Refine search
Actions for selected content:
1 results
Supervised contrastive learning in few-shot soft prompt tuning
-
- Journal:
- Natural Language Processing ,
- Published online by Cambridge University Press:
- 16 April 2026, pp. 1-35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Soft prompt learning methods offer parameter-efficient tuning of pre-trained language models for few-shot scenarios. This study explores the integration of supervised contrastive learning (SCL) into two leading soft prompt tuning models: DifferentiAble pRompT (DART) and PTuning. By incorporating SCL as an auxiliary task, we observe consistent performance enhancements across 13 few-shot natural language understanding tasks, including benchmarks such as SST-2, TREC, MNLI, and real-world datasets such as Overruling, TC, and ADE. We also delve into SCL’s impact in label-imbalanced settings, introducing a novel approach called balanced batch in SCL (BBSCL). BBSCL employs balanced mini-batches, sampling the majority class proportionally to the minority class to stabilize SCL calculations. Our results indicate that SCL and BBSCL significantly boost the performance and robustness of soft prompt learning models, especially on datasets with intricate label spaces. Experimentally, DART + SCL and PTuning + SCL outperform their base models by an average of
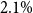 $2.1\%$ across the 13 tasks. Additionally, we find that SCL’s contribution is more substantial in scenarios with complex and less separable label spaces. Compared to large language models such as GPT-3.5 and OpenChat, our enhanced soft prompt learning models with SCL and BBSCL extensions exhibit superior performance in both balanced and imbalanced few-shot settings. This research not only improves the effectiveness of few-shot tuning techniques but also deepens our understanding of this area.
$2.1\%$ across the 13 tasks. Additionally, we find that SCL’s contribution is more substantial in scenarios with complex and less separable label spaces. Compared to large language models such as GPT-3.5 and OpenChat, our enhanced soft prompt learning models with SCL and BBSCL extensions exhibit superior performance in both balanced and imbalanced few-shot settings. This research not only improves the effectiveness of few-shot tuning techniques but also deepens our understanding of this area.