
















1. Introduction
With the rise of adversarial attacks in deep learning (DL) for image classification, the universal instability of DL methods across various scientific fields has become evident [Reference Akhtar and Mian5, Reference Bastounis, Hansen and Vlacic8, Reference Carlini and Wagner20, Reference Choi24, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Madry, Makelov, Schmidt, Tsipras and Vladu54, Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard55, Reference Moosavi-Dezfooli, Fawzi and Frossard56, Reference Qin, Martens and Gowal63, Reference Szegedy, Zaremba and Sutskever67, Reference Tyukin, Higham, Bastounis, Woldegeorgis and Gorban69]. This underscores the urgent need to investigate the stability properties of neural networks (NN). Traditionally, the size of the Lipschitz constant has been a common metric for such investigations [Reference Béthune, González-Sanz, Mamalet and Serrurier14, Reference Bubeck and Sellke17, Reference Ducotterd, Goujon, Bohra, Perdios, Neumayer and Unser33, Reference Huang, Zhang, Shi, Kolter, Anandkumar, Ranzato, Beygelzimer, Dauphin, Liang and Vaughan51]. While this approach is useful in many scenarios, it falls short for discontinuous functions, which have ‘infinite’ Lipschitz constants. Consequently, expecting a NN to accurately approximate a classification function with a ‘small’ Lipschitz constant is unrealistic, given that the target function is inherently unstable. This issue is particularly problematic for DL, whose major strength lies in image recognition [Reference Ferreira, Silva and Renna35, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Madry, Makelov, Schmidt, Tsipras and Vladu54, Reference Oliveira, Renna and Costa59] – an inherently discontinuous task. Empirical observations of instabilities and hallucinations in image recognition further highlight this problem [Reference Antun, Renna, Poon, Adcock and Hansen6, Reference Bastounis, Hansen and Vlačić9, Reference Belthangady and Royer11, Reference Gottschling, Antun, Hansen and Adcock43, Reference Heaven48, Reference Hoffman, Slavitt and Fitzpatrick50, Reference Neyra-Nesterenko and Adcock57, Reference Raj, Bresler and Li64, Reference Sokolić, Giryes, Sapiro and Rodrigues66, Reference Tsipras, Santurkar, Engstrom, Turner and Madry68, Reference Zhang, Cai, Lu, He and Wang75, Reference Zhang, Jiang, He, Wang, Oh, Agarwal, Belgrave and Cho76]. The instability issue in DL is considered one of the key problems in modern AI research, as pointed out by Y. Bengio: ‘For the moment, however, no one has a fix on the overall problem of brittle AIs' (from ‘Why deep-learning AIs are so easy to fool’ [Reference Heaven48]). This leads to the key problem addressed in this paper:
Do stable neural networks exist for classification problems?
Conceptually, there is a lack of a comprehensive theory for the stability of classification functions. While it might be tempting to categorise all classification functions as unstable, this overlooks the varying degrees of instability among discontinuous functions. For instance, the Heaviside step function intuitively appears more stable than the Dirichlet function, which is nowhere continuous. To address this issue, we introduce a new stability measure called class stability. This measure is designed to study the stability of discontinuous functions and their approximations by extending classical measure theory. The proposed stability measure focuses on the closest points with different functional values, capturing the phenomenon more effectively. This concept aligns with the emerging notion of the ‘margin’ in the machine learning community, which is a local measure of stability [Reference Huang, Zhang, Shi, Kolter, Anandkumar, Ranzato, Beygelzimer, Dauphin, Liang and Vaughan51]. Our concept of class stability extends this notion to the entire function across its domain, allowing for a comparison of the stability of different discontinuous functions. We provide two working definitions of class stability: one based on an analytic distance metric, and an alternative defined in a measure theoretic way.
Finally, in the spirit of existing approximation papers [Reference Adcock and Dexter2–Reference Adcock and Huybrechs4, Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel12, Reference Binev, Cohen, Dahmen, DeVore and Temlyakov15, Reference Caragea, Petersen and Voigtlaender19, Reference Celledoni, Ehrhardt and Etmann21, Reference Colbrook, Antun and Hansen27–Reference DeVore, Hanin and Petrova31, Reference Elbrächter, Perekrestenko, Grohs and Bölcskei34, Reference Girshick, Donahue, Darrell and Malik40, Reference Gorban, Golubkov, Grechuk, Mirkes and Tyukin42, Reference Gribonval, Kutyniok, Nielsen and Voigtlaender44, Reference He, Zhang, Ren and Sun47, Reference Hinton and and49, Reference Kutyniok53, Reference Perekrestenko, Grohs, Elbrächter and Bölcskei60–Reference Pinkus62], we prove the existence of NNs with class stabilities approximating the target function. Using results from approximation theory, analysis and measure theory, we prove two major theorems. The first one states that NNs are able to interpolate on sets that have a class stability of at least
 $\epsilon \gt 0$
, thereby proving that NNs can approximate any ‘stable’ function (see Lemma 2.3). The second is regarding the ability for NNs to approximate any function, such that the class stability of the NN is at most
$\epsilon \gt 0$
, thereby proving that NNs can approximate any ‘stable’ function (see Lemma 2.3). The second is regarding the ability for NNs to approximate any function, such that the class stability of the NN is at most
 $\epsilon \gt 0$
smaller than the class stability of the target function. These results demonstrate that the class stability is appropriate to study stability for classification functions.
$\epsilon \gt 0$
smaller than the class stability of the target function. These results demonstrate that the class stability is appropriate to study stability for classification functions.
2. Main result
Our main contribution in this paper is the introduction of ‘class stability’ and two corresponding stability theorems for NNs. The class stability is defined in (2.3) in Section 4. Intuitively, class stability represents the average distance to the decision boundaries of the function. The first of the two theorems addresses the restriction of classification functions to sets where the classification functions have a class stability of at least
 $\epsilon \gt 0$
.
$\epsilon \gt 0$
.
To state the main theorems, we need the following five concepts that will be formally defined later in the paper:
-
(I) (Classification function). We call
 $f\,:\, {\mathcal{M}} \rightarrow \mathcal{Y}$
, where
$\mathcal{M} \subset {\mathbb{R}}^d$
is the input domain and
$\mathcal{Y} \subset \mathbb{Z}^+$
a finite subset, a classification function. This is the function we are typically trying to learn.
$f\,:\, {\mathcal{M}} \rightarrow \mathcal{Y}$
, where
$\mathcal{M} \subset {\mathbb{R}}^d$
is the input domain and
$\mathcal{Y} \subset \mathbb{Z}^+$
a finite subset, a classification function. This is the function we are typically trying to learn. -
(II) (Extension of a classification function). Given a classification function
$f \,:\, {\mathcal{M}} \rightarrow \mathcal{Y}$
, we define its extension to
${\mathbb{R}}^d$
as
$\overline {f}\,:\, {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
such that(2.1)where
\begin{align} \overline {f}(x) = \begin{cases} f(x) \quad & \text{if } x \in {\mathcal{M}} , \\ -1 \quad & \text{otherwise} , \end{cases} \end{align}
$\overline {\mathcal{Y}} = \mathcal{Y} \cup \{-1\}$
.
-
(III) (Distance to the decision boundary). Given the extension of a classification function
$\overline {f}\; :\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
$1 \leq p \leq \infty$
, we define
${h^p_{\bar {f}}}\;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
, the
$\ell ^p$
-distance to the decision boundary, as(2.2)
\begin{align} {h^p_{\bar {f}}}(x) = \inf \{ \|x-z\|_p \;:\;\, \overline {f}(x) \neq \overline {f}(z), \, z \in {\mathbb{R}}^d \}. \end{align}
-
(IV) (Class stability). If
${\mathcal{M}} \subset {\mathbb{R}}^d$
is compact, then, we define the
$\ell _p$
-stability of
$\overline {f}$
to be(2.3)where
\begin{align} \mathcal{S}^p_{{\mathcal{M}}}(\overline {f}) = \int _{{\mathcal{M}}} {h^p_{\bar {f}}} \, d\mu , \end{align}
$\mu$
is the Lebesgue measure on
${\mathbb{R}}^d$
. We will reference this as the class stability of the function
$\overline {f}$
.
-
(V) (Class prediction function). For a given
$n \in \mathbb{N}$
, we define the class prediction function
$p_n\;:\;{\mathbb{R}}^n \rightarrow \{1, \ldots , n\}$
as(2.4)The class prediction function has the same function as the ‘argmax’ function in, for example, the numpy library of python. This function takes a vector and returns the index of the element that has the highest value of all elements. If there are multiple such indices that satisfy the maximality, we return the first index.
\begin{align} p_n(x) = \min \{i \;:\; x_i \geq x_j, \forall j \in \{1, \ldots , n\} \} . \end{align}























We can now state the first of our main theorems.
Theorem 2.1 (Interpolation theorem for stable sets). Let
 ${\mathcal{M}}, {\mathcal{K}} \subset {\mathbb{R}}^d$
, where
${\mathcal{M}}, {\mathcal{K}} \subset {\mathbb{R}}^d$
, where
 $\mathcal{K}$
is compact, and
$\mathcal{K}$
is compact, and
 $f\;:\;{\mathcal{M}} \rightarrow \mathcal{Y} \subset \mathbb{Z}^+$
be a non-constant classification function where
$f\;:\;{\mathcal{M}} \rightarrow \mathcal{Y} \subset \mathbb{Z}^+$
be a non-constant classification function where
 $\mathcal{Y}$
is finite. Define
$\mathcal{Y}$
is finite. Define
 \begin{equation} {\mathcal{M}}_{\epsilon } \;:\!=\; \{x \, \vert \, x \in {\mathcal{M}}, {h^p_{\bar {f}}}(x) \gt \epsilon \}, \quad \epsilon \gt 0, \end{equation}
\begin{equation} {\mathcal{M}}_{\epsilon } \;:\!=\; \{x \, \vert \, x \in {\mathcal{M}}, {h^p_{\bar {f}}}(x) \gt \epsilon \}, \quad \epsilon \gt 0, \end{equation}
as the
 $\epsilon$
-stable set of
$\epsilon$
-stable set of
 $\,\overline {f}$
, where
$\,\overline {f}$
, where
 $h^p_{\bar {f}}$
is the
$h^p_{\bar {f}}$
is the
 $\ell ^p$
-distance to the decision boundary defined in (2.2). Then, for any
$\ell ^p$
-distance to the decision boundary defined in (2.2). Then, for any
 $\epsilon \gt 0$
and any continuous non-polynomial activation function
$\epsilon \gt 0$
and any continuous non-polynomial activation function
 $\rho$
, which is continuously differentiable at least at one point with non-zero derivative at that point, we have the following:
$\rho$
, which is continuously differentiable at least at one point with non-zero derivative at that point, we have the following:
-
(1) There exists one hidden layer (see Lemma 5.1) NN
$\Psi _1 \;:\; {\mathcal{K}} \rightarrow \overline {\mathcal{Y}}$
, with an activation function
$\rho$
, that interpolates
$f$
on
${\mathcal{M}}_{\epsilon }$
, in particular (2.6)where
\begin{align} p_{q}(\Psi _1(x)) = f(x) \quad \forall x \in {\mathcal{M}}_{\epsilon }\cap {\mathcal{K}}, \end{align}
$p_{q}$
is the class prediction function, given by Eq. (2.4), that ‘rounds’ to discrete values and
$q = |\mathcal{Y}|$
.
-
(2) There exists a neural network
$\Psi _2\;:\; {\mathcal{K}} \rightarrow \overline {\mathcal{Y}}$
, using the activation function
$\rho$
, with fixed ‘width’ (see Definition 5.1) of
$d+q+2$
, that interpolates
$f$
on
${\mathcal{M}}_{\epsilon }$
, in particular (2.7)
\begin{align} p_{q}(\Psi _2(x)) = f(x) \quad \forall x \in {\mathcal{M}}_{\epsilon }\cap {\mathcal{K}}. \end{align}













Remark 2.2 (Deep and Shallow neural networks). By a shallow network, we mean a NN Lemma 5.1 with one hidden layer, while the width of
 $d+q+2$
refers to a NN with hidden layers of size less than or equal to
$d+q+2$
refers to a NN with hidden layers of size less than or equal to
 $d+q+2$
.
$d+q+2$
.
Remark 2.3 (Interpretation of Lemma 2.1). This theorem says that NNs are able to interpolate any classification function restricted to compact sets on which the classification function attains some minimal class stability. In a simplified way, one can say that NNs can interpolate on stable sets
 ${\mathcal{M}}_\epsilon$
, which are essentially the original set
${\mathcal{M}}_\epsilon$
, which are essentially the original set
 $\mathcal{M}$
but with a small strip of width
$\mathcal{M}$
but with a small strip of width
 $\epsilon$
removed from the boundary of the set. This way we ensure that we are left with points that are at least
$\epsilon$
removed from the boundary of the set. This way we ensure that we are left with points that are at least
 $\epsilon$
away from the decision boundary, and then we simply interpolate on these sets. It is also important to mention that the approximation theorems utilised here do allow for arbitrary width in the shallow NN case and for arbitrary depth in the deep NN case.
$\epsilon$
away from the decision boundary, and then we simply interpolate on these sets. It is also important to mention that the approximation theorems utilised here do allow for arbitrary width in the shallow NN case and for arbitrary depth in the deep NN case.
The second theorem relates to the ability of NNs to approximate the stability of the original classification function. The advantage of this theorem is that it also applies to the stability measure in a measure theoretic frameworks and is in a sense a generalisation of the first theorem. To state the second theorem, we need to introduce the measure theoretic versions of the distance to the decision boundary and the class stability:
-
(VI) (Measure theoretic distance to the decision boundary). For an extension of a classification function
$\overline {f} \;:\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
$p \geq 1$
, we define
$\tau ^p_{\bar {f}}\;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
the
$l^p$
-distance to the decision boundary asHere,
\begin{align*} \tau ^p_{\bar {f}}(x) = \inf \left \{ r \;:\; \int _{{\mathcal{B}}^p_r(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x)}\, d\mu , r\in [0,\infty ) \right \}. \end{align*}
$\mu$
denotes the Lebesgue measure and
${\mathcal{B}}^p_r(x)$
the unit closed ball with
$p$
-norm, and
$\unicode{x1D7D9}$
is the indicator function.
-
(VII) (Class stability (measure theoretic)). If
${\mathcal{M}} \subset {\mathbb{R}}^d$
is a compact set, we define the (measure theoretic)
$\ell _p$
-stability of
$\overline {f}$
to be(2.8)
\begin{align} \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {f}) = \int _{{\mathcal{M}}} {\tau} \,\,\,\,^p_{\bar {f}}(x) \, d\mu . \end{align}













Theorem 2.4 (Universal stability approximation theorem for classification functions). For any Lebesgue measurable classification function
 $f\;:\; {\mathcal{M}} \subset \mathbb{R}^d \rightarrow \mathcal{Y}$
, where
$f\;:\; {\mathcal{M}} \subset \mathbb{R}^d \rightarrow \mathcal{Y}$
, where
 $\mathcal{M}$
is compact, and
$\mathcal{M}$
is compact, and
 $q = |\mathcal{Y}|$
; any set
$q = |\mathcal{Y}|$
; any set
 $\{(x_i, f(x_i))\}_{i=1}^k$
with
$\{(x_i, f(x_i))\}_{i=1}^k$
with
 $\tau ^p_{\bar {f}}(x_i) \gt 0$
for all
$\tau ^p_{\bar {f}}(x_i) \gt 0$
for all
 $i=1,\ldots ,k$
; and any
$i=1,\ldots ,k$
; and any
 $\epsilon _1, \,\epsilon _2 \gt 0$
, there exists a NN
$\epsilon _1, \,\epsilon _2 \gt 0$
, there exists a NN
 $\psi \in \mathcal{NN}(\rho ,d,q,1,\mathbb{N})$
(see Lemma 5.1) such that we have the following. The class stability (as defined above in Eq. (2.3)) of the NN satisfies
$\psi \in \mathcal{NN}(\rho ,d,q,1,\mathbb{N})$
(see Lemma 5.1) such that we have the following. The class stability (as defined above in Eq. (2.3)) of the NN satisfies
 \begin{align} \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {p_{q}(\psi )}) \geq \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {f}) - \epsilon _1, \end{align}
\begin{align} \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {p_{q}(\psi )}) \geq \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {f}) - \epsilon _1, \end{align}
we can interpolate on the set
 \begin{align} p_{q}(\psi ) = f(x_i) \quad i = 1,\ldots ,k \, , \end{align}
\begin{align} p_{q}(\psi ) = f(x_i) \quad i = 1,\ldots ,k \, , \end{align}
where
 $p_{q}$
is the class prediction function, given by Eq. (2.4), that ‘rounds’ to discrete values, and
$p_{q}$
is the class prediction function, given by Eq. (2.4), that ‘rounds’ to discrete values, and
 \begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq p_{q}(\psi ), x \in {\mathcal{M}}\}, \end{align}
\begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq p_{q}(\psi ), x \in {\mathcal{M}}\}, \end{align}
where
 $\mu$
denotes the Lebesgue measure.
$\mu$
denotes the Lebesgue measure.
Remark 2.5 (Interpretation of Lemma 2.4). This theorem proves that if one wants to use a NN to approximate any fixed classification function, it is possible to achieve with a close to ideal stability, perfect precision (described by the second property) and an arbitrarily good accuracy (third property).
2.1. Computability and GHA vs existence of NNs – Can the brittleness of AI be resolved?
While our results produce a new framework for studying stability of NNs for classification problems and provide theoretical guaranties for the existence of stable NNs for classification functions, the key issue of computability of such NNs is left for future papers. Indeed, as demonstrated in [Reference Colbrook, Antun and Hansen27, Reference Gazdag and Hansen38], based on the phenomenon of generalised hardness of approximation (GHA) [Reference Bastounis, Cucker and Hansen7, Reference Bastounis, Hansen and Vlačić9] in the theory of the Solvability Complexity Index (SCI) hierarchy [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel12, Reference Ben-Artzi, Hansen, Nevanlinna and Seidel13, Reference Colbrook25, Reference Colbrook and Hansen26, Reference Hansen45, Reference Hansen and Nevanlinna46], there are many examples where one can prove the existence of NNs that can solve a desired problem, but they cannot be computed beyond an approximation threshold
 $\epsilon _0 \gt 0$
. Thus, what is needed is a theory that combines our existence theorems with GHA for which one can determine the approximation thresholds
$\epsilon _0 \gt 0$
. Thus, what is needed is a theory that combines our existence theorems with GHA for which one can determine the approximation thresholds
 $\epsilon _0$
that will dictate the accuracy for which the NNs can be computed. This is related to the issue of NN dependency on the input.
$\epsilon _0$
that will dictate the accuracy for which the NNs can be computed. This is related to the issue of NN dependency on the input.
Remark 2.6 (Non-compact domains and dependency on the inputs). Note that our results demonstrate that on compact domains, one can always find a NN
 $\epsilon$
-approximation
$\epsilon$
-approximation
 $\psi$
to the desired classification function
$\psi$
to the desired classification function
 $f$
, where the stability properties of
$f$
, where the stability properties of
 $\psi$
are
$\psi$
are
 $\epsilon$
close to the stability properties of
$\epsilon$
close to the stability properties of
 $f$
. However, if the domain is not compact, this statement seizes to be true. The effect of this is that stable and accurate NN approximations to the classification function
$f$
. However, if the domain is not compact, this statement seizes to be true. The effect of this is that stable and accurate NN approximations to the classification function
 $f$
(on a non-compact domain) can still be found; however, the NN
$f$
(on a non-compact domain) can still be found; however, the NN
 $\psi$
may have to depend on the input. Indeed, by choosing a compact domain
$\psi$
may have to depend on the input. Indeed, by choosing a compact domain
 $K_x$
based on the input
$K_x$
based on the input
 $x$
, one may use our theorem to find a NN
$x$
, one may use our theorem to find a NN
 $\psi _x$
such that
$\psi _x$
such that
 $\psi _x(x) = f(x)$
and
$\psi _x(x) = f(x)$
and
 $\psi _x$
is stable on
$\psi _x$
is stable on
 $K_x$
. However,
$K_x$
. However,
 $\psi _x$
may have to change dimensions as a function of
$\psi _x$
may have to change dimensions as a function of
 $x$
. Moreover, if it is possible to make the mapping
$x$
. Moreover, if it is possible to make the mapping
 $x \mapsto \psi _x$
recursive is a big open problem. In particular, resolving the brittleness issue of moderns AI hinges on this question. We mention in passing that there are papers in the machine learning community that deal with local decision boundary estimates in terms of certificates [Reference Zhang, Jiang, He, Wang, Oh, Agarwal, Belgrave and Cho76], that potentially provide a step towards computing class stable NNs.
$x \mapsto \psi _x$
recursive is a big open problem. In particular, resolving the brittleness issue of moderns AI hinges on this question. We mention in passing that there are papers in the machine learning community that deal with local decision boundary estimates in terms of certificates [Reference Zhang, Jiang, He, Wang, Oh, Agarwal, Belgrave and Cho76], that potentially provide a step towards computing class stable NNs.
2.2. Related work
-
Instability in AI: Our results are intimately linked to the instability phenomenon in AI methods – which is widespread [Reference Akhtar and Mian5, Reference Bastounis, Hansen and Vlacic8, Reference Belthangady and Royer11, Reference Carlini and Wagner20, Reference Choi24, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Madry, Makelov, Schmidt, Tsipras and Vladu54, Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard55, Reference Moosavi-Dezfooli, Fawzi and Frossard56, Reference Qin, Martens and Gowal63, Reference Szegedy, Zaremba and Sutskever67, Reference Tyukin, Higham, Bastounis, Woldegeorgis and Gorban69] – and our results add theoretical understandings to this vast research programme. Notably, our work shares significant connections with the investigations conducted by F. Voigtlaender et al. [Reference Caragea, Petersen and Voigtlaender19], which also deals with classification functions and their approximations via NNs. There has been significant work done on adversarial attacks by S. Moosavi-Dezfooli, A. Fawzi, and P. Frossard et al. [Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard55, Reference Moosavi-Dezfooli, Fawzi and Frossard56]. See also recent developments by D. Higham, I. Tyukin regarding vulnerabilities of neural networks et al. [Reference Beerens and Higham10, Reference Tyukin, Higham, Bastounis, Woldegeorgis and Gorban69]. Furthermore, our research aligns with the exploration of robust learning pursued by L. Bungert, G.Trillos et al. [Reference Bungert, Trillos and Murray18] as well as by S. Wang, N. Si, J. Blanchet [Reference Wang, Si, Blanchet and Zhou71]. The stability problem in NN has also been extensively investigated by V. Antun et al. [Reference Colbrook, Antun and Hansen27], see also the work by B. Adcock and N. Dexter [Reference Adcock and Dexter2].
-
Existence vs computability of stable NNs: There is a substantial literature on existence results of NNs [Reference Bölcskei, Grohs, Kutyniok and Petersen16, Reference Petersen and Voigtlaender61, Reference Yarotsky74], see, for example, the aforementioned work by F. Voigtlaender et al. [Reference Voigtlaender70], review papers by A. Pinkus [Reference Pinkus62] and the work by R. DeVore, B. Hanin and G. Petrova [Reference DeVore, Hanin and Petrova31] and the references therein. For recent results, see the work by G. D‘Inverno, S. Brugiapaglia and M. Ravanelli [Reference D’Inverno, Brugiapaglia and Ravanelli32], by N. Franco and S. Brugiapaglia [Reference Franco and Brugiapaglia37] and by B. Adcock, S. Brugiapaglia, N. Dexter and S. Morage [Reference Adcock, Brugiapaglia, Dexter, Morage, Bruna, Hesthaven and Zdeborova1]. Our work also utilises the approximation theorems obtained by P. Kidger and T. Lyons [Reference Kidger, Lyons, Abernethy and Agarwal52]. However, as established in [Reference Colbrook, Antun and Hansen27] by M. Colbrook, V. Antun et al., only a small subset of the NNs than can be proven to exist can be computed by algorithms. We also need to point out that following the framework of A. Chambolle and T. Pock [Reference Chambolle22, Reference Chambolle and Pock23], the results in [Reference Colbrook, Antun and Hansen27] demonstrate how – under specific assumptions – stable and accurate NNs can be computed. See also the work by P. Niyogi, S. Smale and S. Weinberger [Reference Niyogi, Smale and Weinberger58] on existence results of algorithms for learning.
3. Motivation for new stability measure
In this section, we will motivate the need for a new stability measure for classification functions. We will first discuss the classical approach to stability in NNs, which is based on the Lipschitz continuity and having a bounded Lipschitz constant. We will then demonstrate that the Lipschitz constant is not a suitable measure for classification functions, and introduce the class stability as a new measure for stability.
3.1. Classification functions and Lipschitz continuity
The Lipschitz constant is a standard measure of stability in NNs [Reference Béthune, González-Sanz, Mamalet and Serrurier14, Reference Bubeck and Sellke17, Reference Ducotterd, Goujon, Bohra, Perdios, Neumayer and Unser33, Reference Huang, Zhang, Shi, Kolter, Anandkumar, Ranzato, Beygelzimer, Dauphin, Liang and Vaughan51]. While it is suitable to use the Lipschitz constant for continuous functions, it is not appropriate for classification functions. The main problem is summarised in the following proposition.
Proposition 3.1 (Unbounded Lipschitz continuity for classification functions). Let
 $\mathcal{M}$
be a connected subset of
$\mathcal{M}$
be a connected subset of
 ${\mathbb{R}}^d$
and
${\mathbb{R}}^d$
and
 $f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a classification function that is not a constant function a.e. on
$f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a classification function that is not a constant function a.e. on
 $\mathcal{M}$
. Then,
$\mathcal{M}$
. Then,
 $f$
is not Lipschitz continuous.
$f$
is not Lipschitz continuous.
The proof is elementary and simply follows from the fact that any non-constant discrete function on a connected domain has a discontinuity. This proposition is nothing novel and there are certain methods that researchers have used to deal with the issues caused by the discontinuities. One common assumption that is made is that the classes are separated by some minimal distance, as demonstrated in [Reference Yang, Rashtchian, Zhang, Salakhutdinov and Chaudhuri73]. This is essentially dropping the connectedness from our assumptions. Furthermore, the issue of isolating the Lipschitz constant is highlighted by the fact that the classes themselves can be labelled by arbitrary numbers. This causes a problem for approaches such as the one in [Reference Yang, Rashtchian, Zhang, Salakhutdinov and Chaudhuri73] where the distance between any two examples from different classes is assumed to be at least 2r, for some fixed value
 $r$
. As an example take the following functions
$r$
. As an example take the following functions
Example 3.2. Fix an
 $\epsilon \gt 0$
. Let
$\epsilon \gt 0$
. Let
 $H_1 \;:\; [-1,-\epsilon ]\cup [\epsilon ,1] \rightarrow \{0,1\}$
defined by
$H_1 \;:\; [-1,-\epsilon ]\cup [\epsilon ,1] \rightarrow \{0,1\}$
defined by
 \begin{align*} H_1(x) = \begin{cases} 1 \quad &x\gt 0, \\ 0 \quad &x\lt 0. \end{cases} \end{align*}
\begin{align*} H_1(x) = \begin{cases} 1 \quad &x\gt 0, \\ 0 \quad &x\lt 0. \end{cases} \end{align*}
Similarly, we define the function
 $H_2 \;:\; [-1,-\epsilon ]\cup [\epsilon ,1] \rightarrow \{0,1000\}$
defined by
$H_2 \;:\; [-1,-\epsilon ]\cup [\epsilon ,1] \rightarrow \{0,1000\}$
defined by
 \begin{align*} H_2(x) = \begin{cases} 1000 \quad &x\gt 0, \\ 0 \quad &x\lt 0. \end{cases} \end{align*}
\begin{align*} H_2(x) = \begin{cases} 1000 \quad &x\gt 0, \\ 0 \quad &x\lt 0. \end{cases} \end{align*}
These two examples illustrate two separate problems with using Lipschitz continuity for classifications functions. First, both functions are examples of separating different classes of a Heaviside step function by a small interval
 $(-\epsilon , \epsilon )$
, thereby leading to a finite Lipschitz constant. However, the value of the constant depends on the value of
$(-\epsilon , \epsilon )$
, thereby leading to a finite Lipschitz constant. However, the value of the constant depends on the value of
 $\epsilon$
, and diverges as
$\epsilon$
, and diverges as
 $\epsilon \rightarrow 0$
. The implication of this is that in a machine learning setting, the more data we gather about the target function, the smaller we would expect the minimal distance between different classes to be, which corresponds to a smaller
$\epsilon \rightarrow 0$
. The implication of this is that in a machine learning setting, the more data we gather about the target function, the smaller we would expect the minimal distance between different classes to be, which corresponds to a smaller
 $\epsilon$
. As the target function in common machine learning tasks is discrete, this would lead to an unbounded Lipschitz constant. Second, the two functions demonstrate that the Lipschitz constant is not invariant under rescaling of the inputs. The function
$\epsilon$
. As the target function in common machine learning tasks is discrete, this would lead to an unbounded Lipschitz constant. Second, the two functions demonstrate that the Lipschitz constant is not invariant under rescaling of the inputs. The function
 $H_2$
has a much bigger Lipschitz constant than
$H_2$
has a much bigger Lipschitz constant than
 $H_1$
, even though they are describing the same classification problem. This showcases that the arbitrary choice of representing different classes as integers, has also an effect on the Lipschitz stability of the function, which we argue is not a desired property.
$H_1$
, even though they are describing the same classification problem. This showcases that the arbitrary choice of representing different classes as integers, has also an effect on the Lipschitz stability of the function, which we argue is not a desired property.
3.2. A spectrum of discrete instabilities
Next, we will give examples of functions that all have an unbounded Lipschitz constant, yet somehow one could consider them to have different ‘stability’. These examples will also be used to demonstrate desired properties of a more general stability measure.
Example 3.3.
Let
 $ f_1, f_2, f_3 \;:\; [-1, 1] \rightarrow \{ -1,1 \}$
be defined by:
$ f_1, f_2, f_3 \;:\; [-1, 1] \rightarrow \{ -1,1 \}$
be defined by:
 $ f_1(x) = \textrm{sgn}(x),$
$ f_1(x) = \textrm{sgn}(x),$
 \begin{align*} f_2(x) = \begin{cases} - \textrm{sgn}(x) \quad & \text{if } x \in \{ -0.5, 0.5\}, \\ \textrm{sgn}(x) \quad & \text{otherwise}, \end{cases} \end{align*}
\begin{align*} f_2(x) = \begin{cases} - \textrm{sgn}(x) \quad & \text{if } x \in \{ -0.5, 0.5\}, \\ \textrm{sgn}(x) \quad & \text{otherwise}, \end{cases} \end{align*}
and
 \begin{align*} f_3(x) = \begin{cases} \textrm{sgn}(x) \quad & \text{if } x \in \mathbb{Q} , \\ - \textrm{sgn}(x) \quad & \text{if } x \in {\mathbb{R}} \setminus \mathbb{Q}. \end{cases} \end{align*}
\begin{align*} f_3(x) = \begin{cases} \textrm{sgn}(x) \quad & \text{if } x \in \mathbb{Q} , \\ - \textrm{sgn}(x) \quad & \text{if } x \in {\mathbb{R}} \setminus \mathbb{Q}. \end{cases} \end{align*}
Here, the function
 $\textrm{sgn} \;:\; {\mathbb{R}} \rightarrow \{ -1, 1 \}$
is the sign function (for the sake of the argument, we will assign 0 as positive), that is,
$\textrm{sgn} \;:\; {\mathbb{R}} \rightarrow \{ -1, 1 \}$
is the sign function (for the sake of the argument, we will assign 0 as positive), that is,
 \begin{align*} \textrm{sgn}(x) = \begin{cases} 1 \, &\text{if } x \geq 0, \\ -1 \, & \text{if } x \lt 0. \end{cases} \end{align*}
\begin{align*} \textrm{sgn}(x) = \begin{cases} 1 \, &\text{if } x \geq 0, \\ -1 \, & \text{if } x \lt 0. \end{cases} \end{align*}
All three functions take discrete values, and as such have an unbounded Lipschitz constant. However, one could argue that
 $f_1$
is more stable than
$f_1$
is more stable than
 $f_2$
, which in turn is more stable than
$f_2$
, which in turn is more stable than
 $f_3$
. The function
$f_3$
. The function
 $f_2$
is just a more unstable version of
$f_2$
is just a more unstable version of
 $f_1$
, with
$f_1$
, with
 $f_3$
being a ‘minefield’ of instabilities, as any open interval contains points of different labels. This motivates us to define a local measure which takes into account the discontinuities but also the position of them, since a point close to the discontinuity would be more unstable in the sense of ‘What is the smallest perturbation needed to change the output of the function?’. The three functions are displayed in Figure 1.
$f_3$
being a ‘minefield’ of instabilities, as any open interval contains points of different labels. This motivates us to define a local measure which takes into account the discontinuities but also the position of them, since a point close to the discontinuity would be more unstable in the sense of ‘What is the smallest perturbation needed to change the output of the function?’. The three functions are displayed in Figure 1.

Figure 1. Different classes of unstable classification functions.
4. Class stability as a measure for ‘robustness’
In light of the previous examples, we would like to now define a stability measure that is capable of discerning functions such as
 $f_1, f_2, f_3$
, while yielding the same stability for
$f_1, f_2, f_3$
, while yielding the same stability for
 $H_1$
and
$H_1$
and
 $H_2$
. First, we will remind the reader about the definition of the distance to the decision boundary as stated in the second section.
$H_2$
. First, we will remind the reader about the definition of the distance to the decision boundary as stated in the second section.
Definition 4.1 (Distance to the decision boundary). For the extension of a classification function
 $\overline {f} \;:\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
$\overline {f} \;:\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
 $1 \leq p \leq \infty$
, we define
$1 \leq p \leq \infty$
, we define
 ${h^p_{\bar {f}}}\;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
the
${h^p_{\bar {f}}}\;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
the
 $\ell ^p$
-distance to the decision boundary as
$\ell ^p$
-distance to the decision boundary as
 \begin{equation*} {h^p_{\bar {f}}}(x) = \inf \{ \|x-z\|_p \;:\;\, \overline {f}(x) \neq \overline {f}(z), \, z \in {\mathbb{R}}^d \}. \end{equation*}
\begin{equation*} {h^p_{\bar {f}}}(x) = \inf \{ \|x-z\|_p \;:\;\, \overline {f}(x) \neq \overline {f}(z), \, z \in {\mathbb{R}}^d \}. \end{equation*}
It is easy to check that this definition indeed captures the intuitive notion of the ‘distance to the decision boundary’. Indeed, the decision boundary is really just the closest points where the label flips. Having the local stability measure, we can now proceed to defining a global measure which would help us differentiate the different types of stabilities of, for example, functions
 $f_1$
,
$f_1$
,
 $f_2$
and
$f_2$
and
 $f_3$
. To assess the stability of a compact set
$f_3$
. To assess the stability of a compact set
 $A \subset {\mathbb{R}}^d$
, we define the stability of a function
$A \subset {\mathbb{R}}^d$
, we define the stability of a function
 $\overline {f}$
to be the following:
$\overline {f}$
to be the following:
Definition 4.2 (Class stability of discrete function). Let
 $\overline {f} \;:\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
be a extension of a classification function and
$\overline {f} \;:\; {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
be a extension of a classification function and
 $A \subset {\mathbb{R}}^d$
a compact set. Then, for a real number
$A \subset {\mathbb{R}}^d$
a compact set. Then, for a real number
 $1 \leq p \leq \infty$
, we define the
$1 \leq p \leq \infty$
, we define the
 $\ell _p$
-stability of
$\ell _p$
-stability of
 $\overline {f}$
on
$\overline {f}$
on
 $A$
to be
$A$
to be
 \begin{align*} {h^p_{\bar {f}}}(A) = \int _A {h^p_{\bar {f}}} \, d \mu . \end{align*}
\begin{align*} {h^p_{\bar {f}}}(A) = \int _A {h^p_{\bar {f}}} \, d \mu . \end{align*}
We call this stability measure the class stability of the function
 $\overline {f}$
on the set
$\overline {f}$
on the set
 $A$
.
$A$
.
This measure is a generalisation of the local stability measure, as it takes into account the stability of the function on the whole set. If the original classification function was defined on a compact set
 ${\mathcal{M}} \subset {\mathbb{R}}^d$
, then
${\mathcal{M}} \subset {\mathbb{R}}^d$
, then
 $\mathcal{S}^p(\overline {f})$
the
$\mathcal{S}^p(\overline {f})$
the
 $\ell ^p$
-class stability of
$\ell ^p$
-class stability of
 $\overline {f}$
Eq. (2.3) is well defined.
$\overline {f}$
Eq. (2.3) is well defined.
Let us now examine the
 $\ell ^1$
-stability of the functions
$\ell ^1$
-stability of the functions
 $\overline {f_1}$
,
$\overline {f_1}$
,
 $\overline {f_2}$
and
$\overline {f_2}$
and
 $\overline {f_3}$
on the compact set
$\overline {f_3}$
on the compact set
 ${\mathcal{M}} = [-1,1]$
. For
${\mathcal{M}} = [-1,1]$
. For
 $f_1$
, the distance to the decision boundary for a point
$f_1$
, the distance to the decision boundary for a point
 $x$
is given by
$x$
is given by
 $h^1_{\bar {f}}(x) = |x|$
. A straightforward calculation yields
$h^1_{\bar {f}}(x) = |x|$
. A straightforward calculation yields
 $\mathcal{S}^1(\bar {f_1}) = 1$
. Similarly, we can compute the other values, obtaining
$\mathcal{S}^1(\bar {f_1}) = 1$
. Similarly, we can compute the other values, obtaining
 $\mathcal{S}^1(\bar {f_2}) = 0.5$
and
$\mathcal{S}^1(\bar {f_2}) = 0.5$
and
 $\mathcal{S}^1(\bar {f_3}) = 0$
. While the specific values depend on the
$\mathcal{S}^1(\bar {f_3}) = 0$
. While the specific values depend on the
 $\ell ^p$
norm chosen, the usefulness of this measure lies in its ability to quantify
$\ell ^p$
norm chosen, the usefulness of this measure lies in its ability to quantify
 $\overline {f_3}$
as completely unstable. In fact,
$\overline {f_3}$
as completely unstable. In fact,
 $\overline {f_3}$
is deliberately selected to represent one of the worst cases, where any perturbation can cause an extreme change.
$\overline {f_3}$
is deliberately selected to represent one of the worst cases, where any perturbation can cause an extreme change.
4.1. Properties of the class stability
Consider two classification functions
 $f_1, f_4\;:\; {\mathcal{M}}=[-1,1]\rightarrow \{ -1, 1\}$
where
$f_1, f_4\;:\; {\mathcal{M}}=[-1,1]\rightarrow \{ -1, 1\}$
where
 \begin{align*} f_1(x) = \textrm{sgn}(x), \quad f_4(x) = \textrm{sgn}\big (x+\frac {1}{2}\big ). \end{align*}
\begin{align*} f_1(x) = \textrm{sgn}(x), \quad f_4(x) = \textrm{sgn}\big (x+\frac {1}{2}\big ). \end{align*}
The
 $\ell _1$
class stability of these functions on
$\ell _1$
class stability of these functions on
 $\mathcal{M}$
are 1 and
$\mathcal{M}$
are 1 and
 $\frac {5}{4}$
correspondingly. In fact, it is true for any
$\frac {5}{4}$
correspondingly. In fact, it is true for any
 $p\gt 0$
that the
$p\gt 0$
that the
 $\ell _p$
norm of
$\ell _p$
norm of
 $f_1$
is lower than for
$f_1$
is lower than for
 $f_4$
. We can see from Figure 2 that in both functions, there is a region (shaded blue) for which the points have the exact same stability properties as the relative distance to the decision boundary remains the same. For the remaining points, we can see that the remaining portion
$f_4$
. We can see from Figure 2 that in both functions, there is a region (shaded blue) for which the points have the exact same stability properties as the relative distance to the decision boundary remains the same. For the remaining points, we can see that the remaining portion
 $f_4$
is more stable than the remaining portion of
$f_4$
is more stable than the remaining portion of
 $f_1$
. This property makes sense in the context of how the average stability of the function looks like. If the instability is hidden away from most points, then, in some sense, this is more beneficial to the overall stability.
$f_1$
. This property makes sense in the context of how the average stability of the function looks like. If the instability is hidden away from most points, then, in some sense, this is more beneficial to the overall stability.

Figure 2. Step functions with differently placed steps.
5. Definitions
In order to prove our main theorems, we will need to define some basic concepts.
Definition 5.1 (Neural network). Let
 $\mathcal{NN}^{\rho }_{\mathbf{N},L,d}$
where
$\mathcal{NN}^{\rho }_{\mathbf{N},L,d}$
where
 $\mathbf{N} = (N_L = |\mathcal{Y}|, N_{L-1},\ldots ,N_1,N_0 = d)$
denote the set of all L-layer NNs. That is, all mappings
$\mathbf{N} = (N_L = |\mathcal{Y}|, N_{L-1},\ldots ,N_1,N_0 = d)$
denote the set of all L-layer NNs. That is, all mappings
 $\phi \;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^{N_L}$
of the form:
$\phi \;:\; {\mathbb{R}}^d \rightarrow {\mathbb{R}}^{N_L}$
of the form:
 \begin{equation*}\phi (x) = W_L(\rho (W_{L-1}(\rho (\ldots \rho (W_1(x))\ldots )))), \quad x \in {\mathbb{R}}^d,\end{equation*}
\begin{equation*}\phi (x) = W_L(\rho (W_{L-1}(\rho (\ldots \rho (W_1(x))\ldots )))), \quad x \in {\mathbb{R}}^d,\end{equation*}
where
 $W_l \;:\; {\mathbb{R}}^{N_{l-1}} \rightarrow {\mathbb{R}}^{N_l}, 1 \leq l \leq L$
is an affine mapping and
$W_l \;:\; {\mathbb{R}}^{N_{l-1}} \rightarrow {\mathbb{R}}^{N_l}, 1 \leq l \leq L$
is an affine mapping and
 $\rho \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
is a function (called the activation function) which acts component-wise (Note that
$\rho \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
is a function (called the activation function) which acts component-wise (Note that
 $W_L \;:\; {\mathbb{R}}^{N_{L-1}} \rightarrow {\mathbb{R}}^{|\mathcal{Y}|}$
). Typically this function is given by
$W_L \;:\; {\mathbb{R}}^{N_{L-1}} \rightarrow {\mathbb{R}}^{|\mathcal{Y}|}$
). Typically this function is given by
 $\rho (x) = \max \{0,x\}$
.
$\rho (x) = \max \{0,x\}$
.
 $L$
is also referred to as the number of hidden layers.
$L$
is also referred to as the number of hidden layers.
We will also need to define specific sets of NNs as they are crucial to approximation theorems. To this end, we will use the following notation.
Definition 5.2 (Class of neural networks). Let
 $\mathcal{NN}(\rho , n,m, D,W)$
denote the set of NNs
$\mathcal{NN}(\rho , n,m, D,W)$
denote the set of NNs
 $\mathcal{NN}^{\rho }_{\mathbf{N},L,d}$
with an activation function
$\mathcal{NN}^{\rho }_{\mathbf{N},L,d}$
with an activation function
 $\rho$
, input dimension
$\rho$
, input dimension
 $n$
, output dimension
$n$
, output dimension
 $m$
, depth
$m$
, depth
 $D$
and width
$D$
and width
 $W$
. In relation to the previous definition, this means
$W$
. In relation to the previous definition, this means
 \begin{equation*} \rho = \rho , \quad L = D, \quad d = n, \quad N_L = m, \quad \max _{i=1, \ldots , L-1}{N_i} = W. \end{equation*}
\begin{equation*} \rho = \rho , \quad L = D, \quad d = n, \quad N_L = m, \quad \max _{i=1, \ldots , L-1}{N_i} = W. \end{equation*}
We will also denote the NN class with unbounded depth by
 $\mathcal{NN}(\rho , n,m, \mathbb{N},W)$
, and similarly the NN class with unbounded width by
$\mathcal{NN}(\rho , n,m, \mathbb{N},W)$
, and similarly the NN class with unbounded width by
 $\mathcal{NN}(\rho , n,m, D,\mathbb{N})$
.
$\mathcal{NN}(\rho , n,m, D,\mathbb{N})$
.
Definition 5.3 (Class prediction function). For a given
 $n \in \mathbb{N}$
, we define the class prediction function
$n \in \mathbb{N}$
, we define the class prediction function
 $p_n\;:\;{\mathbb{R}}^n \rightarrow \{1, \ldots , n\}$
as
$p_n\;:\;{\mathbb{R}}^n \rightarrow \{1, \ldots , n\}$
as
 \begin{align} p_n(x) = \min \{i \;:\; x_i \geq x_j, \forall j \in \{1, \ldots , n\} \} . \end{align}
\begin{align} p_n(x) = \min \{i \;:\; x_i \geq x_j, \forall j \in \{1, \ldots , n\} \} . \end{align}
The class prediction function has the same function as the ‘argmax’ function in for example the numpy library of python. This function takes a vector and returns the index of the element that has the highest value of all elements. If there are multiple such indices that satisfy the maximality, we return the first index.
Remark 5.4 (Training a neural network on a classification task). By training a NN on a classification task we mean that we want to approximate a classification function
 $f$
, more precisely, its extension. To illustrate why we want the extension, imagine something simple as MNIST. We have 10 target classes, hence
$f$
, more precisely, its extension. To illustrate why we want the extension, imagine something simple as MNIST. We have 10 target classes, hence
 $\mathcal{Y} = \{1, 2, \ldots , 10\}$
(‘zero’ is represented by 10 and each other number is represented by itself). Then, we either want to learn
$\mathcal{Y} = \{1, 2, \ldots , 10\}$
(‘zero’ is represented by 10 and each other number is represented by itself). Then, we either want to learn
 $f$
which labels well-defined images correctly, while labelling undefined images randomly, or we want to learn
$f$
which labels well-defined images correctly, while labelling undefined images randomly, or we want to learn
 $\overline {f}$
where we label undefined images as
$\overline {f}$
where we label undefined images as
 $-1$
. Here,
$-1$
. Here,
 $f$
is the ground truth (might be debatable whether it actually exists, but for the purpose of the argument assume it does).
$f$
is the ground truth (might be debatable whether it actually exists, but for the purpose of the argument assume it does).
6. Proof of Lemma 2.1
We are now equipped to prove our first main result. Our proof relies on the following two approximation results, the first being the classical approximation theorem for single layer NNs.
Theorem 6.1 (Universal approximation theorem [Reference Pinkus62]). Let
 $\rho \in C({\mathbb{R}})$
(continuous functions on
$\rho \in C({\mathbb{R}})$
(continuous functions on
 $\mathbb{R}$
) and assume
$\mathbb{R}$
) and assume
 $\rho$
is not a polynomial. Then,
$\rho$
is not a polynomial. Then,
 $\mathcal{NN}(\rho ,n,m,1,\mathbb{N})$
(the class of single layer NNs with an activation function of
$\mathcal{NN}(\rho ,n,m,1,\mathbb{N})$
(the class of single layer NNs with an activation function of
 $\rho$
) is dense in
$\rho$
) is dense in
 $C({\mathbb{R}}^n;{\mathbb{R}}^m)$
.
$C({\mathbb{R}}^n;{\mathbb{R}}^m)$
.
The second theorem is a newer result that proves the universal approximation property for fixed width NNs.
Theorem 6.2 (Kidger and Lyons [Reference Kidger, Lyons, Abernethy and Agarwal52]). Let
 $\rho \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
be any non-affine continuous function which is continuously differentiable at at least one point, with non-zero derivative at that point. Let
$\rho \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
be any non-affine continuous function which is continuously differentiable at at least one point, with non-zero derivative at that point. Let
 ${\mathcal{K}} \subset {\mathbb{R}}^n$
be compact. Then,
${\mathcal{K}} \subset {\mathbb{R}}^n$
be compact. Then,
 $\mathcal{NN}(\rho ,n,m,\mathbb{N},n+m+2)$
(the class of NNs with input dimension
$\mathcal{NN}(\rho ,n,m,\mathbb{N},n+m+2)$
(the class of NNs with input dimension
 $n$
, output dimension
$n$
, output dimension
 $m$
and width of at most
$m$
and width of at most
 $n+m+2$
) is dense in
$n+m+2$
) is dense in
 $C(K;\; {\mathbb{R}}^m)$
with respect to the uniform norm.
$C(K;\; {\mathbb{R}}^m)$
with respect to the uniform norm.
Before we prove Lemma 2.1, we will first prove a lemma. We start by defining the following functions. For each
 $i \in \overline {\mathcal{Y}}$
, let us define the functions
$i \in \overline {\mathcal{Y}}$
, let us define the functions
 $H_i \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
as:
$H_i \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
as:
 \begin{align} H_i(x) = \begin{cases} {h^p_{\bar {f}}}(x) \, & \bar {f}(x) = i, \\ 0 \, & \text{otherwise}. \end{cases} \end{align}
\begin{align} H_i(x) = \begin{cases} {h^p_{\bar {f}}}(x) \, & \bar {f}(x) = i, \\ 0 \, & \text{otherwise}. \end{cases} \end{align}
This function can be thought of as an element-wise version of the distance to the decision boundary Eq. (2.2).
Lemma 6.3.
 $H_i$
is continuous for all
$H_i$
is continuous for all
 $i \in \overline {\mathcal{Y}}$
.
$i \in \overline {\mathcal{Y}}$
.
Proof. Let
 $\{x_m\}_{m=0}^{\infty }$
be a sequence in
$\{x_m\}_{m=0}^{\infty }$
be a sequence in
 $\mathcal{K}$
with
$\mathcal{K}$
with
 $x_m \rightarrow x'$
as
$x_m \rightarrow x'$
as
 $m \rightarrow \infty$
, where
$m \rightarrow \infty$
, where
 $x' \in {\mathcal{K}}$
. First, we take care of the simple case where
$x' \in {\mathcal{K}}$
. First, we take care of the simple case where
 $\overline {f}(x') \neq i$
. Then, we know that
$\overline {f}(x') \neq i$
. Then, we know that
 $H_i(x') = 0$
and that for
$H_i(x') = 0$
and that for
 $x_m$
we have
$x_m$
we have
 $ 0 \leq H_i(x_m) \leq \|x_m -x'\|_p.$
Thus,
$ 0 \leq H_i(x_m) \leq \|x_m -x'\|_p.$
Thus,
 $H_i(x_m) \rightarrow H_i(x')$
as
$H_i(x_m) \rightarrow H_i(x')$
as
 $m \rightarrow \infty$
. Therefore, we can assume
$m \rightarrow \infty$
. Therefore, we can assume
 $\overline {f}(x') = i$
in which case we distinguish three cases.
$\overline {f}(x') = i$
in which case we distinguish three cases.
Case 1 :
 $\exists j \in \mathbb{N}$
such that
$\exists j \in \mathbb{N}$
such that
 $\overline {f}(x_m) = i, \, \forall m\gt j$
. Pick an
$\overline {f}(x_m) = i, \, \forall m\gt j$
. Pick an
 $\epsilon \gt 0$
. Then, there exists a
$\epsilon \gt 0$
. Then, there exists a
 $l\in \mathbb{N}$
such that
$l\in \mathbb{N}$
such that
 $ \|x_m - x'\|_{p} \lt \epsilon /2$
for all
$ \|x_m - x'\|_{p} \lt \epsilon /2$
for all
 $m\gt l.$
As
$m\gt l.$
As
 $\overline {f}(x') = i$
, it follows by the definition of
$\overline {f}(x') = i$
, it follows by the definition of
 $h^p_{\bar {f}}$
, that there must exist a sequence of
$h^p_{\bar {f}}$
, that there must exist a sequence of
 $\{z'_\alpha \}_{\alpha = 0}^{\infty }$
such that
$\{z'_\alpha \}_{\alpha = 0}^{\infty }$
such that
 \begin{align*} \|x' - z'_\alpha \|_p \rightarrow {h^p_{\bar {f}}}(x') \quad \text{as } \alpha \rightarrow \infty , \text{ with } \overline {f}(z'_\alpha ) \neq i. \end{align*}
\begin{align*} \|x' - z'_\alpha \|_p \rightarrow {h^p_{\bar {f}}}(x') \quad \text{as } \alpha \rightarrow \infty , \text{ with } \overline {f}(z'_\alpha ) \neq i. \end{align*}
This also means that there exists a
 $\beta ' \in \mathbb{N}$
such that
$\beta ' \in \mathbb{N}$
such that
 $\|x' - z'_\alpha \|_p\lt {h^p_{\bar {f}}}(x') + \epsilon /2$
,
$\|x' - z'_\alpha \|_p\lt {h^p_{\bar {f}}}(x') + \epsilon /2$
,
 $\forall \alpha \gt \beta '$
, hence
$\forall \alpha \gt \beta '$
, hence
 \begin{equation*} {h^p_{\bar {f}}}(x_m) \leq \|x_m - z'_\alpha \|_{p} \leq \|x_m - x'\|_{p} + \|x' - z'_\alpha \|_p \lt {h^p_{\bar {f}}}(x') + \epsilon \quad \forall \alpha \gt \beta ' \text{ and } m\gt l. \end{equation*}
\begin{equation*} {h^p_{\bar {f}}}(x_m) \leq \|x_m - z'_\alpha \|_{p} \leq \|x_m - x'\|_{p} + \|x' - z'_\alpha \|_p \lt {h^p_{\bar {f}}}(x') + \epsilon \quad \forall \alpha \gt \beta ' \text{ and } m\gt l. \end{equation*}
Notice that since
 $f(x_m) = i$
, we also have a sequence
$f(x_m) = i$
, we also have a sequence
 $\{z_\alpha \}_{\alpha = 0}^{\infty }$
such that
$\{z_\alpha \}_{\alpha = 0}^{\infty }$
such that
 \begin{align*} \|x_m - z_\alpha \|_p \rightarrow {h^p_{\bar {f}}}(x_m) \quad \text{as }\alpha \rightarrow \infty , \end{align*}
\begin{align*} \|x_m - z_\alpha \|_p \rightarrow {h^p_{\bar {f}}}(x_m) \quad \text{as }\alpha \rightarrow \infty , \end{align*}
 $\forall m\gt l$
. This also means that there exists a
$\forall m\gt l$
. This also means that there exists a
 $\beta \in \mathbb{N}$
such that
$\beta \in \mathbb{N}$
such that
 \begin{align*} \|x_m - z_\alpha \|_p\lt {h^p_{\bar {f}}}(x_m) + \epsilon /2 \quad \forall \alpha \gt \beta \text{ and }m\gt l, \end{align*}
\begin{align*} \|x_m - z_\alpha \|_p\lt {h^p_{\bar {f}}}(x_m) + \epsilon /2 \quad \forall \alpha \gt \beta \text{ and }m\gt l, \end{align*}
hence
 \begin{align*} {h^p_{\bar {f}}}(x') \leq \|x' - z_\alpha \|_{p} \leq \|x_m - x'\|_{p} + \|x_m - z_\alpha \|_p \lt {h^p_{\bar {f}}}(x_m) + \epsilon \quad \forall \alpha \gt \beta \text{ and }m\gt l. \end{align*}
\begin{align*} {h^p_{\bar {f}}}(x') \leq \|x' - z_\alpha \|_{p} \leq \|x_m - x'\|_{p} + \|x_m - z_\alpha \|_p \lt {h^p_{\bar {f}}}(x_m) + \epsilon \quad \forall \alpha \gt \beta \text{ and }m\gt l. \end{align*}
Putting these together, we obtain
 $|{h^p_{\bar {f}}}(x') - {h^p_{\bar {f}}}(x_m)|_p \lt \epsilon \quad \forall m\gt l, \epsilon \gt 0$
. Thus
$|{h^p_{\bar {f}}}(x') - {h^p_{\bar {f}}}(x_m)|_p \lt \epsilon \quad \forall m\gt l, \epsilon \gt 0$
. Thus
 $ {h^p_{\bar {f}}}(x_m) \rightarrow {h^p_{\bar {f}}}(x')$
as
$ {h^p_{\bar {f}}}(x_m) \rightarrow {h^p_{\bar {f}}}(x')$
as
 $m \rightarrow \infty$
and therefore
$m \rightarrow \infty$
and therefore
 $H_i(x_m) \rightarrow H_i(x')$
as
$H_i(x_m) \rightarrow H_i(x')$
as
 $m \rightarrow \infty$
.
$m \rightarrow \infty$
.
Case 2:
 $\exists j \in \mathbb{N}$
such that
$\exists j \in \mathbb{N}$
such that
 $\overline {f}(x_m) \neq i, \, \forall m\gt j$
. In this case
$\overline {f}(x_m) \neq i, \, \forall m\gt j$
. In this case
 ${h^p_{\bar {f}}}(x') = 0$
, since the subsequence has only points containing points that do not map to label
${h^p_{\bar {f}}}(x') = 0$
, since the subsequence has only points containing points that do not map to label
 $i$
, whereas
$i$
, whereas
 $\overline {f}(x') = i$
. Similarly,
$\overline {f}(x') = i$
. Similarly,
 $\|x_m - x'\|_p$
serves as an upper bound for
$\|x_m - x'\|_p$
serves as an upper bound for
 ${h^p_{\bar {f}}}(x_m)$
for all
${h^p_{\bar {f}}}(x_m)$
for all
 $m\gt j$
, but since
$m\gt j$
, but since
 $x_m \rightarrow x'$
as
$x_m \rightarrow x'$
as
 $m \rightarrow \infty$
, we must also have
$m \rightarrow \infty$
, we must also have
 ${h^p_{\bar {f}}}(x_m)\rightarrow {h^p_{\bar {f}}}(x')$
.
${h^p_{\bar {f}}}(x_m)\rightarrow {h^p_{\bar {f}}}(x')$
.
Case 3:
 $\forall j \in \mathbb{N} \quad \exists m,l \gt j$
such that
$\forall j \in \mathbb{N} \quad \exists m,l \gt j$
such that
 $\overline {f}(x_m) = i$
and
$\overline {f}(x_m) = i$
and
 $\overline {f}(x_l) \neq i$
. In this case, there exists a subsequence
$\overline {f}(x_l) \neq i$
. In this case, there exists a subsequence
 $\{x_{h_k}\}_{k=1}^\infty$
such that
$\{x_{h_k}\}_{k=1}^\infty$
such that
 $\overline {f}(x_{h_k}) \neq i$
for all
$\overline {f}(x_{h_k}) \neq i$
for all
 $ k \in \mathbb{Z}$
and
$ k \in \mathbb{Z}$
and
 $x_{h_k} \rightarrow x'$
as
$x_{h_k} \rightarrow x'$
as
 $k \rightarrow \infty$
. This means that
$k \rightarrow \infty$
. This means that
 ${h^p_{\bar {f}}}(x') = 0$
. To show that
${h^p_{\bar {f}}}(x') = 0$
. To show that
 ${h^p_{\bar {f}}}(x_m)\rightarrow 0$
as
${h^p_{\bar {f}}}(x_m)\rightarrow 0$
as
 $m \rightarrow \infty$
, we use the fact that the sequence is also a Cauchy sequence, and that elements that map to label
$m \rightarrow \infty$
, we use the fact that the sequence is also a Cauchy sequence, and that elements that map to label
 $i$
and ones that do not map to label
$i$
and ones that do not map to label
 $i$
occur infinitely many times in the sequence.
$i$
occur infinitely many times in the sequence.
Combining these gives us
 $H_i(x_m) \rightarrow H_i(x')$
as
$H_i(x_m) \rightarrow H_i(x')$
as
 $m \rightarrow \infty$
as required.
$m \rightarrow \infty$
as required.
With this lemma, we are now ready to prove our first main result Lemma 2.1.
Proof of Theorem 2.1. The proof will rely on two steps. First, we show that we can find a continuous function
 $g \;:\; {\mathcal{K}} \rightarrow [0,1]^{q}$
that satisfies
$g \;:\; {\mathcal{K}} \rightarrow [0,1]^{q}$
that satisfies
 \begin{align*} p_{q}\circ g(x) = f(x) \quad \forall x\in {\mathcal{M}}_{\epsilon }\cap {\mathcal{K}} . \end{align*}
\begin{align*} p_{q}\circ g(x) = f(x) \quad \forall x\in {\mathcal{M}}_{\epsilon }\cap {\mathcal{K}} . \end{align*}
Then, we apply the corresponding form of the universal approximation theorem to find an approximator, which we will show will also be an interpolator.
By the lemma 6.3, we know that
 $H_i \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
(defined in Eq. (6.1)) are all continuous; hence, we can proceed to define the following vector valued function
$H_i \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
(defined in Eq. (6.1)) are all continuous; hence, we can proceed to define the following vector valued function
 $H \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
$H \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
 \begin{align} H(x) = (H_1(x), H_2(x), \ldots , H_{q}(x)) , \end{align}
\begin{align} H(x) = (H_1(x), H_2(x), \ldots , H_{q}(x)) , \end{align}
which must be continuous. Note that
 $p_{q}\circ H(x) = \overline {f}(x) \, for\, x \in {\mathcal{M}}_{\epsilon }$
. As our activation function is a continuous non-polynomial, we can apply the universal approximation theorem [Reference Pinkus62] on the function
$p_{q}\circ H(x) = \overline {f}(x) \, for\, x \in {\mathcal{M}}_{\epsilon }$
. As our activation function is a continuous non-polynomial, we can apply the universal approximation theorem [Reference Pinkus62] on the function
 $H$
. This guarantees us a single layer NN
$H$
. This guarantees us a single layer NN
 $\Psi \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
such that
$\Psi \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
such that
 $ \sup _{x \in {\mathcal{K}}} \|H(x) - \Psi (x)\|_p \lt \epsilon / 2 .$
We will show that
$ \sup _{x \in {\mathcal{K}}} \|H(x) - \Psi (x)\|_p \lt \epsilon / 2 .$
We will show that
 \begin{align} p_{q}\circ \Psi (x) = \overline {f}(x) \quad \forall x \in {\mathcal{M}}_\epsilon \cap {\mathcal{K}}. \end{align}
\begin{align} p_{q}\circ \Psi (x) = \overline {f}(x) \quad \forall x \in {\mathcal{M}}_\epsilon \cap {\mathcal{K}}. \end{align}
Observe that on the sets
 ${\mathcal{M}}_\epsilon$
the function
${\mathcal{M}}_\epsilon$
the function
 $H$
is of the form
$H$
is of the form
 $ H(x) = \lambda *e_{\overline {f}(x)}$
where
$ H(x) = \lambda *e_{\overline {f}(x)}$
where
 $\lambda \in {\mathbb{R}}, \lambda \gt \epsilon$
and
$\lambda \in {\mathbb{R}}, \lambda \gt \epsilon$
and
 $e_k\in {\mathbb{R}}^{q}$
is a k’th unit vector. Therefore,
$e_k\in {\mathbb{R}}^{q}$
is a k’th unit vector. Therefore,
 $ \Psi (x) = (\psi _1(x), \psi _2(x), \ldots , \psi _{q}(x))$
such that
$ \Psi (x) = (\psi _1(x), \psi _2(x), \ldots , \psi _{q}(x))$
such that
 \begin{align*} \psi _i(x) \lt \epsilon /2 \quad \text{if } i \neq \overline {f}(x), \quad \psi _i(x) \gt \epsilon /2 \quad \text{if } i = \overline {f}(x). \end{align*}
\begin{align*} \psi _i(x) \lt \epsilon /2 \quad \text{if } i \neq \overline {f}(x), \quad \psi _i(x) \gt \epsilon /2 \quad \text{if } i = \overline {f}(x). \end{align*}
The result (6.3) follows immediately from this. This proves part (2.6).
For the (2.7), we recall Theorem 6.2. As our activation function was is non-polynomial, therefore, it must also be non-affine, it satisfies all the conditions of Theorem 6.2 and the rest proceeds as in the shallow network case.
Remark 6.4. There are slightly stronger versions of this theorem. If the activation function is only continuous and non-polynomial, then there exists a shallow NN that interpolates
 $f$
on
$f$
on
 $\mathcal{M}$
. On the other hand, if the activation function is non-affine continuous that is continuously differentiable at at least one point, with non-zero derivative at that point, then there exists a deep NN with finite with that interpolates
$\mathcal{M}$
. On the other hand, if the activation function is non-affine continuous that is continuously differentiable at at least one point, with non-zero derivative at that point, then there exists a deep NN with finite with that interpolates
 $f$
on
$f$
on
 $\mathcal{M}$
.
$\mathcal{M}$
.
An interesting note here is that one can notice that the function
 $H$
is in fact 1-Lipschitz, so the proof also shows that there exists a NN that is stable in the Lipschitz framework. The caveat, however, is that in practice, the loss function is minimising the difference between
$H$
is in fact 1-Lipschitz, so the proof also shows that there exists a NN that is stable in the Lipschitz framework. The caveat, however, is that in practice, the loss function is minimising the difference between
 $ \Psi$
and
$ \Psi$
and
 $\overline {f}$
, not
$\overline {f}$
, not
 $p_{q}\circ \Psi$
with
$p_{q}\circ \Psi$
with
 $\overline {f}$
, which means that the algorithms usually do not converge at
$\overline {f}$
, which means that the algorithms usually do not converge at
 $H$
.
$H$
.
Proposition 6.5. For the norm
 $\|\cdot \|_p$
where
$\|\cdot \|_p$
where
 $1 \leq p \leq \infty$
, the function
$1 \leq p \leq \infty$
, the function
 $H\;:\;{\mathbb{R}}^d \rightarrow {\mathbb{R}}^{q}$
has Lipschitz constant 1.
$H\;:\;{\mathbb{R}}^d \rightarrow {\mathbb{R}}^{q}$
has Lipschitz constant 1.
Proof. We want to show that
 $ \| H(x) - H(y)\|_p \leq \| x - y\|_p.$
Recall that H is defined as the vector that consists of
$ \| H(x) - H(y)\|_p \leq \| x - y\|_p.$
Recall that H is defined as the vector that consists of
 $H_i$
Eq. (6.2). From the Eq. (6.1), we see that
$H_i$
Eq. (6.2). From the Eq. (6.1), we see that
 $H(x)$
will have elements equal to 0, unless the index
$H(x)$
will have elements equal to 0, unless the index
 $i$
is equal to
$i$
is equal to
 $\overline {f}(x)$
. Given this, we can distinguish two cases.
$\overline {f}(x)$
. Given this, we can distinguish two cases.
Case 1.
 $\overline {f}(x) = \overline {f}(y)$
We know that there is a sequence
$\overline {f}(x) = \overline {f}(y)$
We know that there is a sequence
 $\{z_i\}_{i=1}^\infty$
such that
$\{z_i\}_{i=1}^\infty$
such that
 \begin{align} \|y - z_i \|_p \rightarrow {h^p_{\bar {f}}}(y), \quad \text{where } \overline {f}(z_i)\neq \overline {f}(y). \end{align}
\begin{align} \|y - z_i \|_p \rightarrow {h^p_{\bar {f}}}(y), \quad \text{where } \overline {f}(z_i)\neq \overline {f}(y). \end{align}
Furthermore,
 $\|x - z_i \|_p\geq {h^p_{\bar {f}}}(x)$
, as
$\|x - z_i \|_p\geq {h^p_{\bar {f}}}(x)$
, as
 $\overline {f}(x) = \overline {f}(y)$
. Without the loss of generality let us assume that
$\overline {f}(x) = \overline {f}(y)$
. Without the loss of generality let us assume that
 ${h^p_{\bar {f}}}(x) \geq {h^p_{\bar {f}}}(y)$
. Since
${h^p_{\bar {f}}}(x) \geq {h^p_{\bar {f}}}(y)$
. Since
 $x,y$
have the same label, we obtain from (6.4) that for any
$x,y$
have the same label, we obtain from (6.4) that for any
 $\epsilon \gt 0$
$\epsilon \gt 0$
 \begin{align*} \|H(x) - H(y)\|_p &= |{h^p_{\bar {f}}}(x) - {h^p_{\bar {f}}}(y)| = {h^p_{\bar {f}}}(x) - {h^p_{\bar {f}}}(y)\\ &\leq \|x - z_i \|_p - \|y - z_i \|_p + \epsilon \leq \| x - y\|_p + \epsilon \quad \forall i \in \mathbb{N}. \end{align*}
\begin{align*} \|H(x) - H(y)\|_p &= |{h^p_{\bar {f}}}(x) - {h^p_{\bar {f}}}(y)| = {h^p_{\bar {f}}}(x) - {h^p_{\bar {f}}}(y)\\ &\leq \|x - z_i \|_p - \|y - z_i \|_p + \epsilon \leq \| x - y\|_p + \epsilon \quad \forall i \in \mathbb{N}. \end{align*}
Taking
 $\epsilon \rightarrow 0$
, we obtain the desired result.
$\epsilon \rightarrow 0$
, we obtain the desired result.
Case 2.
 $\overline {f}(x) \neq \overline {f}(y)$
In this case, let us look at the line segment
$\overline {f}(x) \neq \overline {f}(y)$
In this case, let us look at the line segment
 \begin{align*} \mathcal{L} = \{tx + (1-t)y \;:\; t \in [0,1]\} , \end{align*}
\begin{align*} \mathcal{L} = \{tx + (1-t)y \;:\; t \in [0,1]\} , \end{align*}
and consider the following two points
 $w_1, w_2$
$w_1, w_2$
 $$\begin{align}w_1 & = t_1 x + (1-t_1)y \quad t_1 = \inf \{t \;:\; \overline {f}(tx + (1-t)y)\neq \overline {f}(y) \},\end{align}$$
$$\begin{align}w_1 & = t_1 x + (1-t_1)y \quad t_1 = \inf \{t \;:\; \overline {f}(tx + (1-t)y)\neq \overline {f}(y) \},\end{align}$$
 $$\begin{align}w_2 & = t_2 x + (1-t_2)y \quad t_2 = \sup \{t \;:\; \overline {f}(tx + (1-t)y)\neq \overline {f}(x) \}.\end{align}$$
$$\begin{align}w_2 & = t_2 x + (1-t_2)y \quad t_2 = \sup \{t \;:\; \overline {f}(tx + (1-t)y)\neq \overline {f}(x) \}.\end{align}$$
By linearity, we have
 $\frac {w_1 + w_2}{2} = \frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y$
. Clearly
$\frac {w_1 + w_2}{2} = \frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y$
. Clearly
 $t_1 \leq t_2$
, because otherwise
$t_1 \leq t_2$
, because otherwise
 $t_2 \lt \frac {t_1 + t_2}{2}\lt t_1$
and by the definitions (6.5) , (6.6)
$t_2 \lt \frac {t_1 + t_2}{2}\lt t_1$
and by the definitions (6.5) , (6.6)
 \begin{align*} \overline {f}\left (\frac {w_1 + w_2}{2}\right ) = \overline {f}\left (\frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y\right ) = \overline {f}(y) \quad \text{as } \frac {t_1 + t_2}{2} \lt t_1, \\ \overline {f}\left (\frac {w_1 + w_2}{2}\right ) = \overline {f}\left (\frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y\right ) = \overline {f}(x) \quad \text{as } \frac {t_1 + t_2}{2} \gt t_2. \end{align*}
\begin{align*} \overline {f}\left (\frac {w_1 + w_2}{2}\right ) = \overline {f}\left (\frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y\right ) = \overline {f}(y) \quad \text{as } \frac {t_1 + t_2}{2} \lt t_1, \\ \overline {f}\left (\frac {w_1 + w_2}{2}\right ) = \overline {f}\left (\frac {t_1 + t_2}{2} x + (1-\frac {t_1 + t_2}{2})y\right ) = \overline {f}(x) \quad \text{as } \frac {t_1 + t_2}{2} \gt t_2. \end{align*}
This is a contradiction with
 $\overline {f}(x) \neq \overline {f}(y)$
. Therefore,
$\overline {f}(x) \neq \overline {f}(y)$
. Therefore,
 $t_1 \leq t_2$
and hence
$t_1 \leq t_2$
and hence
 \begin{align*} \|H(x) - H(y)\|_p &= (|{h^p_{\bar {f}}}(x)|^p + |{h^p_{\bar {f}}}(y)|^p)^{1/p} \leq ( |\|x - w_1 \|_p|^p + |\|y- w_2 \|_p|^p)^{1/p} \\ & \leq \|x - w_1 \|_p + \|y- w_2 \|_p \leq \| x - y\|_p . \end{align*}
\begin{align*} \|H(x) - H(y)\|_p &= (|{h^p_{\bar {f}}}(x)|^p + |{h^p_{\bar {f}}}(y)|^p)^{1/p} \leq ( |\|x - w_1 \|_p|^p + |\|y- w_2 \|_p|^p)^{1/p} \\ & \leq \|x - w_1 \|_p + \|y- w_2 \|_p \leq \| x - y\|_p . \end{align*}
Note that we could have also proven the theorem using Urysohn’s lemma, and we would obtain the same result. Using Urysohn’s lemma, we would construct a continuous function
 $H^* \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
such that
$H^* \;:\; {\mathcal{K}} \rightarrow {\mathbb{R}}^{q}$
such that
 $ p_{q}\circ H^*(x) = f(x),$
for all
$ p_{q}\circ H^*(x) = f(x),$
for all
 $x \in {\mathcal{M}}_\epsilon \cap {\mathcal{K}}.$
This would be done by applying Urysohn’s lemma for indicator functions
$x \in {\mathcal{M}}_\epsilon \cap {\mathcal{K}}.$
This would be done by applying Urysohn’s lemma for indicator functions
 $\unicode{x1D7D9}_i \;:\; {\mathcal{K}} \rightarrow \{0,1\}$
for each label
$\unicode{x1D7D9}_i \;:\; {\mathcal{K}} \rightarrow \{0,1\}$
for each label
 $i \in \overline {\mathcal{Y}}$
$i \in \overline {\mathcal{Y}}$
 \begin{align*} \unicode{x1D7D9}_i(x) = \begin{cases} 1 \quad \text{if }f(x) = i, \\ 0 \quad \text{if }f(x) \neq i. \end{cases} \end{align*}
\begin{align*} \unicode{x1D7D9}_i(x) = \begin{cases} 1 \quad \text{if }f(x) = i, \\ 0 \quad \text{if }f(x) \neq i. \end{cases} \end{align*}
on disjoint subsets of
 ${\mathcal{M}}_{\epsilon }$
, call this function obtained from Urysohn’s lemma
${\mathcal{M}}_{\epsilon }$
, call this function obtained from Urysohn’s lemma
 $U_i \;:\; {\mathcal{K}} \rightarrow [0,1]$
. Then, the final function
$U_i \;:\; {\mathcal{K}} \rightarrow [0,1]$
. Then, the final function
 $H^*$
would simply just be
$H^*$
would simply just be
 $H^*(x) = (U_1(x), U_2(x), \ldots , U_{q}(x))$
. The drawback here is that this function does not necessarily have a bounded Lipschitz constant. In the following examples, we will illustrate that there are certain cases where the two functions
$H^*(x) = (U_1(x), U_2(x), \ldots , U_{q}(x))$
. The drawback here is that this function does not necessarily have a bounded Lipschitz constant. In the following examples, we will illustrate that there are certain cases where the two functions
 $H$
and
$H$
and
 $H^*$
have different Lipschitz constants, yet their class stability is the same.
$H^*$
have different Lipschitz constants, yet their class stability is the same.
Example 6.6.
Consider the classification function
 $f_l :[0,2] \rightarrow \{0,1\}$
where
$f_l :[0,2] \rightarrow \{0,1\}$
where
 \begin{align*} f_l = \begin{cases} 0 \quad \text{if }x\lt 1, \\ 1 \quad \text{if }x \geq 1. \end{cases} \end{align*}
\begin{align*} f_l = \begin{cases} 0 \quad \text{if }x\lt 1, \\ 1 \quad \text{if }x \geq 1. \end{cases} \end{align*}
The
 ${\mathcal{M}}_{\epsilon }$
set for
${\mathcal{M}}_{\epsilon }$
set for
 $\epsilon \lt 1$
here would therefore be the set
$\epsilon \lt 1$
here would therefore be the set
 $[0,1-\epsilon )\cup (1+\epsilon , 2]$
. As we have shown in Lemma
6.5
, the function
$[0,1-\epsilon )\cup (1+\epsilon , 2]$
. As we have shown in Lemma
6.5
, the function
 $H$
will always have a Lipschitz constant of 1. However, the function
$H$
will always have a Lipschitz constant of 1. However, the function
 $H^*$
will satisfy
$H^*$
will satisfy
 \begin{align*} H^*(x) = \begin{cases} (1,0) \quad \text{if }x\lt 1-\epsilon , \\ (0,1) \quad \text{if }x\gt 1+\epsilon . \end{cases} \end{align*}
\begin{align*} H^*(x) = \begin{cases} (1,0) \quad \text{if }x\lt 1-\epsilon , \\ (0,1) \quad \text{if }x\gt 1+\epsilon . \end{cases} \end{align*}
This means that we have a lower bound on the Lipschitz constant
 $L$
by
$L$
by
 \begin{equation*} L \geq \frac {\|(1,-1)\|_p}{2\epsilon }. \end{equation*}
\begin{equation*} L \geq \frac {\|(1,-1)\|_p}{2\epsilon }. \end{equation*}
As this expression diverges as
 $\epsilon \rightarrow 0$
, we see that the Lipschitz constant diverges as well. However, for both functions, we have
$\epsilon \rightarrow 0$
, we see that the Lipschitz constant diverges as well. However, for both functions, we have
 \begin{align*} p_{q}\circ H(x) = p_{q}\circ H^*(x) = f_l(x) \quad \forall x \in {\mathcal{M}}_{\epsilon }. \end{align*}
\begin{align*} p_{q}\circ H(x) = p_{q}\circ H^*(x) = f_l(x) \quad \forall x \in {\mathcal{M}}_{\epsilon }. \end{align*}
Thus,
 $p_{q}\circ H$
and
$p_{q}\circ H$
and
 $p_{q}\circ H^*$
have the same class stability.
$p_{q}\circ H^*$
have the same class stability.
7. Stability revised
One relevant question one might have when talking about the class stability is how that relates to measure theory. In fact, if we were to look at the class stability from that point of view, one might argue that of the functions mentioned in Section 3, function
 $f_3$
might be considered the most stable and
$f_3$
might be considered the most stable and
 $f_1, f_2$
equally stable since the unstable points have measure 0. We can define the class stability in the following sense to keep consistency.
$f_1, f_2$
equally stable since the unstable points have measure 0. We can define the class stability in the following sense to keep consistency.
Definition 7.1 (Measure theoretic distance to the decision boundary). For an extension of a classification function
 $\overline {f} \,:\, {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
$\overline {f} \,:\, {\mathbb{R}}^d \rightarrow \overline {\mathcal{Y}}$
and a real number
 $p \geq 1$
, we define
$p \geq 1$
, we define
 $\tau ^p_{\bar {f}}\,:\, {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
the
$\tau ^p_{\bar {f}}\,:\, {\mathbb{R}}^d \rightarrow {\mathbb{R}}^+$
the
 $l^p$
-distance to the decision boundary as
$l^p$
-distance to the decision boundary as
 \begin{align*} \tau ^p_{\bar {f}}(x) = \inf \left \{ r \;:\; \int _{{\mathcal{B}}^p_r(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x)}\, d\mu , r\in [0,\infty ) \right \}. \end{align*}
\begin{align*} \tau ^p_{\bar {f}}(x) = \inf \left \{ r \;:\; \int _{{\mathcal{B}}^p_r(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x)}\, d\mu , r\in [0,\infty ) \right \}. \end{align*}
Here,
 $\mu$
denotes the Lebesgue measure and
$\mu$
denotes the Lebesgue measure and
 ${\mathcal{B}}^p_r(x)$
the unit closed ball with
${\mathcal{B}}^p_r(x)$
the unit closed ball with
 $p$
-norm, and
$p$
-norm, and
 $\unicode{x1D7D9}$
is the indicator function.
$\unicode{x1D7D9}$
is the indicator function.
Correspondingly, we can define the class stability in the following way.
Definition 7.2 (Class stability (measure theoretic)). If
 ${\mathcal{M}} \subset {\mathbb{R}}^d$
is a compact set, we define the (measure theoretic)
${\mathcal{M}} \subset {\mathbb{R}}^d$
is a compact set, we define the (measure theoretic)
 $\ell _p$
-stability of
$\ell _p$
-stability of
 $\overline {f}$
to be
$\overline {f}$
to be
 \begin{align} \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {f}) = \int _{{\mathcal{M}}} \tau ^p_{\bar {f}}(x) \, d\mu . \end{align}
\begin{align} \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {f}) = \int _{{\mathcal{M}}} \tau ^p_{\bar {f}}(x) \, d\mu . \end{align}
Remark 7.3 (Properties of the measure theoretic distance to the decision boundary). One unfortunate thing for this definition is that the function is no longer continuous as can be seen by looking at the following function
 $f_2$
at the point
$f_2$
at the point
 $1/2$
. The stability of that point is
$1/2$
. The stability of that point is
 $0$
, whereas now its neighbourhood has a non-zero stability as
$0$
, whereas now its neighbourhood has a non-zero stability as
 $1/2$
is an isolated point with a different label. Fortunately, we can show that the stability remains measurable if
$1/2$
is an isolated point with a different label. Fortunately, we can show that the stability remains measurable if
 $f$
itself was measurable.
$f$
itself was measurable.
Lemma 7.4 (Measurability of stability). Let
 $f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a measurable classification function. Then, the measure theoretic distance to the decision boundary
$f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a measurable classification function. Then, the measure theoretic distance to the decision boundary
 $\tau ^p_{\bar {f}}$
is measurable.
$\tau ^p_{\bar {f}}$
is measurable.
Proof. To show that
 $\tau ^p_{\bar {f}}$
is measurable, it suffices to show that for every real number
$\tau ^p_{\bar {f}}$
is measurable, it suffices to show that for every real number
 $\alpha \geq 0$
, the set
$\alpha \geq 0$
, the set
 $\{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \}$
is measurable. We will show this by showing that the set
$\{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \}$
is measurable. We will show this by showing that the set
 $\{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \}$
is a countable union of measurable sets. Let
$\{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \}$
is a countable union of measurable sets. Let
 $\alpha \geq 0$
be fixed. Then, we know that
$\alpha \geq 0$
be fixed. Then, we know that
 \begin{equation} \{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \} = \bigcup _{q\in \mathbb{Q}, 0\leq q \lt \alpha } \{x \in {\mathcal{M}} \;:\; \mu \left ({\mathcal{B}}^p_q(x) \cap \{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}\right ) \gt 0\}. \end{equation}
\begin{equation} \{x \in {\mathcal{M}} \;:\; \tau ^p_{\bar {f}}(x) \lt \alpha \} = \bigcup _{q\in \mathbb{Q}, 0\leq q \lt \alpha } \{x \in {\mathcal{M}} \;:\; \mu \left ({\mathcal{B}}^p_q(x) \cap \{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}\right ) \gt 0\}. \end{equation}
Therefore, all we need to show is that the function
 $\phi _q(x) = \mu \left ({\mathcal{B}}^p_q(x) \cap \{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}\right )$
is measurable for every non-negative
$\phi _q(x) = \mu \left ({\mathcal{B}}^p_q(x) \cap \{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}\right )$
is measurable for every non-negative
 $q \in \mathbb{Q}$
. Clearly for
$q \in \mathbb{Q}$
. Clearly for
 $q = 0$
, the function is constant and hence measurable. Hence, we will only consider
$q = 0$
, the function is constant and hence measurable. Hence, we will only consider
 $q \gt 0$
. The function
$q \gt 0$
. The function
 $\phi _q$
can be rewritten as a integral:
$\phi _q$
can be rewritten as a integral:
 \begin{equation} \phi _q(x) = \int _{{\mathbb{R}}^d} \unicode{x1D7D9}_{{\mathcal{B}}^p_q(x)}(z) \unicode{x1D7D9}_{\{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}}(z) {\;\textrm{d}} z. \end{equation}
\begin{equation} \phi _q(x) = \int _{{\mathbb{R}}^d} \unicode{x1D7D9}_{{\mathcal{B}}^p_q(x)}(z) \unicode{x1D7D9}_{\{z \in {\mathbb{R}}^d:\bar {f}(z) \neq \bar {f}(x)\}}(z) {\;\textrm{d}} z. \end{equation}
We will finish of the proof by showing that the integrand is measurable with respect to the product
 $\sigma$
-algebra
$\sigma$
-algebra
 $\sigma ({\mathbb{R}}^d) \otimes \sigma ({\mathbb{R}}^d)$
, as the measurability of
$\sigma ({\mathbb{R}}^d) \otimes \sigma ({\mathbb{R}}^d)$
, as the measurability of
 $\phi _q$
follows by Fubini’s theorem [Reference Wheeden72]. We will look at the two parts of the integrand separately. In both cases, we will show that the underlying set of the indicator function is measurable.
$\phi _q$
follows by Fubini’s theorem [Reference Wheeden72]. We will look at the two parts of the integrand separately. In both cases, we will show that the underlying set of the indicator function is measurable.
For the first term is the indicator function of the set
 $A = \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; z \in {\mathcal{B}}^p_q(x)\}$
. This set is measurable as it is the preimage of
$A = \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; z \in {\mathcal{B}}^p_q(x)\}$
. This set is measurable as it is the preimage of
 $(- \infty , q]$
under the continuous (therefore measurable) function
$(- \infty , q]$
under the continuous (therefore measurable) function
 $h\;:\; {\mathbb{R}}^d \times {\mathbb{R}}^d \rightarrow {\mathbb{R}}$
given by
$h\;:\; {\mathbb{R}}^d \times {\mathbb{R}}^d \rightarrow {\mathbb{R}}$
given by
 $h(x,z) = \|z - x\|_p$
.
$h(x,z) = \|z - x\|_p$
.
The second term is the indicator function of the set
 $B = \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; \bar {f}(z) \neq \bar {f}(x)\}$
. This set can be written as the finite union of sets
$B = \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; \bar {f}(z) \neq \bar {f}(x)\}$
. This set can be written as the finite union of sets
 \begin{align*} B = \bigcup _{i, j \in \overline {\mathcal{Y}}, i \neq j} \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; \bar {f}(x) = j \text{ and } \bar {f}(z) = i\} \end{align*}
\begin{align*} B = \bigcup _{i, j \in \overline {\mathcal{Y}}, i \neq j} \{(x, z) \in {\mathbb{R}}^d \times {\mathbb{R}}^d \;:\; \bar {f}(x) = j \text{ and } \bar {f}(z) = i\} \end{align*}
For each label
 $k \in \overline {\mathcal{Y}}$
, let
$k \in \overline {\mathcal{Y}}$
, let
 $C_k = \{x \in {\mathbb{R}}^d \;:\; \bar {f}(x) = k\}$
. Since the classification function
$C_k = \{x \in {\mathbb{R}}^d \;:\; \bar {f}(x) = k\}$
. Since the classification function
 $\bar {f}$
is measurable, each set
$\bar {f}$
is measurable, each set
 $C_k$
is measurable in
$C_k$
is measurable in
 ${\mathbb{R}}^d$
. Therefore, the set
${\mathbb{R}}^d$
. Therefore, the set
 $\{\left (x,z\right ) \;:\; \bar {f}(x) = y_i \text{ and } \bar {f}(z) = y_j\}$
is simply the Cartesian product
$\{\left (x,z\right ) \;:\; \bar {f}(x) = y_i \text{ and } \bar {f}(z) = y_j\}$
is simply the Cartesian product
 $C_i \times C_j$
, which is measurable in the product
$C_i \times C_j$
, which is measurable in the product
 $\sigma$
-algebra. Since
$\sigma$
-algebra. Since
 $B$
is a finite union of such measurable sets, it is measurable. Therefore, the integrand is measurable with respect to the product
$B$
is a finite union of such measurable sets, it is measurable. Therefore, the integrand is measurable with respect to the product
 $\sigma$
-algebra
$\sigma$
-algebra
 $\sigma ({\mathbb{R}}^d) \otimes \sigma ({\mathbb{R}}^d)$
, and hence the function
$\sigma ({\mathbb{R}}^d) \otimes \sigma ({\mathbb{R}}^d)$
, and hence the function
 $\phi _q$
is measurable.
$\phi _q$
is measurable.
For the rest of the document, we will always assume
 $f$
to be measurable.
$f$
to be measurable.
8. Proof of Lemma 2.4
We are now set to prove our next main result Lemma 2.4. To prove this theorem, we will first show the following theorem.
Proposition 8.1.
Let
 $f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a measurable classification function. Then, for any set of pairs
$f\;:\; {\mathcal{M}} \rightarrow \mathcal{Y}$
be a measurable classification function. Then, for any set of pairs
 $\{(x_i, f(x_i))\}_{i=1}^k$
such that
$\{(x_i, f(x_i))\}_{i=1}^k$
such that
 $\tau ^p_{\bar {f}}(x_i) \gt 0$
for all
$\tau ^p_{\bar {f}}(x_i) \gt 0$
for all
 $i=1,\ldots , k$
(the distance to the decision boundary Eq. (2.2) is non-zero) and
$i=1,\ldots , k$
(the distance to the decision boundary Eq. (2.2) is non-zero) and
 $\epsilon _1, \epsilon _2 \gt 0$
, there exists a continuous function
$\epsilon _1, \epsilon _2 \gt 0$
, there exists a continuous function
 $g \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
such that the class stability Eq. (2.3) satisfies
$g \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
such that the class stability Eq. (2.3) satisfies
 \begin{align} \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {\lfloor g\rceil }) \geq \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {f}) - \epsilon _1 \end{align}
\begin{align} \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {\lfloor g\rceil }) \geq \mathcal{T}^{\;\;\,p}_{{\mathcal{M}}}(\overline {f}) - \epsilon _1 \end{align}
and the functions agree on the set
 $\{x_i\}_{i=1}^k$
, i.e.:
$\{x_i\}_{i=1}^k$
, i.e.:
 \begin{align} f(x_i) = g(x_i) \quad i = 1,\ldots ,k, \end{align}
\begin{align} f(x_i) = g(x_i) \quad i = 1,\ldots ,k, \end{align}
and
 \begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq g(x), x \in {\mathcal{M}}\}, \end{align}
\begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq g(x), x \in {\mathcal{M}}\}, \end{align}
where
 $\mu$
denotes the Lebesgue measure and
$\mu$
denotes the Lebesgue measure and
 $\lfloor \cdot \rceil$
is the function that rounds to the nearest integer.
$\lfloor \cdot \rceil$
is the function that rounds to the nearest integer.
Note that the class stability of
 $\lfloor g \rceil$
is well defined as it is a discrete function defined on a compact set
$\lfloor g \rceil$
is well defined as it is a discrete function defined on a compact set
 $\mathcal{M}$
.
$\mathcal{M}$
.
Proof of Lemma 8.1. We define the following disjoint sets, based on the distance to the decision boundary function Lemma 7.1: For
 $\xi \gt 0$
, let
$\xi \gt 0$
, let
 \begin{align*} S_{\xi } &\;:\!=\; \{x \, \vert \, \tau ^p_{\bar {f}}(x) \geq \xi , x \in {\mathcal{M}}\}, \quad U_{\xi } \;:\!=\; \{x \, \vert \, \tau ^p_{\bar {f}}(x) \lt \xi , x\in {\mathcal{M}}\}, \\ & \qquad \qquad \qquad U\;:\!=\; \{x | \tau ^p_{\bar {f}}(x) = 0\ , x \in {\mathcal{M}}\}. \end{align*}
\begin{align*} S_{\xi } &\;:\!=\; \{x \, \vert \, \tau ^p_{\bar {f}}(x) \geq \xi , x \in {\mathcal{M}}\}, \quad U_{\xi } \;:\!=\; \{x \, \vert \, \tau ^p_{\bar {f}}(x) \lt \xi , x\in {\mathcal{M}}\}, \\ & \qquad \qquad \qquad U\;:\!=\; \{x | \tau ^p_{\bar {f}}(x) = 0\ , x \in {\mathcal{M}}\}. \end{align*}
First, notice that for any
 $\xi _1 \lt \xi _2$
, we have
$\xi _1 \lt \xi _2$
, we have
 $U_{\xi _1} \subset U_{\xi _2}$
and that for any
$U_{\xi _1} \subset U_{\xi _2}$
and that for any
 $\eta \gt 0$
the following holds true
$\eta \gt 0$
the following holds true
 \begin{align} \bigcap \limits _{\xi \lt \eta } U_{\xi } = U. \end{align}
\begin{align} \bigcap \limits _{\xi \lt \eta } U_{\xi } = U. \end{align}
Since
 $\tau ^p_{\bar {f}}$
is measurable and we can write
$\tau ^p_{\bar {f}}$
is measurable and we can write
 $U = \{x \, \vert \, \tau ^p_{\bar {f}}(x) \leq 0\}$
as
$U = \{x \, \vert \, \tau ^p_{\bar {f}}(x) \leq 0\}$
as
 $\tau ^p_{\bar {f}}$
is non-negative, we know that the set
$\tau ^p_{\bar {f}}$
is non-negative, we know that the set
 $U$
is measurable. In fact, by the same reasoning, all three sets are.
$U$
is measurable. In fact, by the same reasoning, all three sets are.
Consider the closure
 $\overline {S_\xi }$
of the set
$\overline {S_\xi }$
of the set
 $S_\xi$
, and the adjusted sets
$S_\xi$
, and the adjusted sets
 $U'_{\xi } = U_{\xi } - \overline {S_\xi }$
and
$U'_{\xi } = U_{\xi } - \overline {S_\xi }$
and
 $U^0_\xi = U - \overline {S_\xi }$
. As
$U^0_\xi = U - \overline {S_\xi }$
. As
 $\overline {S_\xi }$
is closed, it must be measurable and also the difference of two measurable sets is measurable, thus
$\overline {S_\xi }$
is closed, it must be measurable and also the difference of two measurable sets is measurable, thus
 $\overline {S_\xi }, U'_\xi , U^0_\xi$
are all measurable.
$\overline {S_\xi }, U'_\xi , U^0_\xi$
are all measurable.
Claim 1:
 $\mu (U \cap \overline {S_\xi }) = 0$
. To show the claim, we will start by considering the collection
$\mu (U \cap \overline {S_\xi }) = 0$
. To show the claim, we will start by considering the collection
 $\{B^p_{\xi /2}(x) \, \vert \, x \in S_\xi \}$
of open balls or radius
$\{B^p_{\xi /2}(x) \, \vert \, x \in S_\xi \}$
of open balls or radius
 $\xi$
in the p-norm, and noting that it is an open cover of
$\xi$
in the p-norm, and noting that it is an open cover of
 $\overline {S_\xi }$
. Therefore, since
$\overline {S_\xi }$
. Therefore, since
 $\overline {S_\xi } \subset \mathcal{M}$
, which is bounded, and since
$\overline {S_\xi } \subset \mathcal{M}$
, which is bounded, and since
 $\overline {S_\xi }$
is closed, there must exist a finite subcover, in particular there must exist a finite subset
$\overline {S_\xi }$
is closed, there must exist a finite subcover, in particular there must exist a finite subset
 $S^* \subset S_\xi$
such that
$S^* \subset S_\xi$
such that
 $\overline {S_\xi } \subset \bigcup _{x \in S^*} B^p_{\xi /2}(x)$
. Now, suppose that
$\overline {S_\xi } \subset \bigcup _{x \in S^*} B^p_{\xi /2}(x)$
. Now, suppose that
 $\mu (U \cap \overline {S_\xi }) \gt 0$
, then we would neccesarily have
$\mu (U \cap \overline {S_\xi }) \gt 0$
, then we would neccesarily have
 \begin{equation} \begin{split} \mu (U \cap (\bigcup _{x \in S^*} B^p_{\xi /2}(x))) \gt 0, \text{ hence } \mu (\bigcup _{x \in S^*} (U \cap B^p_{\xi /2}(x))) \gt 0. \end{split} \end{equation}
\begin{equation} \begin{split} \mu (U \cap (\bigcup _{x \in S^*} B^p_{\xi /2}(x))) \gt 0, \text{ hence } \mu (\bigcup _{x \in S^*} (U \cap B^p_{\xi /2}(x))) \gt 0. \end{split} \end{equation}
By subadditivity (as
 $S^*$
is finite), there must exist a point
$S^*$
is finite), there must exist a point
 $x_0$
such that
$x_0$
such that
 $\mu (U \cap B^p_{\xi /2}(x_0)) \gt 0$
. Recall that
$\mu (U \cap B^p_{\xi /2}(x_0)) \gt 0$
. Recall that
 $x_0\in S_\xi$
means
$x_0\in S_\xi$
means
 $\tau ^p_{\bar {f}}(x_0) \geq \xi$
which implies
$\tau ^p_{\bar {f}}(x_0) \geq \xi$
which implies
 \begin{align} \inf \{ r\in [0,\infty ) \, \vert \, \int _{{\mathcal{B}}^p_r(x_0)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_0)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x_0)}\, d\mu \} \geq \xi . \end{align}
\begin{align} \inf \{ r\in [0,\infty ) \, \vert \, \int _{{\mathcal{B}}^p_r(x_0)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_0)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x_0)}\, d\mu \} \geq \xi . \end{align}
Thus, the function
 $\overline {f}$
is constant on
$\overline {f}$
is constant on
 $B^p_{\xi /2}(x_0)$
almost everywhere and any point
$B^p_{\xi /2}(x_0)$
almost everywhere and any point
 $z$
of the set
$z$
of the set
 \begin{align} L_{x_0, \xi /2} \;:\!=\; \{z \, \vert \, z \in B^p_{\xi /2}(x_0), \, \overline {f}(z) = \overline {f}(x_0)\} \end{align}
\begin{align} L_{x_0, \xi /2} \;:\!=\; \{z \, \vert \, z \in B^p_{\xi /2}(x_0), \, \overline {f}(z) = \overline {f}(x_0)\} \end{align}
satisfies
 $\tau ^p_{\bar {f}}(z)\geq \xi /2$
as
$\tau ^p_{\bar {f}}(z)\geq \xi /2$
as
 $x_0$
satisfies
$x_0$
satisfies
 $\tau ^p_{\bar {f}}(x_0) \geq \xi$
. This means that
$\tau ^p_{\bar {f}}(x_0) \geq \xi$
. This means that
 $\mu (U \cap L_{x_0, \xi /2} ) = 0$
as all
$\mu (U \cap L_{x_0, \xi /2} ) = 0$
as all
 $z' \in U$
have
$z' \in U$
have
 $\tau ^p_{\bar {f}}(z') = 0$
. Finally, from the fact that
$\tau ^p_{\bar {f}}(z') = 0$
. Finally, from the fact that
 $\overline {f}$
is constant on
$\overline {f}$
is constant on
 $B^p_{\xi /2}(x_0)$
almost everywhere, we must have
$B^p_{\xi /2}(x_0)$
almost everywhere, we must have
 $\mu (B^p_{\xi /2}(x_0) - L_{x_0, \xi /2}) = 0$
, which means that we cannot have
$\mu (B^p_{\xi /2}(x_0) - L_{x_0, \xi /2}) = 0$
, which means that we cannot have
 $\mu (U \cap B^p_{\xi /2}(x_0)) \gt 0$
, giving us the required contradiction and we have shown Claim 1.
$\mu (U \cap B^p_{\xi /2}(x_0)) \gt 0$
, giving us the required contradiction and we have shown Claim 1.
Claim 2:
 $\overline {f}$
is continuous on
$\overline {f}$
is continuous on
 $S_\xi$
and there exists a unique continuous extension of
$S_\xi$
and there exists a unique continuous extension of
 $\overline {f}$
to
$\overline {f}$
to
 $\overline {S_\xi }$
. We start by showing that
$\overline {S_\xi }$
. We start by showing that
 $\overline {f}$
is continuous on
$\overline {f}$
is continuous on
 $S_\xi$
. For any
$S_\xi$
. For any
 $x_0 \in S_\xi$
, consider the neighbourhood
$x_0 \in S_\xi$
, consider the neighbourhood
 $B^p_{\xi /2}(x_0)$
as before and recall that
$B^p_{\xi /2}(x_0)$
as before and recall that
 $\overline {f}$
is constant on this ball almost everywhere, with the constant being
$\overline {f}$
is constant on this ball almost everywhere, with the constant being
 $\overline {f}(x_0)$
. Suppose now that there is a
$\overline {f}(x_0)$
. Suppose now that there is a
 $z \in S_\xi \cap B^p_{\xi /2}(x_0)$
such that
$z \in S_\xi \cap B^p_{\xi /2}(x_0)$
such that
 $\overline {f}(x_0)\neq \overline {f}(z)$
. As
$\overline {f}(x_0)\neq \overline {f}(z)$
. As
 $z \in S_\xi$
(recall (8.6)), we must also have that
$z \in S_\xi$
(recall (8.6)), we must also have that
 $\overline {f}$
constant on
$\overline {f}$
constant on
 $B^p_{\xi /2}(z)$
almost everywhere, with the constant being
$B^p_{\xi /2}(z)$
almost everywhere, with the constant being
 $\overline {f}(z)$
. However, as
$\overline {f}(z)$
. However, as
 $B^p_{\xi /2}(x_0)$
and
$B^p_{\xi /2}(x_0)$
and
 $B^p_{\xi /2}(z)$
intersect, we obtain our contradiction. The second part of this claim follows a similar argument. Let
$B^p_{\xi /2}(z)$
intersect, we obtain our contradiction. The second part of this claim follows a similar argument. Let
 $x^*$
be a limit point of
$x^*$
be a limit point of
 $S_\xi$
. Consider the set
$S_\xi$
. Consider the set
 $B^p_{\xi /2}(x^*) \cap S_\xi$
. By arguing as in the first part of the proof of the claim, no two points in this set can have different labels. Thus, this means that any sequence
$B^p_{\xi /2}(x^*) \cap S_\xi$
. By arguing as in the first part of the proof of the claim, no two points in this set can have different labels. Thus, this means that any sequence
 $x_i \rightarrow x^*\text{ as } i \rightarrow \infty$
with
$x_i \rightarrow x^*\text{ as } i \rightarrow \infty$
with
 $x_i \in S_\xi$
we have
$x_i \in S_\xi$
we have
 $x_i \in B^p_{\xi /2}(x^*) \cap S_\xi$
for all large
$x_i \in B^p_{\xi /2}(x^*) \cap S_\xi$
for all large
 $i$
, and thus all the labels will eventually have to be the same. Therefore, there is a unique way of defining the extension of
$i$
, and thus all the labels will eventually have to be the same. Therefore, there is a unique way of defining the extension of
 $\overline {f}$
to
$\overline {f}$
to
 $\overline {S_\xi }$
, which proves Claim 2. We will call this unique extension
$\overline {S_\xi }$
, which proves Claim 2. We will call this unique extension
 \begin{equation} \overline {f^*}\;:\; \overline {S_\xi } \rightarrow \overline {\mathcal{Y}}. \end{equation}
\begin{equation} \overline {f^*}\;:\; \overline {S_\xi } \rightarrow \overline {\mathcal{Y}}. \end{equation}
Claim 3: Consider any
 $x_0 \in S_\xi$
, and define
$x_0 \in S_\xi$
, and define
 $a = \tau ^p_{\bar {f}}(x_0) - \xi$
. We claim that
$a = \tau ^p_{\bar {f}}(x_0) - \xi$
. We claim that
 $B^p_{a}(x_0) \subset \overline {S_\xi }$
. We first show that
$B^p_{a}(x_0) \subset \overline {S_\xi }$
. We first show that
 $\tau ^p_{\bar {f}} \geq \xi$
on
$\tau ^p_{\bar {f}} \geq \xi$
on
 $B^p_{a}(x_0)$
almost everywhere for any fixed
$B^p_{a}(x_0)$
almost everywhere for any fixed
 $x_0 \in S_\xi$
. As before, it suffices to only consider the points
$x_0 \in S_\xi$
. As before, it suffices to only consider the points
 $z\in B^p_{a}(x_0)$
such that
$z\in B^p_{a}(x_0)$
such that
 $\overline {f}(z) = \overline {f}(x_0)$
, as
$\overline {f}(z) = \overline {f}(x_0)$
, as
 $\overline {f}$
is constant almost everywhere on this set. Suppose there exists
$\overline {f}$
is constant almost everywhere on this set. Suppose there exists
 $z \in L_{x_0,a}$
(as defined in Eq. (8.7)) such that
$z \in L_{x_0,a}$
(as defined in Eq. (8.7)) such that
 $\tau ^p_{\bar {f}}(z) \lt \xi$
. The ball centred at
$\tau ^p_{\bar {f}}(z) \lt \xi$
. The ball centred at
 $x_0$
with a radius
$x_0$
with a radius
 $\|x_0 - z\|_p + \tau ^p_{\bar {f}}(z)$
has to contain the ball centred at
$\|x_0 - z\|_p + \tau ^p_{\bar {f}}(z)$
has to contain the ball centred at
 $z$
with a radius of
$z$
with a radius of
 $\tau ^p_{\bar {f}}(z)$
. Thus, by the definition of the distance to the decision boundary, we must have
$\tau ^p_{\bar {f}}(z)$
. Thus, by the definition of the distance to the decision boundary, we must have
 $\tau ^p_{\bar {f}}(x_0) \leq \|x_0 - z\|_p + \tau ^p_{\bar {f}}(z)\lt a + \xi = \tau ^p_{\bar {f}}(x_0)$
, which gives the contradiction. Therefore,
$\tau ^p_{\bar {f}}(x_0) \leq \|x_0 - z\|_p + \tau ^p_{\bar {f}}(z)\lt a + \xi = \tau ^p_{\bar {f}}(x_0)$
, which gives the contradiction. Therefore,
 $\tau ^p_{\bar {f}} \geq \xi$
on
$\tau ^p_{\bar {f}} \geq \xi$
on
 $B^p_{a}(x_0)$
almost everywhere and hence
$B^p_{a}(x_0)$
almost everywhere and hence
 \begin{align} L_{x_0,a} \subset S_\xi . \end{align}
\begin{align} L_{x_0,a} \subset S_\xi . \end{align}
Now consider any
 $x\in B^p_a(x_0)$
. Since the ball is open, there exists a
$x\in B^p_a(x_0)$
. Since the ball is open, there exists a
 $\delta _0 \gt 0$
, such that
$\delta _0 \gt 0$
, such that
 $B^p_\delta (x) \subset B^p_a(x_0)$
for all
$B^p_\delta (x) \subset B^p_a(x_0)$
for all
 $\delta \lt \delta _0$
. Moreover, as
$\delta \lt \delta _0$
. Moreover, as
 $\mu (B^p_\delta (x))\gt 0$
for any
$\mu (B^p_\delta (x))\gt 0$
for any
 $\delta \gt 0$
, there must be a sequence
$\delta \gt 0$
, there must be a sequence
 $\{x_i\}^\infty _{i=1} \subset L_{x_0, a}$
such that
$\{x_i\}^\infty _{i=1} \subset L_{x_0, a}$
such that
 $x_i \rightarrow x$
as
$x_i \rightarrow x$
as
 $i \rightarrow \infty$
, as
$i \rightarrow \infty$
, as
 $L_{x_0, a} \subset B^p_a(x_0)$
and
$L_{x_0, a} \subset B^p_a(x_0)$
and
 $\mu ( B^p_a(x_0) - L_{x_0, a} ) = 0$
. This means that
$\mu ( B^p_a(x_0) - L_{x_0, a} ) = 0$
. This means that
 $x \in \overline {L_{x_0, a}}$
the closure of
$x \in \overline {L_{x_0, a}}$
the closure of
 $L_{x_0, a}$
and from Eq. (8.9) we obtain
$L_{x_0, a}$
and from Eq. (8.9) we obtain
 $x \in \overline {S_\xi }$
for all
$x \in \overline {S_\xi }$
for all
 $x\in B^p_a(x_0)$
. Therefore
$x\in B^p_a(x_0)$
. Therefore
 $B^p_a(x_0) \subset \overline {S_\xi }$
which proves Claim 3.
$B^p_a(x_0) \subset \overline {S_\xi }$
which proves Claim 3.
Claim 4:
 $\mu (\overline {S_{\xi }} - S_{\xi }) = 0$
. To see this, we first show that for any
$\mu (\overline {S_{\xi }} - S_{\xi }) = 0$
. To see this, we first show that for any
 $x \in \overline {S_{\xi }} - S_{\xi }$
we have
$x \in \overline {S_{\xi }} - S_{\xi }$
we have
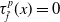 $\tau ^p_{\bar {f}}(x) = 0$
. Since
$\tau ^p_{\bar {f}}(x) = 0$
. Since
 $x \notin S_{\xi }$
, we must have
$x \notin S_{\xi }$
, we must have
 $\tau ^p_{\bar {f}}(x) \lt \xi$
. Suppose
$\tau ^p_{\bar {f}}(x) \lt \xi$
. Suppose
 $\tau ^p_{\bar {f}}(x) = \kappa$
, where
$\tau ^p_{\bar {f}}(x) = \kappa$
, where
 $\xi \gt \kappa \gt 0$
. From the definition of the measure theoretic distance to the decision boundary, we have that
$\xi \gt \kappa \gt 0$
. From the definition of the measure theoretic distance to the decision boundary, we have that
 \begin{equation} \inf \{ r\in [0,\infty ) \, \vert \, \int _{{\mathcal{B}}^p_r(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x)}\, d\mu \} = \kappa \gt 0. \end{equation}
\begin{equation} \inf \{ r\in [0,\infty ) \, \vert \, \int _{{\mathcal{B}}^p_r(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu \neq \int _{{\mathcal{B}}^p_r(x)}\, d\mu \} = \kappa \gt 0. \end{equation}
As a consequence, we must have
 \begin{equation} \int _{{\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu = \int _{{\mathcal{B}}^p_{\frac {1}{2}\kappa (x)}}\, d\mu . \end{equation}
\begin{equation} \int _{{\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)}\, d\mu = \int _{{\mathcal{B}}^p_{\frac {1}{2}\kappa (x)}}\, d\mu . \end{equation}
Furthermore, since
 $x \in \overline {S_{\xi }}$
there must be a sequence
$x \in \overline {S_{\xi }}$
there must be a sequence
 $\{x_i\}^\infty _{i=1} \subset S_{\xi }$
such that
$\{x_i\}^\infty _{i=1} \subset S_{\xi }$
such that
 $x_i \rightarrow x$
as
$x_i \rightarrow x$
as
 $i \rightarrow \infty$
. Pick an
$i \rightarrow \infty$
. Pick an
 $j \in \mathbb{N}$
,such that
$j \in \mathbb{N}$
,such that
 $x_j \in {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)$
. Then, by the definition of the measure theoretic distance to the decision boundary, we must have that
$x_j \in {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)$
. Then, by the definition of the measure theoretic distance to the decision boundary, we must have that
 $\tau ^p_{\bar {f}}(x_j) \geq \xi$
. This means that
$\tau ^p_{\bar {f}}(x_j) \geq \xi$
. This means that
 \begin{equation} \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)}\, d\mu = \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j)}\, d\mu . \end{equation}
\begin{equation} \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)}\, d\mu = \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j)}\, d\mu . \end{equation}
However, as
 $x_j \in {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)$
, we must have that
$x_j \in {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)$
, we must have that
 ${\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)\neq \emptyset$
. Combining this with the fact that
${\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)\neq \emptyset$
. Combining this with the fact that
 $\unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} + \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \leq 1$
, we must have that
$\unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} + \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \leq 1$
, we must have that
 \begin{equation} \begin{split} \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu &\geq \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} + \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \, d\mu \\ &= \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} \, d\mu + \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \, d\mu \\ &= 2\int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu . \end{split} \end{equation}
\begin{equation} \begin{split} \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu &\geq \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} + \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \, d\mu \\ &= \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)} \unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x)} \, d\mu + \int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\unicode{x1D7D9}_{\bar {f}(z) = \bar {f}(x_j)} \, d\mu \\ &= 2\int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu . \end{split} \end{equation}
As the
 $\int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu \gt 0$
, we obtain our contradiction. Hence,
$\int _{{\mathcal{B}}^p_{\frac {1}{2}\xi }(x_j) \cap {\mathcal{B}}^p_{\frac {1}{2}\kappa }(x)}\, d\mu \gt 0$
, we obtain our contradiction. Hence,
 $\tau ^{p}_{\overline {f}}(x) = 0$
for all
$\tau ^{p}_{\overline {f}}(x) = 0$
for all
 $x \in \overline {S_{\xi }} - S_{\xi }$
. This is equivalent to saying that for any
$x \in \overline {S_{\xi }} - S_{\xi }$
. This is equivalent to saying that for any
 $x \in \overline {S_{\xi }} - S_{\xi }$
, we have
$x \in \overline {S_{\xi }} - S_{\xi }$
, we have
 $x \in U$
. Therefore, for any
$x \in U$
. Therefore, for any
 $x \in \overline {S_{\xi }} - S_{\xi }$
, we have
$x \in \overline {S_{\xi }} - S_{\xi }$
, we have
 $x \in U \cap \overline {S_\xi }$
, which by Claim 1 implies that
$x \in U \cap \overline {S_\xi }$
, which by Claim 1 implies that
 $\mu (\overline {S_{\xi }} - S_{\xi }) = 0$
. This proves Claim 4.
$\mu (\overline {S_{\xi }} - S_{\xi }) = 0$
. This proves Claim 4.
Next, we apply Lusin’s Theorem for the function
 $\overline {f}$
on the set
$\overline {f}$
on the set
 $U^0_\xi$
and obtain, for any
$U^0_\xi$
and obtain, for any
 $\alpha \gt 0$
, a closed set
$\alpha \gt 0$
, a closed set
 $U^{\alpha }_\xi \subset U^0_\xi$
such that
$U^{\alpha }_\xi \subset U^0_\xi$
such that
 \begin{align} \mu (U^0_\xi -U^{\alpha }_\xi ) \lt \alpha , \quad \overline {f} \text{ is continuous on } U^{\alpha }_\xi . \end{align}
\begin{align} \mu (U^0_\xi -U^{\alpha }_\xi ) \lt \alpha , \quad \overline {f} \text{ is continuous on } U^{\alpha }_\xi . \end{align}
We can now define
 $g_{\alpha , \xi } \;:\; \overline {S_{\xi }}\cup U^{\alpha }_\xi \rightarrow [a,b]$
, where
$g_{\alpha , \xi } \;:\; \overline {S_{\xi }}\cup U^{\alpha }_\xi \rightarrow [a,b]$
, where
 $a \;:\!=\; \min \{ \mathcal{Y} \}$
and
$a \;:\!=\; \min \{ \mathcal{Y} \}$
and
 $b \;:\!=\; \max \{ \mathcal{Y} \}$
, where
$b \;:\!=\; \max \{ \mathcal{Y} \}$
, where
 \begin{align*} g_{\alpha , \xi }(x) = \begin{cases} \overline {f^*}(x) \quad \text{if }x\in \overline {S_\xi }, \\ \overline {f}(x) \quad \text{if }x\in U^{\alpha }_\xi . \end{cases} \end{align*}
\begin{align*} g_{\alpha , \xi }(x) = \begin{cases} \overline {f^*}(x) \quad \text{if }x\in \overline {S_\xi }, \\ \overline {f}(x) \quad \text{if }x\in U^{\alpha }_\xi . \end{cases} \end{align*}
Finally, as both sets
 $\overline {S_\xi }$
and
$\overline {S_\xi }$
and
 $U^{\alpha }_\xi$
are compact, since they are closed and subsets of
$U^{\alpha }_\xi$
are compact, since they are closed and subsets of
 $\mathcal{M}$
, which is compact, we can apply Tietze’s extension theorem. More precisely, we will use Tietze’s extension theorem to extend the restriction of the function
$\mathcal{M}$
, which is compact, we can apply Tietze’s extension theorem. More precisely, we will use Tietze’s extension theorem to extend the restriction of the function
 $g_{\alpha , \xi } \;:\; \overline {S_{\xi }}\cup U^{\alpha }_\xi \rightarrow [a, b]$
, to a continuous function on the whole set
$g_{\alpha , \xi } \;:\; \overline {S_{\xi }}\cup U^{\alpha }_\xi \rightarrow [a, b]$
, to a continuous function on the whole set
 $\mathcal{M}$
. Then, by Tietze’s extension theorem, we obtain a continuous function
$\mathcal{M}$
. Then, by Tietze’s extension theorem, we obtain a continuous function
 $g^*_{\alpha , \xi } \;:\; {\mathcal{M}} \rightarrow [a,b]$
such that
$g^*_{\alpha , \xi } \;:\; {\mathcal{M}} \rightarrow [a,b]$
such that
 \begin{align*} g^*_{\alpha , \xi }(x) = g_{\alpha , \xi }(x) \quad x \in \overline {S_{\xi }}\cup U^{\alpha }_\xi . \end{align*}
\begin{align*} g^*_{\alpha , \xi }(x) = g_{\alpha , \xi }(x) \quad x \in \overline {S_{\xi }}\cup U^{\alpha }_\xi . \end{align*}
Having constructed the function, all we need to do is to check that the properties (8.1) (8.2) and (8.3) are satisfied for some particular choices of
 $\alpha$
and
$\alpha$
and
 $\xi$
. Let us first estimate the loss in class stability for the rounded function
$\xi$
. Let us first estimate the loss in class stability for the rounded function
 $\lfloor g^*_{\alpha , \xi }\rceil$
. For any fixed
$\lfloor g^*_{\alpha , \xi }\rceil$
. For any fixed
 $\xi$
, we can bound the stability by:
$\xi$
, we can bound the stability by:
 \begin{align*} \mathcal{T}^{\;\;\,p}_{\lfloor g^*_{\alpha , \xi } \rceil } = \int _{\mathcal{M}} \tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }\, d\mu = \int _{\overline {S_{\xi }} \cup U'_{\xi }} \tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }\, d\mu . \end{align*}
\begin{align*} \mathcal{T}^{\;\;\,p}_{\lfloor g^*_{\alpha , \xi } \rceil } = \int _{\mathcal{M}} \tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }\, d\mu = \int _{\overline {S_{\xi }} \cup U'_{\xi }} \tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }\, d\mu . \end{align*}
We know that
 $\overline {f^*}$
(defined in Eq. (8.8)) and
$\overline {f^*}$
(defined in Eq. (8.8)) and
 $g^*_{\alpha , \xi }$
agree on
$g^*_{\alpha , \xi }$
agree on
 $\overline {S_{\xi }}$
, hence
$\overline {S_{\xi }}$
, hence
 $\lfloor g^*_{\alpha , \xi } \rceil$
agrees with
$\lfloor g^*_{\alpha , \xi } \rceil$
agrees with
 $\overline {f^*}$
as well. From Claim 3, we know that for any point
$\overline {f^*}$
as well. From Claim 3, we know that for any point
 $x_0 \in S_\xi , \, B^p_{a}(x_0) \subset \overline {S_\xi }$
, where
$x_0 \in S_\xi , \, B^p_{a}(x_0) \subset \overline {S_\xi }$
, where
 $a =\tau ^p_{\bar {f}}(x_0)-\xi$
, while from Claim 2, we know that
$a =\tau ^p_{\bar {f}}(x_0)-\xi$
, while from Claim 2, we know that
 $\overline {f^*}$
is continuous on
$\overline {f^*}$
is continuous on
 $\overline {S_\xi }$
, therefore
$\overline {S_\xi }$
, therefore
 $\overline {f^*}$
is constant on
$\overline {f^*}$
is constant on
 $B^p_{a}(x_0)$
as it is a discrete function. Thus, we must have
$B^p_{a}(x_0)$
as it is a discrete function. Thus, we must have
 $\tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }(x_0) \geq \tau ^p_{\bar {f}}(x_0)-\xi$
for all
$\tau ^p_{\lfloor g^*_{\alpha , \xi } \rceil }(x_0) \geq \tau ^p_{\bar {f}}(x_0)-\xi$
for all
 $x_0 \in S_\xi$
. This means that
$x_0 \in S_\xi$
. This means that
 \begin{align*} \mathcal{T}^{\;\;\,p}_{\lfloor g_{\alpha , \xi } \rceil } &= \int _{\overline {S_{\xi }} \cup U'_{\xi }} \tau ^p_{\lfloor g_{\alpha , \xi } \rceil }\, d\mu \geq \int _{S_{\xi } \cup U'_{\xi }} \tau ^p_{\lfloor g_{\alpha , \xi } \rceil }\, d\mu \geq \int _{S_{\xi } } \tau ^p_{\bar {f}} -\xi \, d\mu \\ & =\int _{{\mathcal{M}} - U_\xi } \tau ^p_{\bar {f}} \, d\mu - \xi \mu (S_{\xi }) = \mathcal{T}^{\;\;\,p}(f) - \int _{U_\xi }\tau ^p_{\bar {f}} \, d\mu - \xi \mu (S_{\xi }) \\ &\gt \mathcal{T}^{\;\;\,p}(f) - \xi \mu (U_\xi ) - \xi \mu (S_\xi ) = \mathcal{T}^{\;\;\,p}(f) - \xi \mu ({\mathcal{M}}). \end{align*}
\begin{align*} \mathcal{T}^{\;\;\,p}_{\lfloor g_{\alpha , \xi } \rceil } &= \int _{\overline {S_{\xi }} \cup U'_{\xi }} \tau ^p_{\lfloor g_{\alpha , \xi } \rceil }\, d\mu \geq \int _{S_{\xi } \cup U'_{\xi }} \tau ^p_{\lfloor g_{\alpha , \xi } \rceil }\, d\mu \geq \int _{S_{\xi } } \tau ^p_{\bar {f}} -\xi \, d\mu \\ & =\int _{{\mathcal{M}} - U_\xi } \tau ^p_{\bar {f}} \, d\mu - \xi \mu (S_{\xi }) = \mathcal{T}^{\;\;\,p}(f) - \int _{U_\xi }\tau ^p_{\bar {f}} \, d\mu - \xi \mu (S_{\xi }) \\ &\gt \mathcal{T}^{\;\;\,p}(f) - \xi \mu (U_\xi ) - \xi \mu (S_\xi ) = \mathcal{T}^{\;\;\,p}(f) - \xi \mu ({\mathcal{M}}). \end{align*}
The last inequality comes from the fact that
 $\tau ^p_{\bar {f}}(x) \lt \xi$
for
$\tau ^p_{\bar {f}}(x) \lt \xi$
for
 $x \in U_\xi$
. By choosing
$x \in U_\xi$
. By choosing
 $\xi \leq \frac {\epsilon _1}{\mu ({\mathcal{M}})}$
, we obtain Eq. (8.1).
$\xi \leq \frac {\epsilon _1}{\mu ({\mathcal{M}})}$
, we obtain Eq. (8.1).
To ensure (8.2), we simply need to guarantee that the set
 $\{x_i\}_{i=1}^k$
, from the statement of the proposition, satisfies
$\{x_i\}_{i=1}^k$
, from the statement of the proposition, satisfies
 $\{x_i\}_{i=1}^k \subset S_{\xi }$
. This can be achieved by choosing
$\{x_i\}_{i=1}^k \subset S_{\xi }$
. This can be achieved by choosing
 $\xi \lt \min _{i=1,\ldots ,k}\{\tau ^p_{\bar {f}}(x_i)\}$
.
$\xi \lt \min _{i=1,\ldots ,k}\{\tau ^p_{\bar {f}}(x_i)\}$
.
Finally, we observe that
 $R \subset \left (U'_{\xi } - U^\alpha _{\xi }\right ) + \left (\overline {S_{\xi }} - S_{\xi }\right )$
, where we recall
$R \subset \left (U'_{\xi } - U^\alpha _{\xi }\right ) + \left (\overline {S_{\xi }} - S_{\xi }\right )$
, where we recall
 $R$
from Eq. (8.3). Therefore, we have
$R$
from Eq. (8.3). Therefore, we have
 \begin{equation} \begin{split} \mu (R) &\leq \mu \left (U'_{\xi } - U^\alpha _{\xi }\right ) + \mu \left (\overline {S_{\xi }} - S_{\xi }\right ) = \mu \left (U'_{\xi } - U^\alpha _{\xi }\right ) \leq \mu (U'_{\xi } - U^0_{\xi }) + \mu (U^0_{\xi } - U^\alpha _{\xi }) \\ & \lt \mu (U'_\xi -U^0_\xi ) + \alpha = \mu ((U_\xi - \overline {S_\xi }) - (U-\overline {S_\xi })) + \alpha = \mu (U_\xi - U) + \alpha . \end{split} \end{equation}
\begin{equation} \begin{split} \mu (R) &\leq \mu \left (U'_{\xi } - U^\alpha _{\xi }\right ) + \mu \left (\overline {S_{\xi }} - S_{\xi }\right ) = \mu \left (U'_{\xi } - U^\alpha _{\xi }\right ) \leq \mu (U'_{\xi } - U^0_{\xi }) + \mu (U^0_{\xi } - U^\alpha _{\xi }) \\ & \lt \mu (U'_\xi -U^0_\xi ) + \alpha = \mu ((U_\xi - \overline {S_\xi }) - (U-\overline {S_\xi })) + \alpha = \mu (U_\xi - U) + \alpha . \end{split} \end{equation}
Thus, to establish Eq. (8.3), it suffices to show that
 $\mu (U_\xi ) \to \mu (U)$
as
$\mu (U_\xi ) \to \mu (U)$
as
 $\xi \to 0$
, and then by setting
$\xi \to 0$
, and then by setting
 $\alpha = \epsilon _2/2$
we could choose a small enough
$\alpha = \epsilon _2/2$
we could choose a small enough
 $\xi$
to finally obtain (8.3). Thankfully, this is true as we have shown that
$\xi$
to finally obtain (8.3). Thankfully, this is true as we have shown that
 $U_{\xi }$
is decreasing in
$U_{\xi }$
is decreasing in
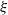 $\xi$
and since
$\xi$
and since
 $U_{\xi } \subset {\mathcal{M}}$
, we know that the measure
$U_{\xi } \subset {\mathcal{M}}$
, we know that the measure
 $\mu (U_{\xi })\leq \mu ({\mathcal{M}})$
. Therefore,
$\mu (U_{\xi })\leq \mu ({\mathcal{M}})$
. Therefore,
 $\mu (U_{\xi })$
is bounded and because of Eq. (8.4) we can apply Theorem 3.26 from [Reference Wheeden72] to obtain
$\mu (U_{\xi })$
is bounded and because of Eq. (8.4) we can apply Theorem 3.26 from [Reference Wheeden72] to obtain
 $\mu (U_\xi ) \to \mu (U)$
as
$\mu (U_\xi ) \to \mu (U)$
as
 $\xi \to 0$
.
$\xi \to 0$
.
Proof of Lemma 2.4. Using Lemma 8.1, we construct a continuous function
 $g \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
that satisfies the conditions. Next, we construct a continuous function
$g \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}$
that satisfies the conditions. Next, we construct a continuous function
 $G \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}^{q}$
such that
$G \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}^{q}$
such that
 \begin{align} \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(p_{q}(G)) \geq \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {f}) - \epsilon _1, \end{align}
\begin{align} \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(p_{q}(G)) \geq \mathcal{T}^{\;\;\,p}_{\mathcal{M}}(\overline {f}) - \epsilon _1, \end{align}
we can interpolate on the set
 \begin{align} p_{q}(G) = f(x_i) \quad i = 1,\ldots ,k \,, \end{align}
\begin{align} p_{q}(G) = f(x_i) \quad i = 1,\ldots ,k \,, \end{align}
and
 \begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq p_{q}(G), x \in {\mathcal{M}}\}, \end{align}
\begin{align} \mu (R) \lt \epsilon _2, \quad R \;:\!=\; \{x \, \vert \, f(x) \neq p_{q}(G), x \in {\mathcal{M}}\}, \end{align}
where
 $\mu$
denotes the Lebesgue measure. Recall from the proof of Lemma 8.1 that
$\mu$
denotes the Lebesgue measure. Recall from the proof of Lemma 8.1 that
 $g$
is constant on
$g$
is constant on
 $\overline {S_\xi }\cup U^\alpha _\xi$
for
$\overline {S_\xi }\cup U^\alpha _\xi$
for
 $\xi \gt 0$
. Furthermore, from the proof it is clear that any function that agrees with
$\xi \gt 0$
. Furthermore, from the proof it is clear that any function that agrees with
 $g$
on the set
$g$
on the set
 $\overline {S_\xi }\cup U^\alpha _\xi$
will also have to satisfy all three conditions of the theorem. Therefore, it is enough to construct
$\overline {S_\xi }\cup U^\alpha _\xi$
will also have to satisfy all three conditions of the theorem. Therefore, it is enough to construct
 $G$
such that
$G$
such that
 $p_{q}(G)$
agrees with
$p_{q}(G)$
agrees with
 $g$
on
$g$
on
 $\overline {S_\xi }\cup U^\alpha _\xi$
. To construct the function
$\overline {S_\xi }\cup U^\alpha _\xi$
. To construct the function
 $G$
, consider the function
$G$
, consider the function
 $\omega \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
defined by
$\omega \;:\; {\mathbb{R}} \rightarrow {\mathbb{R}}$
defined by
 \begin{align} \omega _i(x) = \begin{cases} 0 \quad &x \leq i-1, \\ x-(i-1) \quad &i-1\lt x \leq i, \\ (i+1)-x \quad &i\lt x\leq i+1, \\ 0 \quad &i+1 \leq x. \end{cases} \end{align}
\begin{align} \omega _i(x) = \begin{cases} 0 \quad &x \leq i-1, \\ x-(i-1) \quad &i-1\lt x \leq i, \\ (i+1)-x \quad &i\lt x\leq i+1, \\ 0 \quad &i+1 \leq x. \end{cases} \end{align}
Having this, we can simply define
 $G(x) = (\omega _{1}(g(x)), \ldots , \omega _{q}(g(x)))$
, which will be continuous as
$G(x) = (\omega _{1}(g(x)), \ldots , \omega _{q}(g(x)))$
, which will be continuous as
 $\omega$
is continuous. Furthermore,
$\omega$
is continuous. Furthermore,
 $p_q(G)$
agrees with
$p_q(G)$
agrees with
 $g$
on
$g$
on
 $\overline {S_\xi }\cup U^\alpha _\xi$
and thus satisfies all three conditions of the theorem. We now just need to apply the universal approximation theorem on the function
$\overline {S_\xi }\cup U^\alpha _\xi$
and thus satisfies all three conditions of the theorem. We now just need to apply the universal approximation theorem on the function
 $G$
to obtain a NN
$G$
to obtain a NN
 $\psi \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}^{q}$
that differs from
$\psi \;:\; {\mathcal{M}} \rightarrow {\mathbb{R}}^{q}$
that differs from
 $G$
in the uniform norm by less than
$G$
in the uniform norm by less than
 $1/2$
. This NN will give the same labels on
$1/2$
. This NN will give the same labels on
 $\overline {S_\xi }\cup U^\alpha _\xi$
as
$\overline {S_\xi }\cup U^\alpha _\xi$
as
 $G$
and thus must satisfy all three conditions of the theorem, thereby completing the proof.
$G$
and thus must satisfy all three conditions of the theorem, thereby completing the proof.
9. Emprical estimation of the class stability
Having established the theoretical results, we conclude this paper with a discussion on how one might determine the class stability of a NN in practice. Both versions of the distance to the decision boundary (Eqs. (2.2) and (7.1)) are in practice extremely difficult to compute. To remedy this, we will propose an empirical method to estimate the class stability using a NN.
Instead of calculating the distance to the decision boundary, we can use adversarial attacks to estimate the distance to the decision boundary. More specifically, we can use adversarial attack algorithms to find the smallest perturbation that changes the label of a data point. This perturbation will then be an upper bound on the actual distance to the decision boundary. To highlight the fact that this estimate is contingent on the adversarial attack algorithm used, we will index the estimate with the name of the algorithm.
For the numerical examples, we will use the MNIST dataset and a few NNs with different architectures but similar performance. The models used are two custom networks, a fully connected network (FCNN) and a convolutional network (CNN), a ResNet18 [Reference He, Zhang, Ren and Sun47] and a VGG16 [Reference Simonyan and Zisserman65]. The algorithms used to estimate the distance to the decision boundary are Fast Gradient Sign Method (FGSM) [Reference Goodfellow, Shlens and Szegedy41], DeepFool (DF) [Reference Moosavi-Dezfooli, Fawzi and Frossard56], Projected Gradient Descent (PGD) [Reference Madry, Makelov, Schmidt, Tsipras and Vladu54] and L-infinity Projected Gradient Descent (LinfPGD) [Reference Geisler, Wollschläger, Abdalla, Gasteiger and Günnemann39]. The documentation for the code can be found at https://github.com/zhenningdavidliu/paper_measure_code.
The precise method to estimate the class stability is as follows.
-
(1) Select a problem (e.g. MNIST) and a NN (e.g. a VGG16).
-
(2) Train the NN on the problem.
-
(3) Select an adversarial attack algorithm (e.g. PGD).
-
(4) For each data point in the dataset, use the adversarial attack algorithm to find the smallest perturbation that changes the label of the data point.
-
(5) Use the perturbation to estimate the distance to the decision boundary.
-
(6) Take the sample mean of the estimated distances to obtain an estimate of the class stability.
In other words, we will estimate
 ${h^p_{\bar {f}}}(x)$
by
${h^p_{\bar {f}}}(x)$
by
 $h^{p}_{f,PGD}(x)$
for the PGD attack, where
$h^{p}_{f,PGD}(x)$
for the PGD attack, where
 $h^p_{f,PGD}(x)$
is the empirical estimate of the distance to the decision boundary for the PGD attack for the data point
$h^p_{f,PGD}(x)$
is the empirical estimate of the distance to the decision boundary for the PGD attack for the data point
 $x$
. We will then use this estimate to estimate the class stability by
$x$
. We will then use this estimate to estimate the class stability by
 \begin{equation} \mathcal{S}^p_{{\mathcal{M}}}(\overline {f}) \approx \frac {1}{k} \sum _{i=1}^k h^p_{f,PGD}(x_i), \end{equation}
\begin{equation} \mathcal{S}^p_{{\mathcal{M}}}(\overline {f}) \approx \frac {1}{k} \sum _{i=1}^k h^p_{f,PGD}(x_i), \end{equation}
where
 $k$
is the number of data points in the dataset. To have consistent notation for our tables, we will reference the empirical estimate of the class stability as
$k$
is the number of data points in the dataset. To have consistent notation for our tables, we will reference the empirical estimate of the class stability as
 $\mathcal{S}^p_{{\mathcal{M}}, \Gamma }(\overline {f})$
, where
$\mathcal{S}^p_{{\mathcal{M}}, \Gamma }(\overline {f})$
, where
 $\Gamma$
is the name of the adversarial attack algorithm used. For example,
$\Gamma$
is the name of the adversarial attack algorithm used. For example,
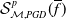 $\mathcal{S}^p_{{\mathcal{M}}, PGD}(\overline {f})$
is the empirical estimate of the class stability for the PGD attack.
$\mathcal{S}^p_{{\mathcal{M}}, PGD}(\overline {f})$
is the empirical estimate of the class stability for the PGD attack.
9.1. Empirical estimation of class stability for neural networks
The empirical class stability provides a way to measure robustness of a model with respect to adversarial attacks. One of the main advantages of this approach is the simplicity of the method, as it only requires running existing adversarial attack algorithms on models, without the need for additional training or optimisation. To demonstrate this, we will use the MNIST dataset and a few NNs with different architectures but similar performance. We use several adversarial attack algorithms to estimate the distance to the decision boundary for each data point in the dataset. We then use the estimated distances to estimate the class stability using the method described above. Table 1 shows the performance and stability of the different models. The higher the score for the stability, the more stable the model is, as it is more difficult to find adversarial examples. The final column shows the minimum
 $\epsilon$
for the aggregate of all the adversarial attack algorithms we used. This is an estimate of the distance to the decision boundary, and thus the higher the score, the more stable the model is.
$\epsilon$
for the aggregate of all the adversarial attack algorithms we used. This is an estimate of the distance to the decision boundary, and thus the higher the score, the more stable the model is.
Table 1. Stability and performance metrics for different models. We have tested two custom networks, a ResNet18 and a VGG16. The custom networks are simple implementations of a fully connected network and a convolutional network, respectively. The algorithms used to estimate the distance to the decision boundary are F: FGSM, D: DPG, P: PGD, and L: LinfPGD. The results suggests that VGG16 is the most stable model, according to the definition of class stability

Funding Statement
ACH acknowledges support from the Simons Foundation Award No. 663281 granted to the Institute of Mathematics of the Polish Academy of Sciences for the years 2021-2023, from a Royal Society University Research Fellowship, and from the Leverhulme Prize 2017.
Competing interests
None.





 Open access
Open access