Refine search
Actions for selected content:
6 results
9 - Deviations of Random Matrices on Sets
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 260-297
-
- Chapter
- Export citation
4 - Random Matrices
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 100-139
-
- Chapter
- Export citation
5 - Concentration without Independence
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 140-170
-
- Chapter
- Export citation

High-Dimensional Probability
- An Introduction with Applications in Data Science
-
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026
Fast principal component analysis for cryo-electron microscopy images
-
- Journal:
- Biological Imaging / Volume 3 / 2023
- Published online by Cambridge University Press:
- 03 February 2023, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Principal component analysis (PCA) plays an important role in the analysis of cryo-electron microscopy (cryo-EM) images for various tasks such as classification, denoising, compression, and ab initio modeling. We introduce a fast method for estimating a compressed representation of the 2-D covariance matrix of noisy cryo-EM projection images affected by radial point spread functions that enables fast PCA computation. Our method is based on a new algorithm for expanding images in the Fourier–Bessel basis (the harmonics on the disk), which provides a convenient way to handle the effect of the contrast transfer functions. For
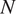 $ N $ images of size
$ N $ images of size 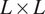 $ L\times L $, our method has time complexity
$ L\times L $, our method has time complexity 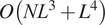 $ O\left({NL}^3+{L}^4\right) $ and space complexity
$ O\left({NL}^3+{L}^4\right) $ and space complexity 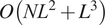 $ O\left({NL}^2+{L}^3\right) $. In contrast to previous work, these complexities are independent of the number of different contrast transfer functions of the images. We demonstrate our approach on synthetic and experimental data and show acceleration by factors of up to two orders of magnitude.
$ O\left({NL}^2+{L}^3\right) $. In contrast to previous work, these complexities are independent of the number of different contrast transfer functions of the images. We demonstrate our approach on synthetic and experimental data and show acceleration by factors of up to two orders of magnitude.
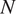
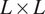
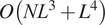
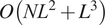
Unbiased risk estimation method for covariance estimation
-
- Journal:
- ESAIM: Probability and Statistics / Volume 18 / 2014
- Published online by Cambridge University Press:
- 25 July 2014, pp. 251-264
- Print publication:
- 2014
-
- Article
- Export citation
