




Highlights
-
• Cognate facilitation effects in bilingual visual word recognition not only depend on shared phonology but also the orthographic depth.
-
• Language-dependent processing mechanisms play a crucial role in bi-script readers, supporting the ODH in bilingualism.
-
• Bilingual word recognition models should incorporate orthographic depth as a factor.
1. Introduction
Most current theories of bilingualism hold the view that the lexical representations of bilinguals’ two languages are integrated at the conceptual/semantic level but are separate at the levels of orthography and phonology (e.g., the Sense Model of Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004; the bilingual interactive activation [BIA+] of Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002). The cross-language masked priming paradigm has provided an extremely productive testing ground to support this claim (e.g., Chen & Ng, Reference Chen and Ng1989; Davis et al., Reference Davis, Sánchez-Casas, Garcia-Albea, Guasch, Molero and Ferré2010; De Groot & Nas, Reference De Groot and Nas1991; Dimitropoulou et al., Reference Dimitropoulou, Duñabeitia and Carreiras2011; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010; Duyck & Warlop, Reference Duyck and Warlop2009; Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004; Gollan et al., Reference Gollan, Forster and Frost1997; Grainger & Frenck-Mestre, Reference Grainger and Frenck-Mestre1998; Jiang & Forster, Reference Jiang and Forster2001; Keatley et al., Reference Keatley, Spinks and de Gelder1994; Perea et al., Reference Perea, Duñabeitia and Carreiras2008; Schoonbaert et al., Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009; Wang, Reference Wang2013, Reference Wang2021; Wang & Forster, Reference Wang and Forster2010; Wang & Forster, Reference Wang and Forster2015; Wang et al., Reference Wang, Taft, Wang and Kim2021; Wang et al., Reference Wang, Steinman and Taft2023, etc.). This paradigm presents one pair of words from each of the two languages sequentially, with a very brief duration for the first word as the prime (50 ms) and a longer duration for the second word as the target (500 ms). Because of the brief presentation of the prime and the presence of a forward mask (####), participants are usually unaware of the prime (Forster & Davis, Reference Forster and Davis1984). If the cognitive system can process primes automatically and unconsciously to influence the subsequent processing of the targets (i.e., show a priming effect), we can draw inferences about the prime–target relationship in the mental lexicon.
Even when primes are under the awareness of bilinguals, priming studies consistently demonstrate cross-language facilitation effects due to either shared orthography and semantics (i.e., cognates, e.g., Davis et al., Reference Davis, Sánchez-Casas, Garcia-Albea, Guasch, Molero and Ferré2010) or shared semantics only (i.e., translation equivalents, e.g., Wang & Forster, Reference Wang and Forster2010). Specifically, masked priming studies have presented a strong test of cross-language activation in bilingual readers whose two languages either use the same writing system (i.e., within-script bilinguals, such as Spanish-English, e.g., Davis et al., Reference Davis, Sánchez-Casas, Garcia-Albea, Guasch, Molero and Ferré2010) or different writing systems (i.e., cross-script bilinguals, such as Chinese-English, e.g., Wang & Forster, Reference Wang and Forster2010). Within-script bilinguals generally show stronger cross-language priming effects in cognates due to the overlap at both orthographic and semantic levels, compared to non-cognate translation equivalents (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Voga & Grainger, Reference Voga and Grainger2007; Zhang et al., Reference Zhang, Wu, Zhou and Meng2019). This cognate facilitation effect has also been observed in bilingual production studies (e.g., Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; Lalor & Kirsner, Reference Lalor and Kirsner2001; Marte et al., Reference Marte, Peñaloza and Kiran2023).
2. The cognate status in the bilingual lexicon
Cognates are those translation words that have similar orthographic-phonological forms in the two languages of a bilingual (e.g., bed-Dutch, bed-English); non-cognates are those translations only sharing their meaning in the two languages (e.g., fiets-Dutch, bike-English). Obviously, the cognate–non-cognate contrast is only meaningful in the context of bilingualism. The cognate facilitation effect has been taken to argue for the shared mental representations cross-linguistically in both forms and meaning. When bilinguals’ two languages are of the same scripts, this effect is usually interpreted as the result of cross-language overlap at both orthographic and phonological levels, in addition to semantic equivalence (e.g., (Brysbaert et al., Reference Brysbaert, Van Dyck and Van de Poel1999; Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010, Dijkstra et al., Reference Dijkstra, Peeters, Hieselaar and Van Geffen2023; Duyck et al., Reference Duyck, Van Assche, Drieghe and Hartsuiker2007, etc.). This is due to the relatively consistent grapheme-to-phoneme correspondence in a writing system where phonological activation occurs automatically at the initial stage of visual word recognition (e.g., Grainger & Ferrand, Reference Grainger and Ferrand1996). For example, Brysbaert et al. (Reference Brysbaert, Van Dyck and Van de Poel1999) showed masked phonological priming in both L1–L2 and L2–L1 directions in Dutch-French bilinguals when the primes were either homophonic or pseudo-homophonic to the targets.
Empirical efforts over cross-script language pairs have demonstrated similar facilitation effects of cognates over non-cognates but with substantial controversies (e.g., Gollan et al., Reference Gollan, Forster and Frost1997; Kim & Davis, Reference Kim and Davis2003; Voga & Grainger, Reference Voga and Grainger2007; etc.). This effect observed in cross-script bilinguals suggests the sole contribution of phonology in bilingual visual word recognition because two scripts/languages have distinct orthographic features (i.e., no orthographic overlap). For example, a variety of bilingual studies investigating language pairs using different writing systems reported this effect, such as the study of Hebrew-English cognates (Gollan et al., Reference Gollan, Forster and Frost1997), Greek-French cognates (Voga & Grainger, Reference Voga and Grainger2007), Japanese-English cognates (Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2013; Nakayama et al., Reference Nakayama, Verdonschot, Sears and Lupker2014) and Chinese-English cognates (Zhang et al., Reference Zhang, Wu, Zhou and Meng2019). As discussed earlier, a notable distinction between cognates in languages of distinct scripts (e.g., Chinese and English) and those in languages of the same scripts (e.g., Dutch and English) is the form level overlap only in phonology but not orthography. This difference provides a unique opportunity to understand the cognitive processes of phonology involved in bilingual word recognition.
When a bilingual’s two languages are typologically distant (e.g., Chinese-English), cognates usually result from the process of borrowing from one language to the other language. A good number of Chinese words are assimilated from English and are phonologically adapted to their corresponding English words, known as loanwords. These loanwords can be categorized into two main types, as described by Kim (Reference Kim2018): sense loans, which adopt only the meaning of the original English word without any phonological resemblance, such as 拳击 (quanji “fist hit,” meaning boxing); and transliterations, which are phonetically similar to the original English words but their morphemic/syllabic combinations are nonsensical in Chinese, often referred to as opaque compound words, like 巴士 (“a type of surname + a type of man,” pronounced as bashi meaning bus). As cognates are typically defined by both semantic and form similarities cross-linguistically, this current study will focus on transliterations. The reverse borrowing process from Chinese to English also yields cognates, as seen in examples like jiaozi (饺子, meaning dumplings) and wonton (云吞, a type of dumpling).
3. Cognate facilitation effects in bi-script readers
Studies of bi-script readers are generally concerned with whether cognates show facilitation effects driven by phonology only, given the minimally shared orthographic features between languages. One of the earliest studies showing the cognate facilitation effect is Gollan et al. (Reference Gollan, Forster and Frost1997). With the lexical decision, the authors investigated the effects of cross-script masked translation priming on cognates and non-cognates among Hebrew-English bilinguals and English-Hebrew bilinguals, examining priming in both language directions (L1–L2 and L2–L1). For each bilingual group and language direction, they assessed three types of priming effects for both cognates and non-cognates: repetition priming within L1, repetition priming within L2 and translation priming. In terms of translation priming, their findings revealed that the L2–L1 direction did not yield any significant priming effects. However, in the L1–L2 direction, both cognate and non-cognate priming effects were observed, with cognate priming being substantially stronger than non-cognate priming. This difference was particularly pronounced among English-dominant bilinguals. These results suggest that the cognate facilitation effect might depend on the scripts as Hebrew is opaquer than English, given the more obviously stronger cognate priming than non-cognate priming in English-dominant bilinguals, compared to Hebrew-dominant bilinguals.
Later, Voga and Grainger (Reference Voga and Grainger2007) proposed a phonological account to explain the cognate facilitation effect, suggesting that it stems from the phonological similarities between primes and targets for both cognates and non-cognates. In line with this hypothesis, they conducted a study comparing the priming effects of Greek-French cognates (e.g., πιάνο/piano/−piano), phonologically similar non-cognate primes (e.g., πιάνω/grasp/− piano) and unrelated primes (e.g., τζάκι/chimney/−piano). The findings revealed that both cognates and phonologically related primes produced similar levels of priming compared to unrelated primes, underscoring the role of phonological overlap in cross-script cognate processing.
While Voga and Grainger’s study was pioneering in advocating for the phonological account of the cognate facilitation effect, it faced criticism from subsequent researchers, including Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013). A significant limitation of their study was that Greek and French are only partially distinct but share some alphabetical letters in their writing systems (e.g., o, p, v, etc.). This could have confounded the results. For instance, the cognate pair πιάνο–piano exhibits a shared letter “o,” complicating the distinction between orthographic and phonological influences on the cognate facilitation effect. This overlap in orthography introduced ambiguity regarding the role of orthography in this effect, casting doubt on the study’s ability to exclusively validate the phonological account.
To address this flaw, Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013, Reference Nakayama, Verdonschot, Sears and Lupker2014) selected languages with completely distinct writing systems, namely, Japanese and English. By examining the cognate priming effects in Japanese-English bilinguals, they aimed to provide a more rigorous test of the phonological account using the masked translation priming paradigm. The distinct writing systems of Japanese and English allowed for a clearer separation of orthographic and phonological effects. Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013) found that the masked translation priming effect was more pronounced for cognates than for non-cognates, with this facilitation observed when both Japanese (Experiment 1) and English (Experiment 2) words served as primes. These findings offered more compelling evidence in support of the phonological account of cognate facilitation, demonstrating that the effect is robust across different writing systems and is primarily driven by phonological overlaps.
However, direct comparisons between Japanese-English cognates and non-cognates present a challenge. This is due to the inherent differences between cognates and non-cognates written in the Japanese language. Japanese employs two scripts: Kana, which is a phonetic script consisting of Katakana and Hirakana, and Kanji, which is a logographic script closely related to Chinese characters (Yamada, Reference Yamada1998). Katakana corresponds to moras, the basic units of Japanese phonology, while Kanji represents meanings or concepts. Japanese-English cognates, such as レモン/remon/ (lemon), are typically written in Katakana, whereas non-cognates, such as 女性/josei/ (woman), are represented by Kanji. Kana is a transparent script which directly maps to phonology; while Kanji is an opaque script whose correspondence to phonology is arbitrary. This script difference between cognates and non-cognates across Japanese and English makes the comparison to show the cognate facilitation effect less straightforward, contradicting the assumption of script homogeneity for cognate and non-cognate primes. Despite Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013, Reference Nakayama, Verdonschot, Sears and Lupker2014) ensuring that primes and targets belonged to different languages of distinct writing systems (Japanese and English), the inherent variability within the Japanese script (between Kana and Kanji) could not be controlled for. Consequently, the language pair of Japanese and English might not be the best candidate to tease apart the relative contributions from orthography and phonology in the cognate facilitation effect.
The language pair of Chinese and English provides a unique case to study the relative contributions of orthography and phonology in the cognate facilitation effect. In a recent study by Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019), the researchers designed an investigation into cross-script cognates across Chinese and English, ensuring that the primes and targets originated from distinctly different writing systems and that primes were in the same script (in contrast to Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2013, Reference Nakayama, Verdonschot, Sears and Lupker2014). In their first experiment, the primes were Chinese words (L1), consisting of both Chinese-English cognates and non-cognates, with the targets being English words (L2). The second experiment reversed the prime and target. Experiment 1 showed no discernible difference in the translation priming effects between cognates and non-cognates when the primes were in L1 Chinese. However, Experiment 2 yielded a different outcome, showing priming only in cognates but not non-cognates when the primes were in L2 English, inconsistent with the results in Gollan et al. (Reference Gollan, Forster and Frost1997) who only found cognate priming in L1–L2.
Thus, Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019) only found cognate facilitation when the primes were in L2 English but not L1 Chinese. This piece of evidence appears to suggest whether and how phonology was effectively computed as masked primes depends on the orthographic depth. That is, an alphabetic language (e.g., English) is more likely to produce cognate facilitation effects due to the grapheme–phoneme correspondence. An opaque orthography (e.g., Chinese characters) is less likely to produce cognate facilitation effects due to the arbitrary correspondence between characters and their phonology. However, Zhang et al.’s design is not able to answer this question due to two reasons. First, cross-language cognate processing is susceptible to priming asymmetry established in the literature (e.g., Finkbeiner et al., Reference Finkbeiner, Forster, Nicol and Nakamura2004; Gollan et al., Reference Gollan, Forster and Frost1997; Jiang, Reference Jiang1999; Wang, Reference Wang2013; Wang & Forster, Reference Wang and Forster2010; etc.); that is, non-cognate L2–L1 translation priming is usually absent but L1–L2 translation priming is usually robust. Therefore, the lack of L2–L1 priming in non-cognates cannot be explained only by the lack of phonological overlap compared to cognates. Second, without a condition where phonological similarities between Chinese and English are controlled and tested for priming, one cannot draw the conclusion whether phonology itself plays a role in cross-script cognate processing.
4. The present study
The ODH was proposed in the monolingual reading literature to argue for the differences among alphabetic orthographies in processing printed words (Katz & Frost, Reference Katz, Frost, Frost and Katz1992). It states that shallow orthographies are more easily able to support the word recognition process that involves the language’s phonology (e.g., Serbo-Croatian, a completely transparent writing system with strict one-to-one mapping between graphemes and phonemes), and deep orthographies encourage a reader to process printed words via the orthographic-lexical route (e.g., Hebrew, an opaque writing system which represents morphological invariance instead of phonemes). The important assumption here is that phonological encoding depends on the degree of consistency in grapheme-to-phoneme correspondence among alphabetic languages. Further, Katz and Frost argued that shallow orthographies are optimized for assembling phonology during lexical access, and they are more easily available to readers pre-lexically than is the case for deep orthographies. In other words, alphabetic orthographies make some use of assembled phonology for word recognition, and phonological encoding is more available to shallow orthographies. Further, Ziegler and Goswami’s more recent grain size theory proposes that phonological representation is influenced by the phonological similarity among words in the mental lexicon, which implies a more consistent mapping between phonemes and graphemes in shallow orthographies, compared to opaque orthographies (Reference Ziegler and Goswami2005). The case of English sits between Serbo-Croatian and Hebrew because English spelling represents a morphophonemic invariance such that there are substantial ambiguities in grapheme-to-phoneme correspondence. Nevertheless, some even argue for the obligatory involvement of phonological encoding in English (e.g., Perfetti et al., Reference Perfetti, Bell and Delaney1988; Van Orden et al., Reference Van Orden, Pennington and Stone1990, etc.).
In contrast, the phonological mediation during lexical access in logographic languages, Chinese for example, is subject to debate. The Chinese writing system is opaque and based on characters, each of which represents a morpheme and syllable. It has been shown that Chinese word recognition bypassed phonology and primarily relied on the orthographic-lexical route (e.g., Chen & Shu, Reference Chen and Shu2001; Yan et al., Reference Yan, Tsang and Pan2024; Zhou & Marslen-Wilson, Reference Zhou and Marslen-Wilson1999, Reference Zhou and Marslen-Wilson2000). Therefore, it is reasonable to assume that phonological encoding in Chinese reading is not as available as that in English. Given this orthographic difference, a bi-script reader, e.g., Chinese-English, would present a unique case to understand how distinct scripts are processed via the orthographic-lexical route and/or orthographic-phonological route in one mind. Chinese is written in a logographic system, while English is written in an alphabetic system. When these two distinct orthographic systems are represented in one mind, one of the key questions is how phonology is involved in visual word recognition.
To test the ODHFootnote 1 in bilingualism, we developed a novel design to investigate whether cross-script cognate facilitation effect depends on the orthographic depth of the script served as primes by testing two different groups of bilinguals, namely, Chinese-English bilinguals (L1-Chinese) and English-Chinese (L1-English) bilinguals. Because L1–L2 priming is much more robust and reliable in bilinguals, testing two groups in their L1s as primes would allow us to answer the above research question (e.g., Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010; Jiang & Forster, Reference Jiang and Forster2001; Wen & van Heuven, Reference Wen and van Heuven2016; Xia & Andrews, Reference Xia and Andrews2015). In addition, we incorporated a phonologically related condition to measure against both cognate and unrelated prime conditions such that a phonological account could be more rigorously tested. This additional condition includes pseudowords that match the cognate primes in phonology, which will enable us to test whether phonological overlap itself without either orthographic similarities or shared lexical representations would play a role in cross-script priming. By comparing the responses to these phonologically related pseudowords with cognates, we aim to gain a clearer understanding of the specific influence of phonological overlap in cross-script cognate processing.
5. Experiment 1
Experiment 1 aims to investigate the cross-script cognate facilitation effect in Chinese-English bilinguals in the L1 (Chinese) to L2 (English) direction, employing the masked translation priming paradigm. To test whether both lexical and non-lexical phonological decoding could be observed in masked primes, we designed two priming conditions, namely, cognate and cross-language pseudo-homophones (See Table 1). The phonologically related condition is designed to determine whether non-lexical phonological similarity alone can elicit priming effects to validate whether translation priming observed in both cognates and non-cognates is partially driven by phonology.
Table 1. Sample stimuli in Experiment 1
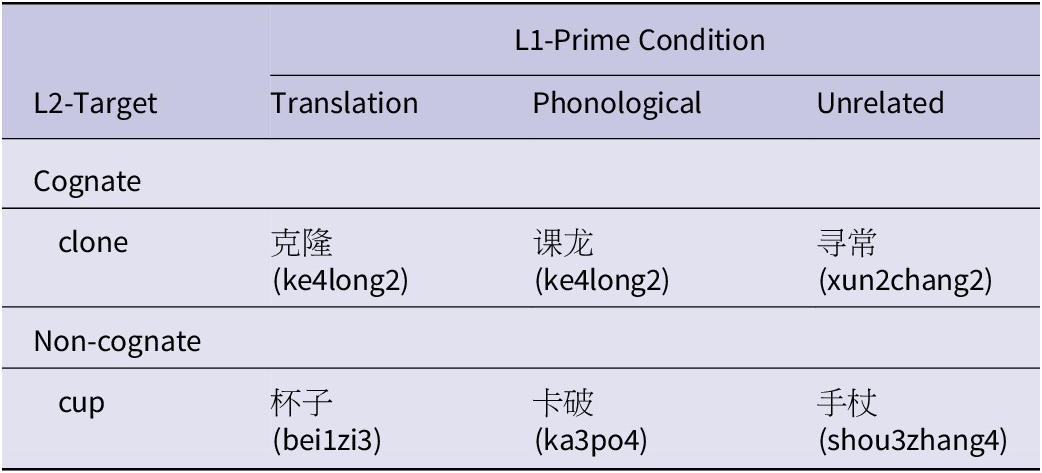
Note: Pinyin of each character is included in parentheses. The numbers indicate the tone of that character.
5.1. Method
5.1.1. Participants
The current study was approved by the National University of Singapore (NUS) (Institution Review Board) IRB Board at the Faculty of Arts. Twenty-five Chinese-English bilinguals were recruited from NUS and paid to participate in Experiment 1. They were all international students from China (mean age of 22.1 ± 2.3 years). Prior to the experiment, each participant completed a language background questionnaire, including self-assessing their language proficiency in reading, writing, speaking and listening in both Chinese and English, using a 7-point Likert scale (with 1 representing “very poor,” 2 as “poor,” 3 as “fair,” 4 as “functional,” 5 as “good,” 6 as “very good,” and 7 as “native-like”).
They were native speakers of Chinese and learned English as a second language around the age of 11. They had all met the standards of the Qualifying English Test (QET), a comprehensive English language examination administered by NUS to assess the English capabilities of students from non-English-speaking countries. A passing grade on the QET is indicative of a high level of English proficiency, exempting students from the need to take supplementary English language courses at NUS.
Their English proficiency levels across various language skills were notably lower compared to their Chinese language abilities, indicating that they were unbalanced bilinguals with a stronger command of their native Chinese than their second language, English. Participants’ self-assessed language proficiency including the mean proficiency scores, and the standard deviations (SD) for each language skill is presented in Table S1 in Supplementary Material or at Open Science Framework (OSF) (https://osf.io/hykmj/). t-tests showed that their four language skills differed significantly between Chinese and English (all p < .05), indicating L1 Chinese is more dominant than L2 English.
5.2. Materials and design
We selected a set of 108 critical stimuli, consisting of 54 Chinese-English cognates and 54 non-cognate translation equivalents. Our design is 3 X 2 factorial (also see Table 1), with three different types of primes (translation versus phonological versus unrelated) and two types of targets (cognate versus non-cognate). The prime type is within item and within participant, while target type is between item but within participant. For example, given an English target in the cognate condition (e.g., clone), three types of L1 Chinese primes were used: its direct translation (e.g., 克隆), a phonologically related prime (e.g., 课龙), and an unrelated prime (e.g., 寻常). The phonologically related primes were created by replacing the characters in the translation primes with different characters but of identical pronunciations and tones, resulting in interlingual pseudo homophones. Critically, these character combinations are non-lexical in Chinese, but they sound like cognates. For non-cognate targets (e.g., cup), similarly, the phonologically related primes were designed as interlingual pseudo-homophones (e.g., 卡破), except that their phonology resembles the targets, but not the translation primes. In both cognate and non-cognate conditions, the unrelated primes served as the baselines without any overlap with the targets. The Chinese primes in the unrelated condition were matched in stroke number and word frequency with the other two conditions. The English targets were matched in letter length to ensure consistency across conditions. Detailed information on the English targets and their corresponding Chinese primes can be found in the Supplementary Materials (Appendix A) or at OSF (https://osf.io/hykmj/).
Nonword targets were created based on the Australian Reading Center (ARC) nonword database (Rastle et al., Reference Rastle, Harrington and Coltheart2002) to match the word targets in length and they were one letter different from a real word. Chinese primes were also generated to match the three prime conditions regarding phonological overlap between the prime and target. Specific statistics such as word frequency, word length and stroke count of stimuli in both languages are presented in Table S2 in Supplementary Material. To ensure that every target was presented in all three priming conditions, three counterbalanced lists were generated for testing.
5.3. Procedure
The experiment was programmed with the DMASTR/DirectX (DMDX) software (Forster & Forster, Reference Forster and Forster2003). The Chinese primes were displayed in SimSun font, size 10 and bolded, while the English targets were shown in Courier New font, size 13.5, in lowercase bold letters. Each trial commenced with a 500 ms forward mask (贔贔贔贔), which was immediately followed by a Chinese prime displayed for 50 ms, and then, the English target word appeared for 500 ms.
Participants were randomly allocated to one of the three experimental lists. Prior to the task, participants were given written instructions in English, which directed them to rapidly determine if the displayed sequence of letters formed a valid word and to respond by pressing either the “YES” or “NO” button accordingly. Ten practice trials proceeded the actual experimental trials.
5.4. Results
Data analyses were based on word trials, excluding those whose error rate was higher than 30%. As a result, one participant was excluded from the analysis and our sample size is 24.
Reaction times (RT) that were either below 200 milliseconds or exceeded 2000 milliseconds were excluded from the analysis. The priming effect was determined by taking the mean RT of a specific condition and subtracting it from the mean RT of the unrelated condition in the target language. The RT data underwent a log transformation prior to analysis. The analysis was conducted using linear mixed-effects modeling with the afex package (Singmann et al., Reference Singmann, Bolker, Westfall, Aust and Ben-Shachar2015) for performing mixed model analyses and the emmeans package (Baayen et al., Reference Baayen, Davidson and Bates2008; Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2018) for post hoc comparisons. This was all done within the R environment (R Core Team, 2015, version 3.2.1) using RStudio as the integrated development environment.
In our analysis, we utilized maximal random effect structures within our models, incorporating random slopes for factors involved in repeated measures to mitigate the risk of type I errors (Barr et al., Reference Barr, Levy, Scheepers and Tily2013). The fixed-effect factors in our models included word type (two levels: cognate and non-cognate) and prime type (three levels: translation, phonological pseudoword and unrelated). Both participants and items were treated as random factors. Our approach to model establishment began with the most comprehensive model allowed by the design, which we then simplified in response to convergence issues (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017).
To address these convergence errors, we undertook a stepwise simplification of an overparameterized model. This involved sequentially removing the least influential elements, such as the correlation parameter, higher-order interactions and random effect terms with the lowest variance (Singmann & Kellen, Reference Singmann, Kellen, Spieler and Schumacher2019). All post hoc analyses were conducted using the emmeans package and were adjusted for multiple comparisons using the Holm–Bonferroni method. Consistent with standard practice, any p-value below .05 was considered to indicate statistical significance. Table 2 presents the mean reaction times (RTs) and error rates for Experiment 1.
Table 2. Lexical decision latencies (RT in ms) and error rates (Error in %) of L2 English (Experiment 1)

Reaction Times Analysis. The final mixed-effects model is a simple one, as in (1), including a random intercept for the participant and a random intercept for the item.
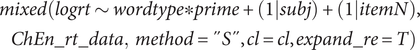 $$ {\displaystyle \begin{array}{l} mixed\Big( logrt\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em ChEn\_ rt\_\mathit{data,}\ method="S", cl= cl, expand\_ re=T\Big)\end{array}} $$
$$ {\displaystyle \begin{array}{l} mixed\Big( logrt\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em ChEn\_ rt\_\mathit{data,}\ method="S", cl= cl, expand\_ re=T\Big)\end{array}} $$
This model showed the main effect of prime: F(2, 2061.60) = 31.09, p < .001, but neither a main effect of word type, F(1, 101.89) = 0.02, p = .880, nor an interaction between word type and prime, F(2, 2061.36) = .87, p = .421, indicating no cognate facilitation effect. Further pairwise contrast analyses (see Table 3) showed significant translation priming for both cognates (73 ms), z = −6.159, p < .0001, and non-cognates (50 ms), z = −4.327, p = .0001. In addition, the difference between the phonological and translation conditions was also significant for both cognates, z = 4.804, p < .0001 and non-cognates, z = 3.653, p = .0008. However, phonological priming was neither significant for cognates, z = −1.325, p = .371, nor for non-cognates, z = −0.680, p = .496. Here, cognates and non-cognates showed exactly the same patterns in all priming conditions: strong translation priming but no phonological priming.
Table 3. Pairwise comparisons between different priming conditions in Experiment 1
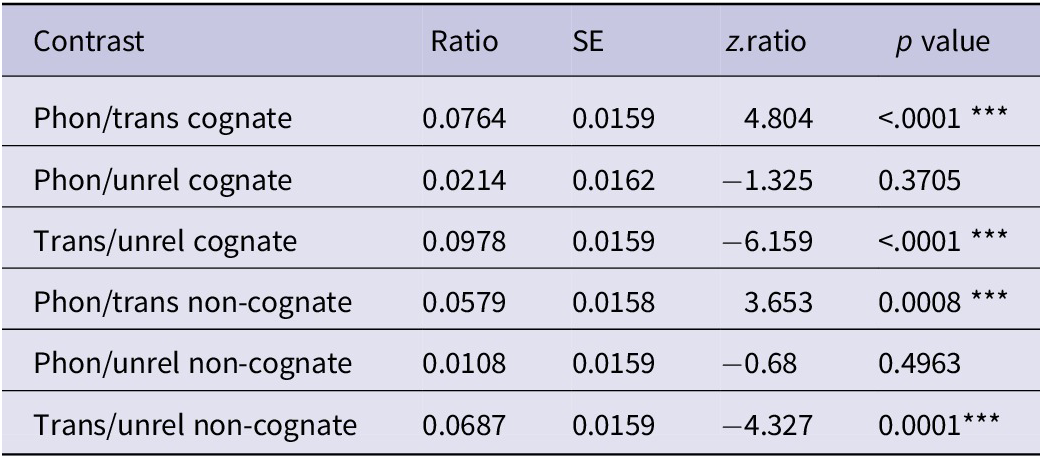
Phon: phonological condition; Trans: translation condition; Unrel: unrelated condition. Degree of freedom is infinity in all tests.
Error Analyses. The simple model of mixed effects with a random intercept for both participants and items was finally fitted to analyze error rates, as in (2).
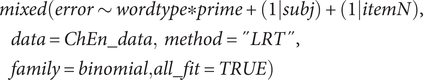 $$ {\displaystyle \begin{array}{l} mixed\Big( error\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em data= ChEn\_\mathit{data,}\ method=" LRT",\\ {}\hskip1em family=\mathit{binomial,} all\_ fit= TRUE\Big)\end{array}} $$
$$ {\displaystyle \begin{array}{l} mixed\Big( error\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em data= ChEn\_\mathit{data,}\ method=" LRT",\\ {}\hskip1em family=\mathit{binomial,} all\_ fit= TRUE\Big)\end{array}} $$
This model revealed a significant main effect of prime, X 2(2) = 7.54, p = .023, but no main effect of word type, X 2(1) = 0.06, p = .802. The interaction between word type and prime was not significant either, X 2(2) = 2.05, p = .359. For cognates, further pairwise contrast analyses showed significant differences between the phonological and translation conditions, z = 2.756, p = .0059, as well as between the translation and unrelated conditions, z = −2.463, p = .0138. However, there were no significant differences between the phonological and unrelated conditions, z = 0.305, p = .760. These results indicate a translation priming but no phonological priming for cognates. For non-cognates, no significant differences across conditions were observed (all ps > 0.05). This pattern is largely consistent with the RT data but differs from RT in that non-cognates failed to show translation priming. R codes of all analyses for Experiment 1 can be found in OSF (https://osf.io/hykmj/).
5.5. Discussion
In Experiment 1, we failed to find significant cognate facilitation effects in masked translation priming from L1 to L2 (Chinese to English). However, we observed robust translation priming effects for both cognates and non-cognates, which is consistent with the literature. The phonologically related conditions neither produced significant priming effects nor interactions, which is inconsistent with the literature (e.g., Brysbaert et al., Reference Brysbaert, Van Dyck and Van de Poel1999). In addition, our phonologically related condition yielded similar RT and ER patterns as the unrelated condition, suggesting the non-lexical phonological overlap was not effectively processed.
These results were consistent with Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019) and Kim and Davis (Reference Kim and Davis2003) as they also found strong and similar translation priming effects for cognates and non-cognates in masked lexical decision tasks, though Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019) did not test for phonological priming. The null cognate facilitation effect is likely due to the opaque orthography of the Chinese primes used. In other words, Chinese characters are not directly mapped to phonology, leading to a greater reliance on the lexical route in processing rather than the phonological route during lexical access, compared to alphabetic languages where a phonological route is critical in word recognition (e.g., Harm & Seidenberg, Reference Harm and Seidenberg2004; Yang et al., Reference Yang, McCandliss, Shu and Zevin2008; Yang et al., Reference Yang, Shu, McCandliss and Zevin2013). This could limit the influence of phonological overlap in both cognates and non-cognates on priming effects.
This logic echoes Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019)’ speculation that the significant cognate facilitation effect found by Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013) was possibly due to the fact that Kana words (the prime) in Japanese have a transparent mapping between orthography and phonology, let alone the strong facilitation effect for cognates in similar scripts in previous studies (e.g., Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010; Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2013; Voga & Grainger, Reference Voga and Grainger2007). However, to test whether the early automatic activation of phonological code in bi-script readers is dependent on the orthographic depth of the primes, we need to run the same experiment with English served as primes and Chinese as targets in English-Chinese bilinguals (Experiment 2). This would be a comparable measure against Experiment 1 to see the effect of grapheme–phoneme correspondence of orthography on cognate facilitation effects.
6. Experiment 2
The design of Experiment 2 was the same as that in Experiment 1 except that the language direction of prime to target was reversed to English to Chinese, but the prime was still bilinguals’ stronger language and target the weaker language to ensure obtaining translation priming. The conditions of prime in this experiment were the same as those in Experiment 1 (see Table 4 as an example).
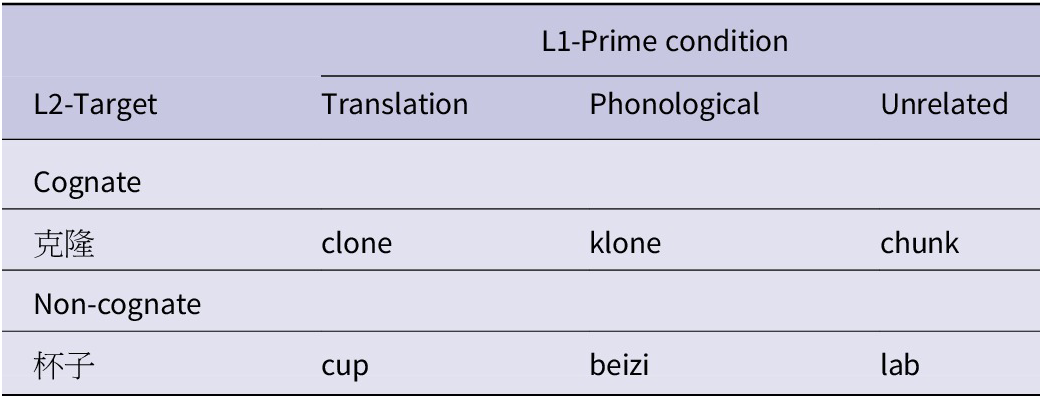
Table 4. Sample stimuli in Experiment 2
7. Method
7.1. Participants
Twenty-four Singaporean undergraduate students (mean age: 20.8 ± 1.21 years) from the same university participated in the experiment and were paid for their participation. These bilinguals grew up in Singapore, where English is the official language, predominantly speaking English as their first language and Chinese as their secondary language. They usually started to learn to read in Chinese as a language subject in school.
Similarly, each participant filled out a language questionnaire prior to the experiment. According to their answers to the questionnaire, they all acquired both English and Chinese at roughly the same age. The participants reported speaking Mandarin at home, but they predominantly used English outside the home. Based on their self-rated proficiency level in reading, writing, speaking and listening, they appeared to be more dominant in English than Chinese; however, the ratings did not differ between English and Chinese statistically (all ps > .05), except for writing (p < .05). See Table S3 in Supplementary Material for self-ratings. This group of bilinguals appeared to be more balanced than those in Experiment 1, with English being slightly more dominant.
7.2. Materials and design
Critical stimuli and the design were the same as those used in Experiment 1. In Experiment 2, primes and targets were exchanged. That is, Chinese words served as targets while English words as primes (see Table 4 as an example). Each Chinese target (e.g., 克隆) was primed by three types of English primes: its cognate translation equivalent (e.g., clone), phonologically related prime (e.g., klone) or unrelated prime (e.g., chunk). The phonologically related primes of the cognate targets were pseudo-homophones of the cognate translation primes, and the phonologically related primes of the non-cognate targets (e.g., beizi) were the pinyin of the Chinese targets (e.g. 杯子). The English pseudo-homophones were selected based on the list of sound–spelling correspondences in the ARC nonword database (Rastle et al., Reference Rastle, Harrington and Coltheart2002). The primes were matched for letter length across conditions. Detailed information on the Chinese targets and their corresponding English and pinyin primes can be found in Appendix B in the Supplementary Materials.
Note that the pinyin is a phonetic system used to support the learning of Chinese characters. In other words, they indicate the pronunciations of Chinese characters. For an adult Chinese reader or someone who is learning Chinese, pinyin is not lexical but is phonologically related to Chinese characters (Chen et al., Reference Chen, Perfetti and Leng2017; Chen et al., Reference Chen, Perfetti, Fang, Chang and Fraundorf2019). The choice of pinyin as the phonological prime to the non-cognate target word fulfills two criteria for the priming condition: (1) alphabetical letters which have transparent grapheme–phoneme-correspondence, and (2) they directly map to Chinese phonology.
Chinese nonwords were created as the result of the illegal combinations of two Chinese characters. The primes for nonword targets matched the primes for word targets in terms of length and phonological overlap. They were constructed to resemble the cognate translation and phonological primes used for word targets. That is, the “cognate primes” of the nonword targets were created such that they were phonologically similar. Three counterbalanced experimental lists were created by rotating the targets across the three prime conditions so that each target appeared only once for a given participant but was tested in all the priming conditions across participants.
To ensure an equal distribution of yes and no responses, an additional set of 108 Chinese nonwords was generated by randomly combining two characters to form illegal words following Wang (Reference Wang2013) and Wang and Forster (Reference Wang and Forster2015).
7.3. Procedure
The procedure of Experiment 2 was the same as Experiment 1. All primes were English Courier New words of size 12 presented in lowercase bold letters. All targets were Chinese SimSun words of size 12 presented in bold characters. For a better masking effect, because the primes were in English script, we used ###### instead of 贔贔贔贔 as the forward mask.
7.4. Results
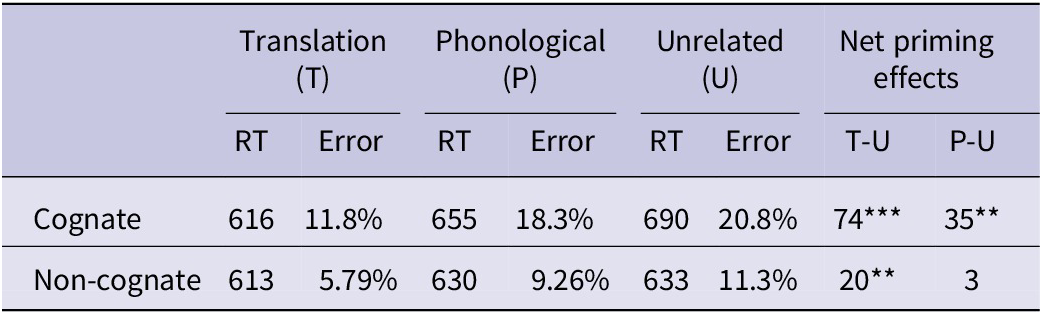
The data analysis followed the same procedure as in Experiment 1. Table 5 presents the mean RTs and error rates of each priming condition from English to Chinese.
Table 5. Lexical decision latencies (RT in ms) and error rates of L2 Chinese (Experiment 2)
Reaction Times Analysis. The ultimate mixed-effects model, which was fitted, incorporated random intercepts by both participants and items, as well as a random slope of prime by participants, as the addition of further parameters resulted in convergence issues. See (3).
 $$ {\displaystyle \begin{array}{l} mixed\Big( logrt\sim wordtype\ast prime+\left( prime\Big\Vert subj\right)\\ {}\hskip1em +\hskip2px \left(1| itemN\right), EnCh\_ rt\_\mathit{data,}\ method="S", cl= cl,\\ {}\hskip1em expand\_ re=T\Big)\end{array}} $$
$$ {\displaystyle \begin{array}{l} mixed\Big( logrt\sim wordtype\ast prime+\left( prime\Big\Vert subj\right)\\ {}\hskip1em +\hskip2px \left(1| itemN\right), EnCh\_ rt\_\mathit{data,}\ method="S", cl= cl,\\ {}\hskip1em expand\_ re=T\Big)\end{array}} $$
The linear mixed-effects model analysis revealed a significant main effect of prime, F (2, 25.66) = 28.50, p < .001, a significant interaction between word type and prime, F (2, 2084.49) = 4.81, p = .008, as well as a marginal effect of word type, F (1, 102.38) = 3.35; p = .07. Further pairwise contrast analyses (see Table 6) showed significant translation priming for both cognates (74 ms), z = −7.357, p < .0001, and non-cognates (20 ms), z = −3.455, p = .002. Similarly, the difference between the phonological and translation conditions was significant for both cognates (39 ms), z = 4.070, p < .001 and non-cognates (17 ms), z = −2.577, p = .020. However, phonological priming was only significant for cognates (35 ms), z = −3.313, p = .0028, but not for non-cognates (3 ms), z = −0.942, p = .346. This pattern shows robust translation priming for both cognates and non-cognates, but phonological priming was only observed in cognates.
Table 6. Pairwise comparisons between different priming conditions in Experiment 2
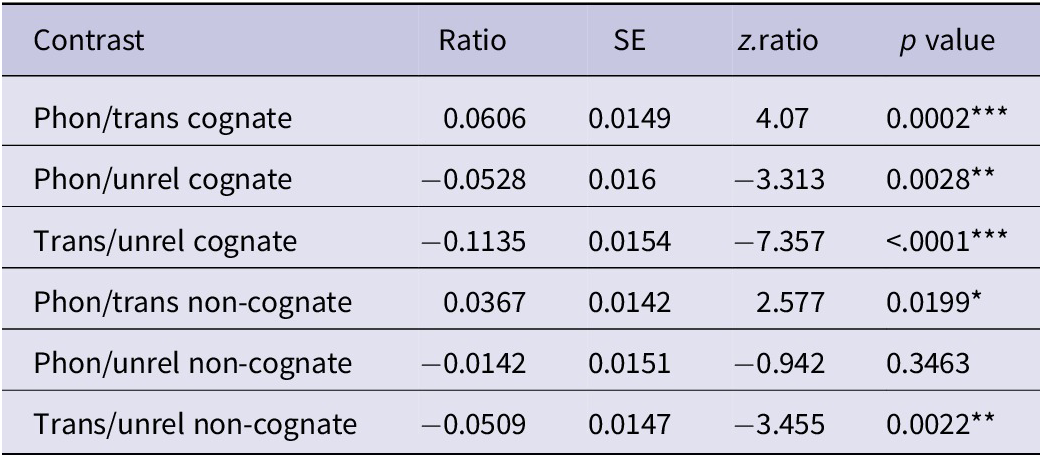
Phon: phonological condition; Trans: translation condition; Unrel: unrelated condition. Degree of freedom is infinity in all tests.
Error Analysis. Again, we used the final simple model for error analysis, as in (4).
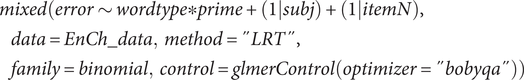 $$ {\displaystyle \begin{array}{l} mixed\Big( error\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em data= EnCh\_\mathit{data,}\ method=" LRT",\\ {}\hskip1em family=\mathit{binomial,}\ control= glmerControl\left( optimizer=" bobyqa"\right)\Big)\end{array}} $$
$$ {\displaystyle \begin{array}{l} mixed\Big( error\sim wordtype\ast prime+\left(1| subj\right)+\left(1| itemN\right),\\ {}\hskip1em data= EnCh\_\mathit{data,}\ method=" LRT",\\ {}\hskip1em family=\mathit{binomial,}\ control= glmerControl\left( optimizer=" bobyqa"\right)\Big)\end{array}} $$
The overall analysis of error rates showed a main effect of word type, X 2 (1) = 10.44, p < .001 and a main effect of prime, X 2 (2) = 25.58, p < .001. There was no interaction between word type and prime, X 2 (2) = 0.03, p = .986. Further, pairwise contrast analyses showed translation priming effects for both cognates, z = −4.068, p < .001, and non-cognates, z = −3.02, p = .0025. Similarly, the differences between the phonological and translation conditions were also significant for both cognates, z = 2.876, p = .004, and non-cognates, z = 1.966, p = .049. However, there was no phonological priming in either cognates, z = −1.276, p = 0.202, or non-cognates, z = −1.110, p = 0.267.
7.5. Discussion
Like Experiment 1, we observed robust English-Chinese translation priming in both cognates and non-cognates (where English is more dominant than Chinese), which is consistent with the literature. Importantly, contrary to the results of Experiment 1, we also observed reliable English-Chinese phonological priming in cognates but not non-cognates. In addition, a significant interaction was observed for both translation and phonological conditions, indicating cognate facilitation effects emerged when English served as the primes and Chinese as the targets. Given that the primary distinction between English–Chinese cognates and non-cognates is the greater phonological overlap in cognates, the observed facilitation effect for cognates is attributed to the phonological overlap between Chinese and English. These results are consistent with the literature where this cognate advantage was observed even with brief prime exposure and participants’ relatively low proficiency in L2 (e.g., Duyck, Reference Duyck2005; Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2013; Zhang et al., Reference Zhang, Wu, Zhou and Meng2019).
In contrast to Experiment 1, Experiment 2 revealed phonological priming effects in cognates but not non-cognates, albeit with a smaller magnitude than the translation condition, as indicated by the interaction effects. Thus, a phonologically related prime to the cognate target produced priming, while the pinyin failed to produce priming in non-cognates. Both types of primes are alphabetical and directly map to the phonology of the target Chinese words. The only explanation is that Chinese-English cognates maintain a special lexical status and drive this phonological effect at the lexical level.
8. General discussion
In the current study, we ask whether a bi-script reader adopts different processing mechanisms in their two different languages due to the difference in mapping between orthography and phonology in different writing systems (i.e., Chinese versus English in this case). Specifically, we examine whether bi-script readers use language-specific phonological encoding mechanisms during earlier and automatic orthographic processing in cross-language activation. If so, this has implications regarding how phonology is involved in word recognition. A unique type of word to investigate this question is cognates that share phonological and semantic representations in bi-script readers. We hypothesize that the cognate facilitation effect, which is primarily driven by cross-language phonological overlap in bi-script readers, depends on the orthographic depth of the writing system in bilingual lexical access. Relative to Chinese, English orthography is much more transparent, and its grapheme-to-phoneme mapping drives this effect, while the Chinese writing system does the opposite. To test this, we ran the same set of stimuli, including both cognates and non-cognates, in Chinese-English (Chinese being more dominant) and English-Chinese (English being slightly more dominant) readers. The choice of this design by the group is due to priming asymmetry established in the literature (e.g., Jiang, Reference Jiang1999; Wang, Reference Wang2013, Reference Wang2014; Wang & Forster, Reference Wang and Forster2010, Reference Wang and Forster2015). That is, most bi-script bilinguals only showed priming from the stronger language (L1) to the weaker language (L2) in non-cognates, but not vice versa. To obtain meaningful comparisons between cognates and non-cognates, we tested groups for whom the primes were the stronger language.
In Experiment 1, Chinese words, which served as primes, were selected to form two priming conditions: translation and phonological. The results showed significant translation priming for both cognates and non-cognates, without interaction. However, there was neither phonological priming for cognates nor for non-cognates. No cognate facilitation effects were observed. These results are inconsistent with most of the literature. In contrast, Experiment 2 showed strong translation priming for both cognates and non-cognates, as well as robust phonological priming for cognates only. Importantly, the significant interaction indicated the contribution of cross-language phonological overlap in bilingual lexical access, and this was only applied to cognates. In other words, cognate facilitation effects were observed when English was the prime, consistent with what was typically reported in the literature (e.g., Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022; Comesaña, Reference Comesaña2012; Marte et al., Reference Marte, Peñaloza and Kiran2023; Voga & Grainger, Reference Voga and Grainger2007; Zhang et al., Reference Zhang, Wu, Zhou and Meng2019). This suggests that cognates, by virtue of their shared phonological and semantic features, may particularly enhance the processing of Chinese words, thereby providing a more efficient cognitive pathway for word recognition in bilingual readers.
The lack of a cognate facilitation effect in Chinese-English readers (Experiment 1), consistent with the finding of Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019), challenges the phonological account of the cognate facilitation effect in cross-script languages (Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2013, Reference Nakayama, Verdonschot, Sears and Lupker2014; Voga & Grainger, Reference Voga and Grainger2007). This account posits that the greater priming effect for cognates is due to additional phonological overlap, as seen in Greek-French cognates (Voga & Grainger, Reference Voga and Grainger2007). Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013) confirmed this account by showing that Japanese-English cognates produced a larger priming effect than non-cognates, even though the orthographies of Japanese and English do not overlap. However, we speculate that this effect was also attributed to the faster phonological activation of Kana words used for cognates driven by their transparent mapping from orthography to phonology in Kana compared to Kanji words used for non-cognates. However, in Chinese, both cognates and non-cognates are represented by opaque characters, allowing for a direct comparison of their priming effects between cognates and non-cognates.
The similar priming effects for Chinese-English cognates and non-cognates in Experiment 1 indicate that phonological overlap across languages is not sufficient to drive cognate facilitation effect and that the mapping between orthography and phonology plays a crucial role. That is, early and automatic phonological activation in masked priming depends on the depth of the orthography: transparent orthography (e.g., English) activates phonology easier and faster than opaque orthography (e.g., Chinese). It has been shown that the less direct mapping from orthography to phonology in Chinese, compared to alphabetic languages like English, influences the cognitive processes in word recognition (e.g., Harm & Seidenberg, Reference Harm and Seidenberg2004; Yang et al., Reference Yang, McCandliss, Shu and Zevin2008, Reference Yang, Shu, McCandliss and Zevin2013). That is, reading Chinese primarily relies on the lexical route and depends less on the phonological route than English (Seidenberg, Reference Seidenberg, McCardle, Miller, Lee and Tzeng2011). For example, Yang et al. (Reference Yang, McCandliss, Shu and Zevin2008) found that Chinese reading proficiency was more influenced by semantic than phonological skills. In addition, some researchers showed that phonological activation in Chinese reading may occur between 57 ms and 200 ms (Perfetti & Tan, Reference Perfetti and Tan1998; Tan & Perfetti, Reference Tan and Perfetti1997). Thus, 50 ms prime duration might be sufficient to compute English phonology but not Chinese phonology in masked priming. Processing Chinese scripts as masked primes may limit the cognate facilitation effect, despite that Chinese-English cognates share both phonology and meaning. The absence of phonologically related priming proved that there was no phonological activation when the primes were in Chinese and the targets in English. However, when the primes were in English and targets in Chinese, the cognate facilitation effect was restored due to phonological overlap as shown in Experiment 2, indicating effective phonological activation in cognates.
Moreover, phonological priming was only observed with cognates from English to Chinese, but not vice versa. These results confirmed that the cognate advantage in translation priming was driven by phonological overlap and that phonological activation was asymmetrical due to the difference in orthographic depth of the primes (Chinese versus English). Within-language and cross-language phonological priming effects have been observed in various alphabetical languages of relatively transparent orthography (e.g., Brysbaert et al., Reference Brysbaert, Van Dyck and Van de Poel1999; Rastle & Brysbaert, Reference Rastle and Brysbaert2006). These effects were attributed to early and automatic activation of phonological codes in visual word recognition. However, opaque orthography could bypass phonology in visual word recognition as shown in Experiment 2 and other studies (e.g., Kim & Davis, Reference Kim and Davis2003; Zhang et al., Reference Zhang, Wu, Zhou and Meng2019), consistent with the contrastive results between Japanese Kana and Kanji (Dylman & Kikutani, Reference Dylman and Kikutani2018).
If phonological activation was observed in cognates in Experiment 2, why was it absent in non-cognates in both translation and phonological conditions? This suggests that phonological activation not only depends on grapheme–phoneme correspondence (i.e., the orthography), but also on the lexical status of the phonological representation. That is, for klone to prime 克隆, phonological activation of the pseudo-homophone boosted the phono-lexical activation of the target shared by both clone and 克隆. In contrast, beizi has no or weak phono-lexical entry to the target 杯子 such that no phonological priming was observed.
Our novel findings shed new light on current bilingual word recognition models, such as the BIA+ model (Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002) and the Multilink (Dijkstra et al., Reference Dijkstra2019). A key assumption of these models is the nonselective access hypothesis, which posits that both languages are automatically activated during word recognition, even in a single language task. This hypothesis is based on the idea that the lexicons of two languages are integrated, encompassing orthography, phonology and semantics. Even for bi-script readers, whose orthographies are distinctly different, Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2012) provided compelling evidence for this idea, showing that Japanese cognate primes and phonologically similar primes significantly boosted the recognition of English target words. It appears that cross-language phonological integration can persist across different scripts (Ando et al., Reference Ando, Jared, Nakayama and Hino2014; Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2012, Reference Nakayama, Sears, Hino and Lupker2013, Reference Nakayama, Verdonschot, Sears and Lupker2014). However, these studies do not detail how varying mappings from orthography to phonology affect word recognition. The relatively transparent mapping in alphabetic languages (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010) and Japanese Kana script (Nakayama et al., Reference Nakayama, Sears, Hino and Lupker2012) leads to a greater reliance on phonological processing, resulting in significant priming effects in both L1–L2 and L2–L1 directions. In contrast, for Chinese, the mapping from orthography to phonology is opaque, leading to a greater reliance on orthographic-lexical processing and reduced engagement of phonological processing. Thus, Zhang et al. (Reference Zhang, Wu, Zhou and Meng2019) proposed that the connection strengths between orthography and phonology and between orthography and semantics differ for Chinese and English. English grants priority access to phonological activation via the phono-lexical route, while Chinese word recognition favors orthographic-lexical processing, strengthening the connection between orthography and semantics over that in English. As a result, priming from Chinese to English differs from English to Chinese with the same sets of cognates, as shown in our current study. That is, Chinese-English cognates produced similar priming effects to Chinese-English non-cognates, while English-Chinese cognates produced larger priming effects than English-Chinese non-cognates. To account for these empirical results, bilingual word recognition models need to incorporate orthographic depth as a factor influencing cross-language activation and competition (Wang et al., Reference Wang, Wang and Malins2017; Wang et al., Reference Wang, Hui and Chen2020).
9. Limitations and future directions
Our study shows the contrast in phonological encoding between Chinese and English during early automatic lexical processing in one mind, and this phonological activation is driven by the degree to which the script corresponds to phonology, consistent with the ODH. However, there are limitations to the current study, and further research is necessary to consolidate our findings and expand this research program.
First, our two groups are not comparable in terms of their relative proficiency in L1 and L2 such that we are not able to make any claims about the relationship between cognate facilitation effects and language directions (L1–L2 versus L2–L1). Here, we primarily focus on the scripts and the same set of items, showing priming driven by phonology and/or semantics within each group, as well as these different patterns across groups due to the difference in phonological encoding of the primes. Our comparison between groups is qualitative, rather than quantitative.
Second, our current data set is based on a modest number of participants due to the practical difficulty of finding suitable bilingual participants. For interaction terms in our analyses, more data points will further consolidate our results in future investigations.
Finally, the way we tested cross-script phonological priming is driven by bottom-up phonological activation without top-down influence at the lexical level. Because literature in cross-language phonological priming within alphabetical languages has shown these types of effects from both pseudo-homophones and (near) homophones as primes (Brysbaert et al., Reference Brysbaert, Van Dyck and Van de Poel1999; Voga & Grainger, Reference Voga and Grainger2007), it is theoretically important to test cross-script phonological effects based on (near) homophones as well to obtain a more comprehensive view of cross-script phonological effects.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S1366728925100217.
Data availability statement
The datasets and R codes are available here, including the appendixes: https://osf.io/hykmj/?view_only=ce4797eeb9d14e9d9cec6774c0812413.
Acknowledgments
The writing was supported by Australian Research Council DP (DP210102789) and Zhejiang Provincial Philosophy and Social Sciences Planning Project (22NDJC037Z). The project was supported by National University of Singapore Faculty Grant to Xin Wang. We thank research assistants Janet Qi and Jie Wang for data collection.
Author contribution
Xin Wang: Conceptualization, methodology, data curation and analysis, original draft preparation, reviewing and editing. Junmi Li: Original draft preparation, reviewing and editing.
Competing interests
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.









 Open access
Open access