

Part III Comparative perspectives on linguistic structures
9 Language internal and external factors in the development of the desiderative in South American indigenous languages
This chapter addresses the frequency and distribution patterns of morpho-syntactic desiderative markers in South American languages and traces the development of contrasting forms in a focal set of families and regions. Based on a sample of eighty-five languages, the results illustrate that desiderative markers are more common in South America than in other parts of the world and indicate a combination of genealogical and geographic effects: in several language families, desiderative markers derive from proto-forms but also reflect internal pressure and contact-induced grammaticalization. This is demonstrated for the Upper Xingú area.
1 Introduction
This chapter investigates in detail the frequent occurrence of morphosyntactic desiderative markers in South American indigenous languages. Although well-known for extensive linguistic diversity, South America has also been said to exhibit typological features that unite it as a linguistic macro-area and thus set it apart from other parts of the world. For example, Campbell (Reference Campbell, Campbell and Grondona2012b: 260) notes the claim that “many SA languages are agglutinative,” although he demonstrates this is both untrue and misleading. Such claims clearly are to be seen as tendencies rather than universals. In the same light, the present study does not claim that expression of the desiderative is a South American language universal but that it is indeed a macro-feature in a more general sense and that its high frequency of occurrence is due to a combination of genealogical, geographic, and typological traits against the unique sociolinguistic background of South America.
In a previous study (Müller Reference Müller2013) of tense, aspect, modality, and evidentiality in a similar but smaller sample, desiderative markers occur most frequently of all investigated modal categories, i.e. in thirty-nine of sixty-three languages. The second most frequent category, dubitative, occurs only in twenty-eight languages. The present study demonstrates that the relatively high frequency of desiderative markers compared to other modals holds true for a larger sample as well.
Recently, Heine and Kuteva (Reference Heine and Kuteva2003, Reference Heine and Kuteva2005, Reference Heine, Kuteva and Hickey2010) proposed that language-internal processes that look like independent developments, perhaps based on universal typological rules, can in fact be the result of contact, i.e. that contact is the trigger for grammaticalization. This is especially interesting regarding the fact that South America has grammaticalized desiderative forms that are not shared cross-linguistically, i.e. are not the result of inheritance, direct borrowing, or diffusion. Additionally, South America provides an ideal forum for contact studies, due to both the great number of language families and the centuries of population movements which resulted in regions where speakers of unrelated languages live closely together, e.g. the Içana-Vaupés basin (Aikhenvald Reference Aikhenvald, Dixon and Aikhenvald1999b). In this chapter, I will first introduce the methodology used in the study and provide a definition of desiderative (Section 2). Section 3 presents the general results and proposes that desiderative marking in South America is more frequent than in other parts of the world. Section 4 represents the main focus of the study and concentrates first on individual language families (4.1 Quechuan, 4.2 Nambikwaran, 4.3 Cariban, 4.4 Tupian) before discussing the special instance of desiderative marking in the Upper Xingú. It will be shown in Section 4.5 that Trumai, an isolate in the Upper Xingú region in Brazil, is likely to have grammaticalized a desiderative due to contact with Kamaiurá, a Tupian language. The last section wraps up the results and suggests avenues of future research.
2 Methodology
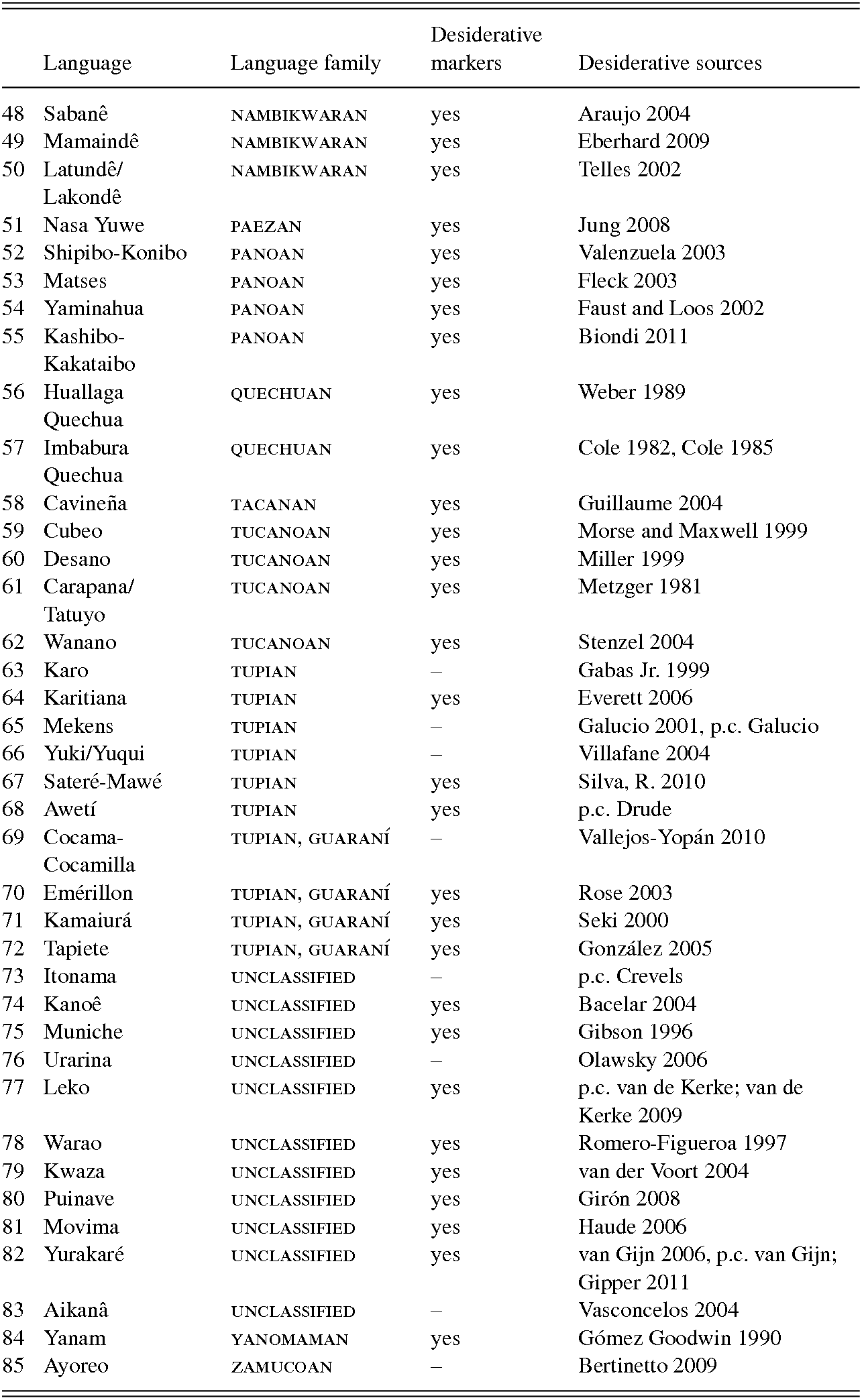
A sample of eighty-five South American indigenous languages was analyzed according to morphosyntactic desiderative marking. The languages were chosen according to maximal geographic and genealogical spread in South America and filtered by availability and quality of sources. Sources are predominantly reference grammars, supplemented by additional published materials and personal communication with language specialists. The original sample of sixty-three languages (Müller Reference Müller2013) was extended to include additional members of selected language families and regions in order to probe for possible genealogical relationships, and preference was given to regions that are proposed linguistic areas as a context for mapping the results. The language families in the sample represented by more than one language are Tupian (10), Arawakan (9), Cariban (7), Macro-Jêan (5), Guaycuruan (4), Panoan (4), Tucanoan (4), Nambikwaran (3), Chibchan (3), Barbacoan (2), Chocoan (2), Nadahup (2), and Quechuan (2). In addition, there are two isolates and eleven unclassified languages in the sample.
The study combines a semantic approach with morphosyntax in that it selects markers that have ‘desire’ as the predominant meaning and that these markers are specified according to morphosyntactic form. Included are affixes, clitics, auxiliaries, and particles. This omits complement clauses, periphrastic constructions, and simple lexemes (e.g. main verbs), although these are discussed where relevant. The selection of forms is deliberately restricted, as a full analysis of ‘want’ structures is beyond the scope of this study. For the same reason, zero markers are not taken into consideration. It goes without saying that in eighty-five language descriptions by different authors one finds different definitions of affixes, clitics, and other parts of speech and that the results are both prone to include markers that are not true desideratives and to miss undetected ones. The goal of the quantitative analysis here is not to arrive at absolute values but instead to serve as a starting point for a detailed analysis of language contact, and therefore a margin of error is considered acceptable.
A desiderative in this study is any kind of morphosyntactic form that has the prototypical meaning of ‘wish’ or ‘desire.’ Originally developed in 1975 by Rosch, prototype theory was first applied to the tense-aspect system by Dahl in 1985. According to prototype theory, a specific marker has a central or core meaning in addition to peripheral meanings. The core meaning in this study is ‘desire.’ Similar meanings such as ‘love’ or ‘like’ were not taken into consideration, although these are often encoded in the same forms (cf. Khanina Reference Khanina2008: 824, who found that 95 of 136 desideratives have additional meanings). Likewise, markers that have desire as a peripheral but not core meaning, such as intention, future, or similar functions, are also not considered desideratives here, although it is accepted that these are likely sources for desiderative grammaticalization paths.1 The type of form considered in this study is illustrated by the desiderative suffix -ene in (1), and example (2) shows the full verb kog ‘want’ as an example of a form outside the definition of desiderative in this study.
(1) Apurinã (Arawakan; Facundes Reference Facundes2000: 316)


The following section presents the results of the study and discusses the regional and genealogical distribution of desiderative markers with special focus on origin and language contact.
3 General results
In the sample, fifty-seven out of eighty-five languages feature morphosyntactic desiderative marking (see Table 9.4 in the appendix). Formal marking ranges from a predominance of suffixes to clitics, auxiliaries, and particles.
Although most of the languages have a single marker, usually in the form of a suffix, some languages have more than one desiderative marker, as will be discussed below.
The quantitative profile of desiderative marking shows both variety and uniformity within different language families in the sample. For example, only three of the nine Arawakan languages have desiderative markers, but all seven Cariban languages do, as well as all four Panoan languages, the two Quechuan, the two Nadahup, the four Tucanoan, the four Guaycuruan, and the three Nambikwaran languages. Only two of the five Macro-Jêan languages and six out of the ten Tupian languages mark the desiderative, while ten of the thirteen unclassified or isolate languages also have desiderative marking. The Chibchan and Chocoan languages do not have desiderative marking at all, with the exception of Kuna (Chibchan).
Compared to the rest of the world, the number of languages with desiderative marking is considerably higher in South America. According to Haspelmath (Reference Haspelmath, Dryer and Haspelmath2011b), in a global sample of 283 languages, 45 express ‘want’ with verbal affixes, 8 with uninflected verbal particles and 230 with complement clauses. The corresponding WALS map demonstrates that the great majority of languages in WALS with affixes and particles occur in North and South America, with minor clusters in North Australia and Papua New Guinea. Another study conducted by Khanina (Reference Khanina2008), who investigated formal properties of ‘want’ structures in 73 languages from 63 different families, yields only 34 morphosyntactically marked desideratives in the entire world. The general tendency of desideratives to occur more frequently in South America than anywhere else is confirmed by this study.
Tracing the origins of desiderative markers is a major topic in this study. Whereas for some languages within the same language family the markers unequivocally are the descendants of a common source, it will be demonstrated below that in several instances desideratives result from contact-induced grammaticalization and borrowing in combination with language internal development. It will be shown that the high frequency of desiderative marking in the sample is due to two facts: on the one hand, desiderative is a common feature within many South American language families, and on the other hand, languages have developed a desiderative as a result of contact with languages that exhibit desideratives in the first place. Before I start to present these two factors, a word about the grammaticalization of desideratives in general is necessary.
It seems natural that markers with a ‘want’ meaning develop from constituents with the same or similar semantics. This is partially observed in the present sample. Desideratives are transparently derived from full verbs with the meaning ‘want’ in Mamaindê and Sabanê (see Section 4.2), Emérillon and Kamaiurá (see Section 4.4), Trumai (see Section 4.5), Kuna (Villalobos Reference Villalobos1987: 32, footnote 13), Hup, and Katukina-Kanamari. It is notable that markers tend to acquire additional meanings and even change their prototypical semantics in the process of grammaticalization. For example, in Hup, the desiderative auxiliary tu/tuk grammaticalized from the verb tuk ‘want,’ and both forms can also encode (immediate) future. According to Epps (Reference Epps2008b: 422), this “grammaticalization of volition to future is cross-linguistically common (e.g., English ‘will’)”.2
(3) Hup (Nadahup; Epps Reference Epps2008b: 423, 148, 174)



Semantic change is not necessarily observed in every desiderative that grammaticalized from a ‘want’ verb, however. In Katukina-Kanamari, the verb wu ‘want’ grammaticalized into the desiderative auxiliary wu, and both the verb and the auxiliary apparently exclusively encode ‘want’ (Silva, Z. Reference Silva2011: 236). This may be due to the fact that this is a relatively recent grammaticalization, and in the course of time the auxiliary may possibly undergo semantic changes similar to those in Hup.
(4) Katukina-Kanamari (Silva, Z. Reference Silva2011: 327, 236)


However, most sources for desideratives remain unknown. The most likely source for a desiderative, a verb meaning ‘want,’ does not show similarities to the desiderative marker in the majority of languages, which points toward less direct paths of development such as language contact or inheritance of obsolete forms. Specific instances of desiderative origins are the main focus of Section 4.
Interestingly, in Mocoví the desiderative suffix -ake can occur on the verb ao ‘want.’ It is unknown whether this signals intensification or has a different effect altogether; in Gualdieri's (Reference Gualdieri1998) examples the verb and the suffix usually occur together. The co-existence of a desiderative on a ‘want’ verb is a rare occurrence in the sample.
(5) Mocoví (Gualdieri Reference Gualdieri1998: 128)

It is not rare for a language to have both a verb ‘want’ and a desiderative, but then one of them usually has a slightly different meaning. For example, in Arawak, the full verb kansin is used for ‘want, like, love,’ while the desiderative suffix -thi expresses ‘want.’
(6) Arawak (Arawakan; Pet Reference Pet2011: 59, 226, 216)



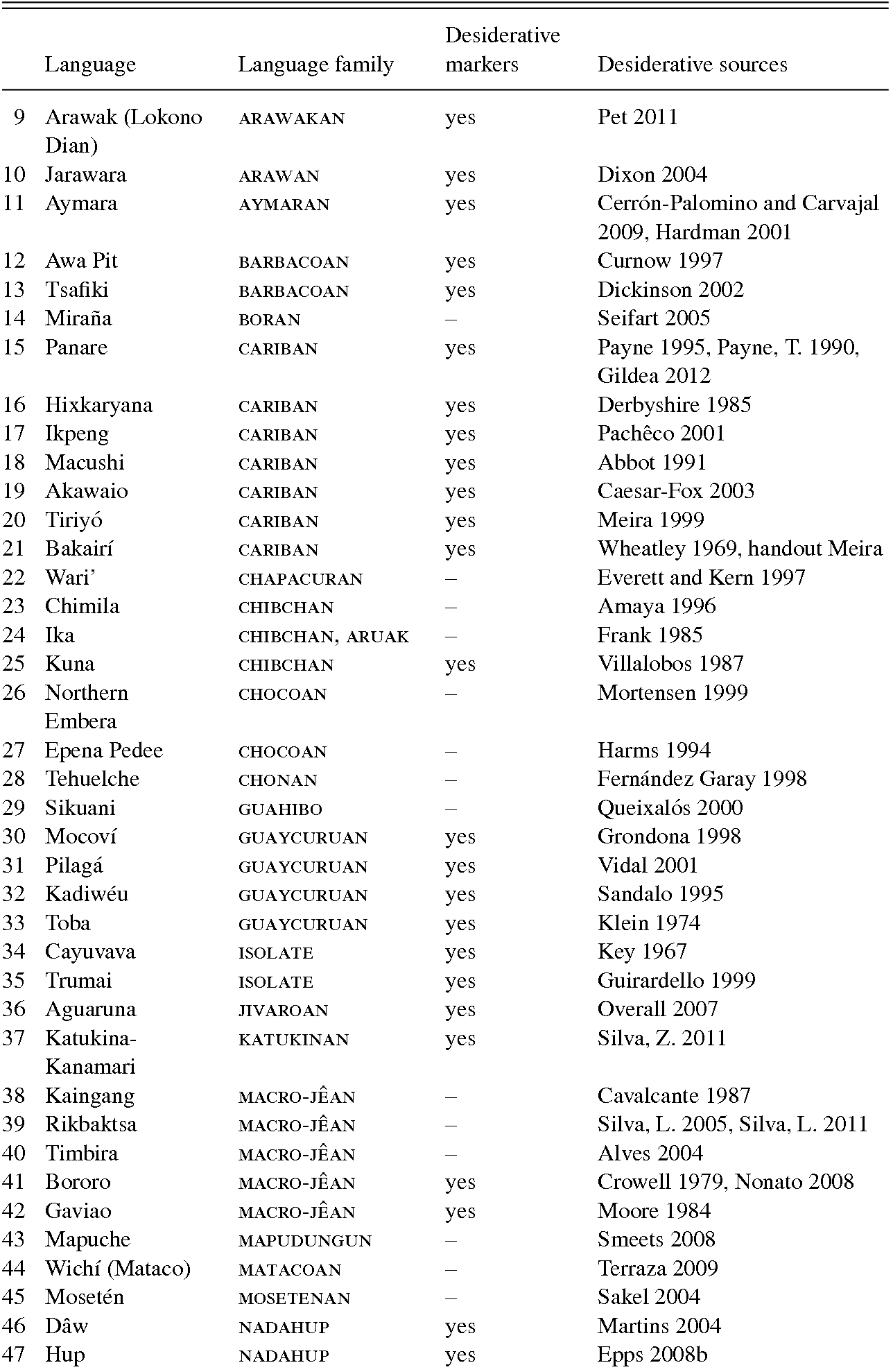
Based on the geographic distribution of desiderative marking (see Map 9.1) several distinctive regions emerge: in the region covering North Brazil, Surinam, Guyana, and East Venezuela, all languages have desiderative marking, and in the region covering North Peru, most do. Previously identified linguistic areas such as the Guaporé-Mamoré area and the Vaupés area show a mixture of marking, whereas the Upper Xingú has exclusively desiderative marking. The following sections investigate how some of these clusters relate to genealogical relations and geographic patterns. Due to the limited scope of this chapter, it is impossible to discuss every potential instance of contact or inheritance scenario. Instead, I will first elucidate desiderative marking within selected language families and then focus on a case study of desiderative in the Upper Xingú.

Map 9.1 Desiderative/no desiderative marking in eighty-five South American languages
4 Genealogical and regional accounts in the development of desiderative markers
In order to establish whether certain desiderative markers result from language contact phenomena, it is necessary to first eliminate those that are the result of genealogical relationships.
The sorting of factors is complicated by the scarcity and uneven quality of historical linguistic material in South America, which can make the proposal of proto-forms problematic. However, based on similarities in phonological material and distribution, it is possible to establish genealogical correlations of desideratives in selected language families. It is an interesting result of this study that in those language families with clear genealogical desideratives, some languages also exhibit desiderative markers that point toward contact effects. This is not apparent in Quechuan but is indeed the case for the Cariban languages Macushi and Akawaio. Several languages exhibit more than one unrelated desiderative marker, such as Mamaindê and Sabanê. In the following sections, I present desiderative marking in Quechuan (4.1), Nambikwaran (4.2), Cariban (4.3), and Tupian (4.4) and then proceed to the analysis of desideratives in the Upper Xingú area (4.5).
It was already mentioned in section 3 that the language families in the sample exhibit different patterns of desiderative marking. To illustrate these differences, I will focus on four families of varied size and geographic scope. I start with Quechuan as an example of a language family where the desiderative markers of the individual family members stem from a common ancestor, and I then proceed to demonstrate that Nambikwaran, Cariban, and Tupian exhibit more complicated patterns.
4.1 Quechuan
Estimated speaker numbers of the varieties of Quechuan range from 8.5 to 10 million in a discontinuous area spanning roughly along the Andes from southern Colombia to northern Argentina (Adelaar with Muysken Reference Adelaar, Adelaar and Muysken2004: 168). Together with Tupian, Quechuan is the biggest language family in the sample regarding both areal coverage as well as speaker number.
The two Quechuan languages in the sample, Imbabura and Huallaga Quechua, have cognate desiderative markers that originate in a Proto-Quechua verb *muna ‘want.’ The verb muna exists in many Quechua variants (see Adelaar with Muysken Reference Adelaar, Adelaar and Muysken2004). Muysken (Reference Muysken, Campbell and Grondona2012b: 241) claims that the desiderative form _Vny, which probably stems from Quechua -na:/-naya, was borrowed from Quechuan into Yanesha’, which is also called Amuesha (Arawakan). When attached to verbs, the desiderative marker -na: in Huallaga Quechua is restricted to bodily functions and the weather (Weber Reference Weber1989: 170–171). Cole (Reference Cole1985: 180) states that the Imbabura Quechua desiderative suffix -naya is fully productive with all verbs, but occurs only on nouns with relation to bodily desires.3 Cole (Reference Cole1982: 181) also states that there is a difference in using muna and -naya: the first refers to a desire by the speaker, but with the latter the desire comes from an intrinsic need (‘I have a yen to eat’ vs. ‘I am hungry’). The Huallaga Quechua desiderative can also occur on a restricted set of nouns (Weber Reference Weber1989: 33).4
(7) Imbabura Quechua (Quechuan; Cole Reference Cole1982: 39; Cole Reference Cole1985: 180)


(8) Huallaga Quechua (Quechuan; Weber Reference Weber1989: 70, 33)

4.2 Nambikwaran
Nambikwaran languages today are situated in the state of Mato Grosso, Brazil. Speakers have suffered severe decimation after the Second World War to the point that there were supposedly about 500 speakers left, although numbers have increased since then (Lowe Reference Lowe, Dixon and Aikhenvald1999: 270). In comparison to large families in the sample such as Quechuan and Tupian, Nambikwaran is a small family in quite a confined area, but it is relatively well studied.
The desiderative markers in the three Nambikwaran languages (Table 9.1) present an interesting case: some are clear examples of reflexes of a common ancestral form, seen in the Sabanê, Mamaindê, and Latundê suffixes -tan, -ten, and -‘ten, respectively, and yet there are additional desiderative markers (-palisin and -sitoh) in Sabanê and Mamaindê. The next section discusses the distribution of these markers individually.
In addition to the desiderative suffix -tan, Sabanê exhibits a second marker, the suffix -palisin, which apparently grammaticalized from the verb root palisin ‘want.’
(9) Sabanê (Nambikwaran; Araujo Reference Araujo2004: 155, 156)



Similarly, in Mamaindê the verb toh ‘want’ can appear as an embedded verb in the suffix position to the main verb. The marker -sitoh, according to Eberhard (Reference Eberhard2009: 423), takes the place of the desiderative suffix -ten. In fact, the marker -ten has developed additional meanings of intention and future, and the shift has progressed so far that the desiderative is now usually expressed by sitoh, while -ten marks future or intention (p. 423).
(10) Mamaindê (Nambikwaran; Eberhard Reference Eberhard2009: 395, 374, 419, 420)




In contrast to Sabanê and Mamaindê, in Latundê there is no apparent grammaticalization of the verb want ‘toh’ as an additional desiderative marker. The desiderative suffix -‘ten remains the only way to express desire morphosyntactically.
(11) Latundê (Nambikwaran; Telles Reference Telles2002: 286)

The Nambikwaran languages in this sample on the one hand exhibit remnants of a proto-desiderative form, but on the other hand two of them (Sabanê and Mamaindê) have grammaticalized additional markers, possibly triggered by the fact (at least in Mamaindê) that the original desiderative suffix has developed into a marker of future and intention. In both languages another desiderative marker grammaticalized from the verb ‘want,’ although the original desiderative suffix is still used to express desire. Latundê does not seem to have undergone a similar process of grammaticalization and retains the original suffix as the sole marker of the desiderative.

4.3 Cariban
Reportedly some 25 Cariban languages are spoken today with a total estimated speaker population between 60,000 and 100,000. Cariban is spread over northern South America, but mostly found in northern Brazil, Venezuela, Guyana, French Guiana, and Surinam (Gildea Reference Gildea, Campbell and Grondona2012: 441).
All Cariban languages in the sample exhibit desiderative marking, but it is apparent that the forms are not all related (Table 9.2). Instead, I argue that only the markers in Akawaio, Hixkaryana, and Tiriyó (and possibly Macushi) stem from a proto-form, and that there is split development of the desiderative in Akawaio and Macushi into coreferential and non-coreferential forms, a split that may have been contact-induced.
Akawaio, Hixkaryana, and Tiriyó exhibit markers that are similar to the proposed pan-Cariban desiderative postposition *ce (Caesar-Fox Reference Caesar-Fox2003: 115).
(12) Tiriyó (Meira Reference Meira1999: 417)

(13) Tiriyó (Derbyshire Reference Derbyshire, Dixon and Aikhenvald1999: 52)

In Macushi, the two desiderative markers are in syntactic complementary distribution: the suffix -pai is used for coreferential desire statements, and the postposition yu'se with non-coreferential ones (Abbott Reference Abbott, Derbyshire and Pullum1991: 79–80). In both cases the main verb is the copula and the desiderative is suffixed to the complement verb:
(14) Macushi (Cariban; Abbott Reference Abbott, Derbyshire and Pullum1991: 79, 80)


This split of desiderative into two markers is only observed in Macushi and the adjacent language Akawaio. Akawaio has a suffix -bai, similar to Macushi -pai, which can only be used with a coreferential subject and is apparently an innovation (Caesar-Fox Reference Caesar-Fox2003: 115). Additionally, Akawaio has a desiderative suffix -che which occurs in a non-coreferential environment, as in example (15b).5 This second desiderative marker in Akawaio seems to originate in the same proto-form *ce as the desiderative markers observed in Hixkaryana and Tiriyó.
(15) Akawaio (Cariban; Caesar-Fox Reference Caesar-Fox2003: 116)


According to Caesar-Fox (Reference Caesar-Fox2003), the source of the Akawaio desiderative suffix -bai is unknown, but it is possibly related to the postposition bai ‘from, through.’ It seems likely that either Macushi or Akawaio acquired a coreferential desiderative form as an innovation which was then borrowed by the neighboring language. In addition, the original Cariban desiderative *ce was pushed in Akawaio to the non-coreferential desiderative slot -che, and in Macushi to the postposition yu'se. Unless more is known about the origins and possible grammaticalization paths of -pai and -bai I cannot claim that they are due to contact with each other, but the similarity of the markers and their distribution strongly suggests borrowing or independent development in both languages inspired by contact.
The other Cariban languages in the sample do not exhibit a similar split in desiderative marking. In Hixkaryana, the marker -xe can occur both in coreferential and non-coreferential environments (16).
(16) Hixkaryana (Derbyshire Reference Derbyshire1985: 39, 20)


In the sources for Panare (Gildea Reference Gildea, Campbell and Grondona2012), Tiriyó (Meira Reference Meira1999), and Ikpeng (Pachêco Reference Pachêco2001) the respective desiderative markers are found only in coreferential environments so all possibilities could not be checked.
To conclude, the desiderative markers in Tiriyó, Hixkaryana, Akawaio, and possibly Macushi (non-coreferential) are probably reflexes of the proto-form *ce. Akawaio and Macushi additionally developed a split into coreferential and non-coreferential desideratives, in which the first is an innovation of unknown origin and the second one stems from the proto-desiderative *ce. Further research has to show how the desiderative markers of Panare, Bakairí, and Ikpeng fit into this pattern (for Ikpeng see also example (22)).

4.4 Tupian
Tupian is one of the largest language families in South America, with approximately seventy languages which are mostly situated in Amazonia and the Amazonian basin (Rodrigues and Cabral Reference Rodrigues, Cabral, Campbell and Grondona2012: 496). Genealogical relationships within Tupian are very well studied and ample descriptions are available for comparative studies.
Jensen (Reference Jensen, Derbyshire and Pullum1998: 536) argues that for the Guaraní branch of Tupian the verb *potar is commonly used for future and sometimes for desiderative. Remnants of this form occur in the sample both as full verbs and as results of grammaticalization, e.g. in Emérillon and Kamaiurá (Table 9.3). For Emérillon, Rose (Reference Rose2003: 426) claims that the desiderative suffix -tanẽ∼-tane derives from the verb potal ‘want, love’ followed by the particle ne∼nẽ ‘contrastive.’ The Emérillon verb potal may also be the origin of the Emérillon future suffix -tal.
(17) Emérillon (Tupian; Rose Reference Rose2003: 33, 219, 81)



In Kamaiurá, the full verb potat ‘want, enjoy’ coexists with the desiderative marker -potat (cf. Seki Reference Seki2000: 132). Additionally, Kamaiurá has another desiderative suffix -wej that seems to have the exact same meaning as -potat.
(18) Kamaiurá (Tupian; Seki Reference Seki2000: 132, 132)

Cocama-Cocamilla does not have a desiderative marker, but it does have the purposive suffix -tara, which Vallejos (2010: 756) argues derives from *potar. In Tapiete, although the desiderative suffixes are -se and -(i)sha, the immediate future suffix is -pota. Thus, the proto-form *potar is the source for full verbs in many Tupian languages of the Guaraní branch and for the subsequent grammaticalizations into future or desiderative markers. There is, however, a case of a non-Tupí-Guaraní language with a similar verb: Ayoreo. Ayoreo does not have a desiderative marker, but it does have a verb pota ‘want.’ Ayoreo is one of two known Zamucoan languages (the other being Chamacoco) and is situated in northern Paraguay. Bertinetto (Reference Bertinetto2009: 2–3) claims there is evidence that the Ayoreo moved from the inner Amazon to the Chaco region, and that “some Chamacocos can even use Guaraní, in addition to Castillian, for communication purposes.” It is therefore possible that the Ayoreo verb pota is the result of language contact between Zamucoan and Guaraní languages, although it is unknown whether this happened before or after the Ayoreo moved to the Chaco.
(19) Ayoreo (Zamucoan; Bertinetto Reference Bertinetto2009: 41)

The sources for the Tupian languages not of the Guaraní branch in the sample do not exhibit desiderative markers or ‘want’ verbs that could be traced to *potar. The proto-verb *potar and the resulting desiderative (and future and purposive) markers are then a trait restricted to Guaraní and not shared by other Tupian languages. They are shared, however, by Nheengatú: Nheengatú has a verb putai ‘want’ (Da Cruz Reference Cruz2011: 429) which probably originates in Tupinamba (Tupian, Guaraní) (cf. Jensen Reference Jensen, Dixon and Aikhenvald1999: 127 for the relationship between Nheengatú and Tupinamba).
Table 9.3 Desiderative markers in ten Tupian languages

4.5 Upper Xingú linguistic area
In this section I argue that the grammaticalization process in Trumai from the verb take ‘want’ into the auxiliary t(a)ke was triggered by language contact with Kamaiurá speakers. In the following paragraphs I will first outline the linguistic evidence of desiderative marking and the socio-linguistic setting of the Upper Xingú that made this grammaticalization possible and then present the data.
Seki (Reference Seki, Dixon and Aikhenvald1999: 417) classifies the Upper Xingú region as an incipient linguistic area because the language contact relations in that region are relatively recent. There has not yet been time to develop a fully established linguistic area, but we can observe the initial stages of contact-induced language change, supported in part by the distribution and function of desiderative markers in languages of that region. The following section discusses the desiderative marker in Trumai as a likely result of contact with Tupí-Guaraní or Cariban languages.
The Trumai auxiliary t(a)ke6 is, according to the grammaticalization scale (Bybee et al. Reference Bybee, Dale Perkins and Pagliuca1994: 40), rather young in its development and therefore an indication that Trumai is the recipient language of a contact-induced grammaticalization process. Other languages with desiderative markers qualify as model languages, as their forms are supposedly older. Two languages in the sample belong to the linguistic Upper Xingú area, as defined by Seki (Reference Seki, Dixon and Aikhenvald1999), and both have desiderative markers as well as presumed contact with Trumai speakers (cf. map 14 in Seki Reference Seki, Dixon and Aikhenvald1999: 418). These are Kamaiurá (Tupian, Guaraní; suffixes -potat and -wej) (Seki Reference Seki2000: 131ff.) and Ikpeng (Cariban; suffix -tɨne) (Pachêco Reference Pachêco2001: 87). Both are obviously not the origin of the direct source of the Trumai auxiliary t(a)ke, the origin of which is fairly transparent: it grammaticalized from the full verb take ‘want to go/be somewhere’ (Guirardello Reference Guirardello1999: Chapter 4.2.2.3) and through semantic bleaching retained only the desiderative meaning. The existence of desiderative markers in close-contact languages may have given rise to the grammaticalization of the verb for ‘want’ in Trumai into the auxiliary. I will now take a closer look at the distribution of the desiderative markers in Trumai, Ikpeng, and Kamaiurá.7
The auxiliary t(a)ke derives from the full verb take ‘want to go/be somewhere.’ The auxiliary does not have a sense of direction anymore and only encodes desire. It obviously has undergone semantic bleaching as well as partial erosion of phonetic material, mostly occurring as tke after vowels (Guirardello Reference Guirardello1999: Chapter 4.3). This establishes the origin of t(a)ke as a grammaticalized form of language internal change and not as a likely borrowed form.



The desiderative marker -potat in Kamaiurá is a full verb but also occurs suffixed to main verbs when used as desiderative to form a complex verb (see Section 4.4 for the origin of -potat). The suffix -wej does not exist as a main verb and is restricted to physical desires (Seki Reference Seki2000: 31–32).
(21) Kamaiurá (Tupí-Guaraní; Seki Reference Seki2000: 132, 132)

The desiderative suffix -tɨne in Ikpeng also occurs verb-finally, either on the main verb or on the auxiliary it ‘be’ (Pachêco 2001: 87–88).
(22) Ikpeng (Cariban; Pachêco Reference Pachêco2001: 87–88)


The origin of the Kamaiurá desiderative marker -potat is the Proto-Tupí-Guaraní form *potar (see 4.4), but nothing is known about the origin of the suffix -wej, or the Ikpeng marker -tɨne. It can be said with some confidence that -tɨne does not originate in Cariban, as the other Cariban languages in the sample have very different forms (4.2), and it is possibly also a result of contact in the Upper Xingú region. The sociolinguistic setting certainly would support an analysis of language contact-induced change between Trumai and both Kamaiurá and Ikpeng. According to Seki (Reference Seki, Dixon and Aikhenvald1999: 425), Kamaiurá and Cariban speakers began to arrive in the seventeenth century; the Trumai are perhaps the most recent settlers. Trumai is in decline, and many speakers are multilingual; many were bilingual with Kamaiurá already in 1938, which supports the theory that the grammaticalization of the Trumai desiderative was triggered by the existence of a grammaticalized desiderative in Kamaiurá. Although Ikpeng is also a candidate for the model language, the fact that Kamaiurá speakers are reportedly in close contact with Trumai speakers places Kamaiurá higher on the list. I therefore propose that contact between Trumai and most likely Kamaiurá was the trigger for the grammaticalization of the verb take into the suffixed auxiliary -t(a)ke. Unfortunately, it is not possible to say whether the process in Trumai was copied from Kamaiurá or is based on universal grammaticalization processes (in Heine and Kuteva's (Reference Heine, Kuteva and Hickey2010) terms: ordinary or replica grammaticalization). Until more is known about the source of the Kamaiurá desiderative marker -wej, this remains an open question.
5 Conclusion
This study has found that in a global perspective morphosyntactic desiderative markers occur more frequently in South American languages than in other parts of the world and that the patterns and variety of desideratives are due to a combination of genealogical and geographic effects. Some language families exhibit related desiderative markers which stem from a proto-form, such as Nambikwaran, Cariban, and the Guaraní branch of Tupian. At the same time, certain languages within these families also show desideratives that developed due to language-internal pressure, as in Mamaindê, where the desiderative marker developed into a future marker, which led to the formation of another desiderative. It was shown that in many cases desideratives grammaticalized from verbs with the meaning ‘want,’ and that in general the grammaticalization path of a desiderative tends towards future meaning (as in Hup and Mamaindê), a tendency already identified by Bybee et al. (Reference Bybee, Dale Perkins and Pagliuca1994). The case of Trumai in the specific sociolinguistic setting of the Upper Xingú area strongly suggests contact-induced grammaticalization of the Trumai desiderative: the development from the verb take ‘want’ to a desiderative auxiliary was likely initiated due to contact with Kamaiurá, which exhibits a desiderative suffix.
It would be interesting to add further regional studies of the desiderative to that of the Upper Xingú; the Guaporé-Mamoré and Içana-Vaupés areas are promising candidates. Furthermore, the noticeable absence of desiderative marking in nearly all the Chocoan and Chibchan languages in the sample is worth a detailed investigation.
Appendix
Table 9.4 Desiderative marking in eighty-five SA languages

1 ‘Desire’ itself is a likely source for developing the morphology to mark future tense (Bybee et al. Reference Bybee, Dale Perkins and Pagliuca1994: 254–258).
2 In Sikuani the verb hitsipa ‘want’ is the source for the auxiliary hitsia ‘immediately’ (Queixalos 1998: 285).
3 The Imbabura desiderative on verbs is possibly also restricted to bodily desires, as a search of Cole (Reference Cole1982) and (Reference Cole1985) suggests.
4 Although Weber does not further comment on the restrictions the examples suggest desires related to the body.
5 Only this one example of -che could be found in Caesar-Fox (Reference Caesar-Fox2003).
6 The similarity between the marker in Trumai and those in Guaycuruan languages Pilagá (-ake), and Toba (-ayke) is probably not an effect of contact or genealogy.
7 The only other language in Seki's list for which material could be obtained is Waurá, and there is no mention of desiderative in Richards (Reference Richards1988).
10 Verbal argument marking patterns in South American languages
As more descriptive data on South American languages have become available, it has become apparent that the continent hosts an incredible diversity of linguistic structures. Various proposals have been made attempting to identify the typological features characteristic of certain regions of the continent, especially regarding the way that these languages mark arguments within the main clause. However, the distribution of relevant properties over the continent as a whole is rarely taken into account when discussing such characteristic features. This chapter systematically explores the distribution of verbal argument marking patterns using a large-scale comparative database composed of sixty-four South American languages. The structural features under consideration include the presence and alignment of argument markers, the locus of marking, and the grammatical categories realized through marking, as well as other alignment-related patterns such as split intransitivity, hierarchical marking, and inverse marking. This chapter addresses the question of whether there are specific geographic patterns in the distribution of the linguistic structures used to index arguments on the verb across these languages and explores possible explanations for these patterns.
1 Introduction
The indigenous languages of South America show a genealogical diversity that has puzzled and intrigued researchers for centuries. While certain attempts at establishing relations between different languages had some success early on, such as in Gilij (Reference Gilij1780–1784) for portions of the Arawakan family, a large number of languages remained unclassified well into the twentieth century, with many still considered isolates or single-language families today.1 Yet in the face of such diversity, many scholars have recognized that certain grammatical patterns occur repeatedly in certain regions, even among languages that do not appear related based on lexical analyses. Such observations led to the birth of what can be called “South American typology,” or rather, the attempt to group languages into different types based on a number of grammatical and phonological features.
Ever since the early work by Lafone Quevedo (Reference Lafone Quevedo1896), and possibly before, the way that languages make reference to the obligatory participants in an utterance, i.e. the arguments, has played a prominent role in the formation of South American language types. Lafone Quevedo classified languages based on the locus of argument marking on the verb, with three major distinctions: (i) suffixing languages like Quechua, (ii) prefixing languages like Guaraní, and (iii) languages with mixed prefixes and suffixes like Mocoví. While this grouping based on a single feature may seem rudimentary, Lafone Quevedo's work served as a starting point for the discussion of South American argument typology that is still going on today.
This chapter addresses the question of whether there are specific geographic patterns in the distribution of the linguistic structures used to index arguments on the verb across a sample of sixty-four South American languages. These patterns are then tested to see whether their distribution is significant within a particular region when compared to the continent as a whole. First, I present the language sample and methodology used in this chapter. In Section 3, I give an overview of the verbal argument marking features under investigation. Section 4 specifically addresses the often discussed typological distinctions between Amazonian and Andean languages. The large number of proposals presented on characteristic features of different regions of the continent does not permit an overview to be presented here (cf. Campbell Reference Campbell, Campbell and Grondona2012b), but the following sections will present the details of claims that make specific reference to the features examined in this chapter. It is concluded that while many of the earlier proposals indeed present observable geographic patterns in argument marking strategies, the data in this study indicate that some patterns are not significant once the continent as a whole is taken into consideration and that a number of previous notions about the distribution of these features must be reexamined entirely.
2 The language sample
The South American continent can be roughly divided into seven regions using the following geographic criteria based on main waterways and mountain ranges:
(1) Northern Andes: Andean Highlands and foothills, stretching from Panama along the Cordillera Real of Ecuador, and from the Pacific Ocean east to the headwaters of the Orinoco River.
(2) Guyana Shield: Tropical forest, plateaus, and coastal areas from the lower Amazon River north to the Caribbean Sea, and from the Atlantic Ocean west to the east banks of the Rio Negro.
(3) Central Andes: From the Peruvian highlands of the Cordillera Central south to the Atacama Desert. The Cordillera Occidental of Bolivia and Argentina is the easternmost extent of this region, and the Argentine Pampa forms the southeastern boundary.
(4) Western Amazonia: From the west banks of the Rio Negro to the headwaters of the Amazonian tributaries. The northwest banks of the Madeira River and the Madre de Dios River form the southern boundary.
(5) Southern Amazonia: From the eastern banks of the Madeira and Madre de Dios rivers to the Xingú River system, with the headwaters of these rivers forming the southern boundary.
(6) Chaco-Planalto: From the Paraná River system across the central plains of Brazil. The Amazonian tributaries and their headwaters form the northern and western boundaries.
(7) Southern Cone: From the Patagonian highlands and the Tierra del Fuego archipelago north, with the Paraná river and its tributaries forming the northern and eastern boundaries.
These seven regions have been selected since they provide independent criteria for dividing the languages geographically, a solution preferable to using strictly cultural or linguistic criteria that might bias the analysis of pattern distribution. However, that is not to say that certain ethnic groups or languages were not or may not still be dominant cultural forces in a particular region. In fact, precisely to make the analysis comparable to previous claims, many of these regions roughly correspond to or include culture or linguistic areas identified in the literature. For example, the region here considered as the Central Andes roughly corresponds to the region that Adelaar with Muysken (Reference Adelaar, Adelaar and Muysken2004) call the “Inca Sphere.” Certain languages, especially along the foothills region between the Amazon and the Andes, have proven somewhat difficult to classify as belonging definitively to one of the seven regions (see van Gijn on the Andean foothills, this volume), and these languages have been classified according to the criterion of whether their traditional territory lies along an Amazonian tributary or not.
While the regions outlined above may represent or include previously defined culture or linguistic areas, it is important to note that contact also occurred between languages that are classified as belonging to different regions. In some instances, this contact may have affected the structure of these languages, as is the case of Quechua influence on Yanesha’ (also called Amuesha; Adelaar Reference Adelaar, Aikhenvald and Dixon2006). As such, the regions are not supposed to represent hard boundaries against the interaction of different ethnolinguistic groups, but rather, are meant to serve as descriptive tools to provide formal criteria for quantitative analysis. Given the geographic constraints on interaction and the socio-historical processes within them, these regions appear to be the most likely venues for contact between different groups.
The languages in the sample are presented in Map 10.1. The sample includes representatives from twenty-seven attested language families and an additional eleven languages are considered isolates given our current state of knowledge. For more details about sample languages and the sources of the language data, see Table 10.2 in the appendix.
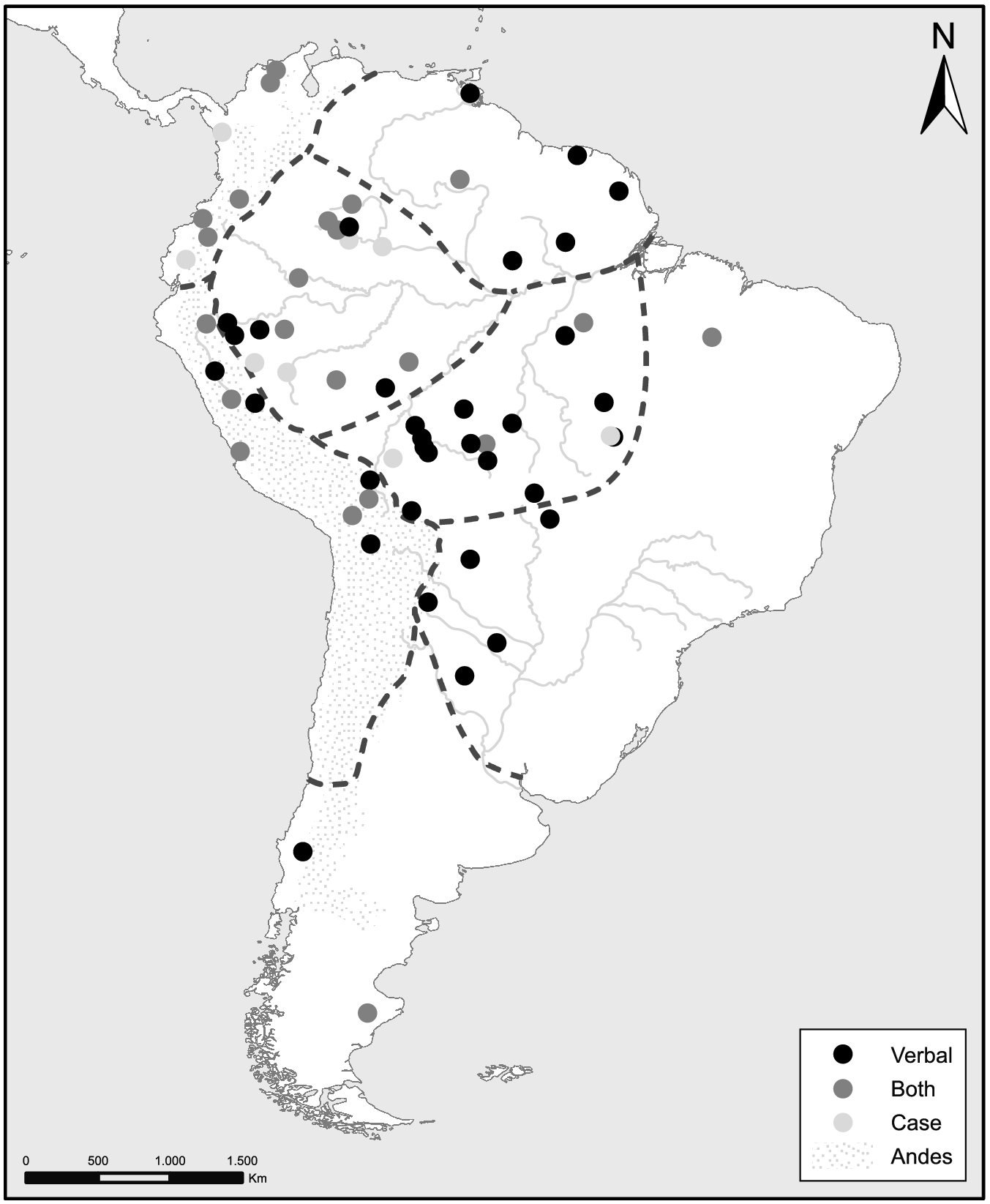
Map 10.1 Languages in the sample, with regions used in this chapter
The language sample was designed to include as much geographic and genealogical diversity as possible, while taking into account the availability of descriptive materials of adequate quality and breadth. All regions have at least six representative languages, with the exception of the Southern Cone. The Western and Southern Amazonian regions contain considerably larger numbers of languages in the sample in order to represent the high genealogical diversity of these regions and allow for the sampling of multiple language isolates alongside representative members of various larger language families. Campbell (Reference Campbell, Campbell and Grondona2012a) states that there are about 420 South American languages still spoken today, and Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999) count approximately 300 languages within the Amazon Basin. Thus, a higher proportion of Amazonian versus non-Amazonian languages in the sample is appropriate given the observed distribution of linguistic diversity on the continent.
For the largest families such as Tupian and Arawakan, languages were sampled to represent different branches of the family as well as the different regions of the continent that these groups inhabit. For example, the Tupí-Guaraní branch of the Tupian family is represented by Tapiete from the Argentinian Chaco, Kamaiurá from the Brazilian Upper Xingú, Emérillon from French Guiana, and Cocama-Cocamilla from the Peruvian Amazon. These languages also are members of different subgroups within the Tupí-Guaraní branch (Jensen Reference Jensen, Dixon and Aikhenvald1999). Also included are four additional Tupian languages, each from a different branch outside of Tupí-Guaraní, albeit all located in the Southern Amazon region.
3 Terms and definitions
The approach to the language data presented in this chapter relies on notions generally accepted within modern language comparison to refer to the distinction between intransitive S(ubjects), transitive A(gents), and transitive O(bjects), in order to describe the formal coding properties of these argument types in basic declarative main clauses (Comrie Reference Comrie1981; Dixon Reference Dixon1994; Haspelmath Reference Haspelmath2011a). To facilitate cross-linguistic comparison, I have relied on the notion of prototypical action for evaluating which of various clause types within a language should be considered most basic. A prototypical action is “an effective volitional discrete action performed by a controlling agent and actually affecting a well individuated patient” (Lazard Reference Lazard2002: 152). Thus, when we speak of an S/A (nominative) verbal argument marking pattern, it is understood that S is indexed on the verb with the same argument marker as A in a prototypical action. While these notions are straightforward in most cases, they become especially relevant for discussing the complex marking patterns found in certain languages in the sample.
Two additional terms are used in the paper that warrant a brief definition: “argument marking” and “indexing.” Argument marking is the more general of the two terms, referring to processes by which languages express the obligatory participants of an utterance, as well as the strategies used to distinguish the semantic and grammatical roles that such participants hold in the clause, whether on the arguments themselves (case marking) or on the predicate (verbal marking). Indexing (or indexation) is a more specific term, adopted from Lazard (Reference Lazard1998), which refers to the process by which grammatical features (such as person, number, and gender) of arguments of the clause occur on the predicate by means of bound argument markers. Indexation as a function of verbal argument markers is preferred here over other commonly used terms, such as “cross-reference” or “agreement,” to avoid the terminological confusion associated with the latter terms and to treat the process of verbal argument marking as a phenomenon sui generis (Haspelmath, Reference Haspelmath, Bakker and Haspelmath2013).
For this study, the structural facts of argument marking strategies were compiled in a way that facilitates comparison and analysis of feature distribution across the continent. In order to be called “typical” or “characteristic” of a particular region, a feature must show a significantly higher concentration in a specific region than across the continent as a whole. An exploration of the distribution of features across aggregate regions is reserved for Section 5.
4 Verbal argument marking patterns
Many South American languages mark the arguments of a main clause through morphemes bound to the verb. The languages in the sample have been evaluated for a number of features relating to the way that arguments are marked on the verb, including:
a. Presence of markers: which arguments are indexed on the verb.
b. Alignment of markers: whether the same set of markers can be used to index different argument types across transitive and intransitive clauses.
c. Locus of markers: whether argument markers occur as a prefix or a suffix, and if two markers can be present, how the markers order with relation to each other.
d. Fusion of arguments: whether multiple arguments within the same clause are indexed through a single marker.
e. Splits in arguments: whether the same argument type is indexed with different sets of markers.2
f. Referentiality of arguments: whether the indexation of a particular argument type depends on its status within the referentiality hierarchy (see Section 4.2.1).
When taken together, these features describe a number of the key aspects of the verbal argument marking system in a language. These features roughly correspond to the factors used by Siewierska (Reference Siewierska2003) to evaluate alignment patterns, but the term “alignment” is used here in a more narrow sense, applying only to the arguments indexed by a particular marker set and not as a characterization of the language as a whole.
Central to the identification of the verbal argument markers is the presence of a morphological distinction between different grammatical categories of person. Languages that solely index number or gender properties of their arguments without any person distinction, such as Northern Embera (Chocoan) or Tsafiki (Barbacoan), are not included in the following discussion. Furthermore, for a language to display a person-based distinction for the indexation of a particular argument, at least two person categories must be morphologically realized. For example, a language like Imbabura Quechua, where only 1st person singular objects are indexed on the verb through the suffix -wa and all other persons are unmarked (Cole Reference Cole1982: 129), is not considered to display verbal argument marking of O in this study, even though other varieties of Quechua do have more morphologically rich systems of O marking on the verb.
The presence of person-based verbal argument marking occurs in fifty-six of the sixty-four languages in the sample, with thirty-three of these languages displaying only verbal marking of arguments and no case marking. The presence of verbal markers for the different argument types, and how these markers align, is subject to considerable variation across the different language families and regions of the continent (Features (a) and (b) above). These features form the basis for exploring Features (c) and (d) as well, while (e) and (f) are explored separately in Section 4.2.
Languages that consistently index the same set of argument types using the same set of argument markers across different classes of verbs and main clause construction types display a simple marking pattern. Simple marking patterns are referred to by the number of morphological slots available for indexation and the alignment of the arguments that are indexed in these slots. Languages with multiple patterns for which arguments are marked on the verb, usually conditioned by verb class, TMA inflection, scenario, or construction type, display a complex marking pattern. The most commonly encountered complex marking patterns are explored after the description of the simple marking patterns. It is important to note that complex marking patterns are generally composed of multiple simple patterns and often show alignment of markers in ways that may allow their classification as predominantly displaying a particular simple pattern as well. A summary of the basic verbal argument pattern for each language in the sample can be found in Table 10.2 in the appendix.
4.1 Simple marking patterns
Languages that index both the S and A arguments with the same set of markers show a nominative pattern. An example of strictly nominative verb marking can be seen for Nasa Yuwe, also known as Paez, in example (1):


Languages that only index O arguments, with no indexation of S or A, show an accusative pattern. An example of this verbal marking pattern can be seen for Juruna in (2):


Languages that index both S and A arguments with the same set of markers and additionally index O on the verb with a separate set of markers in a different locus show a nominative-accusative pattern. This is the most widely attested pattern found in the sample, occurring in twenty-five of the fifty-six languages that display some form of verbal marking of arguments. This pattern can be seen for Muniche in example (3):


The languages shown in examples (1–3) all index different configurations of transitive and intransitive argument, but the marker sets in each of the languages consistently treat the S and A arguments similarly yet distinct from the treatment of O, showing accusative alignment. The following examples (4) and (5) show languages that treat S and O arguments similarly yet distinct from the treatment of A, showing ergative alignment.
Languages that index both S and O arguments with the same set of markers show an absolutive pattern. This pattern can be seen for Mekens in (4):


Correspondingly, languages that index only the A argument, without indexation of S or O, show an ergative pattern, as seen in (5) below.


No languages in the sample present a further logical possibility for verb marking patterns – an ergative-absolutive pattern.
Languages that display verbal marking for A and O conflated into a single portmanteau morpheme in transitive clauses show a fused pattern. An essential characteristic of this pattern is that it is not possible to segment distinct morphemes that refer to only one of the indexed argument types in the majority of cases across the set of argument markers. The Aymaran languages Jaqaru and Aymara show a degree of fusion across their person marking forms, but unlike the Quechuan languages (cf. Weber Reference Weber1989: 96–97 for Huallaga Quechua), the majority of cases do not allow for the segmentation of distinct morphemes referring to each argument individually. In the Jaqaru example in (6), notice the segmentable nature of 2sg.A -ta, 1sg.O -u, and 1pl.O -ush in the present tense verb paradigm, while markers for the other arguments cannot be consistently identified.

A final pattern to be considered concerns argument indexation in ditransitive clauses. The strategies used to mark the semantic theme (T) or recipient (R) in clauses that typically include three arguments, such as those with the verbs ‘give’ or ‘send,’ show considerable variation across the world's languages (Malchukov et al. Reference Malchukov, Haspelmath, Comrie, Malchukov, Haspelmath and Comrie2010). Adopting the terminology used in Dryer (Reference Dryer1986), languages that mark T the same as O in transitive clauses show “direct object” alignment, while languages that mark R the same as O in transitive clauses show “primary object” alignment. An example of a language with direct object alignment (T marked like O) in verbal marking is Puinave in (7), where the theme of the ditransitive verb bώk ‘give’ is indexed on the verb (like O in 7b) and the recipient is not verbally indexed but marked with the oblique case suffix -at.


A language with primary object alignment in ditransitives (R marked like O) can be seen in Aguaruna in (8), where the recipient is indexed on the verb (8a), just as the direct object is in (8b):


All languages of the Central Andes in the sample that index O in transitive clauses also allow R to be indexed in ditransitive clauses. Across the continent, primary object alignment in ditransitive clauses is the most dominant pattern among the languages that index O (58.7 percent).
4.2 Complex marking patterns
Now that the simple verb marking patterns have been introduced, it is possible to turn to the different complex patterns observed in the sample of South American languages. It can be said that many languages in the sample display some form of variation in argument marking strategies, especially if we consider patterns found in subordinate clauses, copular clauses, focus constructions, negated clauses, constructions that require an auxiliary verb, and so forth. However, as noted in the introduction, this chapter focuses on basic constructions in main clauses. Within this more restricted domain, there are two prominently recurring complex patterns within the data: hierarchical marking and split intransitivity.
4.2.1 Hierarchical marking
Hierarchical marking languages select an argument to index on the verb according to whichever is most referential, i.e. the argument that is ranked higher on the referential hierarchy. While there have been various formulations of the referential hierarchy, and various names applied to it such as the animacy, salience, person, or indexability hierarchy, a key aspect of this system with regard to verbal argument marking is that speech act participants (henceforth SAPs; 1st and 2nd person arguments) are considered more referential than non-speech act participants (3rd person arguments). The exact manifestation of the hierarchy varies from language to language, especially with regard to the treatment of SAP arguments that act on other SAP arguments. Languages can also show hierarchical alignment patterns conditioned by the pragmatic status of different 3rd person arguments, as has been well described for Algonquian languages in North America (cf. Zúñiga Reference Zúñiga2006). While these types of systems often function in conjunction with hierarchical marking conditioned on a SAP versus 3rd person distinction, this section does not examine the pragmatically conditioned type.
Transitive clauses where a more referential A acts on a less referential O are considered direct scenarios, and clauses where a less referential A acts upon a more referential O are considered inverse scenarios. Languages that explicitly mark inverse scenarios with verbal morphology distinct from their argument markers have inverse markers. Among the languages in the sample that display hierarchical verb marking patterns, two major groups can be identified: those with hierarchical alignment of verbal markers as well as inverse markers, and those without any separate marking of direction (inversion).
South America hosts a considerable number of languages with hierarchical verb marking patterns, both with and without inverse markers. Hierarchical alignment together with an inverse marker is attested in three languages in the sample: Mapudungun, Yanam, and Itonama. These languages are all unrelated and are found in separate regions of the continent. Mapudungun, also known as Mapuche, has a single set of argument suffixes that index the most referential argument (A or O), two suffixes that index either 3rd person A (9c) or O (9b), and an explicit inverse marker -e (9c).



Itonama shows a slightly different pattern in its hierarchical marking. It has two different sets of argument marking prefixes, one used to index S/A in independent clauses with direct scenarios (10a) and local scenarios (SAP acting on SAP; 10b) and another that indexes O in independent clauses with inverse scenarios (10c) and S/A in dependent clauses (10d), as well as the morpheme k'i- that marks inverse scenarios:




Similar patterns where the referential transitive argument is indexed with one of two different sets of markers that occur in the same slot can be seen in other hierarchical marking languages that do not have an explicit inverse marker. These types of patterns are encountered in a number of Cariban and Tupian languages, as well as certain Guaycuruan languages and some languages of the Northern Andes. An example of how this system works in a language without an inverse marker can be seen in Ikpeng in (11):
(11) Ikpeng (Cariban; Pachêco Reference Pachêco2001: 65, 70–1)
a. m-aranme-lɨ
2sg.I-run-rec.pst
‘You ran’
b. m-eneŋ-lɨ
2sg.I-see-rec.pst
‘You saw him’
c. o-eneŋ-lɨ
2sg.II-see-rec.pst
‘He saw you’
d. o-aginum-lɨ
2sg.II-cry-rec.pst
‘You cried’
Notice in example (11) that the 2nd person subject of the intransitive verb aranme ‘run’ (11a) is indexed in the same way as the subject of the transitive verb eneŋ ‘see’ (11b). The 2nd person object in (11d) is referential since it is a SAP yet is indexed through a different set of markers than that used for S and A in (11a–b). The set of markers used to index O in (11d) is the same as that used to index S of the verb aginum ‘cry,’ showing that Ikpeng has two classes of intransitive verbs that index S with different marker sets (see 4.2.2).
It is interesting to note that no hierarchical marking patterns are found in the languages of the Central Andes nor of Western Amazonia within the sample. Outside of the Northern Andes, where Chimila (Chibchan) and Awa Pit (Barbacoan) present somewhat divergent patterns from those presented above, all languages that show hierarchical marking without an inverse marker also show multiple patterns for the way that intransitive verbs are marked.4 None of the hierarchical marking languages with inverse markers show such a split intransitive pattern.
4.2.2 Split intransitivity
Languages with split intransitivity display different argument marking patterns for different classes of intransitive verbs. Within the sample, twenty-one languages display one of the split intransitive marking patterns discussed below. Before exploring the diversity of the split intransitive systems encountered in the sample, a few useful notions must first be introduced.
Subjecthood is a topic that has frequently been at the center of discussions on linguistic typology and language description. As early as Sapir (Reference Sapir1917), it has been recognized that many languages in the Americas show variation in their treatment of intransitive subjects such that for one class of intransitive verbs the subject is marked like transitive agents in that particular language, while for another class of intransitive verbs subjects are marked like transitive objects. Additionally, it is common for one of the classes of verbs to display certain semantic and pragmatic features typically associated with transitive agents such as high animacy, volition, and topicality (Merlan Reference Merlan, Nichols and Woodbury1985; Foley Reference Foley2005). The class of intransitive verbs whose subjects display most of these prototypical subject properties are referred to here as belonging to the major class of intransitive verbs. The classes of intransitive verbs whose subjects diverge from this prototype are referred to as belonging to a minor class of intransitive verbs.
In many languages of South America, the subjects of major class intransitive verbs are indexed like A, and subjects of the minor class intransitive verbs are indexed like O, as can be seen in (12) for Sateré-Mawé:




As can be seen above, the split intransitive system in Sateré-Mawé operates within the hierarchical verb marking pattern of the language. Notice how S in (12a) is indexed by the same prefix as A in (12b), while S in (12c) is indexed by the same prefix as the referential O in (12d). Such a pattern is typical of many Tupian languages, especially of the Mawetí-Guaraní branch, and is also attested in some Cariban languages, as seen in (13) below, and certain Guaycuruan languages. However, it is not the case that all languages show alignment of markers between S of the major class of intransitive verbs and A of transitive clauses. While only fully attested in one language in the current sample,5Tiriyó, it is possible for S of the major intransitive class of verbs (13a) to align with O of transitive clauses (13b):




Furthermore, the major class of intransitive verbs need not align with either of the transitive argument types, resulting in a tripartite alignment pattern as seen in Wichí:6



While Wichí doesn't display a hierarchical marking pattern for transitive clauses, it uses the same prefix slot with multiple sets of markers to index the subject of the different intransitive verb classes as well as A.
A different split intransitive marking pattern is observed in some of the languages that index both A and O on the verb through separate sets of markers that occur in different loci, such as indexing A with a suffix and O with a prefix. This pattern can be seen in (15d) for the minor class of “impersonal” intransitive verbs in Ika:




Languages with splits manifested primarily through case marking and not verbal marking, as is the case for Tariana (Arawakan; Aikhenvald Reference Aikhenvald2003a), are not considered here, nor are languages with a minor class of verbs that do not display any verbal argument marking. However, languages with a minor class of intransitive verbs that show a distinct marking pattern are considered here, even in cases where the major class of intransitive verbs does not index S. This can be seen in (16) for Sabanê:



A topic that has received considerable attention in the typological literature on split intransitivity is the semantic basis for the division of intransitive verbs into different marking classes (cf. Donohue and Wichmann Reference Donohue and Wichmann2008). While a worthwhile topic for cross-linguistic research, the semantic composition of minor class intransitive verbs is not considered here; the focus remains on the presence of multiple intransitive verb classes and the different argument marking patterns that they present.
5 Geographic distributions
A wealth of proposals have been made regarding the distribution of linguistic features across the continent that appear to be characteristic of particular geographic regions. In this section, a feature is considered “characteristic” of a region if it shows a statistically significant greater distribution in that particular region when compared to the continent as a whole, excluding the region under question (Bickel and Nichols Reference Bickel and Johanna2006; Janssen et al. Reference Janssen, Balthasar and Fernando2006). Significance is tested using a Fisher's exact test on a two by two contingency table, with p < 0.05 interpreted as significant. Since the majority of previous claims have focused on characteristic features of the Amazon and the Andes, an examination of these regions is presented first before looking at a broader East to West split on the continent.7
5.1 Characteristic features of the Amazon
The end of the twentieth century brought about not only a large number of new descriptive materials on Amazonian languages, but also a large number of claims regarding the overall makeup of these languages. Earlier proposals such as Derbyshire (Reference Derbyshire1987) focused on word order correlations and the frequency of ergative and “split ergative” patterns found in a sample of forty Amazonian languages, primarily from the Tupian, Arawakan, Cariban, and Macro-Jêan families. Along with Payne, D. (Reference Payne and Payne1990), these earlier works were primarily descriptive in nature, highlighting interesting patterns observed in newly available data without a systematic effort to quantify patterns or to contrast them with languages outside of Amazonia. Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999: 8–9) take a more explicit approach by listing a number of features that they consider to be “shared by all (or most) languages in the area” while also contrasting these features with a number of those that they consider to be characteristic of Andean languages. Some of the claims presented in these works relate directly to verbal argument marking and are considered below. For the sake of evaluation, all languages belonging to Southern and Western Amazonia as well as the Guyana Shield, as presented in Section 2, are classified in this section as Amazonian languages.
Claim 1: Languages index only one argument on the verb
As shown in Section 4, South America presents a wide diversity of argument marking patterns on the verb. Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999: 8) consider patterns that index only a single argument on transitive verbs as characteristic of the languages of the Amazon. This is undoubtedly the case for a number of prominent Amazonian language families like Tupian, Cariban, and Tucanoan, but is this pattern indeed characteristic of Amazonian languages as a whole?
To explore the distribution of the presence of single argument indexation, the languages in the sample were divided into two groups. The first group is composed of languages that index only a single transitive argument on the verb, including those that show hierarchical marking patterns that only allow for the indexation of a single verbal argument. The second group is composed of languages that can index two transitive arguments on the verb, including languages with fused argument marking patterns. Languages with hierarchical marking in a specific slot but which also allow for two transitive arguments to be indexed on the verb in certain scenarios, such as in Itonama (see example 10b) or Yanam, are considered as members of the latter group.
The data show a roughly equal distribution of single versus double verbal argument marking strategies across the whole sample, with twenty-six languages that only index a single argument versus thirty that can index both arguments in transitive clauses. Based on the sample used in this study, the distribution of languages with verbal argument marking that only index a single argument on the verb is not significant for Amazonia as a whole (p = 0.571). Even when Amazonian languages are evaluated against only the languages of the Northern and Central Andes, the distribution of single argument indexation on the verb is not significant for Amazonia as a whole (p = 0.625).
Claim 2: Verbal arguments are indexed with prefixes
In her discussion of morphological features of lowland South American languages, Payne, D. (Reference Payne and Payne1990: 221) mentions prefixing as a characteristic feature of verbal argument marking. To explore this claim, languages were scored for whether each argument type (major class S, A, and O) is marked by a prefix or a suffix. Languages with markers split between prefixes and suffixes for a particular argument type, as in Itonama where O can be indexed either by a suffix or a prefix (see example 10), have been treated as having both a prefix and a suffix to index that particular argument. For the sake of comparison, languages that use circumfixes to index verbal arguments are treated as displaying both a prefix and a suffix, as in the case of the Guaycuruan languages Pilagá (for S and A) and Mocoví (for S, A, and O). If a language indexes the same argument twice in a clause, such as in Kanoê where S/A arguments are indexed both on the verb with a suffix and on an auxiliary as a prefix, the locus of marking on the verb only is considered. But if a specific argument is indexed only on an auxiliary and not on the main verb in basic constructions, as is the case for A-indexation in Bororo, the locus of marking relative to the auxiliary is included in the calculations.
For Amazonia as a region, the distribution of prefixes as verbal argument markers displays strong significance (p = 0.019). An attempt to recalculate the significance of the claim using only lowland languages has not been carried out, since it is unclear exactly what constitutes a “lowland South American language.” For example, this category could include a number of foothill languages in the sample, as well as languages from the Chaco, which, in accordance with Campbell and Grondona (Reference Campbell, Campbell and Grondona2012: 644), display some support for a near-significant distribution of prefixes as verbal argument markers when compared to the rest of the continent (p = 0.065). The distribution of prefixing versus suffixing verbal argument markers is further explored in Section 5.3.
Claim 3: Amazonian languages show a high degree of ergativity
Amazonian languages are well known for their diversity of alignment types and complex marking patterns. Earlier work on Amazonian languages noted that “ergatively organized systems, in whole or part, are quite common” (Derbyshire Reference Derbyshire1987: 316). This conception of Amazonian languages continues today such that Aikhenvald (Reference Aikhenvald2012: 203) calls Amazonia “the most ergative area in the world.” Even though these claims were presumably intended to include patterns of case marking and subordinate versus main clause ergativity, in addition to ergativity in verbal argument marking in the main clause, they nonetheless bring up an obvious question – do Amazonian languages show a higher degree of ergativity in their verbal marking patterns than other areas of the continent?
To evaluate the distribution of ergativity in Amazonian verbal argument marking, languages with ergative or absolutive simple verb marking patterns as well as languages with an absolutive-aligned minor class of intransitive verbs are considered to display ergativity. Additionally, languages with hierarchical marking that display absolutive alignment in their verbal markers for either direct or inverse scenarios are also considered to display ergativity.8
As opposed to a stricter approach to ergativity that only considers the alignment of verbal markers across major class intransitive verbs, this broader approach is more in line with Dixon and Aikhenvald's (Reference Dixon and Aikhenvald1999: 8–9) statement that in Amazonia, verbal argument marking “can be complex…often giving rise to a ‘split-ergative’ system.” Using this broader approach, there is no support for the significant distribution of languages with ergative and “split-ergative” patterns of verbal argument marking within Amazonia when compared to the rest of the continent (p = 0.433).
5.2 Characteristic features of the Andes
The languages of the Andes present a genealogical diversity that is often overshadowed by the historical dominance of groups speaking Quechuan and Aymaran languages. The multitude of smaller language families of the region, such as Barbacoan, Chibchan, Chocoan, and Uru-Chipayan, as well as the numerous unclassified languages like Cholon, Leko, and Nasa Yuwe, are often overlooked when discussing the characteristic features of Andean languages (cf. Dixon and Aikhenvald Reference Dixon and Aikhenvald1999: 9–10). Adelaar (Reference Adelaar, Lubotsky, Schaeken and Wiedenhof2008a) is an exception to this trend, and presents a careful overview of a number of features that he considers to be common to many of the different languages of the region while also taking cultural considerations into account. Even though his eventual conclusion is that there is “still very little evidence for recognizing and delimiting linguistic typological areas, let alone an Andean linguistic area” (p. 31), a number of claims about Andean languages warrant closer investigation in order to help identify verbal argument marking features that may be characteristic of the region. The aggregated region of the Andes discussed here is composed of the languages of the North and Central Andes, as well as Mapudungun.
Claim 1: Verbal argument markers tend to be suffixes
The suffixing nature of Andean languages has been a recurring component of discussions on the typological profile of the region, especially in reference to the locus of verbal argument marking (Lafone Quevedo Reference Lafone Quevedo1896, Tovar and Tovar Reference Tovar and de Tovar1984, Dixon and Aikhenvald Reference Dixon and Aikhenvald1999, Adelaar Reference Adelaar, Lubotsky, Schaeken and Wiedenhof2008a). To explore this distribution, the statistical significance of the presence of verbal arguments indexed as suffixes in the Andean languages was tested, analogous to the procedure used for argument marking prefixes in Amazonia in Section 5.1. The results show that there is very strong statistical support for the claim that Andean languages tend to index their arguments through verbal suffixes when compared to the rest of the continent (p < 0.001).
Claim 2: Indirect objects are indexed in ditransitive clauses
Many Andean languages index O in transitive clauses; this includes many members of the Quechuan, Aymaran, and Chibchan families, as well as the languages Cholón, Leko, and Nasa Yuwe. Adelaar (Reference Adelaar, Lubotsky, Schaeken and Wiedenhof2008a: 30) states that in ditransitive clauses “the encoded object often represents an indirect (human) object, rather than a direct object,” or in other words, the languages of the Andes tend to show primary object alignment in ditransitive clauses. Given the sample used in this study, the distribution of R-indexation in ditransitive clauses is indeed statistically significant for the languages of the Andes that display O-indexation (p = 0.004).
Claim 3: Verbs index two arguments in transitive clauses
Presumably using Quechua and Aymara as an Andean prototype, it has been claimed that Andean languages tend to index both A and O in transitive clauses (Dixon and Aikhenvald Reference Dixon and Aikhenvald1999: 10). While that claim is accurate for a number of Andean languages, there is no support for the notion that two argument indexation in transitive clauses is a characteristic feature of Andean languages (p = 0.245).
Claim 4: 1st person plural inclusive vs. exclusive is distinguished in verbal argument marking
The ability to distinguish whether 1st person plural pronominal forms include or exclude the addressee in a speech act (2nd person) is a commonly found feature in the languages of the world (Filimonova Reference Filimonova2005). In fact, the earliest attested description of such a distinction comes from a sixteenth-century grammar of Quechua by Domingo de Santo Tomás (Reference Santo Tomás1560). While the 1st person plural inclusive/exclusive distinction occurs in languages of various regions of South America, Adelaar (Reference Adelaar, Lubotsky, Schaeken and Wiedenhof2008a: 31) proposes that such a distinction in verbal argument marking is a characteristic feature of Andean languages. Testing only for the distinction between 1st person inclusive and exclusive in sets of verbal argument markers (and not free pronoun systems or possessive marking), there is no support for a significant distribution of this distinction among Andean languages (p = 0.258).
5.3 Characteristic features of Eastern and Western South America
As seen above, many of the claims regarding the distribution of verbal argument marking patterns as characteristic of either the Amazonian or Andean languages have been supported by a quantitative analysis of the data from the language sample used in this chapter. Other claims were found to have no statistical support for a characteristic regional distribution. However, when examining the data, a more striking pattern emerges than the often-discussed Andean versus Amazonian typological split – a number of the verbal argument marking patterns display a significant distribution when the languages are grouped into Eastern and Western South American aggregated regions.
The Western South America aggregated region is composed of the Northern Andes, Central Andes, Western Amazonia, and Southern Cone regions as defined in Section 2. The Eastern South America aggregated region is composed of the Guyana Shield, Southern Amazonia, and Chaco-Planalto regions. The major difference between this configuration and others, such as a highland versus lowland distinction (Payne, D. Reference Payne and Payne1990) or an Amazonian versus Andean distinction (Dixon and Aikhenvald Reference Dixon and Aikhenvald1999), is that the languages of Western Amazonia are grouped together with the languages of the Andes and the Southern Cone. From an areal perspective, such a configuration seems uncontroversial. First, there are many examples of where languages from the Central Andes, especially Quechua varieties, have likely influenced the development of certain features in the languages of Western Amazonia, such as the emergence of an inclusive/exclusive distinction in Campa Arawakan languages (Crevels and Muysken Reference Crevels, Muysken and Filimonova2005a) or the multiple phonological and grammatical changes that have occurred in Yanesha’ (Adelaar Reference Adelaar, Aikhenvald and Dixon2006). Furthermore, there is ample evidence of Quechua loans in many of the languages of the Western Amazon, especially for numeral systems, as is the case for numerals above five in Urarina (Olawsky Reference Olawsky2006: 275), but also for vocabulary items related to material culture, agriculture, and animal names (Adelaar with Muysken Reference Adelaar, Adelaar and Muysken2004: 500).
As can be seen in Table 10.1, all of the argument marking features shown to be characteristic of the Amazonian or Andean region are also characteristic of the Eastern and Western South America regions. In most cases, the significance of the distribution is more robust in the Eastern or Western region than in the respective Amazonian or Andean region. This suggests that the Eastern–Western distinction in South American argument marking typology is more salient in the data than an Amazonian–Andean distinction, given the sample used for the study.9
Table 10.1 Comparison of characteristic features for Amazon vs. Eastern and Andes vs. Western

There are, however, a few claims that warrant further discussion. For Claim 1 about Amazonian languages, the results show that the indexation of only a single argument is not a characteristic feature of Amazonia nor of Eastern South America. For Claim 1 for the Andes, regarding the prominence of suffixing argument markers, the distribution shows similarly strong significance for either an Andean or a Western South America region, which highlights the fact that the data from the Western Amazonia region do not fit well with the claim that Amazonian languages tend to use prefixes to index arguments. In fact, the languages of the Western Amazon show a roughly equal distribution between the two patterns, with arguments indexed as prefixes in eighteen cases and as suffixes in seventeen cases across the fourteen languages in the sample, and thus does not, as a region, display either prefixing or suffixing of argument markers as a characteristic feature. This could be a reflection of the dominant role that Central Andean languages like Quechua and Aymara have played in the region, especially along the Peruvian foothills where we find a number of Amazonian languages that suffix verbal arguments, such as Aguaruna, Muniche, and Matses.
The most interesting result from the examination of patterns in the Eastern and Western regions concerns the distribution of a 1st person plural inclusive/exclusive distinction in verbal argument markers. As was shown in Section 5.2, this feature is not characteristic of Andean languages; as shown in Table 10.1, nor is it characteristic of the languages of Amazonia. However, the results show that the inclusive/exclusive distinction in verbal argument markers is indeed significant for Western South America – with a significantly lower distribution than the rest of the continent (indicated with an asterisk in Table 10.1). A significantly higher distribution of the inclusive/exclusive distinction is found in the languages of Eastern South America (p = 0.029), showing that it is a characteristic feature of this region.
6 Conclusions
South American languages present a wide diversity of verbal argument marking patterns. Within a sample of sixty-four languages from thirty-eight phylogenetic groupings, many different patterns are encountered, from the cross-linguistically common nominative-accusative marking in Muniche (example 3) to the typologically rarer strict ergative marking in Katukina (example 5). There are also a number of complex marking patterns in the languages, with a variety of different split intransitive and hierarchical marking patterns found all over the continent.
The distribution of the different observed patterns helps to shed light on the typology of South American languages as well as the history of the peoples who spoke them. The work presented here is only a first attempt at quantifying these distributions, but some tentative conclusions can be reached. First, it is important to highlight the fact that certain patterns are observable at different degrees of resolution. Some patterns, such as fused argument markers, are primarily restricted to a family or two; other patterns, such as nominative-accusative marking, show a wider distribution while occurring more frequently in particular geographic regions. Finally, some patterns show a continent-wide distribution but are characteristic of larger geographic regions. This suggests that these features have developed under a variety of historical and sociocultural scenarios that have been in place across different regions of the continent at different timescales. So while the development of an inclusive/exclusive distinction in the verbal markers of Campa Arawakan languages can be attributed to Quechuan influence over a relatively shallow time period, to what can we attribute the striking distribution of an inclusive/exclusive distinction across Eastern South America? In order to understand the dynamics of language change at deep time depths, more research is needed on the languages and the history of their speakers. The first step, however, is to better understand the structural facts of the languages, and this has been one of the primary objectives of this chapter.
While Lafone Quevedo's (Reference Lafone Quevedo1896) three-way typology of verbal argument marking in South America has been shown as too simplistic for the incredible diversity of languages encountered there, he was correct in noticing that there are indeed patterns that occur with great frequency across the continent and whose distributions are statistically significant. The wealth of information already available has proven sufficient to reexamine some commonly held notions of the distribution of certain features across these languages. As further investigation into South American languages is carried out, many more patterns at different geographic and temporal scales are likely to emerge, and with them, our understanding of the historical and linguistic processes that have affected these languages and their speakers will improve.
Appendix
Table 10.2 provides additional information about the languages in the sample, including the language names used in the study, language family, region, verb marking template, the presence of clusivity in the argument marker sets, case marking pattern, R-indexation, and language sources. A number of conventions are employed that warrant further explanation:
Table 10.2 Language sample with additional information (by region)





1 Campbell (Reference Campbell, Campbell and Grondona2012a) provides a conservative estimate of a total of 108 language families in South America, which includes 55 isolates. As he notes, this accounts for over a quarter of all attested language families in the world.
2 This is especially relevant for the discussion on splits in the marking of the sole argument of intransitive clauses.
3 Roman numerals are used to distinguish between different sets of markers that occur in the same slot.
4 See Trillos Amaya (Reference Amaya1996: 125) and Adelaar with Muysken (Reference Adelaar, Adelaar and Muysken2004: 78) for an analysis of the scant data available for this aspect of Chimila. Curnow (Reference Curnow1997) presents a thorough analysis of Awa Pit person marking, which operates on a “locutor/non-locutor” distinction rather than a SAP/3rd person distinction.
5 Hixkaryana shows a similar split in the marking of 2nd person S for different verb classes (Derbyshire Reference Derbyshire1985:188).
6 It is worth noting that the set of markers that index A on the verb (14a) in Wichí share a number of forms with the set of markers that index the subjects of “stative” intransitive verbs as in (14c), most notably 1st person singular/1st person plural exclusive n- and 1st person plural inclusive ya-. See Terraza (Reference Terraza2009: 124–138) for further details.
7 For information about proposals related to the languages of the Chaco, see Campbell and Grondona (Reference Campbell, Grondona, Campbell and Grondona2012).
8 Itonama, Hixkaryana, and Chimila are the languages with hierarchical marking in transitive clauses that do not index S and O with the same set of argument markers (except for Hixkaryana 2nd person major class S).
9 Interestingly, Krasnoukhova (Reference Krasnoukhova2012) also finds a number of features in the noun phrase structure of South American languages that show a striking East versus West distribution.
11 The Noun Phrase: focus on demonstratives, redrawing the semantic map
This chapter deals with the Noun Phrase in indigenous languages of South America, focusing on the phenomenon of semantically rich demonstrative systems which are found in these languages. I show that the range of semantic features reported in Diessel (Reference Diessel1999) can be extended with the following features, if we look at South American languages: perceived physical properties, posture, possession, and temporal distinctions. On the basis of the data, I suggest that although the languages vary in the richness of their demonstrative systems, this variation seems to be highly structured. The semantic features encoded by demonstratives represent a continuum running from prototypically nominal categories to prototypically verbal categories. The languages spoken in the Chaco and the Southwest Amazon region stand out for encoding a number of verbal categories by demonstratives.
1 Introduction
This chapter will deal with the Noun Phrase in the South American indigenous languages and in particular with the semantic features of demonstratives in these languages. Before focusing on the topic of demonstratives, I will present a general profile of Noun Phrases (NPs). This discussion of the NP characteristics builds upon the results presented in Krasnoukhova (Reference Krasnoukhova2012), a typological study of NPs in a sample of fifty-five indigenous languages spoken in this part of the world.
2 Profile of the Noun Phrases in South America
I will focus on integral NPs consisting of a noun and at least one modifier. The most common template in South American languages is one where demonstratives, lexical possessors, and numerals occur before the head noun, while property words occur after the noun. Only a quarter of the languages in the sample always have the head noun at the boundary of the NP, i.e. with modifiers preceding the head noun. There are no languages in the sample with head-initial NPs (i.e. right-branching structures, with all modifiers following the noun). With respect to the flexibility of constituent order relative to the head noun, property words and numerals are more flexible than lexical possessors and these are, in turn, more flexible than demonstratives. In terms of general patterns of constituent order, my results confirm the findings reported in Dryer (Reference Dryer1992). Specifically, in South America, the orders [demonstrative-noun], [possessor-possessed], and [numeral-noun] are much more common in the OV languages than in the VO languages in the sample, and the order [noun-property word] is much more common in OV languages than in VO languages.
An issue of typological interest is the presence of a dedicated class of adjectives in South American languages. Even for the members of the core four semantic types (dimension, age, value, and color) suggested by Dixon (Reference Dixon1982, Reference Dixon2004, Reference Dixon2010), far from all the languages in the sample have morphosyntactically distinct adjectives. Languages without a distinct adjective class much more commonly use verbs than nouns or adverbs to express property concepts. Here a geographic division stands out, in that hardly any language of the Andean sphere encodes property words through verbs, whereas languages in which property concepts are encoded by verbs are predominant in the Northwest Amazon and the Southwest Amazon regions; they are also found in the Chaco (Tapiete and Wichí), eastern and southern part of Brazil (Timbira and Bororo), and in the Southern Cone (Tehuelche). Thus, these results do not support Payne's (Doris L., Reference Payne1987: 41) observation that in languages “within and without the Western Amazon region…[d]escriptive modifiers within noun phrases are usually nominal.” However, the results do support another observation by Payne, Doris L. (Reference Payne1987: 41) that “[i]n various South American languages, the class of adjectives is extremely small.”
The word class of property words determines their morphosyntactic characteristics when they are used as attributive modifiers within the NP. For noun-like property words the most common strategy is direct modification; one language (Wari’) uses possessive constructions. For verb-like property words, the strategy is to use a relative clause construction or nominalization of the verb (which is often the main strategy of a relative clause formation in the South American languages). Finally, about 15 percent of the languages studied do not allow attributive use of property words; these have to be used predicatively or adverbially.
Another typologically interesting issue is the expression of cardinality in South American languages. Nominal number is not a prevailing feature here, with 42 percent of the languages showing optional marking on all nouns and another 20 percent of the languages not marking number within the NP at all. If number marking does occur within the NP, it largely follows the Animacy Hierarchy (number is more frequently marked on human nouns than on other animates, and more frequently on animates than on inanimates). It can also be observed that the presence of a numeral modifying a noun is one of the factors that influences the occurrence of number marking (it can either block number marking or make it even more optional), in addition to factors like the pragmatic status of the referent of the noun (its definiteness and specificity). In about 20 percent of the languages studied, numeral expressions never form part of the NP: they are used either as predicates or as adverbs (this percentage is higher than for adjectives). In the other languages, numeral expressions can have nominal properties in that they pattern like nouns in a language, or they can have verbal properties in that they receive nominalizing morphology in order to be used attributively.
In the sample studied, I also observed that borrowed numerals and property words tend to be borrowed together with their morphosyntactic properties. For instance, in Awa Pit, property words borrowed from Spanish follow the head noun, whereas native forms obligatorily precede the noun (see Curnow Reference Curnow1997: 119). In Shipibo-Konibo, borrowed numerals from Quechua obligatorily precede the head noun (as in Quechua), whereas native forms do not show a fixed order (see Valenzuela Reference Valenzuela2003: 235). In Urarina, borrowed Quechua numerals from six onwards behave like nouns, while the native forms from one to five are verbs and require a nominalizing suffix or participle suffix when used attributively.
Nominal classification is yet another issue of high relevance for South American languages. More than half of the languages studied have either a gender system or a classifier system, or both. Whereas some languages in this part of the world have a prototypical classifier system, a large number of languages have a “multifunctional classifier system.” Instead of the term “multiple classifiers” (see Aikhenvald Reference Aikhenvald2000: 304), which is defined in formal terms, I suggest using the term “multifunctional classifier” system, since the system combines four functions: (i) semantic categorization, (ii) derivation, (iii) syntactic agreement, and (iv) referential function at discourse level. These functions can be manifested to different degrees in different languages, but it is their combination that distinguishes them from more prototypical classifier systems. The typological interest of this type of system has been noted earlier (see Payne, Doris L. Reference Payne1987, Derbyshire and Payne Reference Derbyshire, Payne and Payne1990, Aikhenvald Reference Aikhenvald2000, Grinevald and Seifart Reference Grinevald and Seifart2004, Seifart and Payne Reference Seifart and Payne2007), but it is also interesting from a more theoretical perspective. Namely, the use of classifiers in constructions with a numeral and their interrelation with number marking on nouns has led to a theory about the nature of nouns, developed in Rijkhoff (Reference Rijkhoff2002). South American languages with multifunctional classifier systems pose an interesting challenge to Rijkhoff's theory about noun types. Specifically, these systems allow for typologically curious cases where a numeral is combined with a classifier, and the noun has a plural marker (see Krasnoukhova Reference Krasnoukhova2012: 122–123 for more detailed discussion). Further, in general, languages with multifunctional classifier systems seem to have NPs which are less tight (i.e. more towards the part of the continuum with non-integral NPs). This can largely be explained by the derivational and agreement roles played by classifiers.
There is a certain geographic pattern in the distribution of languages with gender and/or classifiers. Gender distinctions and classifier systems are largely absent in the languages spoken in the western part of the continent, but not without exceptions (Tsafiki and Yanesha’). Nominal classification systems are also absent in some languages spoken in the Western Amazon (e.g. Shipibo-Konibo, Urarina, Matsés, Yaminahua, Apurinã). On the other hand, numerous languages spoken in the North, Northwest, and Southwest Amazon regions, in the Chaco and in the Southern Cone do have gender and/or classifier systems. With respect to languages with multifunctional classifier systems, two separate “epicenters” stand out. One is the Northwest Amazon, which was pointed out by Payne, Doris L. (Reference Payne1987), Derbyshire and Payne (Reference Payne and Payne1990), Aikhenvald (Reference Aikhenvald2000), and Seifart and Payne (Reference Seifart and Payne2007) as prominent in terms of non-prototypical types of complex classifier systems. The other is the Southwest Amazon region, which was first pointed out by Van der Voort (Reference Voort2005).
Another question related to the domain of NP is attributive possession. The most common template with respect to constituent order within the NP is the lexical possessor preceding the possessed noun. Interestingly, four out of five languages with the fixed possessed-possessor order are genetically unrelated and geographically concentrated in the Guaporé-Mamoré region (Baure, Movima, Itonama and Wari’). This is a region for which Crevels and Van der Voort (Reference Crevels, van der Voort and Muysken2008) have argued there are strong characteristics of a linguistic area; however, possessed-possessor order is not given among the features that define the area. With respect to the locus of possession marking, head-marking and dependent-marking strategies are equally common in South American languages, followed by a third strategy where possession is morphologically unmarked but signaled by word order. A double-marking strategy is found in just a few languages (Aymara, some Quechua variants, and Aguaruna). The locus of possession marking has been mentioned in the literature as one of the features that characterize particular linguistic areas in South America. Specifically, Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999: 8) suggest that the head-marking pattern is among the features defining the “Amazonian linguistic area,” whereas the double-marking pattern is among the features of the “Andean linguistic area” (Dixon and Aikhenvald Reference Dixon and Aikhenvald1999: 10). I showed in Krasnoukhova (Reference Krasnoukhova2012: 84–85) that there are no good grounds to generalize that Amazonian languages are predominantly head-marking for possession: both dependent- and head-marking patterns are equally common in the Amazonian languages in the sample. With respect to the double-marking pattern, which is suggested by Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999) as a feature of the “Andean linguistic area,” it is correct to say that possession marked both on the possessor and on the possessed is found predominantly in the languages spoken in the Andes, specifically, in Aguaruna and among the Aymaran and many of the Quechuan variants. But this is not the only possession strategy found in the languages spoken in the Andes. For instance, Chipaya is dependent-marking, as well as Imbabura Quechua, and Uru has morphologically unmarked possessive constructions. In addition, a number of languages spoken in the Andean slopes show various types of possession marking.
The feature of (in)alienability is very common among the languages of this part of the world. About 75 percent of the languages studied have a class of inalienably possessed nouns. However, less than 40 percent of these languages distinguish alienable and inalienable possession structurally. Unlike the locus of marking, the feature of inalienability does have an areal component. As was shown in Krasnoukhova (Reference Krasnoukhova2011, Reference Krasnoukhova2012: 87), a great majority of languages spoken along the western edge of the continent lack a class of inalienable nouns, whereas languages in the rest of the continent predominantly have such a class.
The parameter of (in)alienability interacts with the locus of possession marking, which results in three patterns observed in the data (see Krasnoukhova Reference Krasnoukhova2012: 88). A pattern that has not been reported before (as far as I know) is that inalienable constructions which involve juxtaposition of unmarked possessor and possessed constituents occur only in languages where possessor is marked in alienable constructions. This gives us the following typological implication: if a language uses unmarked juxtaposition of possessor and possessed for inalienable possession, then the language is dependent-marking for alienable possession.
Finally, in South American languages, personal pronouns commonly receive the same possessive markers as nominal possessors, which implies that a fully grammaticalized category of possessive pronouns is rare in this part of the world. A general typological claim that I have presented on the basis of the South American data is that no language will have a grammaticalized category of possessive pronouns for 3rd person, if it does not have a grammaticalized category of possessive pronouns for 1st and 2nd person.
So far I have given a typological profile of NPs in South American languages. An issue briefly addressed next is the geographic division of NP features that emerges from the overall picture. I suggested and illustrated in Krasnoukhova (Reference Krasnoukhova2012) that there is linguistic evidence for a split between languages spoken in the western vs. the eastern part of the continent, rather than the split between the Andes and the Amazon that has traditionally been proposed. The western group consists of languages spoken in the western part of the continent which roughly corresponds with the Andean sphere, while the eastern group consists of languages spoken in the rest of the continent, and thus is not limited to the Amazon region.
For the languages of the western group the following characteristics apply:
(i) pre-head position for all modifiers;
(iii) property words are morphologically nominal;
(iv) lack of inalienable nouns.
For the languages of the eastern group the following characteristics apply:
(i) pre-head position for demonstratives, lexical possessors, and numerals, and posthead position for property words;
(ii) presence of gender and classifiers, often of the multifunctional type;
(iii) property words are verbal;
(iv) presence of inalienable nouns.
The features (i)–(iii) for the western group are consistent with the conclusions reached by Adelaar (Reference Adelaar, Lubotsky, Schaeken and Wiedenhof2008a), who determined the profile of Andean languages. Feature (iv) was first proposed in Krasnoukhova (Reference Krasnoukhova2011). However, the languages of the eastern group are found far beyond the Amazon region and include, for instance, the Chaco, the eastern and southern part of Brazil, and the Southern Cone. While Amazonia has been proposed as a linguistic area on the basis of a number of shared features (e.g. Derbyshire and Pullum Reference Derbyshire, Pullum, Derbyshire and Pullum1986; Derbyshire and Payne Reference Derbyshire, Payne and Payne1990; Dixon and Aikhenvald Reference Dixon and Aikhenvald1999: 8), a careful comparison shows that these features have a much wider distribution than the Amazon and are therefore not exclusive to this region (see Campbell Reference Campbell, Campbell and Grondona2012b: 301–304). This is also the outcome of my study of NP features. There may be more evidence for certain, much smaller, parts of South America as areas with shared structural characteristics: for instance, the Colombia-Central America area (Constenla 1991), the Western Amazon (Payne, D. Reference Payne and Payne1990), the Içana-Vaupés river basin (Sorensen Reference Sorensen1967; Gómez-Imbert Reference Gómez-Imbert, Gumperz and Levinson1996; Aikhenvald Reference Aikhenvald1996, Reference Aikhenvald, Dixon and Aikhenvald1999b, Epps Reference Epps and Wetzels2007b), the Guaporé-Mamoré area (Crevels and Van der Voort Reference Crevels, van der Voort and Muysken2008), and the Gran Chaco area (Campbell and Grondona Reference Campbell, Grondona, Campbell and Grondona2012b, Comrie et al. 2010). In this context, I will not attempt to evaluate these proposed areas on the basis of NP features, since the sample used was designed with a typological aim. Instead, in the rest of the chapter, I will focus on a typologically less common phenomenon, which is especially prominent in the geographic regions of the Chaco area and the Southwest Amazon: semantically rich demonstrative systems.
3 Semantics of demonstratives in the languages of South America
The typological literature has reported on a range of semantic features encoded in demonstratives, some of which are more common than others (cf. Diessel Reference Diessel1999). However, if we look at South American languages, we notice a few strikingly different features that were not discussed in earlier studies. Specifically, in addition to more common features encoded in demonstratives like number and gender, quite a number of South American languages encode typologically less common features like movement, posture, physical properties, possession, and temporal distinctions. Among the less common features, the feature of movement is discussed in Diessel (Reference Diessel1999), and the feature of posture is briefly mentioned in Dixon (Reference Dixon2003: 90). However, the last three categories have not received any attention in the typology of demonstratives so far. Temporal distinctions are of particular interest, since they are prototypically verbal and, thus, are less expected in nominal categories like demonstratives (but see Nordlinger and Sadler Reference Nordlinger and Sadler2004).
In Diessel (Reference Diessel1999), a major cross-linguistic study on demonstratives, South America is represented with eight languages out of a total sample of eighty-five.1 The sample used in this study consists of sixty-one indigenous languages of South America,2 and thus complements Diessel's study by offering an analysis of new South American data for the semantic status of demonstratives.
Here I will follow the definition of demonstratives given by Diessel (Reference Diessel1999: 2), as “deictic expressions which are used to orient and focus the hearer's attention on objects or locations in the speech situation.” Demonstratives can occur in four syntactic contexts in the clause (Diessel Reference Diessel1999: 3–4): as independent pronouns (pronominal demonstratives), as modifiers of nouns (adnominal demonstratives), as modifiers of verbs (adverbial demonstratives), and in copular clauses (identificational demonstratives).
Diessel (Reference Diessel1999: 35, 51) discusses the following list of semantic features encoded in and on demonstratives in his sample, which he groups in terms of two kinds of features (referring to Lyons Reference Lyons1977; Fillmore Reference Fillmore and Klein1982; Rauh Reference Rauh and Rauh1983; Hanks Reference Hanks1989, Reference Hanks1990):
(i) deictic features, i.e. information about the location of the referent in the speech situation relative to a deictic center:
a. distance (neutral, proximal, medial, distal);
b. visibility (visible, invisible);
c. altitude (up, down);
d. geography (uphill, downhill, upriver, downriver);
e. movement (toward the speaker, away from the speaker, across the visual field of the speaker),
(ii) qualitative features, i.e. information characterizing the referent itself:
All of these semantic features are found in the languages considered in this study, except for the feature of “boundedness” in the sense used in Diessel (Reference Diessel1999). This feature involves the distinction bound vs. unbound, where bound forms make reference to an object or location “whose entire extent is comprehensible to the eye in a single glance,” and unbound forms refer to objects or locations “not comprehensible to the eye in a single glance” (Diessel Reference Diessel1999: 49, referring to Denny Reference Denny1982: 360). In addition, however, the languages in this sample also show a number of features that do not occur in Diessel's (Reference Diessel1999) sample. These are listed next.
(A) Physical properties: shape, consistency, structure, etc.
(B) Posture: standing, sitting, lying, hanging.
(C) Possession:possession or control by a non-speech-act participant.
(D) Temporal distinctions: past vs. non-past, presence vs. absence vs. anticipated absence.
I will discuss and exemplify these new features in the following subsections.
3.1 Physical properties
The feature of physical properties overlaps to some extent with the feature of boundedness as reported in Diessel (Reference Diessel1999: 49). Whereas, as specified above, Diessel's feature of “boundedness” involves a more general interpretation of shape, the present feature of physical properties encodes more specific information on the perceived physical characteristics of the referent. The encoding of information on physical properties can be divided into two types here:
(i) specific information on physical properties, such as shape, material, structure, etc. In the sample, such information is morphologically realized by classifiers obligatorily occurring on demonstrative roots;
(ii) information on physical properties in terms of extendedness: vertically extended, horizontally extended, non-extended. In the sample, this is realized morphologically in the demonstrative roots themselves.
Let us examine each type in turn. In the sample, Itonama, Kwaza, Yanesha’, Tariana, Cubeo, Desano, and Miraña are of the first type, i.e. with demonstratives that encode specific information on physical properties of the referent by means of classifiers.
Example (1) is from Itonama, where demonstratives are roots that require further derivation by a classifier in order to be used pronominally or adnominally. The language has seventeen classifiers used on the demonstratives,3 the choice of which depends on number (singular or plural), animacy, posture, and shape of the referent (Crevels Reference Crevels2001, Reference Crevels, Crevels and Muysken2012). The demonstrative roots encode degrees of distance (nV (’V) ‘proximal,’ yV ‘medial,’ and k’V ‘distal’), whereas classifiers are portmanteau morphemes that express a combination of features, which include combinations like animacy + position + number (+ gender, if number is singular), shape + number, position + number, shape, and consistency.
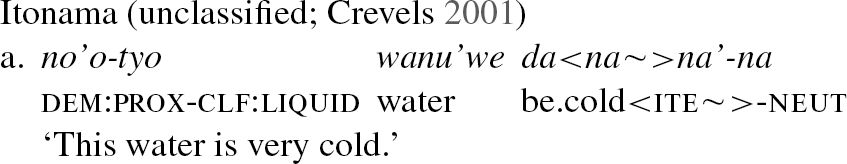

Example (2) is from Cubeo, where demonstratives used with inanimate referents must also use a classifier encoding the shape and structure of the referent.


Mocoví, Pilagá, Selk'nam, Yuki, and Mekens have demonstratives of the second type, where information on the physical properties of an inanimate referent is expressed in terms of extendedness (vertically extended, horizontally extended, and non-extended). For inanimate referents the shape is inferred from the postural orientation, e.g. flat objects would prototypically be horizontally extended (or lying), and high objects would prototypically be vertically extended (or standing). Morphologically, this feature is encoded in a demonstrative root (however, see footnote 4). The following example from Mekens illustrates the use of demonstrative teʔẽ ‘proximal, vertically extended’ with the referent ek ‘house’ (3a) and a distance-neutral demonstrative teita ‘vertically extended’ with the referent kipkiba ‘tree’ (3b).


The choice of these demonstratives is determined by the shape and therefore also the postural orientation of the inanimate referents. Galucio (Reference Galucio2001: 44) notes that demonstratives can occur by themselves, but more generally they combine with the third person singular pronoun te.
3.2 Posture
The choice of demonstratives based on posture is discussed next. The differentiation between the category of posture and the category of physical properties in terms of extendedness occurs with animate vs. inanimate referents. For animate referents, information on postural orientation of the referent is primary, whereas for inanimate referents it is the information on physical characteristics of the referent that can be considered as primary.
Postural orientation or exact posture distinctions like sitting, standing, lying and, in some languages, hanging, are encoded by demonstratives in Mekens, Yuki, Selk'nam, Movima, Pilagá, Mocoví, Kadiwéu, and Itonama. As with the previous feature, information about posture can be realized morphologically either (i) in a demonstrative root, or (ii) by obligatorily used classifiers.
In all these languages except for Itonama, posture is encoded in demonstrative roots. The following example from Yuki illustrates the use of the demonstrative a, which refers to entities with the properties ‘proximal; plural; sitting’ (4a), and the demonstrative kio, which is used to refer to entities with the properties ‘proximal; singular; present; lying’ (4b). The reduplication of the form in (4b) accounts for the interrogative form of the utterance.


In Pilagá, Kadiwéu, and Mocoví demonstrative forms4 encode distinctions like ‘standing/vertically extended,’ ‘sitting/non-extended,’ and ‘lying/horizontally extended’ (Vidal Reference Vidal1997; Sandalo Reference Sandalo1995; Grondona Reference Grondona1998). With human referents the forms ‘standing/vertically extended’ or ‘sitting/non-extended’ are used, depending on the posture of the referent at the moment of speaking (5, 6). With non-human referents, the form ‘sitting/non-extended’ is prototypically used with buildings, mammals, birds, and insects. The form ‘lying/horizontally extended’ is common with names of places, small towns, plain surfaces, and elongated animals. The term is also used in reference to ancestors, dead people, or dead animals (Vidal Reference Vidal1997: 77).



Demonstratives in Movima encode a distinction between entities on the ground and entities that are not on the ground (Haude Reference Haude2006: 178). Reference to entities that are not on the ground will be discussed in more detail further on. With reference to entities on the ground, a posture distinction is made between standing on the ground and non-standing on the ground, with the latter used also for referents that are lying or sitting on the ground. The exact posture distinction can be further specified by a combination with posture verbs. While demonstratives can co-occur with verbs encoding the same posture (7a–c), they cannot be used with verbs encoding a posture that contradicts the one expressed in the demonstrative (7d).




In Itonama, posture semantics are expressed by obligatorily used classifiers. Humans and animates are classified in terms of their canonical positions, namely standing or sitting. Reclassification of animates into the category of lying entities is possible, though. In such cases, the classifier which is normally used for flat, horizontally extended objects is employed. The following examples illustrate the use of the classifier di ‘animate, seated, plural’ on the distal demonstrative nik'o (8a) and the demonstrative form k'ota'na in which the distance parameter, animacy, number, and posture are merged (which implies that it does not have the usual form of a demonstrative root plus a classifier) (8b).


In Mekens, Movima, and Itonama, there is an additional semantic distinction within the posture paradigm, viz. ‘hanging/elevated/suspended.’ In Mekens and Movima, this is encoded in the demonstrative stems, while in Itonama it is expressed by obligatorily used classifiers. Example (9) from Mekens shows the use of the demonstrative tee ‘suspended.’

In Movima, the use of the demonstrative encoding ‘elevation’ is used for reference to entities that are not on the ground. This can either mean that they are suspended in the air or that they are located on top of another object, as illustrated in (10a). It can also be used when the referent is swimming or floating on the water, since the referent does not touch the ground (10b) (Haude Reference Haude2006: 177).


In example (11) the demonstrative form kuwa ‘elevated, masculine’ occurs together with a positional verb, which specifies the exact posture of the referent.

3.3 Possession
Movima is the only language in the current sample for which encoding of the feature of “possession” by demonstratives has been reported. Haude (Reference Haude2006: 186) argues that in Movima, there is a set of demonstratives that refer to objects “in the temporary possession or under control of a non-speech-act participant.” As Haude (Reference Haude2006: 186) notes, a crucial factor for the use of these demonstratives is “a certain kind of control.” These forms are treated as demonstratives because syntactically and morphologically they are part of the paradigm of demonstratives in this language (Katharina Haude, p.c.).
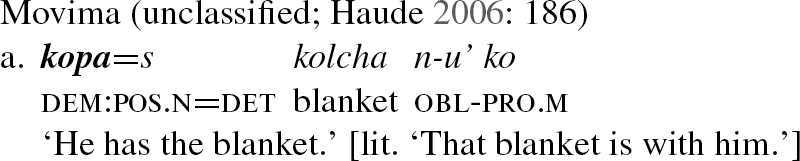

By way of comparison, an example of a possessive construction in Movima is given in (13) below.5 For all persons except the 1st person singular, the possessive personal pronouns are cliticized to the possessed noun. The possessor can also be expressed by a free pronoun or by an NP. In that case the free pronoun or NP can be unmarked, or marked as an oblique, or most commonly, expressed as a relative clause containing the oblique-marked pronoun (Haude Reference Haude2006: 228).

3.4 Temporal distinctions
Finally, there are languages in the sample in which demonstratives encode what I will call “temporal distinctions.” These include semantic distinctions like “no longer existing,” “no longer usable,” “former,” and “absent.” Quite a few South American languages are characterized by the capacity to mark temporal distinctions within the NPs (see Campbell Reference Campbell, Campbell and Grondona2012b: 285). Nordlinger and Sadler (Reference Nordlinger and Sadler2004: 776) offer a cross-linguistic comparison of this phenomenon which, as they argue, “is far less marginal than the general paucity of discussion in the literature might lead one to expect.” This section deals exclusively with the encoding of temporal distinctions on demonstratives (thus narrowing the range of elements within the NP domain that can encode temporal distinctions specifically to demonstratives). Since it is important to determine what exactly is meant by temporal distinctions here, I will briefly comment on this first.
Nordlinger and Sadler (Reference Nordlinger and Sadler2004) postulate two types of nominal tense-aspect-mood (TAM) marking: (i) independent and (ii) propositional. Independent nominal tense markers serve to locate the time at which the property denoted by the nominal holds. Propositional nominal tense markers, on the other hand, provide temporal information for the whole sentence. Nordlinger and Sadler mention that independent nominal tense markers are inflectional affixes, which should be kept apart from derivational affixes like the affix ex- in English. The major difference is that derivational affixes like English ex- are usually restricted in their semantics and can occur with a limited number of words, like nouns denoting occupations (ex-president) and non-kin relationships (ex-wife). The use of this prefix with nouns like ‘cat’ (?ex-cat) or ‘house’ (?ex-house) is much less appropriate. Nordlinger and Sadler (Reference Nordlinger and Sadler2004: 780) argue that “true” tense markers are different in that they are not constrained by the semantics of the noun.
This semantic category is quite complicated, especially if we focus exclusively on demonstrative forms as potential targets for expressing it. However, there is evidence from the data that it is worthwhile to look at this category. In the sample, demonstratives express temporal distinctions in Chorote, Nivaclé, Pilagá, Mocoví, Kadiweu, Movima, Wari’, Yuki, Tiriyó, Hixkaryana, Panare, and probably Selk'nam.6 Morphologically, these distinctions are realized either by separate morphemes occurring on demonstrative roots, or they are encoded by the demonstrative roots themselves. In the Guyacuruan languages Pilagá, Mocoví, and Kadiwéu, as well as in Matacoan languages Nivaclé and Chorote, temporal distinctions are conveyed mainly by deictic elements, directionals and adverbials.
In Nivaclé, temporal interpretations are inferred from demonstratives; verbs have no markers of tense (Campbell Reference Campbell, Campbell and Grondona2012b: 286, p.c.). The tense distinctions are conveyed by the demonstrative form na ‘visible’ for present tense and the form xa ‘not visible, but known from first-hand experience’ for the past tense interpretation. The form pa ‘not visible, no direct knowledge (hearsay)’ can also imply past tense, since it refers to things reported by others (so past) (Lyle Campbell, personal communication). The following example shows the difference in meaning conveyed by the na and xa demonstratives.


In Pilagá, for instance, the semantics of demonstrative forms which encode movement in the spatial domain can be extended to express movement of an entity in the temporal domain. The form soʔ ‘going away/past’ is used with a referent which is ‘becoming absent’ or ‘now absent,’ in other words “not present anymore but the speech participants know that it once was” (Vidal Reference Vidal1997: 80, 93). The form gaʔ ‘absent/distal,’ encodes the semantic features of ‘distalness’ and ‘absence.’ It is used to convey the meaning of “absent prior to the speech event,” i.e. “anticipated absence” (Vidal Reference Vidal1997: 80).
In Tiriyó, there are two suffixes meaning ‘past,’ -npë and -hpë, which are used on nominals “to signal that the referent in question can no longer be accurately described by that stem” (Meira Reference Meira1999: 160). When used on non-possessed forms, the semantic distinctions made by the suffixes can include ‘degraded,’ ‘no longer usable,’ ‘ex-,’ or ‘former.’ When used with possessed forms, the interpretation of past possession is more frequent, i.e. “something which used to belong or be related to the possessor” (Meira Reference Meira1999: 160–161). Example (15) illustrates the use of either of the suffixes -npë and -hpë ‘past’ on a possessed noun ji-pakoro ‘my house.’ This can be an example of the so-called independent nominal tense markers as specified above.
(15) Tiriyó (Cariban; Meira Reference Meira1999: 219)
ji-pakoro-hpë / ji-pakoro-npë
1-house:pos-pst / 1-house:pos-pst
‘my ex-house; the ruins of my house’
The following set of examples shows the use of the suffixes on demonstratives in Tiriyó. In (16a) the suffix -npë ‘past’ occurs on the proximal demonstrative mëe for animate referents (in this case, a part of a dead cow). In (16b) the ‘past’ suffix occurs on the proximal demonstrative senï for inanimate referents (in this case treated as a piece of meat).



The following example of a past marker on a demonstrative is from the description of Tiriyó by Carlin. Carlin (Reference Carlin2004: 157) mentions that in (17) the demonstrative with the past tense marker expresses a former something.

In Movima, a set of so-called “absential” demonstratives (the terminology used by Haude Reference Haude2006) encodes past vs. non-past distinctions. Absential non-past demonstratives are used when the referent is not perceived, or being looked at, by the speaker at the moment of speaking, even though (s)he knows that the referent is present.


Absential past demonstratives, on the other hand, are used when “the situation is not continuing during the moment of speaking, or when the speaker does not know if it is continuing or not” (Haude Reference Haude2006: 191) (19a). The sentence given in (19b) illustrates the contrast between absential non-past (kiro’) and absential past demonstratives (iso’). Haude (Reference Haude2006: 189) mentions, however, that demonstratives which encode temporal distinctions are prototypically used as predicates in existential or locative clauses, but do not occur as demonstrative modifiers.


4 Distribution of semantic features of demonstratives
This section gives a schematic overview of all semantic features found in South American languages of the present sample and addresses their geographic distribution.7 The possibility of demonstratives to encode various semantic features is shown in Table 11.1 in the form of a scale. This distribution suggests that even if the languages of the sample vary considerably in the richness of their demonstrative systems, the variation seems to be structured.
Table 11.1 Distribution of semantic features in the sample


Interestingly, the semantic features given in the first row of the table, except for the feature of distance, can be placed on a continuum running from prototypically nominal categories (number, gender, animacy, physical properties) to prototypically verbal categories (visibility, temporal distinctions, movement, posture, possession) and an adverbial category (geography and altitude). To my knowledge, this has not been noted before, and therefore may deserve further cross-linguistic comparison. The scale is shown in Figure 11.1. The categories on the left end are prototypically used in acts of reference, while the categories to the right are used much less as such. The feature of distance at the left end does not fit in this continuum very neatly, but its appearance there is logical, since this feature is one of the defining semantic properties of demonstratives (see Diessel Reference Diessel1999: 2). Pieter Muysken (personal communication) notes that this hierarchy very roughly correlates with the degree of lexicalization, with some exceptions.

Figure 11.1 Scale of semantic features encoded by demonstratives
This picture emerges on the basis of data from the sixty-one languages. The previous version of this continuum (Krasnoukhova Reference Krasnoukhova2012) was suggested on the data from fifty-five languages, and it does not differ significantly in the distribution of semantic features. The two differences that have occurred are the switches in the positions between posture and movement features, and between possession and altitude.
As can be seen from Figure 11.1, semantic categories like number and gender are much more frequently instantiated in demonstratives than others, like posture or movement. The latter categories are less expected on demonstratives than the former, since this kind of information is prototypically encoded by lexical verbs. It can be observed that in some of these cases demonstratives are related to lexical verbs. For instance, Galucio (Reference Galucio2001: 43, 58) mentions for Mekens that demonstrative stems encoding posture are semantically and formally related to auxiliaries, e.g. the auxiliary -top ‘lying (present progressive)’ / -toa ‘lying (past progressive).’ Example (20a) illustrates the use of the auxiliary ‘lie’ combined with the lexical verb ‘to sleep,’ whereas example (20b) shows the use of a pronominal demonstrative with the semantics ‘that one, lying.’


In Movima, demonstratives meaning ‘non-standing on ground’ (e.g. kude: ‘proximal, non-standing on ground, masculine,’ kinede: ‘proximal, non-standing on ground, feminine,’ kode: ‘proximal, non-standing on ground, neutral,’ kide: ‘proximal, non-standing on ground, plural,’ etc.), seem to be related to the verb de: ‘lie’ (see Haude Reference Haude2006: 143, 558). As noted earlier, demonstratives encoding posture distinctions in Movima can co-occur with verbal predicates encoding the same basic position or a more specific one (see example 7). Demonstratives that encode temporal distinctions are reported by Haude (Reference Haude2006: 189) to be prototypically used as predicates in existential/locative clauses, but never as modifiers.
In Kadiwéu, “the same roots that appear as demonstratives also function as existential/locative verbs and as serial verbs” (Sandalo Reference Sandalo1995: 63).
The category of temporal distinctions encoded by demonstratives seems to be present in languages where the occurrence of this category on the verb is limited. For instance, in Guaycuruan languages, the tense, aspect, mood categories are not expressed on the verb, but are encoded by demonstratives and inferred from the context (Messineo, Carol and Klein Reference Messineo, Carol and Klein2011: 20). In Matacoan languages Chorote and Nivaclé, the situation is similar (see Campbell Reference Campbell, Campbell and Grondona2012b: 286, and Carol Reference Carol2011 for Chorote). On the other hand, morphological encoding of temporal distinctions on verbs is present, for instance, in Yuki, Wari’, and in the Cariban languages of the sample. So it remains to be a question for further research, whether and how the articulation of prototypical verbal categories in the NP domain in a particular language influences presence of such categories on the verb in the same language.
What stands out from the overview is a high concentration of languages in South America with impressively rich demonstrative systems. Not only were all the features described in Diessel (Reference Diessel1999) also found in South America, but we also discovered new semantic features. If we look specifically at the geographic distribution of semantic features in South America, it can be observed that most of the languages with semantically rich demonstrative systems are found in the Chaco and the Southwest Amazon region (e.g. Movima, Itonama, Yuki, Mekens, Wari’). This distribution is shown on Map 11.1.

Map 11.1 Geographic distribution of semantic features encoded by demonstratives
The Bolivian lowland language Movima stands out in that demonstratives encode visibility, temporal distinctions, movement, posture, and possession, in addition to more common features like distance, number, and gender. The Guaycuruan and Matacoan languages spoken in the Chaco are prominent for encoding more than three distance degrees, posture, movement, and temporal distinctions. The Chaco is among the regions which is still evaluated for the status of a linguistic area. Campbell (Reference Campbell, Campbell and Grondona2012b: 301) describes the current situation as follows: “The Chaco has been thought to be a linguistic area,…, although there is not a single linguistic trait found in languages of the Chaco that is not found also in languages beyond the region.” Although this statement is also confirmed for semantic features encoded by demonstratives, this geographic clustering of languages with rich demonstrative systems is noteworthy. Selk'nam, an extinct Chonan language from Tierra del Fuego, is equally remarkable for its demonstrative system. Namely, demonstratives in Selk'nam encode distance, number, gender, physical properties, movement, posture, and geography (South, North, West, East heights and East plains), and probably temporal distinctions (see Najlis Reference Najlis1973: 22, and Adelaar with Muysken Reference Adelaar, Adelaar and Muysken2004: 560). The languages of the Northwest Amazon region are notable for encoding visibility (e.g. Hup and Puinave) and for encoding physical properties in addition to distance, number, and gender (e.g. Cubeo, Desano, Tariana, and Miraña).
5 Conclusion
In the first part of this chapter, I presented a typological profile of South American languages in the domain of the NP. The second part focuses on semantics of demonstratives, since languages spoken on this continent stand out cross-linguistically for their rich demonstrative systems. Based on a sample of sixty-one indigenous languages of South America, I showed that the range of semantic features reported in a major study on demonstratives by Diessel (Reference Diessel1999) can be extended with the following: (i) perceived physical properties (shape, consistency, structure, etc.), (ii) posture (standing, sitting, lying, hanging), (iii) possession (possession or control over the referent), and (iv) temporal distinctions (presence vs. absence, ceased existence). While the feature of posture was briefly mentioned in Dixon (Reference Dixon2003), the other three have not received any attention so far in typological studies. This illustrates an important role that emerging South American data can play in typology. On the basis of the distribution of semantic features I suggested that although the languages vary considerably in the richness of their demonstrative systems, this variation seems to be highly structured. Specifically, semantic features encoded by demonstratives represent a continuum running from prototypically nominal categories (number, gender, shape, animacy) to prototypically verbal categories (visibility, temporal distinctions, movement, posture, possession) and adverbial categories (altitude and geography). Such categories as temporal distinctions, movement, posture, and possession are less expected on demonstratives, since this information is usually encoded by verbs. Looking at the geographic distribution of languages with semantically rich demonstrative systems, the Chaco and the Southwest Amazon region stand out particularly for their encoding of prototypically verbal categories on demonstratives.
Appendix
Table 11.2 Language sample (ordered by language family)


Many thanks to the editors, Loretta O’Connor and Pieter Muysken, for their invaluable comments and suggestions on this chapter. I am grateful to Pieter Muysken, Mily Crevels, Simon van de Kerke, and Jean-Christophe Verstraete for providing most useful feedback on an earlier version of the text. I would also like to thank Lyle Campbell for his extensive comments on Nivaclé, and Sérgio Meira for sharing with me his data and analysis of Tiriyó. An earlier version of this chapter was presented at the “Taalkunde in Nederland-dag” 2009.
1 The eight languages from South America in Diessel's sample are: Apalai and Hixkaryana (Cariban), Barasano (Tucanoan). Canela-Krahô (Ge-Kaingang), Epena Pedee (Chocoan), Urubu-Kaapor (Tupí-Gurani), Wari’ (Chapacuran), and Yagua (Peba-Yaguan).
2 Table 11.2 in the appendix shows the languages included in the sample, with their genetic affiliation and location. Three factors played a role in composing the sample: (i) the requirement of genetic diversity; (ii) the requirement of areal diversity, with maximal geographic spread for members of larger language families; (iii) the existence of good-quality grammatical descriptions for the language. Each of the major language families in South America is represented in the sample.
3 The same set of classifiers is used also on verbs (Crevels Reference Crevels, Crevels and Muysken2012, p.c.).
4 The demonstrative forms in Guaykuruan languages have received various labels in the literature. They have been analyzed as classifiers for Pilagá (Vidal Reference Vidal2001: 122) and as demonstrative roots in Mocoví (Grondona Reference Grondona1998: 80) and Kadiwéu (Sandalo Reference Sandalo1995: 62). This is probably influenced by the fact that the distance parameter can be encoded by additional morphemes in these languages.
5 See Haude (Reference Haude2006: 296) for possessive clauses expressing definite and indefinite possession.
6 The list of languages in which temporal distinctions are encoded within the NP (thus not limited to demonstratives) is much larger, and includes, for instance, such languages in the sample as Baure (Swintha Danielsen, p.c.), Tariana (Aikhenvald Reference Aikhenvald2003a: 183), Puinave (Girón Reference Girón2008: 188–189) and Mamaindê (Eberhard Reference Eberhard2009: 343). In Wichí, demonstratives are realized as clitics and can attach to nouns occurring with nominal tense markers (Terraza Reference Terraza2009: 80).
7 For a full overview of semantic features that can be encoded by demonstratives in a somewhat smaller sample I refer the reader to appendix 3 in Krasnoukhova (Reference Krasnoukhova2012). The overview specifies the exact values for each semantic feature, and also indicates, whenever relevant, whether a feature is found only on pronominal, adnominal, or adverbial demonstratives. For example, a distance degree encoded by adnominal demonstratives can differ from that encoded by adverbial demonstratives, as is the case in Trumai and Puinave. Another example is the plural marker that can occur only on demonstratives used pronominally but not adnominally, as is the case in Emérillon and Imbabura and Huallaga Quechua. In cases when the syntactic context of demonstratives was not indicated in the overview, adnominal demonstratives were taken as the point of reference.
12 Subordination strategies in South America: nominalization
This chapter argues that nominalization, as a subordination strategy, is significantly more pervasive in South America than would be predicted on the basis of global patterns. The patterns found within South America are most consistent with a scenario of several smaller spreads, possibly promoted by a few language families with major extensions (e.g. Quechuan, Tupian, Cariban).
1 Introduction
Nominalized subordinate clauses are extremely common in South American languages and have been mentioned repeatedly as an areal or regional feature for geographic zones of different extensions. For example Dixon and Aikhenvald (Reference Dixon and Aikhenvald1999: 9) claim for the vast Amazon basin: “Subordinate clauses typically involve nominalized verbs, with the type of subordination marked on the verb,” and Crevels and Van der Voort (Reference Crevels, van der Voort and Muysken2008) mention “subordination through nominalization” as one of the areal features of the Guaporé-Mamoré area in northeast Bolivia and Rondônia in western Brazil. But nominalized subordinate clauses are also common in the Andean linguistic area: Mapudungun and the Quechuan and Aymaran languages (see e.g. Torero Reference Torero2002, Adelaar with Muysken Reference Adelaar, Adelaar and Muysken2004) all have several types of nominalized clauses.
Such areal claims suggest a scenario of diffusion through contact of this structure rather than through inheritance or due to chance. Although it is probably not possible to prove or disprove the contact-induced diffusion of nominalized clauses beyond doubt, we can evaluate its likelihood against two other possible explanations: genealogical inheritance and chance. I attempt to do this by answering the following two questions.
(i) Is the distribution of nominalized subordinate clauses geographically skewed towards South America?
A key element for a claim of contact-induced areal spread of a feature is that its distribution should be geographically skewed, i.e. present or preferably even abundant in certain geographic zones while scarce or absent in others (especially adjacent ones). The question of geographic skewing can be answered by looking at the distribution of nominalized subordinate clauses on a global scale, based on the study by Cristofaro (Reference Cristofaro2003). If the presence of nominalized structures does not differ significantly from global distribution, chance, or some more general (e.g. cognitive or diachronic) principle may better explain the presence of the nominalized structures. We can also address this question by looking at South American languages only: do certain geographic zones like the Amazon basin, the Andes, and the Guaporé-Mamoré area stand out from other areas with respect to this feature? If so, contact may still be the factor with the greatest explanatory power, even if the general distribution in South America does not differ significantly from that of global samples.
(ii) Is there variation within the group of nominalized structures, and is that geographically skewed?
“Nominalized subordinate clauses” is a very general term that potentially encompasses a host of different structures. Typological research (e.g. Comrie Reference Comrie1976; Koptjevskaia-Tamm 1993; Malchukov Reference Malchukov2006; Comrie and Thompson Reference Comrie, Thompson and Shopen2007) has shown that nominalized constructions can differ from each other on various parameters, both in terms of their morphosyntax and in their semantics. Therefore, before we can claim diffusion of nominalized subordinate clauses, we need to make sure that we are comparing like with like. If there is much internal variation within the group of nominalized structures, it might shed a more differentiated light on the inheritance or diffusion through contact of particular nominalized structures. It might, for instance, differentiate Andean nominalized structures from Amazonian ones, or it might perhaps show that Quechuan nominalized structures are special structurally, a factor best explained in terms of genealogical inheritance.
The chapter is set up as follows. In Section 2 I will discuss some preliminaries, including the definition of nominalization as a subordination strategy, the description of the South American sample used in this study, and the way in which I measure distances between constructions. Section 3 addresses question (i) above, by comparing the South American sample to the global sample used in Cristofaro (Reference Cristofaro2003) as well as by looking at the South American sample itself. Section 4 discusses the nominalized structures found in South America in more detail, and discusses the internal variation found between them (question (ii) above). Section 5, finally, is a discussion of the results, in which I evaluate possible explanations for the distributional patterns found in South American nominalized clauses.
2 Preliminaries
The data presented in the present chapter are part of a larger project on subordination strategies. The definition of nominalized clauses is based on the set-up of this larger project, so it is useful to start this section by briefly outlining the bigger project.1 The project “Subordination strategies in South American languages” aims at comparing morphosyntactic strategies that languages employ to encode certain semantic relations between events, and measuring the distance between these strategies. The semantic relations taken into account are given in Table 12.1.
Table 12.1 Semantic relations considered for subordination strategies

These semantic relation types are in large part based on Cristofaro (Reference Cristofaro2003), which makes a comparison with her results feasible. Moreover, as argued by Cristofaro (Reference Cristofaro2003), they form a collection of semantic relations that have different basic semantic parameters, so they are likely to yield most if not all subordination strategies in a language. Based on these semantic relation types, different constructions in each of the languages that encode them are selected for comparison. These constructions may in principle differ widely from each other, from bi-clausal structures to derivational affixing, and from fully finite structures to bare infinitives and nominalized structures. In order to be able to compare all these different structures to each other, a questionnaire was developed which targets the subatoms (individual morphosyntactic characteristics) of the constructions. Questions fall into five thematic realms: finiteness, nominalization, flagging, integration, and linearization.
Finiteness relates to the verbal categories that can be marked on the dependent unit (as opposed to an independently used verb) and also pertain to it.2 Since languages can differ considerably in terms of the categories they can mark on a verb, I focus on the more common ones: subject agreement, object agreement, tense, aspect, event modality, epistemic modality, and evidentiality. Nominalization relates to the nominal categories that can be marked on the dependent unit, also focusing on the more common categories: can they take case/adpositions, can they combine with determiners, can their subject or object be encoded as a possessor, can they trigger agreement on other elements, and finally can they take nominal plural markers? Flagging targets overt linguistic signs of dependency, such as complementizers, subordinators, dependency markers, but also nominalizing affixes and special (i.e. deviant from main clauses) markers for tense aspect and/or modality. Integration concerns (apart from whether verbal categories can be marked independently for the dependent unit) whether the independent unit can be negated separately, contiguity of the main and dependent units, or even morphological fusion. Linearization, finally, looks at the position of dependency markers with respect to the dependent unit, the position of the dependent unit with respect to the main unit, and, specifically for relative relations, the position of the relativized noun with respect to the relative clause (or functional equivalent).
Constructions, including nominalizations, can differ from or be similar to each other in all of these respects. This gives a fine-grained comparative measure on the construction level, and it can also produce a measure on the language level, which involves a number of technicalities that need not concern us for this chapter (see Van Gijn and Hammarström in prep. for more details), since we will only measure distances between constructions.
Nominalizations can now quite straightforwardly be defined in terms of the questions on nominalization mentioned above in this chapter. Since nominalization forms the heart of the chapter, I will zoom in on the questions concerning nominalization in slightly more detail. The questions and their possible answers are given in Table 12.2.
Table 12.2 Questions on nominalization

The dependent EDU (event-denoting unit) is the element that refers to the event that either modifies another event (adverbial relations), modifies a participant in another event (relative relations), or is entailed by another event (complement relations) – see Cristofaro (Reference Cristofaro2003). The nominal characteristics of a dependent EDU that are coded in the questionnaire are the ability to be case-marked or to combine with an adposition, the potential to be modified by a determiner or an attributively used demonstrative, the possibility of encoding either the subject and/or the object of the dependent EDU as a possessor, the potential to trigger agreement on other elements (e.g. subject agreement, object agreement, adjective agreement), and finally whether the dependent EDU can be specified for nominal number. As “subject” I mean the A participant in transitive clauses, plus the S participant in intransitive clauses insofar as the latter is encoded in the same way as the former. With “object” I mean the P (or O) participant in a transitive clause, plus the S participant in an intransitive clause insofar as the latter is encoded in the same way as the former. Many South American languages code the possessor in the same way as one of the core arguments, so that it becomes impossible to tell whether the argument encoding in a dependent clause marks a possessor or a subject/object. For this situation, a third possible answer has been created in the questionnaire. For the possessor questions there is a third possible answer which is relevant for many South American languages (see e.g. Dixon and Aikhenvald Reference Dixon and Aikhenvald1999: 9), namely that the encoding of possessor is identical to the encoding of subject or object in independent clauses.
A nominalization can now be defined as a construction for which the answer to one of the questions in Table 12.2 is “yes” (or “B” in the case of the possessor questions – isomorphic possessors are not counted). This means that nominalization is defined independently from deverbalization, as well as from syntactic function.
The sample used for this chapter consists of forty languages spoken throughout South America, but with a clear focus on western South America, where language diversity is greatest.
3 The distribution of nominalization as a subordination strategy in South America vs. the world
Nominalization is a very widespread subordination strategy in South American languages. It has been mentioned as an areal feature for larger and smaller regions (e.g. Dixon and Aikhenvald Reference Dixon and Aikhenvald1999 for the Amazon, Crevels and Van der Voort Reference Crevels, van der Voort and Muysken2008 for the Guaporé-Mamoré), but the distribution seems to extend well beyond both. The question that I address in this section is whether this distribution stands out in some way compared to the distributional patterns of nominalized subordinate clauses on a global scale.
From more theoretical and diachronic perspectives on language, it seems unsurprising that nominalization is a prominent subordination strategy. For instance, Heine and Kuteva (Reference Heine and Kuteva2007) discuss diachronic pathways through which subordinate clauses may arise. For both complement clauses and adverbial clauses, they propose two main pathways, expansion and integration. The latter refers to the reinterpretation of two separate clauses as a single, complex clause; the former is meant as the reinterpretation of a noun phrase as a clause, which is mentioned as an important pathway in particular for complement clauses and adverbial clauses (see Deutscher Reference Deutscher, Givón and Shibatani2009 for relative clauses). Crucially for this paper, Heine and Kuteva (2007: 216–217) mention that “nominal” characteristics often survive such a process of reinterpretation:
a. The marker of subordination resembles a grammatical form associated with noun phrase structure, such as a marker of case, gender, or definiteness, or an adposition.
b. The verb of the subordinate clause is frequently non-finite, encoded like an infinitival, gerundival, participial, or nominalized constituent and takes the case marking of a corresponding nominal participant.
c. The arguments of the subordinate clause are encoded in a form that tends to differ from that of the main clause.
d. The agent or notional subject takes a genitive/possessive or other case form, typically having the appearance of a genitival modifier of the subordinate verb.
e. The patient or notional object may also take a genitive/possessive or other case form.
f. There are severe restrictions on distinctions such as tense, aspect, modality, negation, etc. that can be expressed – in fact, such distinctions may be absent altogether.
Heine and Kuteva's surviving nominal traits a–e correspond to some of the questions on nominalization in the questionnaire discussed above. Since characteristic f is treated as separate from nominalization, it does not play a role in defining a nominalized construction, even though the degree of lack of verbal features does play a role in measuring distances between constructions.
There is, moreover, a functional motivation for a connection between subordinate clauses and nominalization, as discussed by Malchukov (Reference Malchukov2006), based on Croft (Reference Croft1991): on the one hand, subordinate clauses express events, which are normally expressed by verbs; they have a time reference and possibly an internal temporal structure, and they have participants in verbal semantic roles like agent and patient. On the other hand, they function as arguments of verbs, or possibly of adpositions (e.g. to form adverbial modifications). There is, in other words, a category-mismatch between the lexical root (verbal) and the argument function (which expects a referential expression).
Cristofaro (Reference Cristofaro2003) goes one step further by suggesting a deeper, cognitive explanation for the predominance of nominalized structures for referring to dependent events. She argues that dependent events are processed differently than independent events: “By virtue of lacking an autonomous profile, dependent SoAs [States of Affairs – RG] are not scanned sequentially, but construed as a unitary whole, just like things” (p. 262). This, in Cristofaro's view, may explain the predominance of nominal categories in dependent clauses, although nominal characteristics are not equally likely for every relation type, a point to which I come back to below.
In other words, there may be independent reasons that nominalization predominates as a subordination strategy, reasons quite separate from contact or inheritance. It is therefore useful to compare the distribution of data found in the South American sample with distributions on a global scale, provided by Cristofaro (Reference Cristofaro2003). Cristofaro's study contains information on several semantic relations between events in a typologically balanced sample of 80 languages. As mentioned above, many of the semantic relations in her study are taken as a basis in the South American study. Since Cristofaro also looks at constructions for which she keeps track of verbal and nominal categories that can be found on dependent EDUs, this makes the two studies comparable to a large degree. The nominal categories tracked by Cristofaro are case marking and possession. We can now look at two points of comparison between the South American data and the global data: the number of nominalizations found and the distribution of these nominalizations over the different semantic relation types. In order to make the results maximally comparable, I only look at those relation types that are present in both studies, and nominalization will be defined only on the basis of case marking and possession.
Cristofaro (pp. 311–333) lists a total of 423 constructions that are taken into consideration. Sixteen constructions had to be discounted for the comparison because the semantics of those constructions were not, or not sufficiently, comparable,3 represented in the South America questionnaire, leaving a total of 407 constructions. About a quarter of these constructions can be classified as nominalized.4 At the language level, a little less than half (38) of the languages in her sample have nominalized constructions. In my sample of South American languages, fewer than 40 percent of the total number of constructions are nominalized,5 and almost all languages (90 percent) have at least one nominalized construction, as shown in Table 12.3.
Table 12.3 Comparison of global and South American distributions of nominalized structures

The proportion of South American languages that have nominalized constructions compared to the global sample is highly significant (p = 3.26e-06 in a Fisher's exact test), as is the number of nominalized constructions as a proportion of the total number of constructions (p = 0.0001). On the first count then, nominalized structures appear in significantly higher numbers in South America than would be expected on the basis of the global patterns, both in terms of number of constructions and in the number of languages that have nominalized constructions.
A second comparison that can be made to Cristofaro's study is the distribution of nominalized structures over different semantic relation types. Cristofaro (p. 263) mentions that nominalized structures (defined as having case marking possibilities)6 are not evenly distributed over the semantic types, but rather follow a hierarchy, given in (1):
(1) Case/adposition hierarchy (slightly adapted from Cristofaro Reference Cristofaro2003: 230)
Modals, Phasals, Purpose, Desideratives, Manipulatives, Perception, Temporal, Reason > A/S/O relativization > Condition, Knowledge, Utterance, Propositional attitude.
The hierarchy should be read as follows: if a nominalized form (i.e. one that can take case/adposition marking) is used to encode the dependent event at a point on the hierarchy, the points to its left will also allow a nominalized form.
The specific distribution per type in Cristofaro's and my samples are compared in Table 12.4. The numbers do not add up to reflect the number of constructions, because there is often a one-to-many relationship between constructions and meaning. The number of nominalized manipulation predicates is low in Cristofaro's distribution in part because I have only counted direct (make) manipulation.
Table 12.4 Comparison of distribution of nominalized structures per semantic relation type

Although there are differences between the distributions in the samples, none of them is significant, which means that, if there were to be evidence of contact-induced diffusion of nominalized constructions, this is not connected to a particular semantic field. So a next step we can take is to look in more detail into the structural properties of the nominalizations of South American languages.
4 Types of nominalizations in South America and their distribution
It has been recognized by many scholars that the typology of nominalization shows quite a bit of internal structural variation cross-linguistically. For instance, nominalizations may differ from each other in how they encode core arguments (see e.g. Koptjevskaja-Tamm Reference Koptjevskaja-Tamm1993), or in the extent to which they allow for verbal and nominal categories to be marked on the nominalized verb (see e.g. Malchukov Reference Malchukov2006), nominalizations may be flagged in different ways, and of course they can differ in which semantic relation types they can encode.
Because of the potential variation within the group of nominalized structures, it makes sense to evaluate the homogeneity of the nominalizations across the continent, and to see whether the internal variation found can best be explained as a geographic (contact) signal or a phylogenetic signal. For a first impression of the internal variation of nominalized constructions, see Figure 12.1, which gives a visual representation in the form of a NeighborNet network (Bryant and Moulton Reference Bryant and Moulton2004) of the distance between the constructions based on similarity among the input features. The sheer number of the constructions renders the figure rather difficult to read, but the star-shaped form and the general lack of tree-like branches indicate that the nominalizations that are used as subordination strategies are far from homogeneous.

Figure 12.1 NeighborNet of nominalizations as subordination strategies in the languages of the sample
In the remainder of this section, I will look in greater detail at the different nominalizing subordination strategies found in South American languages. I take semantics as a basis for comparison, based on the assumption that, if a language borrows a construction, or if two constructions in different languages converge as a result of contact, they will most likely have comparable semantics. However, defining comparable semantics can be a complex task, since we do not know which semantic building blocks of the different relation types are relevant. The way I approach this problem is to look at every semantic relation type defined in the questionnaire separately, and at its closest neighbors. Closest neighbor is defined on the basis of the frequency that two semantic types are expressed by one and the same construction in the entire subordination database: given semantic type X (e.g. temporal relations) and the set of constructions Y that can encode this type in the entire database, what is the most frequently occurring other semantic type that is expressed by the set of constructions Y? Given these frequencies we can expand to include the closest neighbor(s), and take semantic closeness as a parameter into the equation.
In Table 12.5, an index of semantic closeness is presented in the form of an absolute number of shared constructions per semantic type (see Table 12.1 above) for the entire database. For each semantic type, the two closest neighbors are highlighted in different shades of grey. Table 12.5 shows particularly strong connections between, one the one hand, the relative constructions and, on the other, temporal/reason/condition constructions, and to a lesser extent also with constructions of purpose relations. For complementation strategies the bonds between phasals, modals, and desideratives seem rather strong, as well as those between knowledge, perception, and again desideratives. If there are traces of contact to be found, we particularly expect them between these three types of semantic clusters.
Table 12.5 Overlap of semantic relation types

These different groupings can in turn be correlated to different morphosyntactic forms of the constructions. In particular, I will look at the following parameters:
1. the type of nominalization (participant versus event nominalizations);
2. the expression of core arguments as possessors;
3. case marking.
The subsections are organized according to these three formal parameters, in the order given above, followed by a final section that discusses other issues to do with nominalization.
4.1 The type of nominalization
Comrie and Thompson (Reference Comrie, Thompson and Shopen2007: 334) make a major distinction between nominalizations that name an activity or state (“A forms”), and those that name an argument (“B forms”). They furthermore claim a basis for this division in that “the A forms retain certain properties of the verbs and adjectives they are related to, while those in B behave syntactically like other nouns in the language” (p. 334).
The way the questionnaire is set up, whether or not to count a construction as a participant (argument) nominalization or as an event nominalization is linked to bound flagging. If a dependent EDU is marked by a bound marker, and that marker at the same time singles out a participant, the construction counts as an argument nominalization.7 I focus on those languages that have such markers and look at their distribution over the continent, as well as their distribution over the semantic space.
A total of thirty-one constructions in twenty-one languages meet the narrow definition of participant nominalizations given above. As expected, these constructions are highly skewed in terms of semantics. All of the constructions can encode relative relations, one of the clusters in Table 12.2, and sixteen of them are exclusively used for relative relations. Nevertheless, the constructions differ in terms of the other semantic relation types they can encode, with purposive, spatial, and temporal relations as the most common non-relative semantic types.
There are two broad strategies that participant-nominalizing languages follow in the relativization of core arguments: (i) the underspecification of participant-denoting nominalizers, and (ii) the use of a paradigm of role-specific nominalizers, specifying the semantic role of the relativized argument in the relative clause. The three groups are indicated on Map 12.1: white for no participant nominalizations as relativization strategy; black for those languages that do have participant nominalizations; and grey dots for those languages that have participant nominalizations in a construction where there is a semantically non-specific derivation.

Map 12.1 The use of participant nominalization as a relativization strategy
To illustrate this latter difference, consider examples from Desano (Tucanoan) and Kamaiurá (Tupí-Guaraní), which represent the two types. In Desano, there are animate and inanimate nominalizers. Normally, the animate nominalizers yield an agentive relativization and the inanimates a patientive one, but this is not necessarily so, and as a consequence, animate patients yield ambiguous nominalizations (Miller Reference Miller1999: 142):
(1) buʔe-gi
study-nlz.m.sg
‘the one who teaches/the one who studies’
In Kamaiurá, on the other hand, there are different nominalizers depending on the role of the relativized argument in the relative state of affairs. There are separate markers for deriving S (-ama'e), A (-tat), and P (-ipyt) arguments. Example (2) illustrates the S argument nominalizer (Seki Reference Seki2000: 179).

As mentioned above, some languages allow for other semantic relations to be expressed by these participant nominalizations. These extensions basically follow along the same lines as those mentioned above: non-specific versus paradigmatically opposed specific markers. An example of the first type is the suffix -taĩ in the Jivaroan language Aguaruna, which singles out a participant, broadly defined as non-S/A. The precise interpretation depends on whether it carries a case marker or not (Overall Reference Overall2007: 435).


An example of the second type is the Nambikwaran language Mamainde (Eberhard Reference Eberhard2009: 523–524), where different classifiers, which have a derivational function, can mark different roles in the state of affairs.


There are a few potential areal patterns on Map 12.1: (a) the south-central and north-central Andes and foothills (Cuzco Quechua, Huallaga Quechua, Aymara, and foothill languages Leko and Yurakaré and in the north-central area Awa Pit, Aguaruna, and Huallaga Quechua), (b) Rondônia and adjacent areas in eastern Bolivia (Baure, Itonama, Mekens, Mamaindê, Karo, and Apurinã), and (c) the border area between Colombia and Brazil and northeastern Peru (Puinave, Tariana, Desano, Miraña, Urarina). All three of these loosely defined areas are associated with linguistic areas and diffusion of linguistic features, in respective order: the Andean area (see e.g. Torero), the Guaporé-Mamoré area (Crevels and Van der Voort Reference Crevels, van der Voort and Muysken2008),8 and the Vaupés (Aikhenvald Reference Aikhenvald2002). In particular, there seems to be an Andean tendency for agent nominalizations that can be used as relative clauses, but specific participant nominalizations also occur throughout the Amazon. Semantically neutral markers or strategies are found in some adjacent languages (Itonama and Baure in northeast Bolivia; Desano and Tariana in the Vaupés area in the border area between Colombia and Brazil; and Miraña slightly further off, in the border area between Colombia and Peru).
Furthermore, a functional equivalence between participant nominalizations and relative clauses seems to be a genealogical trait of a few large families, such as Quechuan, Aymaran, Tupian, and Cariban. The general picture, therefore, seems to be a mix of the fact that some of the most widely dispersed families have this characteristic, and that the trait may also have spread through contact in a number of more regional environments.
A curious final point for this section is the fact that there are four languages, spoken in non-adjacent areas, that permit the participant nominalization to mark same-subject purpose clauses. These constructions are cross-linguistically not very common. The examples come from Cuzco Quechua (Lefebvre and Muysken Reference Lefebvre and Muysken1988: 22), Desano (Miller Reference Miller1999: 153), and Kamaiurá (Seki Reference Seki2000: 188), respectively.9



4.2 Possession
An alternative way to express participants in nominalized constructions is by encoding them as possessors. Typological research suggests that S, A, and P participants are all potentially expressed as possessors in nominalizations, but that subject possessors (S/A) are more likely and more frequent than object possessors.
One particular difficulty that arises for South America is that possessors are formally often expressed in the same way as one of the core arguments. For the coding of the questionnaire, this means that there are three answer categories for both subjects and objects: either they are not expressed as a possessor, they are expressed as a possessor, or it is impossible to tell because there is no formal difference between the expression of a possessor and a subject/object.
The three categories are shown on Map 12.2 for the subject category and on Map 12.3 for the object category, with the languages that do not have a construction where the subject/object is expressed as a possessor in white, those that do have constructions where the subject/object is expressed as a possessor in black, and those for which it is impossible to tell in grey.


Map 12.3 The encoding of notional objects as possessors in subordinate clauses
As can be observed on these maps, subject possessors are particularly common in the Andean and adjacent areas – presumably under the influence of Quechuan and Aymaran languages – but they also occur in non-contiguous spots in the Amazon. Object possessors are less common and, moreover, geographically more scattered.
In terms of semantics, the constructions with subject possessors are more or less divided over the range of semantic relation types; the most frequent type is object relativization, illustrated by the contrastive pair from the isolate language Itonama (Crevels Reference Crevels, Malchukov, Haspelmath and Comrie2010: 688), where the b-example is a relative clause, with the subject expressed in the same way as a possessor.


Other slightly more frequent relation types are temporal, reason, purpose, and desiderative relations, partially following Cristofaro's case hierarchy given above.
Given their infrequent occurrence, not much can be said about the semantics of constructions with object possessors. Moreover, the few constructions are more or less evenly divided over the semantic types. Both Cariban languages in the sample, Tiriyó (Meira Reference Meira1999) and Hixkaryana (Derbyshire Reference Derbyshire1979), have constructions with object possessors. This can be connected to a more general characteristic of nominalizations in Cariban languages which follow an ergative pattern in the sense that it is the absolutive argument that is expressed as a possessor (Gildea Reference Gildea1992: 125).
As a general conclusion of this section, it seems that expressing core arguments as possessors is possibly areally diffused in the case of the Andean area, with the Quechuan and Aymaran languages as the most likely agents of the spread. Object possessors are rarer, and more scattered geographically, but Cariban languages in general seem to have absolutive possessors in their nominalized clauses.
4.3 Case and adpositions
One of the more common nominal features acquired by nominalized predicates is the ability to take case markers, or to be the object of an adposition. In fact, all languages of the sample that have case markers and/or adpositions use these in the formation of complex sentences, with the possible exception of Tapiete. It is therefore not very insightful to project this onto a map, so rather than that, I have chosen to look at oblique case only, used in the formation of adverbial clauses, as shown in Map 12.4.

As can be seen, the majority of languages can form adverbial clauses with case markers or adpositions. This makes this type of construction particularly interesting from the perspective of this chapter, as it is a potential candidate for diffusion. Table 12.6 takes a closer look at the case/adposition-marked adverbial clauses in the sample, with each column indicating a different type of adverbial relation and, for each language, the case marker(s) or adposition(s) that can be used to form the respective adverbial relation type. Empty cells do not necessarily mean that cases or adpositions are not used to express those relation types but can also indicate a lack of information. The table describes the potential of constructions to take oblique case markers, not the obligatoriness of the markers. Furthermore, the information only concerns the semantic relation types that are considered in the questionnaire.
Table 12.6 Non-core case markers and adpositions used to form adverbial relations

As shown in Table 12.6, temporal, reason, and locative clauses (partly corresponding to the “adverbial“ cluster in Table 12.5) in particular tend to be marked with an adposition or a case marker. An often observed strategy is the extension of locational markers to encode temporal relations. Some of the languages that follow this strategy are spoken relatively close to each other (Hup and Tariana in the Vaupés area; Huallaga Quechua and Shipibo in northeastern Peru; Cuzco Quechua, Mosetén, Leko, and Yurakaré in the south-central Andean foothills). Others, such as Mekens and Tiriyó, are more isolated geographically. It may be that contact with members of the Quechuan family has promoted the spread of spatial markers to encode temporal clauses. Another recurring strategy is to use instrument markers for reason relations. The languages that do this, however, are not spoken in a shared vicinity.
In summary, case marking, or the use of adpositions, is a common strategy in South American languages to indicate relationships between events. Some of the sub-structures may be connected to proposed linguistic areas, such as the Andean area and the Vaupés. Again, Quechuan languages may have promoted the spread of this feature.
5 Conclusion
I set out to evaluate the claim that nominalization as a subordination strategy has spread through South America by diffusion through contact, rather than through chance or genealogical inheritance. In order to meet this challenge I tried to answer two questions, repeated here:
(i) Is the distribution of nominalized subordinate clauses geographically skewed towards South America?
(ii) Is there variation within the group of nominalized structures, and is that geographically skewed?
On the global level, question (i) can be answered positively: the occurrence of nominalizations as subordination strategies is significantly higher in South America than would be expected on the basis of Cristofaro's (Reference Cristofaro2003) global sample. This fact alone rules out chance as a possible explanation. Within South America, since almost all languages of the sample have nominalized constructions that can be used as a subordination strategy, there is no clear geographic skewing.
The first part of question (ii) can also be answered positively, as can be seen by only a superficial look at the NeighborNet in Figure 12.1. The second part of question (ii), whether the variation is geographically skewed within South America, is less clear. I reviewed three formal parameters along which nominalizations can differ from each other. In particular, participant nominalizations and case marking are very common strategies. Assuming a diffusion through contact scenario, the widespread occurrence of participant nominalization may be related to a combination of the fact that the major families (Quechuan, Tupian, Arawakan, Cariban) have these structures, and the fact that these features have spread in several smaller areas, such as the Vaupés, the Andean area, and Rondônia (the Guaporé-Mamoré). A similar account can be given for the use of case markers to form adverbial relation types, especially for the Andes. Moreover, the semantic coherence of these groups of constructions makes a spread scenario more plausible. With respect to possession, the semantic coherence is less clear, and the occurrence of core argument possessors is also less pervasive. In particular, agent possession seems common in the Andean area and adjacent zones.
The fact that the Andean area is so dominantly present in all of these areas goes against Dixon and Aikhenvald's (Reference Dixon and Aikhenvald1999: 10) claim that clause nominalization is an Amazonian, and not an Andean, phenomenon. The patterns furthermore only partly confirm Crevels and Van der Voort's claims for subordination through nominalization as an areal feature for the Guaporé-Mamoré area. In the first place, as we have seen, clause nominalization is extremely common, and occurs well beyond the Guaporé-Mamoré area, and second, coherent patterns for the linguistic area itself seem to occur mainly on the Brazilian side of the area.
These patterns do not give us a definitive or direct explanation of the skewed distribution, but they are consistent with a scenario of spread through contact: not as the result of a continent-wide spread region, but rather as the result of several smaller spread zones, and through a few language families with major extensions, like Quechuan, Tupian, and Cariban. The patterns found do not completely rule out an inheritance-based account, but because nominalized structures are found throughout the continent and across language families and stocks this would mean that the predominance of nominalizations is an extremely old pattern, and the variation found within the group of nominalized structures does not suggest extreme stability for this structure. Another possible reason for the predominance of nominalized clauses is that it is in a dependency relation to some other widespread, more fundamental structural feature of South American languages. This question falls outside the scope of this chapter, and is left for further research. Further research should also make clear whether similar patterns of regional spread can be found for the underrepresented areas in the sample, in particular towards the east.
The larger project that this study is part of has been made possible by the support of Netherlands Organization for Scientific Research (NWO – grant 275–89–006), carried out at the Radboud University Nijmegen. This support is gratefully acknowledged. I furthermore thank the editors for useful comments on earlier versions of this chapter. Remaining errors are mine.
2 This is meant to exclude instances of clitics that happen to be placed on the dependent unit, but have scope over the whole sentence.
3 I have not counted constructions in Cristofaro's appendix that encoded “order” manipulation, “before” relations, and utterance. Although the last is also a category in the South America database, I have only coded indirect utterance constructions. Cristofaro also counts direct utterance if it is the only way to encode speech complements. I consider Cristofaro's “propositional attitude” relation type comparable to my “evaluative” relation type, because they have the same semantic outline.
4 The actual number may be higher, since only case marking and possession are taken into account, so this should be taken as a minimum number.
5 I have discounted utterance and location clauses, since Cristofaro does not consider the latter; for the former, see above.
6 No hierarchy was proposed for possession, but it follows a similar pattern (Cristofaro Reference Cristofaro2003: 235).
7 This definition is rather narrow and ignores, for instance, unmarked nominalizations or nominalizations marked by a free marker, and it is restricted to core arguments. However, it captures the most common patterns found in the corpus, and can therefore be expected to give meaningful patterns.
8 The extent of this area, especially towards the west in Bolivia, is unclear – and is argued to also include the foothill languages – but the clearest areal patterns seem to be found in Rondônia (see Muysken et al. in press).
9 The fourth language is Huallaga Quechua which, since it is related to Cuzco Quechua, is not represented in the examples.




















