

Part V Formal models of code-switching
18 Generative approaches to code-switching
18.1 Introduction
Code-switching (hereafter CS) is a specific kind of language mixing. Unlike borrowing, which involves the full phonological and morphological integration of a word from one language (say, English type) into another (as Spanish taipiar), CS involves the mixing of phonologically distinctive elements into a single utterance, as illustrated in (1a), where the Spanish phrase mi hermano is mixed into an otherwise English sentence.
(1)
(a.) Mi hermano bought some ice cream.
“My brother . . .”
(b.) *Él bought some ice cream.
“He . . .”
While (1a) is a perfectly natural expression among Spanish–English bilingual code-switchers, (1b) is not. The contrast between (1a) and (1b) shows us that CS is patterned, rule-governed behavior, just like monolingual language. Linguists interested in the grammatical study of CS seek to discover the underlying mechanisms which define patterns of grammaticality for all constructions in any language pair.
At the Thirteenth Annual Round Table Meeting on Linguistics and Languages at Georgetown University, held in 1962, Haugen claimed to have originated the term code-switching. The word first appeared in print in Vogt’s (Reference Vogt1954) review of Weinreich’s (Reference Weinreich1953) Languages in Contact and two years later in Haugen (Reference Haugen1956). Benson (Reference Benson2001) identifies the work of Espinosa (Reference Espinosa1911) as the first scholarly engagement of bilingual language mixing. Although Espinosa noted some tendencies in the frequencies of word classes to be switched, he nonetheless saw CS patterns as essentially random in nature. Despite these early interests, an actual CS research literature did not emerge until the late 1960s and early 1970s, when work focusing on both social and grammatical aspects of language mixing began steadily appearing.
In research on grammatical aspects of CS, Gumperz and his colleagues (Gumperz Reference Gumperz1967, Reference Gumperz and Alatis1970; Gumperz and Hernández-Chávez Reference Gumperz, Hernández-Chávez and Whiteley1971), Hasselmo (Reference Hasselmo, Firchow, Grimstad, Hasselmo and O’Neil1972), Timm (Reference Timm1975), and Wentz (Reference Wentz1977) were among the earliest to observe that there are grammatical restrictions on language mixing: while some switches naturally occur among bilinguals, others are non-occurring or judged to be ill-formed. For example, Timm’s list of restrictions noted that Spanish–English switching between a subject pronoun and a main verb, as in (1b) is ill-formed but not so when the subject pronoun is replaced with a lexical subject, as in (1a). Construction-specific constraints were typical of this early work; however, a literature would soon emerge in which the grammatical mechanisms underlying these descriptive observations were explored.
This chapter presents an overview of generativist approaches to CS, defined as theories of CS which posit explicit grammatical analyses of language mixing phenomena below sentential boundaries, and which rely upon research in mainstream generative grammar to inform their analysis. First we examine early generativist approaches to CS of the 1970s and early 1980s, developed in keeping with the basic framework of Chomsky’s (Reference Chomsky1965) Aspects model. We then turn to proposals advanced in the era of Government–Binding Theory, the 1980s and early 1990s, before examining more recent work put forward in the spirit of the Minimalist Program. We conclude with thoughts on the direction of future theoretical research in CS.
18.2 Aspects era approaches
Chomsky’s (Reference Chomsky1965) Aspects of the Theory of Syntax further developed the theory of transformational–generative grammar introduced in Syntactic Structures (Chomsky Reference Chomsky1957). The basic architecture of the grammar still consisted of a base component, comprised of a set of phrase structure rules that defined the deep structure or initial phrase marker (tree) representation, and a set of transformational rules which mapped phrase marker into phrase marker to generate a surface structure. In the Aspects model, lexical items could be inserted in the tree if their syntactic features matched those generated by the base rules.
18.2.1 Constraints in linguistic theory
As early as 1955, Chomsky had noted that the transformational component in a hybrid generative–transformational system had the disadvantage of vastly increasing the expressive power of the grammar, permitting the formulation of grammatical processes that did not seem to occur in any language. In response to the problem, Chomsky (Reference Chomsky1964, Reference Chomsky1965) and other researchers such as Ross (Reference Ross1967) posited constraints on transformational rules. Ross noticed, for instance, that a Noun Phrase (NP) could not be extracted out of a conjoined phrase, as in (2a), accounting for the ill-formedness in (2b), but could be extracted in the semantically equivalent (but syntactically divergent) example in (2c), where t denotes trace, the point of extraction of the NP, questioned as what.
(2)
(a.) John was having milk and cookies.
(b.) * Whati was John having milk and ti?
(c.) Whati was John having milk with ti?
While the focus of efforts to constrain the grammar was placed primarily on the transformational component, these extended to the phrase structure component as well, culminating in the formulation of X’ Theory in Chomsky (Reference Chomsky, Jacobs and Rosenbaum1970) (see Newmeyer Reference Newmeyer1986). Nonetheless, constraints were typically viewed as psychologically real restrictions on the application of transformations to phrase markers, and were therefore understood to be imposed at the level of surface structure.
The idea of a constraint in syntactic theory appealed to a number of researchers in CS, and was used to articulate the grammatical restrictions observed in CS data. While some thought of these constraints in the technical sense, as actual grammatical constructs, others used the term informally, intending to refer only to descriptive restrictions on language mixing.
18.2.2 Equivalence-based analyses
Several researchers converged simultaneously on the notion that language switching is controlled by some kind of syntactic equivalence requirement. Lipski was among the first to express the idea, hypothesizing that elements appearing in an utterance after a switch must be “syntactically equivalent” (Lipski Reference Lipski and Paradis1978:258). As Pfaff similarly suggested, “Surface structures common to both languages are favored for switches” (Reference Pfaff1979:314). Poplack (Reference Poplack1978, Reference Poplack and Durán1981) articulated this perspective in terms of her well-known Equivalence Constraint, augmented by The Free Morpheme Constraint, given in (3) and (4).
(3) The Equivalence Constraint
Codes will tend to be switched at points where the surface structures of the languages map onto each other.
(4) The Free Morpheme Constraint
A switch may occur at any point in the discourse at which it is possible to make a surface constituent cut and still retain a free morpheme.
As a variationist (see Labov Reference Labov1963), Poplack argues that linguistic rules correlate with social structure and should be stated in terms of statistical frequencies, hence (3) is expressed as a tendency. The general idea is nonetheless clear: CS is allowed within constituents so long as the word order requirements of both languages are met at surface structure. Surface structures derive from the (cyclical) application of transformations to phrase markers, which originate as the output of a phrase structure grammar. The constraint in (4) defines a restriction on morphology in CS contexts, also noted in Wentz and McClure (Reference Wentz, Erica and Ingemann1977) and Pfaff (Reference Pfaff1979). To illustrate, (3) correctly predicts that the switch in (5) is disallowed, because the surface word order of English and Spanish differ with respect to object pronoun (clitic) placement; (4) correctly disallows (6), where an English stem is used with a Spanish bound morpheme without the phonological integration of the stem.
*told le, le told, him dije, dije him
told to-him, to-him I-told, him I-told, I-told him
“(I) told him.”
Research since Poplack’s initial proposals has found persuasive documentation that her Equivalence Constraint is empirically inadequate, that is, it does not account for the full range of relevant data (Stenson Reference Stenson and Hendrick1990; Lee Reference Lee1991; Myers-Scotton Reference Myers-Scotton1993a; Mahootian Reference Mahootian1993; MacSwan Reference MacSwan1999b; Chan Reference Chan1999; Muysken Reference Muysken2000). Note, for example, the contrast in (7) from Spanish–English CS, noted by Belaz et al. (Reference Belazi, Rubin and Toribio1994).
(7)
(a.) The students habían visto la película italiana
(b.) * The student had visto la película italiana
“The student had seen the Italian movie.”
The surface structure of Spanish and English are alike with regard to the construction in (7), yet a switch between the auxiliary and the verb renders the sentence ill-formed, but not so in the case of a switch between the subject and the verb. However, (3) predicts that both examples should be well-formed.
Also consider the examples in (8), from MacSwan (Reference MacSwan1999b), where code switches occur between a subject pronoun and a verb, both in their correct surface structure position for both Spanish and Nahuatl, yet one example is ill-formed and the other well-formed.
(8)
The descriptive adequacy of Poplack’s Free Morpheme Constraint, on the other hand, remains controversial. While it is attested in numerous corpora (Bentahila and Davies Reference Bentahila and Davies1983; Berk-Seligson Reference Berk-Seligson1986; Clyne Reference Clyne1987; MacSwan Reference MacSwan1999b), others claim to have identified some counter-examples (Eliasson Reference Eliasson1989; Bokamba Reference Bokamba1989; Myers-Scotton Reference Myers-Scotton1993a; Nartey Reference Nartey1982; Halmari Reference Halmari1997; Chan Reference Chan1999; Hlavac Reference Hlavac2003). However, in presenting counter-examples to The Free Morpheme Constraint, researchers have often given too little attention to the specific phonological, morphological, and syntactic characteristics of the examples cited, making it difficult to determine whether they are in fact violations. For Poplack, items that are phonologically integrated into the language of the bound morpheme are regarded as borrowings rather than code-switches. This is made explicit in subsequent formulations of the constraint, as in Sankoff and Poplack (Reference Sankoff and Shana1981:5): “A switch may not occur between a bound morpheme and a lexical item unless the latter has been phonologically integrated into the language of the bound morpheme.” Thus, examples in which an other-language stem has been phonologically integrated into the language of an inflectional affix do not constitute counter-examples to The Free Morpheme Constraint.
Poplack’s constraints have been criticized as a third grammar, a term originally coined by Pfaff (Reference Pfaff1979) to designate a system designed to mediate between the two languages present in a mixed utterance, and applied specifically to Poplack’s constraints by Lederberg and Morales (Reference Lederberg and Cesáreo1985), Mahootian (Reference Mahootian1993), and MacSwan (Reference MacSwan2000), among others. As Lipski (Reference Lipski1985:83–84) noted, such mechanisms should be admitted only as a last resort:
Strict application of Occam’s Razor requires that gratuitous meta-structures be avoided whenever possible, and that bilingual language behavior be described as much as possible in terms of already existing monolingual grammars. As a result, preference must initially be given to modifications of existing grammars of Spanish and English, rather than to the formulation of a special bilingual generative mechanism, unless experimental evidence inexorably militates in favor of the latter alternative. Among the proposed integrative models which have been examined, the bilingual tagging mechanism of Sankoff and Poplack (Reference Sankoff and Shana1981) has the greatest degree of promise, since it deals directly with bilingual surface structure and adds no special meta-system to control bilingual language shifting.
However, although Sankoff and Poplack (Reference Sankoff and Shana1981) similarly expressed a strong preference for avoiding CS-specific mechanisms to mediate between the two languages in contact, they nonetheless concluded that something of the sort appeared to be necessary on empirical grounds. Otherwise, the authors argued, the free union of Spanish and English phrase structure grammars would yield ill-formed results. For instance, whereas English requires pre-nominal adjectives (NP → Det Adj N), Spanish requires post-nominal adjective placement (NP → Det N Adj). A speaker is free to select the Spanish rule and lexically insert an English determiner, Spanish noun and English adjective (*the casa white) or even insert English lexical items for all categories (*the house white). Therefore, in order to constrain the grammars so that they do not generate violations of (3), Sankoff and Poplack introduced a superscripting (“bilingual tagging”) mechanism that restricted lexical insertion rules so that the grammar contributing the phrase structure rule would also be the grammar from which lexical insertion rules would be drawn. Hence, under conditions of CS, the Spanish phrase structure rule would be annotated as in (9a), generating (9b). The superscripting conventions followed from heritability conditions, which essentially allowed phrase structure rules to look ahead and restrict the application of lexical insertion rules.
Sankoff and Poplack do not make explicit the mechanisms for superscript insertion; rather, they indicate that phrase structure rules are so superscripted when they are selected in the generation of a code-switched utterance, and are subsequently used to trigger language-specific lexical insertion rules (N → casa, for instance, in the case of Nsp:n). No account is presented as to how the superscript insertion mechanism is able to annotate the appropriate categories correctly – for instance, N and Adj in (9a), but not Det, where either language may be inserted without negative consequences. For these reasons, the superscripting mechanism, like The Equivalence Constraint and The Free Morpheme Constraint, appears to constitute a CS-specific mechanism, a marked disadvantage.1
Woolford (Reference Woolford1983) similarly attempted to derive The Equivalence Constraint working within the basic assumptions of the Aspects model. Like Pfaff (Reference Pfaff1979) and others before her, Woolford emphasized that our best account of CS would avoid reference to any kind of CS-specific grammar. And like Sankoff and Poplack, Woolford recognized the basic dilemma of providing lexical items with access to the structure of the sentence in which they were inserted:
Phrase structure rules are drawn freely from both grammars during the construction of constituent structure trees, but the lexicon of each grammar is limited to filling only those terminal nodes created by phrase structure rules drawn from the same language. Nevertheless, in the event that there are phrase structure rules common to both languages, such rules belong simultaneously to both languages. Lexical items can be freely drawn from either language to fill terminal nodes created by phrase structure rules common to both languages.
In other words, Woolford believed that lexical insertion was unconstrained in the case of phrase structure rules common to both languages; but in the case of phrase structure rules that were not shared, lexical insertion was limited to the terminal nodes associated with the phrase structure rule of the grammar to which it belonged. Woolford’s system does not seem to achieve its intended results, as it predicts that Spanish–English CS would require that a language-unique phrase structure rule (for instance, NP → Det N Adj for Spanish) could only be lexically filled by Spanish items (predicting the casa blanca to be ill-formed, contrary to the facts). In addition, while Woolford’s work is an excellent example of the articulation of the goals of CS research, she does not herself present the formal mechanism that might be responsible for achieving the results expected within her framework. No explanation as to how the unique phrase structure rules get linked to language-specific rules of lexical insertion is offered.
Woolford accounts for Poplack’s Free Morpheme Constraint by postulating that “the lexicons and word formation components of the two grammars remain separate” (Reference Woolford1983:526). While this approach seems preferable to Poplack’s, where the prohibition against word-internal switching is simply stated in descriptive terms, no rationale for the separation of the lexicons in terms of principles independent of CS itself is offered, leaving the basis for asserting that the model is free of any CS-specific mechanisms inexplicit.
18.3 Government–Binding Theory
Government–Binding (GB) Theory (Chomsky Reference Chomsky1981) introduced a number of dramatic shifts in generative grammar. The transformational component was reduced to a single operation, Move α, responsible for moving elements within base-generated phrase markers, and the phrase structure grammar itself was replaced with X’ Theory, a generalized convention for category expansion introduced in Chomsky (Reference Chomsky, Jacobs and Rosenbaum1970) and further developed in Chomsky (Reference Chomsky1981). In GB Theory, the grammar was conceived as a system of interactive modules such as Case Theory, θ-Theory, and Binding Theory. Researchers focused on the discovery of grammatical relations such as c-command and government, and posited abstract principles designed to capture the more general nature of constraints on transformations (see van Riemsdijk and Williams Reference van Riemsdijk and Edwin1986).
18.3.1 The Government Constraint
Working within the GB framework, Di Sciullo et al. (Reference Di Sciullo, Muysken and Singh1986) proposed The Government Constraint, which posited that there is an anti-government requirement on CS boundaries. Using the standard definition of government in (10), the authors posed (11) as a condition on lexical insertion (where q indexes a category to the language-particular lexicon).
X governs Y if the first node dominating X also dominates Y, where X is a major category N, V, A, P and no maximal boundary intervenes between X and Y.
If X governs Y, . . . Xq . . . Yq . . .
Di Sciullo et al.’s intuition was that (11) is a narrower and empirically more accurate version of (12), which they viewed as a common assumption in syntactic theory that is never made explicit.
All elements inserted into the phase structure tree of a sentence must be drawn from the same lexicon.
On these provisions, the authors maintained that CS “can be seen as a rather ordinary case of language use, requiring no specific stipulation” (Di Sciullo et al. Reference Di Sciullo, Muysken and Singh1986:7). In order to permit the head carrying the language index q to percolate up to its maximal projection, they formalized the condition on CS as The Government Constraint, given in (13).
(13) The Government Constraint
(a.) If Lq carrier has index q, then Ymaxq.
(b.) In a maximal projection Ymax, the Lq carrier is the lexical element that asymmetrically c-commands the other lexical elements or terminal phrase nodes dominated by Ymax.
This formalism allows the language of a head to determine the syntax of its maximal projection and imposes the condition that two categories must be in the same language if the government relation holds between them.
Much like Sankoff and Poplack’s (Reference Sankoff and Shana1981) formalism, (13) (like (11)) attempts to trigger language-specific lexical insertion by identifying nodes within a phrase marker with a specific language label (termed a language index). Although the authors maintain that the mechanism underlying the language index is vacuously available to monolinguals as well, it nonetheless appears to add few advantages over Sankoff and Poplack’s version. Indeed, the constraint in (13) must be seen as a primitive in the system of grammar or it would not have the desired effect, and the very motivation for proposing it is to account for the data of CS; hence, (13) also appears to be a CS-specific constraint.
In addition, there are important counter-examples to (13), some of which were noted by Di Sciullo, et al. For instance, because government holds between a verb and its object and between a preposition and its object, (13) predicts that a verb or preposition must be in the language of its complement. This is shown to be incorrect by examples in (14), where switches occur in case-marked positions.
(14)
-
This morning mi hermano y yo fuimos a comprar some milk
“This morning my brother and I went to buy some milk.”
-
J’ai joué avec il-ku:ra
I’have played with the-ball
“I played with the ball.”
-
Mi hermana kitlasojtla in Juan
mi hermana 0-ki-tlasojtla in Juan
my sister 3S-3Os-love in Juan
18.3.2 The Functional Head Constraint
Belazi et al. (Reference Belazi, Rubin and Toribio1994) proposed The Functional Head Constraint (FHC), which took advantage of a recent development in syntactic theory that distinguished between lexical and functional categories (Abney Reference Abney1987). Functional categories, or functional heads, were responsible for selecting complements with specific feature matrices. For example, for is a head (C0) and has a feature specifying that its complement must have the feature [-Tense]. Belazi, Rubin, and Toribio argued that the data of CS can be correctly described in terms of the generalization in (15).
A code-switch may not occur between a functional head and its complement.
The authors developed the FHC, given in (16), intended as a refinement of Abney’s (Reference Abney1987) proposal.
(16) The Functional Head Constraint
The language feature of the complement f-selected by a functional head, like all other relevant features, must match the corresponding feature of that functional head.
By language feature, the authors mean a label identifying the language from which an item was contributed, such as [+Spanish] or [+English]. If the features do not agree (e.g. a Spanish functional head with an English complement), then the code-switch is blocked. Since (16) applies only to f-selected configurations (a complement selected by a functional head), switches between lexical heads and their complements are not constrained.
Mahootian (Reference Mahootian1993) and Muysken (Reference Muysken2000) see the FHC as a further elaboration of The Government Constraint, in that it identifies an independently motivated principle of grammar but incorporates language-specific identifiers (for The Government Constraint, a language index; for the FHC, a language feature). Belazi et al., like Di Sciullo et al. (Reference Di Sciullo, Muysken and Singh1986) with respect to The Government Constraint, maintained that the FHC does not constitute a CS-specific constraint. However, although the constraints were formulated in terms of independently motivated operations, the particular language identifiers were not. Linguists take particular grammars to be derivative in nature, not primitive constructs, and hence positing a label for a particular language as a primitive in syntactic theory leads us to an ordering paradox, as MacSwan (Reference MacSwan1999b) has pointed out. In addition, (15) remains controversial as a descriptive generalization (Mahootian Reference Mahootian1993; MacSwan Reference MacSwan1999b; Muysken Reference Muysken2000).
However, MacSwan (Reference MacSwan1999b) noted that the content of Belaz et al.’s theory is greatly improved if we regard [+English] as an informal reference to a collection of formal features that define English. On this view, names for particular languages act as proxies for bundles of features which formally characterize them. The ordering paradox disappears, because language features like [+English] or [+Spanish] are no longer taken to be primitives in the theory of grammar. To evaluate the FHC, then, particular hypotheses would be needed regarding which features of a language, being distinct from features of another, result in a conflict. Such conflicts might arise in numerous configurations besides those where head-complement relations hold, leading us to move beyond the FHC to propose a wider diversity of grammatical configurations where CS might be illicit.
18.3.3 The Null Theory
Mahootian (Reference Mahootian1993) proposed the Null Theory of CS, formulated within the framework of Tree Adjoining Grammars (TAG) originally introduced by Joshi (Reference Joshi, Dowty, Karttunen and Zwicky1985b) for applications in computational linguistics and natural language processing. TAG differs from mainstream generative grammar in that the lexical items encode partial tree structures, and use operations of substitution and adjunction to assemble larger trees composed of multiple lexical items. For example, the verb build is represented in the lexicon along with its projection, and therefore the branching direction of its complement is lexically specified. A substitution operation allows a DP (e.g. a house) to integrate with build by substituting the DP (along with its category label) with the object category label of build.
Mahootian focused on the complement relation in phrase structure (see Pandit Reference Pandit and Jacobson1990; Nishimura Reference Nishimura1997), and claimed that (17) was adequate to account for the facts of CS.
The language of a head determines the phrase structure position of its complements in code-switching just as in monolingual contexts.
Mahootian (Reference Mahootian1993) used a corpus of Farsi–English CS data that she collected in naturalistic observations. In Farsi, objects occur before the verb, contrasting with basic word order in English. She observed that in CS contexts the language of the verb determines the placement of the object, as (18) illustrates. These facts are consistent with (17).
Mahootian noticed that the TAG formalism provides an advantage for the analysis of CS data. Because structures are encoded in the lexicon, no intervening control mechanism is needed to pair up lexical insertion rules with terminal nodes in a phrase marker, as seen in previous proposals. However, like Belazi et al. (Reference Belazi, Rubin and Toribio1994), Mahootian’s analysis was restricted to head-complement configurations (MacSwan Reference MacSwan1999b; Muysken Reference Muysken2000). Not only was (17) too narrow in this regard, failing to comment on CS in other dimensions of syntax, but it also proved to be insufficiently restrictive. Note, for instance, the examples in (19), a phenomenon observed by Timm (Reference Timm1975). Although all complements are in the correct positions assigned by heads, (19a) is ill-formed but (19b) well-formed. The contrast in grammaticality appears to relate to the nature of the subject, a specifier (XP) rather than a pronominal head (van Gelderen and MacSwan 2008).
(19)
(a.) *Él bought some ice cream.
“He bought some ice cream.”
(b.) Mi hermano bought some ice cream.
“My brother bought some ice cream.”
Furthermore, recall also that in (7), visto “seen,” the complement of habían/had, is in the position assigned by its head, and therefore adheres to (17), yet (7a) is well-formed and (7b) is not. In (20), Spanish and Nahuatl word order is respected with regard to the placement of the verbal complement of negation, yet (20a) is ill-formed but (20b) is not.
(20)
These examples indicate that restrictions on CS are far more pervasive than the head-complement relation alone, and appear to move well beyond issues of phrase structure alone.
18.4 Minimalism
18.4.1 The lexicalist advantage
The importance of constructing a theory of CS that does not appeal to CS-specific mechanisms has been emphasized throughout the history of the field. However, in essential respects, the theoretical contexts in which many influential theories were formulated did not provide the tools needed to permit the implementation of a constraint-free theory of CS. An approach to syntax which built structure from the top down, as in the Aspects and later GB models, postponed lexical insertion until well after the word order had been laid out, posing a significant problem. The structure could not be sensitive to which language contributed a specific lexical item until the end, when lexical insertion occurred, but the language contributing the lexical item appeared to have strong consequences for the syntactic structure at the onset.
The desire to avoid CS-specific mechanisms in accounts of CS goes beyond issues of elegance and economy. The more serious problem is that such mechanisms threaten to trivialize the enterprise. Rather than explaining descriptive restrictions observed in CS data, CS-specific mechanisms simply note these restrictions within the grammar itself so that no explanation is needed, and so one is left still wondering what general principles of grammar might be at work in posing the observed restrictions. Within the Minimalist Program, structures are built from a stock of lexical items, essentially beginning with lexical insertion (formalized as Select). This important development permits CS researchers to probe the structural consequences of particular lexical items from specific languages, with no need to keep track of which languages may contribute which specific lexical elements during a final stage of lexical insertion.
18.4.2 The Minimalist Program
X’ Theory effectively eliminated phrase structure grammar in favor of the view that structures are projected from lexical items; however, remnants remained, with reference to lexical insertion rules reasonably common among GB era syntacticians (Chomsky Reference Chomsky1981; Stowell Reference Stowell1981; Lasnik and Uriagereka Reference Lasnik and Uriagereka1988). Apparent redundancies among various modules of grammar within the GB framework were troubling. Subcategorization, θ-Theory, and X’ Theory all appeared to approach the same basic problems from a different angle, with none sufficient to manage the full array of issues associated with the base generation of an initial phrase marker. According to Chametzky (Reference Chametzky and Hendrick2003), the “lexical entry driven” approach to syntax was part of the general effort underlying X’ reduction, with significant contributions from Stowell (Reference Stowell1981) and Speas (Reference Speas1990), among others. With a return to its derivational roots, Minimalist syntax reduced generation to the simplest possible form – free Merge (Chomsky Reference Chomsky and Kasher1991, Reference Chomsky1994), building structures from the ground (the lexical string) up (the hierarchical phrase structure), based on the specification of lexically encoded features. Independently, Borer (Reference Borer1984) had suggested an account of language variation in which parameters were also associated with the lexicon, rather than with the system of syntactic rules. Hence, the system of rules could be seen as invariant, with all variation associated with the lexicon, the traditional repository of arbitrariness.
In the Minimalist Program there are two components of grammar: Chl, a computational system for human language, believed to be invariant across languages; and a lexicon, to which the idiosyncratic differences observed across languages are attributed. An operation called Select picks lexical items from the lexicon and introduces them into a Numeration or Lexical Array (LA), a finite subset of the lexicon used to construct a derivation. Merge takes items from the LA and forms new, hierarchically arranged syntactic objects. Movement operations (Internal Merge) apply to syntactic objects formed by Merge to re-arrange elements within a tree (Chomsky Reference Chomsky1995, Reference Chomsky, Martin, Michaels and Uriagereka2000). Phrase structure trees are thus built derivationally by the application of the operations Select and Merge, constrained by the condition that lexically encoded features match in the course of a derivation.
Movements are driven by feature valuation, and may be of two types. A head may undergo head movement and adjoin to another head, or a maximal projection may move to the specifier position of a head. In either case, the element moves for the purpose of valuing morphological features of case and φ (number, person, and gender). In addition, its movement may be overt or covert. Overt movements are driven by strong features and are visible at PF (Phonetic Form, where they are pronounced) and LF (Logical Form, where they are interpreted). Covert movements, driven by weak features, are visible only at LF.
Principles of Economy select among convergent derivations. One such principle, Full Interpretation (FI), requires that no symbol lacking a sensorimotor interpretation be admitted at PF. Applied at LF, FI entails that “every element of the representation have a (language-independent) interpretation” (Chomsky Reference Chomsky1995:27). Thus, uninterpretable features (denoted -Interpretable) must be checked and deleted by LF. The +Interpretable features are categorial features plus φ-features of nominals; the +Interpretable features do not require valuation (checking). A derivation is said to converge at an interface level (PF or LF) if it satisfies FI at that level; it converges if FI is satisfied at both levels. A derivation that does not converge is also referred to as one that crashes. If features are not valued, the derivation crashes; if they mismatch, the derivation is canceled (that is, a different convergent derivation may not be constructed).
At some point in the derivation, an operation, Spell-Out, applies to strip away from the derivation those elements relevant only to PF; what remains is mapped to LF by a subsystem of Chl called the covert component. The subsystem of Chl that maps the lexicon to Spell-Out is the overt component. The phonological component is also regarded as a subsystem of Chl. Note that the various components (overt, covert, phonological) are all part of Chl, the computational system for human language. The model could be represented graphically as in Figure 18.1 (MacSwan Reference MacSwan1999a).
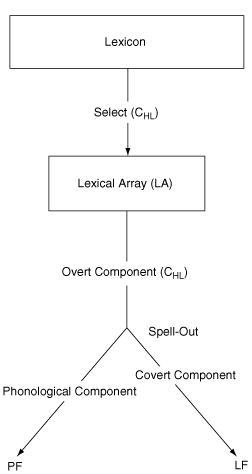
Figure 18.1 Model of the minimalist framework
It may be helpful to consider some illustrations of how feature checking drives movement in the Minimalist Program. As mentioned, movement may be of two types: (1.) a head (or X0) moves by adjunction to another head, forming a complex X0; or (2.) an XP moves to the Specifier position of another XP. Movement is driven by a need to value features, and the configuration into which the element moves for feature valuation constitutes its Checking Domain. XP movement is illustrated in (21). The tree in (21a) is formed by successive application of Merge, which uses lexically encoded categorial features (e.g. V, N, D, T) to build a classical phrase structure representation. The subject bears a case feature. T is a nominative case assigner that attracts the case feature of the subject to its Specifier position, bringing the full DP along. Because case is an uninterpretable feature, it must be valued and deleted before LF, or the derivation will crash. Hence, the DP is attracted to T, and moves to its Checking Domain, the Spec[ifier] of TP, as shown in (21b).
(21)
(a.)

(b.)


There are some terminological departures from earlier generative models. TP, or Tense Phrase, replaces IP, Inflection Phrase; DP, or Determiner Phrase, is headed by a determiner and dominates NP, as illustrated. The subject originates in a VP-internal position, following Koopman and Sportiche (Reference Koopman and Sportiche1991), raising to the Spec of T to check its case feature. t is the trace of movement, co-indexed by i, as in classical approaches. Chomsky (Reference Chomsky1994, Reference Chomsky, Martin, Michaels and Uriagereka2000) adopts a bare phrase structure approach, dispensing with intermediate bar levels when they are not relevant to output conditions. As is traditionally done, we have simplified aspects of the structure in (21) (and elsewhere) that are not relevant in the present context.
Now consider an example of head movement, illustrated in (22). The successive application of Merge results in the formation of a base structure. As in (21), the subject DP moves out of the VP shell to check its case feature. The resulting structure is shown in (22a). V, a head, moves to T by head adjunction in order to value and delete its φ-features, as shown in (22b).
(22)
(a.)
-
(b.)
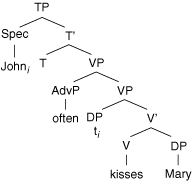

Feature strength (weak, strong) is the primary mechanism in the MP used to account for cross-linguistic variations in word order. Notice, for instance, the contrast in (23).
(23)
(a.) John often kisses Mary
(b.) John completely lost his mind
(c.) Jean embrasse souvent Marie
(d.) Jean perdit complètement la tête
In English, VP-adverbs precede verbs, but in French they follow them. We might assume, then, that in English V moves to T covertly, attracted by T’s weak φ-features. This is represented in (22b) with the use of parentheses around the verb, illustrating that the phonetic features of the V have been left behind. By contrast, in French, T has strong φ-features, resulting in overt movement. In this case, all of V’s features raise, with the result that it appears before its adverbial modifier in (23).
Feature strength can similarly be used to account for word order differences in the case of XP movement. For instance, if the case feature of T is strong, then the subject DP must move overtly out of its VP shell, bringing along its phonetic content. Overt movement of the subject DP results in preverbal subject word order (as in English, French, or Spanish). However, if the case feature is weak, then the subject DP will move covertly, resulting in postverbal word order (e.g. in Irish, Breton, or Zapotec). Let us now turn to an analysis of CS data within the Minimalist Program.
18.4.3 The analysis of code-switching in the Minimalist Program
The leading aim of the Minimalist Program is the elimination of all mechanisms that are not necessary and essential on conceptual grounds alone. Thus, only the minimal theoretical assumptions may be made to account for linguistic data, privileging more simplistic and elegant accounts over complex and cumbersome ones. These assumptions would naturally favor accounts of CS that make use of independently motivated principles of grammar over those that posit rules, principles, or other constructs specific to it. MacSwan (Reference MacSwan1999b, Reference MacSwan, Bhatia and Ritchie2004) presents this research program in the context of the Minimalist Program as in (24), where the minimal CS-specific apparatus is assumed.
Nothing constrains code-switching apart from the requirements of the mixed grammars.
Notice that (24) does not use “constrain” in a descriptive sense, to imply that there are no unacceptable code-switched sentences. Rather, constrain is used in its technical sense here, to mean that there are no statements, rules, or principles of grammar which refer to CS. In other words, (24) posits that all of the facts of CS may be explained just in terms of principles and requirements of the specific grammars used in each case. More formally, the claim is that for Gx a grammar of Lx and Gy a grammar of Ly, CS falls out of the union of the two grammars ({Gx ∪ Gy}) and nothing more (MacSwan Reference MacSwan1999a). In this respect ungrammaticality in CS is understood to relate to mechanisms motivated for the analysis of monolingual language, or which are conceptually necessary for reasons of optimal design.
Note that our conception of these conflicts is very much determined by our conception of the organization of the grammar. In classical GB theory, parametric differences were generally assumed to be properties of the computational system. For instance, noting that some subjacency violations of the English variety are acceptable in Italian, Rizzi (Reference Rizzi1982) proposed that the bounding nodes for the Subjacency Principle were parameterized (NP and IP in English, NP and CP in Italian). On this conception of parametric variation, in which the computational system itself differs across languages, it is very difficult to know how a conflict in language-specific requirements should be precisely defined. In an Italian–English mixed construction, for instance, what determines whether the sentence will be sensitive to IP or CP as a bounding node for the purposes of the Subjacency Principle? The answer depends upon which computational system is in use (Italian or English), and it is very unclear what factors might determine this in the absence of a system permitting CS-specific constraints to mediate conflicts.
In a Minimalist approach to CS which adheres to the research agenda stated in (24), lexical items may be drawn from the lexicon of either language to introduce features into the lexical array, which must then be valued (and deleted by LF, in the case of uninterpretable features) in just the same way as monolingual features must be valued, with no special mechanisms permitted. In this lexicalist approach, no CS-specific mechanism is required to mediate contradictory requirements of the systems in contact. The requirements are simply carried along with the lexical items of the respective languages.
18.4.3.1 Code-switching in head movement contexts
The contrast in (25), a repetition of (20), illustrates the inadequacy of analyses of CS focused exclusively on lexical categories labels (e.g. N, V, D, Adj, Neg).
(25)
Although Spanish and Nahuatl have the same basic word order requirements with respect to negation, and the same basic functional and semantic properties are common to both examples, Spanish negation does not permit a Nahautl verb in its complement position in (25a), but Nahuatl negation followed by a Spanish verb is well-formed in (25b). The question of interest for (25) becomes, what lexically encoded properties distinguishing Nahautl and Spanish negation can reasonably be identified as the cause of the ill-formedness in one case but not in the other?
Zagona (Reference Zagona1988) argues that Spanish no is a syntactic clitic and forms part of the Spanish verbal complex as a result of head movement. To make a case for this analysis, Zagona points out that Spanish no must be fronted with the verb in (26), unlike the adverbs in (27).
¿Qué no dijo Juan?
what not say/1Ss/PAST Juan
“What didn’t Juan say?”
(27)
(a.) *¿Qué sólo leyó Juan?
what only read/1Ss/PAST Juan
“What did Juan only read?”
(b.) *¿Qué meramente leyó Juan?
what merely read/1Ss/PAST Juan
“What did Juan merely read?”
Zagona (Reference Zagona1988) also points out that Spanish no cannot be contrastively stressed in (28a) as its English counterpart in (28b) can be, owing to the fact that clitics are inherently unstressable. The example in (28b) shows that in English, in contrast to Spanish, the negative element is not a syntactic clitic.
(28)
(a.) *Juan no ha no hecho la tarea
Juan not has not done the task
“Juan hasn’t not done the task.”
(b.) Juan hasn’t not done the task
These facts suggest that in Spanish, the verb is a host for negation. Nahuatl, on the other hand, behaves differently from Spanish with regard to negation. A test similar to the one Zagona uses in (28) shows that Nahuatl patterns with English. Since clitics are inherently unstressable, we may conclude from (29) that amo is not a clitic in Nahuatl.
Amo nio amo niktati nowelti
amo ni-o amo ni-k-tati no-welti
not 1S-go amo 1S-3Os-see my-sister
The facts suggest the possibility of a ban on CS in head movement contexts. Such a ban, were it to be attested in a wide range of cases, would only serve as a descriptive generalization, not itself an explanation. An explanation would seek to derive the generalization from independent properties of grammar that prohibit cross-linguistic mixing in these contexts.
Restructuring is a well-studied and classic example of head movement. According to Rizzi (Reference Rizzi1982), Italian modals, aspectuals, and motion verbs comprise the class of restructuring verbs, which behave differently from other verbs, as illustrated in the Italian examples in (30) and (31).
(30)
(a.) Finalmente si comincerà a costruire le nuove case popolari
finally si begin/fut to build the new houses people/gen
(b.) Finalmente le nuove case popolari si cominceranno a costruire
“Finally we’ll begin to build the new houses for the poor.”
(31)
(a.) Finalmente si otterrà di costruire le nuove case popolari
finally si get.permission/fut to build the new houses people/gen
(b.) *Finalmente le nuove case popolari si otterranno di costruire
“Finally we’ll get permission to build the new houses for the poor.”
In Rizzi’s analysis, comincerà “will begin,” but not otterrà “will get permission,” triggers an optional reanalysis of the form Vx (P) V2 ⇒ V, where Vx is a verb of the restructuring class, (P) an optional intervening preposition, and V2 is the verb of the embedded sentence. This restructuring process may be seen as a type of compounding by way of head movement, resulting in [V Vx V2]. In (30) a reanalysis of the constituents allows the object of the embedded clause in an impersonal si construction to move to the subject position of the matrix clause; in (31) this promotion is barred because reanalysis cannot apply for otterrà. Importantly, reanalysis is optional in Italian; it has applied in (30b), allowing the promotion of the embedded object to subject position, but it has not applied in (31a) where the object of the embedded clause remains in situ.
Aspectual essere is used with a past participle in Italian passive impersonal si constructions. In constructions such as (32a), essere too may be viewed as a restructuring verb, allowing promotion of the embedded object to subject position, shown in (32b).
(32)
(a.) Si è dato un regalo
si essere given a gift
“A gift is given.”
(b.) Un regalo si è dato
a gift si essere given
“A gift is given.”
Within Rizzi’s system, restructuring has applied to (32b) but not to (32a), forcing the promotion of [np un regalo] in the former case (see Wurmbrand Reference Wurmbrand1997; Roberts, Reference Roberts1997 for more recent studies of restructuring).
Examples involving the promotion of an embedded subject to the matrix clause correspond with restructuring of the verb complex by means of head movement. To test further whether CS is prohibited in head movement contexts, we may examine cases of CS in this context. Consider the French–Italian CS in (33).
(33)
(a.) Si è donné un cadeau
si essere given a gift
(b.) *Un cadeau si è donné
a gift si essere given
The movement of [np un cadeau] indicates that reanalysis has occurred in (33b), just as it did in (32b). The verbal complexes are identical in (33a) and (33b): a mixture of the Italian aspectual auxiliary è, immediately adjacent to the French past participle donné.
Once again, the facts appear to indicate that CS in restructuring configurations, an instance of head movement, is prohibited, leading us to conclude that a general ban on CS in head movement contexts is at play. As emphasized, the ban so stated is a descriptive generalization. In considering how such a prohibition might arise, we may develop a better understanding of how language mixing in bilinguals is constrained as an independent property of the language faculty, perhaps owing to conditions on interface levels within the organization of the grammar itself.
18.4.3.2 Code-switching and conditions on interface levels
Chomsky (Reference Chomsky, Martin, Michaels and Uriagereka2000, Reference Chomsky2001a) and Boeckx and Stjepanovic (Reference Boeckx and Sandra2001) have recently suggested that head movement is a phonological operation. The motivation for the idea derives from a need to address a range of issues in syntactic theory. In the context of CS research, associating head movement with the phonological component suggests some common ground between the ban on CS in head movement contexts and the prohibition against word-internal CS noted by Poplack (Reference Poplack and Durán1981). In both instances, switching from one phonological representation to another within a word-like unit is disallowed. Recall Poplack’s (Reference Poplack1980) classic examples of the ban on word-internal mixing of the sort illustrated in (34).
(34)
In cases such as (34), CS occurs within a single syntactic head, a structure represented in (35a). In the head movement cases, CS occurs in the context of a complex head, as in (35b).
(35) 
In order to remain true to our goal of positing no CS-specific constraints, the ban on switching in word-internal and head movement contexts may not be declaratively stated as a constraint on syntax, but must be derived from independent principles. As indicated in Figure 18.1, at Spell Out a derivation is split, with features relevant only to Phonetic Form (PF) sent to the phonological component where the phonological system maps them to PF, and interpretable material is treated by further application of the syntactic component in the mapping to Logical Form (LF) in anticipation of semantic interpretation.
A common assumption in CS research is that the linguistic identity of a word (as “Spanish” or “English” or “Arabic”) is established by its morphological and phonological characteristics (Lipski Reference Lipski and Paradis1978; Pfaff Reference Pfaff1979; Woolford Reference Woolford1983; Di Scuillo et al. Reference Di Sciullo, Muysken and Singh1986; Mahootian Reference Mahootian1993; MacSwan Reference MacSwan1999a, Reference MacSwan1999b). For instance, the word taipiar may derive from English type, but taipiar is regarded as a “Spanish word” because it has phonological and morphological properties that are generally compatible with the grammar of the community of speakers known as “Spanish speakers.” The same is true of nonce or novel borrowings. In an important respect, then, CS research is concerned with interface conditions on morphophonology and syntax across discretely represented linguistic systems.
The Minimalist framework assumes that processes of word formation apply before an item is introduced into the Lexical Array when syntactic operations begin (see Figure 18.1) (Chomsky Reference Chomsky1995:20). Chomsky (Reference Chomsky1995, Reference Chomsky, Barbosa, Fox, Hagstrom, McGinnis and Pesetsky1998) stresses that the phonological system has a dramatically different character from the syntactic system. Specifically – with π indicating the PF representation, λ the LF representation, and N the initial collection of lexical items – Chomsky (Reference Chomsky1995:229) posits that:
. . . at the point of Spell-Out, the computation splits into two parts, one forming π and the other forming λ. The simplest assumptions are (1) that there is no further interaction between computations and (2) that computational procedures are uniform throughout: any operation can apply at any point. We adopt (1), and assume (2) for the computation from N to λ, though not for the computation from N to π; the latter modifies structures (including the internal structure of lexical entries) by processes very different from those that take place in the N → λ computation.
We assume that affixation interacts with phonology (at least) pre-lexically (before items are selected into the Lexical Array), and that phonology is sensitive to word boundaries or discrete syntactic heads.
What properties of the grammar might explain the prohibition against switching head-internally, banning language mixing in structures such as (34)? Current approaches in phonology posit that lexical form (input) is mapped to the surface form (output) in one step, with no intermediate representations, and hypothesize that phonological constraints are prioritized with respect to each other on a language-specific basis. Each set of internally ranked constraints is a constraint dominance hierarchy, and a language-particular phonology is a set of constraint dominance hierarchies (see McCarthy Reference McCarthy2002). Since language-particular phonologies differ with respect to their internal rankings, we might reasonably posit that bilinguals have a separately encapsulated phonological system for each language in their repertoire in order to avoid ranking paradoxes resulting from the availability of distinct constraint dominance hierarchies with conflicting priorities. This property of the bilingual language faculty emerges as a result of the design constraints imposed by the phonological system; without it, bilingualism would not be possible. It further leads us to anticipate that phonological systems may be switched between syntactic heads but not within them, since every syntactic head must be phonologically parsed at Spell Out, and the mapping of phonological structure occurs in a single step, with no intermediate representations and therefore no opportunities for switching from one phonological system to another. We state the condition as in (36) as the PF Interface Condition.
(36) The PF Interface Condition
(i.) Phonological input is mapped to the output in one step with no intermediate representations.
(ii.) Each set of internally ranked constraints is a constraint dominance hierarchy, and a language-particular phonology is a set of constraint dominance hierarchies.
(iii.) Bilinguals have a separately encapsulated phonological system for each language in their repertoire in order to avoid ranking paradoxes, which result from the availability of distinct constraint dominance hierarchies with conflicting priorities.
(iv.) Every syntactic head must be phonologically parsed at Spell Out. Therefore, the boundary between heads (words) represents the minimal opportunity for CS.
By stipulating that syntactic heads subject to phonological parsing include both simple and complex heads, as illustrated in (35), we extend (36) to both word-internal CS and CS in head movement contexts. We might alternatively posit that head movement is itself a phonological operation that first builds a complex sequence of phonological features deriving from both adjoined heads, then attempts to subject them to phonological processing as a single word-like unit.
We may now appeal to the PF Interface Condition to account for the ban on CS in head movement contexts. Because the condition follows from independently motivated properties of the grammatical system, it complies with the research agenda articulated in (24), namely, the supposition that there are no rules or principles of grammar that refer to CS. We turn to a final example, CS among languages that differ with respect to their basic word order requirements, calling upon the PF Interface Condition to help identify syntactic properties of lexically null functional categories.
18.4.3.3 Explaining basic word order differences
Within the Minimalist Program, we assume a universal SVO base structure with a VP-internal subject. If the subject overtly raised to the specifier position of T0 within this structure, an SVO order would result, with the subject pronounced above the verb. However, if the subject raises covertly, the resulting word order is VSO. The distinction between overt and covert movement is implemented in terms of feature strength. Weak features may be valued without pied-piping the phonetic content of a lexical item, while strong features require that the phonetic content comes along as well. Thus, the typological distinction between SVO and VSO languages may be captured in terms of the strength of the case feature in T0 that triggers movement of the VP-internal subject.
Now consider the following CS facts involving mixing between SVO and VSO languages (see Chan, this volume):
(37)
(a.)
VS verb (Irish), SV subject (English)
Beidh jet lag an tógáil a pháirt ann
be-fut … taking … its part in-it
“Jet lag will be playing its part in it.”
(Stenson Reference Stenson and Hendrick1990:180)(b.)
VS verb (Irish), SV subject (English)
Fuair sé thousand pounds
get-past he ..
“He got a thousand pounds.”
(c.)
VS verb (Breton), SV subject (French)
Oa ket des armes
be-3S imp neg of-the . . .
“There were no arms.”
(Pensel Reference Pensel1979:68)(d.)
VS verb (SLQ Zapotec), SV subject (Spanish)
S-to’oh mi esposa el coche
def-sell my wife the car
“My wife will definitely sell the car.”
(MacSwan Reference MacSwan, Bhatia and Ritchie2004:305)
Descriptively, the pattern appears to be that the language of the verb determines the placement of the subject. A verb from a VS language places a subject after the verb, regardless of the language of the subject.
As in the analysis of monolingual examples, we assume that V0 raises to T0 to value its φ-features, forming a complex head via head adjunction, as illustrated in (22b). In the previous section, we noted a general prohibition against CS in head movement contexts, deriving from a condition at PF imposed by the architecture of the phonological system. In the present context, the condition guarantees that in any convergent derivation, T0 is in the same language as V0 if V0-to-T0 raising has occurred. As a result, the language of the verb restricts which language may contribute T0, and the strength of the value of the case feature of T0 is guaranteed to be consistent with the language of the verb. The analysis proceeds as follows. In the examples involving CS between a VS verb and an SV subject, the VP-internal subject raises to the specifier position of T0 to value its case feature, as previously illustrated by (21b). Because the case feature of T0 is weak in VS languages, the subject raises covertly, resulting in the attested VS word order. More concretely, consider (25d). The Spanish subject mi esposa raises to the specifier of Zapotec T0 to value its case feature, weak for Zapotec, resulting in covert movement and VS word order.
Now consider the placement of objects in CS contexts. If an object moves covertly out of the VP-shell to the specifier position of v (a preverbal position), then the elements remain in the order SVO at PF. If the object moves overtly, however, an SOV word order is derived. The parameter responsible for this difference is associated with v. If the case feature of v is weak, SVO is formed; if it is strong, SOV results. The verb undergoes a checking relation with v by head movement as it moves up to T, guaranteeing once again that the language of the verb will determine the position of the object, just as in the case of subjects. The expected results are attested:
(38)
(a.)
VO (English) verb, OV object (Farsi)
Tell them you’ll buy xune-ye jaedid when you sell your own house
tell them you’ll buy house-poss new when you sell your own house
“Tell them you’ll buy a new house when you sell your own house.”
(Mahootian Reference Mahootian1993:152)(b.)
OV verb (Farsi), VO object (English)
Ten dollars dad-e
Ten dollars give-perf
(Mahootian Reference Mahootian1993:150)(c.)
VO verb (English), OV object (Japanese)
. . . we never knew anna koto nanka
. . . we never knew such thing sarcasm
“. . . we never knew such a thing as sarcasm.”
(Nishimura Reference Nishimura1985a:76)(d.)
OV verb (Japanese), VO object (English)
In addition, his wife ni yattara
in addition, his wife dat give-cond
“In addition, if we give it to his wife . . .”
(Nishimura Reference Nishimura1985a:129)(e.)
VO verb (English), OV object (Korean)
I ate ceonyek quickly
I ate dinner quickly
“I ate dinner quickly.”
(Lee Reference Lee1991:130)(f.)
OV verb (Korean), VO object (English)
Na-nun dinner-lul pali meokeotta
I-s dinner-o quickly ate
“I ate dinner quickly.”
18.5 Future directions of the field
A strong consensus in the field of CS, nearly since its inception, has been that a good theory of CS, minimally, is one that appeals to no “third grammar” (Pfaff Reference Pfaff1979) or CS-specific device to regulate the interaction of the two systems. However, early non-lexicalist models of syntax posed a significant problem for this goal. In traditional non-lexicalist frameworks, words are only inserted into grammatical structures after they have been built, making it difficult to design a system of grammar that would be sensitive to the language-specific identity of words inserted into a phrase marker. Within the lexicalist proposals of more recent models within generative syntax, the lexicon itself projects the phrase structure, defines movements of elements within the tree, and encodes features responsible for essentially all aspects of language variation. This system thus permits us to identify in a concrete manner which specific features and array of values we should expect to see in any CS construction.
Minimalism, then, provides a framework that permits us to abandon the quest for constraints on CS, and engage in the linguistic analysis of mixed-language utterances in very much the same way we engage in the analysis of monolingual language. Over time, this research project promises to enhance our understanding of the nature of bilingualism, CS, and the architecture of the bilingual language faculty. Very much the same process is at work in contemporary linguistic theory quite generally, as Chomsky (Reference Chomsky1957:5) noted at the onset of the generative enterprise:
The search for rigorous formulation in linguistics has a much more serious motivation than mere concern for logical niceties or the desire to purify well-established methods of linguistic analysis. Precisely constructed models for linguistic structure can play an important role, both negative and positive, in the process of discovery itself. By pushing a precise but inadequate formulation to an unacceptable conclusion, we can often expose the exact source of this inadequacy and, consequently, gain a deeper understanding of the linguistic data.
Although the field of CS has its origins in sociolinguistics, where it has been fruitfully studied by scholars interested in discourse and conversational analysis, it also shares important characteristics with psycholinguistics – more specifically, with the study of language acquisition. In both enterprises, one makes specific assumptions about the special circumstances of language use, and engages in extensive and detailed linguistic analysis in the interest of verifying, rejecting, or refining them. Recent developments in the field of CS have permitted us to move beyond traditional battles over which proposed CS-specific constraint is accurate and which is not, calling upon us to examine CS in the context of specific constructions, operations, and grammatical features across a wide range of language pairs (see Chan, this volume). The goal, as the field continues on its present course, is to propose increasingly better theories about the nature of the bilingual language faculty as a reflection of the facts of CS, informing the field of bilingualism as well as general linguistic theory.
Note
1. Sankoff (Reference Sankoff1998) provides a speech production model of CS which he believes is consistent with The Equivalence Constraint, but with similar limitations.
19 A universal model of code-switching and bilingual language processing and production
19.1 Introduction
The Matrix Language Frame (MLF) model (Myers-Scotton Reference Myers-Scotton1993a, Reference Myers-Scotton1997), augmented by the 4-M model of morpheme classification (Myers-Scotton and Jake Reference Myers-Scotton and Jake2000; Myers-Scotton Reference Myers-Scotton2002a), provides a major linguistic theory of language contact dedicated to bilingual processing and production. This model has inspired many studies of bilingual speech within diverse language pairings and accounts for a variety of bilingual behaviors, principally code-switching (hereafter CS). Unlike most other approaches to CS, the MLF model enjoys widespread appeal among linguists and psycholinguists alike.
19.1.1 No chaos allowed: the Uniform Structure Principle
This chapter elaborates and illustrates the research program framed by the MLF model. What is new is that it emphasizes how a principle of uniform structure drives the explanation of what does and does not occur in CS. The first goal of this chapter is to show how the Uniform Structure Principle (USP) implies a particular view of processing and production in bilingual speech, especially in CS. Bilingual speech is defined as surface level morphemes from two or more language varieties in the same clause. With the 4-M model, the USP clarifies and strengthens the Matrix Language Frame (MLF) model, as a model of CS. A succinct way of viewing the USP is the phrase, “no chaos allowed.” This may be obvious for monolingual speech; that it applies to bilingual speech is not so obvious. A priori, the ways in which languages participate in bilingual speech are unconstrained. In particular, the source of grammatical structure within a bilingual clause could be shared in any number of ways. But this does not happen. For bilingual speech, “no chaos allowed” means a particular asymmetry between the participating languages. This is formalized in the USP, as follows:
A given constituent type in any language has a uniform abstract structure and the requirements of well-formedness for this constituent type must be observed whenever the constituent appears. In bilingual speech, the structures of the Matrix Language (ML) are always preferred. Embedded Language (EL) islands (phrases from other varieties participating in the clause) are allowed if they meet EL well-formedness conditions, as well as those ML conditions applying to the clause as a whole (e.g. phrase placement).
The second goal here is to make more explicit how specific morphemes are classified under the 4-M model and to show how differences in morpheme type explain their distribution in CS. These distributions will be shown to reflect the USP. In doing this, the chapter focuses on CS in general, but gives special attention to prepositions, complementizers, and pronouns.
First, the MLF model of CS and its relation to the USP is summarized. Next, the view of language production motivated by empirical CS data and the MLF model is outlined, as is the 4-M model and how it relates to the USP and the MLF model. Finally, the descriptive sections of the chapter are shown to support the theoretical goal of explaining the asymmetries that pattern CS data. With the USP as an overarching framework in which the MLF and 4-M models add specific hypotheses, a set of principled predictions emerges about what does and does not occur in CS. These predictions should have relevance to other types of contact phenomena as well.
19.2 Summary of the MLF model
The key feature of the MLF model is that it differentiates both the participating languages and morpheme types at a number of abstract levels. It emphasizes asymmetry, claiming crucially a dominant role in the bilingual clause for only one of the participating languages, the ML. That is, reflecting the USP, the MLF model limits the EL’s main role to providing either content morphemes in mixed constituents or EL phrase-level constituents (EL islands), or both. Asymmetry under the model also differentiates content and system morphemes and their participation in CS. The model assumes that these two asymmetries apply universally in Classic CS and empirical evidence largely supports this. Classic CS is defined here as CS in which empirical evidence shows that abstract grammatical structure within a clause comes from only one of the participating languages. Which of the participating languages is the ML is determined for each corpus. Within a corpus, the ML may vary from clause to clause, although this is unusual.
The MLF model has always defined content and system morphemes differently from those classifications based on the lexical vs. functional distinction, or the open vs. closed class distinction. Specifically, system morphemes are not the same as the functional elements or closed-class items in other linguistic models. They are defined in opposition to content morphemes. Content morphemes are defined as assigning or receiving thematic roles; system morphemes do not. Prototypical system morphemes are affixes and some function words that are free forms but do not occur alone, such as determiners and clitics.
The MLF model contains two principles that can be interpreted as hypotheses about the differing roles of the participating languages. These were first presented in Myers-Scotton (Reference Myers-Scotton1993a, Reference Myers-Scotton1997:82) as the Morpheme Order Principle (MOP) and the System Morpheme Principle (SMP). They specify the elements in a bilingual constituent that must come from only one participating language; in effect, support of these principles identifies this language as the ML.
19.2.1 Exemplifying the MLF model
Example (1) comes from a corpus of Turkish–Dutch CS, where elements from the EL appear in italics. Turkish is verb-final, and in this example the inflected (main) verb yap “do” occurs after its predicate (the Dutch infinitive), not before it as it would in Dutch. This configuration supports the MOP, which states that only one of the participating languages supplies morpheme order in such constituents. Note as well that all instances of subject–verb agreement come from Turkish. This supports the SMP, which states that only one of the participating languages supplies a certain type of system morpheme (SM), now called an outsider late SM under the 4-M model. Subject–verb agreement is such a morpheme. Based on the example’s support of the MOP and the SMP, Turkish is identified as the ML.
(1) Turkish–Dutch
Example (2) supports both principles as well. Note the order of certificate and its modifiers; they follow Swahili word order, not that of English. In addition, although the main verb is from English (depend), subject-agreement, an outsider morpheme, (i-, class 9) comes from Swahili, agreeing with a subject mentioned before (saa hiyo is an introductory phrase, not the subject). These data support Swahili as the ML in this example.
(2) Swahili–English
19.2.2 Three premises summarizing the MLF model
Three basic premises have always structured the MLF model (Myers-Scotton Reference Myers-Scotton1993a, Reference Myers-Scotton1997):
(1.) Participating languages do not play equal roles in the bilingual clause.
(2.) In bilingual constituents within this clause, not all morpheme types can come equally from the ML and EL.
(3.) The SMP limits the occurrence of system morphemes that build clausal structure of the ML.
19.2.3 Relating the MLF model to other data
The implicit domain of the MLF model always has been participating varieties that are not mutually intelligible. It may well apply to other varieties, but that would be an unintended bonus. As already noted, the model applies only to what is defined above as Classic CS. This type of CS contrasts with Composite CS in which the abstract grammatical structure underlying surface configurations still comes largely from one language, but also partially from another. The Abstract Level model (see Myers-Scotton and Jake Reference Myers-Scotton, Jake and Nicol2001; Myers-Scotton Reference Myers-Scotton2002a) is especially relevant to Composite CS. More research may show Composite CS to be more common than Classic CS. The USP applies to both types of CS, of course, to the extent there is an ML, and so does the 4-M model; both are universal.
19.3 The language production model
A general language production model of four levels, the conceptual level, the mental lexicon, the formulator, and the surface level (see Levelt Reference Levelt1989) accommodates CS and other contact phenomena. The conceptual level is pre-linguistic, and includes speaker intentions, as well as other cognitive components, such as memory. The critical factor in resolving competition at the conceptual level is which lemma entry (either from the ML or the EL) best conveys the speaker’s semantic and pragmatic intentions (La Heij Reference La Heij, Kroll and de Groot2005). Intentions activate semantic and pragmatic features that are bundled together, pointing to language-specific lemmas in the mental lexicon.
If CS becomes part of the cognitive plan, the ML is selected at the conceptual level. Speakers must be able to produce well-formed utterances for the language selected as the ML because it provides the grammatical frame of the bilingual clause; they may be less proficient in the EL, but are not necessarily so. Often the ML is the speakers’ L1, although not necessarily. Selecting a language as the ML is largely unconscious, although the process draws on various resources, especially the participant’s cognitive system (i.e. memory about social aspects of contexts compared with the nature of current contexts).
But satisfying semantic and pragmatic intentions at the conceptual level is not the only issue. CS data imply a matching process – checking – between the abstract requirements regarding the structural well-formedness of the ML and a potential EL element in a bilingual clause (Myers-Scotton and Jake Reference Myers-Scotton and Jake1995). This is referred to as congruence checking. There must be some degree of semantic match, but more critical is a grammatical match.
Lemmas in the mental lexicon include directions that map semantic information to grammatical structure, directions needed at the next level, the formulator. Thus, lemmas contain information beyond word meaning about thematic roles and selectional restrictions that have syntactic consequences, such as argument structure. For example, the verb hit assigns the thematic roles of Agent and Patient to a subject and object, respectively. Other lemmas in the mental lexicon underlie late SMs that become salient at the level of the formulator and will build syntactic structure (see §19.4.1).
Lemmas point to language-specific morpho-syntactic constraints located in the formulator. The formulator assembles larger constituents. The mental lexicon also contains language-specific Generalized Lexical Knowledge (GLK) that reflects the grammatical competence of speakers in their languages (Myers-Scotton and Jake Reference Myers-Scotton and Jake1995; Myers-Scotton Reference Myers-Scotton2002a). GLK plays an important role in congruence checking between languages and explains how EL lemmas without close ML counterparts occur in CS because their features can be checked against ML Generalized Lexical Knowledge.
Incomplete congruence can have repercussions for CS. Significant incongruence may mean that optimal CS mixed constituents with EL elements entirely framed by the ML do not occur. Instead, compromise strategies such as entire, well-formed phrases in the EL (EL islands), may occur. Sometimes EL content morphemes occur in ML frames as bare forms, without the SMs that would make the phrase well-formed in the ML. Note that the occurrence of bare forms implies that the ML is an abstract construct and not necessarily identical with the morpho-syntax of the language that is its source.
19.4 The 4-M model
The 4-M model does not replace the MLF model; rather, it offers a more precise description of morpheme types by viewing them in terms of their syntactic roles and how they are activated in language production. For convenience, the model employs the term “morpheme” to refer both to the abstract entries in the mental lexicon that underlie surface realizations and to the surface realizations themselves. The model separates out three types of system morpheme: early SMs, and two types of late SMs, bridges and outsiders. The MLF model’s SMP is often misunderstood as applying to all SMs. However, it was always intended to constrain only one type of SM, now called outsiders (Myers-Scotton Reference Myers-Scotton1993a, Reference Myers-Scotton1997:82). The 4-M model keeps the division between content and system morphemes, but explicitly recognizes significant divisions between morpheme types.
The primary division is between morphemes that are conceptually-activated (e.g. nouns and verbs) and those that are structurally-assigned (e.g. AGR elements). Content morphemes are conceptually-activated. They are based on the speaker’s pre-linguistic intentions; recall the semantic/pragmatic feature bundles that speakers’ intentions activate. But early SMs (e.g. plural affixes) are also conceptually-activated; they flesh out the meaning of their content morpheme heads that “indirectly elect” them (see Bock and Levelt Reference Bock, Willem and Gernsbacher1994). Because they are structurally-assigned, late SMs contrast with both content morphemes and early SMs in an important way with many ramifications for both monolingual and language contact data.
19.4.1 The Differential Access Hypothesis
In CS, and in line with what the USP would predict, the distribution of morpheme types across the ML and EL is quite different. Not only are there distribution differences between content and system morphemes, but also within the category of SMs itself. Recognizing this motivates new ways of classifying morphemes and leads to the 4-M model. In turn, how the 4-M model classifies morpheme types leads to a hypothesis that abstract differences at the production level account for surface level differences in morpheme types. The Differential Access Hypothesis (DAH) offers an explanation for the observed differences. The DAH is the following:
The different types of morpheme under the 4-M model are differentially accessed in the abstract levels of the production process. Specifically, content morphemes and early SMs are accessed at the level of the mental lexicon, but late SMs do not become salient until the level of the formulator.
The hypothesis suggests the following scenario. As already noted, lemmas underlying content and early SMs send language-specific directions to the formulator to build larger linguistic units. To build these units, these directions contain information about assigning late SMs. These late SMs become salient only when they are structurally-assigned at the formulator. Separating the activation of abstract elements underlying surface morpheme types echoes Garrett’s view that “major and minor grammatical category words behave quite differently” (Reference Garrett, Blanken, Dittmann, Grimm, Marshall and Wallesch1993:81). However, he and others, such as Ullman (Reference Ullman2001), who posits that the grammar and lexicon are two separate systems, do not differentiate the distribution of different types of SMs.
This theory differs from contemporary linguistic theories that project “functional” elements as the heads of maximal projections. The following sections exemplify EL morphemes in CS in terms of SM types, showing how their distribution follows the USP and implies the DAH.
19.4.2 Early SMs
Early SMs are so-designated because they, along with their content morpheme heads, become salient in the mental lexicon as the basic building blocks of constituent structure, such as NP, VP, AP. Yet, they are still SMs because only content morphemes receive and assign thematic roles. Early SMs typically occur with the content morpheme heads that select them. Early SMs may be free or bound. For example, definite articles are early SMs but always occur with nouns in English.
Plural and derivational affixes are examples of early SMs. Unfortunately, to date, few studies include quantitative evidence on the distribution of either type of early SM. However, in one quantitative study considering determiners in bilingual NPs in a Spanish–English corpus, 151/161 (94%) of English nouns in well-formed mixed NPs occur with Spanish determiners, such as el garage (Jake et al. Reference Jake, Myers-Scotton and Gross2002). Because Spanish can be identified as the ML, the overwhelming number of these mixed NPs supports the USP because ML structure is maintained in these NPs even though the noun is from English. However, as early SMs, definite articles can come from the EL without violating the SMP, and occasionally do, as in Palestinian Arabic–English CS el pharmacy is very boring [. . .] (Okasha Reference Okasha1999:110).
Verb satellites (also called particles) that occur with what are often called phrasal verbs are also early SMs because they depend on their heads for their appearance and they add meaning to their heads. Under the MLF model, these and other derivational morphemes may come from the EL because they are not the type of morpheme that the SMP restricts. EL phrasal verbs often appear with their EL verb satellites. An example from Swahili–English CS shows this, u-na-chase after (“you are chasing after”), as does another example from Arabic–English: [an engine is] locked up. In an Ewe–English example, an Ewe object suffix -e “him” can attach to the verb, as required in Ewe, but the particle remains in the EL, English: keep-e away from Eun (“keep him away from Eun”) (Amuzu Reference Amuzu1998:53). That Ewe supplies the third person singular object suffix shows how the USP is supported as grammatical structure from the ML is maintained.
19.4.2.1 Plural markers as early SMs
Perhaps the most common early SM studied in Classic CS corpora is the plural marker. The language of origin of the plural marker in CS varies in four ways: the possible combinations are these: (1.) EL plural marking only, (2.) no plural marking at all, (3.) ML plural marking only, (4.) plural marked from both the EL and ML.
(1.) Most often, plural is marked on an EL noun by its EL plural affix, but no overt ML affix, as in Welsh–English CS in the phrase: y motorway-s na’r dual carriageway-s (“on the motorways nor the dual carriageways”) (Deuchar 2006). In a Moroccan Arabic–Dutch example, duk artikel-en (“those articles”), the Dutch (EL) noun occurs with a Dutch plural suffix, but its plural determiner from Arabic (ML) shows agreement, thereby maintaining ML structure and the USP’s dictates (Boumans Reference Boumans1998:37). In example (3) workers has no ML plural marking, but its agreements indicate that the EL noun is operating as a class 2 Swahili noun. The demonstrative hawa (“these”) and the associative wa (“of”) show plural agreement (class 2).
(3) Swahili–English
Mbona ha-wa worker-s wa East Africa Power and Lighting
wa-ka-end-a strike [. . .]
Why dem-c.2 worker-PL c.2-assoc East Africa Power and Lighting
c.2-consec-go strike
“Why did workers of East Africa Power and Lighting go [on] strike [. . .]?”
In some language pairs with morphologically rich MLs, this is a frequent pattern. Even though an EL noun occurs without the ML plural marker, there is evidence that the ML assigns plurality features to the EL noun (see Myers-Scotton Reference Myers-Scotton2002a:127–31).
(2.) In some language pairs, an EL noun appears with no plural markings. In na date zingine (“with other dates”) from Swahili–English, even though date has no plural at all, its modifier (zi-ngine) has a prefix from noun class 10 (zi-), indicating date is intended as a class 10 plural.
(3.) Perhaps less frequently, but still often, an ML affix marks plurality and there is no EL plural affix. For example, a Turkish (ML) plural suffix (-lar) occurs in the otherwise Dutch (EL) phrase klant-lar wegjag-en (customer-pl away-chase-INF “chase away customers”) (Boeschoten Reference Boeschoten1991:90).
(4.) Finally, sometimes both EL and ML early SMs occur with an EL content morpheme head; they are usually affixes. Both convey plurality, although they may contain other information as well. This “double morphology” can occur with other early SMs, but occurs most often with plural affixes. For example, in the Acholi–English example lu-civilian-s (“the civilians”), Acholi lu encodes both definiteness and plural (Myers-Scotton Reference Myers-Scotton2005d) and English -s also encodes plural.
19.4.2.2 Early SMs and internal EL islands
When an EL early SM, particularly a plural marker, occurs with its EL content morpheme head, it often occurs in a construction of EL elements framed by the ML, as in Spanish–English tant-a-s thing-s (“so.many-FEM-PL thing-s”). In such instances, early SMs together with their content morpheme heads are small EL islands (internal EL islands). These islands are well-formed in the EL, but are part of a larger mixed constituent framed by the ML. They are like other EL islands, but are smaller than phrasal level constituents, full EL islands (e.g. the PP, on the weekend). Many internal EL islands contain the crucial “chunks” of collocations that are then framed by the ML (see Backus Reference Backus2003, on multi-morphemic “chunks”). For example, French–English la real thing (King Reference King2000:100), Cajun–French le highest class (Brown Reference Brown and Sankoff1986:404), and sa little salary (see (4) below) do not occur as maximal EL constituents. Instead, they occur framed by an ML element. This is evidence that the USP is observed in bilingual speech whenever possible.
19.4.3 Late system morphemes
In contrast to early SMs, two types of late SMs are structurally-assigned. The term “late” suggests that they are not activated until a later production level. While early SMs largely build semantic structure, late SMs build syntactic structure. These late SMs are labeled “bridges” and “outsiders.” The DAH, discussed in §19.4.1, explains observable differences in data distribution by postulating a fundamental difference in how late SMs are accessed. It states that not all morphemes become salient at the same level of language production. Information about content morphemes and early SMs is available at the level of the mental lexicon; late SMs do not become salient until the level of the formulator. The role of late SMs is to construct larger constituents out of conceptually-activated morphemes; they assemble phrases and connect phrases to realize full clauses. Put simply, late SMs satisfy the requirements of the USP that constituents maintain a consistent structure. “The late system morphemes [. . .] indicate relationships within the clauses; they are the cement that holds the clause together” (Myers-Scotton Reference Myers-Scotton2006a:269).
19.4.3.1 Bridge late SMs
Bridge late SMs provide “bridges” between elements that make up larger constituents. There is an important difference between bridge SMs and outsider SMs. For information about their form (and, indeed, their presence), bridges depend on information within their maximal projection, while outsider SMs depend on information outside the maximal projection in which they appear. Also, bridges seem to have an invariant form (they constitute a single allomorph); in contrast, outsiders seem to be part of a paradigm or conjugation (with more than one allomorph). English of is an example of a bridge SM, as in requirements of the college; so is ’s in Lena’s shoe. In French, de is an equivalent bridge, as in le français de Bruxelles (“the French of Brussels”). Example (5) shows a similar bridge from Hindi (kii) with a partitive meaning.
(5) Hindi–English
merii paatnii saaRii kii choice kar-egii
my wife saree of choice do-fut.3sg.fem
“My wife will choose a saree.”
Because language-specific requirements for phrasal well-formedness vary, bridges are required in some languages, but not in others. For example, in many languages, weather expressions require a bridge. In these expressions, the subject pronoun does not receive a thematic role, e.g. French il pleut or English it is raining. In such expressions, the pronoun it is different from referring indefinite/antecedent third person singular it, a content morpheme in English (as in Where is the book? It is on the table.). Similarly, in American English, in certain expressions, determiners are bridges, not early SMs, as in this exchange: Where’s John? He had to go to the hospital. No definite hospital is indicated.
In CS corpora, most bridges come from the ML. Example (6) from an Acholi–English corpus shows a bridge me coming from the ML, Acholi. In the entire corpus, an English bridge occurs in only one formulaic EL island (cost of living). Altogether, 42 Acholi associative constructions have at least one NP from English.
(6) Acholi–English
Chances me accident pol ka i-boarding taxi
chances assoc accident many if 2sg-board taxi
“[The] chances of [an] accident [are] many if you board [a] taxi.”
EL bridges occur very rarely in mixed constituents, although there is an exception noted in the literature. When Arabic is the EL, sometimes it supplies the bridge djal in a clause framed by French as in French–Moroccan Arabic connaissance dyal la personne “knowledge of the person” (Bentahila and Davies Reference Bentahila, Davies and Jacobson1998:38). The presence of dyal in such cases does not violate the SMP. It is clearly a bridge SM, not an outsider.
19.4.3.2 Outsider late SMs
The second type of late SM is the outsider. As noted above, this morpheme type differs from bridges in that the presence and form of an outsider depends on information that is outside of the element with which it occurs. This information can come from another element in another constituent, or from the discourse as a whole. For example, subject–verb agreement is realized by outsider late SMs. However, in pro-drop languages, a late SM may be co-indexed with a null pronoun, whose relevant grammatical features come from the larger discourse. For example, in Spanish, the -en on the verb corr-en (run-3pl) is a late SM when it occurs as los estudiantes corren (“the students run”) or simply corren (“[they] run”).
There is good evidence from various sources that outsiders behave differently from other morphemes in many linguistic phenomena – see Myers-Scotton and Jake (Reference Myers-Scotton and Jake2000) on Broca’s aphasia and second language acquisition; Myers-Scotton (Reference Myers-Scotton2002a) on speech errors and attrition; Myers-Scotton (Reference Myers-Scotton, Matras and Bakker2003) on split or mixed languages; and Wei (Reference Wei2000a) on second language acquisition. There is also scattered evidence in the literature about the distinctive distribution of outsiders in various contact phenomena. For example, Johanson (Reference Johanson, Extra and Verhoeven1998:251–3) notes that Turkic languages frequently borrowed conjunctions from other languages, but they “practically never” borrowed what he calls “relators.” These relators include case markers, which are outsider SMs.
Certainly, outsiders are the most crucial and unambiguous purveyors of grammatical structures. They provide a more precise indexing of relations that extends beyond word order and basic constituent structure. Outsiders “knit together elements at another level” (Myers-Scotton Reference Myers-Scotton2005c:25). The grammatical relations indexed by outsiders reinforce semantic coherence within the clause and within the larger discourse. Furthermore, “[t]hese characteristics are the basis for an argument that outsider morphemes are the main bastion for maintaining uniform structure [the USP] in a clause” (Reference Myers-Scotton2005c:25). Given that these characteristics define outsiders, it follows that the distribution of outsider late SMs should be the most defining feature of Classic CS – and it is. With few exceptions, outsiders always come from the ML in mixed constituents.
In some CS data sets, ML outsiders as AGR features occur with EL verbs, as in example (7): the third person singular prefix i- on appartenir shows subject–verb agreement, referring to richesse, the subject of the clause. The object prefix -tu- (“us”) refers to the speaker and previously mentioned others. In addition, the class 9 prefix y- on y-ote (“of all”) is also an outsider, as is the prefix on y-ake (“his”).
(7) Shaba Swahili–French
Donc, (h)ii richesse y-ote (h)ii i-na-tu-appartenir shi
So, c.9.dem riches c.9-all c.9.dem c.9-non-past.obj.1pl-belong us ba-toto y-ake
c.2-child c.9-his
“So, all these riches, it belongs to us, his children.”
When the ML is a language with case assigning verbs (and/or prepositions), case markers are also outsiders. Almost without exception, EL elements receive the expected ML case marker as in (8), in which Dutch terras receives locative case from Turkish. Similarly, in (9), English grass is inflected with prepositional case from Russian.
(8) Turkish–Dutch
evet, terras-ta oturuyorlar
yes cafe-loc sit-PROG.3pl
“Yes, they are sitting at the outdoor cafe.”
(9) Russian–English
Zachem ty na grass-e valjajesih’sja
what-for you.sg on grass-prep.sg roll-around
“Why are you rolling around on the grass?”
19.5 An overview of morpheme types
An important advantage of the 4-M model over other approaches to classifying morphemes is that it eliminates the problem that lexical category membership does not predict morpheme type. That is, members of a category need not be members of the same 4-M morpheme type. In fact, in terms of the 4-M model’s defining features for morpheme types, some morphemes in the lexical types we consider here (prepositions, pronouns, and complementizers) are content morphemes, but others are early SMs, and still others are either bridge or outsider late SMs. The Chomskyan lexical–functional element dichotomy does not account for these differences. The premises of the 4-M model that allow for such a flexible classification are supported by findings in CS data, other contact phenomena, and evidence from various types of language acquisition and loss. Simply put, not all prepositions, pronouns, or complementizers have the same distribution.
19.5.1 Prepositions
Linguistic theory has long recognized that prepositions do not behave as a uniform class (see e.g. Abney Reference Abney1987). Under the 4-M model, prepositions can be content morphemes or any of the three types of SMs. Sometimes the same phonological form fits into more than one category. For example, in He walked across the street, across assigns a thematic role and is a content morpheme. In CS, content morpheme prepositions can come from the EL, as in (10). There are not many examples of such EL prepositions in mixed constituents; more frequently, they occur in PPs that are EL islands (e.g. before tomorrow evening).
(10) Swahili–English
Labda, [. . .] bring it at my home. U-let-e before kesho jioni.
perhaps, bring it to my home. 2sg-bring-subjunct before tomorrow evening
“Perhaps you should bring it to my house. You should bring it before tomorrow evening.”
Some prepositions can also be indirectly elected at the conceptual level, and are then early system morphemes: in he comes across as ill-prepared, across occurs with come, its content morpheme head. The discussion in §19.4.2 above includes examples in which prepositions are satellites of phrasal verbs, and suggests that the satellite comes from the same language as the verb, either EL or ML verb. However, sometimes such early SMs occur in the EL even when the verb is in the ML. In (11), the expression “change [something] around” is realized in both Spanish and English, with English supplying the preposition around.
(11) Spanish–English
Sometimes prepositions are late SMs that are not activated until the level of the formulator; these primarily contribute structure, and not content. For example, prepositions that are bridge SMs make a phrasal constituent well-formed. Although EL bridge prepositions can occur in mixed constituents, very few actually do. As noted above in some French–Arabic CS, Arabic djal (equivalent to “of”) occurs in associative constituents in French-framed CPs. Below are discussed some instances of EL bridges that occur with more frequency, namely, Comp bridges.
Some locative prepositions are bridges; they do not encode directionality or motion, but locate a figure with respect to a ground (see Talmy Reference Talmy2000). For example, in Joe’s in school, in adds little conceptual information to the mapping of the theme (Joe) to the ground (school). Such bridge prepositions show variation (e.g. Joe’s at school). However, in can also be a content morpheme or an early SM. In He’s all done in, in is an early SM. Further, in is a content morpheme in In this example, they illustrate the distinction; like other content morphemes, the thematic role assigned by in can be questioned, as in Where do they illustrate the distinction?
In some languages, prepositions are also outsiders. Consider Spanish a. It can be a content morpheme assigning directionality, as in va a Hamburg “he/she goes to Hamburg,” or an early SM, as in miremos al año que viene, (“we are looking forward to the coming year”) (al = a + el “to+the.m.def”). As a bridge, it connects purpose infinitives with matrix CPs, as in prepare a venir (“prepare to come”). Finally, a occurs as an outsider when it assigns case to animate direct objects, as in veo a Eva “I see Eva.” The prediction is that as ML, Spanish will supply personal a to objects in mixed constituents, as in refieres a tus coworkers (“you are talking about your coworkers”) (Jake et al. Reference Jake, Myers-Scotton and Gross2002), but that as EL, Spanish NP animate objects do not have to occur with personal a, as in the police officers have seen un ladrón (“The police officers have seen a thief”) (Belazi et al. Reference Belazi, Rubin and Toribio1994:230).
The 4-M model articulates how morphemes are classified. Even so, the fact that one prepositional form can be activated at more than one level and is thus subject to different conditions in CS demands careful analysis. The SMP requires that all outsider prepositions come from the ML in mixed constituents. The distribution of bridges in most CS also supports the USP; one language, the ML, provides most of the grammatical frame.
19.5.2 Pronouns
Pronouns are another lexical category that is not uniform because they can be members of any of the four morpheme types (see Jake Reference Jake1994). Some are content morphemes; i.e. they occur in argument position and receive thematic roles. As content morphemes, EL pronouns can occur in clauses framed by the ML. For example Klintborg (Reference Klintborg1995) reports English pronouns in Swedish-framed clauses in Swedish–American English CS, as in När vi var hemma sista gånge me and min hustru (“When we were home last time me and my wife”) and [. . .] he var smed för tyket (“[. . .] he was a blacksmith by trade”).
But even when pronouns are content morphemes, EL pronouns occur very infrequently except in EL islands. Why? First, preference is for ML elements. Also, ML counterparts play a role. When pronouns in the ML are clitics or affixes licensing null pronouns in argument position, they are outsider SMs and must come from the ML (see the Blocking Hypothesis (Myers-Scotton Reference Myers-Scotton1993a, Reference Myers-Scotton1997:120) which requires congruence with the ML).
However, EL content morpheme pronouns that establish topics or contrast occur widely in bilingual clauses. They convey both conceptual and procedural information, as noted by Wilson and Sperber (Reference Wilson and Dan1993:21). Example (12) shows an English pronoun within a Malay grammatical frame, expressing a “dual notion of fusion and contrast” (Jacobson Reference Jacobson and Jacobson2000:68).
(12) Malay–English
Oh! About the recent controversy? I tak bersetujulah kalau women stay at home.
Oh! About the recent controversy? I not agree-emph if . . .
“Oh! About the recent controversy? I don’t agree that women should stay at home.”
Other examples from diverse language pairs abound. Haust (Reference Haust1995) includes examples of Mandinka emphatic pronouns occurring in English-framed CPs and Wolof-framed CPs. English contrastive topic pronouns occur in Spanish-framed CPs, as in You estás diciéndole [sic] la pregunta in the wrong person (“You are asking the question in the wrong person”) (Sankoff and Poplack Reference Sankoff and Shana1981:13).
Some researchers have commented on “pronoun doubling,” as in (13), but this is not the true doubling that occurs with early SMs. Each pronoun is activated independently and occurs in a separate position in the bilingual CP. In (13), for example, the Arabic discourse emphatic pronoun nta (“you”) is adjoined under Comp and the French tu (“you”) is an agreement clitic not in argument position. A null pronoun is assumed to occur in subject position. In (14), Arabic ?iħna (“we”) is adjoined under Comp and English we occurs in subject position.
(13) Morrocan Arabic–French
nta tu va travailler
2sg.emph 2sg go work-inf
(14) Palestinian Arabic–English
?iħna we are supposed to be nudris-ing
1pl.top . . . study-Prog
“We, we are supposed to be studying.”
And in the Spanish–English example cited above, the English emphatic pronoun you is a topic, and a Spanish null pronoun occurs as the subject.
In sum, the distribution of pronouns in CS reflects their classification under the 4-M model. The requirements of the MLF model foreshadow the import of this classification. Both the SMP, which requires ML outsider pronouns in mixed constituents, and the Blocking Hypothesis, which requires cross-linguistic congruence, imply how critical it is to recognize morpheme type at the abstract level of clause construction. Taken together, they maintain the integrity of the frame in line with the USP.
19.5.3 Complementizers and other clause connectors
Complementizers and complementizer-like elements are similar to prepositions and pronouns in not showing a uniform distribution in CS. In current syntactic theory, COMP is the head of any clause identified as CP, projection of Complementizer. Variation among COMP elements themselves and cross-linguistic variation in their patterning in CS complicate their discussion. Also, there is no uniform agreement regarding what elements are rightly classified under COMP. Complementizers include not just elements such as that, but also subordinating conjunctions, relative clause markers, other elements that indicate clause boundaries, and even coordinating conjunctions. These elements are discussed according to how they are elected and how they participate in the construction of a CP.
Like pronouns, most complementizers convey procedural knowledge. Many constrain the truth-conditions of propositions and participate in the discourse-thematic structure of propositions. For example, porque “because” in (15) assigns a discourse-level thematic role of Cause or Reason.
(15) Spanish–English
trabajé menos porque then I didn’t know some of his business
work.Pret.1SG less because . . .
“I worked less because then [i.e. at that time] I didn’t know some of his business.”
Most complementizers straddle two CPs. In this way, they are at the intersection between inter-sentential CS and intra-sentential CS. In example (15), porque is the head of the subordinate CP (hereafter CP2), yet it is within the domain of a matrix clause (hereafter CP1), and is in the language of CP1.
19.5.3.1 Overview of complementizer types
Several factors play a role in determining the source of complementizers. These include the type of morpheme, the grammatical requirements of the participating languages, and the overall pattern in the discourse. Complementizers from one of the participating languages are preferred if that language is typically the ML in mixed constituents throughout the corpus.
Under the 4-M model, some complementizers and complementizer-like elements are bridge SMs, especially complementizers such as “that.” Similar complementizers are multi-morphemic elements that include a bridge and an outsider SM. For example, in Arabic, ?inn- (“that-”) occurs with a suffix agreeing with the subject of CP2. Finally, many subordinators and coordinators are content morphemes (e.g. French alors “then” or German aber “but”). In many corpora, content morpheme subordinators and coordinators tend to come from the ML of either CP. In (15) above, porque comes from the ML of CP1.
19.5.3.2 The language of the complementizer
If CS occurs at the clause boundary, is the complementizer in the language framing CP1 or CP2? It appears that in some language pairs, the complementizer can come from either language. In Spanish–English CS, for example, que can introduce an English CP (see 16), and that can introduce a Spanish CP (see 17). However, the complementizer can also be in the ML of CP2, as in (18) and (19).
Tonces salió eso que she wanted to take mechanics
“Then it turned out that she wanted to take mechanics.”
They sell so much of it that lo están sacando y many people [. . .]
. . . it be.3pl take-part and . . .
“They sell so much of it that they’re taking it out and many people [. . .]”
Sí, but the thing is que empiezan bien recio and [. . .]
“Yes, but the thing is that [(they)] start[3PL] pretty fast and [. . .]”
El profesor dijo that the student had received an A
“The professor said that the student had received an A.”
19.5.3.3 That-type complementizers as bridges
The distribution of complementizers such as that and que supports their analysis as bridge SMs. That-like complementizers allow a larger constituent, a multi-clause structure, to be constructed out of an embedded CP and a matrix CP. And unlike content morphemes and early SMs, bridges convey little representational meaning. In this way, that-like complementizers are different from other complementizers such as when and before, and their equivalents across languages.
It is not surprising that bridge complementizers can come from either language with CS at clause boundaries. This is because, although bridges join two constituents together, they are invariant placeholders satisfying well-formedness conditions for the larger unit. In some language pairs, that-like complementizers come from one specific participating language, regardless of the ML of CP1 or CP2. For example, in Chicheŵa–English CS, the bridge complementizer always comes from Chicheŵa, as in (20). In Simango’s (Reference Simango1996) corpus, kuti introduces over 20 English-framed clauses, but that never introduces any English clauses.
(20) Chicheŵa–English
[. . .] a-ka-tsimikiz-e kuti this was the end
[. . .] 3sg-consec-confim-subjunct that . . .
“[. . .] he confirms that this was the end.”
This suggests that language-specific factors are involved. For example Chicheŵa requires a complementizer, whereas English does not.
19.5.3.4 Outsider complementizers
As noted above, Arabic ?inn- agrees with the subject of CP2. In Arabic–English CS, these multi-morphemic complementizers always come from Arabic. For example, Okasha (Reference Okasha1999) reports that ?inn- introduces 10 clauses entirely in English, as in (21), and 15 bilingual clauses framed in English. No English complementizers occur with Arabic clauses.
(21) Palestinian Arabic–English
kaan el-doctor yišuk ?innu it is not reliable
perf.3masc.be the-doctor imperf.3masc.doubt that.3masc it is not reliable
‘[he] was, the doctor, doubting that it was not reliable’
In the case of Arabic–English CS, the USP is better satisfied when the complementizer comes from the ML of CP1. This configuration means that the following IP (clause) is in the EL of CP2. That is, ?inn- does not just bridge two CPs; it coindexes an embedded CP with the ML of CP1, and frames the entire multi-clausal constituent in one language, Arabic. Thus the English clause in (21) is an embedded IP island (and English is not the ML of CP2).
Not only are Arabic bridge complementizers inflected with outsider SMs, but so are subordinators, which are content morphemes in many languages. In (22) li?anhum “because” agrees with the third person plural subject they of the English IP.
(22) Palestinian Arabic–English
[. . .] huma biyidfa9ooli kul haga li?anuhum they can afford it
[. . .] they hab.imp.3pl.pay.1sg every thing because.3pl . . .
“[. . .] they pay for everything [for me] because they can afford it.”
19.5.3.5 Content morpheme complementizers
Adverbial-like subordinators are conceptually-activated content morphemes. They introduce discourse-thematic roles. When they are uninflected, the language of the complementizer can be different from the language of the CP it introduces. Thus, porque “because” can introduce an English CP, as in (15) above. And in many other language pairs, the language of such subordinators appears free. For example, in Wolof–French CS, French subordinators introduce clauses that are bilingual or mixed (Swigart Reference Swigart1992a, Reference Swigart1992b, Reference Swigart1992c).
Under the 4-M model, most coordinating conjunctions are also content morphemes. They reflect procedural knowledge and are truth conditional, although some have more procedural content than others. In (23), English conjoins two Xhosa clauses.
(23) Xhosa–English
[. . .] ba-se-msebenzi-ni and umalume be-ka-khal-a kude ku-na-thi [. . .]
[. . .] 2.pl-loc-work-loc and my.uncle pst of-stay-FV far loc-have-us [. . .]
“[. . .] they were at work and my uncle lived far from us [. . .]”
19.5.3.6 Summary: The language of the complementizer
In summary, although EL complementizers do not appear in CS as freely as some categories, participation largely depends on their morpheme type. EL subordinators and coordinators, usually content morphemes, are quite robust. However, subordinators or that-like complementizers that include an outsider seem to always come from the ML, even when the outsider depends on a CP2 whose clause is otherwise framed by the EL. That-like complementizers which are bridges are a mixed bag. With some languages, these complementizers must come from the ML, with others they do not.
When the complementizer of CP2 is in the ML of CP1, it reinforces uniformity across clauses. This suggests that only when the complementizers of the participating languages are congruent enough not to violate language specific requirements do complementizers come from the ML of CP2 (e.g. Spanish–English CS). However, no matter what the morpheme type, whatever ML dominates in the discourse seems to preference complementizers from that language, reflecting a more general organizing principle, the USP.
19.6 Conclusion
One goal of this chapter has been to offer implications for the nature of bilingual production and processing that arise from considering naturally occurring CS corpora in terms of the MLF model and the 4-M model. In turn, this leads us to a more universally applicable characterization of linguistic structure, the Uniform Structure Principle (USP). In bilingual utterances, there is no a priori reason to expect uniformity in clause structure; the significance of the principle for contact linguistics is that the USP predicts uniformity. It preferences the structures of only one of the participating languages. The extent to which this principle is supported implies certain preferences for how the cognitive component supporting bilingual speech is structured.
Early researchers in contact linguistics avoided CS, focusing instead on possible contact-induced change or dialectal variation. For example, the father of modern contact linguistics, Weinreich (Reference Weinreich1954, 1967) famously dismissed bilingual CS clauses in a way that implied that looking for organizing principles in CS was a theoretical dead end. In contrast, the USP, along with the MLF and 4-M models, predict that a principled account of CS is possible. Thus, the mantra of the USP is “no chaos allowed.” Such an account depends on premises about predictable divisions between the roles of participating languages and morpheme types. In turn, these divisions motivate a model of language production and present implications about organization within the cognitive components supporting language.
19.6.1 Predictable patterns
The bulk of this chapter is descriptive, but with the theoretical goal of demonstrating how the asymmetries that one finds in CS show a predictable pattern. The goal here has been to demonstrate that the contributions of morphemes of participating languages depend on the four morpheme types and to relate this observation to production. When one views morphemes in terms of these types and in terms of the Differential Access Hypothesis, a principled explanation for differences in their cross-linguistic distributions in CS is forthcoming. Three examples illustrate insights of this chapter.
First, it is predicted that double plural marking on EL nouns is possible, but that double subject–verb agreement or double case marking is not. This disparity is owed to the difference in how these morphemes are accessed in language production. Plural affixes are early SMs while subject–verb agreement and case markers are outsider SMs. EL early SMs can be accessed with their content heads because they are conceptually activated and available in the mental lexicon, but outsiders become salient only later, at the level of the formulator.
Second, a strong preference for the ML to supply “that-type” complementizers at clause boundaries is predicted. However, subordinating complementizers are less constrained and they come from either language. The reason again is differences in morpheme type and hypotheses about their production history. That-type complementizers are bridge SMs and, although not as critical in building clauses as outsiders, are still part of constituent structure and are salient at the level of the formulator. When they come from the ML, the USP is satisfied. In contrast, many subordinators are content morphemes; they are activated by speakers’ intentions (conceptually activated), and are available in the mental lexicon.
Third, prepositions fall into all four types under the 4-M model, but not all types are predicted to come from the EL, or with the same frequency. In fact, EL prepositions do not occur frequently, and this may be because of their role in structuring constituents and the requirement of uniform structure, i.e. the USP. Among prepositions, early SMs are more frequent, perhaps because they allow for an elaboration of pragmatic and semantic structure without creating syntactic structure. Prepositions that are content morphemes (i.e. that assign thematic roles) are the most unconstrained; even so, they are not frequent.
Of the three types of SMs, early SMs are the least constrained because they are conceptually activated, whereas bridges and outsiders are structurally assigned. Even so, the most frequent early SMs seem to be the most contentful ones, plural affixes and definite articles. Only a few types of EL bridge SMs occur, and no EL outsider SMs occur in mixed constituents (except for fairly rare types of EL islands). More research needs to be done on EL islands, but the overall point about prepositions holds for all lexical categories: morpheme type, as discussed at many points above, makes the difference in their distribution.
19.6.2 Cognitive support systems
Such differences in morpheme distribution across languages are systematic and follow from the MLF and 4-M models, as well as the USP; they are also empirically verifiable. However, these differences also imply some speculations about language production and the cognitive systems supporting language. First, the division of labor between languages in CS, with only one language providing the morpho-syntactic frame of the bilingual clause, seems to imply some sort of divisions within the cognitive component supporting this surface asymmetry. Certainly, any intra-clause CS implies that both languages are active during bilingual production, but that the ML has a higher level of activation.
Second, the USP implies that cognitive energy is conserved by allowing only minor-level switches to EL islands. If we look at the frequency with which EL content morphemes are integrated into an ML-framed structure and juxtapose this frequency with the USP’s injunction against changing languages, one conclusion is that accessing words from the EL requires a different type or level of activation than creating morpho-syntactic structure.
Third, the role of the EL is explicitly limited. Most obviously, the EL never structures any constituents that include ML morphemes. This means that the EL has little opportunity to supply any outsider SMs to the bilingual clause except in EL islands, but typical EL islands have few structures that would require outsiders. Further, except for occasional early SMs or even less frequent bridge SMs, the EL supplies only content morphemes within constituents structured by the ML. The dearth of outsider SMs from the EL motivates the conclusion that the cognitive component supporting this morpheme type may be independent from that which coordinates simpler syntactic constructions. Keep in mind the complex tasks that this mental architecture must accomplish: outsiders are critical in signaling thematic roles and other relationships of the semantic–syntactic interface; without them, there can be no clause.
19.6.3 Testing hypotheses
Finally, as already noted at many points above, CS data support the DAH that is derived from the 4-M model. This hypothesis suggests a language production model in which some of the elements underlying surface level morphemes are salient at one level and others are not salient until another level. Specifically, late SMs are not salient until they are called by the lemmas underlying content morphemes to construct larger constituents in the formulator. Obviously, the extent to which this hypothesis is supported has relevance beyond CS and other types of contact phenomena to both child and second language acquisition, among other topics. The results of psycholinguistic experiments testing this hypothesis will add crucial support to a language processing model that accommodates the notion of saliencies at different levels (Myers-Scotton Reference Myers-Scotton2006b). Not only does this matter for production models, but also for comprehension models.
19.6.4 Supporting the Uniform Structure Principle (USP)
In sum, this chapter has shown how the distribution of morpheme types in Classic CS, at least, is compatible with predictions of the MLF and 4-M models, and the USP. As an empirical window on divisions of labor between participating languages, CS implies intriguing hypotheses about some ways in which language is supported in our cognitive systems.

