

3 Initial processing and use of inflectional markers: evidence from French adult learners of Polish
A student’s eyes light up. “What? Hungarian has how many cases?”
“Approximately 17, depending on the approach you take to analyzing case marking.”
The university student in question has never studied Hungarian, Latin, or any other highly inflected language. In her Introduction to Linguistics course, she is learning how some languages use nominal case marking to express location, motion, thematic relations, and more. The linguistics professor, being of Hungarian origin, illustrates this by teaching the class some Hungarian. Our student is in awe. “How can someone ever learn this?” she asks.
The student’s question reflects the focus of this chapter, a preliminary investigation into how instructed foreign-language learners break into a new system of nominal morphology, extract elements of this new system from the input, judge the correctness of them, use them, and maybe even learn them.1 The target language of the study presented in this chapter is one that has fewer cases than Hungarian but still poses a serious linguistic challenge to its learners: the Polish language with its seven cases and complex gender and number system. The actual target language input to which the learners of the current study were exposed is less complex than this, however. Based on decades of research, our assumption is that instruction renders adult language learning more effective and efficient (cf. Doughty Reference Doughty, Doughty and Long2003), and that careful planning of this instruction is desirable (Ellis Reference Ellis2012). It follows that in a language class for absolute beginners, one should select teaching materials carefully. For this reason, in preparation for a 6.5-hour intensive Polish course for adult native speakers of French with no prior knowledge of Polish, the themes chosen were typical of beginner classes; nationalities and professions were the relevant themes for the part of the study presented in this chapter. This thematic content naturally triggered a frequent usage of two genders (masculine and feminine) and two cases (nominative and instrumental) in Polish. This does not mean that learners did not hear other inflectional forms in the input, but rather, that the majority of nominal forms they heard were of this type. Hence, the precise objective of this study was to observe and describe the development of learners’ ability to judge the correctness of this type of inflectional marking and to make use of these same markers in their first productions.
Input processing and individual differences
As mentioned in the preface to this volume, one primary area of investigation in second language (L2) or target language (TL) acquisition2 research is that of input processing. Essentially, what are the ways in which learners attend to classroom input and use this input as a basis for learning new language forms? Research in language acquisition has long been interested in the learning of new grammatical forms, but few studies have been able to document precisely the links between classroom input and grammar learning in the earliest exposure to a new morphological system:
If we wish to investigate the effects of input and practice on the acquisition of language structure then we need a proper record of learner input. Yet it is virtually impossible to gather a complete corpus of learners’ exposure and production of natural language. How can we ascertain how many types and tokens of regular and irregular inflections have been processed by, for example, learners of English or of German? At best, for natural language, we can only guess by extrapolation of frequency counts from language corpora and unverifiable assumptions about registers.
Much empirical research aiming to control fully the linguistic input at the early stages of TL acquisition has opted for the teaching of artificial languages. Studies of natural language acquisition that record and document the input carefully, however, are necessary to build on the work conducted in laboratory settings (cf. Hulstijn Reference Hulstijn1997). As Ellis and Collins (Reference Ellis and Collins2009: 329) suggest, “despite the long-standing recognition of the importance of input in language acquisition, our research base contains little by way of dense corpora studies describing the evidence, particularly of oral input, upon which learners base their analyses for the development of interlanguage grammars.”
In an attempt to move from artificial to more natural language acquisition, the current study set out to investigate the acquisition of Polish in a classroom setting where the input was fully controlled. As Ellis and Schmidt pointed out, this type of documentation is necessary for a frequency-based account of acquisition. Frequency effects have been the focus of numerous recent studies of the early stages of TL acquisition (e.g., Gullberg et al. Reference Gullberg, Roberts, Dimroth, Veroude and Indefrey2010; Myles Reference Myles2012; Rast Reference Rast2008; Shoemaker & Rast Reference Shoemaker and Rast2013), but the nature of these effects is still not fully understood. Frequency, however, is clearly not the only factor influencing input processing at the early stages (Carroll Reference Carroll2013). Familiar words in the input, such as cognates, also account for some initial receptive or productive activity in the TL (cf. Carroll Reference Carroll1992; Kellerman Reference Kellerman, Gass and Selinker1983; Laufer Reference Laufer1993–1994; Singleton Reference Singleton1999). In particular, there is increasing evidence of a cognate effect in TL speech segmentation. Recently, Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012) found that L2 learners responded faster to cognate words than to non-cognate words on a word-recognition task. Shoemaker and Rast (Reference Shoemaker and Rast2013) found that the transparency of words relative to the learners’ L1 helped learners extract TL words from the speech stream. A cognate effect on other processes, such as breaking into a new morphological system, however, has received limited attention. The current study investigates the effects of frequency and transparency on L1 French learners’ ability to judge the correctness of and to use a limited selection of nominal inflectional markers in TL Polish.
While the nature of the input constitutes one set of parameters in the language-learning process, individual differences between learners constitute another (Carroll Reference Carroll and Diller1981; Dörnyei Reference Dörnyei2005; Dörnyei & Skehan Reference Dörnyei, Skehan, Doughty and Long2003; Robinson Reference Robinson2002; Skehan Reference Skehan1989, Reference Skehan1991); dynamic systems theory hypothesizes that learning outcomes emerge from complex interactions between these multiple components (de Bot et al. Reference de Bot, Lowie and Verspoor2007; Ellis Reference Ellis2007; Larsen-Freeman & Cameron Reference Larsen-Freeman and Cameron2008; van Geert Reference van Geert1991, Reference van Geert, Kail and Hickmann2010). In addition, therefore, to compiling a complete record of classroom input, we also collected information on possible differences between the individual learners composing the group, with a view to going beyond generalizations and group averages, to a more detailed appreciation of individual variation in classroom learning. As for any kind of human learning, learning a new language involves long-term and working memory components, as well as a number of affective and personal variables (as remarkably summarized in Dörnyei Reference Dörnyei2009). Participants in our study therefore completed a modest battery of tests and questionnaires designed to measure differences in long-term verbal memory, working memory, learning preference (or style), and motivation for learning Polish. The instruments and procedures used are described below; the data they provide enable us to identify some characteristics of these learners as a group, but also to interpret some of the individual variation we observed in the early learning of Polish nominal morphology.
The learning problem: nominal inflection
A substantial learning problem for a French learner of Polish is the acquisition of Polish nominal inflectional morphology. To better understand this problem, let us consider inflectional morphology as analyzed by both linguists and psycholinguists. From a linguistic perspective, Aronoff and Fudeman (Reference Aronoff and Fudeman2011) define morphology as “the mental system involved in word formation or to the branch of linguistics that deals with words, their internal structure, and how they are formed” (p. 2; emphasis in original). Morphologists investigate this system through the identification and study of morphemes, defined as “the smallest linguistic pieces with a grammatical function” (p. 2). Aronoff and Fudeman acknowledge that this definition does not include all morphemes, nor does it do justice to the phenomenally complex system of what is referred to as ‘morphology,’ but it is the most common usage of the term, and it suffices for the discussion of data presented in this chapter. Morphemes, of course, do not function in isolation. As Anderson (Reference Anderson and Newmeyer1988: 146) points out, “Morphology is the study of the structure of words, and of the ways in which their structure reflects their relation to other words – both within some larger construction such as a sentence and across the total vocabulary of the language.” More specifically, he suggests that “Inflectional morphology is what is relevant to the syntax” (Reference Anderson1982: 587). Inflection expresses morphosyntactic information, including tense, aspect, number, and case, which cannot be assigned in isolation, but rather, with respect to the larger structure in which a word appears. Finally, given that morphemes are made up of various combinations of consonants and vowels, they essentially involve phonological realizations.
From a psycholinguistic perspective, how children process and acquire inflectional morphology in their first language (L1) and how adults do this in their L2 has been and continues to be a hotly debated topic. The essential questions in this debate are whether models can allow for two ‘routes’ or ways of accessing information, that is, by assembling morphemes or by retrieving the entire item from memory, and to what extent the learner makes use of the similarity and frequency of previously learned items. Researchers who claim innate access to classical syntactic categories (e.g. Caramazza, Laudanna & Romani Reference Caramazza, Laudanna and Romani1988; Pinker Reference Pinker1999; Pinker & Prince Reference Pinker, Prince, Lima, Corrigan and Iverson1994) argue that two distinct mechanisms are at work: (1) a system that applies rules, such as those found in regular inflected forms, and (2) associative memory or patterning that deals with irregular uninflected forms (the bare lexemes), idioms, formulaic chunks, and idiosyncratic irregular forms. Based on his work on the English past tense, Pinker (Reference Pinker1998, Reference Pinker1999), for example, claims a symbolic rule for the regular morpheme and a rote-learned lexical item for the irregular morpheme. The prediction is then that the rule for the regular morpheme will be applied regardless of frequency.
Those who argue against innate access to syntactic categories tell a different story. Bybee (Reference Bybee1995) suggests that a separate morphological level of representation and processing is not necessary because phonological and semantic associations have sufficient explanatory power. Frequency is an essential construct in this usage-based account of syntactic acquisition. As Bybee (Reference Bybee2006) points out, the cognitive representation that can be called ‘a grammar’ is strongly tied to the experience a speaker has had with language. In the same vein, Ellis and Schmidt (Reference Ellis and Schmidt1998) argue that differences between the processing of regular and irregular forms, for example, are due to statistical distributional factors, while Abbot-Smith and Tomasello (Reference Abbot-Smith and Tomasello2006) claim that frequency and similarity of novel items to other previously learned items play a crucial role in generalizing a rule.
Based on empirical work on L1 Polish, the target language of the current study and one in which several inflectional patterns range in regularity, Dąbrowska (Reference Dąbrowska2004, Reference Dąbrowska2008) supports a model in which both routes – assembling morphemes or retrieving an entire item from memory – can be used for regular forms, irregular forms, and forms that lie somewhere in between (see also Gor & Long Reference Gor, Long, Ritchie and Bhatia2009 and Gor & Cook Reference Gor and Cook2010 for a similar approach based on Russian data). This is in line with the theoretical framework proposed by Schreuder and Baayen (Reference Schreuder, Baayen and Feldman1995), which exploits the flexibility of parallel dual-route models (see also Baayen, Dijkstra & Schreuder Reference Baayen, Dijkstra and Schreuder1997 and Baayen et al. Reference Baayen, McQueen, Dijkstra, Schreuder, Baayen and Schreuder2003). In the current study, we adhere to this hybrid approach and assume that when exposed to TL Polish, learners will make use of both routes to process a variety of forms in the input. Our objective is, more specifically, to observe whether French learners of Polish can even begin to extract Polish inflectional markers from the input during the first hours of exposure and to use them appropriately, and if they can, what helps them do this.
It is well known that inflectional morphology is particularly challenging for L2 learners even at advanced levels (cf. Han Reference Han and Han2008; Larsen-Freeman Reference Larsen-Freeman2010a). Decades of research on L2 morphology, beginning with the morpheme-order studies in the 1970s, have raised questions that continue to beg for cross-linguistic investigation regarding the processing and production of morphological marking. When and why do learners pay attention to morphological marking? At what point are learners able to generalize L2 morphological rules and make use of appropriate forms in relevant contexts? Why do some learners pay attention to morphology more than others? In L2 studies focusing on the beginning levels of acquisition, some patterns have been observed. In production, extensive research has found that adult learners of an L2 mark temporal notions with lexical items (e.g., ‘yesterday’) before acquiring the relevant inflectional markers in later stages of acquisition (Bardovi-Harlig Reference Bardovi-Harlig1992; Klein & Perdue Reference Klein and Perdue1997; Meisel Reference Meisel and Pfaff1987; Starren Reference Starren2001). In the realm of input processing, VanPatten (Reference VanPatten and VanPatten2004) claims that learners attend to meaning over form. In utterances where the information is provided by two different means (e.g., the co-occurrence of English ‘-ed’ on the verb and the temporal expression ‘yesterday’), the inflectional marking is treated as redundant in that learners extract the temporal information from the lexical item rather than from the inflected form. Recent research conducted in a variety of research paradigms at first exposure to a novel TL has provided convincing evidence that learners can extract words from the speech stream with very little exposure (cf. Carroll Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012; Gullberg et al. Reference Gullberg, Roberts, Dimroth, Veroude and Indefrey2010; Osterhout et al. Reference Osterhout, McLaughlin, Pitkänen, Frenck-Mestre and Molinaro2006; Rast & Dommergues Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003; Shoemaker & Rast Reference Shoemaker and Rast2013). Encoding inflectional marking at this early stage, however, is another story and has been examined only minimally. Rast (Reference Rast2006, Reference Rast2008) found that some learners were sensitive to morphology at first exposure to the novel TL (see also Park, this volume). When asked to translate isolated words into French from an unknown language (Polish), some of her French native speakers regularly offered information about gender and number based on their interpretation of word endings (e.g., kolegi was translated as ‘collègues’ – colleagues). Other studies of the very early stages of L2 acquisition have also observed some sensitivity to morphological structures. Park (Reference Park2011), for example, studied two different first language (L1) groups (Japanese and English), and found that when learners were exposed to written Korean for the first time, learners of both groups were able to notice certain morphological markers in the input without external enhancement (see also Park, this volume). The current study seeks to investigate such processes further. We imagine, as Gor (Reference Gor2010) suggests in her review of the literature on the acquisition of L2 morphology, that when processing inflectional morphology, learners are constrained by numerous linguistic and extra-linguistic factors, including (but not limited to) the morphological richness of the TL, the properties of inflectional morphology in the L1, the proficiency level in the TL, the amount of exposure to the TL, individual variability, such as verbal working memory capacity, and the properties in the input, such as the position of a morpheme in an utterance and its frequency in the input.
As mentioned above, at the time of testing the learners of this study were exposed to no more than 6.5 hours of instruction-modified Polish. The specific aspects of the input will be described below, but we emphasize here that the instructor used simple but quite natural spoken Polish in the classroom, which contained a fairly wide distribution of inflectional morphology. For this reason, the reader needs to be aware of some of the complexities of the Polish language to understand the nature of the input to which the learners were exposed. Polish attests a system of nominal inflectional morphology made up of three distinct genders, two numbers, and seven cases. Gender, number, and case together determine the word endings of noun phrase elements, such as nouns, adjectives, and numbers. Person and animacy are attested as well within the category of masculine gender. Reid and Marslen-Wilson (Reference Reid, Marlsen-Wilson, Baayen and Schreuder2003: 292–293) offer an excellent account of the system’s complexity:
Almost every word in Polish exists within a very rich inflectional paradigm, declensional for nouns, adjectives, numerals and pronouns or conjugational for verbs. A noun dziewczyn-a ‘a girl,’ for instance, can appear with up to fourteen different inflectional affixes, depending on case and number, ranging from the nominative singular dziewczyn-a to the vocative plural dziewczyn-y. Noun (and adjective) endings vary further as a function of a three-way gender distinction (masculine, feminine, and neuter), with a further subset of variations reflecting animacy.
The learners’ L1 French, on the other hand, shows much less nominal morphology. French nouns do not carry case marking, and they distinguish only two grammatical genders (masculine and feminine) as opposed to three. Gender can be marked in a variety of ways: by means of a final ‘-e’ on the noun in the feminine form (e.g., ‘étudiante’ – student), a double final consonant of the stem (e.g., ‘chien’ vs. ‘chienne’), or a determiner (e.g., ‘le,’ ‘la’). Adjectives agree with nouns and may show the gender even if the noun does not (e.g., ‘robe blanche’ vs. ‘costume blanc’). In some cases, however, the final ‘-e’ on a noun shows no gender difference (e.g., ‘artiste,’ ‘journaliste’) and in others it does not modify pronunciation (e.g., ‘ami’/‘amie’ – friend). Number is usually marked on French nouns in the written language with the final -s, but it is usually silent in spoken French (e.g., ‘étudiants’ – students). Certain plural forms, such as -aux [o], mark the plural (e.g., ‘cheval’ – ‘chevaux’) and are perceivable in both written and spoken language. As with gender, it is often the determiner that signals the plural (e.g., ‘les’). In sum, spoken French shows relatively little regular nominal morphology for gender and number and carries no case marking on its nouns. Given these differences between French and Polish, French learners of Polish will not be able to rely solely on L1 properties to perceive and produce Polish inflection. What then will help them do this?
Although the Polish input addressed to learners of the present study did not contain as rich a variety of inflections as is found in a non-instructional setting, the Polish teacher was instructed to vary forms in her speech addressed to the learners, and the transcripts do indeed reveal a variety of inflectional forms that show case, gender, and number. Our objective was to create a classroom environment based on logical communication-based pedagogical materials in terms of themes and vocabulary. We therefore selected professions and nationalities (typically taught at the beginner level) as our thematic material for the first Polish lesson. This course content was reviewed in all subsequent lessons to ensure that the learners had been regularly exposed to the lexical items that would later appear in the test stimuli. No French translations of Polish were provided: the instructor spoke in Polish only, and vocabulary was taught through images, gestures, and context. In order to examine learners’ acquisition of inflectional morphology, we developed a first lesson that included structures such as ‘I am a student,’ ‘Marie is a student,’ ‘Luc is a student,’ ‘I am French,’ ‘Marie is French,’ and ‘Luc is French’. If French learners rely on their L1 properties, they will assume that ‘student’ (‘étudiant’ or ‘étudiante’) requires an explicit marker for grammatical gender (cf. Jakobson Reference Jakobson1963), and this assumption may help them. This would also be the case for the nationality ‘French’ (‘français’ or ‘française’). The French language, however, does not mark for case, so if French learners rely on their L1 properties, they will not assume any difference between the noun form in ‘This is a student’ (‘C’est un étudiant’) and the one in ‘Luc is a student’ (‘Luc est un étudiant’). In Polish the former structure is used to introduce a person, whereas the latter is used to describe a person who has already been introduced. Polish marks this difference with case inflection, the former with the nominative zero case marking (To jest student) and the latter with the instrumental case marker (Luc jest studentem). In addition, the masculine and feminine markers differ. When referring to ‘Marie,’ the forms are respectively To jeststudentka and Marie jest studentką (ą is pronounced /ã/). The specific learning problem investigated in this chapter is this: How will a native speaker of French learn to map the correct feminine and masculine nominative and instrumental forms onto Polish lemmas when designating nationality and profession in Polish? To begin with, in addition to learning the Polish lemmas (stems), the French learner will need to learn the sound forms for inflections as summarized in Table 3.1.
Table 3.1 Case marking in the Polish test stimuli
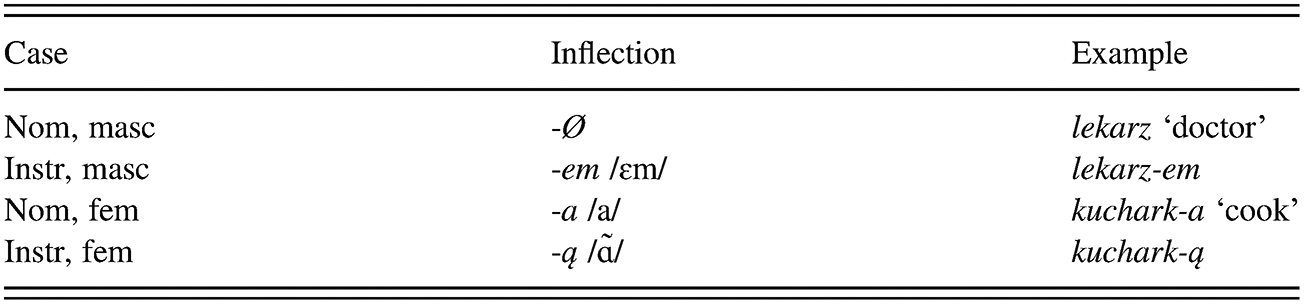
In fact, the learner will need to be able to map the phonetic form to its grammatical function. In order to judge whether a form is correct or not, the learner will need to be able to perceive the phonetic structure of the inflectional marker attached to its stem, while taking into account the structure of the utterance and gender agreement. In order to use these forms correctly, the learner must learn how to pronounce the proper mix of phonemes, again taking into account utterance structure and gender agreement.
The current chapter reports on data collected from a grammaticality judgment task and a sentence production task designed to measure the recognition and production of these inflectional forms within the first hours of exposure to Polish. Our study followed a group of eighteen learners from the moment of first exposure to Polish through the first 6.5 hours of instruction, analyzing their ability to perceive, judge, and use these new Polish forms relative to the input they received, the presence or absence of target items in the input, and the lexical transparency of these items with respect to L1 French.
The study
The Polish course
A first exposure, intensive one-week Polish course, taught by a native speaker of Polish, was designed and conducted at the CNRS-UMR 7023 center in Paris, France. Learners (N=18) were recruited through various websites, selected by means of a questionnaire and an interview, and remunerated for their participation. The goal of the selection process was to constitute a group in which all members had a similar linguistic profile: all were native speakers of French, with English as their first foreign language (L2) and a Romance language as their second (L3), and with no knowledge of Polish or other Slavic languages. Their ages ranged from 19 to 27 years. The learning environment represented a real-life instructed language-learning situation using a method that excluded metalanguage, explicit grammar explanation, and use of the learners’ L1 (French). The teacher used visual input in the form of PowerPoint slides containing illustrations, and some Polish text (although written forms were absent from the first lesson). Learners were told not to take notes or write in class or to consult dictionaries, grammar books, or any outside input for the duration of the data collection period.3 All eighteen learners attended five sessions of the Polish course, taking place on five consecutive weekday mornings. Each session lasted from 75 to 90 minutes, with a 15-minute break halfway through. The themes chosen were typical of beginner language classes: introducing oneself; talking about one’s profession, nationality, languages, and family; describing people’s physical and personality traits (Lessons 1–3); giving spatial directions (Lessons 4–5). Specific grammatical structures and lexical items that appeared in the input are described below in the section on instruments and procedure. The entire course was recorded and filmed; the teacher’s productions were then transcribed in CHAT (Codes for the Human Analysis of Transcripts) format of the CHILDES (Child Language Data Exchange System) project (MacWhinney Reference MacWhinney2000). These transcriptions represent the TL input of this study and were used to calculate word frequencies in the input.
To measure the effects of this input on the learners’ emerging Polish knowledge and skill, several Polish tasks were administered at varying times. This chapter will examine the learners’ performance on two of these tasks: the test of grammaticality judgment (GJ) and the sentence production task (see Appendix A for the scheduling of these tasks). The learners also completed a small battery of tests and questionnaires designed to measure individual differences which may play a role in the noticing (cf. Godfroid, Boers & Housen Reference Godfroid, Boers and Housen2013) and intake of new language forms (cf. Robinson Reference Robinson2000): attentional capacities (focusing and inhibition), phonological memory, metalinguistic awareness, long-term verbal memory, perceptual preference, cognitive style, and motivation for learning Polish. In what follows, we describe learners’ judgments of morphological case marking in simple Polish sentences and their productions of these same markings relative to the Polish input. We also report on possible connections between their performance on these tests, and our measures of individual difference.
Variables and hypotheses
The Polish grammaticality judgment and production tasks were administered to examine, respectively, the learners’ ability to judge the correctness of the target forms and to produce them in simple sentences. Data on both tasks were analyzed in terms of a single dependent variable, ‘accuracy,’ and two independent variables, ‘lexical transparency’ and ‘frequency in the input.’ In addition, prior research on first exposure leads us to predict that learners will improve in judgments and productions over time even with minimal exposure (e.g., Rast Reference Rast2008; Shoemaker & Rast Reference Shoemaker and Rast2013).
Lexical transparency was determined by submitting, in oral form, seventy-one Polish content words from the classroom input to a control group of thirteen native French informants with similar profiles to those of our project participants. They were asked to translate (in writing) any word they felt they could. Words that no informant translated correctly were categorized as ‘opaque’ (e.g., Niemcem ‘Allemand’ German); words that were correctly translated by at least 50 percent of the informants were classified as ‘transparent’ (e.g., fotografem ‘photographe’ photographer). Robust transparency effects (or cognate effects; cf. Carroll Reference Carroll1992) have been found in recent first exposure studies. Rast and Dommergues (Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003) found that transparency played a crucial role in sentence repetitions at first exposure, and although the effect diminished over time, it remained significant throughout the first 8 hours of instruction. Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012) reports that L2 learners responded to cognate words faster than non-cognate words on a word recognition task. Data collected by Shoemaker and Rast (Reference Shoemaker and Rast2013), also from a word recognition task, showed that learners recognized transparent words better than opaque words.4 In the current study, we tested a different type of transparency effect, that is, whether the transparency of stems will aid with the recognition and use of inflected forms attached to these stems. In fact, the sentence repetition and word recognition data suggest that transparency helps learners segment the speech stream at first exposure. We predict that this assistance in segmenting will show a facilitating effect in learners’ judgments and use of TL inflectional markers.
Because of the different nature of the judgment and production tasks, different token frequency criteria were used when selecting target items for the two tasks.5 Based on pilot studies of the grammaticality judgment task, target items were classified as simply ‘absent’ from (0 tokens) or ‘present’ (at least four tokens) in the input, based on lemma frequencies; that is, a nominative and instrumental form of the same lemma were counted as two tokens of that lemma (or word).6 In the production task, on the other hand, the whole-word frequency was taken into account to determine several levels of frequency (e.g., nominative feminine vs. instrumental feminine) enabling us to look more carefully at possible frequency effects in the production of noun morphology: ‘high frequency’ items occurred in the target form in the classroom input eleven times or more; ‘medium frequency’ items occurred in the target form from three to ten times;7 ‘low frequency’ items occurred only one or two times in the target form, and ‘new’ items were words occurring in the input, but not in the form required by the production task. Only one whole-word target figured in both the production and the GJ tasks (Francuzem ‘French’).8
Looking now at the real frequencies in the input of the study (see Appendix C and Appendix D for frequency and distribution of target items in the input), we note that, overall in the input, the masculine forms of both the instrumental and the nominative cases were more frequent than the feminine forms of these two cases, and that nominative complements were relatively infrequent. The two ‘new’ items – words the learners had not heard in the target form – were relatively frequent in the classroom input in other forms (twenty-five times for other inflected forms of Amerikan-ka, and eighteen times for other forms of Rosjanin-Ø).9 Owing to the lack of an appropriate tagging program, we were unable to generate automatic part-of-speech tagging for the Polish transcript. This said, we conducted a manual calculation of occurrences in the input of all masculine and feminine nominative and instrumental forms of the target items present in the two tasks and found that 71.5% of target items heard by the speakers carried the -em ending of masculine instrumental, 12% the uninflected masculine nominative, 16% the feminine instrumental ending -ką, and 0.5% the feminine nominative -ka. Future research of this kind with more detailed coding of the input will allow for analyses that can contribute to discussions about type-token frequency (cf. Ellis & Collins Reference Ellis and Collins2009).
As mentioned above, the precise role of frequency in language acquisition remains controversial. Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012) claims that frequency plays little to no role in segmentation at first exposure. In a similar vein, Shoemaker and Rast (Reference Shoemaker and Rast2013) found no frequency effect in their word recognition data, and Rast and Dommergues (Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003) found a frequency effect in sentence repetition data only after 8 hours of exposure. In contrast, Gullberg, Roberts, and Dimroth (Reference Gullberg, Roberts and Dimroth2012) found robust frequency effects in a word recognition task after very brief exposure. With respect to comprehension and production, extensive research argues clearly for strong frequency effects (e.g., Bybee & Hopper Reference Bybee and Hopper2001; Ellis Reference Ellis2002; Ellis & Collins Reference Ellis and Collins2009). Slobin (Reference Slobin and Perdue1993) suggests that ‘operating principles’ for segmentation of the input that are active in L1 acquisition function as well in L2 acquisition, and that perceptual saliency facilitates the analysis of the input (cf. also Klein & Perdue Reference Klein and Perdue1997). This perceptual saliency can be due to the frequency or regularity of the linguistic element in the input (cf. Peters Reference Peters and Slobin1985; Slobin Reference Slobin and Slobin1985) as well as the simple or conceptually salient nature of the item. For the acquisition of inflectional morphology, we imagine an important role for conceptually salient elements of language and therefore predict a facilitative role for frequency in our learners’ responses, in particular in the sentence production task. We also expect to find an influence of frequency in the GJ results given that learners will need to not only segment the target items from the speech stream, but also judge them relative to morphosyntactic and grammatical gender information.
Finally, measures of individual differences will enable us to discuss possible connections between memory function, learning style, metalinguistic skill, and the morphological knowledge acquired in the initial stages of learning. It is hypothesized that the individual participants will illustrate differing pathways in their acquisition of nominal morphology, and that our measures of individual differences will enable us to explore, in qualitative fashion, some of these differences.
In sum, for the two independent variables, ‘lexical transparency’ and ‘frequency in the input,’ we posited the following hypotheses:
1. Frequency will play an important role in both tasks at all test times. For judgments, learners will be better at judging the grammatical correctness of sentences when the target items are present in the input than when they are not. For production, learners will be better at using correct case marking with words that are frequent or fairly frequent in the input than with words that are rare in the input.
2. Transparency will play an important role in both tasks at all test times. Learners will be better at judging the correctness of case marking and using correct case marking with words that are lexically transparent (with respect to L1 French) than words that are not.
Instruments and procedure
The Polish GJ task consisted of thirty-two test sentences and twenty distracter sentences presented in a forced-choice format. All test sentences were three words in length and of the pattern ‘Proper Noun or Noun + is + nationality or profession,’ a structure that was used frequently by the instructor: Daniel jest Francuzem (DanielNOM is FrenchINSTR) or Marek jest studentem (MarekNOM is a studentINSTR). Of the thirty-two test sentences, sixteen were grammatical, incorporating the instrumental form of the target word (Alan jest rolnikiem, ‘AlanNOM is a farmerINSTR’) and sixteen ungrammatical, incorporating the nominative form of the target word (e.g., *Alan jest rolnik, ‘AlanNOM is a farmerNOM’). In other words, all grammatical items were instrumental -em (/ɛm/) (masculine) or -ką (/kã/) (feminine) forms; the ungrammatical items were nominative -Ø (masculine) or -ka (/ka/) (feminine) forms. The thirty-two test sentences were further classified according to the presence or absence of the target words (nationality or profession) in the input (cumulative lemma frequency count, irrespective of case marking), and their level of transparency (transparent or opaque, as determined by the L1 French control-group translation task). The items were balanced with respect to the two independent variables, resulting in four distributions: transparent and present; transparent and absent; opaque and present; opaque and absent (see Appendix B). Distracter sentences also consisted of three words, but included nominal subjects and more varied verbs, for example, Tancerz zna tango (The dancer knows the tango), to break the consistency of the nominative and instrumental structures and reduce the possibility of a practice effect; all distracter sentences were grammatical.
The same GJ task was administered to all eighteen participants in groups of two or three in a quiet room, at three separate intervals during the five days of instruction: after 1h30 input (T1), after 4h00 (T2, immediately following Session 3), and 4h00 (T3 immediately prior to Session 4).10 We ran the tests at T2 and T3 to see if participants would perform better immediately following exposure to Polish input than they would the following day prior to a new class session. The task was created using E-Prime software (Schneider, Eschman & Zuccolotto Reference Schneider, Eschman and Zuccolotto2002) and was presented on either laptop or desktop computers. Each experimental trial had the following structure: participants heard one of the fifty-two sentences presented binaurally through Dacomex headphones. At the offset of the auditory stimulus, participants indicated whether the sentence was grammatical or ungrammatical by pressing on the computer keyboard either (1) or (2), respectively. Stimuli were presented in randomized order. In order to familiarize themselves with the procedure, participants completed a training portion consisting of eight trials before beginning the experimental portion. Items included in the training portion were not included in the experimental portion. Individual trials were separated by 2000 ms. No response limit was set. Each testing session lasted approximately 12 minutes.
The sentence production task consisted of sixteen items in all, but for our analyses here we have retained only the eleven items that targeted the independent variables of frequency and transparency. The task involved responding to two different questions, asking about the professional role or nationality of men and women pictured in activity cards used to trigger the participant’s responses. Both questions appeared regularly in the input. Together, each question, Kto to jest? (Who is this?) or Kim on/ona jest? (Who is he/she?), along with its response trigger (pictures indicating gender and profession or nationality), was designed to elicit a specific morphological marking on the target item in the expected response, namely masculine or feminine nominative or instrumental marking on the subject complement (C). These questions elicit a certain type of predicate in Polish, a language in which the grammatical subject constrains nominal morphology. When the subject of the copula ‘to be’ is the demonstrative pronoun to (this), the predicate is marked with nominative case. When the subject of the copula is the personal pronoun on/ona (he/she), the predicate requires instrumental case. The four possible morphological markers and their related questions are listed below. Question 1 necessitates a nominative complement, in the masculine or feminine form (depending on the trigger); this question and the elicited response are used for introducing people. During the Polish lessons, the instructor generally used this structure when introducing new pictures of people and talking about them. Questions 2 and 3 necessitate not only an instrumental complement, which differs in the masculine and feminine, but also a change of subject pronoun (on, he, or ona, she). These forms are generally used to refer to people once they have been introduced, and were used by the instructor when asking questions about students in the class and about people in pictures that had already been seen before.
Question: Kto to jest? (Who is this? Qui est-ce?)
Response: To jest + C-Ø. (This is + C-Nominative Masculine)
Ex. To jest Amerykanin. (This is an American. ‘C’est un Américain.’)
Response: To jest + C-a. (This is + C-Nominative Feminine)
Ex. To jest Amerykanka. (This is an American. ‘C’est une Américaine.’)
Question: Kim on jest? (Who is he? Qui est-il?)
Response: Onjest + C-em. (He is + C-Instrumental Masculine)
Ex. On jest Amerykaninem (He is American. ‘Il est Américain.’)
Question: Kim ona jest? (Who is she? Qui est-elle?)
Response: Onajest + C-ą. (She is + C-Instrumental Feminine)
Ex. Ona jest Amerykanką. (She is American. ‘Elle est Américaine.’)
In addition to gender and case, the eleven target complements varied in terms of their frequency (in the classroom input) and their transparency (as determined by the control-group translation task). Table 3.2 lists the elicited target items with their frequency and transparency classifications.
Table 3.2 Elicited items in the sentence production task, indicating frequency and transparency
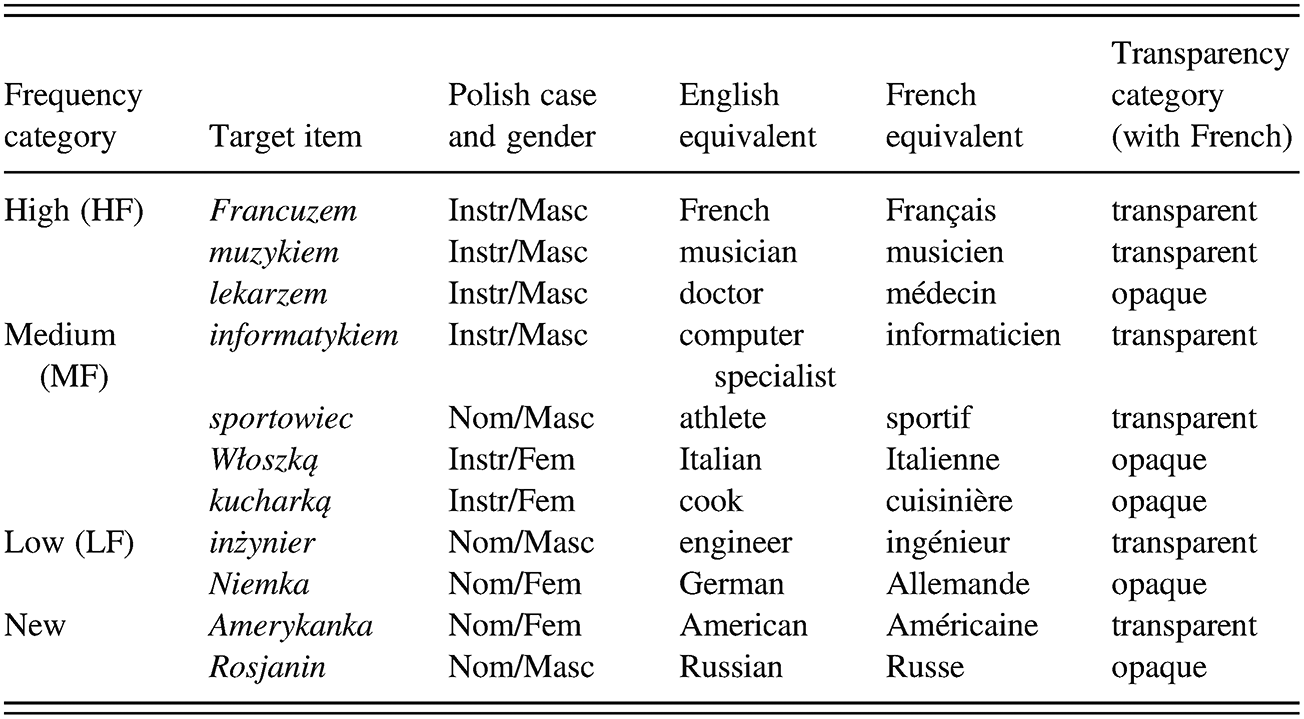
The same sentence production task was administered to all eighteen participants at two time periods, after 2h45 of Polish instruction (T1) and again after 6h30 (T2). Participants were tested and recorded individually by a native speaker of Polish; they were told in French that they would be asked to respond to questions and that their responses should be based on the pictures they would be shown. The interviewer first asked a question, then presented a picture of a man or a woman to indicate the gender of the person, and then presented another picture providing the semantic content of the target item, either nationality (a flag) or profession (a person at work). Participants responded orally to each question; questions, triggers, and the order of the items were the same for all participants. All 198 responses (11 sentences x 18 learners) were transcribed by a native speaker of Polish (a project assistant), trained in CHAT transcription. In order to be considered ‘correct,’ a statement had to satisfy four criteria:
1. Choice of lexical item: target word corresponds semantically to the content represented in the picture (nationality or profession).
2. Utterance structure: response to the question Kto to jest? follows the pattern To jest + C; response to the question Kim on/ona jest? follows the pattern On/Ona jest + C.
3. Choice of declension: response to the question Kto to jest? uses CNOM; response to the question Kim on/ona jest? uses CINSTR.
4. Gender agreement: response with On takes the masculine form; response with Ona takes the feminine form; in both On/Ona jest + C and To jest + C response types, the correct form corresponds to the picture of either a man or a woman.
Individual differences that may play a role in the acquisition of new morphological forms were measured using standardized or known instruments. Two tests of long-term memory for language were administered: a test of L1 vocabulary knowledge (Binois & Pichot Reference Binois and Pichot1959), long associated with language skill (see Carroll Reference Carroll1993: 151–153, for a summary); and a test of ability to infer the grammatical function of new morphemes (Meara Reference Meara2005, based on Carroll & Sapon Reference Carroll and Sapon1955). Two measures of executive function in working memory were obtained, using the d2 test of sustained attention (Brickenkamp & Zilmer Reference Brickenkamp and Zilmer1998), and a French version of the Stroop Task (Bayard, Erkes & Maroni Reference Bayard, Erkes and Moroni2009), as an indicator of executive ‘inhibition,’ since a learner’s ability to inhibit certain automatically activated L1 information might affect certain aspects of learning or using the TL. The phonological component of working memory was assessed using a classic nonword repetition task with L1 phonemes (Casalis Reference Casalis2003). Questionnaires were administered to the participants to determine their motivation for the Polish language and course (in-house questionnaire adapted from Gardner Reference Gardner2004), and their ‘learning style’ – broken down into perceptual preference (visual, auditory, or tactile; Barsch Reference Barsch1980) – and cognitive style (plotted along the intuitive-methodical and reflexive-pragmatic axes; Cahay et al. Reference Cahay, Honorez, Monfort, Remy and Therer1997, following Kolb Reference Kolb1985). These tests were distributed throughout the week of data collection, in the time slots available once the Polish lessons and tests had been completed; the Stroop and nonword repetition tasks were administered in individual interviews by a trained examiner; due to time limitations, all other tests and questionnaires were collectively administered in paper and pencil format, and then scored manually (by the research team, with all scoring triple-checked). This small battery of tests was included to reflect individual differences that may affect various aspects of Polish learning (lexical and phonological, as well as morphological); we will report here on the data that seem most relevant to the more specific theme of this chapter.
Results
Grammaticality judgment
For the GJ task, global accuracy scores were analyzed in a repeated-measures analysis of variance (ANOVA), with Test (T1, T2, and T3), Frequency in the input (present or absent) and Transparency (transparent or opaque) as within-subject variables (see Table 3.3). We first analyzed mean accuracy across the three test sessions, which was 62.7% at T1, 68.9% at T2, and 72.6% at T3. This analysis revealed a main effect across the three sessions, F(2,34)=4.78, p=0.0148. Post-hoc pairwise comparisons (Scheffé) revealed, however, that this difference was significant only between T1 and T3. These results suggest that learners improved in their judging of grammaticality of this type of sentence over time, from 1h30 to 4h00, but not immediately following the fourth hour of exposure. In fact, only after the participants took a break from the Polish exposure and returned the next day were they able to perform as a group significantly better than they did after the first class session. Although these findings support our hypothesis that participants would perform better over time, they also suggest that performance might be affected by factors such as whether learners do tasks immediately following TL exposure or with some delay. In this case, the delay was beneficial. Reaction times were also compared across the three test periods in a repeated-measures ANOVA, which revealed a main effect, F(2,34)=10.95, p=0.0002. Post-hoc tests showed that participants’ responses were significantly faster at T3 than at T2 and at T1, but that there was no significant difference between T1 and T2. The significant improvement found for both accuracy and speed between T1 and T3, but not between T1 and T2, is consistent with research showing that learning is consolidated during sleep (e.g., Fenn, Nusbaum & Margoliash Reference Fenn, Nusbaum and Margoliash2003; Brawn et al. Reference Brawn, Fenn, Nusbaum and Margoliash2010). Interestingly, learners did not perform significantly above chance for absent items or incorrect items at T1, but they did perform above chance on these items at both T2 and T3 (see Table 3.3), suggesting that as time went on, knowledge generalization began to occur.
Table 3.3 Mean accuracy scores on the grammaticality judgment task in three time intervals and as a function of Presence in the input, Transparency, and Grammaticality

T1 (immediately following Lesson 1); T2 (immediately following Lesson 3); T3 (immediately prior to Lesson 4)
* Except where noted by an asterisk, all accuracy rates are significantly above chance performance (p values obtained from two-tailed one-sample t-tests with test value 0.5).
Accuracy scores were then examined as a function of the target word’s Frequency in the input across the three test sessions, which showed a main effect of Frequency, F(1, 17)=19.26, p=0.0004. Participants identified correct grammatical forms of target words that were present in the input significantly better than target words that were absent from the input, confirming that some exposure to these words would help learners judge morphological accuracy as stated in our first hypothesis. Furthermore, there was no interaction between the two factors Frequency in the input and Test, F(2, 34)=0.021, n.s., indicating that the effect of input was equivalent across the three test sessions, which was subsequently confirmed by post-hoc testing. In order to explore whether participants were able to generalize morphological marking to never-before-seen items, we compared correct responses to absent items only across the three test sessions, but no significant difference across the three tests was revealed: F(2, 34)=2.07, n.s.
Accuracy scores were then examined as a function of Transparency across the three test sessions, which showed a significant effect of Transparency, F(1, 17)=4.487, p=0.0492. Participants identified correct grammatical forms of target words that were transparent more accurately than words that were opaque, confirming that familiarity in terms of transparency helped learners judge morphological accuracy as stated in our second hypothesis. There was also no interaction between the two factors Transparency and Test, F(2, 34)=.749, n.s. While the lack of a significant interaction between these two factors would suggest that the effect of Transparency was equivalent across the three test sessions, post-hoc analyses revealed that this was not the case. The effect of Transparency was only significant at T2 and T3. Further post-hoc tests showed that significant improvement was observed for transparent items only. Participants did not improve in the identification of opaque items across the three tests.
Furthermore, there was a significant interaction between Frequency and Transparency: F(1, 17)=30.44, p=<.00001, indicating that the effect of Transparency varied according to Frequency. To further explore whether participants were able to generalize morphological marking to novel items, we examined responses only to opaque items that were absent in the input, which did not reveal a main effect across the three test sessions: F(2,34)=.341, n.s., suggesting that four hours of exposure was not enough for learners to generalize the rules effectively.
We also explored the possibility of asymmetry in response patterns between participants’ acceptance of grammatical items versus their rejection of ungrammatical items in order to determine if participants had more competence in the identification of correct morphological marking than incorrect morphological marking. To test this, mean accuracy scores on grammatical items were compared against mean accuracy scores on ungrammatical items. Participants scored significantly higher in their judgments of grammatical items (73.2%) than of ungrammatical items (62.9%) across the three tests: F(1, 34)=5.149, p=0.0366. A significant interaction was also observed between grammatical/ungrammatical responses and Test: F(2, 34)=8.45, p=0.0011, stemming from the fact that the asymmetry between the acceptance of grammatical items and the rejection of ungrammatical items diminished across the test sessions. Post-hoc comparisons showed further that participants did not improve in their ability to identify correct morphological marking across the three sessions, but that they significantly improved in their ability to recognize incorrect morphological marking.11
Sentence production
For the sentence production task, data were collected at two test times only (T1 and T2 – see Appendix A). At T1 (after 2h45 of exposure) one-third of the Polish sentences produced by the learners were entirely correct, from a lexical and morphosyntactic point of view, and this increased at T2 (after 6h30 of exposure); a Wilcoxon matched-pairs signed-rank test shows this predictable increase to be significant (Z=−2.86, p<0.01).
Figure 3.1 summarizes the distribution of correct responses given, according to the frequency and transparency of each target response. We can see a clear facilitating effect of frequency, with all high frequency targets (HF, left of the graph) correctly produced by eleven or more learners at T1 and two of these produced correctly by everyone at T2; one medium frequency (MF) item is produced correctly by seventeen of the eighteen learners at T2, and two others are mastered by nine or ten learners by T2. Low frequency (LF) items generate few completely correct responses, with only one completely correct response at T1, and three at T2. The generalization of such complex noun morphology is clearly difficult after such limited exposure (and no explicit grammar instruction): the correct ‘new’ form Amerykanka is produced by one learner at T1, but neither of the ‘new’ forms is successfully produced at T2. Transparency (as measured by receptive translation) appears to facilitate the production of correct target forms only slightly, in the case of informatykiem and inżynier, perhaps, but not sportowiec or Amerykanka. Opacity may have contributed to difficulty in producing Niemka and Rosjanin, but did not hamper the correct production of the frequent but opaque lekarzem, and generated difficulty for fewer than half of the group at T1 for the targets kucharką and Włoszką. Overall, correct responses to transparent and opaque items did not vary significantly, at either T1 or at T2 (U(5,6)=15 at T1, 14.5 at T2, p>0.90). In short, higher accuracy in the production of the target forms appears to be linked to frequency ratings, with transparency showing irregular effects. We will look into exactly what the learners attempted in their incorrect forms in the discussion below.

Figure 3.1 Distribution of correct responses on the sentence production task
Group profile
Results on the measures of individual differences between the eighteen participants in the study are presented in Table 3.4, in which we can see that this group of learners displays relatively little variation on several of the measures used: the nonword repetition test (where only one participant had difficulty with the test, all other scores lying between 30 and 34),12 the Stroop Task (the average interference index being very low; only two errors were committed in all for the entire group of learners), and the d2 test of sustained attention, in which our learners demonstrated a very high capacity for concentrated attention overall, an extraordinarily low error rate, seven learners making fewer than ten errors on the test (an unusually high rate of precision), eleven scoring in the fourth quartile, with six learners in the ninety-ninth percentile. From the point of view of working memory and executive function, these are highly functioning young adults. Their verbal knowledge (L1 lexical knowledge as measured by the L1 vocabulary test) and capacity for metalinguistic analysis (as measured by the grammatical inferencing test) show greater variability and range but high overall group performance, with seven subjects scoring from 70 to 90 percent on the grammatical inferencing test (indicating good aptitude for metalinguistic analysis).

The motivation questionnaire reveals a highly motivated group, with only one student reacting negatively to the statement “I like Polish” (‘Le polonais est une langue qui me plaît’), and every participant disagreeing with statements such as “Polish class is boring,” “Polish class is stressful,” “Polish is a waste of time.” Participants disagreed with the statements “Polish is an easy language” and “It’s easy to pronounce Polish”: this is a group that is enthusiastic – but also realistic – about learning languages. The results from the learning style questionnaires (bottom five lines of Table 3.4) also reveal useful information about the learners participating in the study. The Barsch Learning Style Inventory (Barsch Reference Barsch1980), which measures perceptual – visual, auditory, or ‘tactual’ – preferences in learning, shows a group that, overall, has a slight preference for processing information visually and seems less at ease in the auditory mode – a common situation in French-language classrooms due to the heavy visual bias of French schoolroom culture. More precisely, fourteen of the learners scored 28 points or more in their visual preference score (a high score indicating relatively strong reliance on this perceptual channel in the learning process), eleven scored over 28 for tactual preference, and only four attained 28 points or more in the auditory preference score. The visual and auditory scores on this test are negatively correlated (rs=−0.546, p<0.05*), suggesting that strong visual learners do not rely on the auditory mode, and vice versa. In fact (not surprisingly), the Barsch Inventory shows that only two of the participants do, in fact, have a strong perceptual preference (i.e., one preference score ten or more points higher than the other two preference scores); nine of the learners have balanced scores for the three so-called preferences (all three scores falling within ten points of each other), and the seven remaining learners combine high visual and tactile scores. Researchers have long hypothesized that ‘good’ learners are those who manage to adapt their learning style to various situations and are not overly dependent on one perceptual channel in the learning process (cf. Schmeck Reference Schmeck1988); once again, our participant pool appears to be a group of perceptually flexible ‘good’ learners.
The Inventaire des styles d’apprentissage du Laboratoire d’enseignement multimedia (ISALEM-97, Cahay et al. Reference Cahay, Honorez, Monfort, Remy and Therer1997), adapted at the Université de Liège from Kolb’s Learning-Style Inventory (Kolb Reference Kolb1985), determines a subject’s learning profile by plotting the score obtained on an ‘intuitive/methodical’ X axis, and a ‘pragmatic/reflective’ Y axis. There is a group tendency toward the intuitive-pragmatic profile (eight ‘hands-on’ learners), with four methodical-pragmatic ‘problem-solvers,’ four methodical-reflective ‘theorizers,’ and two intuitive-reflective ‘observers.’ What is striking in the ISALEM questionnaire scores (bottom two lines of Table 3.4) are the low values obtained on the questionnaire by the participants, compared to the population norms reported by Cahay and colleagues; all the Polish learners scored at least one standard deviation below the average scores obtained by peers in the standardization process (Cahay et al. Reference Cahay, Honorez, Monfort, Remy and Therer1997: 17–18); these low scores (fifteen of them lying from 0 to 5 on one of the two axes) attest once again to the fact that, overall, the learners in our group do not display a distinct learning style, but tend to adapt their preferences to the actual learning situation.
Polish tasks and individual differences
All significant Spearman rank correlations obtained between the Polish tasks (GJ and sentence production) and various measures of individual difference are presented in Table 3.5. Readers will note that most of these figures concern the GJ task and the measures of learning style (perceptual preference and cognitive profile); the other measures did not enter into significant correlation.


The two working memory measures that were both at ceiling for our group of learners (nonword repetition, the Stroop interference index) did not enter into correlation with the Polish scores. It is more surprising that the more normally distributed grammatical inferencing test did not correlate with accuracy in grammaticality judgment or sentence production. With four exceptions, the correlations presented are not particularly high, but they do give an interesting picture of possible interactions between learning style and behavior on these different types of tasks. Learners with a higher visual score on the Barsch Inventory have marginal difficulty with the aurally presented GJ task (T3), as evidenced by the negative correlations in the third column of the table; yet a positive correlation between a visual perceptual preference and the number of correct sentences produced at T1 suggests that these learners made more use of the visual information in the slides projected during the Polish lessons. Auditory and tactile scores on the Barsch Inventory are, respectively, negatively and positively (moderately) correlated with reaction time gains on the GJ task – an interesting glimpse into the role of non-linguistic factors in task performance. The correlations between scores on the ISALEM-97 questionnaire and reaction times (RTs) in the GJ task reflect a similar effect of cognitive style on task performance: scores representing a methodical or reflexive approach are negatively correlated with speed and RT gains in this decision task; the effect is strong for reaction times to opaque target items on the GJ task (correlation of −0.76** with the methodical-intuitive axis, where positive scores indicate a methodical – and doubtless more time-consuming – approach), and for the overall RT gain in recognizing transparent target items during the five days of the Polish course (correlation of −0.63** with the reflective-pragmatic axis, where positive scores again represent a more time-consuming, reflective style). Motivation is moderately correlated with accuracy in the GJ task at T2 (just after the third lesson), and negatively correlated with response time to frequent words – perhaps more motivated learners take a little longer to ‘get it right.’ Finally, positive measures obtained in the d2 test of concentrated attention correlate (marginally) with GJ accuracy at T1, and with RT gain on opaque words; numbers and percentage of errors committed during the d2 task (lower or less precise attentional capacity) are negatively correlated with gains in accuracy in the GJ task, with a strong effect (−0.66**) at T3, and with reaction times at T1 (overall, and for opaque and absent targets), and T3 (opaque words). Attentional capacity may enable better intake of formal details, as well as better performance on the attentionally demanding E-Prime task.
Discussion
The rich sets of data generated over the five days of Polish classes offer interesting perspectives on how our learners interacted with Polish – individually and as a group – during the first hours of exposure to a novel language. Results on the GJ task show some sensitivity to nominal morphology in Polish as of the first testing period, after 1h30 of exposure, and facilitating effects for transparency and frequency. Learners were better at judging correct target items to be correct after 4h00 of input when testing was delayed (T3) than after 1h30, suggesting that some learning did indeed take place. Frequency and transparency both played a role in the participants’ ability to judge noun morphology accurately. As hypothesized, at each time period, words that were present in the input and/or transparent with respect to French were judged more accurately than words that were absent from the input and/or opaque. We can conclude that first exposure participants did pay attention to morphological marking and appeared to benefit most from this attention when the inflectional markers were attached to items that were present in the input during Polish instruction and/or transparent. Our hypothesis that familiarity – in terms of both frequency and transparency – helps learners judge morphological accuracy is confirmed, at least for the processing of the target inflectional forms of the study. Analyses conducted on absent/opaque items showed no evidence of generalization of morphological rules. However, the fact that participants scored higher on grammatical items (73.2 percent) than on ungrammatical items (62.9 percent) across the three tests, even if this difference missed significance (see above), suggests that these results indicate that some generalization of the instrumental masculine (-em) form has occurred. This was not surprising given the high frequency and saliency of this marker in the input (cf. Slobin Reference Slobin and Perdue1993). In the future, it will be important to include more items that are both absent and opaque in the stimuli to test whether participants can generalize the inflectional rules to these unfamiliar items (only four grammatical items in the GJ test reported here fit this profile). If they are able to generalize, this would suggest that some type of rule learning has taken place.
As mentioned earlier, findings in first exposure studies differ with respect to the role of frequency in the early stages of adult language acquisition. These disparate findings may be due at least partially to the way ‘frequency’ is measured. For Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012 and this volume), frequency is relative to how many instances are needed to ‘learn’ the word. The number of exposures needed in her study was 4–16 (the fastest participant needed only four exposures, whereas the slowest needed sixteen exposures). The same approach to frequency was used in Carroll and Widjaja’s (Reference Carroll and Widjaja2013) study. For simple target forms, the number of exposures needed was between only one and four. More complex forms required more exposures. Building on a range of studies (Ellis Reference Ellis2002; Goldschneider and DeKeyser Reference Goldschneider and DeKeyser2001; Hintzman Reference Hintzman1988; Trueswell Reference Trueswell1996), Rast and Dommergues (Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003) and Rast (Reference Rast2008) assigned the ‘frequent’ category to words that occurred more than twenty times in the input; many target items were in fact much more frequent than this. In Shoemaker and Rast (Reference Shoemaker and Rast2013) and in the current study, frequency means at least four exposures, but again, many target items occurred in the input more frequently than this. For Gullberg et al. (Reference Gullberg, Roberts and Dimroth2012), ‘frequent’ means exactly eight instances of the word.
The disparity in the findings is also likely due to the difference in task, or what Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012: 40) refers to as “the nature of the learning problem.” What are we expecting learners to learn and how do we test this? Carroll’s participants (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012) were asked to learn the names of people depicted in pictures by looking at pictures and simultaneously listening to related sentences using these names. They were subsequently asked to map names to pictures in a question–response task that required making a choice between two names. In Carroll and Widjaja (Reference Carroll and Widjaja2013), participants saw pictures of items and heard sentences that included the name of the item. They were then asked to match these sound forms to pictures of the items. Rast and Dommergues (Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003) asked their participants to listen to a sentence in the TL and repeat it as best they could. In Shoemaker and Rast’s (Reference Shoemaker and Rast2013) study, participants heard a sentence in the TL followed by a TL word and were asked if they thought the word was in the sentence they had just heard or not. In the Gullberg et al. (Reference Gullberg, Roberts and Dimroth2012) study, participants watched a video of a weather report in the TL. Immediately following the video, they listened to TL words and nonwords and were asked to decide if they had heard the item in the weather report or not. These are only some of the tasks conducted during first exposure studies, and although they share aspects (e.g., word recognition, lexical decision, sound form-to-picture mapping), the differences are also evident.
Finally, these studies include a variety of L1–TL combinations. Carroll (Reference Carroll, Braunmüller, Gabriel and Hänel-Faulhaber2012 and this volume) studied English speakers exposed to German; Carroll and Widjaja (Reference Carroll and Widjaja2013) studied English speakers exposed to Indonesian; Rast and Dommergues (Reference Rast, Dommergues, Foster-Cohen and Pekarek Doehler2003), Rast (Reference Rast2008) and Shoemaker and Rast (Reference Shoemaker and Rast2013) studied French learners of Polish; Gullberg et al. (Reference Gullberg, Roberts and Dimroth2012) studied Dutch learners of Mandarin Chinese. Cross-linguistic differences could also explain why frequency effects differ from study to study. Clearly, more cross-linguistic research that replicates other first exposure studies and controls frequency criteria is needed to understand the precise effects of frequency on the acquisition of new systems.
The sentence production task generated interesting data that enable us to compare learners’ judgments with their use of the same markers. This task required learners to produce correct word endings, while activating new syntactic and lexical knowledge (corresponding to picture stimuli); their responses show a strong effect of frequency, as in the GJ task, but differing effects of transparency. Whole-word token frequency appears to have had a facilitating effect, extending even to opaque targets. Transparency, however, did not appear to facilitate the production of several transparent forms: no learners produced the fairly frequent sportowiec correctly at either T1 or T2; only two learners managed to produce the infrequent form inżynier correctly at T2 (none at T1); only one learner managed to generate the new form Amerykanka (T1 only), despite the high degree of transparency of the stem. A closer analysis of learner responses in this task may help understand the processes at work.
With regard to why the target informatykiem was more accurately produced than sportowiec, several explanations are possible. The distribution of the item in the input may in fact play an important role in a learner’s memorization of the form. The Polish instructor produced the word informatykiem three times during Lessons 1–2 and again three times during Lessons 3–5, whereas she produced sportowiec eight times in Lessons 1–2, but never again, suggesting that perhaps the spaced frequency of informatykiem facilitated its retention, compared with the massed frequency of sportowiec. As mentioned earlier, frequency effects have been found in research at the very early stages of L2 acquisition (e.g., Gullberg et al. Reference Gullberg, Roberts and Dimroth2012), but studies rarely consider the distribution of frequency over the corpora. This regularity may be of particular importance, especially at the early stages, and therefore needs to be taken into account. A second possibility is that the phonemic properties of the two items played a role in the learners’ ability to produce these words. This may partially explain the difficulties learners had producing sportowiec, despite the presence of eight tokens in the input before the first testing interval. This is in line with findings in Rast (Reference Rast2008) where phonemic distance (between L1 and TL forms) played a role in the ability of French learners to repeat Polish words on first exposure to Polish and within the first hours that followed. A third possible reason concerns the frequency of the -em masculine instrumental ending (as in informatykiem), which, throughout the five lessons, appeared more frequently on target nouns than the uninflected masculine nominative form (71.5 percent of occurrences of the target items in the input attested the masculine instrumental ending -em). Following Slobin’s (Reference Slobin and Perdue1993: 242) reasoning that learners rely on perceptual saliency when analyzing the input, it is likely that extracting an uninflected stem from the input (e.g., sportowiec) becomes more difficult when the most frequently heard and most perceptually simple or conceptually salient form is inflected (e.g., sportowcem).
Examining the learners’ incorrect answers also provides a means of observing whether or not the frequency of certain inflectional forms in the input plays a role in the overgeneralization of grammatical morphology. This indeed appears to be the case in sentence productions: at T1 48 percent of the responses requiring the nominative form showed an incorrect -em ending, and by T2 this increased to almost two-thirds of the answers (60.5 percent). Sixteen of the eighteen learners produced an -em ending for two or more of the targets Niemka, Rosjanin, sportowiec, and inżynier (with five learners generalizing the-em ending to all four words, and six more generalizing to three of the four). Only two learners resisted this tendency, and they are both learners with a very high score on the motivation questionnaire and the test of grammatical inferencing ability.
One of these two learners (participant number 1106) has an interesting individual profile. This learner, a woman aged 23, has the highest score on the test of L1 lexical knowledge, a (high) score of 80% on the grammatical inferencing test, and a visual perceptual preference – she is obviously a ‘good’ learner, and indeed she is the highest-scoring learner on the GJ task at all three time intervals and produces four completely correct sentences in the first sentence production task, and seven in the second. Her score on the motivation questionnaire is high (140); this is, in fact, the learner who did some reviewing of new Polish words at home in the evenings (see footnote 3). The other learner who did not overgeneralize the -em ending, participant 1110, also produces seven correct sentences at T2 (and five at T1), has the highest motivation and grammatical analysis scores of the group, and has very good attentional capacity, as measured by the d2 test; this young man (aged 21) has a pronounced ‘intuitive-pragmatic’ learning style according to the ISALEM questionnaire (a ‘hands-on’ type of learner, who does not mind taking risks). Despite this productive accuracy, his performance on the GJ task is lower than average at T3 (66%); this lower score seems linked to problems judging the grammaticality of the items that were absent from classroom input (with accuracy dropping to 44%), whereas frequent items are judged correctly 81% of the time, and produced correctly at T2. This is a learner who is probably good at retrieving instances from memory, but not yet ready to generalize a ‘rule’ to new situations.
The second-highest scorer on the GJ task at T3 (participant 1117) is also the learner with the biggest increase in correct sentences from T1 to T2 in the production task, a young woman (age 18) reporting a slight tactile-auditory perceptual preference, with extremely high performance on the attentional measures (both Stroop and d2). Her accuracy in the GJ task increased from 66% to 94% at T2 (and remained stable at T3), with a perfect score of 100% on both frequent and transparent items in this task. She is one of the learners who overgeneralizes the -em ending to the mid- and low frequency items in the production task. Subject 1111 is the lowest-scoring learner on the GJ task, beginning and ending the course with a score of 34% (having peaked at T2 at 63%); this young man of 19 reports a visual-tactile perceptual preference and has particular difficulty judging the correctness of transparent items at T3 (a strangely low 19% accuracy rate at T3) – which could lead us to speculate that he has developed morphological ‘rules,’ or working hypotheses, that lead him to reject correct items at this early stage in the learning process. In the production task, this same learner has indeed added a salient – but erroneous, in the context of the question, -ą ending to Niemk- and Amerykank-, and -em ending to sportowiec and inżynier.13 His motivation score is high, but he reports disliking the E-Prime Polish tests, which may also explain his performance on the GJ task.
Results obtained with the individual participants show a need for more sensitive instruments to measure phonological capacity in adult working memory (cf. Han & Liu Reference Han and Liu2013), and executive capacity for inhibiting unnecessary information. The lack of a correlation between the grammatical inferencing test and performance on the GJ task may reflect the fact that only some learners appear to rely on this type of metalinguistic analysis in the early stages of morphological processing, while others (who might also be quite good at grammatical inferencing) rely more heavily on memory-based retrieval of forms. Further analyses of the complex interactions between the variables measured here, methodological and interactional variables in the Polish classroom, and lexical and morphological acquisition by individual learners will require new analytic techniques, inspired by current work in the dynamic systems paradigm (de Bot, Lowie & Verspoor Reference de Bot, Lowie and Verspoor2007; Ellis & Larsen-Freeman Reference Ellis and Larsen-Freeman2009; Larsen-Freeman Reference Larsen-Freeman and Batestone2010b; Larsen-Freeman & Cameron Reference Larsen-Freeman and Cameron2008).
Concerning our analysis of the overall input relative to learner performance on Polish tasks, several points should be carefully considered for future research. When comparing learner performance on different tasks within the context of a controlled-input study, ideally performance would be measured on both tasks after exposure to the same quantity of input. This was not the case with the GJ and sentence production tasks in the current study, making it difficult to generalize our findings across the tasks. Second, only two independent variables were controlled for and analyzed in this study. Many more are of interest to this research paradigm, such as phonemic distance between L1 forms and TL forms, which may play differing roles in the judgment and production tasks. Third, the transcriptions of the instructor’s input were not entirely coded for inflectional marking. Although this is a critical step for future frequency-based controlled input studies, we must also keep in mind that time and technical support are costly in such studies, as Flege (Reference Flege, Piske and Young-Scholten2009: 190) reminds us:
To adequately assess the role of L2 input, the input that learners of an L2 actually receive must be assessed more accurately. Measuring L2 input may be impossible, but better estimates of L2 input can and must be obtained. Doing this will require the expenditure of substantial resources (time, money, creativity). For this to happen, researchers must first decide to give L2 input a chance to explain variation in L2 learning.
Frequency counts of inflectional marking in this study were limited to the frequencies of target items in our tasks as opposed to frequencies of all items in the input. A cross-linguistic study currently in progress (VILLA)14 has set out to count frequencies of all lexical items and inflectional patterns that appear in the TL input for a proper analysis of type-token frequency. Finally, in order to observe whether learners are capable of generalizing a rule of inflection to an unfamiliar lexeme, more instances of target items that are absent from the input and opaque need to be incorporated into such tests. It is within this space that we can hope to capture some of the creative capacity of the human mind when confronted with a novel linguistic system.
Appendix A: Distribution of Polish input and tasks

Appendix B: Grammaticality judgment task stimuli
Input frequency: P=Present in input; A=Absent in input
Transparency: T=Transparent; O=Opaque
Grammatical sentences
Daniel jest Francuzem (P T)
Marek jest studentem (P T)
Jozef jest profesorem (P T)
Daniel jest fotografem (P T)
Aleksander jest Niemcem (P O)
Alan jest rolnikiem (P O)
Mama jest lekarką (P O)
Weronika jest Rosjanką (P O)
Patryk jest pilotem. (A T)
Ewa jest architektką (A T)
Natalia jest instruktorką (A T)
Sabina jest ekonomistą (A T)
Marian jest Duńczykiem (A O)
Stanislaw jest kominiarzem (A O)
Profesor jest Litwinem (A O)
Profesor jest Chińczykiem (A O)
Ungrammatical sentences
*Daniel jest Francuz (P T)
*Marek jest student (P T)
*Daniel jest fotograf (P T)
*Jozef jest profesor (P T)
*Aleksander jest Niemiec (P O)
*Alan jest rolnik (P O)
*Weronika jest Rosjanka (P O)
*Mama jest lekarka (P O)
*Ewa jest architekt (A T)
*Patryk jest pilot (A T)
*Natalia jest instruktor (A T)
*Sabina jest ekonomista (A T)
*Stanislaw jest kominiarz (A T)
*Marian jest Duńczyk (A T)
*Profesor jest Litwin (A T)
*Profesor jest Chińczyk (A T)
Appendix C: Frequency and distribution of target items for the grammaticality judgment task

Appendix D: Frequency and distribution of target items for the production task

References
1 Many people made this study possible. We wish to thank in particular Paulina Kurzepa, Ewa Lenart, Urszula Paprocka, and Pascale Trévisiol for their invaluable assistance. We also thank our reviewers for their extensive and perceptive comments. This research was supported by a grant from the Programme d’Aide à la Recherche Innovante (2011–2012), Université Paris 8, St.-Denis, France.
2 The term ‘target language acquisition’ encompasses second language (L2) and third language (L3) acquisition as they are traditionally used (cf. De Angelis Reference De Angelis2007 and Hammarberg Reference Hammarberg2010 for further discussion about additional language acquisition).
3 In answer to a questionnaire the participants completed at the end of the week of study, one of the learners admitted to reviewing parts of the lessons at home, “repeating words from the lessons several times.” As far as we know, she is the only project participant who broke our unusual “no homework” rule. Given our specific interest in individual differences during this study, we decided not to remove this learner’s data from the analyses reported here; this extra practice is a manifestation of the student’s high motivation for the Polish course, a variable that teachers encounter every day in real learning situations.
4 The word recognition data from Shoemaker and Rast (Reference Shoemaker and Rast2013) were also collected during the study reported in this chapter, and hence from the same participants, at two time intervals: before the first Polish lesson (zero exposure) and after 6.5 hours of exposure. Results provide evidence that participants were able to segment transparent words at both time periods and that their segmentation capacities improved over time.
5 We follow Gor and Vdovina’s (Reference Gor and Vdovina2010: 8) characterization of token frequency when considering inflection. Token frequency is the frequency of an individual word: “Token frequency is further subdivided into lemma (cumulative) frequency, or the frequency of all the inflected forms of the word combined together, and whole-word (surface) frequency, or the frequency of an individual inflected word.” Type frequency, the frequency of a linguistic pattern, is not analyzed in this study.
6 See Carroll Reference Carroll2013 for discussion about words and word learning at first exposure.
7 All items fit the same frequency category at both testing times with the exception of muzykiem, which counted seven occurrences at T1. Given that it appeared twelve times in the input by T2, and to facilitate discussion, we categorized muzykiem with high frequency items.
8 Although the Polish word Francuzem was the only target item that appeared in both the GJ and the sentence production tasks, other target items shared the same stem but different inflections, such as Niemcem (GJ task) and Niemka (production task). The only case where a contextually incorrect form appeared in the GJ task as a correct target item in the production task was Francuz (Daniel jest Francuz) (incorrect).
9 Two reviewers commented on the distribution of our frequencies. Some final frequency counts were unexpected because the instructor was not asked to follow a word-for-word input script. The lessons were intended to be fairly natural for an instructional setting, so the instructor was given quite a bit of flexibility. This said, the instructor knew which target items needed to be used frequently, and which items were not to be used at all. In the final count, the masculine and feminine forms were not evenly distributed, as can be seen in Appendix C and Appendix D. Future research will need a more complete control of the input frequencies of all aspects of the target items used in the TL tasks.
10 One of our reviewers rightly pointed out that repeating the same task could result in practice effects. We were aware of this problem when designing the study; however, in order to make precise comparisons over time, a certain number of items must be kept constant. Given the limited amount of Polish exposure, there were a limited number of relevant items that could be used in our tests.
11 A reviewer pointed out that the repeated exposure to ungrammatical items in the GJ test could have reinforced memory traces of these items. However, if this were true and had caused problems for the participants in learning to reject ungrammatical forms, then we would not have seen improvement in correct rejections of these items, which we did.
12 This result is not surprising, since the nonword repetition test was originally designed to identify children with phonological processing problems (linked with dyslexia). The ceiling effect observed simply testifies to the fact that – with one exception – this group of university-level learners has normal phonological capacity in working memory.
13 The word sportowiec requires a change of stem in the instrumental case to sportowcem. Only four learners at T1 and one learner at T2 produced this form. In the case of other learners, we found an incorrect usage of -em in the nominative context and on stems that are not attested in Polish, such as sportuzem, sportowikiem, and sportiwkiem.
14 Varieties of Initial Learners in Language Acquisition (VILLA): Controlled classroom input and elementary forms of linguistic organisation, supported by the Open Research Area for Europe in the Social Sciences (cf. Dimroth et al. Reference Dimroth, Rast, Starren and Watorek2013), is a cross-linguistic study of learner varieties at the initial stages of adult language acquisition.






