


1 Introduction
Writing is hard. Linguist Peter Hugoe Matthews (Reference Matthews2003, 16) said of humanity, “No one would describe us as the ‘writing’ species.” At the same time, writing is a pervasive part of contemporary life. The rising ubiquity of writing follows long-term educational and technological trends. In 1900, only one in five people in the world was literate. By the end of the twentieth century, only one in five people was illiterate (van Zanden et al. Reference Zanden, Luiten, d’Ercole, Rijpma and Timmer2014). Further, as Thompson (Reference Thompson2010) notes, “This generation doesn’t make phone calls, because everyone is in constant, lightweight contact in so many other ways: texting, chatting, and social-network messaging.” In contrast to Matthews’ statement two decades ago, now, for many modern, connected and educated people, “Homo scribens” might actually be an appropriate description.
Quantifying sincere attitudes is also hard and a central challenge for social science (Campbell and Stanley Reference Campbell and Stanley1963). Researchers often attempt to gauge affect and behavior through games or by attaching costs or rewards to an action in an effort to encourage subjects to reveal genuine tendencies and tastes (McDermott Reference McDermott2002). These approaches, though, have limitations. Paying subjects additional money to reveal preferences can be expensive. Economic games, such as the “Dictator Game,” may not translate well to real-world situations in which subjects are not participants in a study (Winking and Mizer Reference Winking and Mizer2013). In addition, many measures suffer from concerns about external validity (Findley, Kikuta, and Denly Reference Findley, Kikuta and Denly2021).
Given the cognitive, affective and temporal demands of expression, I propose using simple metadata from open-ended prompts—like nonresponse and number of characters—as alternative measures of effortful action. The nearly universal difficulty of writing combined with its increasing prevalence allows for a measure that is “costly” for subjects but inexpensive for researchers. As Berinsky (Reference Berinsky2013) noted, “respondents must pay costs—albeit small—to form and express their views in a survey” (9). Treating expression as a behavioral measure extends Berinsky’s insight to open-ended text. Open-ended prompts can also be evaluated in ways that are unlikely to be anticipated by subjects and, in many cases, these tasks correspond neatly to many real-world behaviors. I test this text as behavior method across a range of topics, datasets and languages with three simple features of open-ended prompts: character counts, nonresponse and time.
In contrast to methods like sentiment analysis that attempt to extract meaning from terms, I use metadata to determine often-unobserved qualities like effort, preference intensity and ambivalence. I find these simple features of text provide meaningful signals of attitudes and behaviors. All other factors being equal, subjects who are more expressive reveal significantly more intense support, engagement and capacity for relevant action related to that particular topic as compared with subjects who communicate less. Cavaillé, Chen, and Van der Straeten (Reference Cavaillé, Chen and Van der Straeten2025), for example, tested whether conventional survey scales collapse important variation in how much people care about particular issues. Applying the text-as-behavior approach, they showed that character counts in letter-writing tasks on policies like the minimum wage and abortion better capture variation in preference intensity than conventional scales.
Further, I find that subjects with blank responses—whether from skipping a question or replying “No” when prompted to elaborate—tend to exhibit more negative attitudes and conflicted behaviors compared to subjects who express even a single word. While the motivating idea stems from the cognitive demands of writing, I test whether expressive behavior more broadly—typed or transcribed from speech—provides useful signals. In practice, I find that both written and spoken responses yield meaningful results, suggesting the underlying dynamics are not limited to any one mode of expression.
This approach is both a complement to and offers some advantages over many current and more sophisticated methods of measuring attitudes and behavior. First, the use of open-ended prompts is already widespread and growing in social science (Li Reference Li2023). Consequently, applying text-as-behavior methods to existing or planned open-ended prompts adds minimal cost or respondent burden to data collection, yet captures some of the cognitive, affective and temporal demands faced by subjects. In contrast, while adding more survey items can increase reliability, doing so typically raises costs and respondent fatigue.
Second, text responses—whether collected in surveys, transcripts or social media—can offer researchers good equivalence to real-world situations or “mundane realism” (Aronson and Carlsmith Reference Aronson and Carlsmith1968). Third, the demands of expression allow measurement of otherwise hard-to-quantify traits such as the degree of commitment to expressing oneself on political issues and in voting. Fourth, expression can offer a window into psychological states about which a subject may not be fully aware (Wilson Reference Wilson2004). Fifth, blank answers may be informative rather than missing data.
Sixth, the open-ended nature of text responses—and the nearly infinite number of ways they can be quantified—make them difficult to “game.” Rather than relying on what respondents say, metadata about how they respond, such as length or latency, acts like a behavioral “derivative,” capturing traces of engagement apart from content. Because respondents are typically unaware these features are being measured, such implicit indicators benefit from what we might call metric opacity, making them less susceptible to social desirability or other forms of strategic responding.
Seventh, any measure of human attitudes or behavior risks participants inferring the study’s purpose and altering their behavior in response (Mummolo and Peterson Reference Mummolo and Peterson2019). Metadata from open-ended prompts, by contrast, provide hypothesis opacity, reducing the likelihood that respondents anticipate or adapt to researcher expectations. Finally, text as behavior appears to generalize across languages, modes, transcription and translation.
2 Related work
Social scientists now routinely study text as data (Grimmer, Roberts, and Stewart Reference Grimmer, Roberts and Stewart2022; Li Reference Li2023) using methods, such as topic models (Roberts et al. Reference Roberts2014) and forms of sentiment analysis (cf. Bisgaard Reference Bisgaard2019; Mossholder et al. Reference Mossholder, Settoon, Harris and Armenakis1995). In contrast, treating text as a behavioral measure remains less common, though it builds on at least five related bodies of scholarship.
First, scholars employ text to measure emotions, mental states, how subjects acquire information and attributes like political sophistication (Benoit, Munger, and Spirling Reference Benoit, Munger and Spirling2019; Bernhard and Freeder Reference Bernhard and Freeder2020; Gillion Reference Gillion2016; Kraft Reference Kraft2024; Kramer, Guillory, and Hancock Reference Kramer, Guillory and Hancock2014; Pennebaker, Francis, and Booth Reference Pennebaker, Francis and Booth2001; Rude, Gortner, and Pennebaker Reference Rude, Gortner and Pennebaker2004). Kuo, Malhotra, and Mo (Reference Kuo, Malhotra and Mo2017), henceforth KMM, experimentally induced feelings of exclusion and, among other measures, asked subjects to write lists of items they liked and disliked about both the Democratic and Republican Parties. Of particular relevance, KMM note, “This task required a great deal of effort on the part of respondents and therefore can be interpreted as a behavioral manifestation of liking or aversion toward a political party” (27). KMM also found that treated Asian American subjects took significantly longer to complete the survey than expected from additive effects alone (see Section A4 of the Supplementary Material).
Second, researchers analyze text from transcripts, court cases, social media, short messaging services and Internet searches as indicators of bias that may circumvent efforts to offer socially acceptable answers. Scholars draw on Google queries, text logs or surveilled and transcribed speech to identify unvarnished, non-survey alternative indicators of attitudes (Maloney Reference Maloney2021; Stephens-Davidowitz Reference Stephens-Davidowitz2014). Email- and messaging-based correspondence studies offer an additional way to detect bias solely through written responses (Butler and Broockman Reference Butler and Broockman2011; Lowande and Proctor Reference Lowande and Proctor2020; Yan and Bernhard Reference Yan and Bernhard2023). Scientists also study deliberative discussions, Supreme Court interruptions and police stops to understand gender and racial bias (Jacobi and Schweers Reference Jacobi and Schweers2017; Karpowitz, Mendelberg, and Shaker Reference Karpowitz, Mendelberg and Shaker2012; Voigt et al. Reference Voigt2017).
Third, many studies rely on social media to measure attitudes of the mass public and predict a range of future behaviors from voting in elections to movie attendance and disruptive events (cf. Alsaedi, Burnap, and Rana Reference Alsaedi, Burnap and Rana2017; Eady, Hjorth, and Dinesen Reference Eady, Hjorth and Dinesen2023; Tumasjan et al. Reference Tumasjan, Sprenger, Sandner and Welpe2010; Wasow et al. Reference Wasow, Baron, Gerra, Lauderdale and Zhang2010). Researchers also observe interactions that reveal debate strategies, dynamics of status hierarchies, polite or conflictual conversations and perceived violence (Danescu-Niculescu-Mizil et al. Reference Danescu-Niculescu-Mizil, Sudhof, Jurafsky, Leskovec and Potts2013; Jann and Schottmüller Reference Jann and Schottmüller2024; Panteli Reference Panteli2002). This line of work also includes experiments in which both treatments and outcomes are short written exchanges (Mosleh et al. Reference Mosleh, Martel, Eckles and Rand2021; Munger Reference Munger2017).
Fourth, psychologists routinely employ writing tasks as a form of treatment to induce different states of mind, from reducing anxiety and trauma to increasing awareness of certain moral frames (Day et al. Reference Day, Fiske, Downing and Trail2014; Pennebaker Reference Pennebaker1997). Open-ended responses also validate and extend survey instruments (ten Kleij and Musters Reference ten Kleij and Musters2003), serve as a type of mechanism check (KMM) and detect inattentive subjects (Ziegler Reference Ziegler2022). Survey methodologists also analyze character-length metadata to identify mode effects between paper and online surveys (Denscombe Reference Denscombe2008).
While these four literatures treat text as a behavioral signal, the studies are more substantive than methodological. As a result, they offer limited guidance for applying the approach. More broadly, this scholarship lacks a generalizable model of the cognitive, emotional and temporal demands of expression that could help unify seemingly disparate behaviors, from nonresponse to verbosity.
Finally, research on survey nonresponse and missing data is also relevant to understanding situations in which subjects opt out of responding or convey nothing (Berinsky Reference Berinsky2008, Reference Berinsky2013). Scholarship on nonresponse, though, often treats the topic as a form of missing data rather than as a distinct and meaningful form of response. Longford (Reference Longford, Leeuw and Meijer2007), for example, writes:
“Methods for addressing nonresponse can be divided into two categories: those that reduce the dataset (by deleting the records of some units) and those that make up the data so as to generate, structurally, a look-alike of the complete dataset” (380).
Longford’s two categories, however, exclude a third possibility: informative nonresponse.Footnote 1 As I show later, zero-character responses are often not missing data in the traditional sense. Rather, they convey meaningful information that would be lost or destroyed through standard methods like listwise deletion or imputation.
3 Text as behavior
I propose that much of this otherwise disparate scholarship can be unified under the category of text as behavior. Text as behavior is a subset of text as data, focusing on cases where writing or transcribed speech reflects a modestly taxing action (Berinsky Reference Berinsky2013) and, consequently, can help to reveal, validate or predict attitudes, preferences and behaviors. Three bodies of scholarship provide the theoretical foundation for the text-as-behavior approach: (1) expression is often cognitively, affectively and temporally demanding; (2) expressive behavior often follows systematic patterns that reflect latent orientations—such as ideology or group identities—and can function as a behavioral signature; and (3) expressive tasks can provide a partial window into inaccessible, nonnormative or difficult-to-articulate thoughts and feelings.
On the cognitive and affective demands of writing, Hayes (Reference Hayes, Michael Levy and Ransdell1996) details the complex range of capacities that must be coordinated and executed, from visual and motor skills to short-term memory and language abilities. Kellogg (Reference Kellogg1999) argues that writing does “not simply unfold automatically and effortlessly in the manner of a well learned motor skill … writing anything but the most routine and brief pieces is the mental equivalent of digging ditches” (17, quoted in Graham Reference Graham2018). Further, expression is often not just cognitively challenging but emotionally hard, too. Consider, for example, sympathy cards with pre-written inscriptions to help solve the problem of conveying an emotion when one feels at a loss for words. Reviewing several decades of psychology research on the relationship between feelings and thoughts, Wright (Reference Wright2017) concludes there is a “fine entanglement of affect and cognition” (120). Lastly, all forms of expression, whether written or spoken, impose a cost in time.
Metadata from interactions can also be revealing. As early as 1984, Michael Crichton’s short story Mousetrap suggested that behavioral traces in typing and mouse use might be as distinctive as fingerprints (Crichton Reference Crichton1984). While fictional, the narrative prefigures real-world work on what is now called behavioral biometrics. This field uses “the way people do things such as speaking (voice), writing (signature), [and] typing (keystroke dynamics)” to verify identity, often in “stealth mode” (Teh, Teoh, and Yue Reference Teh, Teoh and Yue2013, 2).
In social science, researchers have adapted similar behavioral traces. Response latencies underpin Implicit Association Tests; mouse-tracking captures moment-to-moment hesitation, conflict or confusion (Horwitz, Kreuter, and Conrad Reference Horwitz, Kreuter and Conrad2017) and eye-tracking shows how people allocate attention when evaluating candidates (Jenke et al. Reference Jenke, Bansak, Hainmueller and Hangartner2021). While these methods may not provide an individual-level biometric “fingerprint,” they can yield group-level behavioral signatures, such as “leaning Republican,” even when self-reported party identification differs.
Expressive tasks may also provide insight into the nonconscious perceptual systems used to make sense of and interpret the world (Wilson Reference Wilson2004). Haidt (Reference Haidt2012) offers a useful metaphor, suggesting the mind is divided like “a rider on an elephant.” The rider is that about which we are aware, our conscious reasoning, while the elephant is “the other 99 percent of mental processes—the ones that occur outside of awareness but that actually govern most of our behavior” (xxi). Writing techniques like journaling, free association and automatic writing have all been suggested as tools for surfacing nonconscious thoughts. Though researchers have developed many creative instruments and games to reveal otherwise subterranean thoughts and feelings, open-ended prompts remain underutilized in social science as a window into nonconscious thought processes (Roberts et al. Reference Roberts2014).
4 Data and methods
Table 1 summarizes three studies demonstrating diverse but related applications of text as behavior. Studies 1 and 2 draw on the 2016 ANES base sample; for respondents recontacted, I also use their 2020 and 2024 responses. Study 3 uses the 2016 Afrobarometer.
Overview of studies, outcomes, predictors and generalizable applications

4.1 American National Election Study
The ANES surveyed a cross-section of eligible United States voters both before and after the 2016, 2020 and 2024 elections (2017, 2021, and 2025). The 2016 survey was conducted with both a face-to-face sample (N=1,180) and an Internet sample (N=3,090). In addition to a large battery of multiple-choice survey questions, it included some open-ended prompts. Of particular interest were four items that began with yes/no questions, such as “Is there anything in particular about Hillary Clinton that might make you want to vote against her?” Respondents who answered “Yes” were prompted to elaborate in an open-ended response: “What is that?”
In addition, the 2016 ANES included three open-ended “Most Important Problem” prompts asking respondents to identify and prioritize issues facing the country. A fourth question asked, “Which among mentions is the most important problem?” Also, the 2016 and 2020 ANES provided supplemental data with validated turnout incorporating match probabilities using publicly available voter files (Enamorado, Fifield, and Imai Reference Enamorado, Fifield and Imai2017). Lastly, a subset of 2016 subjects were recontacted for the 2020 ANES (
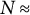 $N \approx $
2,839) and 2024 ANES (
$N \approx $
2,839) and 2024 ANES (
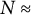 $N \approx $
2,171). I use the panel structure to test whether 2016 measures can also predict outcomes in 2020 and 2024.
$N \approx $
2,171). I use the panel structure to test whether 2016 measures can also predict outcomes in 2020 and 2024.
4.2 Afrobarometer
The 2016 Afrobarometer (Round 6) is a pan-African, non-partisan survey on democracy, governance and society conducted in 36 countries. Interviews with 53,921 respondents were carried out in native languages and translated into English (34,838 cases), French (14,116) or Portuguese (4,693). Respondents answered three open-ended prompts—“What, if anything, does ‘democracy’ mean to you?”—and a battery of closed-ended items on the importance of democratic governance. Study 3 uses these data to test whether simple text-metadata measures (e.g., character counts) can validate survey instruments across languages, transcription and translation.
4.3 Defining measures
Across all studies, I use one or more of three measures: the number of characters in an open-ended response, blank responses (zero characters) and/or completion time for the open-ended task. The specific scales are explained in more detail within each study and follow a common five-step order of operations, summarized below. Steps 2 and 3 apply only to continuous text measures and are skipped for binary indicators and time (see Section A4 of the Supplementary Material).
-
1. Count: For each open-ended response, compute the raw number of characters.
-
2. Deskew: Apply the inverse hyperbolic sine (IHS) transformation to reduce skew and accommodate zeros.
-
3. Normalize: Divide the transformed values by the maximum observed within each survey mode to address mode-specific ceilings (e.g., face-to-face vs. web; see Section A5.1 of the Supplementary Material).
-
4. Pool: Combine responses from related prompts. Use addition for prompts with common valence (e.g., “for Clinton” and “against Trump”) or unidirectional constructs (e.g., overall engagement) and subtraction for directional constructs (e.g., difference in candidate affect).
-
5. Conceptualize: Use techniques like correlation analysis or principal component analysis (PCA) to better understand and define the construct or scale.
To simplify notation across studies, I define a transformation function
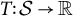 $T \colon \mathcal {S} \to \mathbb {R}$
, where
$T \colon \mathcal {S} \to \mathbb {R}$
, where
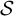 $\mathcal {S}$
is the set of open-ended responses. This function maps a text string s to a normalized, transformed score in three steps: (1) compute the number of characters in s, denoted
$\mathcal {S}$
is the set of open-ended responses. This function maps a text string s to a normalized, transformed score in three steps: (1) compute the number of characters in s, denoted
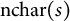 $\mathrm {nchar}(s)$
; (2) reduce skew using IHS function,
$\mathrm {nchar}(s)$
; (2) reduce skew using IHS function,
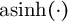 $\operatorname {asinh}(\cdot )$
; and (3) normalize by dividing by the maximum transformed value observed within different survey modesFootnote
2
:
$\operatorname {asinh}(\cdot )$
; and (3) normalize by dividing by the maximum transformed value observed within different survey modesFootnote
2
:
 $$ \begin{align} T(s) = \frac{\operatorname{asinh}(\mathrm{nchar}(s))}{\max_{\text{mode}} \operatorname{asinh}(\mathrm{nchar}(s))}. \end{align} $$
$$ \begin{align} T(s) = \frac{\operatorname{asinh}(\mathrm{nchar}(s))}{\max_{\text{mode}} \operatorname{asinh}(\mathrm{nchar}(s))}. \end{align} $$
After transformation, each response takes on a value from 0 to 1. Like a log, the IHS compresses large values more than small ones and reduces skew. I opt for the IHS over the log, however, because small values are not compressed as severely. This better distinguishes blank from short responses and the IHS handles zeros gracefully, which is helpful for character counts. These transformations harmonize responses across modes with distinct character limits—for example, 60 online versus 1,000 face-to-face in the 2016 ANES—making it possible to combine measures arising from distinct data-generating processes and extract a comparable signal. Diagnostic tests indicate that residual differences are small (see Section A5.1 of the Supplementary Material).
I opt for the number of characters rather than number of words or stemmed terms on the assumption that expression requires effort and, therefore, each keystroke or character is the most granular measure of exertion expended by a subject. Further, other plausible measures, such as counting terms, necessarily discard information when character lengths differ across terms (e.g., “jobs” vs. “unemployment”). Finally, the number of characters succinctly captures the difference between blank responses (zero characters) and response (at least one character). Other reasonable modeling choices and processing orders may be appropriate. I discuss some of these considerations in more detail in Section A5 of the Supplementary Material.
5 Study 1: Text as predictor of candidate choice
Can text metadata, independent of content, predict outcomes like vote choice or party identification? In Study 1, I test whether nonresponse and the number of characters in four open-ended candidate evaluation prompts can improve prediction of key political outcomes.
5.1 Study 1a: Informative nonresponse on candidate choice
Can declining to respond still convey meaning? For writing or speaking tasks, nonresponse could be informative, such as with “ghosting” via text or phone. Discussing narrative in political science, Patterson and Monroe (Reference Patterson and Monroe1998) note: “Silences and gaps can be as telling as what is included. …Like Sherlock Holmes’s silent dog—which did not bark because it knew the intruder—the absence of comment may speak volumes. The challenge for the analyst is to interpret what this silence signifies” (329).
In this case, respondents were first asked whether anything would make them want to vote for or against each candidate; only those who answered “Yes” were prompted to elaborate. Both respondents who said “No” and those who said “Yes” but wrote nothing record zero characters in the open-ended response field. Though these differ procedurally, they yield equivalent data. I therefore treat an explicit “No” and a blank response as forms of informative nonresponse.
I test for informative nonresponse using candidate choice and two partisan-congruent prompts. As shown in Equations (2) and (3), nonresponse is defined as the sum of two binary indicators marking whether each open-ended response was blank. Among Democrats, for example, when asked what would make them vote for Clinton, only 21% have a blank response, while 86% do so when asked about voting for Trump. Republicans show nearly symmetrical patterns (see Table A1.1 in the Supplementary Material).
More blank responses suggest lower support. For simplicity, the measures are labeled with a single candidate, but the equations capture both withheld support for the named candidate and unexpressed opposition to their partisan rival. They are directional signals of partisan alignment, rather than pure measures of candidate affect. All models in Study 1 are limited to registered voters. Controls include party identification, ideology, racial resentment, hostile sexism, authoritarianism, education, age, gender, race, income, political attention and survey mode (face-to-face or web). To account for affective polarization, I control for the difference in feeling thermometer ratings, calculated as Trump minus Clinton (hereafter, candidate affect gap):
 $$ \begin{align} \text{Informative Nonresponse}_{\text{Clinton}} & = \mathbb{I}[\text{nchar}(\mathrm{For Clinton}) = 0] + \mathbb{I}[\text{nchar}(\mathrm{Against Trump}) = 0] \end{align} $$
$$ \begin{align} \text{Informative Nonresponse}_{\text{Clinton}} & = \mathbb{I}[\text{nchar}(\mathrm{For Clinton}) = 0] + \mathbb{I}[\text{nchar}(\mathrm{Against Trump}) = 0] \end{align} $$
 $$ \begin{align} \text{Informative Nonresponse}_{\text{Trump}} & = \mathbb{I}[\text{nchar}(\mathrm{For Trump}) = 0] + \mathbb{I}[\text{nchar}(\mathrm{Against Clinton}) = 0]. \end{align} $$
$$ \begin{align} \text{Informative Nonresponse}_{\text{Trump}} & = \mathbb{I}[\text{nchar}(\mathrm{For Trump}) = 0] + \mathbb{I}[\text{nchar}(\mathrm{Against Clinton}) = 0]. \end{align} $$
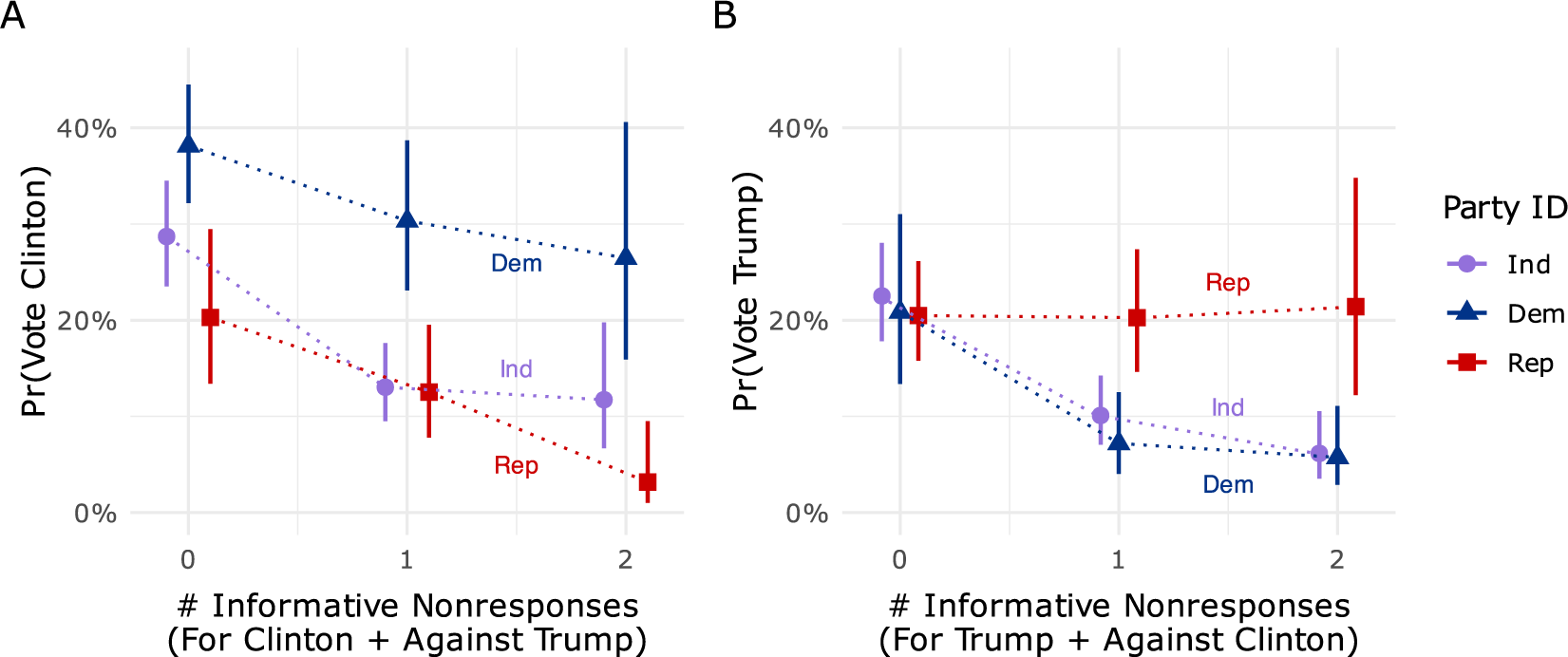
Figure 1, Panel A, shows that, controlling for covariates, more nonresponse to the “for Clinton” and “against Trump” questions is associated with about a 14 percentage point drop in support for Clinton among Republicans and Independents, and an 11-point drop among Democrats. Figure 1, Panel B, shows that more nonresponse on the “for Trump” and “against Clinton” questions is associated with an 18 percentage point decrease in support for Trump among Democrats and a 19-point decrease among Independents. Notably, in Panel B, Democrats and Independents at zero nonresponse are indistinguishable from Republicans in predicted probability of supporting Trump. Among Republicans, the marginal effect of nonresponse is near zero.
Marginal effects of nonresponse on probability of selecting candidate in 2016 (see Table A1.8 in the Supplementary Material).

Both informative nonresponse measures show substantial correlations with the candidate affect gap (
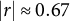 $|r| \approx 0.67$
). Because the models control for this difference in affect, nonresponse can plausibly be interpreted as a form of latent or additional partisan and candidate affect not fully captured by the feeling thermometers and other covariates. Similar results hold when predicting candidate choice in the 2020 and 2024 elections using all nonresponse measures from 2016 (see Section A1.5 of the Supplementary Material).
$|r| \approx 0.67$
). Because the models control for this difference in affect, nonresponse can plausibly be interpreted as a form of latent or additional partisan and candidate affect not fully captured by the feeling thermometers and other covariates. Similar results hold when predicting candidate choice in the 2020 and 2024 elections using all nonresponse measures from 2016 (see Section A1.5 of the Supplementary Material).
5.2 Study 1b: Expressive alignment on candidate choice
In a second set of tests, I investigate whether the number of characters recorded in response to the four ANES candidate evaluation items can predict candidate choice in 2016, 2020 and 2024. As shown in Equations 4–6, I calculate the sum of the transformed character counts for each partisan-congruent pair, take their difference, and divide by two, yielding a scale from
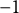 $-1$
to
$-1$
to
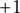 $+1$
.
$+1$
.
I refer to this measure as Expressive Alignment to reflect four key features. First, the scale is derived from respondents’ written or spoken expression, rather than closed-ended survey items. Second, drawing on correlations and PCA (see Section A1.6 of the Supplementary Material), I show that the text metadata meaningfully reflect both partisan identification and affect toward the candidates. Like the informative nonresponse measures, Expressive Alignment correlates strongly with individual candidate feeling thermometers (
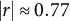 $|r| \approx 0.77$
), the difference between Trump and Clinton feeling thermometers (
$|r| \approx 0.77$
), the difference between Trump and Clinton feeling thermometers (
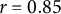 $r = 0.85$
), as well as partisan identification (
$r = 0.85$
), as well as partisan identification (
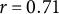 $r = 0.71$
). Third, unlike these direct attitudinal measures, Expressive Alignment is inferred from behavior and may capture implicit or less consciously held sentiments. Fourth, the measure can also capture broader coalitional alignments beyond partisanship—such as divisions that are issue-based, intraparty, or identity-based—making the measure generalizable to contexts where partisan cues are weak or structured differently. In plots, the scale is labeled at either end with “Clinton+” and “Trump+,” but the underlying measure reflects a composite of both support for and opposition to the respective candidates, their parties and associated ideologies.
$r = 0.71$
). Third, unlike these direct attitudinal measures, Expressive Alignment is inferred from behavior and may capture implicit or less consciously held sentiments. Fourth, the measure can also capture broader coalitional alignments beyond partisanship—such as divisions that are issue-based, intraparty, or identity-based—making the measure generalizable to contexts where partisan cues are weak or structured differently. In plots, the scale is labeled at either end with “Clinton+” and “Trump+,” but the underlying measure reflects a composite of both support for and opposition to the respective candidates, their parties and associated ideologies.
Although Expressive Alignment correlates highly with the Trump–Clinton feeling thermometer difference, it captures additional behavioral information not reducible to warmth alone. The measure reflects both affect and openness, that is whether respondents are willing to even consider and articulate reasons for or against a candidate once prompted. Substantial residual variation (about 28%) remains after accounting for the candidate affect gap, and regression results show that Expressive Alignment in 2016 continues to predict candidate choice in later cycles even when other covariates are held constant. Moreover, interactions with Party ID indicate that the measure helps identify cross-pressured or persuadable voters whose expressive behavior diverges from their partisan labels:
 $$ \begin{align} \ \text{Trump Evaluation} & = T(\mathrm{For Trump}) + T(\mathrm{Against Clinton}) \end{align} $$
$$ \begin{align} \ \text{Trump Evaluation} & = T(\mathrm{For Trump}) + T(\mathrm{Against Clinton}) \end{align} $$
 $$ \begin{align} \text{Clinton Evaluation} & = T(\mathrm{For Clinton}) + T(\mathrm{Against Trump}) \end{align} $$
$$ \begin{align} \text{Clinton Evaluation} & = T(\mathrm{For Clinton}) + T(\mathrm{Against Trump}) \end{align} $$
 $$ \begin{align}\ \, \text{Expressive Alignment} & = \frac{\text{Trump Evaluation} - \text{Clinton Evaluation}}{2}. \end{align} $$
$$ \begin{align}\ \, \text{Expressive Alignment} & = \frac{\text{Trump Evaluation} - \text{Clinton Evaluation}}{2}. \end{align} $$
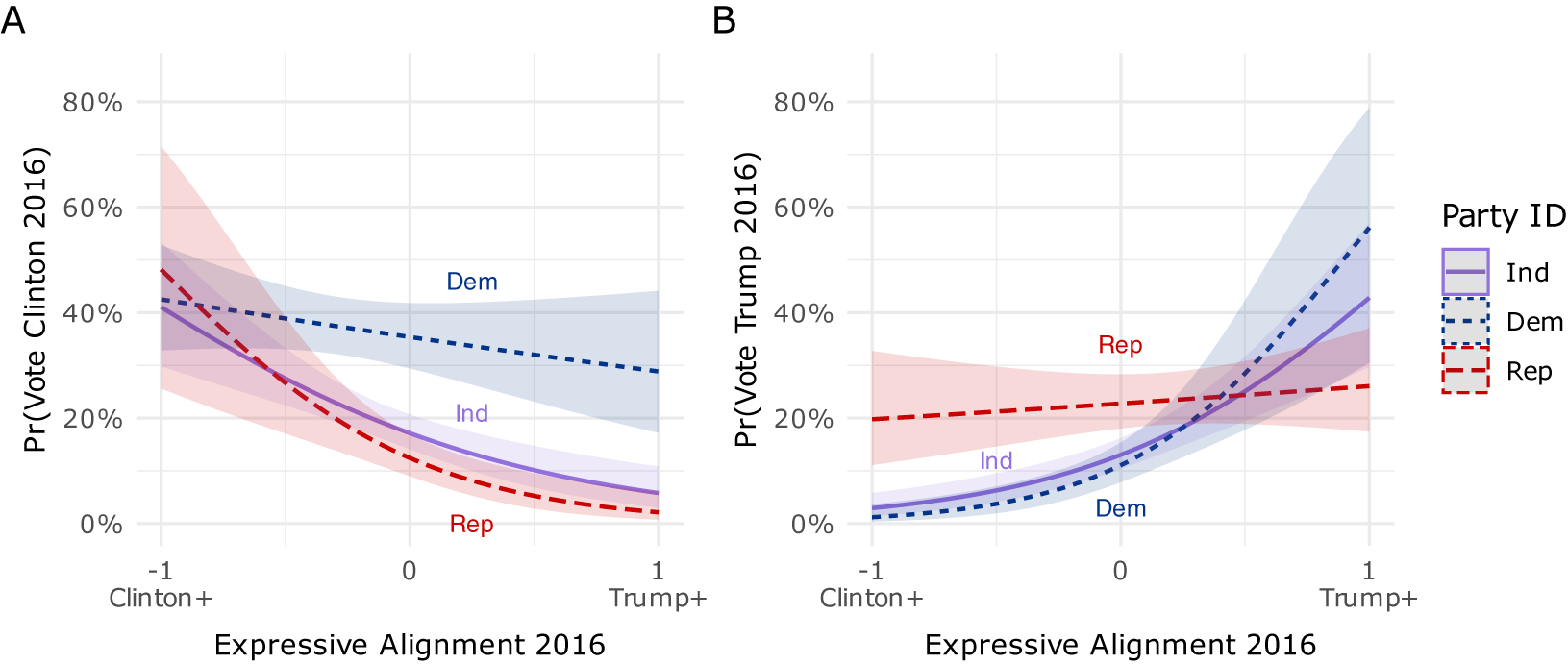
Figure 2, Panels A and B, show the marginal effects of Expressive Alignment on 2016 candidate choice, controlling for the same covariates as in Study 1a. Expressive Alignment predicts substantial shifts in the likelihood of supporting a candidate, particularly among out-party members. As shown in Panel A, Republicans with high Expressive Alignment toward Clinton are statistically indistinguishable from Democrats in their predicted probability of voting for her—increasing by roughly 40 percentage points as Expressive Alignment moves from
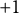 $+1$
(Trump-aligned) to
$+1$
(Trump-aligned) to
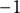 $-1$
(Clinton-aligned), and by about 30 percentage points among Independents. Likewise, in Panel B, Democrats with strong alignment toward Trump resemble Republicans, with the shift from
$-1$
(Clinton-aligned), and by about 30 percentage points among Independents. Likewise, in Panel B, Democrats with strong alignment toward Trump resemble Republicans, with the shift from
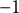 $-1$
to
$-1$
to
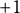 $+1$
corresponding to an increase of about 59 points in the probability of supporting him, and about 43 points among Independents. In contrast, the slopes for co-partisans remain relatively flat, largely reflecting overlap with the feeling thermometer measure included in the model. Overall, Expressive Alignment captures unmeasured variation in candidate choice not explained by ideology or feeling thermometer ratings and continues to predict large shifts in candidate choice through 2020 and 2024 (see Sections A1.7 and A1.8 of the Supplementary Material).
$+1$
corresponding to an increase of about 59 points in the probability of supporting him, and about 43 points among Independents. In contrast, the slopes for co-partisans remain relatively flat, largely reflecting overlap with the feeling thermometer measure included in the model. Overall, Expressive Alignment captures unmeasured variation in candidate choice not explained by ideology or feeling thermometer ratings and continues to predict large shifts in candidate choice through 2020 and 2024 (see Sections A1.7 and A1.8 of the Supplementary Material).
Marginal effects of Expressive Alignment in 2016 on candidate choice in 2016, by party identification (see Table A1.12 in the Supplementary Material).

5.3 Study 2: Text as validated turnout
In Study 2, I test whether text as behavior can also improve prediction of validated turnout. Looking at the 2016 presidential election, Kim, Alvarez, and Ramirez (Reference Kim, Michael Alvarez and Ramirez2020) report they “do not find that many demographic variables were closely associated with turnout in 2016” (979). Common predictors of turnout—such as income, education or political attention—are only rough proxies for the likelihood to vote (Kim et al. Reference Kim, Michael Alvarez and Ramirez2020). An education variable, for instance, does not reflect school quality or an interest in learning about the world, and many college graduates spend more time watching entertainment programming than news. In contrast, open-ended prompts may yield more granular insight into the intensity of individual political engagement. Also, because open-ended prompts require more effort, they may reduce response bias relative to closed-ended items where selecting a more extreme response (e.g., overstating political interest) carries little additional cost.
This analysis draws on a separate 2016 ANES battery in which respondents were asked to name and prioritize the “most important problems in America” (henceforth, MIP) across four open-ended prompts. As these questions are not partisan, I sum transformed character counts across all four responses:
 $$ \begin{align} \text{Expressive Engagement} = T(\mathrm{Problem 1}) + T(\mathrm{Problem 2}) + T(\mathrm{Problem 3}) + T(\mathrm{Problem 4}). \end{align} $$
$$ \begin{align} \text{Expressive Engagement} = T(\mathrm{Problem 1}) + T(\mathrm{Problem 2}) + T(\mathrm{Problem 3}) + T(\mathrm{Problem 4}). \end{align} $$
I refer to this measure as Expressive Engagement to highlight that, while correlated with civic and political engagement, it is rooted in a willingness to articulate political concerns. PCA shows that Expressive Engagement loads most heavily on a dimension that distinguishes articulation (e.g., verbosity) from concrete political behaviors (e.g., donating and volunteering). It also loads more weakly on a second dimension representing conventional political engagement, such as political interest and knowledge (see Section A2.2 of the Supplementary Material). These results suggest that Expressive Engagement reflects both established forms of participation and a more symbolic mode of political involvement through communication.
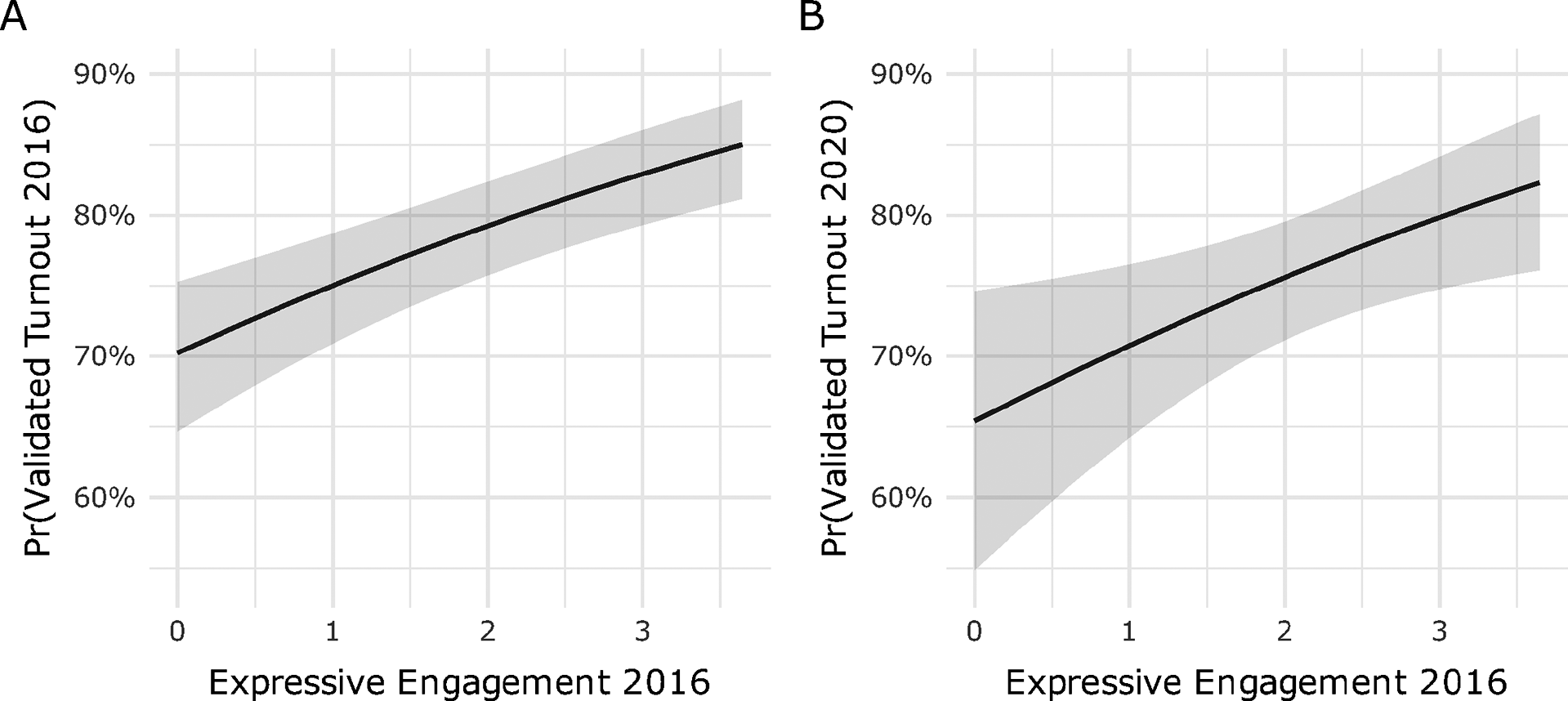
Figure 3 shows the predicted probability of validated turnout as a function of Expressive Engagement among registered voters controlling for sex, education, age, race, income, political attention, survey mode, party identification and self-reported likelihood to vote (for turnout by registration status, see Section A1.2 of the Supplementary Material). Because self-reported likelihood to vote is by far the strongest predictor of turnout, its inclusion makes this a particularly stringent test of the Expressive Engagement scale. Panel A shows that, after adjusting for covariates, moving from zero to nearly four on Expressive Engagement is associated with a significant and meaningful 16 percentage point increase in the predicted probability of voting in 2016. Drawing on the panel structure of the data, Panel B shows the same change in Expressive Engagement in 2016 is associated with a roughly 18 percentage point increase in the likelihood of validated turnout four years later, though estimated with greater uncertainty. Secondary analyses using Expressive Engagement in 2020 on turnout in 2020 and Expressive Alignment in 2016 on turnout in 2016 and 2020 are reported in the Supplementary Material (see Sections A2.4 and A2.5).Footnote 3
Marginal effects of Expressive Engagement in 2016 on validated turnout incorporating match probability in (A) 2016 and (B) 2020 using quasibinomial models (see Table A2.18 in the Supplementary Material).

5.4 Study 3: Text as behavioral outcome
Measuring real-world behavior in survey research is difficult. Researchers often rely on games or incentivized tasks to elicit sincere preferences, but these methods can be costly, artificial or limited in external validity (Findley et al. Reference Findley, Kikuta and Denly2021; McDermott Reference McDermott2002; Winking and Mizer Reference Winking and Mizer2013). In Study 3, I draw on the 2016 Afrobarometer to test whether text metadata can also serve as a behavioral outcome within a traditional survey format (for more on the Afrobarometer, see Section 4.2).
Features of text such as character counts and nonresponse plausibly reflect underlying features of human affect and cognition that operate largely independently of any specific language. I begin with a battery of ten questions measuring support for democratic governance, such as whether respondents prefer to “choose leaders through elections versus other methods.” These ten items are combined into a single “Importance of Democracy” scale, which I validate using the pooled character count from three open-ended prompts asking “What, if anything, does ‘democracy’ mean to you?”
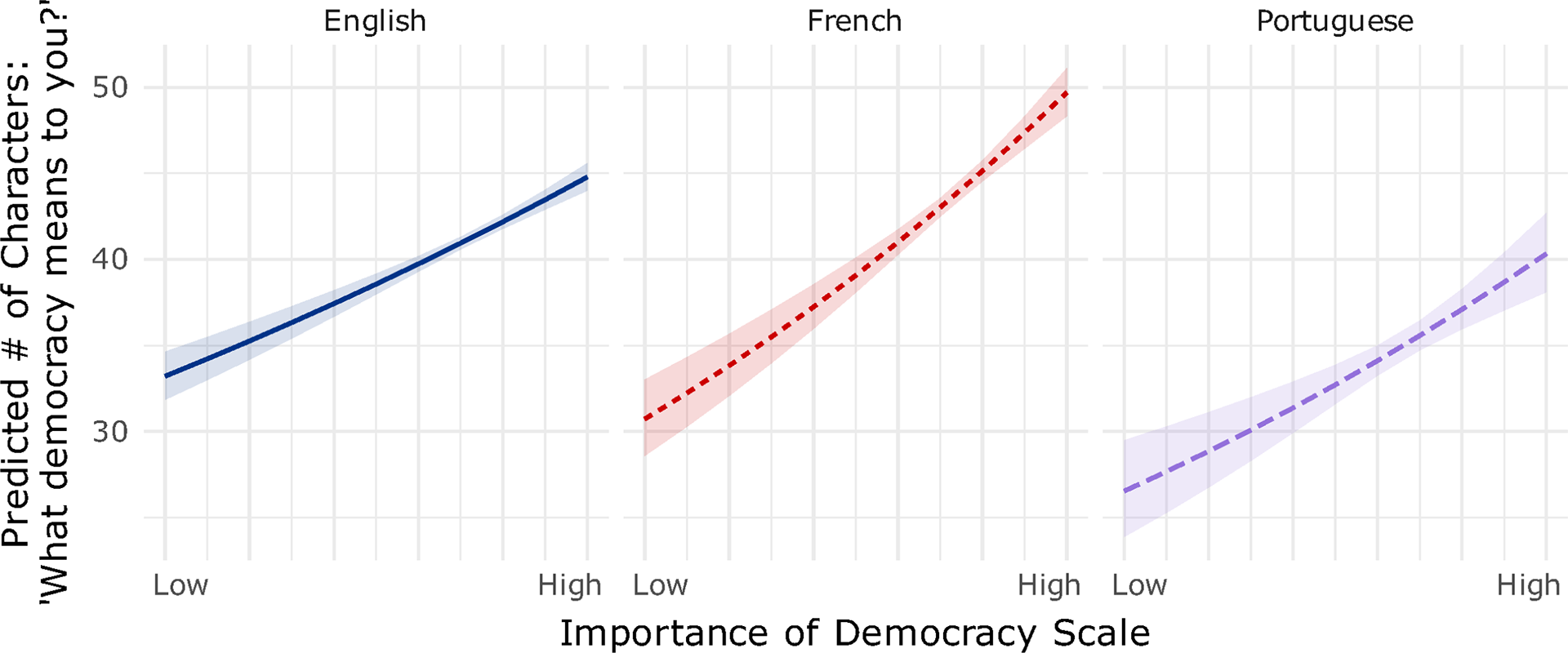
Figure 4 tests whether responses to the ten democracy questions predict the length of responses to the prompt, “What does democracy mean to you?” (controlling for gender, education, age, language, race and income proxy).Footnote 4 I use raw character counts for ease of interpretation, though results are robust to the transformations described in Section 4.3.
Marginal effects of Importance of Democracy Scale on number of characters written in response to open-ended prompts asking “What democracy means to you,” by language. The negative binomial model includes controls for gender, education, age, race and income proxy (see Table A3.26 in the Supplementary Material).

For the purpose of validating the instrument across languages, the key concern is whether the slopes show that the Importance of Democracy scale is associated with more open-ended expression. As shown in Figure 4, the slopes are all positive, significantly different from zero and substantively similar. The French-language slope is statistically significantly steeper than the English baseline, but the magnitude of the difference is modest, and all three languages exhibit similarly sized positive associations between valuing democracy and response length. The intercepts also differ modestly but significantly across the three languages, suggesting baseline differences in verbosity.
In sum, these results suggest that individuals who report valuing democracy in closed-ended questions also tend to “pay costs” by offering longer responses to related open-ended prompts. More broadly, Figure 4 suggests character counts can serve as valid behavioral measures across languages, even after transcription and translation.
6 Discussion
While these studies show metadata from open-ended prompts can serve as useful measures of attitudes and behavior, at least five important questions remain. First, although the results above suggest that certain types of prompts are closely related to specific attitudes and behaviors, more work is needed to map which are most effective for measuring particular beliefs, dispositions and actions. Second, measurement challenges remain. These include how to address skewed distributions (e.g., IHS, log and truncation) and how best to model zero-character responses. Some forms of missing data, such as attrition or saying “Don’t know,” may also constitute types of informative nonresponse. Although I apply this logic to the Afrobarometer data (see Section A3.4 of the Supplementary Material), a fuller treatment falls outside the scope of this article.
Third, more research is needed on detecting fraud in open-ended survey items. As AI tools proliferate, researchers face new forms of automated or AI-assisted deception (Westwood Reference Westwood2025). For example, Veselovsky et al. (Reference Veselovsky, Ribeiro, Cozzolino, Gordon, Rothschild and West2025) capture keystrokes, including copy–paste actions, to identify synthetic text production. Other behavioral traces, such as typing speed, keystroke regularity and mouse movements, can flag automation, though such signals can themselves be forged (Westwood Reference Westwood2025). These process-based indicators differ from the content-level mischief described by Lopez and Hillygus (Reference Lopez and Hillygus2018), where respondents intentionally provide absurd answers for amusement.
Text-as-behavior methods suggest a complementary approach: looking for discrepant-effort patterns such as respondents who report high political interest yet contribute minimal text to related prompts like the “most important problem” questions. Such mismatches could flag inattentive or mischievous respondents who are difficult to detect through content alone. More broadly, incentives can enhance response quality (Li Reference Li2023), and some subtle behavioral measures, like nonresponse, may prove more resistant to forms of AI manipulation.
Fourth, I do not address how to integrate text as behavior with other types of computational text analysis, such as machine learning methods. Finally, although the analyses here suggest that text metadata can be applied across languages, cultures and survey modes, more research is needed to assess their generalizability. Cultural norms about speech, silence or verbosity may affect the interpretability of character counts. The transformations used here, such as deskewing and normalization by mode, usefully merged data across modes but the cognitive dynamics of writing versus speaking may, nevertheless, introduce meaningful variation in metadata signals (Benoit et al. Reference Benoit, Munger and Spirling2019). Topics beyond politics should also be considered. In clinical settings, for example, changes in how much a patient texts with friends and family may signal shifts in well-being that content analysis alone could miss.
7 Conclusion
Quantifying human attitudes and behaviors remains a fundamental challenge in social science. This study proposes extending text-as-data methods by treating text as behavior. Specifically, expression is sufficiently cognitively, affectively and temporally demanding that it should be understood not only as a means of communication, but also as a form of action. As shown in prior scholarship and in the analyses presented here, metadata from open-ended responses can offer insight into underlying mental and emotional states, even when those states are not fully accessible to respondents themselves. Measuring human behavior will always be difficult, but the findings here suggest that treating expression as effortful provides social scientists an additional tool to reveal preferences, commitments and underlying dispositions. As Gloria Steinem once said, “I don’t like writing. I like having written” (Reference Steinem1976).
Acknowledgements
I thank Risa Gelles-Watnick and Christina Im for excellent research assistance. I thank Andrew Little, Elena Llaudet, Daniel Masterson, John Konicki, Zach Hertz, Alexander Agadjanian and three anonymous reviewers for extremely helpful feedback. AI tools used to proofread manuscript and prepare replication archive.
Data availability statement
Replication code for this article has been published in the Political Analysis Harvard Dataverse at https://doi.org/10.7910/DVN/HKBZNG (Wasow Reference Wasow2026).
Competing interests
The author declares no competing interests.
Ethical standards
This study uses publicly available secondary data and did not require IRB approval.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/pan.2026.10041.



 Open access
Open access