

1 Introduction
My first investigations into how visible bodily action functions as utterance (with speech or without) were inspired by Ray Birdwhistell and William Condon.Footnote 1 Their work had aroused my interest in investigating in detail their claims that the bodily movements of speakers when speaking are highly patterned in relation to the phrasing of speech at different levels as well as being expressively coherent with it. My early studies verified these claims, reinforcing the idea that kinesic expression and spoken expression are products of a common process. This prompted me to consider how meaning is achieved in the kinesic medium. In 1978, in the course of fieldwork in the highlands of Papua New Guinea (gathering material for comparative studies of communication conduct), I chanced to film a young deaf woman who used a local sign language. Because I had contact with speaking locals who knew this signing, I was able to make a study of it.
Subsequent to this study, I embarked upon research on sign languages used among indigenous Australians, especially in the central desert regions. These are alternate sign languages, providing for linguistic communication when, for ritual, practical, or environmental reasons, speech is avoided or is inconvenient. They are interesting because, in contrast to deaf sign languages – or primary sign languages, as we may call them – we may expect some kind of direct relationship between the spoken language of their users and any sign language they might develop. Since verbal expression and kinesic expression have different affordances, to what extent and in what ways would or could a kinesic system serving all the functions of speech, developed by speakers as an alternative to speaking, draw upon the spoken language already immediately available to the creators of the kinesic alternative? What might this teach us about the relationship between the modality used and what it can express?
After finishing my Australian work (Reference KendonKendon, 1988), I turned to southern Italy. For the next fifteen years I was based in Naples, attempting an ecologically oriented study of the use of kinesic actions in this region. I went to Naples initially because there were reputed to be communities there in which kinesic actions were used almost as if they were an alternate sign language.Footnote 2 I wanted to know more about this and to understand the circumstances supporting it.
My Neapolitan investigations included a study of a nineteenth-century work on gesture in Naples by a Neapolitan archaeologist, Andrea De Jorio. He had proposed that because of cultural continuities between ordinary Neapolitans and their Ancient Greek predecessors, an understanding of their gesturings could throw useful light upon the various kinds of kinesic actions depicted in the mosaics, wall paintings, and vases unearthed at Pompeii and Herculaneum. De Jorio provided detailed descriptions of the kinesic expressions used by Neapolitans and of how they were used. Effectively, his was an ethnographic study of gesture in Naples unlike anything done before (Reference KendonKendon, 1995a). I published an English translation and a critical study of it in 2000 (Reference De JorioDe Jorio, 2000).
Much of the empirical work I did in Naples, along with similar work in the United States and Great Britain, was brought together in Gesture: Visible action as utterance (Reference KendonKendon, 2004). This book, semiotic and pragmatic in approach, included chapters on the history of the study of gesture, detailed descriptions of gesture use from field recordings exemplifying the diverse use of kinesic expressions by speakers, and a discussion of signing, both as it may be seen in speaker-hearers as well as among the deaf.
The subtitle of the book, “visible action as utterance,” intended to make clear the range of phenomena to be discussed. This would be (to quote definition No. 4 of “gesture” from the Oxford English Dictionary, 1989) “any movement of the body or a part of it that is expressive of thought or feeling” but with the proviso that the expressiveness of these actions is assumed to be in some way under the actor’s voluntary control (not necessarily implying that the actor is aware of them, although it might mean that the actor could become so). An action perceived as a wilful expression is perceived as “giving,” rather than “giving off,” information to use Goffman’s distinction (Reference GoffmanGoffman, 1963, p. 13). It is part of how something is “told” or “said” to another. If we adopt the wider meaning of “utterance,” that of “putting something out” by whatever means (see Reference TylorTylor, 1878, p. 14), a visible action deemed wilfully expressive is, thus, an “utterance visible action.”
How can one decide when a visible action is an utterance visible action? As I will explain below, judging whether a visible bodily action is wilfully expressive or not depends upon how many of a cluster of certain features an action is deemed to have (Reference KendonKendon, 1978; Reference KendonKendon, 2004, Chs. 1–2). A consequence of this is that the boundary between what is and what is not an “utterance visible action” cannot always be sharply drawn.
In treating this domain I have lately preferred, as far as possible, to avoid the term “gesture.” This is because “gesture,” at least in English, has many different senses. It does not always just mean visibly observable bodily actions. In common use the word “gesture” is also used to refer to actions and their outcomes at various levels of abstraction. For example, sending flowers to someone can be called a “gesture of affection,” paying a visit to someone who has been bereaved might be a fine “gesture of sympathy,” a politician attending a controversial public ceremony might be interpreted as a “gesture of support” for a given political doctrine, and so on. Further, in the scholarly literature, “gesture” has been defined and used in several different ways. It can mean any unit of purposive action; a meaningful action where the meaning is encoded analogically as opposed to digitally as language is said to be; it may refer just to actions of the hands; there are gestures in music; there are vocal gestures, and so on. Some authors slide from one of these meanings to another without indicating that they are doing so, which can be confusing (Reference KendonKendon 2017b). Since my focus here is on visible bodily actions that have “utterance” characteristics, I think it better to use an expression that is restricted to this (Reference KendonKendon, 2008, Reference Kendon2012).
In what follows, after describing my early work on speech and “gesticulation,” I consider semantic interaction between speech-concurrent visible bodily action and speech. Then I discuss my work on signing in New Guinea and indigenous Australia. I close with some remarks on the implications of utterance multimodality for the problem of language origins.
2 Speech and Body Motion in Interrelation
I was in Oxford with a project on “social skills” directed by Michael Argyle and E. R. W. F. Crossman when I first became acquainted with the work of Birdwhistell. I learned by way of an article by Albert Scheflen (Reference ScheflenScheflen, 1965) in which he, then collaborating with Birdwhistell, working on communication in psychotherapy interactions, provided a lucid summary of the findings so far developed in their work in kinesics. I was much impressed with what Scheflen described and was determined to follow it up. I was able to visit Scheflen in Philadelphia in 1965. Later he facilitated a Research Fellowship for me at the Western Pennsylvania Psychiatric Institute in Pittsburgh where I would be able to work with some of his colleagues. There I worked with William Condon, who was part of a team doing detailed analyses of sound-film recordings of social interaction to verify and extend the findings of the so-called “Natural History of an Interview” project. This project began in 1955–56 at the Center for the Advanced Study in the Behavioral Sciences in Palo Alto, California. It was probably the first project to use sound-synchronized films of conversations so that a multimodal approach to the analysis of human communication could be undertaken. Reference Leeds-HurwitzLeeds-Hurwitz (1967) gives a detailed account. The participants in this project included psychiatrists Frieda Fromm-Reichman and Henry Brosin, anthropologists Gregory Bateson and Ray Birdwhistell, and linguists Norman McQuown and Charles Hockett. One outcome of the project was the development of what came to be known as “context analysis” (Reference KendonKendon, 1990, pp. 15–48), a precursor to the so-called embodied studies of human interaction which have since been so much further expanded (see Reference Streeck, Goodwin and LeBaronStreeck, Goodwin, & Le Baron, 2011).
Working with William Condon, I became acquainted with his method for identifying movement phrase boundaries using a sound-synchronized hand-operated 16 mm projector. I also became familiar with his ideas on the synchronization of body motion with speech as well as with interactional synchrony. While in Pittsburgh, I used part of a film Birdwhistell had made in a London pub where people compared ideas about British and American national character and I selected a segment where I could study interactional synchrony (Reference KendonKendon, 1970).
After my year in Pittsburgh, I moved to Cornell and while there I worked with another part of Birdwhistell’s pub film, this time studying speech and body motion interrelationships. I used a segment in which there was an extended discourse by an Englishman, expounding on English national character. In my analysis, having divided the speaker’s spoken discourse into tone units, following Reference CrystalCrystal (1969), I showed how they could be linked into higher order groupings. The tone units were grouped into “locutions” which, in turn, were grouped into “locution groups,” which themselves grouped into “clusters,” one or more of which comprised a discourse unit. Then, using the methods of movement phrase boundary analysis learned from Condon, I mapped out the speaker’s movement phrases at several levels of organization and set this mapping against the nested hierarchical organization established for the speech. This showed a good match. Each prosodic phrase was associated with a contrasting pattern of movement in the speaker’s hands; his arm position or head position changed in concordance with each successive locution, and he shifted his whole posture at each locution group or cluster boundary. Thus, the body movements concurrent with speech had to be regarded as integral to the utterance. Uttering involves simultaneous vocal and kinesic expression. The publication of this was Reference Kendon, Siegman and PopeKendon (1972).
A second paper on speech–body movement relations was published with the title “Gesticulation and speech: Two aspects of the process of utterance” (Reference Kendon and KeyKendon, 1980), thus emphasizing the point that body movement is part of the process of utterance. The findings from my earlier paper were restated, and new analyses added in support. The paper also provided a terminology for the different “phases” into which speech accompanying arm-hand movements could be analyzed. The expressive significance of these movements was discussed, which had been little considered in my previous paper (Reference Kendon, Siegman and PopeKendon, 1972).
In my paper of 1980, I proposed the notion of “gesticular phrase” (in Reference KendonKendon, 2004: “gesture phrase”). The hand that is performing a gesticular phrase is moved toward a space where the movement shows a “peaking of effort” (“effort” as in Reference Laban and LawrenceLaban and Lawrence, 1947). The phase showing “effort peaking” was termed the “stroke,” the phase of movement leading to it was termed “preparation.” Thereafter, if the hand was held still, this was termed a “hold.” The phase in which the hand was relaxed and moved toward some position of rest was the “recovery.” A distinction was drawn between a “gesticular unit” (later “gesture unit”) and a “gesticular phrase” (later “gesture phrase”). A “gesture unit” extended from the beginning of any movement leading to a stroke, all the way until the hand or hands reached a rest position. The “gesture phrase” comprised “preparation,” “stroke,” and “hold” – if there was one. This distinction is necessary to allow for the fact that a hand could perform a succession of two or more “strokes” before it is again at rest. That is, a “gesture unit” could contain more than one “gesture phrase.” This terminology, slightly modified (revised and clarified in Reference KendonKendon, 2004, Ch. 7), was adopted by Reference McNeillMcNeill (1992) and adopted and modified by Sotaro Kita (see Reference Kita, van Gijn, van der Hulst, Wachsmuth and FrölichKita, Van Gijn, & van der Hulst, 1998). Since then, many others have used it.
Looking upon these manual movements that speakers make when speaking as movement phrases, and recognizing the various phases these have, allows for a precise examination of how these actions are organized in relation to speech. It is the “stroke” in which the expressive import of the phrase is manifested and which, typically, either just precedes or coincides with the nuclear tone of the tone unit with which it is associated. Taking account of the “preparation” allows one to notice how the stroke is prepared for in advance of the segment of a spoken phrase with which it is semantically coherent. It was this observation that indicated that the kinesic expression and the speech phrase must be generated together and thus are to be seen as two aspects of a common expressive process.
In 1980, I said that what the movements of gesticulation are seen to express covers a wide range, relating meaningfully to spoken discourse in many different ways. Objects, actions, or behavior styles of animate beings mentioned in the verbal discourse may be depicted, and features of the structure of a speaker’s discourse may also be expressed. Hand movements can make visible how successive parts of a discourse are related to one another, often with actions that appear to designate contrasting spaces for contrasting points in the discourse, or that successively indicate a series of points in an argument or successive items in a list.
Some of these different ways in which gesticulation is related semantically to speech within an utterance, mentioned in 1980, had, of course, been mentioned before (notably in Reference EfronEfron, 1941/1972). They have since received treatments by many other gesture scholars, as will be acknowledged in later parts of this chapter.
3 Recognizing Kinesic Expressions
The visible bodily movements made when speaking, especially of the hands, are readily recognized as being done as part of an effort to express meanings. They are not usually mistaken for practical movements, such as picking things up or manipulating them, nor as self-grooming movements or postural adjustments. In Reference KendonKendon (1978) and Reference KendonKendon (2004, pp. 10–15), I tried to clarify what features make movements recognizable as kinesic actions. I suggested that actions are more likely to be deemed expressive if they are seen as “excursions” and do not lead to any sustained change in bodily position, if they are dynamically symmetrical (they look similar whether viewed in forward or reverse), if there are clear boundaries of onset and offset, and if the movement is not made solely under the guidance of gravity. Actions that are judged as being done for practical purposes may be “infused” with features of expressiveness, however: Think of how “elegant ladies” display their fingers when holding a teacup, for example. On the other hand, a conventional kinesic expression may be intentionally disguised so that it may be mistaken for a comfort movement or some other kind of nonexpressive movement; see Reference Morris, Peter, Marsh and O’ShaughnessyMorris, Peter, Marsh, and O’Shaughnessy (1979, pp. 88–89) for how the “Forearm Jerk” can be modified to look as though one is merely rubbing one’s arm. People can manipulate how they perform actions to make them more or less expressive, according to whether they want to make the expressiveness obvious or inconspicuous. People, evidently, have a good understanding of the expressive qualities of movements and can control how they do things, determining whether and how their actions may be expressive or not (see examples in Reference De Joriode Jorio, 2000, pp. 179–180, 185, 188, 260–261).
4 Contributions of Kinesic Actions to Semantic and Pragmatic Meanings
Regarding kinesic actions made in conjunction with speech, what contributions do these make to the semantic and pragmatic meanings of the utterances of which they are a part? First, we discuss actions that contribute to utterance referential content, then those that contribute meta-discursive and pragmatic meanings. There are also kinesic expressions that serve in the management of interaction and interpersonal relations.
4.1 Referential
Kinesic actions contribute to utterance referential content in three ways: by pointing, depiction, and by conventionalized expressions (commonly, “emblems” or “quotable gestures”).
Pointing: In pointing at something, an actor can establish what is being referred to when a deictic expression is used. When, for example, the speaker GB, giving a tour of a church, says “There is Gill Crestwood,” only because he points to the statue of this person as he says this can his recipients interpret this utterance (Reference KendonKendon, 2004, p. 199).
In my work with Laura Versante on pointing (Reference Kendon, Versante and KitaKendon & Versante, 2003), we looked at the different hand shapes used to see if there are consistent differences in the contexts in which these occur. The material studied included video recordings at street stalls in Naples and nearby and a guide conducting a walking tour of a small town in the British Midlands. Six different hand shapes were observed in common use. Comparing the contexts in which they were used suggested that these different hand shapes related to how the speaker was using the object pointed at within his discourse. For example, if it was important for the speaker that recipients distinguish one specific object from another, the extended index finger was common. If the speaker referred to something as an example of a category (“Here you see a fine example of a war memorial”), if he is making a comment about the object indicated, or if there are features of it the guide’s recipients are to take note of (“You can see again the quality of this building”), a palm up or palm vertical open hand is used (Reference KendonKendon, 2004, p. 213).
Such observations suggest that, in pointing to an object (real or notional), the actor does not merely indicate it, but also, according to hand shape, shows how the object indicated is to be treated.Footnote 3 The pointing hand shapes employed are similar to those used in other expressions. Just as “palm-up-open-hand” may be used when a speaker gives an example of something, it is used in pointing when the object indicated is something the speaker wants the recipients to view as an example. In this case, “palm-up-open hand” is used as if to “present” the object to recipients as something to be contemplated. When a recipient only needs to distinguish one object from another, an extended index finger is used, as if the speaker would only touch the object rather than present it.
Depiction: Depiction (“performed depiction” [Reference ClarkClark, 2016]) is when someone acts as if showing what something looks like, how things are disposed in space, the manner in which an object or animate being moves, a pattern of action, to represent an emotional expression, to sketch the size and shape of something, to show how an object is handled, or to simulate using an instrument or tool, to “play at” doing something, or to act out a scene within imagined space. Whether fleeting or elaborate, depictions are widespread in live discourse of all sorts, in speakers and in signers alike.Footnote 4
Kinesic depictions are used by speakers in many ways. An enactment, used in conjunction with a verb phrase, can make the meaning of the verb more specific. For example, a speaker describes how someone used to “throw ground rice” over ripening cheeses to dry them off. As he says “throw” he shapes his hand as if holding a powder and does a double wrist extension as if distributing powder over a surface. The actions referred to by the verb “throw” are thereby given a more specific meaning – “scatter” might be an appropriate word (Reference KendonKendon, 2004, pp. 185–90). The same individual, in another recording, is talking about American soldiers, stationed near a village in England during the Second World War; toward the end of that war, when driving through the village, they sometimes “used to throw oranges and chewing gum (…) all off the lorries to us kids in the streets.” Here, saying “throw,” the speaker twice moves his hand rapidly backward, as if throwing things over his shoulder – a quite different sort of throwing than in the first case (Reference KendonKendon, 2004, p.186, Fig. 10.6).
Kinesic depiction allows a speaker to conjure objects into interactional space. For example, a speaker can indicate features of an object and then act as if it is actually present, holding it up exhibiting it or manipulating it, illustrating its properties: in discussing a new building, a speaker is explaining how a security arrangement will include “a bar across the double doors on the inside.” As he says “bar,” he lifts up his two hands and moves them away from each other, the hands held as if he was sliding them along a horizontally disposed elongate object. In moving apart his hands so posed, his hands seem to create the bar, making it present (Reference KendonKendon, 2004, p. 192, Fig. 10.12). A speaker, recalling lemon curd tarts and jam tarts from her childhood, moves her hands forward, fingers arranged as if holding out a little circular object in front of her (Reference KendonKendon, 2004, p. 192, Fig. 10.11).
The shape, size, and spatial characteristics of something can be shown kinesically. A speaker, explaining an archaeological excavation of an underwater village, describes finding a bronze spearhead underneath a large log. He says: “and underneath that they found a huge bronze spearhead.” When saying “huge bronze spearhead” he lifts up both hands, holding them apart with index fingers extended, depicting the spearhead’s length (also showing how “huge” was to be interpreted) (Reference KendonKendon, 2014a, Fig. 2). Again, a speaker describing how his father, a grocery store owner, received the cheeses he was to sell, said “an’ the cheeses used to come in big crates about as long as that,” holding out both hands as if holding a large elongate object in front of him, making present an imaginary crate (Reference KendonKendon, 2014a, Fig. 1b).
Spatial relationships of objects within a space can be shown, as can how objects move in relation to one another. A girl describing her aquarium refers to the two rocks inside it. As she does so verbally, she holds up her two fists side by side, modeling the rocks and showing how they are spatially disposed within the tank. Then, describing the pipe that provides aeration for the water, she draws her two hands apart, thumb and index finger of each hand extended and held with their tips separated, thus depicting a long thin object, horizontally disposed. Then she moves her two index fingers, directed vertically upwards, alternately up and down, depicting the motions of the air bubbles that come out of the pipe (Reference KendonKendon, 2004, pp. 191–194).
Objects, if depicted as if they are in front of the speaker, can then be acted upon as if still there. A speaker described a Christmas cake placed on a grocery shop counter to be sold in pieces. As he said, “the cake was this sort of size,” he sketched out a rectangular area over the table in front of him with two extended index fingers. Thereafter, as he explains how a customer can request a piece of a given size to be cut off, using a flat hand held vertically to model a knife blade, he acted as he might if cutting into the cake as placed on the table in front of him (Reference KendonKendon, 2004, pp. 194–197).
By means of such depictions, speakers provide cues, often conventionalized, which enable recipients to build in their imagination versions of what the speaker is showing. As Daniel Reference DorDor (2015) might say, they instruct the other’s imagination; the bodily movements themselves creating an imagined space within which movements and objects are shown and their spatial relations established. Verbal descriptions also enable imagined things to be present, but they do this by way of conceptual configurations designated by words. Performed depictions provide cues for percepts which allow for the building of images (Reference ClarkClark, 2016; Reference Huttenlocher, Kavanagh and CuttingHuttenlocher, 1975).
Symbolic or conventionalized kinesic actions Kinesic actions, typically manual, which have a socially shared, conventional (symbolic) meaning (“emblem,” “quotable gesture,” “symbolic gesture”) may be used in alternation with speech, but they are also often used together with speech, sometimes simultaneously with a word that has the same meaning, the speaker thus expressing the same meaning in verbal and kinesic form simultaneously. Such actions are often used to complement or to add to spoken meaning.
In my Neapolitan recordings, using kinesic and verbal forms of a lexical item simultaneously could often be observed. For example, a speaker (a shopkeeper) was explaining that nowadays in Naples there are too many thieves. As she uttered the word ladri (thieves) she used a manual expression which is always glossed with this word. Again, as a speaker said soldi (money), he rubbed the tip of his index finger against the tip of his thumb, an action always glossed as “money.” This practice of pronouncing equivalent verbal and kinesic expressions simultaneously is not seen only in Naples. A British English speaker, describing her job, says “I do everything from the accounts, to the typing, to the telephone, to the cleaning.” As she says “typing” and “telephone” and “cleaning” she does an action, in each case a conventional form, typically glossed with the same word that she utters.
In such cases the hand action seems just to convey the same meaning as the word. However, studying the contexts in which this occurs, taking into consideration how the action is performed, might suggest different effects speakers can achieve by using kinesic expressions with a fixed verbal gloss in this way. For example, duplicating a verbal meaning with a kinesic expression can ensure the meaning is present in conditions where it might not be heard or understood; it can draw the recipient’s attention to the speaker and thus assure the speaker that the recipient will have seen the meaning as well heard it. In many situations in the proverbially noisy circumstances of the Neapolitan street, speakers often find it useful to enhance their performances to facilitate the attention of addressees (Reference KendonKendon, 2004, pp. 349–354). A kinesic action can also be held beyond the duration of its verbal counterpart, thereby giving its meaning a continuing presence. This is another way in which its import can be foregrounded (see Reference KendonKendon, 2004, pp. 177–181 for examples given above).
Kinesic symbolic actions may also be used in parallel with verbal expressions, adding to the speaker’s spoken content. One illustration (Reference KendonKendon, 2004, p. 185, example [32], Fig. 10.5) must suffice: a city bus driver (in Salerno) describes the disgraceful things boys write on bus seat backs. They do this in front of girls, who are not upset but think it fun. As he says this, he holds both hands out, index fingers extended, positioned so that the two index fingers are held parallel to one another. In this way he adds the comment that boys and girls are equal participants in this activity, using here an expression glossed as “same” or “equal,” among other meanings given it (Reference De Joriode Jorio, 2000, p. 90).
4.2 Metadiscursive and Pragmatic Functions
Four ways can be distinguished in which kinesic actions operate metadiscursively in relation to spoken discourse. These are: operational, performative, modal, and parsing or punctuational (Reference KendonKendon, 2017a).
Operational: Head actions that function as an operator in relation to the speaker’s spoken meaning may be exemplified in the use of the head shake negating a verbal expression (Reference KendonKendon, 2002). A widely used hand action also may operate like this. Here the hand, with all fingers extended and adducted (so-called “open hand”), and palm facing downwards, is rapidly moved horizontally and laterally. Such an action is common in relation to negative statements or statements that imply a negative circumstance. For example, a Northampton UK shopkeeper uses this action when saying to a customer “That’s the finish of that particular brie” (Reference KendonKendon, 2004, p. 256); it may also be used with positive absolute statements, as if the hand action serves to forestall any attempts to deny what is being said: As a Neapolitan declares “La cucina di Napoli è la piú bella cucina” (“Neapolitan cooking is the most beautiful cooking”), the horizontal hand action used when saying this acts as if to say that any contrary claim will be denied (Reference KendonKendon, 2004, pp. 255–264).
Modal: Manual actions can provide an interpretative frame for a stretch of speech. The use of the “quotation marks” gesture (“air quotes”) showing that what is being said is “in quotes” is a common example. In a recording made in Salerno in 1991 (AK recording: Bocce I), someone discussing a robbery puts forward a speculation about the robber’s actions. As he does so, he touches the side of his forehead with the fingertips of a “finger bunch” hand and then moves his hand away and upward while spreading his fingers. This action, in Southern Italy, indicates something imagined. Here it serves to frame the speaker’s statement as an hypothesis.
Performative: Hand actions may be used to show the illocutionary force of an utterance. Quintilian described examples, for instance, the hand shape suited to the exordium (Quintilian, Book XI, iii, line 93 et seq. in Reference ButlerButler, 1922). Other examples include “Praying hands” (mani giunte) and “finger bunch” (grappolo), which is used for marking certain questions in Neapolitan speakers (Reference KendonKendon, 1995b; Reference Poggi, Attili and Ricci-BittiPoggi, 1983; and Reference Seyfeddinipur, Müller and PosnerSeyfeddinipur, 2004, for analogous expressions in Iran); Some of the uses of the palm-up-open-hand also serve in this manner, as when such a hand is proffered as a speaker gives an example, or when a speaker asks a question, holding out the palm-up-open-hand as if wanting something to be put in it (Reference KendonKendon, 2004, pp. 264–281; Reference Müller, Müller and PosnerMüller, 2004).
Parsing: A speaker’s actions, especially of hand or head, can serve to parse or punctuate ongoing speech. For example, as a speaker gives an account of a Christmas dinner, she lists what was served: “And then came the mince pies, the bowls of nuts and oranges” (Reference KendonKendon, 2004, p. 269). She repeats with each item an outward wrist rotation with palm up open hand as if “presenting” each item as she utters it. A speaker states four things that he supposes a burglar could have done, extending four fingers in succession, starting with the thumb, a new finger for each possible burglar action (AK recording: Bocce I). Among Neapolitan speakers, when announcing a topic, an associated “finger bunch” (grappolo) is presented, the hand is then moved outward, with the fingers spreading, as the speaker makes his comment. A thumb-tip-to-index-finger-tip “precision grip” is used by Neapolitans to mark a stretch speech of central importance, as when something specific is being said (for descriptions see Reference KendonKendon, 1995b; Reference KendonKendon, 2004, pp. 238–247; for German and American English examples of “precison grip” see Reference Neumann, Müller and PosnerNeumann, 2004 and Reference LempertLempert, 2011, respectively).
A further pragmatic function is interactional relational. This includes waving, embracing or hugging, inviting someone to sit down, offering, withdrawing, beckoning, requesting or halting turns at speaking, and so on. As far as I know, actions with these functions have received little in the way of systematic treatment, but see Reference Bavelas, Chovil, Coates and RoeBavelas, Chovil, Coates and Roe (1995).
4.3 Discussion
When we talk about things or ideas, with our words we conjure them up as objects in a virtual presence and with our kinesic actions, as noted when treating depiction, we may use various strategies to bring aspects of these objects into virtual presence, much as we do in drawing or modeling them, or in using our hands to demonstrate their functions.
These virtual objects are never produced in isolation but always in configurations with other virtual objects. These configurations are established through resources such as syntax, word choice, topic organization, and so on, but may also be established kinesically. Hands used when talking may act as if they are pushing objects into position, touching them or pointing to them, disposing them in relation to one another in space, and other operations of this sort. Many manual actions that serve in these ways are actions that can be understood as being versions of manual manipulations or manual actions upon or in relation to objects of whatever kind. The manual involvements of speaking are often schematic versions of object manipulations, as if, in speaking, objects have been conjured into a virtual space, the speaker’s hands being used to manage them (Reference Kendon, Gambarara and GiviglianoKendon, 2009; Reference StreeckStreeck, 2009).
It should be stressed that a given action can serve in more than one way simultaneously, and a given form may contribute in one way in one context and in a different way in another. The semantic functions of kinesic hand actions cannot be sorted into mutually exclusive categories. Further, the different ways we have outlined in which kinesic actions can contribute to utterance meaning have been arrived at by observers or analysts, after they have reflected upon how the form of a visible action, regarded as in some way intended or meant as part of the speaker’s expression, can be related to the semantic or pragmatic content apprehended from the speech. Our ability to do this is based upon our ability to grasp how these actions are intelligible. How do we do this? Involved here is the question of the intelligibility of kinesic expressions and how this interacts with the intelligibility of the associated spoken expressions. Reference Lascarides and StoneLascarides and Stone (2009) is a recent discussion, but this question deserves further exploration.
Finally, how can we be sure whether these kinesic actions make a difference to how recipients grasp or understand the propositional or pragmatic meanings of the utterances they are a part of? We do know, both from everyday experience and from numerous experimental studies (Reference KendonKendon, 1994 and Reference HostetterHostetter, 2011 are reviews), that these actions do make a difference for recipients, but whether they always do so, and whether they do so in the same way, we cannot say, nor do we have a good understanding of the circumstances in which they may or may not do so (Reference Rimé, Schiaratura, Feldman and RimèRimé & Schiaratura, 1991, pp. 272–275 suggest a start in how this might be investigated).
This brief survey should make clear the diverse ways in which speakers employ kinesic actions. A simple statement cannot be made about what kinesic actions do or what they are for. For me, a consideration of these different kinds of use supports the view that these actions are to be regarded as components of a speaker’s final product. That is, they are not symptoms of processes that lead to verbal expression nor are they actions brought in by the speaker as aids to the task of creating a verbal formulation. Rather, they are integral components of a person’s expression as this is achieved in the immediate circumstances of an utterance’s production. Speakers monitor their outputs and match output against some expression target. Often they follow with revisions of what was just said, and the role of kinesic action in these revisions may differ from its previous role. So although kinesic action in a current utterance can provide something that the speaker can use if a revised version is produced, and in that way “help the speaker,” kinesic expression within a current utterance is part of that utterance. It does not help the speaker’s speaking in that utterance. This is so because it is produced at the same time as the verbal expressions, not beforehand.
5 When Kinesic Action Is the Sole Vehicle for Utterance
I now turn to the work I have done with people who use kinesic action as their sole resource for utterance, either for physiological reasons, as in deafness, or for reasons of choice or convenience, whether for ritual or because of environmental or other social circumstances. As mentioned in Section 1, I first worked on a primary sign language encountered by chance in the Enga province of Papua New Guinea. Then I worked on alternate sign languages used in indigenous communities in central Australia.
5.1 Papua New Guinea
My work on a sign language in Papua New Guinea, published in 1980 as three papers in Semiotica, has since been republished as a monograph (Reference KendonKendon, 2020).Footnote 5 This work begins with a description of the nature of the units of behavior that function as signs and how contrasts between them are established. Then follows an examination of how the form of a sign may be shaped by features of its referent. This includes a comparative study, comparing signs from American Sign Language (ASL) (Reference Stokoe, Casterline and CronebergStokoe, Casterline, & Croneberg, 1965), from an alternate sign language used by the Pitta-Pitta of Northwest Queensland (Reference RothRoth, 1897), and from one used by workers in a sawmill in British Columbia (Reference Meissner and PhilpottMeissner & Philpott, 1975). This was to test a hypothesis that the “iconic device” (Reference Mandel and FriedmanMandel, 1977) a sign language uses is related to the semantic domain of the sign’s signified. A study of how pointing was used in the Enga corpus follows, and after this there is an analysis of utterance construction. Here, actions in the face and eyes concurrent with the production of manual signs are examined for how they contribute to bringing off complex sign combinations. Sign order, subject–object relations in verbal expressions, temporal reference and interrogation are also examined. In this work I used what was then available on ASL by Reference StokoeStokoe (1960), Reference Stokoe, Casterline and CronebergStokoe, Casterline, & Croneberg (1965), Ursula Bellugi and associates (Reference Bellugi, Klima, Kavanagh and CuttingBellugi & Klima, 1975, Reference Bellugi, Klima, Harnard, Steklis and Lancaster1976; Reference Fischer and GoughFischer & Gough, 1978), and by authors in Reference FriedmanFriedman (1977).
I found Enga signers signed at a rate comparable to that reported for ASL signers; they made use of a similar repertoire of locations and movement patterns as Stokoe had described for ASL. The repertoire of contrasting hand shapes was much smaller, however. A comparative analysis of the different “iconic devices” used (using Reference Mandel and FriedmanMandel, 1977, for ASL) showed that the Enga signs and those in the three unrelated sign languages all included enactment, modeling, or sketching and these were related to the semantic domains of the referents in similar ways. Enactment, the most common device, is used when signing bodily actions of all sorts: many animals are signed by enacting a movement pattern selected as characteristic of them, and objects, when they can be designated, by a fragment of an action pattern used in manipulating or using them. Modeling, often combined with enactment, is commonly used for large animals which are not handled or for objects such as tools. Sketching (as in outlining the shape of something) was found to be the least common. These findings suggest that the processes by which signs in a sign language are generated are quite general. This is fully compatible with signs in different sign languages being diverse, not only because features selected for representation can be quite different but also because the processes by which signs are shaped as they become part of a shared system ensure that signs for similar referents in different sign languages are also likely to be different from one another.
Pointing was used by Enga signers in ways very similar to what has been described for this in ASL. Facial, postural, and gaze direction activity in relation to manual signing was shown to serve as a bracketing device, marking out distinct segments of discourse, and providing context for the manual signs, so adding directly to discourse meanings. In a conclusion, I remarked “the functions of concurrent activity in respect to signing are no different from their functions in respect to speech in users of oral language. This points out quite clearly that signing, despite the fact that it makes use of quite different expressive devices, as a functional system, is the exact analogue of speech” (Reference KendonKendon, 2020, p. 112). In the light of what we know today about the functions of mouth actions in sign languages (see Reference Boyes-Braem and Sutton-SpenceBoyes-Braem & Sutton-Spence, 2001), this statement needs some modification. Nevertheless, this foreshadows a point I elaborated much later (e.g. Reference KendonKendon, 2014a), which is that, if sign language and spoken language are to be compared, they should be compared as uttering activities, not as fixed texts. Such comparison reveals how signing and speaking are variations of a fundamentally similar activity, but it also emphasizes the point that is crucial to understanding speaking as a process: Kinesic as well as vocal actions must be taken fully into account. It points to the multimodal character of uttering and suggests that the division between “paralanguage” and “language” cannot be sustained categorically. As we remark below, this has implications for how we conceive of “language” and for how we are to approach the problem of its evolutionary origins.
5.2 Sign Languages in Aboriginal Australia
In a much larger investigation, I examined sign languages in use among Australian Aborigines. In an area of central Australia that stretches northwards from above Alice Springs in the Northern Territory as far as the border with Arnhem Land, a practice is followed in which, when a woman is widowed, for an extended period thereafter, she and certain of her classificatory relatives forego the use of speech. Where this practice is observed, complex sign languages have developed. These are used among women in mourning, but they may also be used in other circumstances of everyday life as a matter of convenience or suitability. There are many interesting aspects of these sign languages, from cultural and semiotic points of view, and when comparing them to other alternate sign languages (such as those reported from North America or in Christian monastic communities – see Reference DavisDavis, 2010; Reference Umiker-Sebeok and SebeokUmiker-Sebeok & Sebeok, 1987) as well as to primary sign languages. It is also useful to compare them with other language codes, such as writing or drum and whistle languages (Reference KendonKendon, 1988, Ch. 13; Reference MeyerMeyer, 2015 is a recent study). Here I comment on just one issue, which was central in my work, and that is how these central Australian sign languages are structurally related to the spoken languages of their users.
A comparison of signing among women of different ages that I undertook at the Warlpiri settlement, Yuendumu (Reference KendonKendon, 1984), suggested that, as users grew more proficient at using their sign language, they came to use, more and more, signs that represent the semantic units expressed by the semantic morphemes of the spoken language. A notable feature is that it appears common for signs to develop which represent the meanings of the morphemes of the spoken language. In consequence, concepts expressed in spoken language by compound morphemes get expressed by compound signs that are the equivalent of these compounds. One example must suffice (for this and other examples, see Reference KendonKendon, 1988, pp. 369–372). In Warlpiri, “scorpion” is kana-parnta, a compound of kana “digging stick” and -parnta, a possessive suffix. Thus “scorpion” in Warlpiri is, literally, “digging stick-having.” In a language of a neighboring community, Warlmanpa, the same creature is known as jalangartata, a compound of jala “mouth” and ngartata “crab” or perhaps “claw.” Note that, in creating a sign for this creature, we do not find a sign for “scorpion” derived from some feature of the animal (its action of raising its tail comes to mind) but signs based on representations of the meanings of the verbal components which make up the verbal expression. Thus, in sign languages of neighboring language communities in this part of Australia, there can be differences in signs for similar things, these differences deriving from the fact that signing in part develops as kinesic representations of the semantic units of their respective spoken languages. It is interesting to compare this with writing (Reference KendonKendon, 1988, Ch. 13).
Detailed information on other alternate sign languages is scant, and there are few studies that have investigated how they might relate to the spoken languages of the communities where they developed. However, surveying such evidence as is available shows that we need not expect other alternate sign languages to be as closely guided by an associated spoken language as the Australian central desert sign languages tend to be (see Reference KendonKendon, 1988, Ch. 13). The so-called Plains Indian Sign Language of North America (in use in the nineteenth century) studied by Reference WestWest (1960) shares many features found in primary sign languages but not found in the Australian central desert sign languages. For example, exploiting space for expressing grammatical relations is found in Plains Indian Sign Language but not in Warlpiri Sign Language. Since Plains Indian Sign Language was used as a lingua franca by people with several different spoken languages, we might not expect its users to structure it according to one specific spoken language. This is what Anastasia Bauer reports in her study of signing used at a multilingual settlement in Arnhem Land (Australia), where it is also shared by deaf persons (Reference BauerBauer, 2015). Further, many of the indigenous spoken languages of North America have “polysynthetic” morphologies. This would make the creation of signs as equivalents of recombinable semantic morphemes (possible in Warlpiri) hard to achieve.
Several aspects of these alternate sign languages are of interest. At least in the central desert sign languages, there are many signs that are used to signify several different semantic morphemes, rather than one only. Studying this throws light on how users cluster meanings into broader categories (see Reference MeggittMeggit, 1954). Examining sign formation processes can also show what gets selected as the bases of iconic signs within the culture. More broadly, perhaps, it is interesting how readily kinesic equivalents of word meanings can be created. This seems to support the idea that many spoken words are closely related to schematic units of action (Reference Gullberg, Pederson and BohnemeyerGullberg, 2011; Reference PulvermullerPulvermuller, 2005). This fits in with the idea that language begins as a form of action; its transformation into a system of abstract symbols is a later development.
6 A General Conclusion
In Section 4, we saw how kinesic action enters into the construction of utterances in which speech is also used. Pointing and kinesic depiction can be done while speaking, adding to utterance content. A speaker’s utterance can thus “escape” the linearity constraints of verbal expression, at least to a degree. Objects and their features, spatial and dynamic, can be depicted directly along with spoken discourse. In sign languages, simultaneous as well as linear constructions must be envisaged as a part of their grammar (Reference Vermeerbergen, Leeson and CrasbornVermeerbergen, Leeson, & Crasborne, 2007). As far as I know, though, it is a ubiquitous speaker practice; combining speech and kinesic action in simultaneous constructions has not become established in any speaker community as a part of the formal grammar of a spoken language.Footnote 6 Nevertheless, it is clearly a feature of speaker uttering which can exploit the same syntactic dimensionality as sign languages do (Reference HockettHockett, 1976), and although this is done differently in speakers than it is in signers, this shows a fundamental continuity between uttering, whatever the modality. Further, this means that in constructing utterances we are not restricted to discrete units. Rather, various elements may be used, fashioned in whatever modalities are available, including highly conventionalized elements (words or lexical signs), elements which may be variable or flexible in form, including “nonce” elements, created in the moment to fill an expression slot with whatever resource is to hand (Reference Lepic, Occhino and BooijLepic & Occhino, 2018).
7 Utterance Visible Action, Uttering, and Language Origins
The expression “utterance visible action” or “utterance dedicated visible action” (or sometimes “kinesic action”) is a term intended to cover the phenomena that are the concern of the work here surveyed. It emphasizes our concern with the visible bodily actions with referential, metadiscursive, or pragmatic functions that humans engage in when uttering. In signing, these actions are the sole means by which all uttering is done. When speakers use them when uttering, they are integral to the project of the utterance of which they are a part.
Uttering refers to the activity of producing the complex ensembles of actions which constitute utterances.Footnote 7 It is these complex ensembles, shaped in the current communicative moment, which must be understood if we want an explanation of how utterances mean. Language refers to the abstracted system that utterers commonly make use of.Footnote 8 (Languageless utterances are common also, however.)Footnote 9 Over the course of several millennia, beginning, perhaps, with the first development of writing, we can see the growth of the idea that language can be regarded as a system existing “out there,” as if it were an external object, a “thing” in the environment, a tool of human invention which has to be learnt if it is to be used. This view of language is a product of human reflection and has given rise to the artifact studied by those who, by the end of the nineteenth century, were known as “linguists.”Footnote 10
Following a number of historical events and processes, including the rise to dominance of the printed word, “language” as it could be written down came to be regarded as the default mode of human communication and thought, all other modalities being marginalized, even ignored.Footnote 11 At least since the 1950s, however, what has become ever clearer is that this “language” is only a part of what has communicative consequence in interaction and is only a part of how humans think. It is more and more recognized that “language” viewed in this way cannot account for human communication. We must also study and understand the orchestrated deployment of multiple expressive modes and the diverse semiotic processes always involved whenever people engage one another with utterances (cf. Reference Ferrara and HodgeFerrara & Hodge, 2018)
Taking this view seriously brings important implications for the problem of language origins. Hitherto, a great deal of thought on this problem begins with the idea that “language” can be thought of as a self-sufficient entity, contained in a separable module of the mind. Thinking in this way, however, makes it difficult to understand how it could have arisen since it seems to have no connections to any other system of expression. This has led some to suppose that there must have been a genetic mutation altering the brain so that, all of a sudden, language was possible.Footnote 12 Although many reject this idea, for it is at odds with how biological evolution happens, even those advocating a more gradualist approach often seem to be wedded to the idea that it is “language” as an abstracted system that should be the target of their theorizing. Advocates of the “gesture first” hypothesis, for example, are faced with the problem of accounting for why the spoken modality is the dominant vehicle for language, which they still seem to think of as discontinuous with other systems. Many “gesture first” theorists think there was a “switch” (or a “transition”) from “gesture” into “speech” whereupon, and only then, we have language proper (Reference Kendon, Napoli and MathurKendon, 2011). This kind of thinking is even found among some of those who take sign languages into account. Those who want to maintain that there is a “cataclysmic break” between “gesture” and “sign” (Reference Goldin-Meadow and BrentariGoldin-Meadow & Brentari 2017; Reference Singleton, Goldin-Meadow, McNeill, Emmorey and ReillySingleton, Goldin-Meadow, & McNeill, 1995) seem to rely on the idea that “language” is something that excludes forms of expression that do not conform to the criteria of discreteness, and arbitrariness in the relation between the signifier and the signified.
Notwithstanding, it is the expansion of our understanding of sign languages from the beginning of the 2000s which is providing some of the best grounds for advocating that a categorical division between what is “linguistic” and what is not, is not sustainable. It is now more widely agreed that in signing there are modes of expression, important to the very working of a sign language, which do not fit a structural linguistic morphosyntactic framework. In depictive modifications of lexical signs, classifier constructions, phenomena of simultaneous construction, and so-called “constructed action,” we have modes of expression that are not categorial but analog, yet integral to the functioning of a sign language as such. Sign languages are, unavoidably, semiotically hybrid systems (see, inter alia, Reference Johnston, Vermeerbergen, Schembri, Leeson, Perniss, Pfau and SteinbachJohnston, Vermeerbergen, Schembri, & Leeson, 2007; Reference KendonKendon, 2014a; Reference LiddellLiddell, 2003).
This is just as true of spoken languages. At least, as soon as we look at uttering speakers we see that they, just like uttering signers, make much use of forms of expression that do not fit with what are commonly understood to be properly “linguistic.” The arbitrary nature of the distinction between “linguistic” and “non-linguistic” was already recognized in 1946 by Dwight Bolinger (Reference BolingerBolinger, 1946), and in 1987 Charles Hockett came to agree that between “language proper” and paralanguage and kinesics “there aren’t any boundaries, just zones of gradual transition” (Reference HockettHockett, 1987, p. 27). Regarding body movement, at first always excluded from “language,” after Birdwhistell had begun a systematic investigation of it, and onward with the work here surveyed, as well as work by Reference McNeillMcNeill (1992), Reference StreeckStreeck (2009), Reference EnfieldEnfield (2009) and Reference CalbrisCalbris (2011), among many others, it now must be seen as integral to utterance. All this supports the conclusion that uttering by people who use speech is just as semiotically “hybrid” as it is when people are uttering by signing (see Reference Lepic, Occhino and BooijLepic & Occhino, 2018).
Uttering, in other words, is multimodal. Whenever an actor engages in uttering, they will always mobilize – albeit to lesser or greater extents – whatever expressive resources they have available, adapting them and orchestrating them in relation one to another, as suits their rhetorical aim within whatever interaction situation they may be in. This, it seems to me, invites the conclusion that, so far as the question of language origins is concerned, it is fruitless to suppose that language first emerged in one modality, switched, eventually, to another (as “gesture firsters” have supposed) or somehow added in other modalities later. The shift to being able to employ and to recognize expressive actions of whatever kind in wilfully deictic and depictive ways was a shift in the perception and production of any sort of action, regardless of the modality employed (Reference KendonKendon, 2016). This shift was the first step that made any sort of language possible. How it took place has not yet been accounted for in any comprehensive theory. We do see hints of it, however, in the behavior of many animals – especially in monkeys and apes and also in many species of birds (in corvids, parrots, and artamidids, such as the Australian magpie [Reference KaplanKaplan, 2015]). A feature of this sort of behavior is that it has characteristics of “try-out” actions and “intention movements” – actions that are purposeful but which do not fully consummate their purpose even though their purpose is recognizable (cf. Reference KendonKendon, 1991). This suggests that in trying to understand the origins of symbolic action, it might be fruitful to look carefully across species at play, ritualized agonistic encounters, and courtship interactions.
After this shift had occurred, and once shared repertoires of symbolic acts began to be established, a system which eventually emerged as “language” would begin to differentiate into an increasingly specialized kind of activity (Reference Kendon, Dor, Lewis and KnightKendon, 2014b). Important for any account of language origins is to understand how this differentiation and specialization into socially shared repertoires of symbolic actions came about. It seems likely that the more complex, stable, and widespread a shared repertoire of symbolic actions becomes, the more it will tend to be modality specific. Space precludes any elaboration here but, in hominins,Footnote 13 that this specialization has favored the modality of articulated vocalization should not surprise us. Evolution builds on what is already there, and the vocal apparatus, already part of the mammalian plan and specialized for communication, would surely not have been left out of the evolutionary processes by which socially shared symbolic systems came to be established (see Reference DarwinDarwin, 1871, pp. 58–59). Nevertheless, the socially shared symbolic systems that have emerged – “languages” – not only could not function as they do today, much less could they have emerged in evolution, unless the way they are connected with the diverse range of expressive actions is fully taken into account.
1 Introduction: Aims and Challenges in Gesture Coding and Annotation
Any analysis of verbo-gestural utterances requires the processing of audiovisual material in usually at least two steps: transcribing spoken utterancesFootnote 1 and coding and annotating gestures. Coding and annotation are usually considered to be analogous and are not clearly separated. However, typically, two aspects are distinguished. The encoding scheme includes linguistic phenomena and determines the categories and the members that are necessary for the description and the analysis. The annotation structure scheme defines structural aspects, such as number of tiers, temporal, and/or hierarchical relations (see e.g. Reference Brugman, Wittenburg, Levinson and KitaBrugman, Wittenburg, Levinson, & Kita, 2002). Annotation is thus understood as the association of descriptive or analytic notation with data and can include many different kinds, such as syntactic labels, part of speech tagging, semantic role labels as well as different layers and levels (Reference Ide, Ide and PustejovskyIde, 2017, p. 2).
In this process, coding and annotation systems for verbo-gestural data are faced with particular challenges. They must reproduce both sensory modalities in their specifics and independent of each other. For gestures, categories are to be found that adequately capture the nature of the gestural sign as precisely as possible in written form. Categories have to be chosen that enrich the raw material sufficiently for the particular research question to be addressed without tampering with the raw material too much. Furthermore, the dynamics of the relation between speech and gestures, along with their simultaneous and successive nature, needs to be preserved. Technical possibilities, such as motion tracking, open up even more questions: How, and to what extent, can and should manual annotation be combined with such data? How reliably can the annotation of motion, for instance, be performed by human coders relying solely on the visual input, or is it necessary to add quantitative tracking to allow for the extraction of particular kinematic features of gestures (Reference MittelbergMittelberg, 2018; Reference Pouw, Trujillo and DixonPouw, Trujillo, & Dixon, 2019)? On another level, requirements such as searchability, browsability, and the extraction of automatic information play a role in the coding and annotation process (Reference Bird and LibermanBird & Liberman, 2001, p. 54). A tagged and searchable verbo-gestural database opens up the possibility of new research questions that rely on larger corpora and a quantitative and corpus-linguistic perspective (see e.g. Reference Steen, Hougaard, Joo, Olza, Cánovas, Pleshakova and WoźnySteen et al., 2018). The questions “How much does one abstract?” (Reference Kipp, Neff and AlbrechtKipp, Neff, & Albrecht, 2007, p. 327) and “How many and what kinds of classes and categories are needed?” thus remain key ones in coding and annotating verbo-gestural data.
This chapter gives a selective overview of the current state of the art on gesture coding and annotation systems. It touches upon the aspects mentioned above in different levels of detail and from various perspectives by reflecting on the interrelation between subject, research question, and coding and annotation systems. Section 2 opens up the discussion by emphasizing that coding and annotations systems are always influenced by the particular theoretical framework in which they are situated. Accordingly, similar to the situation in the analysis of language, a theory-neutral analysis of gestures is not possible. This will be illustrated by consideration of some representative fields of research in gesture studies: language use, language development, cognition, interaction, and human–machine interaction. Section 3 of the chapter discusses different coding and annotation schemes addressing research questions in these fields. Rather than giving an extensive discussion of the individual systems, the section focuses on their general logic for answering a research question from a particular field. Here, differences between systems addressing the same research topic (see e.g. language use) as well as differences across research topics (see e.g. language use vs. interaction) will be explored. Section 4 of the chapter closes with some considerations on the current state of automatic gesture recognition and recording practices and possible future developments in coding and annotating verbo-gestural data.
2 Framework, Subject, and Analysis: On the Interrelation between Theory and Method in Gesture Studies
Looking at the particular chapters included in this Handbook, the ways in which gestures are considered as being part of communication, and how the role of the body in language (use) is looked upon, differ greatly: This is true not only in terms of theoretical perspectives but also in the methodological approaches taken. Hence, there is no single method or approach to coding and annotating gesture. Rather, there are many different ways, and as such, both the theoretical and methodological frameworks provide important orientation points for a study’s scope of explanation. Analyses of linguistic constructions with gestures, for instance, call for a detailed analysis of the verbal construction, its temporal relation with gestures, along with differences in form, meaning, and type of the gesture as well as a quantitative, corpus-linguistic analysis (Reference Zima and BergsZima & Bergs, 2017). Research that focuses on gestures’ relation with the material world needs to put particular emphasis on the environmental setting and the dynamics of the interaction (Reference StreeckStreeck, 2017) and follow a more qualitative perspective on the relation between speaking and gesturing. These two examples show that the particular research question determines the aspects and the level of detail of gesture–speech relations that need to be coded or not. Thus, each interest leads to a specific view on verbo-gestural data that has theoretical and practical implications for coding and annotation. Consequently, no single coding or annotation schema exists with which all possible research questions could be addressed. Rather, an adequate description of specific phenomena always calls for a particular focus and, thus, a specific coding and annotation procedure. Leaving aside for now the particularities of the individual systems and their relation to specific research interests (see Section 3 for a detailed discussion of the systems), Section 2.1 briefly discusses four general differences in current systems: (1) the relation between the verbal and gestural modalities, (2) facets and specifics of coding and annotation, (3) qualitative versus quantitative perspectives, and (4) procedures. All these aspects are influenced by theoretical assumptions about the nature of gesture–speech relations, lead to particular methodological and practical implications in the coding and annotation process, and thus influence the potential outcome of verbo-gestural analyses.
2.1 Relation between Verbal and Gestural Modalities
Speech and gesture are tightly connected on the temporal, semantic, and pragmatic levels (Reference McNeillMcNeill, 1992). For analyzing gesture–speech relations and the design of coding and annotation systems, this close connection of both modalities results in rather practical consequences, because systems have to reproduce this link on different levels. Existing systems, also depending on their technical implementation, solve this problem in different ways. The majority of systems use the transcription of speech as the center for the analysis of gesture–speech relations. As a result, gestures are placed in a position that is secondary to speech, and first steps in coding and annotation concentrate on the analysis of speech (see e.g. Reference McNeillMcNeill, 1992). Gestures are added either by annotating them into speech transcription or by making them hierarchically dependent on the speech transcription. Gestures are thus viewed in relation to speech from the beginning of the analytical process. Other systems allow for a first review and analysis of the data without an instant inclusion of speech and even allow for coding and annotating gestures without sound and, initially, independently of speech. As a result, these systems initially concentrate on the form of the gestures before bringing together speech and gestures in the analytical process (Reference Bressem, Ladewig, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, Ladewig, & Müller, 2013; Reference Lausberg and SloetjesLausberg & Sloetjes, 2009) and thus separate speech and gestures into different parts of the analysis to allow for a preferably nonbiased coding and annotation of gestures.
2.2 Facets and Specifics of Coding and Annotation
Tied to the different possible relations between, and orders of, both modalities in the coding and annotation process are differences in the type and the specificity of the aspects to be coded and annotated. As already mentioned, some systems put particular emphasis on detailed descriptions of gestural forms because this allows one, for instance, to discover regularities and structures on the level of form and meaning, along with gestures’ potential for combinatorics and hierarchical structures,Footnote 2 or the best possible reproduction of gestures in technical systems, such as avatars (Reference Kipp, Neff and AlbrechtKipp et al., 2007; Reference Pouw, Trujillo and DixonPouw et al., 2019) or robots (Jokinen, this volume; Reference Kopp, Church, Alibali and KellyKopp, 2017). Connected to this approach is often the development of particular categories and a separate description of gestural form parameters to make the kinesics and semiotic processes in gestures visible (Reference BoutetBoutet, 2015; Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, 2013a). In contrast to these approaches, other systems carry out, for instance, a selective description of gestural forms that is also dependent on the meaning expressed in speech. The focus of these systems is on a functional analysis of gestures in relation to speech, such that “only the bodily movements maintaining a relation to speech – co-speech gesture – as well as the function of the gesture are of interest to us” (Reference Colletta, Kunene, Venouil, Kaufmann and SimonColletta, Kunene, Venouil, Kaufmann, & Simon, 2008, p. 59). Categories for the description of gestural forms are taken, for instance, from sign language studies and gestures are matched to the sign language alphabet (see e.g. Reference McNeillMcNeill 1992). The differences in describing and categorizing gestural forms discussed above are only meant to exemplify how the specificity of individual systems may vary; they are meant to underline the type of consequences that may be connected to different possible conceptions of, and views on hierarchies in, the relations between speech and gestures. (Further differences in the specificity and details of the particular systems along with the underlying research foci that are decisive for the structure of the systems will be discussed in Section 3.) In general, regardless of the particular approach and focus taken, the basics of current coding and annotation systems are gesture phases, gestural forms, gesture type, a transcription of speech, and the relation between gestures and speech.
2.3 Qualitative Versus Quantitative Perspectives
A further essential difference in existing systems is found in the research perspective. A qualitative perspective is characterized by more openness and flexibility, as well as often more naturalistic data from more ecologically valid settings, by which the dynamics of gesture–speech relations can be captured and hypotheses can be developed from, and based on, the material. By contrast, quantitative research aims at the validation of given hypotheses, replicable data and larger amounts of data, that are statistically evaluable. These two different positions influence the conception and design of coding and annotation systems. Systems with a stronger qualitative emphasis might show greater variability and flexibility (see e.g. Reference Müller, Müller and PosnerMüller, 2004) that is usually not included in systems aiming for a quantitative approach. Connected to this is also the use of larger corpora as data, as well as reliability or intercoder agreement measures (see e.g. Reference Lausberg and SloetjesLausberg & Sloetjes, 2009).
2.4 Procedures for Coding and Annotation
Annotation programs have become the standard for analyzing gesture–speech relations in recent years, both for qualitative and quantitative studies. Through the use of such programs, coding and annotation have become faster and more reliable, in terms of both technical practicability and plausibility. While the majority of studies use ELAN, a program developed by the Max Plank Institute in Nijmegen (Reference Wittenburg, Brugman, Russal, Klassmann and SloetjesWittenburg, Brugman, Russal, Klassmann, & Sloetjes, 2006), researchers also have the option of choosing other programs, such as EXMARaLDA (Reference Schmidt, Mehler and LobinSchmidt, 2004) or ANVIL (Reference KippKipp, 2001). Although the basic setup of these programs is similar, differences in their functionality may lead to differences in the coding and annotation systems. Whereas all kinds of annotation software offer the possibility of including three-dimensional motion data, ANVIL, in addition, allows “spatial annotation” where two points can be marked directly on the video screen so that the distance between two hands can be more accurately annotated (Reference Kipp, Neff and AlbrechtKipp et al., 2007, p. 331). The three annotation programs thus offer fine-grained possibilities for combining visual information only with automatic analyses of movement patterns (see e.g. Reference Ripperda, Drijvers and HollerRipperda, Drijvers, & Holler, 2020) and consequently allow for an analysis of gestural forms based on more material, on larger corpora, and at a more abstract level (Reference MittelbergMittelberg, 2018; Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo, Vaitonyte, Simanova, & Özyürek, 2019). (For an overview and discussion of the different methods in multimodal motion tracking, see Reference Pouw, Trujillo and DixonPouw et al., 2019, and Trujillo, this volume.)
3 Systems of Gesture Coding and Annotation
This section will first consider some general aspects of practices of coding and annotation of gestures, highlighting the fact that theoretical assumptions influence subjects, aspects, and levels of analysis and as such also make themselves visible in annotation systems. We will then turn to an illustration of this in more detail by discussing existing coding and annotation systems from a thematic point of view. Using several research domains in gesture studies as examples, namely language (use), language development, cognition, interaction, and human–machine interaction, the section focuses on the general logic of existing systems for answering the particular research questions at hand. Because only few explicit coding and annotation systems for gestures exist, the following sections address systems as well as procedures and methods followed in studies analyzing gesture–speech relations. We will focus on a selection of systems and of coding and annotations practices that illustrate the link of theory and method for particular thematic areas and/or research questions.
3.1 Words and Gestures: Coding and Annotation for Exploring Language (Use)
Most studies exploring the relation of words and gestures in language (use) assume that usage events are dynamic and multimodal in nature, yet the degree to which gestures are part of language is variable (Reference CienkiCienki, 2015). The relation between speech and gesture is understood to be “reciprocal” such that the “gestural component and the spoken component interact with one another to create a precise and vivid understanding” (Reference KendonKendon, 2004, p. 174, emphasis in original). Spoken words and/or phrases have a close relation with gestures on different linguistic levels (see e.g. phonology, semantics, syntax, pragmatics), but, depending, for instance, on the type of gesture, the communicative context or genre, or the language community, this connection may vary. Starting from this assumption, studies have aimed to discover the tight relation between speech and gestures on these different levels and relations. Depending on the object of investigation, different aspects of coding and annotation become relevant, both regarding the temporal coordination and as the functional relation between the two sensory modalities.
Early on, research showed that the temporal relation between gestures and body movement in general shows a “precise correlation between changes of body motion and the articulated patterns of the speech stream” (Reference Condon and OgstonCondon & Ogston, 1967, p. 227). Accordingly, it is assumed that “the pattern of movement that co-occurs with the speech has a hierarchic organization which appears to match that of the speech units” (Reference Kendon, Seigman and PopeKendon, 1972, p. 190). Research addressing this relation thus requires a coding and annotation system that captures the link of both modalities regarding intonation phrases, stress, and syllables, for instance. In addition, particular movement characteristics, such as the velocity profile, may be of interest (Reference Karpiński, Jarmołowicz-Nowikow and MaliszKarpiński, Jarmołowicz-Nowikow, & Malisz, 2008). Likewise, data from programs such as Praat, a software package for phonetic speech analysis (Reference Boersma and van HeuvenBoersma & van Heuven, 2001), should be integrable. If, for instance, in addition to other factors, the connection of gestures with the narrative structure of speech is to be investigated, gestures’ relation with discursive elements has to be included. For instance, in a study on the Palm Up Open Hand (PUOH) and the type of prosodic and discourse units which are marked by this type of gesture, Reference FerréFerré (2011) transcribes, annotates, and segments speech by using a range of different programs, such as Praat and EasyAlign, and annotates speech for speech acts, intonation phrases, words, syllables, and stress. For gesture annotations, the study uses the annotation programs ELAN and ANVIL, and using the typology of gestures proposed by Reference McNeillMcNeill (1992), codes beat gestures, their phases, and their semantic and discursive functions in discourse. With this, Reference FerréFerré (2011), for instance, shows that beat gestures accompany emphatic stress in the verbal mode and that the PUOH, in particular the hand flick, fulfills different pragmatic functions in discourse and can acquire “a judgmental or epistemic value” (Reference FerréFerré, 2011, p. 16).
If it is assumed that because gestural movement parameters vary in their characteristics depending on their correlation with prosodic characteristics of speech (see e.g. Reference Ruth-Hirrel and WilcoxRuth-Hirrel & Wilcox, 2018), a fine-grained coding of the gestural kinesics is necessary (Reference BoutetBoutet, 2015). This perspective is followed by Reference Shattuck-Hufnagel and RenShattuck-Hufnagel and Ren (2018). Addressing the temporal relationship between gesture and speech with non-referential gestures, the authors applied a coding and annotation system that starts out with an analysis of the gestures without sound, “to avoid any possibility of the labeler’s judgment about events in one channel being influenced by events in the other” (p. 4), and coded gestures for their phases, their forms (hand shape, movement trajectory, location, handedness), referentiality, and their use in sequences. Subsequently, speech was transcribed orthographically and labeled for its intonational structure using Praat and ToBI, segmented into syllables, and annotated for higher-level prosodic constituents. Using this approach, the authors show that trajectory shapes of the gestures that were investigated “are consistent across a higher-level prosodic grouping” and that the category of beats includes “gestures with multiple phases and various types of rhythmicity” (p. 1).
As illustrated by the two examples given above, studies can overlap in the categories and classification applied, in particular with respect to the coding of gestural forms and functions, yet depending on the research focus on different facets. However, annotation systems that specifically address such a prosodic perspective with the aim of providing a general basic structure that may be adjusted to the needs of particular research questions are rare. One example is that proposed by Reference Jarmołowicz, Karpiński, Malisz, Szczyszek, Esposito, Faundez-Zanuy, Keller and MarinaroJarmołowicz, Karpiński, Malisz, & Szczyszek (2007).
Similarly, only a few systems provide a basic outline for analyzing gesture–speech relations from the level of semantics and/or syntax. One system that puts forward a general framework is the Linguistic Annotation System for Gestures, or LASG (Reference Bressem, Ladewig, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem et al., 2013). It provides ways to describe and analyze the motivation of gestural forms (modes of representation, image schemas, motor patterns, and actions), addresses gestures in relation to speech on a range of levels of linguistic description (prosody, syntax, semantics, and pragmatics), and in doing so offers obligatory as well as optional categories for each of the different aspects of linguistic description. Yet, due to its claim to cover all of these levels of description, the system is of course not detailed enough for the investigation of particular semantic or syntactic research questions; it thus needs to be adjusted to address different depths and aspects of the relation of speech and gestures in language (use) (see e.g. Reference Seeling, Fricke, Lynn, Schöller and BullingerSeeling, Fricke, Lynn, Schöller, & Bullinger, 2016, for an adaptation of the system).
The majority of research rather follows the LASG procedure outlined above and, based on generally accepted categories, provides for coding and annotation systems tailored to a specific research question. This will be exemplified in Section 3.2 by studies focusing on verb semantics and their relation to syntactic constructions. Cross-linguistic studies on motion events not only emphasize a tight link between gestures with the semantics of speech, but also show a close connection to syntactic patterns in the spoken utterance (Reference Kita and ÖzyürekKita & Özyürek, 2003). For example, differences in grammatical aspects used in speech are reflected in the gestural forms, the timing of gestures relative to the verbal utterance, and in the information distributed across the modalities (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018; Reference DuncanDuncan, 2005; Reference Gullberg and PavlenkoGullberg, 2011). As a result, coding and annotations schemes need to be able to code and annotate speech in terms of how events, for instance, are semantically and syntactically construed along with gestural form and meaning on different levels. Reference Cienki and IriskhanovaCienki and Iriskhanova (2018), for example, in investigating aspectuality in German, Russian, and French, thus use a coding and annotation scheme that includes a set of verb tense coding categories, “time meaning” (past, present, future, and ø for infinitives and imperatives), gesture phases, and a kinesiological account to determine the category type of a given gestural movement (Reference BoutetBoutet, 2015; Boutet & Cienki, this volume) – that is bounded versus unbounded movements – “without consideration of the type of co-occurring verbal expression” (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018, p. 68). For each of these features, hierarchical relations between the tiers and controlled vocabularies were defined in ELAN. “Each of the verbs or its constituents (auxiliary, participle) was annotated according to the duration of its vocal production” and only gestures “that overlapped [with] the production of a verb” (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018, p. 75) were annotated. In another study (investigating aspectuality and, in particular, Aktionsart, in Mandarin Chinese and English), Reference Duncan and EmmoreyDuncan (2003) included a transcription of speech, along with speech dysfluencies, in which “utterances expressive of the target aspect and Aktionsart distinctions were noted” (Reference Duncan and EmmoreyDuncan, 2003, p. 192) along with the relevant features of grammatical structure. The gestures were coded for phases, form, type, semantic content, and function in relation to the speech; “the timing of the gesture production relative to the speech was exactly coded” (Reference DuncanDuncan, 1996, p. 21), and movements of referential gestures were coded according to Talmy’s classificatory scheme (1985) see e.g. MOTION, PATH, and MANNER. For a study on the English motion construction [V(motion) in circles], Reference ZimaZima (2014) coded gestures for motion components (Manner vs. Path), shape and orientation of palm and fingers, handedness, depiction of number of circles, and type of motion. Speech was coded for the semantic meaning of the construct (see e.g. literal motion, metaphorical use, ambiguous) and discourse genre.
All of these examples given above underline that even with similar research topics, coding and annotation procedures differ immensely between studies, not only for speech but, more importantly, also for gestures. Although similarities between the practices are visible, the biggest differences lie in the amount and degree of detail of the coding of gestural characteristics, on the levels of form, meaning, and function. As mentioned in Section 2, one reason for these differences can be found in the (hierarchical) relation assumed between both modalities and thus the “direction” from which the data is approached (speech first vs. gesture first). Depending on this, the coding and annotation practices differ. Reasons for these differences lie in the underlying research question. Compare, for instance, Reference Cienki and IriskhanovaCienki and Iriskhanova (2018) and Reference ZimaZima (2014). Whereas Reference Cienki and IriskhanovaCienki and Iriskhanova (2018) are interested in whether speakers of French, German, or Russian gesture “similarly or differently (with regard to movement quality) when talking about events in the perfect(ive) versus in the imperfect(ive)” (p. 5), Reference ZimaZima (2014) addresses the question of whether gestures can be a recurrent feature across instantiations of English motion constructions. Due to the fact that Zima is, first and foremost, interested in whether gestures occur often with these constructions, a less detailed form description is given in favor of a number of occurrences of gestures. Reference Cienki and IriskhanovaCienki and Iriskhanova (2018), however, based on their assumption that aspectuality may be visible in gestural movement characteristics, need to take a more fine-grained perspective on these parameters. Both research questions thus take a different look at gestural form characteristics, and, as a result, the coding and annotation procedures put different emphases on the gestural form characteristics.
Similar variations can also be found in studies addressing the relation between speech and gestures on the level of pragmatics.
The functions gestures have as they contribute to or constitute the acts or moves accomplished by utterances, are referred to as pragmatic functions. In the terminology proposed, gestures which show what sort of a move or speech act a speaker is engaging in are said to have performative functions. Gestures are said to have modal functions, if they seem to operate on a given unit of verbal discourse and show how it is to be interpreted. Gestures may serve parsing functions when they contribute to the marking of various aspects of the structure of spoken discourse.
Studies on pragmatic gestures assume that these different functions go hand in hand with differences in their context of use as well as in the gestural forms (Reference KendonKendon, 1995; Reference LadewigLadewig, 2010; Reference Müller, Müller and PosnerMüller, 2004). In order to account for these different aspects, coding and annotation procedures thus call for a detailed description of gestural forms, “micro-analyses of single sequences […] to corroborate the semiotic and context-of-use analysis” (Reference Müller, Müller and PosnerMüller, 2004, p. 12), and the exact timing of the gestures in relation to speech (see also Reference LadewigLadewig, 2010, for an adaption of this method in ELAN). As a result, in their study on discursive function of holding-away gestures, Reference Bressem, Stein and WegenerBressem, Stein, and Wegener (2017) take the form-based linguistic approach with the four-step procedure moving from a context-independent toward a context-sensitive analysis. They take the distribution of the gestures (as proposed in the LASG system) as their starting point, combining it with a functional analysis of discourse markers (Reference FraserFraser, 1999), and add additional layers of analysis to account for the particular focus on discursive functions of gestures. Based on this, the authors illustrate specific forms and a functional diversity of the gestures that are connected to different types of speech units and show that changes in the discourse type and interactional setting lead to specific forms and uses of the holding away gesture. In a study investigating pragmatic functions of pointing gestures, Reference Enfield, Kita and de RuiterEnfield, Kita, and de Ruiter (2007) “suggest that form/function differences between […] two types of pointing gesture reflect distinct types of constraints which interactants have to satisfy in confronting the online problem-solving task of designing utterances in face-to-face interaction” (p. 1724). For this, the authors coded and annotated all utterances with spatially anchored pointing gestures for the “manner of articulation of the gesture, distinguishing formally between B-points (gestures in which the whole arm is used as articulator, outstretched, with elbow fully raised), and S-points (gestures in which the hand is the main articulator, the arm is not fully straightened, typically with faster and more casual articulation)” (p. 1725). Additionally, orientation of the head was coded. Gestures with forms other than those with a single protruding digit and movements that seemed to represent motion were excluded. As the authors were interested in the relation between form and function in these gestures, their focus was on particular and quite restricted form characteristics of the gestures.
All of these examples given above illustrate how a particular focus on exploring gestures in language (use) on different levels of linguistic description may lead to very specific coding and annotation schemes and practices.
3.2 Learning to Speak and Gesture: Coding and Annotation for Examining Language Development
Research on language acquisition that is related to gesture focuses on the role that gestures play in mediating the acquisition of spoken language, in communication, and in cognition (see Morgenstern, this volume; see also Wilcox, this volume, on the place of gesture in sign language acquisition). Studies investigate how gestures develop and change in parallel to spoken language development and what role they play in the prelinguistic period (see Reference Gullberg, De Bot and VolterraGullberg, De Bot, & Volterra, 2008 for an overview). Depending on age groups, different topics emerge. In earliest development, the complex relationship between lexical and syntactic development in comprehension and production is of interest (see e.g. gesture types, difference of actions from gestures, relation with spoken syntagmas, speech acts) (see e.g. Reference AndrénAndrén, 2010; Reference Beaupoil-Hourdel, Morgenstern, Boutet, Larrivée and LeeBeaupoil-Hourdel, Morgenstern, & Boutet, 2016). In older children, their use of iconic gestures (Reference Allen, Özyürek, Kita, Brown, Furman, Ishizuka and FujiiAllen et al., 2007), narrative skills (Reference CollettaColletta, 2009), or marking of focus (Reference Koutalidis, Kern, Németh, Mertens, Abramov, Kopp and RohlfingKoutalidis et al., 2019) are investigated. For each of these topics, slightly different coding and annotation schemes are necessary to address the relation between speech and gestures at different levels of detail. In the rest of Section 3.2, four different coding and annotation practices of studies on first language development will be summarized to illustrate the diversity and variability of the approaches, depending on the research question involved.Footnote 3
In a study on the use of gestures in children between 18 and 30 months, Reference AndrénAndrén (2010) focused on the children’s gestural repertoire, gestural development over time, and the organization of gesture in coordination with other semiotic resources, such as speech. As a result, the coding and annotation scheme includes a transcription of utterances consisting of words and/or gestures in CHATFootnote 4 and the annotation of every instance of a gesture in terms of various deictic, iconic, and conventional features. “These categories were not predetermined before the annotation procedure [was] begun, but emerged in an iterative and ‘dialectic’ fashion during the annotation process itself. This means that all categories are essentially motivated by what was found in the data” (p. 97). In a further step, these basic annotation categories were then specified for a qualitative analysis that focused on “how deictic, iconic, and conventionalized aspects occur together in various sorts of gestures; how the more specific meaning of children’s gestures emerges from an interplay between gestural form, coordination with speech, previous utterances – and other factors” (pp. 332–333). For a study on the use of gestures in joint book reading situations with children at the age of 14 months, Reference Grimminger and RohlfingGrimminger and Rohlfing (2019) annotated all utterances and deictic gestures, specifying as to whether they were pointing, showing, or giving an object, and annotated their semantic relation with the speech (as reinforcing or supplementary). With the coding, the authors wanted to investigate whether the use of pointing gestures in combination with verbal utterances of children and mothers positively affected the lexicon of the children. Based on these annotations, the authors discovered that 98% of the deictic gestures were pointing gestures and that these pointing gestures indeed correlated significantly with the lexicon of the children at 18 months (p. 96). In an exploratory study on the status and evolution of actions, gestures, and words expressing negation between ages 1 and 4, Reference Beaupoil-Hourdel, Morgenstern, Boutet, Larrivée and LeeBeaupoil-Hourdel et al. (2016) developed a coding system combining Excel and Clan, “a program … designed specifically to analyze data transcribed in the CHAT format” (Reference MacWhinneyMacWhinney, 2000, p. 8). With the system, the authors coded all negative communicative acts, the channels of their expression and perception, and their semiotic status, and also distinguished between actions, that is, “movement produced by the child as a reaction to the environment rather than being intentional and conventionalized” (Reference Beaupoil-Hourdel, Morgenstern, Boutet, Larrivée and LeeBeaupoil-Hourdel et al., 2016, p. 101), and gestures. In doing so, they were able to conduct macro- and micro-analyses of the children’s negative occurrences. Based on the system, Reference Beaupoil-Hourdel, Morgenstern, Boutet, Larrivée and LeeBeaupoil-Hourdel et al. (2016) showed that “gestures used prelinguistically are qualitatively different from gestures used once speech is already elaborate” and that there are “different uses of multimodality and therefore, the status of multimodality changes throughout the corpus” (p. 27). Investigating children’s oral and multimodal discourse, and in particular, “linguistic and gesture production of narratives performed by children and adults of different languages, with emphasis [on] the relationship between speech and gesture and how it develops” (p. 59), Reference Colletta, Kunene, Venouil, Kaufmann and SimonColletta, Kunene, Venouil, Kaufmann and Simon (2008) used an annotation system that analyzes speech and gestures in terms of four different blocks: (1) speech transcription and syntactic analysis, (2) narrative analysis, (3) annotation of gestures, and (4) evaluation. For the gestures, they concentrated on gesture phases, the type of gesture (deictic, representational, performative, framing, discursive, interactive, word searching), the gestures’ relation with speech (reinforcing, complementing, supplementing, integrating, contradicting, substituting), the temporal placement of the gestures in relation to speech, and the gestures’ form (hand shape, movement trajectory, and manner). With the annotation system applied in ELAN, the authors point out that it is possible to “identify, count and describe concrete versus abstract representational gestures, marking of connectives, syntactic subordination, the anaphoric recoveries, hesitation phenomena, etc. as well as to study narrative behaviour from a multimodal perspective” (Reference Colletta, Kunene, Venouil, Kaufmann and SimonColletta et al., 2008, p. 66).
Comparing these four examples, it becomes clear that in order to investigate the relation of speech and gestures in language development at different ages and stages, no single approach to the coding and annotation can be taken, as the particular research question always calls for a specific focus that concentrates on certain aspects while neglecting others. As such, the perspective may vary, for instance, in the depth of the analysis both for gestures and speech (micro vs. macro) as may the research perspective (exploratory vs. guided by hypotheses). Both of these aspects highly influence the analysis and thus the results. An open coding procedure, such as the one applied by Reference AndrénAndrén (2010), for instance, leads to the adaptation of categories during the coding and annotation process, allowing for the incorporation of initially unexpected phenomena, thus making for an exploratory investigation. A rather narrow focus on a particular type of gestural phenomenon (deictic gestures), such as the one adapted by Reference Grimminger and RohlfingGrimminger and Rohlfing (2019), does not and is not meant to allow for the exploration of unincorporated phenomena. Accordingly, insights from both analytical and methodological procedures vary by providing different kinds of access to verbo-gestural phenomena of language acquisition.
3.3 Gestures as Windows onto Thinking: Coding and Annotation for Insights into Cognition
Numerous studies show that when people speak, they have, what Kita and Essegeby (2001) call, a “cognitive urge” to gesture, as gestures help us talk and think. They boost language production and comprehension processes (Reference De Ruiter and McNeillDe Ruiter, 2000; Reference Krauss, Chen, Gottesman and McNeillKrauss, Chen, & Gottesman, 2000), reduce cognitive load, are a tool for exploring reasoning and thinking, and especially reveal aspects of children’s cognitive development (see e.g. Reference Goldin-Meadow, Wagner Cook, Holyoak and MorrisonGoldin-Meadow & Wagner Cook, 2012) (see also the chapters by Alibali & Hostetter and Novak & Goldin-Meadow in this volume). In order to explore these aspects, studies addressing the relation between speech, gestures, and cognition are confronted with similar challenges to those already discussed in Section 3.2 on language use, however with slightly different foci. For studying gestures as windows onto the cognitive development of children, for instance, it is crucial to investigate the temporal and semantic relation between the relation of speech and gestures and to examine whether children are producing ‘mismatches’ between them (Reference Alibali and Goldin-MeadowAlibali & Goldin-Meadow, 1993). As a result, such studies and their coding and annotation practices focus on marking of the temporal movement phases of gestures, their semantic function (complementary or contradictory relation), the type of gestures, and aspects of their form (see e.g. Reference Alibali, Spencer, Knox and KitaAlibali, Spencer, Knox, & Kita, 2011). In order to be able to describe the form in more detail, Reference Hilliard and CookHilliard and Cook (2017), for instance, developed a coding system that, in combination with other existing systems, allows for a description of gestural forms that is suited to addressing gesture’s role in cognitive development (Reference Congdon, Novack and Goldin-MeadowCongdon, Novack, & Goldin-Meadow, 2018). Similar foci are also visible in studies addressing questions of cognitive load (Reference Wagner, Nusbaum and Goldin-MeadowWagner, Nusbaum, & Goldin-Meadow, 2004), yet, as mentioned before, approaches to coding and annotation may vary. Reference Chu and KitaChu and Kita (2008), for instance, in their study on mental rotation problems, pursue a different path that focuses not so much on the semantic role and forms of the gestures as on their functional role. Assuming that “when solving novel problems concerning the physical world, adults may start with bodily exploration of the physical world” (Reference Chu and KitaChu & Kita, 2008, p. 708), thus using gestures significantly, the authors coded gestures according to their movement segments and their location in gesture space, and they used a functional gesture classification suited to the tasks at hand (see e.g. hand–object interaction gestures, object-movement gestures, tracing gestures, rotation direction gestures). This functional classification of the gestures was brought together with an analysis of the speech focusing on agentivity, for instance. Based on this, the authors “concluded that the motor strategy becomes less dependent on agentive action on the object, and also becomes internalized over the course of the experiment, and that gesture facilitates the former process” (Reference Chu and KitaChu & Kita, 2008, p. 706).
Again, other foci are visible in studies investigating the relation between speech and gestures in light of production. In a study on speech disfluencies, Reference SeyfeddinipurSeyfeddinipur (2006), for example, pursues a strongly form-based perspective in addressing the question of “whether speech-accompanying gestures are sensitive to speech disfluency and whether gesture can provide evidence for the self-monitoring process in speech production” (p. 81). In order to account for this, Seyfeddinipur develops a particular method for describing gestural movement phases that allows for a detailed coding and annotation of different movement segments and gesture phases, and thus for close examination of speech and gesture in disfluencies.
This short discussion reveals that practices in coding and annotation, also with respect to gesture and cognition, vary greatly due to the vast range of possible research questions and the assumptions connected with them. A system that hopes to provide a perspective that bridges different interests on gesture and cognition is NEUROGES (Reference Lausberg and SloetjesLausberg & Sloetjes, 2009, Reference Lausberg and Sloetjes2015). It is a “research tool for the analysis of hand movement behavior, including gesture, self-touch, shifts, and actions” and assumes that “main kinetic and functional gesture categories are differentially associated with specific cognitive (spatial cognition, language, praxis), emotional, and interactive functions” (Reference Lausberg and SloetjesLausberg & Sloetjes, 2009, p. 1). The scheme implies that different gesture categories may be generated in different brain areas. NEUROGES is composed of three modules: (1) kinetic gesture coding, (2) bimanual relation coding, and (3) functional gesture coding. Module 1 refers to the kinetic features of a hand movement, that is, execution of movement versus no movement, trajectory and dynamics of movements, location of acting as well as contact with the body or not. Module 2 allows for the coding of bimanual relation (e.g. in touch vs. separate, symmetrical vs. complementary, independent vs. dominance). Module 3 brings in the functional aspects and determines the meaning of gestures based on a specific combination of kinetic features (hand shape, orientation, path of movement, effort, and others), which define the various gesture types. NEUROGES offers the option of analyzing gestures independently of speech, and “since it enables the investigation of processes that are not verbalized, its specific potential lies in the exploration of implicit cognitive, emotional, and interactive processes that may be conducted beyond awareness” (Reference Lausberg and SloetjesLausberg & Sloetjes, 2015, p. 2). NEUROGES also offers an ELAN template including controlled vocabularies and template files for statistical analysis, such as in SPSS.
The inclusion in NEUROGES of options for statistical analyses and, in particular, intercoder reliability, can be said to be a strong component in all systems addressing cognition, regardless of their particular research question. Reasons for including these features lie in the fact that studies on cognition usually follow a quantitative research perspective in an experimental setting. Categories for coding and annotation are thus normally designed as less variable and flexible and aim at the testing of given hypotheses using replicable methods and larger amounts of data. With these characteristics, the systems differ greatly from the majority discussed in Section 3.1 and, even more so, from the majority of those designed for exploring interaction, like those discussed in Section 3.4.
3.4 Gestures as Part of a Bodily Ensemble: Coding and Annotation for Exploring Interaction
Gestures, among other bodily movements, are one of the multimodal resources that speakers use in constructing and negotiating interaction. For an analysis of spoken language, approaches from an interactional and/or conversational point of view argue that their holistic and situated role in building human action has to be explained (Reference MondadaMondada, 2016) and that these resources need to be an integral part of the description of interactional practices (Reference Deppermann, Deppermann and ReinekeDeppermann, 2018). Thus, “the embodied way in which people communicate and gather together, as well as the ecology of the activities they engage in, and their material and spatial environment” (Reference MondadaMondada, 2016, p. 337) have to be made part of analyses. For this, actions have to be documented in their temporal and sequential order and the coparticipants’ orientation to these multimodal actions need to be captured. This “embodied turn” (Reference NevileNevile, 2015) in the study of human and social interaction results in theoretical and methodological challenges as to how to deal with the role of video material within such analysis. In general, two methodological lines may be distinguished on how this problem is solved.
On the one hand, some approaches follow a rather “classic,” qualitative conversational approach to the transcription and analysis and include video stills in the verbal transcript (Reference Stukenbrock, Birkner and StukenbrockStukenbrock, 2009). Transcripts contain the trajectories, temporal relations between speaking and other forms of visual communication, and qualities of the multiple resources from the perspective of the doers, meaning “all possibly relevant embodied actions, such as gesture, gaze, body posture, movements, etc. that happen simultaneously to talk or during moments of absence of talk” (Reference MondadaMondada, 2014, p. 1). Embodied actions are described briefly without focusing too much on their physical appearance, varying in the level of detailed description depending on the particular research question. An example illustrating this approach is found in a study on the arrival of guests at a dinner party. Here, Reference Oloff and SchmittOloff (2010) demonstrates how interactants orient themselves toward the sequentiality of the activity of waiting, and by doing so, jointly construct the beginning of the dinner. For the analysis, Reference Oloff and SchmittOloff (2010) concentrates on a precise transcription and coding of the sequentiality and temporality and short description of the bodily actions overlapping with speech (see e.g. “holds up hands,” “opens up bag,” “looks at watch”) and the spatial layout and arrangement of the room along with movements of interactants in space. Using this approach to annotation and coding, Reference Oloff and SchmittOloff (2010, p. 220) uncovers a particular temporal sequence of the individual phases of the activity of waiting and the bodily actions contained therein. In a similar yet slightly different vein, Reference SchmittSchmitt (2005) approaches the turn-taking mechanism from a multimodal perspective. The transcription follows the general principle of including bodily behavior in verbal transcripts by inserting still images. However, short descriptions of the gestures, for instance, are not included in the transcript. Rather, the still image is complemented by a short functional description in the analysis (see e.g. “She starts eye-contact with him, simultaneously lifts her left arm, stretches it completely and realizes a clear signal gesture with her arm and hand” [Reference SchmittSchmitt, 2005, p. 34], translation JB). Following this perspective, Schmitt illustrates that not only the turn and its construction are of interest to conversational analyses but so too is the status of the current speaker as an accomplishment of the other interactants.
On the other hand, studies may also follow a more “technical” way to exploring the body’s role in interaction. Often pursuing a combination of qualitative and quantitative designs, numerous studies include annotation programs for the coding and analysis of gestures. Video material thus assumes a specific role and is exploited differently in the transcription and annotation process than it was in the studies described above. Rather than concentrating on the whole temporal continuity of actions, these studies focus on particular facets of interaction and their relation with gestures and other bodily actions. Using data from head-mounted eye-trackers in a corpus of face-to-face conversations including various conditions, Reference Oben and BrôneOben and Brône (2015), for instance, explore whether gaze “fixations by speakers and fixations by interlocutors have [an effect] on subsequent gesture production by those interlocutors” (p. 546). Focusing on depictive gestures, the authors did not concentrate on a detailed description of the gestures, but rather measured how similar two gestures were to each other. In combination with the coding of regions of interest and fixation duration of the eye-gaze, the authors demonstrate that there is a “significant effect of interlocutor gaze, but not of speaker gaze on the amount of gestural alignment” (Reference Oben and BrôneOben & Brône, 2015, p. 546). Another example combining a corpus-based, bottom-up approach rooted in gesture studies and interactional linguistics exemplifying this second kind of approach is a study by Reference Debras and CienkiDebras and Cienki (2012). In order to account for “the possible functions of two types of gesture during stancetaking in the course of human-human interaction” (p. 932) (lateral head tilts and shoulder shrugs), the authors used a combination of coding and annotation in ELAN and Excel to retrieve the functions of the gestures during conversations. For this, the gestures were first described and annotated for their forms without listening to speech, and in a second step, coded in Excel in relation to verbal and other types of bodily behavior. Using this combination, that allows for a synergy of qualitative and quantitative perspectives, the authors demonstrate that “participants tend to use the two gestures in a similar way when positioning themselves with respect to a prior stance: either to affiliate with their conversation partner’s stance, or to disaffiliate with a third party’s positioning” (Reference Debras and CienkiDebras & Cienki, 2012, p. 937).
Whereas the “classical” approach to interaction analysis gives a more comprehensive understanding of the action of the interactants and of the interaction itself, the last two examples zoom in on particular gestural phenomena in relation to regulating and constructing interactional processes. Both examples therefore illustrate again the point repeatedly made throughout this chapter: Even though research interests may be similar, the methodological approaches and the perspectives taken may differ immensely and thus yield very diverse insights into, for example, interaction.
3.5 Making Gestures Reproducible: Coding and Annotation for Human–Machine Interaction
Other than in the examples given above, in which differences in the approach to coding and annotation are deeply rooted in theoretical assumptions, schemes and practices for coding and annotating human–machine interaction are guided first and foremost by technical requirements to make gestures reproducible. That is, these systems aim at reproducing the kinematics of human gestures along with the gestures’ relation to speech by “imitating” a human speaker’s gesture behavior (Reference Kim, Ha, Bien and ParkKim, Ha, Bien, & Park, 2012; Reference Kipp, Neff and AlbrechtKipp et al., 2007; Reference Theofilis, Nehaniv and DautenhahnTheofilis, Nehaniv, & Dautenhahn, 2014; see also the chapter by Jokinen, this volume). For achieving this, systems have to answer three main questions: (1) When do robots need to generate human-like behavior? (2) What human-like behavior needs to be generated? (3) How is it possible to generate human-like behavior (Reference Kim, Ha, Bien and ParkKim et al., 2012)? As a result, these systems face similar obstacles to the ones discussed in the sections above: Movement phases as well as form characteristics of the gestures need to be identified and coded, the types of gesture have to be accounted for, and of course speech and gestures need to be set in relation to each other. In a last step, these systems face a challenge that is not addressed in the ones discussed so far, namely the evaluation of the coding and annotation by recreating the human gestures; that is, the question of how well the annotation reflects the original gesture. How systems tackle those questions and challenges varies. Human gestures are either manually coded or captured by using motion capture data (for an overview see Reference Kim, Ha, Bien and ParkKim et al., 2012; Trujillo, this volume). Systems thereby concentrate on the hand shape of the gestures, their movement patterns, as well as their spatial arrangement along with their relation to speech (see e.g. Reference Kim, Ha, Bien and ParkKim et al., 2012; Reference Kipp, Neff and AlbrechtKipp et al., 2007; Reference Kopp and WachsmuthKopp & Wachsmuth, 2004; Reference MartellMartell, 2005). However, this approach is very time-consuming and a lot of the complexity, especially of the original movement, is lost. As a result, newer approaches to coding and annotation try to overcome this shortfall by making use of automatic gesture detection (see e.g. Reference Madeo, Lima and PeresMadeo, Lima, & Peres, 2017; Reference Spiro, Taylor, Williams and BreglerSpiro, Taylor, Williams, & Bregler, 2010; Reference Turchyn, Moreno, Cánovas, Steen, Turner, Valenzuela and RayTurchyn et al., 2018).Footnote 5 With these efforts, the systems not only wish to make generation of gestures more accurate for human–machine interaction but also aid gesture research in general by providing support for the coding and annotation of gestures.
4 Summary and Conclusion
The previous sections have shown that there are many different ways of approaching the coding and annotation of gestures, and that a theory-neutral analysis of gestures is not possible. Rather, theoretical assumptions influence the topics, aspects, and levels of analysis, and as such, make themselves visible in coding and annotation systems. Starting out with a discussion on the difference between coding and annotation, the chapter considered the various methodological and theoretical aims and challenges in gesture coding and annotation. In doing so, the chapter reviewed existing systems and practices and reflected on the interrelation between subject, research question, and coding and annotation system. By choosing exemplary research areas (language use, language development, cognition, interaction, and human–machine interaction), the chapter exemplified the different systems and practices by choosing studies and systems that illustrate the link between theory and method. Thereby it was pointed out that four main theoretical assumptions about the nature of gesture–speech relations lead to particular methodological and practical implications in the coding and annotation process, and thus influence the potential outcome of verbo-gestural analyses: (1) the relation between the verbal and gestural modalities, (2) facets and specifics of coding and annotation, (3) qualitative versus quantitative perspective, and (4) procedure. As a result, differences between systems addressing the same research topic (see e.g. language) as well as differences across research topics (see e.g. language vs. interaction) became visible, highlighting the close interrelation between theory and method.
The diversity of the systems and practices could be considered a hindrance in investigating gesture–speech relations because no uniform standard exists. At the same time, however, the spectrum of approaches and perspectives allows for a variety of descriptions that otherwise would be lost and maybe would even prevent insights into particular aspects of how speech and gestures work together in expressing meaning multimodally. Thus, researchers have to be aware of the advantages and challenges that come along with not having a theory of coding and annotating gestures, while at the same time welcoming the opportunities that the absence of a single, uniform system brings for investigating their particular research question.
Currently, as was briefly discussed in Section 3.5, a trend toward automated methods as an assistance to optimize effort and accuracy of manual coding can be noted. It remains to be seen what influence these procedures will have in the long run, both on the description of gestures with regard to the various research topics discussed in this chapter, and on the uniformity and standards of gesture coding and annotation systems.
1 Introduction
This chapter offers a toolbox of Methods for Gesture Analysis (MGA).Footnote 1 It addresses gesture analysis from the point of view of hand gestures and starts from an analysis of gestures as temporal forms. MGA tackles the multimodality of language use as a dynamic process that happens along different timescales. The methods were originally developed in the context of research on emerging protolinguistic structures in co-speech gestures (Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, Ladewig, & Müller, 2013; Reference Müller, Bressem, Ladewig, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfMüller, Bressem, & Ladewig, 2013; Reference Müller, Ladewig, Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfMüller, Ladewig, & Bressem, 2013). The present version of MGA differs from earlier publications (Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, 2013a, Reference Bressem2021) in offering sets of tools for gesture analysis that adapt flexibly to different research questions, that can be extended by future researchers, and that work with various analytical frameworks. In its present form, MGA encourages the researcher to look at gestures from various angles, against the backdrop of diverse frameworks, and to select the tools and theoretical approach that best fit the researcher’s specific interest.
Sections 1.1–1.2 offer an overview of MGA and sketch basic assumptions. Section 2 introduces an example analysis that serves as a point of reference throughout the chapter. In Section 3, variable tools for gesture form analysis are described, and Section 4 outlines different approaches to gesture context analysis.
1.1 Methods for Gesture Analysis: Overview
MGA distinguishes microlevel and macrolevel analysis. The baseline for MGA is a microanalysis that entails some account of the gesture as temporal form, and some analysis of how a gesture, a series of gestures, or a multimodal sequence is placed in an unfolding context-of-use (Figure 8.1).

Figure 8.1 Baseline of MGA: Microlevel analysis
MGA’s toolbox offers a flexible set of tools for descriptive analyses of hand gestures as temporal forms. Temporality is relevant to analysis on multiple scales: on the microlevel of a single gesture or gesture sequence and on the macrolevel of the unfolding of gesture(s) along the temporal dynamics of a discourse or conversational interaction (Figure 8.2).
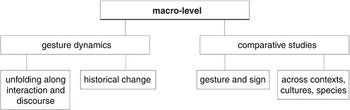
Figure 8.2 Different kinds of macrolevel analyses
Which collection of tools is selected depends upon the researcher’s interest and the theoretical framework adopted. The focus of this chapter lies at the microanalytic level. Microanalytic tools constitute the baseline for macrolevel analysis of gesture dynamics. While an introduction of macroanalytic procedures would extend the scope of this chapter beyond its limit, references below point to examples of macroanalytic studies.
Macrolevel analysis may address temporal dynamics of gesture use as it unfolds across a discourse event or conversational interaction or across historical time spans. Such studies may, for example, concern returns and extensions of gestures along an interactive setting, such as a dance class (Reference Müller and KappelhoffMüller & Kappelhoff, 2018; Reference Müller, Ladewig, Borkent, Dancygier and HinnellMüller & Ladewig, 2013); or the study of historical changes of gestures as processes of stabilizations on different timescales. Examples of macrolevel studies are investigations of recurrent gestures and emblems (Reference KendonKendon, 2004, Ch. 13; Reference Ladewig, Müller, Cienki, Fricke, Ladewig, McNeill and BressemLadewig, 2014, this volume; Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMüller, 2014b, Reference Müller2017a). Macroanalysis of gestures may furthermore contribute to comparative studies of gesture and sign (Reference KendonKendon, 2004, Ch. 15; Reference Kendon and Allen2015; Reference MüllerMüller, 2019a; Reference WilcoxWilcox, 2009; Reference Wilcox, Shaffer, Jarque, Segimon, Pizzuto and RossiniWilcox et al., 2000), of gestures across different cultures (Reference Bressem, Stein and WegenerBressem, Stein, & Wegener, 2017; Reference Bressem and WegenerBressem & Wegener, 2021; Reference KendonKendon, 1981; Reference Morris, Collett, Marsh and O’ShaughnessyMorris, Collett, Marsh, & O’Shaughnessy, 1979; Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMüller, 2014b) or across species (Reference Müller, Liebal, Müller and PikaMüller, 2007).
1.2 Methods for Gesture Analysis: Basic Assumptions
Essential starting points for MGA are an understanding of hand gestures as temporal forms embedded in a dynamically unfolding context; and an understanding of context that itself varies with the adopted framework. Depending on a given research question and its respective theoretical framework, procedures deemed relevant for a given study can be selected from the toolbox. MGA thus offers a flexible set of tools, designed to adjust to variable analytic perspectives and theoretical frameworks. Prerequisite for this flexibility are some basic assumptions concerning the nature and character of gestures outlined in this section.
(1) The term “gesture” refers to movements of the body that people use in conjunction with spoken and signed languages to talk about and act within their life-worlds. Gestures are used to articulate thoughts as much as feelings and they are vital in coordinating communicative actions in social interaction and in the flow of discourse.
(2) Articulatory gestures. MGA focuses on gestures as hand movements, but can serve as a starting point for the inclusion of other body parts. The focus on hand movements responds to the articulatory, enactive, and mimetic complexity of the hands, which are humans’ foremost tool to act upon the world (Reference StreeckStreeck, 2009, Ch. 3). It is not by accident that movements of the hands play a central role in signed languages. The articulatory freedom of the hand rests upon a physiological flexibility of the human hand that is an evolutionary achievement of highest importance to the development of human culture including language – in whatever modality expressed (Reference Corballis, Müller, Cienki., Fricke, Ladewig, McNeill and TeßendorfCorballis, 2013; Reference Leroi-GourhanLeroi-Gourhan, 1964/1993). The hands display a unique articulatory freedom and richness comparable only to the mouth as a tool and locus of fine articulatory movement; hence, the reason why some scholars speak of spoken language as articulatory gestures (Reference Armstrong, Stokoe and WilcoxArmstrong, Stokoe, & Wilcox, 1995).
(3) Gestures are temporal forms. As Kendon points out: “When a person speaks there is always some movement in the body besides the movements of the jaws and lips that are directly involved in speech production” (Reference Kendon and Ritchie KeyKendon, 1980, p. 207). He put forward a description of gestures as movements that unfold in time and whose movement phases typically go from preparation – to stroke – to retraction (Reference Kendon and Ritchie KeyKendon, 1980; Reference Kendon2004, Ch. 7). Conceiving of gestures as a temporal form has since become “common sense” in the field of gesture studies; advancements of the systematics include Reference Bressem and LadewigBressem and Ladewig (2011); Reference Kita, van Gijn, van der Hulst, Wachsmuth and FröhlichKita, van Gijn, and van der Hulst (1998). Starting the analysis of gestures from their temporal nature makes a lot of sense because the recognition of gesture boundaries (i.e. specifying where a gesture begins and where it ends) determines units of analysis in the first place: In quantitative studies, it enables reliable counting, and, in qualitative studies, it creates the object of analysis that then becomes subject to further descriptive (i.e. interactional, conceptual, semiotic, semantic, pragmatic, syntactic, etc.) analysis.
(4) Gestures are embedded in dynamic contexts-of-use. As temporal forms, hand gestures are integrated in the contexts in which they are used. No matter how the notion of context is conceived (cf. Section 4), they are temporally unfolding phenomena; in short, they are dynamic. MGA takes account of these temporal qualities: Note, however, that the separation of gestures as temporal forms from the temporal nature of contexts-of-use is purely an analytic one (Figure 8.1). Gesture, speech, and whole-body movements emerge as one multidimensional gestalt when a person is talking and engaging in an interaction. Gesture analysis decomposes an experiential unity. Coparticipants in a conversation perceive and experience gestures and speech as dynamic and multidimensional gestalts, just as film viewers see the acting of an actor, a landscape, or a race evolving in time as an orchestrated movement image (Reference MüllerMüller, 2019b; Reference Müller and KappelhoffMüller & Kappelhoff, 2018). The type of decomposition of this gestalt is a consequence of the analytical focus and theoretical approach adopted. It is important to note this because any analysis will at some point have to reflect on how the decomposed aspects of gesture forms and contexts relate to the multidimensional unity of experience that characterizes speaking, gesturing, and understanding.
(5) Why microanalysis of the form of gestures is necessary. Why not, if gestures are part and parcel of holistic gestalts, simply skip the laborious analyses of gestures as temporal forms? The answer is that not only does a close form analysis provide a solid ground for seeing gestures as immersed in multidimensional gestalts, but it also prevents researchers from reading meanings ‘into’ the gestures with no substantiation apart from intuition. For example, some analyses of multimodal constructions start from a linguistic form and look for co-occurring gestures without carrying out systematic analyses of the gestural form (Reference SchoonjansSchoonjans, 2018). Often, a gesture form analysis is deemed not necessary because the meaning of the gesture is treated as obvious. To highlight the potential relevance of a close gesture analysis, Reference Bressem and MüllerBressem and Müller (2017) have suggested a gesture-first approach to the analysis of multimodal constructions, that is, starting from recurring gesture forms to identify potential multimodal constructions (see also Reference Mittelberg, Gonzalez-Marquez, Mittelberg, Coulson and SpiveyMittelberg, 2007). However, no matter whether language-first or gesture-first, a close analysis of gesture forms is an essential baseline and provides firm grounds for the analysis.
(6) What is considered “context” for gesture analysis. In gesture studies, “context” or “context-of-use” is mostly used in a rather nonspecific way (exceptions are Reference Kendon, Duranti and GoodwinKendon, 1992; Reference StreeckStreeck, 2009). Moreover, often quite different understandings of context-of-use are implied when using terms such as “multimodality,” “multimodal communication,” “multimodal interaction,” “multimodal utterance,” and so on. The term “multimodality” covers a wide range of different theoretical frameworks with sometimes mutually exclusive concepts of gestures and their contexts. Against this backdrop, specifying the particular theoretical framework and its associated concept of “context” appears as a useful analytic step that directs the researcher’s attention to a critical reflection upon their research focus and the approach they have adopted.
In a nutshell. MGA as a toolkit enables the researcher to work out which kind of form analysis is appropriate and which understanding of context is relevant. It also encourages the researcher to step back and consider the theoretical approach adopted as one of several possible perspectives on gesture analysis.
2 Point of Reference: An Example
The toolbox for gesture analysis is illustrated throughout the rest of this chapter mainly with reference to the example of a story told as part of a conversation between two friends. Returning to this example over and over reveals how changing the analytic perspective and the according analytic tools uncovers different dimensions of gestures and the multimodal utterances they contribute to. It illustrates how there is no such thing as the one and only method of gesture analysis, and how the choice of tool depends upon the analytic perspective and theoretical framework adopted for gesture analysis.
The example comes from a conversation between a German speaker (Paul) and a Spanish speaker (Luis) (the names have been changed). Recorded in Berlin in the early 1990s, the conversation took place at a coffee table in a private apartment and was carried out in Spanish. Having lived for a long period of time in Spain, the German speaker was fluent in Spanish. The two young men knew each other quite well. No specifications concerning the topic of their conversation were given in advance. They were asked to simply chat about whatever they liked. Once the camera was started, they were left alone for 30 minutes.
Luis’ contribution to the discussion of Spanish politics is a family story that took place in 1980/81. A wood-carved portrait of the Spanish King Juan-Carlos hung on the wall in the apartment of Luis’ parents when his family lived in Venezuelan exile. The plot of the story is that this wooden portrait of the king fell off the wall, all by itself, a few days before an attempted coup d’état in Spain, as if foretelling the troubling event.
This first description of the gestural forms that Luis uses is not an interpretation of the gestural meaning in the context of the story. Rather, it offers a simple description of the movements, shapes, actions, and locations of his gestures. Gestures are numbered in Figure 8.3 in their order of use. With his first gesture G1, Luis loosely forms a roundish shape with a molding movement of his two hands. The round shape is vertically oriented and located in the center of the speaker’s gesture space. After a while, the speaker performs G2, positioned in the same location of the gesture space as G1 and also oriented vertically. It is thus spatially connected with G1. It differs from G1 in that it sketches an oval shape with a repeated outlining movement of the index fingers. A one-handed gesture G3 immediately follows G2, staying within the same place in the center of the gesture space and acting as if holding and placing a small object on top of the just outlined round object. G2 and G3 are thus connected spatially and temporally. A moment later in the story-telling, G4 follows. It differs from the first three gestures in that it is located at the left-hand side of the gesture space and, instead of molding or outlining a shape, something is represented by a flat left hand, held high up. Yet G4 still connects with the molding and the outlining gestures (G1 and G2) through the vertical orientation of the shape. G5 is then a quick downward movement of the loosely extended right hand, once again located in the center of the gesture space.
Figure 8.3 Gestures performed alongside the story-telling
A crucial analytical decision to be made is how to transcribe the spoken part of the gesture–speech ensemble. Why is this crucial? Because every notation is already an analysis. It highlights some aspects of the spoken utterances and backgrounds others (see Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, 2013b, this volume). The following extract (Figure 8.4: extract [1]) shows the story-telling between Luis (L) and Paul (P) transcribed and translated into English.

Figure 8.4 Extract 1: Transcription and translation
We now know that Luis’ gestures are part of a story about a family memory in which a portrait of the King plays a major role. Let us take a look at how the gestures deployed are integrated into the story and how, through their precise placement in relation to the spoken utterance, meaning can emerge from their contextual embedding (Figure 8.5: extract [2]). The extract is made as a combination of a simplified Reference McNeillMcNeill (1992) style of gesture annotation, which brackets the gesture phrase from preparation (P) to rest-position (rp) in the speech line, bold type indicating the stroke (S), (R) indicating the start of the recovery or retraction. Instead of short gesture form descriptions, drawings of the gesture strokes are placed above the bold type annotation.

Figure 8.5 Extract (2): Gestures with speech as multimodal temporal form
The round shape gesture (G1) occurs with a search for an appropriate term for the rather unusual portrait of the King (Figure 8.3, Figure 8.5: extract [2]) and accompanies the attribute of an unspoken noun (“a small ___”) and continues through a speech pause. With this placement, the gesture is likely to depict the topic of the story, some kind of round object. What then follows is a verbal description of the object in question: a picture of the King. The next gestures, G2 and G3, follow only in line 7, when a detailed description of the topic of the story that lacks an appropriate Spanish term is given: “with a round frame [G2’s outlining of an oval shape] and a small crown on top [G3’s holding and placing gesture].” Because of their temporal synchronization with this verbal description, the oval shape G2 comes to depict the picture frame, and G3 is seen as placing an imagined crown on top of the ephemeral frame. In line 9, finally, the story-telling moves on toward the plot: here the speaker enacts the spatial setting of the story: While the family was in the dining room, the wooden portrait was hanging in the living room (“she had it there in the other room”). G4 is temporally coordinated with the deictic “there” and only because of this temporal synchronization can the flat hand, held up at the upper edge of the gesture space, be seen as a representation of the wooden portrait of the King hanging in another room. G5 – a downward movement – is coordinated with “fell down” and thus depicts how the portrait fell down from the wall.
Our first encounter with this example shows how, out of the six gestures performed in close succession and integrated with the narrative, five relate to the most important object in the story: the carved portrait of the King. Their formal difference and their subtle integration with speech indicate how meaning emerges from the temporal coordination of gestures with speech: The story-telling is multimodal and temporal. As we proceed, the example will be used to illustrate how different foci of form analysis and different theoretical frameworks may uncover further aspects of the multimodal story-telling.
3 Gesture Form Analysis
In this section, microanalytic tools for gesture form analysis are introduced. The tools address the complexity of gesture forms and assume that even minor changes in gestural forms might be significant in terms of what is being depicted or expressed. When somebody is gesturally depicting how to open a window, it is crucial to recognize which hand shape is used and which direction the hand is turned; when somebody molds or outlines a shape of a picture frame, the ephemeral forms depicted vary in accuracy of shape depiction; when somebody sketches a shape with a delicate or a harsh movement quality, the expressive quality of the gestural movement varies; and when gestures become conventionalized, holistic gestalts may decompose and hybrids of stabilized and idiosyncratic gestural forms emerge (Reference MüllerMüller, 2017a).
Four tools are presented (Figure 8.6), of which the first is indispensable and the others optional: the first one identifies the unit of analysis as a temporal form. The choice of the other three types of tools depends upon one’s research interest and the theoretical framework adopted. Tool (1) determines gesture boundaries and their phase structure, that is, where a gesture begins, where it ends, and whether it is a single gesture or a sequence of gestures. Tool (2) offers a form-based two-way distinction between types of gestures. Tool (3) analyzes depictive and pragmatic gestures in terms of as-if actions. Tool (4) includes three subtools to analyze hands as movement: aspects of kinesic form, gestures as motion events, and gestures as expressive movement.
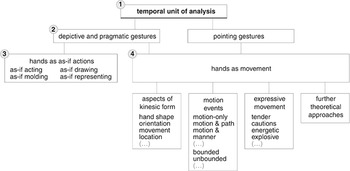
Figure 8.6 Set of tools for gesture form analysis
Combining the microanalytic tools for gesture form analysis allows variable degrees of detail. Which ones to choose and which degree of fine-grained analysis is appropriate depends upon one’s framework of research; an essential element of the research design. Let us return to Luis’ story to illustrate how these different tools may be applied.
3.1 Establishing the Temporal Unit of Analysis
The first tool concerns gesture boundaries, for example, it addresses the establishment of units of analysis. Deciding where a gesture begins and ends may, at first sight, seem obvious. Consider, for example, the “round shape gesture” (G1), from Luis’ story. Here the boundaries of the gesture are clear-cut: the gestural movement unfolds from a rest position, where both hands are resting on the speaker’s lap, moves upward in a preparation phase, performs a stroke (e.g. the molding round shape movement) and then, with a phase of retraction, returns back to the rest position on his lap (Figure 8.7).
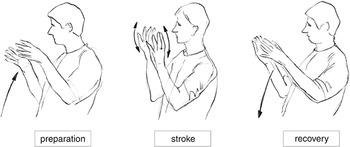
Figure 8.7 G1 as temporal unit
However, even with this apparently simple temporal gestural movement, questions arise as to what is included and excluded. In Kendon’s influential systematics of “gesture units, gesture phrases and the phases of gestural action” (Reference KendonKendon, 2004, p. 111), the temporal unit that is considered as the gesture would only comprise part of the movement described above (G1). In McNeill’s notation system, applied in extract (2) (Figure 8.5), the temporal unit would include the return to rest position. Kendon makes a distinction between gesture phase (preparation, stroke, recovery), gesture phrase, and gesture unit. A Kendonian gesture phrase is defined as preparation plus stroke (including poststroke holds) and does not include the phase of recovery and return to rest position (Reference KendonKendon, 2004, p. 112). Gesture units may thus contain sequences of gestures (e.g. gesture phrases). Figure 8.8 shows a gesture unit as a sequence of two gesture phrases: a succession of outlining (G2) and placing (G3) movements from the story-telling.
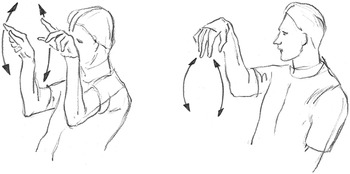
Figure 8.8 A Kendonian gesture unit with two gesture phrases
Between outlining a round frame (G2) and placing a crown on top (G3), one hand returns to rest position. The right hand stays up and moves directly to the position in the gesture space where the stroke (e.g. the placing movement) is made. After that, the right hand returns to rest position too. In Reference KendonKendon’s (2004, p. 112) terms, the gesture unit thus entails two gesture phrases (G2) and (G3), each characterized by a succession of preparation (hand moves into the gesture space) and stroke phase (the phase where the movement reaches its apex and is most clearly articulated, in terms of effort and shape). The concepts of effort and shape are taken from Laban Movement Analysis (Reference Bartenieff and LewisBartenieff & Lewis, 1980; Reference Kennedy, Müller, Cienki., Fricke, Ladewig, McNeill and TeßendorfKennedy, 2013). Applying the tool “establishing the temporal unit of analysis” reveals the internal linear complexity of gestures as temporal forms, which is central to the coordination of gesture and speech.
3.2 Distinguishing Pointing from Depictive and Pragmatic Gestures
For an analysis of different kinds of gestures, different analytic tools might become relevant. Therefore, a basic two-way distinction is made between pointing versus depictive and pragmatic gestures. This distinction refers to level 2 in Figure 8.6.
What motivates the distinction between pointing and other gestures in the first place? Without going into the details of gesture classification systems, it can be seen that a distinction between pointing (or deictics as per Reference EfronEfron, 1941/1972; Reference Fricke, Müller, Cienki, Fricke, Ladewig, McNeill and BressemFricke, 2014, this volume; Reference McNeillMcNeill, 1992, p. 18) and other kinds of gestures appears to be widely accepted in gesture studies. Overviews and discussions of gesture classifications have been offered by several researchers (Reference AndrénAndrén, 2010, pp. 96–105; Reference FrickeFricke, 2007, pp. 156–181; Reference GullbergGullberg, 1998, pp. 47–51; Reference KendonKendon, 2004, Ch. 2; Reference McNeillMcNeill, 1992, Ch. 3; Reference MüllerMüller, 1998b, pp. 91–113). The distinction between depictive and pragmatic gestures is informed by Reference KendonKendon (2004), although “depictive gestures” is used in MGA instead of his “representational gestures” (Reference KendonKendon, 2004, p. 160; Reference StreeckStreeck, 2009, Ch. 6). The term “pragmatic gestures” is used in Reference KendonKendon’s (2004, pp. 158–159) sense. The distinction between depictive and pragmatic gestures is basic because it reflects two essentials of language: reference to the world talked about and communicative action. In using one or the other type of gesture, interactive attention is drawn either to communicative action or to depiction (this holds, notwithstanding that every depiction implies acting communicatively) (Reference MüllerMüller, 2015).
Note that in the McNeillian tradition, depictive gestures are called “iconics.” “Metaphorics” in the McNeillian tradition are depictive gestures used metaphorically as well as pragmatic gestures. Other classifications, however, suggest a further distinction between gestures used to depict some abstract concept and gestures used with a pragmatic function. With respect to depictive gestures used metaphorically, Reference EfronEfron (1941/1972) speaks of ideographic, Reference MüllerMüller (1998b) of abstract referential, Cienki and Reference MüllerMüller (2008a, Reference Cienki, Müller and Gibbs2008b) of metaphoric, and Reference StreeckStreeck (2009, Ch. 7) of ceiving gestures. When describing pragmatic gestures in Kendon’s sense, by contrast, Reference StreeckStreeck (2009, Ch. 8) speaks of speech-handling, and Reference MüllerMüller (1998b) of performative and discursive gestures.
Distinguishing pointing from other kinds of gestures reflects a fundamental semiotic distinction. While pointing gestures are primarily based on indexicality, for other gestures, iconicity plays an important role; although they typically also involve indexical elements (see Fricke, this volume). Mittelberg’s work on the entanglement of metonymic (as indexical) and metaphoric (as iconic) elements of gesture forms disentangles this complexity both theoretically and as a way to approach gesture form analysis (Reference MittelbergMittelberg, 2019b). In semiotic theory, indexicality and iconicity are complex and widely debated issues and are highly relevant to gesture analysis (cf. Reference FrickeFricke, 2007; Reference Mittelberg, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMittelberg, 2014).
Distinguishing pointing gestures from depictive and pragmatic ones responds to differences in kinesic form and in embodied motivation. Only depictive and pragmatic gestures can be accounted for as as-if actions, that is, in terms of their embodied motivation.
The form-based distinction of pointing as opposed to depictive and pragmatic gestures rests upon characteristics of hand shape and movement. Typical pointing hand shapes are the extended index finger, the palm lateral hand, pointing with the little finger, or pointing with the lips (Reference FrickeFricke, 2007; Reference KendonKendon, 2004, pp. 199–200; Reference KitaKita, 2003; Reference SherzerSherzer, 1973). Reference KendonKendon (2004, p. 200) describes how pointing gestures tend to show a characteristic movement pattern “in which the body part carrying out the pointing is moved in a well-defined path, and the dynamics of the movement are such that at least the final path of the movement is linear. Commonly, but not always, once the body part doing the pointing reaches its furthest extent, it is then held in position briefly.” Sometimes, however, pointing may only involve extending the index finger fully. In short, distinguishing pointing from depictive and pragmatic gestures guides further analytic procedures.
While all gestures can be analyzed with regard to aspects of their kinesic form (cf. Section 3.4.1), depictive as well as pragmatic gestures are special in that they are enactments of different kinds of as-if actions (cf. Section 3.3). Attempting to reconstruct which as-if action is performed with a given gesture offers a path not only to the semiotic grounding of the gesture but to an experiential base of the intersubjectivity of embodied understanding (Reference Müller, Zlatev, Sonesson and KonderakMüller, 2016, Reference Müller2019b).
Considering the example above, Luis uses no pointing gestures in his story-telling. In the following, the six gestures he uses illustrate how the different tools for gesture analysis reveal diverse aspects of gestural movements for depictive gestures.
3.3 Analyzing Depictive and Pragmatic Gestures as As-If Actions
This set of tools for gesture form analysis addresses level 3 in Figure 8.6. It concerns the gesturing hands as as-if actions. Experience has shown that the set of tools figuring under the rubric of “Gestures as As-If Actions” offers an excellent starting point for analyzing depictive as well as pragmatic gestures. Often this works best when turning off the sound and trying to answer the question: What kind of as-if action is the gesture carrying out?
The MGA toolbox distinguishes four basic kinds of as-if actions that are applicable to reconstruct a heuristic of the experiential base of depictive and pragmatic gestures: The hands act as if performing a practical action with or without an imagined object, the hands act as if molding an ephemeral object, the hands act as if drawing the shape of an object or the line of a path, the hands act as if they were an object (Figure 8.9).

In Luis’ narration all four are applied: In G1 the speaker acts as if molding an ephemeral round object, in G2 he acts as if drawing a round shape, in G3 he acts as if placing a small object on top of the ephemeral round shape just outlined, in G4 he acts as if his flat hands were some flat object located vertically at the edge of the gesture space, in G5 he acts as-if the hand were some object falling down quickly.
These four different as-if actions involve different kinds of bodily experiences: acting, molding, and drawing are based on haptic manual experiences, and often involve imagined objects; in contrast, when the hands are used as if they were an object, this transformation more likely involves visual perception. We can only mention in passing that these different embodied motivations involve different conceptual viewpoints (Reference Dancygier and SweetserDancygier & Sweetser, 2012; Reference McNeillMcNeill, 1992; Reference Parrill, Lavanty, Bennett and KlcoParrill, Lavanty, Bennett, Klco, & Demir-Lira, 2018; Reference Stec, Sweetser, Dancygier, Wei-Iun and VerhagenStec & Sweetser, 2016). Acting as-if involves a character viewpoint, whereas molding and drawing may imply a character or an observer viewpoint, depending on the focus of the action or the depicted object. Hands representing an object typically involve the perspective of an observer (Reference Bressem, Ladewig, Müller, Hübl and SteinbachBressem, Ladewig, & Müller, 2018). Note that, in most cases, the characterization of an experiential base will be a heuristic assumption, but, if longer segments of talk are considered, the analyst may be able to observe how gestures emerge from practical actions through abstraction and schematization over the course of communicative interactions.
To analyze gestures in terms of as-if actions addresses the iconicity of gestural form in depictive and pragmatic gestures in terms of their embodied motivation. This perspective on gesture form analysis connects with a theoretical perspective that grounds intersubjectivity of understanding (Cuffari, this volume) in the embodied perception of the moving body (Reference MüllerMüller, 2019b). I have discussed this aspect of gesture form analysis in publications over the past two decades under different labels: iconicity (Reference Müller and SantiMüller, 1998a), modes of representation (Reference MüllerMüller, 1998b, Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and Bressem2014a, Reference Müller2017a), and modes of mimesis (Reference Müller, Koch, Voss and VöhlerMüller, 2010, Reference Müller, Zlatev, Sonesson and Konderak2016). The different terms reflect different perspectives on the nature of as-if actions and their grounding of gestural meaning in different kinds of common manual actions.
Approaching the iconicity of gestures resonates with reflections on iconicity of signs in Sign Language Linguistics (Reference Mandel and FriedmanMandel, 1977; Reference TaubTaub, 2001) and with proposals of signed language classifiers (Reference Müller and MalmkjaerMüller, 2009). In gesture studies it connects with Kendon’s discussion of gesture and sign (Reference KendonKendon, 2004, Ch. 15), with Mittelberg’s cognitive-semiotic approach to gesture form (Reference MittelbergMittelberg, 2019a, Reference Mittelberg2019b) and with Reference ZlatevZlatev’s (2014a, Reference Zlatev2014b) work on mimesis, among other things.
Conceiving of gesture forms as as-if actions draws analytic attention to the fact that both depictive and pragmatic gestures operate upon the mode of “as-if.” What is so special about the mode of “as-if?” Instead of performing the action of opening a window, speakers act as if their hands opened a window. The window handle is an imagined handle; the hand shape and movement mime the actual action. Instead of performing the action of physically showing some object on the open hand, speakers act as if some argument were displayed on their open hand. This transformation from object manipulation to acting as if and upon virtual objects characterizes depictive as well as pragmatic gestures. It makes them suitable forms to communicate in the absence of things, actions, and events being talked about.
Some scholars describe pragmatic gestures as “metaphoric” (Reference McNeillMcNeill, 1992) or “speech-handling” (Reference StreeckStreeck, 2009). This terminology risks masking the fact that both depictive and pragmatic gestures are as-if actions (Reference Cienki, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemCienki & Müller, 2014). Both act upon virtual objects and both are recognizable as as-if action through their abstracted and abbreviated performance of a manual action. Moreover, as we know from metaphor research, gestures are frequently used to depict abstract concepts. Accordingly, the term “metaphoric gesture” is reserved here/in MGA for depictive gestures used to express the bodily base of abstract concepts (Cienki & Reference MüllerMüller, 2008a; Reference MüllerMüller, 2008). Consider the following example: In an interview, former US president Obama characterizes the story of America as a kind of “battle” between different ideas of democracy and while saying this he moves his hands and arms as if boxing. His gesture thus depicts the abstract concept of “battle” in terms of a boxing match. Such subjective bodily imaginations are considered here as a bodily base of an abstract concept: Here the gesture metaphorically depicts a political battle as boxing.
When considering pragmatic gestures more closely, we see that it makes sense to conceive of them as as-if actions. Often, experiential roots in practical actions of the hands are quite obvious. Streeck, for example, describes speech-handling gestures as as-if actions (Reference StreeckStreeck, 2009, Ch. 8), where the hands act as if manipulating some imagined object and function as handing over the speech to the next speaker. Pragmatic gestures thus present communicative actions as if they were actions operating upon imagined objects. Examples are the palm-up-open hand (e.g. presenting something as obvious, by acting as if some abstract object sat on the open palm, visible to everybody; cf. Reference Müller, Müller and PosnerMüller, 2004) and the family of “throwing away” gestures (e.g. a dismissive movement of the hand, acting as if throwing away some middle-sized object; cf. Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014a, Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and Bressem2014b; Reference MüllerMüller, 2017a; Reference Teßendorf, Müller, Cienki, Fricke, Ladewig, McNeill and BressemTeßendorf, 2013).
To recap: regarding gestures as as-if actions applies to depictive and pragmatic gestures. While they share the mode of as-if, they differ regarding their communicative function: Depictive gestures embody what is talked about, pragmatic gestures incorporate and perform communicative action.
3.4 Analyzing Hand Gestures as Movement
Analyzing gesture forms as movement concerns depictive, pragmatic, and pointing gestures as well. It addresses the fact that, no matter what, hand gestures are movements of the body. To analyze hand gestures as movement presupposes, however, a specific understanding of body movement. Therefore, the toolbox of MGA offers three different conceptions of accounting for the hands as body movements: kinesic form, motion events, and expressive movement. The three perspectives capture different facets of the gestural movement and are not mutually exclusive in the analytic process. Importantly, the selection is not deemed exhaustive. It complements approaches such as Boutet’s kinesiology of gesture and sign (Boutet, this volume; Reference Boutet, Morgenstern and CienkiBoutet, Morgenstern, & Cienki, 2016, Reference Boutet, Morgenstern, Cienki, Cienki and Iriskhanova2018) and may be supplemented further. This set of tools for gesture form analysis targets level 4 in Figure 8.6.
3.4.1 Kinesic Aspects of Gesture Form
We distinguish four aspects of kinesic form that are simultaneously articulated: hand shape, orientation, movement, and location (level 4 in Figure 8.6, Figure 8.10). Accounting for these aspects of kinesic form targets a level of gesture analysis that is comparable to proposals for the description of sign language phonology. It is inspired by observations concerning sublexical structures of signs (Reference StokoeStokoe, 1960; Reference Wilcox and OcchinoWilcox & Occhino, 2016, p. 4). We know from signed languages how important even minor changes of one of these articulatory characteristics for the meaning and function of a sign may be. But how does this apply to gesture analysis?
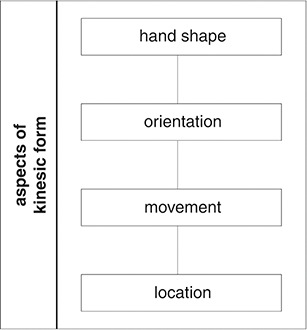
Figure 8.10 Aspects of kinesic form that are simultaneously articulated
Let us reconsider the gestures used in Luis’ story-telling. Quite clearly, the speaker does not draw upon a lexicon of gesture “lexemes.” For example, five of the gestures show an interesting difference with regard to the location, that is, where in the gesture space (Reference FrickeFricke, 2007; Reference McNeillMcNeill, 1992) they are performed. While most gestures (G1, G2, G3, G5) are located in front of the speaker’s body, G4 is performed at the far upper left periphery of the gesture space. This is interesting and may trigger further research questions concerning how the body space is used in gesturing. In this example, it is clear that there is a difference between a semantically relevant location of gestures and a neutral gesture space. While the periphery of the gesture space evokes the actual location of the picture in another room and is thus part of a narrative space, the placement of the other three gestures is not part of the narrative space: For example, the picture in the story was not located in front of the speaker’s chest nor did it fall down in front of his body. Instead, the space is used as a kind of neutral space to depict the shape and falling-down of the picture.
The set of tools marked as “Aspects of kinesic form” may thus become relevant to the analysis of gestures created on the spot (singular gestures) but it applies also to more or less stabilized gestural forms (recurrent and emblematic gestures; cf. Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, 2013a; Ladewig, this volume; Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMüller, 2014b, Reference Müller2017a). Applying these tools to gesture analysis opens up pathways for a comparative analysis of co-speech gestures, cosign gestures, and historical changes in conventionalized gestures and signs (Reference MüllerMüller, 2019a).
3.4.2 Gesture Form in Terms of Motion Events
This perspective addresses gesture form as a bodily conceptualization of motion in a cognitive linguistic sense (see 4.1 below). There is quite a body of research that shows how gestures contribute to multimodal expression of lexicalized motion events (Reference Talmy and ShopenTalmy, 1985, Reference Talmy1991). Talmy’s typological analysis of lexicalization patterns of motion verbs as conceptual structures, and the motion event as a conceptual structure, inspired a large body of cross-linguistic investigations including on gestural expressions of motion events (Reference DuncanDuncan, 2002, Reference Duncan2006; Reference KitaKita, 1997; Reference MüllerMüller, 1998b, Reference Müller2015; Reference Özyürek, Kita, Hahn and StonessÖzyürek & Kita, 1999; Reference Özyürek, Kita, Allen, Brown, Furman and IshizukaÖzyürek et al., 2008). The basic idea is that languages differ typologically in how they lexicalize motion-event structure. For example, German and Spanish differ in where they lexicalize the path of a motion event: in a satellite of the verb (such as a prepositional phrase) or the verb itself, respectively. Kita’s work on Japanese and English use of gestures in motion-event description revealed that gesture usage may reflect those kinds of typological differences. This observation inspired a large body of comparative motion-event based research on gesture and speech, contributing to researching linguistic relativity; the question of linguistic worldviews and their impact on thinking while speaking (Reference Slobin, Levinson and GumperzSlobin, 1996).
Conceiving of gestures as expressing aspects of motion event as a conceptual structure – for example, as bodily performance of lexicalized motion events – may be systematized as follows (Reference MüllerMüller, 1998b). Hand-gestures may enact motion only, for example, when somebody talks about “going to New York” and performs a lax movement with a loose hand. Or they may express motion and path of motion, as when a hand moves down and up to describe the motion and path of somebody going down into a subway station and back up onto the street. Gestures may also express motion and manner of motion, as when somebody moves rotating hands forward to depict how a ball rolls down a street. In Luis’ story, G5 – the gesture that is used to depict the falling-down of the picture – is a gesture that contributes to such a multimodal expression of a motion event: The stroke coincides with the motion verb se cayó (“it fell”), depicting motion and a downward path of the lexicalized motion event.
A further, quite basic, dimension of gestural expressions of motion events is that every gestural movement is a motion event in itself. As such, every gestural performance is either a bounded or unbounded movement. In the example above, a clear case of a gestural expression of a bounded motion event is G5. The movement accelerates and has an accentuated endpoint. (For an elaborate kinesiological framework to gestures as movements of the body, see Reference BoutetBoutet, 2001, Reference Boutet2010; Boutet & Cienki, this volume; Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018.) This characteristic of gestures as body movements may play out in the embodied conceptualization of (lexical and grammatical) aspects as bounded or unbounded event structures (Reference MüllerMüller, 1998b, pp. 158–167). Further views on this matter are offered by Reference DuncanDuncan (2002) and Reference Parrill, Bergen and LichtensteinParrill, Bergen, and Lichtenstein (2013). In a comparative study of French, German, and Russian, this was applied to the multimodal expressions of aspect (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018). In this case, a particularly clear correlation between the grammatical distinction of perfective and imperfective events and the bounded and unbounded performance of coarticulated gestures was found in French speakers.
Summing up, the tools for motion event analysis described above rest upon a cognitive-semantic understanding of language use and offer the possibility for semantic cross-linguistic studies of multimodal language use.
3.4.3 Gesture Form in Terms of Expressive Movement
Analyzing gestures as expressive movements takes account of the affective quality of body movements. As Bühler pointed out in his theory of expression almost a century ago, whenever someone makes a gesture, they perform it with a certain quality of movement: A speaker may outline a picture frame with a sloppy, tender, cautious, energetic, harsh, or explosive quality of movement (Reference BühlerBühler, 1933; Reference MüllerMüller, 1998b, Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and Teßendorf2013), as we see with Luis’ sequence of gestures: The molding round shape gesture G1 is made with a sloppy and lax movement quality, while the outlining round shape gesture G2 is carried out with great care and precision. It is possible then to describe the affective unfolding of multimodal discourse events as an intercorporeal, interaffective process of felt understanding between coparticipants in an interaction (Reference Horst, Boll, Schmitt, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemHorst et al., 2014).
This set of tools rests upon an experiential understanding of gesture usage and conceives of multimodal utterances as multidimensional experiential gestalts whose meanings emerge in a process of embodied perception (Reference Müller and KappelhoffMüller & Kappelhoff, 2018, Ch. 2). Conceiving of gestures as expressive movements implies felt understanding and addresses a quality that gesture and multimodal interaction share with film images, one in which gestures and film images are not seen as sequences of static images but as movement images or as movement gestalts (Reference MüllerMüller, 2019b; Reference Müller and KappelhoffMüller & Kappelhoff, 2018, Ch. 9). These movement images emerge in the perception of the viewers as an embodied experience of time, or as time-images (Reference DeleuzeDeleuze, 2008a, Reference Deleuze2008b; Reference Eisenstein and TaylorEisenstein, 1924/1998; Reference Plessner, Dux, Marquard and StrökerPlessner, 1925/1982). As such, they constitute felt intersubjectivity (Reference Horst, Boll, Schmitt, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemHorst, Boll, Schmitt, & Müller, 2014; Reference Kappelhoff, Curtis, Koch and SiegelKappelhoff, 2013, Reference Kappelhoff, Campe and Weber2014; Reference Kappelhoff and MüllerKappelhoff & Müller, 2011; Reference MüllerMüller, 2019b; Reference Müller and KappelhoffMüller & Kappelhoff, 2018, Ch. 9). Analyzing gesture forms as expressive movement is not restricted to one single gesture; rather, it may entail gesture units of variable complexity (Reference Müller and KappelhoffMüller & Kappelhoff, 2018, Ch. 2).
Tools for describing gestures as expressive movements thus open up a perspective on gestures as movement images and on multimodal utterances as multidimensional experiential gestalts. They allow for studying the affective qualities of gestures and for reconstructing processes of meaning-making as dynamic intercorporeal processes of feeling and perceiving (Reference MüllerMüller, 2019b).
3.5 Summary
The set of tools offered as methods for gesture form analysis addresses four basic aspects of gestural forms (Figure 8.6): (1) the boundaries of gestures as temporal forms, (2) a distinction of pointing from depictive and pragmatic gestures based on hand shape and movement, (3) the embodied motivation of depictive and pragmatic gestures as “as-if” actions, and (4) three possibilities to approach hands as body movement, that is, aspects of kinesic form, hand gestures as motion events, and hand gestures as expressive movements.
Note that the decision as to which aspects of gestural forms are deemed relevant for a given analysis of gestural forms depends upon the research question and the theoretical framework against which it has been formulated. Depending upon the research question, the analytic process might start from a gesture form analysis without sound (Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem’s 2013a and Reference Bressem2021 work on repetition are examples of this procedure) and only include speech analysis in a second analytic step. Another option is to start with gesture analysis and then move back and forth between a close analysis of the gesture forms and their embedding in contexts-of-use: Examples of this type of procedure are what Reference Bressem and MüllerBressem and Müller (2017) termed “gesture-first analysis of multimodal constructions,” or the analysis of multimodal metaphors (their dynamics and foregrounding, cf. Reference MüllerMüller, 2008; Reference Müller and TagMüller & Tag, 2010). Section 4 illustrates how the theoretical frameworks chosen influence the interpretation of gestural forms as contributions to multimodal utterances.
4 Context Analysis: Gestures in Multimodal Utterances
In this section, the second basic set of tools of MGA is introduced. Although in gesture studies the concept of “context” and the formula “context-of-use” are often used in a rather nonspecific way, it is nevertheless crucial in the analytic process to be explicit about one’s particular understanding of context and to reflect how this relates to the research focus one adopts and its theoretical framework.
Context analysis as an analytic step addresses the linkage of gesture forms with spoken utterances. The specific temporal relation of a gesture form with its context is vital to address “how gestures mean.” It is the synchronization of gestural forms with the flow of speech that is essential to disambiguate and specify the local meaning of gestures. Molding a round shape can be used to express all kinds of round objects, concepts, or even actions, and can take over different communicative functions depending on how the gesture is coordinated with the verbal part of a multimodal utterance. It is an essential of the analytic process of MGA to be explicit about the notion of the context applied and the theoretical framework adopted. To illustrate this essential relation between context-of-use and the meaning and functions of gestures, six possible ways of approaching context analysis are outlined (Figure 8.11). Box 7 indicates that further theoretical approaches to context analysis are possible.
Figure 8.11 Possible frameworks for context-analysis
The selection presented in this section is not exhaustive but describes the more frequent approaches to context in the current field of gesture studies. Each of these types of context analysis is described briefly, with reference whenever possible to Luis’ story (for context analysis as specific methodology, see Reference StreeckStreeck, 2009, Ch. 2).
4.1 Cognitive Linguistics: Context as Usage-Based Grammar and Semantics
A cognitive-linguistic analysis leads to context being considered from the point of usage-based grammar and cognitive semantics (Reference BybeeBybee, 2010; Reference Cienki, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfCienki, 2013, Reference Cienki2017; Reference Croft and CruseCroft & Cruse, 2004; Reference FillmoreFillmore, 1985; Reference LangackerLangacker, 2008). Here, the notion of context may refer to specific semantic contexts such as lexicalization patterns of motion events (Reference Talmy and ShopenTalmy, 1985, Reference Talmy1991) but may also address questions of viewpoint (Reference Dancygier and SweetserDancygier & Sweetser, 2012), conceptual blending (Reference Parrill and SweetserParrill & Sweetser, 2004), or metaphor and thought (Reference MüllerCienki & Müller, 2008b). Furthermore, protoforms of grammaticalization in gesture have been subject to a cognitive linguistic interpretation of context-of-use (Reference BressemBressem, 2021; Reference Ladewig, Müller, Cienki, Fricke, Ladewig, McNeill and BressemLadewig, 2014; Reference Müller, Müller and PosnerMüller, 2004, Reference Müller2017a; Reference Müller, Ladewig, Borkent, Dancygier and HinnellMüller & Ladewig, 2013; Reference Müller, Ladewig, Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfMüller et al., 2013), as has the gestural expression of aspectuality in terms of event structure (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018). Context-of-use in cognitive linguistic terms could also include the grammatical integration of gestures in multimodal utterances (Reference LadewigLadewig, 2020). For a cognitive-semiotic framework for gesture analysis within a larger cognitive-linguistic usage-based approach to context, see Mittelberg’s work (Reference MittelbergMittelberg, 2017, Reference Mittelberg2019a, Reference Mittelberg2019b), or, taking a slightly different angle, Reference AndrénAndrén’s (2010) developmental study.
In the analysis of “hand gestures as movements” (Section 3.4.2), the motio-event perspective is formulated within a cognitive semantic framework (Reference Talmy and ShopenTalmy, 1985). The relevant “context” for gesture analysis is here a typological analysis of lexicalization patterns apparent in the motion verbs that are coarticulated with gestural expressions of motion events. This would lead to seeing Luis’ falling-down gesture G5, which is temporally synchronized with the motion verb se cayó, as expressing a path (downward). Analyzed with a cognitive semantic understanding of “context,” the gesture would be analyzed as following the specific lexicalization pattern of Spanish motion verbs which merge motion and path.
Another potentially relevant context within a cognitive-linguistic framework would consider the grammatical notion of “aspect” as a conceptualization of an event-structure that distinguishes bounded from unbounded, or perfective from imperfective, events. Luis’ gesture G5 would then be considered as a case of a bounded gesture. The analytic focus for the gestural movement would be its marked endpoint. When “aspectuality” is taken as the relevant usage-context for gesture analysis, a given gestural movement can have various functions at the same time. It can express a downward path and at the same time be performed in a bounded or unbounded manner.
These examples illustrate that form and context-analysis merge and are informed by the specific theoretical frameworks chosen; here, Talmy’s cognitive-semantic typology (Reference Talmy and ShopenTalmy, 1985) and a cognitive-linguistic understanding of aspectuality (Reference Cienki and IriskhanovaCienki & Iriskhanova, 2018).
4.2 Conversation Analysis: Context as Social Action
Considering gesture form analysis from the point of view of conversation analysis implies an understanding of context as social (inter)action. It highlights the temporal character of gestures as parts and parcels of sequentially structured interactive processes of conversations’ social organization (Reference Mondada, Müller, Cienki., Fricke, Ladewig, McNeill and TeßendorfMondada, 2013a, Reference Mondada, Müller, Cienki., Fricke, Ladewig, McNeill and Teßendorf2013b). It reveals how gestures participate in the taking of turns (Reference BohleBohle, 2007; Reference SchmittSchmitt, 2005) in cooperative actions (Reference GoodwinGoodwin, 2018) and shows how they contribute in a wide range of embodied communicative activities (Reference StreeckStreeck, 2009, Reference Streeck2017). Connecting gesture form analysis with conversation analytic perspectives may help to answer questions such as: Why does the speaker use the gesture “tracing a round frame” to depict this object at that very moment in the conversation? Why doesn’t he simply present the object on his open hand or not use a gesture at all, given that he provides similar “information” verbally: “a round frame”?
Considering the structure of turn-taking as a social activity, we see that both gestures (G2, G3) are coordinated with the core piece of the conversational turn: the turn-constructional component (Reference Sacks, Schegloff and JeffersonSacks, Schegloff, & Jefferson, 1974). Positioned at another site in the conversational sequence, they could function as turn-entry or turn-exit devices. At the beginning of the speaker’s turn, they would indicate the wish to become the next speaker; at the end of the turn, they would complete the turn, for instance, by filling up a speech-pause. If they were placed in the transition space between two conversational turns, they could indicate the wish to maintain the right for the succeeding turn. Furthermore, the fact that the two gestures are placed in synchrony with the verbal turn-constructional-component indicates that they are part of the most relevant part of his turn. By doing this, the speaker draws interactive attention to particular semantic aspects: the roundness of the frame and the fact that it carries a small crown, marking this information as particularly relevant for his attending coparticipant (Reference Müller and TagMüller & Tag, 2010).
Extending the scope of analysis and taking into consideration the larger conversational unit in which this little sequence of gestures is embedded, it becomes clear that the two gestures are part of a conversational activity of explaining something. Notably, this explanatory sequence is a consequence of a longer process of word searches (on the side of the speaker) and requests for clarification on the side of his interlocutor. In this sense, the extremely precise verbal and gestural description of the kind of picture frame, that figures as “main topic” in a narrative of the speaker, is a consequence of the conversational activities preceding them. The foregrounding activity therefore appears as an interactional consequence.
A conversation analysis of gesture forms reveals why the speaker places his gestures at this moment and place in his utterance. It focuses on gestures as communicative social activities and uncovers the concatenation of cooperative activities of coparticipants. Context for gesture form analysis is here the social organization of language use.
4.3 Discourse Dynamics: Context as Dialogic Process of Creating Mutual Understanding
Gestures often take part in dynamic processes of meaning-making. This concerns very small sequences of gestures, such as the succession of G2 and G3 (round-frame drawing followed by crown-placing), but it may also concern the use of gestures over larger time spans, as our example of Luis’ story shows. Used in a loose succession, each of the five gestures displays a different perspective on the same object and participates in different ways in creating the storyline: G1, G2 and G3 introduce the key object in the story (the royal portrait) by forming its shape and character as a royal portrait; G4 prepares the plot, for example, it locates the portrait in another room: and G5 is part of the plot, for example, it depicts how the portrait fell down all by itself. With these gestures, a salience structure on the level of the narrative is established, highlighting new rather than given information; information is foregrounded that is relevant and central to ensuring mutual understanding of the story told in a conversation.
Conducting gesture analysis from a discourse dynamics point of view starts from an understanding of context as a dialogic process of attempted mutual understanding. Cameron’s metaphor-led discourse analysis (Reference Cameron, Maslen, Todd, Maule, Stratton and StanleyCameron et al., 2009) offers a theoretical and methodological background for a form-based gesture analysis (Reference Kappelhoff and MüllerKappelhoff & Müller, 2011; Reference Müller and KappelhoffMüller & Kappelhoff, 2018). Another example for a discourse-based concept of context in gesture studies is McNeill’s adaptation of “communicative dynamism,” which addresses narrative structures as dynamically unfolding within discourse (Reference McNeillMcNeill, 2005, p. 55).
In short, analyzing gesture forms from the perspective of discourse dynamics addresses the contribution of gestures to various dialogic processes of building mutual understanding.
4.4 Expressive Movement: Context as Multidimensional Experiential Gestalt
An analysis of gestures as expressive movements starts from the assumption that the multimodal orchestration of speech and body movement forms multidimensional experiential gestalts which arise in the process of felt perception of interlocutors (Reference Müller and KappelhoffMüller & Kappelhoff, 2018). Contexts-of-use from this perspective are shared realms of experience, or experiential frames, which ground embodied meaning (Reference Müller, Zlatev, Sonesson and KonderakMüller, 2016, Reference Müller2019b) and, when they recur within a community, may become the stabilized “meaning” of a gestural movement (Ladewig, this volume; Reference MüllerMüller, 2017a).
Analyzing gestures in their contexts-of-use from a perspective of expressive movement assumes an understanding of gestures as temporal forms immersed in dynamically evolving contexts-of-use. As outlined and illustrated above (Section 3.4.3), conceiving of contexts as multidimensional experiential gestalts opens up a way of analyzing gesture forms as facets of embodied interaction where intersubjectivity arises from intercorporeal and interaffective understanding (Reference MüllerMüller, 2019b; Reference Müller and KappelhoffMüller & Kappelhoff, 2018). Such a perspective is in line with ecological approaches to gesture analysis (Reference Cuffari, Jensen, Müller, Cienki, Fricke, Ladewig, McNeill and BressemCuffari & Jensen, 2014; Reference Jensen and GreveJensen & Greve, 2019) or approaches to intercorporeality (Reference Meyer, Streeck and JordanMeyer, Streeck, & Jordan, 2017) and interaffectivity (Reference Fuchs, Meyer, Streeck and JordanFuchs, 2017; Reference Horst, Boll, Schmitt, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemHorst et al., 2014; Reference Koch, Fuchs, Summa and MüllerKoch, Fuchs, Summa, & Müller, 2012).
Conceiving of gestures as expressive movements connects with Kendon’s analysis of gestures as movement phases, phrases, and units, that is, as temporal structures (Reference KendonKendon, 2004, p. 112). To define the “stroke” of the gestural movement, Kendon draws on Laban’s dance theoretical analysis of body movements as expressive movements (cf. Reference Kennedy, Müller, Cienki., Fricke, Ladewig, McNeill and TeßendorfKennedy, 2013). The concept of expressive movement has played important roles in the history of philosophical reflections of gesture: Reference WundtWundt (1973) developed a monadic, solipsistic understanding of the concept; Reference BühlerBühler (1933) saw expressive movements as communicative actions; and Reference Plessner, Dux, Marquard and StrökerPlessner (1925/1982) and later Reference Merleau-PontyMerleau-Ponty (1945/2005) underline the intercorporeal and interaffective nature of expressive movements. Granted by bodily perception, understanding is grounded in feeling movement and in moving together. Notably, this notion of expression was central to modern dance as well as to film theory, both facing an inherently temporally structured medium of expression (Reference Kappelhoff and MüllerKappelhoff & Müller, 2011; Reference MüllerMüller, 2019b; Reference Müller and KappelhoffMüller & Kappelhoff, 2018).
Such theories offer paths toward reconstruction of the “meaning” of gestures from expressive movements as multidimensional gestalts in dynamic contexts-of-use. It remains fascinating how, through Kendon’s original analysis of manual co-speech gestures, the temporality of gestural form has created a common ground for analysis in the field of gesture studies.
4.5 Metaphor Research: Context as Multimodal Expression of Metaphoricity
Including gestures in metaphor analysis involves a semantic perspective on the coarticulated verbal utterance. In verbo-gestural metaphors, gesture and speech work together in expressing metaphoricity (Cienki & Reference MüllerMüller, 2008a, Reference Cienki, Müller and Gibbs2008b; Reference MüllerMüller, 2008, Reference Müller and Hampe2017b). Gestures often enact the source domain of a verbal metaphoric expression. For example, when Barack Obama speaks about those American people who look back and cling to the past, and points backward over his right shoulder, the gesture locates “looking back in time” in the space behind the speaker, that is, “Back in Time” is seen as “Back in Space.” In this context-of-use, the gesture is an expression of time as space, where the past is associated with what is behind a speaker and the future is what lies ahead, as is typical for western European languages. Reference Nùnez and SweetserNùnez and Sweetser (2006) have documented how such conceptualizations of time may vary across cultures: For Aymara speakers of the high Andes, they demonstrated that the spatial location of future and past is reversed, and this is reflected in their gesturing.
A careful analysis of gesture forms and their temporal unfolding along an interaction may reveal that sometimes metaphoric verbal expressions evolve from gestural body movements performed in the absence of speech. For example, in a dance training study, the notion of the dancer as standing in the center of a coordinate system emerges as an embodied conceptualization of balance and anchoring (Reference Müller and KappelhoffMüller & Kappelhoff, 2018, Ch. 11).
Analyzing gestures in the context of multimodal expressions of metaphoricity uncovers how metaphors are experienced while speaking, whether – at a given point in time in a discourse – they are foregrounded, “alive and awake” for a given speaker, whether they receive interactive attention, and whether they are taken up and unfold within the dynamics of discourse (Reference Cameron and GibbsCameron, 2008; Reference Cameron, Maslen, Todd, Maule, Stratton and StanleyCameron et al., 2009; Reference MüllerMüller, 2008; Reference Müller and KappelhoffMüller & Kappelhoff, 2018; Reference Müller, Ladewig, Borkent, Dancygier and HinnellMüller & Ladewig, 2013).
4.6 Pragmatics: Context as Communicative Action
Applying a pragmatic perspective to gesture form analysis assumes an understanding of context as communicative action where language use is conceived of as performance of speech acts (Reference AustinAustin, 1962; Reference SearleSearle, 1969). Although speech-act theory has received a lot of criticism, the fact that we “do things with words,” as Austin put it, has inspired much gesture research. Kendon characterizes gestures as “visible actions” that are used as utterances and addresses the pragmatic dimensions of gestures in manifold ways (Reference Kendon, Duranti and GoodwinKendon, 1992; Reference Kendon2004, Chs 9, 10, 12). For example, his pragmatic analysis of the ring gesture (index and thumb forming a ring shape) focuses on the illocutionary force or more generally on the communicative actions performed with a given gestural movement (Reference KendonKendon, 2004, Ch. 12).
For the ring gesture, this means that only because the gesture is performed in the context of a communicative action, the action of picking up some tiny object can be transformed into a communicative action of making precise arguments (Reference MüllerMüller, 2017a). When such a gestural form is repeatedly used within similar contexts-of-use, these repetitions may stabilize and become a conventionalized gestural form, an emblem, such as is the case with the ring gesture used to express excellence and perfection in many Western cultures (Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMüller, 2014b). Another example is the palm-up-open-hand gesture that may be used to depict the handing over of small objects lying on the palm of the hand, or may be used to hand over speaking turns (Reference Streeck, Hartge, Auer and di LuzioStreeck & Hartge, 1992), and thus have a pragmatic function (Reference Müller, Müller and PosnerMüller, 2004). This means that the analytic decision about whether such an as-if movement is used referentially or pragmatically depends upon its placement in a given context-of-use.
Connecting gesture form analysis with a pragmatic perspective addresses gestures as communicative action. It opens up a path to reconstructing the embodied history of some of them, a kind of “etymology” of conventionalized gestures as in the ring or the palm-up-open-hand gesture. It may document the spontaneous emergence of gestural communicative actions from manual actions (Reference StreeckStreeck, 2009, Reference Streeck2017), reveal processes of decomposition of gestural forms (Reference MüllerMüller, 2017a), and show how gestures contribute to multimodal constructions with a pragmatic meaning (Reference Bressem and MüllerBressem & Müller, 2017; Reference LadewigLadewig, 2020).
4.7 Summary
Section 4 has illustrated how context analysis implies a decision to work within a specific theoretical framework. To illustrate potential (and currently common) understandings of context for gesture analysis, a selection of frameworks has been briefly presented: (1) cognitive linguistics, (2) conversation analysis, (3) discourse dynamics, (4) expressive movement, (5) metaphor research, and (6) pragmatics. Some of the tools for gesture form analysis are intrinsically connected with a specific framework: For example, describing gesture form as a motion event implies a cognitive-linguistic understanding of context, whereas analyzing gesture form as expressive movement implies a notion of context where gestures, other body movements, and speech merge in a multidimensional gestalt. Other “tools” go along with several theoretical frameworks: For example, noting down aspects of kinesic forms can be relevant for all theoretical approaches; together with the description of hands as performing as-if actions, they allow for a form-based heuristics of gestural meaning and a gesture-first approach to the analysis of multimodal utterances. The framework chosen can be an entryway to analyzing different aspects and kinds of gestural meaning. Whether a certain gesture form is to be considered as depicting the concrete or the abstract, or whether it is used pragmatically, depends upon the context-of-use with which it is entangled. Applying different frameworks in form-based analysis thus uncovers different ways in which gestures contribute to multimodal utterances in unfolding interactions.
5 Summary and Conclusion
In this chapter, we have offered a toolbox of Methods for Gesture Analysis, and presented a set of possible takes on the analysis of hand gestures. The baseline of any analysis is an explicit account of the gesture form as a temporal form and its temporal integration in the dynamic unfolding of a discursive event. MGA provides the researcher with sets of tools that can and must be flexibly adapted to a given research interest. It offers researchers tools to creatively design their specific procedures and helps to make explicit the different potential frameworks for gesture analysis. Rather than prescribing a fixed set of procedures, or advocating a single specific theoretical approach to gesture analysis, MGA offers a flexible set of analytic tools that encourages critical reflection upon the insights one can gain from analyzing gestures in multimodal communication and interaction. It opens up a way to think about gesture analysis as creative and theoretically variable.
MGA encourages the researcher to creatively select, combine, and further develop tools such as those presented here. Acquiring more expertise with the tools will probably be associated with a need for more refined analytical tools for gesture form analysis and excite curiosity for a deeper understanding of the theoretical frameworks and their respective notions of context. The toolbox also allows extending the analytic scope to macrolevel analysis.
Further questions that are essential for conducting empirical research on gestures in multimodal utterances, but which have not been discussed in this chapter, include technical aspects of video technology related to data collection (gesture phase analysis depends upon the resolution of the video image, annotation systems for speech and gesture, software annotation tools, and motion-capture technology (Boutet & Cienki, this volume; Bressem, this volume; Trujillo, this volume).
Applying MGA to Luis’ story has revealed how analyzing the same piece of data from different methodological and theoretical viewpoints highlights different facets of the same little story. It shows that multimodal interaction is a highly complex phenomenon which cannot be accounted for by applying one and only one tool for gesture form analysis and one particular understanding of context. Whatever we select as a descriptive tool will reveal different facets of this fascinating phenomenon. The goal of the toolbox of MGA is to enable researchers to be explicit about their chosen perspective and to underline the relativity of any analytic attempt to understand this complex “thing” that we call gesture and speech, multimodal utterance, multimodal communication, or multimodal interaction.
The approach presented here, developed by Geneviève Calbris, studies co-speech gesture as an object in itself. It is an object of study anchored in the concrete; living and fluid, it manifests itself through movements of body segments at various levels of the body. These bodily movements that produce acts in the physical world are here producers of signs, signs associated with speech addressed to others. Co-speech gesture is a physical material that carries meaning. On this view, the meaning of an utterance results from interactions between two symbolic systems of different natures – the kinesic and the verbal – and to discover how and what a gesture signifies, first of all, one has to establish how the kinesic system functions. In order to do so, one constitutes a database of referential co-speech gestures classified according to physical criteria to enable the potentialities of the gestural representation system to be revealed. Calbris considers how a gesture is associated with speech by analyzing how gestural information, conveyed by potentially symbolic physical elements, interacts with contextual verbal information in a reciprocal fashion. The verbal information specifies the co-speech gestural information (gestural sign), which in turn interacts with the verbal information (verbal sign) and determines the message conveyed by the utterance as an integral whole.
One of Calbris’ overarching aims is to reconcile systems thinking with a concern for detail – to reconcile the macro and the micro viewpoints on the object of study by continually shifting back and forth between a high-level view of the whole system of signs and a fine-grained analysis of each sign. Her methodology enables one to discover the diverse spectrum of analogical links that may be established between physical and semantic aspects of gestures, and how these links may occur singly or in combination within one gesture. For her, it is a question of researching the gestural sign linking a co-speech gesture to its contextual meaning, the sign being the unity constituted by the association of a physical element to the gesture’s conceptual content (signified). The method consists in identifying the relevant physical element (signifier) of the gesture supporting the natural link of resemblance or contiguity with the gestural signified. The analysis entails differentiating between gesture and gestural sign, gestural component and relevant physical element, and gestural signified and verbal signified. It allows one to see that the signifier–signified link constituting the gestural sign represents a perceptual schema extracted from our perceptual experiences, a schema at the origin of abstractions constituting our mental world, that is, an intermediary between the concrete and the abstract.
1 Context of the Research: The Multichannel Nature of Oral Communication
Teaching French to migrants using the first audiovisual method in the 1960s, Calbris immediately became aware of the multiple channels that oral communication employs. The transmission of information simultaneously uses the verbal channel (to convey uttered text), the audiovocal channel (to convey rhythm and intonation), and the visuokinesic channel (to convey facial expressions and gestures produced by various body segments). These three channels, however, are conduits for two types of signs because the nonverbal sign, transmitted through the vocal or kinesthetic channel, differs from the verbal sign. To elucidate their reciprocal relationships, Reference FónagyIván Fónagy (1983) introduced the concept of a double message, whereby the nonverbal message of sonority and intonation comes to modify the verbal message. Calbris proposed that visually, the nonverbal gestural sign does the same. She initiated three lines of research on nonverbal information conveyed: (1) by the voice and the face, (2) by the face and gesture, and (3) by gesture alone. The method of analysis depended on the various types of corpus and technical means then available (slides, 16 mm film, videodisc).
1.1 Voice and Face
The first line of research focused on the semantic contribution of intonationFootnote 1 that can differentiate many situations expressed by the same sentence. For example, 18 different situations can be evoked by modifying the intonation of “Il a une voiture” (He has a car) (Reference CalbrisCalbris, 1973, pp. 104–117). While recording intonations for an experimental auditory recognition test with 90 French subjects, the performer was not able to produce the appropriate intonation without reproducing the physical attitude associated with it. This finding provided an opportunity to observe that the differentiating intonational attitudes constitute “audio-visual units,” both in transmission and reception, that are structured by the same vocal-kinesic dynamics (Reference Calbris and MontredonCalbris & Montredon, 1980). One of the consequences of this test was to demonstrate that phonogestural parallelism actually manifests itself on many levels: (1) in time, (2) in form, (3) in meaning, (4) in function, and (5) in coding (Reference CalbrisCalbris, 1989).
1.2 Face and Gesture
The second type of research investigated the semantic contribution of speechless facial-gestural expressions (Reference Calbris and MontredonCalbris & Montredon, 1986). This involved testing the meaning and the signifying structure of conventional French facial-gestural expressions (emblems), for example, the gesture of twiddling one’s thumbs meaning “idleness.” Thirty-four emblems involving different body segments at different levels of the body were captured on film simultaneously by two cameras; one filmed the whole expression, the gesture and the face, while the second simultaneously filmed just the gesture. For the purposes of the experiment, the 34 expressions were divided into two equivalent lists of items and presented to two equivalent groups of French subjects. Each subject had to match an expression (signifier), partially or completely presented, to its meaning (signified) on the given list of items. For example, the verbal cliché “il fout rien de la journée” (he does nothing all day) associated with the meaning of the thumb-twiddle emblem appeared on the list and not the verbal cliché “il se tourne les pouces” (he twiddles his thumbs) that describes the emblem. The results of the test (85 percent success rate) show that the gesture was sufficient in 83 percent of the cases to identify the signified. The contribution of the face was most often irrelevant, positive if it disambiguated the gesture, and negative if it was superfluous or if its affective connotation seemed to contradict the connotation signified by the gesture (Reference CalbrisCalbris, 1980; Reference Calbris1990, Ch. 1).
To verify the cultural character of these emblems, the semantic test was repeated with Hungarian subjects, with a different native language but the same Western culture (civilization), and with Japanese subjects, with a different native language and culture. The rate of comprehension decreased from 85 percent for the French group to 46.5 percent and 29 percent for the Hungarian group and Japanese group, respectively. It appears that cultural similarities and differences may be more important than linguistic differences in accounting for these results.
The results of this experimental study demonstrated not only the cultural (or conventional) character of gesture but also its analogical (or motivated) character: by systematically searching for analogical links in the foreign subjects’ data, analysis of the errors revealed the motivated character of gesture and, taking into account the numerous links imagined by these subjects while interpreting the same gesture, the possible plural motivation of one single gesture (Reference CalbrisCalbris, 1981; Reference Calbris1990, Ch. 2).
1.3 Gesture on Its Own as a Nonverbal Sign
The third study concerned the semantic contribution of the gesture as a nonverbal sign. Whereas the verbal sign is generally arbitrary (extrinsic), analytical (discontinuous), and explicit (invariant), the nonverbal sign by contrast, whether vocal or gestural, is generally motivated (intrinsic and part of the referent which it signifies), synthetic (continuous, so that any modification implies a parallel modification of the referent), and probabilistic (e.g. Was that a wink or was there dust in your eye?); as such, the nonverbal sign is ideal for expressing what is implicit (Reference Scherer, St. Clair and GillesScherer, 1980). If the verbal sign is conventional and arbitrary, the nonverbal sign is conventional and motivated (Reference FónagyFónagy, 1961), that is, its physical aspect and its meaning are analogous, even though its meaning differs from one culture to another. For example, the finger Ring, as an emblem or a co-speech gesture, is always an analogical sign (Figure 9.1) because it is always based on a link of contiguity or physical resemblance established through analogy between a relevant physical feature of the gesture and physical experience of the world. This analogical link is the source of the gestural semanticity that is tapped to create the specific contextual meaning of a gesture from a range of possibilities offered by its iconic and cultural nature. Hence the finger Ring is an intercultural analogical sign (compare Malta, France, and Japan). Moreover, it is an intracultural analogical sign: in France, as an emblem, it signifies “perfect” and sometimes “zero,” and the facial expression determines whether it means positive or negative appreciation; as a co-speech gesture accompanying a verbal utterance such as “Cela concerne 0,25% de familles” (That concerns 0.25% of families),Footnote 3 it expresses extreme precision, not by depicting a circular form but fingernail pincers. Both cultural and contextual, the gestural sign is always an analogical sign.

Figure 9.1 The gestural sign is always an analogical signFootnote 2
A parallel attenuation on the physical and the semantic levels confirms the analogical nature of the gestural sign. Figure 9.2 shows four typical gestures that express decreasing degrees of threat from left to right: the surface of the body part (hand/index finger) and the dynamics of the movement (segment shaken/simply lifted) decrease correspondingly with the intensity of the notion expressed. We find this parallel attenuation in the physicosemantic expression of quantity as well as in that of opposition (see Reference CalbrisCalbris, 2011, pp. 167–170). Isomorphism is the term that Reference CalbrisCalbris (1990, Reference Calbris2011) uses to describe such parallelism in gestural signs that share a core meaning and present graded expressions of it.

Figure 9.2 A continuous analogical sign
1.4 Distinction between Gestural Sign and Gesture
The semiotic unit constituted by an analogical sign can be common to several gestural units cumulated for more expressivity within the same kinesthetic ensemble, for example, as shown in the simultaneously raised eyebrows, head, and hand expressing “increasing exclamation” in Figure 9.3. The gestural unit defined by the movement of a body segment is more precisely described by means of the various gestural components detailed in Figure 9.4.

Figure 9.3 Identifying gestural units

Figure 9.4 Gestural components
2 Method of Analysis of the Gestural Sign
The corpus used in the research reported here was compiled from three sources: Source 1 comprises approximately 1,000 co-speech gestures ethnographically recorded in the field (1978–1982), in everyday situations and on television, gestures confirmed by illustrations taken essentially from comic strips, which have the advantage of presenting a direct, attested, and shared association between the drawn and the written signifier (cf. Reference CalbrisCalbris, 1979); Source 2 is a database of gestural data recorded on the prototype videodisc Geste et parole (Reference Calbris1990)Footnote 4 and contains fragments of audiovisual sequences extracted from filmed interviews of intellectuals; Source 3 comprises six televised interviews with the former French prime minister Lionel Jospin broadcast between July 1997 and April 1998. The first source served to study the gestural sign, and the other two served to study its role in utterance.
2.1 Physical Classification of Gestures
The most relevant physical criteria determined the hierarchical presentation of a physicosemantic dictionary of all observed gestures referring to the concrete and to the abstract (Reference CalbrisCalbris, 1984, pp. 330–856; see Reference Calbris1990, pp. 211–227 for excerpts) as shown in Table 9.1:
– According to the active body segment, either mobile (arm(s), hand(s), finger(s)) or not very mobile (head gestures), or the passive object of a gesture (body-focused gestures).
– According to the movement. A distinction must be made between gestures that draw straight lines or flat surfaces (straight-line gestures) and those that draw curved lines or surfaces (curved gestures) because their respective, relevant secondary components differ.
For straight-line gestures, the most relevant physical features are the directional axis of the movement (up–down, front–back, or right–left) in conjunction with the active body part and the plane in which this is oriented (frontal, sagittal, or horizontal). Furthermore, in the case of a flat hand, the palm, fingertips, or the edge of the hand can be relevant (see “Relevant feature” in Figure 9.7).
Table 9.1 Classification of gestures according to pertinent physical criteria
| Body part | ||||
|---|---|---|---|---|
| Active (performer of a gesture) | Passive (object of a gesture) | |||
| Mobile | Not very mobile | Body-focused (36 segments): | ||
| Arm(s) | Hand(s): | Finger(s): | Head | 0 Face (a non-specific part of) |
| A Open configuration | Single | 1 Head | ||
| B Closed configuration | Grouped | 2 Hair | ||
| C Closed in a Fist | 3 Forehead | |||
| D Other configuration | 4 Temple | |||
| Movement | 5 Eyebrow(s) | |||
| Straight line | Curved line | 6 Eyelids | ||
| Directional axis of the movement: | Clockwise/anticlockwise direction | 7 Eye(s) | ||
| Up–down; front–back; right–left | 8 Under the eye | |||
| Plane and orientation of the body part: | Form of the curved movement | … | ||
| Frontal/sagittal/horizontal | (the active body part is not very relevant) | 36 Thighs | ||
For curved gestures, the direction of the circular movement (clockwise/anticlockwise) is of utmost relevance. The active body segment is not really relevant. Curved gestures are therefore classified according to the curved line or surface drawn (e.g. an arc vs. a circle, each possibly repeated with or without displacement) and not according to the active body segment.
2.1.1 Results of the Classification
From the viewpoint of the signified.
The specificity of the signifieds corresponding to body-focused gestures, curved gestures, or certain body segments such as the index finger and the thumb, is immediately apparent.
The clear distinction between straight-line and curved gestures can be found at the symbolic level to oppose certain notions such as direct/indirect, permanence/instability-evolution, element/everything, analysis/synthesis, and class-organization/confusion-chaos – or to nuance about 20 other notions, for example, complete/united “totality” (see Reference CalbrisCalbris, 2011, pp. 149–153 for many examples with diagrammatic illustrations of the corresponding movements).
It is also by the comparison of numerous closely related signifieds, in association with the comparison of their respective signifiers, that we understand the entire semiotic structuring that presides over the gestural expression of time (Reference CalbrisCalbris, 1985b; Reference Calbris2011, pp. 128–144).
From the viewpoint of the signifier.
For the same signified, many substitutions appear between body segments, between planes, and between directional axes for ergonomic reasons. Table 9.2 shows substitutable body parts that were found to express the same kind of meaning linked to direction, here upward and backward.
These substitutions between segments for the same type of movement determine alternative variants, sometimes cumulative at different levels of the body, for example, the head and the hand/thumb/index finger, for more expressive impact (see Section 2.2.1 below).
From the viewpoint of the motivation.
The bodily expressions (vocal-postural-facial-gestural) of “refusal” that replace or accompany speech are extremely numerous and varied; they can express disgust, indifference, or ignorance as well as opposition, restriction, or negative ellipsis. We can speak of the “semantics of physical refusal” in the sense that we can see how humankind has mimed our physical refusals and transferred them into the psychological and conceptual domains (Reference CalbrisCalbris, 1985a; Reference Calbris2011, pp. 198–217).
2.1.2 Summary
A comparison of the entire repertoire reveals, on the one hand, the specificity of a particular body segment with regard to its referential possibilities – inspired by its physical or functional characteristics in everyday life – and, on the other hand, substitutions between physical elements to express the same type of signified. Distinction on the one hand, resemblance on the other; the joint exploitation of these two phenomena allows, through the choice of physical constituents, a precise representation of the referent.
Let us consider just one example. Both the index finger and the thumb, as physically distinct units, can represent “one.” The index finger, a long and thin finger used, among other things, to designate and specify, represents the notion of “uniqueness” while the thumb, a strong finger, represents “priority” or “excellence” (the first, of all).
Researching these distinctive criteria gave rise to a physical dictionary of gestures (Reference CalbrisCalbris, 1984). As such, it reveals the various notions associated with the same gesture as well as the various gestures that, throughout the repertoire, refer to the same notion. It facilitates the recording of the relations between gestures and notions.
2.2 Relations between Gestures and Notions
Polysemy on one side, variation on the other; by comparing gesture variants, the common physical element bearing the analogical link with a common signified is revealed.
2.2.1 Variation
Several gestures, either alternatively or simultaneously (Figure 9.5, right column), can represent one notion. Referring back to Table 9.2 and Figure 9.3, an upward movement of the hand and/or head are gesture variants expressing “increasing exclamation.” Here is another example: One can refer to the recent past by moving the thumb or, alternatively, the head over the shoulder; moving both simultaneously creates a cumulative variant that reinforces the expression (Figure 9.6.1). And to signify “distant past,” the hand and/or head raised high and moved backward refer to a space-time far behind you and no longer just behind you (Figure 9.6.2).

Figure 9.5 Relations between gestures (g/G) and notions

Figure 9.6.1 Recent past

Figure 9.6.2 Distant past
Whereas stylistic variants either amplify or attenuate the degree of expressivity when conveying the same meaning, semantic variants offer the possibility of introducing different shades of meaning when conveying the same basic notion by changing a secondary component.
Variants and motivation.
The four semantic variants of “cutting” are related to the plane in which the cut is made: in the sagittal plane, a “cut in two”; in the frontal plane, a “cut that stops,” and in the horizontal plane, a “total cut” are signified, respectively. In the latter plane, turning the hand so that the palm faces upward to make the transverse cut specifies a “total cut at the base” or “undermining-felling.” Note that the transverse movement is specific to both “total” cuts. But it is the rapid movement of the abruptly stopped cutting edge of the hand expressing the proprioceptive schema of cutting that is common to all the four variants. Each of these variants does not express just one analogical link, but two (Reference CalbrisCalbris, 2003a, pp. 19–46).
2.2.2 Polysemy
One gesture can alternatively represent several notions (Figure 9.5, left column). The best example of polysemous gesture is the transverse movement of the Level Hand(s) in the horizontal plane (Figure 9.7) observed in 131 examples from Source 1; it can represent about 20 different notions depending on the context. This gesture exploits all the relevant elements of the flat hand (fingertips, palm, and edge).
This gesture has not only numerous analogical links, which is why it is said to have plural motivation, but each link is also applicable in numerous domains, giving rise to semantic derivation. For example, directness represented by drawing a straight line from A to B expresses immediacy on the temporal level and an immediate consequence on the logical level, that is, determinism, certainty, or obligation, whereas on the level of moral judgment, directness expresses frankness.

Figure 9.7 The plural motivation of a polysemous gesture
Originating from our motor or perceptual experience, gestures that employ the Fist configuration contain several possible analogical links: A clenched fist (1) is strong, (2) can hold something firmly, and (3) can enclose something. Each of these analogical links may be subject to semantic derivation: strength can be physical (example [1]), psychological (example [2]), or moral (example [3]), and an enclosed object that a fist represents may be real, that is, graspable by the hand, or abstract (example [4]).
1 A pianist is talking about the role of the left hand in Beethoven’s music:
[left fist] La main gauche, c’est une, c’est une, comme ça, une, une présence d’éner [opens] énergétique.
[left fist] The left hand, it’s a, it’s a, like that, a, a presence of ener [opens] energetic.
2 [right fist] Je me suis obligée tous les jours
[right fist] I forced myself every day
3 [both fists] Parce que je pense que on ne peut pas, passée la cinquantaine, ne pas s’occuper des jeunes citoyens.
[both fists] Because I think that one can’t, once past fifty, not do something for young citizens.
4 A psychologist interviewed at home is talking about educational assessment:
[left fist lifts up] tellement c’était un [left hand falls on to the sofa] un secret bien gardé
[left fist lifts up] it was such a [left hand falls on to the sofa] a closely guarded secret
To summarize, the physical polyvalence of the fist determines its polysemy as a sign. The context determines the choice of both the analogical link and the semantic derivation.
Polysign gesture.
In contrast, the polysign gesture simultaneously conveys multiple signs (Figure 9.5, left column) because it contains different analogical links that depend on different relevant physical features associated with the context. Let us take the example of the raised fist that is generally used as a sign of threat. In example (4), it is used as a polysign that provides two simultaneously conveyed pieces of information that are confirmed by the spoken utterance. The analysis of example (4) in Table 9.3 shows that the raised fist contains two physical relevant features: its closed configuration and its upward movement (signifiers) are possible supports of analogical links in accordance with the context. Note that the synthetic gestural information (“so enclosed”) that occurs synchronously with the verbal segment “tellement c’était un …” precedes the confirmatory verbal information “un secret bien gardé.”
Table 9.3 The polysign gesture
Furthermore, more than one sign may be conveyed by just one component, for example, by the type of movement (straight or curved) and by its direction. In example (5), loops, signifying “the course of time,” in combination with their direction toward the speaker, signifying “self-centering,” make the idea of “introspection during action” explicit.
5 Donc on a cette cette double mission de de le faire [the index fingers, facing each other, draw two parallel series of loops going toward the speaker whilst the torso moves backward] et de nous regarder le faisant [smile].
Therefore we have this this twofold mission to to do it [the index fingers, facing each other, draw two parallel series of loops going toward the speaker whilst the torso moves backward] and to watch ourselves doing it [smile].
If we reconsider the gesture variants that signify “cut,” we can see that each variant, nuanced by the plane of cutting, functions as a polysign: cut + division, cut + obstacle, and cut + totality.
Note that the signifying combination of a polysemous configuration (e.g. the Fist) and a polysemous movement (e.g. forward) is apt to produce a large number of varied polysigns. Forward is polysemous: one moves forward to go toward someone/something/somewhere or to counter an opposing force (two analogical links). Moreover, the former link is subject to semantic derivation: spatial or temporal progression. So, according to the context, a fist moving forward can signify: psychological strength + toward something, hence, the effort required to reach for a goal; psychological strength + against something, hence, the will to attack; or strength + temporal progression, hence, strength and even modernism.
Complex gesture.
Finally, the complex gesture is a particular case of the polysign gesture: it performs the respective figurations of two known gestures by creating a third one that synthesizes them in an original way. For example, in order to simultaneously represent mixing, usually signified by the two hands turning around each other (Figure 9.8.1) + approximation, usually signified by a rotational oscillation of the concave palm facing downward (Figure 9.8.2), a screenwriter (example [6]) and a philosopher (example [7]) perform the same synthesis (i.e. an alternating oscillation of the two concave palms, one behind the other, as if they were interlocked*) to express a “kind of confusion” and an “approximate mixture,” respectively.
6 The screenwriter says:
*l’espèce de désarroi dans lequel se trouvent les hommes et les femmes maintenant.
*the sort of disarray (“kind of confusion”) in which men and women find themselves now.
7 Here it is a question of belief:
Je n’aime pas beaucoup *le judéo-chrétien.
I don’t like very much *the [term] Judeo-Christian (“this approximate mixture”).

Figure 9.8 A complex polysign gesture
Here are some examples of a complex head gesture: an abrupt lateral lowering of the head*, combining a movement downward and sideways, is often a way of emphasizing something negative, for example, a way of reacting to the exaggeration of others: “C’est maintenant que tu arrives? (You’re coming now?) *Pas trop tôt! (*Not too early!)” or to strongly disagree: “En 74? (in 74?) *Ca m’étonnerait! (*That would surprise me!).” This synthetic movement (downward and sideways) cumulates the motivations corresponding to each of the directions: pressing downward (insistence) and turning away from (negative element).Footnote 5
2.2.3 Polysemy and Variation
In order to elucidate the polysemy of a gesture, it is sufficient to research the gesture variants of each signified in order to identify the analogical link inherent to it. For example, in France, the lateral shaking of the head is polysemous: as an emblem, it signifies “negation,” and, as a co-speech gesture, it signifies “totality” or “approximation” (Figure 9.1). However, each of these notions is expressed by a gesture variant with a single movement: the lateral shake repeats the lateral turning away from one side to the other (negation), repeats the transverse movement (totality), or repeatedly sweeps the gap between the two designated boundaries on the right and left of the head (approximation). The polysemy of the lateral shaking of the head is elucidated by the single-movement gesture variant of each notion.

Figure 9.9.1 Polysemy

Figure 9.9.2 Variation
Research and confirmation of the analogical link.
In Source 1, the co-speech gestures that refer to the notion of totality are characterized by:
– a transverse movement of one or two Level Hand(s);
– a transverse movement of the head;
– the lateral shaking of the head.
What is the analogical relation between the transverse movement of the head, hand, or fingers and the notion of totality? Logically, it is a natural reference to the horizon signifying “everything, everywhere” (Figure 9.2), concretely represented by a glance that sweeps across the horizon (in a single or repeated movement of the head) or by the palm that glides across it with a transverse movement (symmetrical or not). Transverse movement, the element common to the gesture variants, is the relevant element that can be linked to the common notion. By scanning the entire perceptible field from left to right, it represents the perceptual schema of totality and becomes the gestural signifier of the notion of totality. This is what we see in the following sequence:
8 Je serai un opposant, mais résolu [thumb and index finger form the Ring configuration (representing “precision,” “rigor”)], j’allais presque dire systématique contre la proportionnelle, et ce [transverse movement, (representing “totality”)] à toutes les élections
I will be an opponent, but [a] resolute [thumb and index finger form the Ring configuration (representing “precision,” “rigor”)], I was almost going to say [a] systematic [one] against the proportional system, and this [transverse movement, (representing “totality”)] at all the elections
The transverse movement is performed by the Ring configuration because the rigorous attitude of the speaker concerns all elections. The gestural representation of the idea is thus maintained for as long as the idea lasts (cf. the concept of catchment in Reference McNeill, Quek, McCullough, Duncan, Furuyama, Bryll and AnsariMcNeill et al., 2001, p. 11).
Generalizing from this example, one identifies the analogical links in gestural signs by comparing gestures on the paradigmatic (vertical) axis of substitution and on the syntagmatic (horizontal) axis of combination (Figure 9.10).

Figure 9.10 The analogical link
To conclude this section on Calbris’ approach to analyzing the gestural sign, one can say that the elements of the “symbolic Meccano” game (or “symbolic construction kit”) are the analogical links (Reference CalbrisCalbris, 1987, Reference Calbris2008a). Physicosemantic classification reveals that the polysemy of a gesture is not explained by a simple semantic derivation, but that the gesture that represents several notions is apt to contain several analogical links, alternatively or simultaneously “activated” by the context. There is no correlation between the number of analogical links and the number of kinesic entities. Indeed, one observes that one single link is expressed by the same movement of the hand and the head in a facial-gestural ensemble; conversely, one manual configuration may express several links. The relevance is not in the physical element but in the analogical link it contains.Footnote 6
3. Roles of the Gestural Sign in Utterance
Thanks to the initial physicosemantic classification of gestures, we can discover: (1) the possibility of plural motivation of a gesture and (2) the semantic gesture variants of a notion. This facilitated the semiological analysis of gestures in Sources 2 and 3, that is, the identification of the gestural signs, which often occur simultaneously at a given moment, in the gestural-verbal flow of the utterances.
3.1 Utterance Functions
As shown in Table 9.4, the three communication channels are associated differently to serve different functions: expressive, appellative,Footnote 7 referential (Reference BühlerBühler, 1934), and phatic (Reference Jakobson and SebeokJakobson, 1960). In terms of communication, emblems and co-speech gestures can serve all of these functions. When accompanying speech, gesture also serves utterance functions connected with speech rhythm (a demarcative function) and speech formulation (a predictive function). Gesture thus serves several functions and can simultaneously cumulate them (Reference CalbrisCalbris, 1997).
Table 9.4 The multifunctionality of each communication channel
| Channel | Communicative functions | Utterance functions | ||||
|---|---|---|---|---|---|---|
| Expressive | Conative | Referential | Phatic | Demarcative | Predictive | |
| Verbal | • | • | • | • | ||
| Vocal | • | • | • | • | ||
| Kinesic | • | • | • | • | • | • |
Demarcative function.
It is important to determine, thanks to the verbal-vocal-kinetic context, what pertains to the demarcative and/or referential function(s) in a gesture (Reference CalbrisCalbris, 2001). The method of analysis of the hierarchic segmentation of discourse consists in locating repetitions and vocal-kinesic movement changes, as well as the co-occurrence of movement changes at different levels of the body (Reference CondonCondon, 1976). One notices a hierarchic kinesic segmentation of discourse into ideational units, into rhythmic-semantic groups by a change of gesture, and into words by the different temporal phases of the gesture: beginning, apex, and end (cf. Reference KendonKendon, 2004; Reference McNeill, Quek, McCullough, Duncan, Furuyama, Bryll and AnsariMcNeill et al., 2001). The hierarchic structuring of spoken discourse is underpinned by kinesic units that are nested inside each other. Temporal correlation does not imply semantic correlation. If one looks at how these gestural and verbal units correlate with ideational units, one finds that referential gestures often express ideas that are subsequently verbalized. In fact, as the expression of a perceptual schema at the origin of the concept, gesture often precedes verbal formulation.
Predictive function.
For the speaker, the fact that gesture maintains its preverbal status during utterance production means that it can operate as an aid to the verbalization of thought by concretely maintaining an idea in the speaker’s mind and thus promote its rendering into words. Furthermore, gesture is the only translator and the only evidence of mental imagery during speech production. It also creates cognitive suspense for the interlocutor engaged in the alternating game of tension-relaxation which allows her/him to progressively discover the semantic content of the speaker’s utterance and empathically participate in the elaboration of the content. Hence, referential gesture indirectly serves an interactive function with an instructive character. Preverbal, spontaneous, and often unconscious, the gestural sign that is emitted stimulates the cognitive activity of both partners.
3.2 Alternation and Synchronicity
Gesture and speech may alternate within an utterance in a form of mixed syntax (cf. Reference Slama-CazacuSlama-Cazacu 1977, pp. 118–122). Regardless of whether it occurs before or after speech, a gesture may function as if it were a word or other unit of linguistic expression, hence, as a component of syntax in the construction of the utterance. In this case, gesture substitutes for speech. The speaker can thus exploit it as an implicit, expressive, synthetic sign, for example, to show diplomacy, increase expressiveness, or make the interlocutor wait for what is to be formulated verbally.
When gesture and speech occur simultaneously, the gestural expression and the co-occurring verbal expression may be semantically related in two different ways: (1) as a coverbal sign, gestural expression augments what is being expressed in words, that is, the respective information units are synchronized, or (2) as a preverbal sign, gestural expression anticipates the verbal expression of an idea, that is, there is a synchronization of information units but an asynchronous distribution of the information they convey.
Co-verbal sign.
A complementary piece of information supplied by a co-speech gesture can:
– indicate the speaker’s attitude or comment on what s/he is saying in relation to the object of the utterance (Reference CalbrisCalbris, 2011, pp. 250–252);
– explain something to the interlocutor with a pedagogical aim in mind, for example, giving the visual representation of a spiral quickly helps to make it clear what a spiral staircase is (Reference CalbrisCalbris, 2011, pp. 253–254);
– disambiguate a polysemous word in the verbal message, for example, the French word “régulier” can mean regular, cyclical, uniform, or in accordance with regulations. Accompanying the phrase “c’est pas régulier” (it’s not …), the circular and repetitive movement of the hand drawing vertical loops specifies that “cyclical” is the intended meaning (Reference CalbrisCalbris, 2011, pp. 254–255).
It also happens that the simultaneous confrontation of gestural and verbal information that reciprocally specify each other results in conventional gestures and locutions acquiring a new, original, contextual meaning. Such individual creativity with socially established metaphorical expressions is demonstrated by example (9), produced by a politician who was in the Opposition at the time of the interview. He is complaining that promises have been made that something will be done but, according to the speaker’s media searches, so far nothing has happened:
9 [the left index finger inclines the ear pinna forward as if to hear better] Et depuis un an, [then the left hand forms the Palm Forward configuration] j’attends les actes: [both hands transformed into the Ring configuration, side by side, symmetrically draw a transverse line] je n’ai rien trouvé.
[the left index finger inclines the ear pinna forward as if to hear better] And for a year, [then the left hand forms the Palm Forward configuration] I’ve been waiting for actions: [both hands transformed into the Ring configuration, side by side, symmetrically draw a transverse line] I’ve found nothing.
Figure 9.11 details the process of constructing the meaning of the message, in which each of the three gestures that cut the sentence into rhythmic-semantic groups conveys a complementary piece of information. Derived from action, the gesture of placing the index finger behind the ear and pushing the pinna forward, when seen out of context, means something like “to hear better.” In co-occurrence with the phrase “And for a year” its meaning changes to suggest the idea of a watchdog with his ears pricked up and thus to refer to the figurative French locution “tendre l’oreille” (to prick up one’s ears).

Figure 9.11 Interactive construction of meaning by the two types of sign
The Palm Forward gesture that follows, which may be derived from a self-protective reflex, is essentially a defensive stop. In this context, it signifies that the person has been waiting on standby, immobile, for a year.
The last gesture is a polysign: the Ring gesture used to grasp a very small object refers to something minuscule and precise. As discussed above, transverse movement sweeping the horizon can signify “everywhere.” Out of context, the gestural meanings “minuscule” and “everywhere” combined with the verbal context “I’ve found nothing” become, respectively, “not the least little thing” and “nowhere.”
The interaction between the gestural meaning in context and the meaning of the verbal message produce the total verbal-gestural utterance: “And for a year” I’ve been pricking up my ears, immobile “I’ve been waiting for actions: I’ve found absolutely and strictly nothing.” The gestural contribution confirms the implied metaphor of the alert and motionless watchdog. The referential function is performed by the two channels in interaction. The semantic interaction of gesture and speech reported by Kendon (cf. Reference KendonKendon, 2004, pp. 158–175) in situations referring to the concrete is developed here in the abstract domain.
Preverbal sign.
Diverse examples across the corpus provide Calbris with instances of gesture anticipating speech, whereby there is an asynchronous distribution of information across synchronous kinesic units of gesture and prosodic units of speech. Reference CalbrisCalbris (1998) hypothesizes a relation between the gestural anticipation of speech and the type of mental images involved (Table 9.5). The reasoning is based on a possible correlation between the different types of image and the difficulty of encoding them verbally:
– An original mental image, being initially quite difficult to encode verbally (V), would be formulated gesturally (G) so that its presence in the mind can be maintained concretely for the duration of the verbal formulation. For a fairly uncommon image (i.e. a metaphoric extension or a particular mental image whose verbalization is not automatically available), anticipatory gesturalization would serve as an aid to verbalization (left column).
– Inversely, in the case of a known, commonly shared mental image transformed into a figurative locution, the initially unsynchronized association between gesturalization and verbalization would be readily transformed into a synchronous ensemble due to its frequency of use (central column).
– If a speaker-gesturer is not conscious of the analogical link contained in a figurative locution or its gestural representation that s/he is producing, then habit and automaticity would engender synchronous transmission of the analogous bimodal information (right column).
Table 9.5 Relation between the gestural anticipation of speech and the type of mental imagery
| G –> V | V|G | V G |
|---|---|---|
| Anticipation of gesture for original images | Simultaneity of gesture for common images | Non-consciousness of simultaneous gesture |
Gestural information conveyed during speech production often precedes analogous verbal information (example [4] showed a preverbal polysign); it gives an idea of the content to be put into words. As a preverbal sign, it can:
– summarize the whole content of the utterance that follows and thus function as a gesture-title (Reference CalbrisCalbris, 2011, pp. 257–258);
– help the speaker to find an appropriate formulation for what s/he wants to say and thus function as aid to verbalization (Reference CalbrisCalbris, 2011, pp. 258–263);
– create an interplay between tension and relaxation in communicating information for the interlocutor, who is led to guess what will be said in an intellectual game of switching between the two information channels.
Example (10) produced by the former French prime minister Lionel Jospin shows gestural information preceding each piece of verbal information in an astonishing way. Is this to emphasize his viewpoint right from the very start?
10
[Fingers pointing to the chest] L’euro | [palm opened outward] pour moi | [and moved forward]: c’est un instrument de puissance. [Fingers pointing to the chest] The euro | [palm opened outward] for me | [and moved forward]: it’s an instrument of power. Gestural information: For me it’s it’s that: Verbal information: The euro, for me, it’s an instrument of power.
Let us now consider example (11) showing how gesture can create an interplay between tension and relaxation in the bimodal information that is progressively communicated. It was produced by a technician being interviewed about construction work at the Musée d’Orsay, which he metaphorically refers to as a boat on the banks of the River Seine:
11 Ces micropieux sont ancrés dans le calcaire que l’on retrouve sous le musée pour empêcher le bateau de se soulever avec la montée des crues.
These micropiles are anchored in the limestone that one finds under the museum in order to prevent the boat from rising with the rise of flood waters.
Stripped of its nouns (micropiles; limestone; museum; boat; flood waters), the message is reduced to a skeleton that gesture articulates: “That anchored in that under that raised by that.” Table 9.6 shows gestures representing: (1) the micropiles, by the thumb and the index finger directed outward like hooks, (2) where they provide anchorage, by lowering the palms facing downward, and (3) rising movement, by raising the palms facing upward. A change of gesture (1, 2, 3) initiates a new rhythmic-semantic group, and the modulated repetition of each gesture segments each group into subgroups of meaning (A, B, C):
Table 9.6 Interplay of tension-relaxation between gestural and verbal information
| A | B | C | |
|---|---|---|---|
|
|
| |
|
|
| |
|
|
|
|
A, B, C: rhythmic-semantic subgroups
1, 2, 3: each new type of gesture, accompanied by its contextual meaning
Underlined: gestural information anticipating verbal information
The gestural information conveyed in A anticipates and complements the verbal information conveyed in B and C. For example, Figure 9.12 shows that the visuokinesic information conveyed in (3) is later confirmed by the verbal information. This bimodal structuring of the information flow across the whole sequence creates tension and relaxation as it progresses.

Figure 9.12 Tension-relaxation in the bimodal information progressively communicated
Finally, let us consider example (12) in which gesture is an anticipatory and complementary synthesis of the utterance (Reference CalbrisCalbris, 2011, pp. 303–312). Sitting at his desk, a management specialist is explaining how to design a project in order to achieve an objective:
12 “On part d’un monde | d’hier | dans lequel on entassait les connaissances.”
“One departs from a world | of yesterday | in which one accumulated knowledge.”
He sums up his previous worldview in a single, rapid, transverse movement to the right along the edge of the desk while saying “of yesterday” (Figure 9.13.2). For ergonomic and semantic reasons, he chooses the transverse axis. This allows him to represent: (1) anteriority on the left and two developments that are intimately connected here: (2) the temporal progression from left to right and (3) the cumulative progression of knowledge. Furthermore, (4) the rapidity of the movement of the back of the hand shifting to the right implies that this world is over, and (5) the gesture is performed along the edge of the table in front of his torso, indicating “here and now”: we are in the present. Suddenly motionless and gazing straight into the camera, he says “in which one accumulated knowledge,” and thus verbalizes the information that has already been gesturalized (Figure 9.13.3). The gesture testifies to the cognitive activity that programs the two-channel communication of the idea. The multireferentiality enabled through the gestural channel is confirmed through the verbal channel (Reference Calbris, Rector, Poggi and TrigoCalbris, 2003b). Figure 9.14 gives a visual synthesis of the cases in which gesture anticipates speech.

Figure 9.13.1 On part d’un monde “One departs from a world”

Figure 9.13.2 d’hier “of yesterday”

Figure 9.13.3 dans lequel on entassait les connaissances “in which one accumulated knowledge”

Figure 9.14 Temporal perception of the gestural-verbal flow
4 The Gestural Sign as Interface between the Concrete and the Abstract
Bodily behavior inspires figurative expressions which the body, in turn, illustrates; the description is mutual. By illustrating the concrete origins of a figurative expression or term, a gesture shows itself to be a synchronic link (a metaphoric role) or a diachronic link (an etymological role) between the concrete and the abstract. This is a two-way link since, while it makes the abstract concrete, it often symbolizes the concrete by reproducing not the concrete action but the abstract idea of it. Finally, analysis clearly shows the capacity for abstraction required for (panto)mimic representation and, vice versa, the concrete motivation for apparently abstract gestures (Reference Calbris, Asher, Simpson and MeyCalbris, 1994, p. 1433). Gesture is ideational insofar as mimesis is a mental operation of abstraction with concrete input and output: Selected features of our sensory experience of the world are abstracted and reproduced in kinesic forms of representation. Whether it refers to the concrete or to the abstract, symbolizes the concrete or concretizes the abstract, gesture is situated at the interface between matter and mind (Reference CalbrisCalbris, 2008a, pp. 40–53) (Figure 9.15) As a general rule, it reproduces a perceptual schema, an intermediary between the concrete and the abstract.

Figure 9.15 Gesture at the interface between matter and mind
4.1 Gestural Sign and Perceptual Schema
If we consider the ACTION schema “subject-action-object-result,” the result of the action seems to be the intermediary element between the concrete and the abstract expressed by co-speech gesture:
1. A gesture that accompanies the verbal evocation of a concrete action often shows its result, that is, the idea resulting from the action (the written trace and not the typing on the keyboard). The gesture represents an abstraction made out of the concrete – the result of the concrete action. For example, Can you switch the light off? to “reduce” the light explains the concomitant gesture of lowering the palm.
2. On the other hand, abstract notions derived from the perceived results of a cut are accompanied by a gesture that recalls the original action. The gesture reconcretizes the abstract – deduced from the results of the action. For example, a dichotomy occurs …, “a cut in two” explains the abrupt downward movement of the edge of the hand in the sagittal plane. In the same way, if we consider the OPENING schema “resulting openness-clarity and discovery,” the abstract action (clarification or revelation of content) derived from the concrete result is spontaneously reconcretized by an opening gesture, the opening of configurations with one or both hands (Reference CalbrisCalbris, 2003c), as exemplified in Figure 9.16.
The analysis of gesture reveals that the abstract object is conceived in the image of the physical object, perceptually defined by its contour and shape that determine its mode of prehension. One could call it representational deixis. Indeed, while the speaker is using the index finger to indicate* the abstract object uttered by the interlocutor by saying “*that’s it!”, s/he is positioning and giving shape to the abstract object s/he is thinking about. This is conceived as: a distinct entity (encircled, enclosed by the grasping hand); a definite object (framed by the sagittally held palms); a condensed object (constricted in the hand closed in a Pyramid configuration); a precise object (pointed and able to be grasped by the first three fingers joined together); an extremely precise object (to be grasped between the fingernail pincers of the thumb and the index finger). The speaker reifies the abstract object s/he designates (Reference Calbris, Müller and PosnerCalbris, 2004).

Figure 9.16 Opening a hand configuration to explain something
Whatever the type of abstract object the speaker has in mind, s/he opens it at the moment of giving its content verbally (cf. Reference CalbrisCalbris, 2011, pp. 331–342). In Figure 9.16.1, the object in question is spontaneously delimited by the palms because it is mentally defined, as indicated by the concurrent use of the French demonstrative “ces” (these). In Figure 9.16.2, the object in question is considered essential: an essential value which is … hence the choice of the hand closed in the Pyramid configuration to signify a condensation of something. This OPENING schema is also found in Italy: “the grappolo-to-open is associated with the comment … ” (Reference KendonKendon, 2004, p. 234).
4.2 Multiplicity of Perceptual Schemas Gesturally Represented on the Transverse Axis
The variety of gestural signs expressed on the transverse axis alone (Table 9.7) proves how much our mental world is shaped by our perceptual-motor experiences (Reference CalbrisCalbris, 2002a).
Table 9.7 Physical motivation of notions spatialized on the left and on the right
| Physical Motivation | Spatialization of Notions | |
|---|---|---|
| To the Left | To the Right | |
| Oriented progressions: | ||
| - Growth | Negative | Positive |
| - Walking | Past | Future |
| - Writing | Anteriority-Past | Future-Posteriority |
| Condition-Cause | Consequence-Effect | |
| Body symmetry | X | Y |
| The one | The other | |
| Symmetrical development | < –- Process | Process –- > |
| Bipedal locomotion toward a goal |
| |
| <- Put to one side | Put to one side -> | |
| Digression, Aside | Aside, Digression | |
| Precedence | Others | Oneself |
The three axes – vertical from bottom to top, sagittal from back to front, and transverse from left to right – point in directions according to our perceptual experiences of the process of physical growth upward, the direction of walking forward, and the direction of writing to the right in the West, respectively. For ergonomic reasons, there is a permutation observed between the axes of growth and progression toward the transverse axis, which cumulates their respective symbolic values that are easier to localize on this axis. In addition, the transverse axis reflects another perceptual schema, that of the symmetry in all living bodies (plant, animal, and human) divided into two halves that are equivalent, opposable, complementary, and essential for balance. It makes it possible to create oppositions by localizing symbolic values on the left and on the right, respectively: the bottom and the top, below and above, the lower and the higher, less and more, anteriority and posteriority, the old and the new, the cause and the consequence. In accordance with the symmetrical development of any living body, the comparison of two evolutionary processes is made by the left hand to the left, and by the right hand to the right. Another schema that impresses itself on the mind is our bipedal locomotion toward a goal, which makes us move forward symmetrically (dichotomous enumeration) along a path from which one deviates only momentarily to take a glimpse to one side (digression), indifferently located on the right or on the left. However, an aside, if conceived as a secondary element, is placed on the left. On this axis divided into two halves, the equivalence of two similar entities disappears when it is a question of otherness. The self takes precedence over others. The notion of self (extendable to the group or country to which one belongs) is naturally (logically) expressed on the right for a right-handed person (Reference CalbrisCalbris, 2003c). Last but not least, this axis is the only one that can represent our maximal field of vision of 180° to signify “totality.”
4.3 Multiplicity of Notions Derived from the Schema of Cutting
The schema of cutting appears to be traced in numerous and various notions: SEPARATION, CUTTING INTO PARTS, DIVISION INTO TWO HALVES, BLOCKING, REFUSAL, NEGATION, END, STOP, DECISION, DETERMINATION, MEASUREMENT, CATEGORIZATION, CATEGORICAL CHARACTER, and INTERRUPTION. The action of making a clean cut involves the characteristics of the tool (1) and of the act (2), as well as of its result (3): first of all the hardness and rigidity of the tool (1), then the force and brevity of the strike (2), the impact of the cutting edge against a material object, and finally, the notching and the separation, the production of pieces, and the irreversible nature of the act (3). The schema of cutting is a visual and proprioceptive percept. The meaning is already in the gesture, in the physical feeling of the gesture performed. The understanding of the gesture is physical. Drawing on perception, the semantic extension is already based on the physical and temporal metonymy supported by the act itself, linking the tool, the action, and its result. The gesture thus serves the metaphorical transfer pertaining to each component: instrument, act, and result (Reference CalbrisCalbris, 2003a).
It is important to note that the permanent gestural reactualization of the various foundational perceptual schemas of abstraction at the core of spoken discourse is the most flagrant proof of the physical anchoring of cognition. The premises of the concrete process of abstraction, observed in young children and called “Mimisme” by Reference JousseJousse (1936), seem to be corroborated by the discovery of mirror neurons in humans (Reference Rizzolatti, Fogassi and GalleseRizzolatti, Fogassi, & Gallese, 2001).
4.4 Summary
The analysis of gestural signs referring to the abstract reveals traces of the perceptual schemas that underlie them: our perceptual experiences are bearers of meaning at the origin of our mental constructions, and gesture is the witness of this mental imagery at work during utterance. If a gesture represents the visible form of an idea (i.e. the sketch of a concept), it is to be expected that the gestural formulation anticipates and probably facilitates the verbal formulation of the concept. The gestural sign’s anticipation of the verbal sign is the logical correlate of the gesture’s semiotic specificity.
The gestural expression of a notion anticipating its verbal expression during the utterance process is for Reference FónagyFónagy (2001, pp. 580–581) just the ultimate extension of the essentially preverbal character of gesture that one recognizes in the ontogenesis of language and which may possibly stem from its phylogenetic source.
5. Conclusion
5.1 Research Results Related to Each Source
Source 1. By comparing the physical and semantic data in the database of co-speech gestures referring to the concrete or to the abstract, it was possible to bring to light: (1) at the physical level, the numerous gesture variants of a notion, be they stylistic or semantic variants, (2) at the notional level, the possibility of several gestural signs within the same gesture, be they signs alternatively revealed by the verbal context (polysemous gesture) or simultaneously cumulated (polysign gesture and complex gesture), (3) the discovery of the gestural sign thanks to the gesture variants of a notion, their common physical element being the signifier linked to the gestural signified, and (4) that as a stylized representation of the concrete and a concrete representation of the abstract, gesture is an intermediary between the concrete and the abstract.
Source 2. Facilitated by the software of a prototype videodisc, the meticulous segmentation of the various filmed utterances (first acoustic, then visual by identifying co-occurrent kinesic changes at different levels of the body) and the subsequent identification of verbal and gestural units and the respective information they conveyed enabled their interaction to be studied. An in-depth analysis revealed: (1) complementarity as well as reciprocal disambiguation in the case of concomitant information, (2) the simultaneous multireferentiality of co-speech gesture (polysign gesture), (3) gesture anticipates speech in the spontaneous expression of an original idea to be formulated: In concurrence with speech, the preverbal gesture that visually concretizes an idea maintains its presence in the mind and thus facilitates the verbalization of an idea whose confirmation the interlocutor is waiting for, and (4) gesture is never superfluous: It expresses, animates, explains, synthesizes information, and anticipates speech; it participates and creates participation in the utterance.
Source 3. The statistical analysis of certain recurrent gestures performed during the six television interviews of the former prime minister Lionel Jospin made it possible to show how a frequently occurring gesture potentially reveals the unconscious: (1) the split personality of a person who systematically expresses himself with the left hand as the leader of the Left and with the right hand as a private person, (2) his attitude toward his new function is even reflected in his choice of gesture variant for referring to an abstract object; and (3) gesture reveals the mental imagery underlying utterance (Reference CalbrisCalbris, 2003c; for a review, see Reference De ChanayDe Chanay, 2005; for a video presentation in French, see Reference CalbrisCalbris, 2000 [www.canal-u.tv/intervenants/calbris-genevieve-028605403]).
5.2 Application of the Research to Language Teaching
Based on this research, and since 1975, Calbris has produced pedagogical works in collaboration with Jacques Montredon, pedagogue and linguist, to integrate multichannel communication into the teaching of French as a Foreign Language so that students can physically and intellectually assimilate French prosody (Reference Calbris and MontredonCalbris & Montredon, 1975), voco-kinesic expression (Reference Calbris and MontredonCalbris & Montredon, 1980), gestural expression of notions (Reference Calbris and MontredonCalbris & Montredon, 1986), figurative expression of the language (Reference Calbris and MontredonCalbris & Montredon, 1992), and the semantics of verbal connectors in conversational argumentation (Reference CalbrisCalbris, 2002b; Reference Calbris and MontredonCalbris & Montredon, 2011).
5.3 Position in Relation to Other Researchers
Calbris’ (1983) doctoral dissertation “was one of the first studies ever to attempt a systematic analysis of the ways in which [co-speech gesture] can serve as a vehicle for the representation of conceptual meaning” (Kendon in Reference CalbrisCalbris, 2011, p. xvii). Her work is closely related to the pioneering work of Reference Lakoff and JohnsonGeorge Lakoff and Mark Johnson (1980) on metaphors that draw upon our visual and physical experience of our bodies and of the physical world in which we live. She holds that gesture extracts symbolic material from our physical interactions with the world we inhabit. For her, gesture is situated at the interface between mind and matter and reproduces perceptual schemas (cf. embodied schemata and image schema, Reference JohnsonJohnson, 1987) that underlie verbalization. Hence, her research corroborates Johnson’s theory of “bio-functional embodied understanding” (Reference Johnson2015, p. 7) gained through organism–environment interactions.
Adam Kendon acknowledges that Calbris’ analytic approach partly inspired his concept of gesture families (Reference KendonKendon, 2004; cf. Kendon in Reference CalbrisCalbris, 2011, p. xviii), that is, gestures that share the same configuration and orientation but may differ in respect of movement. Nevertheless, Calbris contends that Kendon overlooks the possibility of the simultaneous plural motivation of gesture that she has found in her corpora (Reference CalbrisCalbris, 2011, p. 283).
Calbris was one of the first researchers to demonstrate and hypothesize about the now widespread observation that gesture often anticipates speech in encoding allied information. Her finding that gesture may aid verbalization concurs with David McNeill’s concept of catchment, that is “recognized from recurrences of gesture form features over a stretch of discourse” (Reference McNeill, Quek, McCullough, Duncan, Furuyama, Bryll and AnsariMcNeill et al., 2001, p. 11), by showing that gestural representation can indeed maintain the presence of an idea over a stretch of discourse. Her investigation of this phenomenon takes into account the possible physical, cognitive, and communicative reasons that may underlie it as well as the perspectives of both communication partners. Her semiological theory of gesture thus interconnects cognitive and communication models of language and furthermore accords with Raymond Gibbs’ theory of “the social nature of embodied, contextually embedded cognition” (Reference GibbsGibbs, 2011, p. 81).
1 Introduction: Background and Context
How might one develop a database of the most common gestures typically used by speakers of a given language? One solution can be found in the work of Elena Grishina, who provided an overview of gestural patterns used by Russian speakers in relation to the lexical, grammatical, semantic, and pragmatic categories in the Russian language. The resulting system entails its own semiotic perspective on gestures, primarily of the hands, head, and eyes. The source for this analysis, discussed in this chapter, was a large corpus of Russian films that were transcribed and annotated for speech and gesture in great detail. The results of this work are valuable in at least four respects. One is that the analysis provides a great deal of information about gesture use from a linguistic point of view for this particular language. A second is that this work can also serve as a model for setting up future projects, showing how such a film database (an audiovisual corpus) can provide a wealth of material for revealing the characteristic gesture forms and functions used by members of a given cultural group. A third is that the qualitative and quantitative methods used can be applied in other analyses of large video databases. A fourth is that the resulting semiotic analysis offers categories that can be applied to investigating gestures used by speakers of other languages. Before delving into specifics, we will begin with some background on the origins of this research and of its main researcher.
1.1 Biographical Note
Elena Aleksandrovna Grishina (1958–2016) graduated from the Department of Russian Studies at Lomonosov Moscow State University, where she also later received her PhD (the Russian “candidates’ degree”). She was the editor of several dictionaries of the Russian language, working as the managing editor for dictionaries of Russian at the Russkij Jazyk (Russian Language) publishing house. After becoming a senior researcher at the Vinogradov Institute of the Russian Language of the Russian Academy of Sciences, she became one of the visionaries and creators of the Russian National Corpus (RNC),Footnote 1 which was specially created by linguists (together with computer scientists) and for linguists. She played a crucial role in setting up the principles behind the corpus and in the annotation of the corpus in the fundamental stages of its development; this included the creation of separate subcorpora for poetry, spoken discourse, and accentology of Russian. Her enthusiasm, collegial support, and selfless dedication created a unique context for working on this project. It was she who came up with the idea of creating a special Multimedia Russian Corpus (MURCO). This corpus is what allowed her to create a fundamental description of the system of Russian gestures in a series of articles as well as in a comprehensive monograph in Russian of 742 pages: Russian gesticulation from a linguistic point of view: Corpus studies,Footnote 2 published posthumously in 2017. She completed the book during the last stages of her final serious illness. The following sections of the present chapter provide an overview of the multimedia corpus and of the findings from Grishina’s detailed analysis of it.
1.2 Ideas and Methodological Starting Points
Grishina’s scholarly work was greatly influenced by two sources: one was the oeuvre of Adam Kendon, as found in his Reference Kendon2004 book and his talks at conferences which she attended; the other was Andrej Zaliznjak’s approach to linguistic material. It was Kendon who convinced her that gesture is an inseparable part of linguistic communication, but one that is underappreciated by linguists; this was something that she also realized in a practical sense. After several years of working on the corpus, she was invited to give a course to the students of theoretical linguistics at Moscow State University in which she pointed out that, watching a video clip without sound and only looking at the gestures, one could reconstitute the emotions, intentions, and possibly even the presumptions of each speaker. (See Reference Savchuk and MakhovaSavchuk & Makhova, 2021, on recent, related research.) She later carried out studies to follow up on this, testing the “deciphering” of the discourse situation of those watching videos without the sound.
The term “decipher” is no accident here. Having been a student and acolyte of Zaliznjak (see Reference Iosad, Koptjevskaja-Tamm, Piperski and SitchinavaIosad, Koptjevskaja-Tamm, Piperski, & Sitchinava, 2018, for an overview of his work), Grishina took part in various projects of his, beginning with the republication of his Grammatical Dictionary of Russian and his work on Russian accentology (Reference ZaliznjakZaliznjak, 2010, Reference Zaliznjak2011). But she was also active in his expeditions to Novgorod to take part in a large project to decipher texts from the tenth to the fourteenth centuries written on birch bark (known as the “birchbark letters”) (see e.g. Reference ZaliznjakZaliznjak, 2004). Zaliznjak’s method of working with this medieval form of writing highlights how researchers solve linguistic problems, bringing to them from the start a confidence that any given puzzle must have a particular solution. It means that the given text, in the form that it has, is meaningful, and that meaning is expressed by its components and their interrelations. This approach demands the full commitment of the researcher to search for systematic rules and correspondences for every sign, and not to take ideas about meaningless accidents such as “scribal errors” as a starting point.
It is this approach which Grishina applied in full in her studies of gesticulation, and she was always fully convinced that every movement accompanying speech was motivated and replete with meaning, semantically or pragmatically: one need only decipher the functions and their combinations incorporated (in all senses of that word) in the gestures. However, to study this, she needed a new tool. This led to the establishment of the multimedia Russian corpus, something which she created practically single-handedly. After preparatory work in the first decade of the 2000s, a pilot version of the multimedia corpus was available, starting in 2010, and even though she was already ill at this time, Grishina worked on this project with complete dedication, providing the lasting legacy we have today.
2 Data: The Multimedia Russian Corpus (MURCO) as a Component of the Russian National Corpus
Grishina’s idea was to create a multimedia corpus that was based not on elicited recordings only available within a given researcher’s lab, but rather on a large number of publicly available “texts” (videos) which – with the proper permissions – could be posted on the Internet for purposes of research and teaching. The idea was that the videos would be posted as separate, specially prepared excerpts. The materials thus came from films or recorded performances in the public domain as well as public lectures.
2.1 Compiling the MURCO Corpus
Building the corpus required dividing up each video with care into self-contained clips which were not too large and of approximately equal size (deleting pauses and also segments without speech), for which the speech in each was carefully transcribed. As a result, each clip was turned into three parts: the video footage, the audio, and the transcribed speech which was available for use in a search engine. The corpus could then be searched for any text (i.e. speech) fragment using the wide range of options available for conducting searches in the RNC. The options then include grammatical and lexical searches, searches by elements of word formation (derivational morphemes) and lexically based grammatical constructions, and others. Conveniently, the searches can be ordered as left-or right-searches (searching for what comes before or after the search term) and in terms of chronological order. The many fragments that can be found in this way can be analyzed for, among other things, their semantics, intonation patterns used with them, or co-occurring gestures.
Consequently, the MURCO corpus contains 4.7 million lexical tokens which have been manually transcribed and morphologically annotated, of which 3.4 million tokens come from Soviet and Russian films and recordings of staged drama and 1.1 million from academic lectures in Russian and documentaries. The films, chosen from those made by the best directors and actors, provide a balanced and representative overview of films in Russian from the era after silent movies, starting in the 1930s.
As an example, a search for Idi[te] sjuda,Footnote 3 “Come here” in the singular and plural imperative forms in Russian, yields 638 clips. Every clip is annotated on several levels (i.e. it is meta-annotated). In addition to the customary attribution of the source, information is provided about the speakers – namely, their sex and age. From the given search, we can note an historical difference in the accompanying gestures. There is a reduction from the gesture of “beckoning with the whole hand” – flapping the hand from the wrist toward oneself – which was practically obligatory in the 1930s (e.g. Rebjata! Idite sjuda! “Guys! Come here!” in the 1935 film Novyj Gulliver “New Gulliver’), to a movement of the head, tilting it to the left and back, as of indicating the intended movement of the subject from his current position toward the speaker (e.g. Slushaj/devockha/idi sjuda. U tebja chego-nibud’ pokushat’ ne najdëtsja? “Hey/miss/come here. You wouldn’t happen to be able to find anything to eat, would you?” in the 1967 film V ogne broda net “There are no shallows in a fire”). Often this head movement is reduced to the point of barely being barely noticeable (e.g. the black marketeer saying Idi sjuda! “Come here!” in the 2008 film Izcheznuvshaja imperija “The disappearing empire”).
Of course, the database of films must be taken on its own terms: it is an empirical question as to what degree the actors’ gestures produced on a film set are representative of what speakers at the time would do gesturally in a conversation that was spontaneous and took place in a location of their choice. For example, it is curious that the gesture of “beckoning with the index finger” is not used in the films with the phrase “Come here,” as might be expected, and rather only appears in an actor’s (I. V. Iljinskij’s) dramatic reading of Anton Chekhov’s short story Khameleon “Chameleon” in 1952. The gestures produced are thus a feature of the genre in which they occur, but nevertheless, they are presumably to be recognizable to viewers who are part of the target-audience-culture (if not also others beyond it), at least at the time the film was made. Following the same principle, the gestures of the characters in the films are taken as “speakers’ gestures” in this research, even though the actors may gesture differently as private individuals, not playing a role and speaking spontaneously.
2.2 Annotation and Coding of Gestures in the Corpus
Compiling the corpus itself was just the first part of Grishina’s work. The second, more significant part, involved the detailed gesture annotation and coding of a rather large portion of the corpus, consisting of six feature-length films, nearly ten hours in total. These are films from different periods that are classics of Russian cinema and reflect a sixty-year period, from 1936 to 1996. All of the gestures in these films have been annotated in the clips excerpted from the movies and have been coded for parameters including the active (moving) body part, any passive body part in the given gesture, the direction of movement, mirrored gestures (repeating an interlocutor’s gesture), and many more categories (described in English here https://ruscorpora.ru/new/en/instruction-murco.html). The categories used for the different parameters are quite detailed: for example, some 50 possible parts are distinguished for the category “active body part.” That list includes not only the fingers, shoulders, head, mouth, eyes, and eyebrows, but also the forehead, lower lip, ear, soles of the feet, and others. For the latter set, various motions are distinguished, such as rubbing one’s forehead, protruding one’s lips (e.g. in excitement or when offended), moving one’s ear up to someone or something (e.g. to listen closely), stamping one’s feet (e.g. alternately, in agitation), tiptoeing, and so forth. Each chapter of the book has a link to an internet database with corresponding illustrative contexts of use of the categories discussed.
The coding of the gestures in the six films was performed by Elena Grishina and refined through repeated checks and revisions. The value of this lies in the consistency with which decisions were made and the level of detail constantly attended to in the forms and movements. Difficult cases were discussed by Grishina and colleagues at conferences and in small seminars to arrive at decisions, but in the end, the corpus is the product of Grishina’s consummate expertise in the study of Russian gesticulation. The principle involved is akin to that described by Reference Stelma and CameronStelma and Cameron (2007); in their case, it concerned the coding of intonation units in transcribed talk. The method described and recommended there involved the annotation and reannotation by a given individual, with refinements over time based on consultation with other experienced researchers, the goal being to produce an expert transcript in which many factors have been taken into consideration.
Ultimately, this multimodal corpus, prepared with such care and expertise (and the expert’s love for her work), constitutes a set of highly valuable material for research in linguistics and gesture analysis. Most prominently, it served as the basis for many of Grishina’s own studies, which are brought together in her Reference Grishina2017 monograph. The book contains four main sections: pointing gestures, representational gestures, auxiliary gestures (a category combining several types of gestures that accompany other functions, such as blinking, licking one’s lips, certain facial expressions, and others, as explained below), and, in conclusion, certain overarching topics (see Reference FedorovaFedorova, 2018, for an overview of the book in Russian). Highlights from each of these parts of the book are provided in Sections 3–6 of this chapter.
3 Pointing Gestures
The topic of deictic gesticulation is considered in relation to pointing with the index finger, the flat hand, the thumb, the head, and gestures pointing at the speaker (autodeixis). Grishina distinguishes several “deictic topoi”: Reference Clark and KitaClark’s (2003) distinction between directing-to and placing-for, and the category of touching (usually with one or more extended fingers) in order to indicate something or to touch someone while speaking to them as an attention-focusing device. In addition to the usual range of hand formations used for pointing, as described in Reference KendonKendon (2004, Ch. 11), for example, a useful qualification is made between fully formed gestural hand shapes and reduced ones, in the sense of involving reduced tension in the hand. See, for example, the index-finger extended, palm down with (a) a tightly gripped hand, (b) half-gripped hand (“semi-bundled,” referring to the grouping of the fingers other than the index finger), or (c) loosely gripped hand (“free bundle”), or (d) a palm-up open hand (PUOH) in the fully tensed form versus (e) with reduced tension, as shown in Figure 10.1. Such distinctions can be very useful, given the frequent nature of relaxed hand shapes in naturally produced gestures which do not appear to neatly fit categories described based on more ideal tense forms (as e.g. shown in Reference Bressem, Müller, Cienki, Fricke, Ladewig, McNeill and TeßendorfBressem, 2013).

Figure 10.1 Full (tense) versus reduced (more relaxed) hand configurations
3.1 Etimons of Pointing Gestures
Another distinction used in Grishina’s system of characterizing deictic gestures is what she calls “etimons.” These are bases of gestural forms, sometimes involving practical actions which can be seen as serving as the “etymology” of certain gesture form/function pairings. The etimons that Grishina describes for deictic gestures are divided into geometric ones and pragmatic ones. The geometric etimons consist of the following:
a point, a unit which cannot be further subdivided, as seen in what the extended index finger points to in a classic pointing gesture;
a line, a distance indicated (one might say traced in the air or on a surface) between two points;
a line segment as an extent, indicated by two endpoints, one of which is the tip of the pointing index finger, and the other being the location of the speaker (compare Reference Hassemer and McClearyHassemer & McCleary’s [2018] model of pointing);
a surface, which may be indicated by the palm of the flat hand, having a given orientation in space;
a volume, which can be shown between flat open hands, or can be understood to be on the palm-side of an open hand, particularly with the palm up, as if holding an object on it by virtue of the force of gravity.
Compare Reference Mittelberg, Evans and ChiltonMittelberg’s (2010) analysis of gestures showing lines, surfaces, and “containers” of volume.
Pragmatic etimons are defined in terms of the pragmatic relation of the speaker and hearer in the act of communication, which, in deictic contexts, is carried beyond the prototypical zone of communication (the space between interlocutors) and related to the referent, indicated via the deixis. Deixis, here, is thus understood more broadly than with the prototypical pointing form, but as generally encompassing gestures with the function of fixating the location of a concrete or abstract referent in space (Reference GrishinaGrishina, 2017, p. 17). Here, the following etimons are described.
The object located on the palm, which of course involves the metaphorical idea expressed with the palm-up open hand, as described in Reference Kendon, Versante and KitaKendon and Versante (2003), Reference Müller, Müller and PosnerMüller (2004), and Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem and Müller (2014b). The palm-up open hand can be used to metaphorically give or request something, with that “thing” usually being a metaphorical discursive object, such as a claim, a question, or another form of speech act.
Suppression – again, metaphorically – of someone’s claim or someone else’s will to do something, controlling the situation in some way with one’s palm-down open hand. (Cf. Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014a, on “away” gestures, of which this is one category; and the discussion of gestural discourse markers in Reference KendonKendon 2004, Ch. 12.)
Vertical orientation of the palm is used with a variety of motions and so covers various types of “away” gestures (Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014a). In that sense, it is characterized as the “null” etimon, in that this palm orientation can serve many functions. It is interesting that it is included with pointing gestures in this classification; whereas other researchers might focus more on the pragmatic functions of such gestures, the idea here is that the palm is still used as the means of orienting deictically to a referent, whether it is physical or abstract.
A vector that can be imagined projected from the tensely extended index finger with other fingers in a grip, as in Fig. 10.1a. This serves such functions as fixation of a referent or more generally as a way of directing the interlocutor’s attention along the axis of the vector.
The “signal” etimon is the engagement of the interlocutor in the communicative context or the drawing of his/her attention to one or another gesture via the increased use of tension of the pointing hand. This tension can occur in the arm, in the hand itself, and/or in the grip of the other fingers with index finger pointing (see in Figure 10.1a, less so in Figure 10.1b, and not at all in Figure 10.1c). As Grishina discusses in Section 2.5.4 of her book, this gestural etimon is often used with explicit, stressed verbal demonstrative expressions, for example, with the open hand, Zachem èto nado bylo davat’ chitat’ {vot èto vot pis’mo} postoronnim ljudjam? “Why in the world did you have to let outsiders read {this very letter}?” (where curly brackets mark the word cooccurring with the gesture, in this case a tense palm-up open hand with the arm stretched straight out) (Reference GrishinaGrishina, 2017, p. 102).
Further analysis of the etimons described above, and the various finger and hand configurations described for deixis, lead to one of the characteristic features of Grishina’s work, which is a set of analyses of co-occurrence patterns. These cover form features occurring with other form features and forms occurring with functions as used by speakers of Russian (compare Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem and Müller’s [2014b] analysis of recurrent form-function pairings for speakers of German). All are counted across the entire video corpus used, and then tested using chi-square analyses to assess which combinations occur significantly more often, statistically speaking. For example, one analysis (total N=1287 gestures) of the form combinations compares use of the orientation of the palm with the extended index finger hand shape (with the other fingers closed in a fist) versus with the open hand. It shows that the palm-up orientation occurs significantly more with the open hand, while the palm-vertical (i.e. palm facing laterally) and palm down occur significantly more with the extended (pointing) index finger. Further analyses consider referential, semantic, and pragmatic factors influencing the configuration of the pointing hand.
3.2 Pointing with the Thumb
To give a further taste of Grishina’s approach to analysis of deictic gestures, we can consider the special attention she gives to pointing with the thumb. According to Grishina, pointing with the thumb, by contrast with pointing with the index finger or the head, has some specific characteristics in the Russian system of gesticulating. Some of these are familiar from descriptions of thumb pointing by speakers of English or Italian, known from Reference KendonKendon (2004), but Grishina’s analysis of them adds some specific insights.
The first specific feature to note with pointing with the thumb in the given corpus concerns its spatial characteristic that it is usually directed to the back, behind the speaker. This means that it is indicating a zone that the speaker cannot see. Therefore, the pointing is, as a rule, not directed at any object in the speaker’s field of vision, and often attributes to this object the quality that its specific localization is not important or is not known.
Deriving from this, the second feature is functional in nature: pointing with the thumb often realizes an anaphoric function. Its meaning is revealed by the previous context, which may have involved pointing with the index finger or the open hand. In addition, whereas the speaker’s gaze when pointing with the index finger may have been directed at a specific concrete object, pointing with the thumb was found to usually be accompanied by gaze at the interlocutor. The anaphoric function appears in the fact that thumb pointing is often used with lexical and morphological units which mark contrast (e.g. use of comparative forms). Pointing with the thumb thus falls under the category of Russian gestures which convey the idea of distancing, and anaphoric contexts can be seen as examples of a form of distancing between a speaker and an object (or referent) which is not located in his or her zone of visibility. This can concern visibility either in the physical sense or metaphorically in the case of abstract referents, for which “visibility” can be understood in terms of cognitive awareness of the referent. Thus, what elsewhere has been named “abstract pointing” (Reference McNeill and LevyMcNeill & Levy, 1993) is labelled “cognitive pointing” by Grishina, and has to do with pointing to spaces to indicate ideas, sometimes using contrasting spaces to differentiate different ideas (see also Reference McNeill, Cassell and LevyMcNeill, Cassell, & Levy, 1993, on “abstract deixis”).
The idea of being distanced can also appear in other ways. For example, pointing with the thumb can orient one to assertions made in the past, rather than in the present. One other phenomenon that is fundamentally communicative is that by pointing with the thumb at someone, speakers may distance themselves from those pointed at in a way that impersonalizes them or objectifies them. It is for this reason that doing this is seen as rude (and not only in Russian culture).
Finally, the lack of concrete localization of an object can be related, in a certain sense, to the opposite situation: rather than distancing oneself from an object or interlocutor, there can be a kind of reduction of distance when an as yet unfamiliar object is introduced in the listener’s attentional field (think of referring to something “on the side”). In this situation, the speaker also might not specifically localize that object in space, but simply inform the listener of its existence through thumb pointing in order to activate that referent in the conversation.
3.3 Pointing with the Head
We can compare this analysis with Grishina’s basic distinction between how deictic head gestures can be differentiated: the inclination of one’s head to the side (tilting), turning one’s head, moving one’s head forward, and pointing with the chin, as illustrated in Figure 10.2.

Figure 10.2 Types of deixis indicated with the head
One of the findings of her analyses of head gestures was that in deictic situations, head pointing always preceded hand pointing. The head and hand pointing can be seen as a deictic configuration in which the head gesture sets up what Grishina called “a degree of abstractness in the indication of an object.” If the deictic referent is located in the general zone of visibility, a forward movement of the head or chin pointing is used. If the object of pointing remains in an invisible zone – then a head tilt or head turn. Following the head gesture, pointing with the hand determines more fine-grained differences more precisely between the potential target referents within the targeted zone and provides a further, more detailed “referential and pragmatic calibration of the object of reference.” However, functionally, the hand pointing correlates with the head pointing and, practically speaking, cannot contradict it. Any head gesture can be combined with pointing with the open hand or the index finger, since these hand gestures can serve for the speaker’s visible zone as well as the zone that is not visible. Pointing with the thumb – as discussed above, connected with the nonvisible zone behind the speaker – correspondingly “prefers” the head tilt or the head turn, but not movement of the head forward or pointing with the chin. Grishina summarizes the various functions of these main categories of head and hand pointing for Russian speakers in Table 10.1.
Table 10.1 Summary of deictic forms and functions for the head and hand (adapted from Reference GrishinaGrishina, 2017, p. 169, Table 4.23, with permission from the publisher)
| Head gesture | Selection of traits | Hand gesture | Selection of traits |
|---|---|---|---|
| Head tilt |
| Open hand |
|
| Head turn |
| Index finger extended |
|
| Head forward |
| Thumb extended |
|
| Chin point |
|
3.4 Pointing Gestures: Some Conclusions
The main idea running through these analyses is one which was noted earlier, particularly for the gestural etimons, namely that of the motivation of a gestural form and the non-randomness of the functional-semantic parameters connected to it. There is an interdependence between them and there is a foundation for this connection, to be found, for example in the use of a specific body part in specific communicative and informational contexts, and this use has certain potential consequences in terms of the possible inferences that can be drawn from it. We can see this in the examples discussed above of the use of the thumb versus the head for pointing, summarized in Table 10.1.
Descriptions of some of the gestural forms considered by Grishina are still relatively rare in the gesture literature, such as head gestures, and among them, pointing with the head (as opposed to with the lips, as described in Enfield, 2009, Ch. 3, and Wilkins, 2003). Furthermore, as with the analysis of thumb pointing, the author pays attention to the combination of several gestures in one situation – and reveals the potential motivation of this combination. Finally, we have observed that Grishina’s analyses do not just speak of the functions (deictic, representational, pragmatic, etc.) of gestures in relation to the forms, but also of the meanings of certain uses of gesture, even using the term “semantics” in doing so. In this way, another aspect of her linguistic point of view on gestures comes through, as the term “semantics” is applied not just to the verbal elements, but also to the gestural ones, allowing for a distinction between semantic and pragmatic functions, as will become clearer below.
4 Representational Gestures
One of the features of Grishina’s approach to the study of gesture is that it is built not only on the relation of specific gestures to particular functions, as is found in many analyses of gesture, but also on other relations, namely those of:
specific linguistic units to the gestures that accompany them
the geometry of movement to its semantics
general grammatical and lexical meanings and functions in language to gestures correlated with them.
We see these categories laid out in detail in the extensive section of her book (278 pages, which could constitute a book in itself) devoted to representational gestures. Here we can only provide a few illustrative examples.
4.1 The Relation of Linguistic Units to the Gestures that Accompany Them
The first theme noted above, the relation of specific linguistic units to the gestures that accompany them, appears to be rather standard in gesture studies, if we think, for example, of the substantive amount of research on the lexicalization of motion events in different languages and the gestures used with them (e.g. Reference Gullberg and PavlenkoGullberg, 2011; Reference Kemmerer, Chandrasekaran and TranelKemmerer, Chandrasekaran, & Tranel, 2007; Reference Kita and ÖzyürekKita & Özyürek, 2003; Reference Özyürek, Kita, Allen, Furman and BrownÖzyürek, Kita, Allen, Furman, & Brown, 2005). In Grishina’s book, however, this theme was picked up in some other ways. For example, a large section is devoted to patterns of gesture used with Russian prefixes and verb roots, with attention to the many lexicogrammatical meanings expressed by Russian prefixes, which are known for their polysemy. One of the results of her research in this area – which, as usual in her work, was illustrated in detail and supported with statistical analyses – was that Russian verb prefixes are distinctly divided into two groups: the “path-based” and the “vector-based.” “Path-based” prefixes include, for example, pere- “re-”Footnote 4 and raz- “apart”; such prefixes can be seen as functioning like analogues of adverbs. The “vector-based” prefixes include v- “into,” do- “as far as,” and na- “upon,” for example. They are usually used in constructions with prepositions that pair with the prefixes (e.g. v-khodit’ v [literally “in-go in”] “to go into,” or do-khodit’ do [lit. “as far as-go as far as”] “to get to”). The vector-based prefixes are often used with verbs in metaphorical senses (e.g. vybrat’ “to choose” [lit. “out-take”], dovesti “to lead to” a given situation [lit. “as-far-as-lead”]).
In terms of gesture use, it is only the path-based prefixes whose trajectory and direction are conveyed in gestures; see Reference GrishinaGrishina’s example (2017, p. 257, example [7.3_14]) for the prefix-suffix combination s- -sja “come together”: “Rjabchik molchit, lesnichij krichit, vse {sbegajutsja}” “The grouse is silent, the forest ranger shouts, and everyone {comes running}” – with a two-handed gesture on the word {sbegajutsja} moving from a peripheral to a central gesture space after making a circular motion (example from the 1979 film Letuchaja mysh’ “The bat” by Ja. Frid et al.). The vector-based prefixes, however, were not found to express trajectory and direction of the motion being verbalized as much as simply indicating the starting points (e.g. with ot- “from,” s- “from,” vy- “out of”) and end points (v- “into,” do- “as far as,” pod- “up to”) of the movement. For example (Reference GrishinaGrishina, 2017, p. 262, example [7.3_24]) for the prefix vy- “out of”: “Vsjo otnjali prokljatye kapitalisty, s {raboty vygnali}!” “The damn capitalists have deprived us of everything, they fired people [lit.: from {work out-chased-they}” – with the speaker’s open left hand, palm down, moving rapidly in a straight line from right to left (from the central to the periphery).
The examination of gestures used with words involving these morphemes thus provides new insights into semantics from a usage-based perspective. This is particularly clear in cognitive linguistics, for example, where meaning can be viewed in terms of the concepts speakers are expressing (Reference Cienki, Müller, Cienki, Ladewig, McNeill and TeßendorfCienki, 2013): gesture can provide additional insights into speakers’ semantics.
4.2 The Relation of the Geometry of Movement to Semantics
The second of the three themes is in itself no trivial matter, and it is one that is also of interest from the point of view of typology. At issue here is how a given spatial trajectory relates cognitively to certain aspects of semantics. Grishina’s book considers, in detail, types of oscillating movements in gestures with two hands (both symmetrically with, and in opposition to, each other) or with one hand making circular movements (as if encircling a sphere or something round, making cyclic rotations, and others) and their general and individual meanings in relation to the speech. This shows in detail how tightly, and in what contexts, oscillating movements are connected with the semantics of “uncertainty” (which one sees even in the linguistic metaphor of to be wavering about something to mean to be uncertain about it), “ambivalence” (e.g. the temperature is vacillating between two values), “variety,” and others; the circular movements, however, convey meanings of “non-specificity,” “repetition,” “transformation of an object,” and others. (Compare the “swaying” gesture with similar functions found among German speakers, reported in Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem and Müller, 2014b, also noted semantically as the “Vague” recurrent gesture in Ladewig, this volume.)
4.3 The Relation of General Grammatical and Lexical Meanings and Functions in Language to Gestures Correlated with Them
The third theme builds a bridge from several large semantic categories – those such as quantifiers, negation, characterization of sizes of objects, expression of realis versus irrealis (hypotheticals), and others – to the gestural layer of communication. On this level of generalization, the research comes full circle: individual gestures and geometric movements express particular meanings and relate to specific situations, and specific types of gestures are characteristically used with particular linguistic units – all of this because there are concepts and categories for which gesture provides a natural, and perhaps necessary, means for marking. Here with representational gestures, we see what could also be considered “etimons” as discussed above – bases of gestural forms which can be seen as constituting the “etymologies” of particular gesture form/function pairings.
While it is known in general that gestures can serve as markers of sizes or quantities that can be easily perceivable visually, Reference GrishinaGrishina’s research shows (2017, p. 563) that in Russian, small sizes and quantities (both physical and abstract/metaphoric ones) are shown with at least three kinds of markers: the “fraction,” in which the pad of the index finger touches the thumbnail; the “pliers,” when the pads of the thumb and index finger as if hold a small object between them; and the three-finger pinch (thumb, index, and middle), as if holding a small amount of a substance, such as salt. These categories reflect specifications of gestures which otherwise might be grouped under a general label of the “precision grip” (cf. some similar but different distinctions made in Reference KendonKendon, 2004, Ch. 12, for Neapolitan Italian).
Gestures corresponding to lexicogrammatical categories are shown in this line of research to express various kinds of abstract meanings. Putting aside negation for the moment, a topic well known to gesture researchers (see Harrison, this volume) which is also illustrated in detail in various sections of Grishina’s book, we find consideration of gestures for the categories of irrealis (p. 244 ff.); in the MURCO corpus, the forms for expressing hypotheses and intentions correspond to gestural marking of future time (e.g. manual gestures with left to right motion), and for unreal conditions they correspond to the marking of past time (e.g. involving movement toward behind the speaker).
Separate sections of the book are devoted to the gestural marking of tense and aspect. In particular, the analysis of aspectual forms in Russian (perfective and imperfective aspect) reveal (pp. 573–587) that it is important to consider not only formal parameters of gestures, like “duration” or their “multiplex” nature (which are typical for use of the imperfect aspect in continuing and iterative contexts), but also the intensity of the gestures (the parameter of “energetics,” characteristic of the perfective aspect), which is connected with how the stroke of the gesture is produced, allowing for a more abrupt motion. It is significant that this semantic category is studied here not as an isolated subject, but in the form of gestalts – that is, the potential mutual influences the grammatical categories and gesture may have on each other. This includes consideration of linguistic parameters on different levels, such as the grammatical factors of tense, aspect, and modality in relation to the pragmatic factor of the type of illocution.
These kinds of interrelations are illustrated well in the detailed analysis of gestures used with quantifier words in Russian (pp. 463–481). In particular, four such words were selected for in-depth study due to their frequent use as quantifiers in the language and the fact that they are known to be semantically rich. These are: ves’ “whole/total,” vse “all,” “kazhdyj “each/every,” and ljuboj “whatever/anybody.” All of them can be used in singular and plural forms with any given lexeme. The gestures used with them, however, indicate that they all differ from each other conceptually. Gestures with ves’ tend to involve representation of a round form, reflecting the referent as a whole object, as if the quantity were being viewed from the outside; however, gestures with vse tend to show the indexical selection of objects in different ways, such as in a row or on a surface, and thus are as if viewing the quantification from the inside. As for kazhdyj, which concerns extensional quantification, the hand typically does not move, but fixates (e.g. with the three-finger pinch) on only one point, presenting in this way the whole selection of referents as a quantum. The quantifier ljuboj, which is semantically similar to kazhdyj in representing positive semantic polarity in this domain, was found to be used with a completely different type of gesturing, namely manual gestures of negation (e.g. palm down, sweeping to the side/peripheral space [as in Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014a]) or a side tilt and turn of the head. This reflects implicit negation, characteristic of the intention to express “it doesn’t matter what kind/it’s all the same which one”; this is negation which, interestingly, does not appear in syntactic constructions with the word ljuboj.
These various strands of research show that gesture accompanying lexicogrammatical categories contributes new qualities to them and creates new connections in terms of their meaning – and this multimodal perspective raises questions about the boundaries of these categories. The following section continues with consideration of movements accompanying speech which play a supporting role – auxiliary gestures, which few scholars in gesture studies have paid attention to before.
5 Auxiliary Gestures
Bodily movements that speakers make which have the function of organizing their utterances, rather than expressing their basic ideas, are what Grishina calls auxiliary gestures. These mainly involve small facial gestures, like those of the eyes and mouth, but some special manual gestures also fall into this category. Auxiliary gestures thus constitute a broader category than what some call discourse-structuring gestures, particularly since the latter are usually only discussed in terms of the role of manual gestures.
An especially important role among the auxiliary gestures is played by the eyes, including gaze direction, whether the eyes are open or closed, and blinking. The first chapter in this section of Grishina’s book is thus entitled “The grammar of gaze” (Grammatika vzgljada), recalling the term “gaze grammar” employed in Reference Wiemann and KnappWiemann and Knapp’s (1975) study on turn-taking in conversation. To take one main issue as an example, analysis of the MURCO corpus shows how important gaze direction is for the organization of dialogue, namely at the edges of turns at talk: The interlocutor takes the floor with his/her eyes, as it were. (Compare the similar findings discussed in Reference GoodwinGoodwin, 1981.) Additional factors that play an influential role here are whether the topic is new or already given (cf. the distinction between Theme and Rheme, known from functional linguistics, or Topic and Comment from the Prague School of linguistics), and how well acquainted the interlocutors are with each other.
A fundamental category that Grishina employs in her discussion of the use of auxiliary gestures is that of the “zone of communication” – the space between speakers, if they are face to face at a standard distance from each other for conversation. For example, eye gaze direction was found to play a distinctive role between “yes” and “no” responses in relation to the zone of communication. Statistical checking of the quantitative results revealed that eye-gaze shifts within the zone of communication were found to be significantly more frequent with yes-responses than with no-responses, whereas eye gaze either starting outside the zone of communication and moving into it, or starting within it and moving out, were significantly more frequent with no-responses. Negation thus occurred more with contrastive eye-gaze movement, in comparison with affirmative responses.
The transition of gaze into or out of the zone of communication – indicating focal topic shifts, among other things – was found to be complemented at times by blinking. Blinking is an auxiliary gesture which, while often more of a physiological reaction to some stimulus, also serves a variety of functions for parsing discourse. Among other things, blinking takes part in the marking of pauses and hesitation, which can be part of the interruption of speech in self-correction. (Compare a similar function in some sign languages, e.g. as Reference ProzorovaProzorova [2009] shows for Russian Sign Language.) In addition, Grishina’s research generally confirms and develops, based on Russian data, the findings of Reference LoehrLoehr (2007) from American English concerning the connection between blinking and word stress in speech. However, some findings of the two works diverge from each other; for example, the claim that closing one’s eyes occurs before the rhythmic peak in one’s speech was not supported by Grishina’s findings. While this may complicate the view that blinking is a general cognitive-physiological mechanism, the different nature of the data in each case (feature films vs. videos of unscripted conversations) could be a factor that can help account for the differing results – leaving a question open for future research. On the whole, one can say that blinking (in combination with eye-gaze movement into, out of, and within the zone of communication) along with head tilts and other movements, serves as a marker of pausing (a kind of embodied punctuation mark), but it is also a marker of the rhythmic structure of phrases (i.e. accentuation).
The topic of blinking also plays a role in a more general chapter that comprises the second part of the section on auxiliary gestures, that is, a chapter on closed eyes. Here the discussion begins with closing one’s eyes as a meaning-bearing gesture, and then blinking as an auxiliary gesture. While closing one’s eyes can clearly constitute a physiological reaction (as when squinting from a bright light), it can also be used as a sign, as something to communicate an idea. For example, it can be used by the speaker to signal that the incoming information is unpleasant, excessive, or too stressful (and so the speaker is as if trying to decrease the burden on themselves by closing their eyes). Among the other interesting points considered is how closing one’s eyes can be part of a “ligature,” as Grishina calls it, a gestural alloy, in which some gestural signs are bound with other accompanying gestures in serving a certain function. Think, for example, of shaking one’s head with closed eyes in the act of negating.
This work on auxiliary gestures not only broadens the traditional scope of gesture research but also provides a unified way of thinking about the behaviors that are studied here. As with all of the sections of Grishina’s monograph, the study of auxiliary gestures, based on the MURCO corpus, moves us away from the tradition of studying these behaviors based on dialogues in English (as she notes [Reference Grishina2017, p. 486]), at one particular time of data collection, and into consideration of them as used by speakers from another language and culture and over a period of several decades. In turn, this provides new bases for cross-cultural comparison of these kinds of gestures in future work based on large video corpora.
6 Cross-Cutting Topics on Gesticulation
The final section of the book under discussion here considers what are called cross-cutting themes in the study of gesture. It concerns meanings/functions which are the most clearly and the most frequently expressed in gesture. It thus sums up the kinds of gestures discussed at various points in the book but does so from a different point of view. There are many grammatical categories which are not expressed gesturally, or for which we as yet have no evidence of their expression in gesture, such as reflexive forms of verbs or the difference between verbs and nouns derived from verbs (all of which are known grammatical phenomena in Russian). But there are other kinds of categories whose expression frequently or even necessarily involves the use of gesture, built in as part of the utterance. (Compare the research on multimodality in construction grammar, e.g. the special issue edited by Reference Zima and BergsZima and Bergs, 2017.)
These categories primarily concern pragmatics – fundamental illocutionary acts, such as posing questions, making assertions, or using imperatives (cf. the recurrent gestures discussed in Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014b), or more superficial ones, such as making an exclamation. The latter could be accompanied by gesture in a more or in a less salient way, for example, raising one’s flat hand upward (with the palm facing the central gesture space) as a kind of intensifier for the whole utterance, or with a small movement of the hand from the waist downward (what Grishina calls a form of “marginalia”; compare verbal marginalia of the type that are said quietly to someone on the side so that others will not hear them). However, in addition to pragmatics, there are some ten important semantic zones which were found to be used with characteristic patterns of gesturing. They are the concepts of multiplicity, definiteness and indefiniteness, activation of a referent, remoteness of a referent, size and quantity, contrast, equality/equivalence versus contrast, activity, and distancing. While space does not allow for elaboration on these here, Grishina provides an overview of each of these in relation to gesture use in Russian, meaning that, in principle, one could use these as a basis for a cross-cultural comparative typology.
The last semantic category considered is that of aspect in Russian and its gestural correlates. The basic distinction made in Russian grammar may appear simple on the surface: that between imperfective versus perfective verb forms. Described simply, perfectivity involves a view of an event as a whole, whereas imperfectivity is the “other” category, often involving viewing an event in terms of its internal constituency. The distinction is one which is notoriously difficult for learners of Russian as a second language to acquire if they do not already speak another Slavic language. Part of the complexity is due to the fact that, morphologically, there are a number of different ways in which perfective and imperfective verb forms may differ in Russian and other Slavic languages, including prefixation, suffixation, and infixation. Yet despite the conceptual and morphological complexities involved in using these verbs, there are surprising correlates in gesture use between certain sets of imperfective and perfective verbs. For example, Grishina found that gestures with imperfective forms were significantly more often longer in their temporal production, and those with perfective verbs were disproportionately often shorter, given the overall production of longer and shorter gestures in the dataset. Gestures with perfective verbs were significantly more likely to be produced with a fist versus a flat hand shape than would be expected by chance, given the overall distribution of these two hand shapes in the data. Of the imperfective verbs, those in the subcategory with a multiplicative meaning were disproportionately more likely to be accompanied by multiplex gestures than simplex gestures. These are a few of the many contrasts that were found.
7 Looking Ahead: Gesture Studies and Corpus Research
The main accent of Grishina’s work was on developing a complete inventory of tags for gesture annotation – something comparable with the inventory of tags for grammatical annotation of a verbal corpus (as Grishina had done with the RNC), the categorization of genres or text types, or the annotation of texts in a poetry corpus for rhythm and rhyme, and so on. In all these cases, the user of the corpus is presented in the search interface with a table that has a selection of features and the possibility of choosing concrete values for each feature to conduct a search. The composition of such a table – even for Russian grammar, which has been described by linguists since the eighteenth century, and for which there are several grammatical dictionaries – is no simple task. That is, even when the grammar of a language is well understood by linguists, the process of turning the known categories into a set of tags that can be applied to a corpus and be used by researchers is quite a challenge.
The complexity that Grishina faced in working with MURCO involved a number of elements. They concerned developing a classification that would be (1) adequate from a scientific point of view, (2) all-inclusive, in the sense of encompassing the very large amount of material constituted by the corpus, and (3) comprehensible to a user of the corpus. All of this had to be done from scratch, as at the time she began, there was no tradition of doing this for gesture. To do this, she had to start from the gestures, determining their meanings in the various contexts in which they occurred (cf. the work of Calbris in this regard [Reference CalbrisCalbris, 2011, and in her chapter with Copple, this volume]), and go from every text fragment (i.e. the semantics of the speech in the clips) to the corresponding gestures in the fragment. This work encompassed not only the manual gestures but all gestures that were visible, including those of the head, the eyes, and even the legs, and involved various possible functions that they might fulfill. Taking into consideration the categories that were already tagged in the RNC, the work involved relating gesture to, for example, the system of Russian deixis, grammatical aspect, the tense system, the lexical taxonomy, and so on, considering how gestures play into these systems and what their special characteristics are. Such a research move was dictated by the existing format in the RNC and by Grishina’s interests as a researcher, and in this, we see her uniqueness.
Therefore her book, and of course the MURCO corpus, can be considered an encyclopedia of Russian gesture, much as Aleksandr Pushkin’s work Eugene Onegin is considered by many an encyclopedia of Russian life of the nineteenth century. Not surprisingly, it lends itself to further analyses in Russian linguistics from a multimodal perspective. One example is a project undertaken by Reference Rakhilina, Bychkova and ZhukovaRakhilina, Bychkova, and Zhukova (2021) involving the study of idiomatic discursive formulas in Russian such as Ne govori! “You said it!” [lit. “not speak”] and Da ladno! “No way!” or “Give me a break!” [lit. “yes fine”], as collected in the Russian Pragmaticon (https://pragmaticon.ruscorpora.ru/). Expressions of refusal and of agreement were analyzed in relation to the gestures commonly used with them. One finding was that often the identical gestures were used for both opposing sets of meaning. For example, the same gesture of moving one’s head back was found to occur in the corpus with both of the following affirmative and negative responses: with the expression a kak zhe (lit. “but how” + emphatic particle) when expressing that one’s agreement with a proposal should be considered obvious (e.g. the question-answer sequence “Za gribami pojdësh’?” “A kak zhe!” “You’re going mushroom picking?” “But of course [I’ll agree to go too]!”) and with the discursive formula da ladno (lit. “yes fine”) in the meaning of disagreement due to disbelief (e.g. On zhenilsja? Da ladno! “He got married? No way!”). This demonstrates either a kind of enantiosemy (autoantonymy) in gesture, of the type seen in words like sanction in English (which can mean either “permit” or “penalize,” depending on the context), or that both expressions have some pragmatic meaning in common, such as presumption in the case of the two examples just given (the presumed obviousness that the speaker would agree to join in for mushroom picking and that the speaker doesn’t believe that the person mentioned is getting married). In this way, the study of gesture tied to corpus linguistics can reveal new categories of language and communication in use.
The book by Grishina can also be used more widely, for comparison with the gestural system of speakers of other languages. But first, more of such descriptions from other languages/cultures will need to become widely available. With the gradual introduction of more search options, instructions, and glosses being provided in English for MURCO, it is the hope that it will help stimulate the development of the typological study of gesture. As a small example, a comparison with Calbris’ work on French (see Calbris & Copple, this volume) shows that approximation in both Russian and French is commonly shown gesturally in the same way (with rotational oscillation of the open, relaxed hand; cf. the wavering hand in German, described in Reference Bressem, Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemBressem & Müller, 2014b). Similarly, finality (e.g. of a decision) in both languages corresponds to the metaphor of cutting, performed with a flat hand in the vertical plane, and the same straight movement and flat handshape, palm down, moving in the horizontal plane corresponds to cutting down. In both languages, close deixis is indicated with a movement of a finger or the head, while distant deixis involves movement of the hand. A more systematic comparison between Reference CalbrisCalbris (2011) and Reference GrishinaGrishina (2017) and the respective corpora used by each would be an excellent starting point for developing the typological study of gesture. Even if the approaches in the two works differ, comparison and contrast between their findings would widen the fields of inquiry within which each one has worked.
Another basis for potential comparative studies is the “MultiPARK” (https://ruscorpora.ru/new/search-multiparc_rus.html), a pilot English-Russian multimodal parallel corpus which Grishina initiated as one of her last accomplishments in 2016. The corpus contains fragments of serials and films in English (serials include dramas and comedies like Big Bang Theory, ER, and Friends), that were dubbed in Russian. Each film has been cut into small segments, consistent with the practice used in MURCO, and provided with the transcription of the original speech in English and the Russian dubbing. Upon performing a search in the corpus, one can view the clip in the original English as well as the dubbed version. Besides allowing for various comparative analyses of English and Russian (e.g. on word order, intonation, phonetic phenomena), the corpus can provide a starting point for comparative English-Russian gestural analysis: one can conduct corpus searches for specific word forms, lemmas, grammatical features, semantic categories, or other features (such as repetitions). Since the search results yield both the English and Russian versions of the video clips and transcripts, one can then use the Russian search results as input for searches in MURCO to see what gestures are used in Russian-language films. New materials continue to be added to this corpus, including performances of translations of some works. For example, a performance in Russian of Anton Chekhov’s play Djadja Vanja (Uncle Vanya) filmed in a theater in St. Petersburg is paired with a film version in English produced by the BBC. This will facilitate direct comparison of gesture use across the two versions of such works. In addition, an English version of the search interface and of the accompanying instructions are currently in preparation. This resource could prove particularly useful for English-speaking students of Russian or for Russian speakers learning English.
Here it is also worth mentioning the development over recent years of the UCLA Library Broadcast NewsScape,Footnote 5 another corpus which has been collecting news-related television programs in English from the United States, but also in other languages from other countries (including in Russian from Russian state television), since 2005. The videos are also searchable via an interface developed by the International Distributed Little Red Hen Lab.Footnote 6 Permission to use the database is required and information on obtaining access is available on the Red Hen site.Footnote 7 A prime feature of the database is that the closed-caption transcription (for the deaf and hearing-impaired television audience) is captured with the videos, allowing for rough searches of the speech. This can permit searches for speech-accompanying gestures not only based on lexical items, but also on parts of speech and other categories made available through the Red Hen search interface. This resource has already served as the basis for a number of research projects and publications.Footnote 8 A similar database, but limited to US programming, is the Television Archive News Search Service,Footnote 9 part of the Internet Archive. The site and search interface are publicly available, and while the range of search options on this site is limited, it has also been used successfully for gesture research (see e.g. Reference Winter, Perlman and MatlockWinter, Perlman, & Matlock, 2013). One point to bear in mind in using such video databases, however, is that any search requires “cleaning” in order to make the results useful: since these databases are not already coded for gestures, any search of the speech transcripts yields many video clips in which the person speaking is not shown, or only the speaker’s head is shown, or the speaker’s gestures are covered by titles or other information superimposed on the bottom of the screen, etc. In that regard, the MURCO corpus yields immediate results with gestures, due to the detailed nature in which it was annotated.
As far as Grishina’s own work with the database she herself compiled, it involved collecting an unprecedented amount of gestural examples that were not only analyzed by her for their forms and functions/meanings (work which was checked and revised based upon multiple passes), but also analyzed in relation to the linguistic categories of the accompanying speech, with all of this having been made accessible and searchable in an online database. The main result obtained from these efforts was the demonstration that the system of gestures accompanying speech in Russian is functionally and semantically rich and is intrinsically connected with use of the Russian language. Thanks to her work, we now have, on the one hand, an openly available linguistic resource which researchers have already been using for a number of years, and on the other hand, what can be called an encyclopedia of Russian gesticulation: A kind of reference work, data, and generalizations from them, which are valuable not only to scholars of Russian, but to the future field of gesture typology.
1 Introduction
This chapter presents the physiologically based approach to gesture analysis that was developed by Dominique Boutet (1966–2020). It was commissioned for this Handbook because of the uniqueness of this system and its rich potential for application. The chapter provides the most extensive presentation of the kinesiological approach available in English; for a shorter introduction to it see Reference Boutet, Morgenstern, Cienki, Cienki and IriskhanovaBoutet, Morgenstern, and Cienki (2018a) and Reference Morgenstern, Chevrefils, Blondel, Vincent, Thomas, Jégo and BoutetMorgenstern et al. (2021 ). An extensive explication of it in French is available in Dominique’s Habilitation (Reference BoutetBoutet, 2018), with the short original overview of the ideas having been introduced in Reference BoutetBoutet (2010) and in Reference Boutet and MorgensternBoutet and Morgenstern (2020).
As explained below, looking at gesture with this system provides insights into the biophysical bases of what someone does when producing a gesture, as opposed to most existing systems, which are based on descriptors of how observers see others’ gestures. In essence, the kinesiological approach looks at gesture from the inside, rather than the outside. The chapter begins with looking at the what, the how, and the where of the traditional approach to gesture analysis before turning to the “muscle and bones” of the kinesiological system. The description goes into some depth in terms of physics and human physiology, the latter in part reflecting Dominique’s original training in the field of medicine. However, even readers not conversant with the technical terminology involved can derive insights from the general principles of the system. The system will also be of interest to those working with motion-capture analysis of gesture, as the parameters can be translated for use with such technology.
2 Outline of the Classical Frameworks for Analyzing Gestures
2.1 On the Hand Only (the “What”)
The typologies frequently used for gesture analysis in the past few decades may have been influenced by, and may be entangled in, an old tradition of taxonomy coming from antiquity (Reference Quintilian and CousinQuintilian & Cousin, 2003, Lib. XI). Quintilian’s classification is based on the hand and fingers. Witness the exaggeration of the hands in the early medieval illustrations of the Roman dramatist Terence’s works (Reference AldreteAldrete, 1999; Reference Radden KeefeRadden Keefe, 2021), and the focus on the hands continuing into Reference BulwerBulwer’s (1644) Chirologia. Reference EfronEfron (1942/1972), too, classified gestures focusing on the hands, leaving the other segments of the upper limb “in limbo.” Reference KendonKendon’s (2004) taxonomy is a hierarchy based first on hand shapes, second on the orientation of the palm, and third on the movement of the hand. Reference CalbrisCalbris’ (1990) typology of gestures highlights the importance of the palm of the hand, the fingers, and the head as “bodily vehicles” of meaning. In all of these approaches to gesture studies, the hand as a tool of interaction with the world is literally considered as the core of gestures. For Sign Languages, the tradition is similar. The first such notation system, created by Reference BébianBébian (1826) for French Sign Language, also focused on the hands. The twentieth century was no different, from Reference StokoeStokoe (1960/2005) to Reference SandlerSandler (1989), Reference BrentariBrentari (1998), Reference CuxacCuxac (2000), or Reference LiddellLiddell (2003). They all present a modeling of the hand excluding, in fact, the forearm, the arm, and the shoulders. The four parameters of Sign Language – the hand shape, the orientation of the palm, the location of the hand in space, and the movement – are all centered on the hand.
The distal part of the upper limb, the hand, is considered as the effective part of bodily communication. In the main studies of gesture, especially during the twentieth century, the part carrying the essential meaning is the hand: the rest of the upper limb is merely considered as a mean of displacement for the hand, allowing it to reach a given location. Reading between the lines, the conception of the meaningful part of gestures has probably been influenced by the practical dimension of gestures and the usefulness of the grasping part of the upper limb – the hand and the fingers.
It is true that analysis of certain gestures considers other segments of the upper limb, for example: shrugs of the shoulders expressing some kind of incapacity (Reference DarwinDarwin, 1872/1998; Reference DebrasDebras, 2017; Reference StreeckStreeck, 2009); quick forward movement of a shoulder expressing disinterest (Reference BoutetBoutet, 2010); a posture of arms akimbo as a mark of social supremacy (Reference Spicer, Bremmer and RoodenburgSpicer, 1991); crossed forearms in front of a speaker meaning prohibition (Reference CaradecCaradec, 2005, p. 145); the phallic forearm jerk as an insult (Reference CalbrisCalbris, 1990, p. 6); the “sidearm gut punch,” as Calbris wrote, expressing a retort (Reference CalbrisCalbris, 1990, p. 4); the forearms beneath one another on the chest in medieval illustrations depicting a situation of distress (Reference GarnierGarnier, 1989, p. 152), to name but a few. However, most of the analyses made during the last century seem to be cut off from or a bit disconnected from this reality of gestures.
2.2 Visuality as Exteriority (the “How”)
Beyond the potential influence of manual praxis on the way gestures have been analyzed, taking the more distal segment – the hand – as the locus of gestural activity could also come from the conception of what is relevant for speech in linguistics. The externalization of speech as a signal cut it off from the body. Apart from an articulatory approach to phonology (e.g. Reference Browman, Goldstein, Kelso, Rubin and SaltzmanBrowman et al., 1984), which seems to constitute a minority in the field, the main trends in phonology are based on acoustics. Therefore, what is seen as significant in speech is the externalized signal and not the possible bodily structuring leading to its production, which could also have been considered as speech. The constraints on how the most widely analyzed means of communication – speech – is most commonly studied skews how most researchers consider gestures.
The attention to externalization, noted above, detached from the producing body, focuses, de facto, on the receptive modality of language: the auditory channel. For gestures, the receptive modality – vision – is obviously sensitive to the segment that moves the most. This trend, considering meaning as an externalization (“ex-pression”), pushes attention toward that side of things more than to the gesture in its own right and in its unfolding. The image produced or the trajectory created, as results, are perceived as having more value than the gesture which builds them. Therefore, awareness of such significance is diverted from the track of production to the manual gesture and the trail it traces. In other words, preference is given to studying frozen drawings (artifacts) over analysis of the quality of the movement – the kinematics of the hand – which comes far before the construction of a gesture along the upper limb, and which has its own geometry, giving rise to how it moves. The latter is what constitutes a kinesiological approach.
Beside the praxiological argument and the “external” one (which is actually more of an epistemological issue), a third reason explaining the focus on the hand may exist. It is linked to the frozen representation we have of symbolic phenomena. As linguists, we are used to working with transcriptions of speech adapted from systems of writing. The flow of the speech is segmented and labelled. Writing fixes speech into static representations (e.g. letters, for languages written with an alphabet). Except for work by linguists who research prosody, a vast majority of publications deal with static representations of language because of the transcriptions used. Our difficulty in grasping dynamic phenomena is related to this kind of representation, namely a writing system. We do not know clearly what is at stake. The writing system could be the basis of our difficulty in understanding the dynamics of what is involved, but, more ontologically, writing could be a solution, coming from our difficulty with embracing dynamics. Regardless of the direction of the causality, transcription leads us toward tracks (writing, in this case) – leaving out, in the shadow, the trails traced and the articulatory gestures of the speech. This has consequences for the visual analysis of gesture, noted above.
Despite the existence of transcription systems for Sign Languages (such as HamNoSys [Reference Prillwitz, Leven, Zienert, Hanke and HenningPrillwitz, Leven, Zienert, Hankke, & Henning, 1989], SignWriting [Reference SuttonSutton, 1995], and the Berkeley Transcription System [Reference Hoiting, Slobin, Morgan and WollHoiting & Slobin, 2002]), none of them have become prominently widespread in their use; they are usually applied locally (e.g. in Hamburg or Berkeley for the systems mentioned). No conventionalized writing system exists for cospeech gestures. This lack is compensated for by using drawings or screenshots of gestures, chosen for their prototypicality, and sometimes complemented by arrows or lines indicating the direction of the movement (trajectories). These photographic representations, appearing to respect what is going on with peculiar gestures, provide the illusion of reality. They freeze gestures into postures, removing the dynamics. These representations cut off the gestures from the naturalness of their embodiment (kinesiology) and, then, the process of their production (kinematics) is devalued, yielding only the benefit of information on the direction of the movement of the hand (sometimes depicted by arrows).
These three reasons give arguments that explain the focus on the hand and the static conception we have of gestures. We describe and preferentially analyze one segment of the gestures, and do so according to an image of one moment; this sort of compression of time primarily creates a representation at the expense of leading to a genuine study of gestures and their deployment. Following the presentations above of the object studied and the conception of time in which it is placed, we present now the frame of reference of the space with which gestures are described.
2.3 Egocentric Frame of Reference (the “Where”)
The question of the space where gesturing unfolds has actually been addressed by Reference Kant, van Cleve and FrederickKant (1768/1991) in a wider spectrum. The issue tackled in his essay concerns the potential bases for differentiating a region of space as a relationship between two entities (situated in relation to one another) as opposed to absolute space – in other words, the question of the grounds on which the geometry rests. In the absence of any Cartesian coordinates or any measurement units, we can situate any object in relation to the living body. The categories left and right, which we always have “on hand,” establish the ultimate ground of this differentiation. In this sense, we do not need any coordinate to localize any entities (Reference Richir and SiksouRichir, 2005). In this way, a hand is situated up or down, a bit higher or less so, at the left or to the right, in front, far in front of myself, or behind. The body as the tool of this conception of measurement seems to be particularly appropriate as the origin and the frame of reference for gestures.
Considering the way gesture has been studied so far, the object of study is roughly unique (the hand), and is as if cut off, at least intellectually, from the upper limb; its representation, in drawings or screenshots, is unique as well, and, hence, determined by the singular point of view of the image. The hand (at the tip of the forearm) is the most mobile segment. It can translate (move without rotation or angular displacement) or rotate in space, if not freely, at least in almost all locations. Considering its distal specificity, almost detached from the body, a similar frame of reference could suffice for the nature of this segment seen in this way: (1) distal, (2) still dependent on the bodyFootnote 1 but not really linked to it, and (3) lateralized. Among the three frames of reference described by Reference Levinson, Bloom, Peterson, Nadel and GarrettLevinson (1996) – absolute (and usually geocentric), intrinsic (and centered according to an entity), and relative (generally oriented according to the speaker) – the last one meets the three features mentioned above: (3) A lateralized, egocentric frame of reference (henceforth: “ego FoR”) applies simultaneously to the (2) specific features, still dependent on the body, and (1) the distal feature of the hand. Reference McNeillMcNeill (1992) situates the location of the hand as being around a speaker, in an ego FoR, as Kendon does (Reference KendonKendon, 2004). All of the approaches in Sign Language phonology (e.g. the Hand Tier Model [Reference SandlerSandler, 1989], the Prosodic Model [Reference BrentariBrentari, 1998], and the Hold-Movement Model [Reference Johnson and LiddellJohnson & Liddell, 2010, Reference Johnson and Liddell2011]) are based on this type of FoR. The terminology could change (ipsilateral vs. contralateral for the lateralization, distal vs. proximal for the distance from the body), but the principles of the location still rely on an ego FoR.
The choice of the ego FoR has another consequence for gestural phenomena. It is quite impossible to situate simultaneously two segments attached by a joint without having to refer to a local landmark situated on the segment considered (maybe an intrinsic FoR) or without any reference to the orientation. The description of any free moving entity in space – as the hand seems to be considered – entails six possible degrees of freedom (logically independent parameters along which values can vary): translational movements in the three directions of space (XX’, YY’, ZZ’) plus three rotations of the entity on itself: the yaw (rotation in the horizontal plane along its vertical axis), the pitch (rotation along its lateral axis), and the roll (rotation along its longitudinal/sagittal axis).
Considering, for instance, a gesture produced with the hand in front of the chest, fingers aligned, pointing toward the central space in front of the speaker, the palm presents several possible locations. The palm might be in a frontal plane in either of two orientations: toward the speaker or away from him. Alternately, the palm might be in a transverse plane in one of two orientations: palm down or up. The palm could be positioned in any intermediate location between these two planes. In this transversal plan where the palm is facing down, the elbow might be elevated higher than the palm, for example, in a gesture of pushing down, or, on the contrary, it might be lower than the palm, as in the beginning of a gesture indicating a growing size. If the elbow is in the same transversal plane of the palm, the gesture might depict a size (“this high”), or the beginning of an expression of totality (with a horizontal movement outward), or any growing or lowering movement. A movement of the wrist might express a withdrawal (extension of the wrist upward), a rollover (rotation of the wrist), or (at least in French culture [Reference Calbris and MontredonCalbris & Montredon, 1986, p. 75]) a “go away” gesture (pulling of the hand outward to the side, away from the median axis of the body, in what is known as abduction of the wrist).
This suggests that the framework of spatial reference above is ill suited to describe the requirement of the movement, and that we need to situate all segments of the upper limb according to their potentialities. A kinesiological basis for gesture analysis thus seems to be needed.
3 Conditions for a Kinesiological Description
The way gesture researchers traditionally use an ego FoR situates the entities and actually blocks any attempt to spell out the interrelations between the segments of the upper limb. It seems to be paradoxical to consider that a unique FoR, covering the whole body, prevents full comprehension of the kinematics of its chained elements (shoulder, arm, forearm, hand, fingers). However, it is a consequence of both gesture researchers’ isolating the hand from the rest of the body, and of the tautology of applying a measure coming from the body to a body.
The fact that we use the ego FoR as a means to situate the hand – considered as an independent segment, which has such mobility that it is almost detached from the body and able to be a complex tool for our communication – forces us to locate it with six degrees of freedom (dof), as we could any free-floating object in space. This conception of gesture is antithetical to the notion of chaining. We certainly know that segments of the upper limb are interrelated, but our habit of analyzing gestures in this way hides this reality.
The second reason for this difficulty with invoking the ego FoR for the analysis of gestures is related to the (too) narrow proximity between the FoR and the object measured. Applying this tautological measurement from a greater distance leads at best to situating segments. Using a bodily form of measurement to characterize the body itself reifies the body as an object. This reification de facto takes away the reality of embodiment (Reference BottineauBottineau, 2012; Reference GuignardGuignard, 2008). The measuring tools we need should not just situate, but must provide the exact potentialities of each segment, no more and no less.
3.1 Intrinsic Frame of Reference on Each Segment
An intrinsic FoR locates the environment according to the entity considered. For the hand or forearm, their environment matches the possibilities of motion, that is, categories grouping the axes of the movements of each segment, in and of themselves, named proper movement. We differentiate a proper movement from a displacement. A forearm might be displaced by a proper movement of the upper arm and hence move incidentally, without any proper movement of the forearm itself, carrying the hand to the same location as the one that could be reached by a proper movement of the forearm.
The geometry of the joints between the segments determines the possible proper movement of each segment itself. Anatomy is relevant here. Movements are categorized according to dof which in this context correspond basically to a rotation of a segment around an axis which is usually situated on a joint. Nevertheless, we distinguish two types of dof: the one whose axis crosses joints, and the other whose axis runs along bones. The second type is distributed in two places: along the humerus (the bone from the shoulder to the elbow), and along the two bones extending from the elbow to the wrist: the radius (the outer and slightly shorter of the two bones) and the ulna (the inner and longer of the two). The other, whose axes cross the joints, are in the complex of the shoulder, in the joint of the arm, in the elbow, in the wrist, and at each knuckle of the fingers.
These dof involve a specific geometry per segment. All movements are generated on axes and each segment turns around them to a certain amplitude. This fact has consequences. It means that straight movements are not simple, but complex, requiring the involvement of at least two segments and three dof. They need a high level of coordination. On the contrary, arc movements may involve just one degree of freedom from one segment. Our conception of gesture complexity is changed. We are not dealing with a disembodied Euclidian space where arcs are the addition of a translation (movement along a line) coupled with a rotation, where circles are the continuity of a certain arc, and where lines seem to be the simplest geometric realization. With the body, space(s)Footnote 2 is/are not just a locus where the hand traces a form, but one(s) where potentially all segments are able to “inform” us. A hierarchy can be drawn up. First, gestures inform us thanks to proper movements. They delineate both forms and the information so designed. We need to find out which gestures are concerned with which forms. Second, movements of segments can be recruited, by the tip of the upper limb – the hand or the fingers – or by any of the dof of any segments, to gesture in order to draw or point to something significant. These latter gestures might be seen in a Euclidian space, and we can speculate in these cases that the traditional ego FoR is available to situate the form drawn.
Two types of gestures have thus been identified here. In the first type, the embodied gestures design meaning by forms in non-Euclidian spaces of gestures, sometimes through their deployment along several segments. The second type depicts meaning in space through the form that is deployed.
3.2 Gestures Are Embodied before They Are Seen
Gestures are embodied before being seen and interpreted as drawings. Their structuration is made first logically and then physiologically by the production part of this gestural/visual channel of expression. The visual way of structuring gestures (categories of depiction and drawings of them, à la Reference Müller, Müller, Cienki, Fricke, Ladewig, McNeill and BressemMüller, 2014) comes afterward. Embodied gestures inhabit gestural forms produced in certain spaces. Obviously, these motions are made in space, but this fact is relevant just for gestures as structured by vision. A gesture structured by the arm puts the hand in a wide but delimited zone. For example, when the arms are pulled backward along one’s sides, with the palms of the hands facing forward (as in Figure 11.13.1), expressing incapacity, the hands might be in a zone which could be covered by a cone with its widest part on the sides of the trunk and in front of the speaker. Within this cone, the space usable by the hand or the forearm when they are not involved in the expression of incapacity might involve gesture structured by the environment – oriented, for instance, toward a situation on the side of the speaker. If the gesture is structured with the hand indicating a refusal (in the traditional description with the palm facing away from the speaker), the hand could be in one of several locations, facing the position of the object refused. For embodied gestures, space is not valuable; the forms of the segments with their movements or their postures are the only elements of meaning. These kinds of gestures can be structured visually at a secondary level, in that their meanings can be anchored in the space of interaction or in the environment. Certainly, the form of the gestures then seems to belong to the environment and, therefore, to be structured by how they are seen, but this only adds an indexical part to the already structured meaning. For the refusal gesture – an embodied gesture – the location of the hand in space certainly comes from the visual structuring. Whenever possible, embodied and visual structuring add to each other in gestures.
We will present the characteristics of embodied gestures through the dof distributed over the segments of the upper limb, focusing on their geometries, and their chaining. We will show how movement is transferred from segment to segment and concentrate on one of the key principles of the distribution of movement: the flow of gestures.
4 Core of the Kinesiological Approach
4.1 Characterization of the Degrees of Freedom (Geometry and Amplitude)
4.1.1 The Arm
The shoulder joint has three dof. Because of these three axes of rotation, it actually belongs to the enarthrosis family of ball and socket joints (Figure 11.1 inspired by Reference KapandjiKapandji, 1997, p. 5). Considering axis 1 in the first image in Figure 11.1, the transverse axis that is contained in the frontal plane, this degree of freedom defines the flexion/extension movement of the arm (Figure 11.1, second image, inspired by Reference KapandjiKapandji, 1997, p. 7), involving movement of the arm in the sagittal plane, passing through the shoulder. The amplitude of the flexion goes from 0° (Figure 11.1, first image) through 90° (Figure 11.1, second image), up to 180° (maximum, Figure 11.1, third image), whereas that of extension reaches a maximum at 50° (Figure 11.1, fourth image). These two extremes are only very rarely used in symbolic gestures and in Sign Language. On the other hand, a range between 30° of extension and 90° of flexion constitutes the usual zone of production for these gestures.

Figure 11.1 The three axes of the arm and the flexion/extension. First image: the three axes. Second and third images: the flexion of the arm. Fourth image: the extension.
The rotation of the shoulder joint around the sagittal axis (axis 2) brings the arm in a frontal plane to move away from the median plane by up to 180° by abduction (see Figure 11.2, second image, inspired by Reference KapandjiKapandji, 1997, p. 9). In the other direction, the arm approaches the median plane by passing in front of the chest up to an amplitude of 30° (Figure 11.2, third image [cf. Reference KapandjiKapandji, 1997, p. 7]). It should be noted that the presence of the trunk prevents a pure adduction (pulling toward the median axis of the body) from occurring. It is always made possible by a flexion of the arm so that it passes in front of the trunk or by extending the combined arm behind the trunk (Figure 11.2, third image). The adduction of the arm behind the trunk is very low. The abduction/adduction ranges used in gestures and Sign Language are between 90° and 20°.

Figure 11.2 Axis 2 and abduction/adduction of the arm. First image: axis 2. Second image: abduction. Third image: adduction.
The third axis of the shoulder runs along the humerus (the bone from the shoulder to the elbow). It defines an internal and external rotational movement (Figure 11.3, second image, adapted from Reference KapandjiKapandji, 1997, p. 11). The maximum amplitude of the exterior rotation is 80°, and the total amplitude of the interior rotation is 95°. The latter is about 30° when the arm remains stuck on the side of the body. To reach the remaining 65°, the arm must be shifted to the side by an abduction movement.
Figure 11.3 Axis 3 and exterior/interior rotation. First image: axis 3. Second image: exterior rotation. Third and fourth images: interior rotation.
4.1.2 The Forearm
The elbow joint is of the trochlear type (pulley-shaped), that is, it involves a fossa (depression or hollow area) on the humerus in front of a corresponding bone ridge on the ulna side. This type of articulation allows only one degree of freedom (axis 1, Figure 11.4). However, there is an overlap between the ulna and the radius (axis 3, see Figure 11.5, first image). It determines a second degree of freedom, as we will see. Thus, on the forearm, including the elbow, two dof exist (Figure 11.4, first image, and 11.5, second image, inspired by Reference KapandjiKapandji, 1997, p. 99). The flexion/extension moves the forearm forward from the frontal plane (around axis 1, see Figure 11.4) or, in other words, it aligns the forearm with the upper arm. The reference position (aligned upper arm and forearm) sets the extension and flexion at 0°. The flexion amplitude does not exceed 145°, the limitation being given by the touching muscle masses. The extension can exceed the set 0°, especially in the case of hyperlaxity (“double-jointedness”). The entire amplitude of this movement is used in both gestures and Sign Languages.

Figure 11.4 Axis 1 and flexion of the forearm. First image: axis 1. Second image: flexion of the forearm.
Pronation-supination is a rotational movement visible on the hand due to the overlapping bones of the forearm (around axis 3, see Figure 11.5). When the palm is turned forward, this is a complete supination position; the ulna and radius are in the same plane and do not cross each other (see Figure 11.5, third image). When the palm faces backward, the position involves a complete pronation; the two bones of the forearm overlap (Figure 11.5, first image). The axis of rotation of this movement runs along the forearm. The maximal amplitude of these two movements (pronation and supination) is 85° to 90° each (Figure 11.5, first and third images; cf. Reference KapandjiKapandji, 1997, p. 107). The neutral position, called the intermediate position of the hand, has the palm facing a sagittal plane, when one stands with one’s arms hanging relaxed on the sides of one’s body (Figure 11.5, second image).

Figure 11.5 Axis 3 and supination/pronation of the forearm. First image: pronation. Second image: axis 3. Third image: supination.
4.1.3 The Hand
The hand has two dof. In the palm plane, an abduction/adduction movement and perpendicular to the palm plane, a flexion/extension movement. In what is called the anatomical position (with hands hanging by one’s sides, but with the palms facing forward), the movement leading to an abduction pushes the distal end of the palm toward the side of the thumb. The amplitude does not exceed 35° (Figure 11.6, third vertical pair of images). Adduction, however, is carried out in the opposite direction, to the pinkie this time, and always in the plane of the palm. Its maximum amplitude is about 45° (Figure 11.6, first vertical pair of images; cf. Reference KapandjiKapandji, 1997, p. 151). This pair of movements involves the smallest amplitudes of the upper limb. We will return in Section 4.2 to the impact that these amplitudes have on the deployment of gestures and signs.

Figure 11.6 Axis 2 and abduction/adduction of the hand (two views of each). First vertical pair of images: adduction. Second vertical pair: axis 2. Third vertical pair: abduction.
The second degree of freedom – flexion/extension – carries the hand in front of the frontal plane for flexion and behind the same average plane of the anatomical position. The amplitudes of these poles are similar: 85° for each (Figure 11.7).

Figure 11.7 Axis 1 and extension/flexion of the hand. First image: extension. Second image: axis 1. Third image: flexion.
4.2 Variations of the Geometry of the Degrees of Freedom during Movement
Beside these simple movements, joints with two dof, such as enarthroses (ball and socket joints) and joints with condyles (bones with a rounded ending), when set in motion together, have an impact on a third dof when it is a longitudinal rotation (interior/exterior rotation for the arm; supination/pronation for the forearm). The two movements in question are referred to as diadochal movements, that is, successive movements around the same joint that are not performed in the same plane (Reference MacConaillMacConaill, 1946, Reference MacConaill1948). To illustrate this type of movement, let us place the left arm along the body; the forearm, in a flexion of 90°, points forward; the hand is in a so-called intermediate position: the palm is in the vertical plane, the fingers pointing forward, the thumb is oriented upward (see Figure 11.8, first image). The forearm is then affected by a movement of exterior rotation (Figure 11.8, first intermediate position). In a second step, the forearm is carried upward by a flexion movement followed by an interior rotation movement that seems parallel to it (see Figure 11.8, second intermediate position). At this high point, the forearm is returned to its initial position by a simple movement of extension. The final position differs from the initial position in that the thumb is now inward, with the palm facing downward (see Figure 11.8, final position). In fact, an involuntary pronation movement has occurred between the initial and final positions without this degree of freedom being set in motion at any time.

Figure 11.8 Pseudo paradox of Codman.
When we break down the voluntary movements, we notice that it is precisely in the sequence of the flexion of the forearm and the interior rotation that this pronation movement appears. The inversion of the order of movements has a repercussion on the dof affected by this involuntary movement. Let us put ourselves in the same initial position and reverse the movements. This time the forearm undergoes an interior rotation initially bringing the inside of the forearm against the chest and then a flexion followed by an exterior rotation. Finally, by the same extension movement of the forearm, we return to the initial position. The palm is in a supination position, turned upward this time. The order of the movements voluntarily activated on the forearm determines the repercussion it has in the involuntary movement.
The same mechanism of appearance of joint movement is at work in what is called Codman’s paradox (Reference CodmanCodman, 1934). This time, the movements of the arm are involved and the repercussion in the form of involuntary movements is spread on the arm as well as on the forearm. Let us start from a position with the arms and forearms along the body, with the palm of the hand in the sagittal plane, facing inward (see Figure 11.9, initial position). A first flexion movement of the arm of 180° carries the hand over the shoulder (see Figure 11.9, second position). A second 180° adduction movement of the arm also brings it back to its initial position on the side. The palm is still in a sagittal plane, but this time it is turned outward (see Figure 11.9, final position). Two conjunct movements have appeared: an exterior rotation of the arm and a complete supination. The hand has turned 180° (90° of exterior rotation and 90° of supination).

Figure 11.9 Codman’s paradox. First image: the initial position. Second image: flexion of the arm. Third image: adduction. Fourth image: final position; notice the position of the thumb.
To show that these last two conjunct movements take part in the cycle of voluntary movements (abduction and flexion of the arm), we start from the same initial position of the arm, but with the palm in the sagittal plane turned outward. The forearm is therefore in a position of total interior rotation and the hand in a position of maximum pronation. In this new initial condition, the abduction movement of the arm does not reach 180°; the arm remains locked around a 90° position. The interior rotation and pronation are already in place, blocking the movement of the arm. The involuntary movements on the forearm and hand therefore serve as an “escape.” Like the diadochal movements seen on the forearm and hand, Codman’s paradox is sensitive to the order in which the cycle of voluntary movement is set in motion.
The third place of conjunct movements is on the hand. It is also due to a biomechanical mechanism and relates to the kinesiological approach to gestures. The situation on the wrist is basically the same as for the elbow and shoulder. The wrist has two dof (flexion/extension and abduction/adduction) on which is added pronation/supination, a longitudinal rotation that corresponds to this escape of a diadochal movement seen for the elbow.
In the same way as forearm movements, hand movements, when combined or sequenced, have an involuntary repercussion on pronation. The sequence of the movements of the two dof specific to the hand gives rise to an involuntary repercussion: pronation or supination, as shown in the images in Fig. 11.10.

Figure 11.10 Gimbal lock on the hand. The alignment is sensitive to the pole maintained. In extension, abduction and pronation are linked, whereas in flexion, abduction and supination are aligned.
A few gestures attest to this type of association between manual abduction/adduction and pronation/supination. The “goodbye” gesture (waving the hand) can be done via a slight oscillation in abduction and adduction or by a repeated movement of supination and pronation (Figure 11.11, first image) when the hand is in a position of extension. In another context, a gesture of reprimand in French culture (“Beware of spanking!”) shows the hand in a marked extension position also oscillating either slightly according to an abduction/adduction movement or according to an alternating and wider pronation/supination movement (Figure 11.11, second image, with the three robots). A third gesture in this extension position means a negation made with the index finger that presents an alternating movement either in abduction/adduction or in a wider way in a combination of pronation and supination (pronosupination, Figure 11.11, third image). A gesture with a marked meaning made in a position of flexion of the hand (expressing the exclamation “Oh là là!” in French) offers both possibilities of movement (abduction/adduction or pronation/supination) for the same meaning (Figure 11.11, fourth image). This last gesture – in a flexed position – reverses the associations. This time abduction is aligned with supination and adduction with pronation. The association of the poles is opposite for gestures in the extension position. These gestures therefore integrate perfectly a biomechanical/kinesiological fact without the alternation of abduction/adduction or pronosupination changing their meaning.

Figure 11.11 Examples of gestures with manual alignments. First image: “goodbye” gesture. Second image: “beware of spanking.” Third image: negation gesture. Fourth image: “Oh là là!” gesture
The three sequences of movement – on the arm (Figure 11.9), forearm (Figure 11.10) and hand (Figure 11.11) – show (1) an involuntary movement on at least one degree of freedom, (2) a polar sensitivity of the involuntary movement to the sequence order, and (3) a physical problem of gimbal lock.
A gimbal is a ring suspended in such a way that it can rotate around an axis. On a ship, one may see several rings mounted inside each other in a fixed frame, holding the ship’s gyroscope level thanks to the different axes of rotation of the rings. However, if two of the gimbals end up in a parallel configuration, one of the axes of possible rotation is lost, which is called a gimbal lock. Similarly, the occurrence of involuntary bodily movement, mentioned above, occurs when two of the three axes are almost aligned, and even as this alignment approaches. Thus, the spaces of the embodied gestures are not Euclidean and they also interpenetrate from one segment to another. Their geometry is modified, reducing the number of dof, in an apparent way. Is the transient reduction in the number of dof – physiological or even kinematic – integrated into the very structure of the meaning of gestures? Or, on the contrary, do these reductions not have any effect on the structuring of meaning? The polar inversion of involuntary movement observed on the hand (the combination of supination/abduction or supination/adduction depending on flexion or extension) answers these questions. The oscillating examples, seen above, show that the meaning of the gestures uses the constraints of the gimbal lock by stabilizing their shapes. In general, the involuntary movements are downward, that is, the gimbal lock exerts its action mainly on the adjacent distal segment (the forearm for the arm, and the hand for the forearm).
After detailing the components of upper limb movement and the kinesiological relationships between dof, it is necessary to define how movement propagates along the upper limb in order to better understand how a regularity of gestural forms provides the stability needed for the emergence of meaning.
After recalling the definitions of proper movement and displacement of each segment, and the movement transferred or received from another segment, we will see how to determine from which segment a gestural movement originates. Finally, after having defined the propagation and origin, we will see that the notion of movement propagation flow allows us to identify the course of movement along the upper limb.
4.3 Proper Movement, Transfer, and Displacement
A segment can move as the result of its own mobility (proper movement), or as a result of the movement of another segment (displacement). These two cases do not produce the same effect. The actual mobility of a segment participates in the process itself, while displacement seems to contribute more to maintaining the gesture during the stroke: to situate it, to show its extent. We can define the proper movement of a segment as the set of rotations around at least one degree of freedom of the target segment, without this movement coming from a degree of freedom of another segment. We will call displacement of a segment a (series of) translation(s) due to a more proximal segment, without any change in the position of the dof of the displaced segment. In cases where a movement affects a segment, a distinction must be made between proper movement and transferred movement. We will call transfer of movement all rotations around at least one axis of one of the dof of the segment involved due to movement of at least one other degree of freedom, that is: Movement of one degree of freedom results in movement of another. This transfer may come from another proximal or distal segment or from the same segment.
Let us consider how these characteristics of movement play out in the gesture of “presentation” (Reference Calbris and MontredonCalbris & Montredon, 1986, p. 29; Reference KendonKendon, 2004, pp. 210–214, 265). A complete execution of this gesture involves movements of supination, abduction, and extension of the hand. This triple movement of the hand spreads over the forearm according to an extension and an interior rotation (see Figure 11.12).

Figure 11.12 Gesture of presentation while the speaker says, and seems to notice, “they have returned” (“Ils sont revenus”). This small clip corresponds to a decomposition of each image. There is a movement of extension, supination, and adduction of the right hand from image 1 to image 6.
The movement(s) of supination, abduction and/or extension of the hand can therefore be totally transferred to the forearm, but then for this gesture to be identified as a presentation, the hand must be in a position of minimum supination. This is then a transfer of movement, and the hand is not “displaced,” as the movement it undergoes is not only due to the movements of a proximal segment, since the movement of the forearm comes from the hand.
Let us now examine the case of a gesture where the forearm moves according to the same factors (extension and exterior rotation) but with the hand held in an intermediate position (neither pronation nor supination) (Figure 11.13, first image, Vladimir Putin’s example).

Figure 11.13 Gestures expressing incapacity. In the first image, Vladimir Putin’s hands are in an intermediate position (neither pronation nor supination), the forearms in an external rotating position and the arms in an abduction position due to the highly visible shrugging of the shoulders. In the second image, Nicolas Sarkozy’s hands are in a position of supination, the forearms in a position of exterior rotation, while the arms stuck to the sides are in an adduction position. Kobe Bryant, the basketball player in the third image, has his hands in a marked supination position with a strong flexion position of the forearms, with his upper arms at his sides. It seems that the supination position does not condition the positions of the forearm or upper arm.
This gesture (Figure 11.13) does not have the same meaning as the previous one (Figure 11.12); it expresses epistemic negation, in the sense that Reference GosselinGosselin (2005, p. 4) defines it, that is, a “de facto judgment resulting from a subjective evaluation,” an incapacity (Reference KendonKendon, 2004, p. 275; see also Reference Calbris and MontredonCalbris & Montredon, 1986, p. 80). Being held in this position, the hand is displaced this time. It could be in a more pronounced position of supination and extension (Figure 11.13 second image, Nicolas Sarkozy). The supination position, in particular, should be marked as in the previous gesture (see Figure 11.12) to allow a transfer of the manual extension as an extension of the forearm and the manual abduction as an exterior rotation. But this is not the case. It can therefore be concluded that the movement of the forearm does not depend on the movement of the hand. But, conversely, the movement of the hand comes from that of the forearm. The propagation of the movement along the upper limb is, this time, proximal-distal.
Does the segment that does not move constitute the origin of the total transfer of the movement or is it only affected by a displacement? To find out, we need to compare the number of dof moving on each of the segments, including the number that would have moved if movements had affected it. The number of oppositional types of movement involved (abduction/adduction, flexion/extension, pronation/supination) determines the origin of the gesture. The smaller the number, the closer we get to the segment that initiated the action. If we review some of the last gestures seen above, the one expressing incapacity (Figure 11.13) shows three kinds of manual movement (supination, extension, and abduction), two kinds on the forearm (exterior rotation and extension), and only one kind on the (upper) arm (adduction). The segment at the origin of this gesture is therefore the (upper) arm. The gesture of presentation – as soon as it shows a supination position, even an average one – can then be performed by an extension movement of the hand and can be transferred to the forearm by an exterior rotation and a movement of extension. The hand is therefore the segment at the origin of this gesture.
Another clue, more related to the deployment of the gesture, consists in looking at how the gesture runs along the upper limb, that is: determining the flow of propagation of the movement. This is what we will see in Section 4.4.
4.4 Flow of the Propagation of the Movement
The upper limb is a portion of the body across which movement propagates in a temporal order. Determining this order is difficult, primarily due to the fact that two time-delayed movements are in a causal relationship. For this, we need to set out rules.
With the inertia rule, proximal segments prevail as the movement proceeds along the upper limb. From the inertial point of view alone, the flow of movement is from the arm to the hand. Indeed, in relation to the body, the average adult proportion of the center of mass of each segment is 2.3 percent for the arm, 1.5 percent for the forearm, and 0.55 percent for the hand (Reference Dumas, Chèze and VerriestDumas, Chèze, & Verriest, 2007). There is therefore a decreasing gradient of the center of mass going from the arm to the hand. The inertia of these segments if they are in motion depends directly on the mass of each segment; it follows the gradient of the center of mass.
A second rule (joint limit rule) is counterbalanced by a gradient that marks the potential for transfers as a movement approaches its maximum amplitude. The effect of this rule may counteract the effects of the previous rule by shifting the transfer of movement to a larger inertia segment. Thus, maximum flexion of the hand boosts a transfer to the forearm, a segment with greater inertia. The abduction/adduction of the hand, whose amplitude is very limited, very often has its movement transferred to the forearm.
The third rule (geometric rule) concerns the parallelism of the axes of rotation between the segments. It concerns the direction of transfers. A motion transfer occurs under the necessary (but not sufficient) condition that the axis of rotation of the movement is parallel and adjacent to the one or ones on which the motion will be transferred. The direction of movement determines the type of the polar transfer (e.g. abduction vs. adduction).
The fourth rule (diadochal rule) concerns involuntary conjunct movements. Involuntary movements occur as soon as a joint has two dof and a movement affects both of them (so-called diadochal movement [Reference MacConaillMacConaill, 1946]). We then have an involuntary conjunct movement of the third degree of freedom.
The movements that appear in a gesture without being in this transfer ratio summarized in Table 11.1 constitute independent movements. Let us consider the cases of movements transferred along the upper limb. Three situations are defined: one for which the flow of movement propagation during a gesture or sign goes from a proximal segment to a distal segment (proximal-distal flow); another for which the flow of propagation goes from a distal segment to a proximal segment (distal-proximal flow); a third possibility for which there is no flow (without flow).
Table 11.1 Summary table of the four rules that affect movement of the upper limb segments
| RULE | AFFECTS | DIRECTION of the TRANSFER |
|---|---|---|
| Inertia Rule | From chest to knuckles | Proximal-distal |
| Joint Limit Rule | Essentially fingers and hand | Dependent on geometric parallelism and the amplitude of the dof. The smaller the amplitude between the joint limits, the greater the transfer. The amplitude of the abduction/adduction of the hand with that of the fingers is the lowest of the upper limbs. As the joint limits are approached, the direction of transfer may be distal-proximal |
| Geometric Rule | Potentially all dof with the exception of interior/exterior rotations and pronosupination | No particular direction |
| Diadochal Rule | Rotation interior/exterior and pronosupination | Sensitive to the order of movement on the other two dof |
These flows are generally detectable by the staggered movement of adjacent segments. The handshape of the sign [PLACE] (“location”) in Figure 11.14 (upper image) in French Sign Language (LSF) starts with a movement of flexion of the proximal knuckles and spreads along the fingers with this movement of flexion before the fingertips come into contact with the pad of the thumb; this movement on the fingers corresponds to the transfer from the hand. The flow is proximal-distal. The handshape of the sign [SAISIR] (“grasp”), Figure 11.14 (lower image), shows an identical flexion movement of the fingers, but propagating from the tip to the root of the fingers. The flow is distal-proximal. The only difference between these two types of hand shape changes is the flow of the movement. Beyond the other differences between these two signs (one hand or two), the gestural expression of the idea of grasping and that related to location can only be distinguished from each other by the flow of the movement.

The two gestures of “presentation” and “epistemic negation,” seen in Figures 11.12 and 11.13, also present opposite flows: The gesture of “presentation” takes place according to a distal-proximal flow, while the gesture of “epistemic negation” shows a proximal-distal flow.
Behind these more obvious examples, some gestures and signs show less discernible flows. Here are some hints to be taken into consideration when determining the flow of movement of a gesture or a sign. The temporality of transfers is different depending on whether they respond to inertia (by a decreasing gradient from arm to hand [inertial rule]) or to a gradient from distal to proximal segments (the closer the movement is to a maximum amplitude, the greater the potential for transfer is [joint limit rule]) or when the movement transferred is involuntary (so-called diadochal movement [eponymous rule]). The latter is obviously the fastest since it is inseparably attached to the other two dof that move. Thus, a movement of flexion and exterior rotation of the forearm instantly implies the occurrence of an involuntary supination movement. In terms of differences in speed, the transfers coming in second place are those related to a movement of a distal segment close to its maximum amplitude (the joint limit rule). Finally, the slowest transfer is the inertial type that occurs on the more distal segments.
In the case of a total transfer of movement from a proximal segment such as the arm to a distal segment such as the hand, can the flow of movement be reversed? In other words, does the flow of movement depend on the gesture when it is moved to another segment or does the flow of movement depend on the segment and its situation? The answer seems to lean in favor of the second option. This is the case with the following “epistemic negation” gesture (Figure 11.15): The movement affects the hands according to an extension and abduction, and then it is transferred to the forearms. Thus, this realization reverses the flow from proximal-distal (seen in the gesture in Figure 11.13) to distal-proximal by motion transfer. It should be noted that the movement of the forearms is much less extensive than that of the hands.

Figure 11.15 Political speech of Nicolas Sarkozy, April 5, 2012. While he says, “There is nothing we can do about it” (“On n’y peut rien”), we notice a movement of extension of the hand and a slight supination between frames 2 and 4 and an abduction of the hand for frames 4 and 5, finally an exterior rotation of the forearm and an abduction of the arm. Here it is a form of epistemic negation whose flow is inverted (distal-proximal) which is similar to that expected for a gesture of presentation.
The complete transfer of movement to a more distal segment can redeploy the course of the gesture or sign by modifying the flow of the movement. If the general shape of the gesture is not modified, the flow can be reversed. The flow does not define a gesture. In some cases, it makes it possible to distinguish between gestures (e.g. a gesture of presentation and a typical gesture of epistemic negation). The flow structures how the gesture unfolds, while encompassing, in the same entity of meaning, the forms captured on the dof or even the segments that the movement affects. Once the movement is extended through the segments, the meaning can be realized on a segment far from the origin of the gesture. Depending on the dof set in motion on this remote segment(s), the flow can be reversed. If this is the case, then the realization borrows the flow of the other gesture in the pair that has the opposing form of flow. For example, in Figure 11.15, there is an “epistemic negation” gesture transferred to the hand and forearm with an inverted flow – distal-proximal – which, therefore, will have a presentational color; the shape deployed on the hand and forearm is still similar to that of the “epistemic negation” gesture. The gesture can then be interpreted as “the presentation of an external reality about which I can do nothing.” The flow takes precedence over the form; it does not supplant it. The gestural form of epistemic negation persists but goes into the background in favor of the flow, which is indeed in this case that of “presentation.” Hybrid gestural forms therefore appear; borrowing from a flow and the form generated by the opposite flow, their meaning is a kind of composite.
4.5 Transfer of Movement, Transfer of Meaning
When the movements are transfers, then the dof affected by them establish by habit a formal genealogy; we can see that the transferred forms share a family resemblance with the initial forms. This family resemblance brings together achievements played out on different segments. They can appear between two dof, for example, one on the hand and the other on the forearm. Thus, a lateral gesture of exterior rotation of the forearm (Reference KendonKendon, 2004, pp. 262–263), sweeping up to its maximum amplitude along a horizontal plane at constant speed, expresses, according to Kendon, an interrupted line of action. The hand in pronation – the palm in the same horizontal plane – follows the movement of the forearm, and therefore does not have its own movement. The meaning ascribed to it, that we prefer to call “totality,” lies in this type of movement of the forearm with this particular quality of constant speed (Figure 11.16).

Figure 11.16 “So there was blood everywhere” (“donc y avait du sang partout”). The gesture begins with a movement of the forearm (exterior rotation of frames 1 to 3), then this movement affects the hand (frames 3 and 4) in the same direction, toward the outside. This gesture corresponds to the expression of totality. Note that the speed of it is important here (seen in the fuzzy image of the hand), remaining relatively constant and high.
Continuing with pronation, if it is the hand that sweeps the horizontal plane of a necessarily shorter trajectory by a movement of adduction up to its maximum amplitude, then the same notion of “totality” emerges, on the express condition that this gesture is made at constant speed. This constant speed is a strong indication that the transfer of movement comes from the forearm. In the event that this hand adduction movement was performed with significant acceleration, then it would have responded to a distal-proximal flow and would have been generated on the hand, thus expressing a “negation” (Figure 11.17). We would then have left this genealogy of form, in favor of the expression of simple negation.

Figure 11.17 “Finally, there were not many of us” (“Enfin, on n’était pas nombreux”). This gesture begins with a movement of the hand (outward). This movement spreads to the forearm (frames 4 and 5) with the same external direction. This gesture corresponds to a negation. During the first three frames, when the hand is moving, the upper part of the right wrist remains in the same place (as can be seen in these frames, given the position of the left elbow in the background). In the sweeping movement to the outside of the hand, one can also see the expression of totality, the hand then covering the supposed extent that the people occupied.
4.6 What Is a Gestural Form?
The concept of gestural form as a carrier of a singular value remains to be defined. There is no constant form/meaning for gestures in the sense of a trajectory deployed in space, as we have seen. There is no single form for any meaning. Therefore, we cannot consider a form in itself. The system of values associated with shapes includes what the recurrent deployment of movements on the upper limb captures in the dof in terms of movement, but also in terms of position. If there is no form in itself independent of the degree(s) of freedom that generate(s) it, there is also no form without considering the flow of propagation of movement. A gestural form (or gestural unit) is constituted by the degree(s) of freedom on which a movement unfolds over all or part of the upper limb and where this movement is frozen, as well as by the order in which this movement unfolds over the dof it passes through.
A gestural form is based on kinesiological considerations of movements or positions transferred between segments. It is based on the stabilized unfolding of a gesture on the upper limb. Let us call this stabilization an action schema. It is a grouping of movements or positions governed by a gestural form or unit determined by the organized sequence of movements of one or more segments.
There are forty simple action schemas in embodied gestures. “Simple,” because they are constrained only by kinesiological principles, without any other external constraints, be they iconic (in the sense of dependent on the environment which they depict or designate) or material (manipulation of objects or any form of coupling with the body). They are also “simple” because they are based on a free transfer of movement to the upper limb and a voluntary movement pulse of two dof on the two extreme segments of the upper limb. Reference BoutetBoutet (2010) gives an inventory of the action schemas; here we provide the action schemas of just two gestural units as examples.
4.7 Circulation of Movement Transfers in Action Schemas
Figures 11.18 and 11.19 represent action schemas in boxes and movement transfers as lines between the boxes. We will look at this in two examples.
The first example (Figure 11.18) shows a distal-proximal flow. The gesture starts on the hand with an adduction and an extension. Any other movements can be considered as transfers of movement. In theory, only manual adduction (Figure 11.18.1)Footnote 3 and extension (Figure 11.18.3) are voluntary movements. The first transfer of movement spreads over the forearm and results in an extension movement of the forearm (Figure 11.18.2). The association of adduction and extension of the hand leads to a diadochal consequence: an involuntary pronation movement is quickly in place (Figure 11.18.4 bis). We can see it in the third photograph (frame 3), which shows an extension of the forearm at its maximum (first intersegmental transfer), a hand in an almost maximum extension position, a manual adduction movement already involved in a transfer in the form of an exterior rotation of the forearm (Figure 11.18.4) and a pronation at its quasi maximum (Figure 11.18.5).
As the palm changes orientation under the effect of pronation, which gradually changes it from an inward orientation to a downward orientation, the transfer of movement on the forearm is also modified: From an extension, it changes to an exterior rotation under the effect of manual adduction. When the extension of the hand is at its maximum (frame 4) and the exterior rotation of the forearm has itself reached the maximum position due to the transfer, then the transfer coming this time from the joint limit of the manual extension is reflected on the forearm by a flexion (Figure 11.18.6) that concludes the intersegmental transfer series.

In the second action schema (Figure 11.19), the gesture is initiated on the arm by two voluntary movements: an abduction (distance in a frontal plane from the plane of sagittal symmetry) and a flexion (movement in the sagittal plane in front of a frontal plane). The gestural unit corresponds to the meaning of disinterest (je m’en fiche “I don’t care”). Abduction causes an interior rotation (Codman’s paradox, Figure 11.19.1) while brachial flexion is transferred to the forearm by flexion for inertial reasons (Figure 11.19.2). In turn, the interior rotation and flexion of the forearm are immediately released by a supination movement (diadochal transfer; Figure 11.19.3). This transfer is done at the same time as the combination of the two forearm movements. It appears in the first position in the line corresponding to the hand. The flexion of the forearm is transmitted by the hand in a flexion movement (Figure 11.19.4). The succession of supination and manual flexion results in a manual adduction movement (Figure 11.19.5) which, in turn, accentuates the interior rotation movement that was already in place (Figure 11.19.6).

Figure 11.19 Action schema of the Gestural Unit je m’en fiche “l don’t care about that.” The flow is proximal-distal and it comes from the two voluntary movements – abduction and flexion – on the arm.
We have thus defined action schemas according to two criteria: movement and position.
4.8 Position or Movement
First, let us define position from a kinematic point of view. A position results from an absence of movement, maintained either by the absence of any muscle contraction or by a contraction of antagonistic muscles that maintain balance. In the case of an absence of muscle contraction, we call it a rest position. In this case, the position is not marked within any degree of freedom; on the contrary, it remains in an intermediate or quasi-intermediate position. In the case of a balance between two antagonistic muscles, the position can be extreme. A movement in a specific direction is obviously different from a position. However, a position maintained which entails a dynamic at work is not so different from a movement. In this case, a position returns to a suspended or maintained movement. This maintained movement is documented in the form of a hold (Reference Kendon, Siegman and PopeKendon, 1972; Reference Kita, van Gijn, van der Hulst, Wachsmuth and FröhlichKita, van Gijn, & van der Hulst, 1998).
4.9 Semiotic Value and Actualization Modes
Another question is: In which cases does the position have the same semiotic value as the one carried by the movement?
The dynamic involved brings semiotic values to a degree of freedom, in the manner of Aristotelian material causality. The movement is then the realization of this dynamic – its implementation – whose value is updated in a coextensive way as it unfolds along the path traversed. Basically, a gestural value is reached by the movement; it does not reside in the movement, otherwise it cannot be present only in the final position. Therefore, this value is coextensive with the degree of freedom. Movement is a way of realizing it in real time. The position of a segment on the extent of its degree of freedom is another way. A position maintained in its movement amplitude is sufficient to carry a value. For the values staggered along a degree of freedom, the movement deployed and the position occupied are two ways to actualize a value.
The actualization modes – movement or position – do not have the same temporal repercussions. Movement cannot be considered outside a temporal sequence; it therefore updates a value within a given time period. Once reached, the position updates the value for the duration that it remains in place. The limits of joint movement are particularly useful for maintaining these meaningful positions. Thus, for the gesture of refusal, a palm forward position, fingers upward, reflects this meaning. The joint-limits rule, the diadochal rule (Add+Exten> Pro), maintains this extreme position and finally semiotizes the space of each segment. Thus, the positional mode of actualization of the values is persistent in time: it can be reached without precise ongoing movement. Its value lasts as long as the position is in place because it is marked by kinesiology.
Another type of position appears here: that of location, as in one of the four parameters that is traditionally used for Sign Language analysis. The particularity of these locations is that the segment that takes place there is not the one that creates the associated positional value. Thus, when the hand is above the shoulder and composes the absence of responsibility (incapacity + disinterest, see Figure 11.13, third image), the value of disinterest was not forged by the hand, but by the arm and forearm. The hand instantiates a position outside itself; this particular position of the arms and forearms becomes a location with a singular value within which the hands take on this particular color of disinterest. An important point, shown here, is that this parameter of location, easily readable in an egocentric reference frame, can perfectly derive from the notion of position, which is part of a so-called intrinsic framing, depending in fact on all the segments of the upper limb. One of the four manual parameters of signed languages thus emerges for gesture.
4.10 Outcomes of Tests Applied to 20 Action Schemas
Of the 40 gesture units (GU) based on action schemas, 20 were tested using independent judges (Reference BoutetBoutet, 2010). To summarize this work, two concepts were tested: the semantic validation of a label for the 20 GUs and the structuring of the meaning involved, based on kinesiological principles.
Semantic validation was performed for 90 percent of the GUs. The only two GUs whose label did not correspond to that expected were for a label whose gestural realization corresponded to a more proximal segmental origin (the arm). It seems that semantic confusion almost systematically operates in the sense of a hyperclass. The fact that it is attached to a proximal segment raises the question of the history of development of gestural semantics. Is the arm the primary substrate of gestural meaning, which then extends to the hand, whose appearance remains to be discovered? Is this semantic subordination to the gestures generated on the arm a historical fact or a kinesiological fact, linked, for example, to the upper inertia of the arm?
Tests of the kinesiological structuring of gestural meaning were conducted by varying the form that the realizations of the 20 action schemas take on one or more segments. Here again, the average recognition rate was very good: 90 percent. It should be noted that the GUs that are structured on the arm are better recognized than those that are structured on the hand. We also note that the choice of labels, when they are not the expected ones, responds to a gradient that follows formal proximity. When proximity is a matter of amplitude, it is coupled with strong semantic proximity. The polar opposite movements (e.g. abduction vs. adduction) show quite clearly that semantic values are attached to them. The updating of these data is possible through the successive cross-references offered by these 20 units. Semantic features associated with the poles and positions in the action schemas must emerge from the formation of minimal pairs and polar inversions,.
5 Conclusion
Gesture does not consist of a simple trace of meaning deposited in space, but of a series of structures, as presented here. The structuring is not so much in the body or in the simple vectors of movement, but inside each part of the upper limb, at the level of each degree of freedom of its segments. We have defined the mobility parameters of the segments, in other words, what the dof over the entire upper limb are with their axes of rotation, as well as the geometric and kinesiological relationships that these dof maintain for each segment and between them. To occur, gestures (and signs of Sign Languages) require movement in the first place. While most of the time the movements are voluntary, some movements are involuntary and yet are involved in meaning-making.
Movement spreads over several dof according to a flow that can be characterized in terms of two main trends: (1) the propagation of the movement from a distal segment to a proximal segment (distal-proximal flow) or (2) the movement first affecting a proximal segment and diffusing toward a distal segment (proximal-distal flow). Determining the flow of movement makes it possible to go back to the origin of the gesture and, therefore, to where the meaning was forged. However, the flow of movement does not always correspond to a time delay in the activation of the segments. A non-temporal definition is therefore required: The number of types of movement per segment determines the origin of the gesture or sign. The smaller the number, the closer we get to the segment that initiated the action.
The foundations of the flow of gestures respond to four rules that guide the propagation of movement in a determined way. For proximal-distal flow, the inertia rule reveals a decreasing natural slope from the shoulders to the last knuckles. In terms of the diadochal rule, according to which for all joints with three dof, one of which is a rotation (exterior/interior rotation and pronation/supination), the setting in motion of the first two dof causes an involuntary and joint movement of the third degree of freedom. Conversely, for distal-proximal flow, the joint limit rule tends to move the gesture up to a more proximal segment each time the movement approaches the joint limit of a degree of freedom. The adduction/abduction of the hand is an essential element with its small amplitude. The transfer of movement that this stop rule brings about is dependent on the last – geometric – rule which concerns the parallelism of the axes of rotation between the segments: The determinable part of a transfer of movement responds ad minima to the parallelism between the axis(es) of rotation of the segment at the origin of the movement and the axis(es) of rotation of the segment(s) on which the transfer takes place. If the flow adds an additional dimension to the circulation of gestural forms and increases the possibilities of meaning, the total transfer of a movement affecting a proximal segment to a distal segment can reverse the flow by reversing the movement backward. In other words, does the flow depend on the gesture when it is moved to another segment or does the flow depend on the segment and its situation? In a first approach, it seems that the flow depends more on the segment and the situation than on the gesture and its meaning. We can therefore consider that flow works as a direction distributor. When the transfer of a movement on a segment goes so far as to reverse the flow expected by more or less preserving the general shape of the gesture appearing without reversing the flow, then the meaning of the gesture becomes a composition of meanings of the two gestures. These gestural hybridizations need to be studied further.
The structuring of the gestures we have developed is based exclusively on kinesiological considerations. What is important to grasp in the general “magma” of gestures is the process of their individuation. We have shown that the latter not only responds to a formal aspect based on kinesiology but extends its influence to the emergence of the levels of Sign Language structure that constitute the traditional parameters of sign form description. Nevertheless, gesture units such as recurrent gestures (Ladewig, this volume; Reference MüllerMüller, 2018) carry the meaning of formal stabilizations of action schemas.
The approach followed throughout this chapter, entirely bottom-up, shows how much the structuring of gestures depends on a very deep formal level: not the one that is played out on the segments, not even below that of the dof, but even lower, at that of movement parameters involving polar oppositions (abduction/adduction, flexion/extension, pronation/supination). The discovery of these levels of structuring has an impact on our conception of what the gesture or sign is. It is no longer a question of limiting it to a trace left in space, but to the trails that the execution of gestures leave. Their structure and meaning are based on structural and dynamic rules that we have begun to determine. For this reason, the kinesiological system is well suited to augment motion-capture analysis of gesture by providing categories for, and using principles of, movement analysis that mesh with those used for motion tracking. (For an example, see Reference Boutet, Jégo and MeyrueisBoutet et al., 2018, which documents a pipeline for gesture analysis; the website Events and Gestures, n.d., includes a tutorial on its use.)
Iconicity then requires a different conception than that of image iconicity alone to account for the bodily structuring of gestures. A bodily based iconicity redraws what was seen from the imagistic point of view; it takes as analogous varied gestural realizations of a given instance of expression that can be deployed with the same action schema. This can allow us to see, for example, what a palm-up open hand gesture of presentation has in common with smaller renditions of it (such as a slight turn-out of the hand at the wrist, or even the lifting of a thumb when one’s hands are folded as one sits at a table): Each of the successively larger gestural forms contains within it all of the movement elements of the smaller forms (Reference CienkiCienki, 2021).
Rather than kinematics, the rules considered here respond to a kinesiological level such that the hand is only one part of the segments that build stabilizations and meaning in which the forearm, upper arm, and fingers participate. Since stabilizations operate primarily on the body, their imagistic or iconic consequences are secondary; indeed, the faculty of vision that allows us to access the gestures/signs of others may only constitute an echo chamber that makes the image.
1 Introduction
Studying gestures typically requires the researcher to annotate video data in order to determine features such as the exact starting and ending points (onsets and offsets) of movement, gesture phases, and any other aspects of the gesture that are of interest, given the research question. While this method has yielded many important insights through the years, it can be a highly time-intensive procedure requiring multiple annotators to go through the video frame-by-frame. Besides being time-intensive, it is also difficult to capture certain motion-based (kinematic) aspects of gesture, such as velocity, and any additional feature that must be coded greatly increases the time required for data processing. This creates a bottleneck for gesture research, in terms of both time and the limitation of what can be manually annotated. Many features of gesture will likely need to be manually annotated for the foreseeable future, for example, semantic or pragmatic content, which currently cannot be reliably extracted from motion data. However, motion-tracking methods can be used to facilitate this process and provide access to more fine-grained kinematic aspects of gestures that may otherwise be overlooked.
Motion tracking here refers to any methodology that automatically tracks the movements of the human body, whether this is in two-dimensional or three-dimensional space. Furthermore, this can be implemented with physical camera systems, or based on algorithms applied to standard video files. The types of motion-tracking technologies currently available and how they work will be discussed in Section 2. Regardless of the type of motion-tracking technology, there are several important implementations of such methods. First, motion tracking can be used to facilitate manual annotation. For example, there are currently toolkits available for automatically finding and marking movement onsets and offsets, as well as movement peaks and movement cessations, which we will discuss in later sections. This can increase the speed and reliability of manual annotation by providing a starting point for annotators to subsequently check and correct, rather than looking for these movements without any starting point. Beyond facilitating previously established annotation practices, motion tracking can also push the boundary of what gesture researchers can investigate. Specifically, movement data can be used to quantify kinematic aspects of gestures, such as the size, timing, velocity, and number of movements. This allows us to increase the precision of kinematic features that have traditionally been determined manually, such as the moment of maximum effort or peak extension (see Reference Wagner, Malisz and KoppWagner, Malisz, & Kopp, 2014), while additionally giving us access to more fine-grained information, such as exact movement trajectories and changes in velocity.
Motion tracking has long been used in other fields of research, such as movement science and the study of motor control. By adopting motion-tracking methods into gesture-research projects, we can streamline manual annotation to make qualitative approaches less time-intensive while additionally expanding our research questions to investigate gestures in new and exciting ways. One exciting avenue of development currently in progress is automatic gesture detection, which also makes use of some of the methods described in this chapter. Automatic gesture recognition will be discussed more in this Handbook’s chapter entitled “Gestural Interfaces in Human–Computer Interaction.” Here, though, I will discuss what types of motion-tracking technologies are available, in particular regarding the differences in how they are utilized and which approaches may be best suited for which questions. I will then provide an overview of how such technologies can be applied to different research questions, including examples of the state of the art of how motion tracking is currently being utilized by gesture researchers. For the purpose of this chapter, I will primarily focus on manual gestures, although many of the methodologies described in this chapter can also be implemented for studying non-manual gestures, such as facial gestures. Finally, I provide some suggestions for how these methods can be further developed, in terms both of their technical implementation and their role in the next generation of gesture studies.
2 Overview of Motion-Tracking Technologies
The term “motion tracking” broadly refers to a number of methodological approaches that are used to find the position of one or multiple body parts in space and across time. There are a variety of ways in which this tracking can be accomplished, but they can be generally grouped into four main categories: Device-based markered tracking; device-based markerless tracking; pixel-based video tracking; and AI-based video tracking. How these approaches can be applied to gesture research will be discussed in the following sections, but first it is important to understand how these different approaches work, and how they differ from one another. This will provide a basis for understanding why some approaches will be better suited for different research questions or datasets. In Section 2.1, I will provide a basic overview of how these different approaches work and how they differ from one another, and provide some general advice about when each approach may be most useful. I will refer to spatial resolution in terms of absolute offset; thus, a resolution of 1 mm means that the tracked point is no more than 1 mm away from the true location of that point. Temporal resolution is given in Hertz, which is the same as the number of frames, or coordinates, recorded per second.
2.1 Methodological Overview
2.1.1 Device-Based Markered Tracking
This type of tracking requires use of a specially designed motion-tracking device (i.e. it is device-based) and requires markers to be placed on the subject’s body (i.e. it is “markered”). This type of tracking is considered the gold-standard for motion tracking as it provides the highest fidelity in terms of tracking accuracy as well as a high temporal resolution. Currently, the most popular forms of device-based markered tracking are optical motion-tracking systems, such as the Vicon and OptiTrak systems, and electromagnetic tracking, such as the Polhemus Liberty.
2.1.1.1 Optical Systems
In the case of optical systems, reflective markers are placed on the subject’s body at any points that should be tracked. A series of cameras throughout the room are used to emit infrared light, which is reflected back by the markers and seen by the cameras. By combining the camera images from all of the cameras, the location of a marker can be reconstructed in three-dimensional space. In some cases, such as with the OptiTrak system (Reference Furtado, Liu, Lai, Lacheray, Desouza-Coelho, Janabi-Sharifi and MelekFurtado, Liu, Lai, Lacheray, & Desouza-Coelho, 2019), the markers are replaced with infrared-emitting diodes, which requires the subject to additionally wear a power-supply and have wires to power the diodes. The actual tracking of these points, whether reflective markers or infrared-emitting diodes, is largely the same. While these systems typically show the highest tracking accuracy, they require line of sight between the cameras and the markers, which means that they are also sensitive to occlusions, such as when one hand blocks the other, which may occur when producing bimanual gestures.
2.1.1.2 Electromagnetic Systems
With electromagnetic tracking, such as the Polhemus Liberty or Polhemus Lats systems, tracking is performed by a system of electronic sensors that are placed on the body. These are attached via wires to a mobile power supply, much like the OptiTrak system. Rather than a series of cameras, the Polhemus system utilizes a single “source” device that creates an electromagnetic field. The position and orientation of the individual sensors are tracked based on this electromagnetic field, with a positional accuracy (i.e. spatial resolution) of <1 mm and orientational accuracy of 0.06° for sensors up to 182 cm away from the source. Accuracy decreases as a function of distance from source, and has a functional range of 150 cm in the standard setup. Polhemus Latus provides a larger range, allowing more freedom for participants, but comes at the cost of lower spatial accuracy (0.25 cm and 0.5° if less than 1.2 m from the source). Similar to the optical tracking systems, the Polhemus provides a high temporal resolution, with 240 Hz for the Liberty or 188 Hz for the Latus. The electromagnetic approach is advantageous because it does not require any line of sight between the source and the sensors. In other words, it is unaffected by occlusions (such as when one hand blocks the camera from seeing the other hand, or one participant blocks the view of the other, which can be particularly problematic in situations where more than two individuals are being recorded) and will provide high-fidelity tracking regardless of what the subject is doing with their hands or body. However, this approach has the same disadvantage as the optical tracking systems in that the subject must remain within the electromagnetic field, thus making it less suitable for non-lab-based procedures.
2.1.1.3 Inertial Systems
In contrast to optical and electromagnetic systems that require a stationary device in the environment, inertial systems such as the Perception Neuron utilize a series of inertial measurement units (IMU) attached to the body. IMUs contain accelerometers, magnetometers, and gyroscopes, allowing each unit to track linear acceleration, rotation angle, and angular velocity (Reference Ahmad, Ghazilla, Khairi and KasiAhman, Ghazilla, Khairi, & Kasi, 2013). By calibrating the set of IMUs in reference to another, it is therefore possible to track the three-dimensional movements of the body, including the hands, at a high temporal resolution (60–120 Hz). When comparing tracking accuracy of the joint angles against gold-standard optical tracking, accuracy for the Perception Neuron system is within 5° for many upper-body joints, including the neck and shoulders (Reference Sers, Forrester, Moss, Ward, Ma and ZeccaSers et al., 2020). However, accuracy for the wrist and elbow is somewhat lower, with errors between 8° and 17° (Reference Robert-Lachaine, Mecheri, Muller, Larue and PlamondonRobert-Lachaine, Mecheri, Muller, Larue, & Plamondon, 2020). Positional accuracy has not been described for the Perception Neuron system at the time of writing this chapter. This system therefore provides a reasonably accurate tracking solution that is unconstrained by a receiver or source unit in the environment. Perception Neuron is also reasonably inexpensive for a markered tracking system, currently costing €1,200–€1,500 for a basic setup. The Perception Neuron is, however, affected by ambient magnetic fields in the environment. Users must therefore check and prepare the environment in which recording will take place and calibrate the system for a particular environment. A detailed pipeline for using the Perception Neuron for gesture research, from data collection to analysis, has been provided by Boutet and colleagues (Reference Boutet, Jégo and MeyrueisBoutet, Jégo, & Meyrueis, 2018).
2.1.1.4 How They Compare
While these systems are all characterized by high spatial and temporal resolution, direct comparisons show that the Vicon optical system provides the best tracking accuracy (Reference Vigliensoni and WanderleyVigliensoni & Wanderley, 2012). However, due to its sensitivity to occlusions, the inertial and electromagnetic systems may provide an advantage when tracking spontaneous behavior.
These systems all require the researcher to consider which points to track and to incorporate this into their data-collection procedure. This makes it unsuitable for retrospective studies (i.e. reanalyzing a dataset that did not originally utilize motion tracking) or those taking place outside of a lab situation. Additionally, the relatively high costs of the high-quality optical or electromagnetic systems (e.g. current prices start at €9,000 for a full optical tracking system) may be prohibitive. However, if high temporal and spatial resolution are important, for example, to find fine-grained differences in movement trajectories or timing, this may be the most reliable approach to motion tracking. Inertial systems, such as Perception Neuron, provide a potentially very useful middle ground between the high-cost, gold-standard optical systems and lower-cost, markerless systems.
2.1.2 Device-Based Markerless Tracking
In contrast to markered tracking, there are also devices that provide three-dimensional tracking without the need to place markers or sensors on the participant’s body. These systems take advantage of computer vision techniques, together with infrared emitters, to track human movement. The two most popular systems for research are the Microsoft Kinect and Leap Motion. While the two are functionally similar, the Kinect is mainly used for whole-body tracking, while the Leap Motion is designed to track the hand and fingers. Although both systems utilize infrared emitters and computer algorithms, they each take a different approach to how this is performed.
2.1.2.1 Whole-Body Tracking
The Microsoft Kinect is a portable device with a specialized camera and infrared emitter. The device uses the time-of-flight method to create a depth map of its field of view, meaning it measures the time between when a given point of infrared light is emitted and the time it is picked up by the camera. Algorithms are then used to infer the position of a human body within this depth map and subsequently track the position of a predetermined set of joints. The Kinect was originally designed for use with the Xbox gaming console, but is also available for direct connection with a computer. Currently, the second version of the Kinect (i.e. Kinect V2) is primarily used for research due to its low cost, high portability, and relative ease of use. This version is also superior to the Kinect V1 in terms of accuracy and reliability (Reference Wasenmüller, Stricker, Chen, Lu and MaWasenmüller & Stricker, 2017). The Kinect captures 25 joints across the body, including neck, shoulders, wrists, and hands, as well as lower-body and some finger joints. While the camera is able to map the depth of the environment up to 8 m away, reliable tracking of the body occurs between 0.5 and 4.5 m from the camera. As tracking is accomplished based on computer-vision algorithms rather than wearable sensors, the Kinect can also track up to six people simultaneously, provided they are all within its field of view (approximately 70.6° × 60°). Tracking accuracy for the Kinect is much lower than that of wearable sensors, however, with a spatial resolution of ~18 mm. Temporal resolution is also much lower at 30 Hz. Therefore, the Kinect is not suitable for capturing fine-grained movements such as finger-tapping or minimal differences in trajectory of movements (Reference Romero, Amaral, Fitzpatrick, Schmidt, Duncan and RichardsonRomero et al., 2017). However, the Kinect is still capable of capturing more coarse-grained movements. For example, this system performs on a par with the Vicon optical system for clinical motor assessments. Furthermore, direct comparisons with Kinect-based annotation, using a custom set of scripts, demonstrated that it can be used to capture gross movement kinematics that are often used in gesture research, such as gesture height, size, and number of movements (Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo, Vaitonyte, Simanova, & Özyürek, 2019). While the Kinect V2 is no longer being produced, it has recently been replaced by the Kinect Azure, which has superior spatial resolution and tracking algorithms. Researchers interested in utilizing device-based, markerless whole-body tracking should therefore utilize the most recent version of the Kinect.
2.1.2.2 Hand Tracking
The Leap Motion contains three infrared emitters and two infrared cameras. By comparing how the position of predefined points (e.g. fingertips) differs between the two cameras, the system is able to compute the object’s three-dimensional position. This is similar to how our two eyes allow the perception of depth, also known as stereoscopic vision, and hence this approach to motion tracking is known as Stereo Vision. The Leap Motion device consists of a single box that contains the infrared emitters and cameras. It is typically placed on a desktop or tabletop, so that its field of view, known as the “interaction space,” is a roughly dome-shaped area above the device. The interaction space for the standard Leap Motion extends approximately 60 cm above the device and 60 cm to the sides, although newer implementations extend this to 80 cm. Temporal resolution for the Leap Motion is higher than that for the Kinect, at 115 Hz, but still lower than markered tracking systems. Tests of the spatial accuracy of the device have shown it to be quite high, at 1.2 mm when tracking dynamic movement (Reference Weichert, Bachmann, Rudak and FisselerWeichert, Bachmann, Rudak, & Fisseler, 2013). The primary constraints to this system are (1) the relatively limited field of view, which constrains participants to sit directly in front of the device, and (2) the fact that the system only tracks the hands. Overall, the system can be highly effective for capturing hand shape and general hand or finger dynamics in a relatively constrained setup.
2.1.2.3 How They Compare
Overall, markerless systems provide a cost-effective way to track body or hand/finger movements, albeit with lower accuracy than more expensive markered systems. As both systems reviewed here are camera-based devices, they also suffer from occlusions, which can constrain the quality of data collected in some setups. However, they are both relatively easy and quick to set up and are highly mobile, making them more suitable for research outside of the lab, or for more dynamic experiments. Finally, while accuracy is lower than for markered systems, these systems can still be reliably used to capture more coarse body movements, such as posture or gross hand kinematics, making them a useful alternative to more expensive or stationary systems, as long as the research questions fit the data that are being collected.
2.1.3 Video-Based Tracking
While the previously discussed methods involve devices that are specially designed for motion tracking, it is also possible to use computer-vision algorithms on normal video data. These methods have the distinct advantage that they do not require specialized equipment for data collection. This means that, if the video quality is sufficient, these techniques can also be applied retrospectively to data that have already been collected.
2.1.3.1 Pixel-Based Frame Differencing
One of the earliest and most simple video-tracking methods is pixel-differentiation. This approach takes advantage of optical flow, or the processing of video, by looking only at what changes from frame to frame. In this case, the body is not tracked in such a specific way as in previous methods, but rather a change score is calculated at each frame transition. The general idea is that when you move your arm to produce a gesture, the change effected in the video allows you to quantify, for example, its velocity and duration (Reference Paxton and DalePaxton & Dale, 2013; Reference Romero, Amaral, Fitzpatrick, Schmidt, Duncan and RichardsonRomero et al., 2017). The basic approach captures change in the entire video, but methods have been developed to segment the screen into areas of interest, such as “left hand,” or even “person on the left, left hand,” allowing more focused analysis (Reference Alviar, Dale and GalatiAlviar, Dale, & Galati, 2019; Reference Danner, Barbosa and GoldsteinDanner, Barbosa, & Goldstein, 2018). However, because no specific tracking is taking place, this approach is highly susceptible to noise if there are any changes in the background, movement of the articulators that are not part of the gesture, problems with the video quality, or occlusions. This can make the approach difficult to use in naturalistic setups, particularly when there are multiple people interacting in close proximity. Despite these constraints, frame-differencing has been successfully applied to assessing synchrony between patients with autism spectrum disorder and their therapist (Reference Romero, Amaral, Fitzpatrick, Schmidt, Duncan and RichardsonRomero et al., 2017), as well as gesture velocity (Reference Pouw, Wassenburg, Hostetter, de Koning and PaasPouw, Wassenburg, Hostetter, de Koning, & Paas, 2020). Furthermore, pixel differencing can successfully capture more fine-grained movements, such as finger tapping (Reference Romero, Amaral, Fitzpatrick, Schmidt, Duncan and RichardsonRomero et al., 2017), as well as overall velocity profiles, such as for quantifying speech–gesture synchrony (Reference Pouw, Trujillo and DixonPouw, Trujillo, & Dixon, 2020).
2.1.3.2 AI-Based Tracking
A more sophisticated approach to motion tracking has been developed from artificial intelligence (AI) methods. These approaches take video data as input and try to infer the location of specific body parts in each frame. This is typically done using deep-learning methods that are trained on other datasets in order to reliably detect certain features. Describing deep-learning in detail is beyond the scope and purpose of this chapter, but the interested reader can find a review of the topic by Reference LeCun, Bengio and HintonLeCun, Bengio, and Hinton (2015). In short, an artificial neural network is trained to find and classify patterns in still images after being provided with large, annotated datasets. Building on this pattern recognition in a single image, videos can be processed frame by frame to find the location, in the video frame, of certain key-points, such as the hand, elbow, or finger. Two of the most promising methods currently available are OpenPose and DeepLabCut.
OpenPose, developed by Reference Cao, Simon, Wei and SheikhCao and colleagues (2017), can track the kind of large body movements other methods do, but is also capable of more fine-grained finger and face tracking (Reference Cao, Simon, Wei and SheikhCao, Simon, Wei, & Sheikh, 2017). This method is superior to the pixel-differencing approach because it can more specifically track various body parts, and also body parts of multiple individuals. However, because it is video-based, it is still vulnerable to occlusions. OpenPose was designed for single images, but recent developments enable three-dimensional tracking when synchronized video is provided from multiple angles. For this multi-camera implementation of OpenPose, 80 percent of tracking errors – that is, in comparison with the gold-standard of optical tracking – are errors of less than 30 mm (Reference Nakano, Sakura, Ueda, Omura, Kimura, Iino and YoshiokaNakano et al., 2020). As gestures may not always occur in perfect vertical or horizontal trajectories with respect to the camera, this is an especially useful development for the utility of video-based tracking. Furthermore, OpenPose is comparable in its gesture-tracking ability to the Kinect (Reference Rahman, Clift and ClarkRahman, Clift, & Clark, 2019), with the primary negative aspects being how it keeps track of multiple individuals, and the relatively high computing power required to run the program. The first issue stems from the fact that OpenPose is principally image-based, with output consisting of a series of keypoint locations in each frame. When multiple individuals are tracked, they are identified according to their location on the screen. This means that even subtle changes in their positioning can lead to changes in their identifying numbers, which can be problematic for data processing.
DeepLabCut (Reference Mathis, Mamidanna, Cury, Abe, Murthy, Mathis and BethgeMathis et al., 2018) is an alternative to OpenPose and is primarily distinguished by its ability to track new points or objects, rather than a prespecified set. In fact, DeepLabCut is built on an earlier method, namely DeeperCut (Reference Insafutdinov, Pishchulin, Andres, Andriluka, Schiele, Leibe, Matas, Sebe and WellingInsafutdinov, Pishchulin, Andres, Andriluka, & Schiele, 2016), which specifically extracted human body-part positions from video data. DeepLabCut essentially uses the same pretrained neural network from DeeperCut, but trains the network to extract novel inputs. While many deep-learning approaches require large amounts of data, DeepLabCut only requires the researcher to label ~200 images to achieve high tracking accuracy. Similar to OpenPose, this approach also requires a lot of computational power. In other words, the approach will be very slow or impossible to carry out on slower or older computers. Although this approach requires more work from the researcher, it is appealing because it provides an additional level of flexibility, for example to track human infants or even other species (Reference Nath, Mathis, Chen, Patel, Bethge and MathisNath et al., 2019).
2.1.3.3 How They Compare
As these techniques are all based on video data and the change in pixels or positions within the video frame, it can be difficult to compare results across participants or groups if the positioning of the camera and participants are not tightly controlled. This can be overcome with additional preprocessing steps, but this will require more expertise from the researcher. However, given the power afforded by AI-based methods for performing motion tracking on standard video data, the AI approaches are likely to become increasingly popular as their full potential is further developed. If the researcher wishes to look at relatively constrained situations and only requires timing or duration (e.g. to detect synchrony), then pixel-based methods may be sufficient. To capture more detailed information about the movements of typical body parts, such as the head or hands, OpenPose is a very useful tool. If one wishes to track non-standard subjects, such as objects, human infants, or non-human animals, then DeepLabCut may provide a powerful alternative. For a discussion on how these methods compare for gesture-recognition implementations, see the chapter “Gestural Interfaces in Human–Computer Interaction” (Stec & Larsen, this volume).
2.2 Summary
In this section, I have provided an overview of some of the major categories of motion tracking, such as markerless, markered, and video-based tracking, and I have described how different implementations compare within each category. Each category, in turn, has its own unique advantages and disadvantages. Markered tracking provides the highest precision but is the most invasive and expensive option. This approach is best when lab-based data collection is not an issue, and high precision for very small or fast movements is required. Markerless tracking sacrifices some precision but is much less invasive and much lower in cost. This approach is useful for capturing three-dimensional movements when multiple camera angles are not possible. Video-based tracking is unique in that it can be applied to data that have already been collected. While tracking based on single videos is restricted to two-dimensional images, multiple angles can provide higher precision and three-dimensional tracking. AI-based tracking with multiple camera angles therefore provides a good trade-off between precision and cost. Overall, most of these approaches currently have software available that makes capturing data relatively straightforward. As the number of tracked points increases, however, the more complex the data and thus the more technical skill will be required from the researcher in order to process the data. Section 3 provides information about some currently available software and toolkits that support the researcher in this. A flowchart for method selection can be found in Figure 12.1.

Figure 12.1 A flowchart providing some suggestions for method selection. Note that this is a simplified version of the arguments, and researchers should also carefully read the subsections devoted to their method of choice
3 Applications for Gesture Production
3.1 Motion Tracking for Qualitative Coding
Gesture researchers typically have the daunting task of manually annotating video data in order to address the research question in which they are interested. As pointed out in Section 1, the process of manual annotation is highly time-intensive and often relies on many subjective decisions being made. In the case of poststroke holds (i.e. the pauses in movement immediately after the main stroke phase of a gesture), for instance, the hands may not remain perfectly still, as people do not tend to remain perfectly still. This can make the exact timing of holds difficult to determine consistently. Even when the features that the researcher is interested in can be reliably defined and annotated, the process remains very time-consuming. Utilizing motion tracking can provide a way to facilitate this annotation process.
Manual annotation may address abstract features not currently available to motion-tracking software, such as the semantic content of a gesture or its pragmatic role. However, any gesture-coding scheme necessarily rests on the gestures themselves first being accurately identified, often including the timing of the onset and offset of the gesture. Onset/offset identification thus relies on the ability to accurately and consistently identify changes in movement speed. Motion tracking provides an ideal tool for this task as the tracked coordinates (i.e. the position of a given articulator, such as the hand) can be easily converted into a measure of speed. By defining a threshold for this speed measure, one can use the objectively calculated speed as a reliable indicator of when a movement has started or stopped. This provides a distinct advantage over manual coding not only in terms of time invested by the researcher, but also in the fact that this measure is not disrupted by a slow “fading out” of the movement. This can happen if a speaker’s hand continues to move after a gesture, but at a continuously slower speed as it gradually returns to rest. The exact offset can be much more difficult to determine by manual coders. Using a speed-based or motion-based threshold, this is no longer an issue. One very simple implementation of this approach is seen in Figure 12.2, where the raw X, Y, and Z coordinates are loaded into ELAN as time series.

Figure 12.2 Three-dimensional coordinates of the right hand visualized in ELAN as individual time series. From bottom to top, the three lines in this figure depict X, Y, and Z coordinate time series of the right hand. Peaks in the time series can be used to find maximum extension or final position of a movement, while changes in the values (i.e. when the time series begins to peak) can be used to find movement onsets.
This technique has recently been developed into a full movement-detection application by Reference Ripperda, Drijvers and HollerRipperda, Drijvers, and Holler (2020 under the name SPUDNIG (Speeding Up the Detection of Non-Iconic and Iconic Gestures). The application has a high accuracy rate for detecting true hand movements (99.5 percent), although not all movements are what researchers might consider true gestures. However, such an approach only requires the gesture researcher to then “clean” the annotations, which are automatically imported into ELAN by SPUDNIG.Footnote 1 As the name implies, manual annotation is thus much faster with this approach (Reference Ripperda, Drijvers and HollerRipperda et al., 2020). An additional advantage of this application is that it comes with OpenPose motion tracking built in, and is operated via a user-friendly graphical user interface (GUI). Similarly, Reference Ienaga, Scotney, Saito, Cravotta and BusàIenega, Scotney, Saito, Cravotta, and Busà (2018) provided a method for detecting and classifying certain basic gesture types, also using movement trajectories as calculated by OpenPose. These gestures included negation (e.g. lateral movements of the hand, with flat palm held downwards or towards the interlocutor), palm up open hand, and “me” (i.e. self-directed deictic gestures, including one or two hands placed over the heart, or pointing with the index finger towards the speaker him/herself). Accuracy for this approach ranged from 92 percent for negation and palm up to 75 percent for “me.” Taking advantage of the depth information in the Microsoft Kinect, Reference Juszczyk, Ciecierski, Brill, Gudberg and SchwabJuszczyk and Ciecierski (2016) developed an application that directly feeds NEUROGES annotations into ELAN, together with the simultaneously recorded video, from the Kinect sensor. This means that a researcher can collect their standard video data and the corresponding annotations simultaneously (Reference Juszczyk, Ciecierski, Brill, Gudberg and SchwabJuszczyk & Ciecierski, 2016). This allows data acquisition conditions (e.g. camera angle, lighting) to be optimized on the spot, potentially leading to higher quality data. Many other approaches for gesture detection and/or classification have been developed for the Microsoft Kinect. These methods have largely been described empirically, and can thus be seen as a proof of concept, but have not been developed as tools that can easily be implemented by gesture researchers. While the Microsoft Kinect V2 is no longer in production, it has been replaced by the Microsoft Kinect Azure. In principle, this proof of concept for Kinect-based gesture detection/classification thus shows that these applications can be similarly implemented with the Kinect, which has a similar functionality, but with improved spatial resolution and tracking capability. While the aforementioned approaches may not provide the end-goal information about a gesture that the researcher is interested in, they can be employed to reduce the burden of annotation by providing a starting point, and by providing timing information that is objectively captured.
Motion-tracking data can also inform more abstract levels of manual annotation, providing new routes for investigation. For example, Reference MittelbergMittelberg (2018, Reference Mittelberg2019) used optical motion tracking to visualize the spatial and temporal dynamics of hand gestures in three dimensions, which then allowed a more holistic analysis of the gestures’ form and dynamics. In this way, we are more able to move beyond the restrictions of viewing single video frames and go towards visualizing the more complex, imagistic aspects of gesture production. This could also be used, for example, for making more accurate comparisons between movement qualities of gestures produced by different individuals or within different contexts.
3.2 Motion Tracking for Quantitative Analysis
Motion tracking not only supports qualitative analysis but can also be used for more quantitative approaches to studying gesture. In this section, I will discuss three possible avenues for such quantitative analysis, which span three levels of investigation: fine-grained finger movements, whole body kinematics, and the relation between gesture and speech.
3.2.1 Kinematics of the Hands
Gestures can be analyzed at multiple levels of description, where the lower levels of description include aspects such as hand shape and movement direction. Hand shape is a potentially difficult feature to code due to the relatively small size of the articulators (i.e. the fingers) in a video. Nonetheless, it is an important aspect of the pragmatic function and semantic meaning of a gesture (Reference KendonKendon, 1997; Reference McNeillMcNeill, 2000). The high resolution of optical motion tracking has been utilized by Hassemer and Winter in order to demonstrate that subtle differences in the shaping of the fingers is informative of whether a particular hold gesture, where the index finger and thumb are curled towards one another, is indicating the height or shape of an object (Reference Hassemer and WinterHassemer & Winter, 2016). This idea was further developed by Hassemer and Winter to suggest that there are key aspects of a gesture that can be spatially quantified, which inform the differential interpretation of very similar gestures (Reference Hassemer and WinterHassemer & Winter, 2018). These studies offer a fine-grained analysis of a very particular type of gesture, but demonstrate the importance of even subtle kinematic differences at the level of finger shaping for decoding the meaning of a gesture. This can be used to inform coding schemes which aim to accurately describe gesture meanings, to find fundamental constituents or rules of how gestures are built up, or potentially to quantify the informativeness or precision of a given gesture.
Moving up the level of description, motion-tracking data can also be used to objectively assess the similarity between more complex, conversational gestures. This approach has been developed by Reference Schüller, Beecks, Hassani, Hinnel, Brenger, Seidl and MittelbergSchüller and colleagues (2017), who used optical motion-tracking data to quantitatively compare gestures of different types. In this study, gestures were first manually annotated for their onsets/offsets as well as type (i.e. spirals, circles, straight paths) and then compared via a mathematical algorithm. The study provides a proof-of-concept that such approaches can be used to quantify the (dis)similarity of even relatively complex gestures, which could be applied to analyzing differences between individuals or communicative contexts.
While the approach by Schüller and colleagues investigated gesture similarity based on overall form, gestures can also be quantified in terms of other kinematic features that are important for their role in human communication. For example, gestures are frequently assessed based on global spatial features, such as their size or the space in which they are produced (e.g. Reference McNeillMcNeill, 2000), and their composition in terms of movements and holds (e.g. Reference Kita, van Gijn, van der Hulst, Wachsmuth and FröhlichKita, van Gijn, & van der Hulst, 1998). For instance, Peeters and colleagues used motion tracking to demonstrate that the communicative context in which deictic gestures are produced modulates the velocity and hold duration of these gestures (Reference Peeters, Hagoort and ÖzyürekPeeters, Hagoort, & Özyürek, 2015). Importantly, although the differences were statistically robust, the effect was relatively small (0.5 cm/s for velocity and ~90 ms for hold duration), which emphasizes the importance of the high-resolution motion tracking. For reference, typical videos are recorded at 25 frames per second (FPS), meaning that the 90 ms difference is equivalent to a difference of only slightly more than two frames. Similarly, Reference Boutet, Jégo and MeyrueisBoutet and colleagues (2018) show how motion tracking can be used to quantify and compare kinesiological features of gestures. This takes into account the range of motion of each segment of the articulator (e.g. upper arm, forearm, hand) in order to have a more biomechanically informed analysis of gesture profiles (Reference Boutet, Morgenstern and CienkiBoutet, Morgenstern, & Cienki, 2016).
Trujillo and colleagues developed a “kinematic feature extraction” toolkit that utilizes motion-tracking data based on Kinect or OpenPose to calculate a set of predetermined gestures’ features. Specifically, given the motion-tracking data and a list of annotated onsets and offsets for the gestures of interest, the toolkit calculates features such as the number of movements, number of holds, overall size, and peak velocity (Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo et al., 2019). These features are relevant as they are characteristic of the communicative intent of the gesturer (Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo, Simanova, Bekkering, & Özürek, 2018) and can determine how well an addressee can determine the meaning and intention of the gesture (Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo et al., 2018; Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo, Simanova, Bekkering, & Özürek, 2020). The toolkit itself consists of a series of open-source scripts that can be implemented in the MATLAB software, requiring minimal scripting from the researcher. Such an approach can provide an additional way to characterize gestures and compare gestures across specific aspects of the spatial and temporal characteristics of a gesture. This can be useful for quantifying how complex gestures differ across different contexts, speakers, or populations of speakers (e.g. clinical populations).
Rather than focusing on how gestures differ from one another, or comparing whole groups, it is also possible to analyze the similarity or coherence the gestures produced by an individual or a pair of interlocutors. Reference Pouw and DixonPouw and Dixon (2020) have recently developed a framework for investigating and visualizing how ensembles of gestures (i.e. all the gestures produced by a single individual or within a given context) fit together in a familiarity matrix. In other words, this approach can be used to discover categorical distinctions between gesture types, that are based on more low-level features, to discover the potential informativeness of a given gesture (or conversely to detect highly informative gestures), or to investigate other questions about large-scale dynamics of how gestures may generally differ across contexts. This approach to using motion tracking provides an example of how quantitative data can open the door to novel approaches to gesture research.
3.2.2 Speech–Gesture and Interpersonal Synchronization
Thus far, I have discussed how motion tracking benefits the study of gestures as such. However, it can also benefit our understanding of gestures in the wider context of communication. For example, there has been a wealth of literature investigating the relationship between speech prosody and gesture production (Reference Chu and HagoortChu & Hagoort, 2014; Reference Esposito, Esposito, Esposito, Vinciarelli, Vicsi, Pelachaud and NijholtEsposito & Esposito, 2011; Reference Esteve-Gibert and GuellaïEsteve-Gibert & Guellaï, 2018; Reference Krivokapic, Tiede, Tyrone and GoldenbergKrivokapic, Tiede, Tyrone, & Goldenberg, 2016). One prominent aspect of speech-gesture synchrony is the finding that gesture peaks coincide with emphatic peaks in speech. These two have been measured based on the peak in the fundamental frequency (i.e. the pitch) of speech, which is taken as a marker for prosodic stress, and the apex (i.e. peak of the movement) of a gesture stroke, which has been termed the “kinetic goal” of the movement (Reference LoehrLoehr, 2004, Reference Loehr2012). Importantly, such research typically has relatively precise timing for speech, but potentially lower precision for gesture peaks, as these must be manually annotated on a frame-by-frame basis, to determine where the peak-of-the-peak of the movement occurs. However, Reference Pouw and DixonPouw and Dixon (2019) have used the Polhemus Liberty motion-tracking system to investigate speech–gesture synchrony under delayed auditory feedback. This allows for a much more precise definition of the gesture peak, thus leading to a more robust and fine-grained analysis of the timing of speech–gesture synchrony. This approach has been further developed in Reference Pouw, Trujillo and DixonPouw, Trujillo and Dixon (2020) and is available as a tutorial and package of scripts for the statistical program R (R Core Team, 2017). The paper provides a step-by-step guide, showing gesture researchers how they can harness motion-tracking data to quantitatively address questions of speech–gesture synchrony. Beyond the general utility to gesture researchers in terms of the step-by-step guide and analysis scripts, this study also shows that, at least for well-recorded data, both pixel-based tracking and machine-learning approaches (in this case, DeepLabCut) provided comparable results for assessing the relationship between speech and gesture. This suggests that these methods are equally robust for assessing speech–gesture synchrony when compared to more high-precision methods such as the Polhemus Liberty.
In addition to synchronization between articulators (i.e. speech and gesture) we can also investigate synchronization between individuals. Researchers in the field of joint-action have long been using motion tracking to capture the dynamics of how two or more individuals interact (see, for an overview of this work, Reference Sebanz, Bekkering and KnoblichSebanz, Bekkering, & Knoblich, 2006). However, this is also a potentially interesting dynamic for gesture researchers for understanding the timing of manual and bodily gestures. One interesting avenue for this type of research is the phenomenon of gestural alignment. Reference Bergmann and KoppBergmann and Kopp (2012), for instance, showed that people’s gestures tend to converge in form during the course of a conversation. Interestingly, the extent to which this happens depends on a multitude of factors relating to, among other factors, the type of gesture, type of interaction, timing of the gesture, and interpersonal differences (Reference Bergmann and KoppBergmann & Kopp, 2012). Similarly, Holler and Wilkin showed that individuals actively do this in order to resolve ambiguities and thus achieve mutual understanding (Reference Holler and WilkinHoller & Wilkin, 2011). Research in this phenomenon could thus greatly benefit from quantitative approaches to gesture analysis that are able to capture aspects of the kinematics, form, and timing of gestures with high fidelity. On a larger timescale, Fujiwara and Daibo utilized video-motion tracking of a natural conversation task, together with a method for calculating synchrony known as wavelet transform, to demonstrate that the movements of the hands and head of two interlocutors are rhythmically synchronized during interaction (Reference Fujiwara and DaiboFujiwara & Daibo, 2016). Given the potentially interesting role of interpersonal dynamics in understanding the form and timing of gestures, motion tracking offers a powerful tool to capture and quantify gesture features at multiple levels of granularity, from finger shaping to larger movement dynamics.
4 Applications for Gesture Comprehension
Motion tracking is useful not only in its ability to study gesture production, but also as a tool to study comprehension. This is due to both the wealth of information that can be extracted from a gesture and the fact that tracked movements can be used and manipulated as stimuli independent from the original gesture production. In this section, I discuss these as two potential routes for gesture researchers to utilize motion tracking to better understand the role of gesture in multimodal language comprehension.
4.1 The Influence of Kinematics on Gesture Comprehension
Perhaps the most straightforward way to utilize motion tracking to study gesture comprehension is by taking advantage of the fine-grained calculations that can be performed on motion-tracking data and utilizing this to model gesture or multimodal language comprehension. This can be particularly informative for studies seeking to examine the role of gestures on addressee comprehension (e.g. Reference Driskell and RadtkeDriskell & Radtke, 2003; Reference Gullberg and KitaGullberg & Kita, 2009; Reference Holler, Shovelton and BeattieHoller, Shovelton, & Beattie, 2009). Some of these studies, such as that of Gullberg and Kita, specifically examined aspects of gesture that can also be captured by kinematic analysis. In this case, it was the use of gesture holds. Extracting features of the gestures of interest, as described in Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo et al., (2019) or Reference Pouw and DixonPouw and Dixon (2020), would allow researchers to test the specific qualities of gestures on an addressee’s comprehension. This approach is relevant for gesture researchers because it allows us to better understand the qualitative and quantitative differences that we find in gesture production, depending on the speaker, context, or other factors.
A simple way to go about utilizing gesture kinematics to study comprehension is to test whether some kinematic feature is correlated with comprehension performance. For example, Reference Gullberg and KitaGullberg and Kita (2009) used short video clips of gestures taken from a larger corpus as stimuli, and the authors tested information uptake based on speaker behavior, finding that uptake of information from a gesture is primarily influenced by whether or not the speaker looks at their own gesture. In a similar type of experiment, Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo et al. (2020) showed videos of people performing pantomime gestures to a naive set of participants and asked them to identify the gesture that they saw. The results showed that the size and number of holds produced in a gesture were related to the accuracy with which the gesture was identified. While these are quite tightly controlled experiments, one could utilize a similar approach for more naturalistic tasks, such as that described by Reference Holler, Shovelton and BeattieHoller et al. (2009). In this study, the authors investigated how iconic gestures influence addressee understanding in face-to-face compared to video-mediated communication. The authors found that gestures produced in the face-to-face condition were equally, if not more, informative than those in the video condition in communicating spatial information. Given the potential heterogeneity present in the form of the gestures themselves, an interesting follow-up would be to use motion tracking to determine the kinematics of these gestures. This would allow us to determine what kinds of gestures are most beneficial in certain kinds of communication, or what features contribute to successful communication.
The approaches discussed above largely relate to empirical studies using experimental approaches. However, utilizing the fine-grained movement information from motion tracking can also be applied to approaches such as Conversation Analysis (see Reference Sidnell and StiversSidnell & Stivers, 2012, for an overview), where video data are increasingly being employed so that movement of the head, hands and body together with speech, eye-gaze, and other relevant cues can be analyzed together as one holistic, multimodal utterance (Reference MondadaMondada, 2016). In addition, in this approach, methods to automatically annotate movements (e.g. Reference Ripperda, Drijvers and HollerRipperda & Drijvers, 2020 and extract relevant kinematic information (e.g. Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo et al., 2019) can be utilized to potentially reduce the burden of manual annotation and allow the researcher to get at more fine-grained aspects of the movements themselves.
4.2 Motion Tracking for Stimulus Design
When studying gestures from a comprehension perspective, perfectly controlling particular aspects of the gesture or its linguistic context can be difficult, if not impossible, in most natural settings. However, such a degree of control is invaluable in empirical research as it allows us to test the specific effects of particular parameters of interest. In the case of gestures, this could be the speech (or the timing thereof) that is paired with a gesture, or something like the size or speed of a gesture. Controlling these features is possible by reducing the visual information available, or by mapping motion-tracking data onto virtual agents, such as avatars.
Multimodal communication is highly complex, involving a multiplex of sometimes very subtle signals (Reference Holler and LevinsonHoller & Levinson, 2019). Thus, trying to investigate any isolated aspect of it can prove difficult. One solution is to use the motion-tracking data directly as stimuli for comprehension experiments. Studies on human perception have long used simplified visual displays to study perceptual processes, allowing the researcher to examine specific phenomena without the presence of extraneous visual information. A classic example that is quite relevant to gesture researchers is the perception of biological motion (Reference JohanssonJohansson, 1973), whereby a human figure is easily identified even when reduced to single points representing the major joints of the body (i.e. point-light displays). Even in such reduced visual displays, people are able to recognize individual actions such as jumping or walking (Reference Manera, Becchio, Schouten, Bara and VerfaillieManera, Becchio, Schouten, Bara, & Verfaille, 2011) as well as communicative gestures (see Reference Manera, Becchio, Schouten, Bara and VerfaillieManera et al., 2011 and Reference Okruszek and ChrustowiczOkruszek & Chrustowicz, 2019, for open databases of point-light gesture videos). Using point-light-displays is useful because it allows the researcher to remove or control other visual features, such as background, body shape, facial expression, and so on. Besides being a useful experimental control, it also makes it easier to utilize such complex movements in neuroimaging studies, where visual information must be carefully controlled, which can be difficult with videos of natural gesture production. One example of such use is in Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo et al. (2020), where stick-figures derived from Kinect motion-tracking data were used to study the neural response to communicatively intended gestures. In this case, the motion-tracking data served to quantify the features of gestures produced in an earlier study, as well as to create well-controlled stimuli. This allowed the authors to test brain responses to specific quantitative differences in the gestures.
Another approach is to take motion-tracking data and map it onto a virtual agent. This allows the researcher to control or manipulate each aspect of behavior individually (e.g. gesture form, motion, or linguistic context) without greatly reducing the visual information available. For example, Reference Hassemer and WinterHassemer & Winter (2018) created a continuum of hand shapes in order to empirically test the hypothesis that finger position influences our interpretation of a particular type of gesture. Even if the behavior is not manipulated, having an interaction with a virtual agent allows the experiment to be much more replicable across participants. This can be particularly relevant for more interactive experiments, allowing researchers to maximize the ecological validity (Reference Holler and LevinsonHoller & Levinson, 2019; Reference Valenti and GoodValenti & Good, 1991) of their findings while still maintaining experimental control. Virtual reality provides a powerful way to place participants in a fully immersive interaction with such experimentally controlled virtual agents. For an overview of how motion tracking can be used to create virtual agents for the study of speech–gesture integration, see Reference Nirme, Haake, Gulz and GullbergNirme, Haake, Gulz, & Gullberg (2020). For an in-depth overview of how virtual reality can be used to study social interaction more broadly, see Reference Pan and HamiltonPan and Hamilton (2018). This approach could allow researchers to test hypotheses about gesture or multimodal communication in an environment that is tightly controlled but could be replicated with other languages, different labs, and so on.
5 Practical Points
Previous sections have described the potential applications and advantages of motion tracking. However, there are also some practical considerations that must be kept in mind for those considering using any motion-tracking approach for their research. In this section I will focus on three important considerations for the gesture researcher interested in motion tracking. These are (1) synchronization between motion tracking and audio/video data, (2) reliability of current methods, and (3) limitations in what is currently possible with motion tracking.
5.1 Synchronization
When working with multiple data streams, it may be necessary to synchronize them in time. For example, if we record motion-tracking data with the Kinect and wish to use this data to inform qualitative coding, or we wish to use qualitative coding to define specific gestures that we wish to analyze with the Kinect data, we need to know which data points in the motion-tracking data correspond to which frames in the video file. Similarly, if we are interested in speech–gesture coordination, we need to know which motion-tracking data points correspond to which time points in the audio file.
The process of synchronizing motion-tracking data will likely be different depending on how the data were collected. One advantage of video-based tracking is that no synchronization should be necessary, as the motion-tracking data are calculated from the video, meaning that the frame numbers will be identical. One notable exception to this is the possibility in OpenPose to specify the frame rate at which it should perform the tracking. This frame rate should be identical to the frame rate of the video recording.
When using device-based motion tracking, motion tracking and video recording must either be started simultaneously, or the two streams must be realigned after data collection. As timing is often needed to be quite precise, it is important that recordings start at nearly the exact same time. While this is practically impossible to do manually, a single computer connected to multiple recording devices can be used to send simultaneous start signals. This approach has been advocated by Reference Pouw, Trujillo and DixonPouw et al. (2020), who also provide working code for the simultaneous recording of Polhemus motion-tracking and audio recordings. With this, researchers can ensure that the two data streams are started at the same moment. As different recording devices likely use different frame rates, it is important to resample the data to ensure that each time point in one data stream has data at the same time point in the other data stream. This can be easily achieved by resampling the “slower” signal (typically motion tracking) to match the higher-rate signal (typically audio). If audio and motion tracking are synchronized in their onset, it is then additionally possible to synchronize both streams to a video recording, provided it also has an audio recording embedded in it. This “chaining synchronization” has also been fully described in a step-by-step fashion by Reference Pouw, Trujillo and DixonPouw et al. (2020). While this paper specifically refers to the Polhemus being synchronized to an audio recording, the code provided by the authors could be modified for other types of data streams and a similar procedure can be followed.
An alternative approach to synchronizing data streams is to provide a signal that can be used to align two or more streams. For example, many standard experiment button-boxes have a light that indicates when a button has been pressed. If this light is visible on camera, and the button sends a signal to the computer controlling the motion tracker, then the timestamp of the button press and the appearance of the light can be used to align the data streams. In this case, the two streams can have these two marks as a “time zero,” where everything is calculated as time after this point. Then, any calculations will be aligned with one another. This approach has been used by Trujillo and colleagues to synchronize Kinect data with video (Reference Trujillo, Simanova, Bekkering and ÖzyürekTrujillo et al., 2018). Other manual approaches include clapping at the beginning of data collection, allowing the motion-tracking frames to be aligned with the video frames.
Regardless of the method chosen, it is important that (1) any data streams being used (e.g. motion, audio, video) have the same starting point, or at least a point that is aligned across all data streams, and (2) that if analyses are directly comparing information in different streams (e.g. for speech–gesture synchrony), the sampling rates are also identical.
5.2 Reliability
Motion-tracking technology is constantly developing, and purely software-based approaches (i.e. video-based tracking) in particular are quickly improving. In general, however, it should be kept in mind that as one moves away from marker- or IMU-based tracking, tracking precision will decrease. This may or may not be an issue for every research question, but one should always ensure that the method chosen fits the research question and study design. Section 2.1 provides information about the precision of different methods and gives some suggestions for what types of data (e.g. precise trajectories, general gesture use) the different approaches are best suited.
Even under ideal recording conditions, there may be errors or artifacts present in the data. Depending on the type of analysis, these can be removed manually (e.g. within the statistical program the researcher is using) when the researcher is confident that a given frame is unreliable, or problematic sections of the data can be excluded from statistical analysis. Therefore, it is also important to check data quality before beginning analyses. Freely available software can be found allowing the researcher to view motion-tracking data as a video, which can be used to check the quality of recordings. An example of such software is Mokka (Reference Barré and ArmandBarré & Armand, 2014).
5.3 Limitations
Motion-tracking technology comes in many varieties, as was discussed in previous sections. This means that tracking can be performed with very high precision of even very small articulators, for example, the fingers. The main limitations in motion tracking are thus not necessarily related to the precision of tracking per se, but rather to the practicalities of data collection and analysis.
In terms of data collection, researchers must decide if they want high-definition tracking using optical or electromagnetic tracking, which may have psychological effects on the participant (e.g. by making participants aware of what is being studied and thus biasing their behavior [Reference Rosenthal and RubinRosenthal & Rubin, 1978], or by the wires and markers influencing how comfortably a participant is moving), or if lower precision tracking is sufficient, which is less costly to acquire and less likely to influence participant behavior. Furthermore, high-definition tracking is typically not feasible outside a lab setting, meaning that lower-precision tracking may also be more flexible for fieldwork or researchers working outside of lab settings. This may impact the ability to accurately capture fine-grained finger movements, although the latest implementation of OpenPose also captures finger movements, and the quality of this tracking seems promising, though rigorous validation tests are lacking. IMU-based tracking, such as Perception Neuron, also provides a promising possibility for high-quality tracking outside of the lab. Field-tests will be needed to determine how much Perception Neuron, or other IMUs, are affected by ambient magnetism, and thus to what extent the system can be used in more naturalistic settings.
The other potential limitation of motion-tracking technology for gesture research is that this type of data requires different skill sets than what typical gesture researchers often have. Unlike video data, motion data are not analyzed visually, unless they are being used as a visual tool for qualitative coding. Motion-tracking data are often highly complex and have many degrees of freedom, as each sensor or tracked joint has positional data for two or three dimensions, plus angle or orientation, and each of these variables extends as a time-series, leaving the researcher with many processing and analytic decisions to make. These processing and analysis steps are typically done using programming scripts written to extract relevant features, find relevant events in the data (e.g. gesture occurrences), or perform more complex analyses. This can be a daunting task, particularly for those who are less skilled in (or even unfamiliar with) scripting. However, this situation is beginning to change, as the move towards more open science has also generated more interest in open code and applications. In just the past couple of years, several open-source tools have become available that make motion tracking more accessible to gesture researchers. Several of these tools are highlighted in Section 6.2.
6 Summary, Resources and Future Developments
6.1 Summary
Motion tracking can provide a powerful tool to support current gesture-research protocols and to advance the way that we study gesture and multimodal communication. Particularly with the rise of lower-cost, mobile tracking systems, the primary hurdles for utilizing these technologies for gesture research at present are (1) selecting the most appropriate method or device based on what it can and cannot do, and (2) knowing how to work with the data once one has it. For the first issue, this chapter has attempted to provide a gentle introduction to the different methodologies and the questions that one can answer with each of them. For the second issue, the chapter indicates some of the currently available software and code packages that researchers can use for their own projects. These will be summarized again in this section, for easy reference, followed by a brief discussion on ways the research community can continue to develop these methodologies.
6.2 Resources
While many applications exist for visualizing or working with motion-tracking data, I will focus here on open-source applications or bundles of code that have been provided by the community. These are particularly valuable because they are available to all researchers and we can continue to shape their development. Table 12.1 gives a brief description of what each resource provides, what type of code is provided, and the reference.
Table 12.1 Some open resources for motion tracking and gesture research
| Resource | Code | Reference |
|---|---|---|
| Data Collection | ||
| Automatic detection of movement from video data; ELAN annotations of the movements |
| Reference Ripperda, Drijvers and HollerRipperda, Drijvers, & Holler, 2020 |
| Overview of how to use pixel-differencing methods; links to relevant software | MATLAB; R | Reference Danner, Barbosa and GoldsteinDanner et al., 2018 |
| Data Processing | ||
| Tutorial and code for aligning auditory and motion-tracking data | R | Reference Pouw, Trujillo and DixonPouw et al., 2020 |
| Extraction of kinematic features from specific gesture events; (video) visualizations of these kinematics | MATLAB | Reference Trujillo, Vaitonyte, Simanova and ÖzyürekTrujillo et al., 2019 |
| Post-Processing | ||
| Visualization of gesture ensembles | R | Reference Pouw and DixonPouw & Dixon, 2019 |
| Pipeline overview of motion-tracking data for gesture avatars in virtual reality | (tutorial) | Reference Nirme, Haake, Gulz and GullbergNirme et al., 2020 |
| Pipeline for motion-tracking data collection, analysis, and three-dimensional visualization | (tutorial) | Reference Boutet, Jégo and MeyrueisBoutet et al., 2018 |
6.3 Future Directions
As we continue to create and publish databases and corpora of motion-tracking data, it will be important to be able to take advantage of that wealth of data. Analyses of motion form (Reference Schüller, Beecks, Hassani, Hinnel, Brenger, Seidl and MittelbergSchüller et al., 2017) could be combined with recently developed algorithms that allow researchers to search motion-tracking databases for similar spatiotemporal patterns (Reference Beecks and GrassBeecks & Grass, 2018). This could open new avenues for gesture research to take advantage of big data analyses, for example, by finding patterns of similar gestures across many different contexts, cultures, and so on. Together with graph-based visualizations, as proposed by Reference Pouw and DixonPouw and Dixon (2020), this could be used to investigate how gestures are (dis)similar on an even larger scale. Future methodological work should also aim to bring together multiple streams of data for visualization in order to take advantage of a more holistic approach to data analysis, similar to the workflow proposed by Reference Jégo, Meyrueis and BoutetJégo and colleagues (2019).
While there are many new and exciting developments being made in applying motion-tracking methods to gesture research, many of these applications require highly specialized knowledge. Therefore, future research should also aim to produce applications and toolboxes that make these approaches more accessible. At the least, those working with motion-tracking approaches can make their analysis code available, allowing others to benefit from the collective knowledge. Overall, this will help to advance gesture research for everyone.
6.4 Conclusion
Motion-tracking technology comes in many forms, which can be intimidating when getting started. However, this variety also ensures that there are methods suited to many different topics and researchers. Whether for supporting manual annotation, analyzing kinematics, or generating more naturalistic virtual stimuli, these motion-tracking methodologies have great potential for further raising the quality and innovativeness of gesture research.






















































