Refine search
Actions for selected content:
9086 results in Discrete Mathematics, Information Theory and Coding
8 - EXPANDER CODES AND FLIPPING ALGORITHM
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 427-436
-
- Chapter
- Export citation
6 - TURBO CODES
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 323-380
-
- Chapter
- Export citation
PREFACE
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp xiii-xvi
-
- Chapter
- Export citation
Authors
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 551-558
-
- Chapter
- Export citation
5 - GENERAL CHANNELS
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 291-322
-
- Chapter
- Export citation
Index
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 559-572
-
- Chapter
- Export citation
Contents
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp vii-xii
-
- Chapter
- Export citation
A - ENCODING LOW-DENSITY PARITY-CHECK CODES
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 437-458
-
- Chapter
- Export citation
4 - BINARY MEMORYLESS SYMMETRIC CHANNELS
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 175-290
-
- Chapter
- Export citation
E - CONVEXITY, DEGRADATION, AND STABILITY
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 537-550
-
- Chapter
- Export citation
1 - INTRODUCTION
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 1-48
-
- Chapter
- Export citation
B - EFFICIENT IMPLEMENTATION OF DENSITY EVOLUTION
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 459-478
-
- Chapter
- Export citation
7 - GENERAL ENSEMBLES
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 381-426
-
- Chapter
- Export citation
C - CONCENTRATION INEQUALITIES
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 479-504
-
- Chapter
- Export citation
2 - FACTOR GRAPHS
-
- Book:
- Modern Coding Theory
- Published online:
- 05 September 2012
- Print publication:
- 17 March 2008, pp 49-70
-
- Chapter
- Export citation
A Note on Freĭman's Theorem in Vector Spaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 297-305
-
- Article
- Export citation
-
A famous result of Freĭman describes the sets A, of integers, for which |A+A| ≤ K|A|. In this short note we address the analogous question for subsets of vector spaces over
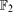 . Specifically we show that if A is a subset of a vector space over with |A+A| ≤ K|A| then A is contained in a coset of size at most 2O(K3/2 log K)|A|, which improves upon the previous best, due to Green and Ruzsa, of 2O(K2)|A|. A simple example shows that the size may need to be at least 2Ω(K)|A|.
. Specifically we show that if A is a subset of a vector space over with |A+A| ≤ K|A| then A is contained in a coset of size at most 2O(K3/2 log K)|A|, which improves upon the previous best, due to Green and Ruzsa, of 2O(K2)|A|. A simple example shows that the size may need to be at least 2Ω(K)|A|.
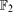 . Specifically we show that if
. Specifically we show that if An Analysis of the Height of Tries with Random Weights on the Edges
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 161-202
-
- Article
- Export citation
On the Number of Tetrahedra with Minimum, Unit, and Distinct Volumes in Three-Space
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 203-224
-
- Article
- Export citation
-
We formulate and give partial answers to several combinatorial problems on volumes of simplices determined by n points in 3-space, and in general in d dimensions.
(i) The number of tetrahedra of minimum (non-zero) volume spanned by n points in
 3 is at most
3 is at most 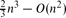 , and there are point sets for which this number is
, and there are point sets for which this number is 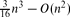 . We also present an O(n3) time algorithm for reporting all tetrahedra of minimum non-zero volume, and thereby extend an algorithm of Edelsbrunner, O'Rourke and Seidel. In general, for every
. We also present an O(n3) time algorithm for reporting all tetrahedra of minimum non-zero volume, and thereby extend an algorithm of Edelsbrunner, O'Rourke and Seidel. In general, for every 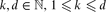 , the maximum number of k-dimensional simplices of minimum (non-zero) volume spanned by n points in d is Θ(nk).
, the maximum number of k-dimensional simplices of minimum (non-zero) volume spanned by n points in d is Θ(nk).(ii) The number of unit volume tetrahedra determined by n points in
3 is O(n7/2), and there are point sets for which this number is Ω(n3 log logn).(iii) For every
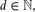 , the minimum number of distinct volumes of all full-dimensional simplices determined by n points in d, not all on a hyperplane, is Θ(n).
, the minimum number of distinct volumes of all full-dimensional simplices determined by n points in d, not all on a hyperplane, is Θ(n).

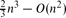 , and there are point sets for which this number is
, and there are point sets for which this number is 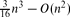 . We also present an
. We also present an 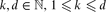 , the maximum number of
, the maximum number of 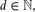 , the minimum number of distinct volumes of all full-dimensional simplices determined by
, the minimum number of distinct volumes of all full-dimensional simplices determined by The Random-Cluster Model, by Geoffrey Grimmett, Springer, 2006, 377pp., £69.00/$125.00/89.95 Euros.
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 317-318
-
- Article
- Export citation
Boundary Classes of Planar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 287-295
-
- Article
- Export citation
