


1. Introduction
Neural networks (NNs) [Reference DeVore, Hanin and Petrova29, Reference Higham and Higham48, Reference Pinkus67] and deep learning (DL) [Reference LeCun, Bengio and Hinton52] have seen incredible success, in particular in classification problems [Reference McKinney58]. However, neural networks become universally unstable (non-robust) when trained to solve such problems in virtually any application [Reference Adcock and Hansen2–Reference Antun, Renna, Poon, Adcock and Hansen4, Reference Beerens and Higham10, Reference Carlini and Wagner20–Reference Choi22, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Heaven47, Reference Huang49, Reference Szegedy, Zaremba and Sutskever74], making the non-robustness issue one of the fundamental problems in artificial intelligence (AI). The vast literature on this issue – often referring to the instability phenomenon as vulnerability to adversarial attacks – has not been able to solve the problem. Thus, we are left with the key question:
Why does deep learning yield universally unstable methods for classification?
In this paper, we provide mathematical answers to this question in connection with Smale’s 18th problem on the limits of AI.
The above problem has become particularly relevant as the instability phenomenon yields non-human-like behaviour of AI with misclassifications by DL methods being caused by small perturbations that are so tiny that human sensor systems such as eyes and ears cannot detect the tiny change. The non-robustness issue has thus caused serious concerns among scientists [Reference Adcock and Hansen2, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Heaven47], in particular in applications where trustworthiness of AI is a key feature. Moreover, the instability phenomenon has become a grave matter for policy-makers for regulating AI in safety critical areas where trustworthiness is a must, as suggested by the European Commission’s outline for a legal framework for AI:
‘In the light of the recent advances in artificial intelligence (AI), the serious negative consequences of its use for EU citizens and organisations have led to multiple initiatives from the European Commission to set up the principles of a trustworthy and secure AI. Among the identified requirements, the concepts of robustness and explainability of AI systems have emerged as key elements for a future regulation of this technology’.
– Europ. Comm. JCR Tech. Rep. (January 2020) [Reference Hamon, Junklewitz and Sanchez42].
‘On AI, trust is a must, not a nice to have. […] The new AI regulation will make sure that Europeans can trust what AI has to offer. […] High-risk AI systems will be subject to strict obligations before they can be put on the market: [requiring] High level of robustness, security and accuracy’.
– Europ. Comm. outline for legal AI (April 2021) [27].
The concern is also shared on the American continent, especially regarding security and military applications. Indeed, the US Department of Defence has spent millions of dollars through DARPA on project calls to cure the instability problem. The strong regulatory emphasis on trustworthiness, stability (robustness), security and accuracy leads to potential serious consequences given that modern AI techniques are universally non-robust. Current state-of-the-art AI techniques may be illegal in certain key sectors given their fundamental lack of robustness. The lack of a cure for the instability phenomenon in modern AI suggests a methodological barrier applicable to current AI techniques and hence should be viewed in connection with Smale’s 18th problem on the limits of AI.
1.1. Main theorems – methodological barriers, Smale’s 18th problem and the limits of AI
Smale’s 18th problem, from the list of mathematical problems for the 21st century [Reference Smale71], echoes Turing’s paper from 1950 [Reference Turing76] on the question of existence of AI. Turing asks if a computer can think and suggests the imitation game (Turing test) as a test for his question about AI. Smale takes the question even further and asks in his 18th problem: what are the limits of AI? The question is followed by a discussion on the problem that ends as follows. ‘Learning is a part of human intelligent activity. The corresponding mathematics is suggested by the theory of repeated games, neural nets and genetic algorithms’.
Our contribution to the program on Smale’s 18th problem are the following limitations and methodological barriers on modern AI highlighted in (I) and (II). These results provide mathematical answers to the question on why there has been no solution to the instability problem.
-
(I) Theorem 2.2 : There are basic methodological barriers in state-of-the-art DL based on ReLU NNs. Indeed, any training procedure based on training ReLU NNs for many simple classification problems with a fixed architecture will yield neural networks that are either inaccurate or unstable (if accurate) – despite the provable existence of both accurate and stable neural networks for the same classification problems. Moreover, variable dimensions on NNs is necessary for stability for ReLU NNs.
Theorem 2.2 points towards the paradox that accurate and stable neural networks exist; however, modern algorithms do not compute them. This yields the question:
If the existence of neural networks can be proven, can one also find algorithms that compute them? In particular, there are cases in mathematics where provable existence implies computability, but will this be the case for neural networks?
We address this question even for provable existence of NNs in standard training scenarios.
-
(II) Theorem 3.5 : There are NNs that provably exist as approximate minimisers to standard optimisation problems with standard cost functions; however, no randomised algorithm can compute them with probability better than
 $1/2$
.
$1/2$
.

A detailed account of the results and the consequences can be found in Sections 2 and 3.
1.2. Phase transitions and generalised hardness of approximation (GHA)
Theorem 3.5 can be understood within the framework of generalised hardness of approximation (GHA) [Reference Adcock and Hansen2, Reference Bastounis, Campodonico, van der Schaar, Adcock and Hansen6, Reference Bastounis, Cucker and Hansen7, Reference Bastounis, Hansen and Vlačić9, Reference Colbrook, Antun and Hansen25, Reference Fefferman, Hansen and Jitomirskaya33, Reference Gazdag and Hansen37, Reference Hansen and Roman45, Reference Wind, Antun and Hansen81], which describes a specific phase transition phenomenon. In many cases, it is straightforward to compute an
 $\epsilon$
-approximation to a solution of a computational problem for
$\epsilon$
-approximation to a solution of a computational problem for
 $\epsilon \gt \epsilon _1 \gt 0$
. However, when
$\epsilon \gt \epsilon _1 \gt 0$
. However, when
 $\epsilon \lt \epsilon _1$
(the approximation threshold), a phase transition occurs, wherein it is suddenly difficult, or even infeasible, to obtain an
$\epsilon \lt \epsilon _1$
(the approximation threshold), a phase transition occurs, wherein it is suddenly difficult, or even infeasible, to obtain an
 $\epsilon$
-approximation. This difficulty could manifest as non-computability or intractability (e.g., non-polynomial time complexity). GHA extends the concept of hardness of approximation [Reference Arora and Barak5] from discrete computations to more general computational problems.
$\epsilon$
-approximation. This difficulty could manifest as non-computability or intractability (e.g., non-polynomial time complexity). GHA extends the concept of hardness of approximation [Reference Arora and Barak5] from discrete computations to more general computational problems.
In particular, Theorem 3.5 establishes lower bounds on the approximation threshold
 $\epsilon _1 \gt 0$
for computing NNs in classification tasks. This theorem builds upon the initial work on GHA introduced in [Reference Bastounis, Hansen and Vlačić9] for convex optimisation (see also Problem 5 (J. Lagarias) in [Reference Fefferman, Hansen and Jitomirskaya33]) and further developed in [Reference Colbrook, Antun and Hansen25, Reference Gazdag and Hansen37] for NNs in AI and inverse problems. The theory of GHA is part of the larger framework of the Solvability Complexity Index (SCI) hierarchy [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel11–Reference Ben-Artzi, Marletta and Rösler13, Reference Colbrook23–Reference Colbrook and Hansen26, Reference Hansen43, Reference Hansen and Nevanlinna44].
$\epsilon _1 \gt 0$
for computing NNs in classification tasks. This theorem builds upon the initial work on GHA introduced in [Reference Bastounis, Hansen and Vlačić9] for convex optimisation (see also Problem 5 (J. Lagarias) in [Reference Fefferman, Hansen and Jitomirskaya33]) and further developed in [Reference Colbrook, Antun and Hansen25, Reference Gazdag and Hansen37] for NNs in AI and inverse problems. The theory of GHA is part of the larger framework of the Solvability Complexity Index (SCI) hierarchy [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel11–Reference Ben-Artzi, Marletta and Rösler13, Reference Colbrook23–Reference Colbrook and Hansen26, Reference Hansen43, Reference Hansen and Nevanlinna44].
2. Main results I – trained NNs become unstable despite the existence of stable and accurate NNs
In this section, we will explain our contributions to understanding the instability phenomenon. We consider the simplest DL problem of approximating a given classification function:
 \begin{equation} f: [0,1]^d \rightarrow \{0,1\}, \end{equation}
\begin{equation} f: [0,1]^d \rightarrow \{0,1\}, \end{equation}
by constructing a neural network from training data. Let
 $\mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
$\mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
 $\mathbf{N}\,:\!=\,(N_L=1,N_{L-1},\dotsc ,N_1, N_0 = d)$
denote the set of all
$\mathbf{N}\,:\!=\,(N_L=1,N_{L-1},\dotsc ,N_1, N_0 = d)$
denote the set of all
 $L$
-layer neural networks (with
$L$
-layer neural networks (with
 $L \geq 2$
) under the ReLU non-linearity with
$L \geq 2$
) under the ReLU non-linearity with
 $N_\ell$
neurons in the
$N_\ell$
neurons in the
 $\ell$
-th layer (see Section 5.1 for definitions and explanations of these concepts). We assume that the cost function
$\ell$
-th layer (see Section 5.1 for definitions and explanations of these concepts). We assume that the cost function
 $\mathcal{R}$
is an element of
$\mathcal{R}$
is an element of
 \begin{equation} \mathcal{CF}_{r} = \{\mathcal{R}\,:\,\mathbb{R}^{r} \times \mathbb{R}^{r} \rightarrow \mathbb{R}_+ \cup \{\infty \} \, \vert \, \mathcal{R}(v,w) = 0 \text{ iff } v = w\}. \end{equation}
\begin{equation} \mathcal{CF}_{r} = \{\mathcal{R}\,:\,\mathbb{R}^{r} \times \mathbb{R}^{r} \rightarrow \mathbb{R}_+ \cup \{\infty \} \, \vert \, \mathcal{R}(v,w) = 0 \text{ iff } v = w\}. \end{equation}
Remark 2.1 (Choice of cost functions). Note that the choice of class of cost functions defined in (2.2) will be used in Theorem 2.2 is to demonstrate how one can achieve great generalisability properties of the trained network. It is worth mentioning however that we show that expanding this class to include, for example, regularised cost functions will not cure the instability phenomenon (see Section 2.1 (II) for more detail).
As we will discuss the stability of neural networks, we introduce the idea of well-separated and stable sets to exclude pathological examples whereby the training and validation sets have elements that are arbitrarily close to each other in a way that could make the classification function jump subject to a small perturbation. Specifically, given a classification function
 $f: [0,1]^d \rightarrow \{0,1\}$
, we define the family of well-separated and stable sets
$f: [0,1]^d \rightarrow \{0,1\}$
, we define the family of well-separated and stable sets
 $\mathcal{S}^f_{\delta }$
with separation at least
$\mathcal{S}^f_{\delta }$
with separation at least
 $2\delta$
according to
$2\delta$
according to
 \begin{align*} \begin{split} &\mathcal{S}^f_{\delta } = \Big \{\{x^1, \ldots , x^m\} \subset [0,1]^d \, \vert \, m \in \mathbb{N}, \\ & \qquad \qquad \min _{x^i\neq x^{\,j}} \|x^i - x^{\,j}\|_{\infty } \geq 2 \delta , f(x^{\,j}+y) = f(x^{\,j}) \text{ for }\|y\|_{\infty } \lt \delta \text{ satisfying }x^{\,j}+y \in [0,1]^d \Big \}. \end{split} \end{align*}
\begin{align*} \begin{split} &\mathcal{S}^f_{\delta } = \Big \{\{x^1, \ldots , x^m\} \subset [0,1]^d \, \vert \, m \in \mathbb{N}, \\ & \qquad \qquad \min _{x^i\neq x^{\,j}} \|x^i - x^{\,j}\|_{\infty } \geq 2 \delta , f(x^{\,j}+y) = f(x^{\,j}) \text{ for }\|y\|_{\infty } \lt \delta \text{ satisfying }x^{\,j}+y \in [0,1]^d \Big \}. \end{split} \end{align*}
We also set
 $r \vee s$
to be the maximum of
$r \vee s$
to be the maximum of
 $r$
and
$r$
and
 $s$
and
$s$
and
 $r \wedge s$
to be the minimum of
$r \wedge s$
to be the minimum of
 $r$
and
$r$
and
 $s$
. Finally, we use the notation
$s$
. Finally, we use the notation
 $\mathcal{B}_{\epsilon }^{\infty }$
to refer to the open ball of radius
$\mathcal{B}_{\epsilon }^{\infty }$
to refer to the open ball of radius
 $\epsilon$
in the
$\epsilon$
in the
 $\ell ^{\infty }$
norm. With this notation established, we are now ready to state our first main result.
$\ell ^{\infty }$
norm. With this notation established, we are now ready to state our first main result.
Theorem 2.2 (Instability of trained NNs despite existence of a stable NN). There is an uncountable collection
 $\mathcal{C}_1$
of classification functions
$\mathcal{C}_1$
of classification functions
 $f$
as in (2.1) – with fixed
$f$
as in (2.1) – with fixed
 $d \geq 2$
– and a constant
$d \geq 2$
– and a constant
 $C\gt 0$
such that the following holds. For every
$C\gt 0$
such that the following holds. For every
 $f \in \mathcal{C}_1$
, any norm
$f \in \mathcal{C}_1$
, any norm
 $\|\cdot \|$
and every
$\|\cdot \|$
and every
 $\epsilon \gt 0$
, there is an uncountable family
$\epsilon \gt 0$
, there is an uncountable family
 $\mathcal{C}_2$
of probability distributions on
$\mathcal{C}_2$
of probability distributions on
 $[0,1]^{d}$
so that for any
$[0,1]^{d}$
so that for any
 $\mathcal{D} \in \mathcal{C}_2$
, any neural network dimensions
$\mathcal{D} \in \mathcal{C}_2$
, any neural network dimensions
 $\mathbf{N} = (N_L=1,N_{L-1},\dotsc ,N_1,N_0=d)$
with
$\mathbf{N} = (N_L=1,N_{L-1},\dotsc ,N_1,N_0=d)$
with
 $L \geq 2$
, any
$L \geq 2$
, any
 $\mathrm{p} \in (0,1)$
, any positive integers
$\mathrm{p} \in (0,1)$
, any positive integers
 $q$
,
$q$
,
 $r$
,
$r$
,
 $s$
with
$s$
with
 \begin{equation} r+s \geq C \, \max \big \{\,\mathrm{p}^{-3} ,\, q^{3/2} \big [(N_1+1) \dotsb (N_{L-1}+1)\big ]^{3/2} \big \}, \end{equation}
\begin{equation} r+s \geq C \, \max \big \{\,\mathrm{p}^{-3} ,\, q^{3/2} \big [(N_1+1) \dotsb (N_{L-1}+1)\big ]^{3/2} \big \}, \end{equation}
any training data
 $\mathcal{T} = \{x^1, \ldots , x^r\}$
and validation data
$\mathcal{T} = \{x^1, \ldots , x^r\}$
and validation data
 $\mathcal{V} = \{y^1, \ldots , y^s\}$
, where the
$\mathcal{V} = \{y^1, \ldots , y^s\}$
, where the
 $x^{\,j}$
and
$x^{\,j}$
and
 $y^j$
are drawn independently at random from
$y^j$
are drawn independently at random from
 $\mathcal{D}$
, the following happens with probability exceeding
$\mathcal{D}$
, the following happens with probability exceeding
 $1-\mathrm{p}$
.
$1-\mathrm{p}$
.
-
(i) (Success – great generalisability). We have
$\mathcal{T}, \mathcal{V} \in \mathcal{S}^f_{\varepsilon ((r\vee s)/\mathrm{p})}$
, where
$\varepsilon (n)=(Cn)^{-4}$
, and, for every
$\mathcal{R} \in \mathcal{CF}_r$
, there exists a
$\phi$
such that(2.4)and
\begin{equation} {\phi } \in \mathop {\mathrm{arg min}}_{\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R} \big (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\big ) \end{equation}
(2.5)
\begin{equation} \phi (x) = f(x) \quad \forall x \in \mathcal{T} \cup \mathcal{V}. \end{equation}
-
(ii) (Any successful NN in
$\mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
– regardless of architecture – becomes universally unstable). Yet, for any
$\hat {\phi } \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
(and thus, in particular, for
$\hat \phi =\phi$
) and any monotonic
$g: {\mathbb{R}} \to {\mathbb{R}}$
, there is a subset
$\mathcal{\tilde T}\subset \mathcal{T} \cup \mathcal{V}$
of the combined training and validation set of size
$|\mathcal{\tilde T}| \geq q$
, such that there exist uncountably many universal adversarial perturbations
$\eta \in \mathbb{R}^d$
so that for each
$x \in \mathcal{\tilde T}$
we have(2.6)
\begin{equation} |g \circ \hat \phi (x+\eta ) - f(x+\eta )| \geq 1/2,\quad \|\eta \| \lt \epsilon , \quad |\text{supp}(\eta )| \leq 2. \end{equation}
-
(iii) (Other stable and accurate NNs exist). However, there exists a stable and accurate neural network
$\psi$
that satisfies
$\psi (x) = f(x)$
for all
$x \in \mathcal{B}_{\epsilon }^{\infty }(\mathcal{T} \cup \mathcal{V})$
, when
$\epsilon \leq \varepsilon ((r\vee s)/\mathrm{p})$
.



















We remark in passing that the training and validation data
 $\mathcal{T}$
and
$\mathcal{T}$
and
 $\mathcal{V}$
in Theorem 2.2 are technically not sets, but randomised multisets, as some of the samples
$\mathcal{V}$
in Theorem 2.2 are technically not sets, but randomised multisets, as some of the samples
 $x^{\,j}$
or
$x^{\,j}$
or
 $y^j$
may be repeated.
$y^j$
may be repeated.
Remark 2.3 (The role of g in (ii) in Theorem 2.2). The purpose of the monotone function
 $g: {\mathbb{R}} \to {\mathbb{R}}$
in (ii) in Theorem 2.2 is to make the theorem as general as possible. In particular, a popular way of creating an approximation to
$g: {\mathbb{R}} \to {\mathbb{R}}$
in (ii) in Theorem 2.2 is to make the theorem as general as possible. In particular, a popular way of creating an approximation to
 $f$
is to have a network combined with a thresholding function
$f$
is to have a network combined with a thresholding function
 $g$
. This would potentially increase the approximation power compared to only having a neural network; however, Theorem 2.2 shows that adding such a function does not cure the instability problem.
$g$
. This would potentially increase the approximation power compared to only having a neural network; however, Theorem 2.2 shows that adding such a function does not cure the instability problem.

Figure 1 (Training with fixed architecture yields instability – variable dimensions on NNs is necessary for stability for ReLu NNs). A visual interpretation of Theorem 2.2. A fixed dimension training procedure can lead to excellent performance and yet be highly susceptible to adversarial attacks, even if there exists a NN which has both great performance and excellent stability properties. However, such a stable and accurate ReLu network must have variable dimensions depending on the input.
2.1. Interpreting Theorem 2.2
In this section, we discuss in detail the implications of Theorem 2.2 with regard to Smale’s 18th problem. First, note that Theorem 2.2 demonstrates a methodological barrier applicable to current DL approaches. This does not imply that the instability problem in classification cannot be resolved, but it does imply that in order to overcome these instability issues one will have to change the methodology. Second, Theorem 2.2 provides guidance on which methodologies will not solve the instability issues. In order to make the exposition easy to read, we will now summarise in non-technical terms what Theorem 2.2 says.
-
(I) Performance comes at a cost – Accurate DL methods inevitably become unstable . Theorem 2.2 shows that there are basic classification functions and distributions where standard DL methodology yields trained NNs with great success in terms of generalisability and performance – note that the size of the validation set
$\mathcal{V}$
in Theorem 2.2 can become arbitrary large. However, (2.3) demonstrates how greater success (better generalisability) implies more instabilities. Indeed, the NNs – regardless of architecture and training procedure – become either successful and unstable, or unsuccessful. -
(II) There is no remedy within the standard DL framework . Note that (ii) in Theorem 2.2 demonstrates that there is no remedy within the standard DL framework to cure the instability issue described in Theorem 2.2. The reason why is that standard DL methods will fix the architecture (i.e., the class
$\mathcal{N}$
of NNs that one minimises over) of the neural networks. Indeed, the misclassification in (2.6) happens for any neural network
$\hat {\phi } \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
. This means that, for example, zero loss training [Reference Papyan, Han and Donoho66], or any attempt using adversarial training [Reference Goodfellow, Shlens and Szegedy39, Reference Madry, Makelov, Schmidt, Tsipras and Vladu56] – that is, computingwhere
\begin{align*} \min _{\phi \in \mathcal{N}} E_{x \sim \mathcal{D}} \max _{z \in \mathcal{U}} \mathcal{L}(\phi (x+z), f(x)), \end{align*}
$\mathcal{N} \subset \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
is any collection of NNs described by a specific architecture,
$\mathcal{U} \subset \mathbb{R}^d$
and
$\mathcal{L}$
is any real-valued cost function – will not solve the problem. In fact, (ii) in Theorem 2.2 immediately implies that adversarial training will reduce the performance if it increases the stability.
-
(III) There are accurate and stable NNs, but DL methods do not find them . Note that (iii) in Theorem 2.2 demonstrates that there are stable and accurate NNs for many classification problems where DL methods produce unstable NNs. Thus, the problem is not that stable and accurate NNs do not exist; instead, the problem is that DL methods do not find them. The reason is that the dimensions and architectures of the stable and accurate networks will change depending on the size and properties of the data set.
-
(IV) Why instability? – Unstable correlating features are picked up by the trained NN . In addition to the statement of Theorem 2.2, the proof techniques illustrate the root causes of the problem. The reason why one achieves the great success described by (i) in Theorem 2.2 is that the successful NN picks up a feature in the training set that correlates well with the classification function but is itself unstable. This phenomenon is empirically investigated in [Reference Ilyas and and50].
-
(V) No training model where the dimensions of the NNs are fixed can cure instability . Note that (ii) in Theorem 2.2 describes the reason for the failure of the DL methodology to produce a stable and accurate NN. Indeed, as pointed out above, the dimensions of the stable and accurate NN will necessary change with the amount of data in the training and validation set.
-
(VI) Adding more training data cannot cure the general instability problem . Note that (2.3) in Theorem 2.2 shows that adding more training data will not help. In fact, it can make the problem worse. Indeed, (2.3) allows
$s$
– the number of elements in the test set – to be set so that
$s = 1$
, and
$r$
– the number of training data – can be arbitrary large. Hence, if
$r$
becomes large and
$s$
is small, then the trained NN – if successful – will (because of (ii)) start getting instabilities on the training data. In particular, the network has seen the data, but will misclassify elements arbitrary close to seen data. -
(VII) Comparison with the No-Free-Lunch Theorem . The celebrated No-Free-Lunch Theorem has many forms. However, the classical impossibility result we refer to (Theorem 5.1 in [Reference Shalev-Shwartz and Ben-David70]) states that for any learning algorithm for classification problems there exists a classification function
$f$
and a distribution
$\mathcal{D}$
that makes the algorithm fail. Our Theorem 2.2 is very different in the way that it is about instability. Moreover, it is an impossibility result specific for DL. Thus, the statements are much stronger. Indeed – in contrast to the single classification function
$f$
and distribution
$\mathcal{D}$
making a fixed algorithm fail in the No-Free-Lunch Theorem – Theorem 2.2 shows the existence of uncountably many classification functions
$f$
and distributions
$\mathcal{D}$
such that for any fixed architecture DL will either yield unstable and successful NNs or unsuccessful NNs. This happens despite the existence of stable and accurate NNs for exactly the same problem. Moreover, Theorem 2.2 shows how NNs can generalise well given relatively few training data compared to the test data, but at the cost of non-robustness (note that this is in contrast to the No-Free-Lunch theorem wherein few training samples leads to a lack of generalisation). See also [Reference Gottschling, Antun, Hansen and Adcock40] for other ‘No-Free-Lunch’ theorems.


















3. Main results II – NNs may provably exist, but no algorithm can compute them
The much celebrated Universal Approximation Theorem is widely used as an explanation for the wide success of NNs in the sciences and in AI, as it guarantees the existence of neural networks that can approximate arbitrary continuous functions. In essence, any task that can be handled by a continuous function can also be handled by a neural network.
Theorem 3.1 (Universal Approximation Theorem [Reference Pinkus67]). Suppose that
 $\sigma \in C(\mathbb{R})$
, where
$\sigma \in C(\mathbb{R})$
, where
 $C(\mathbb{R})$
denotes the set of continuous functions on
$C(\mathbb{R})$
denotes the set of continuous functions on
 $\mathbb{R}$
. Then the set of neural networks with non-linearity
$\mathbb{R}$
. Then the set of neural networks with non-linearity
 $\sigma$
is dense in
$\sigma$
is dense in
 $C(\mathbb{R}^d)$
in the topology of uniform convergence on compact sets, if and only if
$C(\mathbb{R}^d)$
in the topology of uniform convergence on compact sets, if and only if
 $\sigma$
is not a polynomial.
$\sigma$
is not a polynomial.
Theorem 2.2 illustrates basic methodological barriers in DL and suggests the following fundamental question:
If we can prove that a stable and well generalisable neural network exists, why do algorithms fail to compute them?
This question is not only relevant because of Theorem 2.2 but also the Universal Approximation Theorem that demonstrates – in theory – that there are very few limitations on what NNs can do. Yet, there is clearly a barrier that the desirable NNs that one can prove exist – as shown in Theorem 2.2 and in many cases follow from the Universal Approximation Theorem – are not captured by standard algorithms.
3.1. The weakness of the Universal Approximation Theorem – When will existence imply computability?
The connection between the provable existence of a mathematical object and its computability (that there is an algorithm that can compute it) touches on the foundations of mathematics [Reference Smith72]. Indeed, there are cases in mathematics – with the ZFCFootnote 1 axioms – where the fact that one can prove mathematically a statement about the existence of the object will imply that one can find an algorithm that will compute the object when it exists. Consider the following example:
Example 3.2 (When provable existence implies computability). Consider the following basic computational problem concerning Diophantine equations:
Let
 $\Theta$
be a collection of polynomials in
$\Theta$
be a collection of polynomials in
 $\mathbb{Z}[x_1,x_2,\dotsc ,x_n]$
with integer coefficients, where
$\mathbb{Z}[x_1,x_2,\dotsc ,x_n]$
with integer coefficients, where
 $n \in \mathbb{N}$
can be arbitrary. Given a polynomial
$n \in \mathbb{N}$
can be arbitrary. Given a polynomial
 $p \in \Theta$
, does there exist an integer vector
$p \in \Theta$
, does there exist an integer vector
 $a \in \mathbb{Z}^n$
such that
$a \in \mathbb{Z}^n$
such that
 $p(a) = 0$
, and if so, compute such an
$p(a) = 0$
, and if so, compute such an
 $a$
.
$a$
.
Note that in this case we have that ‘being able to prove
 $\Rightarrow$
being able to compute’ as the following implication holds for the ZFC model [Reference Poonen68]:
$\Rightarrow$
being able to compute’ as the following implication holds for the ZFC model [Reference Poonen68]:

The above implication is true, subject to ZFC being consistent and that theorems in ZFC about integers are true [68]. In particular, being able to prove existence or not of integer-valued zeroes of polynomials in
 $\Theta$
implies the existence of an algorithm that can compute integer-valued zeroes of polynomials in
$\Theta$
implies the existence of an algorithm that can compute integer-valued zeroes of polynomials in
 $\Theta$
and determine if no integer-valued zero exists.
$\Theta$
and determine if no integer-valued zero exists.
There is a substantial weakness with the Universal Approximation Theorem and the vast literature on approximation properties of NNs, in that they provide little insight into how NNs should be computed, or indeed if they can be computed. As Example 3.2 suggests, there are cases where provable existence implies computability. Hence, we are left with the following basic problem:
If neural networks can be proven to exist, will there exist algorithms that can compute them? If this is not the case in general, what about neural networks that can be proven to be approximate minimisers of basic cost functions?
As we see in the next sections, the answer to the above question is rather delicate.
Remark 3.3. Although the Universal Approximation Theorem does not directly apply to non-constant classification functions in the class (2.1), if we consider a classification function restricted to a finite set (e.g., training and validation sets), it will have a continuous extension and hence the Universal Approximation Theorem will apply. Furthermore, recent results discuss existence theorems in the general setting of (2.1) [Reference Liu and Hansen53].
3.2. Inexactness and floating point arithmetic
The standard model for computation in most modern software is floating point arithmetic. This means that even a rational number like
 $1/3$
will be approximated by a base-2 approximation. Moreover, the floating point operations yield errors, that – in certain cases – can be analysed through backward error analysis, which typically show how the computed solution in floating point arithmetic is equivalent to a correct computation with an approximated input. Hence, in order to provide a realistic analysis, we use the model of computation with inexact input as emphasised by S. Smale in his list of mathematical problems for the 21st century:
$1/3$
will be approximated by a base-2 approximation. Moreover, the floating point operations yield errors, that – in certain cases – can be analysed through backward error analysis, which typically show how the computed solution in floating point arithmetic is equivalent to a correct computation with an approximated input. Hence, in order to provide a realistic analysis, we use the model of computation with inexact input as emphasised by S. Smale in his list of mathematical problems for the 21st century:
‘But real number computations and algorithms which work only in exact arithmetic can offer only limited understanding. Models which process approximate inputs and which permit round-off computations are called for’.
– S. Smale (from the list of mathematical problems for the 21st century [Reference Smale71])
To model this situation, we shall assume that an algorithm designed to compute a neural network is allowed to see the training set to an arbitrary accuracy decided at runtime. More precisely, for a given training set
 $\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\}$
, we assume that the algorithm (a Turing [Reference Turing75] or Blum-Shub-Smale (BSS) [Reference Blum, Shub and Smale18] machine) is equipped with an oracle
$\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\}$
, we assume that the algorithm (a Turing [Reference Turing75] or Blum-Shub-Smale (BSS) [Reference Blum, Shub and Smale18] machine) is equipped with an oracle
 $\mathscr{O}$
that can acquire the true input to any accuracy
$\mathscr{O}$
that can acquire the true input to any accuracy
 $\epsilon$
. Specifically, the algorithm cannot access the vectors
$\epsilon$
. Specifically, the algorithm cannot access the vectors
 $x^1,x^2,\dotsc ,x^r$
but rather, for any
$x^1,x^2,\dotsc ,x^r$
but rather, for any
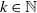 $k \in \mathbb{N}$
, it can call the oracle
$k \in \mathbb{N}$
, it can call the oracle
 $\mathscr{O}$
to obtain
$\mathscr{O}$
to obtain
 $x^{1,k},x^{2,k},\dotsc ,x^{r,k}$
such that
$x^{1,k},x^{2,k},\dotsc ,x^{r,k}$
such that
 \begin{equation} \|x^{i,k} - x^{i}\|_{\infty } \leq 2^{-k}, \qquad \text{ for } i=1,2,\dotsc ,r \text{ and } \, \forall k\in \mathbb{N}, \end{equation}
\begin{equation} \|x^{i,k} - x^{i}\|_{\infty } \leq 2^{-k}, \qquad \text{ for } i=1,2,\dotsc ,r \text{ and } \, \forall k\in \mathbb{N}, \end{equation}
see Section 5.4.4 for details.
Another key assumption when discussing the success of the algorithm is that it must be ‘oracle agnostic’, that is, it must work with any choice of the oracle
 $\mathscr{O}$
satisfying (3.2). In the Turing model, the Turing machine accesses the oracle via an oracle tape and in the BSS model the BSS machine accesses the oracle through an oracle node. This extended computational model of having inexact input is standard and can be found in many areas of the mathematical literature – we mention only a small subset here: Bishop [Reference Bishop17], Cucker & Smale [Reference Cucker and Smale28], Fefferman & Klartag [Reference Fefferman and Klartag34, Reference Fefferman and Klartag35], Ko [Reference Ko51] and Lovász [Reference Lovasz54].
$\mathscr{O}$
satisfying (3.2). In the Turing model, the Turing machine accesses the oracle via an oracle tape and in the BSS model the BSS machine accesses the oracle through an oracle node. This extended computational model of having inexact input is standard and can be found in many areas of the mathematical literature – we mention only a small subset here: Bishop [Reference Bishop17], Cucker & Smale [Reference Cucker and Smale28], Fefferman & Klartag [Reference Fefferman and Klartag34, Reference Fefferman and Klartag35], Ko [Reference Ko51] and Lovász [Reference Lovasz54].
3.3. Being able to prove existence may imply being able to compute – but not in DL
We now examine the difference between being able to prove the existence of a neural network and the ability to compute it, even in the case when the neural network is an approximate minimiser. Recall the typical training scenario of neural networks in (2.4) where one tries to find
 \begin{align*} {\phi } \in \mathop {\mathrm{arg min}}_{\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \end{align*}
\begin{align*} {\phi } \in \mathop {\mathrm{arg min}}_{\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \end{align*}
where
 $f$
is the decision function,
$f$
is the decision function,
 $\mathcal{R}$
is the cost function and
$\mathcal{R}$
is the cost function and
 $\mathcal{T} = \{x^{\,j}\}_{j=1}^r$
is the training set. However, one will typically not reach the actual minimiser, but rather an approximation. Hence, we define the approximate argmin.
$\mathcal{T} = \{x^{\,j}\}_{j=1}^r$
is the training set. However, one will typically not reach the actual minimiser, but rather an approximation. Hence, we define the approximate argmin.
Definition 3.4 (The approximate argmin). Given an
 $\epsilon \gt 0$
, an arbitrary set
$\epsilon \gt 0$
, an arbitrary set
 $X$
, a totally ordered set
$X$
, a totally ordered set
 $Y$
and a function
$Y$
and a function
 $g\colon X\to Y$
, the approximate
$g\colon X\to Y$
, the approximate
 $ {\displaystyle \operatorname {argmin}_{\epsilon }}$
over some subset
$ {\displaystyle \operatorname {argmin}_{\epsilon }}$
over some subset
 $S \subset X$
is defined by
$S \subset X$
is defined by
 \begin{equation} {\underset {x\in S}{\operatorname {argmin}_{\epsilon }}}\,g(x)\,:\!=\,\{x \in S \, \vert \, g(x) \leq g(y) + \epsilon \,\, \forall \, y \in X\} \end{equation}
\begin{equation} {\underset {x\in S}{\operatorname {argmin}_{\epsilon }}}\,g(x)\,:\!=\,\{x \in S \, \vert \, g(x) \leq g(y) + \epsilon \,\, \forall \, y \in X\} \end{equation}
To accompany the idea of the approximate argmin, we will also consider cost functions that are bounded with respect to the
 $\ell ^{\infty }$
norm:
$\ell ^{\infty }$
norm:
 \begin{equation} \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r} = \{\mathcal{R} \in \mathcal{CF}_r\,:\, \mathcal{R}(v,w) \leq \epsilon \implies \|v-w\|_{\infty } \leq \hat \epsilon \}. \end{equation}
\begin{equation} \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r} = \{\mathcal{R} \in \mathcal{CF}_r\,:\, \mathcal{R}(v,w) \leq \epsilon \implies \|v-w\|_{\infty } \leq \hat \epsilon \}. \end{equation}
The computational problem we now consider is to compute a neural network that is an approximate minimiser and evaluate it on the training set (this is the simplest task that we should be able to compute):
 \begin{equation} \phi (x^{\,j}), \qquad {\phi } \in \mathop {\mathrm{arg min}_{\epsilon }}_{\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \quad \epsilon \gt 0, \quad j =1, \ldots , r. \end{equation}
\begin{equation} \phi (x^{\,j}), \qquad {\phi } \in \mathop {\mathrm{arg min}_{\epsilon }}_{\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \quad \epsilon \gt 0, \quad j =1, \ldots , r. \end{equation}
Hence, an algorithm
 $\Gamma$
trying to compute (3.5) takes the training set
$\Gamma$
trying to compute (3.5) takes the training set
 $\mathcal{T}$
as an input (or to be precise, it calls oracles providing approximations to the
$\mathcal{T}$
as an input (or to be precise, it calls oracles providing approximations to the
 $x^{\,j}$
s to any precision, see seeSection 5.4.4 for details) and outputs a vector in
$x^{\,j}$
s to any precision, see seeSection 5.4.4 for details) and outputs a vector in
 $\mathbb{R}^r$
. Hopefully,
$\mathbb{R}^r$
. Hopefully,
 $\|\Gamma (\mathcal{T}) - \{\phi (x^{\,j})\}_{j=1}^r\|$
is sufficiently small.
$\|\Gamma (\mathcal{T}) - \{\phi (x^{\,j})\}_{j=1}^r\|$
is sufficiently small.
The next theorem shows that even if one can prove the existence of neural networks that are approximate minimisers to optimisation problems with standard cost functions, one may not be able to compute them.
Theorem 3.5 (NNs may provably exist, but no algorithm can compute them). There is an uncountable collection
 $\mathcal{C}_1$
of classification functions
$\mathcal{C}_1$
of classification functions
 $f$
as in (2.1) – with fixed
$f$
as in (2.1) – with fixed
 $d \geq 2$
– such that the following holds. For
$d \geq 2$
– such that the following holds. For
-
(1) any neural network dimensions
$\mathbf{N} = (N_L=1,N_{L-1},\dotsc , N_1,N_0=d)$
with
$L \geq 2$
, -
(2) any
$r \geq 3(N_1+1) \dotsb (N_{L-1}+1)$
, -
(3) any
$\epsilon \gt 0$
,
$\hat \epsilon \in (0,1/2)$
and cost function
$\mathcal{R} \in \mathcal{C}\mathcal{F}^{\epsilon ,\hat \epsilon }_r$
, -
(4) any randomised algorithm
$\Gamma$
, -
(5) any
$\mathrm{p} \in [0,1/2)$
,








there is an uncountable collection
 $\mathcal{C}_2$
of training sets
$\mathcal{C}_2$
of training sets
 $\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\} \in \mathcal{S}^f_{\varepsilon '(r)}$
such that for each
$\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\} \in \mathcal{S}^f_{\varepsilon '(r)}$
such that for each
 $\mathcal{T} \in \mathcal{C}_2$
there exists a neural network
$\mathcal{T} \in \mathcal{C}_2$
there exists a neural network
 $\phi$
, where
$\phi$
, where
 \begin{align*} \phi \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \end{align*}
\begin{align*} \phi \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \end{align*}
however, the algorithm
 $\Gamma$
applied to the input
$\Gamma$
applied to the input
 $\mathcal{T}$
will fail to compute any such
$\mathcal{T}$
will fail to compute any such
 $\phi$
in the following way:
$\phi$
in the following way:
 \begin{align*} \mathbb{P}\Big (\|\Gamma (\mathcal{T}) - \{\phi (x^{\,j})\}_{j=1}^r\|_{*} \geq 1/4-3\hat \epsilon /4\Big ) \gt p , \end{align*}
\begin{align*} \mathbb{P}\Big (\|\Gamma (\mathcal{T}) - \{\phi (x^{\,j})\}_{j=1}^r\|_{*} \geq 1/4-3\hat \epsilon /4\Big ) \gt p , \end{align*}
where
 $* = 1,2 \text{ or } \infty$
.
$* = 1,2 \text{ or } \infty$
.
3.4. A missing theory in AI – Which NNs can be computed?
If provable existence results about NNs were to imply that they could be computed by algorithms, the research effort to secure stable and accurate AI would – in most cases – be about finding the right algorithms that we know exist, due to the many neural network existence results [Reference DeVore, Hanin and Petrova29, Reference Pinkus67]. In particular, the key limitation for providing stable and accurate AI via DL – at least in theory – would be the capability of the research community. However, as Theorem 3.5 reveals, the simplest existence results of NNs as approximate minimisers do not imply that they can be computed. Therefore, the research effort moving forward must be about which NNs that can be computed by algorithms and how. Indeed, the limitations of DL as an instrument in AI will be determined by the limitations of existence of algorithms and their efficiency for computing NNs.
Remark 3.6 (Theorem 3.5 is independent of the exact computational model). Note that the result above is independent of whether the underlying computational device is a BSS machine or a Turing machine. To achieve this, we work with a definition of an algorithm termed a general algorithm. The corresponding definitions as well as a formal statement of Theorem 3.5 are detailed inSection 5.4 and Proposition 5.26, respectively.
Remark 3.7 (Irrelevance of local minima). Note that Theorem 3.5 has nothing to do with the potential issue of the optimisation problem having several local minima. Indeed, the general algorithms used in Theorem 3.5 are more powerful than any Turing machine or BSS machine as will be discussed further in Remark 5.13.
Remark 3.8 (Hilbert’s 10th problem). Finally, we mention in passing that Theorem 3.5 demonstrates – in contrast to Hilbert’s 10th problem [57] – that non-computability results in DL do not prevent provable existence results. Indeed, because of the implication in (3.1) and the non-computability of Hilbert’s 10th problem [Reference Matiyasevich57, Reference Poonen68] (when
 $\Theta$
is the collection of all polynomials with integer coefficients in Example 3.2), there are infinitely many Diophantine equations for which one cannot prove existence of an integer solution – or a negation of the statement.
$\Theta$
is the collection of all polynomials with integer coefficients in Example 3.2), there are infinitely many Diophantine equations for which one cannot prove existence of an integer solution – or a negation of the statement.
4. Connection to previous work
The literature documenting the instability phenomenon in DL is so vast that we can only cite a tiny subset here [Reference Adcock and Hansen2–Reference Antun, Renna, Poon, Adcock and Hansen4, Reference Carlini and Wagner20, Reference Fawzi, Fawzi and Fawzi31, Reference Fawzi, Dezfooli and Frossard32, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane36, Reference Goodfellow, Shlens and Szegedy39, Reference Heaven47, Reference Huang49, Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard61, Reference Moosavi-Dezfooli, Fawzi and Frossard62, Reference Shafahi, Huang, Studer, Feizi and Goldstein69, Reference Szegedy, Zaremba and Sutskever74, Reference Tyukin, Higham and Gorban77], see the references in the survey paper [Reference Akhtar and Mian3] for a more comprehensive collection. Below we will highlight some of the most important connections to our work:
-
(i) Universality of instabilities in AI . A key feature of Theorem 2.2 is that it demonstrates how the perturbations are universal, meaning that one adversarial perturbation works for all the cases where the instability occurs – as opposed to a specific input-dependent adversarial perturbation. The DeepFool program [Reference Fawzi, Dezfooli and Frossard32, Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard61, Reference Moosavi-Dezfooli, Fawzi and Frossard62] – created by S. Moosavi-Dezfooli, A. Fawzi, O. Fawzi and P. Frossard – was the first to establish empirically that adversarial perturbations can be made universal, and this phenomenon is also universal across different methods and architectures. For recent and related developments, see D. Higham and I. Tyukin et al. [Reference Tyukin, Higham and Gorban77, Reference Tyukin, Higham, Bastounis, Woldegeorgis and Gorban78] which describe instabilities generated by perturbations to the structure of a neural network, [Reference Bastounis, Gorban, Hansen, Iliadis, Papaleonidas, Angelov and Jayne8, Reference Sutton, Zhou, Tyukin, Gorban, Bastounis and Higham73] wherein instability to randomised perturbations are considered, as well as the results by L. Bungert and G. Trillos et al. [Reference Bungert, Trillos and Murray19], and S. Wang, N. Si, and J. Blanchet [Reference Wang, Si, Blanchet and Zhou79].
-
(ii) Approximation theory and numerical analysis . There is a vast literature proving existence results of ReLU networks for DL, investigating their approximation power, where the recent work of R. DeVore, B. Hanin and G. Petrova [Reference DeVore, Hanin and Petrova29] also provides a comprehensive account of the contemporary developments. The huge approximation literature on existence results and approximation properties of NNs prior to the year 2000 is well summarised by A. Pinkus in [Reference Pinkus67]. Our results suggest a program combining recent approximation theory [Reference DeVore, Hanin and Petrova29, Reference Gottschling, Campodonico, Antun and Hansen41] results with foundations of mathematics and numerical analysis to characterise the NNs that can be computed by algorithms. This aligns with the work of B. Adcock and N. Dexter [Reference Adcock and Dexter1] that demonstrates the gap between what algorithms compute and the theoretical existence of NNs in function approximation with deep NNs. Note that results on existence of algorithms in learning – with performance and stability guarantees – do exist (see the work of P. Niyogi, S. Smale and S. Weinberger [Reference Niyogi, Smale and Weinberger63]), but so far not in DL.
-
(iii) Mathematical explanation of instability and impossibility results . Our paper is very much related to the work of H. Owhadi, C. Scovel and T. Sullivan [Reference Owhadi, Scovel and Sullivan64, Reference Owhadi, Scovel and Sullivan65] who ‘observe that learning and robustness are antagonistic properties’. The recent work of I. Tyukin, D. Higham and A. Gorban [Reference Tyukin, Higham and Gorban77] and A. Shafahi, R. Huang, C. Studer, S. Feizi and T. Goldstein [Reference Shafahi, Huang, Studer, Feizi and Goldstein69] demonstrate how the instability phenomenon increases with dimension showing universal lower bound on stability as a function of the dimension of the domain of the classification function. Note, however, that the results in this paper are independent of dimensions. The work of A. Fawzi, H. Fawzi and O. Fawzi [Reference Fawzi, Fawzi and Fawzi31] is also related; however, their results are about adversarial perturbations for any function, which is somewhat different from the problem that DL is unstable to perturbations that humans do not perceive. In particular, our results focus on how DL becomes unstable despite the fact that there is another device (in our case another NN) or a human that can be both accurate and stable.
-
(iv) Proof techniques – The SCI hierarchy . Initiated in [Reference Hansen43], the mathematics behind the SCI hierarchy provides a variety of techniques to show lower bounds and impossibility results for algorithms – in a variety of mathematical fields – that provide the foundations for the proof techniques in this paper, see the works by V. Antun, J. Ben-Artzi, M. Colbrook, A. C. Hansen, M. Marletta, O. Nevanlinna, F. Rösler and M. Seidel. [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel11–Reference Ben-Artzi, Marletta and Rösler13, Reference Colbrook, Antun and Hansen25, Reference Hansen43]. This is strongly related to the work of S. Weinberger [Reference Weinberger80] on the existence of algorithms for computational problems in topology. The authors of this paper have also extended the SCI framework [Reference Bastounis, Hansen and Vlačić9] in connection with the extended Smale’s 9th problem.
-
(v) Robust optimisation . Robust optimisation [Reference Ben-Tal, Ghaoui and Nemirovski14–Reference Ben-Tal and Nemirovski16], pioneered by A. Ben-Tal, L. El Ghaoui and A. Nemirovski, is an essential part of optimisation theory addressing sensitivity to perturbations and inexact data in optimisation problems. There are crucial links to our results – indeed, a key issue is that the instability phenomenon in DL leads to non-robust optimisation problems. In fact, there is a fundamental relationship between Theorem 2.2, Theorem 3.5 and robust optimisation. Theorem 3.5 yields impossibility results in optimisation, where non-robustness is a key element. The big question is whether stable and accurate NNs – with variable dimensions – that exist as a result of Theorem 2.2 can be shown to be approximate minimisers of robust optimisation problems. This leads to the final question, would such problems be computable and have efficient algorithms? The results in this paper can be viewed as an instance of where robust optimisation meets the SCI hierarchy. This was also the case in the recent results on the extended Smale’s 9th problem [Reference Bastounis, Hansen and Vlačić9].
5. Proofs of the main results
5.1. Some well-known definitions and ideas from DL
In this section, we outline some basic well-known definitions and explain the notation that will be useful for this paper. Many of these definitions can be found in [Reference Goodfellow, Bengio and Courville38]. For a vector
 $x \in {\mathbb{R}}^{N_1}$
, we denote
$x \in {\mathbb{R}}^{N_1}$
, we denote
 $x_i$
by the
$x_i$
by the
 $i$
th coordinate. Similarly, for a matrix
$i$
th coordinate. Similarly, for a matrix
 $A \in {\mathbb{R}}^{N_1 \times N_2}$
for some dimensions
$A \in {\mathbb{R}}^{N_1 \times N_2}$
for some dimensions
 $N_1 \in \mathbb{N}$
and
$N_1 \in \mathbb{N}$
and
 $N_2 \in \mathbb{N}$
, we denote
$N_2 \in \mathbb{N}$
, we denote
 $A_{i,j}$
by the entry of
$A_{i,j}$
by the entry of
 $A$
contained on the
$A$
contained on the
 $i$
th row and the
$i$
th row and the
 $j$
th column.
$j$
th column.
Recall that for natural numbers
 $n_1,n_2$
, an affine map
$n_1,n_2$
, an affine map
 $W: {\mathbb{R}}^{n_1} \to {\mathbb{R}}^{n_2}$
is a map such that there exists
$W: {\mathbb{R}}^{n_1} \to {\mathbb{R}}^{n_2}$
is a map such that there exists
 $A \in {\mathbb{R}}^{n_2 \times n_1}$
and
$A \in {\mathbb{R}}^{n_2 \times n_1}$
and
 $b \in {\mathbb{R}}^{n_2}$
so that for all
$b \in {\mathbb{R}}^{n_2}$
so that for all
 $x \in {\mathbb{R}}^{n_1}$
,
$x \in {\mathbb{R}}^{n_1}$
,
 $Wx = Ax + b$
. Let
$Wx = Ax + b$
. Let
 $L,d$
be natural numbers and let
$L,d$
be natural numbers and let
 $\mathbf{N}\,:\!=\,(N_L=1,N_{L-1},\dotsc ,N_1,N_0)$
be a vector in
$\mathbf{N}\,:\!=\,(N_L=1,N_{L-1},\dotsc ,N_1,N_0)$
be a vector in
 $\mathbb{N}^{L+1}$
with
$\mathbb{N}^{L+1}$
with
 $N_0 = d$
. An neural network with dimensions
$N_0 = d$
. An neural network with dimensions
 $(\mathbf{N},\kern0.3pt L)$
is a map
$(\mathbf{N},\kern0.3pt L)$
is a map
 $\phi\,:\, {\mathbb{R}}^d \to {\mathbb{R}}$
such that
$\phi\,:\, {\mathbb{R}}^d \to {\mathbb{R}}$
such that
 \begin{align*} \phi = W^L \sigma W^{L-1} \sigma W^{L-2}\dotsc \sigma W^1 \end{align*}
\begin{align*} \phi = W^L \sigma W^{L-1} \sigma W^{L-2}\dotsc \sigma W^1 \end{align*}
where, for
 $l=1,2,\dotsc ,\kern0.3pt L$
, the map
$l=1,2,\dotsc ,\kern0.3pt L$
, the map
 $W^l$
is an affine map from
$W^l$
is an affine map from
 ${\mathbb{R}}^{N_{l-1}} \to {\mathbb{R}}^{N_{l}}$
, that is,
${\mathbb{R}}^{N_{l-1}} \to {\mathbb{R}}^{N_{l}}$
, that is,
 $W^l x^l = A^l x^l + b^l$
where
$W^l x^l = A^l x^l + b^l$
where
 $b^l \in {\mathbb{R}}^{N_l}$
and
$b^l \in {\mathbb{R}}^{N_l}$
and
 $A^l \in {\mathbb{R}}^{N_{l} \times N_{l-1}}$
. The map
$A^l \in {\mathbb{R}}^{N_{l} \times N_{l-1}}$
. The map
 $\sigma\,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinate-wise map and is called the non-linearity or activation function: typically,
$\sigma\,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinate-wise map and is called the non-linearity or activation function: typically,
 $\sigma$
is chosen to be continuous and non-polynomial [Reference Pinkus67].
$\sigma$
is chosen to be continuous and non-polynomial [Reference Pinkus67].
In this paper, we focus on the well-known ReLU non-linearity, which we denote by
 $\rho$
. More specifically, for
$\rho$
. More specifically, for
 $x \in {\mathbb{R}}$
, we define
$x \in {\mathbb{R}}$
, we define
 $\rho (x)$
by
$\rho (x)$
by
 $\rho (x) = 0$
if
$\rho (x) = 0$
if
 $x \lt 0$
and
$x \lt 0$
and
 $\rho (x) = x$
if
$\rho (x) = x$
if
 $x \geq 0$
. We denote all neural networks with dimensions
$x \geq 0$
. We denote all neural networks with dimensions
 $(\mathbf{N},\kern0.3pt L)$
and the ReLU non-linearity by
$(\mathbf{N},\kern0.3pt L)$
and the ReLU non-linearity by
 $\mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
. This will be the central object for our arguments.
$\mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
. This will be the central object for our arguments.
Remark 5.1. Although we focus on the ReLU non-linearity, it is possible to use the techniques presented in this paper to prove similar results for other non-linearities like the leaky ReLU [55]
 $\rho ^{\text{leaky}}$
and the parameterised ReLU [46]
$\rho ^{\text{leaky}}$
and the parameterised ReLU [46]
 $\rho ^{param}_{\alpha }$
where
$\rho ^{param}_{\alpha }$
where
 \begin{align*} \rho ^{\text{leaky}}(x) = \begin{cases} 0.01 \cdot x & \text{if } x \lt 0\\ x & \text{ if } x \geq 0 \end{cases}, \quad \rho ^{param}_{\alpha }(x) = \begin{cases} \alpha x & \text{if } x \lt 0\\ x & \text{ if } x \geq 0 \end{cases} \end{align*}
\begin{align*} \rho ^{\text{leaky}}(x) = \begin{cases} 0.01 \cdot x & \text{if } x \lt 0\\ x & \text{ if } x \geq 0 \end{cases}, \quad \rho ^{param}_{\alpha }(x) = \begin{cases} \alpha x & \text{if } x \lt 0\\ x & \text{ if } x \geq 0 \end{cases} \end{align*}
In this paper, the most common norms we use are the
 $\ell ^p$
norms: for a vector
$\ell ^p$
norms: for a vector
 $x \in {\mathbb{R}}^d$
for some natural number
$x \in {\mathbb{R}}^d$
for some natural number
 $d$
and some
$d$
and some
 $p \in [1,\infty )$
, the
$p \in [1,\infty )$
, the
 $\ell ^p$
norm of
$\ell ^p$
norm of
 $x$
(which we denote by
$x$
(which we denote by
 $\|x\|_p$
) is given by
$\|x\|_p$
) is given by
 $\|x\|_p = (\sum _{i=1}^d |x_i|^p)^{1/p}$
. We also define the
$\|x\|_p = (\sum _{i=1}^d |x_i|^p)^{1/p}$
. We also define the
 $\ell ^{\infty }$
norm of
$\ell ^{\infty }$
norm of
 $x$
(which we denote by
$x$
(which we denote by
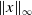 $\|x\|_{\infty }$
) by
$\|x\|_{\infty }$
) by
 $\|x\|_{\infty }\,:\!=\,\max _{i = 1,2,\dotsc ,d} |x_i|$
. It is easy to see the following inequality:
$\|x\|_{\infty }\,:\!=\,\max _{i = 1,2,\dotsc ,d} |x_i|$
. It is easy to see the following inequality:
 $\|x\|_{\infty } \leq \|x\|_2 \leq \|x\|_1$
. We will denote the ball of radius
$\|x\|_{\infty } \leq \|x\|_2 \leq \|x\|_1$
. We will denote the ball of radius
 $\epsilon$
about
$\epsilon$
about
 $x$
in the infinity norm by
$x$
in the infinity norm by
 $\mathcal{B}^{\infty }_{\epsilon }(x)$
, that is,
$\mathcal{B}^{\infty }_{\epsilon }(x)$
, that is,
 $\mathcal{B}^{\infty }_{\epsilon }(x) = \{y \in {\mathbb{R}}^d \, \vert \, \|y-x\|_{\infty } \leq \epsilon \}$
. For a set
$\mathcal{B}^{\infty }_{\epsilon }(x) = \{y \in {\mathbb{R}}^d \, \vert \, \|y-x\|_{\infty } \leq \epsilon \}$
. For a set
 $S$
, we denote
$S$
, we denote
 $\mathcal{B}^{\infty }_{\epsilon }(S)$
by
$\mathcal{B}^{\infty }_{\epsilon }(S)$
by
 $\cup _{x \in S} \mathcal{B}^{\infty }_{\epsilon }(x)$
.
$\cup _{x \in S} \mathcal{B}^{\infty }_{\epsilon }(x)$
.
The cost function of a neural network is used in the training procedure: typically, one attempts to compute solutions to (2.4) where the function
 $\mathcal{R}$
is known as the cost function. In optimisation theory, the cost function is sometimes known as the objective function and sometimes the loss function. Some standard choices for
$\mathcal{R}$
is known as the cost function. In optimisation theory, the cost function is sometimes known as the objective function and sometimes the loss function. Some standard choices for
 $\mathcal{R}$
include the following:
$\mathcal{R}$
include the following:
-
(1) Cross-entropy cost function, where
$\mathcal{R}$
is defined byThe cross-entropy function is only defined if
\begin{align*} \mathcal{R}(\{v^j\}_{j=1}^{r},\{w^j\}_{j=1}^{r})\,:\!=\,-\frac {1}{r}\sum _{j=1}^{r} \left (w^j \log (v^j) + (1-w^j) \log (1-v^j)\right ) \end{align*}
$v^{j} \in [0,1]$
: it is easy to extend this definition to
$\mathcal{R}(\{v^j\}_{j=1}^{r},\{w^j\}_{j=1}^{r})\,:\!=\,\infty$
when
$v^j \notin [0,1]$
for some
$j$
.
-
(2) Mean square error, where
$\mathcal{R}$
is defined by
\begin{align*} \mathcal{R}(\{v^j\}_{j=1}^{r},\{w^j\}_{j=1}^{r})\,:\!=\,\frac {1}{r}\|\{w^j\}_{j=1}^{r} - \{v^j\}_{j=1}^r\|_2^2 \end{align*}
-
(3) Root mean square error, where
$\mathcal{R}$
is defined by
\begin{align*} \mathcal{R}(\{v^j\}_{j=1}^{r},\{w^j\}_{j=1}^{r})\,:\!=\,\frac {1}{r}\|\{w^j\}_{j=1}^{r} - \{v^j\}_{j=1}^r\|_2 \end{align*}
-
(4) Mean absolute error, where
\begin{align*} \mathcal{R}(\{v^j\}_{j=1}^{r},\{w^j\}_{j=1}^{r})\,:\!=\,\frac {1}{r}\|\{w^j\}_{j=1}^{r} - \{v^j\}_{j=1}^r\|_1 \end{align*}











Note that each of these functions are in
 $\mathcal{CF}_{r}$
where
$\mathcal{CF}_{r}$
where
 $\mathcal{CF}_{r}$
is defined in (2.2).
$\mathcal{CF}_{r}$
is defined in (2.2).
5.2. Lemmas and definitions common to the proofs of both Theorems 2.2 and 3.5
For both theorems, the proof relies on the points
 $x^{k,\delta }\in {\mathbb{R}}^{N_0}$
, defined for
$x^{k,\delta }\in {\mathbb{R}}^{N_0}$
, defined for
 $k\in \mathbb{N}$
,
$k\in \mathbb{N}$
,
 $\delta \geq 0$
,
$\delta \geq 0$
,
 $\kappa \in [1/4,3/4]$
and
$\kappa \in [1/4,3/4]$
and
 $a\in [1/2,1]$
as follows:
$a\in [1/2,1]$
as follows:
 \begin{equation} x^{k,\delta }=\begin{cases} (a(k+1-\kappa )^{-1},0,\dotsc ,0),&\text{if $k$ is odd} \\ (a(k+1-\kappa )^{-1},\delta ,0,0,\dotsc ,0), &\text{if $k$ is even} \end{cases}. \end{equation}
\begin{equation} x^{k,\delta }=\begin{cases} (a(k+1-\kappa )^{-1},0,\dotsc ,0),&\text{if $k$ is odd} \\ (a(k+1-\kappa )^{-1},\delta ,0,0,\dotsc ,0), &\text{if $k$ is even} \end{cases}. \end{equation}
Both theorems also rely on some classification functions
 $f_a$
for
$f_a$
for
 $a \in [1/2,1]$
, defined as follows: we set
$a \in [1/2,1]$
, defined as follows: we set
 $f_{a}\,:\,\mathbb{R}^{N_0} \rightarrow \{0,1\}$
$f_{a}\,:\,\mathbb{R}^{N_0} \rightarrow \{0,1\}$
 \begin{equation} f_a(x) = \begin{cases} 1 & \text{ if } \lceil a/x_1\rceil \text{ is an odd integer }\\ 0 & \text{ otherwise } \text{(including } x = 0\text ) \end{cases} \end{equation}
\begin{equation} f_a(x) = \begin{cases} 1 & \text{ if } \lceil a/x_1\rceil \text{ is an odd integer }\\ 0 & \text{ otherwise } \text{(including } x = 0\text ) \end{cases} \end{equation}
In particular, note that for any
 $\delta \geq 0$
,
$\delta \geq 0$
,
 $f_a(x^{k,\delta }) = 1$
if
$f_a(x^{k,\delta }) = 1$
if
 $k$
is even and
$k$
is even and
 $f_a(x^{k,\delta }) = 0$
if
$f_a(x^{k,\delta }) = 0$
if
 $k$
is odd. The following three lemmas will be useful in both proofs. The first of these lemmas shows that finite collections of
$k$
is odd. The following three lemmas will be useful in both proofs. The first of these lemmas shows that finite collections of
 $x^{k,\delta }$
are well separated. Precisely, we will prove the following:
$x^{k,\delta }$
are well separated. Precisely, we will prove the following:
Lemma 5.2. Let
 $a \in [1/2,1]$
,
$a \in [1/2,1]$
,
 $\kappa \in [1/4,3/4]$
and
$\kappa \in [1/4,3/4]$
and
 $\delta \geq 0$
, and consider the points
$\delta \geq 0$
, and consider the points
 $x^{k,\delta }$
as given in (5.1) and
$x^{k,\delta }$
as given in (5.1) and
 $f_a$
given as in (5.2). Then, for every
$f_a$
given as in (5.2). Then, for every
 $K \in \mathbb{N}$
, we have
$K \in \mathbb{N}$
, we have
 $ \{x^{1,\delta }, \ldots , x^{K,\delta }\}\in \mathcal{S}^{f_a}_{\varepsilon '(K)}$
, where
$ \{x^{1,\delta }, \ldots , x^{K,\delta }\}\in \mathcal{S}^{f_a}_{\varepsilon '(K)}$
, where
 $\varepsilon '(n)\,:\!=\,[(4n+3)(4n+4)]^{-1}$
.
$\varepsilon '(n)\,:\!=\,[(4n+3)(4n+4)]^{-1}$
.
The purpose of the next lemma is to show that if
 $\delta \gt 0$
, there is a neural network that matches
$\delta \gt 0$
, there is a neural network that matches
 $f_a$
on the
$f_a$
on the
 $x^{k,\delta }$
:
$x^{k,\delta }$
:
Lemma 5.3. Let
 $d$
be a natural number with
$d$
be a natural number with
 $d\geq 2$
, let
$d\geq 2$
, let
 $a \in [1/2,1]$
,
$a \in [1/2,1]$
,
 $\kappa \in [1/4,3/4]$
and
$\kappa \in [1/4,3/4]$
and
 $\delta \gt 0$
, and consider the points
$\delta \gt 0$
, and consider the points
 $x^{k,\delta }$
as given in (5.1) and
$x^{k,\delta }$
as given in (5.1) and
 $f_a$
given as in (5.2). Fix neural networks dimensions
$f_a$
given as in (5.2). Fix neural networks dimensions
 $\mathbf{N} = (N_L=1,N_{L-1},\dotsc ,N_1,N_0=d)$
with
$\mathbf{N} = (N_L=1,N_{L-1},\dotsc ,N_1,N_0=d)$
with
 $L \geq 2$
. Then there exists a neural network
$L \geq 2$
. Then there exists a neural network
 $\tilde \varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
$\tilde \varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
 $\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
$\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
 $k \in \mathbb{N}$
.
$k \in \mathbb{N}$
.
Finally, the next lemma will be used to give examples of sets of vectors
 $\mathcal{W}$
and functions
$\mathcal{W}$
and functions
 $f$
for which neural networks with fixed dimensions cannot exactly match
$f$
for which neural networks with fixed dimensions cannot exactly match
 $f$
on
$f$
on
 $\mathcal{W}$
. More precisely, we shall show the following:
$\mathcal{W}$
. More precisely, we shall show the following:
Lemma 5.4. Let
 $d,t,m,\kern0.3pt L,N_1,N_2,\dotsc ,N_L$
each be natural numbers and let
$d,t,m,\kern0.3pt L,N_1,N_2,\dotsc ,N_L$
each be natural numbers and let
 $\mathcal{W}$
be a set of vectors with
$\mathcal{W}$
be a set of vectors with
 $\mathcal{W}= \{w^{1},w^{2},\dotsc ,w^{t}\}\subset {\mathbb{R}}^{d}$
. Suppose that each of the following apply
$\mathcal{W}= \{w^{1},w^{2},\dotsc ,w^{t}\}\subset {\mathbb{R}}^{d}$
. Suppose that each of the following apply
-
(1)
$t \geq 3m\cdot (N_1 + 1)(N_2+1)\dotsb (N_L+1)$
. -
(2)
$w^{1}_1 \gt w^{2}_1 \gt w^{3}_1 \gt \dotsb \gt w^{t}_1$
and
$w^{1}_j = w^{2}_j = \dotsb = w^{t}_j = 0$
for
$j=2,\dotsc ,d$
. -
(3)
$f: {\mathbb{R}}^d \to \{0,1\}$
is such that
$f(w^i) \neq f(w^{i+1})$
for
$i=1,2,\dotsc ,t-1$
.







Then for any neural network
 $\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
and any monotonic function
$\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
and any monotonic function
 $g: {\mathbb{R}} \to {\mathbb{R}}$
, there exists a set
$g: {\mathbb{R}} \to {\mathbb{R}}$
, there exists a set
 $\mathcal{U} \subset \mathcal{W}$
such that
$\mathcal{U} \subset \mathcal{W}$
such that
 $|\mathcal{U}| \geq m$
and
$|\mathcal{U}| \geq m$
and
 $|g(\varphi (w)) - f(w)| \geq 1/2$
for all
$|g(\varphi (w)) - f(w)| \geq 1/2$
for all
 $w \in \mathcal{U}$
.
$w \in \mathcal{U}$
.
The remainder of this subsection will be concerned with proving Lemmas5.2–5.4.
5.2.1. Proof of Lemma5.2
Proof of Lemma 5.2. We must verify that
 $\min _{1 \leq i \lt j \leq K} \|x^{i,\delta }-x^{j,\delta } \|_{\infty } \geq 2\varepsilon '(K)$
and that for
$\min _{1 \leq i \lt j \leq K} \|x^{i,\delta }-x^{j,\delta } \|_{\infty } \geq 2\varepsilon '(K)$
and that for
 $k \leq K$
and vectors
$k \leq K$
and vectors
 $y \in {\mathbb{R}}^{N_0}$
with
$y \in {\mathbb{R}}^{N_0}$
with
 $\|y\|_{\infty } \lt \varepsilon '(r)$
we have
$\|y\|_{\infty } \lt \varepsilon '(r)$
we have
 $f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }).$
$f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }).$
For the first part, note that for distinct
 $i,j$
with
$i,j$
with
 $i,j\leq K$
we have
$i,j\leq K$
we have
 \begin{equation} \|x^{i,\delta } - x^{j,\delta }\|_{\infty }\geq \left |\frac {a}{i+1 - \kappa } - \frac {a}{j+1 - \kappa }\right | = \frac {|a(j-i)|}{(i+1 - \kappa )(j+1-\kappa )}\geq \frac {1}{2(K+1 - \kappa )(K-\kappa )} \end{equation}
\begin{equation} \|x^{i,\delta } - x^{j,\delta }\|_{\infty }\geq \left |\frac {a}{i+1 - \kappa } - \frac {a}{j+1 - \kappa }\right | = \frac {|a(j-i)|}{(i+1 - \kappa )(j+1-\kappa )}\geq \frac {1}{2(K+1 - \kappa )(K-\kappa )} \end{equation}
since
 $a|j-i| \geq a \geq 1/2$
and the condition that
$a|j-i| \geq a \geq 1/2$
and the condition that
 $i,j \leq K$
with at least one bounded by
$i,j \leq K$
with at least one bounded by
 $K-1$
implies that
$K-1$
implies that
 $(i+1-\kappa )^{-1}(j+1-\kappa )^{-1} \geq (K+1 - \kappa )^{-1}(K- \kappa )^{-1}$
. Since
$(i+1-\kappa )^{-1}(j+1-\kappa )^{-1} \geq (K+1 - \kappa )^{-1}(K- \kappa )^{-1}$
. Since
 $\kappa \geq 1/4$
, we get
$\kappa \geq 1/4$
, we get
 $\|x^{i,\delta } - x^{j,\delta }\|_{\infty }\geq \left [2(K+1 - 1/4)(K-1/4)\right ]^{-1} \geq 2\varepsilon '(K)$
.
$\|x^{i,\delta } - x^{j,\delta }\|_{\infty }\geq \left [2(K+1 - 1/4)(K-1/4)\right ]^{-1} \geq 2\varepsilon '(K)$
.
Next, we let
 $k\leq K$
and
$k\leq K$
and
 $y \in {\mathbb{R}}^{N_0}$
be such that
$y \in {\mathbb{R}}^{N_0}$
be such that
 $\|y\|_{\infty } \leq \varepsilon '(K)$
. We will establish that
$\|y\|_{\infty } \leq \varepsilon '(K)$
. We will establish that
 $f_a(x^{k,\delta }+y) = f_a(x^{k,\delta })$
. Since
$f_a(x^{k,\delta }+y) = f_a(x^{k,\delta })$
. Since
 $k\leq K$
and
$k\leq K$
and
 $\kappa \in [1/4,3/4]$
, we have
$\kappa \in [1/4,3/4]$
, we have
 \begin{align*} \frac {a(1-\kappa )}{(k+1-\kappa )k}\gt \frac {1}{(4K+3)(2K+2)}\geq y_1 \geq \frac {-1}{(4K+3)(2K+2)} \geq \frac {-a\kappa }{(k+1-\kappa )(k+1)}. \end{align*}
\begin{align*} \frac {a(1-\kappa )}{(k+1-\kappa )k}\gt \frac {1}{(4K+3)(2K+2)}\geq y_1 \geq \frac {-1}{(4K+3)(2K+2)} \geq \frac {-a\kappa }{(k+1-\kappa )(k+1)}. \end{align*}
We claim that this implies
 $a(x^{k,\delta }_1 + y_1)^{-1} \in (k,k+1]$
. For the upper bound, note that
$a(x^{k,\delta }_1 + y_1)^{-1} \in (k,k+1]$
. For the upper bound, note that
 \begin{align*} \frac {y_1}{a} \geq \frac {-\kappa }{(k+1-\kappa )(k+1)} = \frac {1}{k+1} - \frac {1}{k+1-\kappa } = \frac {1}{k+1} - \frac {x^{k,\delta }_1}{a}. \end{align*}
\begin{align*} \frac {y_1}{a} \geq \frac {-\kappa }{(k+1-\kappa )(k+1)} = \frac {1}{k+1} - \frac {1}{k+1-\kappa } = \frac {1}{k+1} - \frac {x^{k,\delta }_1}{a}. \end{align*}
Similarly, for the lower bound, we have
 \begin{align*} \frac {y_1}{a} \lt \frac {1-\kappa }{k(k+1-\kappa )} = k^{-1}\left (\frac {k+1-\kappa }{k+1-\kappa } -\frac {k}{k+1-\kappa }\right ) = \frac {1}{k} - \frac {x^{k,\delta }_1}{a}. \end{align*}
\begin{align*} \frac {y_1}{a} \lt \frac {1-\kappa }{k(k+1-\kappa )} = k^{-1}\left (\frac {k+1-\kappa }{k+1-\kappa } -\frac {k}{k+1-\kappa }\right ) = \frac {1}{k} - \frac {x^{k,\delta }_1}{a}. \end{align*}
Therefore,
 $\lceil a/(x^{k,\delta }_1+y_1) \rceil = k+1$
. Thus, for all
$\lceil a/(x^{k,\delta }_1+y_1) \rceil = k+1$
. Thus, for all
 $\|y\|_{\infty } \lt \varepsilon '(K)$
, we have
$\|y\|_{\infty } \lt \varepsilon '(K)$
, we have
 $f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }) = 1$
for even
$f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }) = 1$
for even
 $k$
and
$k$
and
 $f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }) = 0$
for odd
$f_a(x^{k,\delta }+y) = f_a(x^{k,\delta }) = 0$
for odd
 $k$
, therefore establishing
$k$
, therefore establishing
 $ \{x^{1,\delta }, \ldots , x^{K,\delta }\}\in \mathcal{S}^{f_a}_{\varepsilon '(K)}$
.
$ \{x^{1,\delta }, \ldots , x^{K,\delta }\}\in \mathcal{S}^{f_a}_{\varepsilon '(K)}$
.
5.2.2. Proof of Lemma5.3
Proof of Lemma 5.3. We set
 \begin{align*} \tilde \varphi = W^L \rho W^{L-1} \rho W^{L-2}\dotsc \rho W^1 \end{align*}
\begin{align*} \tilde \varphi = W^L \rho W^{L-1} \rho W^{L-2}\dotsc \rho W^1 \end{align*}
where
 $W^\ell x = A^\ell x + b^\ell$
and
$W^\ell x = A^\ell x + b^\ell$
and
 $A^\ell \in {\mathbb{R}}^{N_{\ell } \times N_{\ell -1}}$
,
$A^\ell \in {\mathbb{R}}^{N_{\ell } \times N_{\ell -1}}$
,
 $b^\ell \in {\mathbb{R}}^{N_\ell }$
are defined as follows: let
$b^\ell \in {\mathbb{R}}^{N_\ell }$
are defined as follows: let
 $A^1_{1,1} = 0$
,
$A^1_{1,1} = 0$
,
 $A^1_{1,2} = \delta ^{-1}$
and
$A^1_{1,2} = \delta ^{-1}$
and
 $A^1_{i,j} = 0$
otherwise, and, for
$A^1_{i,j} = 0$
otherwise, and, for
 $\ell \gt 1$
,
$\ell \gt 1$
,
 $A^{\ell }_{1,1} = 1$
and
$A^{\ell }_{1,1} = 1$
and
 $A^{\ell }_{i,j} = 0$
otherwise, and
$A^{\ell }_{i,j} = 0$
otherwise, and
 $b^\ell = 0$
for every
$b^\ell = 0$
for every
 $\ell$
. Clearly
$\ell$
. Clearly
 \begin{align*} W^1 x^{k,\delta } =\begin{cases} e_1 \in \mathbb{R}^{N_1} &\text{ if } k \text{ is even}\\ \mathbf{0} \in \mathbb{R}^{N_1}& \text{ if } k \text{ is odd}\\ \end{cases} \end{align*}
\begin{align*} W^1 x^{k,\delta } =\begin{cases} e_1 \in \mathbb{R}^{N_1} &\text{ if } k \text{ is even}\\ \mathbf{0} \in \mathbb{R}^{N_1}& \text{ if } k \text{ is odd}\\ \end{cases} \end{align*}
and it is therefore easy to see that
 $\tilde \varphi (x^{k,\delta }) = 1$
if
$\tilde \varphi (x^{k,\delta }) = 1$
if
 $k$
is even and
$k$
is even and
 $\tilde \varphi (x^{k,\delta }) = 0$
if
$\tilde \varphi (x^{k,\delta }) = 0$
if
 $k$
is odd. By the definition of
$k$
is odd. By the definition of
 $x^{k,\delta }$
, we have
$x^{k,\delta }$
, we have
 $f_{a}(x^{k,\delta }) = 1$
if
$f_{a}(x^{k,\delta }) = 1$
if
 $k$
is even and
$k$
is even and
 $f_a(x^{k,\delta }) = 0$
if
$f_a(x^{k,\delta }) = 0$
if
 $k$
is odd, and therefore
$k$
is odd, and therefore
 $\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
$\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
 $k$
.
$k$
.
5.2.3. Proof of Lemma5.4
To prove Lemma5.4, we will state and prove the following:
Lemma 5.5. Fix
 $m, n \in \mathbb{N}$
,
$m, n \in \mathbb{N}$
,
 $A \in {\mathbb{R}}^{N \times N_0}$
,
$A \in {\mathbb{R}}^{N \times N_0}$
,
 $B \in {\mathbb{R}}^{m \times N}$
and
$B \in {\mathbb{R}}^{m \times N}$
and
 $z \in {\mathbb{R}}^{N}$
. Suppose that
$z \in {\mathbb{R}}^{N}$
. Suppose that
 \begin{align*} R = \lbrace \alpha ^q,\alpha ^{q+1},\alpha ^{q+2},\dotsc , \alpha ^{q + r-1}\rbrace \subset {\mathbb{R}}^{N_0} \end{align*}
\begin{align*} R = \lbrace \alpha ^q,\alpha ^{q+1},\alpha ^{q+2},\dotsc , \alpha ^{q + r-1}\rbrace \subset {\mathbb{R}}^{N_0} \end{align*}
is a set such that
 $|R| \geq N+1$
, the sequence
$|R| \geq N+1$
, the sequence
 $\{\alpha ^k_1\}_{k=q}^{q+r-1}$
is strictly decreasing and
$\{\alpha ^k_1\}_{k=q}^{q+r-1}$
is strictly decreasing and
 $\alpha ^k_j=0$
for
$\alpha ^k_j=0$
for
 $j \gt 1$
and all
$j \gt 1$
and all
 $k$
. Then there exist a matrix
$k$
. Then there exist a matrix
 $C \in {\mathbb{R}}^{m \times N_0}$
, a vector
$C \in {\mathbb{R}}^{m \times N_0}$
, a vector
 $v \in {\mathbb{R}}^m$
and a set
$v \in {\mathbb{R}}^m$
and a set
 $\mathcal{S} \subseteq R$
of the form
$\mathcal{S} \subseteq R$
of the form
 $\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
such that
$\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
such that
 $|\mathcal{S}|\geq |R|/(N+1)$
and
$|\mathcal{S}|\geq |R|/(N+1)$
and
 $B \rho (A \alpha + z) = C\alpha + v$
, for all
$B \rho (A \alpha + z) = C\alpha + v$
, for all
 $\alpha \in \mathcal{S}$
.
$\alpha \in \mathcal{S}$
.
Proof of Lemma 5.5. Write
 $B = (b_{j,k})_{j=1,k=1}^{j=m,k=N}$
,
$B = (b_{j,k})_{j=1,k=1}^{j=m,k=N}$
,
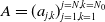 $A = (a_{j,k})_{j=1,k=1}^{j=N,k=N_0}$
. We claim that the set
$A = (a_{j,k})_{j=1,k=1}^{j=N,k=N_0}$
. We claim that the set
 $\mathcal{Q}$
defined by
$\mathcal{Q}$
defined by
 \begin{align*} \mathcal{Q} = \lbrace \left ({\text{sgn}}(a_{1,1}u_1 + w_{1}),{\text{sgn}}(a_{2,1}u_1 + w_{2}),\dotsc ,{\text{sgn}}(a_{N,1}u_1 + w_N)\right ) \, \vert \, u \in R \rbrace . \end{align*}
\begin{align*} \mathcal{Q} = \lbrace \left ({\text{sgn}}(a_{1,1}u_1 + w_{1}),{\text{sgn}}(a_{2,1}u_1 + w_{2}),\dotsc ,{\text{sgn}}(a_{N,1}u_1 + w_N)\right ) \, \vert \, u \in R \rbrace . \end{align*}
contains at most
 $N+1$
(unique) elements, that is,
$N+1$
(unique) elements, that is,
 $|\mathcal{Q}|\leq N+1$
, where we define
$|\mathcal{Q}|\leq N+1$
, where we define
 ${\text{sgn}}(x)=1$
for
${\text{sgn}}(x)=1$
for
 $x\geq 0$
and
$x\geq 0$
and
 ${\text{sgn}}(x)=-1$
for
${\text{sgn}}(x)=-1$
for
 $x\lt 0$
. To see this, note that if we allow the value of
$x\lt 0$
. To see this, note that if we allow the value of
 $\beta$
to vary over
$\beta$
to vary over
 $\mathbb{R}$
, then each of the lines
$\mathbb{R}$
, then each of the lines
 $y = a_{1,1}\beta + z_{1}$
,
$y = a_{1,1}\beta + z_{1}$
,
 $y = a_{2,1}\beta + z_{2}$
, …,
$y = a_{2,1}\beta + z_{2}$
, …,
 $y = a_{N,1}\beta + z_N$
intersect the line
$y = a_{N,1}\beta + z_N$
intersect the line
 $y = 0$
at most once. Between each of these intersections, the vector
$y = 0$
at most once. Between each of these intersections, the vector
 $({\text{sgn}}(a_{1,1}\beta + z_{1}),{\text{sgn}}(a_{2,1}\beta + z_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\beta + z_N))$
is constant. As there are at most
$({\text{sgn}}(a_{1,1}\beta + z_{1}),{\text{sgn}}(a_{2,1}\beta + z_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\beta + z_N))$
is constant. As there are at most
 $N$
such intersections, we note that if
$N$
such intersections, we note that if
 \begin{align*} \mathcal{Q}'\,:\!=\,\lbrace \left ({\text{sgn}}(a_{1,1}\beta + w_{1}),{\text{sgn}}(a_{2,1}\beta + w_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\beta + w_N)\right ) \, \vert \, \beta \in \mathbb{R} \rbrace . \end{align*}
\begin{align*} \mathcal{Q}'\,:\!=\,\lbrace \left ({\text{sgn}}(a_{1,1}\beta + w_{1}),{\text{sgn}}(a_{2,1}\beta + w_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\beta + w_N)\right ) \, \vert \, \beta \in \mathbb{R} \rbrace . \end{align*}
then
 $|\mathcal{Q}'| \leq N+1$
follows because partitioning a line by at most
$|\mathcal{Q}'| \leq N+1$
follows because partitioning a line by at most
 $N$
intersections gives at most
$N$
intersections gives at most
 $N+1$
regions between the intersections. As
$N+1$
regions between the intersections. As
 $\mathcal{Q} \subseteq \mathcal{Q'}$
, the proof that
$\mathcal{Q} \subseteq \mathcal{Q'}$
, the proof that
 $|\mathcal{Q}| \leq N+1$
is complete.
$|\mathcal{Q}| \leq N+1$
is complete.
We can now define
 $\mathcal{S}$
. By the pigeonhole principle and the fact that
$\mathcal{S}$
. By the pigeonhole principle and the fact that
 $|\mathcal{Q}|\leq N+1$
, there exists a subset of
$|\mathcal{Q}|\leq N+1$
, there exists a subset of
 $R$
with cardinality at least
$R$
with cardinality at least
 $|R|/(N+1)$
such that the vector
$|R|/(N+1)$
such that the vector
 \begin{align*} {\text{sgn}}(a_{\,\cdot ,1}\, \alpha _1 + z) = \left ({\text{sgn}}(a_{1,1}\alpha _1 + z_{1}),{\text{sgn}}(a_{2,1}\alpha _1 + z_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\alpha _1 + z_N)\right ) \end{align*}
\begin{align*} {\text{sgn}}(a_{\,\cdot ,1}\, \alpha _1 + z) = \left ({\text{sgn}}(a_{1,1}\alpha _1 + z_{1}),{\text{sgn}}(a_{2,1}\alpha _1 + z_{2}),\dotsc ,{\text{sgn}}(a_{N,1}\alpha _1 + z_N)\right ) \end{align*}
is constant over
 $\alpha$
in this subset. Let
$\alpha$
in this subset. Let
 $\mathcal{S}$
be a subset of
$\mathcal{S}$
be a subset of
 $R$
of maximal cardinality satisfying this constant sign condition. Then clearly
$R$
of maximal cardinality satisfying this constant sign condition. Then clearly
 $|\mathcal{S}| \geq |R|/(N+1)$
. To see that
$|\mathcal{S}| \geq |R|/(N+1)$
. To see that
 $\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
, for some
$\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
, for some
 $s$
and
$s$
and
 $t$
, suppose by way of contradiction that no such
$t$
, suppose by way of contradiction that no such
 $s$
and
$s$
and
 $t$
exist. Then there are
$t$
exist. Then there are
 $j_1$
and
$j_1$
and
 $k_1$
such that
$k_1$
such that
 $j_1 + 1 \lt k_1$
,
$j_1 + 1 \lt k_1$
,
 $\alpha ^{j_1}, \alpha ^{k_1} \in \mathcal{S}$
and
$\alpha ^{j_1}, \alpha ^{k_1} \in \mathcal{S}$
and
 $\alpha ^{j_1+1} \notin \mathcal{S}$
. But then, as
$\alpha ^{j_1+1} \notin \mathcal{S}$
. But then, as
 $\mathcal{S}$
is assumed to be of maximal cardinality, there must be an
$\mathcal{S}$
is assumed to be of maximal cardinality, there must be an
 $\ell$
for which
$\ell$
for which
 ${\text{sgn}}(a_{\ell ,1}\alpha ^{j_1}_1 + z_1) = {\text{sgn}}(a_{\ell ,1}\alpha ^{k_1}_1+z_1) \neq {\text{sgn}}(a_{\ell ,1}\alpha ^{j_1+1}_1 + z_1)$
. However, since
${\text{sgn}}(a_{\ell ,1}\alpha ^{j_1}_1 + z_1) = {\text{sgn}}(a_{\ell ,1}\alpha ^{k_1}_1+z_1) \neq {\text{sgn}}(a_{\ell ,1}\alpha ^{j_1+1}_1 + z_1)$
. However, since
 $\{\alpha ^j_1\}_{j=j_1}^{k_1}$
is a strictly decreasing sequence by assumption, we see that if
$\{\alpha ^j_1\}_{j=j_1}^{k_1}$
is a strictly decreasing sequence by assumption, we see that if
 $a_{\ell ,1} \geq 0$
then
$a_{\ell ,1} \geq 0$
then
 $a_{\ell ,1}\alpha ^{j_1}_1 + z_1 \geq a_{\ell ,1}\alpha ^{j_1+1}_1+z_1 \geq a_{\ell ,1}\alpha ^{k_1}_1+z_1$
and similarly if
$a_{\ell ,1}\alpha ^{j_1}_1 + z_1 \geq a_{\ell ,1}\alpha ^{j_1+1}_1+z_1 \geq a_{\ell ,1}\alpha ^{k_1}_1+z_1$
and similarly if
 $a_{\ell ,1} \lt 0$
then
$a_{\ell ,1} \lt 0$
then
 $a_{\ell ,1}\alpha ^{j_1}_1 + z_1 \lt a_{\ell ,1}\alpha ^{j_1+1}_1+z_1 \lt a_{\ell ,1}\alpha ^{k_1}_1+z_1$
which is a contradiction. This establishes that
$a_{\ell ,1}\alpha ^{j_1}_1 + z_1 \lt a_{\ell ,1}\alpha ^{j_1+1}_1+z_1 \lt a_{\ell ,1}\alpha ^{k_1}_1+z_1$
which is a contradiction. This establishes that
 $\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
, for some
$\mathcal{S} = \lbrace \alpha ^s,\alpha ^{s+1},\dotsc , \alpha ^{s+t-1}\rbrace$
, for some
 $s$
and
$s$
and
 $t$
.
$t$
.
We now show how to construct
 $C$
and
$C$
and
 $v$
. Recall that, for all
$v$
. Recall that, for all
 $\alpha \in \mathcal{S}$
,
$\alpha \in \mathcal{S}$
,
 $\alpha _2 = \alpha _3 = \dotsb = \alpha _{N_0} = 0$
, and so the
$\alpha _2 = \alpha _3 = \dotsb = \alpha _{N_0} = 0$
, and so the
 $i$
-th row of
$i$
-th row of
 $B \rho (A\alpha +z)$
is given by
$B \rho (A\alpha +z)$
is given by
 $\sum _{j=1}^{N} b_{i,j} \rho (a_{j,1}\alpha _1 + z_{j})$
. Since
$\sum _{j=1}^{N} b_{i,j} \rho (a_{j,1}\alpha _1 + z_{j})$
. Since
 ${\text{sgn}}(a_{j,1}\alpha _1 + z_j)$
is constant over
${\text{sgn}}(a_{j,1}\alpha _1 + z_j)$
is constant over
 $\alpha \in \mathcal{S}$
, we must have that for each
$\alpha \in \mathcal{S}$
, we must have that for each
 $j$
either
$j$
either
 $\rho (a_{j,1}\alpha _1 + z_{j}) = 0$
or
$\rho (a_{j,1}\alpha _1 + z_{j}) = 0$
or
 $\rho (a_{j,1}\alpha _1 + w_{j}) = a_{j,1}\alpha _1 + z_j$
, for all
$\rho (a_{j,1}\alpha _1 + w_{j}) = a_{j,1}\alpha _1 + z_j$
, for all
 $\alpha \in \mathcal{S}$
. In the former case, we define
$\alpha \in \mathcal{S}$
. In the former case, we define
 $d_{i,j} =0$
and
$d_{i,j} =0$
and
 $y_{i,j} = 0$
and in the latter case we define
$y_{i,j} = 0$
and in the latter case we define
 $d_{i,j} = b_{i,j} a_{j,1}$
and
$d_{i,j} = b_{i,j} a_{j,1}$
and
 $y_{i,j} = b_{i,j}z_{j}$
. Therefore, by construction, the
$y_{i,j} = b_{i,j}z_{j}$
. Therefore, by construction, the
 $i$
-th row of
$i$
-th row of
 $B \rho (A\alpha + z)$
is given by
$B \rho (A\alpha + z)$
is given by
 $\sum _{j=1}^{N} \left (d_{i,j} \alpha _1 + y_{i,j}\right )$
. Thus, defining the matrix
$\sum _{j=1}^{N} \left (d_{i,j} \alpha _1 + y_{i,j}\right )$
. Thus, defining the matrix
 $C = (c_{i,j})_{i=1,j=1}^{i=m,j=N_0}$
and the vector
$C = (c_{i,j})_{i=1,j=1}^{i=m,j=N_0}$
and the vector
 $v\in {\mathbb{R}}^m$
according to
$v\in {\mathbb{R}}^m$
according to
 \begin{align*} c_{i,1} = \sum _{k=1}^{N} d_{i,k}, \quad c_{i,j} = 0, \text{ for } j \gt 1, \qquad \text{and} \qquad v_i = \sum _{k=1}^{N} y_{i,k} \end{align*}
\begin{align*} c_{i,1} = \sum _{k=1}^{N} d_{i,k}, \quad c_{i,j} = 0, \text{ for } j \gt 1, \qquad \text{and} \qquad v_i = \sum _{k=1}^{N} y_{i,k} \end{align*}
immediately yields that the
 $i$
-th row of
$i$
-th row of
 $B\rho (A\alpha + z)$
satisfies
$B\rho (A\alpha + z)$
satisfies
 $\sum _{k=1}^{N} \left (d_{i,k} \alpha _1 + y_{i,k}\right ) = \sum _{k=1}^N c_{i,k}\alpha _k \,+ v_i$
. As
$\sum _{k=1}^{N} \left (d_{i,k} \alpha _1 + y_{i,k}\right ) = \sum _{k=1}^N c_{i,k}\alpha _k \,+ v_i$
. As
 $i$
and
$i$
and
 $\alpha \in \mathcal{S}$
were arbitrary, this implies that
$\alpha \in \mathcal{S}$
were arbitrary, this implies that
 $B \rho (A\alpha + z) = C\alpha + v$
for all
$B \rho (A\alpha + z) = C\alpha + v$
for all
 $\alpha \in \mathcal{S}$
, thereby concluding the proof of the lemma.
$\alpha \in \mathcal{S}$
, thereby concluding the proof of the lemma.
With Lemma5.5, we can now prove Lemma5.4.
Proof of Lemma 5.4. We begin by proving the following claim:
Claim: There exists a set
 \begin{align*} \mathcal{S} = \{w^s,w^{s+1},w^{s+2},\dotsc , w^{s+n}\} \subset \{w^1,w^2,\dotsc ,w^t\} \end{align*}
\begin{align*} \mathcal{S} = \{w^s,w^{s+1},w^{s+2},\dotsc , w^{s+n}\} \subset \{w^1,w^2,\dotsc ,w^t\} \end{align*}
for some
 $s \in \mathbb{N}$
and
$s \in \mathbb{N}$
and
 $n \in \mathbb{N}$
, a matrix
$n \in \mathbb{N}$
, a matrix
 $ M \in \mathbb{R}^{1 \times N_0}$
and a
$ M \in \mathbb{R}^{1 \times N_0}$
and a
 $z \in \mathbb{R}$
such that, for all
$z \in \mathbb{R}$
such that, for all
 $w \in \mathcal{S}$
, we have
$w \in \mathcal{S}$
, we have
 $ \varphi (w) = Mw + z$
and so that
$ \varphi (w) = Mw + z$
and so that
 $|\mathcal{S}|\geq 3m$
.
$|\mathcal{S}|\geq 3m$
.
To see the validity of this claim, we proceed inductively by showing that there are sets
 $\mathcal{S}_\ell \subset \{w^1,w^2,\dotsc ,w^t\}$
, matrices
$\mathcal{S}_\ell \subset \{w^1,w^2,\dotsc ,w^t\}$
, matrices
 $M^\ell \in {\mathbb{R}}^{N_{\ell } \times N_0}$
and vectors
$M^\ell \in {\mathbb{R}}^{N_{\ell } \times N_0}$
and vectors
 $z^\ell \in {\mathbb{R}}^{N_\ell }$
for
$z^\ell \in {\mathbb{R}}^{N_\ell }$
for
 $\ell =1,\dotsc ,\kern0.3pt L$
such that
$\ell =1,\dotsc ,\kern0.3pt L$
such that
-
(i)
$|\mathcal{S}_\ell | \geq 3m\cdot (N_{\ell }+1) \dotsb (N_{L-1}+1)$
, -
(ii)
$\mathcal{S}_\ell = \lbrace w^{s_\ell }, w^{s_\ell +1},\dotsc , w^{s_\ell +n_\ell }\rbrace$
for some
$s_\ell , n_\ell \in \mathbb{N}$
. -
(iii)
$\varphi (w) = W^L \rho W^{L-1} \rho W^{L-2} \dotsc W^{\ell +1} \rho (M^\ell w+z^\ell )$
whenever
$w \in \mathcal{S}_\ell$
, where the
$W^i$
are affine maps and
$\rho$
is applied coordinatewise.







The induction base is obvious by taking
 $\mathcal{S}_1=\mathcal{W}$
,
$\mathcal{S}_1=\mathcal{W}$
,
 $M^1 = W^1$
and
$M^1 = W^1$
and
 $z^1 = b^1$
. The induction step will follow with the help of Lemma5.5. Indeed, assuming the existence of
$z^1 = b^1$
. The induction step will follow with the help of Lemma5.5. Indeed, assuming the existence of
 $\mathcal{S}_{\ell }$
,
$\mathcal{S}_{\ell }$
,
 $M^\ell$
and
$M^\ell$
and
 $z^\ell$
for some
$z^\ell$
for some
 $\ell \lt L$
, we apply Lemma5.5 with
$\ell \lt L$
, we apply Lemma5.5 with
 $B = A^{\ell +1}, A = M^\ell , R = \mathcal{S}_\ell$
and
$B = A^{\ell +1}, A = M^\ell , R = \mathcal{S}_\ell$
and
 $w = z^\ell$
to obtain some set
$w = z^\ell$
to obtain some set
 $\mathcal{S}_{\ell +1}$
, a matrix
$\mathcal{S}_{\ell +1}$
, a matrix
 $M^{\ell +1}$
and a vector
$M^{\ell +1}$
and a vector
 $v^{\ell +1}$
for which
$v^{\ell +1}$
for which
 $A^{\ell +1} \rho (M^\ell w + z^\ell ) = M^{\ell +1}w + v^{\ell +1}$
for
$A^{\ell +1} \rho (M^\ell w + z^\ell ) = M^{\ell +1}w + v^{\ell +1}$
for
 $w \in \mathcal{S}_{\ell +1}$
, and thus
$w \in \mathcal{S}_{\ell +1}$
, and thus
 $W^{\ell +1} \rho (M^\ell w + z^\ell ) = M^{\ell +1}w + z^{\ell +1}$
, where we set
$W^{\ell +1} \rho (M^\ell w + z^\ell ) = M^{\ell +1}w + z^{\ell +1}$
, where we set
 $z^{\ell +1} = v^{\ell +1} + b^{\ell +1}$
. With the completed induction in hand, the proof of the claim follows by setting
$z^{\ell +1} = v^{\ell +1} + b^{\ell +1}$
. With the completed induction in hand, the proof of the claim follows by setting
 $\mathcal{S} = \mathcal{S}_L$
,
$\mathcal{S} = \mathcal{S}_L$
,
 $s = s_L$
,
$s = s_L$
,
 $n = n_L$
,
$n = n_L$
,
 $M = M^L$
and
$M = M^L$
and
 $z = z^L$
.
$z = z^L$
.
Using the claim, we can now complete the proof of Lemma5.4. Indeed, define the disjoint sets
 $\mathcal{S}^\gt$
,
$\mathcal{S}^\gt$
,
 $\mathcal{S}^\lt$
as follows:
$\mathcal{S}^\lt$
as follows:
 \begin{align*} \mathcal{S}^\gt = \{w \in \mathcal{S} \, \vert \, g(\varphi (w)) \geq 1/2\}, \quad \mathcal{S}^\lt = \{w \in \mathcal{S} \, \vert \, g(\varphi (w)) \lt 1/2\} \end{align*}
\begin{align*} \mathcal{S}^\gt = \{w \in \mathcal{S} \, \vert \, g(\varphi (w)) \geq 1/2\}, \quad \mathcal{S}^\lt = \{w \in \mathcal{S} \, \vert \, g(\varphi (w)) \lt 1/2\} \end{align*}
For any
 $w \in \mathcal{S}$
, we have
$w \in \mathcal{S}$
, we have
 $\varphi (w) = Mw + z$
. Furthermore, any such
$\varphi (w) = Mw + z$
. Furthermore, any such
 $w$
has
$w$
has
 $w_{2} = w_{3} = \dotsb = w_{N} = 0$
. Therefore,
$w_{2} = w_{3} = \dotsb = w_{N} = 0$
. Therefore,
 $\varphi (w) = M_{1,1}w_1 + z$
. In particular,
$\varphi (w) = M_{1,1}w_1 + z$
. In particular,
 $g \circ \varphi$
restricted to
$g \circ \varphi$
restricted to
 $\mathcal{S}$
is monotonic in the first coordinate of vectors in
$\mathcal{S}$
is monotonic in the first coordinate of vectors in
 $\mathcal{S}$
. This implies that
$\mathcal{S}$
. This implies that
 \begin{align*} \mathcal{S}^\gt = \{w^{k_1},w^{k_1 + 1}, w^{k_1 + 2}, \dotsc ,w^{k_1 + t_1-1}\},\quad \mathcal{S}^\lt = \{ w^{k_2}, w^{k_2 + 1}, w^{k_2 + 2} , \dotsc w^{k_2 + t_2-1}\} \end{align*}
\begin{align*} \mathcal{S}^\gt = \{w^{k_1},w^{k_1 + 1}, w^{k_1 + 2}, \dotsc ,w^{k_1 + t_1-1}\},\quad \mathcal{S}^\lt = \{ w^{k_2}, w^{k_2 + 1}, w^{k_2 + 2} , \dotsc w^{k_2 + t_2-1}\} \end{align*}
for some
 $k_1$
and
$k_1$
and
 $k_2$
and
$k_2$
and
 $t_1,t_2$
with
$t_1,t_2$
with
 $t_1 + t_2 = |\mathcal{S}|\geq 3m$
. Furthermore, by 3 and the fact that the range of
$t_1 + t_2 = |\mathcal{S}|\geq 3m$
. Furthermore, by 3 and the fact that the range of
 $f$
is the set
$f$
is the set
 $\{0,1\}$
, we must have
$\{0,1\}$
, we must have
 $f(w^i) = 1$
for all even
$f(w^i) = 1$
for all even
 $i$
and
$i$
and
 $f(w^i) = 0$
for all odd
$f(w^i) = 0$
for all odd
 $i$
or
$i$
or
 $f(w^i) = 0$
for all even
$f(w^i) = 0$
for all even
 $i$
and
$i$
and
 $f(w^i) = 1$
for all odd
$f(w^i) = 1$
for all odd
 $i$
. We will consider these two cases separately
$i$
. We will consider these two cases separately
Case 1:
 $\textit{f}\textbf{(}\textit{w}^{\textit{i}}\textbf{)}\;\textbf{=}\;\textbf{1}$
for all even
$\textit{f}\textbf{(}\textit{w}^{\textit{i}}\textbf{)}\;\textbf{=}\;\textbf{1}$
for all even
 $\textit{i}$
and
$\textit{i}$
and
 $\textit{f}\textbf{(}\textit{w}^{\textit{i}}\textbf{)}\;\textbf{=}\;\textbf{0}$
for all odd
$\textit{f}\textbf{(}\textit{w}^{\textit{i}}\textbf{)}\;\textbf{=}\;\textbf{0}$
for all odd
 $\textit{i}$
. We define the sets
$\textit{i}$
. We define the sets
 \begin{align*} \mathcal{S}^{E, \lt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\lt ,\, i \text{ even}\}, \quad \mathcal{S}^{O, \gt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ odd}\} \end{align*}
\begin{align*} \mathcal{S}^{E, \lt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\lt ,\, i \text{ even}\}, \quad \mathcal{S}^{O, \gt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ odd}\} \end{align*}
For
 $w \in \mathcal{S}^{E,\lt }$
, we have
$w \in \mathcal{S}^{E,\lt }$
, we have
 $f(w) = 1$
and
$f(w) = 1$
and
 $g(\varphi (w)) \lt 1/2$
, whence we obtain
$g(\varphi (w)) \lt 1/2$
, whence we obtain
 $|g(\varphi (w)) - f(w)|\geq 1/2$
. Similarly, for
$|g(\varphi (w)) - f(w)|\geq 1/2$
. Similarly, for
 $w \in \mathcal{S}^{O,\gt }$
we have
$w \in \mathcal{S}^{O,\gt }$
we have
 $f(w) = 0$
and
$f(w) = 0$
and
 $g(\varphi (w)) \geq 1/2$
and we thus obtain
$g(\varphi (w)) \geq 1/2$
and we thus obtain
 $|g(\varphi (w)) - f(w)|\geq 1/2$
. We set
$|g(\varphi (w)) - f(w)|\geq 1/2$
. We set
 $\mathcal{U} = \mathcal{S}^{E,\gt } \cup \mathcal{S}^{O,\lt }$
and conclude that for any
$\mathcal{U} = \mathcal{S}^{E,\gt } \cup \mathcal{S}^{O,\lt }$
and conclude that for any
 $w \in \mathcal{U}$
we have
$w \in \mathcal{U}$
we have
 $|f(w) - g(\varphi (w))| \geq 1/2$
.
$|f(w) - g(\varphi (w))| \geq 1/2$
.
The claim about the cardinality of
 $\mathcal{U}$
follows by noting that
$\mathcal{U}$
follows by noting that
 $|\mathcal{S}^{E,\lt }| \geq \lceil (t_1-1)/2 \rceil$
and that
$|\mathcal{S}^{E,\lt }| \geq \lceil (t_1-1)/2 \rceil$
and that
 $|\mathcal{S}^{O,\gt }| \geq \lceil (t_2-1)/2 \rceil$
. Therefore, (using the disjointedness of
$|\mathcal{S}^{O,\gt }| \geq \lceil (t_2-1)/2 \rceil$
. Therefore, (using the disjointedness of
 $\mathcal{S}^{E,\gt }$
and
$\mathcal{S}^{E,\gt }$
and
 $\mathcal{S}^{O,\lt }$
)
$\mathcal{S}^{O,\lt }$
)
 \begin{align} |\mathcal{U}| = |\mathcal{S}^{E,\gt }| + |\mathcal{S}^{O,\lt }|&\geq \lceil (t_1-1)/2 \rceil + \lceil (t_2-1)/2 \rceil \notag \\&\geq \lceil (t_1 -1 + t_2 -1)/2 \rceil = \lceil (t_1 + t_2)/2 \rceil - 1 \geq \lceil 3m/2 \rceil - 1 \geq m \end{align}
\begin{align} |\mathcal{U}| = |\mathcal{S}^{E,\gt }| + |\mathcal{S}^{O,\lt }|&\geq \lceil (t_1-1)/2 \rceil + \lceil (t_2-1)/2 \rceil \notag \\&\geq \lceil (t_1 -1 + t_2 -1)/2 \rceil = \lceil (t_1 + t_2)/2 \rceil - 1 \geq \lceil 3m/2 \rceil - 1 \geq m \end{align}
Case 2:
 $\textit{f}\textbf{(}\textit{w}^{\textit{i}})\,\textbf{=}\,\textbf{0}$
for all even
$\textit{f}\textbf{(}\textit{w}^{\textit{i}})\,\textbf{=}\,\textbf{0}$
for all even
 $\textit{i}$
and
$\textit{i}$
and
 $\textit{f}\textbf{(}\textit{w}^{\textit{i}})\;\textbf{=}\;\textbf{1}$
for all odd
$\textit{f}\textbf{(}\textit{w}^{\textit{i}})\;\textbf{=}\;\textbf{1}$
for all odd
 $\textit{i}$
. The proof here is similar to that of Case 1. This time however, we define the sets
$\textit{i}$
. The proof here is similar to that of Case 1. This time however, we define the sets
 \begin{align*} \mathcal{S}^{E, \gt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ even}\}, \quad \mathcal{S}^{O, \lt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ odd}\} \end{align*}
\begin{align*} \mathcal{S}^{E, \gt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ even}\}, \quad \mathcal{S}^{O, \lt } = \{w^{i} \, \vert \, w^{i} \in \mathcal{S}^\gt ,\, i \text{ odd}\} \end{align*}
An analogous argument to the above allows us to conclude that
 $|g(\varphi (w)) - f(w)| \geq 1/2$
for all
$|g(\varphi (w)) - f(w)| \geq 1/2$
for all
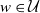 $w \in \mathcal{U}$
, where this time
$w \in \mathcal{U}$
, where this time
 $\mathcal{U} = \mathcal{S}^{E, \gt } \cup \mathcal{S}^{O,\lt }$
. The argument that
$\mathcal{U} = \mathcal{S}^{E, \gt } \cup \mathcal{S}^{O,\lt }$
. The argument that
 $|\mathcal{U}| \geq m$
is identical to (5.4) except we replace references to
$|\mathcal{U}| \geq m$
is identical to (5.4) except we replace references to
 $\mathcal{S}^{E,\lt }$
with
$\mathcal{S}^{E,\lt }$
with
 $\mathcal{S}^{E,\gt }$
and references to
$\mathcal{S}^{E,\gt }$
and references to
 $\mathcal{S}^{O,\gt }$
with
$\mathcal{S}^{O,\gt }$
with
 $\mathcal{S}^{O,\lt }$
.
$\mathcal{S}^{O,\lt }$
.
5.3. Proof of Theorem 2.2
We require two further lemmas specific to the proof of Theorem 2.2. These are stated as Lemmas5.6 and 5.7.
Lemma 5.6. For
 $\gamma \in (1,2)$
, define the probability distribution
$\gamma \in (1,2)$
, define the probability distribution
 $\mathcal{P}=\{\mathrm{p}_j\}_{j=1}^\infty$
on
$\mathcal{P}=\{\mathrm{p}_j\}_{j=1}^\infty$
on
 $\mathbb{N}$
by
$\mathbb{N}$
by
 $\mathrm{p}_{2j-1}=\mathrm{p}_{2j}=\frac {1}{2}C_\zeta (\gamma ) j^{-\gamma }$
, for
$\mathrm{p}_{2j-1}=\mathrm{p}_{2j}=\frac {1}{2}C_\zeta (\gamma ) j^{-\gamma }$
, for
 $j\in \mathbb{N}$
, where
$j\in \mathbb{N}$
, where
 $C_\zeta (\gamma )\,:\!=\,\big (\sum _{j=1}^\infty j^{-\gamma }\big )^{-1}$
is a normalising factor.
$C_\zeta (\gamma )\,:\!=\,\big (\sum _{j=1}^\infty j^{-\gamma }\big )^{-1}$
is a normalising factor.
Fix
 $\theta \in \mathbb{N}$
and let
$\theta \in \mathbb{N}$
and let
 $X_1$
,
$X_1$
,
 $X_2$
,…,
$X_2$
,…,
 $X_\theta$
be i.i.d. random variables in
$X_\theta$
be i.i.d. random variables in
 $\mathbb{N}$
distributed according to
$\mathbb{N}$
distributed according to
 $\mathcal{P}$
. Next, consider the random set whose elements are the values of
$\mathcal{P}$
. Next, consider the random set whose elements are the values of
 $X_1$
,
$X_1$
,
 $X_2$
, …,
$X_2$
, …,
 $X_\theta$
and enumerate it as
$X_\theta$
and enumerate it as
 $S=\{Z_1,Z_2,\dotsc , Z_N\}$
with
$S=\{Z_1,Z_2,\dotsc , Z_N\}$
with
 $Z_1\lt Z_2\lt \dotsb \lt Z_N$
(note that
$Z_1\lt Z_2\lt \dotsb \lt Z_N$
(note that
 $N$
, the number of distinct elements of
$N$
, the number of distinct elements of
 $S$
, is an integer-valued random variable such that
$S$
, is an integer-valued random variable such that
 $N\leq \theta$
). Then, setting
$N\leq \theta$
). Then, setting
 $c_1 =(1-e^{-C_\zeta (\gamma )})/2$
and
$c_1 =(1-e^{-C_\zeta (\gamma )})/2$
and
 $c_2=C_\zeta (\gamma )/(\gamma -1)$
, we have
$c_2=C_\zeta (\gamma )/(\gamma -1)$
, we have
-
(i)
${\mathbb{P}}\big (N\geq c_1 \theta ^{1/\gamma }\big )\geq 1- c_1^{-2}\theta ^{-(2/\gamma -1)}$
, -
(ii)
${\mathbb{P}}(\! \max S \leq n)\geq 1- c_2\, \theta {\lfloor n/2 \rfloor }^{1-\gamma }$
, for all
$n\in \mathbb{N}$
, and -
(iii)
${\mathbb{P}}\left (\! \left .\sum _{j=1}^{N-1} \chi _{\{Z_{j+1}-Z_{j}\text{ odd}\}} \leq n/5 \,\right \rvert \, N=n \right ) \leq e^{-n/100}$
, for all integers
$n$
such that
$10\leq n \leq \theta$
.






Proof. Throughout this proof, we will use the convention that for a random variable
 $Y\,:\,\Omega \to \mathcal{E}$
the notation
$Y\,:\,\Omega \to \mathcal{E}$
the notation
 $\{Y = \mu \}$
for
$\{Y = \mu \}$
for
 $\mu \in \Omega$
means the set
$\mu \in \Omega$
means the set
 $\{\tau \in \Omega \, \vert \, Y(\tau ) = \mu \}$
.
$\{\tau \in \Omega \, \vert \, Y(\tau ) = \mu \}$
.
For item (i), define the random variable
 $M_\theta$
to be the number of different unique values taken by the random variables
$M_\theta$
to be the number of different unique values taken by the random variables
 $\lceil X_1/2 \rceil$
,…,
$\lceil X_1/2 \rceil$
,…,
 $ \lceil X_\theta /2 \rceil$
and note that
$ \lceil X_\theta /2 \rceil$
and note that
 $ {\mathbb{P}}\left ( N\lt \beta \right )\leq {\mathbb{P}} (M_r \lt \beta )$
, for
$ {\mathbb{P}}\left ( N\lt \beta \right )\leq {\mathbb{P}} (M_r \lt \beta )$
, for
 $\beta \in \mathbb{R}$
. Now, as the random variables
$\beta \in \mathbb{R}$
. Now, as the random variables
 $\lceil X_j/2 \rceil$
,
$\lceil X_j/2 \rceil$
,
 $j=1,\ldots ,r$
, are i.i.d. and distributed according to the zeta distribution with parameter
$j=1,\ldots ,r$
, are i.i.d. and distributed according to the zeta distribution with parameter
 $\gamma$
, it follows from [Reference Zakrevskaya and Kovalevskii82, Lemmas 4, 3] that
$\gamma$
, it follows from [Reference Zakrevskaya and Kovalevskii82, Lemmas 4, 3] that
 $ \mathbb{E}[M_\theta ]\gt (1-e^{-C_\zeta (\gamma )}) \theta ^{1/\gamma }$
and
$ \mathbb{E}[M_\theta ]\gt (1-e^{-C_\zeta (\gamma )}) \theta ^{1/\gamma }$
and
 $ \sigma ^2\,:\!=\,\mathrm{Var}[M_\theta ]\leq \mathbb{E}[M_\theta ] \leq \theta$
, and hence Chebyshev’s inequality yields
$ \sigma ^2\,:\!=\,\mathrm{Var}[M_\theta ]\leq \mathbb{E}[M_\theta ] \leq \theta$
, and hence Chebyshev’s inequality yields
 \begin{align*} &{\mathbb{P}}\left ( N\lt \frac {1-e^{-C_\zeta (\gamma )}}{2} \theta ^{1/\gamma } \right )\leq {\mathbb{P}} \left (M_r \lt \frac {1-e^{-C_\zeta (\gamma )}}{2} \theta ^{1/\gamma } \right ) \\ \leq \;& {\mathbb{P}} \left (|M_\theta -\mathbb{E}[M_\theta ]| \gt \frac {1-e^{-C_\zeta (\gamma )}}{2\sigma } \theta ^{1/\gamma } \cdot \sigma \right )\leq \left (\frac {1-e^{-C_\zeta (\gamma )}}{2\sigma } \theta ^{1/\gamma } \right )^{-2}\leq \frac {4 \theta ^{-(2/\gamma -1)}}{(1-e^{-C_\zeta (\gamma )})^{2}} , \end{align*}
\begin{align*} &{\mathbb{P}}\left ( N\lt \frac {1-e^{-C_\zeta (\gamma )}}{2} \theta ^{1/\gamma } \right )\leq {\mathbb{P}} \left (M_r \lt \frac {1-e^{-C_\zeta (\gamma )}}{2} \theta ^{1/\gamma } \right ) \\ \leq \;& {\mathbb{P}} \left (|M_\theta -\mathbb{E}[M_\theta ]| \gt \frac {1-e^{-C_\zeta (\gamma )}}{2\sigma } \theta ^{1/\gamma } \cdot \sigma \right )\leq \left (\frac {1-e^{-C_\zeta (\gamma )}}{2\sigma } \theta ^{1/\gamma } \right )^{-2}\leq \frac {4 \theta ^{-(2/\gamma -1)}}{(1-e^{-C_\zeta (\gamma )})^{2}} , \end{align*}
which implies item (i).
The proof of item (ii) is simple. Note that
 $\{\max S\leq n\}=\bigcap _{j=1}^r\{X_j\leq n\}$
and, for each
$\{\max S\leq n\}=\bigcap _{j=1}^r\{X_j\leq n\}$
and, for each
 $j$
,
$j$
,
 \begin{align*} {\mathbb{P}}(X_j \leq n)=\sum _{j=1}^n \mathrm{p}_j &\geq \sum _{j=1}^{\lfloor n/2 \rfloor } C_\zeta (\gamma )j^{-\gamma }\geq 1- C_\zeta (\gamma )\int _{\lfloor n/2 \rfloor }^\infty t^{-\gamma }\mathrm{d}t \geq 1 - \frac {C_\zeta (\gamma )}{\gamma -1} \lfloor n/2 \rfloor ^{1-\gamma }, \end{align*}
\begin{align*} {\mathbb{P}}(X_j \leq n)=\sum _{j=1}^n \mathrm{p}_j &\geq \sum _{j=1}^{\lfloor n/2 \rfloor } C_\zeta (\gamma )j^{-\gamma }\geq 1- C_\zeta (\gamma )\int _{\lfloor n/2 \rfloor }^\infty t^{-\gamma }\mathrm{d}t \geq 1 - \frac {C_\zeta (\gamma )}{\gamma -1} \lfloor n/2 \rfloor ^{1-\gamma }, \end{align*}
and hence, as the
 $X_j$
are independent,
$X_j$
are independent,
 \begin{align*} {\mathbb{P}}(\! \max S\leq n)= {\mathbb{P}}(X_j \leq n)^\theta \geq \left (1 - \frac {C_\zeta (\gamma )}{\gamma -1} \lfloor n/2 \rfloor ^{1-\gamma }\right )^\theta \geq 1- \frac {C_\zeta (\gamma )}{\gamma -1} \theta \lfloor n/2 \rfloor ^{1-\gamma } \end{align*}
\begin{align*} {\mathbb{P}}(\! \max S\leq n)= {\mathbb{P}}(X_j \leq n)^\theta \geq \left (1 - \frac {C_\zeta (\gamma )}{\gamma -1} \lfloor n/2 \rfloor ^{1-\gamma }\right )^\theta \geq 1- \frac {C_\zeta (\gamma )}{\gamma -1} \theta \lfloor n/2 \rfloor ^{1-\gamma } \end{align*}
where the last inequality follows by Bernoulli’s inequality.
Item (iii) is somewhat more involved. We start by outlining the strategy: the set
 $S$
may contain pairs of the form
$S$
may contain pairs of the form
 $(Z_{j},Z_{j+1})=(2i-1,2i)$
, that is, an odd natural number followed by the next even one. We will condition on the set of
$(Z_{j},Z_{j+1})=(2i-1,2i)$
, that is, an odd natural number followed by the next even one. We will condition on the set of
 $j$
where
$j$
where
 $(Z_j,Z_{j+1})$
is such a pair, as well as the specific value of
$(Z_j,Z_{j+1})$
is such a pair, as well as the specific value of
 $Z_j$
.
$Z_j$
.
More precisely, for fixed sets
 $\mathcal{I}$
and
$\mathcal{I}$
and
 $\mathcal{J}$
with
$\mathcal{J}$
with
 $|\mathcal{I}| = |\mathcal{J}|$
, enumerated by
$|\mathcal{I}| = |\mathcal{J}|$
, enumerated by
 \begin{align*} \mathcal{I} = \{i_1,i_2,\dotsc ,i_m\} \text{ and } \mathcal{J} = \{j_1,j_2,\dotsc ,j_m\}, \end{align*}
\begin{align*} \mathcal{I} = \{i_1,i_2,\dotsc ,i_m\} \text{ and } \mathcal{J} = \{j_1,j_2,\dotsc ,j_m\}, \end{align*}
let
 $\mathcal{A} = \{1,\ldots , N\} \setminus \big ( \mathcal{J} \cup (\mathcal{J}+1)\big )$
where
$\mathcal{A} = \{1,\ldots , N\} \setminus \big ( \mathcal{J} \cup (\mathcal{J}+1)\big )$
where
 $\mathcal{J}+1\,:\!=\,\{j+1\,\vert \,j\in \mathcal{J}\}$
. We will condition on the event
$\mathcal{J}+1\,:\!=\,\{j+1\,\vert \,j\in \mathcal{J}\}$
. We will condition on the event
 $F_{\mathcal{I},\mathcal{J}}$
which occurs precisely when
$F_{\mathcal{I},\mathcal{J}}$
which occurs precisely when
 $N = n$
,
$N = n$
,
 $(Z_{j_\ell },Z_{j_\ell +1})=(2i_\ell -1,2i_\ell )$
for
$(Z_{j_\ell },Z_{j_\ell +1})=(2i_\ell -1,2i_\ell )$
for
 $\ell \in \{1,2,\dotsc ,m\}$
, and, on the indices in
$\ell \in \{1,2,\dotsc ,m\}$
, and, on the indices in
 $\mathcal{A}$
, the set
$\mathcal{A}$
, the set
 $S$
contains no odd–even pairs, that is,
$S$
contains no odd–even pairs, that is,
 $(Z_{a},Z_{a+1})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
for all
$(Z_{a},Z_{a+1})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
for all
 $a \in \mathcal{A}$
with
$a \in \mathcal{A}$
with
 $a \lt n$
and
$a \lt n$
and
 $(Z_{a-1},Z_{a})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
for all
$(Z_{a-1},Z_{a})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
for all
 $a \in \mathcal{A}$
with
$a \in \mathcal{A}$
with
 $a \gt 1$
. With varying
$a \gt 1$
. With varying
 $\mathcal{I}$
and
$\mathcal{I}$
and
 $\mathcal{J}$
, these sets
$\mathcal{J}$
, these sets
 $F_{\mathcal{I},\mathcal{J}}$
partition the event
$F_{\mathcal{I},\mathcal{J}}$
partition the event
 $\{N=n\}$
.
$\{N=n\}$
.
The intuition behind this construction is as follows: conditional on
 $F_{\mathcal{I},\mathcal{J}}$
, whenever
$F_{\mathcal{I},\mathcal{J}}$
, whenever
 $j \in \mathcal{J}$
we have
$j \in \mathcal{J}$
we have
 $Z_{j+1} - Z_j = 1$
and hence
$Z_{j+1} - Z_j = 1$
and hence
 $\chi _{\{Z_{j+1}-Z_{j}\text{ odd}\}} = 1$
. Thus for sets
$\chi _{\{Z_{j+1}-Z_{j}\text{ odd}\}} = 1$
. Thus for sets
 $\mathcal{J}$
with
$\mathcal{J}$
with
 $|\mathcal{J}| \geq n/5$
, we are done. If instead
$|\mathcal{J}| \geq n/5$
, we are done. If instead
 $|\mathcal{J}|$
is small, then
$|\mathcal{J}|$
is small, then
 $|\mathcal{A}|$
will be relatively large. For
$|\mathcal{A}|$
will be relatively large. For
 $a \in \mathcal{A}$
, we will argue that every
$a \in \mathcal{A}$
, we will argue that every
 $Z_a$
has equal probability of being an odd number or the even number following it, owing to the assumption that
$Z_a$
has equal probability of being an odd number or the even number following it, owing to the assumption that
 $\mathrm{p}_{2i-1}=\mathrm{p}_{2i}$
and the assumption that if
$\mathrm{p}_{2i-1}=\mathrm{p}_{2i}$
and the assumption that if
 $a \lt n$
then
$a \lt n$
then
 $(Z_{a},Z_{a+1})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
and if
$(Z_{a},Z_{a+1})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
and if
 $a \gt 1$
then
$a \gt 1$
then
 $(Z_{a-1},Z_{a})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
.
$(Z_{a-1},Z_{a})\notin \{ (2i-1,2i)\,\vert \, i\in \mathbb{N}\}$
.
This will allow us to conclude that the indicator random variables
 $\chi _{\{Z_{a}\text{ odd}\}}$
for
$\chi _{\{Z_{a}\text{ odd}\}}$
for
 $a\in \mathcal{A}$
are independent symmetric Bernoulli random variables (that is to say, they take the values
$a\in \mathcal{A}$
are independent symmetric Bernoulli random variables (that is to say, they take the values
 $1$
and
$1$
and
 $0$
each with probability
$0$
each with probability
 $1/2$
). The desired bound will follow by an application of Hoeffding’s inequality.
$1/2$
). The desired bound will follow by an application of Hoeffding’s inequality.
We are now ready to present the formal proof. If
 $\theta \lt 10$
there is nothing to prove, so assume that
$\theta \lt 10$
there is nothing to prove, so assume that
 $\theta \geq 10$
and fix an
$\theta \geq 10$
and fix an
 $n$
such that
$n$
such that
 $10\leq n\leq \theta$
. Consider arbitrary sets
$10\leq n\leq \theta$
. Consider arbitrary sets
 $\mathcal{I}\subset \mathbb{N}$
and
$\mathcal{I}\subset \mathbb{N}$
and
 $\mathcal{J}\subset \{1,\ldots ,n-1\}$
so that
$\mathcal{J}\subset \{1,\ldots ,n-1\}$
so that
 \begin{equation} m\,:\!=\,|\mathcal{I}|=|\mathcal{J}|\lt n \text{ and } \mathcal{J}\cap (\mathcal{J}+1)=\varnothing , \end{equation}
\begin{equation} m\,:\!=\,|\mathcal{I}|=|\mathcal{J}|\lt n \text{ and } \mathcal{J}\cap (\mathcal{J}+1)=\varnothing , \end{equation}
and define
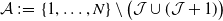 $\mathcal{A}\,:\!=\,\{1,\ldots , N\} \setminus \big ( \mathcal{J} \cup (\mathcal{J}+1) \big )$
. Enumerate
$\mathcal{A}\,:\!=\,\{1,\ldots , N\} \setminus \big ( \mathcal{J} \cup (\mathcal{J}+1) \big )$
. Enumerate
 $\mathcal{I}=\{i_{1},\dotsc ,i_{m}\}$
with
$\mathcal{I}=\{i_{1},\dotsc ,i_{m}\}$
with
 $i_{1}\lt \dotsb \lt i_{m}$
,
$i_{1}\lt \dotsb \lt i_{m}$
,
 $\mathcal{J}=\{j_1,\dotsc ,j_m\}$
with
$\mathcal{J}=\{j_1,\dotsc ,j_m\}$
with
 $j_1\lt \dotsb \lt j_m$
, and
$j_1\lt \dotsb \lt j_m$
, and
 $\mathcal{A}=\{a_1,\dotsc ,a_{n-2m}\}$
with
$\mathcal{A}=\{a_1,\dotsc ,a_{n-2m}\}$
with
 $a_1\lt \dotsb \lt a_{n-2m}$
and define the event
$a_1\lt \dotsb \lt a_{n-2m}$
and define the event
 \begin{align*} \begin{split} F_{\mathcal{I},\mathcal{J}}=\{N=n\}\cap \bigcap _{\ell =1}^m\{(Z_{j_\ell }, Z_{j_\ell +1})&=(2i_\ell -1,2i_\ell )\} \cap \bigcap _{\substack {a\in \mathcal{A}, a\lt n\\ i\in \mathbb{N}}}\{(Z_{a},Z_{a+1})\neq (2i-1,2i)\}\\ &\qquad \cap \bigcap _{\substack {a\in \mathcal{A}, 1\lt a \leq n\\ i\in \mathbb{N}}}\{(Z_{a-1},Z_{a})\neq (2i-1,2i)\}. \end{split} \end{align*}
\begin{align*} \begin{split} F_{\mathcal{I},\mathcal{J}}=\{N=n\}\cap \bigcap _{\ell =1}^m\{(Z_{j_\ell }, Z_{j_\ell +1})&=(2i_\ell -1,2i_\ell )\} \cap \bigcap _{\substack {a\in \mathcal{A}, a\lt n\\ i\in \mathbb{N}}}\{(Z_{a},Z_{a+1})\neq (2i-1,2i)\}\\ &\qquad \cap \bigcap _{\substack {a\in \mathcal{A}, 1\lt a \leq n\\ i\in \mathbb{N}}}\{(Z_{a-1},Z_{a})\neq (2i-1,2i)\}. \end{split} \end{align*}
Note that, for every
 $n\in \mathbb{N}$
, we have
$n\in \mathbb{N}$
, we have
 \begin{equation} \{N=n\}={\bigcup _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}}} F_{\mathcal{I},\mathcal{J}}, \end{equation}
\begin{equation} \{N=n\}={\bigcup _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}}} F_{\mathcal{I},\mathcal{J}}, \end{equation}
that is, the events
 $F_{\mathcal{I},\mathcal{J}}$
for different
$F_{\mathcal{I},\mathcal{J}}$
for different
 $\mathcal{I}$
and
$\mathcal{I}$
and
 $\mathcal{J}$
partition the event
$\mathcal{J}$
partition the event
 $\{N=n\}$
, and thus our strategy will be to prove the bound
$\{N=n\}$
, and thus our strategy will be to prove the bound
 $ {\mathbb{P}}\left (\left .\sum _{j=1}^{N-1} \chi _{\{Z_{j+1}-Z_{j}\text{ odd}\}} \leq n/5 \,\right \rvert \, F_{\mathcal{I},\mathcal{J}} \right ) \leq e^{-n/100}$
for each of these events.
$ {\mathbb{P}}\left (\left .\sum _{j=1}^{N-1} \chi _{\{Z_{j+1}-Z_{j}\text{ odd}\}} \leq n/5 \,\right \rvert \, F_{\mathcal{I},\mathcal{J}} \right ) \leq e^{-n/100}$
for each of these events.
The argument relies on bounding from below the number of indices
 $j$
such that
$j$
such that
 $Z_{j+1}-Z_{j}$
is odd. For
$Z_{j+1}-Z_{j}$
is odd. For
 $j\in \mathcal{J}$
, this will be easy, as
$j\in \mathcal{J}$
, this will be easy, as
 $Z_{j+1}-Z_j=2i_j-(2i_j-1)=1$
is always odd, by definition of
$Z_{j+1}-Z_j=2i_j-(2i_j-1)=1$
is always odd, by definition of
 $F_{\mathcal{I},\mathcal{J}}$
. For
$F_{\mathcal{I},\mathcal{J}}$
. For
 $j\in \mathcal{A}$
, we will need the following claim which we prove last.
$j\in \mathcal{A}$
, we will need the following claim which we prove last.
Claim: For any
 $\mathcal{I}$
,
$\mathcal{I}$
,
 $\mathcal{J}$
and
$\mathcal{J}$
and
 $\mathcal{A}$
as above, the indicator random variables
$\mathcal{A}$
as above, the indicator random variables
 $\chi _{\{Z_{a}\text{ odd}\}}$
,
$\chi _{\{Z_{a}\text{ odd}\}}$
,
 $a\in \mathcal{A}$
, conditional on
$a\in \mathcal{A}$
, conditional on
 $F_{\mathcal{I},\mathcal{J}}$
are independent symmetric Bernoulli variables.
$F_{\mathcal{I},\mathcal{J}}$
are independent symmetric Bernoulli variables.
Armed with the claim, the counting argument is as follows. Note that, on the event
 $F_{\mathcal{I},\mathcal{J}}$
, for
$F_{\mathcal{I},\mathcal{J}}$
, for
 $k\in \{1,\ldots , n-2m-1\}$
such that
$k\in \{1,\ldots , n-2m-1\}$
such that
 $a_{k+1}\gt a_k+1$
, we have that
$a_{k+1}\gt a_k+1$
, we have that
 $\{Z_{a_{k}},\ldots , Z_{a_{k+1}}\}=\{Z_{a_k}, 2i_{t}-1,2i_{t},2i_{t+1}-1,2i_{t+1},\dotsc , 2i_{t+s-1} -1,2i_{t+s-1},Z_{a_{k+1}}\}$
for some
$\{Z_{a_{k}},\ldots , Z_{a_{k+1}}\}=\{Z_{a_k}, 2i_{t}-1,2i_{t},2i_{t+1}-1,2i_{t+1},\dotsc , 2i_{t+s-1} -1,2i_{t+s-1},Z_{a_{k+1}}\}$
for some
 $t \in \{1,2,\dotsc ,m\}$
and where
$t \in \{1,2,\dotsc ,m\}$
and where
 $s=|\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}|$
. Hence,
$s=|\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}|$
. Hence,
 \begin{align} \sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}}&\geq \chi _{\{2i_{t}-1-Z_{a_k}\text{ odd}\}} + \sum _{\ell =0}^{s-1} \chi _{\{ (2i_{t+\ell }) - (2i_{t+\ell }-1) \text{ odd}\}} + \chi _{\{Z_{a_{k+1}}-2i_{t+s-1}\text{ odd}\}}\notag \\ & = \chi _{\{Z_{a_k}\text{ even}\}} + |\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}| + \chi _{\{Z_{a_{k+1}}\text{ odd}\}}\notag \\ & \geq |\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}| + \chi _{\{Z_{a_{k+1}}-Z_{a_k}\text{ even}\}}, \end{align}
\begin{align} \sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}}&\geq \chi _{\{2i_{t}-1-Z_{a_k}\text{ odd}\}} + \sum _{\ell =0}^{s-1} \chi _{\{ (2i_{t+\ell }) - (2i_{t+\ell }-1) \text{ odd}\}} + \chi _{\{Z_{a_{k+1}}-2i_{t+s-1}\text{ odd}\}}\notag \\ & = \chi _{\{Z_{a_k}\text{ even}\}} + |\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}| + \chi _{\{Z_{a_{k+1}}\text{ odd}\}}\notag \\ & \geq |\mathcal{J}\cap \{a_k,\ldots , a_{k+1}-1\}| + \chi _{\{Z_{a_{k+1}}-Z_{a_k}\text{ even}\}}, \end{align}
where we used the simple observation that
 $\chi _{\{Z_{a_k}\text{ even}\}} + \chi _{\{Z_{a_{k+1}}\text{ odd}\}}\geq \chi _{\{Z_{a_{k+1}}-Z_{a_k}\text{ even}\}}$
. This motivates defining random variables
$\chi _{\{Z_{a_k}\text{ even}\}} + \chi _{\{Z_{a_{k+1}}\text{ odd}\}}\geq \chi _{\{Z_{a_{k+1}}-Z_{a_k}\text{ even}\}}$
. This motivates defining random variables
 $E_{a_k}$
with
$E_{a_k}$
with
 $k\in \{1,\ldots , n-2m-1\}$
conditioned on the event
$k\in \{1,\ldots , n-2m-1\}$
conditioned on the event
 $F_{\mathcal{I},\mathcal{J}}$
according to
$F_{\mathcal{I},\mathcal{J}}$
according to
 \begin{align*} E_{a_k}& =\begin{cases} 1,& Z_{a_{k}+1}-Z_{a_k}\text{ is odd}\\[5pt] 0, & Z_{a_{k}+1}-Z_{a_k}\text{ is even} \end{cases}, \quad \text{for $k$ s.t. $a_{k+1}=a_k+1$, and}\\ E_{a_k}&=\begin{cases} 0,& Z_{a_{k+1}}-Z_{a_k}\text{ is odd}\\ 1, & Z_{a_{k+1}}-Z_{a_k}\text{ is even} \end{cases}, \quad \text{for $k$ s.t. $a_{k+1}\gt a_k+1$,} \end{align*}
\begin{align*} E_{a_k}& =\begin{cases} 1,& Z_{a_{k}+1}-Z_{a_k}\text{ is odd}\\[5pt] 0, & Z_{a_{k}+1}-Z_{a_k}\text{ is even} \end{cases}, \quad \text{for $k$ s.t. $a_{k+1}=a_k+1$, and}\\ E_{a_k}&=\begin{cases} 0,& Z_{a_{k+1}}-Z_{a_k}\text{ is odd}\\ 1, & Z_{a_{k+1}}-Z_{a_k}\text{ is even} \end{cases}, \quad \text{for $k$ s.t. $a_{k+1}\gt a_k+1$,} \end{align*}
which, as a consequence of the Claim, are themselves independent symmetric Bernoulli random variables. Thus, writing
 $U\,:\!=\,\sum _{k=1}^{N-1} \chi _{\{Z_{k+1}-Z_{k}\text{ odd}\}}$
, on the event
$U\,:\!=\,\sum _{k=1}^{N-1} \chi _{\{Z_{k+1}-Z_{k}\text{ odd}\}}$
, on the event
 $F_{\mathcal{I},\mathcal{J}}$
we have
$F_{\mathcal{I},\mathcal{J}}$
we have
 \begin{align} U&=\sum _{\ell \lt a_1\text{ or }\, \ell \geq a_{n-2m}} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} + \sum _{k=1 }^{n-2m-1}\sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} \notag \\ &\geq |\mathcal{J}\cap \{1,\ldots , a_1-1\}| + |\mathcal{J}\cap \{a_{n-2m}, \ldots , n\} | \notag \\ &\qquad \qquad + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}=a_k+1}} \chi _{\{Z_{a_{k}+1}-Z_{a_k}\text{ odd}\}} + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}\gt a_k+1}}\sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} \notag \\ &\geq |\mathcal{J}\cap \{1,\ldots , a_1-1\}| + |\mathcal{J}\cap \{a_{n-2m}, \ldots , n\} | \notag \\ &\qquad \qquad + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}=a_k+1}} E_{a_k} + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}\gt a_k+1}}\left ( |\mathcal{J}\cap \{a_k ,\ldots , a_{k+1}-1\}| + E_{a_k} \right ) \notag \\ &=|\mathcal{J}| + \sum _{k=1}^{n-2m-1} E_{a_k}= m+ \sum _{k=1}^{n-2m-1} E_{a_k}, \end{align}
\begin{align} U&=\sum _{\ell \lt a_1\text{ or }\, \ell \geq a_{n-2m}} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} + \sum _{k=1 }^{n-2m-1}\sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} \notag \\ &\geq |\mathcal{J}\cap \{1,\ldots , a_1-1\}| + |\mathcal{J}\cap \{a_{n-2m}, \ldots , n\} | \notag \\ &\qquad \qquad + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}=a_k+1}} \chi _{\{Z_{a_{k}+1}-Z_{a_k}\text{ odd}\}} + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}\gt a_k+1}}\sum _{\ell =a_k}^{a_{k+1}-1} \chi _{\{Z_{\ell +1}-Z_{\ell }\text{ odd}\}} \notag \\ &\geq |\mathcal{J}\cap \{1,\ldots , a_1-1\}| + |\mathcal{J}\cap \{a_{n-2m}, \ldots , n\} | \notag \\ &\qquad \qquad + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}=a_k+1}} E_{a_k} + \sum _{\substack {1\leq k\leq n-2m-1\\a_{k+1}\gt a_k+1}}\left ( |\mathcal{J}\cap \{a_k ,\ldots , a_{k+1}-1\}| + E_{a_k} \right ) \notag \\ &=|\mathcal{J}| + \sum _{k=1}^{n-2m-1} E_{a_k}= m+ \sum _{k=1}^{n-2m-1} E_{a_k}, \end{align}
where the second inequality is due to (5.7) and the penultimate equality follows from the observation that
 $|\mathcal{J}\cap \{a_k ,\ldots , a_{k+1}-1\}| = 0$
whenever
$|\mathcal{J}\cap \{a_k ,\ldots , a_{k+1}-1\}| = 0$
whenever
 $a_{k+1} = a_k + 1$
.
$a_{k+1} = a_k + 1$
.
Now, for sets
 $\mathcal{I}\subset \mathbb{N}$
and
$\mathcal{I}\subset \mathbb{N}$
and
 $\mathcal{J}\subset \{1,\ldots ,n-1\}$
satisfying (5.5) as well as
$\mathcal{J}\subset \{1,\ldots ,n-1\}$
satisfying (5.5) as well as
 $m=|\mathcal{I}|=|\mathcal{J}|\leq n/5$
, we have that (5.8) implies
$m=|\mathcal{I}|=|\mathcal{J}|\leq n/5$
, we have that (5.8) implies
 $U\geq \sum _{k=1}^{n-2m-1} E_{a_k}$
, which together with Hoeffding’s inequality yields
$U\geq \sum _{k=1}^{n-2m-1} E_{a_k}$
, which together with Hoeffding’s inequality yields
 \begin{align*} {\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )& \leq {\mathbb{P}}\Big ( \sum _{k=1}^{n-2m-1} E_{a_k} \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )\\ &\leq \exp \left (-2\Big (\frac {1}{2} - \frac {n/5}{n-2m-1}\Big )^{2}(n-2m-1) \right )\leq \exp \left (- n/100 \right ) \end{align*}
\begin{align*} {\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )& \leq {\mathbb{P}}\Big ( \sum _{k=1}^{n-2m-1} E_{a_k} \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )\\ &\leq \exp \left (-2\Big (\frac {1}{2} - \frac {n/5}{n-2m-1}\Big )^{2}(n-2m-1) \right )\leq \exp \left (- n/100 \right ) \end{align*}
where in the last inequality we used
 $n-2m-1\geq n/2$
(recall that
$n-2m-1\geq n/2$
(recall that
 $n\geq 10$
). On the other hand, in the case when
$n\geq 10$
). On the other hand, in the case when
 $m=|\mathcal{I}|=|\mathcal{J}|\gt n/5$
we have
$m=|\mathcal{I}|=|\mathcal{J}|\gt n/5$
we have
 ${\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )=0$
directly from (5.8).
${\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big )=0$
directly from (5.8).
Therefore, we have shown that for any
 $\mathcal{I}$
,
$\mathcal{I}$
,
 $\mathcal{J}$
satisfying (5.5),
$\mathcal{J}$
satisfying (5.5),
 ${\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big ) \leq \exp (\! -n/100)$
and so using (5.6)
${\mathbb{P}}\Big (U \leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big ) \leq \exp (\! -n/100)$
and so using (5.6)
 \begin{align*} {\mathbb{P}}\Big ( U \leq n/5, N=n \Big )&= \sum _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}} {\mathbb{P}}\Big ( U\leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big ) {\mathbb{P}}(F_{\mathcal{I},\mathcal{J}})\\ &\leq \exp \left (- n/100 \right ) {\mathbb{P}}\Bigg (\bigcup _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}} F_{\mathcal{I},\mathcal{J}} \Bigg ) = \exp \left (- n/100 \right ) {\mathbb{P}}(N=n), \end{align*}
\begin{align*} {\mathbb{P}}\Big ( U \leq n/5, N=n \Big )&= \sum _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}} {\mathbb{P}}\Big ( U\leq n/5 \,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \Big ) {\mathbb{P}}(F_{\mathcal{I},\mathcal{J}})\\ &\leq \exp \left (- n/100 \right ) {\mathbb{P}}\Bigg (\bigcup _{ \substack {\mathcal{I}\subset \mathbb{N}, \mathcal{J}\subset \{1,\ldots ,n-1\}\\\text{satisfying (5.5)}}} F_{\mathcal{I},\mathcal{J}} \Bigg ) = \exp \left (- n/100 \right ) {\mathbb{P}}(N=n), \end{align*}
which yields the desired bound after dividing both sides by
 ${\mathbb{P}}(N=n)$
.
${\mathbb{P}}(N=n)$
.
It remains to prove the Claim. To this end, fix
 $n$
,
$n$
,
 $\mathcal{I}=\{i_1\lt \ldots \lt i_m\}$
,
$\mathcal{I}=\{i_1\lt \ldots \lt i_m\}$
,
 $\mathcal{J}=\{j_1\lt \ldots \lt j_m\}$
and
$\mathcal{J}=\{j_1\lt \ldots \lt j_m\}$
and
 $\mathcal{A}=\{a_1\lt \ldots \lt a_{n-2m}\}$
satisfying (5.5). Then, conditional on
$\mathcal{A}=\{a_1\lt \ldots \lt a_{n-2m}\}$
satisfying (5.5). Then, conditional on
 $F_{\mathcal{I},\mathcal{J}}$
we can write
$F_{\mathcal{I},\mathcal{J}}$
we can write
 $Z_a=2\lceil Z_a/2 \rceil - \chi _{\{Z_{a}\text{ odd}\}}$
, for
$Z_a=2\lceil Z_a/2 \rceil - \chi _{\{Z_{a}\text{ odd}\}}$
, for
 $a\in \mathcal{A}$
, where the
$a\in \mathcal{A}$
, where the
 $\chi _{\{Z_{a}\text{ odd}\}}$
are random variables taking values in
$\chi _{\{Z_{a}\text{ odd}\}}$
are random variables taking values in
 $\{0,1\}$
and the
$\{0,1\}$
and the
 $\lceil Z_a/2 \rceil$
are random variables taking values in
$\lceil Z_a/2 \rceil$
are random variables taking values in
 $\mathbb{N}\setminus \mathcal{I}$
and moreover
$\mathbb{N}\setminus \mathcal{I}$
and moreover
 $\lceil Z_{a_1}/2 \rceil \lt \ldots \lt \lceil Z_{a_{n-2m}}/2 \rceil$
. Now, for a set
$\lceil Z_{a_1}/2 \rceil \lt \ldots \lt \lceil Z_{a_{n-2m}}/2 \rceil$
. Now, for a set
 $\mathcal{U}=\{u_1\lt \ldots \lt u_{n-2m}\}\subset \mathbb{N}\setminus \mathcal{I}$
denote
$\mathcal{U}=\{u_1\lt \ldots \lt u_{n-2m}\}\subset \mathbb{N}\setminus \mathcal{I}$
denote
 $\mathring F_{\mathcal{U}}=\bigcap _{j=1}^{n-2m}\{\lceil Z_{a_j}/2 \rceil =u_j\}$
so that for any
$\mathring F_{\mathcal{U}}=\bigcap _{j=1}^{n-2m}\{\lceil Z_{a_j}/2 \rceil =u_j\}$
so that for any
 $b\in \{0,1\}^{n-2m}$
$b\in \{0,1\}^{n-2m}$
 \begin{align} &{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=b_1,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=b_{n-2m}\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \right )\nonumber\\ &\quad=\,\sum _{\mathcal{U}\subset \mathbb{N}\setminus \mathcal{I}}{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=b_1,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=b_{n-2m}\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}}\cap \mathring F_{\mathcal{U}} \right ) {\mathbb{P}}( \mathring F_{\mathcal{U}} \, \vert \, F_{\mathcal{I},\mathcal{J}}) \nonumber \\ &\quad=\,\sum _{\mathcal{U}\subset \mathbb{N}\setminus \mathcal{I}}{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=0,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=0\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}}\cap \mathring F_{\mathcal{U}} \right ) {\mathbb{P}}( \mathring F_{\mathcal{U}} \, \vert \, F_{\mathcal{I},\mathcal{J}}) \\ &\quad=\,{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=0,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=0\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \right ), \nonumber\end{align}
\begin{align} &{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=b_1,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=b_{n-2m}\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \right )\nonumber\\ &\quad=\,\sum _{\mathcal{U}\subset \mathbb{N}\setminus \mathcal{I}}{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=b_1,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=b_{n-2m}\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}}\cap \mathring F_{\mathcal{U}} \right ) {\mathbb{P}}( \mathring F_{\mathcal{U}} \, \vert \, F_{\mathcal{I},\mathcal{J}}) \nonumber \\ &\quad=\,\sum _{\mathcal{U}\subset \mathbb{N}\setminus \mathcal{I}}{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=0,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=0\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}}\cap \mathring F_{\mathcal{U}} \right ) {\mathbb{P}}( \mathring F_{\mathcal{U}} \, \vert \, F_{\mathcal{I},\mathcal{J}}) \\ &\quad=\,{\mathbb{P}}\left (\{\chi _{\{Z_{a_1}\text{ odd}\}}=0,\; \ldots \; , \chi _{\{Z_{a_{n-2m}}\text{ odd}\}}=0\}\,\Big \rvert \, F_{\mathcal{I},\mathcal{J}} \right ), \nonumber\end{align}
where in (5.9) we used the fact that
 $\mathrm{p}_{2j-1}=\mathrm{p}_{2j}$
, for all
$\mathrm{p}_{2j-1}=\mathrm{p}_{2j}$
, for all
 $j\in \mathbb{N}$
. It hence follows that the
$j\in \mathbb{N}$
. It hence follows that the
 $\chi _{\{Z_{a_j}\text{ odd}\}}$
,
$\chi _{\{Z_{a_j}\text{ odd}\}}$
,
 $1\leq j\leq n-2m$
, conditional on
$1\leq j\leq n-2m$
, conditional on
 $F_{\mathcal{I},\mathcal{J}}$
are independent symmetric Bernoulli variables, establishing the Claim and thus completing the proof.
$F_{\mathcal{I},\mathcal{J}}$
are independent symmetric Bernoulli variables, establishing the Claim and thus completing the proof.
Lemma 5.7. Fix an even
 $K\in \mathbb{N}$
and let
$K\in \mathbb{N}$
and let
 $\{\alpha _j\}_{k=1}^{K}$
be such that
$\{\alpha _j\}_{k=1}^{K}$
be such that
 $0\lt \alpha _{k+1}\lt \alpha _k\lt 1$
for all
$0\lt \alpha _{k+1}\lt \alpha _k\lt 1$
for all
 $1 \leq k \leq K-1$
. Furthermore, let
$1 \leq k \leq K-1$
. Furthermore, let
 $N_0\in \mathbb{N}$
. Then there exists a neural network
$N_0\in \mathbb{N}$
. Then there exists a neural network
 $\psi\,:\,{\mathbb{R}}^{N_0}\to {\mathbb{R}}$
with the ReLU non-linearity
$\psi\,:\,{\mathbb{R}}^{N_0}\to {\mathbb{R}}$
with the ReLU non-linearity
 $\rho (t)=\max \{0,t\}$
such that
$\rho (t)=\max \{0,t\}$
such that
 \begin{equation} \psi (x) =\begin{cases} 0 &\text{ whenever } x_1 \in [\alpha _{k},\alpha _{k - 1}] \text{ with } k \equiv 2 \mod 4\\ 1 & \text{ whenever } x_1 \in [\alpha _{k},\alpha _{k-1}] \text{ with } k \equiv 0 \mod 4 \end{cases},\qquad \text{for all }x\in {\mathbb{R}}^{N_0} \text{ and } k\in \{2,3,\dotsc ,K\}. \end{equation}
\begin{equation} \psi (x) =\begin{cases} 0 &\text{ whenever } x_1 \in [\alpha _{k},\alpha _{k - 1}] \text{ with } k \equiv 2 \mod 4\\ 1 & \text{ whenever } x_1 \in [\alpha _{k},\alpha _{k-1}] \text{ with } k \equiv 0 \mod 4 \end{cases},\qquad \text{for all }x\in {\mathbb{R}}^{N_0} \text{ and } k\in \{2,3,\dotsc ,K\}. \end{equation}
Proof. We may w.l.o.g. assume that
 $K$
is divisible by 4. Indeed, if
$K$
is divisible by 4. Indeed, if
 $K$
is not divisible by
$K$
is not divisible by
 $4$
, we can extend the sequence
$4$
, we can extend the sequence
 $\{\alpha _k\}_{k=1}^{K}$
by adjoining two new elements (say
$\{\alpha _k\}_{k=1}^{K}$
by adjoining two new elements (say
 $\alpha _{K}/2$
and
$\alpha _{K}/2$
and
 $\alpha _K/4$
) at the end of the sequence. We additionally set
$\alpha _K/4$
) at the end of the sequence. We additionally set
 $\alpha _{K+1}=0$
for convenience. Now, for
$\alpha _{K+1}=0$
for convenience. Now, for
 $\ell \in \{1,\ldots , K/4\}$
, define the single-layer neural network
$\ell \in \{1,\ldots , K/4\}$
, define the single-layer neural network
 \begin{align*} \begin{aligned} \psi _\ell (x)&=\left (\alpha _{4\ell -2}-\alpha _{4\ell -1}\right )^{-1} \big ( \rho (\alpha _{4\ell -2} -x_1)- \rho (\alpha _{4\ell -1} -x_1) \big )\\ &\qquad \qquad - \left (\alpha _{4\ell }-\alpha _{4\ell +1}\right )^{-1} \big ( \rho (\alpha _{4\ell } -x_1)- \rho (\alpha _{4\ell +1} -x_1) \big ),\quad \text{for }x\in {\mathbb{R}}^{N_0}. \end{aligned} \end{align*}
\begin{align*} \begin{aligned} \psi _\ell (x)&=\left (\alpha _{4\ell -2}-\alpha _{4\ell -1}\right )^{-1} \big ( \rho (\alpha _{4\ell -2} -x_1)- \rho (\alpha _{4\ell -1} -x_1) \big )\\ &\qquad \qquad - \left (\alpha _{4\ell }-\alpha _{4\ell +1}\right )^{-1} \big ( \rho (\alpha _{4\ell } -x_1)- \rho (\alpha _{4\ell +1} -x_1) \big ),\quad \text{for }x\in {\mathbb{R}}^{N_0}. \end{aligned} \end{align*}
One now easily verifies that
 $\psi _{\ell }(x)=1$
whenever
$\psi _{\ell }(x)=1$
whenever
 $x_1\in [\alpha _{4\ell }, \alpha _{4\ell -1}]$
and
$x_1\in [\alpha _{4\ell }, \alpha _{4\ell -1}]$
and
 $\psi _{\ell }(x)=0$
whenever
$\psi _{\ell }(x)=0$
whenever
 $x_1\in {\mathbb{R}}\setminus (\alpha _{4\ell +1}, \alpha _{4\ell -2})$
. Hence, setting
$x_1\in {\mathbb{R}}\setminus (\alpha _{4\ell +1}, \alpha _{4\ell -2})$
. Hence, setting
 $\psi (x)=\sum _{k=1}^{K/4}\psi _{\ell }(x)$
yields the desired network.
$\psi (x)=\sum _{k=1}^{K/4}\psi _{\ell }(x)$
yields the desired network.
We are now in a position to prove Theorem 2.2:
Proof of Theorem 2.2. We begin by defining the sets
 $\mathcal{C}_1$
and
$\mathcal{C}_1$
and
 $\mathcal{C}_2$
. Let
$\mathcal{C}_2$
. Let
 $\mathcal{C}_1 = \{ f_a: {\mathbb{R}}^d \to [0,1] \, \vert \, a \in [1/2,1]\}$
, where
$\mathcal{C}_1 = \{ f_a: {\mathbb{R}}^d \to [0,1] \, \vert \, a \in [1/2,1]\}$
, where
 $f_a$
is defined as in (5.2). Since all norms on finite dimensional vector spaces are equivalent, let
$f_a$
is defined as in (5.2). Since all norms on finite dimensional vector spaces are equivalent, let
 $D \gt 0$
be such that
$D \gt 0$
be such that
 $\|\cdot \| \leq D \|\cdot \|_1$
. To define the set of distributions, we first set
$\|\cdot \| \leq D \|\cdot \|_1$
. To define the set of distributions, we first set
 $\delta =\epsilon /(2D)$
. For each
$\delta =\epsilon /(2D)$
. For each
 $\kappa \in [1/4,3/4]$
, define the distribution
$\kappa \in [1/4,3/4]$
, define the distribution
 $\mathcal{D}_\kappa$
on
$\mathcal{D}_\kappa$
on
 $[0,1]^{N_0}$
$[0,1]^{N_0}$
 \begin{align*} X\sim \mathcal{D_{\kappa } }\quad \iff \quad {\mathbb{P}}(X=x)=\begin{cases} \mathrm{p}_k & \text{if }x= x^{k,\delta }\\ 0 &\text{otherwise} \end{cases}. \end{align*}
\begin{align*} X\sim \mathcal{D_{\kappa } }\quad \iff \quad {\mathbb{P}}(X=x)=\begin{cases} \mathrm{p}_k & \text{if }x= x^{k,\delta }\\ 0 &\text{otherwise} \end{cases}. \end{align*}
where
 $\mathrm{p}_{2j-1}=\mathrm{p}_{2j}=C_\zeta (3/2)j^{-3/2}$
for
$\mathrm{p}_{2j-1}=\mathrm{p}_{2j}=C_\zeta (3/2)j^{-3/2}$
for
 $j\in \mathbb{N}$
and
$j\in \mathbb{N}$
and
 $x^{k,\delta }$
is defined according to (5.1). We set
$x^{k,\delta }$
is defined according to (5.1). We set
 $\mathcal{C}_2 = \{\mathcal{D}_\kappa \, \vert \, \kappa \in [1/4,3/4]\}$
.
$\mathcal{C}_2 = \{\mathcal{D}_\kappa \, \vert \, \kappa \in [1/4,3/4]\}$
.
Let
 $c_1$
,
$c_1$
,
 $c_2$
and
$c_2$
and
 $C_\zeta (3/2)$
be the constants defined in Lemma5.6 with
$C_\zeta (3/2)$
be the constants defined in Lemma5.6 with
 $\gamma$
set to
$\gamma$
set to
 $3/2$
. We choose the constant
$3/2$
. We choose the constant
 $C$
so that each of the following hold:
$C$
so that each of the following hold:
 \begin{align} C& \geq 4^3c_1^{-6}, \end{align}
\begin{align} C& \geq 4^3c_1^{-6}, \end{align}
 \begin{align} C &\geq 200 \log (8)^{3/2} c_1^{-3/2}, \text{ and} \end{align}
\begin{align} C &\geq 200 \log (8)^{3/2} c_1^{-3/2}, \text{ and} \end{align}
 \begin{align} C &\geq 4\cdot (8c_2)^{2}. \end{align}
\begin{align} C &\geq 4\cdot (8c_2)^{2}. \end{align}
Fix
 $a \in [1/2,1]$
so that
$a \in [1/2,1]$
so that
 $f_a \in \mathcal{C}_1$
and
$f_a \in \mathcal{C}_1$
and
 $\kappa \in [1/4,3/4]$
so that
$\kappa \in [1/4,3/4]$
so that
 $\mathcal{D}_{\kappa } \in \mathcal{C}_2$
. Let
$\mathcal{D}_{\kappa } \in \mathcal{C}_2$
. Let
 $\mathcal{T} = \{x^1, \ldots , x^r\}$
and
$\mathcal{T} = \{x^1, \ldots , x^r\}$
and
 $\mathcal{V} = \{y^1, \ldots , y^s\}$
be the random multisets drawn from this distribution as in the statement of the theorem. Then by the definition of the distribution
$\mathcal{V} = \{y^1, \ldots , y^s\}$
be the random multisets drawn from this distribution as in the statement of the theorem. Then by the definition of the distribution
 $\mathcal{D}_\kappa$
, we can write (after removing repetitions and reordering)
$\mathcal{D}_\kappa$
, we can write (after removing repetitions and reordering)
 $\mathcal{T} \cup \mathcal{V}$
as
$\mathcal{T} \cup \mathcal{V}$
as
 $ S\,:\!=\,\mathcal{T} \cup \mathcal{V} = \{ x^{Z_1,\delta },x^{Z_2,\delta },x^{Z_3,\delta }, \dotsc ,x^{Z_N,\delta }\}$
where the random variable
$ S\,:\!=\,\mathcal{T} \cup \mathcal{V} = \{ x^{Z_1,\delta },x^{Z_2,\delta },x^{Z_3,\delta }, \dotsc ,x^{Z_N,\delta }\}$
where the random variable
 $N$
satisfying
$N$
satisfying
 $N \leq r+s$
is the number of unique elements in
$N \leq r+s$
is the number of unique elements in
 $\mathcal{T}\cup \mathcal{V}$
and where
$\mathcal{T}\cup \mathcal{V}$
and where
 $Z_1 \lt Z_2 \lt \dotsb \lt Z_{N}$
. For shorthand, we also set
$Z_1 \lt Z_2 \lt \dotsb \lt Z_{N}$
. For shorthand, we also set
 $z^j = x^{Z_j,0}$
for
$z^j = x^{Z_j,0}$
for
 $j=1,2,\dotsc ,N$
.
$j=1,2,\dotsc ,N$
.
Since
 $C/2 \geq 2 \cdot (8c_2)^2$
(by (5.13)) and
$C/2 \geq 2 \cdot (8c_2)^2$
(by (5.13)) and
 $C(r\vee s)^2/(2p^2) \geq 4^3c_1^{-6}/2 \geq 2$
(by (5.11) and the facts that
$C(r\vee s)^2/(2p^2) \geq 4^3c_1^{-6}/2 \geq 2$
(by (5.11) and the facts that
 $(r \vee s)/p \geq 1$
and
$(r \vee s)/p \geq 1$
and
 $c_1^{-1} \geq 1$
) we obtain
$c_1^{-1} \geq 1$
) we obtain
 \begin{align*} \frac {C(r\vee s)^2}{p^2} = \frac {C(r\vee s)^2}{2p^2} + \frac {C(r\vee s)^2}{2p^2} \geq 2\cdot \frac {(8c_2)^2(r\vee s)^2}{p^2} +2 \geq 2 \left \lceil {\left (\frac {8c_2 (r \vee s)}{p}\right )^2+1}\right \rceil - 2 \end{align*}
\begin{align*} \frac {C(r\vee s)^2}{p^2} = \frac {C(r\vee s)^2}{2p^2} + \frac {C(r\vee s)^2}{2p^2} \geq 2\cdot \frac {(8c_2)^2(r\vee s)^2}{p^2} +2 \geq 2 \left \lceil {\left (\frac {8c_2 (r \vee s)}{p}\right )^2+1}\right \rceil - 2 \end{align*}
and thus item (ii) of Lemma5.6 with
 $\gamma = 3/2$
yields
$\gamma = 3/2$
yields
 \begin{align} &{\mathbb{P}}\left (\max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T} \cup \mathcal{V} \} \leq \left \lceil {\frac {C (r\vee s)^2}{\mathrm{p}^2}} \right \rceil \right )={\mathbb{P}}\left (Z_N \leq \left \lceil {\frac {C (r\vee s)^2}{\mathrm{p}^2}} \right \rceil \right ) \notag \\ &\quad\geq {\mathbb{P}}\left (Z_N \leq 2{\left \lceil \left (\frac {8c_2 (r \vee s)}{p}\right )^2+1\right \rceil } - 2 \right )\notag \geq 1- \frac {c_2 (r+s)}{\left\lfloor{\left\lceil\left(\frac{8c_2 (r \vee s)}{p}\right)^2+1\right\rceil} - 1 \right\rfloor} \notag \\ &\quad\geq 1- \frac {c_2 (r+s)}{ (8 c_2 (r \vee s)/\mathrm{p})} \geq 1-\mathrm{p}/4. \end{align}
\begin{align} &{\mathbb{P}}\left (\max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T} \cup \mathcal{V} \} \leq \left \lceil {\frac {C (r\vee s)^2}{\mathrm{p}^2}} \right \rceil \right )={\mathbb{P}}\left (Z_N \leq \left \lceil {\frac {C (r\vee s)^2}{\mathrm{p}^2}} \right \rceil \right ) \notag \\ &\quad\geq {\mathbb{P}}\left (Z_N \leq 2{\left \lceil \left (\frac {8c_2 (r \vee s)}{p}\right )^2+1\right \rceil } - 2 \right )\notag \geq 1- \frac {c_2 (r+s)}{\left\lfloor{\left\lceil\left(\frac{8c_2 (r \vee s)}{p}\right)^2+1\right\rceil} - 1 \right\rfloor} \notag \\ &\quad\geq 1- \frac {c_2 (r+s)}{ (8 c_2 (r \vee s)/\mathrm{p})} \geq 1-\mathrm{p}/4. \end{align}
Writing
 $N_{\text{prod}}\,:\!=\,(N_1+1)\cdots (N_{L-1}+1)$
, by the Assumptions (2.3) and (5.12), we obtain
$N_{\text{prod}}\,:\!=\,(N_1+1)\cdots (N_{L-1}+1)$
, by the Assumptions (2.3) and (5.12), we obtain
 \begin{align*} \lfloor c_1 (r+s)^{2/3} \rfloor \geq \lfloor C^{2/3}c_1 qN_{\text{prod}} \rfloor \geq \lfloor 200^{2/3} \log (8)qN_{\text{prod}} \rfloor \geq 30 qN_{\text{prod}}. \end{align*}
\begin{align*} \lfloor c_1 (r+s)^{2/3} \rfloor \geq \lfloor C^{2/3}c_1 qN_{\text{prod}} \rfloor \geq \lfloor 200^{2/3} \log (8)qN_{\text{prod}} \rfloor \geq 30 qN_{\text{prod}}. \end{align*}
Therefore, we can apply item (iii) of Lemma5.6 to see that
 \begin{align} &{\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ f_a(z^{i+1}) \neq f_a(z^{i}) \}} \gt 6 qN_{\text{prod}} \Big ) = {\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ Z_{i+1} - Z_i \text{ odd } \}} \gt 6 qN_{\text{prod}} \Big )\notag \\&\quad\geq \sum _{n=\lfloor c_1(r+s)^{\frac {2}{3}}\! \rfloor }^{r+s} \!\!\!\!\!\!{\mathbb{P}}\Big ( \sum _{i=1}^{n-1} \chi _{\{ Z_{i+1} - Z_i \text{ odd } \}}\gt \frac {n}{5} \,\Big \rvert \, N = n\Big ){\mathbb{P}}(N=n)\notag \\ &\quad\geq \sum _{n=\lfloor c_1(r+s)^{\frac {2}{3}}\! \rfloor }^{r+s} \!\!\!\!\!\!\exp \left (-\frac {n}{100}\right ){\mathbb{P}}(N=n)\notag \\ &\quad\geq \left [1- \exp \left (-\left \lfloor {\frac {c_1 (r+s)^{\frac {2}{3}}} {100}}\right \rfloor \right ) \right ]\cdot {\mathbb{P}}( N \geq \lfloor c_1 (r+s)^{2/3} \rfloor ) \end{align}
\begin{align} &{\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ f_a(z^{i+1}) \neq f_a(z^{i}) \}} \gt 6 qN_{\text{prod}} \Big ) = {\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ Z_{i+1} - Z_i \text{ odd } \}} \gt 6 qN_{\text{prod}} \Big )\notag \\&\quad\geq \sum _{n=\lfloor c_1(r+s)^{\frac {2}{3}}\! \rfloor }^{r+s} \!\!\!\!\!\!{\mathbb{P}}\Big ( \sum _{i=1}^{n-1} \chi _{\{ Z_{i+1} - Z_i \text{ odd } \}}\gt \frac {n}{5} \,\Big \rvert \, N = n\Big ){\mathbb{P}}(N=n)\notag \\ &\quad\geq \sum _{n=\lfloor c_1(r+s)^{\frac {2}{3}}\! \rfloor }^{r+s} \!\!\!\!\!\!\exp \left (-\frac {n}{100}\right ){\mathbb{P}}(N=n)\notag \\ &\quad\geq \left [1- \exp \left (-\left \lfloor {\frac {c_1 (r+s)^{\frac {2}{3}}} {100}}\right \rfloor \right ) \right ]\cdot {\mathbb{P}}( N \geq \lfloor c_1 (r+s)^{2/3} \rfloor ) \end{align}
where the application of Lemma5.6 is justified by the bound
 $\lfloor c_1 (r+s)^{2/3} \rfloor \geq 30 qN_{\text{prod}} \geq 10$
and the initial equality in the first line is justified by the fact that
$\lfloor c_1 (r+s)^{2/3} \rfloor \geq 30 qN_{\text{prod}} \geq 10$
and the initial equality in the first line is justified by the fact that
 $f_a(z^i)$
depends only on the parity of
$f_a(z^i)$
depends only on the parity of
 $i$
, a fact itself readily seen from the definition of
$i$
, a fact itself readily seen from the definition of
 $f_a$
and
$f_a$
and
 $z^i$
.
$z^i$
.
Now, by differentiating it is easy to see that the function
 $p \mapsto p\log (8/p)$
is increasing on
$p \mapsto p\log (8/p)$
is increasing on
 $(0,1)$
. Hence for
$(0,1)$
. Hence for
 $p \lt 1$
, we have
$p \lt 1$
, we have
 $p^{-2}\log (8) \gt p^{-1} \log (8)\gt \log (8/p)$
and so combining this with (2.3) and (5.12) gives
$p^{-2}\log (8) \gt p^{-1} \log (8)\gt \log (8/p)$
and so combining this with (2.3) and (5.12) gives
 \begin{equation} {\left \lfloor \frac {c_1 (r+s)^{2/3}}{100}\right \rfloor } \geq {\left \lfloor \frac {c_1 C^{2/3}\mathrm{p}^{-2}}{100}\right \rfloor } \geq {\left \lfloor \frac {200^{2/3} \mathrm{p}^{-2}\log (8)}{100}\right \rfloor }\geq \mathrm{p}^{-2}\log (8) - 1 \geq \log (8/\mathrm{p}) - 1. \end{equation}
\begin{equation} {\left \lfloor \frac {c_1 (r+s)^{2/3}}{100}\right \rfloor } \geq {\left \lfloor \frac {c_1 C^{2/3}\mathrm{p}^{-2}}{100}\right \rfloor } \geq {\left \lfloor \frac {200^{2/3} \mathrm{p}^{-2}\log (8)}{100}\right \rfloor }\geq \mathrm{p}^{-2}\log (8) - 1 \geq \log (8/\mathrm{p}) - 1. \end{equation}
Furthermore, using item (i) of Lemma5.6 with
 $\gamma =3/2$
, we obtain
$\gamma =3/2$
, we obtain
 ${\mathbb{P}}\big (N \geq c_1 (r+s)^{2/3}\big )\geq 1- c_1^{-2}(r+s)^{-1/3}\geq 1-\mathrm{p}/4,$
where the final bound follows because
${\mathbb{P}}\big (N \geq c_1 (r+s)^{2/3}\big )\geq 1- c_1^{-2}(r+s)^{-1/3}\geq 1-\mathrm{p}/4,$
where the final bound follows because
 $r+s \geq Cp^{-3}$
(which, in turn, is due to the Assumption (2.3)) and (5.11). Using this result together with (5.16) in (5.15) yields
$r+s \geq Cp^{-3}$
(which, in turn, is due to the Assumption (2.3)) and (5.11). Using this result together with (5.16) in (5.15) yields
 \begin{equation} {\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ f_a(z^{j+1}) \neq f_a(z^{j}) \}} \gt 6 qN_{\text{prod}} \Big ) \gt \left ( 1- e\mathrm{p}/8\right )\left (1-\mathrm{p}/{4}\right ) \gt 1- \mathrm{p}/2 \end{equation}
\begin{equation} {\mathbb{P}}\Big (\sum _{i=1}^{N-1} \chi _{\{ f_a(z^{j+1}) \neq f_a(z^{j}) \}} \gt 6 qN_{\text{prod}} \Big ) \gt \left ( 1- e\mathrm{p}/8\right )\left (1-\mathrm{p}/{4}\right ) \gt 1- \mathrm{p}/2 \end{equation}
Combining (5.14) and (5.17), we see that the probability that both
 \begin{equation} \max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T}\cup \mathcal{V}\} \leq {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil } \quad \text{and } \sum _{i=1}^{N-1} \chi _{\{ f_a(z^{i+1}) \neq f_a(z^{i}) \}} \gt 6 qN_{\text{prod}} \end{equation}
\begin{equation} \max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T}\cup \mathcal{V}\} \leq {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil } \quad \text{and } \sum _{i=1}^{N-1} \chi _{\{ f_a(z^{i+1}) \neq f_a(z^{i}) \}} \gt 6 qN_{\text{prod}} \end{equation}
occur is at least
 $1-(\mathrm{p}/4+ \mathrm{p}/2)\gt 1- \mathrm{p}$
. We will now proceed to show that each of (i) through (iii) listed as in the statement of Theorem 2.2 hold assuming that this event occurs.
$1-(\mathrm{p}/4+ \mathrm{p}/2)\gt 1- \mathrm{p}$
. We will now proceed to show that each of (i) through (iii) listed as in the statement of Theorem 2.2 hold assuming that this event occurs.
Proof of (i): Success – great generalisability
To see that
 $\mathcal{T}, \mathcal{V} \in \mathcal{S}^f_{\varepsilon ((r\vee s)/\mathrm{p})}$
, note that (5.12) and
$\mathcal{T}, \mathcal{V} \in \mathcal{S}^f_{\varepsilon ((r\vee s)/\mathrm{p})}$
, note that (5.12) and
 $c_1^{-1} \geq 1$
yields
$c_1^{-1} \geq 1$
yields
 $C^{2}t^{2}\geq (4\lceil t \rceil +3)(4\lceil t \rceil +4)$
for all
$C^{2}t^{2}\geq (4\lceil t \rceil +3)(4\lceil t \rceil +4)$
for all
 $t\geq 1$
. Applying this inequality with
$t\geq 1$
. Applying this inequality with
 $t = C ((r\vee s)/\mathrm{p})^2\geq 1$
, we deduce that
$t = C ((r\vee s)/\mathrm{p})^2\geq 1$
, we deduce that
 \begin{align} \varepsilon \left [\frac {C(r\vee s)}{\mathrm{p}}\right ] = C^{-2} \left ( \frac {C(r\vee s)^2}{\mathrm{p}^2}\right )^{-2}&\leq \left [\left (4 {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil } +3\right )\left (4 {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2}\right \rceil } +4\right )\right ]^{-1}\notag \\&=\varepsilon '\left ({\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2}\right \rceil }\right ) , \end{align}
\begin{align} \varepsilon \left [\frac {C(r\vee s)}{\mathrm{p}}\right ] = C^{-2} \left ( \frac {C(r\vee s)^2}{\mathrm{p}^2}\right )^{-2}&\leq \left [\left (4 {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil } +3\right )\left (4 {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2}\right \rceil } +4\right )\right ]^{-1}\notag \\&=\varepsilon '\left ({\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2}\right \rceil }\right ) , \end{align}
where
 $\varepsilon '(n)=[(4n+3)(4n+4)]^{-1}$
. Therefore because we assume that
$\varepsilon '(n)=[(4n+3)(4n+4)]^{-1}$
. Therefore because we assume that
 $\max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T}\cup \mathcal{V} \} \leq {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil }$
, Lemma5.2 yields
$\max \{k\in \mathbb{N}\,\vert \, x^{k,\delta }\in \mathcal{T}\cup \mathcal{V} \} \leq {\left \lceil \frac {C(r\vee s)^2}{\mathrm{p}^2} \right \rceil }$
, Lemma5.2 yields
 $\mathcal{T},\mathcal{V}\subset \{x^{1,\delta }, \ldots , x^{ \lceil {C(r\vee s)^2/\mathrm{p}^2} ,\delta \rceil } \}\in \mathcal{S}^{f_a}_{\varepsilon '(\lceil {C(r\vee s)^2/\mathrm{p}^2}\rceil )}\subset \mathcal{S}^{f_a}_{\varepsilon (C(r\vee s)/\mathrm{p})}$
.
$\mathcal{T},\mathcal{V}\subset \{x^{1,\delta }, \ldots , x^{ \lceil {C(r\vee s)^2/\mathrm{p}^2} ,\delta \rceil } \}\in \mathcal{S}^{f_a}_{\varepsilon '(\lceil {C(r\vee s)^2/\mathrm{p}^2}\rceil )}\subset \mathcal{S}^{f_a}_{\varepsilon (C(r\vee s)/\mathrm{p})}$
.
The construction of
 $\phi$
satisfying (2.5) is immediate: we take
$\phi$
satisfying (2.5) is immediate: we take
 $\phi$
to be the neural network
$\phi$
to be the neural network
 $\tilde {\varphi }$
defined in Lemma5.3. We conclude that
$\tilde {\varphi }$
defined in Lemma5.3. We conclude that
 ${\phi }(x) = f_a(x)$
for all
${\phi }(x) = f_a(x)$
for all
 $x \in \mathcal{T} \cup \mathcal{V}$
(this establishes (2.5)). Because
$x \in \mathcal{T} \cup \mathcal{V}$
(this establishes (2.5)). Because
 ${\phi }(x) = f_a(x)$
for all
${\phi }(x) = f_a(x)$
for all
 $x \in \mathcal{T}$
and because
$x \in \mathcal{T}$
and because
 $\mathcal{R} \in \mathcal{CF}_{r}$
we conclude that
$\mathcal{R} \in \mathcal{CF}_{r}$
we conclude that
 $\mathcal{R} \left (\{\phi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ) = 0$
. Thus (2.4) holds, completing the proof of (i).
$\mathcal{R} \left (\{\phi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ) = 0$
. Thus (2.4) holds, completing the proof of (i).
Proof of (ii):
Any successful NN in
 $\boldsymbol{\mathcal{NN}}_{\textbf{N},\kern0.3pt \textit{L}}$
– regardless of architecture – becomes universally unstable
$\boldsymbol{\mathcal{NN}}_{\textbf{N},\kern0.3pt \textit{L}}$
– regardless of architecture – becomes universally unstable
Our next task will be to show that if
 $\hat \phi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
and
$\hat \phi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
and
 $g: {\mathbb{R}} \to {\mathbb{R}}$
is monotonic, then there is a subset
$g: {\mathbb{R}} \to {\mathbb{R}}$
is monotonic, then there is a subset
 $\mathcal{\tilde T}\subset \mathcal{T} \cup \mathcal{V}$
of the combined training and validation set of size
$\mathcal{\tilde T}\subset \mathcal{T} \cup \mathcal{V}$
of the combined training and validation set of size
 $|\mathcal{\tilde T}| \geq q$
, such that there exist uncountably many universal adversarial perturbations
$|\mathcal{\tilde T}| \geq q$
, such that there exist uncountably many universal adversarial perturbations
 $\eta \in \mathbb{R}^d$
so that for each
$\eta \in \mathbb{R}^d$
so that for each
 $x \in \mathcal{\tilde T}$
Eq. (2.6) applies.
$x \in \mathcal{\tilde T}$
Eq. (2.6) applies.
To this end, note that (5.18) implies that there exist natural numbers
 $k_1\lt k_2\lt \ldots \lt k_{6qN_{\text{prod}}}$
such that
$k_1\lt k_2\lt \ldots \lt k_{6qN_{\text{prod}}}$
such that
 $z^{k_i}_1\gt z^{k_{i+1}}_1$
and
$z^{k_i}_1\gt z^{k_{i+1}}_1$
and
 $f_a(z^{k_i})\neq f_a(z^{k_{i+1}})$
for all
$f_a(z^{k_i})\neq f_a(z^{k_{i+1}})$
for all
 $i\in \{1,\dotsc , 6qN_{\text{prod}}-1\}$
. Moreover, by the definition of
$i\in \{1,\dotsc , 6qN_{\text{prod}}-1\}$
. Moreover, by the definition of
 $\mathcal{T}$
,
$\mathcal{T}$
,
 $\mathcal{V}$
and
$\mathcal{V}$
and
 $S$
, there exist
$S$
, there exist
 $m_i$
such that
$m_i$
such that
 $z^{k_i}_1 = x^{m_i,\delta }_1$
and such that
$z^{k_i}_1 = x^{m_i,\delta }_1$
and such that
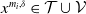 $x^{m_i,\delta } \in \mathcal{T} \cup \mathcal{V}$
. For such
$x^{m_i,\delta } \in \mathcal{T} \cup \mathcal{V}$
. For such
 $i$
and any
$i$
and any
 $\omega \in [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}) )$
, we define the vectors
$\omega \in [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}) )$
, we define the vectors
 $w^{i,\omega } = z^{k_i}+\omega e_1$
. We also define the sets
$w^{i,\omega } = z^{k_i}+\omega e_1$
. We also define the sets
 $\mathcal{W}^{\omega }\,:\!=\,\{ w^{i,\omega } \, \vert \, i\in \{1,\dotsc , 6qN_{\text{prod}}\}\}$
.
$\mathcal{W}^{\omega }\,:\!=\,\{ w^{i,\omega } \, \vert \, i\in \{1,\dotsc , 6qN_{\text{prod}}\}\}$
.
Because of the definition of
 $x^{k,0}$
given in (5.1) and the definition of
$x^{k,0}$
given in (5.1) and the definition of
 $z^{k_i}$
, we have
$z^{k_i}$
, we have
 $z^{k_i}_2 = z^{k_i}_3 = \dotsb = z^{k_i}_d = 0$
and
$z^{k_i}_2 = z^{k_i}_3 = \dotsb = z^{k_i}_d = 0$
and
 $z^{k_i} = x^{m_i,0}$
. In particular,
$z^{k_i} = x^{m_i,0}$
. In particular,
 $\{z^{k_i} \, \vert \, i \in \{1,\dotsc , 6qN_{\text{prod}}\}\} = \{ x^{m_i,0} \, \vert \, i\in \{1,\dotsc , 6qN_{\text{prod}}\} \} \in \mathcal{S}^{f_a}_{\varepsilon ((r\vee s)/\mathrm{p})}$
where we have used Lemma5.2 and the bound (5.19). Since
$\{z^{k_i} \, \vert \, i \in \{1,\dotsc , 6qN_{\text{prod}}\}\} = \{ x^{m_i,0} \, \vert \, i\in \{1,\dotsc , 6qN_{\text{prod}}\} \} \in \mathcal{S}^{f_a}_{\varepsilon ((r\vee s)/\mathrm{p})}$
where we have used Lemma5.2 and the bound (5.19). Since
 $\|z ^{k_i} - w^{i,\omega }\|_{\infty } = \omega \lt \varepsilon ((r\vee s)/\mathrm{p})$
, we conclude that
$\|z ^{k_i} - w^{i,\omega }\|_{\infty } = \omega \lt \varepsilon ((r\vee s)/\mathrm{p})$
, we conclude that
 $f_a(z^{k_i}) = f_a(w^{i,\omega })$
for
$f_a(z^{k_i}) = f_a(w^{i,\omega })$
for
 $i \in \{1,\dotsc , 6qN_{\text{prod}}\}$
. Thus,
$i \in \{1,\dotsc , 6qN_{\text{prod}}\}$
. Thus,
 $f_a(w^{i,\omega }) = f_a(z^{k_i}) \neq f_a(z^{k_{i+1}}) = f_a(w^{i+1,\omega })$
for
$f_a(w^{i,\omega }) = f_a(z^{k_i}) \neq f_a(z^{k_{i+1}}) = f_a(w^{i+1,\omega })$
for
 $i \in \{1,\dotsc , 6qN_{\text{prod}}-1\}$
.
$i \in \{1,\dotsc , 6qN_{\text{prod}}-1\}$
.
We can now use Lemma5.4 to conclude that for each
 $\omega \in [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}) )$
there exists a set
$\omega \in [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}) )$
there exists a set
 $\mathcal{I}^{\omega }$
and a set
$\mathcal{I}^{\omega }$
and a set
 $\mathcal{U}^{\omega }\subset \mathcal{W}^{\omega }$
with the following properties:
$\mathcal{U}^{\omega }\subset \mathcal{W}^{\omega }$
with the following properties:
-
(1)
$\mathcal{I}^{\omega } \subset \{1,2,\dotsc ,6qN_{\text{prod}}\}$
-
(2)
$\mathcal{U}^{\omega } = \{ w^{i,\omega } \, \vert \, i\in \mathcal{I}^{\omega }\}$
-
(3) For all
$w \in \mathcal{U}^{\omega }$
,
$|g(\hat \phi (w)) - f_a(w)| \geq 1/2$
. -
(4)
$|\mathcal{U}^{\omega }| \geq 2q$
.





By the pigeonhole principle and the finiteness of
 $\{1,2,\dotsc ,6qN_{\text{prod}}\}$
, there exists an uncountable set
$\{1,2,\dotsc ,6qN_{\text{prod}}\}$
, there exists an uncountable set
 $\Omega \subset [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}))$
such that for all
$\Omega \subset [0,\delta \wedge \varepsilon ((r\vee s)/\mathrm{p}))$
such that for all
 $\omega \in \Omega$
,
$\omega \in \Omega$
,
 $\mathcal{I}^{\omega }$
is independent of
$\mathcal{I}^{\omega }$
is independent of
 $\omega$
. Let
$\omega$
. Let
 $\mathcal{I}$
denote this common value and let
$\mathcal{I}$
denote this common value and let
 $\mathcal{I}_{E}\,:\!=\,\{i \, \vert \, i \in \mathcal{I}, m_i \text{ even}\}$
and
$\mathcal{I}_{E}\,:\!=\,\{i \, \vert \, i \in \mathcal{I}, m_i \text{ even}\}$
and
 $\mathcal{I}_{O}\,:\!=\,\{i \, \vert \, i \in \mathcal{I}, m_i \text{ odd}\}$
. Note that
$\mathcal{I}_{O}\,:\!=\,\{i \, \vert \, i \in \mathcal{I}, m_i \text{ odd}\}$
. Note that
 $|\mathcal{I}| \geq 2q$
; otherwise,
$|\mathcal{I}| \geq 2q$
; otherwise,
 $|\mathcal{U}^{\omega }| \lt 2q$
for some
$|\mathcal{U}^{\omega }| \lt 2q$
for some
 $\omega$
. Therefore, at least one of
$\omega$
. Therefore, at least one of
 $|\mathcal{I}_E|\geq q$
or
$|\mathcal{I}_E|\geq q$
or
 $|\mathcal{I}_O|\geq q$
: we now split into two cases depending on which of these two sets has cardinality at least
$|\mathcal{I}_O|\geq q$
: we now split into two cases depending on which of these two sets has cardinality at least
 $q$
.
$q$
.
Case 1:
 $|\mathcal{I}_E|\geq q$
.
$|\mathcal{I}_E|\geq q$
.
In this case, we choose
 $\tilde {\mathcal{T}} = \{x^{m_i,\delta } \, \vert \, i \in \mathcal{I}_E\}$
. For each
$\tilde {\mathcal{T}} = \{x^{m_i,\delta } \, \vert \, i \in \mathcal{I}_E\}$
. For each
 $\omega \in \Omega$
, define
$\omega \in \Omega$
, define
 $\eta ^{\omega } = (\omega ,-\delta ,0,\dotsc ,0) \in {\mathbb{R}}^d$
and
$\eta ^{\omega } = (\omega ,-\delta ,0,\dotsc ,0) \in {\mathbb{R}}^d$
and
 $\mathcal{H} = \{ \eta ^{\omega } \, \vert \, \omega \in \Omega \}$
. Then the set
$\mathcal{H} = \{ \eta ^{\omega } \, \vert \, \omega \in \Omega \}$
. Then the set
 $\mathcal{H}$
is uncountable, for each
$\mathcal{H}$
is uncountable, for each
 $i \in \mathcal{I}_E$
and
$i \in \mathcal{I}_E$
and
 $\omega \in \Omega$
we have
$\omega \in \Omega$
we have
 $x^{m_i,\delta } + \eta ^{\omega } = w^{i,\omega }$
,
$x^{m_i,\delta } + \eta ^{\omega } = w^{i,\omega }$
,
 $|g(\hat \phi (x^{m_i,\delta } + \eta ^{\omega })) - f_a(x^{m_i,\delta } + \eta ^{\omega })| = |g(\hat \phi (w^{i,\omega })) - f_a(w^{i,\omega })| \geq 1/2$
and
$|g(\hat \phi (x^{m_i,\delta } + \eta ^{\omega })) - f_a(x^{m_i,\delta } + \eta ^{\omega })| = |g(\hat \phi (w^{i,\omega })) - f_a(w^{i,\omega })| \geq 1/2$
and
 $\|\eta \| \leq D\|\eta ^{\omega }\|_1 = D(\omega + \delta ) \leq 2D\delta \leq \epsilon$
. Furthermore,
$\|\eta \| \leq D\|\eta ^{\omega }\|_1 = D(\omega + \delta ) \leq 2D\delta \leq \epsilon$
. Furthermore,
 $|\text{supp}(\eta ^\omega )| = 2$
. We conclude that (2.6) holds.
$|\text{supp}(\eta ^\omega )| = 2$
. We conclude that (2.6) holds.
Case 2:
 $|\mathcal{I}_O| \geq q$
$|\mathcal{I}_O| \geq q$
In this case, we choose
 $\tilde {\mathcal{T}} = \{x^{m_i,\delta } \, \vert \, i \in \mathcal{I}_O\}$
. For each
$\tilde {\mathcal{T}} = \{x^{m_i,\delta } \, \vert \, i \in \mathcal{I}_O\}$
. For each
 $\omega \in \Omega$
, define
$\omega \in \Omega$
, define
 $\eta ^{\omega } = (\omega ,0,0,\dotsc ,0) \in {\mathbb{R}}^d$
and
$\eta ^{\omega } = (\omega ,0,0,\dotsc ,0) \in {\mathbb{R}}^d$
and
 $\mathcal{H} = \{ \eta ^{\omega } \, \vert \, \omega \in \Omega \}$
. Then the set
$\mathcal{H} = \{ \eta ^{\omega } \, \vert \, \omega \in \Omega \}$
. Then the set
 $\mathcal{H}$
is uncountable, for each
$\mathcal{H}$
is uncountable, for each
 $i \in \mathcal{I}_O$
and
$i \in \mathcal{I}_O$
and
 $\omega \in \Omega$
we have
$\omega \in \Omega$
we have
 $x^{m_i,\delta } + \eta ^{\omega } = w^{i,\omega }$
,
$x^{m_i,\delta } + \eta ^{\omega } = w^{i,\omega }$
,
 $|g(\hat \phi (x^{m_i,\delta } + \eta ^{\omega })) - f_a(x^{m_i,\delta } + \eta ^{\omega })| = |g(\hat \phi (w^{i,\omega })) - f_a(w^{i,\omega })| \geq 1/2$
and
$|g(\hat \phi (x^{m_i,\delta } + \eta ^{\omega })) - f_a(x^{m_i,\delta } + \eta ^{\omega })| = |g(\hat \phi (w^{i,\omega })) - f_a(w^{i,\omega })| \geq 1/2$
and
 $\|\eta ^{\omega }\| \leq D\|\eta ^{\omega }\|_1 = D\omega \leq D\delta \leq \epsilon$
. Furthermore,
$\|\eta ^{\omega }\| \leq D\|\eta ^{\omega }\|_1 = D\omega \leq D\delta \leq \epsilon$
. Furthermore,
 $|\text{supp}(\eta ^\omega )| = 1$
. We conclude that (2.6) holds.
$|\text{supp}(\eta ^\omega )| = 1$
. We conclude that (2.6) holds.
Proof of (iii): Other stable and accurate NNs exist
Finally, we must show the existence of
 $\psi$
, which we do with the help of Lemma5.7. To this end, we set
$\psi$
, which we do with the help of Lemma5.7. To this end, we set
 $K= \lceil C ((r\vee s)/\mathrm{p})^2 \rceil$
and define
$K= \lceil C ((r\vee s)/\mathrm{p})^2 \rceil$
and define
 $\{\alpha _j\}_{j=1}^{2K}$
by
$\{\alpha _j\}_{j=1}^{2K}$
by
 $ \alpha _{2k-1}=x_1^{k,\delta }+ \varepsilon ((r\vee s)/\mathrm{p})$
,
$ \alpha _{2k-1}=x_1^{k,\delta }+ \varepsilon ((r\vee s)/\mathrm{p})$
,
 $ \alpha _{2k}= x_1^{k,\delta }-\varepsilon ((r\vee s)/\mathrm{p})$
for
$ \alpha _{2k}= x_1^{k,\delta }-\varepsilon ((r\vee s)/\mathrm{p})$
for
 $k=1,\ldots , K$
. We first claim that
$k=1,\ldots , K$
. We first claim that
 $0 \lt \alpha _{2K} \lt \alpha _{2K-1} \lt \dotsb \lt \alpha _2 \lt \alpha _1 \lt 1$
.
$0 \lt \alpha _{2K} \lt \alpha _{2K-1} \lt \dotsb \lt \alpha _2 \lt \alpha _1 \lt 1$
.
Because
 $C \geq 4^3$
,
$C \geq 4^3$
,
 $p \leq 1$
and
$p \leq 1$
and
 $(r \vee s) \geq 1$
we have
$(r \vee s) \geq 1$
we have
 \begin{align*} \alpha _1 = \frac {a}{2-\kappa } + \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} \leq \frac {1}{(2-3/4)} + \frac {1}{C^4} \lt 1 \end{align*}
\begin{align*} \alpha _1 = \frac {a}{2-\kappa } + \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} \leq \frac {1}{(2-3/4)} + \frac {1}{C^4} \lt 1 \end{align*}
and similarly we obtain
 $2\lceil C ((r\vee s)/\mathrm{p})^2 \rceil + 1 - \kappa \leq 2(C ((r\vee s)/\mathrm{p})^2) + 2 - \kappa \leq 4(C ((r\vee s)/\mathrm{p})^2)$
. Therefore,
$2\lceil C ((r\vee s)/\mathrm{p})^2 \rceil + 1 - \kappa \leq 2(C ((r\vee s)/\mathrm{p})^2) + 2 - \kappa \leq 4(C ((r\vee s)/\mathrm{p})^2)$
. Therefore,
 \begin{align*} \alpha _{2K} = \frac {a}{2\lceil C ((r\vee s)/\mathrm{p})^2 \rceil + 1 - \kappa } - \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} &\geq \frac {a}{4C ((r\vee s)/\mathrm{p})^2} - \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} \\&\geq \frac {\mathrm{p}^2}{8C (r\vee s)^2} - \frac {\mathrm{p}^2}{4^{12}C (r\vee s)^2}\gt 0 \end{align*}
\begin{align*} \alpha _{2K} = \frac {a}{2\lceil C ((r\vee s)/\mathrm{p})^2 \rceil + 1 - \kappa } - \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} &\geq \frac {a}{4C ((r\vee s)/\mathrm{p})^2} - \frac {\mathrm{p}^4}{C^4 (r\vee s)^4} \\&\geq \frac {\mathrm{p}^2}{8C (r\vee s)^2} - \frac {\mathrm{p}^2}{4^{12}C (r\vee s)^2}\gt 0 \end{align*}
A simple calculation also shows that for each
 $j=1,\ldots , K -1$
$j=1,\ldots , K -1$
 \begin{align*} x^{j,\delta }_1 - x^{j+1,\delta }_1 = \frac {a}{(j+2-\kappa )(j+1-\kappa )} \geq \frac {a}{(K+1-\kappa )(K-\kappa )} \geq [2(K+1-\kappa )(K-\kappa )]^{-1}. \end{align*}
\begin{align*} x^{j,\delta }_1 - x^{j+1,\delta }_1 = \frac {a}{(j+2-\kappa )(j+1-\kappa )} \geq \frac {a}{(K+1-\kappa )(K-\kappa )} \geq [2(K+1-\kappa )(K-\kappa )]^{-1}. \end{align*}
On the other hand, once again employing the result that
 $C^{2}t^{2}\geq (4\lceil t \rceil +3)(4\lceil t \rceil +4)$
, for all
$C^{2}t^{2}\geq (4\lceil t \rceil +3)(4\lceil t \rceil +4)$
, for all
 $t\geq 1$
, (which is a consequence of (5.12)) with
$t\geq 1$
, (which is a consequence of (5.12)) with
 $t = C((r\vee s)/\mathrm{p})^2$
we obtain
$t = C((r\vee s)/\mathrm{p})^2$
we obtain
 \begin{align*} 2\varepsilon ((r\vee s)/\mathrm{p}) = 2 C^{-2} ( C((r\vee s)/\mathrm{p})^2)^{-2}\leq 2[(4K+3)(4K+4)]^{-1} \lt [2(K+1 - \kappa )(K -\kappa )]^{-1}. \end{align*}
\begin{align*} 2\varepsilon ((r\vee s)/\mathrm{p}) = 2 C^{-2} ( C((r\vee s)/\mathrm{p})^2)^{-2}\leq 2[(4K+3)(4K+4)]^{-1} \lt [2(K+1 - \kappa )(K -\kappa )]^{-1}. \end{align*}
We therefore conclude that
 $\alpha _{2j-1} \gt \alpha _{2j} = x^{j,\delta }_1 -\varepsilon ((r\vee s)/\mathrm{p}) \gt x^{j+1,\delta }_1 +\varepsilon ((r\vee s)/\mathrm{p}) = \alpha _{2j+1}$
, and thus the conditions to apply Lemma5.7 are met.
$\alpha _{2j-1} \gt \alpha _{2j} = x^{j,\delta }_1 -\varepsilon ((r\vee s)/\mathrm{p}) \gt x^{j+1,\delta }_1 +\varepsilon ((r\vee s)/\mathrm{p}) = \alpha _{2j+1}$
, and thus the conditions to apply Lemma5.7 are met.
Now, let
 $\psi$
be the network provided by Lemma5.7 with this sequence
$\psi$
be the network provided by Lemma5.7 with this sequence
 $\{\alpha _j\}_{j=1}^{2K}$
. Because of the definition of
$\{\alpha _j\}_{j=1}^{2K}$
. Because of the definition of
 $\alpha _j$
and the conclusion of Lemma5.7 we have
$\alpha _j$
and the conclusion of Lemma5.7 we have
 \begin{align*} \psi (x) = \begin{cases} 0 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is odd} \\ 1 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is even} \end{cases} \end{align*}
\begin{align*} \psi (x) = \begin{cases} 0 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is odd} \\ 1 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is even} \end{cases} \end{align*}
Moreover, because of Lemma5.2, the fact that the value of
 $f_a(x)$
depends only on
$f_a(x)$
depends only on
 $x_1$
and the bound (5.19)
$x_1$
and the bound (5.19)
 \begin{align*} f_a(x) = \begin{cases} 0 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is odd} \\ 1 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is even} \end{cases} \end{align*}
\begin{align*} f_a(x) = \begin{cases} 0 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is odd} \\ 1 & \text{ if } x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})] \text{ and } k \text{ is even} \end{cases} \end{align*}
In particular,
 $\psi (x) = f_a(x)$
whenever
$\psi (x) = f_a(x)$
whenever
 $x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})]$
for any
$x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})]$
for any
 $k \in \{1,2,\dotsc ,K\}$
.
$k \in \{1,2,\dotsc ,K\}$
.
To see that
 $\psi (x) = f_a(x)$
for all
$\psi (x) = f_a(x)$
for all
 $x \in \mathcal{B}_{\varepsilon ((r\vee s)/\mathrm{p})}^{\infty }(\mathcal{T} \cup \mathcal{V})$
, note that, for every
$x \in \mathcal{B}_{\varepsilon ((r\vee s)/\mathrm{p})}^{\infty }(\mathcal{T} \cup \mathcal{V})$
, note that, for every
 $x \in \mathcal{B}_{\varepsilon ((r\vee s)/\mathrm{p})}^{\infty }(\mathcal{T} \cup \mathcal{V})$
, there exists an
$x \in \mathcal{B}_{\varepsilon ((r\vee s)/\mathrm{p})}^{\infty }(\mathcal{T} \cup \mathcal{V})$
, there exists an
 $x^{k,\delta }\in \mathcal{T}\cup \mathcal{V}$
such that
$x^{k,\delta }\in \mathcal{T}\cup \mathcal{V}$
such that
 $\|x^{k,\delta }-x\|_\infty \leq \varepsilon ((r\vee s)/\mathrm{p})$
. Then, by the assumption that
$\|x^{k,\delta }-x\|_\infty \leq \varepsilon ((r\vee s)/\mathrm{p})$
. Then, by the assumption that
 $\max \{\ell \in \mathbb{N}\,\vert \, x^{\ell ,\delta }\in \mathcal{T} \cup \mathcal{V} \} \leq \lceil C ((r \vee s)/\mathrm{p})^2 \rceil$
occurs in (5.18), we have
$\max \{\ell \in \mathbb{N}\,\vert \, x^{\ell ,\delta }\in \mathcal{T} \cup \mathcal{V} \} \leq \lceil C ((r \vee s)/\mathrm{p})^2 \rceil$
occurs in (5.18), we have
 $k\leq K$
, and so
$k\leq K$
, and so
 $x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})]$
. But we have already shown that for such
$x_1 \in [x^{k,\delta }_1 - \varepsilon ((r\vee s)/\mathrm{p}), x^{k,\delta }_1 + \varepsilon ((r\vee s)/\mathrm{p})]$
. But we have already shown that for such
 $x$
,
$x$
,
 $\psi (x) = f_a(x)$
. Thus, the proof of the theorem is complete.
$\psi (x) = f_a(x)$
. Thus, the proof of the theorem is complete.
5.4. Tools from the SCI hierarchy used for Theorem 3.5
In order to formalise the non-computability result stated in Theorem 3.5, we shall summarise appropriate definitions and ideas on the ‘SCI hierarchy’ [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel11–Reference Ben-Artzi, Marletta and Rösler13, Reference Colbrook, Antun and Hansen25, Reference Doyle and McMullen30, Reference Hansen43, Reference McMullen59, Reference McMullen60]. The material in this section very closely follows the definitions and presentation in [Reference Bastounis, Hansen and Vlačić9] with slight adaptations made owing to the different focus of this paper. Working with the SCI hierarchy and general algorithms allows us to show the non-computability is independent of both the underlying computational model (e.g., a Turing machine, BSS machine) and local minima as in Remark 3.7.
It also allows us to easily make non-computability statements applicable to both deterministic and randomised algorithms. We include the ensuing discussion to ensure that this paper is self-contained.
5.4.1. Computational problems
We start by defining a computational problem [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel11]:
Definition 5.8 (Computational problem). Let
 $\Omega$
be some set, which we call the input set, and
$\Omega$
be some set, which we call the input set, and
 $\Lambda$
be a set of complex-valued functions on
$\Lambda$
be a set of complex-valued functions on
 $\Omega$
such that for
$\Omega$
such that for
 $\iota _1, \iota _2 \in \Omega$
, then
$\iota _1, \iota _2 \in \Omega$
, then
 $\iota _1 = \iota _2$
if and only if
$\iota _1 = \iota _2$
if and only if
 $f(\iota _1) = f(\iota _2)$
for all
$f(\iota _1) = f(\iota _2)$
for all
 $f \in \Lambda$
. We call
$f \in \Lambda$
. We call
 $\Lambda$
an evaluation set. Let
$\Lambda$
an evaluation set. Let
 $(\mathcal{M},d_{\mathcal{M}})$
be a metric space, and finally let
$(\mathcal{M},d_{\mathcal{M}})$
be a metric space, and finally let
 $\Xi\,:\,\Omega \to \mathcal{M}$
be a function which we call the solution map. We call the collection
$\Xi\,:\,\Omega \to \mathcal{M}$
be a function which we call the solution map. We call the collection
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
a computational problem.
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
a computational problem.
The set
 $\Omega$
is essentially the set of objects that give rise to the various instances of our computational problem. The solution map
$\Omega$
is essentially the set of objects that give rise to the various instances of our computational problem. The solution map
 $\Xi\,:\, \Omega \to \mathcal{M}$
is what we are interested in computing. Finally, the set
$\Xi\,:\, \Omega \to \mathcal{M}$
is what we are interested in computing. Finally, the set
 $\Lambda$
is the collection of functions that provide us with the information we are allowed to read. As a simple example, if we were considering matrix inversion then
$\Lambda$
is the collection of functions that provide us with the information we are allowed to read. As a simple example, if we were considering matrix inversion then
 $\Omega$
might be a collection of invertible matrices,
$\Omega$
might be a collection of invertible matrices,
 $\Xi$
would be the matrix inversion map taking
$\Xi$
would be the matrix inversion map taking
 $\Omega$
to the set of matrices and
$\Omega$
to the set of matrices and
 $\Lambda$
would consist of functions that allow us to access entries of the input matrices.
$\Lambda$
would consist of functions that allow us to access entries of the input matrices.
In the slightly more complicated context of a computational problem, the neural network problem formulated in Section 3 can be understood as per the following:
Definition 5.9 (Neural network computational problem). Fix
 $d,r \in \mathbb{N}$
, a classification function
$d,r \in \mathbb{N}$
, a classification function
 $f: {\mathbb{R}}^{d} \to \{0,1\}$
, neural network layers and dimensions
$f: {\mathbb{R}}^{d} \to \{0,1\}$
, neural network layers and dimensions
 $L$
and
$L$
and
 $\mathbf{N} = (N_L=1,N_{L-1},\dotsc , N_1,N_0=d)$
, respectively, as well as
$\mathbf{N} = (N_L=1,N_{L-1},\dotsc , N_1,N_0=d)$
, respectively, as well as
 $\epsilon ,\hat \epsilon$
and a cost function
$\epsilon ,\hat \epsilon$
and a cost function
 $\mathcal{R} \in \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
. The neural network computational problem
$\mathcal{R} \in \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
. The neural network computational problem
 \begin{align*} \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\} \end{align*}
\begin{align*} \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\} \end{align*}
is defined as follows:
-
(1) The input set
$\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
is the collection of all
$\mathcal{T}$
with
$\mathcal{T}=\{x^1,\ldots , x^r\}$
a finite subset of
${\mathbb{R}}^d$
such that
$\mathcal{T}\in \mathcal{S}^{f}_{\varepsilon '(K)}$
with
$\varepsilon '(n)\,:\!=\,[(4n+3)(4n+4)]^{-1}$
. -
(2) The metric space
$\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
is set to
$\mathbb{R}^r$
with the distance function induced by
$\|\cdot \|_{*}$
where
$* = 1,2 \text{ or } \infty$
as per the statement of Theorem 3.5. -
(3) The solution map
$\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
is given by the following: for a training set
$\mathcal{T}$
, we letand then
\begin{align*} \mathcal{A}_{\mathcal{T}}^{\epsilon }\,:\!=\,\underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right ), \end{align*}
$\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}(\mathcal{T}) = \{\phi (x^i)\}_{i=1}^{r}$
for
$\phi \in \mathcal{A}^{\epsilon }_{\mathcal{T}}$
. Note that
$\Xi$
is potentially multivalued if
$\mathcal{A}^{\epsilon }_{\mathcal{T}}$
has more than one element – this will not be a problem for our theory and will be explained further in Remark 5.15.
-
(4) The set
$\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
is given by(5.20)where
\begin{equation} \Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}=\{f^{j,k}\}_{j=1,k=1}^{j=d,k=r}, \end{equation}
$f^{j,k}(\mathcal{T})=x_j^k$
gives access to the
$j$
th coordinate of the
$k$
th vector of the training set.






















To reduce the burden on notation, we will abbreviate
 \begin{align*} \{\Xi ^{\mathcal{NN}},\Omega ^{\mathcal{NN}},\mathcal{M}^{\mathcal{NN}},\Lambda ^{\mathcal{NN}}\}= \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\} \end{align*}
\begin{align*} \{\Xi ^{\mathcal{NN}},\Omega ^{\mathcal{NN}},\mathcal{M}^{\mathcal{NN}},\Lambda ^{\mathcal{NN}}\}= \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\} \end{align*}
where there is no ambiguity surrounding the parameters
 $f,r,\epsilon ,\mathcal{R},\mathbf{N},\kern0.3pt L$
.
$f,r,\epsilon ,\mathcal{R},\mathbf{N},\kern0.3pt L$
.
Remark 5.10 (Existence of a neural network). It may not be a priori obvious that the set
 $\mathcal{A}_{\mathcal{T}}^{\epsilon }$
is non-empty and thus
$\mathcal{A}_{\mathcal{T}}^{\epsilon }$
is non-empty and thus
 $\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}(\mathcal{T})$
is well defined. In fact, this is an immediate consequence the fact that the cost function
$\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}(\mathcal{T})$
is well defined. In fact, this is an immediate consequence the fact that the cost function
 $\mathcal{R}$
is a member of
$\mathcal{R}$
is a member of
 $\mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
defined in (3.4) and the definition of
$\mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
defined in (3.4) and the definition of
 $\operatorname {argmin}_{\epsilon }$
given in (3.3). In particular, the existence of an approximate minimiser is guaranteed since
$\operatorname {argmin}_{\epsilon }$
given in (3.3). In particular, the existence of an approximate minimiser is guaranteed since
 $\mathcal{R}$
is bounded from below.
$\mathcal{R}$
is bounded from below.
5.4.2. Algorithms
In this section, we shall describe the algorithms that are designed to approximate the solution map
 $\Xi$
in a computational problem
$\Xi$
in a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
. We shall start with deterministic general algorithms:
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
. We shall start with deterministic general algorithms:
Definition 5.11 (General Algorithm). Given a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, a general algorithm is a mapping
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, a general algorithm is a mapping
 $\Gamma\,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
such that, for every
$\Gamma\,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
such that, for every
 $\iota \in \Omega$
, the following conditions hold:
$\iota \in \Omega$
, the following conditions hold:
-
(i) there exists a non-empty subset of evaluations
$\Lambda _\Gamma (\iota ) \subset \Lambda$
, and, whenever
$\Gamma (\iota ) \neq \text{NH}$
, we have
$|\Lambda _\Gamma (\iota )|\lt \infty$
, -
(ii) the action of
$\,\Gamma$
on
$\iota$
is uniquely determined by
$\{f(\iota )\}_{f \in \Lambda _\Gamma (\iota )}$
, -
(iii) for every
$\iota ^{\prime } \in \Omega$
such that
$f(\iota ^\prime )=f(\iota )$
for all
$f\in \Lambda _\Gamma (\iota )$
, it holds that
$\Lambda _\Gamma (\iota ^{\prime })=\Lambda _\Gamma (\iota )$
.










Remark 5.12 (The purpose of a general algorithm: universal impossibility results). The purpose of a general algorithm is to have a definition that will encompass any model of computation and that will allow impossibility results to become universal. Given that there are several non-equivalent models of computation, impossibility results will be shown with this general definition of an algorithm.
Remark 5.13 (The power of a general algorithm). General algorithms are extremely powerful computational models with every Turing or BSS machine a general algorithm but the converse does not hold. Thus, a non-computability result proven using general algorithms is strictly stronger than one proven only for Turing machines or BSS machines.
In particular, general algorithms are more powerful than any Turing machine or BSS machine, or even such a machine with access to an oracle that provides an approximate minimiser
 \begin{align*} \phi \in \mathop{\mathrm{argmin}_{\epsilon }}_{\tilde \phi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R}\left (\{\tilde \phi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r \right ) \end{align*}
\begin{align*} \phi \in \mathop{\mathrm{argmin}_{\epsilon }}_{\tilde \phi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}} \mathcal{R}\left (\{\tilde \phi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r \right ) \end{align*}
for every inexact input provided to the algorithm, or an oracle that detects when an algorithm has encountered local minima. It is for this reason that we stated in Remark 3.7 that local minima were not relevant to Theorem 3.5.
Remark 5.14 (The non-halting output
 $\text{NH}$
). The non-halting ‘output’
$\text{NH}$
). The non-halting ‘output’
 $\text{NH}$
of a general algorithm may seem like an unnecessary distraction given that a general algorithm is just a mapping, which is strictly more powerful than a Turing or a BSS machine. However, the
$\text{NH}$
of a general algorithm may seem like an unnecessary distraction given that a general algorithm is just a mapping, which is strictly more powerful than a Turing or a BSS machine. However, the
 $\text{NH}$
output is needed when the concept of a general algorithm is extended to a randomised general algorithm (RGA). A technical remark about
$\text{NH}$
output is needed when the concept of a general algorithm is extended to a randomised general algorithm (RGA). A technical remark about
 $\text{NH}$
is also appropriate, namely that
$\text{NH}$
is also appropriate, namely that
 $\Lambda _{\Gamma }(\iota )$
is allowed to be infinite in the case when
$\Lambda _{\Gamma }(\iota )$
is allowed to be infinite in the case when
 $\Gamma (\iota ) = \text{NH}$
. This is to allow general algorithms to capture the behaviour of a Turing or a BSS machine not halting by virtue of requiring an infinite amount of input information.
$\Gamma (\iota ) = \text{NH}$
. This is to allow general algorithms to capture the behaviour of a Turing or a BSS machine not halting by virtue of requiring an infinite amount of input information.
Owing to the presence of the special non-halting ‘output’
 $\text{NH}$
, we have to extend the metric
$\text{NH}$
, we have to extend the metric
 $d_{\mathcal{M}}$
on
$d_{\mathcal{M}}$
on
 $\mathcal{M}\times \mathcal{M}$
to
$\mathcal{M}\times \mathcal{M}$
to
 $d_{\mathcal{M}}:\mathcal{M} \cup \{\text{NH}\} \times \mathcal{M} \cup \{\text{NH}\}\to {\mathbb{R}}_{\geq 0}$
in the following way:
$d_{\mathcal{M}}:\mathcal{M} \cup \{\text{NH}\} \times \mathcal{M} \cup \{\text{NH}\}\to {\mathbb{R}}_{\geq 0}$
in the following way:
 \begin{equation} d_{\mathcal{M}}(x,y) = \begin{cases} d_{\mathcal{M}}(x,y) & \text{ if } x,y \in \mathcal{M} \\ 0 & \text{ if } x = y = \text{NH}\\ \infty & \text{ otherwise.} \end{cases} \end{equation}
\begin{equation} d_{\mathcal{M}}(x,y) = \begin{cases} d_{\mathcal{M}}(x,y) & \text{ if } x,y \in \mathcal{M} \\ 0 & \text{ if } x = y = \text{NH}\\ \infty & \text{ otherwise.} \end{cases} \end{equation}
Definition 5.11 is sufficient for defining a RGA, which is the only tool from the SCI theory needed in order to prove Theorem 3.5.
Remark 5.15 (Multivalued functions). When dealing with optimisation problems, one needs a framework that can handle multiple solutions. As the set-up above does not allow
 $\Xi$
to be multivalued, we need some slight changes. We allow
$\Xi$
to be multivalued, we need some slight changes. We allow
 $\Xi$
to be multivalued, even though a general algorithm is assumed not to be. For
$\Xi$
to be multivalued, even though a general algorithm is assumed not to be. For
 $\iota \in \Omega$
, we define
$\iota \in \Omega$
, we define
 $ \mathrm{dist}_{\mathcal{M}}(\Xi (\iota ),\Gamma (\iota ))\,:\!=\,\inf _{x \in \Xi (\iota )}d_{\mathcal{M}}(x,\Gamma (\iota )).$
That is to say, the error that
$ \mathrm{dist}_{\mathcal{M}}(\Xi (\iota ),\Gamma (\iota ))\,:\!=\,\inf _{x \in \Xi (\iota )}d_{\mathcal{M}}(x,\Gamma (\iota )).$
That is to say, the error that
 $\Gamma$
is assumed to incur in trying to compute
$\Gamma$
is assumed to incur in trying to compute
 $\Xi (\iota )$
is the best (infimum) of all possible errors across all values of
$\Xi (\iota )$
is the best (infimum) of all possible errors across all values of
 $\Xi (\iota )$
.
$\Xi (\iota )$
.
One final definition that is useful is that of the minimum amount of input information, defined if
 $\Lambda$
is countable. Although this definition has its own uses in other work on the SCI hierarchy, in the context of this paper it will only be useful to address a technicality in the next section.
$\Lambda$
is countable. Although this definition has its own uses in other work on the SCI hierarchy, in the context of this paper it will only be useful to address a technicality in the next section.
Definition 5.16 (Minimum amount of input information). Given the computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
 $\Lambda =\{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
and a general algorithm
$\Lambda =\{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
and a general algorithm
 $\Gamma$
, we define the minimum amount of input information
$\Gamma$
, we define the minimum amount of input information
 $T_{\Gamma }(\iota )$
for
$T_{\Gamma }(\iota )$
for
 $\Gamma$
and
$\Gamma$
and
 $\iota \in \Omega$
as
$\iota \in \Omega$
as
 \begin{align*} T_{\Gamma }(\iota ) \,:\!=\,\sup \lbrace m \in \mathbb{N} \, \vert \, f_{m} \in \Lambda _{\Gamma }(\iota ) \rbrace . \end{align*}
\begin{align*} T_{\Gamma }(\iota ) \,:\!=\,\sup \lbrace m \in \mathbb{N} \, \vert \, f_{m} \in \Lambda _{\Gamma }(\iota ) \rbrace . \end{align*}
Note that, for
 $\iota$
such that
$\iota$
such that
 $\Gamma (\iota ) = \text{NH}$
, the set
$\Gamma (\iota ) = \text{NH}$
, the set
 $\Lambda _{\Gamma }(\iota )$
may be infinite (see Definition 5.11), in which case
$\Lambda _{\Gamma }(\iota )$
may be infinite (see Definition 5.11), in which case
 $T_{\Gamma }(\iota )=\infty$
.
$T_{\Gamma }(\iota )=\infty$
.
5.4.3. Randomised algorithms
In many contemporary fields of mathematics of information such as DL, the use of randomised algorithms is widespread. We therefore need to extend the concept of a general algorithm to a randomised random algorithm.
Definition 5.17 (Randomised general algorithm). Given a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
 $\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, a RGA is a collection
$\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, a RGA is a collection
 $X$
of general algorithms
$X$
of general algorithms
 $\Gamma\,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
, a sigma-algebra
$\Gamma\,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
, a sigma-algebra
 $\mathcal{F}$
on
$\mathcal{F}$
on
 $X$
, and a family of probability measures
$X$
, and a family of probability measures
 $\{\mathbb{P}_{\iota }\}_{\iota \in \Omega }$
on
$\{\mathbb{P}_{\iota }\}_{\iota \in \Omega }$
on
 $\mathcal{F}$
such that the following conditions hold:
$\mathcal{F}$
such that the following conditions hold:
-
(Pi) For each
$\iota \in \Omega$
, the mapping
$\Gamma ^{\mathrm{ran}}_{\iota }:(X,\mathcal{F}) \to (\mathcal{M}\cup \{\text{NH}\}, \mathcal{B})$
defined by
$\Gamma ^{\mathrm{ran}}_{\iota }(\Gamma ) = \Gamma (\iota )$
is a random variable, where
$\mathcal{B}$
is the Borel sigma-algebra on
$\mathcal{M}\cup \{\text{NH}\}$
. -
(Pii) For each
$n \in \mathbb{N}$
and
$\iota \in \Omega$
, we have
$\lbrace \Gamma \in X \, \vert \, T_{\Gamma }(\iota ) \leq n \rbrace \in \mathcal{F}$
. -
(Piii) For all
$\iota _1,\iota _2 \in \Omega$
and
$E \in \mathcal{F}$
so that, for every
$\Gamma \in E$
and every
$f \in \Lambda _{\Gamma }(\iota _1)$
, we have
$f(\iota _1) = f(\iota _2)$
, it holds that
$\mathbb{P}_{\iota _1}(E) = \mathbb{P}_{\iota _2}(E)$
.














It is not immediately clear whether condition (Pii) for a given RGA
 $(X,\mathcal{F},\{{\mathbb{P}}_\iota \}_{\iota \in \Omega })$
holds independently of the choice of the enumeration of
$(X,\mathcal{F},\{{\mathbb{P}}_\iota \}_{\iota \in \Omega })$
holds independently of the choice of the enumeration of
 $\Lambda$
. This is indeed the case, but we shall not show this here (see [9] for further information).
$\Lambda$
. This is indeed the case, but we shall not show this here (see [9] for further information).
Remark 5.18 (Assumption (Pii)). Note that (Pii) in Definition 5.17 is needed in order to ensure that the minimum amount of input information (i.e., the amount of input information the algorithm makes use of) also becomes a valid random variable. More specifically, for each
 $\iota \in \Omega$
, we define the random variable
$\iota \in \Omega$
, we define the random variable
 \begin{align*} T_{\Gamma ^{\mathrm{ran}}}(\iota ): X\to \mathbb{N}\cup \{\infty \} \text{ according to } \Gamma \mapsto T_{\Gamma }(\iota ). \end{align*}
\begin{align*} T_{\Gamma ^{\mathrm{ran}}}(\iota ): X\to \mathbb{N}\cup \{\infty \} \text{ according to } \Gamma \mapsto T_{\Gamma }(\iota ). \end{align*}
Assumption (Pii) ensures that this is indeed a random variable.
As the minimum amount of input information is typically related to the complexity of an algorithm, one would be dealing with a rather exotic probabilistic model if
 $T_{\Gamma ^{\mathrm{ran}}}(\iota )$
were not a random variable. Indeed, note that the standard models of randomised algorithms (see [5]) can be considered as RGAs (in particular, they will satisfy (Pii)).
$T_{\Gamma ^{\mathrm{ran}}}(\iota )$
were not a random variable. Indeed, note that the standard models of randomised algorithms (see [5]) can be considered as RGAs (in particular, they will satisfy (Pii)).
Remark 5.19 (The purpose of a randomised general algorithm: universal lower bounds). As for a general algorithm, the purpose of a RGA is to have a definition that will encompass every model of computation, which will allow lower bounds and impossibility results to be universal. Indeed, randomised Turing and BSS machines can be viewed as RGAs.
We will, with a slight abuse of notation, also write
 $\mathrm{RGA}$
for the family of all RGAs for a given a computational problem and refer to the algorithms in
$\mathrm{RGA}$
for the family of all RGAs for a given a computational problem and refer to the algorithms in
 $\mathrm{RGA}$
by
$\mathrm{RGA}$
by
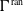 $\Gamma ^{\mathrm{ran}}$
. With the definitions above, we can now make probabilistic version of the strong breakdown epsilon as follows.
$\Gamma ^{\mathrm{ran}}$
. With the definitions above, we can now make probabilistic version of the strong breakdown epsilon as follows.
Definition 5.20 (Probabilistic strong breakdown epsilon). Given a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
 $\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, we define the probabilistic strong breakdown epsilon
$\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, we define the probabilistic strong breakdown epsilon
 $\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}: [0,1) \to \mathbb{R}$
according to
$\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}: [0,1) \to \mathbb{R}$
according to
 \begin{align*} \epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) = \sup \{&\epsilon \geq 0, \, \vert \, \forall \, \Gamma ^{\mathrm{ran}} \in \mathrm{RGA} \,\,\exists \, \iota \in \Omega \text{ such that } \mathbb{P}_{\iota }(\mathrm{dist}_{\mathcal{M}}(\Gamma ^{\mathrm{ran}}_{\iota },\Xi (\iota )) \gt \epsilon ) \gt \mathrm{p}\}, \end{align*}
\begin{align*} \epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) = \sup \{&\epsilon \geq 0, \, \vert \, \forall \, \Gamma ^{\mathrm{ran}} \in \mathrm{RGA} \,\,\exists \, \iota \in \Omega \text{ such that } \mathbb{P}_{\iota }(\mathrm{dist}_{\mathcal{M}}(\Gamma ^{\mathrm{ran}}_{\iota },\Xi (\iota )) \gt \epsilon ) \gt \mathrm{p}\}, \end{align*}
where
 $\Gamma ^{\mathrm{ran}}_{\iota }$
is defined in (Pi) in Definition 5.17.
$\Gamma ^{\mathrm{ran}}_{\iota }$
is defined in (Pi) in Definition 5.17.
Note that the probabilistic strong breakdown epsilon is not a single number but a function of
 $\mathrm{p}$
. Specifically, it is the largest
$\mathrm{p}$
. Specifically, it is the largest
 $\epsilon$
so that the probability of failure with at least
$\epsilon$
so that the probability of failure with at least
 $\epsilon$
-error is greater than
$\epsilon$
-error is greater than
 $\mathrm{p}$
.
$\mathrm{p}$
.
5.4.4. Inexact input and perturbations
Suppose we are given a computational problem
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
, and that
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
, and that
 $ \Lambda = \{f_j\}_{j \in \beta },$
where
$ \Lambda = \{f_j\}_{j \in \beta },$
where
 $\beta$
is some index set that can be finite or infinite. Obtaining
$\beta$
is some index set that can be finite or infinite. Obtaining
 $f_j$
may be a computational task on its own, which is exactly the problem in most areas of computational mathematics. In particular, for
$f_j$
may be a computational task on its own, which is exactly the problem in most areas of computational mathematics. In particular, for
 $\iota \in \Omega$
,
$\iota \in \Omega$
,
 $f_j(\iota )$
could be the number
$f_j(\iota )$
could be the number
 $e^{\frac {\pi }{j} i }$
for example. Hence, we cannot access
$e^{\frac {\pi }{j} i }$
for example. Hence, we cannot access
 $f_j(\iota )$
, but rather
$f_j(\iota )$
, but rather
 $f_{j,n}(\iota )$
where
$f_{j,n}(\iota )$
where
 $f_{j,n}(\iota ) \rightarrow f_{j}(\iota )$
as
$f_{j,n}(\iota ) \rightarrow f_{j}(\iota )$
as
 $n \rightarrow \infty$
. In this paper, we will be interested in the case when this can be done with error control. In particular, we consider
$n \rightarrow \infty$
. In this paper, we will be interested in the case when this can be done with error control. In particular, we consider
 $f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n$
, where
$f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n$
, where
 $\mathbb{D}_n\,:\!=\,\{k\,2^{-n}\, \vert \,k\in \mathbb{Z}\}$
, such that
$\mathbb{D}_n\,:\!=\,\{k\,2^{-n}\, \vert \,k\in \mathbb{Z}\}$
, such that
 \begin{equation} \|\{f_{j,n}(\iota )\}_{j\in \beta } - \{f_j(\iota )\}_{j\in \beta }\|_{\infty } \leq 2^{-n}, \quad \forall \iota \in \Omega . \end{equation}
\begin{equation} \|\{f_{j,n}(\iota )\}_{j\in \beta } - \{f_j(\iota )\}_{j\in \beta }\|_{\infty } \leq 2^{-n}, \quad \forall \iota \in \Omega . \end{equation}
We will call a collection of such functions
 $\Delta _1$
-information for the computational problem. Formally, we have the following.
$\Delta _1$
-information for the computational problem. Formally, we have the following.
Definition 5.21 (
 $\boldsymbol{\Delta _{1}}$
-information). Let
$\boldsymbol{\Delta _{1}}$
-information). Let
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem with
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem with
 $\Lambda = \{f_j\}_{j \in \beta }$
. Suppose that, for each
$\Lambda = \{f_j\}_{j \in \beta }$
. Suppose that, for each
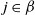 $j\in \beta$
and
$j\in \beta$
and
 $n\in \mathbb{N}$
, there exists an
$n\in \mathbb{N}$
, there exists an
 $f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n$
such that (5.22) holds. We then say that the set
$f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n$
such that (5.22) holds. We then say that the set
 $\hat \Lambda =\{f_{j,n} \, \vert \, j\in \beta ,n\in \mathbb{N}\}$
provides
$\hat \Lambda =\{f_{j,n} \, \vert \, j\in \beta ,n\in \mathbb{N}\}$
provides
 $\Delta _1$
-information for
$\Delta _1$
-information for
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
.
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
.
We can now define what we mean by a computational problem with
 $\Delta _1$
-information.
$\Delta _1$
-information.
Definition 5.22 (Computational problem with
 $\boldsymbol{\Delta _1}$
-information). Given
$\boldsymbol{\Delta _1}$
-information). Given
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
with
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
with
 $\Lambda =\{f_j\}_{j \in \beta }$
, the corresponding computational problem with
$\Lambda =\{f_j\}_{j \in \beta }$
, the corresponding computational problem with
 $\Delta _1$
-information is defined as:
$\Delta _1$
-information is defined as:
 \begin{align*} \{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}\,:\!=\,\{\tilde \Xi ,\tilde \Omega ,\mathcal{M},\tilde \Lambda \}, \end{align*}
\begin{align*} \{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}\,:\!=\,\{\tilde \Xi ,\tilde \Omega ,\mathcal{M},\tilde \Lambda \}, \end{align*}
where
 \begin{equation} \tilde \Omega = \left \{ \tilde \iota = \big \{(f_{j,1}(\iota ), f_{j,2}(\iota ), f_{j,3}(\iota ), \ldots ) \big \}_{j \in \beta } \, \vert \, \iota \in \Omega ,\; f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n \text{ satisfy (5.22)} \right \}, \end{equation}
\begin{equation} \tilde \Omega = \left \{ \tilde \iota = \big \{(f_{j,1}(\iota ), f_{j,2}(\iota ), f_{j,3}(\iota ), \ldots ) \big \}_{j \in \beta } \, \vert \, \iota \in \Omega ,\; f_{j,n}\,:\,\Omega \to \mathbb{D}_n + i \mathbb{D}_n \text{ satisfy (5.22)} \right \}, \end{equation}
 $\tilde \Xi (\tilde \iota ) = \Xi (\iota )$
, and
$\tilde \Xi (\tilde \iota ) = \Xi (\iota )$
, and
 $\tilde \Lambda = \{\tilde f_{j,n}\}_{j,n \in \beta \times \mathbb{N}}$
, where
$\tilde \Lambda = \{\tilde f_{j,n}\}_{j,n \in \beta \times \mathbb{N}}$
, where
 $\tilde f_{j,n}(\tilde \iota ) = f_{j,n}(\iota )$
. Given an
$\tilde f_{j,n}(\tilde \iota ) = f_{j,n}(\iota )$
. Given an
 $\tilde \iota \in \tilde \Omega$
, there is a unique
$\tilde \iota \in \tilde \Omega$
, there is a unique
 $\iota \in \Omega$
for which
$\iota \in \Omega$
for which
 $\tilde \iota =\big \{(f_{j,1}(\iota ), f_{j,2}(\iota ), f_{j,3}(\iota ), \ldots ) \big \}_{j \in \beta }$
(by Definition 5.8). We say that this
$\tilde \iota =\big \{(f_{j,1}(\iota ), f_{j,2}(\iota ), f_{j,3}(\iota ), \ldots ) \big \}_{j \in \beta }$
(by Definition 5.8). We say that this
 $\iota \in \Omega$
corresponds to
$\iota \in \Omega$
corresponds to
 $\tilde \iota \in \tilde \Omega$
.
$\tilde \iota \in \tilde \Omega$
.
Remark 5.23. Note that the correspondence of a unique
 $\iota$
to each
$\iota$
to each
 $\tilde \iota$
in Definition 5.22 ensures that
$\tilde \iota$
in Definition 5.22 ensures that
 $\tilde \Xi$
and the elements of
$\tilde \Xi$
and the elements of
 $\tilde \Lambda$
are well defined.
$\tilde \Lambda$
are well defined.
One may interpret the computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1} = \{\tilde \Xi ,\tilde \Omega ,\mathcal{M},\tilde \Lambda \}$
as follows. The collection
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1} = \{\tilde \Xi ,\tilde \Omega ,\mathcal{M},\tilde \Lambda \}$
as follows. The collection
 $\tilde \Omega$
is the family of all sequences approximating the inputs in
$\tilde \Omega$
is the family of all sequences approximating the inputs in
 $\Omega$
. For an algorithm to be successful for
$\Omega$
. For an algorithm to be successful for
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}$
, it must work for all
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}$
, it must work for all
 $\tilde \iota \in \tilde \Omega$
, that is, for any sequence approximating
$\tilde \iota \in \tilde \Omega$
, that is, for any sequence approximating
 $\iota$
.
$\iota$
.
Remark 5.24 (Oracle tape/node providing
 $\boldsymbol{\Delta _1}$
-information). For impossibility results, we use general algorithms and RGAs (as defined below), and thus, due to their generality, we do not need to specify how the algorithms read the information.
$\boldsymbol{\Delta _1}$
-information). For impossibility results, we use general algorithms and RGAs (as defined below), and thus, due to their generality, we do not need to specify how the algorithms read the information.
The next proposition serves as the key building block for Theorem 3.5 and is proven in [[Reference Bastounis, Hansen and Vlačić9], Proposition 9.5]. Note that the proposition is about arbitrary computational problems and is hence also a tool for demonstrating lower bounds on the breakdown epsilon for general computational problems.
Proposition 5.25. Let
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem with
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem with
 $\Lambda =\{f_k\,\vert \,k\in \mathbb{N}, k\leq |\Lambda | \}$
countable. Suppose that
$\Lambda =\{f_k\,\vert \,k\in \mathbb{N}, k\leq |\Lambda | \}$
countable. Suppose that
 $\iota ^0 \in \Omega$
and that
$\iota ^0 \in \Omega$
and that
 $\{\iota ^1_n\}_{n=1}^{\infty }$
is a sequence in
$\{\iota ^1_n\}_{n=1}^{\infty }$
is a sequence in
 $\Omega$
so that the following conditions hold:
$\Omega$
so that the following conditions hold:
-
(Pa) For every
$k\leq |\Lambda |$
and for all
$n \in \mathbb{N}$
, we have
$|f_k(\iota ^j_n) - f_k(\iota ^0)|\leq 1/4^n$
. -
(Pb) There is a
$\kappa \gt 0$
such that
$ \inf _{\upsilon ^1 \in \Xi (\iota ^1_n), \upsilon ^2 \in \Xi (\iota ^0)}d_{\mathcal{M}}(\upsilon ^1,\upsilon ^2) \geq \kappa$
.





Then the computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}$
satisfies
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1}$
satisfies
 $\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq \kappa /2$
for
$\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq \kappa /2$
for
 $\mathrm{p} \in [0,1/2)$
.
$\mathrm{p} \in [0,1/2)$
.
5.5. Stating Theorem 3.5 in the SCI language - Proposition 5.26
A slightly stronger formal statement of Theorem 3.5 in the SCI language is now as follows.
Proposition 5.26. There is an uncountable collection
 $\mathcal{C}_1$
of classification functions
$\mathcal{C}_1$
of classification functions
 $f$
as in (2.1) – with fixed
$f$
as in (2.1) – with fixed
 $d \geq 2$
– such that for
$d \geq 2$
– such that for
-
(1) any neural network dimensions
$\mathbf{N} = (N_L=1,N_{L-1},\dotsc , N_1,N_0=d)$
with
$L \geq 2$
, -
(2) any
$r \geq 3(N_1+1) \dotsb (N_{L-1}+1)$
, -
(3) and any
$\epsilon \gt 0$
,
$\hat \epsilon \in (0,1/2)$
and cost function
$\mathcal{R} \in \mathcal{C}\mathcal{F}^{\epsilon ,\hat \epsilon }_r$
.






There is an uncountable collection
 $\mathcal{C}_3$
of disjoint subsets of
$\mathcal{C}_3$
of disjoint subsets of
 $\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
so that for each
$\Omega ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}$
so that for each
 $\hat \Omega \in \mathcal{C}_3$
the computational problem
$\hat \Omega \in \mathcal{C}_3$
the computational problem
 \begin{align*} \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\hat \Omega ,\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\}^{\Delta _1} \end{align*}
\begin{align*} \{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\hat \Omega ,\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\}^{\Delta _1} \end{align*}
has breakdown epsilon
 $\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2$
, for all
$\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2$
, for all
 $\mathrm{p} \in [0,1/2)$
.
$\mathrm{p} \in [0,1/2)$
.
To see that Proposition 5.26 implies Theorem 3.5, assume that Proposition 5.26 holds and suppose that
 $\Gamma$
is a randomised algorithm (in either the BSS or Turing models). The existence of
$\Gamma$
is a randomised algorithm (in either the BSS or Turing models). The existence of
 $\phi$
stated in Theorem 3.5 is guaranteed as per the discussion in Remark 5.10. Furthermore,
$\phi$
stated in Theorem 3.5 is guaranteed as per the discussion in Remark 5.10. Furthermore,
 $\Gamma$
is also a RGA and hence we can consider
$\Gamma$
is also a RGA and hence we can consider
 $\Gamma$
restricted to
$\Gamma$
restricted to
 $\hat {\Omega }$
for each
$\hat {\Omega }$
for each
 $\hat {\Omega } \in \mathcal{C}_3$
. Since the computational problem
$\hat {\Omega } \in \mathcal{C}_3$
. Since the computational problem
 $\{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\hat \Omega ,\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\}^{\Delta _1}$
has
$\{\Xi ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\hat \Omega ,\mathcal{M}^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)},\Lambda ^{\mathcal{NN}}_{f,r,\epsilon , \mathcal{R}, (\mathbf{N},\kern0.3pt L)}\}^{\Delta _1}$
has
 $\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2 \gt 1/4 - 3\hat {\epsilon }/4$
, for all
$\epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2 \gt 1/4 - 3\hat {\epsilon }/4$
, for all
 $\mathrm{p} \in [0,1/2)$
there must exist a training set
$\mathrm{p} \in [0,1/2)$
there must exist a training set
 $\mathcal{T} = \mathcal{T}(\hat \Omega )$
with
$\mathcal{T} = \mathcal{T}(\hat \Omega )$
with
 $\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\}$
for which
$\mathcal{T} = \{x^1,x^2,\dotsc ,x^r\}$
for which
 \begin{align*} \mathbb{P}\Big (\|\{\Gamma _{\mathcal{T}}(x^{\,j})\}_{j=1}^r - \{\phi (x^{\,j})\}_{j=1}^r\|_{*} \geq 1/4-3\hat {\epsilon }/4\Big ) \gt \mathrm{p}, \end{align*}
\begin{align*} \mathbb{P}\Big (\|\{\Gamma _{\mathcal{T}}(x^{\,j})\}_{j=1}^r - \{\phi (x^{\,j})\}_{j=1}^r\|_{*} \geq 1/4-3\hat {\epsilon }/4\Big ) \gt \mathrm{p}, \end{align*}
for any
 $ \phi \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right )$
(this is itself a consequence of Remark 5.15).
$ \phi \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R} \left (\{\varphi ({x}^j)\}_{j=1}^r,\{f({x}^j)\}_{j=1}^r\right )$
(this is itself a consequence of Remark 5.15).
We now choose
 $\mathcal{C}_2 = \{\mathcal{T}(\hat \Omega ) \, \vert \, \hat \Omega \in \mathcal{C}_3\}$
. Because
$\mathcal{C}_2 = \{\mathcal{T}(\hat \Omega ) \, \vert \, \hat \Omega \in \mathcal{C}_3\}$
. Because
 $\mathcal{C}_3$
is an uncountable collection of disjoint sets,
$\mathcal{C}_3$
is an uncountable collection of disjoint sets,
 $\mathcal{C}_2$
is uncountable and thus Theorem 3.5 follows.
$\mathcal{C}_2$
is uncountable and thus Theorem 3.5 follows.
5.6. Proof of Proposition 5.26 and Theorem 3.5
As demonstrated in the previous section, to prove Theorem 3.5 it suffices to prove Proposition 5.26. We begin by starting the following useful lemma:
Lemma 5.27. Recall the set-up of Proposition 5.26 and the vectors
 $x^{k,\delta }$
defined in (5.1). For any
$x^{k,\delta }$
defined in (5.1). For any
 $\delta \in (0, \varepsilon '(r))$
and arbitrary
$\delta \in (0, \varepsilon '(r))$
and arbitrary
 \begin{align} \phi &\in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R}\left (\{\varphi (x^{j,\delta })\}_{j=1}^r ,\{f_a(x^{j,\delta })\}_{j=1}^r\right ) \end{align}
\begin{align} \phi &\in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \mathcal{R}\left (\{\varphi (x^{j,\delta })\}_{j=1}^r ,\{f_a(x^{j,\delta })\}_{j=1}^r\right ) \end{align}
we have
 $|\phi (x^{k,\delta }) - f_a(x^{k,\delta })| \leq \hat \epsilon$
for all
$|\phi (x^{k,\delta }) - f_a(x^{k,\delta })| \leq \hat \epsilon$
for all
 $k \in \{1,\dotsc , r\}$
.
$k \in \{1,\dotsc , r\}$
.
Proof. By Lemma5.3, there exists a neural network
 $\tilde \varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
$\tilde \varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}$
with
 $\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
$\tilde \varphi (x^{k,\delta }) = f_a(x^{k,\delta })$
for all
 $k$
. In particular,
$k$
. In particular,
 $ \mathcal{R} \left (\{\tilde \varphi ({x}^{j,\delta })\}_{j=1}^r,\{f({x}^{j,\delta })\}_{j=1}^r\right ) = 0$
. Thus, by (5.24) and the definition of the approximate argmin as in (3.3), we must have that
$ \mathcal{R} \left (\{\tilde \varphi ({x}^{j,\delta })\}_{j=1}^r,\{f({x}^{j,\delta })\}_{j=1}^r\right ) = 0$
. Thus, by (5.24) and the definition of the approximate argmin as in (3.3), we must have that
 \begin{align*} \mathcal{R} \left (\{ \phi ({x}^{j,\delta })\}_{j=1}^r,\{f({x}^{j,\delta })\}_{j=1}^r\right ) \leq \epsilon \end{align*}
\begin{align*} \mathcal{R} \left (\{ \phi ({x}^{j,\delta })\}_{j=1}^r,\{f({x}^{j,\delta })\}_{j=1}^r\right ) \leq \epsilon \end{align*}
and the conclusion of the claim follows because
 $\mathcal{R}\in \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
as defined in (3.4).
$\mathcal{R}\in \mathcal{CF}^{\epsilon ,\hat \epsilon }_{r}$
as defined in (3.4).
Now that we have proven Lemma5.27, we are ready to prove Proposition 5.26.
Proof of Proposition 5.26. As in the proof of Theorem 2.2, we begin by defining the sets
 $\mathcal{C}_1$
and
$\mathcal{C}_1$
and
 $\mathcal{C}_3$
. Let
$\mathcal{C}_3$
. Let
 $\mathcal{C}_1 = \{ f_a: {\mathbb{R}}^d \to [0,1] \, \vert \, a \in [1/2,1]\}$
, where
$\mathcal{C}_1 = \{ f_a: {\mathbb{R}}^d \to [0,1] \, \vert \, a \in [1/2,1]\}$
, where
 $f_a$
is defined as in (5.2). Fix
$f_a$
is defined as in (5.2). Fix
 $a \in [1/2,1]$
and
$a \in [1/2,1]$
and
 $\kappa \in [1/4,3/4]$
, define
$\kappa \in [1/4,3/4]$
, define
 $\mathcal{T}^{\kappa }_{\delta }\,:\!=\,\{x^{1,\delta },x^{2,\delta },\dotsc ,x^{r,\delta }\}$
where the values
$\mathcal{T}^{\kappa }_{\delta }\,:\!=\,\{x^{1,\delta },x^{2,\delta },\dotsc ,x^{r,\delta }\}$
where the values
 $x^{i,\delta }$
(each depending on
$x^{i,\delta }$
(each depending on
 $\kappa$
and
$\kappa$
and
 $a$
) are defined in (5.1). We define
$a$
) are defined in (5.1). We define
 $\hat \Omega ^{\kappa }\,:\!=\,\{\mathcal{T}^{\kappa }_{\delta } \, \vert \, \delta \in [0,\epsilon '(r))$
. By Lemma5.2, we have
$\hat \Omega ^{\kappa }\,:\!=\,\{\mathcal{T}^{\kappa }_{\delta } \, \vert \, \delta \in [0,\epsilon '(r))$
. By Lemma5.2, we have
 $\mathcal{T}^{\kappa }_{\delta } \in \mathcal{S}^{f_a}_{\varepsilon '(r)}$
so that
$\mathcal{T}^{\kappa }_{\delta } \in \mathcal{S}^{f_a}_{\varepsilon '(r)}$
so that
 $\hat \Omega ^{\kappa } \subset \Omega ^{\mathcal{NN}}$
. Note also that noting that the
$\hat \Omega ^{\kappa } \subset \Omega ^{\mathcal{NN}}$
. Note also that noting that the
 $\hat \Omega ^{\kappa }$
are disjoint as an immediate consequence of (5.1). Finally, we set
$\hat \Omega ^{\kappa }$
are disjoint as an immediate consequence of (5.1). Finally, we set
 $\mathcal{C}_3\,:\!=\,\{ \hat \Omega ^{\kappa } \, \vert \, \kappa \in [1/4,3/4]\}$
, .
$\mathcal{C}_3\,:\!=\,\{ \hat \Omega ^{\kappa } \, \vert \, \kappa \in [1/4,3/4]\}$
, .
Now we have defined
 $\mathcal{C}_1$
and
$\mathcal{C}_1$
and
 $\mathcal{C}_3$
, we will show that for any
$\mathcal{C}_3$
, we will show that for any
 $\kappa \in [1/4,3/4]$
the computational problem
$\kappa \in [1/4,3/4]$
the computational problem
 \begin{align*} \{\Xi ^{\mathcal{NN}},\hat \Omega ^\kappa ,\mathcal{M}^{\mathcal{NN}},\Lambda ^{\mathcal{NN}}\}^{\Delta _1} \end{align*}
\begin{align*} \{\Xi ^{\mathcal{NN}},\hat \Omega ^\kappa ,\mathcal{M}^{\mathcal{NN}},\Lambda ^{\mathcal{NN}}\}^{\Delta _1} \end{align*}
has breakdown epsilon
 $\epsilon _{\mathbb{P}h\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2$
, for all
$\epsilon _{\mathbb{P}h\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) \geq 1/4 - \hat {\epsilon }/2$
, for all
 $\mathrm{p} \in [0,1/2)$
. This will be done using Proposition 5.25. We will define
$\mathrm{p} \in [0,1/2)$
. This will be done using Proposition 5.25. We will define
 $\iota ^0\,:\!=\,\mathcal{T}^{\kappa }_{0}$
and
$\iota ^0\,:\!=\,\mathcal{T}^{\kappa }_{0}$
and
 $\iota ^1_n\,:\!=\,\mathcal{T}^{\kappa }_{4^{-n}}$
.
$\iota ^1_n\,:\!=\,\mathcal{T}^{\kappa }_{4^{-n}}$
.
By (5.1), we see that
 $\|x^{\,j,4^{-n}}-x^{j,0}\|_\infty \leq 4^{-n}$
for
$\|x^{\,j,4^{-n}}-x^{j,0}\|_\infty \leq 4^{-n}$
for
 $j=1,2,\dotsc ,r$
. Hence (recalling the definition of
$j=1,2,\dotsc ,r$
. Hence (recalling the definition of
 $\Lambda ^{\mathcal{NN}}$
), property (Pa) from Proposition 5.25 holds.
$\Lambda ^{\mathcal{NN}}$
), property (Pa) from Proposition 5.25 holds.
Fix
 $n \in \mathbb{N}$
sufficiently large and let
$n \in \mathbb{N}$
sufficiently large and let
 $\phi _0$
and
$\phi _0$
and
 $\phi _n$
be arbitrary neural networks so that
$\phi _n$
be arbitrary neural networks so that
 \begin{equation} \begin{split} &\phi _0 \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \left (\{\varphi (x^{j,0})\}_{j=1}^r ,\{f_a(x^{j,0})\}_{j=1}^r\right )\\ &\phi _n \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \left (\{\varphi (x^{j,4^{-n}})\}_{j=1}^r ,\{f_a(x^{j,4^{-n}})\}_{j=1}^r\right ). \end{split} \end{equation}
\begin{equation} \begin{split} &\phi _0 \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \left (\{\varphi (x^{j,0})\}_{j=1}^r ,\{f_a(x^{j,0})\}_{j=1}^r\right )\\ &\phi _n \in \underset {\varphi \in \mathcal{NN}_{\mathbf{N},\kern0.3pt L}}{\operatorname {argmin}_{\epsilon }} \left (\{\varphi (x^{j,4^{-n}})\}_{j=1}^r ,\{f_a(x^{j,4^{-n}})\}_{j=1}^r\right ). \end{split} \end{equation}
By Lemma5.4 and the assumption that
 $|\mathcal{T}^{\kappa }_0| = r \geq 3(N_1+1) \dotsb (N_{L-1}+1)$
, we conclude that
$|\mathcal{T}^{\kappa }_0| = r \geq 3(N_1+1) \dotsb (N_{L-1}+1)$
, we conclude that
 \begin{align*} \max \limits _{j=1,2,\dotsc ,r} |\phi _0(x^{j,0}) - f_a(x^{j,0})| \geq 1/2. \end{align*}
\begin{align*} \max \limits _{j=1,2,\dotsc ,r} |\phi _0(x^{j,0}) - f_a(x^{j,0})| \geq 1/2. \end{align*}
By contrast, Lemma5.27 shows that
 $\max _{j=1,2,\dotsc ,r} |\phi _n(x^{j,4^{-n}}) - f_a(x^{j,4^{-n}})| \leq \hat \epsilon$
. Combining these two results and the fact that
$\max _{j=1,2,\dotsc ,r} |\phi _n(x^{j,4^{-n}}) - f_a(x^{j,4^{-n}})| \leq \hat \epsilon$
. Combining these two results and the fact that
 $f_a(x^{j,0}) = f_a(x^{j,4^{-n}})$
for each
$f_a(x^{j,0}) = f_a(x^{j,4^{-n}})$
for each
 $j=1,2,\dotsc ,r$
yields
$j=1,2,\dotsc ,r$
yields
 \begin{align*} \max _{j=1,2,\dotsc ,r} |\phi _0(x^{j,0}) - \phi _n(x^{j,4^{-n}})| \geq 1/2 - \hat \epsilon . \end{align*}
\begin{align*} \max _{j=1,2,\dotsc ,r} |\phi _0(x^{j,0}) - \phi _n(x^{j,4^{-n}})| \geq 1/2 - \hat \epsilon . \end{align*}
Therefore, since both the
 $\ell ^1$
and
$\ell ^1$
and
 $\ell ^2$
norms are bounded from below by the
$\ell ^2$
norms are bounded from below by the
 $\ell ^{\infty }$
norm and
$\ell ^{\infty }$
norm and
 $\phi _0$
and
$\phi _0$
and
 $\phi _n$
were chosen arbitrarily according to (5.25), we have
$\phi _n$
were chosen arbitrarily according to (5.25), we have
 $ \inf _{\upsilon ^1 \in \Xi (\iota ^1_n), \upsilon ^2 \in \Xi (\iota ^0)}d_{\mathcal{M}}(\upsilon ^1,\upsilon ^2) \geq 1/2 - \hat \epsilon$
where
$ \inf _{\upsilon ^1 \in \Xi (\iota ^1_n), \upsilon ^2 \in \Xi (\iota ^0)}d_{\mathcal{M}}(\upsilon ^1,\upsilon ^2) \geq 1/2 - \hat \epsilon$
where
 $d_{\mathcal{M}}$
is the
$d_{\mathcal{M}}$
is the
 $\ell ^{*}$
norm with
$\ell ^{*}$
norm with
 $*= 1,2$
or
$*= 1,2$
or
 $\infty$
. Hence, property (Pb) from Proposition 5.25 holds with
$\infty$
. Hence, property (Pb) from Proposition 5.25 holds with
 $\kappa = 1/2 - \hat \epsilon$
, thereby concluding the proof.
$\kappa = 1/2 - \hat \epsilon$
, thereby concluding the proof.
Financial support
ACH acknowledges support from the Simons Foundation Award No. 663281 granted to the Institute of Mathematics of the Polish Academy of Sciences for the years 2021–2023, from a Royal Society University Research Fellowship, and from the Leverhulme Prize 2017.
Competing interest
The autors declare no competing interests.






 Open access
Open access