

1. Introduction
According to Chomsky, a visiting Martian scientist would surely conclude that aside from their mutually unintelligible vocabularies, Earthlings speak a single language.
— Steven Pinker (Reference Pinker1994, p. 232)Languages are much more diverse in structure than cognitive scientists generally appreciate. A widespread assumption among cognitive scientists, growing out of the generative tradition in linguistics, is that all languages are English-like but with different sound systems and vocabularies. The true picture is very different: languages differ so fundamentally from one another at every level of description (sound, grammar, lexicon, meaning) that it is very hard to find any single structural property they share. The claims of Universal Grammar, we argue here, are either empirically false, unfalsifiable, or misleading in that they refer to tendencies rather than strict universals. Structural differences should instead be accepted for what they are, and integrated into a new approach to language and cognition that places diversity at centre stage.
The misconception that the differences between languages are merely superficial, and that they can be resolved by postulating a more abstract formal level at which individual language differences disappear, is serious: it now pervades a great deal of work done in psycholinguistics, in theories of language evolution, language acquisition, neurocognition, parsing and speech recognition, and just about every branch of the cognitive sciences. Even scholars like Christiansen and Chater (2008), concerned to demonstrate the evolutionary impossibility of pre-evolved constraints, employ the term Universal Grammar as if it were an empirically verified construct. A great deal of theoretical work within the cognitive sciences thus risks being vitiated, at least if it purports to be investigating a fixed human language processing capacity, rather than just the particular form this takes in some well-known languages like English and Japanese.
How did this widespread misconception of language uniformity come about? In part, this can be attributed simply to ethnocentrism – most cognitive scientists, linguists included, speak only the familiar European languages, all close cousins in structure. But in part it can be attributed to misleading advertizing copy issued by linguists themselves. Unfortunate sociological splits in the field have left generative and typological linguists with completely different views of what is proven science, without shared rules of argumentation that would allow them to resolve the issue – and in dialogue with cognitive scientists it has been the generativists who have been taken as representing the dominant view. As a result, Chomsky's notion of Universal Grammar (UG) has been mistaken, not for what it is – namely, the programmatic label for whatever it turns out to be that all children bring to learning a language – but for a set of substantial research findings about what all languages have in common. For the substantial findings about universals across languages one must turn to the field of linguistic typology, which has laid bare a bewildering range of diverse languages, where the generalizations are really quite hard to extract. Chomsky's views, filtered through various commentators, have been hugely influential in the cognitive sciences, because they combine philosophically sophisticated ideas and mathematical approaches to structure with claims about the innate endowment for language that are immediately relevant to learning theorists, cognitive psychologists, and brain scientists. Even though psychologists learned from the linguistic wars of the 1970s (Newmeyer Reference Newmeyer1986) to steer clear from too close an association with any specific linguistic theory, the underlying idea that all languages share the same structure at some abstract level has remained pervasive, tying in nicely to the modularity arguments of recent decades (Fodor Reference Fodor1983).
It will take a historian of science to unravel the causes of this ongoing presumption of underlying language uniformity. But a major reason is simply that there is a lack of communication between theorists in the cognitive sciences and those linguists most in the know about linguistic diversity. This is partly because of the reluctance by most descriptive and typological linguists to look up from their fascinating particularistic worlds and engage with the larger theoretical issues in the cognitive sciences. Outsiders have instead taken the articulate envoys from the universalizing generativist camp to represent the consensus view within linguistics. But there are other reasons as well: the relevant literature is forbiddingly opaque to outsiders, bristling with arcane phonetic symbols and esoteric terminologies.
Our first goal (sect. 2) in this article, then, is to survey some of the linguistic diversity that has been largely ignored in the cognitive sciences, which shows how differently languages can be structured at every level: phonetic, phonological, morphological, syntactic, and semantic. We critically evaluate (sect. 3) the kind of descriptive generalizations (again, misleadingly called “universals”) that have emerged from careful cross-linguistic comparisons, and we survey the treacherously different senses of “universal” that have allowed the term to survive a massive accumulation of counterevidence.
We then turn to three syntactic features that have recently figured large in debates about the origin of language: grammatical relations (sect. 4), constituency (sect. 5), and recursion (sect. 6). How universal are these features? We conclude that there are plenty of languages that do not exhibit them in their syntax. What does it mean for an alleged universal to not apply in a given case? We will consider the idea of “parameters” and the idea of UG as a “toolkit” (Jackendoff Reference Jackendoff2002).
We then turn (sect. 7) to the question of how all this diversity is to be accounted for. We suggest, first, that linguistic diversity patterns just like biological diversity and should be understood in the same sorts of ways, with functional pressures and systems constraints engineering constant small changes. Finally (sect. 8), we advance seven theses about the nature of language as a recently evolved bio-cultural hybrid. We suggest that refocusing on a unique property of our communication system, namely its diversity, is essential to understanding its role in human cognition.
2. Language diversity
A review of leading publications suggests that cognitive scientists are not aware of the real range of linguistic diversity. In Box 1, for example, is a list of features, taken from a BBS publication on the evolution of language, that all languages are supposed to have – “uncontroversial facts about substantive universals” (Pinker & Bloom Reference Pinker and Bloom1990; a similar list is found in Pinker Reference Pinker1994). But none of these “uncontroversial facts” are true of all languages, as noted in the box.
Box 1. “Every language has X, doesn't it?”: Proposed substantive universals (from Pinker & Bloom Reference Pinker and Bloom1990) supposedly common to all languages
1. “Major lexical categories (noun, verb, adjective, preposition)” (→ sect. 2.2.4)
2. “Major phrasal categories (noun phrase, verb phrase, etc.)” (→ sect. 5)
3. “Phrase structure rules (e.g., “X-bar theory” or “immediate dominance rules”)” (→ sect. 5)
4. “Rules of linear order” to distinguish, for example, subject from object, or “case affixes” which “can take over these functions” (→sect. 5)
5. “Verb affixes” signaling “aspect” and “tense” (including pluperfects) (→ sect. 2.2.3)
6. “Auxiliaries”
7. “Anaphoric elements” including pronouns and reflexives
8. “Wh-movement”
There are clear counterexamples to each of these claims. Problems with the first three are discussed in section 2.2.4 and section 5; here are counterexamples to the others:
(4) Some languages (e.g., Riau Indonesian) exhibit neither fixed word-order nor case-marking (Gil Reference Gil, Newman and Ratliff2001).
(5) Many languages (e.g., Chinese, Malay) do not mark tense (Comrie Reference Comrie1985, pp. 50–55; Norman Reference Norman1988, p. 163), and many (e.g., spoken German) lack aspect (Comrie Reference Comrie1976, p. 8).
(6) Many languages lack auxiliaries (e.g., Kayardild, Bininj Gun-wok).
(7) Many languages (e.g. Mwotlap; François Reference François2005, p. 119) lack dedicated reflexive or reciprocal constructions altogether, so that “they hit them dead” can mean “they killed them,” “they killed themselves,” or “they killed each other” (Levinson 2000, p. 334 ff.). Some Southeast Asian languages lack clear personal pronouns, using titles (of the kind “honorable sir”) instead, and many languages lack third-person pronouns (Cysouw Reference Cysouw2001). Sign languages like ASL (American Sign Language) also lack pronouns, using pointing instead.
(8) Not all languages (e.g., Chinese, Japanese, Lakhota) move their wh-forms, saying, in effect, “You came to see who?” instead of “Who did you come to see _” (Van Valin & LaPolla Reference Van Valin and LaPolla1997, pp. 424–25).
Some further universalizing claims with counterevidence:
(9) Verbs for “give” always have three arguments (Gleitman Reference Gleitman1990); Saliba is a counterexample (Margetts Reference Margetts, Bowerman and Brown2007).
(10) No recursion of case (Pinker & Bloom Reference Pinker and Bloom1990). Kayardild has up to four layers (Evans Reference Evans1995a; Reference Evans and Plank1995c).
(11) No languages have nominal tense (Pinker & Bloom Reference Pinker and Bloom1990) – Nordlinger and Sadler (Reference Nordlinger and Sadler2004) give numerous counterexamples, such as Guarani “my house-FUTURE-FUTURE” “it will be my future house.”
(12) All languages have numerals (Greenberg Reference Greenberg and Greenberg1978b – Konstanz #527). See Everett (Reference Everett2005; Gordon Reference Gordon2004) for counterexample.
(13) All languages have syntactic constituents, specifically NPs, whose semantic function is to express generalized quantifiers over the domain of discourse (Barwise & Cooper Reference Barwise and Cooper1981 – Konstanz #1203); see Partee (Reference Partee, Bach, Jelinek, Kratzer and Partee1995) and sect. 5.
See also collection of “rara” at: http://typo.uni-konstanz.de/rara/intro/index.php
The crucial fact for understanding the place of language in human cognition is its diversity. For example, languages may have less than a dozen distinctive sounds, or they may have 12 dozen, and sign languages do not use sounds at all. Languages may or may not have derivational morphology (to make words from other words, e.g., run>runner), or inflectional morphology for an obligatory set of syntactically consequential choices (e.g., plural the girls are vs. singular the girl is). They may or may not have constituent structure (building blocks of words that form phrases), may or may not have fixed orders of elements, and their semantic systems may carve the world at quite different joints. We detail all these dimensions of variation later, but the point here is this: We are the only known species whose communication system varies fundamentally in both form and content. Speculations about the evolution of language that do not take this properly into account thus overlook the criterial feature distinctive of the species. The diversity of language points to the general importance of cultural and technological adaptation in our species: language is a bio-cultural hybrid, a product of intensive gene:culture coevolution over perhaps the last 200,000 to 400,000 years (Boyd & Richerson 1985; Enfield & Levinson Reference Enfield and Levinson2006; Laland et al. Reference Laland, Odling-Smee and Feldman2000; Levinson & Jaisson Reference Levinson and Jaisson2006).
Why should the cognitive sciences care about language diversity, apart from their stake in evolutionary questions? First, a proper appreciation of the diversity completely alters the psycholinguistic picture: What kind of language processing machine can handle all this variation? Not the conventional one, built to handle the parsing of European sound systems and the limited morphological and syntactic structures of familiar languages. Imagine a language where instead of saying, “This woman caught that huge butterfly,” one says, something like: “Thatobject thissubject hugeobject caught womansubject butterflyobject”; such languages exist (sect. 4). The parsing system for English cannot be remotely like the one for such a language: What then is constant about the neural implementation of language processing across speakers of two such different languages? Second, how do children learn languages of such different structure, indeed languages that vary in every possible dimension? Can there really be a fixed “language acquisition device”? These are the classic questions about how language capacities are implemented in the mind and in the brain, and the ballgame is fundamentally changed when the full range of language diversity is appreciated.
The cognitive sciences have been partially immunized against the proper consideration of language diversity by two tenets of Chomskyan origin. The first is that the differences are somehow superficial, and that expert linguistic eyes can spot the underlying common constructional bedrock. This, at first a working hypothesis, became a dogma, and it is wrong, in the straightforward sense that the experts either cannot formulate it clearly, or do not agree that it is true. The second was an interesting intellectual program that proceeded on the hypothesis that linguistic variation is “parametric”; that is, that there are a restricted number of binary switches, which in different states project out the full set of possible combinations, explaining observed linguistic diversity (Chomsky Reference Chomsky1981; see also Baker Reference Baker2001). This hypothesis is now known to be false as well: its predictions about language acquisition, language change, and the implicational relations between linguistic variables simply fail (Newmeyer 2004; 2005). The conclusion is that the variation has to be taken at face value – there are fundamental differences in how languages work, with long historico-cultural roots that explain the many divergences.
Once linguistic diversity is accepted for what it is, it can be seen to offer a fundamental opportunity for cognitive science. It provides a natural laboratory of variation in a fundamental skill – 7,000 natural experiments in evolving communicative systems, and as many populations of experts with exotic expertise. We can ask questions like: How much longer does it take a child to master 144 distinctive sounds versus 11? How do listeners actually parse a free word order language? How do speakers plan the encoding of visual stimuli if the semantic resources of the language make quite different distinctions? How do listeners break up the giant inflected words of a polysynthetic language? In Bininj Gun-wok (Evans 2003a), for instance, the single word abanyawoihwarrgahmarneganjginjeng can represent what, in English, would constitute an entire sentence: “I cooked the wrong meat for them again.” These resources offered by diversity have scarcely been exploited in systematic ways by the scientific community: We have a comparative psychology across species, but not a proper comparative psychology inside our own species in the central questions that drive cognitive science.
2.1. The current representation of languages in the world
Somewhere between 5,000 and 8,000 distinct languages are spoken today. How come we cannot be more precise? In part because there are definitional problems: When does a dialect difference become a language difference (the “languages” Czech and Slovak are far closer in structure and mutual intelligibility than so-called dialects of Chinese like Mandarin and Cantonese)? But mostly it is because academic linguists, especially those concerned with primary language description, form a tiny community, far outnumbered by the languages they should be studying, each of which takes the best part of a lifetime to master. Less than 10% of these languages have decent descriptions (full grammars and dictionaries). Consequently, nearly all generalizations about what is possible in human languages are based on a maximal 500 languages sample (in practice, usually much smaller – Greenberg's famous universals of language were based on 30), and almost every new language description still guarantees substantial surprises.
Ethnologue, the most dependable worldwide source (http://www.ethnologue.com/), reckons that 82% of the world's 6,912 languages are spoken by populations under 100,000, 39% by populations under 10,000. These small speaker numbers indicate that much of this diversity is endangered. Ethnologue lists 8% as nearly extinct, and a language dies every two weeks. This loss of diversity, as with biological species, drastically narrows our scientific understanding of what makes a possible human language.
Equally important as the brute numbers are the facts of relatedness. The number of language families is crucial to the search for universals, because typologists want to test hypotheses against a sample of independent languages. The more closely two languages are related, the less independent they are as samplings of the design space. The question of how many distinct phylogenetic groupings are found across the world's languages is highly controversial, although Nichols' (Reference Nichols1992) estimate of 300 “stocks” is reasonable, and each stock itself can have levels of divergence that make deep-time relationship hard to detect (English and Bengali within Indo-European; Hausa and Hebrew within Afroa-Asiatic). In addition, there are more than 100 isolates, languages with no proven affiliation whatsoever. A major problem for the field is that we currently have no way of demonstrating higher-level phylogenetic groupings that would give us a more principled way of selecting a maximally independent sample for a set smaller than these 300 to 400 groups. This may become more tractable with the application of modern cladistic techniques (Dunn et al. Reference Dunn, Terrill, Reesink, Foley and Levinson2005; Gray & Atkinson Reference Gray and Atkinson2003; McMahon & McMahon Reference McMahon and McMahon2006), but such methods have yet to be fully adopted by the linguistic community.
Suppose then that we think of current linguistic diversity as represented by 7,000 languages falling into 300 or 400 groups. Five hundred years ago, before the expansion of Western colonization, there were probably twice as many. Because most surviving languages are spoken by small ethnic groups, language death continues apace. If we project back through time, there have probably been at least half a million human languages (Pagel Reference Pagel, Knight, Studdert-Kennedy and Hurford2000), so what we now have is a non-random sample of less than 2% of the full range of human linguistic diversity. It would be nice to at least be in the position to exploit that sample, but in fact, as mentioned, we have good information for only 10% of that. The fact is that at this stage of linguistic inquiry, almost every new language that comes under the microscope reveals unanticipated new features.
2.2. Some dimensions of diversity
In this section we illustrate some of the surprising dimensions of diversity in the world's languages. We show how languages may or may not be in the articulatory-auditory channel, and if they are how their inventories of contrastive sounds vary dramatically, how they may or may not have morphologies (processes of word derivation or inflection), how varied they can be in syntactic structure or their inventory of word classes, and how varied are the semantic distinctions which they encode. We can do no more here than lightly sample the range of diversity, drawing attention to a few representative cases.
2.2.1. Sound inventories
We start by noting that some natural human languages do not have sound systems at all. These are the sign languages of the deaf. Just like spoken languages, many of these have developed independently around the world, wherever a sufficient intercommunicating population of deaf people has arisen, usually as a result of a heritable condition. (Ethnologue, an online inventory of languages, lists 121 documented sign languages, but there are certainly many more.) These groups can constitute both significant proportions of local populations and substantial populations in absolute terms: in India there are around 1.5 million signers. They present interesting, well-circumscribed models of gene-culture coevolution (Aoki & Feldman Reference Aoki and Feldman1994; Durham 1991): Without the strain of hereditary deafness, the cultural adaptation would not exist, whereas the cultural adaptation allows signers to lead normal lives, productive and reproductive, thus maintaining the genetic basis for the adaptation.
The whole evolutionary background to sign languages remains fascinating but obscure – were humans endowed, as Hauser (Reference Hauser1997, p. 245) suggests, with a capability unique in the animal world to switch their entire communication system between just two modalities, or (as the existence of touch languages of the blind-deaf suggest) is the language capacity modality-neutral? There have been two hundred years of speculation that sign languages may be the evolutionary precursors to human speech, a view recently revived by the discovery of mirror-neurons (Arbib Reference Arbib2005). An alternative view is that language evolved from a modality-hybrid communication system in which hand and mouth both participated, as they do today in both spoken and signed languages (cf. Sandler 2009). Whichever evolutionary scenario you favor, the critical point here is that sign languages are an existence proof of the modality-plastic nature of our language capacity. At a stroke, therefore, they invalidate such generalizations as “all natural languages have oral vowels,” although at some deeper level there may well be analogies to be drawn: signs have a basic temporal organization of “move and hold” which parallels the rhythmic alternation of vowels and consonants.
Returning to spoken languages, the vocal tract itself is the clearest evidence for the biological basis for language – the lowering of the larynx and the right-angle in the windpipe have been optimized for speaking at the expense of running and with some concomitant danger of choking (Lenneberg Reference Lenneberg1967). Similar specializations exist in the auditory system, with acuity tuned just to the speech range, and, more controversially, specialized neural pathways for speech analysis. These adaptations of the peripheral input/output systems for spoken language have, for some unaccountable reason, been minimized in much of the discussion of language origins, in favor of an emphasis on syntax (see, for example, Hauser et al. Reference Hauser, Chomsky and Fitch2002).
The vocal tract and the auditory system put strong constraints on what an articulatorily possible and perceptually distinguishable speech sound is. Nevertheless, the extreme range of phonemic (distinctive sound) inventories, from 11 to 144, is already a telling fact about linguistic diversity (Maddieson Reference Maddieson1984). Jakobson's distinctive features – binary values on a limited set of (largely) acoustic parameters – were meant to capture the full set of possible speech sounds. They were the inspiration for the Chomskyan model of substantive universals, a constrained set of alternates from which any particular language will select just a few. But as we get better information from more languages, sounds that we had thought were impossible to produce or impractical to distinguish keep turning up. Take the case of double-articulations, where a consonantal closure is made in more than one place. On the basis of evidence then available, Maddieson (Reference Maddieson1983) concluded that contrastive labial-alveolar consonants (making a sound like “b” at the same time as a sound like “d”) were not a possible segment in natural language on auditory grounds. But it was then discovered that the Papuan language Yélî Dnye makes a direct contrast between a coarticulated “tp,” and a “ṭp” where the ṭ is further back towards the palate (Ladefoged & Maddieson Reference Ladefoged and Maddieson1996, pp. 344–45; Maddieson & Levinson, in preparation).
As more such rarities accrue, experts on sound systems are abandoning the Jakobsonian idea of a fixed set of parameters from which languages draw their phonological inventories, in favor of a model where languages can recruit their own sound systems from fine phonetic details that vary in almost unlimited ways (see also Mielke Reference Mielke2007; Pierrehumbert et al. 2000):
Do phoneticians generally agree with phonologists that we will eventually arrive at a fixed inventory of possible human speech sounds? The answer is no. (Port & Leary Reference Port and Leary2005, p. 927)
And,
Languages can differ systematically in arbitrarily fine phonetic detail. This means we do not want to think about universal phonetic categories, but rather about universal phonetic resources, which are organized and harnessed by the cognitive system … . The vowel space – a continuous physical space rendered useful by the connection it establishes between articulation and perception – is also a physical resource. Cultures differ in the way they divide up and use this physical resource. (Pierrehumbert Reference Pierrehumbert2000, p. 12)
2.2.2. Syllables and the “CV” universal
The default expectation of languages is that they organize their sounds into an alternating string of more versus less sonorant segments, creating a basic rhythmic alternation of sonorous vowels (V) and less sonorous consonants (C). But beyond this, a further constraint was long believed to be universal: that there was a universal preference for CV syllables (like law /l![]() :/ or gnaw /n
:/ or gnaw /n![]() :/) over VC syllables (like awl /
:/) over VC syllables (like awl /![]() :l/ or awn /
:l/ or awn /![]() :n/). The many ways in which languages organize their syllable structures allows the setting up of implicational (if/then) statements which effectively find order in the exuberant variation: No language will allow VC if it does not also allow CV, or allow V if it does not also allow CV:
:n/). The many ways in which languages organize their syllable structures allows the setting up of implicational (if/then) statements which effectively find order in the exuberant variation: No language will allow VC if it does not also allow CV, or allow V if it does not also allow CV:
This long-proclaimed conditional universal (Jakobson & Halle Reference Jakobson and Halle1956; cf. Clements & Keyser Reference Clements and Keyser1983; Jakobson Reference Jakobson1962) has as corollary the maximal onset principle (Blevins Reference Blevins and Goldsmith1995, p. 230): a /….VCV…./ string will universally be syllabified as /…V-CV…/. An obvious advantage such a universal principle would give the child is that it can go right in and parse strings into syllables from first exposure.
But in 1999, Breen and Pensalfini published a clear demonstration that Arrernte organizes its syllables around a VC(C) structure and does not permit consonantal onsets (Breen & Pensalfini 1999). With the addition of this one language to our sample, the CV syllable gets downgraded from absolute universal to a strong tendency, and the status of the CV assumption in any model of UG must be revised. If CV syllables really were inviolable rules of UG, Arrernte would then be unlearnable, yet children learn Arrernte without difficulty. At best, then, the child may start with the initial hypothesis of CVs, and learn to modify it when faced with Arrernte or other such languages. But in that case we are talking about initial heuristics, not about constraints on possible human languages. The example also shows, as is familiar from the history of mathematical induction (as with the Gauss-Riemann hypothesis regarding prime number densities), that an initially plausible pattern turns out not to be universal after all, once the range of induction is sufficiently extended.
2.2.3. Morphology
Morphological differences are among the most obvious divergences between languages, and linguistic science has been aware of them since the Spanish encountered Aztec and other polysynthetic languages in sixteenth-century Mexico, while half a world away the Portuguese were engaging with isolating languages in Vietnam and China. Isolating languages, of course, lack all the inflectional affixes of person, number, tense, and aspect, as well as systematic word derivation processes. They even lack the rather rudimentary morphology of English words like boy-s or kiss-ed, using just the root and getting plural and past-tense meanings either from context or from other independent words. Polysynthetic languages go overboard in the other direction, packing whole English sentences into a single word, as in Cayuga Ęskakheh ![]() na'táyęthwahs “I will plant potatoes for them again” (Evans & Sasse Reference Evans and Sasse2002). Clearly, children learning such languages face massive challenges in picking out what the “words” are that they must learn. They must also learn a huge set of rules for morphological composition, since the number of forms that can be built from a small set of lexical stems may run into the millions (Hankamer Reference Hankamer and Marslen-Wilson1989).
na'táyęthwahs “I will plant potatoes for them again” (Evans & Sasse Reference Evans and Sasse2002). Clearly, children learning such languages face massive challenges in picking out what the “words” are that they must learn. They must also learn a huge set of rules for morphological composition, since the number of forms that can be built from a small set of lexical stems may run into the millions (Hankamer Reference Hankamer and Marslen-Wilson1989).
But if these very long words function as sentences, perhaps there's no essential difference: perhaps, for example, the Cayuga morpheme -h ![]() na - for “potatoes” in the word above is just a word-internal direct object as Baker (Reference Baker and Foley1993; Reference Baker1996) has claimed. However, the parallels turn out to be at best approximate. For example, the pronominal affixes and incorporated nouns do not need to be referential. The prefix ban- in Bininj Gun-wok ka-ban-dung [she-them-scolds] is only superficially like its English free-pronoun counterpart, since kabandung can mean both “she scolds them” and “she scolds people in general” (Evans Reference Evans, Evans and Sasse2002). It seems more likely, then, that much of the obvious typological difference between polysynthetic languages and more moderately synthetic languages like English or Russian needs to be taken at face value: the vast difference in morphological complexity is mirrored by differences in grammatical organization right through to the deepest levels of how meaning is organized.
na - for “potatoes” in the word above is just a word-internal direct object as Baker (Reference Baker and Foley1993; Reference Baker1996) has claimed. However, the parallels turn out to be at best approximate. For example, the pronominal affixes and incorporated nouns do not need to be referential. The prefix ban- in Bininj Gun-wok ka-ban-dung [she-them-scolds] is only superficially like its English free-pronoun counterpart, since kabandung can mean both “she scolds them” and “she scolds people in general” (Evans Reference Evans, Evans and Sasse2002). It seems more likely, then, that much of the obvious typological difference between polysynthetic languages and more moderately synthetic languages like English or Russian needs to be taken at face value: the vast difference in morphological complexity is mirrored by differences in grammatical organization right through to the deepest levels of how meaning is organized.
2.2.4. Syntax and word-classes
Purported syntactic universals lie at the heart of most claims regarding UG, and we hold off discussing these in detail until sections 4 through 6. As a warm-up, though, we look at one fundamental issue: word-classes, otherwise known as parts of speech. These are fundamental to grammar, because the application of grammatical rules is made general by formulating them over word-classes. If we say that in English adjectives precede but cannot follow the nouns they modify (the rich man but not *the man rich), we get a generalization that holds over an indefinitely large set of phrases, because both adjectives and nouns are “open classes” that in principle are always extendable by new members. But to stop it generating *the nerd zappy we need to know that nerd is a noun, not an adjective, and that zappy is an adjective, not a noun. To do this we need to find a clearly delimited set of distinct behaviors, in their morphology and their syntax, that allows us to distinguish noun and adjective classes, and to determine which words belong to which class.
Now it has often been assumed that, across all languages, the major classes – those that are essentially unlimited in their membership – will always be the same “big four”: nouns, verbs, adjectives, and adverbs. But we now know that this is untenable when we consider the cross-linguistic evidence. Many languages lack an open adverb class (Hengeveld Reference Hengeveld, Fortescue, Harder and Kristofferson1992), making do with other forms of modification. There are also languages like Lao with no adjective class, encoding property concepts as a sub-sub-type of verbs (Enfield Reference Enfield, Dixon and Aikhenvald2004).
If a language jettisons adjectives and adverbs, the last stockade of word-class difference is that between nouns and verbs. Could a language abolish this and just have a single word-class of predicates (like predicate calculus)? Here controversy still rages among linguists as the bar for evidence of single-class languages keeps getting raised, with some purported cases (e.g., Mundari) falling by the wayside (Evans & Osada 2005). For many languages of the Philippines and the Pacific Northwest Coast, the argument has run back and forth for nearly a century, with the relevant evidence becoming ever more subtle, but still no definitive consensus has been reached.
A feeling for what a language without a noun-verb distinction is like comes from Straits Salish. Here, on the analysis by Jelinek (1995), all major-class lexical items simply function as predicates, of the type “run,” “be_big,” or “be_a_man.” They then slot into various clausal roles, such as argument (“the one such that he runs”), predicate (“run[s]”), and modifier (“the running [one]”), according to the syntactic slots they are placed in. The single open syntactic class of predicate includes words for events, entities, and qualities. When used directly as predicates, all appear in clause-initial position, followed by subject and/or object clitics. When used as arguments, all lexical stems are effectively converted into relative clauses through the use of a determiner, which must be employed whether the predicate-word refers to an event (“the [ones who] sing”), an entity (“the [one which is a] fish”), or even a proper name (“the [one which] is Eloise”). The square-bracketed material shows what we need to add to the English translation to convert the reading in the way the Straits Salish structure lays out.
There are thus languages without adverbs, languages without adjectives, and perhaps even languages without a basic noun-verb distinction. In the other direction, we now know that there are other types of major word-class – e.g., ideophones, positionals, and coverbs – that are unfamiliar to Indo-European languages.
Ideophones typically encode cross-modal perceptual properties – they holophrastically depict the sight, sound, smell, or feeling of situations in which the event and its participants are all rolled together into an undissected gestalt. They are usually only loosely integrated syntactically, being added into narratives as independent units to spice up the color. Examples from Mundari (Osada 1992) are ribuy-tibuy, “sound, sight, or motion of a fat person's buttocks rubbing together as they walk,” and rawa-dawa, “the sensation of suddenly realizing you can do something reprehensible, and no-one is there to witness it.” Often ideophones have special phonological characteristics, such as vowel changes to mark changes in size or intensity, special reduplication patterns, and unusual phonemes or tonal patterns. (Note that English words like willy-nilly or heeby-jeebies may seem analogous, but they differ from ideophones in all being assimilated to other pre-existing word classes, here adverb and noun.)
Positionals describe the position and form of persons and objects (Ameka & Levinson 2007). These are widespread in Mayan languages (Bohnemeyer & Brown Reference Bohnemeyer and Brown2007; Brown 1994; England Reference England2001; Reference England and Dixon2004). Examples from Tzeltal include latz'al, “of flat items, arranged in vertical stack”; chepel, “be located in bulging bag,” and so on. Positionals typically have special morphological and syntactic properties.
Coverbs are a further open class outside the “big four.” Such languages as Kalam (PNG; Pawley Reference Pawley and Foley1993) or the Australian language Jaminjung (Schultze-Berndt Reference Schultze-Berndt2000) have only around 20 to 30 inflecting verbs, but they form detailed event-descriptors by combining inflecting verbs with an open class of coverbs. Unlike positionals or ideophones, coverbs are syntactically integrated with inflecting verbs, with which they cross-combine in ways that largely need to be learned individually. In Jaminjung, for example, the coverb dibird, “wound around” can combine with yu, “be,” to mean “be wound around,” and with angu, “get/handle,” to mean “tangle up.” (English “light verbs,” as in take a train or do lunch, give a feel for the phenomenon, but of course train and lunch are just regular nouns.)
Classifiers are yet another word class unforeseen by the categories of traditional grammar – whether “numeral classifiers” in East Asian and Mesoamerican languages that classify counted objects according to shape, or the hand-shape classifiers in sign languages that represent the involved entity through a schematized representation of its shape. And further unfamiliar word classes are continuously being unearthed that respect only the internal structural logic of previously undescribed languages. Even when typologists talk of “ideophones,” “classifiers,” and so forth, these are not identical in nature across the languages that exhibit them – rather we are dealing with family-resemblance phenomena: no two languages have any word classes that are exactly alike in morphosyntactic properties or range of meanings (Haspelmath Reference Haspelmath2007).
Once again, then, the great variability in how languages organize their word-classes dilutes the plausibility of the innatist UG position. Just which word classes are supposed to be there in the learning child's mind? We would need to postulate a start-up state with an ever-longer list of initial categories (adding ideophones, positionals, coverbs, classifiers, etc.), many of which will never be needed. And, because syntactic rules work by combining these word-class categories – “projecting” word-class syntax onto the larger syntactic assemblages that they head – each word-class we add to the purported universal inventory would then need its own accompanying set of syntactic constraints.
2.2.5. Semantics
There is a persistent strand of thought, articulated most forcefully by Fodor (Reference Fodor1975), that languages directly encode the categories we think in, and moreover that these constitute an innate, universal “language of thought” or “mentalese.” As Pinker (Reference Pinker1994, p. 82) put it, “Knowing a language, then, is knowing how to translate mentalese into strings of words and vice versa. People without a language would still have mentalese, and babies and many nonhuman animals presumably have simpler dialects.” Learning a language, then, is simply a matter of finding out what the local clothing is for universal concepts we already have (Li & Gleitman Reference Li and Gleitman2002).
The problem with this view is that languages differ enormously in the concepts that they provide ready-coded in grammar and lexicon. Languages may lack words or constructions corresponding to the logical connectives “if” (Guugu Yimithirr) or “or” (Tzeltal), or “blue” or “green” or “hand” or “leg” (Yélî Dnye). There are languages without tense, without aspect, without numerals, or without third-person pronouns (or even without pronouns at all, in the case of most sign languages). Some languages have thousands of verbs; others only have thirty (Schultze-Berndt Reference Schultze-Berndt2000). Lack of vocabulary may sometimes merely make expression more cumbersome, but sometimes it effectively limits expressibility, as in the case of languages without numerals (Gordon Reference Gordon2004).
In the other direction, many languages make semantic distinctions we certainly would never think of making. So Kiowa, instead of a plural marker on nouns, has a marker that means roughly “of unexpected number”: on an animate noun like “man” it means “two or more,” on a word like “leg,” it means “one or more than two,” and on “stone,” it means “just two” (Mithun 1999, p. 81). In many languages, all statements must be coded (e.g., in verbal affixes) for the sources of evidence; for example, in Central Pomo, whether I saw it, perceived it in another modality (tactile, auditory), was told about it, inferred it, or know that it is an established fact (Mithun 1999, p. 181). Kwakwala insists on referents being coded as visible or not (Anderson & Keenan Reference Anderson, Keenan and Shopen1985). Athabaskan languages are renowned for their classificatory verbs, forcing a speaker to decide between a dozen categories of objects (e.g., liquids, rope-like objects, containers, flexible sheets) before picking one of a set of alternate verbs of location, giving, handling, and so on (Mithun 1999, p. 106 ff.). Australian languages force their speakers to pay attention to intricate kinship relations between participants in the discourse – in many to use a pronoun you must first work out whether the referents are in even- or odd-numbered generations with respect to one another, or related by direct links through the male line. On top of this, many have special kin terms that triangulate the relation between speaker, hearer, and referent, with meanings like “the one who is my mother and your daughter, you being my maternal grandmother” (Evans Reference Evans2003b).
Spatial concepts are an interesting domain to compare languages in, because spatial cognition is fundamental to any animal – and if Fodor is right anywhere, it should be here. But, in fact, we find fundamental differences in the semantic parameters languages use to code space. For example, there are numerous languages without notions of “left of,” “right of,” “back of,” “front of” – words meaning “right hand” or “left hand” are normally present, but don't generalize to spatial description. How then does one express, for example, that the book you are looking for is on the table left of the window? In most of these languages by saying that it lies on the table north of the window – that is, by using geographic rather than egocentric coordinates. Research shows that speakers remember the location in terms of the coordinate system used in their language, not in terms of some fixed, innate mentalese (see Levinson Reference Levinson2003; Majid et al. Reference Majid, Bowerman, Kita, Haun and Levinson2004).
Linguists often distinguish between closed-class or function words (like the, of, in, which play a grammatical role) and open-class items or general vocabulary which can be easily augmented by new coinages or borrowing. Some researchers claim that closed-class items reveal a recurrent set of semantic distinctions, whereas the open-class items may be more culture-specific (Talmy Reference Talmy2000). Others claim effectively just the reverse, that relational vocabulary (as in prepositions) is much more abstract, and thus prone to cultural patterning, whereas the open-class items (like nouns) are grounded in concrete reality, and thus less cross-linguistically variable (Gentner & Boroditsky Reference Gentner, Boroditsky, Bowerman and Levinson2001). In fact, neither of these views seems correct, for both ends of the spectrum are cross-linguistically variable. Consider, for example, the difference between nouns and spatial prepositions. Landau and Jackendoff (Reference Landau and Jackendoff1993) claimed that this difference corresponds to the nature of the so-called what versus where systems in neurocognition: nouns are “whaty” in that their meanings code detailed features of objects, while prepositions are “wherey” in that they encode abstract, geometric properties of spatial relations. These researchers thus felt able to confidently predict that there would be no preposition or spatial relator encoding featural properties of objects, for example, none meaning “through a cigar-shaped object” (Landau & Jackendoff Reference Landau and Jackendoff1993, p. 226). But the Californian language Karuk has precisely such a spatial verbal prefix, meaning “in through a tubular space” (Mithun 1999, p. 142)! More systematic examination of the inventories of spatial pre- and post-positions shows that there is no simple universal inventory, and the meanings can be very specific; for example, “in a liquid,” “astraddle,” “fixed by spiking” (Levinson & Meira Reference Levinson and Meira2003) – or distinguish “to (a location below)” versus “to (a location above)” versus “to (a location on a level with the speaker).”
Nor do nouns always have the concrete sort of reference we expect – for example, in many languages nouns tend to have a mass or “stuff”-like reference (meaning, e.g., any stuff composed of banana genotype, or anything made of wax), and do not inherently refer to bounded entities. In such languages, it takes a noun and a classifier (Lucy Reference Lucy1992), or a noun and a classificatory verb (Brown 1994), to construct a meaning recognizable to us as “banana” or “candle.”
In the light of examples like these, the view that “linguistic categories and structures are more or less straightforward mappings from a pre-existing conceptual space programmed into our biological nature” (Li & Gleitman Reference Li and Gleitman2002, p. 266) looks quite implausible. Instead, languages reflect cultural preoccupations and ecological interests that are a direct and important part of the adaptive character of language and culture.
3. Linguistic universals
The prior sections have illustrated the surprising range of cross-linguistic variability at every level of language, from sound to meaning. The more we discover about languages, the more diversity we find. Clearly, this ups the ante in the search for universals.
There have been two main approaches to linguistic universals. The first, already mentioned, is the Chomskyan approach, where UG denotes structural principles which are complex and implicit enough to be unlearnable from finite exposure. Chomsky thus famously once held that language universals could be extracted from the study of a single language:
I have not hesitated to propose a general principle of linguistic structure on the basis of observation of a single language. The inference is legitimate, on the assumption that humans are not specifically adapted to learn one rather than another human language. … Assuming that the genetically determined language faculty is a common human possession, we may conclude that a principle of language is universal if we are led to postulate it as a “precondition” for the acquisition of a single language. (Chomsky Reference Chomsky and Piattelli-Palmarini1980, p. 48)Footnote 1
Chomsky (Reference Chomsky1965, pp. 27–30) influentially distinguished between substantive and formal universals. Substantive universals are drawn from a fixed class of items (e.g., distinctive phonological features, or word classes like noun, verb, adjective, and adverb). No particular language is required to exhibit any specific member of a class. Consequently, the claim that property X is a substantive universal cannot be falsified by finding a language without it, because the property is not required in all of them. Conversely, suppose we find a new language with property Y, hitherto unexpected: we can simply add it to the inventory of substantive universals. Jackendoff (Reference Jackendoff2002, p. 263) nevertheless holds “the view of Universal Grammar as a “toolkit” … : beyond the absolute universal bare minimum of concatenated words … languages can pick and choose which tools they use, and how extensively.” But without limits on the toolkit, UG is unfalsifiable.
Formal universals specify abstract constraints on the grammar of languages (e.g., that they have specific rule types or cannot have rules that perform specific operations). To give a sense of the kind of abstract constraints in UG, consider the proposed constraint called Subjacency (see Newmeyer 2004, p. 537 ff.). This is an abstract principle meant to explain the difference between the grammaticality of the sentence (6) and (7), below, versus the ungrammaticality (marked by an asterisk) of sentence (8):
(6) Where did John say that we had to get off the bus?
(7) Did John say whether we had to get off the bus?
(8) *Where did John say whether we had to get off the bus?
The child somehow has to extrapolate that (6) and (7) are okay, but (8) is not, without ever being explicitly told that (8) is ungrammatical. This induction is argued to be impossible, necessitating an underlying and innate principle that forbids the formation of wh-questions if a wh-phrase intervenes between the “filler” (initial wh-word) and the “gap” (the underlying slot for the wh-word). This presumes a movement rule pulling a wh-phrase out of its underlying position and putting it at the front of the sentence as shown in (9):
(9) *Where did John say whether we had to get off the bus ____?
However, it turns out that this constraint does not work in Italian or Russian in the same way, and theorists have had to assume that children can learn the specifics of the constraint after all, although we do not know how (Newmeyer 2004; Van Valin & LaPolla Reference Van Valin and LaPolla1997, p. 615 ff.). This shows the danger of extrapolations from a single language to unlearnable constraints. Each constraint in UG needs to be taken as no more than a working hypothesis, hopefully sufficiently clearly articulated that it could be falsified by cross-linguistic data.
But what counts as falsification of these often abstract principles? Consider the so-called Binding Conditions, proposed as elements of Universal Grammar in the 1980s (see Koster & May Reference Koster and May1982). One element (condition A) specifies that anaphors (reflexives and reciprocals) must be bound in their governing category, whereas a second (condition B) states that (normal nonreflexive) pronouns must be free in their governing category. These conditions were proposed to account for the English data in (10a–c) and comparable data in many other languages (the subscripts keep track of what each term refers to). The abstract notion of “bound” is tied to a particular type of constituent-based syntactic representation where the subject “commands” the object (owing to its position in a syntactic tree) rather than the other way round, and reflexives are sensitive to this command. Normal pronouns pick up their reference from elsewhere and so cannot be used in a “bound” position.
(10a) Johnx saw himy. (disjoint reference)
(10b) Johnx saw himselfx (conjoint reference)
(10c) *Himselfx saw Johnx/himx.
This works well for English and hundreds, perhaps thousands, of other languages, but it does not generalize to languages where you get examples as in (11a, b) (to represent their structures in a pseudo-English style).
(11a) Hex saw himx,y
(11b) Theyx,y saw thema,b/x,y/y,x.
Many languages (even Old English; see Levinson 2000) allow sentences like (11a) and (11b): the same pronouns can either have disjoint reference (shown as “a,b”), conjoint reference (“x,y”) or commuted conjoint reference (“y,x,” corresponding to “each other” in English). Does this falsify the Binding Principles? Not necessarily, would be a typical response in the generativist position – it may be that there are really two distinct pronouns (a normal pronoun and a reflexive, say) which just happen to have the same form, but can arguably be teased apart in other ways (see, e.g., Chung [Reference Chung, Jaeggli and Safir1989] on Chamorro). But it is all too easy for such an abstract analysis to presuppose precisely what is being tested, dismissing seeming counterexamples and rendering the claims unfalsifiable. The lack of shared rules of argumentation means that the field as a whole has not kept a generally accepted running score of which putative universals are left standing.
In short, it has proven extremely hard to come up with even quite abstract generalizations that don't run afoul of the cross-linguistic facts. This doesn't mean that such generalizations won't ultimately be found, nor that there are no genetic underpinnings for language – there certainly are.Footnote 2 But, to date, strikingly little progress has been made.
We turn now to the other approach to universals, stemming from the work of Greenberg (Reference Greenberg and Greenberg1963a; Reference Greenberg1963b), which directly attempts to test linguistic universals against the diversity of the world's languages. Greenberg's methods crystallized the field of linguistic typology, and his empirical generalizations are sometimes called Greenbergian universals.
First, importantly, Greenberg discounted features of language that are universal by definition – that is, we would not call the object in question a language if it lacked these properties (Greenberg et al. Reference Greenberg, Osgood, Jenkins and Greenberg1963, p. 73). Thus, many of what Hockett (Reference Hockett and Greenberg1963) called the “design features” of language are excluded – for example, discreteness, arbitrariness, productivity, and the duality of patterning achieved by combining meaningless elements at one level (phonology) to construct meaningful elements (morphemes or words) at another.Footnote 3 We can add other functional features that all languages need in order to be adequately expressive instruments (e.g., the ability to indicate negative or prior states of affairs, to question, to distinguish new from old information, etc.).
Second, Greenberg (1960, see also Comrie Reference Comrie1989: 17–23) distinguished the different types of universal statement laid out in Table 1 (the terminology may differ slightly across sources): Although all of these types are universals in the sense that they employ universal quantification over languages, their relations to notions of “universal grammar” differ profoundly. Type 1 statements are true of all languages, though not tautological by being definitional of languagehood. This is the category which cognitive scientists often imagine is filled by rich empirical findings from a hundred years of scientific linguistics – indeed Greenberg (Reference Greenberg1986, p. 14) recollects how Osgood challenged him to produce such universals, saying that these would be of fundamental interest to psychologists. This started Greenberg on a search that ended elsewhere, and he rapidly came to realize “the meagreness and relative triteness of statements that were simply true of all languages” (Greenberg Reference Greenberg1986, p. 15):
Assuming that it was important to discover generalizations which were valid for all languages, would not such statements be few in number and on the whole quite banal? Examples would be that languages had nouns and verbs (although some linguists denied even that) or that all languages had sound systems and distinguished between phonetic vowels and consonants. (Greenberg Reference Greenberg1986, p. 14)
Table 1. Logical types of universal statement (following Greenberg)
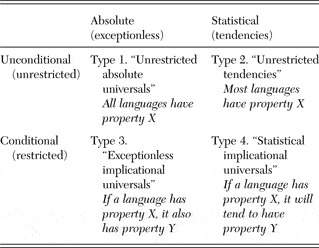
To this day, the reader will find no agreed list of Type 1 universals (see Box 1). This more or less empty box is why the emperor of Universal Grammar has no clothes. Textbooks such as those by Comrie (Reference Comrie1989), Whaley (Reference Whaley1997), and Croft (Reference Croft2003) are almost mum on the subject, and what they do provide is more or less the same two or three examples. For the longest available list of hypotheses, see the online resources at the Konstanz Universals Archive (http://ling.uni-konstanz.de:591/Universals).
The most often cited absolute unrestricted universals are that all languages distinguish nouns and verbs (discussed earlier) and that all languages have vowels. The problem with the notion “all languages have vowels” is that it does not extend to sign languages (see Box 2), as already mentioned. A second problem is that, for spoken languages, if the statement is taken at a phonetic level, it is true, but for trivial reasons: they would otherwise scarcely be audible. A third problem is that, if taken as a phonological claim that all languages have distinctive vowel segments, it is in fact contested: There are some languages, notably of the Northwestern Caucasus, where the quality of the vowel segments was long maintained by many linguists to be entirely predictable from the consonantal context (see Colarusso Reference Colarusso1982; Halle Reference Halle1970; Kuipers Reference Kuipers1960), and although most scholars have now swung round to recognizing two contrasting vowels, the evidence for this hangs on the thread of a few minimal pairs, mostly loanwords from Turkish or Arabic.
Box 2. The challenge of sign languages
Many proposed universals of language ignore the existence of sign languages – the languages of the deaf, now recognized to be full-blown languages of independent origin (Klima & Bellugi Reference Klima and Bellugi1979). Studies of, for example, American Sign Language, British Sign Language, and Indo-Pakistani Sign Language (Zeshan Reference Zeshan2002) show that these are unrelated, complex systems of their own. They can even be said to have “phonologies” – patterns of hand shape, facial expression, and so on, which, although individually meaningless, can be combined to make morphemes or words (Padden & Perlmutter Reference Padden and Perlmutter1987).
The typology of sign languages is in its infancy (see, e.g., Perniss et al. Reference Perniss, Pfau and Steinbach2008; Perniss & Zeshan Reference Perniss and Zeshan2008; Schwager & Zeshan Reference Schwager and Zeshan2008; Zeshan 2006a; 2006b). The Ethnologue lists 121 sign languages, but there are certainly many not yet listed. The major sign languages show some typological similarities, but the smaller ones, only now coming under scrutiny, are typologically diverse (see, e.g., Meir et al., in press).
Sign languages offer a model “organism” for understanding the relation between biological and cultural aspects of language (Aoki & Feldman Reference Aoki and Feldman1994). They also offer unique opportunities to study the emergence of new languages under different conditions: (a) where home-signers (Goldin-Meadow Reference Goldin-Meadow2003) are congregated and a sign language emerges among themselves, as in Nicaragua (Senghas et al. Reference Senghas, Kita and Özyürek2004); and (b) where a localized hereditary deaf population lives among hearers who also sign, as in Bali (Marsaja Reference Marsaja2008) or in a Bedouin group in Israel (Sandler et al. Reference Sandler, Meir, Padden and Aronoff2005). These studies show that although word order constraints may show early, it may take three generations or more to evolve syntactic embedding and morphology.
When due allowance is made for the manual-visual interface, sign languages seem to be handled by the same specialized brain structures as spoken ones, with parallel aphasias, similar developmental trajectories (e.g., infants “babble” in sign), and similar processing strategies as spoken languages (see Emmorey Reference Emmorey2002). The neurocognition of sign does not look, for example, like the neurocognition of gesture, but instead recruits, for example, auditory cortex (MacSweeney et al. Reference MacSweeney, Woll, Campbell, McGuire, David, Williams, Suckling, Calvert and Brammer2002; Nishimura et al. Reference Nishimura, Hashikawa, Doi, Iwaki, Watanabe, Kusuoka, Nishimura and Kubo1999). These results show that our biological endowment for language is by no means restricted to the input/output systems of a particular modality.
This example illustrates the problems with making simple, interesting statements that are true of all languages. Most straightforward claims are simply false – see Box 1. The fact is that it is a jungle out there: languages differ in fundamental ways – in their sound systems (even whether they have one), in their grammar, and in their semantics. Hence, the very type of universal that seems most interesting to psychologists was rapidly rejected as the focus of research by Greenberg.
Linguistic typologists make a virtue out of the necessity to consider other kinds of universals. Conditional or implicational universals of Types 3 and 4 (i.e., of the kind “If a language has property X, it has [or tends to have] property Y”) allow us to make claims about the interrelation of two, logically independent parameters. Statements of this kind, therefore, greatly restrict the space of possible languages: interpreted as logical (material) conditionals, they predict that there are no languages with X that lack Y, where X and Y may not be obviously related at all. Here again, however, exceptionless or absolute versions are usually somewhat trite. For example, the following seem plausible:
(12a) IF a language has nasal vowels, THEN it has oral vowels.
(12b) IF a language has a trial number, THEN there is also a dual. IF there is a dual, THEN there is also a plural.
Statement (12a) essentially expresses the markedness (or recessive character) of nasal vowels. However, most markedness universals are statistical, not absolute. Statement (12b) is really only about one parameter, namely number, and it is not really surprising that a language that morphologically marks pairs of things would want to be able to distinguish singular from plural or trial (i.e., more than two). Nevertheless, there is at least one language that counter-exemplifies: Basic verbs stems in Nen are dual, with non-duals indicated by a suffix meaning “either singular or three-or-more,” the singular and the plural sharing an inflection!
But the main problem with absolute conditional universals is that, again and again (as just exemplified), they too have been shown to be false. In this sense conditional universals follow the same trajectory as unconditional ones, in that hypothesized absolute universals tend to become statistical ones as we sample languages more widely. For example, it was hypothesized as an unconditional universal (Greenberg Reference Greenberg1966, p. 50) that all languages mark the negative by adding some morpheme to a sentence, but then we find that classical Tamil marks the negative by deleting the tense morphemes present in the positive (Master Reference Master1946; Pederson Reference Pederson, Dobrin, Nicholas and Rodriguez1993). We can expect the same general story for conditional universals, except that, given the conditional restriction, it will take a larger overall database to falsify them.
Again making a virtue out of a necessity, Dryer (Reference Dryer1998) convincingly argues that statistical universals or strong tendencies are more interesting anyway. Although at first sight it seems that absolute implications are more easily falsifiable, the relevant test set is after all not the 7,000 odd languages we happen to have now, but the half million or so that have existed, not to mention those yet to come – because we never have all the data in hand, the one counterexample might never show up. In fact, Dryer points out, because linguistic types always empirically show a clustering with outliers, the chances of catching all the outliers are vanishingly small. The classical Tamil counterexample to negative marking strategies is a case in point: it is a real counterexample, but extremely rare. Given this distribution of phenomena, the methods have to be statistical. And as a matter of fact, nearly all work done in linguistic typology concerns Type 4 Universals (i.e., conditional tendencies). Where these tendencies are weak, they may reveal only bias in the current languages we have, or in the sampling methods employed. But where they are strong, they suggest that there is indeed a cognitive, communicative, or system-internal bias towards particular solutions evolving.
With absolute universals, sampling is not an issue: just a single counterexample is needed, and linguists should follow whatever leads they need to find them. For this reason, and because many of the claimed universals we are targeting are absolute, we have not shied away in this article from hand-picking the clearest examples that illustrate our point. But with statistical universals, having the right sampling methods is crucial (Widmann & Bakker Reference Widmann and Bakker2006), and many factors need to be controlled for. Language family (coinherited traits are not independent), language area (convergent traits are not independent), key organizational features (dominant phrase orders have knock-on effects elsewhere), other cultural aspects (speaker population size, whether there is a written language), modality (spoken vs. signed language), and quality of available descriptions all impact on the choice. Employing geographically separate areas is crucial to minimize the risk of convergent mutual influence, but even this is contingent on our current very limited understanding of the higher-level phylogenetic relationships of the world's languages: if languages in two distinct regions (say, inland Canada and Central Siberia) are found to be related, we can no longer assume these two areas supply independent samples. The long-term and not unachievable goal must be to have data on all existing languages, which should be the target for the language sciences.
Where do linguistic universals, of whatever type, come from? We return to this issue in section 6, but here it is vital to point out that a property common to languages need not have its origins in a “language faculty,” or innate specialization for language. First, such a property could be due to properties of other mental capacities – memory, action control, sensory integration, and so on. Second, it could be due to overall design requirements of communication systems. For example, most languages seem to distinguish closed-class functional elements (cf. English the, some, should) from open-class vocabulary (cf. eat, dog, big), just as logics distinguish operators from other terms, allowing constancies in composition with open-ended vocabularies and facilitating parsing.
Universals can also arise from so-called functional factors, that is to say, the machining of structure to fit the uses to which it would be put. For example, we can ask: Why are negatives usually marked in languages with a positive “not” morpheme rather than by a gap as in classical Tamil? Because (a) we make more positive than negative assertions, so it is more efficient to mark the less common negatives, and (b) it is crucial to distinguish what is said from its contrary, and a non-zero morpheme is less likely to escape notice than a gap.
In addition, given human motivations, interests and sensory perception together with the shared world we live in, we can expect all sorts of convergences in, for example, vocabulary items – most if not all languages have kin terms, body part terms, words for celestial bodies. The appeal to innate concepts and structure should be a last resort (Tomasello Reference Tomasello1995).
Finally, a word needs to be said about the metalanguage in which typological (statistical) universals are couched. The terms employed are notions like subject, adjective, inflection, syllable, pronoun, noun phrase, and so on – more or less the vocabulary of “traditional grammar.” As we have seen, these are not absolute universals of Type 1. Rather, they are descriptive labels, emerging from structural facts of particular languages, which work well in some languages but may be problematic or absent in others (cf. Croft Reference Croft2001). Consequently, for the most part they do not have precise definitions shared by all researchers, or equally applicable to all languages (Haspelmath Reference Haspelmath2007). Does this vitiate such research? Not necessarily: the descriptive botanist also uses many terms (“pinnate,” “thorn,” etc.) that have no precise definition. Likewise, linguists use notions like “subject” (sect. 4) in a prototype way: a prototypical subject has a large range of features (argument of the predication, controller of verb agreement, topic, etc.) which may not all be present in any particular case. The “family resemblance” character of the basic metalanguage is what underlies the essential nature of typological generalizations, namely that of soft regularities of association of traits.
4. How multiple constraints drive multiple solutions: Grammatical subject as a great (but not universal) idea
We can use the notion of grammatical subject to illustrate the multi-constraint engineering problems languages face, the numerous independent but convergent solutions that cluster similar properties, and at the same time the occurrence of alternative solutions in a minority of other languages that weight competing design motivations differently.
The “grammatical relations” of subject and object apply unproblematically to enough unrelated languages that Baker (Reference Baker2003) regards them as part of the invariant machinery of universal grammar. Indeed, many languages around the world have grammatical relations that map straightforwardly onto the clusterings of properties familiar from English “subject” and “object.” But linguists have also known for some time that the notion “subject” is far from universal, and other languages have come up with strikingly different solutions.
The device of subject, whether in English, Warlpiri, or Malagasy, is a way of streamlining grammars to take advantage of the fact that three logically distinct tasks correlate statistically. In a sentence like “Mary is trying to finish her book,” the subject “Mary” is:
(a) a topic – what the sentence is about;
(b) an agent – the semantic role of the instigator of an action;
(c) the “pivot” – the syntactic broker around which many grammatical properties coalesce
Having a subject relation is an efficient way to organize a language's grammar because it bundles up different subtasks that most often need to be done together. But languages also need ways to indicate when the properties do not coalesce. For example, when the subject is not an agent, this can be marked by the passive: John was kissed by Mary.
“Subject” is thus a fundamentally useful notion for the analysis of many, probably most, languages. But when we look further we find many languages where the properties just described do not line up, and the notion “subject” can only be applied by so weakening the definition that it is near vacuous. For example, the semantic dimension of case role (agent, patient, recipient, etc.) and the discourse dimension of topic can be dissociated, with different grammatical mechanisms assigned to deal with each in a dedicated way: this is essentially how Tagalog works (Schachter Reference Schachter and Li1976). Or a language may use its case system to reflect semantic roles more transparently, so that basic clause types have a plethora of different case arrays, rather than funnelling most event types down to a single transitive type, as in the Caucasian language Lezgian (Haspelmath Reference Haspelmath1993). Alternatively, a language may split the notion subject by funnelling all semantic roles into two main “macro-roles” – “actor” (a wider range of semantic roles than agent) and “undergoer” (corresponding to, e.g., the subject of English, John underwent heart surgery). The syntactic privileges we normally associate with subjects then get divided between these two distinct categories (as in Acehnese; Durie Reference Durie1985).
Finally, a language may plump for the advantages of rolling a wide range of syntactic properties together into a single syntactic broker or “pivot,” but go the opposite way to English, privileging the patient over the agent as the semantic role that gets the syntactic privileges of the pivot slot. Dyirbal (Dixon Reference Dixon1972; Reference Dixon and Li1977) is famous for such “syntactic ergativity.” The whole of Dyirbal's grammatical organization then revolves around this absolutive pivot – case marking, coordination, complex clause constructions. To illustrate with coordination, take the English sentence “The woman slapped the man and ø laughed.” The “gap” (represented here by a zero) is interpreted by linking it to the preceding subject, forcing the reading “and she laughed.” But in the Dyirbal equivalent, yibinggu yara bunjun ø miyandanyu, the gap is linked to the preceding absolutive pivot yara (corresponding to the English object, the man), and gets interpreted as “and he laughed.”
Dyirbal, then, is like English in having a single syntactic “pivot” around which a whole range of constructions are organized. But it is unlike it in linking this pivot to the patient rather than the agent. Because this system probably strikes the reader as perverse, it is worth noting that a natural source is the fact that cross-linguistically most new referents are introduced in “absolutive” (S or O) roles (Dubois Reference Dubois1987), making this a natural attractor for unmarked case and thus a candidate for syntactic “pivot” status (see also Levinson, under review).
Given languages like Dyirbal, Acehnese, or Tagalog, where the concepts of “subject” and “object” are dismembered in language-specific ways, it is clear that a child pre-equipped by UG to expect its language to have a “subject” could be sorely led astray.
5. The claimed universality of constituency
In nearly all recent discussions of syntax for a general cognitive science audience, it is simply presumed that the syntax of natural languages can basically be expressed in terms of constituent structure, and thus the familiar tree diagrams for sentence structure (Hauser et al. Reference Hauser, Chomsky and Fitch2002; Jackendoff Reference Jackendoff2002; Reference Jackendoff2003a; Pinker Reference Pinker1994, p. 97 ff.).
In the recent debates following Hauser et al. (Reference Hauser, Chomsky and Fitch2002), there is sometimes a conflation between constituent structure and recursion (see, e.g., Pinker & Jackendoff Reference Pinker and Jackendoff2005, p. 215), but they are potentially orthogonal properties of languages. There can be constituent structure without recursion, but there can also be hierarchical relations and recursion without constituency. We return to the issue of recursion in the next section, but here we focus on constituency.
Constituency is the bracketing of elements (typically words) into higher-order elements (as in [[[[the][tall [man]]] [came]] where [[[the][tall [man]]] is a Noun Phrase, substitutable by a single element (he, or John). Many discussions presume that constituency is an absolute universal, exhibited by all languages. But in fact constituency is just one method, used by a subset of languages, to express constructions which in other languages may be coded as dependencies of other kinds (Matthews Reference Matthews1981; Reference Matthews2007). The need for this alternative perspective is that many languages show few traces of constituent structure, because they scramble the words, as in the following Latin line from Virgil (Matthews Reference Matthews1981, p. 255):
Here the lines link the parts of two noun phrases, and it makes no sense to produce a bracketing of the normal sort: a tree diagram of the normal kind would have crossing lines. A better representation is in terms of dependency – which parts depend on which other parts, as in the following diagram where the arrowhead points to the dependent item:
Classical Latin is a representative of a large class of languages, which exhibit free word order (not just free phrase order, which is much commoner still). The Australian languages are also renowned for these properties. In Jiwarli and Thalanyji, for example, all linked nominals (part of a noun phrase if there was such a thing) are marked with case and can be separated from each other; there is no evidence for a verb phrase, and there are no major constraints on ordering (see Austin & Bresnan 1996). Example (15) illustrates a discontinuous sequence of words in Thalanyji, which would correspond to a constituent in most European languages; “the woman's dog” is grouped as a single semantic unit by sharing the accusative case.![]()
Note how possessive modifiers – coded by a special use of the dative case – additionally pick up the case of the noun they modify, as with the accusative –nha on “dog” and “woman-Dat” in (15). In this way multiple case marking (Dench & Evans Reference Dench and Evans1988) allows the grouping of elements from distinct levels of structure, such as embedded possessive phrases, even when they are not contiguous. It is this case-tagging, rather than grouping of words into constituents, which forms the basic organizational principle in many Australian languages (see Nordlinger Reference Nordlinger1998 for a formalization).
It is even possible in Jiwarli to intermingle words that in English would belong to two distinct clauses, since the case suffixes function to match up the appropriate elements. These are tagged, as it were, with instructions like “I am object of the subordinate clause verb,” or “I am a possessive modifier of an object of a main clause verb.” By fishing out these distinct cases, a hearer can discern the structure of a two-clause sentence like “the child (ERG) is chasing the dog (ACC) of the woman (DAT-ACC) who is sitting down cooking meat (DAT)” without needing to attend to the order in which words occur (Austin & Bresnan 1996). The syntactic structure here is most elegantly represented via a dependency formalism (supplemented with appropriate morphological features) rather than a constituency one.
Although languages like Jiwarli have been increasingly well documented over the last forty years, syntactic theories developed in the English-speaking world have primarily focussed on constituency, no doubt because English fits this bill. In the Slavic world, by contrast, where languages like Russian have a structure much more like Jiwarli or Latin, models of syntactic relations have been largely based on dependency relations (Melčuk Reference Melčuk1988). The most realistic view of the world's languages is that some yield completely to one representational system, some to the other, most to a mix. Some outgrowths of generative theory, such as Lexical-Functional Grammar (LFG), effectively incorporate analogues of dependency representations alongside constituency-based ones, in the form of f-structures besides c-structures, with an interface system linking the two structures (see Bresnan Reference Bresnan2001; Hudson Reference Hudson, Jacobs, von Stechow, Sternefelt and Vennemann1993, p. 329). It is also worth emphasizing, at this point, that dependency-based representations are just as capable of expressing recursive structure as constituency-based ones are.
A way of saving the claimed primacy of word order and constituency would be to impose an English-like structure on a sentence like the Latin one given earlier (reordered, say, as [ [ [[ultima][aetas]] [[carminis][Cumae]] ] [[iam] [venit]]] ) and then to scramble the words with a secondary operation (see Matthews Reference Matthews2007, for critical review). A more sophisticated variant is to separate out the hierarchical from the ordering information and specify them separately in a differently construed version of a Phrase Structure Grammar (PSG) (Gazdar & Pullum Reference Gazdar and Pullum1982). But the point is that order and constituency are playing no signalling role for the hearer – they cannot therefore play a role in the parsing of such a sentence. In all the recent applications in the cognitive sciences mentioned earlier, where recursion has played such an important theoretical role, the experimental evidence was from a comprehension or parsing perspective where the universality of constituency was assumed (Fitch & Hauser 2004; Friederici Reference Friederici2004). A further point is that there is not the slightest evidence for the psychological reality of any such imposed constituent structure in a language like Jiwarli. (Researchers on Australian languages have repeatedly reported the inability of speakers to repeat a sentence with the same word order: for Warlpiri “sentences containing the same content words in different linear arrangements count as repetitions of one another” [Hale Reference Hale1983, p. 5] and “[w]hen asked to repeat an utterance, speakers depart from the ordering of the original more often than not” [Hale et al. Reference Hale, Laughren, Simpson, Jacobs, von Stechow, Sternefeld and Vennemann1995, p. 1431].)
Syntactic constituency, then, is not a universal feature of languages.Footnote 4 Just like dependency relations, it is simply one possible way to mark relationships between the parts of a sentence. Just like the grammatical relation of subject (sect. 5), employing constituency as a coding device is a common and workable solution that many languages have evolved, but it is totally absent in others, while in others again it is in the process of evolving without having yet quite crystallized (Himmelmann Reference Himmelmann1997).
It follows that any suggestion about UG that presumes the universality of constituent structure will be false. Models of the evolution of language (e.g., Bickerton 1981) that presume the operation of phrase-structure grammar (PSG) generating sentences with surface constituency (Hauser et al., p. 1577) are also therefore aimed at a particular kind of (English-like) language as the target of evolutionary development. But it is clear that the child must be able to learn (at least) both types of system, constituency or dependency. It will not always be the case that the child needs to use constituency-detecting abilities in constructing its grammar, because constituency relations are, as shown, not universal.
6. Recursion in syntax as a non-universal
We turn now to recursion, the feature which is at the heart of recent heated discussions: Indeed, Hauser et al. (p. 1569) hypothesize that recursion is “the only uniquely human component of the faculty of language.”Footnote 5 Recent findings are said to show that “animals lack the capacity to create open-ended generative systems,” whereas human “languages go beyond purely local structure by including a capacity for recursive embedding of phrases within phrases” (Hauser et al. Reference Hauser, Chomsky and Fitch2002, p. 1577). Recursion, in syntax, is commonly defined as the looping back into a set of rules of its own output, so as to produce a potentially infinite set of outputs. It is sometimes assumed in the debate that recursion is defined over constituent structure, in that recursion “consists of embedding a constituent in a constituent of the same type” (Pinker & Jackendoff Reference Pinker and Jackendoff2005, p. 211). However, because dependency structures are also generated by rule, it is equally possible to have recursive structures that employ dependency relations rather than constituency structures (Levelt Reference Levelt2008, Vol 2, pp. 134 ff.).
The terms of the debate were set fifty years ago by Chomsky (Reference Chomsky1955; Reference Chomsky1957) when he introduced the hierarchy of formal languages, using methods from logic and mathematics, and applied them to constituent structure. He showed that English constituent structure could not be generated by a grammar limited to state transitions (a finite state grammar, or FSG). Rather, the indefinitely embedded structures of English required at least a phrase-structure grammar, or PSG, as in “If A, then B,” where A itself could be of the form “X and Y,” and “X” of the form “W or Z.” Taken as a whole, this generates structures like If John comes or Mary comes and Bill agrees, let's go to the movies. Chomsky has consistently held that this recursion in constituent structure is the magic ingredient in language, which gives it its expressive power.
Since then, a vast amount of work in theoretical linguistics has elaborated on the mathematical properties of abstract grammars (Gazdar et al. Reference Gazdar, Klein, Pullum and Sag1985; Partee et al. Reference Partee, ter Meulen and Wall1990), while many non-Chomskyan linguistic theories have moved beyond this syntactic focus, developing models of language that reapportion generativity to other components of grammar (see, e.g., Bresnan Reference Bresnan2001; Jackendoff Reference Jackendoff2003a; Reference Jackendoff2003b). But recently this classic “syntactocentricism” (as Jackendoff [2003b] has called it), never relinquished by Chomsky, has re-emerged centrally in interdisciplinary discussions about the evolution of language, re-enlivened by Hauser et al.'s (2002) proposal that the property of recursion over constituent structures represents the only key design feature of language that is unique to humans: sound systems and conceptual systems (which provide the semantics) are found in other species. Fitch and Hauser (2004) have gone on to show that despite impressive learning powers over FSGs, tamarin monkeys don't appear to be able to grasp the patterning in PSG-generated sequences, while O'Donnell et al. (Reference O'Donnell, Hauser and Fitch2005) argue that comparative psychology should focus on these formal features of language. Meanwhile Friederici (Reference Friederici2004), on the basis of these developments, suggests different neural systems for processing FSG versus PSGs, which she takes to be the critical juncture in the evolution of human language.
In this context where recursion has been suggested to be the criterial feature of the human language capacity, it is important for cognitive scientists to know that many languages show distinct limits on recursion in this sense, or even lack it altogether.
First, many languages are structured to minimize embedding. For example, polysynthetic languages – which typically have extreme levels of morphological complexity in their verb, but little in the way of syntactic organization at the clause level or beyond – show scant evidence for embedding. In Bininj Gun-wok, for example (Evans 2003a, p. 633), the doubly-embedded English sentence “[They stood [watching us [fight]]]” is expressed, without any embedding, as “they_stood / they_were_watching_us / we_were_fighting_each_other,” where underscores link morphemes within a word. In fact, the clearest cases of embedding are morphological (within the word) rather than syntactic: to a limited degree one verb can be incorporated within another, for example: barri-kanj-ngu-nihmi-re [they-meat-eat-ing-go], “they go along eating meat.” But this construction has a maximum of one level of embedding – so that even if it were claimed that polysynthetic languages simply shift the recursive apparatus out of the syntax into the morphology (Baker Reference Baker1988), the limit to one degree of embedding means it can be generated by a finite state grammar in Bininj Gun-wok. Mithun (Reference Mithun1984) counted the percentage of subordinate clauses (embedded or otherwise) in a body of texts for three polysynthetic languages and found very low levels in all three: 7% for oral Mohawk texts, 6% in Gunwinggu (a dialect of Bininj Gun-wok), and just 2% in Kathlamet. Examples like this show how easily a language can dispense with subordination (and hence with the primary type of recursion), by adopting strategies that present a number of syntactically independent propositions whose relations are worked out pragmatically.
Kayardild is another interesting case of a language whose grammar allows recursion, but caps it at one level of nesting (see Evans Reference Evans1995a; Reference Evans and Plank1995c). Kayardild forms subordinate clauses in two ways: either it can nominalize the subordinate verb (something like English -ing), or it can use a finite clause for the subordinate clause. Either way, it makes special use of a case marking – the oblique (OBL) – which can go on all or most clausal constituents. This oblique case marker then stacks up outside any other case markers that may already be there independently. We shall illustrate with the nominalized variant, but identical arguments carry through for the finite version. For example, to say, “I will watch the man spearing the turtle,” you say,![]()
The object marker on “man” is required because it is the object of “watch,” and the object marker on “turtle” because it is the object of “spear.” Of particular relevance here is that “turtle” is marked with the object case plus the oblique case because the verb “spear” of which it is the object has been nominalized.
Now the interesting thing is that, even though in general Kayardild (highly unusually) allows cases to be stacked up to several levels, the oblique case has the particular limitation (found only with this one case) that it cannot be followed by any other case. This morphological restriction, combined with the fact that subordinate clauses require their objects and other non-subject NPs to be marked with an oblique for the sentence to be grammatical, means that the morphology places a cap on the syntax: at most, one level of embedding.
In discussions of the infinitude of language, it is normally assumed that once the possibility of embedding to one level has been demonstrated, iterated recursion can then go on to generate an infinite number of levels, subject only to memory limitations. And it was arguments from the need to generate an indefinite number of embeddings that were crucial in demonstrating the inadequacy of finite-state grammars. But, as Kayardild shows, the step from one-level recursion to unbounded recursion cannot be assumed, and once recursion is quarantined to one level of nesting it is always possible to use a more limited type of grammar, such as a finite state grammar, to generate it.
The most radical case would be of a language that simply disallows recursion altogether, and an example of this has recently been given for the Amazonian language Pirahã by Everett (Reference Everett2005), which lacks not only subordination but even indefinitely expandable possessives like “Ko'oi's son's daughter.” This has been widely discussed, and we refer the reader to Everett's paper for the details. Village-level sign languages of three generations' depth or more also systematically show an absence of embedding (Meir et al., in press), suggesting that recursion in language is an evolved socio-cultural achievement rather than an automatic reflex of a cognitive specialism.
The languages we have reviewed, then, show that languages can employ a range of alternative strategies to render, without embedding, meanings whose English renditions normally use embedded structures. In some cases the languages do, indeed, permit embedding, but it is rare, as with Bininj Gun-wok or Kathlamet. In other cases, like Kayardild nominalized clauses, embedding is allowed, but to a maximum of one iteration. Moreover, since this is governed by clear grammatical constraints, it is not simply a matter of performance or frequency. Finally, there is at least one language, Pirahã, where embedding is impossible, both syntactically and morphologically. The clear conclusion that these languages point to is that recursion is not a necessary or defining feature of every language. It is a well-developed feature of some languages, like English or Japanese, rare but allowed in others (like Bininj Gun-wok), capped at a single level of nesting in others (Kayardild), and in others, like Pirahã, it is completely absent. Recursion, then, is a capacity languages may exhibit, not a universally present feature.
The example of Pirahã has already been raised in debate with Chomsky, Hauser, and Fitch, by Pinker and Jackendoff (Reference Pinker and Jackendoff2005). Fitch et al. (Reference Fitch, Hauser and Chomsky2005) replied that “the putative absence of obvious recursion in one of these languages is no more relevant to the human ability to master recursion than the existence of three vowel languages calls into doubt the human ability to master a five- or ten-vowel language” (p. 203). That is, despite the fact that recursion is the “only uniquely human component of the language faculty,” recursion is not an absolute universal, but just one of the design features provided by UG from which languages may draw: “as Jackendoff (Reference Jackendoff2002) correctly notes, our language faculty provides us with a toolkit for building languages, but not all languages use all the tools” (2002, p. 204).
But we have already noted that the argument from capacity is weak. By parity of argument, every feature of every language that has ever been spoken must then be part of the language faculty or UG. This seems no more plausible than claiming that, because we can learn to ride a bicycle or read music, these abilities are part of our innate endowment. Rather, it is the ability to learn bicycle riding by putting together other, more basic abilities which has to be within our capacities, not the trick itself. Besides, if syntactic recursion is the single core feature of language, one would surely expect it to have the strong form of a “formal universal,” a positive constraint on possible rule systems, not just an optional part of the toolkit, in the style of one of Chomsky's “substantive universals.”
No one doubts that humans have the ability to create utterances of indefinite complexity, but there can be serious doubt about where exactly this recursive property resides, in the syntax or elsewhere. Consider that instead of saying, “If the dog barks, the postman may run away,” we could say: “The dog might bark. The postman might run away.” In the former case we have syntactic embedding. In the latter the same message is conveyed, but the “embedding” is in the discourse understanding – the semantics and the pragmatics, not the syntax. It is because pragmatic inference can deliver embedded understandings of non-embedded clauses that languages often differ in what syntactic embeddings they allow. For example, in Guugu Yimithirr there is no overt conditional – and conditionals are expressed in the way just outlined (Haviland Reference Haviland, Blake and Dixon1979).
In these cases, the expressive power of language lies outside syntax. It is a property of conceptual structure, that is, of the semantics and pragmatics of language. This is a central problem for the “syntactocentric” models associated with Chomsky and his followers, but less so of course for the kind of view championed by Jackendoff in these pages (see Jackendoff Reference Jackendoff2003a), where semantics or conceptual structure is also argued to have generative capacity. More specifically, the generative power would seem to lie in the semantics/pragmatics or the conceptual structure in all languages, but only in some is it also a property of the syntax.
To recapitulate:
1. Many languages do not have syntactic constituent structure. As such, they cannot have embedded structures of the kind indicated by a labelled bracketing like [A[A]]. Most of the suggestions for rule constraints (like Subjacency) in UG falsely presume the universality of constituency. The Chomsky, Hauser, and Fitch versus Pinker and Jackendoff controversy simply ignores the existence of this wide class of languages.
2. Many languages have no, or very circumscribed recursion in their syntax. That is, they do not allow embedding of indefinite complexity, and in some languages there is no syntactic embedding at all. Fitch et al's (2005) response that this is of no relevance to their selection of syntactic recursion as the single unique design feature of human language reveals their choice to be empirically arbitrary.
3. The cross-linguistic evidence shows that although recursion may not be found in the syntax of languages, it is always found in the conceptual structure, that is, the semantics or pragmatics – in the sense that it is always possible in any language to express complex propositions. This argues against the syntacticocentrism of the Chomskyan paradigm. It also points to a different kind of possible evidence for the evolutionary background to language, namely, the investigation of embedded reasoning across our nearest phylogenetic cousins, as is required, for example, in theory of mind tasks, or spatial perspective taking. Even simple tool making can require recursive action patterning (Greenfield Reference Greenfield1991).
7. The new synthesis: Evolutionary approaches to language
A linguist who asks “Why?” must be a historian.
—Martin Haspelmath (Reference Haspelmath1999, p. 205)Our message has been that the languages of the world offer a real challenge to current theory and analysis about the place of language in human cognition. From the perspective of some approaches, the message of diversity may suggest that there is no clear way forward. In fact, however, there is a growing body of work that shows exactly where the language sciences are headed, which is to tame the diversity with theories and methods that stem ultimately from the biological sciences. Evolutionary approaches, in the broadest sense, are transforming the theoretical terrain.
This work is of different kinds. In the first instance, there is a great deal of speculation, elegant theory, and mathematical modelling aimed at the problem of language origins (Christiansen & Kirby Reference Christiansen and Kirby2003). Some of this is devoted to the preconditions – for example, the origin of human cooperation (Boyd & Richerson Reference Boyd, Richerson, Levinson and Jaisson2005; Tomasello Reference Tomasello2000, 2008), or the properties of human interaction or theory of mind (Enfield & Levinson Reference Enfield and Levinson2006). Other work is centrally concerned with the coevolution of cognition and culture generally, arguing for a twin-track model in which biological and cultural evolution run partially independently, but with reciprocal interaction (Durham 1991; Levinson & Jaisson Reference Levinson and Jaisson2006). This provides a mechanism for the biological evolution of traits adaptive to cultural environments, for which the neuroanatomical foundations for language must be a prime example.Footnote 6
Language diversity can best be understood in terms of such a twin-track model, with the diversity largely accounted for in terms of diversification in the cultural track, in which traits evolve under similar processes to those in population genetics, by drift, lineal inheritance, recombination, and hybridization. These create the population conditions in which new variants arise in separate social groups. A range of selectors – characteristics of the brain and vocal tract, constraints on the communicative channel, internal constraints within the system, and transition constraints on what can turn into what – then shape the chances of different variants catching on.
Historical linguistics is the oldest branch of scientific linguistics, with long-standing interests in lineal inheritance versus horizontal transfer through contact and borrowing. Its greatest achievement was the development of rigorous methods for the tracking of vocabulary through descendant languages. But brand new is the application of bioinformatic techniques to linguistic material, allowing the quantification of inheritance versus borrowing in vocabulary (McMahon & McMahon Reference McMahon and McMahon2006); see also Pagel et al. (Reference Pagel, Atkinson and Meade2007) and Atkinson et al. (Reference Atkinson, Meade, Venditti, Greenhill and Pagel2008) for further examples of statistical phylogenetic approaches to understanding language evolution. Application of cladistics and Bayesian phylogenetics to vocabulary allow much firmer inferences about the date of divergences between languages (Atkinson & Gray Reference Atkinson, Gray, Lipo, O'Brien, Shennan and Collard2005; Gray & Atkinson Reference Gray and Atkinson2003). These methods can also be applied to the structural (phonological and grammatical) features of language, and this can be shown to replicate the findings based on traditional vocabulary methods (Dunn et al. Reference Dunn, Terrill, Reesink, Foley and Levinson2005; Dunn et al. Reference Dunn, Levinson, Lindström, Reesink and Terrill2008), while potentially reaching much further back in time. These explicit methods allow the comparison between, for example, linguistic phylogeny, human genetics, and the diversification of cultural traits in some area of the world. A stunning result is that, in at least some parts of the world, linguistic traits are the most tree-like, least hybridized properties of any human population (Hunley et al. Reference Hunley, Dunn, Lindström, Reesink, Terrill, Norton, Scheinfeldt, Friedlaender, Merriwether, Koki, Friedlaender and Friedlaender2007), with stable linguistic groupings solidly maintained across thousands of years despite enormous flows of genes and cultural exchange across groups.
These bioinformatic methods throw new light on the nature of Greenbergian universals (Dunn et al. Reference Dunn, Levinson, Lindström, Reesink and Terrill2008). Using Bayesian phylogenetics, we can reconstruct family trees with the structural properties at each node, right back to the ancestral proto-language of a family. We can then ask how much these structural features are, over millennia, codependent (i.e., changing together, or instead evolving independently). First impressions from these new methods show that the great majority of structural features are relatively independent; only a few resemble the Greenbergian word-order conditional universals, with closely correlated state-transitions. The emerging picture, then, confirms the view that most linguistic diversity is the product of historical cultural evolution operating on relatively independent traits. On the other hand, some derived states are inherently instable and unleash chains of changes till a more stable overall state is reached. As Greenberg once put it, “a speaker is like a lousy auto mechanic: every time he fixes something in the language, he screws up something else” (quoted in Croft 2002, p. 5).
In short, there are evolutionarily stable strategies, local minima as it were, that are recurrent solutions across time and space, such as the tendency to distinguish noun and verb roots, to have a subject role, or mutually consistent approaches to the ordering of head and modifier, which underlie the Greenbergian statistical universals linking different features. These tendencies cannot plausibly be attributed to UG, since changes from one stable strategy to another take generations (sometimes millennia) to work through. Instead, they result from myriad interactions between communicative, cognitive, and processing constraints which reshape existing structures through use. A major achievement of functionalist linguistics has been to map out, under the rubric of grammaticalization, the complex temporal sub-processes by which grammar emerges as frequently used patterns sediment into conventionalized patterns (Bybee Reference Bybee, Broe and Pierrehumbert2000; Givón Reference Givón2008). Cultural preoccupations may push some of these changes in particular directions, such as the evolution of kinship-specific pronouns in Australia (Evans Reference Evans2003b). And social factors, most importantly the urge to identify with some groups by speaking like them, and to maximize distance from others by speaking differently (studied in fine-grained detail by Labov Reference Labov and Labov1980), act as an amplifier on minor changes that have arisen in the reshaping process (Nettle Reference Nettle1999).
Gaps in the theoretically possible design space can be explained partly by the nature of the sample (we have 7,000 survivors from an estimated half-million historical languages), partly by chance, partly because the biased state changes above make arriving at, or staying in, some states rather unlikely (Dunn et al. Reference Dunn, Levinson, Lindström, Reesink and Terrill2008; Evans Reference Evans and Plank1995c).
An advantage to this evolutionary and population biology perspective is that it more readily accounts for the cluster-and-outlier pattern found with so many phenomena when a broad sample of the world's languages is plumbed. We know that “rara” are not cognitively impossible, because there are speech communities that learn them, but it may be that the immediately preceding springboard state requires such specific and improbable collocations of rare features that there is a low statistical likelihood of such systems arising (Harris Reference Harris and Good2008). It also accounts for common but not universal clusterings, such as grammatical subject, through the convergent functional economies outlined in section 4, making an all-purpose syntactic pivot an efficient means of dealing with the statistically correlated roles of agent and discourse topic in one fell swoop. And it explains why conditional universals, as well, almost always turn out to be mere tendencies rather than absolute universals: Greenberg's word-order correlations – for example, prepositions where verb precedes object, postpositions where verb follows object – are functionally economical. They allow the language user to consistently stick to just one parsing strategy, right- or left-branching as appropriate, and channel state transitions in particular directions that tend to maintain the integrity of the system. For example, where adpositions derive from verbs, if the verb follows its object it only has to stay where it is to become a post- rather than a pre-position.
The fertile research program, briefly summarized in the preceding paragraphs, allows us to move our explanations for the recurrent regularities in language out of the prewired mind and into the processes that shape languages into intricate social artefacts. Cognitive constraints and abilities now play a different role to what they did in the generative program (cf. Christiansen & Chater 2008): their primary role is now as stochastical selective agents that drive along the emergence and constant resculpting of language structure.
We emphasize that this view does not, of itself, provide a solution to the other great Chomskyan question: What cognitive tools must children bring to the task of language learning? If anything, this question has become more challenging in two vital respects, and here we part company with Christiansen and Chater (2008), who assume a much narrower spectrum of structural possibilities in language than we do: First, because the extraordinary structural variation sketched in this article presents a far greater range of problems for the child to solve than we were aware of fifty years ago; and second, because the child can bring practically no specific hypotheses, of the UG variety, to the task. But, however great it is, this learning challenge is not peculiar to language – it was set up as the crucial human cognitive property when we moved into a coevolutionary mode, using culture as our main means of adaptation to environmental challenges, well over a million years ago.
8. Conclusion: Seven theses about the nature of language and mind
The new and more complex emerging picture that we have sketched here, however uncomfortable it may be for models of learning that minimize the challenge by postulating some form of universal grammar, in fact promises us a much better understanding of the nature of language and the cognition that makes it possible.
On the one hand, there are thousands of diverse languages, with the organizing principles that sort them being largely similar to the radiation and diversification of species. In other words, language diversification and hybridization works just like the evolution of biological species – it is a historical process, following the laws of population biology. Consider the fact that linguistic diversity patterns just like biological diversity generally, so that the density of languages closely matches the density of biological species across the globe, correlating with rainfall and latitude (Collard & Foley Reference Collard and Foley2002; Mace & Pagel Reference Mace and Pagel1995; Nettle Reference Nettle1999; Pagel Reference Pagel, Knight, Studdert-Kennedy and Hurford2000). Minor genetic differences between human populations may act as “attractors” for certain linguistic properties which are then easier to acquire and propagate (Dediu & Ladd 2007).
On the other hand, the human cognition and physiology that has produced and maintained this diversity is a single system, late evolved and shared across all members of the species. It is a system that is designed to deal with the following shared Hockettian design features of spoken languages: the use of the auditory-vocal channel with its specialized (neuro)anatomy, fast transmission with output-input asymmetries (with a production-comprehension rate in the proportion 1:4, see Levinson 2000, p. 28), multiple levels of structure (phonological, morphosyntactic, semantic) bridging sound to meaning, linearity combined with nonlinear structure (constituency and dependency), and massive reliance on inference. The learning system has to be able to cope with an amazing diversity of linguistic structures, as detailed in this article. Despite this, the hemispherical lateralization and neurocognitive pathways are largely shared across speakers of even the most different languages, to judge from comparative studies of European spoken and signed languages (Emmorey Reference Emmorey2002). Yet there is increasing evidence that few areas of the brain are specialized just for language processing (see, e.g., recent work on Broca's area in Fink et al. Reference Fink, Manjaly, Stephen, Gurd, Zilles, Amunts, Marshall, Amunts and Grodzinsky2005 and Hagoort Reference Hagoort2005).
How are we to reconcile diverse linguistic systems as the product of one cognitive system? Once the full diversity is taken into account, the UG approach becomes quite implausible – we would need to stuff the child's mind with principles appropriate to thousands of languages working on distinct structural principles. That leaves just two possible models of the cognitive system. Either the innate cognitive system has a narrow core, which is then augmented by general cognition and general learning principles to accommodate the additional structures of a specific language (as in, e.g., Elman et al. Reference Elman, Bates, Johnson and Karmiloff–Smith1996), or it is actually a “machine tool,” prebuilt to specialize and construct a machine appropriate to indefinitely variable local conditions – much the picture assumed in cross-linguistic psycholinguistics of sound systems (Kuhl Reference Kuhl, Brauth, Hall and Dooling1991). Either way, when we look at adult language processing, we find a hybrid: a biological system tuned to a specific linguistic system, itself a cultural historical product.
The fact that language is a bio-cultural hybrid is its most important property, and a key to understanding our own place in nature. For human success in colonizing virtually every ecological niche on the planet is due to adaptation through culture and technology, made possible by brains gradually evolved specifically to do that. The rapidly expanding theory of coevolution explores the twin-track descent mechanisms of culture and biology, and the feedback loops between them (Boyd & Richerson Reference Boyd, Richerson, Levinson and Jaisson2005; Durham 1991; Laland et al. Reference Laland, Odling-Smee and Feldman2000; Odling-Smee et al. Reference Odling-Smee, Laland and Feldman2003). Language is one of the best exemplars of such coevolution, with evolved biological underpinnings for culturally variable practices, where the biology constrains and canalizes but does not dictate linguistic structures.
We may summarize this emerging general picture in the following seven theses, each linked to a specifically implicated research initiative. Some of these initiatives are already under way across a range of subliteratures (linguistic typology, cognitivist and functionalist treatments, optimality theory), others not. But in either case the initiatives need to be linked across schools into an integrated general theory with hypothesis-testing procedures accepted by the whole field.
1. The diversity of language is, from a biological point of view, its most remarkable property – there is no other animal whose communication system varies both in form and content. It presupposes an extraordinary plasticity and powerful learning abilities able to cope with variation at every level of the language system. This has to be the central explicandum for a theory of human communication. (It seems inevitable that part of the explicans will be that language has coevolved with culture, which itself evolved to give rapid adaptation to fast-changing environments and migration across niches; see thesis 5.) Research initiative: a principled and exhaustive global mapping of the world's linguistic diversity.
2. Linguistic diversity is structured very largely in phylogenetic (cultural-historical) and geographical patterns. Understanding these patterns basically involves the methods of population biology and cladistics, together with the principles that generate change and diversity. To the extent that there are striking similarities across languages, they have their origin in two sources: historical common origin or mutual influence, on the one hand, and on the other, from convergent selective pressures on what systems can evolve. The relevant selectors are the brain and speech apparatus, functional and cognitive constraints on communication systems, including conceptual constraints on the semantics, and internal organizational properties of viable semiotic systems. Research initiatives: First, a global assessment of structural variability comparable to that geneticists have produced for human populations, assembled in accessible synthesis like the World Atlas of Language Structures (WALS) (http://WALS.info/) and the structural phylogenetics database (Reesink et al. under review). Second, we need a full and integrated account of how selectors generate structures.
3. Language diversity is characterized not by sharp boundaries between possible and impossible languages, between sharply parameterized variables, or by selection from a finite set of types. Instead, it is characterized by clusters around alternative architectural solutions, by prototypes (like “subject”) with unexpected outliers, and by family-resemblance relations between structures (“words,” “noun phrases”) and inventories (“adjectives”). Hypothesis: There are cross-linguistically robust system-preferences and functions, with recurrent solutions (e.g., subject) satisfying several highly ranked preferences, and outliers either satisfying only one preference, or having low-probability evolutionary steps leading to their states.
4. This kind of statistical distribution of typological variation suggests an evolutionary model with attractors (e.g., the CV syllable, a color term “red,” a word for “arm”), “canals,” and numerous local peaks or troughs in an adaptive landscape. Some of the attractors are cognitive, some functional (communicational), some cultural-historical in nature. Some of the canalization is due to systems-biases, as when one sound change sparks off a chain of further changes to maintain signalling discreteness. Research initiative: Each preference of this kind calls for its own focussed research in terms of which selectors are at work, along with a modelling of system interactions – for example, computational simulations of the importance of these distinct factors along the lines reported by Steels and Belpaeme (Reference Steels and Belpaeme2005).
5. The dual role of biological and cultural-historical attractors underlines the need for a coevolutionary model of human language, where there is interaction between entities of completely different orders – biological constraints and cultural-historical traditions. A coevolutionary model explains how complex socially shared structures emerge from the crucible of biological and cognitive constraints, functional constraints, and historically inherited material. Such a model unburdens the neonate mind, reapportioning a great deal of the patterning to culture, which itself has evolved to be learnt. Initiative: Coevolutionary models need to work for two distinct phases: one for the intensely coevolutionary period leading to modern humans, where innovations in hardware (human physiology) and software (language as cultural institution) egged each other on, and a second phase where the full variety of modern languages mutate regularly between radically different variants against a relatively constant biophysical backdrop, although population genetics may nevertheless predispose to specific linguistic variants (Dediu & Ladd 2007).
6. The biological underpinnings for language are so recently evolved that they cannot be remotely compared, for example, to echolocation in bats (pace Jackendoff Reference Jackendoff2002, p. 79). Echolocation is an ancient adaptation shared by 17 families (the Microchiroptera) with nearly 1,000 species and over 50 million years of evolution (Teeling et al. Reference Teeling, Springer, Madsen, Bates, O'Brien and Murphy2005), whereas language is an ability very recently acquired along with spiralling culture in perhaps the last 200,000 to 300,000 years by a single species.Footnote 7 Language therefore must exploit pre-existing brain machinery, which continues to do other things to this day. Language processing relies crucially on plasticity, as evidenced by the modality switch in sign languages. The major biological adaptation may prove to be the obvious anatomical one, the vocal tract itself. The null hypothesis here is that all needed brain mechanisms, outside the vocal-tract adaptation for speech, were co-opted from pre-existing adaptations not specific to language (though perhaps specific to communication and sociality in a more general sense).
7. The two central challenges that language diversity poses are, first, to show how the full range of attested language systems can evolve and diversify as sociocultural products constrained by cognitive constraints on learning, and second, to show how the child's mind can learn and the adult's mind can use, with approximately equal ease, any one of this vast range of alternative systems. The first of these challenges returns language histories to centre stage in the research program: “Why state X?” is recast as “How does state X arise?”. The second calls for a diversified and strategic harnessing of linguistic diversity as the independent variable in studying language acquisition and language processing (Box 3): Can different systems be acquired by the same learning strategies, are learning rates really equivalent, and are some types of structure in fact easier to use?
Box 3. Using linguistic diversity as a “natural laboratory” in cognitive science
Instead of yearning for simple language universals, cognitive scientists should embrace the diversity and use it for what it is good for: supplying rich independent variables for experimental purposes. Listed here are some of the existing outstanding uses of this natural laboratory of variation in the communication system of our species (see also Bates et al. Reference Bates, Devescovi and Wulfeck2001; Guo et al. Reference Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Ozcaliskan2008; Li et al. Reference Li, Hai Tan, Bates and Tzeng2006; Nakayama et al. Reference Nakayama, Mazuka and Shirai2006; Slobin Reference Slobin1997a).
Modality: Sign versus Speech
The modality transfer in sign versus spoken language can be exploited to explore the nature of language processing when the input/output systems are switched, thus allowing glimpses into language-specific cognition beyond the vocal-auditory specializations (Emmorey Reference Emmorey2002; MacSweeney et al. Reference MacSweeney, Woll, Campbell, McGuire, David, Williams, Suckling, Calvert and Brammer2002).
Sound Systems and How We Process Them
Kuhl (Reference Kuhl, Brauth, Hall and Dooling1991; Reference Kuhl2004) and Werker and Tees (Reference Werker and Tees2005) have exploited cross-linguistic differences in sound systems, showing that infants from 6 months of age are already “tuning” their acoustic space to the sound system of the language they are learning.
Cutler et al. (Reference Cutler, Mehler, Norris and Segui1983) have shown that parsing the sound stream for word recognition crucially involves the rhythmic structure of the language, which can be of at least three distinct kinds: based on syllable timing (e.g., Spanish), stress timing (e.g., English) and on the mora (e.g., Japanese). Even the best bilinguals tend to use only one system (Cutler et al. Reference Cutler, Mehler, Norris and Segui1989).
Morphology
Psycholinguists have exploited structural differences between languages to explore, for example, the cognitive effects of gender systems (Boroditsky et al. Reference Boroditsky, Schmidt, Phillips, Gentner and Goldin-Meadow2003) or the effects on processing (Vigliocco et al. Reference Vigliocco, Vinson, Paganelli and Dworzynski2005).
Syntax
The full variety of syntax types has hardly begun to be exploited by psycholinguists (but see MacWhinney & Bates Reference MacWhinney and Bates1989). For some first psycholinguistic investigations of a free word order language (Odawa), see Christianson and Ferreira (Reference Christianson and Ferreira2005).
Semantics and Conceptual Structure
Differences in the linguistic coding of, for example, space can be shown to correlate with differences in the non-linguistic conceptual coding (Levinson Reference Levinson2003; Levinson & Wilkins Reference Levinson and Wilkins2006; Majid et al. Reference Majid, Bowerman, Kita, Haun and Levinson2004), suggesting that linguistic distinctions affect how we think (see also Boroditsky Reference Boroditsky2001; Lucy Reference Lucy1992; Lucy & Gaskins Reference Lucy, Gaskins, Bowerman and Levinson2001).
Lexicon
Lexical gaps can impact perception (e.g., of color: Davidoff et al. Reference Davidoff, Davies and Roberson1999; Kay & Kempton Reference Kay and Kempton1984) and cognition (e.g., of number: Gordon Reference Gordon2004). Meaning diversity has obvious implications for language acquisition: do we name pre-existing concepts or construct the concepts during learning (Bowerman & Levinson Reference Bowerman and Levinson2001)?
Acquisition of Morphosyntax
The diversity of the child's target has been the focus of a great deal of acquisition research (see, e.g., Slobin Reference Slobin1997a). Controlled comparison across languages can be very revealing of children's learning strategies (Pye et al. Reference Pye, Pfeiler, de León, Brown, Mateo and Blaha Pfeiler2007).
This picture may seem to contrast starkly with the assumption that was the starting point for classic cognitive science, namely, the presumption of an invariant mental machinery, both in terms of its psychological architecture and neurocognitive underpinnings, underlying the common cognitive capacities of the species as a whole.
Two points need to be made here. First, there is no logical incompatibility with the classic assumption, it is simply a matter of the level at which relative cognitive uniformity is to be sought. On this new view, cognition is less like the proverbial toolbox of ready-made tools than a machine tool, capable of manufacturing special tools for special jobs. The wider the variety of tools that can be made, the more powerful the underlying mechanisms have to be. Culture provides the impetus for new tools of many different kinds – whether calculating, playing the piano, reading right to left, or speaking Arabic.
Second, the classic picture is anyway in flux, under pressure from increasing evidence of individual differences. Old ideas about expertise effects are now complemented with startling evidence for plasticity in the brain – behavioral adaptation is reflected directly in the underlying wetware (as when taxi drivers' spatial expertise is correlated with growth in the hippocampal area; Maguire et al. Reference Maguire, Gadian, Johnsrude, Good, Ashburner, Frackowiak and Frith2000). Conversely, studies of individual variance show that uniform behavior in language and elsewhere can be generated using distinct underlying neural machinery, as shown for example in the differing degrees of lateralization of language in individuals (see, e.g., Baynes & Gazzaniga Reference Baynes and Gazzaniga2005; Knecht et al. Reference Knecht, Deppe, Dräger, Bobe, Lohmann, Ringelstein and Henningsen2000).
Thus, the cognitive sciences are faced with a double challenge: culturally variable behavior running on what are, at a “zoomed-out” level of granularity, closely related biological machines, and intra-cultural uniformity of behavior running on what are, from a zoomed-in perspective, individually variable, distinct machines. But that is the human cognitive specialty that makes language and culture possible – to produce diversity out of biological similarity, and uniformity out of biological diversity. Embedding cognitive science into what is, in a broad sense including cultural and behavioral variation, a population biology perspective, is going to be the key to understanding these central puzzles.
ACKNOWLEDGMENTS
This work was partially supported by the Australian Research Council (Social Cognition and Language Grant DP878126) to Nicholas Evans, and by the Max Planck Society to Stephen Levinson. Author order is alphabetical. We thank Jos van Berkum, Lera Boroditsky, Morten Christiansen, Peter Hagoort, Martin Haspelmath, Wolfgang Klein, Asifa Majid, Fritz Newmeyer, and Karl-Magnus Petersson for helpful comments; Barbara Finlay, Adele Goldberg, Russell Gray, Shimon Edelman, Mark Pagel, and two further anonymous BBS referees for their suggestions on improvement; and Edith Sjoerdsma for her work on the manuscript.

