
I. INTRODUCTION
The recent development of multimedia devices and editing tools, together with the proliferation of communication infrastructures and content sharing applications, has made the acquisition, the editing, and the diffusion of images and videos relatively-easy tasks. A single multimedia content downloaded from the internet can be the outcome of a long chain of processing steps. This fact introduces several concerns about the origin, the authenticity, and the trustability of images and videos downloaded from the network [Reference Piva1, Reference Milani2]. Moreover, identifying the origin and the authenticity (i.e., the absence of alterations after acquisition) of images proves to be a crucial element in court cases for the validation of evidences [Reference Farid3]. Moreover, detecting alterations permits inferring an objective quality evaluation of the analyzed multimedia content.
From these premises, multimedia forensic analysts have been recently focusing on detecting alterations on images since they can be easily acquired and modified even by a non-expert user. In order to fulfill this task, many of the proposed works aim at identifying images, which have been compressed more than once estimating the coding parameters that characterize the coding stages that precede the last one [Reference Lukás and Fridrich4]. This fact is justified by the observation that most of the digital multimedia contents are available in compressed format. Indeed, most of the images distributed over the internet are coded according to the JPEG standard [Reference Wallace5].
All the solutions proposed in the literature aim at detecting double compression on images assuming that some alterations can be performed between the first and the second compression stages. However, we believe that this assumption does not hold in many practical scenarios since analyzing the feasible processing chains for a given downloaded image it is deducible that more than two compression stages may have been applied. As an illustrative example, let us consider an image, which is originally compressed by the acquisition device (i.e., a video or photo camera) to be stored in the onboard memory. A second compression is performed by the owner, after editing the image to enhance the perceptual quality and adjust the format (e.g., brightness/contrast adjustment, rescaling, cropping, color correction, etc.). A third compression is performed whenever the content is uploaded to a blog or to an on-line photo album. As a matter of fact, it is reasonable to assume that a large number of digital images available on-line have gone through more than two compression stages performed by its owner, and could be further compressed by other users. In these cases, a method that identifies the number of compression stages proves to be extremely important in reconstructing the processing history of a content [Reference Milani, Tagliasacchi and Tubaro6].
This paper aims at identifying traces of multiple JPEG compression reconstructing the number of compression stages that have been operated on it. The proposed approach extends some of the techniques adopted by previous double compression detectors, which typically look for irregularities in the statistics of discrete cosine transform (DCT) coefficients [Reference Pevny and Fridrich7,Reference Galvan, Puglisi, Bruna and Battiato8]. More precisely, our analysis considers the most significant decimal digit or first digit (FD) of DCT coefficient absolute values. For images compressed only once, the probability mass function (pmf) of FDs presents a regular behavior modelled by the so-called Benford's law [Reference Benford9]. Conversely, the pmf of FDs for double or multiple compressed images departs from this behavior [Reference Pérez-González, Heileman and Abdallah10].
Even if several literature contributions have analyzed this fact (e.g., [Reference Lukás and Fridrich4]), we provide some experimental results that clearly show the validity of this assertion. Moreover, in the simplified hypothesis that DCT coefficients follows a Laplacian statistics [Reference Lam and Goodman11].
Then, it is showed that the characteristics of these deviations can be related to the number of compressions applied to the content. Experimental results show that it is indeed possible to infer the number of compression stages from the FD statistics with an average accuracy around 85%.
The proposed technique can be employed in different application scenarios, including steganalysis [Reference Pevny and Fridrich7], detection of image manipulation (when the original image is decompressed, modified, and recompressed), forgery identification [Reference Wang and Farid12], and quality assessment. As an example, image tampering can be localized by looking for regions that have been compressed a different amount of times with respect to the remaining image. Moreover, given the correlation between the compression operations and the editing stages applied on an image, the authenticity and the real origin of an image can be discussed by analyzing the number of compressions.
The rest of the paper is organized as follows. Section II overviews some of the published works related to double compression. Section III describes the behavior of FD statistics, as they go through multiple quantization stages, while Section IV presents the proposed classification method. Experimental results are reported in Section V and final conclusions are drawn in Section VI.
II. RELATED WORKS
Although the problem of multiple compression detection is relatively new in the multimedia forensics, several works on double compression detection have been presented in the literature. Some of the proposed solutions analyze the statistics of DCT coefficients [Reference Pevny and Fridrich7]. The second compression implies a re-quantization of DCT coefficients that are re-distributed among the bins of the second quantizer following a different statistics with respect to single compressed images. In [Reference Lin, He, Tang and Tang13], Lin et al. observe that double quantization introduces periodicities in coefficient statistics, which can be exploited to reveal double compression and the set of parameters used. Similarly, the work in [Reference Pevny and Fridrich7] detects the peculiar modifications on coefficients statistics brought by double quantization using an support vector machine (SVM) classifier. The approach in [Reference Fu, Shi and Su14] generalizes the Benford's law for the DCT coefficients and checks its consistency on the analyzed image (more details will be provided in Section III). Other strategies rely on the assumption that quantization is an idempotent operation, i.e., requantizing DCT coefficients with the same quantizer leads to reconstructed values highly-correlated with its input [Reference Xian-Zhe, Shao-Zhang and Jian-Chen15]. In [Reference Barni, Costanzo and Sabatini16], the authors detect double compression by studying coding artifacts. In [Reference Qu, Luo and Huang17] a convolutive mixing model is presented in order to deal with the problem of shifting the image between the first and the second compression. Other methods rely on modelling the statistics of natural images. These include the approaches based on the analysis of the distribution of the first significant digits, which can be modeled according to Benford's law [Reference Li, Shi and Huang18].
Many of these solutions are employed to detect tampering [Reference Lukás and Fridrich4], steganalysis [Reference Pevny and Fridrich7], or forgery localization [Reference Bianchi, Rosa and Piva19]. The main idea lying at the base of these approaches is that distinguishing double compressed regions from single compressed regions permit identifying which parts have been modified and which are original.
In the following, we will show how it is possible to extend the approaches based on Benford's law to the detection of multiple compression on images.
III. MULTIPLE COMPRESSIONS AND COEFFICIENTS STATISTICS
A) The JPEG compression standard
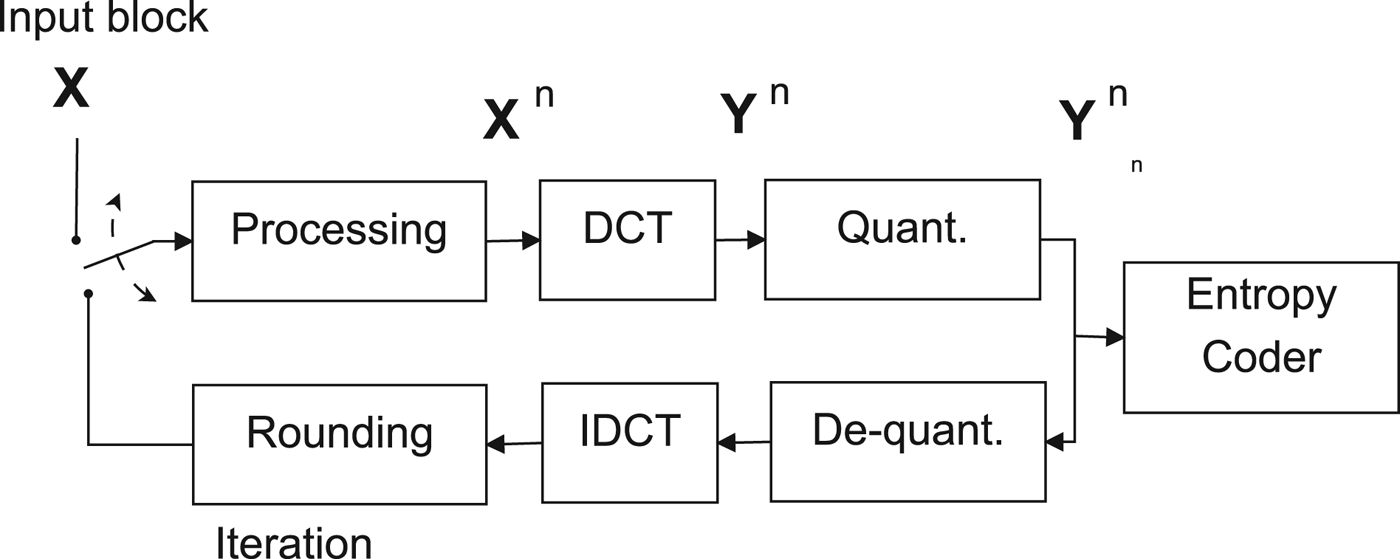
The JPEG image compression standard defines a block-based transform coder (see Fig. 1), which partitions the input image into 8 × 8 pixel blocks X and computes the DCT of each block. Transform coefficients Y are quantized into integer-valued quantization levels Y Δ1 1
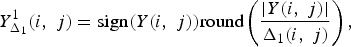 $$Y_{\Delta_1}^1\lpar i \comma \; j\rpar = \hbox{sign}\lpar Y\lpar i\comma \; j\rpar \rpar \hbox{round} \left(\displaystyle{{\vert Y\lpar i\comma \; j\rpar \vert }\over{\Delta_1\lpar i\comma \; j\rpar }} \right)\comma \;$$
$$Y_{\Delta_1}^1\lpar i \comma \; j\rpar = \hbox{sign}\lpar Y\lpar i\comma \; j\rpar \rpar \hbox{round} \left(\displaystyle{{\vert Y\lpar i\comma \; j\rpar \vert }\over{\Delta_1\lpar i\comma \; j\rpar }} \right)\comma \;$$
where the indexes (i, j), i, j = 0, …, 7, denote the position of the elements in the 8 × 8 block. The values Y Δ1 1 (i, j) are converted into a binary stream by an entropy coder following a zig-zag scan that orders coefficients according to increasing spatial frequencies. The coded block can be reconstructed by applying an inverse DCT transform on the rescaled coefficients Y r 1(i, j) = Y Δ1 1 (i, j) · Δ1 (i, j). Note that the quantization step Δ1 (i, j) changes according to the index (i, j) of the DCT coefficient and is usually defined by means of a quantization matrix. In the Independent JPEG Group (IJG) implementation, the quantization matrix is selected by adjusting a quality factor (QF), which varies in the range [0, 100]. The higher QF, the higher the quality of the constructed image.
Bock diagram for multiple JPEG compression.
When the image is encoded a second time, the resulting quantization levels are
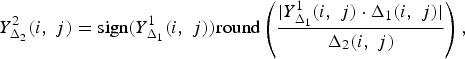 $$Y_{\Delta_2}^2 \lpar i\comma \; j\rpar = \hbox{sign}\lpar Y_{\Delta_1}^1 \lpar i\comma \; j\rpar \rpar \hbox{round}\left(\displaystyle{{\vert Y_{\Delta_1}^1\lpar i\comma \; j\rpar \cdot \Delta_1\lpar i\comma \; j\rpar \vert }\over{\Delta_2\lpar i\comma \; j\rpar }} \right)\comma \;$$
$$Y_{\Delta_2}^2 \lpar i\comma \; j\rpar = \hbox{sign}\lpar Y_{\Delta_1}^1 \lpar i\comma \; j\rpar \rpar \hbox{round}\left(\displaystyle{{\vert Y_{\Delta_1}^1\lpar i\comma \; j\rpar \cdot \Delta_1\lpar i\comma \; j\rpar \vert }\over{\Delta_2\lpar i\comma \; j\rpar }} \right)\comma \;$$
where Δ2(i, j) are the quantization steps of the second compression stage.Footnote 1 It is possible to iterate the compression process N times leading to the quantization levels Y Δ N N (i, j).
B) The FD law
Many fraud detection algorithms departs from the assumption that the analyzed data are well modeled by pre-defined stochastic models that present peculiar characteristics. A similar assumption is adopted by many approaches aiming at detecting double JPEG compression. More precisely, some of the proposed works rely on detecting the violation of the so-called Benford's law (also known as FD law or significant digit law) [Reference Wang, Cha, Cho and Kuo20]. Many fraud detection algorithms departs from the assumption that the analyzed data are well modeled by pre-defined stochastic models that present peculiar characteristics. One of these is the FD rule, which proves to be satisfied for many distributions. The most significant digit or FD for a strictly-positive integer Y (in base-10 notation) can be computed as
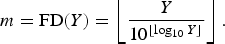 $$m = {\rm FD}\lpar Y\rpar = \left\lfloor \displaystyle{{Y}\over{10^{\lfloor \log_{10} Y\rfloor}}} \right\rfloor.$$
$$m = {\rm FD}\lpar Y\rpar = \left\lfloor \displaystyle{{Y}\over{10^{\lfloor \log_{10} Y\rfloor}}} \right\rfloor.$$
It is possible to state that Benford's law [Reference Benford9] is satisfied whenever the pmf of m can be well approximated by the equation
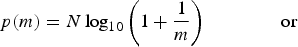 $$p\lpar m\rpar = N \log_{10}\left(1 + \displaystyle{{1}\over{m}}\right)\quad \quad \quad \quad{\rm or }$$
$$p\lpar m\rpar = N \log_{10}\left(1 + \displaystyle{{1}\over{m}}\right)\quad \quad \quad \quad{\rm or }$$
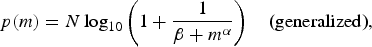 $$p\lpar m\rpar = N \log_{10}\left(1 + \displaystyle{{1}\over{\beta + m^\alpha }}\right)\quad \hbox{\lpar generalized \rpar \comma}$$
$$p\lpar m\rpar = N \log_{10}\left(1 + \displaystyle{{1}\over{\beta + m^\alpha }}\right)\quad \hbox{\lpar generalized \rpar \comma}$$
where N is a normalizing factor and α,β are the parameters characterizing the model. This property can be verified for many real-life sources of data and can be effectively used to detect alterations on the analyzed data. Indeed, whenever some kind of modification has been performed on a dataset that originally satisfies Benford's law, the resulting distribution no longer satisfies this property. This fact has been widely employed in fraud detection in different fields (elections [Reference Battersby21, Reference Deckert, Myagkov and Ordeshook22], budget [Reference Nigrini23, Reference Müller24], etc.), as well as in detecting double compression in JPEG images [Reference Fu, Shi and Su14].
C) Statistics of coefficients and FDs after multiple compressions
The single and double compressions of an image leave different peculiar traces on the statistics of coefficients and their FDs. Most of the double compression detectors use these traces to decide whether an image has been compressed once or not. For the sake of conciseness, we will refer to the absolute DCT quantized coefficients after the Nth compression as y N = |Y Δ N N | (position indexes (i, j) have been omitted for the sake of clarity) and their corresponding FDs m N = FD(y N ).
When multiple compressions are applied, each compression stage modifies the statistics of coefficients and their corresponding FDs leaving denotative elements.
Fig. 2 reports the pmf of FDs for DCT coefficients at different coding stages for the image house of the Kodak dataset. The adopted quantization factors are QF 4 = 85, QF 3 = 76, QF 2 = 80, and QF 1 = 85. The same figure also reports the discrete fourier transform (DFT) of the difference (parameter χ) between the actual pmf of FDs and its interpolated version following Benford's law, i.e., χ(m N ) = P[m N = k] − p(m N ). Figures 2(e)–2(h) show that the most significant oscillations take place at peculiar normalized frequencies of DFT coefficients. For single compressed images, oscillations are quite limited (DFT coefficients are lower than 0.17). In case an image is double compressed (Fig. 2(f)), part of the energy of χ is concentrated around F = 0.2 (where F is the normalized frequency for DFT transform). Note that in this case the maximum value of DFT coefficients is higher with respect to the case of images compressed once. For images compressed three times, the DFT plots show that two oscillating modes appear at F ≃ 0.18 and F ~ 0.28 (Fig. 2(g)), while four compressions lead to stronger oscillations dominated by the component at F = 0.34 (FFT results highly peaked in Fig. 2(h)).
Probability mass functions of FDs and frequency spectra of their differences χ(y N ) with respect to a Benford's model at different coding stages. The parameter F denotes the normalized frequency for DFT coefficients of χ. The graphs are related to coefficient at position (1, 0) for image house. (a) P[m 1 = k]. (b) P[m 2 = k]. (c) P[m 3 = k]. (d) P[m 4 = k]. (e) DFT(χ(m 1)). (f) DFT(χ(m 2)). (g) DFT(χ(m 3)). (h) DFT(χ(m 4)).

Ad-hoc solutions need to be designed in order to reveal the presence of these oscillations in the statistics of the FD for transform coefficients. In fact, previous solutions targeted simple double compression detection, i.e., were aimed at verifying the regularity of the actual FD statistics
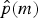 $\hat{p} \lpar m\rpar$
. Multiple compression detection requires characterizing the characteristics of deviations from Benford's law. As a result, double compression detectors fail in discriminating the number of coding stages and the corresponding coding parameters.
$\hat{p} \lpar m\rpar$
. Multiple compression detection requires characterizing the characteristics of deviations from Benford's law. As a result, double compression detectors fail in discriminating the number of coding stages and the corresponding coding parameters.
It is possible to overcome this problem by combining a set of classifiers, as it will be described in the next section.
IV. THE PROPOSED DETECTION ALGORITHM
The estimation of the number of coding stages N requires to select a set of robust features that present a strong correlation with the traces left by quantization. From this selection, it is possible to design a set of classifiers associated to each compression stage. Their outputs can be combined estimating the number of compressions operated on the image under analysis.
To this purpose, we generated an exhaustive dataset of compressed images, where the number of compressions operated on each picture can vary from 1 to 4. The adopted JPEG codec is the one implemented in the MATLAB software. The quality factor QF i of the ith compression stage is selected randomly within an interval of possible values [QF N − dQF, QF N + dQF], where QF N is the QF of the last compression stage and dQF is the halved width of the interval. This limit was imposed in order to constrain the quality degradation in the final image since significant variations in the QF values across the different compression stages introduce evident unnatural artifacts on the reconstructed pictures.
Moreover, we also imposed that the difference between the chosen QFs of two consecutive compression stages must be higher than a threshold T QF , i.e. |QF i − QF i+1| > T QF . This constraint was introduced in order to make the quantization steps for all the considered DCT coefficients change from one compression stage to the following.
In the literature, the set and the number of analyzed DCT coefficients employed by different double compression detectors can change. In [Reference Li, Shi and Huang18], 20 spatial frequencies were considered, while in the approach [Reference Pevny and Fridrich7] only 9 frequencies are considered. Note that most of these frequencies lies at low frequencies since DCT coefficients at low frequencies proves to be more regular and changes less significantly according to the characteristics of the image with respect to those located at high frequencies. Moreover, high-frequency coefficients are often quantized to zero, and therefore, their statistics can only be computed from a limited amount of data. In this approach, we adopted the set of coefficients in [Reference Pevny and Fridrich7]. Then, we set T QF = 5 since, according to the values of the quantization matrix of the JPEG codec implemented by MATLAB, it ensures that none of the DCT coefficients at compression stage i is quantized with Δ i = Δ i−1.
Three different datasets were generated. In a first dataset D 0, the compression grids of images are aligned, i.e., no transformation was operated on the image between one compression stage and the following. In a second dataset D 1, images were rescaled at a random compression stage, where the rescaling factor was randomly-chosen in the interval [0.9, 1.1]. In the third dataset D 2, images are rotated of a random angle included in the interval [−5, 5] at a randomly-selected compression stage. In this way, datasets D 1 and D 2 introduce the possibility that the compression grids could not be aligned (since they include both transformed and unaltered images).
In the following, we will describe the feature extraction process and the training of the classifiers for the dataset D 0. The same operations are applied on the datasets D 1 and D 2 as well.
A) Feature selection
Given a JPEG image I
n
which has been compressed n times, most of the approaches existing in the literature extract the quantized DCT coefficients of the luma component and compute a set of features from their statistics. Features may include the simple FD statistics for the DCT coefficients at low frequencies [Reference Li, Shi and Huang18] or the relative difference between the actual pmf and the Benford's equation, i.e.
 $\chi\lpar m\rpar = \lpar p\lpar m\rpar - \hat{p}\lpar m\rpar \rpar /\hat{p}\lpar m\rpar $
[Reference Fu, Shi and Su14].
$\chi\lpar m\rpar = \lpar p\lpar m\rpar - \hat{p}\lpar m\rpar \rpar /\hat{p}\lpar m\rpar $
[Reference Fu, Shi and Su14].
In our approach, we adopted the first possibility computing the pmfs of FDs on the set of nine spatial frequencies reported in [Reference Pevny and Fridrich7]. This would lead to a feature array of 9 × 8 = 72 values,Footnote 2 but we aim at reducing this size by properly selecting those features that are extremely sensible to the number of compression stages. More precisely, Fig. 2 shows that the probabilities for some FD values are more sensitive to multiple compression than others, i.e., the deviation from Benford's law equation is more discriminative. From this premise, it is possible to select a subset of l probability values p(k 1), … , p(k l ) from the pmf of FD digits (k 1, …, k 2 ∈ [1, 9]).
Naming
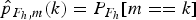 $\hat{p}_{F_{h}\comma m}\lpar k\rpar = P_{F_{h}}\lsqb m == k\rsqb $
the probability that the FD value m for the coefficients located at spatial frequency F
h
is equal to k, it is possible to gather the features in a common array
$\hat{p}_{F_{h}\comma m}\lpar k\rpar = P_{F_{h}}\lsqb m == k\rsqb $
the probability that the FD value m for the coefficients located at spatial frequency F
h
is equal to k, it is possible to gather the features in a common array
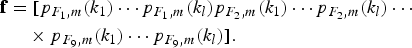 $$\eqalign{{\bf f} &= \lsqb p_{F_1\comma m}\lpar k_1\rpar \cdots p_{F_1\comma m}\lpar k_l\rpar p_{F_2\comma m}\lpar k_1\rpar \cdots p_{F_2\comma m}\lpar k_l\rpar \cdots\cr &\quad \times p_{F_9\comma m}\lpar k_1\rpar \cdots p_{F_9\comma m}\lpar k_l\rpar \rsqb .}$$
$$\eqalign{{\bf f} &= \lsqb p_{F_1\comma m}\lpar k_1\rpar \cdots p_{F_1\comma m}\lpar k_l\rpar p_{F_2\comma m}\lpar k_1\rpar \cdots p_{F_2\comma m}\lpar k_l\rpar \cdots\cr &\quad \times p_{F_9\comma m}\lpar k_1\rpar \cdots p_{F_9\comma m}\lpar k_l\rpar \rsqb .}$$
Note that features are already limited in the range [0, 1] since they are related to pmf of FD values.
In order to find the optimal set of features, we considered different sets of
 $\hat{p} \lpar m\rpar$
values changing both the values k
1, …, k
l
and their number l. To this purpose, we randomly selected 1200 images from the UCID dataset [Reference Schaefer and Stich25] which were compressed once and twice with different quantization parameters QF. The quantization parameter of the last coding stage is fixed (since it is known from the coded bit stream), while the QF adopted in the first stage is randomly chosen in the interval [QF − 10, QF − 5] ∪ [QF + 5 , QF + 10]. In this part, 10 different realizations were generated for every image. From these images, we computed the vectors f and used them in training a binary SVM classifier that discriminates single from double compressed images. The remaining 100 images in the UCID dataset were double compressed in a similar manner and used for testing the accuracy of the classifier. In this case, the double compression detector is taken as a simplification of the multiple compression detector for the sake of complexity since training the full multiple compression detector for all the configurations would require a significant time.
$\hat{p} \lpar m\rpar$
values changing both the values k
1, …, k
l
and their number l. To this purpose, we randomly selected 1200 images from the UCID dataset [Reference Schaefer and Stich25] which were compressed once and twice with different quantization parameters QF. The quantization parameter of the last coding stage is fixed (since it is known from the coded bit stream), while the QF adopted in the first stage is randomly chosen in the interval [QF − 10, QF − 5] ∪ [QF + 5 , QF + 10]. In this part, 10 different realizations were generated for every image. From these images, we computed the vectors f and used them in training a binary SVM classifier that discriminates single from double compressed images. The remaining 100 images in the UCID dataset were double compressed in a similar manner and used for testing the accuracy of the classifier. In this case, the double compression detector is taken as a simplification of the multiple compression detector for the sake of complexity since training the full multiple compression detector for all the configurations would require a significant time.
Fig. 3(a) reports the average detection using a feature array f with l = 3, where the feature array has been created selecting only a subset (k 1, k 2, k 3) of possible FD values, i.e., f = [p F h,m (k 1) p F h,m (k 2) p F h,m (k 3)] F h . The different results have been obtained considering all the possible combinations for k 1, k 2, k 3. For the sake of clarity, the triplet [k 1, k 2, k 3] is indexed by the value (k 1 − 1) + (k 2 − 1) 9 + (k 3 − 1) 81 (reported on the x-axis). It is possible to see that the triplet [Reference Milani2, Reference Wallace5, Reference Milani, Tagliasacchi and Tubaro6] permits obtaining the highest accuracy. Note also that the length of the feature vector is 27. It is also possible to verify that the obtained accuracy is comparable with that obtained by decomposing the feature array f with l = 8 using a principal component analysis (PCA) and selecting the three most relevant components. Building a new classifier on this feature array obtained from PCA, it is possible to obtain an average accuracy of 92%. Nevertheless, the PCA-based classifier requires computing all the features in advance and then transform the feature array into its principal component representation. The proposed solution requires to compute only three features for each spatial frequency.
Accuracy of single versus double compression detector for different feature arrays. (a) three p(m) values, (b) two p(m) values, and (c) four p(m) values.
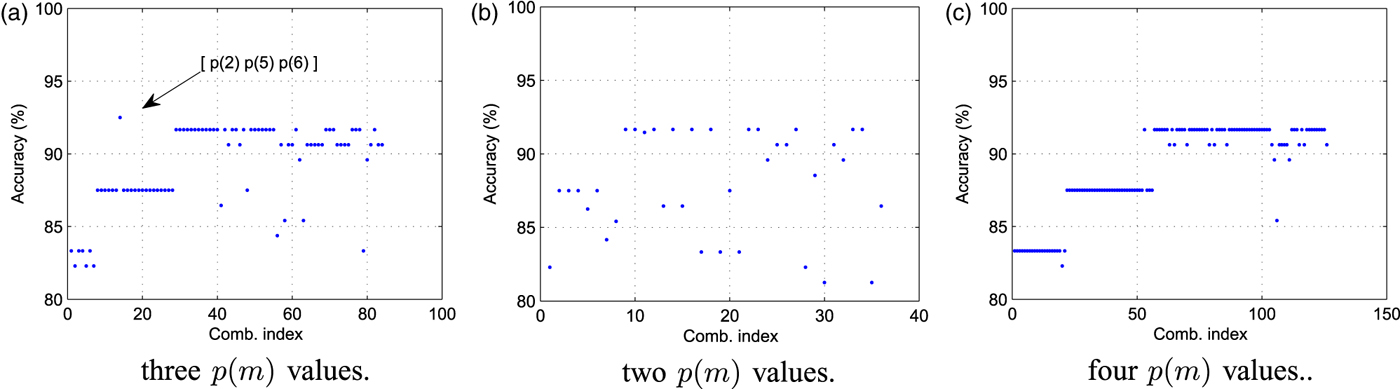
We also considered the possibility of increasing or reducing the number l of features in f. Additional Figs 3(b) and 3(c) report the average accuracy of the detector when l = 2 (f = [p F h ,m (k 1) p F h ,m (k 2)] F h ) and l = 4 (f = [p F h ,m (k 1) p F h ,m (k 2) p F h ,m (k 3) p F h ,m (k 4)] F h ), respectively. Note that this would lead to feature arrays of 18 and 36 elements. The adopted set k 1, …, k l of probability values is changed as for Fig. 3(a) and each configuration is indexed by the values (k 1 − 1) + (k 2 − 1) 9 for l = 2 and (k 1 − 1) + (k 2 − 1) 9 + (k 3 − 1) 81 + (k 4 − 1) * 729 for l = 4. Indexes are reported on the x axes.
It is evident that using 3 values proves to be the best solution since the maximum average accuracy is higher than using 2 or 4 probability values. In the first case, the feature space does not allow an effective clustering, whereas in the second the additional feature does not improve the classification accuracy.
As a results, each image is represented with a feature vector f of 27 elements (i.e., approximately six times smaller than in [Reference Li, Shi and Huang18]).
The following section will show how the final classifiers are designed starting from the feature vectors f.
B) Design of the classifiers
Given the dataset D 0, we computed the features f with k 1 = 2, k 2 = 5, and k 3 = 6 for every image. The dataset was divided into two subsets D 0 t , D 0 v to train (D 0 t ) and validate (D 0 v ) the detector, respectively.
Assuming that the quality factor QF of the last compression stage is known (from the available bitstream), we built a set of N
T
binary SVM classifiers,
 ${\cal S}_{QF\comma k} \lpar k = 1\comma \; \ldots\comma \; N_{T}\rpar $
, where each classifier
${\cal S}_{QF\comma k} \lpar k = 1\comma \; \ldots\comma \; N_{T}\rpar $
, where each classifier
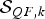 ${\cal S}_{QF\comma k}$
is able to detect whether the input image has been coded k-times or not.
${\cal S}_{QF\comma k}$
is able to detect whether the input image has been coded k-times or not.
In designing
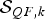 ${\cal S}_{QF\comma k}$
, we adopted the exponential kernel
${\cal S}_{QF\comma k}$
, we adopted the exponential kernel
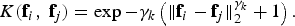 $$K \lpar {\bf f}_i\comma \; {\bf f}_j\rpar = \exp -\gamma_k \left(\Vert {\bf f}_i - {\bf f}_j \Vert _2^{\gamma_k} + 1 \right).$$
$$K \lpar {\bf f}_i\comma \; {\bf f}_j\rpar = \exp -\gamma_k \left(\Vert {\bf f}_i - {\bf f}_j \Vert _2^{\gamma_k} + 1 \right).$$
The parameter γ k and the kernel type were optimized in the training phase computing the structure that gives the optimal performance. In this process, we adopted a cross-validation optimization based on the RANSAC algorithm. The training is carried out looking for the best γ k value that maximizes the recall value for each class, i.e., maximizing the probability of correct classification for each subset of training images coded N times. Each classifier also outputs a confidence value w k that reports the distance from the discriminating hyperplane and permits evaluating the reliability of the classification.
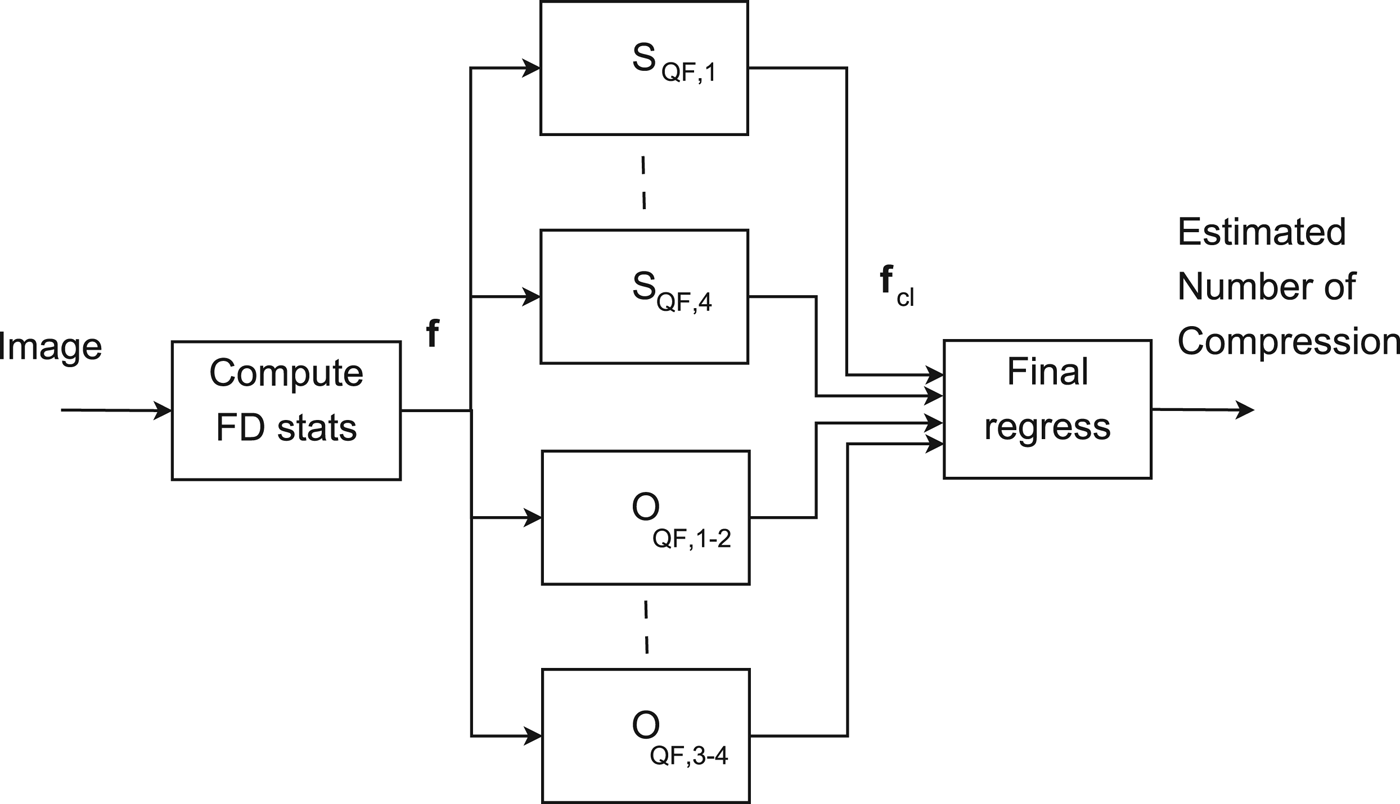
Similarly, second set of classifiers, named O QF, k−t , is generated which discriminate whether an images has been coded either k or t times. Naming s k the output of the classifier S QF, k and o k−t the output of O QF, k−t , the outcomes of the different classifiers are combined together in order to make the estimation more robust.
Outputs are combined in the feature vector
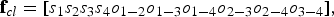 $${\bf f}_{cl} = \lsqb s_1 s_2 s_3 s_4 o_{1-2} o_{1-3} o_{1-4} o_{2-3} o_{2-4} o_{3-4}\rsqb \comma \;$$
$${\bf f}_{cl} = \lsqb s_1 s_2 s_3 s_4 o_{1-2} o_{1-3} o_{1-4} o_{2-3} o_{2-4} o_{3-4}\rsqb \comma \;$$
which has to be related to the number of compression. It is possible to relate f cl to the unknown number of compressions N that were applied to the analyzed image by training an regressor processing f cl . Figure 4 reports the whole detection scheme.
Block diagram of the proposed detector.
Performance was tested on the validation dataset D 0 v and results are reported in the following section. A similar procedure was applied on the datasets D 1 and D 2.
V. EXPERIMENTAL RESULTS
As it was reported in the previous section, the detector was designed from a training database of images compressed up to four times. In order to generate the training database, we randomly selected the 100 images from the UCID dataset [Reference Schaefer and Stich25]. Each image was coded up to four times with a random sequence of quality factors QF i for each compression stage. The quantization factor QF i at stage i is randomly chosen in the interval [QF i+1 l − 12, QF i+1 l − 6] ∪ [QF i+1 u + 6, QF i+1 u + 12], where QF i+1 l and QF i+1 u are the lower and upper QF limits that ensure that the quantization steps related to QF i differ with respect to those of QF i+1.
These images were included in the datasets D 0 t , D 1 t , and D 2 t . A set of 200 images among the remaining pictures of the UCID dataset were compressed in the same ways and included in the datasets D 0 v , D 1 v , and D 2 v .
Since the dataset was extended with respect to the tests in [Reference Milani, Tagliasacchi and Tubaro6], the performance proves to be slightly worse on average despite the approach proves to be effective in many cases. To provide evidence for this, we make available a demo version of the multiple compression detection algorithm for download at [Reference Milani26].
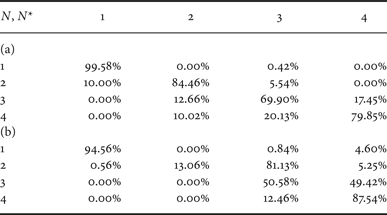
Table 1(a) shows a confusion matrix for dataset D 0. The real number of compression stages is reported along the rows while the estimated number of compressions is reported along the columns. Each cell (u, v) reports the percentage of images compressed u times that were detected as compressed v times. It is possible to notice that the case of a single compression stage is always correctly identified. In the case an image was compressed 1, 2 or 3 times, the proposed method performs quite well since the probability of correct detection is above 84.8%. The average accuracy is around 83%. We compare the performance with that of a classifier designed adapting the work in [Reference Li, Shi and Huang18] in order to detect the number of compression stages. The confusion matrix, which is shown in Table 1(b), demonstrates that the two methods achieve nearly the same results for N = 1, but the average accuracy of the second solution is lower (~62%) with respect to the proposed solution. In this latter case, a significant performance loss is evident for N = 2. This is due to the difficulty in identifying an adequate set of support vectors, because of the high dimensionality of feature vectors and the increased amount of compression noise introduced. The performance increases for N > 2 since the availability of the full pmf of the FDs permits including those features that present wider oscillations whenever the image is compressed three or four times (e.g., p(2) and p(5) as Figs 2(c) and 2(d) show).
Confusion matrix for QF N = 75 and dataset D 0. (a) Proposed method, (b) classifier in [Reference Li, Shi and Huang18] (adapted).
Results for quality factor QF = 80 are reported in Table 2. In this case, the average precision is 88% but the performance of the detector in identifying N = 3 or 4 compressions improves. In this case, the adopted quantization steps are smaller and the amount of compression noise is lower permitting a more accurate detection even after more than two compression stages. Also in this case the approach in [Reference Li, Shi and Huang18] (adapted to detect multiple compressions) presents a lower accuracy (~85%).
Confusion matrix for QF N = 80 and dataset D 0. (a) Proposed method, (b) classifier in [Reference Li, Shi and Huang18] (adapted).
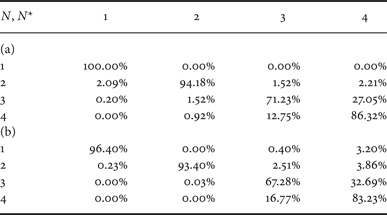
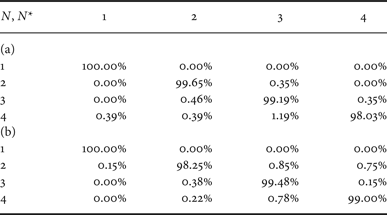
Table 3 reports the confusion matrix when QF N = 90. It is possible to notice that the difference between the performances of the two approaches is significantly reduced. This fact is mainly correlated with the percentage of non-null quantized coefficients in each image. At low QF values, many coefficients are quantized to zero, and therefore, the FD probabilities are computed from a reduced amount of coefficients. Since in this case the statistics is diluted, many probability values with l = 8 are not reliable features for the classification. Shrinking the array f to the subset of the most reliable features permits increasing the accuracy of the detection.
Confusion matrix for QF N = 90 and dataset D 0. (a) Proposed method, (b) classifier in [Reference Li, Shi and Huang18] (adapted).
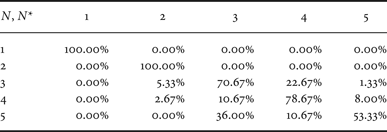
In the end, we also evaluated the possibility of detecting five compression steps for the images adopted to generate dataset D 0. In this case, confusion matrix for the proposed approach is reported in Table 4. It is possible to notice that, although the average accuracy is decreased to 80%, the capability of detecting N < 5 compression stages is increased. This fact is mainly due to the fact that the detectors are trained with images coded more than four times, and as a consequence, the partitionings of features space operated by the SVM classifiers are more accurate.
Confusion matrix with QF N = 80 on dataset D 0 for the detection of five compression stages (proposed algorithm).
It is possible to notice that the accuracy of the method based on [Reference Li, Shi and Huang18] (adapted) increases as the compression quality increases. This fact is mainly correlated with the percentage of non-null quantized coefficients in each image.
At low QF values, many coefficients are quantized to zero, and therefore, many probability values
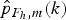 $\hat{p}_{F_{h}\comma m}\lpar k\rpar $
are computed from a reduced set of data and do not provide reliable features for the classification. Shrinking the array f to the subset of the most reliable features permits increasing the accuracy of the detection. It is possible to notice that at high QF values (low distortion) the accuracy of the approach in [Reference Li, Shi and Huang18] get closer to that of the proposed approach.
$\hat{p}_{F_{h}\comma m}\lpar k\rpar $
are computed from a reduced set of data and do not provide reliable features for the classification. Shrinking the array f to the subset of the most reliable features permits increasing the accuracy of the detection. It is possible to notice that at high QF values (low distortion) the accuracy of the approach in [Reference Li, Shi and Huang18] get closer to that of the proposed approach.
The proposed method is characterized by a lower computational complexity with respect to the approach in [Reference Li, Shi and Huang18], since the size of the feature vector is much smaller.
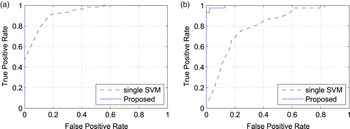
We also tested the improved accuracy of the proposed classifier in a simple double compression detection (i.e., verifying whether an image has been compressed once or more times). More precisely, tested the SVM classifier proposed in [Reference Li, Shi and Huang18] with respect to the classifier using the features in equation (8), which compose different SVM classifiers using a reduced set of features. Figure 5 reports the receiver operating characteristic (ROC) curves of the two approaches for different QFs. It is possible to see that the proposed detector is much more effective in detecting double compression.
ROC curves of different double compression detectors for different QFs on dataset D 0. (a) QF = 70, (b) QF = 80.
Computational time for the proposed method and the classifier in [Reference Li, Shi and Huang18] (adapted).

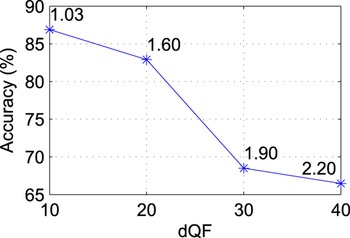
Furthermore, we considered the robustness of the approach changing the range of variation for the QF parameters. More precisely, we changed the width dQF of the interval where QF values are randomly chosen. Figure 6 reports the average accuracy obtained changing the width of the interval as a function of dQF. It is possible to notice that increasing the range of QF values leads to a decrement of the detection performance and of the average peak signal-to-noise ratio (PSNR) value after N coding stages.
Accuracy versus dQF for images coded with QF N = 70 on dataset D 0. The graph also reports the average PSNR decrement (dB) for each point.
Finally, we also tested the robustness of the approach in case an image is manipulated between consecutive compression stages. More precisely, we assumed that image manipulation took place at the processing block in Fig. 1, before one of the coding stages.
In the processing chain, we introduced a random manipulation which could consist either in a rescaling or in a rotation. The idea is to disalign the block grid of JPEG compression in order to test the robustness of the detector. The parameter values for each transformation are random as well and can vary in the intervals [.9, 1.1] for the rescaling (the parameter is the pixel width ratio), and [−5, 5] for the rotation angle. These limits are justified by the need of avoiding a significant decrement of the image quality and keeping the size of the transformed image close to that of the original one. These data were collected in the datasets D 1 and D 2.
The confusion matrix in Table 6 was obtained from dataset D 1 and show that the proposed classifier permits obtaining an average accuracy of 65%. Note also that increasing the size of the feature vector f (see Table 6(b)) does not bring significant improvements in terms of performance, made exception for the detection of three compression stages. The approach in [Reference Li, Shi and Huang18] permits obtaining an average accuracy equal to 62% in presence of random rescalings.
Confusion matrix for QF N = 80 from datasets D 1. (a) Proposed method, (b) classifier in [Reference Li, Shi and Huang18] (adapted).
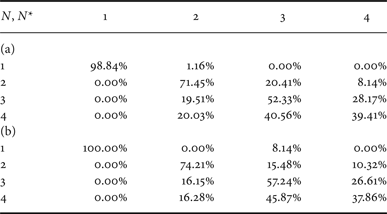
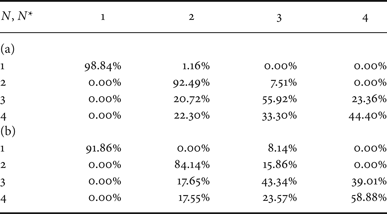
As for the dataset D 2, Table 7 shows that the proposed solution permits obtaining an average accuracy equal to 75%, while the solution derived from [Reference Li, Shi and Huang18] permits having an average accuracy of 69%.
Confusion matrix for QF N = 80 from datasets D 2. (a) Proposed method, (b) classifier in [Reference Li, Shi and Huang18] (adapted).
VI. CONCLUSIONS
The paper describes a classification strategy that permits detecting the number of JPEG compression stages performed on a single image. The approach relies on a set of SVM classifiers applied to features based on the statistics of the FDs of quantized DCT coefficients. The proposed solution performs well with respect to previous approaches, while employing a reduced set of features. Future research will be devoted to investigate other possible antiforensics strategies that could fool the proposed solution and to extend the approach to the case of video signals.
ACKNOWLEDGEMENTS
The project REWIND acknowledges the financial support of the Future and Emerging Technologies (FET) programme within the Seventh Framework Programme for Research of the European Commission, under FET-Open grant number, 268478.
Simone Milani is currently Assistant Professor at the University of Padova, Italy. From this institution, he received the Laurea degree in Telecommunication Engineering in 2002, and the Ph.D. degree in Electronics and Telecommunication Engineering in 2007. In 2006, he was a visiting Ph.D. student at the University of California, Berkeley under the supervision of Professor K. Ramchandran. In 2007, he was a Post-doc researcher at the University of Udine, Italy, collaborating with Professor R. Rinaldo. In 2011, he joined the group of Professor Stefano Tubaro at the Politecnico di Milano, Italy working as an assistant researcher within the ICT-FP7 FET-Open Project REWIND. Dr. Milani co-authored more than 70 papers in international journals and conferences, including award winning papers at MMSP 2013, MMSP2012. His main research topics are digital signal processing, image, and video coding, 3D image and video acquisition and processing, 3DTV compression, multimedia forensics.
Marco Tagliasacchi is currently an Assistant Professor at the “Dipartimento di Elettronica e Informazione – Politecnico di Milano”, Italy. He received the “Laurea” degree (2002, cum Laude) in Computer Engineering and the Ph.D. in Electrical Engineering and Computer Science (2006), both from Politecnico di Milano. He was visiting academic at the Imperial College London (2012) and visiting scholar at the University of California, Berkeley (2004). His research interests include multimedia forensics, multimedia communications (visual sensor networks, coding, quality assessment), and information retrieval. Dr. Tagliasacchi co-authored more than 120 papers in international journals and conferences, including award winning papers at MMSP 2013, MMSP2012, ICIP 2011, MMSP 2009, and QoMex 2009. He has been actively involved in several EU-funded research projects. He is currently co-coordinating two ICT-FP7 FET-Open projects (GreenEyes – www.greeneyesproject.eu, REWIND – www.rewindproject.eu).
Stefano Tubaro completed his studies in Electronic Engineering at the Politecnico di Milano, Italy, in 1982. Since December 2004 he has been appointed as Full Professor of Telecommunication at the Dipartimento di Elettronica, Informazione e Bioingegneria of the Politecnico di Milano (DEIB-PoliMi). His current research interests are on advanced algorithms for video and sound processing. Stefano Tubaro authored over 150 publications on international journals and congresses. In the past few years, he has focused his interest on the development of innovative techniques for image and video tampering detection and, in general, for the blind recovery of the “processing history” İ of multimedia objects. Stefano Tubaro is the Head of the Telecommunication Section of DEIB-PoliMi, and the Chair of the IEEE SPS Italian Chapter; moreover he coordinates the research activities of the Image and Sound Processing Group (ISPG). He is a member of the IEEE MMSP and IVMSP TCs.














 Open access
Open access