


The rapid evolution of Generative Artificial Intelligence (GenAI) has provided social scientists with powerful new tools. Existing research has focused on text-based applications, such as classifying data (e.g., Heseltine and Clemm von Hohenberg Reference Heseltine and Clemm von Hohenberg2024; Mellon et al. Reference Mellon, Bailey, Scott, Breckwoldt, Miori and Schmedeman2024; Ornstein, Blasingame, and Truscott Reference Ornstein, Blasingame and Truscott2025) and simulating survey responses based on demographic profiles (e.g., Argyle et al. Reference Argyle, Busby, Fulda, Gubler, Rytting and Wingate2023; Kim and Lee Reference Kim and Lee2024; Kozlowski, Kwon, and Evans Reference Kozlowski, Kwon and Evans2024). We instead consider GenAI’s “vision” capabilities,—where Large Language Models (LLMs) can respond to images. Just as LLMs increasingly dominate text analysis tasks, Large Multimodal Models (LMMs) are increasingly used in place of traditional computer vision algorithms (e.g. Bontempi et al. Reference Bontempi2025; Luckey et al. Reference Luckey, Fritz, Legatiuk, Dragos and Smarsly2020; Melegrito et al. Reference Melegrito2024; Tselentis, Papadimitriou, and van Gelder Reference Tselentis, Papadimitriou and van Gelder2023; Tukur et al. Reference Tukur, Uwishema, Akbay, Sheikhah and Correia2025). We assess LMMs as a potential solution to the challenge of systematically measuring subjective context. It is well established that people respond to subjective perceptions of their environments (Herda Reference Herda2010; Laméris, Hipp, and Tolsma Reference Laméris, Hipp and Tolsma2018; Lippmann Reference Lippmann1922; Semyonov et al. Reference Semyonov, Raijman, Tov and Schmidt2004; Wong et al. Reference Wong, Bowers, Rubenson, Fredrickson and Rundlett2025). Yet, capturing these subjective perceptions systematically and at scale remains a major challenge (Wong et al. Reference Wong, Bowers, Williams and Simmons2012, Reference Wong, Bowers, Rubenson, Fredrickson and Rundlett2020). We explore whether the latest developments in GenAI can help circumvent this by providing a scalable proxy for human subjective evaluations.
We turn to street view images, which are increasingly used to study context (Hwang and Naik Reference Hwang and Naik2023; Hwang et al. Reference Hwang, Dahir, Sarukkai and Wright2023; LeVan Reference LeVan2020; Sampson and Raudenbush Reference Sampson and Raudenbush1999). Using a crowdsourced dataset of street view images from Detroit, Michigan, we assess how well three leading LMMs align with a national sample and local sample of Americans on perceptions of wealth, safety, and disorder. Our approach yields a distribution of assessments for each image from five distinct sources, enabling both correlation comparisons across images and evaluations of GenAI versus humans separately for each image.Footnote 1 This dual approach highlights both relative performance (how GenAI assessments correlate with human perspectives overall) and absolute performance (how closely GenAI matches human appraisals on a per-image basis).
Our findings have important implications for using GenAI in social science research, and for labeling or rating tasks more broadly. First, when assessing street view images, LMMs most accurately reflect broad, national patterns rather than local nuances. This distinction is important because local residents provide insight into community-specific concerns that national assessments overlook. For locally salient issues such as safety and neighborhood conditions, resident perspectives remain essential, and GenAI evaluations are a poor substitute. Second, prompting LMMs to adopt locally or demographically tailored personas does not improve performance and, in many cases, diminishes it. This has implications for the applicability of “synthetic sampling” across research contexts. Third, we document demographic and geographic biases in GenAI responses across several policy-relevant themes. Many policy and practitioner use cases of LMMs blur the line between “objective” and “subjective” evaluation tasks, as illustrated by a 2024 European Union report describing potential applications of AI to categorize images or activities as “suspicious” and automatically report potential threats, public disturbances, and safety hazards (Europol 2024, 22–23). Our results suggest that user discretion is warranted, especially where categorization tasks are more subjective. We also focus on gender, which shapes perceptions of public spaces, especially around safety and risk (Alsharawy et al. Reference Alsharawy, Spoon, Smith and Ball2021; Ouali et al. Reference Ouali, Graham, Barron and Trompet2020). Finally, as researchers and practitioners increasingly rely on machine learning (ML) methods to extract insights from large datasets, we offer systematic evidence that the identities and representativeness of the labelers who create training data matter.
1 Data and Methods
Our image data come from Mapillary, an open-source platform for street view images. We randomly sample 85 images from Detroit and pre-process each image as described in Section S9 of the Supplementary Material. For each image in our sample, we obtain a distribution of ratings across neighborhood attributes from a nationally representative human sample, a Detroit representative human sample, and five vision- and text-enabled GenAI models: OpenAI’s GPT-4o and GPT-4.1, Google’s Gemini 1.5 Pro and Gemini 2.5 Pro, and Meta’s open-source Llama 4 (see Section S1 of the Supplementary Material). Here, we present results from the best performing model, GPT-4o; see Tables SI1 and SI5 in the Supplementary Material for other results. To account for their non-deterministic nature, we query these models 30 times for every question-image pair.
In addition to GenAI evaluations, we field two human surveys: a U.S. nationally representative survey via Prolific and a Detroit representative survey conducted as part of the Detroit Metro Area Community Study (DMACS) at the University of Michigan. DMACS recruits a representative sample of approximately 2,430 Detroit residents (see Section S11 of the Supplementary Material). Detroit’s unique history—most notably the rise and fall of the auto industry in the 20th Century—sets it apart from the US overall. Roughly three-quarters of residents identify as Black, and socioeconomic indicators fall below national averages. These features make it an ideal setting to explore how GenAI models align with national versus local perspectives.
In the national sample, 800 Prolific respondents each evaluated three randomly selected images. In the DMACS sample, 2,430 Detroit residents each assessed one randomly selected image. For each image, respondents answered questions about the featured area’s daytime and nighttime safety, wealth, and disorder. In total, we collect 61,200 ratings per LMM (
$n=30$
 per image-question pair) and 3,230 human-generated ratings (on average
$n=28$
per image-question pair) and 3,230 human-generated ratings (on average
$n=28$
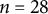 per image-question pair for each sample) across the 85 images, providing a distribution of responses for each image-question.
per image-question pair for each sample) across the 85 images, providing a distribution of responses for each image-question.
2 Results
What does it mean for the outputs of an LLM to be aligned with the views of a population? We adopt two main approaches to analyzing the relationship between GenAI and human responses. In the first, we measure how well GenAI correlates with each human sample at the image level across repeated ratings. In the second, we conduct pairwise comparisons between the average GenAI rating and the average human rating, demonstrating how often the two diverge significantly. Figure 1 presents results from these approaches, focusing on comparisons between human evaluations and those of GPT-4o. Sections S3 and S4 of the Supplementary Material show results from Gemini 2.5 and Llama 4, respectively.
GPT’s average evaluations of wealth, daytime safety, nighttime safety, and disorder compared to average evaluations of U.S. and Detroit samples.
Note: The top panel shows human samples’ average perceptions plotted against GPT’s average assessments. Each dot represents an image. The diagonal dashed line represents where the two are perfectly equivalent. Correlation coefficients and LOESS and linear regression lines with 95% confidence intervals are shown. The bottom panel displays the outcome of pairwise two-sample t-tests comparing the means of human- and GPT-derived ratings for each image.

Figure 1 Long description
The top section is a grid of twelve scatter plots arranged in three rows and four columns. The x-axis represents Human Ratings from 0 to 10, and the y-axis represents G P T Ratings from 0 to 10. Each plot includes a red dashed diagonal line, a blue regression line with a gray confidence interval, and a correlation coefficient r.
* Row 1 (Americans versus L M M): Wealth r equals 0.83, Safety-day r equals 0.81, Safety-night r equals 0.83, and Disorder r equals 0.8. Data points cluster closely around the diagonal.
* Row 2 (Detroit versus L M M): Wealth r equals 0.73, Safety-day r equals 0.6, Safety-night r equals 0.58, and Disorder r equals 0.16. The Disorder plot shows a horizontal cloud with no clear linear trend.
* Row 3 (Detroit versus L M M with ‘You live in Detroit’ prompt): Wealth r equals 0.68, Safety-day r equals 0.6, Safety-night r equals 0.59, and Disorder r equals 0.15.
The bottom section contains twelve horizontal stacked bar charts showing the Proportion of Images from 0.00 to 1.00. A legend indicates: light tan for Non-Significant Difference, orange for G P T Significantly Under-Estimates, and dark red for G P T Significantly Over-Estimates.
* For Americans versus L M M, G P T mostly under-estimates across all categories.
* For Detroit versus L M M, G P T shows a higher proportion of over-estimation, particularly in Safety-night and Disorder.
* For Detroit versus L M M with the specific prompt, the proportions are similar to the second row but with slightly more non-significant differences in Wealth.
The top panel of Figure 1 summarizes the overall relationship, across images, between each sample pair. With each point representing ratings of a single image, it shows the degree of linear correlation between human samples’ average perceptions and GPT-4o’s average assessments, separately for each neighborhood attribute. The relationship between GPT-4o’s assessments and the U.S. sample’s perceptions tends to be positive and roughly linear. However, there is a high degree of variation between human samples and across neighborhood attributes. First, GPT-4o consistently shows a weaker correlation with the local Detroit sample than the national sample for all neighborhood attributes. Second, GPT-4o tends to perform worse on questions about safety and disorder than those about wealth. For neighborhood wealth, GPT-4o approximates both the national and Detroit sample well
$(r_{US} = 0.83, r_{Detroit} = 0.73)$
 . Large disparities emerge when comparing performance on the other neighborhood attributes: for safety and disorder assessments, GPT-4o’s ratings align well with the national sample (
$r_{US} = [0.8, 0.83]$
. Large disparities emerge when comparing performance on the other neighborhood attributes: for safety and disorder assessments, GPT-4o’s ratings align well with the national sample (
$r_{US} = [0.8, 0.83]$
 ) but range from very weak (
$r_{Detroit} = 0.16$
) but range from very weak (
$r_{Detroit} = 0.16$
 for disorder) to moderate (
$r_{Detroit} = [0.58, 0.6]$
for disorder) to moderate (
$r_{Detroit} = [0.58, 0.6]$
 for safety) correlations with the Detroit sample. These patterns persist when we explicitly prompt GPT to rate as though “you live in Detroit” (
$r_{Detroit} = 0.15$
for safety) correlations with the Detroit sample. These patterns persist when we explicitly prompt GPT to rate as though “you live in Detroit” (
$r_{Detroit} = 0.15$
 for disorder;
$r_{Detroit} = [0.59, 0.60]$
for disorder;
$r_{Detroit} = [0.59, 0.60]$
 for safety). Gemini and Llama produce the same pattern, though the correlations are typically weaker (see Table SI1 in the Supplementary Material).
for safety). Gemini and Llama produce the same pattern, though the correlations are typically weaker (see Table SI1 in the Supplementary Material).
The bottom panel of Figure 1 shows our second approach. For each image, we conduct a t-test on the difference in means between GPT-4o’s assessments and the human assessments of each neighborhood attribute to determine whether the two are statistically different (at
$p<0.05$
 ). This approach allows us to identify the overall direction of the GenAI’s statistically significant bias. The beige area of the bars represents the proportion of images for which GPT-4o and human assessments are not statistically different from each other, while the brown represents where GPT-4o significantly overestimates relative to humans, and the coral where it underestimates.
). This approach allows us to identify the overall direction of the GenAI’s statistically significant bias. The beige area of the bars represents the proportion of images for which GPT-4o and human assessments are not statistically different from each other, while the brown represents where GPT-4o significantly overestimates relative to humans, and the coral where it underestimates.
Even in cases where the distribution of GPT-4o ratings strongly correlates with that of human sample ratings (as measured by correlation coefficients), its ratings of individual images tend to stray from those of humans. That is, GenAI is better at recovering relative, rather than absolute ratings.
For neighborhood wealth, despite relatively strong linear correlations, GPT-4o significantly under-estimates both U.S. and Detroit samples’ ratings in 67% and 38% of the images, respectively. Prompting GPT-4o to respond as a Detroit resident worsens the latter to 55%.
Safety assessments show no clear pattern. GPT-4o significantly under-estimates the U.S. sample’s daytime safety ratings in 39% of images, while significantly over-estimating nighttime safety in 19%. GPT-4o under-estimates daytime safety ratings of Detroit residents in 11% (38% when prompted with “you live in Detroit”) of images and over-estimates it in 18% (2% when prompted), but over-estimates nighttime safety in 52% (16% when prompted) and under-estimates it in 1% (4% when prompted).
Finally, the greatest disparities appear in disorder ratings, where GPT-4o significantly over- or under-estimates compared with the U.S. sample in 49% of images and with the Detroit sample in 67% (64% when prompted with “you live in Detroit”).
Figures 2 and 3 visualize the extent to which LMM assessments align with those of humans across gender, which is known to be highly relevant to perceptions of neighborhoods (Alsharawy et al. Reference Alsharawy, Spoon, Smith and Ball2021; Ouali et al. Reference Ouali, Graham, Barron and Trompet2020). Because the (human) sample size is halved when looking within each gender, we focus on the correlation between the average ratings of GPT-4o and human respondents. Full t-test results are presented in Table SI1 in the Supplementary Material.
GPT’s average evaluations of wealth, daytime safety, nighttime safety, and disorder compared to average evaluations of women in the U.S. and Detroit samples.
Note: The top panel shows human samples’ average perceptions plotted against GPT’s average assessments. Each dot represents an image. The diagonal dashed line represents where the two are perfectly equivalent. Correlation coefficients and LOESS and linear regression lines with 95% confidence intervals are shown.

Figure 2 Long description
A grid of sixteen scatter plots arranged in four rows and four columns. The horizontal x axis represents Human Ratings and the vertical y axis represents G P T Ratings, both scaled from 0 to 10. A red dashed diagonal line indicates perfect equivalence. Each plot includes a black dot for each image, a blue linear regression line, and a wavy L O E S S line with gray 95 percent confidence intervals.
Columns from left to right are Wealth, Safety dash day, Safety dash night, and Disorder.
Rows from top to bottom represent different human versus L M M comparisons.
Row 1: Women versus L M M. Correlation coefficients r range from 0.69 for Disorder to 0.8 for Wealth.
Row 2: Women versus L M M with the prompt You are a woman. Correlation coefficients r range from 0.69 for Disorder to 0.8 for Wealth and Safety dash night.
Row 3: Detroit Women versus L M M. Correlation coefficients r drop significantly for Disorder to 0.19, while others range from 0.63 to 0.74.
Row 4: Detroit Women versus L M M with the prompt You are a woman and live in Detroit. Correlation coefficients r are similar to row 3, with Disorder at 0.2 and others between 0.63 and 0.72.
In most panels, the data points cluster along the diagonal, showing a positive linear increase, except for the Disorder category in the Detroit Women rows where the data is more dispersed and the regression line is nearly flat.
GPT’s average evaluations of wealth, daytime safety, nighttime safety, and disorder compared to average evaluations of men in the U.S. and Detroit samples.
Note: The top panel shows human samples’ average perceptions plotted against GPT’s average assessments. Each dot represents an image. The diagonal dashed line represents where the two are perfectly equivalent. Correlation coefficients and LOESS and linear regression lines with 95% confidence intervals are shown.

Figure 3 Long description
The grid consists of four rows and four columns. The X-axis for all panels is Human Ratings from 0 to 10, and the Y-axis is G P T Ratings from 0 to 10. A red dashed diagonal line indicates perfect correlation.
Columns from left to right represent Wealth, Safety-day, Safety-night, and Disorder.
Rows from top to bottom represent different comparison groups:
1. Men versus L M M: Shows strong positive linear correlations with r values of 0.80, 0.77, 0.77, and 0.75. Data points cluster closely along the diagonal.
2. Men versus L M M with ‘You are a man’ prompt: Shows similar strong positive correlations with r values of 0.79, 0.74, 0.77, and 0.75.
3. Detroit Men versus L M M: Shows significantly weaker correlations. Wealth remains moderate at r equals 0.63, but Safety-day drops to 0.33, Safety-night to 0.25, and Disorder to 0.03. The L O E S S and linear regression lines are much flatter compared to the first two rows.
4. Detroit Men versus L M M with ‘You are a man and live in Detroit’ prompt: Shows the weakest correlations. Wealth is at r equals 0.58, Safety-day at 0.33, Safety-night at 0.23, and Disorder at r equals 0. The data points are widely scattered with nearly horizontal regression lines for the safety and disorder categories.
In the national sample, GPT-4o strongly aligns with both genders on safety. In the Detroit sample, GPT-4o consistently aligns more closely with women than with men across all neighborhood attributes, a trend especially pronounced for questions about safety. Gemini and Llama responses again follow a similar pattern, consistently correlating less well with human responses compared to GPT-4o while displaying the same biases along gender and geographic lines (see Table SI1 and Figures SI2 and SI3 in the Supplementary Material). As before, prompt tailoring—asking the GenAI to adopt a particular identity when providing ratings—does little to improve correlations.
3 Discussion
We ask whose perspectives GenAI aligns with more closely: the generalized perspectives of the national sample or the localized, context-sensitive views of residents. By some metrics, GenAI is capable of broadly reflecting Americans’ average perceptions of neighborhoods based on street view images. For some research or policy applications—those which require reasonable fidelity to a distribution of responses taken from a national sample—this may be sufficient. However, for other types of applications, its usefulness should be questioned.
First, where researchers seek subjective assessments of a small number of images, or where evaluations of individual images matter, GenAI can mislead. This includes use cases in the public sector, such as policing, as well as in the private sector, where in consumer research synthetic sampling is being used to evaluate visual stimuli such as images of product packaging (Sarstedt et al. Reference Sarstedt, Adler, Rau and Schmitt2024). We urge caution in use cases, where judgments based on individual images are important.
Second, GenAI is unreliable where the goal is to approximate specific populations. Prompting LLMs to take the view of local residents does not address their biases and, in some cases, exacerbates them. We also find evidence that the more difficult-to-reach a population, the worse models perform at representing their views. In our tests, the largest disparities in the models’ performance emerge between men and women residents of Detroit. This gap is most apparent when it comes to evaluations of safety, with GenAI aligning better with women than with men. Overall, GenAI is especially misaligned for men in Detroit, the majority of whom identify as Black or African American, a group with historically low research involvement (e.g., George, Duran, and Norris Reference George, Duran and Norris2014). This finding is consistent with research that has demonstrated biases against African Americans in training data and in algorithms (e.g., Davidson, Bhattacharya, and Weber Reference Davidson, Bhattacharya and Weber2019; Mehrabi et al. Reference Mehrabi, Morstatter, Saxena, Lerman and Galstyan2021). However, Detroit’s racial makeup does not explain our results. We show in Section S6 of the Supplementary Material that Black Detroiters’ ratings are more similar to those of non-Black Detroiters than they are to those of Black U.S. residents (Table SI7 in the Supplementary Material). Moreover, GenAI aligns much more closely with assessments of non-Black U.S. residents than those of non-Black Detroiters (Table SI9 in the Supplementary Material).
One important limitation of our findings is that they merely reflect a “snapshot” of rapidly improving GenAI models. However, we have reason to believe that the ability of these models to reflect the voices of hard-to-reach populations is unlikely to improve drastically, as survey data from these populations is scarce and typically incompatible with market incentives. We further show in Section S5 of the Supplementary Material that the latest iteration of the GPT model exhibits worse performance than its older counterpart. Given concerns over the reproducibility of GenAI models, we also detail in Section S10 of the Supplementary Material steps we took to address these issues as per Barrie, Palmer, and Spirling (Reference Barrie, Palmer and Spirling2025).
Our focus on subjective assessments raises broader questions about how researchers should define “bias” and identify a relevant “ground truth” in image-based evaluations. In many social science applications of ML or GenAI, models are judged by how well they approximate an external standard. Yet in tasks involving subjective perceptions—such as detecting hateful speech or incivility online (Davidson et al. Reference Davidson, Warmsley, Macy and Weber2017; Southern and Harmer Reference Southern and Harmer2021), identifying trash on sidewalks (Hwang et al. Reference Hwang, Dahir, Sarukkai and Wright2023), or classifying aesthetics (Isola et al. Reference Isola, Xiao, Parikh, Torralba and Oliva2013)—there may be no single, objective truth. What counts as “good quality” data in labeling? Perceived characteristics of environments shape outcomes independently of objective measures (Bowers et al. Reference Bowers, Wong, Rubenson, Fredrickson and Rundlett2025; Gimpelson and Treisman Reference Gimpelson and Treisman2018). In such cases, bias may mean deviation not from fixed reality, but from average human judgment—where “relevant” is defined by the use case. Our findings underscore the need to align model output with human perceptions when those perceptions drive behavior. As GenAI tools enter high-stakes contexts, researchers must ask not only what models get “right,” but for whom—and by what standard.
Acknowledgments
The authors thank Ala’ Alrababah, Daniel de Kadt, Elias Dinas, Liz Gerber, Ethan Porter, and audiences at Trinity College Dublin Department of Political Science Friday Seminar, the George Washington University American Politics Workshop, University of Barcelona IPERG Seminar Series, the Department of Politics and International Relations at Oxford University Comparative Politics Seminar, European University Institute and CIVICA Public Lecture Series Tours d’Europe, LSE Department of Methodology’s Generative AI in Social Science Research Conference, the American Political Science Association 2024 Annual Meeting, and the Thought Summit on the Future of Survey Science at Cornell University for their invaluable feedback on early iterations of this project, and Muxuan Qu for research assistance.
Funding Statement
Data included in this report were collected and provided by the Detroit Metro Area Communities Study (DMACS). DMACS is a University of Michigan initiative that regularly surveys a broad, representative group of Detroit residents about their communities, including their experiences, perceptions, priorities, and aspirations. Support for DMACS comes from the University of Michigan Gerald R. Ford School of Public Policy, Institute for Social Research and Poverty Solutions. DMACS is also supported by the Knight Foundation, the Kresge Foundation and Ballmer Group. Learn more about DMACS at www.detroitsurvey.umich.edu and contact us at DMACS-info@umich.edu.
We received in-kind support from DMACS and a grant funded by the London School of Economics LSE Research Impact and Support Fund 2024.
Data Availability Statement
Replication materials can be accessed at https://doi.org/10.7910/DVN/7RN8QO (Bollen et al. Reference Bollen, Higton and Sands2025). Further code for the LMM queries can be accessed at https://github.com/joehigton/GenAILocalBias.
Author Contributions
P.B., J.H., and M.L.S. contributed equally to this work. Authors are listed in alphabetical order
Competing Interests
The authors declare none.
Ethical Standards
The research involving human subjects was reviewed and approved by the Harvard University Institutional Review Board (Protocol Number: IRB23-1746) and the London School of Economics Research Ethics Committee (Reference Number: 311794).
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2025.10022.






 Open access
Open access