

Introduction
The long history of research on memory for gist vs. surface linguistic information seems to converge on the assumption that linguistic information is not retained verbatim, but converted to conceptual form, which is then stored in long-term memory. Unless required by an additional task (e.g., an announced memory test), the low-level, surface information is assumed to be available immediately after the sentence processing, but to decay as soon as hierarchically superior structures (e.g., propositional representation) are built (e.g., Anderson, Reference Anderson1974; Caplan, Reference Caplan1972; Gernsbacher, Reference Gernsbacher1985; Jarvella, Reference Jarvella1971; Jarvella & Herman, Reference Jarvella and Herman1972; Johnson-Laird & Stevenson, Reference Johnson-Laird and Stevenson1970; Sachs, Reference Sachs1967, Reference Sachs1974; for more recent studies, e.g., Holtgraves, Reference Holtgraves2008; Just & Carpenter, Reference Just and Carpenter1992; Lombardi & Potter, Reference Lombardi and Potter1992; Potter & Lombardi, Reference Potter and Lombardi1998; Rummer & Engelkamp, Reference Rummer and Engelkamp2001; Rummer, Schweppe & Martin, Reference Rummer, Schweppe and Martin2013).
At the same time, usage-based theories of grammar acquisition assume that grammatical knowledge is derived from a database of memorised chunks (Bybee, Reference Bybee1985; Ellis, Reference Ellis1996; Goldberg, Reference Goldberg2006; Langacker, Reference Langacker and Rudzka-Ostyn1988; Tomasello, Reference Tomasello2003). Within this theoretical framework, it is assumed that sequences of words, which are stored verbatim in memory, are used to abstract regularities and that mental grammar develops through gradual assembling of knowledge about distributional and semantic-distributional relationships between words.
The two above-mentioned lines of research, which reach conclusions that might seem difficult to reconcile at the first sight, differ in populations on which each of them focuses. While research on memory for the two types of information (gist vs. verbatim) typically addresses performance of adult native speakers, usage-based theories focus on language acquisition, i.e., on children and non-native speakers. In the present study, we want to test the hypothesis that adult L2 learners outperform L1 speakers in memory for surface linguistic information. We assume that this ability would subserve the assembly of the chunk database necessary for the development of implicit grammatical knowledge. In particular, we want to compare the degree of retention of surface lexical (synonyms) and structural (active/passive alternation) information during reading in L1 and L2 German.
Since we explore verbatim memory in reading, the research question can also be formulated within the context of text comprehension. During reading, readers construct a mental text model, a higher-level mental representation of affairs conveyed by a text. It contains both propositional meaning and additional information contributed by the reader (inferences, world knowledge) (Field, Reference Field2004, p. 176). The model is dynamic, both because more information from the text is gradually integrated into it, and some of the earlier information fades from the memory (Bernhardt, Reference Bernhardt2011; Kintsch, Reference Kintsch1988, Reference Kintsch1998; Stanovich, Reference Stanovich2000; van Dijk & Kintsch, Reference van Dijk and Kintsch1983). It is considered that “a primary property of mental models is that they represent what the text is about (the events, objects, and processes described in the text), rather than features of the text itself” (Glenberg, Meyer & Lindem, Reference Glenberg, Meyer and Lindem1987, p. 69). The research on text models thus complies with the literature on memory in that it assumes that verbatim information is not replicated in the mental representation (Garnham, Reference Garnham, Oakhill and Garnham1996; Johnson-Laird, Reference Johnson-Laird1977). However, also in this area comparisons between L1 and L2 speakers with respect to retention of verbatim information are missing. In our study, we investigate to what degree surface linguistic information becomes a part of the mental text representation of these two populations and whether there is a difference in the degree in which L1 or L2 speakers rely on this type of information during reading.
Despite the general consensus that verbatim information is retained in memory only very briefly, several recent studies indicate that surface linguistic information does not fade from memory as fast and completely as previously believed. Gurevich, Johnson, and Goldberg (Reference Gurevich, Johnson and Goldberg2010) carefully reviewed the previous literature on the topic and concluded that “various factors have conspired to downplay the importance of memory for language in past research” (Gurevich et al., Reference Gurevich, Johnson and Goldberg2010, p. 49). The emphasis of the studies had been on memory for content or gist which always trumps the verbatim memory; the latter, however, does not seem to be as uninvolved in naturalistic contexts as claimed. As an example, Gurevich et al. (Reference Gurevich, Johnson and Goldberg2010) mention a study by Kintsch and Bates (Reference Kintsch and Bates1977) which showed that participants recognise sentences they had heard in a regular university lecture significantly better than their paraphrases.
In their own recognition and recall experiments, Gurevich et al. (Reference Gurevich, Johnson and Goldberg2010) used texts and illustrations from children's storybooks as stimuli. Participants first listened to the recorded texts while corresponding pictures were presented to them. In the recognition task, written clauses were displayed on the screen and subjects were asked to answer ‘yes’ or ‘no’ to whether or not they had heard that exact clause in the story. In the recall task, participants were asked to retell the story from the pictures. The story had two versions; the second being a paraphrase of the first using different formulations to express the same content. The research question was whether participants who had heard a particular formulation were more likely to recognise/produce that formulation than subjects who had heard a paraphrase of the same content. This turned out to be the case. Gurevich and colleagues could demonstrate that explicit verbatim memory for language in naturalistic settings persists longer than had been believed and that it extends beyond memory for individual lexical items (cf. Gibbs, Reference Gibbs1981; Kintsch & Bates, Reference Kintsch and Bates1977). Their results challenge the previous finding that downplays the significance of verbatim memory.
Interestingly – and perhaps because these L1 results have remained unchallenged for so many years – there is to our knowledge only one study that has directly addressed the retention of surface information in L2. In a cued sentence recall procedure, Sampaio and Konopka (Reference Sampaio and Konopka2013) showed that while L1 and L2 speakers recall equally well the gist of a sentence like “The bullet STRUCK the bull's eye”, the L2 speakers recall better the verbatim phrasing of sentences with non-preferred lexical items (e.g., STRUCK vs. HIT) and are thus more sensitive to synonymous lexical substitutions in such sentences. According to the authors, the L1 vs. L2 difference arises due to the nature of the lexical-semantic pathways that support processing in L1 and L2. They interpret their finding within the Revised Hierarchical Model (RHM) of Kroll and Stewart (Reference Kroll and Stewart1990, Reference Kroll and Stewart1994) and claim that the engagement of the L2-L1 route (as opposed to the route that links the words directly with the conceptual store) leads L2 speakers to more intensive lexical processing, which benefits the retention of the L2 surface form (i.e., verbatim memory). However, due to the design of the study, it does not address the results of the L1 participants in the same way: it shows that L2 recall of verbatim phrasing is better than recall in L1, but due to a missing baseline for L1, it does not answer the question, whether also recall within L1 is above chance, or not (i.e., whether also L1 participants retain surface forms in L1).
Other recent studies also support the assumption that L2 learners engage more intensely with low-level text information than native speakers. As an example, in a series of studies on incidental vocabulary acquisition, Bordag and colleagues (Bordag, Kirschenbaum, Tschirner & Opitz, Reference Bordag, Kirschenbaum, Tschirner and Opitz2015; Bordag, Kirschenbaum, Opitz & Tschirner, Reference Bordag, Kirschenbaum, Opitz, Tschirner, Torrens and Escobar2014; Bordag, Kirschenbaum, Opitz, Rogahn & Tschirner, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016a, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016b) revealed that syntactically complex texts trigger a shift of attention from the global aim of text comprehension to individual lexical items and their properties in L2 learners, but not in L1 speakers. In contexts that were demanding (i.e., syntactically complex) for L2 learners, these acquired better both the meaning and the grammatical properties of unknown words during reading compared to L1 speakers and compared to the condition when they read syntactically undemanding texts. Such findings indicate that the focus of less proficient readers/speakers might be more directed at lower-level information than that of adult L1 speakers and that this behaviour does not have to be limited to individual lexical items as suggested by Sampaio and Konopka (Reference Sampaio and Konopka2013).
In addition to the recent research studies mentioned above, existing cognitive, acquisition, and processing theories make assumptions that support the hypothesis of verbatim retention in L2 readers, too.
The Fuzzy Trace Theory (FTT), a cognitive theory originally proposed by Ch. Brainerd and V. F. Reyna in the 1990s (Reyna & Brainerd, Reference Reyna and Brainerd1995), is employed especially in research on decision making and false memories, but it makes assumptions that are very relevant for the present purposes.Footnote 1 As a dual process theory, it assumes two types of representation of past events: meaning-based gist representations, which support fuzzy (yet advanced) intuition, and superficial verbatim representations of information, which support precise analysis (Reyna, Reference Reyna2012, p. 332). Both types of representations are encoded in parallel, can be retrieved independently from each other and have different forgetting rates (with verbatim traces becoming inaccessible at a faster rate than gist traces). Studies have shown that the dominance of one of the two representation types depends on a number of factors, including expertise. Reyna (Reference Reyna2012) reports several studies (e.g., Reyna, Reference Reyna2004; Reyna & Lloyd, Reference Reyna and Lloyd2006; Reyna, Lloyd & Brainerd, Reference Reyna, Lloyd, Brainerd, Schneider and Shanteau2003) showing that experts rely on simpler gist-based representations, use less information, and process it less precisely to make decisions. At the same time, they have better discrimination than novices regarding predictions of outcomes in their area of expertise (Lloyd & Reyna, Reference Lloyd and Reyna2009; Reyna & Lloyd, Reference Reyna and Lloyd2006). In the area of second language acquisition, a study of Arndt and Beato (Reference Arndt and Beato2017) not only shows that non-native speakers are less likely to produce false memories for critical words in Deese-Roediger-McDermott paradigm lists than native speakers, but also that less proficient L2 speakers produce fewer false memories than highly proficient L2 speakers (cf. equivalent results for younger vs. older children, e.g., Metzger, Warren, Shelton, Price, Reed & Williams, Reference Metzger, Warren, Shelton, Price, Reed and Williams2008). Such results support the assumption of FTT that older children, adults, and proficient L2 speakers are more susceptible to false memories because their encoding is more based on gist.
As suggested by studies of Bordag and colleagues (Bordag et al., Reference Bordag, Kirschenbaum, Opitz, Tschirner, Torrens and Escobar2014; Reference Bordag, Kirschenbaum, Tschirner and Opitz2015; Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016a, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016b), differences in L1 and L2 reading and the related success in incidental language acquisition may crucially depend on the degree of difficulty that the reading process poses for readers or, in other words, on their novice vs. expert status to the task. Consequently and in accordance with the hypothesis that we test, we might expect that not fully proficient L2 learners might deal with L2 reading as novices and rely more on verbatim-based analysis than proficient adult speakers. Interestingly, this assumption is also supported by a study by Keysar, Hayakawa, and Sun Gyu (Reference Keysar, Hayakawa and Sun Gyu2012) who have shown that gain vs. loss framing effects, which are known to arise due to gist-based intuition, disappear when decisions are made in an L2, thus supporting the notion that L2 text processing may depend more on verbatim-based analysis.Footnote 2
Among acquisition approaches, it is especially the Declarative/Procedural model (DPM) (Ullman, Reference Ullman2004) and its claims about the differences in L1 and L2 processing that are complementary to our hypothesis. According to DPM, procedural memory that subserves the rule-governed sequential and hierarchical computation of complex linguistic structures (i.e., crucial aspects of mental grammar) declines with age (Ullman, Reference Ullman2004). Its decline is accompanied by improvement of declarative memory, which underlies the mental lexicon that contains word-specific knowledge and memorised complex forms (Ullman, Reference Ullman2004, 2016; Ullman & Lovelett, Reference Ullman and Lovelett2018). Along with usage-based theories, the DPM assumes that children initially learn both idiosyncratic and complex forms in declarative memory, while the procedural system gradually acquires the grammatical knowledge underlying rule-governed combination. Due to the decline of the procedural system, L2 learners tend to rely more strongly on declarative memory, even for functions that depend on the procedural system in L1. Reliance on verbatim storage in declarative memory and on associative generalisations over them could thus compensate for the limited L2 ability to acquire and process grammar procedurally.
Along the lines sketched above, the overrepresentation of verbatim information in L2 mental text models also complies with the Shallow Structure Hypothesis (SSH) by Clahsen and Felser (Reference Clahsen and Felser2006, Reference Clahsen and Felser2017). Clahsen and Felser (Reference Clahsen and Felser2017) explicitly classify SSH as a multiple-pathways model that assumes at least two processing routes that operate in parallel similar to the two types of representation encoding in FTT. One of the routes involves creating detailed syntactic structures; the other one is syntactically shallower. Shallow processing (characterized by deficiencies in hierarchical syntactic organisation) is accompanied by reliance (or overreliance) on “semantic, pragmatic, probabilistic, or surface-level information” (Clahsen & Felser, Reference Clahsen and Felser2017, p. 694, bold by the authors). Similar to FTT, SSH also assumes that the dominance of one of the two routes may depend on various factors such as task or language proficiency. According to the hypothesis, L2 learners dispose of the same processing architecture and mental-processing mechanisms as L1 speakers, but they have “problems building or manipulating abstract syntactic representations in real time” (Clahsen & Felser, Reference Clahsen and Felser2017, p. 2) and underuse syntactic information in online processing. Consequently, they are more likely to rely, e.g., on surface linguistic information than native speakers, which is in accordance with our hypothesis.
We surveyed three theoretical approaches to show that there are cognitive, acquisition-related, and processing grounds, based on which we might expect that despite previous findings focussing predominately on L1, L2 learners do retain verbatim information and represent it in their mental text model during reading. The following study delivers evidence that L2 learners are more sensitive to such information than native speakers.
The present study
In the present study, participants read six short texts twice while their eye movements were tracked. There were eight regions of interest (ROIs) in each text. Four ROIs involved nouns (lexical conditions) and the other four ROIs involved two sentences in active and two in passive voice (syntactic conditions). The second version (V2) of each text differed from the first version (V1) in that two ROIs always remained the same and two were changed. In the lexical conditions, the noun was exchanged for its near-synonym. In the syntactic conditions, active was transformed into passive and vice versa. The reading behaviour was evaluated at the critical ROIs in same (i.e., no change) vs. changed conditions in V2. The rationale of the design was that if readers represent verbatim surface information in their mental text model, they should be sensitive to the changes in V2 and respond to them with longer fixation times.
Contrary to most previous studies based on single sentences or very brief texts, the participants in our study read texts of c. 300-400 words. This aspect is important because according to, e.g., Gernsbacher (Reference Gernsbacher1985), coherent texts are assumed to facilitate the creation of a summary gist and therefore the integration of sentences into coherent semantic representations is causally involved in the loss of verbatim memory. At the same time, our participants knew they would have to answer questions about the contents of the texts, but the task did not include anything that could draw their attention to the surface form of the texts. For the participants, the focus on content questions justified the second reading. Thus, though being indeed different from a leisure reading situation, the testing situation in our study was close to a natural situation when students read and reread a text for a studying purpose. Importantly, the experimental measurements took place during a phase preceding the assumed testing phase (i.e., answering the comprehension questions). In addition, the data collection through eye-tracking did not require any explicit recall or sentence generation as is the case in most previous studies in this area. Thus, it was possible to address the type of knowledge which might be stored in the mental text model but is not accessible for explicit recall. Research on vocabulary acquisition has repeatedly shown that more lexical knowledge is stored (often associated with the so-called passive vocabulary) than what is revealed through explicit vocabulary tests (active vocabulary) (Bordag et al., Reference Bordag, Kirschenbaum, Opitz, Tschirner, Torrens and Escobar2014, Reference Bordag, Kirschenbaum, Tschirner and Opitz2015, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016a, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016b; Ellis, Reference Ellis2004, Reference Ellis2005; Laufer, Reference Laufer1998).
The critical syntactic manipulation of the present study (active vs. passive alternation) resembles manipulations applied in structural priming. Structural priming studies have demonstrated that the processing of a linguistic unit is facilitated by the recent processing of a structurally equivalent form (see Pickering & Ferreira, Reference Pickering and Ferreira2008, for a review) and that the priming effect persists also when the sentence prime and the target picture are separated by unrelated filler sentences (Bock & Griffin, Reference Bock and Griffin2000; Bock, Dell, Chang & Onishi, Reference Bock, Dell, Chang and Onishi2007, for replication). Interpretations of this phenomenon are based on activation networks that represent phrasal constituents as nodes and explain the priming effects either as facilitation due to recency of activation (Pickering & Branigan, Reference Pickering and Branigan1998; Roelofs, Reference Roelofs1992, Reference Roelofs1993, for lexical priming), or as a form of implicit learning (Bock & Griffin, Reference Bock and Griffin2000; Chang, Dell & Bock, Reference Chang, Dell and Bock2006; Chang, Dell, Bock & Griffin, Reference Chang, Dell, Bock and Griffin2000). However, the crucial difference between a structural priming manipulation and the manipulation in the present study is that while the prime and the target sentences are separated by (both structurally and semantically) unrelated filler sentences in the syntactic priming studies, in the present study the critical sentence in V1 is separated from the critical sentence in V2 by coherent text passages that include sentences with the structure counterparts (e.g., other passive and active sentences were read before the target active/passive sentence in V2 was reached). Consequently, the expected effect in the present study is unlikely to be attributed to syntactic priming, which is assumed to persist only until its syntactic counterpart is encountered (e.g., Bernolet, Collina & Hartsuiker, Reference Bernolet, Collina and Hartsuiker2016, p. 100). In addition, the lexical overlap between the prime and the target sentence in syntactic priming is either absent or only partial (typically the verb, cf. lexical boost effect) to reduce the effect of explicit memory for the prime sentence. In the present study, the lexical material in the critical sentence in V1 and in V2 is identical (as all non-critical sentences in V1 and V2); only its syntactic structure alternates. Similar to syntactic priming studies, we assume that the repeated lexical material acts as a retrieval cue, so that the reader is more likely to recall the critical sentence from V1 (from the prime sentence in the syntactic priming studies) from memory and anticipate or predict it – including its structure – during reading of V2 (reuse it in syntactic priming studies). However, such an anticipation effect can be expected only if participants stored verbatim the surface linguistic information of the sentence, not just its gist or lexical content (cf. Freunberger & Roehm, Reference Freunberger and Roehm2016, who show that L1 readers predict conceptual-semantic information but not specific surface-form information).
Method
In the present study, we tested two groups of participants, L1 native German speakers and advanced L2 German learners. Since the method was the same, we will present it together for both groups, highlighting the differences where relevant.
Participants
L1: Twenty-four students at the University of Leipzig participated in the experiment. They were all native speakers of German who had normal or corrected-to-normal vision. Their mean age was 24.5 years (min = 20, max = 33).
L2: Twenty-four exchange students at the University of Leipzig participated in the experiment. They were native speakers of Slavic (8) and Romance (16) languagesFootnote 3 with German knowledge at B2-C1 level (typically B2 in productive and C1 in comprehension skills). They had normal or corrected-to-normal vision. Their mean age was 26.3 years (min. 21, max. 39).
Materials
Six texts were constructed, which each participant read in two versions, V1 and V2. The topics of the texts were Languages of the World, Beethoven, Coffee, Depression, Museums, and Nutella. The average length of each text was 350 words (min. 319, max. 391). They were of average difficulty with LIX index (following Björnsson, Reference Björnsson1968) between 46.4 and 55.2 (see Table 1). The texts contained only vocabulary and grammar familiar to German learners at B2 level as assessed in a pre-test.Footnote 4
Table 1. Overview of texts statistics

There were eight ROIs in each text, none of them appeared in the two first sentences or in the last sentence of the text. The ROIs of the four lexical conditions consisted of single nouns; the four syntactic ROIs were sentences. The items in the lexical conditions were 24 synonym or contextual-synonym pairs; the items in the syntactic conditions were 24 active/passive sentence pairs. Critical lexical items or sentences were always separated by at least one line on the screen. The synonym pairs were constructed such that the two nouns were fully exchangeable in the given context. One pair member always had lower frequency compared to the other pair member. The difference between the frequencies between the pair members was always at least two frequency classes according to Deutscher WortschatzFootnote 5 (Goldhahn, Eckart & Quasthoff, Reference Goldhahn, Eckart, Quasthoff, Calzolari, Choukri, Declerck, Doğan, Maegaard, Mariani and Piperidis2012), see Appendix S1 (Supplementary Material). At the same time, the low-frequency nouns were also longer (high 7.67 (SD = 2.91), low 9.79 (SD = 4.29) letters on average). The critical nouns always appeared only once in all texts.
Given the analytic way of constructing German passives, the passive sentences were always longer than active sentences (i.e., they contained an auxiliary verb, see (1) and (2)). The readability of the texts was assessed in the same pre-test in which the interchangeability of the synonyms was assessed and there was no statistical difference in the readability ratings between the text versions.
(1) active:
Jedes Jahr am 1. Oktober veranstaltet die European Depression Association (EDA)
[every year at 1.October organizes the European Depression Association (EDA)]
deswegen den Europäischen Tag der Depression.
[therefore the European Day of Depression]
“The European Depression Association (EDA) thus organizes European Day of Depression every year on October 1.”
(2) passive:
Jedes Jahr am 1. Oktober wird deswegen von der European Depression
[every year at 1. October AUX.PASSIVE therefore of the European Depression]
Association (EDA) der Europäische Tag der Depression veranstaltet.
[Association (EDA) the European Day of Depression organized.PASSIVE]
“European Day of Depression is thus organized by the European Depression Association (EDA) every year on October 1.”
In each text and in each version, there were always two items of each type in each condition, i.e., two high-frequency synonyms and two low-frequency synonyms; and two active sentences and two passive sentences. ROIs of the lexical conditions did not overlap with ROIs of the syntactic conditions. Versions V1 and V2 differed in which ROIs were changed and which remained the same. In each V2, two syntactic and two lexical ROIs remained the same as in V1; the two other ROIs were exchanged for the other pair member (see Figure 1). Which ROIs remained the same and which were changed was determined by rotations according to the Latin square design and cross-balanced over all participants.

Fig. 1. Scheme of the Experimental Manipulation.
The critical comparisons of reading behaviour were at the same vs. changed ROIs in lexical and syntactic conditions during second reading (V2), e.g., total fixation durations at the word “Talent” after “Talent” in V1, or after “Begabung” in V1 (see Table 2) and at the active sentence after the active sentence in V1, or after its passive counterpart in V1.
Table 2. Examples for Same/Changed Alternations for the Lexical Conditions

Procedure
Participants were told that they would read a text twice, solve some mathematical tasks before the second reading and answer comprehension questions afterwards. The sequence of the main events during the experiment was as follows: 1) V1 text was presented; 2) participants solved two non-trivial mathematical tasks; 3) V2 text was presented; 4) participants answered two comprehension questions. Both the mathematical tasks and the comprehension questions were multiple-choice questions in which participants had to choose from four (mathematical questions) or three (comprehension questions) options. An example of a mathematical question would be “What is the value of x in: x = 5–2 * 5 + 2?” with possible answers 21, 17, -3, and -5. The purpose of the mathematical questions was to distract participants from the text and prevent them from consciously rehearsing parts of the text. The purpose of the comprehension questions was primarily to justify the second reading of the text and to check participants’ comprehension. The questions targeted both text details and inferencing that required close reading. There was a short break after the third text was read. The order of text presentation rotated according to Latin square design.
During the experiment, participants were seated approximately 60 cm from a monitor. Both eyes were tracked using either an SMI eye-tracker REDm or RED 250mobile. The calibration took place at the beginning of the session and before the fourth text (after the break). Each text was split into parts respecting paragraph beginnings and ends, and presented on 6-7 successive screens. All texts were presented double-spaced, in 21-point Courier New font, left aligned on the display in black letters on a light-grey background. Gaze direction was sampled at a rate of 250 Hz (RED 250mobile) for half of the participants and at 120 Hz (REDm) for the other half.Footnote 6 Apart from the use of two different eye-trackers, the experimental material was presented to all participants identically on the same screen (Hannspree JC199D, 19 inches) with the same screen resolution (1280 by 1024 pixels, 60Hz). The session started with a short practice text (77 words, two screens) presented in the same format as the critical texts, but with no manipulations between V1 and V2. At the end of the experiment participants filled in a questionnaire. The L2 questionnaire also included language-history questions and a detailed self-assessment questionnaire, which was shown to correspond well with proficiency tests in previous studies (Bordag et al., Reference Bordag, Kirschenbaum, Opitz, Tschirner, Torrens and Escobar2014, Reference Bordag, Kirschenbaum, Tschirner and Opitz2015, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016a, Reference Bordag, Kirschenbaum, Opitz, Rogahn and Tschirner2016b). The entire experimental session took approximately 75 minutes for the L1 and c. 90 minutes for the L2 participants.
Data analysis
The same procedures for cleaning and analysing the eye-tracking data were performed for the L1 and L2 data. For the lexical conditions (synonyms), the critical word was defined as ROI and the following two words were defined as potential spill-over regions. For the syntactic conditions (active-passive alternation), the entire clause was defined as ROI. All ROIs were defined using the software BeGaze (version 3.6). In addition, data in ROIs were scanned manually and drifts were corrected prior to further analyses (8% of fixations). For detection of fixations and saccades, BeGaze 3.6 was used with default settings. Fixations with durations shorter than 80 ms were removed. We also removed fixations with durations exceeding a participant's mean plus 3.5 standard deviations (excluding c. 0.5% and 0.7% of the ROI data in the L1 and L2 experiment, respectively).Footnote 7 In addition, we excluded three participants (two L1 and one L2) who reported that they noticed a word or two had been changed in the texts at the debriefing.
Since the experiment had an identical design in L1 and L2, both language groups were analysed in one statistical analysis, with the factor Language comprising two levels (L1 vs. L2). The analyses were performed using linear mixed-effect models employing the software R (R Core Team, 2018 with packages lmerTest (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017) and afex (Singmann, Bolker, Westfall, Aust & Ben-Shachar, Reference Singmann, Bolker, Westfall, Aust and Ben-Shachar2020). By default, categorial independent variables were effect coded. All models included a maximum random effect structures with all fixed effects and their interactions as both intercepts and slopes for participants and items (Barr, Levy, Scheepers, and Tily, Reference Barr, Levy, Scheepers and Tily2013). Fixation times as dependent variables were log-transformed for the analyses (model structures, i.e., the R model call, are given in corresponding Table legends). Fixed effects were Language (L1 vs. L2), Alternation (same vs. changed), and Form (high versus low-frequency member of the synonym pair; active versus passive voice of the syntactic alternation). Significance of fixed-effects was determined by model comparisons using likelihood ratio tests; fixed effect terms were computed with Satterthwaite method for denominator degrees of freedom for t tests. Relevant outcomes of the analyses are reported in the following section (Results), a full report of all statistics is provided in Appendix S2 (Supplementary Material) Footnote 8.
According to the rationale of the study, the main focus of the critical analyses was on reading behaviour of the second presentation of the texts, comparing ROIs that were either ‘changed’ or ‘same’ with respect to corresponding ROIs of the first presentation (factor ‘Alternation’).Footnote 9 We expected that participants should fixate critical ROIs in the ‘changed’ conditions more than in the ‘same’ conditions as a result of a surprisal effect. Under the assumption that participants stored the previous verbatim wording, such an effect could be caused by the fact that a new, previously unencountered word or structure was perceived. Thus, we expected changes in the reading behaviour especially in the total fixation durations measure and in the number of fixations for the syntactic conditions given the length of the ROIs (in the lexical conditions, we considered differences in the number of fixations less likely, since only single words were concerned). These were thus the two measures that we analysed. Lexical conditions (synonyms) and syntactic conditions (active-passive alternation) were analysed separately and are reported in two subsections.
To assess baseline differences between the two tested populations with respect to the first and second reading of the texts, we additionally compared reading behaviour for all unchanged (‘same’) regions of V1 and V2.
Though the primary purpose of the content questions was to justify the second reading of the text and to keep participants attentive to the content, we analysed the responses to these questions as well. They are reported at the end of the Results section.
Results
Lexical conditions (synonyms)
Results for lexical conditions are summarised in Table 3. Analysis of mean number of fixations in each ROI revealed main effects of Language (β = −0.187, SE = 0.067, p = .008)Footnote 10 and Form (β = −0.219, SE = 0.077, p = .009) indicating that, in general, the L2 participants produced more fixations than the L1 participants (2.19 vs. 1.82) and that low-frequency, longer members of the synonym pairs elicited more fixations than their high-frequency, shorter counterparts (2.23 vs. 1.78). However, there was no effect for the factor Alternation (β = -0.053, SE = 0.039, p = .182), nor was there any significant interactions of the fixed effects (all p > .20)Footnote 11.
Table 3. Results of Lexical Conditions (Synonyms) in L1 and L2

Note: high vs. low are abbreviations for the high- versus low-frequency member of a synonym pair, e.g., Talent “talent” (H, more frequent) vs. Begabung “giftedness” (L, less frequent)
The analyses of total fixation durations yielded main effects of Language (β = −0.156, SE = 0.028, p < .001), Form (β = −0.125, SE = 0.032, p = .001) and Alternation (β = −0.049, SE = 0.016, p = .003). Thus, beyond the fact that the L2 participants fixated the critical regions longer than the L1 participants (514.2 ms vs. 379.6 ms) and that total fixation durations were also longer for low-frequency items compared to high-frequency counterparts (518.5 ms vs.389.2 ms), the statistical analyses provided evidence that the main experimental manipulation (Alternation) had an influence on total fixation durations in the expected direction. Participants fixated regions in the changed conditions longer (475.5 ms) than in the same conditions (428.0 ms). Although the numerical difference for same vs. changed regions was larger in L2 (16.7 ms in L1 and 78.4 ms in L2), the corresponding Interaction Language vs. Alternation failed to be significant (β = 0.013, SE = 0.018, p = .473).Footnote 12 The results for total fixation durations are illustrated in Figure 2.

Fig. 2. Summary of total fixation durations during second reading for the lexical conditions (means of log-transformed latencies with SE).
Results for the lexical conditions (synonym alternations) can thus so far be summarised in that the experimental manipulation had an influence on participants’ fixation latencies. Participants fixated regions with exchanged lexical material significantly longer than unaltered regions. Although this effect was numerically more pronounced for L2 participants, statistically no significant interaction of Language and Alternation was observed.Footnote 13 As expected, participants also showed longer fixation durations for the low-frequency member of the synonym pair than for its more frequent counterpart. But importantly, this main effect did not interact with the Alternation manipulation. This shows that the alternation effect was not driven by cases when high-frequency, shorter nouns were exchanged by their low-frequency, longer synonyms (which could be viewed as more salient for noticing) during the second reading. The significant frequency effect also indicates that both groups of participants were sensitive to the lexical properties of the critical words and that the smaller L1 effects cannot be attributed to e.g., skimming of the given text part. To sum up, the results of the analyses of the lexical conditions provide evidence that both groups of participants are sensitive to changes in surface linguistic information on the lexical level.
Syntactic conditions (active – passive alternation)
Results for the syntactic conditions are summarised in Table 4. In the analyses of the number of fixations, main effects were observed for the factors Language (β = −0.669, SE = 0.294, p = .027) and Form (β = −0.942, SE = 0.129, p < .001): L2 participants produced more fixations than L1 participants and passive sentences led to more fixations than active sentences.Footnote 14 Although there was no main effect for Alternation (β = −0.257, SE = 0.171, p = .151), the interaction between Language and Alternation was significant (β = 0.519, SE = 0.209, p = .024). This interaction indicates, in contrast to the lexical conditions, that the syntactic alternation (i.e., the change from active to passive and vice versa) influenced reading behaviour differently for participants in L1 and L2. To resolve this interaction, both groups were subsequently analysed separately. This revealed that only L2 participants were sensitive to the Alternation manipulation (main effect of Alternation: β = −0.814, SE = 0.348, p = .032). They produced more fixations in the changed ROIs (12.71) than in the same ROIs (10.35). No such significant difference was observed for the L1 participants (10.63 vs. 10.34; β = 0.243, SE = 0.151, p = .121).
Table 4. Results of Syntactic Conditions (Active – Passive) in L1 and L2

The analysis of total fixation durations revealed a similar pattern. Again there were main effects for Language (β = −0.114, SE = 0.032, p = .001) and Form (β = −0.095, SE = 0.018, p < .001), but no main effect for the factor Alternation (β = −0.020, SE = 0.014, p = .180). However, there was a significant interaction between the factors Language and Alternation (β = 0.034, SE = 0.015, p = .040). Separate analyses revealed that the main effect of Alternation was significant only for L2 (β = −0.058, SE = 0.027, p = .046), but not for the L1 participants (β = 0.013, SE = 0.016, p = .400). The L2 participants thus produced shorter fixation times in the unchanged ROIs (2328.8 ms) than in changed ROIs (2960.9 ms). The (numerically very small) difference (−48 ms) was not significant for the L1 participants. Additionally, there was no significant interaction of Form with Alternation (β = 0.007, SE = 0.014, p = .611), indicating that the effect of the experimental manipulation (i.e., increased fixation times in the changed conditions) was independent of the direction of that change, i.e., the same effect was seen for sentences in active and passive voice. The results for total fixation durations are also illustrated in Figure 3.

Fig. 3. Summary of total fixation durations during second reading for the syntactic conditions (means of log-transformed latencies with SE).
In sum, the results from the syntactic conditions revealed that the L2 participants produced more fixations and longer total fixation times than the L1 participants did in general. Most interestingly, the significant interactions of Language and Alternation show that only for the L2 participants there were more fixations and longer total fixation durations for ROIs in the ‘changed’ compared to the ‘same’ conditions. No such difference was observed for the L1 participants. This observation supports the initial hypothesis that the L2 learners are more sensitive to changes in surface form than the L1 speakers.
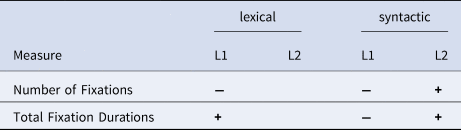
The pattern of significant effects for the factor Alternation (changed versus same conditions) is summarised in Table 5.
Table 5. Pattern of significant effects of Alternation (significance level p < .05)
Comparison between first and second reading
For all unchanged ROIs, an additional comparison was carried out for the first versus second reading of the texts. This analysis can be regarded as a baseline and diagnostic to assess whether L1 and L2 participants benefitted to the same degree from the repetition of the texts in general. Analyses were carried out over all unchanged (i.e., ‘same’) ROIs with the additional factor Reading (V1 vs. V2). The changed conditions were not included in the analyses, because it involves the confounding factor of the changed linguistic material (that was expected to increase the reading times and to affect the L2 readers more than the L1 readers).
Lexical conditions
With respect to the number of fixations, we observed a significant difference for Language (β = −0.210, SE = 0.046, p < .001) and Form (β = −0.191, SE = 0.069, p = .011), but no significant difference for Reading (β = 0.018, SE = 0.034, p < .601) nor any interaction of this factor with other factors (all p > .100). For total fixation durations, again effects for Language (β = −0.167, SE = 0.026, p < .001) and Form (β = −0.116, SE = 0.027, p < .001) were observed. This time, an additional effect for Reading was seen, too (β = 0.047, SE = 0.017, p = .009). However, the factor Reading did not interact with Language (β = −0.022, SE = 0.017, p < .195). Thus, for the lexical conditions, a general effect of shorter fixation times was seen for the second reading of the text, but this difference was statistically indistinguishable for both groups of participants.
Syntactic conditions
Analyses of the number of fixations only revealed significant main effects for Reading (β = 0.399, SE = 0.108, p = .003), and Form (β = −0.884, SE = 0.218, p = .002). Regarding total fixation times, beyond a main effect of Language (β = −0.087, SE = 0.032, p = .009), the analyses showed also main effects of Form (β = −0.079, SE = 0.022, p = .003), and Reading (β = 0.050, SE = 0.012, p < .001). These results show that the active sentences were read faster than passive sentences and that both active and passive sentences were read faster during the second reading. Importantly, none of the interactions reached significance. Crucially, the non-significant interaction of Language and Reading (β = −0.012, SE = 0.010, p = .241) indicates that the effect of repetition on reading times was identical for L1 (diff. = 166.7 ms) and L2 (diff. = 154.9 ms). For detailed analyses including a Figure comparing all conditions of the first and second reading see Appendix S3 (Supplementary Material). Thus, a repetition effect of the same size was observed in both L1 and L2 in the second reading, which complies with the finding that when readers read the same text twice, they speed up on second reading (Hyönä & Niemi, Reference Hyönä and Niemi1990; Raney & Rayner, Reference Raney and Rayner1995).
Importantly, though, the pattern of results shows that the different effects for the factor Alternation in the syntactic conditions in L2 cannot be explained by, e.g., a combination of frequency and repetition effects: in the lexical conditions, the repetition effect was the same in L1 and L2, and there was no significant difference in the alternation effect for the two language groups. In the syntactic conditions, the repetition effect was again the same in L1 and L2, and yet we observed a robust alternation effect in L2 only. The alternation effect in the syntactic conditions thus cannot be attributed just to slower reading in L2 per se.
Content questions
Answers to the content questions were analysed using a generalised mixed-effect model with a binomially distributed dependent variable Answer (correct vs. incorrect). The factor Language was set as a fixed effect and text and participant as random effects with a maximum random-effects structure justified by the experimental design. Results revealed that, although both groups of participants differed numerically in their accuracy rates (L1: 76.8% vs. L2: 72.3%), the difference between the two groups was not significant (β = −0.302, SE = 0.211, p = .154). This result also shows that even though the L2 participants read more slowly, this did not result—in general—in better memory for information contained in the text. We thus assume that slower reading per se is not responsible for better memory for linguistics structure in L2. Previous research also indicates that longer reading times in L2 are due to various factors such as e.g., slower word recognition processes rather than to a deeper or more thorough processing (Grabe, Reference Grabe2008: 122ff).
General discussion
Previous research in L1 generally converges on the claim that readers do not retain surface linguistic information verbatim during reading and this view has not been challenged until recently (Gurevich et al., Reference Gurevich, Johnson and Goldberg2010). At the same time, usage-based theories about language acquisition made assumptions that lead us to the hypothesis that the situation might be different for language learners. In particular, we hypothesised that L2 readers retain surface linguistic information and rely on it more than L1 readers. The results of our experiment supported this assumption.
In accordance with the previous L1 research, we did not find convincing evidence that verbatim information would be represented in L1 mental text models. Though the lack of an interaction between the factors Language and Alternation indicates that both L1 and L2 learners were sensitive to substitutions at the lexical level, the effect of Alternation in L1 was numerically rather small (16.7 ms compared to 47.5 ms in L2) and could be also explained by lexical-semantic differences between the synonyms (see below). The effect manifested itself only in the analyses of total readings times. Given that the ROIs comprised only one word, it is not surprising that no effect was observed in the number of fixations measure (as hypothesized).
In the syntactic conditions, the interaction between the factors Language and Alternation was significant and subsequent analyses showed that no differences in reading behaviour of the changed vs. same regions were observed for L1 participants. There was no evidence that L1 readers were sensitive to the introduced changes at the syntactic level.
Thus, we found only weak support for the finding of Gurevich et al. (Reference Gurevich, Johnson and Goldberg2010) which indicated that surface information might be retained in L1. At the same time, our results do not rule out the possibility that also L1 speakers represent and retain surface linguistic information, but rely on it less than L2 learners. Readers (or listeners, as in Gurevich et al.'s study) can, for example, show different sensitivity to different language structures. Our study involved only (contextual) synonym substitutions and active/passive alternations. In Gurevich et al.'s study, the authors employed a wide range of structures and rephrasings. It is a question for future research as to what degree different structures or formulations are retained verbatim in L1 mental text models and which further factors (like, e.g., the modality of presentation, involvement of lexical semantics) possibly influence their retention and the role they play during processing.
The question why the sensitivity to the changes in L1 in our study is limited only to the lexical items and does not include syntactic structures needs to be addressed in detail, too. We hypothesize that if L1 readers represent only propositional contents of the text in their mental text model, mental representations of lexical units, but not particular syntactic structures, might be comprised in the model. In the experiment, some of the synonyms were fully exchangeable only in the given contexts, but would have only partially overlapping semantic representations as isolated words (e.g., theory vs. hypothesis). Lexical differences between the synonyms thus might result in different conceptual-semantic representations at the propositional level, which is a part of the mental text model. When the changes concerned only the surface information (while lexical semantics were identical) as it was in the syntactic conditions, L1 readers showed no indication that this information would be a part of their mental text model. This is in accordance with studies on prediction that provide evidence that native speakers predict conceptual-semantic information, but not form-specific information during reading (Freunberger & Roehm, Reference Freunberger and Roehm2016).
In contrast to the results of the L1 speakers, we found robust evidence that L2 learners retain surface linguistic information during reading and that they rely on its representation more than L1 speakers as evidenced especially by the results in the syntactic conditions, for which differences were significant only for L2 learners. The effect was observed both in the analysis of the total reading times and the number of fixations.
The results of the experiment support the initial hypothesis that verbatim information plays a different role in native and non-native reading. L2 participants were sensitive to the verbatim changes in both the lexical and syntactic conditions. This sensitivity implies that they retained the surface linguistic information of the first text version in memory, because only in this case they could show a surprisal effect at encountering an alternative lexical or syntactic form in the second text version (while the semantic and propositional content remained the same). The eye-movement data thus offer unambiguous evidence that L2 learners retain verbatim information in memory and that they are more sensitive to it than L1 speakers at least on the syntactic level. Importantly, being explicitly asked about whether they noticed anything interesting or worth mentioning after the experimental session, none of the participants included in the analyses reported noticing that words or formulations changed between the text versions. Typically, they commented on the mathematical tasks and the content questions. This indicates that participants were not explicitly aware of the text manipulation, though their eye-tracking data reveal that they reacted to it.
Our study thus supports the results of Sampaio and Konopka (Reference Sampaio and Konopka2013), but advances them in two important directions. First, unlike Sampaio and Konopka or also, e.g., Kintsch and Bates (Reference Kintsch and Bates1977) and Gibbs (Reference Gibbs1981), we did not test verbatim memory of open-class lexical items only, but also of syntactic information. The inclusion of the syntactic conditions is important because it demonstrates that verbatim memory goes beyond a memory for particular words (cf. Gurevich et al., Reference Gurevich, Johnson and Goldberg2010, p. 48). Second, we did not test verbatim memory within isolated sentences, but within coherent texts. This aspect is crucial because, as pointed out (by, e.g., Gernsbacher, Reference Gernsbacher1985), the integration of sentences into coherent semantic representations is causally involved in the loss of verbatim memory – coherent texts are assumed to facilitate the creation of a summary gist. The results of our study thus have direct relevance also for theories of mental text models: to our knowledge, our study is the first to show not only that L2 readers represent verbatim information and rely on this representation more than L1 readers, but that the retention of the surface linguistic information persists also during reading of coherent texts. A pioneering aspect of our study is the employment of eye-tracking to explore information retention during reading. In the previous research (also that including exploration of mental text models) participants have typically been asked to give explicit judgements (e.g., the recognition experiment by Gurevich et al., Reference Gurevich, Johnson and Goldberg2010, or the task in Sampaio & Konopka, Reference Sampaio and Konopka2013) or to productively recall the critical sentences/text (e.g., production experiment of Gurevich et al., Reference Gurevich, Johnson and Goldberg2010). Such approaches enable an assessment of explicit knowledge that participants are able to retrieve, yet the human brain stores much more than what can be consciously accessed or actively produced. In fact, we do not know how much of what we cannot say or report is actually lost, and what is still stored in memory but cannot be retrieved (cf. Pierce, Klein, Chen, Delcenserie & Genesee, Reference Pierce, Klein, Chen, Delcenserie and Genesee2014). Employing the eye-tracking technology might offer insights into processing and representation of linguistic information that go beyond findings accessible to methods which rely on overt knowledge retrieval.
In the introductory section we have shown that though our hypothesis regarding the overreliance on surface linguistic information by L2 learners compared to L1 speakers is novel, it can be predicted based on assumptions made by cognitive, acquisition, and processing theories. Our results comply with theories postulating different processing for individuals with a different degree of expertise. L2 learners can be seen as novices in L2 reading compared to L1 readers who – at least in the case of university students as typical participants in psycholinguistic studies with adults – can be classified as experts. According to the FTT theory, the dominance of verbatim representations of past events (of which a recently read text is an instance) is associated with lower expertise, while experts rely more on gist-based information. This claim is in accordance with our result that while L2 learners demonstrate stronger reliance on surface linguistic information than L1 speakers, they do not outperform native speakers in answering the content questions. Further research is necessary to determine whether reliance on verbatim information is specific to L2 processing, or whether it is a more general cognitive strategy of novices as suggested by the FTT theory (Experiment 3 in Arndt & Beato, Reference Arndt and Beato2017, suggests that it is the latter).
The SSH links the L2 focus on “surface” to a deficit in building abstract syntactic representations. During processes like reading, online analysis of hierarchical syntactic structure may be very demanding or even impossible for L2 learners, navigating them towards a mental text representation that deviates from that of L1 speakers in the amount of surface linguistic information that it contains and/or in the degree on how much they rely on it. Verbatim representation and reliance on it would thus compensate for the (unavailable) results of a deeper syntactic analysis by synthesis of a complete and fully specified syntactic representation. It is an intriguing question for further research whether there might be a causal relationship between non-building a hierarchical syntactic structure and non-decaying of the low-level, surface information that is otherwise assumed to decay immediately after sentence processing (i.e., after the hierarchical syntactic structure had been built).
The results of our study also comply with the DP model: while morphosyntactic processing in L1 proceeds primarily via the procedural memory, L2 learners are assumed to employ the declarative system to process also grammar (Ullman, Reference Ullman and Sanz2005). The difficulties L2 learners might have with building abstract syntactic structure due to their limited ability to use the procedural system might thus be compensated by means of representation of verbatim information in declarative memory and by relying more on it than on procedural processing. Interestingly, such compensation could not only ease the reading process by partial relocation of the cognitive load from the procedural module to the declarative system; it could also contribute to an enhancement of the L2 repertoire of stored verbatim chunks that can thus be used for acquisition and/or productive use of the L2. Consequently, a representation that is a result of a limitation would at the same time contribute to its overcoming.
Our study brought important evidence concerning the role of surface linguistic information in L1 and L2 reading. While our findings comply with current cognitive, acquisition and processing theories and add a new dimension to their empirical and theoretical bases, they also clearly reveal the need for further research on the topic. We indicated several novel questions that the findings open, and there are indeed more such as, e.g., the actual length of verbatim retention, whether L2 readers – contrary to native speakers – also employ form-specific information in prediction, or whether the fact that L2 readers retain more surface linguistic information has a positive effect on the L2 acquisition process, or whether it might actually hinder it. Also, while our data deliver evidence that L2 readers retain verbatim information and rely on it more than L1 readers, the question about the L1 retention of especially structural verbatim information during reading (and without surface information oriented tasks) still remains open. In the present study, we found no evidence for it, but different approaches or paradigms might be needed to decide whether native readers only rely less on such type of information, or whether they also underrepresent it compared to L2 learners.
Acknowledgements
The authors are grateful to the company SMI for lending their eye-tracker and to Hana Marschner and Raphael Münz for their help with running the experiments and preparing the data.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728920000772
List of Supplementary Materials
Appendix S1: Appendix S1 List of Lexical Items.pdf
Appendix S2: Appendix S2 Statistical Tables.pdf
Appendix S3: Appendix S3 Supplementary Analyses.pdf










 Open access
Open access