

Be thou assured, if words be made of breath,
And breath of life, I have no life to breath
What thou hast said to me.
1.1 Introduction
Have you ever wondered, if we didn’t need to inhale and exhale regularly, would we speak without pausing, constructing sentences of infinite length? Would the variations in speech amplitude and fundamental frequency resemble what we observe today? Might our conversational turns become more extended? In exploring these questions, any speaker is likely to acknowledge that their manner of speaking, particularly the rhythmic organization of speech and conversational turns, is significantly influenced by breathing. As briefly outlined in Section 1.2, respiration is a complex physiological system greatly influenced by behavioral and environmental factors. Acquiring the skill of speaking also entails acquiring a particular control over breathing. The rhythm of breathing is significantly molded by speech production, yet the imperative to breathe also exerts a profound influence on speech rhythm at different levels.
The complexity of the influence of breathing on speech becomes even more apparent when one speaks while concurrently performing another motor activity. As indicated by previous research, limb motion may have a specific impact on real-time spoken language. Section 1.3 delves into the repercussions of two distinct forms of limb motion that are prevalent during spoken communication. First, numerous studies have underscored the significance of co-speech gestures in spoken communication, and various pieces of evidence highlight the structuring or influence of these gestures on speech rhythm. Second, speech often occurs during various noncommunicative activities that involve motions of our hands and/or other parts of our body. As such, speech is part of a dynamic sensorimotor system working as a whole. Interactions among various processes occur at neurophysiological, biomechanical, and thus behavioral levels, resulting in coordinated temporal patterns.
Sections 1.4 and 1.5 address the tripartite relationship between speech, breathing, and limb movements. Breathing is indeed a central aspect of limb motion, speech, and, more recently, cognition research. The reciprocal influences between limbs and speech may occur through the respiratory system, as suggested recently. The connections between limb motion’s motor control, physiology, and spoken language present new challenges and perspectives that will also be discussed.
1.2 Speech Breathing: Where Linguistic and Physiological Rhythms Meet
1.2.1 A Brief Description of the Breathing System
Breathing is a gas exchange mechanism between the air and the bloodstream (oxygen in and carbon dioxide out) through a cyclical series of inhalations and exhalations. It is supported by a physiological system involving peripheral organs and a complex neural control that interacts with other behavioral functions (Hoit et al., Reference Hoit, Weismer and Story2021).
Gas exchanges occur in the lungs within the thoracic cavity. Inhalation involves the contraction of intercostal muscles and the diaphragm, expanding lung volume (Figure 1.1A, left). As the lung volume increases, keeping the air quantity constant, negative pressure in the rib cage draws air into the lungs. At rest, exhalation is initiated passively as the relaxation of external intercostal muscles and the diaphragm leads to a reduction in lung volume. During active processes such as speech, additional muscles, including internal intercostal and abdominal muscles, contribute to controlled air expulsion. The larynx, comprising the epiglottis and vocal cords, plays a predominant role in controlling the flow of exhaled air during speech (Hoit et al., Reference Hoit, Weismer and Story2021).
Illustration of breathing process and control
Mechanism of inspiration and expiration phases;
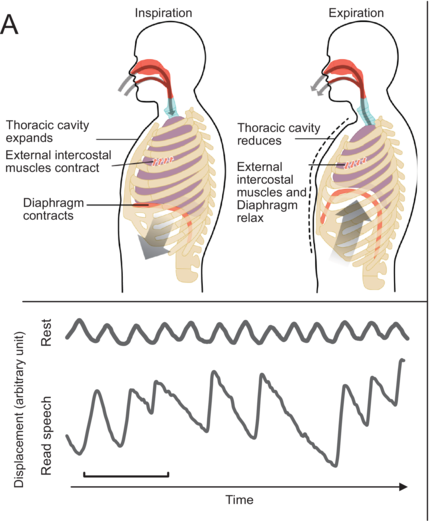
Figure 1.1(A) Long description
Part A: Top. 2 line drawings of the human torso are labeled Inspiration and Expiration, respectively. Left. The labels include thoracic cavity expands, external intercostal muscle contracts and diaphragm contracts. Right. The labels include Thoracic cavity reduces, External intercostal muscles and Diaphragm relax. Bottom: A line graph of displacement versus time plots two fluctuating lines for rest and read speech.
top: Centers of the brain involved in breathing control; (B) bottom: Example of rib cage breathing movement at rest (tidal breathing) and speech breathing (read speech) monitored using inductive plethysmography.
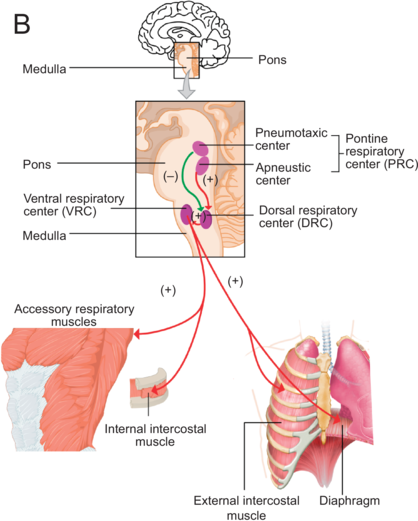
Figure 1.1(B) Long description
Part B: An illustration of a human brain with a rectangular box marking the medulla and pons. The marked region is expanded below to show Pneumotaxic center, Apneustic center, Pontine, respiratory center, Dorsal respirator, Pons, Ventral respiratory center, and medulla. Three arrows originate from the ventral respiratory center and point at the illustrations, including accessory respiratory muscles, internal intercostal muscle and external intercostal muscle and diaphragm.
The control of breathing is influenced by various nervous system structures (Shea, Reference Shea1996; Hoit et al., Reference Hoit, Weismer and Story2021) and governed by metabolic and behavioral needs. Under automatic control, a central pattern generator (CPG) in the brainstem (Figure 1.1B) regulates rhythmic inhalation and exhalation patterns, involving the medullary respiratory center (MRC) and the pontine respiratory center (PRC). During inhalation, the MRC’s dorsal and ventral respiratory centers stimulate the contraction of the diaphragm and of the external intercostal muscles. The ventral center also inhibits muscles for exhalation. Both centers receive information from the PRC that comprises the pneumotaxic and apneustic centers. The PRC sends inhibitory and stimulatory signals to the MRC, regulating the duration and intensity of breathing phases. The CPG communicates with muscles through spinal cord phrenic, intercostal, and abdominal motoneurons. Cortical centers controlling voluntary breathing send messages to the CPG that also receives feedback from peripheral structures, central chemoreceptors, and lung stretch receptors, impacting the regulation of respiration (Del Negro et al., Reference Del Negro, Funk and Feldman2018; Ben-Tal et al., Reference Ben-Tal, Wang and Leite2019).
Subcortical structures and cortical areas associated with various behaviors also significantly impact respiration regulation in humans, rendering breathing sensitive and adaptive to sensory stimuli, emotional responses, and changes in cognitive or physical activity levels. Breathing adapts particularly to behaviors requiring airflow, such as speech sound production, and those increasing muscle oxygenation needs, such as limb movements. The unique link between speech and breathing arises from the animated structures of the vocal tract, shaping inspiratory and respiratory flows into articulated sounds.
1.2.2 Insights into Recording and Analyzing Speech Breathing
Breathing can be monitored using different devices, such as the pneumotachograph, which directly measures the airflow in the respiratory system. Pneumotachographs are commonly employed in medical and physiological research using face masks and have been adapted to record speech breathing (Rothenberg, Reference Rothenberg1977; Ghio and Teston, Reference Ghio and Teston2004). However, speaking with a facial mask is unnatural and alters speech articulation as well as breathing (Shea, Reference Shea1996). Alternative methods, such as inductance plethysmography, record variations in thoracic and abdominal volumes thanks to elastic straps with insulated wires around the speaker’s abdomen and chest. During inhalation and exhalation, the cross-sectional areas of the rib cage and abdomen expand and compress, altering the self-inductance of the coils and the frequency of their oscillation, which is converted into a digital waveform. The shape of the waveform is proportional to the inhaled or exhaled breath volume (see Figure 1.1B). Despite its sensitivity to motion artifacts, inductance plethysmography is suitable for estimating breathing in various tasks, including speech (Caretti et al., Reference Caretti, Pullen, Premo and Kuhlmann1994; Clarenbach et al., Reference Clarenbach, Senn, Brack, Kohler and Bloch2005). It provides displacement data over time and allows the extraction of parameters such as respiratory rate and amplitude. Calibration is necessary for converting amplitude into volumetric units (Banzett et al., Reference Banzett, Mahan, Garner, Brughera and Loring1995; McKenna and Huber, Reference McKenna and Huber2019). The symmetry between inhalation and exhalation durations is a crucial parameter for studying speech breathing, characterized by unique specificities compared to silent breathing at rest or in different activities (Fuchs and Rochet-Capellan, Reference Fuchs and Rochet-Capellan2021).
1.2.3 Speech Breathing as a Multidetermined Rhythm
During speech, the regulation of breathing is intertwined with the planning of speech motor functions, involving a dynamic interaction between the forebrain, particularly cortical structures for speech production, and subcortical structures (Fuchs and Rochet-Capellan, Reference Fuchs and Rochet-Capellan2021). This interaction results in significant alterations in breathing patterns, notably a pronounced asymmetry between rapid inhalation and slow exhalation during speech (see Figure 1.1B). Variability in speech breathing cycles, in terms of duration and volume of air inhaled and exhaled, is influenced by linguistic, cognitive, and interactive factors (Conrad and Schönle, Reference Conrad and Schönle1979; McFarland, Reference McFarland2001; Fuchs and Rochet-Capellan, Reference Fuchs and Rochet-Capellan2021).
For example, in reading and spontaneous speech, inhalation duration and depth correlate with the upcoming utterance’s length, although correlations are smaller in spontaneous speech (Sperry and Klich, Reference Sperry and Klich1992; Winkworth et al., Reference Winkworth, Davis, Ellis and Adams1994, Reference Winkworth, Davis, Adams and Ellis1995; Rochet-Capellan and Fuchs, Reference Rochet-Capellan and Fuchs2013). The flexibility of breathing in adapting to speech demands allows for variability in extemporaneous speech, enabling the expression of communicative cues such as F0 modulation (Fuchs et al., Reference Fuchs, Reichel and Rochet-Capellan2015).
During speech, inhalation phases are coordinated with syntax. Readers tend to breathe predominantly at syntactic boundaries, and the amplitude of the breathing cycle correlates with the type of boundary, such as greater amplitude before a new paragraph than before a new sentence in the same paragraph (Conrad et al., Reference Conrad, Thalacker and Schönle1983). As speech rate increases, the frequency of breathing pauses decreases, defining a “syntactic tempo” observed in both text reading and spontaneous speech (Grosjean and Collins, Reference Grosjean and Collins1979; Rochet-Capellan and Fuchs, Reference Rochet-Capellan and Fuchs2013; Werner et al., Reference Werner, Trouvain and Möbius2022).
In conversation, breathing becomes intricately linked to turn-taking, with partners displaying coordinated breathing at turn-taking events and the shape of breathing cycles specific to conversational events (McFarland, Reference McFarland2001; Rochet-Capellan and Fuchs, Reference Rochet-Capellan and Fuchs2014). Holding one’s breath in a silent breathing cycle may signal intentions related to turn-taking, influencing the perception of speech pauses (Wlodarczak and Heldner, Reference Wlodarczak and Heldner2020). Ultimately, the presence of inbreath noises significantly influences the perception of speech pauses (MacIntyre and Scott, Reference MacIntyre and Scott2022). These noises are influenced by the configuration of the vocal tract, suggesting that breathing may acoustically convey specific information that merits further investigation (Werner et al., Reference Werner, Fuchs and Trouvain2023). This critical information can influence the behavior of a dialogue partner. Moreover, breathing interactions between communicative partners appear to develop early, as observed in mother–infant interactions (McFarland et al., Reference McFarland, Fortin and Polka2020).
The adaptability of the breathing system is crucial to support spoken communication. However, as discussed in Fuchs and Rochet-Capellan (Reference Fuchs and Rochet-Capellan2021), spoken communication is also constrained by the intricate interplay between breathing, cognitive abilities, and lung volume capacity. Consequently, speech breathing is highly individualized, exhibiting significant variations among speakers.
1.2.4 Speech Breathing as a Speaker-Specific Tempo
The exploration of individual breathing characteristics began with an examination of tidal breathing. Dejours noted variations in ventilation characteristics among participants even under identical conditions, leading to the concept of “ventilatory personality” (Dejours, Reference Dejours1966; Shea and Guz, Reference Shea and Guz1992). Consistency in breathing patterns over time was confirmed by Bennchetrit et al. (Reference Bennchetrit, Shea and Dinh1989), with monozygotic twins displaying more similar tidal breathing than random or dizygotic pairs, hinting at potential genetic or physiological influences (Kawakami et al., Reference Kawakami, Yamamoto, Yoshikawa and Shida1984; Shea et al., Reference Shea, Horner, Benchetrit and Guz1990). However, task-specific variations in breathing individuality exist, with stability observed within tasks such as tidal breathing or exercise but not consistently between them (Eisele et al., Reference Eisele, Wuyam and Savourey1992; Besleaga et al., Reference Besleaga, Blum and Briot2016).
Speech breathing is influenced by various speaker-specific parameters. Aging, for example, leads to declines in breathing capacities, affecting speech production, with older adults requiring higher lung volumes for speech initiation (Hoit and Hixon, Reference Hoit and Hixon1987; Sperry and Klich, Reference Sperry and Klich1992; Huber, Reference Huber2008). Factors such as weight, stature, age, sex, developmental processes, or diseases such as Parkinson’s or asthma also impact speech breathing (Hoit and Hixon, Reference Hoit and Hixon1986, Reference Hoit and Hixon1987; Loudon et al., Reference Loudon, Lee and Holcomb1988; Hoit et al., Reference Hoit, Hixon, Watson and Morgan1990; Solomon and Hixon, Reference Solomon and Hixon1993; Boucher and Lalonde, Reference Boucher and Lalonde2015), suggesting that breathing is determined by speaker-specific factors related to both bodily and cognitive constraints.
Despite ample evidence of speaker-specific breathing profiles during speech, recent work by Serré et al. (2020) also highlights individual consistency in speech breathing. They found that while the period of the speech breathing cycle differs among participants, it remains remarkably consistent for the same individual, even during light exercise. This underscores the high variability and specificity of speech breathing in each speaker.
Speech rhythm is also influenced by limb movements co-occurring when speaking. This relation between speech and limb movements may involve breathing, as discussed in Section 1.3.
1.3 The Influence of Limb Movements on Speech Rhythm
Limb movements are ubiquitous in spoken communication. Communicative limb movements, especially those executed with the arms and hands, are intrinsic to human conversation. Gestures accompanying speech, in particular hand gestures, have been extensively studied and exhibit a multilayered relationship with speech (see also Chapter 4 in this volume). At the level of speech production, representational gestures can help lexical access and speech fluency, thereby influencing speech rate and acting as essential pacing cues during conversations. At the sensorimotor level, the coordination between upper-body movements and vocalization is a key step of language development and still observed in adulthood.
1.3.1 Gestures as an Essential Component of Speech Production
Gestures, and especially hand gestures, appear to serve different purposes in spoken communication. The multitude of connections between gestures and speech has sparked numerous studies and hypotheses exploring the interplay between these two systems and their roles in communication and language.
1.3.1.1 Effect of Gestures on Speech Conceptualization
Speech planning and speech fluency are tightly linked. Numerous studies emphasize the supportive role of gestures in accessing lexical items or concepts during speech production (Graham and Heywood, Reference Graham and Heywood1975; Morsella and Krauss, Reference Morsella and Krauss2004; Hostetter et al., Reference Hostetter, Alibali and Kita2007; Hoetjes et al., Reference Hoetjes, Krahmer and Swerts2014; Cravotta et al., Reference Cravotta, Busà and Prieto2019). These studies looked at the effect of gesturing (compared to not being able to gesture) on lexical content, but also on the number of pauses, speech rate, and prosody. The lexical retrieval hypothesis, supported by Krauss (Reference Krauss1998) and Ruiter (Reference Ruiter1998), posits that gestures play a crucial role in lexical access, facilitating access to concepts and words in memory. This theory echoes studies highlighting the neural connections between semantic comprehension of actions and corresponding sensorimotor circuits (Pulvermüller and Fadiga, Reference Pulvermüller and Fadiga2010; Bidet-Ildei et al., Reference Bidet-Ildei, Beauprez and Badets2020). Besides aiding memory retrieval, gestures help organize information for verbal encoding, especially spatio-motoric details (Alibali et al., Reference Alibali, Kita and Young2000; Kita et al., Reference Kita, Alibali and Chu2017). Gestures support the activation of spatio-motoric information and problem-solving in both concrete and abstract thinking, potentially influencing the course of speaking, facilitating novel ideas and affecting discourse orientation. Through this process, gestures influence the packaging of verbal information into clauses. For example, when describing the manner (e.g., rolling) and path (e.g., down) of a motion with two separate gestures, participants tend to produce a two-clause verbal description, while a single gesture leads to a single-clause verbal description (see Kita et al., Reference Kita, Alibali and Chu2017 for references). This role attributed to gestures may have correlates in speech rhythms that require further investigation.
Various hypotheses surround the roles of gestures – whether they serve conceptual or communicative purposes – prompted by the question of whether speech and gestures are distinct or stem from a unified internal representation. Beyond their communicative role, gestures serve pragmatic functions, supporting interpersonal coordination in spoken conversations.
1.3.1.2 Role of Gestures in Conversational Stream
The role of nonverbal communication in dialogue is briefly highlighted here, emphasizing gestures’ contribution to the rhythm of interpersonal verbal exchanges. Gestures serve as visual cues in conversations and convey a variety of information supporting interpersonal convergence and coordination (Holler, Reference Holler2022). They often precede the verbal message or convey additional information without interrupting speech. Specifically, gestures are integral to backchannels and turn-taking processes (Wagner et al., Reference Wagner, Malisz and Kopp2014), which are indispensable for dialogue fluidity and pace. Gestures, and nonverbal communication in general, offer real-time feedback to speakers, aiding in understanding listener processing without disrupting ongoing discourse. This mechanism allows speakers to assess communication success, aiding anticipation of semantic shifts, topic changes, and turn-taking events (Holler and Levinson, Reference Holler and Levinson2019). For instance, Ter Bekke et al. (Reference Ter Bekke, Drijvers and Holler2024) found quicker responses to questions accompanied by iconic gestures. Electroencephalographic studies show that brain responses in dyadic interactions are modulated by the processing of nonverbal cues (Zhang et al., Reference Zhang, Frassinelli, Tuomainen, Skipper and Vigliocco2021). More specifically, beat gestures facilitate semantic processing (Wang and Chu, Reference Wang and Chu2013) and syntactic parsing (Obermeier and Gunter, Reference Obermeier and Gunter2014; Biau et al., Reference Biau, Fromont and Soto‐Faraco2018).
Co-speech gestures significantly influence the timing of spoken communication, affecting thinking, speech production, and conversational tempo. Coordination between speech and co-speech gestures is proposed to be rooted in the conceptual phase, relying on common meaning (McNeill, Reference McNeill1992). Additionally, sensorimotor connections between articulatory and limb control, especially hand and mouth, may underpin coordination between speech and co-speech gestures.
1.3.2 Speech and Co-speech Gestures Acting in Synchrony
Regardless of speech content, sensorimotor connections are at play in the coordination between speech gestures and co-speech gestures. These connections emerge early during development, in the course of speech acquisition. Similar coordination patterns are observed between noncommunicative vocalization and limb movements during adulthood, suggesting that the hand and the mouth share common control mechanisms.
1.3.2.1 Manual and Vocal Development towards Spoken Language
Low-level motor links appear early in ontogenesis and may establish the connection between speech and co-speech gestures (see also Chapter 38). Fetal initiation of facial touching, particularly around the mouth, begins between 12 and 15 weeks of gestation (Gallagher, Reference Gallagher, Bermúdez, Eilan and Marcel1995; Fagard, Reference Fagard2013). At birth, about one-third of hand movements result in hand–mouth contact, with coordination advancing rapidly, especially when the child is hungry (Gallagher, Reference Gallagher, Bermúdez, Eilan and Marcel1995). Rhythmic coupling between limb motion and vocal tract control for vocalization typically begins around six months, serving as a basis for hand-to-mouth coordination development (Iverson and Thelen, Reference Iverson and Thelen1999). In particular, a peak in the frequency of occurrence of rhythmic hand activities, such as rattle shaking, is observed at the onset of canonical babbling (see Iverson and Wozniak, Reference Iverson and Wozniak2007). These concurrent activities also influence each other, with babbling accompanied by hand movements displaying longer syllable lengths than babbling without hand movements (Ejiri and Masataka, Reference Ejiri and Masataka1999). Repetitive entrainments between hand movements and the vocal tract may set the stage for the speech–gesture system’s emergence in the last month of the first year, featuring more controlled gestures such as pointing, followed by spoken words a few weeks later. Gestures play an important role in both lexical and syntactic development and are combined with speech to convey meaning through more and more complex morphosyntax (Iverson and Goldin-Meadow, Reference Iverson and Goldin-Meadow2005; Özçalışkan and Goldin-Meadow, Reference Özçalışkan and Goldin-Meadow2005). Low-level sensorimotor coupling persists in adults, providing insights into the enduring link between co-speech gestures and speech in communication.
1.3.2.2 Speech–Gesture Synchrony: A Somatosensory Phenomenon?
Pointing gestures have been a focal point in the speech–gesture coordination investigation (Levelt et al., Reference Levelt, Richardson and La Heij1985; Rochet-Capellan et al., Reference Rochet-Capellan, Laboissière, Galván and Schwartz2008; Chu and Hagoort, Reference Chu and Hagoort2014). Bidirectional adaptations between speech and pointing gestures have been observed during perturbation of either gestures or speech, preserving their synchronization (Chu and Hagoort, Reference Chu and Hagoort2014). More specifically, Rochet-Capellan et al. (Reference Rochet-Capellan, Laboissière, Galván and Schwartz2008) found that mutual adaptation occurs between speech and pointing gestures, such as to synchronize the lexical stress with the gesture apex and pointing phase. Another type of gestures related to speech prosody are beat gestures. Beat gestures are rhythmic, baton-like gestures that have been shown to modulate prosodic prominence (Krahmer and Swerts, Reference Krahmer and Swerts2007; Pouw et al., Reference Pouw, Harrison and Dixon2020a; see also Section 1.4 of this chapter).
In spontaneous narration, McNeill (Reference McNeill1992) found gestures and speech synchrony to be unaffected by delayed auditory feedback (DAF) but disrupted in scripted situations. These findings align with the Growth Point hypothesis suggesting that synchronization is rooted in the conceptual phase. According to Pouw and Dixon (Reference Pouw and Dixon2019), the coupling between gestures and speech is even more stable under DAF conditions, which suggests that “gesture with its own intrinsic dynamics (and thus different entrainment to DAF) can be utilized to resist DAF in speech production” (p. 27).
Coordination patterns between speech and hand motion have also been found through noncommunicative movements. Studies of spatiotemporal coupling between vocalizations and finger tapping (Kelso et al., Reference Kelso, Tuller, Harris and MacNeilage1983; Parrell et al., Reference Parrell, Goldstein, Lee and Byrd2014; Zelic et al., Reference Zelic, Kim and Davis2015) have found some evidence of hand and mouth being controlled as a single coordinative structure. Their results suggest that the coupling between prosody and hand movements may rely on broad motor control and somatosensory feedback not specific to speech, as it persists during silent speech. Finally, the hand and the mouth seem to be controlled by a common motor command (Gentilucci and Volta, Reference Gentilucci and Volta2008): during the co-occurrence of object picking and vocalizing, the lip aperture and the first formant increase with object size. Further support for this hypothesis comes from neurophysiological findings about Broca’s area, believed to exert control over both the mouth and the hand (Fadiga et al., Reference Fadiga, Craighero and D’Ausilio2009). The sensorimotor connections and common rhythmic patterns between speech and limb movements have been shown to play a key role in speech rehabilitation for patients with Parkinson’s disease and patients with stuttering symptoms (see also Chapter 45).
However, the generalization of synchronization patterns of natural speech with hand movements remains incompletely understood (Parrell et al., Reference Parrell, Goldstein, Lee and Byrd2014). While cognitive processes related to spoken language or motor-level origins for speech–limb coordination are open questions, recent exploration suggests breathing may play a significant role in this coordination.
1.4 Breathing: A Bridge between Speech and Limb Movements
Section 1.2 of this chapter delved into the dual nature of breathing, serving both automatic and voluntary functions, and highlighted its adaptability to diverse mental and physical states. The coordination of breathing with speech involves balancing linguistic, communicative, and physiological factors, where ventilation constraints shape spoken communication rhythms. Simultaneous speech and limb movements introduce complexity, prompting adjustments in breathing and vocalizations. This complexity is evident in physical exercise studies exploring the interplay between speech, breathing, and limb movement. Breathing serves as a shared resource linking speech and body motion, motivating comprehensive empirical and theoretical approaches to understand their interaction. The intricate relationship between speech, breathing, and limb movements fosters various research perspectives, which are briefly outlined in this last section.
1.4.1 Talking and Breathing during Physical Effort
Engaging in physical exercise imposes constraints on breathing via limb movements, creating a unique context for exploring the interaction between speech breathing and limb actions. In the absence of speech during exercise, the breathing cycle is limited by the oxygen requirements of the muscles. The respiratory system dynamically adjusts to meet the escalating demand for oxygen, revealing an intricate interplay between central and peripheral mechanisms (see Shevtsova et al., Reference Shevtsova, Marchenko and Bezdudnaya2019). Behaviorally, the initiation of exercise results in a swift elevation of respiration frequency and tidal volume (Whipp et al., Reference Whipp, Ward, Lamarra, Davis and Wasserman1982). An intriguing question arises: Does this observed pattern persist when individuals converse during exercise?
1.4.1.1 Effect of Exercise on Speech Breathing and Pauses
When speaking during physical exercise, speech breathing must accommodate the heightened oxygenation needs of the body. Unlike speaking at rest, speaking during physical activity involves shorter exhalations, increased airflow during exhaling, and longer, deeper inhalations (Hixon et al., Reference Hixon, Goldman and Mead1973, Reference Hixon, Mead and Goldman1976). Consequently, the syntactic structure of speech undergoes modifications. Baker et al. (Reference Baker, Hipp and Alessio2008) examined the impact of different physical effort intensities in cycling on a reading speech task. They observed an increase in the number of non-syntactic pauses, a reduction in syllable count within breath groups, and an increase in articulation rate. Fuchs et al. (Reference Fuchs, Reichel and Rochet-Capellan2015) found that while engaged in semi-spontaneous speech, individuals exhibited a heightened frequency of breathing when cycling compared to speaking alone. Moreover, this trend became more pronounced with an increased level of biking effort. Trouvain and Truong (Reference Trouvain and Truong2015) investigated reading speech before and after volitional exhaustion on a treadmill. They found that both the duration and the intensity of inbreath segments increase from before to after, and a tendency to observe a higher count of inbreath tokens per second in the post-phase compared to the pre-phase.
1.4.1.2 Effect of Speech on Exercise Breathing
Despite changes in speech organization and in particular pauses induced by physical effort, there is an adaptation in breathing patterns to preserve speech quality. Interestingly, the elevation in ventilation during vocalization is less noticeable, and the respiratory frequency is lower, in comparison to exercising without speaking (Doust and Patrick, Reference Doust and Patrick1981). However, there is a limit to sustaining speech quality when physiological demands reach a certain threshold. In sports studies, the talk test instrumentalized speech during exercise to evaluate and guide exercise training intensity for each individual. The exercise intensity at which individuals initially “experience difficulty speaking comfortably” (utilizing various speech stimuli) serves as a dependable indicator of the ventilatory threshold in healthy individuals (see Foster et al., Reference Foster, Porcari and Ault2018). Recent research indicates that the point at which normal speech can no longer be maintained aligns with the onset of metabolic acidosis during escalating exercise intensity (De Lucca et al., Reference De Lucca, de Oliveira, Foster and Carminatti2021). While sports studies traditionally overlook speech changes induced by physical exertion, recent research in language and cognitive sciences has witnessed a growing interest in investigating these phenomena.
1.4.1.3 Effect of Exercise on Speech Signals
The intricate relationship between speech breathing and physical effort extends to speech acoustics, where parameters change with increased exertion, including a rise in average intensity and fundamental frequency (F0) during biking (Mohler, Reference Mohler1982; Fuchs et al., Reference Fuchs, Reichel and Rochet-Capellan2015; Weston et al., Reference Weston, Fuchs and Rochet-Capellan2020; Serré et al., Reference Serré, Dohen, Fuchs, Gerber and Rochet-Capellan2022) or treadmill tasks (Primov-Fever et al., Reference Primov-Fever, Lidor, Meckel and Amir2013; Trouvain and Truong, Reference Trouvain and Truong2015). Trouvain and Truong proposed that this F0 increase may be attributed to heightened subglottal pressure during physical exertion. Conflicting findings on F0 changes during limb movements and exertion levels highlight significant inter-speaker variability, presenting diverse and sometimes opposing behaviors (Godin and Hansen, Reference Godin and Hansen2008, Reference Godin and Hansen2015; Weston et al., Reference Weston, Fuchs and Rochet-Capellan2020). The relationship between exertion level and F0 in speech is complex. Johannes et al. (Reference Johannes, Wittels and Enne2007) observed that F0 is primarily affected by exercise near exhaustion. These varied outcomes suggest that the impact of physical stress on speech acoustics is neither linear nor constant, emphasizing the need for a detailed examination at smaller scales. Crucial factors include the unique articulation space for each consonant, affecting sensitivity to subglottal pressure fluctuations, and considerable variability in limb movement dynamics influenced by biomechanical mechanisms (Godin and Hansen, Reference Godin and Hansen2011) that may also involve breathing (Pouw et al., Reference Pouw, De Jonge-Hoekstra, Harrison, Paxton and Dixon2020b).
1.4.2 Multilayer Connections between Speech, Breathing, and Limb Movement
Understanding the intricate interplay of speech, breathing, and limb movement is essential to understand their coexistence in facilitating human communication. This involves exploring their contributions across the evolutionary and developmental aspects of spoken language. Previous research indicates the involvement of various factors, including low-level biomechanical as well as physiological and cognitive aspects. Additionally, learning from sensorimotor and social experiences may contribute to shaping the influence of physiological rhythms on communicative ones.
1.4.2.1 A Biomechanical Anchor of Speech–Breathing–Limb Interaction
Pouw et al. (Reference Pouw, Harrison and Dixon2020a, Reference Pouw, De Jonge-Hoekstra, Harrison, Paxton and Dixon2020b) found correlates of arm motions in vocalizations. In particular, when participants imitated a beat gesture in a rhythmic fashion during syllable production or spontaneous speech, the amplitude envelope and F0 increased close to the deceleration peak of the arm movement. The authors introduce the hypothesis of a biomechanical interplay between arm breathing and speech in relation to anatomical constraints between the arms and the breathing system. While moving the arms, thoracic muscles are activated to maintain posture and support limb movements. This activation triggers rib cage displacements, impacting the lungs. When the arms move such as in beat gestures, this induces changes in the respiratory system, leading to an increase in subglottal pressure, and changes in acoustical parameters of co-occurring vocalizations. In line with this idea, Serré et al. (Reference Serré, Dohen, Fuchs, Gerber and Rochet-Capellan2022) observed a correlation between the amplitude envelope of speech acoustic peaks and leg deceleration events during biking, further supporting possible biomechanical interplays involving body movement, breathing, and speech production, not limited to the arms.
Recently, Pouw and Fuchs (Reference Pouw and Fuchs2022) argue that this biomechanical entanglement extends beyond immediate physiological effects, potentially influencing coordinated speech patterns. They propose that this link may have evolutionary significance, contributing to the development of finely tuned vocalizations in species with a diverse coupling of breathing and limb movements, particularly in bipedal species where upper bodies are liberated during locomotion.
However, as much as the biomechanical entanglement of limb, respiratory, and vocal systems can explain the impact of limb movements on speech acoustics, and may contribute to speech and gesture coordination, it can’t account for the entire variability of speech. If speech, breathing, and limb movements obviously share the same physical body substrate, and if motion in one part of this body might spread to others through biomechanical constraints, they also share the same brain as well as sensorimotor and social experiences.
1.4.2.2 The Interplay between Cognitive and Physiological Factors
Distinguishing between the effect of cognitive and physiological factors on speech is not always easy, and hypotheses assuming only one cause often end in a chicken-and-egg loop. For example, in ontogenesis, researchers noted a correlation between the growth of lung capacity and the increasing length of utterances (Bouchet and Lalonde, Reference Boucher and Lalonde2015). However, at the same time, cognitive abilities are also changing. In adulthood, there is no clear evidence that speakers with higher lung capacity are likely to produce longer utterances (Heldner et al., Reference Heldner, Carlsson and Wlodarczak2019). While exploring the involvement of the forebrain in individual tidal breathing patterns, Shea et al. (Reference Shea, Horner, Benchetrit and Guz1990) noted varying cycle shapes among individuals with similar body types and observed diverse body types exhibiting similar cycle shapes. Moreover, motor-respiratory coordination in humans is highly flexible, sensitive to factors such as cognitive effort (Hessler and Amazeen, Reference Hessler and Amazeen2014). New MRC patterns can also be intentionally learned to improve energy consumption during specific physical effort (Hessler and Amazeen, Reference Hessler and Amazeen2014). Furthermore, the modification of speech breathing through learning is evident, as seen in actors and actresses (Master et al., Reference Master, Guzman, Azócar, Muñoz and Bortnem2015). Breathing is also intertwined with cognition, attention processes (Allen et al., Reference Allen, Varga and Heck2023), as well as various behavioral factors related to motor, emotional, physiological, and cognitive processes (Shea, Reference Shea1996; Grassman et al., Reference Grassmann, Vlemincx, Von Leupoldt, Mittelstädt and Van den Bergh2016; Park et al., Reference Park, Barnoud and Trang2020). In this respect, the breathing profiles are markers of ongoing activities of the body and mind as well as speaker specificities and training. The study of the impact of practices such as swimming, free diving, or yoga on breathing during speech and the organization of pauses could bring forth interesting insights regarding the effects of training.
Investigating speech breathing consistency over time and across different limb movements (leg versus arm biking), Serré et al. found that speech breathing cycles are consistent over time and across tasks, despite a significant effect of the limb deceleration on speech acoustics observed in the same dataset (Reference Serré, Dohen, Fuchs, Gerber and Rochet-Capellan2022). The temporal scale of this latter biomechanical aspect is less than a second, while speech breathing cycles take place over three to four seconds on average. The entanglement of these different scales suggests a complex interaction between multilevel rhythms shaping spoken communication (Pouw et al., Reference Pouw, Proksch and Drijvers2021). The emergence of such rhythms might depend on the speaker’s environment and peculiarities such as breathing capacities or spontaneous speech rate, embedded in speech control across individual experience.
1.4.2.3 Breathing as a Bridge Built through Grounded Experiences
Speech, breathing, and limb movements exhibit an interconnected evolution in both phylogenesis and ontogenesis (see also Chapter 7). This coevolution stems from anatomical overlap and connections among the three systems, further supported by the intricate development of peripheral and central nervous systems. This development occurs through concurrent activation in daily communicative experiences from birth. Despite their interdependence, research has predominantly explored speech, breathing, and limb movements separately or in pairs. On the one hand, studies on breathing and limb movements are often driven by sports and physiological approaches, to investigate energy expenditure and expert motor control. On the other hand, fields related to linguistics and cognition focus on the relationship between speech and breathing, neglecting limb movements, with minimal consideration for breathing. As evidenced in this chapter, breathing is a resource intrinsic to speech and limb movements and adapts to speech via utterance planning and to limb movements via afferent connections and chemoreceptors that transmit metabolic needs. Since limb and speech movements frequently co-occur, the brain may have developed specific abilities to control them jointly (Bernstein, Reference Bernstein1967; Latash et al., Reference Latash, Scholz and Schöner2007) and the shape of our evolved behaviors might be strongly determined by physiological factors. Coordinative structures between speech, breathing, and limbs might be learned in a specific way through experiences. Adopting an integrated view of this three-bodies issue might shed light on the complex nature of speech rhythms and their grounding in breathing and body movements.
1.5 Conclusion
The chapter discusses the intertwined relationship between breathing, limb movements, and speech rhythms, drawing on interdisciplinary evidence. It reveals that speech is organized into breath groups, influenced by cognitive, physical, and speaker-specific factors. Limb movements affect speech production by influencing conceptual, executive, and interactive aspects. Recent research suggests biomechanical connections between limb movements and speech acoustics via the respiratory system. This triadic interaction remains understudied, despite its potential significance in understanding creativity and communication. Holistic approaches hold promise for uncovering vital insights into the collaborative work of speech, breathing, and limb movements. However, studying the three-level interaction among complex systems poses challenges, necessitating interdisciplinary methods and expertise. Research perspectives on the interaction between speech, breathing, and limb movements may finally benefit from delving into more ecological as well as longitudinal investigations.
Summary
Research has shown that (1) speech is structured in breath groups, delineated by inhalation pauses aligned with syntactic as well as communicative events; (2) this coordination is yet subject to adaptation based on both cognitive and physical factors as well as speaker-specific influences; and (3) gestures and other limb movements influence speech rhythms by impacting conceptual, executive, and interactive aspects of speech production.
Implications
Speech, breathing, and limb movements exhibit an interconnected evolution in both phylogenesis and ontogenesis. This coevolution stems from anatomical overlap and connections among the three systems, further supported by the intricate development of peripheral and central nervous systems. As such, the brain likely integrates concurrent leg or arm movements into speech planning and speech motor control early on.
Gains
Despite their interdependence, research has predominantly explored speech, breathing, and limb movements separately or in pairs. Adopting an integrated view might shed light on the complex nature of speech rhythms and their grounding in breathing and body movements. Holistic approaches hold promise for uncovering vital insights, leading to more ecological investigations.
2.1 Introduction
This chapter approaches the topic of language rhythm from an articulatory point of view. It is divided into six sections where we present and discuss data on articulation, acoustics, and perception, with a focus on the jaw. The proposal is that articulatory patterns, specifically how much the jaw opens for each syllable, reflect the abstract hierarchical metrical structure of a spoken language (see, for example, work by Liberman and Prince, Reference Liberman and Prince1977; Selkirk, Reference Selkirk1982; Hayes, Reference Hayes1995); it is these metrically derived patterns of syllable prominence and phrasing, observed in the articulatory patterns, that provide a basis for language “rhythm.” In an English utterance, the metrical hierarchy manifests itself such that each syllable has an n-ary degree of prominence/stress, depending on its position in the hierarchy, with the nuclear stress syllable (or the emphasized/focused syllable) having the largest stress value, then subsequently the phrasally stressed and foot-stressed syllables, respectively, with the reduced syllables having relatively little jaw displacement.
2.1.1 Utterance Prominence and Acoustic Characteristics
In English, there is lexical stress, such that a word with more than one syllable has one syllable that receives more stress than others. The position of the stress is lexically fixed such that with the word linguistics, for example, the stressed syllable is the second one. Phrasal stress/prominence, in a sense, is like word stress: that is, with word stress, one syllable in the word receives more stress/prominence than the others; with phrase stress, one word (syllable) within the phrase receives more stress/prominence than the others.Footnote 1
In a simple utterance, such as I like dates, the word dates probably receives the largest amount of prominence. In English, the syllable/word in an utterance with the largest prominence is referred to as having utterance stress, also referred to as nuclear stress, with the default nuclear stress/utterance stress on the last content word of the utterance (e.g., Cole et al., Reference Cole, Hualde and Smith2019). In a more complex utterance, such as I saw five bright highlights in the sky tonight, there are perhaps three phrases: (I saw)(five bright highlights)(in the sky tonight). The second phrase (five bright highlights) consists of two smaller units (five bright) and (highlights), which we refer to as foot units. We suggest that for this utterance, the first member of each foot is more prominent than the second member (e.g., Erickson et al., Reference Erickson, Suemitsu, Shibuya and Tiede2012, Reference Erickson, Kawahara, Shibuya, Suemitsu and Tiede2014).
In English, speakers generally have choices about which words to group together in a phrase, and which word in that phrase gets the most stress. But the utterance prominence rule seems to be that no matter how the syllables are grouped into phrases, there will be only one syllable in the phrase that will be the most prominent. It is this pattern of prominence/stress that underlies English “rhythm.”
A hypothesis is that the abstract metrical hierarchical organization of an English utterance is realized such that each syllable in an utterance has an n-ary degree of prominence/stress; the nuclear stress syllable has the largest stress value, and then subsequently the phrasally stressed and foot-stressed syllables, respectively. The acoustic consequences of stress/prominence in English tend to be increased duration, increased intensity, increased or decreased fundamental frequency (F0) (e.g., H* or L* patterns), and more extreme formants (e.g., Fry, Reference Fry1955; Lehiste, Reference Lehiste1970; Cooper et al., Reference Cooper, Eady and Mueller1985; Beckman, Reference Beckman1986; Turk and Sawusch, Reference Turk and Sawusch1996; Kochanski et al., Reference Kochanski, Grabe, Coleman and Rosner2005).
2.1.2 Utterance Prominence Patterns and Articulation
In terms of articulation, the proposal in this chapter is that the amount of jaw displacement for each syllable (i.e., how much the jaw opens for each syllable) is commensurate to the amount of prominence/stress for that syllable (e.g., Erickson et al., Reference Erickson, Suemitsu, Shibuya and Tiede2012). The hypothesis explored is that the patterns of varying amounts of jaw displacement provide a window into the metrical organization of spoken language; that is, we implement/translate the abstract metrical rhythm of our spoken language in terms of how much we open our jaw for each syllable in an utterance.
The jaw, thus, is a prosodic articulator, in addition, of course, to the larynx. Here we focus on the jaw. This chapter has the following sections: (2.2) A review of findings about jaw displacement and emphasis; (2.3) a review of jaw displacement and utterance prominence patterns; (2.4) the relation between segment articulation and syllable articulation; (2.5) new articulatory, acoustic, and perceptual findings about jaw displacement and how these relate to utterance prominence and phrase boundary patterns in American English (AE) utterances; and (2.6) jaw and phrasal stress in other languages and applications for language teaching, along with plans for future research.
2.2 Jaw Displacement and Emphasis
Jaw displacement increases with prominence, including contrastive emphasis, not only for low vowels (e.g., Kent and Netsell, Reference Kent and Netsell1971; Stone, Reference Stone1981; Summers, Reference Summers1987; Macchi, Reference Macchi1988; Westbury and Fujimura, Reference Westbury and Fujimura1989; Beckman and Edwards, Reference Beckman, Edwards and Keating1994; de Jong, Reference de Jong1995; Erickson, Reference Erickson1998, Reference Erickson2002, Reference Erickson2004; Harrington et al., Reference Harrington, Fletcher, Beckman, Broe and Pierrehumbert2000; Menezes, Reference Menezes2003, Reference Menezes2004) but also for high vowels (Harrington et al., Reference Harrington, Fletcher, Beckman, Broe and Pierrehumbert2000; Erickson, Reference Erickson2002) and mid vowels (Erickson, Reference Erickson2002). Increased jaw displacement with increased prominence has also been reported for French (Loevenbruck, Reference Loevenbruck1999; Tabain, Reference Tabain2003) and Japanese (Erickson et al. Reference Erickson, Hashi and Maekawa2000).
An acoustic consequence of increased jaw displacement for emphasis is formant (F) changes. Jaw lowering changes the size and shape of the vocal tract; in order to produce the same phonological vowel with a larger jaw opening, the tongue must move accordingly. Erickson (Reference Erickson2002) reported that when a vowel is emphasized, the jaw lowers and the tongue of necessity also changes position – more up and forward for high vowels, more low and back for low vowels. For emphasized high vowels, F2 becomes higher while F1 tends to lower; for emphasized low vowels, F2 lowers while F1 raises, resulting in the emphasized vowels positioned at the more extreme edges of the vowel triangle. Findings of increased F1 with increased jaw displacement for low vowels have also been reported by, for example, Menezes (Reference Menezes2003).
Here we report on a pilot articulatory and perceptual study of emphasis in English (Erickson et al., Reference Erickson, Kim and Kawahara2015). Jaw displacement patterns were examined for two North American English speakers (one male, one female) for the utterance Pam said bat that fat cat at that mat, spoken in five different emphasis conditions: emphasis on bat, that, fat, cat, and no emphasis. Note that vowel quality also affects jaw displacement (i.e., a low vowel has about 4 mm lower jaw displacement than a high vowel) (Menezes and Erickson, Reference Menezes and Erickson2013; Williams et al., Reference Williams, Erickson and Ozaki2013); thus, all vowels in the utterance must be phonologically the same in order to see the effects of utterance prominence. For tracking the jaw movement, we used electromagnetic articulography (EMA), where a sensor was glued to the middle of the two lower incisor teeth just above the gumline. MView (Tiede, Reference Tiede2010) was used to measure the point in each vowel where the jaw was at its maximally lowest position from the bite plane.
Figure 2.1 shows the average amount of jaw displacement for each of the syllables in the five different emphasis conditions. The height of each bar represents the jaw displacement (mm) for each syllable. Notice that the emphasized word (underlined in capital letters) always has the largest jaw displacement in the utterance. As reported in Kim et al. (Reference Kim, Erickson and Lee2015), t-tests with Bonferroni post hoc tests showed that the difference was significant for that and fat for both speakers, but not for bat for A05, while neither of the two speakers showed a significant difference for cat.
Jaw displacement values for different emphasis conditions.
Jaw displacement values (mm) for each syllable in the utterance Pam said bat that fat cat at that mat, spoken in five utterance conditions by a single speaker. The emphasized words, from top to bottom, are BAT, THAT, FAT, CAT, and no emphasis.
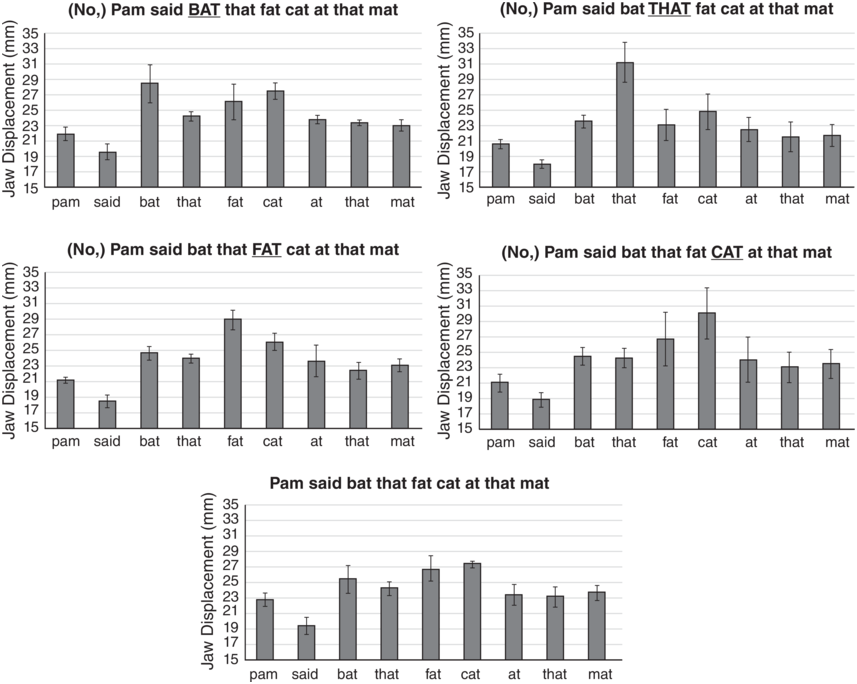
Figure 2.1 Long description
The highest to lowest mean jaw displacement values for various utterances are as follows. First. 28.5 for Bat, 27 for Cat, 26 for Fat, 25 for that and mat, 24.5 for that and at, 22 for pam and 20 for said. Second. 31 for That, 24 for bat, 25 for Cat, 23 for fat, 23 for fat, 22 for At, 21.5 for That and mat, 20.9 for pam and 18 for Said. Third. 29 for Fat, 26 for Cat, 24.8 for bat. 23 for That. 23 for Mat. 23.5 for At. 21 for Pam. 18.8 for Said. Fourth. 30 for Cat. 27 for Fat. 24.8 for Bat. 24 for At. 23.2 for Mat. 23 for That. 21 for Pam. 19 for Said. Fifth. 27.2 for Cat. 27 for Fat. 25.2 for Bat. 24 for That. 23.5 for Mat. 23 for Pam. 23 for At. 19 for Said. The values are estimated.
The bottom panel of Figure 2.1 shows the jaw displacement pattern for the utterance type spoken without emphasis on any word. Notice that in the no-emphasis utterance, there is still one word, cat, which shows the largest jaw displacement in the utterance, suggesting that nuclear stress is on cat. Notice also the strong–weak pattern of jaw displacement for the first two pairs of words (Pam said, bat that) in the utterance; if the second member is emphasized, we then see a weak–strong pattern. But, for the third pair of words, fat cat, unless fat is emphasized, we see a weak–strong pattern of jaw displacement such that cat has more jaw displacement than fat. We suggest that this is because for this speaker, the nuclear stress is on cat. These jaw displacement patterns suggest that in some inherent way, jaw articulation patterns form a framework for English rhythmic prominence patterns.
What about perception? Do jaw displacement patterns affect listeners’ perception of prominence? In order to test the hypothesis that the patterns of jaw displacement “match/reflect” the prominence patterns of an utterance, an online rapid prosodic transcription (RPT) listening test was done (Cole et al., Reference Cole, Hualde and Smith2019). A total of 50 listeners (18 for the 26 tokens of A03, and 32 for the 24 tokens of A05) were asked to evaluate each token twice: first to mark with a vertical line between each word where they heard phrase breaks, and second to underline which word or words “stood out” more than the others, that is, which word seemed louder, longer, or higher pitched. Listeners could listen to each token as many times as they wished. Results of the RPT perception test indicated a significant relation (p <. 001) between jaw displacement and perceived prominence for both speakers (r=0.60 for A03; r=0.68 for A05). We also see a significant, but less strong, relation between jaw displacement and perceived boundaries, with one speaker (A03, r=0.43, p < 0.001) showing a slightly stronger relation than the other (A05, r=0.18, p < 0.05). The interaction between phrase boundaries and prominence, both in terms of perception and articulation, is explored further in the following sections.Footnote 2
Given that jaw displacement increases for emphasized words, in the next section, we explore further how jaw displacement patterns vary with utterance prominence patterns. The hypothesis is that we will see patterns of increased jaw displacement that correspond to, for example, foot stress, phrasal stress, and utterance nuclear stress.
2.3 Jaw Displacement and Utterance Prominence Patterns
As seen in the previous sections, not only does jaw displacement increase for emphasis, it also increases for utterance (nuclear) stress. Here we report on findings from earlier studies (e.g., Erickson et al., Reference Erickson, Suemitsu, Shibuya and Tiede2012, Reference Erickson, Kawahara, Shibuya, Suemitsu and Tiede2014; Huang and Erickson, Reference Huang and Erickson2019; Erickson and Niebuhr, Reference Erickson and Niebuhr2023). Articulatory and acoustic recordings by a number of AE speakers were made for the utterance I saw five bright highlights in the sky tonight. This utterance was chosen because the vowels in the content words are all /aɪ/ diphthongs (except for the word saw in the phrase I saw, and this phrase was excluded from the analysis); also, as briefly described above, the utterance has the two phrases five bright highlights and in the sky tonight. The first phrase consists of two two-word feet: five bright and highlights. (The first phrase could be referred to as an accent phrase, or an intermediate phrase, but here we refer to it simply as a phrase.) Maximum jaw displacement was measured during the vowel /a/ of the diphthong.
Figure 2.2 (top) shows jaw tracings of an AE speaker producing the utterance (I saw) five bright highlights in the sky tonight. The valleys indicate when the jaw is lowered/open, as measured from the occlusal (bite) plane. We observe that for the top jaw tracing (gray arrows), (1) there are valleys (jaw openings) for each syllable; (2) the depth of the valleys varies, even though the vowel is always /aɪ/; and (3) the biggest valley (jaw displacement) occurs for sky, then for high of highlights, and then for five of five bright.
Samples of default and intent nuclear stress.
Jaw tracings for AE speakers for the utterance I saw five bright highlights in the sky tonight. For the top figure, gray arrows from left to right point to foot stress on five, phrase stress on the first syllable of the compound word highlights, and utterance (nuclear) stress on sky. For the bottom figure, nuclear stress is instead on high(lights), phrasal stress is on sky, and foot stress is on five, as indicated by the white arrows.
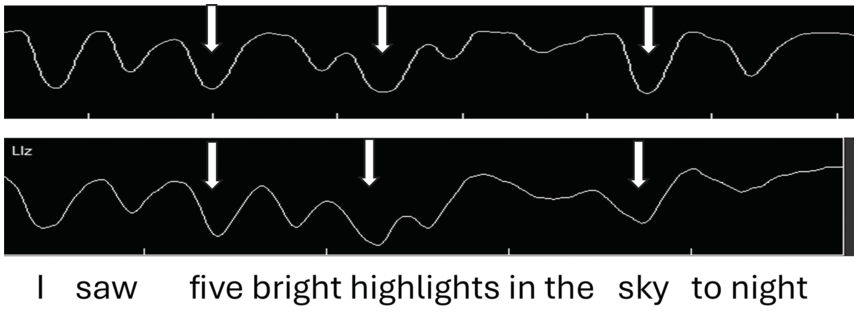
The jaw displacement patterns for the top jaw tracing in Figure 2.2 (seen for the four English speakers reported in Huang and Erickson, Reference Huang and Erickson2019), with nuclear stress on sky, can be depicted in terms of a metrical arrangement of syllable stress patterns along the lines of, for example, Liberman and Prince (Reference Liberman and Prince1977), Selkirk (Reference Selkirk1982), and Hayes (Reference Hayes1995), as shown in the top part of the metrical grid displayed in Table 2.1. The word sky has utterance nuclear stress (level 5 stress), high has phrasal stress (level 4 stress), and five has foot stress (level 3 stress). Notice that for this speaker, nuclear stress occurs in the default position, that is, the last content word of the utterance. (Note that tonight is not a content word but rather an adverb.) The stress pattern in this utterance would be 3-2-4-1/5-2 (where a slash indicates a syntactic phrasal break).
Metrical grids for two types of nuclear stress productions for the utterance (Yes, I saw) five bright highlights in the sky tonight (along the lines of, for example, Hayes, Reference Hayes1995). Both productions show foot stress on five, but the top grid shows default type nuclear stress on sky and phrasal stress on highlights; the bottom grid shows intent nuclear stress on highlights, and phrasal stress on sky.
| Utterance | x | |||||
| Phrase | x | x | ||||
| Foot | x | x | x | |||
| Word | x | x | x | x | x | |
| Syllable | x | x | x | x | x | x |
| Stress level | 3 | 2 | 4 | 1 | 5 | 2 |
| (Yes, I saw) | five | bright | high | lights | sky | night |
| Utterance | x | |||||
| Phrase | x | x | ||||
| Foot | x | x | x | |||
| Word | x | x | x | x | x | |
| Syllable | x | x | x | x | x | x |
| Stress level | 3 | 2 | 5 | 1 | 4 | 2 |
| (Yes, I saw) | five | bright | high | lights | sky | night |
When AE speakers are asked to read a sentence with no prior context, they have choices of where to put nuclear stress, as indicated by the bottom jaw tracing of Figure 2.2. In the bottom tracing, the pattern of jaw displacement shows the largest stress in the utterance on high(lights), perhaps because the word highlights seemed to carry a certain amount of salience for these speakers. Thus, the stress pattern in this utterance would be 3-2-5-1/4-2 (where a slash indicates a syntactic phrasal break).
The metrical grid for this utterance, with the largest jaw displacement on highlights, typical for three of the four AE speakers reported in Erickson et al. (Reference Erickson, Suemitsu, Shibuya and Tiede2012), might be as represented in the bottom metrical grid portrayed in Table 2.1. The largest jaw displacement is hypothesized to be the utterance nuclear stress high(lights), while the phrasal stress is sky and the foot stress is five, with a stress pattern of 3-2-5-1/4-2. Another speaker in the Erickson et al. (Reference Erickson, Suemitsu, Shibuya and Tiede2012) study, however, put the most jaw displacement/prominence on five, and for this speaker, there would be yet another different pattern of utterance stress: 5-2-3-1/4-2 (Figure 2.1; Erickson et al., Reference Erickson, Suemitsu, Shibuya and Tiede2012). Our findings suggest that nuclear stress in AE may be of two types: default type, which occurs on the last content word of the utterance, and intent type, which occurs on the content word that seems to be most salient to the speaker.
Erickson et al. (Reference Erickson, Suemitsu, Shibuya and Tiede2012) reported that increased jaw displacement showed a significant relation with F1 for three of the four speakers; moreover, both jaw displacement and F1 showed a significant relation with the metrical grid as shown in Table 2.1 (bottom part). These findings lend support to the jaw as being the metrical prosodic organizer of English utterances, with increased F1 being one of the acoustic changes. The Huang and Erickson (Reference Huang and Erickson2019) study investigating utterances with mid front vowel /ɛ/ also addresses possible effects on jaw displacement due to interactions among the tongue body together with formant changes and F0 (see also Chen et al., Reference Chen, Whalen and Tiede2019, as well as Erickson, Reference Erickson2002).
A question is to what extent jaw displacement patterns affect/influence listeners’ perceptions of utterance prominence. Pilot studies suggest that the word with the largest jaw displacement is also perceived as having the most prominence (e.g., Erickson et al., Reference Erickson, Kim and Kawahara2015, Reference Erickson, Huang and Menezes2020a). What in the acoustic signal is related to increased jaw displacement and prominence perception? These questions are explored in Section 2.5, reporting on new articulatory, acoustic, and perceptual data. In addition to jaw data, we report on vowel acoustic measurements (F1, F2, F0, intensity, and duration) along with listeners’ assessment of prominence and phrase boundaries. However, first we wish to report on some recent findings concerning the relationship between segmental articulation and syllabic articulation, and to present ideas on how this relationship might be affected by prominence.
2.4 Relation between Segment Articulation and Syllable Articulation
The pattern of jaw displacement reflects the abstract metrical prosodic hierarchy of a spoken utterance (see, for example, Erickson et al., Reference Erickson, Suemitsu, Shibuya and Tiede2012). These rhythmic closed and opened periods of the jaw underlying each syllable must synchronize with the alternating degrees of constriction of consonants and vowels for the syllable. In this section we examine segmental articulation and how it might time with syllabic articulation. Here, we review recent work by Svensson Lundmark (Reference Svensson Lundmark2023), who describes segmental articulation in terms of de/acceleration peaks of the articulators (here the slash refers to both deceleration and acceleration) where the acceleration and deceleration peaks of the segmental articulators align with acoustic segment boundaries. This approach is centered around the concept of acceleration which is a movement characteristic of a mass (= an articulator). Both acceleration (movement initiation) and deceleration (movement “braking”, approaching a target) involve positive muscle forces—generated by agonist or antagonist muscles, respectively. The amount and type of force applied determine articulatory speed. The moments of maximal acceleration or deceleration (de/acceleration peaks) divide the articulatory movement into postures/steady states, which are delimited by very fast intervals. It is specifically the postures of the crucial segmental articulators of the consonant production, that is, the lips for a bilabial segment, that align with the acoustic consonant segment. For more details concerning this approach, we refer to Svensson Lundmark (Reference Svensson Lundmark2023) and Svensson Lundmark and Erickson (Reference Svensson Lundmark and Erickson2024).
As for vowel segment duration, the relationship to the de/acceleration peaks is different: as the consonantal production is of an instantaneous nature, layered on top of vowels (Öhman, Reference Öhman1966), the vowel segment duration is the result of when the consonant segments are produced. More specifically, the acceleration peak at the end of the syllable onset consonant forms the vowel segment onset, and the deceleration peak of the coda consonant forms the vowel segment offset, as indicated in the schematized kinematic trajectories of a CVC (consonant-vowel-cononant) sequence in Figure 2.3. Note that the de/acceleration peaks of the tongue body for vowel targets do not align with the segment boundaries, but instead shape a much shorter tongue body posture (Svensson Lundmark, Reference Svensson Lundmark2023). In other words, the duration of the acoustic vowel segment is a reflection of when in time the first crucial segmental articulator (for the syllable onset) leaves its position, be it the tongue tip or the lips, and when the second crucial segmental articulator (for the syllable coda) arrives at its target destination.
Schematized steady stades and fast transit intervals.
A schematized figure on steady states (thick solid lines) and fast transit intervals (solid lines with arrows) of a syllable, as divided by de/acceleration peaks. The areas marked CVC are the duration of the acoustic segments. The steady states of the crucial segmental articulators (here, vertical positions of the tongue tip or lower lip) form the CVC segments. The syllable articulator (the jaw) displays shorter steady states than both C and V segments. Note that the steady state of the tongue body (a low vowel) does not align with the V segment. Still unresolved questions are marked with dotted lines. The schematized figure is based on findings of Svensson Lundmark (Reference Svensson Lundmark2023) and Svensson Lundmark and Erickson (Reference Svensson Lundmark and Erickson2024).
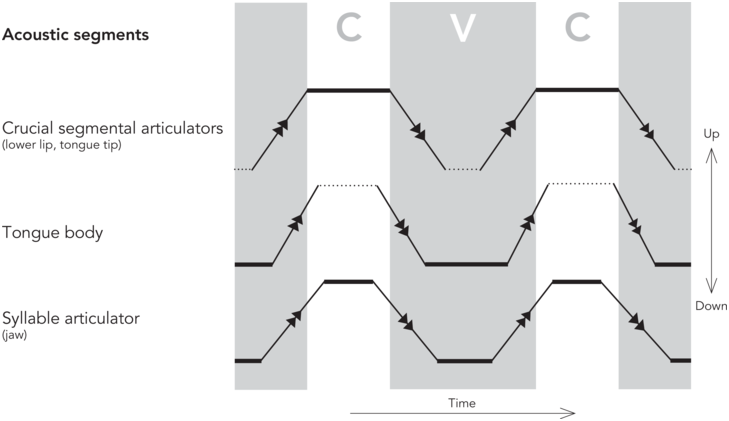
The duration of the vowel segment is connected to jaw displacement by the nature of the jaw cycle; the vowel appers during its open state, while the closed steady states of the jaw (when the jaw stays up) are when the onset and coda appear, as shown in Figure 2.3 (Svensson Lundmark and Erickson, Reference Svensson Lundmark and Erickson2024). Furthermore, the steady states of the jaw are shorter than the steady states of the crucial segmental articulators, as also indicated in Figure 2.3 (Svensson Lundmark and Erickson, Reference Svensson Lundmark and Erickson2024). We suggest that these timing differences between the steady states/postures on the jaw cycle and the ones on the crucial segmental articulators could be because the syllabic jaw movements and the segmental articulators have inherently different rhythmic patterns. We intend to follow up this approach in future research.
Although the nature of the timing of the de/acceleration peaks is still unclear, it’s related to how fast the articulators are moving. We know that the speed of the segmental articulators is affected by the distance to the target and what type of target is made (the task difficulty) (Bootsma et al., Reference Bootsma, Fernandez and Mottet2004). While task difficulty is related to how the constriction is manifested (and therefore possibly related to deceleration), the distance to the target is manifested by the size of the oral cavity, that is, how long/far the articulator has to travel. If the tongue is producing a low vowel, the tongue tip might need to travel further to make the following coda constriction at the palate, whereas for a high vowel, the tongue tip is presumably already near the target constriction. We presume these conditions affect the timing of the de/acceleration peaks, hence directly having an impact on the posture and the resulting acoustic segment duration. Furthermore, as the size of the oral cavity changes according to jaw displacement and longer distances for the articulators to travel for a more prominent syllable, this would possibly affect tongue body positions, leading to even more variants of travel distances for the tongue tip between, for example, a prominent /a/ and a prominent /i/. However, this relationship still needs to be investigated.
The vowel segment differences are also dependent on what type of syllable onset or coda constriction, that is, manner, place, and voicing, the segmental articulator is making, as the de/acceleration peaks of the segmental articulators determine the acoustic vowel segment boundaries. Thus, where a segmental articulator travels from and where it is going next affects the distance to the target and its velocity, which ultimately affects the acceleration and the deceleration phase, and the timing of those de/acceleration peaks. In other words, any correlation between vowel segment duration and jaw displacement is dependent on the timing of the segmental articulators (= the consonants) and the context in which they are produced.
2.5 Articulatory, Acoustic, and Perceptual Study of AE Utterance Prominence Patterns: New Data
In Section 2.3, we established that the greatest jaw displacement corresponds to the perception of contrastive emphasis in utterances containing the diphthong /aɪ/. This section continues to investigate utterance prominence in terms of articulation, perception, and acoustic cues.
Here we look at the utterance Pam had a chance to chat and nap as spoken by five AE speakers (three male, two female). This utterance was selected because (1) the content words, Pam, chance, chat, and nap, all contain the phonological AE /æ/ vowel, and (2) it has two phrases, Pam had a chance and to chat and nap. Looking at jaw displacement across the same vowels allows us to see prominence effects; looking at an utterance with two phrases allows us to see possible differences in articulation of phrasal stress and nuclear stress.
2.5.1 Articulatory and Acoustic Study
The acoustic and articulatory recordings were done with EMA at Professor Jianwu Dang’s laboratory at the Japan Advanced Institute of Science and Technology, Nomi, Japan (see Section 2.2 for an explanation of sensor placement). The target sentence was read in five different randomizations for four of the speakers, and for S4 there were eight randomizations of the target sentence. MView (Tiede, Reference Tiede2010) was used to measure the amount of maximum jaw displacement from the occlusal plane during each vowel. The average F1, F2, F0, intensity, and duration for each vowel was estimated using Praat (Boersma and Weenink, Reference Boersma and Weenink2025) to mark TextGrids, and a customized Praat script. Perception tests to assess listeners’ perceptions of prominence and phrase break/boundary were conducted using an online interface.
Figure 2.4 shows the mean values of jaw displacement for each of the five speakers. In the bar graphs, the height of each bar represents the average amount of jaw displacement for each of the one-syllable content words, Pam, chance, chat, and nap. As discussed in the previous sections, bar graphs convey relative syllable size, that is, big (more prominent) syllables will have larger y-values (mm) than smaller ones. Thus, the y-axis values reflect the relative values of jaw displacement (syllable stress) within the utterance.
Jaw displacement patterns for five speakers.
Bar graph displays of average amount of jaw displacement (mm) shown on y-axis with content word on the x-axis (Pam, chance, chat, nap), for each of the five speakers (S1, S2, S3, S4, and S5). Jaw displacement ranges from 15 to 30 mm for S1, 10 to 30 mm for S2, 21 to 31 mm for S3, 5 to 20 mm for S4, and 45 to 53 mm for S5.

Figure 2.4 Long description
The highest to lowest mean jaw displacement values for five speakers are as follows. S 1: 26, 25.5, 24, and 17. S 2: 24, 22, 17, and 15. S 3: 28.5, 27.5, 27.5, and 23. S 4: 16, 14, 13, and 10. S 5: 50.5, 48.5, and 47.5. The values are estimated.
As discussed in the above paragraph, the bar graphs suggest that in terms of an abstract metrical prosodic hierarchy, the word with the largest jaw displacement in the utterance carries the nuclear stress of the utterance; when there is more than one phrase, the word in each phrase that has the largest jaw displacement is referred to as having phrasal stress, and often this is the word with the second largest jaw displacement. These data suggest that for this sentence, we can have at least two types of nuclear stress intent type – that is, either chat or Pam can have nuclear stress.
Table 2.2 shows acoustic measurements related with the average jaw displacements for each of the content words. The word with the largest jaw displacement also has the largest F1 value; peak F0 always occurs on the initial word, with the final word having the lowest F0; intensity is greatest on the initial word of the utterance for three of the speakers, but on the initial word of the second phrase for the other two speakers; acoustic duration is longest on the initial word of the utterance for two of the speakers, while the other three speakers show the longest duration on chance, chat, or nap. In Section 2.5.3, we discuss some of the acoustic cues listeners may be listening to in order to hear increased prominence on a syllable in an utterance.
Average jaw displacement and average acoustic values of the content words for the five speakers. Bold numbers indicate the largest value for each measurement across the content words for each of the speakers.
| Sub | N | word | Jaw | F0Av | F1 | F2 | IntAv | vowel dur (s) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | 5 | Pam | 23.7 | 1.1 | 244.8 | 5.3 | 726.8 | 10.4 | 1229.8 | 78.8 | 52.8 | 0.3 | 0.17 | 0.01 |
| 5 | chance | 18.1 | 0.9 | 191.2 | 3.3 | 661.8 | 7.8 | 1401.5 | 167.0 | 49.0 | 0.9 | 0.19 | 0.02 | |
| 5 | chat | 25.4 | 0.6 | 189.8 | 5.4 | 890.4 | 40.9 | 1429.9 | 140.0 | 49.5 | 1.2 | 0.19 | 0.02 | |
| 5 | nap | 26.3 | 0.5 | 152.4 | 16.0 | 914.8 | 61.8 | 1547.8 | 93.8 | 42.3 | 1.6 | 0.16 | 0.01 | |
| S2 | 5 | Pam | 21.9 | 1.1 | 153.3 | 6.6 | 666.9 | 20.9 | 1367.7 | 189.4 | 33.9 | 2.2 | 0.13 | 0.01 |
| 5 | chance | 15.5 | 0.5 | 116.0 | 2.6 | 612.6 | 24.2 | 1443.8 | 153.0 | 33.9 | 1.0 | 0.14 | 0.01 | |
| 5 | chat | 18.3 | 0.5 | 110.7 | 1.9 | 695.5 | 12.1 | 1357.3 | 38.1 | 39.9 | 1.5 | 0.14 | 0.02 | |
| 5 | nap | 23.3 | 1.4 | 98.2 | 10.3 | 769.7 | 30.6 | 1416.0 | 103.5 | 28.2 | 1.9 | 0.13 | 0.01 | |
| S3 | 5 | Pam | 27.7 | 1.8 | 137.6 | 8.7 | 560.6 | 16.8 | 1746.5 | 32.2 | 59.9 | 1.4 | 0.18 | 0.01 |
| 5 | chance | 23.2 | 0.9 | 110.7 | 7.9 | 475.4 | 34.0 | 1708.1 | 48.0 | 56.7 | 0.9 | 0.15 | 0.01 | |
| 5 | chat | 27.6 | 0.7 | 105.4 | 9.0 | 583.8 | 30.1 | 1600.9 | 31.4 | 52.8 | 1.4 | 0.16 | 0.02 | |
| 5 | nap | 28.3 | 2.2 | 81.5 | 1.4 | 600.6 | 45.0 | 1718.1 | 52.3 | 48.8 | 1.4 | 0.16 | 0.02 | |
| S4 | 8 | Pam | 13.3 | 0.9 | 119.1 | 4.4 | 728.6 | 15.6 | 1632.2 | 73.9 | 54.6 | 0.5 | 0.23 | 0.02 |
| 8 | chance | 10.5 | 0.6 | 106.7 | 4.0 | 659.6 | 19.5 | 1775.0 | 30.0 | 51.3 | 0.6 | 0.17 | 0.01 | |
| 8 | chat | 15.7 | 0.8 | 102.6 | 2.1 | 690.2 | 11.2 | 1470.9 | 22.5 | 55.3 | 1.2 | 0.16 | 0.01 | |
| 8 | nap | 13.9 | 0.9 | 91.8 | 2.4 | 752.6 | 16.9 | 1510.0 | 13.6 | 49.0 | 1.4 | 0.17 | 0.02 | |
| S5 | 5 | Pam | 48.5 | 1.6 | 247.9 | 9.6 | 682.6 | 34.8 | 1593.9 | 224.3 | 46.0 | 1.1 | 0.16 | 0.03 |
| 5 | chance | 47.6 | 1.9 | 196.8 | 8.4 | 699.2 | 20.2 | 1653.6 | 124.1 | 39.9 | 1.8 | 0.19 | 0.01 | |
| 5 | chat | 50.5 | 1.6 | 184.5 | 6.1 | 804.4 | 5.1 | 1190.7 | 39.9 | 44.3 | 1.5 | 0.16 | 0.01 | |
| 5 | nap | 49.2 | 1.1 | 161.6 | 8.2 | 621.9 | 34.6 | 1040.6 | 88.9 | 34.7 | 0.9 | 0.19 | 0.0 |
Linear correlation results with jaw displacement and acoustic measurements indicate that four of the five speakers showed a significant relation between the amount of jaw displacement and F1 (p < 0.001), indicating that as jaw displacement increases, F1 raises; three other speakers showed significant relations between jaw displacement and F2 minus F1, indicating that as the distance between F2 and F1 decreases, the low vowel became even more extreme and compact, as discussed in Erickson (Reference Erickson2002).
No significant relations for the five speakers were found between amount of jaw displacement and the acoustic measures of F0 and duration. Only one speaker (S4) showed a significant positive relation between jaw displacement and intensity (p < 0.001); another speaker (S1) showed a significant negative relation between jaw and vowel duration. When we look at each speaker separately (Figure 2.5), four of the speakers (S1, S2, S4, and S5) show negative linear correlation between vowel duration and jaw displacement for each of the content words, while only S3 shows a positive correlation. These findings are surprising given that increased F0 and duration are what has been reported for increased prominence/stress (e.g., Turk and Sawusch, Reference Turk and Sawusch1996).
Correlation of vowel duration and jaw displacement.
Correlation plot on acoustic vowel duration (s) and jaw displacement (mm) for each speaker. Jaw displacement is mean-centered for reasons of clarity. The four content words are represented by different symbols.
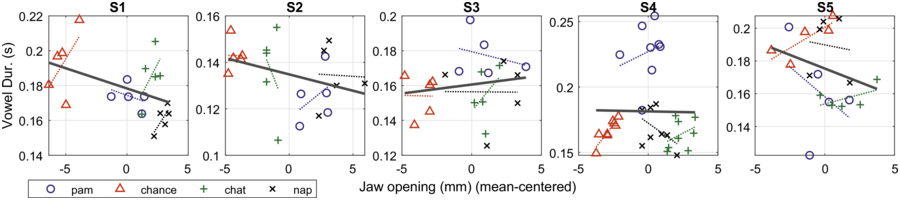
Figure 2.5 Long description
The horizontal axis represents the jaw opening which ranges from minus 5 through 5, and the vertical axis represents the vowel duration which ranges from 0.14 through 0.22, 0.1 through 0.16, 0.12 through 0.2, 0.15 through 0.25, 0.15 through 0.25, and 0.14 through 0.2, respectively. The data sets representing pam, chance, chat, and nap are plotted in a random trend around the best-fit line. The best fit line originates at (minus 5, 0.19) and terminates at (4, 0.17) in S 1, originates at (minus 5, 0.14) and terminates at (5, 0.13) in S 2, originates at (minus 5, 0.158) and terminates at (4.5, 0.16) in S 3, originates at (minus 5, 0.158) and terminates at (4.5, 0.16) in S 3, originates at (minus 5, 0.4) and terminates at (4, 0.4) in S 4 and originates at (minus 5, 0.16) and terminates at (4, 0.16) in S 5. The values are estimated.
In the next section, we examine how listeners hear prominence/stress in English utterances – specifically, the probability of stress perception as a function of both prosodic articulation (i.e., jaw displacement) and prosodic acoustic measurements (F0, F1, F2, intensity, and vowel duration). Since, in addition, prosodic boundaries also affect utterance prominence (e.g., Fujimura, Reference Fujimura2000; Erickson et al., Reference Erickson, Kawahara, Shibuya, Suemitsu and Tiede2014; Cole et al., Reference Cole, Hualde and Smith2019), we also include boundary perception in the next section.
2.5.2 Pilot Study of Perception of Prominence and Boundaries in Utterances
Here we introduce some preliminary results about the extent to which perception of nuclear (utterance) and phrasal stress and phrase boundaries relate to jaw displacement. Twenty-eight AE listeners participated in our two experiments designed respectively for perceiving nuclear stress and phrasal boundaries in a neutral context. For each experiment, we recruited 14 participants (aged 18–78), who voluntarily participated or attended for course credit at the University of Arizona.
As described in Section 2.5.1, five native speakers of AE produced the utterance Pam had a chance to chat and nap. We selected one token from each speaker (S1 token 55; S2 token 115; S3 token 16; S4 token 64; S5 token 001) as the stimuli investigated in our perception tests. The reason for doing this was because we felt having listeners try to hear differences in prominence and boundaries within a single speaker as well as across speakers might be too difficult, given that most listeners are usually not familiar with listening to stress patterns. Also, based on the intra-speaker variations in jaw displacement, it seemed that speakers may have been inconsistent in their stress patterns. The present study employed two small-scaled RPT experiments. Sixteen stimuli (= (5 target sentences + 3 filler sentences) × 2 repetitions) were presented randomly online to each participant. An inter-stimulus interval (ISI) of 200 ms was used. Because perceiving utterance stress or boundaries is not something that most listeners are consciously aware of, before starting each of the tests, in order to help the subject “tune their ears” for prominent words, or for boundaries, subjects were asked to listen to a brief one-minute training video prepared by the first author. In the video for prominence testing, the listeners were asked to hear the difference between I like red apples, where apples had more stress, and I like RED apples, where red had more stress. After the training session, the participants were instructed to do the online RPT over their headphones in a quiet room. In the nuclear stress experiment, the listeners (2 males, 12 females) were asked to choose which word bore nuclear stress after hearing the given utterance. For the phrasal boundary experiment, the listeners (3 males, 11 females) were told to determine after what words they considered a boundary occurred.
2.5.2.1 Perceived Prominence and Boundaries
Not surprisingly, our results revealed that stress is perceptible on content words (i.e., Pam, chance, chat, nap), but not on function words (i.e., a, to, and). Listeners reported nuclear stress on Pam for three of the speakers, and chat and chance for the other two speakers. However, it seems that the relation between articulation of prominence (i.e., amount of jaw displacement) and perception of prominence (listener ratings) is not necessarily straightforward. For example, Figure 2.6 shows the relation of jaw displacement with vowel duration, and the probability of listeners hearing nuclear stress and boundaries. Figure 2.6b shows S2 had a preference for nuclear stress on Pam (35.7%), even though the jaw displacement was only the second largest (22.63 mm), and the phrasal stress was on chat (28.6%), even though nap had the largest jaw displacement. In the case of S2, thus, listeners’ perceptions of stress and speakers’ articulations of stress (i.e., jaw displacement) do not align.
Probability of perceived prominence and boundaries.
(Top) jaw displacement for the utterance; (bottom) probability of nuclear prominence (dash lines with circle symbols) and phrase boundaries for each word produced by (a) S1, (b) S2, (c) S3, (d) S4, and (e) S5.
Figure 2.6 Long description
Each set plots a wavy line for jaw movement and three zig zag lines for probability and duration. The wavy line originates at minus 18, minus 19, minus 22, minus 8, and minus 45, and terminates at minus 8, minus 19, minus 20, minus 9, and minus 45 in sets labeled S 1 through S 5. The zig-zag lines originate at (0.6, 1), (0.8, 1), and (0.3, 1) and terminate at (2.8, 7), (2.8, 5) and (2.8, 3) in S 1. The lines originate at (0.5, 0.5), (0.5, 0.3), and (0.5, 0.1) and terminate at (2.7, 6), (2.7, 6) and (2.7, 3.5) in S 2. The lines originate at (0.5, 0.5), (0.5, 0.3), and (0.5, 0.1) and terminate at (2.7, 6), (2.7, 6) and (2.7, 3.5) in S 2. The lines originate at (0.5, 0.7), (0.5, 0.5), and (0.5, 0.2) and terminate at (2.25, 8), (2.25, 6) and (2.25, 2.25) in S 3. The lines originate at (0.5, 0.7), (0.5, 0.5), and (0.5, 0.2) and terminate at (2.25, 8), (2.25, 6) and (2.25, 2.25) in S 3. The values are estimated.
For S4 (Figure 2.6d), the words Pam and chat are perceived as equally prominent (35.7%), but note that jaw displacement is largest for chat (16.15 mm), followed by Pam (11.27 mm). The suggestion here is that the nuclear utterance stress is on chat, with the phrasal stress on Pam, but in terms of perception it is somewhat ambivalent. Nevertheless, we see an alternating strong–weak pattern of jaw displacement within each of the phrases, as well as an alternating pattern of perceived stress. For S5 (Figure 2.6e) the likelihood of perceiving stress on chance was highest (67.9%), but jaw displacement was smallest (49.50 mm). We discuss this pattern later.
As for boundary perception, the amount of jaw displacement can account for both syllable prominence as well as phrasal boundaries (see also, for example, Fujimura, Reference Fujimura2000; Erickson et al., Reference Erickson, Kim and Kawahara2015).
In order to further investigate the relationship between the amount of jaw displacement with the probability of perceived prominence and that of phrase boundaries for each syllable across the five speakers, a linear correlation analysis was applied. By-speaker z-score normalization of articulatory measurements were done before entering correlation analyses to resolve inter-speaker physiological differences. We found a significant difference between jaw displacement and phrase boundaries (p < .05). For instance, for S3 (Figure 2.6c), the largest amount of jaw displacement corresponds with the greatest number of perceived breaks. These results suggest that the more open the jaw, the larger the number of perceived boundaries; in contrast, there was only a marginally significant difference observed for prominence in relation to jaw displacement (r=−0.281).
2.5.3 Acoustic Cues for Perception
In this section, we explore some acoustic cues that might affect listeners’ perception of prominence and boundaries. We measured duration, mean F0, mean intensity, and the first two formants (F1, F2) for the vowel /æ/ of the content words (Pam, chance, chat, and nap). A linear correlation analysis was taken to assess the relation of each acoustic measure with perceived prominence and boundaries. Acoustic measurements underwent by-speaker z-score normalization before entering correlation analyses.
Table 2.3 presents the correlation results for the acoustic cues related to perceived prominence. Prominent syllables are significantly longer, have significantly higher maximum F0, have marginally significantly higher mean F0, and are significantly louder. That syllables that are longer, louder, and higher in F0 were rated as more prominent is not surprising, given the literature about acoustic cues of stress/prominence, for example, Lehiste (Reference Lehiste1970) and Erickson and Niebuhr (Reference Erickson and Niebuhr2023); also see Section 2.2.
The correlation analysis for perceived prominence and vowel acoustic measurements – mean duration, mean F0, mean intensity, F1, and F2. *** indicates significance < 0.001, ** indicates significance < 0.01, * indicates significance < 0.05, and † indicates significance < 0.1 (marginally significant).
| Variables | R | p-value |
|---|---|---|
| Prominence and duration | 0.740 | (< .001) *** |
| Prominence and mean F0 | 0.302 | (0.065) † |
| Prominence and max F0 | 0.442 | (0.005) ** |
| Prominence and intensity | 0.381 | (0.015) * |
| Prominence and F1 | 0.053 | (0.743) |
| Prominence and F2 | 0.353 | (0.026) * |
As for formant values, perceived prominent syllables have significantly higher F2 values (p < .05), implying the vowel /æ/ tends to be more fronted when it is perceived as having nuclear stress. Pam produced by three of the speakers has higher F2 (see Table 2.5) and is perceived as having nuclear (utterance) stress for four of the speakers. (Note that for S2, Pam is perceived has having nuclear stress, but nap has the highest F2.) Interestingly, however, F1 values in this current study are not remarkably raised for the perceived prominent syllable, even though we see significant correlation with increased F1 and articulatory prominence, that is, jaw displacement, both in this study as well as previous studies.
For perceived boundaries, as shown in Table 2.4, vowel duration is also significantly correlated with phrase boundaries. Long syllables tend to be followed by a phrase boundary. This is confirmed in our study. In addition, perceived phrase boundaries have marginally significantly higher mean F0, and significantly higher vowel mid-point F0, indicating listeners’ sensitivities to changes in F0 when a boundary is perceived. Intensity is nonsignificant. Also, the F1 value tends to be increased for syllables with a perceived boundary; specifically, it is relatively high in chance or nap, which are perceived as the final syllables in the phrases. To summarize, based on this small data set, increased duration, heightened F0, and raised F1 tend to cue phrase boundaries. Similar findings about duration and F0 as cues to phrase boundaries have been reported by, for example, Yang et al., Reference Yang, Shen, Li and Yang2014, but as far as we know, no one has reported raised F1 as a cue.
The correlation analysis for perceived boundary and mean duration, mean F0, mean intensity, F1, and F2. *** indicates significance < 0.001, * indicates significance < 0.05, and † indicates significance < 0.1 (marginally significant).
| Variables | R | p-value |
|---|---|---|
| Boundary and duration | 0.740 | (< .001) *** |
| Boundary and mean F0 | −0.316 | (0.053) † |
| Boundary and mid F0 | −0.371 | (0.022) * |
| Boundary and intensity | −0.193 | (0.233) |
| Boundary and F1 | 0.310 | (0.052) † |
| Boundary and F2 | 0.240 | (0.136) |
Average F2 values (in Hz) for the four syllables for each of the five speakers’ utterances. F2 values in bold indicate the highest value among the four syllables in the utterance. Asterisks mark perceived nuclear stress.
| Pam | chance | chat | nap | |
|---|---|---|---|---|
| S1 | *2284.8 | 1985.7 | 2002.2 | 2086.1 |
| S2 | 1634.7 | 1592.6 | 1646.1 | *1671.1 |
| S3 | *1889.6 | 1612.4 | 1515.5 | 1875.0 |
| S4 | *1851.4 | 1843.7 | 1463.8 | 1514.7 |
| S5 | 2043.8 | *2109.8 | 1995.9 | 2023.3 |
Our data suggest that when one’s jaw is open more, the acoustic cues including duration, F0, and intensity seem to increase, which in turn affects our judgment of prominence and boundaries. However, the interaction between perception of prominence, phrase boundaries, and articulation of prominence is complex and needs to be explored further.
2.6 Jaw and Phrasal Stress in Other Languages and Applications for Language Teaching
This section is a brief review of jaw studies (e.g., Vatikiotis-Bateson and Kelso, Reference Vatikiotis-Bateson and Kelso1993; Erickson et al., Reference Erickson, Kawahara, Shibuya, Suemitsu and Tiede2014, Reference Erickson, Iwata and Suemitsu2016; Kawahara et al., Reference Kawahara, Erickson, Moore, Suemitsu and Shibuya2014a; Erickson and Kawahara, Reference Erickson and Kawahara2016; Smith et al., Reference Smith, Erickson and Savariaux2019; Erickson, Reference Erickson2021) showing how patterns of jaw displacement are language-specific, reflecting the prominence patterns (metrical organization) of the language; being aware of these language-specific differences has applications for teaching second language prosody. The above sections discussed jaw displacement patterns of English utterances. Here we look at jaw displacement patterns of languages that are purported to be edge-strengthening languages (e.g., Jun Reference Jun and Jun2005, Reference Jun and Jun2014), such as French, Japanese, and Mandarin.
As shown in Figure 2.7, jaw displacement increases at the end of each phrase, with the largest amount of jaw displacement at the end of the utterance – which is in accord with these languages being called edge-strengthening. For the Japanese and Mandarin utterances, we also see increased jaw displacement at the beginning of the utterance, as if the speaker uses increased jaw displacement to indicate “I’m starting to speak” and “I’ve finished speaking.”
Jaw displacement patterns for French, Japanese, and Mandarin.
Jaw displacement patterns from top to bottom for French (Natacha didn’t attach her cat, Pasha, who escaped), Japanese (That’s why Mana’s hair is smooth), and Mandarin (Mother curses the horse). The term AP refers to accent phrase, and the final AP is referred to as an IP (intonational phrase).
Figure 2.7 Long description
Each graph shows the acoustic properties of the speech sounds. The horizontal axis represents the following range of values. 1000 to 3500, 1000 to 3000 and 1000 to 2200. Arrows pointed at A P 1, A P 2, A P 3, A P 4, I P, m a 1, m a, m a 4 and m a 3 mark specific acoustic segments of the words. The sets are labeled with words of foreign languages like French, Japanese and Mandarin.
In learning a second language, beginners tend to carry over their first language jaw displacement patterns to their second language (e.g., Wilson et al., Reference Wilson, Erickson, Vance and Moore2020; Erickson and Niebuhr, Reference Erickson and Niebuhr2023) – see Figure 2.8.
Jaw displacement for L2 Japanese and French speakers, and an L1 English speaker.
Jaw displacement patterns for L1 Japanese (top row), L1 French (middle row) and L1 English (bottom row) speakers for the utterance I saw five bright highlights in the sky tonight.
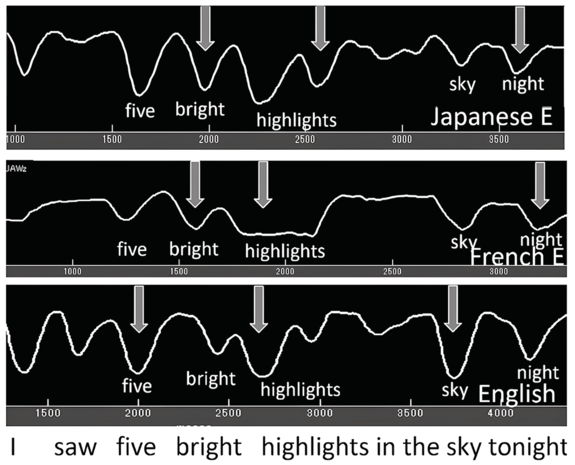
In Figure 2.8, the L1 English speaker (bottom row) shows clear patterns of strong–weak jaw displacement, with the largest jaw displacement on nuclear utterance stress sky, the next largest on phrasal stress highlights, and then on foot stress five. The speakers of Japanese (top) and French (middle), both L1 speakers of edge-strengthening languages, show different patterns of jaw displacement when speaking English. The L1 Japanese speaker shows more jaw displacement on highlights and on five, but no clear reduction on bright and lights, as seen for the L1 English speaker. This makes sense since Japanese does not reduce vowels. For the L1 French speaker, the largest jaw displacement is at the end of the phrase, highlights, produced with one sustained jaw lowering; for the foot, five bright, more jaw displacement is on the final member of this foot, bright. These patterns suggest that the French speaker may be carrying over her L1 edge-strengthening pattern of increased jaw displacement for phrase-final positions. As for the final phrase, sky tonight, both L1 Japanese and French speakers carry over their phrase-final jaw patterns to produce the utterance-final word night with more jaw displacement than on sky – a jaw pattern not seen with L1 AE speakers. All AE speakers put reduced jaw movement on night, resulting in a more shwa-like vowel for this word.
Recent work with teaching English jaw displacement patterns to Japanese learners of English (Wilson et al., Reference Wilson, Erickson, Kawahara and Monou2019, Reference Wilson, Erickson, Vance and Moore2020) suggests that when a Japanese speaker acquires an English pattern of jaw displacement, not only does the stressed word have larger jaw displacement but the following word has less jaw displacement. The acoustic results were increased F1 and decreased F2 on the stressed word (with the low vowel /a/) and decreased F1/increased F2 on the following word (also a low vowel /a/), thus making the second vowel reduced, and resulting in a more English-type strong–weak rhythm. These results encourage teaching second language prosody using a kinematic approach.
The results also encourage thinking about jaw mechanics; perhaps the jaw cannot make two consecutive large jaw displacements without pause or resetting. To produce two or three consecutive syllables, one jaw opening will be stronger than the adjacent ones. In an oft-times called stress-timed language such as English, where increased prominence/jaw displacement occurs within each prosodic structure (e.g., word, foot, phrase, utterance), the other syllables in the prosodic structure will be produced with less displacement. Studying displacement patterns of various languages and how to kinematically teach these to second language learners can lead to an increased understanding of the biophysical constraints of our articulators, and also the segmental articulators, for example, the lips, tongue, and velum, since syllable prominence affects both the vowel nucleus as well as the onset and coda segmental articulators (e.g., Heldner, Reference Heldner, van Dommelen and Fretheim2001; Giavazzi, Reference Giavazzi2010; Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2013; Svensson Lundmark et al., Reference Svensson Lundmark, Ambrazaitis and Ewald2017, for discussion of how prominence can affect segmental phonology; Kawahara et al., Reference Kawahara, Masuda and Erickson2014b, for discussion of the interaction between jaw and segment acoustics in Japanese; de Jong et al., Reference de Jong, Beckman and Edwards1993, reporting that stressed syllables show less coarticulatory overlap than non-stressed syllables).
This chapter has focused on the jaw as a prosodic syllable articulator; work is underway for further exploration into the interactions between crucial segmental articulators and the syllabic articulator, as they work together to orchestrate the rhythm of a language.
Future work into the relation between utterance prominence, jaw displacement, and language rhythm requires, first and foremost, more articulatory data. Since articulatory data collection is still a relatively expensive undertaking both in terms of time and money – for example, EMA-type facilities – currently, some new approaches are being developed for recording articulatory data. One of them is being developed by Oliver Niebuhr at the University of Southern Denmark – the MARRYS hat – which registers jaw displacement via two bending sensors in the cheek straps on both sides, timed with the audible voice signal; it is cheaper and also requires reduced preparation and processing times, allowing the collection of jaw data from a large number of speakers – even in the field, given its mobility (Erickson et al., Reference Erickson, Niebuhr, Gu, Huang and Geng2020b; Niebuhr and Gutnyk, Reference Niebuhr and Gutnyk2021; Svensson Lundmark et al., Reference Svensson Lundmark2023; Svensson Lundmark and Niebuhr Reference Svensson Lundmark and Niebuhr2025; Weston et al., Reference Weston, Svensson Lundmark, Erickson and Niebuhr2023).
To summarize, we suggest that speech rhythm is based on an abstract metrical hierarchical organization of syllable stress patterns. These stress patterns are implemented by jaw articulation patterns, that is, how much the jaw lowers for each syllable within the utterance. For English, within each prosodic unit (word, foot, phrase, utterance), one syllable has incrementally the largest jaw displacement, such that the word/syllable with the most prominence in the utterance also has the largest jaw displacement. Languages such as French, Japanese, and Mandarin have different underlying metrical structures, and hence different patterns of jaw articulation from English. Previous studies of jaw displacement patterns for English utterances show how the patterns relate to metrical patterns of utterance stress, and how increased jaw displacement is always accompanied by formant changes – specifically, increased F1 (or decreased F2 minus F1) for low vowels. Since jaw patterns vary depending on the language, language learners often apply their first language jaw displacement patterns to produce the second language.
Summary
Articulatory, acoustic, and perceptual data examined in this study suggests that spoken language rhythm is a dynamic system involving (a) an abstract metrical structure implemented by jaw articulation patterns, (b) segmentally modified syllable articulation, and (c) perceptual sensitivities of listeners to the segmental and syllabic articulations.
Implications
Speech rhythm can best be understood by examining the interactions and constraints between segmental and syllabic articulation. The implications are invitations to further explore language rhythm from an articulatory framework, similar to the one introduced here.
Gains
The gain is a framework to explore language rhythm across numerous languages and speakers, leading to innovative ways to understand and mediate first and second language acquisition.
3.1 Origin and Measurement of Endogenous Brain Rhythms
Rhythmic activity in measured brain signals is observed virtually everywhere in the brain. In humans, these brain rhythms have been associated with perceptual and cognitive processes and are usually measured with noninvasive tools such as electroencephalography (EEG) or magnetoencephalography (MEG), but also using intracranial recordings such as electrocorticography (ECoG). Importantly, rhythmic neural activity is also present spontaneously, when there is no sensory input or cognitive tasks.
To understand the origins of the various brain rhythms, which may reflect multiple mechanisms, it is useful to consider different levels of observation (for review: Cannon et al., Reference Cannon, McCarthy and Lee2014; Pittman-Polletta et al., Reference Pittman-Polletta, Kocsis, Vijayan, Whittington and Kopell2015; Doelling et al., Reference Doelling, Herbst, Arnal, van Wassenhove, Wöllner and London2023). As shown in animal research, at the microscopic level, individual neurons respond optimally at preferred “resonance” frequencies, which depend on neuronal membrane properties that act as high- and low-pass filters (Llinás, Reference Llinás1988; Hutcheon and Yarom, Reference Hutcheon and Yarom2000; Buzsáki and Draguhn, Reference Buzsáki and Draguhn2004). Importantly, spontaneous self-sustained oscillations in neurons, at their preferred frequency, arise from the interplay of currents that destabilize the resting membrane potential (Hutcheon and Yarom, Reference Hutcheon and Yarom2000). At the macroscopic level, by measuring activity arising from several thousands of neurons, brain rhythms reflect synchronized rhythmic activity of neuronal populations, either locally or across areas. Locally, such synchronized activity has been described as arising from excitatory-inhibitory circuitry (Skinner et al., Reference Skinner, Kopell and Marder1994; Whittington et al., Reference Whittington, Traub, Kopell, Ermentrout and Buhl2000; Rotstein et al., Reference Rotstein, Pervouchine and Acker2005; Klausberger and Somogyi, Reference Klausberger and Somogyi2008; Buzsáki and Watson, Reference Buzsáki and Watson2012; Hyafil et al., Reference Hyafil, Giraud, Fontolan and Gutkin2015a). Importantly, it is thought that the macroscopic rhythmic activity that can be measured during rest is related – likely in a complex manner reflecting interactions of multiple mechanisms (Rotstein, Reference Rotstein2017; Stark et al., Reference Stark, Levi and Rotstein2022) – to the microscopic frequency preferences of the underlying neurons (Hutcheon and Yarom, Reference Hutcheon and Yarom2000).
3.1.1 Macroscopic Measures of Preferred Neural Frequencies
Preferred frequencies of neuronal populations can be identified in various ways. Using noninvasive transcranial magnetic stimulation (TMS) and EEG, it has been shown that stimulating a brain region with a single impulse leads to resonance activity at the population’s preferred (“natural”) frequency (Marshall and Fox, Reference Marshall and Fox2004; Rosanova et al., Reference Rosanova, Adenauer and Valentina2009). This line of research has demonstrated that the occipital cortex shows dominant activity in the alpha frequency range (8–14 Hz), the parietal cortex in the beta frequency range (15–30 Hz), and the frontal cortex in the gamma frequency range (above 30 Hz) (Rosanova et al., Reference Rosanova, Adenauer and Valentina2009). Regarding the temporal cortex, it is currently unfeasible to use TMS to identify its preferred frequencies due to the proximity to facial muscles and resulting severe muscle artifacts. Instead, sensory stimulation methods have been used. For example, when participants listen to rhythmic sounds at different rates, the auditory cortex shows an auditory steady-state response (ASSR) (Picton et al., Reference Picton, John, Dimitrijevic and Purcell2003) that is largest at the system’s preferred frequency. ASSR research indicated that the auditory cortex shows a preferred frequency in the beta/gamma range, often averaging at around 40 Hz, although there are large inter-individual differences (i.e., between 30 and 80 Hz across participants) (Zaehle et al., Reference Zaehle, Rach and Herrmann2010; Baltus and Herrmann, Reference Baltus and Herrmann2016; Teng et al., Reference Teng, Tian, Rowland and Poeppel2017). Additionally, this method revealed a topographic organization within the auditory cortex, with different neural populations along the auditory pathway showing different frequency preferences (Weisz and Lithari, Reference Weisz and Lithari2017). In sum, magnetic or sensory rhythmic stimulation are a feasible way to identify the preferred or natural frequencies of large neuronal populations, and the results are relatively well grounded in underlying neuronal resonance phenomena.
3.1.2 Networks of Endogenous Brain Rhythms
Another line of research into intrinsic or “endogenous” brain activity uses MEG or EEG resting state data to identify long-range connectivity patterns (Brookes et al., Reference Brookes, Woolrich and Luckhoo2011; Vidaurre et al., Reference Vidaurre, Hunt and Quinn2018). These networks have originally been studied in functional magnetic resonance imaging (fMRI) data (e.g., Fox and Raichle, Reference Fox and Raichle2007), but recent findings highlight that these networks can be further specified by underlying frequency-specific functional connections. Using MEG, prominent networks in the alpha and beta frequency ranges have been identified by analyzing correlations between band-pass filtered amplitude envelopes across brain areas (Brookes et al., Reference Brookes, Woolrich and Luckhoo2011). For example, the default mode network (DMN) has been associated with alpha-band connectivity within and across medial-frontal and parietal cortices, whereas the sensorimotor network has been associated with beta-band connections in corresponding areas (Brookes et al., Reference Brookes, Woolrich and Luckhoo2011). Using phase-coupling, it has been shown that the brain engages in different states characterized by frequency-specific connectivity patterns, for example posterior alpha and anterior delta/theta (below 4 Hz and 4–8 Hz, respectively) network activity (Vidaurre et al., Reference Vidaurre, Hunt and Quinn2018). Overall, functional connectivity networks highlight long-range frequency-specific activity during rest, but the varied and diverse rhythmic activity of different brain areas can be more granularly captured by taking a closer look at region-specific patterns of brain activity, as captured, for example, by spectral profiles (Keitel and Gross, Reference Keitel and Gross2016; Mellem et al., Reference Mellem, Wohltjen, Gotts, Avniel and Martin2017; Capilla et al., Reference Capilla, Arana and García-Huéscar2022; Komorowski et al., Reference Komorowski, Rykaczewski and Piotrowski2023; Lubinus et al., Reference Lubinus, Keitel, Obleser, Poeppel and Rimmele2023).
3.1.3 Spectral Profiles
The above-described research shows the large-scale organization of endogenous brain rhythms related to preferred neuronal frequency and network-associated brain activity. Another line of research has focused on analyzing local spectral power to characterize the prevalence of brain rhythms. This method is often used to find the dominant frequency of brain regions (or prevalent mixtures of dominant frequencies), but the underlying “mechanisms” (e.g., resonance phenomena or frequency-specific network activity) are less clear. For example, using ECoG data, it has been shown that the theta rhythm is the most prominent across the cortex, while alpha is prominently present in posterior brain regions and beta is mostly present in central areas (Groppe et al., Reference Groppe, Bickel and Keller2013). In MEG data, it has been shown that the dominant peak frequency of regional brain rhythms is not randomly distributed but follows a cortical gradient from faster (“sensory”) to slower (“higher-level”) peak frequencies along the posterior–anterior axis (Mahjoory et al., Reference Mahjoory, Schoffelen, Keitel and Gross2020; but see Mellem et al., Reference Mellem, Wohltjen, Gotts, Avniel and Martin2017). These studies successfully highlight the across-participant similarities in regional spectral activity. Spectral profiles, however, are not only characteristic for specific brain areas but also show unique patterns for individuals that allow for the classification of people based on the spectral power distributions (da Silva Castanheira et al., Reference da Silva Castanheira, Orozco Perez, Misic and Baillet2021).
Instead of looking at the single most prominent spectral peak to characterize rhythmic activity, it is also possible to analyze consistent patterns or combinations of brain rhythms in a given brain region (Keitel and Gross, Reference Keitel and Gross2016; Komorowski et al., Reference Komorowski, Rykaczewski and Piotrowski2023). This has shown that each brain area engages in different spectral “modes” over time (between two and nine across different cortical areas), and that these rhythmic patterns are characteristic enough to be used for classification of brain areas (Keitel and Gross, Reference Keitel and Gross2016; Lubinus et al., Reference Lubinus, Orpella and Keitel2021). Language-relevant areas, such as auditory, motor, and frontal areas, are often characterized by prominent spectral peaks in the delta, theta, and beta frequency bands (see Figure 3.1). As highlighted in the following, these endogenous brain rhythms make them ideally suited to process speech (Giraud and Poeppel, Reference Giraud and Poeppel2012).
Spectral profiles of language-relevant brain areas.
Normalized power spectra as found in Keitel and Gross (Reference Keitel and Gross2016) for 12 brain areas according to the automated anatomical labelling (AAL) atlas (Tzourio-Mazoyer et al., Reference Tzourio-Mazoyer, Landeau and Papathanassiou2002; Bohland et al., Reference Bohland, Bokil, Allen and Mitra2009). Upper rows show the left hemisphere, lower rows the right hemisphere (see schematic area projections for area locations). Shaded error bars illustrate the standard error of the mean across participants. Power peaks are labelled according to their peak frequency (e.g., delta, theta, alpha, beta).
Figure 3.1 Long description
The horizontal axis represents the frequency in hertz and the vertical axis represents the normalized power. The first set is labeled auditory and auditory association areas, which include Heschl gyrus, Superior temporal gyrus, and middle temporal gyrus. It shows 6 graphs arranged in three columns. These graphs plot fluctuating curves for delta, theta, alpha and beta in Heschl gyrus, delta, theta and beta in superior temporal gyrus, and delta and alpha in the middle temporal gyrus. The first set is labeled auditory and auditory association areas, which include Heschl gyrus, Superior temporal gyrus, and middle temporal gyrus. The second set is labeled motor areas, which include precentral gyrus, supplementary motor area and opercular I F G.
3.2 Brain Rhythms Involved in Speech and Language Processing
As discussed above, spectral profiles indicate complex patterns of endogenous brain rhythms that characterize different brain areas. Importantly, it has been suggested that brain rhythms observed during rest indicate the functional architecture of the brain and can be related to specific cognitive processes (Deco et al., Reference Deco, Jirsa and McIntosh2011; Siegel et al., Reference Siegel, Donner and Engel2012; Keitel and Gross, Reference Keitel and Gross2016). In the following, we discuss how different brain rhythms have been related to speech and language processing (Table 3.1).
| Brain rhythm | Frequency | Speech (and general) candidate functions |
|---|---|---|
| Delta | 0.5–4 Hz | Tracking of prosodic and phrasal information Prosodic segmentation Syntactic processing Temporal (motor) predictions |
| Theta | 4–8 Hz | Tracking of syllabic information Syllable segmentation Uncertainty processing |
| Alpha | 8–14 Hz | Gating of information |
| Beta | 15–30 Hz | Higher-level linguistic processing Linguistic predictability Temporal (motor) predictions Encoding of syllabic information Maintenance (working memory) Decision processes |
| Gamma | > 30 Hz | Encoding of syllabic information Bottom-up processing Higher-level linguistic processing Auditory sampling |
3.2.1 Theta Brain Rhythms and Their Role in Syllable Segmentation
Identifying linguistic units from spoken language is nontrivial because of the lack of invariance in the continuous speech signal – that is, the speech acoustics vary depending on the speaker and the context. Segmenting the speech acoustics allows the generation of neural representations of the appropriate temporal granularity that match a given linguistic unit and can be forwarded to subsequent processes such as phoneme encoding (Ghitza, Reference Ghitza2011, Reference Ghitza2012; Giraud and Poeppel, Reference Giraud and Poeppel2012). Across languages, speech acoustics show dominant slow-amplitude modulations in the theta frequency range, a timescale that has been originally suggested to correspond to the syllabic rate in speech (Ding et al., Reference Ding, Patel and Chen2017; Varnet et al., Reference Varnet, Ortiz-Barajas, Guevara Erra, Gervain and Lorenzi2017). Such slow-amplitude modulations (reflecting the “speech envelope”) pass the cochlear filter and are represented in the auditory cortex (Rosen, Reference Rosen1992; Shamma, Reference Shamma2001). Despite the lack of explicit cues, acoustic landmarks in the speech envelope have been suggested to aid speech segmentation by aligning the high excitability phase of endogenous auditory cortex theta brain rhythms to the syllabic rate, termed “entrainment” or “speech tracking” (Giraud et al., Reference Giraud, Kleinschmidt and Poeppel2007; Luo and Poeppel, Reference Luo and Poeppel2007; Ghitza and Greenberg, Reference Ghitza and Greenberg2009; Giraud and Poeppel, Reference Giraud and Poeppel2012; Peelle and Davis, Reference Peelle and Davis2012; Gross et al., Reference Gross, Hoogenboom and Thut2013; Haegens and Zion Golumbic, Reference Haegens and Zion Golumbic2018; Kösem et al., Reference Kösem, Bosker and Takashima2018; Rimmele et al., Reference Rimmele, Morillon, Poeppel and Arnal2018; Poeppel and Assaneo, Reference Poeppel and Assaneo2020). Accordingly, relevant syllabic information has been suggested to fluctuate at this time scale (Sun and Poeppel, Reference Sun and Poeppel2023). It has been debated whether acoustic landmarks are defined by the rapid increases in acoustic energy in the envelope, the energy peaks related to mid-vowels, or linguistic syllable onsets (Ghitza, Reference Ghitza2011; Gross et al., Reference Gross, Hoogenboom and Thut2013; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Aubanel et al., Reference Aubanel, Davis and Kim2016; Oganian and Chang, Reference Oganian and Chang2019). Thus, syllable segmentation may be achieved by speech envelope landmarks and, at the neural level, endogenous theta brain rhythms constraining the “search space for segmentation” (for review and a critical discussion: Adolfi et al., Reference Adolfi, Wareham and van Rooij2023). According to a large corpus analysis, actually only a small percentage of the slow-amplitude modulations in the speech envelope correlates with syllable onsets, suggesting that the brain may apply additional computations to extract syllable boundaries from the envelope (c.f. Schmidt et al., Reference Schmidt, Chen and Keitel2023; Zhang et al., Reference Zhang, Zou and Ding2023). Although stronger speech tracking has been observed for intelligible compared to unintelligible speech (Luo and Poeppel, Reference Luo and Poeppel2007; Peelle and Davis, Reference Peelle and Davis2012; Gross et al., Reference Gross, Hoogenboom and Thut2013), speech tracking and comprehension seem not to be directly related. For example, tracking occurs for unattended (Zion Golumbic et al., Reference Zion Golumbic, Ding and Bickel2013; Rimmele et al., Reference Rimmele, Zion Golumbic, Schröger and Poeppel2015), unintelligible, or backwards speech (Howard and Poeppel, Reference Howard and Poeppel2010), whereas higher-level processing areas more selectively track relevant speech (Zion Golumbic et al., Reference Zion Golumbic, Ding and Bickel2013; Keitel et al., Reference Keitel, Gross and Kayser2018). However, speech tracking might be related to comprehension indirectly through the interaction with other processes (Pefkou et al., Reference Pefkou, Arnal, Fontolan and Giraud2017). In addition, in the context of predictive coding approaches, theta tracking has been assigned a specific role in uncertain speech contexts (Donhauser and Baillet, Reference Donhauser and Baillet2020). While it is a matter of ongoing debate whether speech tracking reflects an oscillatory mechanism or merely evoked potentials (Doelling and Assaneo, Reference Doelling and Assaneo2021; Oganian et al., Reference Oganian, Kojima and Breska2023), some have suggested that both contribute (Doelling et al., Reference Doelling, Assaneo, Bevilacqua, Pesaran and Poeppel2019).
Typically, syllable tracking has been observed in the auditory cortex (e.g., Luo and Poeppel, Reference Luo and Poeppel2007; Zion Golumbic et al., Reference Zion Golumbic, Ding and Bickel2013; Gross et al., Reference Gross, Hoogenboom and Thut2013; Park et al., Reference Park, Ince, Schyns, Thut and Gross2015), but also in frontal (including inferior frontal gyrus [IFG]) motor cortices (Park et al., Reference Park, Ince, Schyns, Thut and Gross2015; Assaneo et al., Reference Assaneo, Rimmele and Orpella2019; Rimmele et al., Reference Rimmele, Poeppel and Ghitza2021), or middle temporal brain areas (Rimmele et al., Reference Rimmele, Poeppel and Ghitza2021). Spectral profiles suggest endogenous theta brain rhythms in the bilateral auditory cortex and auditory association areas (Heschl’s gyrus, superior temporal gyrus [STG], left middle temporal gyrus [MTG]), the bilateral motor cortex, and the (pre-)frontal cortex (see Figure 3.1 – note that theta is also typically observed in the hippocampus and other brain areas that are not reported here) (Giraud et al., Reference Giraud, Kleinschmidt and Poeppel2007; Keitel and Gross, Reference Keitel and Gross2016; Lubinus et al., Reference Lubinus, Orpella and Keitel2021). In addition to measures during rest, endogenous auditory cortex theta rhythms have been indicated using other approaches (Teng et al., Reference Teng, Tian, Rowland and Poeppel2017, Reference Teng, Tian, Doelling and Poeppel2018). Importantly, auditory cortex syllable tracking and endogenous theta rhythms have been putatively linked, as theta power increases during comprehension compared to rest (Keitel and Gross, Reference Keitel and Gross2016) (for further evidence: Wilsch et al., Reference Wilsch, Neuling, Obleser and Herrmann2018; Zoefel et al., Reference Zoefel, Allard, Anil and Davis2019; Becker and Hervais-Adelman, Reference Becker and Hervais-Adelman2023).
3.2.2 Endogenous Gamma and Theta-Gamma Coupling during Speech Comprehension
Another brain rhythm that has been related to speech processing is the gamma brain rhythm observed in the auditory cortex (Lakatos et al., Reference Lakatos, Shah and Knuth2005; Fontolan et al., Reference Fontolan, Morillon, Liegeois-Chauvel and Giraud2014). Within a spectral profiling approach, gamma peaks are difficult to observe when averaging spectral activity across participants, due to the large inter-individual variance in gamma peak frequencies (Baltus and Herrmann, Reference Baltus and Herrmann2016).
An approach that assigns a generic role to gamma is the communication-through-coherence (CTC) framework. In CTC, neural communication channels are established through brain rhythm synchronization with suggested roles of different brain rhythms across the brain (Fries, Reference Fries2005, Reference Fries2015; for a criticism of CTC: Schneider et al., Reference Schneider, Broggini and Dann2021). Gamma has been suggested to reflect bottom-up processing across sensory domains and processes. Although this has mostly been tackled in the visual domain, evidence for gamma being related to bottom-up processing of speech comes from human depth-electrode recordings showing that gamma activity in the primary auditory cortex is related to bottom-up processing that is modulated by the phase of delta-beta brain rhythms in the association auditory cortex (AAC) (Fontolan et al., Reference Fontolan, Morillon, Liegeois-Chauvel and Giraud2014). Such bottom-up processing has been interpreted in the predictive coding framework (Rao and Ballard, Reference Rao and Ballard1999; Friston, Reference Friston2005; Fontolan et al., Reference Fontolan, Morillon, Liegeois-Chauvel and Giraud2014).
Another line of research suggests a more specific role of gamma brain rhythms reflecting computations for syllable encoding (Shamir et al., Reference Shamir, Ghitza, Epstein and Kopell2009; Ghitza, Reference Ghitza2011; Giraud and Poeppel, Reference Giraud and Poeppel2012), in contrast to the more generic communication channel interpretation of CTC. During speech processing, theta–gamma phase–amplitude coupling (PAC) in the auditory cortex has been proposed to reflect the encoding of the fine-grained phonemic information of a syllabic unit (Shamir et al., Reference Shamir, Ghitza, Epstein and Kopell2009; Ghitza, Reference Ghitza2011; Giraud and Poeppel, Reference Giraud and Poeppel2012; Gross et al., Reference Gross, Hoogenboom and Thut2013; Hyafil et al., Reference Hyafil, Giraud, Fontolan and Gutkin2015a; Lizarazu et al., Reference Lizarazu, Lallier and Molinaro2019). Although some studies suggested higher-level linguistic processing beyond encoding (Palva et al., Reference Palva, Palva and Shtyrov2002; Di Liberto et al., Reference Di Liberto, O’Sullivan and Lalor2015), others showed that theta-gamma coupling follows the input and likely reflects encoding processes (Gross et al., Reference Gross, Hoogenboom and Thut2013; Lizarazu et al., Reference Lizarazu, Lallier and Molinaro2019). Theta-gamma coupling strength has been observed to vary with speech intelligibility (Gross et al., Reference Gross, Hoogenboom and Thut2013; Pefkou et al., Reference Pefkou, Arnal, Fontolan and Giraud2017; Lizarazu et al., Reference Lizarazu, Lallier and Molinaro2019). In line with an encoding interpretation, Lizarazu et al. (Reference Lizarazu, Lallier and Molinaro2019) showed that the peak of the gamma response was coupled to the theta phase and followed the speech rate when speech was intelligible. Interestingly, developmental work suggests enhancement of gamma brain rhythms during a period of increased (sub)phonemic learning (Barajas et al., Reference Barajas, Erra and Gervain2021). Such a bottom-up encoding view is also compatible with neurophysiologically inspired computational models of speech recognition that show theta-gamma coupling can improve syllable recognition (Hyafil et al., Reference Hyafil, Fontolan, Kabdebon, Gutkin and Giraud2015b; Hovsepyan et al., Reference Hovsepyan, Olasagasti and Giraud2020) (see also brain–computer interface decoding studies: Proix et al., Reference Proix, Delgado Saa and Martin2022).
Apart from a role of theta-gamma coupling for syllable encoding, endogenous gamma activity in the auditory cortex has also been connected to auditory and language processing. In particular, the individual peak of gamma oscillations measured through ASSRs, which reflects an individual’s endogenous auditory resonance frequency, is thought to determine the rate at which auditory information is sampled (Baltus and Herrmann, Reference Baltus and Herrmann2016). This individual auditory temporal resolution has been connected with general auditory processing (Baltus and Herrmann, Reference Baltus and Herrmann2015) as well as speech and language-specific features (Lehongre et al., Reference Lehongre, Ramus, Villiermet, Schwartz and Giraud2011). It is particularly informative that an “oversampling,” that is, a higher individual gamma frequency, putatively resulting in sub-optimal phonemic processing, has been shown to predict several linguistic deficits in individuals with dyslexia (Lehongre et al., Reference Lehongre, Ramus, Villiermet, Schwartz and Giraud2011). In addition, individuals with dyslexia show weaker entrainment to the phonemic rate (around 30 Hz) than individuals without dyslexia (Lehongre et al., Reference Lehongre, Ramus, Villiermet, Schwartz and Giraud2011), and enhancing low-gamma activity using transcranial alternating current stimulation (tACS) shows improved phonemic processing (Marchesotti et al., Reference Marchesotti, Nicolle and Merlet2020). The power of gamma activity during rest has also been shown to predict speech-in-noise perception (Houweling et al., Reference Houweling, Becker and Hervais-Adelman2020), further supporting a role of endogenous gamma activity in speech processing.
3.2.3 Delta Brain Rhythms Related to Prosodic Processing
Slower brain rhythms below 2 Hz observed in auditory (and motor) cortices match the timescale of speech prosody and have been suggested to be involved in its neural tracking (Bourguignon et al., Reference Bourguignon, De Tiege and De Beeck2013; Meyer et al., Reference Meyer, Henry, Gaston, Schmuck and Friederici2016; Molinaro et al., Reference Molinaro, Lizarazu, Lallier, Bourguignon and Carreiras2016; Kotz et al., Reference Kotz, Ravignani and Fitch2018; Rimmele et al., Reference Rimmele, Poeppel and Ghitza2021). Endogenous delta brain rhythms are also evident in the spectral profiles of these brain areas (Keitel and Gross, Reference Keitel and Gross2016; Lubinus et al., Reference Lubinus, Orpella and Keitel2021; see Figure 3.1), although this endogenous activity has not been explicitly related to prosody tracking during speech processing. Prosody is reflected in the melodic pitch contour of speech with several supra-segmental acoustic features contributing to prosody perception, including the rise and fall time of pitch (tone), stress (based on changes in pitch, segment length, and loudness), and rhythmic aspects (Bourguignon et al., Reference Bourguignon, De Tiege and De Beeck2013; Paulmann, Reference Paulmann, Hickok and Small2016; also see Section 3 in this volume). Prosody can mark linguistic boundaries but also reflect emotional states (Paulmann, Reference Paulmann, Hickok and Small2016; Inbar et al., Reference Inbar, Grossman and Landau2020; Pell and Kotz, Reference Pell and Kotz2021; van Rijn and Larrouy-Maestri, Reference van Rijn and Larrouy-Maestri2023). Neural tracking of prosody has been typically observed in the right lateralized auditory cortex (Sammler et al., Reference Sammler, Grosbras, Anwander, Bestelmeyer and Belin2015). A particularly relevant landmark for the alignment of brain rhythms to prosodic information seems to be the pauses in the speech signal, which delta tracking has been specifically connected to (Bourguignon et al., Reference Bourguignon, De Tiege and De Beeck2013; Chalas et al., Reference Chalas, Daube and Kluger2023). Delta tracking, however, might reflect speech onset processing rather than sustained rhythmic activity (Chalas et al., Reference Chalas, Daube and Kluger2023).
3.2.4 Hemispheric Lateralization of Brain Rhythms
It has been argued that, after an initial bilaterally symmetric neural representation of speech in the primary auditory cortex, an auditory hemispheric asymmetry allows for an optimization of auditory processing in general, and speech processing specifically, with complementary and parallel processing in the two hemispheres (Zatorre and Belin, Reference Zatorre and Belin2001; Zatorre et al., Reference Zatorre, Belin and Penhune2002; Poeppel, Reference Poeppel2003; Washington and Tillinghast, Reference Washington and Tillinghast2015; Zatorre, Reference Zatorre2022; Robert et al., Reference Robert, Zatorre and Gupta2024). In the right hemisphere, slower delta-theta brain rhythms (~4–8 Hz) are observed, while the left hemisphere shows a regime of faster gamma brain rhythms (~40 Hz) (Poeppel, Reference Poeppel2003). For auditory processing in general, it has been argued that the right hemisphere is involved in the processing of spectral modulations relevant for object discrimination and the left hemisphere in temporal modulations relevant for action processing (Zatorre et al., Reference Zatorre, Belin and Penhune2002; Albouy et al., Reference Albouy, Benjamin, Morillon and Zatorre2020; Robert et al., Reference Robert, Zatorre and Gupta2024). Along those lines, melody processing is thought to depend more on spectral cues and speech perception more on temporal cues (Albouy et al., Reference Albouy, Benjamin, Morillon and Zatorre2020). For speech processing, it has been argued that the slower delta-theta brain rhythms in the right hemisphere reflect long integration windows (~150–250 ms) relevant for prosodic and syllable segmentation, while the faster brain rhythms reflect short integration windows (~20–40 ms) involved in processing fast formant transitions in stop consonants (here, formant transitions indicate rapid changes in vocal tract resonances at the release of the stop constriction) relevant for phoneme encoding (Poeppel, Reference Poeppel2003).
These theories suggest a differential specialization for acoustic modulations based on the spectral profiles and prevailing brain rhythms of the two hemispheres. Recently, top-down influences have been suggested to affect such lateralization, particularly for the processing of slower spectro-temporal modulations, and explain the more heterogeneous findings reported in the literature (Assaneo et al., Reference Assaneo, Rimmele and Orpella2019; Flinker et al., Reference Flinker, Doyle, Mehta, Devinsky and Poeppel2019; Albouy et al., Reference Albouy, Benjamin, Morillon and Zatorre2020). Interestingly, for endogenous brain rhythms recorded during a resting state, typically lateralization is not explicitly analyzed and rhythmic patterns appear to be mostly bilateral (Keitel and Gross, Reference Keitel and Gross2016; Mellem et al., Reference Mellem, Wohltjen, Gotts, Avniel and Martin2017; Vidaurre et al., Reference Vidaurre, Hunt and Quinn2018; Capilla et al., Reference Capilla, Arana and García-Huéscar2022). Some, however, report a lateralization of resting state brain rhythms in line with the hemispheric lateralization accounts (Giraud et al., Reference Giraud, Kleinschmidt and Poeppel2007), and others (Giroud et al., Reference Giroud, Trébuchon and Schön2020) used transient pure tone stimuli in intracerebral recordings in epilepsy patients to reveal hemispheric lateralization of intrinsic brain rhythms.
3.2.5 Brain Rhythms Related to Higher-Level Linguistic Processing
Beta and delta are the brain rhythms that have been most frequently related to higher-level linguistic processing (Weiss and Mueller, Reference Weiss and Mueller2012; Bonhage et al., Reference Bonhage, Meyer, Gruber, Friederici and Mueller2017; Schaller et al., Reference Schaller, Weiss and Müller2017; Martorell et al., Reference Martorell, Morucci, Mancini, Molinaro, Grimaldi, Brattico and Shtyrov2023; Tavano et al., Reference Tavano, Rimmele, Michalareas, Poeppel, Grimaldi, Brattico and Shtyrov2023). Spectral profiles suggest endogenous delta brain rhythms in auditory and language-processing-relevant auditory association cortices (Figure 3.1; Keitel and Gross, Reference Keitel and Gross2016; Heschl’s gyrus, STG, MTG), in prefrontal areas (opercular IFG), and in motor cortices (precentral gyrus, supplementary motor areas [SMAs]) (see also Lubinus et al., Reference Lubinus, Orpella and Keitel2021). Endogenous beta rhythms are typically reported in the motor cortices and prefrontal areas, but also in Heschl’s gyrus, left STG, and prefrontal areas, but typically not in MTG (Keitel and Gross, Reference Keitel and Gross2016; Lubinus et al., Reference Lubinus, Orpella and Keitel2021).
Beta brain rhythms have been related to several higher-level linguistic processes. In the predictive coding context particularly, they have been associated with the predictability of various types of linguistic information (Meyer et al., Reference Meyer, Obleser and Friederici2012; Weiss and Mueller, Reference Weiss and Mueller2012; Lewis et al., Reference Lewis, Wang and Bastiaansen2015; Bonhage et al., Reference Bonhage, Meyer, Gruber, Friederici and Mueller2017; Schaller et al., Reference Schaller, Weiss and Müller2017; Martorell et al., Reference Martorell, Morucci, Mancini, Molinaro, Grimaldi, Brattico and Shtyrov2023) and temporal predictions from the motor cortex during speech comprehension (Keitel et al., Reference Keitel, Gross and Kayser2018; Morillon et al., Reference Morillon, Arnal, Schroeder and Keitel2019; see also Morillon and Baillet, Reference Morillon and Baillet2017). Computational modelling work suggests the beta rhythm might indicate the precision modulation of the prediction error during speech comprehension (see also Fontolan et al., Reference Fontolan, Morillon, Liegeois-Chauvel and Giraud2014; Cao et al., Reference Cao, Thut and Gross2016; Sedley et al., Reference Sedley, Gander and Kumar2016; Chao et al., Reference Chao, Takaura, Wang, Fujii and Dehaene2018; Weissbart et al., Reference Weissbart, Kandylaki and Reichenbach2020). For example, beta tracking of surprisal (using temporal response functions [TRFs]) has been related to word predictability in continuous speech (Weissbart et al., Reference Weissbart, Kandylaki and Reichenbach2020; Zioga et al., Reference Zioga, Weissbart, Lewis, Haegens and Martin2023). Others suggest a role of beta suppression in the combination of words into meaning through its reflection of a general-purpose inhibitory system involved in word negation (Zuanazzi et al., 2022; for review: Beltrán et al., Reference Beltrán, Liu and de Vega2021), or its role in word category discrimination, action semantics, semantic memory, and working memory during language comprehension (Haarmann et al., Reference Haarmann, Cameron and Ruchkin2002; Piai et al., Reference Piai, Roelofs, Rommers and Maris2015; for review: Weiss and Mueller, Reference Weiss and Mueller2012). Furthermore, beta might be involved in sentence structure-based processing, with beta power increasing with syntactic processing demands, or for sentences compared to word lists (Bastiaansen and Hagoort, Reference Bastiaansen and Hagoort2006; Bastiaansen et al., Reference Bastiaansen, Magyari and Hagoort2009; Meyer et al., Reference Meyer, Obleser and Friederici2012). Beta is typically observed in several areas of the motor cortex (McCarthy et al., Reference McCarthy, Moore-Kochlacs and Gu2011; Pavlides et al., Reference Pavlides, Hogan and Bogacz2015), suggesting a close relationship between motor processing and language comprehension (Weiss and Mueller, Reference Weiss and Mueller2012). Computational modelling work supports the idea that the beta brain rhythm is particularly suitable for maintaining and preserving neural activity in time to link past and present input (Roopun et al., Reference Roopun, Kramer and Carracedo2008; Engel and Fries, Reference Engel and Fries2010; Kopell et al., Reference Kopell, Whittington and Kramer2011; Gelastopoulos et al., Reference Gelastopoulos, Whittington and Kopell2019) (for a decision multiplexing framework, see Rassi et al., Reference Rassi, Zhang and Mendoza2023).
As discussed above, delta brain rhythms are observed in auditory, auditory association, and motor cortices, and have been suggested to be involved in prosody tracking. More recently, it has been argued that these slow brain rhythms might also reflect the tracking of the syntactic phrasal structure in the absence of acoustic (prosodic) cues (Meyer et al., Reference Meyer, Obleser and Friederici2012; Ding et al., Reference Ding, Melloni, Tian and Poeppel2016; Meyer et al., Reference Meyer, Henry, Gaston, Schmuck and Friederici2016; Bonhage et al., Reference Bonhage, Meyer, Gruber, Friederici and Mueller2017; Meyer, Reference Meyer2018; Meyer et al., Reference Meyer, Sun and Martin2020; Henke and Meyer, Reference Henke and Meyer2021; Lu et al., Reference Lu, Jin, Pan and Ding2022). Ding et al. (Reference Ding, Melloni, Tian and Poeppel2016) interpreted such tracking to indicate hierarchical syntactic processing (for a criticism of this interpretation: Frank and Christiansen, Reference Frank and Christiansen2018; Kazanina and Tavano, Reference Kazanina and Tavano2023; Lo et al., Reference Lo, Henke, Martorell and Meyer2023). Computational modelling research suggests neural oscillatory mechanisms as possible candidates for delta brain rhythms underlying hierarchical linguistic processing (Martin and Doumas, Reference Martin and Doumas2017; ten Oever and Martin, Reference ten Oever and Martin2021). Currently, research is lacking that systematically relates endogenous brain rhythms in the delta band to higher-level linguistic processing during speech comprehension.
3.2.6 Motor Cortex Brain Rhythms Recruited during Speech and Language Processing
When using fine-grained spectral profiling, intrinsic rhythmic activity in cortical motor areas (including precentral gyri, supplementary motor areas, and also inferior frontal gyrus as speech-motor-related brain areas) is consistently characterized by peaks in the delta, theta, and beta frequency bands (see Figure 3.1). Traditionally, the motor cortex has mostly been associated with prominent beta activity (Pfurtscheller et al., Reference Pfurtscheller, Stancák and Neuper1996). This characteristic beta power, as now established, is not due to sustained rhythmic activity but reflects transient “beta bursts” (Jones, Reference Jones2016; Sherman et al., Reference Sherman, Lee and Law2016). As mentioned above, beta activity in general is associated with higher-level linguistic and predictive processing. In the motor cortex specifically, beta activity has been connected to motor control (Pfurtscheller et al., Reference Pfurtscheller, Stancák and Neuper1996) and top-down interactions with the auditory cortex (Abbasi and Gross, Reference Abbasi and Gross2020).
Apart from beta activity, rhythmic delta activity in the motor cortex has gained attention in auditory and speech perception research. The “active sensing” framework postulates that cortical motor activity shapes sensory processing (Morillon et al., Reference Morillon, Hackett, Kajikawa and Schroeder2015). In particular, rhythmic delta activity in the motor cortex is thought to impose temporal constraints on auditory sampling and is involved in generating temporal predictions for acoustic stimuli, including speech (Keitel et al., Reference Keitel, Gross and Kayser2018). In line with this, it has been shown that the left motor cortex tracks slow delta band fluctuations in continuous speech and that the strength of this tracking predicts comprehension in noise (Keitel et al., Reference Keitel, Gross and Kayser2018). Furthermore, delta-beta phase-amplitude coupling in left motor areas also predicts speech-in-noise comprehension (Keitel et al., Reference Keitel, Gross and Kayser2018), highlighting a potential role of oscillatory cross-frequency mechanisms for temporal predictions in auditory perception (Arnal et al., Reference Arnal, Doelling and Poeppel2014; Fontolan et al., Reference Fontolan, Morillon, Liegeois-Chauvel and Giraud2014; Morillon and Baillet, Reference Morillon and Baillet2017).
Motor cortices also show prominent endogenous activity in the theta band, similar to auditory and other frontal areas (see Figure 3.1). Interestingly, a theta-frequency-specific coupling between auditory and motor cortices has been found that matches the average syllabic rate, which has been termed “intrinsic speech-motor rhythm” (see also He et al., Reference Becker and Hervais-Adelman2023; Barchet et al., Reference Barchet, Henry, Pelofi and Rimmele2024). Importantly, behavioral studies have related individual intrinsic motor rhythms in the theta band (quantified by the speaking rate) and individual synchronization tendencies (mapping auditory-motor coupling strength) to speech perception skills (Assaneo et al., Reference Assaneo, Rimmele and Orpella2019, Reference Assaneo, Rimmele, Sanz Perl and Poeppel2021; Lubinus et al., Reference Lubinus, Keitel, Obleser, Poeppel and Rimmele2023; see also Pfordresher et al., Reference Pfordresher, Greenspon, Friedman and Palmer2021). Notably, the relationship between endogenous motor rhythms and perception has also been behaviorally estimated and computationally modelled in the field of music research (Zamm et al., Reference Zamm, Wang and Palmer2018; Roman et al., Reference Roman, Roman, Kim and Large2023). Besides these attempts on the behavioral and theoretical level, we note again that research that systematically relates endogenous brain rhythms in the motor cortex to the brain rhythms observed during task-related processing is scarce.
The motor cortex also shows other important frequency-specific interactions with the auditory cortex. For example, during listening to speech, delta and theta band activity in left precentral gyrus influence the phase of same-band activity in the left auditory cortex, and this is associated with the strength of auditory speech tracking (Park et al., Reference Park, Ince, Schyns, Thut and Gross2015). Similarly, alpha-band power in several central brain regions (including bilateral precentral gyri and supplementary motor areas) influences speech tracking in the delta band in the left auditory cortex (Keitel et al., Reference Keitel, Ince, Gross and Kayser2017). The above findings are in line with a role of the motor cortex in predicting the timing of events and controlling neural excitability, also in the auditory cortex (Arnal and Giraud, Reference Arnal and Giraud2012). Taken together, these findings show that motor cortex activity can influence auditory speech tracking in a top-down manner using different frequency channels.
3.3 Conclusion
Endogenous brain rhythms measured during rest reflect the functional organization of the brain and are thought to be recruited during speech and language processing. Specific roles for endogenous brain rhythms have been proposed for speech and syllable segmentation, phonetic encoding, prosodic segmentation, but also higher-level linguistic predictions and temporal predictions. Recently, there have been methodological advances in the analysis of endogenous rhythmic activity, revealing complex patterns of brain rhythms as well as frequency-specific networks. Crucially, more work is required that directly relates endogenous brain rhythms observed during rest to brain rhythms observed during task-related processing. Possibly, future research would use invasive single-cell recordings to unambiguously show that the same neurons that display rhythmic activity during rest are also involved in task-related operations. Additionally, altering endogenous brain rhythms through noninvasive brain stimulation and testing behavioral consequences is a promising route to test causal relationships. Furthermore, more differentiation of the various brain rhythms observed in different brain areas regarding their characteristic features is required. For example, do brain rhythms of a brain area reflect transient bursts, continuous rhythmic activity, or aperiodic activity, and to what extent do they reflect local or global neural circuitry? Ultimately, testing the functional relevance of endogenous brain rhythms is a crucial bottleneck for proving influential neural oscillatory theories of speech and language processing.
3.4 Acknowledgements
Anne Keitel was supported by the Medical Research Council (grant number MR/W02912X/1). Both Johanna M. Rimmele and Anne are members of the Scottish-EU Critical Oscillations Network (SCONe), funded by the Royal Society of Edinburgh (RSE Saltire Facilitation Network Award to Anne, Reference Number 1963). Johanna was supported by the Max Planck Institute for Empirical Aesthetics and the Max Planck NYU Center for Language, Music, and Emotion (CLaME).
Summary
An important cornerstone to understand ubiquitous neural oscillations is the link between endogenous brain rhythms measured during rest and brain rhythms measured during task processing. We reviewed the literature on brain rhythms involved in speech and language processing, and their putative link to endogenous brain rhythms, especially in the theta, gamma and delta, and beta frequency ranges.
Implications
Neural oscillatory models to date include different levels of language processing. Attempts to directly relate these brain rhythms observed during task-related processing to endogenous brain rhythms are sparse. We provide a road map for future research on how to tackle the currently missing explicit links between endogenous brain rhythms and their role in speech and language processing for novices and experts.
Gains
To understand the neural underpinnings of speech and language will allow us to explain a wide variety of phenomena in the future, ranging from lower-level processes such as speech segmentation and syllable encoding up to higher-level language processing, including phrasal and prosodic processing. It is one crucial piece of the puzzle of why speech and language are temporally organized as they are.
4.1 Introduction
Seated on a train waiting to leave the station, you notice movement out of the corner of your eye and think to yourself, “Finally, we’re on our way!” However, as the train on the adjacent track continues to move, you realize that your own train is still stationary. This phenomenon, known as vection, is an illusion of self-motion thought to arise due to conflicting signals from the visual system and the vestibular system (Dichgans and Brandt, Reference Dichgans, Brandt, Held, Leibowitz and Teuber1978). The vestibular system includes a sophisticated set of organs in the inner ear responsible for detecting changes in self-motion and orientation in space. Historically, these organs and their connections across multiple cortical and subcortical brain areas have received limited attention in cognitive neuroscience, as they have been assumed to be predominantly relevant for functions such as postural control (vestibulocollic reflexes), gaze stabilization (vestibular-ocular reflexes), and autonomic regulation (Angelaki and Cullen, Reference Angelaki and Cullen2008).
However, a growing body of evidence suggests vestibular information contributes to a variety of cognitive processes (Mast and Ellis, Reference Mast and Ellis2015; Harris, Reference Harris2020). Following this trend, we suggest that the computational properties of the vestibular system make it useful for processing the prosodic elements of speech. We focus on a phenomenon we refer to as multimodal prosody: aspects of the prosodic signal in speech that are reliably paired with visual information from the speaker’s body. Dynamic changes of suprasegmental components of speech, including pitch and amplitude, are mirrored in co-speech gestures (Wagner et al., Reference Wagner, Malisz and Kopp2014). In this chapter we present the sensorimotor account of multimodal prosody (SAMP) that links the vestibular system to multimodal prosody and motivates novel hypotheses regarding speech-gesture integration and how attention is structured during language exchange.
We begin below with a brief introduction to the anatomy and physiology of the vestibular system. In Section 4.3, we review evidence showing that the vestibular system contributes to dynamic attentional control, timekeeping functions, and musical rhythm perception. In Section 4.4, we discuss a potential role for the vestibular system in the perception of rhythm in speech. Because human vocalization provides an above-threshold mechanical stimulus for the vestibular end organs, we propose that the brain treats speech as an acoustic-vestibular stimulus, and thus a form of self-motion. Moreover, because speech production is both accompanied and constrained by movements of the body, vestibular mechanisms are likely involved in encoding and decoding prosodic features of multimodal discourse. We present our sensorimotor account of multimodal prosody (SAMP) in Section 4.5, and conclude in Section 4.6 by highlighting the potential clinical relevance of the proposal for populations with language and/or rhythmic processing difficulties.
4.2 The Vestibular System: New Perspectives
For the purposes of this chapter, discussion of the vestibular system will generally focus on the information processing capacity of the otolith organs, which are constantly stimulated by downward gravitational forces, and encode linear translations of the head. We begin by highlighting basic anatomical and physiological principles of the peripheral vestibular function, and how vestibular information is integrated with exteroceptive and interoceptive information from early stages in the cortical hierarchy. Following this, we briefly discuss the predictive coding scheme that characterizes vestibular information processing in the brain.
4.2.1 Anatomy, Physiology, and Functional Principles
Within each ear, three semicircular canals encode rotational movements of the head, and two otoliths detect gravito-inertial acceleration, that is, the vector sum of linear head translations and gravity (see Figure 4.1). The otolith organs contain particles of calcium carbonate suspended in a membrane that flows according to inertial changes in head tilt or motion. Head motion and gravitational forces cause mechanical displacement of hair cell stereocilia and generate potentials that propagate to the vestibular nuclei in the medulla, where information about head motion is relayed to various regions of the cortex, both directly from the brainstem as well as through the thalamus (Kirsch et al., Reference Kirsch, Keeser and Hergenroeder2016; Cullen, Reference Cullen2019). Vestibular mechanoreceptors are highly sensitive to physical perturbations; for example, afferent nerves can ignite in response to hair cell deflections of less than half a nanometer (Curthoys et al., Reference Curthoys, Grant and Burgess2018).
Vestibular anatomy.
During head rotations, endolymph fluid lags behind angular rotation of the head due to inertia, and its displacement bends the cilia of the hair cells in one of the three canals, anterior, lateral, and posterior.
Within the macula of the utricle and saccule, which encode horizontal and vertical accelerations of the head, respectively, the otolith crystals move in response to gravity and head motion, bending stereocilia of the hair cells and triggering an afferent response.
The signal transduced by the otoliths is called gravito-inertial acceleration, which is the vector sum of forces due to gravity and inertial motion of the head. These have the same physical consequences on the otolith organs, such that tilting the head backward and accelerating forward with the head upright results in the same signal to the brain via cranial nerve VIII.
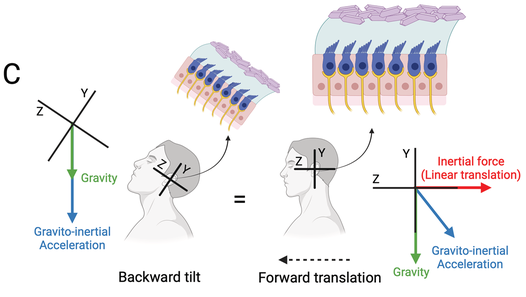
Figure 4.1C: Long description
Part C depicts the mechanics of how the otolith organs detect linear acceleration and head tilt. Two intersecting lines depict gravito-inertial acceleration. A figure of a human head labeled backward tilt. The intersecting lines marked on the same head indicate a block of hair cells, followed by an equal symbol, a figure of a human head labeled forward translation. The intersecting lines marked on the same head indicate a block of hair cells. A coordinate system. The Y-axis is vertical, the Z-axis is horizontal, and the X-axis is perpendicular to both. A vector pointing to the right in the Y-Z plane represents the inertial force due to linear translation. A vector pointing downwards in the Y-axis represents the force of gravity. The X-axis represents the gravito-inertial acceleration.
Vestibular afferent information is extensively connected to the cerebellum, basal ganglia, and other subcortical structures important for movement control (Stiles and Smith, Reference Stiles and Smith2015; Rühl et al., Reference Rühl, Kimmel, Ertl, Conrad and Zu Eulenburg2023). In humans, vestibular-sensitive regions of the cortex are very diverse and have been identified in areas near the temporoparietal junction, including the supramarginal and angular gyri, and the posterior superior temporal gyrus, parietal operculum, and posterior insular cortex (see Lopez et al., Reference Lopez, Blanke and Mast2012, for a review). Notably, there is considerable overlap between vestibular-sensitive regions of the cortex and traditional areas of the language network as defined by Hickok and Poeppel (Reference Hickok and Poeppel2007), including the superior planum temporale (SPT), BA 21, BA 22 (Wernicke’s area), and BA 44/45 (Broca’s area) (Gattie et al., Reference Gattie, Lieven and Kluk2021).
The vestibular system is unusual for several reasons – one of which is its inherent multimodal nature; that is, all neurons in the brain that respond to vestibular stimulation are also activated by some other source of sensory stimulation (Dieterich and Brandt, Reference Dieterich and Brandt2015). Vestibular afferent information becomes integrated with visual, somatosensory, and proprioceptive signals at very early processing stages in the brainstem (Cullen, Reference Cullen2019). In contrast to other afferent systems in the central nervous system (CNS) (e.g., Heschl’s gyrus, V1, S1), it is generally accepted that no true “primary” vestibular cortex exists. An interesting corollary of its multisensory nature is that the vestibular system is important for regulating afferent gain across other sensory modalities, including vision (e.g., Voros et al., Reference Voros, Sherman and Rise2021), somatosensation (Ferrè et al., Reference Ferrè, Walther and Haggard2015), proprioception (Ponzo et al., Reference Ponzo, Kirsch, Fotopoulou and Jenkinson2019), and even nociception (Ferrè et al., Reference Ferrè, Bottini, Iannetti and Haggard2013).
Cell populations in the peripheral organs of the vestibular system are categorized by their firing regularity at resting state. Irregular afferents demonstrate relatively high resting-state firing variability, are particularly sensitive to changes in head motion by their use of spike timing precision, and help ensure maintenance of posture during changes in self-motion. By contrast, regular afferents exhibit low firing-rate variability during rest, and become rapidly integrated with eye movement signals to mediate reflex-arcs, such as the vestibulo-ocular reflex, that improve gaze fixation during head motion (Sadeghi et al., Reference Sadeghi, Chacron, Taylor and Cullen2007). Besides the time course of head motion, regular afferents’ use of a rate-coding strategy makes them well suited to encode temporal information more generally (Jamali et al., Reference Jamali, Carriot, Chacron and Cullen2019).
4.2.2 Modeling Self-Location
The vestibular system makes critical contributions to dynamic representations of the movement and location of the organism, providing continuous signals about angular and linear acceleration of the head by the semicircular canals and otoliths, respectively (Laurens and Droulez, Reference Laurens and Droulez2007). Information from other sensory modalities, such as vision and proprioception, also constrains estimates of these parameters. In fact, some inherent limitations of the vestibular end organs mean that multisensory integration is imperative for successful self-motion encoding in the brain (Laurens and Angelaki, Reference Laurens and Angelaki2011). This capacity of the vestibular system for multisensory integration makes it well suited for coding correlated streams of information from different modalities, such as the acoustic properties of speech and movements associated with accompanying gestures.
Further, the vestibular system has been shown to issue predictions about the consequences of bodily movements, that is, how motor commands are expected to impact signals from the semicircular canals and otoliths (Laurens and Angelaki, Reference Laurens and Angelaki2017). Indeed, the earliest level of convergence between the vestibular periphery and the nervous system involves a comparison between the expected consequences of self-motion against the actual dynamic vestibular afferent signal (Dale and Cullen, Reference Dale and Cullen2019). In order to predict afferent information transmitted by the vestibular periphery, the vestibular system needs to internally represent features of the environment likely to influence how the head registers changes in forces, including gravity and biomechanical properties of the organism’s own body (e.g., Laurens et al., Reference Laurens, Meng and Angelaki2013; Martin et al., Reference Martin, Lapierre, Haché, Lucien and Green2021).
4.3 Temporal Expectations in the Body
Besides its accepted role in maintaining balance, the vestibular system has also been implicated in temporal cognition and dynamic attention. The SAMP is that vestibular contributions to speech processing are similar to those it makes in the processing of another sort of structured sound – music. Moreover, just as dance facilitates the perception of rhythm in music, co-speech gestures facilitate the perception of meter in speech. In this section, we describe how precise auditory processing in time relates to the ability to control the body, arguing that vestibular information processing is relevant for movement-related enhancement of dynamic attention. We go on to highlight the sensorimotor theory of rhythm and beat induction (SMT) that suggests metrical accents in music are encoded by the vestibular system as self-motion variables.
4.3.1 Self-Motion Structures Attention
In addition to the classic spatial attention system, cognitive neuroscientists have suggested the brain also utilizes a distinct dynamic attention system to understand rapidly changing stimuli. Dynamic attention relies on the brain’s ability to make predictions about space and time, and serves to facilitate the processing of stimuli that occur both where and when they were predicted (Arnal and Giraud, Reference Arnal and Giraud2012). This is especially true for the processing of sound sequences, in which the brain makes a variety of predictions about their temporal structure.
Mechanistically, the motor system is thought to play an important role in dynamic attention and active perception, and several accounts link temporal aspects of sensory processing with mechanisms that guide the timing of physical actions (Coull and Droit-Volet, Reference Coull and Droit-Volet2018). For example, while temporal regularity improves performance on target detection tasks (e.g., Jones et al., Reference Jones, Moynihan, MacKenzie and Puente2002), additional performance benefits are observed when participants physically move in time with the stimuli relative to passive listening conditions (e.g., Schmidt-Kassow et al., Reference Schmidt-Kassow, Heinemann, Abel and Kaiser2013; Morillon and Baillet, Reference Morillon and Baillet2017).
Although the precise mechanisms that link motor activity to dynamic attention are unclear, there is growing evidence that some of the benefits associated with auditory-motor synchronization derive from the vestibular system. Rather than asking participants to tap in time with a tone sequence, Schmidt-Kassow et al. (Reference Schmidt-Kassow, Wilkinson, Denby and Ferguson2016) combined the auditory oddball paradigm with the administration of galvanic vestibular stimulation (GVS), a technique used to directly stimulate the vestibular afferent nerve (Dlugaiczyk et al., Reference Dlugaiczyk, Gensberger and Straka2019). Administering subliminal GVS pulses either in or out of phase with simple auditory tone sequences, these investigators observed P300 enhancement when vestibular stimulation was temporally aligned with the auditory tones, but not when stimulation was out of phase (Schmidt-Kassow et al., Reference Schmidt-Kassow, Wilkinson, Denby and Ferguson2016). This finding suggests the vestibular system makes an independent contribution to the enhanced processing in this paradigm.
The patient literature also points to a critical role for the vestibular system in dynamic attention (Bigelow and Agrawal, Reference Bigelow and Agrawal2015). Populations with vestibular dysfunction show abnormal P300 responses in oddball detection tasks (e.g., El-Gharib et al., Reference El-Gharib, Nada and Lasheen2018; Wang et al., Reference Wang, Huang and Feng2022). Moreover, studies carried out during spaceflight suggest that endogenous attentional control is gravity-dependent – and thus may recruit vestibular processing resources (e.g., Salatino et al., Reference Salatino, Iacono and Gammeri2021; Takács et al., Reference Takács, Barkaszi and Czigler2021).
4.3.2 Dynamic Attention to Rhythms in Music
Interactions between motor activity and dynamic attention are also relevant for the perception of rhythm in music, in which people lock onto an underlying frequency, referred to as the beat. In fact, some theories treat rhythm perception as mediated by the vestibular system (Todd, Reference Todd1999; Todd and Lee, Reference Todd and Lee2015). According to the SMT of rhythm and beat induction, rhythm perception is a form of sensory-guided action, such that the sensory components initiating body movements are vestibular mechanisms that contribute to the representation of the self in space.
The SMT motivates predictions about human rhythmic capacities that align well with principles of vestibular physiology. The so-called phase transition phenomenon shows how beat perception spontaneously adjusts to the note value (whole, half, quarter note, etc.) that people can most consistently move their body to in time (1–2 Hz) (Haegens and Zion Golumbic, Reference Haegens and Zion Golumbic2018). Notably, this frequency (~1.7 Hz) is a sort of “Goldilocks” rate for the integrity of a variety of otolith-driven reflexes (MacDougall and Moore, Reference MacDougall and Moore2005), and is also the optimal rate for performance on auditory oddball tasks (Zalta et al., Reference Zalta, Petkoski and Morillon2020).
The SMT also suggests that movement-driven enhancement of rhythm perception results because head movement stimulates the vestibular system. Accordingly, research with infants and adults shows it is possible to bias the perception of ambiguous rhythms (i.e., rhythms without physical accents that demarcate beat periods) to align in time with either phasic stimulation of the vestibular nerve or physical movement of the head (Phillips-Silver and Trainor, Reference Phillips-Silver and Trainor2005, Reference Phillips-Silver and Trainor2008; Trainor et al., Reference Trainor, Gao, Lei, Lehtovaara and Harris2009). These studies support a critical role of vestibular information processing for musical rhythm perception.
Beyond this, while acceleration of the head is the primary stimulus for type I receptors in the otoliths, bone-conducted and air-conducted (sound) vibrations can also stimulate the vestibular afferents (see Curthoys et al., Reference Curthoys, Grant and Pastras2019, for a review). Vestibular acoustic sensitivity is restricted to relatively low frequencies (300–1,000 Hz), thus offering a potential explanation for why low-frequency tones are more likely to be interpreted as marking the beat structure of rhythms (Møller et al., Reference Møller, Stupacher, Celma-Miralles and Vuust2021), improve synchronization performance, and elicit spontaneous sensorimotor entrainment (e.g., Varlet et al., Reference Varlet, Williams and Keller2020).
4.3.3 Self-Motion in Musical Rhythms
Predictive coding perspectives treat physical action as the brain’s attempt to minimize errors between predicted and actual incoming sensory inputs, rather than the result of motor commands per se (Adams et al., Reference Adams, Shipp and Friston2013). The SMT suggests that in addition to auditory and proprioceptive predictions, the brain issues vestibular predictions. Because the otolith organs encode information about forces experienced by the head, one way to ascertain the involvement of the vestibular system in rhythm perception is to measure the timing and magnitude of force parameters during dance.
If vestibular codes are recruited for rhythm perception, the body movements that track the beat should be those that signal changes in forces experienced by the head and body. When people hear rhythms, they tend to “bounce” regularly in ways that recruit the head or the trunk (e.g., Toiviainen et al., Reference Toiviainen, Luck and Thompson2010; Janata et al., Reference Janata, Tomic and Haberman2012) and thereby involve vestibular stimulation. Rhythmic arm movements often involve the controlled timing of variations in velocity, that is, transient periods of acceleration and deceleration especially along the vertical axis (Luck and Sloboda, Reference Luck and Sloboda2009; Colley et al., Reference Colley, Varlet, MacRitchie and Keller2018), and these too are likely registered by the vestibular system. In this way, nonlocal consequences of limb movement can be reflected in changes in the force the ground exerts on the support surface of the body – a measurement called the vertical ground reaction force (GRF).
Consistent with a vestibular encoding for rhythm, the spatial properties of arm movements during dance are less relevant for tracking the beat than their force-related properties. For example, when asked to judge whether a dancer’s movements were synchronized to music, participants seemed to exploit the dancer’s vertical GRF (Takehana et al., Reference Takehana, Uehara and Sakaguchi2019). The perception of synchrony was apparently unrelated to purely spatiotemporal descriptions of their movements and was instead related to the way the dancer’s arm movements transferred momentum across the body (Takehana et al., Reference Takehana, Uehara and Sakaguchi2019).
In sum, when people encounter musical rhythms, the brain not only issues temporally organized predictions about impending auditory events but also predictions that are interoceptive in nature and explicitly tied to self-motion. An afferent vestibular prediction shifted forward in time is what “leads” the body to act out rhythms. Likewise, the perception of audiovisual synchrony in dance suggests a multimodal encoding of rhythm that is sensitive to the force of the dancer’s movements (see also Su, Reference Su2014).
4.4 Vestibular Rhythms in Speech
In the previous section, we reviewed evidence illustrating how temporal predictions – especially those facilitated by movement – interact with attentional gain and can enhance the perception of target stimuli presented periodically or in musical rhythms. In this section, we consider how vestibular information processing may also be relevant for structuring attention to speech.
In noting the potential relevance of articulatory gestures of the face and the body for the perception of speech, the SAMP is in some ways reminiscent of the motor theory of speech perception. Through various iterations, the motor theory involves the proposal that speech is perceived by direct apprehension of a speaker’s vocal and articulatory gestures (Liberman et al., Reference Liberman, Cooper, Shankweiler and Studdert-Kennedy1967), and involves the recruitment of the motor system (Galantucci et al., Reference Galantucci, Fowler and Turvey2006). Although speech perception is best construed as subserved by the auditory system, it involves coordination with other neural processing systems (see Holt and Peele, Reference Holt, Peelle, Holt, Peelle, Coffin, Popper and Fay2022, for a review). In accordance with modern accounts of active inference (e.g., Adams et al., Reference Adams, Shipp and Friston2013), the SAMP postulates that any embodied contribution to speech perception would be served in part by dynamic activity in systems relevant for vocalization.
As argued below, the claim in the SAMP is that the vestibular system aids the apprehension of metrical structure, thus influencing the perception of speech. Below, we describe the biomechanical link between the peripheral organs in the vestibular system and the act of speaking. Because speech stimulates the otoliths, it sets up the need for the vestibular system to model the acoustic energy in terms of its impact on self-motion variables.
4.4.1 Vestibular Rhythms in Prosody
Vibrational energy from the larynx during vocalization offers a mechanical stimulus above the sensitivity threshold for the vestibular end organs (Curthoys et al., Reference Curthoys, Grant and Pastras2019), raising the possibility that they play some role in regulating speech. Trivelli et al. (Reference Trivelli, Potena and Frari2013) found that the integrity of saccular function, that is, neural activity in the vestibular system that encodes vertical head movement, predicts speech rehabilitation success in individuals with bilateral sensorineural hearing loss. They suggest that in the absence of normal hearing, the vestibular apparatus may play a direct role in regulating vocal behavior, and that vocal-mechanical imprints sensed by the saccule could serve as a target for speech sound representations and facilitate aspects of articulation (see also Sheykholeslami and Kaga, Reference Sheykholeslami and Kaga2002).
The biomechanical link between the larynx and the vestibular periphery raises the possibility that some aspect of vestibular information is directly encoded in speech, perhaps because speech alters neural precision weighting in the vestibular system (Weissman et al., Reference Weissman, Ekelman, DiScenna and Leigh1989; Diaz-Artiles and Karmali, Reference Diaz-Artiles and Karmali2021). Analogous to the way loud bass tones in musical rhythms would be registered and thus modeled by the vestibular system, it is likely that the vestibular system also models the physical consequences of the act of speaking (Curthoys et al., Reference Curthoys, Grant and Pastras2019), and this may be particularly relevant for the neural representation of prosody.
A speaker’s prosody, that is, modulations of amplitude, duration, or pitch accents in the speech envelope, involves the expression of intonation and lexical stress. The timescale of important prosodic events is well suited for vestibular encoding. Acoustic correlates of prosody are slower than the timescale of phonetic or syllabic information and unfold at a rate (< 3 Hz) suitable for interactions between motor activity and attention, as well as hypothesized comparisons between rhythmic processing in speech and music (Gordon et al., Reference Gordon, Magne and Large2011; Magne et al., Reference Magne, Jordan and Gordon2016; see Chapter 35). In particular, the rate of variation in vocal stress may support “rhythmic attending” to spoken language, akin to the pulse in musical rhythms (see Haegens and Zion Golumbic, Reference Haegens and Zion Golumbic2018).
Because the activation of the vestibular system results from sonorant (voiced) properties of speech, vowels would disproportionately be registered by the vestibular organs. Accordingly, a study using the tapping task showed that participants tap at the onset of vowels, especially metrically strong vowels (Rathcke et al., Reference Rathcke, Lin, Falk and Bella2021; see Chapter 2). Just as participants in rhythm perception studies tap with greater force on strong beats than on weak ones (Benedetto and Baud-Bovy, Reference Benedetto and Baud-Bovy2021), speakers tap more forcefully when they produce stressed syllables than unstressed ones (Parrell et al., Reference Parrell, Goldstein, Lee and Byrd2014).
As the natural alignment between motor behavior and auditory events reveals the dynamics of attentional gain, there are performance benefits for detecting target speech sounds or mispronunciations that occur on stressed syllables relative to unstressed syllables (e.g., Cole and Jakimik, Reference Cole and Jakimik1980). Performance on phoneme detection and syntactic judgment tasks improves if sentences are preceded by a rhythmic prime that matches the prosodic structure of the upcoming speech (Cason et al., Reference Cason, Astésano and Schön2015; see also Chapters 22 and 25). Moreover, the detection of target words improves when participants actively tap in time with stressed syllables relative to unstressed syllables in naturally spoken sentences (Falk and Dalla Bella, Reference Falk and Dalla Bella2016).
In keeping with a vestibular encoding, evidence suggests that mechanisms associated with “rhythmic attending” are sensitive to the vocal energy patterns in speech. Although speech lacks the stable periodicity that defines rhythms found in music (Dalla Bella et al., Reference Dalla Bella, Białuńska and Sowiński2013; see also Chapter 26), it may nonetheless benefit from mechanisms that support precise sensorimotor synchronization and auditory processing in time (Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020), including sensitivity to the body movements that accompany speech.
4.4.2 Prosody across the Body
In natural communication settings, discourse is an exhibition of fully embodied activity. The prominent phase of co-speech-gesture activity is often mirrored in dynamic changes of suprasegmental components of prosody (McNeill, Reference McNeill, Sebeok and Umiker-Sebeok1995; Loehr, Reference Loehr2007). Machine-learning algorithms trained on multimodal discourse corpora can synthesize remarkably natural co-speech movements from novel speech input – bolstering the idea that vocal acoustics reflect information about the speaker’s concurrent bodily motion (Bozkurt et al., Reference Bozkurt, Yemez and Erzin2016). In particular, the apex of manual gesture activity often coincides with salient prosodic contours in the speech signal (e.g., Leonard and Cummins, Reference Leonard and Cummins2011). This correspondence is perhaps most apparent when speakers use beat gestures – downward, pulsing movements of the hand to signal emphasis – and is generally invariant to a gesture’s communicative function (e.g., Rochet-Capellan et al., Reference Rochet-Capellan, Laboissière, Galván and Schwartz2008).
Importantly, co-speech gestures that reflect the rise and fall of the speech signal manifest across the entire body, including movements of the torso and the head (Cvejic et al., Reference Cvejic, Kim and Davis2010; Kim et al., Reference Kim, Cvejic and Davis2014). It has been estimated that the head moves around 90% of the time when people talk (Hadar et al., Reference Hadar, Steiner, Grant and Rose1983), and the apex in motion coincides with peaks in amplitude and/or pitch, such that alignment prefers phrasal, rather than syllabic, components of speech (e.g., Krahmer and Swerts, Reference Krahmer and Swerts2007). The rhythmic body movements accompanying speech may thus be understood as aimed at minimizing prediction error arising from the vestibular impact of speaking, as moments of vocal stress are accompanied by changes in head acceleration.
The natural relationship between co-speech movements and speech is a deeply embedded feature of spoken language and affects speech processing in several ways, such as enhancing speech-in-noise comprehension (Munhall et al., Reference Munhall, Jones, Callan, Kuratate and Vatikiotis-Bateson2004) and facilitating speech segmentation (Kitamura et al., Reference Kitamura, Guellaï and Kim2014). Visual correlates of prosody are even robust enough to shape how speakers are ultimately heard by others. The relative timing of co-speech gestures can bias the perception of spoken emphasis (lexical stress) (e.g., Treffner et al., Reference Treffner, Peter and Kleidon2008), and when lexical stress patterns determine their identity – for example, in the contrast between the English verb “object” (ob-JECT) and the noun “object” (OB-ject) – spoken word recognition is systematically influenced by the exact moment that simple beat gestures land during listening (Bosker and Peeters, Reference Bosker and Peeters2021).
Besides lexical identity, prosodic cues can serve to disambiguate phrase structure during sentence comprehension. In a study that compared the relative influence of acoustic versus gestural timing on the processing of syntactically ambiguous phrases, Guellaï and colleagues found that listeners give more weight to the timing of co-speech gestures than to speech acoustics (Guellaï et al., Reference Guellaï, Langus and Nespor2014). The timing of co-speech gestures thus influences linguistic processing of the speech at multiple different levels and does so in a way that coincides with prosodic cues in the acoustic signal.
Whereas previous scholars have used the phrase “visual prosody” to describe how the kinematics of co-speech movements abstractly mirror intonational or stress fluctuations in the speech signal (Graf et al., Reference Graf, Cosatto, Strom and Huang2002), we prefer multimodal prosody. The use of “visual” presumes that prosody is an acoustic phenomenon supported by gestural information, while the use of “multimodal” is meant to emphasize prosody’s inherent basis in multiple modalities. For the speaker, speech is at least both an acoustic stimulus and a vibrotactile one (see Orepic et al., Reference Orepic, Kannape, Faivre and Blanke2023). The SAMP suggests prosodic rhythms, both seen and heard in face-to-face conversation, recruit a perceptual model grounded in a multimodal representation of the speaking body that also includes vestibulo-motor information.
4.5 A Sensorimotor Account of Multimodal Prosody
The remainder of this chapter will outline the SAMP. The SAMP suggests that during typical face-to-face interactions, the temporal mapping of speaker emphasis may be extracted through both auditory and visual channels together with vestibular codes regarding the inertial motion of the speaker. Cross-modal integration between speech and gesture in communicative contexts might reflect vestibular information processing used for audiovisual binding in the context of full-body activity – especially regarding the way speech is bound to the visual constituents of prosody. Sensitivity to this information may act as a driving force and a functional bridge that promotes attentional alignment between individuals during communication.
4.5.1 Self-Motion in Speaking
One hint that the vestibular system might mediate the production of co-speech gestures comes from patient data that highlight a dissociation between the neurocognitive mechanisms normally important for motor control and those for communicative movements. Consider, for example, the deafferented patient IW who suffers from a neurological condition that resulted in a loss of his proprioceptive sense from the neck down (Cole and Sedgwick, Reference Cole and Sedgwick1992). Although IW relies heavily on vision for normal motor control in space, his co-speech gestures are naturally coordinated in time with his speech – even when his own body is restricted from view (McNeill, Reference McNeill, Sebeok and Umiker-Sebeok1995). As IW has largely intact vestibular reflexes (see Day and Cole, Reference Day and Cole2002, for a discussion), his spared ability to speak and gesture with relative fluidity may be due to information processing involving acoustic-vestibular integration.
A key tenet of the SAMP is that speech production is an action taken by the entire body that requires predictions about its afferent consequences that are at least both acoustic and vestibular in nature. Because the vestibular system models how movements of the body engender change sensed by the semicircular canals and otoliths, the sensory “target” associated with expressive co-speech movements could feasibly be tied to self-motion variables that reflect various biomechanical consequences of vocal expression. We have already seen that one such target involves the physical impact of vocalization on the vestibular system. Another is the way that co-speech gestures affect the acoustic parameters of speech (Pouw and Fuchs, Reference Pouw and Fuchs2022). The correlation in visual and acoustic aspects of the prosodic signals arises at least in part from the fact that strong arm movements perturb the respiratory system and can modulate the amplitude (and occasionally the pitch) of the speech signal (Pouw et al., Reference Pouw, Harrison and Dixon2020).
But in addition to their impact on speech production, arm movements also affect balance. Particularly for downward movements, momentum transfer from upper limb activity mandates muscle activity in the torso to maintain postural control. Just as a kinetic (force-related) description of overt dance movements revealed how musical rhythms were embodied, kinetic properties of co-speech movements are also relevant for their temporal relation to continuous speech (Tuite, Reference Tuite1993). As noted above, speaking often occurs with movement of the head (Tiede et al., Reference Tiede, Mooshammer and Goldstein2019), and the degree of physical impulses through manual gesture correlates with the magnitude of concurrent head movements (Pouw et al., Reference Pouw and Fuchs2022). We suggest that the correlated nature of head and arm movements is not a coincidence, but rather arises because co-speech movements are partially designed to create a mechanical stimulus detectable by the vestibular periphery.
4.5.2 Modeling Self-Motion during Multimodal Discourse Comprehension
From the perspective of comprehension, the SAMP suggests the integration of speech and gestures should benefit from perceptual mechanisms that compute information about forces experienced by the speaking body. Notably, this would include the way that our physical movements are affected by gravity. Evidence suggests the vestibular system contributes to an internal model of gravity critical for mediating perception and action in time (see Jörges and López-Moliner, Reference Jörges and López-Moliner2017, for a review). Because the force-related properties of movement are relevant for respiration and vocal expression, the brain’s modeling of various force parameters might be recruited when co-speech movements are perceptually relevant for the apprehension of speech.
The vestibular system might also contribute to gesture comprehension in a manner inspired by traditional notions of embodied simulation (e.g., Gallese, Reference Gallese2005). In other words, vestibular codes relevant for movement control may be reused to represent self-motion information associated with the observed actions of other people (Jeannerod, Reference Jeannerod1994). Dynamic representations of self-motion information encoded by the vestibular periphery represent not only current, veridical movements of the head or body but also hypothetical ones (Mast and Ellis, Reference Mast and Ellis2015). Dynamic percepts that exhibit self-motion, such as other people, would surely be a sensible target for this type of function (Deroualle and Lopez, Reference Deroualle and Lopez2014; Lopez et al., Reference Lopez, Falconer, Deroualle and Mast2015). Vestibular resources involved in the dynamic modeling of self-motion information might also be exploited for perception of co-speech gestures, especially so-called beat gestures that coincide with the rhythmic qualities of speech. Particularly in rich, communicative contexts, constructs amenable to interpretation by the vestibular system may be precisely what the brain is motivated to decode from audio and visual signals.
4.5.3 Multisensory Integration and Dynamic Attention
This review has highlighted work across several disciplines showing how the vestibular system is relevant for various aspects of temporal cognition and dynamic attentional control. As such, it could serve as a critical axis for embodied engagement with sensory information – including the quasi-rhythmic information in speech. For example, motor-related oscillatory dynamics are implicated in structuring temporal predictions in the context of musical rhythms, speech, and speech-gesture integration during discourse processing (Arnal et al., Reference Arnal, Doelling and Poeppel2015; Keitel et al., Reference Keitel, Gross and Kayser2018; Biau et al., Reference Biau, Schultz, Gunter and Kotz2022; see also Chapter 13). In these contexts, the vestibular system likely contributes to motor-driven temporal predictions that improve how attention is structured in time.
Vestibular information processing is especially relevant in multimodal interactional contexts between embodied agents. Above, we noted cross-modal influences on the perception of talkers. Seeing a speaker’s gestures can influence the perception of metrical aspects of their speech. The SAMP suggests this is because body movements engage a common underlying action representation relevant for sensorimotor timing. Moreover, perceptual inference about inertial properties of biological motion, such as the vertical GRF, may direct cross-modal integration in ways that are relevant for the perception of meter in speech (see Figure 4.2).
Force transfer and multimodal prosody.
Graphical depiction of audio and visual components of naturalistic speech recorded using a motion capture setup. Top: the vertical acceleration for four different mocap markers. Below: estimate of the speaker’s vertical GRF. The lowpass envelope is superimposed. Bottom: raw speech signal.
The figures above show the speaker at each time frame associated with the time points demarcated by the vertical lines across the four plots (see x-axis). The stressed syllable in “ground” manifests closely in time with the contour of the GRF estimate – a function of the peak in downward acceleration of the speaker’s head, trunk, and arm movements.
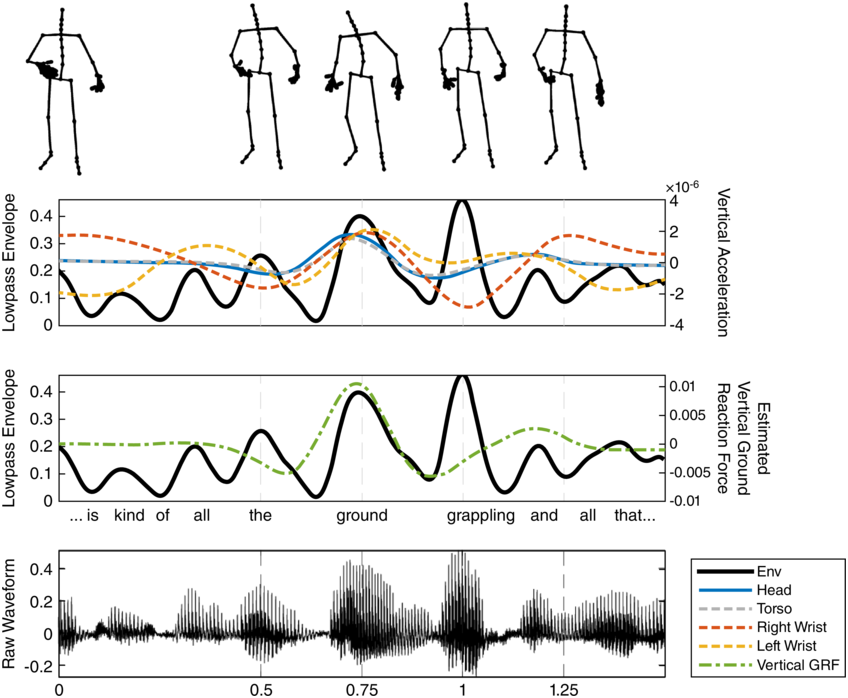
Figure 4.2 Long description
A dual-axis multiline graph compares low-pass envelope and vertical acceleration. It plots a combination of five solid and dashed lines for Env, head, torso, right wrist, left wrist, and vertical G R F. These lines fluctuate horizontally. Below it, another dual-axis multiline graph compares the lowpass envelope and the estimated vertical ground reaction force. It plots a solid and a dashed line for Env and torso. These lines fluctuate horizontally. At the bottom, a raw waveform is depicted. The horizontal axis represents time and the vertical axis represents amplitude. The waveform displays a complex, fluctuating signal over a period of approximately 1.25 seconds. The legends for Env, head, torso, right wrist, left wrist, and vertical G R F are given at the bottom right.
4.6 Conclusions
This chapter suggests that neural mechanisms relevant for vestibular information processing are likely recruited for the neural representation of speech, especially its prosodic qualities. Vestibular-sensitive mechanisms may assist in coding latent variables about speaker movement during the processing of co-speech gestures, during the processing of unaccompanied speech, and during the processing of biological motion. The SAMP is that the multimodal integration in the prosodic signal arises via the convergence of visual information conveyed by head and full-body movements with acoustic information conveyed in the prosodic contours of speech via a common vestibulo-motor representation of the speaker’s behavior.
Although we have focused on the theoretical implications of the SAMP for the mechanisms involved in structuring attention to multimodal discourse, the proposal also has clinical implications. Given the high comorbidity rates between problems with speech-language, motor-timing, and rhythmic faculties (e.g., Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021), clinical researchers should explore vestibular contributions to language functions. In particular, speech scientists should investigate the integrity of peripheral or central vestibular mechanisms in these populations. Such work will allow us to develop a more detailed understanding of vestibular contributions to the production and comprehension of speech and may lead to the discovery of clinical interventions. In the meantime, theoretical details are not necessary for the identification of reliable biomarkers useful for early diagnosis and therapeutic routing (see Efimova and Nikolaeva, Reference Efimova and Nikolaeva2020).
Summary
We present a novel hypothesis regarding the neural mechanisms important for speech-gesture integration and attention to discourse. The SAMP suggests that neural codes for the inertial motion of the body are recruited for the representation of speech, and support the encoding and decoding of the prosodic features of multimodal discourse.
Implications
Dynamic changes of suprasegmental components of spoken prosody are often mirrored in prominent aspects of the speaker’s co-speech gestures. Considering speech as an action taken by the entire body offers new ways to understand how rhythms are embodied in linguistic and musical contexts.
Gains
Considering the biophysical connection between the vestibular system and speech together with evidence for vestibular contributions to cognition, the SAMP motivates novel lines of research regarding the neurobiology of spoken language. We highlight the potential to identify biomarkers for atypical language and rhythm development.
5.1 Introduction
As expert listeners, we do not always notice how complex speech decoding is. Understanding speech means handling a continuous stream with unclear acoustic boundaries between elements and in which approximately 200 words occur per minute. Yet we have to decode this information in a handful of seconds. In the highly sophisticated cascade of processes that enables the achievement of this, one of the first steps is to segment the incoming signal into discrete elements onto which linguistic information can then be mapped. To this aim, listeners exploit a fundamental property of speech, its rhythmicity. Rhythm also characterizes intrinsic brain activity: without the need for any external stimulus, neuronal populations naturally show cyclic variations of excitability at different frequencies (see also Chapter 3). As nature knows best, brain oscillations are able to synchronize to the different timescales in speech, a process thought to be central to discretize the signal into phoneme-, syllable-, and word-sized chunks. After sketching the importance of rhythm in speech and introducing current oscillatory models of speech perception, this chapter reviews neurophysiological evidence for the coupling of neural oscillations to speech modulations, syllabic rhythm in particular. Our aim is not to provide an exhaustive review of the literature but to draw attention to topics that may help the reader to better grasp the neural oscillatory dynamic underlying speech perception. We specifically consider speech rate variations as good candidates to examine brain tracking of speech rhythm and also discuss the functional relationship between neural oscillations and speech intelligibility. We finally review some evidence supporting a role of motor regions as temporal predictors for speech parsing.
5.2 The Processing Benefits of (Quasi-)Rhythmic Information in Speech
The (quasi-)rhythmicity of speech is central for listeners to parse the continuous acoustic stream into distinct linguistic elements. Despite not being strictly periodic, the temporal structure of connected speech shows acoustic cues that occur at fairly regular intervals (see also Chapters 9 and 14). Syllables are produced at a frequency of ~5 Hz across languages (Poeppel and Assaneo, Reference Poeppel and Assaneo2020), and stressed syllables marking phrasal units occur approximately every 500 ms, at 2 Hz. These recurrent speech patterns over time serve as landmarks to predict the upcoming critical information, therefore facilitating speech segmentation and ultimately comprehension. Early on during language development, listeners exploit and take advantage of this rhythmical organization of prominences in speech to extract phonological, lexical, and morphosyntactic information (Christophe et al., Reference Christophe, Gout, Peperkamp and Morgan2003). English infants are, for instance, able to segment disyllabic words from unfolding speech based on stress cues, namely the strong–weak syllabic structure typical of words from their native language (Jusczyk et al., Reference Jusczyk, Friederici, Wessels, Svenkerud and Jusczyk1993). Sidiras et al. (Reference Sidiras, Iliadou, Nimatoudis, Reichenbach and Bamiou2017) additionally revealed that 10-year-old Greek-native children better identified two-syllable words in a babble when these were presented in synchrony with a previous isochronous rhythmic sequence, that is, when a prominent element was expected to occur. The benefit of rhythm for speech processing is also manifest in adults. Detecting a target phoneme in disyllabic English words is easier if stressed syllables carrying this phoneme are presented at regular temporal intervals (Quené and Port, Reference Quené and Port2005; see also Roncaglia-Denissen et al., Reference Roncaglia-Denissen, Schmidt-Kassow and Kotz2013, for evidence of syntactic processing). In the same vein, listening to nonverbal rhythmic sequences improves subsequent phonological processing in nonwords, provided that target phonemes appear on beat with the rhythmical prime (Cason and Schön, Reference Cason and Schön2012). The study by Ghitza and Greenberg (Reference Ghitza and Greenberg2009) perfectly illustrates the use of temporal expectations in speech processing. They assessed the intelligibility of sentences time-compressed to one third of their original duration, with silent intervals of varying durations inserted periodically or aperiodically between consecutive speech fragments. Sentence identification was maximal when silences were inserted periodically so as to restore the initial temporal structure of speech. In other words, despite the fact speech fragments were compressed and had limited intelligibility, hearing them at the time they were expected was sufficient to increase intelligibility (see also Ghitza, Reference Ghitza2014; Penn et al., Reference Penn, Ayasse, Wingfield and Ghitza2018). What counts for successful speech decoding is therefore not only the content of the information but when this information is likely to happen. Along this line, the surrounding speech rate can shape phonemic perception, a process known as rate normalization. Hearing a sentence at a fast rate biases subsequent perception towards longer speech sounds compared to when the sentence is produced at a slower rate (Bosker, Reference Bosker2017; Bosker and Ghitza, Reference Bosker and Ghitza2018; Dilley and Pitt, Reference Dilley and Pitt2010; Maslowski et al., Reference Maslowski, Meyer and Bosker2019; Reinisch, Reference Reinisch2016; Reinisch and Sjerps, Reference Reinisch and Sjerps2013; see also Lamekina and Meyer, Reference Lamekina and Meyer2022). As an example, Dutch words embedding an ambiguous vowel between short /ɑ/ and long /a:/ are identified as /ta:k/ (“task”) following a fast-rate carrier sentence, but as /tɑk/ (“branch”) after a sentence at a slower rate (Kösem et al., Reference Kösem, Bosker and Takashima2018). The rationale here is that listeners make some expectations about the occurrence of the future syllables based on the syllabic rate in the previous carrier sentence. For a fast rate, short syllables are expected, hence leading to an overestimation of the target vowel duration: vowels are perceived as longer than they actually are.
Altogether, these lines of research emphasize the predictive function of (quasi-)rhythmic information in speech. One computational mechanism that has been suggested to underpin the establishment of these predictions is the synchronization of brain rhythmic activity to speech temporal structure.
5.3 Neuronal Oscillations as a Key Mechanism for Speech Parsing
Endogenous oscillatory brain activity (Buzsáki and Draguhn, Reference Buzsáki and Draguhn2004; Fries, Reference Fries2005, Reference Fries2015; Varela et al., Reference Varela, Lachaux, Rodriguez and Martinerie2001) plays a crucial role in speech processing (see Chapter 3). By synchronizing, or entraining, to the quasi-rhythmic modulations in the acoustic signal, neuronal oscillations discretize the incoming stream into “packets” of different sizes that can then be mapped onto linguistic units. Contemporary neurocognitive models of speech processing advocate a close correspondence between the timescales in speech (Rosen, Reference Rosen1992) and auditory cortical activity in the delta (~1–4 Hz), theta (~4–8 Hz), and low-gamma (~25–45 Hz) frequency bands (Ghitza, Reference Ghitza2011; Giraud and Poeppel, Reference Giraud and Poeppel2012; Peelle and Davis, Reference Peelle and Davis2012; Poeppel, Reference Poeppel2003; see also Chapter 9). The phase of delta band oscillations parses the signal into large units such as words and phrases, thus encoding prosodic information, whereas theta activity phase-locks to the low-frequency modulations in the amplitude envelope, peaking at 4–7 Hz and conveying syllabic information. On the other hand, the low-gamma amplitude encodes faster modulations pertaining to phonetic features such as voicing and formant transitions. The parsing into speech units of varying sizes furthermore operates simultaneously but hierarchically through theta/gamma nesting, where the phase of theta oscillations drives gamma amplitude. Substantial evidence from electro- and magnetoencephalography (E/MEG) supports this brain dynamic during speech processing, highlighting how neuronal oscillations at different frequencies orchestrate to deal with the multi-time resolution of speech. In the following sections, we review the main existing findings for brain-to-speech coupling, focusing on theta band tracking of syllabic information in the case of speech rate variations. We then discuss whether and how oscillatory coupling is modulated by and contributes to speech intelligibility, a topic that is still debated in the literature. Lastly, we review evidence that beyond the auditory cortex, brain motor regions functionally contribute to speech decoding via top-down temporal predictions.
5.3.1 Cortical Tracking of Syllabic Structure: The Case of Speech Rate Variations
Since the coupling of theta band cortical activity to the speech envelope is thought to track syllabic modulations, one way to put it to the test has been to vary the syllable rate of incoming speech. Speech rate variations are ubiquitous in everyday life, and increasing speech rate, either naturally or artificially, is known to hinder speech intelligibility (Gordon-Salant et al., Reference Gordon-Salant, Zion and Espy-Wilson2014; Guiraud et al., Reference Guiraud, Bedoin and Krifi-Papoz2018; Janse, Reference Janse2004; Janse et al., Reference Janse, Nooteboom and Quené2003; Park and Jang, Reference Park and Jang2012). Studies in young normal listeners reported that 50% intelligibility (i.e., 50% of correct identification) was reached when compressed speech was three to four times faster than the normal rate, namely at ~12 syllables/s in German and Dutch and ~16 syllables/s in Mandarin (Meng et al., Reference Meng, Wang and Cai2019; Schlueter et al., Reference Schlueter, Lemke, Kollmeier and Holube2014; Versfeld and Dreschler, Reference Versfeld and Dreschler2002). Fast speech therefore increases processing demands, as quantified by higher-rated listening effort and larger pupil dilation with respect to slower speech (Koch and Janse, Reference Koch and Janse2016; Müller et al., Reference Müller, Wendt, Kollmeier, Debener and Brand2019). Despite comprehension of accelerated speech being challenging at first, other work showed that listeners are able to adapt relatively quickly (Adank and Devlin, Reference Adank and Devlin2010; Adank and Janse, Reference Adank and Janse2009; Golomb et al., Reference Golomb, Peelle and Wingfield2007; Peelle and Wingfield, Reference Peelle and Wingfield2005). Speech perception indeed improves after short exposure to artificially speeded sentences, and this adaptation is robust to changes in speakers’ characteristics (Dupoux and Green, Reference Dupoux and Green1997) and in languages provided they share some phonological and rhythmic properties (Pallier et al., Reference Pallier, Sebastian-Gallés, Dupoux, Christophe and Mehler1998; Sebastián-Gallés et al., Reference Sebastián-Gallés, Dupoux, Costa and Mehler2000).
Neural tracking of the slow envelope fluctuations may be one of the primary mechanisms used by the brain to adapt to speech rate variations, both within and between speakers. Most E/MEG studies that measured brain coupling to syllable rate changes have accelerated – and sometimes decelerated – speech artificially. In their seminal work, Ahissar et al. (Reference Ahissar, Nagarajan and Ahissar2001) reported that the auditory cortex phase-locked to amplitude modulations in English sentences compressed to 75% and 50% of their original duration, that is, at a syllable rate ranging between ~4 and ~6 syllables/s. However, for higher compression ratios (35% and 20%) with syllable rates between ~9 and ~14 syllables/s, neural oscillations no longer coupled to the envelope. These conditions were also the ones showing a drop of sentence intelligibility (see Section 5.3.2). These data seem to fit Ghitza’s assumption that speech comprehension is constrained by our capacity to decode syllables within a theta cycle, that is, at a maximal frequency of ~9 Hz (Ghitza, Reference Ghitza2011, Reference Ghitza2014). The results by Pefkou et al. (Reference Pefkou, Arnal, Fontolan and Giraud2017), however, challenge this view as oscillations in auditory regions tracked the envelope of French sentences time-compressed by a factor of 3 (up to 10–14 Hz), beyond the upper limit of the canonical theta band (see also Nourski et al., Reference Nourski, Reale and Oya2009, and Section 5.3.2).
Without pushing the limits this far, other studies converge to show that oscillatory activity dynamically adapts to changes in speech rate. In the work by Lizarazu et al. (Reference Lizarazu, Lallier and Molinaro2019), maximal brain-to-speech coupling in bilateral auditory regions was found at 4.5–7.5 Hz (peaking at 5.6 Hz) for normal-rate sentences in Spanish (~173 words/min). These values slightly decreased to 4–6.5 Hz (peaking at 4.7 Hz) for sentences that were artificially slowed down (~139 words/min), but increased to 5.5–8.5 Hz (peaking at 6.6 Hz) for accelerated sentences (~208 words/min). Note that the syllable rate was unfortunately not provided by the authors, making the comparison with other work rather difficult. Given the coupling frequencies reported, the syllable rate, however, seemed to remain within the theta band boundaries. Theta/gamma coupling also varied with speech rate in this study. The phase of theta oscillations in the three previously mentioned frequency ranges modulated the amplitude of gamma oscillations at 20–37 Hz for normal-rate speech, 18–34 Hz for decelerated speech, and 23–43 Hz for accelerated speech. Such rate-dependent gamma activity was assumed to reflect the encoding of fine acoustic information in speech.
A further step was taken by Kösem et al. (Reference Kösem, Bosker and Takashima2018) who nicely demonstrated that not only do neural oscillations adjust to speech rate but that coupling persists after the changes, thus biasing subsequent speech comprehension. Echoing the aforementioned behavioral studies on rate normalization (see Section 5.2), their MEG results revealed that listening to a carrier sentence (in Dutch) artificially accelerated at 5.5 Hz entrained neural oscillations at this frequency in a sustained manner, so that an ambiguous vowel in a following normal-rate word was perceived as long (e.g., /a:/). On the contrary, when the syllable rate of the carrier sentence was decelerated to 3 Hz, the subsequent vowel was perceived as short (e.g., /ɑ/). This study exemplifies the capacity of our brain to generate predictions based on the temporal pattern of incoming speech, thus functionally contributing to its decoding.
To the best of our knowledge, studies investigating the neural tracking of natural speech rate changes have been scarce, possibly because of methodological challenges. Yet examining the case of naturally accelerated (or decelerated) speech may prove highly informative to better grasp the oscillatory dynamic underlying naturalistic speech perception (see Alexandrou et al., Reference Alexandrou, Saarinen, Kujala and Salmelin2020, for similar arguments). Naturally speaking faster induces additional spectro-temporal changes in the speech signal compared to time compression, in particular by increasing coarticulation and assimilation between speech segments (Berry, Reference Berry2011; Janse et al., Reference Janse, Nooteboom and Quené2003). This complexifies speech decoding for the listeners (Janse, Reference Janse2004), and accordingly, processing of natural and artificial speech rate variations may involve different oscillatory mechanisms, at least partly. Alexandrou et al. (Reference Alexandrou, Saarinen, Kujala and Salmelin2018) compared brain oscillatory coupling to naturally produced speech extracts in Finnish, with syllable rates ranging from ~2.6 (slow) to ~4.7 (normal) to ~6.8 (fast) syllables/s. In the delta (2–4 Hz) and theta (4–7 Hz) bands used for analysis, normal-rate speech elicited stronger synchronization than slower and faster speech in the bilateral superior temporal cortex (for delta) and the right paracentral lobule (for theta). Slow speech increased theta coupling in the right parietal cortex with respect to normal-rate speech. Based on the study by Lizarazu et al. (Reference Lizarazu, Lallier and Molinaro2019), it is quite surprising that delta tracking was not stronger for slow-rate speech compared to the two other conditions. Similarly, fast-rate speech did not enhance brain coupling in the high theta band as one could have expected. One strength of this MEG study is undeniably the use of connected speech that was spontaneously produced at different rates, whereas most other work that examined neural tracking of speech rate variations included isolated sentences or read-aloud texts. One caveat, however, may be that coupling was measured in fixed, generic frequency bands, potentially preventing the researchers from observing changes in frequency coupling as a function of the syllable rate. The average normal and fast rates in this study were both circumscribed to the theta range, towards the lower (~4.7 Hz) or the upper (~6.8 Hz) band limits, respectively. The use of more flexible frequency windows for analysis might have revealed more specific coupling patterns depending on the two speaking rates (see Keitel et al., Reference Keitel, Gross and Kayser2018). In an MEG study (Hincapié Casas et al., Reference Hincapié Casas, Lajnef and Pascarella2021), we used this latter approach to compare neural tracking of French sentences naturally produced at a normal rate (~6.7 syllables/s) or at a fast rate (~9.1 syllables/s), or of sentences time-compressed to the same fast rate. We examined brain-to-speech coupling in two frequency bands defined from the spectral power of the sentence envelopes in each condition, namely 6.25 Hz ± 1 Hz for normal-rate speech and 8.75 ± 1 Hz for fast-rate/compressed speech. Our results showed that neural oscillations in right auditory and motor regions were tuned to natural speech rate variations at frequencies specifically matching the syllabic rate. No significant coupling was observed for time-compressed speech in the corresponding frequency band (8.75 ± 1 Hz), despite the fact sentences had a similar rate as natural fast speech. We suggested a possible preference of cortical oscillations to align to naturally produced speech rather than to artificially accelerated speech, which is not physiologically plausible. To our knowledge, this study is the first to provide evidence for a specific oscillatory signature of natural fast speech compared to artificially accelerated speech (see also Section 5.3.3 for a discussion of the motor cortex involvement).
Altogether, these findings underscore the need for future studies to consider natural speech rate variations in connected speech to refine neurocognitive models of speech perception. A further issue to dig into, and which is actively debated, is whether the rhythmic neural response to the speech envelope truly involves endogenous oscillatory generators or whether it reflects steady-state evoked responses to acoustic landmarks in the speech stream. Evidence for sustained oscillatory activity after speech offset (Kösem et al., Reference Kösem, Bosker and Takashima2018; van Bree et al., Reference van Bree, Sohoglu, Davis and Zoefel2021) and for neural responses at frequencies that are not physically present in the acoustic signal but that match mentally constructed linguistic units (Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Zoefel and VanRullen, Reference Zoefel and VanRullen2016) clearly speaks in favor of the oscillatory model (Zoefel et al., Reference Zoefel, Archer-Boyd and Davis2018, for a review; see also Hincapié Casas et al., Reference Hincapié Casas, Lajnef and Pascarella2021, for a lack of power increase accompanying enhanced phase-locking to sentences). Other studies nevertheless reported that cortical coupling to speech is mainly driven by a linear convolution of evoked responses at the frequency of acoustic edges in the input (Oganian and Chang, Reference Oganian and Chang2019; Oganian et al., Reference Oganian, Kojima and Breska2023; Novembre and Iannetti, Reference Novembre and Iannetti2018; Zou et al., Reference Zou, Xu and Luo2021). Future work should systematically attempt to delineate the contribution of oscillatory versus evoked activity to speech neural tracking, bearing in mind that the two may not be mutually exclusive.
5.3.2 Brain-to-Speech Coupling and Intelligibility: A Bidirectional Relationship?
Increasing speaking rate can obviously reduce speech intelligibility up to a point where the listener is no longer able to comprehend. The question therefore arises as to whether neural tracking of speech varies with intelligibility and contributes to it. A number of E/MEG studies tackled this issue to better characterize the functional role of neural oscillations in speech decoding. The already mentioned work by Ahissar et al. (Reference Ahissar, Nagarajan and Ahissar2001) showed that cortical coupling to speech significantly declined for time-compressed sentences that were not intelligible. The authors hence proposed that speech comprehension depends on neural tracking, which would only be possible if the speech rate is close to the intrinsic oscillatory frequency of the auditory cortex (see Ghitza, Reference Ghitza2011, Reference Ghitza2014).
According to Ahissar’s interpretation, speech becomes unintelligible because neural tracking fails, meaning that effective brain-to-speech coupling is mandatory for successful speech decoding. The reverse question could, however, also be raised: Does oscillatory coupling fail because speech is not intelligible? To put it differently, does this coupling need intelligible speech to occur? One way to address the latter question is to test if neural tracking is also found for unintelligible stimuli, which would be evidence that it does not hinge on speech intelligibility. This would in turn provide insights, at least to some extent, to the first point, namely whether brain coupling is necessary or not for speech decoding. Neural tracking of unintelligible speech would indeed suggest that this process alone cannot fully account for intelligibility. Undertaking this issue also requires examining whether speech can be understood in the absence of neural tracking.
5.3.2.1 Does Neural Tracking Need Intelligible Speech to Occur?
Nourski et al. (Reference Nourski, Reale and Oya2009) reported in an electrocorticography (ECoG) study that Heschl’s gyrus only phase-locked to intelligible time-compressed sentences in English, in agreement with Ahissar et al. (Reference Ahissar, Nagarajan and Ahissar2001). However, further analyses revealed that high-frequency (70–250 Hz) power in the same region was modulated by the speech envelope irrespective of compression ratios, that is, even when speech was not understood. This casts doubt on the fact that neural tracking of speech modulations relies on intelligibility. Reconciling these contradictory findings, another ECoG study (Davidesco et al., Reference Davidesco, Thesen and Honey2018) showed that the ability of neural oscillations to synchronize to intelligible and/or unintelligible speech may depend on the cortical site along the processing hierarchy. Whereas low-level early-auditory areas, at the vicinity of the primary auditory cortex, tracked time-compressed speech outside the intelligibility range, higher-order areas such as secondary auditory areas in the superior temporal gyrus and the inferior frontal gyrus only synchronized to intelligible speech. E/MEG studies using time compression, time reversion, or vocoding provided further evidence that the brain tracks envelope modulations in both intelligible and unintelligible speech (Luo and Poeppel, Reference Luo and Poeppel2007; Pefkou et al., Reference Pefkou, Arnal, Fontolan and Giraud2017; Zoefel and VanRullen, Reference Zoefel and VanRullen2016; see Kösem and van Wassenhove, Reference Kösem and van Wassenhove2016, for a review). Howard and Poeppel (Reference Howard and Poeppel2010) showed that the theta band phase in the auditory cortex could equally discriminate between spoken English sentences and their time-reversed, non-intelligible counterparts. Converging results were found by Millman et al. (Reference Millman, Johnson and Prendergast2015), with similar coupling to physically identical sentences that solely differed in intelligibility (see also Baltzell et al., Reference Baltzell, Srinivasan and Richards2017). Kösem et al. (Reference Kösem, Dai, McQueen and Hagoort2023) also recently failed to find differential delta/theta neural tracking of noise-vocoded Dutch sentences that were intelligible or not. Altogether, these findings suggest that brain-to-speech coupling does not need intelligible speech to occur, and that it may be driven by acoustic cues rather that by linguistic information per se.
The conclusion is, however, not so straightforward given evidence that neural tracking of speech varies with intelligibility, as reflected by stronger phase-locking to the envelope for intelligible than for unintelligible speech (Dimitrijevic et al., Reference Dimitrijevic, Smith, Kadis and Moore2019; Ding et al., Reference Ding, Chatterjee and Simon2014; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Pérez et al., Reference Pérez, Carreiras, Gillon Dowens and Duñabeitia2015). In the MEG study by Gross et al. (Reference Gross, Hoogenboom and Thut2013), delta/theta phase-locking in bilateral auditory regions was enhanced for intact compared to reversed stories in English. Stronger theta phase/gamma amplitude coupling was additionally observed when speech was intelligible. The same year, Peelle et al. (Reference Peelle, Gross and Davis2013) also reported increased theta coupling in the left temporal cortex to intelligible vocoded English sentences more than to unintelligible ones, despite having the same spectral complexity. They suggested that although neural oscillations can be entrained by speech lacking intelligibility, such a process would not only depend on bottom-up synchronization to the acoustic rhythmic fluctuations but also to higher-level linguistic content. Rimmele et al. (Reference Rimmele, Golumbic, Schröger and Poeppel2015) reached a somewhat similar conclusion. In a multi-talker paradigm, they showed similar neural tracking (2–8 Hz) of intact and vocoded sentences as long as participants ignored them. When speech was attended, stronger coupling was found only in the intact condition. According to the authors, cortico-acoustic coupling mainly reflects brain responses to slow acoustic modulations in the envelope, but for attended speech, processing of the fine structure can enhance the temporal precision of tracking (see also Zion Golumbic et al., Reference Zion Golumbic, Ding and Bickel2013). Linguistic information therefore seems to affect neural oscillatory coupling, a process that may operate nonlinearly, as revealed by Hauswald et al. (Reference Hauswald, Keitel, Chen, Rösch and Weisz2022). In this study, low-frequency (1–7 Hz) coupling in bilateral middle temporal and left frontal regions followed an inverted U-shaped curve. It was maximal for challenging yet intelligible (moderately vocoded) speech in German, reflecting the enhanced use of speech temporal structure, but it decreased to its lowest value for very easily (intact) or barely understandable (strongly vocoded) speech. Note that by using different parameters on the same dataset and by separating periodic from aperiodic components in the coupling spectrum, the research team did not replicate these results exactly (Schmidt et al., Reference Schmidt, Chen and Keitel2023). They instead showed a gradual decrease of neural tracking with the decline in speech intelligibility (in line with Gross et al., Reference Gross, Hoogenboom and Thut2013; Peelle et al., Reference Peelle, Gross and Davis2013), an effect yielded by the aperiodic components. The results on the periodic components exhibited a different pattern. As vocoded speech became less intelligible, neural tracking shifted from the syllabic rate (linguistic level) to the modulation rate of the envelope (acoustic level). This was shown by an increase of the coupling frequency and a narrowing of the frequency bandwidth (i.e., frequency tuning) around the higher frequencies of acoustic modulations for more vocoded, less intelligible speech. Accordingly, whereas neural oscillations would track both syllabic and acoustic information in the envelope of intact speech (leading to an increased frequency bandwidth), listeners would preferably rely on acoustic fluctuations when linguistic information such as syllable boundaries is more difficult to extract (see also Verschueren et al., Reference Verschueren, Gillis, Decruy, Vanthornhout and Francart2022, for acoustic versus linguistic tracking with speech rate increase). Disentangling the syllable rate from the envelope modulation rate in future studies (see Zhang et al., Reference Zhang, Zou and Ding2023), including those on speech rate variations, may prove efficient to better characterize the complex relationship between brain oscillations and low-level acoustic information on the one hand and higher-level linguistic content on the other.
Coming back to our initial question as to whether intelligibility is a prerequisite for neural tracking, the reviewed evidence is rather negative. Brain-to-speech coupling is also found for unintelligible speech, and it may thus be largely driven by acoustic modulations in the speech signal. Still, the coupling strength can be enhanced by intelligible speech. This suggests that linguistic content plays an important role in the oscillatory dynamic, which cannot be seen as a purely rhythmic acoustic cortical response.
5.3.2.2 Is Neural Tracking Necessary for Successful Speech Decoding?
Determining whether neural coupling is a limiting factor for comprehension may appear a bit more complex. The fact that brain oscillatory activity synchronizes to speech that is not intelligible, as reviewed above, provides some arguments that speech does not become intelligible only because neural oscillations phase-lock to its (quasi-)rhythmic fluctuations. Still, this does not allow to firmly conclude that neural tracking is not a necessary ingredient. We would in fact like to underline that as far as we are aware, no evidence for intelligible speech without concurrent auditory cortical coupling has been reported. Such coupling could thus be essential, albeit not sufficient, for speech decoding.
Convincing evidence for a causal role of neural tracking in speech processing and intelligibility comes from studies using transcranial alternating current stimulation, or tACS (Kadir et al., Reference Kadir, Kaza, Weissbart and Reichenbach2020; Keshavarzi et al., Reference Keshavarzi, Kegler, Kadir and Reichenbach2020; Riecke et al., Reference Riecke, Formisano, Sorger, Başkent and Gaudrain2018; Wilsch et al., Reference Wilsch, Neuling, Obleser and Herrmann2018; Zoefel et al., Reference Zoefel, Archer-Boyd and Davis2018, Reference Zoefel, Allard, Anil and Davis2020). Zoefel et al. (Reference Zoefel, Archer-Boyd and Davis2018) showed that tACS (~3 Hz) over left auditory regions decreased the functional magnetic resonance imaging (fMRI) response in the bilateral superior and middle temporal gyri for vocoded yet intelligible speech (i.e., sequences of monosyllabic words at ~3 Hz). The behavioral performance in an irregularity detection task was, however, unaffected. A follow-up study (Zoefel et al., Reference Zoefel, Allard, Anil and Davis2020) nonetheless revealed that bilateral, but not left-lateralized, tACS disrupted word report accuracy, suggesting that changes in neural oscillatory activity can impair speech perception. Conversely, enhanced speech comprehension has been reported after stimulation of neural oscillatory activity (Riecke et al., Reference Riecke, Formisano, Sorger, Başkent and Gaudrain2018). By applying a current carrying slow envelope modulations (4 Hz) over the bilateral auditory cortex, Riecke et al. could improve Dutch sentence recognition in a two-talker situation. A second experiment confirmed that biasing neural oscillations towards speech temporal structure benefitted speech processing. In a single-talker situation, participants were instructed to identify barely understandable sentences in which low-frequency envelope information (<16 Hz) had been removed. When auditory regions were stimulated with a current shaped with exactly this rhythmic information, sentence intelligibility increased, especially when the current preceded speech stimuli by 375 ms. Using electroencephalography (EEG), the same group then showed that delivering envelope information through vibrotactile stimulation applied to the participants’ fingers increased neural speech tracking but failed to improve behavioral outcome during sentence repetition (Riecke et al., Reference Riecke, Snipes, van Bree, Kaas and Hausfeld2019; see their discussion for methodological considerations). Positive evidence was yet provided by Guilleminot and Reichenbach (Reference Guilleminot and Reichenbach2022): Tactile stimulation delivered at the syllable rate (theta frequency 4.5 Hz) enhanced both brain-to-speech coupling in bilateral auditory regions and intelligibility of speech in noise.
Overall, these findings suggest that neural coupling to speech functionally contributes to and can aid speech perception. In this view, they open new avenues to improve speech processing in hearing-impaired or dyslexic people who show differential oscillatory mechanisms (for hearing impairment, for example: Decruy et al., Reference Decruy, Vanthornhout and Francart2020; Gillis et al., Reference Gillis, Kries, Vandermosten and Francart2023; Petersen et al., Reference Petersen, Wöstmann, Obleser and Lunner2017; for dyslexia: Goswami, Reference Goswami2011; Lehongre et al., Reference Lehongre, Morillon, Giraud and Ramus2013; Lizarazu et al., Reference Lizarazu, Scotto di Covella and van Wassenhove2021b). First studies in this direction revealed that tACS at appropriate frequencies can enhance speech-in-noise perception in hearing-impaired, elderly participants (Erkens et al., Reference Erkens, Schulte, Vormann, Wilsch and Herrmann2021) as well as phonological processing in dyslexic adults (Marchesotti et al., Reference Marchesotti, Nicolle and Merlet2020).
To conclude, the empirical evidence available so far seems to provide arguments that speech comprehension depends on neural tracking, at least to some extent. Brain-to-speech coupling may indeed be necessary, although not sufficient, for intelligibility. On the other hand, as we have seen, neural tracking does not need intelligible speech to occur. Nevertheless, linguistic information can affect the strength of the coupling, suggesting a bidirectional functional relationship between the two.
5.3.3 Motor Regions as Temporal Predictors for Speech Decoding
Low-frequency coupling to speech in auditory regions is also top-down modulated by alpha and beta activity in motor regions. Crucially, the stronger this cortico-cortical coupling, the stronger the auditory neural tracking of the speech input (Assaneo and Poeppel, Reference Assaneo and Poeppel2018, for syllable trains at 4.5 Hz; Park et al., Reference Park, Ince, Schyns, Thut and Gross2015, for intact versus reversed speech). Alpha and beta power modulations in fronto-central regions were moreover shown to precede coupling to speech in the auditory cortex, supporting their anticipatory role in lower-level speech processing (Keitel et al., Reference Keitel, Ince, Gross and Kayser2017; see also Di Liberto et al., Reference Di Liberto, Lalor and Millman2018; Hovsepyan et al., Reference Hovsepyan, Olasagasti and Giraud2023). In line with their involvement in predictive coding (Arnal, Reference Arnal2012; Morillon et al., Reference Morillon, Schroeder and Wyart2014; Schroeder et al., Reference Schroeder, Wilson, Radman, Scharfman and Lakatos2010) and temporal processing (Coull, Reference Coull and Toga2015; Schubotz, Reference Schubotz2007), motor regions are therefore able to extract the (quasi-)rhythmicity of speech and generate temporal predictions so as to optimize speech sampling.
Motor regions do not only modulate auditory cortex activity; they also synchronize their own oscillations to speech fluctuations at the phrasal and syllabic scales. Keitel et al. (Reference Keitel, Gross and Kayser2018) reported stronger delta band (0.6–1.3 Hz) left premotor tracking of speech for correctly identified sentences in English. Delta/beta (13–30 Hz) phase/amplitude coupling within this premotor cluster predicted comprehension as well, emphasizing the role of motor regions in predicting the likely occurrence of upcoming words. At the syllabic level, the right motor cortex was shown to track the isochronous rhythm of Chinese monosyllabic words at 4 Hz (Sheng et al., Reference Sheng, Zheng and Lyu2019) as well as the fast syllable rate (~9 syll/s) in French sentences (Hincapié Casas et al., Reference Hincapié Casas, Lajnef and Pascarella2021). For the latter, the motor cortex furthermore increased its connectivity with a left fronto-parieto-temporal network, probably belonging to the speech sensorimotor dorsal stream (Hickok and Poeppel, Reference Hickok and Poeppel2007). Such sensorimotor interactions may reflect the encoding of articulatory information as well as the use of internal models for phonological-articulatory mapping in challenging listening situations (see Chapter 6 for sensorimotor interactions during speech processing). Interestingly, listeners’ sensorimotor abilities predict the ability of motor oscillations to align to speech syllabic structure (Assaneo et al., Reference Assaneo, Ripolles and Orpella2019). Coupling of bilateral frontal regions to trains of random syllables at 4.5 Hz was indeed stronger in English participants who better synchronized their own syllabic production to the perceived rate. These “high synchronizers” additionally showed microstructural white matter differences, namely stronger left lateralization in a territory of the arcuate fasciculus compared to “low synchronizers.” Such anatomical changes could increase information transfer between auditory and motor regions underpinning speech perception and production, and consequently improve neural tracking of speech.
A growing body of evidence therefore converges in favor of a contribution of motor regions to the parsing of speech into syllable- and word/phrase-size packets, either through top-down predictions or direct synchronization to the signal (quasi-)rhythmic fluctuations. More work is nevertheless needed to understand the role of the different motor rhythms, in the delta, theta, and beta bands in particular, in deciphering the temporal structure of speech.
5.4 Concluding Remarks and Future Directions
The reviewed E/MEG findings generally corroborate oscillatory models of speech perception by revealing that low-frequency (theta band) oscillations in the auditory cortex synchronize to syllabic rhythmic information and modulate gamma amplitude, although only a few studies eventually examined this cross-frequency coupling. Theta activity can also adapt to speech rate variations (mostly investigated through artificial manipulation), at least to a certain extent. As we underlined, future work should, however, consider more naturalistic settings, using connected speech naturally produced at different rates and analyzing coupling to global but also local rate changes, to better grasp the underlying oscillatory dynamic and thus advance current neurolinguistic models. It is also striking that, despite some studies assessing neural tracking in bilinguals (Di Liberto et al., Reference Di Liberto, Nie and Yeaton2021; Lizarazu et al., Reference Lizarazu, Carreiras, Bourguignon, Zarraga and Molinaro2021a; Lu et al., Reference Lu, Deng, Xiao, Jiang and Gao2023; Peña and Melloni, Reference Peña and Melloni2012; Pérez et al., Reference Pérez, Carreiras, Gillon Dowens and Duñabeitia2015; Reetzke et al., Reference Reetzke, Gnanateja and Chandrasekaran2021), the effects of cross-linguistic differences, regardless of comprehension, have so far been largely ignored in the field. The question as to whether neural tracking is sensitive to the languages’ rhythmic properties per se, and not only to the listeners’ native language, indeed remains open. Yet investigating this issue could be highly informative in delineating the correspondence between neural oscillations and the timescales in speech, for instance by comparing brain-to-speech coupling for languages belonging to different rhythmic classes. We are only aware of one recent study that tackled this issue. Using EEG, Özer et al. (Reference Özer, Pereira and Sebastian-Galles2023) examined theta band phase-locking to the speech envelope in English and Spanish adults while they listened to resynthesized incomprehensible sentences from English (a stress-timed language), Spanish (syllable-timed), and Japanese (mora-timed). Neural tracking was weakest for English, intermediate for Spanish, and strongest for Japanese, irrespective of the participants’ mother tongue. Hence, brain-to-speech coupling reflected the rhythmic regularities of the heard languages, entailing syllabic complexity (from the least in English to the highest in Japanese), rather than processing of the native language.
When it comes to the functional relationship between brain coupling and speech intelligibility, the picture gets a bit complex with (at least partly) contradictory findings. We again emphasize that no study to the best of our knowledge has reported that speech could be intelligible without auditory oscillatory coupling to its envelope. Neural tracking of the signal could therefore be a necessary though insufficient step to support speech decoding. Bottom-up acoustic coupling in the auditory cortex is indeed modulated by speech intelligibility and occurs in parallel to, or under the influence of, other top-down processes, some of them arising from the motor cortex. By temporally structuring oscillatory activity in auditory regions and by directly synchronizing their own rhythms to speech modulations, motor regions optimize speech decoding. Although we did not address this issue in the present chapter, other high-level predictions generated from lexico-semantic and syntactic knowledge obviously also enable inferences on the incoming speech signal (e.g., Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Kaufeld et al., Reference Kaufeld, Bosker and ten Oever2020; Lo et al., Reference Lo, Tung, Ke and Brennan2022; Meyer et al., Reference Meyer, Sun and Martin2019). Examining the dynamic interplay between predictions of different natures, for neural tracking of speech at different frequencies in distributed brain regions, appears crucial to capture how speech units are hierarchically organized and combined to ultimately comprehend spoken language.
Summary
We reviewed evidence that theta range neural oscillations in auditory regions track syllabic rhythm and adapt to speech rate variations. This coupling contributes to speech intelligibility, while at the same time being modulated by linguistic information. By extracting temporal regularities in the signal, motor regions also contribute to this temporal dynamic.
Implications
We draw attention to topics for future research to improve oscillatory models of speech perception. This includes investigating neural tracking of naturally produced connected speech at different rates, also in light of cross-linguistic differences, and examining the interplay between motor and auditory rhythms as well as their interactions with higher-level linguistic predictive processes.
Gains
This non-exhaustive review provides a better understanding of the functional relationship between neural oscillations and speech (quasi-)rhythmic information. Considering important issues such as dynamic coupling to speech rate changes, the influence of linguistic information, and the role of motor regions may prove valuable to refine oscillatory models of speech perception.
6.1 Speech and the Temporal Coordination of Behavior
The main purpose of language is to exchange information in communication with others. In the case of spoken language, all acoustic information is conveyed through the spectrally and temporally fluctuating patterns of the sound signal (Martin, Reference Martin1972; Rosen, Reference Rosen1992). These evolve over time and into dialogue in an alternation of speaking and listening. In this rhythmic aspect, speech is ultimately a form of adaptive sensorimotor behavior that is shaped by our perpetual interaction with the environment. This implies that we need to be able to flexibly adjust behavior due to rapidly changing circumstances, goals, and demands. The successful use of speech therefore not only requires situational balancing of goals and demands but also adequate use of limited neural and cognitive resources. This necessitates precise temporal coordination of dynamics as diverse as turn-taking, signal encoding and decoding, interfacing with short-term and long-term memory, allocating attention, and combining temporally distinct speech elements to optimize communication. Yet, how temporal coordination is achieved within and between speakers and listeners remains a challenging question, as perhaps best expressed in Lashley’s original reflection on the problem of serial order in behavior (Lashley, Reference Lashley and Jeffress1951).
Some acoustic signal dynamics have been shown to directly map onto neurophysiological signatures in speech processing. Compelling evidence showed that neural oscillatory activity mirrors rhythmic features of the speech signal (Giraud et al., Reference Giraud, Kleinschmidt and Poeppel2007; Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; see Chapters 3 and 5). The links between the acoustic signal and brain rhythms imply that speech is at least in parts both a reflection and a driver of neural signaling and cognitive mechanisms such as attention allocation that themselves are not restricted to speech. However, so far, it is still mostly unclear how acoustic rhythms interact with neural rhythms and the dynamic allocation of memory and attention or across domains, as indicated by visual enhancement effects (Schroeder and Lakatos, Reference Schroeder and Lakatos2008; Schroeder et al., Reference Schroeder and Lakatos2008). A better understanding of how these interactions shape and are themselves shaped by speech rhythms would therefore not only improve any explanation of human speech capacities but could also inform new perspectives on biological and cognitive aspects of ontogenetic and phylogenetic speech development. This extended approach might provide explanations on how successful temporal coordination emerges from the “composite of many interactive systems” that make up cerebral functions, thus delivering a crucial building block to answering the question of how the human brain factors time into the “problem of serial order in behavior” (Lashley, Reference Lashley and Jeffress1951, p. 135).
6.2 Linking Production and Perception Cycles to Temporal Processing
Considering the complex rhythmic structure of speech, one basic domain-general mechanism that might interleave with speech processing is temporal processing, that is, a mechanism underlying the encoding, decoding, and use of temporal information in motor and nonmotor behavior (Buhusi and Meck, Reference Buhusi and Meck2005; Ivry and Schlerf, Reference Ivry and Schlerf2008). Other possible interactions between “systems” emerge from the need to rapidly activate and flexibly allocate attention and memory resources to particular speech events as they unfold in time (Large and Jones, Reference Large and Jones1999; Schroeder and Lakatos, Reference Schroeder and Lakatos2008). Here, speaking and listening to speech share a common denominator in the encoding and decoding of temporal structure, the dynamic allocation of attention and memory, and the temporal coordination of these processes with the overarching goal to ensure stable speech processing and consequently successful communication.
Temporal processing has been attributed to a distributed brain network (Ivry and Schlerf, Reference Ivry and Schlerf2008; Merchant et al., Reference Merchant, Harrington and Meck2013; Wiener, Reference Wiener, Merchant and de Lafuente2024). The main nodes of this network are the basal ganglia, the supplementary motor area (SMA) and prefrontal cortical areas, and the cerebellum, each of which seems to support specific aspects of temporal processing. Current views on these classically denoted motor areas extend to perception as well (e.g., Petacchi et al., Reference Petacchi, Laird, Fox and Bower2005; Chen et al., Reference Chen, Penhune and Zatorre2008; Baumann et al., Reference Baumann, Borra and Bower2015), and thus questions emerged as to if, how, and why this potentially domain-general temporal processing network might interface with speech production and perception (Schirmer, Reference Schirmer2004; Buhusi and Meck, Reference Buhusi and Meck2005; Kotz and Schwartze, Reference Kotz and Schwartze2010).
Answering these questions relates back to the notion of speech communication as a form of adaptive behavior. The intricate interplay of production and perception in conversation can be subsumed but also further differentiated considering the organizational structure of the perception–action (PA) cycle framework (Fuster, Reference Fuster, Grafman, Holyoak and Boller1995, Reference Fuster2004; Fuster and Bressler, Reference Fuster and Bressler2015). The PA cycle is a neurofunctional implementation of the fundamental principle of biological adaptation, expressed in the notion that environmental events change the activity of neural receptors to generate adaptive motor behavior, which, in turn, generates environmental events that induce further changes and thus give rise to a self-contained periodic cycle or function circle (Uexküll, Reference Uexküll1926, p. 126; Fuster and Bressler, Reference Fuster and Bressler2015). The PA cycle framework suggests that the development of the human prefrontal cortex (PFC) during the course of evolution added unparalleled capacities for temporal coordination and the timely (predictive) activation of memory to the PA cycle (Fuster and Bressler, Reference Fuster and Bressler2015). As the PFC coordinates motor and perceptual brain networks, it essentially exerts a “temporal syntactic function,” which Fuster operationally defined as the “bridging of temporally separate elements of a behavioral gestalt,” such as words forming an utterance (Fuster, Reference Fuster, Grafman, Holyoak and Boller1995, p. 175). In interaction with other brain areas, this bridging function denotes the PFC as the highest node within executive and perceptual hierarchies that govern the temporal coordination of all goal-directed behavior (Fuster and Bressler, Reference Fuster and Bressler2015).
Brain areas that connect to the PFC in support of this temporal syntactic function comprise neocortical areas such as primary sensory and association cortices but also the same subcortical areas that are implicated in temporal processing, namely the basal ganglia and the cerebellum that might exert a modulatory influence on the PA cycle (Fuster, Reference Fuster, Grafman, Holyoak and Boller1995; Fuster and Bressler, Reference Fuster and Bressler2015). Nevertheless, the parallel enlargement of the cerebellum and the PFC throughout evolution (MacLeod et al., Reference MacLeod, Zilles, Schleicher, Rilling and Gibson2003; Habas, Reference Habas2021) and the well-documented cerebellar connectivity with the thalamus and basal ganglia as well as with central executive, default mode, salience, attentional, and language networks, stand exemplary for a wider network that might allow for more specialized interactions such as that of temporal processing and the PA cycle suggested here (Ramnani, Reference Ramnani2006; Krienen and Buckner, Reference Krienen and Buckner2009; Strick et al., Reference Strick, Dum and Fiez2009). It is of note, though, that within the PA cycle, temporal processing is not conceived as processing of time but processing in time (Fuster, Reference Fuster, Grafman, Holyoak and Boller1995). Currently, it is also computationally largely unspecified how the PFC performs its temporal syntactic function. Nevertheless, the central notion of repeated and predictive activation that defines the PA cycle, potentially in a periodic fashion, points to the fundamental role of the corresponding neural rhythms in the temporal coordination of goal-directed behavior. In a similar vein, Lashley noted that temporal coordination of behavior may be achieved through “temporally spaced waves” that govern states of “facilitative excitation” (Lashley, Reference Lashley and Jeffress1951, p. 127). One may speculate that at least in those instances in which behavioral rhythms directly map onto neural rhythms, as shown for speech, neural oscillatory activity and temporal processing mechanisms instantiate a “master clock signal” that facilitates temporal coordination. This would essentially mean combining processing in time with processing of time, thus adding temporal specificity to the PA cycle with the aim to tune the PFC temporal syntactic function for optimal predictive adaptation.
6.3 The Complexity of Predicting “When”
Being able to predict what elements occur in an utterance is a powerful way to guide speech communication. However, to optimally adapt to an inherently dynamic environment, the human brain might likewise aim to predict specifically when something occurs (Schwartze and Kotz, Reference Schwartze and Kotz2013). Neural oscillations across different frequency bands offer a solution for the coding of temporal information and the generation of temporal predictions, directing neural and cognitive resources to specific points in time. Whereas associations or feedforward and feedback networks are good at predicting what occurs, temporal coordination and temporal prediction are achieved most directly and in an energy-efficient manner by oscillations and by oscillation-based synchrony (Buzsaki and Draguhn, Reference Buzsaki and Draguhn2004).
Due to the rhythmic complexity of speech, it is often difficult to maintain any strict differentiation of processing in time and of time or of what as opposed to when predictions. According to Rosen (Reference Rosen1992), the acoustic signal carries rhythmic features on at least three distinct levels: envelope (fluctuations in overall amplitude at rates between 2 and 50 Hz), periodicity (50–500 Hz), and fine structure (0.5–10 kHz), each of which is defined by characteristic acoustic, auditory, and perceptual manifestations and their specific roles in linguistic contrasts. Correspondingly, Lashley discussed a series of hierarchies of organization for speech, ranging from the order of vocal movements to the discourse level (Lashley, Reference Lashley and Jeffress1951). This complexity leaves it open as to whether the interaction of temporal processing with the PA cycle would manifest in one or multiple rhythms and which feature or organizational level(s) would carry it. Human multitasking abilities seem to imply parallel processing in several PA cycles (Fuster and Bressler, Reference Fuster and Bressler2015). However, if the notion of a “master clock signal” that governs temporal coordination holds true, it suggests a special status of one rhythm and that neural oscillatory activity in the respective frequency band is used for specific temporal prediction. This raises the issue of potential interference effects and confusion between production and perception as speakers almost simultaneously are listeners to their own speech and perceivers of their surroundings, including the environment and the interlocutor. Although different rhythms can in principle coexist in the same and different brain areas, but also interact with each other (Buzsaki and Draguhn, Reference Buzsaki and Draguhn2004), parallel processing of the same rhythm likely requires a more fine-grained differentiation of brain areas and connections implied in temporal processing and the PA cycle. For example, it has been shown that the dentate nucleus, the main output relay of the cerebellum, divides into motor and cognitive subcompartments with distinct connectivity patterns to the SMA (Dum and Strick, Reference Dum and Strick2003; Akkal et al., Reference Akkal, Dum and Strick2007). Engagement of the SMA in temporal processing can be differentiated along an anterior–posterior axis (Schwartze et al., Reference Schwartze, Rothermich and Kotz2012). This organization is maintained for connections from the anterior SMA to the PFC and from the posterior SMA to premotor areas, and connections from both to the basal ganglia (Kotz et al., Reference Kotz, Anwander, Axer and Knösche2013). Although the picture is far from complete in this regard, such a configuration might allow parallel processing of the same rhythm in neighboring areas in production and perception.
6.4 Tracing a Fundamental Driving Rhythm
Lashley was not only positive that rudiments of every human behavioral mechanism can be traced down the evolutionary scale but also that they are represented in “primitive activities” (i.e., simple and evolutionarily ancient) of the nervous system (Lashley, Reference Lashley and Jeffress1951, p. 134). Several potential candidates have been put forward. However, following Lashley’s rationale, a way to identify a likely driving rhythm is to reduce the rhythmic and organizational complexity of the speech signal to a simpler and evolutionary ancient level. The frame/content (f/c) theory of the origin of speech differentiates such a level, considering that speech is first and foremost a motor behavior that is expressed through serially organized movements while speaking (MacNeilage, Reference MacNeilage1998, Reference MacNeilage2008). Its central tenet is the mandibular cycle, that is, alternating opening and closing mouth movements, which constitute a general-purpose carrier or frame into which vowels and consonants are combined to form specific content (MacNeilage, Reference MacNeilage1998, Reference MacNeilage2008; see Chapter 2). Viewed at this level, continuous speech is carried by the biphasic cycles of a mandibular oscillation that can take simple contrastive forms such as baba but also all of the more complex forms found in speech (MacNeilage, Reference MacNeilage2008). Accordingly, opening the mouth to produce vowels and closing it to produce consonants is regarded as the most fundamental organizational level of serial order in speech (MacNeilage, Reference MacNeilage2008).
The corresponding articulatory gestures and the resultant syllables are associated with a fluctuation in sound energy that reaches peaks with maxima of oral aperture, giving rise to a syllabic rhythm (Greenberg, 2006). During conversation, this syllabic rhythm is conveyed to the listener but also as feedback to the speaker, designating it as an anchor for temporal coordination and the driver of predictive adaptation (Figure 6.1). Syllabic rhythm is typically realized at rates that correspond to delta and theta frequencies (ca. 2–8 Hz), that is, a relatively slow neural rhythm with a period in the hundreds-of-milliseconds range. The correspondence between syllabic rhythm and neural activity is most directly expressed in the concept of the theta syllable, conceived as a unit of speech information that is defined by cortical function (Ghitza, Reference Ghitza2013).
Syllabic rhythm in the speech perception–action cycle.
Speakers (left) produce an utterance with a syllabic rhythm through opening and closing movements of the mouth (mandibular cycle) and associated fluctuations in sound energy. Maximized oral aperture during vowel production generates energy peaks that define the rhythm’s rate over successive inter-peak intervals. In speakers (through feedback, left) and listeners (right), this rhythm maps onto neural oscillations in the delta-to-theta frequency range (about 2–8 Hz). This direct mapping and/or the repeated use of interval-based temporal processing mechanisms allows for factoring “time” into behavior and into intrapersonal and interpersonal adaptation. Adaptation entails timely and predictive activation to optimally allocate neural and cognitive resources in production and perception. At the highest level of the underlying processing hierarchy, the PFC provides the temporal integration and coordination capacities that bridge the temporally separate elements of the utterance into one behavioral gestalt for monitoring, planning, and comprehension.
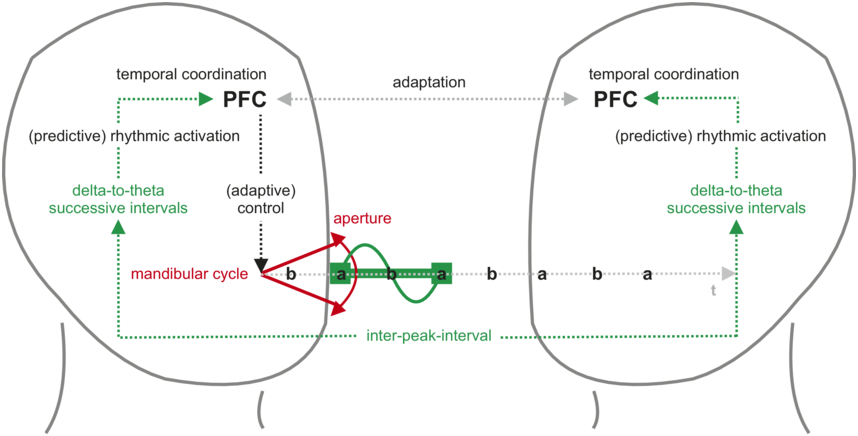
Figure 6.1 Long description
The delta-to-theta successive intervals represent the rhythmic brainwave activity. The arrow indicates that the P F C is receiving information about these intervals. This is the cyclical movement of the jaw. The diagram shows the cycle as a series of points: b, a, b, a, b, a, b, a, b, a, and so on. The flow of the mandibular cycle in each hemisphere is as follows: P F C leads to adaptive control, followed by delta to theta successive intervals, rhythmic activation and temporal activation. A double-headed arrow between the P F Cs of the left and right hemisphere labels adaptation and another arrow labels inter-peak interval.
As an acoustically and neurally defined concept, the theta syllable rhythm does not draw on orthography, instead suggesting that information transmission in speech communication operates on syllabic “packets” (Ghitza and Greenberg, Reference Ghitza and Greenberg2009). This has important implications for signal processing as it shifts the focus from abstract points in time such as word or sentence boundaries to the concrete physical markers of time that are instantiated by successive energy peaks, potentially defining one driving rhythm across speech production and perception on the one hand and speech-related temporal processing and temporal coordination mechanisms on the other (Schwartze and Kotz, Reference Schwartze and Kotz2013; Kotz and Schwartze, Reference Kotz, Schwartze, Hickok and Luck2016).
6.5 Towards Cycles of Interaction
If the same low-frequency driving rhythm underlies the interaction of production and perception, temporal processing, and temporal coordination, it would have a broad range of implications for adaptive behavior. However, identification of this rhythm and the corresponding frequency range also imply specific limits and a potential differentiation of the role of oscillation- and interval-based temporal processing mechanisms.
Speaking and listening ultimately involve parallel acts of synchronizing information flow between the encoding and decoding capacities of speakers and listeners (Greenberg, Reference Greenberg, Greenberg and Ainsworth2012). In a similar vein, the f/c theory emphasizes the key role of the sociocultural dyad from an evolutionary perspective: “Language must have been a sociocultural invention. The first word only became a word when a receiver and a sender came to treat a particular sound complex as standing for a particular concept” (MacNeilage, Reference MacNeilage2008, p. 44). Temporal processing mechanisms may facilitate temporal coordination and synchronization also at this interpersonal level, which adds the rhythm of interaction as another temporal level to the threefold rhythmic differentiation (Rosen, Reference Rosen1992) of the acoustic signal. However, whereas oscillations and oscillation-based synchrony provide the most efficient means to synchronize encoding and decoding capacities at faster rates, interval-based temporal processing might be most efficient at rates in the hundreds-of-millisecond to seconds range and in guiding temporally predictive adaptation in the socially interactive PA cycles that are essential for the development of speech communication capacities.
Throughout the human lifespan, social interaction shapes and improves linguistic competence (Tomasello, Reference Tomasello2000; Kuhl, Reference Kuhl2007; Mundy and Jarrold, Reference Mundy and Jarrold2010; Dikker et al., Reference Dikker, Wan and Davidesco2017; Mundy, Reference Mundy2018) such as learning and proficiency in a nonnative language (Perani et al., Reference Perani, Abutalebi and Paulesu2003; Jeong et al., Reference Jeong, Sugiura and Sassa2010, Reference Jeong, Hashizume and Sugiura2011; Consonni et al., Reference Consonni, Cafiero and Marin2013; Verga and Kotz, Reference Verga and Kotz2013, Reference Verga and Kotz2019; Kuhlen et al., Reference Kuhlen, Bogler, Brennan and Haynes2017), while its absence can lead to linguistic deficits (Krashen, Reference Krashen1973; Fromkin et al., Reference Fromkin, Krashen, Curtiss, Rigler and Rigler1974; Curtiss, Reference Curtiss1977). The reason is debated. However, several theories converge on defining a social partner as an attentional enhancer/modulator based on two interrelated characteristics of social contexts, namely that i) they are intrinsically multimodal (Gogate and Bahrick, Reference Gogate and Bahrick2001; Gogate et al., Reference Gogate and Bahrick2001), and ii) two partners mutually and dynamically join attention in a common ground (Hollich et al., Reference Hollich, Hirsh-Pasek and Golinkoff2000; Tomasello, Reference Tomasello2000; Kuhl, Reference Kuhl2007; Sage and Baldwin, Reference Sage and Baldwin2010). In this shared conversational ground, a speaker and a listener can become temporally aligned at multiple levels, as indicated by converging speech rates (Schultz et al., Reference Schultz, O’Brien and Phillips2016), phonetic realizations (Mukherjee et al., Reference Mukherjee, Badino and Hilt2019), body postures (Shockley et al., Reference Shockley, Santana and Fowler2003, Reference Shockley, Baker, Richardson and Fowler2007), gaze (Richardson and Dale, Reference Richardson and Dale2005; Richardson et al., Reference Richardson, Dale and Kirkham2007), but also neural activity (Stephens et al., Reference Stephens, Silbert and Hasson2010). By contrast, reduced listener/speaker coupling is associated with difficulties in speech understanding (e.g., Liu et al., Reference Liu, Ding and Li2021).
In conversations, this mutual exchange may assume a rhythmic quality through the smooth transition of turns between a speaker and a listener, which has been suggested to rely on avoiding both long silences and long overlaps (Stivers et al., Reference Stivers, Enfield and Brown2009; Garrod and Pickering, Reference Garrod and Pickering2015). Rudimental forms of turn-taking have been observed in interactive communication in many other species (Ghazanfar and Takahashi, Reference Ghazanfar and Takahashi2014; Takahashi et al., Reference Takahashi, Fenley and Ghazanfar2016; Ravignani et al., Reference Ravignani, Verga and Greenfield2019). In humans, it is assumed that interactive alignment provides the backbone for turn-taking: By allowing conversing partners to match their mental representations (Garrod and Pickering, Reference Garrod and Pickering2004; Pickering and Garrod, Reference Pickering and Garrod2004; Menenti et al., Reference Menenti, Pickering and Garrod2012), it facilitates the prediction not only of what is coming next (i.e., a response from the listener) but also – most importantly – of when the next conversational turn should start. This efficient cognitive strategy (Koban et al., Reference Koban, Ramamoorthy and Konvalinka2019; Mukherjee et al., Reference Mukherjee, Badino and Hilt2019) benefits from nonlinguistic convergence (e.g., shared gaze and attention; Richardson and Dale, Reference Richardson and Dale2005; Menenti et al., Reference Menenti, Pickering and Garrod2012). Yet, linguistic information deriving from the jaw movements subtending syllable production has been proposed to drive the mutual entrainment of endogenous oscillators in the speaker’s and listener’s brains (Wilson and Wilson, Reference Wilson and Wilson2005; Kotz et al., Reference Kotz, Ravignani and Fitch2018; see Figure 6.1). Thus, even in dyadic conversations, syllables emerge as basic fundamental units of speech in relation to mouth and jaw movements in an action–perception cycle (MacNeilage, Reference MacNeilage2008). Thus, dyadic mutual alignment is expected to elicit fronto-central brain activity, reflecting an action–perception feedback loop (Pulvermüller, Reference Pulvermüller2018). Indeed, neural activity peaks in the mouth motor region (Glanz et al., Reference Glanz, Derix and Kaur2018) and ventral premotor cortex (Wilson et al., Reference Wilson, Saygin, Sereno and Iacoboni2004; Gordon et al., Reference Gordon, Tranel and Duff2014; Glanz et al., Reference Glanz, Derix and Kaur2018). Interestingly, similar orofacial movements such as lip-smacking in nonhuman animals have gained attention as possible precursors of cyclic speech components in the theta range (MacNeilage, Reference MacNeilage1998; Ghazanfar et al., Reference Ghazanfar, Morrill and Kayser2013; Kotz et al., Reference Kotz, Ravignani and Fitch2018). Lip-smacking is an affiliative signal observed in many primate species and is characterized by the rhythmic (vertical) opening and closing of the jaws. During the evolution of the human lineage, lip-smacking may have coupled with vocal signals to produce babbling (i.e., consonant-vocal speech-like sounds; MacNeilage, Reference MacNeilage1998, Reference MacNeilage2008; Ghazanfar and Takahashi, Reference Ghazanfar and Takahashi2014).
6.6 Conclusion
Speech communication generates acoustic and interpersonal rhythms that span multiple timescales. However, the mere fact that all speech communication is rhythmic does by no means imply that the role of the respective temporal information for speech processing is trivial. Speech serves to communicate meaning, and the acoustic signal encodes the respective information over time. Time and temporal coordination are thus not only crucial factors for the “logical and orderly arrangement of thought and action” that is at the heart of the problem of serial order of behavior (Lashley, Reference Lashley and Jeffress1951) but also for the reconstruction of orderly thought and action from the acoustic signal. The perception–action cycle framework (Fuster, Reference Fuster, Grafman, Holyoak and Boller1995) defines the basis for the arrangement and the perceptual bridging of speech events over time. However, to continuously optimize predictive adaptation to the environment, this cycle may interface with other mechanisms and with other sensory domains. To this end, oscillation- and interval-based temporal processing mechanisms may guide a temporally specific variant of the perception–action cycle to integrate what and when aspects of speech for successful communication.
Summary
Speech communication evokes rhythms that span multiple timescales. The acoustic signal evolves serially, necessitating adequate temporal coordination in production and perception. To optimize temporal coordination of neural and cognitive mechanisms, temporal processing mechanisms may exploit rhythmic speech features to guide a temporally specific variant of the perception–action cycle.
Implications
Rhythmic speech features indicate various neural and movement mechanisms. Rhythmic features in the delta-to-theta range might establish the common ground for interactions of evolutionarily ancient serial ordering, temporal processing, and higher-order temporal coordination mechanisms. This integrative perspective offers starting points for investigating the relation of speech and temporal processing capacities.
Gains
A concrete form of linguistic performance, speech communication directly reflects fundamental neural and cognitive mechanisms including rhythmic motor control, serial ordering, temporal coordination, or attention and memory allocation. A better understanding of how speech rhythm interfaces with temporal processing in perception and action can thus inform about key aspects of cognition.
7.1 Introduction
The production and perception of acoustic communication signals in different species, including humans, have intrigued scientists all over the world and from diverse research fields such as linguistics, biology, and psychology. Some questions are important to answer in all fields. One is about the temporal structure of acoustic communication, and how it is used to convey information. These temporal structures or rhythms can act on different levels, within a phrase or between phrases, and they can also help in determining phrase boundaries. Perspectives on these connected questions are manifold, and cross-talk between the three disciplines is often limited. In this chapter, we are advocating for more cross-talk using two prosodic markers connected to rhythms as examples to showcase the advantages of combining linguists’ and biologists’ knowledge about the respective phenomena.
Rhythms can be defined in various ways (for an overview, see Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013). One example is given by Patel, where rhythm is the “systematic patterning of sounds in terms of timing, accent and grouping” (Reference Patel2008:96). Building on this, we consider rhythm as a nonrandom, ordered, predictable, and repeated alternation of different elements in a sequence. The motivation to use this definition is to be relatively independent of theoretical concepts in one or the other research domain. We think a broader perspective including humans and nonhuman animals is important because it allows us to better understand the underlying principles and may root rhythms of human language in evolution.
According to this definition, the building blocks of rhythm are elements in a sequence. Even if it is a challenge on its own (Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010), determining these elements in a known human language, that is, linguistic units such as syllables, words, and prosodic phrases, might be more straightforward than determining the building blocks of rhythm in nonhuman vocalizations. Among other approaches, rhythmic markers might be a way to tackle this issue in nonhuman animals. We will focus on two prosodic markers of rhythm, fundamental frequency (f0) declination and final lengthening. Both are frequently found in human communication and have also been reported in nonhuman communication.
Final lengthening refers to a phenomenon where a final or penultimate syllable of an utterance or prosodic phrase is produced for a longer duration than when the same is uttered within an utterance or prosodic phrase (Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010) (Figure 7.1A). Lengthening can signal the end of a unit, which varies nonlinearly with the strength of a boundary (Kentner et al., Reference Kentner, Franz, Knoop and Menninghaus2023). It can co-occur with pauses and f0 lowering (Petrone et al., Reference Petrone, Truckenbrodt and Wellmann2017). From a perceptual side, it is a phonetic signature that might help to mark the end of a unit (Schel et al., Reference Schel, Tranquilli and Zuberbühler2009).
Explanation of f0 declination and final lenghthening in two examples.
A) Oscillogram of human language. The spoken text is: “Always there had been war between the giants and the gods.” The duration of the “s” of “giants” and “gods” is annotated, and the final “s” is much longer, demonstrating final lengthening. B) The spectrogram for the same human sentence is shown with a solid line indicating the f0. A clear f0 decline is visible. C) An oscillogram of a budgerigar twittering. D) The corresponding spectrogram of the twittering. The f0 is shown as an extra solid line, and an f0 decline is visible.
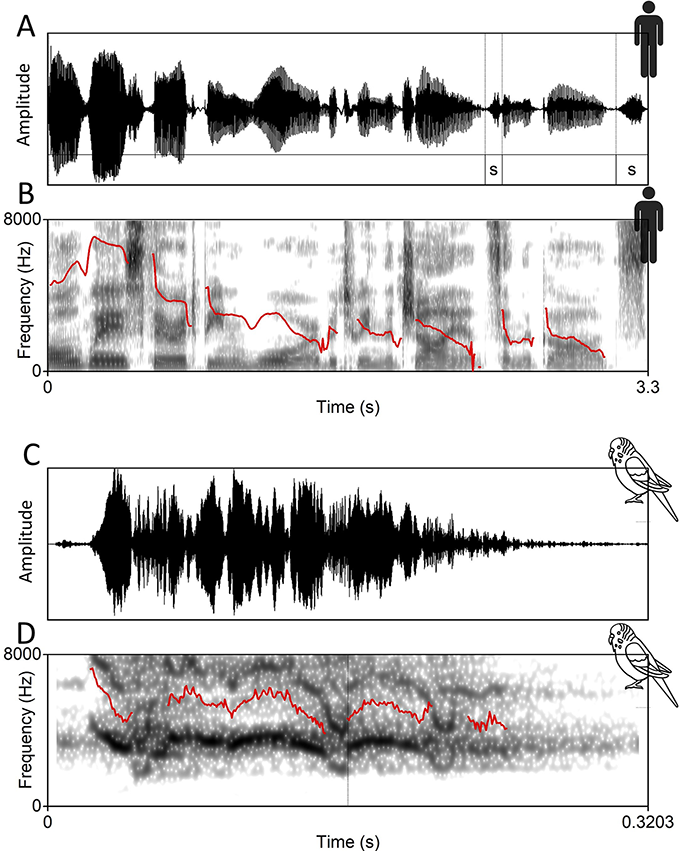
Figure 7.1 Long description
Panel A. A waveform, showing the sound's amplitude over time. Darker areas represent louder parts of the sound. A small graphic of a person is depicted at the top right. Panel B: A spectrogram, showing the sound's frequency over time. Darker areas represent higher sound energy at a given frequency. A small graphic of a person is depicted at the top right. Panel C: Another waveform, similar to panel A, along with a bird graphic at the top right. Panel D: Another spectrogram, similar to panel B, along with a bird graphic is present.
F0 declination has been widely discussed in phonological (Ladd, Reference Ladd1988, Reference Ladd2008) and phonetic terms (Strik and Boves, Reference Strik and Boves1995). We broadly define f0 declination as “the gradual decrease of f0 throughout an utterance” (Fuchs et al., Reference Fuchs, Petrone, Rochet-Capellan, Reichel and Koenig2015:35) to be as inclusive as possible concerning nonhuman animal communication (Figure 7.1A–D). F0 declination is common in statements as opposed to questions. From a phonetic perspective, it is calculated as a linear regression through f0 values in a given temporal window (e.g., 1–4 s in Yuan and Liberman, Reference Yuan and Liberman2014:69) that often corresponds to interpausal units or annotated prosodic phrases. The linear regression slope is negative by definition (f0 decline) and flattens with utterance length (e.g., Cooper and Sorensen, Reference Cooper and Sorensen1981; Swerts et al., Reference Swerts, Strangert and Heldner1996; Fuchs et al., Reference Fuchs, Petrone, Rochet-Capellan, Reichel and Koenig2015).
Together, f0 declination and final lengthening can be used to create a sense of units in a rhythmic sequence, helping to signal boundaries between units and convey information about the length of a unit in the sequence itself that may be repeated over time to produce structured time events.
There is a lot of potential in studying this in a comparative way between species. Linguistics could help to answer long-standing questions in animal communication, for example using knowledge of human languages to determine phrase boundaries or meaningful units. The other way around, we can use knowledge about animal communication and the opportunities we might have when studying a wide variety of animal species with different cognitive abilities or physical constraints to solve debates in linguistics on how to delineate phenomena influenced by cognitive abilities or biophysical mechanisms. There might be universal underlying motor principles in humans and nonhuman animals that we can only find when studying and comparing both.
We can observe variations in pitch and timing in nonhuman animal communication similar to prosodic features in human speech (Briefer, Reference Briefer2012; Hotchkin and Parks, Reference Hotchkin and Parks2013; Filippi, Reference Filippi2016). Oftentimes, these changes are caused by physiological alterations (for example the emotional state can influence muscle tension [Briefer, Reference Briefer2012]). Different kinds of information can be conveyed by those changes, whether it be individual identity in birds (and many other species, e.g., Linhart et al., Reference Linhart, Mahamoud-Issa, Stowell and Blumstein2022) or context in primates (Crockford et al., Reference Crockford, Gruber and Zuberbühler2018), among others.
There have been many recently published papers finding more and more similarities in human and nonhuman animal communication, for example finding that both penguins and gibbons also adhere to Zipf’s Law of Brevity, where the most frequent elements in communication are shorter in duration (Favaro et al., Reference Favaro, Gamba and Cresta2020; Huang et al., Reference Huang, Ma, Ma, Garber and Fan2020; Valente et al., Reference Valente, De Gregorio and Favaro2021). In biology, more research is needed to explore the extent and complexity of prosodic features in nonhuman communication. Animal communication may resemble human prosody, but there are important differences as far as we know now: Many animal vocalizations are innate, not learned through acquisition, and may be less flexible and expressive than human speech (Janik and Slater, Reference Janik and Slater2000; Tyack, Reference Tyack2019). At the same time, the spectrum between innate, adjusted, and learned vocalizations gives interesting options to study the prerequisites for prosodic phenomena.
To illustrate another field that would highly benefit from the comparative approach, we will focus on acoustic signals of humans and nonhuman animals using two concrete phenomena: final lengthening and f0 declination. These two phonetic markers have been chosen because they are involved in determining the units that can form a rhythmic sequence. Final lengthening is a phonetic signature of the end of a phrase and signals a boundary, while the slope of f0 declination can signal the length of an entire phrase. Both are frequent in human communication, and they have been considered as being universal even if language-specific modifications may be found (Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010). There have been debates about the origin of prosodic phenomena in general, for example whether they rely on linguistic representations or general physical properties. Similar to other scientists (Pika et al., Reference Pika, Wilkinson, Kendrick and Vernes2018; Matzinger and Fitch, Reference Matzinger and Fitch2021; Pouw and Fuchs, Reference Pouw and Fuchs2022; Hersh et al., Reference Hersh, Ravignani and Burchardt2023; Hoeschele et al., Reference Hoeschele, Wagner and Mann2023), we strongly believe that more interdisciplinary cross-fertilization is needed to better understand what properties are shared among human and nonhuman animals in their rhythm communication. By comparing the use of prosodic features in human and nonhuman animal communication, we can get insights into their evolutionary origins and development of speech rhythms. We can also shed light on the cognitive and biological underpinnings of human language and communication. On a different level, the comparative approach can provide a valuable perspective on the diversity of prosodic features used across different languages and language families and therefore might raise new questions in more specific research areas. We will be able to better identify universal patterns and language-specific variations. The road toward such interdisciplinary exchange is not without obstacles, but the joint venture, in our case between a biologist and a linguist, can enhance the collection of species producing selected phenomena, can initiate new recording and open source databases (Hersh et al., Reference Hersh, Ravignani and Burchardt2023), and may reduce the human-centric view on the evolution of complex acoustic communication and the insider bias when doing comparative work (Hoeschele et al., Reference Hoeschele, Wagner and Mann2023).
7.2 F0 Declination in Acoustic Signals: Human versus Nonhuman Animals
7.2.1 Characteristics of F0 Declination in Human Speech
F0 declination, the gradual decrease of f0 throughout an utterance, spans several words in human language and is a macro rhythm (rhythms with longer time units) in human speech. Strik and Boves (Reference Strik and Boves1995), among others, proposed to start analyzing time units larger than 1 second; otherwise, the calculation of the declination slope might be heavily affected by local f0 variations. F0 declination is not a rhythm in itself, but similar to final lengthening, it is a prosodic signature of a unit that can be repeated over time and form a rhythm.
While more cross-linguistic work on f0 declination using the same methodology is missing, it has been reported for various languages, such as Danish, Dutch, English, French, German, Greek, Japanese, and Spanish (see Fuchs et al., Reference Fuchs, Petrone, Rochet-Capellan, Reichel and Koenig2015, for an overview), so there is reason to believe it is a relatively robust phenomenon (Hauser and Fowler, Reference Hauser and Fowler1992), at least in Indo-European languages. However, it is not mandatory and can be modulated; for example, f0 can rise at the end of a phrase (called continuation rise) to signal the speaker’s motivation to continue talking, or it can rise signaling question intonation. There are also language specificities as well as other factors. For example, Lieberman et al. (Reference Lieberman, Katz, Jongman, Zimmerman and Miller1985) found more negative slopes in reading than in spontaneous speech.
A potential physiological origin of this phenomenon has been postulated. Lieberman (Reference Lieberman1967) measured subglottal pressure and f0 declination in three human participants reading declarative sentences and found a positive correlation between the two variables. He therefore suggested a potential origin in respiratory behavior, because respiration is a driving force of phonation. Others have argued that muscular tension in the vocal folds may be at the origin of f0 declination (e.g., Ohala, Reference Ohala and Fromkin1978) and that tensioning of the vocal folds is independent of respiration because the primary function of the larynx is to save lives and protect the lungs from foreign bodies, hence it must be independent and quick (Ohala, Reference Ohala and Hardcastle1990). The challenge for or against one or the other argument or a mix of the two is that measuring subglottal pressure and laryngeal tension is very invasive, so empirical data is limited.
Apart from the physiological origin of f0 declination, cognitive processes seem plausible as well. Since the slope of the f0 declination is correlated with the length of the upcoming utterance, some anticipatory planning may be involved (Yuan and Liberman, Reference Yuan and Liberman2014).
7.2.2 F0 Declination in Nonhuman Animal Communication
We occasionally find descriptions hinting at f0 declination in monkeys. For example, in a description of the vocalizations of the black and white colobus monkey, we find the following: “The final phrase is often deeper pitched than the others” (Marler, Reference Marler1972:181). This refers to the alarm call “roar.” This leads Schel et al. (Reference Schel, Tranquilli and Zuberbühler2009) to hypothesize that this phenomenon is perceptually conspicuous and marks the end of the sequence. In colobus monkeys a roaring sequence consists of one or more roaring phrases, where a phrase is a basic unit, made up of ~15 “pulses,” each with an average duration of 0.7 seconds, which makes a whole phrase around 10 seconds (Marler, Reference Marler1972).
Confusingly, in the same species, the exact opposite was reported, at least for the black colobus monkey (Colobus satanas): “Initial phrases all decreased in pitch during delivery, the terminal phrases all increased” in pitch (Oates and Trocco, Reference Oates and Trocco1983:100). This could have different explanations: The phenomenon could be dependent on unknown parameters that have differed between the studies, or coincidentally the decline in final phrases was observed in a different colobus monkey species.
The most detailed study on f0 declination in nonhuman animals was conducted in vervet monkeys (Cercopithecus aethiops) and rhesus macaques (Macaca mulatta), two very common model species (Hauser and Fowler, Reference Hauser and Fowler1992). For both species, vocal production also shows f0 declination, which is suggested to serve a similar communicative function as in human language (Hauser and Fowler, Reference Hauser and Fowler1992). Under investigation were vocalizations uttered during aggressive interaction for vervet monkeys in the wild and an affiliative vocalization for wild rhesus macaques. For both species an almost linear decline in f0 could be shown over call bouts of two calls and of three calls. Furthermore, for two call bouts of vervet monkeys, a correlation between the duration of the bout and f0 decline could be shown, as expected from human language literature (e.g., Yuan and Liberman, Reference Yuan and Liberman2014). No correlation could be found between the duration of the bout and the magnitude of the f0 decline in rhesus macaques. Another interesting thing to note is that the structured decline of f0 in vervet monkeys could only be seen in adults, not in juveniles, which could be explained by the fact that inter-call intervals in juveniles are generally longer, indicating juveniles might take a breath between calls, in contrast to adults. This makes it even more interesting to study the phenomenon further.
Another instance of f0 declination being reported in monkeys stems from baboons, where f0 is also reported to decline within bouts of calling. This is described to be independent of rank and age in a species where f0 generally is highly correlated to these two parameters (Fischer et al., Reference Fischer, Kitchen, Seyfarth and Cheney2004), making it a more general phenomenon worthy of further investigation.
In birds, f0 decline was found in the vocalizations of the budgerigar (Melopsittacus undulatus). Here, “mean F0 measurements were lower for segments in syllable-final position when compared to medial segments” (Mann et al., Reference Mann, Fitch, Tu and Hoeschele2021:6, Figure 4 caption).
7.2.3 Comparing F0 Declination in Human and Nonhuman Animal Communication
The number and detail of papers published on f0 declination are clearly more substantial in the linguistic domain, which shouldn’t imply that this is an exclusively human phenomenon. Papers published on f0 declination in animal communication include primates and birds. They often lack empirical work on the underlying mechanisms (different for final lengthening – see below). While papers on animal communication are a stepping stone toward a broader perspective, they are mostly descriptive.
Whether or not f0 declination is primarily the result of a decrease in subglottal pressure, a reduction in laryngeal tension throughout an utterance, a marker of anticipatory planning of an utterance, or a mixture of these is still unclear. The invasiveness of recording data in favor of the first two explanations limits the empirical evidence in humans.
There may also be some challenges when comparing humans and nonhuman animals. The minimum length of an utterance that can be considered for calculating the f0 declination slope may have to be adjusted for various animal species, similar to the terminology used. For an untrained linguist, the term “syllable” that is used in animal communication may have a very different connotation than for a biologist, for whom it may be clear that this is an utterance between silent pauses. Joint venture investigations on humans and nonhuman animals might also reveal deeper insights because they differ in their respiratory, vocal, and cognitive repertoire.
7.3 Final Lengthening: Humans versus Nonhuman Animals
7.3.1 Final Lengthening in Human Speech
Phonetic studies in a variety of languages found that final lengthening is a reliable phonetic marker determining the end of a speech chunk and is very pronounced next to a following pause (e.g., Klatt, Reference Klatt1976; Edwards et al., Reference Edwards, Beckman and Fletcher1991; for a review on languages, see Paschen et al., Reference Paschen, Fuchs and Seifart2022). There have also been considerations that the lengthening of the final segment is part of the pause (e.g., Krivokapić et al., Reference Krivokapić, Styler and Byrd2022) or can, in extreme cases, be produced instead of a pause in fast speech. Indeed, a pause is an important determiner of rhythm.
Final lengthening has been claimed to be universal in human language (Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010) with additional language specificities (e.g., Nakai et al., Reference Nakai, Kunnari, Turk, Suomi and Ylitalo2009). Since the term “universal” can be ambiguous in meaning (Bickel, Reference Bickel2011), we refer to statistical universal here, which relies on robust statistical evidence across languages but also allows for exceptions. There is only recent empirical evidence, using the same methodology for 25 mostly understudied languages, that the lengthening of vowels is a statistically robust cross-linguistic phenomenon (Paschen et al., Reference Paschen, Fuchs and Seifart2022). Language-specific variations, driven by phonological vowel length, were found as well. Sound-specific variations have also been reported, for example in Berkovits (Reference Berkovits1993) for Hebrew, who described stronger lengthening effects for final fricatives than stops. Paschen (Reference Paschen, Skarnitzl and Volín2023) provided evidence for Lower Sorbian that lengthening occurs in vowels, sonorants, and fricatives, but not in stops. While these latter segmental influences may be specific to human language, they may also give some hints that continuous airstream mechanisms make final lengthening more likely.
The degree of lengthening has been extensively discussed. For example, the pi-gesture model (Byrd and Saltzman, Reference Byrd and Saltzman2003) proposes that the longer the segments, the closer they are to the boundary. Moreover, lengthening varies with the boundary type. Final segments at major boundaries, for example at the end of a sentence, may be longer than segments at phrase boundaries within a sentence. While language-specific variants exist, this does not exclude the assumption that the underlying principles are physical in nature but have been shaped in various ways by the properties of the sounds and the users of individual languages.
What are the underlying mechanisms that may cause final lengthening? Do we also find them in other behavior or other species?
7.3.2 Final Lengthening in Nonhuman Animal Communication
Final lengthening is getting increased attention in nonhuman animal acoustic studies. It was found in birds and primates. We can find it as well as f0 declination in the budgerigar, a vocal learning parrot. It was reported that segments at the end of vocalizations were more likely to be longer. In 14 adult budgerigars, it was found that segments in syllable-final positions are on average longer than medial segments (Mann et al., Reference Mann, Fitch, Tu and Hoeschele2021). The budgerigar, thus, is the only nonhuman species so far where both final lengthening and f0 declination were observed. This is likely a sampling bias, where those phenomena have not been studied in many species. In another study on 80 different songbirds, the same could be shown: Song-final notes were significantly longer than nonfinal notes (Tierney et al., Reference Tierney, Russo and Patel2011). This is especially impressive as the analysis wasn’t conducted per species but across all species, indicating this to be a generally observable phenomenon in songbirds. A more detailed analysis to find possible differences between families would be interesting. Both papers argue that final lengthening can be observed in these songbirds as well as in humans, because of similar motor constraints. Both humans and songbirds show high control of their vocal articulators with the possibility to rapidly adjust them during vocal production. Nevertheless, abrupt termination of these movements might be difficult, as opposed to a gradual relaxation and therefore slowing of articulators, resulting in final lengthening. This argument is further strengthened by the fact that budgerigar segments in particular are produced within a single breath (Tierney et al., Reference Tierney, Russo and Patel2011; Mann et al., Reference Mann, Fitch, Tu and Hoeschele2021). It would be interesting to investigate respiratory kinematics and final lengthening in human speech production.
Final lengthening was also found in at least three different primate species: two crested gibbon species and the indri (Huang et al., Reference Huang, Ma, Ma, Garber and Fan2020; Valente et al., Reference Valente, De Gregorio and Favaro2021). In gibbons, this effect was found on two different structural levels, in vocal sequences and in bouts (where a vocal sequence is a short unit and a bout is made up of several sequences). The suggested reasons differ from those discussed in humans. The authors suggest a connection to males advertising their quality; that is, gibbons might be modulating the frequency of their calls rapidly at the end of sequences to advertise their individual quality to females as potential mating partners. An increase in frequency modulations, even though fast, would potentially lead to an increase in the duration of notes (Huang et al., Reference Huang, Ma, Ma, Garber and Fan2020). If this is true, the observed phenomenon of final lengthening in crested gibbons would only be a byproduct of other processes.
7.3.3 Comparing Final Lengthening in Human and Nonhuman Animal Communication
There are different explanations for final lengthening in the literature. It has been understood as a general motor property rather than being innate. Tierney et al. (Reference Tierney, Russo and Patel2011) attribute it to the energy efficiency of the underlying motor actions in humans and singing birds. As mentioned above, Huang et al. (Reference Huang, Ma, Ma, Garber and Fan2020) explain it as a byproduct rather than a phenomenon on its own. Matzinger and Fitch (Reference Matzinger and Fitch2021) mention the possibility that the slowing down of articulators could be a result of a change from exhalation to inhalation; that is, respiratory dynamics and the occurrence of a breathing pause cause final lengthening. We think that it could be a plausible explanation for those species that produce segments within one breath, but in humans, final lengthening can also be found without a change from exhalation to inhalation. Nevertheless, the relation of one breath to one segment (or one phrase in human communication) may have been at the origin of human language evolution. In spontaneous interactive dialogues, more than 50% of all turns consisted of only one breathing cycle (Rochet-Capellan and Fuchs, Reference Rochet-Capellan and Fuchs2014). Linguistic studies have mostly focused on language- and segment-specific properties in the implementation of final lengthening. Because the number of published papers on these specificities is so much more than in animal communication, one may implicitly assume that it is a phenomenon of human language.
Even if language variations exist, it does not exclude the possibility of an underlying motor principle. Humans and nonhuman animals clearly have motor constraints, but these may not be persistent under each and every situation, and all animals may also be able to compensate for it if needed. Monocausalities are rather rare in biological systems. For example, the available exhalation air in human speech may be physically constrained by the lung volume (vital capacity) of a speaker. In human and nonhuman acquisition, a high positive correlation between lung volume and utterance/vocalization length has been found (see the review in Fuchs and Rochet-Capellan, Reference Fuchs and Rochet-Capellan2021). Evidence for a similarly strong correlation between utterance length and vital capacity in adults is missing, because humans with smaller lung capacities may adjust their laryngeal resistance and lose less expiratory air to compensate for their physical constraints.
All in all, evidence for final lengthening in nonhuman animals has changed the perspective that the phenomenon is a purely linguistic one to the notion that it might be grounded in general motor constraints.
7.4 Future Directions
7.4.1 A Roadmap
In the venture of finding the biological underpinnings of prosodic phenomena such as f0 declination and final lengthening through a comparative approach combining knowledge and advantages from studying human and nonhuman communication, there are several issues to overcome and steps to take. We will lay out a possible roadmap to achieve this here, with concrete steps.
1) Establishing a common vocabulary and conceptual framework: This touches on issues mentioned earlier, where terms such as “syllable” might be understood differently between linguists and biologists, but also within biology. Clear terminology and glossaries and clear but adjustable definitions and criteria for measuring and analyzing features are important steps.
2) Establishing the necessary data basis: We would need to develop a comprehensive database of vocalizations from a wide range of species to study these and other phenomena comparatively. A database should optimally include both natural or spontaneous and elicited vocalizations. Most importantly, meta-information about the social or ecological contexts is important to know, as well as potential age and sex.
3) Identifying universal and species-specific patterns: Once established, researchers can begin to identify robust patterns in the use of prosodic features across species, as well as species-specific variations, utilizing the database. Eventually, this can help to shed light on the evolutionary and ecological factors that shape the use of these features in different species with different needs and skills.
4) Integrating insights from different disciplines: With a comprehensive knowledge of theories, mechanisms, and constraints in linguistics, biology, psychology, and neuroscience from interdisciplinary collaborations, we can identify new research questions and generate novel insights into the biological and cognitive foundations of communication.
7.4.2 Prosodic Rhythm Markers and Respiration
A future endeavor toward a better understanding of prosodic markers of rhythm could be to investigate the interaction between respiration, phonation (voice quality), and anticipatory planning in humans and nonhuman animals. Respiration itself is a biological rhythm, and the duration of breathing cycles can constrain how long an animal can phonate. At the end of long sequences when lung volume is reduced, laryngeal adjustments may be required to continue phonation. While this has been modelled for humans (Zhang, Reference Zhang2016), it may also exist in nonhuman animals. The amount of air inhaled may further shape acoustic properties such as intensity and to some extent f0 (Watson et al., Reference Watson, Ciccia and Weismer2003).
Vocalizations in nonhuman primates such as screams or grunts may have specific prosodic features that can be shaped by respiratory control. Birds have more complex respiratory and laryngeal systems than humans, including not only lungs but several additional air sacs that are necessary during avian flight. Phonation is produced with a syrinx that is much closer to the lungs than in humans, at the place where the trachea forks into the lungs. These physiological differences and control mechanisms are, on the one hand, a big challenge for comparative work; on the other hand, they may give us insights into which physiological or cognitive systems can produce these patterns and which features they have. Recent technological developments in thermography allow us to record breathing and acoustics even in free-ranging animals (Demartsev et al., Reference Demartsev, Manser and Tattersall2022).
7.5 Conclusion
This chapter examined the intersection between biophysical and cognitive constraints on vocal communication. To that end, we investigated what is known about two concrete prosodic phenomena connected to rhythm in human language and nonhuman animal communication: final lengthening and f0 declination. Both prosodic phenomena have been found in different nonhuman animal species, mostly in birds but also in primates. We are sure that more examples will be found in different species. For final lengthening the evidence in nonhuman animals has changed the perspective that the phenomenon is a purely linguistic one to the notion that it might be grounded in general motor constraints. There is clearly an advantage when humans and nonhuman animals are taken into account, to find these explanations.
Summary
Focusing on final lengthening and f0 declination as prosodic rhythm markers in human language and nonhuman animal communication, we explored the intersection of biophysical and cognitive factors. Examples from birds and primates challenge the notion of them being purely linguistic, suggesting a basis in general motor constraints. Further cross-species investigation promises additional insights.
Implications
F0 declination and final lengthening have been discussed as two properties demarcating the unit of a rhythm. Descriptions of rhythms in speech communication would benefit from the inclusion of nonhuman animal data for a better understanding of the underlying principles, and rooting rhythms of communication in evolution.
Gains
The evidence for f0 declination and final lengthening in nonhuman animals may change our human-centric perspective from purely linguistic phenomena to grounding it in general motor constraints, learned and innate behavior. A potential road toward further comparative analyses has been described.
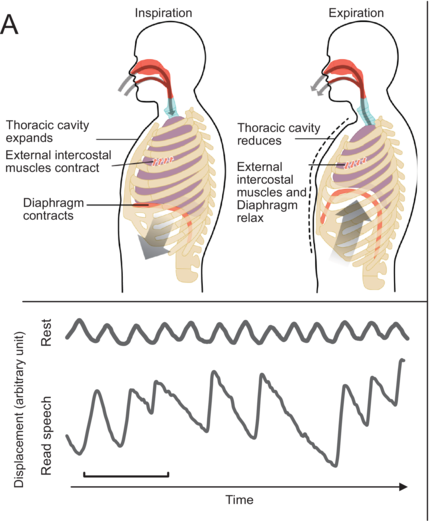
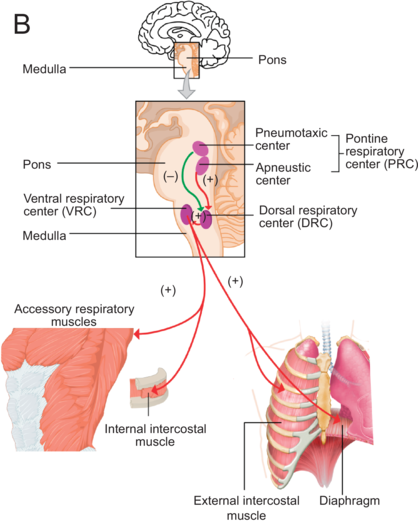
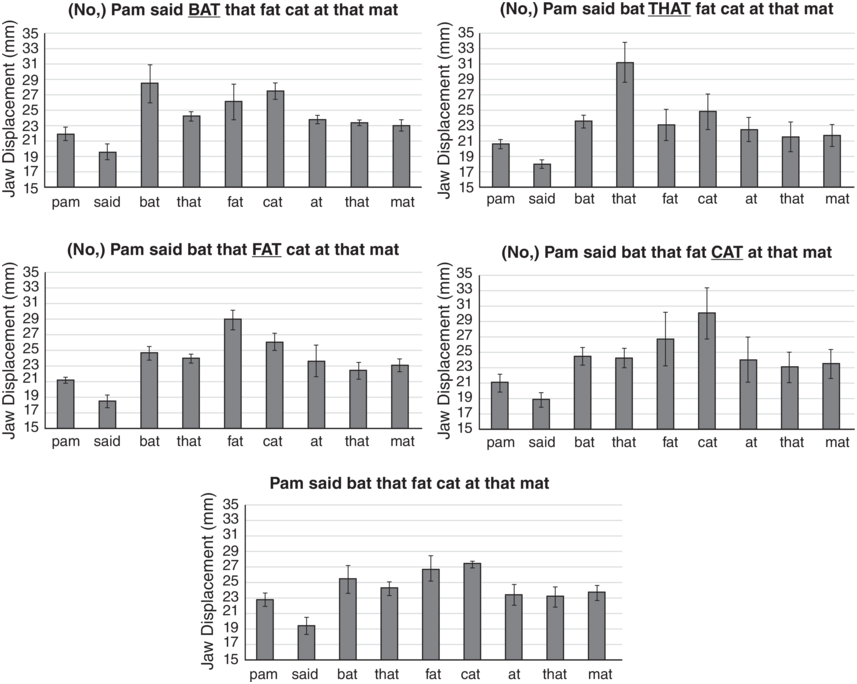
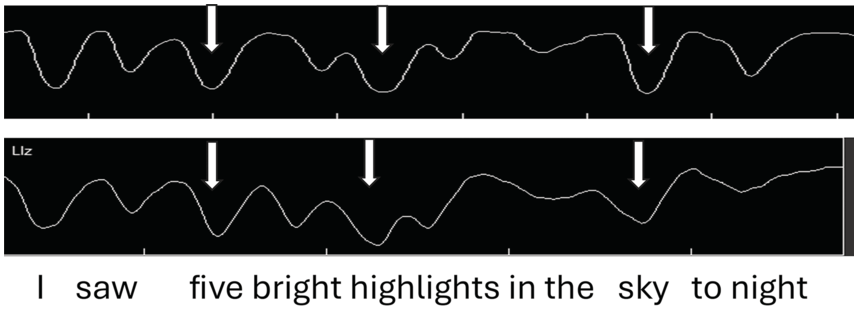
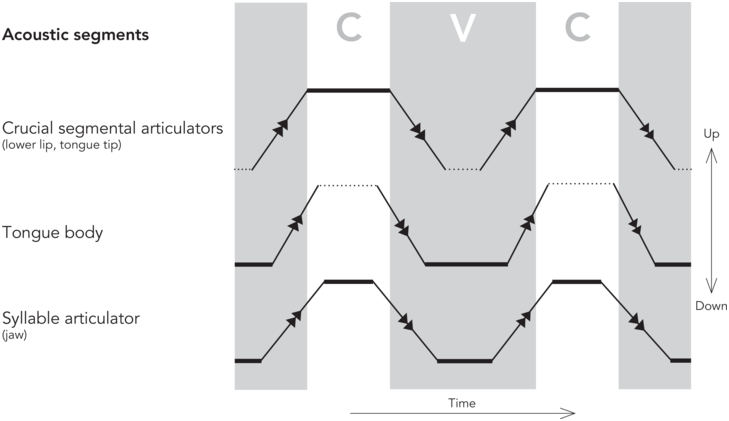

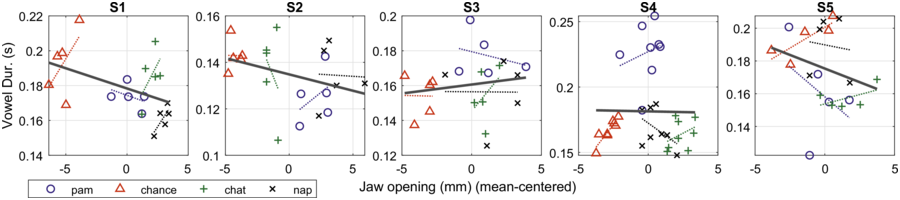
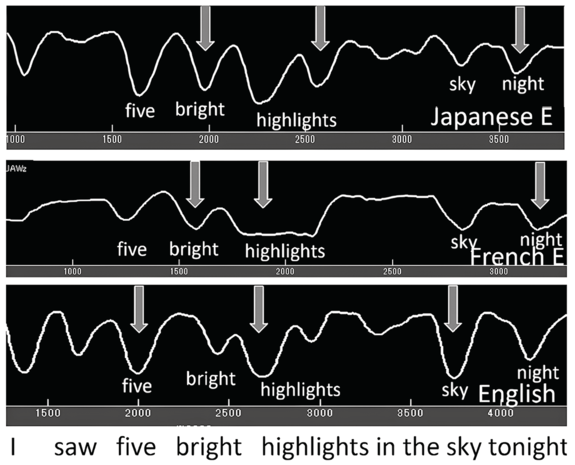
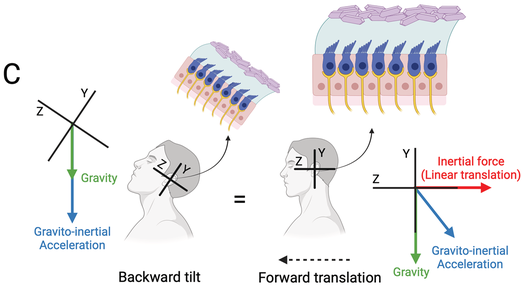
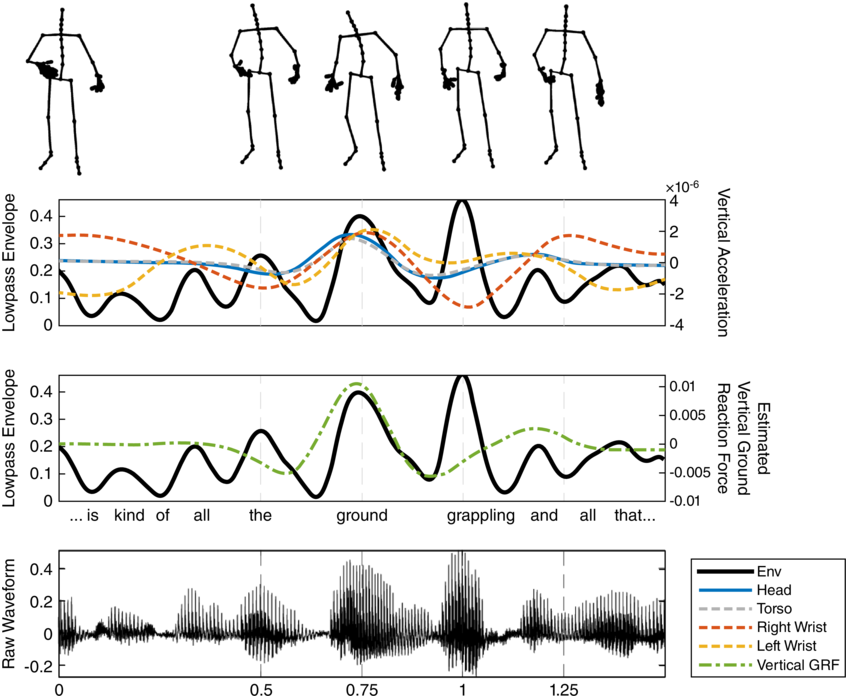
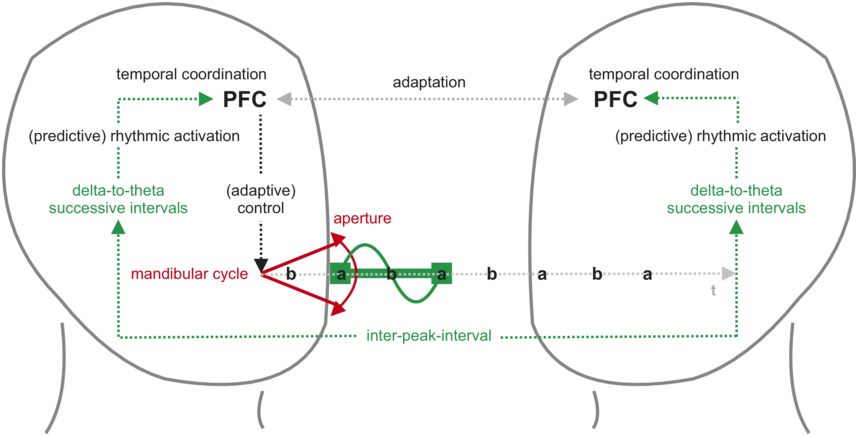
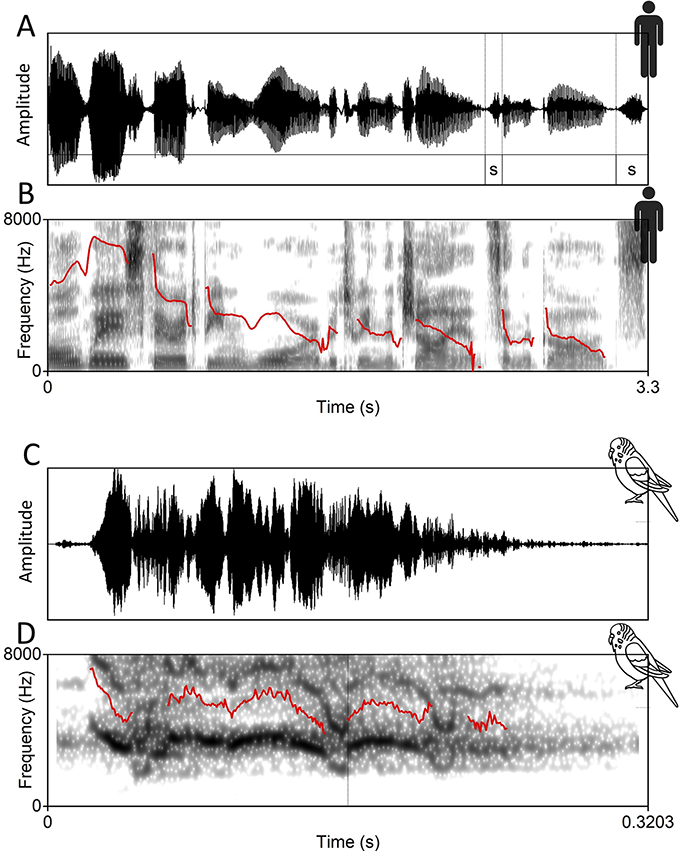

 Open access
Open access