


Introduction
When teaching students and practitioners about defaults – pre-selecting one choice option to increase the likelihood of its uptake – a figure that depicts the effect of defaults on organ donation often features prominently (Johnson & Goldstein, Reference Johnson and Goldstein2003). Organ donation defaults can be very simple, even consisting of the one-word difference between “If you want to be an organ donor, please check here” (opt-in) and “If you don't want to be an organ donor, please check here” (opt-out). However, the ensuing difference in organ donation signup is dramatic, with percentages in the high nineties for opt-out countries and in the tens for opt-in countries (Johnson & Goldstein, Reference Johnson and Goldstein2003). These results seem to have influenced countries to change defaults: Argentina became an opt-out country in 2005 (La Nacion, 2005), Uruguay in 2012 (Trujillo, Reference Trujillo2013), Chile in 2013 (Zúñiga-Fajuri, Reference Zúñiga-Fajuri2015) and Wales in 2015 (Griffiths, Reference Griffiths2013), and The Netherlands and France will become opt-out countries by 2020 (Willsher, Reference Willsher2017; Leung, Reference Leung2018).
The attractiveness of defaults as a choice architecture tool stems from their apparent effectiveness in a variety of different contexts and their relative ease of implementation. As a result, policy-makers and organizations regard defaults as a viable tool to guide individuals’ behaviors (Kahneman, Reference Kahneman2011; Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012; Beshears et al., Reference Beshears, Choi, Laibson, Madrian and Wang2015; Steffel et al., Reference Steffel, Williams and Pogacar2016; Benartzi et al., Reference Benartzi, Beshears, Milkman, Sunstein, Thaler, Shankar and Galing2017). For example, one study showed that employees are 50% more likely to participate in a retirement savings program when enrollment is the default (i.e., they are automatically enrolled, with the option to reverse that decision) than when not enrolling is the default (Madrian & Shea, Reference Madrian and Shea2001). In response, Sen. Daniel Akaka (D-HI) introduced the Save More Tomorrow Act of 2012, which now provides opt-out enrollment in retirement savings for federal employees (Thaler & Benartzi, Reference Thaler and Benartzi2004; Akaka, Reference Akaka2012). Across many other domains and governments, defaults have also attracted increasing attention from policy-makers (Felsen et al., Reference Felsen, Castelo and Reiner2013; Sunstein, Reference Sunstein2015; Tannenbaum et al., Reference Tannenbaum, Fox and Rogers2017).
However, the rise of defaults’ popularity should be seen in context: they are only a single tool in the choice architect's toolbox (Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012). For example, while citizens could be defaulted into health insurance plans, they could also be asked to select their health insurance plan from a smaller, curated choice set (Johnson et al., Reference Johnson, Hassin, Baker, Bajger and Treuer2013). Similarly, employees could be defaulted into retirement savings plans when joining a company, but alternatively, they could be given a limited time window in which to sign up (O'Donoghue & Rabin, Reference O’Donoghue and Rabin1999). Likewise, although consumers could be defaulted into more environmentally friendly automobile choices, gas mileage information could instead be presented in a more intuitive way to sway decisions toward more environmentally friendly options (Larrick & Soll, Reference Larrick and Soll2008; Camilleri & Larrick, Reference Camilleri and Larrick2014). Finally, instead of shifting toward an opt-out doctrine, policy-makers could also design active choice settings where individuals are required to make a choice (Keller et al., Reference Keller, Harlam, Loewenstein and Volpp2011). Policy-makers thus have a large array of options to choose from, beyond defaults, when determining how to use choice architecture to attain desired outcomes.
Making an informed decision when selecting a choice architecture tool therefore requires information on how effective a tool is, as well as information about why a tool's effectiveness might vary. A maintenance worker's toolbox serves as a helpful analogy: to fix a problem, he or she must understand when the use of what tool may be more or less appropriate and how the tool should be handled to best address the underlying issue. However, because choice architects commonly do not have access to this information and are often inaccurate in their estimations of the default effect (Zlatev et al., Reference Zlatev, Daniels, Kim and Neale2017), they may frequently fail to choose the most appropriate choice architecture tool or may deploy it inappropriately. In addition, in some cases, the implementation of an opt-out default may even reduce the take-up of the pre-selected option (Krijnen et al., Reference Krijnen, Tannenbaum and Fox2017). In fact, choice architects currently do not know how effective they can expect an implementation of a default to be, nor which factors in the design decisions may systematically alter how influential the application of a default may be. The current research seeks to address these issues by investigating how effective defaults are and when and why defaults’ effectiveness varies.
We subsequently proceed as follows: we first present a meta-analysis of default studies that estimates the size of the default effect and its variability in prior research. We find that defaults have a sizeable and robust effect but that their effectiveness varies substantially across studies. We also investigate possible publication bias and find that – if anything – larger effect sizes are underreported.
We then explore the factors that may explain the observed variability of default effects in two different ways. We highlight that choice architects often make inadvertent decisions in studying default effects because they do not have perfect insight into which factors drive a default's effectiveness (Zlatev et al., Reference Zlatev, Daniels, Kim and Neale2017). As a result, the variability in their design decisions allows us to investigate whether study factors systematically influence a default's effectiveness, with the hope that our findings can subsequently inform the future and more deliberate design of defaults.
First, we examine whether study characteristics such as the choice domain or response mode can explain some of this variability, and we find that defaults that involve consumer decisions are more likely to be effective and defaults that involve environmental decisions are less likely to be effective. Second, we draw on an existing theoretical framework of default effects (Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011) to explore whether the variability in default effects could also be caused by differences in the mechanisms that may underlie the default effect in each study. Past research has demonstrated that defaults are multiply determined, depending on the extent to which they activate endorsement, endowment, and ease, and we find that both the nature and the number of mechanisms that are activated through the design of the default influence its effectiveness. We end with a discussion of possible directions for a future research program on defaults, including potential additional moderators, and implications for policy-makers interested in the implementation and evaluation of defaults.
Estimating the size and modeling the variability of default effects
We first aim to provide an estimate of the size and variability of default effects by conducting a meta-analysis of existing default studies. A meta-analysis combines the results of multiple studies to improve the estimate of an effect size by increasing the statistical power (Griffeth et al., Reference Griffeth, Hom and Gaertner2000; Judge et al., Reference Judge, Heller and Mount2002; Hagger et al., Reference Hagger, Wood, Stiff and Chatzisarantis2010).
Inclusion criteria
We define the default effect as the difference in choice between the opt-out condition versus that in the opt-in condition. We include studies with both binary measures of choice (i.e., the percentage who choose the desired outcome in each condition) and continuous measures of choice (e.g., the average amount donated or invested in each condition). If a study has multiple relevant dependent measures, we include each measure as a separate observation. This is true of one study in our data, which looked at both the percentage who chose the desired outcome and their willingness to pay (Pichert & Katsikopoulos, Reference Pichert and Katsikopoulos2008). If a study included multiple groups that should or could not be combined, an effect size is calculated for each. This is true of two studies in our data, one of which had two different pricing programs in their field study (Fowlie et al., Reference Fowlie, Wolfram, Spurlock, Todd, Baylis and Cappers2017) and another which looked at parents with different HPV vaccination intentions (Reiter et al., Reference Reiter, McRee, Pepper and Brewer2012).
Because we define the default effect using opt-in and opt-out conditions, we focus only on studies that explicitly compare these two conditions. We exclude any studies that explore defaults but do not contain a comparison between opt-in and opt-out conditions (e.g., they compare opt-out and forced choice or opt-in and forced choice). If a study investigates more conditions than just opt-in and opt-out (e.g., also includes forced choice), we only look at the data for the two relevant conditions. If a study looks at independent variables other than our two default conditions, we include only the effect of defaults on choice. Additionally, we exclude any studies for which missing information (such as means or standard deviations) prevents Cohen's d from being calculated. Finally, we include studies regardless of their publication date.
Data collection
We searched the EBSCO, ProQuest, ScienceDirect, PubMed and SAGE Publications databases and conference abstracts (Behavioral Decision Research in Management; Behavioral Science and Policy; Society for Judgment and Decision-Making; and Subjective Probability, Utility and Decision-Making) using the following search terms: ‘Defaults’ or ‘Default Effect’ or ‘Advance Directives’ or ‘Opt-out’ or ‘Opt-in’ AND ‘Decisions’ or ‘Decision-Making’ or ‘Environmental Decisions’ or ‘Health Decisions’ or ‘Consumer Behavior’. We also sent requests for papers to two academic mailing lists: SJDM and ACR. Our search concluded in May 2017.
In total, we found 58 datasets from 55 studies included in 35 articles that fit our inclusion criteria (n = 73,675, ranging from 51 to 41,952Footnote 1). These articles come from a variety of journals, including, but not limited to, Science, Journal of Marketing Research, Journal of Consumer Psychology, Medical Decision Making, Journal of Environmental Psychology and Quarterly Journal of Economics. The meta-analysis data and code are publicly available via the Open Science Framework (https://osf.io/tcbh7).
Effect size coding
To combine all individual studies into one meta-analytic model, we calculate the Cohen's d for the differences between the opt-out and the opt-in conditions. We code effects so that a positive d-value is associated with greater choice in the opt-out condition and a negative d-value is associated with greater choice in the opt-in condition. For dependent variables that are measured on a continuous scale (e.g., the amount of money donated or invested), we calculate Cohen's d as the difference between the means, divided by the pooled standard deviation (Cohen, Reference Cohen1988). For dependent variables that are measured on a binary scale, we calculate the Cohen's d using an arcsine transformation (Lipsey & Wilson, Reference Lipsey and Wilson2001; Scheibehenne et al., Reference Scheibehenne, Greifeneder and Todd2010; Chernev et al., Reference Chernev, Bockenholt and Goodman2012).
Due to the high level of variation in the results of our selected studies, we use a random-effects model via the restricted maximum likelihood estimator method. All analyses were conducted in R version 1.1.383 using the ‘metafor’ package (Viechtbauer, Reference Viechtbauer2010). The studies are weighted using inverse-variance weights, which has been shown to perform better than weighting by sample size in random-effects analysis (Marín-Martínez & Sánchez-Meca, Reference Marín-Martínez and Sánchez-Meca2010).
Since the data are nested (58 observations from 55 studies in 35 articles), we also use a random-effects model that accounts for three levels: individual observations; observations within the same study (either separate groups from the same study or multiple dependent measures from the same study); and studies within the same article. By using these three levels, we can take into account that observations derived from the same study or article are likely to be more similar than observations from different studies or articles (Rosenthal, Reference Rosenthal1995; Thompson & Higgins, Reference Thompson and Higgins2002; Sánchez-Meca et al., Reference Sánchez-Meca, Marín-Martínez and Chacón-Moscoso2003; Chernev et al., Reference Chernev, Bockenholt and Goodman2012).
Results: effect size
Our analysis reveals that opt-out defaults lead to greater uptake of the pre-selected decision than opt-in defaults (d = 0.68, 95% confidence interval [CI] = 0.53–0.83], p < 0.001), producing a medium-sized effect given conventional criteria (Cohen, Reference Cohen1988). This is robust to running the model that accounts for the three levels: the observation level, the study level and the article level (d+ = 0.63, 95% CI = 0.47–0.80], p < 0.001). In other words, when we account for observations within the same study, those that come from separate groups or different dependent measures, as well as studies that come from the same articles, our results largely do not differ. In comparison to a decision where participants must explicitly give their consent to follow through with a desired course of action, a decision with a pre-selected option increases the likelihood that the option is chosen by 0.63–0.68 standard deviations. Figure 1 illustrates this result in a forest plot.
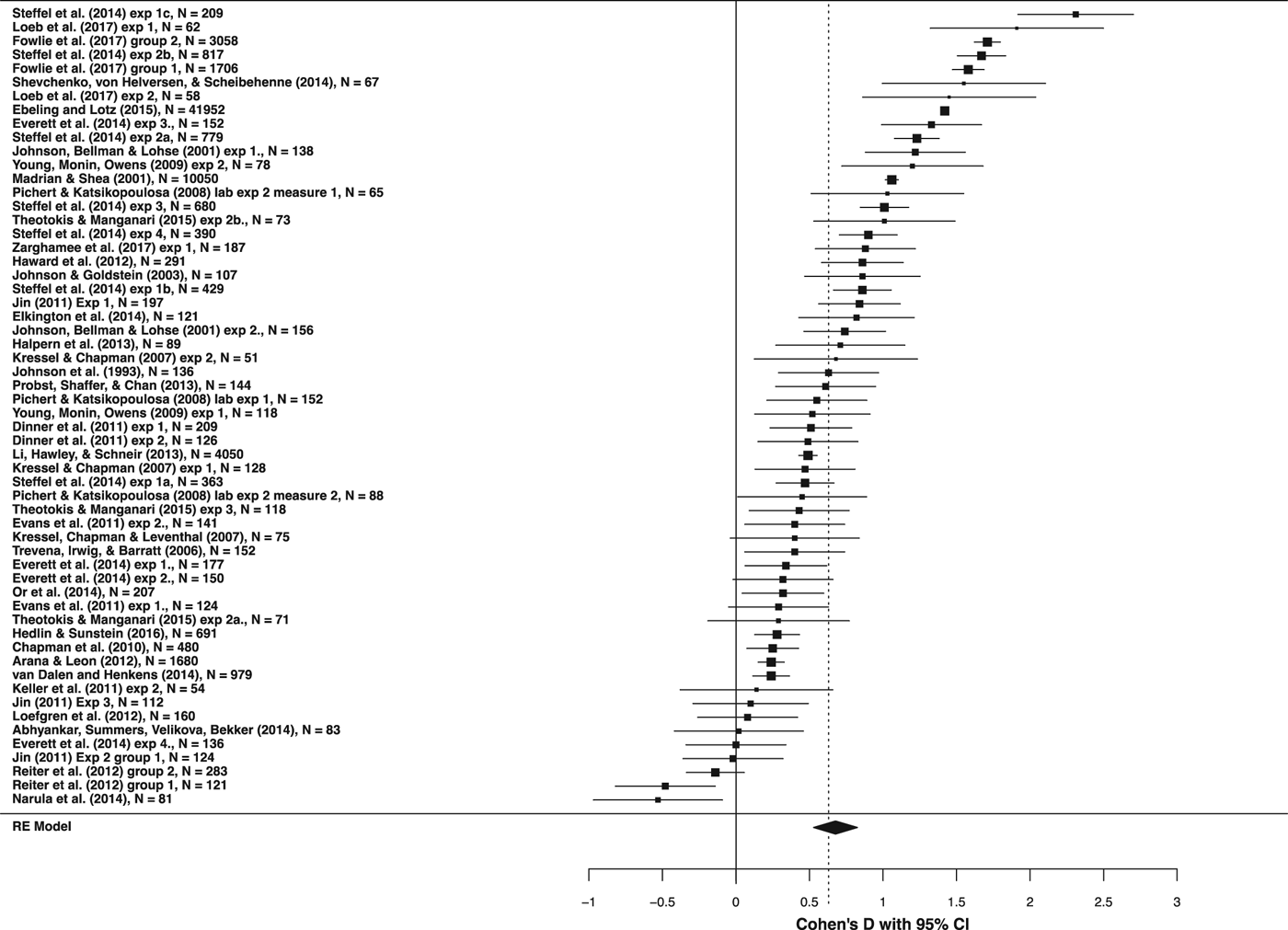
Figure 1. Forest plot of default effect size (all studies)
Binary studies
We also examine the Cramér's V for all binary dependent measure observations in our analysis – a measure of association for nominal values that gives a value between 0 (no association between variables) and 1 (perfect association between variables) – which we calculate by taking the square root of the chi-squared statistic divided by the sample size and the minimum dimension, minus 1 (Cramér, Reference Cramér1946). We note that this calculation is not new or different information, but merely a translation of the Cohen's d results to a different scale for interpretation purposes for binary choice datasets (38 out of 58). We again find that opt-out defaults lead to significantly greater uptake of the pre-selected decision than opt-in defaults (V+ = 0.29, 95% CI = 0.21–0.37], p < 0.001) by an absolute average of 27.24%. Hence, our meta-analysis indicates that defaults, in aggregate, have a considerable influence on decision-making outcomes.
Publication bias
We next estimate the extent of publication bias in the published defaults literature (see also Duval & Tweedie, Reference Duval and Tweedie2000; Carter & McCullough, Reference Carter and McCullough2014; Franco et al., Reference Franco, Malhotra and Simonovits2014; Simonsohn et al., Reference Simonsohn, Nelson and Simmons2014; Dang, Reference Dang2016). It is possible that there is a file-drawer problem, in which non-significant default studies are not published. To investigate this, we first create a funnel plot that plots the treatment effect of studies in a meta-analysis against a measure of study precision: in this case, Cohen's d as a function of the standard error (see Figure 2). Each black dot in Figure 2 represents an effect size. Higher-powered studies are located higher, and lower-powered studies are located lower. In the absence of publication bias, studies should be distributed symmetrically, depicted by the white shading in Figure 2. Reviewing the funnel plots highlights that several observations appear outside of the funnel on both sides, suggesting potential publication bias (Duval & Tweedie, Reference Duval and Tweedie2000).
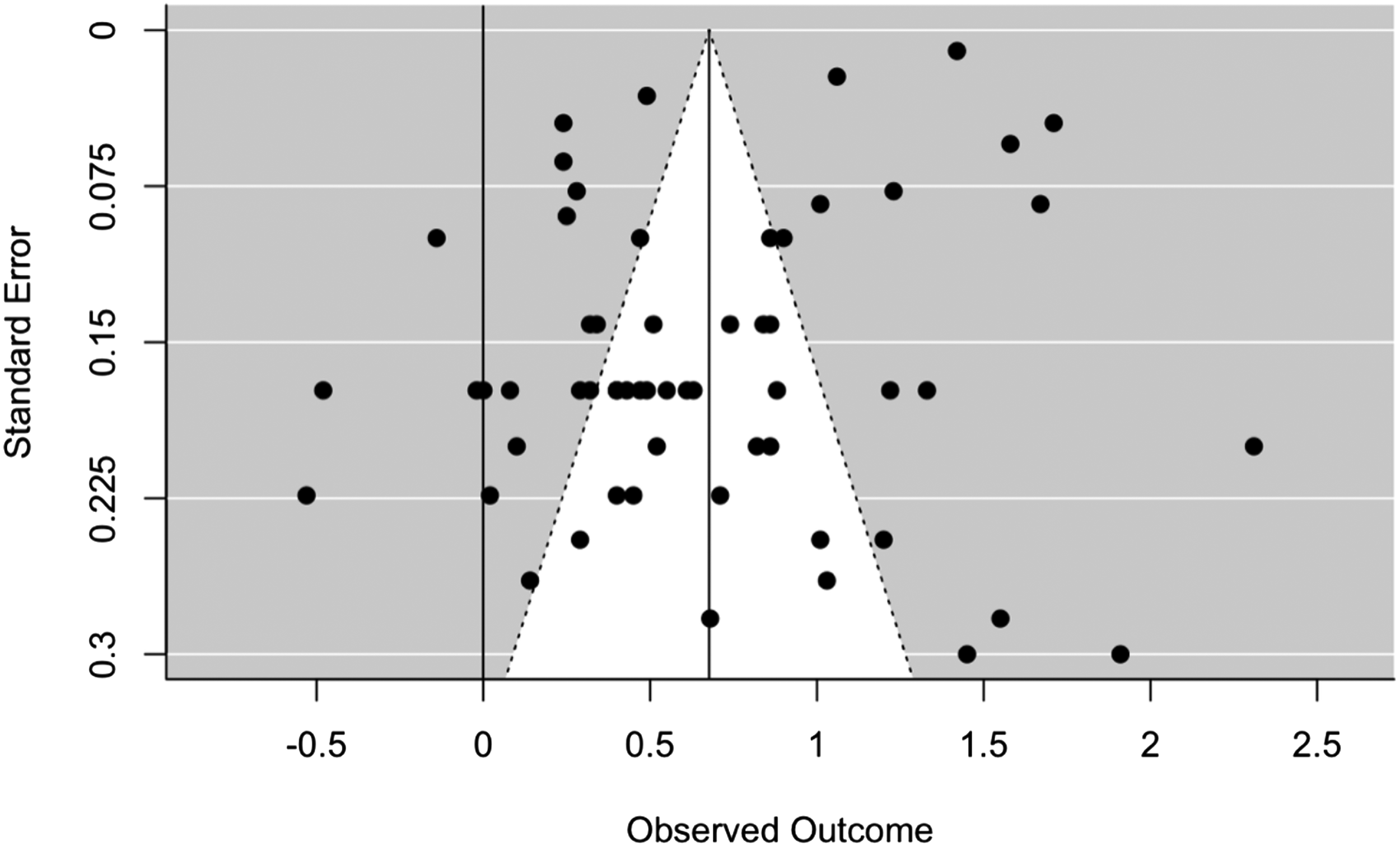
Figure 2. Funnel plot of individual effect sizes
We next conduct the trim-and-fill method, an iterative nonparametric test that attempts to estimate which studies are likely missing for a variety of reasons, such as publication bias, but also including other forms of bias (such as poor study design; Duval & Tweedie, Reference Duval and Tweedie2000). In simple terms, this method investigates which effect size estimates are missing, since, in the absence of any form of bias, the funnel should be symmetric. This analysis reveals that eight studies are missing from the funnel plot (represented by the white dots in Figure 3). Including these studies increases the overall effect to d+ = 0.80, 95% CI = 0.65–0.96, p < 0.001; this estimate remains directionally the same as our prior analysis and is significantly different from zero. This indicates that, if anything, default studies finding larger effects are missing from the literature. However, because Egger et al.’s (Reference Egger, Davey Smith, Schneider, Minder, Mulrow, Egger and Olkin1997) test for asymmetry of the funnel plot is not significant (t(56) = –0.39, p = 0.69), the likely absence of studies does not lead to inadequate estimation of the default effect. While this result is encouraging, Egger's regression is prone to Type I errors in cases where heterogeneity is high (Sterne et al., Reference Sterne, Sutton, Ioannidis, Terrin, Jones, Lau and Higgins2011), as is the case in the current meta-analysis. These results should thus be interpreted with caution.

Figure 3. Trim-and-fill funnel plot
Why do default effects vary?
While Figure 1 shows a sizeable average default effect, it also highlights significant variation in the effect size. Even by visually assessing the effect sizes in Figure 1, it becomes apparent that the default effect size varies widely: 46 observations find a statistically significant and positive effect (i.e., the observations are to the right of 0 and the confidence interval excludes 0), ten observations do not find a statistically significant effect (i.e., the confidence interval includes 0) and two observations find a statistically significant and negative effect (i.e., the observations are to the left of 0 and the confidence interval excludes 0).
To quantify the extent of the variability of the default effect, we conduct analyses that assess this heterogeneity using the I 2 statistic, a measure that reflects both the variability in the default effect and the variability in the sampling error. In our base model, we find an I 2 of 98.21%. We employ methods that apply the use of I 2 to multilevel meta-analytic models (Nakagawa & Santos, Reference Nakagawa and Santos2012) and find an I 2 of 98.01% for our three-level model (observation level, study level, and article level), which is considered to be very high heterogeneity (Higgins et al., Reference Higgins, Thompson, Deeks and Altman2003). This result is consistent with other analyses that find that the heterogeneity of effect sizes tends to increase as the effect size increases (Klein et al., Reference Klein, Ratliff, Vianello, Adams, Bahník, Bernstein and Nosek2014).
We further refine this analysis to distinguish between-cluster heterogeneity from within-cluster heterogeneity (Cheung & Chan, Reference Cheung and Chan2014). We do this because our model contains multiple variance components: for the article level (between-cluster) and for observations within the same studies and studies within the same articles (within-cluster heterogeneity). Parceling out these distinct sources, we find that 30.21% of the heterogeneity is at the article level, 63.58% is at the studies within-articles level, 4.21% is at the observations within-studies level, and the remaining 2.00% is due to sampling variance. This analysis suggests that there is significant variability in the size of default effects.
Given this variation in the size of defaults effect, we next explore potential explanations for it. We specifically examine two potential factors: (1) Do defaults differ because of the characteristics of the studies? (2) Do default studies that use different mechanisms produce different-sized default effects?
Do characteristics of the studies explain the default effect size?
To investigate whether characteristics of default studies partially explain some of the differences in effect sizes, we use methods from prior meta-analyses to assess additional study attributes (e.g., Carter et al., Reference Carter, Kofler, Forster and McCullough2015).
Study characteristics
Domain
We first code each study into three main types of domain: ‘environmental’ (‘0’ for non-environmental and ‘1’ for environmental, defined as making a choice that is related to pro-environmental behavior), ‘consumer choice’ (‘0’ for non-consumer choice and ‘1’ for consumer choice, defined as decisions related to buying a product or service) and ‘health’ (‘0’ for non-health and ‘1’ for health, defined as making a choice related to health care treatment, organ donation or health behaviors). We note that ten studies are coded as being in more than one domain (e.g., consumer choice of environmental products). The first two authors of the current manuscript coded each study's domain, and interrater reliability was high (Cohen's κ = 0.94).
Field experiment
We next code for the type of study it was: a field experiment, coded as ‘1’, or lab experiment, coded as ‘0’. We did so in order to determine whether studies in a real-world choice setting varied in default effect size in comparison to those in a hypothetical choice setting (online or in person). Some have suggested that lab experiments should have larger effect sizes due to a larger amount of control over the experiment (Cooper, Reference Cooper1981). However, others have found that field studies can elicit larger effect sizes than lab studies, in part because they are often preceded by a viability study, making those field studies that are conducted more likely to find a stronger effect (Peterson et al., Reference Peterson, Albaum and Beltramini1985).
Location
We then code for the study location (i.e., whether it was conducted in the USA, coded as ‘1’, or not in the USA, coded as ‘0’). In other words, this coding was conducted to explore whether the location of the participants who took part in the study influenced the default effect (see also Cadario & Chandon, Reference Cadario and Chandon2018).
Time of publication
We also code for the decade in which a paper was published, with ‘1’ being the 1990s, ‘2’ being the 2000s and ‘3’ being the 2010s. We specifically code for decade to determine whether default effect sizes have changed over the time that they have been studied, as effect sizes in published research frequently decrease over time (Szucs et al., Reference Szucs, Ioannidis, Nosek, Alter, Banks, Borsboom and Motyl2015).
Response mode
We characterize the dependent variables as binary (‘yes’ or ‘no’ choice), coded as ‘1’, or continuous (e.g., the amount of money invested or donated), coded as ‘0’. Given that these dependent variables involve a different type of choice, we aim to determine whether the default effect size varies based on which type of choice is made.
Sample size
We also code each observation for the total sample size, with ‘0’ reflecting a sample size below 1000 and ‘1’ reflecting a sample size above 1000. While effect size calculations should be independent of sample size, we explore whether the size of the default effect varies with the sample size across the studies. Since studies are more likely to be published if they find a statistically significant effect and it takes a larger effect size to achieve statistical significance in a small study than a large one, small studies may be more likely to be published if their effects are large (Slavin & Smith, Reference Slavin and Smith2009). Additionally, small studies tend to be of lesser methodological quality, leading to greater variability from studies with smaller sample sizes, which could introduce a higher probability of positive effect sizes (Kjaergard et al., Reference Kjaergard, Villumsen and Gluud2001).
Presentation mode
We also distinguish between studies where the default is presented online, coded as ‘1’, or not presented online, coded as ‘0’. For example, some defaults are presented via an in-person form, such as a default for a carbon-emission offset on a form, whereas others are presented via the internet, such as a default for a product selection while shopping online. We code for this to examine whether differences in presentation mode influence default efficacy.
Benefits self vs. others
To explore whether differences in who benefits from the choice influences the size of the default effect, we code for differences in the nature of the choice facing the participants; that is, whether the choice would be more beneficial to the self or to others. Choices that benefited the self more were coded as ‘1’ and choices that benefited others more were coded as ‘0’.
Financial consequence
Finally, to explore whether choices that involved a financial consequence would alter the default effect, we code for whether the choice that the participant made resulted in an actual financial consequence (i.e., donating a portion of their participation reimbursement to charity). Studies that included a financial consequence of choice were coded as ‘1’ and those that did not were coded as ‘0’.
Results: study characteristics
We add study characteristics as moderators to the prior random-effects model. For this model, only the regression coefficient for consumer domains (b = 0.73, SE = 0.23, p = 0.003; see Table 1) is statistically significant and positive, while the regression coefficient for environmental domains is marginally significant and negative (b = –0.47, SE = 0.27, p = 0.08). Including study characteristics as moderators reduces the heterogeneity by 4.67% to I 2 = 93.54%. Given that we extracted multiple effect sizes from some of the studies, we also re-ran the analysis using robust variance estimation using the ‘clubSandwich’ package (Pustejovsky, Reference Pustejovsky2015). However, the results of the analyses did not meaningfully change when using this estimation.
Table 1. Model results including study characteristics

Do study characteristics explain the variation in default effect size? Our analysis suggests that defaults are more effective in consumer domains and that the default effect may be weaker in environmental domains. No other study characteristic explained any further systematic variance in the variability of default effects present in prior studies. We next investigate whether the presence or absence of different mechanisms known to produce default effects partially explains why a default's effectiveness varies across studies.
Do different channels explain variation in default effect size?
A theory-based approach to meta-analyses suggests that insights from prior research can inform which factors may account for variation and can indicate how to investigate if the observed outcomes are following an expected pattern (Becker, Reference Becker2001; Higgins & Thompson, Reference Higgins, Thompson, Deeks and Altman2002). We use prior research to further investigate factors that explain the variation in defaults’ effectiveness. In particular, we draw on the framework developed by Dinner et al. (Reference Dinner, Johnson, Goldstein and Liu2011), who propose that defaults influence decisions through three psychological channels – endorsement, ease, and endowment – that can play a role both individually and in parallel (drawing on prior research, e.g., McKenzie et al., Reference McKenzie, Liersch and Finkelstein2006, on endorsement; and Choi et al., Reference Choi, Laibson, Madrian and Metrick2002, on the path of least resistance). That is, decision-makers are more likely to choose the pre-selected option because: (1) they believe that the intentions of the choice architect, as suggested through the choice design, are beneficial to them; (2) they can exert less effort when staying with the pre-selected option; and/or (3) they will evaluate other options in reference to the pre-selected option with which they are already endowed (Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011).
One interpretation of these findings is that defaults are more effective when they activate more channels; that is, the effects of the underlying mechanisms are additive. Similarly, defaults may be less effective – or may not influence decisions at all – if they activate fewer of the psychological channels in the minds of decision-makers. Because choice architects may not have perfect knowledge of the underlying drivers of defaults’ effectiveness, it is likely that there are systematic differences in the design of defaults and the activation of the channels driving its effects (Zlatev et al., Reference Zlatev, Daniels, Kim and Neale2017). We intend to exploit this occurrence and use it to evaluate the relative importance of each underlying driver to the default effect. We next describe each channel in more detail and describe how we code each study for the strength of each mechanism. Our aim is to examine whether the variation in default effects is partially driven by the extent to which different defaults activate these three channels.
The three channels: endorsement, ease, and endowment
Individuals commonly perceive defaults as conveying an endorsement by the choice architect (McKenzie et al., Reference McKenzie, Liersch and Finkelstein2006). As a result, a default's effectiveness is in part determined by whom decision-makers perceive to be the architect of the choice and by what their attitudes toward this perceived choice architect are. For example, one study finds that defaults are less effective when individuals do not trust the choice architect because the individuals believe that the choice design was based on intentions differing from their own (Tannenbaum et al., Reference Tannenbaum, Fox and Rogers2017). Endorsement is thus one mechanism that drives a default's effectiveness: the more decision-makers believe that the default reflects a trusted recommendation, the more effective the default is likely to be.
Decision-makers may also favor the defaulted choice option because it is easier to stay with the pre-selected option than to choose a different option. When an option is pre-selected, individuals may not evaluate every presented option separately, but rather may simply assess whether the default option satisfies them (Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012). In addition, different default designs differ in how easy it is for the decision-maker to change away from the default; when more effort is necessary to switch away from the pre-selected option, decision-makers may be more likely to stick with the default. Ease is thus a second mechanism that drives a default's effectiveness: the harder it is for decision-makers to switch away from the pre-selected option, the more effective the default is likely to be.
A third channel that drives the effectiveness of a default is endowment, or the extent to which decision-makers believe that the pre-selected option reflects the status quo. The more decision-makers feel endowed with the pre-selected option, the more likely they are to stay with the default as a result of reference-dependent encoding and loss aversion (Kahneman & Tversky, Reference Kahneman and Tversky1979). For example, one study finds that arbitrarily labeling a policy option as the ‘status quo’ increases the attractiveness of that option (Moshinsky & Bar-Hillel, Reference Moshinsky and Bar-Hillel2010). Endowment is thus a third mechanism that drives a default's effectiveness: the more decision-makers feel that the default reflects the status quo, the more effective the default is likely to be.
Coding the activation of the three default channels
It is not straightforward to identify whether the variation in default effects is explained by the activation of each of the three default channels. Ideally, we would have access to study respondents’ ratings of the choice architect to evaluate endorsement (as collected by Tannenbaum et al., Reference Tannenbaum, Fox and Rogers2017, and Bang et al., Reference Bang, Shu and Weber2018), measures of reaction time to evaluate ease (as collected by Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011) and measures of thoughts to evaluate endowment (as collected by Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011). However, these data are not available in the vast majority of default studies.
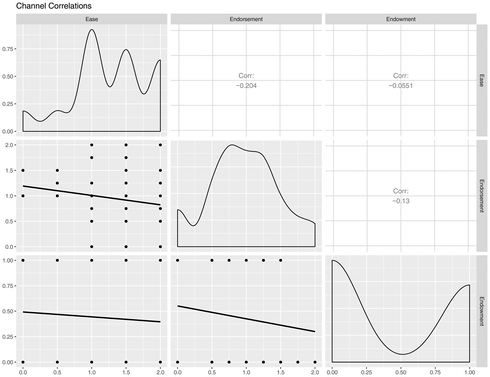
In the absence of such information, we trained two coders – a graduate student and a senior research assistant, who are not part of the author team – to rate each default study on the extent to which its design likely triggered each of the three channels (endorsement, ease and endowment; see Cadario & Chandon, Reference Cadario and Chandon2018, and Jachimowicz, Wihler et al., Reference Jachimowicz, Hauser, O’Brien, Sherman and Galinsky2018, for similar approaches). The two coders were first trained with a set of default studies that did not meet the inclusion criteria and next coded each default study on each of the three channels. Endorsement and ease were coded on a scale ranging from ‘0’ (this channel did not play a role) to ‘1’ (this channel played somewhat of a role) and ‘2’ (this channel played a role), rated on half-steps. For endowment, in trialing the coding scheme, we recognized that a scale of ‘0’ (this channel did not play a role) and ‘1’ (this channel played a role) is more appropriate. Appendix A contains a detailed description of the coding scheme. Interrater reliability, calculated via Cohen's κ, was acceptable for endorsement (κ = 0.59), ease (κ = 0.58) and endowment (κ = 0.80; Landis & Koch, Reference Landis and Koch1977). Correlations between channels are not statistically significant (see Appendix B for scatter plots and correlations).
Results: default channels
We subsequently add the coding for default channels to the prior random-effects model as moderators to evaluate whether these partially account for the variability of default effects. The analysis reveals that, as predicted, both endorsement (b = 0.32, SE = 0.15, p = 0.038) and endowment (b = 0.31, SE = 0.15, p = 0.044) are significant moderators of the default effect (see Table 2). Contrary to our prediction, ease is not a significant moderator (b = –0.05, SE = 0.15, p = 0.75). The addition of the coding for default channels further reduces heterogeneity to I 2 = 92.32%.
Table 2. Model results including default channels

As in the previous model, consumer domains remain statistically significant and positive (b = 0.89, SE = 0.23, p = 0.0003), and the environmental domain is now statistically significant and negative (b = –0.60, SE = 0.26, p = 0.028). We also re-ran the model using robust variance estimation using the ‘clubSandwich’ package (Pustejovsky, Reference Pustejovsky2015), and we find that in this analysis the endowment channel (b = 0.31, SE = 0.16, p = 0.081) and the environmental domain (b = –0.60, SE = 0.28, p = 0.056) drop to marginal significance; all other results hold in this specification. Finally, we test for multicollinearity by examining the correlation matrix of the independent variables and do not find evidence for multicollinearity, as all correlations were small to moderate, and most were nonsignificant.Footnote 2
General discussion
Defaults have become an increasingly popular policy intervention, and rightly so, given that our meta-analysis shows that defaults exert a considerable influence on individuals’ decisions: on average, pre-selecting an option increases the likelihood that the default option is chosen by 0.63–0.68 standard deviations, or a change of 27.24% in studies that report binary outcomes. If anything, our publication bias analyses highlight that larger effect sizes are underreported, suggesting that researchers may not bother to report replications of what are believed to be strong effects. While it is difficult to compare the effectiveness of defaults with other interventions outside of one focal study, we note that the effect for defaults we find in the current meta-analysis is considerably larger than a recent meta-analysis evaluation of healthy eating nudges (including plate size changes or nutrition labels, d = 0.23; Cadario & Chandon, Reference Cadario and Chandon2018), a recent meta-analysis of the effect of Opower's descriptive social norm intervention on energy savings (d = 0.32; Jachimowicz, Hauser et al., Reference Jachimowicz, Hauser, O’Brien, Sherman and Galinsky2018), as well as a meta-analysis of framing effects on risky choice (d = 0.31; Kühberger, Reference Kühberger1998). Thus, defaults constitute a powerful intervention that can meaningfully alter individuals’ decisions.
In addition, our analysis also reveals that there is substantial variation in the effectiveness of defaults, which indicates that a choice architect who deploys a default may have difficulty estimating the effect size he or she can expect from an implementation of defaults; this effect size may be substantially lower or higher than the meta-analytic average. This complicates the implementation of defaults by policy-makers, who, in order to decide which choice architecture tool to use, would like to know how large a default effect they can expect (Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012; Benartzi et al., Reference Benartzi, Beshears, Milkman, Sunstein, Thaler, Shankar and Galing2017). We note that this variation is likely driven by choice architects’ imperfect understanding of the consequences of differences in default designs (Zlatev et al., Reference Zlatev, Daniels, Kim and Neale2017).
To better understand the effectiveness of defaults and to enable policy-makers to better consider when and how to use defaults, we next examined factors that may at least partially explain the variation in defaults’ effectiveness, drawing on an earlier framework proposed by Dinner et al. (Reference Dinner, Johnson, Goldstein and Liu2011) and empirically supported by several subsequent studies (e.g., Tannenbaum et al., Reference Tannenbaum, Fox and Rogers2017; Bang et al., Reference Bang, Shu and Weber2018). Such an analysis is complicated by the fact that both study characteristics and potential mechanisms do not reflect systematic variation, but rather reflect the decisions of researchers about what studies to conduct and how to implement the default intervention. In addition, this analysis relies on our coders’ ability to identify which channel is activated, which may be called into question. With this caveat, we believe that there are two substantial insights to be gained from our analysis.
First, there are domain effects worth exploring. We find that consumer domains show larger default effects and environmental domains have smaller default effects. We can only speculate about why this occurs, identifying it as a question that awaits further research. Perhaps consumer preferences are less strongly held than preferences in other domains and environmental preferences more strongly – a hypothesis described in more detail in the ‘Limitations and future directions’ section below. Second, we show that if the design of the default activates two of the three previously hypothesized channels of defaults’ effectiveness (Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011), there is a significant increase in the size of the default effect.
However, we urge caution in interpreting these results, including the absence of an effect for ease. The ways that the three channels are measured in the current research are only noisy approximations, which attenuates our ability to detect systematic differences in the variability in defaults’ effectiveness. While our coding provides a tentative examination of these issues, this approach is useful only because the underlying mechanisms have not been measured in the vast majority of prior default studies. In particular, ease does not seem to be systematically manipulated in studies, but is often varied in real-world applications. For example, Chile changed the means of opting out of being an organ donor from checking a box during the renewal of national identity cards to requiring a notarized statement (Zúñiga-Fajuri, Reference Zúñiga-Fajuri2015), thus increasing the difficulty of switching away from the default. The set of studies included in our meta-analysis lacks this kind of variation, which may partially account for the lack of a statistically significant effect for ease.
For policy-makers, our findings contain an important lesson: design choices that may have come about inadvertently and may seem inconsequential can have substantial consequences for the size of the default effect. As a result, choice architects may want to more systematically consider the extent to which, for example, the decision-maker believes that the choice architect has their best interests in mind (endorsement), or to what extent decision-makers believe that the default is the status quo (endowment). Indeed, what may reflect more inadvertent decisions could turn into systematically made design decisions that could make the future implementation of defaults more successful. We next detail further necessary changes to help ensure this outcome is achieved.
Limitations and future directions
Defaults are often easy to implement, and this creates a temptation: to influence behavior, choice architects may prefer to set a default over other choice architecture tools. However, defaults vary in their effectiveness, and setting a default may not always be the most suitable intervention. In addition, choice architects are often inaccurate in their estimations of the default effect (Zlatev et al., Reference Zlatev, Daniels, Kim and Neale2017). Our analysis underscores that when implementing defaults, one must test applications rigorously, rather than just assuming that they will always work as expected (Jachimowicz, Reference Jachimowicz2017).
Our findings also suggest that future default studies should include measures of the default channels (endorsement, ease, and endowment). Where possible, choice architects could assess how decision-makers evaluate the choice architect's intentions, how easy decision-makers felt it was to opt out, or to what extent decision-makers believed that the default reflected the status quo. Ideally, these three mechanisms should be measured or manipulated systematically to better understand the size of default effects and the influence of context. For example, to test the endorsement channel of default effects, future research could systematically manipulate the source of who instituted the default (e.g., their status, purpose, etc.). In addition, we call on future studies to make more detailed information – including the original stimuli – publicly available in order to further help us to understand which channels may be driving a particular default's effectiveness. We note that studies have begun to explore the causal effects of these mechanisms, and we echo the call for future research to further advance this direction, especially as to how these effects may play out across different domains (e.g., Dinner et al., Reference Dinner, Johnson, Goldstein and Liu2011; Tannenbaum et al., Reference Tannenbaum, Fox and Rogers2017; Bang et al., Reference Bang, Shu and Weber2018).
In addition, because choice architects have many ways of influencing choices beyond defaults (Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012), we call on future research to evaluate defaults relative to alternative choice architecture tools. In our introduction, we describe the analogy of a worker's toolbox, who must understand when the use of what tool may be more or less appropriate. While gaining a deeper appreciation of the effect size and reasons underlying the variability of default effects is a first important step toward this end, we note that future research comparing default effects to alternative choice architecture interventions is a necessary complement. Such research would allow future studies to provide further insight into when and how defaults are more likely to exert a larger effect on decisions and in what cases policy-makers and other choice architects should rely on other tools in the toolbox (Johnson et al., Reference Johnson, Shu, Dellaert, Fox, Goldstein, Häubl and Weber2012; Benartzi et al., Reference Benartzi, Beshears, Milkman, Sunstein, Thaler, Shankar and Galing2017).
In addition, the effectiveness of defaults is particularly important given that prior research finds that public acceptance of choice-architecture interventions rests in part on their perceived effectiveness (Bang et al., Reference Bang, Shu and Weber2018; Davidai & Shafir, Reference Davidai and Shafir2018). That is, an increase in the perceived effectiveness of choice-architecture interventions makes others view the intervention as more acceptable. To improve rates of acceptance of choice-architecture interventions more broadly, and of defaults more specifically, future studies could explore how the communication of the default effect found in the meta-analysis presented here would influence the evaluation of their further implementation. An application of defaults across policy-relevant domains may therefore rest on the communication of their effectiveness (Bang et al., Reference Bang, Shu and Weber2018; Davidai & Shafir, Reference Davidai and Shafir2018).
We also propose additional variables that may moderate the default effect but could not be included in the current study due to a lack of available data, and we call on future research to either measure or manipulate these variables. One such variable is the intensity of a decision-maker's underlying preferences – what one might call ‘preference strength’. When individuals care deeply about their inclination regarding a particular choice, they are more likely to have thought about their decisions and to be resistant to outside influence (Eagly & Chaiken, Reference Eagly, Chaiken, Petty and Krosnick1995; Crano & Prislin, Reference Crano and Prislin2006). In other words, defaults may be less likely to influence those who have strong preferences. Our finding that defaults in consumer domains are more effective and defaults in environmental domains less effective could in part be explained by this perspective, as preferences for consumption may be less strongly held than preferences for environmental choices.
A closely related but distinct moderator may focus on how important a particular decision is to an individual – what one might call ‘decision importance’. That is, while individuals may believe that a particular decision is important, they may not have strongly formed preferences to help inform them how to respond. In cases where decision importance is high, individuals may be especially motivated to seek out novel information or otherwise exert effort to ascertain their decision. As a result, defaults that operate primarily through the ease channel may be less likely to have an effect in such circumstances, as individuals will be more motivated to exert effort.
Another important factor may be the distribution of underlying preferences. In some cases, the population of decision-makers may largely agree on what they want; in other cases, they may vastly differ in opinion. This perspective is built into the design of defaults, which are based on the assumption that they allow those whose preferences are different from the default option to easily select an alternative (Thaler & Sunstein, Reference Thaler and Sunstein2008). However, this also suggests that defaults may be less effective in settings where preferences vary more widely than in instances where individuals’ preferences diverge less, as the prevalence of decision-makers who disagree with the default is higher. We note that there may also be cases where the variance in underlying preferences is low, but because they are misaligned with the default, it may also be less effective.
Future research could therefore further investigate how the underlying preferences of the population presented with the default shape the default's effectiveness. That is, researchers and policy-makers interested in deploying defaults may have to consider what the distribution of decision-makers’ underlying preferences is and how strongly these individuals hold such preferences. This could be done by including a forced-choice condition to assess what occurs in the absence of defaults, which would also allow the choice architect to see what the distribution of preferences might be in the absence of the intervention. We note that one consequence of a better understanding of the heterogeneity of underlying preferences could be the design of ‘tailor-made’ defaults, whereby the pre-selected choice differs as a function of the decision-makers’ likely preferences (Johnson et al., Reference Johnson, Hassin, Baker, Bajger and Treuer2013). Evaluating the intended population's preferences may therefore reflect a crucial component in deciding when to deploy defaults.
Conclusion
On average, defaults exert a considerable influence on decisions. However, our meta-analysis also reveals substantial variability in defaults’ effectiveness, suggesting that both when and how defaults are deployed matter. That is, both the context in which a default is used and whether the default's design triggers its underlying channels partially explain the variability in the default effect. To design better defaults in the future, policy-makers and other choice architects should consider this variability of default studies and the dynamics that may underlie it.
Appendix A. Default meta-analysis coding scheme
The following coding scheme was developed to investigate possible underlying channels of default effects in existing studies. A channel is a pathway through which the effects of making one choice option the default can occur. For example, a default's effectiveness may unfold through the endorsement that is implied by the default; namely, decision-makers may believe that the choice of default suggests which course of action is recommended by the choice architect.
Three channels for defaults’ effectiveness have been identified in the prior literature, and the effect of any given default in a study may happen through three, two, one or none of these channels. Presumably, a default has a stronger effect if more channels are involved. The default effect may also vary depending on how strongly each channel is involved.
The aim of this coding scheme is for you to provide expert judgment of whether and how strongly each of the three channels should be expected to be involved in each of the default studies that we have identified.
Below, we outline what each of the three channels is. We hope that, in the end, you will be able to provide three scores for each default study, describing the extent to which you think each of the three channels is involved in that study (i.e., one score for each channel). Obviously, this is a subjective assessment, but your training and your personal introspection will hopefully allow you to make this type of assessment.
Endorsement
The decision-maker perceives the default as conveying what the choice architect thinks the decision-maker should do. For example, setting organ donation as the default communicates to decision-makers what the choice architect believes is the ‘right’ thing to do. One factor that may therefore influence how much this channel will influence a default's effectiveness is how much the decision-makers trust and respect the architect of the decision-making design.
For this rating/code, we would like you to rate the extent to which you think decision-makers perceived the default as a favorable recommendation from the choice architect. The scale has three levels: ‘0’ (this channel does not play a role), ‘1’ (this channels plays somewhat of a role) and ‘2’ (this channel plays a role).
Ease
Defaults are effective in part because it is easier for individuals to stay with the pre-selected option than to choose a different option. The decision of whether or not to stay with the default may then be influenced by how difficult it is to change the default. For example, if it is particularly difficult to opt out of a default (i.e., when the steps that one has to take in order to switch the default require a lot of effort), then ease may underlie the default's effectiveness. The more effort it takes to change the default, the more likely individuals may be to stay with the pre-selected option.
For this rating/code, we would like you to rate how difficult you think changing the default option was. The scale has three levels: ‘0’ (this channel does not play a role), ‘1’ (this channels plays somewhat of a role) and ‘2’ (this channel plays a role).
Endowment
The effectiveness of a default also varies depending on the extent to which decision-makers think about the pre-selected option as the status quo. The more decision-makers feel endowed with the pre-selected option and evaluate other options in comparison to it, the more likely they are to stay with the default. For example, if the default has been in place for a while and therefore has been part of the decision-maker's life, then they are likely to feel more endowed with it. Endowment with the default may be greater when the default is presented in a way that reinforces the belief that the default is the status quo. Endowment with the default may also be greater when the decision-maker has little experience in the choice domain.
For this rating/code, we would like you to rate how much you think decision-makers felt endowed with the default option. The scale is binary: ‘0’ (this channel does not play a role) or ‘1’ (this channel plays a role).
Appendix B. Default meta-analysis channel scatter plot and correlations






 Open access
Open access