


The influence of socio-economic status (SES) on health has been observed for all age groups. Due to the differences in health-related behaviours, health knowledge, housing conditions, psychosocial stressors, access to health care, etc., people living under lower socio-economic conditions have a heavier burden of disease compared with their better-off counterparts( Reference Marmot 1 , Reference Mackenbach, Stirbu and Roskam 2 ). More specifically, diet quality and food consumption have been shown to be associated with several indicators of SES (e.g. income and educational attainment) and to factors leading to social vulnerability (e.g. migration), which, in turn, can affect overall health and increase the predisposition to developing certain disorders such as overweight and obesity( Reference Nicklas, Baranowski and Cullen 3 , Reference Darmon and Drewnowski 4 ).
Previous studies focusing on the associations between indicators of SES and food intake in children and adolescents reported a lower intake of fruits and vegetables and a higher intake of energy-dense foods in lower-SES groups( Reference Van der Horst, Oenema and Ferreira 5 , Reference Sausenthaler, Kompauer and Mielck 6 ). Other studies have focused on dietary patterns instead and their associations with indicators of SES( Reference Richter, Heidemann and Schulze 7 , Reference Craig, McNeill and Macdiarmid 8 ). Indeed, considering diet as a whole is of great relevance for describing groups at a higher risk of developing overweight and obesity, as the overall diet seems to be a more important determinant of weight gain compared with single dietary components( Reference Moreira, Santos and Padrao 9 , Reference Hu 10 ).
Dietary pattern analysis has been increasingly applied in recent years to assess the relationship between overall diet and the risk of chronic diseases( Reference Hu 10 ). Cluster analysis, a commonly applied method to derive dietary patterns, clusters individuals into non-overlapping groups that reflect relatively homogeneous dietary patterns within groups and distinct dietary patterns between groups. Various studies have applied this method to derive dietary patterns in children and adolescents and explored their associations with indicators of SES( Reference Pryer and Rogers 11 – Reference Smith, Emmett and Newby 13 ). Moreover, exploring the changes in children's diet over time and the relationship between these changes and indicators of SES may help to identify the changes in dietary patterns and/or children changing their dietary patterns, thus allowing a better understanding of the impact of social inequalities on diet. Changes in diet over time have been previously explored using the principal components analysis (PCA); however, to the best of our knowledge, there is as yet only one report examining children's dietary patterns over time using cluster analysis( Reference Northstone, Smith and Newby 14 ). The PCA provides linear combinations of foods instead of referring to identifiable groups of individuals, while cluster analysis identifies relatively homogeneous groups of children based on their food consumption. Applying cluster analysis to describe longitudinal changes in dietary patterns can provide further insight into changes in children's dietary patterns and the identification of groups with persistently unhealthier diets.
Therefore, the primary aim of the present study was to describe dietary patterns by applying cluster analysis to children participating in the baseline and follow-up surveys of the Identification and Prevention of Dietary- and Lifestyle-induced Health Effects in Children and Infants (IDEFICS) Study. The secondary aim was to describe the cluster memberships of children over time and their associations with SES.
Subjects and methods
The IDEFICS Study is a multi-centre, population-based study of children aged 2–9 years upon recruitment in selected regions of eight European countries (Belgium, Cyprus, Estonia, Germany, Hungary, Italy, Spain and Sweden)( Reference Ahrens, Bammann and Siani 15 , Reference Bammann, Peplies and Sjöström 16 ). Each participating country included one intervention region, where the community intervention programme took place, and an equivalent control region( Reference Bammann, Gwozdz and Lanfer 17 ). The present study conducted two main surveys (baseline (T0) and follow-up after the intervention (T1)) in pre-schools and primary school classes (first and second grades at baseline). The baseline survey (September 2007 to May 2008) included 16 228 children aged 2–9 years (median age 6·3 (range 7·7) years). The follow-up survey (September 2009 to May 2010) reached an overall response rate of 68 % and included 11 038 children aged 4–11 years. The general design of the IDEFICS Study has been described elsewhere( Reference Ahrens, Bammann and Siani 15 , Reference Bammann, Peplies and Sjöström 16 ). The present study includes only children with < 50 % of missing values in FFQ data at T0 and T1 and for whom information on socio-economic variables and anthropometric measures was available (n 9301 children; 50·3 % boys; Fig. 1). Each participating centre obtained ethical approval from its health research ethics authority. All children provided oral consent and their parents provided written informed consent for all examinations and for the collection of samples, analysis and storage of personal data and collected samples.
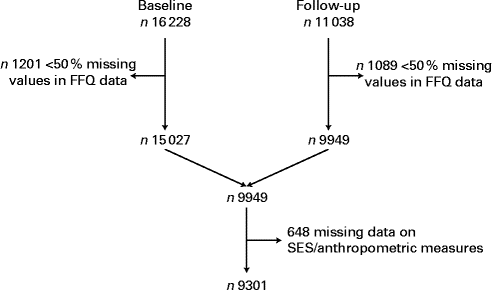
Fig. 1 Selection of the final study sample. SES, socio-economic status.
Measurements
Dietary data were obtained at both T0 and T1 using the food frequency section of the Children's Eating Habits Questionnaire-FFQ (CEHQ-FFQ)( Reference Huybrechts, Bornhorst and Pala 18 ), a validated screening tool in which the frequency of the child's consumption of selected food items during the preceding 4 weeks was reported by the parents. In order to assess meals under parental control, the questionnaire referred to meals outside the school canteen or childcare meal provision settings only( Reference Huybrechts, Bornhorst and Pala 18 , Reference Lanfer, Hebestreit and Ahrens 19 ). The CEHQ-FFQ, which consists of forty-three food items clustered into fourteen food groups, was applied as a screening instrument to investigate the consumption of foods shown to be related, either positively or negatively, to overweight and obesity in children. The CEHQ-FFQ was not designed to provide an estimate of total energy intake or total food intake( Reference Lanfer, Hebestreit and Ahrens 19 ). Response options displayed from left to right were as follows: never/less than once per week; one to three times per week; four to six times per week; one time per d; two times per d; three times per d; four or more times per d; I have no idea. For the analysis of dietary patterns, a conversion factor was used to transform the answers in the questionnaire into weekly consumption frequencies, represented by a number ranging from 0 to 30. Only children with < 50 % of missing values and with valid data on anthropometric measures and socio-economic variables were included in the analyses( Reference Pala, Lissner and Hebestreit 20 ). Multiple imputation was applied using sex, age, BMI and country as predictors for the remaining missing values (median number of available items 43 (sd 2·55))( Reference Graham 21 ).
During the baseline and follow-up surveys, parents completed a self-administered questionnaire on parental attitudes, children's behaviour and social environment. Parental education and income were self-reported. Parental education level was categorised according to the International Standard Classification of Education-97( Reference UNE SaCOIfS 22 ). Household income was assessed using nine country-specific categories based on the median equivalent income. The gained amount was then equalised to the number of household members using the square root scale provided by the Organisation for Economic Co-operation and Development( 23 ). Additionally, migrant background was assessed. A migrant background was assumed if one or both of the parents were born in another country.
Trained staff carried out anthropometric measurements at T0 and T1 following a standardised procedure. Body height (cm) was measured without shoes and all plaits undone using a portable stadiometer (SECA 225). Weight (kg) was measured using a child-adapted version of the electronic scale Tanita BC 420 SMA with the children in the fasting state (>8 h since the last meal) and wearing only underwear( Reference Stomfai, Ahrens and Bammann 24 ). BMI and age- and sex-specific BMI z-scores were calculated and categorised according to the criteria proposed by the International Obesity Task Force( Reference Cole and Lobstein 25 ).
Statistical analyses
K-means cluster analysis was performed to identify clusters of children with similar dietary patterns( Reference Newby and Tucker 26 ). First, all the variables in the FFQ were checked for their suitability in cluster analysis in terms of relevance. The item ‘meat replacement products’ was not included in the set of variables as more than 95 % of the subjects reported ‘never/less than once per week’ as the frequency of consumption. Second, correlations between single food items were checked to assess multi-collinearity. The assessment of their correlations showed no redundant variables. Therefore, all the remaining (forty-two) food items were taken into account. The relative frequency of consumption was calculated for each food item by dividing the frequency of consumption of a specific food item by the sum of the consumption frequencies of all the food items reported for each single subject. The z-scores of the relative consumption frequency were calculated to standardise the dataset before clustering, as differences in variances of the variables may otherwise affect the resulting clusters( Reference Everitt, Landau and Leese 27 ). A positive value indicates a higher frequency of consumption and a negative value reflects a lower frequency of consumption. The K-means algorithm was applied with a pre-defined maximum of 100 iterations to generate separate cluster solutions for two to six clusters. In order to find a stable clustering pattern, several solutions were obtained with different starting seeds. Iterations were generated until no change in cluster centroids was observed. The stability of the final solution was examined by randomly splitting the database into half and repeating the same clustering procedure, until satisfactory results were observed (a maximum of 327 children in the baseline clustering and 495 children in the follow-up clustering being allocated to different clusters, representing 3·5 and 5·3 % of the total sample, respectively). This procedure was applied for both baseline and follow-up datasets.
The stability of the cluster solutions and the interpretability of the clusters were considered as the criteria for choosing the final number of clusters to be retained. The clusters were labelled based on the z-scores of the food items.
Distribution of children in different clusters was calculated, stratified by sex, age, BMI status and country, both at T0 and T1. To assess the changes in dietary patterns over time, the cluster memberships of children at T0 and T1 were cross-tabulated, showing the proportion of children being allocated to the same or different clusters. Based on logistic regression models, OR for being allocated to the same cluster at T0 and T1 (i.e. healthy, sweet or processed at both time points; three models) or for changing the cluster (processed/sweet to healthy or vice versa; two models) were calculated, where the alternative category consisted of all the remaining combinations of cluster memberships in each model. Sex, age group, BMI status, migrant status, maternal and paternal education level, household income, country, and a dummy variable indicating intervention v. control region were assessed at both time points and included as covariates in all the models. The significance level was set at P≤ 0·05. The analyses were performed using the Statistical Package for the Social Sciences (version 20.0; SPSS, Inc.).
Results
Based on the forty-two food items and their relative frequency of consumption, the three cluster solutions were considered the most interpretable and stable for both baseline and follow-up datasets and therefore were retained. The following labels were assigned to the three clusters: processed (n 4427 at T0, n 2554 at T1); sweet (n 1910 at T0, n 1939 at T1); healthy (n 2964 at T0, n 4808 at T1). Tables 1 and 2 present the mean z-scores and standard deviations of all the food items in the three clusters at T0 and T1. Dietary data for both surveys were more likely to be available for children with lower-educated parents and lower household income and for children with lower BMI compared with the complete IDEFICS Study samples (data not shown). The cluster solutions obtained were similar in terms of interpretability at both time points. The mean values of the majority of the food items differed markedly between the three clusters (Tables 1 and 2).
Table 1 z-Scores of relative consumption frequencies in the three clusters at baseline (Mean values and standard deviations)

a,b,cMean values within a row with unlike superscript letters were significantly different (P< 0·05).
* The lowest mean value within a row.
† The highest mean value within a row.
Table 2 z-Scores of relative consumption frequencies in the three clusters at follow-up (Mean values and standard deviations)

a,b,cMean values within a row with unlike superscript letters were significantly different (P< 0·05).
* The lowest mean value within a row.
† The highest mean value within a row.
Compared with the other clusters, the processed cluster presented at both time points had higher relative frequencies of consumption of takeaway and high-fat foods, such as savoury pastries and fritters; pizza as main dish; fried potatoes; hamburgers, hot dogs, kebabs and wraps; and crisps, maize (corn) crisps and popcorn. Products such as wholemeal bread, cooked vegetables, raw vegetables, and fresh fruits without added sugar scored lowest. At both time points, the sweet cluster had higher values for sugar-rich products, such as chocolate- or nut-based spreads; sweetened drinks; fruit juices; diet drinks; candies, loose candies and marshmallows; and biscuits, packaged cakes, pastries and puddings, and had the lowest scores for water; porridge, oat meal, gruel, cereals and muesli, unsweetened; raw vegetables; plain unsweetened milk; and plain unsweetened yogurt and kefir. The healthy cluster had at both time points higher values for low-fat foods, foods rich in vitamins and whole-grain foods, e.g. raw vegetables; fresh fruits without added sugar; porridge, oat meal, gruel, cereals and muesli, unsweetened; and plain unsweetened milk, and lower values for high-fat and high-sugar products, such as fried potatoes; sweetened drinks; sweetened milk; mayonnaise and mayonnaise-based products; chocolate- or nut-based spreads; crisps, maize (corn) crisps and popcorn; and biscuits, packaged cakes, pastries and puddings.
Table 3 summarises the distribution of age, sex, BMI status and country in the three clusters at T0 and T1. The percentage of girls in the healthy cluster was slightly higher than that in the other two clusters, while a higher percentage of boys were allocated to the processed and sweet clusters. Older children represented a higher percentage in the processed and sweet clusters compared with younger children. The processed cluster included a lower percentage of normal-weight children and a higher percentage of obese children compared with the other two clusters. The biggest differences were observed between the countries, i.e. certain countries represented up to 46 % of one cluster. Thus, the sweet cluster was mainly represented by Belgian and German children, the processed cluster by Italian, Cypriot, Estonian and Spanish children, while the healthy cluster included a high percentage of Swedish children.
Table 3 Description of the included study population, stratified by cluster membership, at baseline (T0) and follow-up (T1) (Number of participants and percentages)

Table 4 summarises the percentage of children being allocated to the same cluster at T0 and T1 and those being allocated to different clusters (see online supplementary Table S1 for the same proportions taking into account only subjects with complete information). With 85 % of the children being allocated to the healthy cluster at both T0 and T1, this cluster was the one with the greatest stability. Only 46 % of the children in the processed cluster at T0 remained in this cluster at T1, while 43 % switched to the healthy cluster at T1. Also, 382 children (20 %) allocated to the sweet cluster at T0 changed to the healthy cluster at T1. No differences in the percentage of children allocated to the same or different clusters at T0 and T1 were found between the interventions and the control regions (data not shown).
Table 4 Cross-tabulation between the cluster memberships of children at baseline (T0) and follow-up (T1) (Number of participants and percentages)
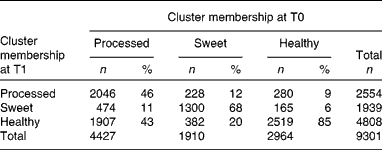
Table 5 presents OR and 95 % CI for the associations between the identified dietary patterns and socio-economic characteristics. Girls (OR 0·88, 95 % CI 0·79, 0·98) and children with higher-educated fathers (OR 0·73, 95 % CI 0·59, 0·91) were less likely to be included in the processed cluster at T0 and T1, while the OR were higher for older children (OR 1·23, 95 % CI 1·10, 1·38) and migrants (OR 1·24, 95 % CI 1·05, 1·46) than for younger children and non-migrants. Girls (OR 0·78, 95 % CI 0·66, 0·92), migrants (OR 0·40, 95 % CI 0·31, 0·52), and children with the highest educated mothers (OR 0·65, 95 % CI 0·47, 0·89) and fathers (OR 0·73, 95 % CI 0·54, 0·99) and highest household income (OR 0·77, 95 % CI 0·61, 0·97) were less lik ely to be allocated to the sweet cluster at T0 and T1. Obese children (OR 1·37, 95 % CI 1·08, 1·74) and children with higher-educated mothers (OR 1·61, 95 % CI 1·28, 2·04) and fathers (OR 1·51, 95 % CI 1·20, 1·90) were more likely to be allocated to the healthy cluster at both time points. Girls (OR 1·16, 95 % CI 1·04, 1·31) and children with the highest household income (OR 1·31, 95 % CI 1·12, 1·53) were also more likely to be allocated to the healthy cluster at T0 and T1. Older children (OR 0·65, 95 % CI 0·58, 0·73) were less likely to be allocated to the healthy cluster. Girls (OR 1·18, 95 % CI 1·07, 1·31), obese children (OR 1·41, 95 % CI 1·12, 1·78) and children with higher-educated fathers (OR 1·24, 95 % CI 1·02, 1·50) were more likely to change from the processed/sweet cluster at T0 to the healthy cluster at T1. Finally, obese children (OR 0·54, 95 % CI 0·35, 0·85) were less likely to change from the healthy cluster at T0 to the processed/sweet cluster at T1.
Table 5 Associations between the cluster memberships over time (each group compared with all the other combinations of cluster memberships) and socio-economic characteristics* (Odds ratios and 95 % confidence intervals)

T0, baseline; T1, follow-up after the intervention; ISCED, International Standard Classification of Education.
* All the models were adjusted for country and study region (intervention v. control) and for all the other factors presented in the table.
Discussion
The present study derived dietary patterns based on a cluster analysis performed at two different time points in 2- to 9-year-old children participating in the IDEFICS Study. Overall, three consistent dietary patterns were identified at T0 and T1: a processed cluster, showing higher frequencies of consumption of snacks and fast food and lower frequencies of vegetables and wholemeal products; a sweet cluster, showing higher frequencies of consumption of biscuits and sweet products, candies, and sweetened drinks; a healthy cluster, showing higher frequencies of consumption of fruits, vegetables and wholemeal products, and lower frequencies of consumption of processed food products. These three patterns presented similar profiles of relative frequencies of food consumption at each time point, allowing us to assess which children remained in the same patterns and who changed their dietary patterns between T0 and T1. The cluster membership was additionally found to be associated with a number of socio-economic indicators, namely paternal and maternal education levels, household income and migrant status.
Although dietary patterns are dependent on the population considered and therefore not completely comparable between studies, previous reports extracting dietary patterns of children using cluster analysis found similar results. A British study in children aged 1–4 years has also identified three clusters that were labelled as healthy diet, convenience diet and traditional diet( Reference Pryer and Rogers 11 ). Another recent British study in 7-year-old children has singled out processed, plant-based and traditional British clusters( Reference Smith, Emmett and Newby 13 ). A study among Chinese children aged 6–13 years has also found three clusters: a healthy pattern; a transitive pattern; a Western pattern( Reference Shang, Li and Liu 28 ). However, also different numbers of dietary patterns have been described, ranging from two to seven clusters( Reference Okubo, Miyake and Sasaki 12 , Reference Northstone, Smith and Newby 14 , Reference Knol, Haughton and Fitzhugh 29 , Reference Rodriguez-Ramirez, Mundo-Rosas and Garcia-Guerra 30 – Reference Kim, Kim and Lee 33 ). The heterogeneity of the reference populations from different countries and continents, the different dietary assessment methods (FFQ v. dietary records), the different number and types of food items included and the use of different clustering algorithms (e.g. K-means and Ward's method) are likely explanations for the different results. Nevertheless, similar variations in certain patterns have been repeatedly reported across different populations. This is especially true for the patterns labelled as healthy or health-conscious( Reference Newby and Tucker 26 ).
A previous study has derived four dietary patterns from the IDEFICS baseline data by applying the PCA( Reference Pala, Lissner and Hebestreit 20 ). The first pattern was labelled ‘snacking’, with the highest loadings for hamburgers, hot dogs, butter, savoury pastries and white bread. The sweet and fat pattern showed the highest loadings for sweet products such as chocolate- or nut-based spreads, cakes, puddings and cookies. The third pattern was labelled ‘vegetables and wholemeal’, with the highest loadings for vegetables, fruits and wholemeal bread. Finally, the protein and water pattern presented the highest loadings for fish, water, eggs and meat. Our cluster solution presents groupings that are similar to the PCA solution. Nevertheless, it also reflects different aspects and detects a different number of factors/clusters. Other studies exist that have compared dietary patterns obtained by applying the PCA and cluster analysis to the same samples( Reference Smith, Emmett and Newby 13 , Reference Reedy, Wirfalt and Flood 34 , Reference Crozier, Robinson and Borland 35 ). The results showed a general correlation between the methods, although the two methods describe diet in a different way.
Although it was not the focus of the study, we found a higher percentage of overweight/obese children allocated to the healthy cluster than those allocated to the sweet pattern. The results also showed that obese children were more likely to be allocated to the healthy cluster at both time points. The parents of overweight/obese children might be more prone to under-reporting or providing socially acceptable answers than those of normal-weight children, which is also the case among obese adults. Another plausible explanation is that our dietary instrument, similar to most instruments assessing children's diet, reflects the information provided by proxy reporters (parents) and therefore only includes meals under parental control. As a result, this questionnaire might not have been able to adequately capture the consumption of certain high-fat, high-sugar foods, potentially beyond parental control( Reference Pala, Lissner and Hebestreit 20 ).
The present study found that children's membership in a specific cluster was associated with parental education. Specifically, children with higher-educated mothers and fathers were more likely to remain in the healthy cluster at the two time points or to change from the processed/sweet cluster to the healthy one. Notably, the association was found to be stronger for paternal education. Most of the findings in the literature have shown a stronger association with maternal education. Nevertheless, few studies have also described a strong paternal influence on children's dietary intake( Reference Lee and Reicks 36 , Reference Hebestreit, Keimer and Hassel 37 ), suggesting that higher-educated fathers might communicate beneficial roles and healthy behaviour more clearly than lower-educated fathers. The lack of studies showing paternal influence on children's dietary intake underlines the importance of our findings and the need for further evidence. Previous results from the IDEFICS Study also pointed out the association between parental education and children's food consumption( Reference Fernandez-Alvira, Mouratidou and Bammann 38 ). A recent publication describing four clusters (processed, healthy, traditional and packed lunch) at three different time points in a sample of British children has also found an association between a child's cluster membership over time and maternal education level( Reference Northstone, Smith and Newby 14 ). In particular, children with lower-educated mothers were more likely to be allocated to the processed cluster at all time points, while children with higher-educated mothers were more likely to remain in the healthy cluster. The present study also found this association in the case of paternal education. Although similar associations have been reported previously using dietary patterns derived from the PCA( Reference Northstone and Emmett 39 ), the use of cluster analysis to describe dietary patterns over time makes it possible to track which children remain in a specific cluster, thus providing more insight into specific subgroups that consistently show unhealthy dietary patterns.
The present study is subject to a number of limitations. First, the IDEFICS Study was not designed to be nationally representative. Participation in the IDEFICS Study was voluntary, which means that some population groups, e.g. lower-educated or high-income individuals, may have been less willing to take part in the study. The direction of a possible bias cannot be predicted because no systematic information on non-participants is available. Moreover, the direction of the bias usually points in opposite directions for lower and higher SES. A further limitation is the fact that 43 % of the initial baseline cohort did not participate at follow-up and/or did not provide complete data, precluding their inclusion in the present study. Excluded participants showed a higher prevalence of overweight/obesity and a higher percentage of lower-educated parents (see online supplementary Table S2). Consequently, a selection bias cannot be ruled out. Additionally, participants without valid information on maternal education were more likely to be allocated to the processed cluster at both time points, which is another reason why a selection bias cannot be ruled out. The CEHQ-FFQ was not designed to reflect total food intake, but rather to capture information on parent-supervised meals. The number of meals under parental control varied between countries. Sweden, for example, had a higher number of meals and a higher percentage of children eating at school. This might partially explain the differences observed in dietary patterns between countries. However, it was still possible to describe socio-economic differences in dietary patterns, as mainly family socio-economic characteristics influence meals under parental control, as opposed to meals at school.
To the best of our knowledge, this is the first multi-centre European study assessing dietary patterns over time using cluster analysis. The large sample size, the wide variety of dietary habits and cultural backgrounds across eight European countries, and the use of a validated dietary instrument shown to provide reproducible estimates of consumption frequencies are the main strengths of the present study. The use of cluster analysis for deriving dietary patterns at two time points allowed us to identify groups of children with persistently unhealthier dietary profiles and to characterise them according to socio-economic indicators. Healthy eating interventions may benefit from the results of the present study, taking the results into consideration to specifically address groups presenting persistently unhealthier dietary patterns.
Supplementary material
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/S0007114514003663
Acknowledgements
The authors gratefully acknowledge the children and parents who participated in the IDEFICS Project. The present study, being part of the IDEFICS Project, was published on behalf of the IDEFICS European Consortium (http://www.idefics.eu). The present study was supported by the European Community's Sixth RTD Framework Programme Contract no. 016181 (FOOD).
The authors' contributions are as follows: J. M. F.-A. carried out the statistical analyses with the help of C. B. and I. P. and drafted the manuscript; K. B. supervised the quality-control study protocol; K. B., W. G., V. K., L. R. and I. P. developed the measurement instruments; A. H., G. B., G. E., I. I., T. V., Y. A. K., E. K., I. H. and L. A. M. supervised the national data collection procedures. All authors read and critically reviewed the manuscript.
None of the authors has any conflicts of interest to declare.








