

6.1 Introduction: Varieties of Data in EU Legal Scholarship
The present chapter offers an overview of the varieties of data that are used in EU law scholarship. The chapter is based on a systematic analysis of data sources used in 248 academic articles on EU law, particularly on EU courts.Footnote 1 Each article was analysed with respect to its geographical coverage, empirical approach, qualitative or quantitative focus, methods, data, as well as the opportunities and limitations arising from the data and method employed. The aim of this chapter is threefold. First, it offers an overview of the types of data in EU legal scholarship on courts. Second, it engages critically with the possibilities and limitations of different data sources and the associated research methods and how the understanding of these can improve the study of EU law. Finally, the chapter seeks to stimulate a critical discussion on to what extent the emerging and non-traditional data sources complement or challenge the traditional understandings of what counts as law.
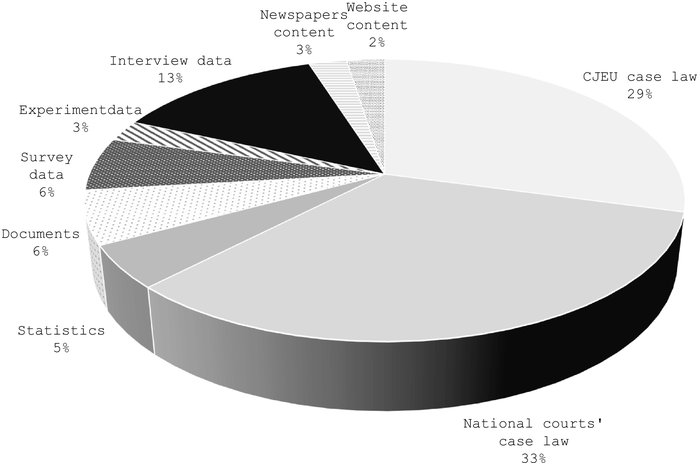
The outcome of the systematic literature review was unsurprising: doctrinal legal research continues to dominate the study of EU courts. Of the 248 articles analysed,Footnote 2 142 (57 per cent) involve doctrinal legal research based on, most commonly, courts’ case lawFootnote 3 and other legal documents.Footnote 4 This is expected, considering that legal research dominated scholarship on EU law throughout the twentieth century.Footnote 5 Other non-empirical contributions, although only a small number (12 in total), are from disciplines such as public administration,Footnote 6 sociology,Footnote 7 or finance.Footnote 8 The remainder of this chapter is based on an analysis of the 82 papers from the literature review (33 per cent) that are of empirical nature: either based on qualitative, quantitative, or mixed data. In Section 6.1.1, I start by examining the most common source of data: case law, both from the Court of Justice of the EU (CJEU) and national courts (62 per cent). Next, in Section 6.1.2, I explore data deriving from other official sources, such as reports, statistics, and other documents (11 per cent), which often complement the data based on the case law. Section 6.1.3 looks at expert data from other sources: interviews, surveys, experiments, newspapers, media, and courts’ websites (27 per cent). The distribution of data sources discussed in this chapter is illustrated in Figure 6.1.
6.1.1 Data from Case Law
More than 60 per cent of the studies analysed rely on case law as a primary data source (see Figure 6.1). However, it is important to distinguish between studies relying on data based on the CJEU’s case law (29 per cent) and those based on national courts’ case law (33 per cent).
6.1.1.1 The CJEU’s Case Law
The CJEU’s Curia database is a goldmine for researchers across the disciplines interested in EU law. At the time of writing, EU courts have delivered over 40,000 decisions, with almost 3,000 cases currently pending.Footnote 9 Early work on the CJEU written during the 1980s and 1990s came primarily from legal scholars such as Stein,Footnote 10 Snyder,Footnote 11 Shapiro,Footnote 12 Rasmussen,Footnote 13 Lenaerts,Footnote 14 Arnull,Footnote 15 and Weiler.Footnote 16 They focused on the interpretation of the CJEU’s judgments, explaining the origin and formal consequences of EU law doctrines such as supremacy, direct effect, or state liability,Footnote 17 as well as on the impact of the CJEU on the European integration processes and the development of a ‘symbiotic relationship between national courts and the Court of Justice’Footnote 18 via the preliminary ruling procedure.Footnote 19 Other scholars soon joined the debate, contributing new insights and data. In the mid-1990s, the literature on European legal integration expanded dramaticallyFootnote 20 and, by the turn of the century, American political scientists had published more work on the CJEU than on any other court except for the US Supreme Court.Footnote 21
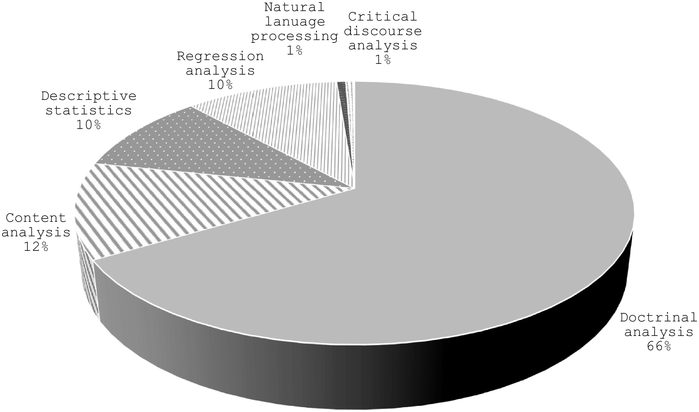
Based on the systematic literature review, the most prevalent method used to analyse the CJEU case law after doctrinal legal analysis (66 per cent; see Figure 6.2) is qualitative content analysis (12 per cent), which involves analysing and interpreting the content of textual data in order to ‘provide a systematic way to identify patterns, concepts, and larger themes within the data to gain insight into the meaning and context of the content’.Footnote 22 For example, Passalacqua analysed 291 CJEU rulings in the field of EU migration law to map migrants’ rights defenders before the Luxembourg court,Footnote 23 while Pavelek and Zajíčková analysed 98 Court decisions in the area of data protection to map the trends and actors involved in these proceedings.Footnote 24 Other methods include descriptive statistics,Footnote 25 critical discourse analysis,Footnote 26 and natural language processing.Footnote 27
Methods of EU scholarship to analyse the CJEU’s case law.
Most studies use EurLex or Curia as primary data sources, either by hand-coding or web scraping the data. In 1999, Stone Sweet and Brunnel published the largest data collection study in EU law of the time,Footnote 28 with ample information about the preliminary ruling procedure across time, Member States (MS), and subject matter areas.Footnote 29 This dataset was later updated by Naurin et al. and Dyevre et al.Footnote 30 Similar research efforts were made with respect to CJEU’s infringement proceduresFootnote 31 and actions for annulment.Footnote 32 Scholars have, however, raised questions regarding the reliability of the metadata available on Curia, arguing, for example, that the subject matter of preliminary references is manually assigned by the CJEU’s legal service and does not completely capture the topic of the judgment.Footnote 33
The majority of similar datasets are smaller and produced for a specific MS,Footnote 34 policy area,Footnote 35 or time period.Footnote 36 Although of a smaller scale, these datasets offer important insights into certain country-specific drivers of referral rates, such as a country’s legal cultureFootnote 37 or the behaviour of the CJEU under the threat of override.Footnote 38 They are often based on qualitative content analysis, offering more detailed insights into specific cases and the broader context surrounding them. Yet, the question of the extent to which such insights can be generalised remains.
Large datasets of the CJEU’s case law are rare because they require a long and tedious process of hand-coding references submitted to the CJEU – which, at the time of the writing, totals 12,550 cases.Footnote 39 Besides being time-consuming, hand-coding requires ample resources. Some scholars have resorted to web scraping, text mining, and network analysis to derive insights. For example, Dyevre et al.’s analysis of more than 200,000 legislative acts produced by the EU since the 1950s showed that the most prevalent topics in EU legislation are related to Common Agricultural Policy (CAP) and the single market, and not constitutional issues as one would conclude from legal journals.Footnote 40 Meanwhile, Derlén and Lindholm used network analysis of the CJEU’s citations to challenge a traditional picture of EU law that portraits van Gend en Loos as a central case.Footnote 41
Thus, while we see an increase in the availability of data on the CJEU’s case law (see Table 6.1), ‘these data-collection efforts [are] overlapping, uncoordinated, and not always easily accessible’.Footnote 42 The IUROPA Project, founded in 2018, has tried to address this issue, together with many other difficulties associated with large-scale data collections based on the CJEU’s case law.Footnote 43 The project’s CJEU Database is the most complete collection of data on the CJEU to date and, importantly, it is regularly updated.Footnote 44 This cannot be said for other similar databases where data collection efforts are often discontinued when funding ends. One exception is the Judicial Proceedings in the European Union dataset by Ovádek, which is updated automatically.Footnote 45
| Project/author | Scope | Publicly available | Time frame |
|---|---|---|---|
| Evolution of European Union Law (EvoEU) Database Fjelstul (Reference Fjelstul2023)Footnote 48 | Connections between EU law, the CJEU’s case law, national case law that applies EU law, and national law that implements EU law | Yes (https://jfjelstul.github.io/evoeu/) | 1951–2015 |
| The European Union case law corpus (EUCLCORP) Trklja and McAuliffe (2018)Footnote 49 | Standardised, multidimensional and multilingual corpus of terminological and phraseological phrases in the CJEU case law | Yes, only to registered users (https://llecj.karenmcauliffe.com/euclcorp/) | 1952–2018 |
| IUROPA Database PlatformFootnote 50 | 9 datasets, each with a different unit of observation: cases, proceedings, decisions, parties, procedures, assignments, submissions, citations, and judges | Yes, upon request (https://www.iuropa.pol.gu.se/) | 1953–ongoing |
| Centrality Over Time of CJEU Decisions Derlén and Lindholm (Reference Derlén and Lindholm2014)Footnote 51 | Case citations in all CJEU judgments | Yes (https://data.mendeley.com/datasets/c8tg89hrbr/1) | 1954–2011 |
| Project/author | Scope | Publicly available | Time frame |
|---|---|---|---|
| The Archives project Database on Cases and Lawyers of the CJEU Avril and Brissaud (2021)Footnote 52 | All parties in the cases before the CJEU | No | 1954–2020 |
| Judicial Proceedings in the European Union Ovádek (2021)Footnote 53 | All CJEU judicial proceedings | Yes (https://michalovadek.github.io/eucourt/) | 1957–ongoing |
| EUTHORITY Project Preliminary References Dataset Dyevre et al. (Reference Dyevre, Glavina, Lampach, Ovádek and Wijtvliet2018)Footnote 54 | Preliminary ruling procedure | Yes (https://euthority.eu/?page_id=795) | 1958–2020 |
| EUTHORITY Project GEOCOURT Dataset Dyevre and Lampach (Reference Dyevre and Lampach2021)Footnote 55 | Geographic coordinates of the courts that have submitted preliminary references | Yes (https://euthority.eu/?page_id=795) | 1958–2020 |
| Stone Sweet and McCrown (2004)Footnote 56 | Infringement proceedings and preliminary ruling procedure – free movement of goods | No | 1961–1998 |
| Carrubba and Gabel (Reference Carrubba and Gabel2015)Footnote 57 | Infringement proceedings | Yes (https://polisci.emory.edu/home/people/biography/carrubba-clifford.html) | 1961–1999 |
| Project/author | Scope | Publicly available | Time frame |
|---|---|---|---|
| Data Set on Preliminary References in EC Law (Art. 234) Brunell and Stone Sweet (1998)Footnote 58 | Preliminary ruling procedure | Yes (https://glpn.la.utexas.edu/2018/05/19/18-0024-data-set-on-preliminary-references-in-ec-law-art-234-1961-2006/) | 1961–2006 |
| Larsson and Naurin (Reference Larsson and Naurin2016)Footnote 59 | Infringement proceedings | No | 1961–2016 |
| Berlin Infringement Database Börzel (2021)Footnote 60 | Infringement proceedings | Yes (https://www.polsoz.fu-berlin.de/en/polwiss/forschung/international/europa/bid/index.html) | 1978–2019 |
| Castro-Montero et al. (2018)Footnote 61 | Infringement proceedings | No | 2000–2017 |
Large-scale datasets such as these are mostly used to explore the drivers of national courts’ referral behaviour – very often complemented by other data sources including official statistics, reports, and other documents (see Section 6.1.2) – or the extent to which different parties (MSFootnote 46 or litigantsFootnote 47) impact the decision-making of the Court. Some studies have tried to uncover individual voting preferences of the CJEU’s judges based on the Court’s case law, in an attempt to address the ‘black box’ problem of European judicial politics. For example, Malecki showed that judges do not share uniform preferences in favour of EU integration: instead, their preferences lie on a continuum ranging from Europhilia to Euroscepticism.Footnote 62 Wijtvliet produced similar findings for judges of the General Court.Footnote 63
The field keeps evolving. Machine learning – probably the most contested method used to analyse the courts – is now being used on case law data to predict future decision-making. While this has so far been more successful in the case of the European Court of Human Rights (ECtHR),Footnote 64 EU law scholars have resorted to using Advocate General (AG) opinions to predict the Court’s decisions; the Court follows the AG’s opinion in 67–88 per cent of cases, depending on the study.Footnote 65 A recent study by Fjelstul uses a case-space model and machine learning to generate predictions on the impact of the panel size on the outcome of the CJEU’s infringement cases.Footnote 66 However, in 2019, France passed a controversial law that criminalised research on the behaviour of individual judicial behaviour in order to protect judges’ independence and reputation.Footnote 67 Developments such as these are particularly damaging for big data-driven projects that use machine learning and prediction algorithms.Footnote 68
6.1.1.2 National Courts’ Case Law
EU law scholarship relying on national courts’ case law as the main data source often tries to account for the limitations of existing EU law datasets. One of the limitations is the fact that for the last three decades legal scholars and political scientists have focused largely on preliminary ruling procedure as the most visible aspect of EU law use.Footnote 69 Hübner’s 2015 study is one of the few attempts to estimate the bulk of national case law that relates to EU law outside of the preliminary ruling procedure.Footnote 70 She introduced the Dec.Nat. Database (National Decisions Database) which contains 36,400 national decisions involving EU law.Footnote 71 The database, however, suffers from a couple of weaknesses. First, selection bias: the database covers only those national decisions that the CJEU, its administrators, and/or national courts have deemed important for the purpose of monitoring national case law relating to EU law,Footnote 72 whereby the selection process is not motivated by systematic criteria.Footnote 73 Second, since 2003 and under resource pressure, the database has been limited to decisions issued by national courts of the last instance and to those decisions that consider ‘innovative points of law and legal reasoning’.Footnote 74 Other comparable data collection efforts such as the JuriFast, Caselex, or CODICES databases suffer from similar shortcomings.Footnote 75
Other notable large-scale databases of national case law include the European Commission for the Efficiency of Justice (CEPEJ) and the EU Justice Scoreboard data. The CEPEJ was established by the Council of Europe (CoE) in 2002 with the aim of improving the efficiency and functioning of justice in CoE MS. Following the establishment of the CEPEJ, in 2013 the Commission launched its own evaluation instrument called the EU Justice Scoreboard, with the aim of helping EU MS to improve the efficiency of their justice systems. Since its launch, the CEPEJ has been contributing data on several indicators: courts’ caseload, length of proceedings, and courts’ staff. When assessing the efficiency of justice of CoE and EU MS, courts’ workload and the timeframe to solve cases take centre stage.Footnote 76 While the CEPEJ and EU Justice Scoreboard data has been extremely valuable in practice, sparking policy changes at the national levelFootnote 77 and being increasingly used in academicFootnote 78 and political debates, scholars suggest extreme caution ‘when using such data for scholarly, legislative or policy discourses’.Footnote 79 Limitations include historical data series inconsistencies, as well as inconsistencies in the category, nature, and status of cases. Similar to the Dec.Nat database, divergences in MS’ methodologies and definitions, as well as the lack of systematic selection criteria, make data difficult to compare robustly between the MS.
Other scholarly efforts in collecting national courts’ case law are of a smaller scale, focusing primarily on a limited number of MSFootnote 80 or a specific policy area.Footnote 81 For example, Conant collected French, German, and British courts’ citations of the CJEU’s case law and EU law sources and reported that ‘national judges who do invoke European provisions in their decisions are likely to interpret the treaties, regulations, and directives without any explicit reliance on ECJ case law’.Footnote 84 Furthermore, Obermaier explored the role of national courts in the implementation and enforcement of EU law, focusing primarily on MS’ acceptance of the Kohll/Decker doctrine, to explore how far the national courts’ rulings were decisive in the implementation of the CJEU’s doctrines into national social security legislation. Also looking at France, Germany, and the UK, he found that implementation of the CJEU’s rulings takes place faster and smoother when national courts accept and apply CJEU doctrine. In all three MS, national courts successfully influenced the implementation of the Kohll/Decker doctrine by forcing the legislator to incorporate the doctrine into national social law.Footnote 85
Chalmers, too, warned that EU scholarship on legal integration focuses too narrowly on ‘those minority of judgments referred to the ECJ from national jurisdictions’.Footnote 86 He collected all reported judgments between 1971 and 1998 in which British judges addressed a question of EU law or British accession to the EU (n = 1,088). He concluded that British judges’ engagement with EU law is very narrow both with respect to legal areas it covers and the change it provoked: only in 8 per cent of cases have the litigants successfully invoked economic freedoms governed by EU law.Footnote 87 Chalmers concluded that ‘it is difficult to believe that the British experience on the narrow application of EC law is unique’.Footnote 88 Dyevre subsequently compiled a new dataset coding doctrinal positions of 34 national courts at the highest level (supreme and constitutional courts) to capture courts’ doctrinal responses to European integration.Footnote 89 These data collection efforts have been further extended by EUTHORITY’s Domestic Judicial Response (DJR) Dataset, which collects and hand-codes information on the decisions issued by 64 highest-level national courts in the EU on the relationship between EU law and domestic law – although official publications from this project are still pending.Footnote 90
Nyikos went further and examined the enforcement of the preliminary ruling procedure, exploring how often the referring court complies with the preliminary ruling issued by the CJEU. She found that the level of compliance among national courts is extremely high: the CJEU’s ruling was implemented in 96 per cent of cases. The referring court evaded or did not implement the CJEU’s ruling in less than 4 per cent of cases – either by reinterpreting the facts of the case or claiming that the CJEU had exceeded its jurisdiction.Footnote 91 The latter situation was documented in the famous Arsenal v. Reed case where the British judge refused to follow part of the CJEU’s ruling under the rationale that the ruling concerned the facts of the case which, in this judge’s view, was outside of the CJEU’s jurisdiction.Footnote 92 This example, according to Davies, ‘serves as a reminder that the Court is dependent upon national judges and has good reasons to be sensitive to the division of functions between them’.Footnote 93
The majority of these studies focus on (Western) MS, with a handful of them examining the impact of EU law and the CJEU’s case law on EU candidate states or neighbouring countries. For example, Reich and Micklitz collected and analysed citations of the CJEU’s judgments by national courts in Armenia, Azerbaijan, Georgia, Israel, Jordan, Russia, Switzerland, Tunisia, Turkey, Ukraine, and the Eurasian Economic Union.Footnote 94
While studies focusing on national courts’ case law offer valuable information on the actual enforcement and reception of EU law on the ground, they suffer from several shortcomings. First – and similar to CJEU case law databases – data collection efforts on national case law involving EU law have been equally overlapping, uncoordinated, and even more inaccessible (see Table 6.2). Furthermore, collecting data from tens of thousands of courts across the EU – who adjudicate hundreds of thousands of cases each year – by manual coding or web scraping would be a mammoth effort and create noise in the data. More importantly, many courts do not publish their judgments online; this is especially true for lower national courts. Researchers interested in obtaining this data should, therefore, be prepared to enter a court’s archives and manually analyse judgments of interest.Footnote 95 Because of limited access to this data, many studies narrow their focus to specific MS (France, Germany, and the UK are particularly popular), a specific type of court (e.g., supreme and/or constitutional courts, whose workload is not as heavy and whose decisions are generally accessible online), or a specific policy area. To circumvent the fundamental problem of access, some studies even employ surveys or experiments in the classroom, where students act as judges.Footnote 96 Again, this raises the issue of the generalisability of findings to the entire EU.
| Project/author | Scope | Publicly available | Time frame |
|---|---|---|---|
| EUTHORITY Project Domestic Judicial Response (DJR) Dataset | Doctrinal positions of 34 highest national courts towards European integration | No | 1958–2020 |
| Dec.Nat. Database (National Decisions Database) | National courts’ decisions involving EU law (since 2003 only highest courts’ decisions) | Yes (https://www.aca-europe.eu/index.php/en/dec-nat-en) | 1959–ongoing |
| Nyikos | Enforcement of preliminary ruling procedure by referring court (Germany, France, Netherlands, Belgium, UK) | No | 1961–1994 |
| CODICES database Council of Europe (CoE) | Constitutional courts’ decisions (EU MS and other countries) | Yes (https://codices.coe.int/) | 1965–ongoing |
| Conant (Reference Conant2002)Footnote 82 | French, German and British courts’ citation of the CJEU’s case law and EU law sources | No | 1983–1999 |
| Chalmers | Judgments of British courts that address a question of EU law or British accession to the EU | No | 1971–1998 |
| Obermaier (2008)Footnote 83 | French, German and UK courts’ implementation and enforcement of EU law | No | 1998–2006 |
| Project/author | Scope | Publicly available | Time frame |
|---|---|---|---|
| JuriFast Database ACA Europe | Most important cases in which national highest courts apply EU law | Yes (https://www.aca-europe.eu/index.php/en/jurifast-en) | 2000–ongoing |
| Ceselex database | National courts’ case law linked to EU law | No | 2000–2010 |
| CEPEJ (European Commission for the Efficiency of Justice) Council of Europe (CoE) | Data related to judicial systems of CoE MS | Yes (https://www.coe.int/en/web/cepej/cepej-stat) | 2010–ongoing (every two years) |
| EU Justice Scoreboard | Overview of indicators on the efficiency, quality and independence of justice systems in EU MS | Yes (https://commission.europa.eu/strategy-and-policy/policies/justice-and-fundamental-rights/upholding-rule-law/eu-justice-scoreboard_en) | 2015–ongoing |
6.1.2 Data from Official Statistics, Reports, and Other Documents
Case law data is often complemented by data based on official statistics, court or county official reports, and other documents. The preliminary ruling procedure is a prime example of a topic where these two data sources meet. The doctrinal debate on what drives a national court’s preliminary questions to the CJEU revolved primarily around the obligation versus discretion of national courts to refer questions to Luxembourg, yet legal scholarship had failed to offer convincing empirical evidence to account for the referral activity of national courts.Footnote 97 This is where the empiricists came in: some of the empirical factors put forth by the political science and economics literature include macro-level factors such as divergences in MS intra-EU trade,Footnote 98 GDP,Footnote 99 population size,Footnote 100 or years of EU membership,Footnote 101 as well as meso-level factors such as and type and level of the courtFootnote 102 or court’s workload,Footnote 103 and micro-level factors such as judges’ knowledge of, experiences with, and attitudes towards EU law.Footnote 104
To explore this topic many studies have combined preliminary reference data based on the CJEU’s case law (see Section 6.1.1.1) with other external datasets and data sources such as Eurobarometer, Eurostat, or the Commission’s Annual Macro-Economic database (AMECO)Footnote 105 (see also Figure 6.1). This data is, however, much more suited to exploring macro-level variables such as the effect of intra-EU trade, GDP, or population size, for which there is also easily accessible data, than it is for exploring meso- and micro-level variables such as judges’ knowledge of EU law, experiences with EU law, and their attitudes towards the EU.Footnote 106 The ability to draw inferences about the distinct influences of micro- and meso-level variables is severely restricted by the lack of data on national judiciaries. To explore these factors, scholars have often resorted to proxies. For example, Hornuf and Voight use the number of graduates from the College of Europe in Bruges as a proxy for the familiarity with EU law,Footnote 107 while Dyevre and Lampach rely on the years of a country’s EU membership.Footnote 108 Such use of proxies has not been without criticism.Footnote 109
Other sources of data present in EU scholarship on courts include a range of reports and official documents, including official documents and statements of EU Presidencies,Footnote 110 Commission’ decisions and speeches of Commissioners,Footnote 111 the European Court of Auditors annual reports,Footnote 112 the CJEU’s annual reports on judicial activity,Footnote 113 and European Ombudsman decisions.Footnote 114 These are often combined with judicial’ case law. For example, Kameoka combines the qualitative content analysis of the CJEU’s case law with the analysis of the Commission’s official documents to explore how legal professional privilege is interpreted in EU competition law,Footnote 115 while Stylianou and Iacovides supplement the CJEU’s case law and AG’s opinions with the Commission’s decisions and speeches from Commissioners for Competition to reveal the underlying goals of EU competition law.Footnote 116 Regarding the preliminary ruling procedure, Pavone combines data based on local courts’ referrals to the CJEU with interview results, newspaper records, and public opinion data to demonstrate the transformation of Italian port law following the ‘Port of Genoa’ case.Footnote 117
While such data sources are useful for data triangulation, thereby raising the reliability and validity of results, they suffer from a key weakness: access. Some official statistics may not be available for a desired time period. Examining limited access to documents, Leino-Sandberg argued that, while EU institutions, offices, and bodies are in possession of various documents that are of high importance for legislative and policy outcomes in the EU (and, therefore, for EU law scholarship), ‘beyond leaks that sometimes appear in Politico or the Financial Times, access to legal opinions remains highly restricted and largely relies on individuals making public access requests under the EU’s public access legislation’.Footnote 118 While the EU courts and the European Ombudsman played an important role in facilitating public access to such documents, Leino-Sandberg remains sceptical that future research employing such data ‘is threatened by an increasing problem of empty archives’, with institutions ‘actively engaged in destroying existing records to avoid public scrutiny’.Footnote 119
6.1.3 Data from Experts
The two data sources explored in the section above (case law and official statistics) tell us little about the role of individual actors in shaping the decision-making of the EU courts, or about the acceptance and perception of EU law by different actors at the national and EU level. As discussed in detail above, nor is this data suitable for exploring meso- or micro-level variables. Additionally, there is growing criticism that EU scholarship focuses too much on CJEU case law that is itself too narrowly focuses on the minority of cases which end up at the CJEU, ignoring the fact that the majority of enforcement of EU law happens at the national level by national courts and other authorities.Footnote 120 For instance, regarding the preliminary ruling procedure, scholars have been criticised for ignoring the fact that preliminary references do not originate from MS or their courts but are rather a work of individual judges.Footnote 121
To account for this criticism, a new generation of scholars has started looking at court composition and the role of individual actors and their ideologies, attitudes, knowledge, and experiences in the process of the application of EU law. However, instead of using proxies (see Section 6.1.1.1), they resort to different types of data: secondary data on judges’ biographies, interviews, and survey data.
6.1.3.1 Interviews
The second-most used data after judicial’ case law is interview data (13 per cent; see Figure 6.1). Until the early 2000s, EU law scholarship focused primarily on MS’ and national courts’ acceptance of EU law, ignoring the role of individual judges, référendaires, law clerks, and litigants. This changed in the mid-2010s.
In 2013, Nowak et al. launched a study on the knowledge experiences and attitudes of Dutch and German judges towards the EU and EU law.Footnote 122 Interviews on the incentives and constraints in the application of EU law were later undertaken by Jaremba in PolandFootnote 123 and Glavina in Slovenia and Croatia.Footnote 124 All three studies show striking similarities: judges do not think they encounter EU law cases very often, are not so sure about their knowledge of EU law, and often do not apply EU law because of a lack of time, knowledge, and resources to engage with ‘such a complicated topic’.Footnote 125 Tatham interviewed Hungarian judges regarding their experiences with EU law and – similar to GlavinaFootnote 126 – he identified foreign language skills and EU law training as two key elements that would encourage the application of EU law by national judges.Footnote 127 Krommendijk’s work tackled the reasons that Dutch and Irish judges tend not to refer preliminary questions,Footnote 128 and Leijon’s study on Swedish judges further explored judges’ reasoning for providing (or not) their own opinions in their references for a preliminary ruling.Footnote 129 Only one study in the literature review involved interviews with référendaires.Footnote 130
Interviews with judges are a rewarding tool for exploring how EU law is applied in practice and how it is perceived. They help to shed light on the reality of EU law and uncover factors that could not be detected through purely legal or quantitative analysis. However, interview-based research suffers from several, very often practical, shortcomings. The most visible issue is once again: access. No study has employed in-depth interviews to explore the attitudes and experiences of CJEU judges. Indeed, this is a difficult task: political elites such as judges are unlikely to participate in studies or offer (fully) honest answers,Footnote 131 making any conclusions unreliable. Popular interviews with CJEU judges, such as Judge Sasha Prechal’s interview with the European Law Blog,Footnote 132 are not scientific and are light on content. This is why scholars interested in judicial politics have resorted to using votes,Footnote 133 or other proxies such as the party affiliation of the appointing presidentFootnote 134 or the appointing government,Footnote 135 as explanations for judges’ behaviour. National supreme or constitutional court justices are also rarely included in studies because – with these highest courts hosting only a handful of justices – it is difficult to grant full anonymity. Lower court judges can more easily preserve anonymity and, ideally, speak openly. Furthermore, unlike judges sitting on constitutional or supreme courts, lower court judges are rarely considered political elites or celebrities.Footnote 136 Worth mentioning, however, is that it is difficult to ensure a participant’s anonymity when conducting an interview: the process inevitably involves the exchange of private information, such as name and contact details, and often involves a face-to-face meeting. The best the researcher has to offer is pseudonymisation of the research data (preceded by obtaining a strict ethical approval).Footnote 137
Access to lower-court’ judges also presents a challenge because judges must be approached through the president of a court.Footnote 138 Furthermore, interviewing judges often requires permission from relevant authorities, such as the ministry of justice, the council of the judiciary, or the (supreme) court presidents, which can take time. Glavina referenced two court presidents who refused to forward the call for research to judges because their ‘judges are too busy to participate in the study’.Footnote 139
Another methodological issue with interview data is the problem of self-selection bias and the generalisability of results. First, studies on the application of EU law at the national level are naturally more likely to attract more Europhilic judges or judges who more often deal with EU law in their daily work.Footnote 140 Is the sample then representative of the population? This problem may to some extent be addressed with a sampling strategy that includes different levels and types of courts, different regions, or MS, generating a more representative sample.Footnote 141 Finally, researchers may encounter potential struggles for control of the data, whereby the interviewee attempts to manage the interview process or data interpretation.Footnote 142 Interviewees, of course, have the full right to withdraw their consent to participate in the study at any point, even after the interview has been conducted.Footnote 143 Yet, the question of usability of such data remains.
Judges are, however, not the only actors of EU law that have been covered by interviews. In his seminal work on the transformation of Italian port law,Footnote 144 Pavone conducted interviews with Genoese legal professionals, twenty lawyers, seven judges, and ten law professors. Pavone followed the work of two Eurolawyers – Giuseppe Conte and Giuseppe Giacomini – who used EU competition law as a basis to challenge a centuries-long monopoly over the Genova port by the dockworkers’ union.Footnote 145 Another example includes the work of Everson and Eisner who interviewed lawyers and judges of the High Court of England and Wales to uncover the leading role of lawyers in accepting the supremacy of EU law.Footnote 146 Kilpatrick’s study similarly uncovered that a high number of gender equality preliminary questions from North West Germany was driven by a small number of Europhilic lawyers.Footnote 147 Interviews with lawyers, too, pose challenges that are not sufficiently addressed by empirical legal research. Here, we also encounter issues of access and confidentiality, as well as potential struggles for control of the data.
Recent research efforts have started looking at the role of those who mobilise EU law. After all, without litigants there are no cases that could reach the CJEU.Footnote 148 The literature has focused on NGOs, equality bodies, trade unions, and human rights associations in EU non-discrimination law,Footnote 149 migration law,Footnote 150 and environmental law.Footnote 151 While many of these studies relied on the CJEU’s case law as their main data source,Footnote 152 other studies use interview data with NGOs and equality bodies involved in initiating some of the landmark EU law cases: Muir and Kolf uncovered the crucial role of the Belgian equality body CGKR (‘Centre for equal opportunities and opposition to racism’) in the development of EU racial discrimination law.Footnote 153 Similarly, Miller combined interviews with case law, documents, and newspaper analyses to trace the transformation of Danish disability law through legal mobilisation of EU law and the preliminary ruling procedure.Footnote 154 Passalacqua mapped collective actors in the field of migration law (so called ‘migrant rights defenders’) that helped to change restrictive national migration laws and policies,Footnote 155 while, in a very recent study, van der Pas uncovered the conditions under which actors mobilise EU law.Footnote 156
6.1.3.2 Surveys and Experiments
Survey data can reflect public opinion or expert opinion. Studies of public opinion on courts are a more recent development. Consider the Eurobarometer public opinion surveys: questions about the European Parliament (EP) and the Commission were already a part of these in the 1980s;Footnote 157 questions about the EU courts (the CJEU and the Court of Auditors) were added much later.Footnote 158 Once this data became available, scholars started looking into the levels and drivers of public support towards the CJEU via a range of related concepts: trust, confidence, public support, diffuse support, or legitimacy.Footnote 159
Caldeira and Gibson’s Reference Caldeira and Gibson1995 study building on the Eurobarometer data did not find much diffuse support for the CJEU among the public, arguably because the CJEU was still a young institution at the time; they did expect the Court’s visibility and support to increase in the future. Their findings further highlighted that public attitudes towards the CJEU are partly shaped by public attitudes towards the EU.Footnote 160 Also relying on Eurobarometer’s data, Kelemen’s 2012 study showed that that the CJEU is consistently and by far the most trusted institution in the EU.Footnote 161 Finally, Arnold et al. used the Eurobarometer data to explore the drivers of citizens’ trust in EU political institutions and found that the MS’ corruption levels are the most important drivers of the relationship between national and EU institutional trust: lower levels of perceived national corruption go hand in hand with more trust in the CJEU.Footnote 162 Furthermore, their findings suggested that women are less inclined to trust the CJEU compared to men, which is in line with earlier research that important CJEU decisions in favour of women’s interest had had no impact on women’s support for the Court.Footnote 163
Other studies go beyond the large-scale Eurobarometer data. Grosfeld et al., for example, collected survey data on 1,180 individuals from Finland, France, Germany, Italy, Netherlands, and Poland via the online participant platform Prolific. They demonstrated that value alignment plays an important role in the perceived legitimacy of the CJEU and the EU.Footnote 164 Other uses of large-scale surveys on public opinion include the European Social Survey (ESS), which captures Europhilic/Eurosceptic attitudes, and Google Trends data to capture public interest in the CJEU.Footnote 165 Studies using experiment-based data are not uncommon either. Cheruvu, for example, relies on a vignette experiment with the German public to uncover public support for EU law. His results show that when a local court decides an issue of EU law based on the CJEU’s preliminary ruling, this increases citizens’ support for EU law.Footnote 166
Other types of survey data on EU law capture experts’ opinions, most commonly national judges. Already in 2007, the European Parliament published a report based on a survey of more than 2,300 judges on the role of national judges in the European judicial system.Footnote 167 The report revealed significant disparities in the knowledge of EU law among judges, a limited awareness of EU law, a lack of knowledge of the preliminary ruling procedure, difficulties with accessing information on EU law, a perception of EU law as excessively complex and opaque, and the need to enhance judicial knowledge of foreign languages.Footnote 168 Following on from this report, Nowak et al. emphasised the disparity between the academic literature and the reality that judges face when applying EU law.Footnote 169 They identified three general clusters of problems that could affect national judges’ ability to fulfil the EU’s expectations: (a) judicial experiences with the application of EU law in their daily work, (b) judicial knowledge of EU law, and (c) attitudes of individual judges towards the EU, EU law, or their new role as European judges.Footnote 170 Similar results were later obtained by Jaremba on Polish judges,Footnote 171 Mayoral on Spanish judges,Footnote 172 and Glavina on Slovenian and Croatian judges.Footnote 173 Their research efforts resulted in several combined empirical outcomes.Footnote 174
Other studies have surveyed other court staff such as law clerks and assistants to, for example, assess the training needs with regard to EU law;Footnote 175 policy-makers, civil servants, companies, interest groups, and scientific experts to assess the level of (non-)compliance of MS with EU law;Footnote 176 and experts on EU law to assess the strength of the European Court of AuditorsFootnote 177 or the ideology of judges serving on the General Court.Footnote 178
Survey-based research on EU law has been extremely valuable in uncovering the reality of EU law application at the national level and all the challenges that come with EU membership. Yet, similar challenges as with the interview-based research arise. As already discussed above, the principal practical challenge is access to respondents – and, thus, data (see Section 6.3.2). Another problem is the response rate: for example, a 2012 European Parliament study received 6,000 responses from judges and prosecutors, representing only 5 per cent of all judges and prosecutors in the EU.Footnote 179 Mayoral’s study on Spanish judges received a response rate of only 2.3 per cent;Footnote 180 Jaremba’s study on Polish judges 8 per cent;Footnote 181 Nowak et al.’s study on German judges 10 per cent.Footnote 182 Glavina’s response rate from Croatian and Slovenian judges was 16.6 and 14.7 per cent respectively.Footnote 183 Only in the Netherlands has the response rate been higher – 32 per cent – which the authors attribute to Dutch judges already being acquainted with participating in online surveys.Footnote 184 This raises the question of what level of response rate is sufficient to make valid and generalisable results? Of course, a higher response rate is preferable because missing data is never random.Footnote 185 However, boosting response rates within such an inaccessible group as judges poses a considerable challenge.
Self-assessment reports such as surveys have further been characterised as problematic as the data is often not able to be verified by other means. Furthermore, respondents such as judges may answer in a way that portrays themselves in a better light. Thus, the validity of the data depends very much on the sincerity of the respondents. In contrast, some of the novel literature defends the idea of using self-assessment reports with the argument that individual judges are the best experts on their own attitudes.Footnote 186 Respondents are also more likely to fill in a survey when it is about themselves.Footnote 187 In fact, motivation was found to be the strongest predictor of the validity of self-assessment reports.Footnote 188 Further methodological problems may arise when both dependent and independent variables are collected from the same source, which is known as the ‘problem of common method variance’.Footnote 189 This is common to studies on EU law that rely on regression analysis to analyse survey results, such as Glavina’s study on the drivers of referral behaviour among national judgesFootnote 190 or Grosfeld et al.’s study on public opinion about the EU,Footnote 191 although many other studies of survey results rely on descriptive statistics.Footnote 192
While it is important to acknowledge the problems associated with the use of self-reporting, there is no foolproof method to explore perceptions of judges and other experts in EU law. Focusing on the CJEU’s case law and the preliminary ruling procedure, for example, overlooks the bulk of cases that never reached Luxembourg; using judicial votes is not possible in many cases as they are not made public (in the case of the CJEU); or there may be a limited access to the case law (in the case of national courts). Using proxies, such as judges’ appointments and statements, is not ideal either, which will be discussed in more detail in the following section.
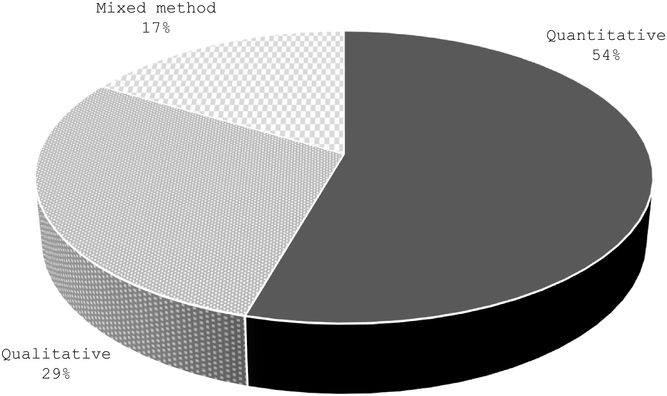
Some pitfalls may be addressed by data triangulation or adopting a mixed-method research design. Such a research design was adopted by 16.5 per cent of the empirical studies included in the literature review. Despite the advantages, mixed-method research remains rare in EU law scholarship (see Figure 6.3). This perhaps reflects the complexity of mastering multiple research methods, especially due to a lack of training of legal scholars in empirical methods.Footnote 193 But quantitative scholars should equally not rush to dismiss qualitative methods or data as ‘an easy way of conducting research’, because qualitative data has the potential to enhance their research in its own way.
6.1.3.3 Judges’ Biographies, Websites, and Newspapers
Because judges are such a hard group to gain access to, many scholars have resorted to proxies. This has introduced a whole new source of data: newspapers, social media, and other online information. While the use of data on judicial appointments,Footnote 194 party affiliations,Footnote 195 pre-nomination speeches by high-ranking justices,Footnote 196 or their statements in newspaper editorialsFootnote 197 has a prominent standing in the US, using this type of data in EU law scholarship is still relatively new.
Judicial Biographies.
Because of the secrecy of decision-making in European courts, particularly the CJEU, scholars interested in the voting preferences of judges have had to resort to secondary data. The most commonly used source of data in this respect is judicial biographies. For example, Malecki’s studyFootnote 198 on ideological preferences of the ECJ’s judges used a measure for the left–right composition of the appointing government based on the manifesto scores dataset by Kim and Fording.Footnote 199 Favale then looked at the practice of assigning copyright cases at the CJEU based on judges’ prior specialisation. To do so, she relied on judges’ biographical data from the Court’s website.Footnote 200 The CJEU’s website may, however, lack a lot of background data – whether because it is missing or deliberately omitted (e.g., a judge’s party affiliation).
To account for the limited data, Zhang et al. collected a whole range of background characteristics of judges to explore their potential effect on the outcome of competition law cases.Footnote 201 This included data on the judges’ country of origin, prior work experience (academic, civil servant, private practitioner, and judge), last job before joining the CJEU, country of legal training, age, and gender. In addition, they used the political ideology of the appointing governments as a proxy for the judge’s ideology. However, the country of origin is an imperfect proxy as it tells us little about whether a judge has lived or studied abroad and so been shaped by other legal traditions. The authors acknowledge that data from the CJEU’s website or annual reports is incomplete and supplement it with information from the European Council: whenever MS appoint a judge to the CJEU, the European Council publishes their resumes. When resumes were missing, the researchers made a formal information request to the European Council.Footnote 202 Yet, even there, crucial information on the judges’ background can be missing.
Comparable research efforts were conducted by the aforementioned IUROPA Project (see Section 6.3.1.1) where the JUDGES Dataset contains the name of the judges, their MS of origin, gender, positions at the Court, and professional background (judge, academic, civil servant, practicing lawyer, politician).Footnote 203 Although limited, similar research on collecting biographies has also been conducted on Advocates GeneralFootnote 204 and national judges.Footnote 205
News Articles.
Another source of data in EU law scholarship is news articles, based either on traditional or modern news sources. For example, Pavone’s seminal work on the port of Genoa made use of local and national papers, ranging from labour-friendly to more liberal outlets, and showed how Eurolawyers have strategically mobilised local press to sensitise public opinion and increase public awareness of EU law and the CJEU.Footnote 206 Miller used a similar approach on data triangulation, combining interview data, case law, and Danish newspaper analysis to illustrate the transformation of Danish anti-discrimination law,Footnote 207 while Schenk relied on newspaper articles, semi-structured expert interviews, and policy documents to explore the development of EU students’ free movement and cross-border welfare rights in England.Footnote 208 Finally, Glavina’s recent study on the emergence of dissenting opinions in the Croatian Constitutional Court relies on online newspaper data to track the appointing government as a proxy for judicial ideologies, and newspaper coverage of judges’ private lives as a proxy for judicial temperament.Footnote 209
Turning to the salience of the CJEU’s decisions, Dedeke explored the conditions under which CJEU decisions are subject to discussions in the news based on newspaper reports in eight broadsheets in six MS. His results showed that national media plays an important role in the way the CJEU’s decisions are observed and evaluated by the public.Footnote 210
Data based on secondary sources such as websites and newspapers offer a way to place legal developments in (historical) context. However, this data source also has several limitations. Chiefly, again, the problem of access. For example, older newspapers that are not fully digitalised may not be easily accessible and researchers may need to be prepared to enter physical archives to collect the data of interest. Furthermore, researchers using this type of data may easily find themselves in danger of selection bias, selecting news sources which lean more towards one side of the political spectrum, including that on European integration.
6.2 Concluding Remarks
This chapter has offered an overview of the varieties of data used in EU law scholarship and reflected on the opportunities and limitations of different data sources and their associated research methods.
This concluding section reflects on the sources of data which are underexplored in EU law research with the aim of stimulating a critical discussion of how such emerging and non-traditional data sources either complement or challenge traditional understandings of what counts as law. Underexplored sources of data include national courts’ case law, which remains very fragmented and limited to a handful of MS (Germany, France, and the UK). Research efforts that do cover all EU MS, such as the EUTHORITY Project’s DJR Dataset or the Dec.Nat. Dataset cover only the highest national courts. The extent to which lower national courts engage with EU law is still a vastly unexplored research area.
Another gap remains in respect to legal mobilisation in the EU. The legal construction of Europe via the preliminary ruling procedure has long been seen as an interaction among litigants, national courts, and the CJEU.Footnote 211 Yet, the questions of how, why, and when EU law is mobilised, and by which actors (public interest groups, businesses, individuals), remain unanswered. Recent research efforts by Glavina uncovered the leading role of businesses (private-interest actors) in the construction of Europe, critiquing EU legal mobilisation scholarship for its limited focus on public interest groups.Footnote 212 Glavina’s effort to theorise legal mobilisation of private-interest actors alongside the inclusion of information on the parties in the IUROPA CJEU Database Platform is a start, but more research is needed into who these private-interest actors are, their strategies for mobilising EU law, and how they differ from those developed by public-interest actors.
Finally, as noted by Brekke et al., there is surprisingly little research on the role of judges’ characteristics in the decision-making of European and national courts.Footnote 213 How does a judge’s MS of origin, gender, appointing party ideology, and professional background influence the working of the CJEU? The IUROPA dataset, which contains information on the background of judges, again, serves as a useful starting point in this regard.
A final word on whether legal and empirical research can be reconciled: throughout this chapter, I have critically reflected on what empiricists and legal scholars can learn from each other. To date, there have been five AG opinions on the referral behaviour of national judges, yet none of them makes references to any of the empirical literature on the topic.Footnote 214 This once again confirms the reality that the two disciplines – law and empirical perspectives – continue to operate in isolation. Legal doctrinal research has long been criticised for lacking any (empirical) evidence to support its normative claims; empirical legal studies (ELS), as Davies noted, can offer EU lawyers a new academic home – a place of asylum – offering empirical data and knowledge of methods to make their findings applicable beyond doctrine and to have a greater impact on society and policy-making.Footnote 215 On the other hand, legal scholars bring to the table a deep understanding of complex legal structures, without which an empirical scholar ‘has no idea whether what they are measuring has anything to do with the law’.Footnote 216 As argued by Naurin et al., deciphering judicial reasoning without legal training is at least as hard as crafting credible empirical research designs without proper training in research methods.Footnote 217 EU lawyers can, in that sense, be seen as natural partners to empiricists.Footnote 218 Yet, despite this, the two disciplines continue to operate in isolation: Epstein has shown that the percentage of empirical legal articles in traditional law journals is remarkably low – 5–8 per cent, depending on the study.Footnote 219 In contrast, journals with an ELS focus are much more open to papers from other disciplines, including law (66 per cent of covered European journals fall into the ELS category).
It seems that while ELS is ready to embrace legal scholars as their natural partners, law scholars continue to act as gatekeepers of the field, whether because of ignorance or an ambition to protect the traditional art of studying law. One thing is certain: legal scholarship is becoming more open to ELS. The question is who will board the boat and who will miss it.
7.1 Introduction
So far, empirical research in EU law has focused on courts and is heavily dominated by quantitative approaches, as if legal debates took place in judicial institutions and could be analysed numerically. This focus disregards qualitative empirical analysis of law and institutions, ignoring the political and administrative processes, from preparatory stages to implementation, where the law is interpreted and operationalised every day. Key actors in these processes include lawyers and legal experts operating in various roles in the EU institutions.Footnote 1 This chapter zooms in on legal data, such as legal opinions and other types of advice, and soft law documents involving the interpretation of law, outside the judicial context, in particular in the Commission and the Council.Footnote 2 Their legal services are particularly powerful in EU policy-making. Their mutual relationship is competitive yet symbiotic.Footnote 3 Legal services shape political decision-making in their institutions acting in the ‘background’, exercising their power of framing.Footnote 4 I understand EU law primarily as a language of argumentation to justify the choice in the service of a particular purpose. I treat internal legal work within the EU institutions as an exercise in professional legal speech that makes certain outcomes seem credible, necessary, or even unavoidable.Footnote 5 When legal doctrinal analysis reveals a range of possible interpretations, legal experts add professional judgment, which makes some interpretations plausible and others implausible according to ‘the conventions of their expertise and the pratices of their profession’.Footnote 6 Qualitative research methods can be used to make these interpretative practices visible and mirror them against alternative readings of the law that may lead to other consequences and priorities becoming dominant, enabling a critical examination of the politics involved. Access to data is key to knowledge. This point is regrettably often ignored when scholars construct research agendas and ask research questions based on the availability of data. I believe that there is a need to look deeper than the data that the institutions provide on their websites or make proactively available through their public registers.
In this chapter, I argue that systematically used access to documents (ATD) requests can be a source of data about the law-making and governance practices for a study of how law operates in the EU’s political and executive institutions. Unlike EU primary or secondary law or case law, this kind of legal data is not traditionally understood as an authoritative source of EU law. However, for practical purposes in EU governance processes internal legal documents are influential. They provide an authoritative reading of legal requirements for the purposes of institutional decision-making. In social sciences, ATD requests are used to empirically document the workings of elite power, authority, and governance.Footnote 7 In such research methodologies the information-brokering process is also considered a valuable source of research data.Footnote 8 The objective is to gain access to streams of information that illustrate everyday practices of government agencies and produce records that can be further analysed using various qualitative data analysis techniques. Such records include various texts used in government processes or produced as part of governing, including also unofficial data never intended for public circulation, such as notes, internal memos, and emails.Footnote 9 As a method, ATD is ‘bound to attract all who are curious, passionate about research, and who are interested in investigating practices and processes of governing’.Footnote 10
Despite this promise, ATD and freedom of information (FOI) requests have been little used as a systematic method in the context of EU legal scholarship. Article 15 TFEU and Article 42 CFR establish a right to access documents held by the EU institutions.Footnote 11 It is unclear whether the limited use of this right is more due to the lack of knowledge about its existence or difficulties in gaining access to this material. Yet, given the narrative of the centrality of law and lawyers in the European integration process, there remains a great deal to study. Various historical studies have demonstrated how through the process of intepreting the Treaties, lawyers working in the EU institutions have played a deeply political role in European integration, picking, for a purpose, the winning arguments. This professional legal speech is largely invisible outside the EU institutions and can only be studied based on internal data. When a legal issue reaches a policy-maker for determination, a legal expert has typically framed the possible alternatives, thus exercising ineradicable influence on policy outcomes. It is easy to find such examples in the EU’s daily law-making practices, where a competent legal expert may frame the same question as a matter of environmental policy or social policy;Footnote 12 or as an exercise of cohesion policy or economic and fiscal policy (which this chapter uses as an example). This choice settles the EU’s Treaty competence to legislate and the impact its legislative action has on national policy choices. This framing is conducted in legal language, and guided by institutional preferences.Footnote 13 This kind of legal data includes in particular legal advice, which the Court has defined as
advice relating to a legal issue, regardless of the way in which that advice is given. In other words, it is irrelevant […] whether the document containing that advice was provided at an early, late or final stage of the decision-making process. In the same way, the fact of the advice having been given in a formal or informal context has no effect on the interpretation of those words.Footnote 14
The data may also include legal documents originally drafted outside the institutions. The Court has accepted that even informal ‘exchanges of legal views between the legal services of three institutions in order to reach a compromise regarding a legislative text in the context of a trilogue may, where appropriate, be described as legal advice’.Footnote 15 While the role of lawyers and legal argumentation has so far been primarily studied in historical contexts, their impact has become particularly crucial during the past ten years when invisible ‘legal engineering’ within the institutions, in particular in the context of crises, has become a substitute for Treaty reform.Footnote 16
I build on a combination of methods, including the use of expert interviews.Footnote 17 Like many others, I would caution against overreliance on interviews as a single source of empirical data on government practices. Officials – and EU officials very specificallyFootnote 18 – are often ‘restricted in what they can say, calling the validity of such data into question’.Footnote 19 There is a risk of ‘spin and bowdlerization’, where interviews easily turn into an exercise in impression management.Footnote 20 While ATD requests do not exclude the risk of spin entirely, they are directed at disclosure of internal government recordsFootnote 21 and thus provide a way to ‘peer into the everyday worlds of these insulated communities and organisations’.Footnote 22 Ideally, the resulting data is triangulated with interviews and analysis of official organisational discourses, used to complement and contextualise the data.Footnote 23 Since ATDs also enable the disclosure of even politically sensitive and potentially contentious data,
It is the promise of revelation, its power as investigative tool and the credibility and trustworthiness of FOI disclosures as the ‘raw’ stuff of bureaucratic governance that makes FOI such a powerful and exciting research technique.Footnote 24
My background is in the critical school, which seldom engages with ‘empirical’ evidence of the social ‘impact’ of law or the behaviour of legal actors.Footnote 25 Legal data gained through ATD can be used for qualitative, critical, and post-structural analysis of policy-making, law, and institutions. In particular discourse analysis on legal data provides additional perspectives in allowing moving ‘outside the text’Footnote 26 to study the ‘subtext, and representation to uncover issues of power relationships that inform what people think and do’.Footnote 27 It can be used to ‘identify the regulatory frameworks within which groups of statements are produced, circulated, and communicated within which people construct their utterances and thoughts’; and ‘uncover the support or internal mechanisms that maintain certain structures and rules over statements about people … as unchallengeable, “normal” or “common-sense”’.Footnote 28 From the internal perspective of law, the way of organising and selecting legal arguments to support particular political aims is particularly interesting. In addition to studying arguments, the method also studies the silences of texts, as well as questions of when, where, how, and why a text was produced.Footnote 29
This chapter starts by describing the legal data which exists in the Commission and the Council and the key processes in which it is produced. The application of ATD as a method requires
self-critical mirror facing … in all phases of the project, from the formulation of a research question, to data production, to data analysis, through to writing and audience reception and response related to a publication. Reflexivity is not simply a moment for researchers to vent about the challenges of doing research … or what Bourdieu … critiques as ‘self-fascinated observation of the observer’s writings and feelings.’ Instead, a major facet of reflexivity is as a tool that researchers constantly use to assess how they do what they do in terms of knowledge production.Footnote 30
The chapter describes the process of gaining public access to legal data. My requests have usually led to confirmatory applications and action before the EU Courts and the European Ombudsman. I will also present examples of legal data gained through ATDs and how they can be used in research. Finally, the chapter will discuss how more recently, in particular, the Commission has restricted access further by making ATD dependent on what legal analyses have been entered into formal registers, excluding more informally provided advice from the scope of ATD. This section relies on an ATD request made specifically for the purposes of this chapterFootnote 31 and raises concern about the future possibilities of conducting research on the handling of legal questions within the institutions, which is threatened by an increasing problem of empty archives.
7.2 What Legal Data?
Lawyers take many roles within the EU’s political institutions. Officials with legal training often work in Directorate-Generals (DGs) and as policy advisors. The most important legal work, however, takes place in the legal services of the institutions. These units have the formal institutional position and the related authority to solve legal questions for the purposes of institutional decision-making.Footnote 32 Most of their legal work is technical routine and takes place below the political radar. A key part is anticipating how the Court would evaluate the situation at hand, which de facto serves as the ex ante constitutionality control conducted in the EU institutions.Footnote 33 Few matters are ever appealed to the Courts. If they are, lawyers from the legal services will assume centre stage defending their institutions, building on legal argumentation carefully developed during the preceding stages of policy-making. They will also exercise authority to determine what policy implications rulings of the Court will have after a judgment has been delivered.
The Commission Legal Service is closely integrated into Commission decision-making. Invisible to outside audiences, it is present whenever decisions are made and new EU policies developed. According to the Commission website, during 2021 the Legal Service replied to 17,318 consultations of which 10,536 were on legislative drafts.Footnote 34 It is big and well-resourced with around 445 staff members.Footnote 35 Its power stems from its formal role in the Commission decision-making procedure. Other Commission services have a duty to consult its Legal Service ‘on all drafts or proposals for legal instruments and on all documents which may have legal implications’.Footnote 36 On most technical matters the Legal Service has a full veto, so the relevant DG must work in cooperation with the Legal Service.Footnote 37 Advice is given orally or in emails between DG officials and members of the Legal Service.Footnote 38 The Legal Service does not dominate political decision-making in the Commission, but often shapes its decisions and determines their reach. The Commission is a collegial body, and the Legal Service’s job is to defend its agenda. Its formal role is particularly strong when the College takes decisions by way of a written procedure,Footnote 39 as the procedure is available only with the approval of the Legal Service. While many Commission Legal Service members are well-known profiles in the legal academia,Footnote 40 they seldom make appearances outside the Commission in inter-institutional contexts. However, if fundamental disagreements appear with the Council lawyers, the Commission may send its legal advisers to defend its position and even produce a non-paper. With these rare exceptions, most Commission legal advice is intended for its internal use and is invisible in public registers.Footnote 41 What therefore is usually most interesting for legal research is not the formal position of the Legal Service in the final inter-service consultation required by the Commission Rules of Procedure (often half a sentence in an Excel sheet), but the advice given when Commission proposals or other actions are planned, in other words, how the Legal Service has interpreted the legal requirements forming and shaping future EU action.Footnote 42 This advice is offered in emails, memos, or as track changes to Word documents.
The Council Legal Service (CLS) is equally powerful, but in a different way.Footnote 43 It is a much smaller unit that provides a first-instance peer review for the legal solutions suggested by the Commission. When Council or inter-institutional decision-making runs into trouble, the CLS smooths political fractures through legal language. Its proposals constitute the foundations of Council decision-making, and it is present in drafting sessions used to prepare Presidency proposals. It is the most powerful Legal Service at the point where final decisions are taken. Unlike the Commission, the Council is not a collegial institution, and its political will is more heterogeneous, which grants the Council’s Legal Service a great deal of leeway in defining its goals. It is always present in Council bodies and exercises an independent, strong voice. As the key consumers of its opinions, the Member States, screen and assess its work. However, the view of the Legal Service also influences the position of many Member States. Much of its advice is provided orally, some of which may be recorded in other Council documents. The CLS also gives formal written opinions when requested to do so by the Council. These contributions can usually be found in the Council’s public register, but are seldom proactively disclosed.
Even if legal opinions are well protected, I have gained access to many. The notes and opinions of the legal services describe the state of the law, with references to case law and EU legislation, sometimes from a completely different field. They may include concrete suggestions for amendments, as well as recommendations against certain approaches and in favour of others. In external relations, legal services engage with the process of signature, provisional application, conclusion and implementation of international agreements.Footnote 44 Legal opinions outline the choice for a correct legal basis, and assess the compatibility of envisaged measures with already existing internal rules or the EU Treaties.Footnote 45 Legal Services may also be asked for reports, studies, research notes or documentation, ‘a systematic presentation of the case law of the ECJ or, failing that, of the precedents in the institution’.Footnote 46 Whether a document is called ‘legal opinion’ is irrelevant. According to the Court, ‘[o]ver and above the way a document is described, it is for the institution to satisfy itself that that document does indeed concern such advice’.Footnote 47
The expertise of institutional lawyers is collective and cumulating knowledge, which is recorded in these opinions and approved collegially. Legal opinions are discussed within each legal service to ensure historical and horizontal consistency. Conceptual distinctions are stabilised in path-dependent ways. Through this process, a doctrine is developed and refined, which will then be reflected and referenced in future opinions.Footnote 48 This method also ensures a continuous and coherent line of interpretation and gives findings a sense of permanency and credibility. This language is different from the ‘law in books’ taught in law schools. It includes bureaucratic expertise of knowing the EU’s inner workings. It is produced by EU officials, paid to see things from the institutional perspectiveFootnote 49 – a perspective that they either prepossess or assume efficiently. As Jean-Claude Piris, the former highly influential Director-General of the Council’s Legal Service put it, ‘you have to know precedents, but you have to be creative. So you do not consult books or scholars, but political people involved in the matter. You have to follow the fight.’Footnote 50 ‘Following the fight’ may also involve realities that persuade a legal service to engage in serious re-interpretation of its own doctrine.Footnote 51 These instances (where the illegal may suddenly become legal) are a particularly interesting source of critical analysis. They may build on highly selective use of case law or silences as regards the choice of sources or arguments, gearing conclusions to support specific political outcomes.
In addition to studying legal advice, writing ‘about law’ requires taking into account its actual operation. In addition to actual legal advice, the institutions possess various legal documents that take the form of internal working documents and arrangements, often formally non-binding. An example is my recent attempt to examine the practical implications of the conclusions of the July 2020 European Council to task the Economic and Financial Committee (EFC), to oversee disbursements from the Recovery and Resilience Facility.Footnote 52 My ATD request filed with the Council resulted in three documents, which the Council first agreed to disclose on appeal. These guidelines were worthy of trouble, as they reveal the practical operation of the Facility: scrutiny is abstract, conducted under tight deadlines, and very limited by scarce resources. The documents also reveal a process that most resembles a formality: the idea of ‘very tight control’ reflected in the European Council Conclusions is watered down by bureaucratic routine. This is an empirical reality that could not possibly be grasped by looking at the secondary legislation and will form the basis of our forthcoming monograph.
7.3 How to Access Legal Data in the EU Institutions
Beyond leaks that sometimes appear in Politico or the Financial Times, access to EU institutional legal opinions remains highly restricted and relies on public access requests under the EU’s public access legislation.Footnote 53 Regulation No. 1049/2001 establishes the principles and rules concerning access to documents held by the Commission, Council, and the European Parliament. Unlike in some national systems,Footnote 54 ATD for research purposes has no specific status in Regulation No. 1049/2001. It is also possible to file more general FOI requests using the ‘Europe Direct’ platform, which may be a quick and efficient means to gather information that is not recorded in any document.Footnote 55 This section describes the process under Regulation 1049/2001 (the Regulation) while also offering some examples of legal issues that have proved interesting for my own research.
The Regulation establishes that all documents held by the institutions are, as the main rule, public. They can however be fully or partially withheld in case their substance relates to a protected interest. As far as legal documents are concerned, Article 4(2) enables the institutions to refuse access in case disclosure would undermine the protection of ‘court proceedings and legal advice’. The institutions may also refuse access to documents ‘drawn up by an institution for internal use’ and relating ‘to a matter where the decision has not been taken by the institution’, in some cases even after the relevant decision has been taken. However, both of these exceptions require the institution to balance the potential harm from disclosure against an overriding public interest in disclosure. Under established case law, the risk to protected interests must be reasonably foreseeable and not purely hypothetical.Footnote 56 Under Article 12(2), legislative documents, understood as those ‘drawn up or received in the course of procedures for the adoption of acts which are legally binding in or for the Member States’, should be made directly accessible through public registers.
For those documents that have not been proactively disclosed (as is typical with legal data), the Regulation lays down a two-stage administrative procedure requiring the institution to examine the requested documents and provide an answer within fifteen working days. Alternatively, the institution can provide the reasons for the total or partial refusal, which enables the applicant to ask the institution to reconsider its position in a confirmatory application. Further, ‘[i]n exceptional cases, for example in the event of an application relating to a very long document or to a very large number of documents, the time-limit … may be extended by 15 working days, provided that the applicant is notified in advance and that detailed reasons are given’ (Article 7–8).
It has been difficult to convince the institutions about the merits of the regime, and the lawyers working for them are no exception. Lawyers very much like to keep the circle where the evaluation of their work takes place small, and insist that their advice should be kept confidential. They rely on the principle of non-accountability, which is a classic part of legal professional rules even if it is questionable how it applies to officials working in public institutions.Footnote 57 In responding to ATD requests and subsequent challenges before the Courts, the institutions emphasise how ‘public interest requires that the EU institutions should be able to benefit from the advice of its legal service, given in full independence’; how their legal advice is to be understood as ‘purely internal exchanges’ that should ‘be as a rule protected as part of the institution’s “space to think”’, and justify this conclusion with reference to ‘the specific dual nature of the Legal Service, as both the sword and the shield of the legality of Union acts’. Their ‘advice should always be “frank, objective and comprehensive”’.Footnote 58
What advice counts as ‘frank, objective and comprehensive’ is primarily a matter for other legal professionals to assess with reference to their shared professional standards and skill.Footnote 59 The institutions have been unified in their opposition to disclosing their work to broader outside scrutiny, and insisted that these standards can only be upheld in case their legal advice remains confidential. The EU Courts have not been convinced, but instead clearly established that public access should, as the main rule, be granted in the legislative context:
[A]n overriding public interest is constituted by the fact that disclosure of documents containing the advice of an institution’s legal service on legal questions arising when legislative initiatives are being debated increases the transparency and openness of the legislative process and strengthens the democratic right of European citizens to scrutinize the information which has formed the basis of a legislative act.Footnote 60
The legal services further argued that disclosure of legal advice might ‘lead to doubts as to the lawfulness of the legislative act concerned’. However, the Court has stressed:
It is in fact rather a lack of information and debate which is capable of giving rise to doubts in the minds of citizens, not only as regards the lawfulness of an isolated act, but also as regards the legitimacy of the decision-making process as a whole. Furthermore, the risk that doubts might be engendered in the minds of European citizens as regards the lawfulness of an act adopted by the Community legislature because the Council’s legal service had given an unfavourable opinion would more often than not fail to arise if the statement of reasons for that act was reinforced, so as to make it apparent why that unfavourable opinion was not followed.Footnote 61
The Court accepted that access to legal opinions can be denied temporarily and in exceptional cases if the advice is ‘of a particularly sensitive nature or having a particularly wide scope that goes beyond the context of the legislative process in question’.Footnote 62 With this passage, it created a fresh battleground for later court cases.
Both the Commission and the Council have put a great deal of effort into exploring the boundaries of this exemption. When Samuli Miettinen applied for access to certain legal opinions for the purpose of his PhD thesis in EU criminal law, which examines the contours of the EU’s criminal law competence under Article 83 TFEU, including how the institutions’ themselves have analysed their competence to act, the Council was unwilling to support his critical exploration. It argued that ‘particularly sensitive’ could apply to whole policy areas (such as EU criminal law) and that there was institutional disagreement on the legal basis. Particular sensitivity could also be justified with how the relevant legal basis was ‘new’, not yet well defined, involved horizontal questions, and had not yet been addressed by the Court, making it likely that the directive would be challenged before the Courts.Footnote 63 All of these factors obviously also highlight a research interest in some of the most fundamental questions: how legal actors make law. The General Court rejected these arguments, emphasising the need to evaluate sensitivity based on substantive content.Footnote 64 The Court framed the choice of legal basis as ‘an essential question in the legislative process’ underlining how a ‘proposal is designed to be debated, in particular as regards the choice of legal basis’.Footnote 65 The Court noted that it is precisely when ‘dealing with novel questions that the institutions request advice from their legal service’, therefore, ‘conferring particularly sensitive character on all legal advice concerning a novel question would result in impeding in practice the disclosure of a large proportion of that advice’.Footnote 66 This jurisprudence has not in practice led to more legal data being proactively disclosed; instead, the institutions recycle their old arguments already defeated in Court when responding to new ATD requests.
The institutions often justify their refusals to share legal data with reference to potential legal challenges, as if these institutions would routinely fail to comply with the Treaties. This suggests that some of this data could be understood as ‘dirty data’ in the meaning of Gary Marx, as ‘information which is kept secret and whose revelation would be discrediting or costly in terms of various types of sanctioning’. While data can be ‘dirty’ in different ways, according to Marx, this kind of data
runs contrary to widely (if not necessarily universally) shared standards and images of what a person or group should be. … Dirty data at the organizational level ought to be of particular concern to the social problems researcher. Issues of hidden and dirty data are likely to be involved to the extent that the study of social problems confronts behavior that is illegal, the failure of an agency or individual to meet responsibilities, cover-ups, and the use of illegal or immoral means.Footnote 67
In the context that I study, ‘dirty data’ could be advice that has not been followed, and which therefore could be – if disclosed – compromising for the decision-maker, and result in demands for accountability. But data could also be ‘dirty’ specifically because it fails to fulfil the criteria of being ‘frank, objective and comprehensive’, and thus raise questions about the professional ethics or standards of the lawyers producing it, and whether they had given in to political pressure. Both of these are important research perspectives where public debate could significantly strengthen the EU’s democratic governance or lead to reforms in the EU institutions.
ATD requests often result in lengthy application procedures with highly uncertain outcomes. The applicant is placed in a position of arguing against the lawyers who produce those documents and wish to maintain their confidentiality.Footnote 68 Writing confirmatory applications is cumbersome, as is keeping track of procedures and deadlines, which the institutions do not follow rigorously. While the Council remains more respectful of deadlines, the Commission employs systematic delays as a means of avoiding disclosure obligations.Footnote 69 Moreover, the institutions often provide only partial access to their data, such as the few introductory paragraphs of opinions describing the legislative proposal. One example involves the recent debate among the Member States, NGOs, and legal academia concerning the EU’s possibility of leaving the Energy Charter Treaty, which led me to seek public access to the Commission’s legal opinion on the matter.Footnote 70 The response arrived six months later, after all the vital decisions had been taken, and was of little use.Footnote 71 ‘Partial access’ was limited to the highly interesting title and equally interesting subtitles of the opinion while every sentence of the legal analysis was redacted, strategically preventing any public evaluation of this legal advice.
These difficulties of gaining access resemble other ATD contexts where the process of ‘data production’ provides an active role for both the researcher and the official in charge in shaping the outcome of the request.Footnote 72 The researcher needs to be ‘moving from observer to participant and back, stretching our capacities, using our emotions, working actively with those barriers that confront us – we may learn more from those very obstacles than if they had never presented themselves’.Footnote 73 By using both active and passive research strategies barriers can not only be overcome, but can also be used as sources of important data.Footnote 74 When debating disclosure with the institutions, the researcher also engages in co-creation of research material, as the correspondence is reflected in the institutional responses. Their decisions on non-disclosure typically explain the stage of decision-making, the substance of the requested documents, and their broader relevance for the development of the EU legal framework, including pointing out potential horizontal issues. This information also provides insight into the development of legal debate within the institutions, which would not otherwise be publicly available.
In legal opinions, silences can be powerful, and a significant characteristic of the research data. These include strategic silences in terms of matters that are not addressed by opinions, and choices between arguments that are used and not used. Such silences are often used to smooth the decision-making procedure, in particular to diminish the risk of democratic complications, especially at national level. One example of this is the EU–UK Trade and Cooperation Agreement.Footnote 75 Agreements of this kind have generally been concluded as mixed agreements, requiring a separate national approval round. This time, the decision to sign the agreement as an EU-only agreement was taken between Boxing Day and New Year’s Eve, relying on a confidential but leaked CLS opinion, which openly admits that it ‘does not provide an in-depth examination of all of its aspects, nor does it provide a comprehensive and detailed competence analysis’.Footnote 76 The opinion illustrates how the CLS understood its function as promoting the ‘Council’s interest’; in this case, saving the EU from a no-deal Brexit and enabling the conclusion of the EU–UK Trade and Cooperation Agreement (TCA) without additional procedural hurdles that a more serious engagement with the limits of EU competence would have required. In practice, the CLS empowered the national governments against their own parliaments by providing them with an authoritative analysis justifying the existence of ‘exceptional circumstances’, which are more political than legal.Footnote 77 The Council lawyers define the EU’s economic and political interest and find legal arguments to promote it. This legal opinion demonstrates the deeply political role assumed by Council lawyers, and how the relationship between legal advice, democratic politics, and parliamentary scrutiny is far from straightforward.
Much of my recent research has circled around the legal and constitutional transformation around the EU’s COVID-19 response, NextGenerationEU (NGEU).Footnote 78 Questions involving the use of these funds have also occupied investigative journalists, which has enabled ‘pooling resources, findings, and analyses’,Footnote 79 and resulted in ‘qualitative inquiry that breaks down barriers between academics and other knowledge communities’.Footnote 80 In addition to questions of financial accountability, I examined the history of the legal construction. Just before the approval of NGEU, the Council and the Commission – highly exceptionally, strategically, and proactively – disclosed a legal opinion and a Q&A document, which demonstrate a complete U-turn of earlier and well-documented legal interpretations by these two institutions. However, while providing legal justifications for why certain innovative solutions should not be seen as problematic, these opinions remained silent on several key aspects of the legal framework. An ATD request for the legal advice preceding the NGEU construction to both institutions in March 2023 resulted in the Commission’s disclosure of a few documents involving minor technical amendments to draft proposals from the final inter-service consultation preceding their formal approval, a discussion I return to below. However, the Council disclosed its advice in full after some initial hesitation.Footnote 81 These opinions provide ample ground for discourse analysis, since they effectively show how the difference between cohesion policy, on the one hand, and economic and related fiscal policies, on the other, as separate policy fields was diluted based on a highly selective reading of the case law. The opinions include effective silences on matters that would have spoken against the line of argumentation that the CLS opted for, certainly under considerable political pressure. The opinions also demonstrate how a new legal interpretation was first introduced and then gradually sedimentedFootnote 82 without public debate and only with limited analysis of risks and consequences.
ATD may require confrontational tactics to work around the official response tactics aiming at stonewalling requests.Footnote 83 First-round rejections are the institutions’ standard way of testing whether the applicant is indeed determined, and need to be followed up by a confirmatory application that they hopefully engage more seriously with. If the institution insists on refusing access, the applicant can appeal to the General Court or the European Ombudsman. My first appeal to the EU Courts involved the European ParliamentFootnote 84 and was related to the transparency of trilogues,Footnote 85 with discussion evolving around the pending Court case de Capitani v. the European Parliament. I sought access to the administrative decision with which the European Parliament had denied access, to study its legal reasoning and its relationship to political pro-transparency rhetoric. But instead of formally disclosing the decision, the EP referred me to de Capitani’s personal website. The Court of Justice agreed with me that I had retained ‘a genuine interest in obtaining access to an authenticated version of the requested document … guaranteeing that that institution is the author and that the document expresses its official position’.Footnote 86 As the Court passed the case back to the General Court for final ruling, overall, Court litigation in this case took five years, one month, and twenty-two days.Footnote 87
My second court case originated in a research project on the legitimacy of the ongoing climate transformation and involved a Council legal opinion assessing whether the Commission proposal updating the EU’s Aarhus Regulation lives up to the requirements of the Aarhus Convention, in particular as regards the negative findings of the Committeee supervising compliance with it.Footnote 88 The Council’s claim that public debate on EU compliance by the applicants – an environmental NGO and a legal academic – constituted ‘external pressure’ seemed particularly questionable, given that the Convention concerns access to information and public participation. The ‘external pressure’ had taken the form of a blogpost that I had published in the European Law Blog.Footnote 89 The General Court annulled the Council decision repeating why openness in the legislative process matters:
the Council’s mere unsupported statements regarding the possibility of ‘external pressure’ on its legal service do not make it possible to consider that disclosure of the requested document would give rise to a real risk that is reasonably foreseeable and not purely hypothetical that the independence of that service would be undermined. … In any event, even assuming that pressure might be applied for the purpose of influencing the content of opinions issued by the Council’s legal service, according to the case-law, it would be that pressure, and not the possibility of the disclosure of legal opinions, which would compromise that institution’s interest in receiving frank, objective and comprehensive advice and it would clearly be incumbent on the Council to take the necessary measures to put a stop to it.Footnote 90
Despite these judicial successes, the difficulties involved in engaging the Court are obvious. Even if a decision refusing access provides the applicant with standing to bring the case, the time frame is short. In practice, there is a need to appoint a legal representative;Footnote 91 there is a risk of costsFootnote 92 and the length of proceedings prevents using this route for any short-term research interests. Overall, however, using ATDs has enabled collecting unique data of legal sources that would otherwise remain unavailable to the public, including the data from the actual ATD processes that frequently underpins my research.
7.4 Open Access: Empty Archives
Collecting data via ATD from the Commission legal advice relating to the NGEU legal model also highlighted a deeper systemic issue with ATD requests: what documents do the institutional registers actually contain and how should the relationship between a register and public access be understood? The Regulation establishes a right to access to documents, defined broadly as ‘any content whatever its medium … concerning a matter relating to the policies, activities and decisions falling within the institution’s sphere of responsibility’. The European Ombudsman has consistently maintained that whether or not a document is registered in a document management system has no bearing on whether they fall within the scope of the public access rules.Footnote 93
A request for Commission legal advice on the NGEU model led the Commission to maintain that its registers contained nothing beyond a few technical documents issued in the final interservice consultation. I triangulated this position with the formal role of the Legal Service under Article 21 of the Commission Rules of Procedure and a working paper published by a member of its Legal Service in 2019.Footnote 94 In this paper, Leo Flynn – charged with the relevant files at the time – explains the engagement of the Legal Service with these very same questions over a period of several years. He describes how cohesion policy, primarily geared under Article 174 TFEU at ‘reducing disparities between the levels of development of the various regions and the backwardness of the least favoured regions’, had been firmly identified by the EU institutions as a way to fill the ‘gaps’ in the ‘incomplete policy side of EMU’. Treaty constraints on that side were considered ‘challenging’ and ‘limit the possibility for the Union institutions to adopt measures that are binding as to how the Member States conduct their economic policies’. It seemed highly unlikely that the Legal Service would have provided no written advice on this legal transformation, which took place over a period of time stretching over several years preceding the completion of the various Commission proposals in this area. But how to turn from speculation to evidence?
Many of the documents that were initially identified by the Commission as a response to my request were blanked out.Footnote 95 However, a comment box in the margin of one disclosed documentFootnote 96 revealed that more would have existed, as the ‘SJ referred to its full set of drafting suggestions as well as observations in writing that had been made ahead of the FT ISC meeting’ and that further suggestions had been elaborated in an ‘accompanying email’. Neither of these documents were listed as falling under my request. In my cofirmatory request I clarified that my interest related to the Commission analyses on the applicable legal bases, since
as the Commission is well aware, some of these instruments are legally framed as cohesion policy instruments while others are understood as parts of the EU’s economic governance framework. I find it unlikely that no legal analyses would have been conducted in the Commission relating to the choice of legal basis for these instruments. The instruments also introduce a new interpretation of EU cohesion policy with constitutional importance for Union development in particular as regards spending. I find it unlikely that this change would not have been subject to careful analysis in the Commission legal service, and hereby request the Commission [to] reconsider its position on these aspects, as legal advice on these matters, given in the context of a legislative procedure, should be disclosed. …
Since the Commission reply was delayed, I contacted the European Ombudsman.Footnote 97 The Commission’s confirmatory decision arrived five months after the initial request was filed,Footnote 98 and claimed that my argumentation presented a forbidden attempt to broaden the initial request. No further documents could be identified, and no new documents needed to be created. Finally, the Commission observed, if an institution claims not to hold any documents, there is a presumption of lawfulness attached to the declaration,Footnote 99 unless the applicant can rebut it by relevant and consistent evidence.Footnote 100 The Commission argued, the ‘mere suspicion that there must be a document does not suffice to put in question the presumption of legality of the institution’s statement’. Instead, its advice was to file a new request for ‘additional documents’. Unlike the Ombudsman has required in its practice, the Commission made no attempt to ‘engage with requesters openly and constructively at all stages, and ensure they are provided with all necessary information that may enable them to clarify their requests (for example by providing a list of documents that potentially fall within the scope of the request)’.Footnote 101 I consulted the Ombudsman who found a new request ‘the more appropriate course of action. We have asked the Commission to treat any such follow-up public access request promptly.’Footnote 102
The new request specified that my requested access related to
to all stages of preparatory work preceding the respective Inter-Service Consultations and also covers informal advice offered in the form of e-mail messages or other informal corrspondence between the Legal Service and the DGs that were in charge of preparing the proposals and that may have influenced how the proposals were formulated.
The wording of the request was based on the Grand Chamber ruling in ClientEarth v. the Commission, where the Court not only recognised the Commission as a ‘key player in the legislative process’ but also underlined the need of transparency in the preparatory phase of legislative proposals, which ‘enables citizens to understand the options envisaged and the choices made by that institution and, thus, to be aware of the considerations underlying the legislative action of the European Union’.Footnote 103 However, in response, the Commission reiterated that despite ‘a thorough search in their corporate document management systems’, the Legal Service and the competent DGs had failed to identify any further documents.Footnote 104
Upon a confirmatory application, which the Commission again failed to consider in due time, I submitted another complaint to the Ombudsman in December 2023.Footnote 105 The Ombudsman proposed broader access of documents that the Commission claimed did not exist. The internal discussions between the Commisison and the Obudsman were not disclosed, with the reasoning that ‘disclosure of this document is prevented by the need to protect the Ombudsman’s ongoing inquiry’.Footnote 106 Overall, the Ombudsman seemed at a loss with the Commission’s refusal to answer my request.
Internal consultations within the Commission took altogether sixteen months from the initial access request.Footnote 107 However, in June 2024 it identified twelve new and more informal documents from the relevant time period. While the Commission did disclose some of the queries from the DGs that its lawyers had been reacting to, it redacted all the actual legal advice, because it ‘concern[ed] purely internal exchanges related not even to any draft versions of future proposals (and therefore not part of [any] legislative file) and thus should be as a rule protected as part of the institution’s “space to think”’.Footnote 108 When triangulated with publicly available information such as Commission work programmes, Euro Summit conclusions, and letters by the Commission President, this statement seems factually wrong: legislative drafting was definitely ongoing. A final appeal is pending with the European Ombudsman. While the Commission is unlikely to volunteer to disclose the information, the process reveals the institutional strategy: first, the claim that documents do not exist; then stall Ombudsman investigations; and finally play with time. This strategy does not become the ‘Guardian of Legality’, suggesting that it sees the data as something worthy of protection.
The queries from DGs disclosed by the Commission demonstrate that the Commission lawyers were working their ways around key Treaty constraints, which suggests that the data could indeed be ‘dirty’. But it is difficult to see what consequences this might have at this stage beyond the public image of the Commission and the professional reputation of its lawyers; both paid for by European taxpayers who also have a Treaty-based right to know the legal foundations of decisions that concern them. The Commission proposals concerned by the above requests either stalled in the legislative process or were replaced by other proposals that have already entered into force, thus making annulment cases a highly unlikely scenario.Footnote 109
The Commission insistence that its registers contained no documents matching the search criteria raises the question of how the search was conducted and what the registers contain. The past couple of years have seen a great deal of discussion about investigative journalists’ attempts to gain access to the Commission President’s text messages relating to the so-called Pfizergate.Footnote 110. According to Vice-President Jourova, the Commission follows three registration criteria:
1. The information relates to the policies, activities or decisions falling within the institution’s sphere of responsibility;
2. The information concerned is important and not short-lived;
3. The information concerned has been drawn up or received by the Commission.Footnote 111
The same idea of ‘short-lived’ documents is also repeated in Council rules, to which I sought access for the purposes of this chapter. However, the Council rules also stress that the purpose of data retention is to ‘guarantee the medium- and long-term preservation and availability of documents and official files, in view of their administrative, legal or historical value’, but also to ‘enhance transparency and make it easier for the public to gain access to documents’.Footnote 112 While the focus of the debate has been on text messages that can probably more seldom be understood as containing ‘legal data’, the question of what is registered and what happens to non-registered documents remains valid. Legal advice is given about matters that fall under the institution’s duties. Spiegel reports that
everything that isn’t uploaded to that register or saved in a personal file falls victim after six months to an automated system of ‘instant mass-deletion’ that has been in place since July 2015. When asked, the Commission couldn’t even provide an estimate of how many documents have disappeared for good since then.Footnote 113
Six months is a short time for legal research, given that the Commission routinely takes over a year to respond to requests and strategically delays their handling. Since legal advice is often considered informal in the Commission, my ATD requests suggest that it is seldom registered. However, even such non-existing advice seems retrievable, presuming that the Commission can be convinced to engage in such an exercise. This highlights the Commission’s own discretion in identifying the relevant documents and possibly deleting ‘dirty data’, which may result in a new version of the ‘open access – empty archives’ argument. According to the classic version of this argument, disclosure of documents deters actors from writing their positions, which is feared to damage the quality of records and impoverish the content of future archives.Footnote 114 In the new version, it seems that the institutions may also be actively engaged in destroying existing records to avoid public scrutiny. This means that in the process of discovering dirty data, the researcher
must judiciously walk a hazy line between the unacceptable extremes of taking the world at face value and believing that what is unseen is unimportant, as against thinking that nothing is what it appears to be and that whatever is hidden must, therefore, be significant. The presence of secrecy is a guarantee of neither theoretical nor social relevance. … increased attention to dirty data methods, topics, and issues is one factor required for better understanding of social problems.Footnote 115
7.5 Conclusions
It is in the interest of EU institutions but also EU citizens that the legal data that the EU institutions rely on is indeed ‘frank, objective and comprehensive’. Being able to anchor its actions into the Treaties has been significant for the EU’s authority over the years.
Legal debates in the institutions help to explain how law operates and how it is understood to frame the choices of policy-makers. While the institutional legal services routinely claim that ensuring the quality and objectivity of their advice demands that they remain confidential, the opposite might be true. When examining the doctrine that legal service opinions create, there is no doubt that the function of the EU is to move forward, and the job of the legal experts is to remove obstacles to progress. Given this paradigm, it is evident that even the most confidential advice sometimes fails to fulfil the criteria of being ‘frank, objective, and comphrehensive’. In this process of interpretation, democracy, transparency, or stronger citizen involvement are frequently sacrificed to pave the way for deeper integration, stronger control from the middle, and swift approval processes. It would be important for EU legal scholarship to make these interpretative choices visible and subject them to critical analysis. Access to data is key to any research, qualitative or quantitative, because it effectively determines what questions we can ask – and if we are in fact asking relevant questions and launching relevant critique of the practice. This also ensures that legal academia and legal practice engage in a constructive conversation. I believe that the institutions have a responsibility to contribute to this conversation.
8.1 Introduction: Background and Aims of a Multi-user Database in EU Law
Empirical legal studies (ELS) in Europe have successfully overcome the inertia of publication outlets, competition for institutional support, and absence from law school curricula and university chairs. It is beginning to build durable research structures, calling for huge investments in projects with uncertain gains. Against this backdrop, ELS in EU law will prosper as a grassroots movement, building and sharing reliable and relevant data resources, collectively adapting to the climate of the day. We initiated the IUROPA CJEU Database Project (IUROPA) in that spirit. The collaborators set out to compile and publish an open source, accessible multi-user database that would increase the visibility of the decision-makers and the decision-making of the Court of Justice of the European Union (CJEU).Footnote 1
The United States Supreme Court (USSC) Database offered a gold standard and an inspiration.Footnote 2 As the most successful social science database facilitating quantitative research on judicial politics in the United States and beyond, it built an entire interdisciplinary field of judicial behaviour, while also supporting other endeavours such as the ELS movement.Footnote 3 The challenges of replicating it were both practical and legal. The USSC Database is focused on a court with substantively different institutional features and strongly exercised docket control, operating in a stable national legal system with solidified institutional structures. Moreover, political scientists are its primary creators, users, and audiences. Scholars approaching the database have typically received post-graduate (PhD) training in social sciences; they are adapted to working with data and are typically versed in empirical qualitative or quantitative methodology, dwelling less on questions of legal complexity and detail.
As a supranational, multicultural, and multilingual (23 languages) Court that insists on complete secrecy regarding its deliberations, and neither publishes the votes of its members in concrete cases nor allows dissents, the CJEU has dealt a more frustrating hand to ELS researchers. The CJEU issues hundreds of judgments and thousands of decisions yearly, rotates chambers, presidents, and members irregularly and adheres to an abstract, repetitive, and formulaic reasoning style.Footnote 4 With few exceptions, the CJEU judges keep a distinctly low profile, often engaging with narrower national academic, judicial, or political circles and professional associations.Footnote 5 They employ ‘faceless’ legal clerks,Footnote 6 who expertly analyse cases and draft the initial reports summarising the facts, the arguments of the parties, and the relevant case law in the cabinet of the individual judge before the deliberations in the chambers.Footnote 7 The public and many academics have not been paying attention to the detailed procedural arrangements and their effect on the working culture and the outcomes, the work of the Registry and other departments that support the CJEU’s judicial activity.Footnote 8 The power of the President to influence the procedure and substance of a ruling is only slowly being demystified.Footnote 9
IUROPA’s resolve to design a database should be understood in this environment. So should its adoption of the criteria for databases, proposed by Weinshall and Epstein: that a database addresses real-world problems, that it is open and accessible, reliable and reproducible, and finally, sustainable and foundational.Footnote 10 This chapter explains these criteria and the related trade-offs in the context of the CJEU and the EU legal order.
The chapter proceeds in two parts. The first part briefly describes the process of developing the CJEU Database within the IUROPA project (Section 8.2). The second part is organised in sections addressing the four criteria above and the challenges they presented to IUROPA. In brief, any database on national and supranational courts that features information about judgments, judges, and the institution intuitively meets the first criterion. However, a database for multidisciplinary use might need to consider that legal realities are realities, too,Footnote 11 meaning that legal scholars have a keen interest in legal concepts for their own sake.Footnote 12 The requirement of openness and accessibility may appear equally obvious in the digitalisation age and in view of growing demands on open source and open access from research funders and publishers alike. As the inclusion of personal data, including sensitive data, is all but unavoidable, these laudable ambitions are, however, challenged by both ethical and legal concerns. The latter are particularly prominent in the European setting, with EU data protection laws being among the strictest in the world. Striking an adequate balance between these interests is a delicate task, whose stakes are risen by the possibility of legal liability for the creators of the database and the institutions that maintain them.
Meeting the criterion of reliable and reproducible data includes producing and publishing code books and reliability reports that help prospective users understand the data and evaluate its quality. It may also trigger hard choices to discard unreliable, incomplete, or low-quality data. In a multidisciplinary setting, the notion of validity becomes germane, as disciplines seek different information and levels of detail in the judgments – such as judicial reasoning and case outcomes.
The sustainable and foundational database criterion requires that the data is easily calibrated, updated, and age/time-resistant. Foundational means that researchers can use the database for their own creative research purposes, reliably transforming and adding to it when answering their research questions. The variables in the database must be clearly defined and substantiated, allowing researchers unfamiliar with the data collection to make informed decisions about the data’s relevance and validity. Among the trade-offs here are the balance between automatic data collection using web scraping, and resource-heavy data collection through hand-coding; sustainability and human intervention are inversely proportionate.
All of these criteria and trade-offs are illustrated with examples from the IUROPA database. The chapter closes with a discussion of how ELS in EU law can leverage and support the available data infrastructure to enrich the knowledge of EU law and courts.
8.2 IUROPA as the Infrastructure for ELS in EU Law
The IUROPA database establishes the necessary infrastructure for empirical legal studies in European Union law. It has collected, pre-processed, and systematised the information including past and present members of the CJEU, Member State governments submitting observations or acting as parties to the case, European institutions, national courts submitting preliminary questions, litigants (including firms and NGOs), legal counsel, and legal agents acting on behalf of the European institutions in the proceedings.
IUROPA is a long-term project that has grown and developed over a decade. Initially, it consolidated existing datasets on EU law and politics.Footnote 13 Then, it worked around the expansive interpretation of data protection rules which restricted data access to completed cases, to collect new data from court and Member State files, such as the submissions of the parties and the reports for the hearings. With the rise of optical character recognition (OCR) and large language models, it developed new ambitions to understand legal developments from the text of the judgments.Footnote 14 Given the CJEU’s institutional traits described above, the database had to be interdisciplinary, the ‘legal content’ of the decisions complementing the analysis of judicial choices and other observable information about the judges.
IUROPA harvests the growing scholarly interest in how law, politics, and society interact. Its backbone is the synergy between legal scholars and political scientists to answer the questions of how to explain legal change, what motivates the decisions of European judges, and whether the legislator can constrain and control judicial power – and thus the process of European integration – through law. This combined legal information with circumstantial information about the judges and the judgments, finding ways of articulating and measuring the CJEU’s legal choices and potentially also assessing their societal implications.
The database caters to legal scholars and political scientists, potentially extending further, supporting empirical studies generally – history, sociology, linguistics, and anthropology come to mind. This is reflected in its structure, or separation of data into the so-called (sub-)components. These include information about (1) cases; (2) proceedings, which are individual or joined cases that can result in decisions; (3) decisions issued by the CJEU, including judgments, orders, and Advocate General (AG) opinions; (4) data on the parties in each proceeding; (5) the composition of the chamber/sitting judges; (6) positions, meaning observations and interventions submitted in the proceedings; (7) national courts submitting preliminary references; (8) citations to case law, Treaties, and legislation; (9) current and former Members of the CJEU (judges and Advocates General); and (10) legal issues and doctrine.Footnote 15 The datasets are available separately but can be easily combined for diverse research needs through common identifiers. IUROPA offers a download tool through which variables can be selected from different components and be merged into a single spreadsheet/database. It also functions as a filter and can convert data (i.e., years into days).
From the outset, IUROPA could capitalise on the increased convenience of publicly available data on the CJEU on EUR-Lex and Curia. In the future, IUROPA and similar projects will be able to benefit from the CJEU’s increasing openness. Over the past couple of years, the CJEU’s public face has become more transparent, obliging, and cooperative, and its PR more forthcoming and wide-ranging, with short YouTube clips and animated presentations on its website, frequent press releases about its rulings, an agreement to deposit older dossiers into the Archives of the European Union, publication of orders for reference from referring national courts on its website, progressive publication of the submissions of the parties and the participants in closed cases, and, most recently, selected final judgments in the main proceedings of national referring courts in preliminary reference decisions.Footnote 16
The development of the IUROPA database has been guided throughout by the four criteria for databases identified by Weinshall and Epstein, as set out in the introduction to this chapter. The work has demonstrated that, while these criteria apply globally, they need to be adjusted locally to match the specific characteristic of the court in question and the jurisdiction in which it operates (and in which the database is being created). The following sections address the individual criteria and the specific challenges they pose for ELS, demonstrating and explaining why databases should be societally relevant, open and accessible, sustainable and foundational, reliable and reproducible.
8.3 Societally Relevant: A Real-World Problem and EU Law
A societally relevant database must capture societally relevant processes, actors, and decisions. A database on courts, including supranational courts, intuitively flies high above the threshold of this criterion. Political scientists studying the CJEU have long collected data to answer questions about its relationship with political actors, the choices its judges make, and the effect of their choices on society.Footnote 17 That said, a database for interdisciplinary use must consider and accept that different disciplines construct their object of inquiry differently. To a legal scholar, a hypothetical normative gap amounts to a viable and worthy object of normative inquiry, regardless of its practical or political implications. Legal linguists are concerned with variations of phrases or divergent descriptions of the same concept, regardless of case outcomes. Political scientists are mostly interested in the political nature of courts debated in many jurisdictions worldwide and often focused on individual justices. In EU law, without a smoking gun, the debate of judicial politics has primarily concerned the CJEU’s methodology and modes of reasoning, forcing the debate into a more legally oriented direction.Footnote 18
The IUROPA database includes information about all the judges of the European Court of Justice and the General Court (GC), established in 1989, such as nationality or professional background, information on the judgments that individual judges have participated in, and the outcomes of the judgments for direct actions and internal market cases. However, the positions of actors appearing before the CJEU can often only be guessed based on their overall function, or at best summarily read from the judgment of the CJEU (which is not always a reliable source as it may not reflect their actual positions well).Footnote 19 Addressing this issue, the Issues and Positions component contains data on the position taken by intervening Member States and EU institutions as well as by the CJEU and the Advocate General (AG) on each legal issue raised in a preliminary reference proceeding.Footnote 20 The information about Member States’ positions were gathered from the Reports for the Hearings, since the actual briefs have not been made public. Unfortunately, the CJEU stopped producing these reports in 2012, which makes it difficult to systematically analyse positions in more recent years.
A legal scholar might be mostly interested in legal concepts or general principles, particularly their (strategic) use or conceptual evolution over time. The Legal Issues and Doctrine component supports such systematic investigation. For instance, Figure 8.1 presents the CJEU’s use of proportionality in all judgments, showing an increase in two policy areas, free movement of persons and freedom of establishment, and a decrease in one, free movement of goods. The findings can contribute to the study of Member State autonomy to introduce, maintain, and enforce national regulatory choices. Additionally, the finding can potentially corroborate the claims raised in recent literature that proportionality is a form of judicial deference to the political actors,Footnote 21 or a form of abdication of judicial constitutional authority and responsibility.Footnote 22
The share of judgments with proportionality review of national measures over time. The solid line shows free movement of goods, the dashed line the free movement of persons, and the short dashed line the freedom to provide services and freedom of establishment. The shaded area indicates the accuracy of the measure (standard errors).
Figure 8.1 Long description
The y-axis represents the proportionality test, ranging from 0.0 to 0.4. The X-axis represents years from 1970 to 2020. The graph plots three distinct lines, each representing a different category, namely, movement of goods, movement of persons, and services and establishment. Each line is accompanied by a shaded area, indicating the uncertainty around the trend. The line for the movement of goods starts at 0.1 in 1970, gradually increases to 0.22 in 2004, and decreases to 0.13 in 2020. The line for the movement of persons begins at approximately 0.1 in 1970, steadily increases over time, and reaches around 0.3 in 2020. The line for services and establishments begins at 0.01 in 1970, forms a concave up increasing curve, followed by 0.03 in 1980, 0.05 in 1990, and 0.15 in 2000, and then a concave down increasing curve following 0.25 in 2010 and 0.29 in 2020. Note, all data are approximated.
A note for the future: while the CJEU’s decision-making has been subject to data collection and countless studies in law, political science, sociology, and history, its homogeneity and diversity in terms of race, ethnicity, political beliefs, and genderFootnote 23 remains underexplored and the implications for the law unexplained. This goes for the judges, Advocates General, the CJEU’s secretariat, staff of the cabinets, and the support services.Footnote 24 Collecting information about these characteristics would considerably enrich our understanding of the CJEU’s law-making, completing the groundbreaking contributions by SolankeFootnote 25 and Guth and ElfvingFootnote 26 in the socio-legal domain, VauchezFootnote 27 in the sociology of law, and FritzFootnote 28 in legal history.
8.4 Open and Accessible: FAIR
The second criterion for a high-quality data infrastructure is openness and accessibility. Access to knowledge, in other words, must literally be free and unrestricted. This means, first, full transparency regarding what data exists,Footnote 29 how it is structured, how it can be interpreted,Footnote 30 how it has been collected, how reliable it is, and so on. Second, data infrastructure must support data-sharing in a narrow sense, while also enabling, supporting, and ideally encouraging the broadest possible participation and collaboration. Removing barriers to data access will empower stakeholders from different disciplines to contribute their unique perspectives and expertise, enriching the data ecosystem and enhancing its value for everyone.
There are strong and compelling reasons to encourage and even demand that researchers who have collected data as part of their research share their data. Making data publicly available is necessary to verify the integrity and reproducibility of conducted studies. Collected data is also a significant research output in and of itself,Footnote 31 useful for answering a variety of research questions beyond those that originally motivated data collection.Footnote 32
The authors of a multi-user database do not know who will be using or contributing to the database over the course of its lifetime, nor how or why they will do so. Multi-user databases in the legal realm are in this sense like other data infrastructures, meaning that they must comply with four foundational principles of data management: Findable, Accessible, Interoperable, and Reusable (FAIR).Footnote 33
Accordingly, there are growing expectations, emphasis, and frequent demands from scientific journals, research funders, and legislators that research data should be treated as a collective resource and shared publicly.Footnote 34 This preference for open research data can be seen as a specific element of the broader Open Data movement,Footnote 35 as well as the academic Open Science movementFootnote 36 ‘with its emphasis on ensuring that research outputs, components and methods are widely disseminated, scrutinised and reused for the good of science and society …’.Footnote 37
Openness competes with other societal interests and values, especially in the EU. It often demands considerable attention from database designers and data collectors. Concretely, the value of openness must be weighed against (1) the protection of privacy of individuals included in the dataset, and (2) the intellectual property rights of any commercial and non-commercial actors that have generated any underlying data. Striking a workable balance between these interests is an ethical and professional responsibility for researchers that increasingly includes legal considerations. In recent years, scholars have faced complex and even contradictory demands. The stakes could be perceived to be high for the scholars and the higher-education institutions in which they work, with potentially severe professional, legal, and economic consequences from poor decisions. These factors explain the slow and uneven adoption of Open Data in academic practice across disciplines.Footnote 38
The exact requirements depend on the type of data and its location. Judicial data has some key features, such as the focus on legal rules, legal issues, or personal information about the judges. It may seem counterintuitive that the data’s geographic locality should matter in such a globalised and digitalised era, but this is nevertheless the case.
Building a multi-user database focused on EU judicial data in the European Union involves, in addition, specific challenges and trade-offs. The EU has been highly active in data regulation; most readers will be familiar with EU legal measures seeking to protect personal information and individual privacy. Fewer may know, however, that the EU has also taken action to enhance the collection and sharing of data, that is, to strengthen the free movement of data.Footnote 39 Free movement of data is part of the EU’s Digital Single Market StrategyFootnote 40 and the European strategy for data.Footnote 41 The plan is to set up a comprehensive regulatory framework that can support the use of data to drive development and progress while simultaneously protecting personal data and fundamental rights. The establishment of the European data space is the central point of this vision: ‘a genuine single market for data, open to data from across the world’.Footnote 42 While much of this plan focuses on commercial use and economic development, it does also seek to promote collecting, using, and sharing data for purpose of conducting research.Footnote 43 In this spirit, the EU and European bodies that fund research generally condition the financing on open data sharing.Footnote 44 Research into courts and judicial behaviour is generally included in such requirements.
This might seem like fertile conditions for the development of multi-user databases. However, at the same time, the EU has some of the world’s strictest privacy laws. Squeezed between the principles and ideals of Open Science on the one hand, and privacy and data protection on the other, European scholars are facing harder choices than many of their peers in other jurisdictions. The EU General Data Protection Regulation (GDPR)Footnote 45 has recently imposed new and stricter legal limits on researchers. The practical obstacles these pose for constructing judicial databases which unavoidably contain personal information, such as the names of judges, parties, and lawyers, as well as sensitive personal information, such as information on racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, or even criminal convictions, is beyond significant.Footnote 46 Entirely excluding sensitive personal information in a judicial database is near impossible, and entirely impossible if that database is to include a corpus of entire texts of judgments.
The European system for handling research data is based on the principle of proportionality: ‘as open as possible, as closed as necessary’.Footnote 47 To justify collecting, organising, structuring, storing, and disseminating judicial data that contains personal data, European database designers must, in lieu of individual approval (which is generally not a feasible option), (1) have a pre-defined aim that is legitimate, and (2) show that the processing of such information is proportionate to that aim. This involves a careful consideration of two questions. First, what legitimate aims will such a database fulfil? This is reinforced by the requirement that a database should address real-world problems, as discussed above. The processing of personal information – and potentially sensitive personal information about actors with significant political power and legal authority, including judges – is thus easily justifiable. Second, what is the potential and likely harm to privacy that the collection and dissemination of data may cause? The answer to this question hinges on the nature of the underlying data and on database design choices. However, the greater the care database designers put into effectively protecting personal information where it is not strictly needed, the greater the chance of achieving proportionality. The important interests of transparency and accountability of judicial and political institutions, which judicial databases serve, would make the design and the establishment of judicial databases in Europe possible.
Multi-user judicial databases pose a dilemma: one of the ‘basic rules’ of collecting judicial data and building judicial databases is ‘the more data the better’.Footnote 48 While it remains relatively unproblematic to maintain a Gotta-Catch-’Em-All approach to non-personal data, its application to personal data directly conflicts with two of the GDPR’s basic principles: the principle of purpose limitationFootnote 49 and the principle of data minimisation.Footnote 50 Compliance with these principles requires a demonstration of a specific purpose. Defining such a specific aim is obviously difficult when it comes to a database intended to be used by unknown users for unknown reasons to study unknown problems.
Within this context, the IUROPA CJEU Database was developed with security and privacy issues front of mind. The Database only includes personal information that is publicly available through public sources. Moreover, the names of natural person parties have been anonymised where feasible in order to minimise privacy harm. We have sought and received approval for the compilation and dissemination of the IUROPA CJEU Database from the Swedish Ethical Review Authority (nr 2020-04273), which, under Swedish law, constitutes compliance with EU data privacy law.
In sum, while full openness and accessibility to extensive data is laudable, the ethical benchmark of privacy should be considered and applied in a way that does not render the creators, maintainers, or users of the database open to legal liability – understanding, too, that these two criteria are not always in sync.
8.5 Sustainable and Foundational: Standing the Test of Time
A sustainable database is easy to maintain and stands the test of time. Here, however, the aim of providing relevant data and valid measurements capable of addressing real-world problems comes up against the limitation of resources. While automated data collection in the form of, for example, web scraping is more sustainable, resource-heavy data collection like manual hand-coding potentially increases the quality – accuracy and validity – of the data.
The foundational criterion can be addressed through the following reminder from Tim Berners-Lee, one of the founders of the worldwide web: ‘[d]ata is a precious thing and will last longer than the systems themselves’.Footnote 51 Data infrastructure must be technically, structurally, and conceptually flexible and inclusive. New users can easily calibrate foundational databases to their own creative purpose, with the data lending itself to accurate transformation and development, when three requirements are met: (1) that the database includes clear definitions of variables and outcomes, coding protocols and coding instructions; (2) that the process of collection, the criteria of data selection (inclusion), and the content of the database are clearly described in supporting documents or a user manual; and (3) that the database includes information about the reliability of data such as inter-coder reliability tests (see also Section 8.6 on reliability and reproducibility).
IUROPA’s National Courts component, which contains data on the national courts that have referred questions to the CJEU for preliminary rulings under Article 267 of the Treaty on the Functioning of the EU (TFEU), illustrates the trade-off between maintenance and relevance, and between the criteria of sustainability and tackling real-world problems.Footnote 52 While the data were hand-coded, most variables were designed so that coders with a legal background could easily acquire the necessary expertise, for instance through searching for information on whether the court operates as part of a national hierarchy and, if so, at what level and whether it has general or specialised jurisdiction. These variables are comparatively straightforward and stable, standing the test of time (bar a complete overhaul of the judicial system). To add new courts to the dataset at their first referral is a simple process because coders can draw on the existing units: for example, if the dataset already includes the Bezirksgerichte (‘district courts’) of Bregenz, Dombim, and Linz, the addition of the Bezirksgericht of Villach will present no difficulties and could easily be automated, subject only to random expert quality checks.
Ensuring that the data will be useful for deeper enquiry, the National Courts component also features more challenging variables which require legal expertise. One example is the variable concerning whether the court in question typically sits as a single judge or a collegiate court, where the coding requires some knowledge of procedural law of the Member State. Another is court prestige, which supports the categorisation of specialised courts operating outside of the judicial hierarchy. These include constitutional courts, but also specialised courts that act simultaneously as first and last instance. The coding of such variables was accomplished with the assistance of national legal experts, who provided the initial classification for the prestige variable, checked the coding of the collegiality variable and responded to the queries of non-expert coders. The upkeep of these variables could prove more challenging and would need to be weighed against their added value of more nuanced explanations of the functioning of the EU legal system. Coding protocols, codebooks, and user manuals will, however, give users the necessary tools to update the database, which is always more efficient than developing new protocols, codebooks, and manuals. Often, these ‘start-up’ tasks take a disproportionately long time in such projects.
Another example requiring manual coding and expertise on the part of the coder is the component on Legal Issues and Doctrine,Footnote 53 which currently includes all judgments issued in three central policy areas of the internal market where the CJEU played a key role:Footnote 54 the free movement of persons and European citizens, the free movement of goods, and the freedom of establishment and services.Footnote 55 Hand-coded variables capture information about the parties to the case such as gender or legal status, the legal questions or issues raised in the dispute, the strictness of judicial review expressed in proportionality tests, and the allocation of decision-making authority between the European and the national levels. The latter is typically conceptualised in legal terms as deference, or in social science terms as national regulatory autonomy. The information offers a concise but detailed overview of legal outcomes – of what the CJEU decided, such as the decisions about the compatibility of national measures and policies with European Union law. Crucially, this information cannot be easily compiled from the official data repositories like CuriaFootnote 56 or EUR-Lex.Footnote 57 Of twenty-two observed legal characteristics (variables) included in the Legal Issues and Doctrine component of the IUROPA CJEU Database, eight are common to all policy areas and potentially to all judgments, and fourteen are policy-specific, meaning that they are narrower, addressing legal issues of the disputes typically attached to one of a handful of policy areas.
Such information is relevant for empirical legal studies in law and political science. For example, Figure 8.2 illustrates the patterns in the litigation of free movement and European Union citizenship rights.Footnote 58 The initial Treaties supported the free movement of workers as essential to the establishment and the functioning of the European internal market. The Treaty of Maastricht (1992) introduced the concept of EU citizenship in an attempt to bring the EU closer to its citizens.Footnote 59 Figure 8.2 shows that the share of judgments including workers or economically active persons moving across state borders (dotted line) decreased from more than 70 per cent in the early 1960s to less than 50 per cent during the 2010s. Second, the share of judgments where the CJEU upheld the applicant’s claims based on free movement and European citizenship rights (dashed line), decreased from over 80 per cent in the 1960s to less than 60 per cent after 2015. These findings imply that the type of free movement of persons cases, the type of the applicants litigating their free movement rights, and the CJEU’s willingness to recognise the rights of the applicants have changed.
The share of free movement of persons judgments (y-axis) over time where the CJEU rules in favour of private individuals (dashed line) and the share of judgments where the applicant is economically active (dotted line). The x-axis represents the date of the judgment. The shaded area indicates the Standard Error intervals.
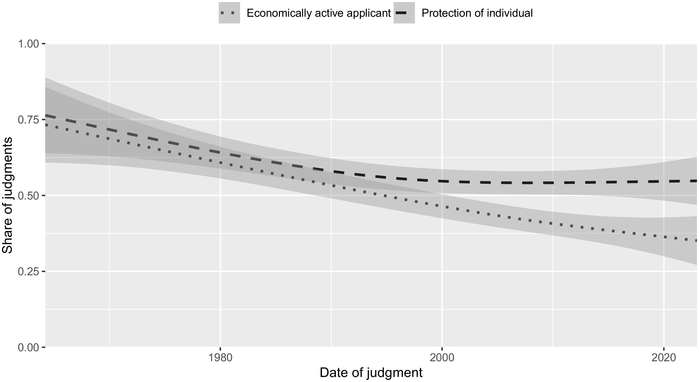
Figure 8.2 Long description
The X-axis represents the date of judgment, ranging from 1960 to 2020. The Y-axis represents the share of judgments, ranging from 0 to 1. It plots lines for economically active applicants and the protection of individuals. The lines have a shaded area around them to indicate the confidence interval. The line for the protection of individual begins at 0.76 in 1964, follows a concave up declining curve with 0.63 in 1980, 0.60 in 1990, 0.57 in 2000, 0.57 in 2010, and 0.58 in 2020. The line for economically active applicant begins at 0.74 in 1964, decreases to 0.60 in 1970, 0.58 in 1980, 0.54 in 1990, 0.47 in 2000, 0.40 in 2010, and 0.35 in 2020. Note, all data are approximated.
Further analysis can unpack these patterns and changes, contributing to various strands of literature. Most relevantly, it could help clarify the effect of political pressure from Member State governments on the CJEU, or the effect of the financial crisis on the rights of economically inactive migrants. Those have typically – even if often inaccurately – been portrayed in public debate as taking resources away from citizens.Footnote 60
Scholars aspiring to update the Issues and Positions and Legal Issues and Doctrine components will observe two things: first, manual coding requires resources. Future data collection efforts might address some of the challenges and limitations, especially with the help of machine learning, natural language processing (NLP), and large language models in annotating the judgments in lieu of human coders. This would not only considerably lower the cost of repeated calibration, rounds of recoding, inter-coder reliability tests, updating codebooks, and extensive training of research assistants,Footnote 61 but also increase sustainability by enabling computerised database expansion and updates. Second, the doctrinally most interesting questions are rare in the case law. In the context of free movement of persons, this includes issues such as the occurrence of a purely internal situation (a dispute entirely confined to the legal system or the territory of the state, lacking a connection to EU law, and thus excluding the competence of the EU and potentially the CJEU’s jurisdiction), recognition of derived rights of third-country nationals caring for young European citizens, and even questions related to the protection of public finances. Coding these variables might not merit the coding effort. Legal analysis of the few relevant judgments identified by transparent search criteria in the official case law repositories will be far more productive and rewarding.
Epstein and Weinshall wisely caution against data exuberance. A reasonable balance must be struck between the ambition of including analytical legal information on the one hand and burdening the database with data unsuitable for ELS methods on the other. With doctrinally interesting matters not only being rare but also complex, this is also a question of reliability.
8.6 Reliable and Reproducible
Reliability and validity are concepts that communicate the trustworthiness of data and thus, of the research based on it. A multi-user database should enable wider use of data while preventing the creation of sub-par surrogates and bad research.Footnote 62 Because creators of multi-user databases must assume that the database will outlive them, enhancing reliability and reproducibility is a top priority. Epstein and Weinshall suggest that the criterion of reliability and reproducibility obliges the database developers and users to treat all observations and variables as part of a chain of evidence; we must be able to explain and recall how they were generated. Further, anyone with sufficient skill should be able to understand, evaluate, and reproduce the content without the collaboration of the creators.Footnote 63 This task becomes easier if the database includes an explanation of how the variables were selected and constructed. Striving for reliability and facilitating reproduction, a database for multidisciplinary use should also minimise the use of monodisciplinary jargon or find efficient ways to convey specificities.
The process starts by carefully considering the extraction of necessary and useful information from the judgments.Footnote 64 Legal researchers must think beyond doctrine and concepts of political and social reality; political scientists must think beyond outcomes and ways to extract individual votes from collegiate decisions – beyond power politics. Both must consider which types of information will lend themselves to systematic coding by human coders, which information could be recorded automatically or semi-automatically from text of the judgment, and which information could be harvested and organised from official data sources and repositories (metadata). When deciding on the list of variables to use for conducting research based on the data, researchers must make sure that the measurements reflect the phenomena they aim to study. The validity of measurements should be obvious to researchers adding to the dataset or creating similar measurements.
For instance, legal scholars and political scientists often speak of judicial deference to political actors. In the EU context this deference can be expressed through deference from the CJEU to the national court deciding the dispute in the main proceedings under the preliminary reference procedure (Article 267 TFEU). Some observers would not consider deference from one court to another court in a case that concerns a correct interpretation of EU rules as a primarily ‘political’ or ‘strategic’ move of the CJEU. This point would become clearer when explaining that deference to national courts is typically synonymous with deference to Member States, as most referrals concern the compatibility between national legal acts and EU law and national courts. The matter can be further unpacked. A legal scholar would reluctantly accept the CJEU’s deference as primarily strategic in the context of Article 267 TFEU, because national courts often ask fuzzy questions, supply patchy information to the CJEU, and draft their questions from the perspective of the national legal systems for shortsighted and narrow purposes.Footnote 65 The CJEU cannot always offer clear and precise answers to such questions. But this does not mean that it defers important legal decisions to the national courts. Also, Article 267 TFEU includes a division of labour – the national courts decide the case at hand based on the interpretation of the rule by the CJEU. The CJEU has no competence to rule in the case, thus inevitably leaving the decision of whether and how to apply the interpretation of the rule to the national court. In this sense, the CJEU must always defer, at least minimally. This debate touches on a familiar question of validity, highlighting the importance of clear, legally correct, and transparent definitions.
The Legal Issues and Doctrine component captures the established concepts and doctrine. It is designed to closely correspond to legal reality – meaning that the variables are valid proxies for the CJEU’s decision-making – including the methods of interpretation, judicial tests, and normative implications. The problem of validity and replicability can be solved by explaining that the deference variable captures the CJEU’s passing of decision-making (in this case also interpretive) power and important legal choices to the national courts and by extension to the Member States, which exceeds the necessary division of labour inherent in Article 267 TFEU. Further, the researchers must select a reasonable number of values that a variable can assume. While coding deference as a binary variable, with outcomes deference_yes and deference_no, would render higher inter-coder reliability scores and possibly also lend itself to automated coding,Footnote 66 it might not be informative enough for legal scholars trying to systematise the case law on the scale of deference or devise specific types of deference.
Multi-user databases will not satisfy all research requirements and aims. This must, however, be made clear from the outset. The publication of codebooks and inter-coder reliability scores offer a simple and effective solution but raise a dilemma: When is data ‘good enough’?
We would all agree that unreliable data should not be published and that the question of reliability should be answered based on accurate and full information supplied by the creator of the data. What is trickier is agreeing on when data is reliable enough. Existing metrics are often developed in the context of natural science and medical research requiring high inter-coder reliability before data can be published and reused. Legal scholars engaging with ELS must live up to high standards. Even when they code their data individually, they must ensure to code the data consistently (internal consistency/internal validity). When they solicit the opinion of close colleagues, incorporating their input, they must report this even if omitting a full inter-coder reliability report in the form of written notes of disagreement. While the Issues and Positions component includes strict reliability tests, the National Courts component combined hand-coding of most variables about national referring courts with consistent expert checks. This involved two steps: first, the project team hand-coded the data based on the code book and then national legal experts performed quality checks. In this sense, it did not lower the standards but adapted them to the nature of the data and the task.
Moreover, legal scholars disagree about the importance of a ruling, its contribution to doctrine, its landmark character, and symbolic importance.Footnote 67 The disagreement translates into low inter-coder reliability scores for variables such as case importance. Fine-tuning of codebooks, extensive training of research assistants, hand-coding, and often several rounds of recoding might prove prohibitive for short-term projects or smaller teams under pressure to publish research findings and data. Even for larger, generously financed teams, the gains of such enterprise would not compensate the cost. Many variables must simply be scrapped, and the data discarded as unreliable.Footnote 68 That said, legal scholars might find value in such data. For instance, they might find it useful to select and carefully examine judgments marked as important or use codebooks and the results of inter-coder reliability checks in developing their own measurements and learning from existing errors. Again, this does not lower the standards of ELS but tailors them to the research needs – a legal scholar using the ‘data’ will not claim that they are engaging in empirical research.
By analogy to the recording of language patterns and the meaning of text in content analysis, the coding of legal texts and legal meaning is typically more objective and reliable if content is manifest rather than latent.Footnote 69 Legal concepts are expressed using different terms and coders must bring in subjective interpretation. While all trained coders can be confident in the accuracy of their own interpretations, new coders and the users of data will suggest alternative interpretations. Providing concrete examples in the codebook can help ensure that coders understand and code variables with more than two outcomes in the same way and that future contributors can code future cases in the same way.
High inter-coder reliability may be reasonably expected for the coding of textual information (such as gender of the applicants), but it is harder for the coding of legal meaning and concepts (such as the proportionality test). The more coders are asked to make difficult judgments, the more they bring subjective understanding and pre-conceptions into play, and codebooks will not always offer the necessary guidance to approximate the coding to a simple task of recording instances.
Moreover, reliability issues at times arise because of class imbalance, meaning that one of the variable’s values occurs much more often than the others.Footnote 70 For example, for the deference variable in the Legal Issues and Doctrine component it is very common to observe the CJEU’s decision not to defer, while it is much less common that the CJEU defers. Consequently, an inattentive coder who always codes no_deference is statistically likely to have a high level of agreement with the careful coder who identifies the few cases of deference. A reliability coefficient such as Krippendorff’s Alpha considers this situation of by-chance agreement. When comparing reliability scores across different studies it should be noted that disagreements among coders tend to result in a lower Krippendorff’s Alpha score in cases with class imbalance compared to coding a variable whose values are more evenly distributed.Footnote 71
8.7 Conclusion: Why Invest in a Common Future?
This chapter has reflected on the trade-offs and considerations involved in the building and maintenance of multi-user databases which live up to four criteria proposed by Epstein and Weinshall: they address real-world problems; they are open and accessible; they deliver reliable and reproducible data; and they are ageless and easily calibrated to research purposes unknown at the time of data collection and cleaning. The most obvious and hardest choices when trying to live up to these criteria include decisions about the sufficient reliability of data, whether to discard or improve upon imperfect data, and whether to publish or postpone the publication of incomplete data. Furthermore, the sustainability criterium can more easily be satisfied when the need for human intervention in the updating and maintaining the data is minimal. This could push scholars to strive for the most accurate (valid) or most reasonable measurements for pragmatic reasons. By consequence, it will not support the ambition of obtaining the most nuanced and legally relevant information. The quest for openness and maximum data moreover clashes with the protection of privacy regulation, imposing the principles of purpose limitation and data minimisation.
Looking back, IUROPA was an enormous investment, requiring significant financial resources, organisation, and management with an uncertain outcome and potentially limited payoff for individual researchers. Yet, regardless of these challenges and trade-offs, we should invest in multi-user databases in EU law. High-quality data enriches inquiry, generates new questions, increases the quality of research findings, and in turn improves our understanding of the EU legal system. Thereby, it underwrites the relevance, contribution, and legitimacy of ELS, a field that has expanded from isolated studies and events into a lively community of scholars pursuing similar goals and sharing an interest in data-based or data-driven work.Footnote 72
We should also invest in multi-user databases to avoid unproductive conversations about the merits of ELS in EU law. Until ELS has a firm data foundation, it will continue to struggle for recognition, university chairs, and inclusion in the law curriculum. We should invest in multi-user databases to grow a scientific community rather than an echo chamber. A scientific community is a group of scholars working on shared problems in parallel or together, who mostly agree about methods, standards, valid research questions, and approaches.Footnote 73 However, a dynamic scientific community with a common future must share information, and progress towards consensus over standards and knowledge claims.Footnote 74 Data sharing is progress.
9.1 Introduction
Doctrinal research in European Union (EU) law engages in the analysis and critique of law found in the judgments of the Court of Justice of the European Union (CJEU) and the legislative texts issued by the EU’s political institutions. Through its critical reflections on what are typically landmark judgments or pieces of legislation, the discipline illuminates the underlying principles and values of the EU’s legal system. Empirical legal studies in EU law, on the other hand, aims to identify patterns and relationships among the often-abstract phenomena that characterise the EU’s legal system. In other words, ELS in EU law relies on empirical evidence to uncover what the law obscures through abstract legal concepts.Footnote 1 Has the CJEU’s jurisprudence become more deferential towards national authorities in the EU’s Member States over time? Is judicial independence declining in some Member States, and if so, how are the EU’s institutions responding to this trend? Are Member State governments able to shape the CJEU’s jurisprudence by signalling their positions on important legal questions? Empirical legal scholars – irrespective of their research focus or differences in approach and methodology – have in common that they use data, that is, facts about the world, to answer the questions that motivate their research.Footnote 2
The sources of such data are generally diverse, ranging from expert interviews to publicly available documents, academic literature, archival material, social media accounts, online surveys, and more. In ELS in EU law in particular, text plays a prominent role as a source of data. It is the primary medium through which EU law is communicated, for instance via directives and regulations drafted by the EU’s political institutions, the CJEU’s jurisprudence, preliminary references submitted by national courts, and observations filed by Member State governments. We can reasonably assume that most scholars wishing to study EU law empirically find it helpful to turn to text as a source of data to answer their research questions. Sometimes, the required information for their research projects exists in the shape of already compiled datasets. Single-user databases are tailored to serve the narrowly defined purposes of a specific research project, whereas multi-user databases allow several individuals to access the data at the same time and for different research purposes.Footnote 3 However, oftentimes researchers do not have the luxury of being handed a dataset that is ready for use for their particular study. In most instances, they will have to collect (at least some of) the relevant evidence for their research projects themselves. For empirical legal scholars of EU law, this typically involves ‘processing’ legal text, that is, converting unstructured information found in texts into a format that is useful for the researcher and conducive to subsequent empirical analyses.Footnote 4
Extracting useful information from text requires several steps. First, researchers must think carefully about how to render abstract phenomena measurable. For instance, what do researchers mean when they refer to ‘deference’ or ‘judicial independence’, and how can they identify their absence or presence? Put simply, researchers must conceptualise a phenomenon of interest and develop an instrument allowing them to measure variation in that phenomenon. Second, researchers need to implement their measurement instruments and systematically record the desired data for each unit of analysis (e.g., a sample of CJEU judgments) in their study, a process commonly referred to as coding. Finally, researchers need to evaluate their measurement instruments, engaging in a process of critical self-reflection to ensure that the measures they put forward do not fall short of reflecting the true meaning of the concept under examination, and that the instruments produce the same results regardless of who is carrying out the measurements.Footnote 5
In this chapter, we describe each of these steps in greater detail and provide practical guidance on how empirical legal scholars should approach them. Along the way, we highlight challenges that are particular to empirical legal research in EU law. We begin by discussing how researchers should conceptualise abstract phenomena and offer guidance on the development of instruments that allow researchers to measure them. We then discuss key considerations that researchers should be mindful of during the coding process. The chapter’s final section then centres on evaluating measurement instruments, specifically discussing ways to improve an instrument’s validity and reliability.
9.2 Developing Concepts and Measurement Instruments
While the measurement of physical properties such as length, time, or velocity is expressed in standardised units of measurement such as metres, seconds, and metres per second, measuring legal concepts is likely to be a more complicated matter. This is mainly because legal concepts are theoretical, latent constructs that can assume a variety of different meanings depending on the contextual circumstances. The main task of the empirically minded researcher thus consists in building a bridge between these unobservable constructs and empirical facts by identifying observable indicators that can serve as their concrete manifestations.Footnote 6
However, identifying indicators that capture the correct and full sense of a legal concept will be difficult when the meaning of that concept itself is shrouded in uncertainty. One of the particularities of the EU legal system is that it operates with a plethora of vaguely framed terms that are inconclusive and inherently value-laden, which renders their interpretation susceptible to divergent views and subject to ongoing academic controversy. This is particularly true in the case of general principles of EU law. With respect to their recognition and interpretation, Advocate General Mazák once remarked that it is ‘the nature of general principles of law, which are to be sought rather in the Platonic heaven of law than in the law books, that both their existence and their substantive content are marked by uncertainty’.Footnote 7 As prescribed in Article 19 (1) TEU it is the task of the CJEU to develop the law and clarify its meaning through interpretation. In doing so, it has frequently relied on the teleological method as the interpretation of the Treaty provisions is entirely grounded in the idea that there are objectives of pivotal constitutional importance the Union must achieve.Footnote 8 It becomes evident that EU law is a discipline that is characterised by purpose-driven functionalism.Footnote 9
For better illustration, take the legal concept of ‘judicial independence’, which most people will associate with safeguarding the judicial branch from any form of external political interference.Footnote 10 In search of what judicial independence means in the EU context, it makes sense to scrutinise the case law of the CJEU. In its recent case law, the Court has made use of the teleological method of interpretation to clarify what it perceives to be minimum common standards for ensuring the independence of European judges. Relying on common values such as effective judicial protection, the right to a fair trial, and the rule of law, the Court has reminded the Member States of their duty to fulfil the commitments they had made upon joining the Union. Based on this line of case law, potential attributes of the concept of judicial independence could be, for example, freedom from any constraints influencing the (re)appointment and promotion of judges,Footnote 11 the security of judges’ tenure,Footnote 12 or insulation from budgetary pressuresFootnote 13 exerted by the executive and legislative branches to control the judiciary’s performance. If we focus solely on the attribute of tenure security, an observable indicator that immediately comes to mind is the duration of the judges’ tenure of office in high courts across different Member States of the EU, assuming that longer terms in office foster judges’ independence and vice versa (see Figure 9.1). A researcher may distinguish between appointments that allow judges to serve for more than twelve years on a court, appointments for five to twelve-year terms, and finally, any appointments lasting under five years. Assuming that rules concerning the security of judges’ tenure are a valid attribute of the concept of judicial independence (see our discussion below on validity), and that the duration of judges’ tenure is a sensible indicator for this attribute, a researcher may then conclude that systems providing judges with more than twelve years of tenure are characterised by higher levels of judicial independence than systems providing five to twelve-year terms, while the lowest level of judicial independence is found in systems providing judges with terms that last less than five years.
An example of an attribute and indicator for the concept of judicial independence.

Figure 9.1 Long description
The following are labeled from top to bottom in order. Concept, judicial independence, high courts. Attribute, tenure security. Indicator, tenure duration of judges. Measurement scale, ordinal, with more than 12-year appointments, 5 to 12-year appointments, and less than 5-year appointments.
Identifying appropriate attributes of a concept and their observable indicators, however, is not always as straightforward as our example of judicial independence suggests. The concepts typically examined by scholars conducting empirical legal studies in EU law are often complex and characterised by more than one attribute. Recently, scholars working in the field of ELS have turned to large language models (LLMs) to summarise legal documents or retrieve information from legal texts (see Ovádek’s Chapter on machine learning and large language models in this volume). Given that the performance and accuracy of LLMs is only going to improve, much of the time- and resource-intensive collection of data currently carried out by human coders will likely be outsourced to machines (see also our discussion in Section 9.4 below). The formation of concepts and the development of instruments measuring them, however, requires conscious choices from researchers themselves, who should have explanations at hand for why they picked a particular conceptual attribute or selected a particular indicator.
Of course, researchers may find it challenging to determine whether they have identified every essential attribute to clearly communicate the sense or meaning of a concept. One way to ensure that the conceptual attributes identified by a researcher are collectively exhaustive (in other words, to ensure that no essential attributes are omitted from their concept) is to think of attributes as individually necessary and collectively sufficient conditions. To illustrate, consider again our earlier example of judicial independence. We can think of fixed tenure rules as an individually necessary condition for judicial independence. A legal system that does not provide fixed tenures for high-court judges cannot embody judicial independence. However, fixed tenure rules alone may not necessarily capture the meaning of judicial independence. For instance, existing literature has identified financial autonomy for high courts and governments’ consistent faithful implementation of high court judgments as additional essential attributes of judicial independence. Hence, judicial independence is then only given in systems where all three of these individually necessary attributes – fixed tenure, financial autonomy, and consistent implementation of judgments – are collectively present. We want to stress that there is no definitive answer to whether a particular attribute is individually necessary for a concept, and we expect these decisions to often be the subject of debate in the scholarly literature. We consider debates over the meaning of a concept to be necessary and fruitful, and we encourage scholars to articulate the attributes of their concepts in a transparent manner to facilitate such debates.
An issue when it comes to the selection of appropriate indicators for conceptual attributes that is specific to ELS in EU law is the veil of secrecy surrounding the decision-making process at the Court of Justice. The opaqueness of the decision-making process, non-disclosure of judicial votes, and restricted access to documents such as case files, the pleadings of the parties, and reports of the hearings are serious obstacles put in the way of anyone wishing to study the Court empirically. Thus, empirical legal scholars often have no other choice but to rely on publicly available sources when selecting indicators that could provide a glimpse into the decision-making process. The legal texts they will primarily consult are the Treaties, secondary legislation, national laws of the Member States, as well as the judgments of the CJEU. A major drawback is that the information gleaned from such publicly available texts often does not constitute a first-hand account of the discussions and events that took place behind closed doors.
In addition to institutional policies restricting access to documents, one of the EU’s founding Member States, France, has criminalised research on individual judicial behaviour, placing it under the looming threat of a maximum sentence of up to five years in prison.Footnote 14 Imagine some researcher finding unassailable proof for the fact that one particular judicial actor at the CJEU pursues a particularly neoliberal agenda and has exerted a remarkable influence on decisional outcomes. For fear of repercussions, the researcher may look for alternatives, replacing the identity of the judicial actor with a placeholder such as, for example, economic expertise when it is obvious that only certain actors, including that particular individual, possess such qualifications. Framing economic expertise as the driver of decisional outcomes would conceal the true nature of the relationship, leading to sub-standard theorisation and conceptualisation. It becomes evident that institutional practices restricting access or outright bans not only have a muting effect on intellectual innovation, but also impinge upon the ability of researchers to devise high-quality measurement instruments.
9.3 Implementing Measurement Instruments
Coding constitutes a central task for scholars of ELS, which, depending on the type of variable, can come with varying degrees of difficulty. In the following, we distinguish between textual and interpretive variables. Textual variables are simple to code as they allow researchers to assign values almost exclusively from reading the wording of the judgment or any other document. It is for this type of variable that machine learning classifiers and LLMs hold the greatest potential (see Chapter 10 by Ovádek in this volume). Machines can easily identify linguistic patterns and pick out words in context. For example, determining whether a free movement of services case explicitly mentions issues related to public procurement or not would be a textual variable.
In contrast to that, interpretive variables are more complex and typically require coders to assign values by interpreting the Court’s decision and reasoning against the body of case law and legal literature – a task that presupposes expert legal knowledge and familiarity with the jurisprudence of the Court. Further, the meaning of words or linguistic patterns may change over time, and it may make a difference whether we find a particular word in a judgment issued by the Court of Justice in the 1960s or in the late 2010s. An illustrative example is a variable we call ‘doctrinal outcome’.Footnote 15 The Court can entrench, strengthen, or expand existing doctrines, or create new concepts and principles. Such instances would be assigned the value ‘strong doctrinal outcome’. By contrast, the Court can soften its strong doctrinal positions or apply established doctrines, concepts, and principles, without further developing their scope. This would prompt the value ‘weak doctrinal outcome’. Interpretive variables strongly draw on prior knowledge of substantive EU law and coding them will be difficult to reproduce by non-lawyers, let alone machine-learning algorithms. Furthermore, interpretive variables are naturally context-dependent. New challenges arising from changing political and economic realities will require the Court to reconfigure its goals and sometimes to chart a new path. Due to the dynamic nature of EU law concepts, it is likely that measurement instruments considered appropriate for studying one particular issue will be of limited usefulness for other questions. Against this backdrop, data generated through the hand-coding of interpretive variables inevitably entails a trade-off: as these variables are highly complex, updating the data on a regular basis will prove challenging, leading to the risk that the compiled datasets become historical artefacts representing huge coding efforts with little increasing returns.
The choice between textual and interpretive variables will largely depend on the goals the researcher is pursuing. If the goal is to provide a qualitative empirical overview of the manifold approaches and interpretations put forward by the Court, designing extremely detailed instruments accounting for the smallest deviations in the case law may make sense. However, if the goal is to collect data for a quantitative analysis that allows researchers to draw generalisable inferences, a measurement instrument for a particular variable should capture values that occur frequently enough to be reasonably included in a statistical model. To illustrate, deference granted by the Court to the European Commission could be measured by distinguishing between different standards of review, equating a laxer review standard that only asks whether the Commission has committed any manifest error of assessment with more deference. Coding this interpretive variable will require a close reading of the text of the judgments, as there have been instances in which the Court formally recalled the manifest error test, but in fact, showed greater willingness to scrutinise the Commission’s analysis, concentrating on factual accuracy, consistency, reliability, and exhaustiveness of the Commission’s arguments.Footnote 16 Furthermore, the number of cases in which the Court explicitly used the doctrine of marginal review is relatively small, rendering it unsuitable for inclusion in statistical models. A simpler measure would be the rate at which the Court of Justice upholds Commission decisions in appeals cases, which could indicate the Court’s acknowledgement of the enforcer’s superior economic expertise.Footnote 17 Such a measure could serve as an outcome variable in a statistical model that seeks to explain variation in the Court’s showing of deference to the Commission over time. Arguably, the latter measure is quite crude as it exclusively focuses on the outcome as stated in the operative part, and not so much on the legal reasoning that has led to its adoption. For the purposes of conducting a quantitative analysis, however, it may be necessary to sacrifice the nuance of detail, albeit at the cost of simplifying. To reiterate, which of the two options outlined in this example is appropriate to capture deference is dependent on the researcher’s goal. Whichever choice a researcher makes while remaining within the realms of what is possible, it is important that they communicate this choice transparently to allow others to comprehend and possibly critique their reasoning.
Whether we formulate a variable as a textual or interpretive one will also have consequences for the choice of measurement scale. In our previous example (Figure 9.1), tenure duration was represented on an ordinal scale with three categories. It would also have been possible to opt for a ratio scale, discrete with whole numbers or continuous with fractional numbers. Scales that are quantitative in nature contain more information and allow researchers to appraise differences with great exactitude. However, this does not imply that researchers should always strive to measure their indicators on an interval or ratio scale. In most instances, the concepts subject to scholarly inquiry will be less conducive to being treated as interval or ratio scaled. Unlike with physical or chemical properties, we cannot assume that, for example, the distances between the values denoting different judicial attitudes are equal. Thus, opting for a nominal or ordinal one to measure a legal concept will often be the natural choice. Ultimately, researchers should carefully reflect on their specific research question and always select the measurement scale that fits the objectives of the study best, rather than simply refer to the superior information of certain scales when considered in the abstract.Footnote 18
To clarify any inconclusive points, researchers should compile a codebook containing clear coding instructions and annotations serving the disambiguation between outcomes as well as conceptually similar variables. Sometimes even variables that may appear simple at first glance can prove challenging to code. Take, for instance, the question of whether a case was decided for or against the Commission. Most appeals cases will invoke several grounds of appeal, and if an appeal is partly dismissed and partly upheld, determining who emerges as the winner of the proceedings can be difficult.Footnote 19 Carefully documenting each step along the way and spelling out the reasons behind the decisions made in the coding will allow researchers to revisit, reflect on, and sublimate the data generation process.
The codebook is a guide researchers can consult at any time to produce consistent and systematic data which also renders the coding process more transparent and reproducible. At which stage of the research process a codebook is assembled depends on the research design. Coding can be inductive, meaning that researchers start with an experimental sample to make some observations and then compile the codebook. This bottom-up approach derives the measurement instruments from the data, letting the narrative or theory emerge from it. Qualitative empirical work using interviews will most likely take the information gleaned from the interviews as a starting point for exploring possible themes, theories, and ideas. Deductive coding, on the other hand, refers to the top-down practice of having the theory and a codebook containing an intitial set of measurements first, and then coding the sample.Footnote 20 That said, inductive and deductive coding are not mutually exclusive, and most researchers will engage in an iterative process of review and refinement.
9.4 Evaluating Measurement Instruments
In this final section of the chapter, we offer guidance on how to evaluate the usefulness of the instruments that measure our concepts of interest. Our discussion revolves around two objectives. First, we want our measurement instruments to be valid, that is, the indicators we selected for our conceptual attributes should collectively capture the meaning of the relevant concept.Footnote 21 Second, we want our measurement instruments to be reliable. Following Hayes and Krippendorff, we think of measurement instruments as reliable if they, ‘serving as common instructions to different observers of the same set of phenomena, yield[s] the same data within a tolerable margin of error’.Footnote 22
9.4.1 Validity
Studying EU law empirically does not absolve researchers of analytical rigour and critical self-reflection. In selecting observable indicators for each conceptual attribute, researchers are advised to pay attention to content validity to ensure that those indicators capture the correct and full sense of the concept being measured.Footnote 23 In essence, researchers want to make sure that any indicator they select closely reflects the corresponding attribute of the concept. For example, identifying the duration of high court judges’ tenure allows us to conclude whether judges enjoy fixed tenures, which itself is an essential attribute of judicial independence. When defining the possible values for an indicator, researchers should make sure that these values are mutually exclusive and collectively exhaustive. As an illustration, consider our earlier example of high court judges’ tenure duration as an indicator. Had we only distinguished between high court judges’ appointments for five to twelve-year terms and appointments for five years or less, then the values on our indicator would have been neither mutually exclusive nor exhaustive. We simply would not know into which category we should sort a system that provides exactly five-year appointments for high court judges (the two categories are not mutually exclusive). Further, we would not know how to code systems that provide high court judges with lifetime tenure (the two categories are not exhaustive). To ensure that the values on indicators are mutually exclusive and exhaustive, it is advisable that researchers carry out a pilot study, or even engage in multiple rounds of coding to capture all relevant values for every indicator.Footnote 24
Second, new measurement instruments should generally produce results that converge with already existing, albeit possibly less fine-grained, measures of the same concept. Likewise, researchers should be sceptical if their own instruments suggest empirical patterns that starkly contrast with patterns identified in existing, well-established scholarship.Footnote 25 To illustrate, a researcher may develop a novel instrument to improve on the measurement of judicial independence, particularly with respect to capturing lacking judicial independence in what would otherwise be considered consolidated democracies. While some consolidated democracies may indeed fail to adequately protect the independence of their judiciaries, a measurement instrument suggesting that most states considered fully democratic in existing research lack judicial independence should be viewed with some scepticism. Of course, divergences between novel and existing measurement instruments may not necessarily mean that the former is doing a poor job. As Adcock and Collier point out, none of the existing indicators against which a researcher validates their own measurement instrument may be very good in capturing the systematised concept. Nonetheless, if researchers wish to introduce a novel way of measuring a particular concept, it is advisable that they submit their measurement instruments to various plausibility probes. As concepts are open to contestation, validity requires that only such concepts are included that can be justified on theoretical grounds. In this vein, it makes sense to triangulate the coded data with data from other sources or obtained by employing different data collection methods as a plausibility probe.Footnote 26
9.4.2 Reliability
We complement the advice on concept formation and the improvement of their validity with guidance on how the measurement of concepts should be carried out in practice, particularly with respect to research projects that rely on gathering information from texts and with a focus on improving the reliability of measurement instruments. Our discussion is structured around the following three guiding principles:
1. First, efforts to assess and monitor the reliability of measurement instruments should be made as early as possible in any research project that collects original data.
2. Second, researchers planning for a project that involves data collection should seek to reduce the number of steps that coders must perform in carrying out a coding task wherever possible.
3. Third, researchers should acknowledge that a measurement instrument’s reliability is decreasing with the complexity of the concept that coders are trying to measure, which has implications for the number of variables that can be measured by human coders.
Ensuring the reliability of measurement instruments is critical to the success or failure of any research project that gathers empirically novel data. Yet, developing reliable measurement instruments is difficult, particularly in the field of ELS in EU law where our research revolves around legal concepts that are difficult to grasp, let alone observe. However, we believe that careful planning can effectively mitigate the challenges faced by research projects that gather original data and that undertaking these projects is worth the risks.
9.4.2.1 Monitoring Reliability
Poor reliability of a measurement instrument comes with poor quality of the collected data.Footnote 27 Imagine two coders reading the same set of judgments issued by the CJEU to find out whether the Court showed deference to Member States’ national authorities in these judgments. If these two coders frequently arrived at different conclusions despite using the same measurement instrument, then researchers engaging with the collected data face a dilemma. Which of the two coders’ assessments should we trust and what inferences can we draw from the evidence they collected? Unfortunately, no measurement instrument applied by a human coder is perfectly reliable. In every instance of a coder using an instrument to measure the presence, absence, or degree of a concept, there is a chance that a different coder would arrive at a different conclusion. Even if the same coder would look at the same evidence twice, using the same measurement instrument, they may not perfectly replicate a measurement they had made previously.
There are myriad reasons why coders may arrive at different measurements despite applying the same measurement instrument (e.g., personal biases, experience, or fatigue). Researchers should try to identify and address these issues as early as possible in their research projects, and concerns about the reliability of measurement instruments should already feature in their development. How complex are the instructions that are passed on to coders who are using the measurement instrument? How likely is it that coders will misunderstand (parts of) these instructions? How long will it take coders on average to code a single case?
Whether a measurement instrument is sufficiently reliable can only be answered by putting the instrument to the test. Researchers should allow for a testing phase as early as possible in their projects where multiple coders independently apply the measurement instrument to the same sample of cases to evaluate the instrument’s reliability. This sample should be sufficiently large as coding only a handful of cases is unlikely to yield any useful insights, and drawn at random. Researchers may feel inclined to assess a measurement instrument’s reliability for a hand-picked sample of well-known cases, such as landmark judgments of the CJEU. However, such landmark cases may systematically differ in many respects from the average case that coders will encounter most frequently in their work. Learning that an instrument proves reliable for landmark cases then tells us little about its reliability when it is used to measure a concept in the run-of-the-mill cases.
There is an extensive literature introducing coefficients that provide a numerical summary of the reliability of a measurement instrument. Prominent examples here are Krippendorff’s Alpha or Fleiss’s Kappa.Footnote 28 These coefficients account for the likelihood of agreement by chance between different coders and are therefore preferable over calculating the percentages of agreement between coders.Footnote 29 Researchers should select a reliability coefficient that is appropriate for the scale of their measurement instrument (e.g., some reliability coefficients are designed for ordered or unordered categorical measurement scales), and store the collected data in a spreadsheet format that easily lends itself for a reliability analysis using statistical software.Footnote 30 A debriefing with the coders about their experience using the instrument may also reveal typical sources of disagreement.
Whether a phase in which a sufficiently large sample of cases is assigned to multiple coders should be extended after an initial assessment of a measurement instrument’s reliability is an important judgment call. This decision is conditional on the instrument’s performance. This decision is conditional on the instrument’s performance (i.e., whether the recorded reliability was above an acceptable threshold for the reliability coefficient, acceptable, or poor) and the extent of any subsequent changes made to the coding instructions and procedure. In principle, the more significant the changes, the stronger the case for extending the phase. When significant changes were made, cases that had been coded using the original instructions should be coded again to ensure that all measurements were made following the same instructions. These can be difficult choices, given that coding even a limited sample of cases several times requires resources like time and money which are typically not available in abundance. Nonetheless, investing these resources early on is preferable to realising that a measurement instrument’s reliability is unacceptably poor only after every case has been coded.
Before we move on to the next guiding principle, we briefly reflect on the advice discussed above in the context of research projects that involve only one researcher, such as a dissertation project. How can a measurement instrument’s reliability be monitored if the coding is carried out by a single coder? First, coders themselves may simply code a sufficiently large sample of cases twice. The downside here is that coding decisions are not made independently from each other. A coder may remember their previous measurement which will influence their choice once a case is coded for the second time. Yet, observing poor reliability scores would still indicate issues with the coding instructions or the underlying concept being measured. For example, coding instructions may require attention to contextual details that can be easily missed when a coder becomes fatigued. Second, while the bulk of cases for a research project may be coded by a single coder, assistance of other coders may be enlisted only for evaluating an instrument’s reliability at the early stages of a research project. University departments and funding institutions often offer small grants that can be allocated to hire assistance for coding a sample of cases to assess the reliability of a measurement instrument. Finally, even if no other coder(s) are involved in the data collection, writing out the coding instructions, sharing them with academic peers or supervisors, and receiving feedback on these instructions prior to carrying out the coding is the minimum that researchers working individually can do to improve the reliability of their measurement instruments.
9.4.2.2 Reducing the Complexity of Coding Procedures
In most research projects that task human coders with extracting information from legal texts, coders are presented with a document and collect data based on the instructions of a codebook. Consider our earlier example of coders identifying whether the CJEU showed deference to national authorities in its preliminary rulings. Not every part of the CJEU’s preliminary rulings is relevant for this task. Coders looking for signs of the Court showing deference would search in vain in the judgment’s summary of the case in the national court and are best advised to focus their attention on the substantive parts of the Court’s answers to the referred questions. Even here, it is not a priori clear in which paragraph(s) the coder finds relevant evidence. The coder must first identify which paragraph(s) in the judgment contain the evidence, which then allows them to make a subsequent, second decision whether the Court showed deference to a national authority in the judgment. It may seem superfluous to distinguish between a coder deciding which segment of a document is relevant for a coding task and the coder deciding how to interpret the evidence in this segment. However, for the sake of improving the reliability of a measurement instrument, we believe it is important to acknowledge these two steps.
Imagine a project leader setting up two tests to assess the reliability of a measurement instrument used in the coding task described above. In one of the tests, coders receive a set of unprocessed documents, for instance, complete CJEU judgments. In the other, coders receive only the paragraph(s) from each judgment that another researcher had previously identified as relevant. We can reasonably assume that coders involved in the second test are more likely to agree among each other, as they were able to focus their full attention on interpreting the substance of these paragraphs, while the coders working with complete documents not only had to read more text but also had to decide which of the paragraphs were relevant before proceeding to interpret the evidence from these paragraphs. Additional steps in the coding procedure allow for more room for error, and the likelihood that different coders arrive at different values increases with the procedural complexity of the task, a function of the number of steps a coder must complete before they can decide on how to code a particular case.
Supervised and unsupervised machine learning classifiers as well as LLMs can help researchers reduce the procedural complexity of coding tasks (see also Ovádek Chapter 10 in this volume). Fine-tuned machine learning models excel at classifying text based on recurring linguistic patterns, and we are optimistic that recent advances in tuning LLMs for text classification will improve classification performances even further. To illustrate, Schroeder and Lindholm programmed several classifiers to identify paragraphs in CJEU preliminary rulings that mark the beginning and end of each of the Court’s individual answers to national courts’ referred questions.Footnote 31 Drawing on common linguistic patterns in the CJEU’s judgments, classifiers were able to pick out these paragraphs with high accuracy and allowed the authors to split judgment texts into separate segments that only comprised the CJEU’s substantive answers to the referred questions. While such a classification does not tell us anything about the substance of the CJEU’s answers, it removes a step in a coding task that would ask coders to, for instance, identify the area of law that is dealt with in a particular answer.
9.4.2.3 Placing Priority on Conceptual Complexity
Complex concepts that require contextual knowledge to be accurately measured are often at the centre of our research. To illustrate, consider a task that requires coders to identify to what extent a CJEU preliminary ruling further restricts Member States’ future policy options.Footnote 32 To start with, coders would need to know the extent to which the CJEU’s jurisprudence had placed limitations on Member States’ policy-making prior to the judgment in question being issued. Second, while coders may find a paragraph in the judgment which suggests that the Court is tightening restrictions, the Court may have tied its ruling closely to the facts of the case heard by the referring national court. Hence, while the Court is indeed adding restrictions to Member States’ policy-making in scenarios that mirror the facts of the case heard by the referring national court, Member States could easily argue that these limitations do not apply in scenarios that differ, even slightly, from those facts.Footnote 33 Here, coders would not make their coding decisions based on a single paragraph alone, but in the context of other parts of the judgment, the CJEU’s previous decisions, and the likely responses of Member States in the future.
The complexity of a concept and the contextual knowledge required to accurately measure it are inversely related to the reliability of the instrument that is measuring the concept. This presents a challenge for project leaders, succinctly summarised by Mikhaylov, Laver, and Benoit: ‘Coding schemes must balance the researcher’s desire to reflect accurately the complexity of the reality represented by a text, with the practical requirements of keeping coding schemes simple enough that they can be implemented by human coders reliably.’Footnote 34 In order to balance the competing objectives of capturing complex realities and ensuring measurement reliability, coders should focus their attention on a limited number of variables that require detailed coding instructions and contextual knowledge. Any other variables can be coded with the assistance of or entirely by machines, making use of recurring linguistic or structural patterns in texts. For instance, information on variables such as the number of citations to CJEU case law in the Court’s own judgments can be fully coded by machines through pattern recognition techniques. To illustrate, using regular expressions, a machine can easily pick up citations following patterns like ‘C‑340/22’, which represents the code for an existing CJEU judgment. Here, apart from programming a machine to identify such patterns, no coder needs to be involved in collecting this information and their attention can be focused elsewhere.
Machines are most likely able to replace human coders for variables that require little to no contextual knowledge, such as citations, or simple counts of certain expressions in a judgment text. Even when some contextual knowledge is required, machines may significantly lighten the workload of coders. For instance, a researcher might explore the sentiment of paragraphs in preliminary rulings that include citations to existing case law, distinguishing, for example, between ‘positive’, ‘negative’, and ‘neutral’ sentiments. They may look for particular words or phrases that indicate that the referenced case law is useful for answering a national court’s question, or vice versa words and phrases which indicate that the Court believes the referenced case law does not help to answer the question. Recognising these patterns requires some contextual knowledge, and an off-the-shelf classifier using a dictionary of words for sentiment analysis is unlikely to suffice. Yet, coders’ annotations can be used to train a supervised classifier to capture sentiment in paragraphs that the coders have not yet reviewed. Programming a classifier reduces the workload of coders significantly, as they no longer have to code the bulk of cases themselves and instead only have to validate a sample of the machine’s classifications. However, researchers should be aware that any bias among coders who collected the data that is then used to train a machine learning classifier logically also affects the predictions made by that classifier. This reinforces the advice that researchers should debrief with coders early in the project to identify whether disagreements in measurements are, inter alia, caused by coders’ personal biases.
Figure 9.2 illustrates how the involvement of coders is tied to the complexity of a concept and the contextual knowledge that is required to make accurate measurement decisions. When context becomes more relevant for accurate measurement, the necessity to involve coders increases. The number of concepts coders must measure without the assistance of machines should be limited, so they can focus theit attention on fewer, more time-consuming, and error-prone tasks. At the other end of the spectrum, however, no such limitations exist for concepts that can be measured without having to interpret context. Adding concepts that can be easily measured by a machine, such as using a simple classifier working with regular expressions, requires minimal respources, apart from the initial programming effort, and places no additional burden on coders. We encourage researchers to carefully consider the portfolio of concepts that need to be measured in the context of their projects and avoid tasking coders with measuring several concepts that require highly contextual knowledge. Clearly, this also entails accepting trade-offs as the latter types of concepts are often the most central to research in the field of ELS in EU law. However, when faced with the choice between assigning coders the task of measuring several complex concepts with low reliability, and measuring a single concept with high reliability, we always favour the latter.
The extent to which contextual knowledge is required to make accurate coding decisions determines whether human coders need to be involved in the measurement of a concept. The number of concepts that need to be measured by human coders without the aid of machines should be limited.

Figure 9.2 Long description
The pyramid diagram has three sections from top to bottom. Human coding. Hybrid coding processes like training data, supervised classification, and manual checks. Fully automated coding processes such as regular expressions, dictionary, word counts, and unsupervised classification. An upward arrow on the left represents increasing complexity levels from bottom to top. Low complexity. Example, simple pattern recognition like source citations, actor names, and subject keywords. Medium complexity. Example, words in context like paragraph sentiment, and paragraph or text segmentation. High complexity. Example, abstract concepts like deference shown in judgements and autonomy implications of rulings.
9.5 Conclusion
In this chapter, we discussed how scholars in the field of ELS in EU law should conceptualise abstract phenomena and how they can develop measurement instruments that capture the meaning of these concepts. In essence, we believe that scholars should be transparent and explicit about the concepts they employ in their work. While many concepts in this field are characterised by complexity and are difficult to grasp, clearly identifying every attribute of a concept helps researchers to select appropriate observable indicators for these attributes. Further, we offered practical advice on the implementation of measurement instruments, including advice on how researchers can improve the reliability of their measurement instruments. The complexity of many concepts at the centre of empirical legal studies in EU law presents a challenge for researchers, specifically when it comes to developing reliable measurement instruments.
However, we believe that careful planning from project leaders, allowing for reliability evaluations early on in research projects and enabling coders to focus their attention on only a limited number of complex coding tasks, possibly through the use of deep learning classifiers, can effectively mitigate these challenges and significantly improve the quality of the data that is collected.
10.1 Introduction
The empirical study of European Union (EU) law has evolved significantly in the last few decades, driven by both advances in theoretical understanding and methodological innovations.Footnote 1 Traditionally, this field has relied on doctrinal analyses of case law, legislative texts, and policy documents to draw insights into the functioning and development of EU law. However, the emergence of large language models (LLMs) presents a novel and potentially transformative tool for scholars in this domain. This chapter examines the integration of LLMs into empirical legal studies of EU law, focusing on some of their capabilities, associated challenges, and future prospects.
Large language models are a type of machine learning algorithm (or artificial intelligence) that processes and most commonly generates human-like text based on patterns learned from vast amounts of data. These models, most famously exemplified by technologies such as OpenAI’s Generative Pre-trained Transformer (GPT) series, have demonstrated remarkable capabilities in generating coherent and contextually appropriate text outputs. For legal scholars, the allure of LLMs lies in their ability to digest and analyse large corpora of legal texts much more swiftly and comprehensively than human researchers could. This capability not only enhances the effesseliciency of research but also opens up new avenues for hypothesis testing and data-driven insights.
Employing LLMs in the study of EU law can help uncover latent patterns and trends across numerous legal documents, including judgments of the Court of Justice of the European Union (CJEU) and EU legislation. By analysing these texts, LLMs can assist scholars in identifying shifts in legal reasoning, changes in policy focus, and the evolution of legal norms within the EU. Moreover, these models can facilitate comparative analysis, helping legal researchers to draw parallels or highlight differences between various jurisdictions within the EU, a task that is particularly challenging given the multilingual nature of law in the EU. While multilingualism is not a unique property of EU law, it sets it apart from most domestic jurisdictions and as such poses an additional set of challenges for the study of EU law.Footnote 2
However, the application of LLMs in legal studies is not without challenges. One significant concern is the accuracy and reliability of the outputs generated by these models. While LLMs are proficient at mimicking the structure and style of legal texts, their understanding of complex legal concepts and the nuances of legal reasoning can be superficial. This limitation raises questions about the validity of conclusions drawn solely from LLM-generated analyses. Therefore, it is imperative for legal scholars to critically assess the outputs of LLMs and, where necessary, complement them with different methods. Furthermore, ethical considerations must be addressed when integrating LLMs into legal research. Issues such as data privacy, consent, and the potential for algorithmic bias are particularly pertinent in the legal domain. These models are trained on existing legal documents, and thus, they may perpetuate existing biases found in the source material. Legal scholars must be vigilant about these risks and work towards developing methodologies that mitigate bias and uphold the ethical standards of legal research.
This chapter provides an introduction to LLMs and highlights the key challenges of using them in empirical legal research. The next section explains in non-technical terms what LLMs are and how they differ from smaller language models. Subsequently, I look at perhaps the most common use-case of LLMs in legal research, namely information retrieval. I then discuss the practical costs and benefits of using LLMs relative to smaller models before turning to what I see as the most important aspect of deploying LLMs in research – validating their outputs and how to use them in downstream empirical analysis.
10.2 What Are LLMs?
LLMs represent a critical development of natural language processing technologies, a key subset of machine learning and artificial intelligence aimed at enabling machines to understand and generate human language.Footnote 3 These models differ from earlier language models not only in scale but also in their capacity to handle a broader array of linguistic tasks due to their architecture and the sheer volume of data they are trained on.Footnote 4
At their core LLMs utilise the transformer architecture, which is pivotal for handling sequential data – in this case words – more effectively than previous models that relied on recurrent neural networks (RNNs) or convolutional neural networks (CNNs). The transformer uses an attention mechanism that allows the model to weigh the importance of different words in a sentence or passage dynamically, regardless of their position. This mechanism enables the model to generate more contextually appropriate outputs, maintaining coherence over longer stretches of text.Footnote 5
The training process for LLMs involves extensive pre-training on diverse datasets comprising a wide range of internet-sourced texts, including books, articles, and websites.Footnote 6 This phase is generally unsupervised, with the model learning to predict the next word in a sequence without direct task-specific guidance. Such extensive pre-training helps the model develop a generalised understanding of language, grammar, and context. Fine-tuning usually follows, where the LLM is trained on more specific data, enhancing its capabilities for particular tasks through supervised learning, where it adjusts based on feedback tied to specific objectives.
What sets LLMs apart from smaller language models that also use the transformer architecture – such as the Bidirectional Encoder Representations from Transformers (BERT) class of models – is primarily their scale. LLMs such as GPT-4 are characterised by a much larger number of parameters, often in the hundreds of billions. This scale allows for a more nuanced understanding of language and enables the models to perform a wider variety of tasks with higher accuracy and less input from users once training is complete.
Moreover, the volume and diversity of the training data for LLMs exceed what smaller transformer-based models typically process.Footnote 7 This extensive training allows LLMs to generalise across more contexts, making them versatile tools for applications that require understanding and generating human-like text across diverse domains and styles. This capability is critical in areas like legal analysis, where the ability to parse through and synthesise vast amounts of complex textual information is necessary. All of this comes at a much higher computational – and by extension economic and environmental – cost.
In addition, the LLM paradigm has come with natural language control and zero- to few-shot learning. When fine-tuning BERT models, users typically use structured datasets with many examples of what the model is meant to learn, for example a label that should be associated with certain patterns in text. When fine-tuning or tasking LLMs, users can instead rely on natural language prompts which the model is capable of interpreting as instructions. And unlike BERT-sized models, LLMs tend to perform well on many tasks with only the content of the natural language prompt without needing to first learn from a large, task-specific dataset (although mileage will vary depending on the quality of the model and difficulty of the task).
As we shall see, however, the creation of LLMs has not fully crowded out smaller – especially BERT-like – models. On the contrary, the artificial intelligence research community has been looking for ways to leverage the power of LLMs in conjunction with smaller models as a means of reducing computational cost, increasing speed, and in some cases even improving overall performance.
10.3 Information Retrieval
Perhaps the most obvious task in which LLMs can assist EU lawyers is legal information retrieval (LIR).Footnote 8 LIR encompasses the processes and methodologies employed to locate and extract relevant legal information, such as statutes, regulations, and court decisions, from vast and potentially complex legal databases. It is a critical aspect of legal research and practice, enabling legal professionals to access precedents, interpret laws, and formulate legal arguments with precision and efficiency. The importance of LIR lies in its ability to facilitate informed decision-making and ensure that legal practitioners can swiftly and accurately navigate the law. However, achieving effective LIR has historically posed significant challenges due to the intricate and often arcane nature of legal language, the vast volume of legal documents, and the necessity for contextual understanding. Traditional search techniques frequently fall short in addressing these complexities, leading to incomplete or imprecise results. Even state-of-the-art pre-LLM methods have produced relatively paltry retrieval accuracy.Footnote 9
More specifically, a core challenge in legal research is the extraction of legally relevant information – such as the identity of the applicant and legal claims being made – from court decisions. Traditionally, this is a laborious manual process whereby a legal expert or assistant reads through the decisions and notes down key information. Scaling it up to thousands of decisions is prohibitively expensive, especially for academic researchers. As shown in a recent study on extracting legal information from UK employment tribunal decisions, LLMs might be capable of performing this task very well.Footnote 10 Compared with human annotations of the same decisions, the authors adjudged the LLM to have extracted the correct information between 90 and 100 per cent of the time, depending on what specifically was being extracted.
I showcase the method on an example from EU law. I only very slightly simplify the prompt developed by de Faria et al. for this purpose and apply it to the well-known Portuguese Judges judgment concerning judicial independence, handed down by the CJEU in 2018.Footnote 11 I prompt GPT-4o in the following way:
You are a legal assistant. Your task is to read through the court decisions which I will send you, and extract the following information for each input: 1. facts of the case of the specific court decision; 2. claims made in the specific court decision and considered in the specific court decision. Do not include any claim which has already been decided in any previous decision; 3. any references to legal statutes, acts, regulations, provisions and rules, including the specific number(s), section(s) and article(s) of each of them, and including procedural rules; 4. references to precedents and other court decisions; 5. general case outcome; 6. general case outcome summarised using one of the following four labels – ‘claimant wins’, ‘claimant loses’, ‘claimant partly wins’ and ‘other’. Note that the label ‘other’ is to be reserved for situations in which the result cannot be determined or where the outcome cannot be described in terms of winning or losing.
<text of the ruling>
We receive the following response from the LLM:
1. Facts of the Case:
The Associação Sindical dos Juízes Portugueses (ASJP), representing members of the Tribunal de Contas (Court of Auditors, Portugal), challenged temporary salary reductions imposed on the court’s members. These reductions were part of the Portuguese State’s budgetary policy aimed at reducing the excessive budget deficit, based on Law No 75/2014. The ASJP argued that these reductions violated the principle of judicial independence enshrined in the Portuguese Constitution and EU law.
2. Claims:
The primary claim considered in this decision was whether the principle of judicial independence under the second subparagraph of Article 19(1) TEU and Article 47 of the Charter of Fundamental Rights of the European Union precludes the implementation of salary reduction measures on members of the judiciary, such as those imposed by Law No 75/2014.
3. References to Legal Statutes, Acts, Regulations, Provisions, and Rules:
Article 19(1) TEU: Pertaining to judicial independence and effective judicial protection.
Article 47 of the Charter: Right to an effective remedy and a fair trial.
Portuguese Law No 75/2014: Mechanisms for the temporary reduction of remuneration in the public sector.
Portuguese Law No 159-A/2015: Gradual elimination of remuneration reduction measures.
Lei n.º 98/97: Organization and procedure of the Tribunal de Contas.
4. References to Precedents and Other Court Decisions:
Judgment of 4 May 2016, Philip Morris Brands and Others (C‑547/14): Relevance of the reasons for interpreting EU law.
Judgment of 21 December 2016, Associazione Italia Nostra Onlus (C‑444/15): Grounds for refusal to rule on a question.
Judgment of 3 October 2013, Inuit Tapiriit Kanatami and Others v Parliament and Council (C‑583/11 P): Effective judicial protection and rule of law.
Judgment of 28 April 2015, T & L Sugars and Sidul Açúcares v Commission (C‑456/13 P): Judicial review and compliance with EU law.
Judgment of 16 February 2017, Margarit Panicello (C‑503/15): Criteria for determining a ‘court or tribunal’ under EU law.
Judgment of 26 May 2016, Județul Neamț and Județul Bacău (C‑260/14 and C‑261/14): Application or interpretation of EU law by national courts.
Judgment of 19 September 2006, Wilson (C‑506/04): Protection of judicial independence.
5. General Case Outcome:
The Court of Justice of the European Union (CJEU) ruled that the principle of judicial independence under EU law does not preclude general salary reduction measures, such as those implemented by Law No 75/2014, from being applied to the members of the judiciary, provided that the measures are general in nature, not specifically aimed at the judiciary, and are justified by overriding reasons of public interest.
6. General Case Outcome Label:
Claimant loses
The extracted information is largely correct. In simplified terms, ASJP did indeed lose, as the CJEU legitimised the Portuguese government’s austerity measures. The main issue for the model is identifying all court citations (although it also missed Article 2 TEU). It missed references to six out of thirteen rulings cited by the CJEU, probably also because it did not recognise Opinions (1/09 and 2/13) as decisions. This indicates worse performance than that reported by de Faria et al., but it should be noted that I made few adaptations to their prompt which was designed to extract information from a rather different legal context. It is likely that EU law-specific prompt engineering would yield better results, as would additional fine-tuning on EU law texts.Footnote 12
At the same time, we do not know whether the ASJP decision was included in GPT-4o’s training data, but as CJEU rulings are publicly available, this is likely. As such, the LLM would be likely to perform worse on texts which it had not seen prior. The extent to which this constitutes a problem for the researcher-user depends on their specific task and data, but it is certainly something one should be cognisant of in the process of working with LLMs.
Furthermore, it is worth noting the breadth of information the LLM is capable of extracting from the text using only a simple prompt, which speaks to the model’s versatility. There is in fact no other technology that would be able to reliably retrieve certain kinds of information from a large unstructured text input, such as what claims ASJP made in the legal proceedings. However, as the omissions in the citations indicate, LLMs can struggle with highly factual tasks that require a lot of precision. As a result, computer scientists developed a workflow called retrieval-augmented generation (RAG) which combines LLMs’ generative capabilities with access to factual information.Footnote 13
How can RAGs help with our citation extraction problem? We can create a database of CJEU court citationsFootnote 14 – for example using a smaller but specialised named entity recognition (NER) model – and connect the LLM to it. The level of sophistication involved in linking the user’s natural language prompts, the LLMs generative process, and access to the citation database will vary depending on how the data is structured. The simplest version of RAGs uses (cosine) similarity between the prompt and the documents stored in the database to retrieve the most relevant entries to ‘augment’ the LLM’s generative response. A more performant but also technically involved solution would entail translating the user’s prompt into a structured-query language prompt which identifies exactly the necessary information in the database.Footnote 15 The individual-database RAG idea can be generalised into a broader notion of agentic workflows whereby the process of generating an answer to a prompt involves decomposing the problem into smaller tasks which are subsequently tackled with greater accuracy by specialised machine learning models (known as agents).Footnote 16 From the user’s perspective, a great deal of the attraction of this system is that it can still be controlled using natural language instructions, showing how LLMs also contribute to bridging the skill gap between researchers with (most quantitative social scientists) and without (most legal scholars) programming skills.
10.4 Scaling Up, Scaling Down
At the time of writing, it is generally true that LLMs are slower and much more expensive to train and run than smaller models. Training GPT-4, the state-of-the-art model as of 2024, cost upwards of 100 million USD.Footnote 17 Its faster iteration, GPT-4o is priced by OpenAI as of May 2024 at 5 USD per 1 million input tokens and 15 USD for every 1 million output tokens. For illustration, the full prompt from our example above had 6,405 tokens (cost: 0.032 USD), while GPT’s response was 672 tokens long (cost: 0.01 USD). The ASJP ruling is on the shorter end of the spectrum, however, so let’s assume an average CJEU decision to cost at least 5 cents USD to process in the way shown above. Given that there are approximately 48,000 decisions (in French) across the General Court and the Court of Justice, scaling up the processing would cost at least ~ 2,500 USD. In other words, an LLM can under some conditions parse the entire CJEU corpus for the equivalent of a month’s salary of a research assistant.
For larger or more complex tasks, the costs can become too high – and environmental costs are even higher. However, and in any case, we might be interested in models that produce simpler outputs faster, and LLMs can still be helpful. For example, let’s say we are interested in finding out whether the CJEU agrees or disagrees (or neither) with the Commission in each paragraph. Instead of feeding an LLM millions of paragraphs, we can ask it to answer the question for a sample of a few thousand paragraphs and subsequently use this ‘synthetic’ dataset to train a BERT model.Footnote 18 This is the equivalent of asking a research assistant – or several, we can ask an LLM for multiple evaluations – to label the data to subsequently use for model training, but significantly more cheaply. The performance of the smaller model can be as high as that of the LLM, although results will vary depending on the complexity of the specific task. The fine-tuned BERT model will operate faster and at a fraction of the cost (both environmental and financial) than the LLM.
‘Scaling down’ or distilling the LLM knowledge into smaller models is going to work best for relatively straightforward tasks, such as text classification (labelling), which leverage more the LLM’s superior understanding of text patterns than its generative capabilities. Similarly, a core limitation of this approach is the size of the context – how much text the LLM is able to ‘read’ when answering a query – necessary to make good inferences about the text. In our proposed task, the information the model needs is normally present within a single paragraph (the unit of analysis). We are relying on the assumption that most of the time when the CJEU discusses the arguments of the parties or interveners, such as the Commission, the identity of the actor and the Court’s own position are present within the same paragraph. However, in more complex tasks, a paragraph or another relatively short unit of text might not contain all the necessary information, such as when the Court refers to an argument or precedent discussed in a previous paragraph. In such cases, the larger context size which LLMs work with (and smaller models do not) is likely to be critical to performance.
10.5 Validation, Validation, Validation
I have so far at most alluded to a core challenge of doing research with LLMs. How do we know whether the LLM output is useful? Tackling this question appropriately is perhaps the most important role of applied researchers. The consensus in computational social science for the time being considers expert, human evaluation as the gold standard by which to judge any machine-generated output, including that of LLMs. Despite the fact that defining the gold standard is frequently a fraught affair – as demonstrated by plenty of research on coder reliabilityFootnote 19 – machine outputs ultimately serve the ends of human-led research and not vice versa (at least for now). In practice, this means that LLM output requires human – frequently expert – validation.
The main difference between validating LLM output compared to previous generations of text models is that our baseline expectations about the LLM’s performance are considerably higher and generally more transferable. Several studies have shown that LLMs are capable of outperforming human annotators on certain labelling and sentiment detection tasks.Footnote 20 This makes sense – machines have the advantage of not suffering from inattention and fatigue and can therefore produce more consistent output than humans. Nonetheless, and somewhat paradoxically, the only way we can evaluate the performance of the models is by agreeing on a gold standard of what constitutes the ground truth. It requires deciding whether, for example, in the following paragraph the CJEU states that a rule of EU law has direct effect:
Whilst it is true, as observed by the Italian and Danish Governments, that a directive cannot of itself impose obligations on an individual and cannot therefore be relied on as such against an individual (see Case C-91/92 Faccini Dori [1994] ECR I-3325, paragraph 20), that case-law does not apply where non-compliance with Article 8 or Article 9 of Directive 83/189, which constitutes a substantial procedural defect, renders a technical regulation adopted in breach of either of those articles inapplicable.
Human coders in the IUROPA project believed the answer is ‘yes’.Footnote 21 GPT-4o instructed with the following prompt believes the answer is ‘no’:
You are an expert in European Union law. Your sole task is to classify paragraphs of CJEU judgments. Specifically, you must decide whether the Court of Justice states in the paragraph that a rule of EU law has direct effect. Before making the choice [yes/no], read the paragraph carefully and reflect on the reasons that lead you to either conclusion. Answer with your reasoning and the choice made.
Where might the difference between human and GPT judgment arise from? The most likely culprit for the model’s divergent interpretation is likely to be found in the overall tendencies in its training data. The model is presented with a difficult and rather marginal example of direct effect (incidental direct effect). There will be very few positive examples of this type of direct effect discussed in the training data. The LLM therefore likely veers off towards its more general knowledge of the doctrine, which does not deal with or attribute direct effect to incidental situations.
There are no guarantees that the LLM will perform well on every task and there is no way of knowing this a priori. The machine will struggle, similarly to humans, on relatively more difficult tasks. Human disagreement is in principle an indicator for how well we should expect an LLM to perform a task and answer legal questions. Nonetheless, the manner and extent to which difficulty translates from humans to LLMs is going to be context-dependent. The existence of LLMs will invite constant experimentation to identify (difficult) tasks that the machine will do well (overperform or at least not significantly underperform humans). There is no theoretical upper bound on task difficulty that could not be tackled by the most powerful LLMs. In due time and with enough resources – including very large context windows enabling the feeding of thousands of pages of text – the best models should be able to, for example, analyse judicial doctrine as well as humans in a fraction of the time. In general, reasoning models are likely to perform better at complex classification tasks than non-reasoning models.
Establishing a gold-standard benchmark for the evaluation of LLMs requires following the same procedures as creating any human-coded dataset, that is, defining and delineating concepts and preparing a codebook explaining how labels relate to observations (input text) (see Chapter 9, Kim and Schroeder in this volume).Footnote 22 In some cases, the creation of the gold-standard dataset is uncontroversial, as with validating which precedents were cited by the CJEU in a decision. In others, coding agreement can be more difficult to find. Depending on the distribution of the underlying concepts, different sampling strategies might be appropriate. Frequently, we are working with imbalanced data in EU law. For example, there are many more cases without a direct effect angle than those with, and it might be more important to us theoretically to evaluate the positive class. Sampling for the validation set can be even more purposive if we are trying to extract maximum value from each sample, which is commonly done using some form of ‘active learning’.Footnote 23
The ground-truth dataset serves the crucial role of assessing the performance of the LLM on the task of interest. Classification output is most commonly assessed using the F1 score, which is the harmonic mean of recall and precision. Recall is the number of model ‘hits’ (true positives, e.g., cases about direct effect) divided by true positives and false negatives (cases the model incorrectly identified as not being about direct effect), while precision is the number of true positives divided by true positives and false positives (cases the model incorrectly identified as being about direct effect). Matthew’s correlation coefficient (MCC) is another useful option, as it explicitly targets accuracy in imbalanced datasets.
There is no single F1 or MCC value at which we can generally say that the output of LLMs is accurate, but values above 0.9 (maximum 1) tend to be practically widely accepted. A key concern emerging out of literature on statistical inference in recent years is the fact that most researchers ignore measurement error as a source of uncertainty in downstream tasks.Footnote 24 Social scientists, including empirical legal scholars, are most likely to use LLMs to produce labels or quantities which feed into subsequent, typically regression, analysis. The problem is that if unaccounted for, measurement error will bias the downstream inferences.
In order to tackle this issue, Egami et al. draw on the doubly-robust machine learning literatureFootnote 25 to derive what they call a design-based supervised learning estimator.Footnote 26 Their estimator leverages the fact that LLM users are producing gold-standard datasets to evaluate their performance anyway. The gold-standard data can, however, also be used to improve downstream statistical inference. In the common setting where outcomes are measured from text with error – for example, asking an LLM whether the CJEU agreed with the Commission in a decision – we can use the gold-standard labels to learn a model that will construct bias-corrected LLM outcomes conditional on document covariates. The subsequent regression of text-based outcomes on covariates of interest has the advantage of both asymptotic unbiasedness and better coverage than using LLM outputs outright in downstream analysis.
10.6 Synthetic Samples and Simulations
One completely new avenue of research opened by LLMs is the creation of synthetic data and increasingly realistic simulations of real-world processes and outcomes. The extensive and wide-ranging knowledge of LLMs of the world can be leveraged to create synthetic observations in order to test hypotheses of interest. This line of research will be more speculative than using LLMs for classification, but as models improve and their legal capabilities in specific areas of law become validated, LLMs are likely to see increased uptake for evaluating alternative legal scenarios and predicting outcomes.Footnote 27
In survey research, LLMs are used to create synthetic samples of respondents’ answers to survey questions.Footnote 28 This allows researchers to evaluate a study’s likely result without having to contact real respondents. In a similar fashion, legal scholars could create synthetic cases, party briefs, and judgments and study the effects of manipulating one or multiple variables which might be difficult to study in real-world conditions. For example, EU law researchers might ask what the impact of parties’ legal briefs on CJEU decisions is. With access to data in this domain being limited, and given considerable heterogeneity in parties’ propensity to submit observations to the Court, we could ask an LLM to write synthetic legal briefs based on each party’s and its legal representation’s characteristics, given some case facts. We could subsequently have the LLM write judgments based on the case facts and the synthetic briefs received from the parties. Varying the number and type of briefs received, we could estimate the impact of a party’s synthetic brief on the ruling.
With the researcher being able to both control every variable and repeat the process again and again with the same or different parameters, LLMs can be powerful tools for the simulation of legal processes, provided there is fidelity between the synthetic data and its real-world counterparts. Similar to validating classification output, establishing that a synthetic legal brief of, for example, the French government in Cassis de Dijon is comparable to the real thing is going to be the most important and difficult aspect of LLM-based simulation studies. The training and validation of LLMs specialising in the production of EU legal advice in the case of legal briefs and CJEU rulings in the case of judgments will likely be necessary for such simulations to achieve their full potential.
10.7 Choosing An LLM
Although GPT-4 is currently the most popular series of LLMs, there is a plethora of ever-expanding options to choose from as large companies and startups compete for a share of the market. The considerations guiding the choice of which LLM to use for researchers are slightly different from commercial applications, however.
First of all, in empirical research we care about replicability and understanding the tools we are working with. Closed-source LLMs like GPT-4 do not enable users to peer into how the model was trained and the architecture it uses to generate output. In addition, the ability of future scholars to replicate work using closed-source LLMs controlled by their owners is questionable, because there is no guarantee that the company will still be serving the LLM in the same version when the replication is attempted. Given widespread consensus about the need for science to be open and transparent, closed-source LLMs leave much to be desired. Luckily, there are a number of powerful open-source models, such as Llama 3, developed by Meta. Such models come with complete documentation of training and data. Researchers need to ensure that their methods and findings are replicable and trustworthy. This openness allows for scrutiny, enabling researchers to identify and mitigate any biases or errors in the model’s outputs. Transparency also fosters a collaborative environment where legal scholars can share methodologies, validate each other’s work, and build upon existing research. Such openness is essential for maintaining the rigour and credibility of empirical legal studies, ultimately contributing to more robust and reliable legal scholarship. In addition, open-source LLMs make it possible to fine-tune models for specific domains and tasks, something that should naturally appeal to EU empirical legal researchers.
The closed or open nature of LLMs speaks to ethical concerns about their use as well. Providers who do not disclose the data and code used for their training obscure what may have amounted to questionable (privacy and copyright violating) data collection practices. Lack of access to the training data also prevents a deeper examination of the sources of bias in the output given by the LLM. Relatedly, using closed, proprietary LLMs means sharing potentially sensitive data with the provider company, the exploitation of which for further LLM training might require explicit opt-outs. In short, the training and deployment of LLMs, even in research, raises a plethora of ethical and legal questions.
Another consideration of particular importance to empirical legal scholars in the EU is LLMs’ multilingual performance. Member States’ jurisdictions bring EU law into direct contact with over twenty national languages, which traditionally created hurdles for comparative analyses of, for example, national implantation of EU directives. All LLMs are to some extent multilingual, but their performance across different languages varies as a function of their size (in parameters), architecture, and training data.Footnote 29 The performance drop-off is particularly noticeable for low-resource languages. While gap between the most commonly used European languages – English, French, German – and the rest is likely to persist, the vast majority of European languages have enough text data in them to train performant LLMs. One reason for this is the EU itself, as thousands of dense texts emanating from the EU’s institutions – laws, speeches, and policy documents – are translated into smaller European languages.
10.8 Conclusion
The integration of LLMs into the empirical study of EU law represents a significant leap forward in the capabilities and methodologies available to legal scholars. These models, with their remarkable ability to process and generate human-like text, offer unprecedented efficiency in analysing vast corpora of legal documents, uncovering patterns, and providing data-driven insights. Despite their transformative potential, the use of LLMs in legal research is not without challenges. Concerns about the accuracy and reliability of LLM-generated outputs and the necessity for human validation are critical issues that must be addressed by every researcher using LLMs. There will also undoubtedly be technical barriers to adoption in the legal research community, in particular, as a result of its overall poorer training than other social science disciplines. Nonetheless, it is likely that at least some of these barriers will be overcome through the development of bespoke software applications – of which ChatGPT was perhaps the most successful example – which will require no knowledge of programming to use.Footnote 30
Looking ahead, the future of LLMs in empirical legal studies hinges on the careful balance between leveraging their capabilities and mitigating their limitations. As the technology continues to evolve – we have not touched upon the multimodal nature of many LLMs, for example – it will be essential for legal scholars to develop methodologies for validating and complementing LLM outputs, ensuring that the insights derived are reliable. Moreover, the ongoing refinement of LLMs, coupled with the exploration of hybrid approaches such as RAG, promises to enhance their applicability and performance in legal research. By embracing these advancements while maintaining a critical perspective, the empirical study of EU law can harness the full potential of LLMs, driving forward our understanding of legal systems and decision-making.
11.1 Introduction
Are there (un)written rules about how to use interviews when writing a book chapter or an article? Is there a recommended style or format for presenting findings from qualitative research? Are expert interviews with lawyers the same as any other expert interviews and can they be used in the same way? In the roughly ten years that I have been conducting and discussing interviews, these questions have seldom been raised, and I believe many colleagues who focus on qualitative research would share a similar experience. In every research process, there comes a point when we turn to our data we have collected to begin writing about it, and yet this writing phase is hardly reflected upon in any meaningful way.Footnote 1 There are usually one or two chapters on the ‘academic writing of qualitative research’,Footnote 2 but these often feel like an afterthought rather than part of the main plot.
For me, however, the writing process continually generates inquiries for which there are no clear answers or existing manuals. If one looks at the literature on interviews, it becomes clear that much of it focuses on the practices employed before or during the interviews. Authors share their experiences on various aspects such as how to approach interviewees, choosing between email or phone for the initial contact, note-taking techniques, crafting non-manipulative questions, and the strategic decision of whether to appear knowledgeable or take a naive stance. While these insights are undoubtedly valuable, particularly for newcomers to the field, they also offer points for reflection for seasoned qualitative researchers. However, one encounters only silence when it comes to presenting the findings (often referred to in academic jargon as the ‘write-up’).Footnote 3 This silence may stem from the assumption that writing is a skill that academics inherently possess. We are, or at least should be, familiar with how to write an article or other forms of academic text, and it is assumed that we can apply this skill to interpret and use interviews without much further consideration.
Nevertheless, we must also think and write about the writing process. This chapter represents my attempt to break the silence surrounding the writing-up stage and to articulate the complex mix of confusion, uncertainty, but also discovery and joy that accompany the process of turning to interviews to write about them and with them. This dual approach informs my thinking in this chapter. I do not view interviews solely as a source of raw data for analysis to support my argument (writing about interviews). I also see interviews as an ongoing dialogue that extends from the interviews to the writing-up stage (writing with interviews), requiring me to constantly reflect on how I construct my argument and communicate it. Moreover, I believe it is crucial to consider how we report on interviews, as it is the final written research that will be read and will have impact, not the meticulously conducted interviews themselves, which will often be archived or, in the case of expert interviews, disposed of after the research project concludes. As Vrasti notes, ‘no matter how we go about collecting our data, the most powerful methodological tool in all social research remains writing’.Footnote 4 Finally, I hope that this chapter advances discussions around writing in doctrinal research, because there is little debate about doctrinal writing. What is the purpose and style of doctrinal writing? Is it merely about identifying inconsistencies and patching them, or about recognising and navigating legal hierarchies? What I write here about using interviews can hopefully be applied and reflected upon by doctrinal researchers when working for instance with court judgments.Footnote 5
The chapter offers some thoughts on the use of interviews in EU legal research. I first discuss expert interviews, which are especially important for EU legal scholars. In EU legal research, these interviews usually deal with intricate and deeply rooted issues involving key political and legal figures who are highly sensitive to breaches of anonymity. Such interviews are often conducted within research projects that have substantial policy relevance and far-reaching impacts beyond the academic sphere.Footnote 6 I then discuss how such expert interviews can be used. I provisionally explore three guiding principles: situatedness, transparency, and integrity, for qualitative legal researchers writing both about and with interviews. It is fair to warn, however, that none of these concepts offers quick fixes or guarantees of academic recognition or accolades.
I illustrate my arguments with my research project because the choices the researcher makes when using interviews are rarely made visible and cannot be inferred from someone else’s published and polished work. These choices are often fraught with difficulties and lose-lose situations that typically remain hidden and are only shared among close colleagues. My concrete examples relate to the ongoing research project REVOLVE, funded by the Research Council of Finland, which examines the phenomenon of revolving doors – movement of people in and out of government positions and its regulation. As of the time of writing (October 2024), I have conducted 38 interviews with former ministerial aides of former Finnish Prime Minister Sanna Marin’s government.Footnote 7
11.2 Situating the Research
This contribution focuses on writing, specifically on writing about interviews in law, and even more specifically, in EU law. This objective immediately requires three clarifications. First, the way I have framed my objective in this chapter presents an overly stylised and simplistic view of the research process. Often, writing begins before all interviews have even been conducted, transcribed, and analysed, so the phases of data collection, analysis, and writing up inevitably intertwine. However, for the sake of clarity, I conceptualise the write-up as the final stage in conducting qualitative research. Before this stage, the researcher would have typically conducted and transcribed the interviews (‘raw data’) as well as analysed the data, either manually or using software such as ATLAS.ti. The final stage is to ‘pull it all together’ and ‘tell a story’, both of which misleadingly imply how easy this process is.Footnote 8
Second, my articulation may imply that interviews conducted in the legal field by legal researchers differ from those conducted by non-lawyer social scientists, thereby justifying a chapter specifically on the use of interviews in legal research.Footnote 9 However, this is not my intention. There are two issues here. Regarding lawyers as qualitative researchers, I do not believe that the interviews conducted by lawyers differ significantly from those conducted by non-lawyer social scientists. For instance, access to professionals is often a challenging phase for researchers across all disciplines, and legal researchers are no exception. Elsewhere, I have argued that a shared identity as lawyers may facilitate access, but this is not always the case.Footnote 10 I do not deny that, in some cases, having a legal background can be helpful when reaching out to legal experts for interviews. But what about lawyers as interviewees? Legal research often involves interviews with legal professionals, such as civil servants, practicing lawyers, policy-makers, politicians, judges, and others. Should we assume that they differ from non-legal professionals in other fields of social science? Lawyers, especially practicing ones, may be difficult to approach, and, in some cases, more challenging to interview than non-lawyers. Furthermore, lawyers often lack methodological skills, as these are typically not part of legal education. This may have implications not only for their roles as qualitative scholars but also for their roles as interviewees. However, I do not believe that interviewing legal professionals is a specialised art form or that it requires a legal education.
This is, of course, a lawyer’s narrow (and possibly privileged) view. Sociologist Lola Avril interestingly writes how lawyers hold a ‘position of disciplinary domination over political scientists and sociologists’.Footnote 11 She describes how the law’s universal force and its social capacity places ‘the sociologist in a position of inferiority, or even subordination’.Footnote 12 Her concrete experiences in fancy offices of Brussels-based law firms are not very far from my own (more limited) encounters with law-firm lawyers, which suggests that even an academic lawyer, as a qualitative researcher, may find herself in a position of inferiority or subordination, regardless of a law degree as a marker of shared identity.
Third, expert interviews are common in law and social sciences, raising the question of whether there is something particular about interviewing EU legal experts compared to national or international legal experts. I suggest that when writing about interviews conducted with EU legal experts, there may be specific considerations to bear in mind during the writing-up stage. I do not mean to suggest that these characteristics are exclusive to EU legal research, but rather that they appear more prominent there than, so far, in predominantly national contexts. Before describing the three distinctive characteristics of interviews conducted in EU legal research, I will discuss the trend of expert interviews in empirical legal research.
11.3 Empirical Legal Research: Expert Interviews as a Trend
Empirical research has, for some time, enjoyed increasing popularity within legal scholarship. There is growing data to support the claim that empirical legal articles are on the rise, particularly in specific fields such as environmental law or EU law.Footnote 13 For example, Steven Vaughan, based on an analysis of articles published in the Journal of Environmental Law, notes an increase in the number of empirical legal articles.Footnote 14 Further insights come from Linda Mulcahy and Rachel Cahill-O’Callaghan, who examined 427 such articles published over a 15-year period in eight socio-legal and generalist journals. Their findings show that qualitative research overwhelmingly dominates, with 87 per cent of empirical legal scholarship classified as either qualitative (75 per cent) or mixed methods (12 per cent).Footnote 15 This trend likely holds true for EU law as well.Footnote 16
In qualitative empirical legal research, interviews stand out as the most common method, particularly in studies about institutions, processes, and decisions – typically the focus of legal scholarship. Although other methods, such as participatory observation or focus groups are less commonly used in legal research, they are gaining traction. Given their growing popularity in political science,Footnote 17 legal researchers are also catching up, albeit typically one or two ‘seasons’ behind.
Interviews serve a broadly similar purpose in legal research and other social sciences research, functioning as a common method for collecting qualitative data about specific groups or places to contribute to broader knowledge of the social world. They can take various forms – structured, semi-structured, or open – and fulfil different functions, such as exploring the field, collecting data, understanding social realities, or testing hypotheses. Depending on their aim, interviews may involve a range of subjects from ordinary citizens to experts. My own interviews have primarily focused on experts, aligning with a broader trend in legal scholarship. An expert interview is a qualitative method used to gather in-depth insights from individuals with specialised knowledge, which is in most cases combined with the expert’s ‘vastly disproportionate control over or access to a resource’.Footnote 18 Experts often represent an elite group, and sometimes elite and expert interviews are used interchangeably.Footnote 19 Expert interviews with lawyers are usually also elite interviews, because in most contexts, lawyers or people with a legal education belong to administrative, legal, or political elites in the societies in which they operate. In this chapter, I use the term ‘expert interview’.
Expert interviews are essential in research aimed at understanding the ‘causes of social problems or the origins of public policies’,Footnote 20 highlighting the critical role experts play in the societies under study. This rationale, with some variations, applies to many research projects that rely on expert interviews. The popularity of this method is evident in the substantial body of methodological literature dedicated to it. Much of this literature addresses issues such as defining an expert for a specific project, gaining access, navigating power imbalances between the researcher and participant, and selecting the appropriate experts.Footnote 21 One recent aspect of this methodological debate concerns the role of status. Von Soest argues that ‘for most research objectives, the selection of expert interview partners should … be problem- and expertise-centered rather than status-oriented’.Footnote 22 Li adopts a more fine-grained distinction. For her, elite interviews are either ‘problem/policy-oriented research’ or ‘experience-oriented research’.Footnote 23 However, there is no real choice because the selection of experts for interviews is always status and expertise-oriented. For instance, when interviewing ‘revolvers’ – individuals who have moved from the public sector to the private sector – I selected them because of their expertise (or experience) and the status of (former) ministerial aides.
While it is safe to say that expert interviews are now an established part of legal scholarship, this was not always the case. Historically, legal research tended to focus less on those we now consider experts. I have argued elsewhere that early empirical legal research, which focused on the ‘users’ of the legal system,Footnote 24 conducted interviews primarily to extract their experiences. When discussing the experiences of crime victims, consumers, children, or immigrant workers, interviews typically involved vulnerable individuals or individuals in other sensitive positions. Interviewing such groups imposes a range of ethical expectations and obligations on the researcher, and for good reasons.Footnote 25 While interviewing people in vulnerable situations has not become obsolete in EU legal research,Footnote 26 nor have their experiences become irrelevant, there has been a shift towards interviewing experts in EU legal research.
This shift has important implications for researchers, because civil servants, practicing lawyers, policy-makers, politicians, judges, and similar professionals are not in vulnerable positions. One could argue that, in researching them, it is the researchers who may find themselves in vulnerable or inferior positions. This practice of ‘studying up’ – interviewing individuals in higher hierarchical positions in society – can disrupt the traditional power dynamics where the researcher is thought to call the shots. As Li notes, ‘interviewees are often the powerholders, rather than the researchers’.Footnote 27 Research ethics is another area where this ‘bias’ for interviewees as vulnerable people is evident. Ethics clearance and relevant guidelines typically concentrate on projects where the interviewees need protection, while paying little or no attention to projects where interviewees are experts or otherwise in privileged positions, and where researchers may be those in vulnerable positions.Footnote 28
Yet the status of experts as public figures confers a different type of risk or vulnerability. In her discussion of elite interviewing, Morris suggests that while elite interviewing is often seen as problematic for a researcher because the interviewees are powerful figures, she argues that researchers ‘have power over the respondent through the process of research … control of what is published and control of meaning’.Footnote 29 In other words, the researcher retains a form of authority, regardless of the interviewee’s status, because they control the interpretation and meaning of the data as well as the writing process. This focus on sense-making highlights that power can shift throughout the research process and is not constant. While the interviewee might hold power during the interview, the researcher assumes power during the writing-up stage. Expert interviewees are also vulnerable to breaches of anonymity, an issue revisited below.
11.4 Unpacking the Question of Writing: Quality and Representation
In a sense, writing about the use of interviews is challenging, because it is widely recognised that presenting data is an uncontrolled and dynamic process. Researchers must exercise their judgement in presenting ‘unwieldy amounts of “raw” data in the form of interview data or ethnographic fieldnotes’,Footnote 30 and turning a creative chaos into order. There is no singular style for reporting findings from qualitative research to help us begin. Indeed, ‘there is no format or template there when we start writing’.Footnote 31 Qualitative scholars often emphasise that not only does the researcher choose which story to tell, but also how to tell it.Footnote 32
One way to begin unpacking the question of ‘how’ is by considering the quality of empirical work.Footnote 33 While the quality of qualitative empirical work is shaped by many factors, it is often during the writing and publishing stage that the assessment of quality – specifically the choices made during the conduct of interviews – becomes possible.Footnote 34 Steven Vaughan, reflecting on the empirical legal articles published in JEL, argues that authors often fail to provide insights into their methodological choices. He explains that rigorous qualitative legal scholarship should at least inform the reader about the following: ‘research question(s), epistemological and theoretical stances, method, sampling techniques (random, purposive, systemic, snowball, convenience), sample size, approach to saturation; modes and mechanisms of data collection and data analysis (including approaches to coding, issues of triangulation, and what to do with outlier or deviant case data, and researcher positionality and bias (including research ethics))’.Footnote 35 In his analysis, many published articles surprisingly lack this critical information.Footnote 36 Some of the responsibility here also falls on editors and publishers, as legal journals either do not require such baseline information or dismiss it as superfluous during peer review to save space.Footnote 37
When considering the quality of qualitative research and how to present interview data, transparency is often regarded as the most important virtue. Without transparency, it is impossible to assess the quality and rigour of qualitative work.Footnote 38 The reader ‘requires sufficient detail to be able to follow the [empirical] process and judge how “fair”, “reasonable” or “regular” the process or steps taken were’.Footnote 39 In this context, the issue of writing up is part of the broader debate on quality and transparency, aimed at convincing the reader that the research has followed a ‘standard’ process and provides all the necessary information. While transparency is undoubtedly crucial, it should not monopolise our attention entirely. The goal of writing up expert interviews is not to create a ‘city of glass’ where outsiders can see everything, as argued below.
Another way to approach the ‘how’ question comes from ethnography, particularly from its focus on representation. It is a fundamental issue in ethnographic research, especially when writing is involved, as it touches on the assumed right to tell stories about others.Footnote 40 This issue becomes especially relevant when researchers spend time in the field and develop relationships with their subjects. While legal scholars using expert interviews rarely spend extended periods of time in the field with their subjects, even brief interactions can raise questions about representation and how to truthfully incorporate interviews into their writing.Footnote 41 To address the ‘paralysing’ effect of representation,Footnote 42 ethnographers are encouraged to engage in self-reflexivity, acknowledging their role in both conducting and writing up the research. Self-reflexivity, however, offers little concrete guidance in the writing-up stage.
Take, for instance, the power dynamics between the researcher and subject in the context of expert interviews. Czarniawska notes while a ‘dialogue’ between researcher and subject is important, it should not turn into a ‘duet’.Footnote 43 The researcher should avoid the trap of thinking that their writing, while aiming to accurately represent the subjects, must also be agreeable to them. While I endorse this in principle, applying it to research, which has the potential to upset interviewees higher up the hierarchy, is less straightforward. For instance, on one occasion, a peer-reviewer strongly suggested that I use more assertive language to describe a phenomenon they considered ‘a sham’. After much deliberation, I decided against using that word or any other word such as ‘mockery’ implying any deliberate intent. This highlights that power dynamics can intensify during the writing-up phase, often more so than during the interviews themselves. Despite the time elapsed since the interviews and the absence of direct temporal or physical proximity between the researcher and influential interviewees, these dynamics can remain complex and challenging.
11.5 Zooming In: Writing about Expert Interviews in EU Law
Should we then simply throw in the towel, concluding that nothing meaningful can be said about writing about interviews? I do not think so. To discuss writing, we must first look more closely at the types of interviews conducted by EU legal scholars.
Expert interviews in EU legal research have three distinctive characteristics. I have adapted these three features from Rebecca Willis, who discusses the use of interviews that she has conducted with UK politicians. In her article, she introduces the use of ‘composite narratives’ to report interviews with politicians. By composite narratives, she refers to the practice of combining multiple interviews and presenting them as the story of a single individual. Although this approach is rarely used, she notes that it is an effective response in situations where the researcher must present ‘an authentic yet anonymous story’. She explains that when writing interviews her aim was not to distinguish between politicians through comparisons and categorisations. Instead, it was to investigate how politicians, as (a group of) people, navigate their life and work. She notes that the only modification is to present data obtained from several interviewees as if it were from a single individual.Footnote 44 I do not further discuss her take on composite narratives but, rather, I discuss the reasons she gives for adopting the practice of composite narratives. These three reasons characterise well the environment in which the EU legal scholar conducts interviews.Footnote 45
First, expert interviews in EU legal scholarship often involve complex, embedded situations, and the accounts provided by research subjects blend descriptions of intricate policy environments with personal reflections on their role within them. The discussions frequently delve into context-specific narratives and technical details. This is not to suggest that interviews with non-experts are less complex, but in expert interviews, the presence of technical details, policy implications, or legal facts is particularly pronounced. Additionally, such facts are often known and understood by only a small group of individuals, which highlights the sensitive nature of these interviews.
Second, these interviews frequently involve influential figures in politics and law, whose identities are sensitive and require protection. As a result, maintaining anonymity is crucial, leading to the general practice of not naming interviewees, disclosing minimal information about their organisations, and not making interview transcripts public. However, it is not only the general public that the interviewees are concerned about. Expert interviewees often worry that their identities could be recognised by other research participants, who are more likely than the general reader to identify or plausibly guess who was interviewed. These individuals are also ‘powerholders’, requiring the researcher to reflect on their own position relative to the participant during writing up.
Third, expert interviews often contribute to research that is ‘future-forming’,Footnote 46 meaning that it has significant policy relevance and the potential to influence future policies. This raises ethical questions about the role of the researcher when using material that could have a substantial impact on future policy-making. What is the ethical responsibility of the researcher in such situations?
While these considerations are important during the interview process, they are equally, if not more, crucial when reporting on these interviews. All three of these characteristics present distinct challenges for qualitative researchers. These challenges exist during the interview process – particularly in gaining access – but my focus is on how the researcher, having overcome access issues and completed the interviews, then uses them while giving due respect to the characteristics described above. In the following, I will discuss each of these features to encourage reflection. I tentatively examine three key notions – situatedness, transparency, and integrity – for qualitative legal researchers when writing about and with interviews in their work.
11.5.1 Situatedness as a Response to Writing up in Complex Policy Environments
When dealing with complex policy environments, researchers often assume that the best way to manage this complexity is through detailed description. This approach, influenced by Geertz’s concept of ‘thick description’ in ethnographic research,Footnote 47 aims to convey the intricacies of the field. However, excessive description is not always the best solution. Excessive description can be overwhelming, and a key updated principle for qualitative researchers becomes clear: ‘After getting the data, the major task in qualitative research is to “get rid of it”’.Footnote 48 Data should be used selectively to exemplify, illustrate, or illuminate the story the researcher wants to tell. Second, excessive description can compromise the anonymity of research subjects.
Instead, I advocate for an approach I call ‘situatedness’. I prefer the term situatedness because, unlike self-reflexivity, it is more concretely tied to the act of writing.Footnote 49 Situatedness can take several forms. Iver B. Neuman, a Norwegian anthropologist, describes ‘textual situatedness’ as considering how to write up findings in a way that situates them within the academic field while also reflecting the ethical aspects of fieldwork and the trust established during it.Footnote 50 Textual situatedness requires researchers to understand and explain how their findings relate to existing research. Identifying ‘markers’ in the literature can help the researcher in writing up expert interviews. For instance, when interviewing ‘revolvers’, I knew that the existing literature emphasises the contacts these individuals acquire during their time in government service. However, the interviewees’ frequent mentions of civil servants’ phone numbers led me to realise that the research should focus on just contacts broadly, but specifically on bureaucratic contacts, which unlike political ones, remain ‘valid’ for years, if not decades.
Textual situatedness also involves linking interview data with other sources. In legal research, as well as in the social sciences more generally, interview data is rarely the only source. Legislation, policy documents, archival data, and academic literature can also be used to triangulate findings from interviews. Research subjects often promise to provide additional documents during interviews that could help verify their statements, but these documents rarely arrive post-interview. In my experience, they usually surface during the interview itself, if at all. The promise of additional documents can also affect the power dynamic between researcher and interviewee.Footnote 51 If the researcher is promised more data, they may ‘censor’ their writing in the hope of eventually receiving the information, particularly when more research is to be conducted in the same field or with the same participants.
Self-censorship is a form of textual situatedness, shaped by how researchers position their findings in relation to their subjects and other academics in the field. It is a practice that researchers seldom acknowledge in their publications. Self-censorship can take many forms, but perhaps most commonly we omit passages we feel might be excessive, or we adjust our tone and style to avoid seeming too critical. We might do it out of fear of creating bad blood or facing repercussions that we are not even sure what they could be, or because we feel a ‘debt’ to interviewees for agreeing to speak with us. Whatever the reason, it feels like a failure, something shared only with close colleagues or in the intimate setting of an academic workshop. Self-censorship can also be a tool of shame among peers. At a recent workshop I attended, a senior academic presented her research that involved expert interviews in an organisation where the entry is strictly controlled. She noted that the research participants (to whom she had previously presented her provisional findings) had not liked all of her findings. After her presentation, another senior academic in the audience argued that she should soften her critical findings not to upset the participants. The goal was not to please the participants as such, but to ensure that future scholars would still be granted access to this institution and others known for strictly regulating research entry. This would be a clear example of the dangers of ‘duet’ writing, but it also highlights how writing is influenced by considerations of access, and how power dynamics exist not only between the researcher and the subject, but also between researchers.
Another form of situatedness is ‘role situatedness’, which some equate with self-reflexivity. For instance, Ntienjom Mbohou and Tomkinson describe it as a process of ‘turning of the researcher lens back onto oneself to recognise and take responsibility for one’s own situatedness within the research and the effect that it may have on the setting and people being studied, questions being asked, data being collected and its interpretation’.Footnote 52 What they do not discuss is the extent to which the results of this self-reflexivity must be made part of the writing. Obvious biases and conflicts of interest with research participants must be disclosed, but other situations where the researcher’s own role may influence the research subjects abound. For instance, in my interviews with ‘revolvers’, participants were aware of my previous research on lobbying transparency. They then frequently differentiated themselves from others who took jobs in public affairs consultancy firms, signalling that they would never accept private sector jobs and seeking my ‘approval’ for their choices.
Acknowledging and reflecting on these forms of situatedness helps to make sense of the complexity that interviews aim to capture. But what if considerable time has passed between the interviews and the writing? And what if the interviews have blurred into a haze? Field notes, often used by ethnographers, can be helpful here. This practice is also common among qualitative researchers who take notes during interviews, especially if the interview is recorded, allowing them to document feelings and observations about the interviewee’s demeanour. For researchers writing up their findings, field notes ‘can be useful in describing the setting, contextualising the research, and in situating the researcher in a particular place and time since the researcher is the social scientific instrument in qualitative research’.Footnote 53 If field notes (or excerpts from them) are made public, they can also benefit readers. Reyes notes that knowing researchers’ thoughts and real-time analyses aids readers in gaining a clearer understanding of the data and arguments presented, while sharing field notes allows readers to identify potential flaws in the researchers’ reasoning and perspectives.Footnote 54 However, this raises the question: can there be too much transparency? Are we, as scholars, absolving ourselves of the responsibility to make hard choices by putting everything out there and expect the reader to make informed choices and judgments on our behalf?
11.5.2 Can There Be Transparency about Expert Interviews?
It is common to advocate for making the production of knowledge more transparent and visible to other researchers,Footnote 55 particularly when it comes to the presentation of interview data. But what does transparency mean in this context? Kapiszewski defines transparency as being precise about how the information and evidence supporting the study’s claims and conclusions were collected; detailing the processes of interpretation and analysis used to develop those claims and conclusions; and ensuring that this information and evidence are accessible to others.Footnote 56 No simple answer to how qualitative inquiries should be made transparent has been put forward.Footnote 57 Kapiszewski also notes that there is no single method of ‘making qualitative social inquiry transparent’,Footnote 58 and illustrates this through four possible approaches: preregistration, research appendices, ATI (annotation for transparent inquiry), and data sharing.Footnote 59 Majic also argues that research transparency is not ‘a coherent and normatively agreed-upon practices. Instead … a variety of factors, including but not limited to, the research project’s epistemological orientation, the context and vulnerability of participants, and labour demands must shape how one understands and operationalises them’.Footnote 60
Reyes identifies three models of transparency: naming places, naming people, and sharing data. These refer to whether researchers should name a region, city, or specific neighbourhood; whether primary participants or public officials should be named; and whether interview guides, transcripts, or various field notes should be shared.Footnote 61 In expert interviews conducted in EU legal research, naming places is usually unnecessary, and if places names are included, they are usually not particularly relevant. A variation on naming places is mentioning an institutional background or nationality. For example, if all participants come from the same sector, such as NGOs,Footnote 62 disclosing this may be relatively risk-free. However, if the sample is small, it may be necessary to obscure institutional affiliations to protect anonymity. Naming people is rare, as most experts agree to participate in interviews on the condition of anonymity.Footnote 63 A similarly cautious approach applies to sharing raw data, such as transcripts, which are typically kept confidential.Footnote 64 This is often because interviewees agree to participate only on the condition that their transcripts will not be made publicly available, linking issues of access with those of transparency. Full data transparency may also reduce the quality of responses if interviewees are reluctant to speak freely, knowing their words could be made public. Furthermore, researchers invest considerable effort in conducting interviews, referred to as ‘sweat equity’, which may also influence the decision not to share raw data.Footnote 65
In EU legal scholarship, there is an emphasis on anonymity across these three areas – naming places, naming people, and sharing data, which then underscores the need for transparency in reporting findings. Transparency in reporting anonymous interviews is essential, but it does not mean we should violate the promises made to participants by naming them or sharing transcripts. Majic argues that researchers’ ethical responsibility to safeguard human participants and their communities should take precedence over sharing information with the audience of their research.Footnote 66 So, how can we be transparent about interviews we cannot share? Majic suggests that researchers can be explicit about their research project and process. This involves being precise about the research goals, clearly stating one’s positionality and subjectivity, and detailing any risks and conflicts in the research – returning to the idea of situatedness discussed earlier. Additionally, transparency in the process of generating and analysing evidence involves, for example, indicating how representative a specific quote is compared to all interview statements, and noting the level of consensus among experts.Footnote 67
This is neither simple nor straightforward – something a qualitative researcher can summarise in half a page and move on from. Data from a research project ‘are often analyzed individually or in small groups, with references to them laced throughout the text of the associated manuscript. Making qualitative inquiry with these characteristics transparent thus requires introducing evidence and discussing its generation and analysis at multiple points in a manuscript’.Footnote 68 Moreover, the analytical processes present additional challenges. For scholars whose information is ‘co-created’ through interactions with participants,Footnote 69 involving the creation of meaning, and therefore partially reflects the researchers’ unique experiences, frameworks, and interpretations, sharing data may be pointless and misguided, while sharing their analytical process can be practically difficult.
The level of transparency must always be determined in relation to the specific project.Footnote 70 Transparency is a decision that must consider the research subjects, and qualitative researchers often frame this in terms of participants who are at risk or marginalised.Footnote 71 Yet confidentiality protection is also crucial for members of various elites and experts,Footnote 72 who may have much to lose if they can be identified, especially by their peers or line managers.Footnote 73 This is not to argue that anonymity is less important for non-elite research subjects. Reyes emphasises that researchers do not always foresee or understand unintended consequences, both when ‘studying down’ – working with participants who have less education or lower socio-economic status – or ‘studying up’ – engaging with those who are equally or more educated and affluent.Footnote 74
Sometimes both types of considerations are present in the same research, or as is often the case for me, ‘studying up’ and ‘studying even higher up’. Using homelessness as an example, Reyes explains that while participants (those experiencing homelessness) should remain anonymous, policy officials can be named, because engaging with someone in a position of power acting in an official capacity is fundamentally different from interacting with individuals who have little or no power and may be among the most vulnerable.Footnote 75 This distinction between those who speak in an official capacity and primary participants who may be vulnerable is also relevant for expert interviews. For instance, in my case, ‘revolvers’ – most of them facing the pressures of family, career, and mortgages in their mid-thirties – remain anonymous, while interviews with their employers, who are acting in an official capacity, can be disclosed.
One final consideration is whether transparency can help prevent corruption or abuse of power, just as we like to think when we address the integrity of decision-makers and those with power. Is transparency important to avoid the misuse of an academic’s power?Footnote 76 Could researchers hide behind anonymity to construct narratives not fully supported by data? Like all humans, academics are susceptible to the misuse of power. However, it is difficult to see how researchers could misuse anonymity in qualitative interviews. Most researchers send either the interview transcript or the final version of the manuscript to participants for review. I, for example, do the latter. This practice ensures transparency and prevents abuses of anonymity, but it also exposes researchers to the risk of self-censorship, particularly when working with influential participants.
11.5.3 Integrity as a Means to Counterbalance the Research’s High Impact
The ‘future-forming’ aspect of research often leads to a high policy impact. This does not imply that such research has ‘political’, or interventionist aims.Footnote 77 Rather, it means that this kind of research can inform how laws and policies should be changed, influence the opinions of parliamentarians and policy-makers or be used by advocacy networks to promote certain policies. Researchers must be aware of this responsibility when presenting their findings. While both legal and non-legal research can shape the future, I believe legal research frequently plays a key role in this regard.Footnote 78
What does this ‘awareness’ mean in concrete terms? Some strategies of awareness are familiar. Researchers should use interview transcripts cautiously, avoiding selective quoting (cherry-picking) and providing context for quotes. Quotes should not be used decoratively, merely to convince the reader that the researcher’s descriptions have a basis in ‘real life’. Researchers often use extracts from interviews to capture aspects of empirical reality in a concise and vivid manner. While conducting interviews, a clever phrase might stand out, tempting the researcher to include it in their text. However, it is important to relate these extracts to the broader empirical data, countering the common accusation that expert interview quotes are ‘cherry-picked’.Footnote 79 Cherry-picking is often accompanied by an excessive use of interview quotations. The cautious approach that sparsely uses quotations helps protect the confidentiality of expert interviewees and the integrity of research, especially in areas with high political stakes.
This is particularly important because, due to ethical and methodological constraints, expert interview transcripts cannot usually be made public, making it impossible for other researchers or participants to verify how quotes were selected or whether they represent the ‘typical’ interviewee. Tripp has called for transparency, emphasising that ‘To overcome the power of the good quote and avoid biases in using references, scholars should clearly catalogue the procedures guiding the aggregation and interpretation of information.’Footnote 80 For legal scholars, selecting quotes from interviews parallels the choices made when using court judgments. There is a similar temptation to select a particularly striking quote without placing it in the full context of the judgment or within the context of several judgments. However, since court judgments are public, readers can always contextualise them. This is not the case with expert interview data, where quotes may lack the necessary context.
Integrity in writing requires resisting the temptation to use striking quotes and, at times, deciding not to include references from certain interviews. It also involves the obligation to provide proper context for the quotes used and to clearly indicate if any quotes represent outliers. The decisions a researcher makes in the name of integrity are not always transparent. For example, while researchers may incorporate decisions about complexity or situating themselves and their subjects into the text, integrity as a guiding principle may lead to choices that cannot be fully explained. A researcher is unlikely to receive praise for avoiding cherry-picking or for providing thorough context, and peer-reviewers may even criticise the use of empirical material as bland or overly detailed. Tripp’s suggestion of establishing clear procedures, while valuable, is often insufficient in practice.
When writing about interviews, the researcher must also consider the role of the research participant. As noted earlier, expert interviews serve to gather expert knowledge and subjective perceptions. Both types of data can be collected within the same research project,Footnote 81 but this dual purpose must be considered when writing and using quotations. Subjective perceptions and attitudes can and should be used, but it would lack integrity to conclude that a system is ineffective simply by citing a participant’s personal frustration with it.
11.6 Discussion
I began this chapter by posing two questions: are there unwritten rules about how to use interviews when writing a book chapter or article? And how should findings from expert interviews in EU legal research be presented?
There are no formal or informal rules about using interviews. This chapter has attempted to show that there are many personal and sometimes painful recollections, shared in footnotes or at workshop dinners, about the challenges of writing academic work. Qualitative scholars take their responsibility seriously. If I were to offer one guiding principle, it would be: do not view interviews solely as a source of raw data for analysis to support an argument (writing about interviews). Instead, see interviews as something that demands continuous engagement (writing with interviews), requiring constant reflection on how they shape the argument you formulate by writing.
What about interviews in EU legal scholarship? As noted above, qualitative interviews in this field are often expert interviews, frequently with lawyers working as professionals in various contexts. These interviews typically concern complex policy environments, involve influential individuals, and carry high stakes. While these characteristics affect how researchers secure access and conduct interviews, they become even more relevant when the researcher is sitting at her laptop with the analysed data. How should these interviews be used most effectively and responsibly? There are no simple answers.
I first discussed the concept of situatedness, which means that the researcher must situate herself both in terms of the text and her role. This involves multiple layers of reflection such as how participants perceive themselves in relation to the researcher (Do they try to present themselves favourably? Do I try to present their statements favourably?), and how their statements might not align neatly with the research findings. The writing process, then, becomes a way to build bridges between these complexities. In this regard, expert interviews involve risks, as researchers may self-censor to gain further information, defer to influential individuals, or keep opportunities open for junior researchers.
The issue of transparency in qualitative research has been widely discussed, often overshadowing other considerations. Transparency has many advantages – it helps build synergies, dispel suspicions of unethical conduct, and clarify what remains to be discovered. While the level of transparency is always determined by the need to protect participants (how much can be disclosed without compromising the promises made to them), it is offered primarily to the academic community. Just think about tools to improve transparency: preregistration, research appendices, ATI (annotation for transparent inquiry), and data sharing. They are all designed with another academic in mind. As academics, we tend to focus on transparency within our own circles. But what about transparency for participants or the broader policy community? Research funders also play a significant role, with national and EU funders increasingly directing research towards open and accessible data. A key aspect of this shift is the requirement for open-access publishing, which is now a common condition for funding. While funders do not mandate to make qualitative data public, they expect it to be accessible. Consequently, qualitative researchers must frequently justify why their data remains confidential. This emphasis on open data is at odds with the typical confidentiality of qualitative (expert) interview data, presenting a tension that may ultimately favour one priority over the other. Time will tell which considerations prove more enduring.
Conducting expert interviews can sometimes place the researcher in a unique position, where they hold data relevant to debates dominating the front pages of newspapers they browse over breakfast. This is where the issue of integrity arises. By the time the researcher submits their final proof, the public controversy may have shifted, but this does not diminish the future-forming potential of their research. In these situations, the researcher typically reflects carefully on their own role and that of their participants. Choices are made to exclude certain quotations or to provide additional context – often more than editors or peer-reviewers deem necessary. This is where transparency offers no guidance, as these choices rarely make it into published text. Is integrity worth it without a good qualitative scholar prize?
11.7 Conclusion
Writing up research often escapes scholarly scrutiny, despite its significant consequences for research participants, the environments in which they live, and the policy recommendations that stem from research findings. This stage represents a critical moment for scholars to become accountable to themselves, to their research subjects, and the broader communities affected by their work. While transparency is a vital aspect of this accountability, it is not the only element to consider. Transparency often takes on an outsised role, as it is a goal and a tool for demonstrating compliance and to validate our research against the set standards.
However, writing does not create a ‘glass house’ that provides access to other researchers, research participants, and the public. Full transparency is not only impractical, but it can also contradict our aims for accountability. It risks shifting the responsibility for understanding coding protocols and raw data and for making difficult and unrewarding decisions away from the scholar to those interested in our research. In contrast, concepts like situatedness and integrity offer a more balanced approach to accountability without being as extreme. Finally, interviews involve human beings, and we should treat them with respect, curiosity, and care. Interviews are not material extensions of individuals, yet we must resist the temptation to view them as sources of extraction when we ‘mine’ for useful material. Instead, we should respectfully engage with them as part of the shared world in which we all participate and make sense of things that interest us.
12.1 Introduction
Inspired by natural sciences and psychology, experiments have become more dominant in the social sciences as they allow researchers to establish strong causal relationships in complex societal contexts and situations, even within the legal domain. While mainstream observational studies are crucial for revealing correlations determining why certain legal phenomena occur, our capacity to control for all the variables that may influence a particular result in real life is still limited.
The virtue of experiments is that they provide a very useful method for testing hypotheses in controlled settings, where the impact of other relevant factors (or variables) is minimised, isolating the effect of our main explanatory variables of interest. As a result, experiments allow researchers to determine whether one factor directly affects another – that is, that a certain cause produces a certain outcome. This is especially valuable in fields such as economics, psychology, and political science, where complex environments and interactions make causality challenging to discern.
As in the social sciences, law has been no exception. The growing field of empirical legal studiesFootnote 1 is also shifting towards more experimental approaches due to its advantages for causal inference. Pioneered by Law & Economics scholars, predominantly from the USA, this method has travelled to other legal empirical sub-fields like international law,Footnote 2 and more recently to European Union (EU) law. Its adoption in EU law has been driven by political scientists, motivated by their specific research interests and the rigorous methodological standards of their discipline.
The first section of this chapter provides a review of the implementation of experiments that captures the incipient interest in empirical studies seeking to understand and analyse the functioning of EU law and institutions, like the Court of Justice of the European Union (CJEU). However, its application is still limited and circumscribed to social science topics and questions, mostly focused on public opinion. The primary objective of this review is to provide a state of the art on these contributions and their methodological nuances of experimental research within the study of EU law. Additionally, it identifies common and emerging trends and research questions for future empirical investigation of EU law.
The next section assesses the extent to which diverse experimental approaches or types may enrich our understanding of legal decision-making and the functioning, performance, and effectiveness of EU institutions and law. This will offer a prospective analysis of the future role of experiments in EU law research and considers potential ways for refinement and expansion to other research themes.
By exploring these issues, this chapter contributes to the methodological advancement and empirical rigour of the multidisciplinary scholarship devoted to the study of EU law. It offers an introduction for scholars seeking to leverage experimental methodologies in their pursuit of nuanced and evidence-based analyses of EU law. Ultimately, this comprehensive presentation intends to serve as a foundational resource, useful for scholars, policy-makers, and legal practitioners, for advancing empirical research and policy design in the dynamic landscape of EU law.
12.2 Emerging Experimental Insights in EU Law
EU law scholarship frequently uses the term ‘experiment’ to describe the European Union as an unprecedented and evolving integration projectFootnote 3 – a ‘trial’ among sovereign states in which new supranational institutions and regulations are tested to promote peace, governance, economic growth, and well-being. However, the application and understanding of experimentation as a research method within EU legal studies remains underexplored.
This limitation can be attributed, first, to the persistent resistance from European law schools to introduce empirical methods into their curriculum,Footnote 4 despite the emerging efforts coming from diverse universities, research centres, projects, networks, and conferences in promoting empirical legal training and research. A second factor discouraging the use of experimental methods, as argued by Epstein and Martin,Footnote 5 is the conditions necessary to organise experiments: researchers randomly select subjects from the population of interest (random sampling) to better reflect the diversity of the population. This technique improves the equal distribution of cofounding variables, thus improving the representativeness of the findings. Researchers also randomly assign these selected subjects to treatment and control conditions (random assignment) to establish causation by formulating appropriate comparisons.Footnote 6
Experiments on legal matters hardly achieve these standards. First, random sampling is not prioritised in lab experiments as researchers recruit university students or volunteers who do not necessarily represent the broader population. Similarly, field experiments often involve studying individuals or specific groups who are difficult to access, such as officials, judges, lawyers, vulnerable groups, or litigants. Challenges arise from professional, institutional, or ethical barriers, such as the lack of time or interest in legal research, which make it difficult to create random samples from certain communities or groups. Consequently, researchers often rely on non-probabilistic samplingFootnote 7 alternatives to ensure that key characteristics like gender, education, experience, or ideology are represented in the sample, allowing for more generalisable conclusions.
This limits the generalisability of lab and field experiments, focusing instead on random assignment to establish causality. Nevertheless, randomisation is not always easy to achieve in the case of field experiments, as intervening in real-world legal procedures can influence legal outcomes, potentially violating principles of equality, fairness, and justice (e.g., assigning certain litigants to specific legal procedures while withholding them from others).
This explains why the first EU experimental legal studies were conducted outside of courts, focusing instead on public opinion and attitudes towards the functioning of EU law and the institutions shaping it such as the Court or the Commission. These studies have been facilitated by the introduction of online survey platforms, which provide easy access to large and representative samples of the general public while significantly reducing the costs and complexities of implementing random assignment to experimental conditions in scenario-based experiments.Footnote 8 Nevertheless, the main caveat here is whether the results obtained in a controlled and simplified experiment carried out on a particular sample of citizens are in fact generalisable to the more complex, real-world scenarios and real-world population, since we ask the participants to imagine situations. In this regard, the ‘external validity’ of the experiment can be ensured by accurately designing scenarios as proxies for real-world legal situations applicable across judges with different backgrounds.Footnote 9
Against this background, an incipient number of political scientists have begun to use experiments as a tool for testing theories of compliance and enforcement of EU law, EU legal interventions, regulatory decisions, and CJEU rulings and their impact in the public.Footnote 10 These studies converge around the EU’s challenges in enforcing norms and maintaining legitimacy by analysing the complex dynamics between EU institutions, Member States, and citizens. While enforcement is critical for upholding EU norms, these studies underline the importance of mitigating backlash and fostering public support when applying EU remedies. In this regard, they emphasise the need for EU institutions to balance the effective enforcement of legal values, such as judicial independence and rule of law, simultaneously maintaining legitimacy in the eyes of the general public to avoid undermining trust in EU governance.
By mostly using (scenario-based) survey experiments, these studies investigate whether enforcement actions and rulings influence public attitudes, finding that the content of decisions often outweighs procedural concerns.Footnote 11 Such studies also observed the prevalence of personal traits like education, religiosity, and political orientation in EU law enforcement, rather than national or cultural differences. Moreover, it was found that supranational enforcement rarely triggers substantial public backlash that can be strategically mobilised by EU opposers, provided that interventions align with public values or are framed effectively. For example, while additional information about EU actions does little to affect public opinion,Footnote 12 public awareness of widespread support for rule of law increases the perceived legitimacy of sanctions.Footnote 13 More specifically for courts, studies have shown the extent to which CJEU legitimacy is embedded in the legitimacy and support of their national counterparts, showing how Member States’ courts play a crucial role in legitimising CJEU rulings by fostering public support for expansive interpretations of EU law.Footnote 14
While survey experiments have mainly been used to test public reactions to hypothetical scenarios on law enforcement and compliance, some quasi-experimental designsFootnote 15 have been implemented to analyse the impact of EU policiesFootnote 16 or court rulingsFootnote 17 in real-world settings, improving the external validity or generalisation of the findings compared to artificial scenarios. In this regard, quasi-experiments are more feasible (when observational data is available on the issues) and useful to overcome problems of randomisation due to impractical or unethical reasons (see example above on litigants).Footnote 18
In quasi-experiments, the objects of study (individuals, countries, law cases, policies, etc.) are assigned to groups based on existing conditions, natural events, or non-random criteria.Footnote 19 Cheruvu and Fjelstul use a quasi-experimental design on observational data to estimate the effect of the EU Pilot programme on the efficiency of pretrial bargaining during infringement procedures.Footnote 20 Using infringement cases as the unit of analysis, they define the participation of certain countries in the EU Pilot as a treatment.Footnote 21 Since Member States self-select into the programme, the treatment is not randomly assigned as it would be in a controlled trial. The treatment group consists of cases involving participants in the EU Pilot and the control group consists of cases involving Member States not participating in the programme. Once the allocation is done, they apply a difference-in-difference statistical analysis that allows them to estimate a treatment effect on the Member States participating the in EU Pilot compared with those who are not part of the EU Pilot. While researchers rely on statistical methods to account for these differences produced in quasi-experiments, causal inferences are weaker because groups may differ systematically in ways unrelated to the treatment, introducing potential confounding variables or alternative explanations that might affect the internal validity and reliability of the results compared to experimental designs.Footnote 22
Similarly, Dyevre et al.Footnote 23 treat Brexit as a quasi-natural experiment to evaluate how political uncertainty discouraged British litigants and judges to invoke EU law and to refer cases to the CJEU, accelerating the process of legal disintegration. For that purpose, they implemented a difference-in-difference design to reproduce the conditions of a randomised experiment by comparing post-intervention change in the dependent variable (referral activity) in the treatment group (British courts) to a control group (courts in the rest of the EU) and compared the UK’s referral activity before and after the Brexit referendum. In this design, the treatment group is exposed to a certain policy intervention under the key assumption that, in the absence of a Brexit referendum, the unobserved differences between the treatment and control group will remain constant over time.
Recently, researchers in EU law started to apply experiments to study EU legal decision-making with law studentsFootnote 24 as a strategy to address the challenges of accessing legal professionals. Building on behavioural legal research, Ovádek’s paper examines how the framing of legal arguments on the application of EU legislation (e.g., attaching political motivations to them) affects an argument’s perceived legitimacy and attractiveness.Footnote 25 His ‘apolitical hypothesis’ suggests that adding political reasons to legal arguments reduces their appeal to legal professionals. The experimental results confirm this hypothesis, showing that a political frame made law students 12–24 per cent more likely to select the ‘apolitical’ legal option.
Although still in its early stages, all these research contributions exemplify how experiments are gradually gaining relevance and attractiveness in EU empirical legal scholarship. This impulse is driven, in part, by the need for improved methodologies that enhance the explanatory power of our theories on the legal integration of Europe.Footnote 26 As we will see in the next section, while experimental design and implementation presents a great challenge and requires reflection on causal relations in the EU legal domain, the discipline is moving towards more experimentation.
12.3 Exploring the Untapped Experimental Potential in EU Law
This section presents different experimental designs available for studies of EU law. It describes their value in aiding our understanding of how EU law and actors operate in practice, as well as their associated challenges, in order to inspire researchers in the field to consider experiments for exploring dynamics in the legal realm.
12.3.1 Scenario/Vignettes Survey Experiments
The use of scenarios in survey research is not new in the empirical research of EU law where vignettes have been used to describe hypothetical real-life situations in which judges choose to follow certain courses of action with regards to EU law application.Footnote 27 The experimental use of scenarios has been promoted thanks to studies listed in the previous section investigating the public’s reaction to CJEU rulings, sanctions, and EU legislation.
The key distinction between experimental and non-experimental survey scenarios lies in their design. In non-experimental surveys, all participants respond to the same vignette(s) where critical information varies, and their reactions are recorded. In contrast, experimental surveys require participants to be randomly assigned to at least two different scenarios: one that includes the treatment and another serving as a control.
For example, consider a study conductedFootnote 28 to examine how Polish judges would react to a case of compatibility between EU and Polish law if the Polish Constitutional Court (PCC) had restricted the application of EU law. The 113 judges participating were presented with the following two scenarios:
Scenario 1 without the intervention of the PCC: ‘You are uncertain whether or not a national provision conflicts with an EU provision. In this case, the national provision is central to the resolution of the case. However, one of the litigants invokes a CJEU ruling stating that the national legislation is contrary to EU law and not applicable. Consequently …’
Scenario 2 with the intervention of the PCC: ‘You are uncertain whether or not a national provision conflicts with an EU provision. In this case, the national provision is central to the resolution of the case. However, one of the litigants invokes a CJEU ruling stating that the national legislation is contrary to EU law and not applicable. By contrast, the Constitutional Court has ruled that this EU provision should be applied restrictively because it is affecting fundamental national legal rules or values. Consequently …’ (emphasis added)
For each scenario, the judges were presented with three courses of action to choose from:
1. I would secure the national provision from the CJEU’s interpretation./I would follow the Constitutional Court’s interpretation.
2. I would interpret national law in accordance with EU law.
3. I would follow the CJEU’s interpretation and apply EU law instead of the national law.
The researchers then checked whether the judges’ responses changed based on the intervention of the PCC. The proportion of judges who said they would secure the national provision from the CJEU (option A) increased from 11.50 per cent for scenario 1 to 58.26 per cent for scenario 2.
However, this strategy has several problems. One of them is so-called ‘order effects’;Footnote 29 the responses might be affected by the sequencing of the vignettes. For instance, the participants might frame scenario 2 in contrast to scenario 1, exaggerating their responses to differentiate the two situations and, hence, amplifying the effect of the PCC’s intervention as well.Footnote 30 A second issue arising from the lack of random assignment is the difficulty in establishing strong causality. Without randomisation of judges between scenarios, it remains unclear whether changes in the judges’ responses are genuinely due to the PCC intervention or merely a result of the contrast with the preceding scenario.
Scenario survey experiments can fix these situations by ensuring that participants are randomly assigned either to scenario 1 (as a control group) or 2 (as a treatment group), enhancing the causal link between the judges’ responses and the intervention of the PCC. Although the setting in which individuals respond is not fully controlled, this method still allows for some manipulation of how participants are assigned to different conditions. These experiments are also highly flexible, as they can be conducted outside of labs or courthouses and distributed in many ways (on paper, via interviews, or online), making it much easier to reach the target respondents. However, this is also its main disadvantage as respondents complete the survey in uncontrolled environments (e.g., at home, at work, alone or with someone, on a computer or mobile, etc.), which introduces variability in how they engage with the experiment and where interruptions, misunderstanding of scenarios, or a lack of interest can influence their responses.
Scenario survey experiments can be applied in several modes. The literature demonstrates how these methods are used to explain the public’s attitudes towards EU law and the functioning and interventions of EU institutions. By varying, for instance, the content of court rulings, researchers evaluate how these differences influence perceptions of legitimacy or public support.Footnote 31 Another option is short stories where individuals are required to imagine that they are part of a narrative and respond to questions.Footnote 32 In these scenarios, researchers can play with the type of information that they present to the participants and ask them to place themselves in a situation, context, or interaction (court hearing, in a undemocratic country, in an exchange with lawyers) or add information about the behaviour of other actors, such as judges, litigants, politicians, and so on.
Another possibility is the use of quasi-experimental settings when expected or unexpected events occur during a regular survey. This approach helps to identify causal effects of important events on survey outcomes. With this technique, researchers do not have control over participants’ group assignment as this is instead determined by the event in question. For example, Turnbull-Dugarte and DevineFootnote 33 applied quasi-experimentation to study the impact of CJEU rulings on public opinion, taking as a reference the announcement of the salient and highly politicised Junqueras rulingFootnote 34 in Spain. The content of the ruling was published on 19 December 2019, during the fieldwork period for Wave 9 of the European Social Survey (ESS) conducted between 8 November 2019 and 27 January 2020. The unexpected character of the CJEU ruling created a quasi-experiment with (naturally) exogenous random assignment of exposure to the CJEU’s decision.Footnote 35 Randomly selected ESS respondents interviewed before the ruling served as the control group, while those interviewed after its announcement constituted the treatment group.
Stiansen et al.Footnote 36 also benefited from unexpected events during their survey to study how Polish citizens’ views on the Law and Justice (PiS) government’s judicial reforms are influenced by information concerning the battle between the EU and the Polish government over these measures. While data was being collected in Poland, the European Commission announced an infringement proceeding against Poland for violating EU law with respect to a new law targeting Russian meddling with the upcoming Polish elections. This unexpected development provided an opportunity to design a quasi-experiment, allowing the authors to test the extent to which Polish citizens take cues from EU enforcement actions.
12.3.2 Laboratory Experiments
Lab(oratory) experiments comprise a sample of individuals assigned to a hypothetical framing or scenario in a controlled situation and with controlled procedures in order to study a decision, behaviour, or opinion. Such experiments might simulate court trial decisions, judicial dialogues, or situations where different actors interact in the legal domain. In the lab, researchers can randomly allocate the conditions to the participants, as in survey experiments, but in a more carefully controlled environment where researchers limit the impact of external factors to ensure the experiment’s integrity. These situations are set up so that only the variables of interest or treatment are allowed to vary, while other potentially confounding factors are kept constant.
Normally, samples of law students are used as they are easier to access. However, lab experiments might also involve non-student subjects like lawyers or judges, especially when studying the legal decision-making of these professionals. These experiments are also referred to as an artefactual field experiment as they confront an imaginary lawsuit, and participants must take action or a decision as in real life.Footnote 37
In the worst-case scenario – that is, if access to legal professionals is significantly limited – experiments can be conducted with comparable populations. These may include legal advisors in courts, candidates from judicial training schools, lawyers, or law students. Several studies have compared undergraduates and political and legal elites, and they have found that judges and law students differ systematically in their ability to apply legal rules.Footnote 38 Nevertheless, several techniques on preparation, framing, and training of the participants might reduce these differences by, for instance, offering a brief informational sessions on EU law to the participants to give some practical legal information and guidance on legal reasoning.Footnote 39 Another way to improve the readiness of students before the survey is by practising EU law cases, similar to those that students will encounter in the experiment, to ensure they feel confident and familiar with legal reasoning.
Normally, experiments collect participants’ self-reports on their responses to various experimental scenarios and measure their reaction times to each one. Additionally, integrating biometric technologies into lab experiments allows researchers to capture physical responses, such as those measured by a pupilometer. This device assesses cognitive effort by tracking pupil dilation, as greater task demands (like complex legal cases) normally lead to increased pupil size.Footnote 40
Lab experiments, due to the random assignment of the selected subjects to treatment and control conditions in a controlled environment, provide an advantage for establishing causal relationships that improve internal validity, compared to field and scenario experiments. Nevertheless, this is often achieved at the cost of external validity or generalisation. It is important to indicate that even if experiments might be abstract, they should not be unrealistic. Although researchers try to approximate common real-world circumstances as much as they can in their labs, they are more interested in testing whether the experiment design gives a specific outcome. In this regard, several strategies might be applied to demonstrate that the effects found in lab experiments happen in the real world, such as combining lab experiments with field experimentation, frequency surveys, or interviews to show that the observed effect is found in other data and its interpretation is solid across methods. Additionally, the external validity of the experiment is also ensured by the accurate design and pre-test in collaboration with legal experts to create experiments that resemble real-life legal situations.
To date, except for Ovádek’s in-class experiment,Footnote 41 no research publications using lab experiments on EU law exist, which leaves a vast untapped field for exploring legal behaviour, attitudes, and decision-making. Building on the Law & Economics scholarship,Footnote 42 experimental labs can be used to understand how legal reasoning, doctrines, methods of interpretation, or even personal (e.g., EU identity) or political characteristics impact case decisions on EU law. Using the example of methods of interpretation, we could create a lab experiment where participants (ideally judges) were randomly assigned to one or more of the methods of interpretationFootnote 43 used by the CJEU in a ruling and ask them whether they would comply or not with it. This lab experiment would give more clarity to the important issue of judicial compliance by also establishing strong causal claims on the impact of the methods of interpretation on judges’ behaviour and, hence, its relevance for the legal integration of Europe.
Lab experiments are also suitable for reviewing current research questions on the extent to which legal behaviour or decision-making is influenced by factors such as the identity of the litigants (e.g., Member State, Commission, business, or individuals),Footnote 44 the precedents set by earlier CJEU rulings,Footnote 45 among others. Translating these discussions into lab experiments could refine longstanding questions or uncover new nuances in our theoretical understanding of the legal construction of Europe.Footnote 46
12.3.3 Field Experiments
Empirical research in EU law can benefit from changes, interventions, or differences occurring in the fabric of EU law (legal/policy settings, jurisdictions, etc.).Footnote 47 Normally, a field experiment takes place in a court where we can introduce new modes of legal reasoning, institutional reforms, staff, and so on, and see how it affects the way judges deal with their cases before and after this change or intervention is made. We can formulate field experiments where we establish within-subjects and between-subjects comparisons, each with its pros and cons.Footnote 48 For example, a suitable within-subjects comparison would involve judges who previously rendered judgments on EU law matters without specialised training in the field, compared to their performance after completing a specialised course in EU law. We can also conduct a between-subjects comparison by examining judges from courts that attended these specialised courses and comparing them to those who did not.
As a main advantage, within-subject comparisons offer a straightforward analysis by examining the same individuals across different conditions. However, they can generate test-retest effects, where participants’ previous responses influence their later answers. In contrast, between-subject comparisons avoid this issue by comparing different groups. However, they may reduce comparability due to differences between the groups, especially if random assignment is not possible, as naturally occurring groups may vary in uncontrollable ways.
Due to the difficulty of setting experiments in courtrooms, field experiment design frequently depends on naturally occurring differences, turning them into quasi-experiments where researchers lack control over participant selection. This is important in experiments because it ensures that the treatment and control groups are comparable, which strengthens the validity of causal inferences. While randomisation provides the gold standard for causal inference, quasi-experiments, even without random assignment, often provide sufficient causal evidence by demonstrating consistent effects across similar comparisons between groups that differ naturally in exposure to a treatment.Footnote 49
Some of the reviewed works adopted this type of design to measure the impact of events like Brexit on national courts’ preliminary referencesFootnote 50 and the EU Pilot programme on infringement procedures.Footnote 51 Using the infringement procedure as a policy field, Cheruvu and Fjelstul did not randomly assign Member States to a treatment group (participants in the EU Pilot programme) or a control group (no participation in EU Pilot). Instead, the variation occurred naturally. Ideally, researchers would use randomised controlled experiments in field settings, where participants are randomly assigned to experimental or control groups. However, such opportunities are rare and difficult in policy and legal contexts, despite their methodological advantages.
Finally, we should stress the potential that field experiments have for studying the implementation and effect of EU legislation on the behaviour of Member States or other actors (e.g., corporations, workers, citizens, etc.). By designing field experiments or quasi-experiments, we could assess the extent to which certain environmental regulations, consumer protection laws, or competition rules have an impact or achieve their objectives depending on heterogeneous national or sub-national preferences, capacities, and conditions.Footnote 52 For instance, a quasi-experimental setting could address corporate compliance with EU law depending on the enforcement mechanisms deployed by national authorities to enforce this regulation. In this regard, a treatment group might consist of firms operating in Member States with active enforcement of the selected legislation – that is, where monitoring and penalties are visibly enforced – while a control group could be made of firms in Member States with weaker enforcement mechanisms or delayed implementation timelines.
An observational design of the same situation would analyse compliance levels across all firms in different Member States, identifying statistical associations or correlations between variables without controlling for confounders. This lack of control increases the risk of bias from unobserved variables.Footnote 53 This risk is mitigated in the quasi-experiment design, which compares two groups of firms operating with strong and weak enforcement. By employing techniques such as difference-in-differences, this research strategy allows for causal inference while controlling for time-invariant unobserved confounders.Footnote 54
12.4 Conclusion
Legal experimentation offers a powerful empirical methodology for understanding and improving the design and effectiveness of EU law. It enables researchers to test new initiatives or changes that might affect legal decision-making or behaviour, measure their impact, and identify the most effective solutions for broader application.
This method is particularly useful in the European context, where EU law often operates in diverse and complex real-world settings due to the decentralised, and sometimes discretionary, national enforcement of EU law. This method might provide useful insights into what works under certain settings, helping judiciaries, national governments and, most importantly, EU institutions to identify more efficient legal interventions. Such an evidence-based approach can bridge the gap between legal design and actual legal decision-making and implementation of EU law, addressing problems of effectiveness, uniform judicial application, and compliance.
Building on the earlier example of judicial training, a more precise field experiment with straightforward policy implications could be designed to investigate the impact of judicial training on the uniform application of the Digital Services Act (DSA) across Member States in collaboration with the European Judicial Training Network (EJTN). In this experiment, judges in the treatment group would attend a training module emphasising strict enforcement of the DSA, focusing on transparency and accountability requirements for online services. In the control group, judges would receive no training before ruling on EU law cases related to the enforcement of the DSA. This would help researchers and policy-makers to assess whether specialised judicial training influences how national judges apply the DSA and the extent to which it contributes to its uniform implementation across Member States.
Despite these advantages, experiments in the legal realm face significant challenges, especially in the case of lab experiments. Random selection and random assignment are particularly difficult to achieve, not only due to ethical issues and the safeguarding of legal principles of equality, fairness, and justice, but also due to the contextual and heterogeneous nature of national legal systems where EU law is applied by judges and national authorities. Differences in institutional structures, legal cultures, and procedural norms across jurisdictions can complicate the design and generalisability of experiments. These challenges necessitate creative methodological solutions and careful consideration of contextual factors to ensure meaningful and credible results.
In sum, while challenging, conducting experiments in the field of EU law unquestionably has the potential to transform and advance EU law research. By leveraging experimentation, researchers can contribute to a deeper understanding of EU legal decision-making, rulings, and legislation and their impact, providing valuable tools for crafting judicial proceedings and laws that are not only effective but also adaptable to the complexities of the European Union’s legal and policy diversity.
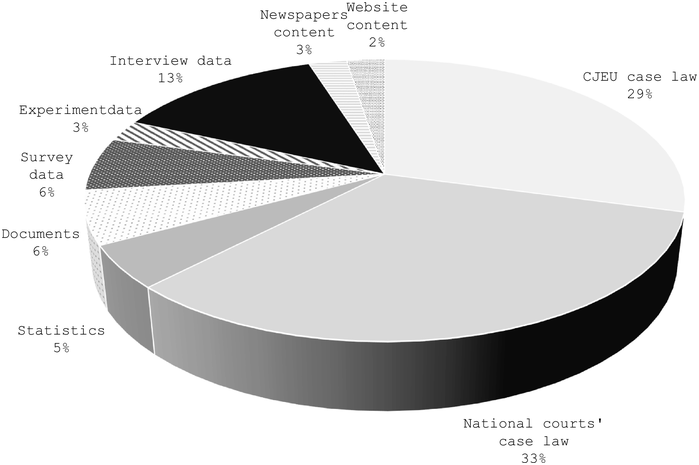
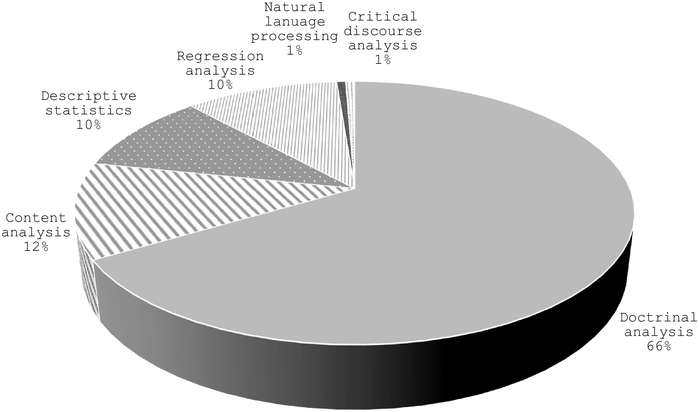
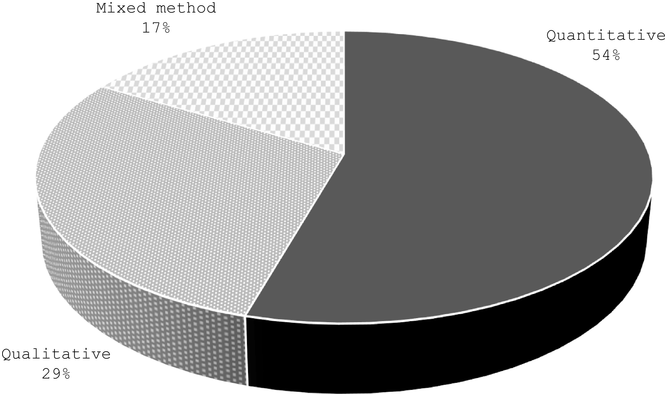
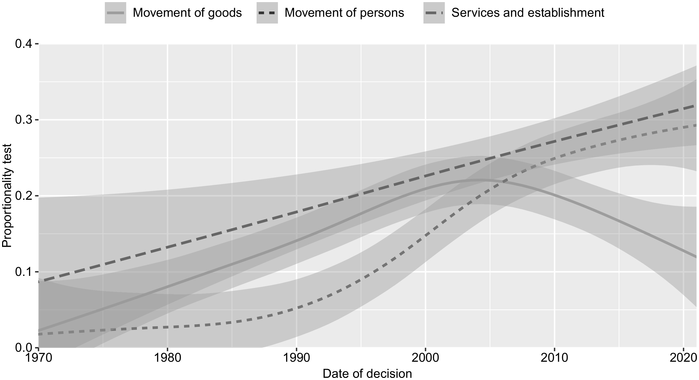
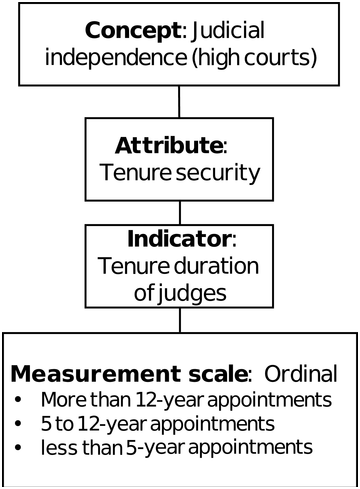
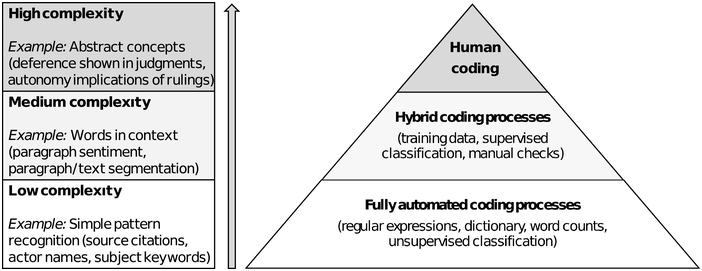

 Open access
Open access