sigma _{a_k}$
 and
$\sigma _{b_k}$
and
$\sigma _{b_k}$
 , respectively. A latent response variable is used to specify the random item parameter model with
$Z_{ijk}$
, respectively. A latent response variable is used to specify the random item parameter model with
$Z_{ijk}$
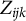 a normally distributed latent response of person i in group j for item k. Then, the random item effects model is represented by
a normally distributed latent response of person i in group j for item k. Then, the random item effects model is represented by

where
$\epsilon _{a_{k_j}}\theta _{ij}$
 and
$\epsilon _{b_{k_j}}$
and
$\epsilon _{b_{k_j}}$
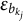 represents an item’s person–group interaction (DIF in discrimination) and an item–group interaction (DIF in difficulty) in group j, respectively, and assumed to be normally distributed with mean zero and variance
$\sigma _{a_k}$
represents an item’s person–group interaction (DIF in discrimination) and an item–group interaction (DIF in difficulty) in group j, respectively, and assumed to be normally distributed with mean zero and variance
$\sigma _{a_k}$
 and
$\sigma _{b_k}$
and
$\sigma _{b_k}$
 , respectively. The random measurement error
$e_{ijk}$
, respectively. The random measurement error
$e_{ijk}$
 is assumed to be standard normally distributed. Following Fox et al. (Reference Fox, Koops, Feskens and Beinhauer2020), the BCSM-MI is derived by integrating out the random item parameters. Without conditioning on the group-specific item parameters, they show that the covariance among two latent responses to item k in group j is given by
is assumed to be standard normally distributed. Following Fox et al. (Reference Fox, Koops, Feskens and Beinhauer2020), the BCSM-MI is derived by integrating out the random item parameters. Without conditioning on the group-specific item parameters, they show that the covariance among two latent responses to item k in group j is given by

Given this result, the BCSM-MI for responses to item k in group j, including the dependence structure of the DIF effects, can be represented by

where
$\boldsymbol {\theta }_j \sim \mathcal {N}\left (\mu _{\theta _j}, \sigma _{\theta _j}\mathbf {I}_{n_j} \right )$
 and
$\mathbf {Z}_{jk}\in \boldsymbol {\Omega }(\mathbf {z}_{jk})$
and
$\mathbf {Z}_{jk}\in \boldsymbol {\Omega }(\mathbf {z}_{jk})$
 with
$\boldsymbol {\Omega }(\mathbf {z}_{jk}) =\{\mathbf {z}_{jk}, z_{ijk}\le 0 \text { if } y_{ijk}=0, z_{ijk}>0 \text { if } y_{ijk}=1 \}$
with
$\boldsymbol {\Omega }(\mathbf {z}_{jk}) =\{\mathbf {z}_{jk}, z_{ijk}\le 0 \text { if } y_{ijk}=0, z_{ijk}>0 \text { if } y_{ijk}=1 \}$
 representing the allowable region for the latent responses. The
$\mathbf {J}_{n_{j}}$
representing the allowable region for the latent responses. The
$\mathbf {J}_{n_{j}}$
 is a matrix of dimension
$n_j$
is a matrix of dimension
$n_j$
 with all elements equal to one and
$\mathbf {I}_{n_j}$
with all elements equal to one and
$\mathbf {I}_{n_j}$
 is the identity matrix.
is the identity matrix.
To illustrate the modeling of DIF through the structured covariance matrix, the conditional expectation of
$Z_{ijk}$
 is derived under the BCSM-MI given item and person parameters and remaining latent responses in group j, denoted as
$\mathbf {Z}_{(-i)jk}$
is derived under the BCSM-MI given item and person parameters and remaining latent responses in group j, denoted as
$\mathbf {Z}_{(-i)jk}$
 . When
$\sigma _{b_k}=0$
. When
$\sigma _{b_k}=0$
 representing no DIF in difficulty parameter
$b_k$
representing no DIF in difficulty parameter
$b_k$
 , it is shown that this conditional expectation equals the mean term
$\mu _{ijk}=a_k\theta _{ij} -b_k$
, it is shown that this conditional expectation equals the mean term
$\mu _{ijk}=a_k\theta _{ij} -b_k$
 plus an item–person–group interaction,
$\theta _{ij}\epsilon _{a_{k_j}}$
plus an item–person–group interaction,
$\theta _{ij}\epsilon _{a_{k_j}}$
 , according to Equation (1). From Equation (1), with
$\epsilon _{b_{k_j}}=0,$
, according to Equation (1). From Equation (1), with
$\epsilon _{b_{k_j}}=0,$
 it follows that the ordinary least squares estimator of
$\epsilon _{a_{k_j}}$
it follows that the ordinary least squares estimator of
$\epsilon _{a_{k_j}}$
 can be expressed as
can be expressed as

where observation
$Z_{ijk}$
 is excluded in the estimator for the
$\epsilon _{a_{k_j}}$
is excluded in the estimator for the
$\epsilon _{a_{k_j}}$
 .
.
According to the BCSM-MI, the conditional expectation of
$Z_{ijk}$
 given
$\mathbf {Z}_{(-i)jk}$
given
$\mathbf {Z}_{(-i)jk}$
 can be expressed as (see Appendix A)
can be expressed as (see Appendix A)

where, in the last term, a Bayes estimator of the
$\epsilon _{a_{k_j}}$
 can be recognized, in which a positive
$\sigma _{a_k}$
can be recognized, in which a positive
$\sigma _{a_k}$
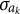 arranges shrinkage of the effect toward zero. As a conclusion, under the BCSM-MI, the expected latent response
$Z_{ijk}$
arranges shrinkage of the effect toward zero. As a conclusion, under the BCSM-MI, the expected latent response
$Z_{ijk}$
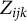 depends on the item–person–group interaction, which represents the contribution of DIF in discrimination parameter
$a_k$
depends on the item–person–group interaction, which represents the contribution of DIF in discrimination parameter
$a_k$
 . When
$\sigma _{a_k}=0$
. When
$\sigma _{a_k}=0$
 , the covariance support for this interaction effect is not present in the structured covariance matrix in Equation (3). Subsequently, the expression in Equation (5) is only defined for
$\sigma _{a_k} \ne 0$
, the covariance support for this interaction effect is not present in the structured covariance matrix in Equation (3). Subsequently, the expression in Equation (5) is only defined for
$\sigma _{a_k} \ne 0$
 .
.
The structured covariance matrix needs to be positive definite, which restricts the parameter space of the covariance parameters. When
$\sigma _{b_k}=0$
 , the determinant of the covariance matrix needs to be positive and implies a restriction on the
$\sigma _{a_k}$
, the determinant of the covariance matrix needs to be positive and implies a restriction on the
$\sigma _{a_k}$
 . It follows that
. It follows that

Subsequently, the covariance matrix is positive definite if
$\sigma _{a_k}> -1/\sum _{i}\theta ^2_{ij}$
 . The parameter space of the covariance parameter
$\sigma _{a_k}$
. The parameter space of the covariance parameter
$\sigma _{a_k}$
 represents three different types of non-uniform DIF. The common non-uniform DIF in discrimination is represented by
$\sigma _{a_k}>0$
represents three different types of non-uniform DIF. The common non-uniform DIF in discrimination is represented by
$\sigma _{a_k}>0$
 , which states a non-uniform difference in item characteristic curves across groups. There is no DIF in discrimination if
$\sigma _{a_k}=0$
, which states a non-uniform difference in item characteristic curves across groups. There is no DIF in discrimination if
$\sigma _{a_k}=0$
 . When
$\sigma _{a_k} \in \left (-1/\sum _{i}\theta ^2_{ij},0\right )$
. When
$\sigma _{a_k} \in \left (-1/\sum _{i}\theta ^2_{ij},0\right )$
 , there is DIF in discrimination within each group j. This means that for persons in group j, the item discriminates differently and this is referred to as within-group non-uniform DIF. Within each group, the item discriminates more highly to some than other group members, and this is manifested as a negative correlation among the (latent) item responses. Within-group DIF is beyond the scope of this research. Nielsen et al. (Reference Nielsen, Smink and Fox2021) and Fox and Smink (Reference Fox and Smink2023) discuss the modeling of negative associations among clustered measurements and the interpretation of negative clustering effects.
, there is DIF in discrimination within each group j. This means that for persons in group j, the item discriminates differently and this is referred to as within-group non-uniform DIF. Within each group, the item discriminates more highly to some than other group members, and this is manifested as a negative correlation among the (latent) item responses. Within-group DIF is beyond the scope of this research. Nielsen et al. (Reference Nielsen, Smink and Fox2021) and Fox and Smink (Reference Fox and Smink2023) discuss the modeling of negative associations among clustered measurements and the interpretation of negative clustering effects.
3 Related methods on detecting DIF
The psychometric literature on DIF is huge and shows intensive research in assessing the fairness of measurement instruments. The IRT-based methods condition on the latent variable and are originally designed for a two-group comparison (Camilli & Shepard, Reference Camilli and Shepard1994; Millsap, Reference Millsap2011). A likelihood-ratio (LR) test can be applied to test for differences in item parameters across groups (Thissen et al., Reference Thissen, Steinberg, Wainer, Wainer and Braun1988). These methods require prior knowledge about anchor items assumed to be free of DIF. Results from a stepwise procedure to identify anchor items can be sensitive to the initial choice of anchors. Uncertainty in the model selection process can lead to an incorrect selection of items free of DIF. Due to the stepwise procedure of model selection, the validity of the statistical inference on the DIF parameters is not guaranteed. Disadvantages of DIF methods based on pre-knowledge of anchoring items have been discussed by Chen et al. (Reference Chen, Li, Ouyang and Xu2023).
Recent extensions in IRT-based DIF modeling consider additional group-specific parameters for differences across groups in item discrimination and difficulty for several items. Although an IRT-based LR test can be used to identify variations in item discriminations across groups, due to the increase in the number of model parameters maximum likelihood estimation is more likely to fail. Furthermore, the LR method seriously increases the required sample size in each group for accurate parameter estimation.
The performance of DIF detection methods have not been extensively studied, mainly due to the computational burden. Finch (Reference Finch2005) provides an overview of the performance of several popular methods (e.g., MIMIC, Mantel–Haenszel, and LR test), which require anchor items and they are meant for a two-group comparison. It is shown that the performances depend on the number of anchor items, where more anchors increased the power of DIF detection. Anchors containing DIF negatively affect the performances. Furthermore, the Type-1 error was beyond the nominal level especially for relatively short tests (around 20 items). For longer tests, the MIMIC model showed only a small inflation in the Type-I error. Shih and Wang (Reference Shih and Wang2009) examined the performance of the MIMIC model for DIF detection and showed acceptable (average) Type-I error rates. However, for a group size of 500 and 1,000, the mean power (true positive rate) was around 50%–60% and 80%–90%, respectively, where the difference in difficulty parameters between the reference and focal groups was set at 0.4. It is well known that conditional DIF methods, in which DIF effects are estimated and assessed for significance, require moderate to large sample sizes to perform well (Fox et al., Reference Fox, Koops, Feskens and Beinhauer2020).
Due to page limit, a further discussion of more recently developed DIF methods (e.g., regularized DIF and model-based recursive partitioning) is given in Section S1 of the Supplementary Material. Subsequently, in Section S2 of the Supplementary Material, a comparison in performance between regularized DIF and the BCSM-MI method is given through a simulation study.
The BCSM-MI has several advantages over other DIF methods. For each item parameter, DIF can be assessed for any number of groups with a single covariance parameter. The BCSM-MI method avoids the model selection problem to detect anchor items by modeling simultaneously DIF in all items. The item DIF is simultaneously assessed for significance, which leads to a valid inference procedure. The proposed BF test for a covariance parameter is an omnibus test for (non-)uniform DIF across all groups thereby avoiding multiple hypothesis testing problem. The method does not rely on any anchor items to measure all persons on the same scale. The DIF in each item is modeled through the covariance matrix, which adjusts the person and item parameter estimates but this does not lead to changes in the scale of the person parameters. Therefore, the BCSM-MI can be identified by restricting the mean and variance of the scale of the person parameters (possibly of a reference group), independent of the number of items showing DIF.
4 MCMC estimation of BCSM-MI
The MCMC algorithm for the estimation of the BCSM-MI parameters is described in Appendix C. The sampling of the covariance parameters is done through slice sampling and discussed in more detail in this section. The other model parameters are sampled directly from their conditional distributions given augmented item response data. A Metropolis–Hastings step is defined for the sampling of person parameters, when negative covariance values are sampled (see Appendix D).
The BCSM-MI is identified in the same way as an MG-IRT model. The mean and variance of the person parameters of the reference group are restricted to 0 and 1, respectively. It is also possible to place restrictions on the item difficulty and discrimination parameters to identify the latent scale.
4.1 Posterior distribution (DIF) covariance parameters
To obtain an analytical expression for the posterior distribution of each covariance parameter, a novel method is applied based on eigenvector transformations of the latent item response data. This method generalizes the procedure of Fox (Reference Fox2024), in which one covariance parameter is considered. The method is based on recognizing that the covariance structure of the BCSM-MI in Equation (3) consists of two rank-one components to describe dependence among item responses due to DIF. The two non-zero eigenvalues can be expressed as a function of the covariance parameters. The transformation of the (latent) item response data with the eigenvectors is considered, which has a bivariate normal distribution with a covariance matrix containing the two non-zero eigenvalues. Another set of eigenvectors can be computed which diagonalize this covariance matrix with respect to one of the covariance parameters. Then, an analytical expression of each covariance parameter is obtained by considering the distribution of the latent item response data transformed by both eigenvectors.
By definition, the transformation of the (latent) response data by eigenvectors is sufficient for the covariance parameters. Furthermore, any correlation between the DIF in difficulty and discrimination will not bias the estimation results. The second eigenvector decomposition is an orthogonal transformation with respect to the other covariance parameter thereby properly avoiding the influence of any correlation between the two covariance parameters.
4.1.1 Eigenvector transformations
This procedure starts with the computation of the eigenvectors with non-zero eigenvalues for the two rank one components in the covariance matrix. The following definitions follow directly from theory of a rank-1 matrix. Let
$\mathbf {v}_{a_{jk}}=\boldsymbol {\theta }_j/\|\boldsymbol {\theta }_j \|$
 be the eigenvector which diagonalize the covariance matrix component
$\sigma _{a_k}\boldsymbol {\theta }_j\boldsymbol {\theta }^t_j$
be the eigenvector which diagonalize the covariance matrix component
$\sigma _{a_k}\boldsymbol {\theta }_j\boldsymbol {\theta }^t_j$
 with eigenvalue
$\sigma _{a_k}\boldsymbol {\theta }^t_j\boldsymbol {\theta }_j$
with eigenvalue
$\sigma _{a_k}\boldsymbol {\theta }^t_j\boldsymbol {\theta }_j$
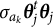 , where
$\|\boldsymbol {\theta }_j \|$
, where
$\|\boldsymbol {\theta }_j \|$
 represents the Frobenius norm of
$\boldsymbol {\theta }_j$
represents the Frobenius norm of
$\boldsymbol {\theta }_j$
 . The eigenvector
$\mathbf {v}_{b_{jk}}=\mathbf {1}_{n_j}/\|\mathbf {1}_{n_j} \|$
. The eigenvector
$\mathbf {v}_{b_{jk}}=\mathbf {1}_{n_j}/\|\mathbf {1}_{n_j} \|$
 diagonalizes the covariance matrix component
$\sigma _{b_k}\mathbf {J}_{n_j}$
diagonalizes the covariance matrix component
$\sigma _{b_k}\mathbf {J}_{n_j}$
 with eigenvalue
$\sigma _{b_k}n_j$
with eigenvalue
$\sigma _{b_k}n_j$
 . The eigenvectors are stored in matrix
$\mathbf {v}_{jk}=(\mathbf {v}_{a_{jk}},\mathbf {v}_{b_{jk}})$
. The eigenvectors are stored in matrix
$\mathbf {v}_{jk}=(\mathbf {v}_{a_{jk}},\mathbf {v}_{b_{jk}})$
 . Then,
$\tilde {\mathbf {z}}_{jk} = \mathbf {v}^t_{jk}(\mathbf {z}_{jk}-\boldsymbol {\mu }_{jk})$
. Then,
$\tilde {\mathbf {z}}_{jk} = \mathbf {v}^t_{jk}(\mathbf {z}_{jk}-\boldsymbol {\mu }_{jk})$
 has a bivariate normal distribution with mean zero and covariance matrix
$\mathbf {v}^t_{jk}\boldsymbol {\Sigma }_{jk} \mathbf {v}_{jk}$
has a bivariate normal distribution with mean zero and covariance matrix
$\mathbf {v}^t_{jk}\boldsymbol {\Sigma }_{jk} \mathbf {v}_{jk}$
 .
.
Consider the projection matrix
$\mathcal {P}_a$
 and
$\mathcal {P}_b$
and
$\mathcal {P}_b$
 orthogonal to the column space of
$\mathbf {v}^t_{jk}\mathbf {1}_{n_j}$
orthogonal to the column space of
$\mathbf {v}^t_{jk}\mathbf {1}_{n_j}$
 and
$\mathbf {v}^t_{jk}\boldsymbol {\theta }_j$
and
$\mathbf {v}^t_{jk}\boldsymbol {\theta }_j$
 , respectively, which are given by
, respectively, which are given by

respectively. The projection matrices
$\mathcal {P}_a$
 and
$\mathcal {P}_b$
and
$\mathcal {P}_b$
 are each of rank one. Let
$\mathbf {w}_{a_{jk}}$
are each of rank one. Let
$\mathbf {w}_{a_{jk}}$
 and
$\mathbf {w}_{b_{jk}}$
and
$\mathbf {w}_{b_{jk}}$
 be the eigenvector of projection matrices
$\mathcal {P}_a$
be the eigenvector of projection matrices
$\mathcal {P}_a$
 and
$\mathcal {P}_b$
and
$\mathcal {P}_b$
 , respectively, each corresponding to the one non-zero eigenvalue. Then, by definition,
$\mathbf {w}_{a_{jk}}$
, respectively, each corresponding to the one non-zero eigenvalue. Then, by definition,
$\mathbf {w}_{a_{jk}}$
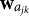 and
$\mathbf {w}_{b_{jk}}$
and
$\mathbf {w}_{b_{jk}}$
 diagonalize the covariance matrix
$\mathbf {v}^t_{jk}\boldsymbol {\Sigma }_{jk}\mathbf {v}_{jk}$
diagonalize the covariance matrix
$\mathbf {v}^t_{jk}\boldsymbol {\Sigma }_{jk}\mathbf {v}_{jk}$
 with respect to
$\sigma _{a_k}$
with respect to
$\sigma _{a_k}$
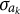 and
$\sigma _{b_k}$
and
$\sigma _{b_k}$
 , respectively. For instance, eigenvectors
$\mathbf {w}_{a_{jk}}$
, respectively. For instance, eigenvectors
$\mathbf {w}_{a_{jk}}$
 and
$\mathbf {v}_{jk}$
and
$\mathbf {v}_{jk}$
 diagonalize covariance matrix
$\boldsymbol {\Sigma }_{jk}$
diagonalize covariance matrix
$\boldsymbol {\Sigma }_{jk}$
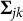 with respect to
$\sigma _{a_k}$
with respect to
$\sigma _{a_k}$
 :
:

where
$\tilde {\mathbf {w}}^t_{a_{jk}}=\mathbf {w}^t_{a_{jk}}\mathbf {v}^t_{jk}$
 and
$\tilde {\mathbf {w}}^t_{a_{jk}}\mathbf {1}_{n_j}=\mathbf {0}$
and
$\tilde {\mathbf {w}}^t_{a_{jk}}\mathbf {1}_{n_j}=\mathbf {0}$
 , since
$\mathcal {P}_a$
, since
$\mathcal {P}_a$
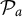 is orthogonal to the column space of
$\mathbf {v}^t_{jk}\mathbf {1}_{n_j}$
is orthogonal to the column space of
$\mathbf {v}^t_{jk}\mathbf {1}_{n_j}$
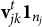 .
.
4.1.2 Posterior distribution of
$\sigma _{a_k}$


Consider the distribution of
$\tilde {\tilde {z}}_{a_{jk}}=\tilde {\mathbf {w}}^t_{a_{jk}}\tilde {\mathbf {z}}_{jk}$
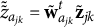 . Let
$s_{a_{jk}}=\tilde {\mathbf {w}}^t_{a_{jk}}\tilde {\mathbf {w}}_{a_{jk}}$
. Let
$s_{a_{jk}}=\tilde {\mathbf {w}}^t_{a_{jk}}\tilde {\mathbf {w}}_{a_{jk}}$
 and
$\lambda _{a_{jk}}=\tilde {\mathbf {w}}^t_{a_{jk}}\boldsymbol {\theta }_j\boldsymbol {\theta }_j^t\tilde {\mathbf {w}}_{a_{jk}}$
and
$\lambda _{a_{jk}}=\tilde {\mathbf {w}}^t_{a_{jk}}\boldsymbol {\theta }_j\boldsymbol {\theta }_j^t\tilde {\mathbf {w}}_{a_{jk}}$
 . The distribution of
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
. The distribution of
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
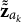 given
$\sigma _{a_k}$
given
$\sigma _{a_k}$
 ,
$s_{a_{jk}}$
,
$s_{a_{jk}}$
 , and
$\lambda _{a_{jk}}$
, and
$\lambda _{a_{jk}}$
 is the product of independently normally distributed variables and is represented by
is the product of independently normally distributed variables and is represented by

where
$SS_{a_{jk}}= \left (\tilde {\tilde {z}}_{a_{jk}}\right )^2$
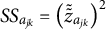 .
.
There are two restrictions on the parameter space of
$\sigma _{a_k}$
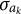 . The first restriction states that
$\sigma _{a_k}\lambda _{a_{jk}} +s_{a_{jk}}$
. The first restriction states that
$\sigma _{a_k}\lambda _{a_{jk}} +s_{a_{jk}}$
 is greater than zero for all j, since it represents an eigenvalue of the covariance matrix
$\boldsymbol {\Sigma }_{jk}$
is greater than zero for all j, since it represents an eigenvalue of the covariance matrix
$\boldsymbol {\Sigma }_{jk}$
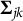 . A lower bound for
$\sigma _{a_{k}}$
. A lower bound for
$\sigma _{a_{k}}$
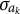 can be derived, and it follows that
$LB_1(\sigma _{a_k}) = -\min _j s_{a_{jk}}/\lambda _{a_{jk}}$
can be derived, and it follows that
$LB_1(\sigma _{a_k}) = -\min _j s_{a_{jk}}/\lambda _{a_{jk}}$
 .
.
The second restriction follows from the positive-definite restriction on the covariance matrix
$\boldsymbol {\Sigma }_{jk}$
 for all j. The determinant of the covariance matrix can be explicitly derived though the matrix determinant lemma (Appendix B). It follows that
for all j. The determinant of the covariance matrix can be explicitly derived though the matrix determinant lemma (Appendix B). It follows that

Then, a shifted-inverse gamma prior can be defined for
$\sigma _{a_k}$
 , which integrates the lower bound restrictions. Therefore, let
$s_{\sigma _{a_k}}=\min \left (-LB_1\left (\sigma _{a_k}\right ), -LB_2\left (\sigma _{a_k}\right ) \right )$
, which integrates the lower bound restrictions. Therefore, let
$s_{\sigma _{a_k}}=\min \left (-LB_1\left (\sigma _{a_k}\right ), -LB_2\left (\sigma _{a_k}\right ) \right )$
 , and
, and

The posterior distribution of
$\sigma _{a_k}$
 is proportional to the product of the conditional distribution in Equation (7) and the prior in Equation (9), and cannot be obtained in closed form.
is proportional to the product of the conditional distribution in Equation (7) and the prior in Equation (9), and cannot be obtained in closed form.
4.1.3 Posterior distribution of
$\sigma _{b_k}$
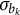
The restrictions on parameter
$\sigma _{b_k}$
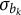 follow in a similar way. The eigenvalue
$\sigma _{b_k}\lambda _{b_{jk}} +s_{b_{jk}}$
follow in a similar way. The eigenvalue
$\sigma _{b_k}\lambda _{b_{jk}} +s_{b_{jk}}$
 is greater than zero for all j, which leads to a lower bound for
$\sigma _{b_{k}}$
is greater than zero for all j, which leads to a lower bound for
$\sigma _{b_{k}}$
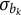 ,
$LB_1(\sigma _{b_k}) = -\min _j \frac {s_{b_{jk}}}{\lambda _{b_{jk}}}$
,
$LB_1(\sigma _{b_k}) = -\min _j \frac {s_{b_{jk}}}{\lambda _{b_{jk}}}$
 . The determinant of the covariance matrix needs to be greater than zero, which also restricts the parameter space for
$\sigma _{b_{k}}$
. The determinant of the covariance matrix needs to be greater than zero, which also restricts the parameter space for
$\sigma _{b_{k}}$
 , and it follows that
, and it follows that

Then, let
$s_{\sigma _{b_k}}=\min \left (-LB_1\left (\sigma _{b_k}\right ), -LB_2\left (\sigma _{b_k}\right ) \right )$
 , and a prior for
$\sigma _{b_k}$
, and a prior for
$\sigma _{b_k}$
 is a shifted-inverse gamma distribution represented by
is a shifted-inverse gamma distribution represented by

To define the posterior distribution of
$\sigma _{b_k}$
 , consider the distribution of
$\tilde {\tilde {\mathbf {z}}}_{b_k} = \tilde {\mathbf {w}}^t_{b_{jk}}\tilde {\mathbf {z}}_{jk}$
, consider the distribution of
$\tilde {\tilde {\mathbf {z}}}_{b_k} = \tilde {\mathbf {w}}^t_{b_{jk}}\tilde {\mathbf {z}}_{jk}$
 . Let
$s_{b_{jk}}=\tilde {\mathbf {w}}^t_{b_{jk}}\tilde {\mathbf {w}}_{b_{jk}}$
. Let
$s_{b_{jk}}=\tilde {\mathbf {w}}^t_{b_{jk}}\tilde {\mathbf {w}}_{b_{jk}}$
 and
$\lambda _{b_{jk}}=\tilde {\mathbf {w}}^t_{b_{jk}}\boldsymbol {\theta }_j\boldsymbol {\theta }_j^t\tilde {\mathbf {w}}_{b_{jk}}$
and
$\lambda _{b_{jk}}=\tilde {\mathbf {w}}^t_{b_{jk}}\boldsymbol {\theta }_j\boldsymbol {\theta }_j^t\tilde {\mathbf {w}}_{b_{jk}}$
 . The distribution of
$\tilde {\tilde {\mathbf {z}}}_{b_k}$
. The distribution of
$\tilde {\tilde {\mathbf {z}}}_{b_k}$
 given
$\sigma _{b_k}$
given
$\sigma _{b_k}$
 ,
$s_{b_{jk}}$
,
$s_{b_{jk}}$
 , and
$\lambda _{b_{jk}}$
, and
$\lambda _{b_{jk}}$
 is represented by
is represented by

where
$SS_{b_{jk}}= \left (\tilde {\tilde {z}}_{b_{jk}}\right )^2$
 . It follows that the posterior distribution of
$\sigma _{b_k}$
. It follows that the posterior distribution of
$\sigma _{b_k}$
 is proportional to the product of the prior in Equation (11) and the conditional distribution in Equation (12).
is proportional to the product of the prior in Equation (11) and the conditional distribution in Equation (12).
5 Bayes factor tests for non-uniform DIF
The BF is used to assess hypotheses concerning the covariance parameters
$\sigma _{a_k}$
 and
$\sigma _{b_k}$
and
$\sigma _{b_k}$
 . For each covariance parameter, there are three hypotheses of interest. The covariance parameter can be equal to zero, for instance,
$H_0: \sigma _{a_k}=0$
. For each covariance parameter, there are three hypotheses of interest. The covariance parameter can be equal to zero, for instance,
$H_0: \sigma _{a_k}=0$
 , which represents no DIF in discrimination for item k. The parameter can be greater than zero,
$H_2: \sigma _{a_k}>0$
, which represents no DIF in discrimination for item k. The parameter can be greater than zero,
$H_2: \sigma _{a_k}>0$
 , which represents DIF in discrimination. A special case can be considered,
$H_1: \sigma _{a_k} < 0$
, which represents DIF in discrimination. A special case can be considered,
$H_1: \sigma _{a_k} < 0$
 , where DIF is present among group members (instead of DIF between groups). The practical application of this case is not explored in this study. The main purpose of the BF tests is to measure the data support in favor of no (non-uniform) DIF (
$H_0$
, where DIF is present among group members (instead of DIF between groups). The practical application of this case is not explored in this study. The main purpose of the BF tests is to measure the data support in favor of no (non-uniform) DIF (
$H_0$
 ) and DIF (
$H_2$
) and DIF (
$H_2$
 ). An unrestricted hypothesis
$H_u$
). An unrestricted hypothesis
$H_u$
 is used as a reference to examine the preference of each hypothesis in comparison to the unrestricted hypothesis.
is used as a reference to examine the preference of each hypothesis in comparison to the unrestricted hypothesis.
The normalizing constant of the marginal likelihood of the (latent) item response data given the covariance parameter in Equations (7) and (12) is unknown. A parameter transformation is used to avoid the computation of a normalizing constant under each hypothesis. It is shown that the marginal likelihood under each hypothesis for the transformed parameter is computationally much more efficient.
5.1 Change of variables
The distribution of
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
 given
$\sigma _{a_k}$
given
$\sigma _{a_k}$
 is a product of independently normally distributed variables with different variance components, but each including
$\sigma _{a_k}$
is a product of independently normally distributed variables with different variance components, but each including
$\sigma _{a_k}$
 (Equation (7)). A parameter transformation is considered for which the posterior distribution has a known analytical form. The transformation function
$\omega _{a_k} = \frac {\sigma _{a_k}\lambda _{a_{jk}}}{\sigma _{a_k}\lambda _{a_{jk}}+s_{a_{jk}}}$
(Equation (7)). A parameter transformation is considered for which the posterior distribution has a known analytical form. The transformation function
$\omega _{a_k} = \frac {\sigma _{a_k}\lambda _{a_{jk}}}{\sigma _{a_k}\lambda _{a_{jk}}+s_{a_{jk}}}$
 is defined with inverse function and derivative
is defined with inverse function and derivative

respectively. It can be shown that the distribution of the
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
 given
$\omega _{a_k}$
given
$\omega _{a_k}$
 is a gamma distribution
is a gamma distribution

where
$\tilde {\omega }_{a_k}=1-\omega _{a_k}$
 , and assume a gamma prior for
$\tilde {\omega }_{a_k}$
, and assume a gamma prior for
$\tilde {\omega }_{a_k}$
 . Then,
$\tilde {\omega }_{a_k}$
. Then,
$\tilde {\omega }_{a_k}$
 has a gamma posterior distribution given
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
has a gamma posterior distribution given
$\tilde {\tilde {\mathbf {z}}}_{a_k}$
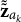 with shape parameter
$g_1+J/2$
with shape parameter
$g_1+J/2$
 and scale parameter
$g_2+\sum _j SS_{a_{jk}}/(2s_{a_{jk}})$
and scale parameter
$g_2+\sum _j SS_{a_{jk}}/(2s_{a_{jk}})$
 . The lower bound for
$\sigma _{a_k}$
. The lower bound for
$\sigma _{a_k}$
 is translated to a boundary value for
$\omega _{a_k}$
is translated to a boundary value for
$\omega _{a_k}$
 , denoted as
$UB(\tilde {\omega }_{a_k})$
, denoted as
$UB(\tilde {\omega }_{a_k})$
 .
.
In the same way, it can be shown with transformation function
$\omega _{b_k} = \frac {\sigma _{b_k}\lambda _{b_{jk}}}{\sigma _{b_k}\lambda _{b_{jk}}+s_{b_{jk}}}$
 that
$\tilde {\omega }_{b_k}=1-\omega _{b_k}$
that
$\tilde {\omega }_{b_k}=1-\omega _{b_k}$
 has a gamma distribution. Then, with a gamma prior for the
$\tilde {\omega }_{b_k}$
has a gamma distribution. Then, with a gamma prior for the
$\tilde {\omega }_{b_k}$
 , the posterior distribution of
$\tilde {\omega }_{b_k}$
, the posterior distribution of
$\tilde {\omega }_{b_k}$
 is a gamma distribution with shape parameter
$g_1+J/2$
is a gamma distribution with shape parameter
$g_1+J/2$
 and scale parameter
$g_2+\sum _j SS_{b_{jk}}/(2s_{b_{jk}})$
and scale parameter
$g_2+\sum _j SS_{b_{jk}}/(2s_{b_{jk}})$
 , where
$SS_{b_{jk}} = (\tilde {\tilde {z}}_{b_{jk}})^2$
, where
$SS_{b_{jk}} = (\tilde {\tilde {z}}_{b_{jk}})^2$
 . An upper bound for
$\tilde {\omega }_{b_k}$
. An upper bound for
$\tilde {\omega }_{b_k}$
 ,
$UB(\tilde {\omega }_{b_k})$
,
$UB(\tilde {\omega }_{b_k})$
 , follows from the lower bound restriction on
$\sigma _{b_k}$
, follows from the lower bound restriction on
$\sigma _{b_k}$

5.2 Bayes factor testing
The hypotheses for
$\sigma _{a_k}$
 can be translated to those for
$\tilde {\omega }_{a_k}$
can be translated to those for
$\tilde {\omega }_{a_k}$
 , taking into account that the upper bound
$UB\left (\tilde {\omega }_{a_k}\right )$
, taking into account that the upper bound
$UB\left (\tilde {\omega }_{a_k}\right )$
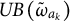 is greater than one (
$LB\left (\sigma _{a_k}\right )$
is greater than one (
$LB\left (\sigma _{a_k}\right )$
 is less than zero). For hypothesis
$H_2 (\sigma _{a_k}>0)$
is less than zero). For hypothesis
$H_2 (\sigma _{a_k}>0)$
 ,
$\tilde {\omega }_{a_k} \in (-\infty ,1)$
,
$\tilde {\omega }_{a_k} \in (-\infty ,1)$
 , for
$H_1 (\sigma _{a_k}<0)$
, for
$H_1 (\sigma _{a_k}<0)$
 ,
$\tilde {\omega }_{a_k} \in (1,UB\left (\tilde {\omega }_{a_k}\right )$
,
$\tilde {\omega }_{a_k} \in (1,UB\left (\tilde {\omega }_{a_k}\right )$
 , and for
$H_0 (\sigma _{a_k}=0), \tilde {\omega }_{a_k}=1$
, and for
$H_0 (\sigma _{a_k}=0), \tilde {\omega }_{a_k}=1$
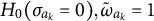 . For the unrestricted hypothesis, let
$\pi _u\left (\tilde {\omega }_{a_k}\right )$
. For the unrestricted hypothesis, let
$\pi _u\left (\tilde {\omega }_{a_k}\right )$
 be the (unrestricted) gamma prior for
$\tilde {\omega }_{a_k}$
be the (unrestricted) gamma prior for
$\tilde {\omega }_{a_k}$
 with shape
$g_1$
with shape
$g_1$
 and scale parameter
$g_2$
and scale parameter
$g_2$
 . Following the encompassing prior approach (Böing-Messing & Mulder, Reference Böing-Messing and Mulder2020; Klugkist & Hoijtink, Reference Klugkist and Hoijtink2007), for each hypothesis
$H_t$
. Following the encompassing prior approach (Böing-Messing & Mulder, Reference Böing-Messing and Mulder2020; Klugkist & Hoijtink, Reference Klugkist and Hoijtink2007), for each hypothesis
$H_t$
 for
$t=0,1,2$
for
$t=0,1,2$
 , the prior under
$H_t$
, the prior under
$H_t$
 is a restricted version of the encompassing gamma prior,
$\pi _t\left (\tilde {\omega }_{a_k}\right ) = \pi _u\left (\tilde {\omega }_{a_k}\right )\chi \left (\tilde {\omega }_{a_k} \mid H_t\right )$
is a restricted version of the encompassing gamma prior,
$\pi _t\left (\tilde {\omega }_{a_k}\right ) = \pi _u\left (\tilde {\omega }_{a_k}\right )\chi \left (\tilde {\omega }_{a_k} \mid H_t\right )$
 , where
, where

The BF for the restricted hypothesis
$H_t$
 for item k concerning
$\tilde {\omega }_{a_k}$
for item k concerning
$\tilde {\omega }_{a_k}$
 against the unrestricted hypothesis
$H_u$
against the unrestricted hypothesis
$H_u$
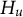 can be expressed as
can be expressed as

where
$\mathbb {Z}_k$
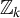 represents the support for
$\tilde {\tilde {\mathbf {z}}}_{k}$
represents the support for
$\tilde {\tilde {\mathbf {z}}}_{k}$
 . The BF in Equation (14) is expressed as the expected value of a ratio of gamma cumulative distribution functions, which leads to an easy computation of the BF. Furthermore, the BF for two constrained hypotheses also follows easily, since
$BF_{tt'}=BF_{tu}/BF_{t'u}$
. The BF in Equation (14) is expressed as the expected value of a ratio of gamma cumulative distribution functions, which leads to an easy computation of the BF. Furthermore, the BF for two constrained hypotheses also follows easily, since
$BF_{tt'}=BF_{tu}/BF_{t'u}$
 for
$t,t'=0,1,2$
for
$t,t'=0,1,2$
 . The logarithm of the BF (log-BF) can be computed, where a log-
$BF_{tt'}$
. The logarithm of the BF (log-BF) can be computed, where a log-
$BF_{tt'}$
 of 3–5 is considered strong evidence and above 5 very strong (decisive) evidence in favor of hypothesis t (Kass & Raftery, Reference Kass and Raftery1995).
of 3–5 is considered strong evidence and above 5 very strong (decisive) evidence in favor of hypothesis t (Kass & Raftery, Reference Kass and Raftery1995).
Let
$\pi _u\left (\tilde {\omega }_{b_k}\right )$
 denote an unrestricted gamma prior for
$\tilde {\omega }_{b_k}$
denote an unrestricted gamma prior for
$\tilde {\omega }_{b_k}$
 with shape
$g_1$
with shape
$g_1$
 and scale parameter
$g_2$
and scale parameter
$g_2$
 . Then, for each hypothesis, the prior under
$H_t$
. Then, for each hypothesis, the prior under
$H_t$
 is a restriction on the encompassing gamma prior. Subsequently, the BFs for examining hypotheses about
$\sigma _{b_k}$
is a restriction on the encompassing gamma prior. Subsequently, the BFs for examining hypotheses about
$\sigma _{b_k}$
 follow in a similar way and can also be expressed as a ratio of gamma cumulative distribution functions, while using the appropriate upper bound for
$\tilde {\omega }_{b_k}$
follow in a similar way and can also be expressed as a ratio of gamma cumulative distribution functions, while using the appropriate upper bound for
$\tilde {\omega }_{b_k}$
 . The corresponding hypotheses for
$\tilde {\omega }_{b_k}$
. The corresponding hypotheses for
$\tilde {\omega }_{b_k}$
 are given by
$H_2$
are given by
$H_2$
 (
$\sigma _{b_k}>0$
(
$\sigma _{b_k}>0$
 ),
$\tilde {\omega }_{b_k} \in (-\infty ,1)$
),
$\tilde {\omega }_{b_k} \in (-\infty ,1)$
 ,
$H_1 (\sigma _{b_k}<0), \tilde {\omega }_{b_k} \in (1,UB(\tilde {\omega }_{b_k}))$
,
$H_1 (\sigma _{b_k}<0), \tilde {\omega }_{b_k} \in (1,UB(\tilde {\omega }_{b_k}))$
 , and
$H_0 (\sigma _{b_k}=0)$
, and
$H_0 (\sigma _{b_k}=0)$
 ,
$\tilde {\omega }_{b_k}=1$
,
$\tilde {\omega }_{b_k}=1$
 .
.
The BF for covariance parameters can be applied to any number of groups and for any number of items. It provides information about which hypothesis is more likely without requiring that any of the hypotheses is true. The BF for testing a precise null hypothesis (
$H_0$
 ) against an unconstrained alternative hypothesis (
$H_u$
) against an unconstrained alternative hypothesis (
$H_u$
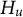 ) is not favoring the null regardless of the information in the data (known as Bartlett’s paradox), since the prior probability of
$\tilde {\omega }_{b_k}=1$
) is not favoring the null regardless of the information in the data (known as Bartlett’s paradox), since the prior probability of
$\tilde {\omega }_{b_k}=1$
 is not sensitive to changes in the variance of the gamma prior.
is not sensitive to changes in the variance of the gamma prior.
6 Simulation study
For each data replication, cluster sizes were sampled from a uniform distribution between (
$n-10$
 ,
$n+10$
,
$n+10$
 ) with n the average cluster size and
$n_j$
) with n the average cluster size and
$n_j$
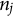 the size of cluster j. The discrimination and difficulty parameters were sampled from a log-normal and normal distribution with mean zero and standard deviation 0.2 and 0.5, respectively. Subject parameters were sampled from a standard normal distribution. Interest was in the covariance parameters, although (latent) cluster means were also estimated. True covariance values for
$\sigma _{a_{k}}$
the size of cluster j. The discrimination and difficulty parameters were sampled from a log-normal and normal distribution with mean zero and standard deviation 0.2 and 0.5, respectively. Subject parameters were sampled from a standard normal distribution. Interest was in the covariance parameters, although (latent) cluster means were also estimated. True covariance values for
$\sigma _{a_{k}}$
 and
$\sigma _{b_{k}}$
and
$\sigma _{b_{k}}$
 were fixed across data replications and are given in the first column of Table 1. The covariances values were set at
$-$
were fixed across data replications and are given in the first column of Table 1. The covariances values were set at
$-$
 0.002 and increased with a step size of 0.02 from item 1 to 10. A positive covariance value represents variance across group-specific item parameters. The grid of covariance values reflects no DIF, low, to a high level of DIF across item parameters. Thus, for instance, item 3, the
$\sigma _{a_{k}}=0.038$
0.002 and increased with a step size of 0.02 from item 1 to 10. A positive covariance value represents variance across group-specific item parameters. The grid of covariance values reflects no DIF, low, to a high level of DIF across item parameters. Thus, for instance, item 3, the
$\sigma _{a_{k}}=0.038$
 represents a range of
$a_k \pm 0.40$
represents a range of
$a_k \pm 0.40$
 for the group-specific discriminations. For item 10, it is approximately
$a_k \pm 0.84$
for the group-specific discriminations. For item 10, it is approximately
$a_k \pm 0.84$
 . The grid of covariance values, specifying the level of DIF, was equal for the discrimination and difficulty parameters.
. The grid of covariance values, specifying the level of DIF, was equal for the discrimination and difficulty parameters.
Simulation study: Covariance estimation results for different sample sizes averaged across 1,000 data replications

Table 1 Long description
The table is divided into three horizontal sections based on sample size parameters. The columns are Item (1 to 10), True sigma a = sigma b, and two sets of results for sigma a and sigma b, each containing Median, S E, and B F sub 0 2.
* Section 1: J = 10, n = 200. True values range from -0.002 to 0.178. For sigma a, B F sub 0 2 starts at 6.939 for Item 1 and decreases to -114.539 for Item 10. For sigma b, B F sub 0 2 starts at 8.314 and decreases to -142.483.
* Section 2: J = 5, n = 200. True values range from -0.002 to 0.178. For sigma a, B F sub 0 2 starts at 6.917 and decreases to -40.667. For sigma b, B F sub 0 2 starts at 5.594 and decreases to -71.162.
* Section 3: J = 2, n = 250. True values range from -0.002 to 0.178. For sigma a, B F sub 0 2 starts at 7.230 and decreases to -1.440. For sigma b, B F sub 0 2 starts at 7.130 and decreases to -30.487.
S E represents the Monte Carlo standard error, and B F sub 0 2 represents the log-B F of no D I F versus between-cluster D I F.
Note: SE represents the Monte Carlo standard error, and
$BF_{02}$
 represents the log-BF of no DIF versus (between-cluster) DIF.
represents the log-BF of no DIF versus (between-cluster) DIF.
The BCSM-MI was identified by restricting the scale of the person parameters to have a mean of zero and a variance of one. The prior for each covariance parameter is a shifted-inverse gamma, in Equations (9) and (11), with shape and rate parameter equal to 0.001. The hyper prior parameter settings were equal to those specified in Fox (Reference Fox2024, Appendix C).
Three conditions were considered with 10 items, and J = 10, 5, and 2 clusters, and with average cluster sizes n = 200, 200, and 250, respectively. A total of 1,000 data replications were made in each condition. Average results are reported in Table 1. The MCMC algorithm was ran for 5,000 iterations with a burn-in period of 1,000 iterations. The effective sample size was at least 400 for each parameter for each data set. The log-BFs were computed of the null hypothesis
$H_0$
 :
$\sigma _{a_k}=0$
:
$\sigma _{a_k}=0$
 (no DIF) versus the alternative hypothesis
$H_2$
(no DIF) versus the alternative hypothesis
$H_2$
 :
$\sigma _{a_k}> 0$
:
$\sigma _{a_k}> 0$
 (DIF), represented as
$BF_{02}$
(DIF), represented as
$BF_{02}$
 , for all items k. A similar log-BF was computed for
$\sigma _{b_k}$
, for all items k. A similar log-BF was computed for
$\sigma _{b_k}$
 for all items k.
for all items k.
6.1 Covariance point estimates
From Table 1, for 10 clusters (J = 10), it follows that the median estimates (averaged across replications) of the covariance parameters are close to the true values. For small true values, the posterior distribution of the covariance parameters is very skewed to the right. Subsequently, the median point estimate is greater than the mode, which led to a small overestimation of the true value. The average median estimates of
$\sigma _{b_{k}}$
 for assessing uniform DIF were slightly closer to the true values than the median estimates of
$\sigma _{a_{k}}$
for assessing uniform DIF were slightly closer to the true values than the median estimates of
$\sigma _{a_{k}}$
 for assessing non-uniform DIF. Higher true values of
$\sigma _{a_{k}}$
for assessing non-uniform DIF. Higher true values of
$\sigma _{a_{k}}$
 were slightly underestimated.
were slightly underestimated.
The (Monte carlo) standard error (SE) increases for increasing true values of the covariance parameters. It is noteworthy that the SEs of the
$\sigma _{a_{k}}$
 are quite comparable to those of the
$\sigma _{b_{k}}$
are quite comparable to those of the
$\sigma _{b_{k}}$
 . For lower true values, the SE of the
$\sigma _{a_{k}}$
. For lower true values, the SE of the
$\sigma _{a_{k}}$
 estimates is slightly higher than those of the
$\sigma _{b_{k}}$
estimates is slightly higher than those of the
$\sigma _{b_{k}}$
 estimates, where for higher true values, this is reversed. The scale of the difficulties supports more easily large between-cluster differences than the scale of the discriminations. Therefore, it was more difficult to recover the high true values of
$\sigma _{a_{k}}$
estimates, where for higher true values, this is reversed. The scale of the difficulties supports more easily large between-cluster differences than the scale of the discriminations. Therefore, it was more difficult to recover the high true values of
$\sigma _{a_{k}}$
 than of
$\sigma _{b_{k}}$
than of
$\sigma _{b_{k}}$
 .
.
For five clusters—the average total sample size was reduced to 1,000—the average estimates of the covariance parameters show a similar pattern as to those for 10 clusters. However, there is slightly more discrepancy between the true and estimated covariance values. By reducing the number of clusters, there was more sampling variation, and the SEs increased compared to those for 10 clusters. For high true covariance values, the SEs of the
$\sigma _{b_k}$
 are higher than those of the
$\sigma _{a_k}$
are higher than those of the
$\sigma _{a_k}$
 , since the distribution for generating difficulties had more variance than the one for generating discriminations. The lower bound was closer to zero due to a higher average cluster size. Subsequently, the posterior distributions were more skewed to the right than for 10 clusters.
, since the distribution for generating difficulties had more variance than the one for generating discriminations. The lower bound was closer to zero due to a higher average cluster size. Subsequently, the posterior distributions were more skewed to the right than for 10 clusters.
For two clusters and a total of 500 observations, the SEs increased rapidly and becoming larger than the covariance values. Low and high true covariance values are overestimated for the discrimination and difficulties. For smaller sample sizes, the posterior distribution of the covariance parameter is more skewed to the right, since there is less data information. The posteriors have a longer right tail, which led to a lower performance of the median point estimator.
The mean squared error (MSE) of the discrimination and difficulty estimates show accurate estimation results across all conditions. The MSE slightly increased for increasing covariance values and when decreasing the sample size. The MSEs of the
$\sigma _{a_k}$
 are comparable to those of the
$\sigma _{b_k}$
are comparable to those of the
$\sigma _{b_k}$
 , and only slightly smaller for high true covariance values.
, and only slightly smaller for high true covariance values.
6.2 DIF Bayes factor results
The log-BF was computed for the discriminations and difficulties, where positive (negative) values support the null (alternative) hypothesis in the numerator (denominator). The rows in gray in Table 1 show data evidence in favor of no DIF (null hypothesis) for discriminations and/or difficulties (under the header
$BF_{02}$
 ). When increasing the level of DIF, there is a consistent decrease in the
$BF_{02}$
). When increasing the level of DIF, there is a consistent decrease in the
$BF_{02}$
 showing more and more support for DIF (alternative hypothesis). This pattern is clearly visible for the discriminations and difficulties. Furthermore, for a decreasing sample size, evidence in favor of DIF was more difficult to achieve. That is, for smaller sample sizes, a higher level of DIF was required to obtain (substantial) evidence in favor of DIF. Decisive evidence of DIF was easier obtained for the difficulty than for the discrimination. For the relatively small sample size of 500 (J = 2), the
$BF_{02}$
showing more and more support for DIF (alternative hypothesis). This pattern is clearly visible for the discriminations and difficulties. Furthermore, for a decreasing sample size, evidence in favor of DIF was more difficult to achieve. That is, for smaller sample sizes, a higher level of DIF was required to obtain (substantial) evidence in favor of DIF. Decisive evidence of DIF was easier obtained for the difficulty than for the discrimination. For the relatively small sample size of 500 (J = 2), the
$BF_{02}$
 still shows a consistent decrease in value, when the true covariance value increases. Although the point estimates of the true covariances have a relatively high SE, the
$BF_{02}$
still shows a consistent decrease in value, when the true covariance value increases. Although the point estimates of the true covariances have a relatively high SE, the
$BF_{02}$
 which is based on the posterior and prior densities shows consistent results.
which is based on the posterior and prior densities shows consistent results.
7 Real data study
Data from the Programme for International Student Assessment or PISA was analyzed for DIF between countries and mode of administration. A total of 14 math items of booklet B_2015_52 was administered through a computer-based assessment (CBA) in PISA 2015 (OECD, 2016). The same set of items was administered within “standard” paper-based assessment (PBA) in 2012 in booklet B_2012_4. The item responses from Belgium (BEL), Germany (DEU), and The Netherlands (NED) were considered. The response patterns of 249 (BEL), 148 (DEU), and 183 (NED) respondents were collected from a PBA in 2012, and of 677 (BEL), 338 (DEU), and 351 (NED) respondents from a CBA in 2015.
An overview of assessment and score differences between the 2012 and 2015 cycle is given by Jerrim (Reference Jerrim2016). It was concluded that pupils who did the computer-based test under performed to those who did the paper-based test. The mode of test administration had an impact on the pupils’ scores. For several items, there was a mode effect in which, for instance, items appeared to be less difficult in a PBA than in a CBA. The BCSM-MI method was used to examine country-specific item–mode interactions and country–item-specific person–mode interactions, while accounting for latent group means and variances. The BCSM-MI did not require any anchor items, which enabled a simultaneous DIF analysis of the 14 items across the three selected countries, each with two modes of administration.
In Table 2, for each item parameter, the covariance value, SE, and the level of
$BF_{02}$
 (no DIF versus between-cluster DIF) are given. For item discrimination 10, the
$BF_{02}$
(no DIF versus between-cluster DIF) are given. For item discrimination 10, the
$BF_{02}$
 shows decisive evidence in favor of DIF. Although the
$BF_{02}$
shows decisive evidence in favor of DIF. Although the
$BF_{02}$
 is also negative for item discrimination 7, it shows only weak evidence in favor of DIF. For item difficulties 1, 2, and 12, there is also decisive evidence in favor of DIF. For the item parameters associated with DIF, the size of the
$BF_{02}$
is also negative for item discrimination 7, it shows only weak evidence in favor of DIF. For item difficulties 1, 2, and 12, there is also decisive evidence in favor of DIF. For the item parameters associated with DIF, the size of the
$BF_{02}$
 is associated with the level of covariance, where more negative
$BF_{02}$
is associated with the level of covariance, where more negative
$BF_{02}$
 values correspond to higher covariance values. According to the BF results, those items (rows) shown in light gray have a negative
$BF_{12}$
values correspond to higher covariance values. According to the BF results, those items (rows) shown in light gray have a negative
$BF_{12}$
 for at least one item parameter, and item parameters in dark gray show DIF.
for at least one item parameter, and item parameters in dark gray show DIF.
PISA 2012–2015: DIF examination of paper-based and computed-based assessed math items across three countries

Table 2 Long description
The table is divided into two main sections: Discrimination (sigma sub a) and Difficulty (sigma sub b), each listing items 1 through 14.
Columns include:
* Item number
* Median
* S E (Monte Carlo standard error)
* B F sub 0 2
* L R (Likelihood-ratio test)
* P (L R) (P-value L R test)
* L R sub seq (sequential final L R test)
* P (L R sub seq) (P-value sequential final L R test)
* M D (mean deviation)
* R M S D (root mean square deviation)
Key data points in Discrimination section:
* Item 1: Median 0.011, S E 0.002, B F sub 0 2 8.104, L R 5.576, P (L R) 0.350.
* Item 10: Median 0.115, S E 0.007, B F sub 0 2 minus 33.694, L R 34.445, P (L R) 0.000, L R sub seq 34.221, P (L R sub seq) 0.000.
Key data points in Difficulty section:
* Item 1: Median 0.111, S E 0.007, B F sub 0 2 minus 34.109, L R 67.065, P (L R) 0.000, L R sub seq 67.065, P (L R sub seq) 0.000, M D 0.141, R M S D 0.120.
* Item 12: Median 0.060, S E 0.003, B F sub 0 2 minus 11.973, L R 31.068, P (L R) 0.000, L R sub seq 31.068, P (L R sub seq) 0.000, M D 0.086, R M S D 0.045.
Note: SE represents the Monte Carlo standard error.
$LR$
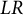 : Likelihood-ratio test.
$P(LR)$
: Likelihood-ratio test.
$P(LR)$
 : P-value LR test.
$LR_{seq}$
: P-value LR test.
$LR_{seq}$
 (sequential) final LR test.
$P(LR_{seq})$
(sequential) final LR test.
$P(LR_{seq})$
 : P-value (sequential) final LR test, MD: mean deviation, and RMSD: root mean square deviation.
: P-value (sequential) final LR test, MD: mean deviation, and RMSD: root mean square deviation.
The items for which the
$BF_{12}$
 was positive for discrimination and difficulty were considered invariant and used as anchors (i.e., free of DIF) in an MG-IRT analysis. A baseline MG-IRT model was defined using the anchors for an LR test procedure (Millsap, Reference Millsap2011). The latent mean and variance parameters were considered free parameters, given a reference group for which the latent mean and variance were restricted to 0 and 1, respectively. Items 1, 2, 7, 10, and 12 were examined for DIF in discrimination and difficulty, which are colored light gray in Table 2. The R-package mirt (Chalmers, Reference Chalmers2012) was used to perform LR testing for DIF by comparing the baseline model to various constrained MG-IRT models, in which item parameters were constrained to be equal across groups.
was positive for discrimination and difficulty were considered invariant and used as anchors (i.e., free of DIF) in an MG-IRT analysis. A baseline MG-IRT model was defined using the anchors for an LR test procedure (Millsap, Reference Millsap2011). The latent mean and variance parameters were considered free parameters, given a reference group for which the latent mean and variance were restricted to 0 and 1, respectively. Items 1, 2, 7, 10, and 12 were examined for DIF in discrimination and difficulty, which are colored light gray in Table 2. The R-package mirt (Chalmers, Reference Chalmers2012) was used to perform LR testing for DIF by comparing the baseline model to various constrained MG-IRT models, in which item parameters were constrained to be equal across groups.
For each item examined for DIF, an MG-IRT model with the discrimination parameter constrained was compared to the baseline model using the LR test. In a similar way, MG-IRT models were defined for which each of the item difficulty parameters was restricted. Thus, a total of 10 models were needed to examine each item parameter of the five examined items. In Table 2, the LR values and corresponding P-values for the discriminations and difficulties are given under the header LR and P(LR), respectively. High LR values correspond to negative
$BF_{02}$
 values and small P-values. There appears to be an agreement between the methods about which item parameters show DIF. However, the difficulty parameter of item 7 appears to show DIF according to the LR test, while the BF test shows weak support for no DIF. For the discrimination parameter of item 7, the
$BF_{02}$
values and small P-values. There appears to be an agreement between the methods about which item parameters show DIF. However, the difficulty parameter of item 7 appears to show DIF according to the LR test, while the BF test shows weak support for no DIF. For the discrimination parameter of item 7, the
$BF_{02}$
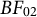 shows weak evidence for DIF, while the LR test does not. However, note that the log-BF test is a simultaneous DIF analysis of all items and is not based on a comparison(s) with a baseline model.
shows weak evidence for DIF, while the LR test does not. However, note that the log-BF test is a simultaneous DIF analysis of all items and is not based on a comparison(s) with a baseline model.
Subsequently, DIF in discriminations and difficulties was each sequentially tested under the MG-IRT model. In this sequential procedure, items were restricted to be invariant when satisfying the AIC criterion, and the remaining set of items was examined until no more invariant items were found. In Table 2, for the final set of item parameters that displayed DIF the LR statistic and P-value are reported, which are denoted as
$LR_{seq}$
 and
$P(LR_{seq})$
and
$P(LR_{seq})$
 , respectively. For the discriminations, items 10 and 12 are marked as DIF, and for the difficulties, items 1, 2, 7, and 12. However, when using the sample-adjusted BIC as a selection criterion to decide on which item is restricted to be invariant, the LR sequential test results changed. In that case, only the discrimination parameter of item 10 is still marked to show DIF, while the discrimination of item 12 is considered to be free of DIF. This is in line with the BCSM-MI analysis. Furthermore, only the difficulties of items 1 and 12 show DIF, and difficulties of items 2 and 7 do not show DIF. This is not in line with the BCSM-MI results, where the difficulty of item 2 also showed DIF.
, respectively. For the discriminations, items 10 and 12 are marked as DIF, and for the difficulties, items 1, 2, 7, and 12. However, when using the sample-adjusted BIC as a selection criterion to decide on which item is restricted to be invariant, the LR sequential test results changed. In that case, only the discrimination parameter of item 10 is still marked to show DIF, while the discrimination of item 12 is considered to be free of DIF. This is in line with the BCSM-MI analysis. Furthermore, only the difficulties of items 1 and 12 show DIF, and difficulties of items 2 and 7 do not show DIF. This is not in line with the BCSM-MI results, where the difficulty of item 2 also showed DIF.
The mean deviation (MD) and the root mean square deviation (RMSD) were computed for each item (Köhler et al., Reference Köhler, Hartig, Khorramdel and Pokropek2024, Equations (2) and (3)). In a baseline MG-IRT model, all item parameters were restricted across groups to estimate the common set of item parameters. Subsequently, group-specific item parameters were estimated using the anchors from the BCSM-MI analysis. In Table 2, for the examined set of items, the maximum MD and RMSD across groups are represented in the rows of the difficulty parameters. The MD is considered to assess the difference in item difficulty between the group specific item response function and the common item response function, where the RMSD measures this (squared) difference with respect to difficulty and discrimination. The estimated levels of MD are in correspondence with the BF. Items 1, 2, and 12 have relatively high MD values corresponding with high BF values for the difficulty parameters. Item 7 has a relatively high MD value for which the RMSD value is also relatively high, which corresponds to the weak support of the BF for DIF in discrimination.
In the PISA study of Köhler et al. (Reference Köhler, Hartig, Khorramdel and Pokropek2024), under a two-parameter IRT model, an item’s response function is considered to differ across groups, when the RMSD and the absolute value of MD are greater than 0.12. According to that criterion, only item 1 is considered to show DIF. It could be that for large sample sizes comparable to PISA studies, this threshold leads to acceptable Type-1 errors. Obviously, a high threshold will reduce the number of false positives. However, for item 1, an estimated difficulty covariance of 0.111 indicates that the range of difficulty values across groups is around
$\pm 0.67$
 . An RMSD value greater than 0.15 to identify items behaving differently across groups was used in von Davier et al. (Reference von Davier, Yamamoto, Shin, Chen, Khorramdel, Weeks, Davis, Kong and Kandathil2019). When using this threshold, none of the items would be classified to show DIF. Note that the simulation study showed that for five groups with a group size of around 200, a discrimination covariance of 0.06, and a difficulty covariance of 0.06, already led to strong evidence in favor of DIF. Therefore, the item response function of item 10 differs across groups with respect to the discrimination. The item response functions of items 1, 2, and 12 also differ across groups with respect to the item difficulty. For these item response functions, the log-BF shows very strong evidence in favor of DIF, and the very high LR values also lead to rejecting the null hypothesis of a constrained (invariant) item parameter.
. An RMSD value greater than 0.15 to identify items behaving differently across groups was used in von Davier et al. (Reference von Davier, Yamamoto, Shin, Chen, Khorramdel, Weeks, Davis, Kong and Kandathil2019). When using this threshold, none of the items would be classified to show DIF. Note that the simulation study showed that for five groups with a group size of around 200, a discrimination covariance of 0.06, and a difficulty covariance of 0.06, already led to strong evidence in favor of DIF. Therefore, the item response function of item 10 differs across groups with respect to the discrimination. The item response functions of items 1, 2, and 12 also differ across groups with respect to the item difficulty. For these item response functions, the log-BF shows very strong evidence in favor of DIF, and the very high LR values also lead to rejecting the null hypothesis of a constrained (invariant) item parameter.
8 Discussion
The BCSM-MI is proposed for non-uniform DIF testing for any number of groups and unbalanced test designs. All item parameters can be examined simultaneously for DIF without needing any anchor items or a sequential test procedure. The method does not require selecting any anchor items, before DIF testing a set of items. This avoids the problem that DIF results from a sequential procedure depends on the set of anchor items—the specification of a baseline model—and on the order in which the items are sequentially tested.
The BCSM-MI does not include group-specific item parameters, which relaxes restriction on the sample size to obtain stable model parameter estimates. The DIF for each item parameter is represented by a single covariance parameter, and an increasing level of covariance is associated with an increase in the level of DIF across groups. In an MG-IRT model, partial item invariance across groups can be modeled by including group-specific item parameters. In the PISA study with many countries, the number of group-specific item parameters can increase rapidly, which can also lead to scaling problems due to a lack of invariant items. Therefore, groups showing a similar level of item misfit receive the same (unique) group-specific item parameter, to restrict the total set of item parameters to be calibrated (von Davier et al., Reference von Davier, Yamamoto, Shin, Chen, Khorramdel, Weeks, Davis, Kong and Kandathil2019). The BCSM-MI uses a single covariance parameter for each item parameter to allow for DIF independent on the number of groups. From a fitted BCSM-MI, group-specific item parameters can be computed for items showing DIF. This would lead to a calibrated set of common and unique item parameters without specifying anchor items beforehand.
In Section S2 of the Supplementary Material, for the simulation design discussed in Section 6, superiority of the BCSM-MI over regularized DIF is shown with respect to the true and false positive rates.
In the PISA study, the BCSM-MI models DIF in discrimination and difficulty. Therefore, latent variable estimates are free of (non)-uniform DIF with respect to clusters defined by countries and mode of administration. The BCSM-MI can be used to detect DIF, but also to compute latent variable estimates corrected for possible DIF bias. Subsequently, country-specific latent variable estimates and between-country and between-mode of administration differences are corrected for DIF effects. Post-hoc (cluster-specific) DIF effects can be computed under the BCSM-MI, which can provide further information about which clusters differ with respect to the functioning of items.
The shifted-inverse gamma prior is defined for each covariance parameter to allow for negative as well as positive covariance values, while accounting for the positive-definite restriction of the covariance matrix, which implies a lower bound restriction on the covariance parameter. More research is needed to examine the impact of the shifted-inverse gamma prior on the shape of the posterior. The posterior distribution of the covariance parameter is often skewed to the right, which makes it more difficult to estimate the mode. The simulation results showed that 95% highest posterior density (HPD) intervals had the tendency to include small covariance values (associated with high posterior density) and exclude high covariance values (associated with low posterior density). This led to conservative coverage rates, especially for true small covariance values. Subsequently, evaluation of the DIF hypotheses through posterior probability computing usually favored the DIF hypotheses and disfavored the non-DIF hypotheses, since most of the posterior mass was located above zero covariance. This motivated the use of the BF for DIF testing, because it is based on (marginal) likelihoods to make inferences about the DIF hypotheses. The (conjugate) gamma prior for the
$\omega $
 parameter is an encompassing prior, which facilitates much easier computation of the BF. More research is needed to examine the influence of the prior on the BF results, and performance differences of the BF under different priors.
parameter is an encompassing prior, which facilitates much easier computation of the BF. More research is needed to examine the influence of the prior on the BF results, and performance differences of the BF under different priors.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psy.2026.10101.
Data availability statement
The R-package BCSMMI for Bayesian covariance modeling of DIF can be found on www.Jean-PaulFox.com under Software.
Funding statement
This research received no grant funding from any funding agency, commercial or not-for-profit sectors. Open access funding provided by University of Twente.
Competing interests
The author declares none.
Appendix A Conditional expectation latent response
The expression for the conditional expectation of the latent response in Equation (5) is derived from the multivariate normal distribution. The multivariate normal distribution of the latent responses in group j has structured covariance matrix
$\boldsymbol {\Sigma }_{jk}$
 according to Equation (3). Consider
$\sigma _{b_k}=0$
according to Equation (3). Consider
$\sigma _{b_k}=0$
 , then the inverse of the covariance matrix is given by
, then the inverse of the covariance matrix is given by

where
$\lambda _j = 1/\sigma _{a_k}+\sum _{s}\theta ^2_{sj}$
 . Using this expression for the covariance matrix and
$\mu _{ijk}=a_k\theta _{ij}-b_k$
. Using this expression for the covariance matrix and
$\mu _{ijk}=a_k\theta _{ij}-b_k$
 , the multivariate normal density of
$\mathbf {Z}_{jk}$
, the multivariate normal density of
$\mathbf {Z}_{jk}$
 can be expressed as
can be expressed as

where
$\lambda _{ij}=1/\sigma _{a_k}+\sum _{s \ne i} \theta _{sj}^2$
 . The expression of the multivariate normal density reveals that it consists of a product of conditionally normally distributed variables
$Z_{ijk}$
. The expression of the multivariate normal density reveals that it consists of a product of conditionally normally distributed variables
$Z_{ijk}$
 given
$\mathbf {Z}_{(-i)jk}$
given
$\mathbf {Z}_{(-i)jk}$
 , with conditional expected values
, with conditional expected values

which represents the expression in Equation (5).
Appendix B Restrictions on the parameter space
An analytical expression for the inverse of the covariance matrix is obtained using the Sherman–Morrison formula. This formula is applied by partitioning the covariance matrix in the sum of an invertible matrix
$\mathbf {A}_{jk}$
 and the outer product of
$\boldsymbol {\theta }_j$
and the outer product of
$\boldsymbol {\theta }_j$
 . Then, the inverse of the matrix
$\mathbf {A}_{jk}$
. Then, the inverse of the matrix
$\mathbf {A}_{jk}$
 is derived by applying once more the Sherman–Morrison formula. This way an analytical expression for the inverse is obtained
is derived by applying once more the Sherman–Morrison formula. This way an analytical expression for the inverse is obtained

and subsequently, the
$\mathbf {A}_{jk}^{-1}$
 is given by
is given by

Note that the inverse of the covariance matrix for any partitioned response set, in which, for instance, a person i is excluded, can be derived in a similar way.
The determinant of the covariance matrix can be explicitly derived though the matrix determinant lemma. It follows that

The determinant of the covariance matrix
$\boldsymbol {\Sigma }_{jk}$
 needs to be greater than zero, which leads to restrictions on the parameter space of
$\sigma _{a_k}$
needs to be greater than zero, which leads to restrictions on the parameter space of
$\sigma _{a_k}$
 and
$\sigma _{b_k}$
and
$\sigma _{b_k}$
 . For
$\sigma _{b_k}$
. For
$\sigma _{b_k}$
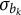 , the following lower bound is derived:
, the following lower bound is derived:

For
$\sigma _{a_k}$
 , the following lower bound is derived:
, the following lower bound is derived:

In the sampling step for
$\alpha _{jk}$
 , the expression of the posterior variance
$\Psi _{a_{jk}}$
, the expression of the posterior variance
$\Psi _{a_{jk}}$
 in Equation (C3) is restricted to be positive. This also implies the restriction that
$\sigma _{b_k}> -1/n_{j}$
in Equation (C3) is restricted to be positive. This also implies the restriction that
$\sigma _{b_k}> -1/n_{j}$
 . This does not lead to a change in the lower bound for
$\sigma _{a_k}$
. This does not lead to a change in the lower bound for
$\sigma _{a_k}$
 . The variance
$\Psi _{a_{jk}}$
. The variance
$\Psi _{a_{jk}}$
 is restricted to be positive, which leads to the same lower bound restriction for
$\sigma _{a_k}$
is restricted to be positive, which leads to the same lower bound restriction for
$\sigma _{a_k}$
 :
:

When
$\sigma _{b_k}> \frac {-1}{n}$
 , the denominator is restricted to be positive. Furthermore, the numerator is also restricted to be positive, since
$\boldsymbol {\theta }^t_j\boldsymbol {\theta }_j> \sum _{i\mid j}\left (\theta _{ij}-\overline {\theta }_{j}\right )^2$
, the denominator is restricted to be positive. Furthermore, the numerator is also restricted to be positive, since
$\boldsymbol {\theta }^t_j\boldsymbol {\theta }_j> \sum _{i\mid j}\left (\theta _{ij}-\overline {\theta }_{j}\right )^2$
 .
.
Appendix C MCMC algorithm
The steps of the MCMC scheme are described. For the (shifted) inverse gamma prior, general prior parameters
$g_1$
 and
$g_2$
and
$g_2$
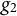 are used, which can be adjusted in each step.
are used, which can be adjusted in each step.
-
- The latent item response $Z_{ijk}$
is conditionally sampled given the remaining latent responses in cluster j and the observed item response
$Y_{ijk}$
. The conditional distribution of the latent response is truncated normal with mean (C1) $$ \begin{align} \mu_{z_{ijk}} & = \left(a_k\theta_{ij}-b_k\right) + \boldsymbol{\Sigma}_{(i,-i){jk}} \boldsymbol{\Sigma}^{-1}_{(-i,-i){jk}}\left(\mathbf{z}_{(-i)jk} - \left(a_k\boldsymbol{\theta}_{(-i)j}-b_k\right) \right) \end{align} $$
and variance
(C2) $$ \begin{align} \sigma_{z_{ijk}} & = \boldsymbol{\Sigma}_{(i,i)jk} - \boldsymbol{\Sigma}_{(i,-i)jk} \boldsymbol{\Sigma}^{-1}_{(-i,-i)jk}\boldsymbol{\Sigma}_{(-i,i)jk,} \end{align} $$
where the indices $(-i)$
represent all i in group j excluding i, and
$Z_{ijk} \ge 0$
when
$Y_{ijk}=1$
, and
$Z_{ijk} < 0$
otherwise. The inverse of the covariance matrix is obtained by applying the Sherman–Morrison formula (Appendix B). An analytical expression for the inverse of the covariance matrix excluding row and column i,
$\boldsymbol {\Sigma }^{-1}_{(-i,-i)jk}$
, can be obtained in a similar way. -
- Let $\theta _{ij} \sim \mathcal {N}\left (\mu _{\theta _{j}},\sigma _{\theta _j}\right )$
. When
$\sigma _{a_k}> 0$
, group-specific discrimination parameters
$a_{jk}$
are sampled. When
$\sigma _{a_k} \le 0$
, the
$a_{jk}=a_k$
for all j. For
$\sigma _{a_k}> 0$
, the posterior distribution of the group-specific discrimination parameter
$a_{jk}$
is normal with variance (C3) $$ \begin{align} \Psi_{a_{jk}} & = \left(\left(\boldsymbol{\theta}^t_{j} \boldsymbol{\theta}_j - \frac{\left(\boldsymbol{\theta}^t_j\mathbf{1}_{n_j}\right)^2}{1/\sigma_{b_k}+n_j}\right)+1/\sigma_{a_k}\right)^{-1} \end{align} $$
and mean
(C4) $$ \begin{align} \mu_{a_{jk}} & = \Psi_{a_{jk}} \left(\left(\boldsymbol{\theta}^t_j\left(\mathbf{z}_{jk}+b_k \right) - \frac{\left(\boldsymbol{\theta}^t_j\mathbf{1}_{n_j}\right)\left(\mathbf{1}^t_{n_j}\left(\mathbf{z}_{jk}+b_k\right)\right)}{1/\sigma_{b_k}+n_j}\right) + \frac{a_k}{\sigma_{a_k}}\right). \end{align} $$
The expression for the variance in Equation (C3) restricts the $\sigma _{b_k}$
to be greater than
$-1/n_j$
. Otherwise, the variance term
$\Psi _{a_{jk}}$
is no longer restricted to be positive (see Appendix B). This lower bound is slightly above the lower bound in Equation (10) to ensure a positive-definite covariance matrix. Therefore, this lower bound is only implied in the sampling step for the
$\theta _{ij}$
. The posterior distribution of
$\boldsymbol {\theta }$
given the group-specific item discriminations,
$\mathbf {a}_{j}$
, is multivariate normal with covariance matrix $$ \begin{align*} \boldsymbol{\Psi}^{-1}_{\theta_j} & = \left(\sum_k \alpha^2_{jk} \left(\mathbf{I}_{n_j} - \frac{\mathbf{J}_{n_j}}{1/\sigma_{b_k} + n_j} \right)\right) + \sigma_{\theta_j}^{-1}\mathbf{I}_{n_j} \end{align*} $$
and mean
(C5) $$ \begin{align} \boldsymbol{\mu}_{\theta} & = \boldsymbol{\Psi}^{-1}_{\theta_j}\left(\sum_k \alpha_{jk} \left(\left(\mathbf{z}_{jk} + b_k\right)-\frac{\sum_{i\mid j} z_{ijk} + b_k}{1/\sigma_{b_k}+n_j} \right) + \mu_{{\theta}_j}/\sigma_{\theta_j}\right). \end{align} $$
This procedure is used in the simulation study (Section 6) and shows good performance. However, it ignores the impact of a negative $\sigma _{a_k}$
. In Appendix D, it is shown how a Metropolis–Hastings step can be defined to account for negative covariances. The posterior sampling steps for
$\mu _{{\theta }_j}$
and
$\sigma _{\theta _j}$
can be found in Fox (Reference Fox2010, Chapter 7). -
- The (invariant) discrimination parameters $a_k$
are sampled from a normal distribution with variance (C6) $$ \begin{align} \Psi_{a_k} & = \left(\sum_j\boldsymbol{\theta}^t_j\boldsymbol{\Sigma}^{-1}_{jk} \boldsymbol{\theta}_j + 1/\sigma^2_a\right)^{-1} \end{align} $$
and mean
(C7) $$ \begin{align} \mu_{a_k} & = \Psi_{a_k}\left(\sum_j \boldsymbol{\theta}^t_j\boldsymbol{\Sigma}^{-1}_{jk} \left(\mathbf{z}_{jk}+b_k\right) + \mu_a/\sigma^2_a\right). \end{align} $$
-
- The (invariant) difficulty parameters $b_k$
are sampled from a normal distribution with variance (C8) $$ \begin{align} \Psi_{b_k} & = \left(\sum_j\mathbf{1}^t_j\boldsymbol{\Sigma}^{-1}_{jk} \mathbf{1}_j + 1/\sigma^2_b\right)^{-1} \end{align} $$
and mean
(C9) $$ \begin{align} \mu_{b_k} & = \Psi_{b_k}\left(\sum_j \mathbf{1}^t_j\boldsymbol{\Sigma}^{-1}_{jk} \left(\mathbf{z}_{jk}-a_k\boldsymbol{\theta}_j\right) + \mu_b/\sigma^2_b\right). \end{align} $$
-
- The discrimination parameters have a normal prior with mean $\mu _a$
and variance
$\sigma ^2_a$
. For the hyper priors, a normal inverse-gamma prior is used, with
$\sigma ^2_a \sim \mathcal {IG}(g_1,g_2)$
and
$\mu _a \sim \mathcal {N}\left (\mu _{a_0}, \sigma ^2_a/n_{a_0} \right )$
. The posterior distribution of
$\mu _a$
and variance
$\sigma ^2_a$
is given by $$ \begin{align*} \mu_a \mid \mathbf{a},\sigma^2_a &\sim \mathcal{N}\left(\frac{n_{a_0}}{m+n_{a_0}}\mu_{a_0} + \frac{m}{m+n_{a_0}}\overline{a},\frac{\sigma^2_a}{m+n_{a_0}} \right) \\ \sigma^2_a \mid \mathbf{a} &\sim \mathcal{IG}\left(g_1 + m/2,g_2+(\sum_k(a_k-\overline{a})^2+\frac{mn_{a_0}}{m+n_{a_0}}\left(\overline{a}-\mu_{a_0}\right)^2)/2 \right), \end{align*} $$
respectively.
-
- The prior parameters $\mu _b$
and variance
$\sigma ^2_b$
have a normal inverse-gamma hyper prior with
$\sigma ^2_b \sim \mathcal {IG}(g_1,g_2)$
and
$\mu _b \sim N\left (\mu _{b_0}, \sigma ^2_b/n_{b_0} \right )$
. Then, the posterior distribution of
$\mu _b$
and variance
$\sigma ^2_b$
is given by $$ \begin{align*} \mu_b \mid \mathbf{b},\sigma^2_b &\sim \mathcal{N}\left(\frac{n_{b_0}}{m+n_{b_0}}\mu_{b_0} + \frac{m}{m+n_{b_0}}\overline{b},\frac{\sigma^2_b}{m+n_{b_0}} \right) \\ \sigma^2_b \mid \mathbf{b} &\sim \mathcal{IG}\left(g_1 + m/2,g_2+\left(\sum_k(b_k-\overline{b})^2+\frac{mn_{b_0}}{m+n_{b_0}}\left(\overline{b}-\mu_{b_0}\right)^2\right)/2 \right), \end{align*} $$
respectively.
-
- The sampling of covariance parameters $\sigma _{a_{k}}$
is done with slice sampling. Therefore, a uniformly distributed value u under the posterior density of
$\sigma ^{(m-1)}_{a_k}$
is sampled, where
$\sigma ^{(m-1)}_{a_k}$
is retrieved in iteration
$m-1$
. Then,
$\sigma ^{(m)}_{a_k}$
can be uniformly sampled conditional on the sampled u. That is, (C10) $$ \begin{align} u_j & \sim \mathcal{U}\left(0, p\left(\sigma^{(m-1)}_{a_k} \mid \tilde{\tilde{z}}_{a_{jk}} , \lambda_{a_{jk}}, s_{a_{jk}} \right)\right) \end{align} $$
(C11) $$ \begin{align} \sigma^{(m)}_{a_k} & \sim \mathcal{U}\left(S_a\left(u\right) \right), \end{align} $$
where $S_a\left (u\right ) = \bigcap _j S_{a_j}\left ( u_j \right )$
and
$S_{a_j}\left ( u_j \right ) = \left \{\sigma _{a_k} : p\left (\sigma _{a_k} \mid \tilde {\tilde {z}}_{a_{jk}} , \lambda _{a_{jk}}, s_{a_{jk}} \right )> u_j \right \} $
. The set
$S_a\left (u\right )$
can be obtained using the Lambert W function (Corless et al., Reference Corless, Gonnet, Hare, Jeffrey and Knuth1996). An upper bound can be placed on the parameter space of
$\sigma _{a_{k}}$
, and this upper bound is easily integrated in the target space
$S_a\left (u\right )$
from which
$S_a\left (u\right )$
is sampled. -
- The covariance parameter $\sigma _{b_{k}}$
is sampled using slice sampling. A uniformly distributed value u under the posterior density of
$\sigma ^{(m-1)}_{b_k}$
is sampled, where
$\sigma ^{(m-1)}_{b_k}$
is retrieved in iteration
$m-1$
. The
$\sigma ^{(m)}_{a_k}$
is uniformly sampled given u (C12) $$ \begin{align} u_j & \sim \mathcal{U}\left(0, p\left(\sigma^{(m-1)}_{b_k} \mid \tilde{\tilde{z}}_{b_{jk}} , \lambda_{b_{jk}}, s_{b_{jk}} \right)\right) \end{align} $$
(C13) $$ \begin{align} \sigma^{(m)}_{b_k} & \sim \mathcal{U}\left(S_b\left(u\right) \right), \end{align} $$
where $S_b\left (u\right ) = \bigcap _j S_{b_j}\left ( u_j \right )$
and
$S_{b_j}\left ( u_j \right ) = \left \{\sigma _{b_k} : p\left (\sigma _{b_k} \mid \tilde {\tilde {z}}_{b_{jk}} , \lambda _{b_{jk}}, s_{b_{jk}} \right )> u_j \right \} $
. An upper bound can also be placed on the parameter space of
$\sigma _{b_{k}}$
, which can be integrated in the allowable set
$S_b\left (u\right )$
.


























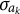


















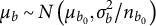


























Appendix D Sampling person parameters
The sampling of the person parameters is complicated, since the person parameters are also involved in the structured covariance matrix of the BCSM-MI. When
$\sigma _{a_k}>0$
 , and assuming a normal distribution for the random discrimination parameters with mean
$a_k$
, and assuming a normal distribution for the random discrimination parameters with mean
$a_k$
 , the BCSM-MI can be redefined with a random discrimination parameter in the mean term. It follows that
, the BCSM-MI can be redefined with a random discrimination parameter in the mean term. It follows that

where
$a_{jk} \sim \mathcal {N}\left (a_k,\sigma _{a_k} \right )$
 ,
$\boldsymbol {\theta }_{j} \sim \mathcal {N}\left (0,\sigma _{\theta _j}\mathbf {I}_{n_j}\right )$
,
$\boldsymbol {\theta }_{j} \sim \mathcal {N}\left (0,\sigma _{\theta _j}\mathbf {I}_{n_j}\right )$
 , and
$\boldsymbol {\Sigma }_{j_b} = \mathbf {I}_{n_j} + \sigma _{b_k}\mathbf {J}_{n_j}$
, and
$\boldsymbol {\Sigma }_{j_b} = \mathbf {I}_{n_j} + \sigma _{b_k}\mathbf {J}_{n_j}$
 .
.
When at least one
$\sigma _{a_k} < 0$
 , a Metropolis–Hastings step can be defined to draw a value for
${\theta }_{ij}$
, a Metropolis–Hastings step can be defined to draw a value for
${\theta }_{ij}$
 . Let the set
$\Omega _j = \{s \mid \sigma _{a_s}>0\}$
. Let the set
$\Omega _j = \{s \mid \sigma _{a_s}>0\}$
 represent the items s for which
$\sigma _{a_s} \ge 0$
represent the items s for which
$\sigma _{a_s} \ge 0$
 . Subsequently, let
$\mathbf {z}_{js} (s\in \Omega _j)$
. Subsequently, let
$\mathbf {z}_{js} (s\in \Omega _j)$
 represent the corresponding item responses in group j. Then, group-specific discriminations
$a_{js}$
represent the corresponding item responses in group j. Then, group-specific discriminations
$a_{js}$
 are sampled for all items
$s\in \Omega _j$
are sampled for all items
$s\in \Omega _j$
 . A candidate value for
$\boldsymbol {\theta }^*_j$
. A candidate value for
$\boldsymbol {\theta }^*_j$
 is sampled given the group-specific discriminations
$a_{js}$
is sampled given the group-specific discriminations
$a_{js}$
 , according to the model specification in Equation (D1). The candidate value is compared to the former value using the following acceptance ratio:
, according to the model specification in Equation (D1). The candidate value is compared to the former value using the following acceptance ratio:

When
$\sigma _{a_k} < 0$
 for all k, a candidate value can be generated by assuming that
$a_{kj}=a_{k}$
for all k, a candidate value can be generated by assuming that
$a_{kj}=a_{k}$
 for all j and k.
for all j and k.
The acceptance ratio in Equation (D2) equals one, when
$\sigma _{a_k}> 0$
 for all k. In that case, the terms conditioning on
$\boldsymbol {\theta }_{j}$
for all k. In that case, the terms conditioning on
$\boldsymbol {\theta }_{j}$
 and those on
$\boldsymbol {\theta }^*_{j}$
and those on
$\boldsymbol {\theta }^*_{j}$
 cancel out. The distribution of the (latent) item response data for group j is expressed as follows:
cancel out. The distribution of the (latent) item response data for group j is expressed as follows:

which is allowed when
$\sigma _{a_k}>0$
 for all k. The acceptance ratio can be shown to equal one by plugging in the expression for the distribution of the item response data under the BCSM-MI given
$\boldsymbol {\theta }_j$
for all k. The acceptance ratio can be shown to equal one by plugging in the expression for the distribution of the item response data under the BCSM-MI given
$\boldsymbol {\theta }_j$
 (Equation (D3)) and given
$\boldsymbol {\theta }^*_j$
(Equation (D3)) and given
$\boldsymbol {\theta }^*_j$
 . It follows that
. It follows that






 Open access
Open access