

Appendix A: The Feature Sets and Decisions for Pooling
Le Roux and Rouanet (Reference Le Roux and Rouanet2010) advise that very infrequent features (e.g. those that occur in <5 per cent of the data) either need to be pooled with other related features or they might need to be discarded because infrequent features can overly influence the axes, as they contribute more to the overall variance. The list following presents the features occurring in fewer than 5 per cent of the turns in the TLC and the decisions that were made with respect to pooling or deleting features from the final dataset. The justifications for these decisions are also presented in the Table A1. Infrequent features that were specific types of a broader part-of-speech category were pooled into the broader part-of-speech or ‘other’ category. For example, the feature set distinguishes between different kinds of adverbs (e.g. place, time, downtoner, amplifier, quantifying adverbs), and then any other adverbs that are not one of these types are tagged as ‘other adverb’. Quantifying adverbs do not occur in more than 5 per cent of the tweets. Therefore, this feature was pooled with the ‘other adverb’ category. Essentially, because it does not occur frequently, the feature is dropped from the feature set, meaning that if quantifying adverb wasn’t included in the tagger, any occurrence of a quantifying adverb would be classed as an instance of ‘other adverb’. Thus, this is the logical category in which to place it. When there was more than one option (deleting or pooling including the feature in multiple categories), many of these options were tested by running several MCAs on different feature sets depicting the different pooling options. For example, copular verbs that are not be as a main verb did not occur in more than 5 per cent of the tweets, whereas be as a main verb did. Both features are part of the broader category of ‘stative forms’, and so they could be pooled together into one broad category, or copular verbs could be deleted from the feature set. To test the effect of either decision, two data matrices were created and each was subjected to MCA: one with all other linguistic features but with copular verbs deleted, and the other involving copular verbs being pooled with be as the main verb into the new category of ‘stative forms’. Although the active variables in each MCA are different, the individual turns are the same, meaning that they can be compared. Consequently, the coordinates and contributions of the individuals in each MCA were correlated to the other to observe if there was a substantial difference between the two feature sets. For the most part, the decision to delete a feature or pool it with other categories or broader features made little difference to the position of the turns, where the dimensions (at least the first ten) from one MCA were strongly positively correlated to the corresponding dimensions in the other MCA with regard to the contributions and coordinates of the individual tweets.
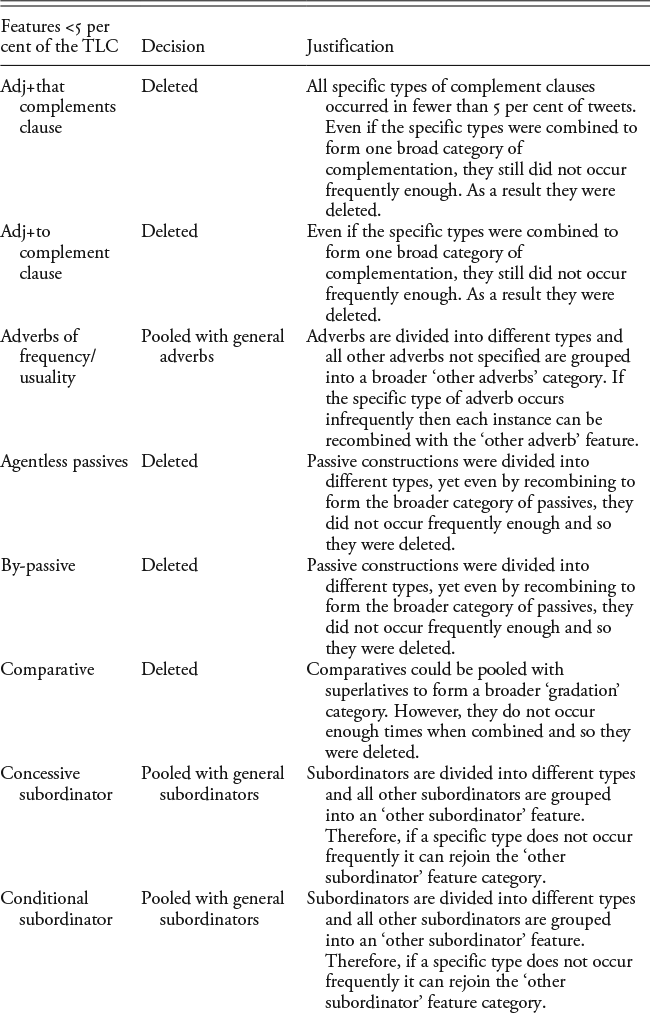




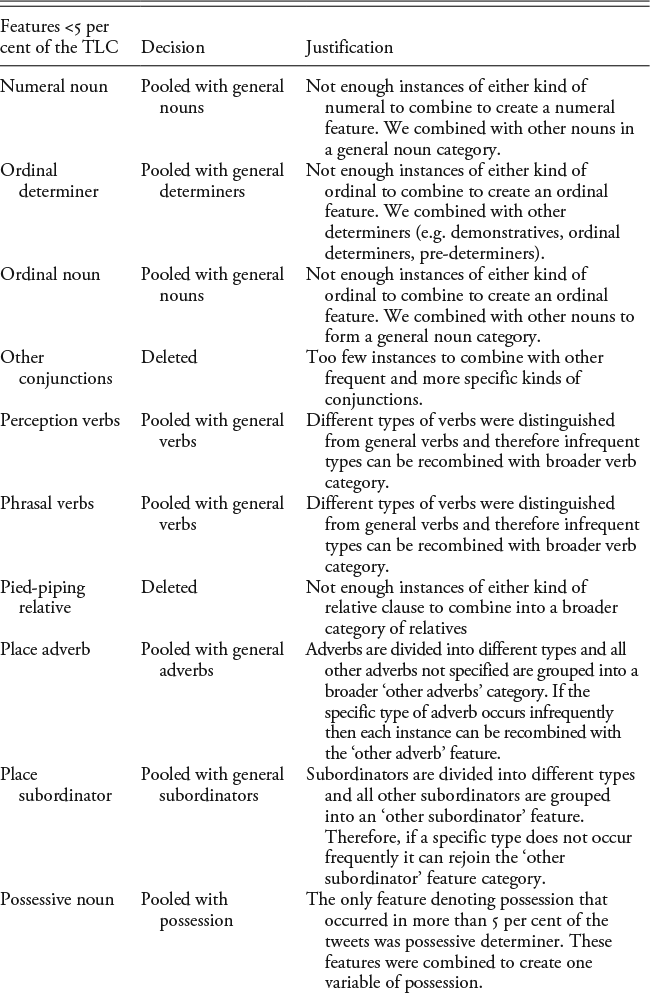
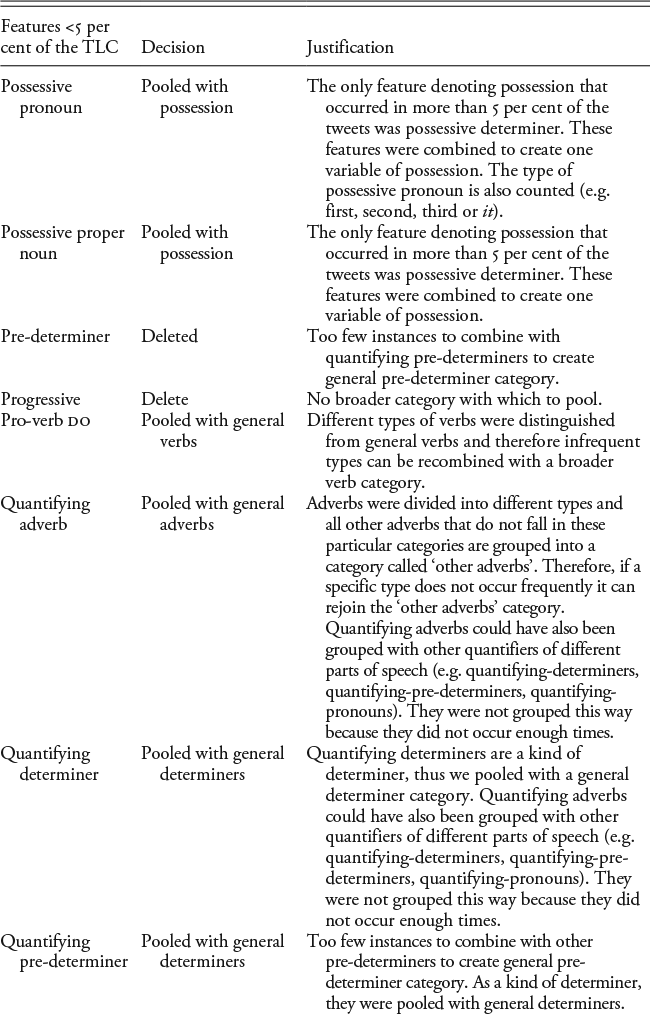
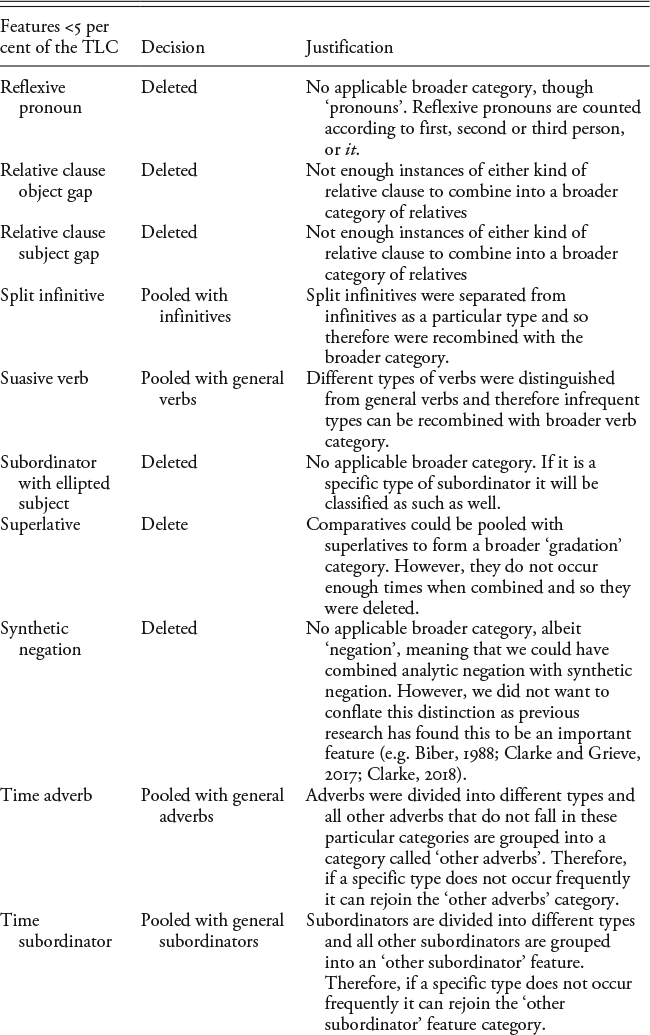


The following are the features occurring in fewer than 5 per cent of the turns of the TLC. These are listed with the decisions and justifications for inclusion/exclusion in the final feature set.
After this pooling process was completed, each turn was analysed for the presence or absence of the following linguistic features.

 Open access
Open access