


According to Crystal's (Reference Crystal2008) “A Handbook of Linguistics and Phonetics,” cognates are words that are “historically derived from the same source as another […] form” (p. 83). Due to this shared etymological background, cognates are often similar in how they are pronounced and written across languages (A. Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000). Examples for cognates are GRAVE (/greiv/Footnote 1) and GRAB (/graːp/) or FISH (/fɪʃ/) and FISCH (/fɪʃ/) (English/German). Cognates can range from being identical across languages to having more limited overlap (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012; Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020). Importantly, studying cognates can help us understand how languages are represented and interact with each other during language acquisition and processing (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Guediche et al., Reference Guediche, Baart and Samuel2020; Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). In this context, cognates are both studied as the focal point of interest (e.g., are cognates represented differently in the bilingual mind than other types of words?; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) as well as a proxy to better understand the impact of cross-language similarity of words on bilingual language processing (e.g., does overlap of translation-equivalent words facilitate language naming and switching?; A. Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; Declerck et al., Reference Declerck, Koch and Philipp2012; Hoshino & Kroll, Reference Hoshino and Kroll2008; Li & Gollan, Reference Li and Gollan2018; Muylle et al., Reference Muylle, Van Assche and Hartsuiker2022). Despite a continued strong interest in cognates and a general consensus that cognates are words from two different languages that share meaning and form (orthographic and/or phonological), the exact definition of what a cognate is varies widely within the literature. Thus, it is critical to have a closer look at how cognates – and non-cognates – are defined across different studies. The goal of this research note is to raise awareness of how differently cognate status has been operationalized across psycholinguistic studies and to help establish guidelines for future research on cognates.
1. Cognate definitions and cross-language similarity for cognate stimuli within the literature
To better understand how cognates are conceptualized within the field of psychology, we conducted a literature review and analysis. We did a Scopus searchFootnote 2 (www.scopus.com) to find articles that included the word “cognate” in its title, abstract or keywords. We further limited our search to the categories “social sciences” and “journal articles” to have a clear focus on experimental research. These restrictions resulted in over 1,700 articles, with a substantial portion being clearly not relevant. Thus, we decided to limit our analysis to three journals that commonly publish high-quality psycholinguistic and experimental research on bilinguals (Bilingualism: Language and Cognition, Journal of Memory and Language and Journal of Experimental Psychology: Learning, Memory and Cognition). By doing so, we were able to guarantee that the results presented here are representative for experimental, cognitive and psycholinguistic research on bilingualism. These restrictions resulted in 91Footnote 3 articles (published between 1989 and 2022), from which we then extracted how cognates/non-cognates were defined and, if the study was experimental, operationalized as well as other more general information (e.g., task performed by participants, languages investigated). When available, we entered stimuli into a common document and calculated cross-language similarity of word pairs (see more on this later). The results of the literature search and analysis are publicly available at: https://osf.io/x9ur3/?view_only=.
To summarize, the majority of reviewed articles was experimental, including tasks such as picture naming, lexical decision or sentence reading. The articles studied a relatively diverse set of languages, even as a high proportion focused on Western languages with English, Spanish and Dutch being the most frequent. Most, but not all, articles included a definition for cognates in their introduction. In contrast to the linguistic definition included earlier (Crystal, Reference Crystal2008), these definitions commonly focused on the shared meaning and form overlap of cognate words, sometimes highlighting phonological similarities (e.g., Colomé & Miozzo, Reference Colomé and Miozzo2010; Ramon-Casas et al., Reference Ramon-Casas, Fennell and Bosch2017; Sudarshan & Baum, Reference Sudarshan and Baum2019), orthographic similarities (e.g., Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010, Reference Dijkstra, Van Hell and Brenders2015) or both (e.g., Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Miwa et al., Reference Miwa, Dijkstra, Bolger and Baayen2014; Pureza et al., Reference Pureza, Soares and Comesaña2016; Robinson Anthony & Blumenfeld, Reference Robinson Anthony and Blumenfeld2019), often depending on the task that participants had to perform. That is, a definition was more likely to highlight cognates' orthographic overlap if words were presented visually/had to be written during the study's experiment(s) and their phonological overlap if words were presented auditorily/had to be spoken. Dijkstra et al. (Reference Dijkstra, Grainger and Van Heuven1999) note that most studies define cognates as having identical orthographic forms. Based on our review, this is not true anymore with most definitions allowing for some mismatches in form. Variations in the definitions of cognates make it harder to compare experimental results across studies (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999).
We then looked at how many articles operationalized cognate status (i.e., the extent to which translation-equivalent word pairs shared orthographic and/or phonological form). Here, we defined operationalization broadly, meaning that authors verified cognate status with an empirical procedure (e.g., by collecting similarity ratings for word pairs) and reported this as part of the manuscript. Interestingly, shared overlap was operationalized only in approximately 60% of the experimental articles that used cognates as stimuli (43/72 manuscripts). The remaining studies did not specify how cognates were selected. Most frequently, the latter meant that it was simply stated that there would be two different stimulus groups with no further reference to cross-language similarity (e.g., Declerck et al., Reference Declerck, Koch and Philipp2012; Li & Gollan, Reference Li and Gollan2018; Vorwerg et al., Reference Vorwerg, Suntharam and Morand2019).
Operationalizations of cognate status varied greatly across studies, though three methods were most common: (1) similarity was quantified by using some kind of norming procedure to obtain similarity ratings (i.e., people either classified word pairs as cognate/non-cognate or rated them on a similarity scale; N = 13), (2) (normalized) Levenshtein distance (LD) (N = 14; Levenshtein, Reference Levenshtein1966; Schepens et al., Reference Schepens, Dijkstra and Grootjen2012) or (3) Van Orden's (Reference Van Orden1987) graphemic similarity algorithm (N = 11; four studies used more than one method).
LD is a measure of string similarity denoting the minimum number of operations (substitution, insertion or deletion) that need to be performed to turn one word into another (Levenshtein, Reference Levenshtein1966). It can be used to quantify both orthographic as well as phonological similarity (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012, Reference Schepens, Dijkstra, Grootjen and van Heuven2013). For example, LOUSE (English; /laus/) and LAUS (German; /laus/) have an orthographic LD of two because one letter has to be substituted and another subtracted/added. Similarly, its phonological LD is zero because they are pronounced identically. LD can be normalized with a simple formula that takes the maximum length of the words into account (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). Van Orden's (Reference Van Orden1987) graphemic similarity algorithm is calculated based on whether two words share the first and last letter or not, the number of pairs of letters shared (both forward and in reverse order), number of single letters shared across words as well as word length measures. Possible values for the normalized LD and the graphemic similarity algorithm range from 0 to 1, and an arbitrary cut-off point of .5 to classify cognate status was used for each (Arêas Da Luz Fontes & Schwartz, Reference Arêas Da Luz Fontes and Schwartz2015; Gullifer & Titone, Reference Gullifer and Titone2019; Schepens et al., Reference Schepens, Dijkstra and Grootjen2012) with some exceptions that implemented different thresholds (Schwartz & Tarin, Reference Schwartz and Tarin2021; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011).
When an operationalization was included, articles often lacked the detail needed to understand the degree of similarity needed for word pairs in order to qualify as cognates or not. For example, studies reported that cognate status was verified by raters that did not participate in the main study (e.g., Ghazi-Saidi & Ansaldo, Reference Ghazi-Saidi and Ansaldo2017; Libben & Titone, Reference Libben and Titone2009; Sudarshan & Baum, Reference Sudarshan and Baum2019), but did not specify what exact ratings were necessary for a word to qualify as a cognate. Similarly, some studies listed average cross-language similarity values per stimulus category, but did not report a range or what similarity cut-off was used to determine group membership or referred to an earlier study for more details on stimulus selection. About 25% of the reviewed experimental articles included a continuous measure of word pair similarity in at least a subset of their analyses.
The findings that (1) many studies did not operationalize cognate status, (2) if they did, a range of measures plus cut-off points was used, (3) studies only reported mean similarity values but no range or cut-off for group membership, make it hard to draw any definite conclusions on how uniformly cognate status is conceptualized across studies. Thus, in a next step, we calculated the similarity of cognates and non-cognates. To operationalize orthographic similarity for studies that used a visual task or written response, we used the normalized LD (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). Normalized LD scores have been found to correlate highly with similarity ratings and can be calculated automatically for a large set of translation-equivalent word pairs (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). While normalized LD is well established as a measure of orthographic similarity, there is no such comparable index for phonological similarity (A. S. Costa et al., Reference Costa, Comesaña and Soares2022). Thus, to operationalize phonological similarity for studies that used an auditory task or spoken response, we had to focus on a smaller subset of studies for which phonological similarity values could be extracted from the recently published PHOR-in-One database (A. S. Costa et al., Reference Costa, Comesaña and Soares2022). This database includes phonological similarity scores for European Portuguese, Spanish, English and German based on the phoneme distance algorithm introduced by Schepens (Reference Schepens2010; see also Schepens et al., Reference Schepens, Dijkstra, Grootjen and van Heuven2013). We were not able to calculate phonological similarity based on published stimuli because only five studies that used an auditory task/spoken response included stimuli's phonological forms (and almost never reported its source).
We were able to extract stimuli from 47 studies that used distinct stimulus categories (approx. 25% of experimental studies did not make their stimuli publicly available). On further inspection, we had to focus our analysis on 23 studies for which we calculated stimuli's orthographic similarity and six studies for which we calculated stimuli's phonological similarity. We were not able to use all studies, as not all provided the word form for both languages, languages used different scripts (which makes it e.g., impossible to use normalized LD to quantify orthographic similarity) or the language combination examined was not included in the PHOR-in-One database.
As summarized in Table 1, median orthographic and phonological similarity was higher for cognates than for non-cognates. Even if not stated explicitly by researchers, cognate status is often operationalized by whether word pairs overall “look/sound similarly.” Likewise, non-cognates are operationalized as word pairs that “do not look/sound similarly.” Nevertheless, in practice, this means that translation-equivalent word pairs that are classified as cognates and non-cognates can vary significantly in sound and spelling similarity.
Table 1. Overview of the results for the stimulus analysis. For visual/written experiments, orthographic similarity (operationalized as normalized LD) was analyzed. For auditory/spoken experiments, phonological similarity (operationalized as normalized LD as published in the PHOR-in-One database) was analyzed
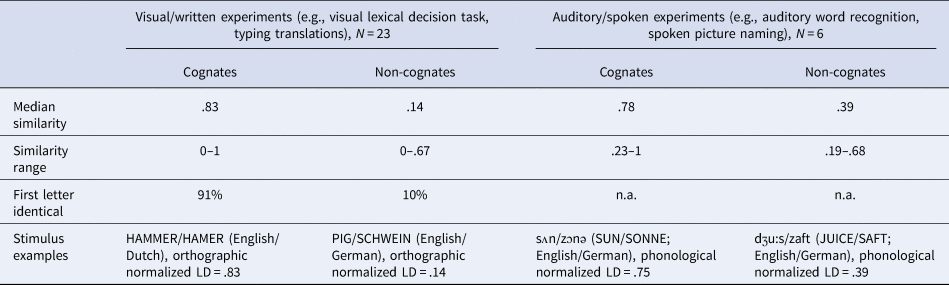
Note: Each cognate and non-cognate pair (within each study) was treated as its own data point. Cognates that share form but no meaning were included in the cognate category. There were nine studies that had both visual/written and auditory/spoken components; these were included in both average calculations (if possible). For example, reading sentences aloud would be considered to have both visual/written (visual presentation) as well as auditory/spoken (spoken production) components. The reason why the orthographic similarity range for cognates includes 0 is that FIRE/VUUR (English/Dutch; orthographic normalized LD = 0) was used once as a cognate pair in a visual task (de Groot & Nas, Reference de Groot and Nas1991). Phonological transcriptions are retrieved from the PHOR-in-One database (A. S. Costa et al., Reference Costa, Comesaña and Soares2022).
To visualize the range of similarity within each stimulus category (cognate or non-cognate), we plotted normalized LD for each word pair and task type (visual/written or auditory/spoken) across studies as histograms (see Figure 1). For visual/written tasks, it can be seen that many of the studies included highly similar cognates, whereas not all studies included non-cognates (leading to lower overall frequency counts). In addition, there was a lot of diversity in the cross-language orthographic similarity within each category, resulting in the histograms to overlap around a normalized LD of .4, with some studies including translation pairs as cognates with orthographic normalized LDs between .1 and .4 (see Figure 1A). That is, there were stimuli with the same orthographic similarity score that were in some studies classified as cognates and in others as non-cognates. For example, SHIP/SCHIFF (English/German) has an orthographic normalized LD score of .5 and was classified as a cognate in a vocabulary learning task where participants were presented with both the written and spoken forms of words (Salomé et al., Reference Salomé, Casalis and Commissaire2022); KORREL/KORN (Dutch/German) has the same score but was considered a non-cognate in a written lexical decision and spoken production task (Lemhöfer et al., Reference Lemhöfer, Spalek and Schriefers2008). Similarly, the word pair KING/KONING (English/Dutch; orthographic normalized LD = .67) was classified as a cognate (de Groot & Nas, Reference de Groot and Nas1991) and a non-cognate (Muylle et al., Reference Muylle, Van Assche and Hartsuiker2022; Poort et al., Reference Poort, Warren and Rodd2016). For auditory/spoken tasks, a similar pattern can be observed (though it should be noted that the overall contributing number of stimuli was much smaller than for visual/written tasks), with an overlap of the two categories around a phonological normalized LD of .5.
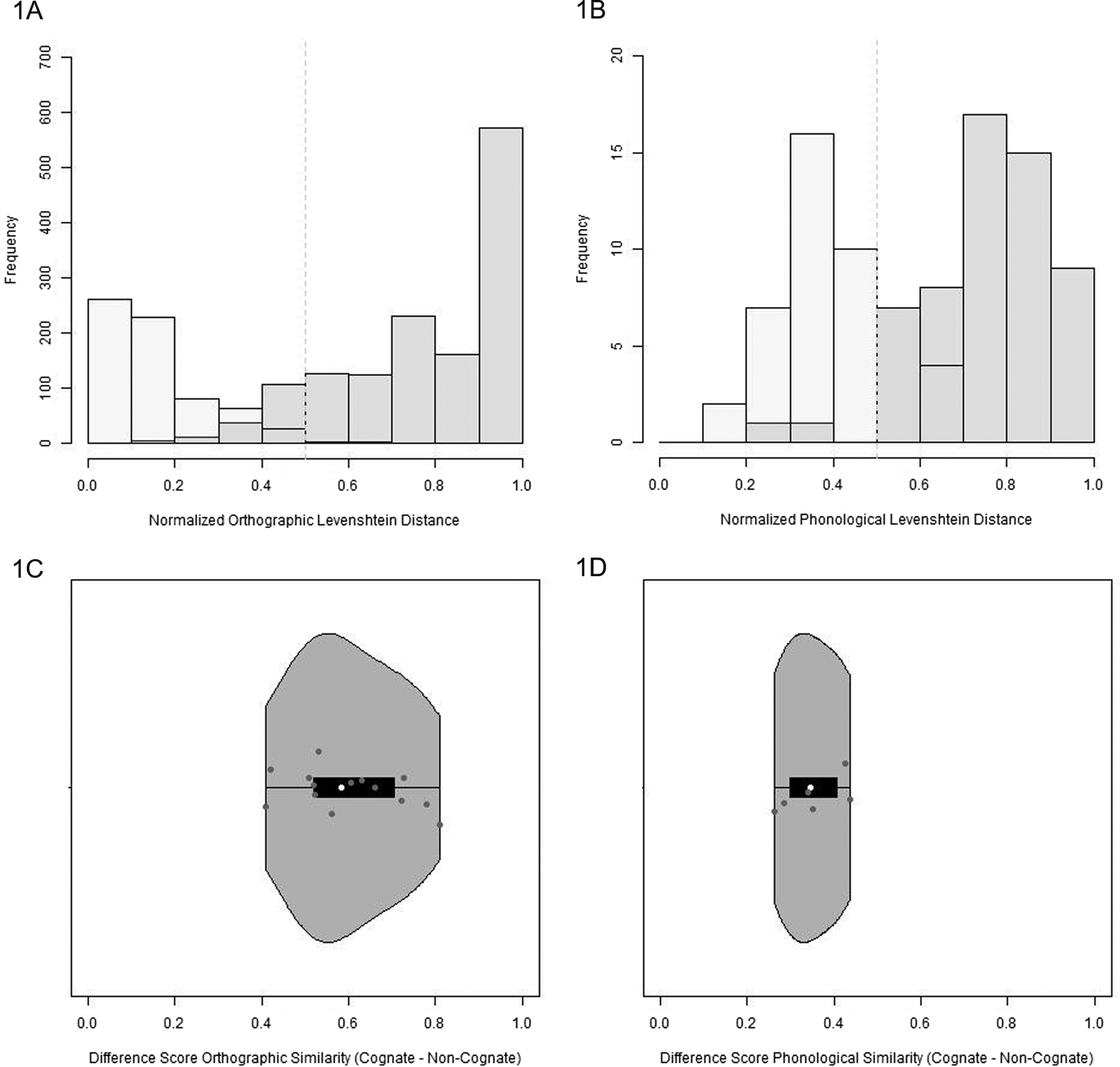
Figure 1. Histograms of normalized LD for stimuli categorized as cognates (dark gray) or non-cognates (light gray) for visual/written tasks (orthographic normalized LD; panel A) and auditory/spoken tasks (phonological normalized LD; panel B). Violin plots of difference score (cognates minus non-cognates) of normalized LD in studies that included both cognates and non-cognates for visual/written tasks (panel C) and auditory/spoken tasks (panel D). Higher, more extreme values represent larger differences in normalized LD scores between cognates and non-cognates.
We then calculated average orthographic and phonological similarity per stimulus category and a difference score (average similarity for cognates minus non-cognates) for each study that included both cognates and non-cognates (visual/written tasks: N = 14; auditory/spoken tasks: N = 6). As can be seen in Figures 1C and 1D, there was again a fair amount of variability across studies, with some contrasting word pairs that are, on average, at the extreme ends of the similarity scores (resulting in a very high difference score), whereas others concentrated on more similar ones. This variability may impact how likely it is that a study finds a difference between how cognates and non-cognates are processed by bilinguals.
To summarize, while it is clear that cognates and non-cognates differed, on average, in their cross-language similarity, our analysis also highlights that there was a considerable, potentially meaningful range in orthographic and phonological overlap across both categories. For both task types, similarity was more varied for cognates than for non-cognates, likely because cognates constitute for many of the studied language combinations the minority of translation-equivalents, leaving a smaller pool of stimuli to choose from.
2. Theoretical and practical implications for research on bilingualism
Using variable criteria and thresholds for cognates adds noise to our data and may make it harder to understand how cognates and non-cognates are processed by bilinguals (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999). The impact of this noise may be considerable, as cognate effects are nuanced and depend on several characteristics (e.g., list composition, bilinguals' proficiency, the context in which a stimulus is presented in; Guediche et al., Reference Guediche, Baart and Samuel2020). Effects of noisy definitions may be compounded when interactions with other variables are the research focus (e.g., when investigating how cognate status impacts language switch costs; Declerck et al., Reference Declerck, Koch and Philipp2012; Li & Gollan, Reference Li and Gollan2018). In other words, ignoring this impreciseness in cognate definitions may lead to conflicting results across studies and make it harder to develop theories of bilingual language processing.
When the focus of a study is on how cognates are processed, researchers need to actually consider if words are etymologically related given this is the linguistically accurate definition (Crystal, Reference Crystal2008). When, however, the goal of a study is to use cognates and non-cognates as a proxy of cross-language similarity (which may in turn mediate how activation flows within languages), we need to be more precise as to what we mean by these categories. Thus, we urge researchers to be more explicit in their methods as to how they determined cognate status (i.e., what criteria were used to determine a word was a cognate). In addition, a list of the items used should always be openly available (in the form of an appendix or supplementary material/an open science deposit). Finally, researchers should describe the different sets continuously (e.g., by using normalized LD; Schepens et al., Reference Schepens, Dijkstra and Grootjen2012) in the methods. If phonological similarity of words is quantified, phonological transcriptions should be reported and it should be specified where they were retrieved, given there are considerable differences in how words are pronounced and thus described phonologically in databases. For example, the English word TIGER is transcribed as /ˈtaigə(r)/ in the Langenscheidt Dictionary (commonly used by German speakers; Langenscheidt, n.d.) and as /ˈtʌɪɡə/ (British English) and /ˈtaɪɡər/ (U.S. American English) in the Oxford English Dictionary (Oxford English Dictionary, n.d.). These differences may seem subtle but would result in different similarity values as calculated by normalized LD. Table 2 provides a summary of our suggestions.
Table 2. Overview of practical suggestions for studying cognates in research on bilingualism

In general, the way forward may be to step away from using categories such as “cognates” and “non-cognates” when the real goal is to investigate the impact of phonological and orthographic similarity across words from different languages and to quantify similarity continuously instead (Broersma et al., Reference Broersma, Carter, Donnelly and Konopka2020), especially when analyzing data and/or when languages do not share many morphemes (Miwa et al., Reference Miwa, Dijkstra, Bolger and Baayen2014). In fact, analyzing cognateness as a continuous variable was not uncommon in the articles we screened (even if only in a sub-analysis). As in other areas of research, information gets lost when a continuous variable is dichotomized, sacrificing statistical power and yielding potentially misleading results (Baayen & Milin, Reference Baayen and Milin2010; Cohen, Reference Cohen1983; MacCallum et al., Reference MacCallum, Zhang, Preacher and Rucker2002). Consistent with this, Miwa et al. (Reference Miwa, Dijkstra, Bolger and Baayen2014) for example found that participants' eye movements were co-determined by phonological and semantic similarities (among other factors) but not by the dichotomous cognate status of word pairs (see for more detailed discussions on how continuous measures of cross-language similarity may enrich research on bilingual processing elsewhere, e.g., Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; A. S. Costa et al., Reference Costa, Comesaña and Soares2022; Fahey, Reference Fahey2021).
Having said that, the last suggestions assume that words' relevant similarity can be captured (easily) continuously. While (normalized) LD is a straightforward way to do so, its applicability is unfortunately narrow: it only captures string similarity of the same scripts. Additionally, even as phonological similarity can be quantified by using LD, it is less straightforward to do so (A. S. Costa et al., Reference Costa, Comesaña and Soares2022; Schepens et al., Reference Schepens, Dijkstra, Grootjen and van Heuven2013). Moreover, it may be harder to assess cross-language similarity for verbs than for nouns, as it is less clear which form should be compared (Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017), and for words embedded in text than for isolated ones (Balling, Reference Balling2013).
One way to quantify similarity that works for all language combinations and similarity dimensions is having a separate group of people with the same language backgroundFootnote 4 as the participants of the main study rate a word pair's semantic, phonological and orthographic similarity. As mentioned earlier, this is indeed a method that has been used repeatedly (e.g., Cai et al., Reference Cai, Pickering, Yan and Branigan2011; de Groot & Nas, Reference de Groot and Nas1991; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Ghazi-Saidi & Ansaldo, Reference Ghazi-Saidi and Ansaldo2017; Titone et al., Reference Titone, Libben, Mercier, Whitford and Pivneva2011). However, there appears to be little agreement on how many independent raters are necessary for such a similarity measure to be valid (e.g., in our review, stimuli were rated by between 2 [the authors of the specific article] and 60 people with a median of 10 raters). In addition, such an approach, while universally applicable, can unfortunately be labor- and time-intensive if a high number of stimuli has to be rated (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012) and/or access to the relevant participant population is limited.
3. Conclusions
Cognates are a pivotal tool when investigating how multiple known languages interact during language processing. Despite this, there is no consensus on how cognateness should be measured. As a result, a significant subset of reviewed experimental studies failed to include an operationalization of cognate status in their methods. Moreover, our analysis revealed that cognates and non-cognates differed widely in their similarity across studies, likely adding noise to the data collected and impeding our understanding of bilingual language processing. We make practical suggestions for researchers who want to study cognates in the future.
Data availability statement
Results of the literature search (annotated table and stimulus analysis; results from database search) are located at: https://osf.io/x9ur3/?view_only=
Acknowledgments
We thank Maria Bruggaier for helping with the categorization and annotation of articles that investigated cognates. Also, we thank Dr. Sarah Colby and Dr. Marc Brysbaert for helpful discussions on how to quantify phonological similarity of words. We appreciate Dr. Montserrat Comesaña and her PhD student for helpful feedback on previous versions of this manuscript.
Competing interests
None.




 Open access
Open access