1. Introduction
Cross-linguistic comparisons have shown similarities across children's expressive vocabularies (e.g., Gopnik and Choi Reference Gopnik and Choi1990, Jackson-Maldonado et al. Reference Jackson-Maldonado, Thal, Marchman, Bates and Gutierrez-Clellen1993, Caselli et al. Reference Caselli, Bates, Casadio, Fenson, Fenson, Sanderl and Weir1995, Thordardottir and Weismer Reference Thordardottir and Weismer1996, Caselli et al. Reference Caselli, Casadio and Bates1999, Hamilton et al. Reference Hamilton, Plunkett and Schafer2000, Maital et al. Reference Maital, Dromi, Sagi and Bornstein2000). In fact, as they acquire their mother tongue, all children go through the same developmental levels: vocabulary size and age of acquisition have been shown to be very similar for French and English (Poulin-Dubois et al. Reference Poulin-Dubois, Graham and Sippola1995), but also in other Romance languages such as Mexican Spanish (Jackson-Maldonado et al. Reference Jackson-Maldonado, Thal, Marchman, Bates and Gutierrez-Clellen1993), and Italian (Caselli et al. Reference Caselli, Bates, Casadio, Fenson, Fenson, Sanderl and Weir1995). Two different levels are generally acknowledged across languages. These levels are characterised by different rhythms in new word acquisition and by the use of words belonging to different grammatical categories. On the whole, despite crosslinguistic or inter-individual differences, the same reorganisations in children's vocabulary occur with regard to word class between 12 and 36 months of age. A first level is characterised by rather slow acquisition of words that are mostly nouns (Jackson-Maldonado et al. Reference Jackson-Maldonado, Thal, Marchman, Bates and Gutierrez-Clellen1993, Caselli et al. Reference Caselli, Bates, Casadio, Fenson, Fenson, Sanderl and Weir1995, Bassano Reference Bassano1998, Maital et al. Reference Maital, Dromi, Sagi and Bornstein2000, Kauschke and Hofmeister Reference Kauschke and Hofmeister2002, Bornstein et al. Reference Bornstein, Cote, Maital, Painter, Park, Pascual, Pêcheux, Ruel, Venuti and Vyt2004), followed by vocabulary spurt and first word combinations. Nevertheless, variability among children has been argued to be a result of various factors, including gender (girls having slightly larger productive vocabularies, as shown by Eriksson et al. (Reference Eriksson, Marschik, Tulviste, Almgren, Pereira, Wehberg, Marjanovič-Umek, Gayraud, Kovacevic and Gallego2012) using adapted Communicative Development Inventories (CDIs) for 10 non-English language communities) birth rank (e.g., Bates et al. Reference Bates, Bretherton and Snyder1991, Fenson et al. Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994, Maital et al. Reference Maital, Dromi, Sagi and Bornstein2000) and differences in input. Input may vary both qualitatively and quantitatively as a result of socio-economic status (SES), the type of the language being acquired and the interactions or activity types. The impact of endogenous factors as well as SES has been controlled for in our study, but will not be dealt with in this paper, since our interest here lies in input differences. In what follows, we discuss studies that look at parents' behaviour and input as possible explanations for variability in children's language.
1.1 Input and linguistic environment
Input is crucial to language acquisition. Quantity and quality of input have been singled out as predictors of language development, from the very first levels, as well as in later levels of development (Huttenlocher et al. Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991, Hart and Risley Reference Hart and Risley1995, Bornstein et al. Reference Bornstein, Haynes and Painter1998, Florin Reference Florin1999, Weizman and Snow Reference Weizman and Snow2001). From the point of view of quantity, various studies have indeed shown the impact of frequency on the order of acquisition of lexical items (Huttenlocher et al. Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991, Goodman et al. Reference Goodman, Dale and Li2008). Thus, in 16-month-old children, order of acquisition is closely linked with the relative frequency of words acquired in parents' speech (Huttenlocher et al. Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991). Overall, the words and grammatical categories heard the most often should be learned earlier by children (Choi and Gopnik Reference Choi and Gopnik1995, Tardif Reference Tardif1996, Goodman et al. Reference Goodman, Dale and Li2008). Together with quantity, quality is a possible source of variation which has been analysed in caregiver-child interaction, for example, based on mothers' responsiveness and volubility (Vanormelingen and Gillis Reference Vanormelingen and Gillis2016) or on the pragmatic values of caregiver utterances (see Farran and Haskins Reference Farran and Haskins1980, Hoff Reference Hoff2006, Rowe Reference Rowe2008 on the impact of directives versus conversational utterances). Looking at the children's linguistic environment, studies have shown that cross-linguistic differences affecting morphology, salience, as well as frequency and pragmatic aspects had an impact on lexical development, especially on vocabulary composition. For example, a noun bias in expressive vocabulary is observed in children acquiring English (e.g., Au et al. Reference Au, Dapretto and Song1994, Bates et al. Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994, Fenson et al. Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994, Tardif et al. Reference Tardif, Shatz and Naigles1997, Goldfield Reference Goldfield2000), Italian (e.g., Caselli et al. Reference Caselli, Bates, Casadio, Fenson, Fenson, Sanderl and Weir1995, Tardif et al. Reference Tardif, Shatz and Naigles1997), Spanish (Jackson-Maldonado et al. Reference Jackson-Maldonado, Thal, Marchman, Bates and Gutierrez-Clellen1993), French (Poulin-Dubois et al. Reference Poulin-Dubois, Graham and Sippola1995, Bassano Reference Bassano2000, Parisse and Le Normand Reference Parisse and Le Normand2000), and Hebrew (Maital et al. Reference Maital, Dromi, Sagi and Bornstein2000), but these results could not be replicated in other languages like Korean and Mandarin, where conflicting evidence has been found (see Gentner Reference Gentner1982, versus Au et al. Reference Au, Dapretto and Song1994). One way of accounting for observed differences has been to look at pragmatic aspects of language. Different linguistic and cultural communities also differ as regards the focus of caregivers' discourse to children, emphasizing different environmental and linguistic aspects during caregiver-child interaction (Bornstein et al. Reference Bornstein, Tamis-LeMonda, Tal, Ludemann, Toda, Rahn, Pêcheux, Azuma and Vardi1992). For example, American mothers tend to focus on objects and request object labels from their children for a variety of socio-cultural reasons: they have been shown to focus more on objects than Chinese and Japanese mothers (Tamis-LeMonda et al. Reference Tamis-LeMonda, Bornstein, Cyphers, Toda and Ogino1992, Fernald and Morikawa Reference Fernald and Morikawa1993, Gopnik et al. Reference Gopnik, Choi and Baumberger1996). More recently, variation has been shown to depend more on context differences than on language typology: in Altınkamış et al. (Reference Altınkamış, Kern and Sofu2014), nouns prevailed in both French and Turkish child-directed speech in book-reading contexts, and there were more verbs in toy play. In an effort to “put the noun bias in context” (Tardif et al. Reference Tardif, Gelman and Xu1999), such studies show an effect of context on linguistic measures, with possible impacts on child language acquisition. A different approach, going back to Bruner's (Reference Bruner1981) analyses, consists in starting from context and analysing how it relates to language acquisition.
1.2 Influence of context on interactions and input
In the wake of Vygotsky's social interactional conception of language, Bruner insists on social context for language acquisition, underlining the importance of what he called formats in social interaction and showing that they are a crucial level in language development (Bruner Reference Bruner1981). Bruner's seminal work has certainly influenced methods and topics in the field, but to our knowledge, research linking context with language acquisition is still relatively scarce, more focused on specific contexts like meals or book reading, and mostly aimed at demonstrating SES- or community-related differences (e.g., the part played by parents' free time and dedication to children's development – and notably time spent reading (Weizman and Snow Reference Weizman and Snow2001) – and the impact of engagement and stability of mother-child dyads on later development (Leyendecker et al. Reference Leyendecker, Lamb, Schölmerich and Fricke1997b)). Such studies outline input characteristics and link this input to child language development, for example for mealtime context (Ely et al. Reference Ely, Gleason, MacGibbon and Zaretsky2001, Snow and Beals Reference Snow and Beals2006), book reading (Reese and Cox Reference Reese and Cox1999, Choi Reference Choi2000, Raikes et al. Reference Raikes, Alexander, Luze, Tamis-LeMonda, Brooks-Gunn, Constantine, Tarullo, Raikes and Rodriguez2006), or free play (Choi Reference Choi2000, Newland et al. Reference Newland, Roggman and Boyce2001). The variety of contexts (Hoff-Ginsberg Reference Hoff-Ginsberg1991) as well as duration of caregiver-child interaction (Snow et al. Reference Snow, Dubber, Blauw, Vernon-Feagans and Farrar1982, Hoff et al. Reference Hoff, Laursen, Tardif and Bornstein2002) have been shown to have an impact. This line of research has also related certain kinds of more specific activities to more advanced language abilities like literacy. The next paragraph is a summary of the general contribution of previous studies to our understanding of the part played by social interactional contexts in language development. In line with Bruner's work, play activities are often related to joint attention (e.g., Newland et al. Reference Newland, Roggman and Boyce2001) and more generally to fundamental pragmatic characteristics of interaction. Interactions in play contexts have also been used to assess the quality, stability, engagement and sensitivity of caretakers interacting with their children (interactional style) (Masur and Gleason Reference Masur and Gleason1980, Tamis-LeMonda et al. Reference Tamis-LeMonda, Bornstein, Baumwell and Damast1996, Leyendecker et al. Reference Leyendecker, Lamb and Schölmerich1997a, Leyendecker et al. Reference Leyendecker, Lamb, Schölmerich and Fricke1997b, Newland et al. Reference Newland, Roggman and Boyce2001, Yont et al. Reference Yont, Snow and Vernon-Feagans2003, Tamis-LeMonda et al. Reference Tamis-LeMonda, Shannon, Cabrera and Lamb2004). Although SES-related differences are generally observed across contexts, book-reading contexts are a notable exception, in which both working-class and middle-class mothers have been shown to interact with their children in supportive ways (Snow et al. Reference Snow, Arlman-Rupp, Hassing, Jobse, Joosten and Vorster1976, Lewis and Gregory Reference Lewis and Gregory1987, Wiley et al. Reference Wiley, Shore and Dixon1989, Hoff-Ginsberg Reference Hoff-Ginsberg1991). Indeed, because mothers use more referential language while reading (Raikes et al. Reference Raikes, Alexander, Luze, Tamis-LeMonda, Brooks-Gunn, Constantine, Tarullo, Raikes and Rodriguez2006), and because of the more complex nature of child-directed speech in such contexts (from the point of view of both lexical and syntactic diversity), large-scale studies have shown a positive impact of the time spent reading (Weizman and Snow Reference Weizman and Snow2001) with no clear SES-related differences (Hindman et al. Reference Hindman, Skibbe and Foster2014). Another line of research sought to go against the bias towards contexts “defined by researchers – usually toy play and book reading” (Hoff-Ginsberg Reference Hoff-Ginsberg1991: 782) by looking at interactions in contexts such as mealtime or other goal-directed caretaking interactions, such as dressing or household chores, in order to capture “most children's typical experiences” (Hoff-Ginsberg Reference Hoff-Ginsberg1991: 782) Such contexts have been shown to differ from more usually studied contexts, in that they had smaller rates of child-directed speech and higher rates of conversation-eliciting utterances, together with lower lexical diversity (Hoff-Ginsberg Reference Hoff-Ginsberg1991). The above-mentioned studies generally link the behaviour of dyads at a given time to later language and cognitive development of children. A different line of research has focused on a given linguistic feature of language development, for example the nouns bias (Choi Reference Choi2000, Kern et al. Reference Kern, Chenu and Türkay2012, Altınkamış et al. Reference Altınkamış, Kern and Sofu2014), or on mothers' conversational style (Bornstein et al. Reference Bornstein, Tamis-LeMonda, Tal, Ludemann, Toda, Rahn, Pêcheux, Azuma and Vardi1992, Haden and Fivush Reference Haden and Fivush1996, Kloth et al. Reference Kloth, Janssen, Kraaimaat and Brutten1998, Flynn and Masur Reference Flynn and Masur2007, Golinkoff et al. Reference Golinkoff Michnick, Can, Soderstrom and Hirsh-Pasek2015, Kelly et al. Reference Kelly, Forshaw, Nordlinger and Wigglesworth2015) in order to track variation or show stability across contexts. Such studies have shown, for instance, that mothers used more action-oriented utterances and hence more verbs in toy-play contexts than in book-reading contexts (Kern et al. Reference Kern, Chenu and Türkay2012). A final line of research has taken activities into account with a view to contextualising vocabulary development within the Human Speechome corpus (D. Roy et al. Reference Roy, Patel, DeCamp, Kubat, Fleischman, Roy, Mavridis, Tellex, Salata, Guinness, Levit, Gornia, Vogt, Sugita, Tuci and Nehaniv2006a, Reference Roy, Patel, DeCamp, Kubat, Fleischman, Roy, Mavridis, Tellex, Salata, Guinness, Levit and Gornia2006b; D. Roy Reference Roy2009; B. C. Roy et al. Reference Roy, Frank and Roy2009, Reference Roy, Frank and Roy2012; B. C. Roy et al. Reference Roy, Frank, DeCamp, Miller and Roy2015). Roy et al. have contributed to operationalising Bruner's format by establishing an exhaustive list of activities with dense and longitudinal data about one child. The idea behind the Speechome corpus is to gain insight into the influence of family environment on language acquisition, thus taking both linguistic and non-linguistic behaviours into account. B. C. Roy (Reference Roy2014) has explored activities in terms of spatial and temporal distribution as well as word use. Having built a model of context distributions and mapped it on every individual word in the corpus, he was able to single out more or less distinctive words along that dimension. The main finding is that “words used in distinctive spatial, temporal, and linguistic contexts are produced earlier, suggesting they are easier to learn” (B. C. Roy et al. Reference Roy, Frank, DeCamp, Miller and Roy2015: 1). B. C. Roy et al.’s ground-breaking operationalisation of activity contexts is, to our knowledge, unparalleled in the literature. However, it remains to be seen how their methods could be applied to more traditional longitudinal data, which are still widely used in language acquisition studies. In the present study we use activity contexts in longitudinal data for six children, across three different languages. Our coding system and analyses are presented here as a possible application of B. C. Roy et al.’s methods: we discuss results with a view to assessing what could be achieved if it were to be used on more data.
1.3 Our study
As shown in our analysis of previous literature, the notion of the context where acquisition takes place has not often been analysed as such. And yet, we know that context has an impact: according to the type of social activity, linguistic input changes in terms of quantitative, qualitative and pragmatic vocabulary. Inspired by recent research on activity contexts, the aim of the present exploratory study is twofold. Our first goal is to observe which kinds of activities occur in longitudinal video recordings of different families, languages and cultures: our study thus focuses on three developmental levels and three different languages. Second, we would like to see if activity types may be linked with variations in child-directed speech. In order to address these goals, we made two hypotheses. According to our first hypothesis, while different patterns of activities will be found in each recording, regularities may emerge if activities are categorised into a limited number of activity types. According to our second hypothesis, differences in child-directed speech may be observed as a function of activity types.
2. Method
We used longitudinal recordings of children from six different families and three different languages and cultures to test our hypotheses. Rather than focusing on linguistic features like morphology and salience, or social features like birth order, this article starts from an analysis of the context of speech productions and seeks to show whether and how it relates to linguistic factors like input frequency, diversity or complexity.
2.1 Corpus, population, and description
Our data consist of longitudinal recordings from three distinct linguistic communities: one Romance language (French) one West Germanic language (American English) and one Semitic language standing outside existing classifications, being non Indo-European (Tunisian Arabic). As shown in a recent paper (Kelly et al. Reference Kelly, Forshaw, Nordlinger and Wigglesworth2015), while the literature is very dense about language development in some linguistic communities, investigation of some less-documented languages remains a major challenge. Thus, there are very few studies on the acquisition of Arabic, and even fewer studies on children acquiring dialectical Arabic (Badry Zalami Reference Badry Zalami2006). When such studies exist, they deal with either children's learning of formal and so-called “standard Arabic”, which is a later acquisition, or with the acquisition of certain varieties like the Egyptian Arabic dialect (Omar Reference Omar2007) or the Jordanian dialect (Amayreh Reference Amayreh2003).
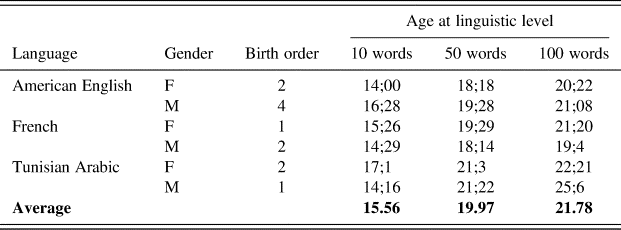
The same recording procedure was followed for all three corpora, namely one-hour recordings at 15-day intervals at the child's home. The instructions given were always the same: behave exactly as you would if there was no observer (Pellegrini et al. Reference Pellegrini, Symons and Hoch2004). Our three datasets are taken from the Providence corpus (Demuth et al. Reference Demuth, Culbertson and Alter2006) for American English, from the PREMS corpus (Kern et al. Reference Kern, Davis, Zink, d'Errico and Hombert2009) for Tunisian Arabic and from the French OHLL corpus (Kern Reference Kern and Hombert2005). We used data from two children per language: one boy and one girl. All families have a high SES. Birth rank was not controlled, but the information was collected for each child and is set out in Table 1. Participants are not shown in the table, but they were coded as headers in each transcription and taken into account in our analyses.
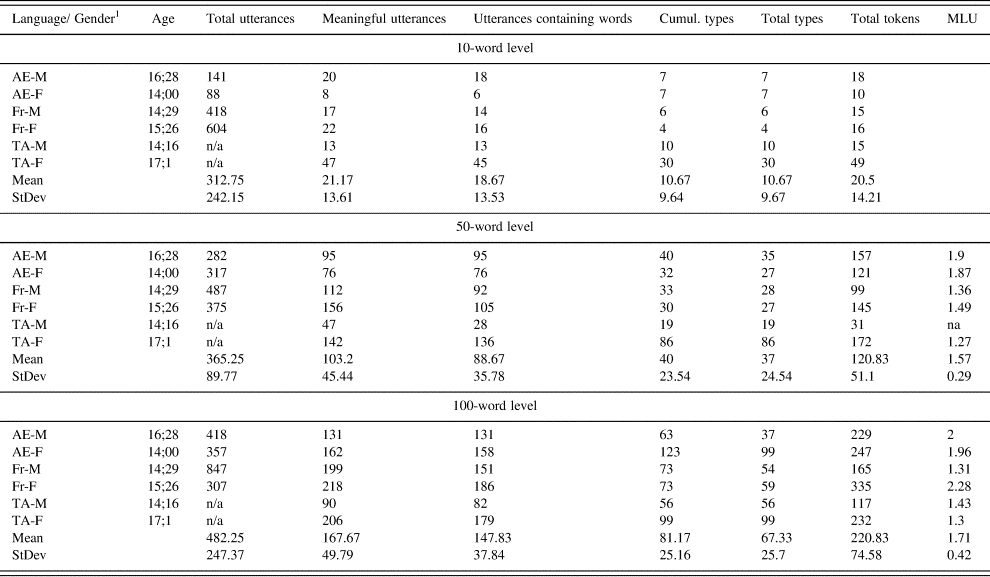
Table 1: Corpus description.
The children were recorded before the first word and until they produced 200 different words, but for the purpose of our fine-grained analyses of activity contexts we used data at only three key linguistic levels, that is to say 10, 50 and 100 words produced. Each session was 50 minutes long. The 10-word level was the most homogeneous early level in our data, and it corresponds to a well-described milestone in language development (Tardif et al. Reference Tardif, Fletcher, Liang, Zhang, Kaciroti and Marchman2008). The same is true of the 50- and 100-word levels, which precede and follow the lexical spurt (Bloom Reference Bloom1973, Benedict Reference Benedict1979, Huttenlocher et al. Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991, Fenson et al. Reference Fenson, Dale, Resnick, Thal, Bates, Hartung, Pethick and Reilly1993, Kern Reference Kern2010). Thus, we worked on 2.5 hours of recording for each child and 5 hours for each linguistic level, amounting to a total of 15 hours of recording.
In order to obtain equivalent linguistic levels while maximising comparability across datasets, we calculated cumulated types across all recordings, so that each linguistic level takes into account every word produced by the child up to that point. As can be seen in Table 2, where both raw and cumulated scores appear, for each session chosen for analysis we have rather homogeneous results across children and languages.
Table 2: Children's linguistic measures at each level
1AE: American English; Fr: French; TA: Tunisian Arabic; M: male; F: female.
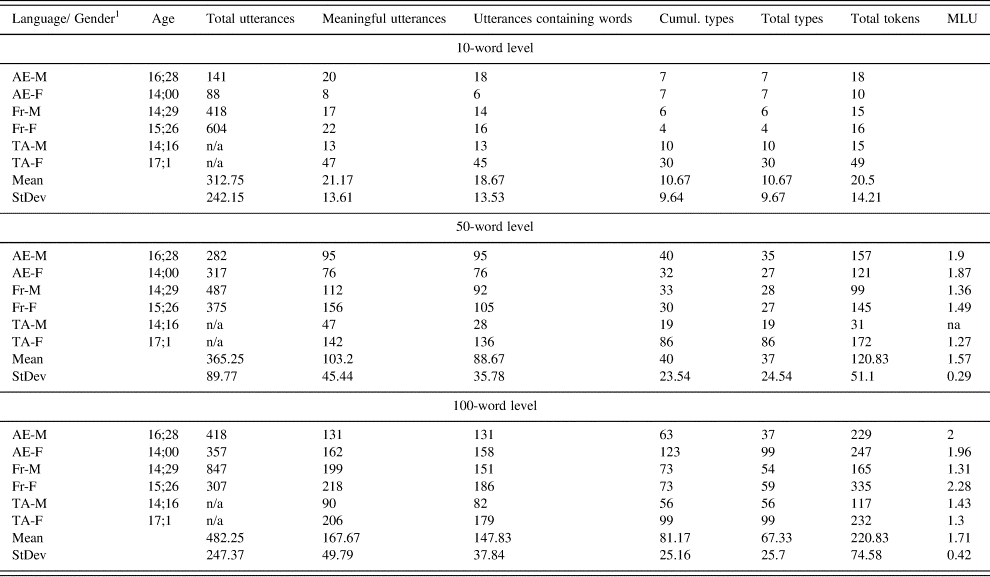
As expected, when looking at those measures no child stands out across all levels. Nevertheless, for the 100-word level girls systematically score above boys in word type in all three linguistic groups: 99 versus 37 for US children, 59 versus 32 for French children and 99 versus 50 for Tunisian children.
We computed mean length of utterance (MLU) from the second level onward. More variation can be seen in MLU counts, which are not necessarily a function of lexical diversity. In our data, they are probably more of an index of the children's conversational style. Indeed, the French girl's longer MLU is linked with repeated utterances based on the same chunks.Footnote 1 As a result, the number of types remains relatively low. The MLU for the Tunisian children does not change as quickly, but this is probably the result of Phon transcriptions of this Semitic language (Omar Reference Omar2007: 9): each transcribed word includes affixes and may correspond to several words in English or French. This had no impact on the comparability of our data, however, since types were retrieved and counted manually in order to establish cut-off points for the three developmental levels.
2.2 Transcription and coding
This section is mainly concerned with coding, but since the process of transcription required decisions that were likely to have an impact on our analyses (especially as regards the linguistic measures), we begin by explaining how we transcribed. We focused on child-directed speech only, since other utterances were hardly ever relevant to ongoing caregiver-child activities. Besides, quantity of child-directed speech is the best predictor of overall discourse quantity heard by a child (Weisleder and Fernald Reference Weisleder and Fernald2013). In addition, because only mothers' and children's utterances could be transcribed in our Tunisian dataset, we restricted our analyses to mother-child interactions in all three languages. This did not lead us to exclude much in the French and American data, especially since the observer was often the only other person present and was not supposed to take part in interactions.
2.2.1 Transcription
All main speakers in our recordings – that is, at least child and mother – were orthographically transcribed with Phon software (Rose et al. Reference Rose, MacWhinney, Byrne, Hedlund, Maddocks, O'Brien and Wareham2005) using CHILDES rules (MacWhinney Reference MacWhinney2009). A major problem in transcribing and analysing our data was to find a common definition for a word in all three languages. As a rule, we used the widely accepted definition by Vihman and McCune (Reference Vihman and McCune1994). We considered as a word any linguistic form spontaneously produced, in an appropriate or relevant context, when this linguistic form was near or similar to the adult form. Besides, since we focused on lexical diversity, we included for instance, alphabet letters in our transcriptions and analyses.Footnote 2 Only unintelligible items (coded yyy in CHILDES datasets) were excluded. We assigned word limits based on written language (Vihman and McCune Reference Vihman and McCune1994).
2.2.2 Grammatical categories
We focused on two grammatical categories that previous research has shown to be relevant both cross-linguistically and across activity contexts: nouns and verbs. Each word in the corpus was coded as a noun, as a verb, or as neither, which we treated as a third generic category.
In order to obtain comparable data, we adopted the coding categories used in previous studies (Choi Reference Choi2000). Thus, our noun category included proper names, kinship terms like maman and common nouns, but excluded pronouns. Our category of verbs included main verbs, but excluded auxiliaries and copulas. This was particularly helpful in Tunisian Arabic, since auxiliaries and main verbs often appeared as one word in our transcriptions. Besides, since our coding was done manually, it enabled us to distinguish noun-verb homonyms, as illustrated by the two sentences read by the American boy's mother to her son in our data:
(1) The count loves counting things Ernie loves to drum.
(2) Here's a drum to bang here's a phone to ring.
Last but not least, no lemmatisation was performed on our data, because it could not be done for Tunisian Arabic. Thus, in what follows, we chose to present tokens rather than non-lemmatised types.
2.2.3 Ethological coding
Although the premise of our approach is original, the resulting categorisation of activities is not unique: previous research used equivalent taxonomies of child activity. For example in Leyendecker et al. (Reference Leyendecker, Lamb and Schölmerich1997a) and Leyendecker et al. (Reference Leyendecker, Lamb, Schölmerich and Fricke1997b), activities were divided into five exclusive and exhaustive contexts: feeding, caretaking, toy play, social interaction and no interaction. Overall, functional and social contexts clearly had an effect on interactional experiences. SES effects on verbal and other interactional measures were limited to a subset of contexts and may thus represent the infants' overall experiences quite poorly. Such results show that comparisons based on a single context may be inadequate for studies of participants from differing socioeconomic backgrounds and point to the need for further explorations of contexts. In line with Bruner's (Reference Bruner1981) notion of format and B. C. Roy et al.'s (Reference Roy2013) operationalisation of the notion as a core element in defining activity contexts, we coded the contexts of mother-child interactions. In contrast to what was done with Speechome data, however, we designed our own method and coding scheme. Using traditional tools of ethological measurement, we first drafted a map of activities occurring in our families on the entire French corpus, that is to say on 330 hours of video recording. Thus we coded for a wide variety of activities. Having done that, we distinguished three main activities that occur regularly in any child's day: exploration, maintenance, and social activities. As shown in Table 3, we consider as solitary activity all activities of environment exploration (e.g., looking out the window) and solitary play (e.g., playing alone with a toy). Maintenance activities include all activities revolving around food (dinners or snacks), health and hygiene (bath time, blowing the child's nose), while social activities include all activities of social play, book reading, and social speech (e.g., discussing previous experience).
Table 3: Coding categories of activities.
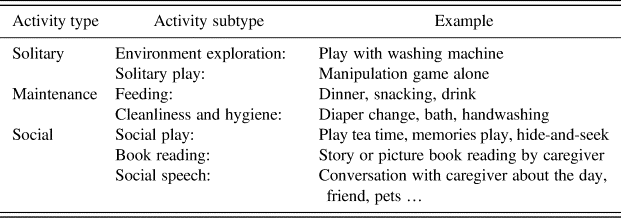
We started by looking for regularities and variation across our three main types of activities but went back to our finer-grained subtypes where appropriate. We did not, however, code for activities that included only a few utterances and were nested in a previous activity which continued afterwards. Most of the time, those nested activities were failed attempts to change the focus of the interaction. For example, if while book reading a mother tries to give a glass of water to her child and the child refuses and continues to read so that book reading with mother starts again, we included all utterances in a book reading activity. Examples from our corpus are available in Appendix 1. Each of the first three authors of this paper was responsible for coding in one language, and there were regular meetings to discuss coding and to check reliability across languages. Time spent interacting or doing things without speaking is not taken into account and not coded, so we do not have measures of total time for activities in our recordings. Our measures include total number of utterances as well as global duration of activities including verbal productions by at least one participant.
2.3 Measures
Even if a child needs to hear a certain quantity of input before acquiring a word, raw frequency is probably not the best predictor for word learning; quality and interaction may be more accurate (Clark Reference Clark2009, Cartmill et al. Reference Cartmill, Armstrong, Gleitman, Goldin-Meadow, Medina and Trueswell2013). In what follows, we began with raw measures and then computed more qualitative measures such as lexical diversity and noun-verb proportion. We measured activity duration for each level and child. This enabled us, first, to see how activities were spread in the sessions we analysed, and second, to adjust lexical measures depending on durations. Additionally, we computed overall durations for each activity type over each recorded session. All linguistic measures were computed using CLAN software. At each linguistic level, for whole sessions, and depending on the activity when we had enough data, we calculated token and types of word, number of utterances and mean length of utterance as well as lexical diversity, using the D measure (Malvern et al. Reference Malvern, Richards, Chipere and Durán2004) and the VOCD (Vocabulary Diversity) command in CLAN. Considering the importance of noun versus verb differences in the literature and the observed variations across activities, we also calculated the number of nouns, verbs, and other words in each recorded session, as well as for each activity. Proportions of nouns and verbs (tokens) per utterance were computed for each activity type, as was done in Choi's landmark study (Choi Reference Choi2000). Using per-utterance ratios also helped us correct for the differences that resulted from our definition of word boundaries in Tunisian Arabic.
3. Analyses
Our study is aimed at assessing the impact of recorded activities on the linguistic measures that can be obtained based on longitudinal corpora. Because of the relatively small size of our sample, it is unlikely that major differences linked with different genders or birth-ranks will be found. Thus, in what follows we will not take gender or birth-rank into account unless we notice differences that might be linked with those characteristics.
Besides, due to the complexity and exploratory character of data collection, coding and analysis, we did not have enough data to run powerful statistical tests. The relatively small size of our sample, which includes data from only six children, does not allow for any inferential statistics. Indeed, the probability that our tests will result in type I error is stronger than that of finding any effect. In order to avoid overgeneralising from a small amount of data, we present only descriptive statistics that will be analysed and interpreted as such. We sought to produce a coherent overview of our data by using the same bar charts for all the measures presented in this section.
3.1 Duration of activities
In order to assess the relevance of our first hypothesis and track the presence or absence of regularities in the distribution of activities, we started from our three main types of activities and compared durations across languages, children and developmental levels.
3.1.2 Global duration
Across all languages and developmental levels, a large majority of coded activities are social activities: they represent more than half of all the coded data. Solitary activities make up about a quarter of the data, and maintenance activities cover an hour and a half only (Figure 1).
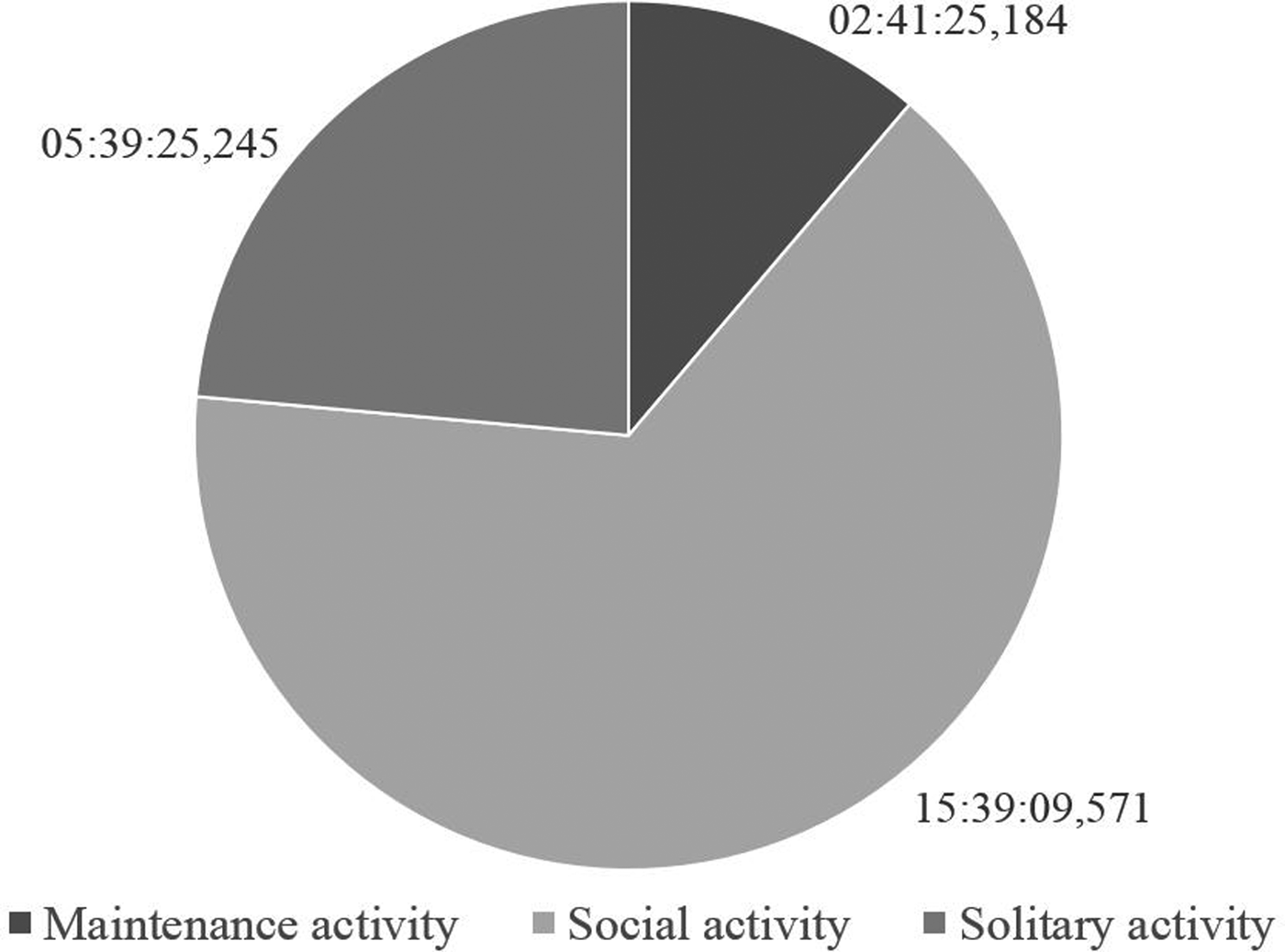
Figure 1: All corpus activities.
3.1.3 Detailed duration of activities
In spite of clear variation across datasets, Figure 2 shows that social activities (including play interaction, discussion, etc.) are the most stable across our coded sessions and children: they amount to 10.51 minutes minimum and 42.48 minutes maximum in our 50-minute recordings. Solitary activities are less important but present in nearly all sessions, amounting to a maximum of 35 minutes and a minimum of less than 1 minute per session. Finally, maintenance activities are relatively infrequent and by far the least represented category in our data. Maintenance activities have been found in only 9 out of 15 coded sessions, and they cover less than 5 minutes altogether, including mostly short activities that are linked with snacking or blowing the child's nose.

Figure 2: Activity duration per language, gender, and developmental level (labels corresponding to minutes spent).
Beyond the sheer variety, visual patterns seem to appear vertically rather than horizontally, which points to variation across languages, and no clear impact of developmental levels on activity types, apart from the French dataset where an increase of social activities and a corresponding decrease of solitary activities are observed for both children. When we look at the overall recorded duration per children, pooling all sessions together, the main result is the quantity of social activity for all children. Duration of social activity never falls under 50 minutes, that is a third of the overall recording. The maintenance and solitary activities are more variable.
On the whole, rather than showing differences at each developmental level, or as a result of the different languages and cultures, the observed variability in recorded activities points to subtle differences in what is actually going on in the data, and it is worth noting that those differences are seldom mentioned in longitudinal studies of language development. Indeed, although recording methods are generally similar, and similar instructions are given to families – telling them to interact with their child as they usually do – recorded activities may differ considerably as a result of various external constraints, including the observer's presence. In our Tunisian data, there were many more child-observer interactions, and the child's siblings and cousins were more often around, so that social activities were predominant. These elements are crucial in order to understand the findings presented here. Therefore, more detailed elements are provided and discussed in section 4.
3.2 Common lexical measures: variation across activities
In order to assess the relevance of our second hypothesis, according to which activity types may have an impact on linguistic measures, we looked for differences in child-directed speech across our three main types of activities, again as a function of languages, children and developmental levels. The first element to be taken into account as regards child-directed speech is the existence of disparities in the amount of speech addressed to the children in our recordings. We used utterance and word counts to assess these differences.
3.2.1 Utterances
As shown in Figure 3, the total number of utterances directed to children in two and a half hours of recording varies a lot, with Tunisian Arabic child-directed speech clearly standing out as containing fewer utterances. This is partly due to the fact that the observer in Tunisian recordings interacted more with the child than was the case in the other two languages, and observer speech was not included in the present study.
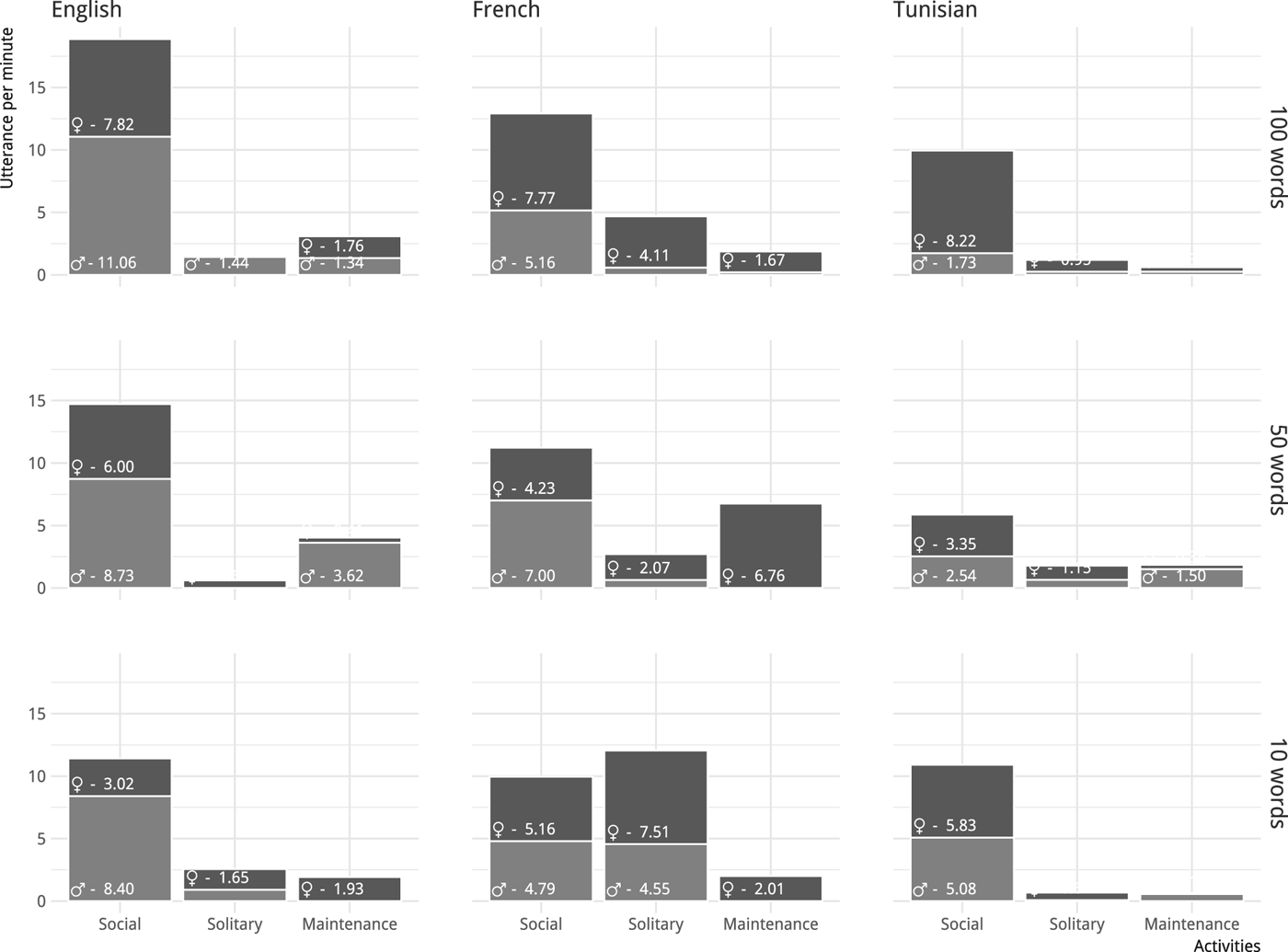
Figure 3: Utterances in child-directed speech per minute as a function of context and language.
The overall proportion of utterances in each activity context, language and level is by and large similar to the activity durations recorded in Figure 2, which suggests that verbal interactions are constant throughout the recordings, with only a few exceptions – notably, the small amount of speech addressed to the children in solitary contexts (with the exception of the French girl), which suggests that for some time at least, there is very little dialogue. The same trend is observed for our Tunisian data in social contexts. It is also worth noticing that in the American recordings only, utterances per minute become more numerous at each developmental level (especially in social context), so that mothers appear to be adjusting to their child's linguistic development.
3.2.2 Word tokens
While observed proportions of word tokens in CDS (Figure 4) are not considerably different from the above proportions of utterances, they provide evidence for one trend which was less clear when looking at utterances only: the overall amount of speech addressed to girls is greater than that directed to boys. This seems to be the case across languages, and more clearly so in the 100-word level.
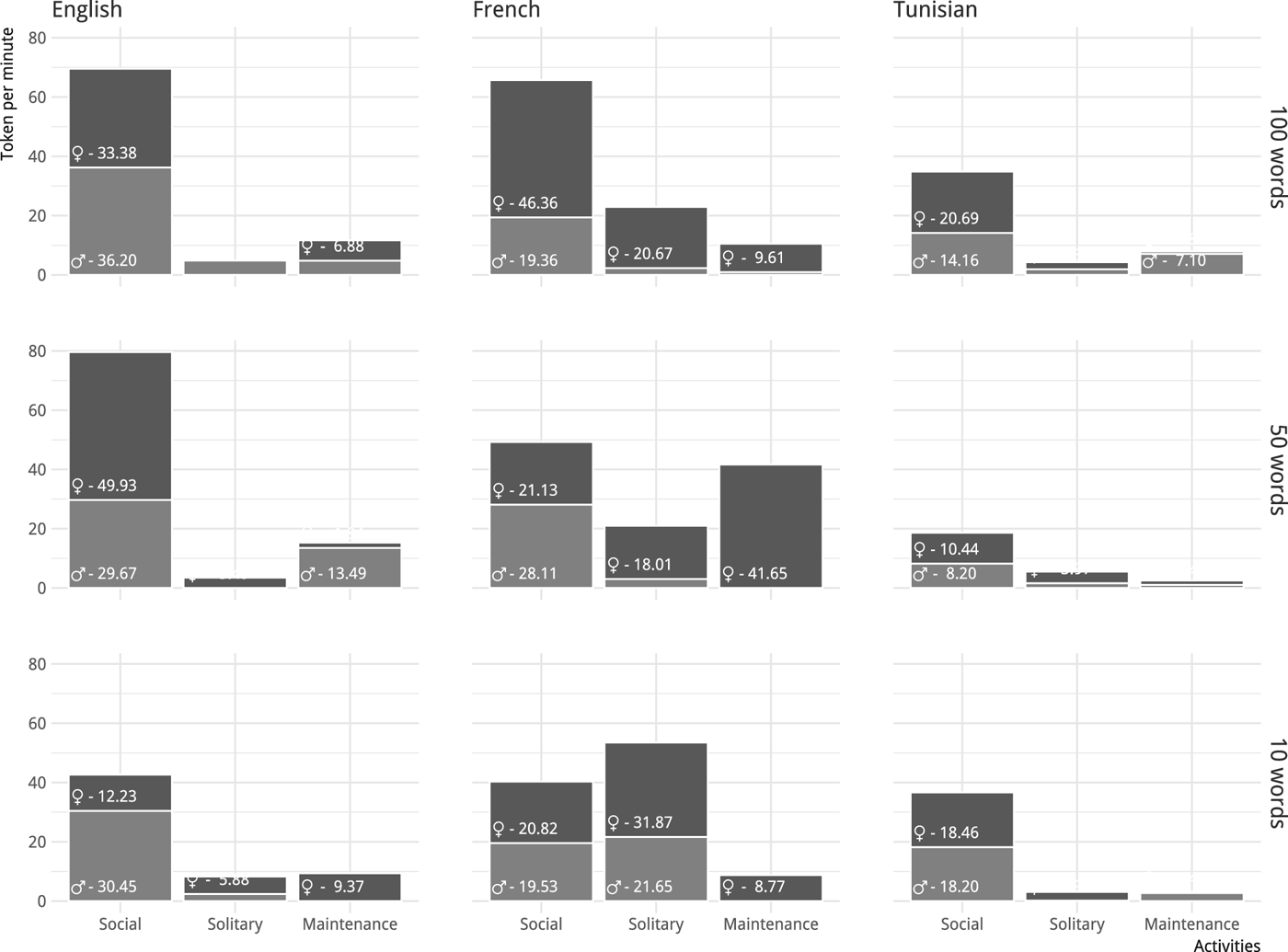
Figure 4: Word tokens in child-directed speech per minute as a function of context and language.
3.2.3 Lexical diversity in child-directed speech (VOCD)
Although the D measure is less sensitive to sample size than type-token ratio and therefore more reliable with our data, the measure can only be computed if sufficient data have been gathered (Silverman and Ratner Reference Silverman and Ratner2002): fifty words are needed for the VOCD command to work in CLAN. Thus, we could not get a reliable D measure for each activity type and child at each level, and we had to pool all three linguistic levels together, as shown in Figure 5.
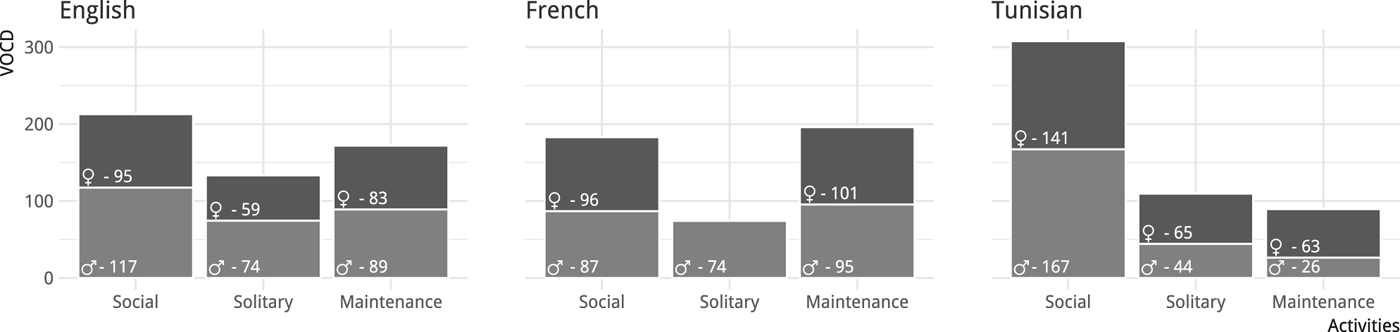
Figure 5: Lexical diversity (VOCD) in child-directed speech as a function of context and language (labels corresponding to different D values).
Caretaker VOCD measures are higher in social contexts than in the other two contexts for American and Tunisian children. For French children however, caretaker VOCD is the highest in the maintenance context. We did not have enough data in solitary context, for the French girl, to compute VOCD. In the social contexts VOCD reaches its highest level for the Tunisian boy and its lowest one for the French boy. Differences across children in maintenance contexts are also quite striking, with measures for the French girl amounting to almost four times those for the speech directed to the Tunisian boy, who has the most reduced VOCD in this context. For solitary contexts, we find again the lowest measure with the Tunisian boy, but with much less marked differences.
3.3 Mean length of child-directed utterances
Variability across families and contexts is also observed for mean length of utterances (Figure 6). Overall, no clear developmental progression is observed, and utterances are almost always longer in the maintenance contexts than in the social contexts. Solitary play comes third, except for the French boy and the Tunisian girl. The mean length of utterances directed to the French boy is the same across maintenance and solitary context (4.8) and longer than in social contexts (4.3). Although observed differences are relatively small, some children stand out. For all three contexts, the French girl's child-directed speech is composed of longer utterances (ranging between 4 and 5.2). On the other hand, the lowest mean length of utterances is found in Tunisian children: in social and maintenance contexts, the Tunisian girl has the shortest utterances directed to her, and for solitary contexts it is the Tunisian boy who receives the shortest utterances.
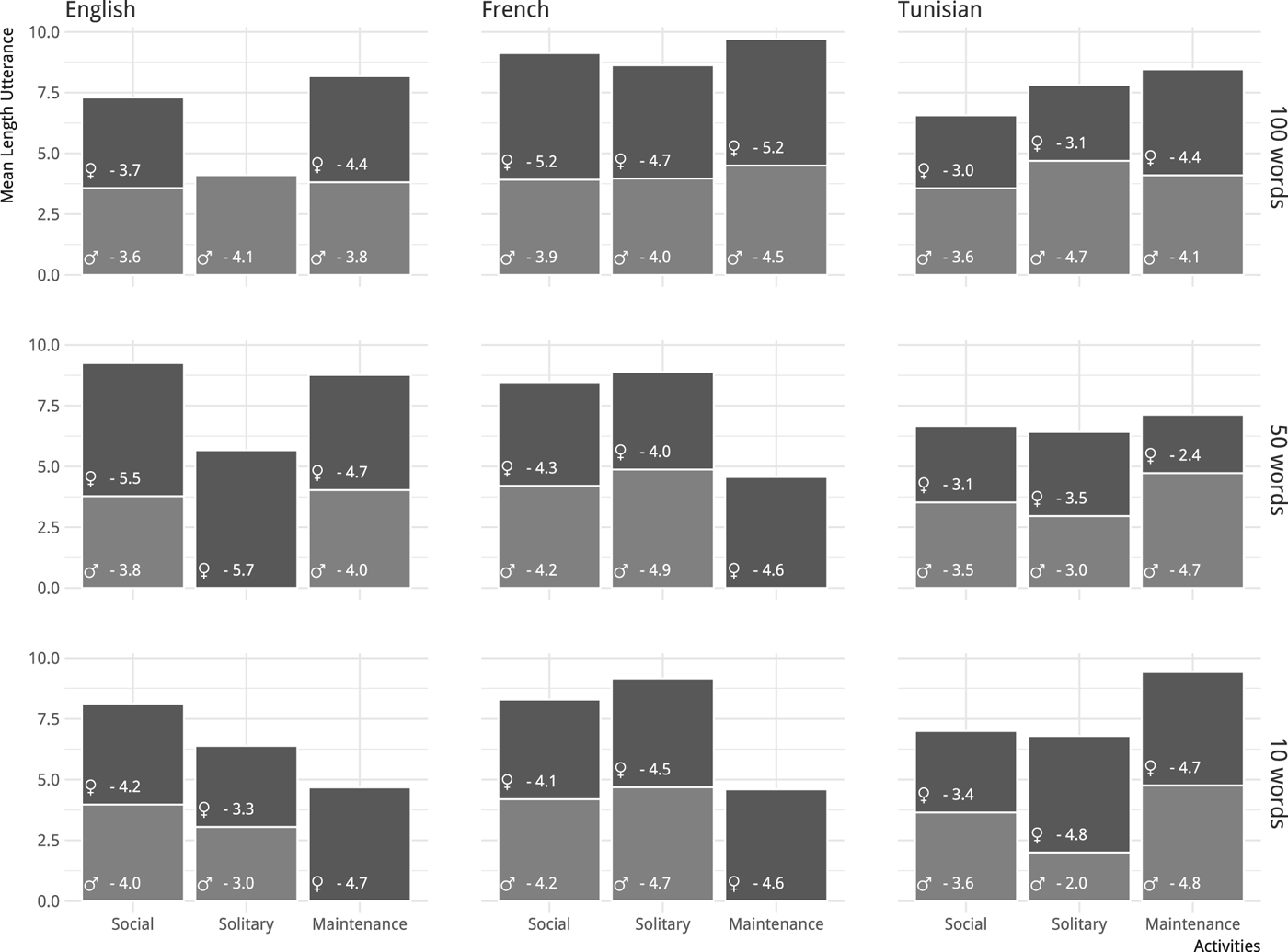
Figure 6: MLU in child-directed speech as a function of context and language (label corresponding to different MLU).
3.4 Noun-verb proportion in child-directed speech depending on activity
While no strong cross-linguistic differences emerged in previously discussed measures, Tunisian Arabic clearly stands out when looking at proportions of nouns and verbs. More similarities are observed in French and English, with relatively stable ratios and a slightly higher proportion of nouns in all coded data (Figure 7). Although further analyses are needed on Tunisian Arabic, the higher ratios of verbs that are observed in mothers' utterances are reminiscent of Choi's results with Korean data in toy play contexts (Choi Reference Choi2000: 80) or Tardif's results with Mandarin (Tardif Reference Tardif1996).
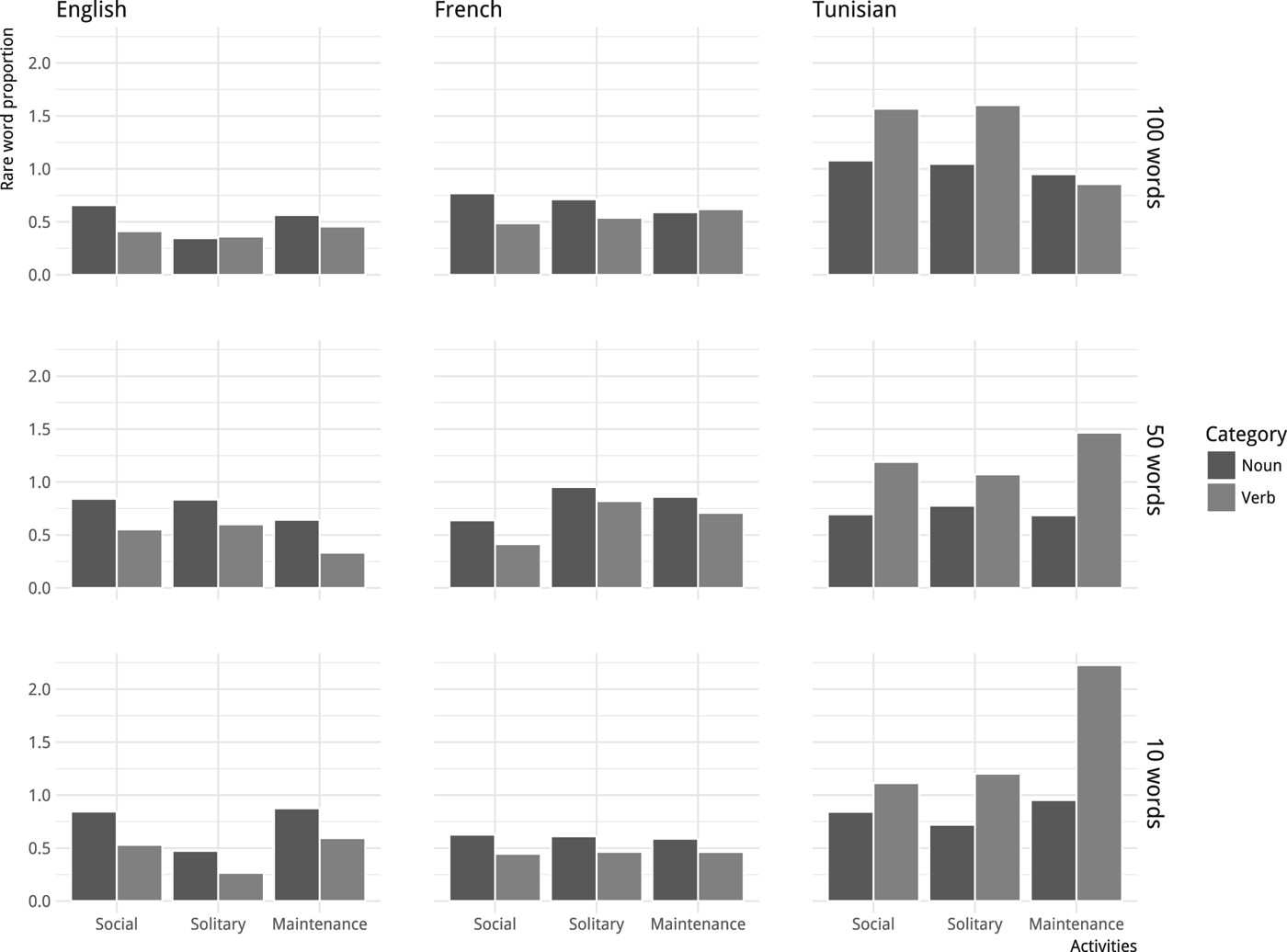
Figure 7: Nouns and verbs (tokens per utterance) in CDS as a function of context, language and developmental level.
In terms of activity types, more variability is observed in maintenance activities. This trend is particularly difficult to analyse since these activities are seldom described in the literature, and notably absent from studies on the acquisition of nouns and verbs. While the greater variability may stem from the smaller quantity of data, it certainly calls for further investigation.
In terms of developmental progression, the final level stands out across languages and exhibits smaller differences between noun and verb ratios. This is especially true for maintenance activities, again calling for analyses on a bigger sample.
4. Discussion
On the whole, this study of activity contexts has revealed differences in activity duration and distribution across levels and languages, and differences in child-directed speech that are greater across activity contexts than across levels and languages. We did not, however, seek to arrive at broad generalisations. In this section, we look at means, in order to consolidate our results while avoiding overgeneralisations.
4.1 Activity patterns across sessions
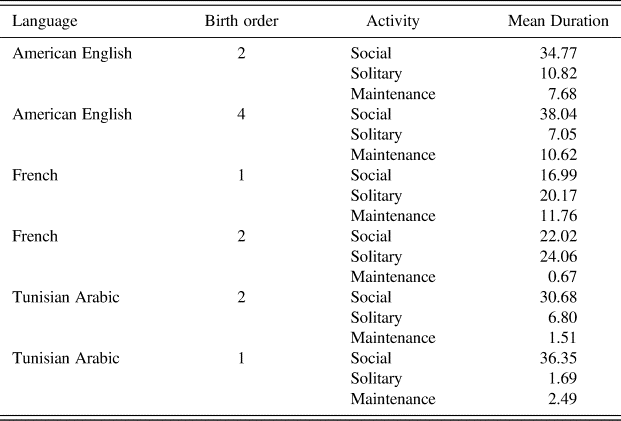
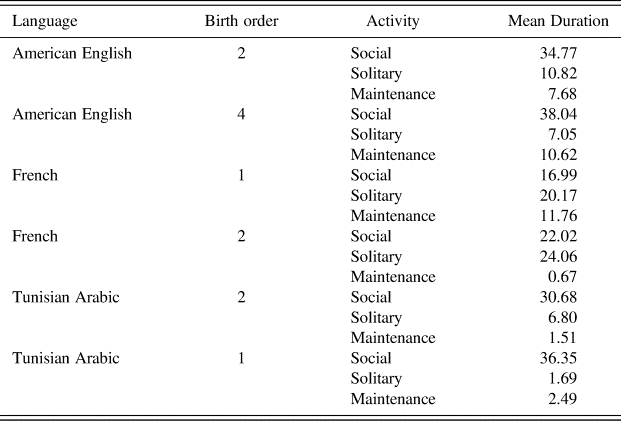
The first objective of our study was to convey a detailed picture of activity contexts in longitudinal corpora across languages, and in doing this we observed variety in and across contexts, across children and languages. Table 4 gives an overview of activity patterns by providing mean durations for each child, indicating, language, birth order, and activity.
While means confirm overall trends such as the prevalence of social activities, they also point to notable exceptions. The prevalence of solitary activities in both the French girl's and the French boy's recordings is striking. It could hardly result from linguistic and cultural differences, considering the relative homogeneity of our data and recording procedures. We hypothesise that such differences point to an intricate network of uncontrolled parameters, which characterise naturalistic recordings.
Table 4: Mean activity duration by language, birth order, and activity.
Indeed, the activity contexts in our video recordings depend on various factors like the family schedule, the presence of brothers and sisters, fathers, and other family members, the child's age and the time of recording. Attention must be paid to this complexity if we are to understand the variety of activity contexts in our recordings, especially since all these factors are interconnected. For instance, while birth order may have been used to account for the presence of more solitary activities in first-born children, it is not necessarily the case that siblings are present in the recordings. Besides, variations in the observer's presence and involvement are also likely to have an impact on the diversity of recorded activities. In the French dataset, it was observed that maintenance activities such as diaper change or bath could be recorded only when the observer was there to move the camera around and adjust to what was going on. In most of the American recordings, the observer was there at the beginning of the session but then left the camera on a tripod for an hour, which constrains maintenance activities to snacking when recording in the kitchen or living room – as was often the case. In addition to the constraints listed above, recorded activities seem to depend on the moment of recording (time of day), which in turn depends on the availability and schedule of each family, as a result of an array of individual and social factors.
The presence of other participants has an influence on interaction, which is why in most studies the dyadic situation is preferred (Leyendecker et al. Reference Leyendecker, Lamb, Schölmerich and Fricke1997b). However, this specific situation is not the most frequent for children, and even in recordings such as ours that are primarily focused on dyads, we do not have only dyadic interactions. There are moments when the child is alone, other moments the child is with both parents or even with a sibling. In order to maximise comparability across datasets, we restricted our coding to dyads (child – parents), as is the case in most studies of child-directed speech. However, it is worth noting that as a result of this choice we missed an important part of the children's daily interactional experience (Leyendecker et al. Reference Leyendecker, Lamb, Schölmerich and Fricke1997b).
The father's presence is also variable in our data, and when fathers are present they may or may not interact with the child. In our French data, the father of the French boy is present just once among the three sessions, and he doesn't really interact with his child, while the father of the French girl is present for two sessions out of three, and interacts a lot with his daughter. Fathers are not often present and do not often interact with the Tunisian girl and boy: he is seen either as he arrives or as he leaves. In the US data, the girl's father is present in one of our recordings but only because he is having a short conversation with his wife before leaving and going to work, so that there are very few utterances directed to the child. The American boy's father also appears at some points in the recordings but not in any of our analysed files. As for siblings, they are not often present. We have one session in which the French boy's sister was present. In this session we observe social play with sister while mother was busy doing other things, and when joint activity takes place, as in social, toy play and book reading, we have more tantrums and the sister who constantly helps the child and leads the way.
The moment of the day when recording was done is indeed variable, notably because some mothers did not have a full time job: both French mothers were the only caretakers of their children (no nurse or childcare), as was also the case for the two American corpora, where lots of recordings were made in the morning. For Tunisian data, both children were video-recorded by an observer who had a job, so the time of recording was limited to the evening. In addition, French recording is variable for the French girl, mostly in morning or afternoon, but more homogeneous for the French boy where video recording took place in the afternoon. Those differences have a clear impact, notably on maintenance activities: depending on the time of recording, we may have more or less chance to observe bath and mealtime.
Granularity also accounts for our results. Gender-related differences are more likely to appear in fine-grained analyses of subtypes of activities; that is, there is a lot of toy play in the recorded interactions with our Tunisian boy and much more conversation with the Tunisian girl. Contexts such as play, feeding, and caretaking have been shown to have an influence on the quantity of dyadic interaction observed (O'Brien and Nagle Reference O'Brien and Nagle1987, O'Brien et al. Reference O'Brien, Johnson and Anderson-Goetz1989) and can mask certain differences which may be found across social classes as well as regarding the extent and nature of maternal discourse (Snow Reference Snow1972, Wootton Reference Wootton1974, Dunn et al. Reference Dunn, Wooding and Herman1977, Hoff-Ginsberg Reference Hoff-Ginsberg1991). These elements are of interest to our results, since we found considerable variation in maintenance activities across sessions. However, we will need more data to get robust results on linguistic measures in maintenance contexts.
Given the potential influence of social and functional contexts, as described above, we would like to emphasise that selecting and controlling observation procedures in order to gather representative and reliable data remains a challenge, which may be exacerbated by differences in SESFootnote 3. Consequently, our study reinforces the claim that activity context should be taken into account and could even be used as a means to have valid, reliable and significant observations for estimated child experience (Leyendecker et al. Reference Leyendecker, Lamb, Schölmerich and Fricke1997b).
4.2 Child-directed speech description
A second objective of the present study was to grasp fine-grained characteristics of child-directed speech, by comparing activity contexts rather than full recordings. In doing so, we tried to shed further light on the complexity of children's input (see Gentner and Borodisky Reference Gentner, Borodisky, Bowerman and Levinson2001) and to single out possible factors of variation.
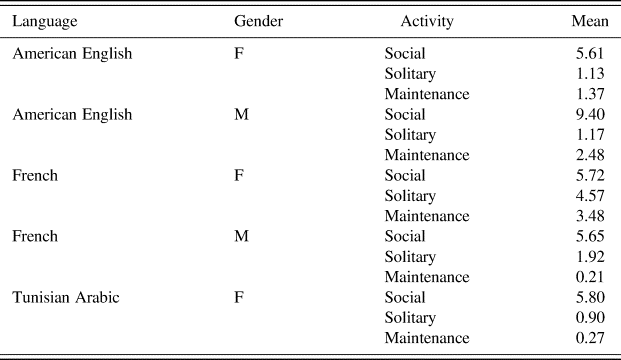
First, this study has shown differences in total number of utterances addressed to children, as a result of variation in the children's interlocutors. Indeed, the French boy received fewer utterances than the French girl or either of the American children, as is clear from Table 5. This is linked with the fact that the boy's mother regularly talked to the observer, the grandmother when she was present, and she talked a lot on the phone. As a result, less of her time was spent speaking to the French boy. Tunisian children received less than half the number of utterances addressed to all other children. However in the recordings the children are often found interacting with other members of the family, like the grandmother, brothers and sisters. Our failure to take these interactions into account is one clear limitation of our methodology, which could not be overcome because to date we have only partial transcriptions of the data for Tunisian Arabic. Integrating the whole of child-directed speech seems highly desirable in future studies, in order to better grasp who speaks to the children and how, and gain a better picture of activity contexts.
Table 5: Mean number of utterances per minute by language, gender, and activity.
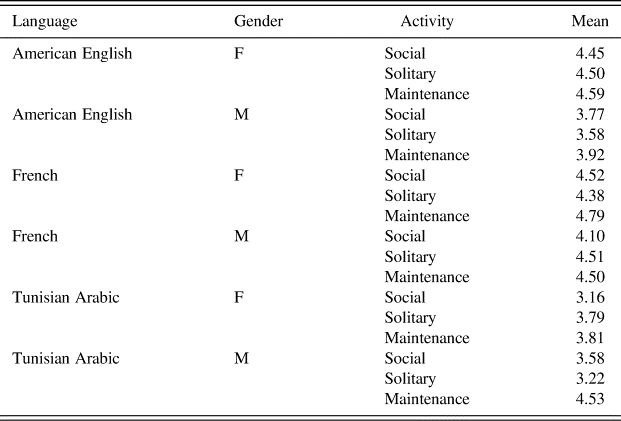
As regards MLU, the tendency for utterances to be longer in maintenance contexts is confirmed by mean values given in Table 6. This is rather unexpected, as MLU is often understood as an index of complexity and richness (Brown Reference Brown1973, Rondal et al. Reference Rondal, Ghiotto, Bredart and Bachelet1987, Bates and Carnevale Reference Bates and Carnevale1993).
Table 6: Mean Length Utterance by language, gender, and activity.
In order to account for this, we looked at the mothers' productions in maintenance contexts and found that in many situations (including hygiene and snacking) there was a stronger need to provide the child with arguments, and thus use more complex utterances. Table 7 provides two examples from our US data.
Table 7: Examples of utterances during maintenance activity.

Another interesting feature of MLU is that it seems to vary according to the child's gender (Table 8). On the whole, utterances directed to boys are shorter across all contexts, with smaller differences in maintenance contexts, and larger differences in solitary contexts. This may be linked with differences in mothers' verbal style (responsiveness and directiveness) which have been evidenced as a function of gender: mothers' responsiveness was shown to be stronger with girls while directiveness prevailed with boys (Flynn and Masur Reference Flynn and Masur2007).
Table 8: Mean Length of Utterance by gender and activity.

Finally, we used nouns and verbs as a well-described index of cross-linguistic differences, and one that has often been shown to vary across contexts. We expected to find more nouns in the speech of American caretakers than in that of speakers from the other two languages, and indeed this was the case for most of our data. Overall, if previous studies have shown that in several linguistic communities mothers used more nouns than verbs (see Fernald and Morikawa Reference Fernald and Morikawa1993, Goldfield Reference Goldfield1993, Poulin-Dubois et al. Reference Poulin-Dubois, Graham and Sippola1995, Gopnik et al. Reference Gopnik, Choi and Baumberger1996, Tardif et al. Reference Tardif, Shatz and Naigles1997, Choi Reference Choi1998, Kim et al. Reference Kim, McGregor and Thompson2000) the reverse seems to be true for Tunisian Arabic, which to our knowledge has never been studied in terms of noun and verb proportions in CDS. However, contrary to recent studies about nouns and verbs which situate linguistics measures in context (Choi Reference Choi2000, Altınkamış et al. Reference Altınkamış, Kern and Sofu2014) we find more homogeneity across activities than across languages. Our results are not fully comparable, however, since we are dealing with longitudinal recordings that were not structured according to activity types. We also collapsed toy play and book reading activities in the social context. With more data, it will be possible to look at subtypes, which may give more illuminating results for nouns and verbs.
4.3 Rare words
Before concluding, we would like to discuss more qualitative analyses which were conducted in order to shed light on lexical diversity. Because lexical diversity measures did not yield the expected results, we looked for rare words in CDS as an indication of increased diversity (Beals Reference Beals1997), and tried to see if their use was tied to specific activity contexts. To date, rare words have been studied with varied objectives and methods: while Snow and Beals (Reference Snow and Beals2006) focused on family dinners and started from an existing list, Parisse (Reference Parisse2014) started from dense corpora to extract word frequencies and isolated rare words within a zipfian distribution. In order to find rare words in our data, we used a method that could be replicated cross-linguistically and did not depend on pre-existing lists. We computed the frequencies of the words occurring in our data and compared them to frequencies across all 14 transcripts available for each dataset (i.e., our French, English and Tunisian transcriptions).Footnote 4 Table 9 gives examples of rare words found in our French data.
Table 9: Example of rare words in the French boy's corpus.

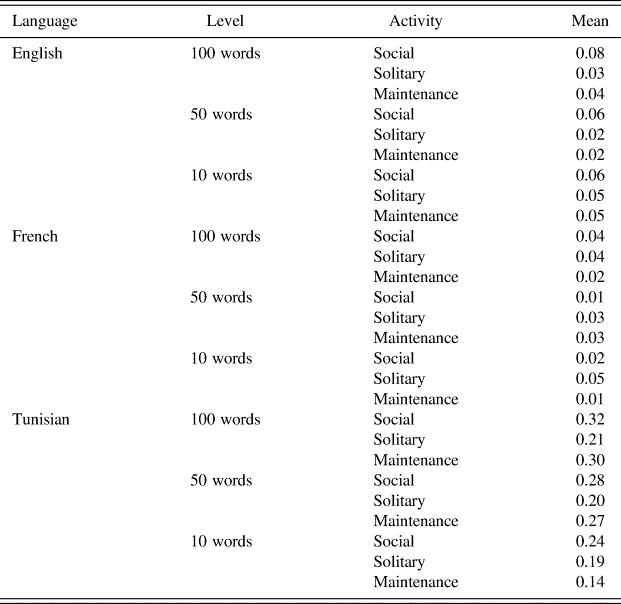
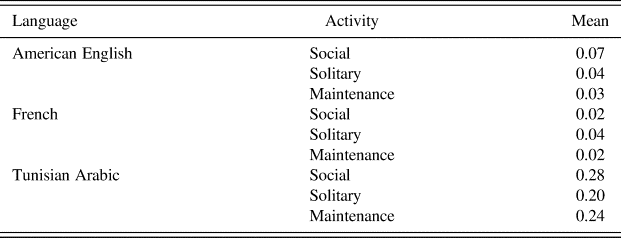
In order to determine which context our rare words predominantly appeared in, we computed means according to language and activity (Table 10). Different means appear for Tunisian due to the lack of transcribed dataFootnote 5 in which to find rare words. In the other two languages, however, regularities emerge, with a greater proportion of rare words found in English social activities and French solitary activities.
Table 10: Mean rare word percent age by language and activity.
Looking at the detailed occurrences at each level (see Table 11), we see more occurrences of rare words in maintenance contexts at the 10-word level for English children, and in solitary contexts again at the 10-word level for French children.
Table 11: Mean rare word percentage by language, level, and activity.
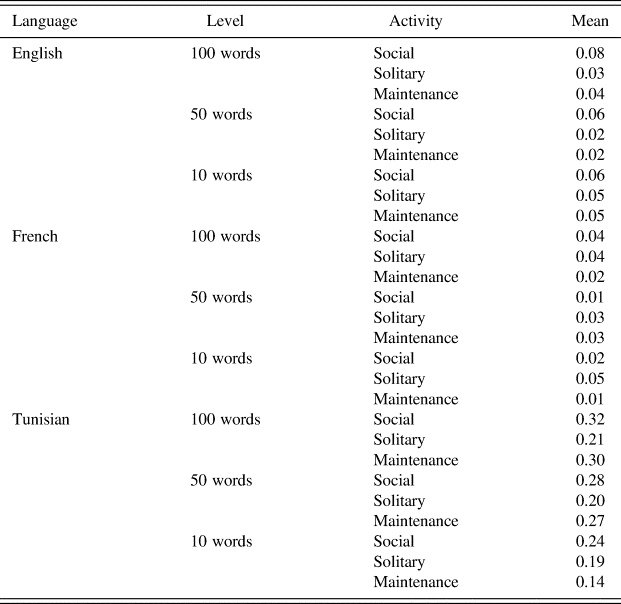
Besides, the noun bias is confirmed in both our French and English rare word lists. Only our Tunisian list contains more verbs than nouns, in accordance with the higher verb ratios found. When we add all developmental levels per children, French and American caretakers' rare words contain more nouns than verbs, but the opposite is true for Tunisian caretakers.
Finally, in terms of the pragmatic value of utterances, it is worth emphasising that in our findings, rare words appear most often when the mother comments on the child activity. Using existing pragmatic coding in other datasets might enable us to see whether it is indeed the case that mothers' well-described vocabulary simplification (Hayes and Ahrens Reference Hayes and Ahrens1988) stops in these small pieces of speech where they do not address the child directly.
4.4. Conclusion
The main finding of our study is that apparent subcultural differences are maximised by focusing on single contexts and minimised by averaging across a variety of naturally occurring contexts. Our study confirms that observation across a variety of uncontrolled activity contexts raises comparability issues (Stevenson et al. Reference Stevenson, Leavitt, Roach, Chapman and Miller1986, Lewis and Gregory Reference Lewis and Gregory1987, O'Brien and Nagle Reference O'Brien and Nagle1987, Lewedag et al. Reference Lewedag, Oller and Lynch1994). It suggests that we need more fine-grained observations of language acquisition and input in cross-cultural studies. This is especially true for our category of maintenance, which corresponds to activities that are seldom described in the literature: we have shown that child-directed speech in maintenance activities was rich and varied. Our analyses thus call for more detailed studies of feeding or bath-time activities. This could be done in naturalistic yet standardised situations (see Bornstein and Haynes Reference Bornstein and Haynes1998) and perhaps more specifically by zooming in on mealtime interactions (Pan et al. Reference Pan, Perlmann, Snow, Menn and Ratner1999) to overcome the obstacles described in this study. Ultimately, our study questions the level of granularity that is desirable when studying language development with longitudinal data. Finer categories could indeed be isolated even within our subcategories, since mothers or children sometimes engage in very short activities before returning to what they were doing. In the present study, we proposed a three-fold coding system, which evidenced major trends in longitudinal corpora, where social activities dominate, and solitary and maintenance activities are much less frequent. We hope that this finding, together with the variety we discussed, will bring new insights into existing data and foster data collection in less represented activity contexts.
Corpora
Human Speechome Corpus <https://www.media.mit.edu/cogmac/projects/hsp.html>
Providence corpus <https://phonbank.talkbank.org/access/Eng-NA/Providence.html>
PREMS corpus <http://www.ddl.cnrs.fr/projets/prems/index.asp?Langue=EN&Page=Home>
OHLL corpus <https://phonbank.talkbank.org/access/French/KernFrench.html>
Appendix 1: Examples of activities in French corpus (French girl at 100-word level)
Exploratory activity (exploration)

Exploratory activity (solitary play)

Social activity (manners routine)

Social activity (teach routine)

Maintenance activity (toilet-training)

Maintenance activity (bath routine)